
1. Introduzione
In questo codelab imparerai a utilizzare BigQuery Graph per risolvere problemi complessi di catena di fornitura e logistica.
Creerai un modello di rete della catena di fornitura di un ristorante incentrato sulla sicurezza alimentare e sul controllo qualità. Quando si verifica un problema di sicurezza alimentare, ad esempio un ingrediente contaminato di un fornitore, il tempo è essenziale. Identificare il "raggio di impatto" ed eseguire rapidamente un ritiro chirurgico può ridurre i costi e proteggere i clienti.

I modelli relazionali tradizionali richiedono operazioni JOIN complesse e in più fasi per tracciare gli articoli in più fasi (fornitore -> centro di distribuzione -> centro di produzione -> negozio -> articolo finito). Con BigQuery Graph, modelliamo queste connessioni direttamente, consentendo query intuitive e veloci utilizzando lo standard ISO GQL (Graph Query Language).
Obiettivi didattici
- Come definire un modello di grafo sopra le tabelle BigQuery esistenti.
- Come creare un grafico delle proprietà in BigQuery.
- Come eseguire query di attraversamento per tracciare gli impatti upstream e downstream.
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione abilitata.
- Google Cloud Shell.
Stima dei costi
Questo lab dovrebbe costare meno di 5$ in termini di tariffe di analisi di BigQuery, un importo ben al di sotto delle allocazioni del Livello senza costi per i nuovi utenti.
2. Configurazione e requisiti
Apri Cloud Shell
Svolgerai la maggior parte del lavoro in Cloud Shell, un ambiente precaricato con tutto il necessario per utilizzare Google Cloud.
- Vai alla console Google Cloud.
- Fai clic sull'icona Attiva Cloud Shell nella barra degli strumenti in alto a destra.
- Se richiesto, fai clic su Continua.
Configura le variabili di ambiente
In Cloud Shell, imposta l'ID progetto per semplificare i comandi futuri.
export PROJECT_ID=$(gcloud config get-value project)
Abilita API BigQuery
Assicurati che l'API BigQuery sia abilitata. Di solito è abilitato per impostazione predefinita, ma è meglio andare sul sicuro.
gcloud services enable bigquery.googleapis.com
3. Creare lo schema e le tabelle
