
1. Introduzione

1. La sfida
Negli scenari di risposta ai disastri, il coordinamento dei sopravvissuti con competenze, risorse ed esigenze diverse in più località richiede funzionalità di gestione e ricerca intelligenti dei dati. Questo workshop ti insegna a creare un sistema di AI di produzione che combina:
- 🗄️ Database a grafo (Spanner): memorizza le relazioni complesse tra sopravvissuti, competenze e risorse
- 🔍 Ricerca basata sull'AI: ricerca ibrida semantica e per parole chiave utilizzando gli incorporamenti
- 📸 Elaborazione multimodale: estrai dati strutturati da immagini, testo e video
- 🤖 Orchestrazione multi-agente: coordina agenti specializzati per workflow complessi
- 🧠 Memoria a lungo termine: personalizzazione con Vertex AI Memory Bank
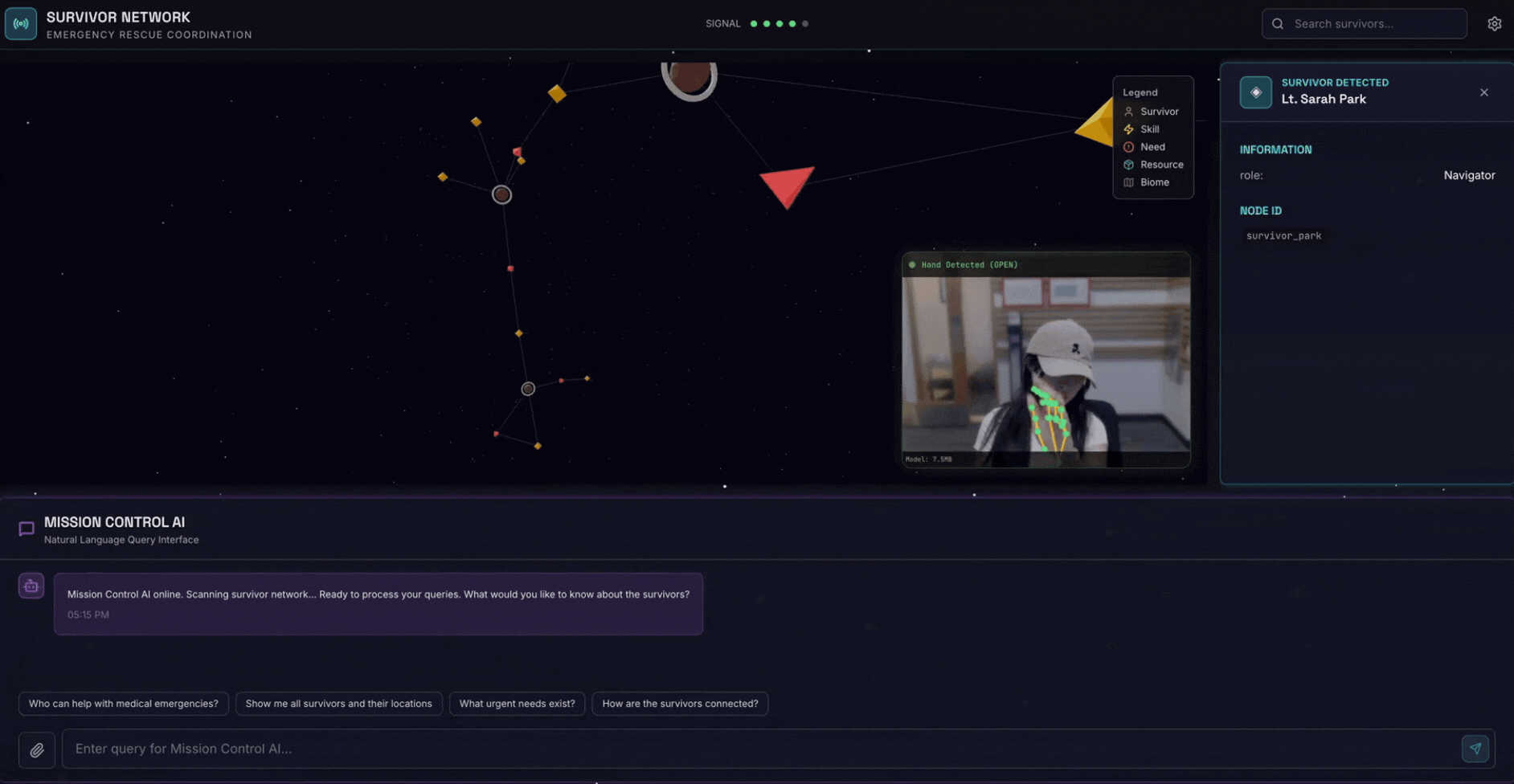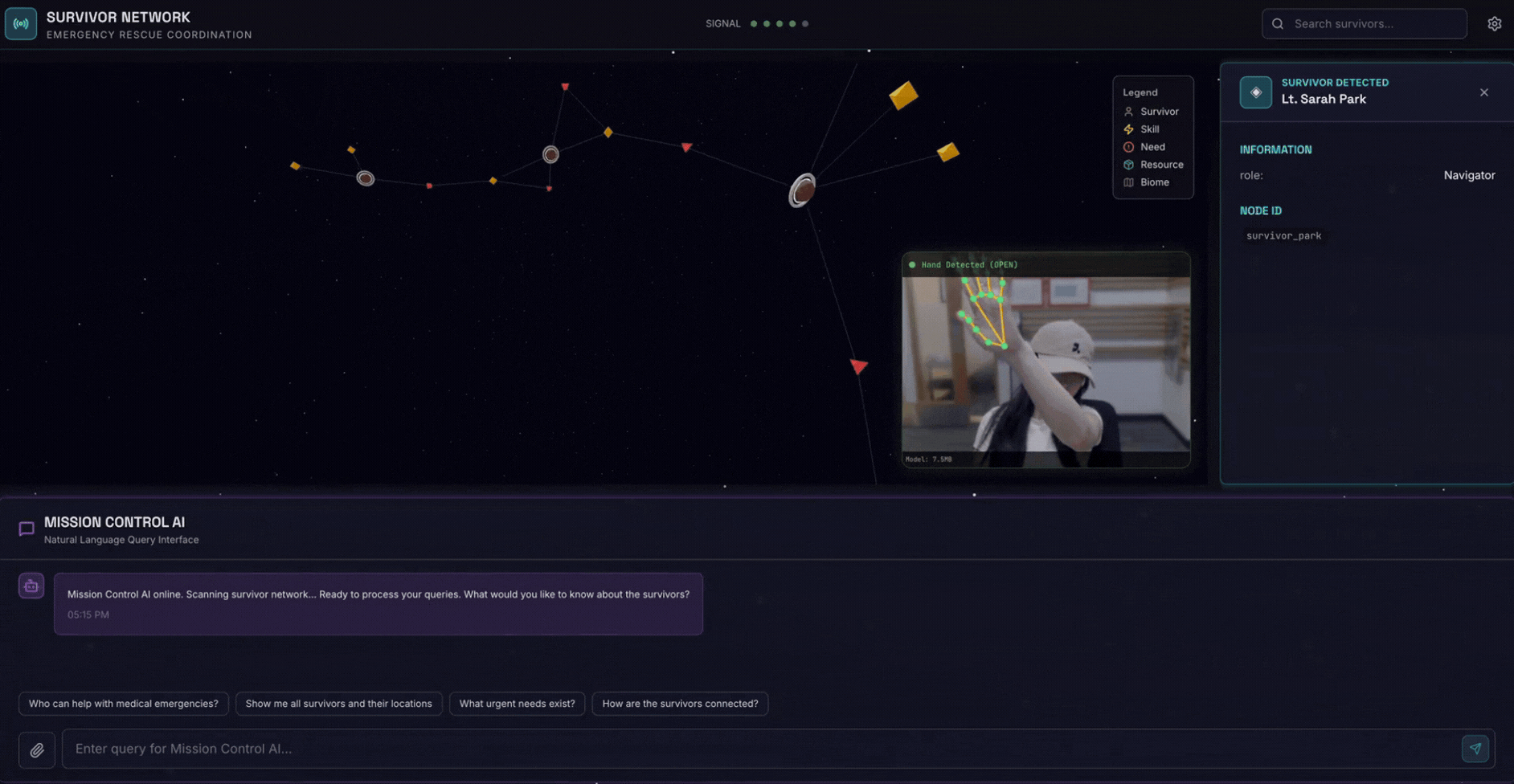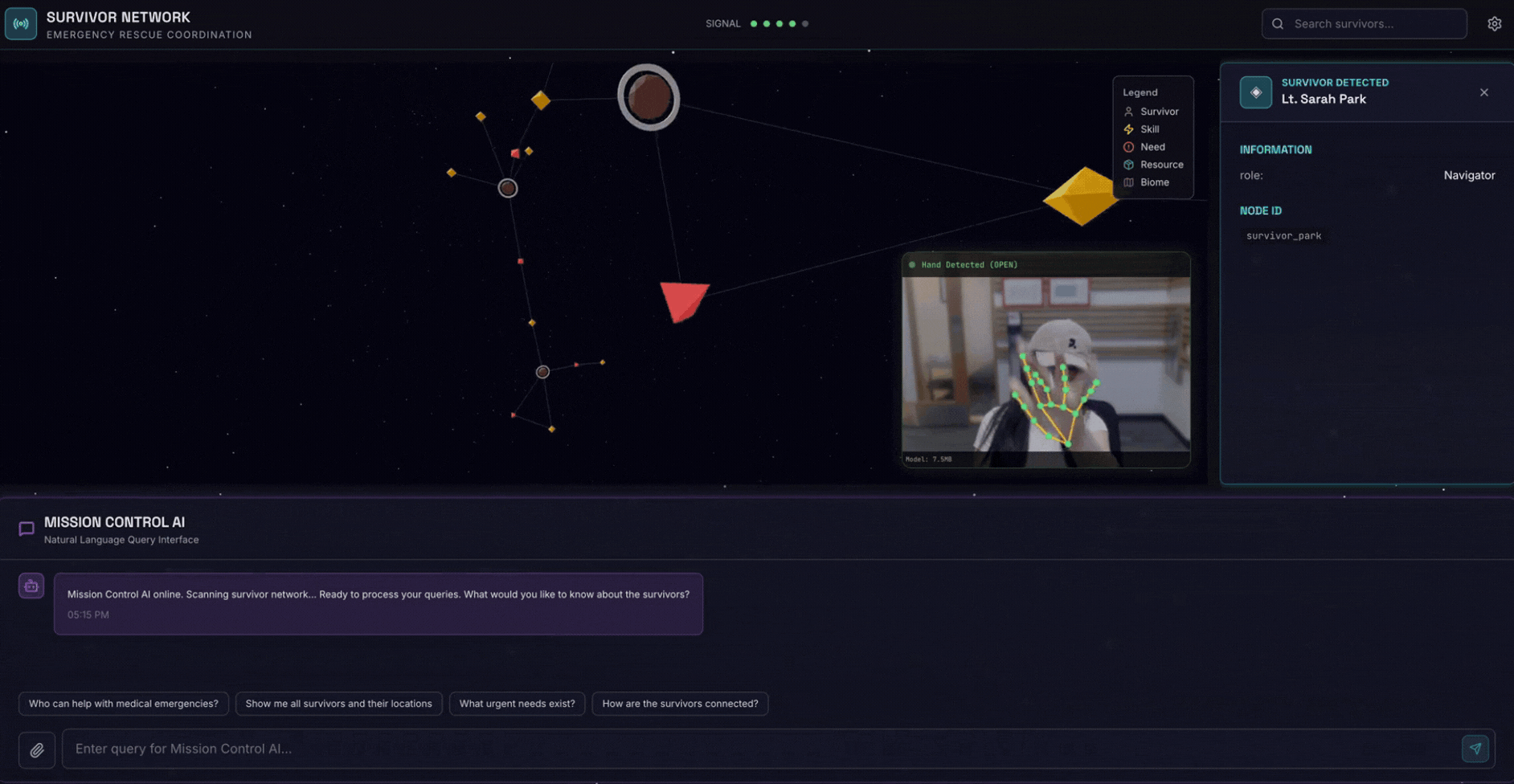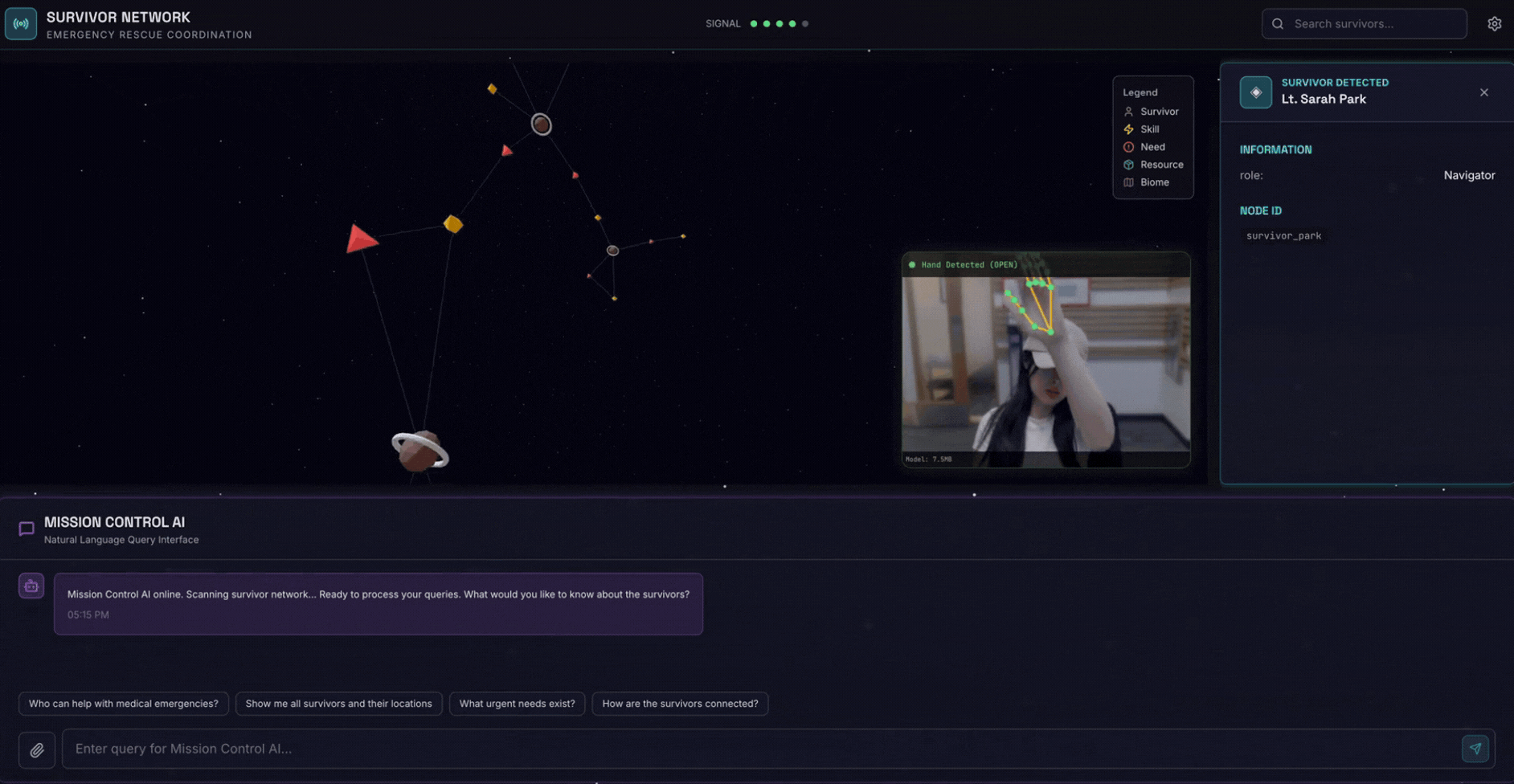
2. Cosa creerai
Un database del grafico della rete di sopravvissuti con:
- 🗺️ Visualizzazione interattiva del grafico 3D delle relazioni tra i sopravvissuti
- 🔍 Ricerca intelligente (per parole chiave, semantica e ibrida)
- 📸 Pipeline di caricamento multimodale (estrai entità da immagini/video)
- 🤖 Sistema multi-agente per l'orchestrazione di attività complesse
- 🧠 Integrazione di Memory Bank per interazioni personalizzate
3. Tecnologie di base
Componente | Tecnologia | Finalità |
Database | Cloud Spanner Graph | Nodi (sopravvissuti, competenze) e archi (relazioni) |
AI Search | Gemini + Embeddings | Comprensione semantica + ricerca per similarità |
Framework dell'agente | ADK (Agent Development Kit) | Orchestrare i workflow di AI |
Memoria | Vertex AI Memory Bank | Archiviazione delle preferenze degli utenti a lungo termine |
Frontend | React + Three.js | Visualizzazione interattiva del grafico 3D |
2. 🛠️ Preparazione dell'ambiente (salta se partecipi al workshop)
Parte 1: abilita l'account di fatturazione
Per eseguire questo codelab, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Parte 2: Open Environment
- 👉 Fai clic su questo link per passare direttamente all'editor di Cloud Shell
- 👉 Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
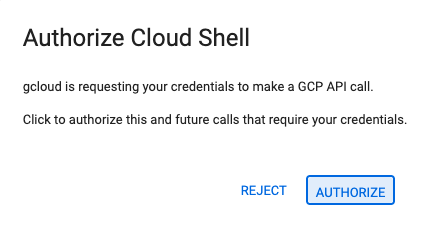
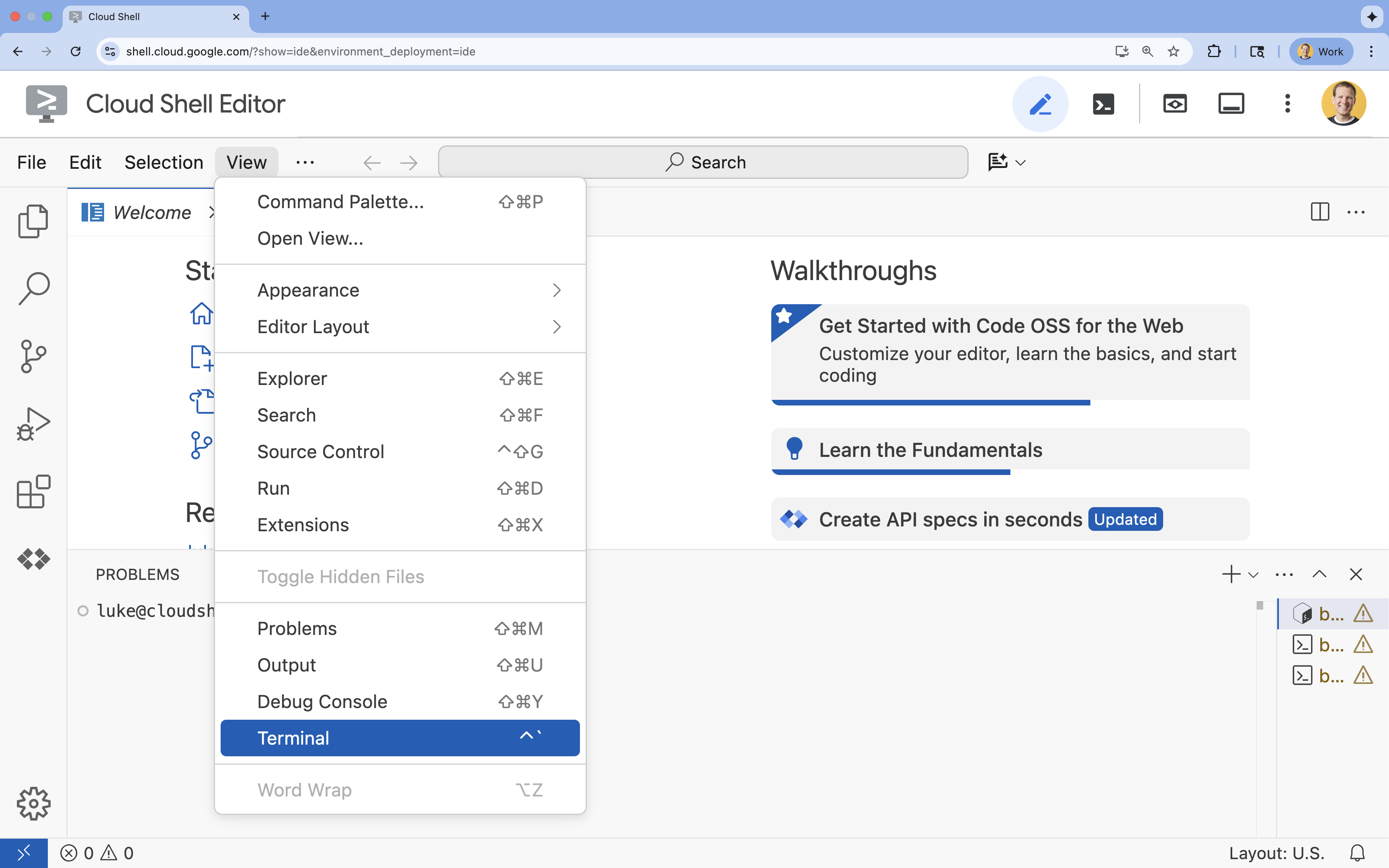
- 👉 Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- 👉💻 Nel terminale, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list - 👉💻 Clona il progetto di bootstrap da GitHub:
git clone https://github.com/gca-americas/way-back-home.git
Parte 3: crea un nuovo progetto
👉💻 Nel terminale, rendi eseguibile lo script init ed eseguilo:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Configurazione dell'ambiente
1. Apri Cloud Shell
Nel terminale Cloud Shell Editor, se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale.
