
1. Introducción

1. El desafío
En situaciones de respuesta ante desastres, coordinar a los sobrevivientes con diferentes habilidades, recursos y necesidades en varias ubicaciones requiere capacidades inteligentes de administración de datos y búsqueda. En este taller, aprenderás a crear un sistema de IA de producción que combina lo siguiente:
- 🗄️ Base de datos de gráficos (Spanner): Almacena relaciones complejas entre sobrevivientes, habilidades y recursos
- 🔍 Búsqueda potenciada por IA: Búsqueda híbrida semántica y de palabras clave con embeddings
- 📸 Procesamiento multimodal: Extrae datos estructurados de imágenes, texto y video.
- 🤖 Organización de varios agentes: Coordina agentes especializados para flujos de trabajo complejos
- 🧠 Memoria a largo plazo: Personalización con Memory Bank de Vertex AI
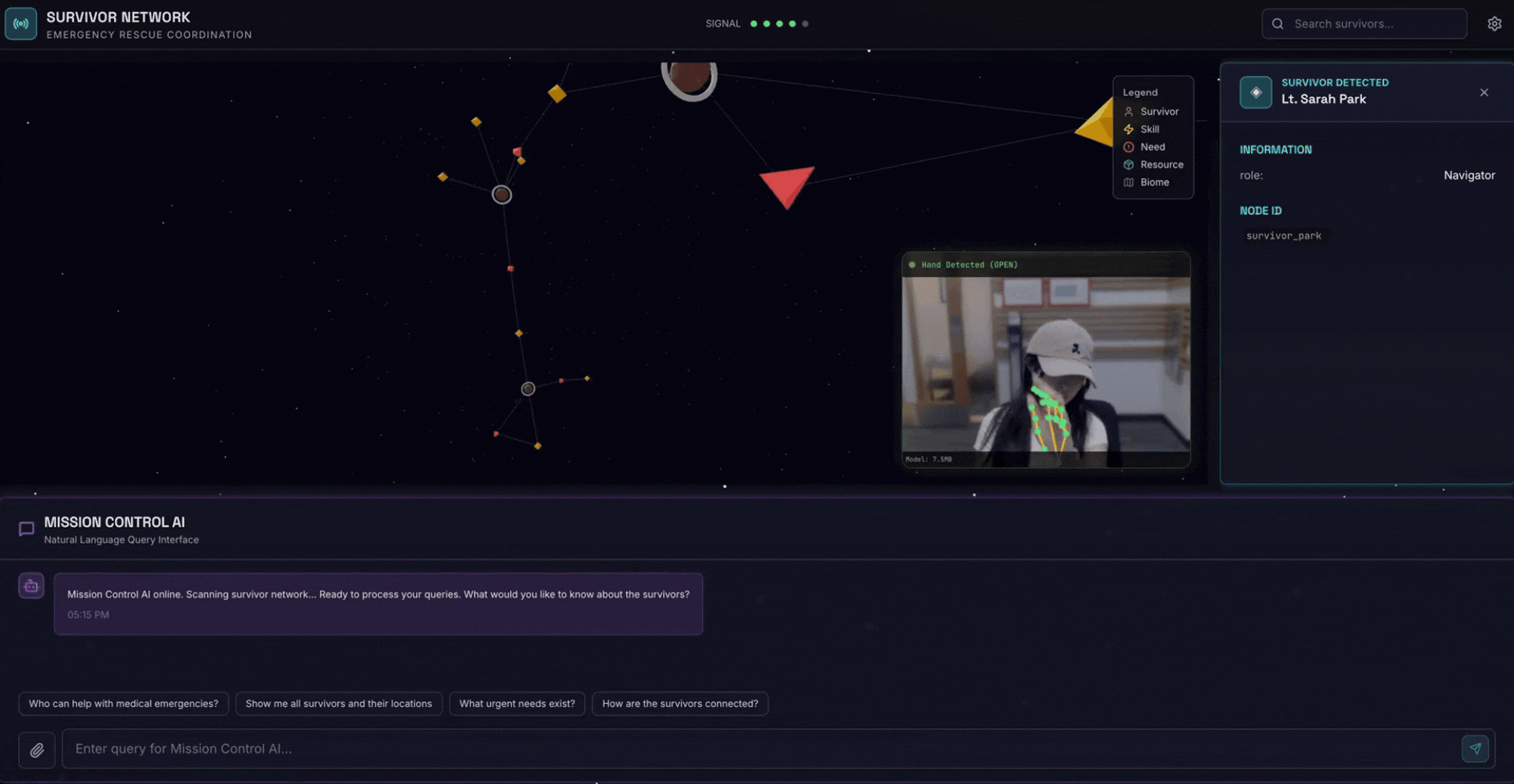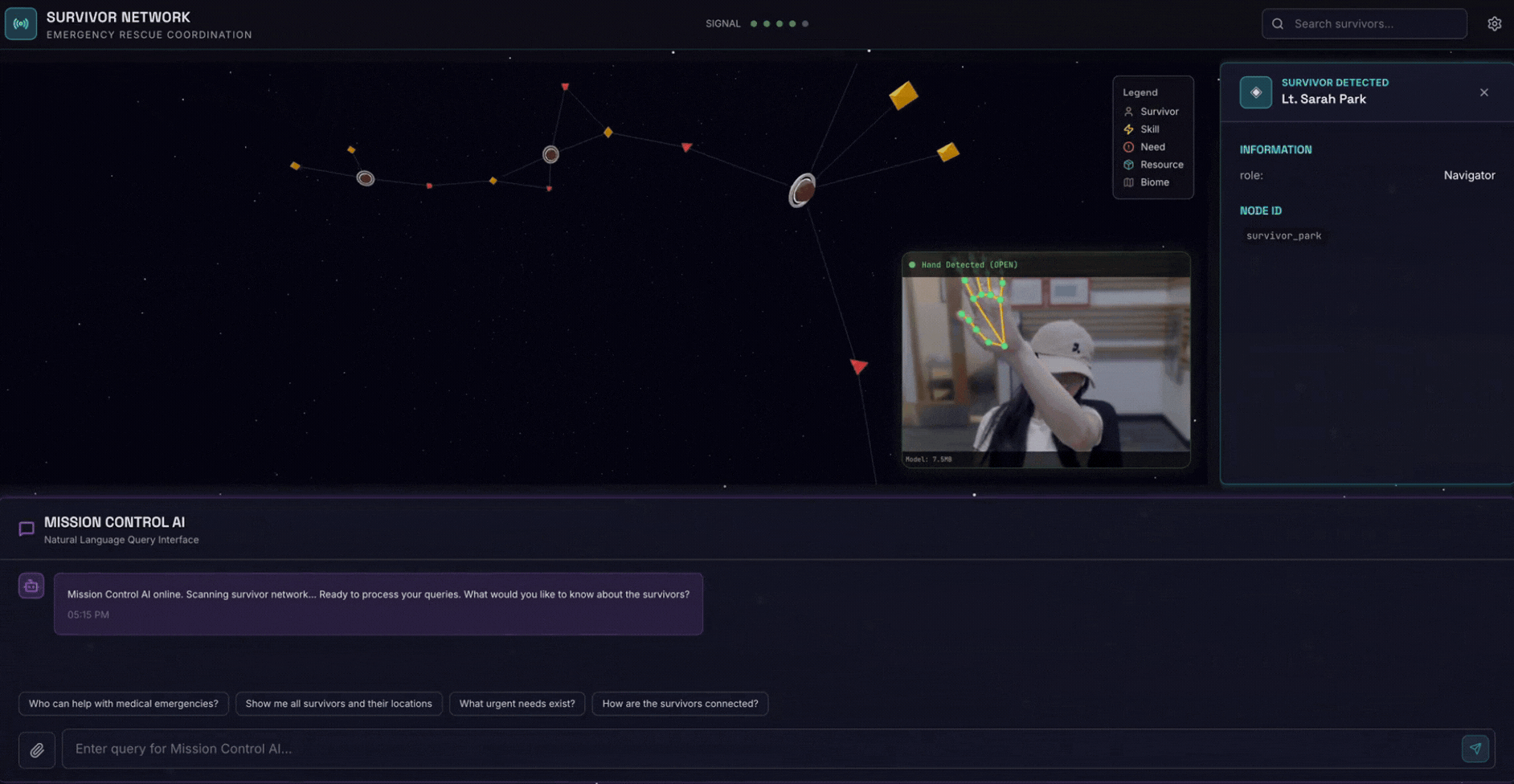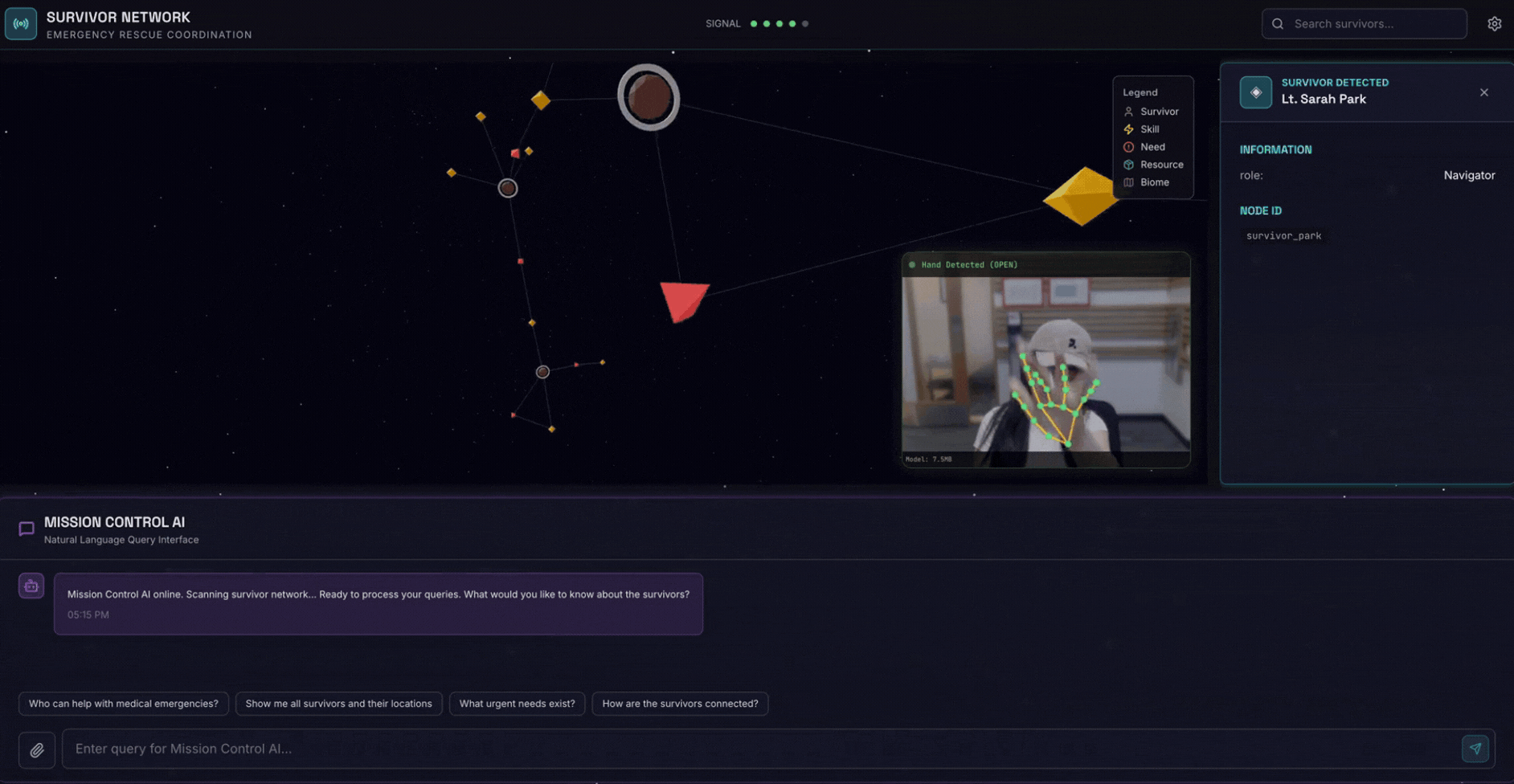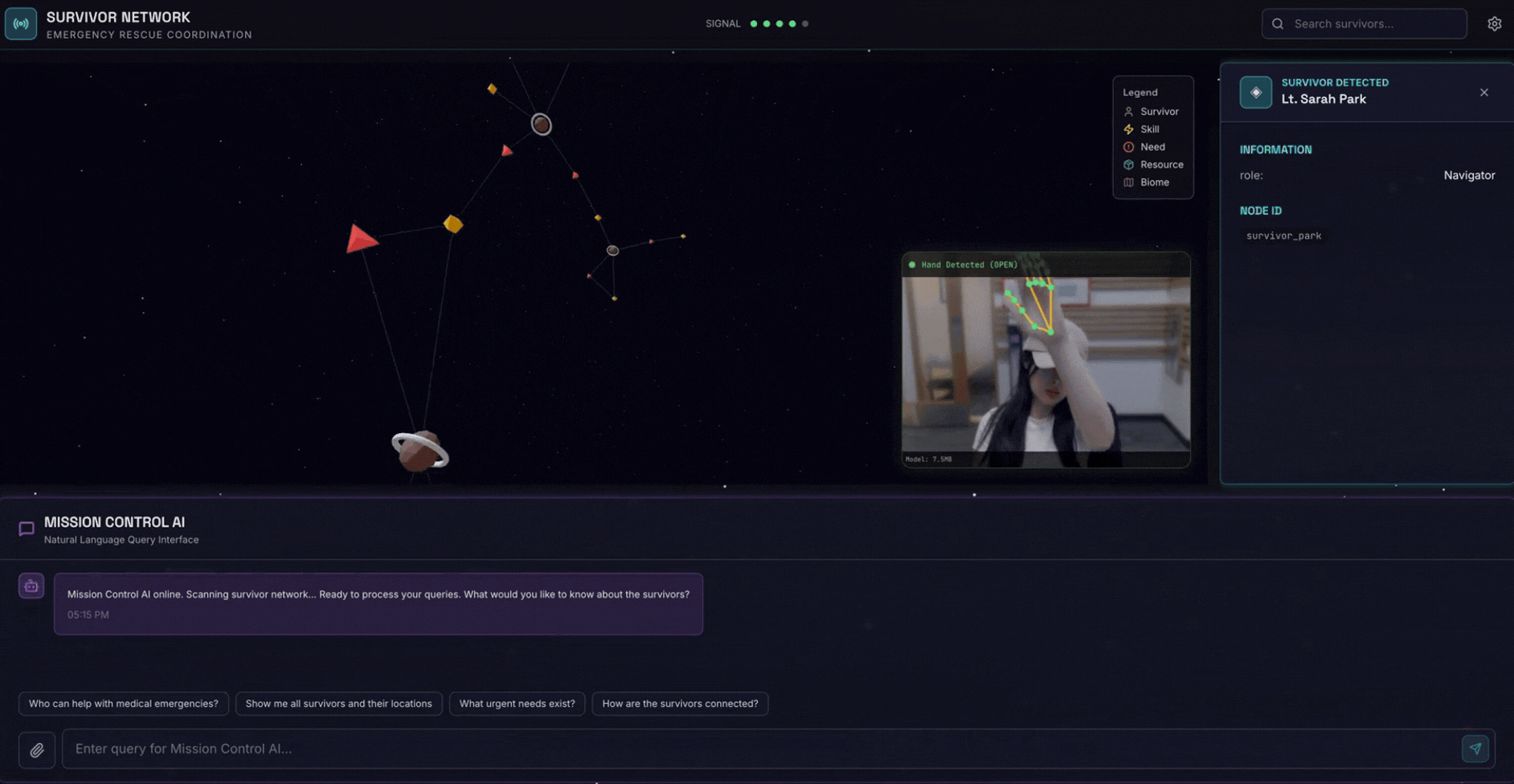
2. Qué compilará
Una base de datos de grafos de la red de sobrevivientes con lo siguiente:
- 🗺️ Visualización interactiva en 3D del gráfico de las relaciones entre sobrevivientes
- 🔍 Búsqueda inteligente (híbrida, semántica y de palabras clave)
- 📸 Canalización de carga multimodal (extrae entidades de imágenes o videos)
- 🤖 Sistema multiagente para la organización de tareas complejas
- 🧠 Integración de Memory Bank para interacciones personalizadas
3. Tecnologías principales
Componente | Tecnología | Objetivo |
Base de datos | Cloud Spanner Graph | Almacena nodos (supervivientes, habilidades) y aristas (relaciones) |
AI Search | Gemini y Embeddings | Comprensión semántica y búsqueda de similitud |
Framework del agente | ADK (Kit de desarrollo de agentes) | Organiza flujos de trabajo de IA |
Memoria | Banco de memoria de Vertex AI | Almacenamiento a largo plazo de las preferencias del usuario |
Frontend | React y Three.js | Visualización de gráficos 3D interactivos |
2. 🛠️ Preparación del entorno (omite este paso si estás en el taller)
Parte uno: Habilita la cuenta de facturación
Para ejecutar este codelab, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Parte dos: Entorno abierto
- 👉 Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- 👉 Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- 👉 Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- 👉💻 En la terminal, verifica que ya te autenticaste y que el proyecto esté configurado con tu ID del proyecto usando el siguiente comando:
gcloud auth list - 👉💻 Clona el proyecto de arranque desde GitHub:
git clone https://github.com/gca-americas/way-back-home.git
Parte tres: Crea un proyecto nuevo
👉💻 En la terminal, haz que la secuencia de comandos de inicialización sea ejecutable y ejecútala:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Configuración del entorno
1. Abre Cloud Shell
En la terminal del Editor de Cloud Shell, si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
2. Configurar proyecto
👉💻 En la terminal, establece tu ID del proyecto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Habilita las APIs obligatorias (esto tarda entre 2 y 3 minutos):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Ejecutar secuencia de comandos de configuración
👉💻 Ejecuta la secuencia de comandos de configuración:
cd ~/way-back-home/level_2
./setup.sh
Esto creará .env para ti. En Cloud Shell, abre way_back_homeproject. En la carpeta level_2, verás que se creó el archivo .env. Si no lo encuentras, puedes hacer clic en View -> Toggle Hidden File para verlo. 
