
1. Einführung
In diesem Codelab erfahren Sie, wie Sie BigQuery Graph nutzen können, um komplexe Probleme in der Lieferkette und Logistik zu lösen.
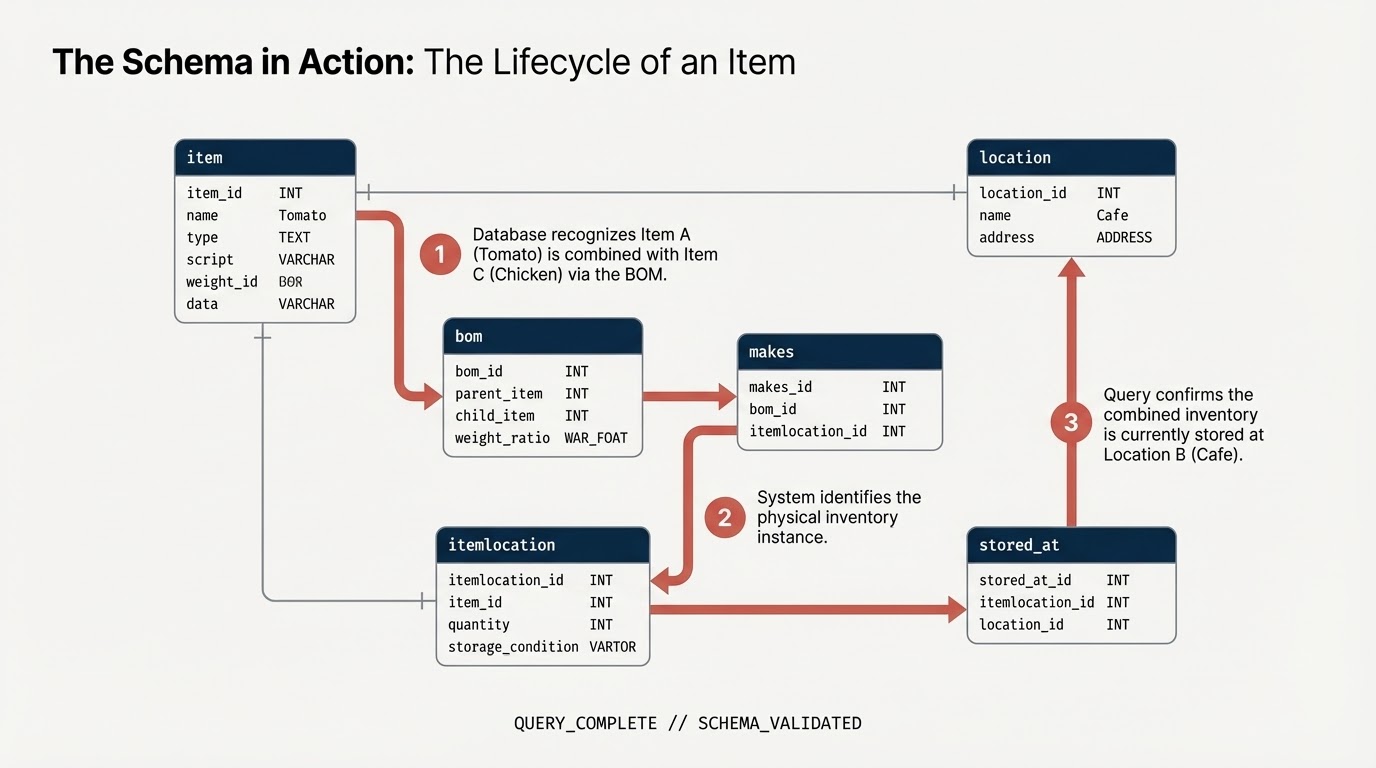
Sie modellieren ein Lieferkettennetzwerk für ein Restaurant mit Schwerpunkt auf Lebensmittelsicherheit und Qualitätskontrolle. Wenn ein Problem mit der Lebensmittelsicherheit auftritt, z. B. eine kontaminierte Zutat von einem Lieferanten, ist Zeit ein entscheidender Faktor. Wenn Sie den „Blast Radius“ ermitteln und einen chirurgischen Rückruf schnell ausführen, können Sie Kosten sparen und Kunden schützen.

