
۱. مقدمه

۱. چالش
در سناریوهای واکنش به بلایا، هماهنگی بازماندگان با مهارتها، منابع و نیازهای مختلف در مکانهای مختلف، نیازمند مدیریت هوشمند دادهها و قابلیتهای جستجو است. این کارگاه به شما میآموزد که یک سیستم هوش مصنوعی تولیدی بسازید که موارد زیر را ترکیب کند:
- 🗄️ پایگاه داده گراف (Spanner) : روابط پیچیده بین بازماندگان، مهارتها و منابع را ذخیره کنید
- 🔍 جستجوی مبتنی بر هوش مصنوعی : جستجوی ترکیبی معنایی + کلمه کلیدی با استفاده از جاسازیها
- 📸 پردازش چندوجهی : استخراج دادههای ساختاریافته از تصاویر، متن و ویدیو
- 🤖 ارکستراسیون چندعاملی : هماهنگسازی عوامل تخصصی برای گردشهای کاری پیچیده
- 🧠 حافظه بلندمدت : شخصیسازی با بانک حافظه هوش مصنوعی ورتکس
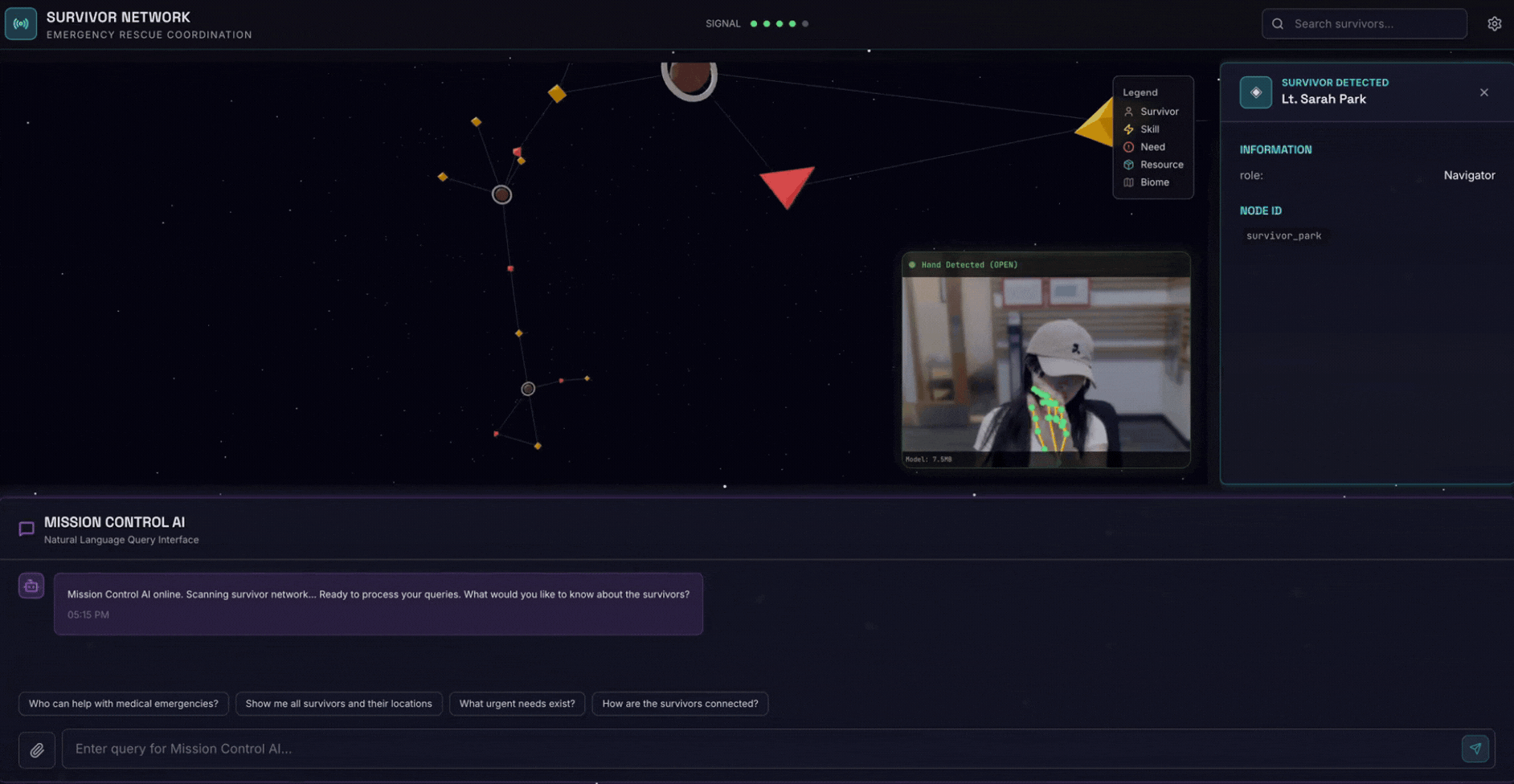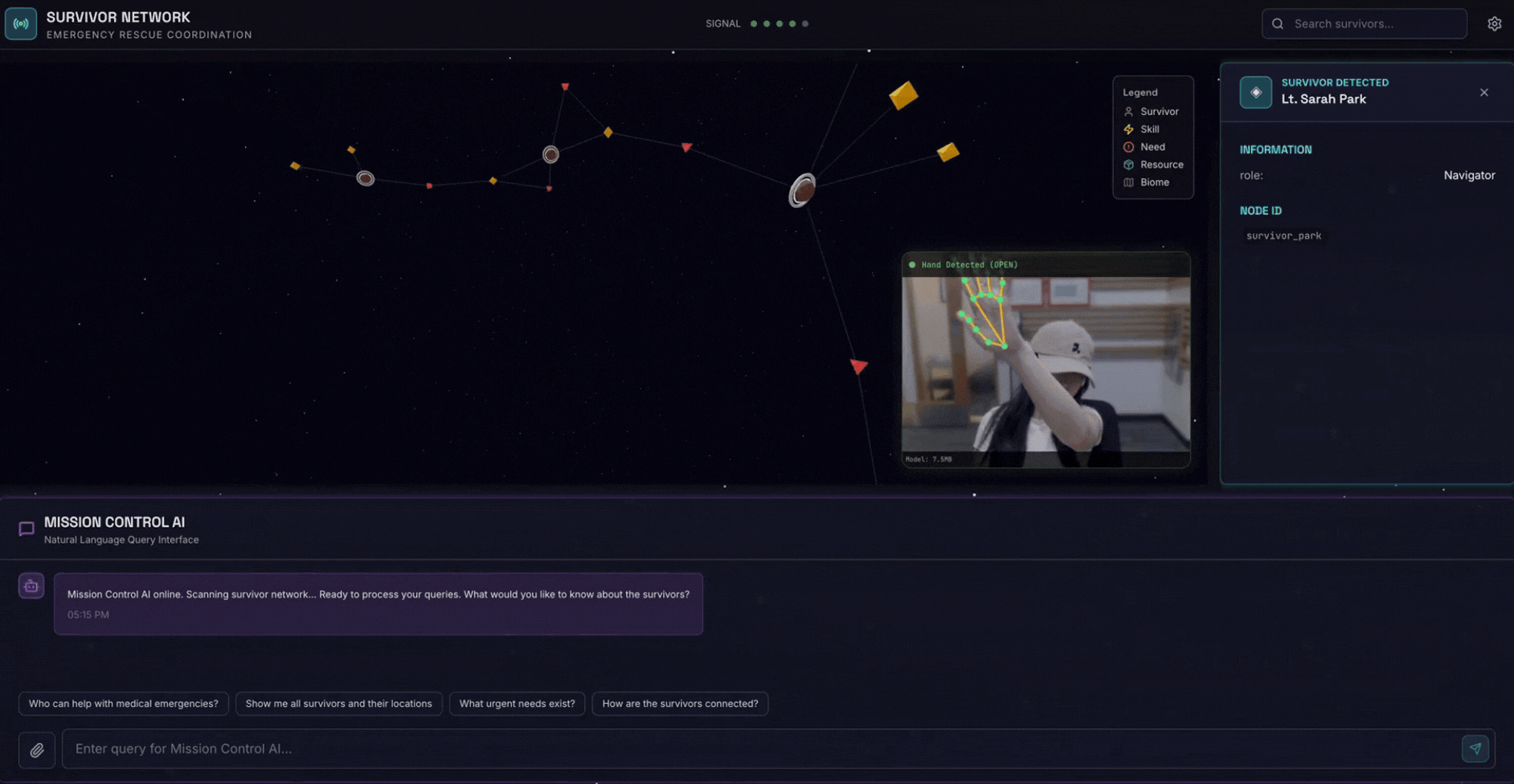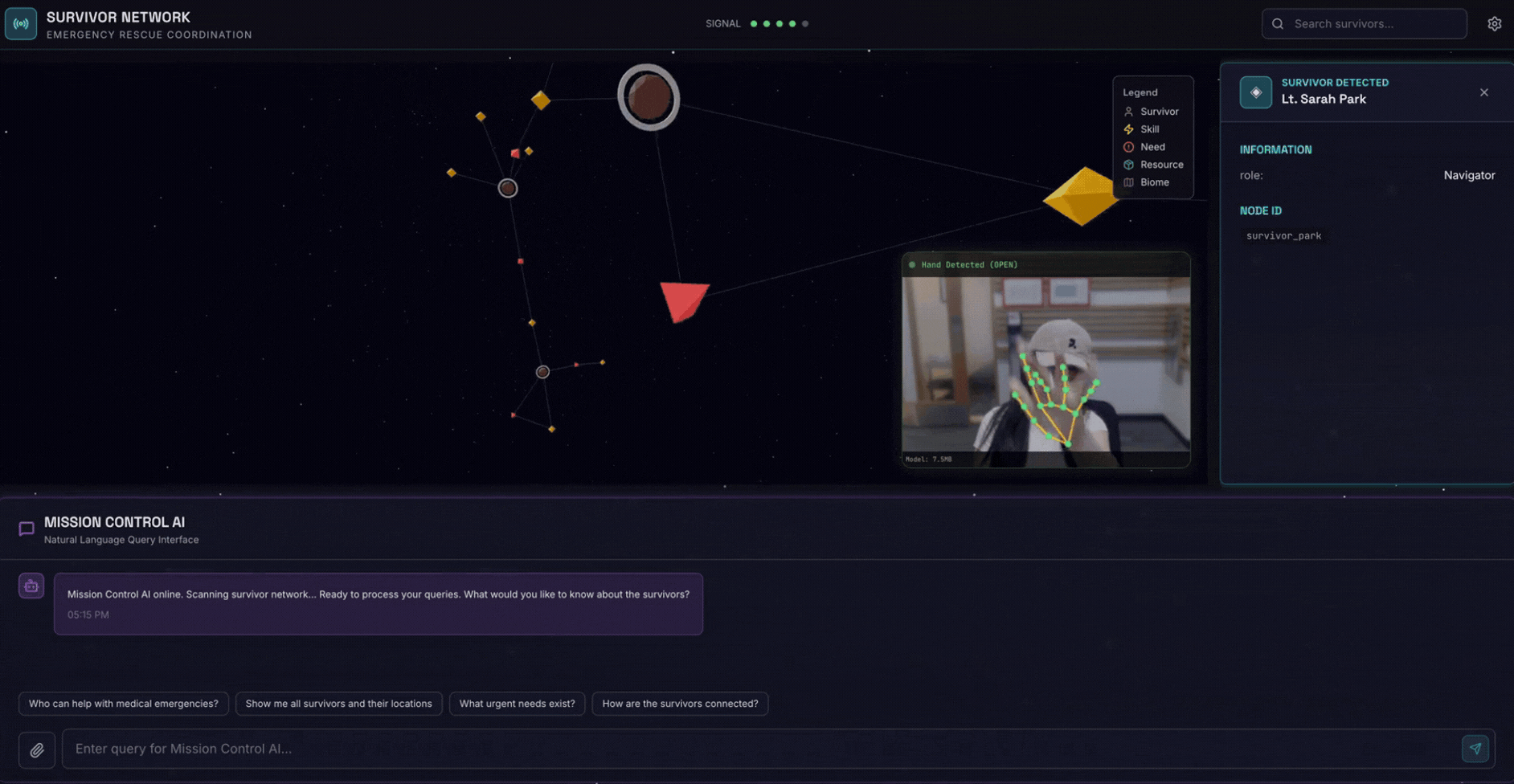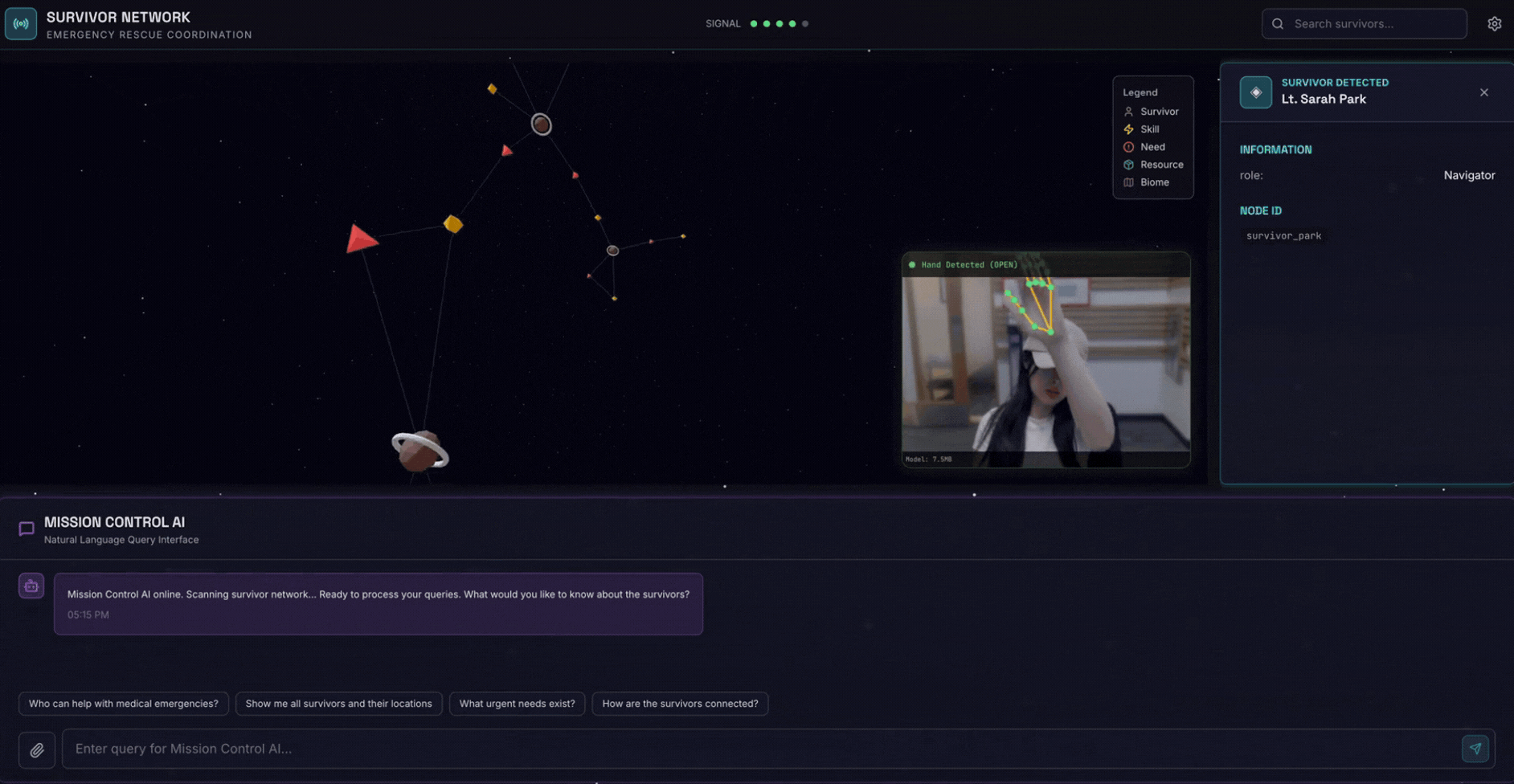
۲. آنچه خواهید ساخت
یک پایگاه داده گراف شبکه بازماندگان با:
- 🗺️ تجسم نمودار تعاملی سهبعدی از روابط بازماندگان
- 🔍 جستجوی هوشمند (کلمه کلیدی، معنایی و ترکیبی)
- 📸 خط لوله آپلود چندوجهی (استخراج موجودیتها از تصاویر/ویدیو)
- 🤖 سیستم چندعاملی برای تنظیم وظایف پیچیده
- 🧠 ادغام بانک حافظه برای تعاملات شخصیسازیشده
۳. فناوریهای اصلی
کامپوننت | فناوری | هدف |
پایگاه داده | گراف آچار ابری | گرههای فروشگاه (بازماندگان، مهارتها) و لبهها (روابط) |
جستجوی هوش مصنوعی | جمینی + جاسازیها | درک معنایی + جستجوی شباهت |
چارچوب عامل | ADK (کیت توسعه عامل) | هماهنگسازی گردشهای کاری هوش مصنوعی |
حافظه | بانک حافظه هوش مصنوعی ورتکس | ذخیرهسازی بلندمدت ترجیحات کاربر |
ظاهر (فرانتاند) | واکنش + Three.js | تجسم تعاملی نمودار سهبعدی |
۲. 🛠️ آمادهسازی محیط (اگر در کارگاه هستید، از آن صرف نظر کنید)
بخش اول: فعال کردن حساب صورتحساب
برای اجرای این codelab، به یک حساب کاربری billing با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب کاربری billing متصل هستید، میتوانید از این مرحله صرف نظر کنید.
بخش دوم: محیط باز
- 👉 برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید
- 👉 اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی «مجوز دادن» کلیک کنید.
- 👉 اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- 👉💻 در ترمینال، با استفاده از دستور زیر تأیید کنید که از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است:
gcloud auth list - 👉💻 پروژه بوتاسترپ را از گیتهاب کپی کنید:
git clone https://github.com/gca-americas/way-back-home.git
بخش سوم: ایجاد یک پروژه جدید
👉💻 در ترمینال، اسکریپت init را قابل اجرا کنید و آن را اجرا کنید:
cd ~/way-back-home/level_2
./init.sh
۳. 🛠️ تنظیمات محیط
۱. پوسته ابری را باز کنید
در ترمینال ویرایشگر Cloud Shell ، اگر ترمینال در پایین صفحه نمایش داده نمیشود، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
۲. پیکربندی پروژه
👉💻 در ترمینال، شناسه پروژه خود را تنظیم کنید:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 فعال کردن API های مورد نیاز (این کار حدود ۲-۳ دقیقه طول میکشد):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
۳. اجرای اسکریپت راهاندازی
👉💻 اسکریپت راهاندازی را اجرا کنید:
cd ~/way-back-home/level_2
./setup.sh
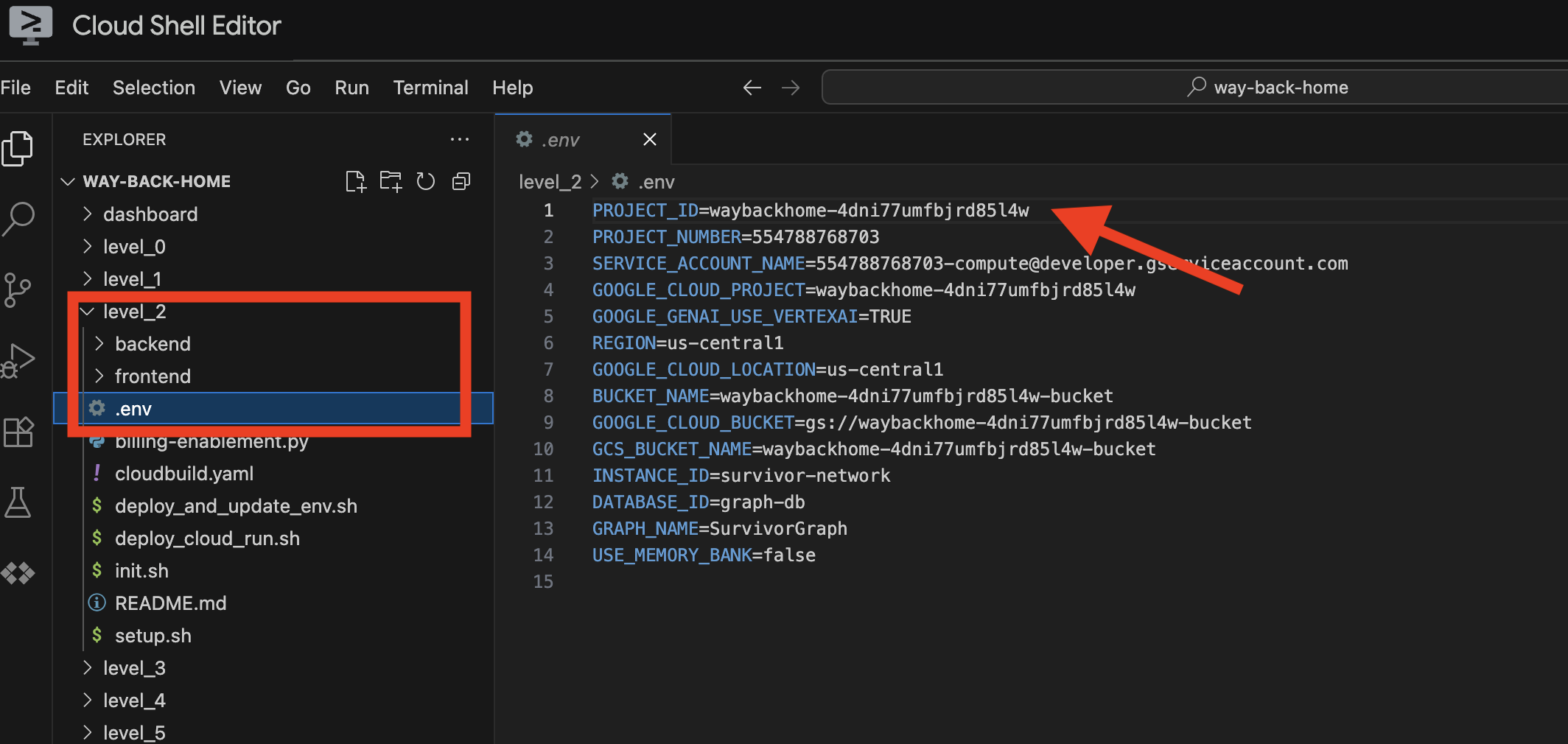
این فایل .env برای شما ایجاد میکند. در cloudshell خود، پروژه way_back_home را باز کنید. در زیر پوشه level_2 ، میتوانید فایل .env را که برای شما ایجاد شده است، ببینید. اگر نمیتوانید آن را پیدا کنید، میتوانید برای مشاهده آن روی View -> Toggle Hidden File کلیک کنید. 