4. Carga datos de muestra
👉💻 Navega al backend y, luego, instala las dependencias:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Carga los datos iniciales de los sobrevivientes:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Esto crea lo siguiente:
- Instancia de Spanner (
survivor-network) - Base de datos (
graph-db) - Todas las tablas de nodos y aristas
- Gráficos de propiedades para consultar el resultado esperado:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
Si haces clic en el vínculo después de Access your database at en el resultado, puedes abrir Spanner en la consola de Google Cloud.

Verás Spanner en la consola de Google Cloud.
4. 🚀 Visualiza datos de gráficos en Spanner Studio
En esta guía, se explica cómo visualizar los datos del gráfico de Survivor Network y cómo interactuar con ellos directamente en la consola de Google Cloud con Spanner Studio. Esta es una excelente manera de verificar tus datos y comprender la estructura del gráfico antes de compilar tu agente de IA.
1. Accede a Spanner Studio
- En el último paso, asegúrate de hacer clic en el vínculo y abrir Spanner Studio.
2. Comprensión de la estructura del gráfico (el "panorama general")
Piensa en el conjunto de datos de Survivor Network como un acertijo lógico o un estado del juego:
Entidad | Rol en el sistema | Analogía |
Survivors | Los agentes o jugadores | Jugadores |
Biomas | Dónde se encuentran | Zonas del mapa |
Habilidades | Qué pueden hacer | Habilidades |
Necesidades | Lo que falta (crisis) | Misiones |
Recursos | Elementos que se encuentran en el mundo | Botín |
El objetivo: El trabajo del agente de IA es conectar habilidades (soluciones) con necesidades (problemas), teniendo en cuenta los biomas (restricciones de ubicación).
🔗 Aristas (relaciones):
SurvivorInBiome: Seguimiento de ubicaciónSurvivorHasSkill: Inventario de habilidadesSurvivorHasNeed: Lista de problemas activosSurvivorFoundResource: Inventario de artículosSurvivorCanHelp: Relación inferida (la IA calcula esto).
3. Cómo consultar el gráfico
Ejecutemos algunas consultas para ver la "historia" en los datos.
Spanner Graph usa GQL (Graph Query Language). Para ejecutar una consulta, usa GRAPH SurvivorNetwork seguido de tu patrón de coincidencia.
👉 Consulta 1: La lista global (¿quién está dónde?) Esta es tu base: comprender la ubicación es fundamental para las operaciones de rescate.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Se espera que veas el siguiente resultado: 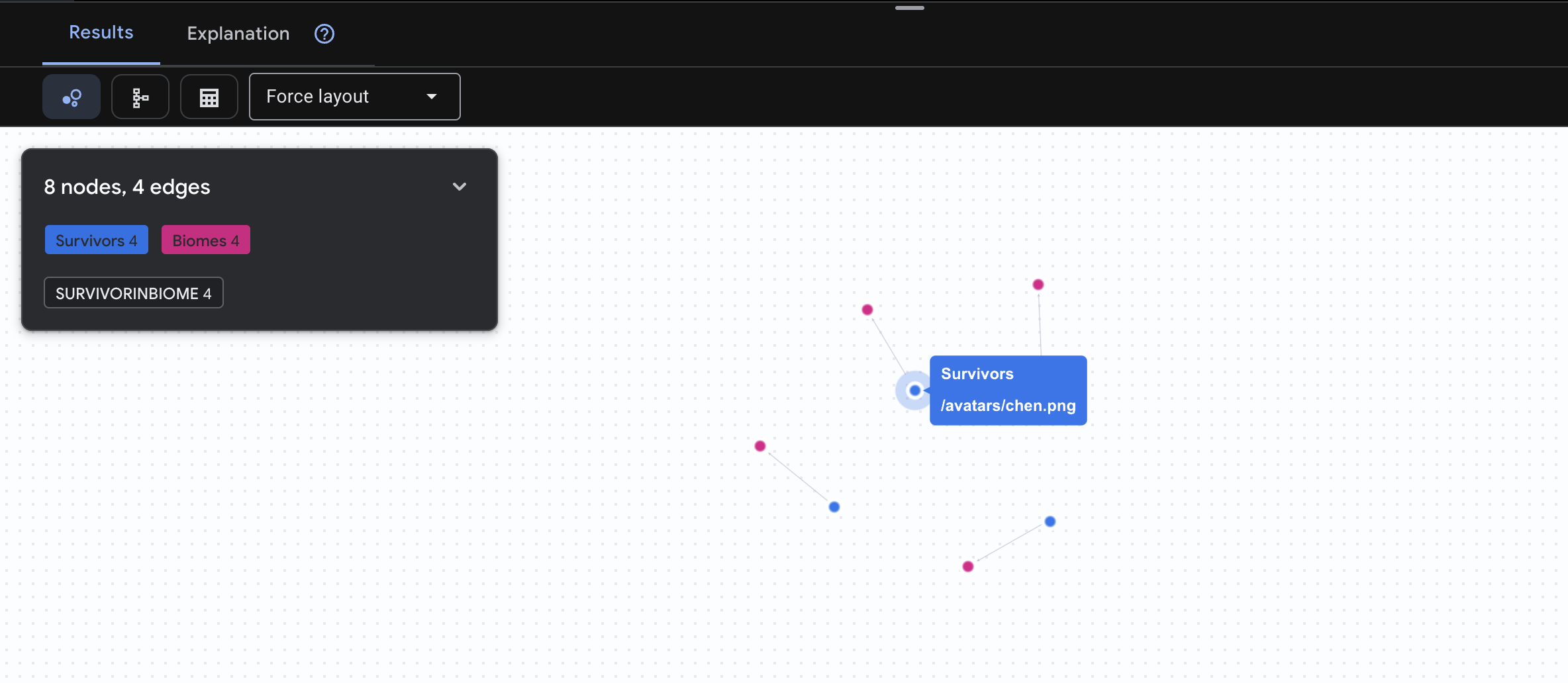
👉 Pregunta 2: La matriz de habilidades (capacidades) Ahora que sabes dónde está cada persona, descubre qué puede hacer.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Se espera que veas el siguiente resultado: 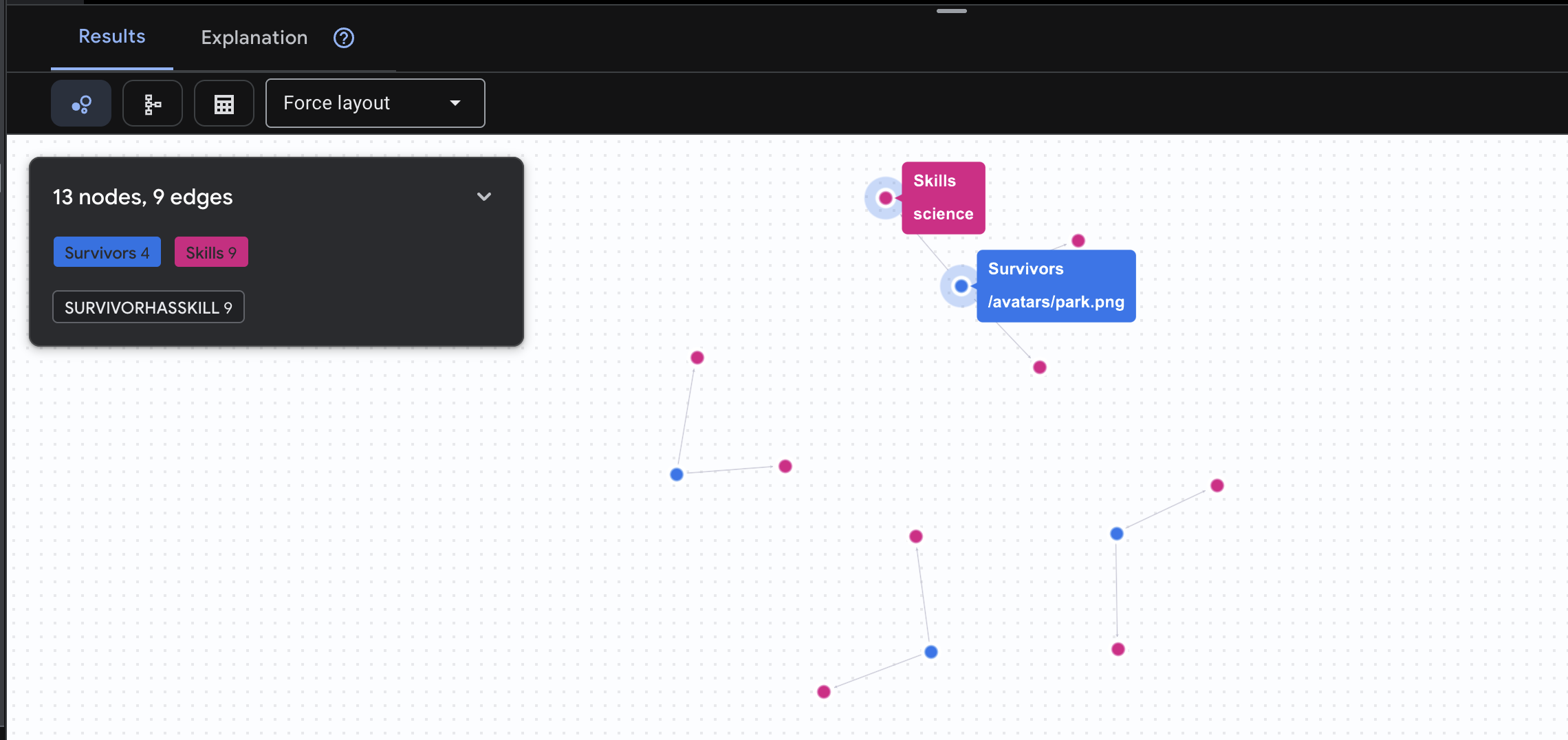
👉 Consulta 3: ¿Quién está en crisis? (El "Tablero de misiones") Consulta qué sobrevivientes necesitan ayuda y qué necesitan.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Se espera que veas el siguiente resultado: 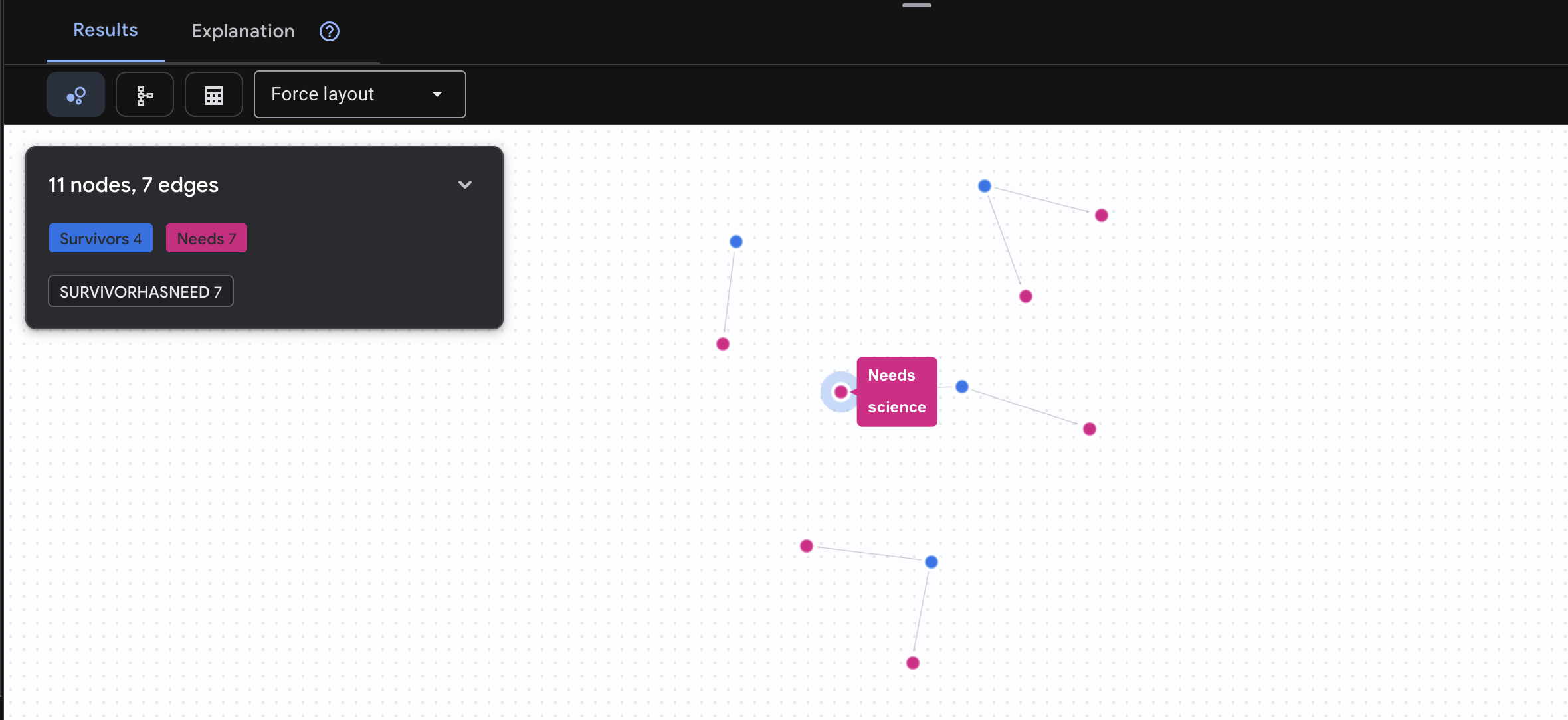
🔎 [Opcional] Matchmaking: ¿Quién puede ayudar a quién?
Aquí es donde el gráfico se vuelve poderoso. Esta búsqueda encuentra sobrevivientes que tienen habilidades para satisfacer las necesidades de otros sobrevivientes.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Se espera que veas el siguiente resultado: 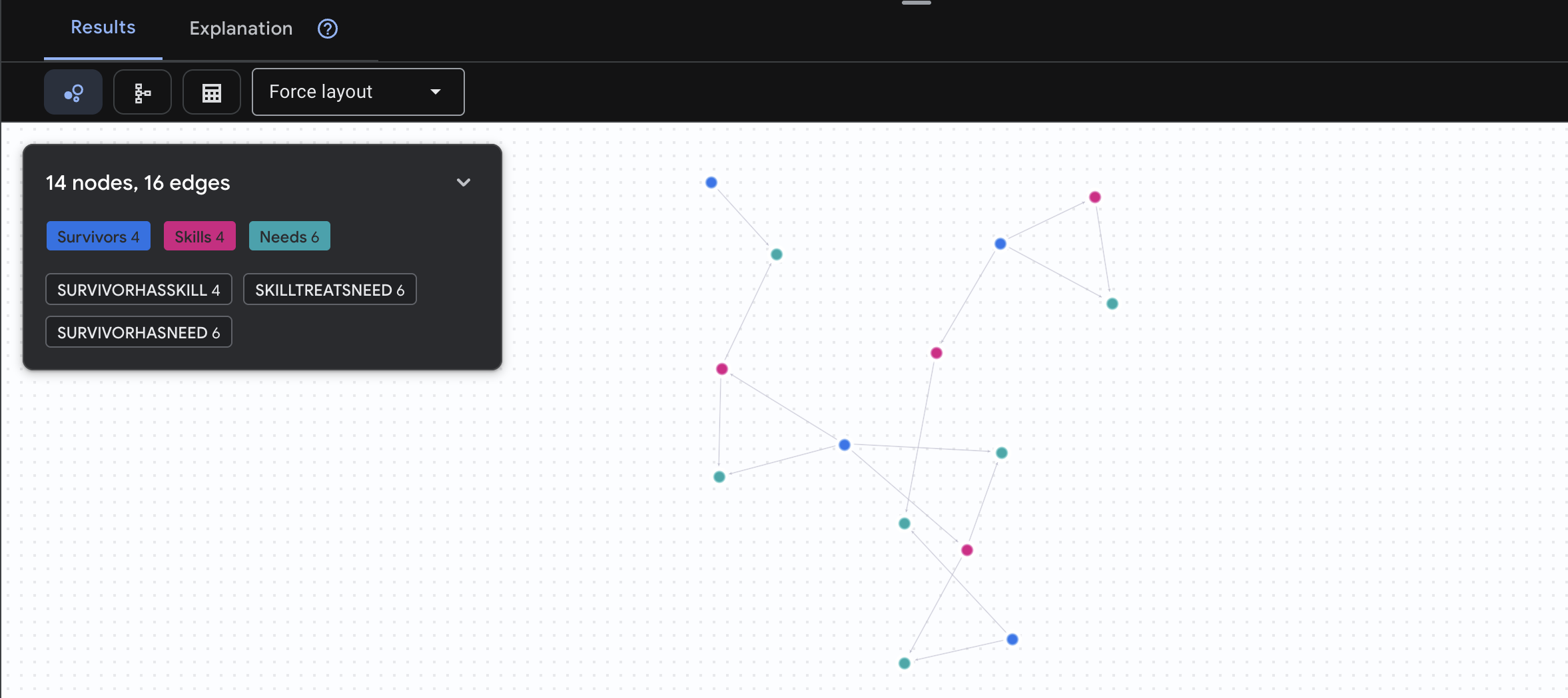
aside positive Qué hace esta búsqueda:
En lugar de solo mostrar "Los primeros auxilios tratan las quemaduras" (lo que es obvio a partir del esquema), esta búsqueda encuentra lo siguiente:
- Dra. Elena Frost (que tiene capacitación médica) → puede tratar a → Capitán Tanaka (que tiene quemaduras)
- David Chen (que tiene conocimientos de primeros auxilios) → puede tratar a → Teniente Park (que tiene un esguince de tobillo)
Por qué es importante:
Qué hará tu agente de IA:
Cuando un usuario pregunta "¿Quién puede tratar quemaduras?", el agente hará lo siguiente:
- Ejecuta una consulta de gráfico similar
- Devolución: "El Dr. Frost tiene capacitación médica y puede ayudar al capitán Tanaka"
- El usuario no necesita saber sobre las tablas o las relaciones intermedias.