Für herkömmliche relationale Modelle sind komplexe, mehrstufige JOIN-Vorgänge erforderlich, um Artikel durch mehrere Phasen zu verfolgen (Lieferant –> Verteilzentrum –> Großküche –> Geschäft –> Fertigartikel). Mit BigQuery Graph modellieren wir diese Verbindungen direkt, was intuitive und schnelle Abfragen mit dem ISO-Standard GQL (Graph Query Language) ermöglicht.
Lerninhalte
- So definieren Sie ein Diagrammmodell auf Grundlage vorhandener BigQuery-Tabellen.
- Property Graph in BigQuery erstellen.
- Informationen zum Ausführen von Traversierungsabfragen, um vorgelagerte und nachgelagerte Auswirkungen zu ermitteln.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion
- Google Cloud Shell.
Kostenschätzung
Die Kosten für dieses Lab sollten weniger als 5$ an BigQuery-Analysegebühren betragen und damit deutlich unter den Zuweisungen der kostenlosen Stufe für neue Nutzer liegen.
2. Einrichtung und Anforderungen
Cloud Shell öffnen
Die meiste Arbeit erledigen Sie in Cloud Shell, einer Umgebung, die alles enthält, was Sie für die Verwendung von Google Cloud benötigen.
- Rufen Sie die Google Cloud Console auf.
- Klicken Sie in der Symbolleiste rechts oben auf das Symbol Cloud Shell aktivieren.
- Klicken Sie auf Weiter, wenn Sie dazu aufgefordert werden.
Umgebungsvariablen einrichten
Legen Sie in Cloud Shell Ihre Projekt-ID fest, um zukünftige Befehle zu vereinfachen.
export PROJECT_ID=$(gcloud config get-value project)
BigQuery API aktivieren
Die BigQuery API muss aktiviert sein. Sie ist in der Regel standardmäßig aktiviert.
gcloud services enable bigquery.googleapis.com
3. Schema und Tabellen erstellen
Sie erstellen ein Dataset und Tabellen, die die Komponenten Ihrer Lieferkette darstellen:
item: Die allgemeine Artikeldefinition (z.B. „Tomate“, „Hähnchen“).location: Einrichtungen (Lieferanten, Verteilzentren, Cafés).itemlocation: Die Schnittmengentabelle, die Inventarstandorte darstellt.bom: Materialliste (definiert Gewichtsbeziehungen, z.B. Artikel A gehört zu Artikel B).makes: Ordnetitemlocationderitemzu.stored_at: Mapsitemlocationtolocation.
Dataset erstellen
Sie können die SQL-Befehle in diesem Lab entweder mit Cloud Shell oder mit der BigQuery Console ausführen.
So verwenden Sie die BigQuery-Konsole:
- Öffnen Sie die BigQuery Console in einem neuen Tab.
- Fügen Sie jedes SQL-Snippet aus diesem Lab in den Editor ein und klicken Sie dann auf die Schaltfläche Ausführen, um es auszuführen.
Führen Sie den folgenden Befehl in Cloud Shell aus oder verwenden Sie die BigQuery-Konsole, um das Schema zu erstellen. Sie verwenden Knotenvariablen in Ihrem SQL-Code.
Hinweis: (1) Wenn Sie diesen Code in Google Colab ausführen möchten, können Sie auch die BigQuery-Magic-Befehle verwenden: %%bigquery. Mit dem folgenden Snippet wird das Restaurantschema in Ihrem Projekt erstellt, in dem Ihre Grafdaten gespeichert werden. (2) Wenn Sie Google Colab verwenden, müssen Sie %%bigquery –project <PROJECT_ID> verwenden. Achten Sie darauf, dass das Feld PROJECT_ID dem entsprechenden Projekt zugeordnet ist, das Sie verwenden möchten: PROJECT_ID = "argolis-project-340214" # @param {"type":"string"} (3) Wenn Sie Colab verwenden, müssen Sie je nach Bedarf einige Bibliotheken installieren. Wenn Sie die Graphvisualisierung verwenden möchten, müssen Sie die Bibliothek mit pip installieren: spanner-graph-notebook==1.1.5
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
Tabellen erstellen
Führen Sie den folgenden SQL-Code aus, um die Tabellen zu erstellen.