۴. بارگذاری دادههای نمونه
👉💻 به بخش مدیریت بروید و وابستگیها را نصب کنید:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 بارگذاری دادههای اولیه بازمانده:
uv run python ~/way-back-home/level_2/backend/setup_data.py
این باعث ایجاد موارد زیر میشود:
- نمونهی اسپنر (
survivor-network) - پایگاه داده (
graph-db) - تمام جداول گره و لبه
- نمودارهای ویژگی برای پرس و جو خروجی مورد انتظار :
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
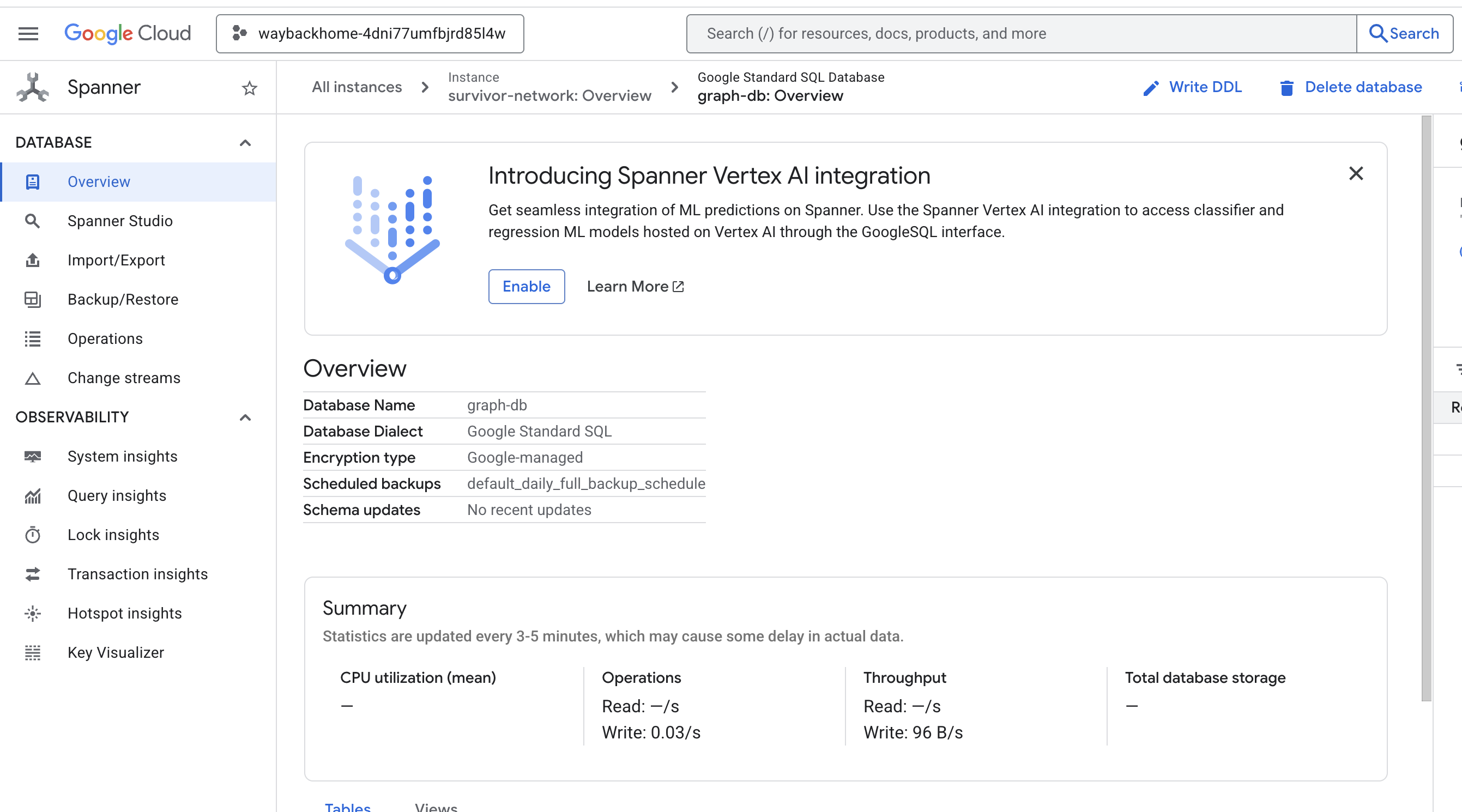
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
اگر پس از Access your database at خروجی، روی لینک کلیک کنید، میتوانید Google Cloud Console Spanner را باز کنید.

و شما Spanner را در کنسول ابری گوگل خواهید دید!
۴. 🚀 مصورسازی دادههای نموداری در Spanner Studio
این راهنما به شما کمک میکند تا دادههای گراف شبکه Survivor را مستقیماً در کنسول Google Cloud با استفاده از Spanner Studio تجسم کرده و با آنها تعامل داشته باشید. این یک روش عالی برای تأیید دادههای شما و درک ساختار گراف قبل از ساخت عامل هوش مصنوعی شماست.
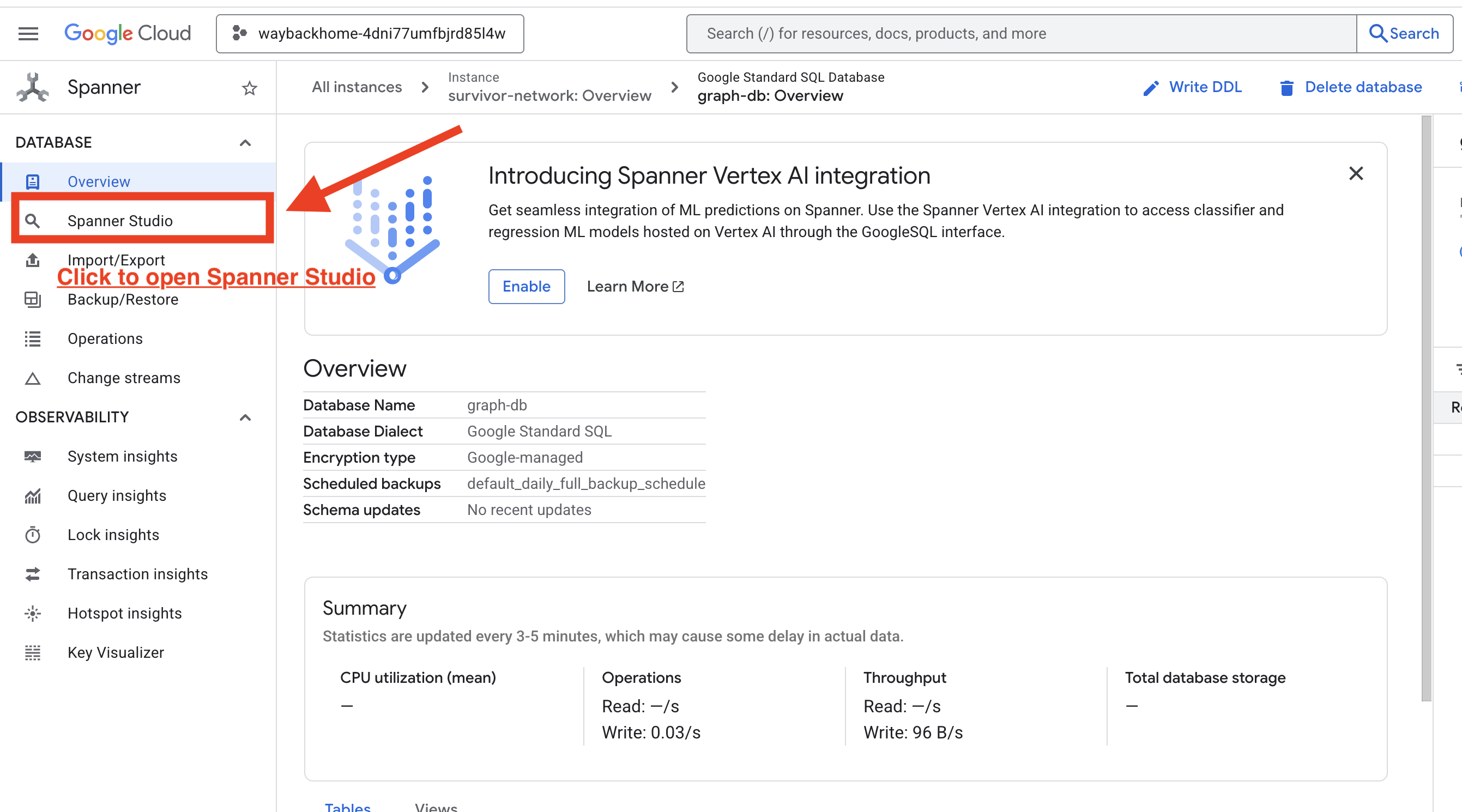
۱. اکسس اسپنر استودیو
- در آخرین مرحله، مطمئن شوید که روی لینک کلیک کرده و Spanner Studio را باز میکنید.
۲. درک ساختار نمودار ("تصویر بزرگ")
مجموعه داده Survivor Network را به عنوان یک پازل منطقی یا یک حالت بازی در نظر بگیرید:
نهاد | نقش در سیستم | مقایسه |
بازماندگان | ایجنتها/بازیکنان | بازیکنان |
زیستبومها | جایی که آنها قرار دارند | مناطق نقشه |
مهارتها | کاری که میتوانند انجام دهند | تواناییها |
نیازها | آنچه کم دارند (بحرانها) | ماموریتها/ماموریتها |
منابع | اشیاء یافت شده در جهان | غارت |
هدف : وظیفه عامل هوش مصنوعی، اتصال مهارتها (راهحلها) به نیازها (مشکلات) با در نظر گرفتن زیستبومها (محدودیتهای مکانی) است.
🔗 لبهها (روابط):
-
SurvivorInBiome: ردیابی موقعیت مکانی -
SurvivorHasSkill: فهرست تواناییها -
SurvivorHasNeed: فهرست مشکلات فعال -
SurvivorFoundResource: فهرست اقلام -
SurvivorCanHelp: رابطه استنباطی (هوش مصنوعی این را محاسبه میکند!)
۳. پرسوجو از گراف
بیایید چند کوئری اجرا کنیم تا «داستان» (Story) را در دادهها ببینیم.
Spanner Graph از GQL (زبان پرسوجوی گراف) استفاده میکند. برای اجرای یک پرسوجو، GRAPH SurvivorNetwork و به دنبال آن الگوی تطبیق خود استفاده کنید.
👉 سوال اول: فهرست جهانی (چه کسی کجاست؟) این پایه و اساس شماست - درک مکان برای عملیات نجات بسیار مهم است.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
انتظار میرود نتیجه به صورت زیر باشد: 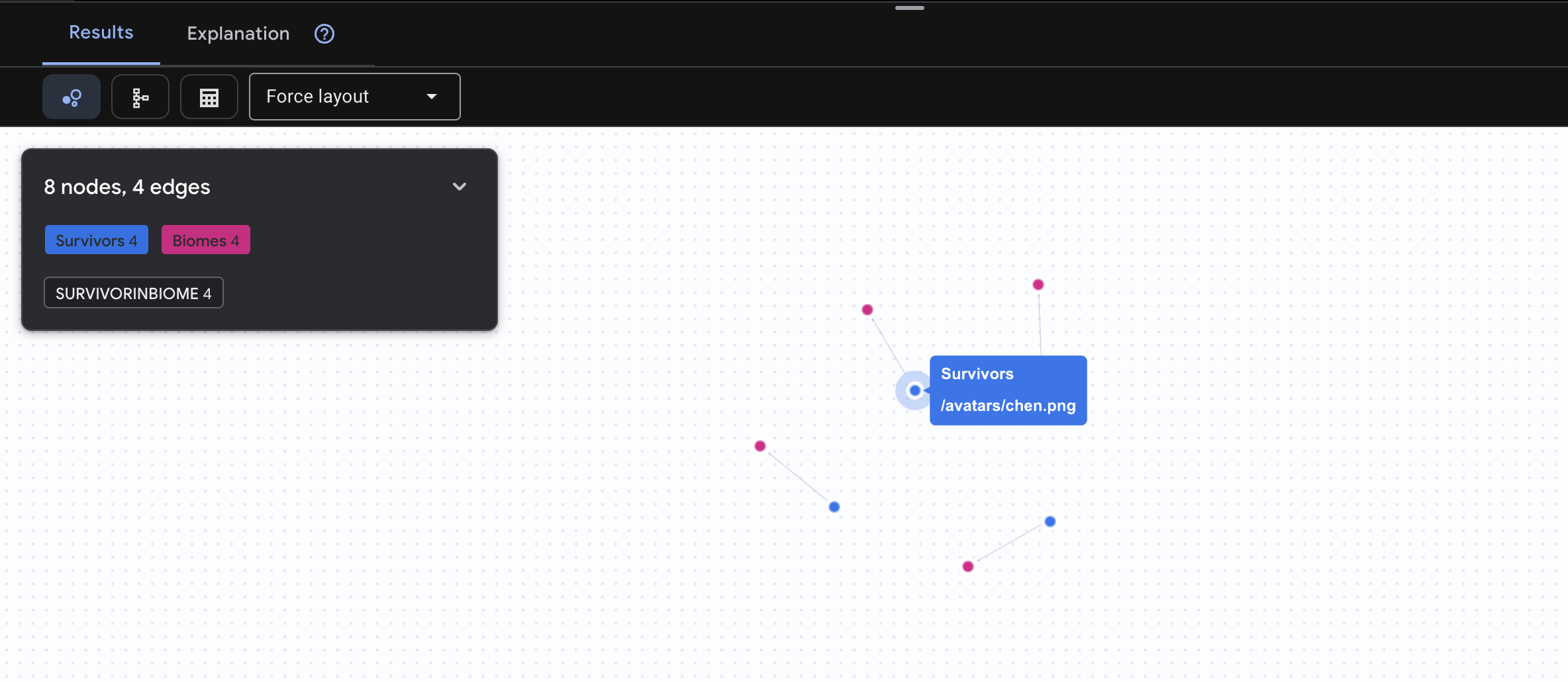
👉 سوال دوم: ماتریس مهارت (قابلیتها) حالا که میدانید هر کسی در چه جایگاهی قرار دارد، ببینید چه کارهایی از دستش برمیآید .
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
انتظار میرود نتیجه به صورت زیر باشد: 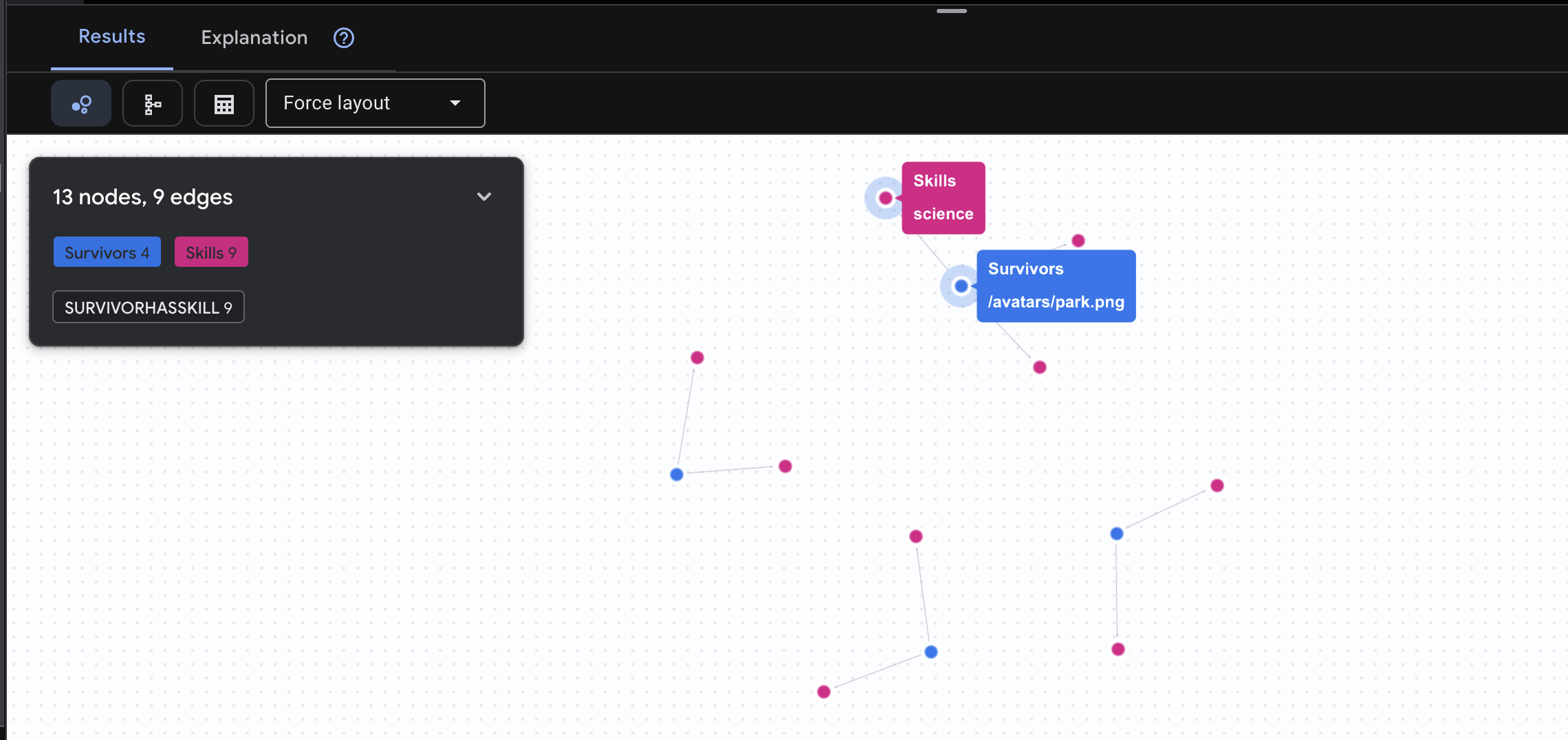
👉 سوال ۳: چه کسی در بحران است؟ ("هیئت ماموریت") بازماندگانی را که به کمک نیاز دارند و آنچه نیاز دارند، ببینید.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
انتظار میرود نتیجه به صورت زیر باشد: 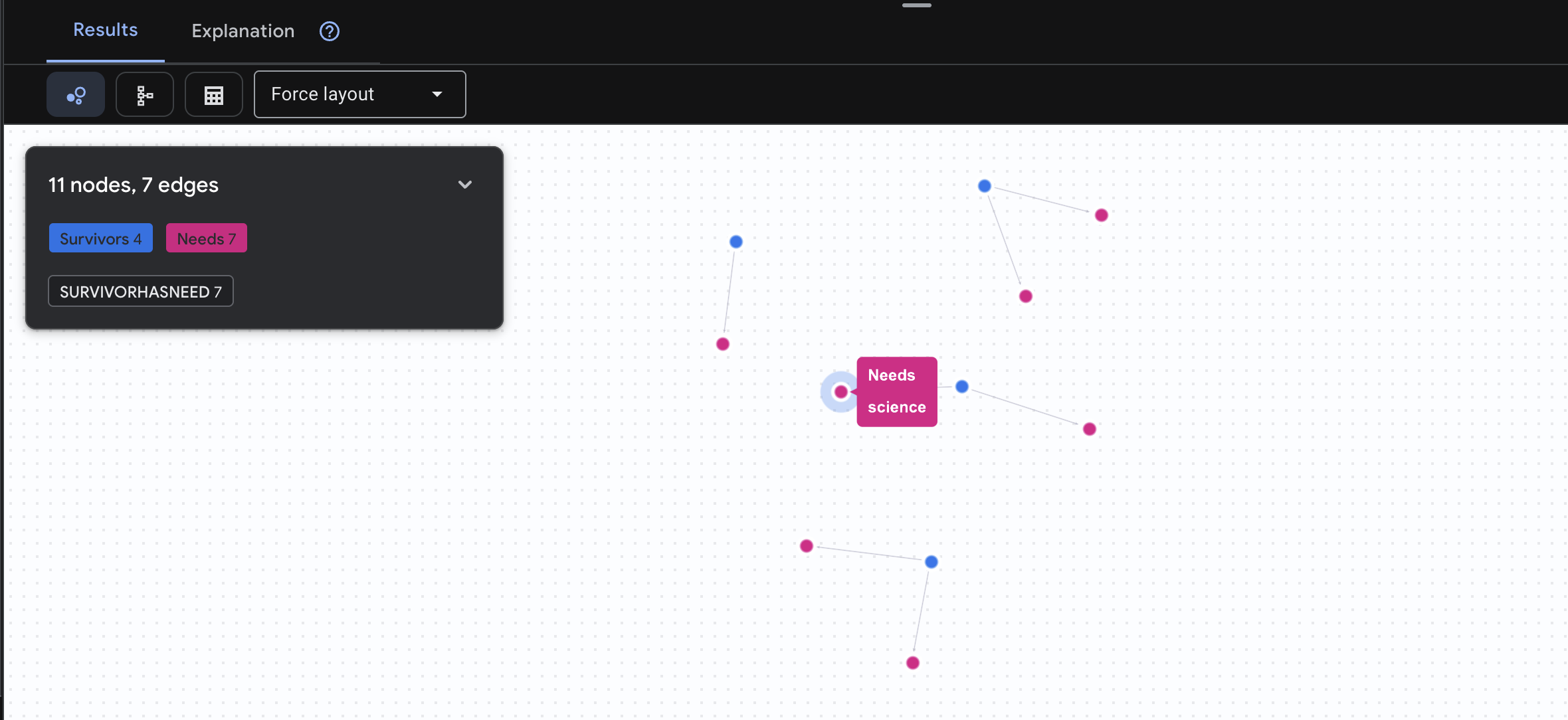
🔎 [اختیاری] همسریابی - چه کسی میتواند به چه کسی کمک کند؟
اینجاست که نمودار قدرتمند میشود! این پرسوجو بازماندگانی را پیدا میکند که مهارتهایی دارند که میتوانند نیازهای سایر بازماندگان را برطرف کنند .
