
1. Introduction

1. Le défi
En cas de catastrophe, la coordination des survivants ayant des compétences, des ressources et des besoins différents dans plusieurs lieux nécessite des capacités intelligentes de gestion et de recherche de données. Cet atelier vous apprend à créer un système d'IA de production qui combine :
- 🗄️ Base de données graphiques (Spanner) : stockez les relations complexes entre les survivants, les compétences et les ressources.
- 🔍 Recherche optimisée par l'IA : recherche hybride sémantique et par mot clé à l'aide d'embeddings
- 📸 Traitement multimodal : extraire des données structurées à partir d'images, de texte et de vidéos
- 🤖 Orchestration multi-agent : coordonnez des agents spécialisés pour les workflows complexes.
- 🧠 Mémoire à long terme : personnalisation avec Vertex AI Memory Bank
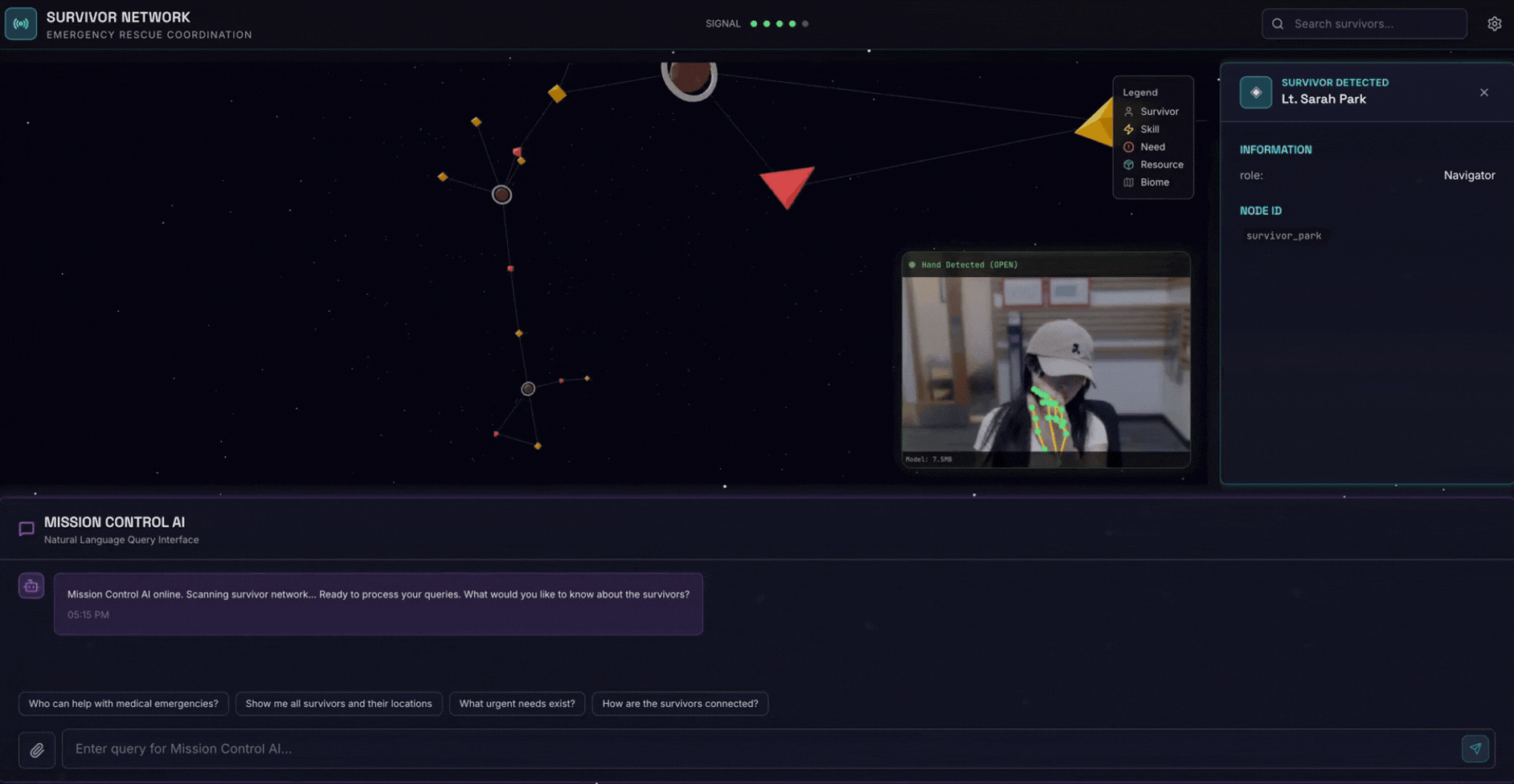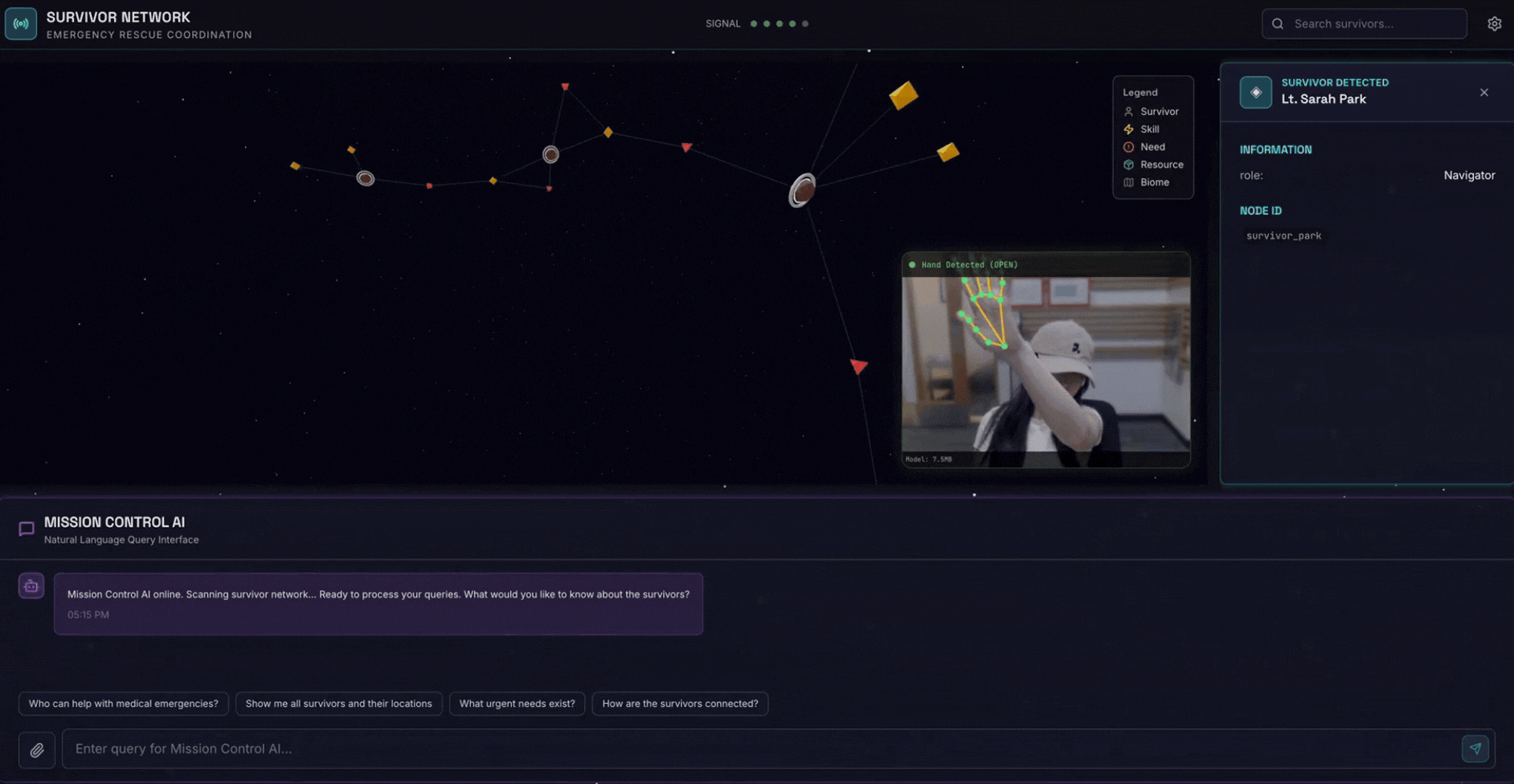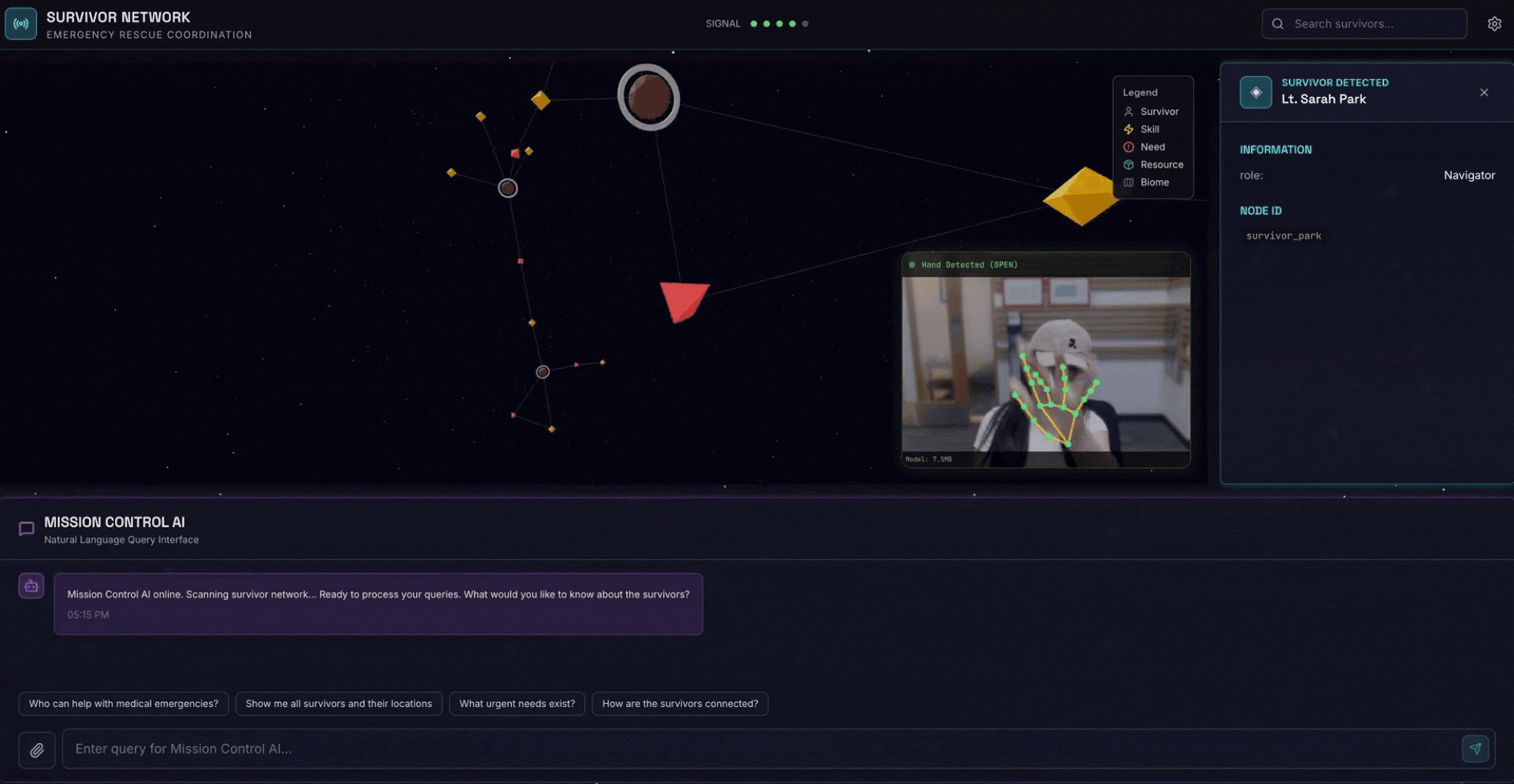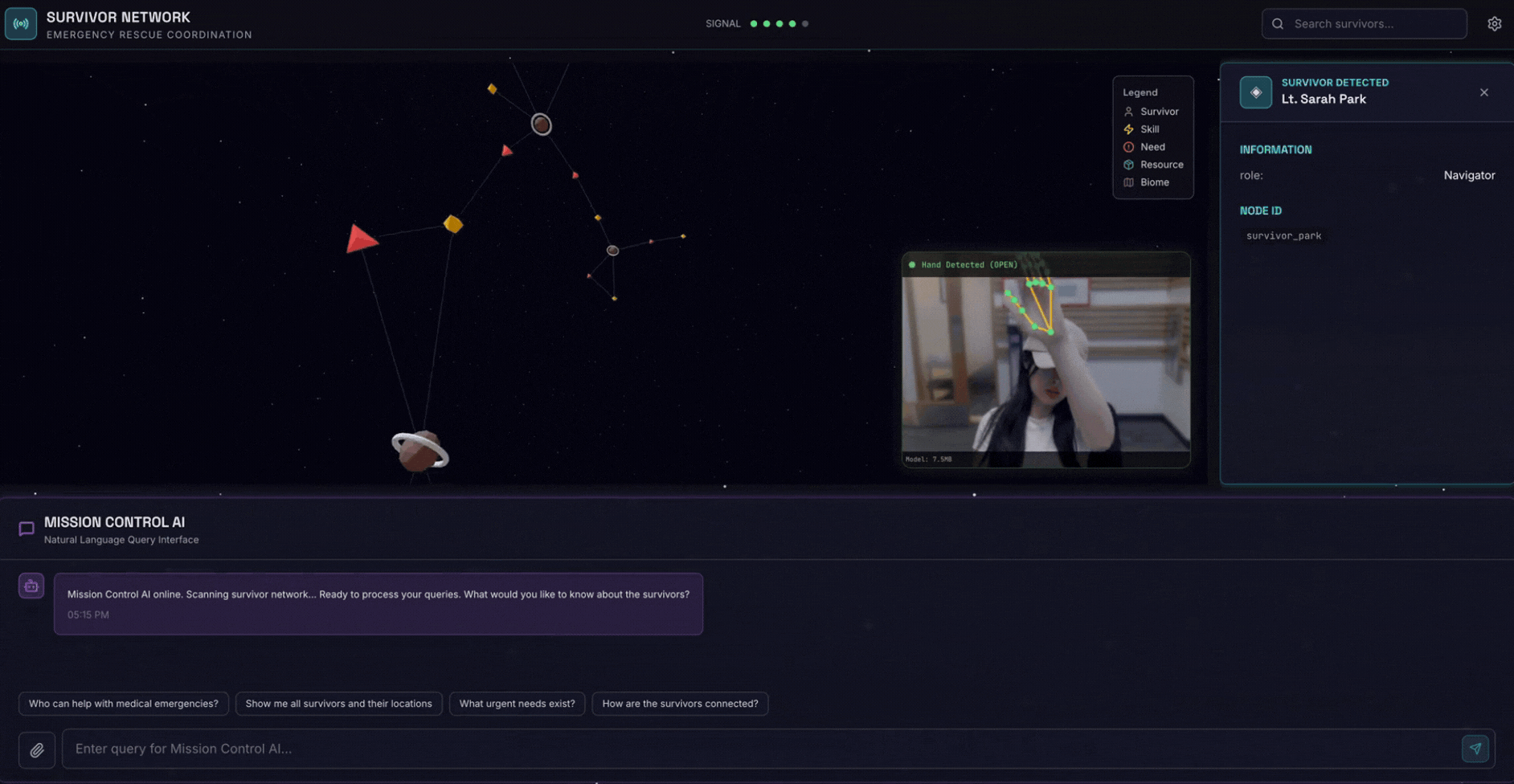
2. Objectifs de l'atelier
Une base de données de graphiques du réseau de survivants avec :
- 🗺️ Visualisation interactive en 3D des relations entre les survivants
- 🔍 Recherche intelligente (par mots clés, sémantique et hybride)
- 📸 Pipeline d'importation multimodal (extraire des entités à partir d'images/vidéos)
- 🤖 Système multi-agents pour l'orchestration de tâches complexes
- 🧠 Intégration de la banque de mémoire pour des interactions personnalisées
3. Technologie principale
Composant | Technologie | Objectif |
Database (Base de données) | Cloud Spanner Graph | Stocker les nœuds (survivants, compétences) et les arêtes (relations) |
AI Search | Gemini + Embeddings | Compréhension sémantique et recherche par similarité |
Framework de l'agent | ADK (Agent Development Kit) | Orchestrer les workflows d'IA |
Mémoire | Vertex AI Memory Bank | Stockage à long terme des préférences utilisateur |
Frontend | React + Three.js | Visualisation interactive de graphiques 3D |
2. 🛠️ Préparation de l'environnement (à ignorer si vous participez à un atelier)
Première partie : Activer le compte de facturation
Pour effectuer cet atelier de programmation, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Deuxième partie : Environnement ouvert
- 👉 Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- 👉 Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- 👉 Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- 👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list - 👉💻 Clonez le projet bootstrap depuis GitHub :
git clone https://github.com/gca-americas/way-back-home.git
Troisième partie : Créer un projet
👉💻 Dans le terminal, rendez le script d'initialisation exécutable et exécutez-le :
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Configurer l'environnement
1. Ouvrir Cloud Shell
Dans le terminal de l'éditeur Cloud Shell, si le terminal n'apparaît pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
2. Configurer le projet
👉💻 Dans le terminal, définissez l'ID de votre projet :
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Activez les API requises (cela prend environ deux à trois minutes) :
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Exécuter le script de configuration
👉💻 Exécutez le script d'installation :
cd ~/way-back-home/level_2
./setup.sh
Cela créera .env pour vous. Dans votre Cloud Shell, ouvrez le projet way_back_home. Sous le dossier level_2, vous pouvez voir que le fichier .env a été créé pour vous. Si vous ne le trouvez pas, cliquez sur View > Toggle Hidden File pour l'afficher. 
