
1. مقدمة

1. التحدّي
في سيناريوهات الاستجابة للكوارث، يتطلّب تنسيق جهود الناجين الذين يملكون مهارات وموارد مختلفة ولديهم احتياجات متنوعة في مواقع متعددة إمكانات ذكية لإدارة البيانات والبحث. تعلمك ورشة العمل هذه كيفية إنشاء نظام ذكاء اصطناعي جاهز للإنتاج يجمع بين:
- 🗄️ قاعدة بيانات رسومية (Spanner): لتخزين العلاقات المعقّدة بين الناجين والمهارات والموارد
- 🔍 البحث المستند إلى الذكاء الاصطناعي: بحث مختلط دلالي ومستند إلى الكلمات الرئيسية باستخدام التضمينات
- 📸 المعالجة المتعددة الوسائط: استخراج البيانات المنظَّمة من الصور والنصوص والفيديوهات
- 🤖 تنظيم مهام الوكلاء المتعدّدين: تنسيق عمل الوكلاء المتخصّصين لتنفيذ مهام سير عمل معقّدة
- 🧠 الذاكرة الطويلة الأمد: التخصيص باستخدام Vertex AI Memory Bank
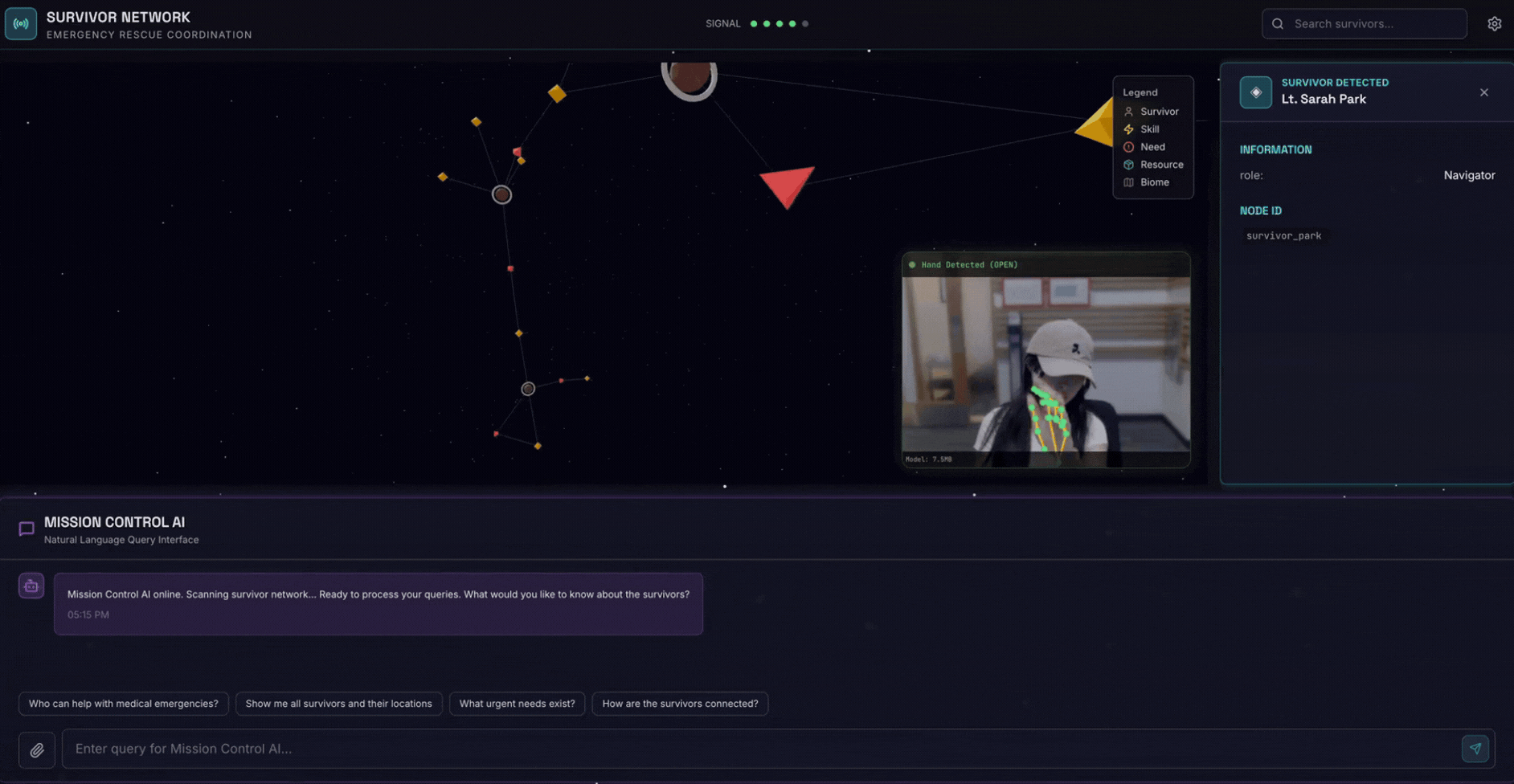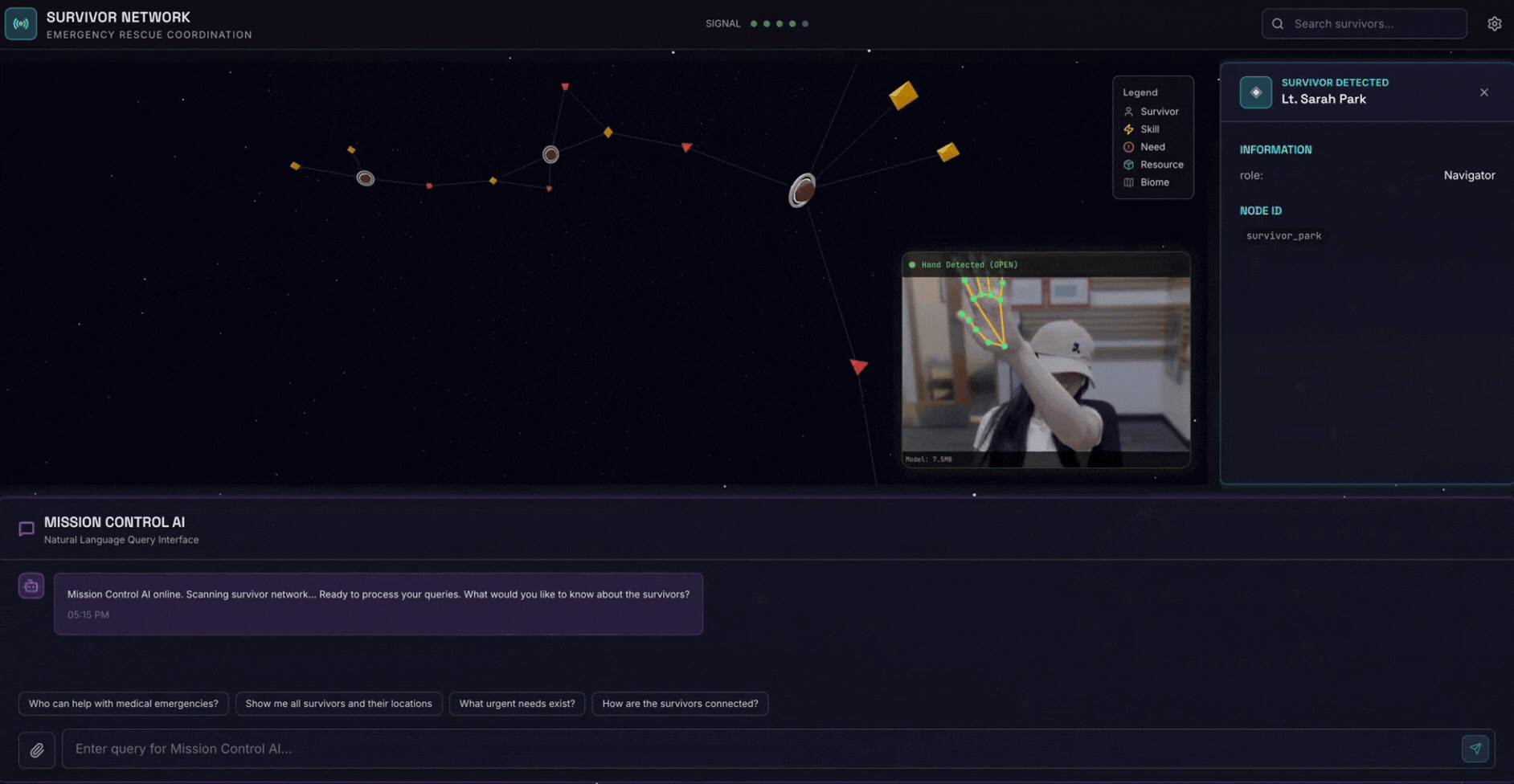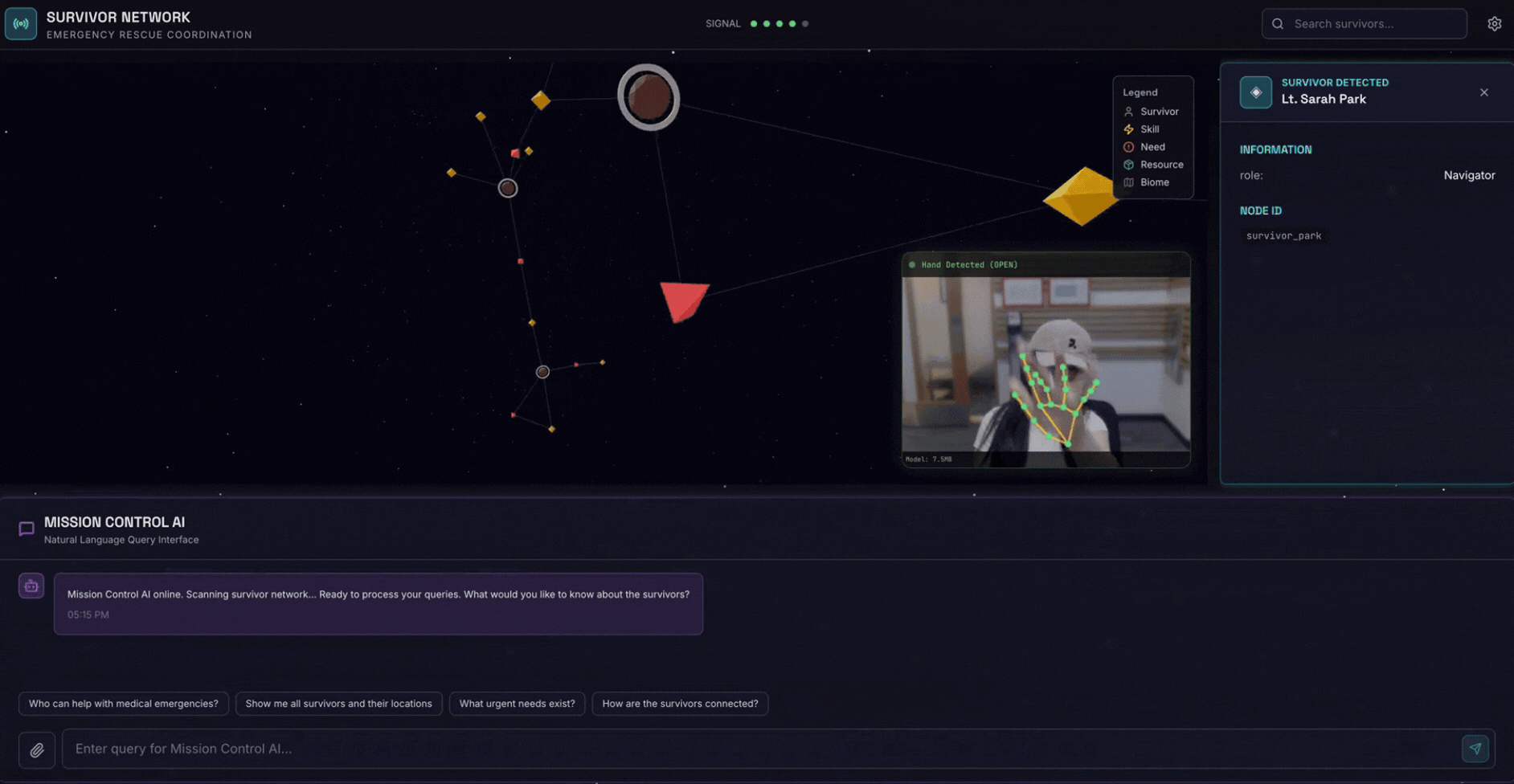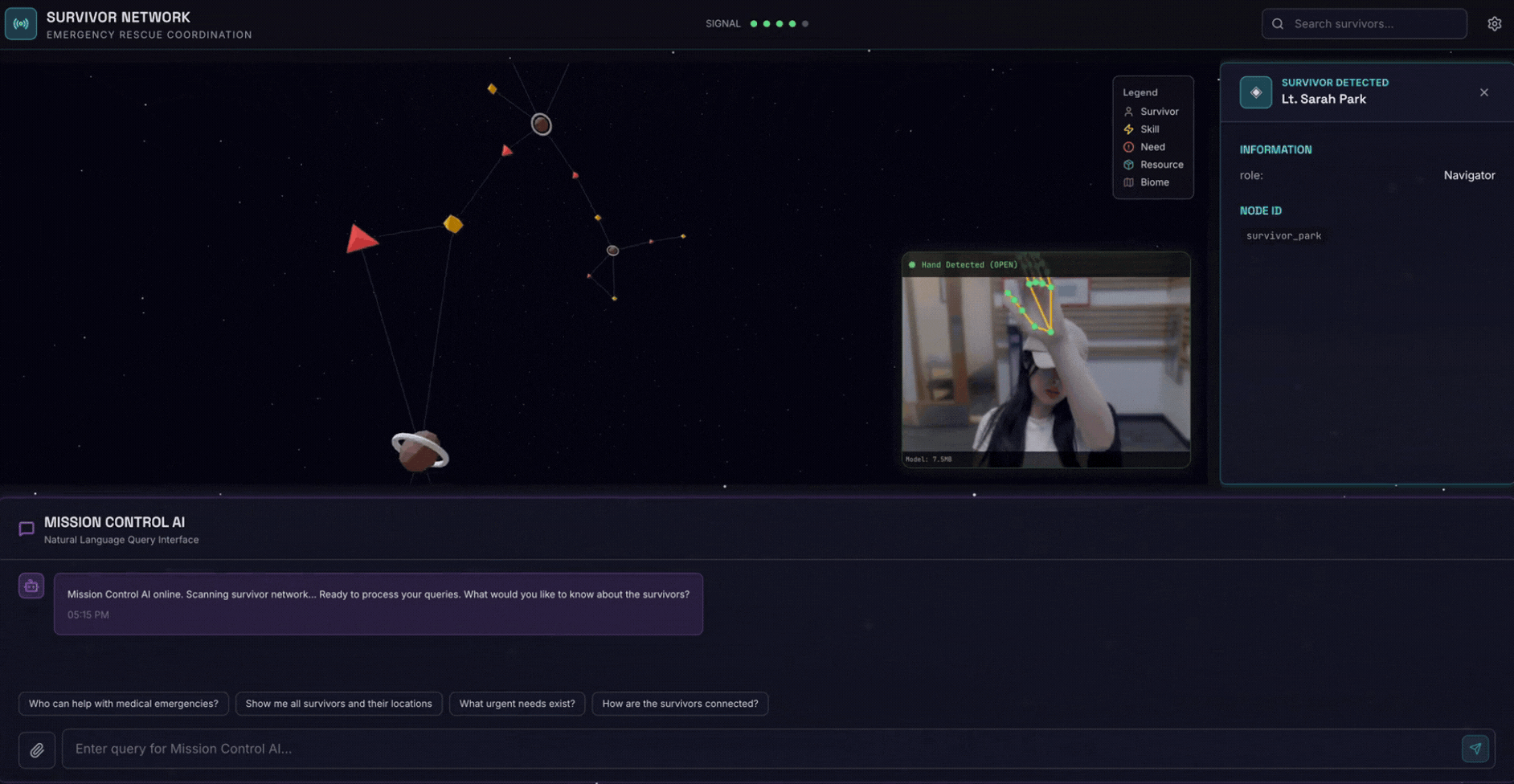
2. ما ستنشئه
قاعدة بيانات رسوم بيانية لشبكة الناجين تتضمّن:
- 🗺️ تصوّر تفاعلي ثلاثي الأبعاد للرسم البياني لعلاقات الناجين
- 🔍 البحث الذكي (الكلمات الرئيسية والدلالي والمختلط)
- 📸 مسار التحميل المتعدد الوسائط (استخراج الكيانات من الصور أو الفيديو)
- 🤖 نظام متعدّد الوكلاء لتنظيم المهام المعقّدة
- 🧠 دمج Memory Bank لتفاعلات مخصّصة
3- التقنيات الأساسية
المكوّن | تكنولوجيا | الغرض |
قاعدة البيانات | Cloud Spanner Graph | تخزين العُقد (الناجون والمهارات) والحواف (العلاقات) |
AI Search | Gemini + Embeddings | الفهم الدلالي + البحث عن التشابه |
Agent Framework | حزمة تطوير الوكلاء (ADK) | تنظيم مهام سير عمل الذكاء الاصطناعي |
الذاكرة | Vertex AI Memory Bank | تخزين الإعدادات المفضّلة للمستخدم على المدى الطويل |
Frontend | React + Three.js | تمثيل بصري تفاعلي ثلاثي الأبعاد للرسوم البيانية |
2. 🛠️ إعداد البيئة (يمكنك تخطّي هذه الخطوة إذا كنت في "ورشة عمل")
الجزء الأول: تفعيل حساب الفوترة
لتشغيل هذا الدرس التطبيقي حول الترميز، يجب أن يكون لديك حساب الفوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. إذا كنت مرتبطًا بحساب فوترة، يمكنك تخطّي هذه الخطوة.
الجزء الثاني: البيئة المفتوحة
- 👉 انقر على هذا الرابط للانتقال مباشرةً إلى محرّر Cloud Shell
- 👉 إذا طُلب منك منح الإذن في أي وقت اليوم، انقر على تفويض للمتابعة.
- 👉 إذا لم تظهر نافذة Terminal في أسفل الشاشة، افتحها باتّباع الخطوات التالية:
- انقر على عرض.
- انقر على Terminal
- 👉💻 في نافذة الوحدة الطرفية، تأكَّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list - 👉💻 استنسِخ مشروع bootstrap من GitHub:
git clone https://github.com/gca-americas/way-back-home.git
الجزء الثالث: إنشاء مشروع جديد
👉💻 في الوحدة الطرفية، اجعل النص البرمجي الأولي قابلاً للتنفيذ وشغِّله:
cd ~/way-back-home/level_2
./init.sh
3- 🛠️ إعداد البيئة
1. فتح Cloud Shell
في نافذة محرِّر Cloud Shell، إذا لم تظهر النافذة الطرفية في أسفل الشاشة، افتحها باتّباع الخطوات التالية:
- انقر على عرض.
- انقر على Terminal.
2. ضبط إعدادات المشروع
👉💻 في نافذة الوحدة الطرفية، اضبط رقم تعريف مشروعك:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 فعِّل واجهات برمجة التطبيقات المطلوبة (يستغرق ذلك من دقيقتَين إلى 3 دقائق تقريبًا):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3- تشغيل نص الإعداد البرمجي
👉💻 نفِّذ نص الإعداد البرمجي:
cd ~/way-back-home/level_2
./setup.sh
سيؤدي ذلك إلى إنشاء .env لك. في Cloud Shell، افتح way_back_homeproject. ضمن المجلد level_2، يمكنك الاطّلاع على الملف .env الذي تم إنشاؤه لك. إذا لم تتمكّن من العثور عليه، يمكنك النقر على View -> Toggle Hidden File لرؤيته. 
