
1. はじめに
この Codelab では、BigQuery Graph を活用して、複雑なサプライ チェーンとロジスティクスの問題を解決する方法について学習します。
食品の安全性と品質管理に重点を置いて、レストランのサプライ チェーン ネットワークをモデル化します。サプライヤーから汚染された食材が届いたなど、食品の安全性に関する問題が発生した場合、迅速な対応が不可欠です。「影響範囲」を特定し、迅速にリコールを実施することで、コストを削減し、顧客を保護できます。

従来のリレーショナル モデルでは、複数の段階(サプライヤー -> DC -> コミサリー -> 店舗 -> 完成品)でアイテムを追跡するために、複雑な複数ステップの JOIN オペレーションが必要です。BigQuery Graph では、これらの接続を直接モデル化し、ISO GQL(Graph Query Language)標準を使用して直感的かつ高速なクエリを実行できます。
学習内容
- 既存の BigQuery テーブルの上にグラフモデルを定義する方法。
- BigQuery 内にプロパティ グラフを作成する方法。
- トラバース クエリを実行して、アップストリームとダウンストリームの影響を追跡する方法。
必要なもの
- 課金が有効な Google Cloud プロジェクトが用意されていること。
- Google Cloud Shell。
費用の見積もり
このラボでは、BigQuery の分析費用が 5 ドル 未満になると予想されます。これは、新規ユーザー向けの無料枠の範囲内です。