4. Charger des exemples de données
👉💻 Accédez au backend et installez les dépendances :
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Chargez les données initiales des survivants :
uv run python ~/way-back-home/level_2/backend/setup_data.py
Cela crée :
- Instance Spanner (
survivor-network) - Base de données (
graph-db) - Toutes les tables de nœuds et d'arêtes
- Graphiques de propriétés pour les requêtes Résultat attendu :
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
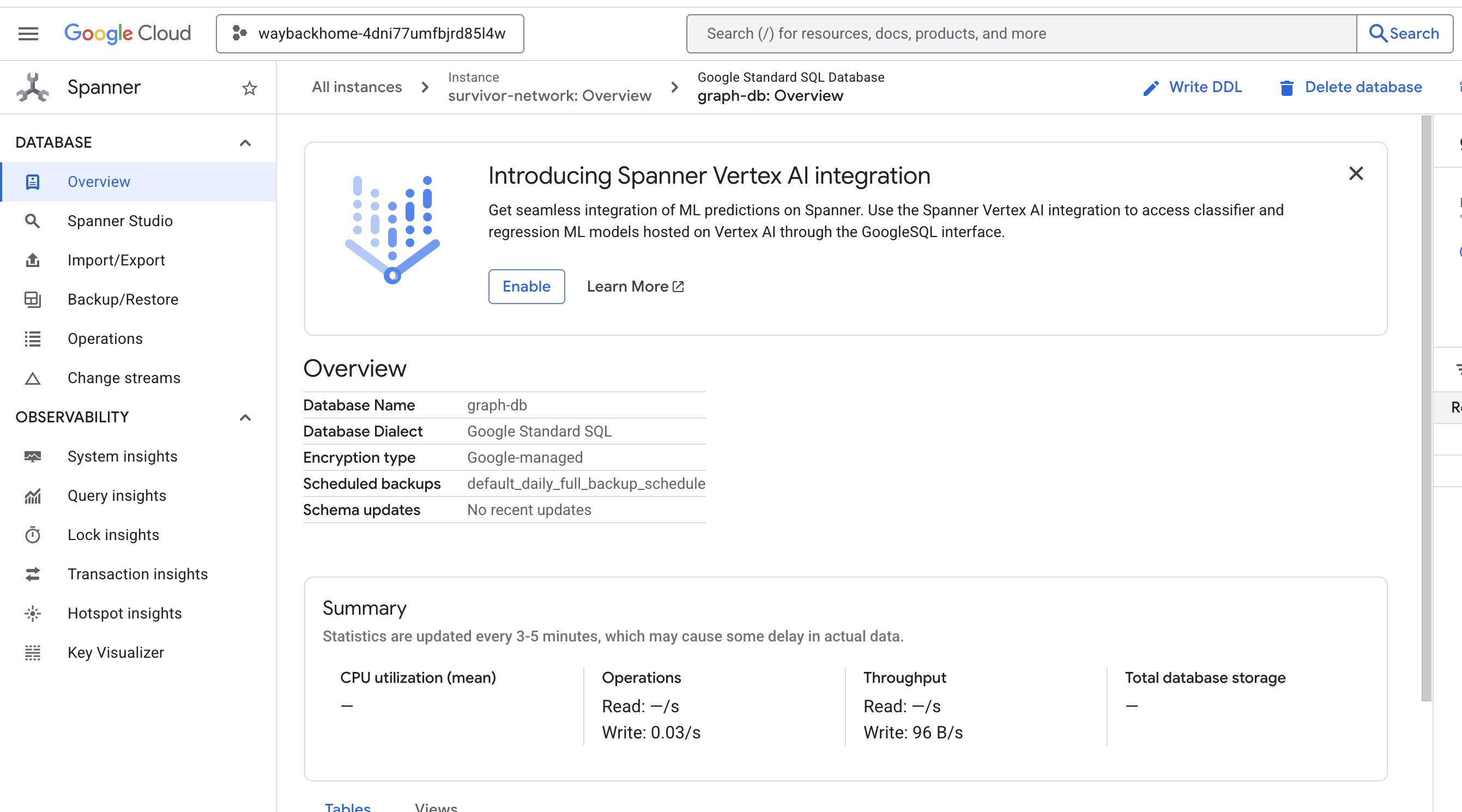
Si vous cliquez sur le lien après Access your database at dans le résultat, vous pouvez ouvrir la console Google Cloud Spanner.

Vous verrez Spanner dans la console Google Cloud.
4. 🚀 Visualiser des données graphiques dans Spanner Studio
Ce guide vous aide à visualiser les données du graphique Survivor Network et à interagir avec elles directement dans la console Google Cloud à l'aide de Spanner Studio. C'est un excellent moyen de vérifier vos données et de comprendre la structure du graphique avant de créer votre agent d'IA.
1. Accéder à Spanner Studio
- À la dernière étape, veillez à cliquer sur le lien et à ouvrir Spanner Studio.
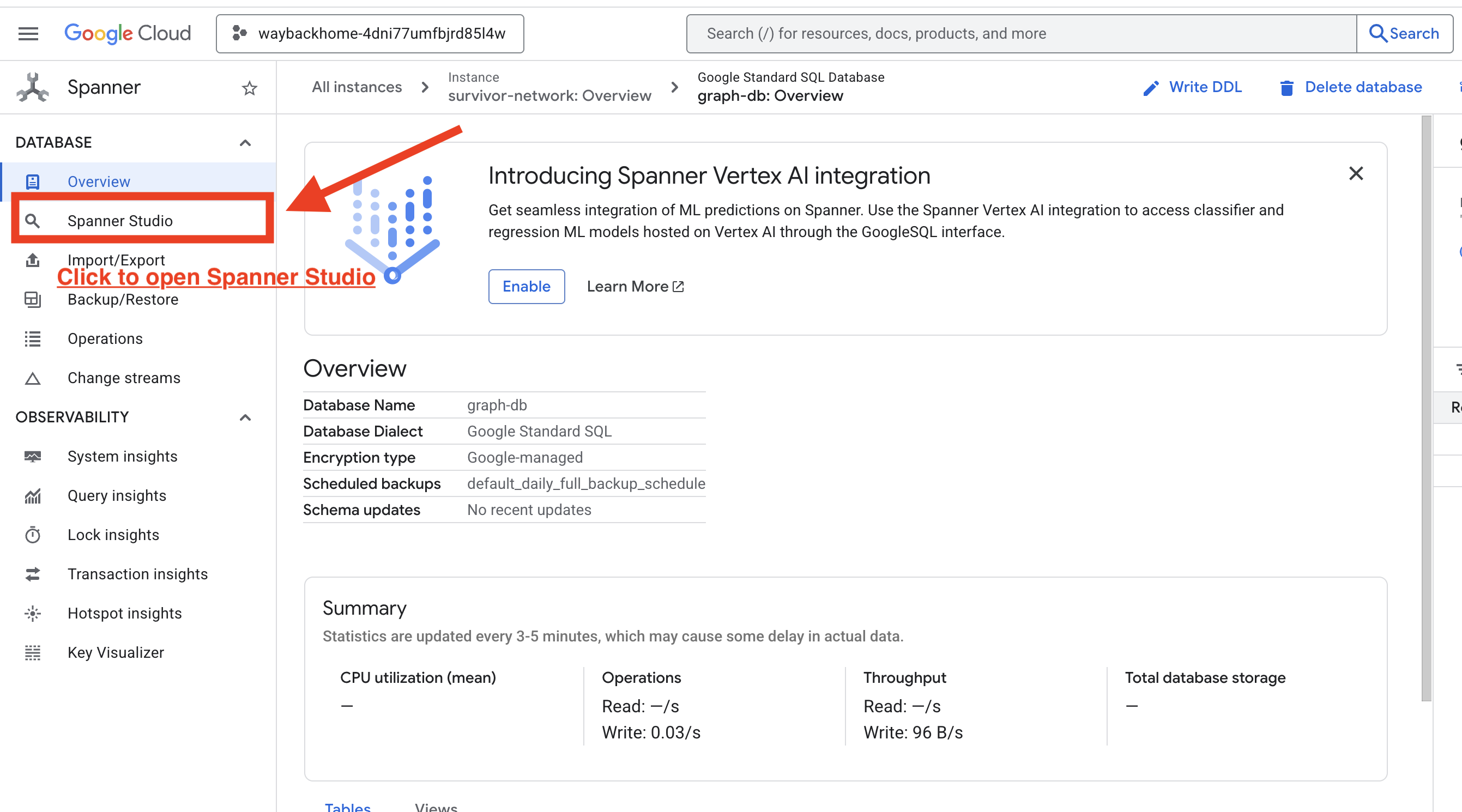
2. Comprendre la structure du graphique ("vue d'ensemble")
Considérez l'ensemble de données Survivor Network comme un puzzle logique ou un état de jeu :
Entité | Rôle dans le système | Analogie |
Survivants | Les agents/joueurs | Joueurs |
Biomes | Où se trouvent-ils ? | Zones de carte |
Compétences | Ce qu'ils peuvent faire | Fonctionnalités |
Besoins | Ce qui leur manque (crises) | Quêtes/Missions |
Ressources | Éléments trouvés dans le monde | Loot |
Objectif : l'agent d'IA doit associer des compétences (solutions) à des besoins (problèmes), en tenant compte des biomes (contraintes de localisation).
🔗 Arêtes (relations) :
SurvivorInBiome: suivi de la positionSurvivorHasSkill: Inventaire des capacitésSurvivorHasNeed: liste des problèmes actifs.SurvivorFoundResource: inventaire des articlesSurvivorCanHelp: relation inférée (l'IA la calcule).
3. Interroger le graphique
Exécutons quelques requêtes pour découvrir l'histoire qui se cache derrière les données.
Spanner Graph utilise le langage GQL (Graph Query Language). Pour exécuter une requête, utilisez GRAPH SurvivorNetwork suivi de votre modèle de correspondance.
👉 Requête 1 : Le roster mondial (qui est où ?) C'est votre base : comprendre la localisation est essentiel pour les opérations de sauvetage.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Le résultat devrait être le suivant : 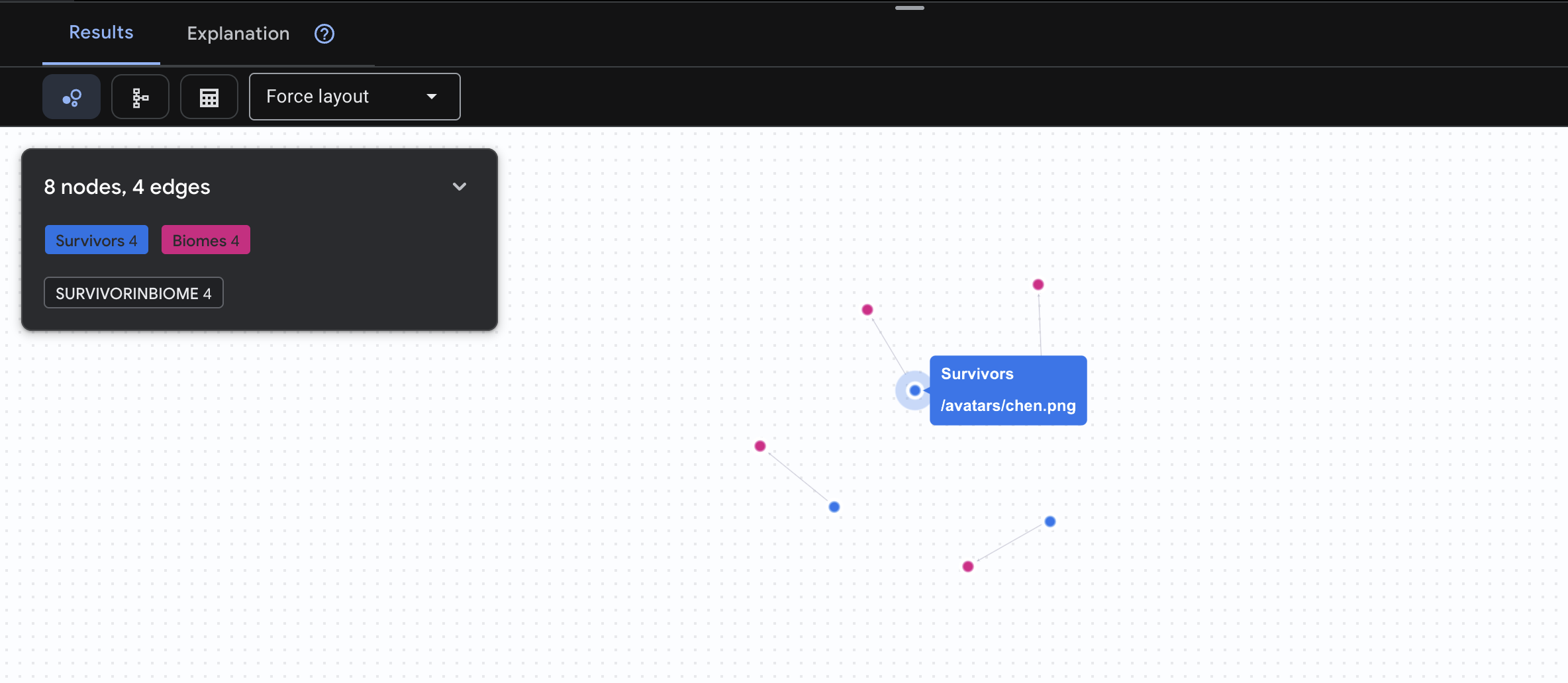
👉 Requête 2 : La matrice de compétences (capacités) Maintenant que vous savez où se trouve chaque personne, découvrez ce qu'elle peut faire.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Le résultat devrait être le suivant : 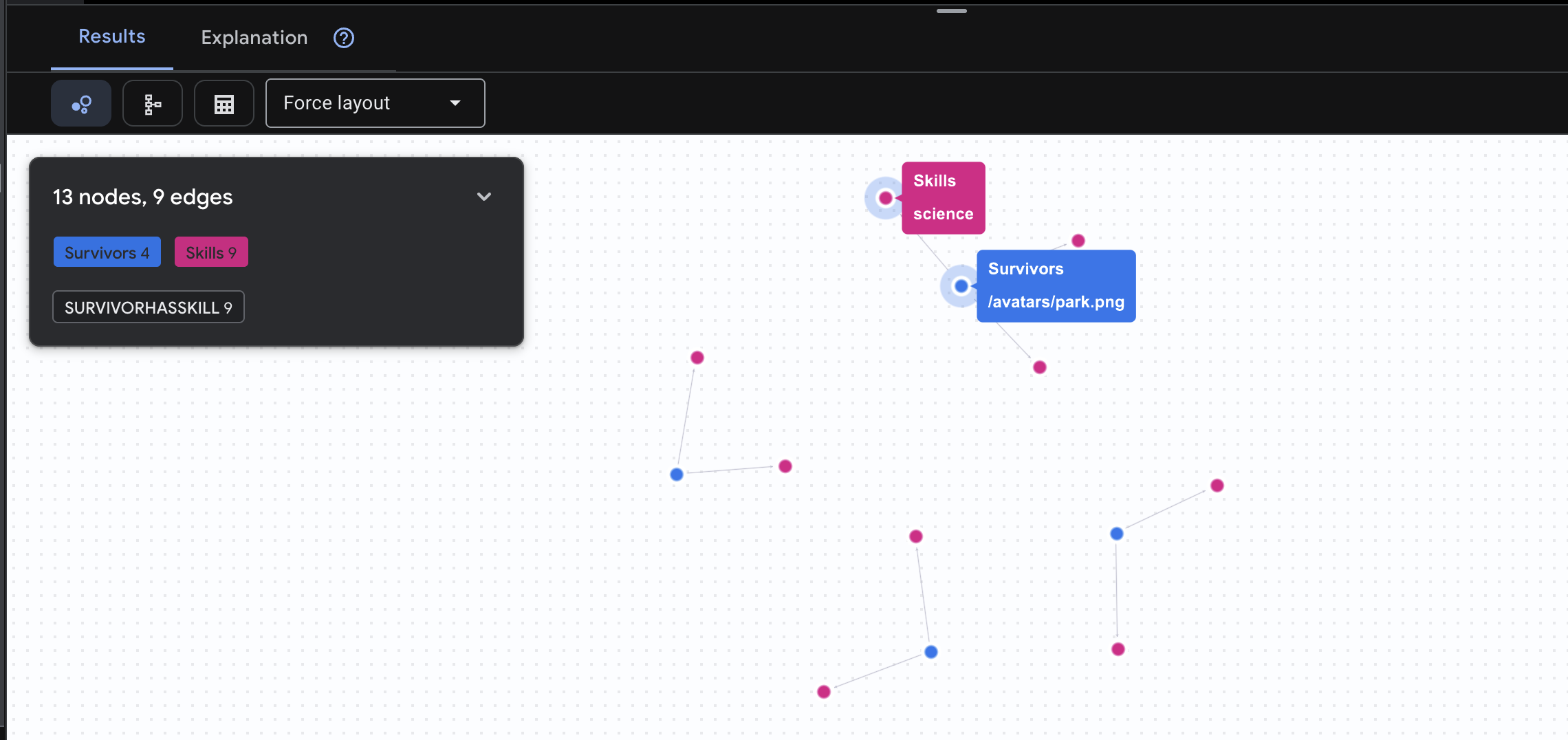
👉 Requête 3 : Qui est en crise ? (Le tableau des missions) : découvrez les survivants qui ont besoin d'aide et ce dont ils ont besoin.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Le résultat devrait être le suivant : 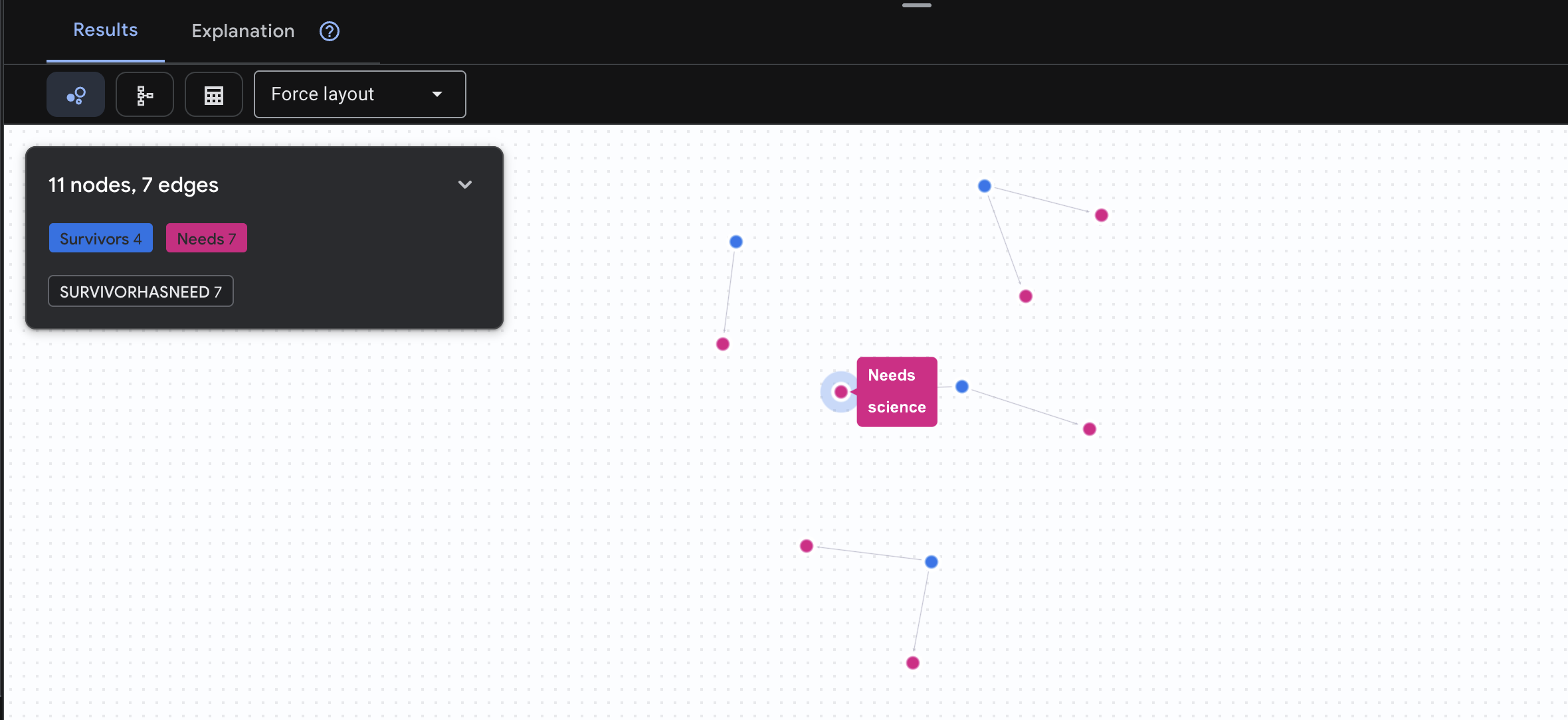
🔎 [Facultatif] Mise en relation : qui peut aider qui ?
