
1. מבוא

1. האתגר
בתרחישים של תגובה לאסונות, נדרשות יכולות חכמות של ניהול נתונים וחיפוש כדי לתאם בין ניצולים עם כישורים, משאבים וצרכים שונים בכמה מיקומים. בסדנה הזו תלמדו איך לבנות מערכת AI לייצור שמשלבת:
- 🗄️ מסד נתונים של גרפים (Spanner): אחסון של קשרים מורכבים בין ניצולים, כישורים ומשאבים
- 🔍 חיפוש מבוסס-AI: חיפוש היברידי סמנטי + מילות מפתח באמצעות הטמעות
- 📸 עיבוד מולטי-מודאלי: חילוץ נתונים מובְנים מתמונות, מטקסט ומסרטונים
- 🤖 תזמור של כמה סוכנים: תיאום בין סוכנים מיוחדים לתהליכי עבודה מורכבים
- 🧠 זיכרון לטווח ארוך: התאמה אישית באמצעות Vertex AI Memory Bank
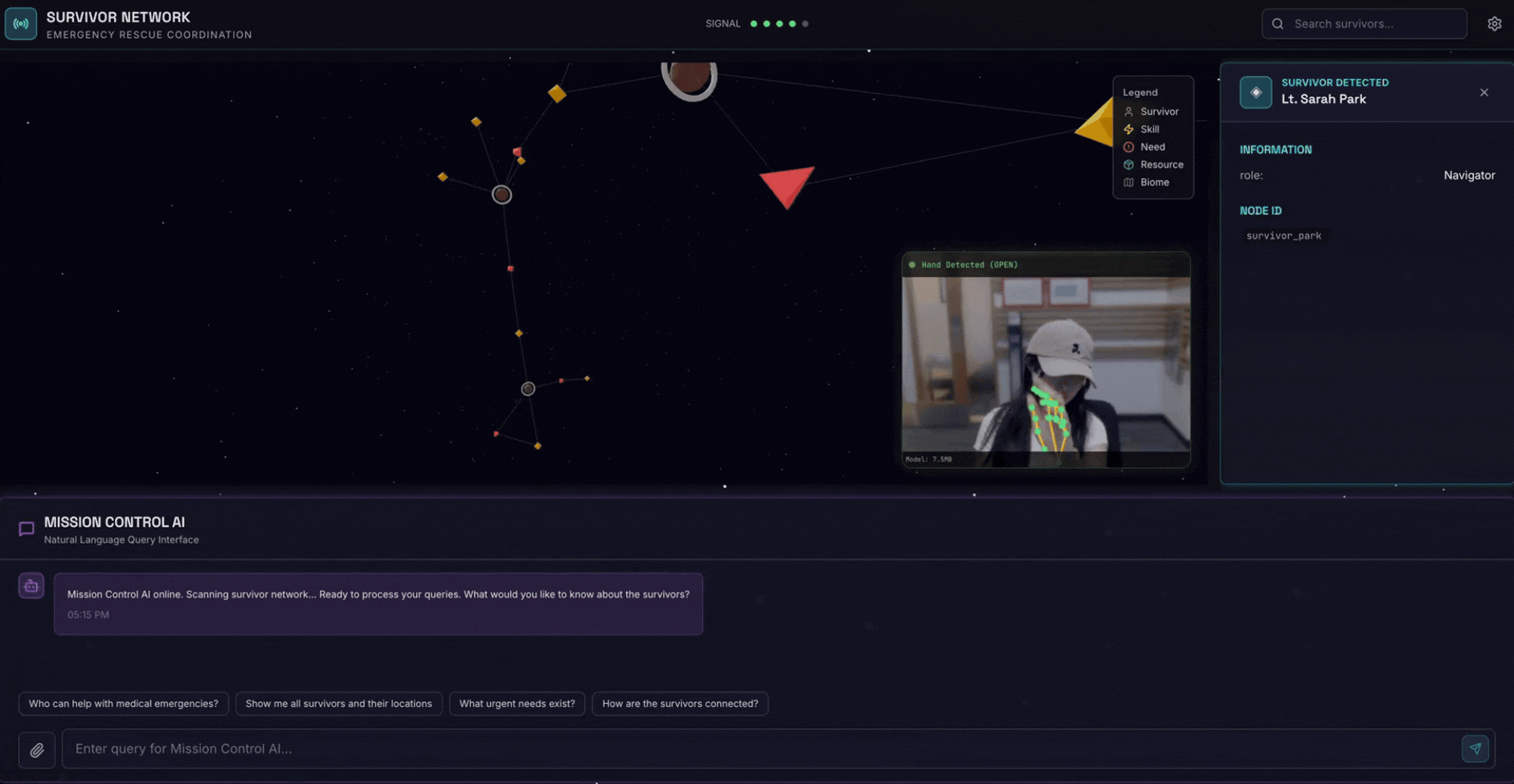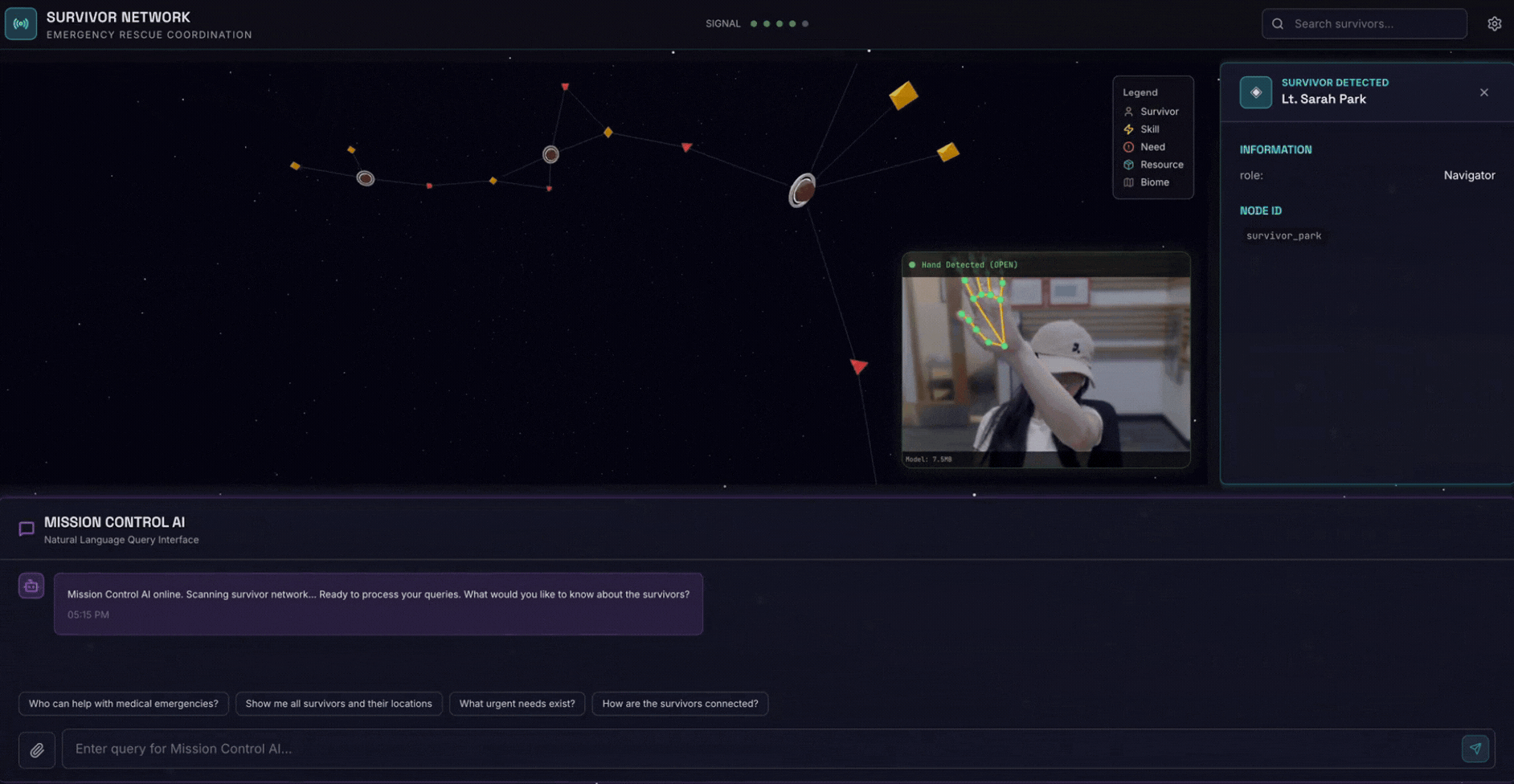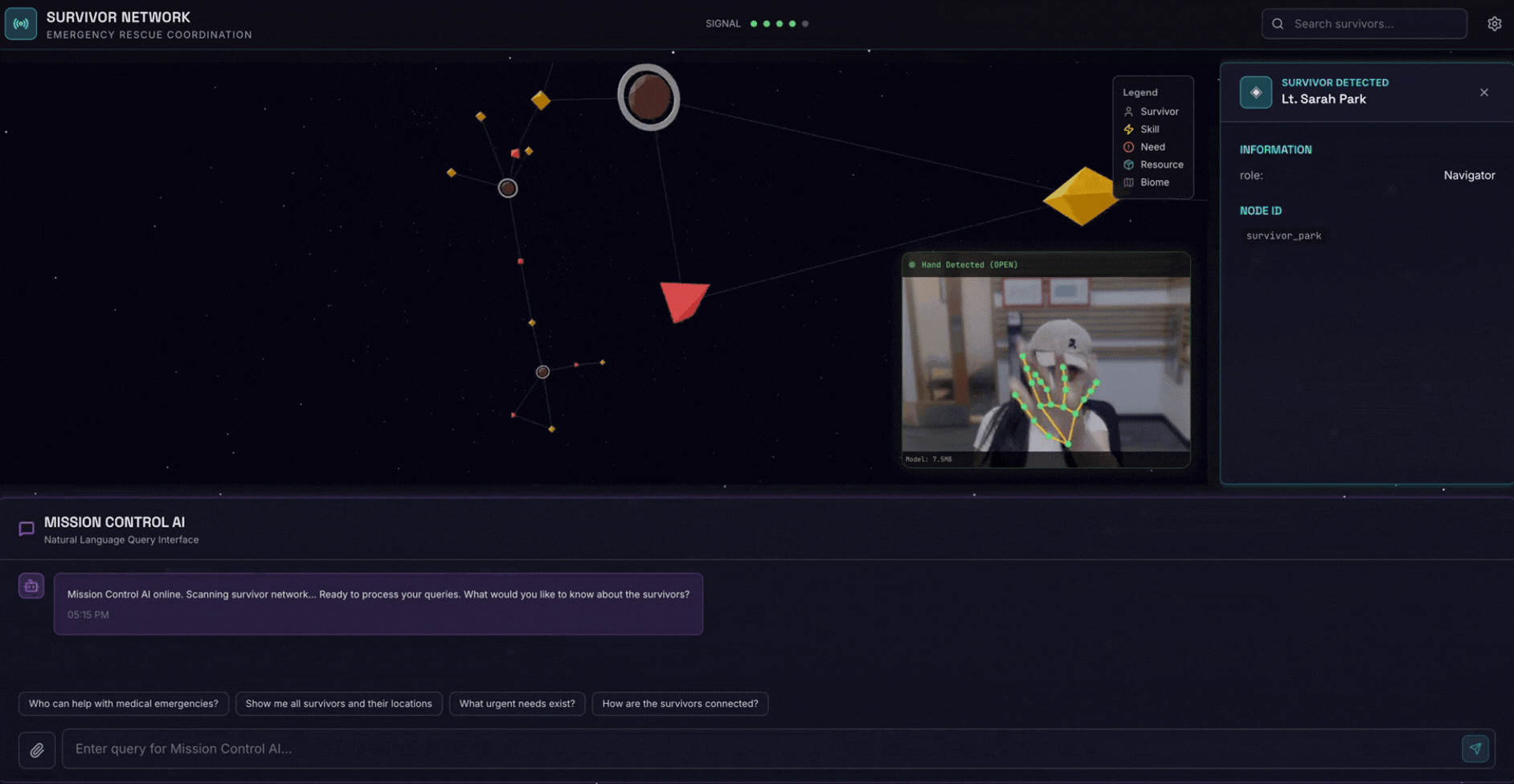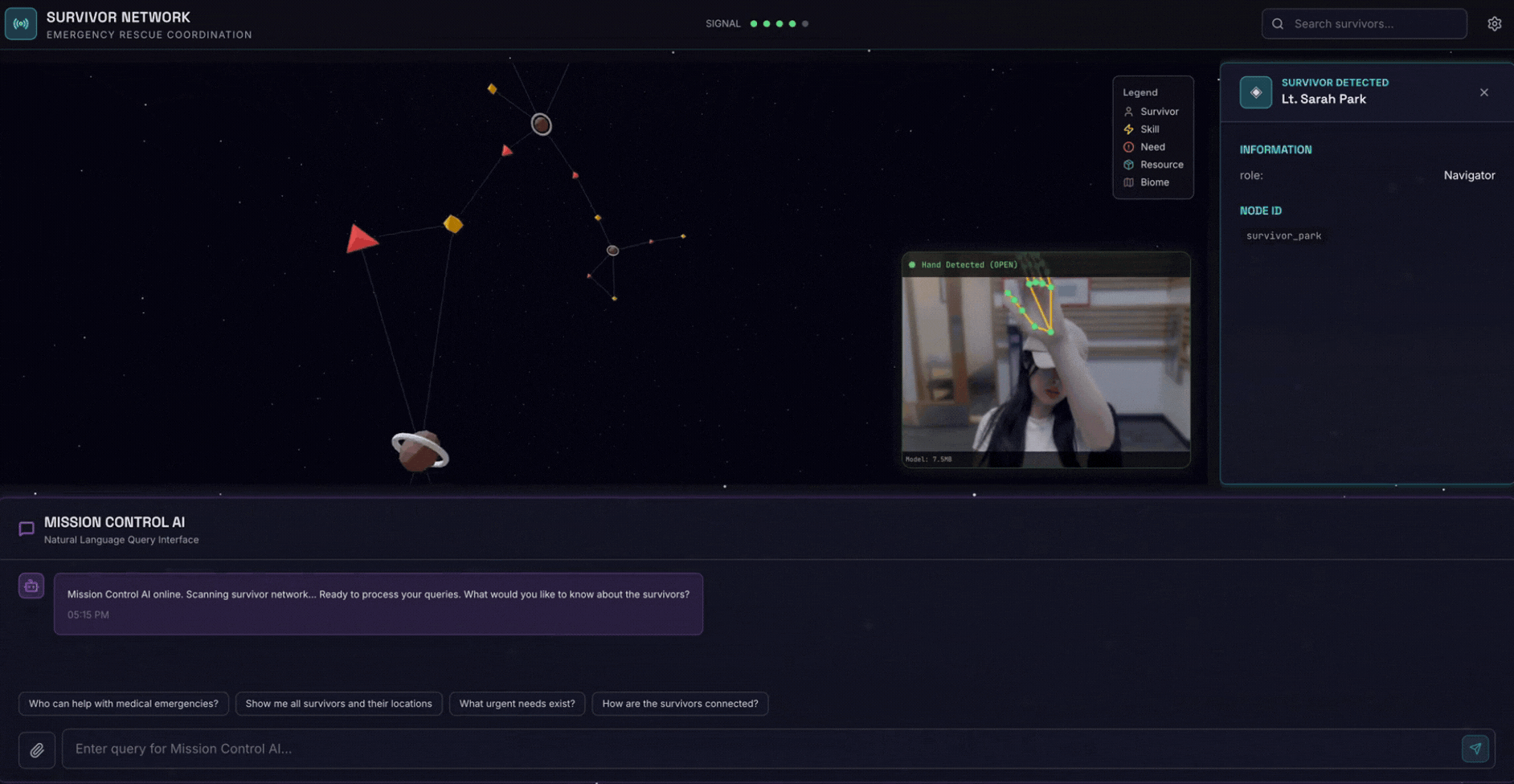
2. מה תפַתחו
מסד נתונים של גרף רשת ניצולים עם:
- 🗺️ 3D Interactive Graph Visualization of survivor relationships
- 🔍 חיפוש חכם (מילות מפתח, סמנטי והיברידי)
- 📸 פייפליין העלאה מולטימודאלית (חילוץ ישויות מתמונות או מסרטונים)
- 🤖 Multi-Agent System לתזמור משימות מורכבות
- 🧠 Memory Bank Integration לאינטראקציות בהתאמה אישית
3. טכנולוגיות ליבה
רכיב | טכנולוגיה | מטרה |
מסד נתונים | Cloud Spanner Graph | אחסון של צמתים (שורדים, מיומנויות) וקשתות (קשרים) |
חיפוש מבוסס-AI | Gemini + הטמעות | הבנה סמנטית + חיפוש דמיון |
Agent Framework | ADK (ערכה לפיתוח סוכנים) | תזמור תהליכי עבודה של AI |
זיכרון | Vertex AI Memory Bank | אחסון העדפות משתמש לטווח ארוך |
Frontend | React + Three.js | הדמיה אינטראקטיבית של תרשים תלת-ממדי |
2. 🛠️ הכנת הסביבה (אפשר לדלג אם אתם משתתפים בסדנה)
חלק ראשון: הפעלת החשבון לחיוב
כדי להריץ את ה-codelab הזה, צריך חשבון לחיוב עם קרדיט. כדי להתחיל, משתמשים בקרדיטים שמופיעים בבאנר בחלק העליון של ה-codelab. אם כבר קישרתם חשבון לחיוב, אתם יכולים לדלג על השלב הזה.
חלק שני: סביבה פתוחה
- 👈 לוחצים על הקישור הזה כדי לעבור ישירות אל Cloud Shell Editor
- 👉 אם מתבקשים לאשר בשלב כלשהו היום, לוחצים על אישור כדי להמשיך.
- 👈 אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף)
 .
.
- 👈💻 בטרמינל, מוודאים שכבר עברתם אימות ושהפרויקט מוגדר למזהה הפרויקט שלכם באמצעות הפקודה הבאה:
gcloud auth list - 👈💻 משכפלים את פרויקט ה-bootstrap מ-GitHub:
git clone https://github.com/gca-americas/way-back-home.git
חלק שלישי: יצירת פרויקט חדש
👈💻 בטרמינל, הופכים את סקריפט ההפעלה לקובץ הפעלה ומפעילים פתרונות חכמים:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ הגדרת הסביבה
1. פתיחת Cloud Shell
בטרמינל של Cloud Shell Editor, אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף).
2. הגדרת הפרויקט
👈💻 במסוף, מגדירים את מזהה הפרויקט:
gcloud config set project $(cat ~/project_id.txt) --quiet
👈💻 מפעילים את ממשקי ה-API הנדרשים (הפעולה הזו אורכת כ-2-3 דקות):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. הרצת סקריפט ההגדרה
👈💻 מריצים את סקריפט ההגדרה:
cd ~/way-back-home/level_2
./setup.sh
המערכת תיצור בשבילכם את .env. ב-Cloud Shell, פותחים את way_back_homeproject. בתיקייה level_2, אפשר לראות שנוצר בשבילכם הקובץ .env. אם לא מוצאים אותו, אפשר ללחוץ על View -> Toggle Hidden File כדי לראות אותו. 