2. 設定と要件
Cloud Shell を開く
作業のほとんどは、Google Cloud の使用に必要なものがすべて揃ったロード済み環境である Cloud Shell で行います。
- Google Cloud コンソール に移動します。
- 右上のツールバーにある [Cloud Shell をアクティブにする] アイコンをクリックします。
- メッセージが表示されたら、[続行] をクリックします。
環境変数を設定する
Cloud Shell でプロジェクト ID を設定して、以降のコマンドを簡素化します。
export PROJECT_ID=$(gcloud config get-value project)
BigQuery API を有効化
BigQuery API が有効になっていることを確認します。通常はデフォルトで有効になっていますが、安全のために確認することをおすすめします。
gcloud services enable bigquery.googleapis.com
3. スキーマとテーブルを作成する
サプライ チェーン コンポーネントを表すデータセットとテーブルを作成します。
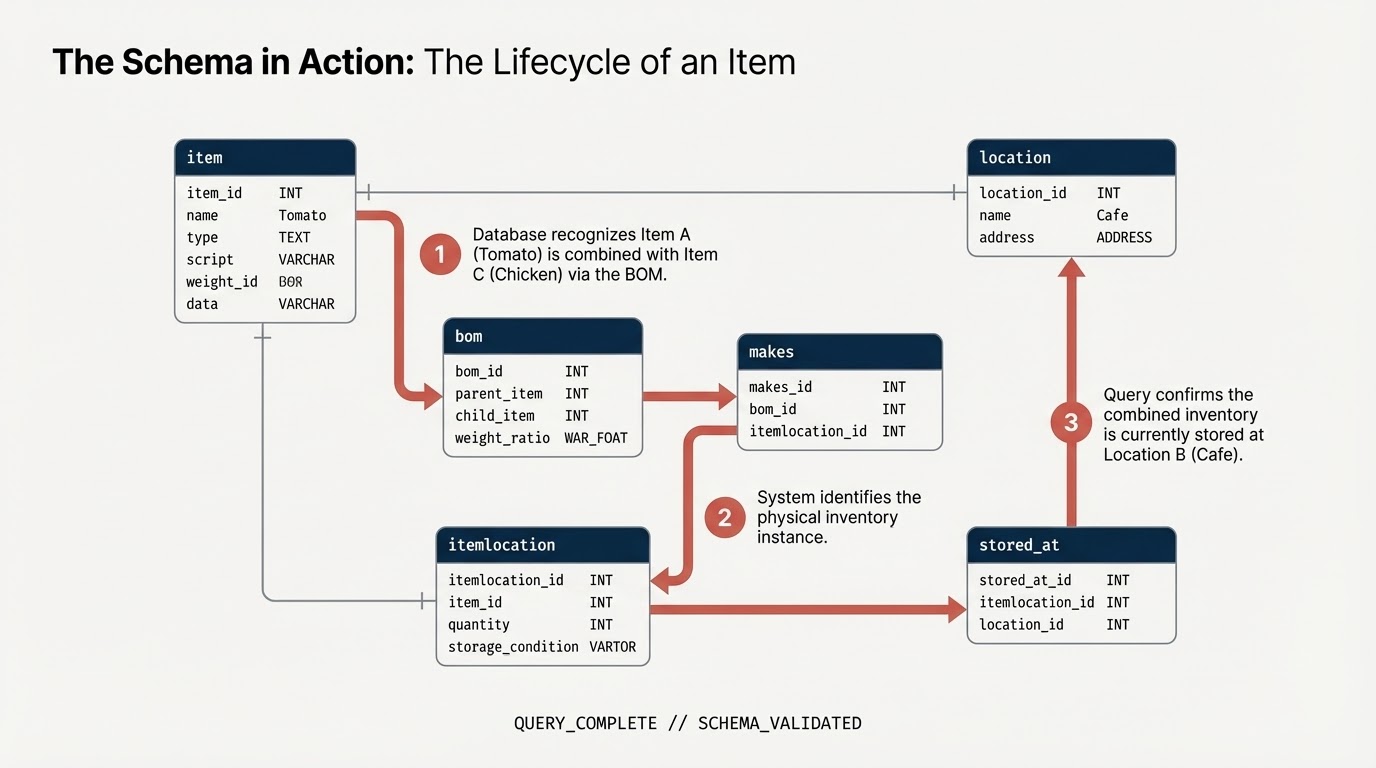
item: 汎用アイテムの定義(トマト、鶏肉など)。location: 施設(サプライヤー、配送センター、カフェ)。itemlocation: インベントリの場所を表す交差テーブル。bom: 部品構成表(重量関係を定義します。例: アイテム A がアイテム B に入る)。makes:itemlocationをitemにマッピングします。stored_at:itemlocationをlocationにマッピングします。
