
1. Introduction
Dans cet atelier de programmation, vous allez découvrir comment tirer parti de BigQuery Graph pour résoudre des problèmes complexes liés à la chaîne d'approvisionnement et à la logistique.
Vous allez modéliser un réseau de chaîne d'approvisionnement pour un restaurant en vous concentrant sur la sécurité alimentaire et le contrôle qualité. Lorsqu'un problème de sécurité alimentaire survient, par exemple un ingrédient contaminé provenant d'un fournisseur, le temps est un facteur essentiel. Identifier le "rayon d'impact" et exécuter un rappel chirurgical rapidement peut permettre de réduire les coûts et de protéger les clients.

Les modèles relationnels traditionnels nécessitent des opérations JOIN complexes en plusieurs étapes pour suivre les articles à travers plusieurs étapes (fournisseur -> centre de distribution -> cuisine centrale -> magasin -> article fini). Avec BigQuery Graph, nous modélisons ces connexions directement, ce qui permet d'effectuer des requêtes intuitives et rapides à l'aide de la norme ISO GQL (Graph Query Language).
Points abordés
- Définir un modèle de graphe au-dessus des tables BigQuery existantes
- Créer un graphe de propriétés dans BigQuery
- Exécuter des requêtes de balayage pour suivre les impacts en amont et en aval
Ce dont vous avez besoin
- Projet Google Cloud avec facturation activée
- Google Cloud Shell
Estimation du coût
Cet atelier devrait coûter moins de 5$US en frais d'analyse BigQuery, ce qui est bien inférieur aux allocations du niveau sans frais pour les nouveaux utilisateurs.
2. Préparation
Ouvrir Cloud Shell
La plupart des tâches s'effectueront dans Cloud Shell, un environnement chargé qui contient tout ce dont vous avez besoin pour utiliser Google Cloud.
- Accédez à la Google Cloud Console.
- Cliquez sur l'icône Activer Cloud Shell dans la barre d'outils en haut à droite.
- Cliquez sur Continuer si vous y êtes invité.
et configurer des variables d'environnement
Dans Cloud Shell, définissez l'ID de votre projet pour simplifier les commandes futures.
export PROJECT_ID=$(gcloud config get-value project)
Activer l'API BigQuery