4. טעינת נתונים לדוגמה
👈💻 עוברים לחלק האחורי של האתר ומתקינים את יחסי התלות:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 טעינת נתוני הניצולים הראשוניים:
uv run python ~/way-back-home/level_2/backend/setup_data.py
הפעולה הזו יוצרת:
- מכונת Spanner (
survivor-network) - מסד נתונים (
graph-db) - כל טבלאות הצמתים והקשתות
- תרשימי מאפיינים לשאילתות הפלט הצפוי:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
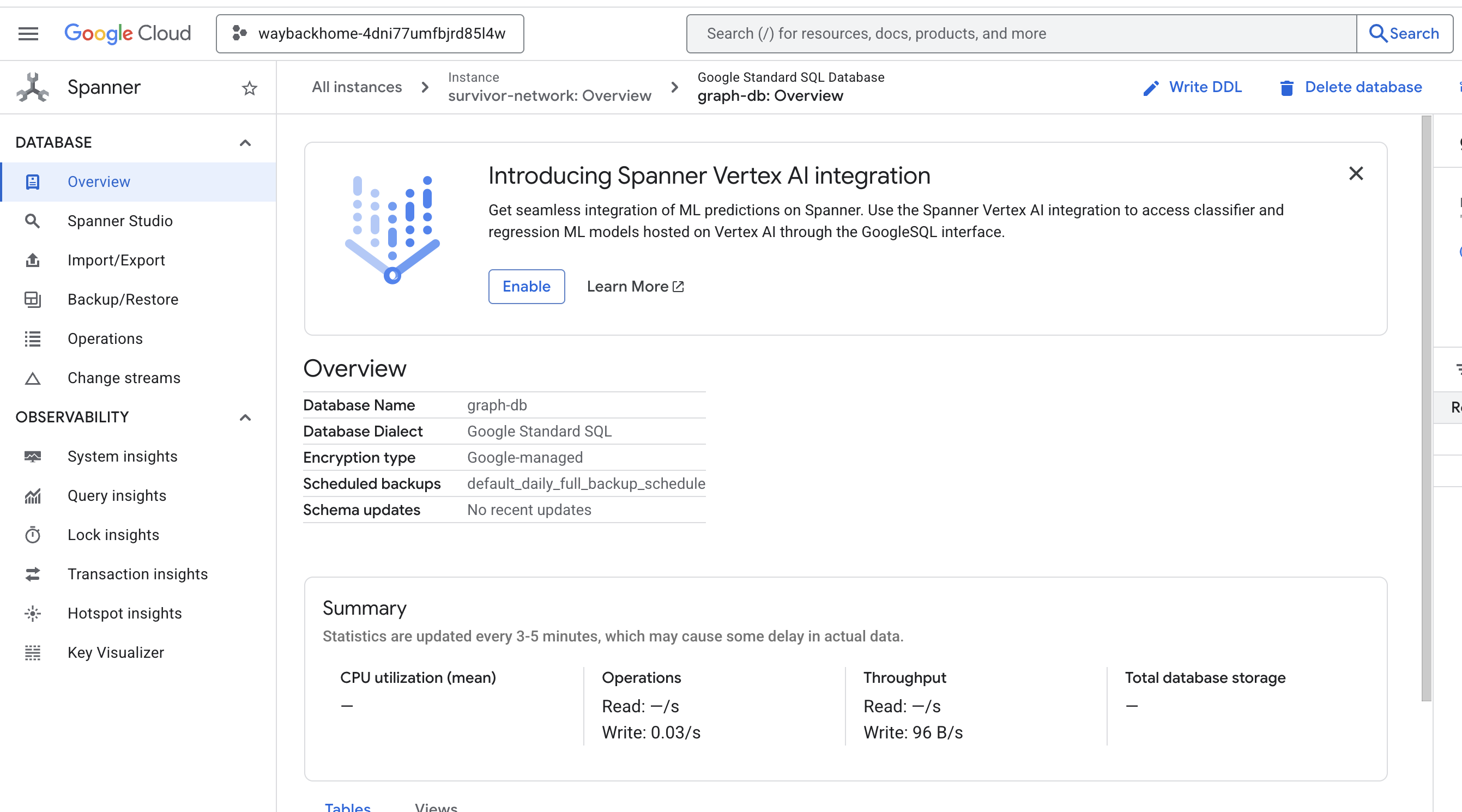
אם לוחצים על הקישור אחרי Access your database at בפלט, אפשר לפתוח את מסוף Google Cloud Spanner.

Spanner יופיע במסוף Google Cloud.
4. 🚀 המחשה חזותית של נתוני גרף ב-Spanner Studio
במדריך הזה נסביר איך להציג את הנתונים של גרף רשת הניצולים ולקיים איתם אינטראקציה ישירות במסוף Google Cloud באמצעות Spanner Studio. זו דרך מצוינת לאמת את הנתונים ולהבין את מבנה הגרף לפני שיוצרים את סוכן ה-AI.
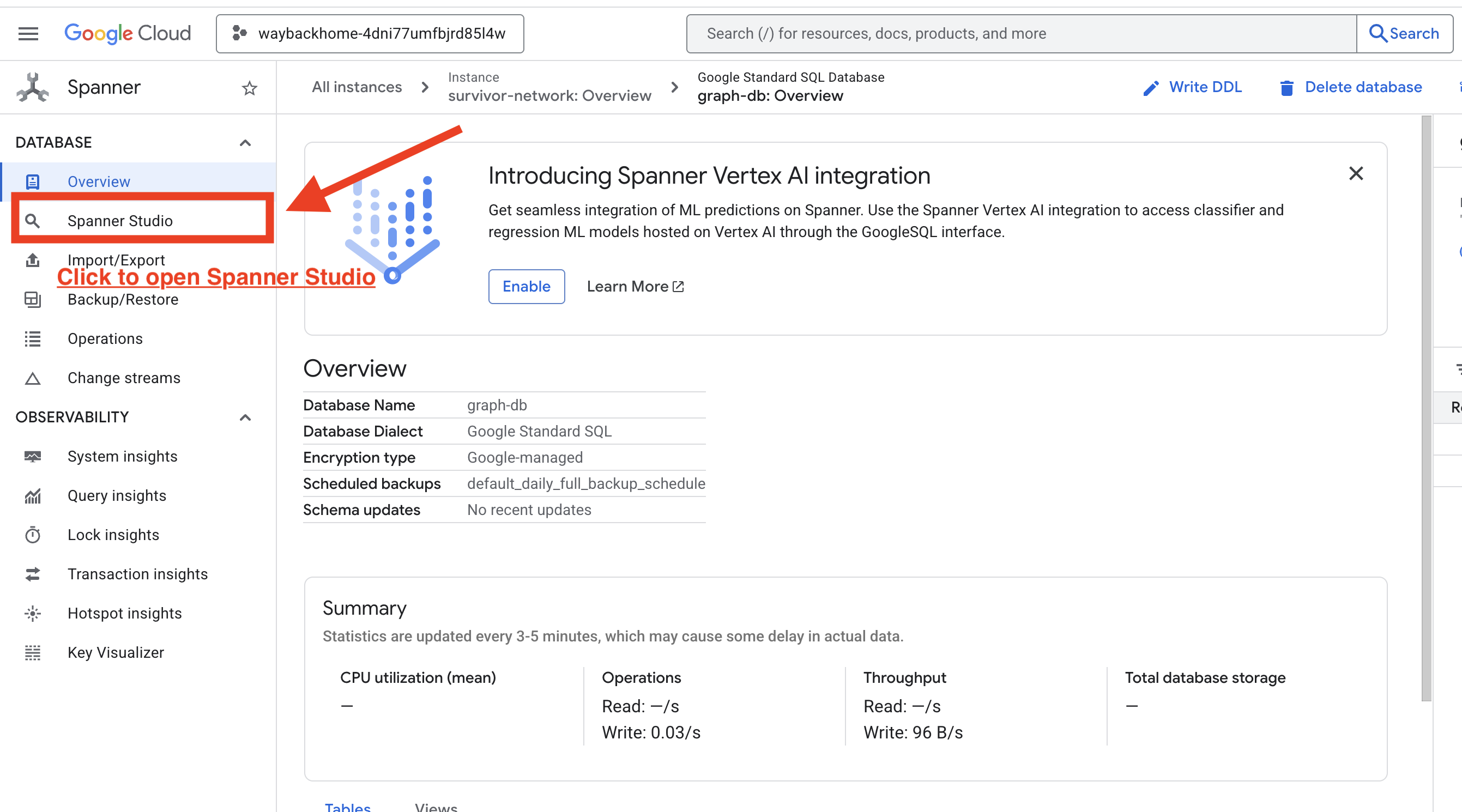
1. גישה ל-Spanner Studio
- בשלב האחרון, לוחצים על הקישור ופותחים את Spanner Studio.
2. הסבר על מבנה הגרף (התמונה הגדולה)
אפשר לחשוב על מערך הנתונים של Survivor Network כעל חידה לוגית או מצב משחק:
ישות | תפקיד במערכת | אנלוגיה |
Survivors | הסוכנים/השחקנים | שחקנים |
Biomes | איפה הם נמצאים | אזורים במפה |
מיומנויות | מה הם יכולים לעשות | פעולות שניתן לבצע |
צריך | מה חסר להם (משברים) | קווסטים/משימות |
מקורות מידע | פריטים שנמצאו בעולם | שלל |
המטרה: התפקיד של סוכן ה-AI הוא לקשר בין כישורים (פתרונות) לבין צרכים (בעיות), תוך התחשבות בביומים (מגבלות מיקום).
🔗 קצוות (קשרים):
-
SurvivorInBiome: מעקב אחר מיקום -
SurvivorHasSkill: מלאי יכולות SurvivorHasNeed: רשימת הבעיות הפעילות-
SurvivorFoundResource: מלאי פריטים -
SurvivorCanHelp: קשר משוער (ה-AI מחשב את זה!)
3. שאילתות בגרף
נריץ כמה שאילתות כדי לראות את הסיפור שמאחורי הנתונים.
Spanner Graph משתמש ב-GQL (Graph Query Language). כדי להריץ שאילתה, משתמשים ב-GRAPH SurvivorNetwork ואחריו בדפוס ההתאמה.
👈 שאילתה 1: רשימת התלמידים הגלובלית (מי נמצא איפה?) זהו הבסיס שלכם – הבנה של מיקום היא קריטית לפעולות חילוץ.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
התוצאה שצפויה להתקבל היא: 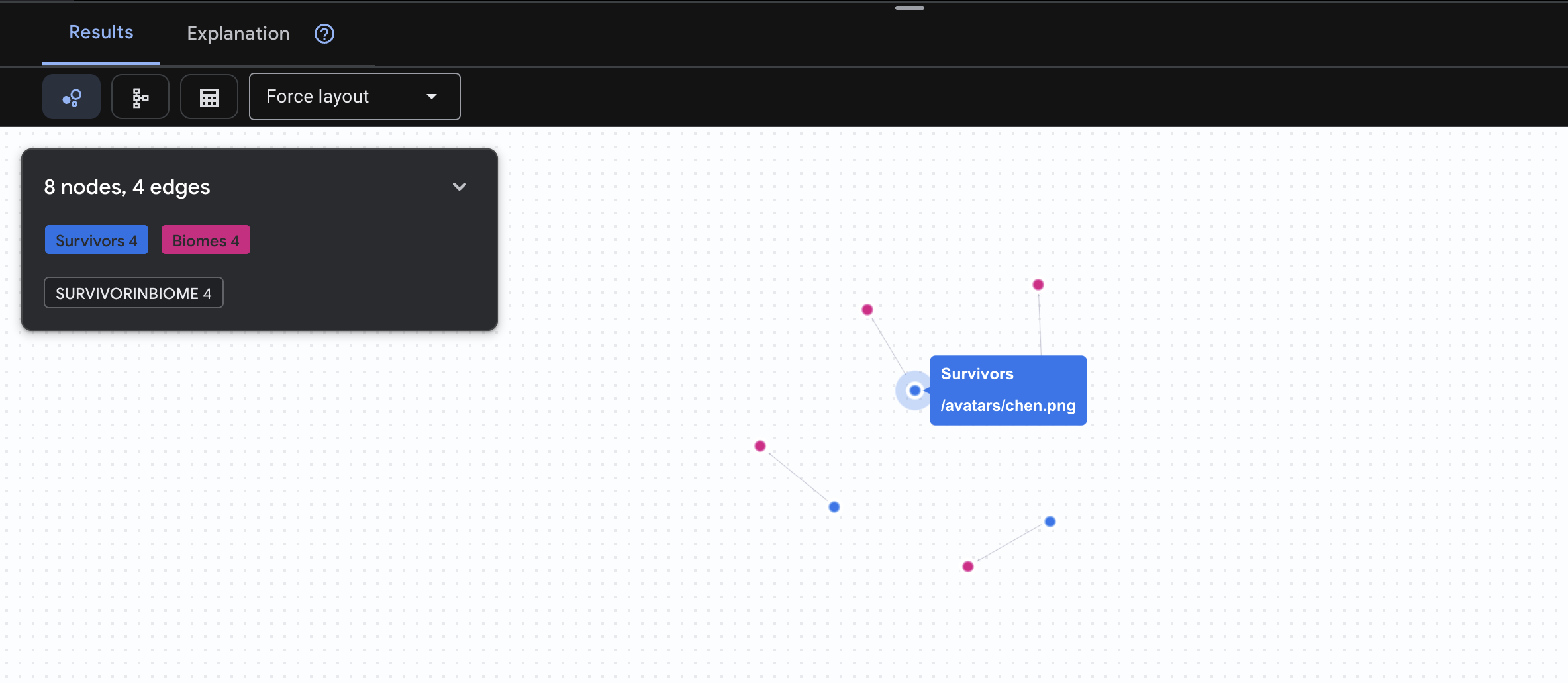
👉 שאילתה 2: מטריצת הכישורים (יכולות) אחרי שגיליתם איפה כולם נמצאים, הגיע הזמן לגלות מה הם יכולים לעשות.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
התוצאה שצפויה להתקבל היא: 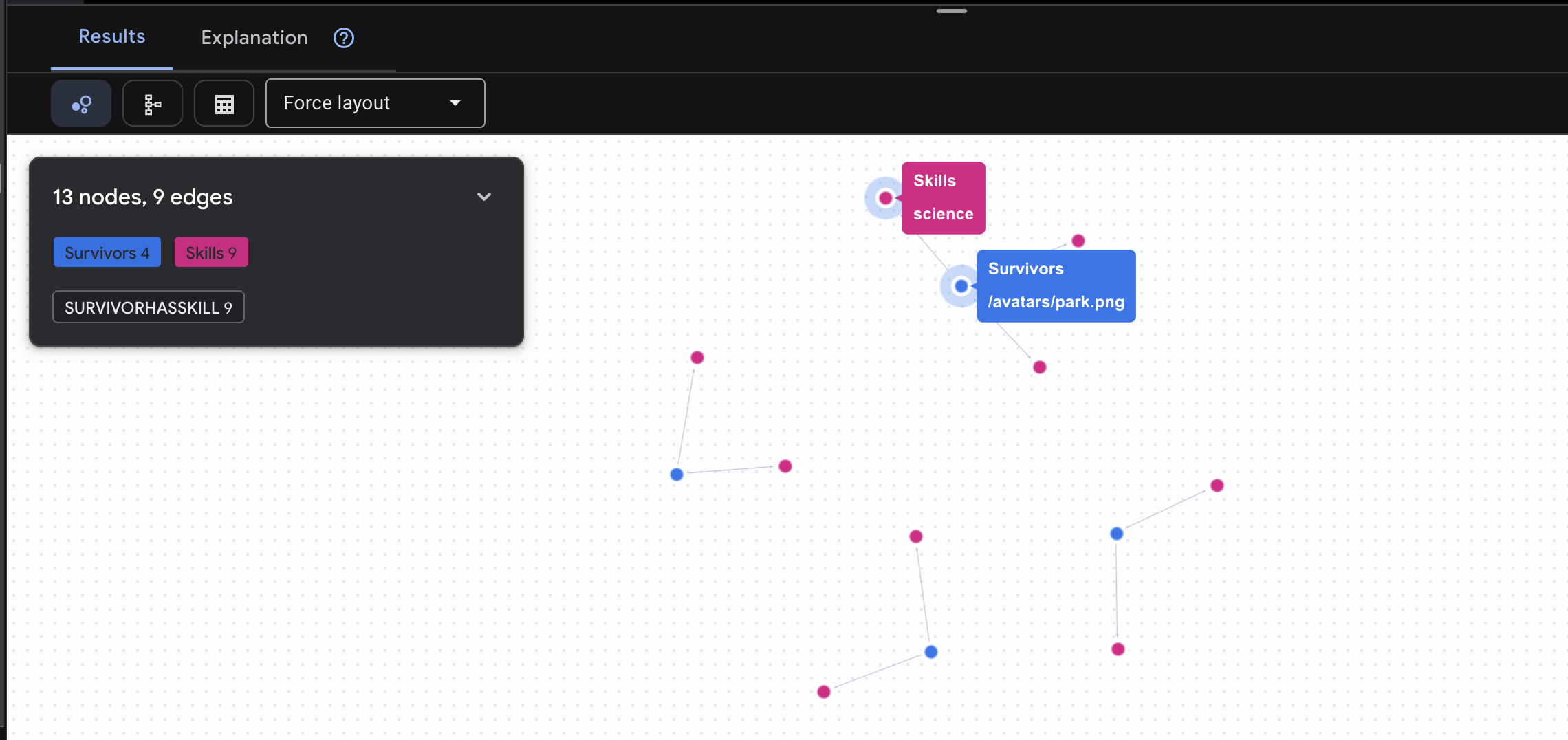
👉 שאילתה 3: מי נמצא במשבר? (לוח המשימות) אפשר לראות את הניצולים שזקוקים לעזרה ואת מה שהם צריכים.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
התוצאה שצפויה להתקבל היא: 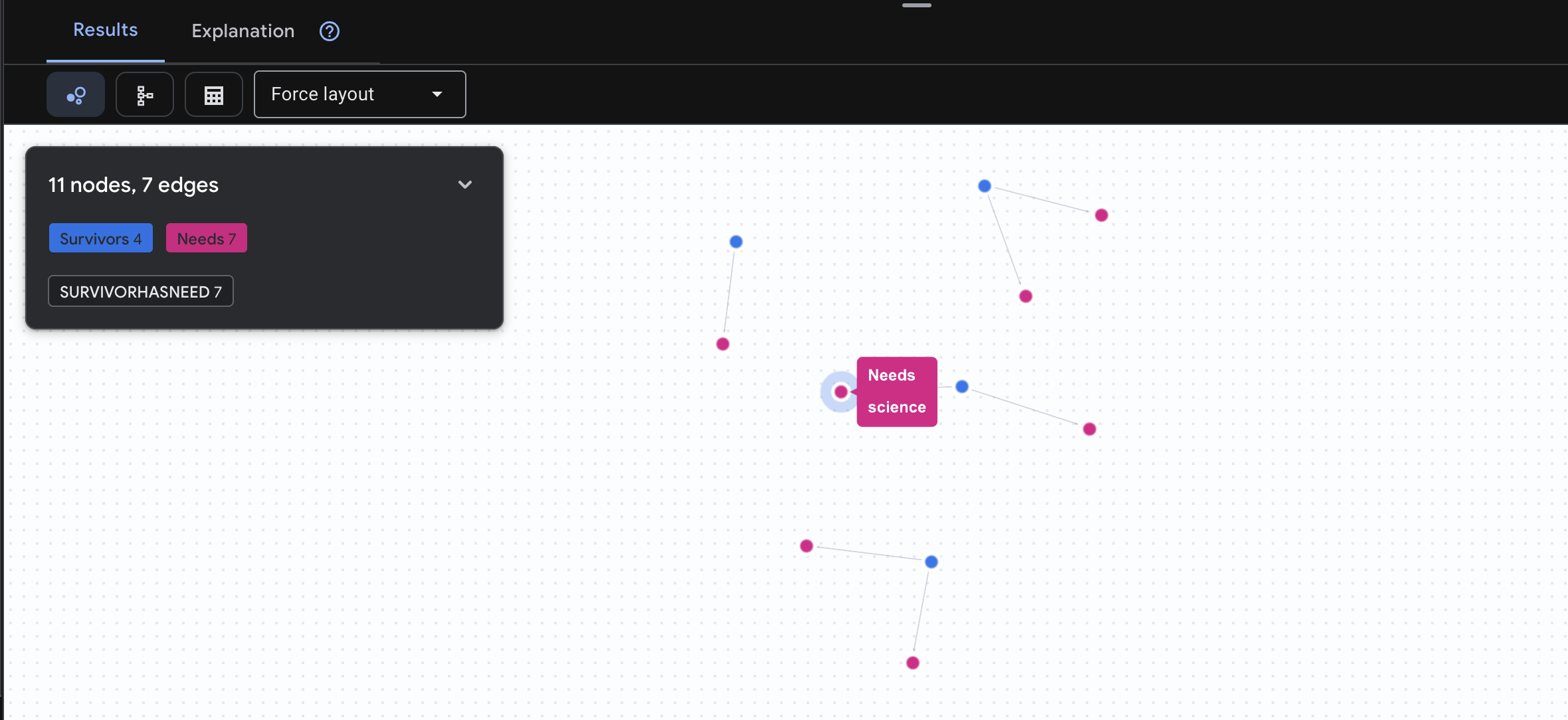
🔎 [אופציונלי] שידוך – מי יכול לעזור למי?
