
1. Wprowadzenie
W tym module dowiesz się, jak wykorzystać BigQuery Graph do rozwiązywania złożonych problemów związanych z łańcuchem dostaw i logistyką.
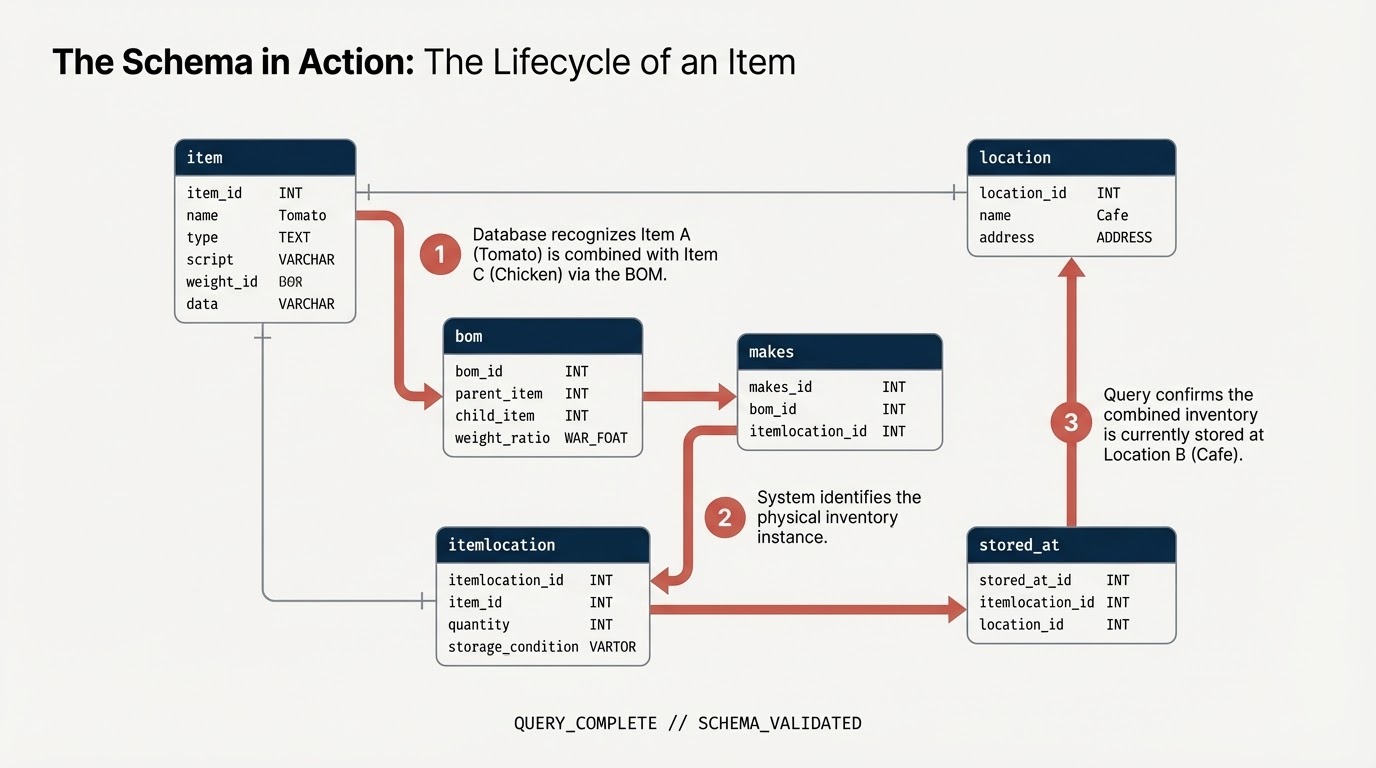
Zaprojektujesz sieć łańcucha dostaw restauracji, koncentrując się na bezpieczeństwie żywności i kontroli jakości. Gdy pojawia się problem związany z bezpieczeństwem żywności, np. skażony składnik od dostawcy, czas ma kluczowe znaczenie. Określenie „strefy rażenia” i szybkie przeprowadzenie precyzyjnego wycofania może przynieść oszczędności i ochronić klientów.