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
انتظار میرود نتیجه به صورت زیر باشد: 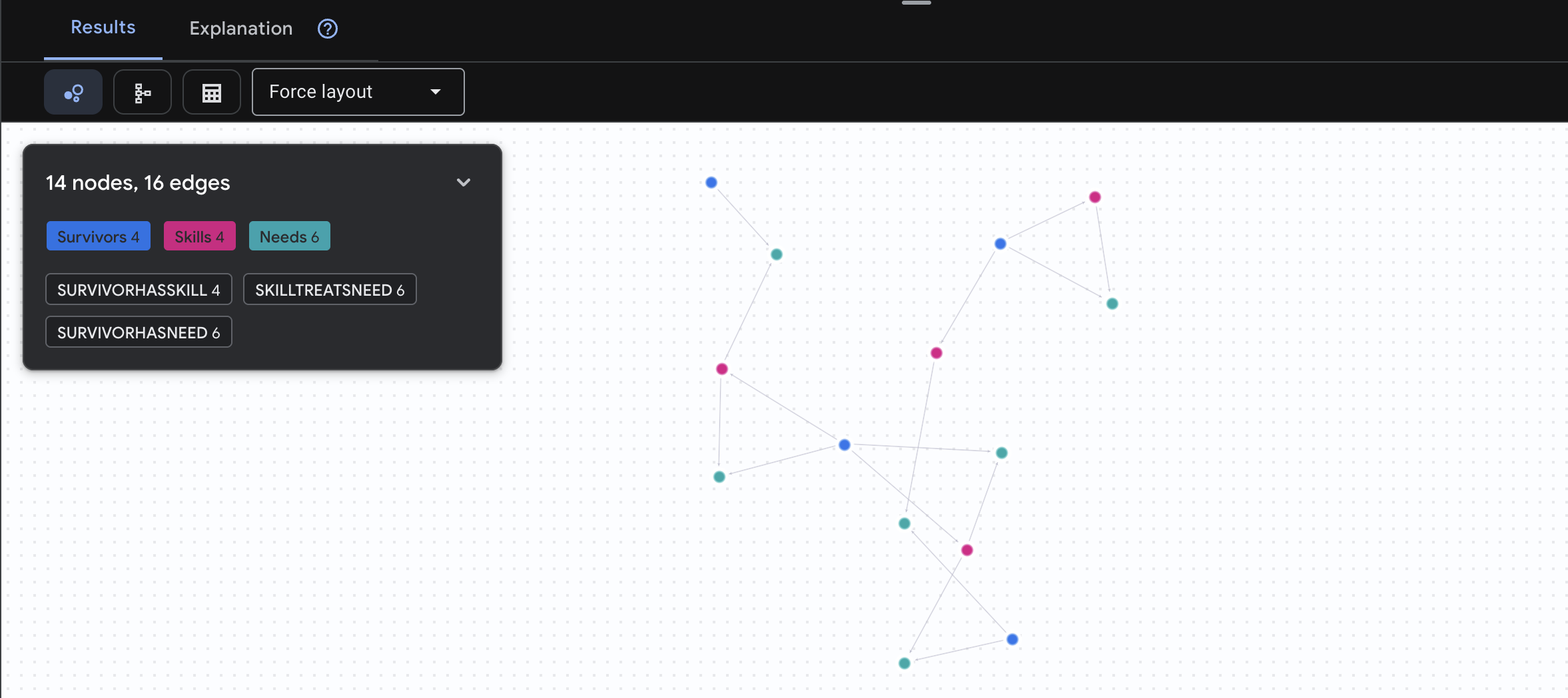
گذشته از مثبت، این کوئری چه کاری انجام میدهد:
به جای اینکه فقط عبارت «کمکهای اولیه سوختگی را درمان میکند» را نشان دهد (که از طرحواره مشخص است)، این کوئری عبارت زیر را پیدا میکند:
- دکتر النا فراست (که آموزش پزشکی دارد) → میتواند → کاپیتان تاناکا (که دچار سوختگی شده است) را درمان کند
- دیوید چن (که کمکهای اولیه دارد) → میتواند → ستوان پارک (که مچ پایش پیچ خورده است) را درمان کند
چرا این قدرتمند است:
کاری که عامل هوش مصنوعی شما انجام خواهد داد:
وقتی کاربری میپرسد «چه کسی میتواند سوختگیها را درمان کند؟» ، عامل:
- یک کوئری گراف مشابه اجرا کنید
- بازگشت: «دکتر فراست آموزش پزشکی دارد و میتواند به کاپیتان تاناکا کمک کند»
- کاربر نیازی به دانستن در مورد جداول واسطه یا روابط ندارد!
۵. 🚀 جاسازیهای مبتنی بر هوش مصنوعی در Spanner
۱. چرا جاسازیها؟ (بدون هیچ عملی، فقط خواندنی)
در سناریوی بقا، زمان بسیار مهم است . وقتی یک بازمانده وضعیت اضطراری را گزارش میدهد، مثلاً I need someone who can treat burns یا Looking for a medic ، نمیتواند وقت خود را برای حدس زدن نام دقیق مهارتها در پایگاه داده تلف کند.
سناریوی واقعی : بازمانده: Captain Tanaka has burns—we need medical help NOW!
جستجوی سنتی کلمه کلیدی برای "medic" → 0 نتیجه ❌
جستجوی معنایی با جاسازیها → «آموزش پزشکی» و «کمکهای اولیه» را پیدا میکند ✅
این دقیقاً همان چیزی است که کارشناسان جستجو به آن نیاز دارند: جستجوی هوشمند و انسانی که قصد و نیت کاربر را درک میکند، نه فقط کلمات کلیدی.
۲. ایجاد مدل جاسازی
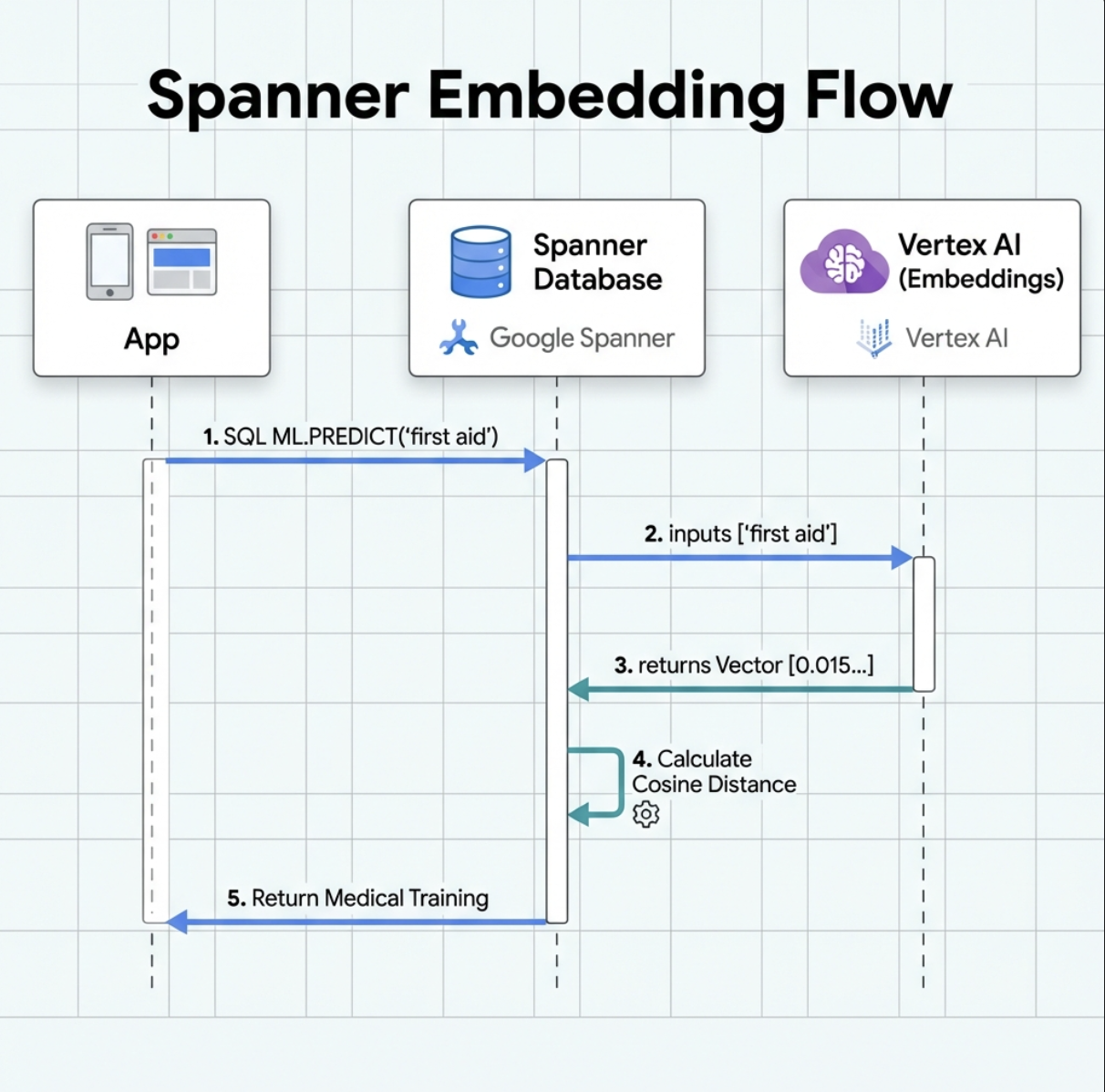
حالا بیایید مدلی بسازیم که متن را با استفاده از text-embedding-004 گوگل به جاسازی تبدیل کند.
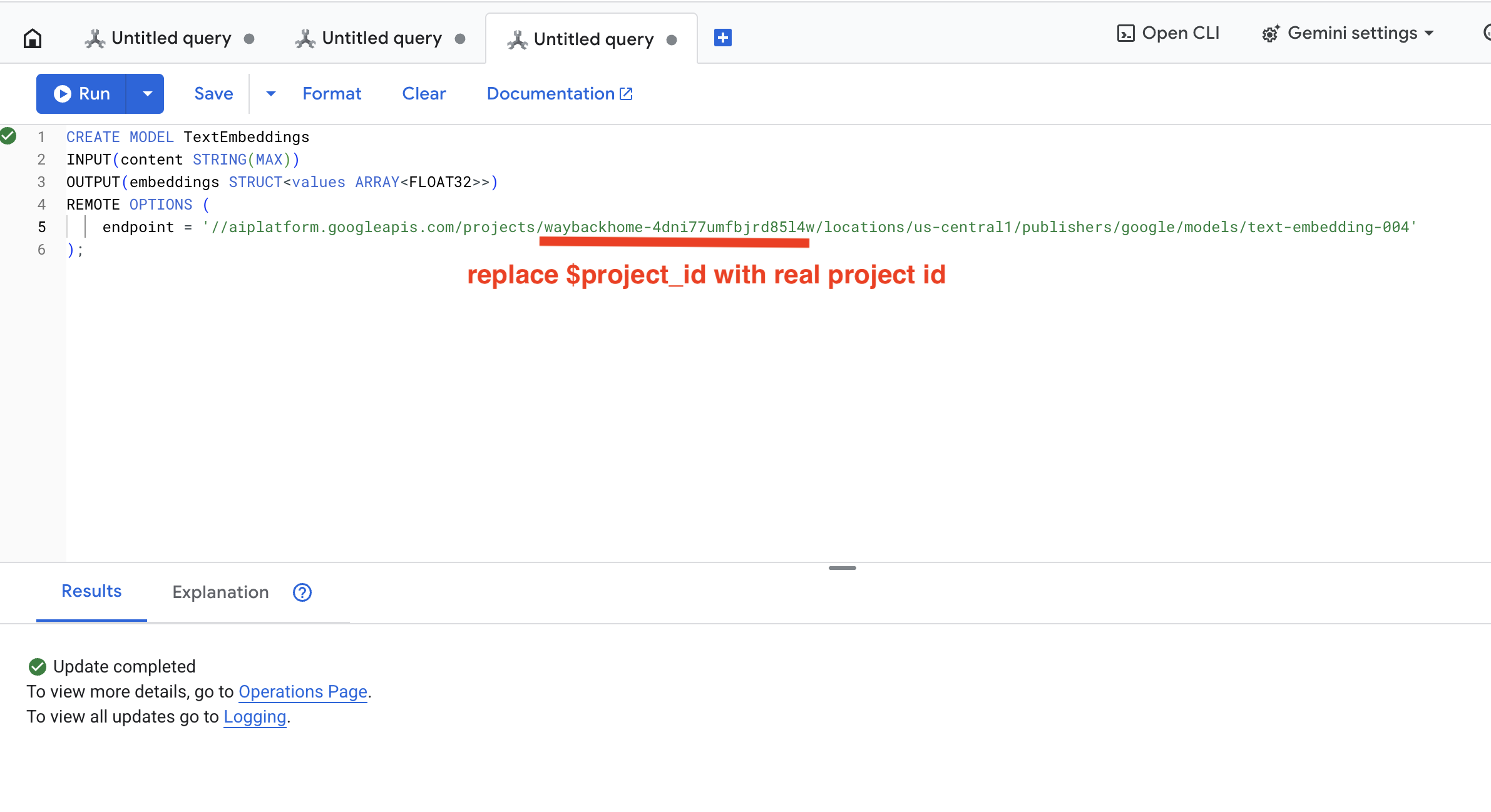
👉 در Spanner Studio، این SQL را اجرا کنید (به جای $YOUR_PROJECT_ID ، شناسه پروژه واقعی خود را قرار دهید):
‼️ در ویرایشگر پوسته ابری، برای مشاهده کل پروژه، مسیر File -> Open Folder -> way-back-home/level_2 را باز کنید.
👉 این کوئری را در Spanner Studio با کپی کردن و جایگذاری کوئری زیر اجرا کنید و سپس روی دکمه اجرا کلیک کنید:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
این چه کاری انجام میدهد :
- یک مدل مجازی در Spanner ایجاد میکند (وزنهای مدل به صورت محلی ذخیره نمیشوند)
- به
text-embedding-004گوگل در Vertex AI اشاره دارد - قرارداد را تعریف میکند: ورودی متن است، خروجی یک آرایه اعشاری ۷۶۸ بعدی است
چرا «گزینههای از راه دور»؟
- اسپانر خودش مدل را اجرا نمیکند
- وقتی از
ML.PREDICTاستفاده میکنید، Vertex AI را از طریق API فراخوانی میکند. - Zero-ETL : نیازی به خروجی گرفتن دادهها به پایتون، پردازش و وارد کردن مجدد آنها نیست
روی دکمهی Run کلیک کنید، پس از موفقیتآمیز بودن، میتوانید نتیجه را به صورت زیر مشاهده کنید:
۳. اضافه کردن ستون جاسازی
👉 یک ستون برای ذخیره جاسازیها اضافه کنید:
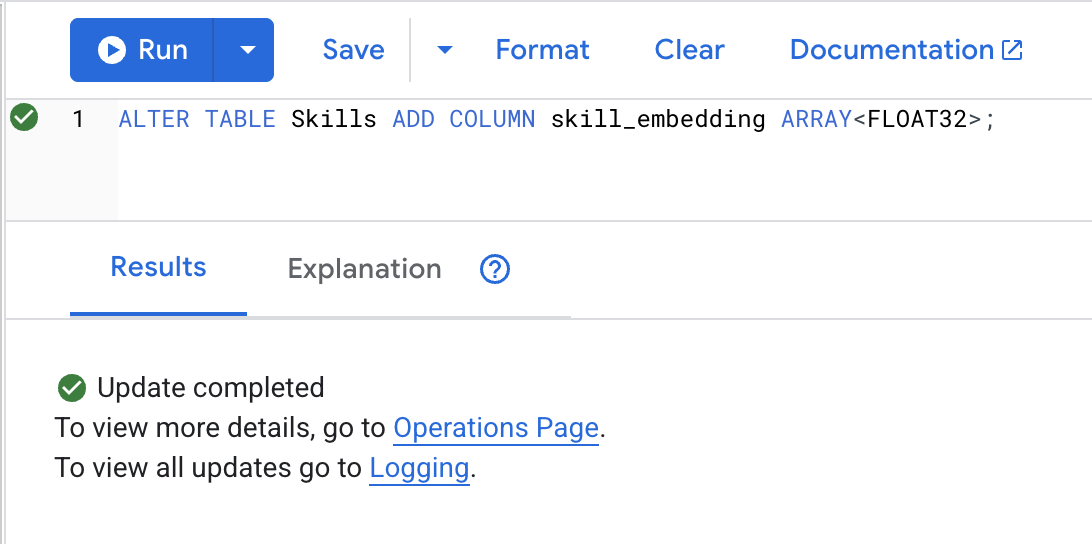
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
روی دکمهی Run کلیک کنید، پس از موفقیتآمیز بودن، میتوانید نتیجه را به صورت زیر مشاهده کنید:
۴. ایجاد جاسازیها
👉 از هوش مصنوعی برای ایجاد جاسازیهای برداری برای هر مهارت استفاده کنید:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
روی دکمهی Run کلیک کنید، پس از موفقیتآمیز بودن، میتوانید نتیجه را به صورت زیر مشاهده کنید:
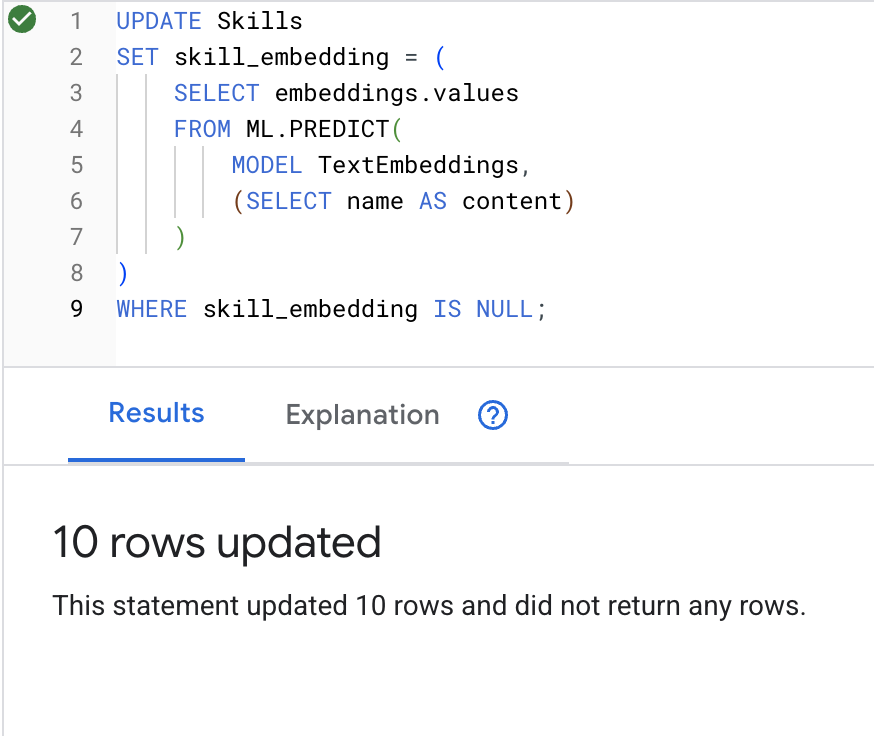
چه اتفاقی میافتد : نام هر مهارت (مثلاً «کمکهای اولیه») به یک بردار ۷۶۸ بُعدی تبدیل میشود که معنای معنایی آن را نشان میدهد.
