
1. Introdução
Neste codelab, você vai aprender a usar o BigQuery Graph para resolver problemas complexos de cadeia de suprimentos e logística.
Você vai modelar uma rede de cadeia de suprimentos de restaurantes com foco na segurança alimentar e no controle de qualidade. Quando surge um problema de segurança alimentar, como um ingrediente contaminado de um fornecedor, o tempo é essencial. Identificar o "raio de impacto" e executar um recall cirúrgico rapidamente pode economizar custos e proteger os clientes.

Os modelos relacionais tradicionais exigem operações JOIN complexas e de várias etapas para rastrear itens em várias fases (fornecedor -> CD -> cozinha central -> loja -> item final). Com o BigQuery Graph, modelamos essas conexões diretamente, permitindo consultas intuitivas e rápidas usando o padrão ISO GQL (Graph Query Language).
O que você vai aprender
- Como definir um modelo de gráfico nas tabelas atuais do BigQuery.
- Como criar um gráfico de propriedades no BigQuery.
- Como executar consultas de travessia para rastrear impactos upstream e downstream.
O que é necessário
- um projeto do Google Cloud com faturamento ativado
- Google Cloud Shell
Custo estimado
Espera-se que este laboratório custe menos de US$5 em taxas de análise do BigQuery, bem dentro das alocações do nível sem custo financeiro para novos usuários.
2. Configuração e requisitos
Abrir o Cloud Shell
A maior parte do trabalho será realizada no Cloud Shell, um ambiente carregado com tudo o que você precisa para usar o Google Cloud.
- Acesse o Console do Google Cloud.
- Clique no ícone Ativar o Cloud Shell na barra de ferramentas no canto superior direito.
- Clique em Continuar , se solicitado.
Configurar as variáveis de ambiente
No Cloud Shell, defina o ID do projeto para simplificar comandos futuros.
export PROJECT_ID=$(gcloud config get-value project)
Ativar a API BigQuery
Verifique se a API BigQuery está ativada. Ela geralmente é ativada por padrão, mas é melhor se prevenir.
gcloud services enable bigquery.googleapis.com
3. Criar o esquema e as tabelas
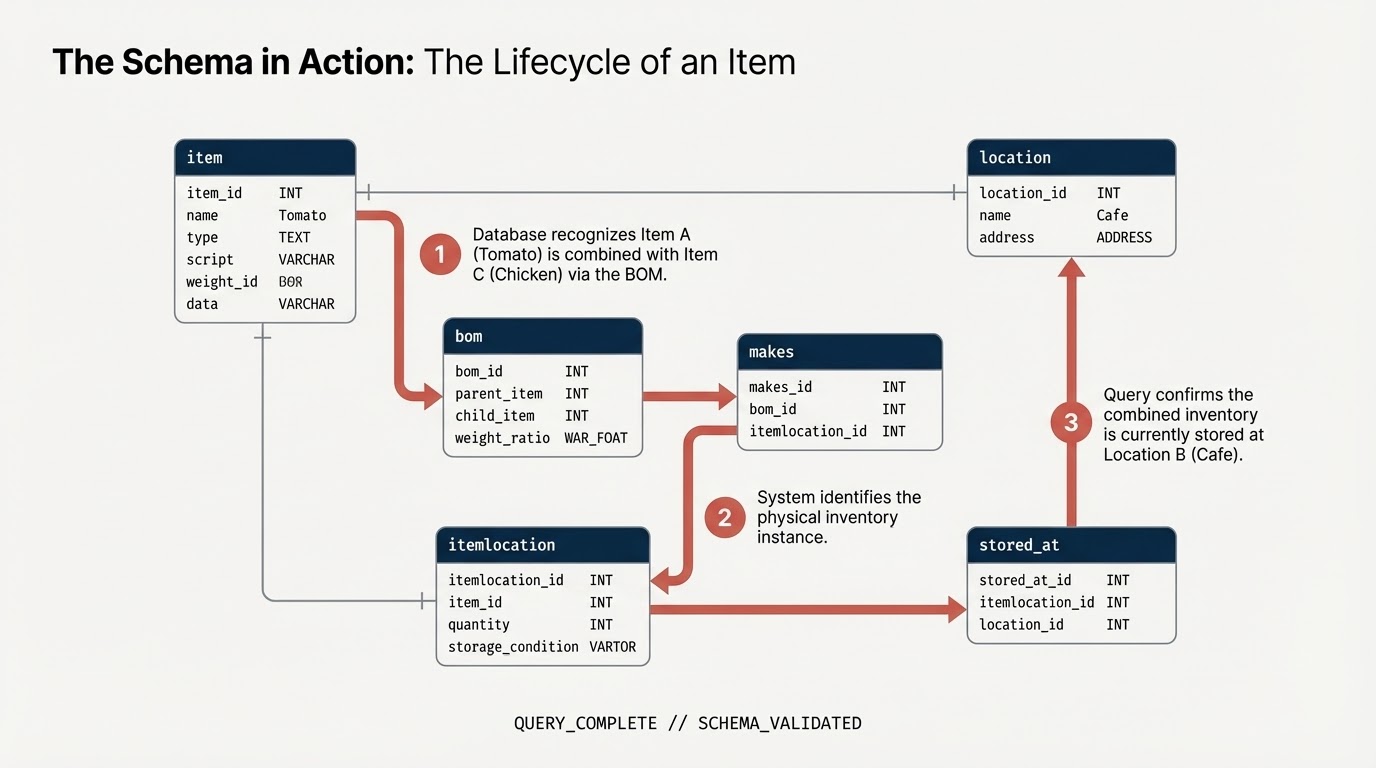
