
1. Einführung

1. Die Herausforderung
Bei der Katastrophenhilfe ist es wichtig, Überlebende mit unterschiedlichen Fähigkeiten, Ressourcen und Bedürfnissen an verschiedenen Orten zu koordinieren. Dazu sind intelligente Datenverwaltungs- und Suchfunktionen erforderlich. In diesem Workshop lernen Sie, wie Sie ein KI-System für die Produktion erstellen, das Folgendes kombiniert:
- 🗄️ Graph Database (Spanner): Speichern komplexer Beziehungen zwischen Überlebenden, Fähigkeiten und Ressourcen
- 🔍 KI-basierte Suche: Hybridsuche mit semantischen und Keyword-Einbettungen
- 📸 Multimodale Verarbeitung: Strukturierte Daten aus Bildern, Text und Video extrahieren
- 🤖 Orchestrierung mehrerer Agents: Spezialisierte Agents für komplexe Workflows koordinieren
- 🧠 Langzeitspeicher: Personalisierung mit Vertex AI Memory Bank
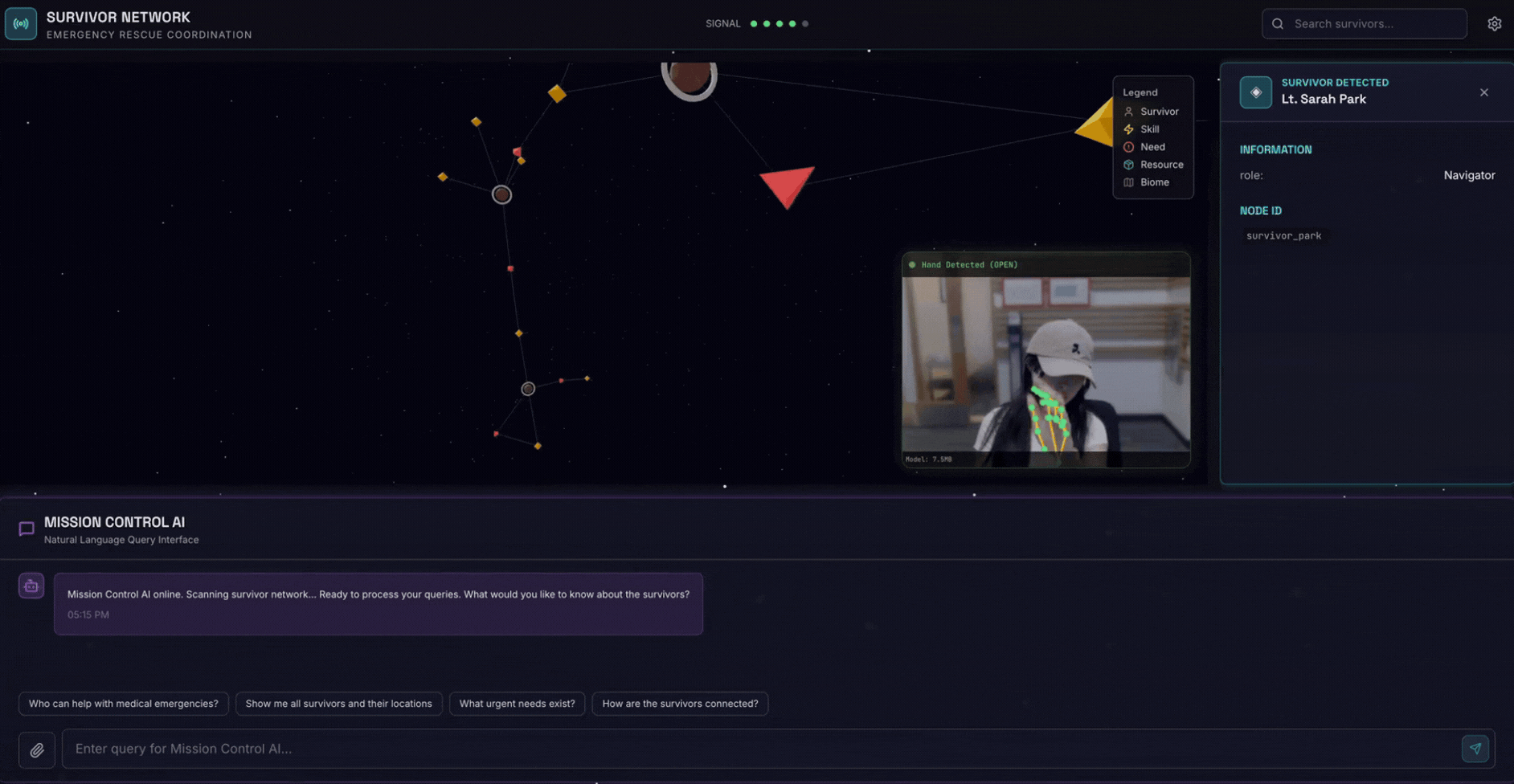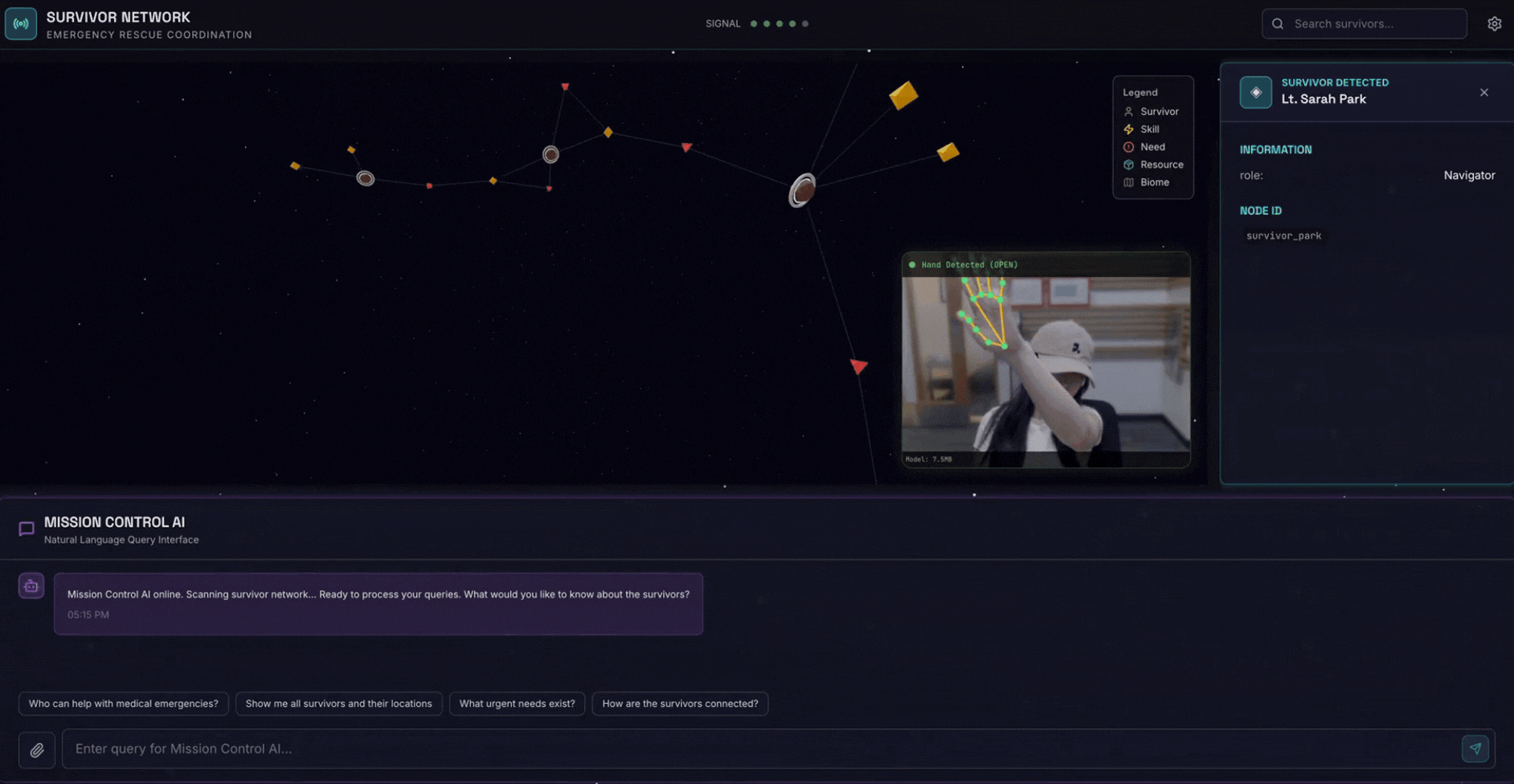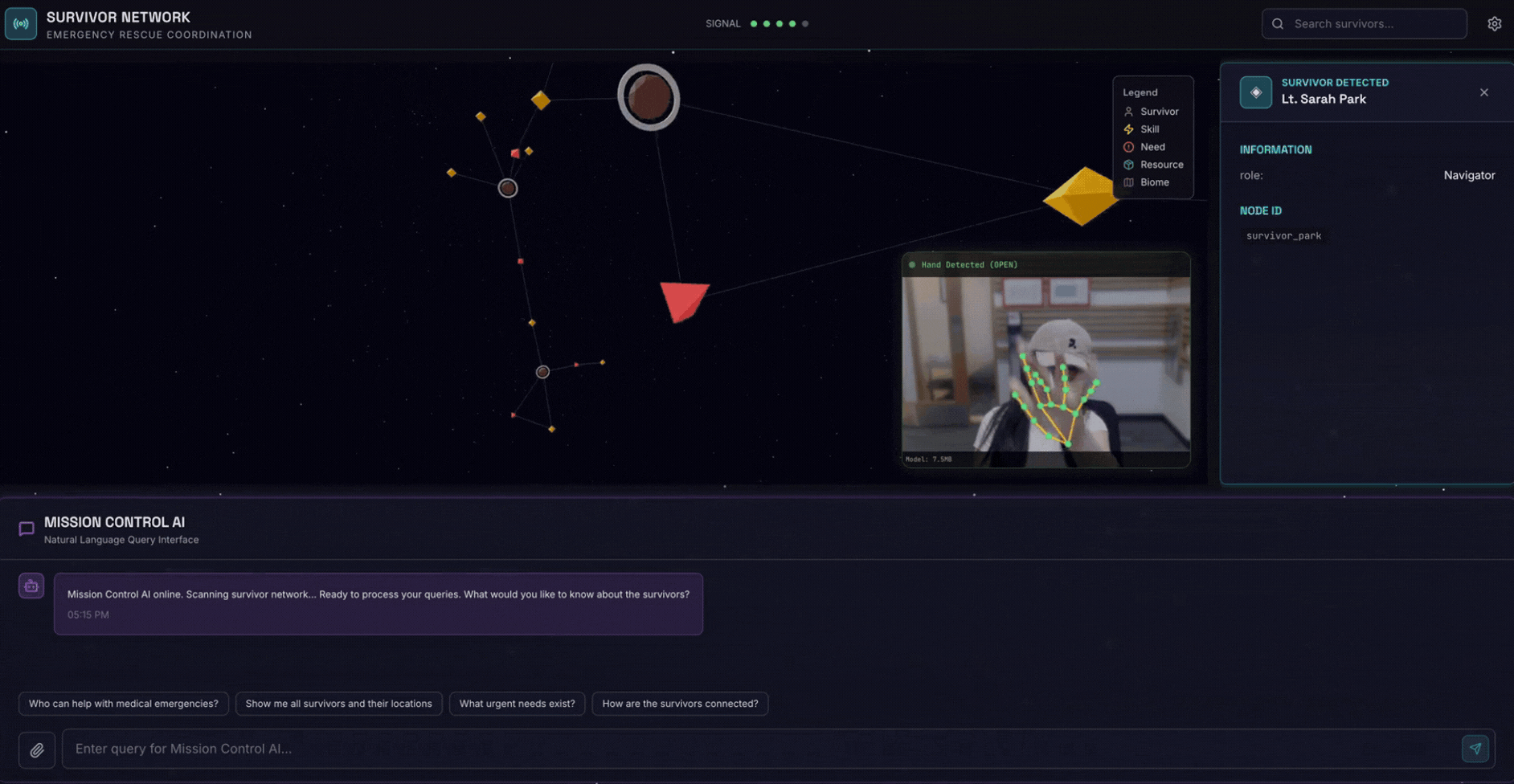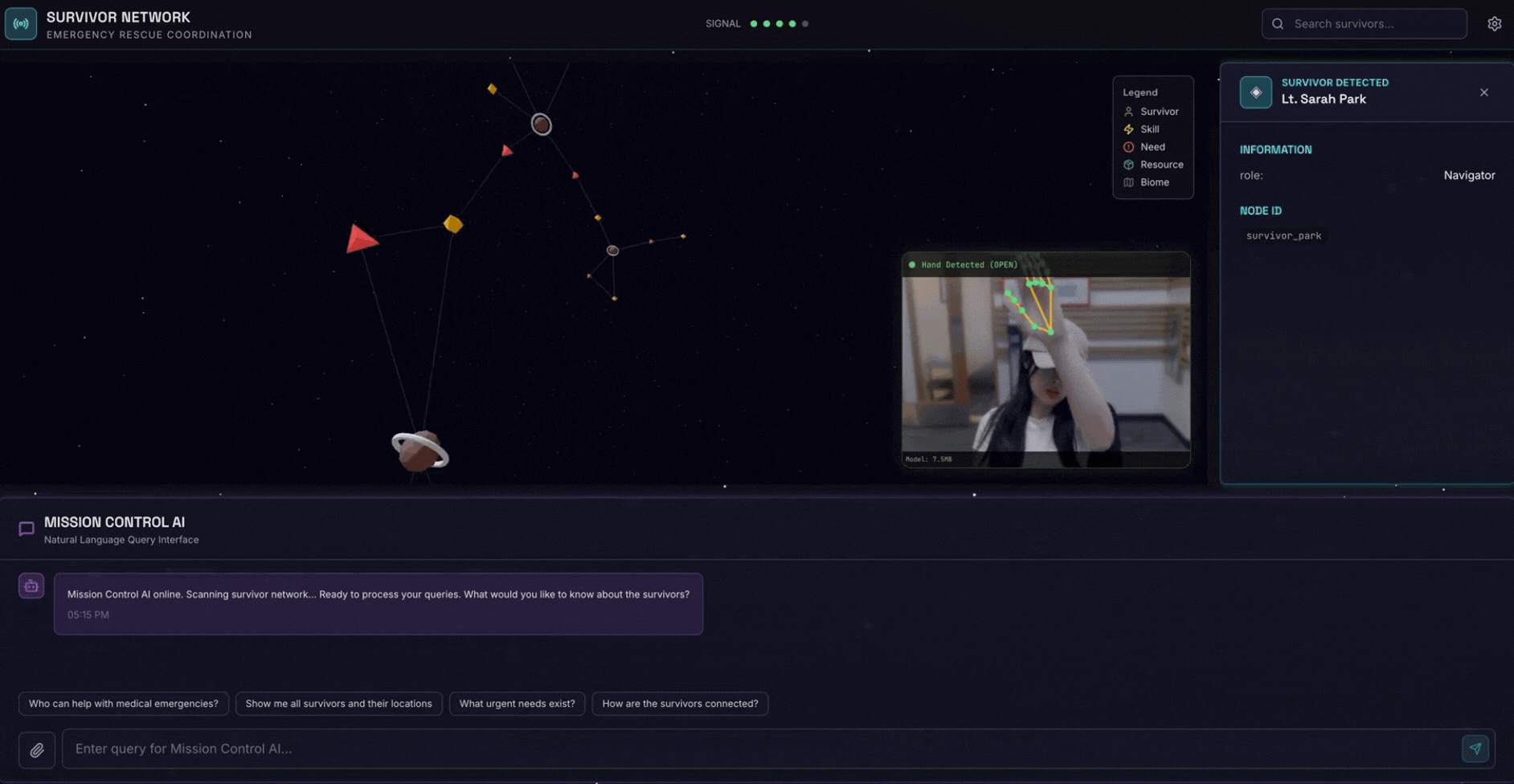
2. Umfang
Eine Graphdatenbank für das Überlebendennetzwerk mit:
- 🗺️ Interaktive 3D-Diagrammvisualisierung der Beziehungen zwischen Überlebenden
- 🔍 Intelligent Search (Stichwort-, semantische und hybride Suche)
- 📸 Multimodale Upload-Pipeline (Entitäten aus Bildern/Videos extrahieren)
- 🤖 Multi-Agent System für die Orchestrierung komplexer Aufgaben
- 🧠 Memory Bank-Integration für personalisierte Interaktionen
3. Kerntechnologien
Komponente | Technologie | Zweck |
Datenbank | Cloud Spanner Graph | Knoten (Überlebende, Fähigkeiten) und Kanten (Beziehungen) speichern |
AI Search | Gemini und Embeddings | Semantisches Verständnis + Ähnlichkeitssuche |
Agenten-Framework | ADK (Agent Development Kit) | KI-Workflows orchestrieren |
Arbeitsspeicher | Vertex AI Memory Bank | Langfristige Speicherung von Nutzereinstellungen |
Frontend | React + Three.js | Interaktive 3D-Visualisierung von Grafiken |
2. 🛠️ Umgebung vorbereiten (überspringen, wenn Sie an einem Workshop teilnehmen)
Teil 1: Rechnungskonto aktivieren
Für dieses Codelab benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Teil 2: Offene Umgebung
- 👉 Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- 👉 Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- 👉 Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- 👉💻 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list - 👉💻 Bootstrap-Projekt von GitHub klonen:
git clone https://github.com/gca-americas/way-back-home.git
Teil 3: Neues Projekt erstellen
👉💻 Machen Sie das Initialisierungsskript im Terminal ausführbar und führen Sie es aus:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Umgebung einrichten
1. Cloud Shell öffnen
Wenn das Terminal im Cloud Shell-Editor nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal.
2. Projekt konfigurieren
👉💻 Legen Sie im Terminal Ihre Projekt-ID fest:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Erforderliche APIs aktivieren (dauert ca. 2–3 Minuten):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Setupskript ausführen
👉💻 Führen Sie das Setupscript aus:
cd ~/way-back-home/level_2
./setup.sh
Dadurch wird .env für Sie erstellt. Öffnen Sie in Cloud Shell das Projekt way_back_home. Im Ordner level_2 sehen Sie die Datei .env, die für Sie erstellt wurde. Wenn Sie sie nicht finden, können Sie auf View -> Toggle Hidden File klicken, um sie aufzurufen. 