4. تحميل نموذج البيانات
👉💻 انتقِل إلى الخلفية وثبِّت الطلبات المرتبطة:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 تحميل البيانات الأولية للناجين:
uv run python ~/way-back-home/level_2/backend/setup_data.py
يؤدي ذلك إلى إنشاء ما يلي:
- مثيل Spanner (
survivor-network) - قاعدة البيانات (
graph-db) - جميع جداول العُقد والحواف
- الرسومات البيانية الخاصة بالسمات لطلب البحث عن الناتج المتوقَّع:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
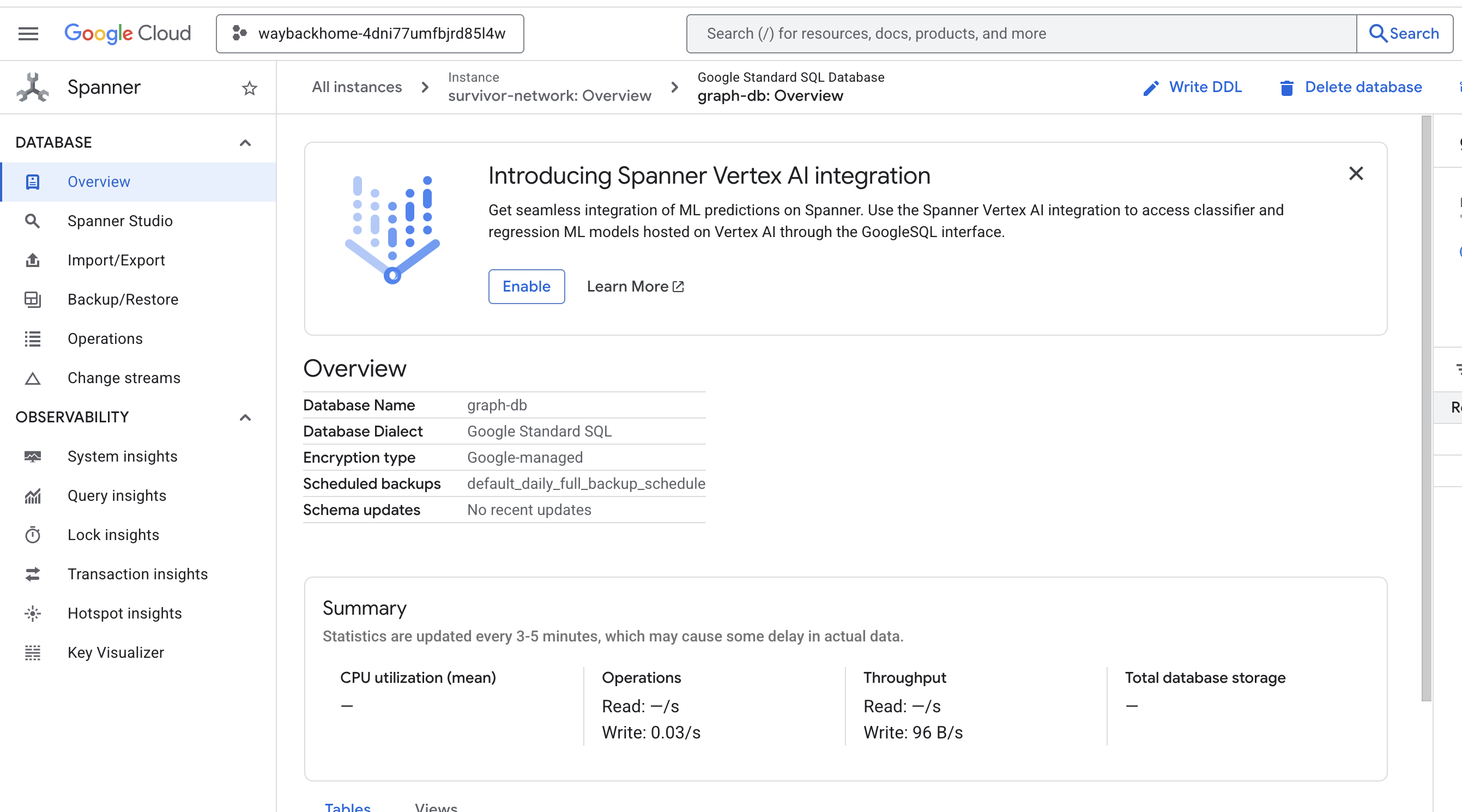
إذا نقرت على الرابط بعد Access your database at في الناتج، يمكنك فتح Google Cloud Console Spanner.

وسيظهر لك Spanner في Google Cloud Console.
4. 🚀 عرض بيانات الرسم البياني بشكل مرئي في Spanner Studio
يساعدك هذا الدليل في عرض بيانات الرسم البياني لشبكة الناجين والتفاعل معها مباشرةً في Google Cloud Console باستخدام Spanner Studio. هذه طريقة رائعة للتحقّق من بياناتك وفهم بنية الرسم البياني قبل إنشاء وكيل الذكاء الاصطناعي.
1. الوصول إلى Spanner Studio
- في الخطوة الأخيرة، احرص على النقر على الرابط وفتح Spanner Studio.
2. فهم بنية الرسم البياني ("الصورة الكبيرة")
يمكنك اعتبار مجموعة بيانات "شبكة الناجين" بمثابة لغز منطقي أو حالة لعبة:
الكيان | الدور في النظام | التشبيه |
Survivors | الوكلاء/اللاعبون | اللاعبون |
المناطق الأحيائية | موقعها الجغرافي | مناطق الخريطة |
المهارات | الإجراءات التي يمكنهم اتّخاذها | الإمكانات |
الاحتياجات | النقاط السلبية (الأزمات) | المهام |
المراجع | العناصر التي تم العثور عليها في العالم | غنيمة |
الهدف: مهمة وكيل الذكاء الاصطناعي هي ربط المهارات (الحلول) بالاحتياجات (المشاكل)، مع مراعاة المناطق الأحيائية (قيود الموقع الجغرافي).
🔗 الحواف (العلاقات):
SurvivorInBiome: تتبُّع الموقع الجغرافي-
SurvivorHasSkill: مستودع القدرات SurvivorHasNeed: قائمة بالمشاكل النشطة-
SurvivorFoundResource: مستودع السلع SurvivorCanHelp: علاقة مستنتَجة (يحسبها الذكاء الاصطناعي)
3- الاستعلام عن الرسم البياني
لننفّذ بعض طلبات البحث للاطّلاع على "القصة" في البيانات.
يستخدم Spanner Graph لغة طلبات الرسم البياني (GQL). لتنفيذ طلب بحث، استخدِم GRAPH SurvivorNetwork متبوعًا بنمط المطابقة.
👉 طلب البحث 1: قائمة المستخدمين العالمية (من أين؟) هذه هي المعلومات الأساسية، إذ إنّ فهم الموقع الجغرافي أمر بالغ الأهمية لعمليات الإنقاذ.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
من المتوقّع أن تظهر النتيجة كما يلي: 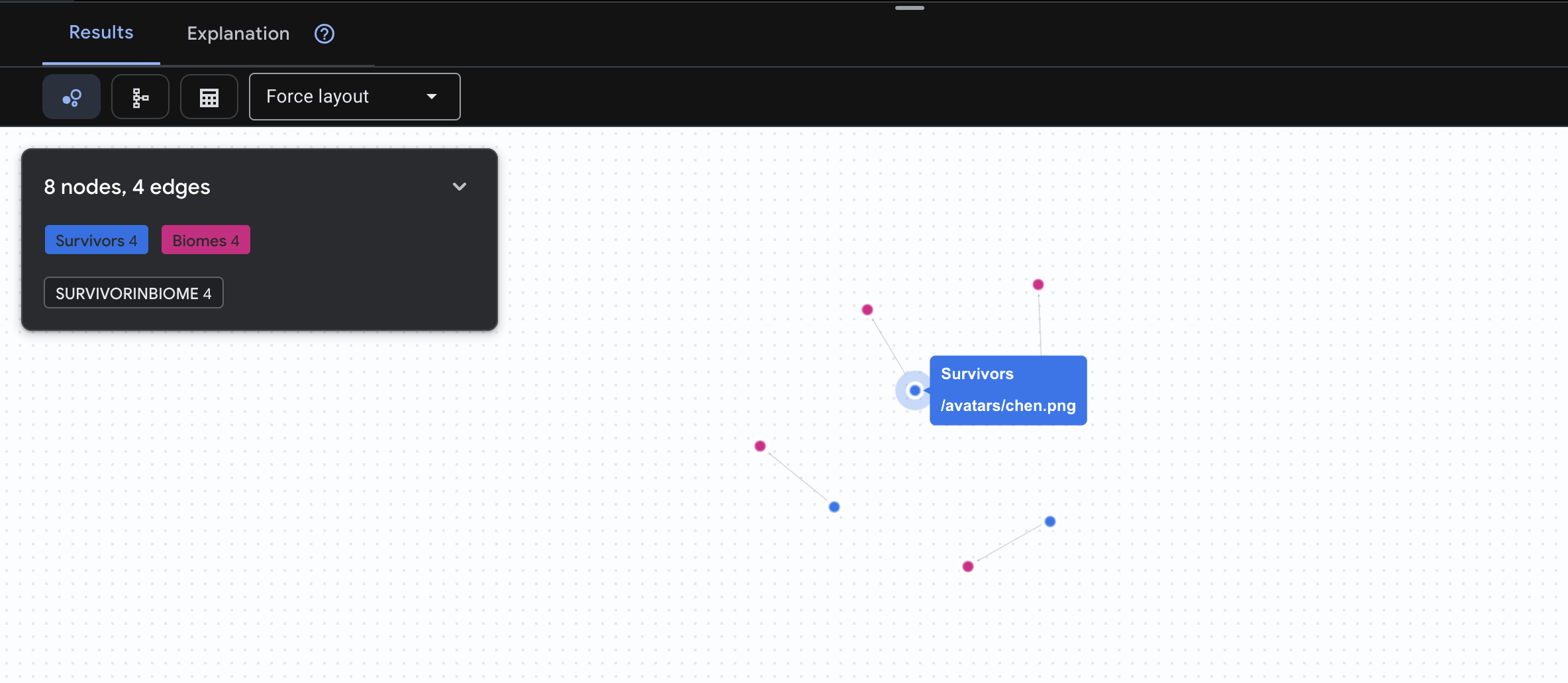
👉 طلب البحث 2: مصفوفة المهارات (الإمكانات) بعد أن عرفت مكان كل شخص، يمكنك الآن معرفة ما يمكنه فعله.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
من المتوقّع أن تظهر النتيجة كما يلي: 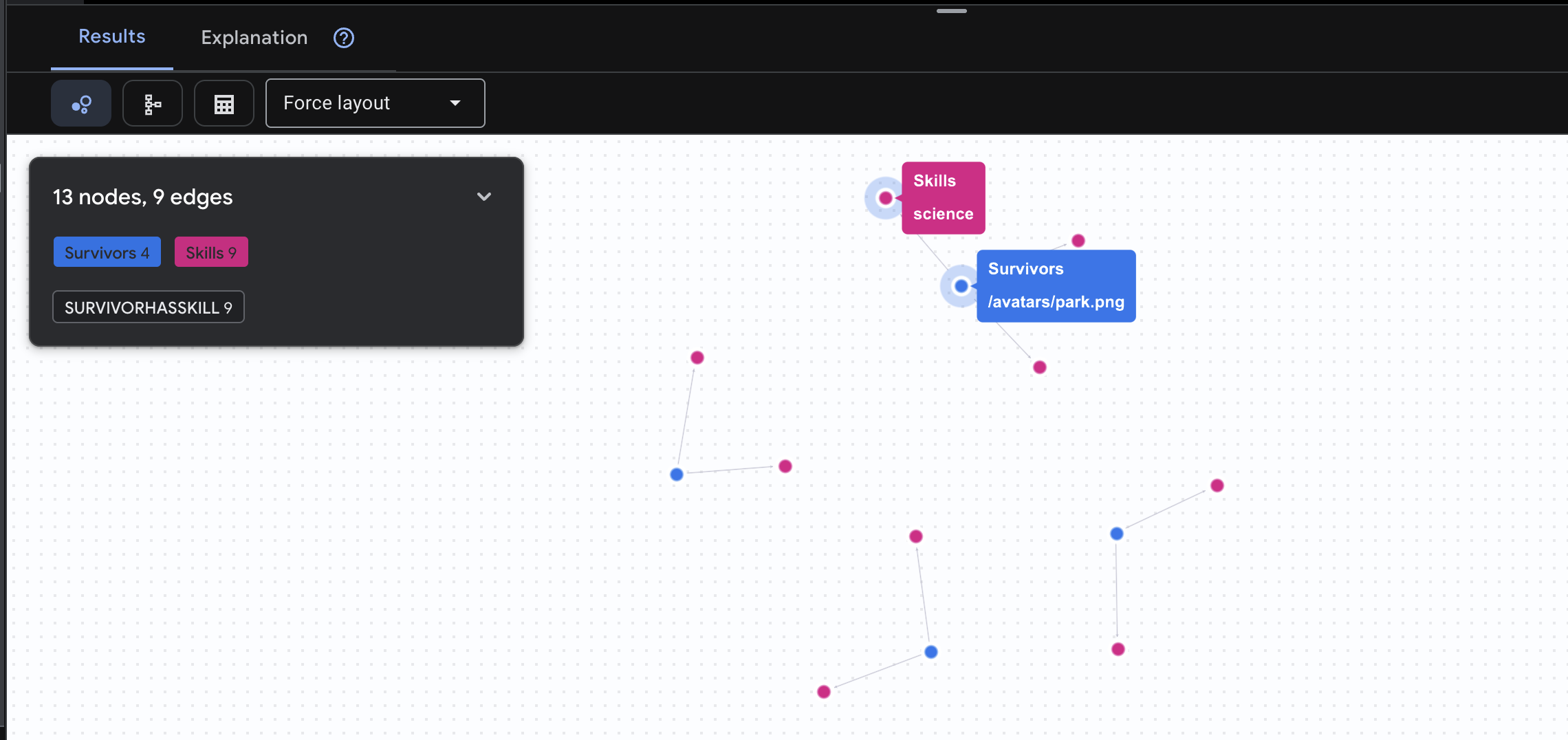
👉 طلب البحث 3: مَن هم الأشخاص الذين يواجهون أزمة؟ (لوحة المهام) يمكنك الاطّلاع على الناجين الذين يحتاجون إلى المساعدة ونوع المساعدة التي يحتاجون إليها.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
من المتوقّع أن تظهر النتيجة كما يلي: 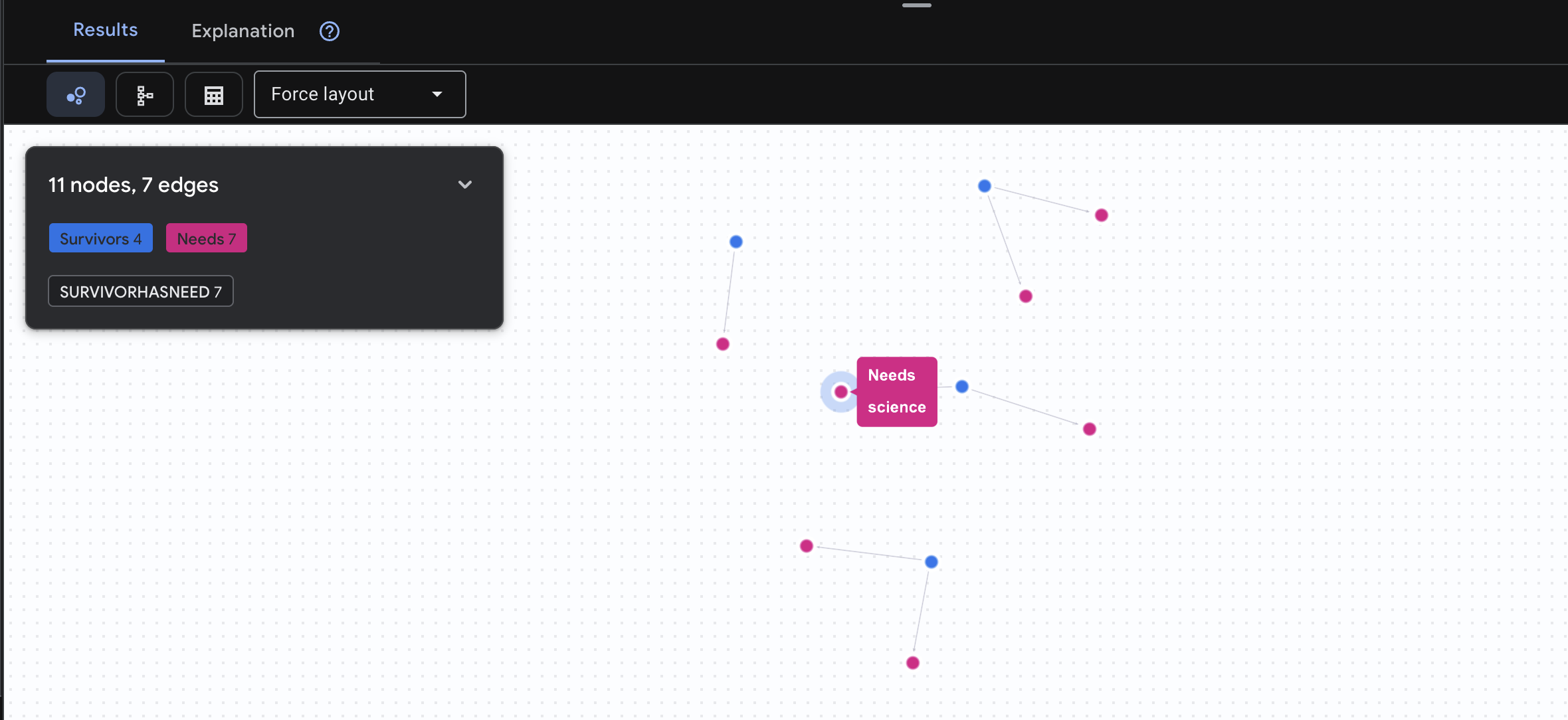
🔎 [اختياري] التوفيق بين الأشخاص - مَن يمكنه مساعدة مَن؟
هنا يصبح الرسم البياني قويًا. يبحث هذا الاستعلام عن الناجين الذين لديهم مهارات يمكنهم من خلالها تلبية احتياجات الناجين الآخرين.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
من المتوقّع أن تظهر النتيجة كما يلي: 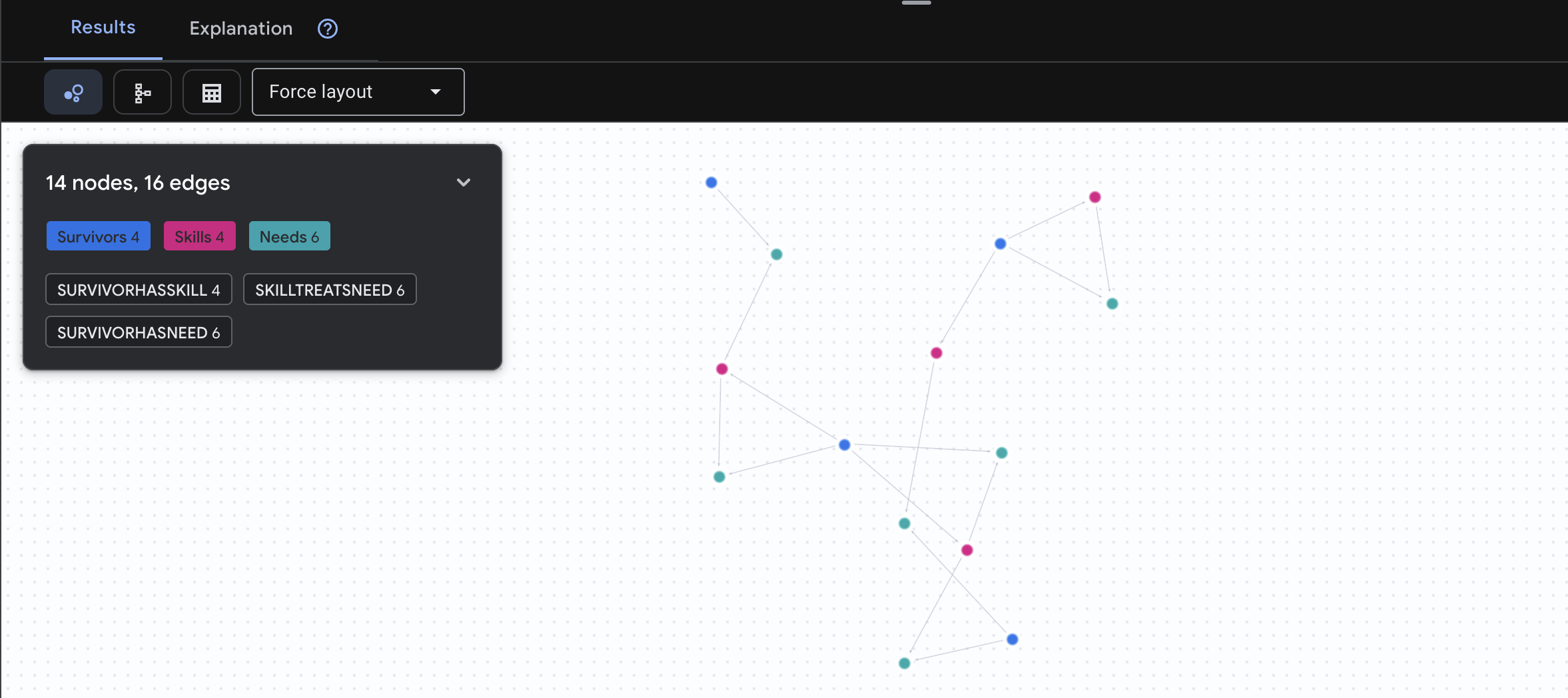
aside positive الغرض من طلب البحث هذا:
بدلاً من عرض "الإسعافات الأولية لعلاج الحروق" فقط (وهو أمر واضح من المخطط)، يعثر طلب البحث هذا على:
- الدكتورة "إيلينا فروست" (التي لديها تدريب طبي) → يمكنها علاج → الكابتن "تاناكا" (الذي يعاني من حروق)
- ديفيد تشين (الذي لديه شهادة في الإسعافات الأولية) → يمكنه علاج → الملازم بارك (الذي يعاني من التواء في الكاحل)
أهمية هذه الميزة:
المهام التي سينفّذها وكيل الذكاء الاصطناعي:
عندما يطرح مستخدم السؤال "من يمكنه معالجة الحروق؟"، سيفعل الوكيل ما يلي:
- تنفيذ طلب بحث مشابه للرسم البياني
- النتيجة: "يملك الدكتور فروست تدريبًا طبيًا ويمكنه مساعدة الكابتن تاناكا"
- ولا يحتاج المستخدم إلى معرفة الجداول أو العلاقات الوسيطة.