Você vai criar um conjunto de dados e tabelas que representam os componentes da cadeia de suprimentos:
item: a definição genérica do item (por exemplo, tomate, frango).location: instalações (fornecedores, centros de distribuição, cafés).itemlocation: a tabela de interseção que representa locais de inventário.bom: lista de materiais (define relações de peso, por exemplo, o item A entra no item B).makes: mapeiaitemlocationpara oitem.stored_at: mapeiaitemlocationparalocation.
Criar conjunto de dados
É possível executar os comandos SQL neste laboratório usando o Cloud Shell ou o console do BigQuery.
Para usar o console do BigQuery:
- Abra o console do BigQuery em uma nova guia.
- Cole cada snippet de SQL deste laboratório no editor e clique no botão Executar para executá-lo.
Execute o comando a seguir no Cloud Shell ou use o console do BigQuery para criar o esquema. Você vai usar variáveis de nó no SQL.
Observação: (1) para executar isso no Google Colab, também é possível usar os comandos mágicos do BigQuery: %%bigquery O snippet a seguir cria o esquema do restaurante no seu projeto para hospedar os dados do gráfico. (2) Você precisará usar %%bigquery –project <PROJECT_ID> se estiver executando em um Google Colab. Verifique se o campo PROJECT_ID está mapeado para o projeto apropriado que você pretende usar: PROJECT_ID = "argolis-project-340214" # @param {"type":"string"} (3) Se você estiver usando o Colab, dependendo dos seus requisitos, será necessário instalar algumas bibliotecas. Se você for usar a visualização de gráficos, instale a biblioteca: spanner-graph-notebook==1.1.5
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
Criar tabelas
Execute o código SQL a seguir para criar as tabelas.
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
4. Carregar dados de amostra
Para tornar este laboratório totalmente independente, você vai preencher as tabelas com dados de amostra usando instruções SQL LOAD DATA puras. Isso representa uma rede que começa com um fornecedor, passa por um centro de distribuição (CD) e uma cozinha central e chega a um café de varejo.