4. Beispieldaten laden
👉💻 Wechseln Sie zum Backend und installieren Sie die Abhängigkeiten:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Erste Überlebensdaten laden:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Dadurch wird Folgendes erstellt:
- Spanner-Instanz (
survivor-network) - Datenbank (
graph-db) - Alle Knoten- und Kantentabellen
- Attributgrafiken für Abfragen Erwartete Ausgabe:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
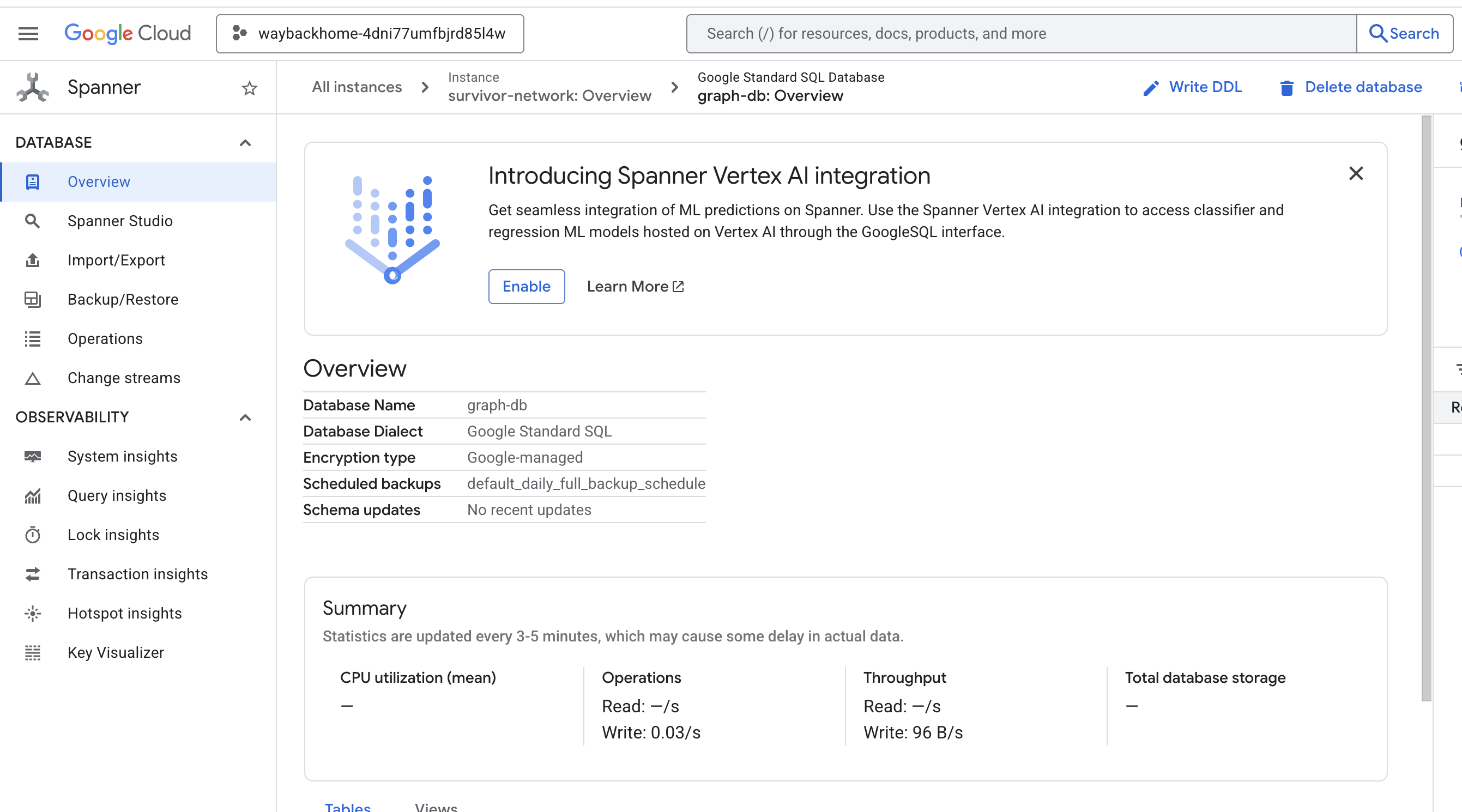
Wenn Sie nach Access your database at in der Ausgabe auf den Link klicken, können Sie die Google Cloud Console für Spanner öffnen.

Spanner wird in der Google Cloud Console angezeigt.
4. 🚀 Graphendaten in Spanner Studio visualisieren
In diesem Leitfaden erfahren Sie, wie Sie die Daten des Survivor Network-Diagramms mit Spanner Studio direkt in der Google Cloud Console visualisieren und damit interagieren können. So können Sie Ihre Daten überprüfen und die Struktur des Diagramms nachvollziehen, bevor Sie Ihren KI-Agenten erstellen.
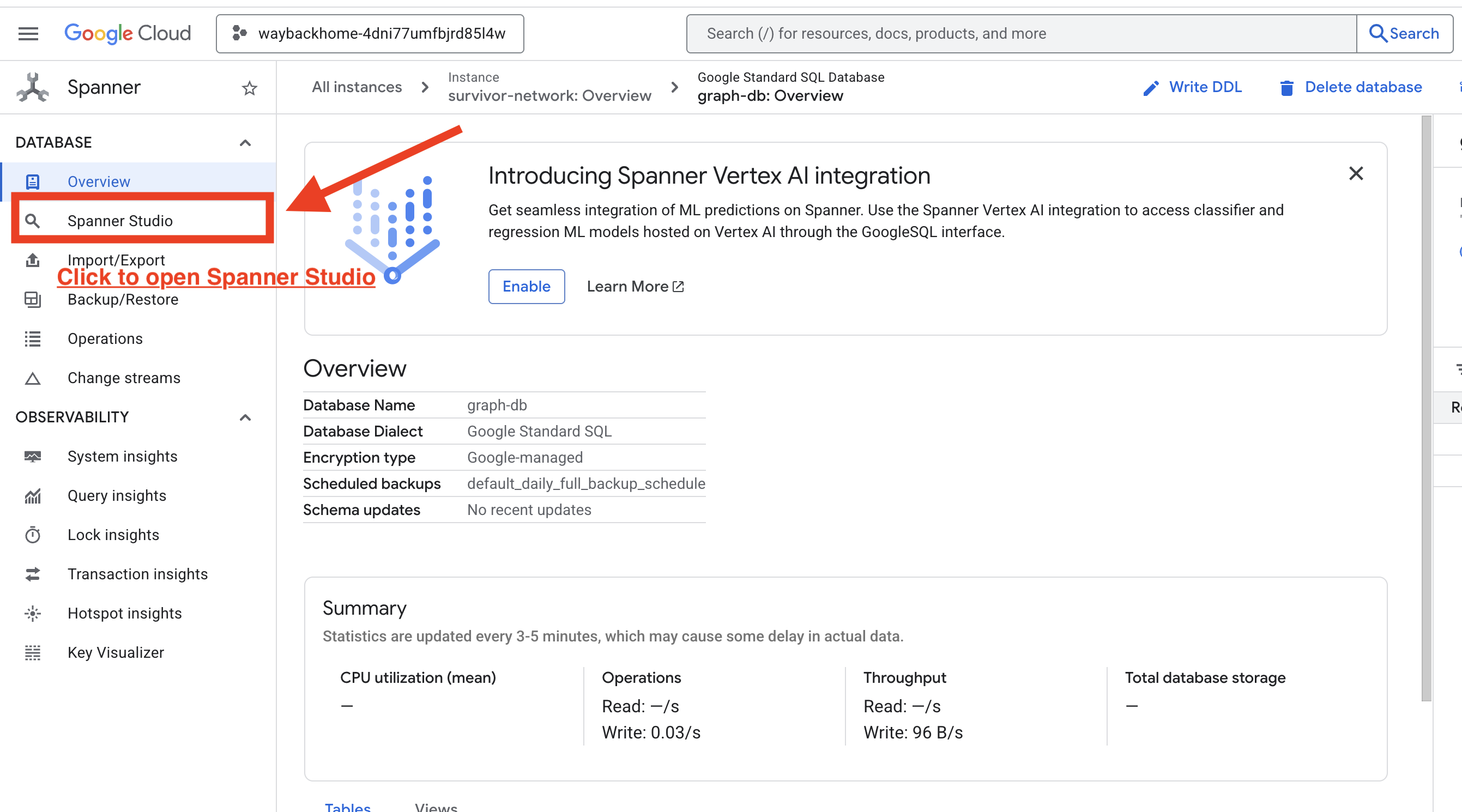
1. Auf Spanner Studio zugreifen
- Klicken Sie im letzten Schritt auf den Link, um Spanner Studio zu öffnen.
2. Diagrammstruktur verstehen (das „große Ganze“)
Das Survivor Network-Dataset ist wie ein Logikrätsel oder ein Game State:
Entität | Rolle im System | Analogie |
Überlebende | Die Agents/Spieler | Spieler |
Biom | Wo sich die Zielgruppe befindet | Zonen auf der Karte |
Kompetenzen | Was sie tun können | Funktionen |
Anforderungen | Was fehlt (Krisen) | Aufgaben/Missionen |
Ressourcen | Gefundene Gegenstände | Beute |
Ziel: Die Aufgabe des KI-Agents besteht darin, Skills (Lösungen) mit Needs (Problemen) zu verknüpfen und dabei Biomes (Standortbeschränkungen) zu berücksichtigen.
🔗 Kanten (Beziehungen):
SurvivorInBiome: StandortbestimmungSurvivorHasSkill: Inventar der FähigkeitenSurvivorHasNeed: Liste der aktiven ProblemeSurvivorFoundResource: Inventar der ArtikelSurvivorCanHelp: Abgeleitete Beziehung (wird von der KI berechnet)
3. Graph abfragen
Führen wir einige Abfragen aus, um die „Geschichte“ in den Daten zu sehen.
Spanner Graph verwendet GQL (Graph Query Language). Um eine Abfrage auszuführen, verwenden Sie GRAPH SurvivorNetwork gefolgt von Ihrem Muster.
👉 Abfrage 1: Die globale Liste (Wer ist wo?) Das ist Ihre Grundlage – das Verständnis des Standorts ist für Rettungseinsätze von entscheidender Bedeutung.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Das Ergebnis sollte so aussehen: 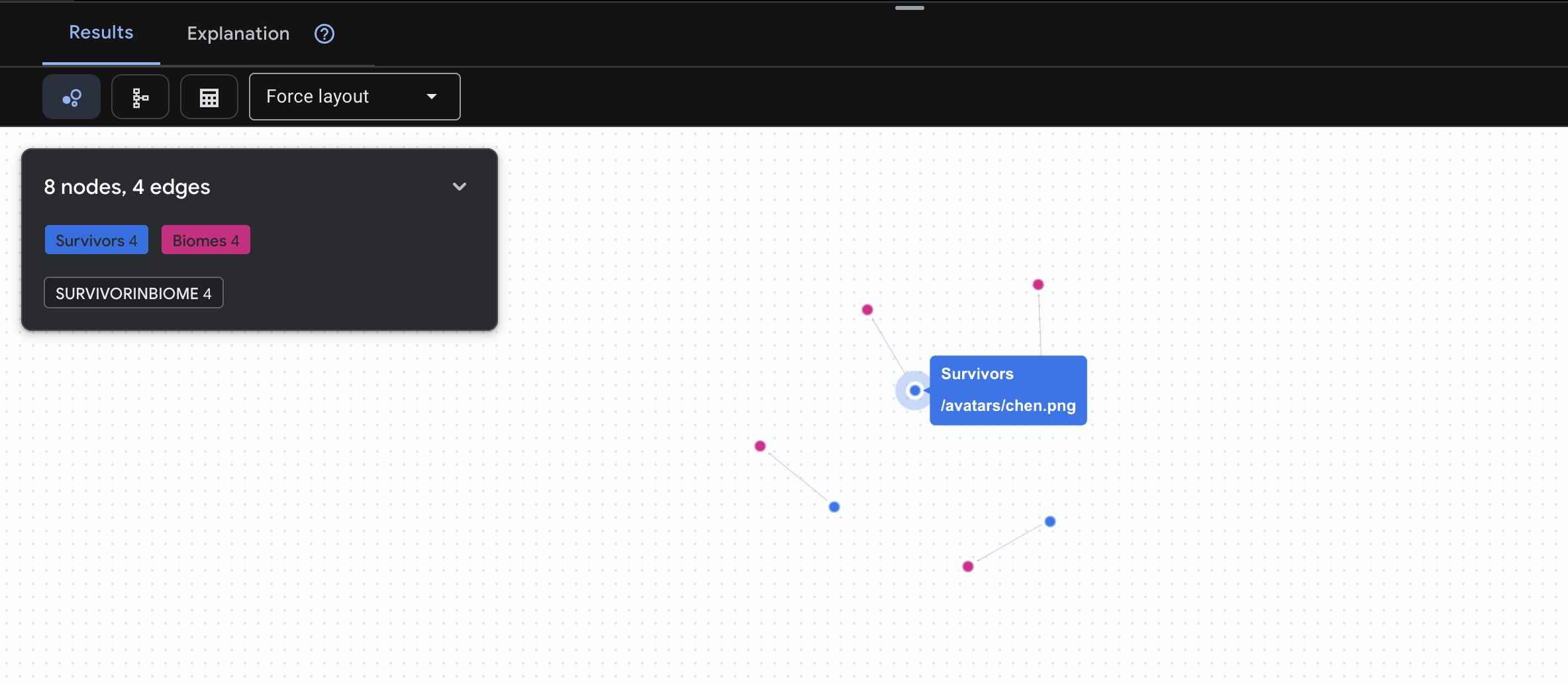
👉 Anfrage 2: Die Skill-Matrix (Fähigkeiten) Nachdem Sie nun wissen, wo sich alle befinden, können Sie herausfinden, was sie tun können.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Das Ergebnis sollte so aussehen: 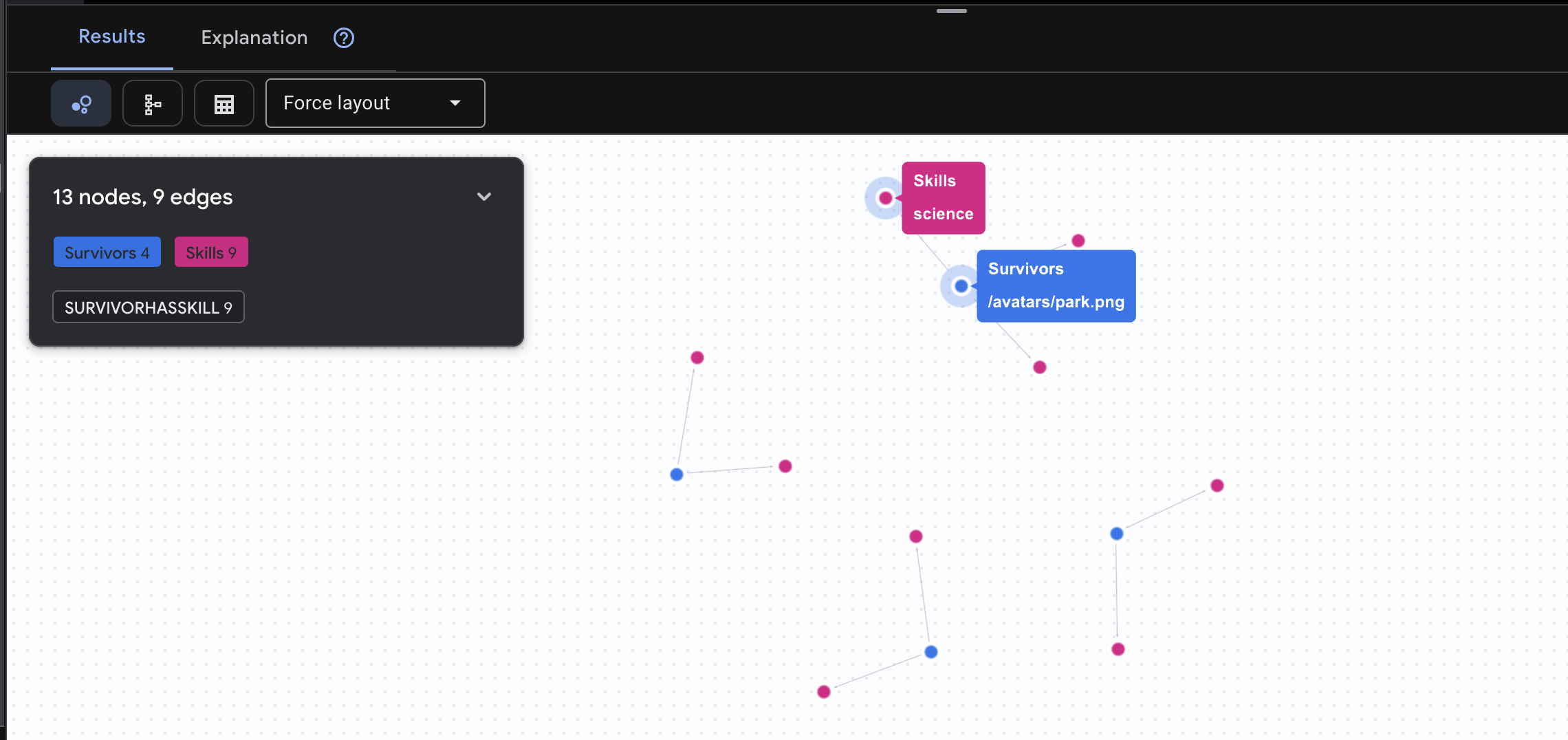
👉 Anfrage 3: Wer befindet sich in einer Krise? (Das „Einsatzboard“) Hier sehen Sie, welche Überlebenden Hilfe benötigen und was sie brauchen.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Das Ergebnis sollte so aussehen: 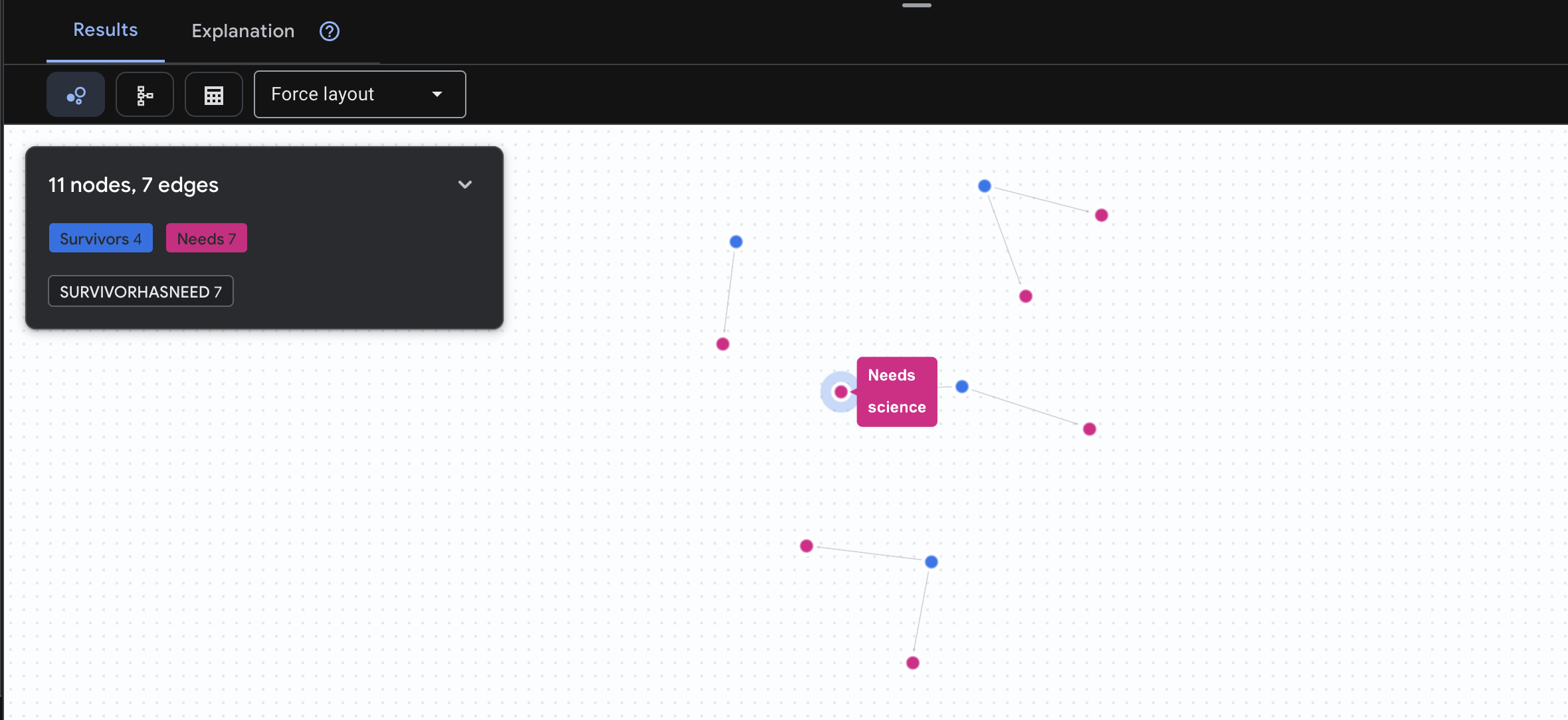
🔎 [Optional] Matchmaking – Wer kann wem helfen?