C'est là que le graphique devient puissant. Cette requête permet de trouver les survivants qui possèdent des compétences permettant de répondre aux besoins des autres survivants.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Le résultat devrait être le suivant : 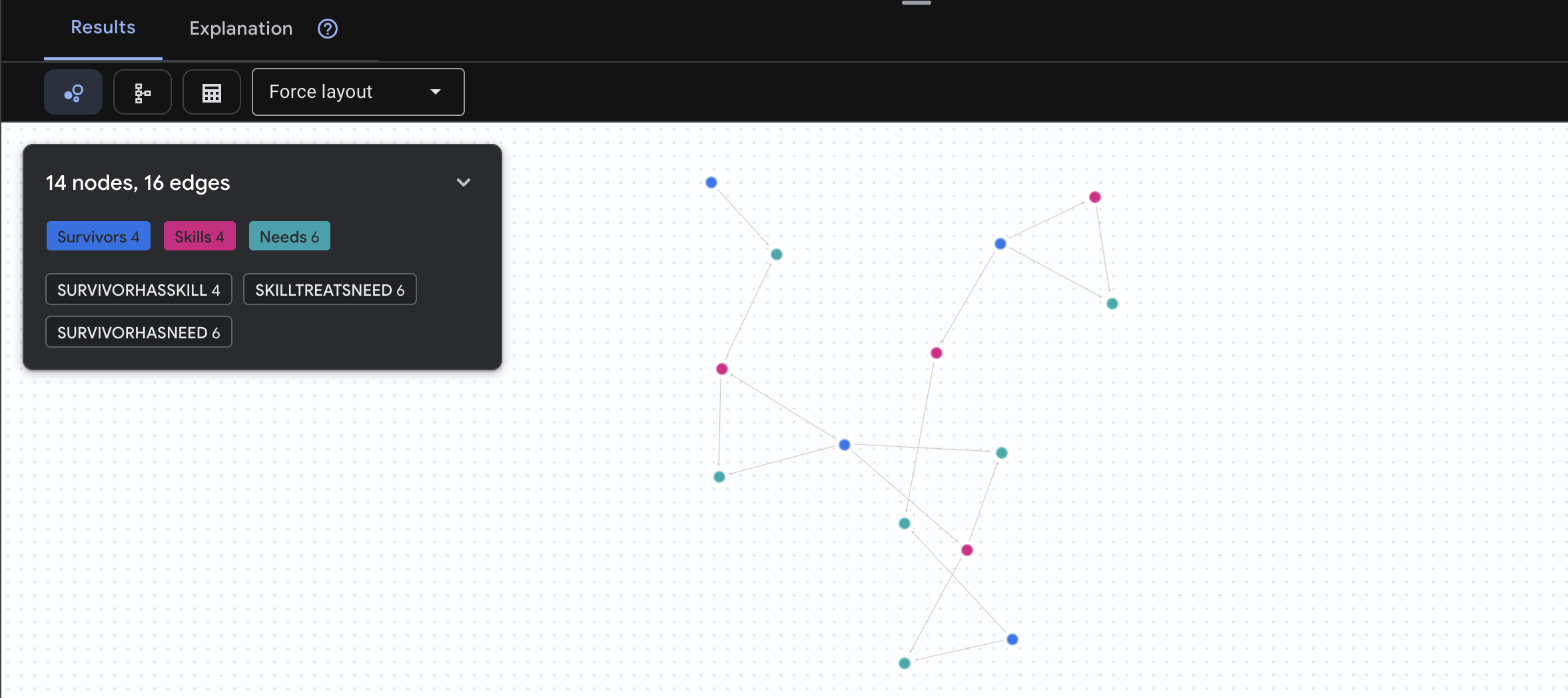
aside positive Que fait cette requête ?
Au lieu de simplement afficher "Les premiers secours traitent les brûlures" (ce qui est évident d'après le schéma), cette requête trouve :
- Dr. Elena Frost (qui a une formation médicale) → peut soigner → Capitaine Tanaka (qui a des brûlures)
- David Chen (qui a suivi une formation de secouriste) → peut soigner → Lt. Park (qui s'est foulé la cheville)
Pourquoi cette fonctionnalité est-elle efficace ?
Ce que votre agent d'IA fera :
Lorsqu'un utilisateur pose la question Qui peut soigner les brûlures ?, l'agent :
- Exécuter une requête de graphe similaire
- Réponse : "Dr. Frost a une formation médicale et peut aider le capitaine Tanaka"
- L'utilisateur n'a pas besoin de connaître les tables ni les relations intermédiaires.
5. 🚀 Intégrations optimisées par l'IA dans Spanner
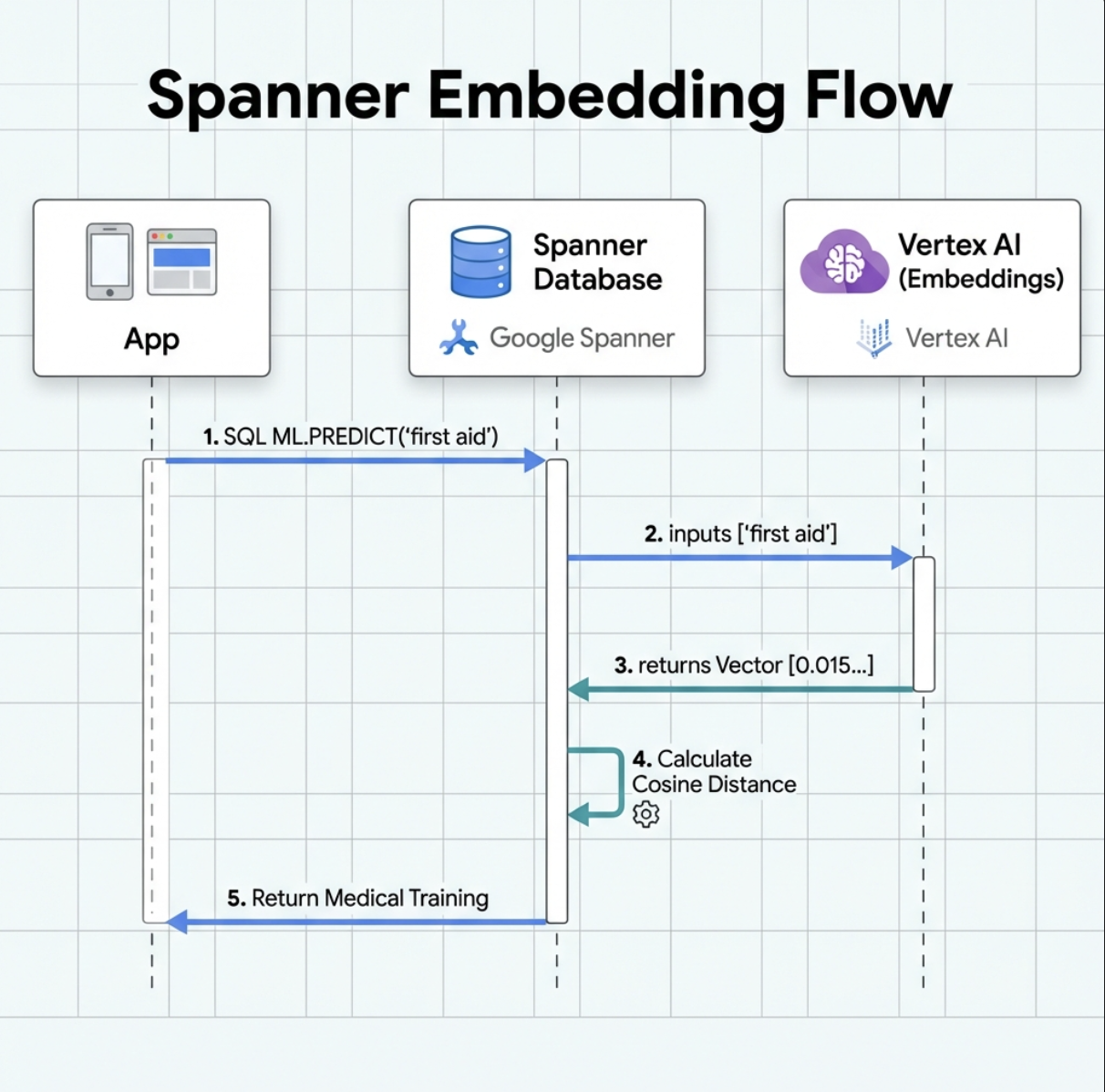
1. Pourquoi utiliser des embeddings ? (Aucune action, lecture seule)
Dans le scénario de survie, le temps est compté. Lorsqu'un survivant signale une urgence, comme I need someone who can treat burns ou Looking for a medic, il ne peut pas perdre de temps à deviner les noms exacts des compétences dans la base de données.
Scénario réel : Survivor : Captain Tanaka has burns—we need medical help NOW!
Recherche traditionnelle par mot clé pour "médecin" → 0 résultat ❌
Recherche sémantique avec des embeddings : trouve "Formation médicale" et "Premiers secours" ✅
C'est exactement ce dont les agents ont besoin : une recherche intelligente et humaine qui comprend l'intention, et pas seulement les mots clés.
2. Créer un modèle d'embedding
Nous allons maintenant créer un modèle qui convertit le texte en embeddings à l'aide de text-embedding-004 de Google.
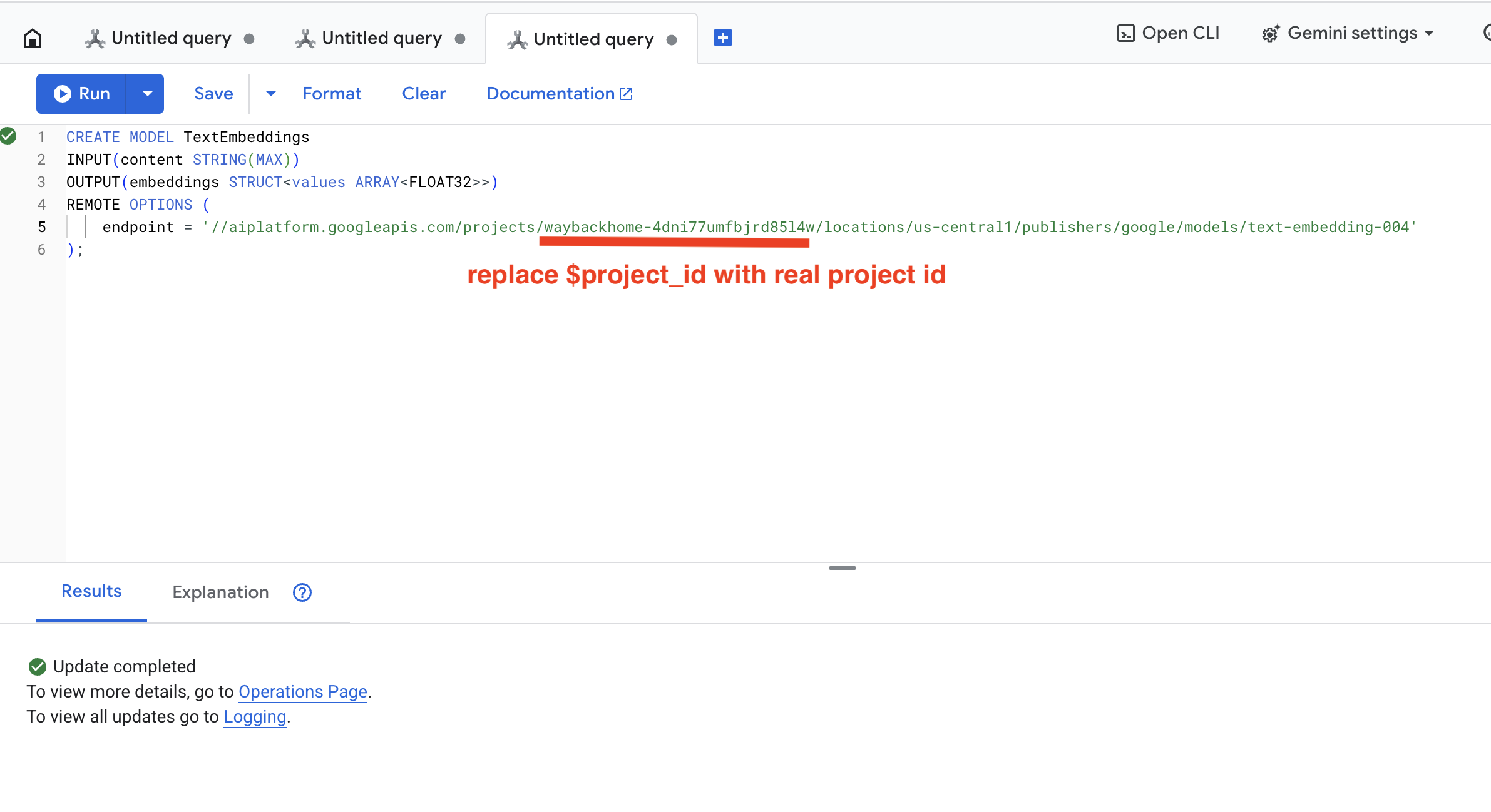
👉 Dans Spanner Studio, exécutez cette requête SQL (remplacez $YOUR_PROJECT_ID par l'ID de votre projet) :
‼️ Dans l'éditeur Cloud Shell, ouvrez File > Open Folder > way-back-home/level_2 pour afficher l'intégralité du projet.
👉 Exécutez cette requête dans Spanner Studio en copiant et en collant la requête ci-dessous, puis en cliquant sur le bouton "Exécuter" :
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Fonctionnement :
- Crée un modèle virtuel dans Spanner (aucune pondération de modèle n'est stockée en local).
- Pointe vers
text-embedding-004de Google sur Vertex AI - Définit le contrat : l'entrée est du texte, la sortie est un tableau flottant de 768 dimensions.
Pourquoi "OPTIONS À DISTANCE" ?
- Spanner n'exécute pas le modèle lui-même
- Il appelle Vertex AI via l'API lorsque vous utilisez
ML.PREDICT. - Zero-ETL : pas besoin d'exporter les données vers Python, de les traiter et de les réimporter
Cliquez sur le bouton Run. Une fois l'opération réussie, vous pouvez voir le résultat ci-dessous :
3. Ajouter une colonne d'embedding
👉 Ajoutez une colonne pour stocker les embeddings :
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Cliquez sur le bouton Run. Une fois l'opération réussie, vous pouvez voir le résultat ci-dessous :
4. Générer des embeddings
👉 Utilisez l'IA pour créer des embeddings vectoriels pour chaque compétence :
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Cliquez sur le bouton Run. Une fois l'opération réussie, vous pouvez voir le résultat ci-dessous :
Ce qui se passe : chaque nom de skill (par exemple, "premiers secours") est converti en un vecteur de 768 dimensions représentant sa signification sémantique.
5. Valider les embeddings
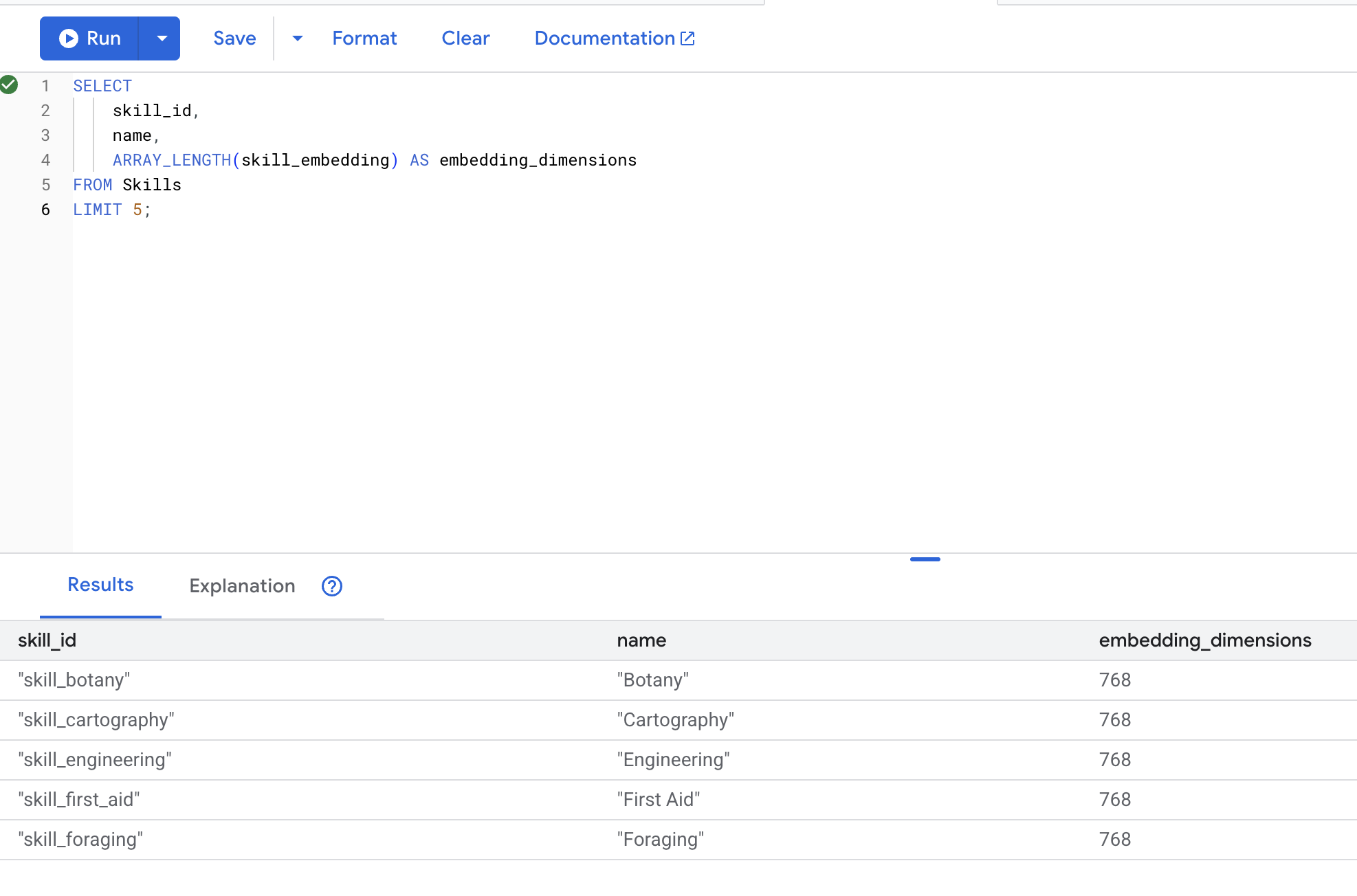
👉 Vérifiez que les embeddings ont été créés :
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Résultat attendu :
6. Tester la recherche sémantique
Nous allons maintenant tester le cas d'utilisation exact de notre scénario : trouver des compétences médicales à l'aide du terme "médecin".