2. Configura il progetto
👉💻 Nel terminale, imposta l'ID progetto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Abilita le API richieste (operazione che richiede circa 2-3 minuti):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Esegui lo script di configurazione
👉💻 Esegui lo script di configurazione:
cd ~/way-back-home/level_2
./setup.sh
In questo modo verrà creato .env. In Cloud Shell, apri way_back_homeproject. Nella cartella level_2, puoi vedere che è stato creato il file .env. Se non riesci a trovarlo, puoi fare clic su View -> Toggle Hidden File per visualizzarlo. 
4. Carica dati di esempio
👉💻 Vai al backend e installa le dipendenze:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Carica i dati iniziali dei sopravvissuti:
uv run python ~/way-back-home/level_2/backend/setup_data.py
In questo modo viene creato:
- Istanza Spanner (
survivor-network) - Database (
graph-db) - Tutte le tabelle dei nodi e degli archi
- Grafici delle proprietà per l'esecuzione di query Risultato previsto:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
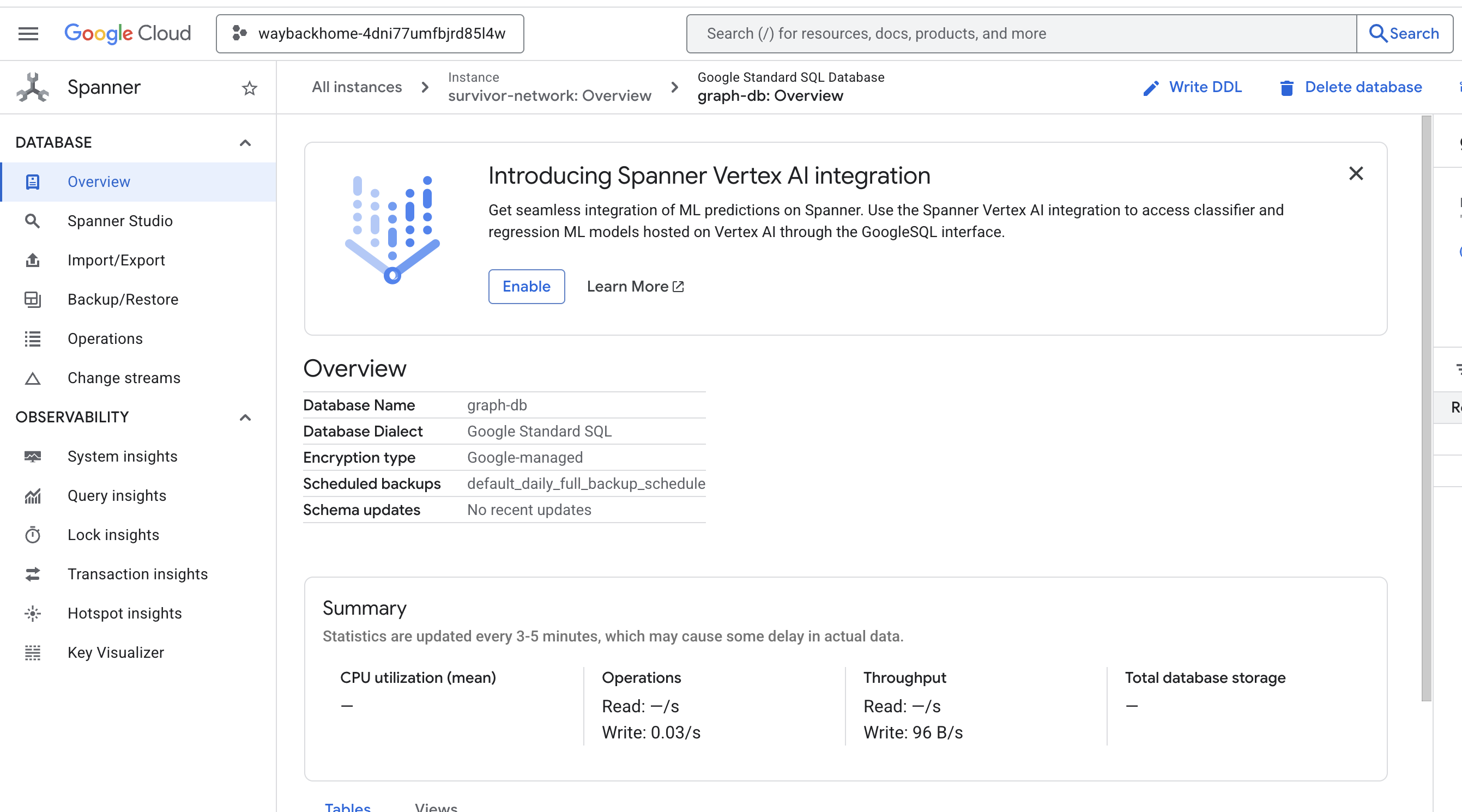
Se fai clic sul link dopo Access your database at nell'output, puoi aprire Spanner nella console Google Cloud.

e vedrai Spanner nella console Google Cloud.
4. 🚀 Visualizzazione dei dati del grafico in Spanner Studio
Questa guida ti aiuta a visualizzare e interagire con i dati del grafico Survivor Network direttamente nella console Google Cloud utilizzando Spanner Studio. Questo è un ottimo modo per verificare i dati e comprendere la struttura del grafico prima di creare l'agente AI.
1. Accedere a Spanner Studio
- Nell'ultimo passaggio, assicurati di fare clic sul link e di aprire Spanner Studio.
2. Comprendere la struttura del grafico (il quadro generale)
Considera il set di dati Survivor Network come un puzzle logico o uno stato del gioco:
Entità | Ruolo nel sistema | Analogia |
Survivors | Gli agenti/giocatori | Giocatori |
Biomi | Dove si trovano | Zone della mappa |
Competenze | Cosa può fare | Funzionalità |
Necessità | Cosa manca (crisi) | Quest/missioni |
Risorse | Elementi trovati nel mondo | Loot |
L'obiettivo: il compito dell'agente AI è collegare le competenze (soluzioni) ai bisogni (problemi), tenendo conto dei biomi (vincoli di posizione).
🔗 Bordi (relazioni):
SurvivorInBiome: Monitoraggio della posizioneSurvivorHasSkill: Inventario delle funzionalitàSurvivorHasNeed: Elenco dei problemi attiviSurvivorFoundResource: Inventario degli articoliSurvivorCanHelp: Relazione dedotta (calcolata dall'AI)
3. Esecuzione di query sul grafico
Eseguiamo alcune query per visualizzare la "storia" nei dati.
Spanner Graph utilizza GQL (Graph Query Language). Per eseguire una query, utilizza GRAPH SurvivorNetwork seguito dal pattern di corrispondenza.
👉 Query 1: The Global Roster (Who is where?) Questa è la base: comprendere la posizione è fondamentale per le operazioni di soccorso.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Dovresti visualizzare un risultato simile a questo: 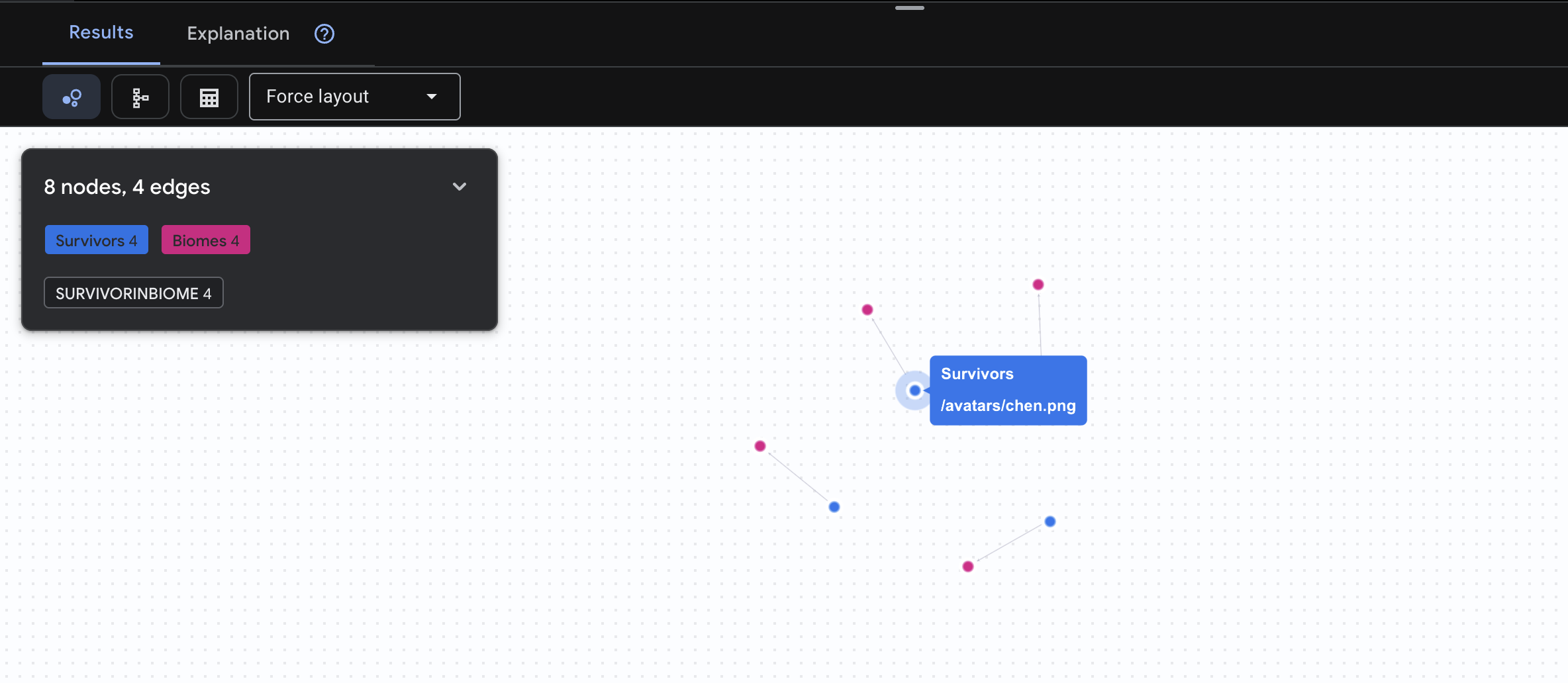
👉 Query 2: la matrice delle competenze (capacità) Ora che sai dove si trova ogni persona, scopri cosa può fare.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Dovresti visualizzare un risultato simile a questo: 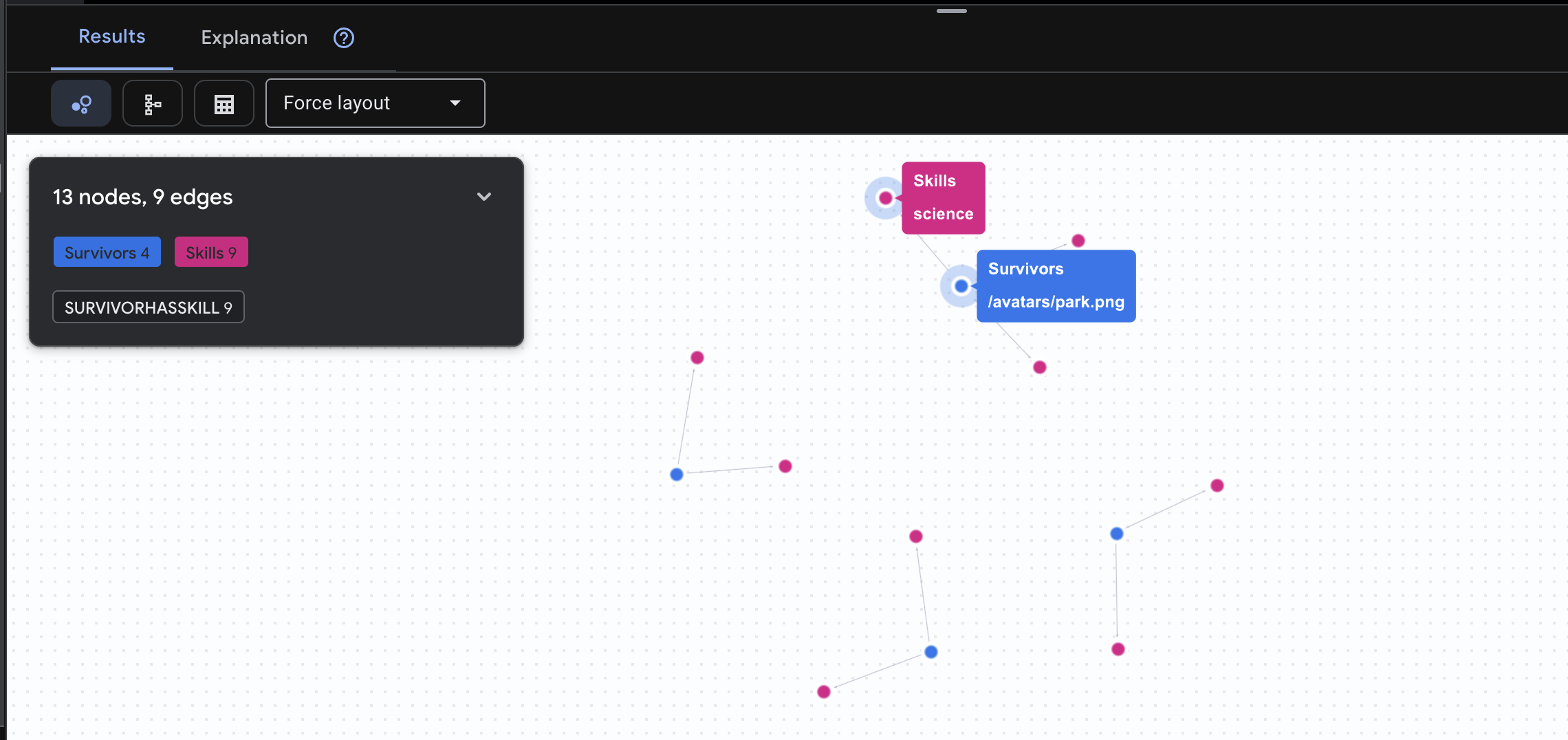
👉 Query 3: Who is in Crisis? (Chi è in crisi?) (La "Bacheca delle missioni") Vedi i sopravvissuti che hanno bisogno di aiuto e di cosa hanno bisogno.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Dovresti visualizzare un risultato simile a questo: 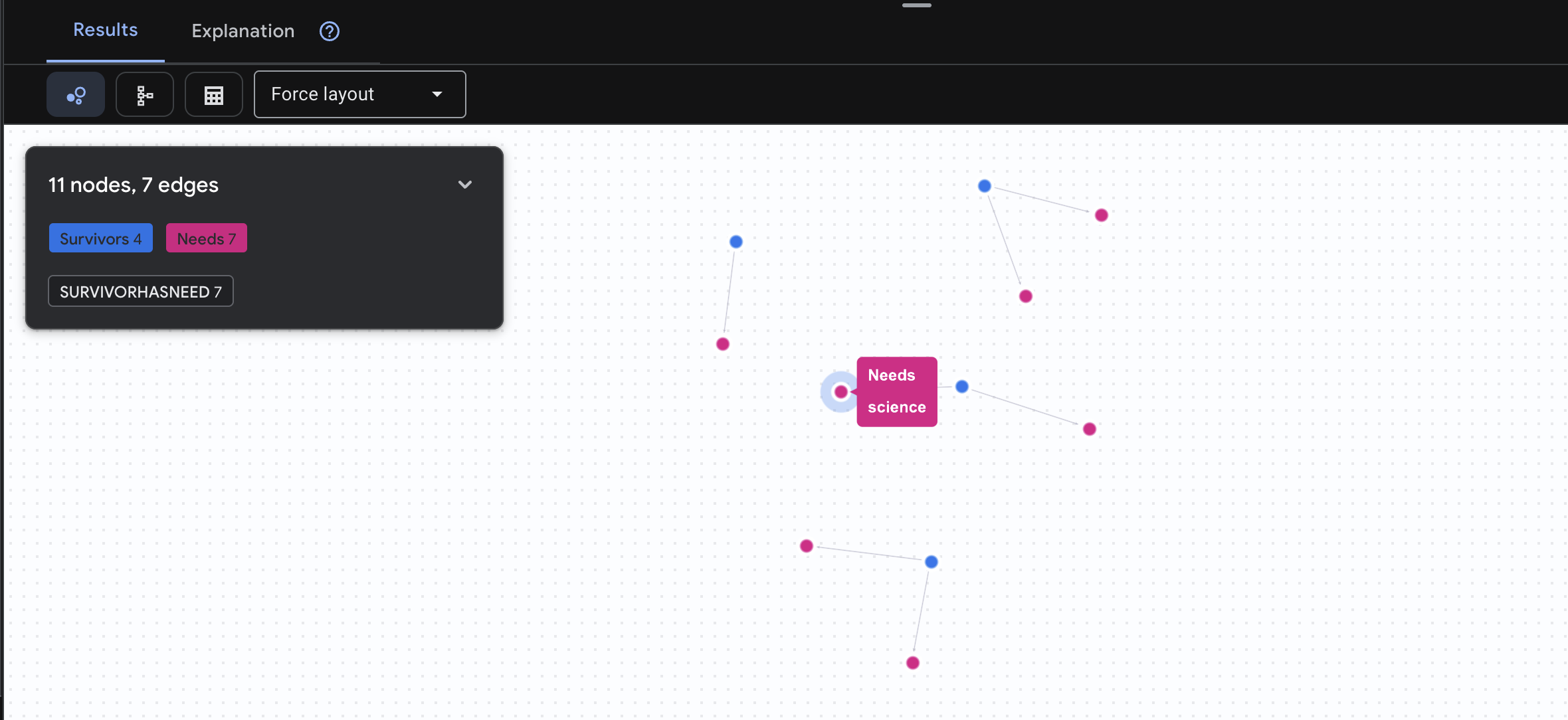
🔎 [Facoltativo] Abbinamento: chi può aiutare chi?