Hier kommt das Diagramm ins Spiel. Mit dieser Anfrage werden Überlebende mit Fähigkeiten gefunden, die die Bedürfnisse anderer Überlebender erfüllen können.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Das Ergebnis sollte so aussehen: 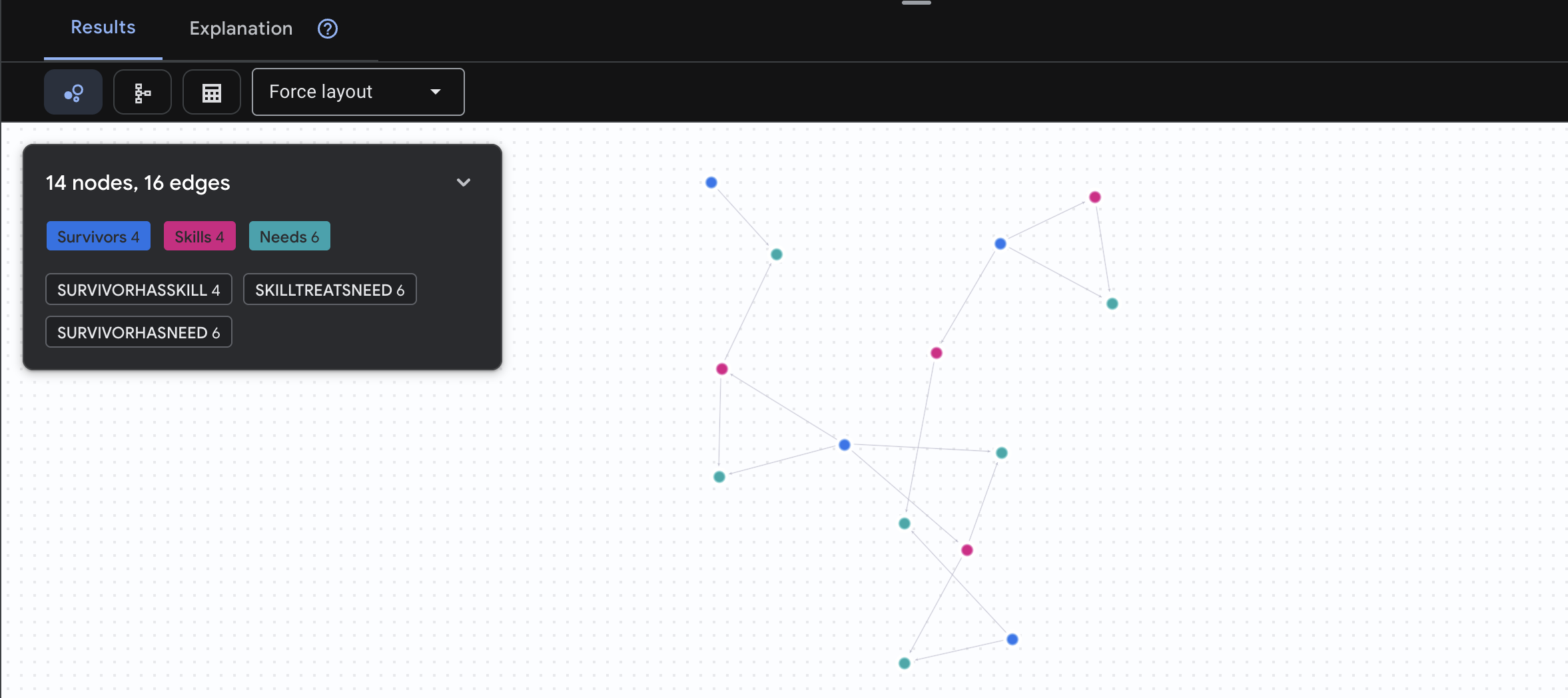
aside positive Wozu dient diese Abfrage?
Anstatt nur „Erste Hilfe bei Verbrennungen“ anzuzeigen (was aus dem Schema hervorgeht), wird bei dieser Anfrage Folgendes gefunden:
- Dr. Elena Frost (mit medizinischer Ausbildung) → kann behandeln → Captain Tanaka (mit Verbrennungen)
- David Chen (mit Erste-Hilfe-Kenntnissen) → kann behandeln → Lt. Park (mit verstauchtem Knöchel)
Warum das so wirkungsvoll ist:
Was Ihr KI-Agent tun wird:
Wenn ein Nutzer fragt: „Wer kann Verbrennungen behandeln?“, geht der Kundenservicemitarbeiter so vor:
- Ähnliche Diagrammabfrage ausführen
- Rückgabe: „Dr. Frost hat eine medizinische Ausbildung und kann Captain Tanaka helfen.“
- Der Nutzer muss nichts über Zwischentabellen oder Beziehungen wissen.
5. 🚀 KI-gestützte Einbettungen in Spanner
1. Warum Einbettungen? (Keine Aktion, schreibgeschützt)
Im Überlebensszenario ist die Zeit entscheidend. Wenn ein Überlebender einen Notfall meldet, z. B. I need someone who can treat burns oder Looking for a medic, darf er keine Zeit damit verschwenden, die genauen Skill-Namen in der Datenbank zu erraten.
Reales Szenario: Überlebender: Captain Tanaka has burns—we need medical help NOW!
Traditionelle Stichwortsuche nach „Sanitäter“ → 0 Ergebnisse ❌
Semantische Suche mit Einbettungen → findet „Medical Training“ (Medizinische Ausbildung), „First Aid“ (Erste Hilfe) ✅
Genau das brauchen KI-Agenten: eine intelligente, menschenähnliche Suche, die die Absicht und nicht nur Keywords versteht.
2. Einbettungsmodell erstellen
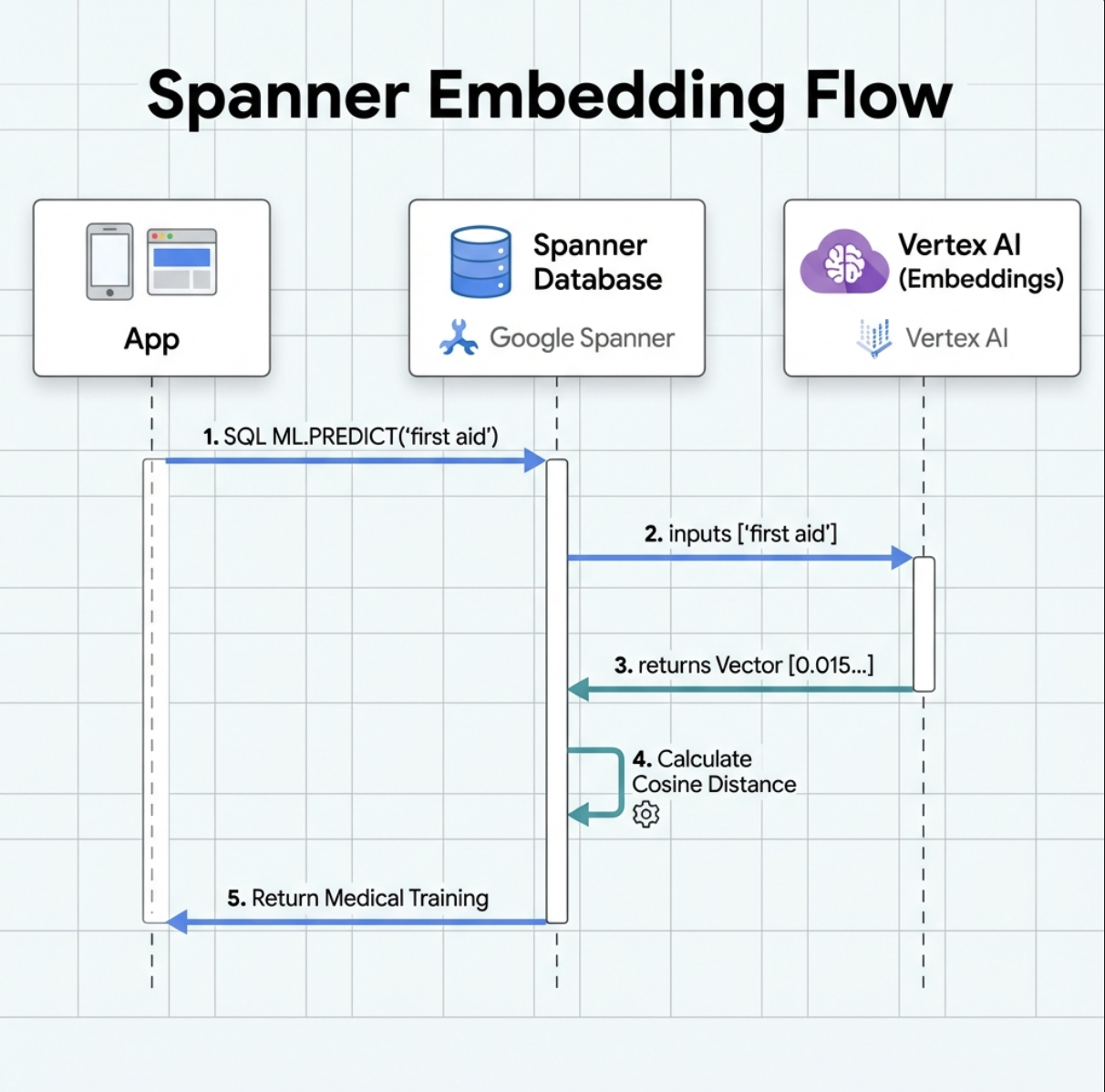
Jetzt erstellen wir ein Modell, das Text mithilfe von text-embedding-004 in Einbettungen umwandelt.
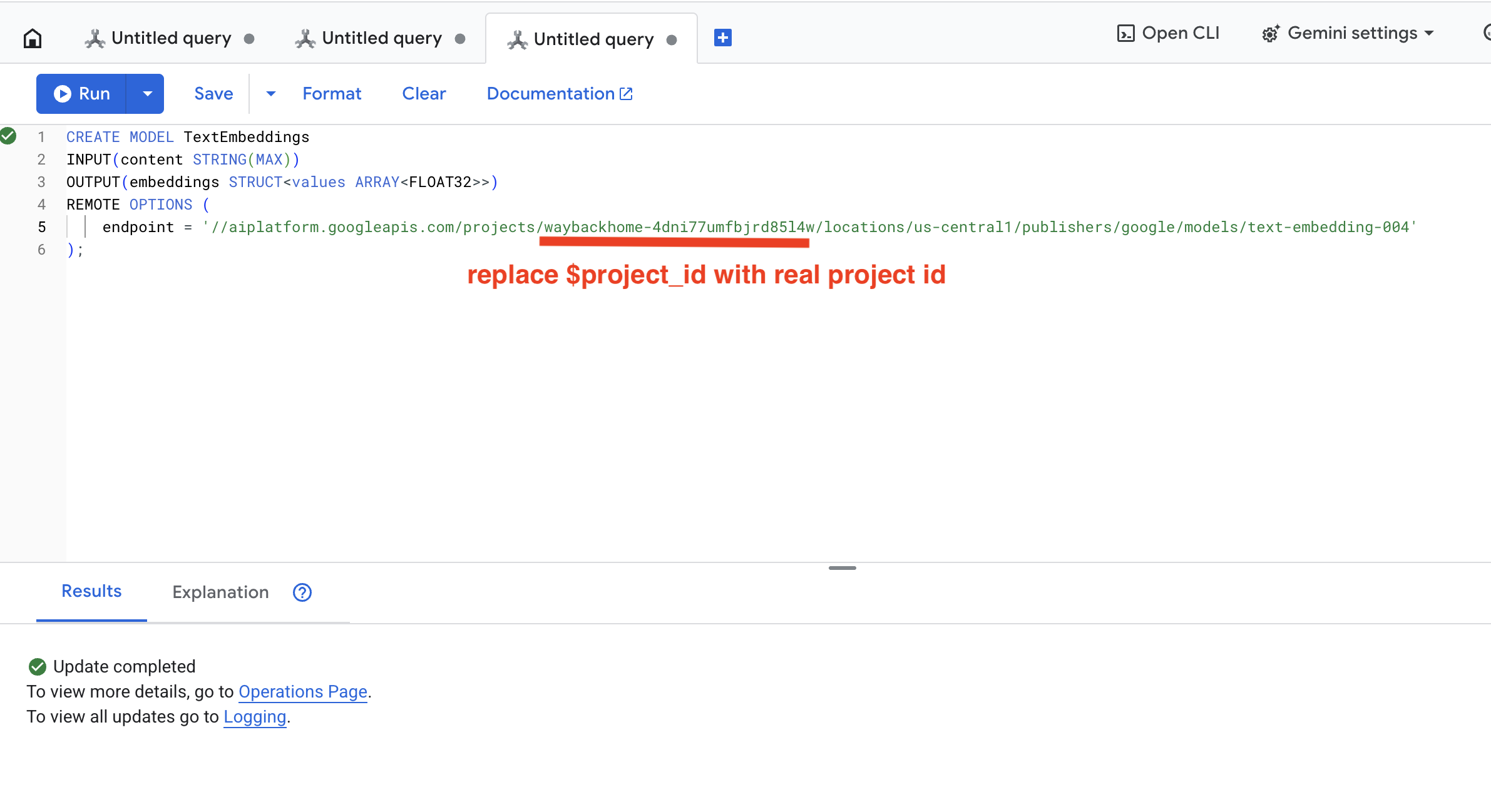
👉 Führen Sie in Spanner Studio diesen SQL-Befehl aus und ersetzen Sie $YOUR_PROJECT_ID durch Ihre tatsächliche Projekt-ID:
‼️ Öffnen Sie im Cloud Shell-Editor File -> Open Folder -> way-back-home/level_2, um das gesamte Projekt zu sehen.
👉 Führen Sie diese Abfrage in Spanner Studio aus. Kopieren Sie dazu die Abfrage unten und klicken Sie auf die Schaltfläche „Ausführen“:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Funktionsweise:
- Erstellt ein virtuelles Modell in Spanner (keine lokal gespeicherten Modellgewichte)
- Verweist auf
text-embedding-004von Google in Vertex AI - Definiert den Vertrag: Die Eingabe ist Text, die Ausgabe ist ein 768-dimensionales Float-Array.
Warum „REMOTE OPTIONS“?
- Spanner führt das Modell nicht selbst aus
- Wenn Sie
ML.PREDICTverwenden, wird Vertex AI über die API aufgerufen. - Zero-ETL: Daten müssen nicht exportiert, in Python verarbeitet und wieder importiert werden.
Klicken Sie auf die Schaltfläche Run. Wenn der Vorgang erfolgreich war, sehen Sie das Ergebnis wie unten dargestellt:
3. Embedding-Spalte hinzufügen
👉 Spalte zum Speichern von Einbettungen hinzufügen:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Klicken Sie auf die Schaltfläche Run. Wenn der Vorgang erfolgreich war, sehen Sie das Ergebnis wie unten dargestellt:
4. Einbettungen generieren
👉 KI zum Erstellen von Vektoreinbettungen für jede Fähigkeit verwenden:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Klicken Sie auf die Schaltfläche Run. Wenn der Vorgang erfolgreich war, sehen Sie das Ergebnis wie unten dargestellt:
Was passiert: Jeder Skill-Name (z.B. „Erste Hilfe“) wird in einen 768-dimensionalen Vektor umgewandelt, der seine semantische Bedeutung repräsentiert.
5. Einbettungen überprüfen
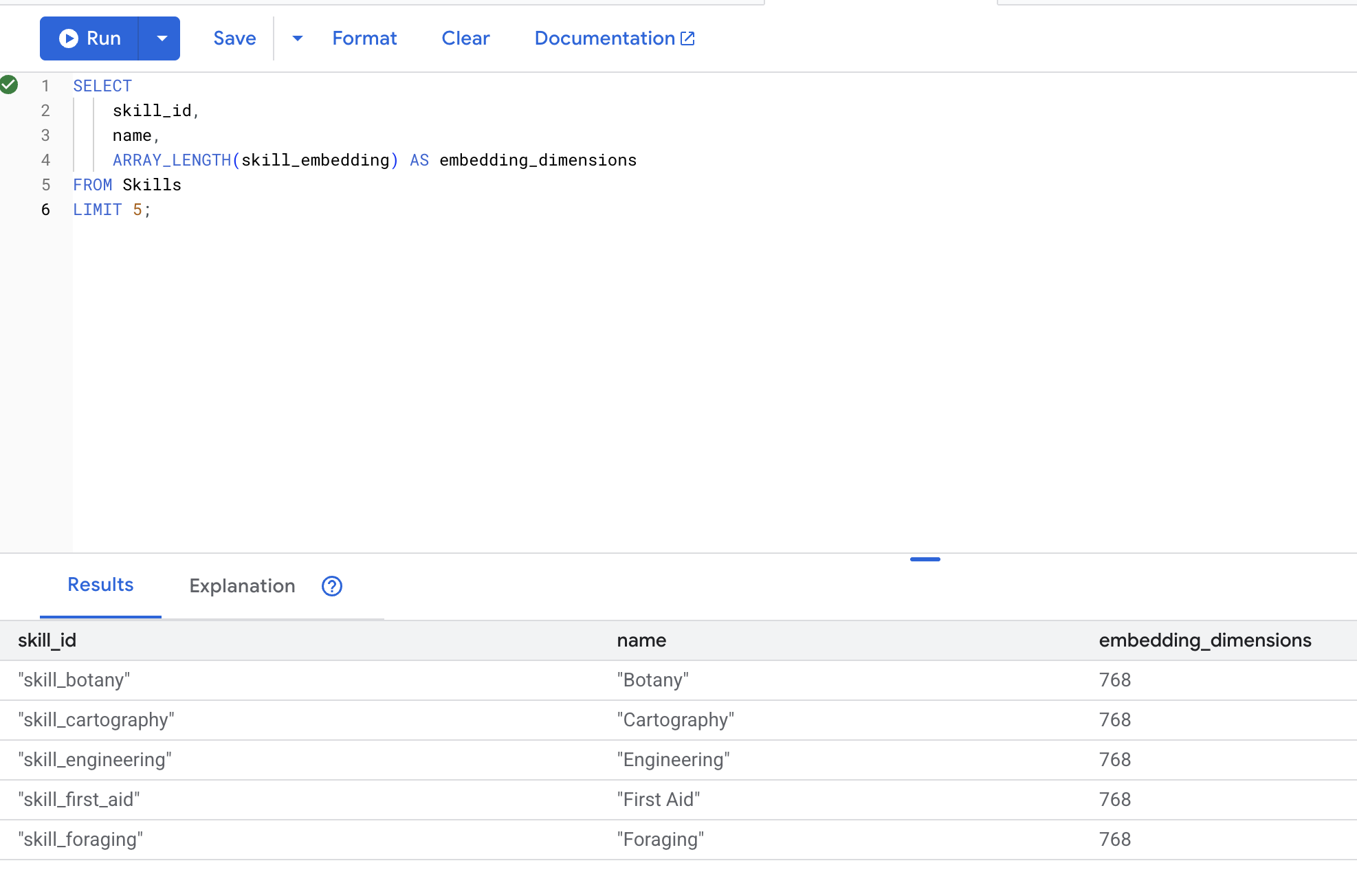
👉 Prüfen Sie, ob Einbettungen erstellt wurden:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Erwartete Ausgabe:
6. Semantische Suche testen
Nun testen wir den genauen Anwendungsfall aus unserem Szenario: medizinische Fähigkeiten mit dem Begriff „Sanitäter“ finden.