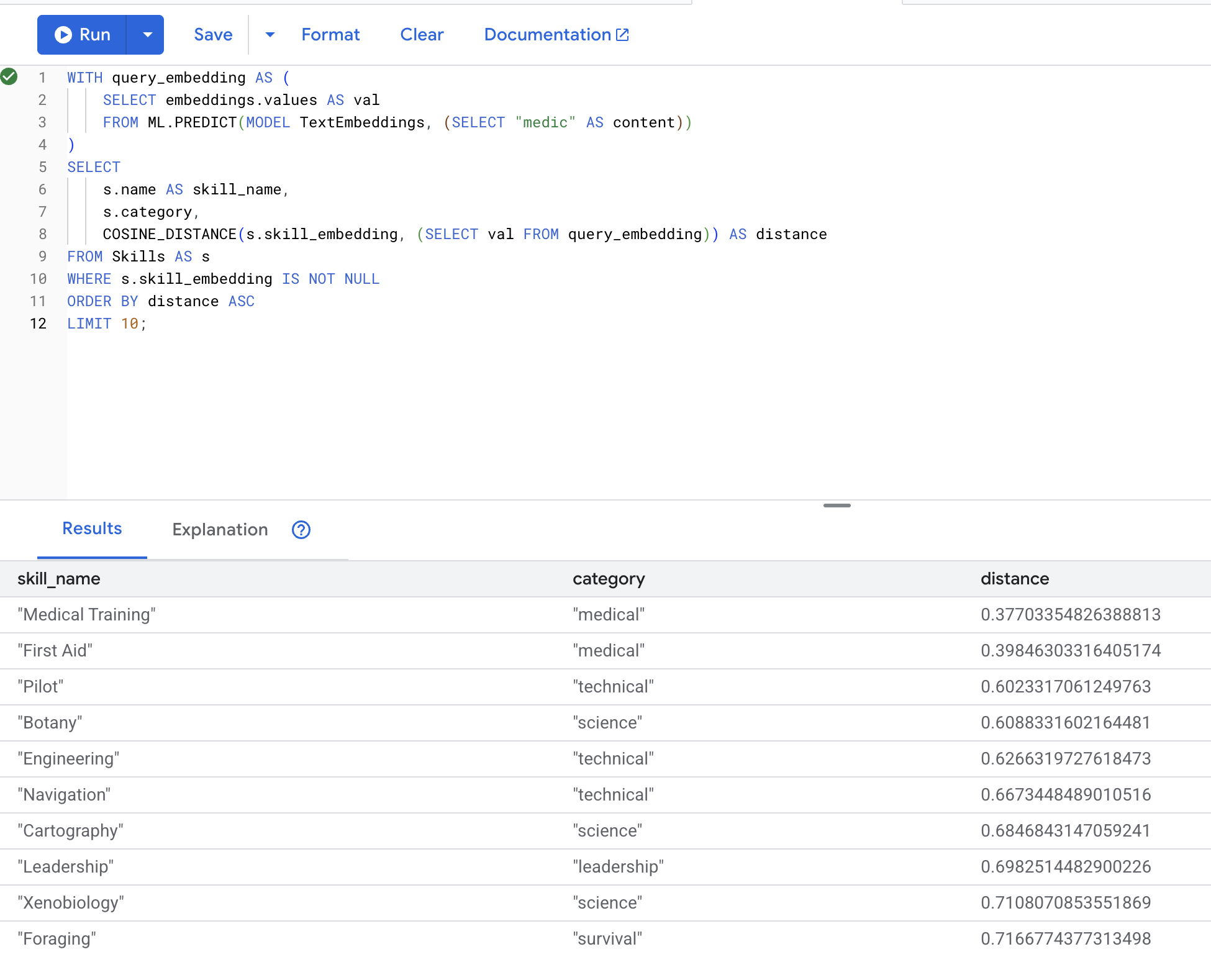
👉 Trouver des compétences semblables à "médecin" :
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Convertit le terme de recherche "médecin " de l'utilisateur en embedding
- Stocke les données dans la table temporaire
query_embedding
Résultats attendus (plus la distance est faible, plus les éléments sont similaires) :
7. Créer un modèle Gemini pour l'analyse
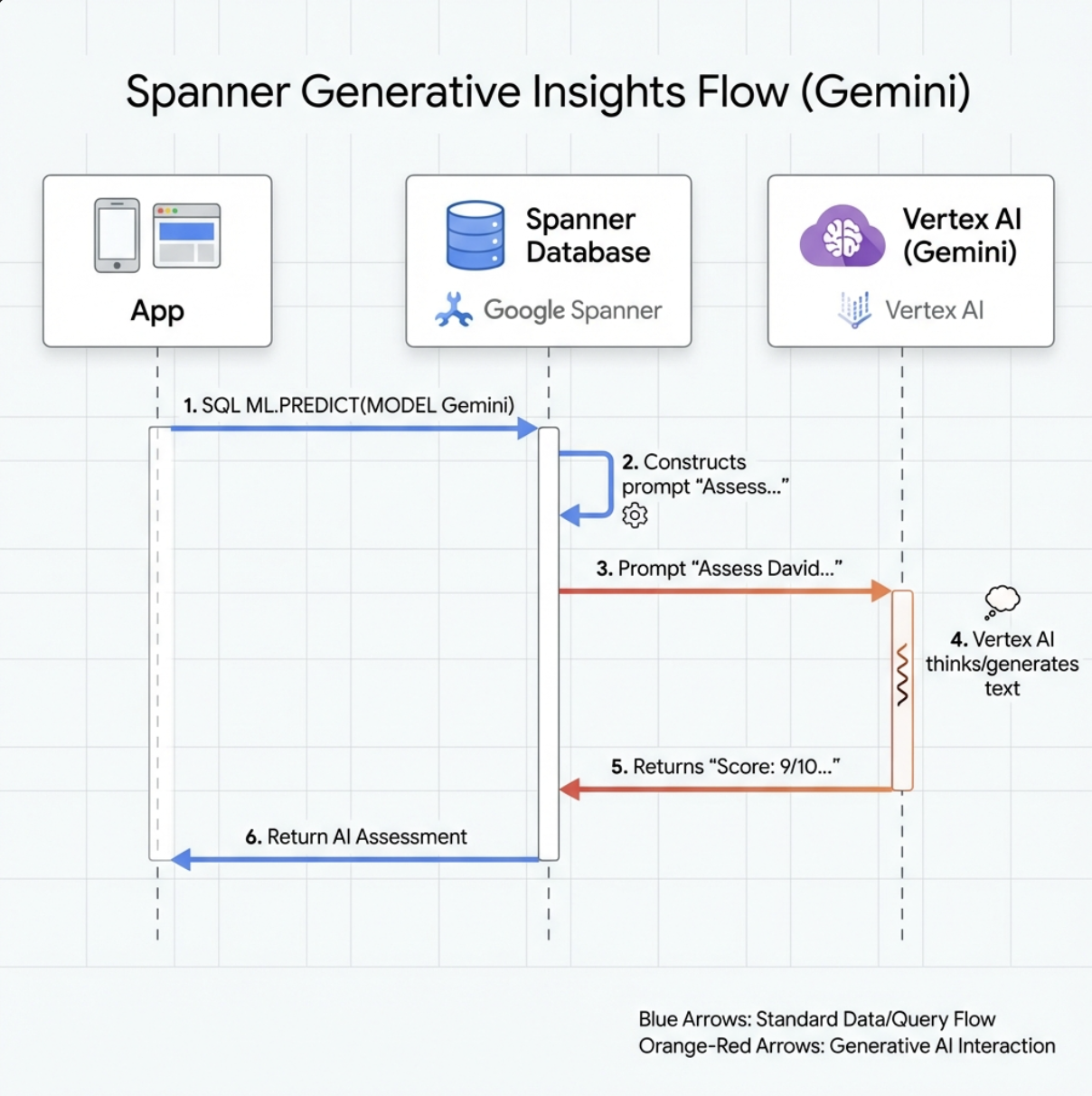
👉 Créez une référence de modèle d'IA générative (remplacez $YOUR_PROJECT_ID par l'ID de votre projet) :
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Différence par rapport au modèle d'embeddings :
- Embeddings : texte → vecteur (pour la recherche de similarités)
- Gemini : texte → texte généré (pour le raisonnement/l'analyse)
8. Utiliser Gemini pour l'analyse de la compatibilité
👉 Analysez les paires de survivants pour vérifier leur compatibilité avec la mission :
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Résultat attendu :
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Créer votre agent Graph RAG avec la recherche hybride
1. Présentation de l'architecture du système
Cette section explique comment créer un système de recherche multiméthode qui permet à votre agent de gérer différents types de requêtes de manière flexible. Le système comporte trois couches : couche de l'agent, couche de l'outil et couche de service.
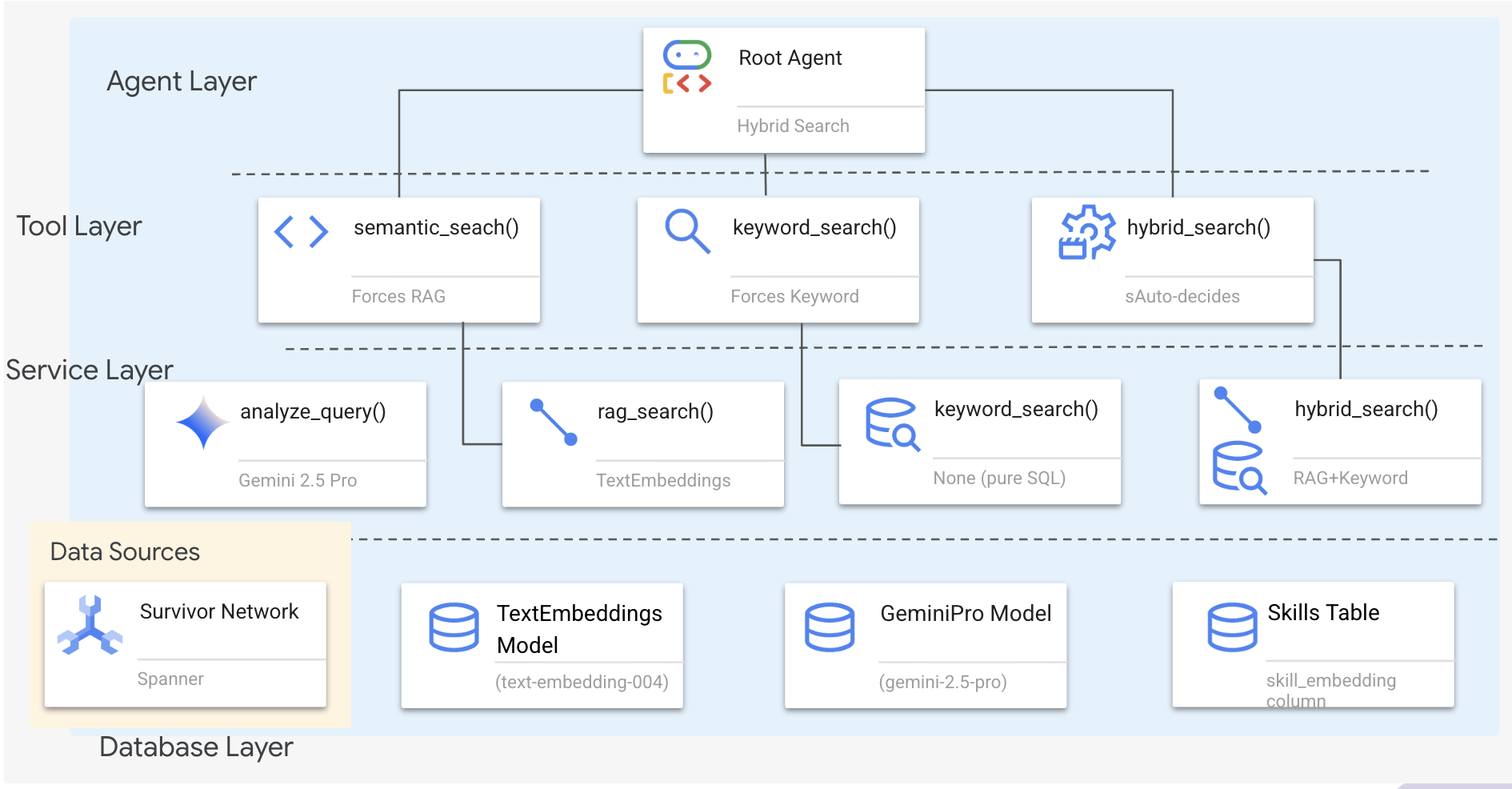
Pourquoi trois couches ?
- Séparation des tâches : l'agent se concentre sur l'intention, les outils sur l'interface et le service sur l'implémentation.
- Flexibilité : l'agent peut forcer des méthodes spécifiques ou laisser l'IA effectuer le routage automatique.
- Optimisation : possibilité d'ignorer l'analyse d'IA coûteuse lorsque la méthode est connue
Dans cette section, vous allez principalement implémenter la recherche sémantique (RAG), qui consiste à trouver des résultats en fonction de leur signification et pas seulement de leurs mots clés. Nous expliquerons plus tard comment la recherche hybride fusionne plusieurs méthodes.
2. Implémentation du service RAG
👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Recherchez le commentaire # TODO: REPLACE_SQL.
Remplacez toute cette ligne par le code suivant :
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Définition de l'outil de recherche sémantique
👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
Dans hybrid_search_tools.py, localisez le commentaire # TODO: REPLACE_SEMANTIC_SEARCH_TOOL.
👉 Remplacez toute cette ligne par le code suivant :
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Quand l'agent utilise :
- Requêtes demandant une similarité ("trouve des éléments semblables à X")
- Requêtes conceptuelles ("capacités de guérison")
- Lorsque la compréhension du sens est essentielle
4. Guide de décision de l'agent (instructions)
Dans la définition de l'agent, copiez-collez la partie liée à la recherche sémantique dans l'instruction.
👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
L'agent utilise cette instruction pour sélectionner l'outil approprié :
👉 Dans le fichier agent.py, recherchez le commentaire # TODO: REPLACE_SEARCH_LOGIC, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉 Localisez le commentaire # TODO: ADD_SEARCH_TOOLReplace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
semantic_search, # Force RAG
5. Comprendre le fonctionnement de la recherche hybride (lecture seule, aucune action requise)
Dans les étapes 2 à 4, vous avez implémenté la recherche sémantique (RAG), la méthode de recherche principale qui trouve des résultats par signification. Mais vous avez peut-être remarqué que le système s'appelle "Recherche hybride". Voici comment tout cela s'imbrique :
Fonctionnement de la fusion hybride :
Dans le fichier way-back-home/level_2/backend/services/hybrid_search_service.py, lorsque hybrid_search() est appelé, le service exécute LES DEUX recherches et fusionne les résultats :
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Pour cet atelier de programmation, vous avez implémenté le composant de recherche sémantique (RAG), qui constitue la base. Les méthodes par mots clés et hybrides sont déjà implémentées dans le service. Votre agent peut utiliser les trois.
Félicitations ! Vous avez terminé de créer votre agent Graph RAG avec la recherche hybride.
7. 🚀 Tester votre agent avec ADK Web
Le moyen le plus simple de tester votre agent est d'utiliser la commande adk web, qui lance votre agent avec une interface de chat intégrée.
1. Exécuter l'agent
👉💻 Accédez au répertoire backend (où votre agent est défini) et lancez l'interface Web :
cd ~/way-back-home/level_2/backend
uv run adk web
Cette commande démarre l'agent défini dans .
agent/agent.py
et ouvre une interface Web pour les tests.
👉 Ouvrez l'URL :
La commande génère une URL locale (généralement http://127.0.0.1:8000 ou similaire). Ouvrez-le dans votre navigateur.
Une fois que vous avez cliqué sur l'URL, l'interface utilisateur Web de l'ADK s'affiche. Assurez-vous de sélectionner l'agent en haut à gauche.
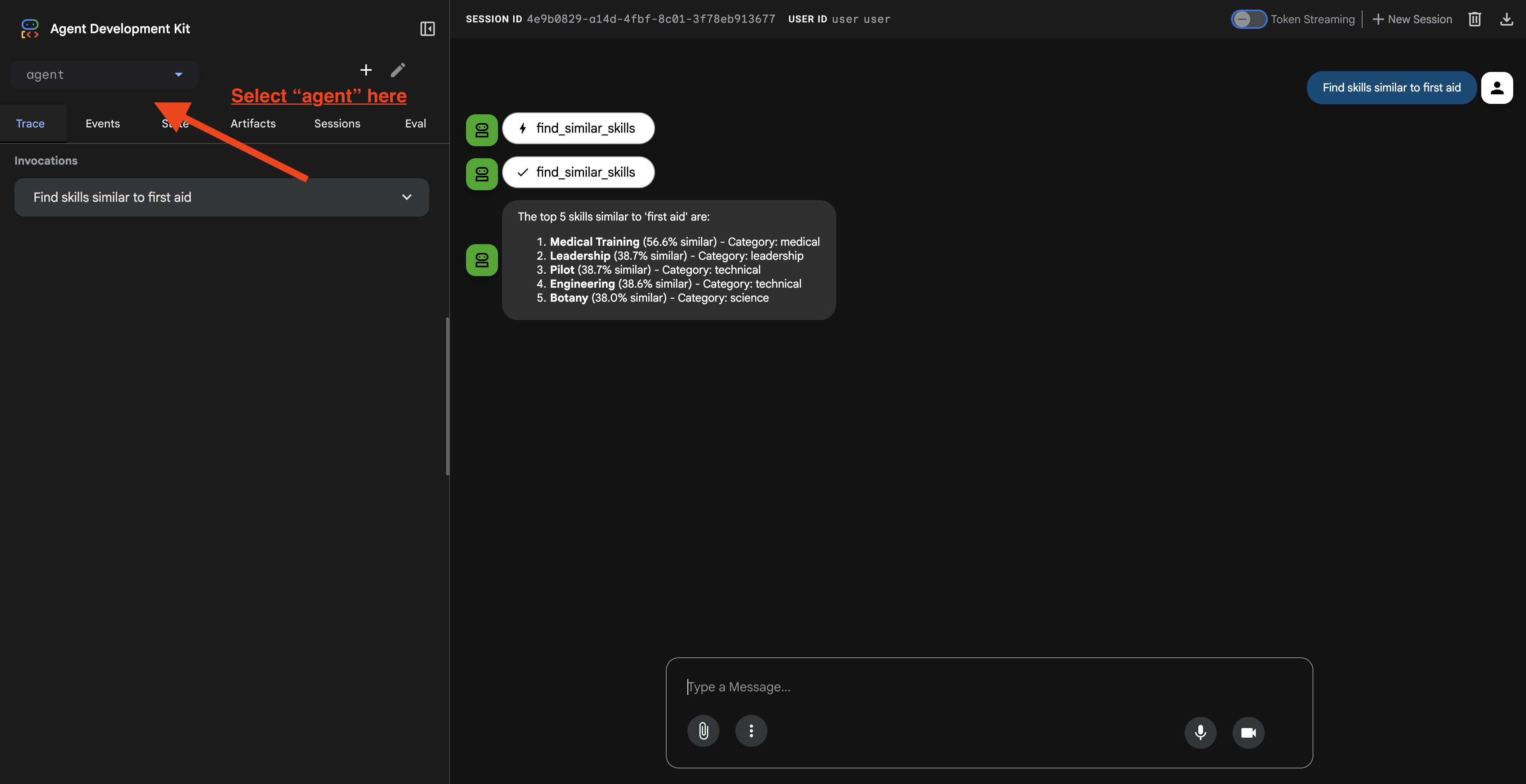
2. Tester les fonctionnalités de recherche
L'agent est conçu pour acheminer intelligemment vos requêtes. Essayez les entrées suivantes dans la fenêtre de chat pour voir différentes méthodes de recherche en action.