È qui che il grafico diventa potente. Questa query trova sopravvissuti con competenze che possono soddisfare le esigenze di altri sopravvissuti.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Dovresti visualizzare un risultato simile a questo: 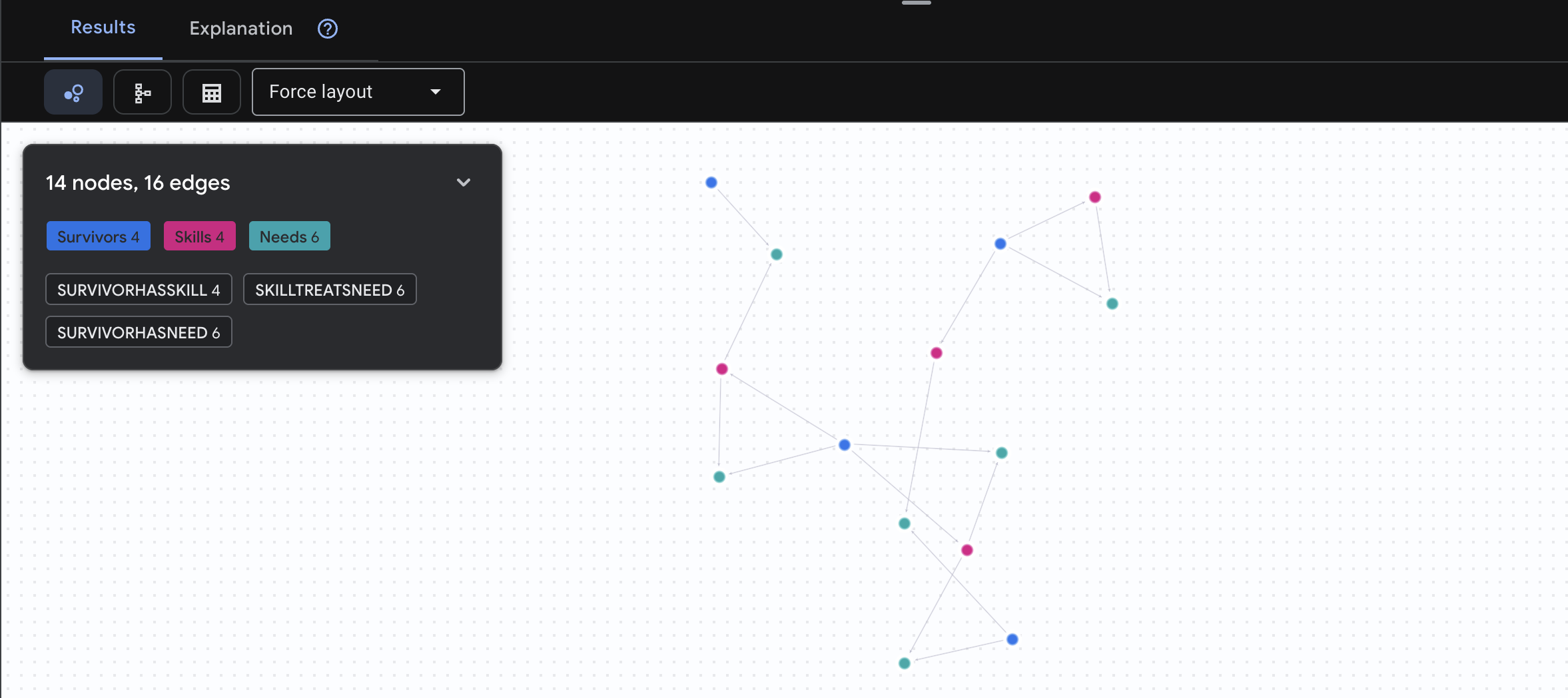
aside positive Funzione di questa query:
Anziché mostrare solo "Il primo soccorso cura le ustioni" (ovvio dallo schema), questa query trova:
- Dott. ssa Elena Frost (con formazione medica) → può curare → Capitano Tanaka (che ha ustioni)
- David Chen (che ha il kit di pronto soccorso) → può curare → il tenente Park (che ha una distorsione alla caviglia)
Perché è importante:
Cosa farà il tuo agente AI:
Quando un utente chiede "Chi può curare le ustioni?", l'agente:
- Eseguire una query di grafi simili
- Restituisci: "Il dottor Frost ha una formazione medica e può aiutare il capitano Tanaka"
- L'utente non ha bisogno di conoscere tabelle o relazioni intermedie.
5. 🚀 Incorporamenti basati sull'AI in Spanner
1. Perché gli incorporamenti? (Nessuna azione, sola lettura)
Nello scenario di sopravvivenza, il tempo è fondamentale. Quando una persona sopravvissuta segnala un'emergenza, ad esempio I need someone who can treat burns o Looking for a medic, non può perdere tempo a indovinare i nomi esatti delle competenze nel database.
Scenario reale: Survivor: Captain Tanaka has burns—we need medical help NOW!
Ricerca tradizionale per parole chiave di "medico" → 0 risultati ❌
Ricerca semantica con incorporamenti → Trova "Medical Training", "First Aid" ✅
È esattamente ciò di cui hanno bisogno gli agenti: una ricerca intelligente e simile a quella umana che comprenda l'intento, non solo le parole chiave.
2. Crea modello di incorporamento
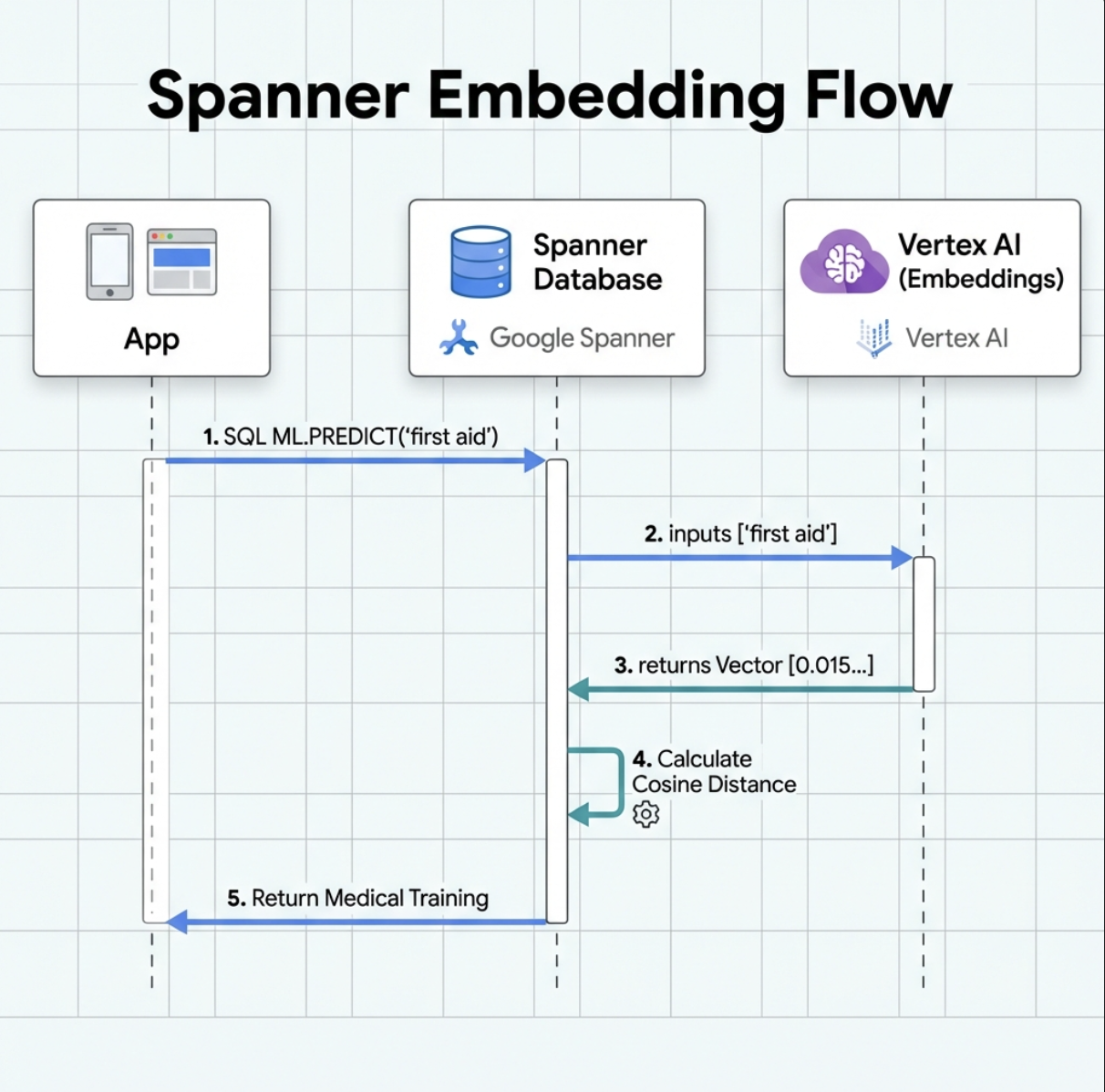
Ora creiamo un modello che converte il testo in embedding utilizzando text-embedding-004 di Google.
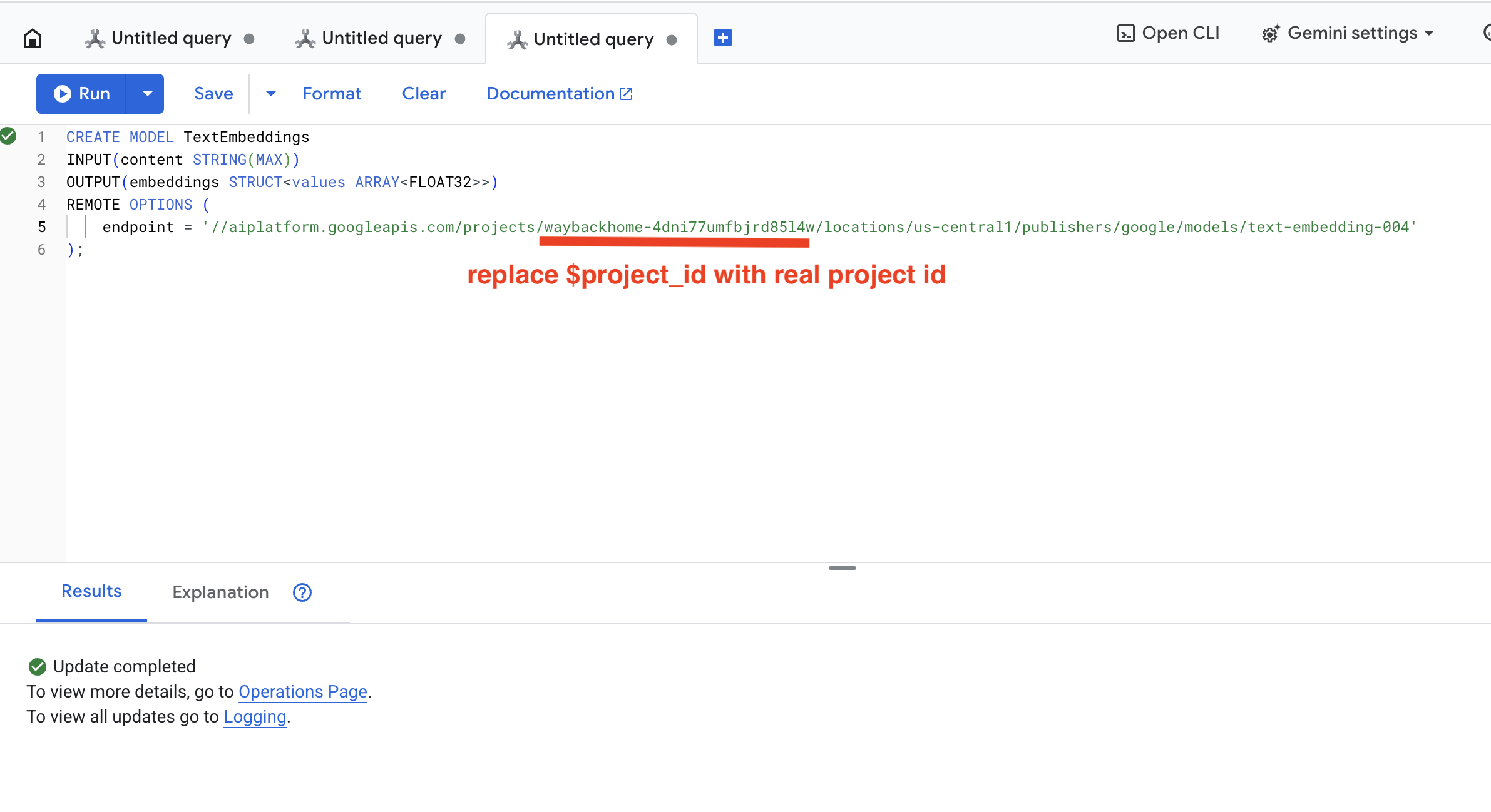
👉 In Spanner Studio, esegui questo SQL (sostituisci $YOUR_PROJECT_ID con l'ID progetto effettivo):
‼️ Nell'editor di Cloud Shell, apri File -> Open Folder -> way-back-home/level_2 per visualizzare l'intero progetto.
👉 Esegui questa query in Spanner Studio copiandola e incollandola di seguito, quindi fai clic sul pulsante Esegui:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Cosa fa:
- Crea un modello virtuale in Spanner (nessun peso del modello archiviato localmente)
- Punta a
text-embedding-004di Google su Vertex AI - Definisce il contratto: l'input è testo, l'output è un array float a 768 dimensioni
Perché "OPZIONI REMOTO"?
- Spanner non esegue il modello stesso
- Chiama Vertex AI tramite API quando utilizzi
ML.PREDICT - Zero-ETL: non è necessario esportare i dati in Python, elaborarli e importarli di nuovo
Fai clic sul pulsante Run. Una volta completata l'operazione, puoi visualizzare il risultato come mostrato di seguito:
3. Aggiungere la colonna di incorporamento
👉 Aggiungi una colonna per archiviare gli embedding:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Fai clic sul pulsante Run. Una volta completata l'operazione, puoi visualizzare il risultato come mostrato di seguito:
4. Genera incorporamenti
👉 Utilizza l'AI per creare vector embedding per ogni competenza:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Fai clic sul pulsante Run. Una volta completata l'operazione, puoi visualizzare il risultato come mostrato di seguito:
Cosa succede: ogni nome di competenza (ad es. "primo soccorso") viene convertito in un vettore a 768 dimensioni che ne rappresenta il significato semantico.
5. Verifica degli incorporamenti
👉 Controlla che siano stati creati gli incorporamenti:
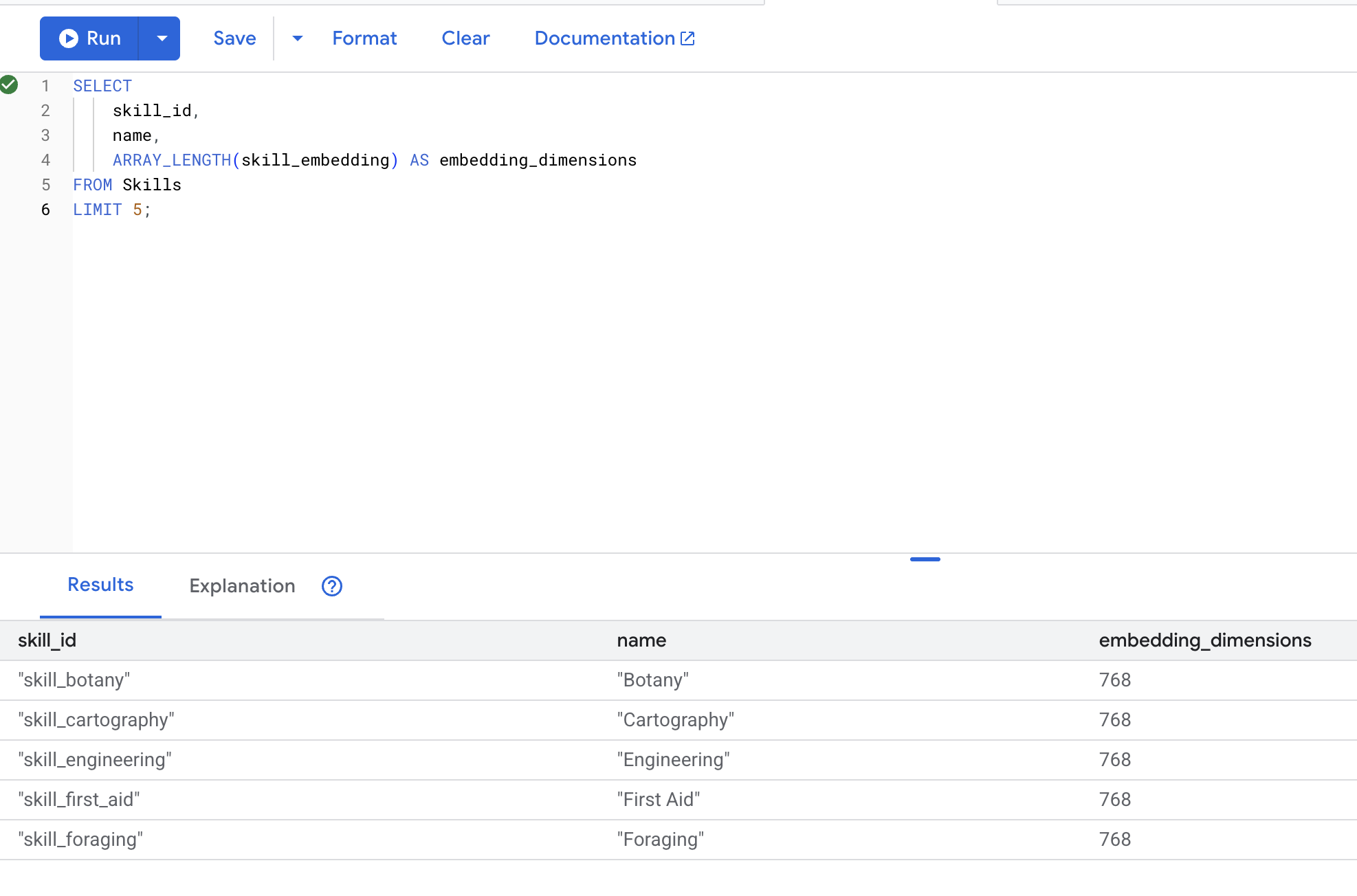
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Output previsto:
6. Testare la ricerca semantica
Ora testiamo il caso d'uso esatto del nostro scenario: trovare competenze mediche utilizzando il termine "medico".