Vérifiez que l'API BigQuery est activée. Elle est généralement activée par défaut, mais il est préférable de s'en assurer.
gcloud services enable bigquery.googleapis.com
3. Créer le schéma et les tables
Vous allez créer un ensemble de données et des tables représentant les composants de votre chaîne d'approvisionnement :
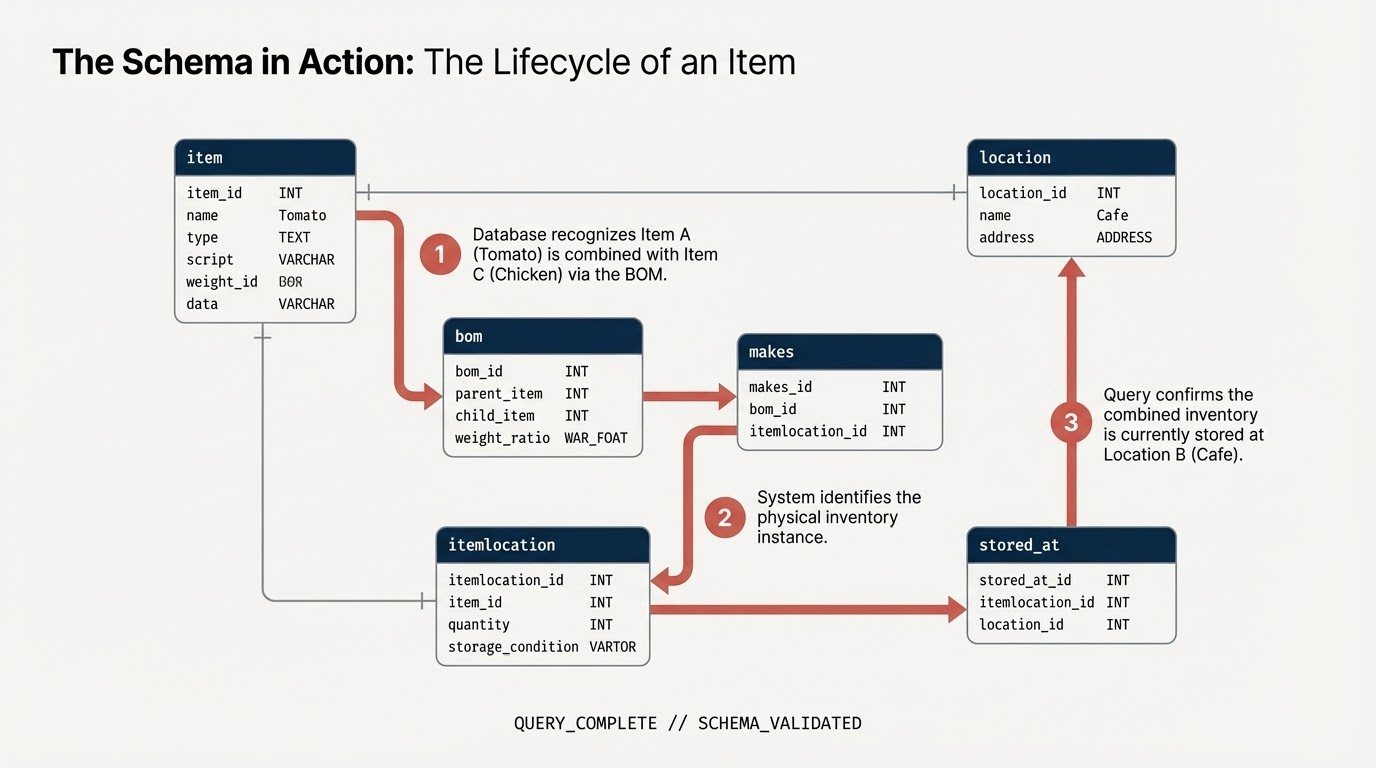
item: définition générique de l'article (par exemple, tomate, poulet)location: installations (fournisseurs, centres de distribution, cafés)itemlocation: table d'intersection représentant les emplacements des stocksbom: nomenclature (définit les relations de poids, par exemple, l'article A entre dans l'article B)makes: mappeitemlocationàitemstored_at: mappeitemlocationàlocation
Créer un ensemble de données
Vous pouvez exécuter les commandes SQL de cet atelier à l'aide de Cloud Shell ou de la console BigQuery.
Pour utiliser la console BigQuery :
- Ouvrez la console BigQuery dans un nouvel onglet.
- Collez chaque extrait SQL de cet atelier dans l'éditeur, puis cliquez sur le bouton Exécuter pour l'exécuter.
Exécutez la commande suivante dans Cloud Shell ou utilisez la console BigQuery pour créer le schéma. Vous utiliserez des variables de nœud dans votre code SQL.
Remarque : (1) Pour exécuter cette commande dans Google Colab, vous pouvez également utiliser les commandes magic BigQuery : %%bigquery L'extrait suivant crée le schéma du restaurant dans votre projet pour héberger vos données de graphe. (2) Vous devrez utiliser %%bigquery –project <PROJECT_ID> si vous exécutez la commande à partir de Google Colab. Assurez-vous que le champ PROJECT_ID est mappé au projet approprié que vous comptez utiliser : PROJECT_ID = "argolis-project-340214" # @param {"type":"string"} (3) Si vous utilisez Colab, vous devrez installer certaines bibliothèques en fonction de vos besoins. Si vous prévoyez d'utiliser la visualisation de graphes, assurez-vous d'installer la bibliothèque à l'aide de la commande pip : spanner-graph-notebook==1.1.5
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
Créer des tables
Exécutez le code SQL suivant pour créer les tables.