כאן הגרף הופך ליעיל במיוחד. השאילתה הזו מוצאת שורדים שיש להם כישורים שיכולים לעזור לשורדים אחרים.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
התוצאה שצפויה להתקבל היא: 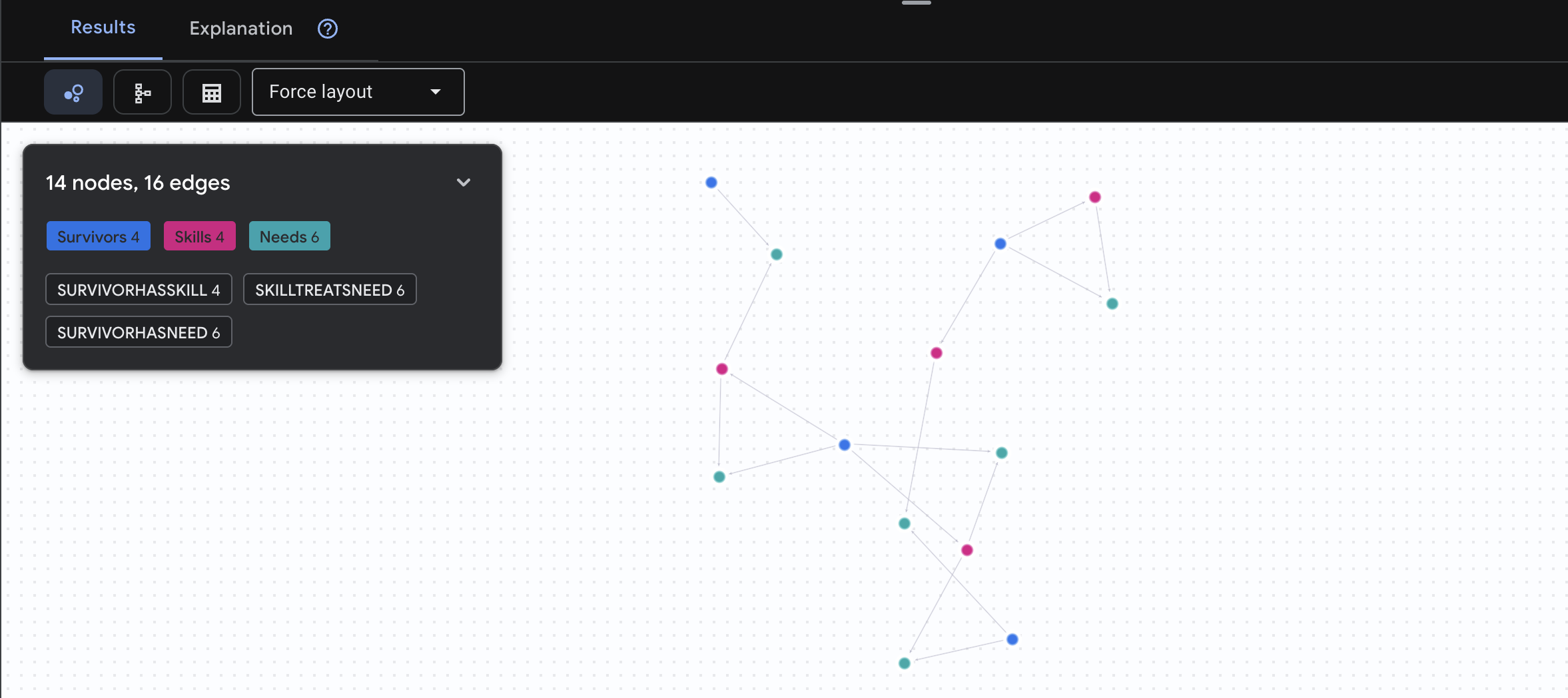
aside positive What This Query Does:
במקום להציג רק את התוצאה 'עזרה ראשונה לטיפול בכוויות' (שברורה מהסכימה), השאילתה הזו מוצאת:
- ד"ר אלנה פרוסט (שיש לה הכשרה רפואית) ← יכולה לטפל ב- ← קפטן טנאקה (שסובל מכוויות)
- דוד כהן (שיש לו ציוד לעזרה ראשונה) ← יכול לטפל ב- ← סגן פארק (שנקע את הקרסול)
למה זה חשוב:
מה סוכן ה-AI יעשה:
כשמשתמש ישאל "מי יכול לטפל בכוויות?", הסוכן יבצע את הפעולות הבאות:
- הרצת שאילתת גרף דומה
- החזרה: "Dr. Frost has Medical Training and can help Captain Tanaka"
- המשתמש לא צריך לדעת על טבלאות או קשרים ביניים.
5. 🚀 AI-Powered Embeddings in Spanner
1. למה כדאי להשתמש בהטמעות? (ללא פעולה, קריאה בלבד)
בתרחיש ההישרדות, הזמן הוא קריטי. כשניצול או ניצולה מדווחים על מקרה חירום, כמו I need someone who can treat burns או Looking for a medic, הם לא יכולים לבזבז זמן בניסיון לנחש את השמות המדויקים של הכישורים במסד הנתונים.
תרחיש אמיתי: Survivor: Captain Tanaka has burns—we need medical help NOW!
חיפוש מילות מפתח מסורתי של 'רופא' → 0 תוצאות ❌
חיפוש סמנטי עם הטמעות ← מוצא את 'הדרכה רפואית', 'עזרה ראשונה' ✅
זה בדיוק מה שהסוכנים צריכים: חיפוש חכם שדומה לחיפוש של בני אדם ומבין את הכוונה, ולא רק מילות מפתח.
2. יצירת מודל הטמעה
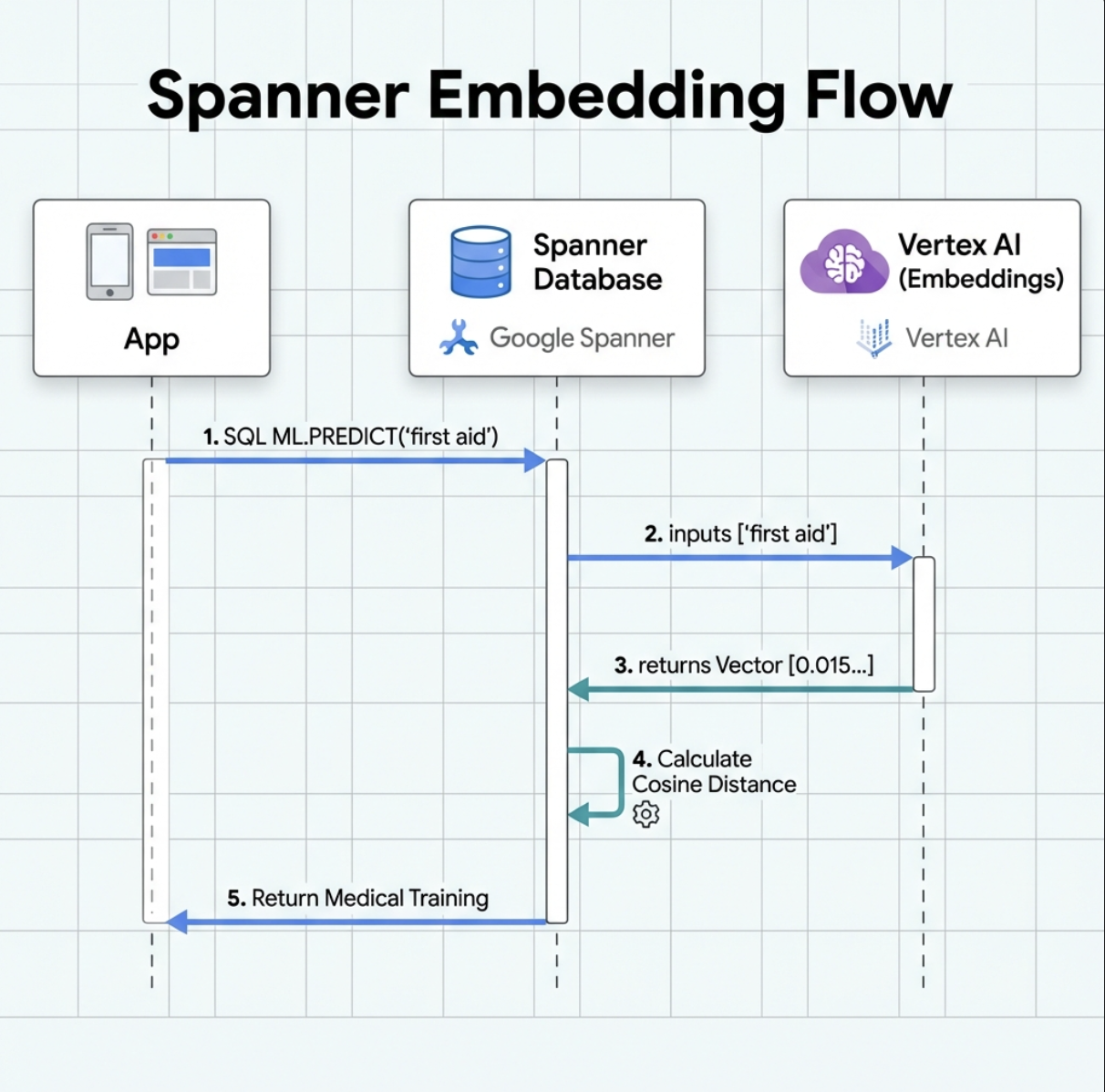
עכשיו ניצור מודל שממיר טקסט להטמעות באמצעות text-embedding-004 של Google.
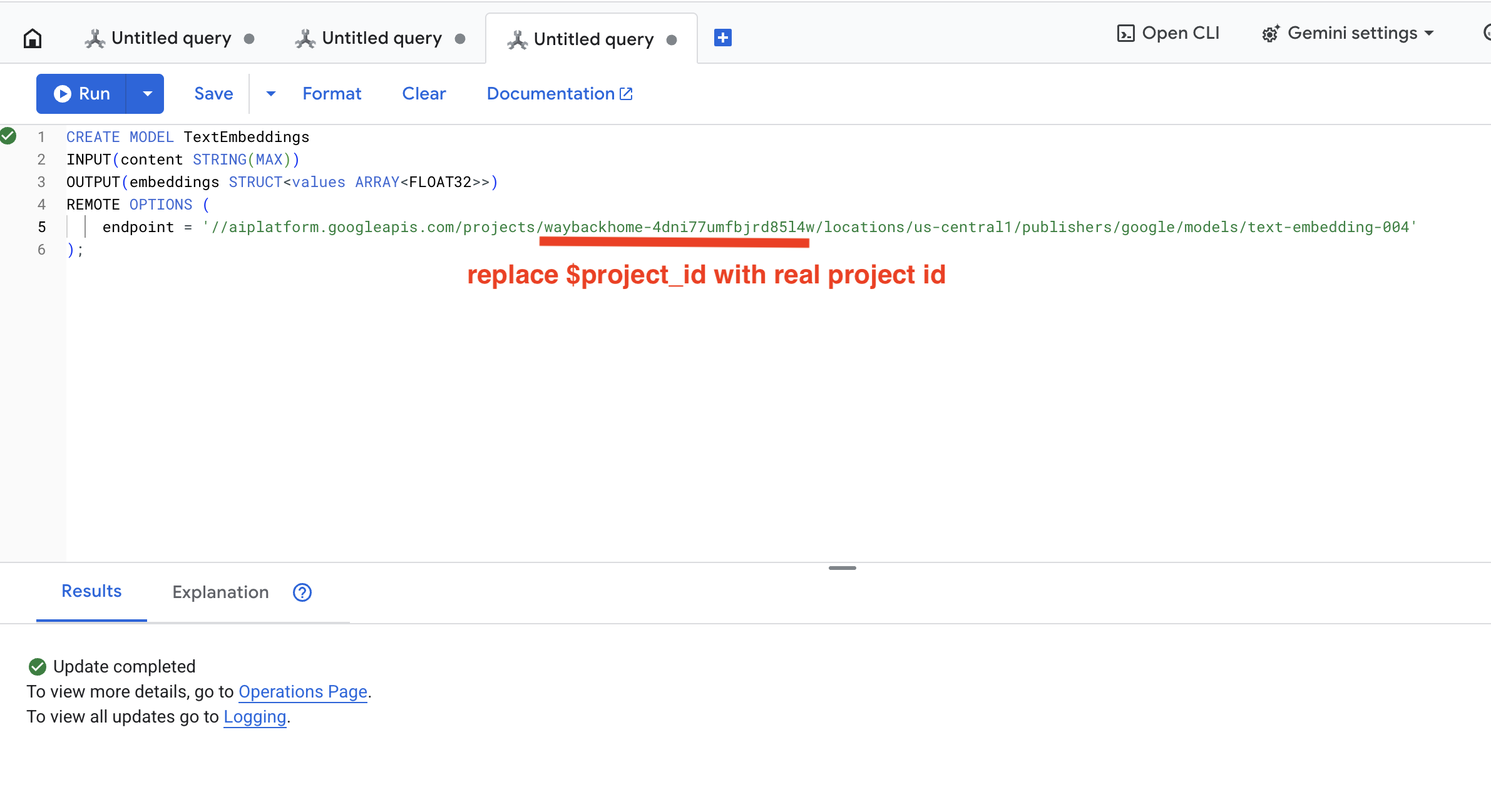
👈 ב-Spanner Studio, מריצים את ה-SQL הזה (מחליפים את $YOUR_PROJECT_ID במזהה הפרויקט בפועל):
‼️ בעורך של Cloud Shell, פותחים את File -> Open Folder -> way-back-home/level_2 כדי לראות את הפרויקט כולו.
👈 מריצים את השאילתה הזו ב-Spanner Studio על ידי העתקה והדבקה של השאילתה שלמטה, ואז לוחצים על הלחצן Run:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
מה זה עושה:
- יוצרת מודל וירטואלי ב-Spanner (משקלי המודל לא נשמרים באופן מקומי)
- נקודות ל-
text-embedding-004של Google ב-Vertex AI - הגדרת החוזה: הקלט הוא טקסט, הפלט הוא מערך של מספרים ממשיים עם 768 ממדים
למה 'אפשרויות מרחוק'?
- Spanner לא מפעיל את המודל עצמו
- הוא קורא ל-Vertex AI באמצעות API כשמשתמשים ב-
ML.PREDICT - Zero-ETL: אין צורך לייצא נתונים ל-Python, לעבד אותם ולייבא אותם מחדש
לוחצים על הלחצן Run. אחרי שהפעולה תצליח, התוצאה תופיע כמו בדוגמה הבאה:
3. הוספת עמודה של הטמעה
👉 מוסיפים עמודה לאחסון הטמעות:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
לוחצים על הלחצן Run. אחרי שהפעולה תצליח, התוצאה תופיע כמו בדוגמה הבאה:
4. יצירת הטמעות
👉 שימוש ב-AI כדי ליצור הטמעות וקטוריות לכל מיומנות:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
לוחצים על הלחצן Run. אחרי שהפעולה תצליח, התוצאה תופיע כמו בדוגמה הבאה:
מה קורה: כל שם של מיומנות (למשל, "עזרה ראשונה") מומר לווקטור של 768 ממדים שמייצג את המשמעות הסמנטית שלו.
5. אימות ההטמעות
👈 בודקים שההטמעות נוצרו:
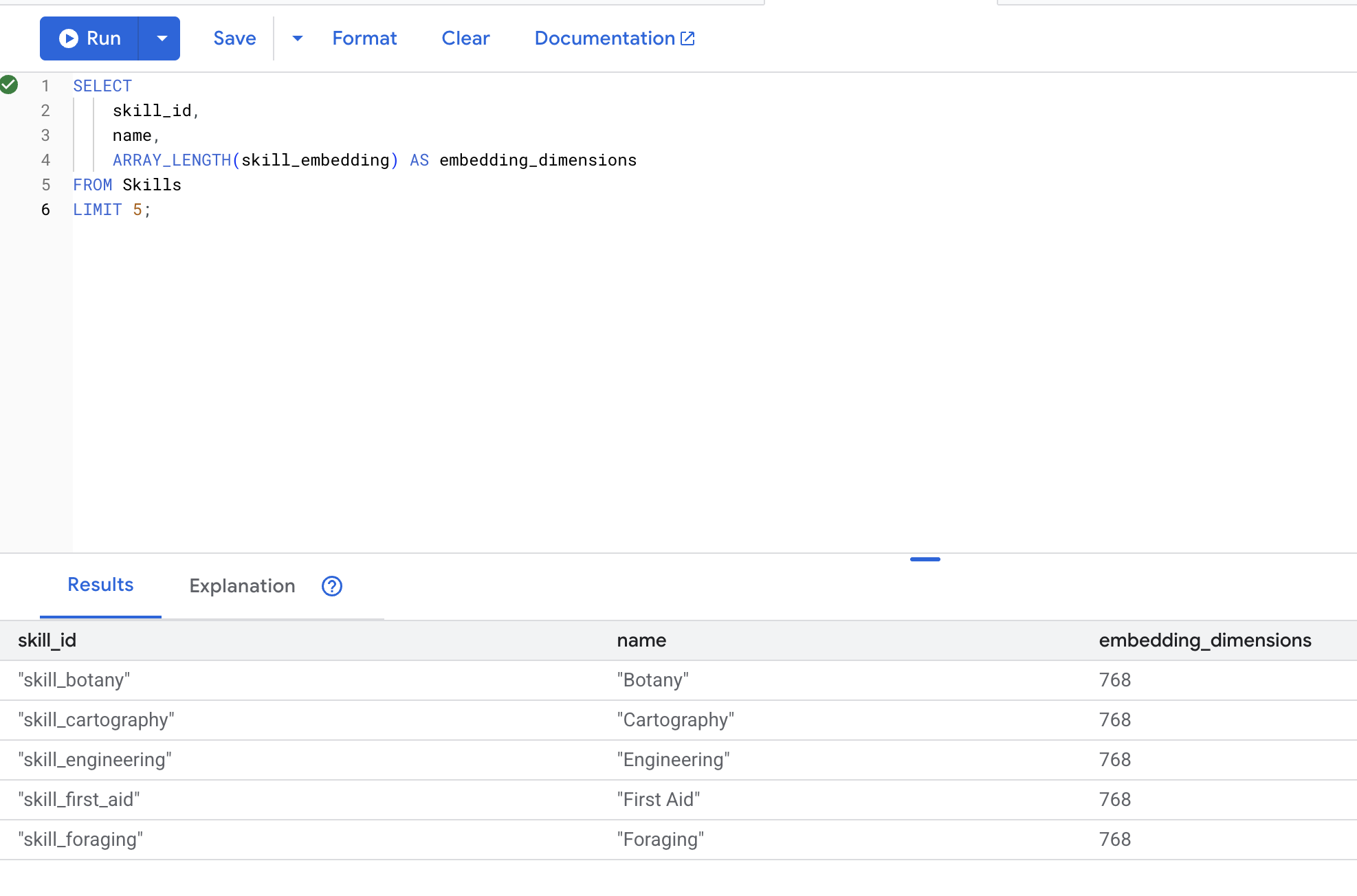
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
הפלט המצופה:
6. בדיקת חיפוש סמנטי
עכשיו נבדוק את תרחיש השימוש המדויק מהדוגמה שלנו: חיפוש כישורים רפואיים באמצעות המונח "חובש".
