
1. 소개

1. 과제
재난 대응 시나리오에서는 여러 위치에 있는 다양한 기술, 리소스, 요구사항을 가진 생존자를 조정하려면 지능형 데이터 관리 및 검색 기능이 필요합니다. 이 워크숍에서는 다음을 결합하는 프로덕션 AI 시스템을 빌드하는 방법을 알아봅니다.
- 🗄️ 그래프 데이터베이스 (Spanner): 생존자, 기술, 리소스 간의 복잡한 관계를 저장합니다.
- 🔍 AI 기반 검색: 임베딩을 사용한 시맨틱 + 키워드 하이브리드 검색
- 📸 멀티모달 처리: 이미지, 텍스트, 동영상에서 구조화된 데이터 추출
- 🤖 멀티 에이전트 조정: 복잡한 워크플로를 위해 전문 에이전트 조정
- 🧠 장기 기억: Vertex AI 메모리 뱅크를 사용한 맞춤설정
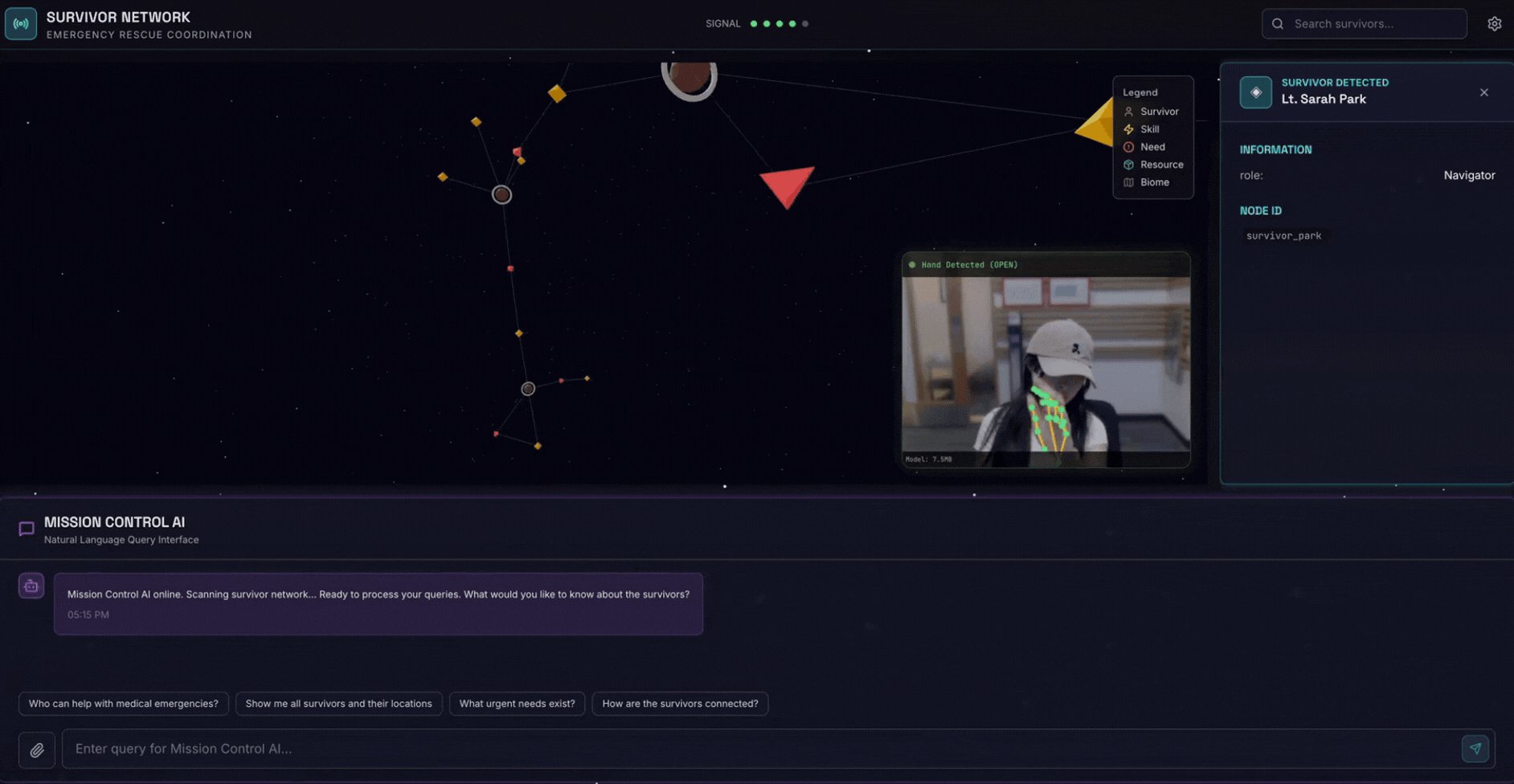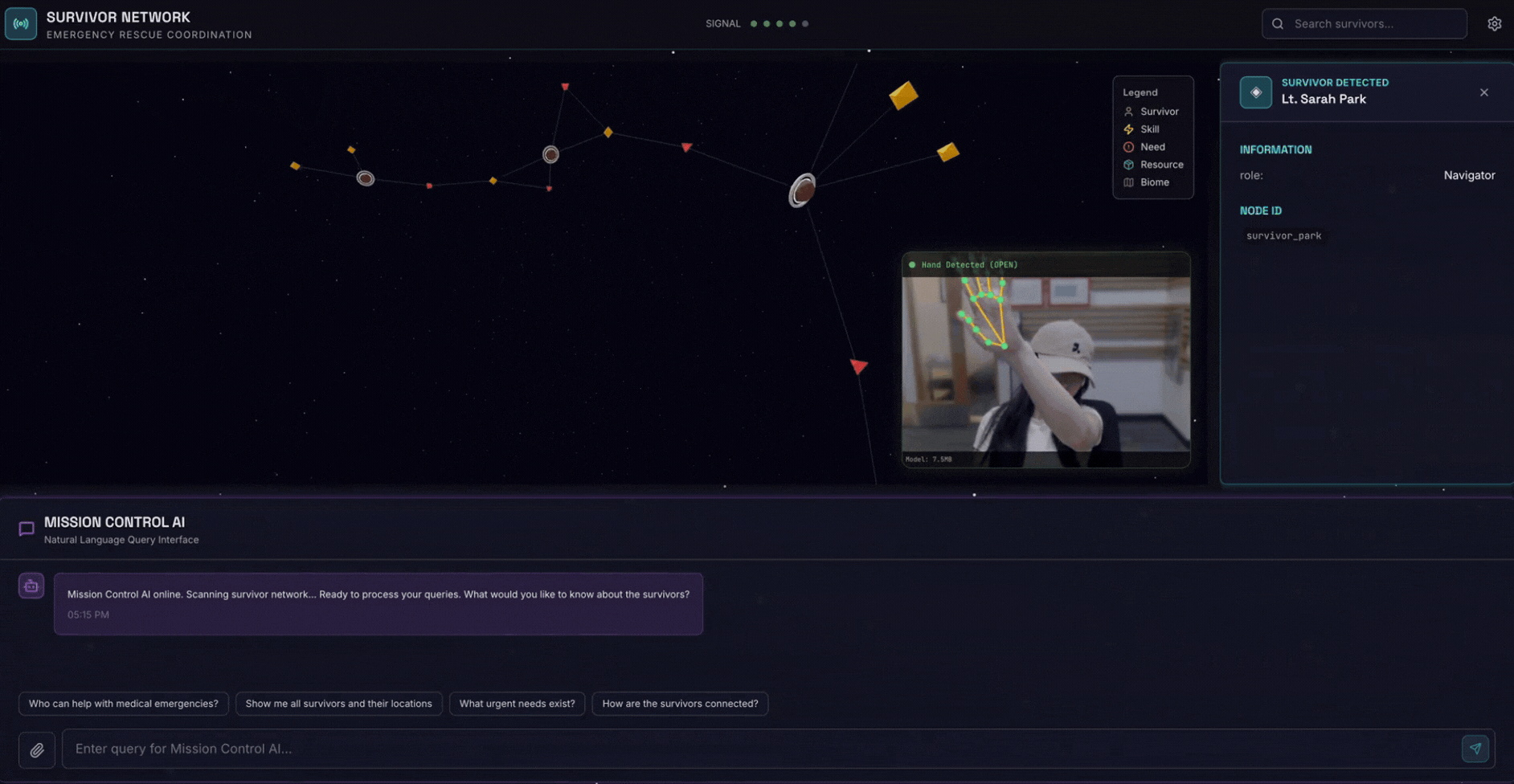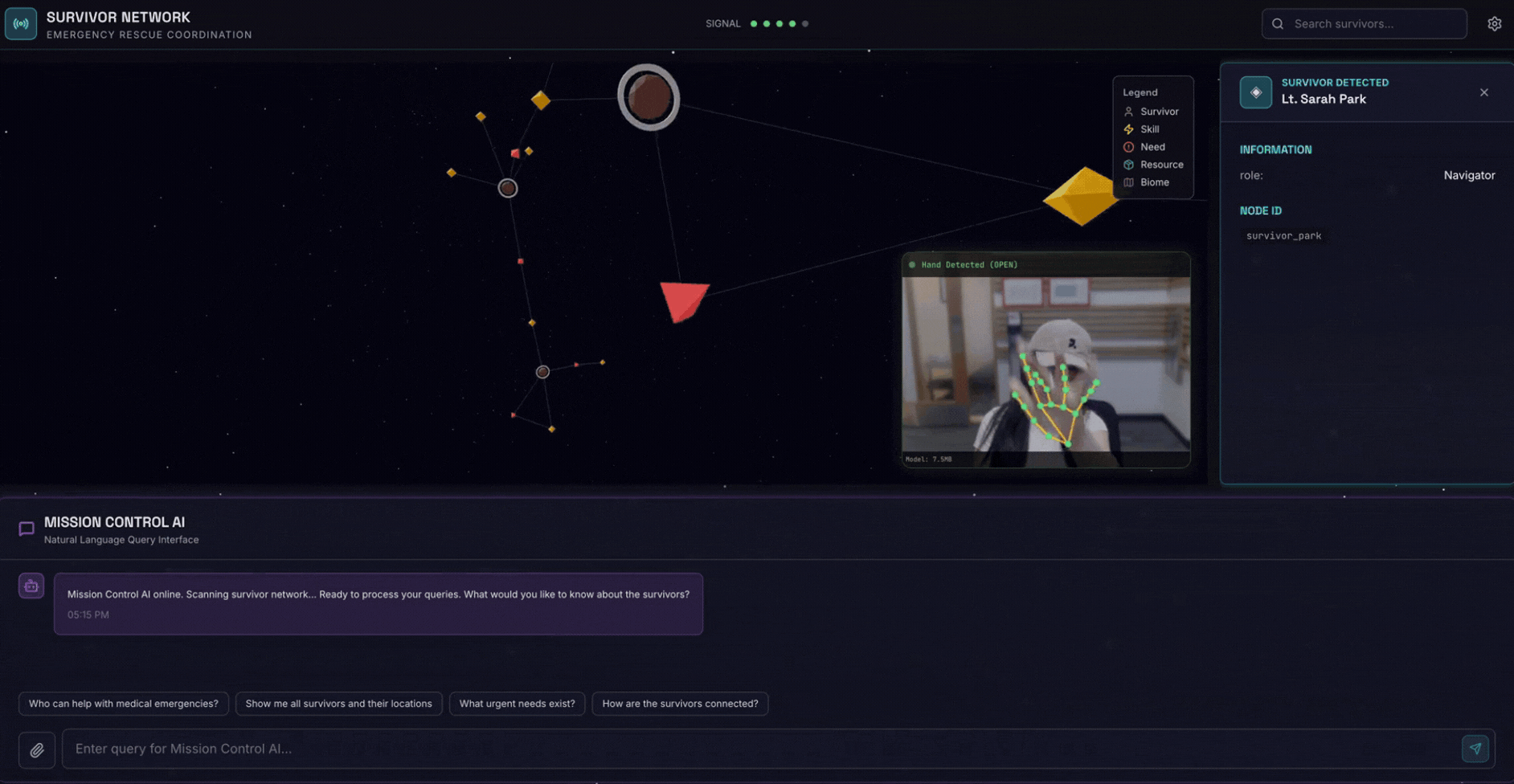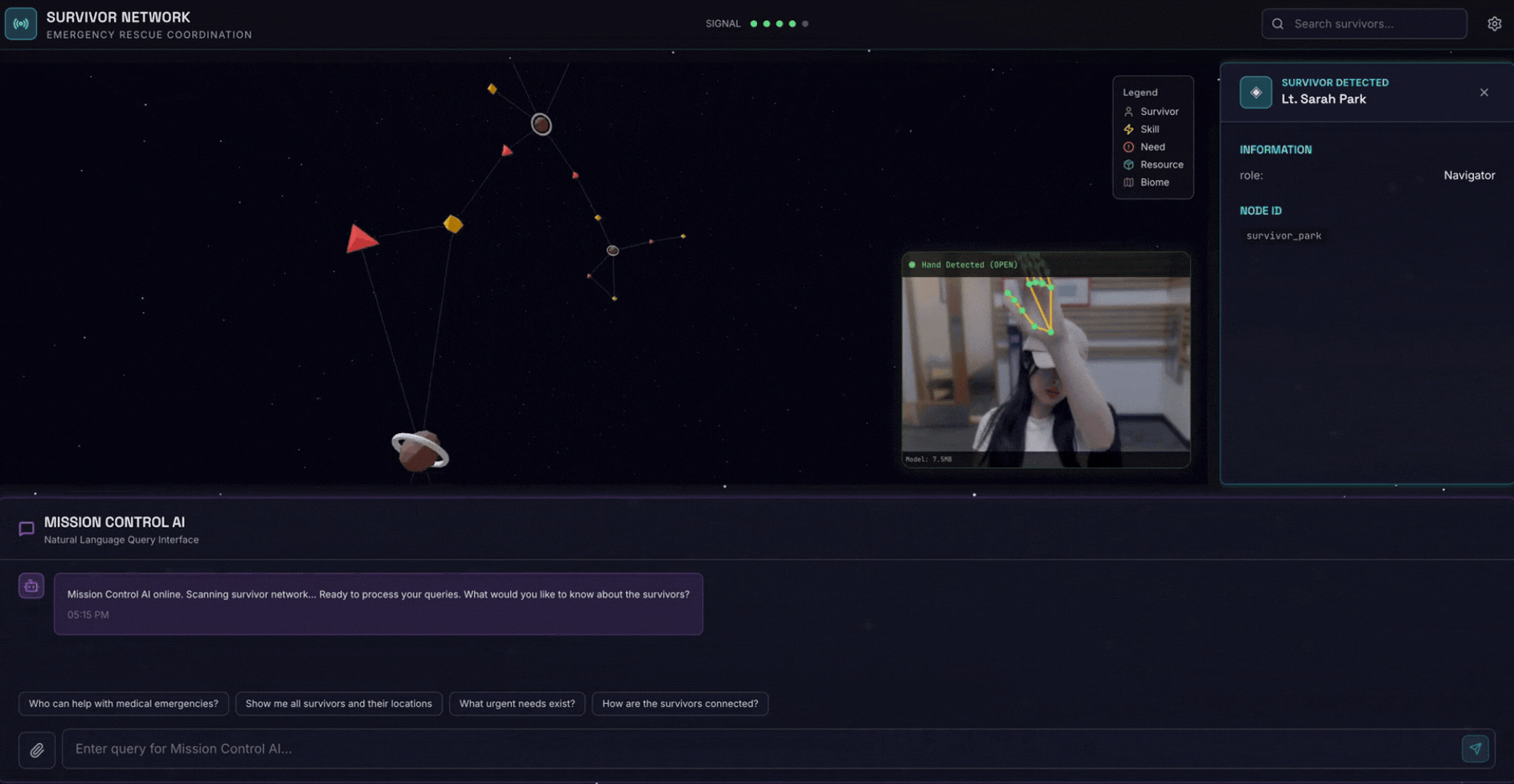
2. 빌드할 항목
다음과 같은 생존자 네트워크 그래프 데이터베이스:
- 🗺️ 생존자 관계의 3D 대화형 그래프 시각화
- 🔍 지능형 검색 (키워드, 시맨틱, 하이브리드)
- 📸 멀티모달 업로드 파이프라인 (이미지/동영상에서 엔티티 추출)
- 🤖 복잡한 작업 조정을 위한 멀티 에이전트 시스템
- 🧠 맞춤형 상호작용을 위한 메모리 뱅크 통합
3. 핵심 기술
구성요소 | 기술 | 목적 |
데이터베이스 | Cloud Spanner 그래프 | 노드 (생존자, 기술) 및 에지 (관계) 저장 |
AI Search | Gemini + 임베딩 | 의미론적 이해 + 유사성 검색 |
에이전트 프레임워크 | ADK (에이전트 개발 키트) | AI 워크플로 조정 |
메모리 | Vertex AI Memory Bank는 | 장기 사용자 환경설정 저장소 |
프런트엔드 | React + Three.js | 대화형 3D 그래프 시각화 |
2. 🛠️ 환경 준비 (워크숍에 참여하는 경우 건너뛰기)
1부: 결제 계정 사용 설정
이 Codelab을 실행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
2부: 개방형 환경
- 👉 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 👉 오늘 언제든지 승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
- 👉 터미널이 화면 하단에 표시되지 않으면 다음을 따라 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
- 👉💻 터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list - 👉💻 GitHub에서 부트스트랩 프로젝트를 클론합니다.
git clone https://github.com/gca-americas/way-back-home.git
3부: 새 프로젝트 만들기
👉💻 터미널에서 init 스크립트를 실행 가능하게 만들고 실행합니다.
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ 환경 설정
1. Cloud Shell 열기