5- 🚀 تضمين مستند إلى الذكاء الاصطناعي في Spanner
1. لماذا التضمينات؟ (بدون اتّخاذ أي إجراء، للقراءة فقط)
في سيناريو البقاء على قيد الحياة، الوقت مهم جدًا. عندما يبلغ أحد الناجين عن حالة طوارئ، مثل I need someone who can treat burns أو Looking for a medic، لا يمكنه إضاعة الوقت في تخمين أسماء المهارات الدقيقة في قاعدة البيانات.
السيناريو الحقيقي: Survivor: Captain Tanaka has burns—we need medical help NOW!
البحث التقليدي عن الكلمات الرئيسية "مسعف" → 0 نتيجة ❌
البحث الدلالي باستخدام التضمينات → العثور على "التدريب الطبي" و"الإسعافات الأولية" ✅
وهذا هو بالضبط ما تحتاجه البرامج: بحث ذكي يشبه البحث الذي يجريه الإنسان ويفهم النية، وليس الكلمات الرئيسية فقط.
2. إنشاء نموذج تضمين
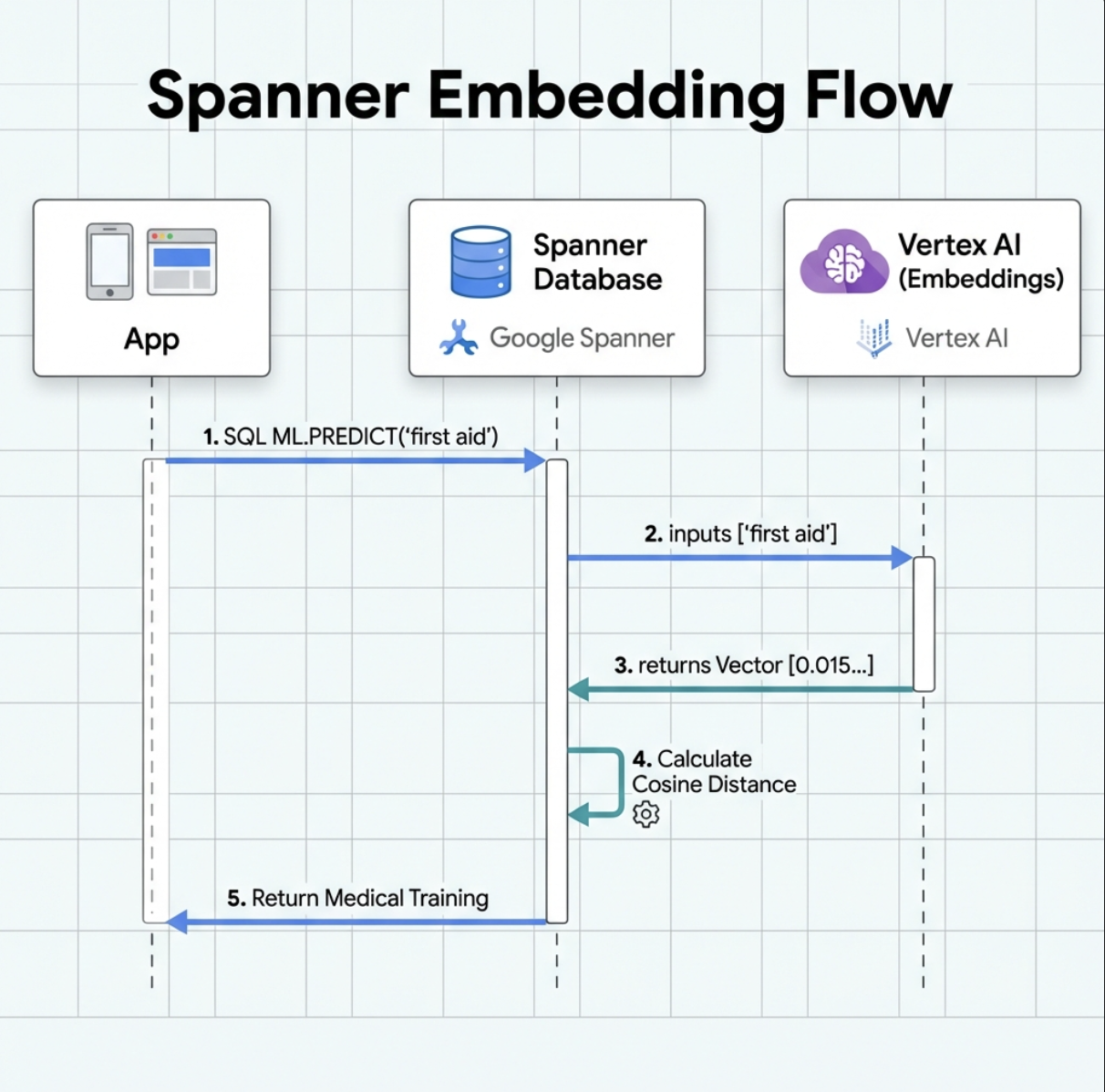
لننشئ الآن نموذجًا يحوّل النص إلى عمليات تضمين باستخدام text-embedding-004 من Google.
👉 في Spanner Studio، شغِّل SQL هذا (استبدِل $YOUR_PROJECT_ID برقم تعريف مشروعك الفعلي):
‼️ في محرّر Cloud Shell، افتح File -> Open Folder -> way-back-home/level_2 للاطّلاع على المشروع بأكمله.
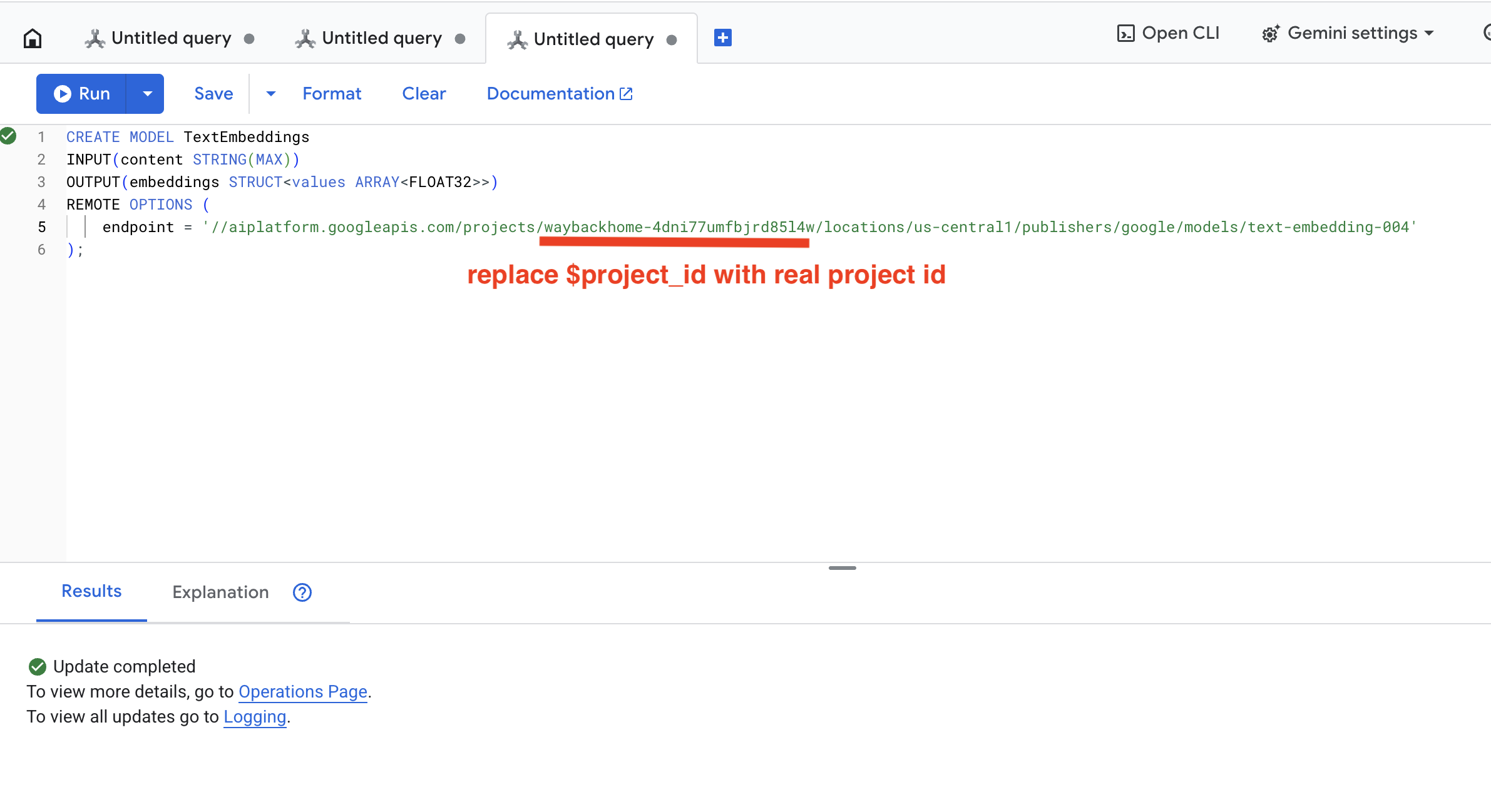
👉 شغِّل هذا الاستعلام في Spanner Studio من خلال نسخ الاستعلام أدناه ولصقه، ثم النقر على الزر "تشغيل":
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
وظيفة هذه الميزة:
- إنشاء نموذج افتراضي في Spanner (بدون تخزين أوزان النموذج محليًا)
- نقاط إلى
text-embedding-004من Google على Vertex AI - تحديد العقد: الإدخال هو نص، والإخراج هو مصفوفة عائمة ذات 768 بُعدًا
لماذا "خيارات عن بُعد"؟
- لا ينفّذ Spanner النموذج نفسه
- يتم استدعاء Vertex AI من خلال واجهة برمجة التطبيقات عند استخدام
ML.PREDICT - Zero-ETL: لا حاجة إلى تصدير البيانات إلى Python ومعالجتها وإعادة استيرادها
انقر على الزر Run، وبعد نجاح العملية، يمكنك الاطّلاع على النتيجة كما هو موضّح أدناه:
3- إضافة عمود التضمين
👉 إضافة عمود لتخزين التضمينات:
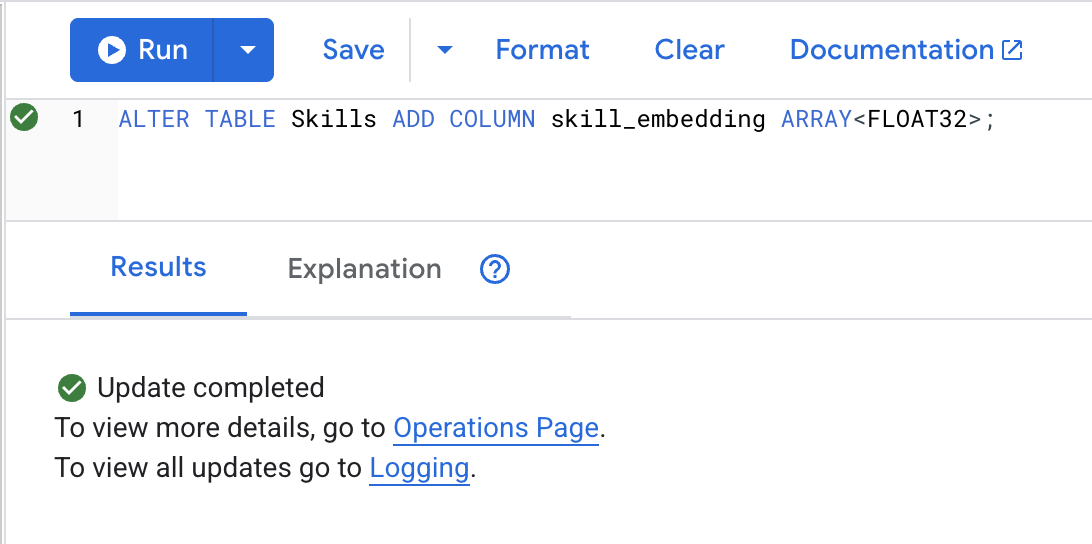
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
انقر على الزر Run، وبعد نجاح العملية، يمكنك الاطّلاع على النتيجة كما هو موضّح أدناه:
4. إنشاء تضمينات
👉 استخدِم الذكاء الاصطناعي لإنشاء تضمينات متجهة لكل مهارة:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
انقر على الزر Run، وبعد نجاح العملية، يمكنك الاطّلاع على النتيجة كما هو موضّح أدناه:
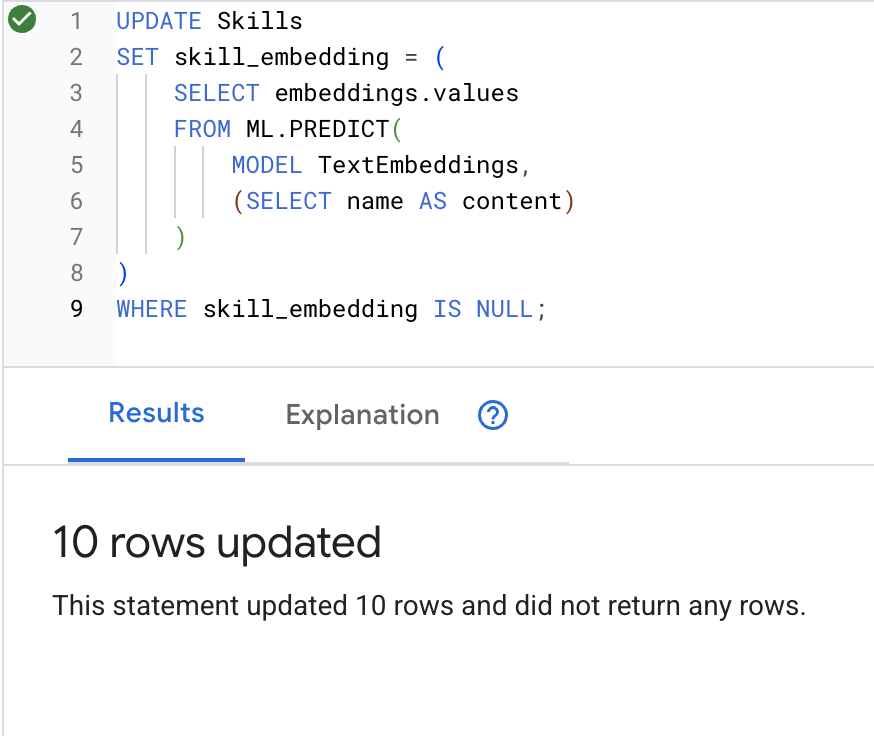
ما يحدث: يتم تحويل كل اسم مهارة (مثل "الإسعافات الأولية") إلى متجه ذي 768 بُعدًا يمثّل معناه الدلالي.
5- التحقّق من صحة عمليات التضمين
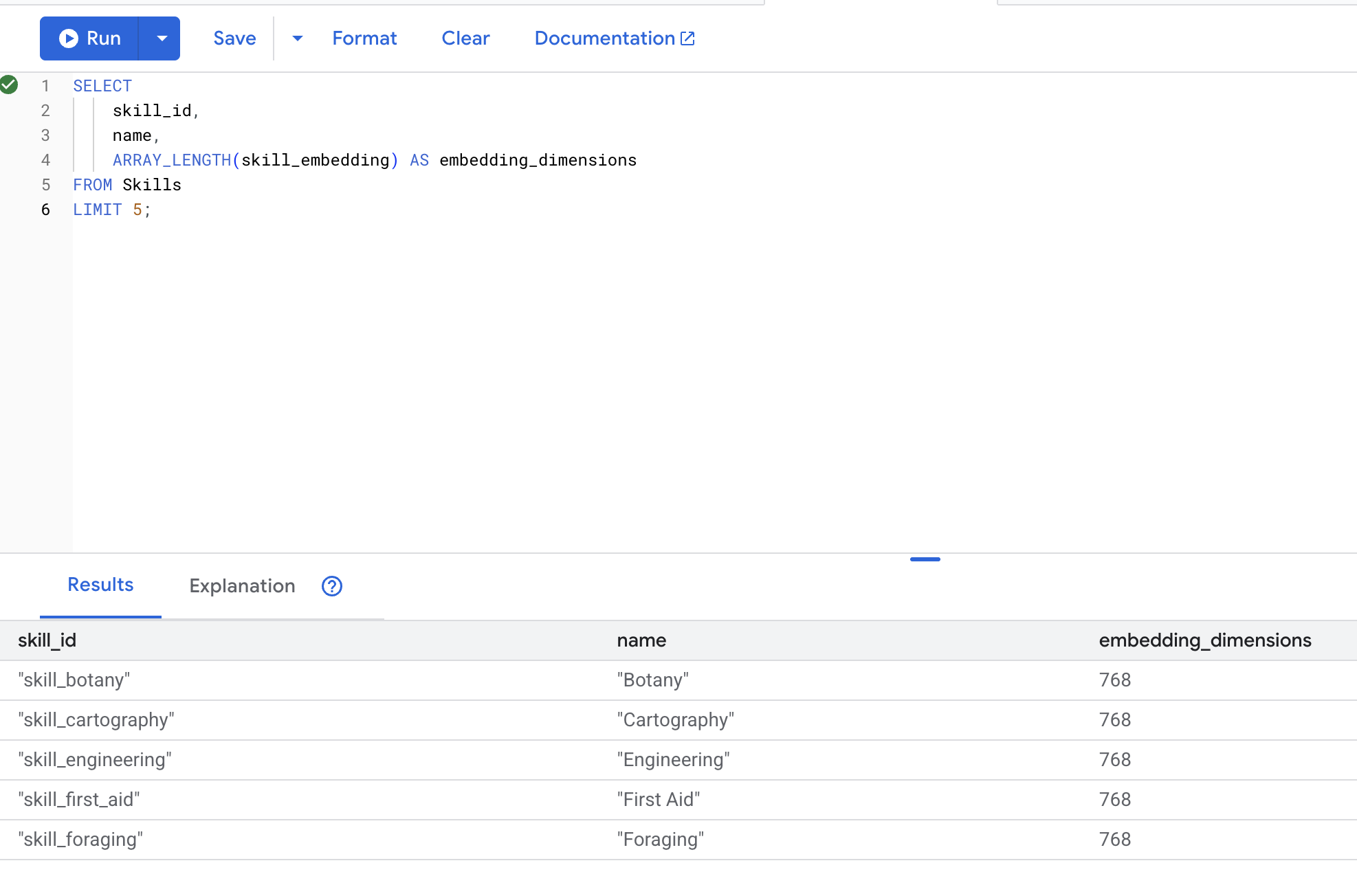
👉 تأكَّد من إنشاء عمليات التضمين:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
الناتج المتوقَّع:
6. اختبار البحث الدلالي
الآن، نختبر حالة الاستخدام المحدّدة من السيناريو: العثور على مهارات طبية باستخدام المصطلح "طبيب".