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
4. Charger des exemples de données
Pour que cet atelier soit entièrement autonome, vous allez remplir les tables avec des exemples de données à l'aide d'instructions SQL LOAD DATA pures. Cela représente un réseau commençant par un fournisseur, passant par un centre de distribution et une cuisine centrale, et se terminant dans un café de vente au détail.
Exécutez les requêtes SQL suivantes pour charger les données :

Remarque : Vous pouvez omettre %%bigquery si vous exécutez la commande directement dans BigQuery Studio.
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
5. Ajouter des contraintes et définir un graphe
Avant de créer le graphe, déclarez les relations sémantiques à l'aide des contraintes de clé primaire et de clé étrangère SQL standard. Elles aident BigQuery à comprendre les identifiants de nœud et à connecter les tables d'arêtes aux tables de nœuds.
Créer un graphe de propriétés
Vous allez maintenant regrouper ces tables dans une seule structure de graphe cohérente appelée restaurant.bombod.
Vous définissez les éléments suivants :
- Nœuds :
item,location,itemlocation - Arêtes :
makes,stored_atetconsists_of(nomenclature)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
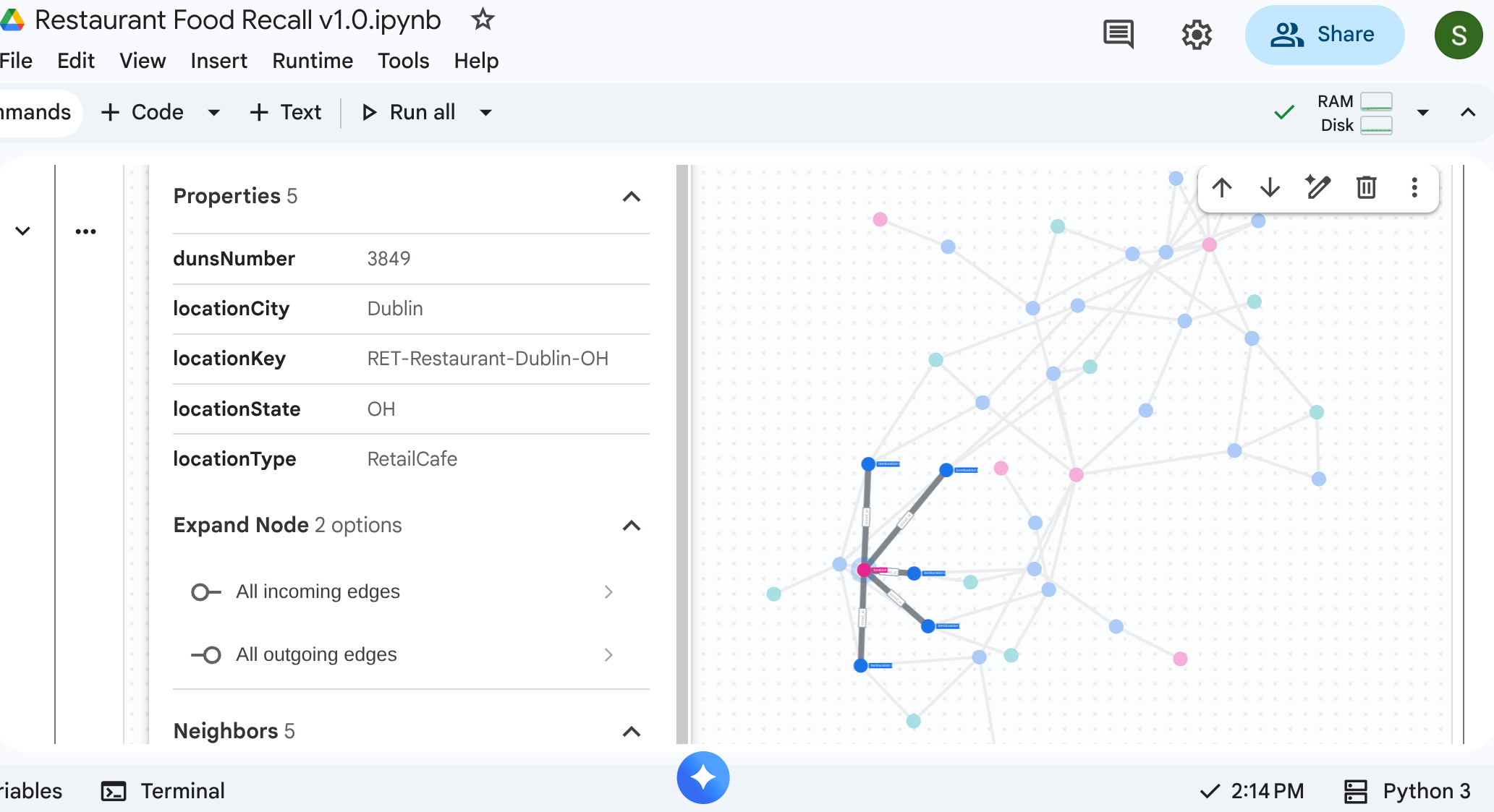
6. Visualiser la chaîne d'approvisionnement
Vous pouvez exécuter une requête de balayage descendante pour afficher l'ensemble du réseau de la chaîne d'approvisionnement. Dans un notebook ou une interface utilisateur standard compatible (comme %%bigquery --graph), cela renvoie une carte visuelle.
Utilisez des requêtes de graphe absolues pour configurer les nœuds et les arêtes.
Remarque : Comme indiqué précédemment, pour exécuter cette commande dans Google Colab ou dans des notebooks Colab Enterprise, vous pouvez également utiliser les commandes magic BigQuery : %%bigquery Pour visualiser le graphe dans Google Colab ou dans des notebooks Colab Enterprise, incluez également l'indicateur –graph comme suit : %%bigquery –graph