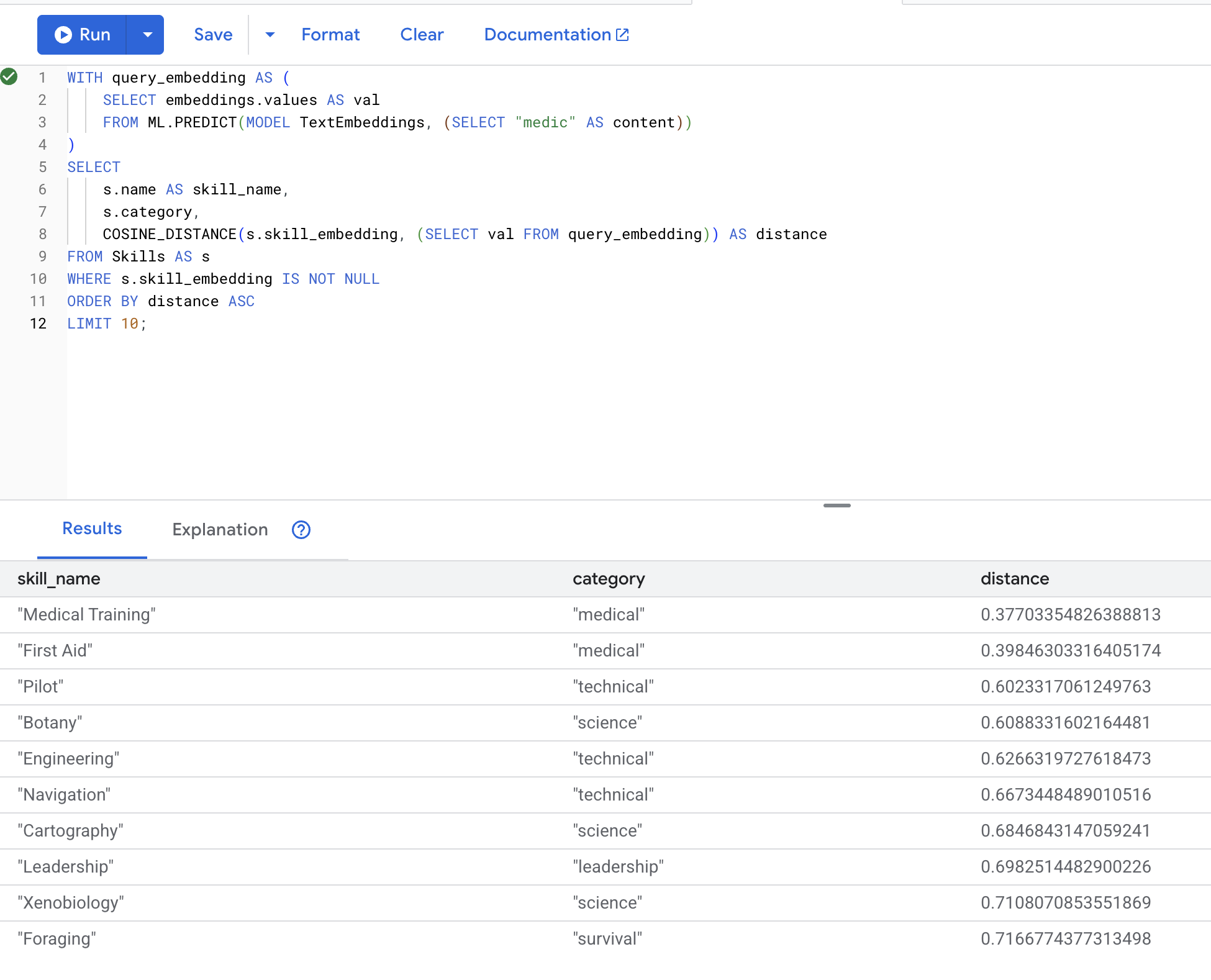
👉 Trova competenze simili a "medico":
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Converte il termine di ricerca "medico " dell'utente in un embedding
- Lo memorizza nella
query_embeddingtabella temporanea
Risultati previsti (distanza inferiore = maggiore somiglianza):
7. Crea modello Gemini per l'analisi
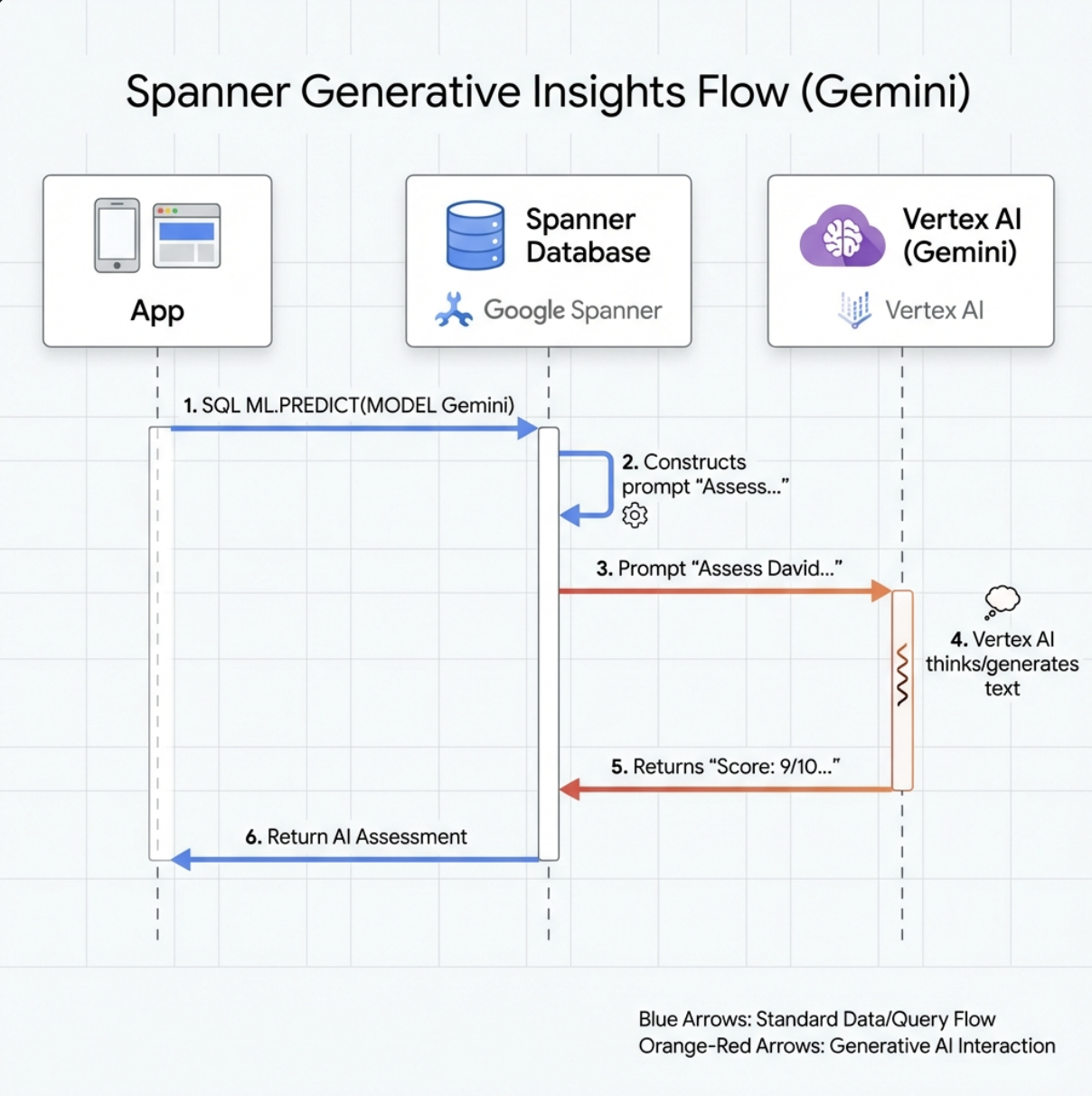
👉 Crea un riferimento al modello di AI generativa (sostituisci $YOUR_PROJECT_ID con l'ID progetto effettivo):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Differenza rispetto al modello di incorporamento:
- Embedding: testo → vettore (per la ricerca di somiglianze)
- Gemini: Testo → Testo generato (per ragionamento/analisi)
8. Utilizzare Gemini per l'analisi della compatibilità
👉 Analizza le coppie di sopravvissuti per la compatibilità con la missione:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Output previsto:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Creazione dell'agente Graph RAG con la ricerca ibrida
1. Panoramica dell'architettura di sistema
Questa sezione crea un sistema di ricerca multimetodo che offre all'agente la flessibilità di gestire diversi tipi di query. Il sistema ha tre livelli: livello agente, livello strumento e livello servizio.
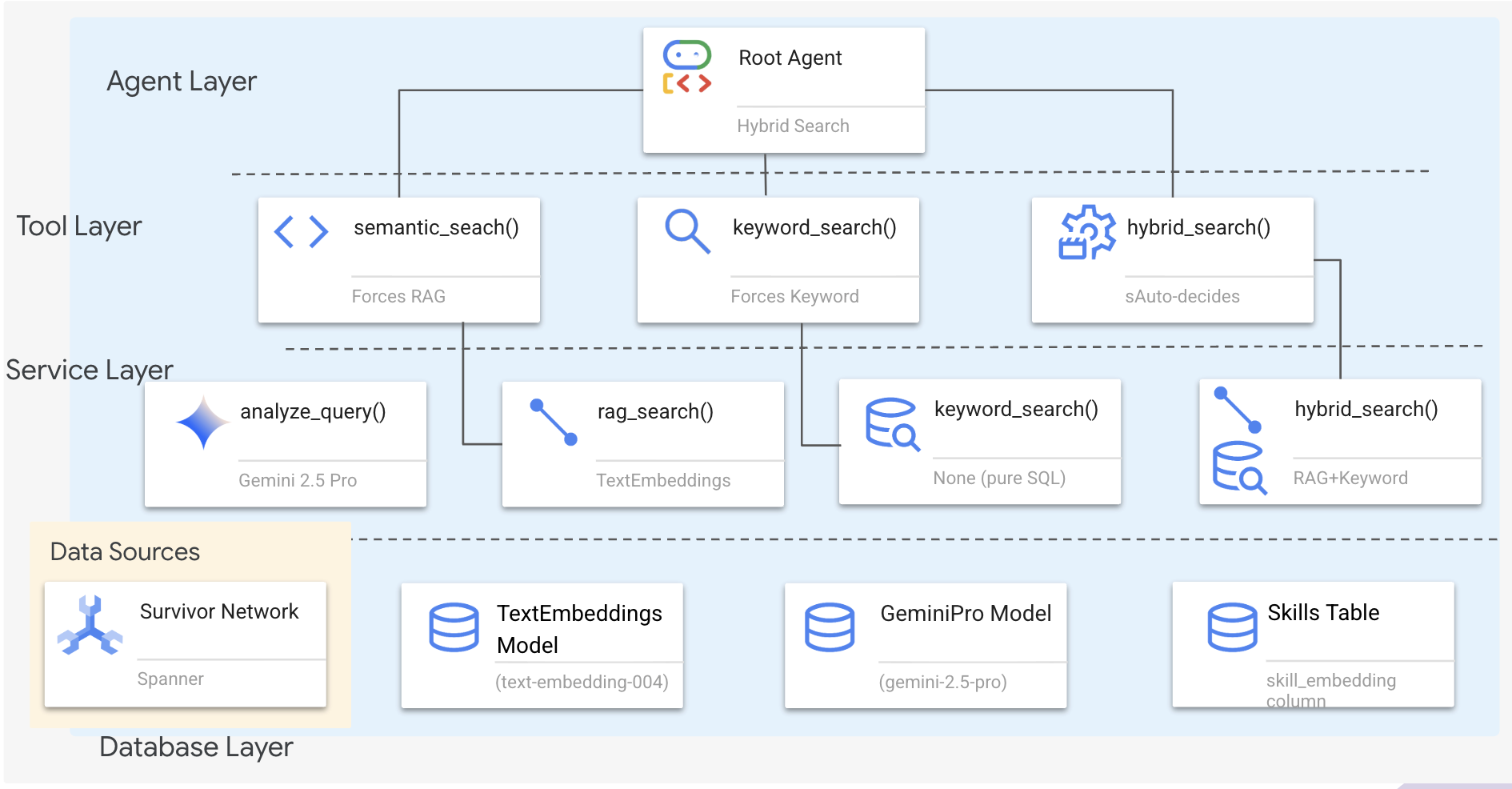
Perché tre livelli?
- Separazione delle competenze: l'agente si concentra sull'intent, gli strumenti sull'interfaccia e il servizio sull'implementazione
- Flessibilità: l'agente può forzare metodi specifici o lasciare che l'AI esegua il routing automatico
- Ottimizzazione: può saltare l'analisi AI costosa quando il metodo è noto
In questa sezione, implementerai principalmente la ricerca semantica (RAG), ovvero la ricerca di risultati in base al significato, non solo alle parole chiave. Più avanti spiegheremo come la ricerca ibrida unisce più metodi.
2. Implementazione del servizio RAG
👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Individua il commento # TODO: REPLACE_SQL
Sostituisci l'intera riga con il seguente codice:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Definizione dello strumento di ricerca semantica
👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
In hybrid_search_tools.py, individua il commento # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉Sostituisci l'intera riga con il seguente codice:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Quando l'agente utilizza:
- Query che chiedono similarità ("trova contenuti simili a X")
- Query concettuali ("capacità di guarigione")
- Quando comprendere il significato è fondamentale
4. Guida alle decisioni dell'agente (istruzioni)
Nella definizione dell'agente, copia e incolla la parte relativa alla ricerca semantica nelle istruzioni.
👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
L'agente utilizza questa istruzione per selezionare lo strumento giusto:
👉 Nel file agent.py, individua il commento # TODO: REPLACE_SEARCH_LOGIC, sostituisci l'intera riga con il seguente codice:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉 Individua il commento # TODO: ADD_SEARCH_TOOLReplace this whole line e sostituisci l'intera riga con il seguente codice:
semantic_search, # Force RAG
5. Understanding How Hybrid Search Works (Read Only, No Action Needed)
Nei passaggi 2-4, hai implementato la ricerca semantica (RAG), il metodo di ricerca principale che trova i risultati in base al significato. Tuttavia, potresti aver notato che il sistema si chiama "Ricerca ibrida". Ecco come si combinano:
Come funziona l'unione ibrida:
Nel file way-back-home/level_2/backend/services/hybrid_search_service.py, quando viene chiamato hybrid_search(), il servizio esegue ENTRAMBE le ricerche e unisce i risultati:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Per questo codelab, hai implementato il componente di ricerca semantica (RAG), che è la base. I metodi basati su parole chiave e ibridi sono già implementati nel servizio. Il tuo agente può utilizzarli tutti e tre.
Complimenti! Hai completato l'agente Graph RAG con la ricerca ibrida.
7. 🚀 Testare l'agente con ADK Web
Il modo più semplice per testare l'agente è utilizzare il comando adk web, che lo avvia con un'interfaccia di chat integrata.
1. Esecuzione dell'agente
👉💻 Vai alla directory di backend (dove è definito l'agente) e avvia l'interfaccia web:
cd ~/way-back-home/level_2/backend
uv run adk web
Questo comando avvia l'agente definito in
agent/agent.py
e si apre un'interfaccia web per il test.
👉 Apri l'URL:
Il comando restituirà un URL locale (di solito http://127.0.0.1:8000 o simile). Apri questo link nel browser.
Una volta fatto clic sull'URL, vedrai la UI web dell'ADK. Assicurati di selezionare l'agente nell'angolo in alto a sinistra.
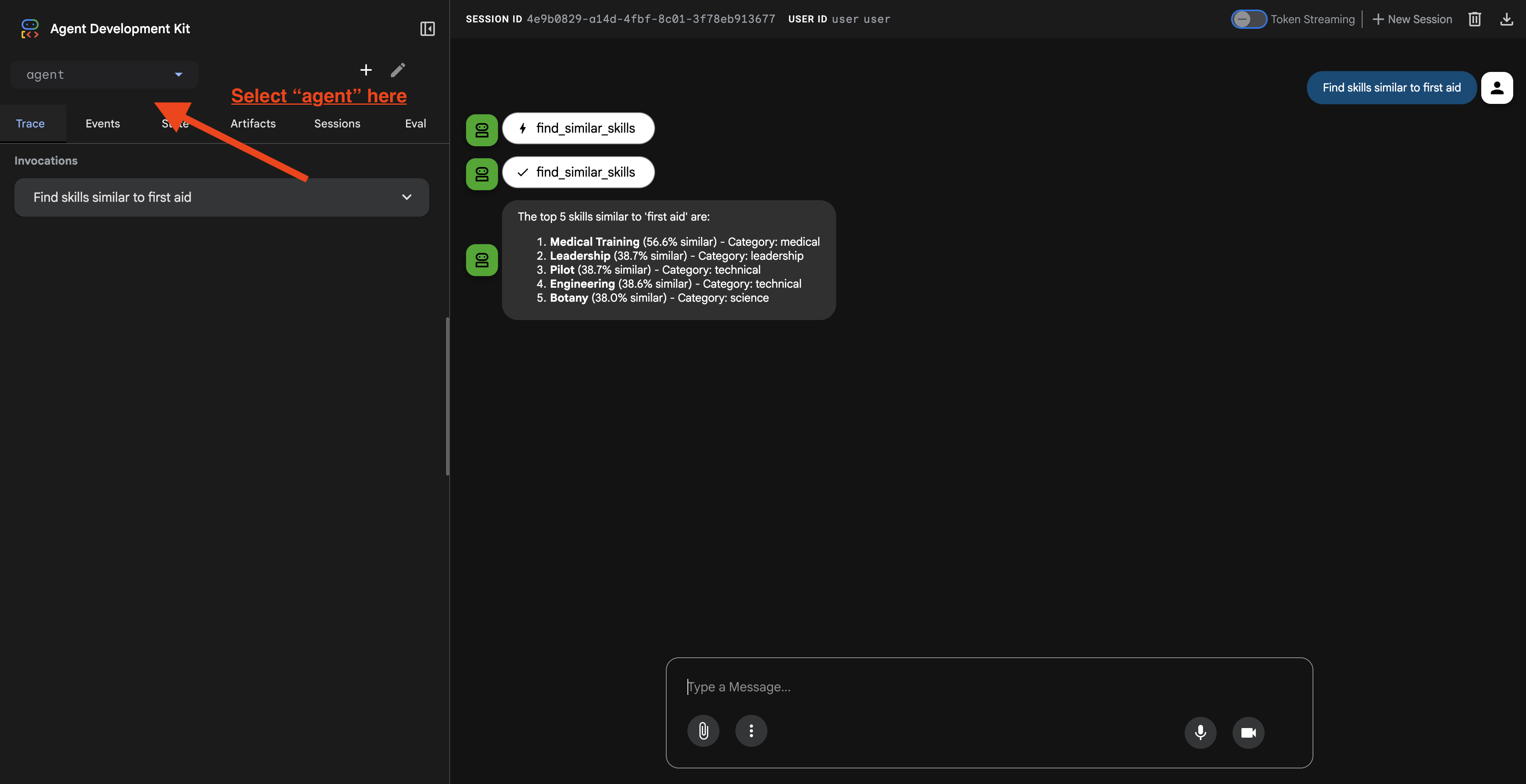
2. Testare le funzionalità di ricerca
L'agente è progettato per indirizzare in modo intelligente le tue query. Prova i seguenti input nella finestra della chat per vedere diversi metodi di ricerca in azione.