Cloud Shell 편집기 터미널에서 터미널이 화면 하단에 표시되지 않으면 다음을 실행하여 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
2. 프로젝트 구성
👉💻 터미널에서 프로젝트 ID를 설정합니다.
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 필요한 API를 사용 설정합니다 (2~3분 소요).
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. 설정 스크립트 실행
👉💻 설정 스크립트를 실행합니다.
cd ~/way-back-home/level_2
./setup.sh
이렇게 하면 .env가 생성됩니다. Cloud Shell에서 way_back_homeproject를 엽니다. level_2 폴더 아래에 .env 파일이 생성됩니다. 찾을 수 없는 경우 View -> Toggle Hidden File를 클릭하여 확인할 수 있습니다. 
4. 샘플 데이터 로드
👉💻 백엔드로 이동하여 종속 항목을 설치합니다.
cd ~/way-back-home/level_2/backend
uv sync
👉💻 초기 생존자 데이터 로드:
uv run python ~/way-back-home/level_2/backend/setup_data.py
그러면 다음이 생성됩니다.
- Spanner 인스턴스 (
survivor-network) - 데이터베이스(
graph-db) - 모든 노드 및 에지 테이블
- 예상 출력을 쿼리하기 위한 속성 그래프:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
출력에서 Access your database at 뒤에 있는 링크를 클릭하면 Google Cloud 콘솔 Spanner가 열립니다.

Google Cloud 콘솔에 Spanner가 표시됩니다.
4. 🚀 Spanner Studio에서 그래프 데이터 시각화
이 가이드에서는 Spanner 스튜디오를 사용하여 Google Cloud 콘솔에서 직접 서바이버 네트워크 그래프 데이터를 시각화하고 상호작용하는 방법을 설명합니다. AI 에이전트를 빌드하기 전에 데이터를 확인하고 그래프 구조를 파악하는 데 유용합니다.
1. Spanner Studio 액세스
- 마지막 단계에서 링크를 클릭하여 Spanner Studio를 열어야 합니다.
2. 그래프 구조 이해하기('큰 그림')
생존자 네트워크 데이터 세트를 논리 퍼즐 또는 게임 상태로 생각하세요.
항목 | 시스템 내 역할 | 비유 |
생존자 | 상담사/플레이어 | 플레이어 |
생물 군계 | 위치 | 지도 영역 |
기술 | 할 수 있는 작업 | 기능 |
필요한 항목 | 부족한 부분 (위기) | 퀘스트/미션 |
리소스 | 월드에서 발견된 항목 | 전리품 |
목표: AI 에이전트의 역할은 생태계 (위치 제약 조건)를 고려하여 기술 (솔루션)을 필요 (문제)에 연결하는 것입니다.
🔗 에지 (관계):
SurvivorInBiome: 위치 추적SurvivorHasSkill: 능력 인벤토리SurvivorHasNeed: 활성 문제 목록SurvivorFoundResource: 상품 인벤토리SurvivorCanHelp: 추론된 관계 (AI가 계산함)
3. 그래프 쿼리
몇 가지 쿼리를 실행하여 데이터의 '스토리'를 확인해 보겠습니다.