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
Résultat :
7. Exemple d'utilisation 1 : Suivre une réclamation en amont
Scénario : Un client se plaint de la qualité du poulet dans son sandwich au magasin de New York. Vous devez suivre l'article fini à l'envers pour voir ses étapes d'assemblage immédiates.
Requête de balayage
Exécutez la requête au format de requête de balayage de graphe. Elle examine les arêtes consists_of qui relient les assemblages en aval aux ingrédients en amont.
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
En raison du sens de la flèche dans la table d'arêtes consists_of (Ingredient -> Finished), une recherche en amont génère rapidement des liens qui isolent les matériaux dépendants et les emplacements de stockage.
Résultat : 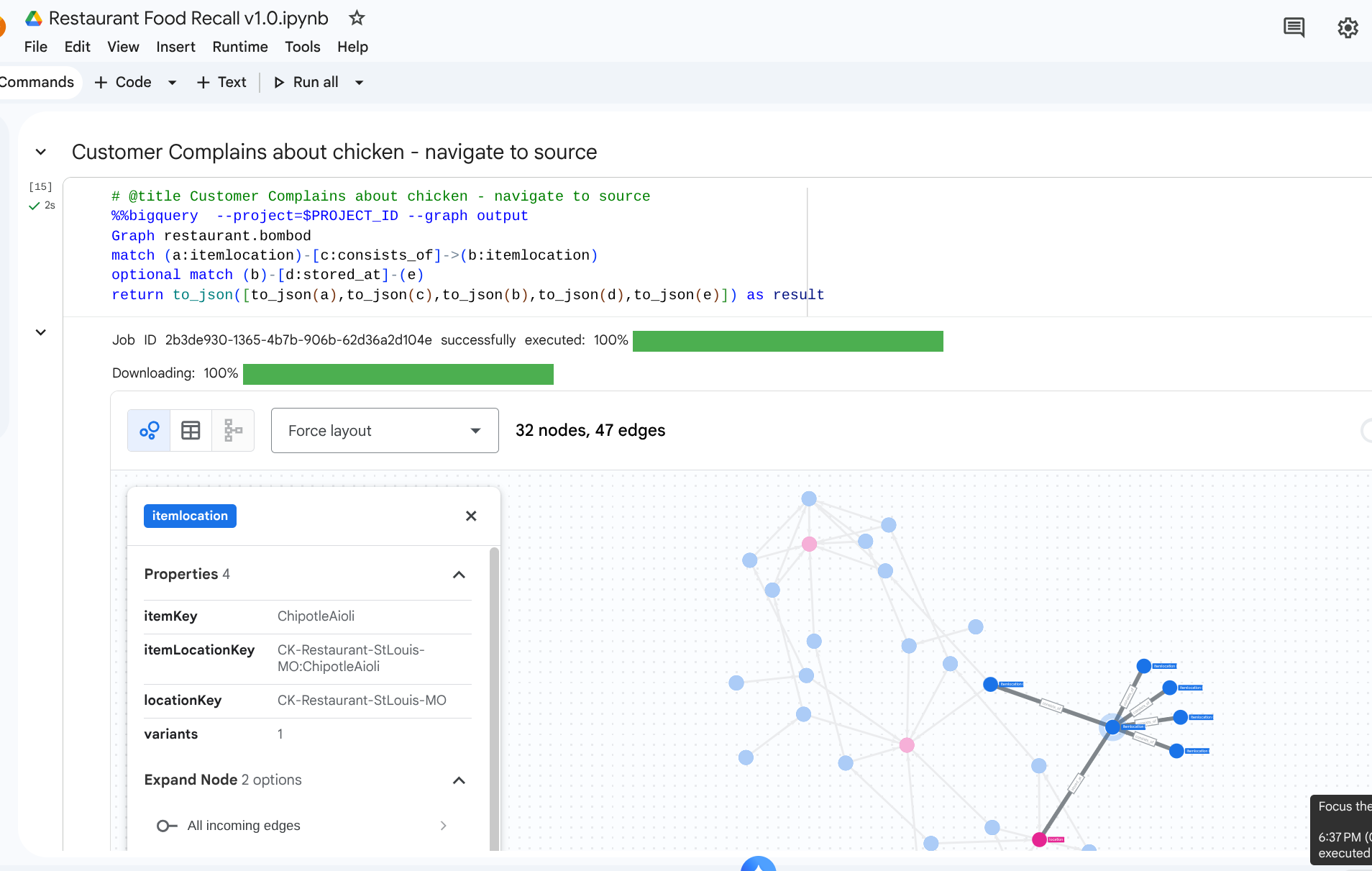
8. Exemple d'utilisation 2 : Analyse d'impact
Scénario : Une tempête de neige a fermé le centre de distribution de Columbus, dans l'Ohio. Vous devez savoir quelles préparations ou quels articles finis en aval sont immédiatement concernés.