Tradycyjne modele relacyjne wymagają złożonych, wieloetapowych operacji JOIN, aby śledzić produkty na różnych etapach (dostawca –> centrum dystrybucji –> kuchnia –> sklep –> gotowy produkt). W BigQuery Graph modelujemy te połączenia bezpośrednio, co umożliwia intuicyjne i szybkie wykonywanie zapytań za pomocą standardu ISO GQL (Graph Query Language).
Czego się nauczysz
- Jak zdefiniować model wykresu na podstawie istniejących tabel BigQuery.
- Jak utworzyć wykres właściwości w BigQuery.
- Jak uruchamiać zapytania przechodzenia, aby śledzić wpływ na elementy nadrzędne i podrzędne.
Czego potrzebujesz
- projekt Google Cloud z włączonymi płatnościami;
- Google Cloud Shell.
Szacowane koszty
Koszt tego laboratorium w postaci opłat za analizę w BigQuery powinien być niższy niż 5 USD, co mieści się w przydziałach poziomu bezpłatnego dla nowych użytkowników.
2. Konfiguracja i wymagania
Otwieranie Cloud Shell
Większość pracy wykonasz w Cloud Shell, czyli w środowisku zawierającym wszystko, czego potrzebujesz do korzystania z Google Cloud.
- Otwórz konsolę Google Cloud.
- Na pasku narzędzi w prawym górnym rogu kliknij ikonę Aktywuj Cloud Shell.
- W razie potrzeby kliknij Dalej.
Konfigurowanie zmiennych środowiskowych
W Cloud Shell ustaw identyfikator projektu, aby uprościć przyszłe polecenia.
export PROJECT_ID=$(gcloud config get-value project)
Włącz API BigQuery
Sprawdź, czy masz włączony interfejs BigQuery API. Zwykle jest domyślnie włączona, ale warto się upewnić.
gcloud services enable bigquery.googleapis.com
3. Tworzenie schematu i tabel
Utworzysz zbiór danych i tabele reprezentujące komponenty łańcucha dostaw:
item: ogólna definicja produktu (np. pomidor, kurczak).location: obiekty (dostawcy, centra dystrybucji, kawiarnie);itemlocation: tabela przecięcia reprezentująca lokalizacje asortymentu.bom: Lista materiałów (BoM) (określa relacje wagowe, np. produkt A wchodzi w skład produktu B).makes: Mapujeitemlocationnaitem.stored_at: Mapyitemlocation–location.
Utwórz zbiór danych
Polecenia SQL w tym module możesz uruchamiać w Cloud Shell lub w konsoli BigQuery.
Aby korzystać z konsoli BigQuery:
- Otwórz konsolę BigQuery w nowej karcie.
- Wklej do edytora każdy fragment kodu SQL z tego modułu, a następnie kliknij przycisk Uruchom, aby go wykonać.
Uruchom w Cloud Shell to polecenie lub użyj konsoli BigQuery, aby utworzyć schemat. W SQL będziesz używać zmiennych węzła.
Uwaga: (1) Aby wykonać to w Google Colab, możesz też użyć poleceń magicznych BigQuery: %%bigquery Poniższy fragment kodu tworzy w projekcie schemat restauracji, w którym będą przechowywane dane wykresu. (2) Jeśli korzystasz z Google Colab, musisz użyć polecenia %%bigquery –project <PROJECT_ID>. Sprawdź, czy pole PROJECT_ID jest mapowane na odpowiedni projekt, którego chcesz użyć: PROJECT_ID = "argolis-project-340214" # @param {"type":"string"} (3) Jeśli używasz Colab, w zależności od wymagań musisz zainstalować niektóre biblioteki. Jeśli zamierzasz używać wizualizacji grafu, zainstaluj bibliotekę za pomocą polecenia pip: spanner-graph-notebook==1.1.5
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
Tworzenie tabel
Aby utworzyć tabele, wykonaj ten kod SQL.