データセットの作成
このラボの SQL コマンドは、Cloud Shell または BigQuery コンソール を使用して実行できます。
BigQuery コンソールを使用するには:
- 新しいタブで BigQuery コンソール を開きます。
- このラボの各 SQL スニペットをエディタに貼り付け、[実行] ボタンをクリックして実行します。
Cloud Shell で次のコマンドを実行するか、BigQuery コンソールを使用してスキーマを作成します。SQL でノード変数を使用します。
注: (1)Google Colab で実行するには、BigQuery マジック コマンド %%bigquery を使用することもできます。次のスニペットは、グラフデータを格納するために、プロジェクト内にレストラン スキーマを作成します。(2)Google Colab から実行する場合は、%%bigquery –project <PROJECT_ID> を使用する必要があります。フィールド PROJECT_ID が、使用するプロジェクトにマッピングされていることを確認します。PROJECT_ID = "argolis-project-340214" # @param {"type":"string"}(3)Colab を使用している場合は、要件に応じてライブラリをインストールする必要があります。グラフの可視化を使用する場合は、ライブラリ spanner-graph-notebook==1.1.5 を pip でインストールしてください。
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
テーブルを作成する
次の SQL コードを実行してテーブルを作成します。
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
4. サンプルデータを読み込む
このラボを完全に自己完結型にするため、純粋な SQL LOAD DATA ステートメントを使用して、テーブルにサンプルデータを入力します。これは、サプライヤー から始まり、配送センター(DC) と コミサリー キッチン を経由して、小売カフェ に到着するネットワークを表します。
次の SQL クエリを実行してデータを読み込みます。

注: BigQuery Studio で直接実行する場合は、%%bigquery を省略できます。
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
5. 制約を追加してグラフを定義する
グラフを構築する前に、標準 SQL 主キーと外部キーの制約を使用してセマンティック関係を宣言します。これにより、BigQuery はノード識別子を理解し、エッジテーブルをノードテーブルに接続できます。
プロパティ グラフを作成する