Requête de balayage
Vous commencez par l'élément location spécifique représentant le centre de distribution, identifiez les stocks qui y sont stockés et voyez quels articles finis en ont besoin.
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
Résultat : 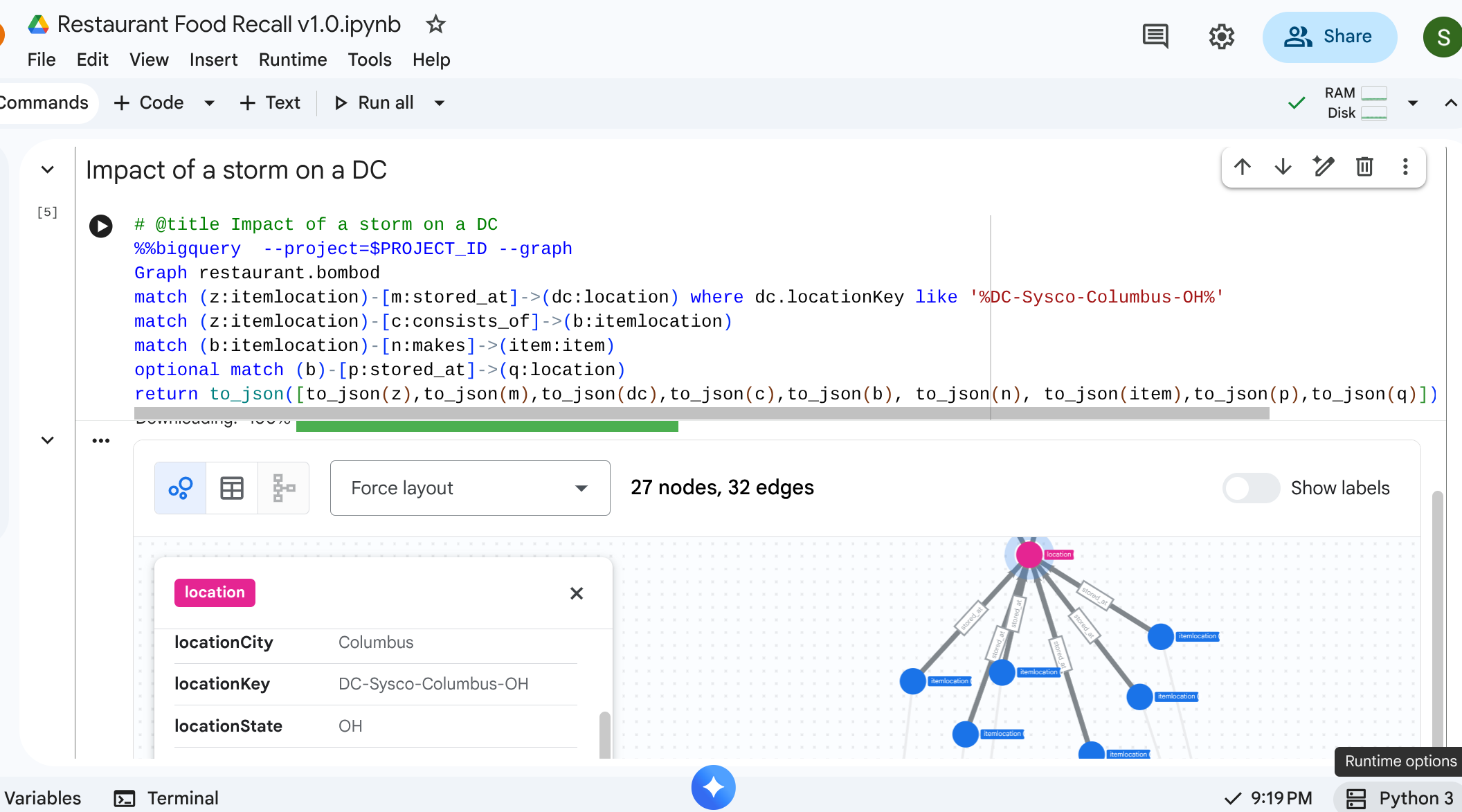
9. Exemple d'utilisation 3 : Rappel en aval
Scénario : Un fournisseur vous informe d'un lot spécifique de produits contaminés : tomates mûries sur pied provenant du fournisseur. Vous devez trouver tous les éléments de menu finaux concernés dans les cafés.
Requête de balayage
Vous recherchez l'emplacement de la matière première contaminée, puis effectuez un balayage de chemin en aval pour trouver les articles finaux concernés.
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
Cette requête localise tous les éléments qui correspondent au modèle "Tomate" et qui sont liés à la relation en amont, ce qui en fait un mappage puissant qui se propage pour découvrir quels éléments de café doivent être rappelés.