👉 חיפוש מיומנויות דומות ל'חובש':
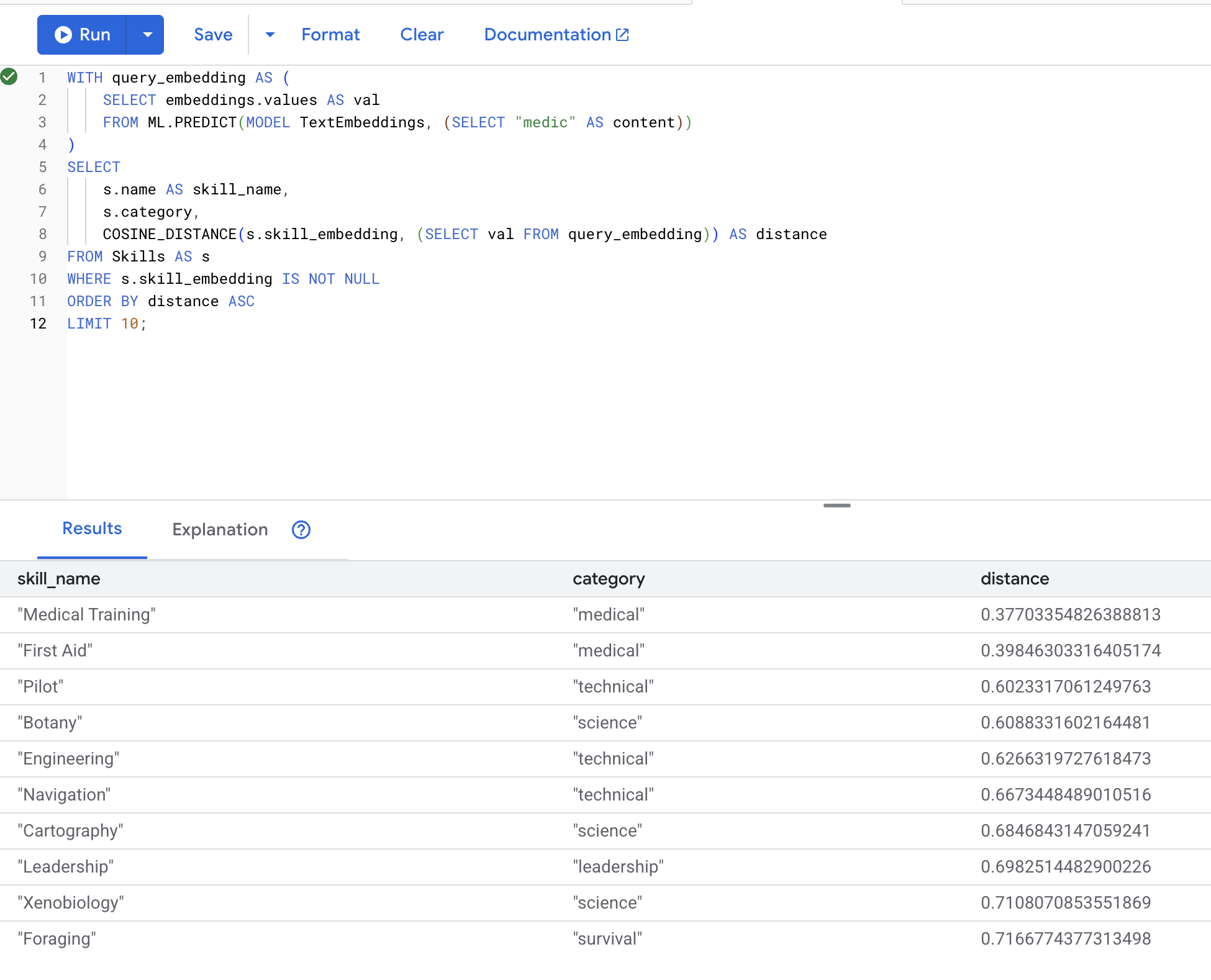
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- המרת מונח החיפוש של המשתמש 'רופא' להטמעה
- מאחסן אותו ב
query_embeddingטבלה זמנית
התוצאות הצפויות (מרחק קטן יותר = דמיון רב יותר):
7. יצירת מודל Gemini לניתוח
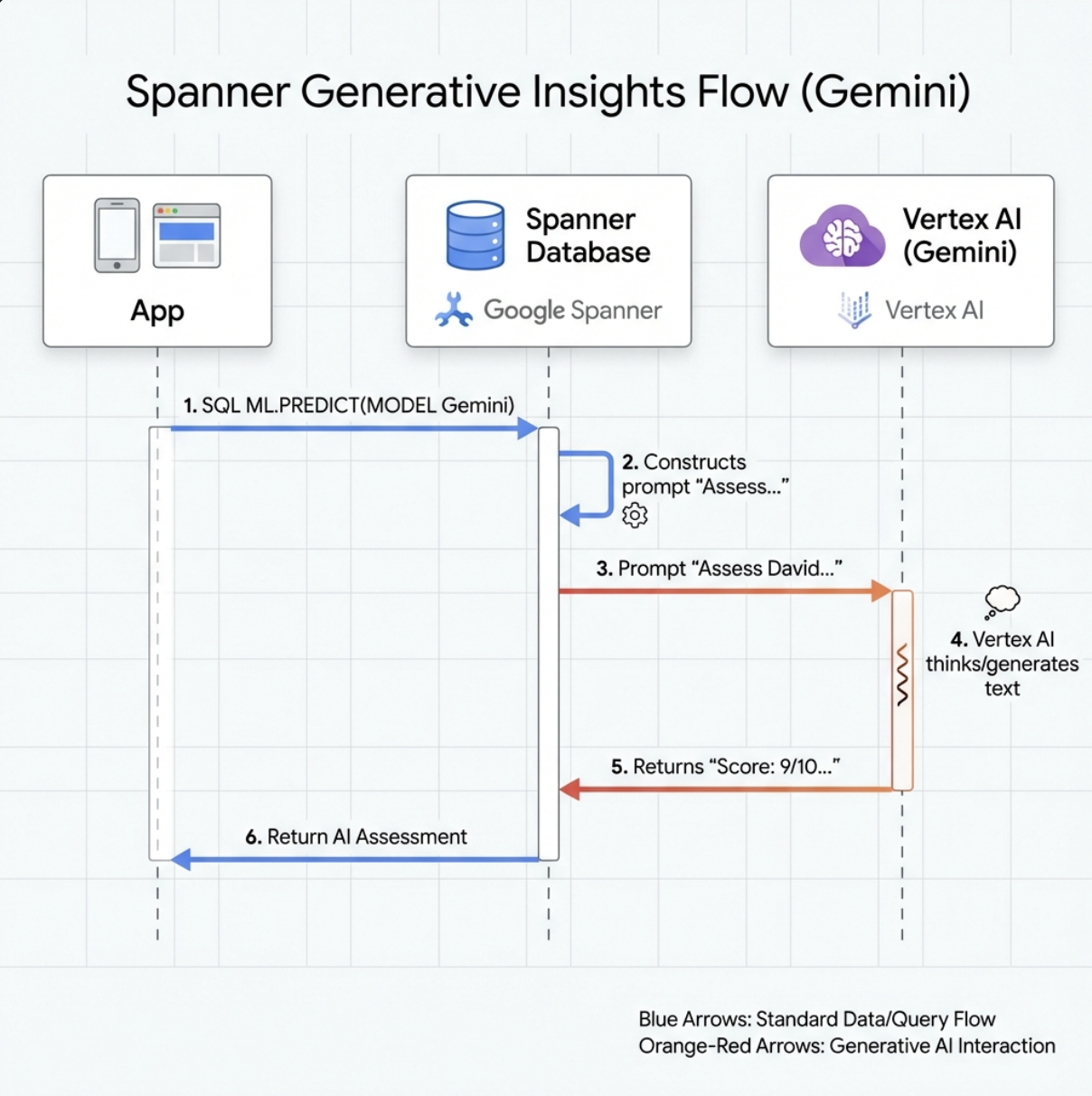
👈 יוצרים הפניה למודל AI גנרטיבי (מחליפים את $YOUR_PROJECT_ID במזהה הפרויקט בפועל):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
הבדל ממודל ההטמעות:
- הטמעות: טקסט → וקטור (לחיפוש דמיון)
- Gemini: טקסט ← טקסט שנוצר (לנימוק או לניתוח)
8. שימוש ב-Gemini לניתוח תאימות
👉 ניתוח של זוגות שורדים לצורך התאמה למשימה:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
הפלט המצופה:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 יצירת סוכן Graph RAG באמצעות חיפוש היברידי
1. סקירה כללית של ארכיטקטורת המערכת
בקטע הזה נבנה מערכת חיפוש מרובת שיטות שמאפשרת לסוכן לטפל בגמישות בסוגים שונים של שאילתות. למערכת יש שלוש שכבות: שכבת הסוכן, שכבת הכלים ושכבת השירות.
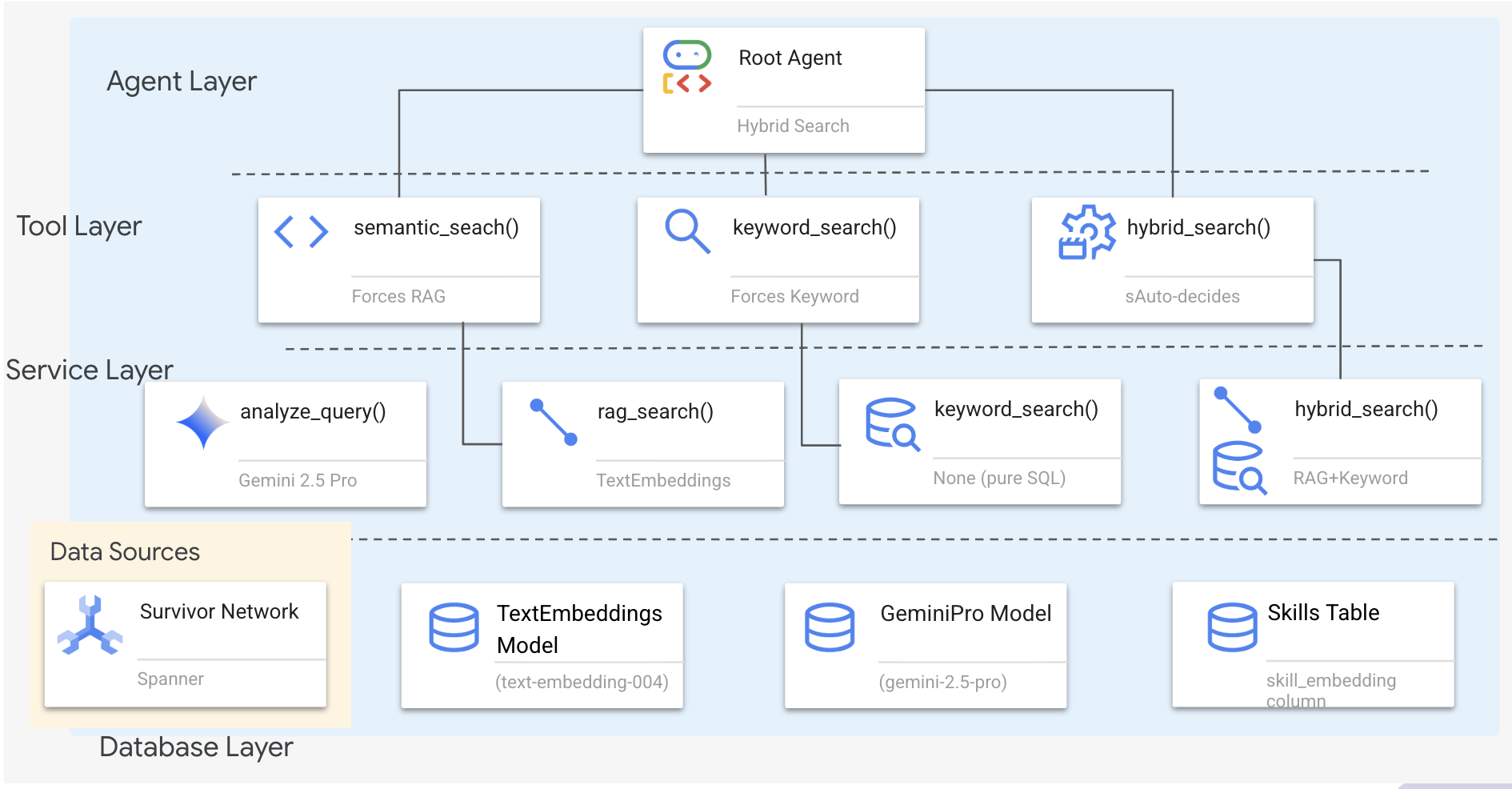
למה שלוש שכבות?
- הפרדה בין תחומים: הסוכן מתמקד בכוונה, כלי העבודה בממשק והשירות בהטמעה
- גמישות: הסוכן יכול להפעיל שיטות ספציפיות או לאפשר ל-AI לבצע ניתוב אוטומטי
- אופטימיזציה: אפשר לדלג על ניתוח יקר של AI כשהשיטה ידועה
בקטע הזה, תטמיעו בעיקר חיפוש סמנטי (RAG) – חיפוש תוצאות לפי משמעות ולא רק לפי מילות מפתח. בהמשך נסביר איך חיפוש היברידי משלב כמה שיטות.
2. הטמעה של שירות RAG
👈💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
איתור התגובה # TODO: REPLACE_SQL
מחליפים את כל השורה הזו בקוד הבא:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. הגדרה של כלי לחיפוש סמנטי
👈💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
ב-hybrid_search_tools.py, מאתרים את התגובה # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👈Replace this whole line with the following code:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
When Agent Uses:
- שאילתות שבהן מבקשים למצוא משהו דומה ("find similar to X")
- שאילתות מושגיות ("יכולות ריפוי")
- מתי חשוב להבין את המשמעות
4. מדריך להחלטות של סוכן (הוראות)
בהגדרת הסוכן, מעתיקים ומדביקים את החלק שקשור לחיפוש סמנטי להוראה.
👈💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
הסוכן משתמש בהוראה הזו כדי לבחור את הכלי המתאים:
👈 בקובץ agent.py, מאתרים את התגובה # TODO: REPLACE_SEARCH_LOGIC, Replace this whole line ומחליפים אותה בקוד הבא:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉מאתרים את ההערה # TODO: ADD_SEARCH_TOOLReplace this whole line ומחליפים אותה בקוד הבא:
semantic_search, # Force RAG
5. הסבר על אופן הפעולה של חיפוש היברידי (לקריאה בלבד, לא נדרשת פעולה)
בשלבים 2-4, הטמעתם חיפוש סמנטי (RAG), שיטת החיפוש העיקרית שמוצאת תוצאות לפי משמעות. אבל יכול להיות ששמתם לב שהמערכת נקראת 'חיפוש היברידי'. כך הכל מתחבר:
איך מיזוג היברידי עובד:
בקובץ way-back-home/level_2/backend/services/hybrid_search_service.py, כשקוראים ל-hybrid_search(), השירות מריץ את שני החיפושים וממזג את התוצאות:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
ב-codelab הזה הטמעתם את רכיב החיפוש הסמנטי (RAG), שהוא הבסיס. השיטות של מילות המפתח והשיטה ההיברידית כבר מוטמעות בשירות – הנציג שלכם יכול להשתמש בכל שלוש השיטות.
מעולה! סיימתם בהצלחה את סוכן ה-RAG שלכם עם חיפוש היברידי!
7. 🚀 בדיקת הסוכן באמצעות ADK Web
הדרך הקלה ביותר לבדוק את הסוכן היא באמצעות הפקודה adk web, שמפעילה את הסוכן עם ממשק צ'אט מובנה.
1. הרצת הסוכן
👈💻 עוברים לספריית ה-Backend (שבה מוגדר הנציג) ומפעילים את ממשק האינטרנט::
cd ~/way-back-home/level_2/backend
uv run adk web
הפקודה הזו מפעילה את הסוכן שמוגדר ב-
agent/agent.py
ונפתח ממשק אינטרנט לבדיקה.
👉 פותחים את כתובת ה-URL:
הפקודה תחזיר כתובת URL מקומית (בדרך כלל http://127.0.0.1:8000 או דומה). פותחים את הקובץ בדפדפן.
אחרי שתלחצו על כתובת ה-URL, תראו את ממשק האינטרנט של ADK. חשוב לוודא שבוחרים את הסוכן בפינה הימנית העליונה.