Spanner Graph는 GQL (Graph Query Language)을 사용합니다. 쿼리를 실행하려면 GRAPH SurvivorNetwork를 사용하고 그 뒤에 일치 패턴을 입력합니다.
👉 질문 1: 전 세계 명단 (누가 어디에 있나요?) 이것이 구조 작업의 기초입니다. 위치를 이해하는 것은 구조 작업에 매우 중요합니다.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
아래와 같은 결과가 표시됩니다. 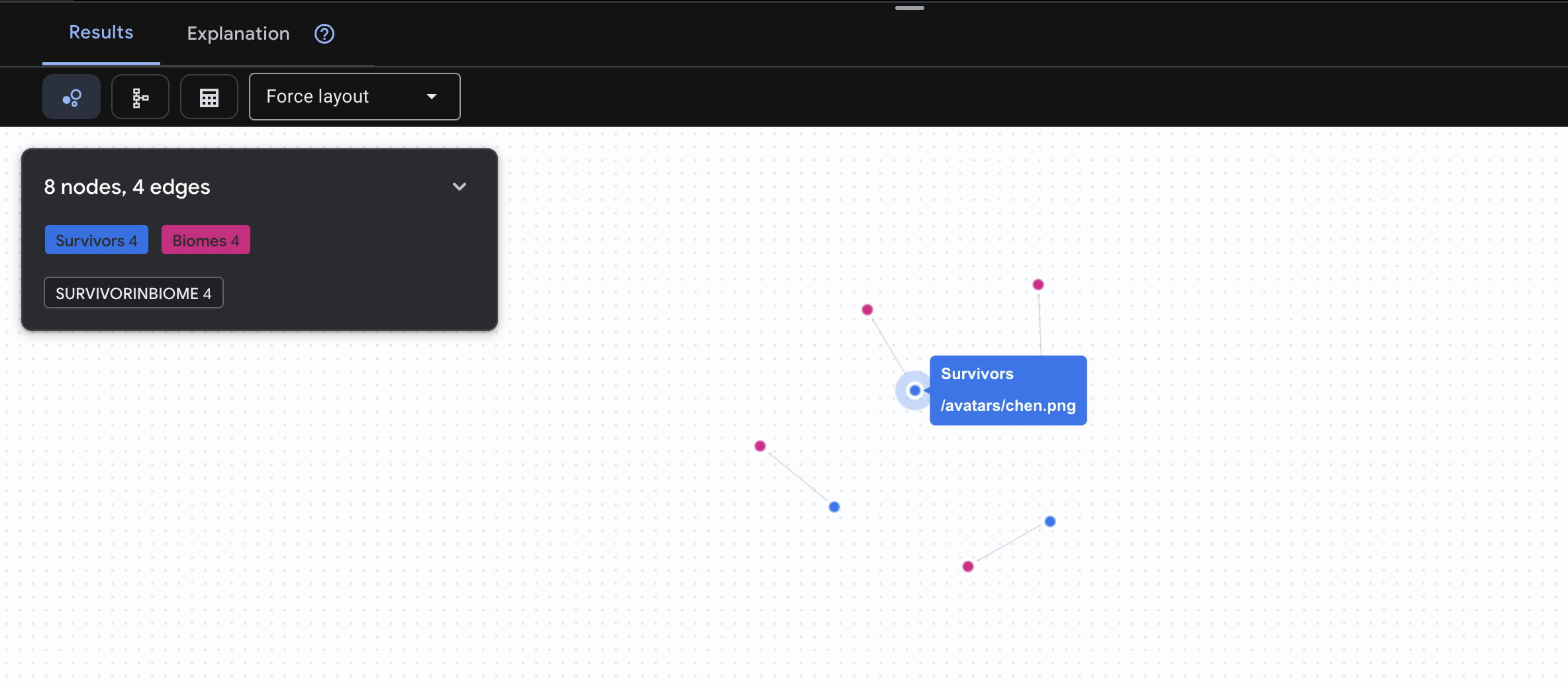
👉 질문 2: 기술 매트릭스 (역량) 이제 모든 사람의 위치를 알았으니 할 수 있는 일을 알아보세요.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
아래와 같은 결과가 표시됩니다. 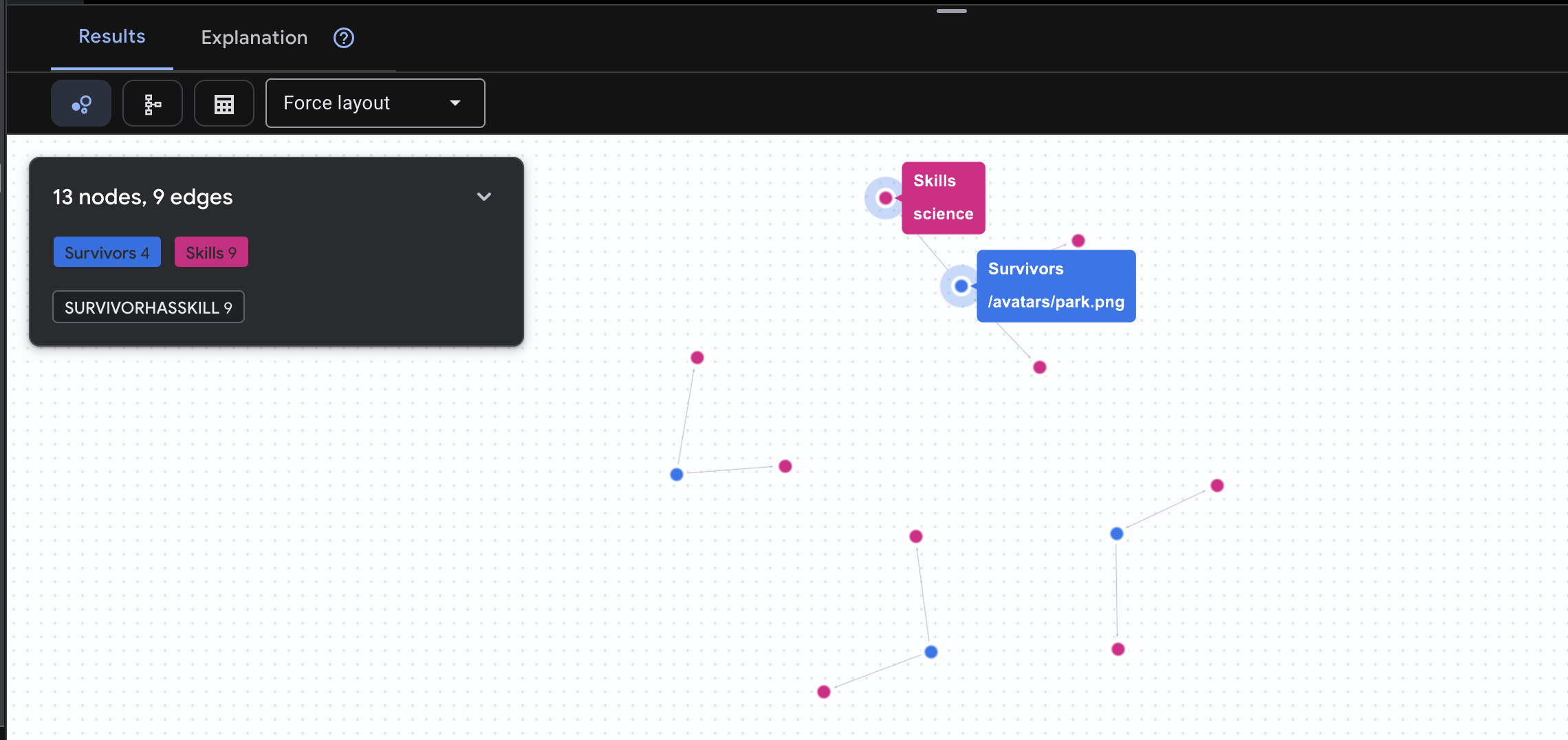
👉 질문 3: 누가 위기에 처해 있나요? ('미션 게시판') 도움이 필요한 생존자와 필요한 물품을 확인하세요.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
아래와 같은 결과가 표시됩니다. 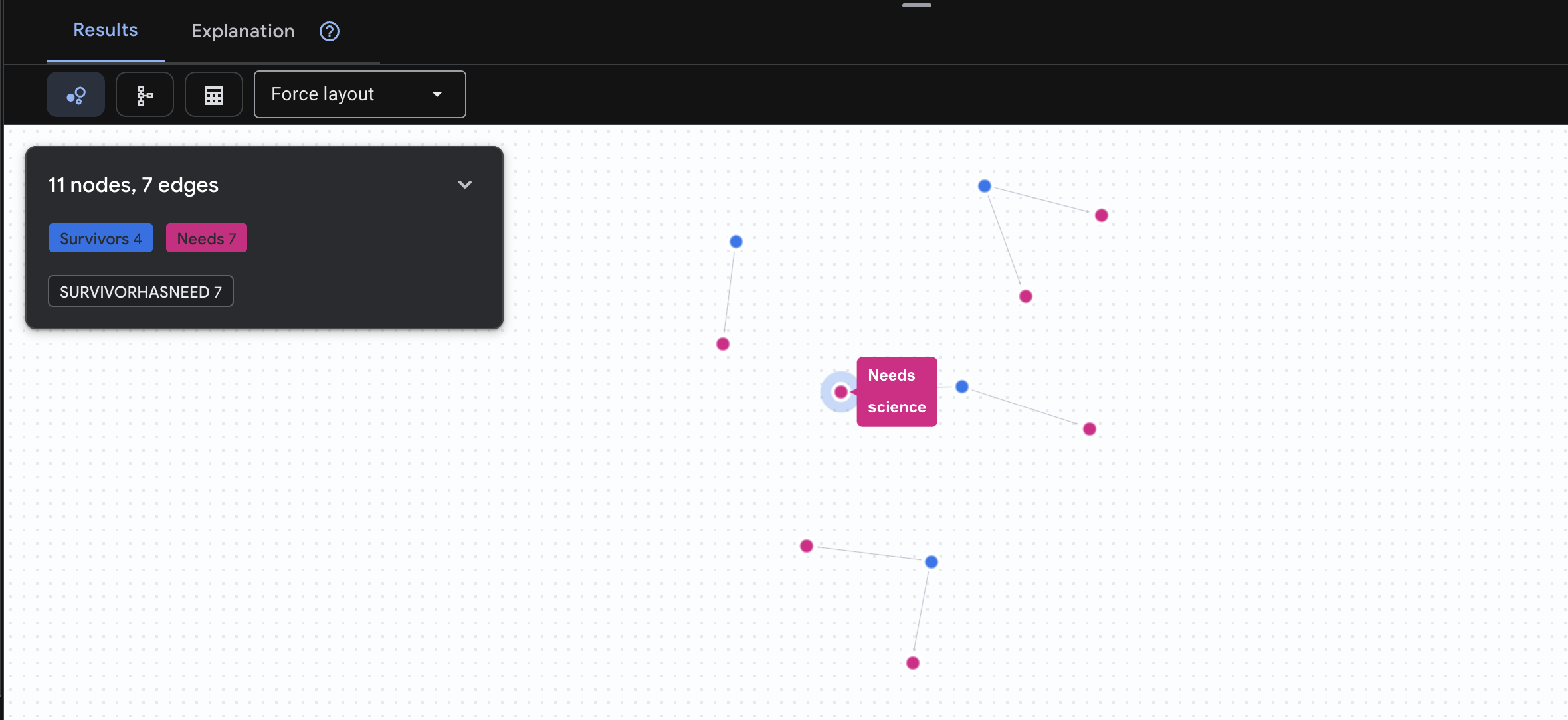
🔎 [선택사항] 매치메이킹 - 누가 누구를 도울 수 있나요?
여기서 그래프가 강력해집니다. 이 쿼리는 다른 생존자의 요구사항을 처리할 수 있는 기술을 보유한 생존자를 찾습니다.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
아래와 같은 결과가 표시됩니다. 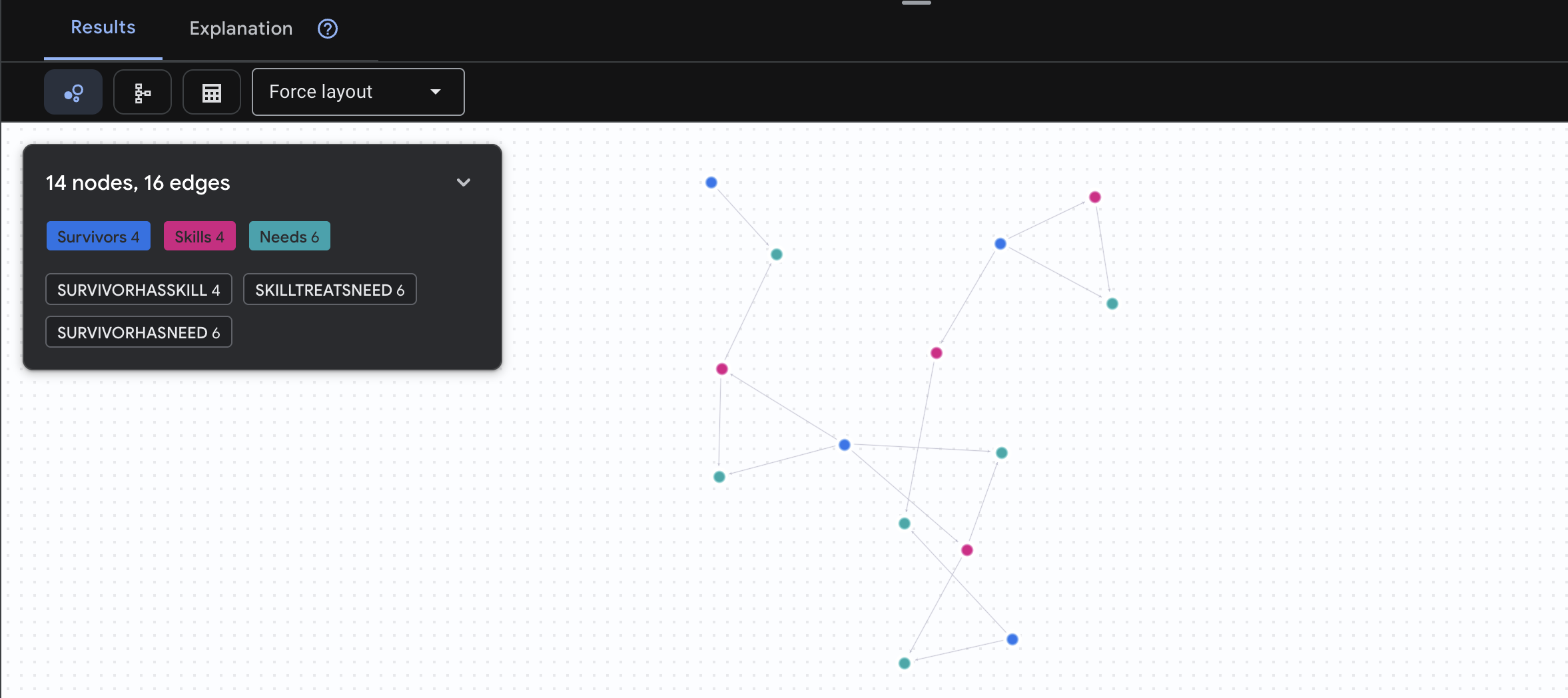
aside positive 이 쿼리의 기능:
이 쿼리는 스키마에서 명확한 '응급 처치로 화상을 치료합니다'를 표시하는 대신 다음을 찾습니다.
- 엘레나 프로스트 박사 (의료 교육을 받음) → 치료 가능 → 다나카 대장 (화상을 입음)
- 데이비드 첸 (응급 처치 보유) → 치료 가능 → 박 중위 (발목 염좌)
이 기능이 강력한 이유:
AI 에이전트가 할 수 있는 작업:
사용자가 '화상을 치료할 수 있는 사람은 누구인가요?'라고 질문하면 상담사는 다음과 같이 대답합니다.
- 유사한 그래프 쿼리 실행
- 대답: '프로스트 박사는 의료 교육을 받았으며 다나카 대장을 도울 수 있습니다.'
- 사용자는 중간 테이블이나 관계에 대해 알 필요가 없습니다.
5. 🚀 Spanner의 AI 기반 임베딩
1. 임베딩이 필요한 이유 (조치 없음, 읽기 전용)
생존 시나리오에서는 시간이 매우 중요합니다. 생존자가 I need someone who can treat burns 또는 Looking for a medic과 같은 긴급 상황을 신고할 때 데이터베이스에서 정확한 기술 이름을 추측하는 데 시간을 낭비할 수 없습니다.
실제 시나리오: 생존자: Captain Tanaka has burns—we need medical help NOW!
'의무병'에 대한 기존 키워드 검색 → 결과 0개 ❌
임베딩을 사용한 시맨틱 검색 → '의료 교육', '응급 처치'를 찾습니다. ✅
이것이 바로 에이전트에게 필요한 것입니다. 키워드뿐만 아니라 의도를 이해하는 지능형의 인간과 유사한 검색입니다.