Creerai un set di dati e tabelle che rappresentano i componenti della tua catena di fornitura:
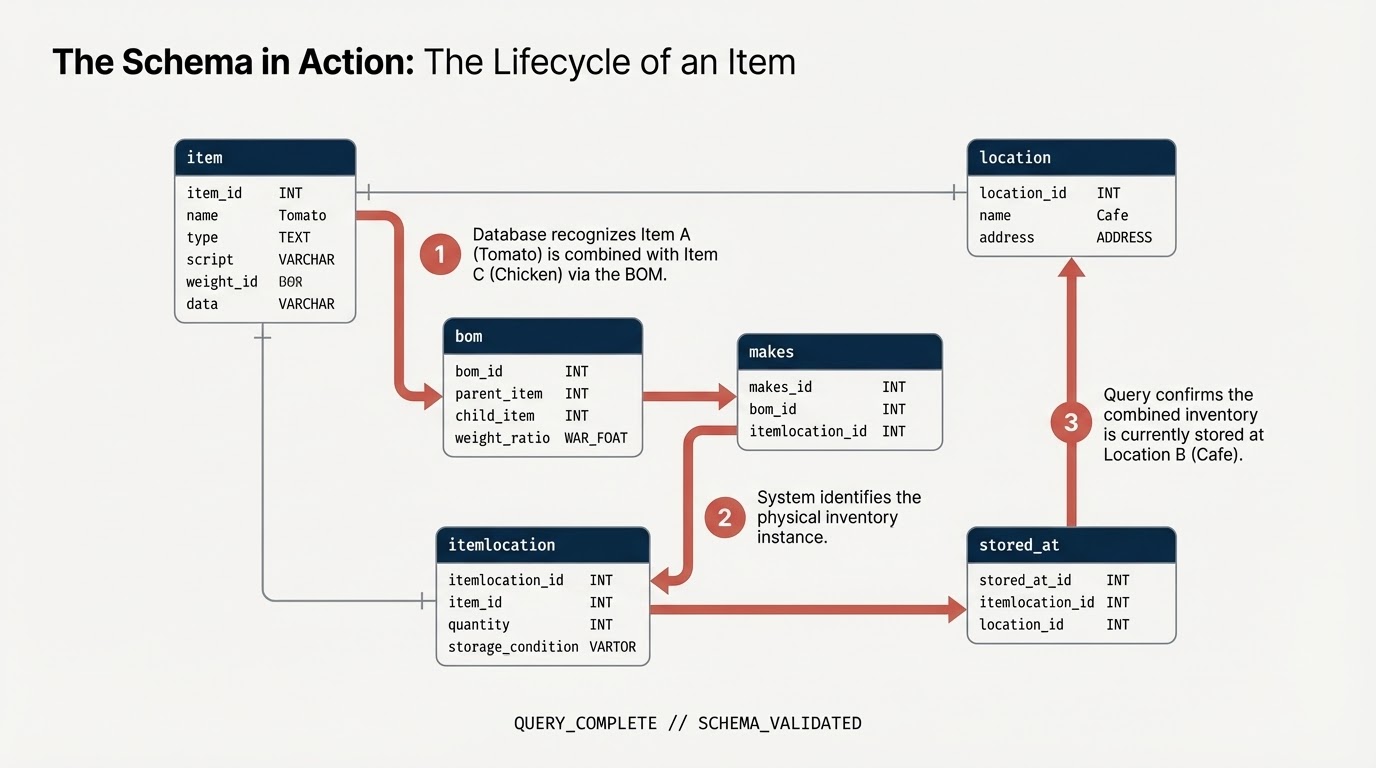
item: la definizione generica dell'articolo (ad es. pomodoro, pollo).location: strutture (fornitori, centri di distribuzione, caffè).itemlocation: la tabella di intersezione che rappresenta le sedi dell'inventario.bom: Distinta base (definisce le relazioni di peso, ad es. l'articolo A fa parte dell'articolo B).makes: Mapsitemlocationto theitem.stored_at: Mapsitemlocationtolocation.
Crea set di dati
Puoi eseguire i comandi SQL in questo lab utilizzando Cloud Shell o la console BigQuery.
Per utilizzare la console BigQuery:
- Apri la console BigQuery in una nuova scheda.
- Incolla ogni snippet SQL di questo lab nell'editor, quindi fai clic sul pulsante Esegui per eseguirlo.
Esegui il seguente comando in Cloud Shell o utilizza la console BigQuery per creare lo schema. Utilizzerai le variabili dei nodi in SQL.
Nota: (1) Per eseguire questa operazione in Google Colab, puoi anche utilizzare i comandi magici BigQuery: %%bigquery Il seguente snippet crea lo schema del ristorante all'interno del tuo progetto per ospitare i dati del grafico. (2) Se esegui l'operazione da Google Colab, devi utilizzare %%bigquery –project <PROJECT_ID>. Assicurati che il campo PROJECT_ID sia mappato al progetto appropriato che intendi utilizzare: PROJECT_ID = "argolis-project-340214" # @param {"type":"string"} (3) Se utilizzi Colab, a seconda dei tuoi requisiti dovrai installare alcune librerie. Se intendi utilizzare la visualizzazione dei grafici, assicurati di installare la libreria: spanner-graph-notebook==1.1.5
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
Crea tabelle
Esegui il seguente codice SQL per creare le tabelle.
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
4. Caricamento dei dati di esempio in corso…
Per rendere questo lab completamente autonomo, popolerai le tabelle con dati di esempio utilizzando istruzioni SQL LOAD DATA pure. Rappresenta una rete che inizia con un fornitore, attraversa un centro di distribuzione e una cucina centralizzata e arriva a un caffè al dettaglio.