🧬 A. Graph RAG (recherche sémantique)
Trouve des éléments en fonction de leur signification et de leur concept, même si les mots clés ne correspondent pas.
Requêtes de test : (choisissez l'une des options ci-dessous)
Who can help with injuries?
What abilities are related to survival?
Éléments à prendre en compte :
- Le raisonnement doit mentionner la recherche sémantique ou RAG.
- Vous devriez obtenir des résultats conceptuellement liés (par exemple, "Chirurgie" lorsque vous demandez "Premiers secours").
- Les résultats seront accompagnés de l'icône 🧬.
🔀 B. Recherche hybride
Combine les filtres de mots clés avec la compréhension sémantique pour les requêtes complexes.
Requêtes de test : (choisissez l'une des options ci-dessous)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Éléments à prendre en compte :
- La justification doit mentionner la recherche hybride.
- Les résultats doivent correspondre aux DEUX critères (concept + lieu/catégorie).
- Les résultats trouvés par les deux méthodes sont accompagnés de l'icône 🔀 et sont classés en premier.
👉💻 Une fois les tests terminés, mettez fin au processus en appuyant sur Ctrl+C dans votre ligne de commande.
8. 🚀 Exécuter l'application complète
Présentation de l'architecture Full Stack
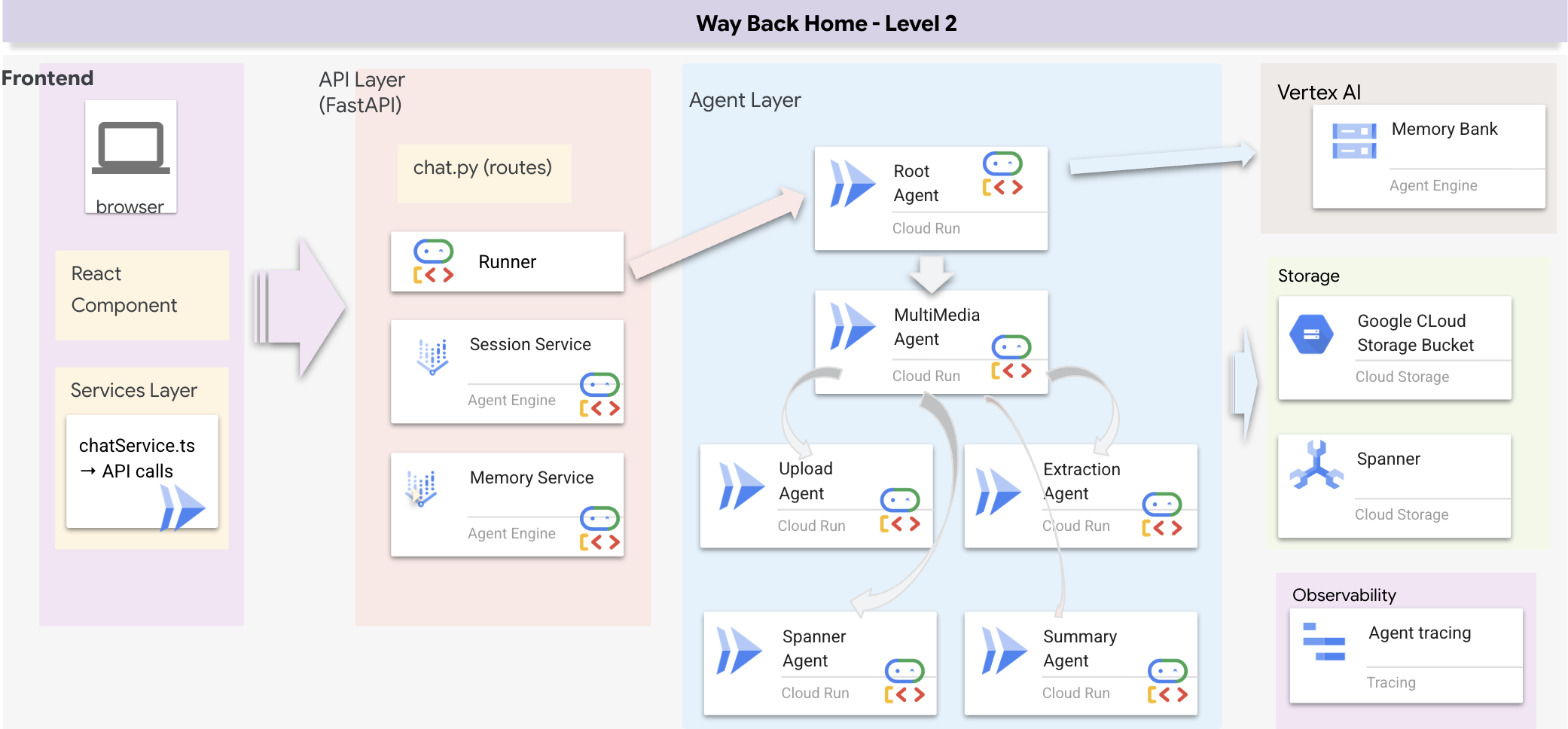
Ajouter SessionService et Runner
👉💻 Dans le terminal, ouvrez le fichier chat.py dans l'éditeur Cloud Shell en exécutant la commande suivante (assurez-vous d'avoir appuyé sur Ctrl+C pour mettre fin au processus précédent avant de continuer) :
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 Dans le fichier chat.py, recherchez le commentaire # TODO: REPLACE_INMEMORY_SERVICES, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉 Dans le fichier chat.py, recherchez le commentaire # TODO: REPLACE_RUNNER, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Commencer l'inscription
Si le terminal précédent est toujours en cours d'exécution, mettez-y fin en appuyant sur Ctrl+C.
👉💻 Démarrer l'application :
cd ~/way-back-home/level_2/
./start_app.sh
Lorsque le backend démarre correctement, Local: http://localhost:5173/" s'affiche, comme suit : 
👉 Cliquez sur Local : http://localhost:5173/ dans le terminal.
2. Tester la recherche sémantique
Requête :
Find skills similar to healing
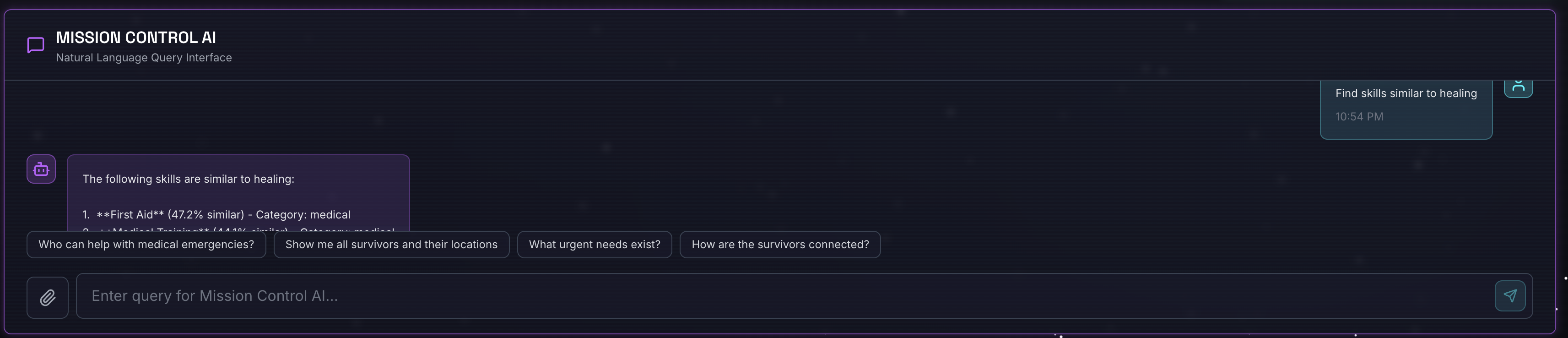
Ce qui se passe :
- L'agent reconnaît la demande de similarité
- Génère un embedding pour "guérison"
- Utilise la distance de cosinus pour trouver des compétences sémantiquement similaires
- Résultats : premiers secours (même si les noms ne correspondent pas à "soins")
3. Tester la recherche hybride
Requête :
Find medical skills in the mountains
Ce qui se passe :
- Composant de mot clé : filtrer pour
category='medical' - Composant sémantique : intégrer "médical" et classer par similarité
- Fusionner : combine les résultats en privilégiant ceux trouvés par les deux méthodes 🔀
Requête(facultatif) :
Who is good at survival and in the forest?
Ce qui se passe :
- Mots clés trouvés :
biome='forest' - Résultats sémantiques : compétences similaires à "survie"
- La méthode hybride combine les deux pour obtenir les meilleurs résultats.
👉💻 Lorsque vous avez terminé les tests, appuyez sur Ctrl+C dans le terminal pour y mettre fin.
4. (!UNIQUEMENT POUR LES PARTICIPANTS À L'ATELIER) Mettre à jour votre position
👉 💻 Exécutez le script de finalisation :
cd ~/way-back-home/level_2
./set_level_2.sh
Ouvrez waybackhome.dev. Vous verrez que votre position a été mise à jour. Félicitations, vous avez terminé le niveau 2 !

9. ☕️ [Facultatif] Pipeline multimodal (lecture seule) : couche d'outils
Pourquoi avons-nous besoin d'un pipeline multimodal ?
Le réseau de survie n'est pas qu'un texte. Les survivants sur le terrain envoient des données non structurées directement par chat :
- 📸 Images : photos de ressources, de dangers ou d'équipements
- 🎥 Vidéos : rapports d'état ou diffusions SOS
- 📄 Texte : notes ou journaux de terrain
Quels fichiers traitons-nous ?
Contrairement à l'étape précédente, où nous avons recherché des données existantes, nous allons ici traiter les fichiers importés par l'utilisateur. L'interface chat.py gère les pièces jointes de manière dynamique :
Source | Contenu | Objectif |
Association d'utilisateurs | Image/Vidéo/Texte | Informations à ajouter au graphique |
Contexte du chat | "Voici une photo des fournitures" | Intention et informations supplémentaires |
Approche prévue : pipeline d'agents séquentiels
Nous utilisons un agent séquentiel (multimedia_agent.py) qui enchaîne les agents spécialisés :
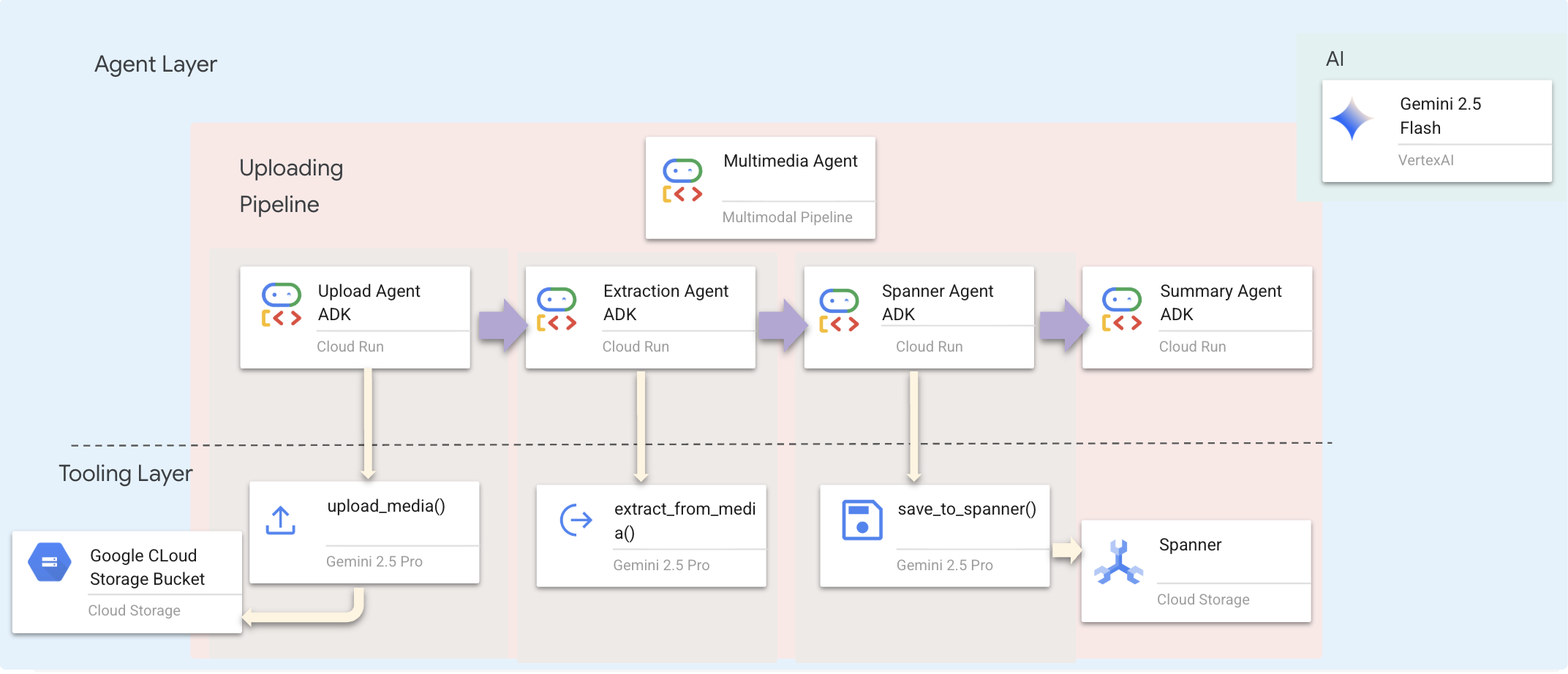
Ce paramètre est défini dans backend/agent/multimedia_agent.py en tant que SequentialAgent.
La couche d'outillage fournit les capacités que les agents peuvent invoquer. Les outils gèrent le "comment" : importer des fichiers, extraire des entités et enregistrer dans la base de données.
1. Ouvrir le fichier d'outils
👉💻 Ouvrez le fichier level_2/backend/agent/tools/extraction_tools.py ou en saisissant la commande suivante dans le terminal. Ouvrez un nouveau terminal. Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell :
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Implémenter l'outil upload_media
Cet outil importe un fichier local dans Google Cloud Storage.
👉 Dans def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, le code suivant explique comment importer des fichiers dans GCS et détecter leur type :
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Implémenter l'outil extract_from_media
Cet outil est un routeur : il vérifie le media_type et l'envoie à l'extracteur approprié (texte, image ou vidéo).
👉 Dans async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, le code suivant explique comment extraire des entités et des relations à partir des contenus multimédias importés.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Informations clés sur l'implémentation :
- Entrée multimodale : nous transmettons à
generate_contentà la fois la requête textuelle (_get_extraction_prompt()) et l'objet image. - Sortie structurée :
response_mime_type="application/json"garantit que le LLM renvoie un JSON valide, ce qui est essentiel pour le pipeline. - Association visuelle d'entités : la requête inclut des entités connues afin que Gemini puisse reconnaître des personnages spécifiques.
4. Implémenter l'outil save_to_spanner
Cet outil conserve les entités et les relations extraites dans la base de données Spanner Graph.
👉 Dans def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, le code suivant explique comment enregistrer les entités et les relations extraites dans la base de données Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
En fournissant aux agents des outils de haut niveau, nous assurons l'intégrité des données tout en tirant parti de leurs capacités de raisonnement.
5. Mettre à jour le service GCS
GCSService gère l'importation du fichier vers Google Cloud Storage.
👉💻 Ouvrez le fichier level_2/backend/services/gcs_service.py. Vous pouvez également saisir la commande suivante dans le terminal pour ouvrir le fichier dans l'éditeur Cloud Shell :
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 Dans def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, le code suivant explique comment enregistrer les entités et les relations extraites dans la base de données Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
En abstrayant cela dans un service, l'agent n'a pas besoin de connaître les buckets GCS, les noms de blobs ni la génération d'URL signées. Il vous demande simplement d'importer le fichier.
6. Pourquoi les workflows agentifs sont-ils plus efficaces que les approches traditionnelles ?
L'avantage de l'agentivité :
Fonctionnalité | Pipeline par lot | En fonction des événements | Workflow agentif |
Complexité | Faible (1 script) | Élevé (5 services ou plus) | Faible (1 fichier Python : |
Gestion de l'état | Variables globales | Élevée (découplée) | Unifié (état de l'agent) |
Traitement des erreurs | Plantages | Journaux silencieux | Interactif ("Je n'ai pas pu lire ce fichier") |
Commentaires des utilisateurs | Impressions sur console | Recherche nécessaire | Immédiat (partie du chat) |
Adaptabilité | Logique fixe | Fonctions rigides | Intelligent (le LLM décide de la prochaine étape) |
Conscience du contexte | Aucun | Aucun | Complète (connaît l'intention de l'utilisateur) |
Pourquoi est-ce important ? En utilisant multimedia_agent.py (un SequentialAgent avec quatre sous-agents : Upload → Extract → Save → Summary), nous remplaçons une infrastructure complexe ET des scripts fragiles par une logique d'application intelligente et conversationnelle.
10. ☕️ [Facultatif] Pipeline multimodal (lecture seule) : couche d'agent
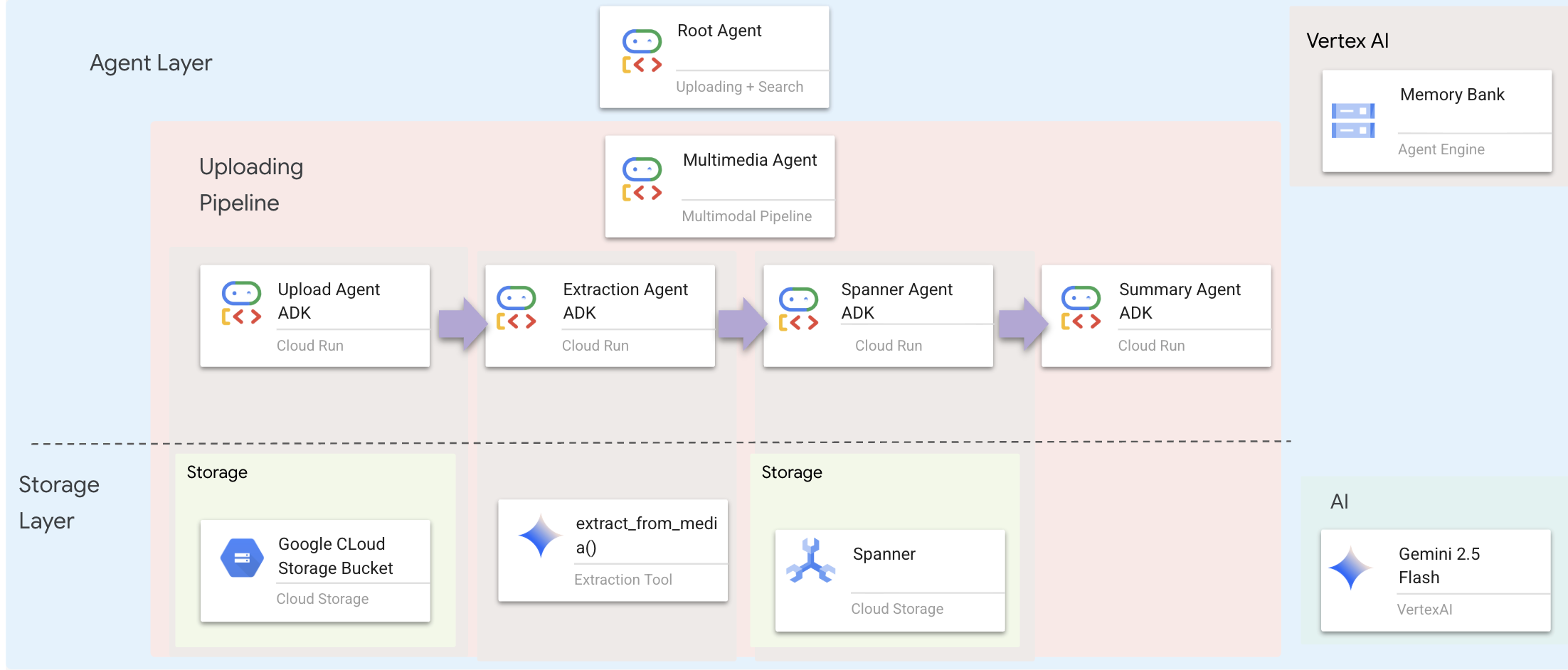
La couche d'agent définit l'intelligence, c'est-à-dire les agents qui utilisent des outils pour accomplir des tâches. Chaque agent a un rôle spécifique et transmet le contexte à l'agent suivant. Vous trouverez ci-dessous un schéma d'architecture pour un système multi-agents.