🧬 A. Graph RAG (ricerca semantica)
Trova elementi in base al significato e al concetto, anche se le parole chiave non corrispondono.
Query di test: (scegli una delle seguenti)
Who can help with injuries?
What abilities are related to survival?
Cosa cercare:
- Il ragionamento deve menzionare la ricerca semantica o RAG.
- Dovresti visualizzare risultati concettualmente correlati (ad es. "Intervento chirurgico" quando chiedi "Pronto soccorso").
- I risultati avranno l'icona 🧬.
🔀 B. Ricerca ibrida
Combina i filtri per parole chiave con la comprensione semantica per query complesse.
Query di test:(scegli una delle seguenti)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Cosa cercare:
- Il ragionamento deve menzionare la ricerca ibrida.
- I risultati devono corrispondere a ENTRAMBI i criteri (concetto + località/categoria).
- I risultati trovati con entrambi i metodi avranno l'icona 🔀 e si troveranno in cima alla classifica.
👉💻 Al termine del test, termina la procedura premendo Ctrl+C nella riga di comando.
8. 🚀 Esecuzione dell'applicazione completa
Panoramica dell'architettura full-stack
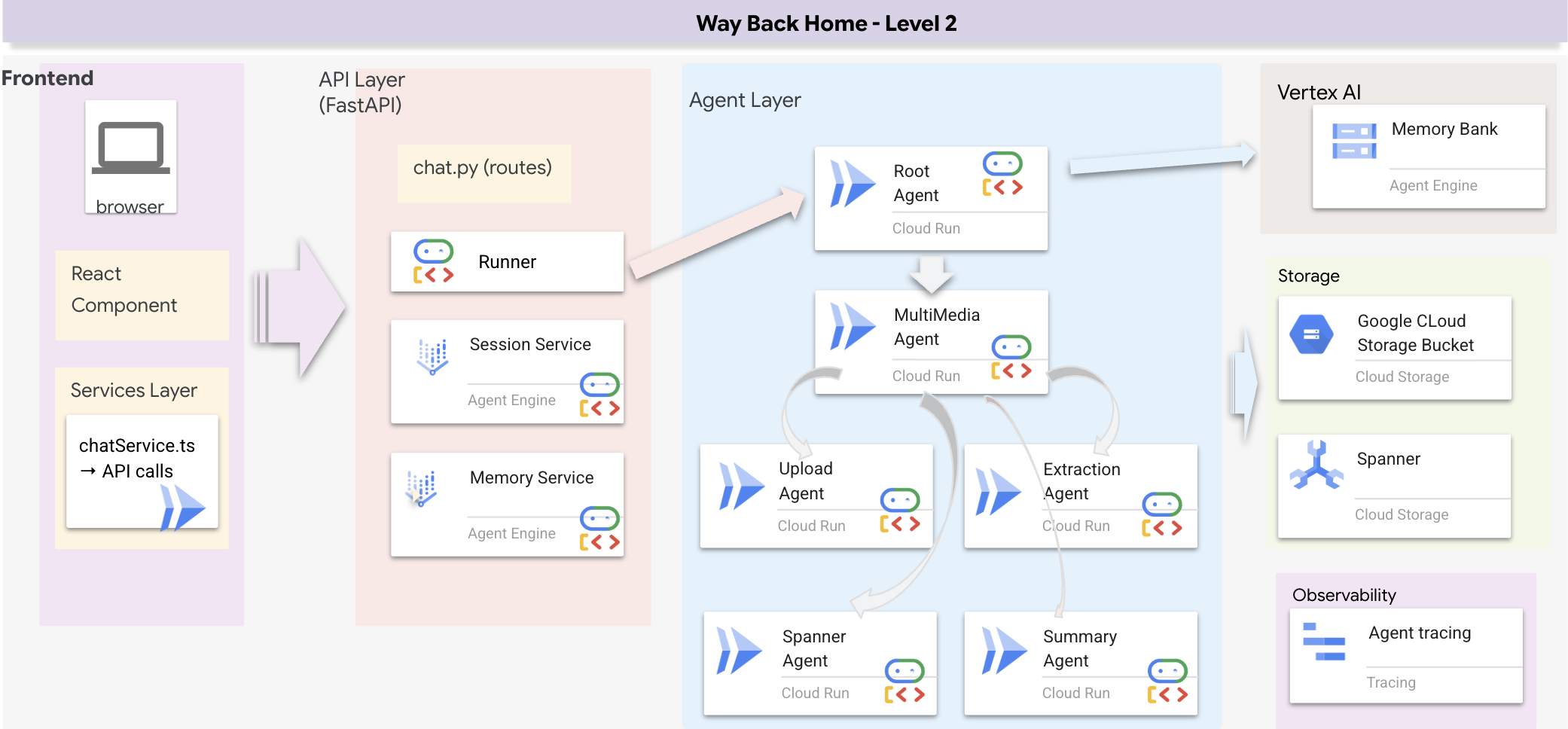
Aggiungi SessionService e Runner
👉💻 Nel terminale, apri il file chat.py nell'editor di Cloud Shell eseguendo (assicurati di aver premuto "Ctrl+C" per terminare il processo precedente prima di procedere):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 Nel file chat.py, individua il commento # TODO: REPLACE_INMEMORY_SERVICES, sostituisci l'intera riga con il seguente codice:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉 Nel file chat.py, individua il commento # TODO: REPLACE_RUNNER, sostituisci l'intera riga con il seguente codice:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Avvia la domanda
Se il terminale precedente è ancora in esecuzione, termina l'operazione premendo Ctrl+C.
👉💻 Avvia app:
cd ~/way-back-home/level_2/
./start_app.sh
Quando il backend viene avviato correttamente, vedrai Local: http://localhost:5173/" come mostrato di seguito: 
👉 Fai clic su Local: http://localhost:5173/ dal terminale.
2. Testare la ricerca semantica
Query:
Find skills similar to healing
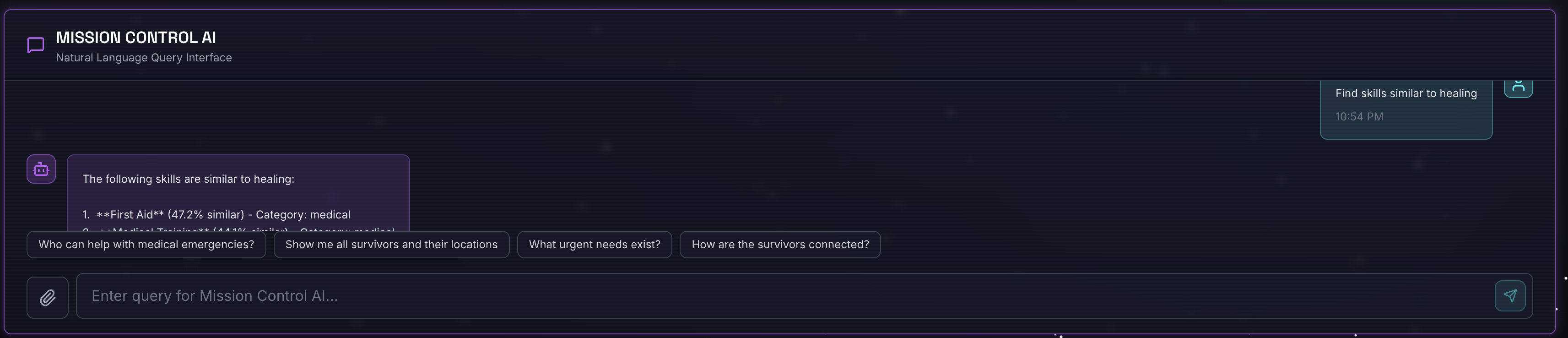
Cosa succede:
- L'agente riconosce la richiesta di similarità
- Genera l'incorporamento per "guarigione"
- Utilizza la distanza del coseno per trovare competenze semanticamente simili
- Resi: pronto soccorso (anche se i nomi non corrispondono a "guarigione")
3. Testare la ricerca ibrida
Query:
Find medical skills in the mountains
Cosa succede:
- Componente parola chiave: filtra per
category='medical' - Componente semantico: incorpora "medico" e classifica in base alla somiglianza
- Unisci: combina i risultati, dando la priorità a quelli trovati con entrambi i metodi 🔀
Query(facoltativa):
Who is good at survival and in the forest?
Cosa succede:
- Risultati della parola chiave:
biome='forest' - Risultati semantici: competenze simili a "sopravvivenza"
- La modalità ibrida combina entrambe le opzioni per ottenere risultati ottimali.
👉💻 Al termine del test, nel terminale, termina premendo Ctrl+C.
4. (!SOLO PER I PARTECIPANTI AL WORKSHOP) Aggiornare la posizione
👉💻 Esegui lo script di completamento:
cd ~/way-back-home/level_2
./set_level_2.sh
Ora apri waybackhome.dev e vedrai che la tua posizione è stata aggiornata. Congratulazioni per aver completato il livello 2.

9. ☕️ [Facoltativo] Pipeline multimodale (sola lettura) - Livello di strumenti
Perché abbiamo bisogno di una pipeline multimodale?
La rete di sopravvivenza non è solo testo. I sopravvissuti sul campo inviano dati non strutturati direttamente tramite la chat:
- 📸 Immagini: foto di risorse, pericoli o attrezzature
- 🎥 Video: report sullo stato o trasmissioni SOS
- 📄 Testo: note o log del campo
Quali file elaboriamo?
A differenza del passaggio precedente, in cui abbiamo cercato i dati esistenti, qui elaboriamo i file caricati dagli utenti. L'interfaccia chat.py gestisce gli allegati dei file in modo dinamico:
Origine | Contenuti | Obiettivo |
User Attachment | Immagine/video/testo | Informazioni da aggiungere al grafico |
Contesto della chat | "Ecco una foto delle forniture" | Intento e dettagli aggiuntivi |
L'approccio pianificato: pipeline degli agenti sequenziale
Utilizziamo un agente sequenziale (multimedia_agent.py) che collega agenti specializzati:
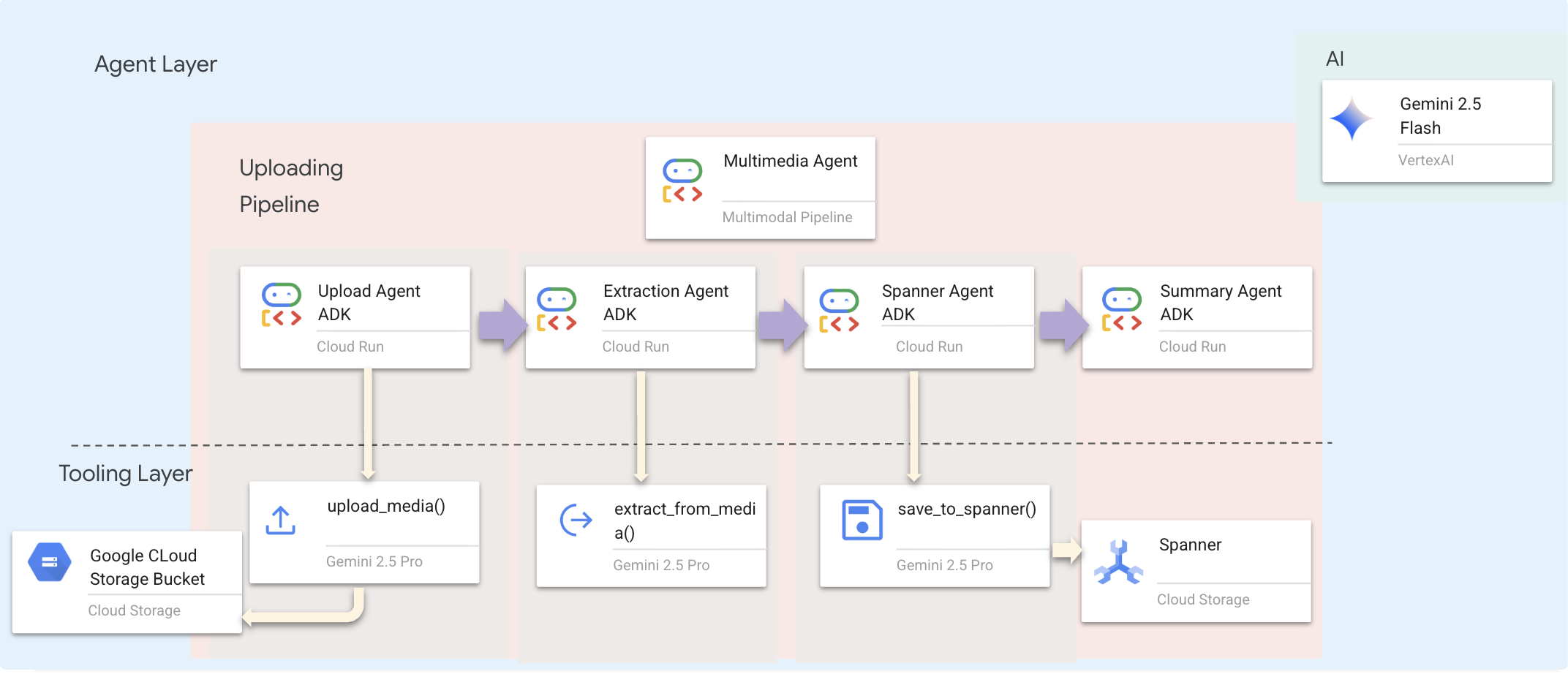
Questo valore è definito in backend/agent/multimedia_agent.py come SequentialAgent.
Il livello di strumenti fornisce le funzionalità che gli agenti possono richiamare. Gli strumenti gestiscono il "come": caricamento dei file, estrazione delle entità e salvataggio nel database.
1. Apri il file degli strumenti
👉💻 Apri il file level_2/backend/agent/tools/extraction_tools.py o digitando questo comando nel terminale. Apri un nuovo terminale. Nel terminale, apri il file nell'editor di Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Implementa lo strumento upload_media
Questo strumento carica un file locale su Google Cloud Storage.
👉 In def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, il seguente codice mostra come caricare i file su GCS e rilevarne il tipo:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Implementa lo strumento extract_from_media
Questo strumento è un router: controlla media_type e invia all'estrattore corretto (testo, immagine o video).
👉 In async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, il seguente codice mostra come estrarre entità e relazioni dai contenuti multimediali caricati.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Dettagli chiave dell'implementazione:
- Input multimodale: trasmettiamo sia il prompt di testo (
_get_extraction_prompt()) sia l'oggetto immagine agenerate_content. - Output strutturato:
response_mime_type="application/json"garantisce che l'LLM restituisca un JSON valido, fondamentale per la pipeline. - Collegamento visivo delle entità: il prompt include entità note, in modo che Gemini possa riconoscere personaggi specifici.
4. Implementa lo strumento save_to_spanner
Questo strumento salva le entità e le relazioni estratte nel database Spanner Graph.
👉 In def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, il seguente codice mostra come salvare le entità e le relazioni estratte nel database Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Fornendo agli agenti strumenti di alto livello, garantiamo l'integrità dei dati sfruttando le capacità di ragionamento dell'agente.
5. Aggiornare il servizio GCS
GCSService gestisce il caricamento effettivo del file su Google Cloud Storage.
👉💻 Apri il file level_2/backend/services/gcs_service.py oppure puoi digitare nel terminale per aprire il file nell'editor di Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 In def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, il seguente codice mostra come salvare le entità e le relazioni estratte nel database Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Se viene eseguita l'astrazione in un servizio, l'agente non deve conoscere i bucket GCS, i nomi dei blob o la generazione di URL firmati. Chiede solo di "caricare".
6. Perché il workflow agentico è migliore degli approcci tradizionali?
Il vantaggio dell'agente:
Funzionalità | Pipeline batch | Basato sugli eventi | Flusso di lavoro agentico |
complessità | Basso (1 script) | Alto (5 o più servizi) | Basso (1 file Python: |
Gestione dello stato | Variabili globali | Hard (disaccoppiato) | Unificato (stato dell'agente) |
Gestione degli errori | Arresti anomali | Log silenziosi | Interattivo ("Non riesco a leggere il file") |
Feedback degli utenti | Stampe della console | Necessità di polling | Immediato (parte della chat) |
Adattabilità | Logica fissa | Funzioni rigide | Intelligente (il modello LLM decide il passaggio successivo) |
Context Awareness | Nessuno | Nessuno | Completa (conosce l'intent dell'utente) |
Perché è importante:utilizzando multimedia_agent.py (un SequentialAgent con 4 sub-agenti: Upload → Extract → Save → Summary), sostituiamo l'infrastruttura complessa E gli script fragili con una logica applicativa intelligente e conversazionale.