Esegui le seguenti query SQL per caricare i dati:

Nota: puoi omettere %%bigquery se esegui l'operazione direttamente in BigQuery Studio
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
5. Aggiungere vincoli e definire il grafico
Prima di creare il grafico, dichiari le relazioni semantiche utilizzando i vincoli di chiave primaria e chiave esterna SQL standard. Questi guidano BigQuery nella comprensione degli identificatori dei nodi e nel collegamento delle tabelle Edge alle tabelle Node.
Crea grafico delle proprietà
Ora unisci queste tabelle in un'unica struttura di grafici coesa chiamata restaurant.bombod.
Definisci:
- Nodi:
item,location,itemlocation - Bordi:
makes,stored_ateconsists_of(distinta base)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
6. Visualizzare la catena di fornitura
Puoi eseguire una query di attraversamento dall'alto verso il basso per visualizzare l'intera rete della catena di fornitura. In un notebook standard o in un'interfaccia utente che lo supporta (come %%bigquery --graph), viene restituita una mappa visiva.
Utilizza le query del grafico assoluto per configurare nodi e archi.
Nota: come accennato in precedenza, per eseguire questa operazione in Google Colab o nei notebook Colab Enterprise, puoi anche utilizzare i comandi magici BigQuery: %%bigquery. Inoltre, per visualizzare il grafico in Google Colab o nei notebook Colab Enterprise, includi il flag –graph come: %%bigquery –graph
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
Output:
7. Caso d'uso 1: tracciamento di un reclamo a monte
Scenario: un cliente si lamenta della qualità del pollo nel suo panino nel negozio di New York. Devi tracciare l'articolo finito a ritroso per vedere le fasi di assemblaggio immediate.
Query di attraversamento
Esegui la query utilizzando il formato di query Graph Traversal. Vengono esaminati i bordi consists_of che collegano gli assemblaggi downstream agli ingredienti upstream.
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
A causa della direzione della freccia nella consists_of tabella Edge (Ingredient -> Finished), una ricerca a monte produce link che isolano rapidamente i materiali dipendenti e le posizioni di archiviazione.
Output: 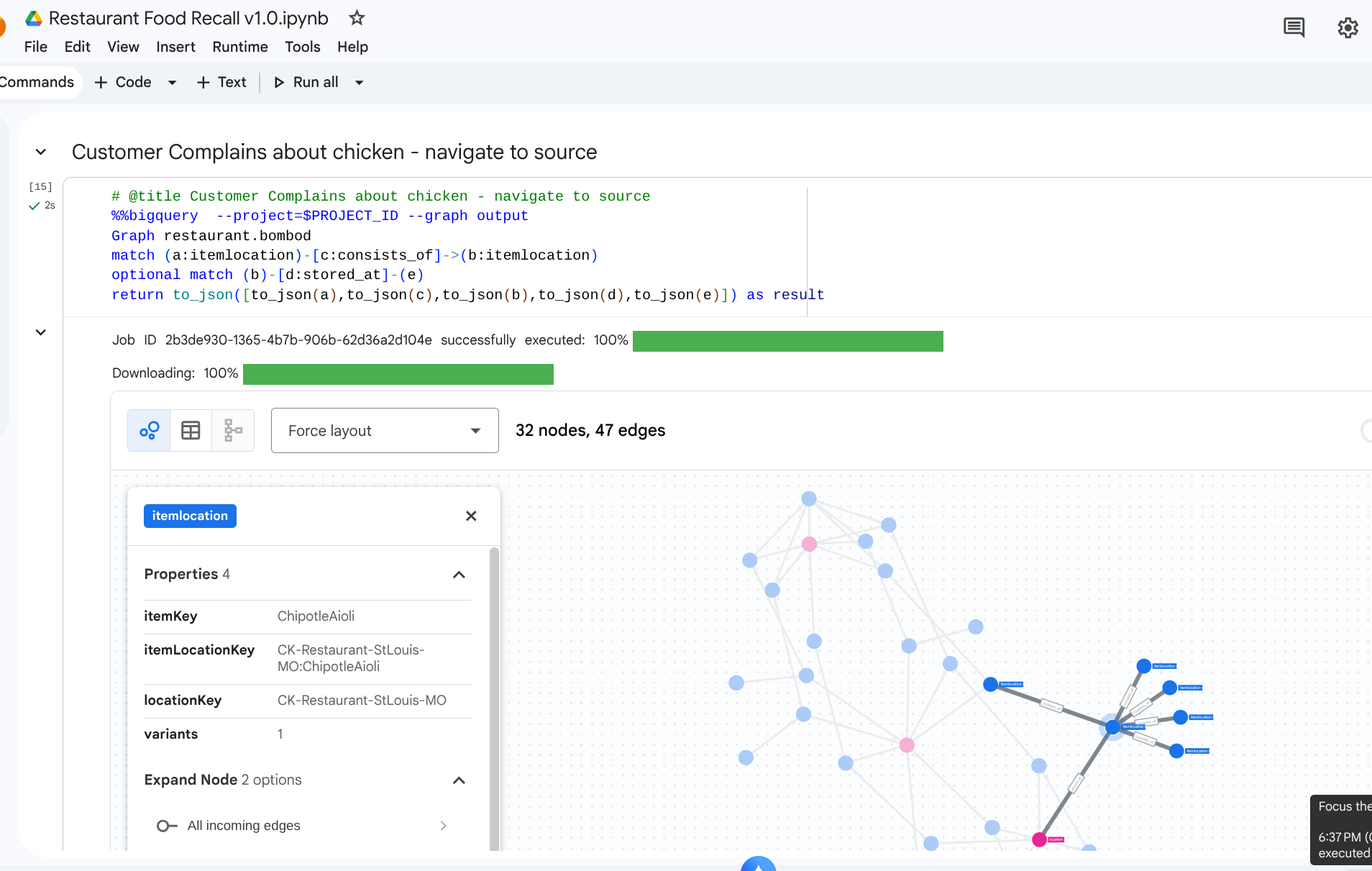
8. Use Case 2: Impact Analysis