2. 임베딩 모델 만들기
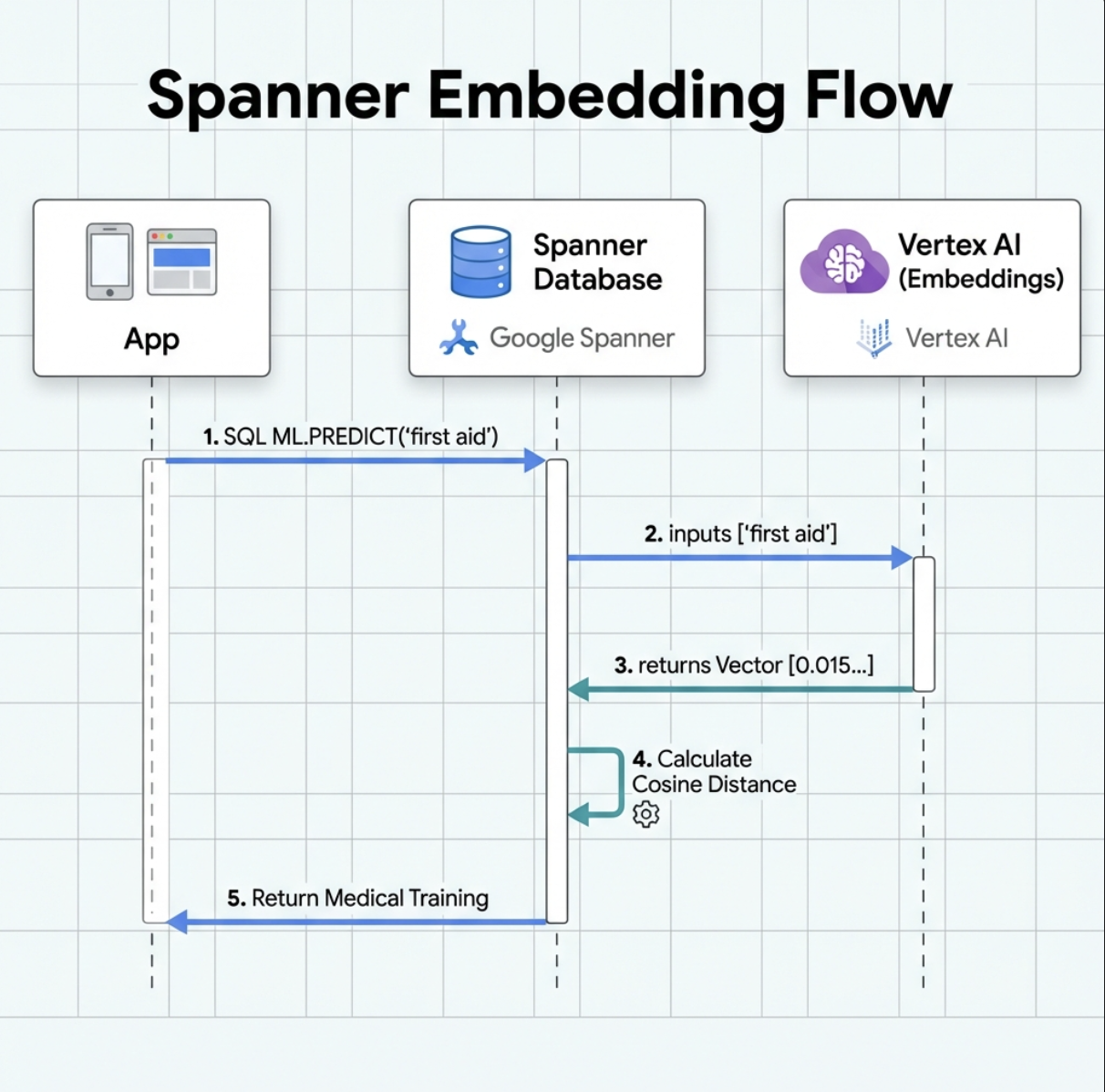
이제 Google의 text-embedding-004를 사용하여 텍스트를 임베딩으로 변환하는 모델을 만들어 보겠습니다.
👉 Spanner Studio에서 다음 SQL을 실행합니다 ($YOUR_PROJECT_ID를 실제 프로젝트 ID로 대체).
‼️ Cloud Shell 편집기에서 File -> Open Folder -> way-back-home/level_2를 열어 전체 프로젝트를 확인합니다.
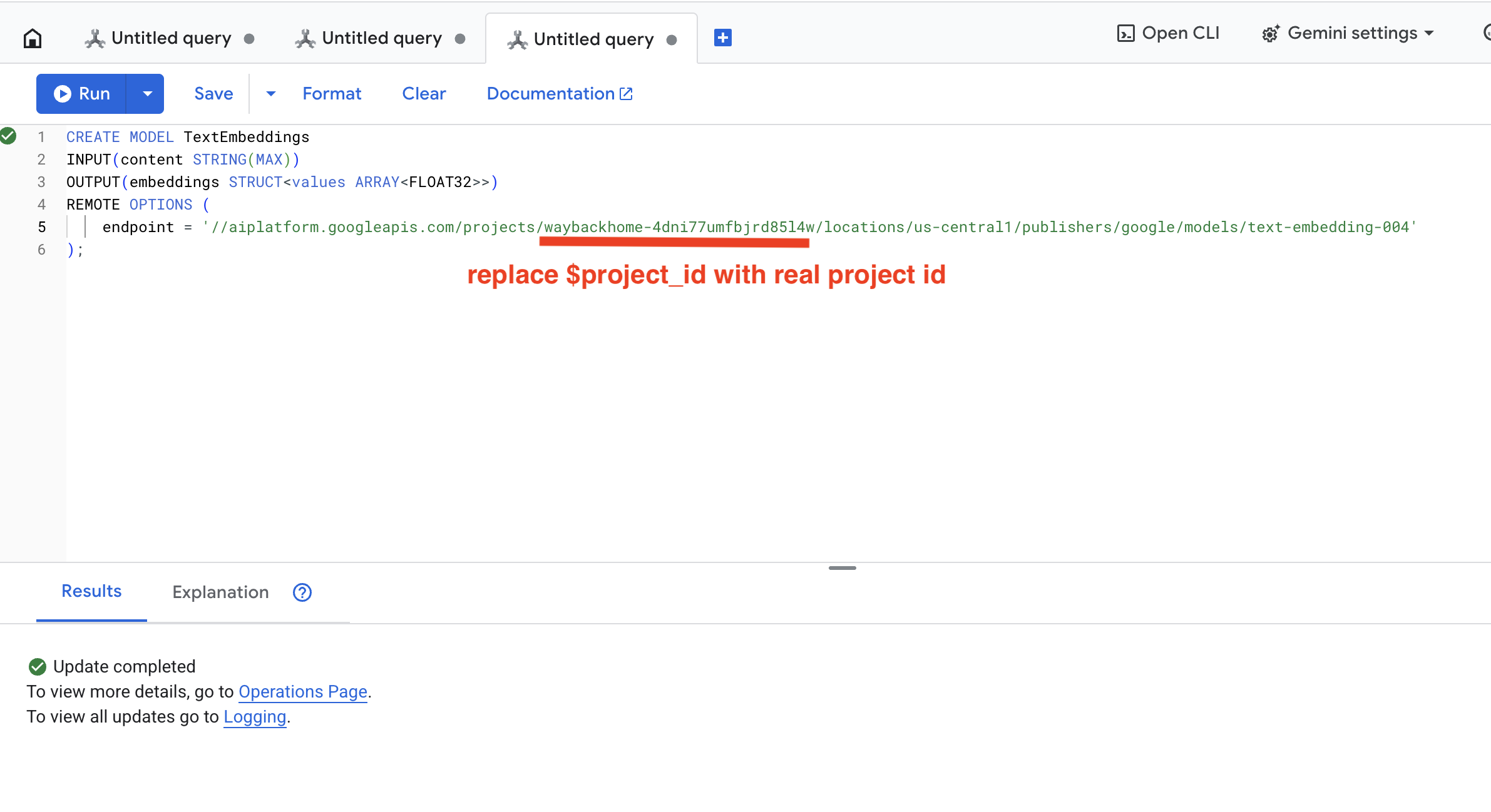
👉 아래 쿼리를 복사하여 붙여넣은 다음 실행 버튼을 클릭하여 Spanner Studio에서 이 쿼리를 실행합니다.
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
기능:
- Spanner에서 가상 모델을 만듭니다 (모델 가중치는 로컬에 저장되지 않음).
- Vertex AI의 Google
text-embedding-004를 가리킵니다. - 계약을 정의합니다. 입력은 텍스트이고 출력은 768차원 부동 소수점 배열입니다.
'원격 옵션'을 선택해야 하는 이유는 무엇인가요?
- Spanner는 모델 자체를 실행하지 않습니다.
ML.PREDICT를 사용하면 API를 통해 Vertex AI를 호출합니다.- 제로 ETL: 데이터를 Python으로 내보내 처리하고 다시 가져올 필요가 없습니다.
Run 버튼을 클릭합니다. 성공하면 아래와 같이 결과가 표시됩니다.
3. 임베딩 열 추가
👉 임베딩을 저장할 열을 추가합니다.
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Run 버튼을 클릭합니다. 성공하면 아래와 같이 결과가 표시됩니다.
4. 임베딩 생성
👉 AI를 사용하여 각 기능의 벡터 임베딩을 만듭니다.
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Run 버튼을 클릭합니다. 성공하면 아래와 같이 결과가 표시됩니다.
결과: 각 스킬 이름 (예: '응급 처치')이 의미를 나타내는 768차원 벡터로 변환됩니다.
5. 임베딩 확인
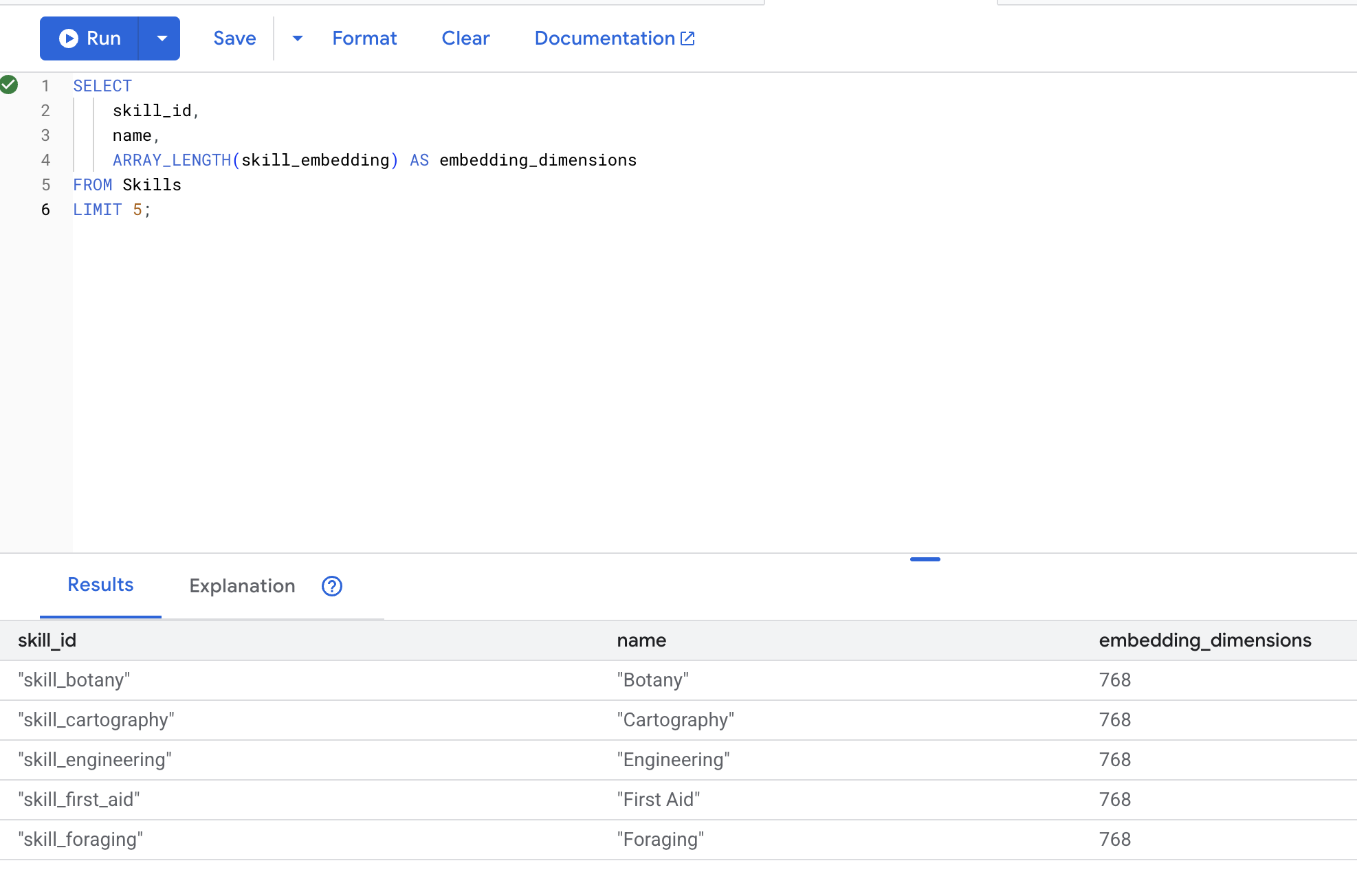
👉 삽입이 생성되었는지 확인합니다.