10. ☕️ [Facoltativo] Pipeline multimodale (sola lettura) - Livello agente
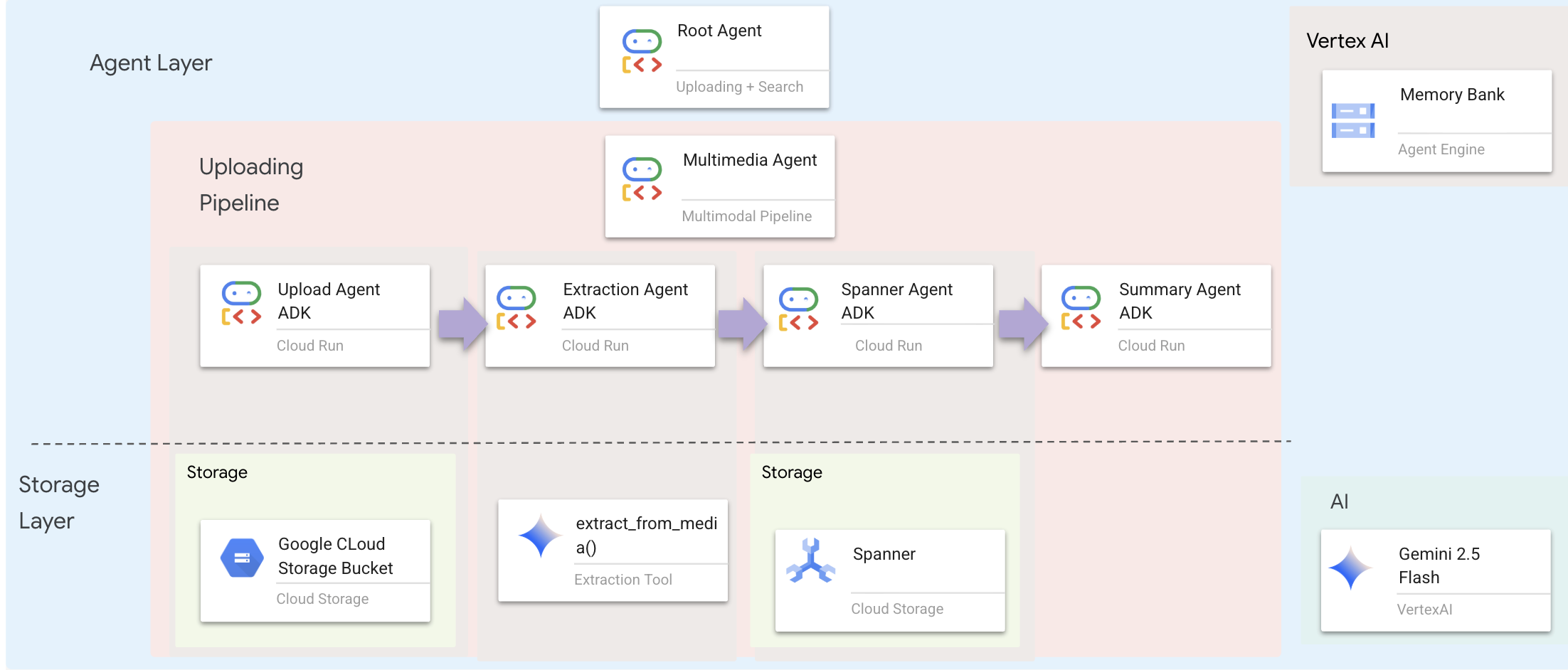
Il livello degli agenti definisce l'intelligenza, ovvero gli agenti che utilizzano strumenti per svolgere attività. Ogni agente ha un ruolo specifico e passa il contesto al successivo. Di seguito è riportato il diagramma dell'architettura del sistema multiagente.
1. Apri il file dell'agente
👉💻 Apri il file level_2/backend/agent/multimedia_agent.py o digitando questo comando nel terminale. Apri un nuovo terminale. Nel terminale, apri il file nell'editor di Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Definisci l'agente di caricamento
Questo agente estrae un percorso del file dal messaggio dell'utente e lo carica su GCS.
👉 Nel file multimedia_agent.py, con il seguente codice, viene creato upload_agent che viene caricato in GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Definisci l'agente di estrazione
Questo agente "vede" i contenuti multimediali caricati ed estrae i dati strutturati utilizzando Gemini Vision.
👉 Nel file multimedia_agent.py, con il seguente codice, viene creato extraction_agent che estrae le informazioni dai contenuti multimediali caricati:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Nota come instruction faccia riferimento a {upload_result}: in questo modo lo stato viene trasmesso tra gli agenti in ADK.
4. Definisci l'agente Spanner
Questo agente salva le entità e le relazioni estratte nel database del grafico.
👉 Nel file multimedia_agent.py, con il seguente codice, viene creato spanner_agent che salva le informazioni estratte nel database:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Questo agente riceve il contesto da entrambi i passaggi precedenti (upload_result e extraction_result).
5. Definisci l'agente di riepilogo
Questo agente sintetizza i risultati di tutti i passaggi precedenti in una risposta di facile utilizzo.
👉 Nel file multimedia_agent.py, con il seguente codice, viene definito il prompt per summary_agent che riassume il risultato:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Questo agente non ha bisogno di strumenti: legge il contesto condiviso e genera un riepilogo pulito per l'utente.
🧠 Riepilogo dell'architettura
incorporato | File | Responsabilità |
Strumenti |
| Come: carica, estrai, salva |
Agent |
| Cosa: orchestra la pipeline |
11. 🚀 Pipeline di dati multimodali - Orchestrazione
Il fulcro del nostro nuovo sistema è il MultimediaExtractionPipeline definito in backend/agent/multimedia_agent.py. Utilizza il pattern Sequential Agent di ADK (Agent Development Kit).
1. Perché Sequential?
L'elaborazione di un caricamento è una catena di dipendenze lineare:
- Non puoi estrarre i dati finché non hai il file (caricamento).
- Non puoi salvare i dati finché non li estrai (estrazione).
- Non puoi riassumere finché non hai i risultati (Salva).
Un SequentialAgent è perfetto per questo. Passa l'output di un agente come contesto/input al successivo.
2. Definizione dell'agente
Vediamo come viene assemblata la pipeline nella parte inferiore di multimedia_agent.py: 👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Riceve input da entrambi i passaggi precedenti. Individua il commento # TODO: REPLACE_ORCHESTRATION. Sostituisci l'intera riga con il seguente codice:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Contatta l'agente principale
👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Individua il commento # TODO: REPLACE_ADD_SUBAGENT. Sostituisci l'intera riga con il seguente codice:
sub_agents=[multimedia_agent],
Questo singolo oggetto raggruppa in modo efficace quattro "esperti" in un'unica entità chiamabile.
4. Flusso di dati tra gli agenti
Ogni agente memorizza il proprio output in un contesto condiviso a cui possono accedere gli agenti successivi:
5. Apri l'applicazione (salta questo passaggio se l'app è ancora in esecuzione)
👉💻 Avvia app:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Fai clic su Local: http://localhost:5173/ dal terminale.
6. Caricamento di prova dell'immagine
👉 Nell'interfaccia della chat, scegli una delle foto qui e caricala nella UI:
Nell'interfaccia della chat, comunica all'agente il tuo contesto specifico:
Here is the survivor note
Quindi allega l'immagine qui.

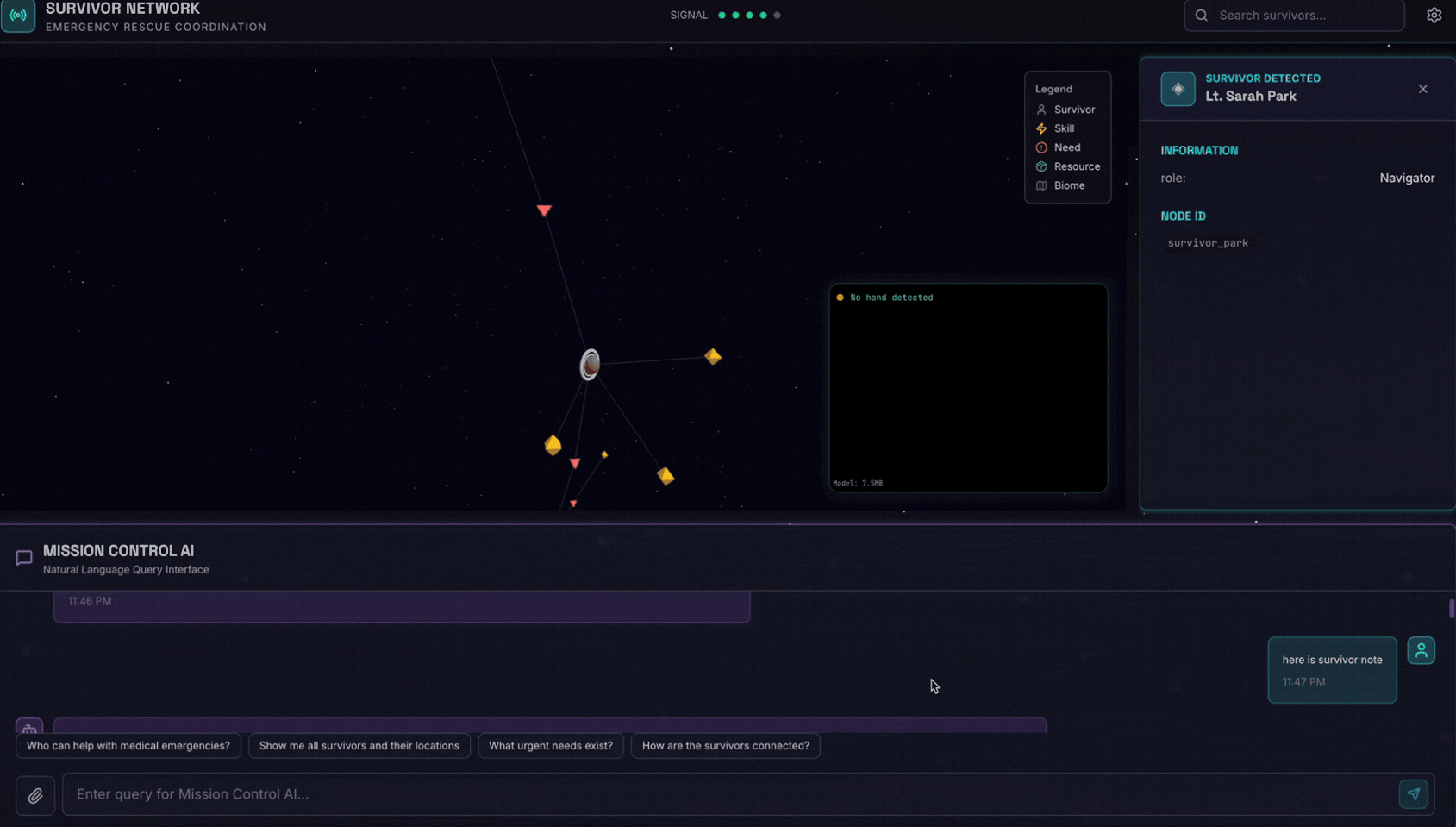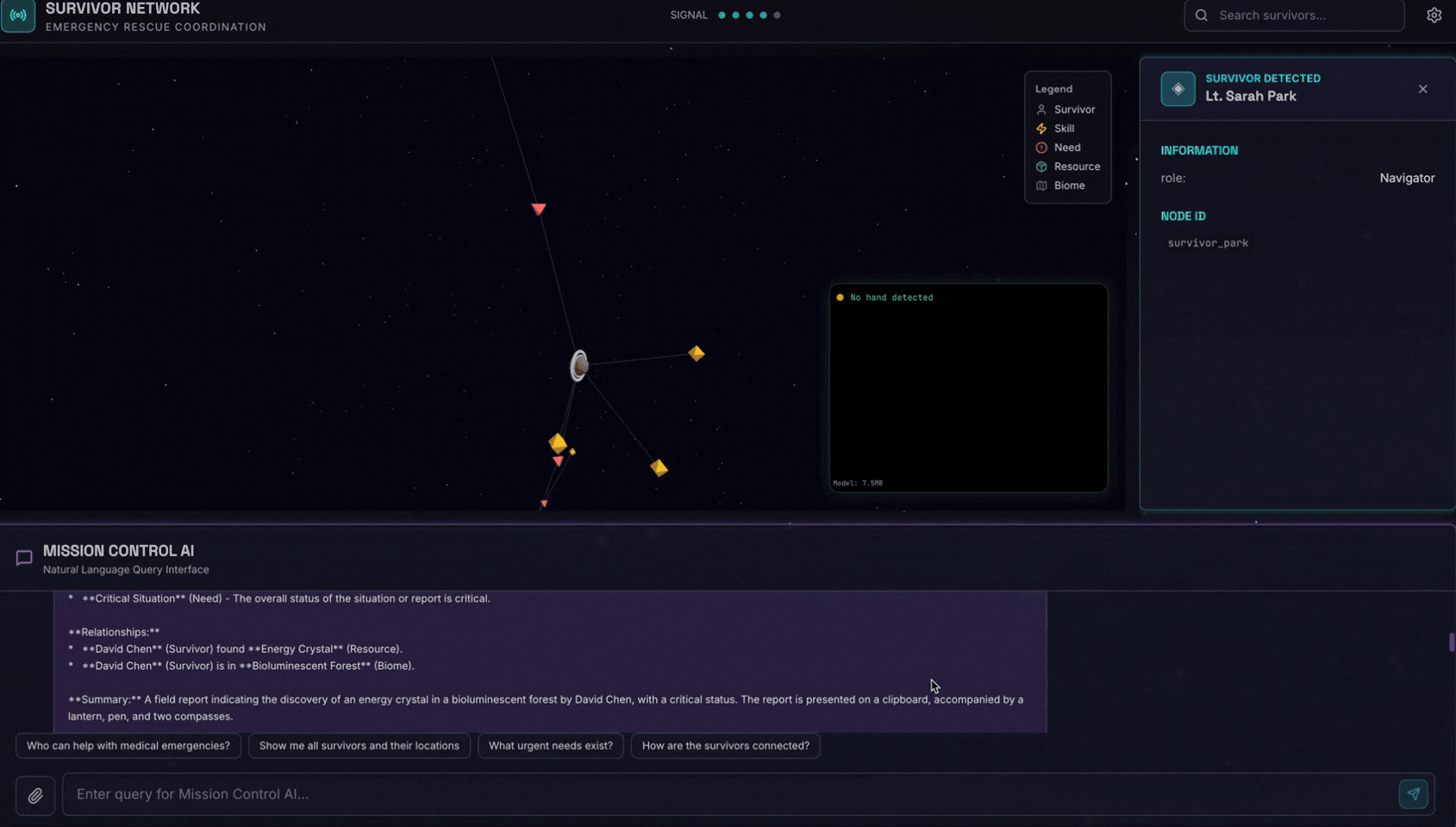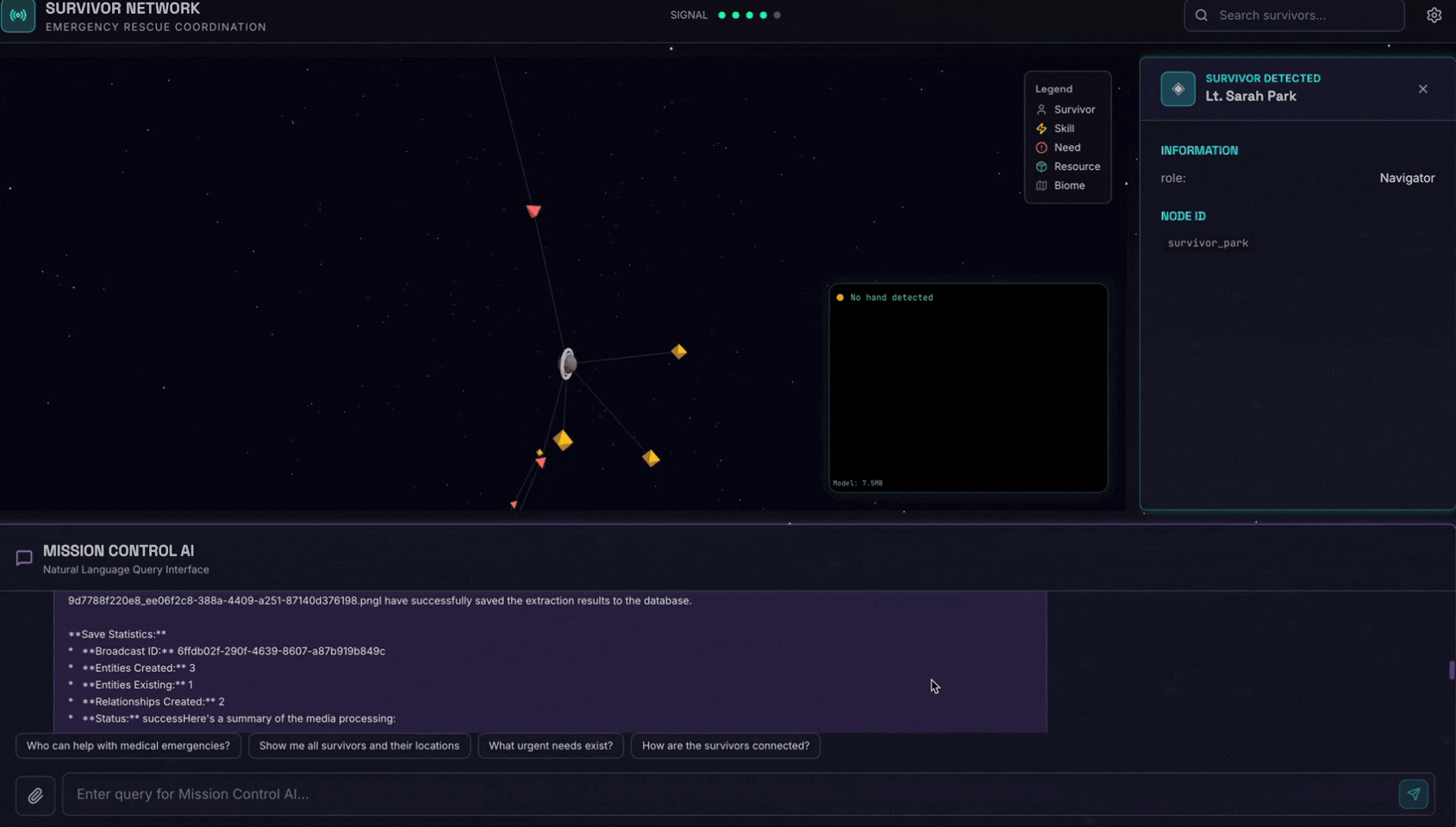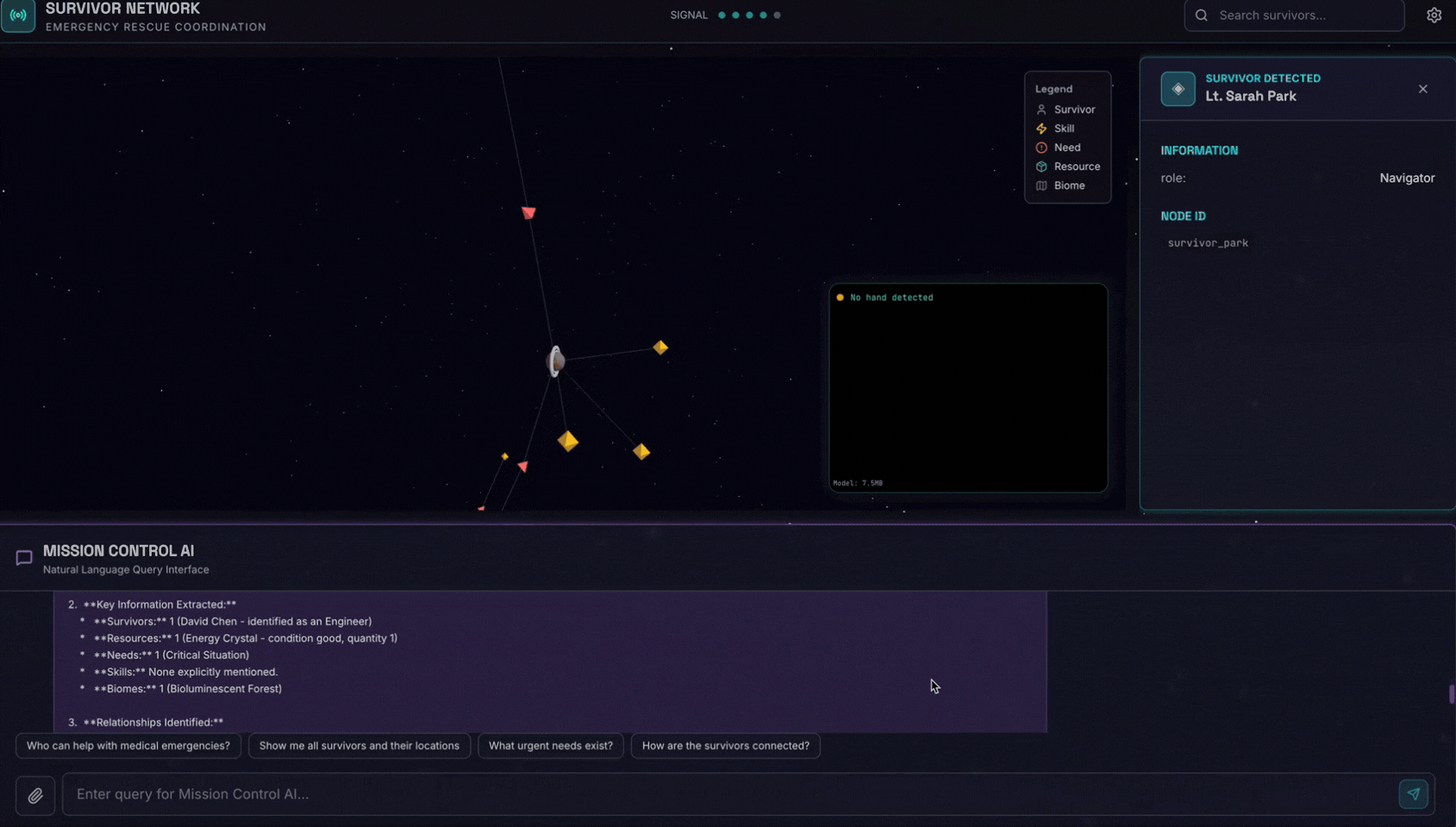
👉💻 Nel terminale, al termine del test, premi "Ctrl+C" per terminare il processo.