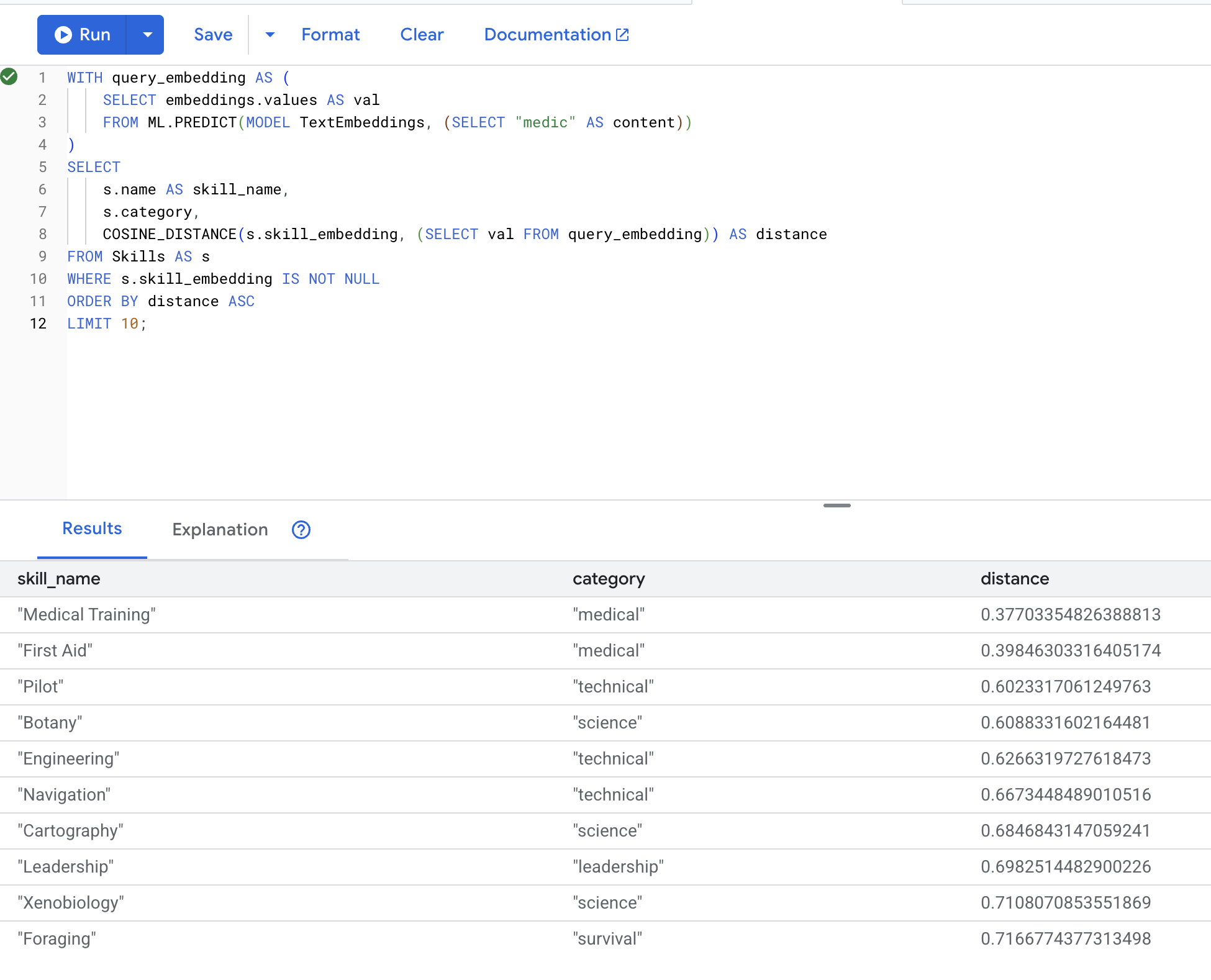
👉 العثور على مهارات مشابهة لـ "مسعف":
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- تحويل عبارة البحث "طبيب" التي أدخلها المستخدم إلى تضمين
- يخزّنها في الجدول المؤقت
query_embedding
النتائج المتوقّعة (المسافة الأقصر تعني التشابه الأكبر):
7. إنشاء نموذج Gemini للتحليل
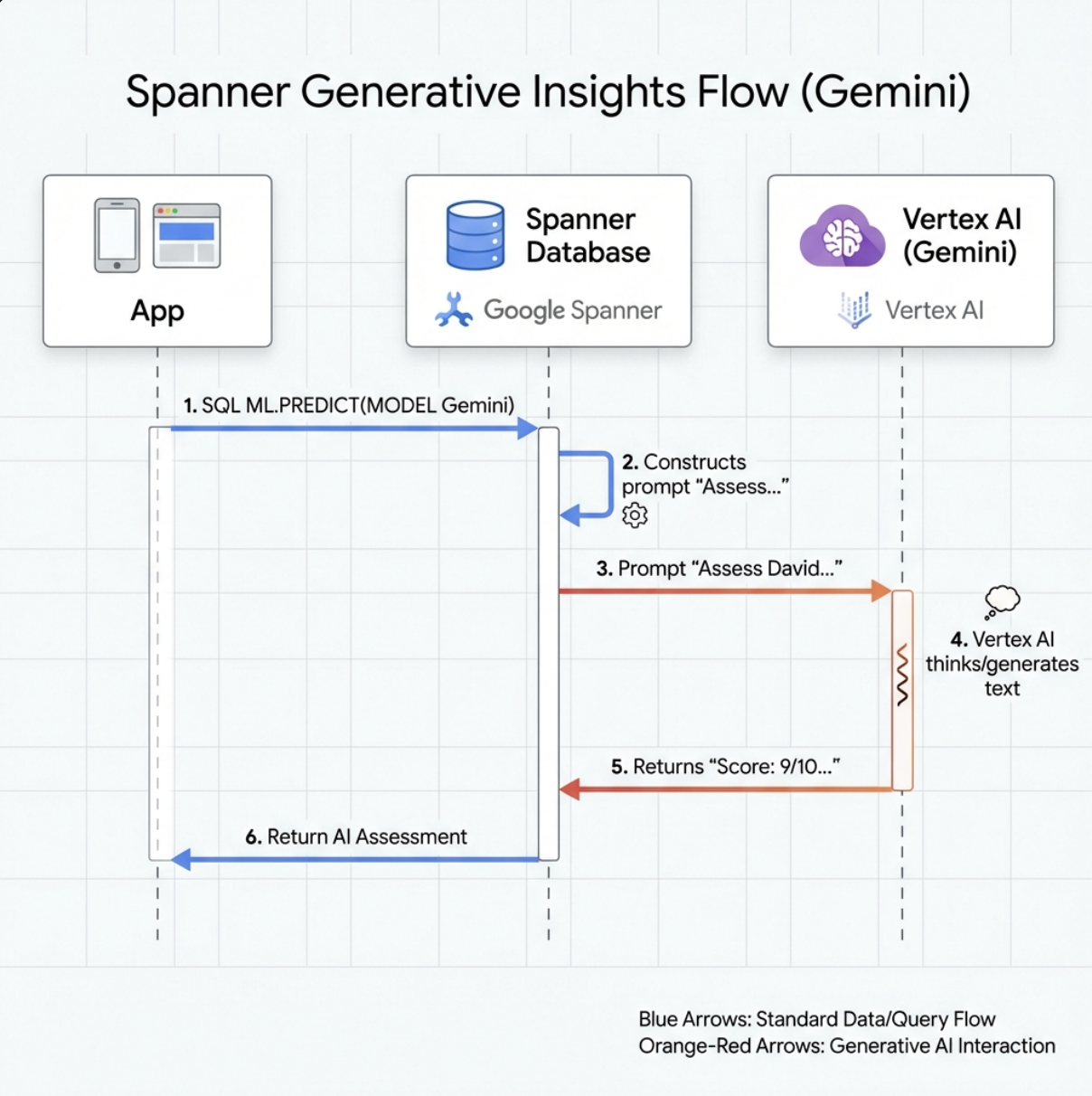
👉 أنشئ مرجعًا لنموذج الذكاء الاصطناعي التوليدي (استبدِل $YOUR_PROJECT_ID برقم تعريف مشروعك الفعلي):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
الاختلاف عن "نموذج التضمينات":
- التضمينات: نص ← متّجه (للبحث عن التشابه)
- Gemini: نص → نص تم إنشاؤه (للاستدلال/التحليل)
8. استخدام Gemini لتحليل التوافق
👉 تحليل أزواج الناجين لمعرفة مدى توافقهم مع المهمة:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
الناتج المتوقَّع:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 إنشاء وكيل Graph RAG باستخدام البحث المختلط
1. نظرة عامة على بنية النظام
يبني هذا القسم نظام بحث متعدد الطرق يمنح وكيلك المرونة اللازمة للتعامل مع أنواع مختلفة من طلبات البحث. يتضمّن النظام ثلاث طبقات: طبقة الوكيل وطبقة الأدوات وطبقة الخدمات.
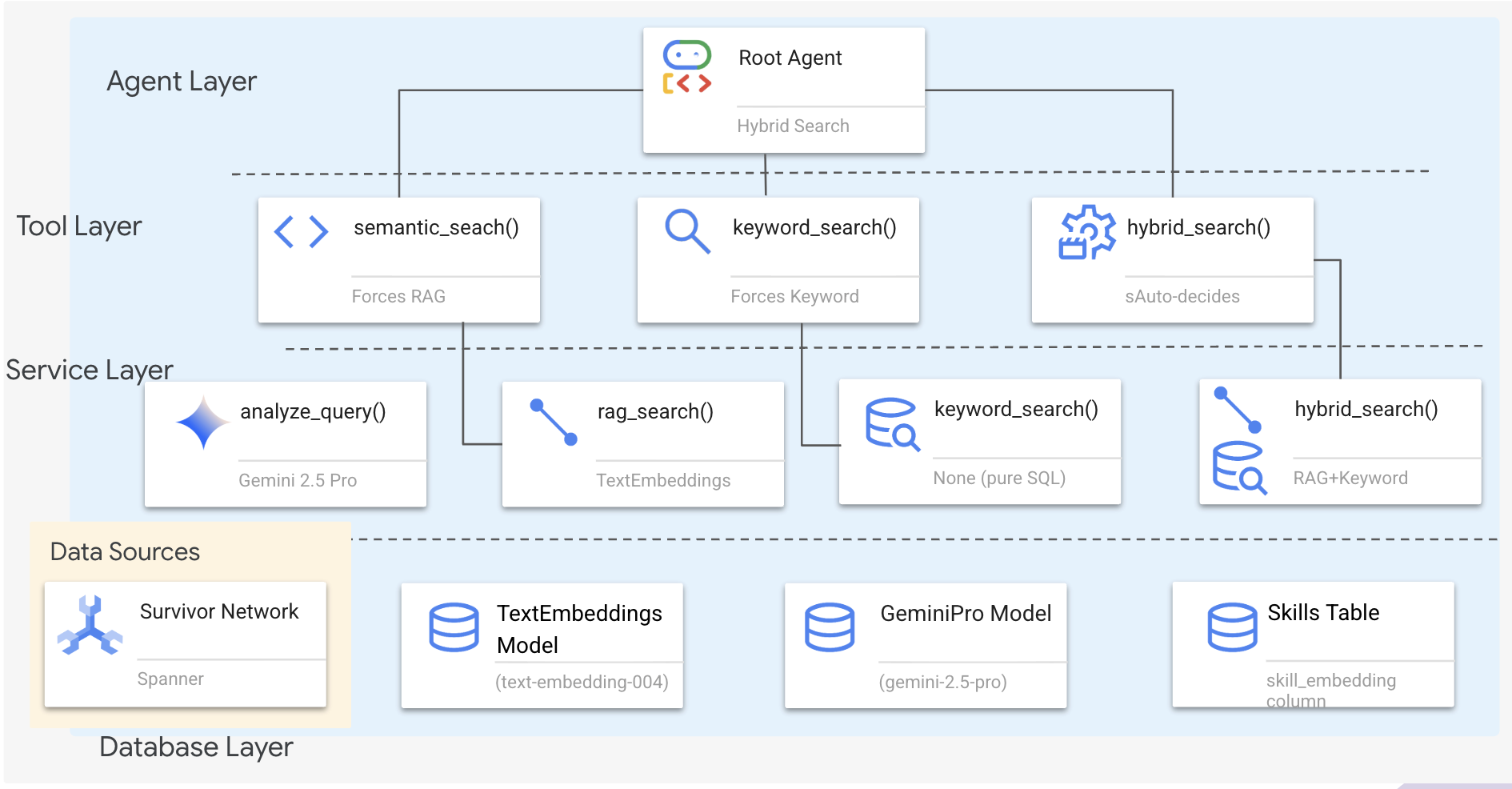
لماذا ثلاث طبقات؟
- فصل الاهتمامات: يركّز الوكيل على النية، وتركّز الأدوات على الواجهة، وتركّز الخدمة على التنفيذ
- المرونة: يمكن للوكيل فرض طرق معيّنة أو السماح للذكاء الاصطناعي بتحديد المسار تلقائيًا.
- التحسين: يمكن تخطّي تحليل الذكاء الاصطناعي المكلف عندما تكون الطريقة معروفة
في هذا القسم، ستنفّذ في المقام الأول البحث الدلالي (RAG)، أي العثور على النتائج حسب المعنى وليس الكلمات الرئيسية فقط. في وقت لاحق، سنشرح كيف تدمج البحث المختلط عدة طرق.
2. تنفيذ خدمة RAG
👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
تحديد مكان التعليق # TODO: REPLACE_SQL
استبدِل هذا السطر بالكامل بالرمز التالي:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3- تعريف أداة البحث الدلالي
👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
في hybrid_search_tools.py، ابحث عن التعليق # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉استبدِل هذا السطر بالكامل بالرمز التالي:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
حالات استخدام الوكيل:
- طلبات البحث التي تسأل عن التشابه ("البحث عن محتوى مشابه لـ X")
- طلبات البحث المفاهيمية ("قدرات الشفاء")
- عندما يكون فهم المعنى أمرًا بالغ الأهمية
4. دليل اتخاذ القرارات من الوكيل (التعليمات)
في تعريف الوكيل، انسخ الجزء المرتبط بالبحث الدلالي والصقه في التعليمات.
👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
يستخدم الوكيل هذه التعليمات لاختيار الأداة المناسبة:
👉في ملف agent.py، ابحث عن التعليق # TODO: REPLACE_SEARCH_LOGIC، استبدِل هذا السطر بالكامل بالرمز التالي:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉ابحث عن التعليق # TODO: ADD_SEARCH_TOOLReplace this whole line واستبدله بالرمز التالي:
semantic_search, # Force RAG
5- فهم طريقة عمل البحث المختلط (للقراءة فقط، لا يلزم اتّخاذ أي إجراء)
في الخطوات من 2 إلى 4، نفّذت البحث الدلالي (التوليد المعزّز بالاسترجاع)، وهو طريقة البحث الأساسية التي تعثر على النتائج حسب المعنى. ولكن ربما لاحظت أنّ اسم النظام هو "البحث المختلط". إليك كيفية عمل كل ذلك معًا:
طريقة عمل ميزة "الدمج المختلط":
في الملف way-back-home/level_2/backend/services/hybrid_search_service.py، عند طلب hybrid_search()، تُجري الخدمة عمليتَي البحث وتدمج النتائج:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
في هذا الدرس التطبيقي حول الترميز، نفّذت مكوّن البحث الدلالي (RAG)، وهو الأساس. تمّت إضافة طريقتَي الكلمات الرئيسية والطريقة المختلطة إلى الخدمة، ويمكن أن يستخدم الوكيل الطرق الثلاث.
تهانينا! لقد أتممت بنجاح إنشاء Graph RAG Agent باستخدام البحث المختلط.
7. 🚀 اختبار الوكيل باستخدام ADK Web
أسهل طريقة لاختبار الوكيل هي استخدام الأمر adk web، الذي يشغّل الوكيل مع واجهة محادثة مدمجة.
1. تشغيل الوكيل
👉💻 انتقِل إلى دليل الخلفية (الذي تم فيه تحديد الوكيل) وشغِّل واجهة الويب::
cd ~/way-back-home/level_2/backend
uv run adk web
يبدأ هذا الأمر الوكيل المحدّد في
agent/agent.py
ويفتح واجهة ويب لإجراء الاختبار.
👉 فتح عنوان URL:
سيُخرج الأمر عنوان URL محليًا (عادةً http://127.0.0.1:8000 أو ما شابه ذلك). افتح هذا الرابط في المتصفّح.
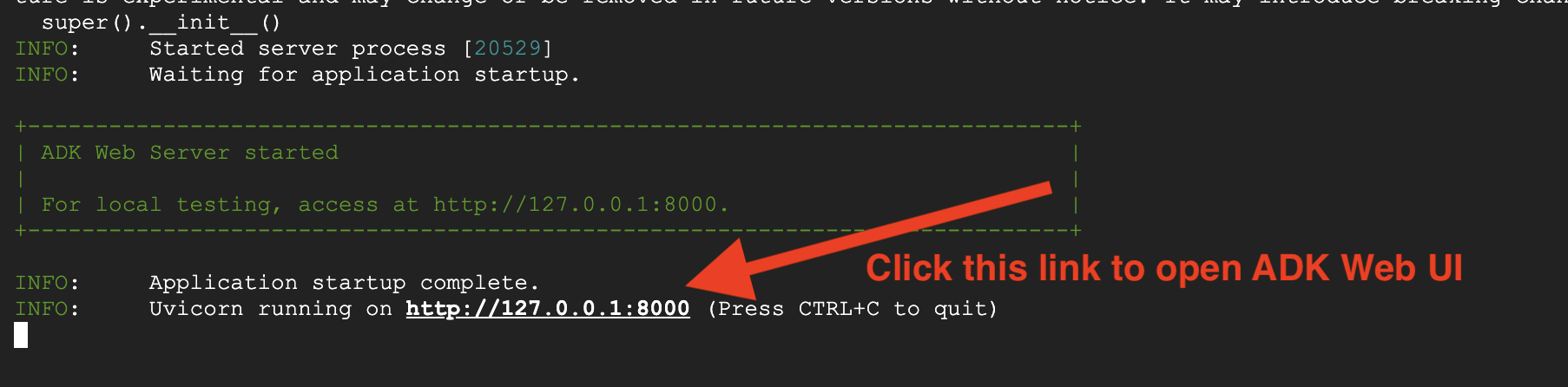
بعد النقر على عنوان URL، ستظهر لك واجهة مستخدم ADK على الويب. تأكَّد من اختيار "المشرف" من أعلى يمين الصفحة.
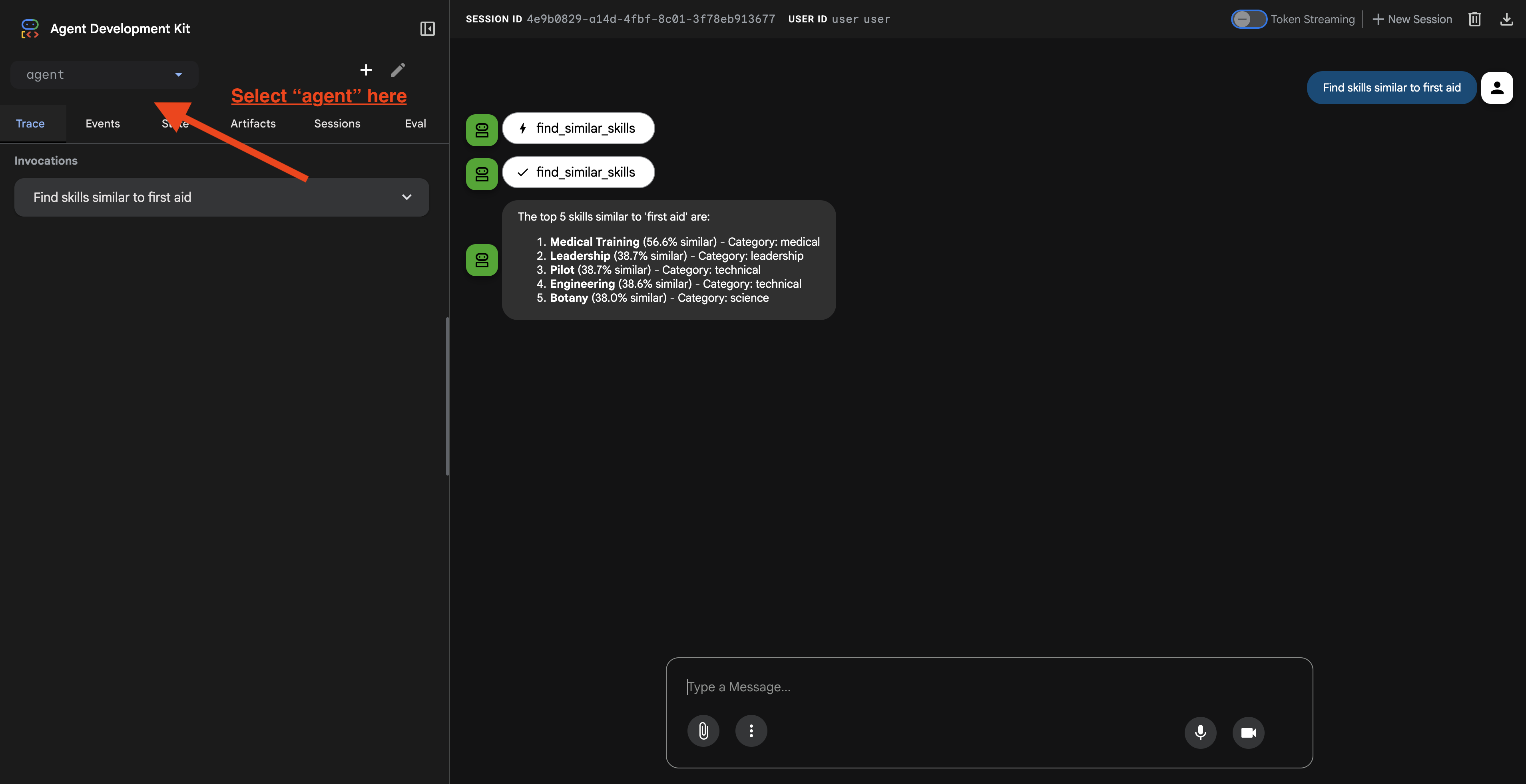
2. اختبار إمكانات البحث
تم تصميم الوكيل لتوجيه طلباتك بذكاء. جرِّب إدخال ما يلي في نافذة المحادثة للاطّلاع على طرق البحث المختلفة أثناء عملها.