Scenario: una tempesta di neve ha chiuso il centro di distribuzione di Columbus, Ohio. Devi sapere quali preparazioni o articoli finiti a valle sono immediatamente interessati.
Query di attraversamento
Inizi dal location specifico che rappresenta il centro di distribuzione, identifichi l'inventario ivi archiviato e vedi quali articoli finiti lo richiedono.
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
Output: 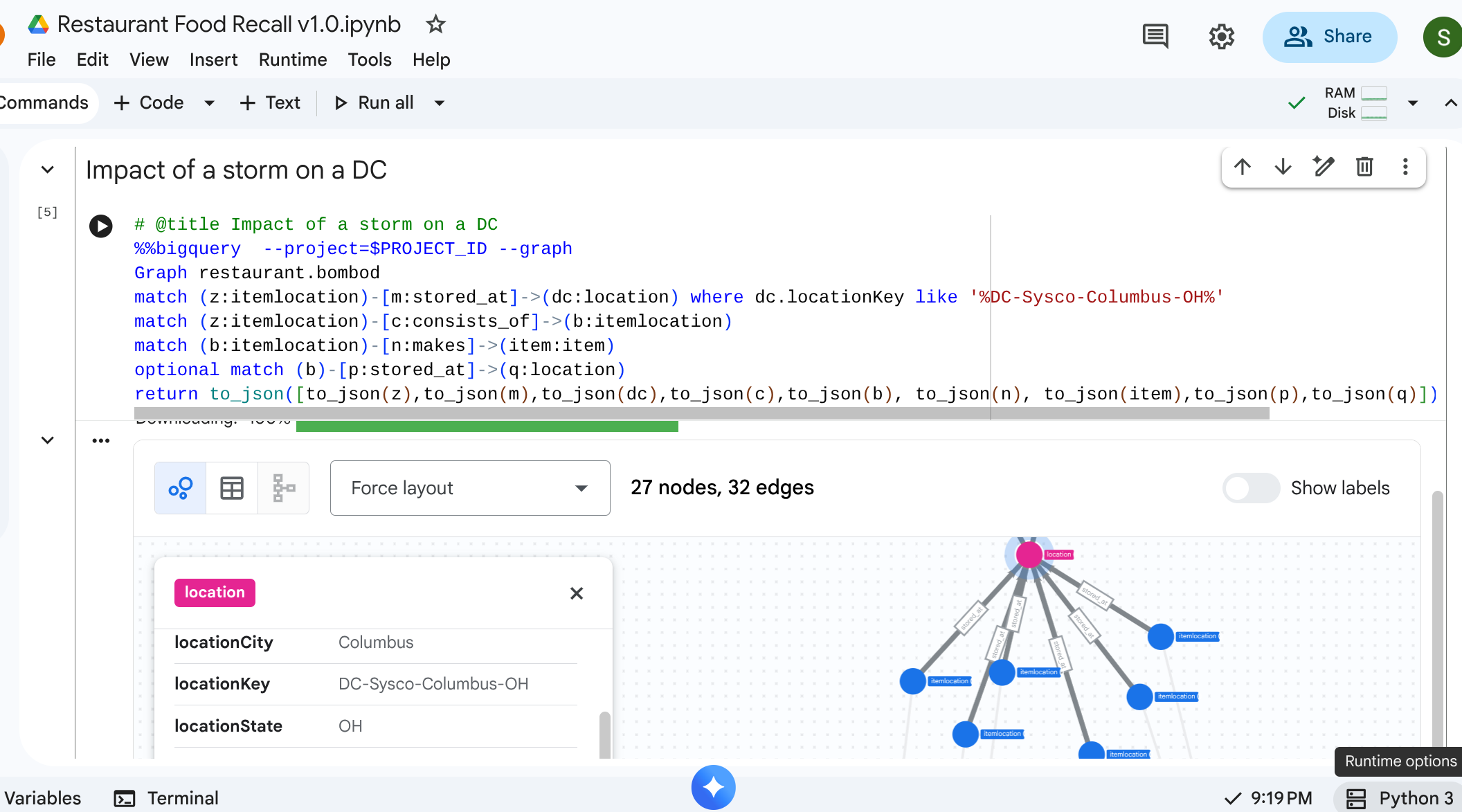
9. Use Case 3: Downstream Recall
Scenario: un fornitore ti comunica un lotto specifico di prodotto contaminato: pomodori maturati sulla pianta del fornitore. Devi trovare tutti gli elementi del menu finale interessati nei caffè.
Query di attraversamento
Cerchi la posizione della materia prima contaminata, quindi esegui un path traversal a valle per trovare gli elementi interessati finali.
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
Questa query individua tutti gli elementi che corrispondono al pattern "Pomodoro" e che sono intrecciati con la relazione upstream, il che la rende una mappatura efficace che si propaga per scoprire quali articoli del bar devono essere ritirati.