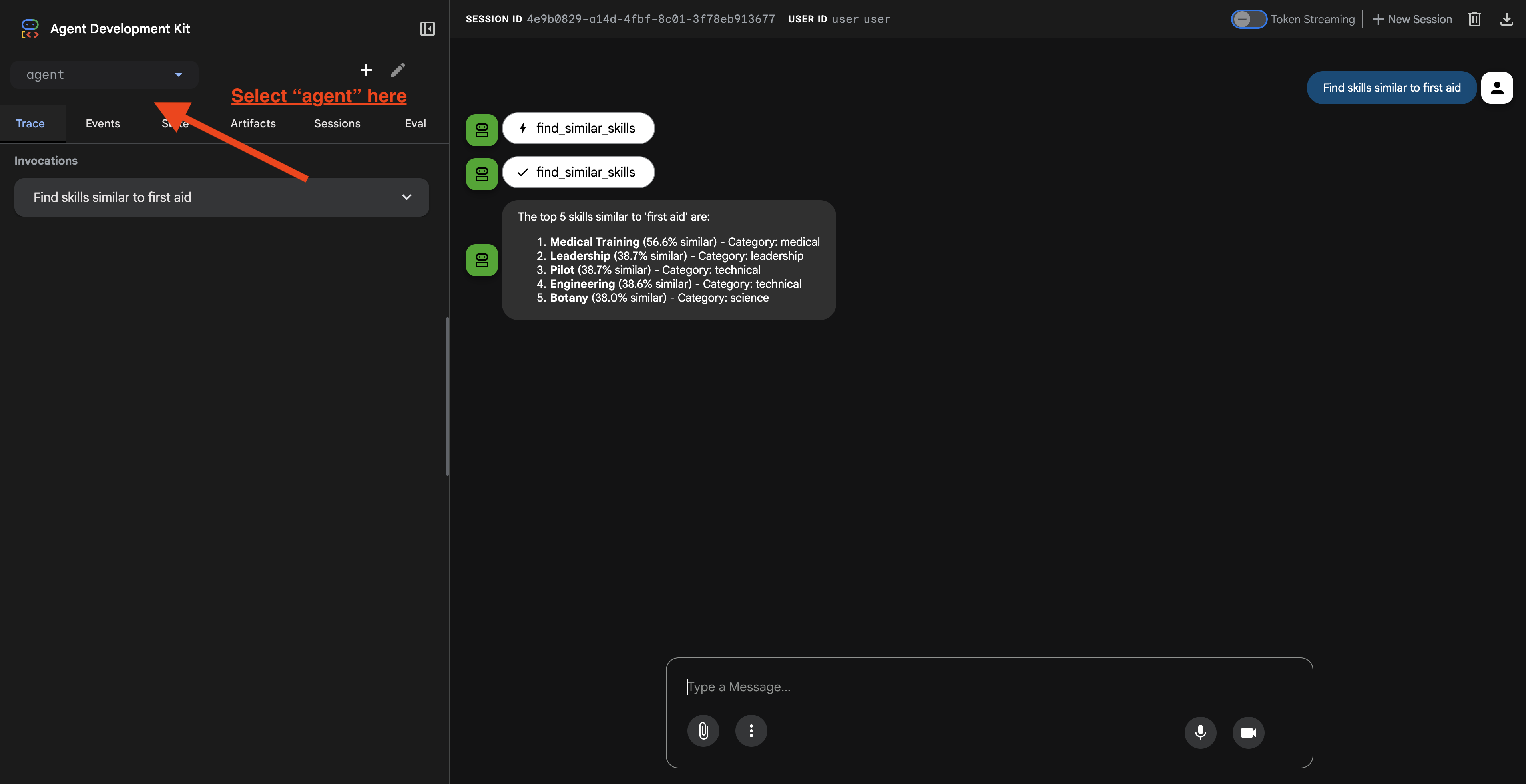
2. בדיקת יכולות החיפוש
הסוכן נועד לנתב את השאילתות שלכם בצורה חכמה. כדי לראות שיטות חיפוש שונות בפעולה, נסו להזין את הקלט הבא בחלון הצ'אט.
🧬 א. Graph RAG (חיפוש סמנטי)
החיפוש מתבצע על סמך משמעות ומושג, גם אם מילות המפתח לא תואמות.
שאילתות לבדיקה: (בוחרים אחת מהאפשרויות הבאות)
Who can help with injuries?
What abilities are related to survival?
מה צריך לחפש:
- ההסבר צריך לכלול את המילים סמנטי או RAG.
- אמורות להופיע תוצאות שקשורות מבחינה רעיונית (לדוגמה, 'ניתוח' כשמבקשים 'עזרה ראשונה').
- התוצאות יכללו את הסמל 🧬.
🔀 ב. חיפוש היברידי
משלב בין מסנני מילות מפתח לבין הבנה סמנטית של שאילתות מורכבות.
שאילתות לבדיקה:(בוחרים אחת מהאפשרויות הבאות)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
מה צריך לחפש:
- בהסבר צריך לציין חיפוש היברידי.
- התוצאות צריכות להתאים לשני הקריטריונים (קונספט + מיקום/קטגוריה).
- לתוצאות שנמצאו בשתי השיטות יופיע הסמל 🔀 והן ידורגו במקום הגבוה ביותר.
👈💻 כשמסיימים את הבדיקה, מקישים על Ctrl+C בשורת הפקודה כדי לסיים את התהליך.
8. 🚀 הפעלת האפליקציה המלאה
סקירה כללית על ארכיטקטורת Full Stack
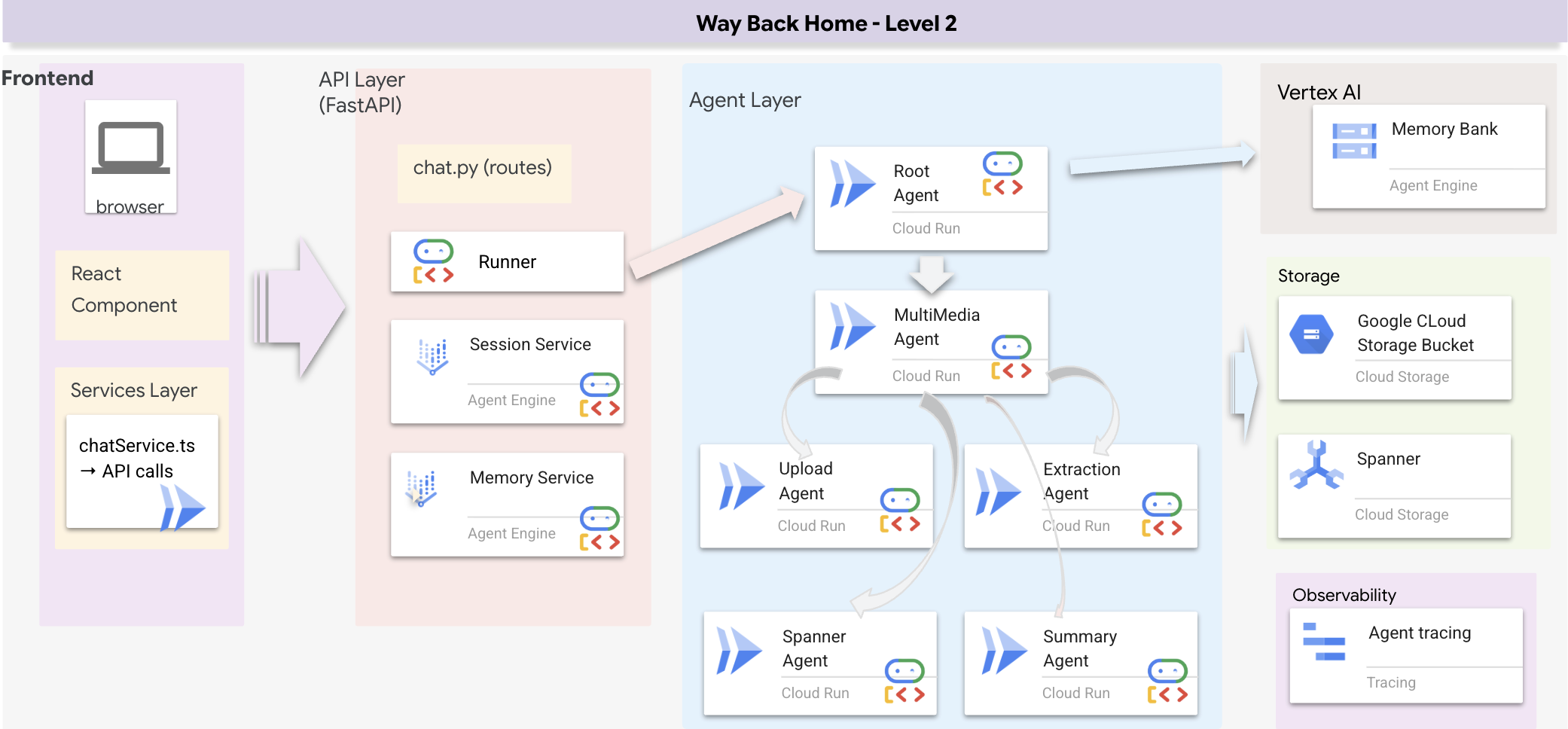
הוספת SessionService ו-Runner
👈💻 בטרמינל, פותחים את הקובץ chat.py ב-Cloud Shell Editor על ידי הפעלת הפקודה (חשוב לוודא שלחצתם על Ctrl+C כדי לסיים את התהליך הקודם לפני שתמשיכו):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👈בקובץ chat.py, מאתרים את התגובה # TODO: REPLACE_INMEMORY_SERVICES, Replace this whole line ומחליפים אותה בקוד הבא:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👈בקובץ chat.py, מאתרים את התגובה # TODO: REPLACE_RUNNER, Replace this whole line ומחליפים אותה בקוד הבא:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. הגשת בקשה
אם הטרמינל הקודם עדיין פועל, מקישים על Ctrl+C כדי לסיים את הפעולה שלו.
👉💻 הפעלת האפליקציה:
cd ~/way-back-home/level_2/
./start_app.sh
כשהקצה העורפי יופעל בהצלחה, תופיע ההודעה Local: http://localhost:5173/" כמו בדוגמה הבאה: 
👈 לוחצים על Local: http://localhost:5173/ במסוף.
2. בדיקת חיפוש סמנטי
שאילתה:
Find skills similar to healing
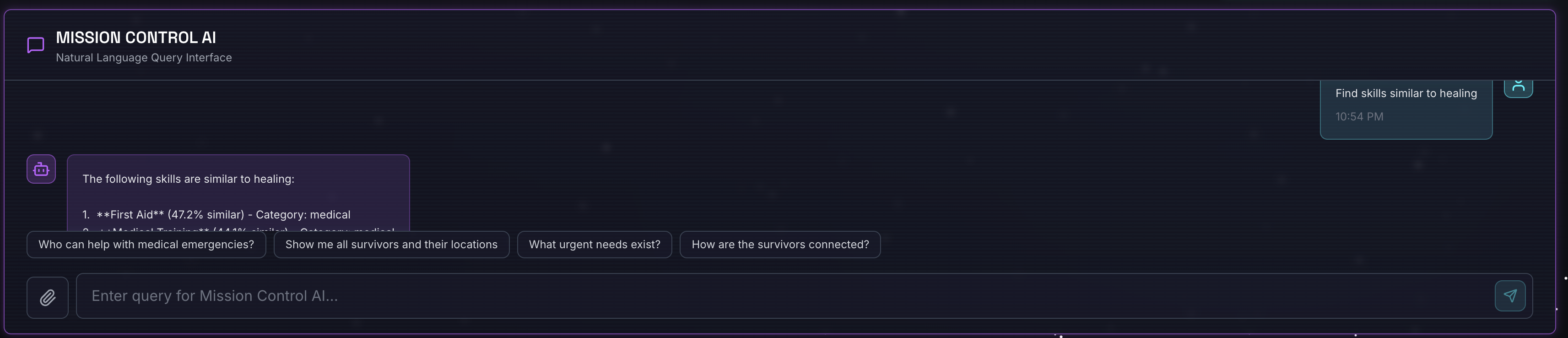
מה קורה:
- הסוכן מזהה בקשה לחיפוש דמיון
- יוצר הטמעה של המילה healing
- משתמש במרחק קוסינוס כדי למצוא מיומנויות דומות מבחינה סמנטית
- התוצאה: עזרה ראשונה (למרות שהשמות לא תואמים ל'ריפוי')
3. בדיקת חיפוש היברידי
שאילתה:
Find medical skills in the mountains
מה קורה:
- רכיב מילות מפתח: סינון לפי
category='medical' - רכיב סמנטי: הטמעה של 'רפואי' ודירוג לפי דמיון
- מיזוג: שילוב התוצאות, עם עדיפות לתוצאות שנמצאו בשתי השיטות 🔀
שאילתה(אופציונלי):
Who is good at survival and in the forest?
מה קורה:
- מילות מפתח שנמצאו:
biome='forest' - חיפוש סמנטי: מיומנויות דומות ל'הישרדות'
- השיטה ההיברידית משלבת בין שתי השיטות כדי להשיג את התוצאות הטובות ביותר
👈💻 כשמסיימים את הבדיקה, מקישים על Ctrl+C במסוף כדי לסיים אותה.
4. (!רק למשתתפי הסדנה) עדכון המיקום
👈💻 מריצים את סקריפט ההשלמה:
cd ~/way-back-home/level_2
./set_level_2.sh
עכשיו פותחים את waybackhome.dev ורואים שהמיקום עודכן. כל הכבוד, סיימת את רמה 2!

9. ☕️ [אופציונלי] פייפליין מולטי-מודאלי (לקריאה בלבד) – שכבת כלי פיתוח
למה צריך פייפליין מולטי-מודאלי?
הרשת לתמיכה בניצולי אלימות היא לא רק טקסט. ניצולים בשטח שולחים נתונים לא מובנים ישירות דרך הצ'אט:
- 📸 תמונות: תמונות של משאבים, סיכונים או ציוד
- 🎥 סרטונים: דוחות סטטוס או שידורי SOS
- 📄 Text: הערות או יומנים מהשטח
אילו קבצים אנחנו מעבדים?
בניגוד לשלב הקודם שבו חיפשנו נתונים קיימים, כאן אנחנו מעבדים קבצים שהמשתמש העלה. הממשק של chat.py מטפל בקבצים מצורפים באופן דינמי:
מקור | תוכן | יעד |
User Attachment | תמונה/סרטון/טקסט | מידע להוספה לתרשים |
הקשר בצ'אט | "Here is a photo of the supplies" | כוונה ופרטים נוספים |
הגישה המתוכננת: פייפליין סוכנים רציף
אנחנו משתמשים בסוכן רציף (multimedia_agent.py) שמשלב בין סוכנים מיוחדים:
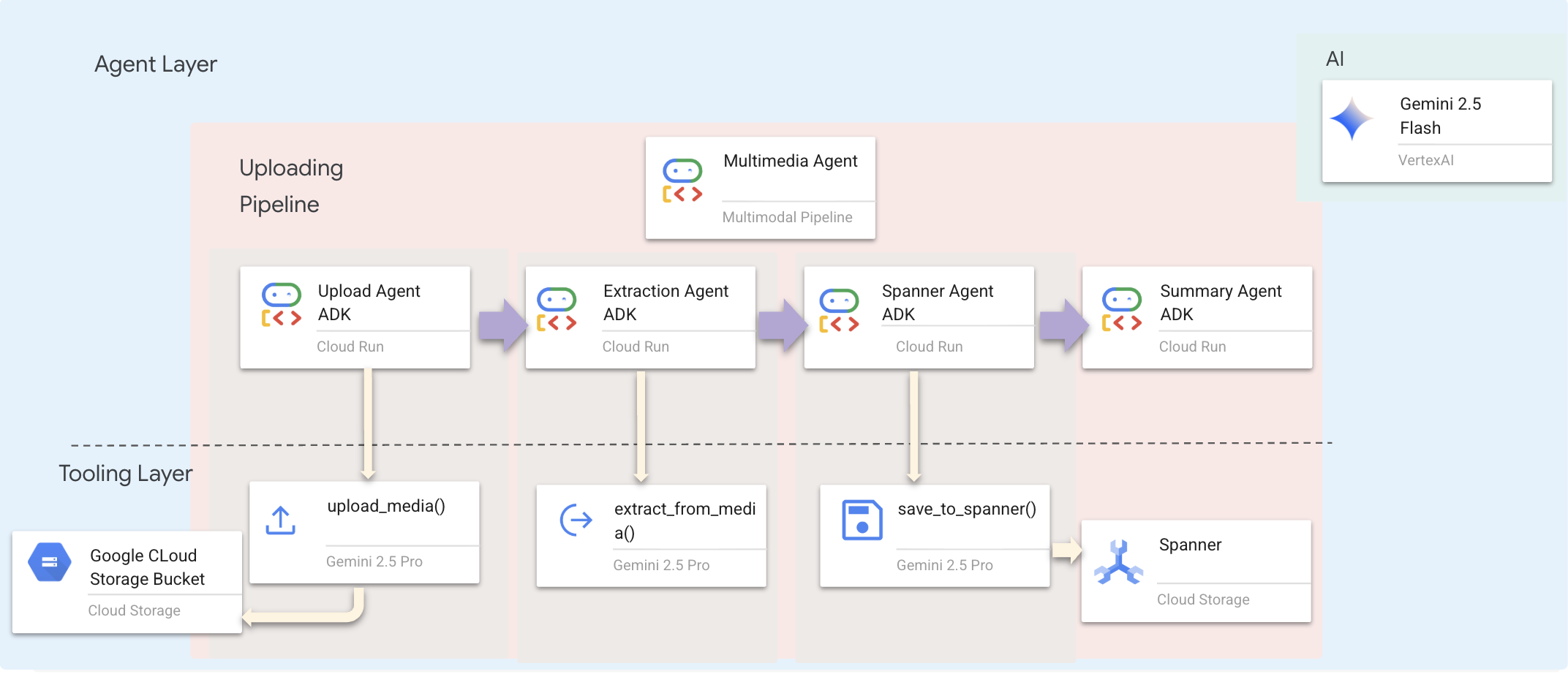
הוא מוגדר ב-backend/agent/multimedia_agent.py כSequentialAgent.
שכבת כלי העבודה מספקת את היכולות שהסוכנים יכולים להפעיל. הכלים מטפלים ב'איך' – העלאת קבצים, חילוץ ישויות ושמירה במסד הנתונים.
1. פתיחת קובץ הכלים
👈💻 פותחים את הקובץ level_2/backend/agent/tools/extraction_tools.py או מקלידים את הפקודה הבאה בטרמינל. פותחים טרמינל חדש. בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. הטמעה של כלי upload_media
הכלי הזה מעלה קובץ מקומי ל-Google Cloud Storage.
👈 ב-def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, הקוד הבא מתייחס להעלאת קבצים ל-GCS ולזיהוי הסוג שלהם:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. הטמעה של כלי extract_from_media
הכלי הזה הוא נתב – הוא בודק את media_type ושולח את הנתונים לחילוץ הנכון (טקסט, תמונה או סרטון).
👈 ב-async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, הקוד הבא מתייחס לאופן שבו מחלצים ישויות וקשרים מפריטי מדיה שהועלו.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
פרטי הטמעה חשובים:
- קלט מולטימודאלי: אנחנו מעבירים גם את הנחיית הטקסט (
_get_extraction_prompt()) וגם את אובייקט התמונה אלgenerate_content. - פלט מובנה:
response_mime_type="application/json"מוודא שמודל ה-LLM מחזיר JSON תקין, וזה קריטי לפייפליין. - קישור חזותי לישויות: ההנחיה כוללת ישויות מוכרות כדי ש-Gemini יוכל לזהות דמויות ספציפיות.
4. הטמעה של כלי save_to_spanner
הכלי הזה שומר את הישויות והקשרים שחולצו במסד הנתונים של Spanner Graph.
👉 ב-def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, קטע הקוד הבא מסביר איך לשמור ישויות ויחסים שחולצו במסד נתונים של Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
אנחנו מספקים לסוכנים כלים ברמה גבוהה כדי להבטיח תקינות נתונים, תוך ניצול יכולות ההסקה של הסוכן.
5. עדכון שירות GCS
הקובץ GCSService מטפל בהעלאה בפועל של הקובץ ל-Google Cloud Storage.
👈💻 פותחים את הקובץ level_2/backend/services/gcs_service.py, או מקלידים בטרמינל כדי לפתוח את הקובץ ב-Cloud Shell Editor:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 ב-def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, קטע הקוד הבא מסביר איך לשמור ישויות ויחסים שחולצו במסד נתונים של Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
ההפשטה הזו לשירות מאפשרת לסוכן לא לדעת על דלי GCS, על שמות של אובייקטים בינאריים גדולים (BLOB) או על יצירה של כתובות URL חתומות. הוא רק מבקש "להעלות".
6. למה כדאי להשתמש בתהליך עבודה מבוסס-סוכן > בגישות מסורתיות?