🧬 أ. التوليد المعزّز بالاسترجاع المستند إلى الرسم البياني (البحث الدلالي)
العثور على العناصر استنادًا إلى المعنى والمفهوم، حتى إذا لم تتطابق الكلمات الرئيسية
طلبات الاختبار: (اختَر أيًا مما يلي)
Who can help with injuries?
What abilities are related to survival?
ما يجب البحث عنه:
- يجب أن يشير الاستدلال إلى البحث الدلالي أو RAG.
- من المفترض أن تظهر لك نتائج ذات صلة من الناحية المفاهيمية (مثل "جراحة" عند البحث عن "إسعافات أولية").
- ستتضمّن النتائج الرمز 🧬.
🔀 ب. Hybrid Search
تجمع هذه الميزة بين فلاتر الكلمات الرئيسية وفهم المعنى للتعامل مع طلبات البحث المعقّدة.
طلبات الاختبار:(اختَر أيًا مما يلي)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
ما يجب البحث عنه:
- يجب أن يذكر السبب البحث الهجين.
- يجب أن تتطابق النتائج مع المعيارَين (المفهوم والموقع الجغرافي/الفئة).
- ستظهر النتائج التي تم العثور عليها باستخدام كلتا الطريقتَين مع الرمز 🔀، وسيتم ترتيبها في أعلى القائمة.
👉💻 عند الانتهاء من الاختبار، أنهِ العملية بالضغط على Ctrl+C في سطر الأوامر.
8. 🚀 تشغيل التطبيق الكامل
نظرة عامة على بنية Full Stack
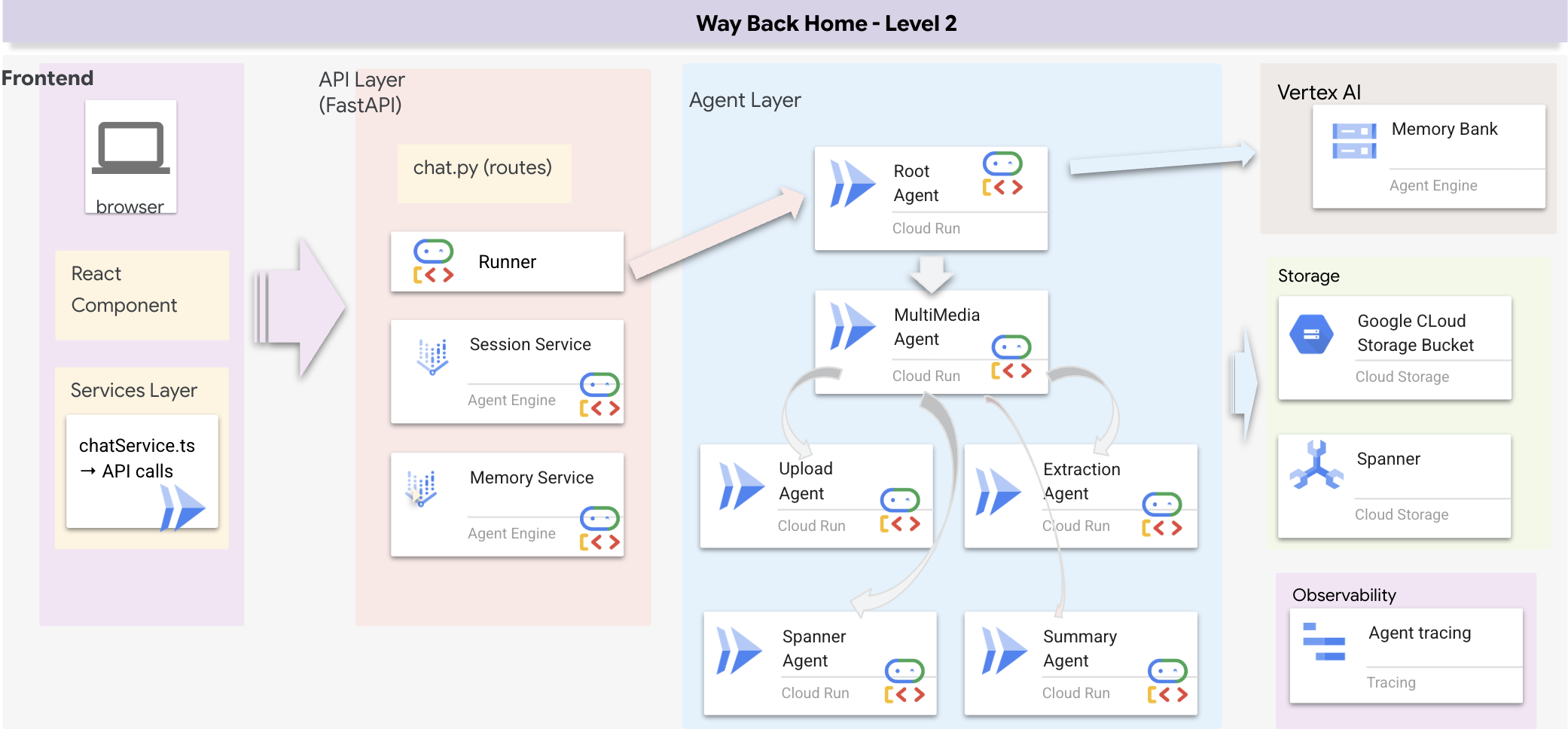
إضافة SessionService وRunner
👉💻 في الوحدة الطرفية، افتح الملف chat.py في "محرّر Cloud Shell" من خلال تنفيذ ما يلي (تأكَّد من الضغط على ctrl+C لإنهاء العملية السابقة قبل المتابعة):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉في ملف chat.py، ابحث عن التعليق # TODO: REPLACE_INMEMORY_SERVICES، ثم استبدِل هذا السطر بالكامل بالرمز التالي:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉في ملف chat.py، ابحث عن التعليق # TODO: REPLACE_RUNNER، ثم استبدِل هذا السطر بالكامل بالرمز التالي:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. بدء الطلب
إذا كانت الوحدة الطرفية السابقة لا تزال قيد التشغيل، يمكنك إنهاءها بالضغط على Ctrl+C.
👉💻 بدء التطبيق:
cd ~/way-back-home/level_2/
./start_app.sh
عند بدء الخلفية بنجاح، سيظهر لك Local: http://localhost:5173/" كما يلي: 
👉 انقر على Local: http://localhost:5173/ من نافذة Terminal.
2. اختبار البحث الدلالي
طلب البحث:
Find skills similar to healing
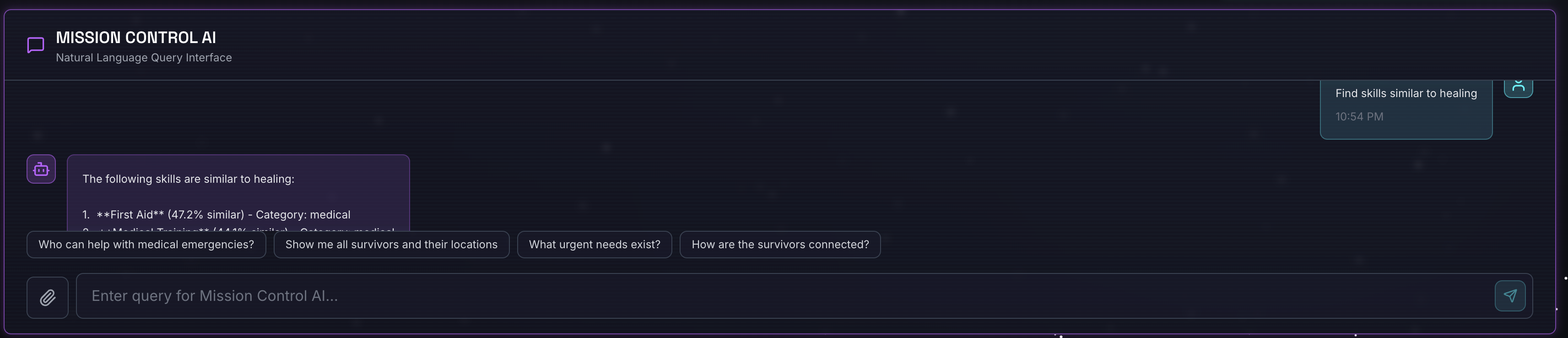
ما يحدث:
- يتعرّف الموظّف على طلب التشابه
- إنشاء تضمين لكلمة "شفاء"
- تستخدِم مسافة جيب التمام للعثور على مهارات متشابهة دلاليًا
- النتائج: الإسعافات الأولية (على الرغم من أنّ الأسماء لا تتطابق مع "الشفاء")
3- اختبار Hybrid Search
طلب البحث:
Find medical skills in the mountains
ما يحدث:
- مكوّن الكلمات الرئيسية: فلترة حسب
category='medical' - المكوّن الدلالي: تضمين "طبي" والترتيب حسب التشابه
- دمج: يتم دمج النتائج مع إعطاء الأولوية لتلك التي تم العثور عليها باستخدام كلتا الطريقتين 🔀
طلب البحث(اختياري):
Who is good at survival and in the forest?
ما يحدث:
- نتائج البحث عن الكلمات الرئيسية:
biome='forest' - نتائج البحث الدلالي: مهارات مشابهة لـ "البقاء على قيد الحياة"
- تجمع الطريقة المختلطة بين الطريقتين لتحقيق أفضل النتائج
👉💻 عند الانتهاء من الاختبار، اضغط على Ctrl+C في الوحدة الطرفية.
4. (!ONLY FOR WORKSHOP ATTENDEE) تعديل موقعك الجغرافي
👉💻 شغِّل نص الإكمال البرمجي:
cd ~/way-back-home/level_2
./set_level_2.sh
افتح الآن waybackhome.dev، وسيظهر لك أنّ موقعك الجغرافي قد تم تعديله. تهانينا على إكمال المستوى 2.

9- ☕️ [اختياري] مسار متعدد الوسائط (للقراءة فقط) — طبقة الأدوات
لماذا نحتاج إلى مسار متعدد الوسائط؟
شبكة النجاة ليست مجرد نص. يرسل الناجون في الميدان بيانات غير منظَّمة مباشرةً من خلال المحادثة:
- 📸 الصور: صور للموارد أو المخاطر أو المعدّات
- 🎥 الفيديوهات: تقارير الحالة أو رسائل البث في حالات الطوارئ
- 📄 النص: ملاحظات أو سجلّات الحقل
ما هي الملفات التي نعالجها؟
على عكس الخطوة السابقة التي بحثنا فيها عن البيانات الحالية، نعالج هنا الملفات التي حمّلها المستخدم. تتعامل واجهة chat.py مع مرفقات الملفات بشكل ديناميكي:
المصدر | المحتوى | الهدف |
مرفق المستخدم | صورة/فيديو/نص | المعلومات المطلوب إضافتها إلى الرسم البياني |
سياق المحادثة | "إليك صورة للّوازم" | النية والتفاصيل الإضافية |
الأسلوب المخطَّط له: مسار الإجراءات التسلسلي للوكيل
نستخدم وكيلًا تسلسليًا (multimedia_agent.py) يربط الوكلاء المتخصّصين معًا:
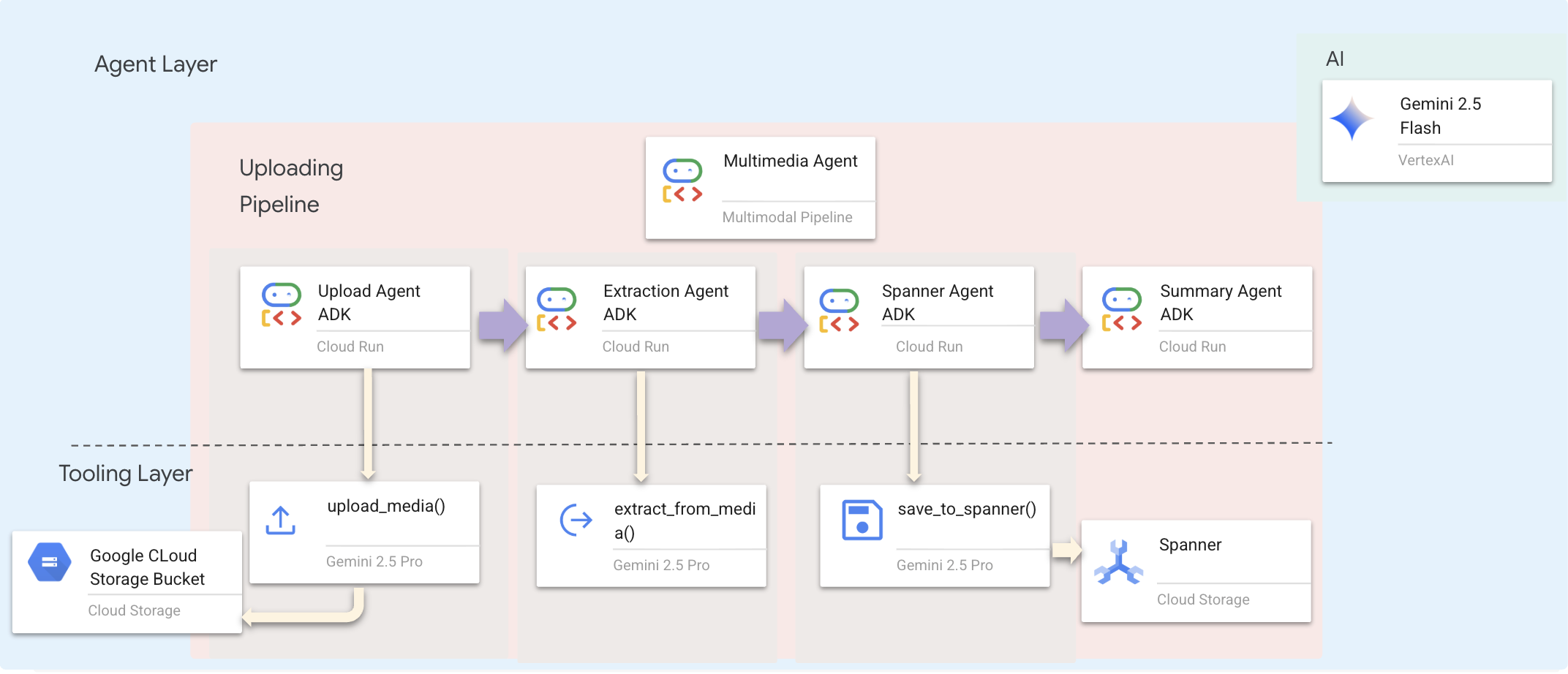
يتم تحديد ذلك في backend/agent/multimedia_agent.py على أنّه SequentialAgent.
توفّر طبقة الأدوات الإمكانات التي يمكن للوكلاء استخدامها. تتعامل الأدوات مع "كيفية" تنفيذ المهام، مثل تحميل الملفات واستخراج الكيانات وحفظها في قاعدة البيانات.
1. فتح ملف الأدوات
👉💻 افتح الملف level_2/backend/agent/tools/extraction_tools.py أو من خلال كتابة الأمر التالي في الوحدة الطرفية. افتح نافذة وحدة طرفية جديدة. في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell":
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. تنفيذ أداة upload_media
تحمّل هذه الأداة ملفًا محليًا إلى Google Cloud Storage.
👉 في def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:، يوضّح الرمز البرمجي التالي كيفية تحميل الملفات إلى GCS والتعرّف على نوعها:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3- تنفيذ أداة extract_from_media
هذه الأداة هي جهاز توجيه، فهي تتحقّق من media_type وترسلها إلى أداة الاستخراج المناسبة (نص أو صورة أو فيديو).
👉 في async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:، يتناول الرمز التالي كيفية استخراج الكيانات والعلاقات من الوسائط التي تم تحميلها.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
تفاصيل التنفيذ الرئيسية:
- الإدخال المتعدد الوسائط: نمرّر كلاً من الطلب النصي (
_get_extraction_prompt()) وعنصر الصورة إلىgenerate_content. - الناتج المنظَّم: تضمن
response_mime_type="application/json"أن يعرض نموذج اللغة الكبير JSON صالحًا، وهو أمر بالغ الأهمية في مسار العمل. - ربط الكيانات المرئية: يتضمّن الطلب كيانات معروفة ليتمكّن Gemini من التعرّف على شخصيات معيّنة.
4. تنفيذ أداة save_to_spanner
تحتفظ هذه الأداة بالكيانات والعلاقات المستخرَجة في قاعدة بيانات Spanner Graph.
👉 في def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:، يتناول الرمز التالي كيفية حفظ الكيانات والعلاقات المستخرَجة في قاعدة بيانات Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
من خلال تزويد الوكلاء بأدوات رفيعة المستوى، نضمن صحّة البيانات مع الاستفادة من قدرات الوكيل على الاستدلال.
5- تعديل خدمة GCS
يتولّى GCSService عملية تحميل الملفات إلى Google Cloud Storage.
👉💻 افتح الملف level_2/backend/services/gcs_service.py، أو يمكنك الكتابة في الوحدة الطرفية لفتح الملف في "محرِّر Cloud Shell":
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 في def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:، يتناول الرمز التالي كيفية حفظ الكيانات والعلاقات المستخرَجة في قاعدة بيانات Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
من خلال تجريد هذه العملية إلى خدمة، لا يحتاج "الوكيل" إلى معرفة تفاصيل حول حِزم GCS أو أسماء الكائنات الثنائية الكبيرة أو إنشاء عناوين URL موقّعة. يطلب منك فقط "تحميل" الملف.
6. لماذا يُعدّ "سير العمل المستند إلى الوكلاء" أفضل من "النُهج التقليدية"؟
ميزة الحلول المستندة إلى الذكاء الاصطناعي الوكيل:
الميزة | مسار المعالجة على دفعات | مستنِد إلى الأحداث | سير العمل المستند إلى الذكاء الاصطناعي الوكيل |
التعقيد | منخفضة (نص برمجي واحد) | مرتفع (5 خدمات أو أكثر) | منخفض (ملف Python واحد: |
إدارة الحالة | المتغيّرات العمومية | صعب (غير مرتبط) | موحَّد (حالة الوكيل) |
التعامل مع الأخطاء | الأعطال | السجلات الصامتة | تفاعلية ("تعذّر عليّ قراءة هذا الملف") |
ملاحظات المستخدمين | لوحات مطبوعة | الحاجة إلى إجراء استطلاع | مباشرة (جزء من المحادثة) |
القدرة على التكيّف | المنطق الثابت | الدوال الثابتة | ذكي (يقرّر النموذج اللغوي الكبير الخطوة التالية) |
الوعي بالسياق | بدون | بدون | كاملة (تعرف نية المستخدم) |
أهمية ذلك: باستخدام multimedia_agent.py (وهو SequentialAgent يتضمّن 4 وكلاء فرعيين: تحميل → استخراج → حفظ → ملخّص)، نستبدل البنية الأساسية المعقّدة والبرامج النصية الهشة بمنطق تطبيق ذكي قائم على المحادثة.