1. Ouvrir le fichier de l'agent
👉💻 Ouvrez le fichier level_2/backend/agent/multimedia_agent.py ou en saisissant la commande suivante dans le terminal. Ouvrez un nouveau terminal. Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell :
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Définir l'agent d'importation
Cet agent extrait un chemin d'accès à un fichier du message de l'utilisateur et l'importe dans GCS.
👉 Dans le fichier multimedia_agent.py, le code suivant crée upload_agent qui est importé dans GCS :
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Définir l'agent d'extraction
Cet agent "voit" le contenu multimédia importé et extrait des données structurées à l'aide de Gemini Vision.
👉 Dans le fichier multimedia_agent.py, le code suivant crée extraction_agent qui extrait les informations du contenu multimédia importé :
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Notez que instruction fait référence à {upload_result}. C'est ainsi que l'état est transmis entre les agents dans ADK.
4. Définir l'agent Spanner
Cet agent enregistre les entités et les relations extraites dans la base de données graphiques.
👉 Dans le fichier multimedia_agent.py, avec le code suivant, il crée spanner_agent qui enregistre les informations extraites dans la base de données :
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Cet agent reçoit le contexte des deux étapes précédentes (upload_result et extraction_result).
5. Définir l'agent Summary
Cet agent synthétise les résultats de toutes les étapes précédentes en une réponse conviviale.
👉 Dans le fichier multimedia_agent.py, le code suivant définit l'invite pour summary_agent qui résume le résultat :
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Cet agent n'a pas besoin d'outils. Il se contente de lire le contexte partagé et de générer un résumé clair pour l'utilisateur.
🧠 Résumé de l'architecture
intégrée | Fichier | Responsabilité |
Outils |
| Comment faire ? : importer, extraire, enregistrer |
Agent |
| Quoi : orchestrer le pipeline |
11. 🚀 Pipeline de données multimodales : orchestration
Le cœur de notre nouveau système est le MultimediaExtractionPipeline défini dans backend/agent/multimedia_agent.py. Il utilise le modèle Sequential Agent de l'ADK (Agent Development Kit).
1. Pourquoi choisir la couverture séquentielle ?
Le traitement d'un import est une chaîne de dépendances linéaires :
- Vous ne pouvez pas extraire de données tant que vous n'avez pas le fichier (importation).
- Vous ne pouvez pas enregistrer de données tant que vous ne les avez pas extraites.
- Vous ne pouvez pas résumer tant que vous n'avez pas les résultats (Enregistrer).
Un SequentialAgent est idéal pour cela. Il transmet la sortie d'un agent en tant que contexte/entrée à l'agent suivant.
2. Définition de l'agent
Examinons comment le pipeline est assemblé en bas de multimedia_agent.py : 👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Il reçoit des entrées des deux étapes précédentes. Recherchez le commentaire # TODO: REPLACE_ORCHESTRATION. Remplacez toute cette ligne par le code suivant :
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Contacter l'agent racine
👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Recherchez le commentaire # TODO: REPLACE_ADD_SUBAGENT. Remplacez toute cette ligne par le code suivant :
sub_agents=[multimedia_agent],
Cet objet unique regroupe quatre "experts" en une seule entité appelable.
4. Flux de données entre les agents
Chaque agent stocke sa sortie dans un contexte partagé auquel les agents suivants peuvent accéder :
5. Ouvrez l'application (ignorez cette étape si l'application est toujours en cours d'exécution).
👉💻 Démarrer l'application :
cd ~/way-back-home/level_2/
./start_app.sh
👉 Cliquez sur Local : http://localhost:5173/ dans le terminal.
6. Tester l'importation d'images
👉 Dans l'interface de chat, choisissez l'une des photos ci-dessous et importez-la dans l'interface utilisateur :
Dans l'interface de chat, expliquez à l'agent votre contexte spécifique :
Here is the survivor note
Joignez ensuite l'image ici.

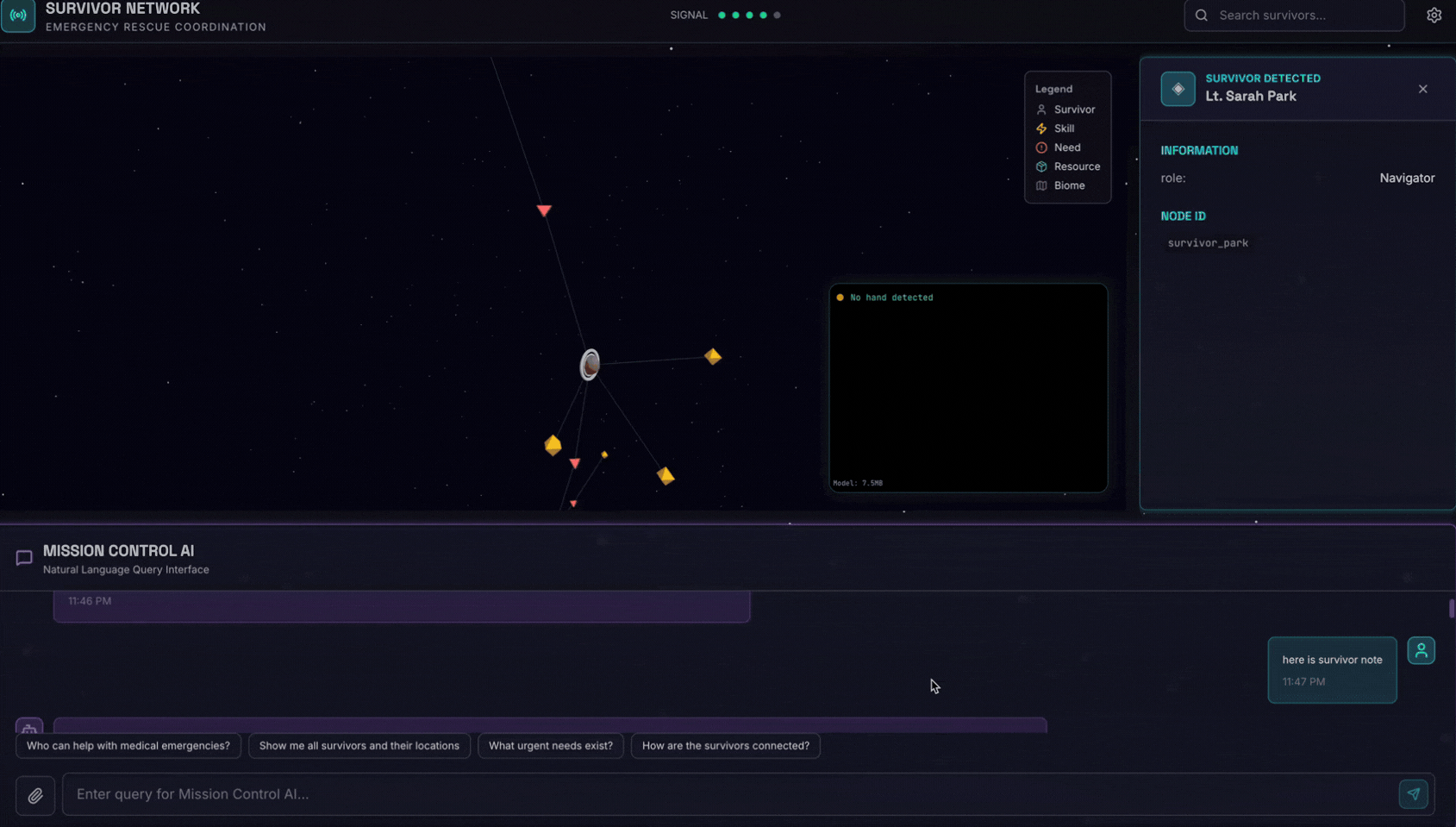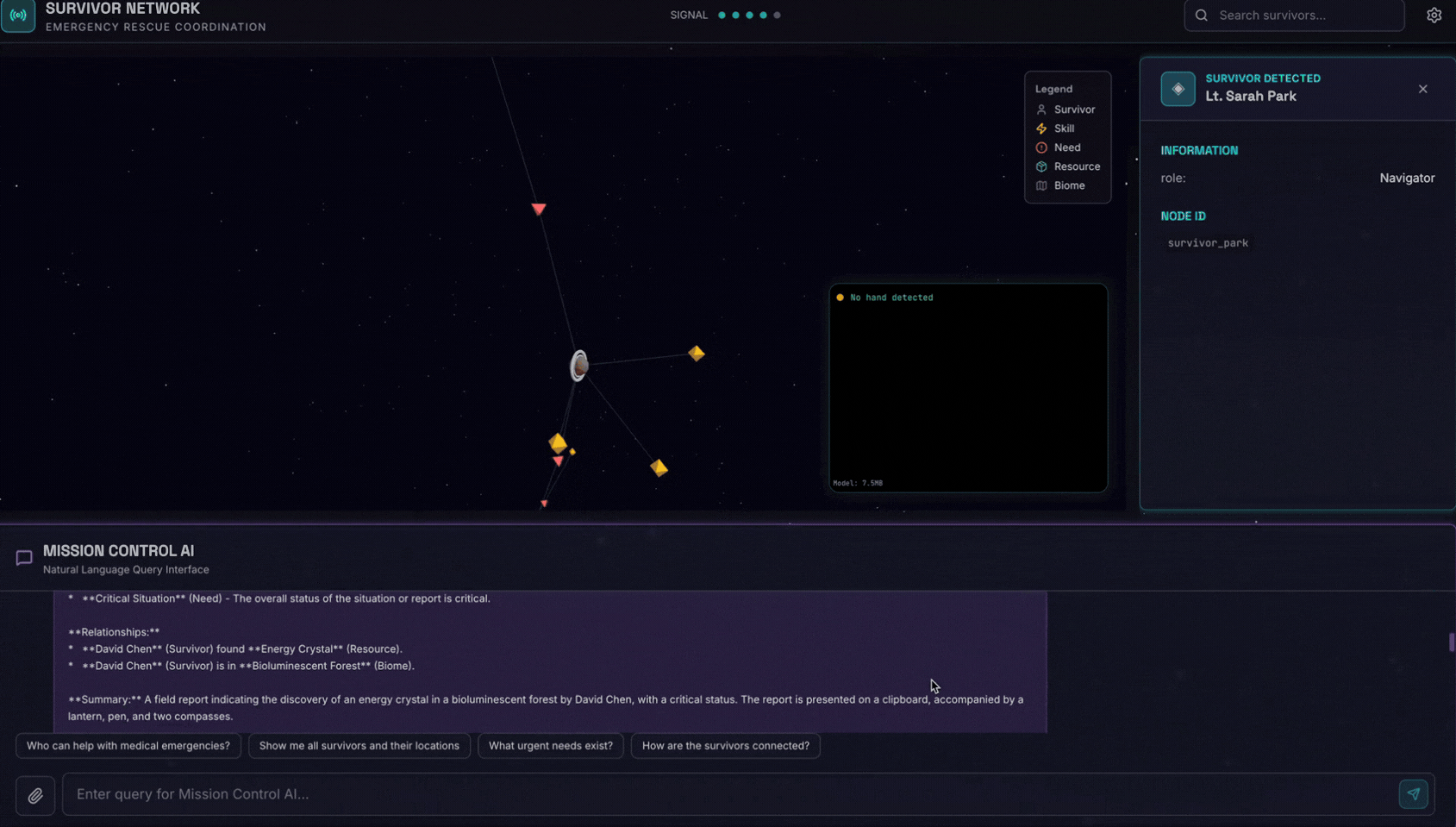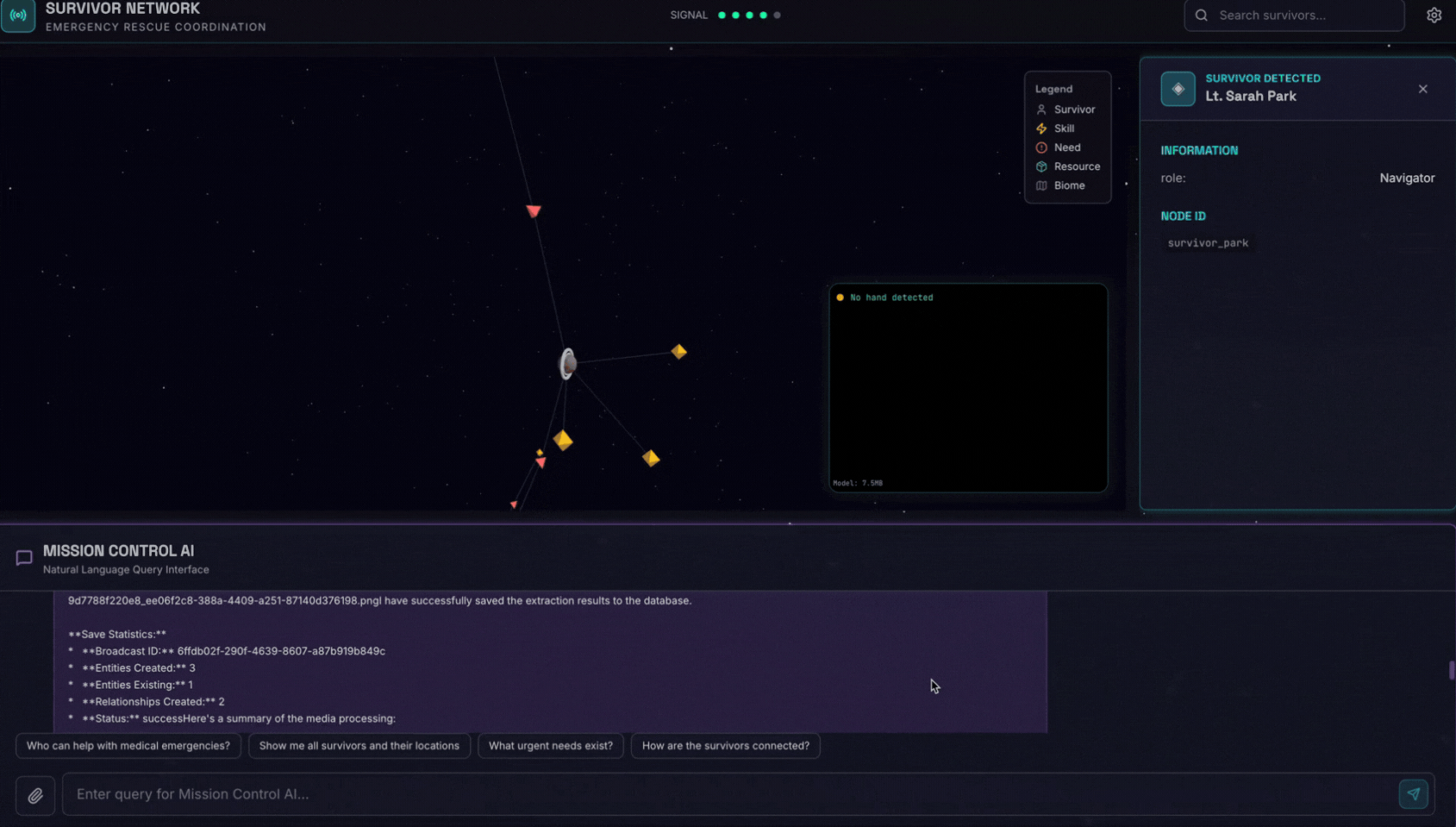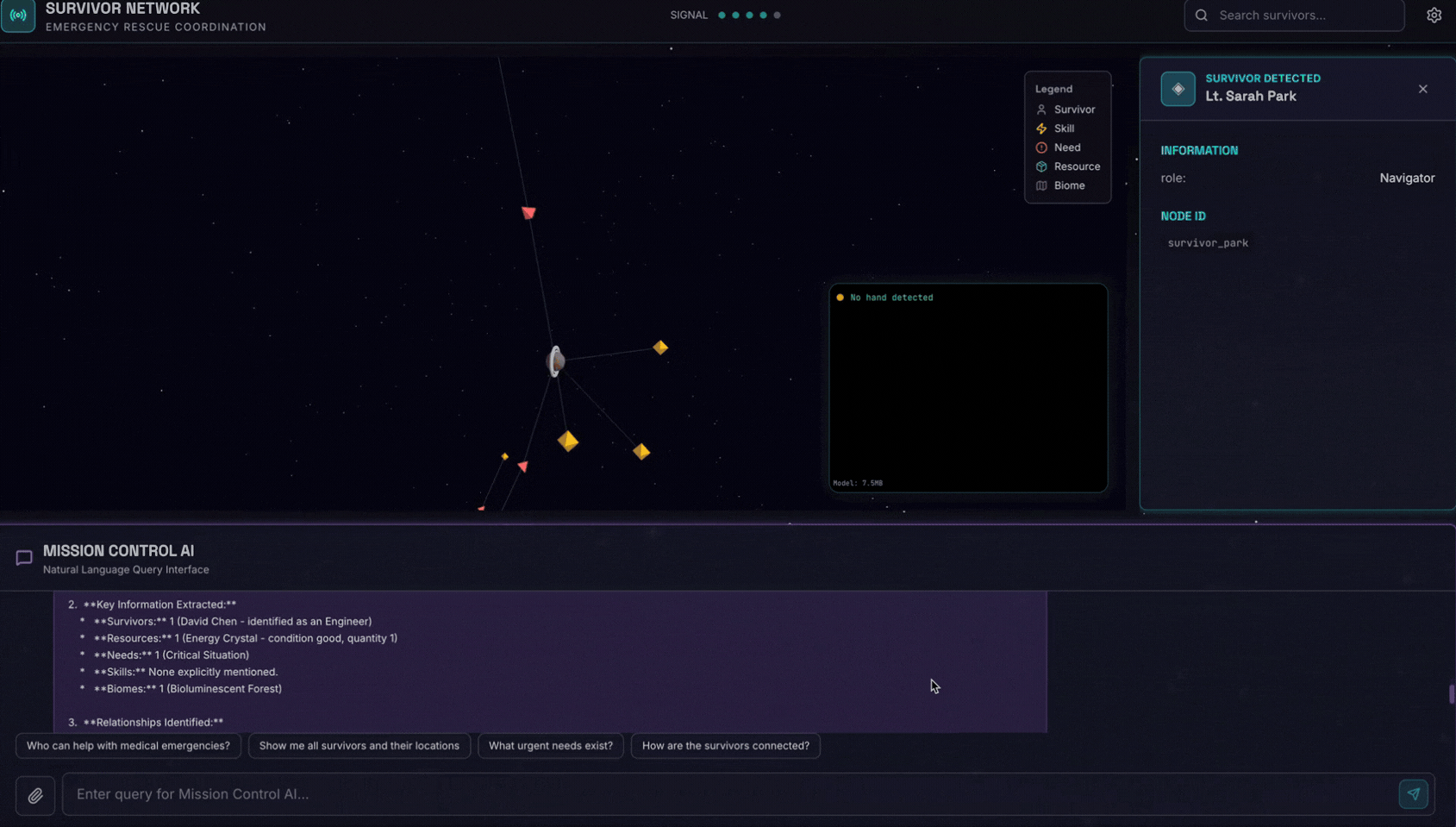
👉💻 Dans le terminal, une fois les tests terminés, appuyez sur "Ctrl+C" pour mettre fin au processus.