Résultat : 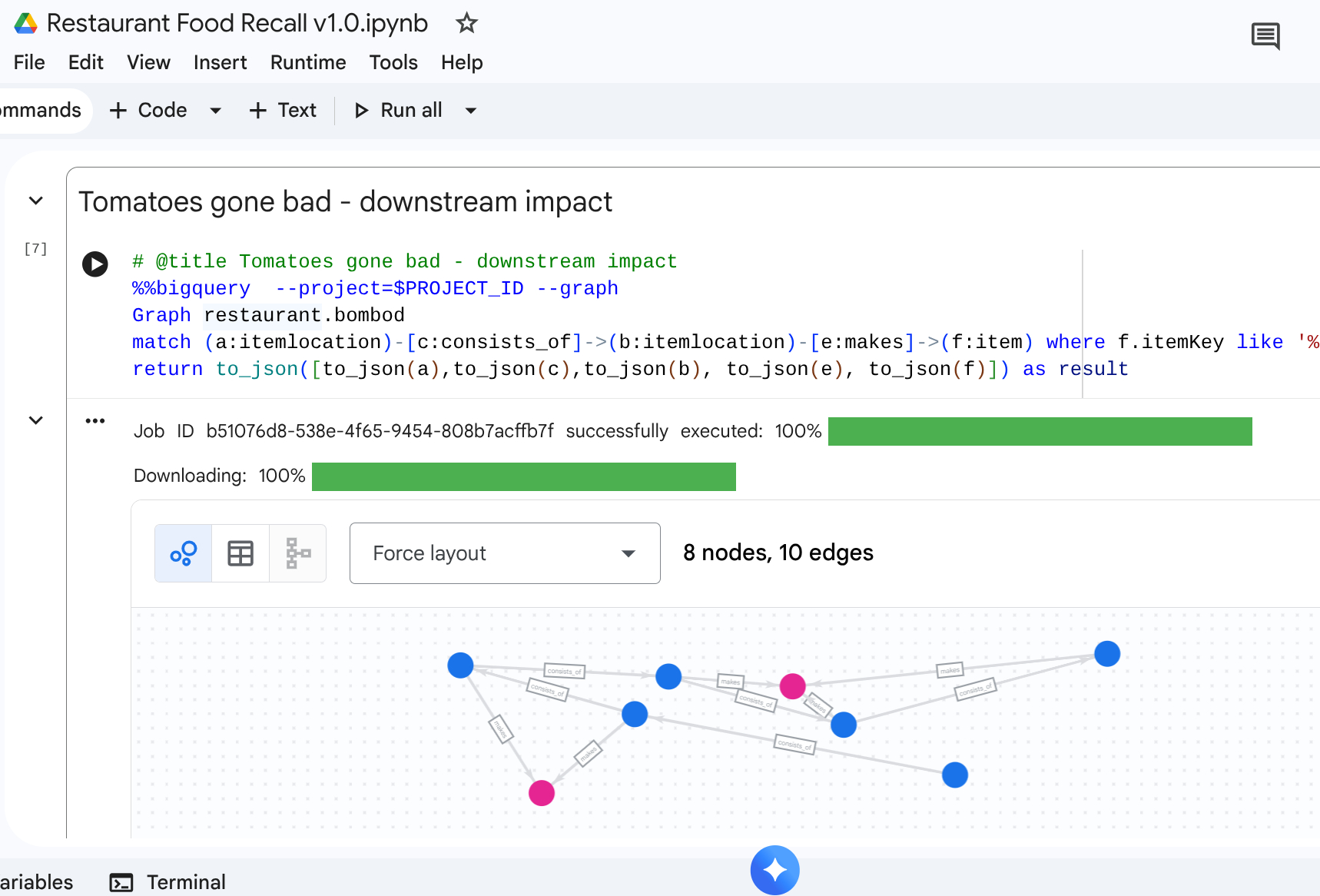
10. Effectuer un nettoyage
Supprimez les ressources une fois les étapes de la procédure pas à pas terminées pour éviter des frais résiduels dans votre espace de travail.
DROP SCHEMA `restaurant` CASCADE;
11. Conclusion
Félicitations ! Vous avez modélisé une chaîne d'approvisionnement et effectué une analyse d'impact à l'aide de BigQuery Graph.
Conclusion
Vous savez désormais :
- Déclarer des relations relationnelles axées sur les graphes avec des clés primaires/étrangères
- Créer un graphe de propriétés unifié
- Naviguer efficacement dans les relations à plusieurs nœuds à l'aide de la logique de balayage des requêtes de graphe
Pour en savoir plus sur l'architecture des graphes, consultez la documentation Google Cloud.