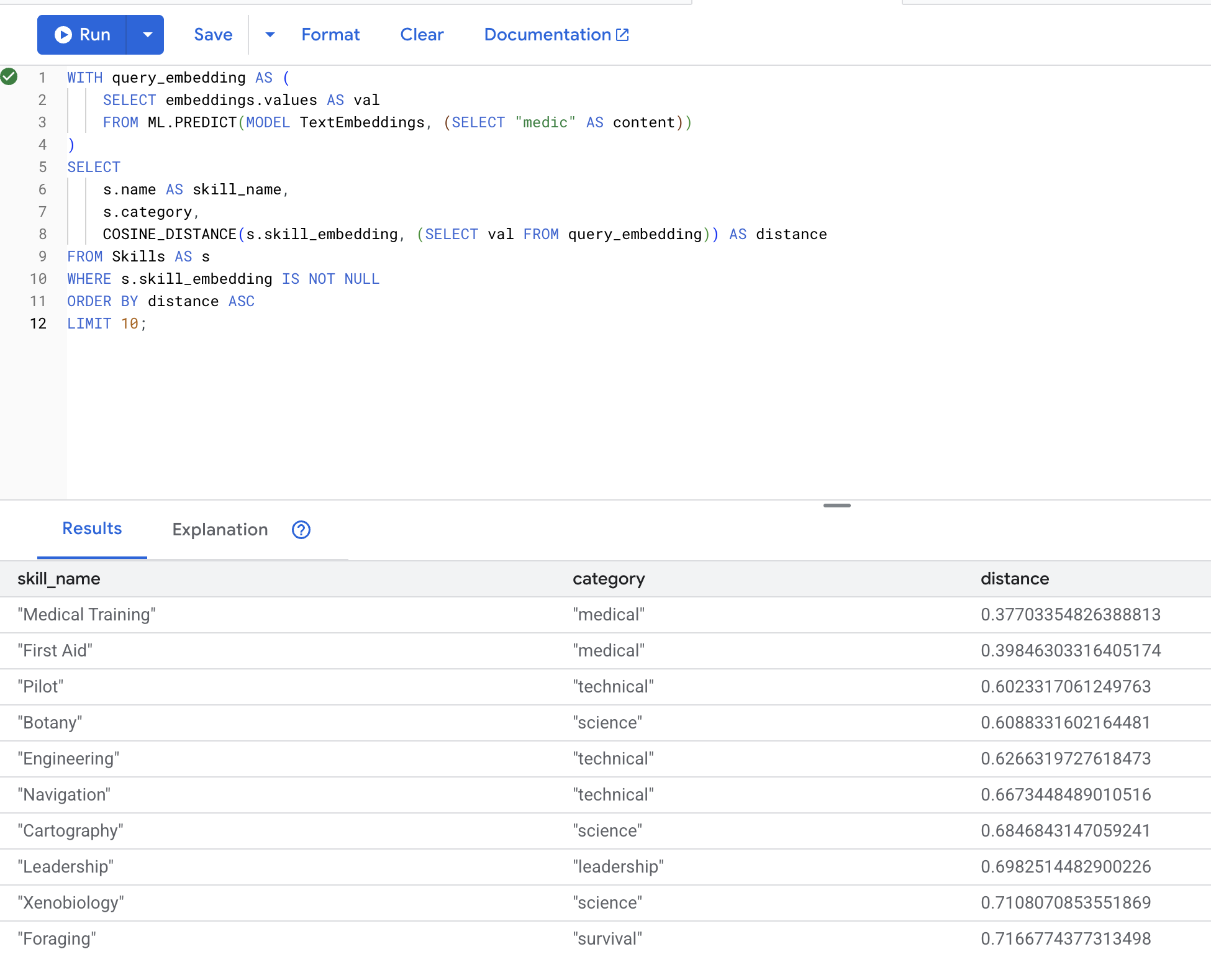
👉 Ähnliche Fähigkeiten wie „Sanitäter“ finden:
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Konvertiert den Suchbegriff „Arzt“ des Nutzers in eine Einbettung.
- Speichert sie in der temporären Tabelle
query_embedding.
Erwartete Ergebnisse (geringere Distanz = ähnlicher):
7. Gemini-Modell für die Analyse erstellen
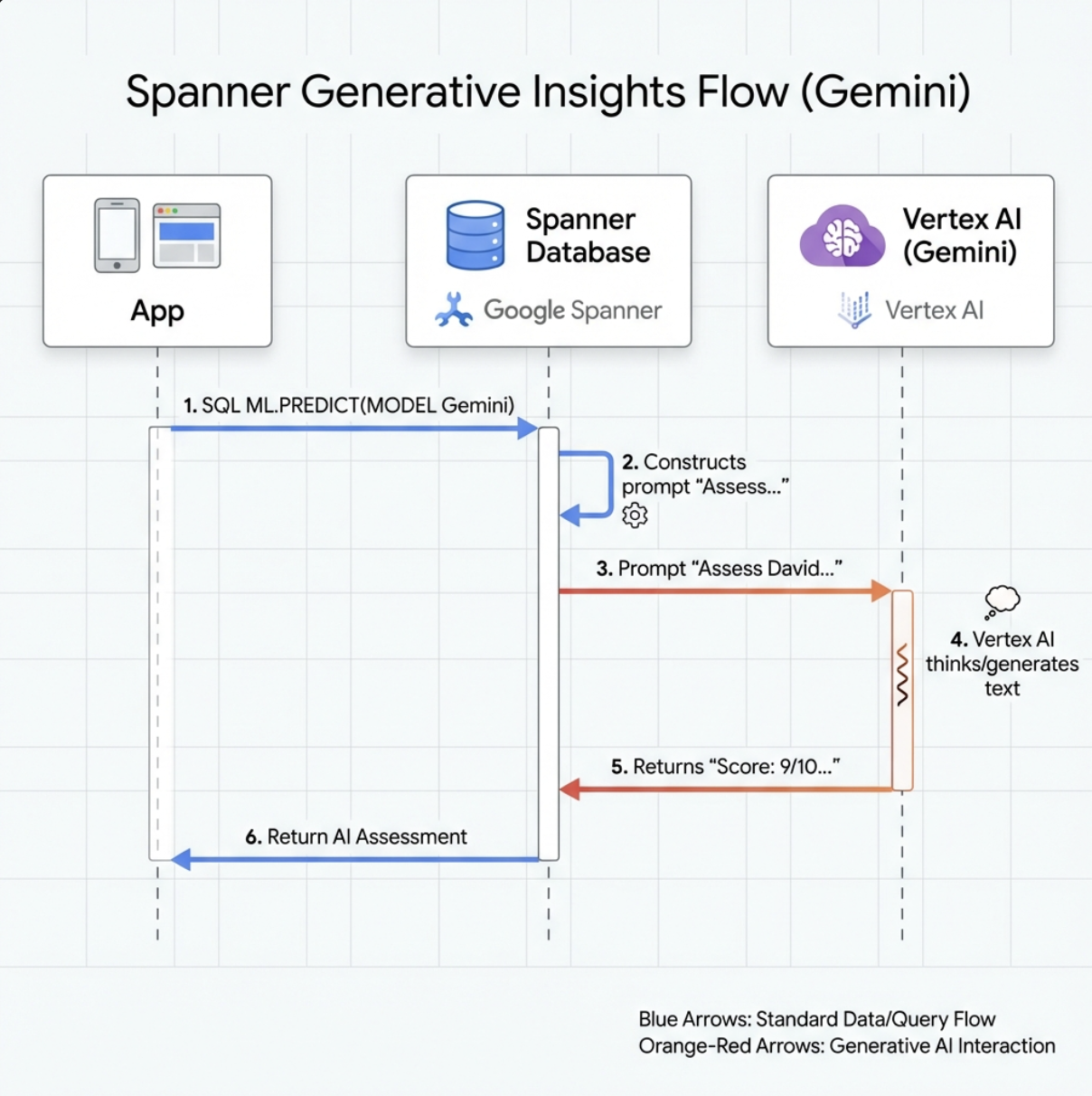
👉 Generative KI-Modellreferenz erstellen (ersetzen Sie $YOUR_PROJECT_ID durch Ihre tatsächliche Projekt-ID):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Unterschied zum Einbettungsmodell:
- Einbettungen: Text → Vektor (für die Ähnlichkeitssuche)
- Gemini: Text → Generierter Text (für Argumentation/Analyse)
8. Gemini für die Kompatibilitätsanalyse verwenden
👉 Überlebendenpaare auf Kompatibilität mit der Mission analysieren:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Erwartete Ausgabe:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Graph RAG-Agenten mit Hybridsuche erstellen
1. Übersicht über die Systemarchitektur
In diesem Abschnitt wird ein Suchsystem mit mehreren Methoden erstellt, mit dem Ihr Agent verschiedene Arten von Anfragen flexibel bearbeiten kann. Das System hat drei Ebenen: Agent Layer (Agentenebene), Tool Layer (Toolebene) und Service Layer (Diensteebene).
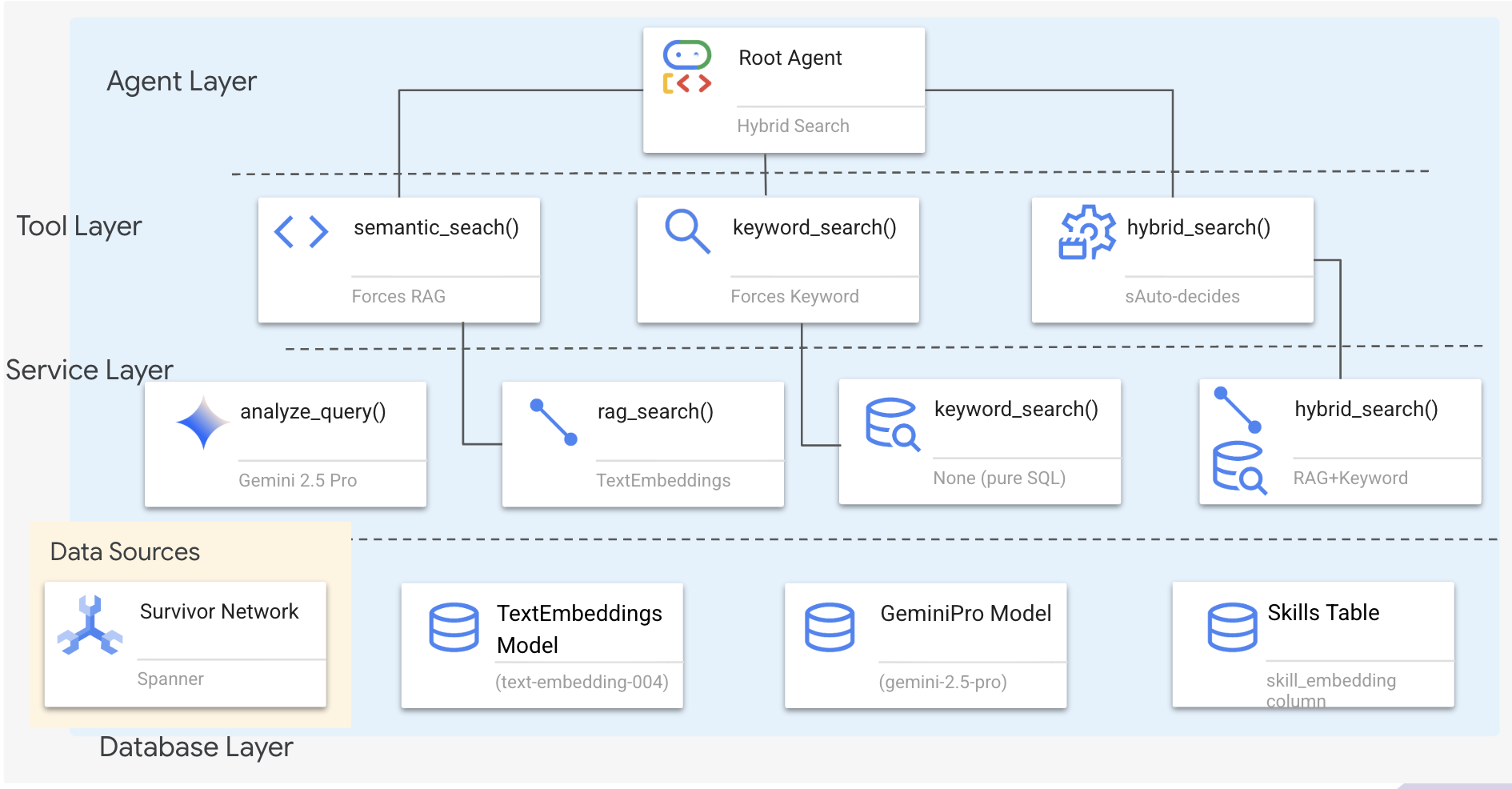
Warum drei Ebenen?
- Trennung der Zuständigkeiten: Der Agent konzentriert sich auf die Intention, die Tools auf die Schnittstelle und der Dienst auf die Implementierung.
- Flexibilität: Der Kundenservicemitarbeiter kann bestimmte Methoden erzwingen oder die KI automatisch weiterleiten lassen.
- Optimierung: Teure KI-Analysen können übersprungen werden, wenn die Methode bekannt ist.
In diesem Abschnitt implementieren Sie hauptsächlich die semantische Suche (RAG), bei der Ergebnisse anhand der Bedeutung und nicht nur anhand von Suchbegriffen gefunden werden. Später erklären wir, wie bei der hybriden Suche mehrere Methoden zusammengeführt werden.
2. Implementierung des RAG-Dienstes
👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Suchen Sie den Kommentar # TODO: REPLACE_SQL.
Ersetzen Sie diese gesamte Zeile durch den folgenden Code:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Definition des Tools für die semantische Suche
👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
Suchen Sie in hybrid_search_tools.py nach dem Kommentar # TODO: REPLACE_SEMANTIC_SEARCH_TOOL.
👉Ersetzen Sie diese gesamte Zeile durch den folgenden Code:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Wann der Agent verwendet wird:
- Anfragen, in denen nach Ähnlichkeit gefragt wird („Finde etwas Ähnliches wie X“)
- Konzeptionelle Anfragen („Heilfähigkeiten“)
- Wenn es auf die Bedeutung ankommt
4. Leitfaden für Agent-Entscheidungen (Anleitung)
Kopieren Sie in der Agent-Definition den Teil, der sich auf die semantische Suche bezieht, und fügen Sie ihn in die Anleitung ein.
👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Der Agent verwendet diese Anleitung, um das richtige Tool auszuwählen:
👉 Suchen Sie in der Datei agent.py nach dem Kommentar # TODO: REPLACE_SEARCH_LOGIC und ersetzen Sie die gesamte Zeile durch den folgenden Code:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉 Suchen Sie den Kommentar # TODO: ADD_SEARCH_TOOLReplace this whole line und ersetzen Sie ihn durch den folgenden Code:
semantic_search, # Force RAG
5. Funktionsweise der Hybridsuche (nur lesen, keine Aktion erforderlich)
In den Schritten 2 bis 4 haben Sie die semantische Suche (RAG) implementiert, die wichtigste Suchmethode, mit der Ergebnisse anhand ihrer Bedeutung gefunden werden. Vielleicht ist Ihnen aber aufgefallen, dass das System „Hybridsuche“ heißt. So funktioniert das Ganze:
So funktioniert die Hybridzusammenführung:
Wenn in der Datei way-back-home/level_2/backend/services/hybrid_search_service.py hybrid_search() aufgerufen wird, führt der Dienst BEIDE Suchvorgänge aus und führt die Ergebnisse zusammen:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
In diesem Codelab haben Sie die Komponente für die semantische Suche (RAG) implementiert, die die Grundlage bildet. Die Keyword- und Hybridmethoden sind bereits im Dienst implementiert. Ihr Agent kann alle drei verwenden.
Glückwunsch! Sie haben Ihren GraphRAG-Agenten mit hybrider Suche erfolgreich fertiggestellt.
7. 🚀 KI‑Agenten mit ADK Web testen
Am einfachsten testen Sie Ihren Agenten mit dem Befehl adk web. Dadurch wird Ihr Agent mit einer integrierten Chatoberfläche gestartet.
1. Agent ausführen
👉💻 Wechseln Sie zum Backend-Verzeichnis (in dem Ihr Agent definiert ist) und starten Sie die Weboberfläche::
cd ~/way-back-home/level_2/backend
uv run adk web
Mit diesem Befehl wird der in definierte Agent gestartet.
agent/agent.py
und öffnet eine Weboberfläche zum Testen.
👉 Öffnen Sie die URL:
Der Befehl gibt eine lokale URL aus (normalerweise http://127.0.0.1:8000 oder ähnlich). Öffnen Sie diesen Link in Ihrem Browser.
Wenn Sie auf die URL klicken, wird die ADK-Web-UI angezeigt. Achten Sie darauf, dass Sie oben links den „Kundenservicemitarbeiter“ auswählen.
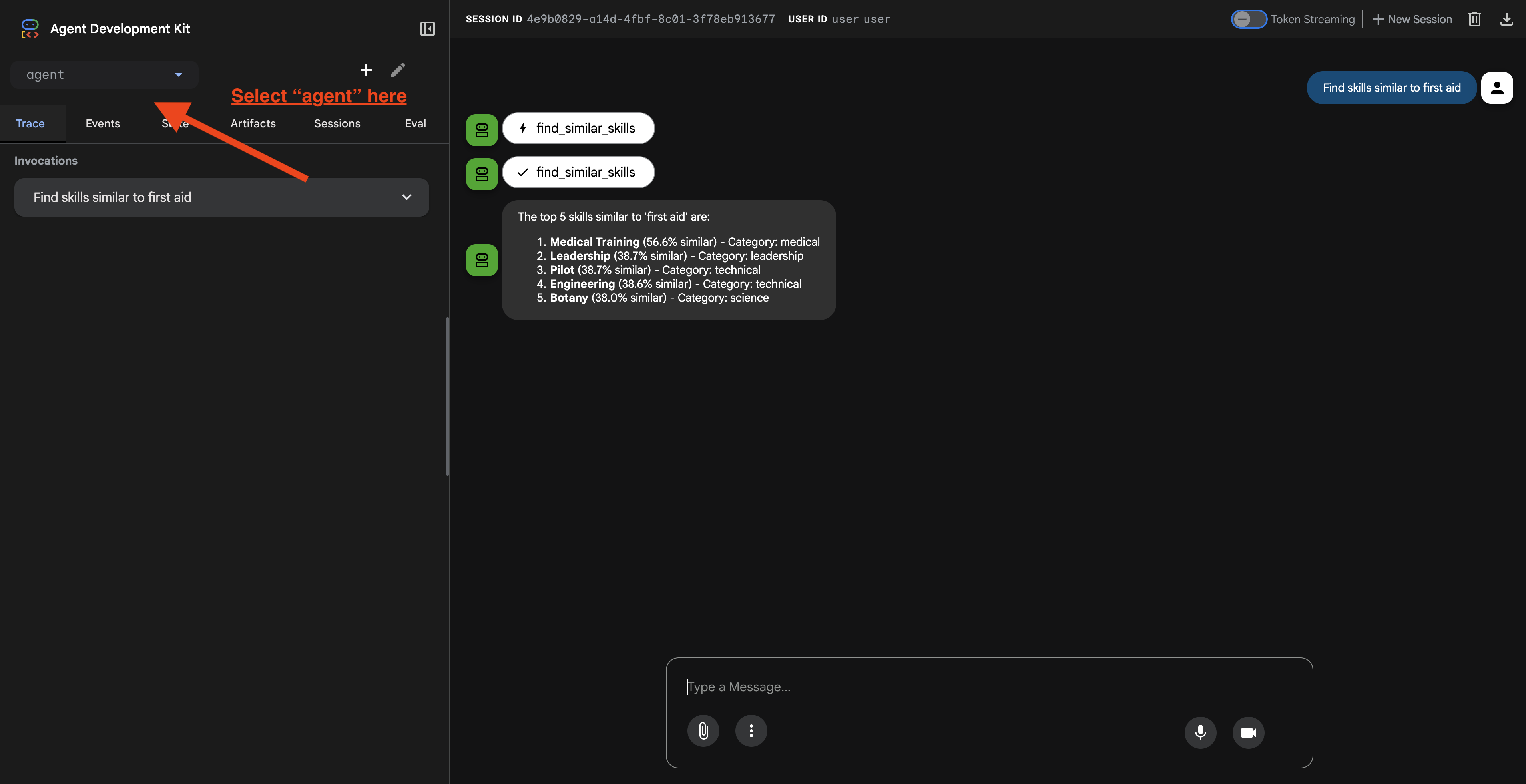
2. Suchfunktionen testen
Der KI-Agent wurde entwickelt, um Ihre Anfragen intelligent weiterzuleiten. Probieren Sie die folgenden Eingaben im Chatfenster aus, um verschiedene Suchmethoden in Aktion zu sehen.
🧬 A. Graph RAG (semantische Suche)
Es werden Elemente anhand von Bedeutung und Konzept gefunden, auch wenn die Keywords nicht übereinstimmen.
Testanfragen:Wählen Sie eine der folgenden Optionen aus.
Who can help with injuries?
What abilities are related to survival?
Darauf sollten Sie achten:
- In der Begründung sollte die semantische oder die RAG-Suche erwähnt werden.
- Sie sollten Ergebnisse sehen, die konzeptionell verwandt sind, z.B. „Operation“ bei der Frage nach „Erste Hilfe“.
- Ergebnisse werden mit dem 🧬-Symbol gekennzeichnet.