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
4. Beispieldaten werden geladen
Damit dieses Lab in sich abgeschlossen ist, füllen Sie die Tabellen mit Beispieldaten mithilfe von reinen SQL-LOAD DATA-Anweisungen. Dies stellt ein Netzwerk dar, das mit einem Lieferanten beginnt, über ein Verteilzentrum und eine Großküche verläuft und in einem Einzelhandels-Café endet.
Führen Sie die folgenden SQL-Abfragen aus, um die Daten zu laden:

Hinweis: Sie können %%bigquery weglassen, wenn Sie die Abfrage direkt in BigQuery Studio ausführen.
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
5. Einschränkungen hinzufügen und Diagramm definieren
Bevor Sie den Graphen erstellen, deklarieren Sie die semantischen Beziehungen mit Standard-SQL-Einschränkungen für Primär- und Fremdschlüssel. Sie helfen BigQuery, Knoten-IDs zu verstehen und Edge-Tabellen mit Knotentabellen zu verbinden.
Attributgrafik erstellen
Nun werden diese Tabellen in einer einzigen zusammenhängenden Diagrammstruktur namens restaurant.bombod zusammengeführt.
Sie definieren:
- Knoten:
item,location,itemlocation - Kanten:
makes,stored_atundconsists_of(BOM)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
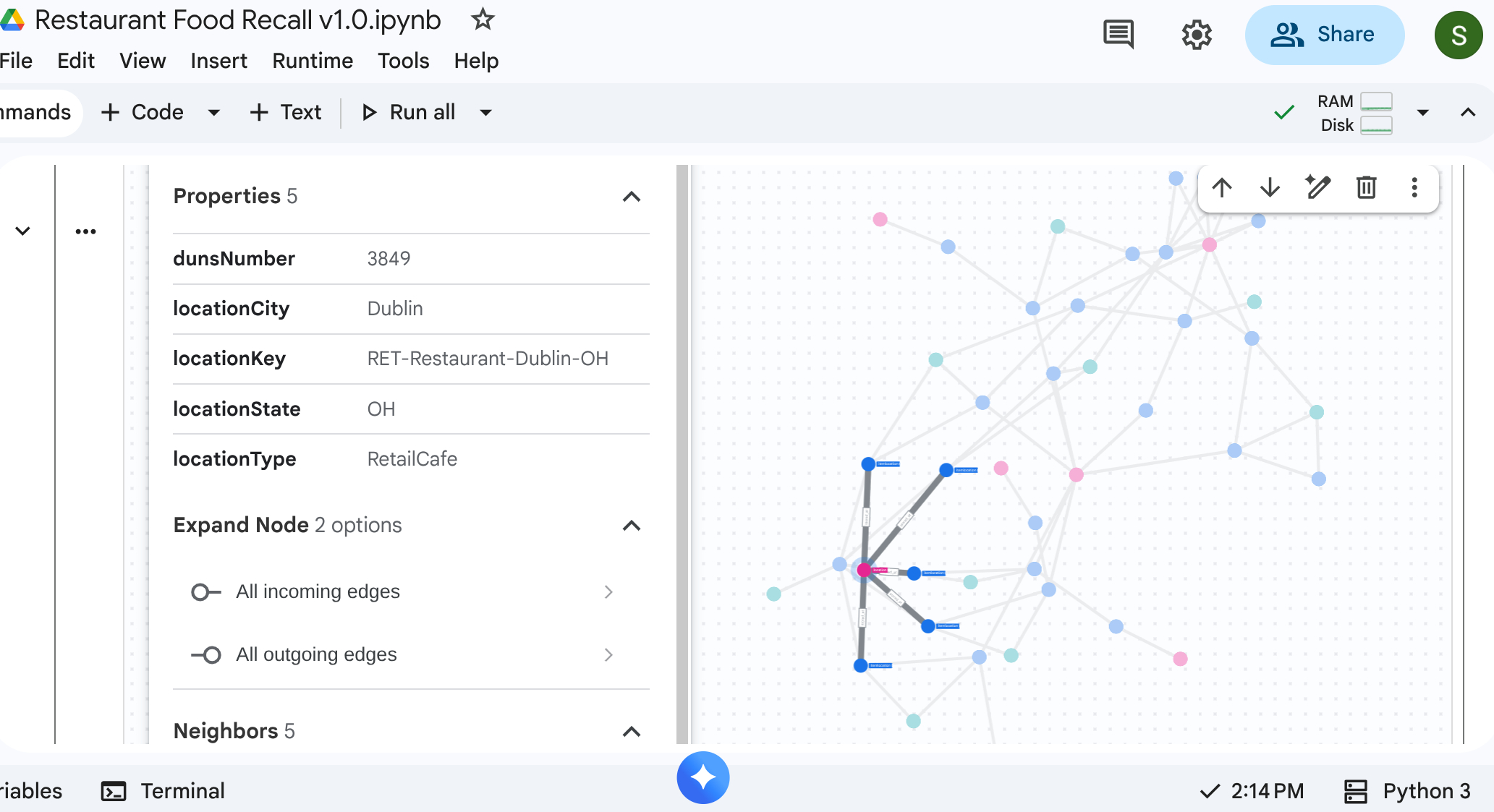
6. Lieferkette visualisieren
Sie können eine Top-down-Traversierungsabfrage ausführen, um das gesamte Lieferkettennetzwerk zu sehen. In einem Standard-Notebook oder einer Benutzeroberfläche, die dies unterstützt (z. B. %%bigquery --graph), wird eine visuelle Karte zurückgegeben.
Verwenden Sie absolute Diagrammabfragen, um Knoten und Kanten einzurichten.
Hinweis: Wie bereits erwähnt, können Sie für die Ausführung in Google Colab- oder Colab Enterprise-Notebooks auch die BigQuery-Magic-Befehle verwenden: %%bigquery. Wenn Sie das Diagramm in Google Colab- oder Colab Enterprise-Notebooks visualisieren möchten, fügen Sie das Flag „–graph“ ein: %%bigquery –graph.
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
Ausgabe:
7. Anwendungsfall 1: Beschwerde nachverfolgen