次に、これらのテーブルを restaurant.bombod という単一のまとまりのあるグラフ構造に統合します。
次のように定義します。
- ノード:
item、location、itemlocation - エッジ:
makes、stored_at、consists_of(BOM)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
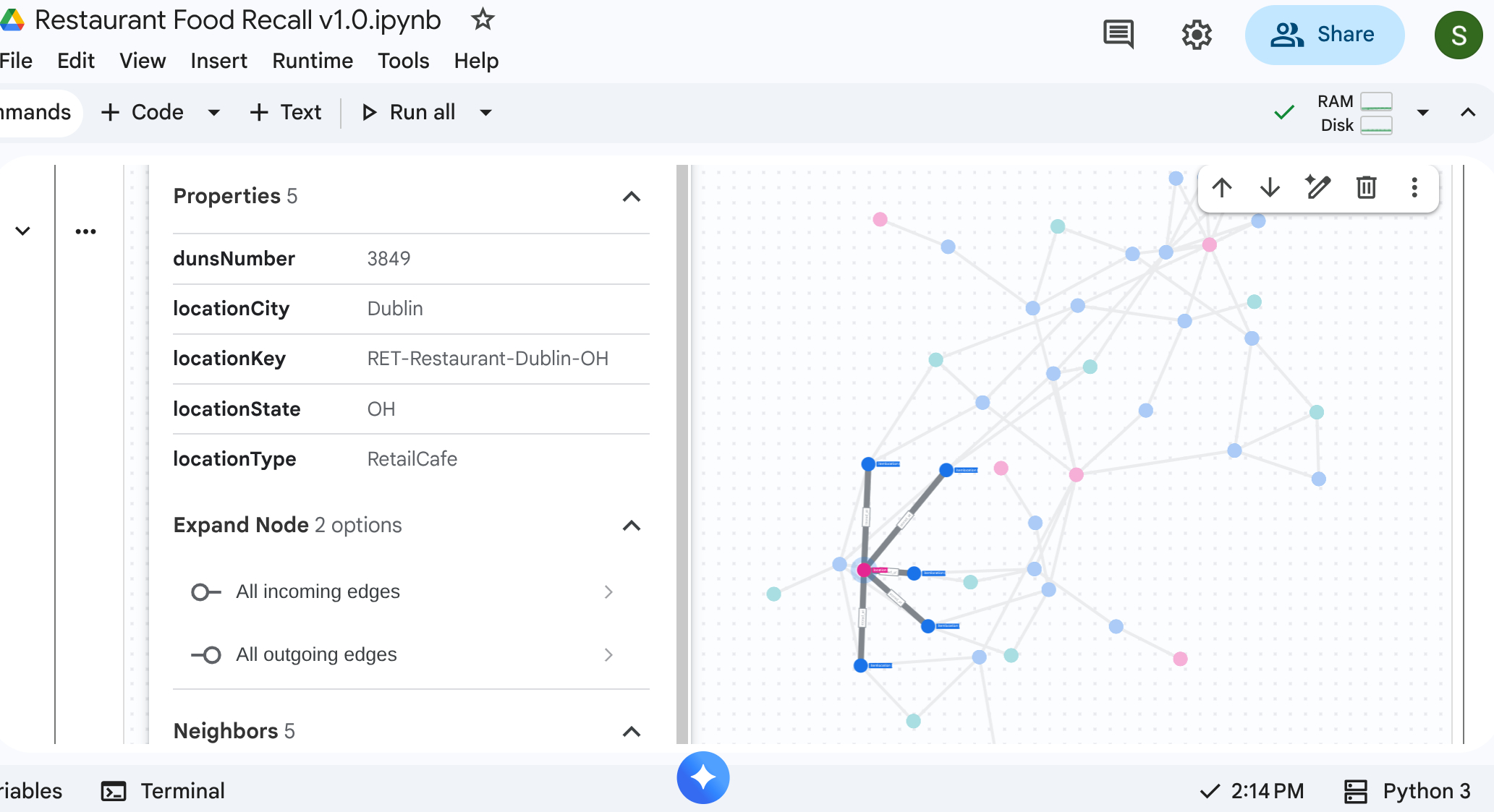
6. サプライ チェーンを可視化する
トップダウン トラバース クエリを実行して、サプライ チェーン ネットワーク全体を確認できます。標準のノートブックまたはサポートする UI(%%bigquery --graph など)では、ビジュアル マップが返されます。
絶対グラフクエリを使用して、ノードとエッジを設定します。
注: 前述のように、Google Colab または Colab Enterprise ノートブックで実行するには、BigQuery マジック コマンド %%bigquery を使用することもできます。また、Google Colab または Colab Enterprise ノートブックでグラフを可視化するには、%%bigquery –graph のように –graph フラグを含めます。
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
出力:
7. ユースケース 1: アップストリームの苦情を追跡する