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
4. Wczytuję przykładowe dane
Aby ten moduł był w pełni samodzielny, wypełnisz tabele przykładowymi danymi za pomocą instrukcji SQL LOAD DATA. Reprezentuje sieć zaczynającą się od dostawcy, przechodzącą przez centrum dystrybucji i kuchnię, a kończącą się w kawiarni.
Aby wczytać dane, uruchom te zapytania SQL:

Uwaga: możesz pominąć %%bigquery, jeśli uruchamiasz zapytanie bezpośrednio w BigQuery Studio.
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
5. Dodawanie ograniczeń i definiowanie wykresu
Przed utworzeniem wykresu deklarujesz relacje semantyczne za pomocą ograniczeń klucza podstawowego i klucza obcego w standardowej wersji SQL. Pomagają one BigQuery w rozpoznawaniu identyfikatorów węzłów i łączeniu tabel krawędzi z tabelami węzłów.
Tworzenie wykresu właściwości
Teraz połącz te tabele w jedną spójną strukturę wykresu o nazwie restaurant.bombod.
Określasz:
- Węzły:
item,location,itemlocation - Krawędzie:
makes,stored_aticonsists_of(BOM)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
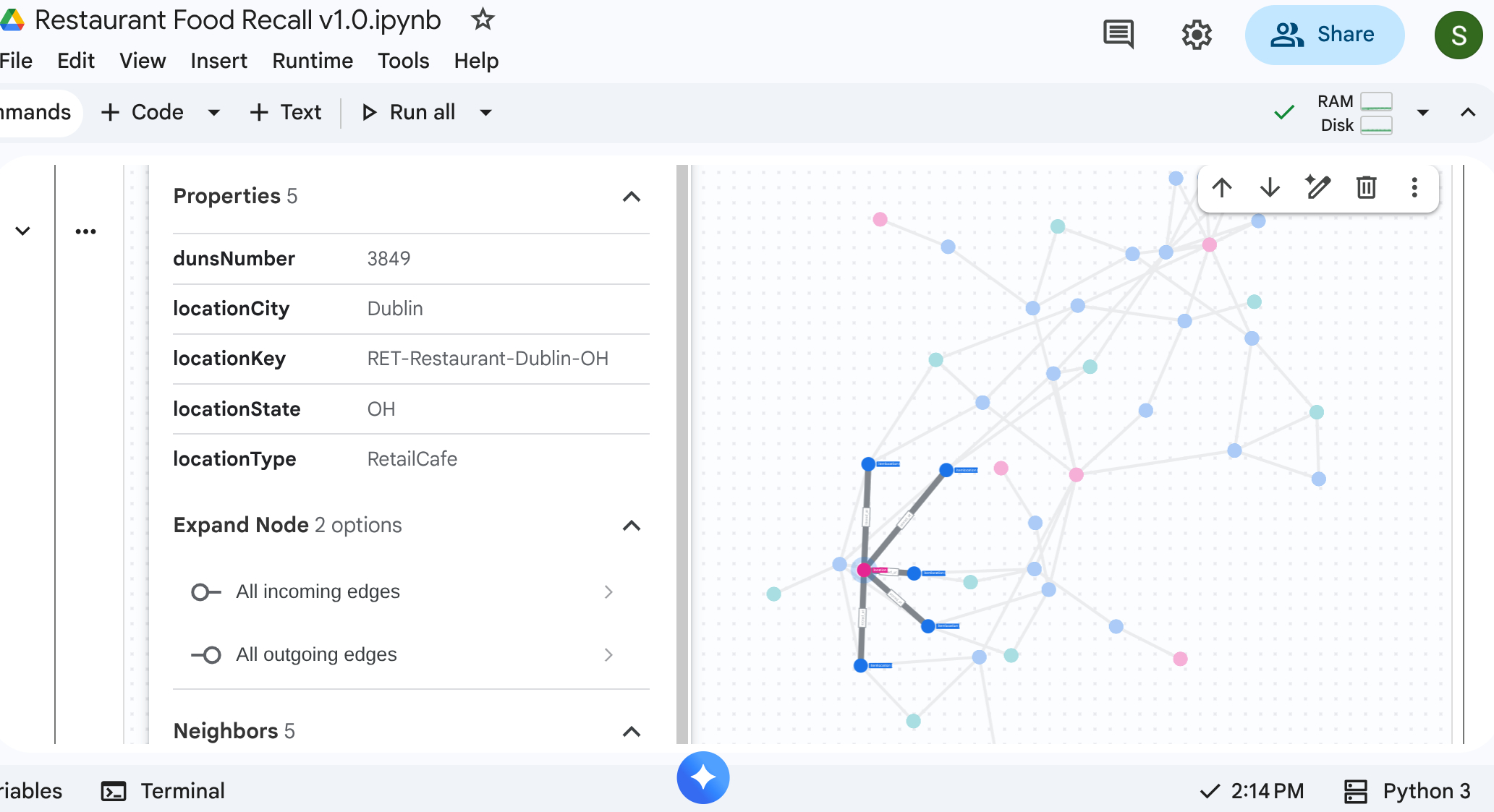
6. Wizualizacja łańcucha dostaw
Możesz uruchomić zapytanie o przechodzenie od góry do dołu, aby zobaczyć całą sieć łańcucha dostaw. W standardowym notatniku lub interfejsie, który to obsługuje (np. %%bigquery --graph), zwraca wizualną mapę.
Użyj zapytań dotyczących wykresu bezwzględnego, aby skonfigurować węzły i krawędzie.
Uwaga: jak wspomnieliśmy wcześniej, aby wykonać to w notatnikach Google Colab lub Colab Enterprise, możesz też użyć poleceń magicznych BigQuery: %%bigquery. Aby wyświetlić wykres w notatnikach Google Colab lub Colab Enterprise, dodaj też flagę –graph: %%bigquery –graph.
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
Dane wyjściowe:
7. Przypadek użycia 1. Śledzenie skargi dotyczącej podmiotu wyższego szczebla
Scenariusz: klient skarży się na jakość kurczaka w kanapce w sklepie w Krakowie. Musisz prześledzić gotowy produkt wstecz, aby zobaczyć jego bezpośrednie etapy montażu.