6. Vérifier l'importation multimodale dans un bucket GCS
- Ouvrez Google Cloud Console Storage.
- Sélectionnez "bucket" dans Cloud Storage.
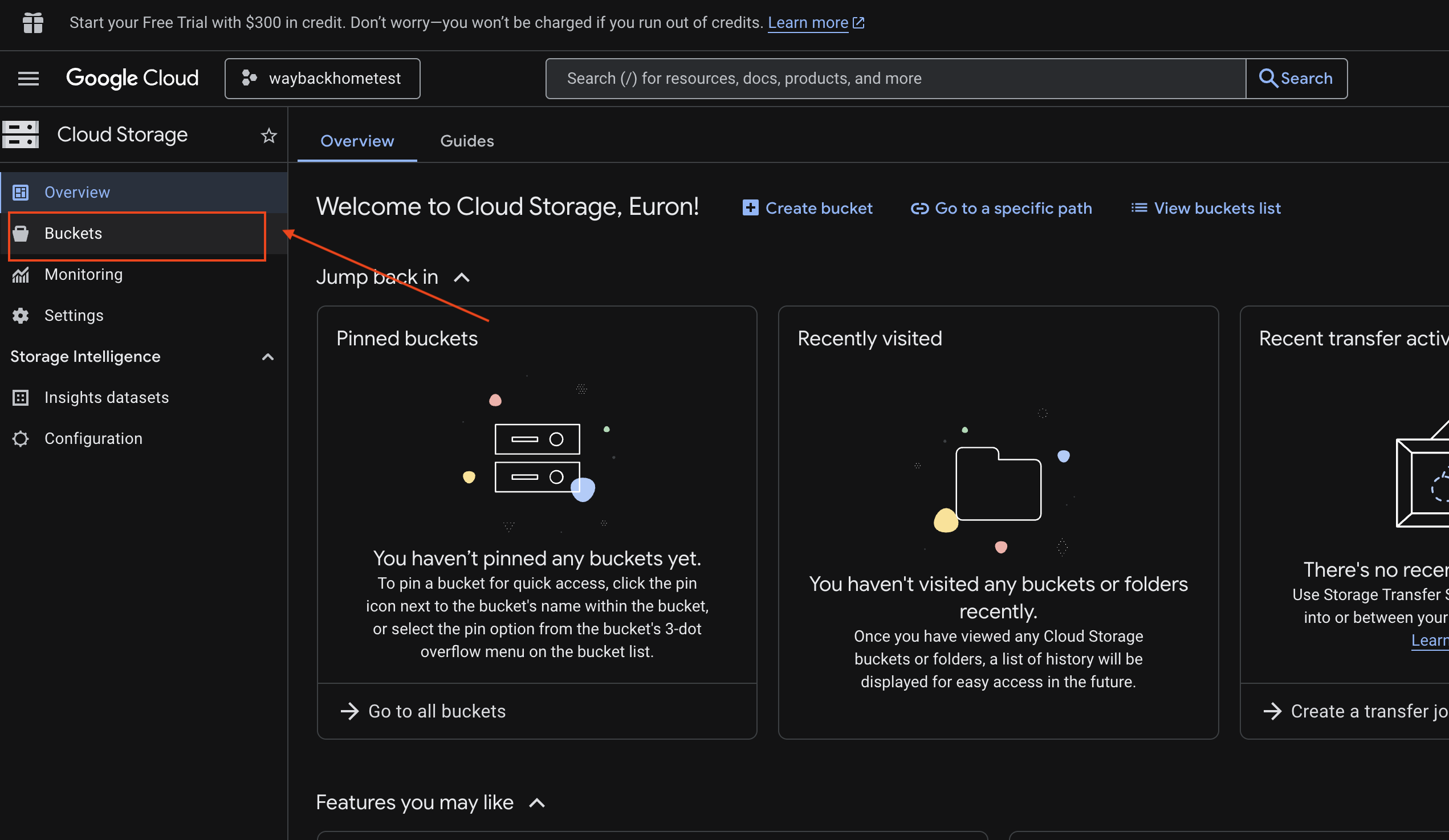
- Sélectionnez votre bucket, puis cliquez sur
media.
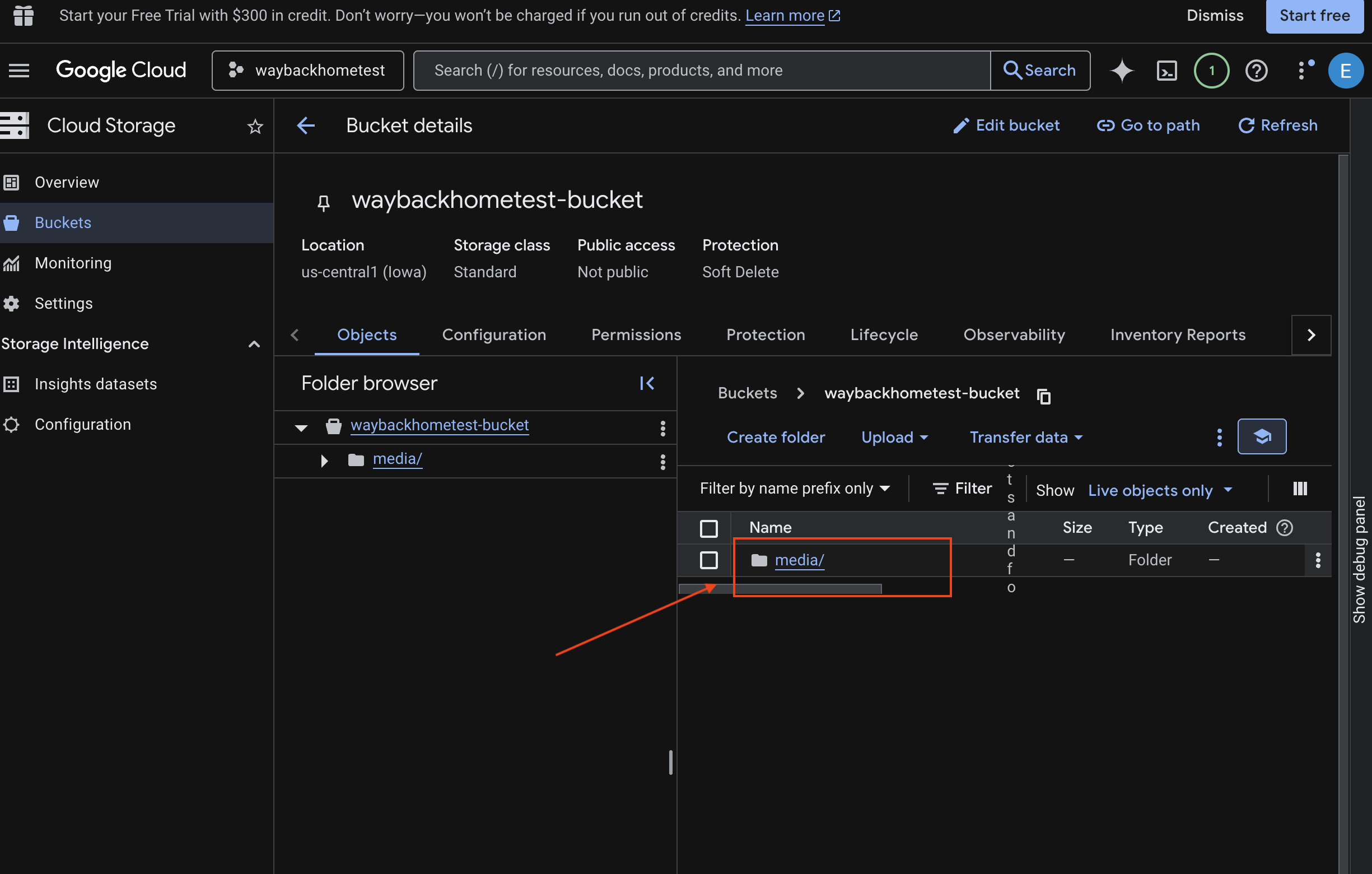
- Affichez l'image que vous avez importée ici.
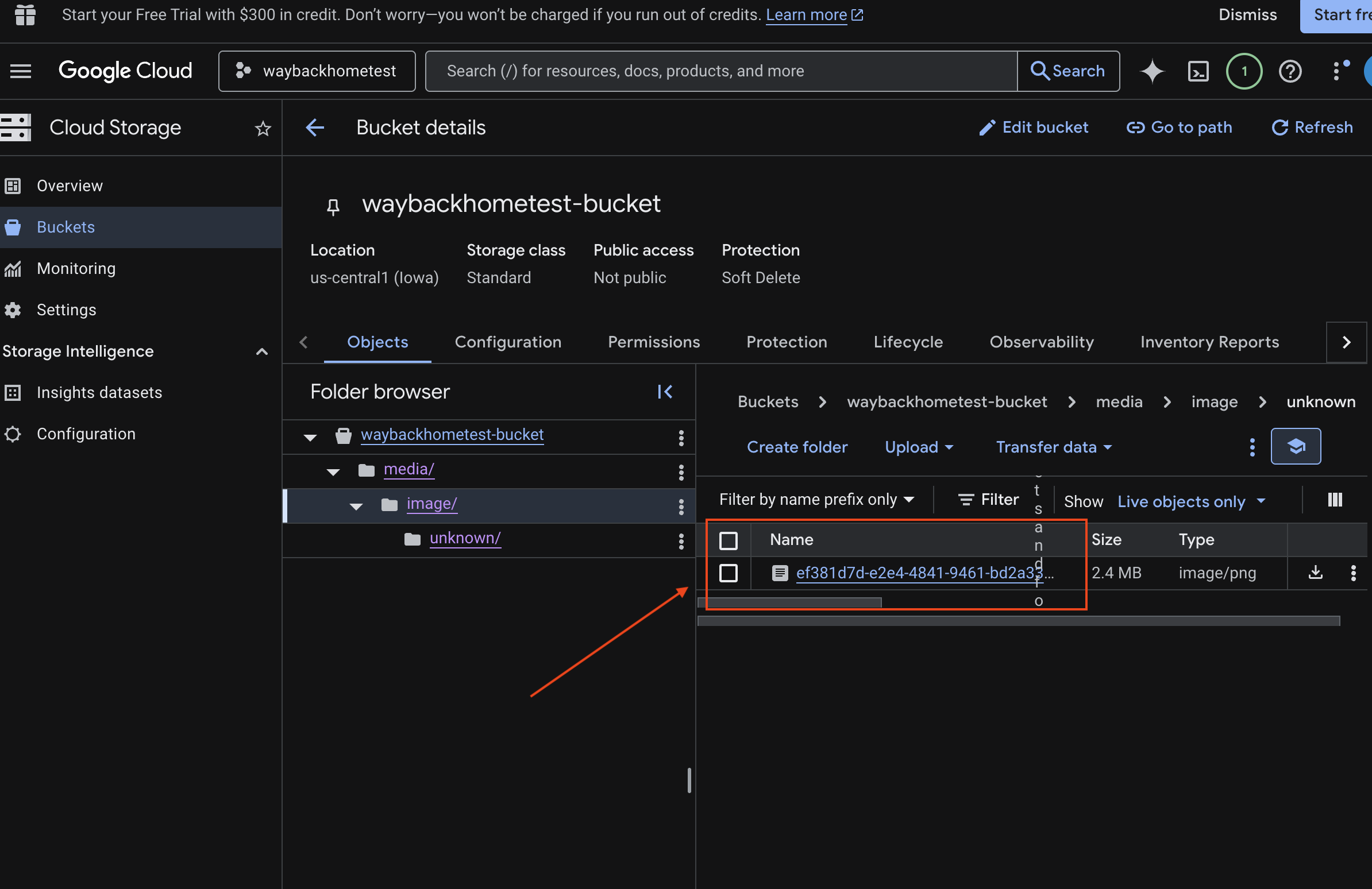
7. Vérifier l'importation multimodale dans Spanner (facultatif)
Vous trouverez ci-dessous un exemple de résultat dans l'UI pour test_photo1.
- Ouvrez Google Cloud Console Spanner.
- Sélectionnez votre instance :
Survivor Network - Sélectionnez votre base de données :
graph-db - Dans la barre latérale de gauche, cliquez sur Spanner Studio.
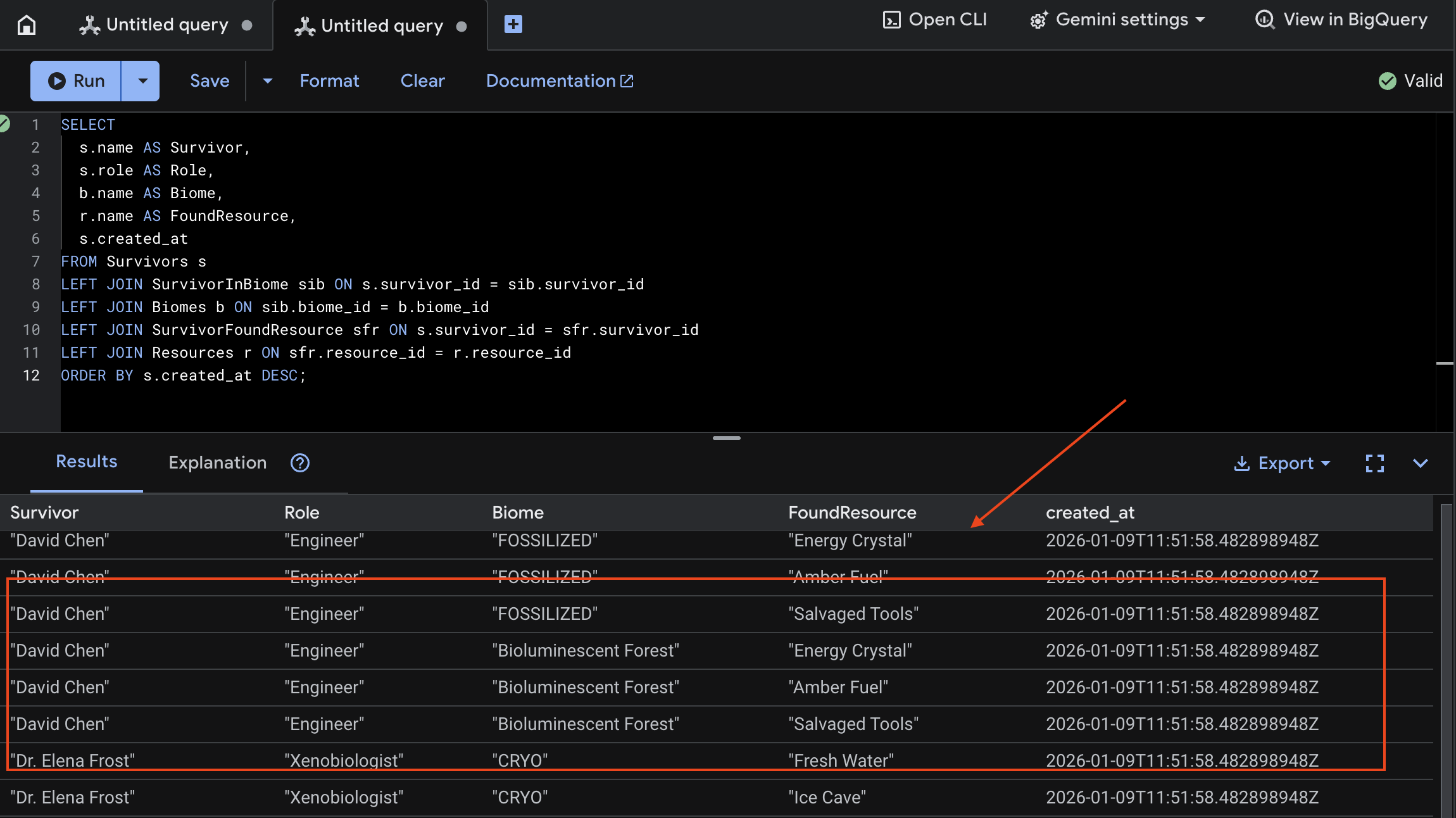
👉 Dans Spanner Studio, interrogez les nouvelles données :
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Nous pouvons le vérifier en consultant le résultat ci-dessous :
12. ☕️ [Facultatif] Banque de mémoire avec Agent Engine
1. Fonctionnement de la mémoire
Le système utilise une approche à double mémoire pour gérer à la fois le contexte immédiat et l'apprentissage à long terme.
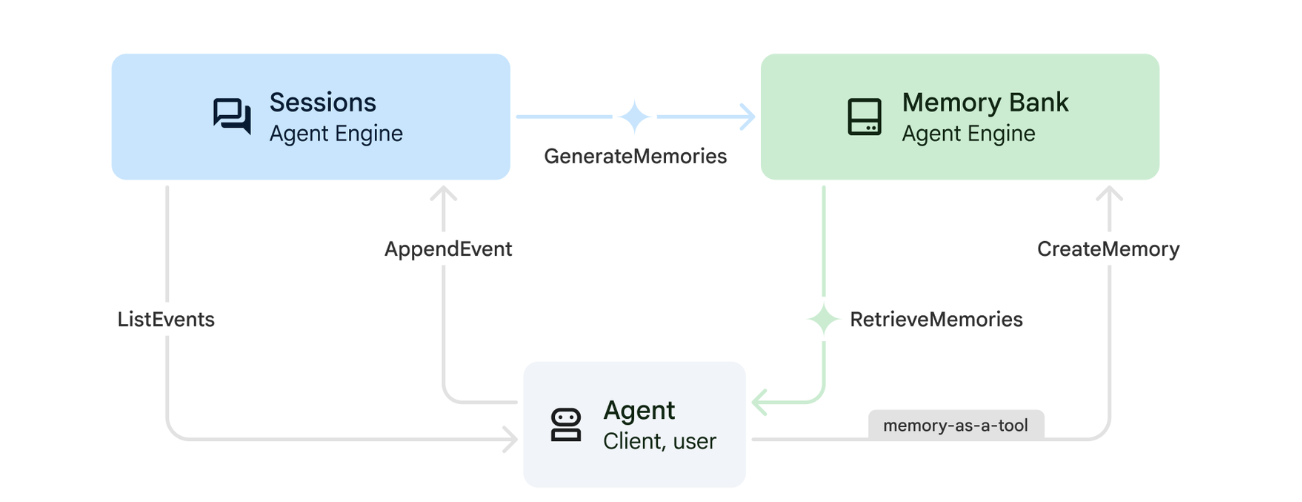
2. Que sont les thèmes de souvenirs ?
Les thèmes de mémoire définissent les catégories d'informations que l'agent doit mémoriser au cours des conversations. Considérez-les comme des classeurs pour différents types de préférences utilisateur.
