
1. Pengantar

1. Tantangan
Dalam skenario respons bencana, mengoordinasikan korban selamat dengan berbagai keterampilan, sumber daya, dan kebutuhan di beberapa lokasi memerlukan kemampuan penelusuran dan pengelolaan data yang cerdas. Workshop ini mengajarkan cara membangun sistem AI produksi yang menggabungkan:
- 🗄️ Database Grafik (Spanner): Menyimpan hubungan kompleks antara penyintas, keterampilan, dan sumber daya
- 🔍 Penelusuran yang Didukung AI: Penelusuran campuran semantik + kata kunci menggunakan embedding
- 📸 Pemrosesan Multimodal: Mengekstrak data terstruktur dari gambar, teks, dan video
- 🤖 Orkestrasi Multi-Agen: Mengoordinasikan agen khusus untuk alur kerja yang kompleks
- 🧠 Memori Jangka Panjang: Personalisasi dengan Vertex AI Memory Bank
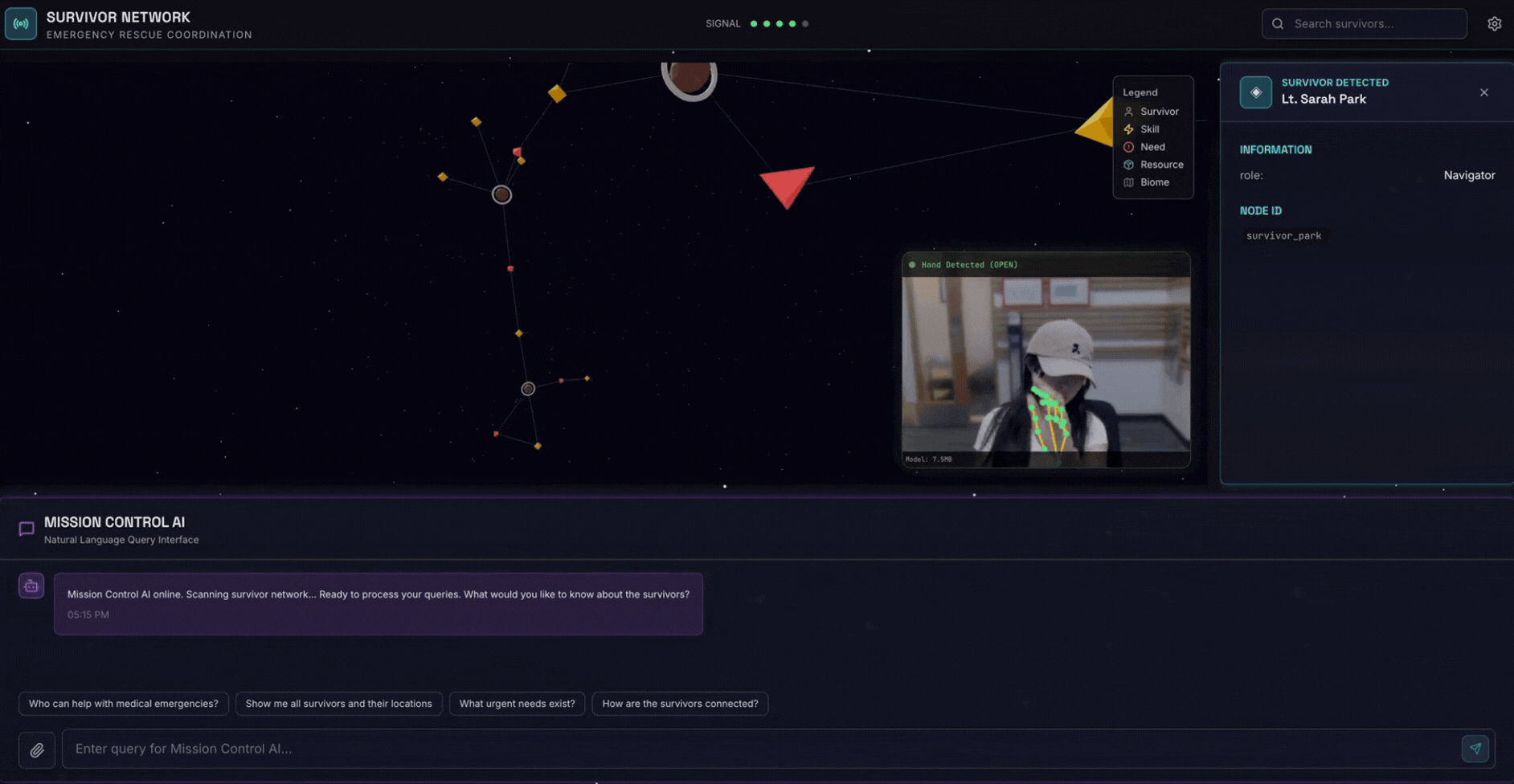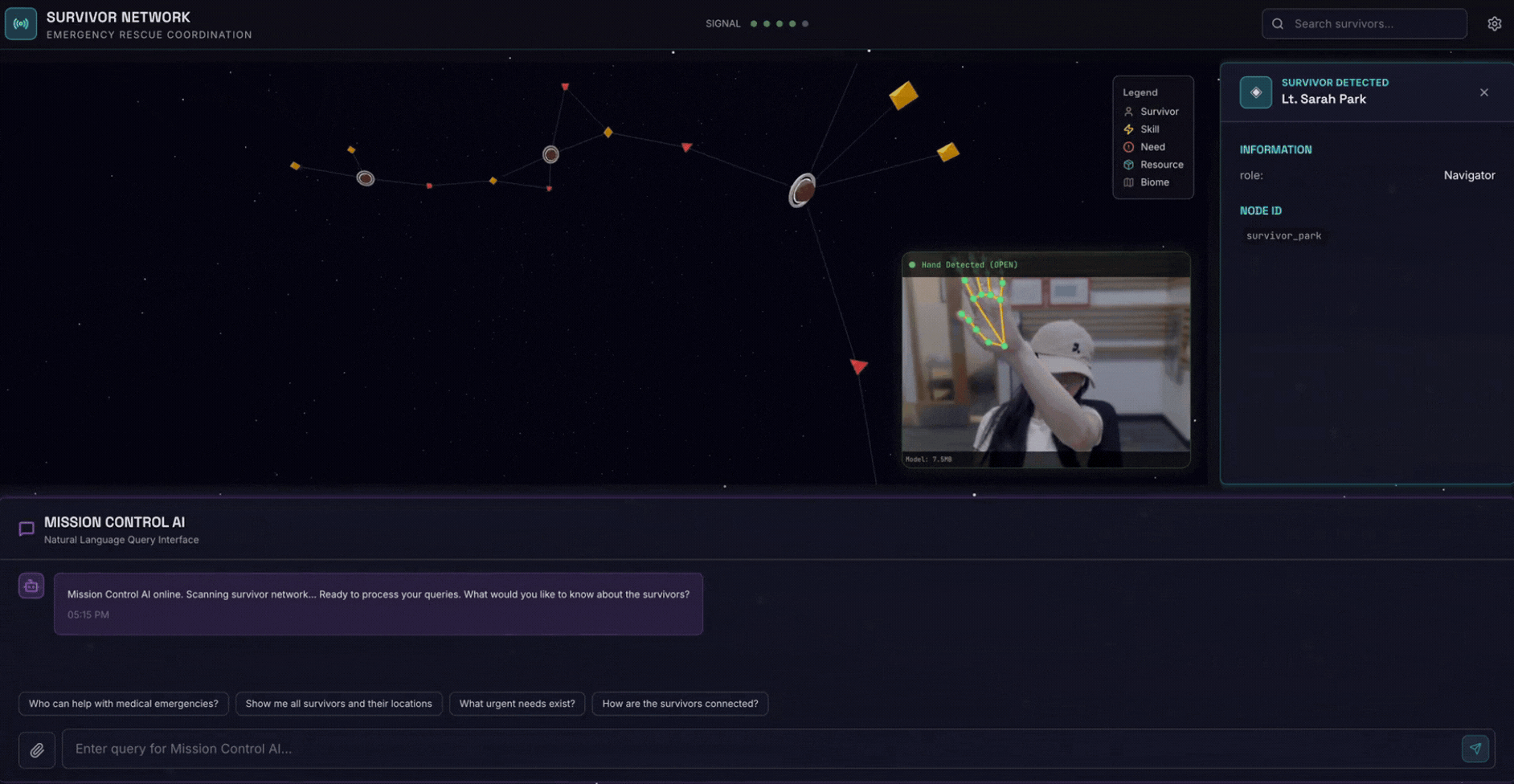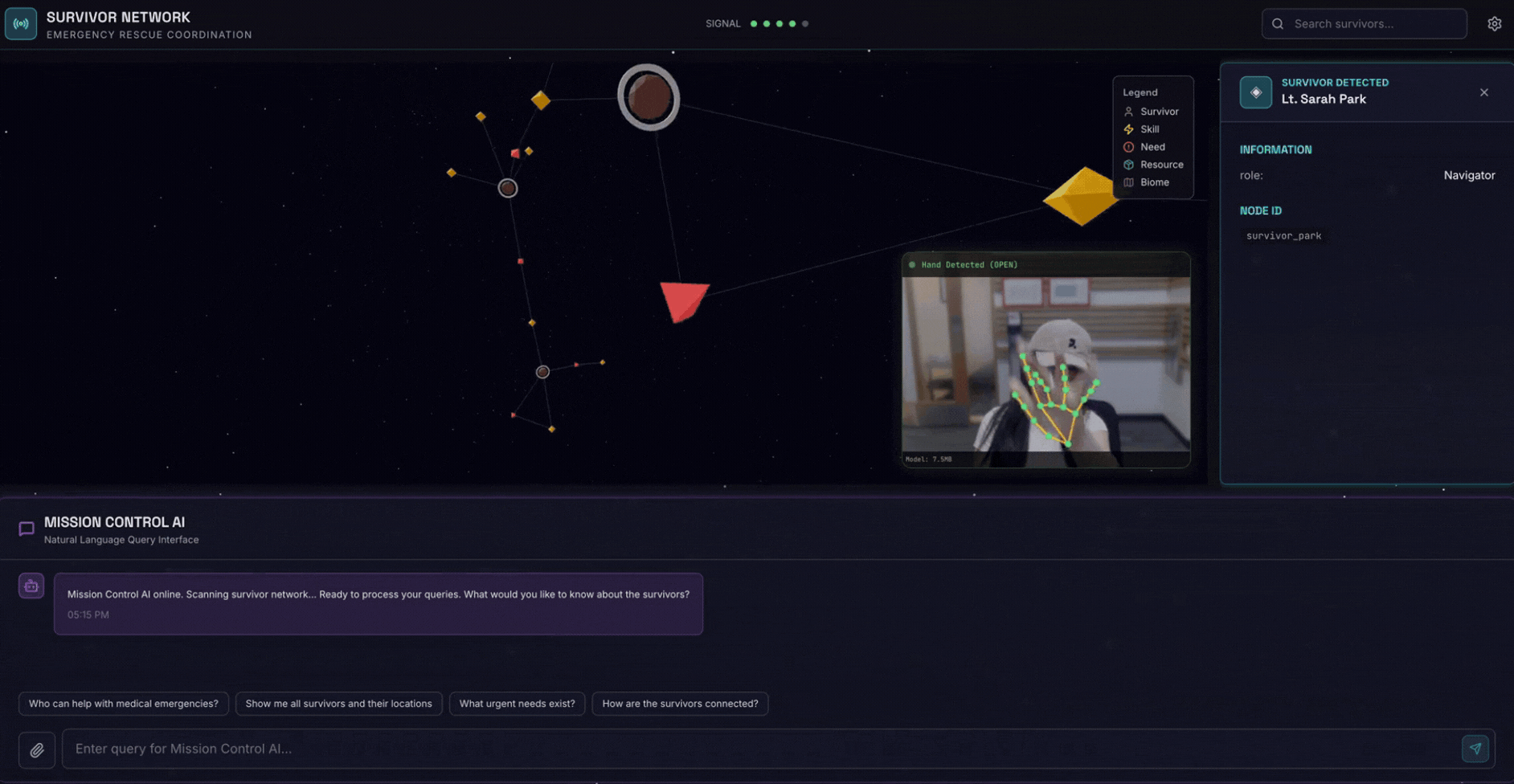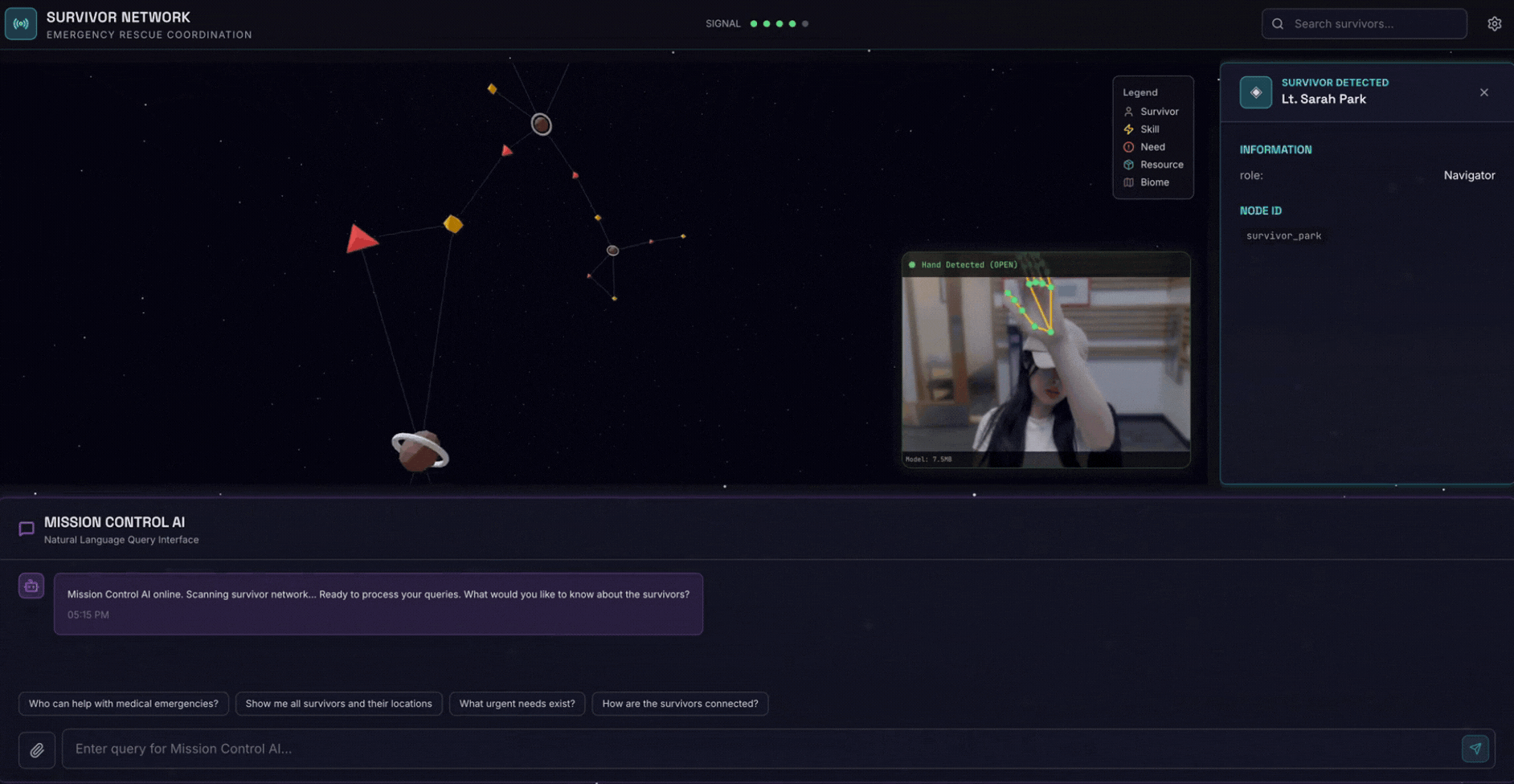
2. Yang Akan Anda Buat
Database Grafik Jaringan Penyintas dengan:
- 🗺️ Visualisasi Grafik Interaktif 3D hubungan antar-korban
- 🔍 Penelusuran Cerdas (kata kunci, semantik, dan campuran)
- 📸 Pipeline Upload Multimodal (mengekstraksi entitas dari gambar/video)
- 🤖 Sistem Multi-Agen untuk orkestrasi tugas yang kompleks
- 🧠 Integrasi Memory Bank untuk interaksi yang dipersonalisasi
3. Teknologi Inti
Komponen | Teknologi | Tujuan |
Database | Grafik Cloud Spanner | Menyimpan node (penyintas, keterampilan) dan edge (hubungan) |
AI Search | Gemini + Embeddings | Pemahaman semantik + penelusuran kemiripan |
Framework Agen | ADK (Agent Development Kit) | Mengorkestrasi alur kerja AI |
Memori | Vertex AI Memory Bank | Penyimpanan preferensi pengguna jangka panjang |
Frontend | React + Three.js | Visualisasi grafik 3D interaktif |
2. 🛠️ Persiapan Lingkungan (Lewati jika Anda mengikuti Workshop)
Bagian Satu: Aktifkan Akun Penagihan
Untuk menjalankan codelab ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Bagian Dua: Lingkungan Terbuka
- 👉 Klik link ini untuk langsung membuka Cloud Shell Editor
- 👉 Jika diminta untuk memberikan otorisasi kapan saja hari ini, klik Authorize untuk melanjutkan.
- 👉 Jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
- 👉💻 Di terminal, verifikasi bahwa Anda sudah diautentikasi dan project disetel ke project ID Anda menggunakan perintah berikut:
gcloud auth list - 👉💻 Clone project bootstrap dari GitHub:
git clone https://github.com/gca-americas/way-back-home.git
Bagian Tiga: Membuat project baru
👉💻 Di terminal, Jadikan skrip init dapat dieksekusi dan jalankan:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Penyiapan Lingkungan
1. Buka Cloud Shell
Di terminal Cloud Shell Editor, jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
2. Konfigurasi Project
👉💻 Di terminal, tetapkan project ID Anda:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Aktifkan API yang diperlukan (proses ini memerlukan waktu sekitar 2-3 menit):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Jalankan Skrip Penyiapan
👉💻 Jalankan skrip penyiapan:
cd ~/way-back-home/level_2
./setup.sh
Tindakan ini akan membuat .env untuk Anda. Di cloudshell, buka way_back_homeproject. Di folder level_2, Anda dapat melihat file .env yang dibuat untuk Anda. Jika tidak dapat menemukannya, Anda dapat mengklik View -> Toggle Hidden File untuk melihatnya. 
4. Memuat Data Sampel
👉💻 Buka backend dan instal dependensi:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Muat data awal penyintas:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Tindakan ini akan membuat:
- Instance Spanner (
survivor-network) - Database (
graph-db) - Semua tabel node dan edge
- Grafik properti untuk membuat kueri Hasil yang diharapkan:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
Jika mengklik link setelah Access your database at di output, Anda dapat membuka Spanner di Konsol Google Cloud.

Anda akan melihat Spanner di Konsol Google Cloud.
4. 🚀 Memvisualisasikan Data Grafik di Spanner Studio
Panduan ini membantu Anda memvisualisasikan dan berinteraksi dengan data grafik Survivor Network secara langsung di Konsol Google Cloud menggunakan Spanner Studio. Cara ini adalah cara yang bagus untuk memverifikasi data Anda dan memahami struktur grafik sebelum membangun agen AI.
1. Mengakses Spanner Studio
- Pada langkah terakhir, pastikan Anda mengklik link dan membuka Spanner Studio.