5. 🚀 Incorporaciones potenciadas por IA en Spanner
1. ¿Por qué usar embeddings? (Sin acción, solo lectura)
En la situación de supervivencia, el tiempo es fundamental. Cuando un sobreviviente informa una emergencia, como I need someone who can treat burns o Looking for a medic, no puede perder tiempo adivinando los nombres exactos de las habilidades en la base de datos.
Situación real: Sobreviviente: Captain Tanaka has burns—we need medical help NOW!
Búsqueda tradicional con palabras clave de "médico" → 0 resultados ❌
Búsqueda semántica con incorporaciones → Encuentra "Capacitación médica" y "Primeros auxilios" ✅
Esto es exactamente lo que necesitan los agentes: una búsqueda inteligente y similar a la humana que comprenda la intención, no solo las palabras clave.
2. Crea un modelo de embedding
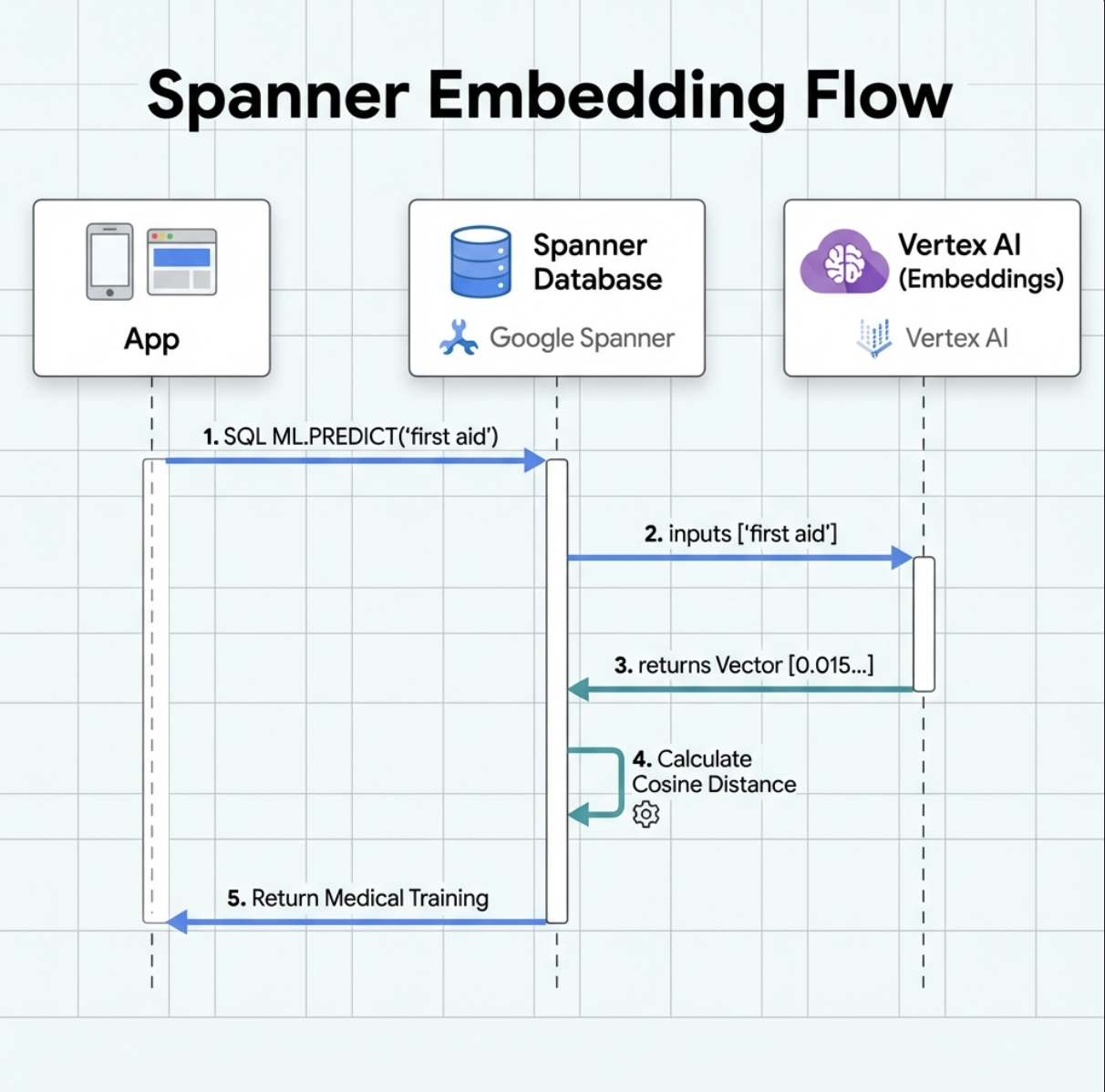
Ahora, creemos un modelo que convierta texto en embeddings con text-embedding-004 de Google.
👉 En Spanner Studio, ejecuta este SQL (reemplaza $YOUR_PROJECT_ID por el ID de tu proyecto real):
‼️ En el editor de Cloud Shell, abre File -> Open Folder -> way-back-home/level_2 para ver todo el proyecto.
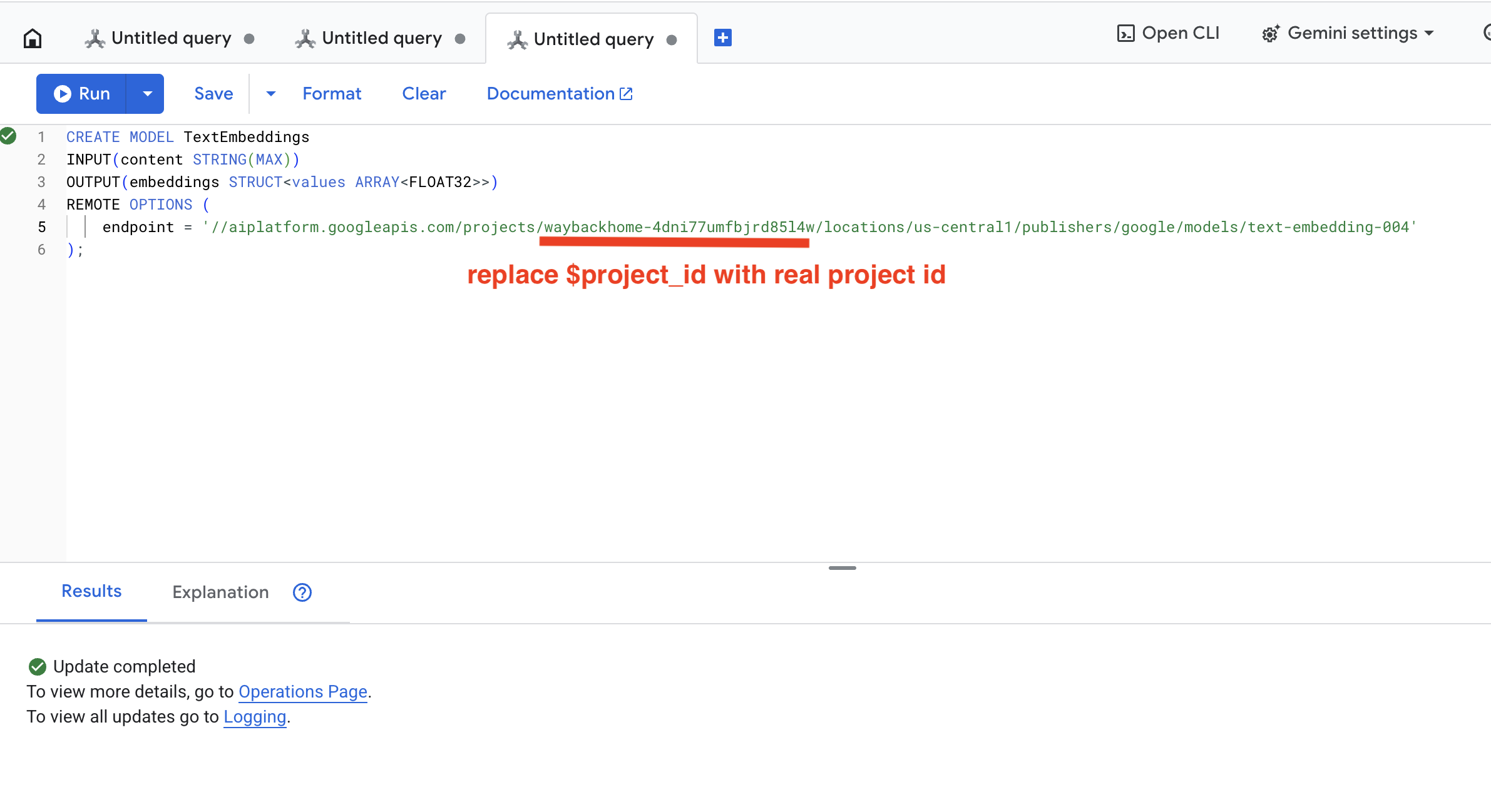
👉 Ejecuta esta consulta en Spanner Studio. Para ello, copia y pega la siguiente consulta y, luego, haz clic en el botón Ejecutar:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Qué hace:
- Crea un modelo virtual en Spanner (no se almacenan pesos del modelo de forma local).
- Señala la
text-embedding-004de Google en Vertex AI - Define el contrato: La entrada es texto y la salida es un array de números de punto flotante de 768 dimensiones.
¿Por qué "OPCIONES REMOTAS"?
- Spanner no ejecuta el modelo en sí
- Llama a Vertex AI a través de la API cuando usas
ML.PREDICT. - Zero-ETL: No es necesario exportar datos a Python, procesarlos y volver a importarlos
Haz clic en el botón Run. Una vez que se complete la acción, verás el resultado como se muestra a continuación:
3. Agregar columna de incorporación
👉 Agrega una columna para almacenar embeddings:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Haz clic en el botón Run. Una vez que se complete la acción, verás el resultado como se muestra a continuación:
4. Genera embeddings
👉 Usa la IA para crear embeddings vectoriales para cada habilidad:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Haz clic en el botón Run. Una vez que se complete la acción, verás el resultado como se muestra a continuación:
Qué sucede: Cada nombre de habilidad (p.ej., "primeros auxilios") se convierte en un vector de 768 dimensiones que representa su significado semántico.
5. Verifica las incorporaciones
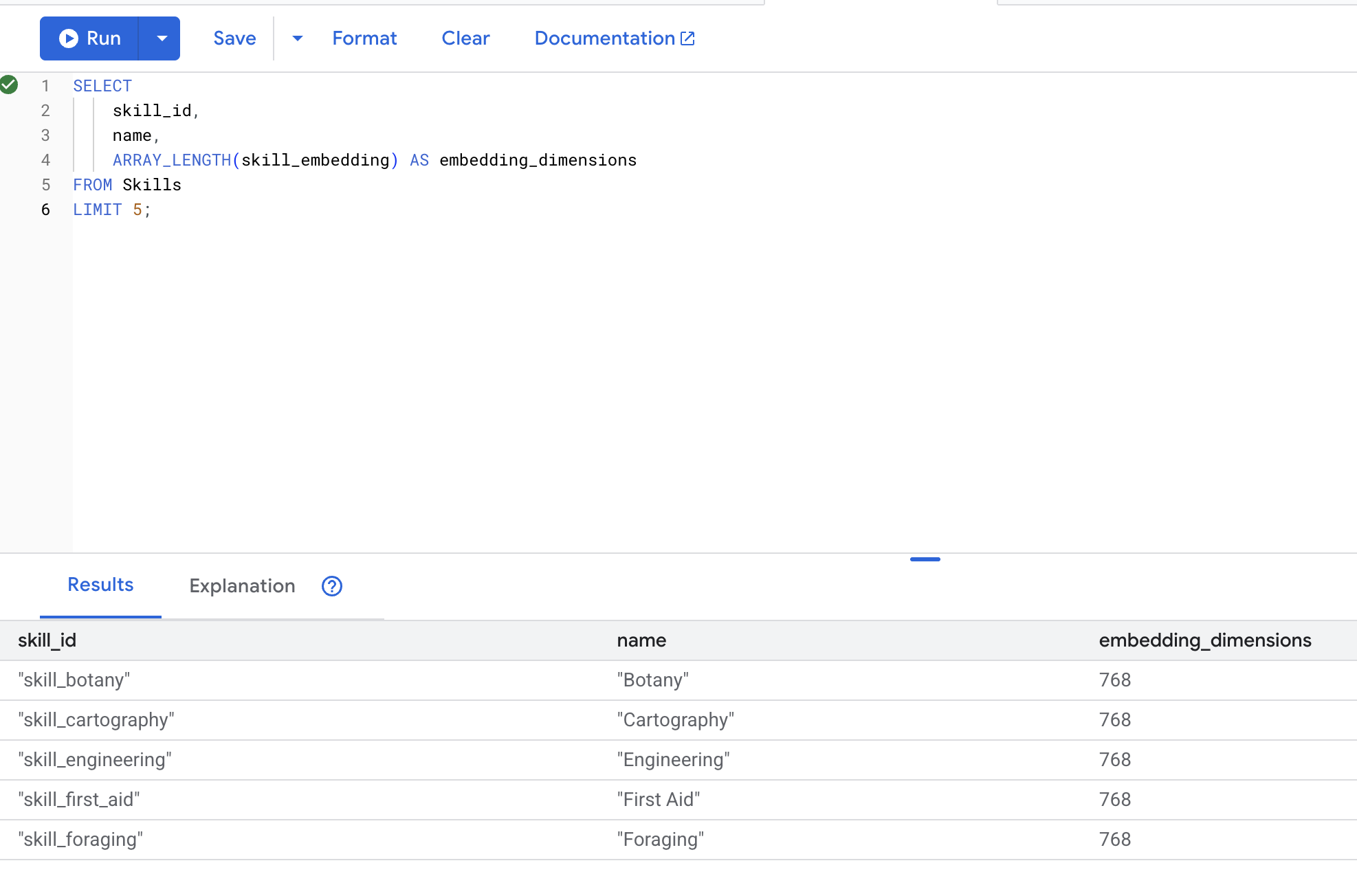
👉 Verifica que se hayan creado las incorporaciones:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Resultado esperado:
6. Prueba la Búsqueda semántica
Ahora probemos el caso de uso exacto de nuestra situación: encontrar habilidades médicas con el término "médico".
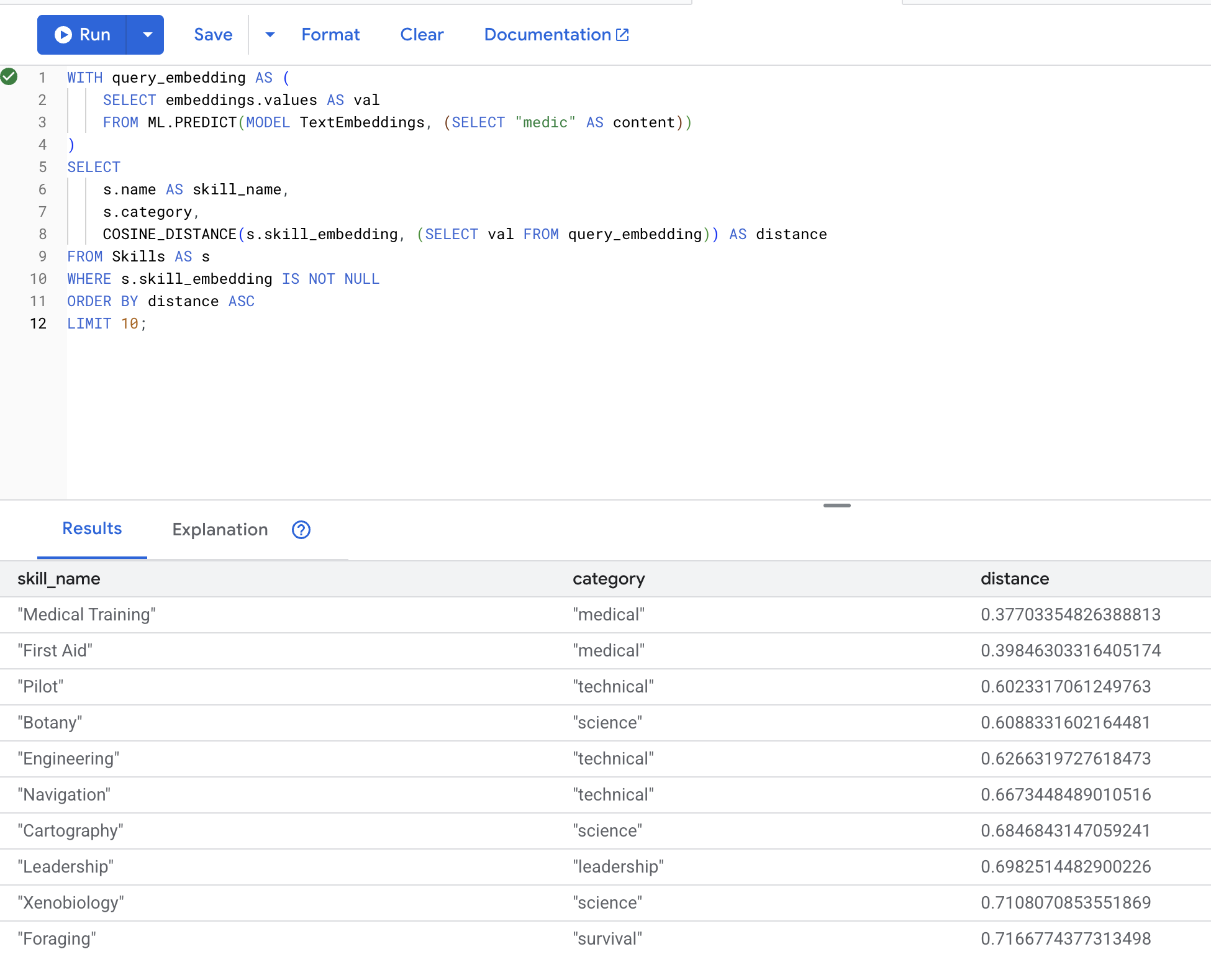
👉 Busca habilidades similares a "médico":
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Convierte el término de búsqueda del usuario "médico" en un embedding.