Execute as consultas SQL a seguir para carregar os dados:

Observação: é possível omitir %%bigquery se você estiver executando diretamente no BigQuery Studio.
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
5. Adicionar restrições e definir o gráfico
Antes de criar o gráfico, declare as relações semânticas usando as restrições de chave primária e chave estrangeira do SQL padrão. Elas orientam o BigQuery na compreensão dos identificadores de nós e na conexão de tabelas de borda a tabelas de nós.
Criar gráfico de propriedades
Agora, você une essas tabelas em uma única estrutura de gráfico coesa chamada restaurant.bombod.
Você define:
- Nós:
item,location,itemlocation - Bordas:
makes,stored_ateconsists_of(BOM)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
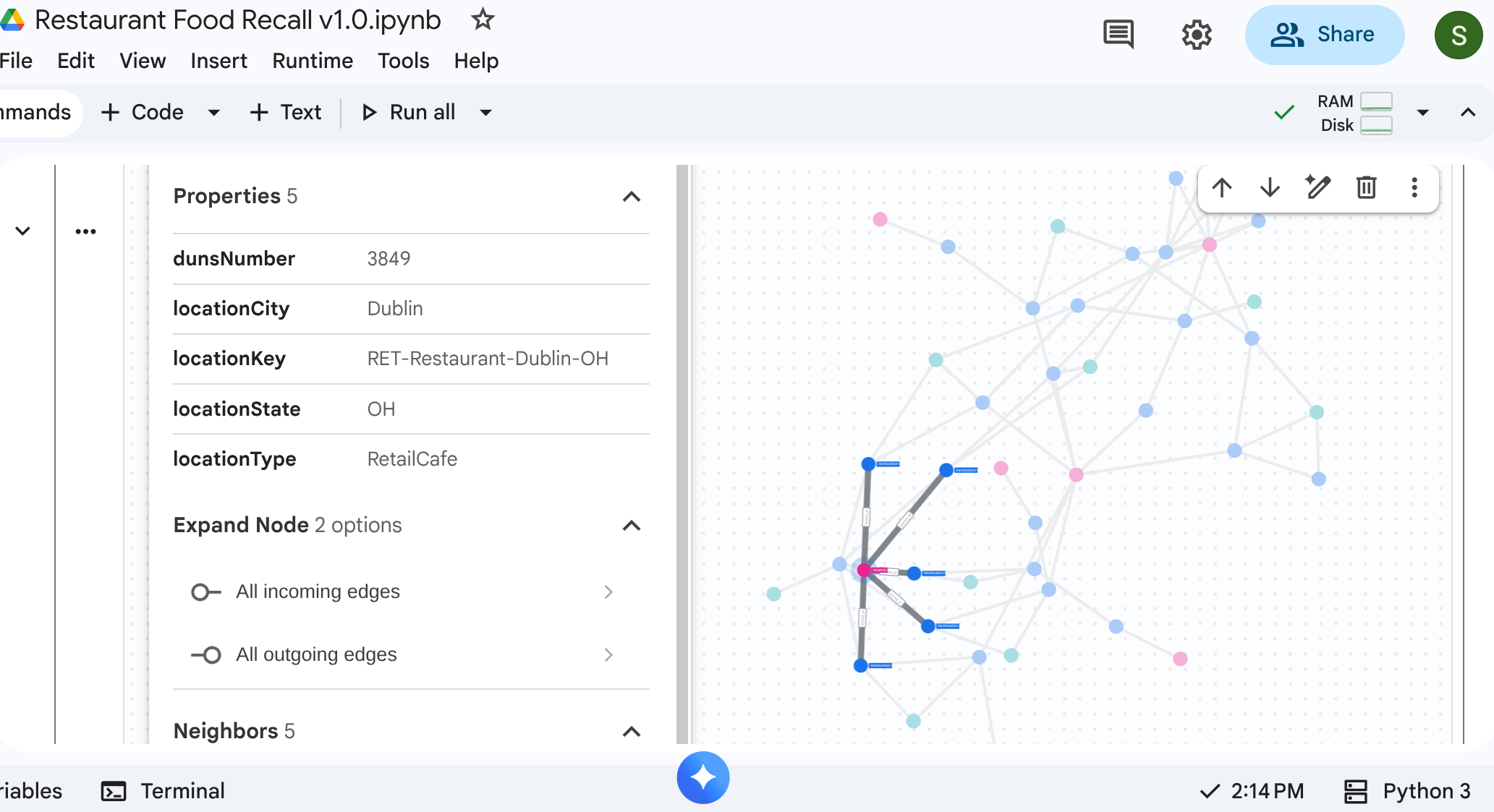
6. Visualizar a cadeia de suprimentos
É possível executar uma consulta de travessia de cima para baixo para conferir toda a rede da cadeia de suprimentos. Em um notebook ou interface padrão que oferece suporte a isso (como %%bigquery --graph), isso retorna um mapa visual.