היתרון של סוכנים:
תכונה | צינור עיבוד נתונים באצווה | מבוסס על אירועים | תהליך עבודה אג'נטי |
מורכבות | נמוכה (סקריפט אחד) | גבוהה (5 שירותים ומעלה) | נמוך (קובץ Python אחד: |
State Management | משתנים גלובליים | קשה (לא משולב) | מאוחד (סטטוס של סוכן) |
טיפול בשגיאות | קריסות | יומנים שקטים | אינטראקטיבי ("לא הצלחתי לקרוא את הקובץ הזה") |
משוב ממשתמשים | הדפסות קונסולה | צריך להשתמש בסקר | מיידי (חלק מהצ'אט) |
גמישות | לוגיקה קבועה | פונקציות קשיחות | חכם (מודל LLM מחליט מה השלב הבא) |
Context Awareness | ללא | ללא | מלאה (מזהה את כוונת המשתמש) |
למה זה חשוב: באמצעות multimedia_agent.py (SequentialAgent עם 4 סוכני משנה: Upload → Extract → Save → Summary), אנחנו מחליפים תשתית מורכבת ותסריטים שבירים בלוגיקה חכמה של אפליקציה שיכולה לנהל שיחה.
10. ☕️ [אופציונלי] צינור עיבוד נתונים מולטימודאלי (קריאה בלבד) – שכבת הסוכן
שכבת הסוכנים מגדירה את האינטליגנציה – סוכנים שמשתמשים בכלים כדי לבצע משימות. לכל סוכן יש תפקיד ספציפי, והוא מעביר את ההקשר לסוכן הבא. בהמשך מופיע תרשים ארכיטקטורה של מערכת מרובת סוכנים.
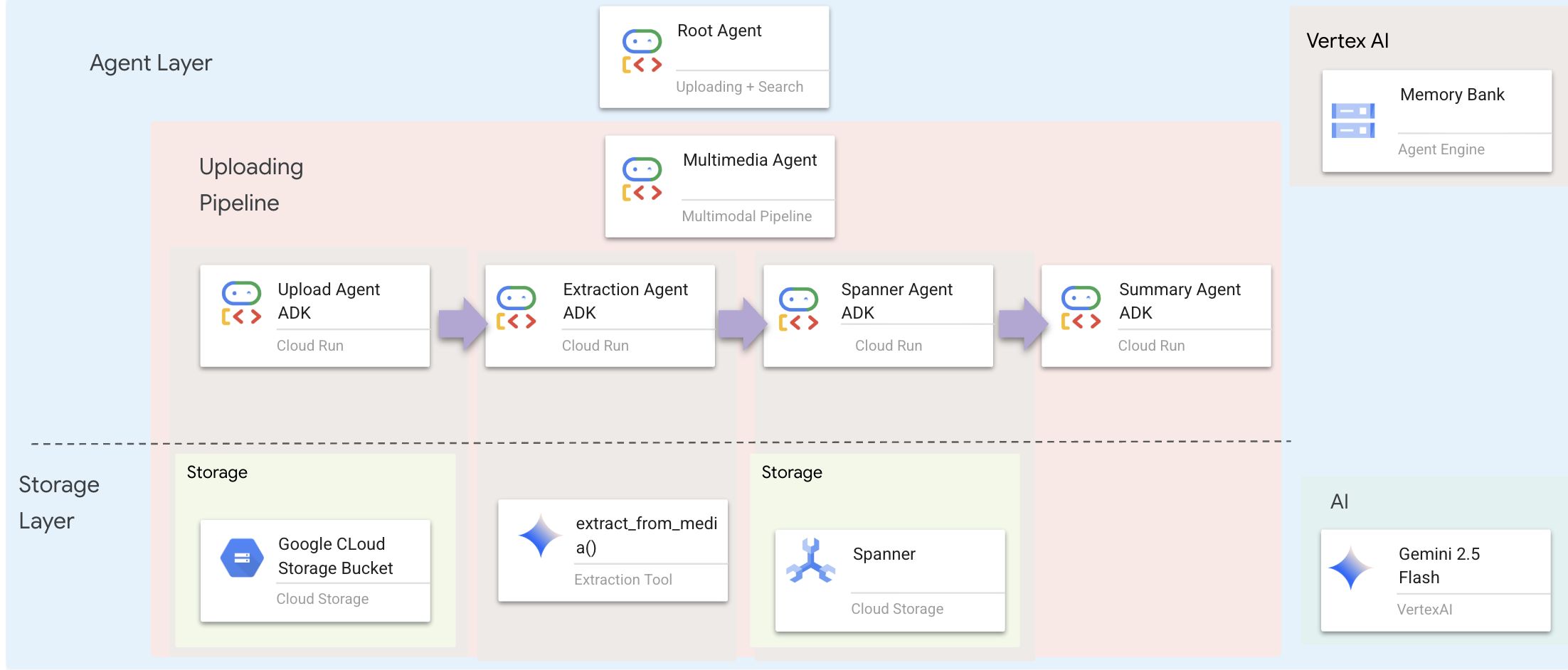
1. פתיחת קובץ הסוכן
👈💻 פותחים את הקובץ level_2/backend/agent/multimedia_agent.py או מקלידים את הפקודה הבאה בטרמינל. פותחים טרמינל חדש. בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. הגדרת סוכן ההעלאה
הסוכן הזה מחלץ נתיב קובץ מההודעה של המשתמש ומעלה אותו ל-GCS.
👈 בקובץ multimedia_agent.py, עם הקוד הבא, נוצר upload_agent שמועלה ל-GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. הגדרת סוכן החילוץ
הסוכן הזה 'רואה' את המדיה שהועלתה ומחלץ נתונים מובְנים באמצעות Gemini Vision.
👉בקובץ multimedia_agent.py, עם הקוד הבא, נוצר extraction_agent שמחלץ מידע מהמדיה שהועלתה:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
שימו לב לאופן שבו instruction מפנה אל {upload_result} – כך הסטטוס מועבר בין סוכנים ב-ADK.
4. הגדרת סוכן Spanner
הסוכן הזה שומר את הישויות והקשרים שחולצו במסד הנתונים הגרפי.
👈בקובץ multimedia_agent.py, עם הקוד הבא, נוצר spanner_agent ששומר את המידע שחולץ במסד הנתונים:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
הנציג הזה מקבל הקשר משני השלבים הקודמים (upload_result ו-extraction_result).
5. הגדרת סוכן הסיכום
הסוכן הזה מסכם את התוצאות מכל השלבים הקודמים לתשובה ידידותית למשתמש.
👈 בקובץ multimedia_agent.py, הקוד הבא מגדיר את ההנחיה ל-summary_agent שמסכמת את התוצאה:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
הסוכן הזה לא צריך כלים – הוא רק קורא את ההקשר המשותף ומפיק סיכום ברור למשתמש.
🧠 סיכום הארכיטקטורה
שכבה | קובץ | אחריות |
כלים |
| איך — העלאה, חילוץ ושמירה |
Agent |
| מה – תזמור הפייפליין |
11. 🚀 צינור עיבוד נתונים מולטימודאלי – תזמור
הליבה של המערכת החדשה שלנו היא MultimediaExtractionPipeline שמוגדר ב-backend/agent/multimedia_agent.py. הוא מבוסס על התבנית Sequential Agent מתוך ADK (ערכה לפיתוח סוכנים).
1. למה כדאי להשתמש בשיטה עוקבת?
עיבוד של העלאה הוא שרשרת של תלות לינארית:
- אי אפשר לחלץ נתונים עד שהקובץ (ההעלאה) יהיה זמין.
- אי אפשר לשמור נתונים לפני שמחלצים אותם (חילוץ).
- אי אפשר לסכם לפני שמקבלים את התוצאות (שמירה).
SequentialAgent הוא הפתרון המושלם. הוא מעביר את הפלט של סוכן אחד כהקשר או כקלט לסוכן הבא.
2. הגדרת הסוכן
בקטע הבא נראה איך הצינור מורכב בחלק התחתון של multimedia_agent.py: 👉💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הרצת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
הוא מקבל קלט משני השלבים הקודמים. מחפשים את התגובה # TODO: REPLACE_ORCHESTRATION. מחליפים את כל השורה הזו בקוד הבא:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. יצירת קשר עם נציג
👈💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
מחפשים את התגובה # TODO: REPLACE_ADD_SUBAGENT. מחליפים את כל השורה הזו בקוד הבא:
sub_agents=[multimedia_agent],
האובייקט הזה מאגד ארבעה "מומחים" בישות אחת שאפשר להפעיל.
4. זרימת נתונים בין סוכנים
כל סוכן שומר את הפלט שלו בהקשר משותף שסוכנים עוקבים יכולים לגשת אליו:
5. פתיחת האפליקציה (אפשר לדלג אם האפליקציה עדיין פועלת)
👉💻 הפעלת האפליקציה:
cd ~/way-back-home/level_2/
./start_app.sh
👈 לוחצים על Local: http://localhost:5173/ במסוף.
6. בדיקת העלאת תמונה
👈 בממשק הצ'אט, בוחרים תמונה ומעלים אותה לממשק:
בממשק הצ'אט, מסבירים לסוכן את ההקשר הספציפי:
Here is the survivor note
ואז לצרף את התמונה כאן.

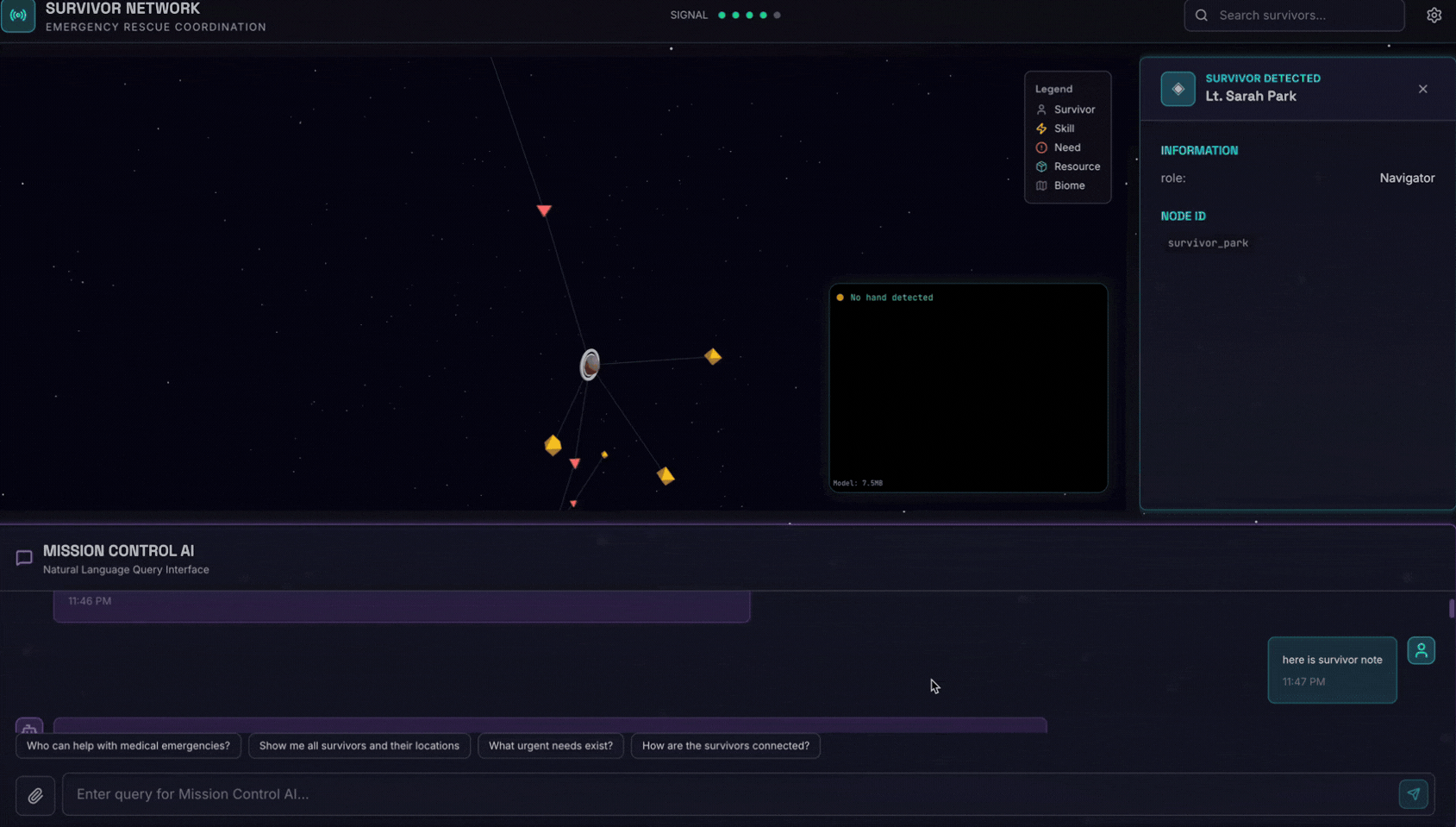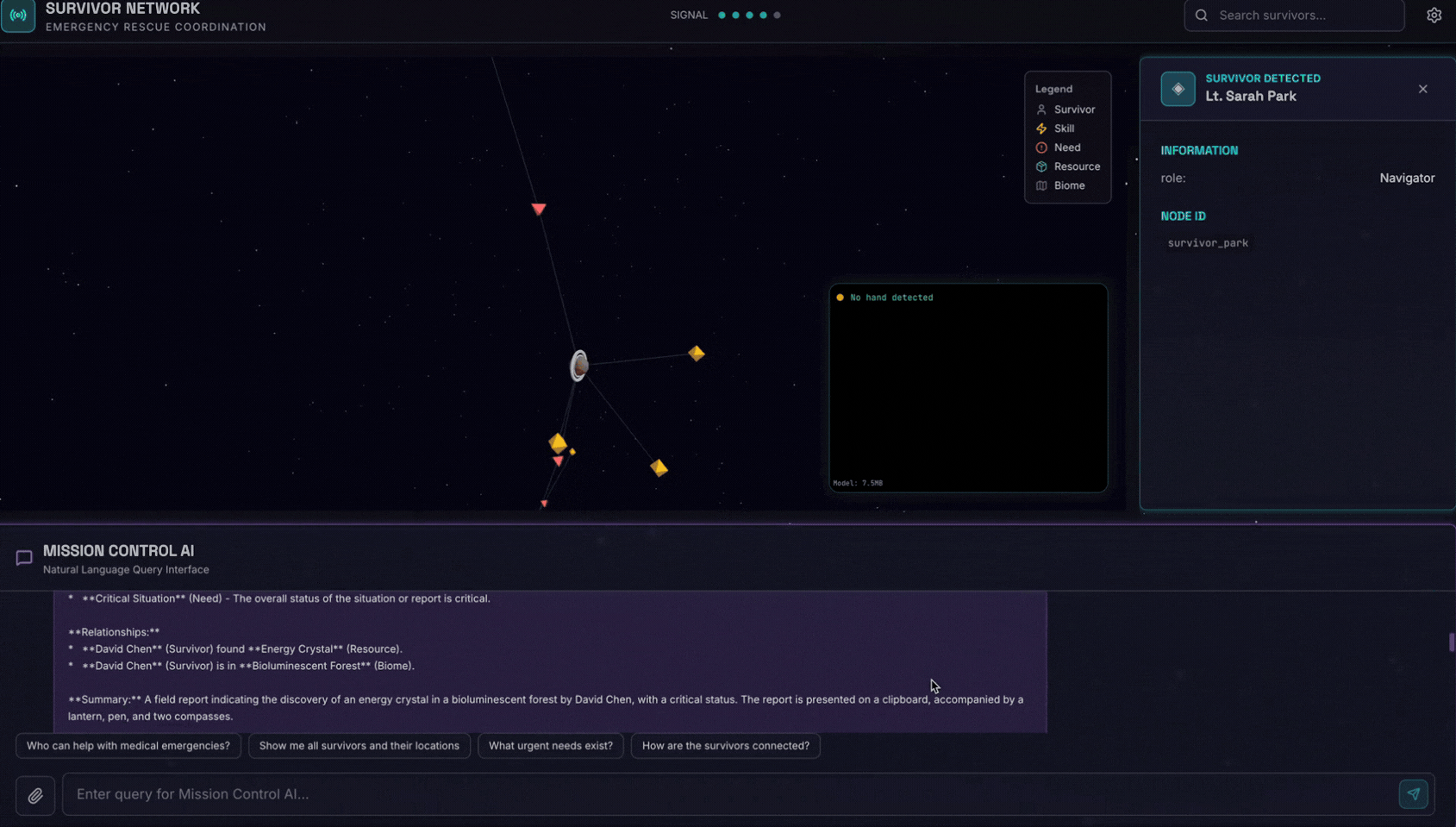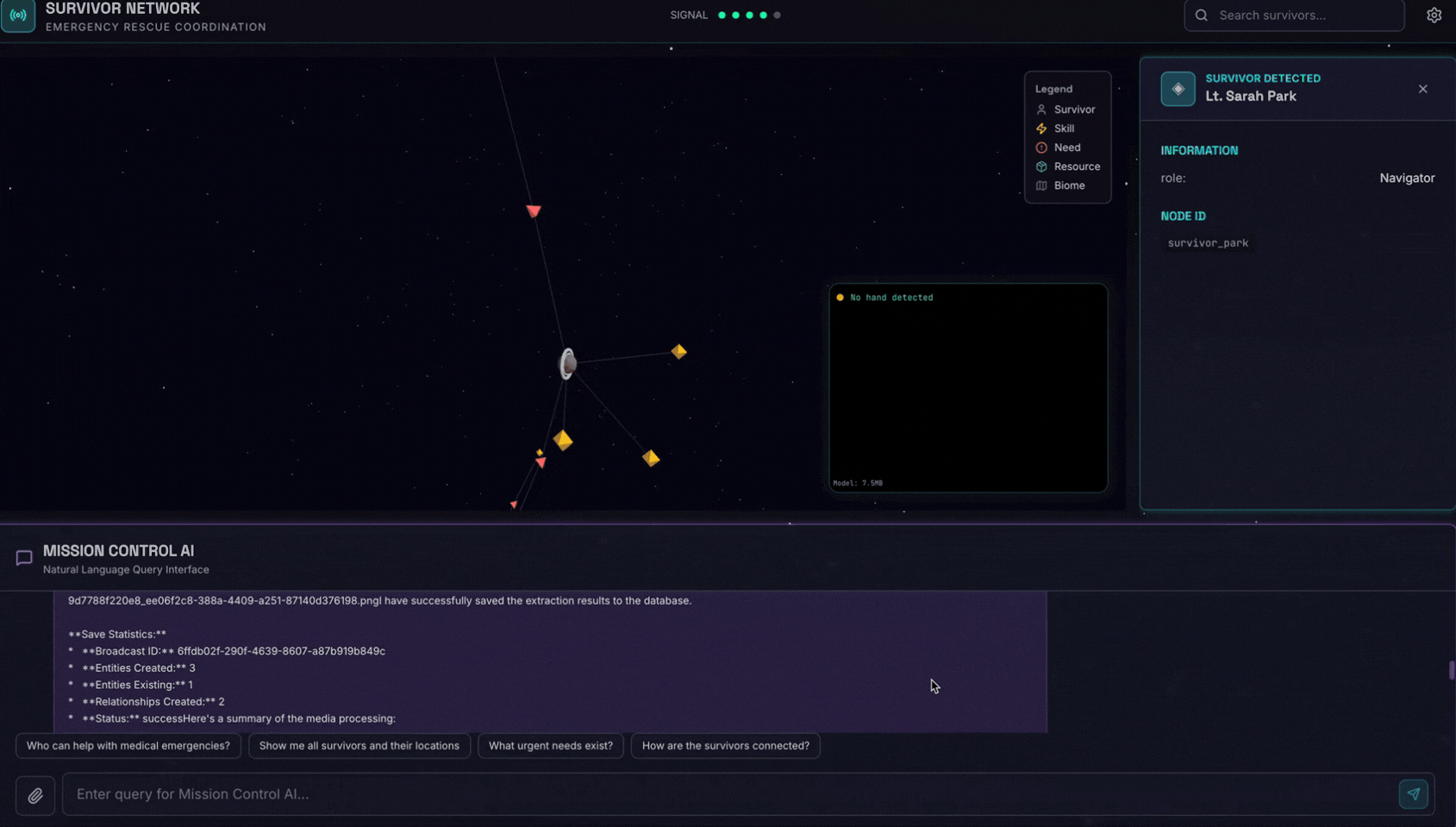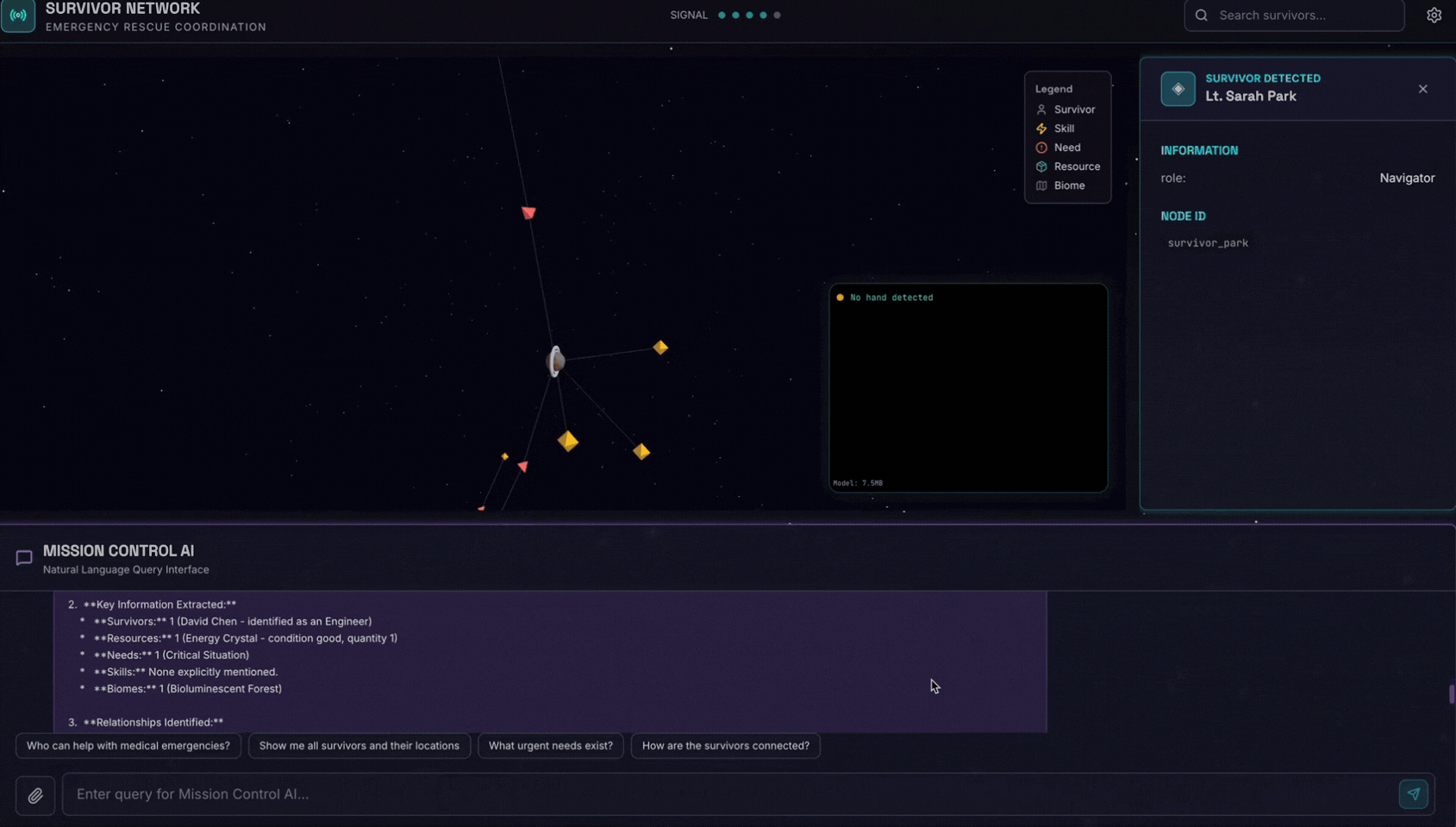
👈💻 במסוף, כשמסיימים את הבדיקה, מקישים על Ctrl+C כדי לסיים את התהליך.