۵. تأیید جاسازیها
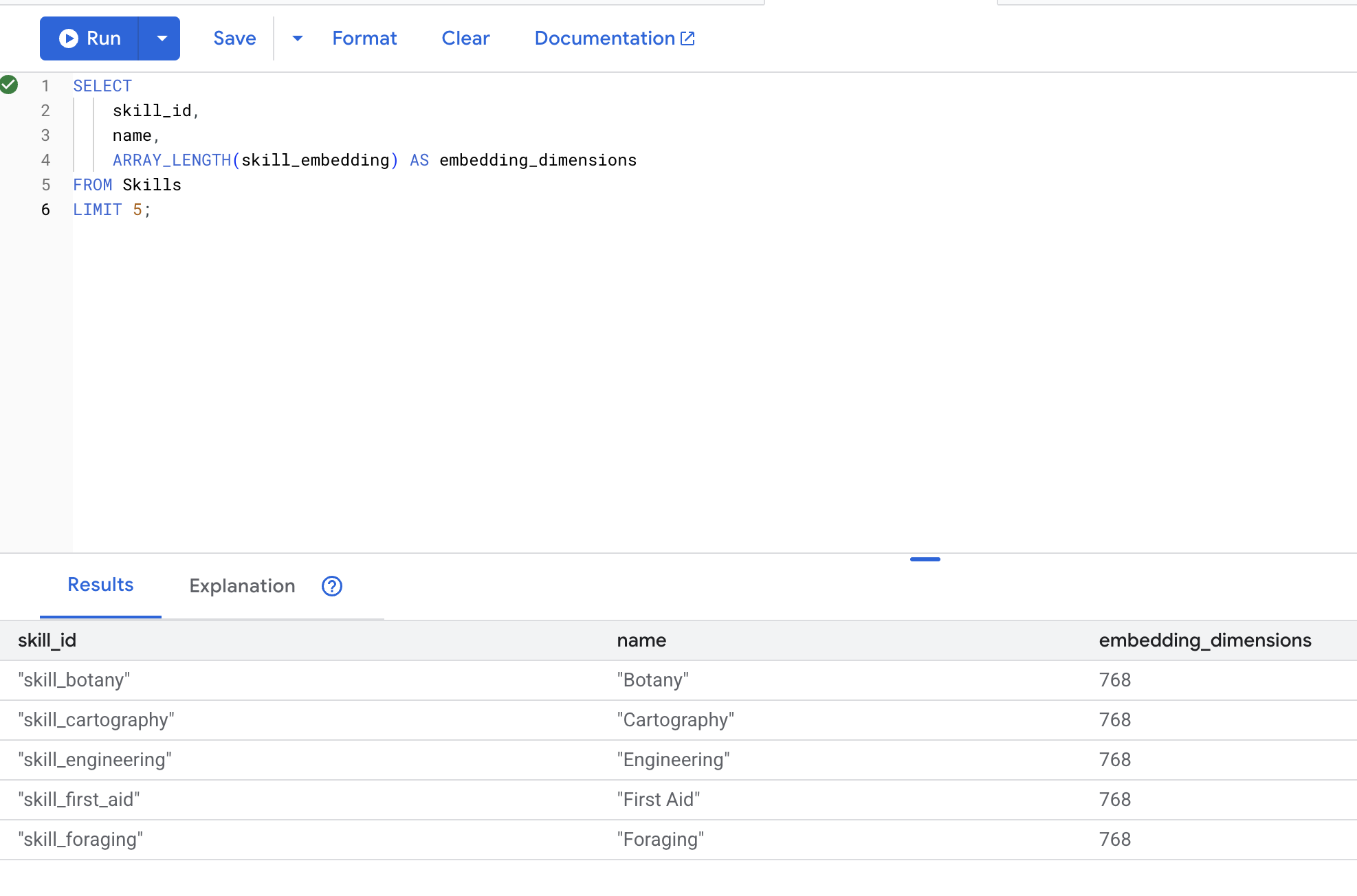
👉 بررسی کنید که جاسازیها ایجاد شدهاند:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
خروجی مورد انتظار :
۶. جستجوی معنایی را آزمایش کنید
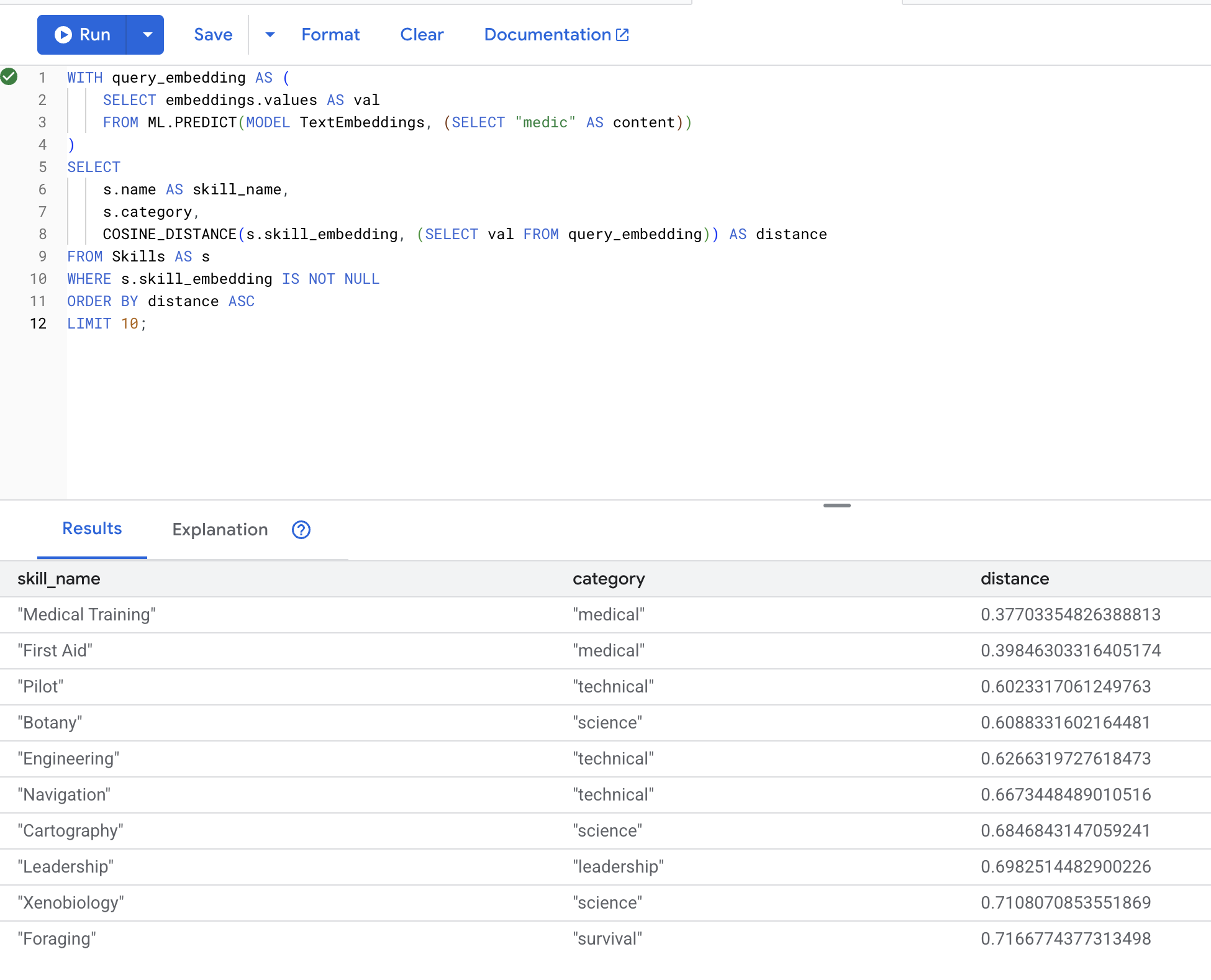
اکنون مورد استفاده دقیق سناریوی خود را آزمایش میکنیم : یافتن مهارتهای پزشکی با استفاده از اصطلاح "پزشک".
👉 مهارتهای مشابه با «پزشکی» را پیدا کنید:
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- عبارت جستجوی کاربر "medic" را به یک جاسازی تبدیل میکند.
- آن را در جدول موقت
query_embeddingذخیره میکند.
نتایج مورد انتظار (فاصله کمتر = شباهت بیشتر):
۷. ایجاد مدل Gemini برای تحلیل
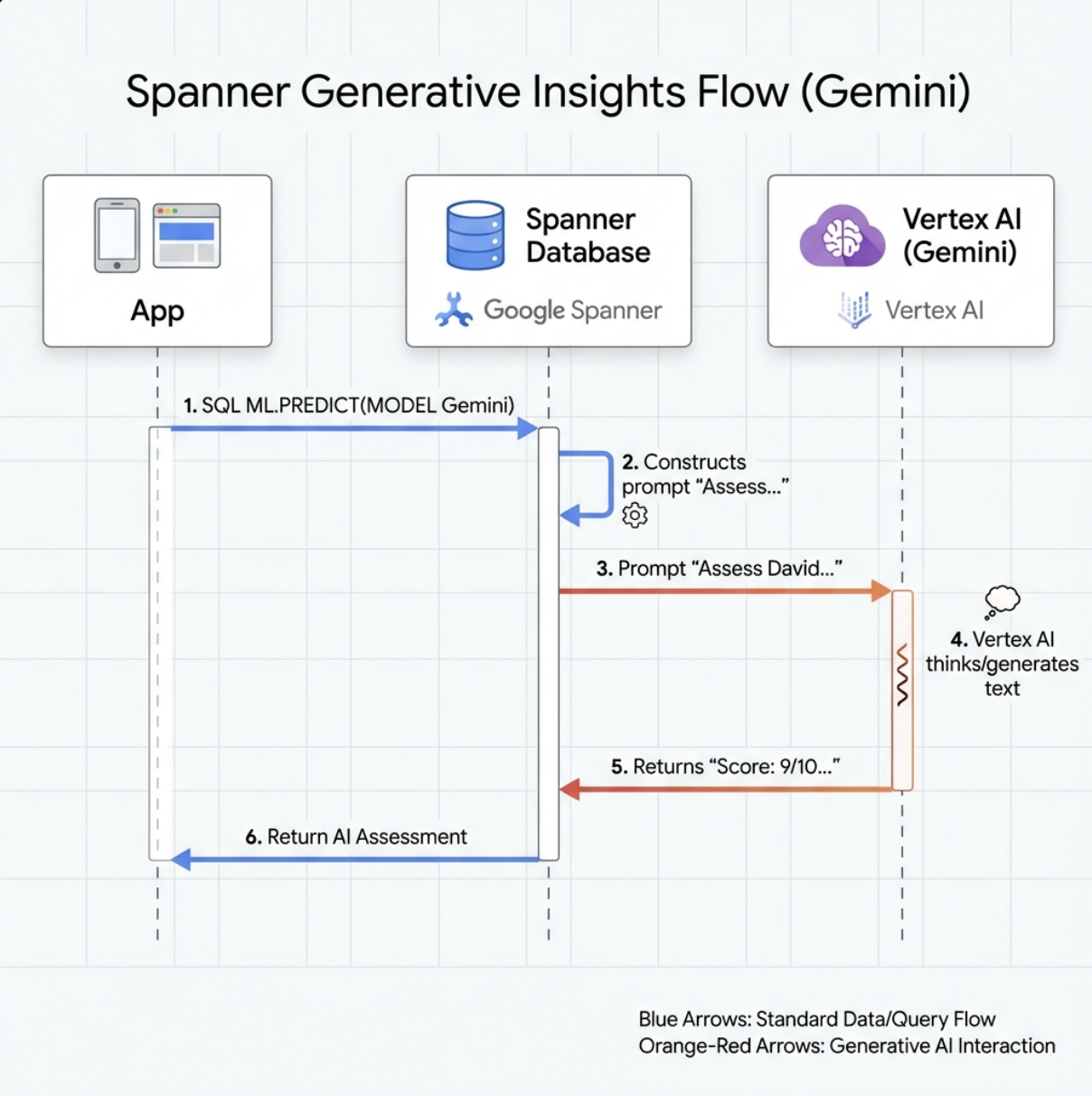
👉 یک مرجع مدل هوش مصنوعی مولد ایجاد کنید (به جای $YOUR_PROJECT_ID ، شناسه پروژه واقعی خود را قرار دهید):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
تفاوت با مدل Embeddings :
- جاسازیها : متن → بردار (برای جستجوی شباهت)
- جمینی : متن → متن تولید شده (برای استدلال/تحلیل)
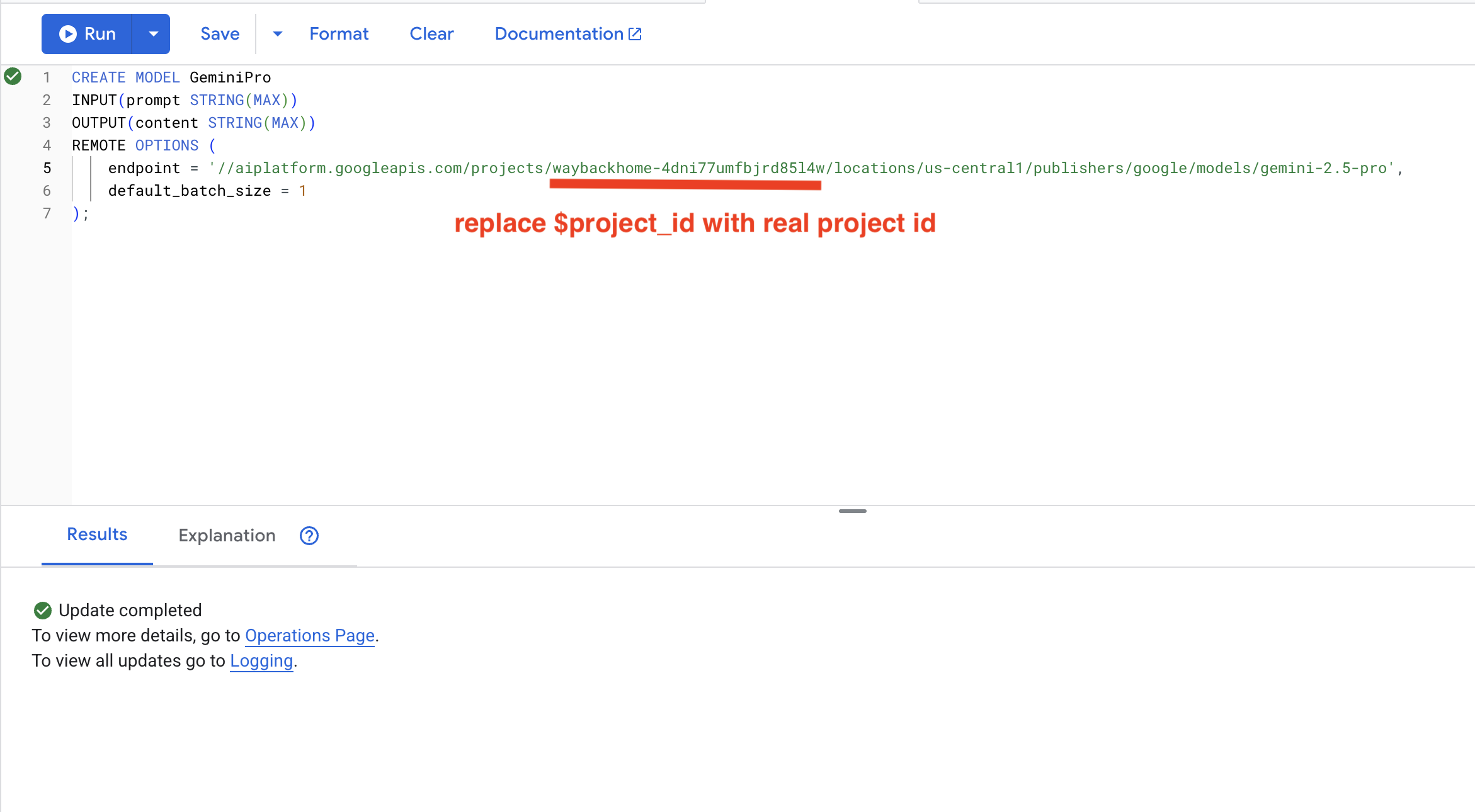
۸. از Gemini برای تحلیل سازگاری استفاده کنید
👉 جفتهای بازمانده را برای سازگاری ماموریت تجزیه و تحلیل کنید:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
خروجی مورد انتظار :
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
۶. 🚀 ساخت عامل RAG گراف خود با جستجوی ترکیبی
۱. بررسی اجمالی معماری سیستم
این بخش یک سیستم جستجوی چند روشی ایجاد میکند که به اپراتور شما انعطافپذیری لازم برای مدیریت انواع مختلف پرسوجوها را میدهد. این سیستم دارای سه لایه است: لایه اپراتور ، لایه ابزار ، لایه سرویس .
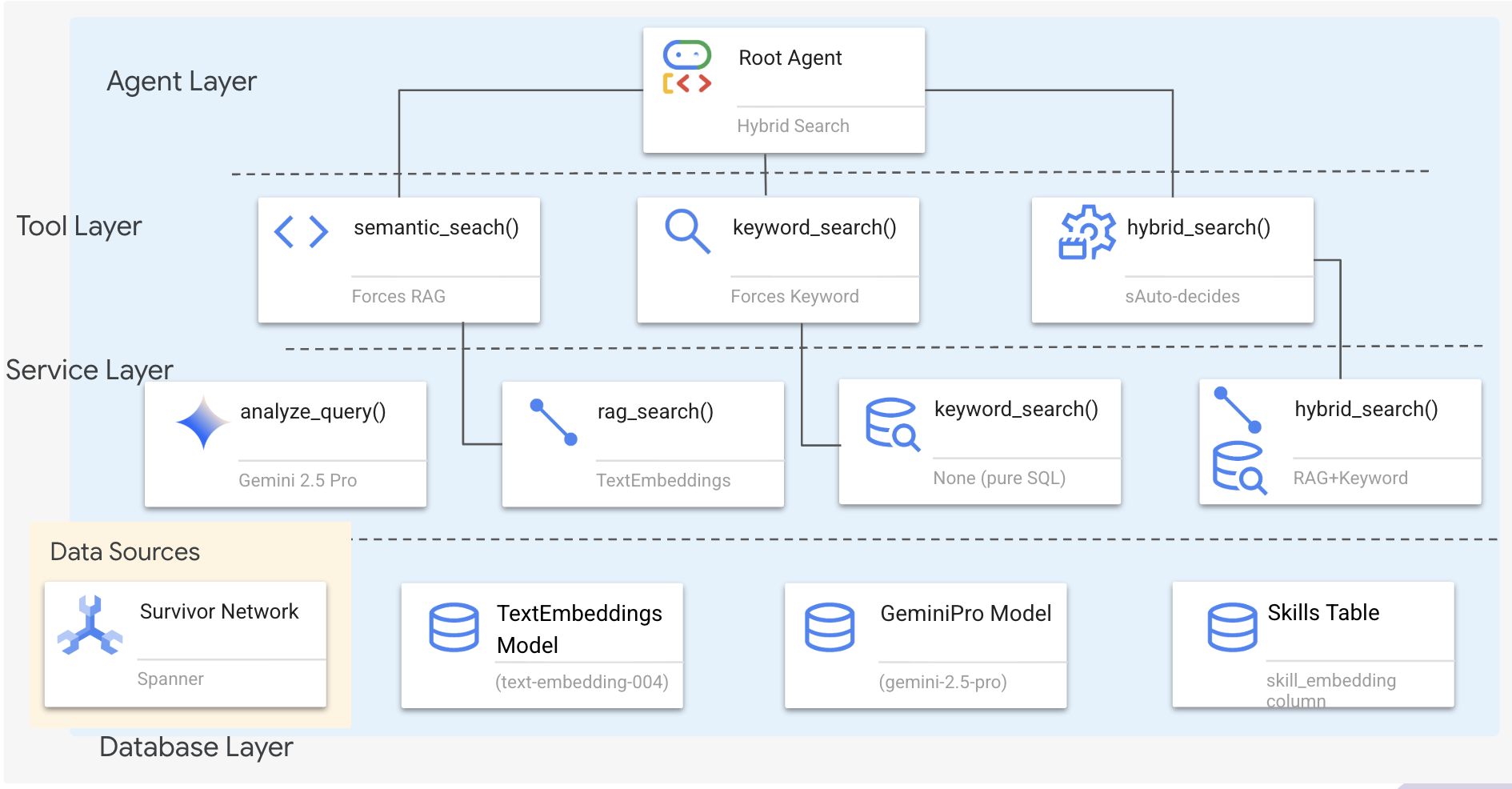
چرا سه لایه؟
- تفکیک دغدغهها : عامل بر قصد، ابزارها بر رابط و سرویس بر پیادهسازی تمرکز دارد.
- انعطافپذیری : عامل میتواند روشهای خاصی را اعمال کند یا به هوش مصنوعی اجازه دهد تا به صورت خودکار مسیریابی کند.
- بهینهسازی : وقتی روش شناخته شده باشد، میتوان از تحلیلهای گرانقیمت هوش مصنوعی صرفنظر کرد.
در این بخش، شما در درجه اول جستجوی معنایی (RAG) را پیادهسازی خواهید کرد - یافتن نتایج بر اساس معنی نه فقط کلمات کلیدی. بعداً توضیح خواهیم داد که چگونه جستجوی ترکیبی چندین روش را ادغام میکند.
۲. پیادهسازی سرویس RAG
👉💻 در ترمینال، فایل را در ویرایشگر Cloud Shell با اجرای دستور زیر باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
کامنت # TODO: REPLACE_SQL را پیدا کنید
کل این خط را با کد زیر جایگزین کنید :
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
۳. تعریف ابزار جستجوی معنایی
👉💻 در ترمینال، فایل را در ویرایشگر Cloud Shell با اجرای دستور زیر باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
در hybrid_search_tools.py ، عبارت # TODO: REPLACE_SEMANTIC_SEARCH_TOOL را پیدا کنید.
👉 کل این خط را با کد زیر جایگزین کنید :
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
چه زمانی عامل استفاده میکند :
- پرسوجوهایی که درخواست شباهت میکنند ("یافتن مشابه X")
- پرسشهای مفهومی ("تواناییهای درمانی")
- وقتی درک معنا حیاتی است
۴. راهنمای تصمیمگیری نماینده (دستورالعملها)
در تعریف عامل، بخش مربوط به جستجوی معنایی را در دستورالعمل کپی پیست کنید.