Use consultas de gráfico absolutas para configurar nós e bordas.
Observação: como mencionado anteriormente, para executar isso no Google Colab ou nos notebooks do Colab Enterprise, também é possível usar os comandos mágicos do BigQuery: %%bigquery Além disso, para visualizar o gráfico no Google Colab ou nos notebooks do Colab Enterprise, inclua a flag –graph como: %%bigquery –graph
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
Saída:
7. Caso de uso 1: rastrear uma reclamação upstream
Cenário: um cliente reclama da qualidade do frango no sanduíche na loja de Nova York. Você precisa rastrear o item final para trás para conferir as fases de montagem imediatas.
Consulta de travessia
Execute a consulta usando o formato de consulta de travessia de grafo. Isso analisa as bordas consists_of que relacionam as montagens downstream até os ingredientes upstream.
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
Devido à direção da seta na tabela de borda consists_of (Ingredient -> Finished), uma pesquisa que flui upstream gera links que isolam rapidamente os materiais dependentes e os locais de armazenamento.
Saída: 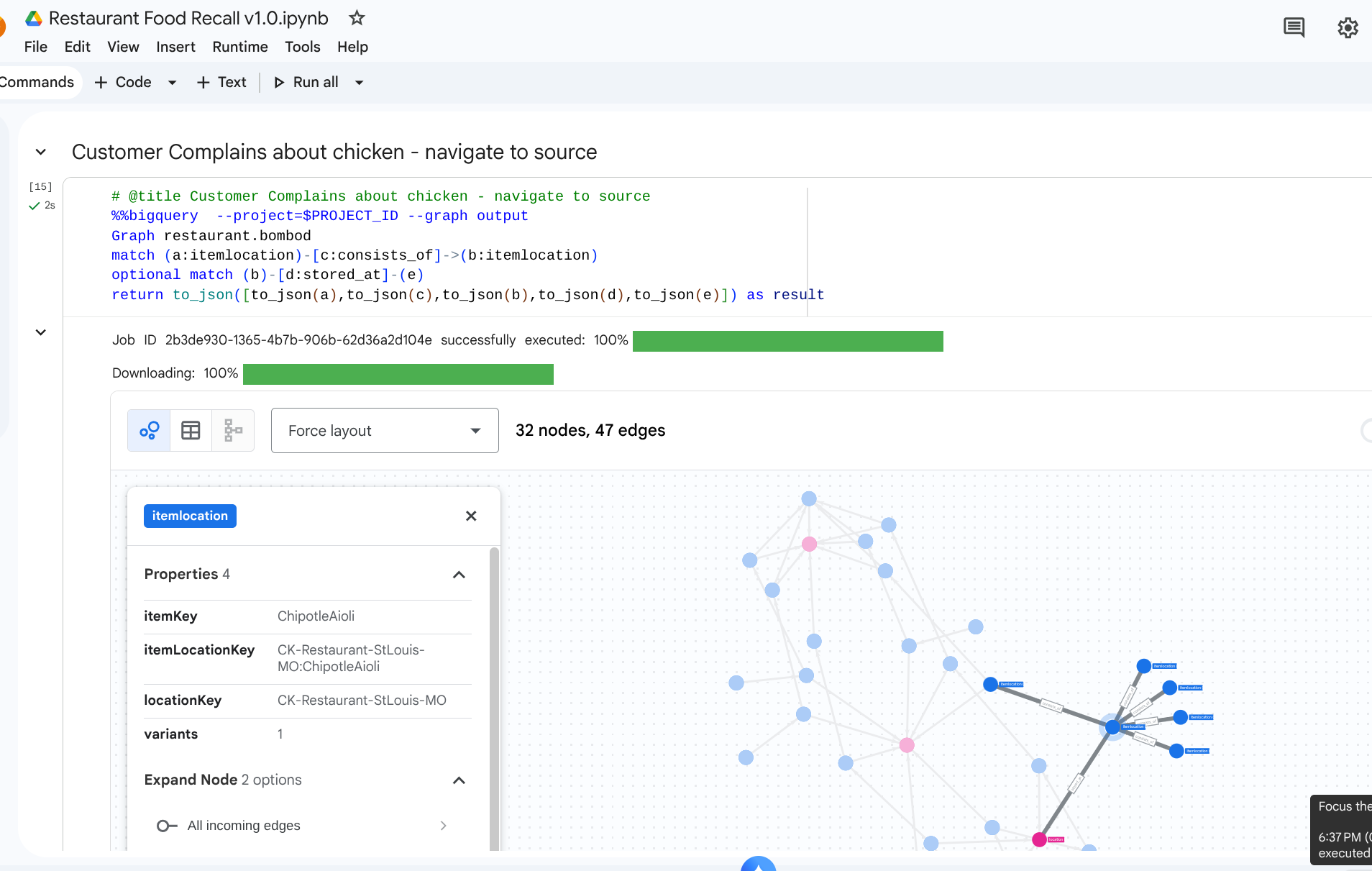
8. Caso de uso 2: análise de impacto
Cenário: uma nevasca fechou o centro de distribuição em Columbus, Ohio. Você precisa saber quais preparações downstream ou itens finais são afetados imediatamente.
Consulta de travessia
Você começa no location específico que representa o centro de distribuição, identifica o inventário armazenado lá e confere quais itens finais precisam dele.