10. ☕️ [اختياري] مسار متعدد الوسائط (للقراءة فقط) — طبقة الوكيل
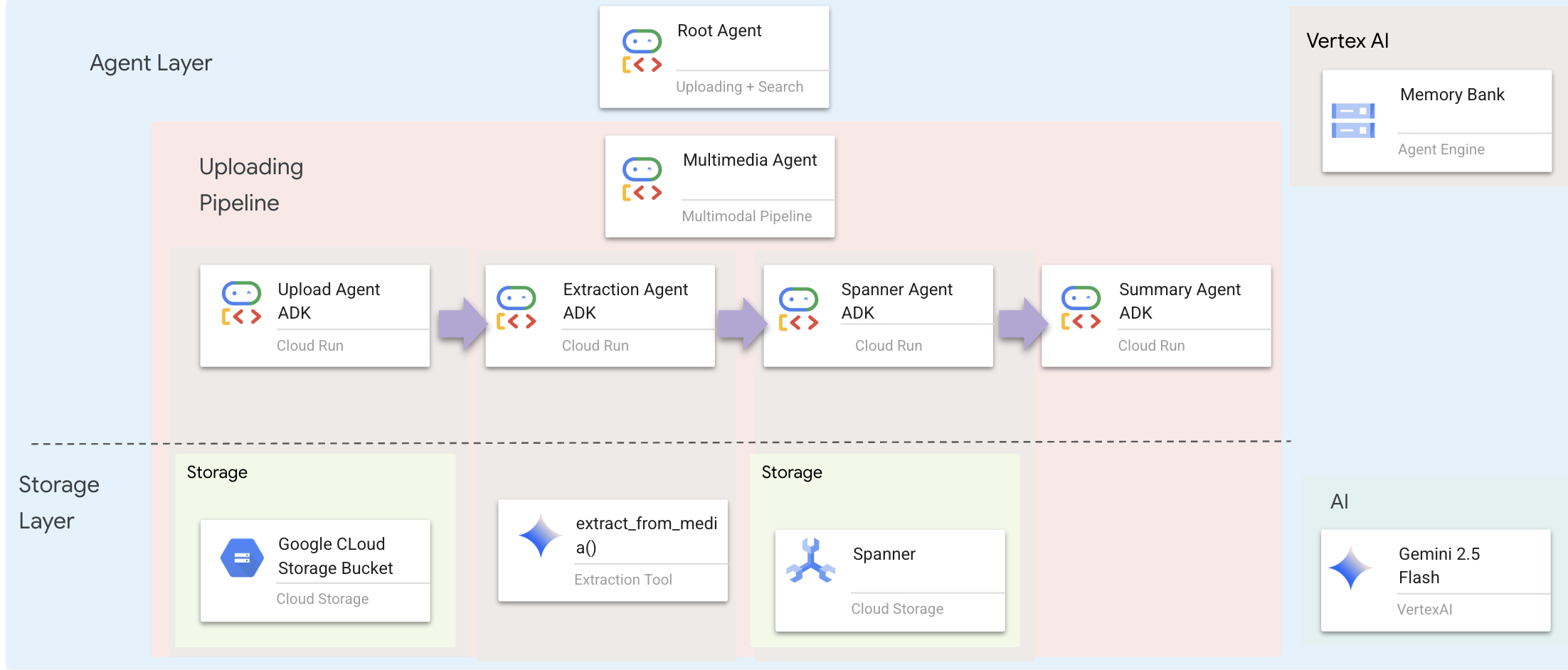
تحدّد طبقة الوكلاء الذكاء، أي الوكلاء الذين يستخدمون الأدوات لإنجاز المهام. لكل وكيل دور محدّد وينقل السياق إلى الوكيل التالي. في ما يلي رسم تخطيطي لبنية نظام يستند إلى عدّة وكلاء.
1. فتح ملف الوكيل
👉💻 افتح الملف level_2/backend/agent/multimedia_agent.py أو من خلال كتابة الأمر التالي في الوحدة الطرفية. افتح نافذة وحدة طرفية جديدة. في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell":
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. تحديد "وكيل التحميل"
يستخرج هذا الوكيل مسار ملف من رسالة المستخدم ويحمّله إلى GCS.
👉في الملف multimedia_agent.py، يتم إنشاء upload_agent الذي يتم تحميله إلى GCS باستخدام الرمز التالي:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3- تحديد "وكيل الاستخراج"
يستطيع هذا الوكيل "رؤية" الوسائط التي تم تحميلها واستخراج البيانات المنظَّمة باستخدام Gemini Vision.
👉في الملف multimedia_agent.py، باستخدام الرمز التالي، يتم إنشاء extraction_agent الذي يستخرج المعلومات من الوسائط التي تم تحميلها:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
لاحظ كيف يشير instruction إلى {upload_result}، فهذه هي الطريقة التي يتم بها تمرير الحالة بين الوكلاء في ADK.
4. تحديد Spanner Agent
يحفظ هذا الوكيل الكيانات والعلاقات المستخرَجة في قاعدة بيانات الرسومات البيانية.
👉في الملف multimedia_agent.py، باستخدام الرمز التالي، يتم إنشاء spanner_agent الذي يحفظ المعلومات المستخرجة في قاعدة البيانات:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
يتلقّى هذا الوكيل سياقًا من كلتا الخطوتَين السابقتَين (upload_result وextraction_result).
5- تحديد "وكيل الملخّص"
يجمع هذا الوكيل النتائج من جميع الخطوات السابقة في ردّ سهل الاستخدام.
👉في الملف multimedia_agent.py، باستخدام الرمز التالي، يتم تحديد الطلب الخاص بـ summary_agent الذي يلخّص النتيجة:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
لا يحتاج هذا الوكيل إلى أدوات، بل يقرأ السياق المشترك وينشئ ملخّصًا واضحًا للمستخدم.
🧠 ملخّص البنية
طبقة | ملف | المسؤولية |
الأدوات |
| كيفية — التحميل والاستخراج والحفظ |
الوكيل |
| ماذا: تنسيق مسار التعلّم |
11. 🚀 مسار البيانات المتعدّدة الوسائط — التنسيق
إنّ أساس نظامنا الجديد هو MultimediaExtractionPipeline المحدّد في backend/agent/multimedia_agent.py. يستخدم هذا التطبيق نمط الوكيل التسلسلي من "حزمة تطوير الوكلاء" (ADK).
1. لماذا Sequential؟
معالجة ملف تم تحميله هي سلسلة تبعية خطية:
- لا يمكنك استخراج البيانات إلا بعد الحصول على الملف (تحميل).
- لا يمكنك حفظ البيانات إلى أن تستخرجها (الاستخراج).
- لا يمكنك تلخيص النتائج إلا بعد الحصول عليها (حفظ).
SequentialAgent هي الأنسب لهذا الغرض. وينقل ناتج أحد الوكلاء كسياق/مدخل إلى الوكيل التالي.
2. تعريف الوكيل
لنلقِ نظرة على كيفية تجميع خط أنابيب المعالجة في أسفل multimedia_agent.py: 👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
يتلقّى هذا الإجراء مدخلات من كلتا الخطوتَين السابقتَين. ابحث عن التعليق # TODO: REPLACE_ORCHESTRATION. استبدِل هذا السطر بالكامل بالرمز التالي:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3- التواصل مع موظّف الدعم الأساسي
👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
ابحث عن التعليق # TODO: REPLACE_ADD_SUBAGENT. استبدِل هذا السطر بالكامل بالرمز التالي:
sub_agents=[multimedia_agent],
يجمع هذا العنصر الفردي أربعة "خبراء" في كيان واحد قابل للاستدعاء.
4. تدفّق البيانات بين الوكلاء
يخزّن كل وكيل الناتج في سياق مشترك يمكن للوكلاء اللاحقين الوصول إليه:
5- افتح التطبيق (تخطَّ هذه الخطوة إذا كان التطبيق لا يزال قيد التشغيل)
👉💻 بدء التطبيق:
cd ~/way-back-home/level_2/
./start_app.sh
👉 انقر على Local: http://localhost:5173/ من نافذة Terminal.
6. اختبار تحميل الصورة
👉 في واجهة المحادثة، اختَر أيًا من الصور هنا وحمِّلها إلى واجهة المستخدم:
في واجهة المحادثة، أخبر الموظّف عن سياقك المحدّد:
Here is the survivor note
بعد ذلك، أرفِق الصورة هنا.

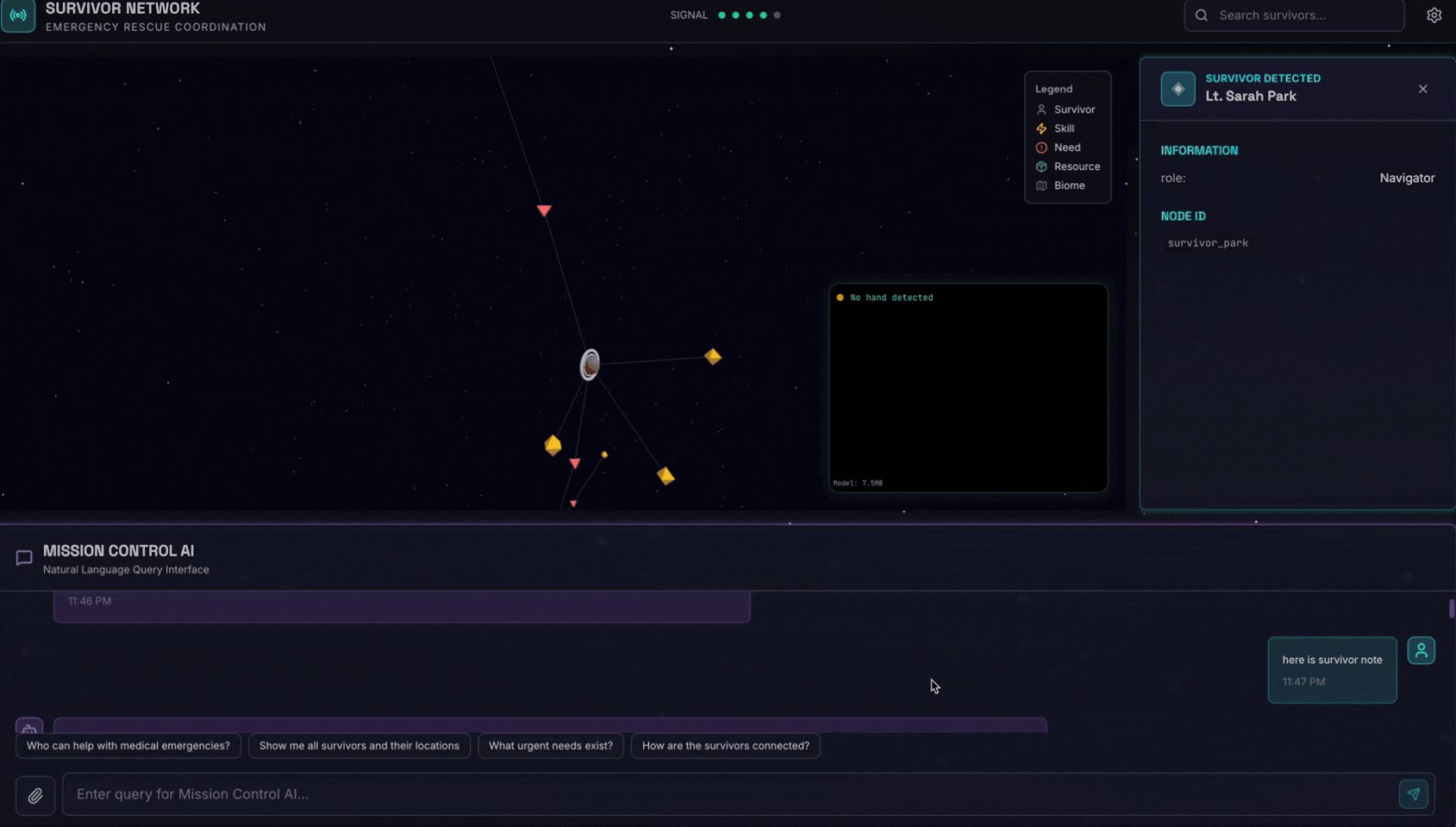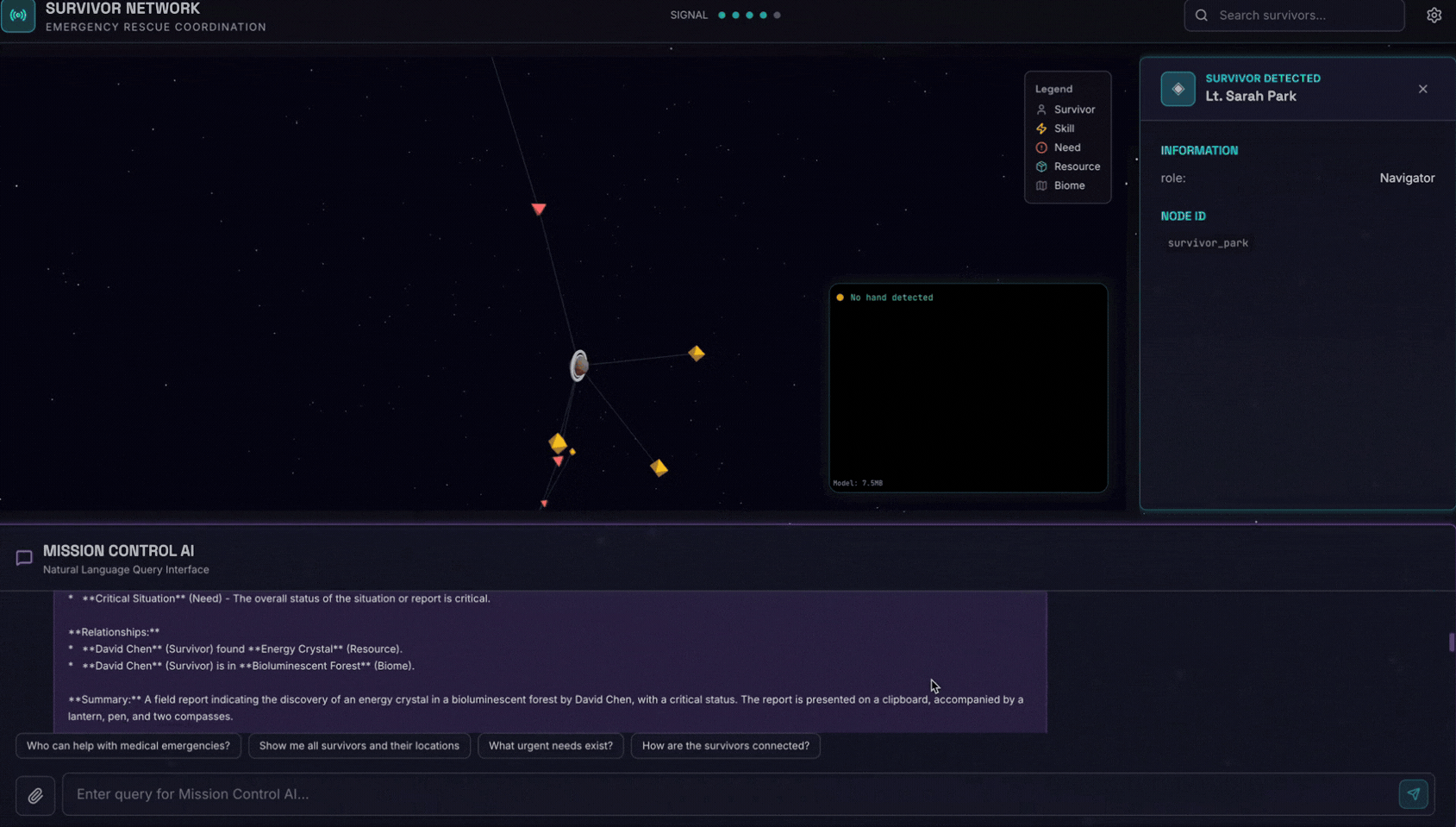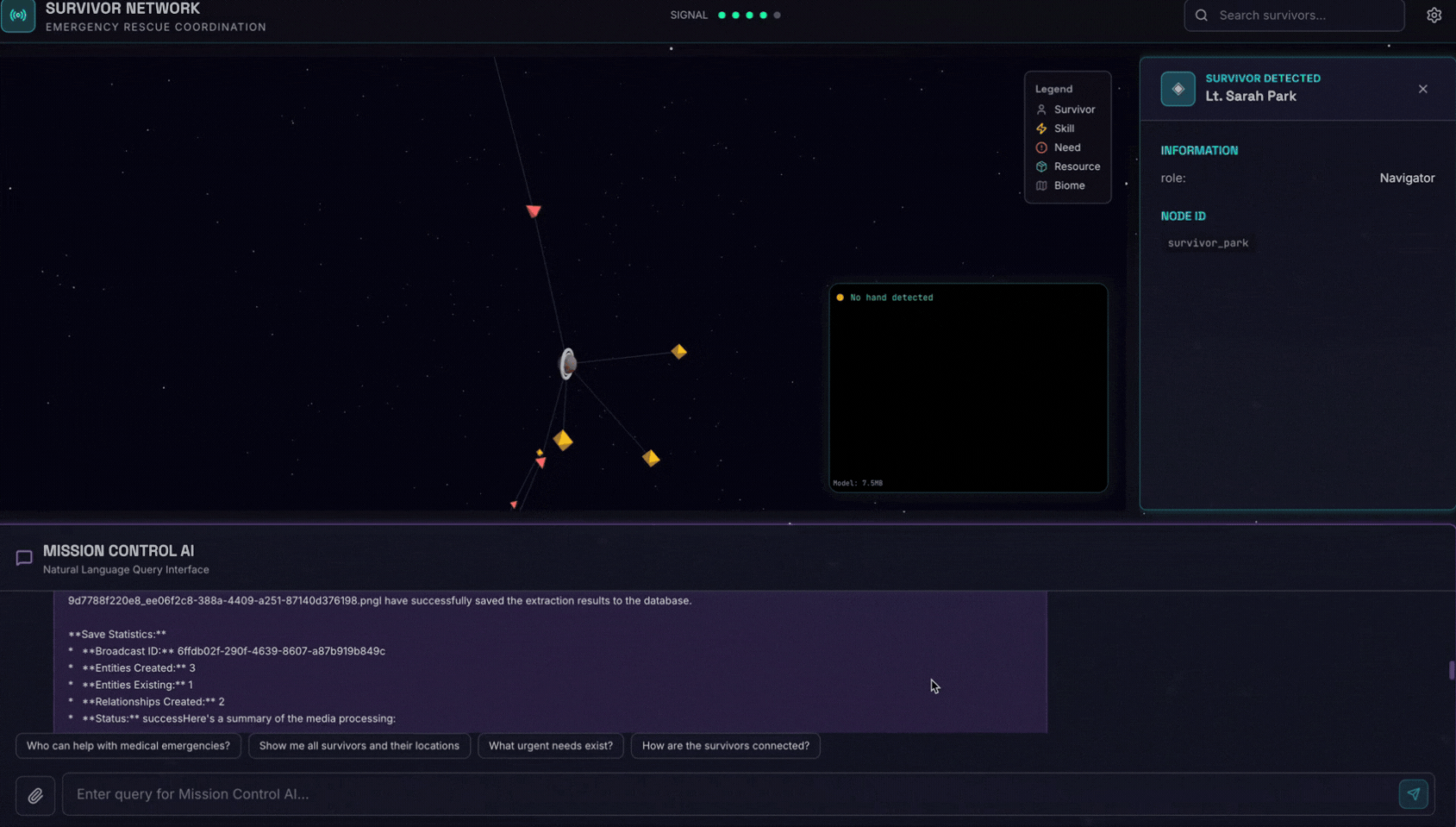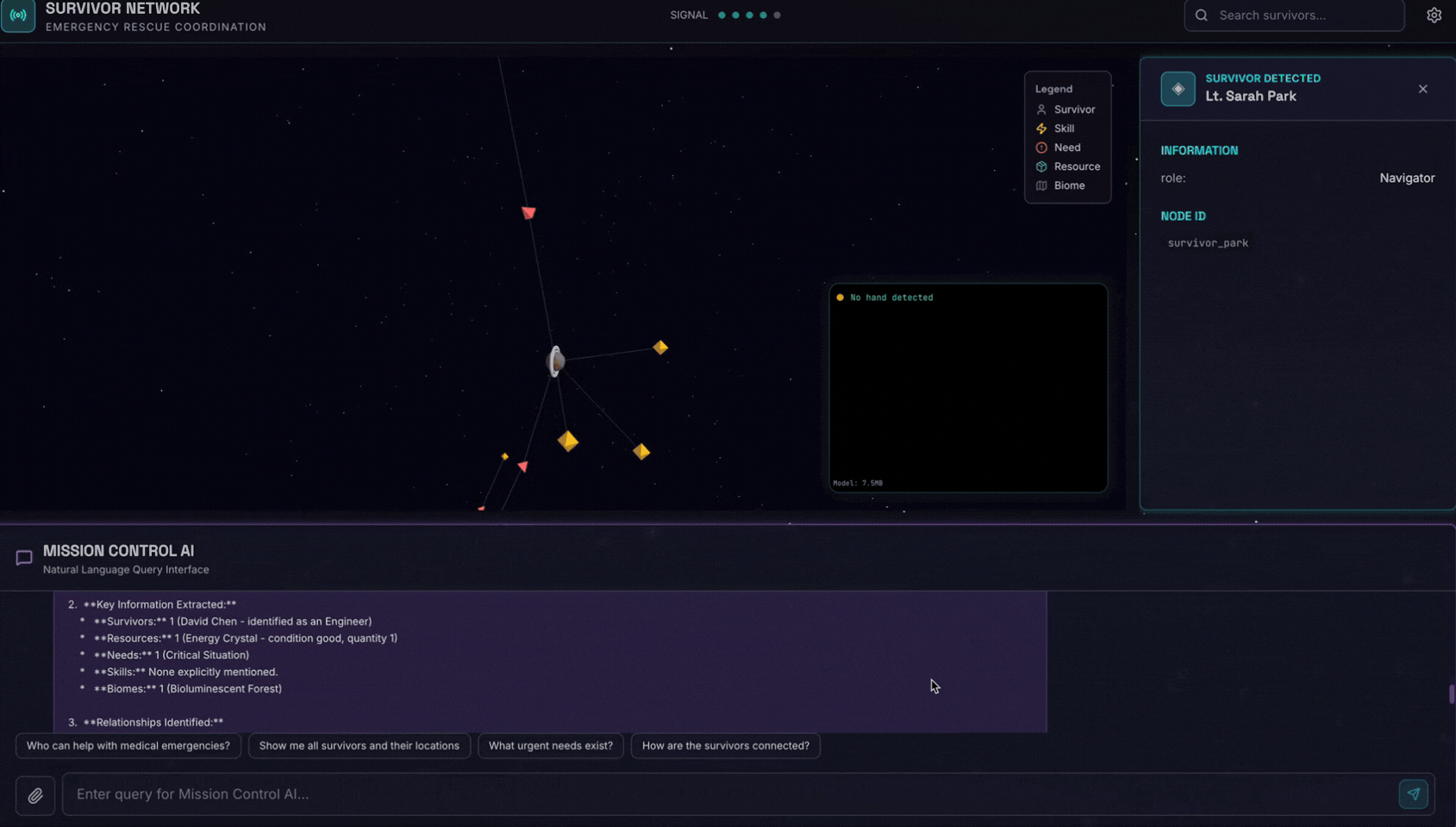
👉💻 في الوحدة الطرفية، بعد الانتهاء من الاختبار، اضغط على "Ctrl+C" لإنهاء العملية.