2. Memahami Struktur Grafik ("Gambaran Besar")
Anggap set data Survivor Network sebagai teka-teki logika atau Status Game:
Entitas | Peran dalam Sistem | Analogi |
Pemberlakuan | Agen/pemain | Pemain |
Bioma | Lokasi mereka | Memetakan Zona |
Keterampilan | Yang dapat mereka lakukan | Kemampuan |
Kebutuhan | Apa yang kurang (Krisis) | Misi/Quest |
Referensi | Item yang ditemukan di dunia | Loot |
Tujuan: Tugas agen AI adalah menghubungkan Keterampilan (Solusi) dengan Kebutuhan (Masalah), dengan mempertimbangkan Bioma (Batasan lokasi).
🔗 Tepi (Hubungan):
SurvivorInBiome: Pelacakan lokasiSurvivorHasSkill: Inventaris kemampuanSurvivorHasNeed: Daftar masalah aktifSurvivorFoundResource: Inventaris itemSurvivorCanHelp: Hubungan yang disimpulkan (AI menghitungnya!)
3. Membuat Kueri Grafik
Mari kita jalankan beberapa kueri untuk melihat "Kisah" dalam data.
Spanner Graph menggunakan GQL (Graph Query Language). Untuk menjalankan kueri, gunakan GRAPH SurvivorNetwork yang diikuti dengan pola kecocokan Anda.
👉 Kueri 1: Daftar Global (Siapa di mana?) Ini adalah fondasi Anda - memahami lokasi sangat penting untuk operasi penyelamatan.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Anda akan melihat hasil seperti di bawah ini: 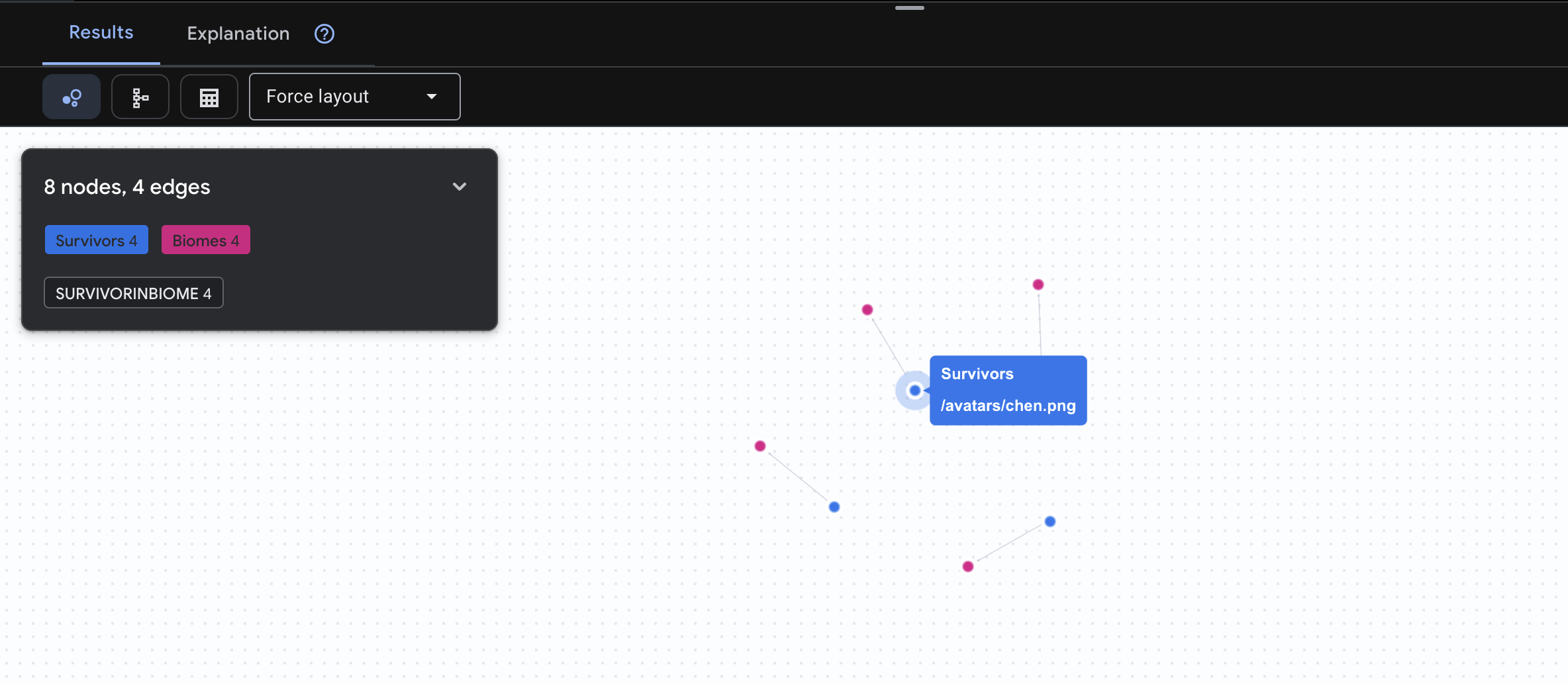
👉 Pertanyaan 2: Matriks Keterampilan (Kemampuan) Setelah mengetahui lokasi semua orang, cari tahu apa yang dapat mereka lakukan.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Anda akan melihat hasil seperti di bawah ini: 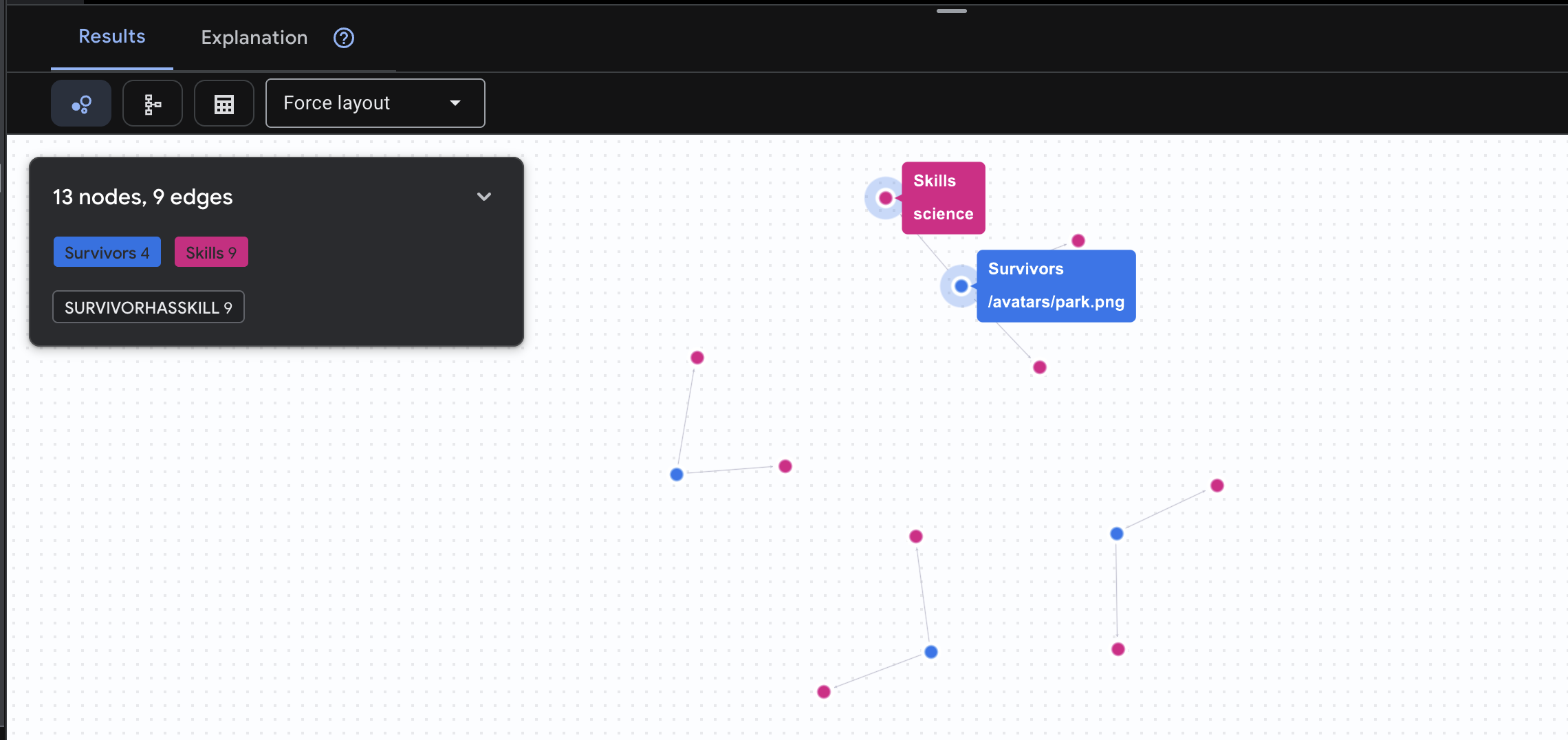
👉 Kueri 3: Siapa yang sedang dalam Krisis? (Papan Misi) Lihat para penyintas yang membutuhkan bantuan dan apa yang mereka butuhkan.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Anda akan melihat hasil seperti di bawah ini: 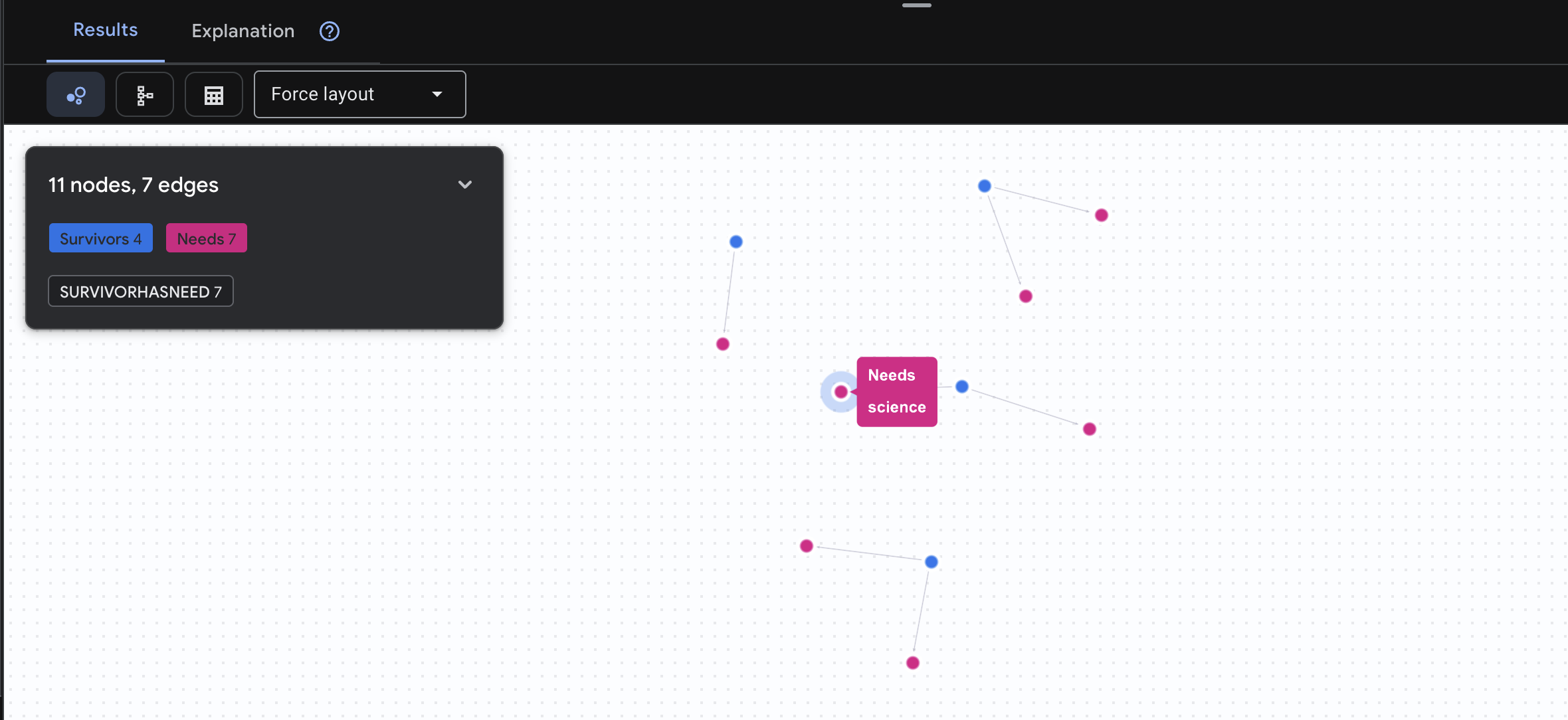
🔎 [Opsional] Mencari Pasangan - Siapa yang Dapat Membantu Siapa?
Di sinilah grafik menjadi sangat berguna. Kueri ini menemukan penyintas yang memiliki keterampilan yang dapat memenuhi kebutuhan penyintas lain.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Anda akan melihat hasil seperti di bawah ini: 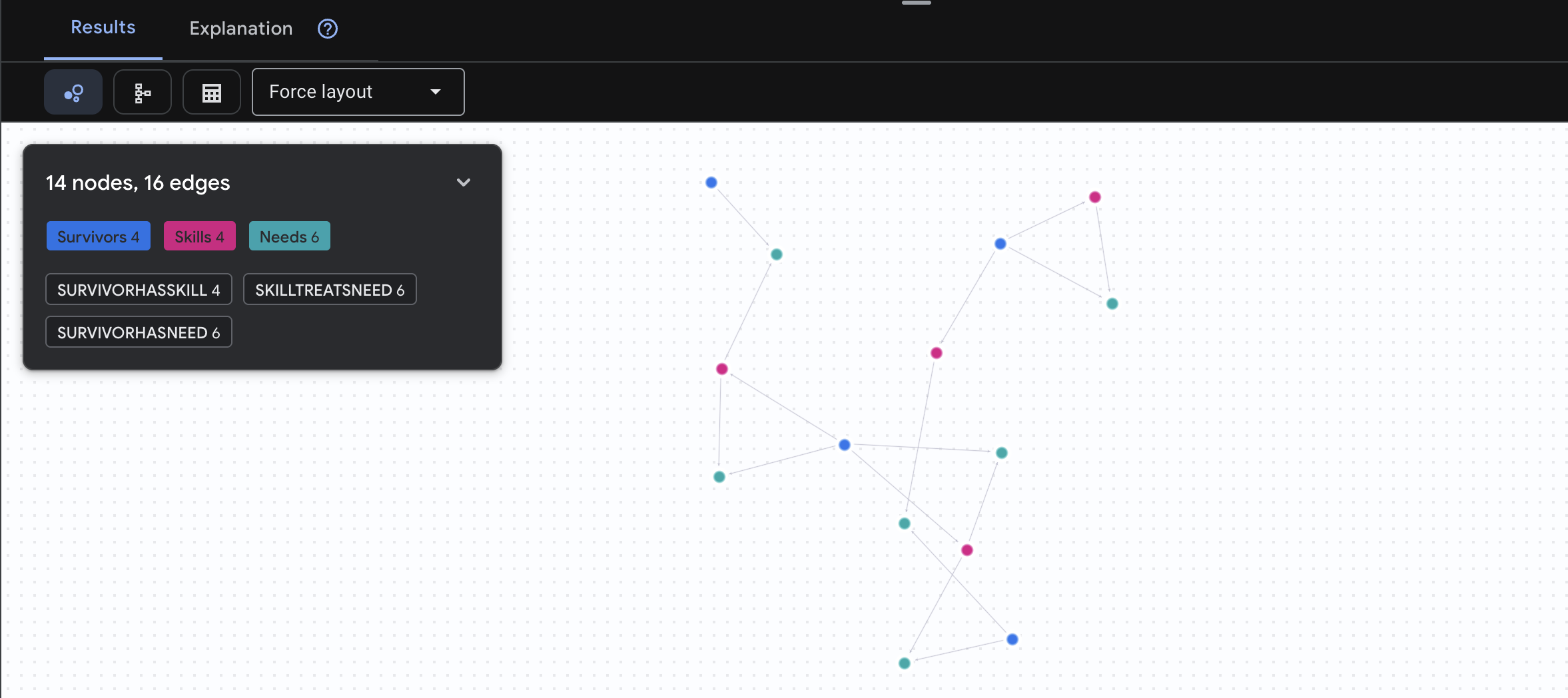
positif Fungsi Kueri Ini:
Daripada hanya menampilkan "Pertolongan Pertama mengobati luka bakar" (yang jelas dari skema), kueri ini menemukan:
- Dr. Elena Frost (yang memiliki Pelatihan Medis) → dapat mengobati → Kapten Tanaka (yang mengalami luka bakar)
- David Chen (yang memiliki pengetahuan P3K) → dapat mengobati → Lt. Park (yang mengalami keseleo pada pergelangan kaki)
Alasan Hal Ini Efektif:
Tindakan yang Akan Dilakukan Agen AI Anda:
Saat pengguna bertanya "Siapa yang dapat mengobati luka bakar?", agen akan:
- Menjalankan kueri grafik serupa
- Hasil: "Dr. Frost memiliki Pelatihan Medis dan dapat membantu Kapten Tanaka"
- Pengguna tidak perlu mengetahui tabel atau hubungan perantara.
5. 🚀 Embedding yang Didukung AI di Spanner
1. Mengapa Embedding? (Tidak ada tindakan, hanya baca)
Dalam skenario bertahan hidup, waktu sangat penting. Saat melaporkan keadaan darurat, seperti I need someone who can treat burns atau Looking for a medic, penyintas tidak dapat membuang waktu dengan menebak nama skill yang tepat dalam database.
Skenario Nyata: Survivor: Captain Tanaka has burns—we need medical help NOW!
Penelusuran kata kunci tradisional untuk "tenaga medis" → 0 hasil ❌
Penelusuran semantik dengan embedding → Menemukan "Pelatihan Medis", "Pertolongan Pertama" ✅
Inilah yang dibutuhkan agen: penelusuran cerdas seperti manusia yang memahami maksud, bukan hanya kata kunci.