- Almacena el resultado en la tabla temporal
query_embedding.
Resultados esperados (cuanto menor sea la distancia, más similares serán los resultados):
7. Crea un modelo de Gemini para el análisis
👉 Crea una referencia de modelo de IA generativa (reemplaza $YOUR_PROJECT_ID por el ID de tu proyecto real):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Diferencia con el modelo de Embeddings:
- Incorporaciones: Texto → Vector (para la búsqueda de similitud)
- Gemini: Texto → Texto generado (para razonamiento o análisis)
8. Usa Gemini para el análisis de compatibilidad
👉 Analiza los pares de sobrevivientes para determinar la compatibilidad con la misión:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Resultado esperado:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Cómo crear tu agente de Graph RAG con la búsqueda híbrida
1. Descripción general de la arquitectura del sistema
En esta sección, se compila un sistema de búsqueda de varios métodos que le brinda a tu agente la flexibilidad necesaria para controlar diferentes tipos de preguntas. El sistema tiene tres capas: capa de agente, capa de herramientas y capa de servicio.
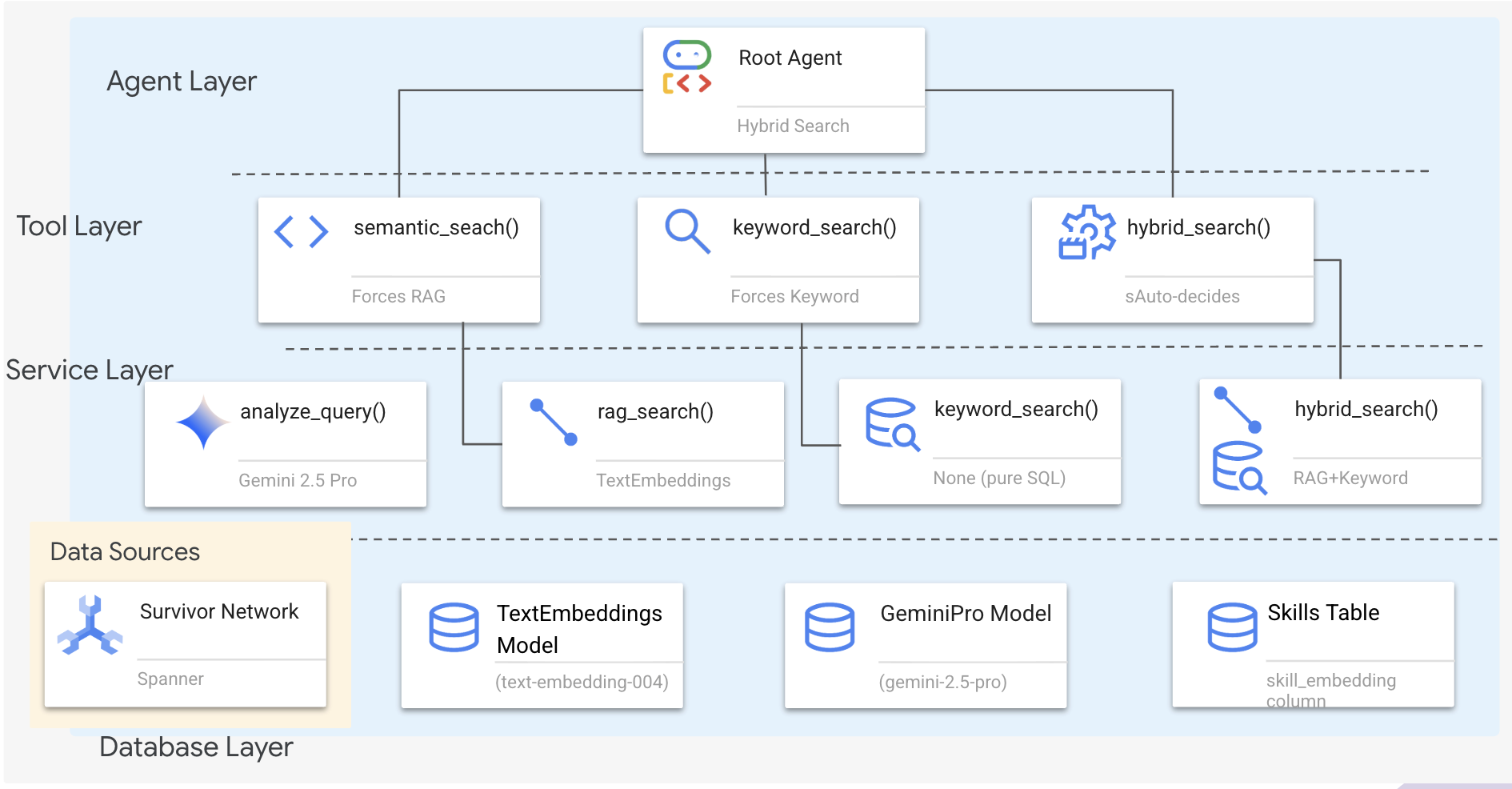
¿Por qué tres capas?
- Separación de preocupaciones: El agente se enfoca en la intención, las herramientas en la interfaz y el servicio en la implementación
- Flexibilidad: El agente puede forzar métodos específicos o permitir el enrutamiento automático de la IA.
- Optimización: Se puede omitir el análisis costoso de la IA cuando se conoce el método.
En esta sección, implementarás principalmente la búsqueda semántica (RAG), que encuentra resultados por significado y no solo por palabras clave. Más adelante, explicaremos cómo la búsqueda híbrida combina varios métodos.
2. Implementación del servicio de RAG
👉💻 En la terminal, ejecuta el siguiente comando para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Ubica el comentario # TODO: REPLACE_SQL
Reemplaza toda esta línea por el siguiente código:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Definición de la herramienta de búsqueda semántica
👉💻 En la terminal, ejecuta el siguiente comando para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
En hybrid_search_tools.py, busca el comentario # TODO: REPLACE_SEMANTIC_SEARCH_TOOL.
👉Reemplaza toda esta línea por el siguiente código:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Cuándo usa el agente:
- Consultas que solicitan similitud ("busca algo similar a X")
- Consultas conceptuales ("habilidades de recuperación")
- Cuando es fundamental comprender el significado
4. Guía de decisiones del agente (instrucciones)
En la definición del agente, copia y pega la parte relacionada con la búsqueda semántica en la instrucción.
👉💻 En la terminal, ejecuta el siguiente comando para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
El agente usa esta instrucción para seleccionar la herramienta adecuada:
👉 En el archivo agent.py, busca el comentario # TODO: REPLACE_SEARCH_LOGIC y reemplaza toda esta línea por el siguiente código:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉 Busca el comentario # TODO: ADD_SEARCH_TOOLReplace this whole line y reemplázalo por el siguiente código:
semantic_search, # Force RAG
5. Understanding How Hybrid Search Works (Read Only, No Action Needed)
En los pasos 2 a 4, implementaste la búsqueda semántica (RAG), el método de búsqueda principal que encuentra resultados por significado. Sin embargo, es posible que hayas notado que el sistema se llama "Búsqueda híbrida". Así es como se relaciona todo:
Cómo funciona la combinación híbrida:
En el archivo way-back-home/level_2/backend/services/hybrid_search_service.py, cuando se llama a hybrid_search(), el servicio ejecuta AMBAS búsquedas y combina los resultados:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
En este codelab, implementaste el componente de búsqueda semántica (RAG), que es la base. Los métodos de palabras clave e híbridos ya están implementados en el servicio. Tu agente puede usar los tres.
¡Felicitaciones! Completaste correctamente tu agente de Graph RAG con búsqueda híbrida.
7. 🚀 Prueba tu agente con ADK Web
La forma más sencilla de probar tu agente es usar el comando adk web, que lo inicia con una interfaz de chat integrada.
1. Cómo ejecutar el agente
👉💻 Navega al directorio de backend (donde se define tu agente) y lanza la interfaz web::
cd ~/way-back-home/level_2/backend
uv run adk web
Este comando inicia el agente definido en
agent/agent.py
y abre una interfaz web para realizar pruebas.
👉 Abre la URL:
El comando generará una URL local (por lo general, http://127.0.0.1:8000 o similar). Abre este vínculo en tu navegador.
Una vez que hagas clic en la URL, verás la IU web del ADK. Asegúrate de seleccionar el "agente" en la esquina superior izquierda.
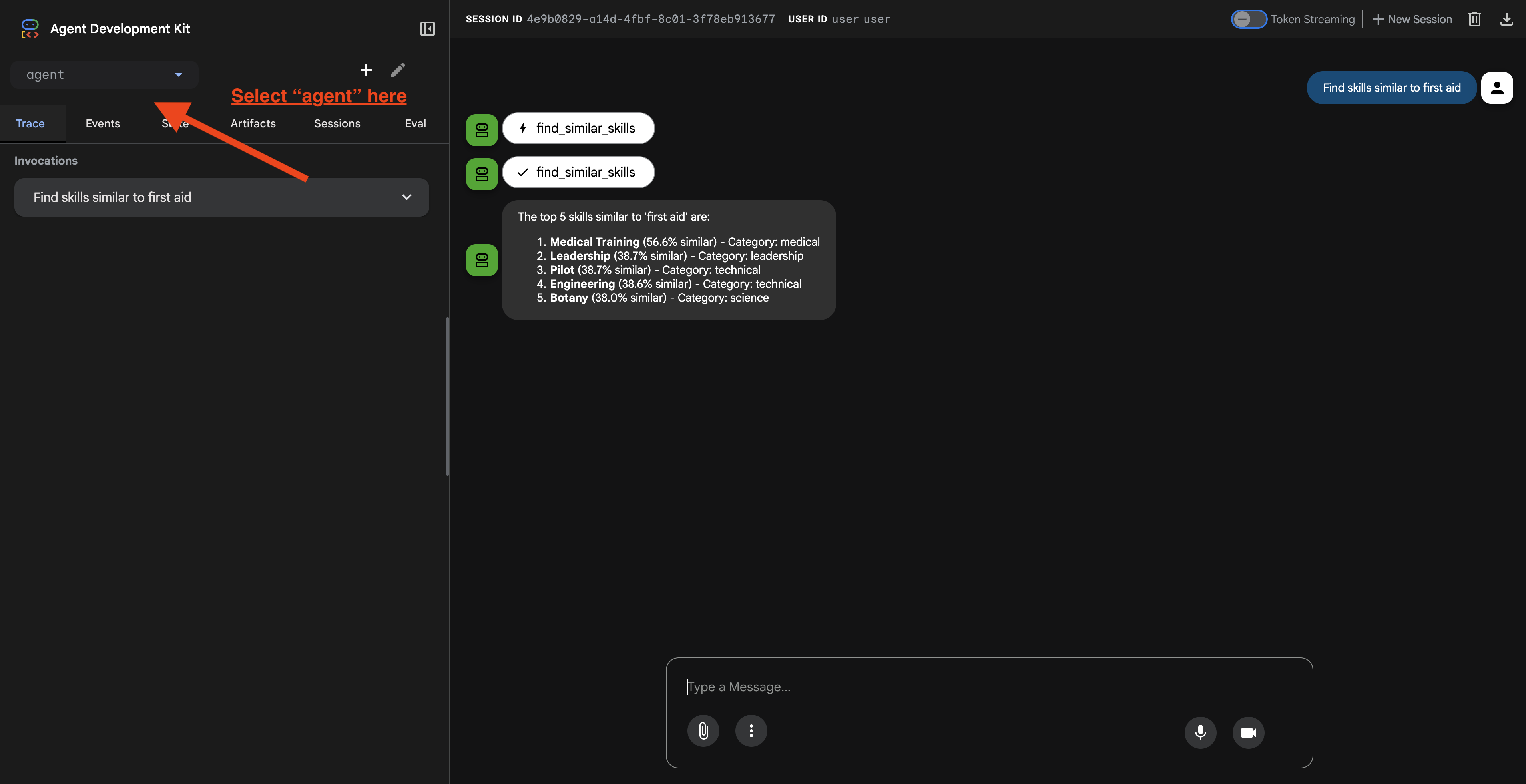
2. Prueba de las funciones de búsqueda
El agente está diseñado para enrutar tus consultas de forma inteligente. Prueba las siguientes entradas en la ventana de chat para ver diferentes métodos de búsqueda en acción.
🧬 A. Graph RAG (búsqueda semántica)
Encuentra elementos según el significado y el concepto, incluso si las palabras clave no coinciden.
Consultas de prueba: (elige cualquiera de las siguientes)
Who can help with injuries?
What abilities are related to survival?
Qué debes buscar:
- El razonamiento debe mencionar la búsqueda semántica o la búsqueda con RAG.
- Deberías ver resultados que estén relacionados conceptualmente (p.ej., "Cirugía" cuando pides "Primeros auxilios").
- Los resultados tendrán el ícono de 🧬.
🔀 B. Búsqueda híbrida
Combina filtros de palabras clave con comprensión semántica para consultas complejas.
Consultas de prueba:(elige cualquiera de las siguientes)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Qué debes buscar:
- La explicación debe mencionar la búsqueda híbrida.
- Los resultados deben coincidir con AMBOS criterios (concepto y ubicación o categoría).
- Los resultados que se encuentren con ambos métodos tendrán el ícono 🔀 y se clasificarán en el puesto más alto.
👉💻 Cuando termines de probar, presiona Ctrl+C en la línea de comandos para finalizar el proceso.
8. 🚀 Ejecuta la aplicación completa
Descripción general de la arquitectura de pila completa
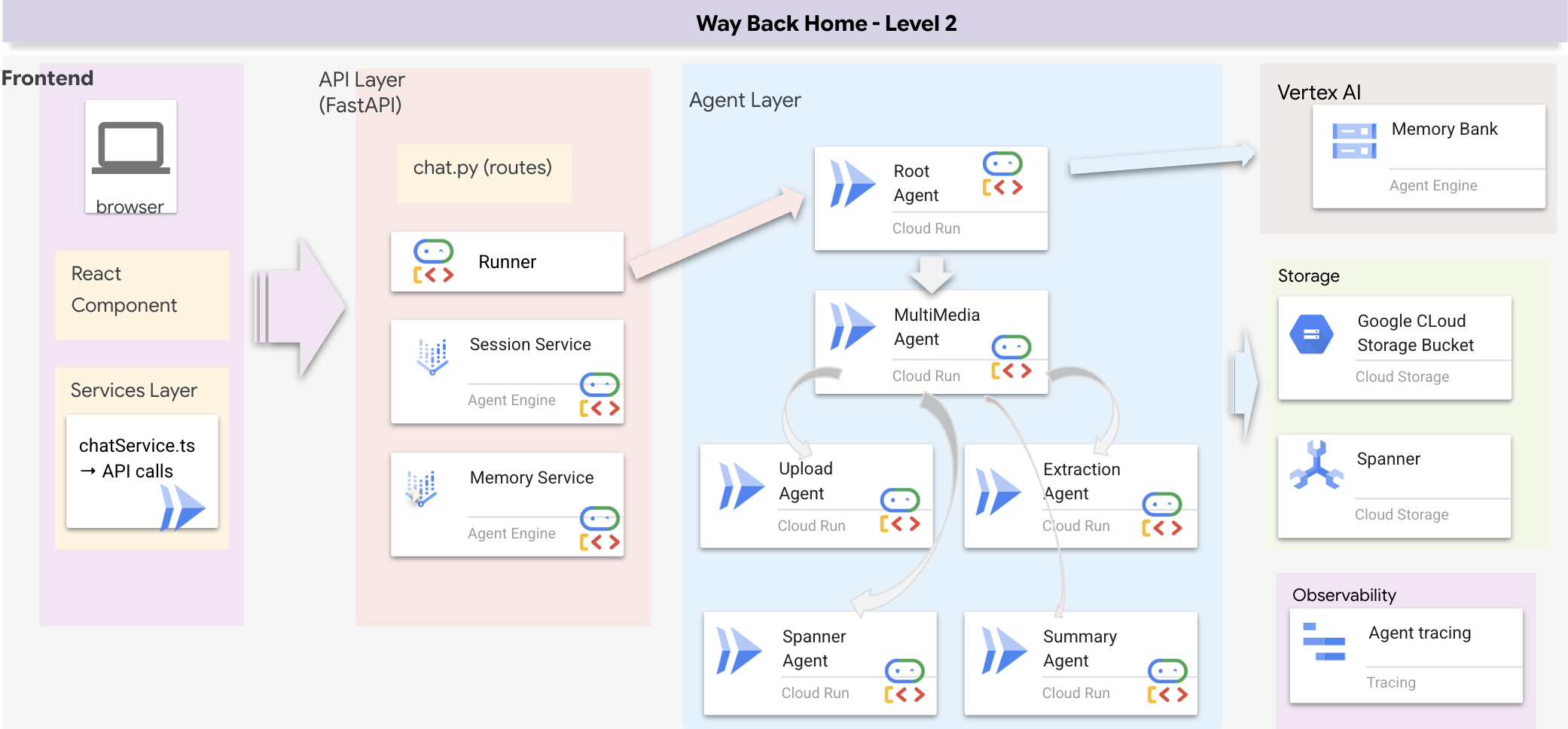
Agrega SessionService y Runner
👉💻 En la terminal, abre el archivo chat.py en el editor de Cloud Shell ejecutando el siguiente comando (asegúrate de haber presionado "Ctrl + C" para finalizar el proceso anterior antes de continuar):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 En el archivo chat.py, busca el comentario # TODO: REPLACE_INMEMORY_SERVICES, reemplaza toda esta línea por el siguiente código:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉 En el archivo chat.py, busca el comentario # TODO: REPLACE_RUNNER, reemplaza toda esta línea por el siguiente código:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Comenzar la solicitud
Si la terminal anterior aún se está ejecutando, presiona Ctrl+C para detenerla.