6. التحقّق من إمكانية تحميل الوسائط المتعدّدة في حزمة GCS
- افتح Google Cloud Console Storage.
- اختَر "حزمة" في Cloud Storage
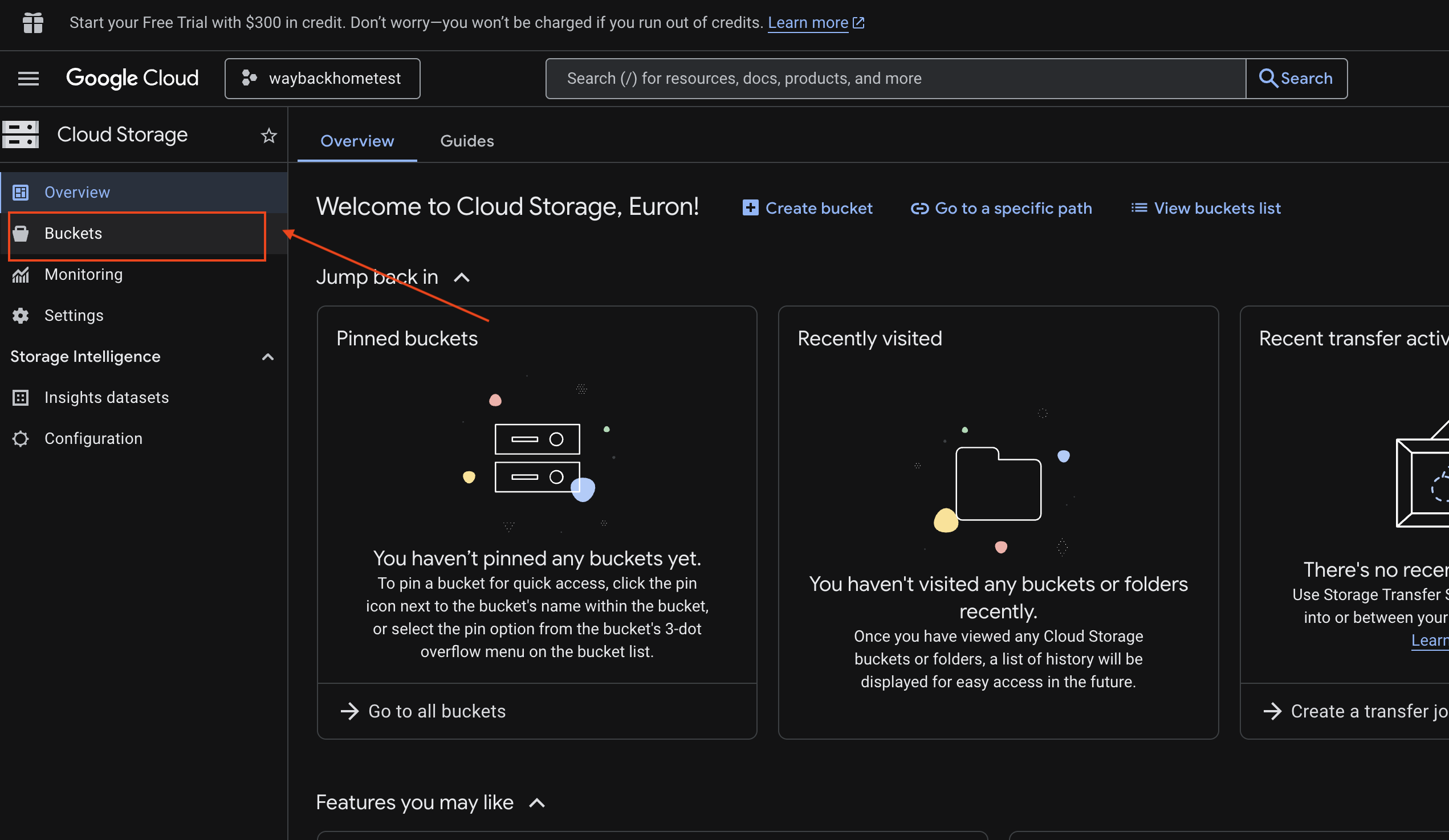
- اختَر الحزمة وانقر على
media.
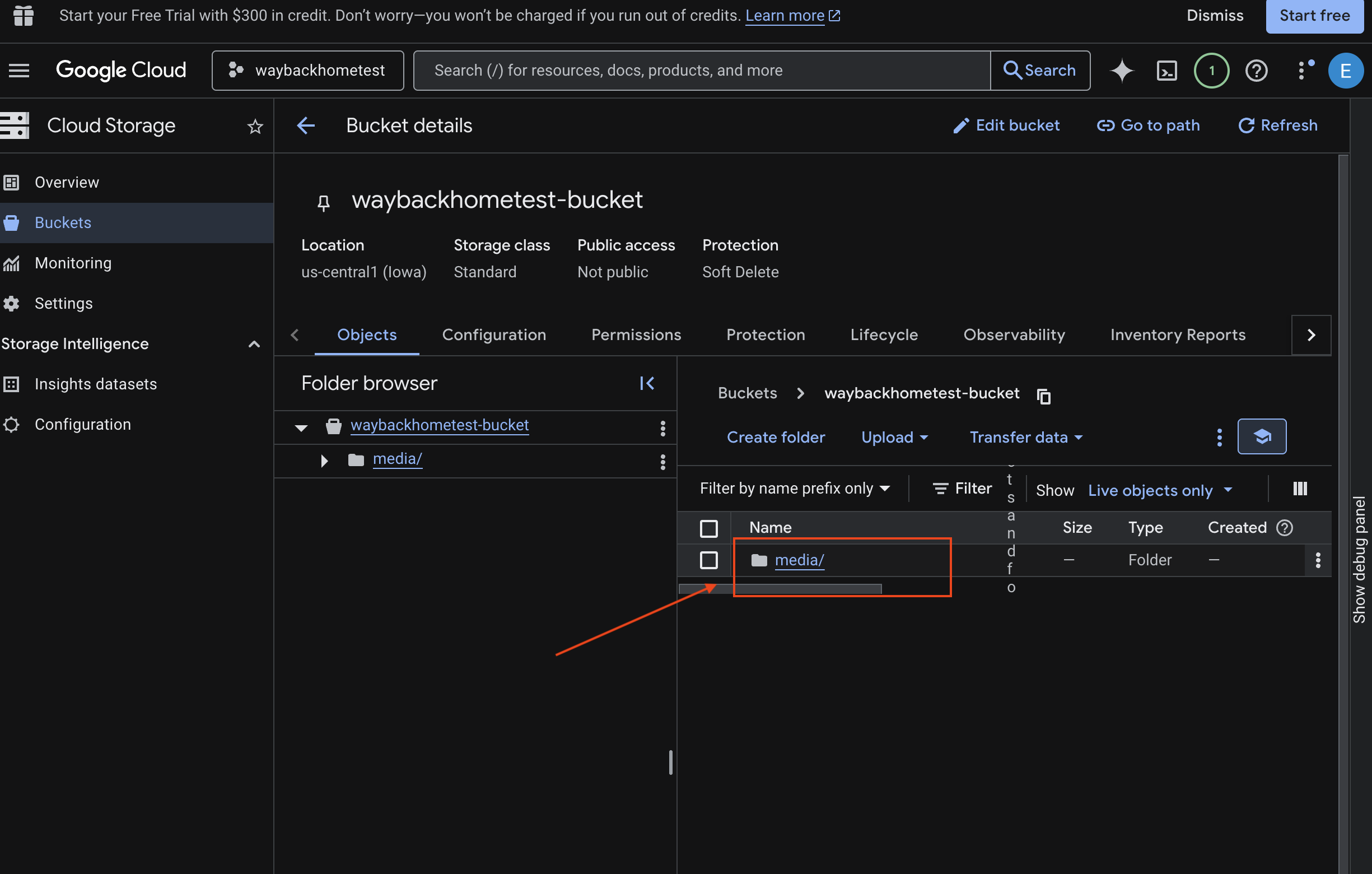
- يمكنك الاطّلاع على الصورة التي حمّلتها هنا.
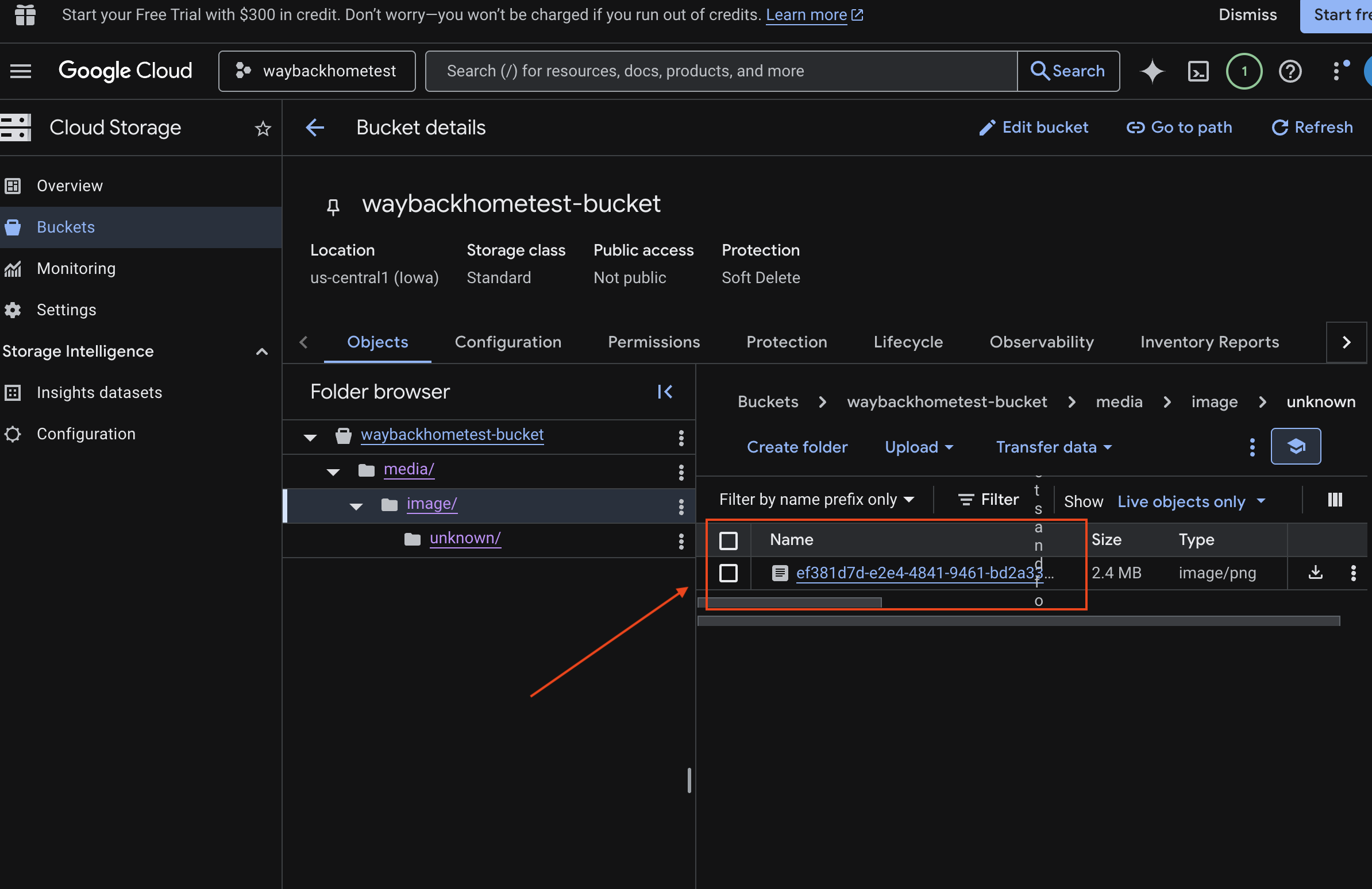
7. التحقّق من ميزة "التحميل المتعدّد الوسائط" في Spanner (اختياري)
في ما يلي مثال على الناتج في واجهة المستخدم test_photo1.
- افتح Google Cloud Console Spanner.
- اختَر مثيلك:
Survivor Network - اختَر قاعدة البيانات:
graph-db - في الشريط الجانبي الأيمن، انقر على Spanner Studio.
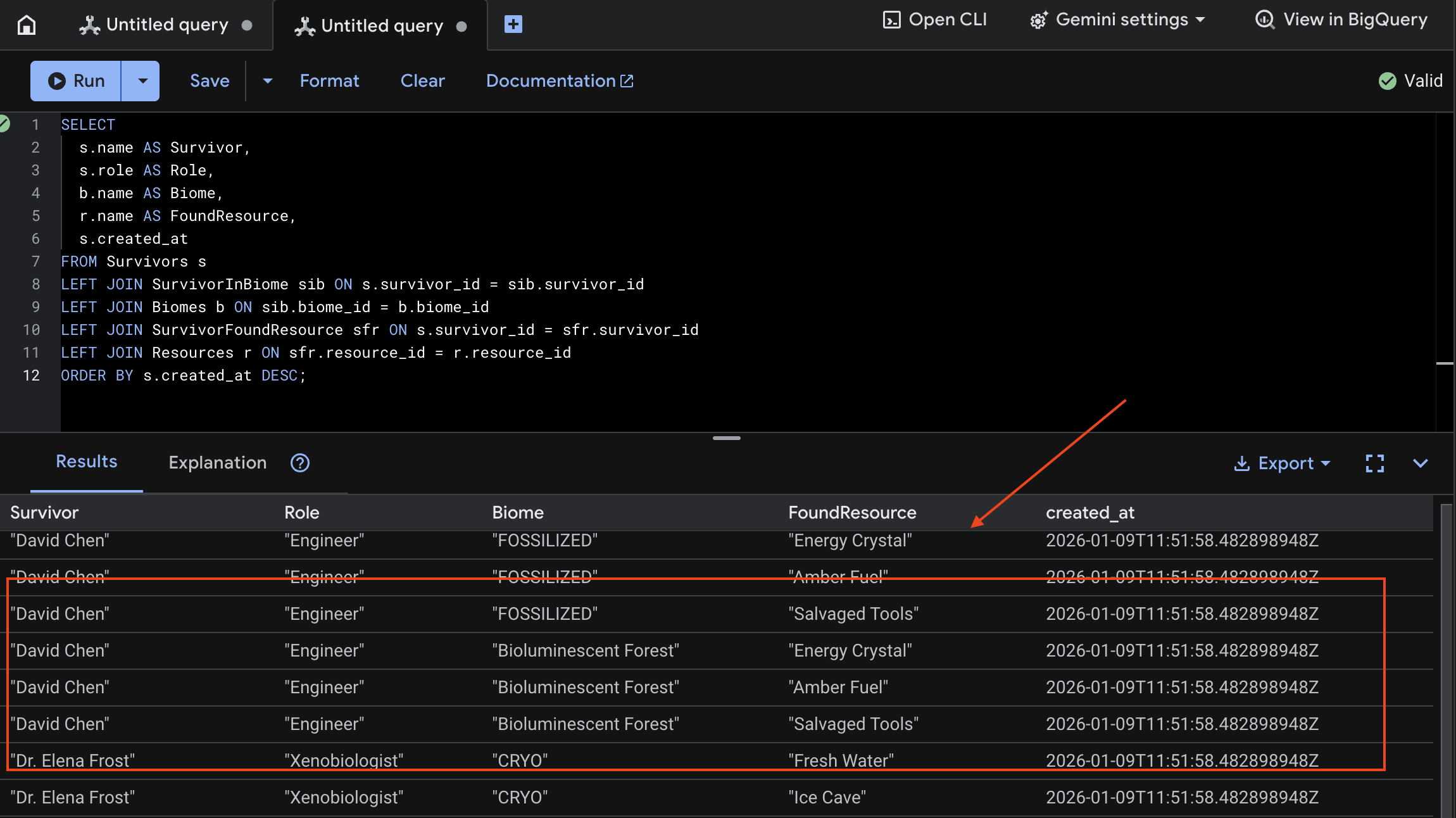
👉 في Spanner Studio، استخدِم طلب بحث عن البيانات الجديدة:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
يمكننا التحقّق من ذلك من خلال الاطّلاع على النتيجة أدناه:
12. ☕️ [اختياري] "بنك المعلومات" مع "محرك المساعد"
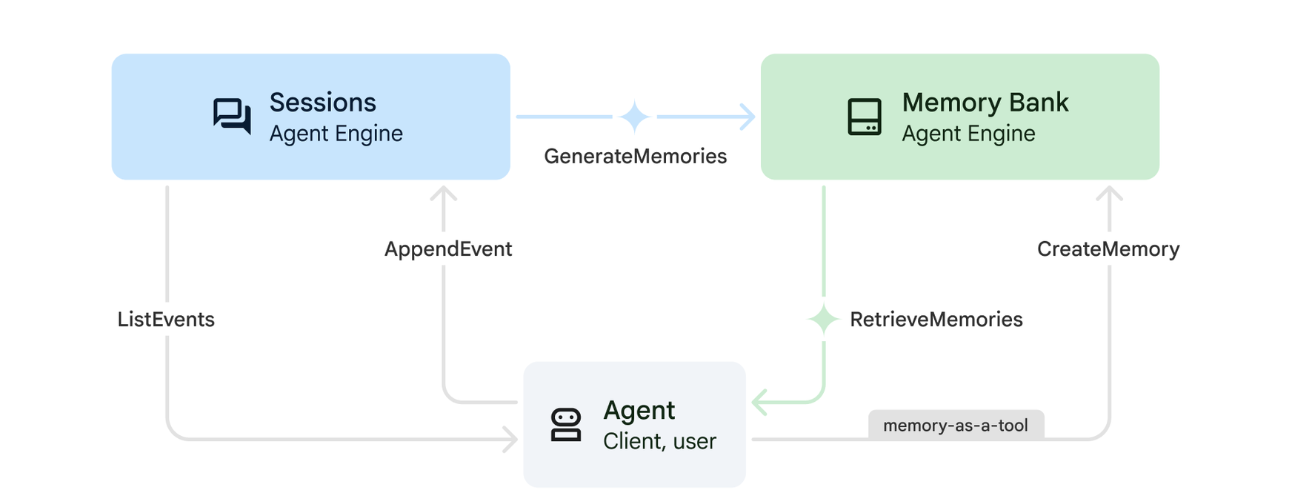
1. طريقة عمل ميزة "هذه السنة"
يستخدم النظام نهج الذاكرة المزدوجة للتعامل مع السياق الفوري والتعلم على المدى الطويل.
2. ما هي مواضيع الذكريات؟
تحدّد مواضيع الذاكرة فئات المعلومات التي يجب أن يتذكّرها الوكيل في المحادثات. يمكنك اعتبارها خزائن لحفظ أنواع مختلفة من إعدادات المستخدم المفضّلة.