2. Membuat Model Embedding
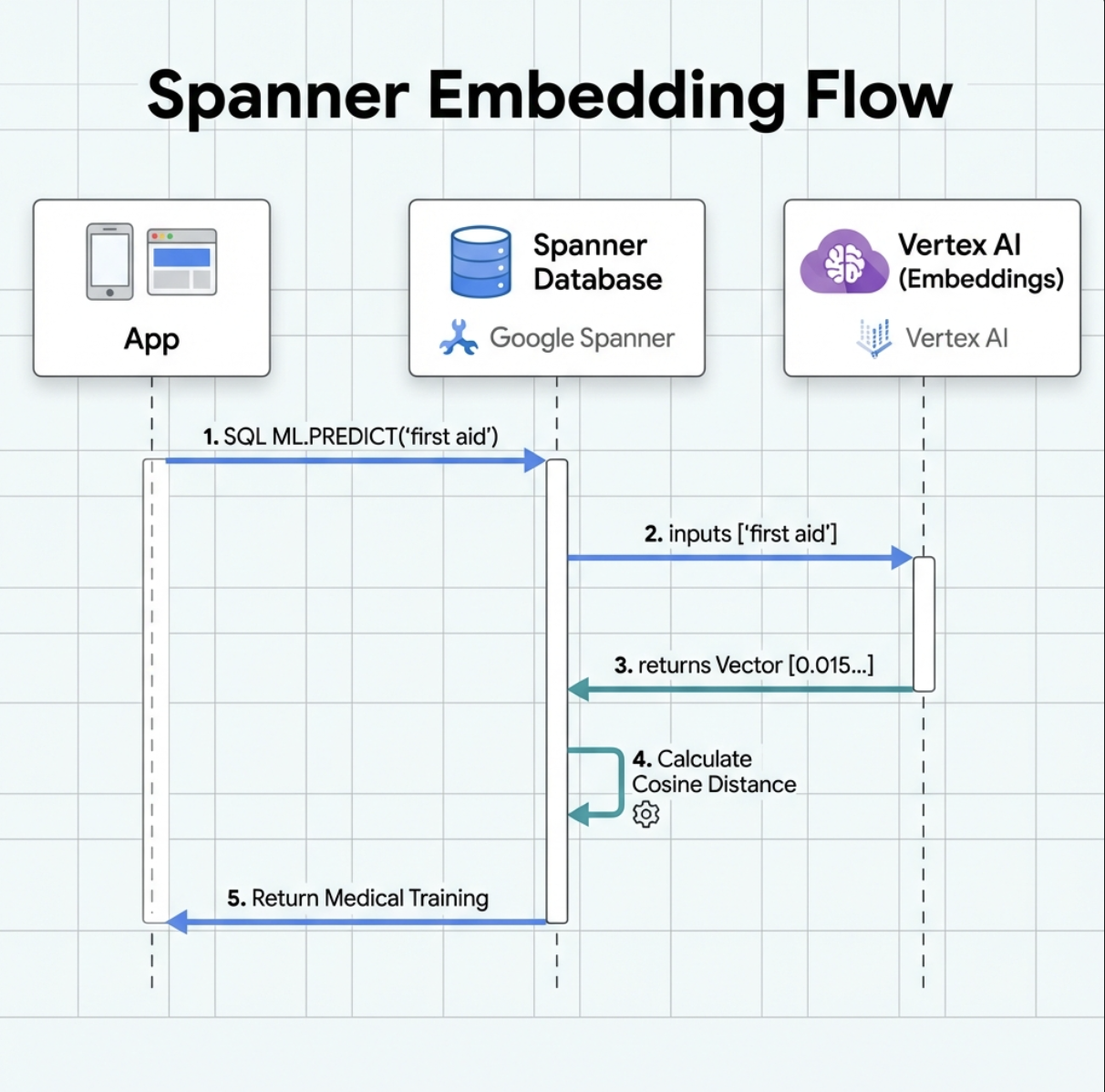
Sekarang, mari kita buat model yang mengonversi teks menjadi embedding menggunakan text-embedding-004 Google.
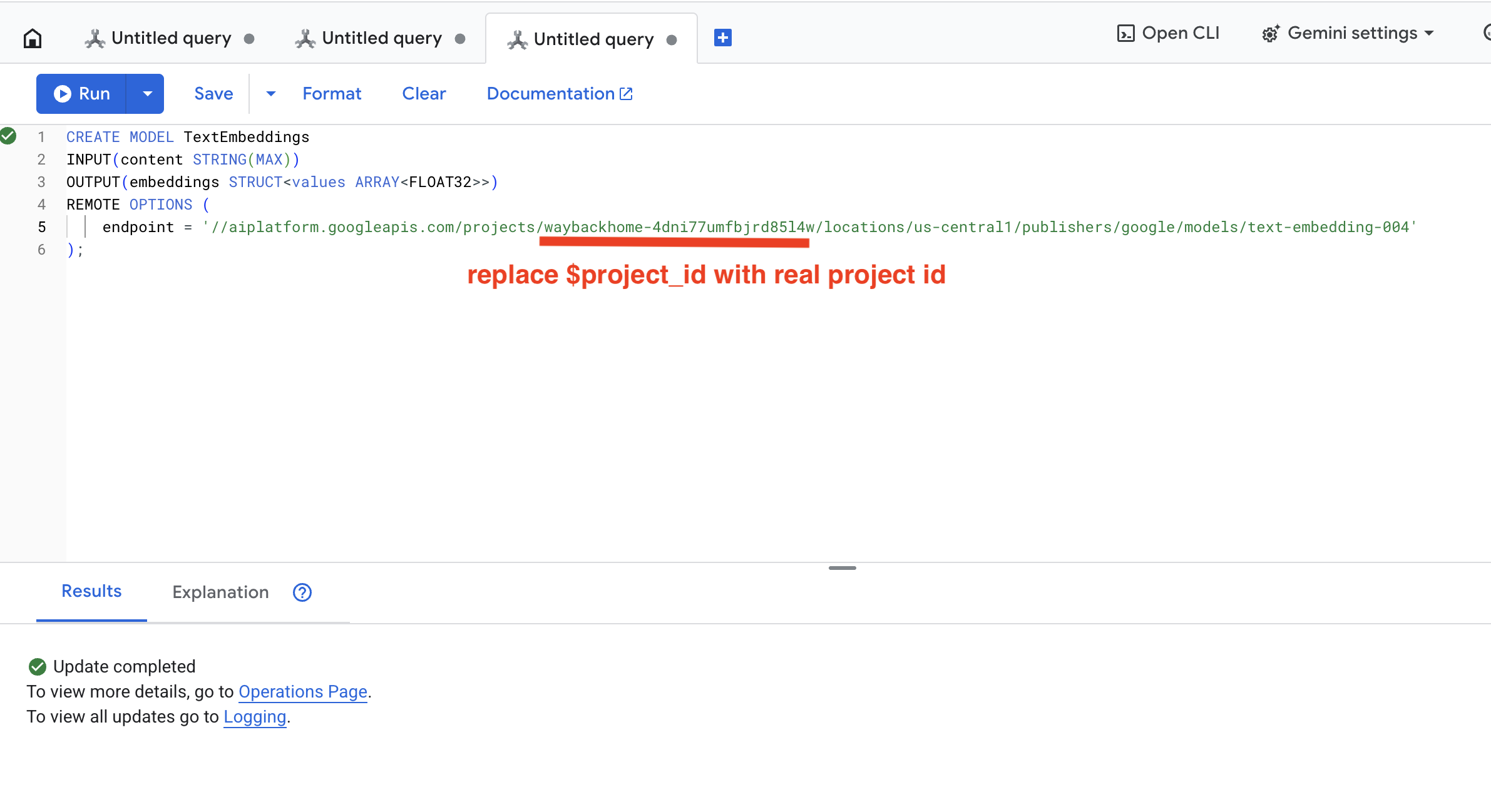
👉 Di Spanner Studio, jalankan SQL ini (ganti $YOUR_PROJECT_ID dengan project ID Anda yang sebenarnya):
‼️ Di editor Cloud Shell, buka File -> Open Folder -> way-back-home/level_2 untuk melihat seluruh project.
👉 Jalankan kueri ini di Spanner Studio dengan menyalin dan menempelkan kueri di bawah, lalu klik tombol Jalankan:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Fungsi Fitur Ini:
- Membuat model virtual di Spanner (tanpa bobot model yang disimpan secara lokal)
- Menunjuk ke
text-embedding-004Google di Vertex AI - Menentukan kontrak: Input adalah teks, output adalah array float 768 dimensi
Mengapa "REMOTE OPTIONS"?
- Spanner tidak menjalankan model itu sendiri
- Vertex AI akan dipanggil melalui API saat Anda menggunakan
ML.PREDICT - Zero-ETL: Tidak perlu mengekspor data ke Python, memproses, dan mengimpor ulang
Klik tombol Run, setelah berhasil, Anda dapat melihat hasilnya seperti di bawah ini:
3. Menambahkan Kolom Embedding
👉 Tambahkan kolom untuk menyimpan embedding:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Klik tombol Run, setelah berhasil, Anda dapat melihat hasilnya seperti di bawah ini:
4. Membuat Embedding
👉 Gunakan AI untuk membuat penyematan vektor untuk setiap keterampilan:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Klik tombol Run, setelah berhasil, Anda dapat melihat hasilnya seperti di bawah ini:
Yang terjadi: Setiap nama skill (misalnya, "pertolongan pertama") dikonversi menjadi vektor 768 dimensi yang merepresentasikan makna semantiknya.
5. Memverifikasi Embedding
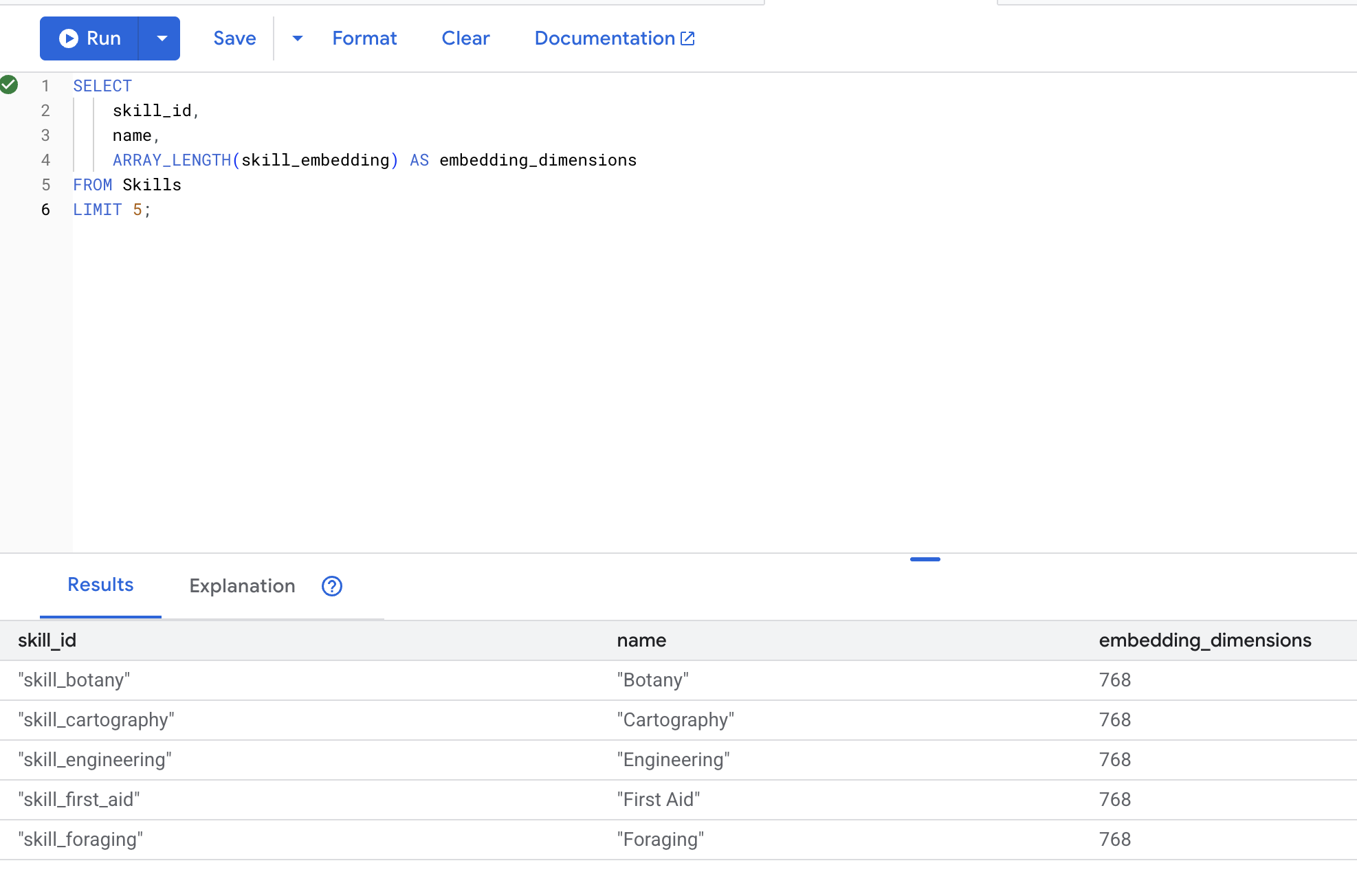
👉 Periksa apakah embedding telah dibuat:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Output yang diinginkan:
6. Menguji Penelusuran Semantik
Sekarang kita menguji kasus penggunaan yang tepat dari skenario kita: menemukan keterampilan medis menggunakan istilah "paramedis".
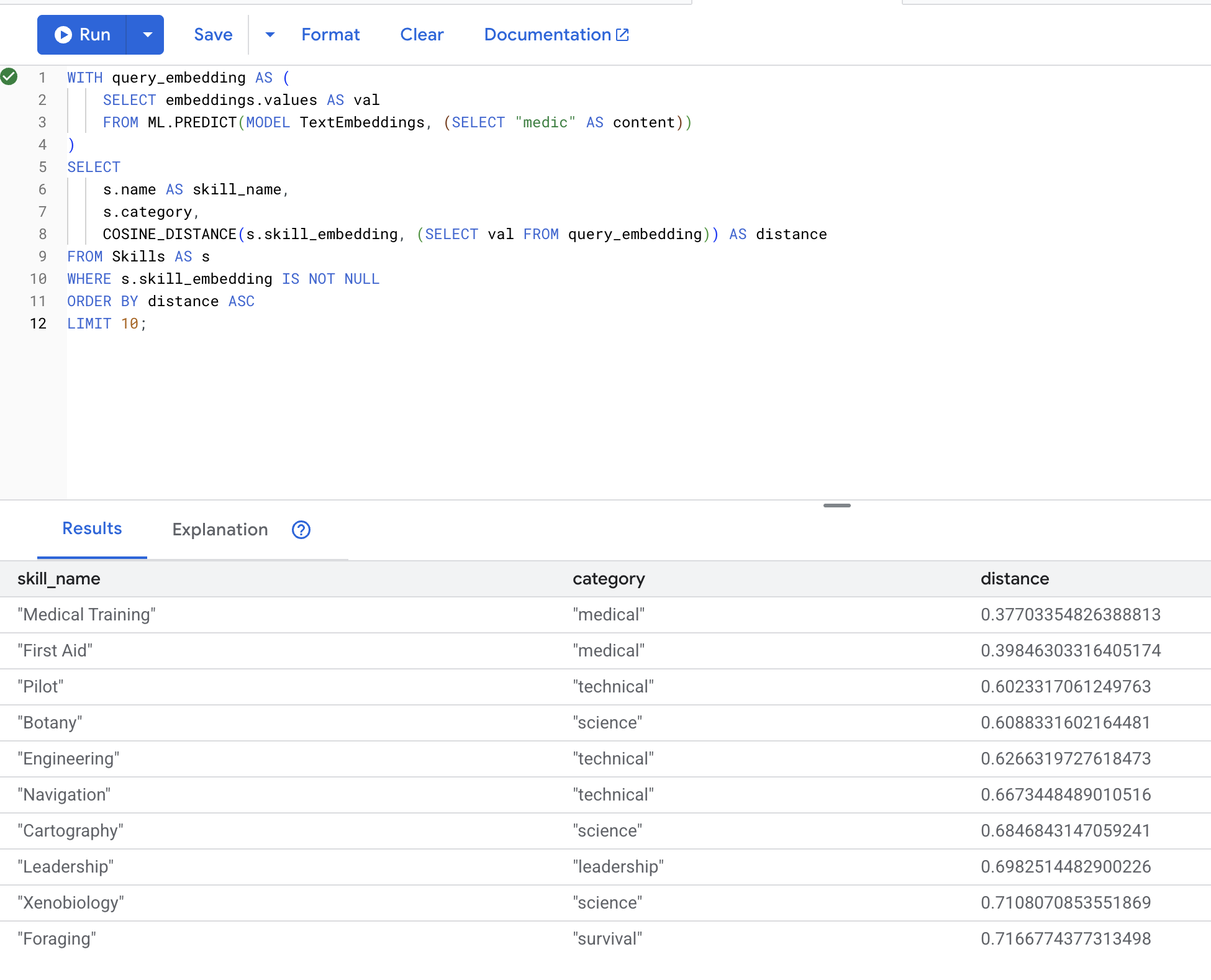
👉 Temukan keterampilan yang mirip dengan "tenaga medis":
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Mengonversi istilah penelusuran pengguna "medic" menjadi embedding
- Menyimpannya dalam tabel sementara
query_embedding
Hasil yang diharapkan (jarak yang lebih rendah = lebih mirip):
7. Membuat Model Gemini untuk Analisis
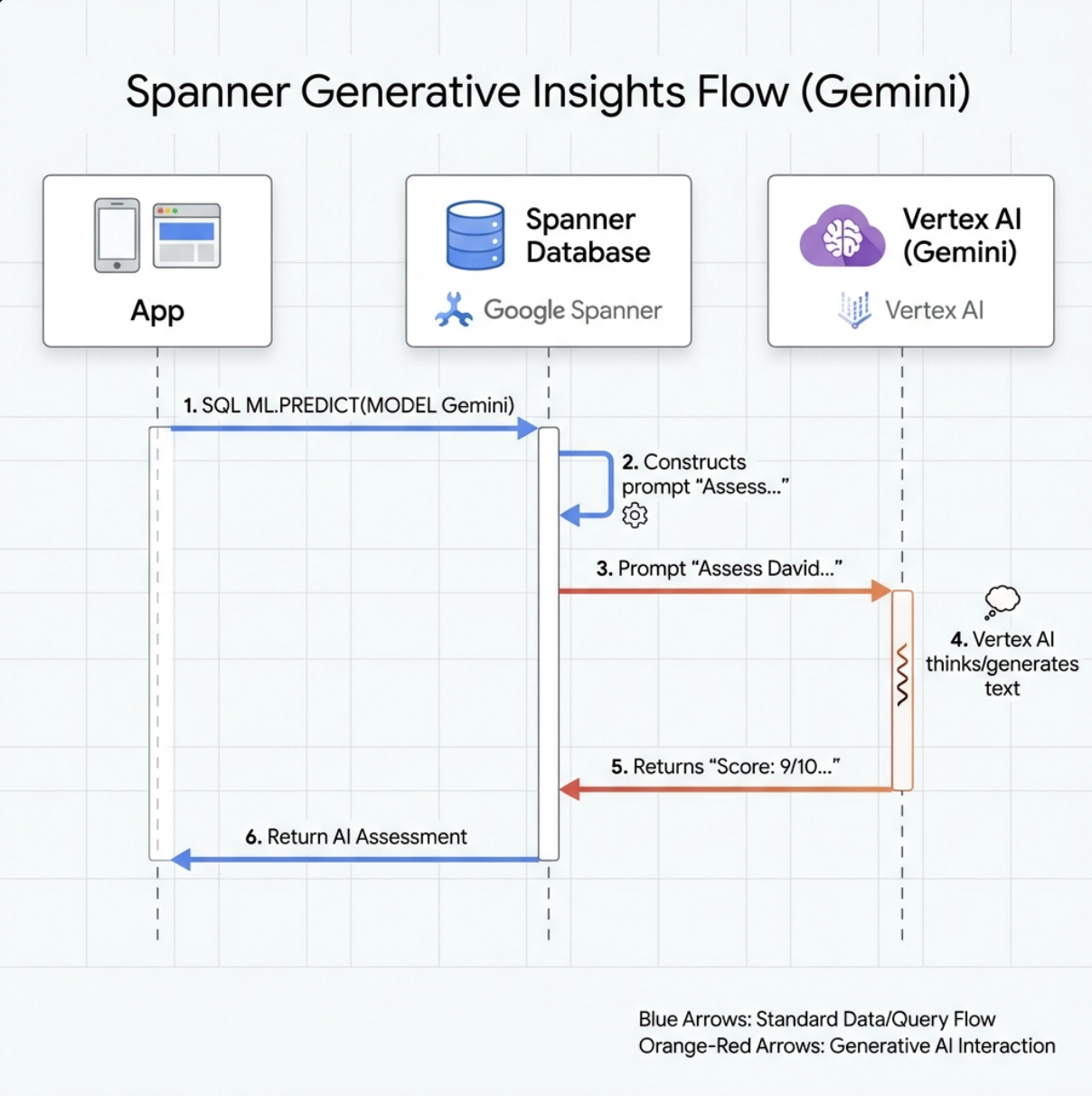
👉 Buat referensi model AI generatif (ganti $YOUR_PROJECT_ID dengan project ID Anda yang sebenarnya):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Perbedaan dari Model Embedding:
- Embedding: Teks → Vektor (untuk penelusuran kemiripan)
- Gemini: Teks → Teks yang Dihasilkan (untuk penalaran/analisis)
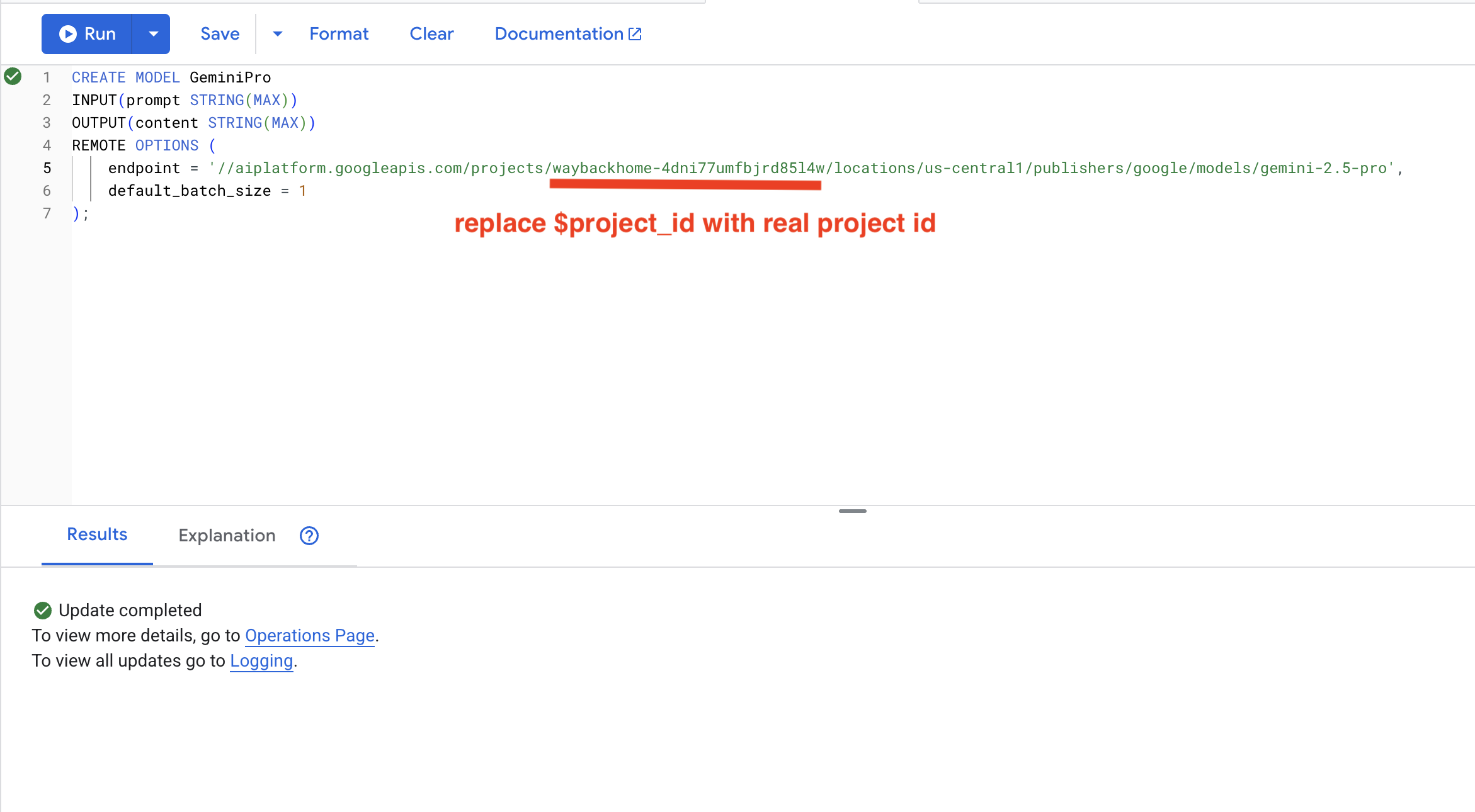
8. Menggunakan Gemini untuk Analisis Kompatibilitas
👉 Menganalisis pasangan penyintas untuk kompatibilitas misi:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Output yang diinginkan:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Membangun Agen RAG Grafik dengan Penelusuran Hybrid
1. Ringkasan Arsitektur Sistem
Bagian ini membangun sistem penelusuran multi-metode yang memberikan fleksibilitas pada agen Anda untuk menangani berbagai jenis kueri. Sistem ini memiliki tiga lapisan: Lapisan Agen, Lapisan Alat, Lapisan Layanan.