🔀 B. Hybridsuche
Kombiniert Keyword-Filter mit semantischem Verständnis für komplexe Anfragen.
Testanfragen: (Wählen Sie eine der folgenden Optionen aus.)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Darauf sollten Sie achten:
- In der Begründung sollte die Hybridsuche erwähnt werden.
- Die Ergebnisse sollten BEIDEN Kriterien entsprechen (Konzept + Standort/Kategorie).
- Ergebnisse, die mit beiden Methoden gefunden wurden, sind mit dem Symbol 🔀 gekennzeichnet und werden am höchsten eingestuft.
👉💻 Wenn Sie mit dem Testen fertig sind, beenden Sie den Vorgang, indem Sie in der Befehlszeile Ctrl+C drücken.
8. 🚀 Vollständige Anwendung ausführen
Übersicht über die Full-Stack-Architektur
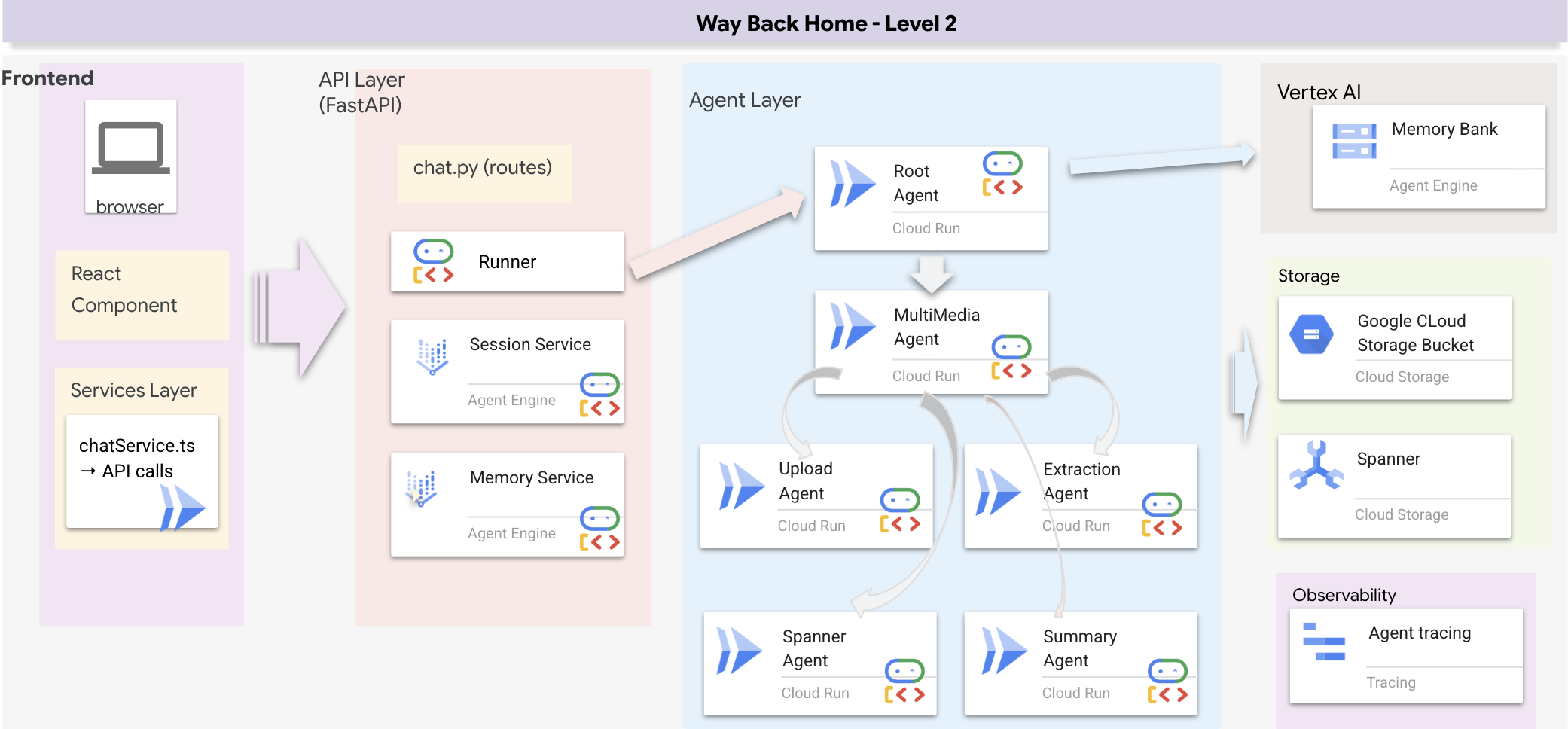
SessionService und Runner hinzufügen
👉💻 Öffnen Sie im Terminal die Datei chat.py im Cloud Shell-Editor. Führen Sie dazu den folgenden Befehl aus. Achten Sie darauf, dass Sie den vorherigen Prozess mit „Strg+C“ beendet haben, bevor Sie fortfahren:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 Suchen Sie in der Datei chat.py nach dem Kommentar # TODO: REPLACE_INMEMORY_SERVICES und ersetzen Sie die gesamte Zeile durch den folgenden Code:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉 Suchen Sie in der Datei chat.py nach dem Kommentar # TODO: REPLACE_RUNNER und ersetzen Sie die gesamte Zeile durch den folgenden Code:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Bewerbung starten
Wenn das vorherige Terminal noch läuft, beenden Sie es, indem Sie Ctrl+C drücken.
👉💻 App starten:
cd ~/way-back-home/level_2/
./start_app.sh
Wenn das Backend erfolgreich gestartet wurde, wird Local: http://localhost:5173/" wie unten dargestellt angezeigt: 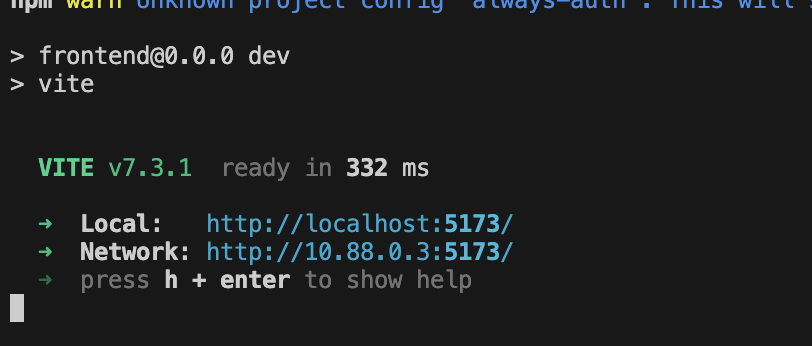
👉 Klicken Sie im Terminal auf Local: http://localhost:5173/.
2. Semantische Suche testen
Abfrage:
Find skills similar to healing
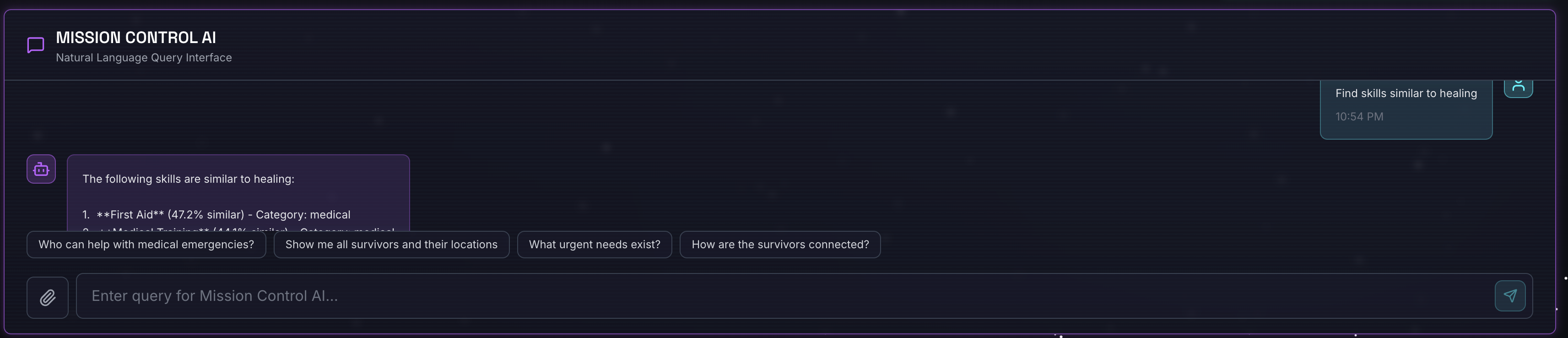
Was passiert?
- Der Agent erkennt die Anfrage nach Ähnlichkeit.
- Generiert eine Einbettung für „Heilung“
- Verwendet die Kosinus-Distanz, um semantisch ähnliche Skills zu finden
- Gibt „Erste Hilfe“ zurück (obwohl die Namen nicht mit „Heilung“ übereinstimmen)
3. Hybridsuche testen
Abfrage:
Find medical skills in the mountains
Was passiert?
- Schlüsselwortkomponente: Nach
category='medical'filtern - Semantische Komponente: „medizinisch“ einbetten und nach Ähnlichkeit sortieren
- Zusammenführen: Ergebnisse kombinieren und Ergebnisse, die mit beiden Methoden gefunden wurden, priorisieren 🔀
Abfrage(optional):
Who is good at survival and in the forest?
Was passiert?
- Keyword-Treffer:
biome='forest' - Semantische Ergebnisse: Fähigkeiten, die „Überleben“ ähneln
- Hybrid kombiniert beide für optimale Ergebnisse
👉💻 Wenn Sie mit dem Testen fertig sind, beenden Sie den Vorgang im Terminal mit Ctrl+C.
4. (!ONLY FOR WORKSHOP ATTENDEE) Update your location
👉💻 Führen Sie das Vervollständigungsskript aus:
cd ~/way-back-home/level_2
./set_level_2.sh
Öffnen Sie jetzt waybackhome.dev. Ihr Standort wurde aktualisiert. Herzlichen Glückwunsch zum Abschluss von Level 2!

9. ☕️ [Optional] Multimodale Pipeline (schreibgeschützt) – Tooling Layer
Warum benötigen wir eine multimodale Pipeline?
Das Survival-Netzwerk besteht nicht nur aus Text. Überlebende vor Ort senden unstrukturierte Daten direkt über den Chat:
- 📸 Bilder: Fotos von Ressourcen, Gefahren oder Ausrüstung
- 🎥 Videos: Statusberichte oder SOS-Meldungen
- 📄 Text: Feldnotizen oder Protokolle
Welche Dateien werden verarbeitet?
Im Gegensatz zum vorherigen Schritt, in dem wir nach vorhandenen Daten gesucht haben, verarbeiten wir hier von Nutzern hochgeladene Dateien. Die chat.py-Oberfläche verarbeitet Dateianhänge dynamisch:
Quelle | Inhalt | Ziel |
Nutzerzuordnung | Bild/Video/Text | Informationen, die dem Diagramm hinzugefügt werden sollen |
Chat-Kontext | „Hier ist ein Foto der Materialien.“ | Intention und zusätzliche Details |
Geplanter Ansatz: Sequenzielle Agent-Pipeline
Wir verwenden einen sequenziellen Agenten (multimedia_agent.py), der spezialisierte Agenten miteinander verknüpft:
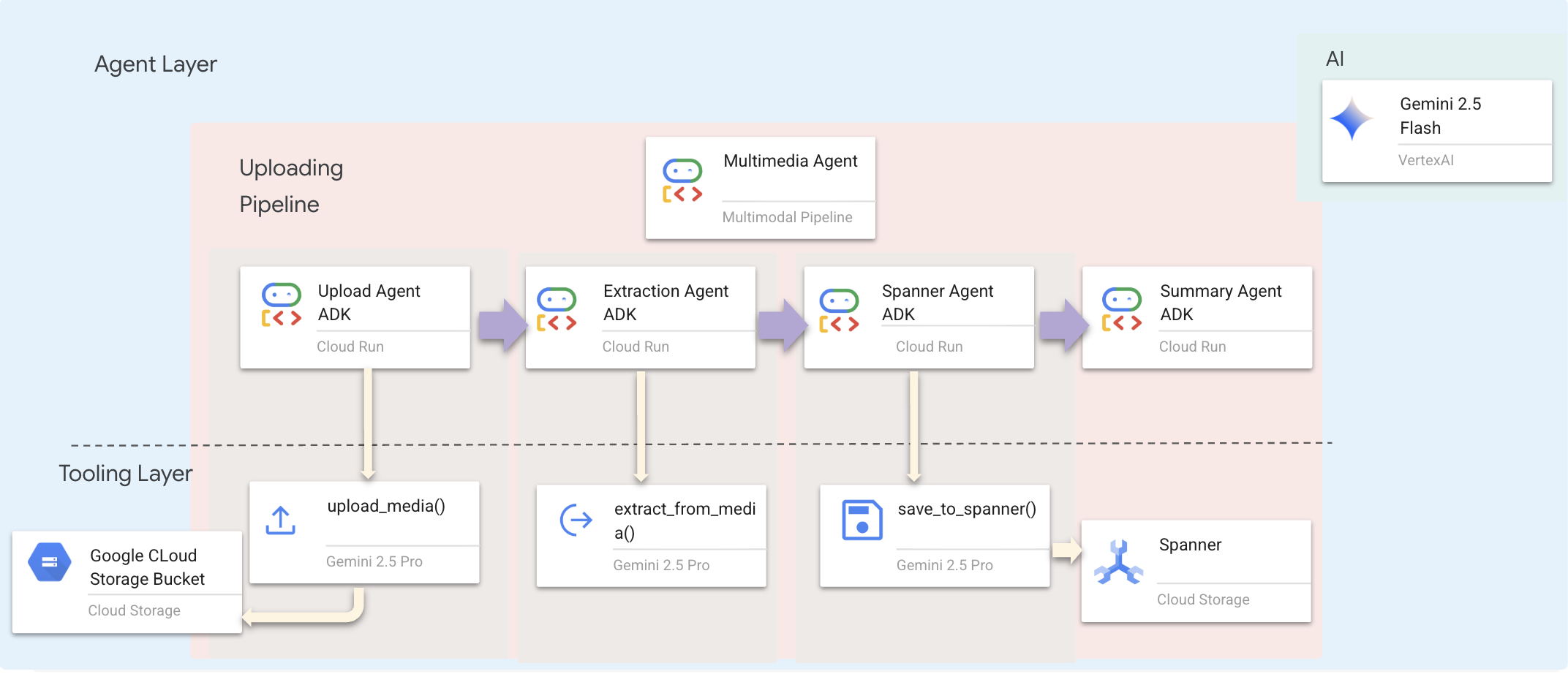
Dies ist in backend/agent/multimedia_agent.py als SequentialAgent definiert.
Die Tooling-Ebene bietet die Funktionen, die von Agents aufgerufen werden können. Tools übernehmen das „Wie“ – das Hochladen von Dateien, das Extrahieren von Entitäten und das Speichern in der Datenbank.
1. Tools-Datei öffnen
👉💻 Öffnen Sie die Datei level_2/backend/agent/tools/extraction_tools.py oder geben Sie den folgenden Befehl im Terminal ein. Öffnen Sie ein neues Terminal. Öffnen Sie die Datei im Terminal im Cloud Shell-Editor:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. upload_media-Tool implementieren
Mit diesem Tool wird eine lokale Datei in Google Cloud Storage hochgeladen.
👉 Im folgenden Code in def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: wird beschrieben, wie Dateien in GCS hochgeladen und ihr Typ erkannt wird:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. extract_from_media-Tool implementieren
Dieses Tool ist ein Router. Es prüft die media_type und leitet sie an den richtigen Extractor (Text, Bild oder Video) weiter.
👉 In async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: wird beschrieben, wie Sie Entitäten und Beziehungen aus hochgeladenen Medien extrahieren.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Wichtige Implementierungsdetails:
- Multimodale Eingabe: Wir übergeben sowohl den Text-Prompt (
_get_extraction_prompt()) als auch das Bildobjekt angenerate_content. - Strukturierte Ausgabe:
response_mime_type="application/json"sorgt dafür, dass das LLM gültiges JSON zurückgibt, was für die Pipeline entscheidend ist. - Visuelle Verknüpfung von Entitäten: Der Prompt enthält bekannte Entitäten, damit Gemini bestimmte Zeichen erkennen kann.
4. save_to_spanner-Tool implementieren
Mit diesem Tool werden die extrahierten Entitäten und Beziehungen in der Spanner Graph-Datenbank gespeichert.
👉 Im folgenden Codebeispiel in def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: wird gezeigt, wie extrahierte Entitäten und Beziehungen in der Spanner Graph-Datenbank gespeichert werden.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Durch die Bereitstellung von Tools auf hoher Ebene für Agents sorgen wir für Datenintegrität und nutzen gleichzeitig die Reasoning-Funktionen des Agents.
5. GCS-Dienst aktualisieren
Die Datei GCSService übernimmt den eigentlichen Dateiupload in Google Cloud Storage.
👉💻 Öffnen Sie die Datei level_2/backend/services/gcs_service.py. Alternativ können Sie im Terminal eingeben, dass die Datei im Cloud Shell-Editor geöffnet werden soll:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 Im folgenden Codebeispiel in def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: wird gezeigt, wie extrahierte Entitäten und Beziehungen in der Spanner Graph-Datenbank gespeichert werden.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Durch die Abstraktion in einen Dienst muss der Agent nichts über GCS-Buckets, Blob-Namen oder die Generierung signierter URLs wissen. Es wird nur „Hochladen“ angezeigt.
6. Warum ist der agentische Workflow besser als herkömmliche Ansätze?
Vorteile von Agentic AI:
Funktion | Batchpipeline | Ereignisgesteuert | Agentic Workflow |
Komplexität | Niedrig (1 Script) | Hoch (mind. 5 Dienste) | Niedrig (1 Python-Datei: |
Statusverwaltung | Globale Variablen | Schwer (entkoppelt) | Zusammengeführt (Agentenstatus) |
Fehlerbehandlung | Abstürze | Stille Logs | Interaktiv („Ich konnte die Datei nicht lesen“) |
Nutzerfeedback | Konsolenausdrucke | Abfrage erforderlich | Sofort (Teil des Chats) |
Anpassungsfähigkeit | Feste Logik | Starre Funktionen | Intelligent (LLM entscheidet über den nächsten Schritt) |
Kontextsensitivität | Keine | Keine | Vollständig (Nutzerabsicht bekannt) |
Warum ist das wichtig? Durch die Verwendung von multimedia_agent.py (ein SequentialAgent mit 4 Unter-Agents: „Upload“ → „Extract“ → „Save“ → „Summary“) ersetzen wir komplexe Infrastruktur UND anfällige Skripts durch intelligente, konversationelle Anwendungslogik.
10. ☕️ [Optional] Multimodale Pipeline (schreibgeschützt) – Agent-Ebene
Die Agentenebene definiert die Intelligenz – Agents, die Tools verwenden, um Aufgaben zu erledigen. Jeder Agent hat eine bestimmte Rolle und übergibt den Kontext an den nächsten. Unten sehen Sie ein Architekturdiagramm für ein Multi-Agent-System.