الموضوعان اللذان اخترناهما:
search_preferences: طريقة البحث المفضّلة لدى المستخدم- هل يفضّلون البحث عن الكلمات الرئيسية أو البحث الدلالي؟
- ما هي المهارات أو المناطق الأحيائية التي يبحثون عنها غالبًا؟
- مثال على الذاكرة: "يفضّل المستخدم البحث الدلالي عن المهارات الطبية"
urgent_needs_context: الأزمات التي يتم تتبّعها- ما هي الموارد التي تتم مراقبتها؟
- ما هي الفئات التي تثير قلقهم؟
- مثال على الذاكرة: "يتتبّع المستخدم نقص الأدوية في معسكر الشمال"
3- إعداد مواضيع الذكريات
تحدّد مواضيع الذاكرة المخصّصة ما يجب أن يتذكّره الوكيل. يتم ضبط هذه الإعدادات عند نشر Agent Engine.
👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
سيؤدي ذلك إلى فتح ~/way-back-home/level_2/backend/deploy_agent.py في المحرِّر.
نحدّد عناصر بنية MemoryTopic لتوجيه النموذج اللغوي الكبير بشأن المعلومات التي يجب استخراجها وحفظها.
👉في الملف deploy_agent.py، استبدِل # TODO: SET_UP_TOPIC بما يلي:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. دمج الوكيل
يجب أن يكون رمز الوكيل على دراية بـ "بنك الذاكرة" لحفظ المعلومات واسترجاعها.
👉💻 في الوحدة الطرفية، افتح الملف في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
سيؤدي ذلك إلى فتح ~/way-back-home/level_2/backend/agent/agent.py في المحرِّر.
إنشاء وكيل
عند إنشاء البرنامج، نمرّر after_agent_callback لضمان حفظ الجلسات في الذاكرة بعد التفاعلات. يتم تشغيل الدالة add_session_to_memory بشكل غير متزامن لتجنُّب إبطاء ردّ المحادثة.
👉في الملف agent.py، ابحث عن التعليق # TODO: REPLACE_ADD_SESSION_MEMORY، استبدِل هذا السطر بالكامل بالرمز التالي:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
الحفظ في الخلفية
👉في الملف agent.py، ابحث عن التعليق # TODO: REPLACE_ADD_MEMORY_BANK_TOOL، استبدِل هذا السطر بالكامل بالرمز التالي:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉في الملف agent.py، ابحث عن التعليق # TODO: REPLACE_ADD_CALLBACK، استبدِل هذا السطر بالكامل بالرمز التالي:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
إعداد خدمة جلسات Vertex AI
👉💻 في الوحدة الطرفية، افتح الملف chat.py في "محرِّر Cloud Shell" من خلال تنفيذ الأمر التالي:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉في ملف chat.py، ابحث عن التعليق # TODO: REPLACE_VERTEXAI_SERVICES، ثم استبدِل هذا السطر بالكامل بالرمز التالي:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [اختياري] ربط الوكيل بـ Agent Engine
1. الإعداد والنشر
قبل اختبار ميزات الذاكرة، عليك نشر الوكيل مع مواضيع الذاكرة الجديدة والتأكّد من إعداد بيئتك بشكل صحيح.
لقد وفّرنا نصًا برمجيًا مناسبًا للتعامل مع هذه العملية.
تشغيل نص برمجي للنشر
👉💻 في الوحدة الطرفية، شغِّل نص النشر البرمجي:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
ينفِّذ هذا النص البرمجي الإجراءات التالية:
- يتم تنفيذ
backend/deploy_agent.pyلتسجيل الوكيل ومواضيع الذاكرة في Vertex AI. - تعرض هذه السمة معرّف محرّك بحث الوكيل الجديد.
- يتم تعديل ملف
.envتلقائيًا باستخدامAGENT_ENGINE_ID. - تأكَّد من ضبط
USE_MEMORY_BANK=TRUEفي ملف.env.
[!IMPORTANT] إذا أجريت تغييرات على custom_topics في deploy_agent.py، عليك إعادة تشغيل هذا النص البرمجي لتعديل Agent Engine.
التحقّق من "بنك الذاكرة"
يمكنك الآن التأكّد من أنّ بنك الذاكرة يعمل من خلال تعليم الوكيل أحد التفضيلات والتحقّق من استمراره في الجلسات المختلفة.
الخطوة الأولى افتح التطبيق
افتح التطبيق مرة أخرى باتّباع التعليمات أدناه: إذا كانت نافذة الوحدة الطرفية السابقة لا تزال قيد التشغيل، أنهِها بالضغط على Ctrls+C.
👉💻 بدء التطبيق:
cd ~/way-back-home/level_2/
./start_app.sh
👉 انقر على Local: http://localhost:5173/ من نافذة Terminal.
الخطوة الثانية: اختبار "بنك الذاكرة" باستخدام النص
في واجهة المحادثة، أخبر الموظّف عن سياقك المحدّد:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 انتظِر لمدة 30 ثانية تقريبًا حتى تتم معالجة الذاكرة في الخلفية.
الخطوة الثالثة: بدء جلسة جديدة
أعِد تحميل الصفحة لمحو سجلّ المحادثات الحالي (الذاكرة القصيرة المدى).
اطرح سؤالاً يعتمد على السياق الذي قدّمته سابقًا:
"What kind of missions am I interested in?"
الردّ المتوقّع:
"استنادًا إلى محادثاتك السابقة، أنت مهتم بما يلي:
- مهمات الإنقاذ الطبي
- عمليات في الجبال أو على ارتفاعات عالية
- المهارات المطلوبة: الإسعافات الأولية، التسلق
هل تريد أن أعثر لك على ناجين يستوفون هذه المعايير؟"
الخطوة الرابعة: الاختبار باستخدام ميزة "تحميل صورة"
حمِّل صورة واطرح السؤال التالي:
remember this
يمكنك اختيار أي من الصور هنا أو صورتك الخاصة وتحميلها إلى واجهة المستخدم:
الخطوة الخامسة: التأكّد من صحة المعلومات في Vertex AI Agent Engine
الانتقال إلى Google Cloud Console Agent Engine
- تأكَّد من اختيار المشروع من أداة اختيار المشاريع في أعلى يمين الصفحة:
- تحقَّق من محرك الوكيل الذي نشرته للتو من الأمر السابق
use_memory_bank.sh: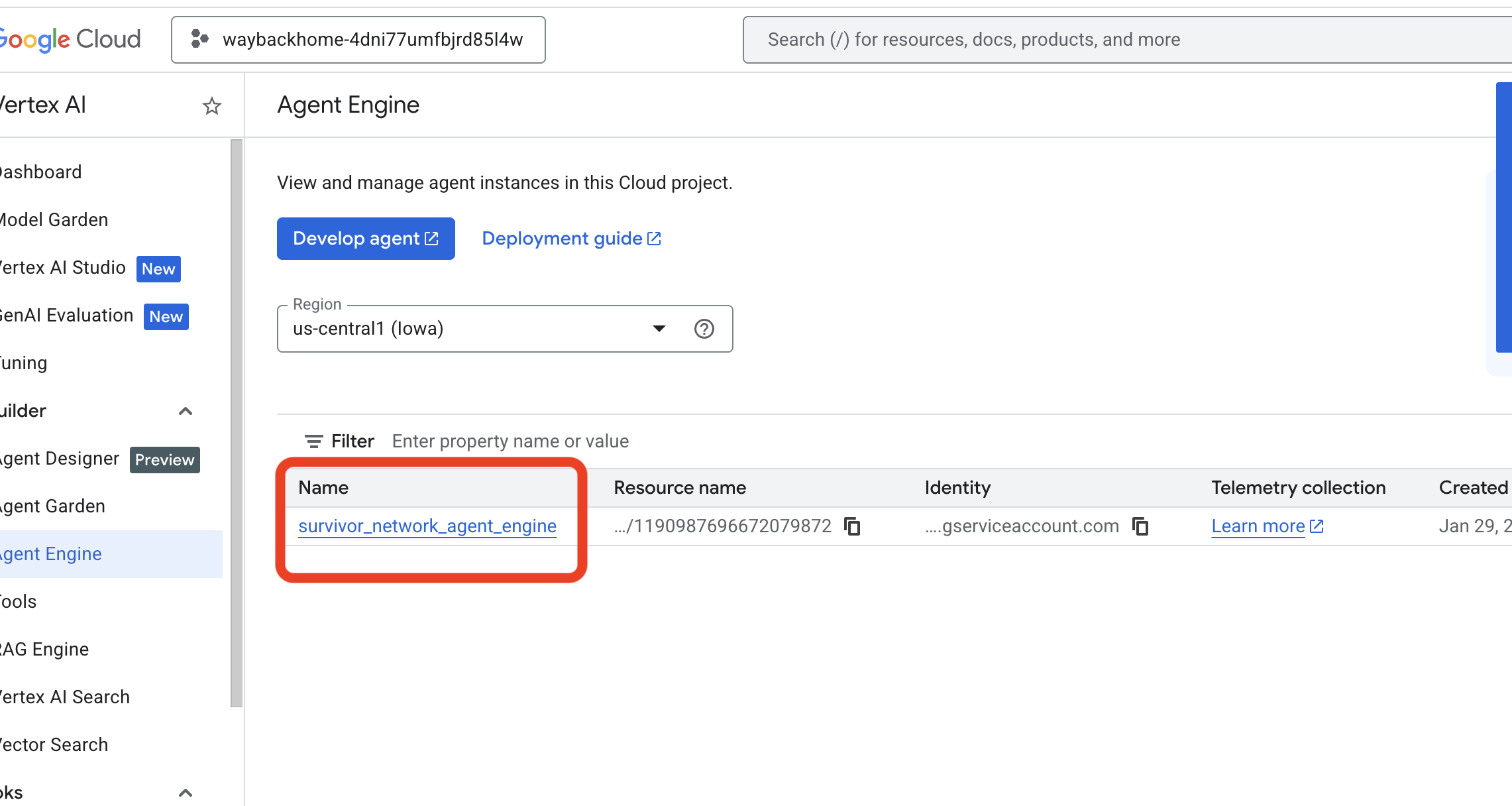 انقر على محرك الوكيل الذي أنشأته للتو.
انقر على محرك الوكيل الذي أنشأته للتو. - انقر على علامة التبويب
Memoriesفي هذا الوكيل الذي تم نشره، ويمكنك الاطّلاع على كل الذكريات هنا.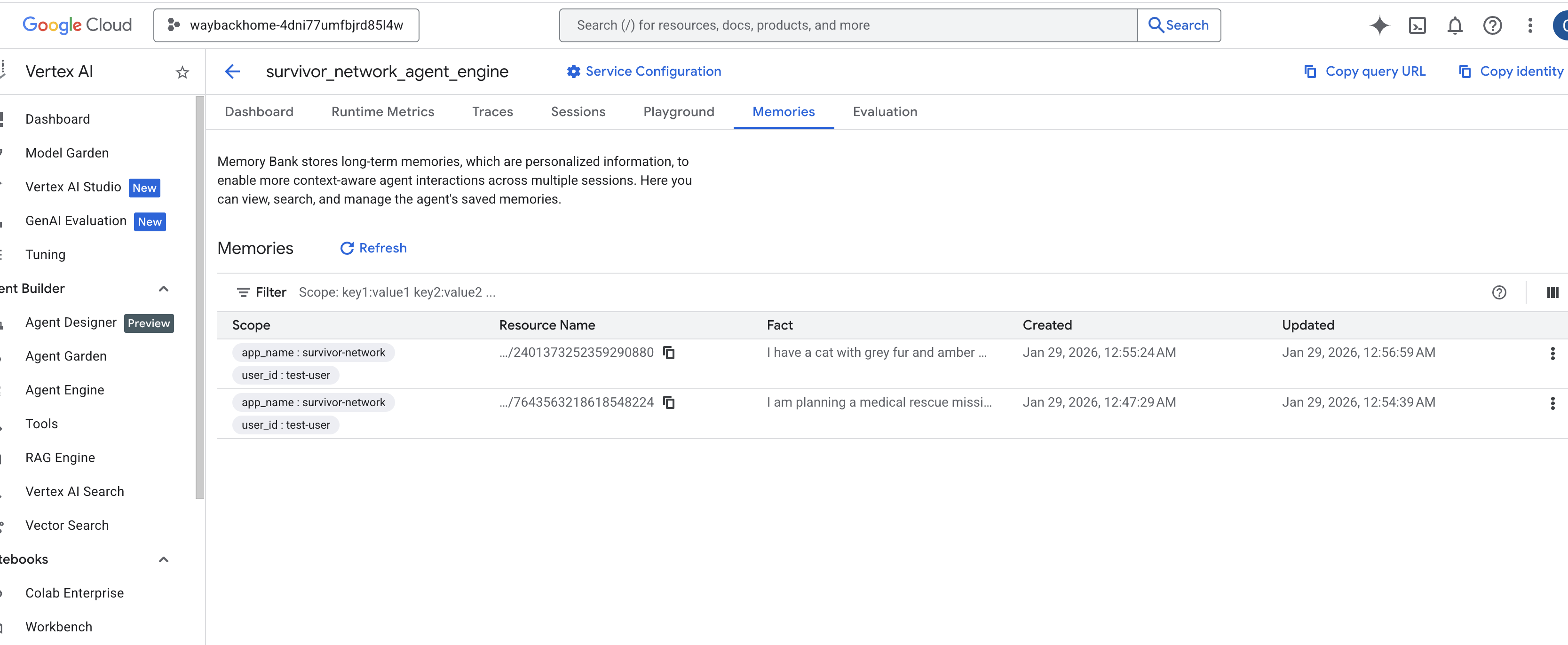
👉💻 عند الانتهاء من الاختبار، انقر على "Ctrl + C" في الوحدة الطرفية لإنهاء العملية.
🎉 تهانينا! لقد أضفت للتوّ قاعدة بيانات الذاكرة إلى الوكيل.
14. ☕️ [اختياري] النشر على Cloud Run
1. تشغيل نص النشر البرمجي
👉💻 شغِّل نص النشر البرمجي:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
بعد نشرها بنجاح، سيتوفّر لديك عنوان URL، وهو عنوان URL الذي تم نشره. 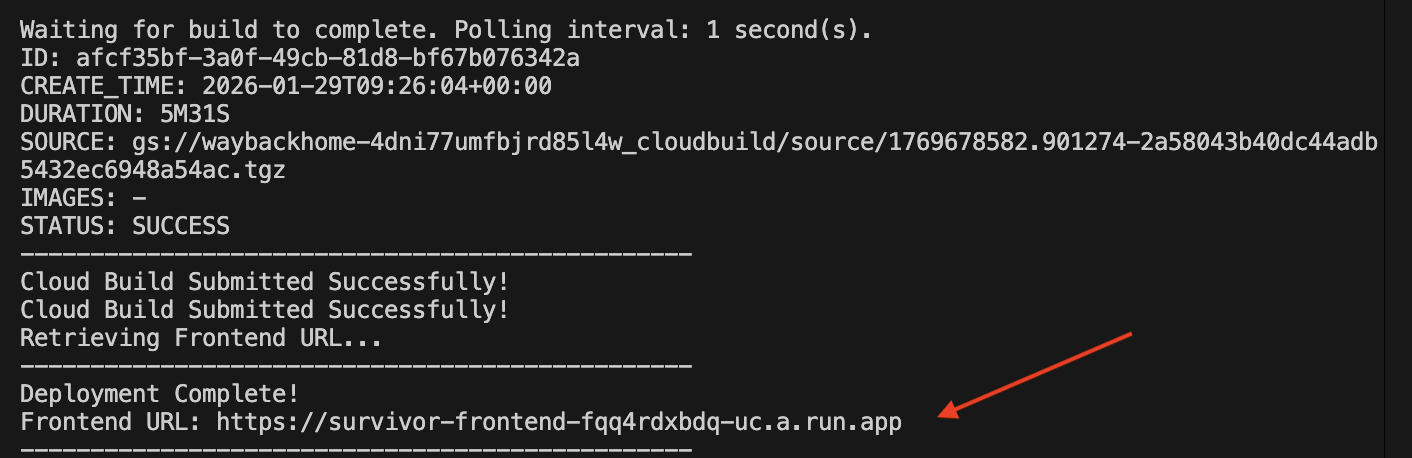
👉💻 قبل الحصول على عنوان URL، امنح الإذن من خلال تنفيذ ما يلي:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
انتقِل إلى عنوان URL الذي تم نشره، وسيظهر تطبيقك مباشرةً هناك.
2. التعرّف على مسار الإنشاء
يحدّد ملف cloudbuild.yaml الخطوات التسلسلية التالية:
- إنشاء الخلفية: ينشئ صورة Docker من
backend/Dockerfile. - نشر الخلفية: ينشر حاوية الخلفية إلى Cloud Run.
- عنوان URL لعملية الالتقاط: يحصل على عنوان URL الجديد للخادم الخلفي.
- إنشاء الواجهة الأمامية:
- تثبيت التبعيات
- ينشئ تطبيق React، مع إدخال
VITE_API_URL=.
- صورة الواجهة الأمامية: تنشئ صورة Docker من
frontend/Dockerfile(تغليف مواد العرض الثابتة). - تفعيل الواجهة الأمامية: يقوم بتفعيل حاوية الواجهة الأمامية.
3- التحقّق من عملية النشر
بعد اكتمال عملية الإنشاء (راجِع رابط السجلات الذي يوفّره النص البرمجي)، يمكنك التأكّد مما يلي:
- انتقِل إلى وحدة تحكّم Cloud Run.
- ابحث عن خدمة
survivor-frontend. - انقر على عنوان URL لفتح التطبيق.
- أدخِل طلب بحث للتأكّد من أنّ الواجهة الأمامية يمكنها التواصل مع الواجهة الخلفية.
(اختياري) 4. النشر اليدوي
إذا كنت تفضّل تنفيذ الأوامر يدويًا أو فهم العملية بشكل أفضل، إليك كيفية استخدام cloudbuild.yaml مباشرةً.
كتابة cloudbuild.yaml
يخبر ملف cloudbuild.yaml خدمة Google Cloud Build بالخطوات التي يجب تنفيذها.
- الخطوات: قائمة بالإجراءات المتسلسلة. يتم تنفيذ كل خطوة في حاوية (مثل
dockerوgcloudوnodeوbash). - عمليات الاستبدال: المتغيّرات التي يمكن تمريرها في مدّة التصميم (مثل
$_REGION). - مساحة العمل: دليل مشترك يمكن للخطوات مشاركة الملفات فيه (مثل طريقة مشاركة
backend_url.txt).
تنفيذ عملية النشر
للنشر يدويًا بدون النص البرمجي، استخدِم الأمر gcloud builds submit. يجب تمرير متغيّرات الاستبدال المطلوبة.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. الخاتمة
1. المشاريع التي أنشأتها
✅ قاعدة بيانات الرسومات البيانية: Spanner مع عُقد (الناجون والمهارات) وحواف (العلاقات)
✅ بحث مستنِد إلى الذكاء الاصطناعي: البحث المستنِد إلى الكلمات الرئيسية والدلالات والبحث المختلط باستخدام عمليات التضمين
✅ مسار متعدد الوسائط: استخراج الكيانات من الصور أو الفيديوهات باستخدام Gemini
✅ نظام متعدد الوكلاء: سير عمل منسَّق باستخدام "حزمة تطوير التطبيقات"
✅ بنك الذاكرة: تخصيص طويل الأمد باستخدام Vertex AI
✅ النشر في مرحلة الإنتاج: Cloud Run + Agent Engine
2. ملخّص البنية
3- النقاط الرئيسية التي تم تعلّمها
- التوليد المعزّز بالاسترجاع (Graph RAG): يجمع بين بنية قاعدة بيانات الرسوم البيانية والتضمينات الدلالية لإجراء بحث ذكي
- أنماط الوكلاء المتعدّدين: مسارات متسلسلة لسير العمل المعقّد والمتعدّد الخطوات
- الذكاء الاصطناعي المتعدد الوسائط: استخراج بيانات منظَّمة من وسائط غير منظَّمة (صور/فيديوهات)
- الوكلاء ذوو الحالة: تتيح Memory Bank التخصيص على مستوى الجلسات
4. محتوى ورشة العمل
- Level0: التعريف عن نفسك
- Level1: تحديد الموقع الجغرافي بدقة
- Level2 This One: إنشاء وكيل ذكاء اصطناعي متعدد الوسائط باستخدام Graph RAG وADK وMemory Bank
- Level3: إنشاء وكيل بث ثنائي الاتجاه في حزمة تطوير التطبيقات (ADK)
- Level4: نظام مباشر ثنائي الاتجاه ومتعدد الوكلاء
- Level5: بنية مستندة إلى الأحداث باستخدام "حزمة تطوير التطبيقات على Android" من Google وA2A وKafka