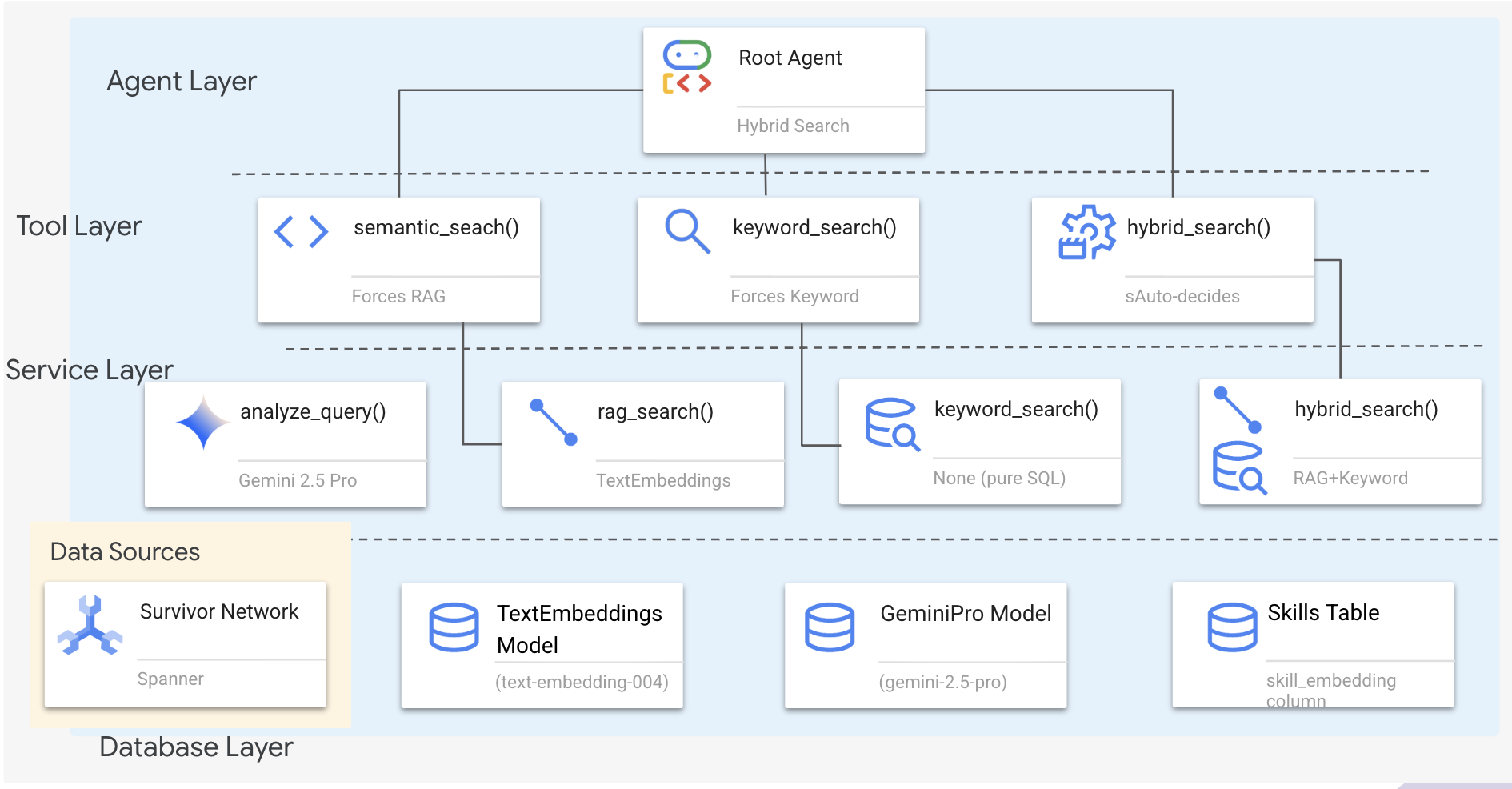
Mengapa Tiga Lapisan?
- Pemisahan tanggung jawab: Agen berfokus pada maksud, alat berfokus pada antarmuka, layanan berfokus pada penerapan
- Fleksibilitas: Agen dapat memaksakan metode tertentu atau membiarkan perutean otomatis AI
- Pengoptimalan: Dapat melewati analisis AI yang mahal jika metode diketahui
Di bagian ini, Anda terutama akan menerapkan penelusuran semantik (RAG) - menemukan hasil berdasarkan makna, bukan hanya kata kunci. Selanjutnya, kami akan menjelaskan cara penelusuran hibrida menggabungkan beberapa metode.
2. Implementasi Layanan RAG
👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Cari komentar # TODO: REPLACE_SQL
Ganti seluruh baris ini dengan kode berikut:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Definisi Alat Penelusuran Semantik
👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
Di hybrid_search_tools.py, temukan komentar # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉Ganti seluruh baris ini dengan kode berikut:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Saat Agen Menggunakan:
- Kueri yang meminta kemiripan ("temukan yang mirip dengan X")
- Kueri konseptual ("kemampuan penyembuhan")
- Saat pemahaman makna sangat penting
4. Panduan Keputusan Agen (Petunjuk)
Dalam definisi agen, salin tempel bagian terkait penelusuran semantik ke petunjuk.
👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Agen menggunakan petunjuk ini untuk memilih alat yang tepat:
👉Di file agent.py, cari komentar # TODO: REPLACE_SEARCH_LOGIC, Replace this whole line dengan kode berikut:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉Cari komentar # TODO: ADD_SEARCH_TOOLReplace this whole line dengan kode berikut:
semantic_search, # Force RAG
5. Memahami Cara Kerja Penelusuran Hybrid (Hanya Baca, Tidak Perlu Tindakan)
Pada langkah 2-4, Anda menerapkan penelusuran semantik (RAG), metode penelusuran inti yang menemukan hasil berdasarkan makna. Namun, Anda mungkin melihat bahwa sistem ini disebut "Penelusuran Hybrid". Berikut cara semuanya terhubung:
Cara Kerja Penggabungan Hybrid:
Dalam file way-back-home/level_2/backend/services/hybrid_search_service.py, saat hybrid_search() dipanggil, layanan menjalankan KEDUA penelusuran dan menggabungkan hasilnya:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Untuk codelab ini, Anda menerapkan komponen penelusuran semantik (RAG), yang merupakan dasarnya. Metode kata kunci dan hibrida sudah diterapkan dalam layanan - agen Anda dapat menggunakan ketiganya.
Selamat! Anda telah berhasil menyelesaikan Agen RAG Grafik dengan penelusuran hibrida.
7. 🚀 Menguji Agen Anda dengan ADK Web
Cara termudah untuk menguji agen Anda adalah dengan menggunakan perintah adk web, yang meluncurkan agen Anda dengan antarmuka chat bawaan.
1. Menjalankan Agen
👉💻 Buka direktori backend (tempat agen Anda ditentukan) dan luncurkan Antarmuka Web::
cd ~/way-back-home/level_2/backend
uv run adk web
Perintah ini memulai agen yang ditentukan dalam
agent/agent.py
dan membuka antarmuka web untuk pengujian.
👉 Buka URL:
Perintah ini akan menampilkan URL lokal (biasanya http://127.0.0.1:8000 atau yang serupa). Buka ini di browser Anda.
Setelah mengklik URL, Anda akan melihat UI Web ADK. Pastikan Anda memilih "agen" dari pojok kiri atas.
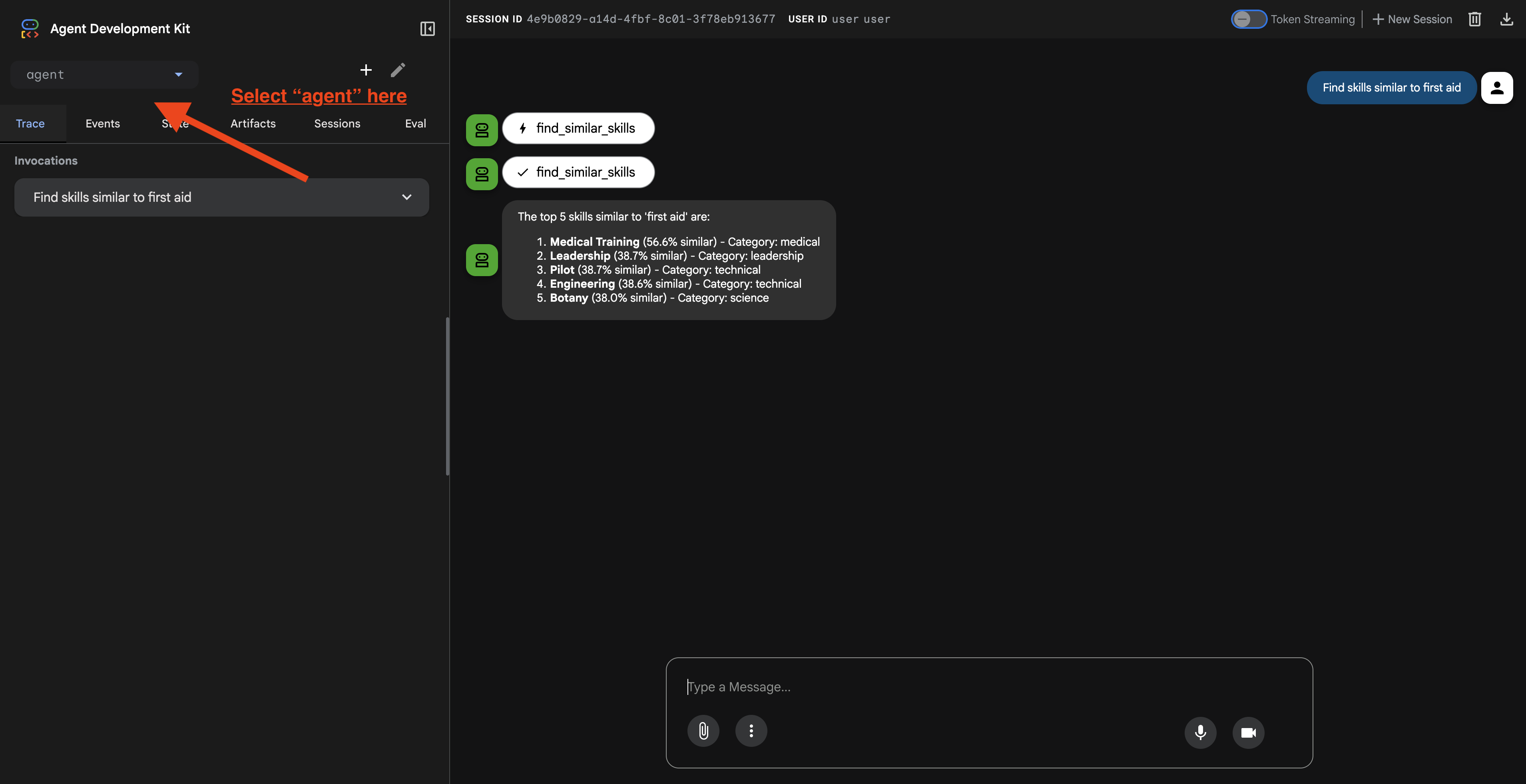
2. Menguji Kemampuan Penelusuran
Agen ini dirancang untuk merutekan kueri Anda secara cerdas. Coba input berikut di jendela chat untuk melihat berbagai metode penelusuran berfungsi.
🧬 A. Graph RAG (Penelusuran Semantik)
Menemukan item berdasarkan makna dan konsep, meskipun kata kuncinya tidak cocok.
Kueri Pengujian: (Pilih salah satu di bawah)
Who can help with injuries?
What abilities are related to survival?
Yang harus diperhatikan:
- Alasannya harus menyebutkan penelusuran Semantik atau RAG.
- Anda akan melihat hasil yang terkait secara konseptual (misalnya, "Operasi" saat meminta "Pertolongan Pertama").
- Hasil akan memiliki ikon 🧬.
🔀 B. Penelusuran Hybrid
Menggabungkan filter kata kunci dengan pemahaman semantik untuk kueri yang kompleks.
Kueri Pengujian:(Pilih salah satu di bawah)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Yang harus diperhatikan:
- Alasannya harus menyebutkan penelusuran Hybrid.
- Hasil harus cocok dengan KEDUA kriteria (konsep + lokasi/kategori).
- Hasil yang ditemukan dengan kedua metode akan memiliki ikon 🔀 dan diberi peringkat tertinggi.
👉💻 Setelah selesai menguji, akhiri proses dengan menekan Ctrl+C di command line.