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
Saída: 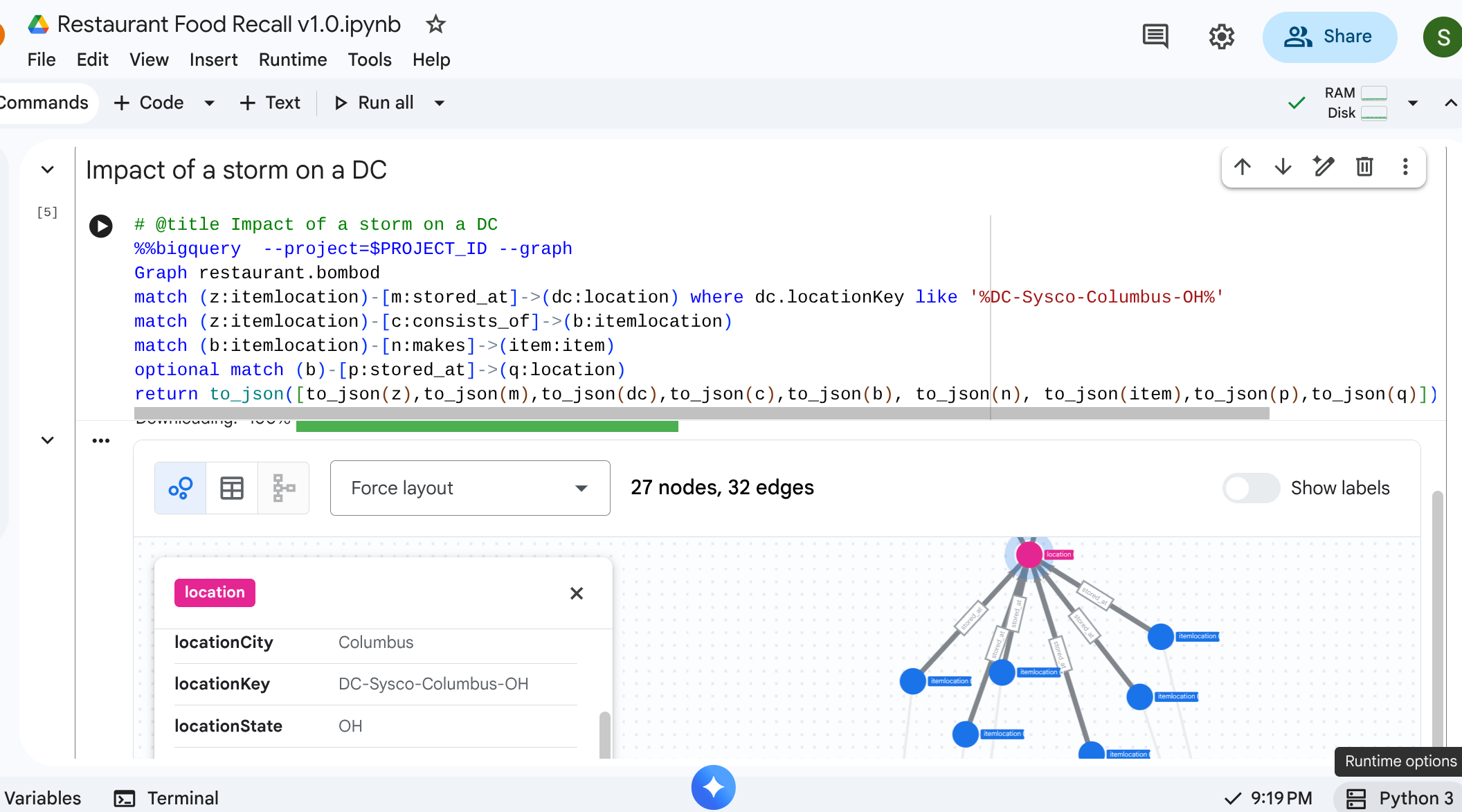
9. Caso de uso 3: recall downstream
Cenário: um fornecedor notifica você sobre um lote específico de produto contaminado: tomates maduros do fornecedor. Você precisa encontrar todos os itens de menu finais afetados nos cafés.
Consulta de travessia
Você procura o local da matéria-prima contaminada e, em seguida, realiza uma travessia de caminho que flui downstream para encontrar os itens afetados finais.
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
Essa consulta localiza todos os itens que correspondem ao padrão "Tomate" e que estão interligados ao relacionamento upstream, tornando-o um mapeamento eficiente que se propaga para descobrir quais itens de café precisam ser recolhidos.