Szenario: Ein Kunde beschwert sich über die Qualität des Hähnchens in seinem Sandwich in der Filiale in Berlin. Sie müssen das fertige Produkt rückwärts verfolgen, um die unmittelbaren Montageschritte zu sehen.
Traversal-Abfrage
Führen Sie die Abfrage im Graph Traversal-Abfrageformat aus. Hier werden die consists_of-Kanten betrachtet, die Baugruppen downstream bis hin zu den Upstream-Bestandteilen verknüpfen.
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
Aufgrund der Pfeilrichtung in der consists_of-Edge-Tabelle (Ingredient -> Finished) werden bei einer Suche in Richtung Upstream schnell Links zu abhängigen Materialien und Speicherorten angezeigt.
Ausgabe: 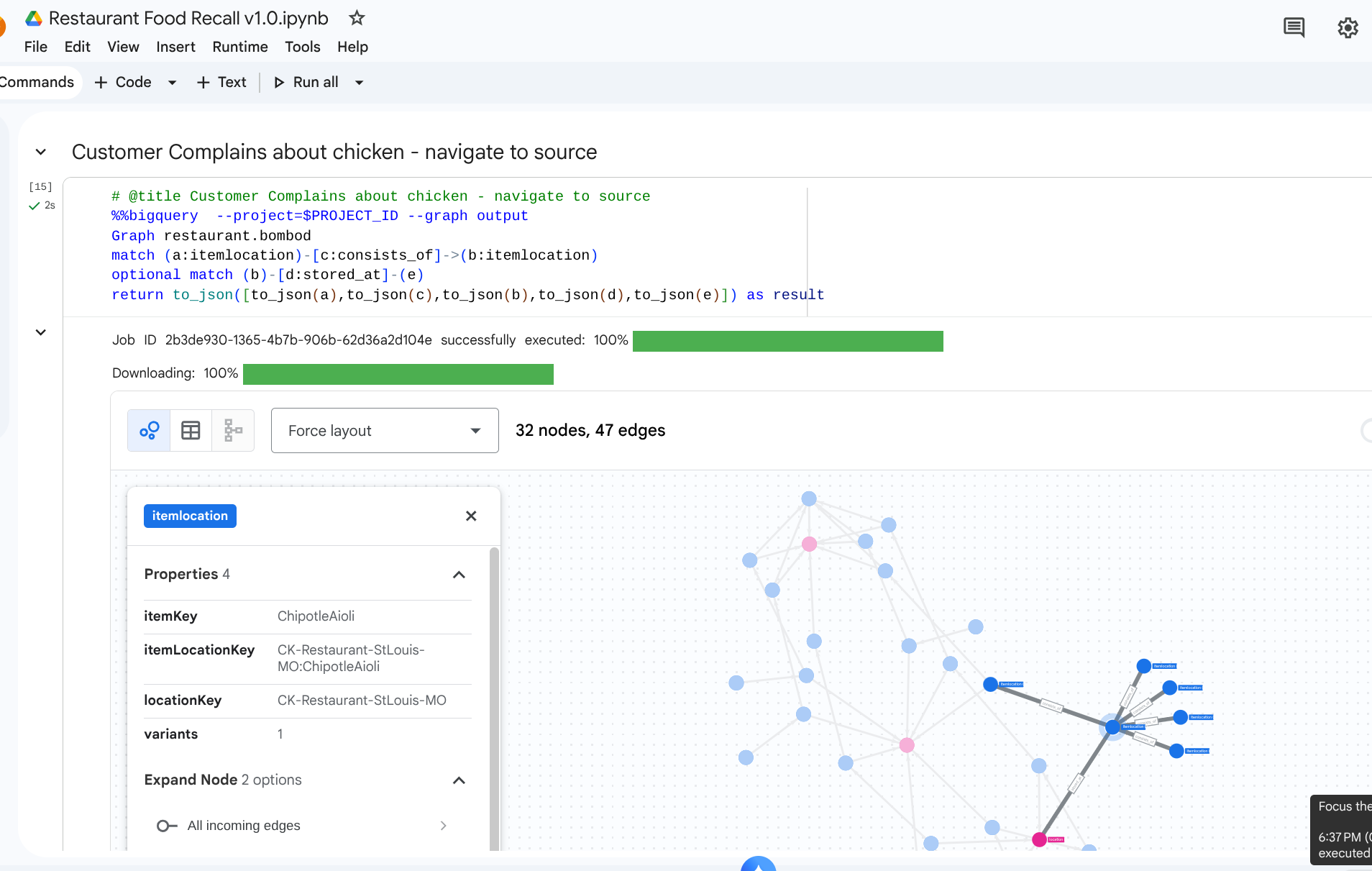
8. Anwendungsfall 2: Wirkungsanalyse
Szenario: Ein Schneesturm hat das Verteilzentrum in Columbus, OH, geschlossen. Sie müssen wissen, welche nachgelagerten Vorbereitungen oder fertigen Artikel sofort betroffen sind.
Traversal-Abfrage
Sie beginnen mit dem spezifischen location, das das Verteilzentrum darstellt, ermitteln den dort gelagerten Bestand und sehen, für welche fertigen Artikel er benötigt wird.