👉💻 در ترمینال، فایل را در ویرایشگر Cloud Shell با اجرای دستور زیر باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
عامل از این دستورالعمل برای انتخاب ابزار مناسب استفاده میکند:
👉 در فایل agent.py ، کامنت # TODO: REPLACE_SEARCH_LOGIC را پیدا کنید و کل این خط را با کد زیر جایگزین کنید :
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉 کامنت را پیدا کنید # TODO: ADD_SEARCH_TOOL کل این خط را با کد زیر جایگزین کنید :
semantic_search, # Force RAG
۵. درک نحوه عملکرد جستجوی ترکیبی (فقط خواندنی، نیازی به انجام کاری نیست)
در مراحل ۲ تا ۴، جستجوی معنایی (RAG) را پیادهسازی کردید، روش جستجوی اصلی که نتایج را بر اساس معنا پیدا میکند. اما ممکن است متوجه شده باشید که این سیستم «جستجوی ترکیبی» نامیده میشود. در اینجا نحوهی کنار هم قرار گرفتن همه چیز آمده است:
نحوه عملکرد ادغام هیبریدی :
در فایل way-back-home/level_2/backend/services/hybrid_search_service.py ، وقتی hybrid_search() فراخوانی میشود، سرویس هر دو جستجو را اجرا کرده و نتایج را ادغام میکند:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
برای این آزمایشگاه کد ، شما کامپوننت جستجوی معنایی (RAG) را پیادهسازی کردید که پایه و اساس کار است. متدهای کلمه کلیدی و ترکیبی از قبل در سرویس پیادهسازی شدهاند - عامل شما میتواند از هر سه استفاده کند!
تبریک! شما با موفقیت جستجوی ترکیبی Graph RAG Agent خود را به پایان رساندید!
۷. 🚀 تست عامل خود با ADK Web
سادهترین راه برای آزمایش عامل شما استفاده از دستور adk web است که عامل شما را با یک رابط چت داخلی راهاندازی میکند.
۱. اجرای عامل
👉💻 به دایرکتوری backend (جایی که agent شما تعریف شده است) بروید و رابط وب را اجرا کنید::
cd ~/way-back-home/level_2/backend
uv run adk web
این دستور، عامل تعریف شده در
agent/agent.py
و یک رابط وب برای آزمایش باز میکند.
👉 آدرس اینترنتی را باز کنید:
این دستور یک URL محلی (معمولاً http://127.0.0.1:8000 یا مشابه آن) را نمایش میدهد. آن را در مرورگر خود باز کنید.
پس از کلیک روی URL، رابط کاربری وب ADK را مشاهده خواهید کرد. مطمئن شوید که از گوشه بالا سمت چپ، گزینه "agent" را انتخاب کردهاید.
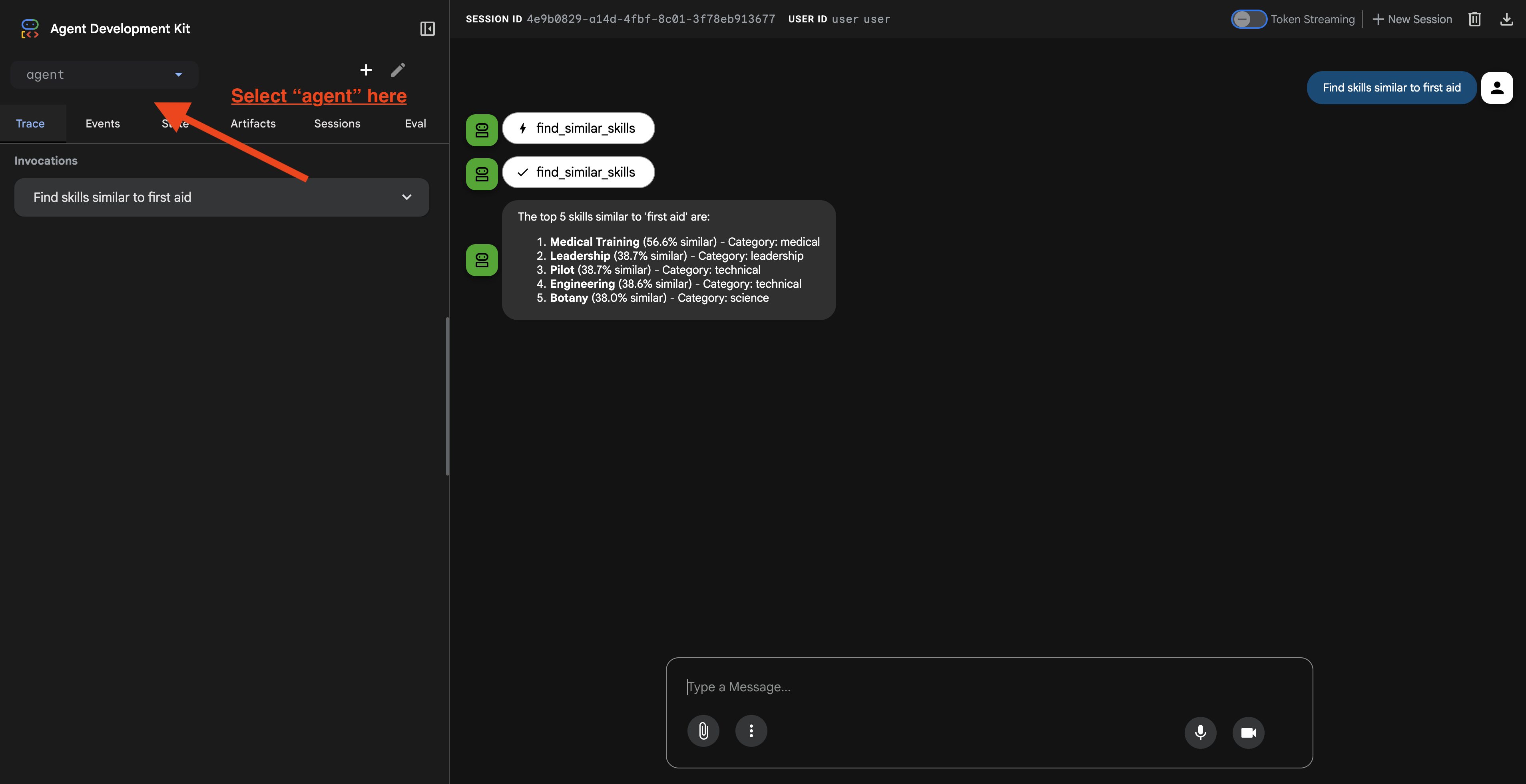
۲. آزمایش قابلیتهای جستجو
این عامل به گونهای طراحی شده است که به طور هوشمندانه درخواستهای شما را مسیریابی کند. ورودیهای زیر را در پنجره چت امتحان کنید تا روشهای مختلف جستجو را در عمل مشاهده کنید.
الف) جستجوی معنایی گراف RAG
موارد را بر اساس معنی و مفهوم پیدا میکند، حتی اگر کلمات کلیدی با هم مطابقت نداشته باشند.
سوالات آزمون: (یکی از موارد زیر را انتخاب کنید)
Who can help with injuries?
What abilities are related to survival?
چه چیزی را باید جستجو کرد:
- در استدلال باید به جستجوی معنایی یا RAG اشاره شود.
- شما باید نتایجی را ببینید که از نظر مفهومی مرتبط هستند (مثلاً «جراحی» هنگام درخواست «کمکهای اولیه»).
- نتایج دارای آیکون 🧬 خواهند بود.
🔀 ب. جستجوی ترکیبی
فیلترهای کلمات کلیدی را با درک معنایی برای پرسوجوهای پیچیده ترکیب میکند.
سوالات آزمون: (یکی از موارد زیر را انتخاب کنید)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
چه چیزی را باید جستجو کرد:
- در استدلال باید به جستجوی ترکیبی اشاره شود.
- نتایج باید با هر دو معیار (مفهوم + مکان/دستهبندی) مطابقت داشته باشند.
- نتایجی که با هر دو روش پیدا شوند، آیکون 🔀 را خواهند داشت و بالاترین رتبه را کسب میکنند.
👉💻 وقتی آزمایش تمام شد، با فشردن Ctrl+C در خط فرمان، فرآیند را خاتمه دهید.
۸. 🚀 اجرای کامل برنامه
بررسی اجمالی معماری فول استک
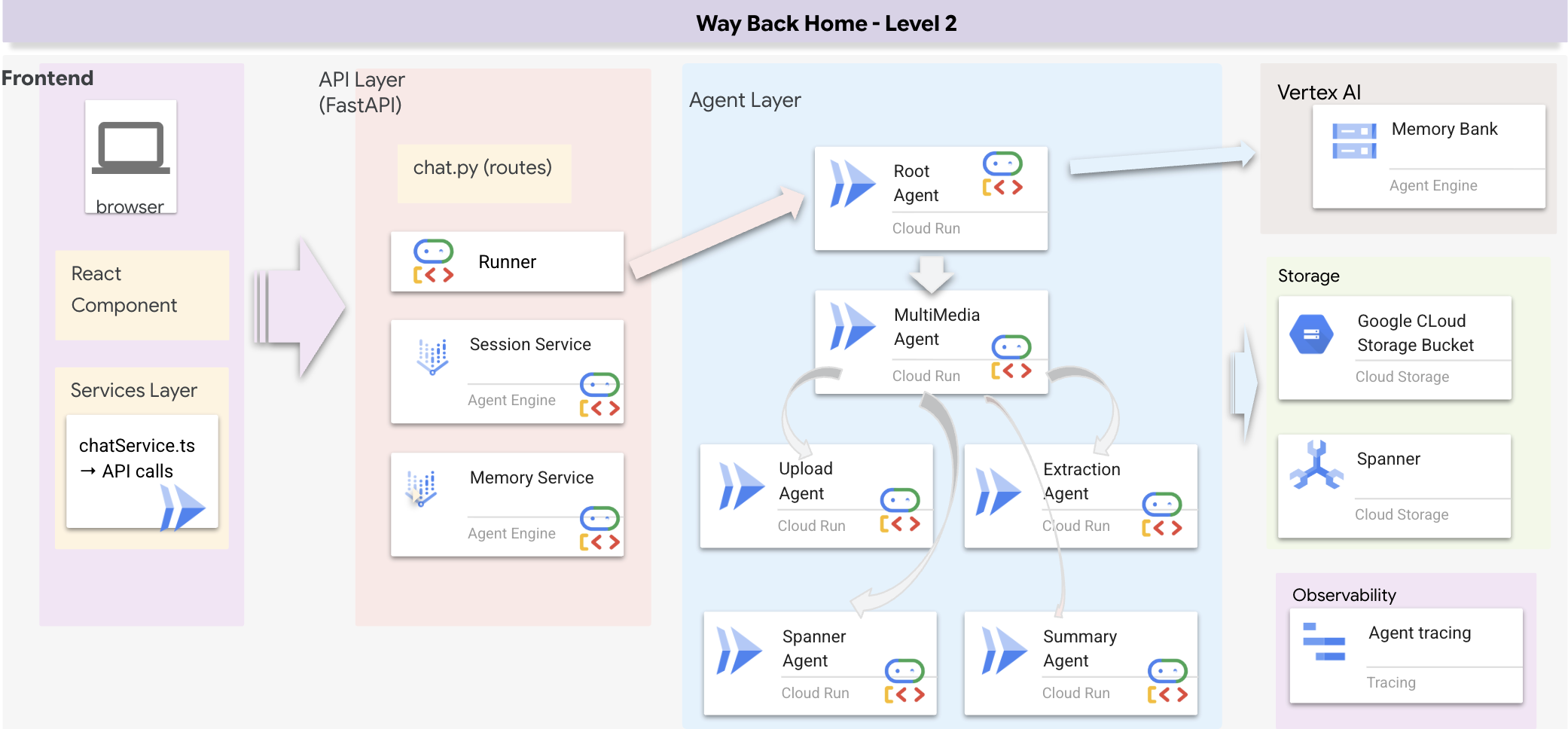
اضافه کردن SessionService و Runner
👉💻 در ترمینال، فایل chat.py را در ویرایشگر Cloud Shell با اجرای دستور زیر باز کنید (قبل از ادامه، مطمئن شوید که برای پایان دادن به فرآیند قبلی، کلیدهای "ctrl+C" را فشار دادهاید):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 در فایل chat.py ، کامنت # TODO: REPLACE_INMEMORY_SERVICES را پیدا کنید و کل این خط را با کد زیر جایگزین کنید :
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉 در فایل chat.py ، کامنت # TODO: REPLACE_RUNNER را پیدا کنید و کل این خط را با کد زیر جایگزین کنید :
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
۱. شروع برنامه
اگر ترمینال قبلی هنوز در حال اجرا است، با فشردن Ctrl+C آن را ببندید.
👉💻 شروع برنامه:
cd ~/way-back-home/level_2/
./start_app.sh
وقتی که با موفقیت backend شروع به کار کرد، Local: http://localhost:5173/" را مانند تصویر زیر مشاهده خواهید کرد: 
👉 در ترمینال روی Local: http://localhost:5173/ کلیک کنید.
۲. جستجوی معنایی را آزمایش کنید
پرس و جو :
Find skills similar to healing
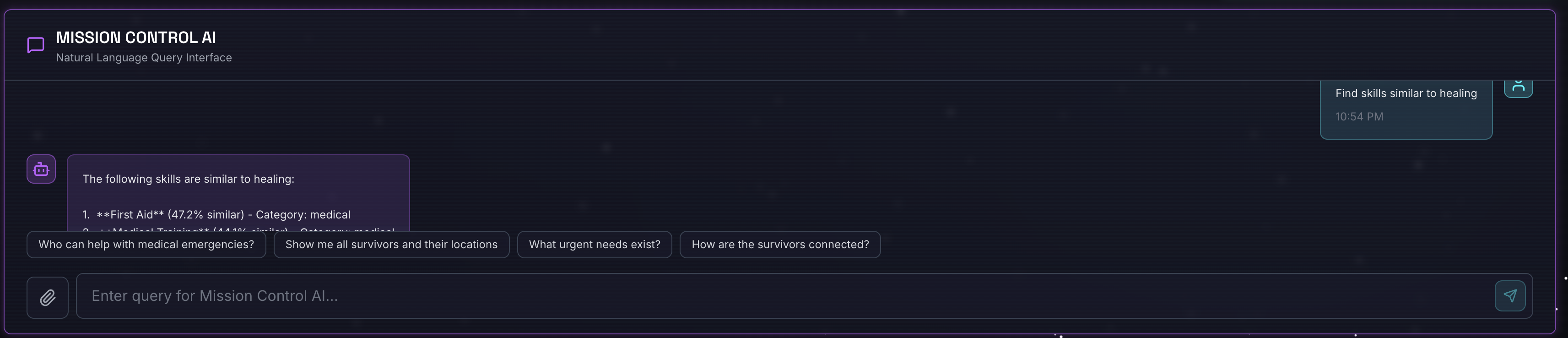
چه اتفاقی میافتد :
- عامل درخواست شباهت را تشخیص میدهد
- ایجاد جاسازی برای "درمان"
- از فاصله کسینوسی برای یافتن مهارتهای مشابه از نظر معنایی استفاده میکند.
- بازده: کمکهای اولیه (حتی اگر نامها با «درمان» مطابقت نداشته باشند)
۳. جستجوی ترکیبی را آزمایش کنید
پرس و جو :
Find medical skills in the mountains
چه اتفاقی میافتد :
- کامپوننت کلمه کلیدی : فیلتر برای
category='medical' - مؤلفه معنایی : کلمه "پزشکی" را جاسازی کنید و بر اساس شباهت رتبهبندی کنید
- ادغام : نتایج را ترکیب کنید، و نتایجی را که با هر دو روش پیدا شدهاند اولویتبندی کنید 🔀
پرس و جو (اختیاری) :
Who is good at survival and in the forest?
چه اتفاقی میافتد :
- یافتههای کلمه کلیدی:
biome='forest' - یافتههای معنایی: مهارتهایی مشابه «بقا»
- ترکیبی از هر دو برای بهترین نتیجه
👉💻 وقتی تست تمام شد، در ترمینال، با فشردن Ctrl+C آن را خاتمه دهید.
۴. (فقط برای شرکتکنندگان کارگاه!) موقعیت مکانی خود را بهروزرسانی کنید
👉💻 اسکریپت تکمیل را اجرا کنید:
cd ~/way-back-home/level_2
./set_level_2.sh
حالا waybackhome.dev را باز کنید، خواهید دید که موقعیت مکانی شما بهروزرسانی شده است. تبریک میگویم که مرحله ۲ را تمام کردید!

۹. ☕️ [اختیاری] خط لوله چندوجهی (فقط خواندنی) — لایه ابزارسازی
چرا به خط لوله چندوجهی نیاز داریم؟
شبکه بقا فقط پیامک نیست. بازماندگان در میدان نبرد، دادههای بدون ساختار را مستقیماً از طریق چت ارسال میکنند:
- 📸 تصاویر : عکسهایی از منابع، خطرات یا تجهیزات
- 🎥 ویدیوها : گزارش وضعیت یا پخش پیامهای اضطراری
- 📄 متن : یادداشتهای میدانی یا گزارشها
چه فایلهایی را پردازش میکنیم؟
برخلاف مرحله قبل که در آن دادههای موجود را جستجو کردیم، در اینجا فایلهای آپلود شده توسط کاربر را پردازش میکنیم. رابط chat.py فایلهای پیوست را به صورت پویا مدیریت میکند:
منبع | محتوا | هدف |
پیوست کاربر | تصویر/ویدئو/متن | اطلاعاتی که باید به نمودار اضافه شود |
زمینه چت | «اینم عکس لوازم مورد نیاز» | قصد و جزئیات تکمیلی |
رویکرد برنامهریزیشده: خط لوله عامل ترتیبی
ما از یک عامل ترتیبی ( multimedia_agent.py ) استفاده میکنیم که عاملهای تخصصی را به هم زنجیر میکند:
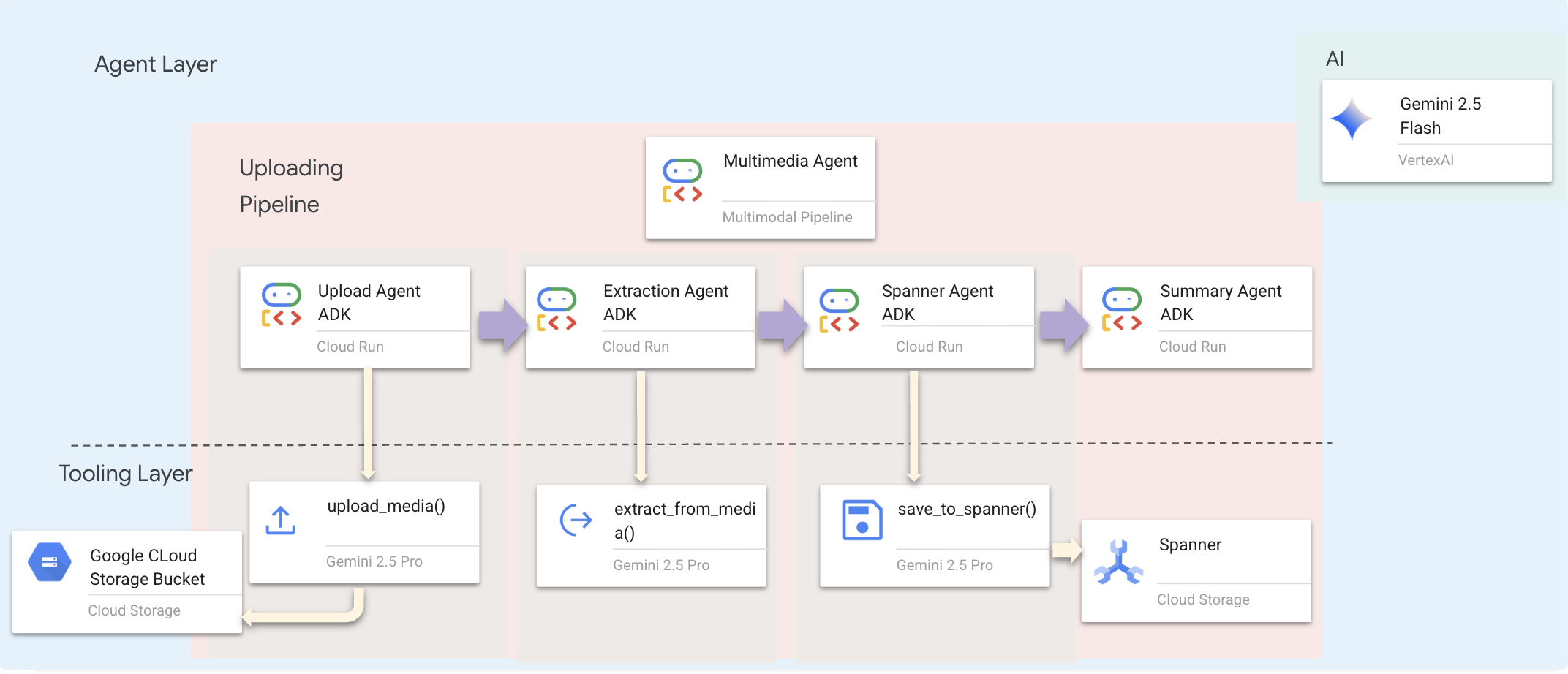
این در backend/agent/multimedia_agent.py به عنوان یک SequentialAgent تعریف شده است.
لایه ابزار، قابلیتهایی را فراهم میکند که عاملها میتوانند آنها را فراخوانی کنند. ابزارها «چگونگی» کار را مدیریت میکنند - آپلود فایلها، استخراج موجودیتها و ذخیره در پایگاه داده.