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
예상 출력:
6. 시맨틱 검색 테스트
이제 시나리오의 정확한 사용 사례인 '의사'라는 용어를 사용하여 의료 기술을 찾는 것을 테스트합니다.
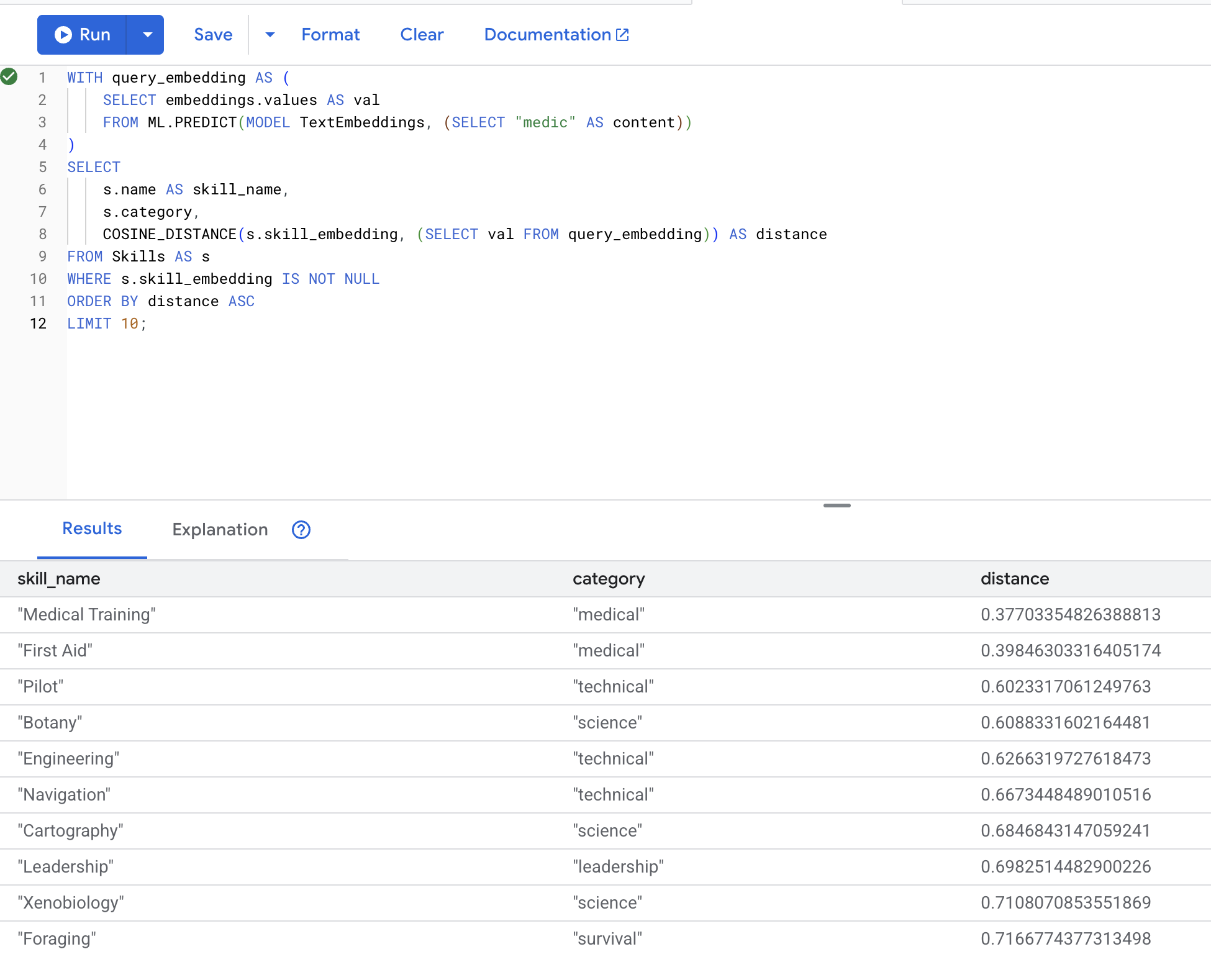
👉 '의사'와 유사한 기술 찾기:
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- 사용자의 검색어 'medic'을 임베딩으로 변환
query_embedding임시 테이블에 저장합니다.
예상 결과 (거리가 낮을수록 유사함):
7. 분석을 위한 Gemini 모델 만들기
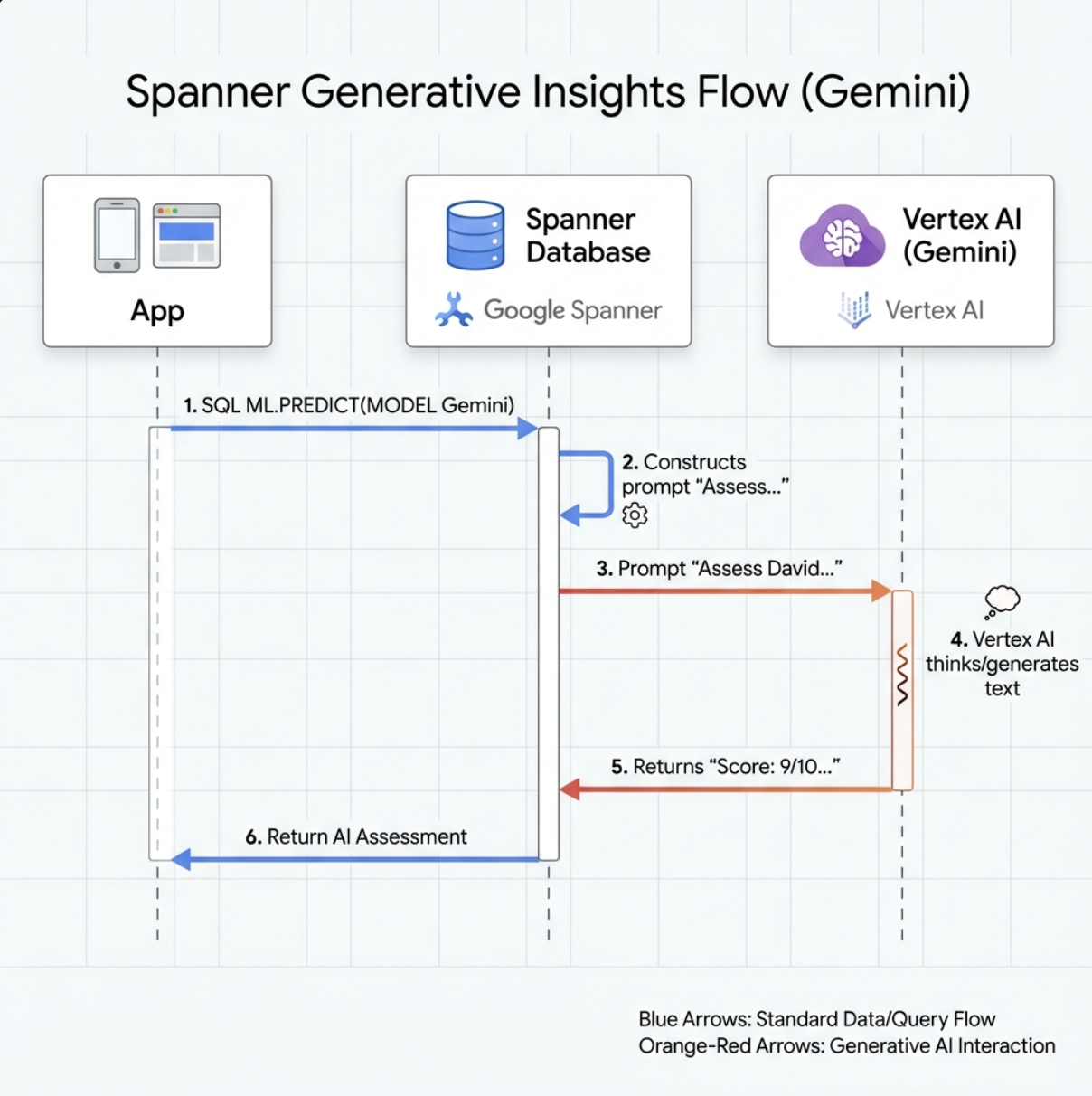
👉 생성형 AI 모델 참조를 만듭니다 ($YOUR_PROJECT_ID를 실제 프로젝트 ID로 바꿈).
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
임베딩 모델과의 차이점:
- 임베딩: 텍스트 → 벡터 (유사성 검색용)
- Gemini: 텍스트 → 생성된 텍스트 (추론/분석용)
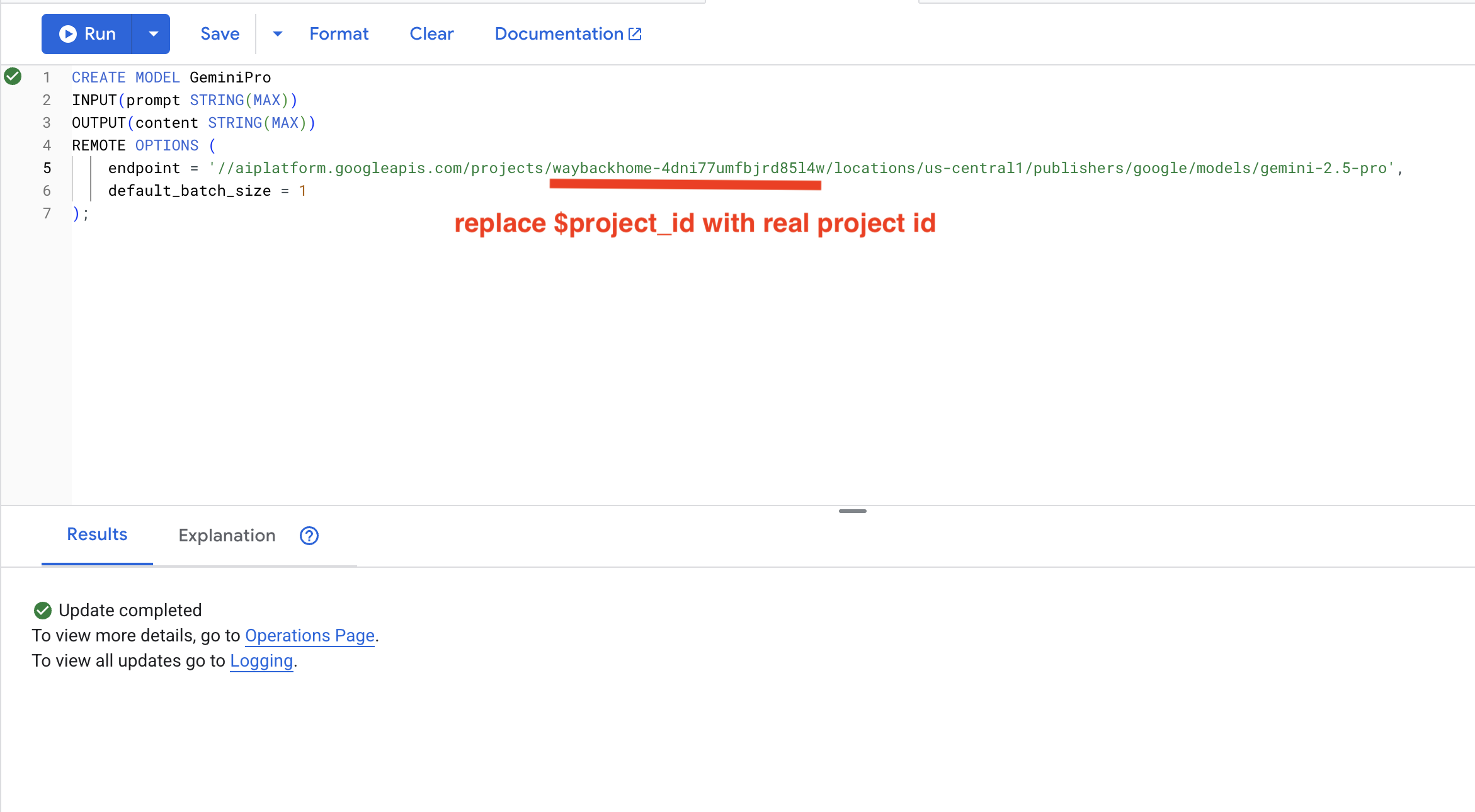
8. 호환성 분석을 위해 Gemini 사용하기
👉 생존자 페어의 임무 호환성 분석:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
예상 출력:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 하이브리드 검색으로 그래프 RAG 에이전트 빌드하기
1. 시스템 아키텍처 개요
이 섹션에서는 에이전트가 다양한 유형의 질문을 유연하게 처리할 수 있는 다중 메서드 검색 시스템을 빌드합니다. 시스템에는 에이전트 레이어, 도구 레이어, 서비스 레이어의 세 가지 레이어가 있습니다.