Output: 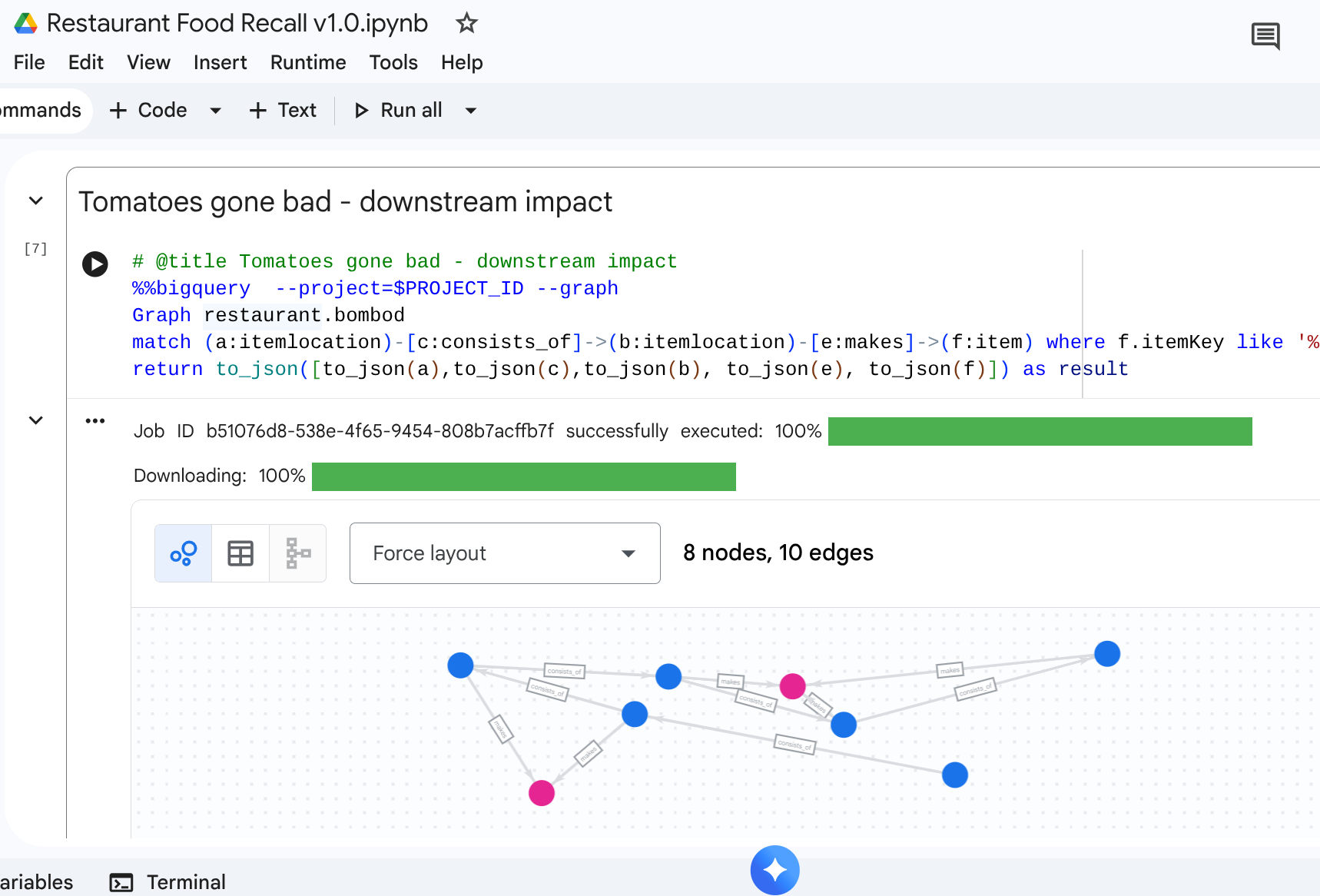
10. Elimina
Elimina le risorse una volta completati i passaggi della procedura dettagliata per evitare addebiti residui nel tuo workspace.
DROP SCHEMA `restaurant` CASCADE;
11. Conclusione
Complimenti! Hai modellato una catena di fornitura ed eseguito l'analisi dell'impatto utilizzando BigQuery Graph.
Conclusione
Hai imparato a:
- Dichiara relazioni relazionali incentrate sul grafico con chiavi primarie/esterne.
- Crea un grafico delle proprietà unificato.
- Naviga in modo efficiente nelle relazioni tra più nodi utilizzando la logica di attraversamento delle query del grafico.
Per ottenere ulteriori informazioni sull'architettura del grafico, consulta la documentazione di Google Cloud.