۱. فایل ابزارها را باز کنید
👉💻 فایل level_2/backend/agent/tools/extraction_tools.py را باز کنید یا دستور زیر را در ترمینال تایپ کنید. یک ترمینال جدید باز کنید. در ترمینال، فایل را در ویرایشگر Cloud Shell باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
۲. ابزار upload_media را پیادهسازی کنید
این ابزار یک فایل محلی را در فضای ذخیرهسازی ابری گوگل آپلود میکند.
👉 در def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: ، کد زیر در مورد نحوه آپلود فایلها به GCS است که نوع آنها را تشخیص میدهد:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
۳. ابزار extract_from_media را پیادهسازی کنید
این ابزار یک روتر است - media_type بررسی میکند و به استخراجکنندهی صحیح (متن، تصویر یا ویدیو) ارسال میکند.
👉 در async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: ، کد زیر در مورد نحوه استخراج موجودیتها و روابط از رسانههای آپلود شده است.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
جزئیات کلیدی پیادهسازی:
- ورودی چندوجهی : ما هم متن اعلان (
_get_extraction_prompt()) و هم شیء تصویر را بهgenerate_contentارسال میکنیم. - خروجی ساختاریافته :
response_mime_type="application/json"تضمین میکند که LLM، JSON معتبری را برمیگرداند، که برای خط لوله حیاتی است. - پیوند موجودیت بصری : این اعلان شامل موجودیتهای شناختهشده است تا Gemini بتواند کاراکترهای خاص را تشخیص دهد.
۴. ابزار save_to_spanner را پیادهسازی کنید
این ابزار موجودیتها و روابط استخراجشده را در پایگاه داده Spanner Graph حفظ میکند.
👉 در def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: ، کد زیر در مورد نحوه ذخیره موجودیتها و روابط استخراجشده در پایگاه داده Spanner Graph است.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
با ارائه ابزارهای سطح بالا به عاملها، ما یکپارچگی دادهها را تضمین میکنیم و در عین حال از قابلیتهای استدلال عامل بهره میبریم.
۵. بهروزرسانی سرویس GCS
GCSService آپلود فایل واقعی را در Google Cloud Storage مدیریت میکند.
👉💻 فایل level_2/backend/services/gcs_service.py را باز کنید، یا میتوانید در ترمینال تایپ کنید تا فایل در ویرایشگر Cloud Shell باز شود:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 در def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: ، کد زیر در مورد نحوه ذخیره موجودیتها و روابط استخراجشده در پایگاه داده Spanner Graph است.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
با خلاصه کردن این موضوع در یک سرویس، عامل نیازی به دانستن در مورد سطلهای GCS، نامهای blob یا تولید URL امضا شده ندارد. فقط درخواست "آپلود" میکند.
۶. چرا گردش کار عاملگرا بر رویکردهای سنتی ارجحیت دارد؟
مزیت عامل:
ویژگی | خط لوله دسته ای | رویداد محور | گردش کار عامل |
پیچیدگی | کم (۱ اسکریپت) | زیاد (۵+ سرویس) | کم (۱ فایل پایتون: |
مدیریت دولتی | متغیرهای سراسری | سخت (جدا شده) | یکپارچه (حالت عامل) |
مدیریت خطا | خرابیها | لاگهای بیصدا | تعاملی ("من نتوانستم آن فایل را بخوانم") |
بازخورد کاربر | چاپ کنسول | نیاز به نظرسنجی | فوری (بخشی از چت) |
سازگاری | منطق ثابت | توابع صلب | هوشمند (LLM گام بعدی را تعیین میکند) |
آگاهی از زمینه | هیچکدام | هیچکدام | کامل (قصد کاربر را میداند) |
چرا این موضوع مهم است: با استفاده از multimedia_agent.py (یک SequentialAgent با ۴ زیرعامل: آپلود → استخراج → ذخیره → خلاصه)، ما زیرساختهای پیچیده و اسکریپتهای شکننده را با منطق کاربردی هوشمند و محاورهای جایگزین میکنیم.
۱۰. ☕️ [اختیاری] خط لوله چندوجهی (فقط خواندنی) — لایه عامل
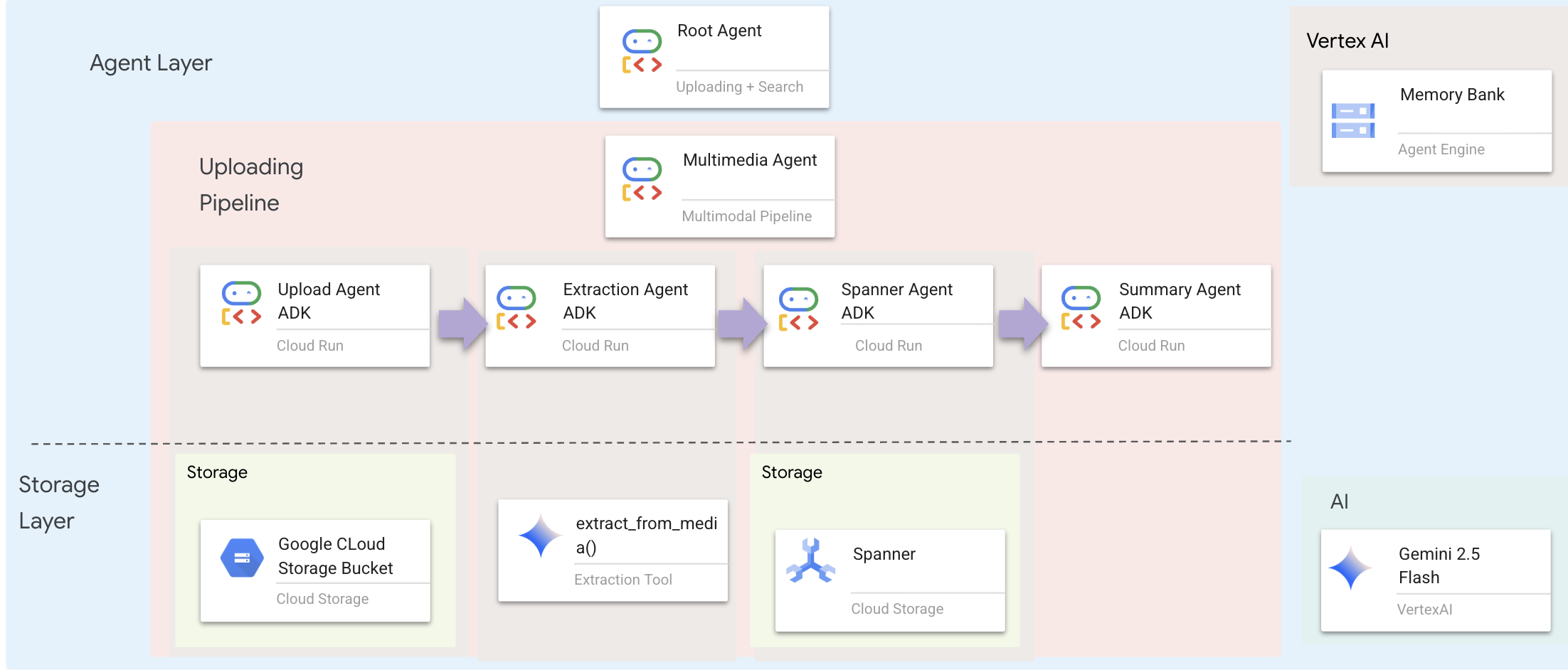
لایه عامل، هوش را تعریف میکند - عواملی که از ابزارها برای انجام وظایف استفاده میکنند. هر عامل نقش خاصی دارد و زمینه را به عامل بعدی منتقل میکند. در زیر نمودار معماری سیستم چندعاملی آمده است.
۱. فایل عامل را باز کنید
👉💻 فایل level_2/backend/agent/multimedia_agent.py را باز کنید یا دستور زیر را در ترمینال تایپ کنید. یک ترمینال جدید باز کنید. در ترمینال، فایل را در ویرایشگر Cloud Shell باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
۲. عامل آپلود را تعریف کنید
این عامل مسیر فایل را از پیام کاربر استخراج کرده و آن را در GCS بارگذاری میکند.
👉 در فایل multimedia_agent.py ، با کد زیر، upload_agent ایجاد میشود که در GCS آپلود میشود:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
۳. عامل استخراج را تعریف کنید
این عامل، رسانه آپلود شده را «میبیند» و با استفاده از Gemini Vision دادههای ساختاریافته را استخراج میکند.
👉 در فایل multimedia_agent.py ، با کد زیر، extraction_agent ایجاد میشود که اطلاعات را از رسانه آپلود شده استخراج میکند:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
توجه کنید که instruction چگونه به {upload_result} ارجاع میدهد - اینگونه است که حالت بین عاملها در ADK منتقل میشود .
۴. عامل آچار را تعریف کنید
این عامل، موجودیتها و روابط استخراجشده را در پایگاه داده گراف ذخیره میکند.
👉 در فایل multimedia_agent.py ، با کد زیر، spanner_agent ایجاد میشود که اطلاعات استخراج شده را در پایگاه داده ذخیره میکند:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
این عامل، زمینه را از هر دو مرحله قبلی ( upload_result و extraction_result ) دریافت میکند.
۵. عامل خلاصه را تعریف کنید
این عامل نتایج تمام مراحل قبلی را در قالب یک پاسخ کاربرپسند ترکیب میکند.
👉 در فایل multimedia_agent.py ، با کد زیر، اعلانی برای summary_agent تعریف میشود که نتیجه را خلاصه میکند:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
این عامل به ابزار خاصی نیاز ندارد — فقط زمینه مشترک را میخواند و خلاصهای تمیز برای کاربر تولید میکند.
🧠 خلاصه معماری
لایه | فایل | مسئولیت |
ابزارسازی | | چگونه - آپلود، استخراج، ذخیره |
عامل | | چه چیزی - خط لوله را هماهنگ کنید |
۱۱. 🚀 خط لوله داده چندوجهی — ارکستراسیون
هسته سیستم جدید ما MultimediaExtractionPipeline است که در backend/agent/multimedia_agent.py تعریف شده است. این سیستم از الگوی Sequential Agent از ADK (کیت توسعه عامل) استفاده میکند.
۱. چرا ترتیبی؟
پردازش یک آپلود یک زنجیره وابستگی خطی است:
- تا زمانی که فایل را نداشته باشید (آپلود نکنید)، نمیتوانید دادهها را استخراج کنید.
- تا زمانی که دادهها را استخراج نکنید (استخراج)، نمیتوانید آنها را ذخیره کنید.
- تا زمانی که نتایج را نداشته باشید، نمیتوانید خلاصه کنید (ذخیره کنید).
یک SequentialAgent برای این کار عالی است. این عامل، خروجی یک عامل را به عنوان زمینه/ورودی به عامل بعدی ارسال میکند.
۲. تعریف عامل
بیایید نگاهی به نحوه مونتاژ خط لوله در پایین فایل multimedia_agent.py بیندازیم: 👉💻 در ترمینال، فایل را در ویرایشگر Cloud Shell با اجرای دستور زیر باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
این تابع ورودیها را از هر دو مرحله قبلی دریافت میکند. کامنت # TODO: REPLACE_ORCHESTRATION را پیدا کنید. کل این خط را با کد زیر جایگزین کنید :
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
۳. با Root Agent ارتباط برقرار کنید
👉💻 در ترمینال، فایل را در ویرایشگر Cloud Shell با اجرای دستور زیر باز کنید:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
کامنت # TODO: REPLACE_ADD_SUBAGENT را پیدا کنید. کل این خط را با کد زیر جایگزین کنید :
sub_agents=[multimedia_agent],
This single object effectively bundles four "experts" into one callable entity.
4. Data Flow Between Agents
Each agent stores its output in a shared context that subsequent agents can access:
5. Open application (skip if app is still running)
👉💻 Start App:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Click Local: http://localhost:5173/ from the terminal.
6. Test Image Upload
👉 In the chat interface, choose any of the photo here and upload to the UI:
In the chat interface, tell the agent about your specific context:
Here is the survivor note
And then attach the image here.

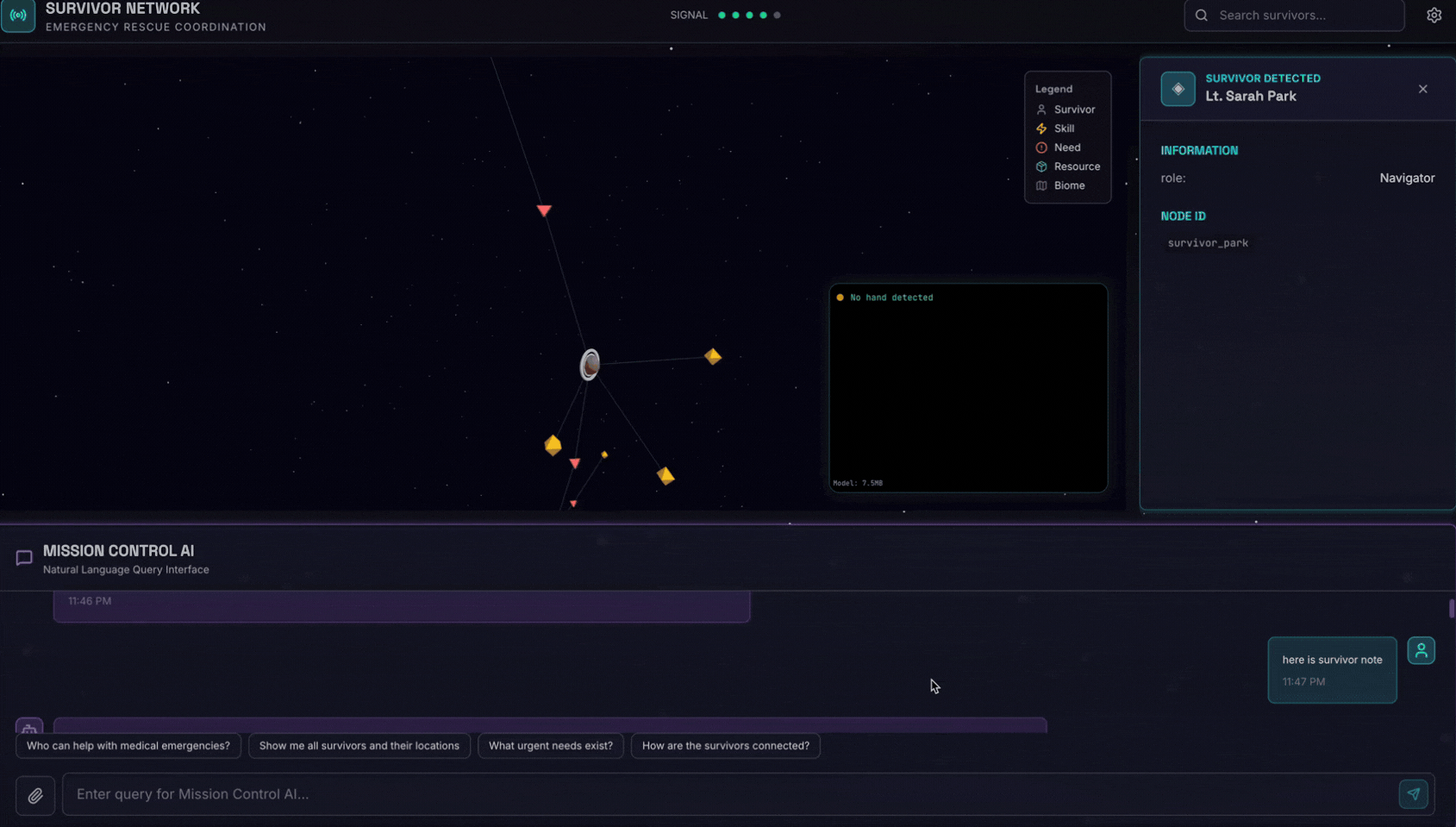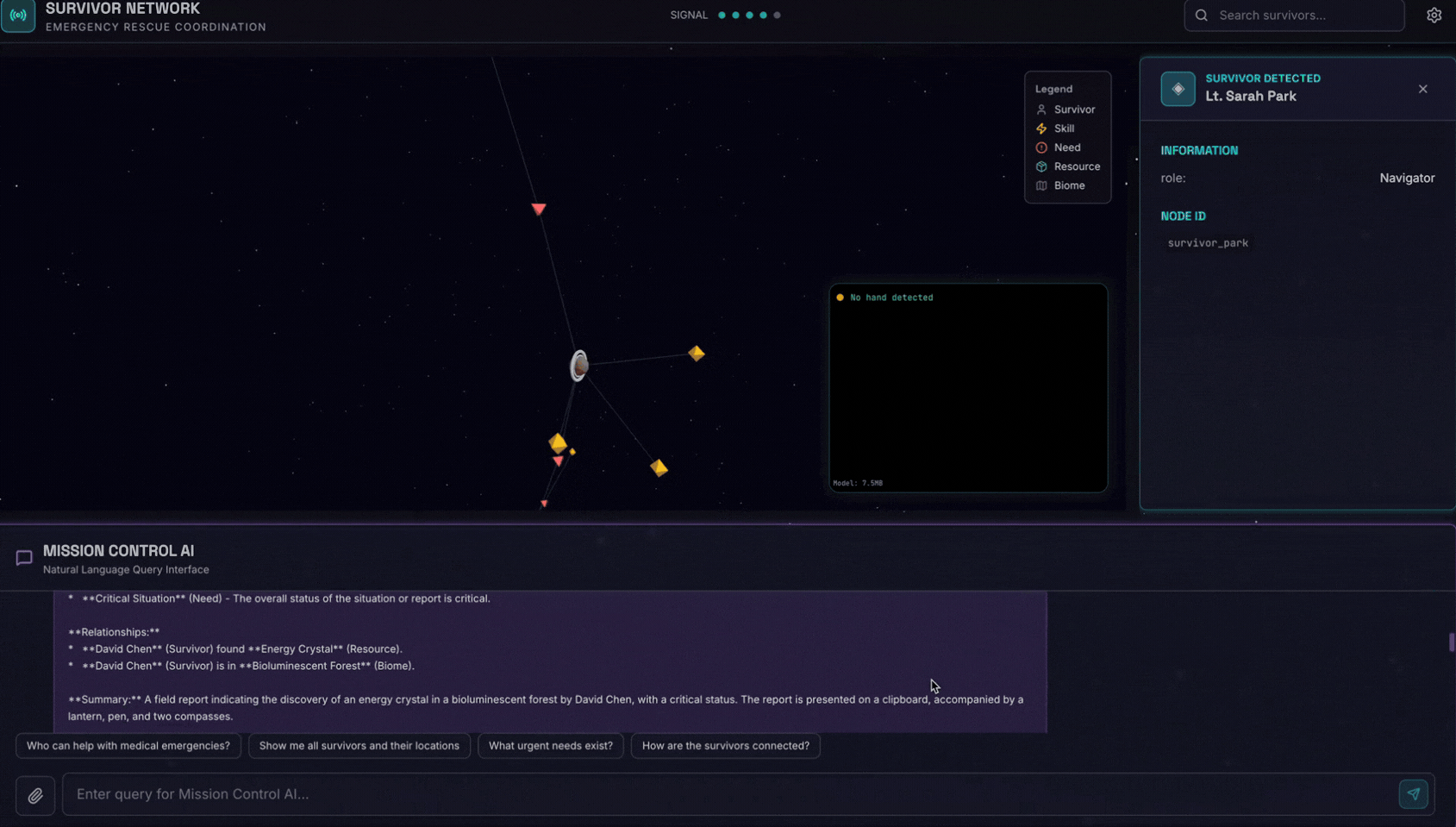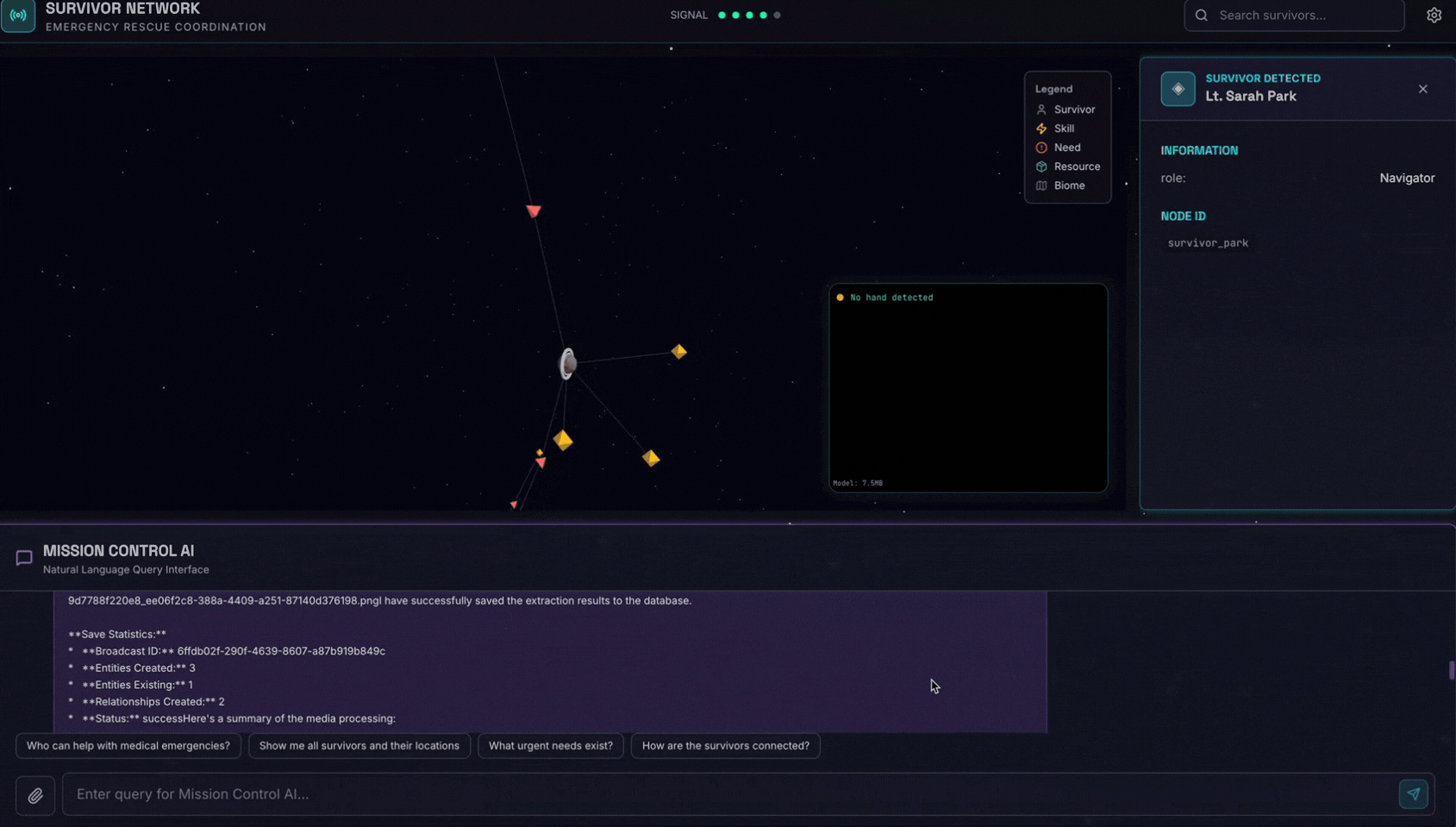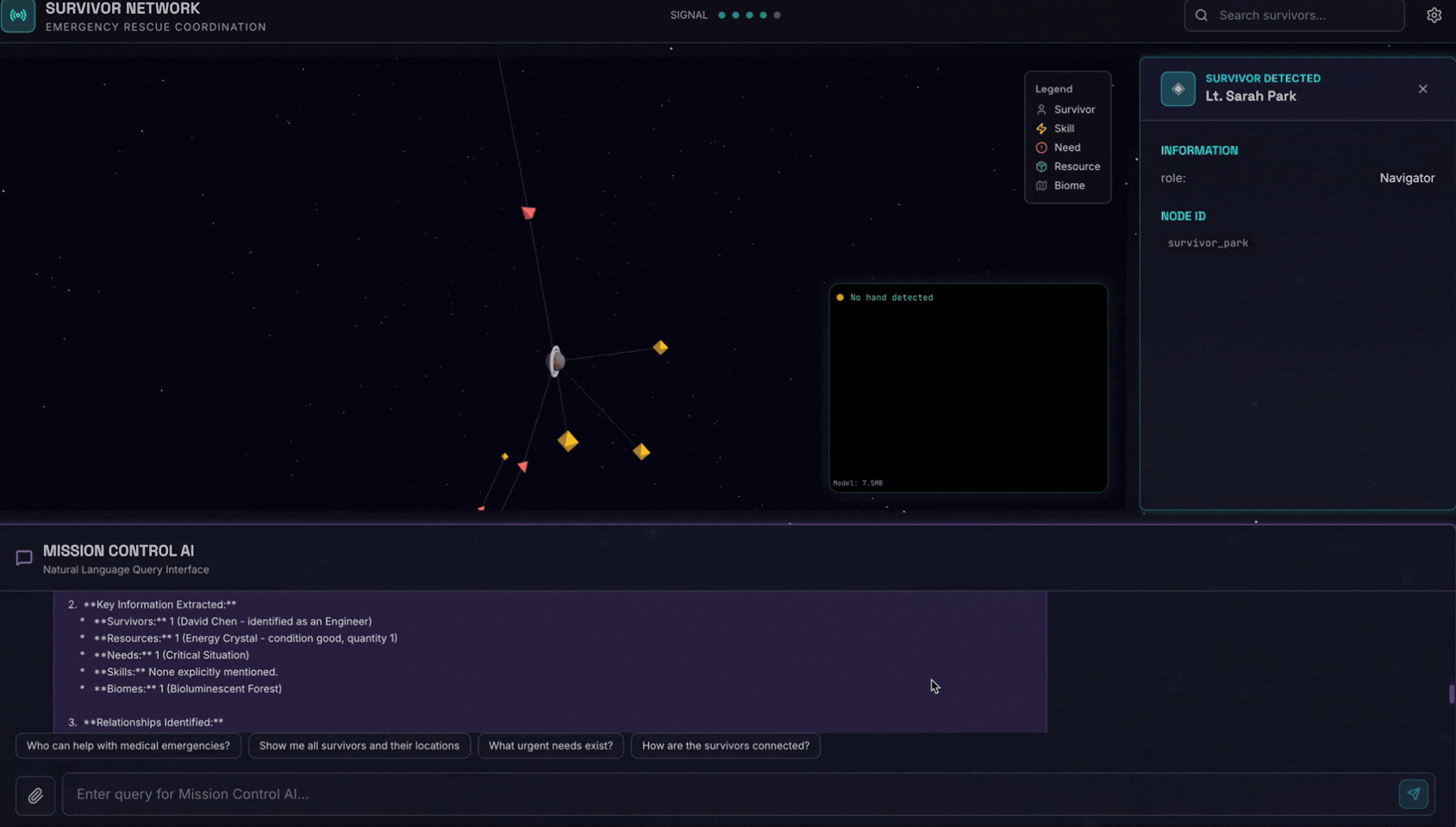
👉💻 In the terminal, when you finished testing, press "Ctrl+C" to end the process.