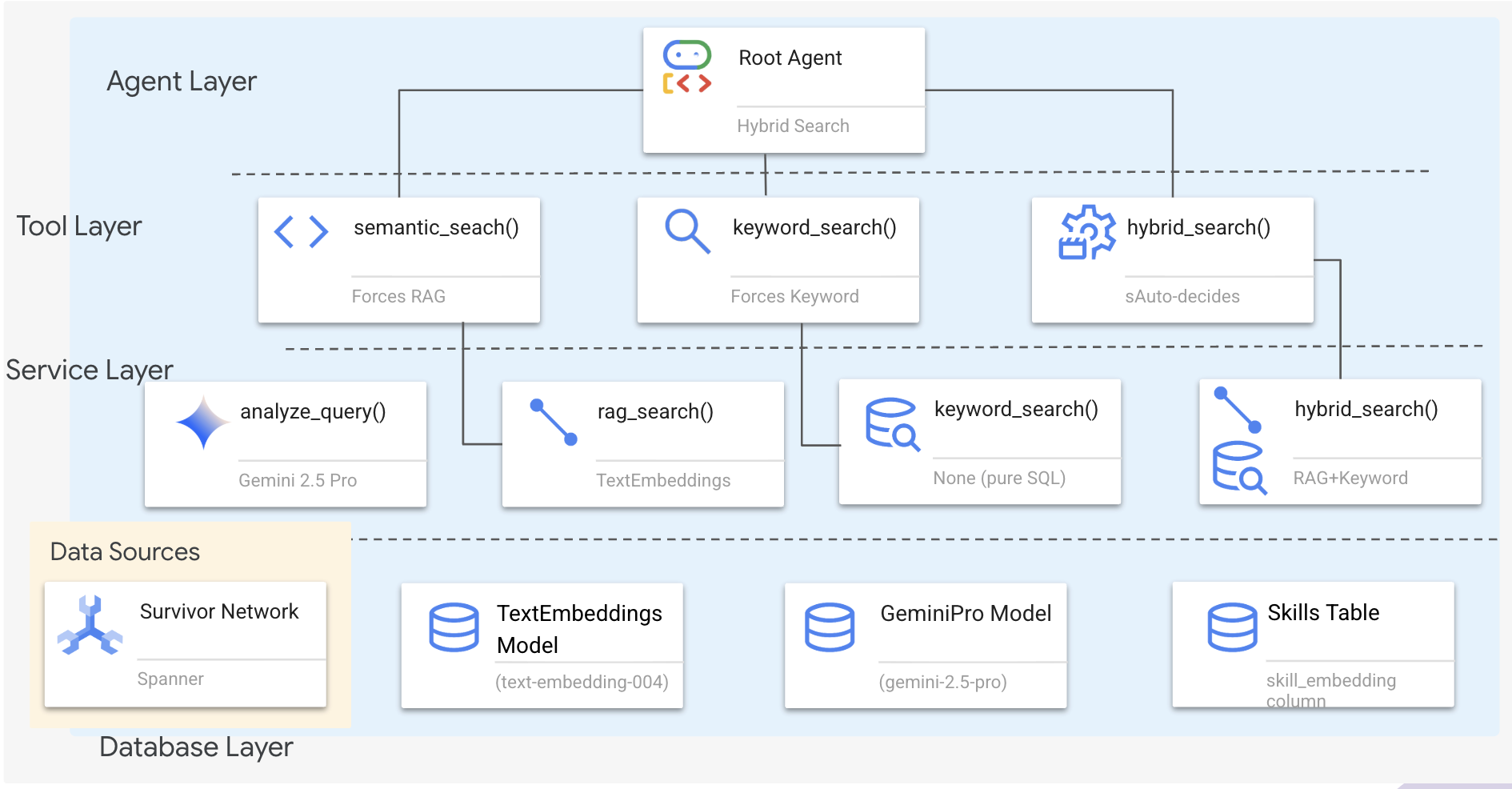
3개의 레이어를 사용하는 이유
- 관심사 분리: 에이전트는 인텐트에, 도구는 인터페이스에, 서비스는 구현에 집중
- 유연성: 상담사가 특정 메서드를 강제하거나 AI가 자동 라우팅하도록 허용할 수 있음
- 최적화: 방법을 알고 있는 경우 비용이 많이 드는 AI 분석을 건너뛸 수 있음
이 섹션에서는 주로 시맨틱 검색 (RAG)을 구현합니다. 즉, 키워드뿐만 아니라 의미를 기반으로 결과를 찾습니다. 나중에 하이브리드 검색이 여러 방법을 병합하는 방법을 설명하겠습니다.
2. RAG 서비스 구현
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
댓글 # TODO: REPLACE_SQL 찾기
이 전체 행을 다음 코드로 바꿉니다.
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. 시맨틱 검색 도구 정의
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
hybrid_search_tools.py에서 댓글 # TODO: REPLACE_SEMANTIC_SEARCH_TOOL을 찾습니다.
👉이 전체 행을 다음 코드로 바꿉니다.
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
에이전트 사용 시기:
- 유사성을 묻는 질문 ('X와 유사한 항목 찾기')
- 개념적 질문 ('치유 능력')
- 의미를 이해하는 것이 중요한 경우
4. 상담사 결정 가이드 (안내)
에이전트 정의에서 시맨틱 검색 관련 부분을 명령어에 복사하여 붙여넣습니다.
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
상담사는 이 안내를 사용하여 적절한 도구를 선택합니다.
👉agent.py 파일에서 # TODO: REPLACE_SEARCH_LOGIC 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉# TODO: ADD_SEARCH_TOOL이 전체 줄을 다음 코드로 바꿉니다라는 주석을 찾아 다음 코드로 바꿉니다.
semantic_search, # Force RAG
5. 하이브리드 검색 작동 방식 이해 (읽기 전용, 조치 필요 없음)
2~4단계에서는 의미를 기준으로 결과를 찾는 핵심 검색 방법인 시맨틱 검색 (RAG)을 구현했습니다. 하지만 시스템 이름이 '하이브리드 검색'인 것을 알 수 있습니다. 다음은 이 모든 요소가 어떻게 작동하는지 보여줍니다.
하이브리드 병합 작동 방식:
way-back-home/level_2/backend/services/hybrid_search_service.py 파일에서 hybrid_search()가 호출되면 서비스는 두 검색을 모두 실행하고 결과를 병합합니다.
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
이 Codelab에서는 기반이 되는 시맨틱 검색 구성요소 (RAG)를 구현했습니다. 키워드 및 하이브리드 메서드는 이미 서비스에 구현되어 있으므로 상담사는 세 가지를 모두 사용할 수 있습니다.
축하합니다. 하이브리드 검색을 사용하여 그래프 RAG 에이전트를 완료했습니다.
7. 🚀 ADK 웹으로 에이전트 테스트하기
에이전트를 테스트하는 가장 쉬운 방법은 adk web 명령어를 사용하는 것입니다. 이 명령어는 내장 채팅 인터페이스로 에이전트를 실행합니다.
1. 에이전트 실행
👉💻 백엔드 디렉터리 (에이전트가 정의된 위치)로 이동하여 웹 인터페이스를 실행합니다.
cd ~/way-back-home/level_2/backend
uv run adk web
이 명령어는
agent/agent.py
테스트를 위한 웹 인터페이스를 엽니다.
👉 URL 열기:
이 명령어는 로컬 URL (일반적으로 http://127.0.0.1:8000 또는 이와 유사한 URL)을 출력합니다. 브라우저에서 엽니다.
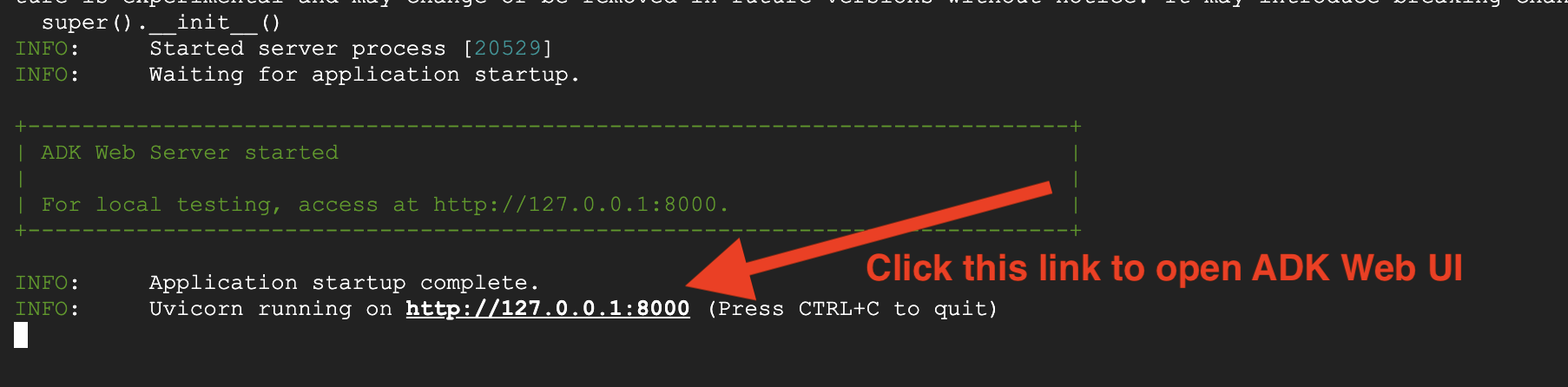
URL을 클릭하면 ADK 웹 UI가 표시됩니다. 왼쪽 상단에서 'agent'를 선택해야 합니다.
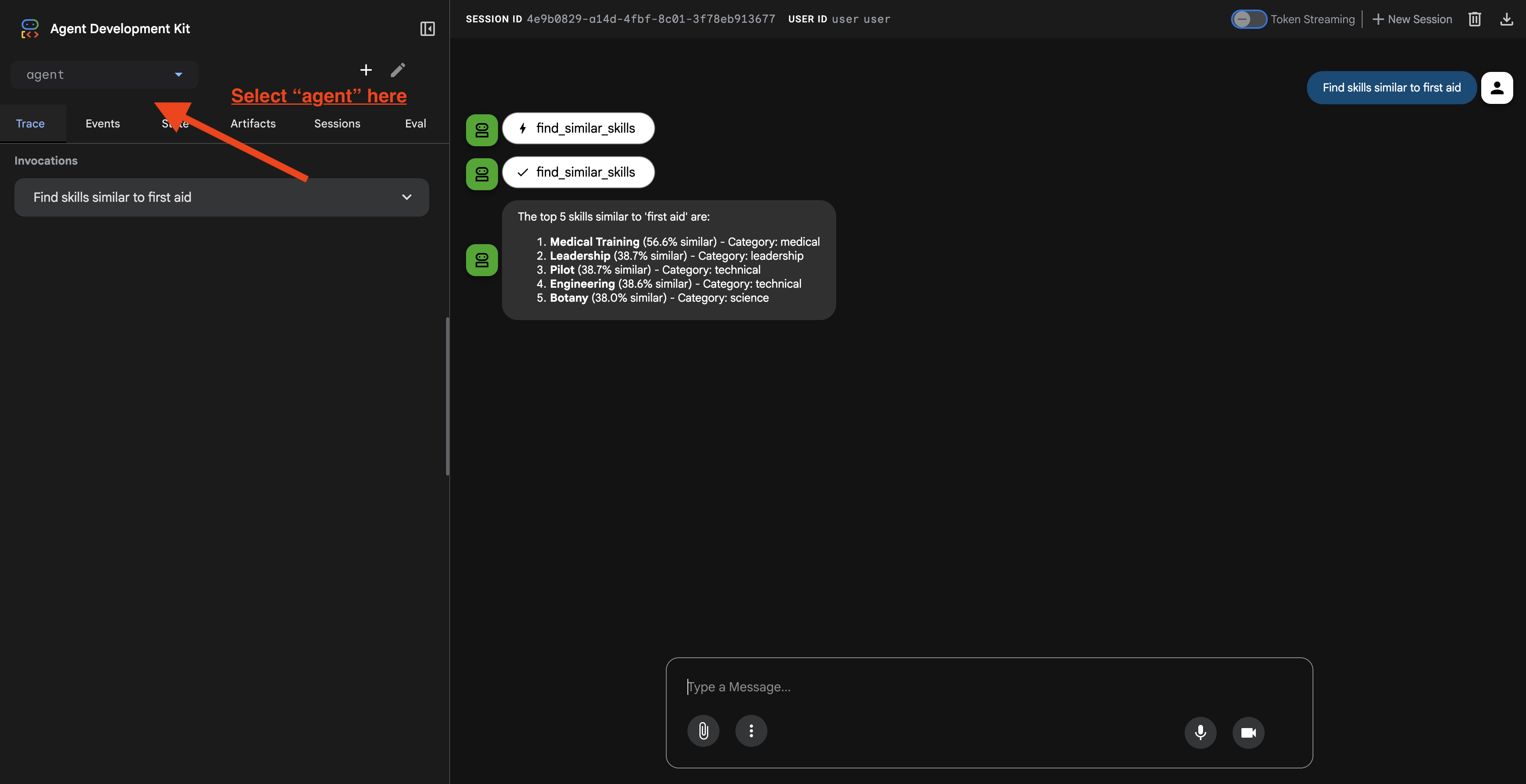
2. 검색 기능 테스트
상담사는 쿼리를 지능적으로 라우팅하도록 설계되었습니다. 채팅 창에 다음 입력을 시도하여 다양한 검색 방법이 작동하는지 확인하세요.