8. 🚀 Menjalankan Aplikasi Lengkap
Ringkasan Arsitektur Full Stack
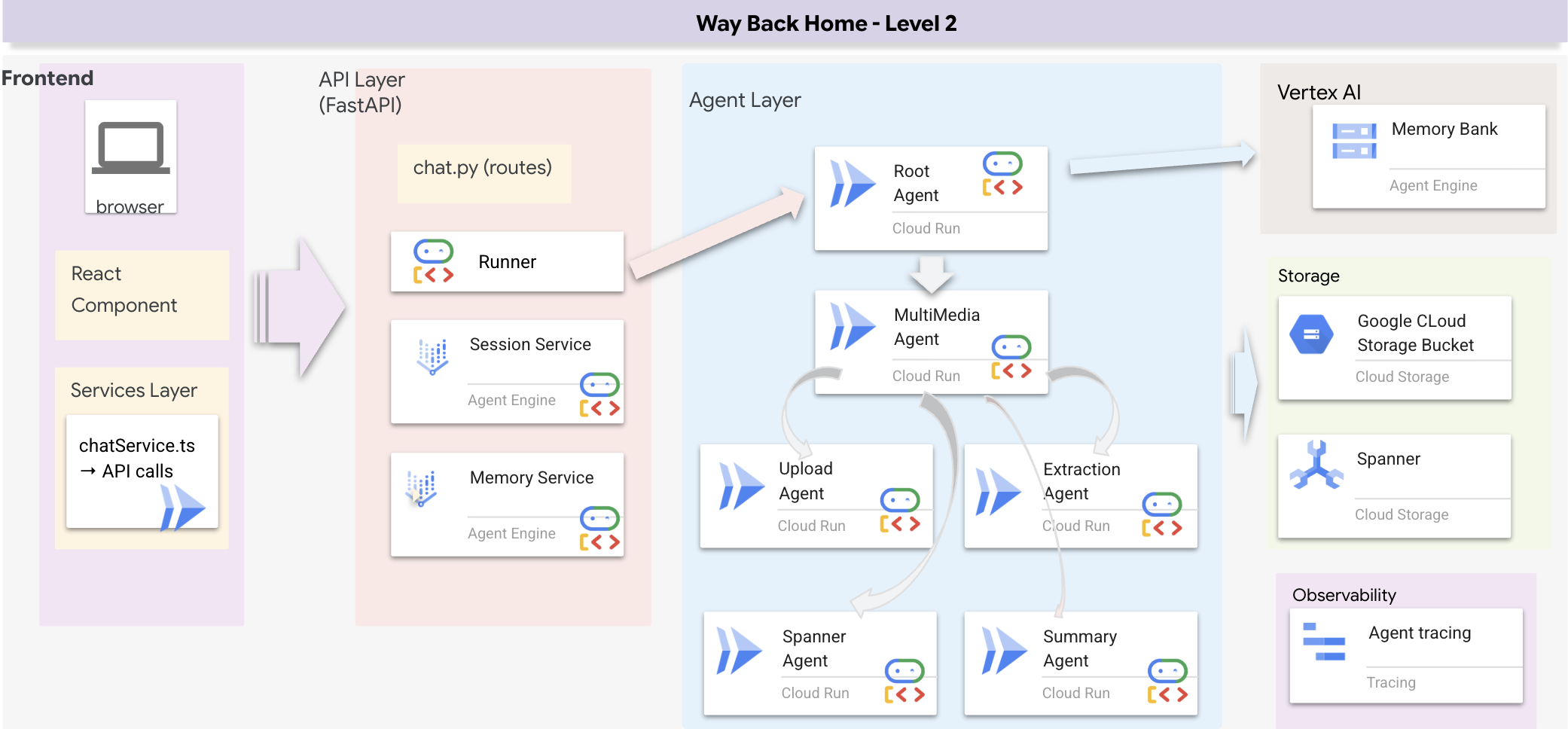
Tambahkan SessionService & Runner
👉💻 Di terminal, buka file chat.py di Cloud Shell Editor dengan menjalankan (pastikan Anda menekan "ctrl+C" untuk mengakhiri proses sebelumnya sebelum melanjutkan):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉Di file chat.py, cari komentar # TODO: REPLACE_INMEMORY_SERVICES, Ganti seluruh baris ini dengan kode berikut:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉Di file chat.py, cari komentar # TODO: REPLACE_RUNNER, Ganti seluruh baris ini dengan kode berikut:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Mulai Permohonan
Jika terminal sebelumnya masih berjalan, akhiri dengan menekan Ctrl+C.
👉💻 Mulai Aplikasi:
cd ~/way-back-home/level_2/
./start_app.sh
Jika backend berhasil dimulai, Anda akan melihat Local: http://localhost:5173/" seperti di bawah: 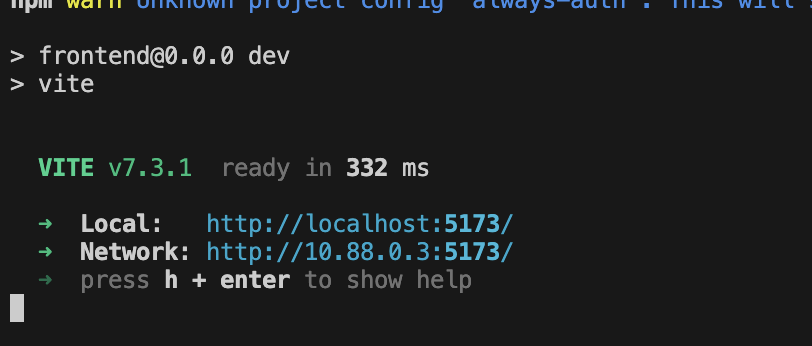
👉 Klik Local: http://localhost:5173/ dari terminal.
2. Menguji Penelusuran Semantik
Kueri:
Find skills similar to healing
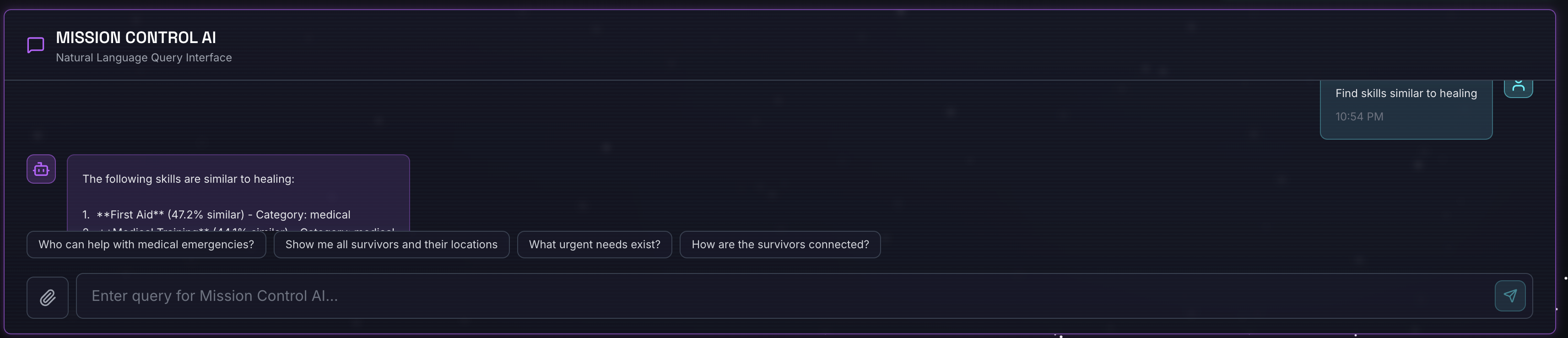
Yang terjadi:
- Agen mengenali permintaan kesamaan
- Membuat embedding untuk "penyembuhan"
- Menggunakan jarak kosinus untuk menemukan keterampilan yang mirip secara semantik
- Menampilkan: pertolongan pertama (meskipun namanya tidak cocok dengan "penyembuhan")
3. Menguji Penelusuran Hybrid
Kueri:
Find medical skills in the mountains
Yang terjadi:
- Komponen kata kunci: Filter untuk
category='medical' - Komponen semantik: Sematkan "medis" dan urutkan berdasarkan kemiripan
- Gabungkan: Gabungkan hasil, dengan memprioritaskan hasil yang ditemukan oleh kedua metode 🔀
Kueri(opsional):
Who is good at survival and in the forest?
Yang terjadi:
- Temuan kata kunci:
biome='forest' - Temuan semantik: keterampilan yang mirip dengan "bertahan hidup"
- Hybrid menggabungkan keduanya untuk mendapatkan hasil terbaik
👉💻 Setelah selesai menguji, di terminal, akhiri pengujian dengan menekan Ctrl+C.
4. (!KHUSUS PESERTA WORKSHOP) Memperbarui lokasi Anda
👉💻 Jalankan skrip penyelesaian:
cd ~/way-back-home/level_2
./set_level_2.sh
Sekarang buka waybackhome.dev, dan Anda akan melihat lokasi Anda telah diperbarui. Selamat Anda telah menyelesaikan level 2!

9. ☕️ [Opsional] Pipeline Multimodal (Hanya Baca) — Lapisan Alat
Mengapa Kita Memerlukan Pipeline Multimodal?
Jaringan penyelamat bukan hanya teks. Korban di lapangan mengirimkan data tidak terstruktur langsung melalui chat:
- 📸 Gambar: Foto sumber daya, bahaya, atau peralatan
- 🎥 Video: Laporan status atau siaran SOS
- 📄 Teks: Catatan atau log lapangan
File Apa yang Kami Proses?
Berbeda dengan langkah sebelumnya saat kita menelusuri data yang ada, di sini kita memproses File yang Diupload Pengguna. Antarmuka chat.py menangani lampiran file secara dinamis:
Sumber | Konten | Sasaran |
Lampiran Pengguna | Gambar/Video/Teks | Informasi yang akan ditambahkan ke grafik |
Konteks Chat | "Berikut foto perlengkapannya" | Maksud dan detail tambahan |
Pendekatan yang Direncanakan: Pipeline Agen Berurutan
Kami menggunakan Sequential Agent (multimedia_agent.py) yang menggabungkan agen khusus:
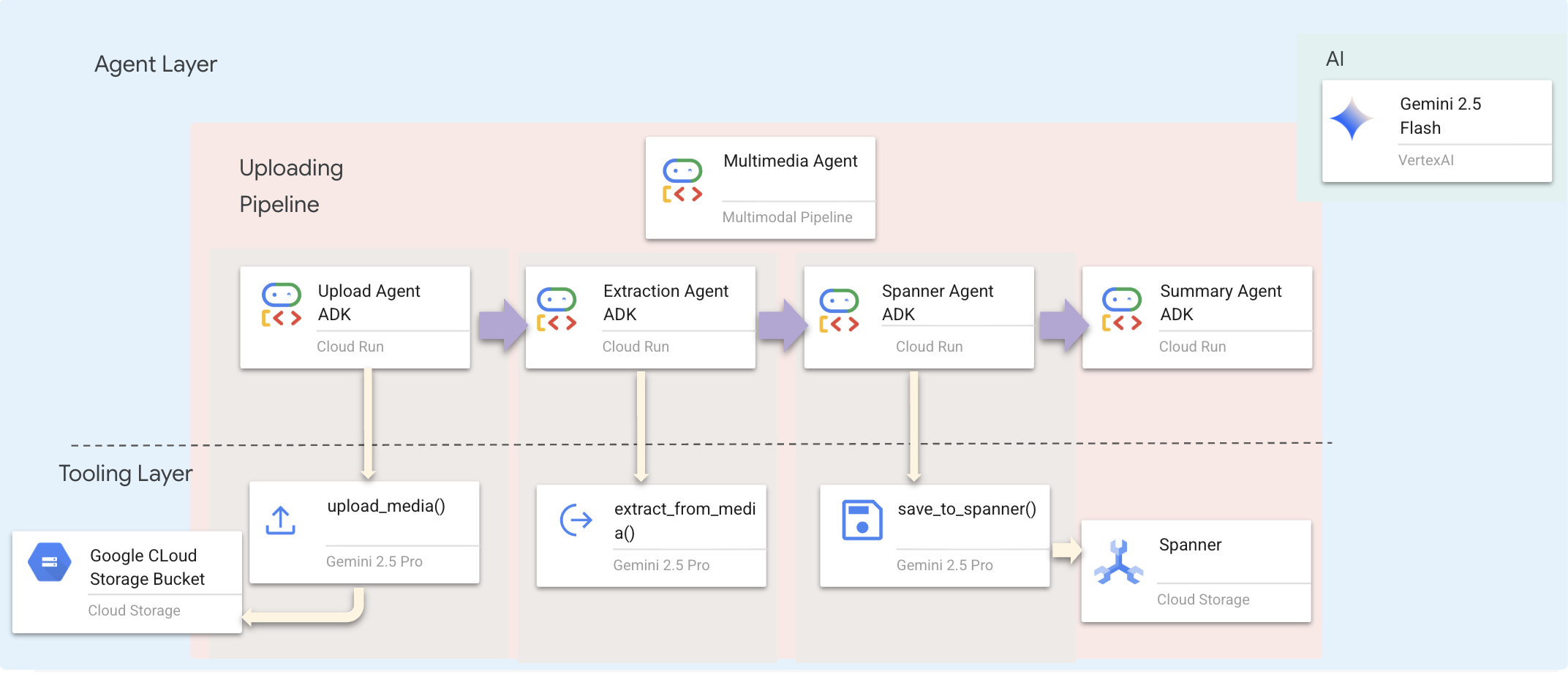
Hal ini ditentukan dalam backend/agent/multimedia_agent.py sebagai SequentialAgent.
Lapisan alat menyediakan kemampuan yang dapat dipanggil oleh agen. Alat menangani "bagaimana" — mengupload file, mengekstrak entitas, dan menyimpan ke database.
1. Membuka File Alat
👉💻 Buka file level_2/backend/agent/tools/extraction_tools.py atau dengan mengetik perintah berikut di terminal. Buka terminal baru. Di terminal, buka file di Cloud Shell Editor:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Menerapkan Alat upload_media
Alat ini mengupload file lokal ke Google Cloud Storage.
👉 Di def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, kode berikut menjelaskan cara mengupload file ke GCS dan mendeteksi jenisnya:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Menerapkan Alat extract_from_media
Alat ini adalah router — alat ini memeriksa media_type dan mengirim ke ekstraktor yang benar (teks, gambar, atau video).
👉 Di async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, kode berikut menjelaskan cara mengekstrak entitas dan hubungan dari media yang diupload.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Detail Penerapan Utama:
- Input Multimodal: Kita meneruskan perintah teks (
_get_extraction_prompt()) dan objek gambar kegenerate_content. - Output Terstruktur:
response_mime_type="application/json"memastikan LLM menampilkan JSON yang valid, yang sangat penting untuk pipeline. - Penautan Entitas Visual: Perintah menyertakan entitas yang diketahui sehingga Gemini dapat mengenali karakter tertentu.
4. Menerapkan Alat save_to_spanner
Alat ini mempertahankan entity dan hubungan yang diekstrak ke DB Spanner Graph.
👉 Di def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, kode berikut menjelaskan cara menyimpan entitas dan hubungan yang diekstrak ke Spanner Graph DB.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Dengan memberikan alat tingkat tinggi kepada agen, kami memastikan integritas data sekaligus memanfaatkan kemampuan penalaran agen.
5. Layanan Update GCS
GCSService menangani upload file sebenarnya ke Google Cloud Storage.
👉💻 Buka file level_2/backend/services/gcs_service.py, atau Anda dapat mengetik di terminal untuk membuka file di Cloud Shell Editor:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 Di def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, kode berikut menjelaskan cara menyimpan entitas dan hubungan yang diekstrak ke Spanner Graph DB.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Dengan mengabstraksi ini ke dalam layanan, Agen tidak perlu mengetahui bucket GCS, nama blob, atau pembuatan URL yang ditandatangani. Hanya meminta untuk "mengupload".
6. Mengapa Alur Kerja Agentic > Pendekatan Tradisional?
Keunggulan Agentic:
Fitur | Pipeline Batch | Berbasis Peristiwa | Alur Kerja Agentik |
Kompleksitas | Rendah (1 skrip) | Tinggi (5+ layanan) | Rendah (1 file Python: |
Pengelolaan Status | Variabel global | Keras (terpisah) | Terpadu (Status agen) |
Penanganan Error | Error | Log senyap | Interaktif ("Saya tidak dapat membaca file itu") |
Masukan Pengguna | Cetakan konsol | Perlu polling | Segera (Bagian dari percakapan) |
Kemampuan adaptasi | Logika tetap | Fungsi kaku | Cerdas (LLM memutuskan langkah berikutnya) |
Kesadaran Konteks | Tidak ada | Tidak ada | Penuh (Mengetahui maksud pengguna) |
Pentingnya Hal Ini: Dengan menggunakan multimedia_agent.py (SequentialAgent dengan 4 sub-agen: Upload → Ekstrak → Simpan → Ringkasan), kita mengganti infrastruktur yang kompleks DAN skrip yang rentan dengan logika aplikasi percakapan yang cerdas.
10. ☕️ [Opsional] Pipeline Multimodal (Hanya Baca) — Lapisan Agen
Lapisan agen menentukan kecerdasan — agen yang menggunakan alat untuk menyelesaikan tugas. Setiap agen memiliki peran tertentu dan meneruskan konteks ke agen berikutnya. Di bawah ini adalah diagram arsitektur untuk sistem multi-agen.
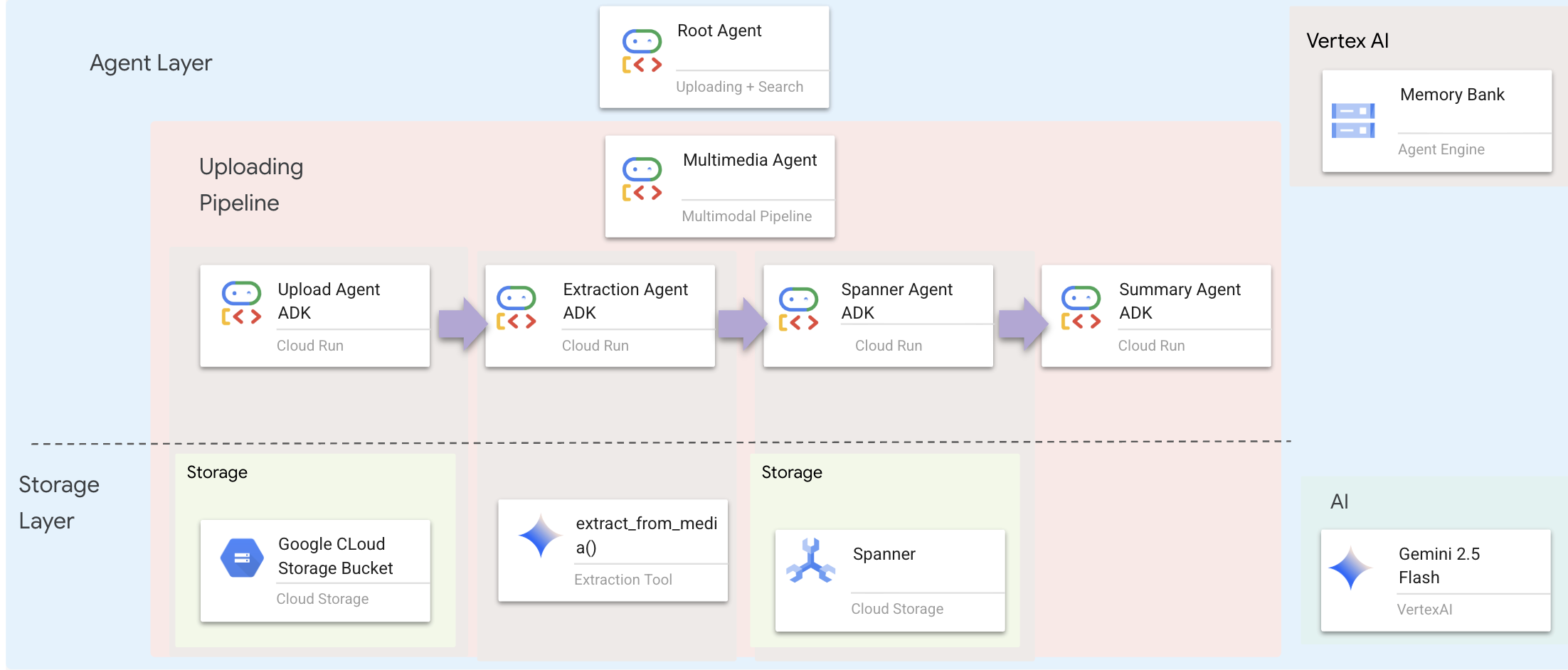
1. Buka File Agen
👉💻 Buka file level_2/backend/agent/multimedia_agent.py atau dengan mengetik perintah berikut di terminal. Buka terminal baru. Di terminal, buka file di Cloud Shell Editor:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Menentukan Agen Upload
Agen ini mengekstrak jalur file dari pesan pengguna dan menguploadnya ke GCS.
👉Dalam file multimedia_agent.py, dengan kode berikut, upload_agent dibuat untuk diupload ke GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Menentukan Agen Ekstraksi
Agen ini "melihat" media yang diupload dan mengekstrak data terstruktur menggunakan Gemini Vision.
👉Dalam file multimedia_agent.py, dengan kode berikut, extraction_agent dibuat untuk mengekstrak informasi dari media yang diupload:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Perhatikan cara instruction mereferensikan {upload_result} — ini adalah cara status diteruskan antar-agen di ADK.
4. Menentukan Agen Spanner
Agen ini menyimpan entity dan hubungan yang diekstrak ke database grafik.
👉Di file multimedia_agent.py, dengan kode berikut, spanner_agent dibuat untuk Menyimpan informasi yang diekstrak ke database:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Agen ini menerima konteks dari kedua langkah sebelumnya (upload_result dan extraction_result).