6. Verify Multimodal Uploading in GCS Bucket
- Open the Google Cloud Console Storage .
- Select "bucket" in cloud storage
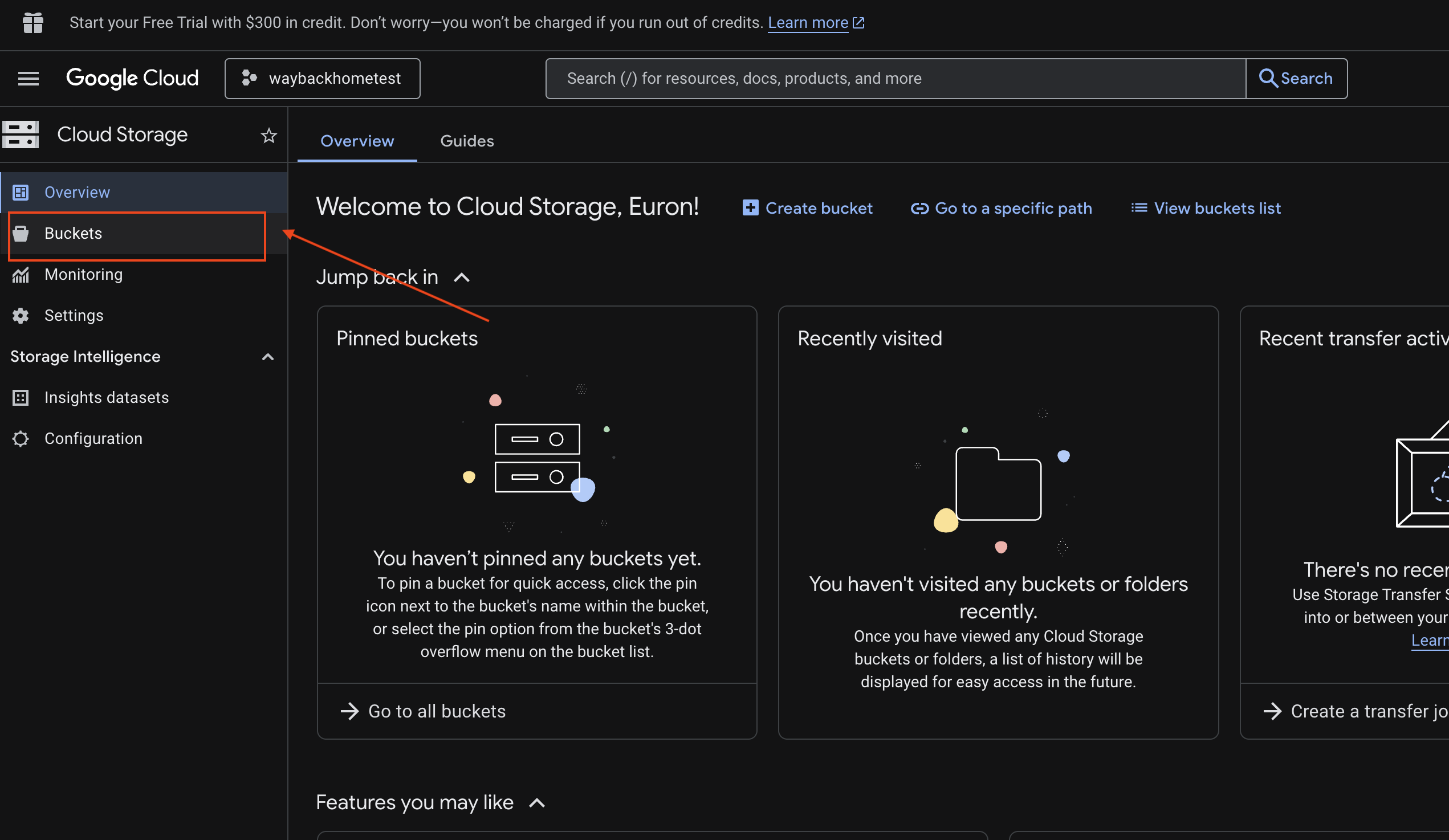
- Select your bucket and click into
media.
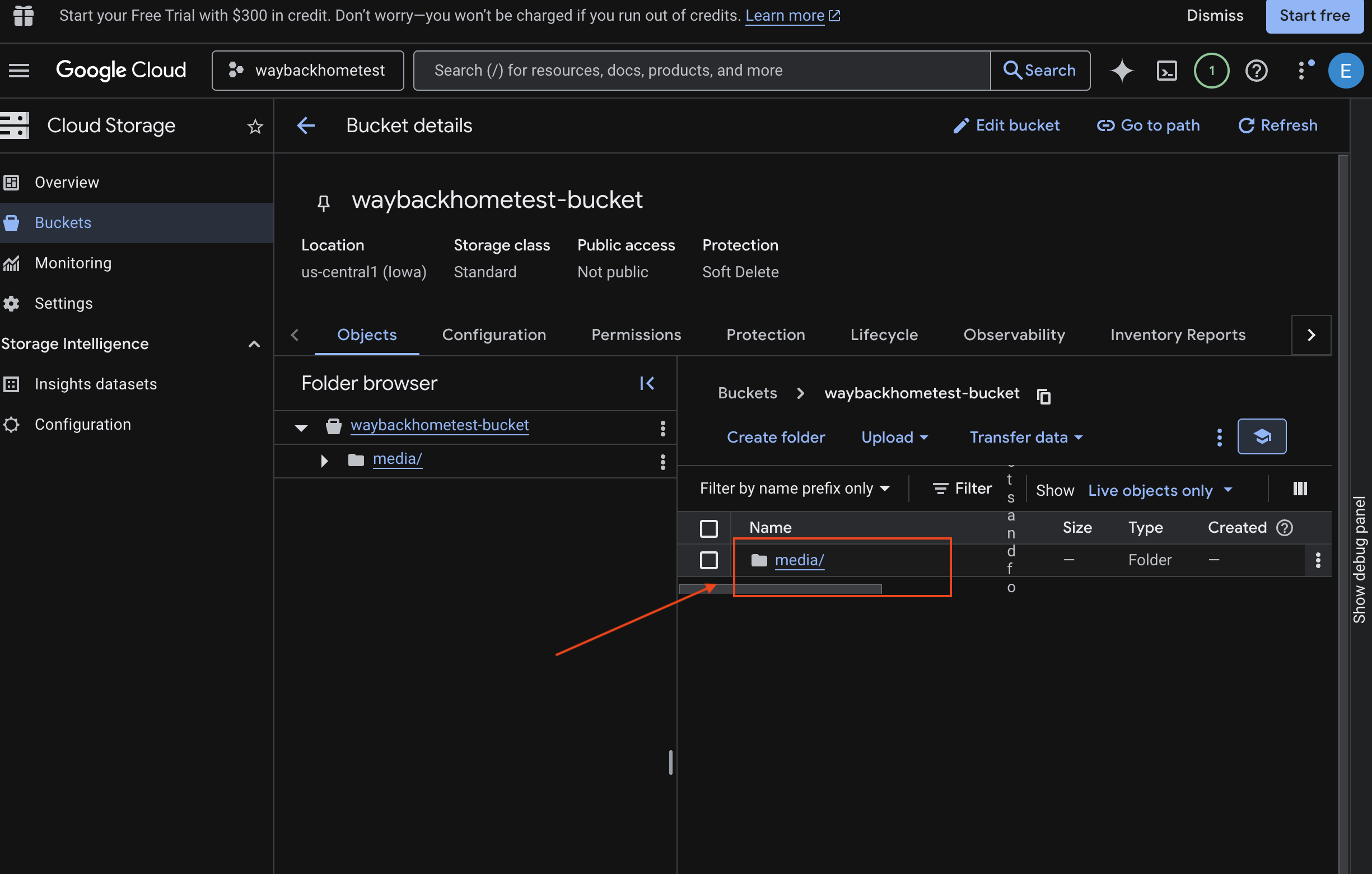
- View your uploaded image here.
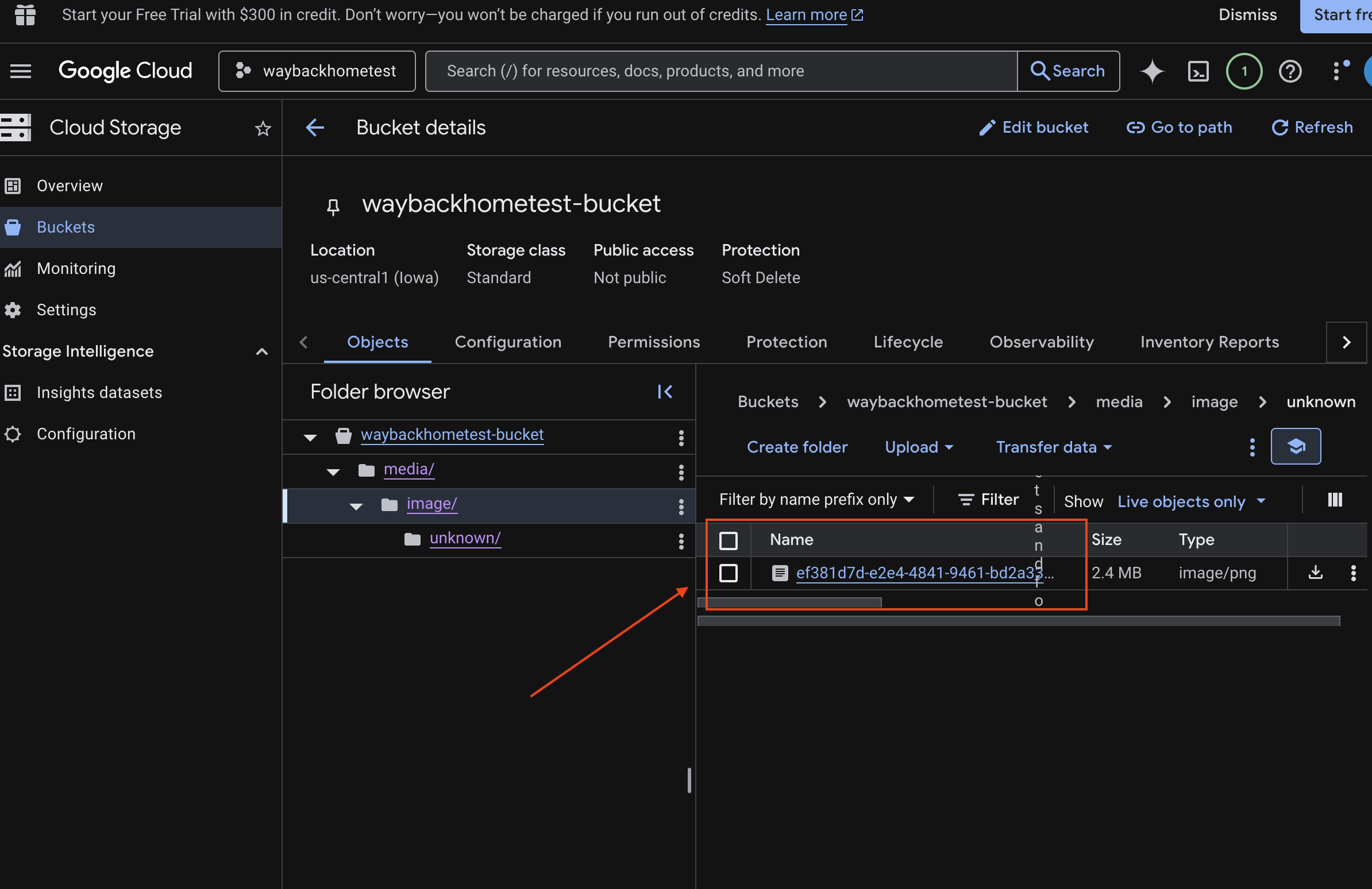
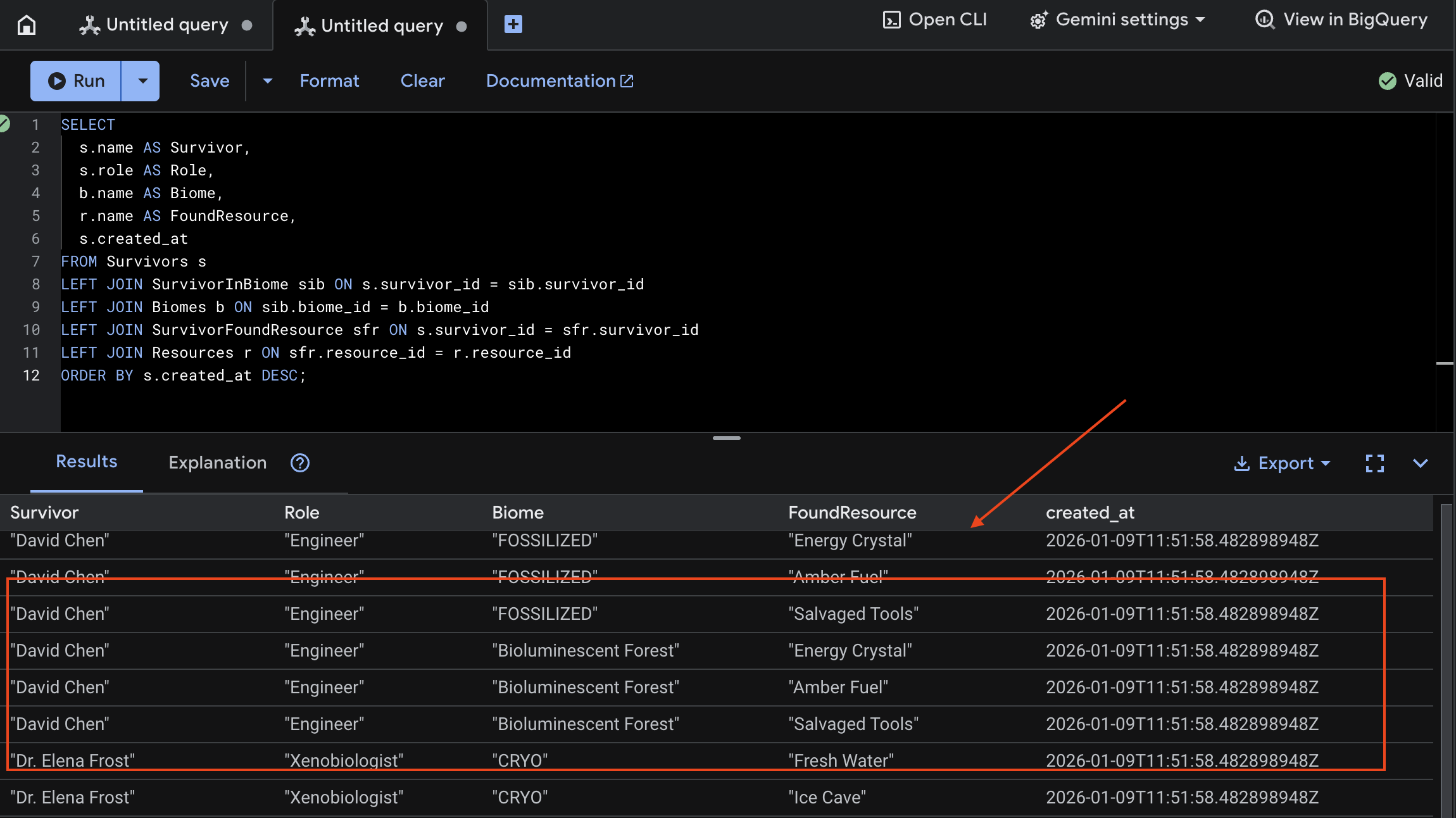
7. Verify Multimodal Uploading in Spanner (Optional)
Below is example output in UI for test_photo1 .
- Open the Google Cloud Console Spanner .