🧬 A. 그래프 RAG (시맨틱 검색)
키워드가 일치하지 않더라도 의미와 개념을 기반으로 상품을 찾습니다.
테스트 질문: (아래 중 하나 선택)
Who can help with injuries?
What abilities are related to survival?
확인해야 할 사항:
- 추론에는 시맨틱 또는 RAG 검색이 언급되어야 합니다.
- 개념적으로 관련된 결과가 표시됩니다 (예: '응급 처치'를 요청하면 '수술'이 표시됨).
- 결과에 🧬 아이콘이 표시됩니다.
🔀 B. 하이브리드 검색
복잡한 쿼리를 위해 키워드 필터와 시맨틱 이해를 결합합니다.
테스트 질문:(아래 중 하나 선택)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
확인해야 할 사항:
- 근거에 하이브리드 검색이 언급되어야 합니다.
- 결과는 두 기준 (개념 + 위치/카테고리)을 모두 충족해야 합니다.
- 두 방법으로 모두 찾은 결과에는 🔀 아이콘이 표시되며 순위가 가장 높습니다.
👉💻 테스트를 마치면 명령줄에서 Ctrl+C를 눌러 프로세스를 종료합니다.
8. 🚀 전체 애플리케이션 실행
전체 스택 아키텍처 개요
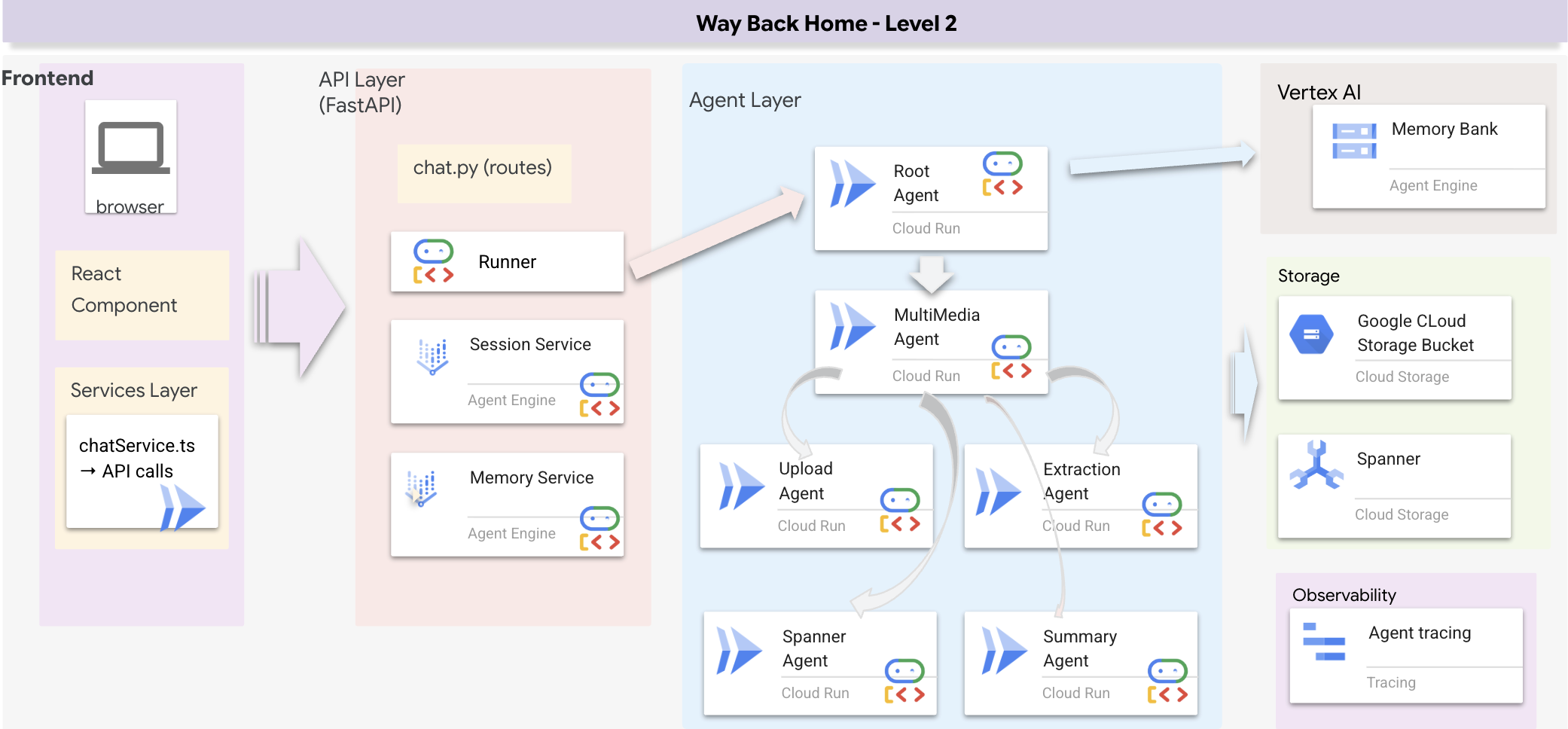
SessionService 및 러너 추가
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 chat.py 파일을 엽니다 (진행하기 전에 이전 프로세스를 종료하기 위해 'ctrl+C'를 눌렀는지 확인하세요).
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉chat.py 파일에서 # TODO: REPLACE_INMEMORY_SERVICES 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉chat.py 파일에서 # TODO: REPLACE_RUNNER 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. 신청 시작
이전 터미널이 아직 실행 중인 경우 Ctrl+C를 눌러 종료합니다.
👉💻 앱 시작:
cd ~/way-back-home/level_2/
./start_app.sh
백엔드가 성공적으로 시작되면 아래와 같이 Local: http://localhost:5173/"이 표시됩니다. 
👉 터미널에서 Local: http://localhost:5173/을 클릭합니다.
2. 시맨틱 검색 테스트
쿼리:
Find skills similar to healing
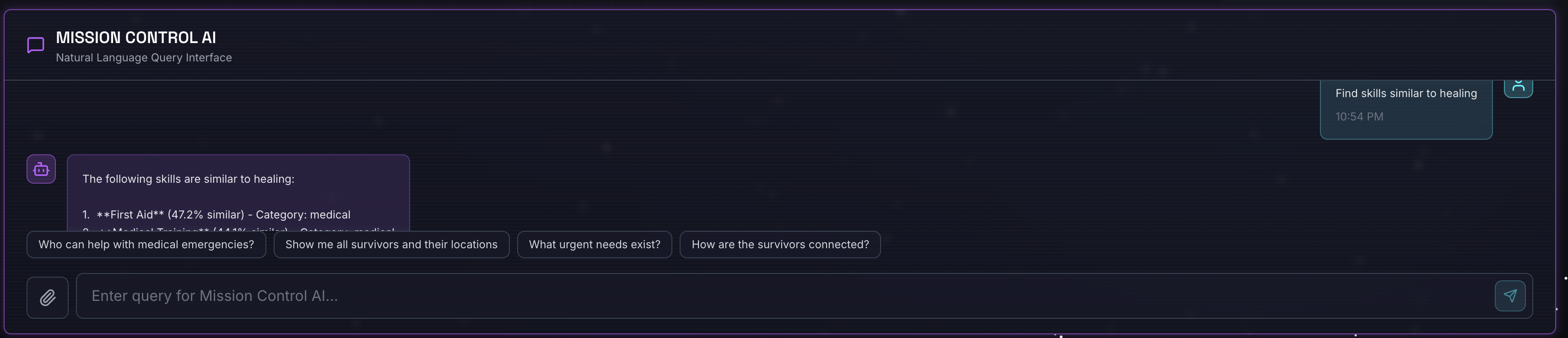
발생하는 상황:
- 상담사가 유사성 요청을 인식함
- '치유'의 임베딩을 생성합니다.
- 코사인 거리를 사용하여 의미적으로 유사한 스킬 찾기
- 반환: 응급 처치('치료'와 이름이 일치하지 않음)
3. 하이브리드 검색 테스트
쿼리:
Find medical skills in the mountains
발생하는 상황:
- 키워드 구성요소:
category='medical'필터링 - 시맨틱 구성요소: '의료'를 삽입하고 유사성별로 순위 지정
- 병합: 결과를 결합하고 두 방법 모두에서 찾은 결과를 우선시합니다. 🔀
질문(선택사항):
Who is good at survival and in the forest?
발생하는 상황:
- 키워드 발견:
biome='forest' - 의미 검색: '생존'과 유사한 스킬
- 하이브리드는 최상의 결과를 위해 두 가지를 모두 결합합니다.
👉💻 테스트가 끝나면 터미널에서 Ctrl+C를 눌러 종료합니다.
4. (!워크숍 참석자만 해당) 위치 업데이트
👉💻 완성 스크립트를 실행합니다.
cd ~/way-back-home/level_2
./set_level_2.sh
이제 waybackhome.dev를 열면 위치가 업데이트된 것을 확인할 수 있습니다. 레벨 2를 완료하신 것을 축하드립니다.

9. ☕️ [선택사항] 멀티모달 파이프라인 (읽기 전용) - 도구 레이어
멀티모달 파이프라인이 필요한 이유
생존 네트워크는 텍스트만 있는 것이 아닙니다. 현장의 생존자는 채팅을 통해 비정형 데이터를 직접 전송합니다.
- 📸 이미지: 리소스, 위험 또는 장비 사진
- 🎥 동영상: 상태 보고서 또는 SOS 방송
- 📄 텍스트: 필드 참고사항 또는 로그
처리되는 파일
기존 데이터를 검색한 이전 단계와 달리 여기서는 사용자 업로드 파일을 처리합니다. chat.py 인터페이스는 파일 첨부파일을 동적으로 처리합니다.
소스 | 콘텐츠 | 목표 |
사용자 첨부파일 | 이미지/동영상/텍스트 | 그래프에 추가할 정보 |
채팅 컨텍스트 | '용품 사진입니다.' | 의도 및 추가 세부정보 |
계획된 접근 방식: 순차적 에이전트 파이프라인
전문 에이전트를 연결하는 Sequential Agent (multimedia_agent.py)를 사용합니다.