👉💻 Inicia la app:
cd ~/way-back-home/level_2/
./start_app.sh
Cuando se inicie correctamente el backend, verás Local: http://localhost:5173/" como se muestra a continuación: 
👉 Haz clic en Local: http://localhost:5173/ en la terminal.
2. Prueba la Búsqueda semántica
Consulta:
Find skills similar to healing
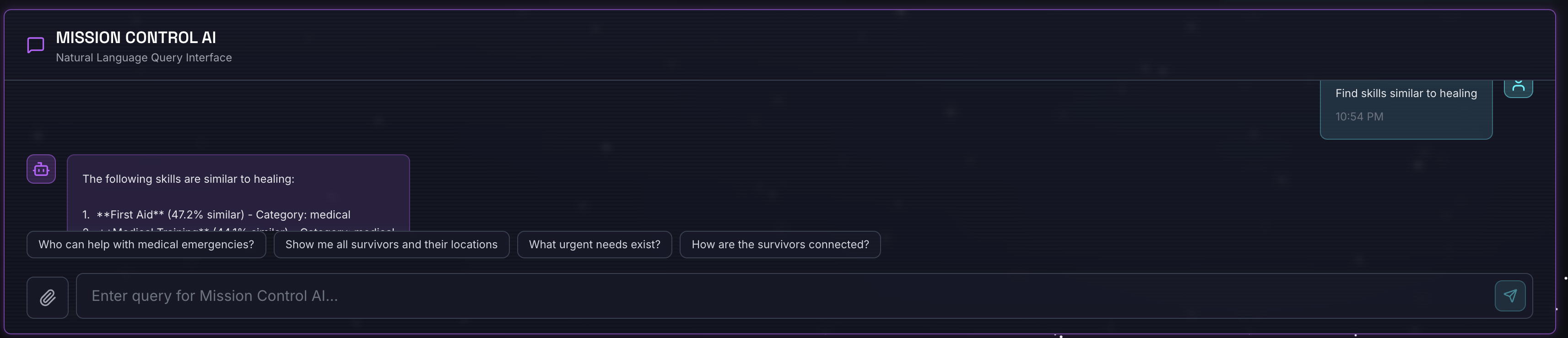
Qué sucede:
- El agente reconoce la solicitud de similitud
- Genera un embedding para "curación"
- Usa la distancia de coseno para encontrar habilidades semánticamente similares
- Devuelve: primeros auxilios (aunque los nombres no coincidan con "curación")
3. Prueba la Búsqueda híbrida
Consulta:
Find medical skills in the mountains
Qué sucede:
- Componente de palabras clave: Filtra por
category='medical' - Componente semántico: Incorpora "médico" y clasifica por similitud
- Combinar: Combina los resultados y prioriza los que se encontraron con ambos métodos 🔀
Consulta(opcional):
Who is good at survival and in the forest?
Qué sucede:
- Hallazgos de palabras clave:
biome='forest' - Búsquedas semánticas: Habilidades similares a "supervivencia"
- La búsqueda híbrida combina ambos tipos para obtener los mejores resultados
👉💻 Cuando termines de probar, presiona Ctrl+C en la terminal para finalizar.
4. (!SOLO PARA ASISTENTES AL TALLER) Actualiza tu ubicación
👉💻 Ejecuta la secuencia de comandos de finalización:
cd ~/way-back-home/level_2
./set_level_2.sh
Ahora abre waybackhome.dev y verás que se actualizó tu ubicación. ¡Felicitaciones por completar el nivel 2!

9. ☕️ [Opcional] Canalización multimodal (solo lectura): capa de herramientas
¿Por qué necesitamos una canalización multimodal?
La red de supervivencia no es solo texto. Los sobrevivientes en el campo envían datos no estructurados directamente a través del chat:
- 📸 Imágenes: Fotos de recursos, peligros o equipos
- 🎥 Videos: Informes de estado o transmisiones de SOS
- 📄 Texto: Notas o registros de campo
¿Qué archivos procesamos?
A diferencia del paso anterior, en el que buscamos datos existentes, aquí procesamos los archivos subidos por el usuario. La interfaz chat.py controla los archivos adjuntos de forma dinámica:
Fuente | Contenido | Objetivo |
Adjunto del usuario | Imagen, video o texto | Información para agregar al gráfico |
Contexto del chat | "Aquí tienes una foto de los suministros". | Intención y detalles adicionales |
El enfoque planificado: canalización de agentes secuenciales
Usamos un agente secuencial (multimedia_agent.py) que encadena agentes especializados:
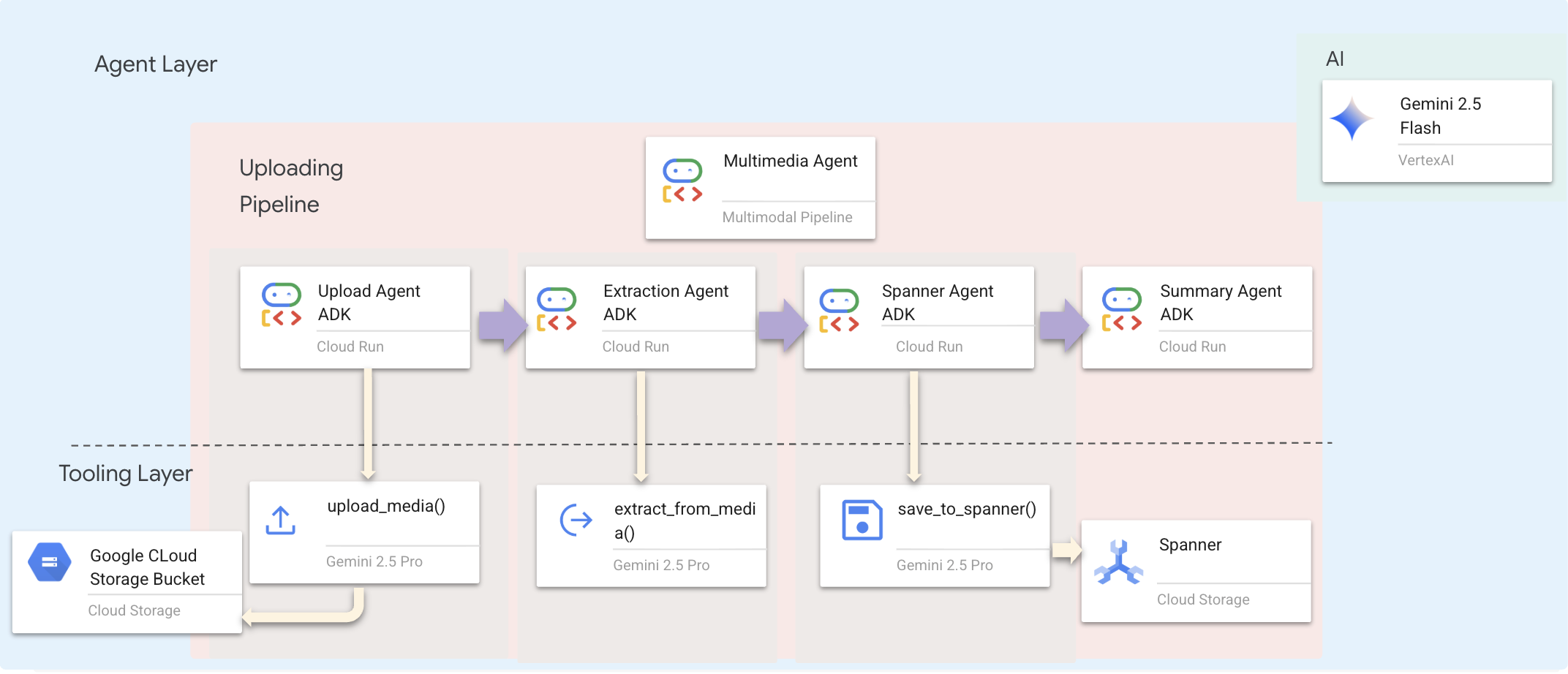
Esto se define en backend/agent/multimedia_agent.py como un SequentialAgent.
La capa de herramientas proporciona las capacidades que los agentes pueden invocar. Las herramientas se encargan del "cómo": subir archivos, extraer entidades y guardar en la base de datos.
1. Abre el archivo de herramientas
👉💻 Abre el archivo level_2/backend/agent/tools/extraction_tools.py o escribe el siguiente comando en la terminal. Abre una terminal nueva. En la terminal, abre el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Implementa la herramienta upload_media
Esta herramienta sube un archivo local a Google Cloud Storage.
👉 En def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, el siguiente código muestra cómo subir archivos a GCS y detectar su tipo:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Implementa la herramienta extract_from_media
Esta herramienta es un enrutador: verifica el media_type y lo envía al extractor correcto (texto, imagen o video).
👉 En async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, el siguiente código muestra cómo extraer entidades y relaciones de los medios subidos.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Detalles clave de la implementación:
- Entrada multimodal: Pasamos la instrucción de texto (
_get_extraction_prompt()) y el objeto de imagen agenerate_content. - Resultados estructurados:
response_mime_type="application/json"garantiza que el LLM devuelva un JSON válido, lo que es fundamental para la canalización. - Vinculación visual de entidades: La instrucción incluye entidades conocidas para que Gemini pueda reconocer personajes específicos.
4. Implementa la herramienta save_to_spanner
Esta herramienta persiste las entidades y las relaciones extraídas en la base de datos de Spanner Graph.
👉 En def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, el siguiente código muestra cómo guardar las entidades y las relaciones extraídas en la base de datos de Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Al proporcionarles a los agentes herramientas de alto nivel, garantizamos la integridad de los datos y aprovechamos las capacidades de razonamiento del agente.
5. Actualizar el servicio de GCS
El objeto GCSService controla la carga del archivo real en Google Cloud Storage.
👉💻 Abre el archivo level_2/backend/services/gcs_service.py o escribe en la terminal para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 En def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, el siguiente código muestra cómo guardar las entidades y las relaciones extraídas en la base de datos de Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Al abstraer esto en un servicio, el agente no necesita saber sobre los buckets de GCS, los nombres de los BLOB ni la generación de URLs firmadas. Solo pide que se "suba".
6. ¿Por qué el flujo de trabajo con agentes es mejor que los enfoques tradicionales?
La ventaja de la capacidad de agente:
Función | Canalización por lotes | Basadas en eventos | Flujo de trabajo de agentes |
Complejidad | Baja (1 secuencia de comandos) | Alto (más de 5 servicios) | Baja (1 archivo de Python: |
Administración del estado | Variables globales | Hard (sin acoplamiento) | Unificado (estado del agente) |
Manejo de errores | Fallas | Registros silenciosos | Interactivo ("No pude leer ese archivo") |
Comentarios de los usuarios | Impresiones de consola | Necesita sondeo | Inmediato (parte del chat) |
Adaptabilidad | Lógica fija | Funciones rígidas | Inteligente (el LLM decide el siguiente paso) |
Conocimiento del contexto | Ninguno | Ninguno | Completo (conoce la intención del usuario) |
Por qué es importante: Con multimedia_agent.py (un SequentialAgent con 4 subagentes: Cargar → Extraer → Guardar → Resumen), reemplazamos la infraestructura compleja Y los scripts frágiles por lógica de aplicación inteligente y conversacional.
10. ☕️ [Opcional] Canalización multimodal (solo lectura): capa del agente
La capa de agentes define la inteligencia, es decir, los agentes que usan herramientas para completar tareas. Cada agente tiene un rol específico y pasa contexto al siguiente. A continuación, se muestra el diagrama de arquitectura del sistema multiagente.
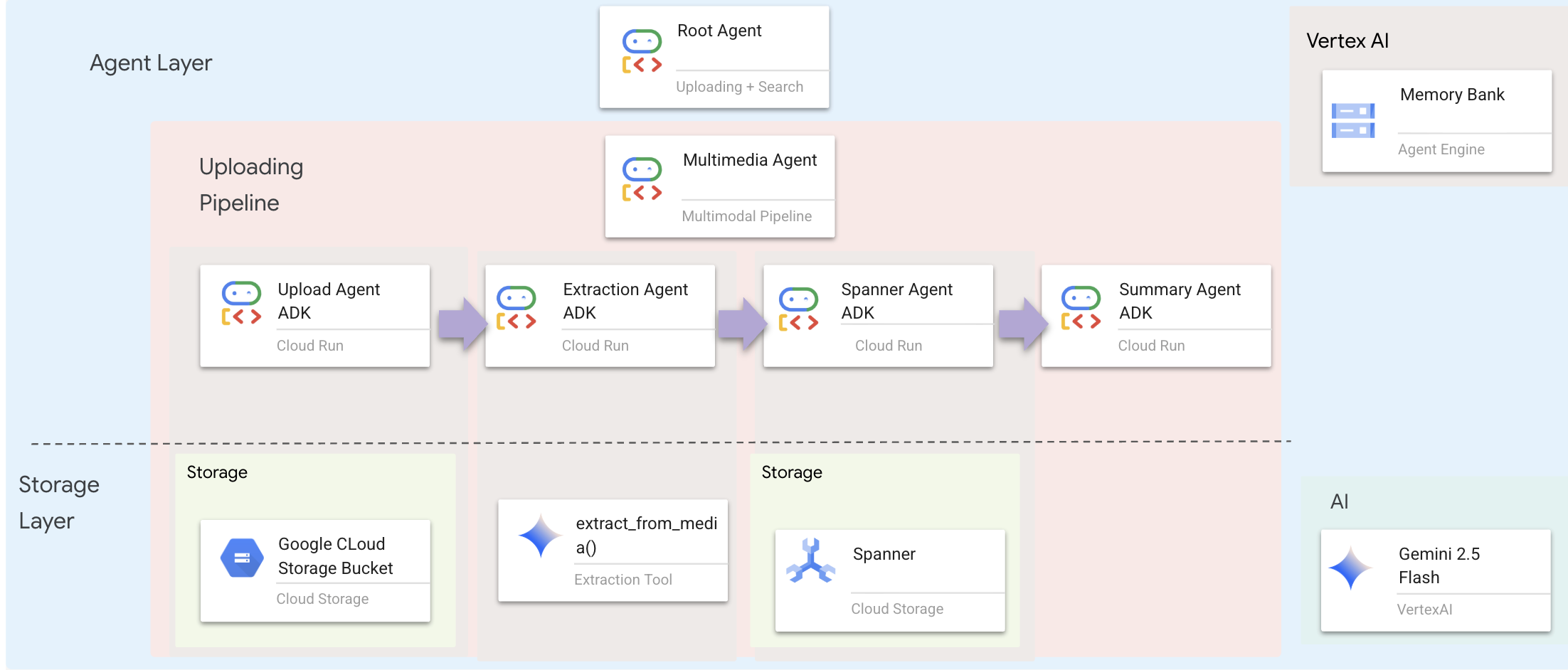
1. Abre el archivo del agente
👉💻 Abre el archivo level_2/backend/agent/multimedia_agent.py o escribe el siguiente comando en la terminal. Abre una terminal nueva. En la terminal, abre el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Define el agente de carga
Este agente extrae una ruta de acceso al archivo del mensaje del usuario y la sube a GCS.
👉 En el archivo multimedia_agent.py, con el siguiente código, se crea upload_agent que se sube a GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Define el agente de extracción
Este agente "ve" el contenido multimedia subido y extrae datos estructurados con Gemini Vision.
👉 En el archivo multimedia_agent.py, con el siguiente código, se crea extraction_agent que extrae información del contenido multimedia subido:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Observa cómo instruction hace referencia a {upload_result}. Así es como se pasa el estado entre los agentes en el ADK.
4. Define el agente de Spanner
Este agente guarda las entidades y las relaciones extraídas en la base de datos de grafos.
👉 En el archivo multimedia_agent.py, con el siguiente código, se crea spanner_agent que guarda la información extraída en la base de datos:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Este agente recibe contexto de ambos pasos anteriores (upload_result y extraction_result).
5. Define el agente de resumen
Este agente sintetiza los resultados de todos los pasos anteriores en una respuesta fácil de usar.
👉 En el archivo multimedia_agent.py, con el siguiente código, se define la instrucción para summary_agent que resume el resultado:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Este agente no necesita herramientas, solo lee el contexto compartido y genera un resumen claro para el usuario.
🧠 Resumen de la arquitectura
Capa | Archivo | Responsabilidad |
Herramientas |
| Cómo: Subir, extraer y guardar |
Agent |
| Qué: Organiza la canalización |
11. 🚀 Canalización de datos multimodales: organización
El núcleo de nuestro nuevo sistema es el MultimediaExtractionPipeline definido en backend/agent/multimedia_agent.py. Utiliza el patrón Sequential Agent del ADK (Kit de desarrollo de agentes).
1. ¿Por qué usar la opción secuencial?
El procesamiento de una carga es una cadena de dependencias lineal:
- No puedes extraer datos hasta que tengas el archivo (carga).
- No puedes guardar datos hasta que los extraigas (extracción).
- No puedes generar un resumen hasta que tengas los resultados (Guardar).
Un SequentialAgent es perfecto para esto. Pasa el resultado de un agente como contexto o entrada al siguiente.