Nos deux thèmes :
search_preferences: la façon dont l'utilisateur aime effectuer des recherches- Préfèrent-ils la recherche par mots clés ou la recherche sémantique ?
- Quelles compétences/quels biomes recherchent-ils souvent ?
- Exemple de mémoire : "L'utilisateur préfère la recherche sémantique pour les compétences médicales"
urgent_needs_context: les crises qu'ils suivent- Quelles ressources surveillent-ils ?
- Quels survivants sont concernés ?
- Exemple de mémoire : "L'utilisateur suit la pénurie de médicaments dans le camp nord"
3. Configurer des thèmes de mémoire
Les thèmes de mémoire personnalisés définissent ce que l'agent doit retenir. Ils sont configurés lors du déploiement d'Agent Engine.
👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
~/way-back-home/level_2/backend/deploy_agent.py s'ouvre dans votre éditeur.
Nous définissons des objets de structure MemoryTopic pour indiquer au LLM les informations à extraire et à enregistrer.
👉 Dans le fichier deploy_agent.py, remplacez # TODO: SET_UP_TOPIC par ce qui suit :
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Intégration de l'agent
Le code de l'agent doit connaître la Memory Bank pour enregistrer et récupérer des informations.
👉💻 Dans le terminal, ouvrez le fichier dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
~/way-back-home/level_2/backend/agent/agent.py s'ouvre dans votre éditeur.
Création d'agents
Lorsque nous créons l'agent, nous transmettons le after_agent_callback pour nous assurer que les sessions sont enregistrées en mémoire après les interactions. La fonction add_session_to_memory s'exécute de manière asynchrone pour éviter de ralentir la réponse du chat.
👉 Dans le fichier agent.py, recherchez le commentaire # TODO: REPLACE_ADD_SESSION_MEMORY, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Enregistrement en arrière-plan
👉 Dans le fichier agent.py, recherchez le commentaire # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉 Dans le fichier agent.py, recherchez le commentaire # TODO: REPLACE_ADD_CALLBACK, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Configurer le service de session Vertex AI
👉💻 Dans le terminal, ouvrez le fichier chat.py dans l'éditeur Cloud Shell en exécutant la commande suivante :
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 Dans le fichier chat.py, recherchez le commentaire # TODO: REPLACE_VERTEXAI_SERVICES, Replace this whole line (Remplacez toute cette ligne) et remplacez-le par le code suivant :
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Facultatif] Associer l'agent à Agent Engine
1. Configuration et déploiement
Avant de tester les fonctionnalités de mémoire, vous devez déployer l'agent avec les nouveaux thèmes de mémoire et vous assurer que votre environnement est correctement configuré.
Nous avons fourni un script pratique pour gérer ce processus.
Exécuter le script de déploiement
👉💻 Dans le terminal, exécutez le script de déploiement :
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Ce script effectue les actions suivantes :
- Exécute
backend/deploy_agent.pypour enregistrer les thèmes de l'agent et de la mémoire auprès de Vertex AI. - Capture le nouvel ID du moteur d'agent.
- Mise à jour automatique de votre fichier
.envavecAGENT_ENGINE_ID. - Assurez-vous que
USE_MEMORY_BANK=TRUEest défini dans votre fichier.env.
[!IMPORTANT] Si vous apportez des modifications à custom_topics dans deploy_agent.py, vous devez réexécuter ce script pour mettre à jour Agent Engine.
Valider Memory Bank
Vous pouvez maintenant vérifier que la banque de mémoire fonctionne en enseignant une préférence à l'agent et en vérifiant si elle persiste d'une session à l'autre.
Étape 1 : Ouvrir l'application
Ouvrez à nouveau l'application en suivant les instructions ci-dessous : si le terminal précédent est toujours en cours d'exécution, mettez-y fin en appuyant sur Ctrls+C.
👉💻 Démarrer l'application :
cd ~/way-back-home/level_2/
./start_app.sh
👉 Cliquez sur Local : http://localhost:5173/ dans le terminal.
Étape 2 : Tester la banque de mémoire avec du texte
Dans l'interface de chat, expliquez à l'agent votre contexte spécifique :
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Patientez environ 30 secondes pour que la mémoire soit traitée en arrière-plan.
Étape 3 : Démarrer une nouvelle session
Actualisez la page pour effacer l'historique des conversations en cours (mémoire à court terme).
Posez une question qui s'appuie sur le contexte que vous avez fourni précédemment :
"What kind of missions am I interested in?"
Réponse attendue :
"D'après vos conversations précédentes, vous vous intéressez à :
- Missions de sauvetage médical
- Opérations en montagne/en haute altitude
- Compétences requises : premiers secours, escalade
Voulez-vous que je trouve des survivants correspondant à ces critères ?"
Étape 4 : Tester l'importation d'images
Importez une image et posez la question suivante :
remember this
Vous pouvez choisir l'une des photos ici ou la vôtre, puis l'importer dans l'UI :
Étape 5 : Vérifier dans Vertex AI Agent Engine
Accédez à Agent Engine dans la console Google Cloud.
- Assurez-vous de sélectionner le projet dans le sélecteur de projets en haut à gauche :
- Vérifiez le moteur d'agent que vous venez de déployer à partir de la commande précédente
use_memory_bank.sh: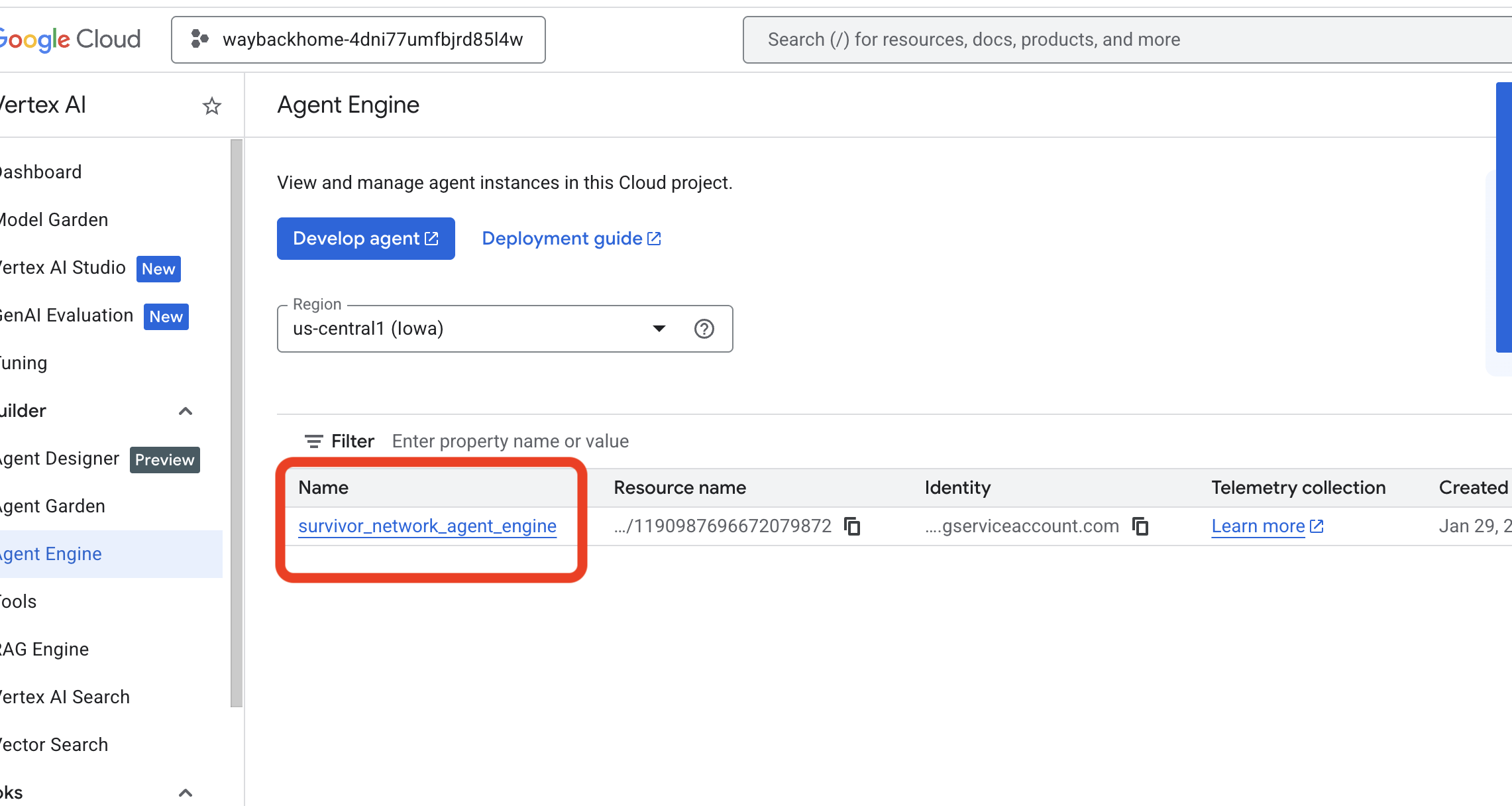 Cliquez sur le moteur d'agent que vous venez de créer.
Cliquez sur le moteur d'agent que vous venez de créer. - Cliquez sur l'onglet
Memoriesde cet agent déployé pour afficher toute la mémoire.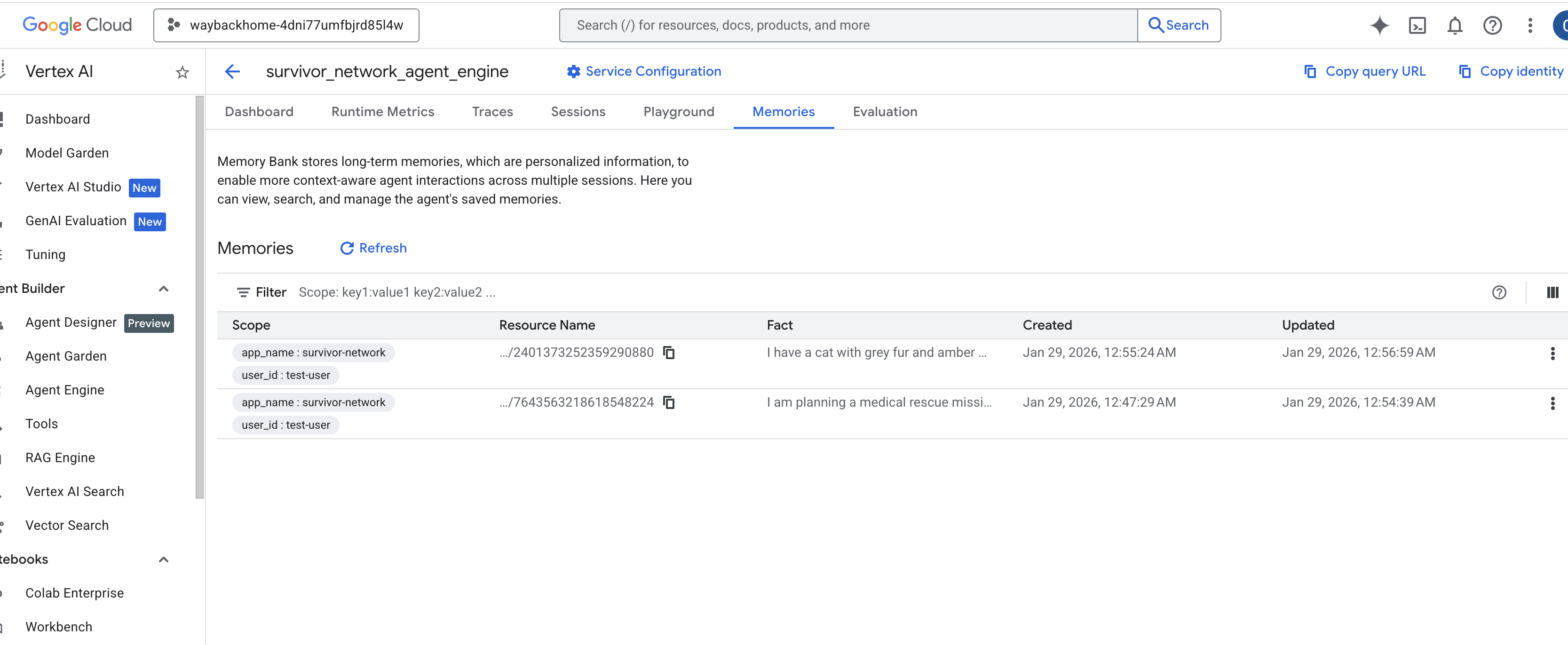
👉💻 Lorsque vous avez terminé les tests, cliquez sur "Ctrl+C" dans votre terminal pour mettre fin au processus.
🎉 Félicitations ! Vous venez d'associer la Memory Bank à votre agent.
14. ☕ [Facultatif] Déployer sur Cloud Run
1. Exécuter le script de déploiement
👉💻 Exécutez le script de déploiement :
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Une fois le déploiement réussi, vous obtiendrez l'URL de déploiement : 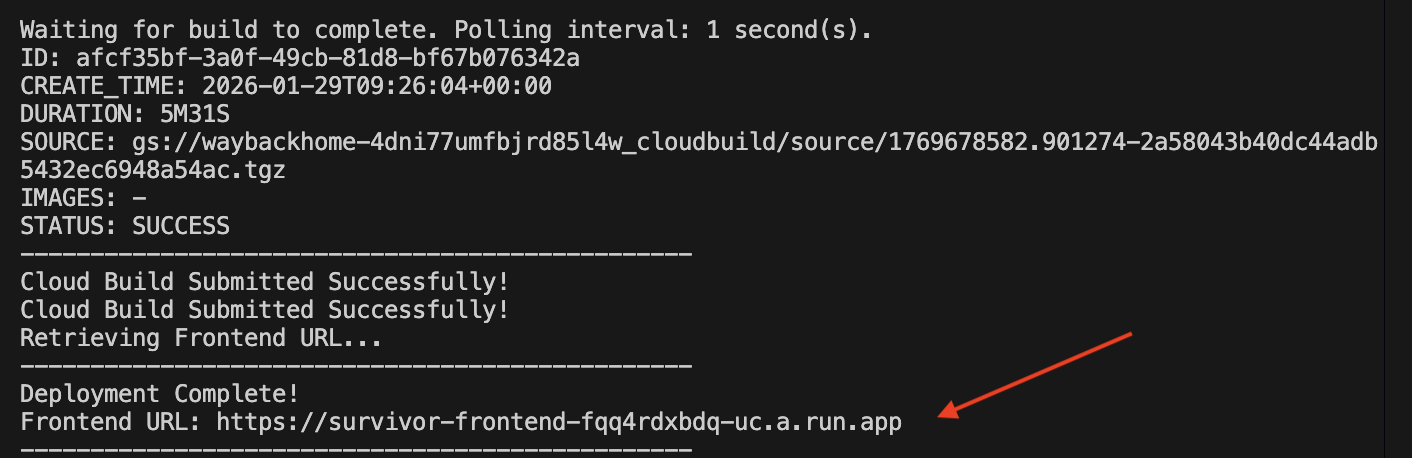 .
.
👉💻 Avant de récupérer l'URL, accordez l'autorisation en exécutant la commande suivante :
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Accédez à l'URL déployée pour voir votre application en direct.
2. Comprendre le pipeline de compilation
Le fichier cloudbuild.yaml définit les étapes séquentielles suivantes :
- Compilation du backend : compile l'image Docker à partir de
backend/Dockerfile. - Déploiement du backend : déploie le conteneur de backend sur Cloud Run.
- Capture URL : obtient la nouvelle URL du backend.
- Compilation du frontend :
- Installe les dépendances.
- Crée l'application React en injectant
VITE_API_URL=.
- Image de l'interface : crée l'image Docker à partir de
frontend/Dockerfile(en empaquetant les éléments statiques). - Frontend Deploy : déploie le conteneur de l'interface.
3. Vérifier le déploiement
Une fois la compilation terminée (consultez le lien vers les journaux fourni par le script), vous pouvez vérifier les points suivants :
- Accédez à la console Cloud Run.
- Recherchez le service
survivor-frontend. - Cliquez sur l'URL pour ouvrir l'application.
- Exécutez une requête de recherche pour vous assurer que le frontend peut communiquer avec le backend.
(FACULTATIF) 4. Déploiement manuel
Si vous préférez exécuter les commandes manuellement ou mieux comprendre le processus, voici comment utiliser cloudbuild.yaml directement.
Écriture cloudbuild.yaml
Un fichier cloudbuild.yaml indique à Google Cloud Build les étapes à exécuter.
- steps : il s'agit d'une liste d'actions séquentielles. Chaque étape s'exécute dans un conteneur (par exemple,
docker,gcloud,node,bash). - substitutions : variables pouvant être transmises au moment de la compilation (par exemple,
$_REGION). - workspace : répertoire partagé dans lequel les étapes peuvent partager des fichiers (comme nous partageons
backend_url.txt).
Exécuter le déploiement
Pour effectuer le déploiement manuellement sans le script, utilisez la commande gcloud builds submit. Vous DEVEZ transmettre les variables de substitution requises.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Conclusion
1. Ce que vous avez créé
✅ Base de données graphiques : Spanner avec des nœuds (survivants, compétences) et des arêtes (relations)
✅ Recherche par IA : recherche par mots clés, sémantique et hybride avec des embeddings
✅ Pipeline multimodal : extraction d'entités à partir d'images/vidéos avec Gemini
✅ Système multi-agents : workflow coordonné avec ADK
✅ Banque de mémoire : personnalisation à long terme avec Vertex AI
✅ Déploiement en production : Cloud Run + Agent Engine
2. Résumé de l'architecture
3. Points clés
- Graph RAG : combine la structure de la base de données graphiques avec des embeddings sémantiques pour une recherche intelligente
- Modèles multi-agents : pipelines séquentiels pour les workflows complexes à plusieurs étapes
- IA multimodale : extraire des données structurées à partir de contenus multimédias non structurés (images/vidéos)
- Agents avec état : la banque de mémoire permet la personnalisation entre les sessions
4. Contenu de l'atelier
- Level0 : Identifiez-vous
- Level1 : Emplacement précis
- Niveau 2 : celui-ci : Créer un agent d'IA multimodal avec Graph RAG, ADK et Memory Bank
- Level3 : Créer un agent de streaming bidirectionnel ADK
- Level4 : Système multi-agents bidirectionnel en direct
- Level5 : Architecture événementielle avec Google ADK, A2A et Kafka