- Select your instance:
Survivor Network - Select your database:
graph-db - In the left sidebar, click Spanner Studio
👉 In Spanner Studio, query the new data:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
We can verify it by see the result below:
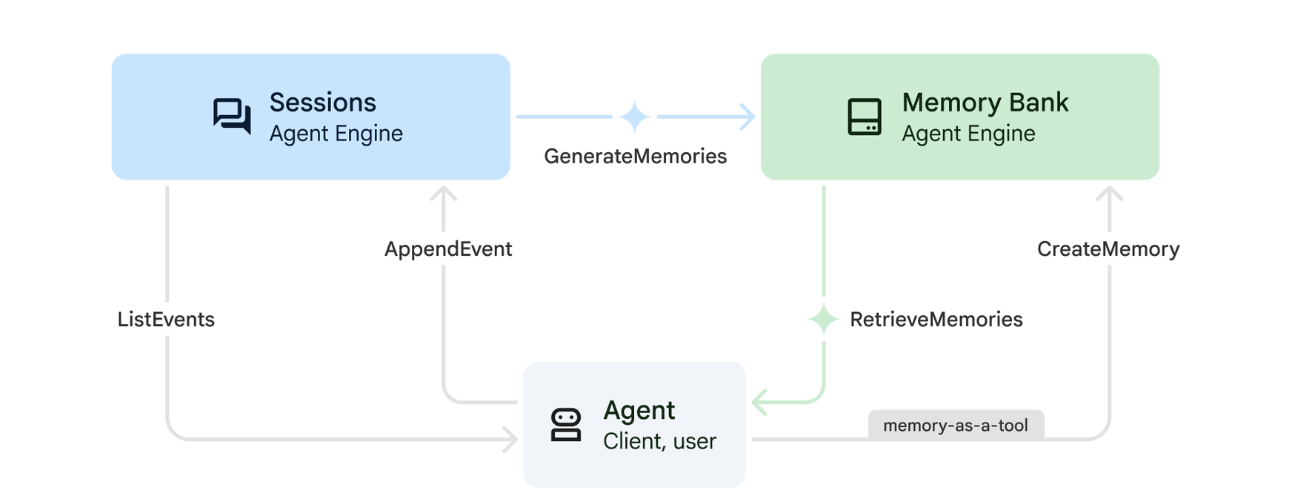
12. ☕️ [Optional] Memory Bank with Agent Engine
1. How Memory Works
The system uses a dual-memory approach to handle both immediate context and long-term learning.
2. What Are Memory Topics?
Memory Topics define the categories of information the agent should remember across conversations. Think of them as filing cabinets for different types of user preferences.
Our 2 Topics:
-
search_preferences: How the user likes to search- Do they prefer keyword or semantic search?
- What skills/biomes do they search for often?
- Example memory: "User prefers semantic search for medical skills"
-
urgent_needs_context: What crises they're tracking- What resources are they monitoring?
- Which survivors are they concerned about?
- Example memory: "User is tracking medicine shortage in Northern Camp"
3. Setting Up Memory Topics
Custom memory topics define what the agent should remember. These are configured when deploying the Agent Engine.
👉💻 In the terminal, open the file in the Cloud Shell Editor by running:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
This opens ~/way-back-home/level_2/backend/deploy_agent.py in your editor.
We define structure MemoryTopic objects to guide the LLM on what information to extract and save.
👉In the file deploy_agent.py , replace the # TODO: SET_UP_TOPIC with the following:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Agent Integration
The agent code must be aware of the Memory Bank to save and retrieve information.
👉💻 In the terminal, open the file in the Cloud Shell Editor by running:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
This opens ~/way-back-home/level_2/backend/agent/agent.py in your editor.
Agent Creation
When creating the agent, we pass the after_agent_callback to ensure sessions are saved to memory after interactions. The add_session_to_memory function runs asynchronously to avoid slowing down the chat response.
👉In the file agent.py , locate the comment # TODO: REPLACE_ADD_SESSION_MEMORY , Replace this whole line with the following code:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Background Saving
👉In the file agent.py , locate the comment # TODO: REPLACE_ADD_MEMORY_BANK_TOOL , Replace this whole line with the following code:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉In the file agent.py , locate the comment # TODO: REPLACE_ADD_CALLBACK , Replace this whole line with the following code:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Set Up Vertex AI Session Service
👉💻 In the terminal, open the file chat.py in the Cloud Shell Editor by running:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉In chat.py file, locate the comment # TODO: REPLACE_VERTEXAI_SERVICES , Replace this whole line with the following code:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Optional] Attach Agent with Agent Engine
1. Setup & Deployment
Before testing the memory features, you need to deploy the agent with the new memory topics and ensure your environment is configured correctly.
We have provided a convenience script to handle this process.
Running the Deployment Script
👉💻 In the terminal, run the deployment script:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
This script performs the following actions:
- Runs
backend/deploy_agent.pyto register the agent and memory topics with Vertex AI. - Captures the new Agent Engine ID .
- Automatically updates your
.envfile withAGENT_ENGINE_ID. - Ensures
USE_MEMORY_BANK=TRUEis set in your.envfile.
[!IMPORTANT] If you make changes to custom_topics in deploy_agent.py , you must re-run this script to update the Agent Engine.
Verify Memory Bank
Now you can verify that the memory bank is working by teaching the agent a preference and checking if it persists across sessions.
Step One. Open the application
Open the Application again by following the instruction below: If the previous terminal is still running, end it by pressing Ctrls+C .
👉💻 Start App:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Click Local: http://localhost:5173/ from the terminal.
Step Two. Testing Memory Bank with Text
In the chat interface, tell the agent about your specific context:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Wait ~30 seconds for the memory to process in the background.
Step Three. Start a New Session
Refresh the page to clear the current conversation history (short-term memory).
Ask a question that relies on the context you provided earlier:
"What kind of missions am I interested in?"
Expected Response :
"Based on your previous conversations, you're interested in:
- Medical rescue missions
- Mountain/high-altitude operations
- Skills needed: first aid, climbing
Would you like me to find survivors matching these criteria?"
Step Four. Test with Image Upload
Upload an image, and ask:
remember this
You can choose any of the photo here or your own and upload to the UI:
Step Five. Verify in Vertex AI Agent Engine
Go to Google Cloud Console Agent Engine
- Make sure you select the project from top left project selector:
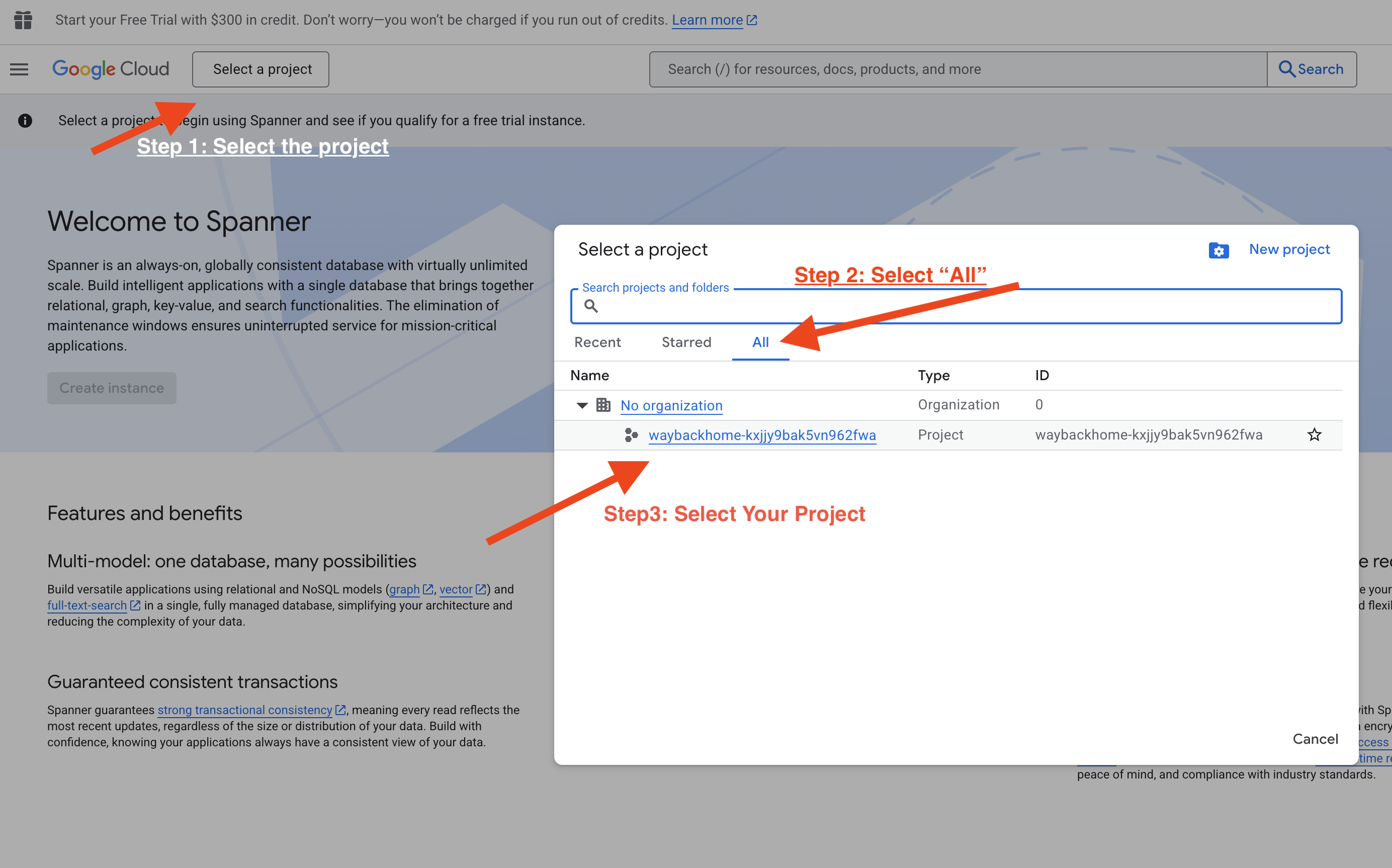
- Verify the agent engine you just deployed from previous command
use_memory_bank.sh: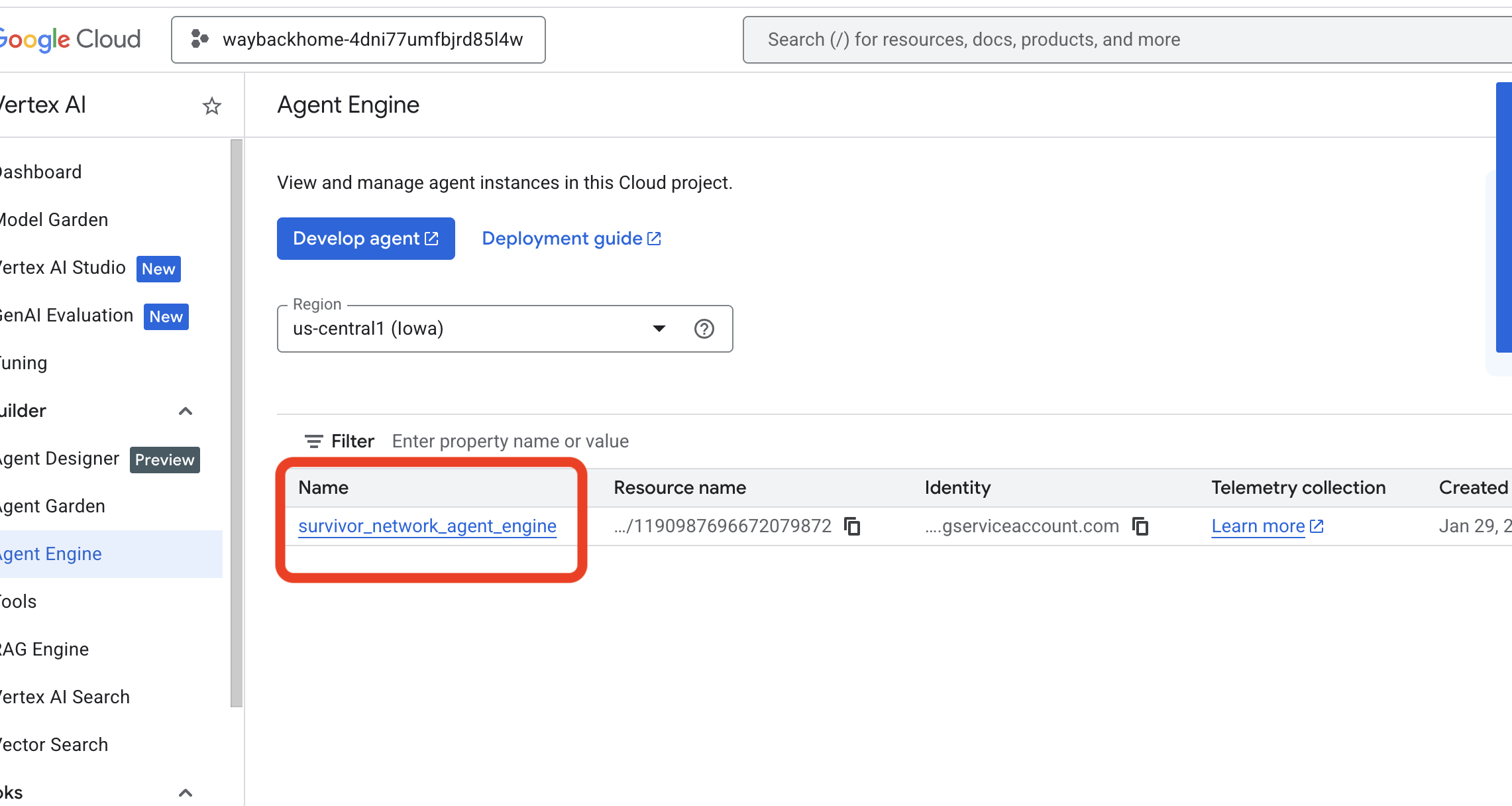 Click into the agent engine you just created.
Click into the agent engine you just created. - Click the
MemoriesTab in this deployed agent, you can view all the memory here.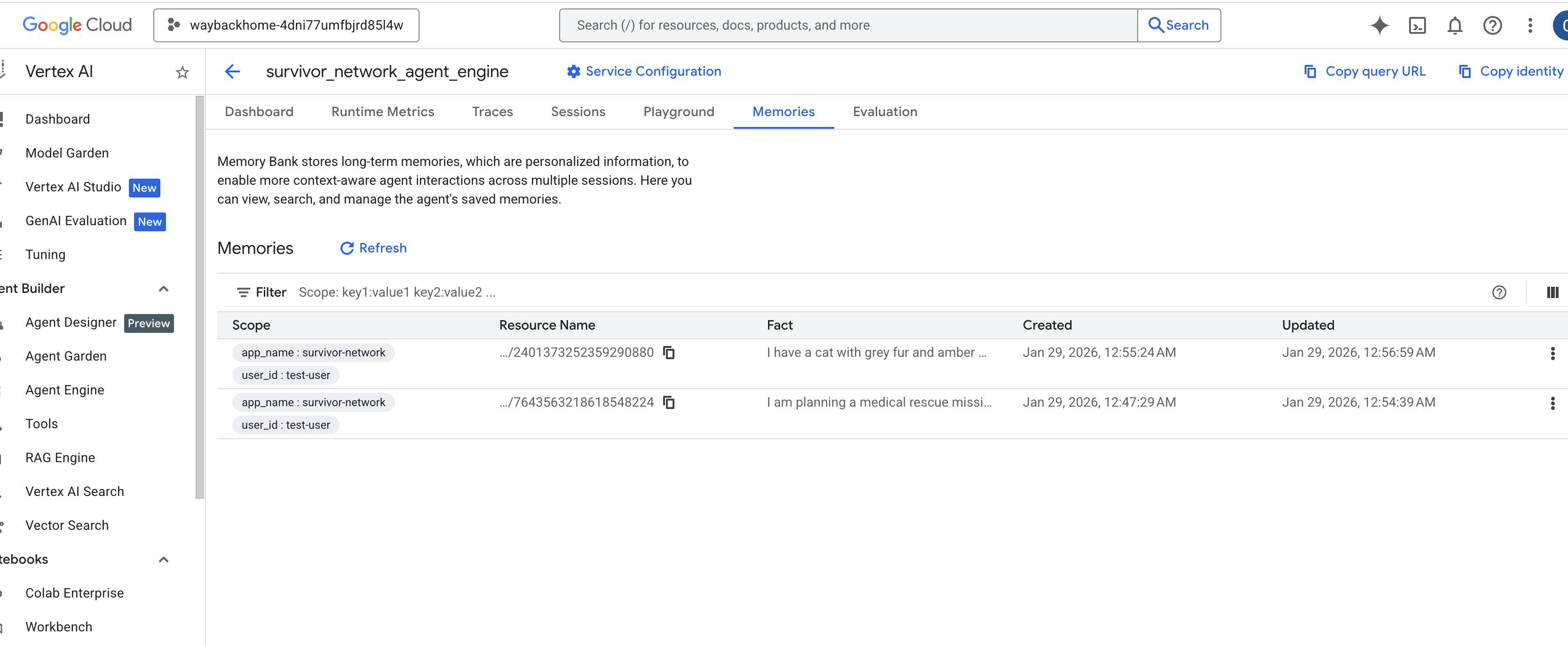
👉💻 When you finish testing, in you terminal, click "Ctrl + C" to end the process.
🎉 Congratulations! You just attached the memory bank to your agent!
14. ☕️ [Optional] Deploy to Cloud Run
1. Run the Deployment Script
👉💻 Run the deployment script:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
After it successfully deployed, you will have the url, this is deployed url for you! 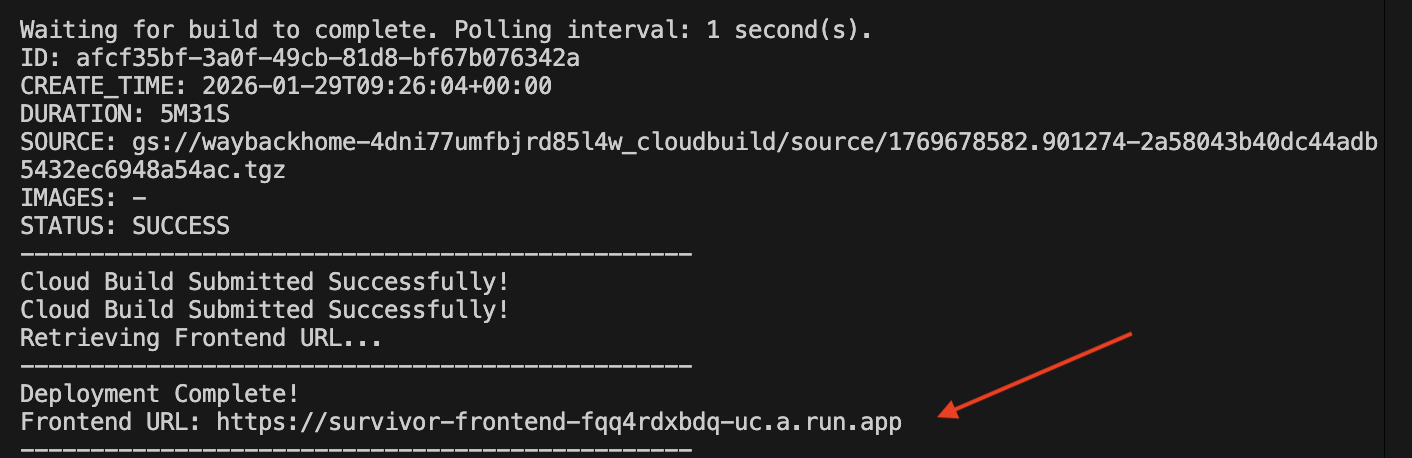
👉💻 Before you grab the url, grant the permission by running:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Go to the deployed url, and you will see you application live there!
2. Understanding the Build Pipeline
The cloudbuild.yaml file defines the following sequential steps:
- Backend Build : Builds the Docker image from
backend/Dockerfile. - Backend Deploy : Deploys the backend container to Cloud Run.
- Capture URL : Gets the new Backend URL.
- Frontend Build :
- Installs dependencies.
- Builds the React app, injecting
VITE_API_URL=.
- Frontend Image : Builds the Docker image from
frontend/Dockerfile(packaging the static assets). - Frontend Deploy : Deploys the frontend container.
3. Verify Deployment
Once the build completes (check the logs link provided by the script), you can verify:
- Go to the Cloud Run Console .
- Find the
survivor-frontendservice. - Click the URL to open the application.
- Perform a search query to ensure the frontend can talk to the backend.
(OPTIONAL) 4. Manual Deployment
If you prefer to run the commands manually or understand the process better, here is how to use cloudbuild.yaml directly.
Writing cloudbuild.yaml
A cloudbuild.yaml file tells Google Cloud Build what steps to execute.
- steps : A list of sequential actions. Each step runs in a container (eg,
docker,gcloud,node,bash). - substitutions : Variables that can be passed at build time (eg,
$_REGION). - workspace : A shared directory where steps can share files (like how we share
backend_url.txt).
Running the Deployment
To deploy manually without the script, use the gcloud builds submit command. You MUST pass the required substitution variables.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Conclusion
1. What You've Built
✅ Graph Database : Spanner with nodes (survivors, skills) and edges (relationships)
✅ AI Search : Keyword, semantic, and hybrid search with embeddings
✅ Multimodal Pipeline : Extract entities from images/video with Gemini
✅ Multi-Agent System : Coordinated workflow with ADK
✅ Memory Bank : Long-term personalization with Vertex AI
✅ Production Deployment : Cloud Run + Agent Engine
2. Architecture Summary
3. Key Learnings
- Graph RAG : Combines graph database structure with semantic embeddings for intelligent search
- Multi-Agent Patterns : Sequential pipelines for complex, multi-step workflows
- Multimodal AI : Extract structured data from unstructured media (images/video)
- Stateful Agents : Memory Bank enables personalization across sessions
4. Workshop Content
- Level0 : Identify Yourself
- Level1 : Pinpoint Location
- Level2 This One : Build a Multimodal AI Agent with Graph RAG, ADK & Memory Bank
- Level3 : Building an ADK Bi-Directional Streaming Agent
- Level4 : Live Bidirectional Multi-Agent system
- Level5 : Event-Driven Architecture with Google ADK, A2A, and Kafka