Zapytanie przechodzące
Uruchom zapytanie w formacie zapytań Graph Traversal. W tym przypadku sprawdzamy krawędzie consists_of, które łączą zespoły z komponentami podrzędnymi i nadrzędnymi.
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
Ze względu na kierunek strzałki w consists_oftabeli krawędziowejIngredient -> Finished wyszukiwanie w górę szybko zwraca linki, które wyodrębniają materiały zależne i lokalizacje przechowywania.
Wyjście: 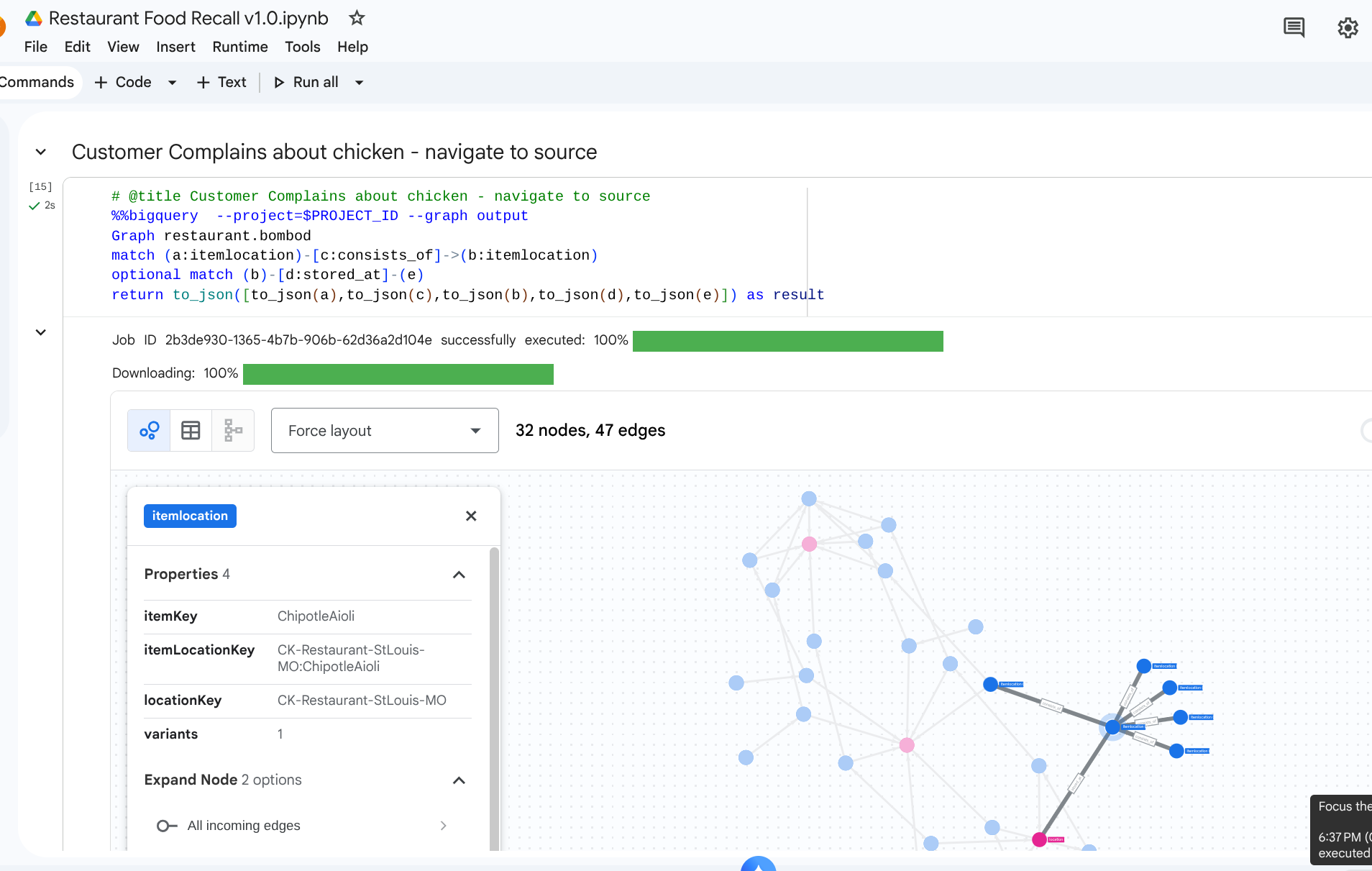
8. Przypadek użycia 2. Analiza wpływu
Scenariusz: burza śnieżna spowodowała zamknięcie centrum dystrybucji w Columbus w stanie Ohio. Musisz wiedzieć, które przygotowania lub gotowe produkty są natychmiast dotknięte tym problemem.
Zapytanie przechodzące
Zaczynasz od konkretnego location reprezentującego centrum dystrybucji, identyfikujesz przechowywane tam zapasy i sprawdzasz, które produkty gotowe ich wymagają.