2. Definición del agente
Veamos cómo se ensambla la canalización en la parte inferior de multimedia_agent.py: 👉💻 En la terminal, abre el archivo en el Editor de Cloud Shell ejecutando el siguiente comando:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Recibe entradas de ambos pasos anteriores. Ubica el comentario # TODO: REPLACE_ORCHESTRATION. Reemplaza toda esta línea por el siguiente código:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Conéctate con el agente raíz
👉💻 En la terminal, ejecuta el siguiente comando para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Ubica el comentario # TODO: REPLACE_ADD_SUBAGENT. Reemplaza toda esta línea por el siguiente código:
sub_agents=[multimedia_agent],
Este único objeto agrupa de manera eficaz a cuatro "expertos" en una sola entidad invocable.
4. Flujo de datos entre agentes
Cada agente almacena su salida en un contexto compartido al que pueden acceder los agentes posteriores:
5. Abre la aplicación (omite este paso si la app sigue en ejecución).
👉💻 Inicia la app:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Haz clic en Local: http://localhost:5173/ en la terminal.
6. Prueba de carga de imágenes
👉 En la interfaz de chat, elige cualquiera de las fotos que se muestran aquí y súbelas a la IU:
En la interfaz de chat, cuéntale al agente sobre tu contexto específico:
Here is the survivor note
Luego, adjunta la imagen aquí.

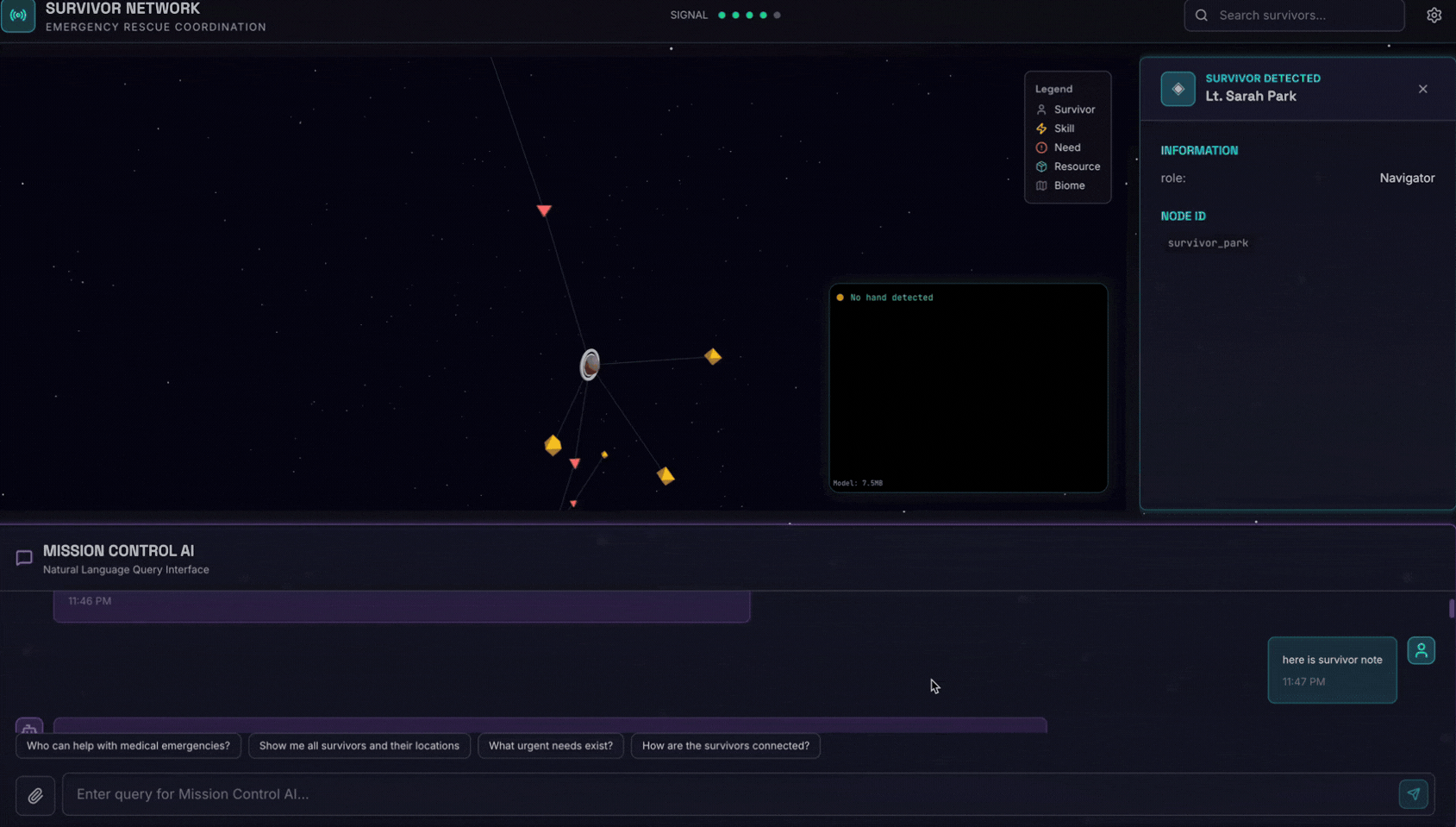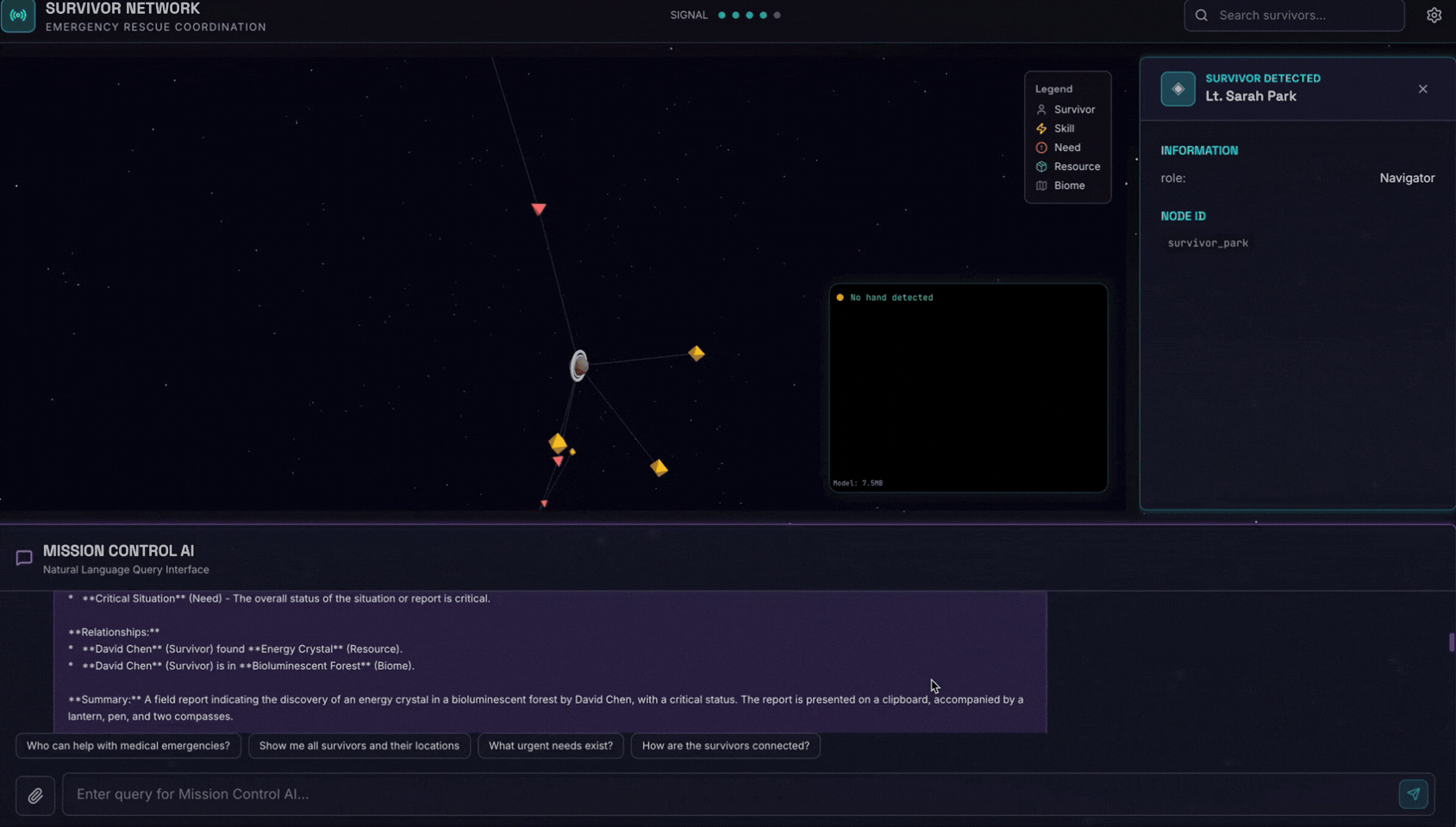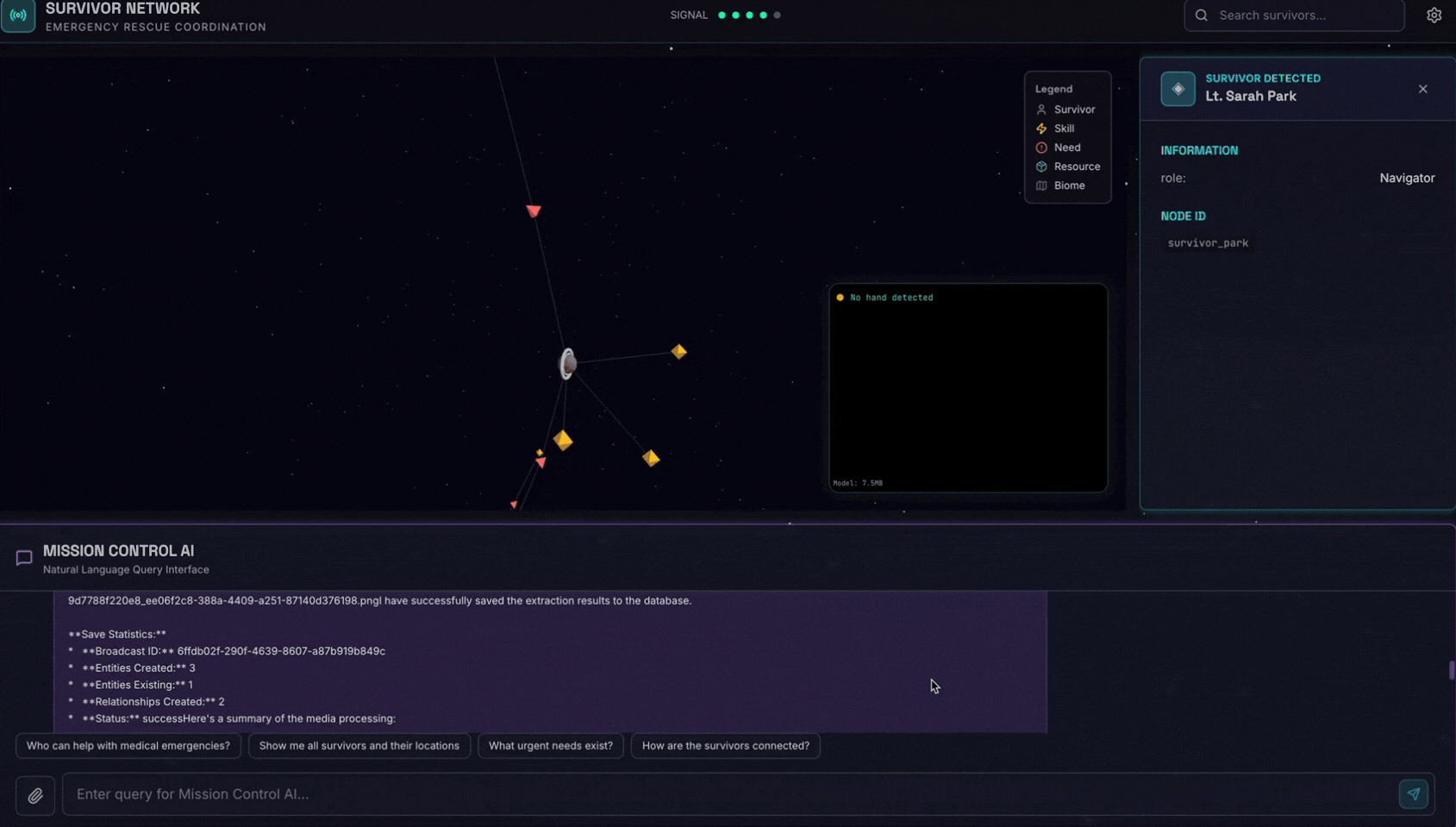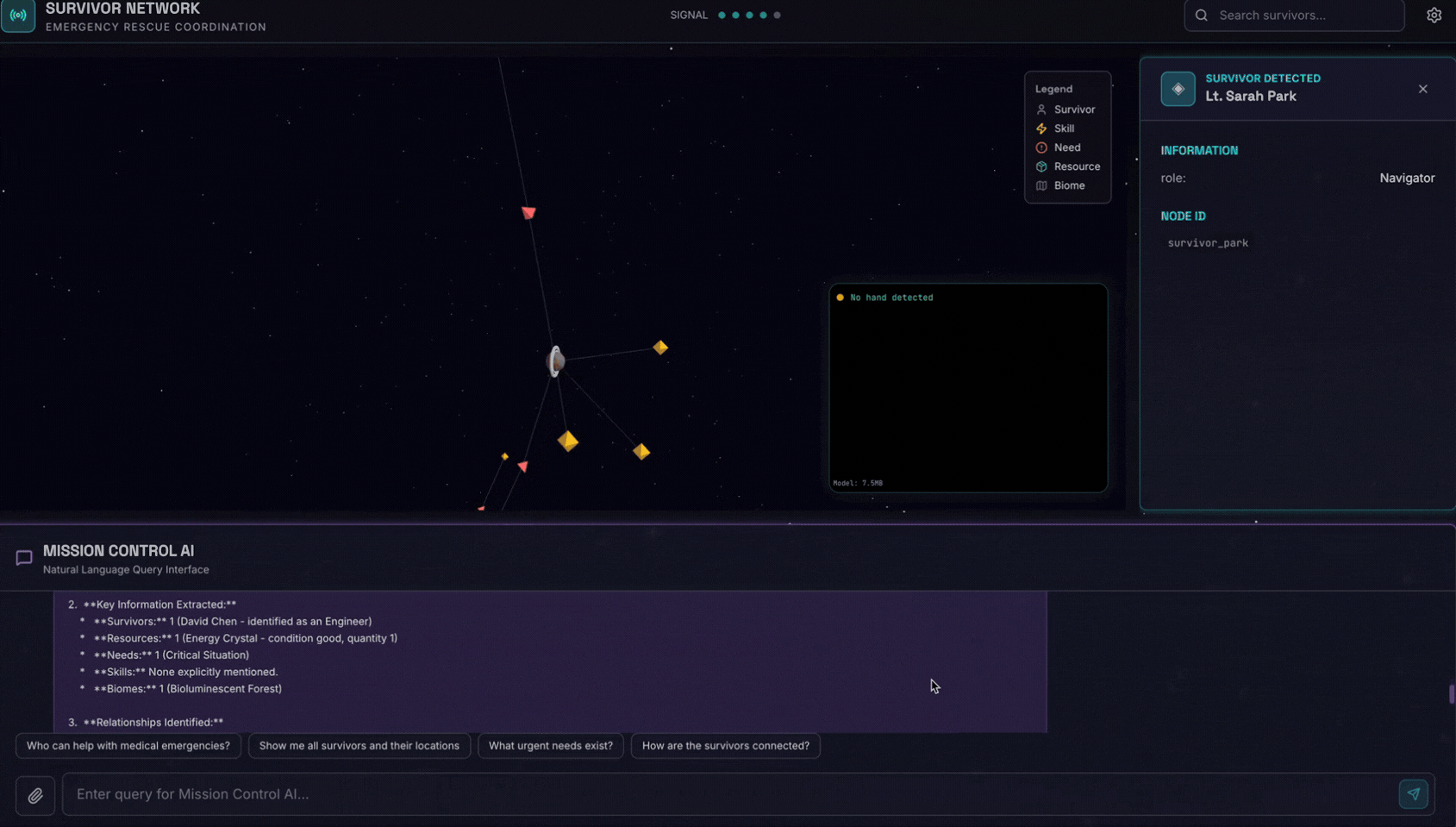
👉💻 En la terminal, cuando termines de probar, presiona "Ctrl + C" para finalizar el proceso.
6. Verifica la carga multimodal en el bucket de GCS
- Abre Google Cloud Console Storage.