5. Menentukan Agen Ringkasan
Agen ini menyintesis hasil dari semua langkah sebelumnya menjadi respons yang mudah dipahami pengguna.
👉Di file multimedia_agent.py, dengan kode berikut, perintah untuk summary_agent yang merangkum hasilnya ditentukan:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Agen ini tidak memerlukan alat — agen ini hanya membaca konteks yang dibagikan dan membuat ringkasan yang jelas untuk pengguna.
🧠 Ringkasan Arsitektur
Lapisan | File | Tanggung jawab |
Alat |
| Cara — Upload, ekstrak, simpan |
Agent |
| Apa — Mengorkestrasi pipeline |
11. 🚀 Pipeline Data Multimodal — Orkestrasi
Inti dari sistem baru kami adalah MultimediaExtractionPipeline yang ditentukan dalam backend/agent/multimedia_agent.py. Agen ini menggunakan pola Sequential Agent dari ADK (Agent Development Kit).
1. Mengapa Berurutan?
Memproses upload adalah rantai dependensi linear:
- Anda tidak dapat mengekstrak data hingga Anda memiliki file (Upload).
- Anda tidak dapat menyimpan data hingga Anda mengekstraknya (Ekstraksi).
- Anda tidak dapat membuat ringkasan sebelum mendapatkan hasilnya (Simpan).
SequentialAgent sangat cocok untuk hal ini. Output satu agen diteruskan sebagai konteks/input ke agen berikutnya.
2. Definisi Agen
Mari kita lihat cara merakit pipeline di bagian bawah multimedia_agent.py: 👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Langkah ini menerima input dari kedua langkah sebelumnya. Cari komentar # TODO: REPLACE_ORCHESTRATION. Ganti seluruh baris ini dengan kode berikut:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Terhubung dengan Agen Root
👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Cari komentar # TODO: REPLACE_ADD_SUBAGENT. Ganti seluruh baris ini dengan kode berikut:
sub_agents=[multimedia_agent],
Satu objek ini secara efektif menggabungkan empat "pakar" menjadi satu entitas yang dapat dipanggil.
4. Aliran Data Antar-Agen
Setiap agen menyimpan outputnya dalam konteks bersama yang dapat diakses oleh agen berikutnya:
5. Buka aplikasi (lewati jika aplikasi masih berjalan)
👉💻 Mulai Aplikasi:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Klik Local: http://localhost:5173/ dari terminal.
6. Pengujian Upload Gambar
👉 Di antarmuka chat, pilih salah satu foto di sini dan upload ke UI:
Di antarmuka chat, beri tahu agen tentang konteks spesifik Anda:
Here is the survivor note
Kemudian, lampirkan gambar di sini.

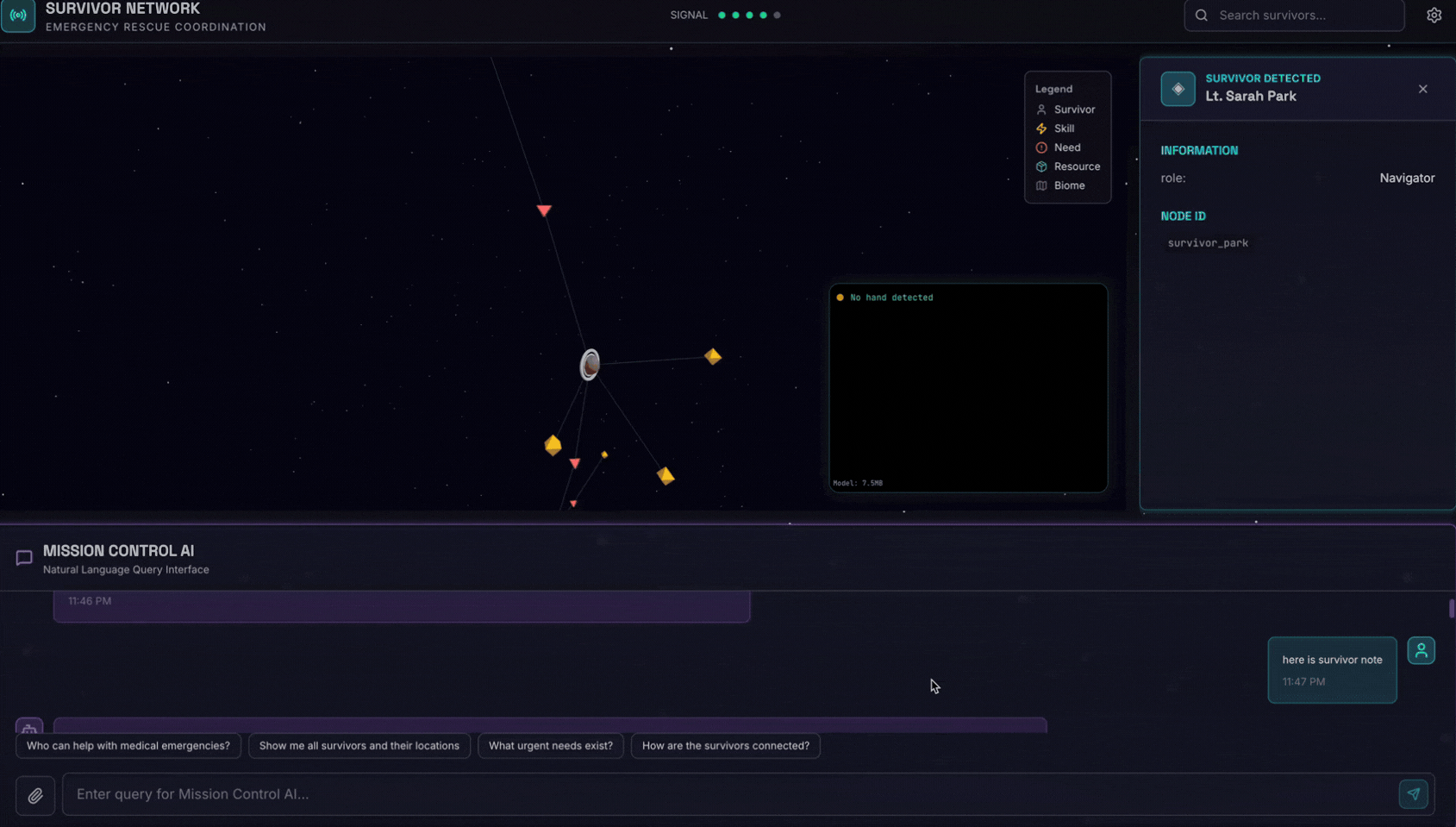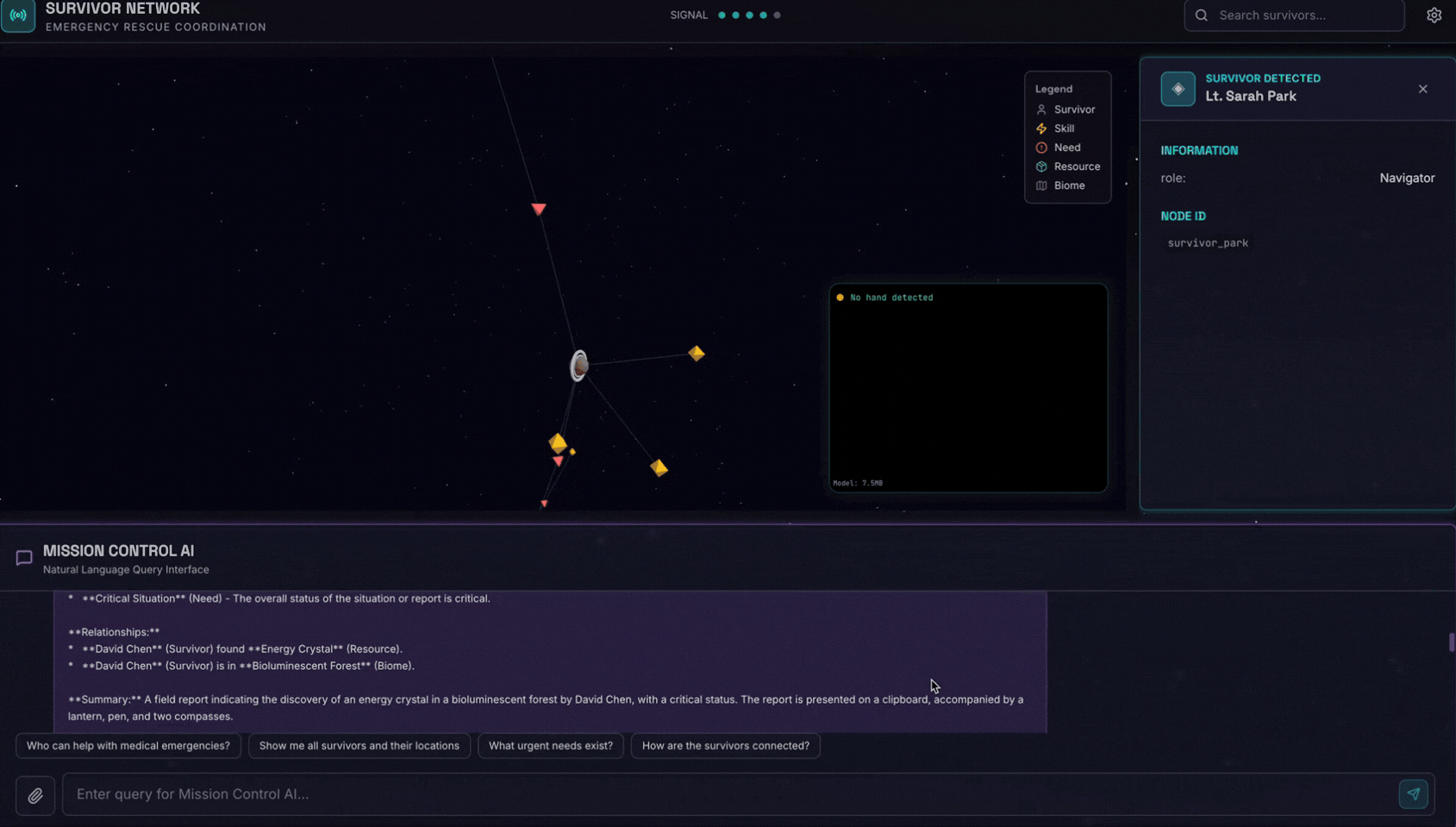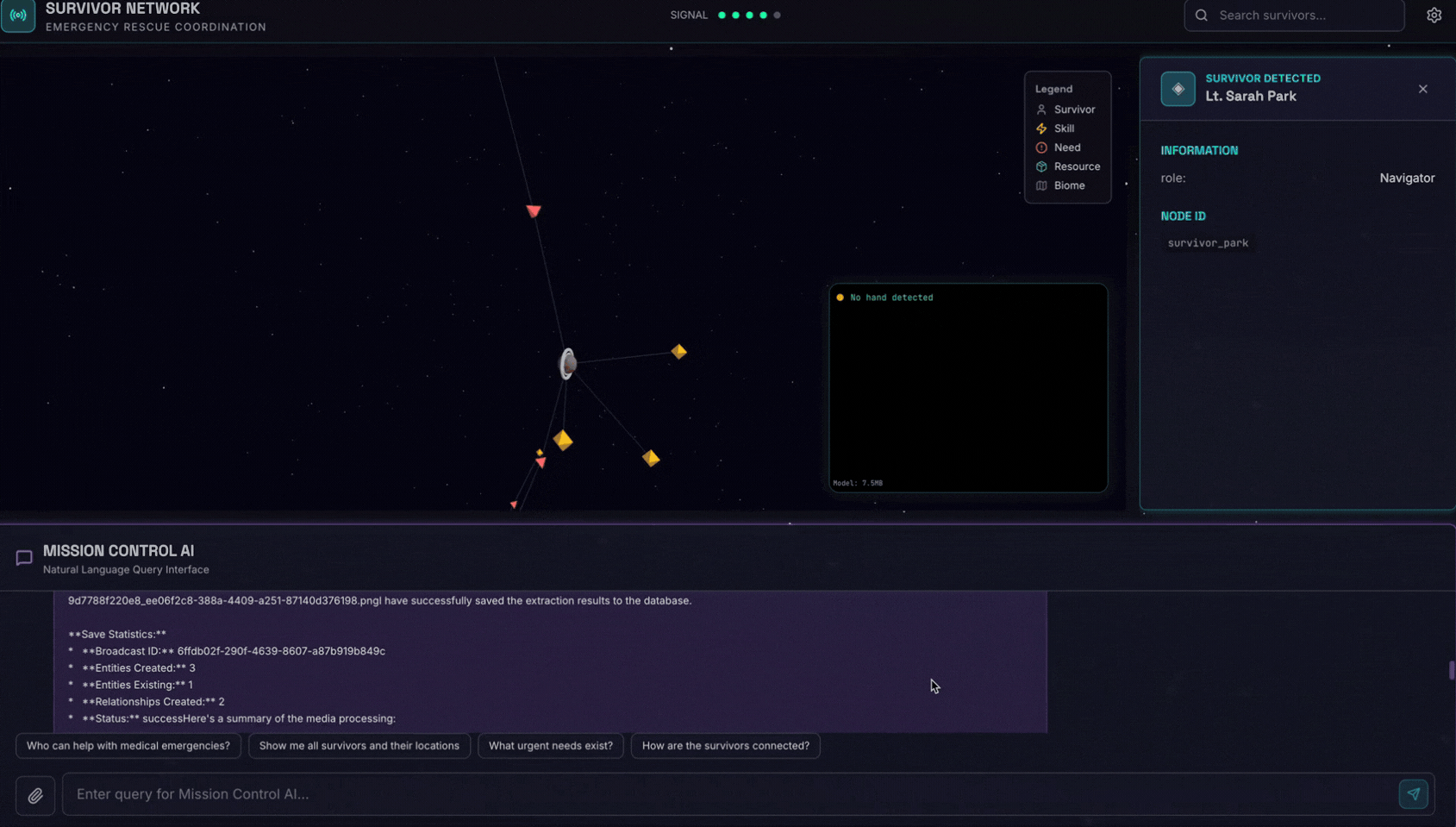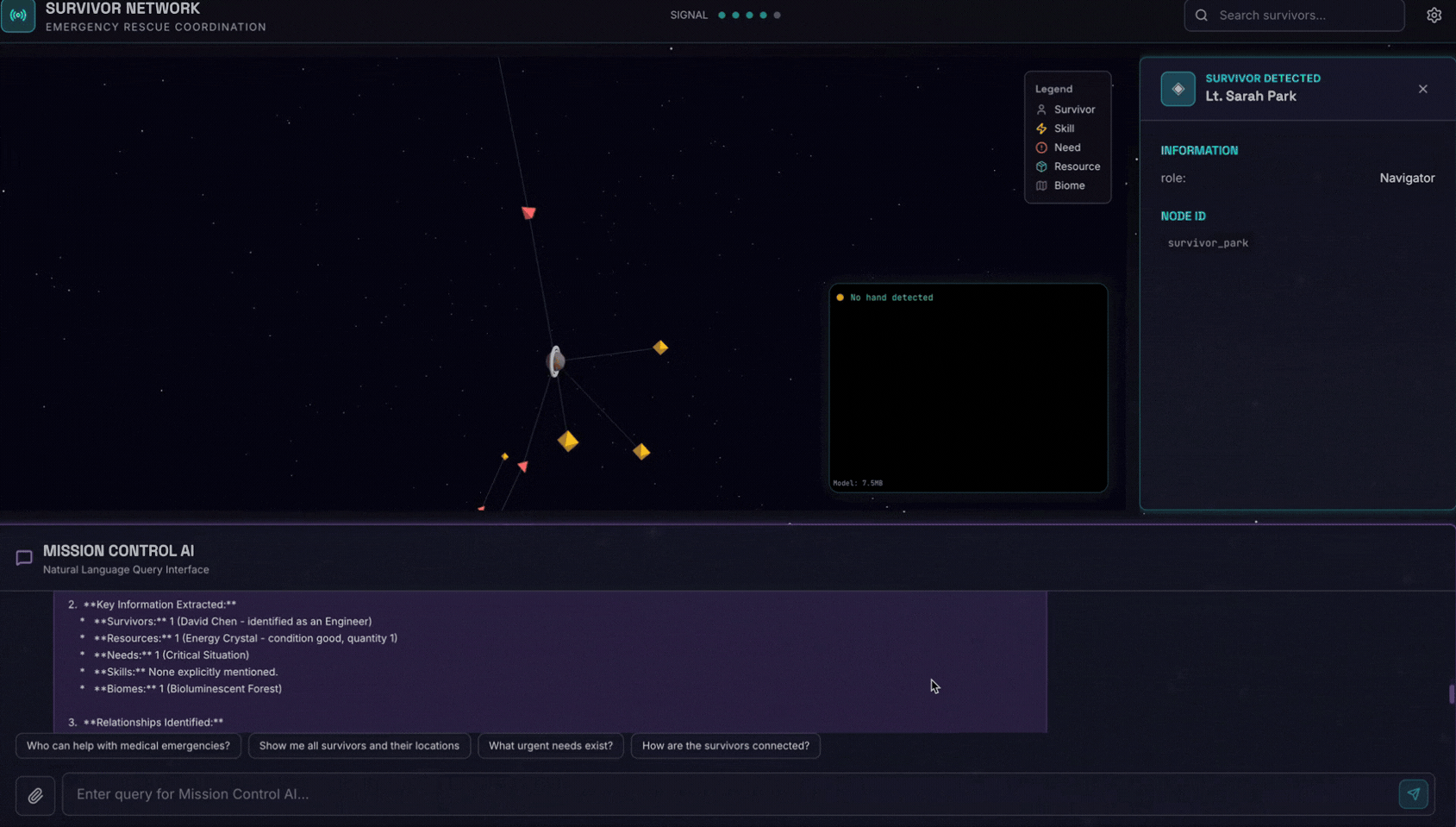
👉💻 Di terminal, setelah Anda selesai menguji, tekan "Ctrl+C" untuk mengakhiri proses.