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
Ausgabe: 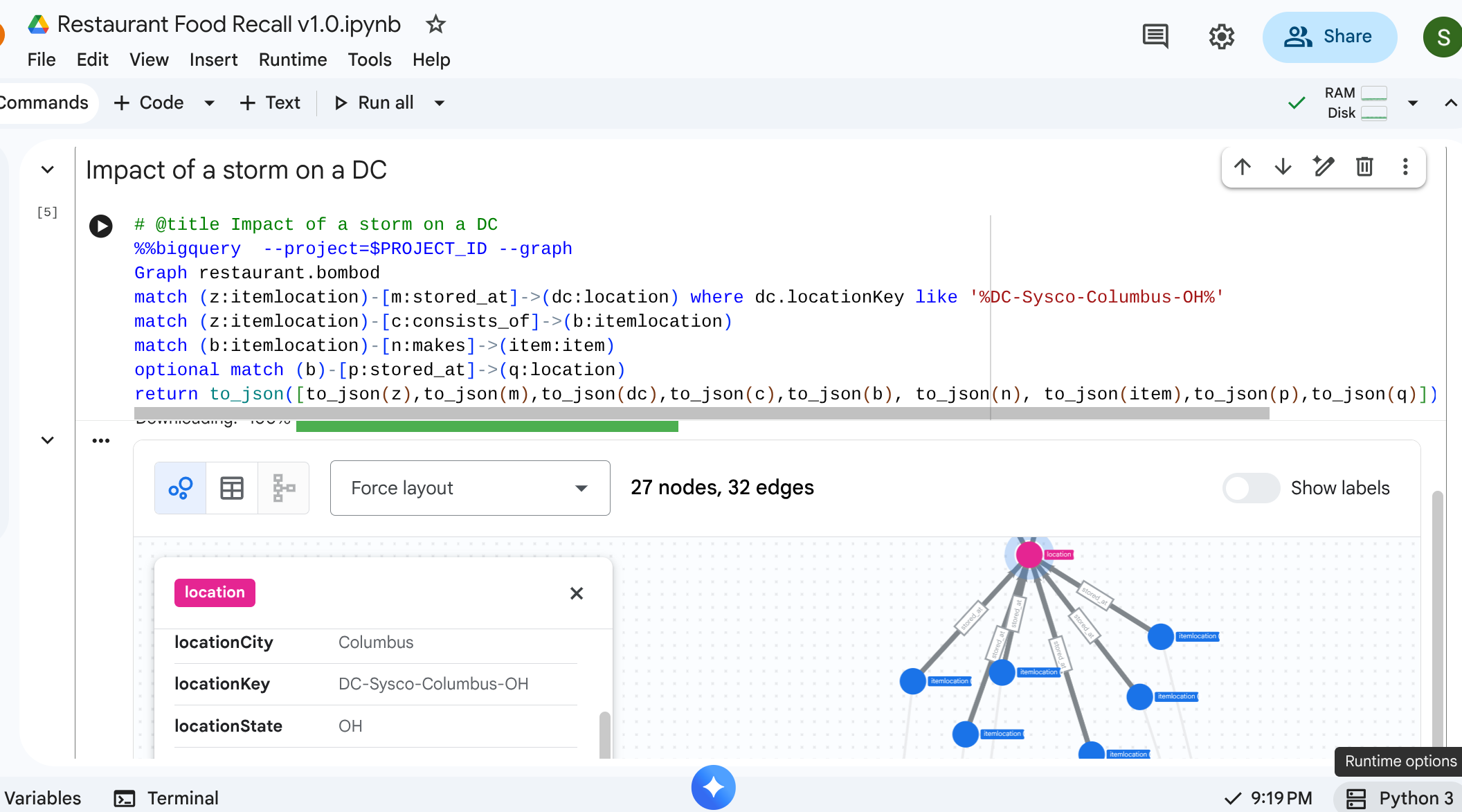
9. Anwendungsfall 3: Rückruf nachgelagerter Produkte
Szenario: Ein Lieferant benachrichtigt Sie über eine bestimmte Charge kontaminierter Produkte: Tomaten, am Strauch gereift vom Lieferanten. Sie müssen alle betroffenen endgültigen Menüpunkte in den Cafés finden.
Traversal-Abfrage
Sie suchen nach dem Ort des kontaminierten Rohmaterials und führen dann eine Path Traversal in Richtung nachgelagerter Prozesse durch, um die letztendlich betroffenen Elemente zu finden.
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
Mit dieser Abfrage werden alle Artikel gefunden, die dem Muster „Tomato“ entsprechen und mit der Upstream-Beziehung verknüpft sind. So lässt sich ermitteln, welche Café-Artikel zurückgerufen werden müssen.