シナリオ: ニューヨークの店舗で、サンドイッチの鶏肉の品質についてお客様から苦情がありました。完成品を逆方向に追跡して、直前の組み立て段階を確認する必要があります。
走査クエリ
グラフ トラバーサル クエリ形式を使用してクエリを実行します。これにより、ダウンストリームのアセンブリからアップストリームの食材に関連する consists_of エッジが確認されます。
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
consists_of エッジテーブル(Ingredient -> Finished)の矢印の方向により、アップストリームに流れる検索では、依存する材料と保管場所を迅速に特定するリンクが生成されます。
出力: 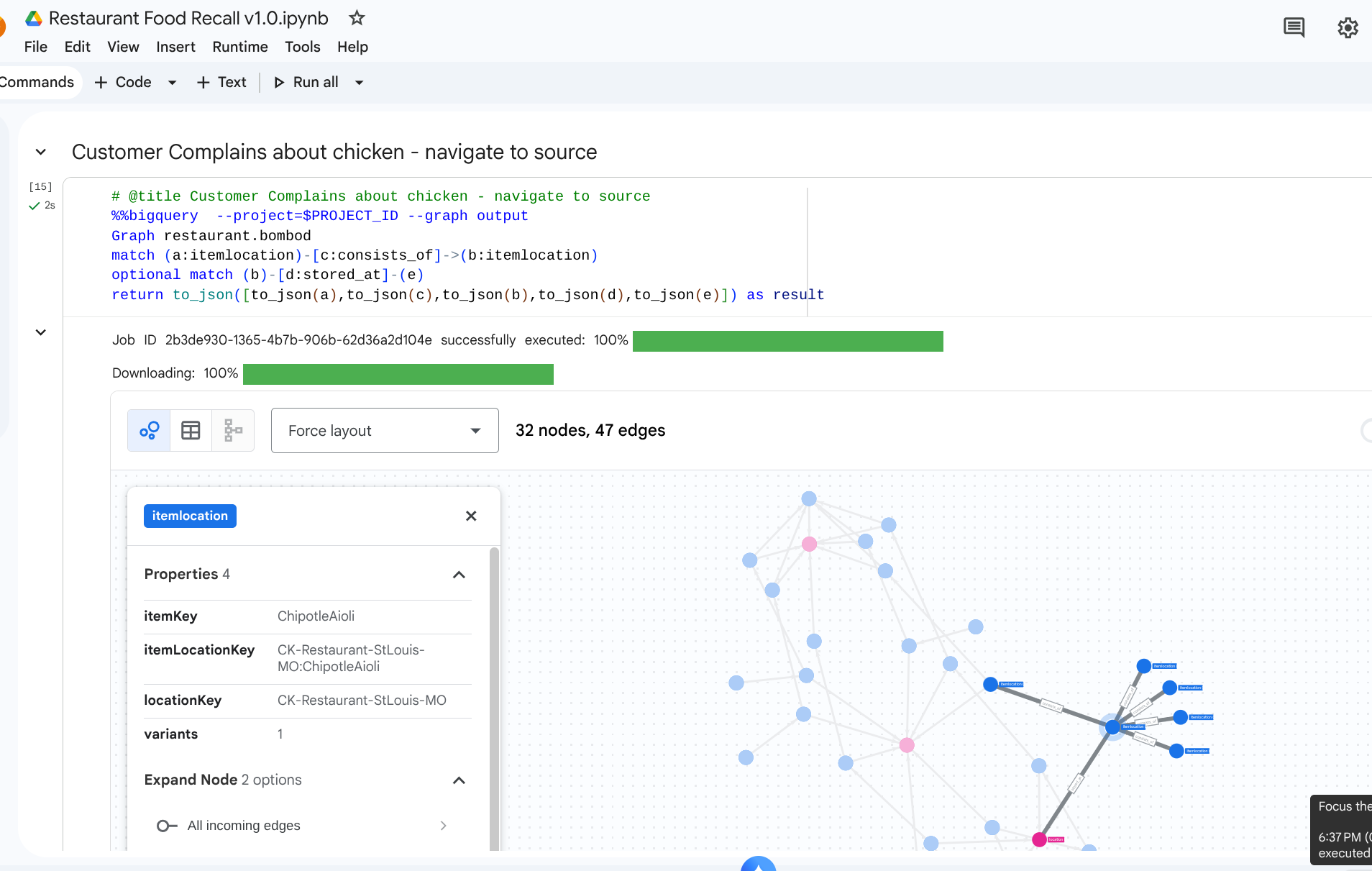
8. ユースケース 2: インパクト分析
シナリオ: オハイオ州コロンバスの配送センターが吹雪で閉鎖されました。ダウンストリームの準備や完成品にすぐに影響があるかどうかを確認する必要があります。
走査クエリ
配送センターを表す特定の location から開始し、そこに保管されているインベントリを特定して、どの完成品が必要かを確認します。
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
出力: 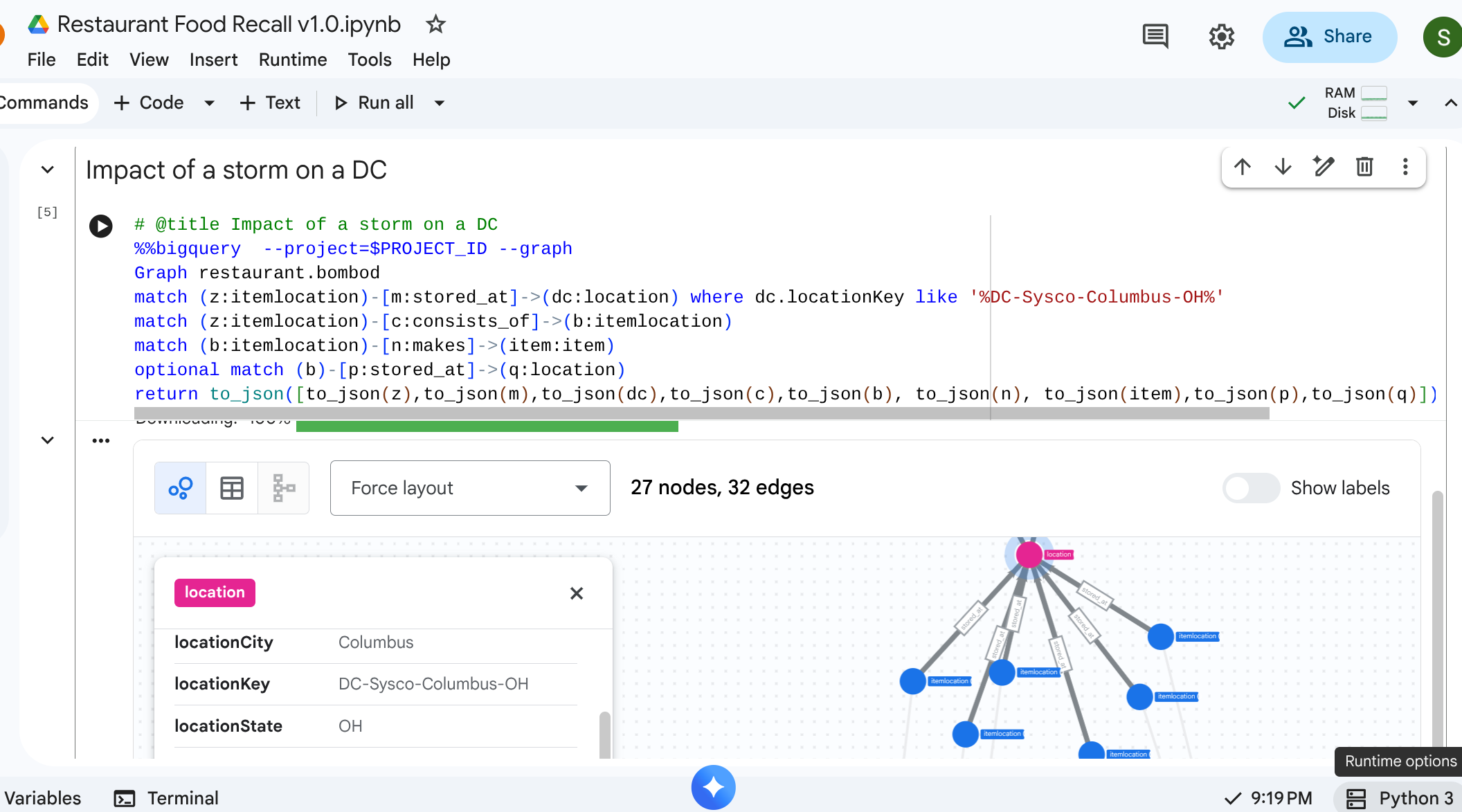
9. ユースケース 3: ダウンストリームのリコール