6. אימות העלאה מולטי-מודאלית בדלי GCS
- פותחים את האחסון במסוף Google Cloud.
- בוחרים באפשרות 'קטגוריה' באחסון בענן
- בוחרים את הקטגוריה ולוחצים על
media.
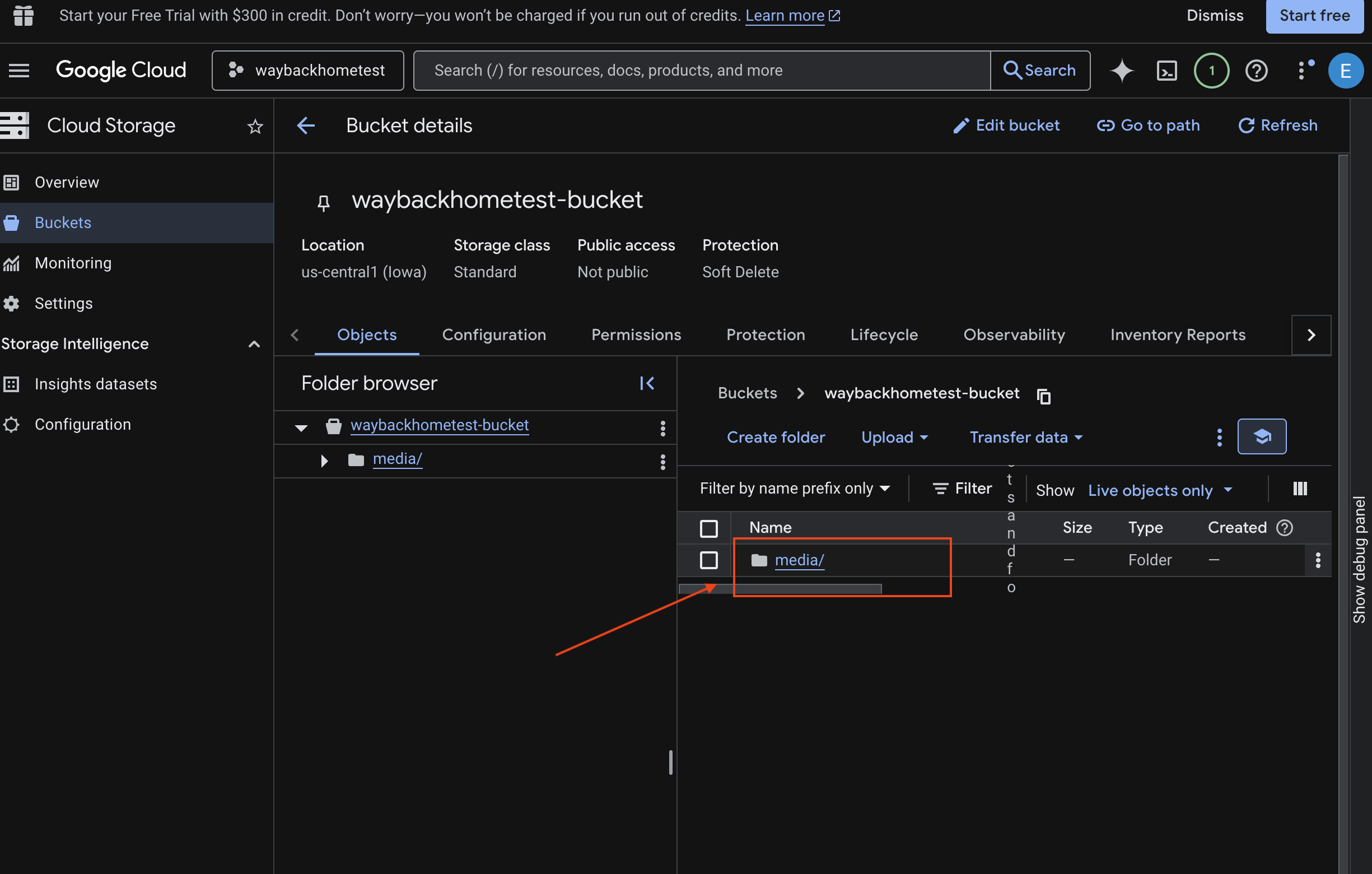
- כאן אפשר לראות את התמונה שהעליתם.
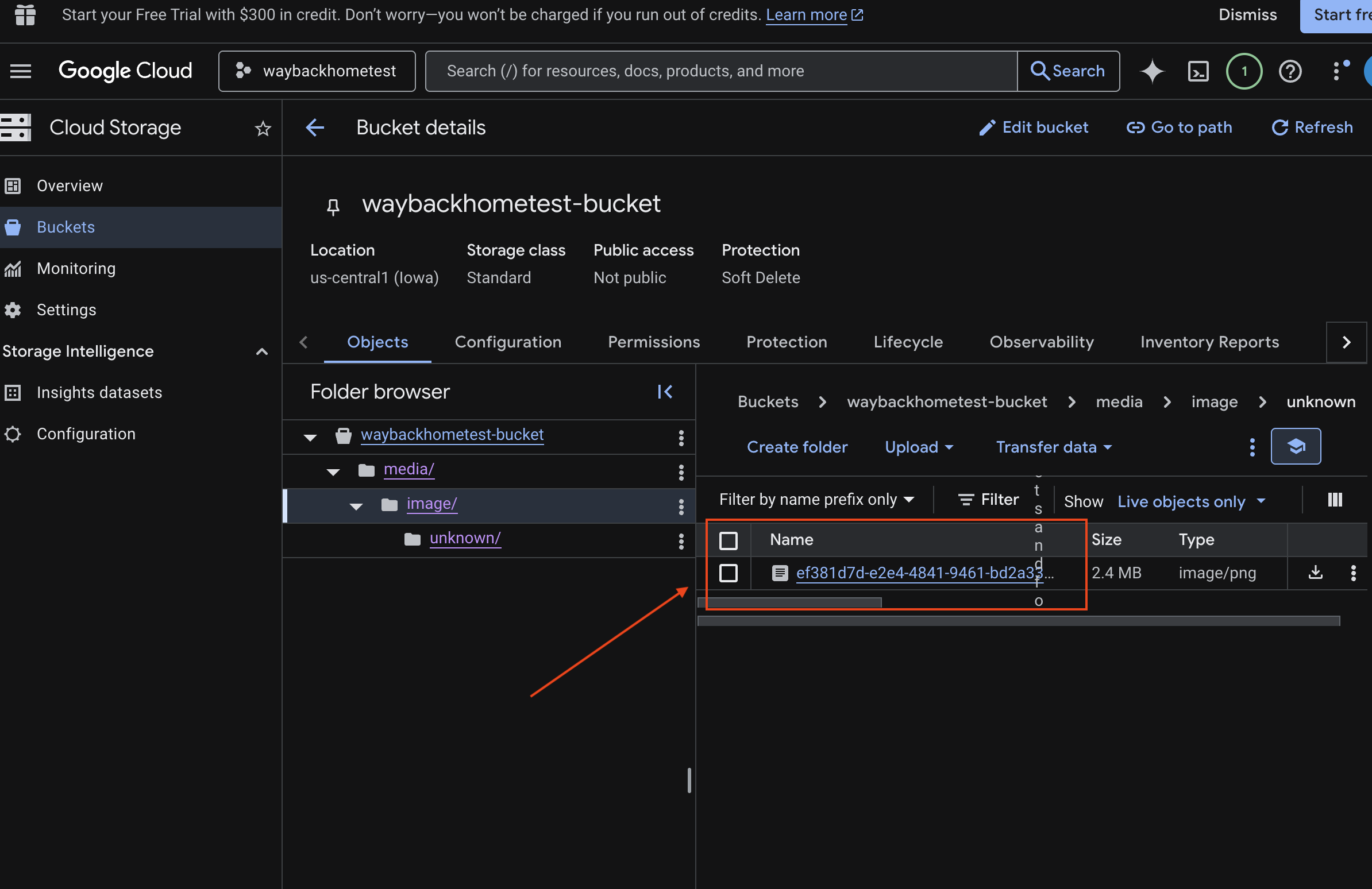
7. אימות ההעלאה של נתונים מרובי-אופנים ב-Spanner (אופציונלי)
למטה מוצגת דוגמה לפלט בממשק המשתמש של test_photo1.
- פותחים את מסוף Google Cloud Spanner.
- בוחרים את המופע:
Survivor Network - בוחרים את מסד הנתונים:
graph-db - בסרגל הצדדי הימני, לוחצים על Spanner Studio.
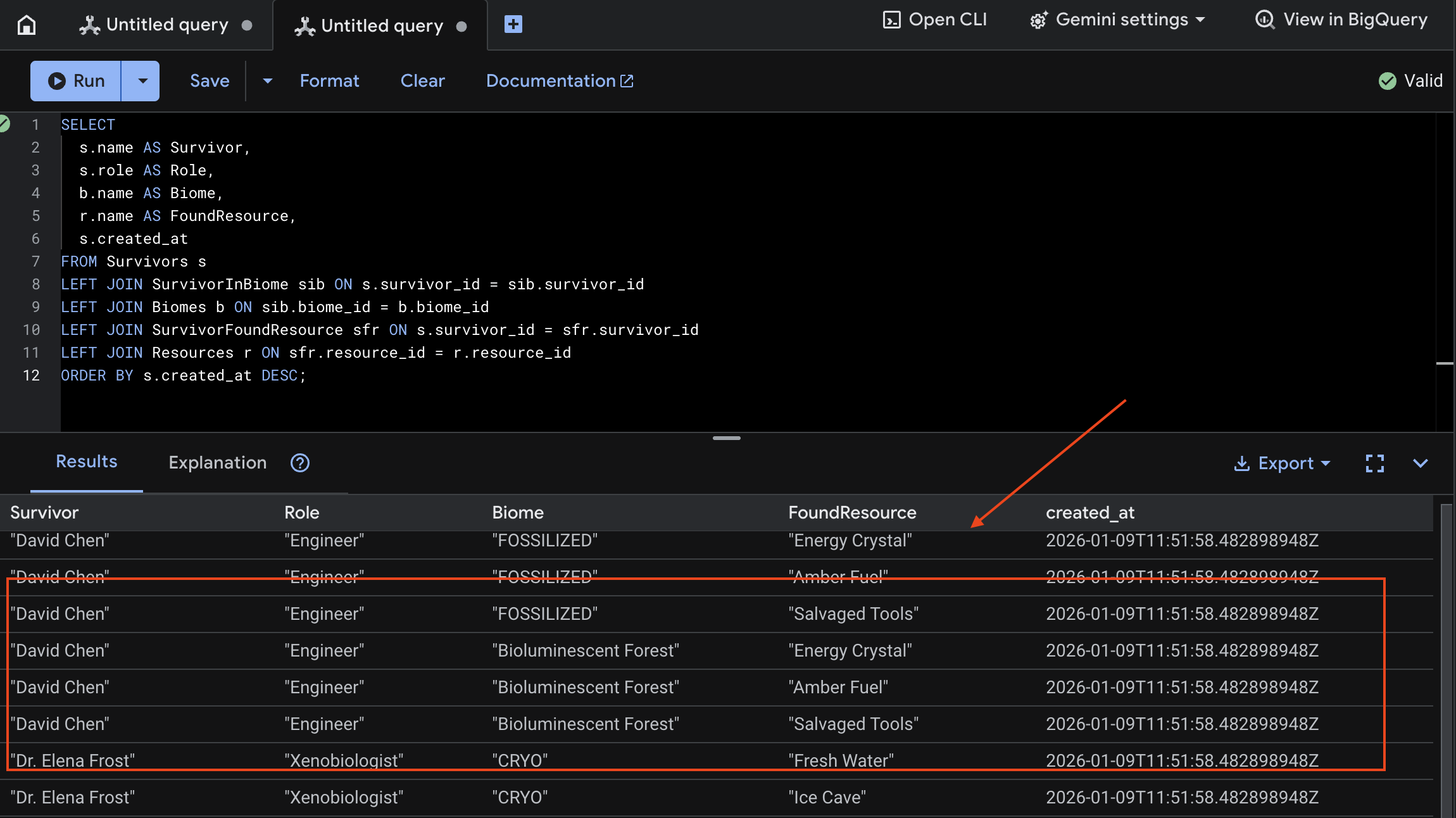
👈 ב-Spanner Studio, מריצים שאילתה על הנתונים החדשים:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
אנחנו יכולים לאמת את זה באמצעות התוצאה שמופיעה למטה:
12. ☕️ [Optional] Memory Bank with Agent Engine
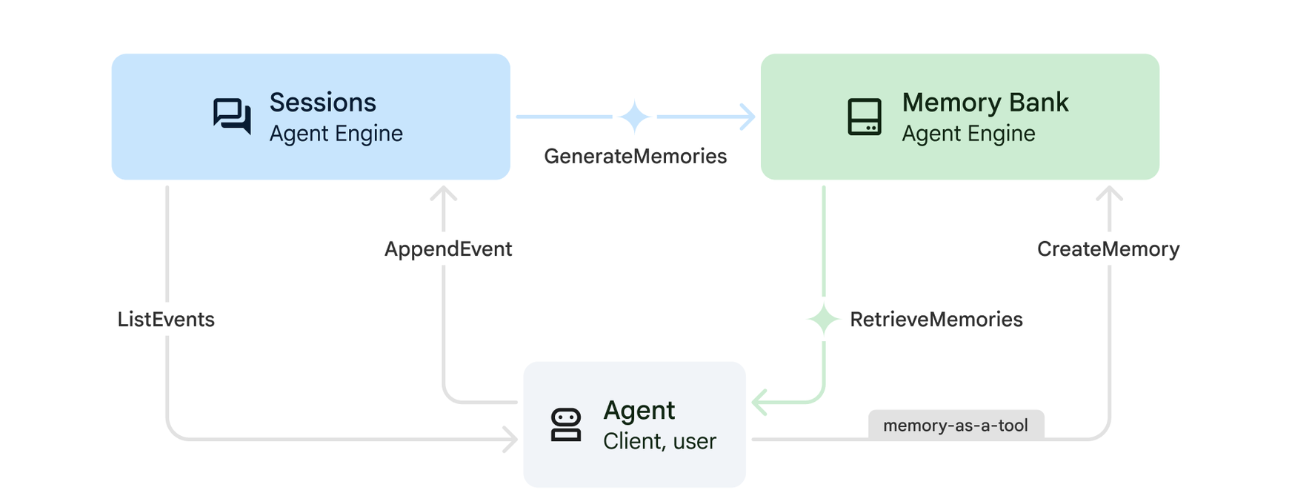
1. איך הזיכרון פועל
המערכת משתמשת בגישה של זיכרון כפול כדי לטפל בהקשר מיידי וגם בלמידה לטווח ארוך.
2. מהם נושאי זיכרון?
נושאי הזיכרון מגדירים את הקטגוריות של המידע שהנציג צריך לזכור לאורך השיחות. אפשר לחשוב עליהם כמו ארונות תיוק להעדפות משתמשים מסוגים שונים.
שני הנושאים שלנו:
-
search_preferences: איך המשתמש אוהב לחפש- האם הם מעדיפים חיפוש לפי מילות מפתח או חיפוש סמנטי?
- אילו מיומנויות או ביומים הם מחפשים לעיתים קרובות?