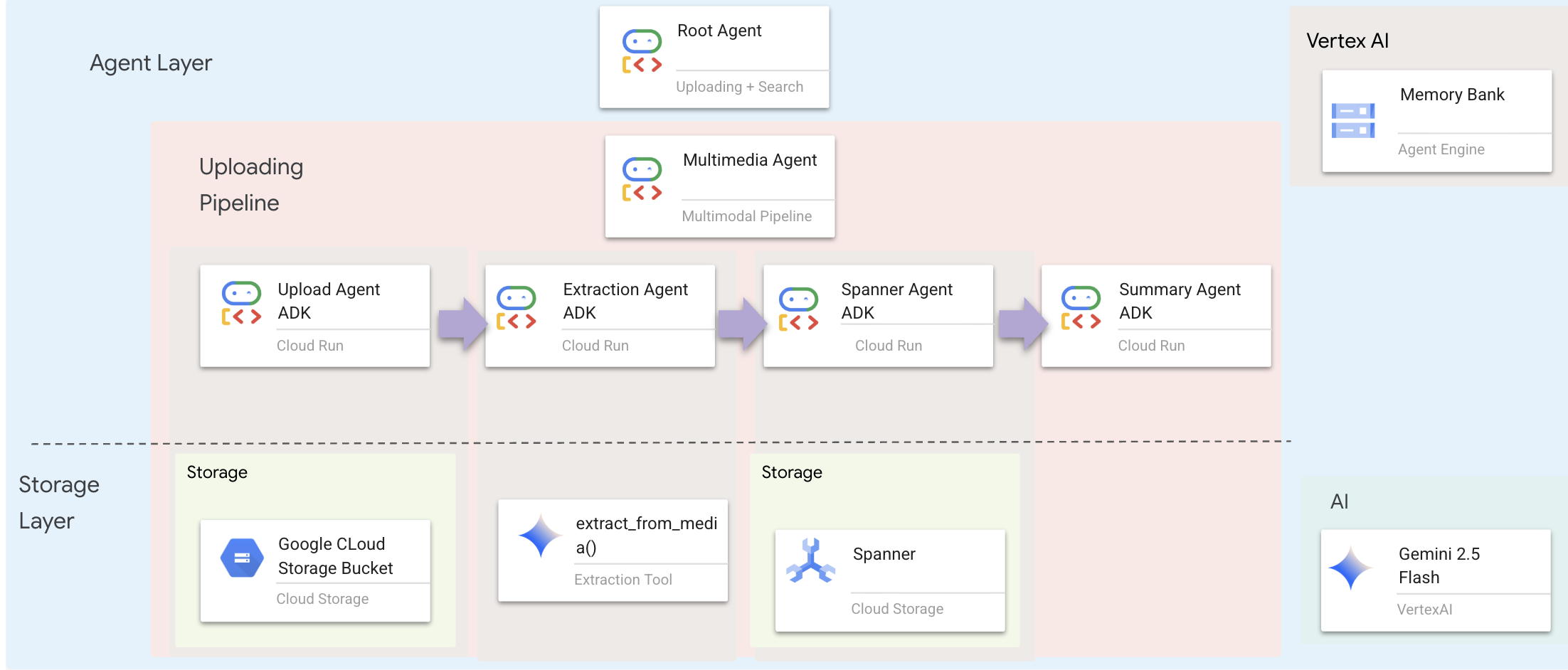
1. Agent-Datei öffnen
👉💻 Öffnen Sie die Datei level_2/backend/agent/multimedia_agent.py oder geben Sie den folgenden Befehl im Terminal ein. Öffnen Sie ein neues Terminal. Öffnen Sie die Datei im Terminal im Cloud Shell-Editor:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Upload-Agent definieren
Dieser Agent extrahiert einen Dateipfad aus der Nachricht des Nutzers und lädt ihn in GCS hoch.
👉 In der Datei multimedia_agent.py wird mit dem folgenden Code upload_agent erstellt, das in GCS hochgeladen wird:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Extraktions-Agent definieren
Dieser Agent „sieht“ die hochgeladenen Medien und extrahiert strukturierte Daten mit Gemini Vision.
👉 In der Datei multimedia_agent.py wird mit dem folgenden Code extraction_agent erstellt, das Informationen aus den hochgeladenen Medien extrahiert:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Beachten Sie, wie instruction auf {upload_result} verweist. So wird der Status zwischen Agenten im ADK übergeben.
4. Spanner-Agent definieren
Dieser Agent speichert die extrahierten Entitäten und Beziehungen in der Graphdatenbank.
👉 In der Datei multimedia_agent.py wird mit dem folgenden Code spanner_agent erstellt, in der die extrahierten Informationen in der Datenbank gespeichert werden:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Dieser Agent erhält Kontext aus beiden vorherigen Schritten (upload_result und extraction_result).
5. Zusammenfassungs-Agent definieren
Dieser Agent fasst die Ergebnisse aller vorherigen Schritte in einer nutzerfreundlichen Antwort zusammen.
👉 In der Datei multimedia_agent.py wird mit dem folgenden Code der Prompt für summary_agent definiert, der das Ergebnis zusammenfasst:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Dieser Agent benötigt keine Tools. Er liest einfach den freigegebenen Kontext und erstellt eine übersichtliche Zusammenfassung für den Nutzer.
🧠 Zusammenfassung der Architektur
Ebene | Datei | Verantwortung |
Tools |
| Vorgehensweise: Hochladen, extrahieren, speichern |
Agentenmodus |
| Was: Pipeline orchestrieren |
11. 🚀 Multimodale Datenpipeline – Orchestrierung
Das Herzstück unseres neuen Systems ist die MultimediaExtractionPipeline, die in backend/agent/multimedia_agent.py definiert ist. Dabei wird das Muster Sequential Agent aus dem ADK (Agent Development Kit) verwendet.
1. Warum sequenziell?
Die Verarbeitung eines Uploads ist eine lineare Abhängigkeitskette:
- Sie können erst Daten extrahieren, wenn Sie die Datei haben (Upload).
- Sie können Daten erst speichern, wenn Sie sie extrahiert haben (Extraktion).
- Sie können erst eine Zusammenfassung erstellen, wenn Sie die Ergebnisse haben (Speichern).
Dafür ist eine SequentialAgent perfekt geeignet. Die Ausgabe eines Agents wird als Kontext/Eingabe für den nächsten Agenten übergeben.
2. Die Agent-Definition
Sehen wir uns an, wie die Pipeline unten in multimedia_agent.py zusammengestellt wird: 👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Sie erhält Eingaben aus beiden vorherigen Schritten. Suchen Sie den Kommentar # TODO: REPLACE_ORCHESTRATION. Ersetzen Sie diese gesamte Zeile durch den folgenden Code:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Mit Root-Agent verbinden
👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Suchen Sie den Kommentar # TODO: REPLACE_ADD_SUBAGENT. Ersetzen Sie diese gesamte Zeile durch den folgenden Code:
sub_agents=[multimedia_agent],
Dieses einzelne Objekt bündelt vier „Experten“ in einer aufrufbaren Einheit.
4. Datenfluss zwischen KI-Agenten
Jeder Agent speichert seine Ausgabe in einem gemeinsamen Kontext, auf den nachfolgende Agents zugreifen können:
5. Anwendung öffnen (überspringen, wenn die App noch ausgeführt wird)
👉💻 App starten:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Klicken Sie im Terminal auf Local: http://localhost:5173/.
6. Testbild hochladen
👉 Wählen Sie in der Chatoberfläche ein beliebiges Foto aus und laden Sie es in die Benutzeroberfläche hoch:
Geben Sie in der Chatoberfläche Folgendes ein, um dem Agenten Ihren spezifischen Kontext zu erläutern:
Here is the survivor note
Hängen Sie das Bild dann hier an.

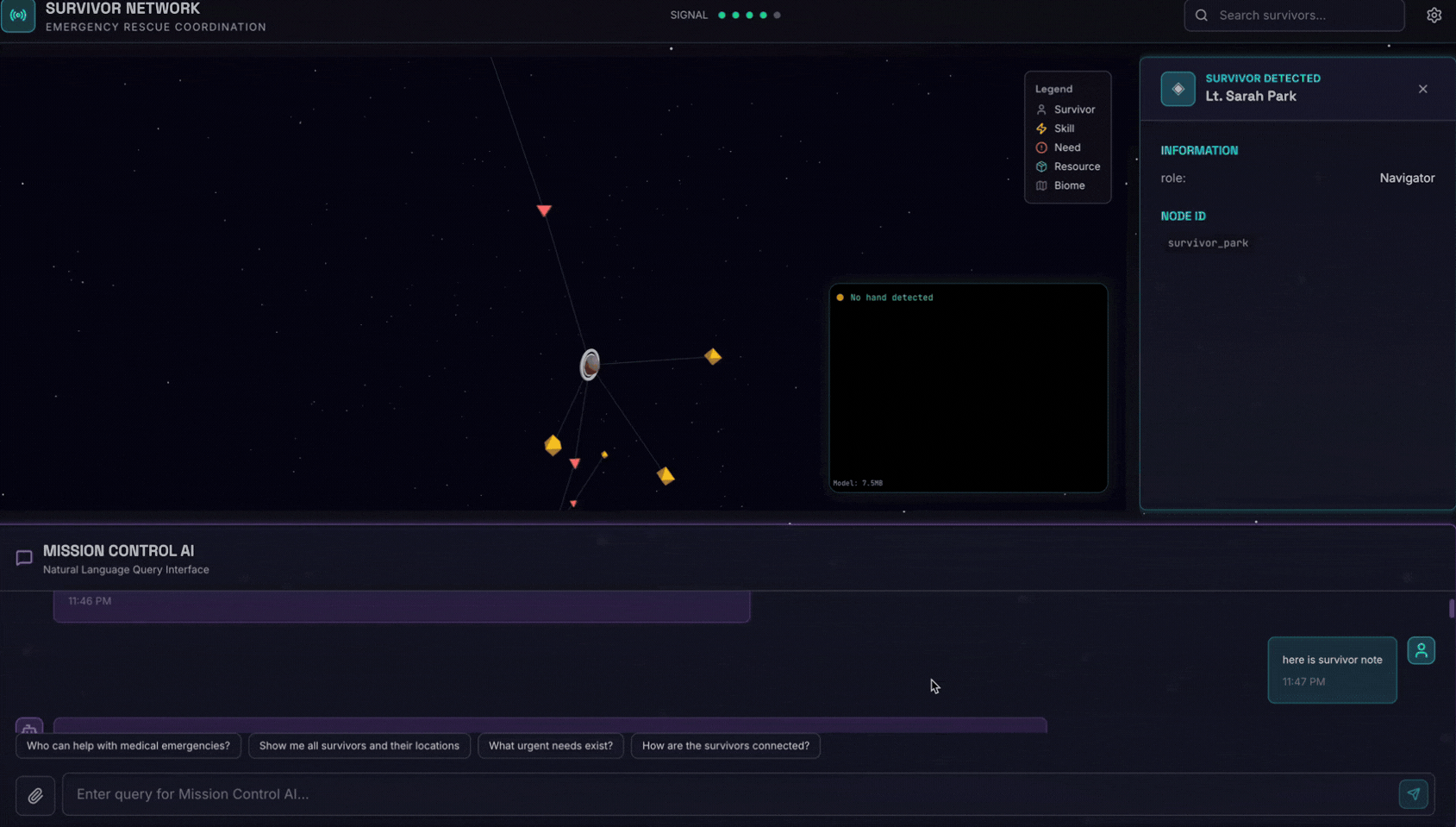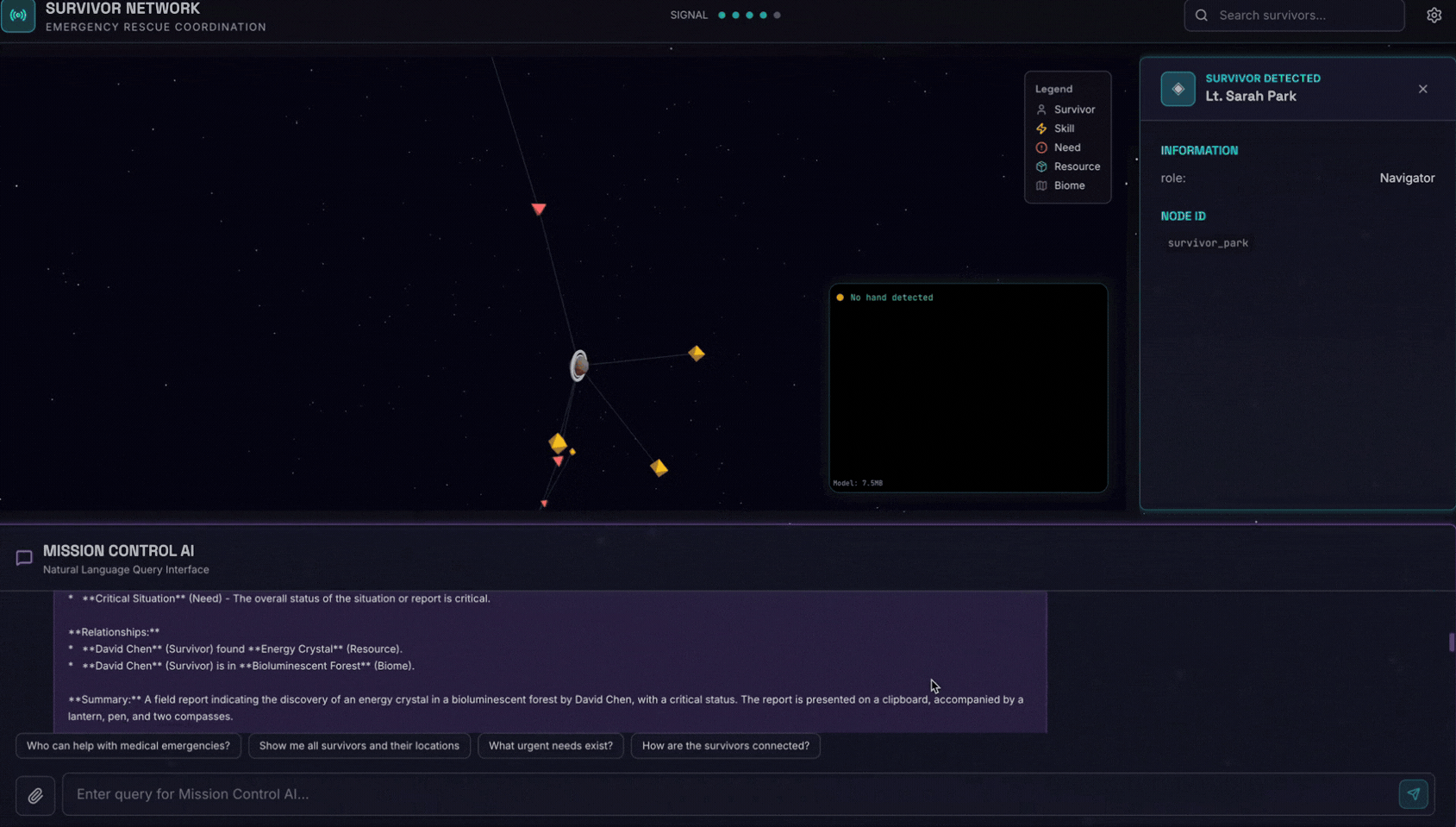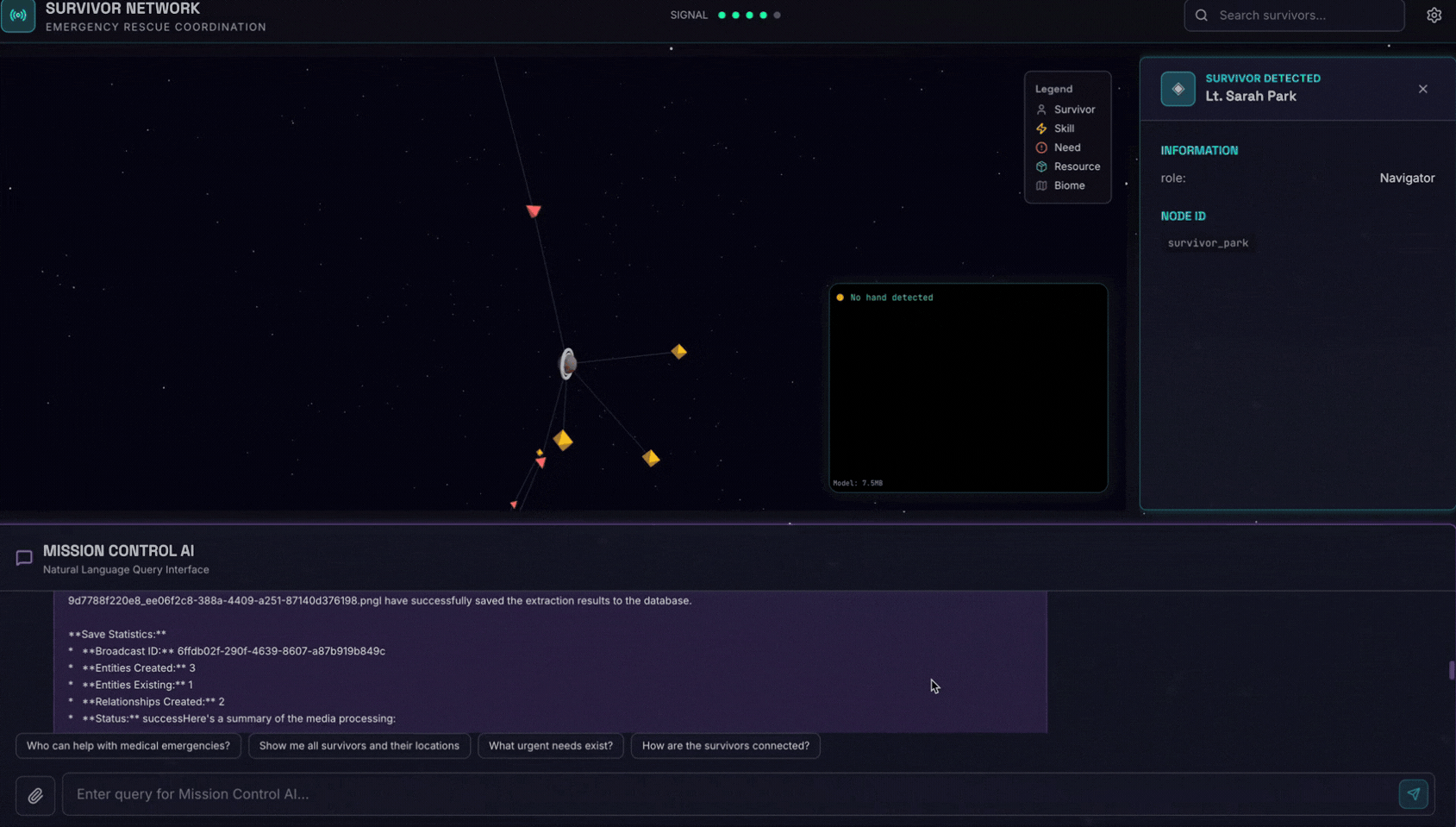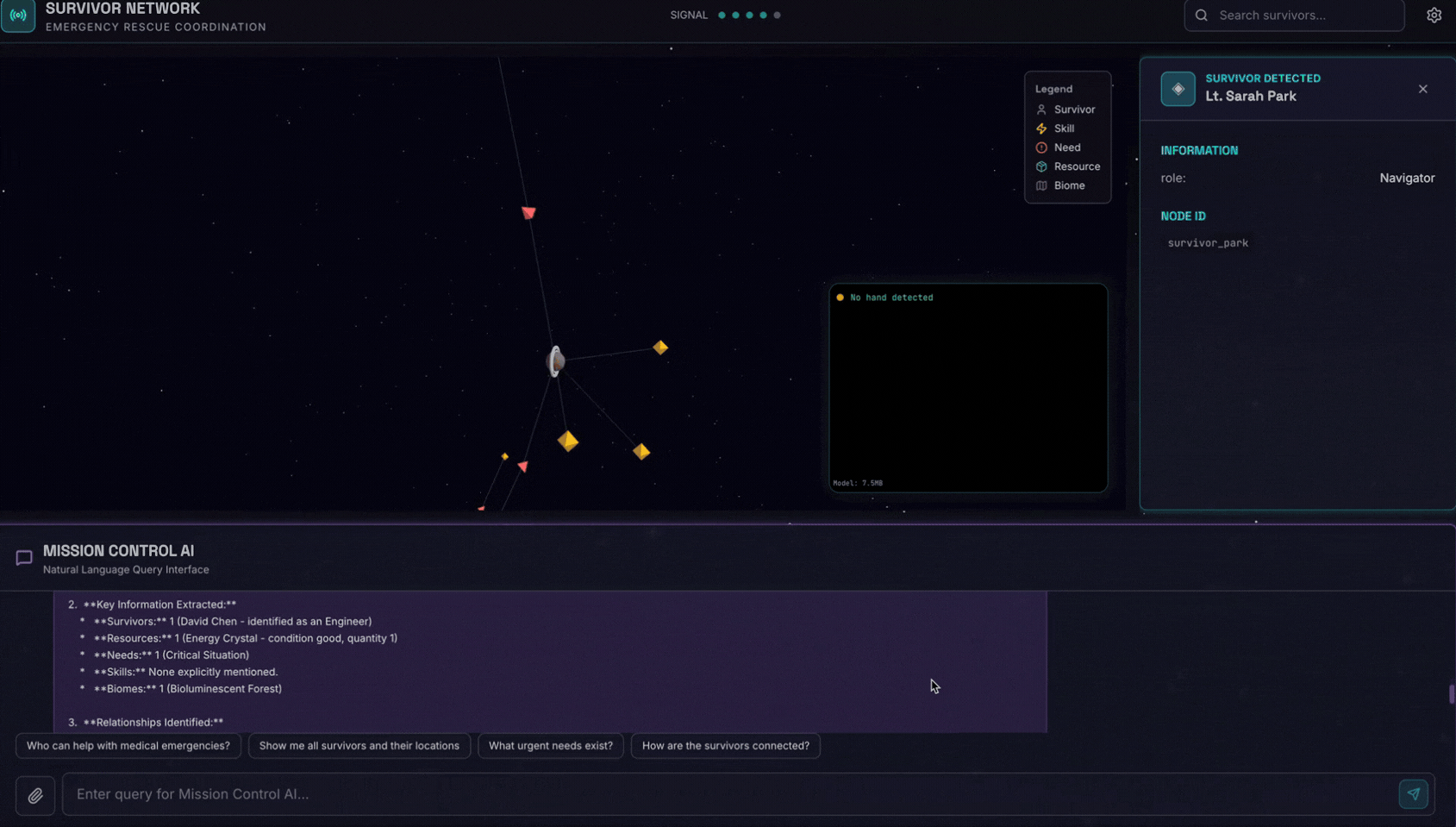
👉💻 Drücken Sie im Terminal nach Abschluss der Tests „Strg + C“, um den Vorgang zu beenden.