Ausgabe: 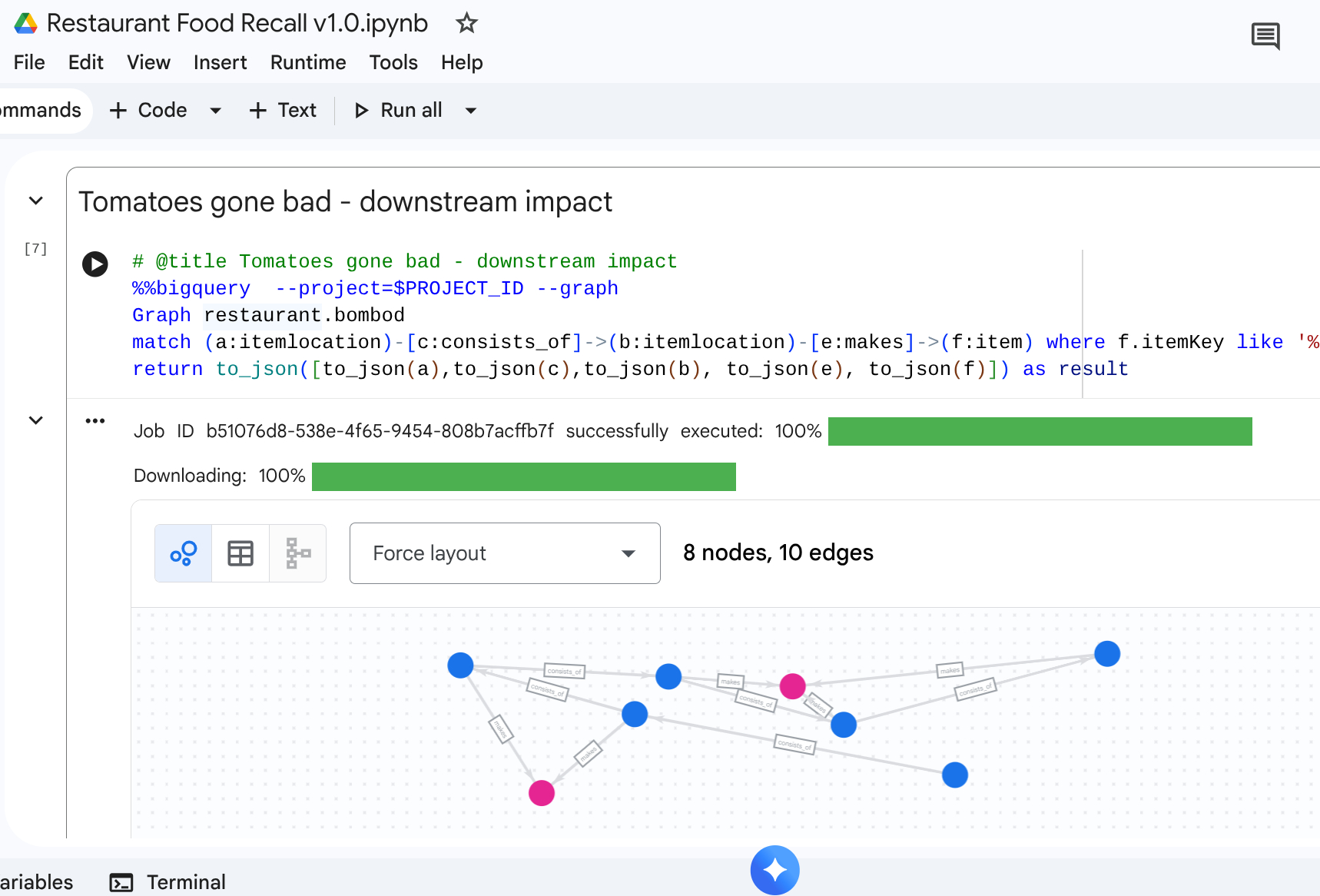
10. Bereinigen
Löschen Sie Ressourcen, sobald Sie die Schritte der Anleitung abgeschlossen haben, um Restkosten in Ihrem Arbeitsbereich zu vermeiden.
DROP SCHEMA `restaurant` CASCADE;
11. Fazit
Glückwunsch! Sie haben eine Lieferkette modelliert und eine Wirkungsanalyse mit BigQuery Graph durchgeführt.
Zusammenfassung
Sie haben Folgendes gelernt:
- Deklarieren Sie graphzentrierte relationale Beziehungen mit Primär- und Fremdschlüsseln.
- Erstellen Sie einen einheitlichen Property Graph.
- Beziehungen zwischen mehreren Knoten effizient mithilfe der Graph Query-Traversierungslogik durchlaufen.
Weitere Informationen zur Diagrammarchitektur finden Sie in der Google Cloud-Dokumentation.