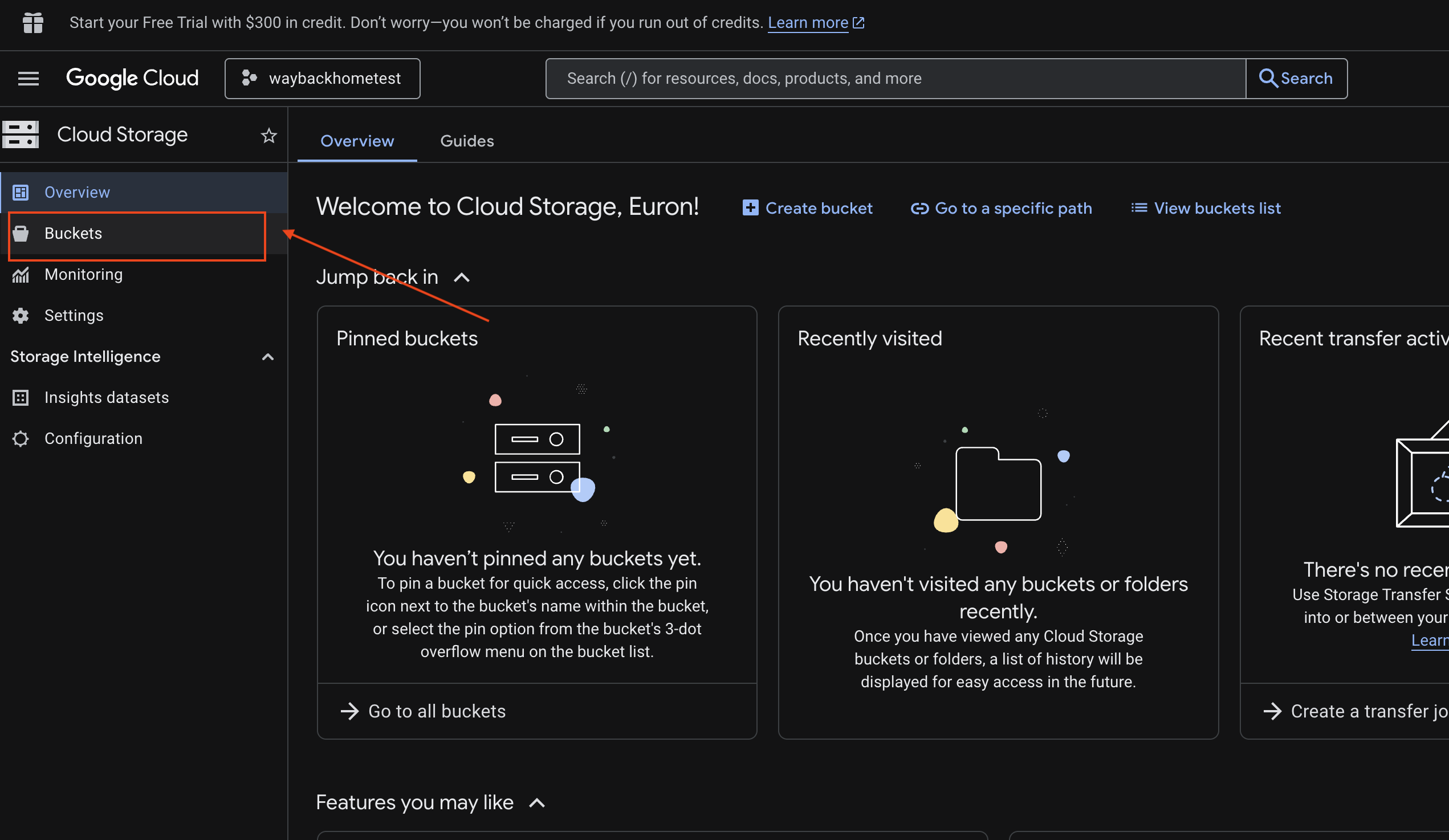
6. Memverifikasi Upload Multimodal di Bucket GCS
- Buka Penyimpanan Konsol Google Cloud.
- Pilih "bucket" di Cloud Storage
- Pilih bucket Anda, lalu klik
media.
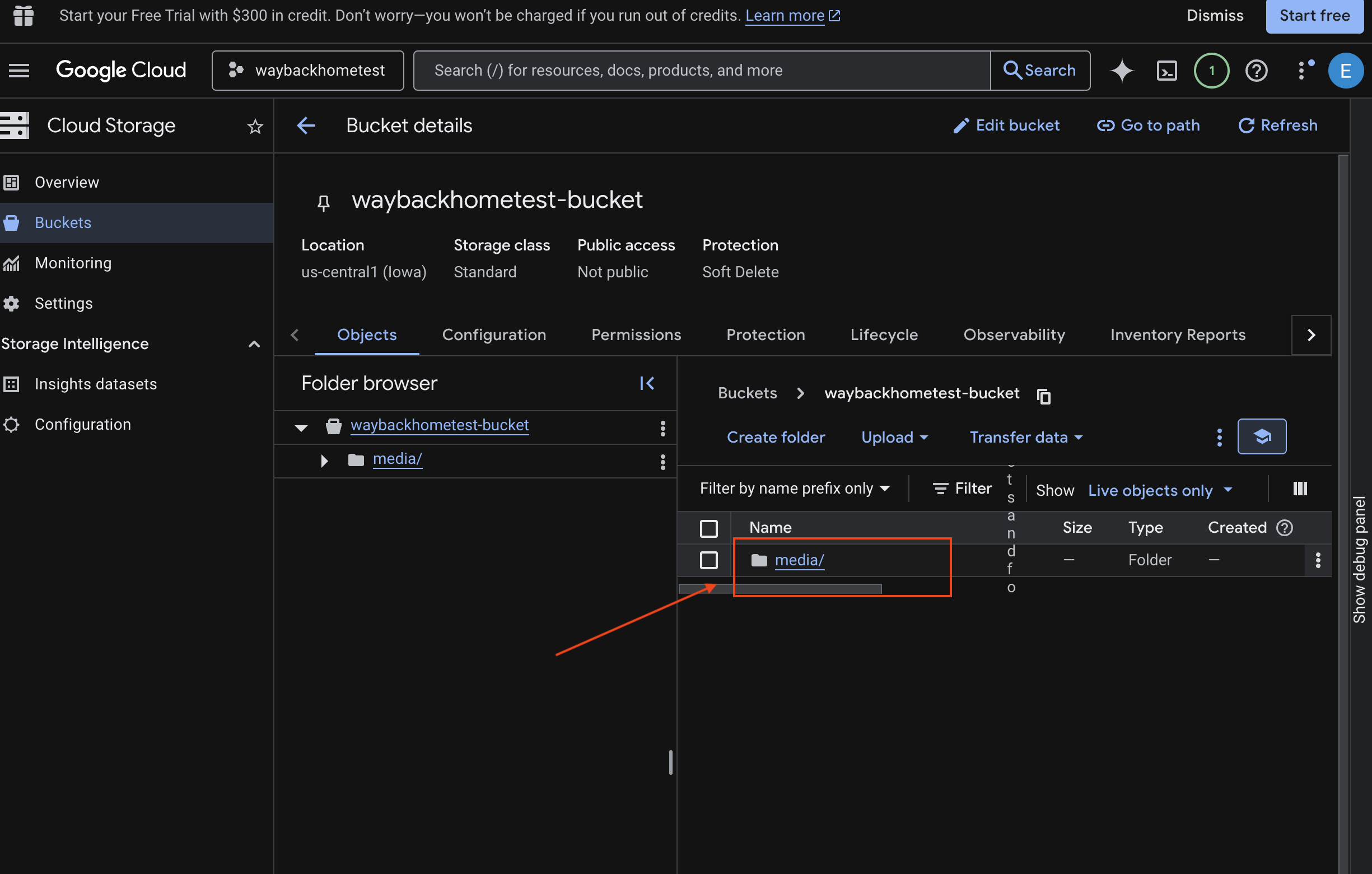
- Lihat gambar yang Anda upload di sini.
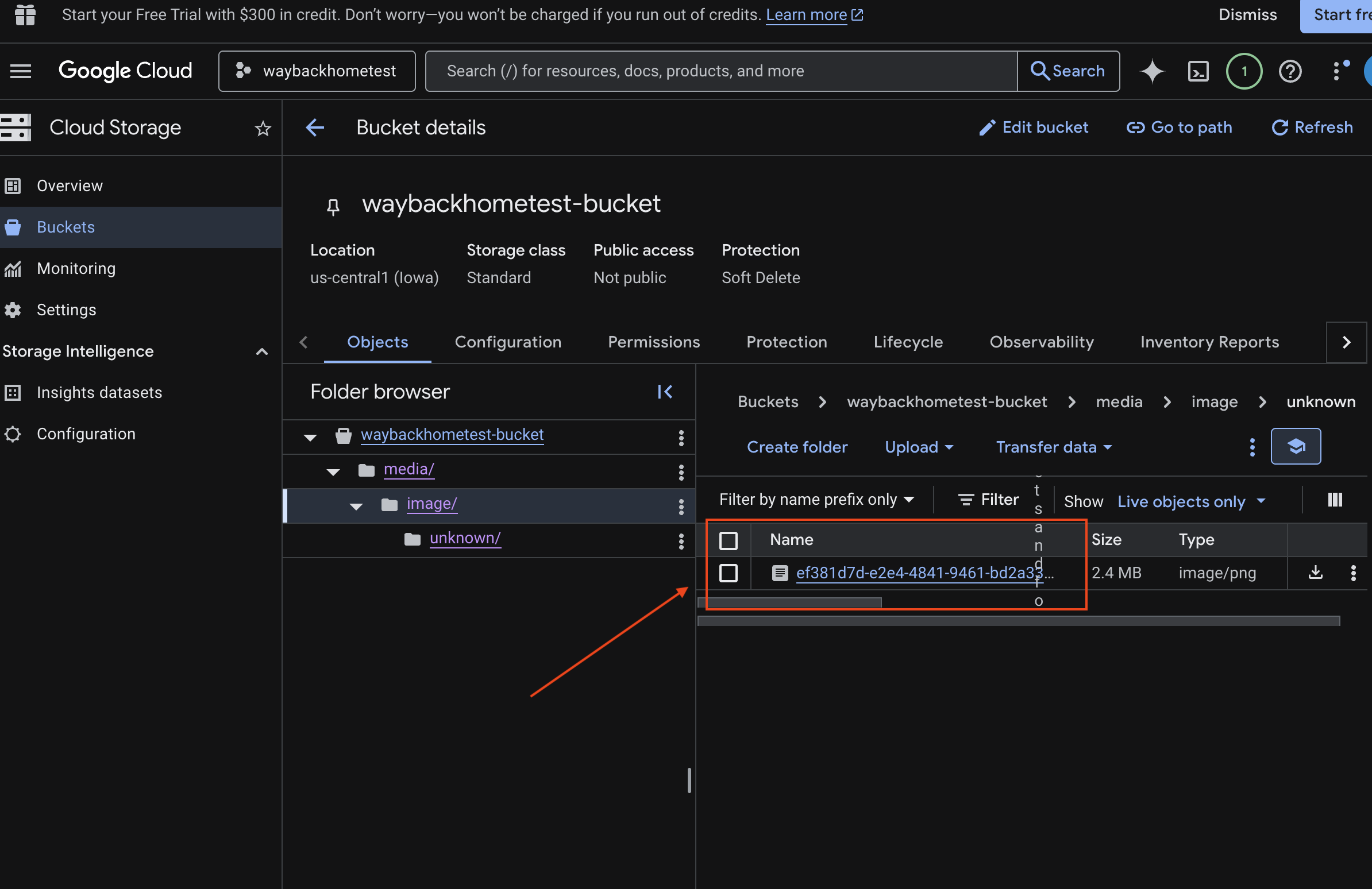
7. Memverifikasi Upload Multimodal di Spanner (Opsional)
Di bawah ini adalah contoh output di UI untuk test_photo1.
- Buka Google Cloud Console Spanner.
- Pilih instance Anda:
Survivor Network - Pilih database Anda:
graph-db - Di sidebar kiri, klik Spanner Studio
👉 Di Spanner Studio, buat kueri data baru:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Kita dapat memverifikasinya dengan melihat hasil di bawah:
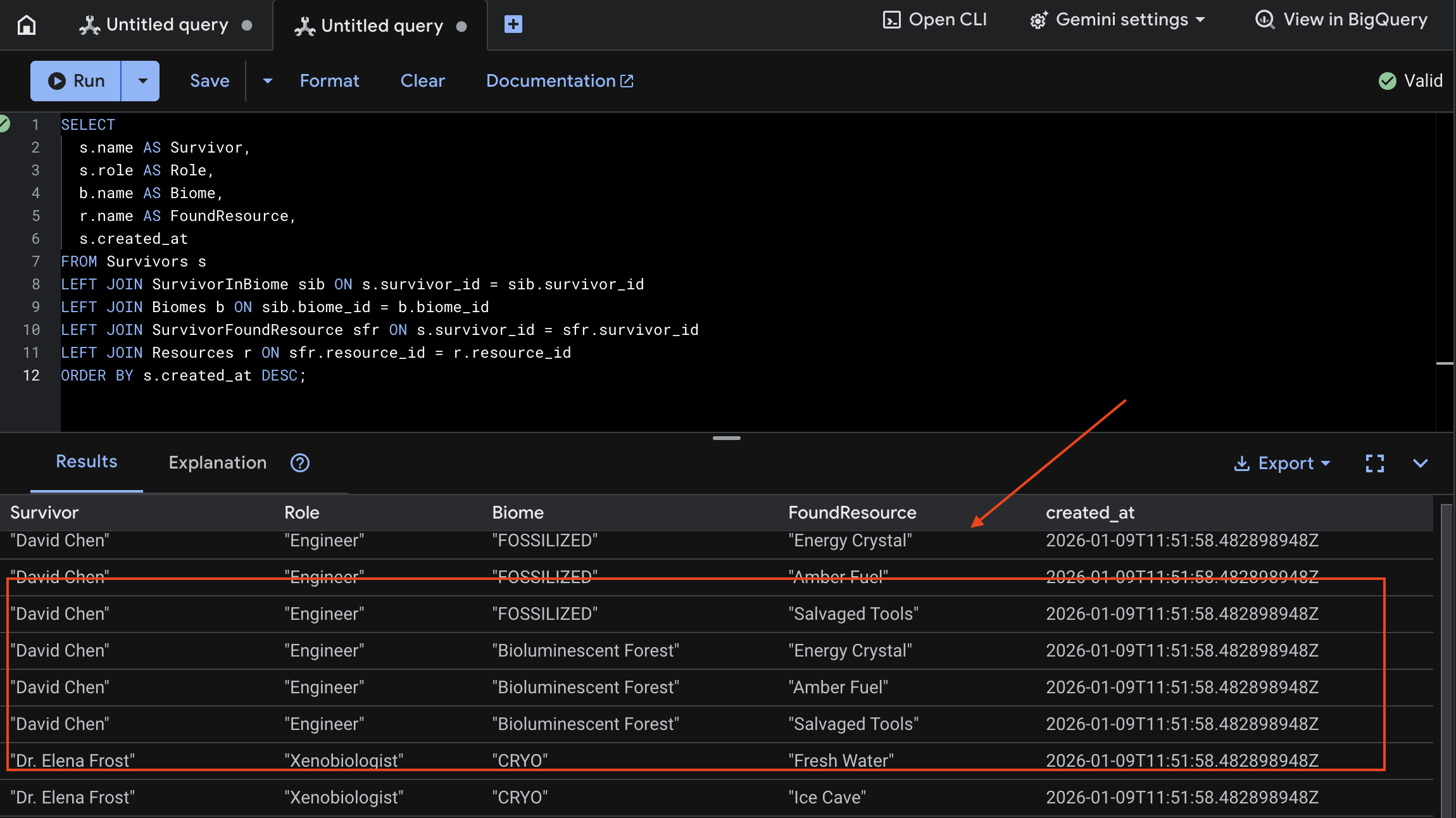
12. ☕️ [Opsional] Memory Bank dengan Agent Engine
1. Cara Kerja Memori
Sistem ini menggunakan pendekatan memori ganda untuk menangani konteks langsung dan pembelajaran jangka panjang.
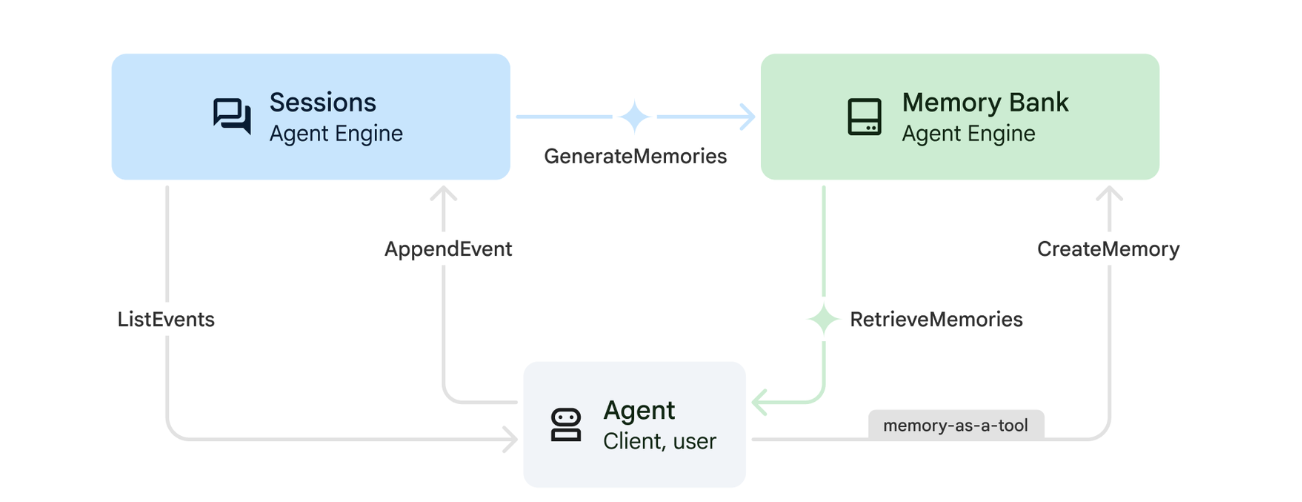
2. Apa yang dimaksud dengan Topik Memori?
Topik Memori menentukan kategori informasi yang harus diingat agen di seluruh percakapan. Anggap saja seperti lemari arsip untuk berbagai jenis preferensi pengguna.
2 Topik Kami:
search_preferences: Cara pengguna melakukan penelusuran- Apakah mereka lebih memilih penelusuran kata kunci atau semantik?
- Keterampilan/bioma apa yang sering mereka cari?
- Contoh memori: "Pengguna lebih memilih penelusuran semantik untuk keterampilan medis"
urgent_needs_context: Krisis yang mereka pantau- Resource apa yang mereka pantau?
- Korban selamat mana yang mereka khawatirkan?
- Contoh memori: "Pengguna melacak kekurangan obat di Northern Camp"
3. Menyiapkan Topik Kenangan
Topik memori kustom menentukan apa yang harus diingat oleh agen. Setelan ini dikonfigurasi saat men-deploy Agent Engine.
👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Tindakan ini akan membuka ~/way-back-home/level_2/backend/deploy_agent.py di editor Anda.
Kita menentukan objek struktur MemoryTopic untuk memandu LLM tentang informasi apa yang harus diekstrak dan disimpan.
👉Di file deploy_agent.py, ganti # TODO: SET_UP_TOPIC dengan kode berikut:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Integrasi Agen
Kode agen harus mengetahui Bank Memori untuk menyimpan dan mengambil informasi.
👉💻 Di terminal, buka file di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Tindakan ini akan membuka ~/way-back-home/level_2/backend/agent/agent.py di editor Anda.
Pembuatan Agen
Saat membuat agen, kita meneruskan after_agent_callback untuk memastikan sesi disimpan ke memori setelah interaksi. Fungsi add_session_to_memory berjalan secara asinkron untuk menghindari perlambatan respons chat.
👉Di file agent.py, cari komentar # TODO: REPLACE_ADD_SESSION_MEMORY, Replace this whole line dengan kode berikut:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Penyimpanan Latar Belakang
👉Di file agent.py, cari komentar # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, Replace this whole line dengan kode berikut:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉Di file agent.py, cari komentar # TODO: REPLACE_ADD_CALLBACK, Replace this whole line dengan kode berikut:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Menyiapkan Layanan Sesi Vertex AI
👉💻 Di terminal, buka file chat.py di Cloud Shell Editor dengan menjalankan:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉Di file chat.py, cari komentar # TODO: REPLACE_VERTEXAI_SERVICES, Ganti seluruh baris ini dengan kode berikut:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Opsional] Menghubungkan Agen dengan Agent Engine
1. Penyiapan & Penerapan
Sebelum menguji fitur memori, Anda perlu men-deploy agen dengan topik memori baru dan memastikan lingkungan Anda dikonfigurasi dengan benar.
Kami telah menyediakan skrip praktis untuk menangani proses ini.