6. Verifica il caricamento multimodale nel bucket GCS
- Apri console Google Cloud Storage.
- Seleziona "bucket" in Cloud Storage
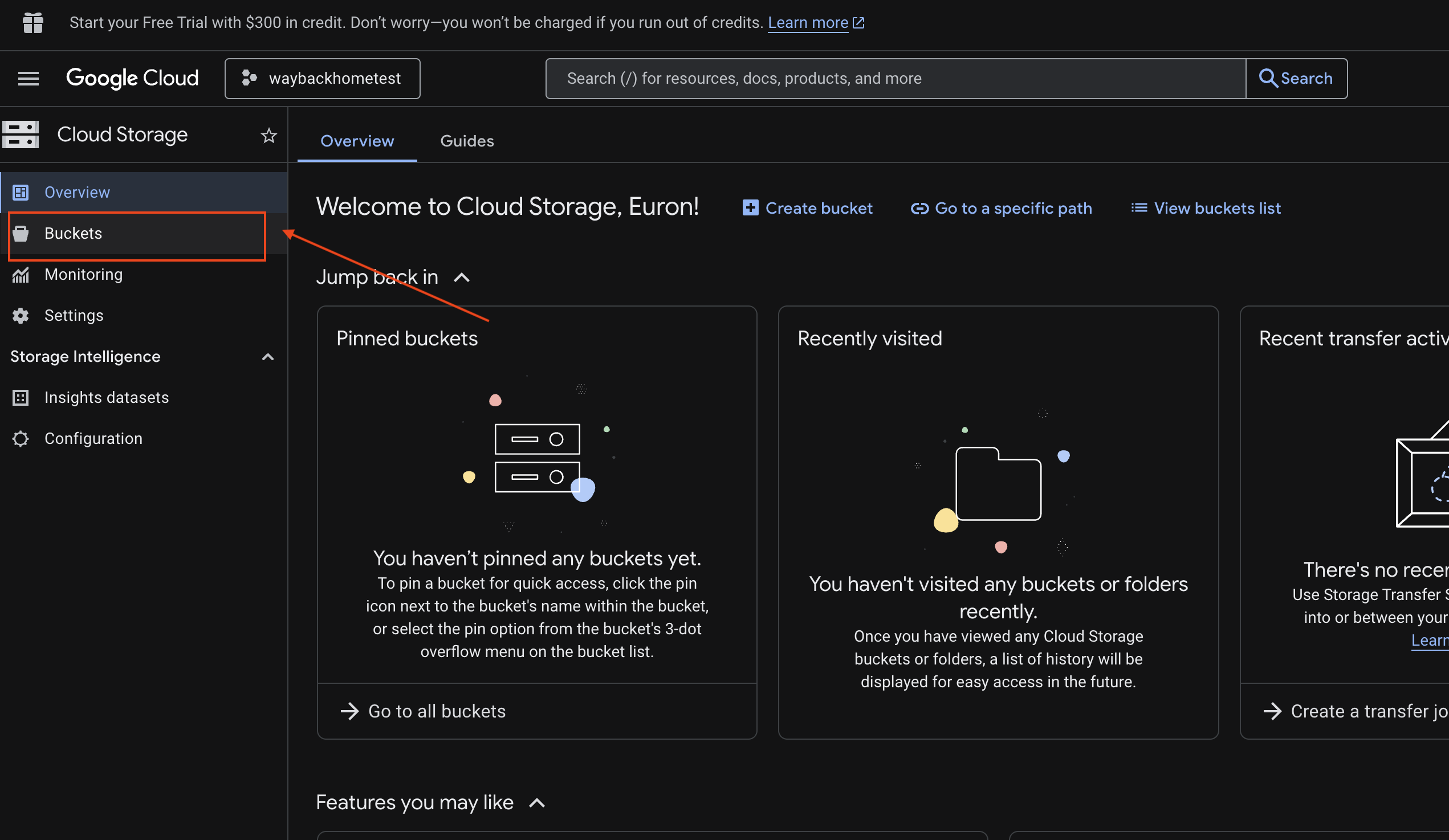
- Seleziona il bucket e fai clic su
media.
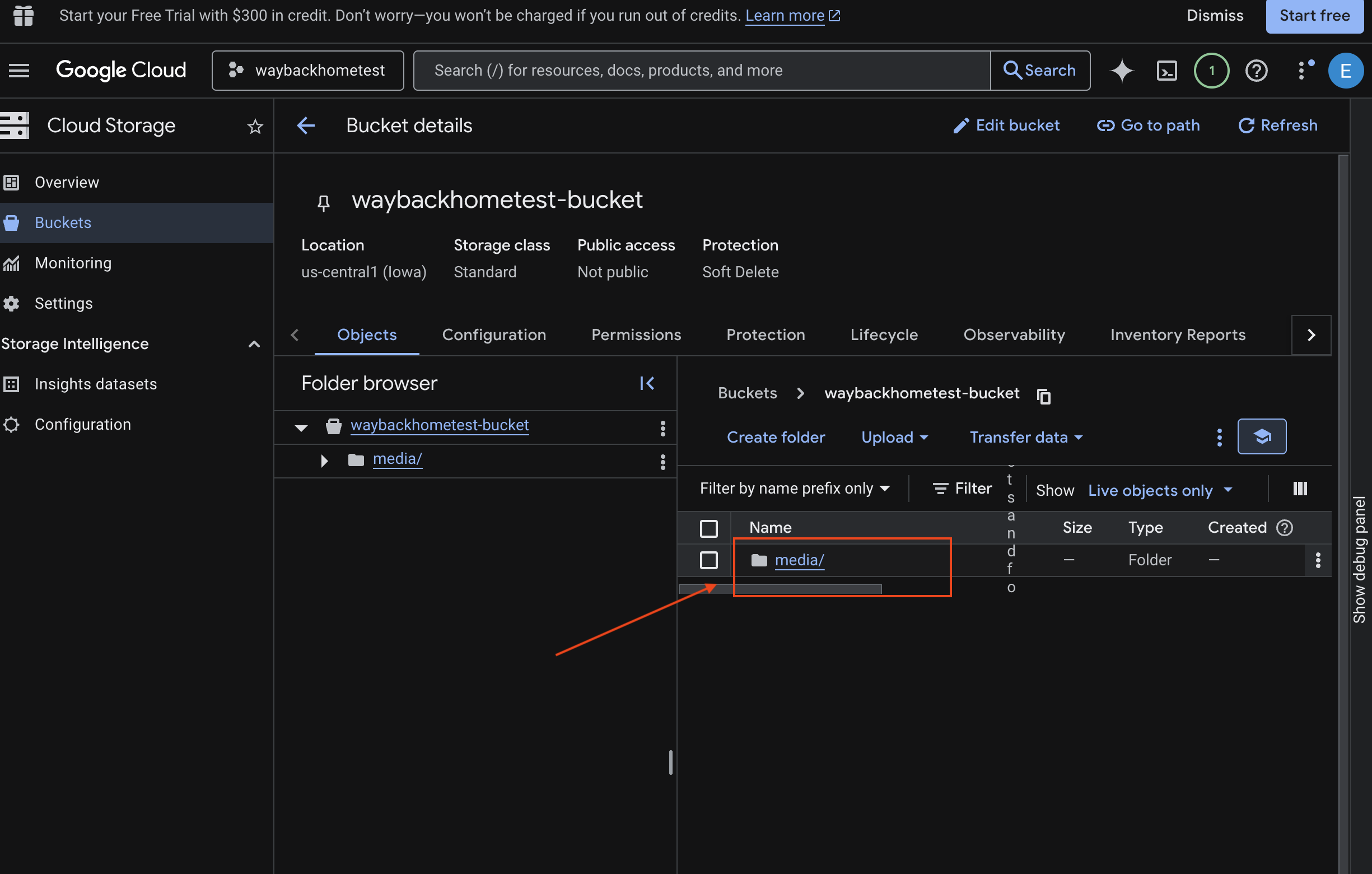
- Visualizza l'immagine caricata qui.
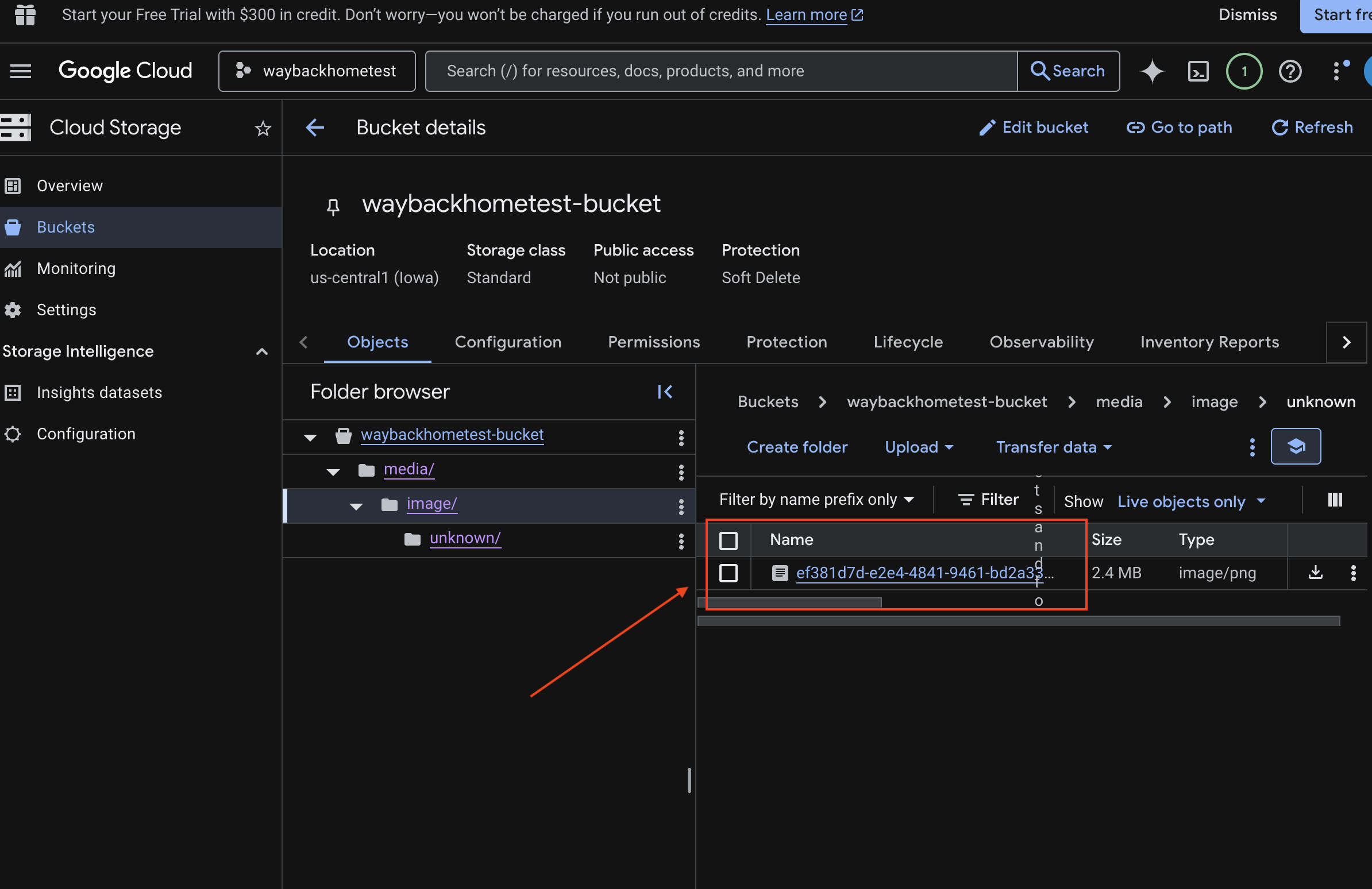
7. (Facoltativo) Verifica il caricamento multimodale in Spanner
Di seguito è riportato un output di esempio nell'interfaccia utente per test_photo1.
- Apri console Google Cloud Spanner.
- Seleziona la tua istanza:
Survivor Network - Seleziona il database:
graph-db - Nella barra laterale sinistra, fai clic su Spanner Studio.
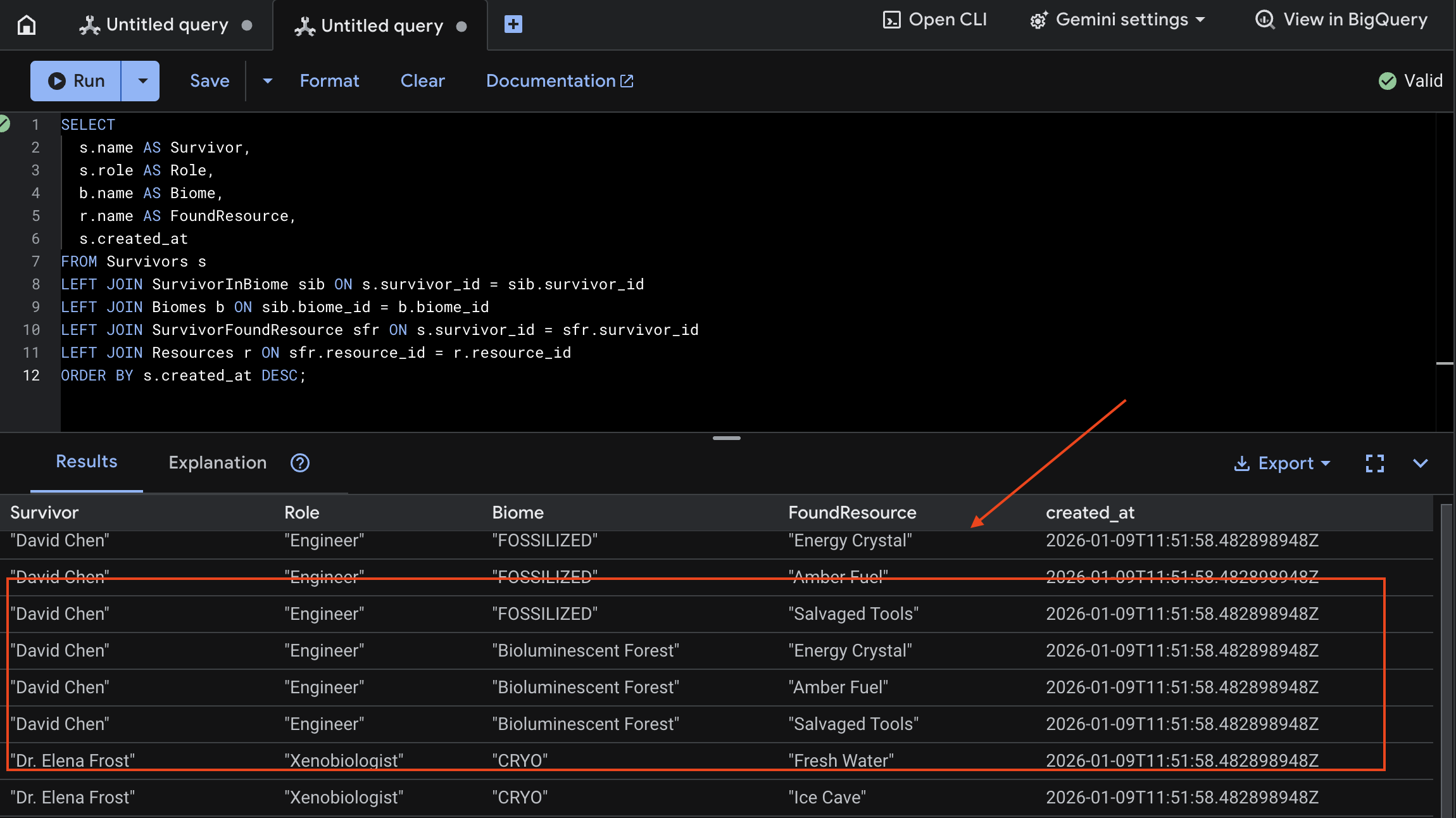
👉 In Spanner Studio, esegui una query sui nuovi dati:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Possiamo verificarlo visualizzando il risultato di seguito:
12. ☕️ [Facoltativo] Memory Bank con Motore agente
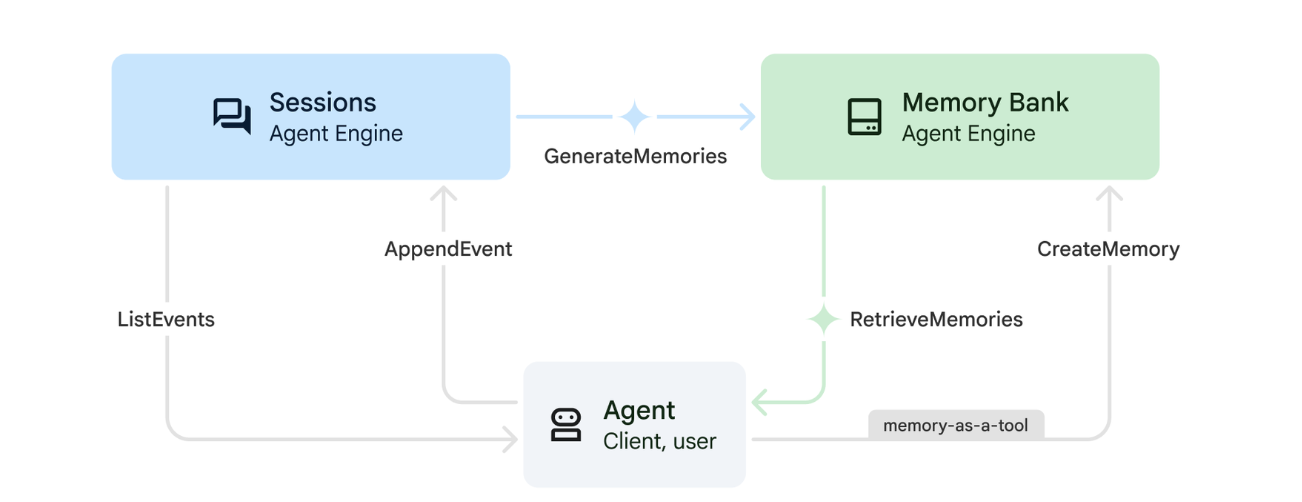
1. Come funziona Memorie
Il sistema utilizza un approccio a doppia memoria per gestire sia il contesto immediato sia l'apprendimento a lungo termine.