Saída: 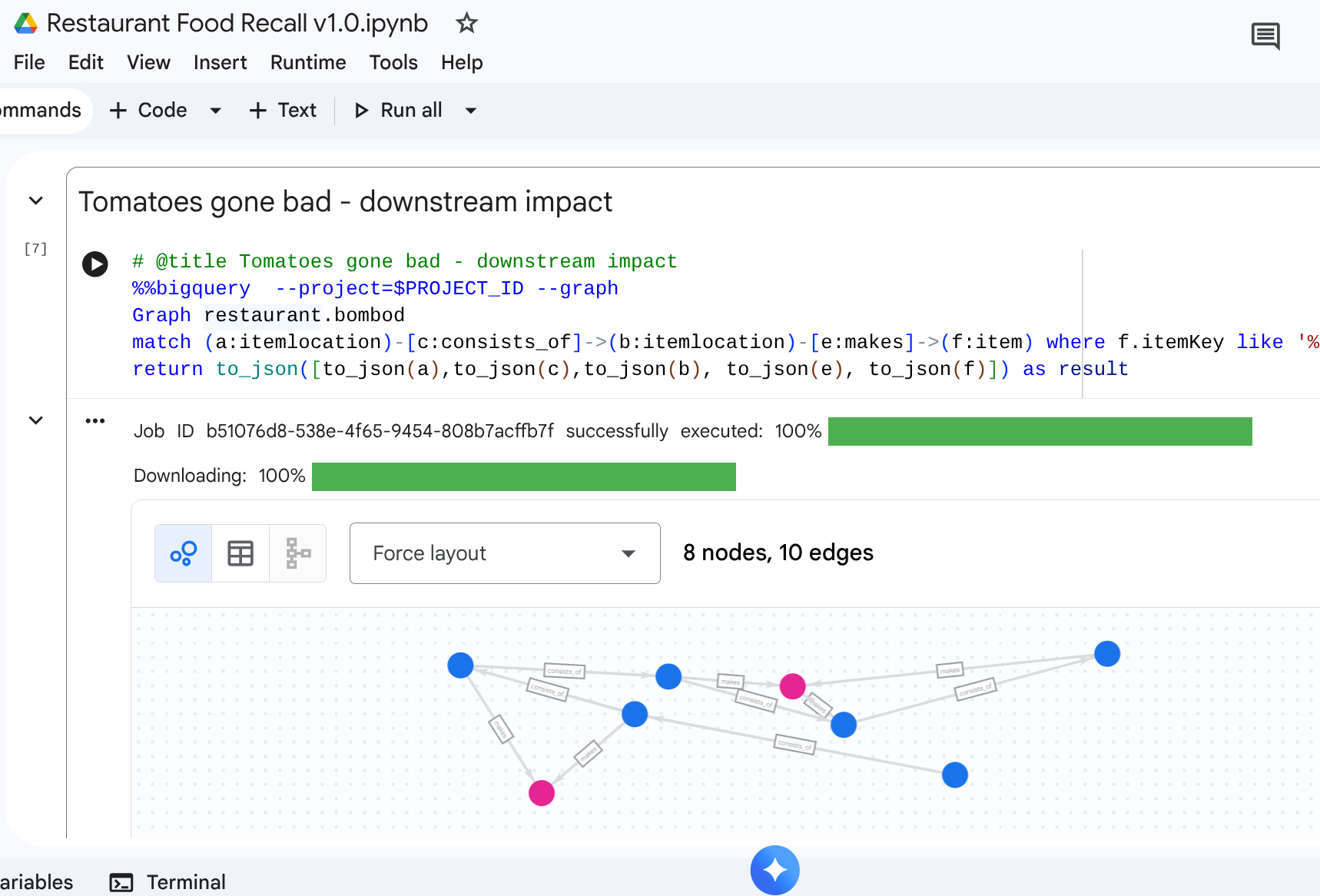
10. Limpeza
Exclua os recursos depois de concluir as etapas do tutorial para evitar cobranças residuais no seu espaço de trabalho.
DROP SCHEMA `restaurant` CASCADE;
11. Conclusão
Parabéns! Você modelou uma cadeia de suprimentos e executou uma análise de impacto usando o BigQuery Graph.
Conclusão
Você aprendeu a:
- Declarar relações relacionais centradas em gráficos com chaves primárias/estrangeiras.
- Criar um gráfico de propriedades unificado.
- Navegar em relações de vários nós de maneira eficiente usando a lógica de travessia de consulta de gráfico.
Para mais informações sobre arquitetura de gráficos, acesse os documentos do Google Cloud.