6. Multimodalen Upload in GCS-Bucket prüfen
- Öffnen Sie Google Cloud Console Storage.
- „Bucket“ in Cloud Storage auswählen
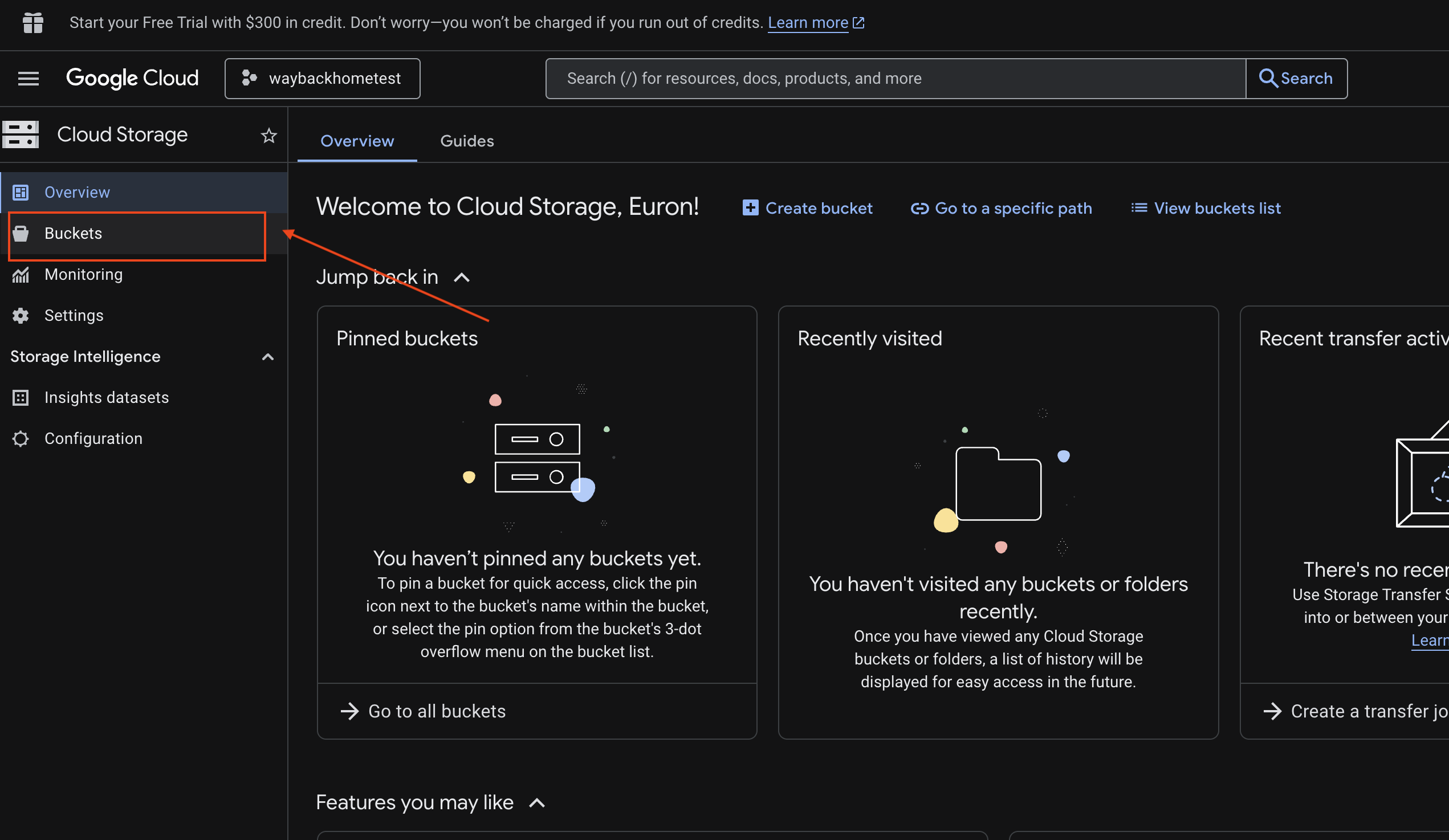
- Wählen Sie Ihren Bucket aus und klicken Sie auf
media.
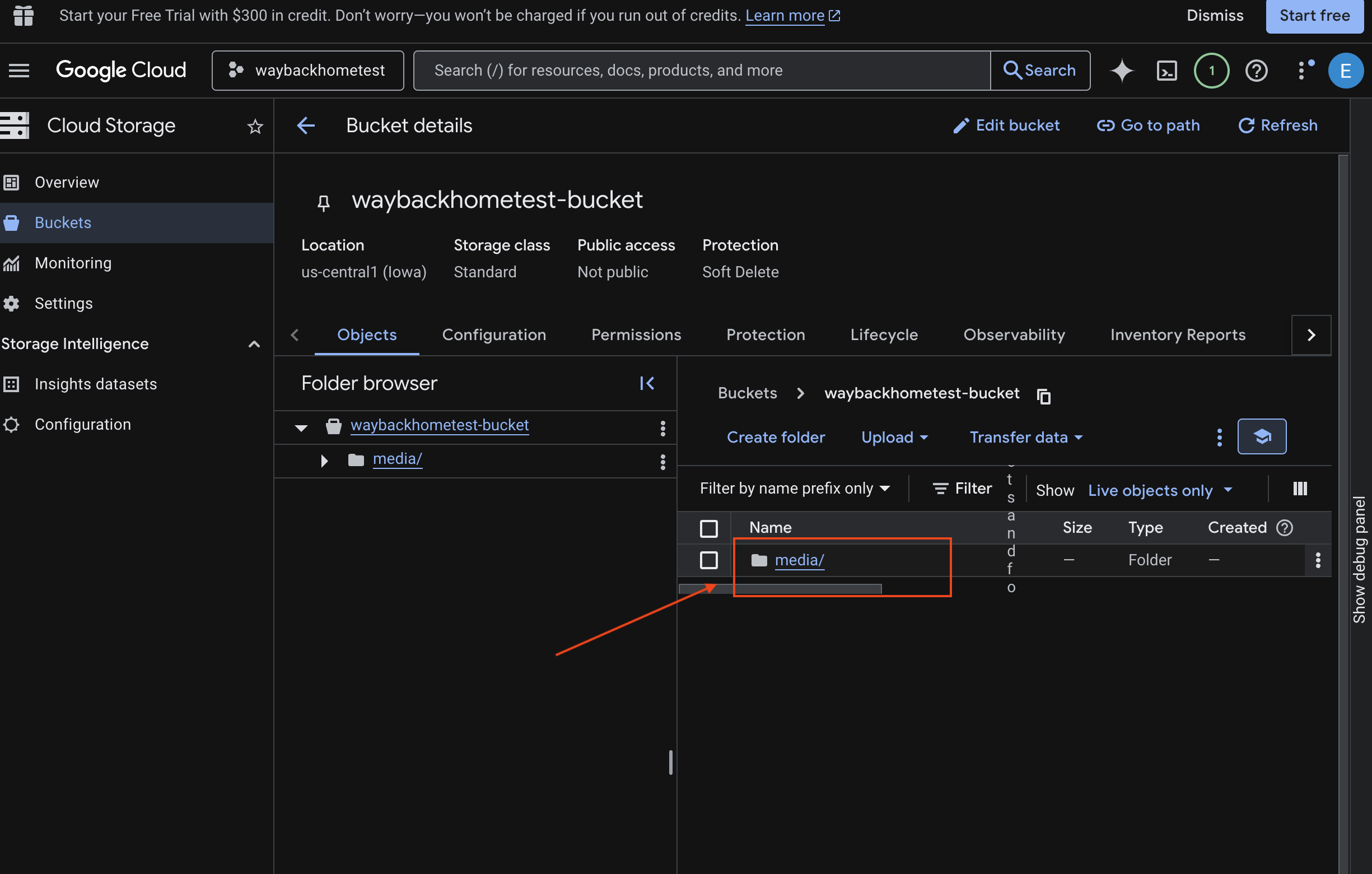
- Hier sehen Sie Ihr hochgeladenes Bild.
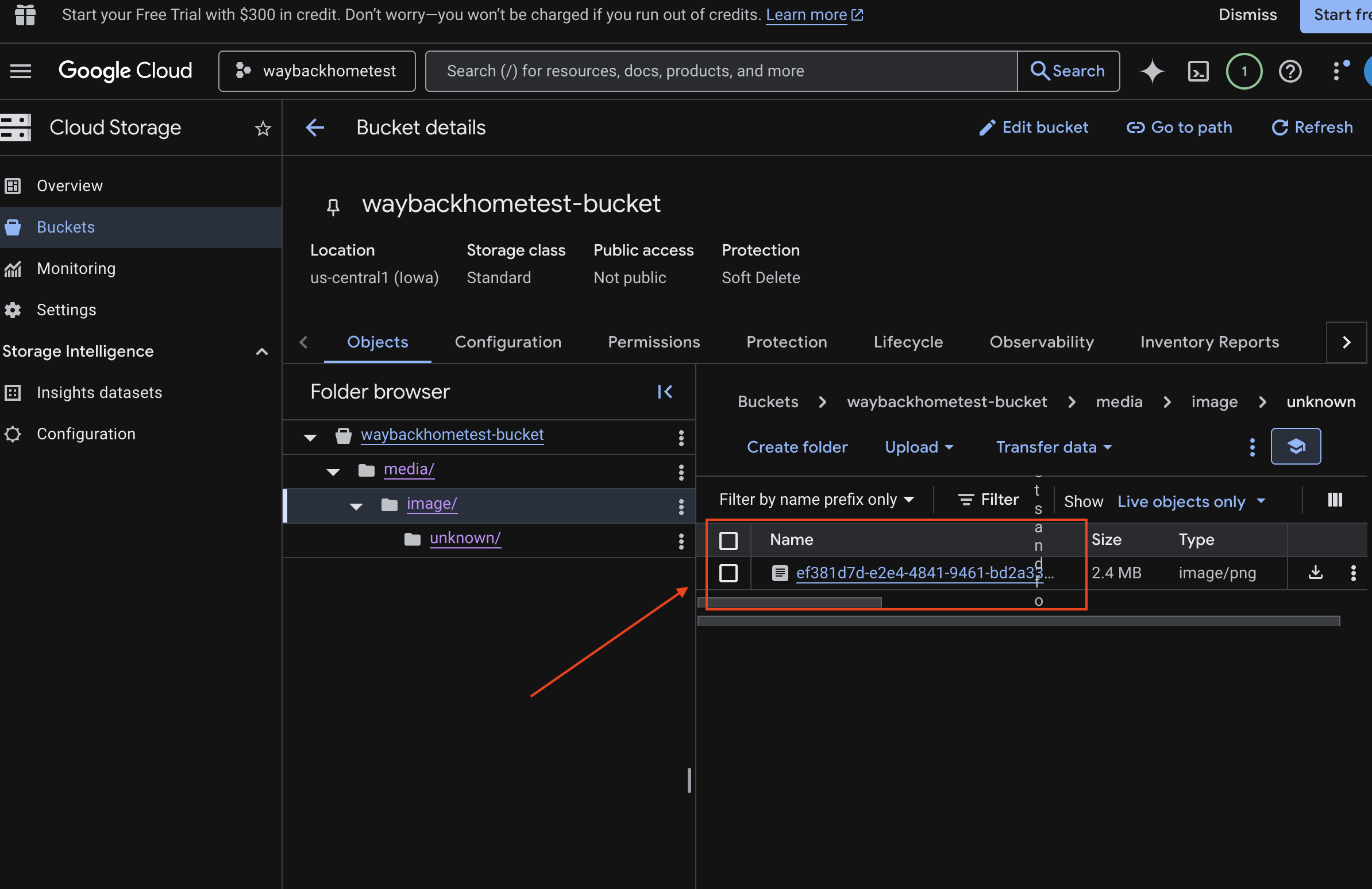
7. Multimodales Hochladen in Spanner prüfen (optional)
Unten sehen Sie ein Beispiel für die Ausgabe in der Benutzeroberfläche für test_photo1.
- Öffnen Sie Google Cloud Console Spanner.
- Wählen Sie Ihre Instanz aus:
Survivor Network - Wählen Sie Ihre Datenbank aus:
graph-db - Klicken Sie in der linken Seitenleiste auf Spanner Studio.
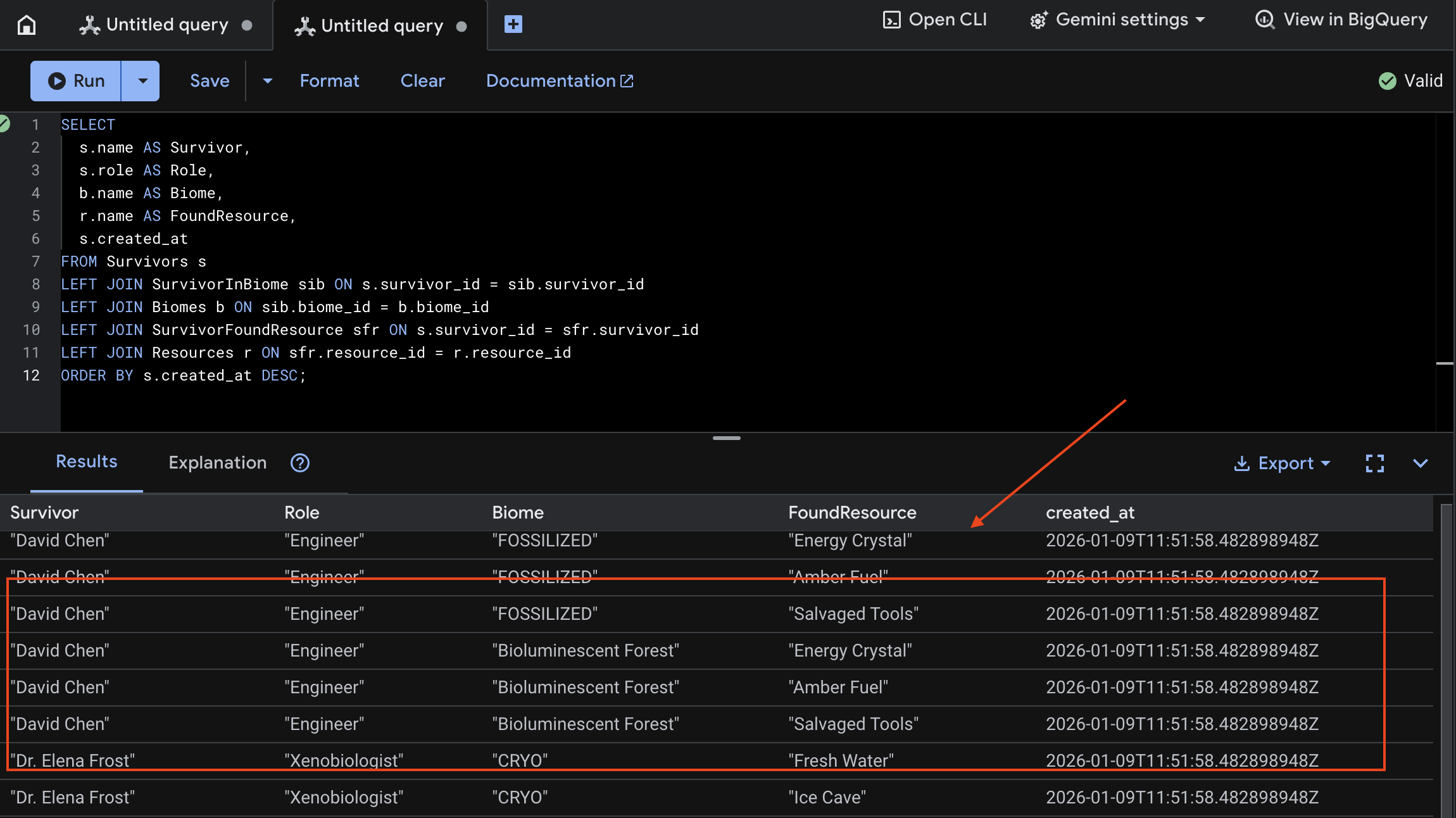
👉 Fragen Sie die neuen Daten in Spanner Studio ab:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Das Ergebnis unten zeigt, dass die Überprüfung erfolgreich war:
12. ☕️ [Optional] Memory Bank mit Agent Engine
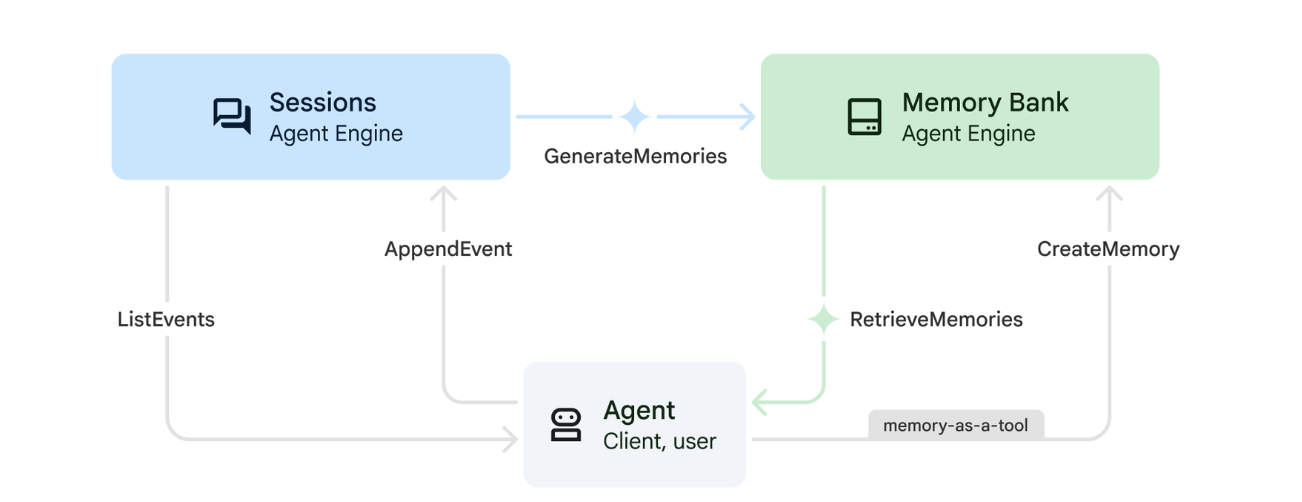
1. So funktioniert der Arbeitsspeicher
Das System verwendet einen Dual-Memory-Ansatz, um sowohl den unmittelbaren Kontext als auch das langfristige Lernen zu berücksichtigen.