- Selecciona "bucket" en Cloud Storage
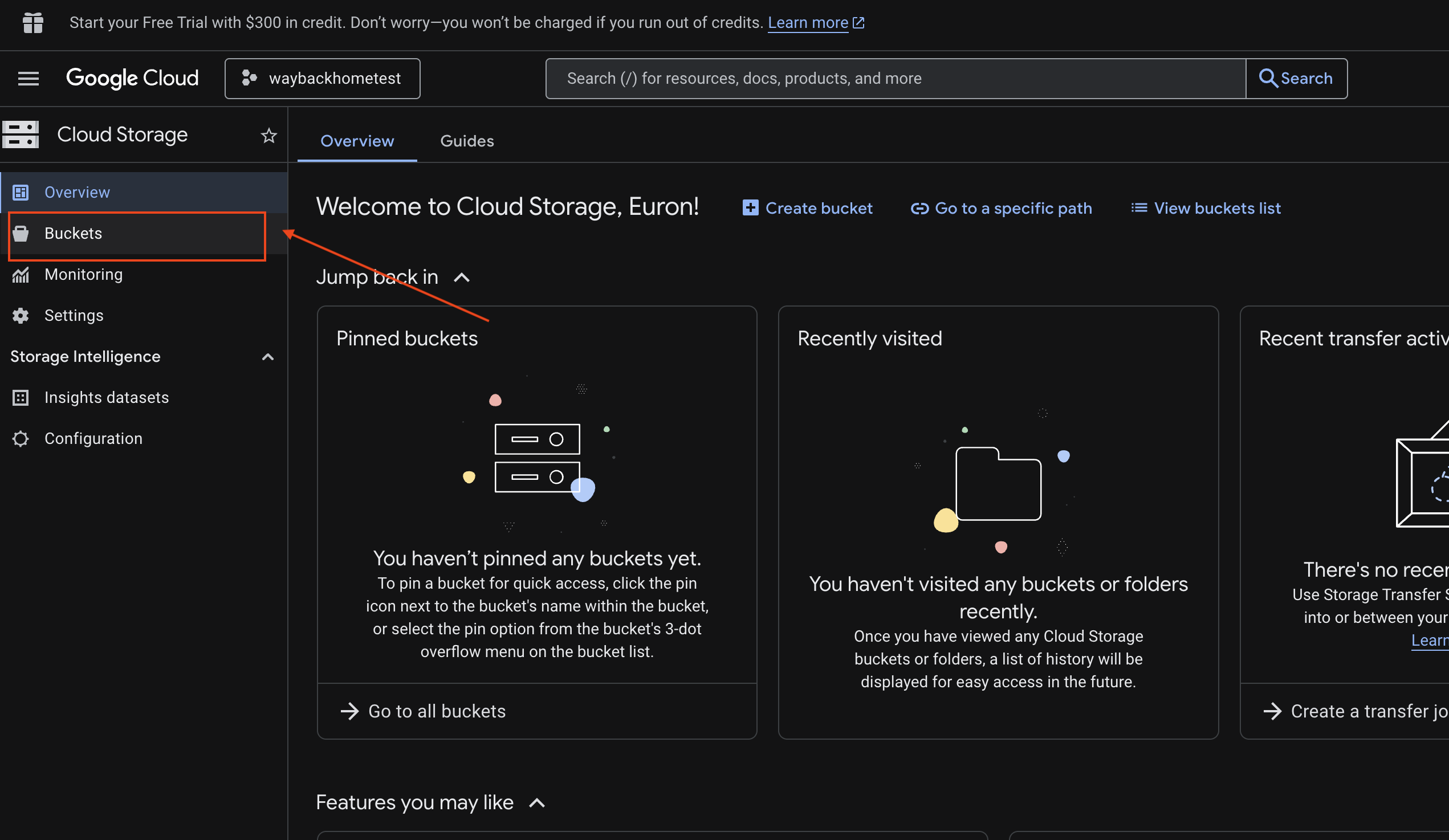
- Selecciona tu bucket y haz clic en
media.
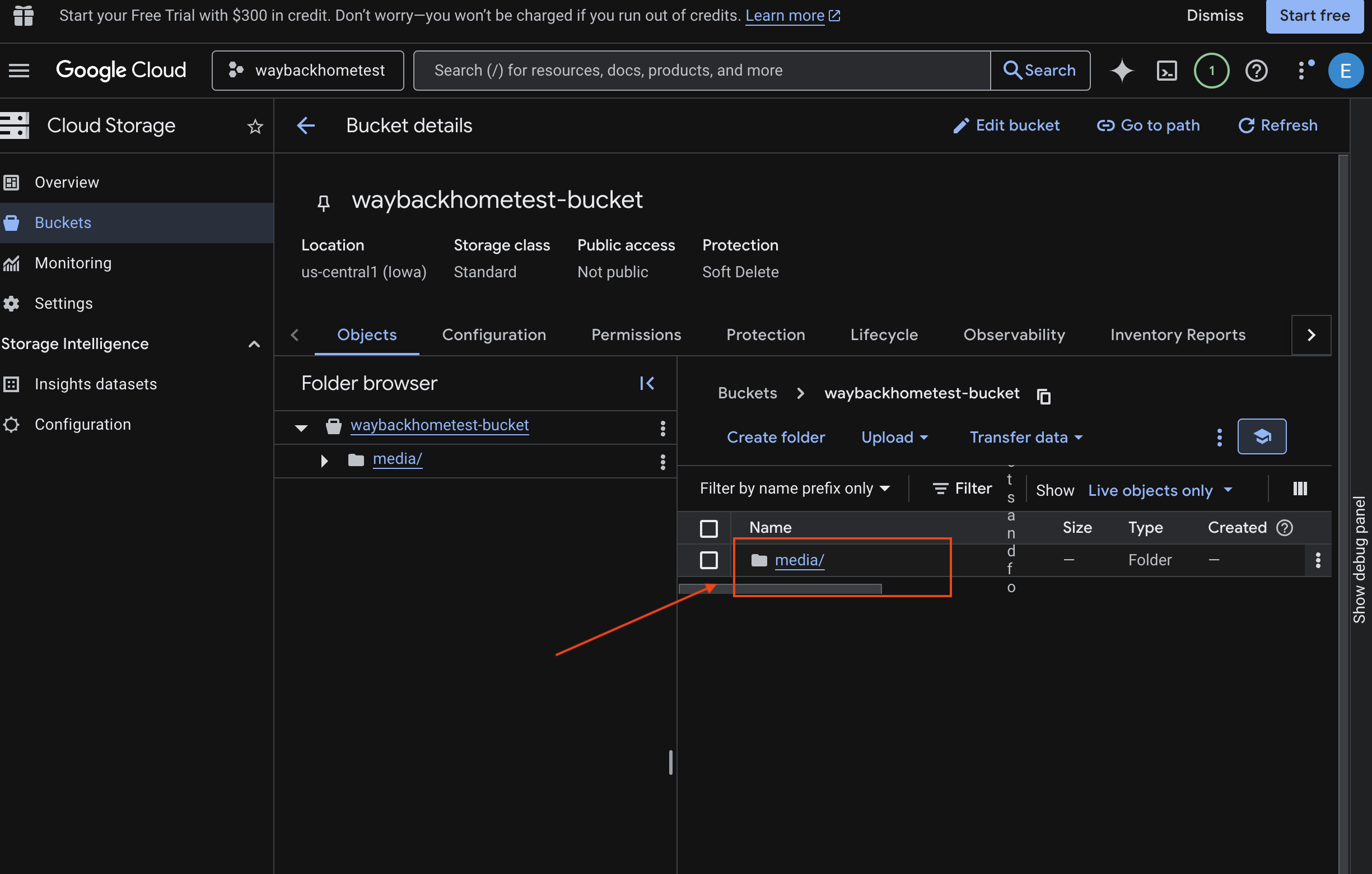
- Aquí puedes ver la imagen que subiste.
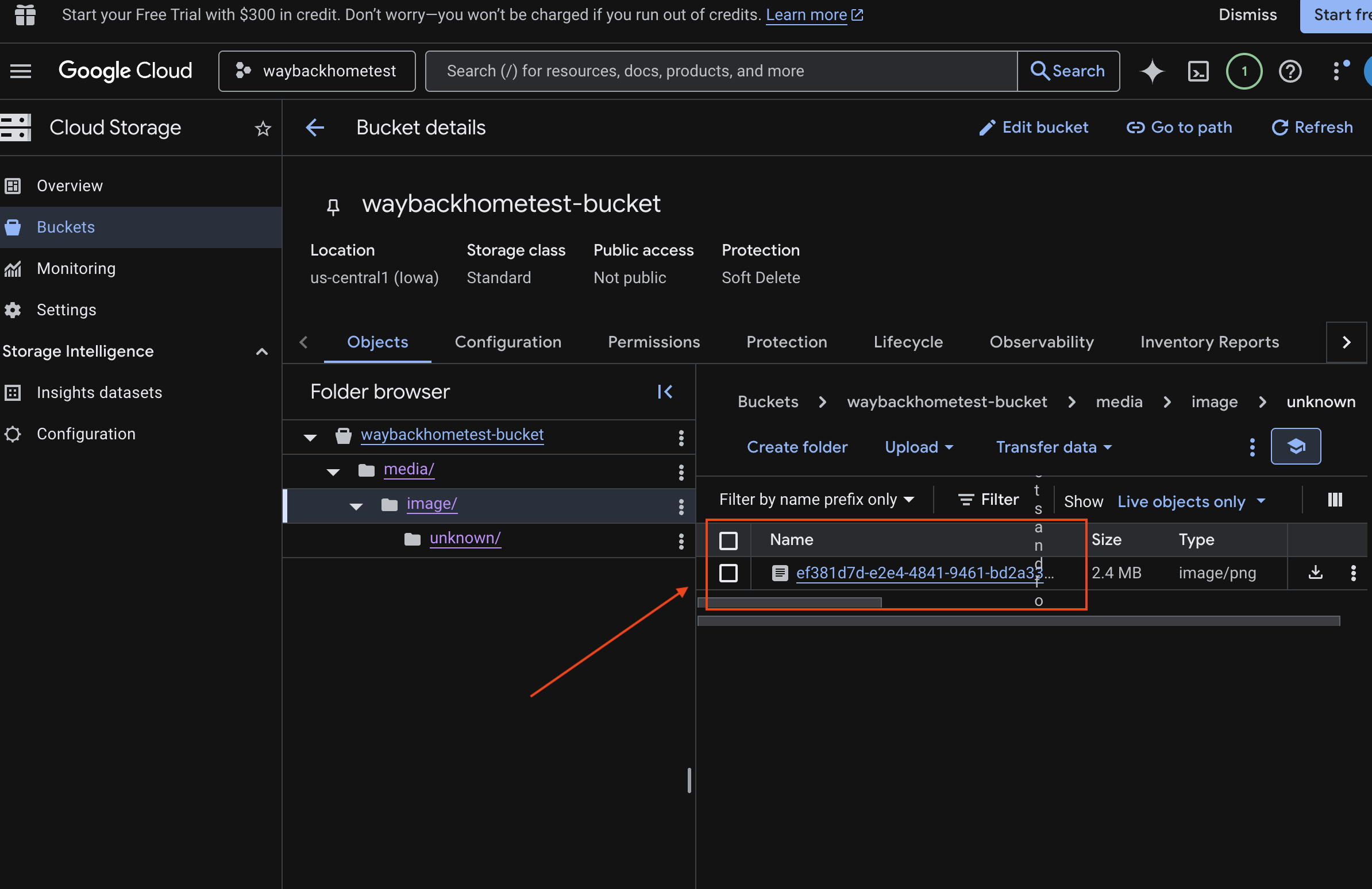
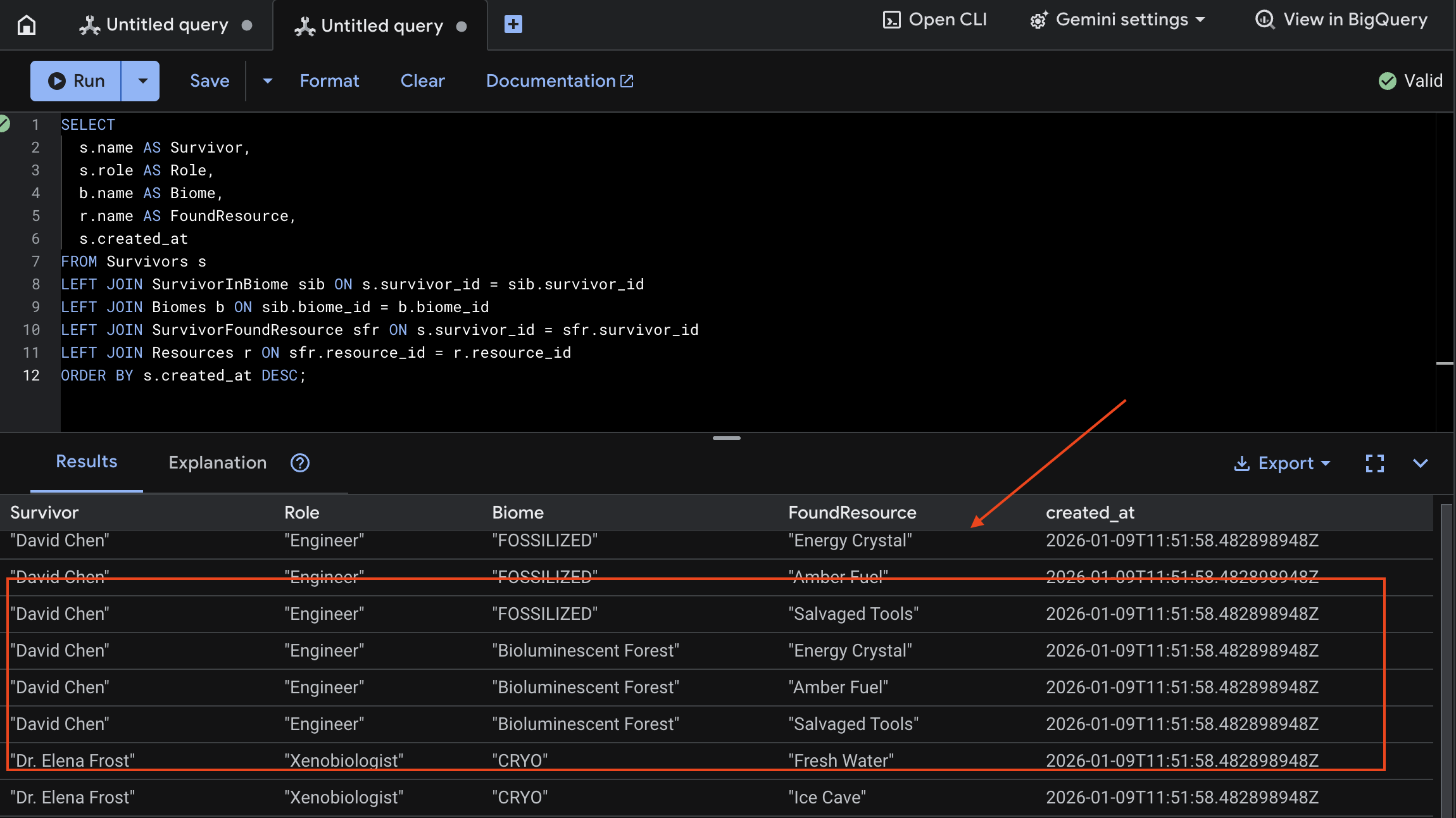
7. Verifica la carga multimodal en Spanner (opcional)
A continuación, se muestra un ejemplo del resultado en la IU para test_photo1.
- Abre Spanner en la consola de Google Cloud.
- Selecciona tu instancia:
Survivor Network - Selecciona tu base de datos:
graph-db - En la barra lateral izquierda, haz clic en Spanner Studio.
👉 En Spanner Studio, consulta los datos nuevos:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Podemos verificarlo viendo el siguiente resultado:
12. ☕️ [Opcional] Memory Bank con Agent Engine
1. Cómo funciona la función Recuerdos
El sistema utiliza un enfoque de memoria dual para controlar el contexto inmediato y el aprendizaje a largo plazo.
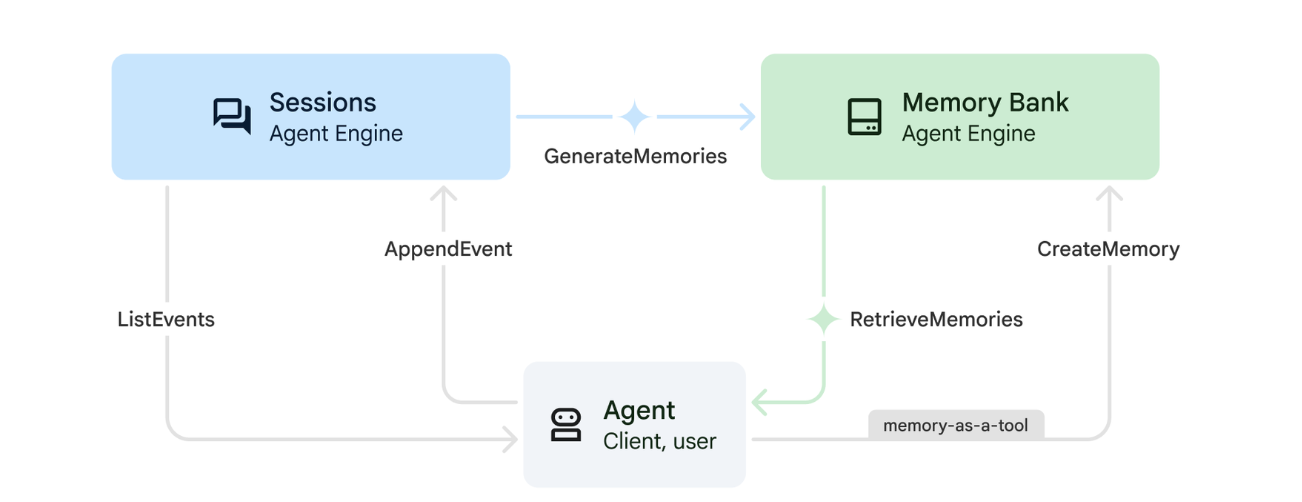
2. ¿Qué son los Temas de memoria?
Los Temas de memoria definen las categorías de información que el agente debe recordar en las conversaciones. Piensa en ellos como archivadores para diferentes tipos de preferencias del usuario.
Nuestros 2 temas:
search_preferences: Cómo le gusta buscar al usuario- ¿Prefieren la búsqueda semántica o por palabra clave?
- ¿Qué habilidades o biomas buscan con frecuencia?
- Ejemplo de memoria: "El usuario prefiere la búsqueda semántica para las habilidades médicas".
urgent_needs_context: Las crisis que supervisan- ¿Qué recursos supervisan?
- ¿Qué sobrevivientes les preocupan?