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
Wyjście: 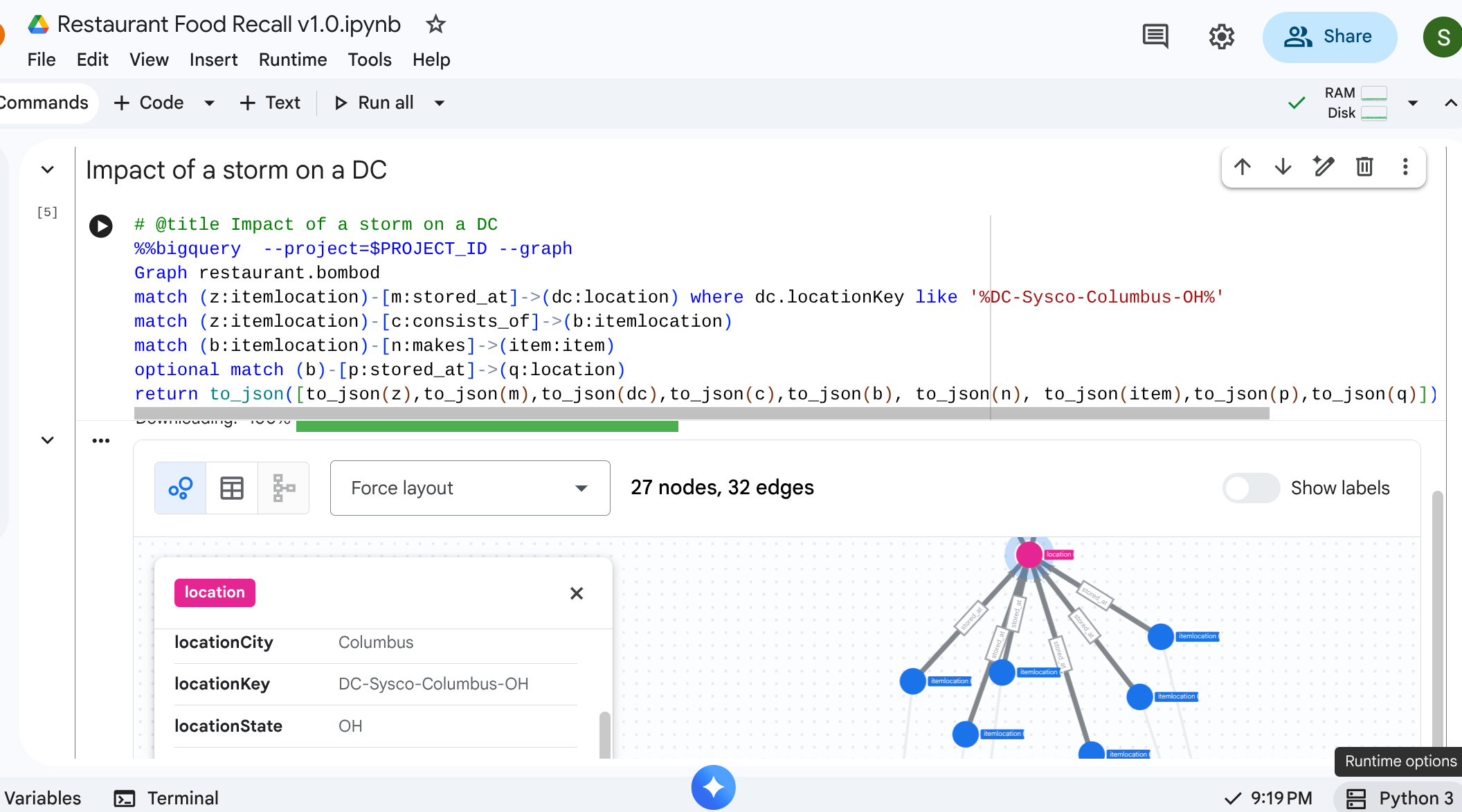
9. Przypadek użycia 3. Wycofanie produktu z rynku
Scenariusz: dostawca powiadamia Cię o konkretnej partii zanieczyszczonego produktu: pomidorów dojrzewających na krzaku. Musisz znaleźć wszystkie produkty z menu, których dotyczy problem, w kawiarniach.
Zapytanie przechodzące
Szukasz lokalizacji skażonego surowca, a następnie wykonujesz [atak typu] path traversal w dół, aby znaleźć ostateczne produkty, na które miało to wpływ.
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
To zapytanie znajduje wszystkie produkty, które pasują do wzorca „Tomato” i są powiązane z relacją nadrzędną, co sprawia, że jest to skuteczne mapowanie, które rozprzestrzenia się, aby wykryć, które produkty w kawiarni muszą zostać wycofane.