2. Was sind Memory-Themen?
Mit Themen für gemerkte Informationen werden die Kategorien von Informationen definiert, die sich der Agent über Unterhaltungen hinweg merken soll. Sie sind sozusagen Aktenschränke für verschiedene Arten von Nutzereinstellungen.
Unsere beiden Themen:
search_preferences: Wie der Nutzer am liebsten sucht- Wird die Stichwortsuche oder die semantische Suche bevorzugt?
- Nach welchen Fähigkeiten/Biomen suchen sie häufig?
- Beispiel für Speicher: „Nutzer bevorzugt semantische Suche für medizinische Fähigkeiten“
urgent_needs_context: Welche Krisen werden beobachtet?- Welche Ressourcen werden überwacht?
- Um welche Überlebende geht es?
- Beispiel für Kontext: „Der Nutzer verfolgt den Medikamentenmangel in Northern Camp.“
3. Memory-Themen einrichten
Mit benutzerdefinierten Speicherthemen wird definiert, was sich der Agent merken soll. Diese werden beim Bereitstellen der Agent Engine konfiguriert.
👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Dadurch wird ~/way-back-home/level_2/backend/deploy_agent.py im Editor geöffnet.
Wir definieren MemoryTopic-Objekte, um das LLM darüber zu informieren, welche Informationen extrahiert und gespeichert werden sollen.
👉 Ersetzen Sie in der Datei deploy_agent.py den # TODO: SET_UP_TOPIC durch Folgendes:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Agent-Integration
Der Agent-Code muss die Memory Bank kennen, um Informationen zu speichern und abzurufen.
👉💻 Öffnen Sie die Datei im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Dadurch wird ~/way-back-home/level_2/backend/agent/agent.py im Editor geöffnet.
Agent-Erstellung
Beim Erstellen des Agenten übergeben wir after_agent_callback, damit Sitzungen nach Interaktionen im Speicher gespeichert werden. Die Funktion add_session_to_memory wird asynchron ausgeführt, um die Chat-Antwort nicht zu verlangsamen.
👉 Suchen Sie in der Datei agent.py nach dem Kommentar # TODO: REPLACE_ADD_SESSION_MEMORY und ersetzen Sie die gesamte Zeile durch den folgenden Code:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Speichern im Hintergrund
👉 Suchen Sie in der Datei agent.py nach dem Kommentar # TODO: REPLACE_ADD_MEMORY_BANK_TOOL und ersetzen Sie die gesamte Zeile durch den folgenden Code:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉 Suchen Sie in der Datei agent.py nach dem Kommentar # TODO: REPLACE_ADD_CALLBACK und ersetzen Sie die gesamte Zeile durch den folgenden Code:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Vertex AI Session Service einrichten
👉💻 Öffnen Sie die Datei chat.py im Terminal im Cloud Shell-Editor, indem Sie Folgendes ausführen:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 Suchen Sie in der Datei chat.py nach dem Kommentar # TODO: REPLACE_VERTEXAI_SERVICES und ersetzen Sie die gesamte Zeile durch den folgenden Code:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Optional] Agent mit der Agent Engine verknüpfen
1. Einrichtung und Bereitstellung
Bevor Sie die Memory-Funktionen testen, müssen Sie den Agent mit den neuen Memory-Themen bereitstellen und dafür sorgen, dass Ihre Umgebung richtig konfiguriert ist.
Wir haben ein praktisches Script bereitgestellt, um diesen Prozess zu vereinfachen.
Bereitstellungsskript ausführen
👉💻 Führen Sie im Terminal das Bereitstellungsskript aus:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Dieses Skript führt die folgenden Aktionen aus:
- Führt
backend/deploy_agent.pyaus, um den Agent und die Memory-Themen bei Vertex AI zu registrieren. - Erfasst die neue Agent Engine-ID.
- Aktualisiert Ihre
.env-Datei automatisch mitAGENT_ENGINE_ID. - Prüfen Sie, ob
USE_MEMORY_BANK=TRUEin Ihrer.env-Datei festgelegt ist.
[!IMPORTANT] Wenn Sie Änderungen an custom_topics in deploy_agent.py vornehmen, müssen Sie dieses Skript noch einmal ausführen, um die Agent Engine zu aktualisieren.
Memory Bank bestätigen
Sie können jetzt prüfen, ob die Memory Bank funktioniert, indem Sie dem Agenten eine Präferenz beibringen und prüfen, ob sie über Sitzungen hinweg bestehen bleibt.
Schritt 1: App öffnen
Öffnen Sie die Anwendung noch einmal, indem Sie der Anleitung unten folgen: Wenn das vorherige Terminal noch ausgeführt wird, beenden Sie es, indem Sie Ctrls+C drücken.
👉💻 App starten:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Klicken Sie im Terminal auf Local: http://localhost:5173/.
Schritt 2: Memory Bank mit Text testen
Geben Sie in der Chatoberfläche Folgendes ein, um dem Agenten Ihren spezifischen Kontext zu erläutern:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Warte etwa 30 Sekunden, bis das Bild im Hintergrund verarbeitet wurde.
Schritt 3: Neue Sitzung starten
Aktualisieren Sie die Seite, um den aktuellen Unterhaltungsverlauf (Kurzzeitgedächtnis) zu löschen.
Stellen Sie eine Frage, die auf dem Kontext basiert, den Sie zuvor angegeben haben:
"What kind of missions am I interested in?"
Erwartete Antwort:
„Basierend auf Ihren bisherigen Unterhaltungen interessieren Sie sich für:
- Medizinische Rettungseinsätze
- Betrieb in den Bergen/in großer Höhe
- Erforderliche Fähigkeiten: Erste Hilfe, Klettern
Soll ich Überlebende suchen, die diese Kriterien erfüllen?“
Schritt 4: Mit Bild-Upload testen
Laden Sie ein Bild hoch und fragen Sie:
remember this
Sie können eines der Fotos hier oder ein eigenes Foto auswählen und in die Benutzeroberfläche hochladen:
Schritt 5: In Vertex AI Agent Engine überprüfen
Zur Google Cloud Console Agent Engine
- Achten Sie darauf, dass Sie das Projekt oben links in der Projektauswahl auswählen:
- Prüfen Sie die Agent-Engine, die Sie gerade mit dem vorherigen Befehl bereitgestellt haben
use_memory_bank.sh: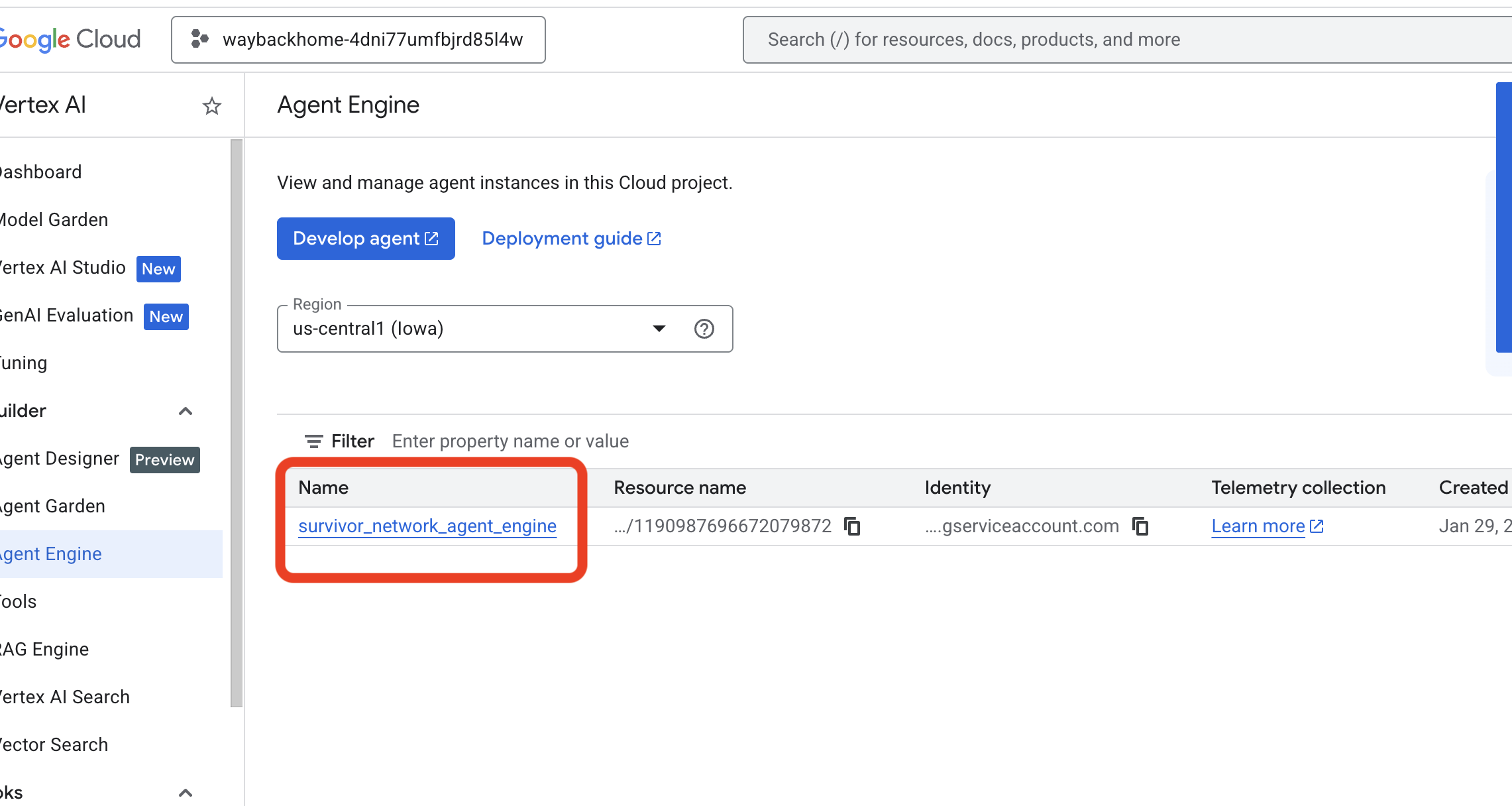 Klicken Sie auf die Agent-Engine, die Sie gerade erstellt haben.
Klicken Sie auf die Agent-Engine, die Sie gerade erstellt haben. - Klicken Sie in diesem bereitgestellten KI-Agenten auf den Tab
Memories, um alle gemerkten Informationen anzusehen.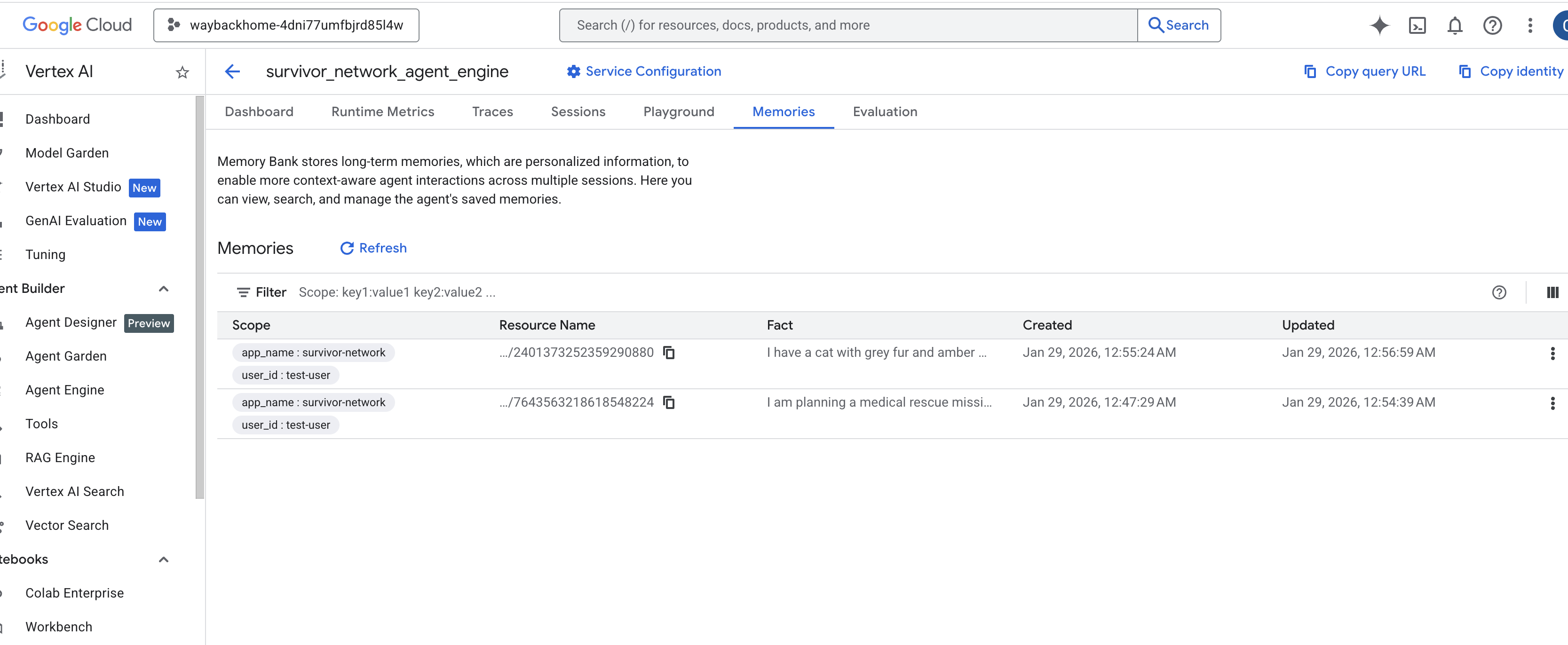
👉💻 Wenn Sie mit dem Testen fertig sind, drücken Sie im Terminal „Strg + C“, um den Vorgang zu beenden.
🎉 Glückwunsch! Sie haben die Memory Bank gerade an Ihren Agent angehängt.
14. ☕️ [Optional] In Cloud Run bereitstellen
1. Bereitstellungsskript ausführen
👉💻 Führen Sie das Bereitstellungsskript aus:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Nach der erfolgreichen Bereitstellung erhalten Sie die URL: 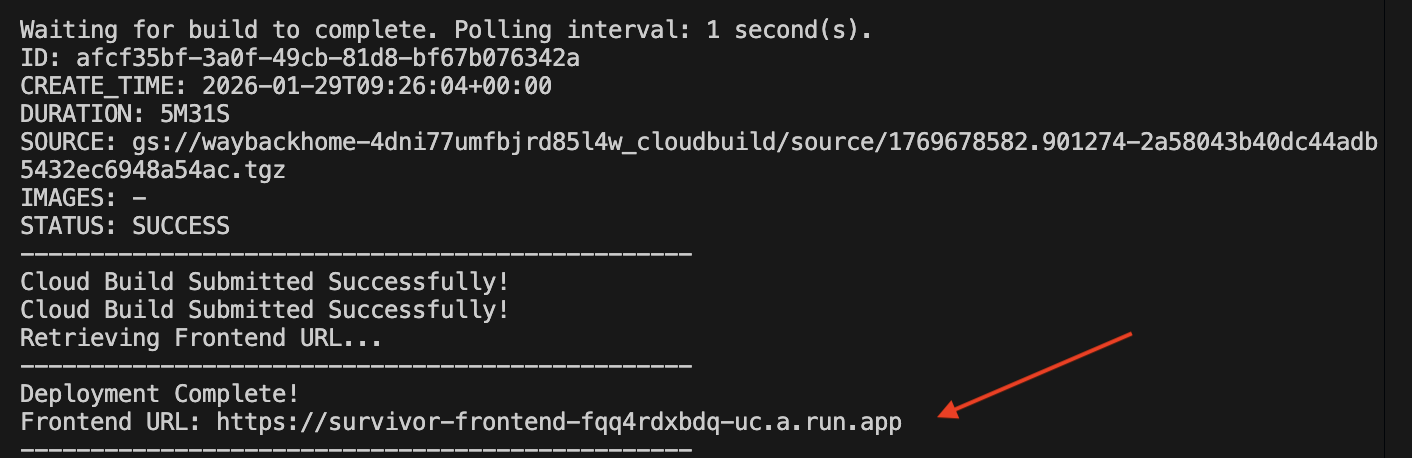 .
.
👉💻 Bevor Sie die URL abrufen, müssen Sie die Berechtigung mit folgendem Befehl erteilen:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Rufen Sie die bereitgestellte URL auf. Dort sehen Sie Ihre Anwendung live.
2. Build-Pipeline
In der Datei cloudbuild.yaml werden die folgenden sequenziellen Schritte definiert:
- Backend Build: Erstellt das Docker-Image aus
backend/Dockerfile. - Backend Deploy: Stellt den Backend-Container in Cloud Run bereit.
- Capture URL (URL erfassen): Ruft die neue Backend-URL ab.
- Frontend-Build:
- Installiert Abhängigkeiten.
- Erstellt die React-App und fügt
VITE_API_URL=ein.
- Frontend-Image: Erstellt das Docker-Image aus
frontend/Dockerfile(Verpacken der statischen Assets). - Frontend Deploy: Stellt den Frontend-Container bereit.
3. Deployment prüfen
Nachdem der Build abgeschlossen ist (prüfen Sie den vom Script bereitgestellten Link zu den Logs), können Sie Folgendes überprüfen:
- Rufen Sie die Cloud Run Console auf.
- Suchen Sie nach dem Dienst
survivor-frontend. - Klicken Sie auf die URL, um die Anwendung zu öffnen.
- Führen Sie eine Suchanfrage aus, um sicherzustellen, dass das Frontend mit dem Backend kommunizieren kann.
(OPTIONAL) 4. Manuelle Bereitstellung
Wenn Sie die Befehle lieber manuell ausführen oder den Prozess besser verstehen möchten, finden Sie hier eine Anleitung zur direkten Verwendung von cloudbuild.yaml.
Schreiben von cloudbuild.yaml
Eine cloudbuild.yaml-Datei gibt an, welche Schritte von Google Cloud Build ausgeführt werden sollen.
- steps: Eine Liste sequenzieller Aktionen. Jeder Schritt wird in einem Container ausgeführt, z.B.
docker,gcloud,node,bash. - substitutions: Variablen, die zur Build-Zeit übergeben werden können (z.B.
$_REGION). - Arbeitsbereich: Ein gemeinsames Verzeichnis, in dem Schritte Dateien freigeben können (ähnlich wie bei der Freigabe von
backend_url.txt).
Bereitstellung ausführen
Wenn Sie die Bereitstellung manuell ohne das Skript vornehmen möchten, verwenden Sie den Befehl gcloud builds submit. Sie MÜSSEN die erforderlichen Ersatzvariablen übergeben.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Fazit
1. Was Sie erstellt haben
✅ Graph Database: Spanner mit Knoten (Überlebende, Fähigkeiten) und Kanten (Beziehungen)
✅ AI Search: Keyword-, semantische und hybride Suche mit Einbettungen
✅ Multimodal Pipeline: Entitäten aus Bildern/Videos mit Gemini extrahieren
✅ Multi-Agent System: Koordinierter Workflow mit ADK
✅ Memory Bank: Langfristige Personalisierung mit Vertex AI
✅ Production Deployment: Cloud Run + Agent Engine
2. Zusammenfassung der Architektur
3. Wichtige Erkenntnisse
- Graph-RAG: Kombiniert die Struktur von Graphdatenbanken mit semantischen Einbettungen für intelligente Suche
- Multi-Agent-Muster: Sequenzielle Pipelines für komplexe, mehrstufige Workflows
- Multimodale KI: Strukturierte Daten aus unstrukturierten Medien (Bilder/Videos) extrahieren
- Zustandsbehaftete Agents: Memory Bank ermöglicht die Personalisierung über Sitzungen hinweg
4. Workshop-Inhalte
- Level0: Identifizieren Sie sich.
- Level1: Genaue Position
- Level2 This One: Build a Multimodal AI Agent with Graph RAG, ADK & Memory Bank
- Level3: ADK-Agent für bidirektionales Streaming erstellen
- Level4: Bidirektionales Multi-Agent-System in Echtzeit
- Level5: Event-Driven Architecture with Google ADK, A2A, and Kafka (Ereignisgesteuerte Architektur mit Google ADK, A2A und Kafka)