- Ejemplo de memoria: "El usuario está haciendo un seguimiento de la escasez de medicamentos en Northern Camp".
3. Cómo configurar temas de memoria
Los temas de memoria personalizados definen qué debe recordar el agente. Estos se configuran cuando se implementa Agent Engine.
👉💻 En la terminal, ejecuta el siguiente comando para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Se abrirá ~/way-back-home/level_2/backend/deploy_agent.py en el editor.
Definimos objetos de estructura MemoryTopic para guiar al LLM sobre qué información extraer y guardar.
👉 En el archivo deploy_agent.py, reemplaza # TODO: SET_UP_TOPIC por lo siguiente:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Integración del agente
El código del agente debe conocer el Memory Bank para guardar y recuperar información.
👉💻 En la terminal, ejecuta el siguiente comando para abrir el archivo en el Editor de Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Se abrirá ~/way-back-home/level_2/backend/agent/agent.py en el editor.
Creación del agente
Cuando creamos el agente, pasamos el after_agent_callback para garantizar que las sesiones se guarden en la memoria después de las interacciones. La función add_session_to_memory se ejecuta de forma asíncrona para evitar que se ralentice la respuesta del chat.
👉 En el archivo agent.py, busca el comentario # TODO: REPLACE_ADD_SESSION_MEMORY, Reemplaza toda esta línea por el siguiente código:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Guardado en segundo plano
👉 En el archivo agent.py, busca el comentario # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, Reemplaza toda esta línea por el siguiente código:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉 En el archivo agent.py, busca el comentario # TODO: REPLACE_ADD_CALLBACK, Reemplaza toda esta línea por el siguiente código:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Configura Vertex AI Session Service
👉💻 En la terminal, abre el archivo chat.py en el Editor de Cloud Shell ejecutando el siguiente comando:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 En el archivo chat.py, busca el comentario # TODO: REPLACE_VERTEXAI_SERVICES, reemplaza toda esta línea por el siguiente código:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Opcional] Adjunta el agente con Agent Engine
1. Configuración e implementación
Antes de probar las funciones de memoria, debes implementar el agente con los nuevos temas de memoria y asegurarte de que tu entorno esté configurado correctamente.
Proporcionamos una secuencia de comandos de conveniencia para controlar este proceso.
Ejecuta la secuencia de comandos de implementación
👉💻 En la terminal, ejecuta la secuencia de comandos de implementación:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Esta secuencia de comandos realiza las siguientes acciones:
- Ejecuta
backend/deploy_agent.pypara registrar los temas del agente y la memoria en Vertex AI. - Captura el nuevo ID del motor de agentes.
- Actualiza automáticamente tu archivo
.envconAGENT_ENGINE_ID. - Asegúrate de que
USE_MEMORY_BANK=TRUEesté configurado en tu archivo.env.
[!IMPORTANT] Si realizas cambios en custom_topics en deploy_agent.py, debes volver a ejecutar este script para actualizar Agent Engine.
Verifica Memory Bank
Ahora puedes verificar que el banco de memoria funcione enseñándole al agente una preferencia y comprobando si persiste en las sesiones.
Paso uno. Abre la aplicación
Vuelve a abrir la aplicación siguiendo las instrucciones que se indican a continuación: Si la terminal anterior aún se está ejecutando, presiona Ctrls+C para detenerla.
👉💻 Inicia la app:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Haz clic en Local: http://localhost:5173/ en la terminal.
Paso dos. Prueba de Memory Bank con texto
En la interfaz de chat, cuéntale al agente sobre tu contexto específico:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Espera unos 30 segundos para que la memoria se procese en segundo plano.
Paso tres. Cómo iniciar una sesión nueva
Actualiza la página para borrar el historial de conversación actual (memoria a corto plazo).
Haz una pregunta que se base en el contexto que proporcionaste anteriormente:
"What kind of missions am I interested in?"
Respuesta esperada:
"Según tus conversaciones anteriores, te interesan los siguientes temas:
- Misiones de rescate médico
- Operaciones en montañas o a gran altitud
- Habilidades necesarias: primeros auxilios y escalada
¿Quieres que busque sobrevivientes que cumplan con estos criterios?"
Paso cuatro. Prueba con la carga de imágenes
Sube una imagen y haz preguntas como las siguientes:
remember this
Puedes elegir cualquiera de las fotos que se muestran aquí o una propia y subirla a la IU:
Paso cinco. Verifica en Vertex AI Agent Engine
Ve a consola de Google Cloud Agent Engine.
- Asegúrate de seleccionar el proyecto en el selector de proyectos de la parte superior izquierda:
- Verifica el motor del agente que acabas de implementar con el comando anterior
use_memory_bank.sh: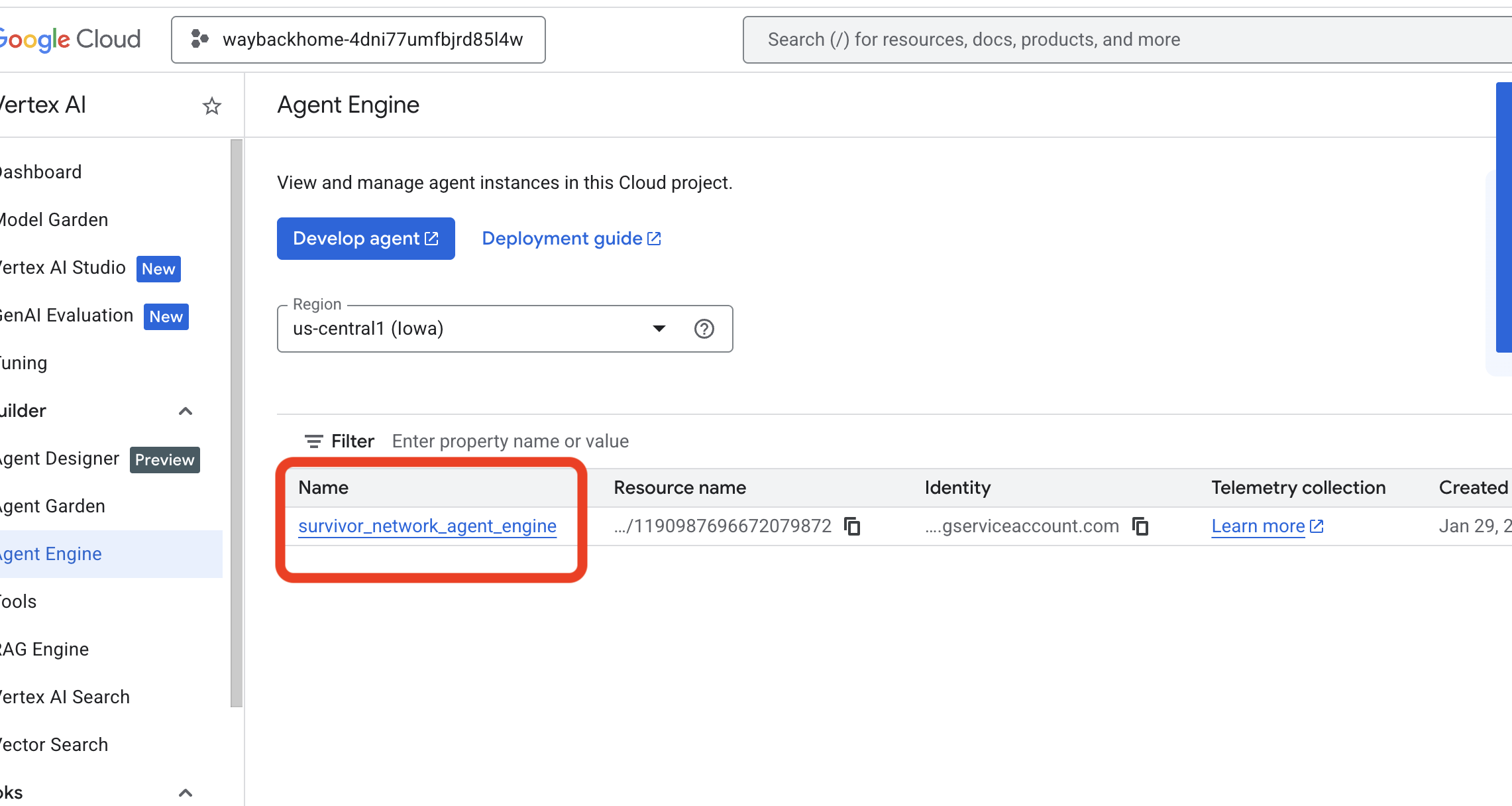 Haz clic en el motor del agente que acabas de crear.
Haz clic en el motor del agente que acabas de crear. - Haz clic en la pestaña
Memoriesen este agente implementado para ver toda la memoria aquí.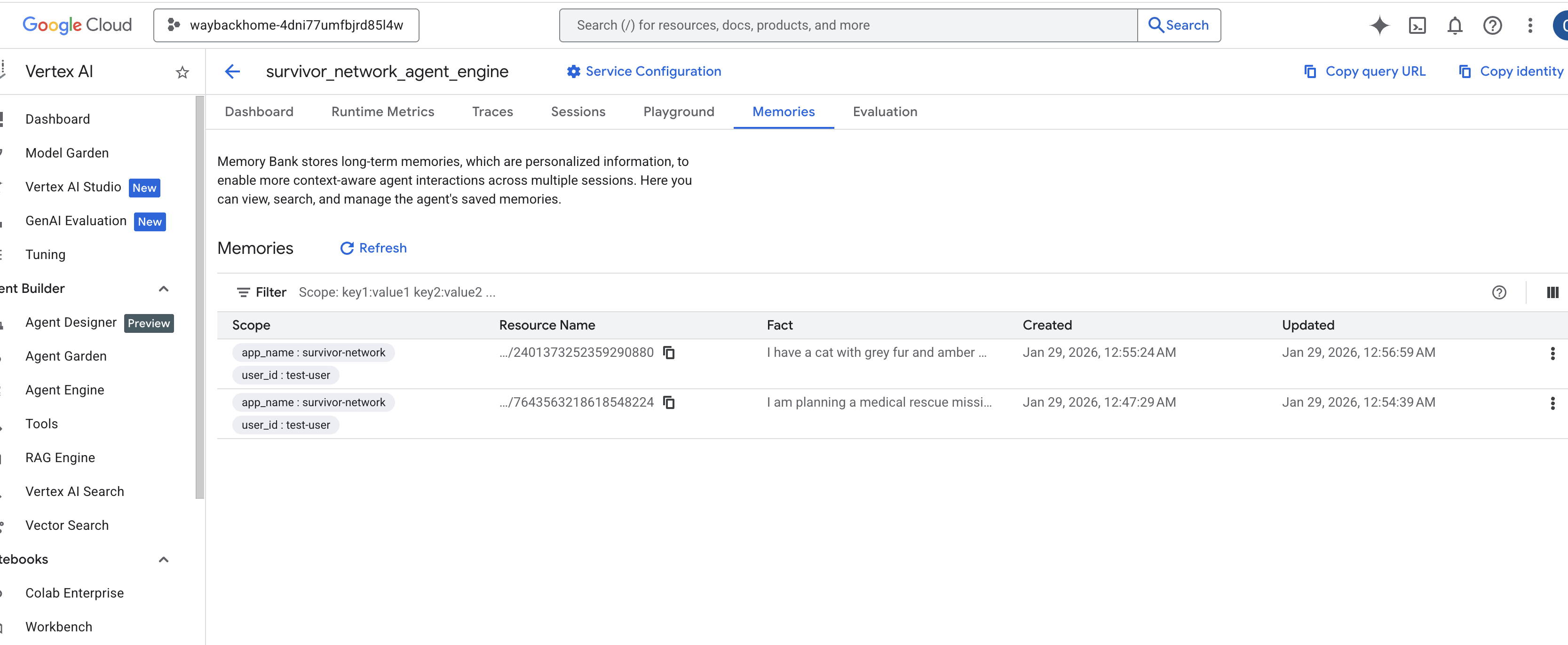
👉💻 Cuando termines de probar, haz clic en "Ctrl + C" en la terminal para finalizar el proceso.
🎉 ¡Felicitaciones! Acabas de adjuntar el banco de memoria a tu agente.
14. ☕️ [Opcional] Implementa en Cloud Run
1. Ejecuta la secuencia de comandos de implementación
👉💻 Ejecuta la secuencia de comandos de implementación:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Una vez que se implemente correctamente, tendrás la URL. Esta es la URL de implementación. 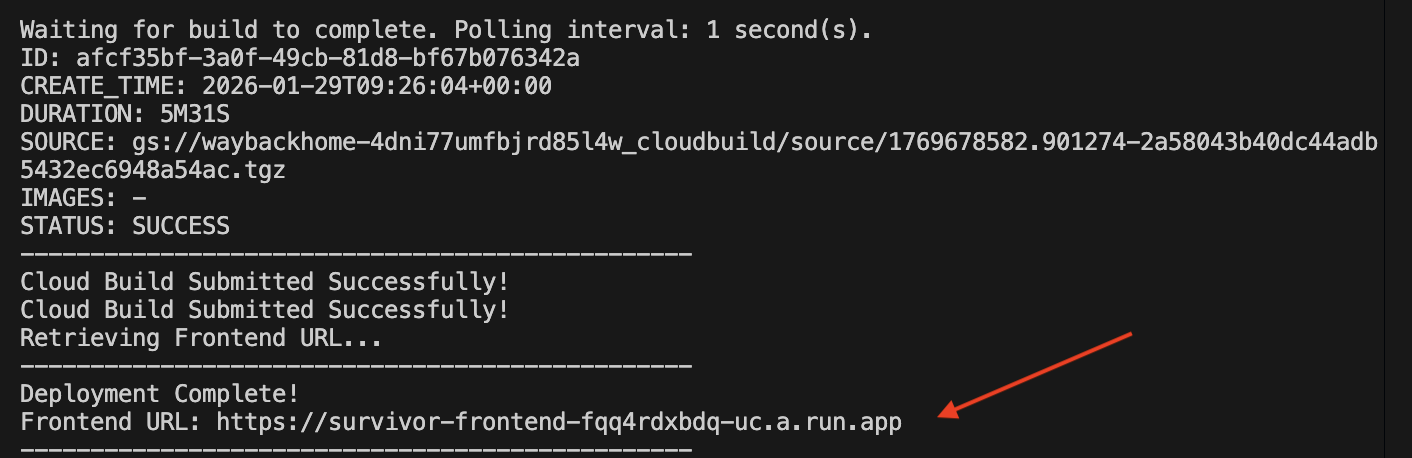
👉💻 Antes de obtener la URL, otorga el permiso con el siguiente comando:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Ve a la URL implementada y verás tu aplicación en vivo.
2. Información sobre la canalización de compilación
El archivo cloudbuild.yaml define los siguientes pasos secuenciales:
- Backend Build: Compila la imagen de Docker desde
backend/Dockerfile. - Backend Deploy: Implementa el contenedor de backend en Cloud Run.
- Capture URL: Obtiene la nueva URL de backend.
- Compilación de frontend:
- Instala las dependencias.
- Compila la app de React y, luego, inyecta
VITE_API_URL=.
- Imagen de frontend: Compila la imagen de Docker desde
frontend/Dockerfile(empaqueta los recursos estáticos). - Frontend Deploy: Implementa el contenedor de frontend.
3. Verifique el recurso Deployment
Una vez que se complete la compilación (consulta el vínculo a los registros que proporciona la secuencia de comandos), puedes verificar lo siguiente:
- Ve a la consola de Cloud Run.
- Busca el servicio
survivor-frontend. - Haz clic en la URL para abrir la aplicación.
- Realiza una búsqueda para asegurarte de que el frontend pueda comunicarse con el backend.
(OPCIONAL) 4. Implementación manual
Si prefieres ejecutar los comandos de forma manual o comprender mejor el proceso, aquí te explicamos cómo usar cloudbuild.yaml directamente.
Escribiendo cloudbuild.yaml
Un archivo cloudbuild.yaml le indica a Google Cloud Build qué pasos debe ejecutar.
- steps: Una lista de acciones secuenciales. Cada paso se ejecuta en un contenedor (p.ej.,
docker,gcloud,node,bash). - sustituciones: Variables que se pueden pasar en el momento del tiempo de compilación (p.ej.,
$_REGION). - workspace: Es un directorio compartido en el que los pasos pueden compartir archivos (como compartimos
backend_url.txt).
Ejecuta la implementación
Para realizar la implementación de forma manual sin la secuencia de comandos, usa el comando gcloud builds submit. DEBES pasar las variables de sustitución requeridas.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Conclusión
1. Qué compilaste
✅ Base de datos de grafos: Spanner con nodos (supervivientes, habilidades) y aristas (relaciones)
✅ Búsqueda con IA: Búsqueda híbrida, semántica y por palabras clave con incorporaciones
✅ Canalización multimodal: Extracción de entidades de imágenes o videos con Gemini
✅ Sistema multiagente: Flujo de trabajo coordinado con ADK
✅ Memory Bank: Personalización a largo plazo con Vertex AI
✅ Implementación en producción: Cloud Run + Agent Engine
2. Resumen de la arquitectura
3. Aprendizajes clave
- RAG basado en gráficos: Combina la estructura de la base de datos de gráficos con embeddings semánticos para realizar búsquedas inteligentes
- Patrones multiagente: Canalizaciones secuenciales para flujos de trabajo complejos de varios pasos
- IA multimodal: Extrae datos estructurados de contenido multimedia no estructurado (imágenes o videos)
- Agentes con estado: Memory Bank permite la personalización en todas las sesiones
4. Contenido del taller
- Level0: Identifícate
- Level1: Ubicación de Pinpoint
- Level2 This One: Crea un agente de IA multimodal con Graph RAG, ADK y Memory Bank
- Level3: Cómo compilar un agente de transmisión bidireccional del ADK
- Level4: Sistema multiagente bidireccional en vivo
- Level5: Arquitectura basada en eventos con Google ADK, A2A y Kafka