Wyjście: 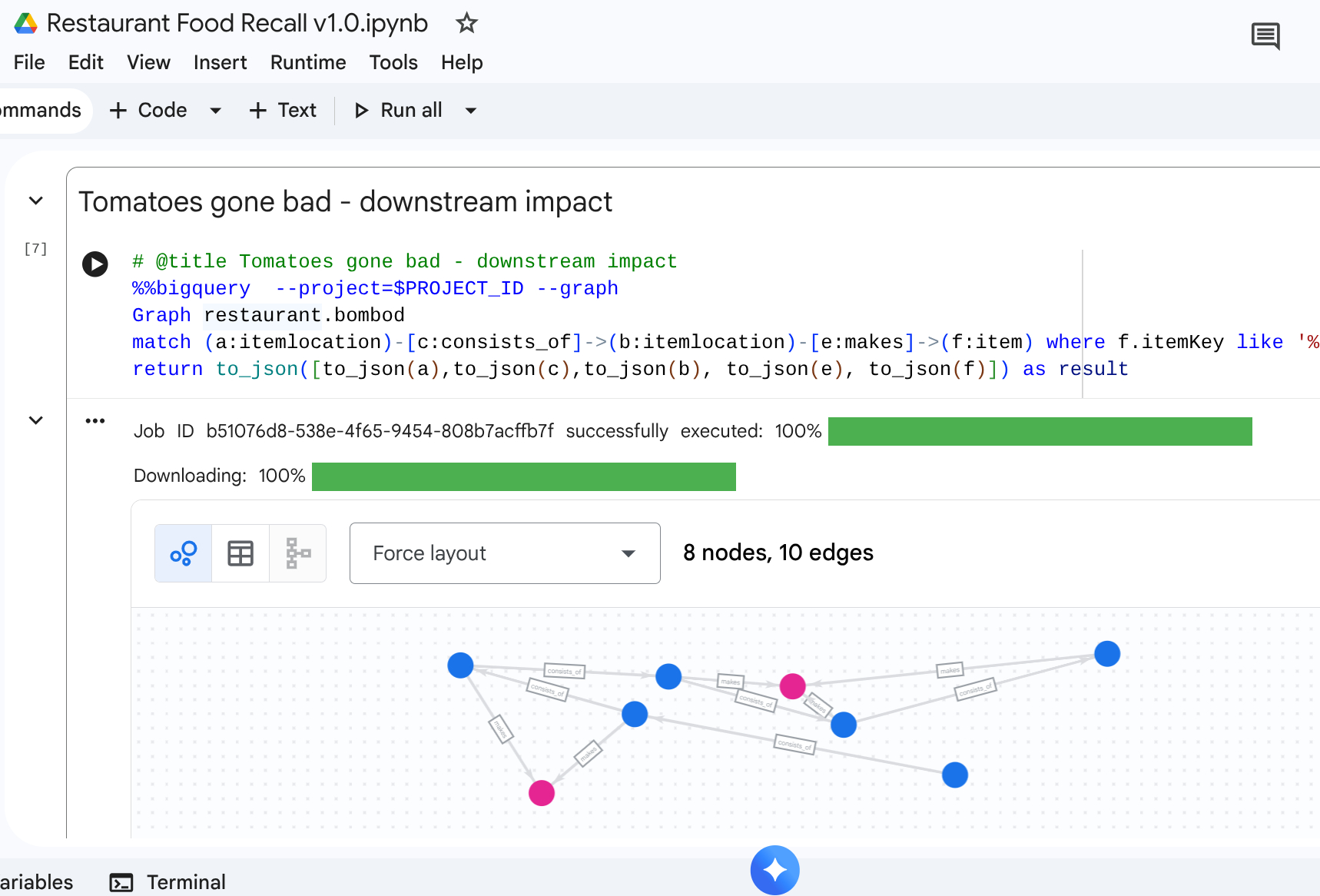
10. Czyszczenie
Po wykonaniu wszystkich kroków przewodnika usuń zasoby, aby uniknąć opłat za nie w obszarze roboczym.
DROP SCHEMA `restaurant` CASCADE;
11. Podsumowanie
Gratulacje! Modelujesz łańcuch dostaw i przeprowadzasz analizę wpływu za pomocą grafu BigQuery.
Podsumowanie
Dowiesz się, jak:
- Deklaruj relacje relacyjne oparte na grafach za pomocą kluczy podstawowych i obcych.
- Utwórz ujednolicony graf usług.
- Skutecznie poruszaj się po relacjach między wieloma węzłami za pomocą logiki przechodzenia zapytań do grafu.
Więcej informacji o architekturze wykresów znajdziesz w dokumentacji Google Cloud.