- דוגמה לזיכרון: "המשתמש מעדיף חיפוש סמנטי כדי למצוא מידע על כישורים רפואיים"
-
urgent_needs_context: אילו משברים הם עוקבים אחרי- אילו משאבים הם מנטרים?
- אילו שורדים מעוררים את הדאגה שלהם?
- דוגמה לזיכרון: "המשתמש עוקב אחרי מחסור בתרופות במחנה הצפוני"
3. הגדרת נושאי זיכרון
נושאי זיכרון בהתאמה אישית מגדירים מה הסוכן צריך לזכור. ההגדרות האלה נקבעות כשפורסים את Agent Engine.
👈💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
~/way-back-home/level_2/backend/deploy_agent.py ייפתח בכלי העריכה.
אנחנו מגדירים אובייקטים של מבנה MemoryTopic כדי להנחות את ה-LLM לגבי המידע שצריך לחלץ ולשמור.
👉 בקובץ deploy_agent.py, מחליפים את # TODO: SET_UP_TOPIC בטקסט הבא:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. שילוב סוכנים
קוד הסוכן צריך לדעת על Memory Bank כדי לשמור ולאחזר מידע.
👈💻 בטרמינל, פותחים את הקובץ ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
~/way-back-home/level_2/backend/agent/agent.py ייפתח בכלי העריכה.
יצירת סוכן
כשיוצרים את הסוכן, מעבירים את after_agent_callback כדי לוודא שהסשנים נשמרים בזיכרון אחרי האינטראקציות. הפונקציה add_session_to_memory פועלת באופן אסינכרוני כדי למנוע האטה בתשובות של הצ'אט.
👈 בקובץ agent.py, מאתרים את התגובה # TODO: REPLACE_ADD_SESSION_MEMORY, מחליפים את כל השורה הזו בקוד הבא:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
שמירה ברקע
👈 בקובץ agent.py, מאתרים את התגובה # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, מחליפים את כל השורה הזו בקוד הבא:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👈 בקובץ agent.py, מאתרים את התגובה # TODO: REPLACE_ADD_CALLBACK, מחליפים את כל השורה הזו בקוד הבא:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
הגדרה של שירות הסשנים של Vertex AI
👈💻 בטרמינל, פותחים את הקובץ chat.py ב-Cloud Shell Editor על ידי הפעלת הפקודה:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👈בקובץ chat.py, מאתרים את התגובה # TODO: REPLACE_VERTEXAI_SERVICES, Replace this whole line ומחליפים אותה בקוד הבא:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [אופציונלי] צירוף סוכן באמצעות Agent Engine
1. הגדרה ופריסה
לפני שבודקים את תכונות הזיכרון, צריך לפרוס את הנציג עם נושאי הזיכרון החדשים ולוודא שהסביבה מוגדרת בצורה נכונה.
לנוחותכם, סיפקנו סקריפט שיטפל בתהליך הזה.
הרצת סקריפט הפריסה
👈💻 בטרמינל, מריצים את סקריפט הפריסה:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
הסקריפט הזה מבצע את הפעולות הבאות:
- מריצים את הפקודה
backend/deploy_agent.pyכדי לרשום את הסוכן ואת נושאי הזיכרון ב-Vertex AI. - מזהה Agent Engine חדש.
- עדכון אוטומטי של קובץ
.envבאמצעותAGENT_ENGINE_ID. - מוודאים שהערך
USE_MEMORY_BANK=TRUEמוגדר בקובץ.env.
[!IMPORTANT] אם מבצעים שינויים ב-custom_topics ב-deploy_agent.py, צריך להריץ מחדש את הסקריפט הזה כדי לעדכן את Agent Engine.
אימות של Memory Bank
עכשיו אפשר לוודא שמאגר הזיכרון פועל. לשם כך, מלמדים את הסוכן העדפה מסוימת ובודקים אם היא נשמרת בין סשנים.
שלב ראשון. פתיחת האפליקציה
פותחים שוב את האפליקציה לפי ההוראות הבאות: אם הטרמינל הקודם עדיין פועל, מסיימים אותו על ידי לחיצה על Ctrls+C.
👉💻 הפעלת האפליקציה:
cd ~/way-back-home/level_2/
./start_app.sh
👈 לוחצים על Local: http://localhost:5173/ במסוף.
שלב שני. בדיקת Memory Bank באמצעות טקסט
בממשק הצ'אט, מסבירים לסוכן את ההקשר הספציפי:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👈 מחכים כ-30 שניות עד שהזיכרון יעובד ברקע.
שלב שלישי. התחלת סשן חדש
כדי לנקות את היסטוריית השיחות הנוכחית (זיכרון לטווח קצר), צריך לרענן את הדף.
לשאול שאלה שמבוססת על ההקשר שסיפקתם קודם:
"What kind of missions am I interested in?"
התשובה הצפויה:
"על סמך השיחות הקודמות שלך, נראה שאתה מתעניין בנושאים הבאים:
- משימות הצלה רפואיות
- פעולות בהרים או בגובה רב
- מיומנויות נדרשות: עזרה ראשונה, טיפוס
רוצה שאמצא ניצולים שעומדים בקריטריונים האלה?"
שלב רביעי. בדיקה באמצעות העלאת תמונה
מעלים תמונה ושואלים:
remember this
אתם יכולים לבחור כל תמונה שמופיעה כאן או תמונה משלכם ולהעלות אותה לממשק המשתמש:
שלב חמישי. אימות ב-Vertex AI Agent Engine
כניסה אל Agent Engine במסוף Google Cloud
- חשוב לבחור את הפרויקט מהתפריט לבחירת פרויקט בפינה הימנית העליונה:
- מאמתים את מנוע הנציג שפרסתם באמצעות הפקודה הקודמת
use_memory_bank.sh: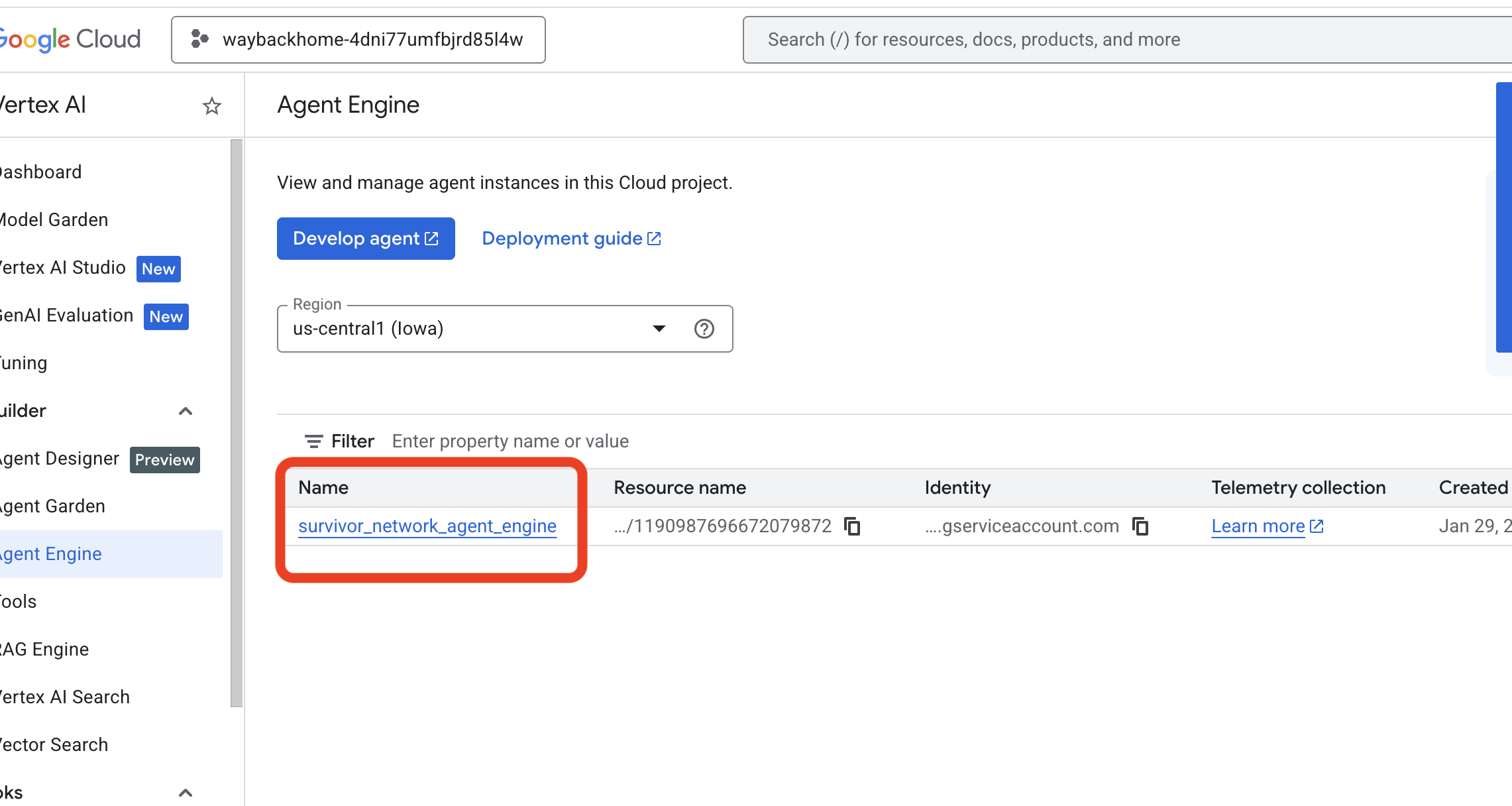 לוחצים על מנוע הנציג שיצרתם.
לוחצים על מנוע הנציג שיצרתם. - לוחצים על הכרטיסייה
Memoriesבסוכן הזה שהופעל, ואז אפשר לראות את כל הזיכרון.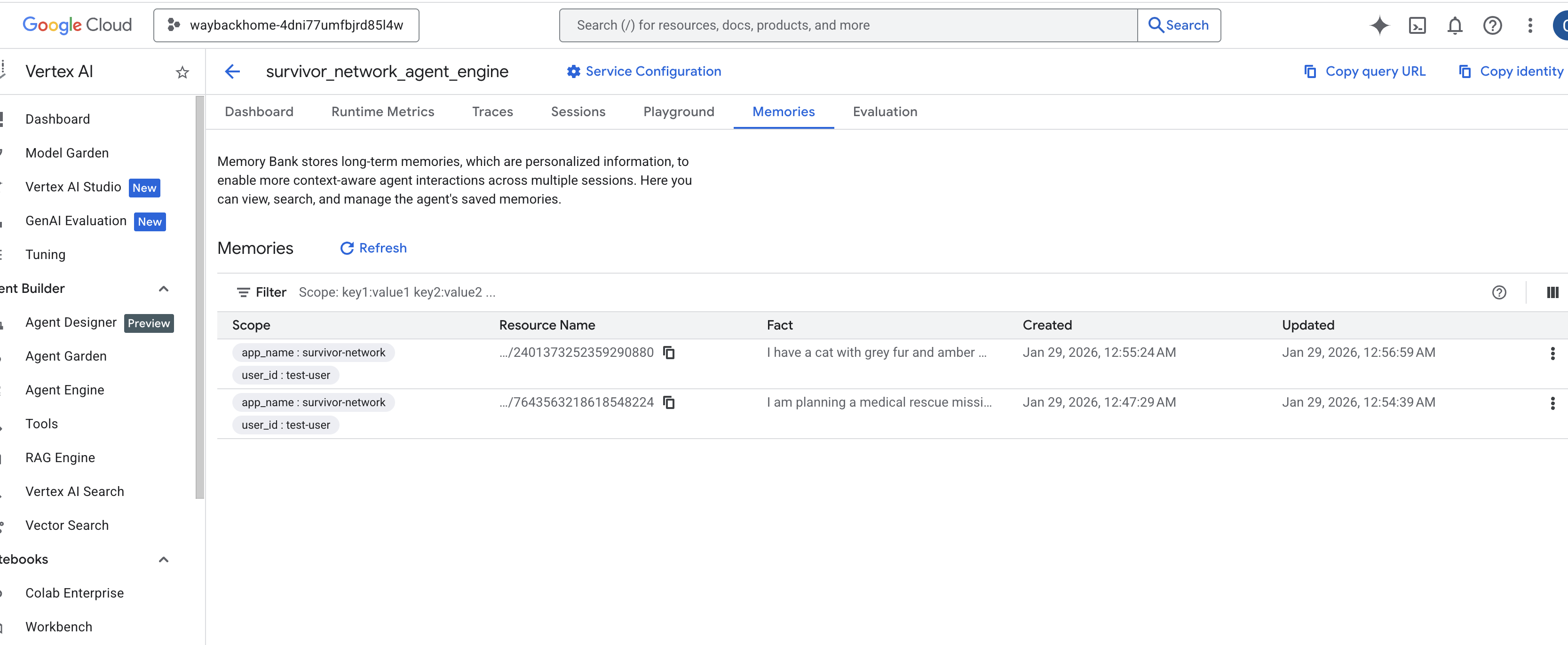
👉💻 בסיום הבדיקה, במסוף, לוחצים על Ctrl + C כדי לסיים את התהליך.
🎉 מזל טוב! הרגע צירפת את בנק הזיכרון לסוכן שלך!
14. ☕️ [אופציונלי] פריסה ב-Cloud Run
1. הפעלת סקריפט הפריסה
👉💻 מריצים את סקריפט הפריסה:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
אחרי שהפריסה תתבצע בהצלחה, תקבלו את כתובת ה-URL. זו כתובת ה-URL של הפריסה שלכם. 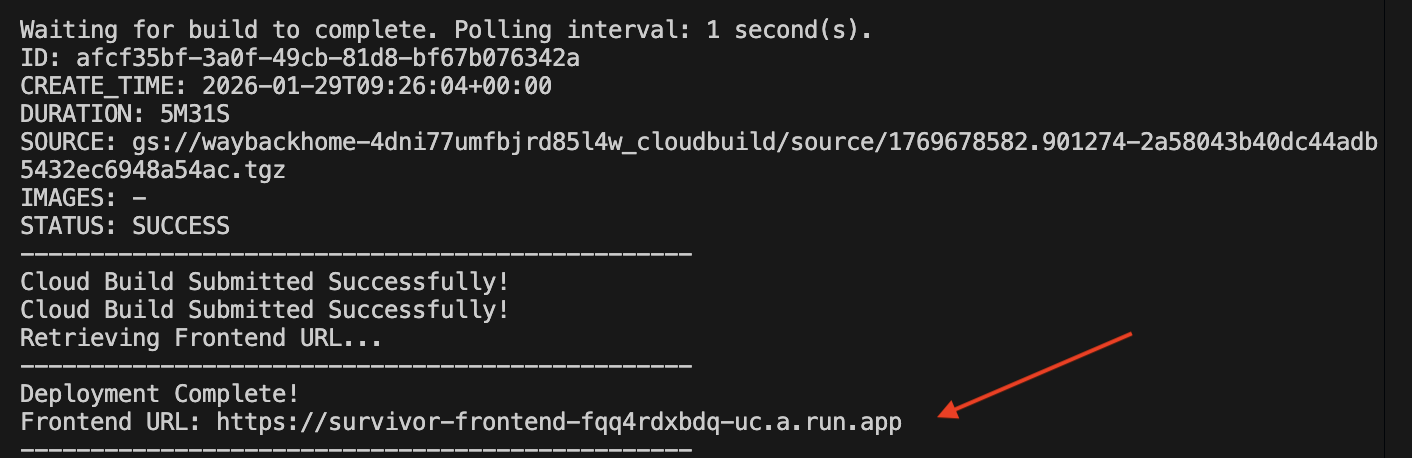
👈💻 לפני שמקבלים את כתובת ה-URL, מריצים את הפקודה הבאה כדי להעניק את ההרשאה:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
עוברים לכתובת ה-URL של הפריסה, והאפליקציה תופיע שם בשידור חי.
2. הסבר על צינור העיבוד (Pipeline) של Build
בקובץ cloudbuild.yaml מוגדרים השלבים הבאים:
- Backend Build: יצירת קובץ אימג' של Docker מ-
backend/Dockerfile. - Backend Deploy (פריסת קצה עורפי): פריסת הקונטיינר של הקצה העורפי ב-Cloud Run.
- Capture URL (תפיסת כתובת URL): מקבל את כתובת ה-URL החדשה של ה-Backend.
- Frontend Build:
- התקנת יחסי תלות.
- מבצעים Build לאפליקציית React, ומזריקים את
VITE_API_URL=.
- Frontend Image: יוצר את קובץ האימג' של Docker מ-
frontend/Dockerfile(אריזת הנכסים הסטטיים). - Frontend Deploy: פריסה של קונטיינר הקצה הקדמי.
3. אימות הפריסה
אחרי שהבנייה מסתיימת (אפשר לבדוק את הקישור ליומנים שסופק על ידי הסקריפט), אפשר לאמת:
- עוברים אל Cloud Run Console.
- מאתרים את השירות
survivor-frontend. - לוחצים על כתובת ה-URL כדי לפתוח את האפליקציה.
- מריצים שאילתת חיפוש כדי לוודא שהחלק הקדמי של האתר יכול לתקשר עם החלק האחורי.
(אופציונלי) 4. פריסה ידנית
אם אתם מעדיפים להריץ את הפקודות באופן ידני או להבין טוב יותר את התהליך, הנה הסבר איך להשתמש ב-cloudbuild.yaml ישירות.
כתיבה של cloudbuild.yaml
קובץ cloudbuild.yaml מציין ל-Google Cloud Build אילו שלבים לבצע.
- steps: רשימה של פעולות עוקבות. כל שלב מופעל בקונטיינר (לדוגמה,
docker, gcloud, node, bash). - substitutions: משתנים שאפשר לקבוע ערך (pass) משך זמן של תהליך build (לדוגמה,
$_REGION). - סביבת עבודה: ספרייה משותפת שבה שלבים יכולים לשתף קבצים (בדומה לשיתוף
backend_url.txt).
הפעלת הפריסה
כדי לבצע פריסה ידנית בלי הסקריפט, משתמשים בפקודה gcloud builds submit. חובה להעביר את משתני ההחלפה הנדרשים.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. סיכום
1. מה יצרתם
✅ Graph Database: Spanner with nodes (survivors, skills) and edges (relationships)
✅ AI Search: Keyword, semantic, and hybrid search with embeddings
✅ Multimodal Pipeline: Extract entities from images/video with Gemini
✅ Multi-Agent System: Coordinated workflow with ADK
✅ Memory Bank: Long-term personalization with Vertex AI
✅ Production Deployment: Cloud Run + Agent Engine
2. סיכום הארכיטקטורה
3. תובנות מרכזיות
- Graph RAG: שילוב של מבנה מסד נתונים גרפי עם הטבעות סמנטיות לחיפוש חכם
- תבניות של כמה סוכנים: צינורות עיבוד נתונים רציפים לתהליכי עבודה מורכבים עם כמה שלבים
- AI מולטימודאלי: חילוץ נתונים מובְנים ממדיה לא מובְנית (תמונות או סרטונים)
- סוכנים עם שמירת מצב: Memory Bank מאפשר התאמה אישית בין סשנים
4. תוכן הסדנה
- Level0: Identify Yourself
- Level1: מיקום מדויק
- Level2 This One: Build a Multimodal AI Agent with Graph RAG, ADK & Memory Bank
- Level3: יצירת סוכן ADK לסטרימינג דו-כיווני
- Level4: מערכת דו-כיוונית של כמה סוכנים בזמן אמת
- Level5: Event-Driven Architecture with Google ADK, A2A, and Kafka