2. Che cosa sono gli argomenti di memoria?
Gli argomenti della memoria definiscono le categorie di informazioni che l'agente deve ricordare nelle conversazioni. Considerali come schedari per diversi tipi di preferenze degli utenti.
I nostri due argomenti:
search_preferences: Come l'utente preferisce effettuare le ricerche- Preferiscono la ricerca per parole chiave o semantica?
- Quali competenze/biomi cercano spesso?
- Esempio di memoria: "L'utente preferisce la ricerca semantica per le competenze mediche"
urgent_needs_context: Quali crisi sta monitorando- Quali risorse monitorano?
- Quali sopravvissuti sono interessati?
- Esempio di memoria: "L'utente sta monitorando la carenza di farmaci nel campo settentrionale"
3. Configurare gli argomenti dei ricordi
Gli argomenti della memoria personalizzata definiscono cosa deve ricordare l'agente. Questi vengono configurati durante il deployment di Agent Engine.
👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Si apre ~/way-back-home/level_2/backend/deploy_agent.py nell'editor.
Definiamo gli oggetti della struttura MemoryTopic per indicare all'LLM quali informazioni estrarre e salvare.
👉 Nel file deploy_agent.py, sostituisci # TODO: SET_UP_TOPIC con quanto segue:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Integrazione dell'agente
Il codice dell'agente deve conoscere la Memory Bank per salvare e recuperare le informazioni.
👉💻 Nel terminale, apri il file nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Si apre ~/way-back-home/level_2/backend/agent/agent.py nell'editor.
Creazione dell'agente
Quando creiamo l'agente, passiamo after_agent_callback per garantire che le sessioni vengano salvate in memoria dopo le interazioni. La funzione add_session_to_memory viene eseguita in modo asincrono per evitare di rallentare la risposta della chat.
👉 Nel file agent.py, individua il commento # TODO: REPLACE_ADD_SESSION_MEMORY, sostituisci l'intera riga con il seguente codice:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Salvataggio in background
👉 Nel file agent.py, individua il commento # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, sostituisci l'intera riga con il seguente codice:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉 Nel file agent.py, individua il commento # TODO: REPLACE_ADD_CALLBACK, sostituisci l'intera riga con il seguente codice:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Configura il servizio di sessione Vertex AI
👉💻 Nel terminale, apri il file chat.py nell'editor di Cloud Shell eseguendo:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 Nel file chat.py, individua il commento # TODO: REPLACE_VERTEXAI_SERVICES, sostituisci l'intera riga con il seguente codice:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Facoltativo] Collega l'agente con Agent Engine
1. Configurazione e deployment
Prima di testare le funzionalità di memoria, devi eseguire il deployment dell'agente con i nuovi argomenti di memoria e assicurarti che l'ambiente sia configurato correttamente.
Abbiamo fornito uno script di utilità per gestire questa procedura.
Esecuzione dello script di deployment
👉💻 Nel terminale, esegui lo script di deployment:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Questo script esegue le seguenti azioni:
- Esegue
backend/deploy_agent.pyper registrare l'agente e gli argomenti della memoria con Vertex AI. - Acquisisce il nuovo ID Agent Engine.
- Aggiorna automaticamente il file
.envconAGENT_ENGINE_ID. - Assicura che
USE_MEMORY_BANK=TRUEsia impostato nel file.env.
[!IMPORTANT] Se apporti modifiche a custom_topics in deploy_agent.py, devi eseguire di nuovo questo script per aggiornare Agent Engine.
Verificare Memory Bank
Ora puoi verificare che la banca della memoria funzioni insegnando all'agente una preferenza e controllando se viene mantenuta nelle varie sessioni.
Passaggio 1. Apri l'applicazione
Apri di nuovo l'applicazione seguendo le istruzioni riportate di seguito: se il terminale precedente è ancora in esecuzione, termina premendo Ctrls+C.
👉💻 Avvia app:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Fai clic su Local: http://localhost:5173/ dal terminale.
Passaggio 2. Testare Memory Bank con Text
Nell'interfaccia della chat, comunica all'agente il tuo contesto specifico:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Attendi circa 30 secondi affinché la memoria venga elaborata in background.
Passaggio 3. Avviare una nuova sessione
Aggiorna la pagina per cancellare la cronologia della conversazione corrente (memoria a breve termine).
Fai una domanda che si basa sul contesto che hai fornito in precedenza:
"What kind of missions am I interested in?"
Risposta prevista:
"In base alle tue conversazioni precedenti, ti interessano:
- Missioni di soccorso medico
- Operazioni in montagna/ad alta quota
- Abilità necessarie: primo soccorso, arrampicata
Vuoi che cerchi sopravvissuti che corrispondono a questi criteri?"
Passaggio 4. Test con caricamento immagine
Carica un'immagine e chiedi:
remember this
Puoi scegliere una delle foto qui o una tua e caricarla nella UI:
Passaggio 5. Verifica in Vertex AI Agent Engine
Vai a console Google Cloud Agent Engine
- Assicurati di selezionare il progetto dal selettore di progetti in alto a sinistra:
- Verifica il motore dell'agente di cui hai appena eseguito il deployment dal comando precedente
use_memory_bank.sh: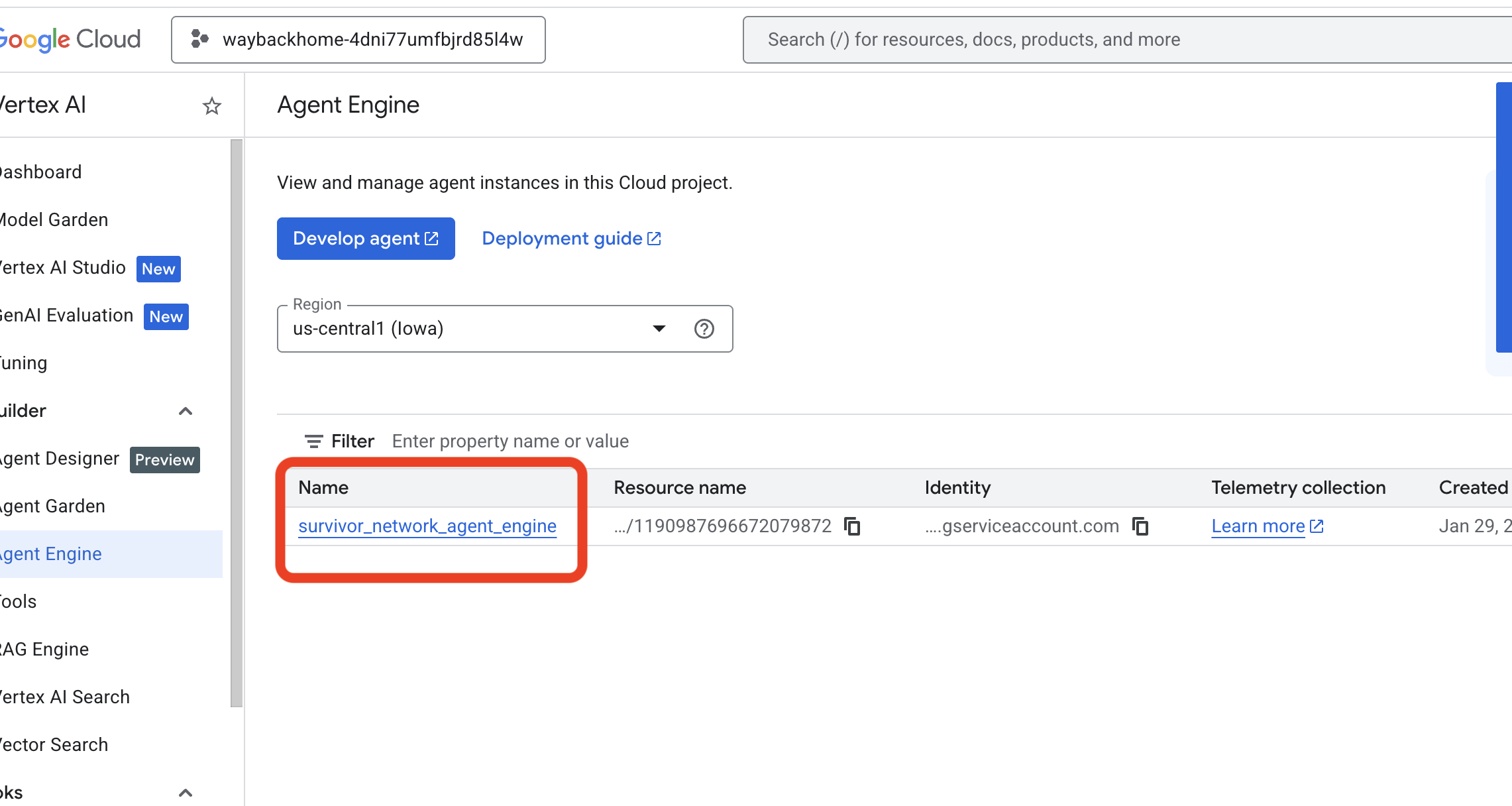 fai clic sul motore dell'agente che hai appena creato.
fai clic sul motore dell'agente che hai appena creato. - Fai clic sulla scheda
Memoriesin questo agente di cui è stato eseguito il deployment per visualizzare tutte le memorie.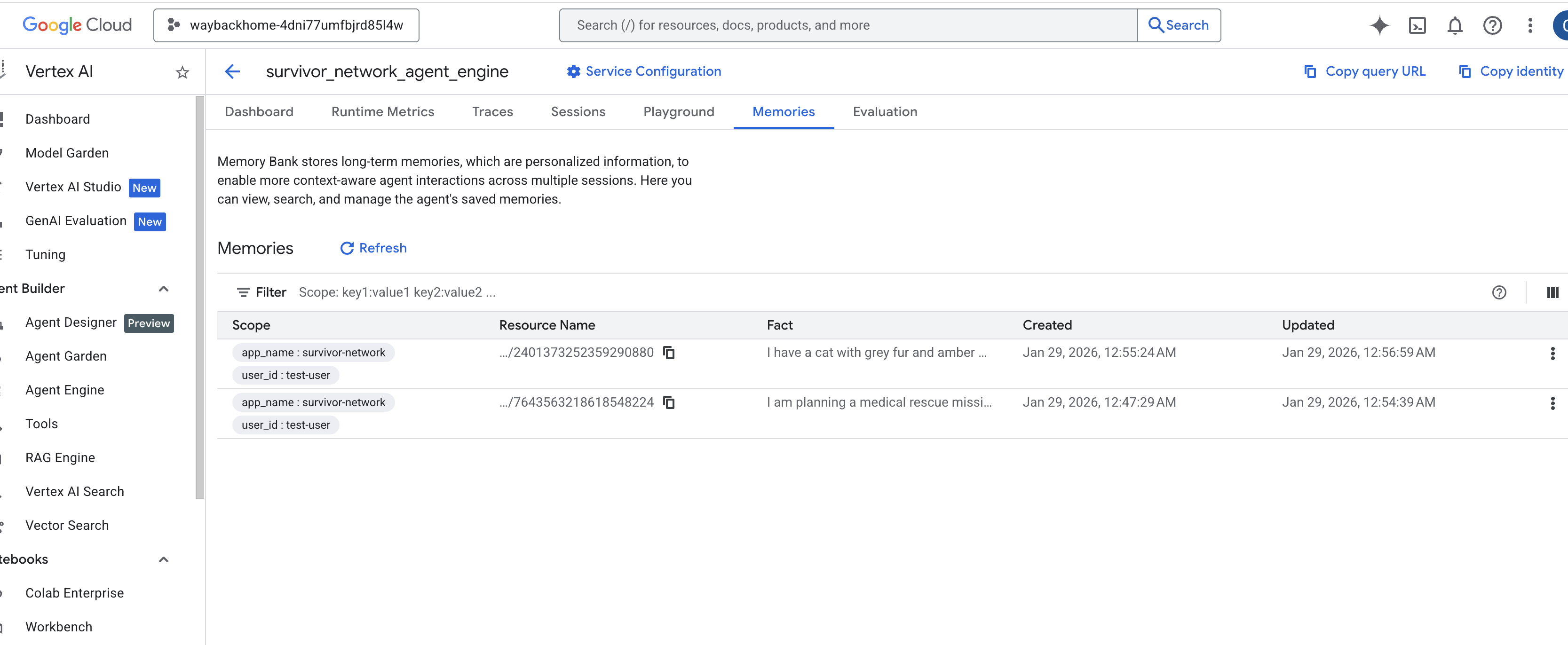
👉💻 Al termine del test, nel terminale fai clic su "Ctrl + C" per terminare la procedura.
🎉 Complimenti! Hai appena collegato Memory Bank al tuo agente.
14. ☕️ [Facoltativo] Esegui il deployment in Cloud Run
1. Esegui lo script di deployment
👉💻 Esegui lo script di deployment:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Una volta eseguito il deployment, avrai l'URL. Questo è l'URL di deployment. 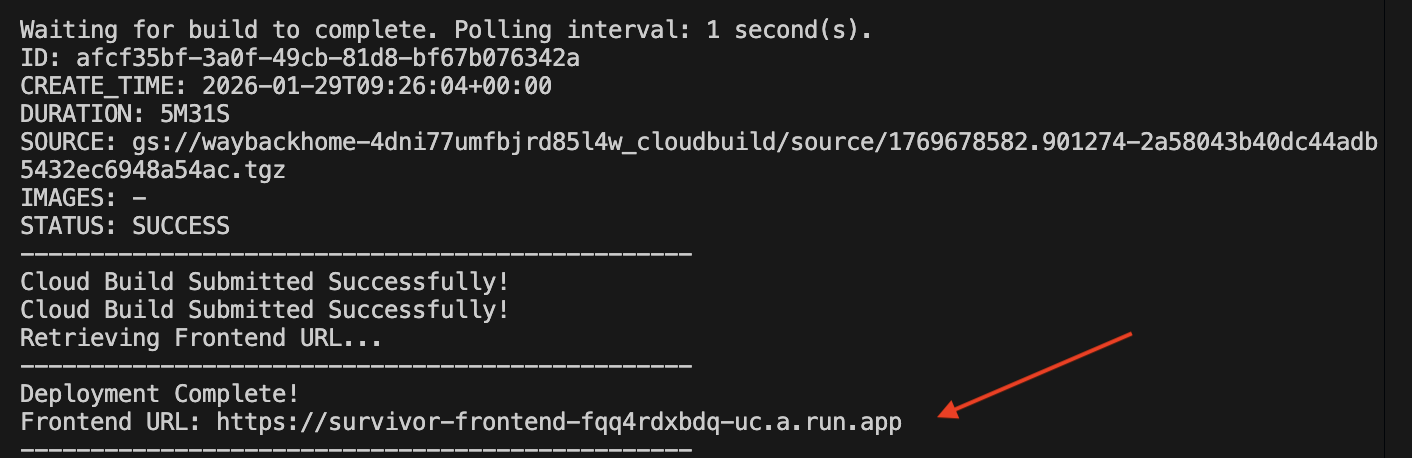
👉💻 Prima di prendere l'URL, concedi l'autorizzazione eseguendo:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Vai all'URL di cui hai eseguito il deployment e vedrai la tua applicazione live.
2. Informazioni sulla pipeline di build
Il file cloudbuild.yaml definisce i seguenti passaggi sequenziali:
- Backend Build: crea l'immagine Docker da
backend/Dockerfile. - Backend Deploy: esegue il deployment del container di backend in Cloud Run.
- Acquisisci URL: recupera il nuovo URL backend.
- Frontend Build:
- Installa le dipendenze.
- Crea la build dell'app React, inserendo
VITE_API_URL=.
- Immagine frontend: crea l'immagine Docker da
frontend/Dockerfile(pacchettizzazione degli asset statici). - Frontend Deploy: esegue il deployment del container frontend.
3. Verifica il deployment
Una volta completata la build (controlla il link ai log fornito dallo script), puoi verificare:
- Vai alla console Cloud Run.
- Trova il servizio
survivor-frontend. - Fai clic sull'URL per aprire l'applicazione.
- Esegui una query di ricerca per assicurarti che il frontend possa comunicare con il backend.
(FACOLTATIVO) 4. Deployment manuale
Se preferisci eseguire i comandi manualmente o comprendere meglio la procedura, ecco come utilizzare cloudbuild.yaml direttamente.
Scrittura di cloudbuild.yaml
Un file cloudbuild.yaml indica a Google Cloud Build quali passaggi eseguire.
- passaggi: un elenco di azioni sequenziali. Ogni passaggio viene eseguito in un container (ad es.
docker,gcloud,node,bash). - sostituzioni: variabili che possono essere trasmesse in fase di compilazione (ad es.
$_REGION). - workspace: una directory condivisa in cui i passaggi possono condividere file (come condividiamo
backend_url.txt).
Esecuzione del deployment
Per eseguire il deployment manualmente senza lo script, utilizza il comando gcloud builds submit. DEVI trasmettere le variabili di sostituzione richieste.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Conclusione
1. Cosa hai creato
✅ Graph Database: Spanner con nodi (sopravvissuti, competenze) e bordi (relazioni)
✅ AI Search: ricerca per parole chiave, semantica e ibrida con incorporamenti
✅ Multimodal Pipeline: estrai entità da immagini/video con Gemini
✅ Multi-Agent System: flusso di lavoro coordinato con ADK
✅ Memory Bank: personalizzazione a lungo termine con Vertex AI
✅ Production Deployment: Cloud Run + Agent Engine
2. Riepilogo dell'architettura
3. Nozioni principali
- RAG basato su grafici: combina la struttura del database a grafo con gli embedding semantici per una ricerca intelligente
- Pattern multi-agente: pipeline sequenziali per workflow complessi in più fasi
- AI multimodale: estrai dati strutturati da contenuti multimediali non strutturati (immagini/video)
- Agenti stateful: Memory Bank consente la personalizzazione tra le sessioni
4. Contenuti del workshop
- Level0: Identificati
- Level1: Posizione esatta
- Level2 This One: Build a Multimodal AI Agent with Graph RAG, ADK & Memory Bank
- Level3: creazione di un agente di streaming bidirezionale ADK
- Level4: sistema multi-agente bidirezionale in tempo reale
- Level5: Architettura basata sugli eventi con Google ADK, A2A e Kafka