Menjalankan Skrip Deployment
👉💻 Di terminal, jalankan skrip deployment:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Skrip ini melakukan tindakan berikut:
- Menjalankan
backend/deploy_agent.pyuntuk mendaftarkan topik agen dan memori dengan Vertex AI. - Mencatat ID Agent Engine baru.
- Secara otomatis memperbarui file
.envAnda denganAGENT_ENGINE_ID. - Memastikan
USE_MEMORY_BANK=TRUEditetapkan di file.envAnda.
[!IMPORTANT] Jika Anda melakukan perubahan pada custom_topics di deploy_agent.py, Anda harus menjalankan kembali skrip ini untuk memperbarui Agent Engine.
Memverifikasi Memory Bank
Sekarang Anda dapat memverifikasi bahwa bank memori berfungsi dengan mengajari agen preferensi dan memeriksa apakah preferensi tersebut tetap ada di seluruh sesi.
Langkah Pertama. Membuka aplikasi
Buka kembali Aplikasi dengan mengikuti petunjuk di bawah: Jika terminal sebelumnya masih berjalan, akhiri dengan menekan Ctrls+C.
👉💻 Mulai Aplikasi:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Klik Local: http://localhost:5173/ dari terminal.
Langkah Kedua. Menguji Memory Bank dengan Teks
Di antarmuka chat, beri tahu agen tentang konteks spesifik Anda:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Tunggu ~30 detik agar memori diproses di latar belakang.
Langkah Ketiga. Mulai Sesi Baru
Muat ulang halaman untuk menghapus histori percakapan saat ini (memori jangka pendek).
Ajukan pertanyaan yang mengandalkan konteks yang Anda berikan sebelumnya:
"What kind of missions am I interested in?"
Respons yang Diharapkan:
"Berdasarkan percakapan Anda sebelumnya, Anda tertarik dengan:
- Misi penyelamatan medis
- Operasi di pegunungan/ketinggian
- Keterampilan yang diperlukan: pertolongan pertama, panjat tebing
Apakah Anda ingin saya menemukan korban selamat yang cocok dengan kriteria ini?"
Langkah Empat. Menguji dengan Upload Gambar
Upload gambar, lalu tanyakan:
remember this
Anda dapat memilih salah satu foto di sini atau foto Anda sendiri dan menguploadnya ke UI:
Langkah Kelima. Verifikasi di Vertex AI Agent Engine
Buka Google Cloud Console Agent Engine
- Pastikan Anda memilih project dari pemilih project di kiri atas:
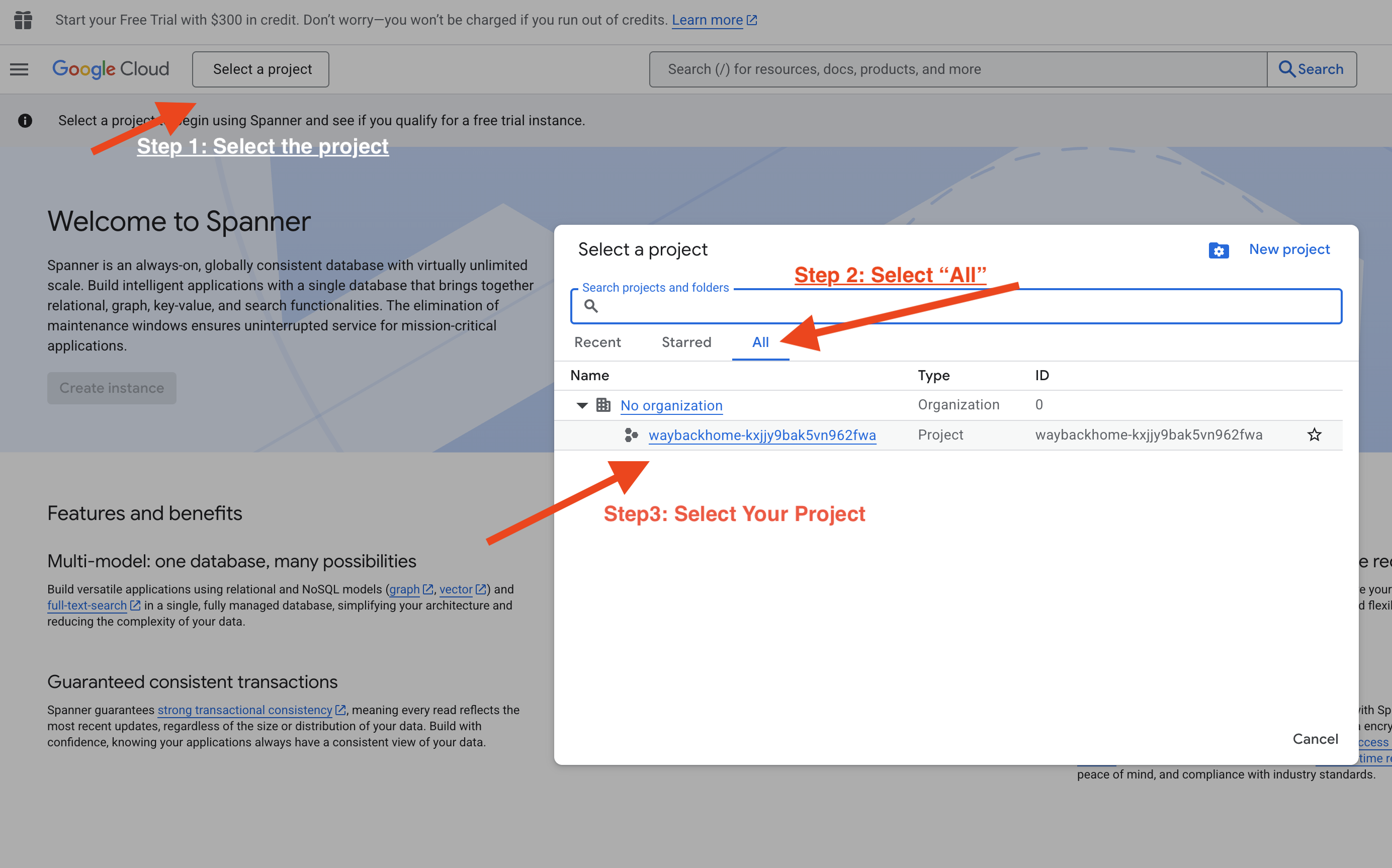
- Verifikasi mesin agen yang baru saja Anda deploy dari perintah sebelumnya
use_memory_bank.sh: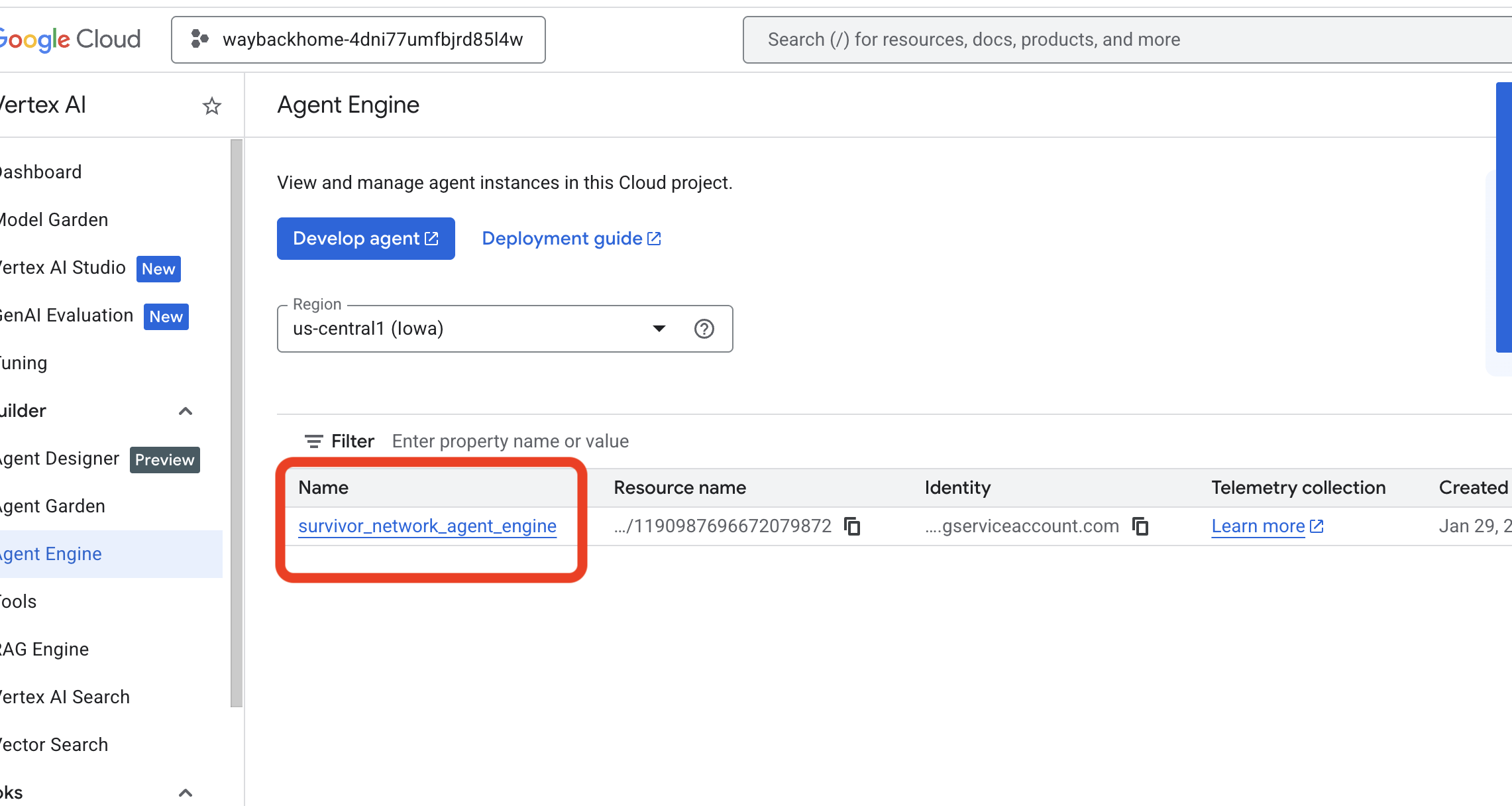 Klik mesin agen yang baru saja Anda buat.
Klik mesin agen yang baru saja Anda buat. - Klik Tab
Memoriesdi agen yang di-deploy ini, Anda dapat melihat semua memori di sini.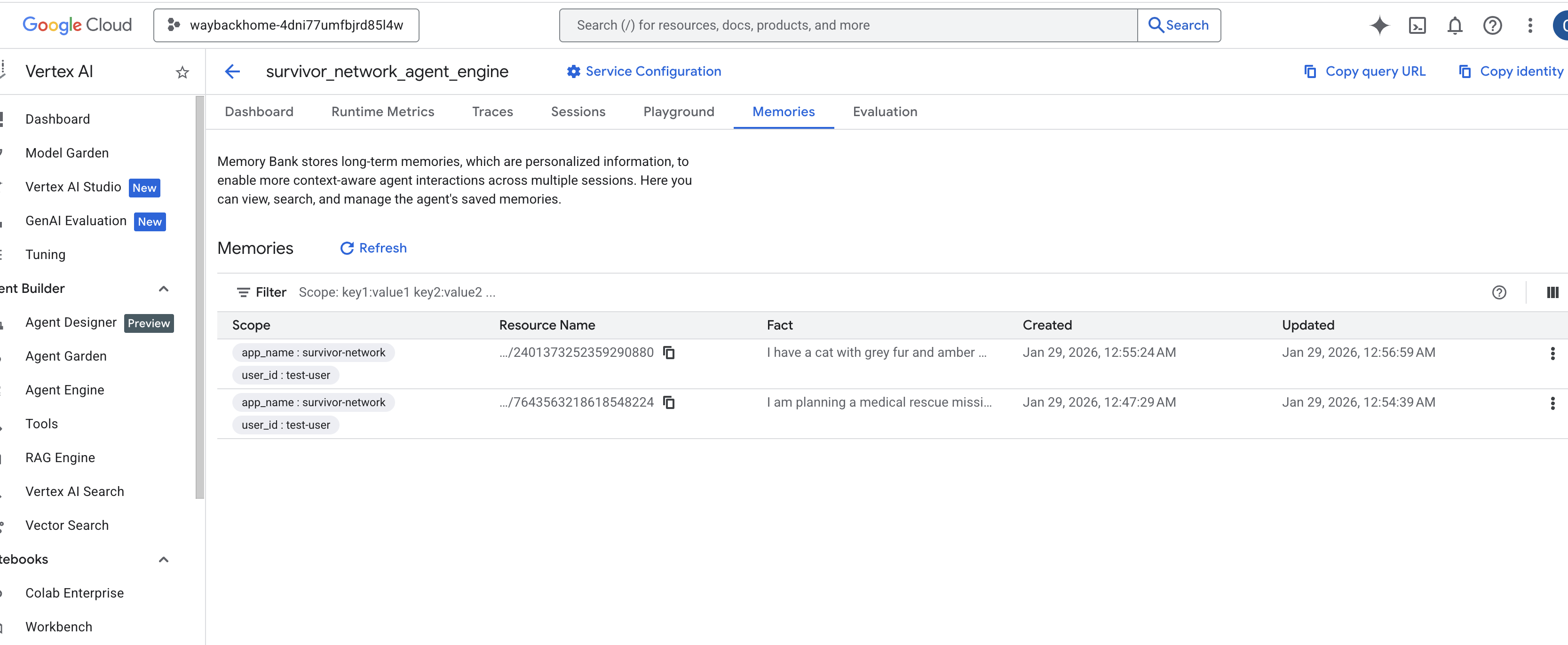
👉💻 Setelah Anda selesai menguji, di terminal, klik "Ctrl + C" untuk mengakhiri proses.
🎉 Selamat! Anda baru saja melampirkan bank memori ke agen Anda.
14. ☕️ [Opsional] Deploy ke Cloud Run
1. Jalankan Skrip Deployment
👉💻 Jalankan skrip deployment:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Setelah berhasil di-deploy, Anda akan memiliki URL, ini adalah URL yang di-deploy untuk Anda. 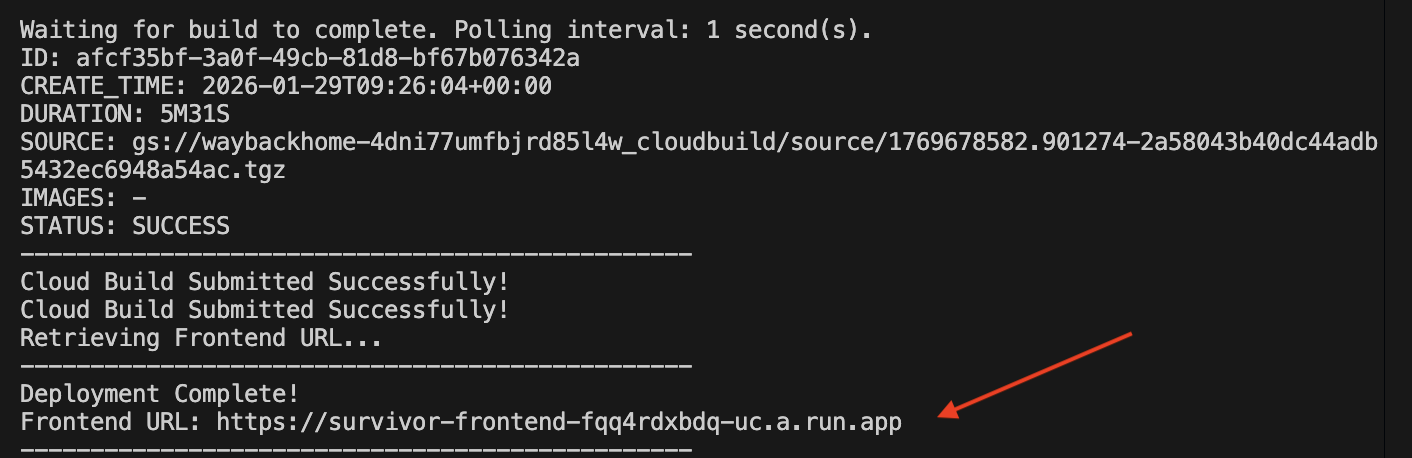
👉💻 Sebelum Anda menyalin URL, berikan izin dengan menjalankan:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Buka URL yang di-deploy, dan Anda akan melihat aplikasi Anda aktif di sana.
2. Memahami Pipeline Build
File cloudbuild.yaml menentukan langkah-langkah berurutan berikut:
- Backend Build: Membangun image Docker dari
backend/Dockerfile. - Backend Deploy: Men-deploy container backend ke Cloud Run.
- Capture URL: Mendapatkan URL Backend baru.
- Frontend Build:
- Menginstal dependensi.
- Membangun aplikasi React, menyuntikkan
VITE_API_URL=.
- Frontend Image: Membangun image Docker dari
frontend/Dockerfile(mengemas aset statis). - Frontend Deploy: Men-deploy container frontend.
3. Memverifikasi Deployment
Setelah build selesai (periksa link log yang disediakan oleh skrip), Anda dapat memverifikasi:
- Buka Konsol Cloud Run.
- Temukan layanan
survivor-frontend. - Klik URL untuk membuka aplikasi.
- Lakukan kueri penelusuran untuk memastikan frontend dapat berkomunikasi dengan backend.
(OPSIONAL) 4. Deployment Manual
Jika Anda lebih suka menjalankan perintah secara manual atau memahami prosesnya dengan lebih baik, berikut cara menggunakan cloudbuild.yaml secara langsung.
Menulis cloudbuild.yaml
File cloudbuild.yaml memberi tahu Google Cloud Build langkah-langkah yang harus dijalankan.
- langkah-langkah: Daftar tindakan berurutan. Setiap langkah berjalan di container (misalnya,
docker,gcloud,node,bash). - penggantian: Variabel yang dapat diteruskan pada waktu build (misalnya,
$_REGION). - workspace: Direktori bersama tempat langkah-langkah dapat berbagi file (seperti cara kita berbagi
backend_url.txt).
Menjalankan Deployment
Untuk men-deploy secara manual tanpa skrip, gunakan perintah gcloud builds submit. Anda HARUS meneruskan variabel substitusi yang diperlukan.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Kesimpulan
1. Yang Telah Anda Buat
✅ Graph Database: Spanner dengan node (survivor, keterampilan) dan edge (hubungan)
✅ AI Search: Penelusuran kata kunci, semantik, dan hybrid dengan penyematan
✅ Multimodal Pipeline: Mengekstrak entitas dari gambar/video dengan Gemini
✅ Multi-Agent System: Alur kerja terkoordinasi dengan ADK
✅ Memory Bank: Personalisasi jangka panjang dengan Vertex AI
✅ Production Deployment: Cloud Run + Agent Engine
2. Ringkasan Arsitektur
3. Pelajaran Utama
- Graph RAG: Menggabungkan struktur database grafik dengan embedding semantik untuk penelusuran cerdas
- Pola Multi-Agen: Pipeline berurutan untuk alur kerja multi-langkah yang kompleks
- AI Multimodal: Mengekstrak data terstruktur dari media tidak terstruktur (gambar/video)
- Agen Stateful: Memory Bank memungkinkan personalisasi di seluruh sesi
4. Konten Workshop
- Level0: Identifikasi Diri Anda
- Level1: Pinpoint Location
- Level2 This One: Membangun Agen AI Multimodal dengan Graph RAG, ADK & Memory Bank
- Level3: Membangun Agen Streaming Dua Arah ADK
- Level4: Sistem Multi-Agen Bidireksional Langsung
- Level5: Event-Driven Architecture with Google ADK, A2A, and Kafka