シナリオ : サプライヤーから、汚染された特定のバッチの商品(サプライヤーからの完熟トマト )について通知がありました。カフェで影響を受ける最終メニュー項目をすべて見つける必要があります。
走査クエリ
汚染された原材料の場所を探し、ダウンストリームに流れるパス トラバーサルを実行して、最終的に影響を受けるアイテムを見つけます。
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
このクエリは、「トマト」とパターン マッチングするすべてのアイテムを特定し、アップストリームの関係と絡み合っているため、どのカフェ アイテムをリコールする必要があるかを検出する強力なマッピングになります。
出力: 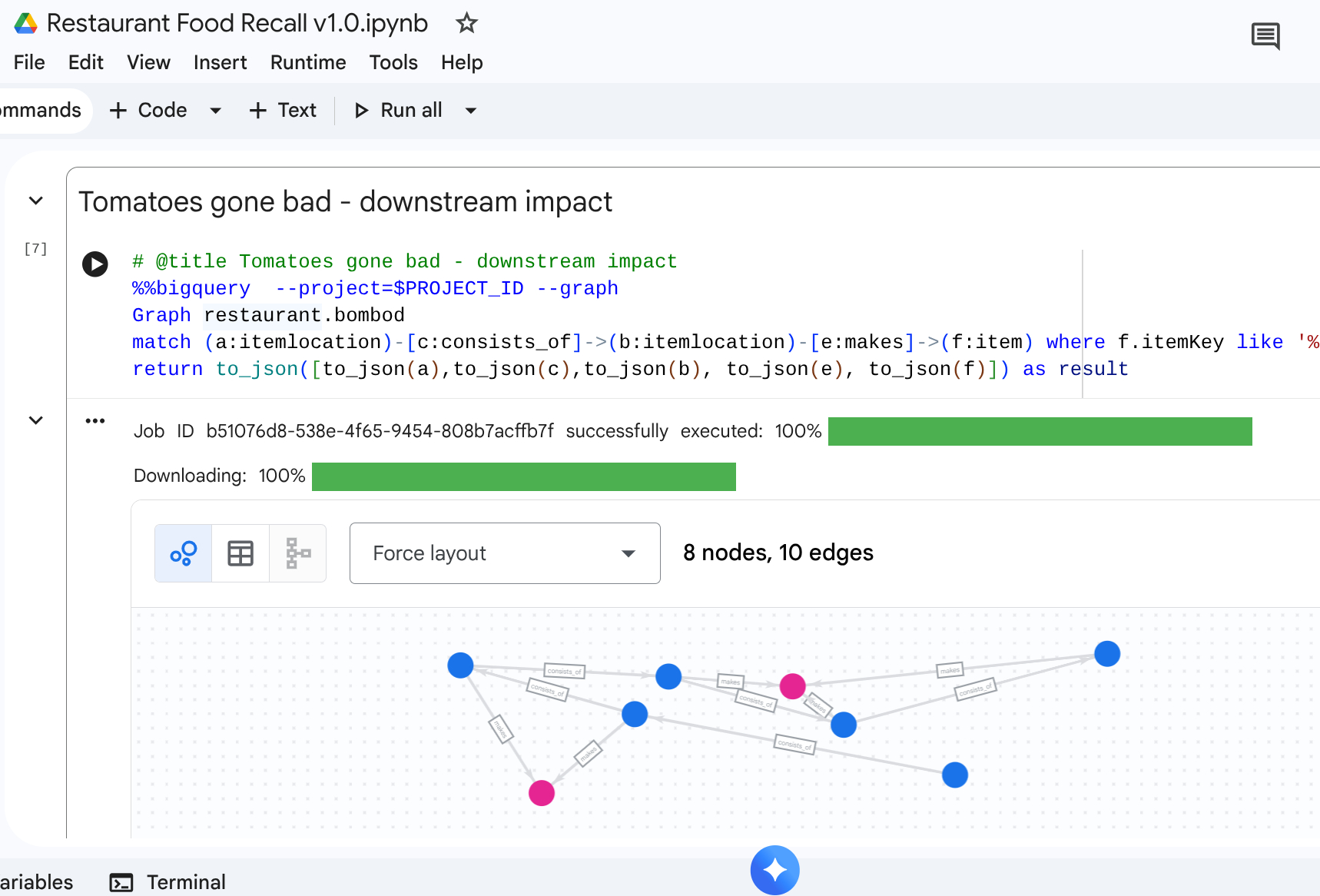
10. クリーンアップ
チュートリアルの手順を完了したら、ワークスペースに残留する料金が発生しないように、リソースを削除します。
DROP SCHEMA `restaurant` CASCADE;
11. まとめ
おめでとうございます!BigQuery Graph を使用してサプライ チェーンをモデル化し、影響分析を実行しました。
まとめ
学習内容:
- 主キーと外部キーを使用して、グラフ中心のリレーショナル関係を宣言する。
- 統合されたプロパティ グラフ を作成する。
- グラフクエリ トラバース ロジックを使用して、マルチノード関係を効率的にナビゲートする。
グラフ アーキテクチャの詳細については、Google Cloud のドキュメントをご覧ください。