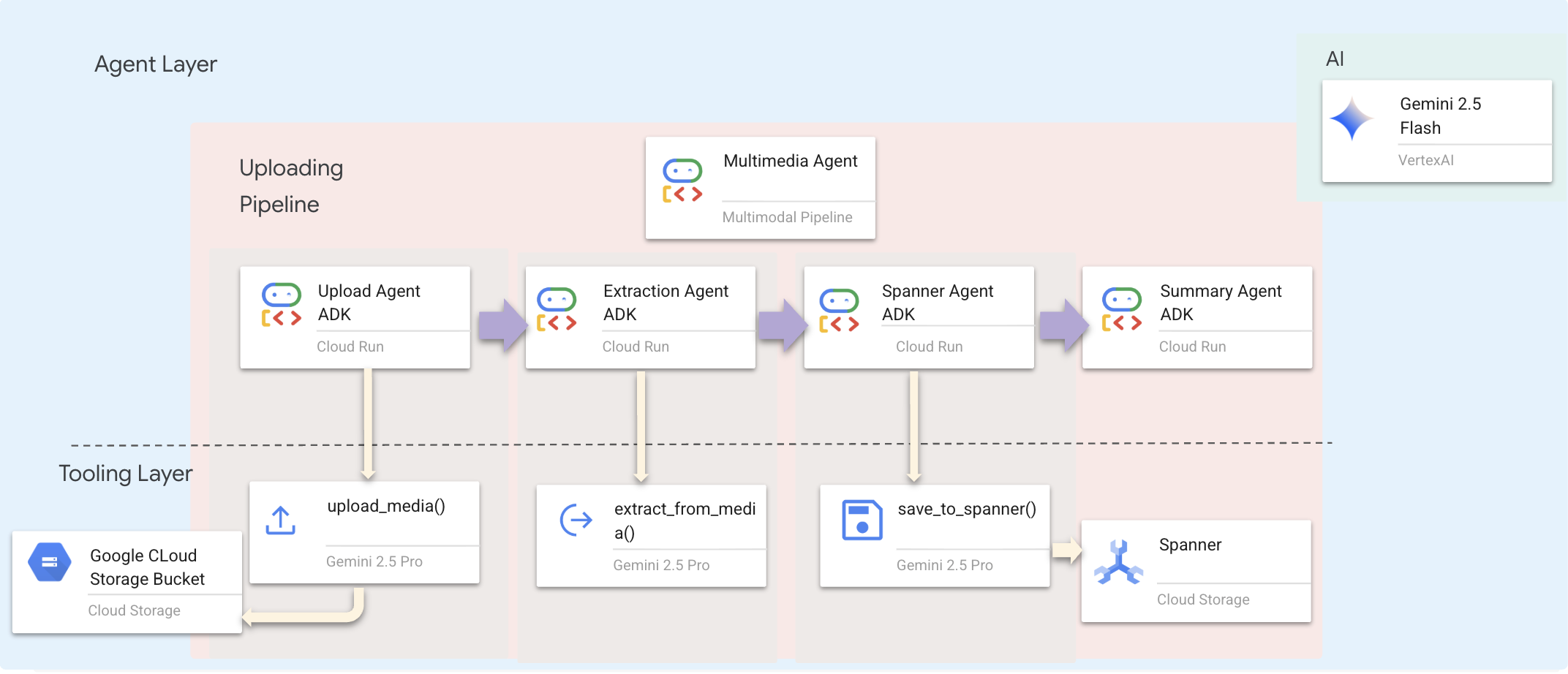
이는 backend/agent/multimedia_agent.py에서 SequentialAgent로 정의됩니다.
도구 계층은 에이전트가 호출할 수 있는 기능을 제공합니다. 도구는 파일 업로드, 항목 추출, 데이터베이스 저장 등 '방법'을 처리합니다.
1. 도구 파일 열기
👉💻 터미널에서 다음 명령어를 입력하여 level_2/backend/agent/tools/extraction_tools.py 파일을 엽니다. 새 터미널을 엽니다. 터미널에서 Cloud Shell 편집기로 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. upload_media 도구 구현
이 도구는 로컬 파일을 Google Cloud Storage에 업로드합니다.
👉 def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:에서 다음 코드는 파일을 GCS에 업로드하고 유형을 감지하는 방법을 보여줍니다.
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. extract_from_media 도구 구현
이 도구는 라우터로, media_type를 확인하고 올바른 추출기 (텍스트, 이미지 또는 동영상)로 디스패치합니다.
👉 async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:에서 다음 코드는 업로드된 미디어에서 항목과 관계를 추출하는 방법을 보여줍니다.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
주요 구현 세부정보:
- 멀티모달 입력: 텍스트 프롬프트 (
_get_extraction_prompt())와 이미지 객체를 모두generate_content에 전달합니다. - 구조화된 출력:
response_mime_type="application/json"를 사용하면 LLM이 유효한 JSON을 반환하므로 파이프라인에 매우 중요합니다. - 시각적 항목 연결: 프롬프트에 알려진 항목이 포함되어 있어 Gemini가 특정 문자를 인식할 수 있습니다.
4. save_to_spanner 도구 구현
이 도구는 추출된 항목과 관계를 Spanner Graph DB에 유지합니다.
👉 def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:에서 다음 코드는 추출된 항목과 관계를 Spanner Graph DB에 저장하는 방법을 보여줍니다.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
에이전트에게 고급 도구를 제공하여 에이전트의 추론 기능을 활용하면서 데이터 무결성을 보장합니다.
5. GCS 서비스 업데이트
GCSService는 Google Cloud Storage에 대한 실제 파일 업로드를 처리합니다.
👉💻 level_2/backend/services/gcs_service.py 파일을 열거나 터미널에 입력하여 Cloud Shell 편집기에서 파일을 열 수 있습니다.
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:에서 다음 코드는 추출된 항목과 관계를 Spanner Graph DB에 저장하는 방법을 보여줍니다.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
이를 서비스로 추상화하면 에이전트가 GCS 버킷, 블롭 이름 또는 서명된 URL 생성에 대해 알 필요가 없습니다. '업로드'하라는 메시지만 표시됩니다.
6. 에이전트형 워크플로가 기존 접근 방식보다 나은 이유
에이전트의 이점:
기능 | 일괄 파이프라인 | 이벤트 기반 | 에이전트 워크플로 |
복잡성 | 낮음 (스크립트 1개) | 높음 (5개 이상의 서비스) | 낮음 (Python 파일 1개: |
상태 관리 | 전역 변수 | 어려움 (분리됨) | 통합 (상담사 상태) |
오류 처리 | 비정상 종료 | 자동 로그 | 대화형 ('파일을 읽을 수 없습니다') |
사용자 의견 | 콘솔 인쇄 | 폴링 필요 | 즉시 (채팅의 일부) |
적응성 | 고정된 로직 | 엄격한 함수 | 지능형 (LLM이 다음 단계를 결정함) |
컨텍스트 인식 | 없음 | 없음 | Full (사용자 의도를 알고 있음) |
중요한 이유: multimedia_agent.py (4개의 하위 에이전트가 있는 SequentialAgent: 업로드 → 추출 → 저장 → 요약)를 사용하여 복잡한 인프라와 취약한 스크립트를 지능형 대화형 애플리케이션 로직으로 대체합니다.
10. ☕️ [선택사항] 멀티모달 파이프라인 (읽기 전용) - 에이전트 레이어
에이전트 레이어는 인텔리전스, 즉 도구를 사용하여 작업을 완료하는 에이전트를 정의합니다. 각 에이전트는 특정 역할을 수행하고 다음 에이전트에게 컨텍스트를 전달합니다. 아래는 멀티 에이전트 시스템의 아키텍처 다이어그램입니다.
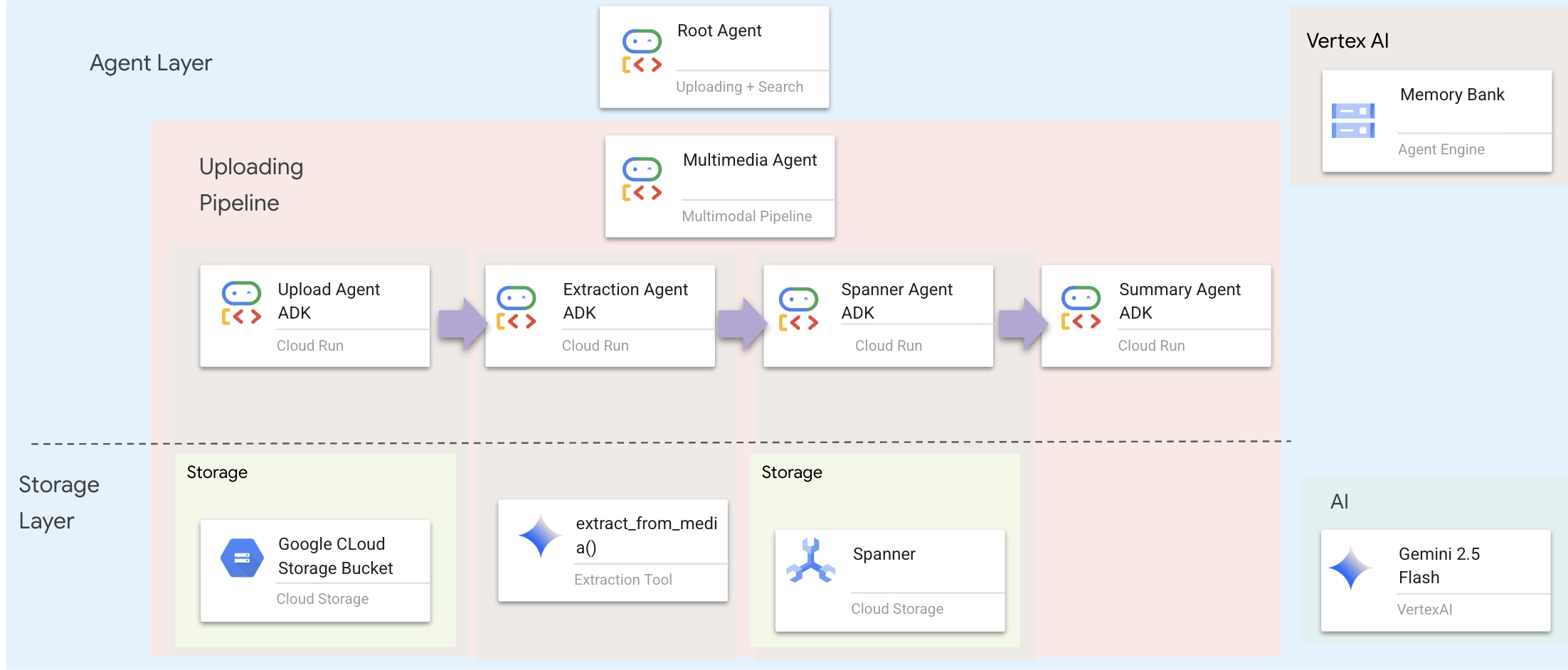
1. 에이전트 파일 열기
👉💻 터미널에서 다음 명령어를 입력하여 level_2/backend/agent/multimedia_agent.py 파일을 엽니다. 새 터미널을 엽니다. 터미널에서 Cloud Shell 편집기로 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. 업로드 에이전트 정의
이 에이전트는 사용자의 메시지에서 파일 경로를 추출하여 GCS에 업로드합니다.
👉다음 코드가 포함된 multimedia_agent.py 파일에서 GCS에 업로드되는 upload_agent를 만듭니다.
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. 추출 에이전트 정의
이 에이전트는 업로드된 미디어를 '보고' Gemini Vision을 사용하여 구조화된 데이터를 추출합니다.
👉multimedia_agent.py 파일에서 다음 코드를 사용하여 업로드된 미디어에서 정보를 추출하는 extraction_agent를 만듭니다.
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
instruction가 {upload_result}를 참조하는 방식을 확인하세요. 이것이 ADK에서 에이전트 간에 상태가 전달되는 방식입니다.
4. Spanner 에이전트 정의
이 에이전트는 추출된 항목과 관계를 그래프 데이터베이스에 저장합니다.
👉multimedia_agent.py 파일에서 다음 코드를 사용하여 추출된 정보를 데이터베이스에 저장하는 spanner_agent를 만듭니다.
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
이 에이전트는 두 이전 단계 (upload_result 및 extraction_result)의 컨텍스트를 수신합니다.
5. 요약 에이전트 정의
이 에이전트는 이전 단계의 결과를 모두 종합하여 사용자 친화적인 대답을 생성합니다.
👉multimedia_agent.py 파일에서 다음 코드를 사용하여 결과를 요약하는 summary_agent의 프롬프트를 정의합니다.
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
이 에이전트는 도구가 필요하지 않습니다. 공유된 컨텍스트를 읽고 사용자에게 깔끔한 요약을 생성하기만 하면 됩니다.
🧠 아키텍처 요약
레이어 | 파일 | 책임 |
도구 |
| 방법: 업로드, 추출, 저장 |
Agent |
| 무엇 — 파이프라인 조정 |
11. 🚀 멀티모달 데이터 파이프라인 - 오케스트레이션
새 시스템의 핵심은 backend/agent/multimedia_agent.py에 정의된 MultimediaExtractionPipeline입니다. ADK (에이전트 개발 키트)의 Sequential Agent 패턴을 사용합니다.
1. 순차적이어야 하는 이유
업로드 처리는 선형 종속 항목 체인입니다.
- 파일 (업로드)이 있어야 데이터를 추출할 수 있습니다.
- 데이터를 추출 (추출)할 때까지는 데이터를 저장할 수 없습니다.
- 결과를 저장하기 전에는 요약할 수 없습니다.
SequentialAgent가 이 용도에 적합합니다. 한 에이전트의 출력을 다음 에이전트의 컨텍스트/입력으로 전달합니다.
2. 에이전트 정의
multimedia_agent.py 하단에서 파이프라인이 어떻게 조립되는지 살펴보겠습니다. 👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
두 이전 단계에서 입력을 받습니다. # TODO: REPLACE_ORCHESTRATION 댓글을 찾습니다. 이 전체 행을 다음 코드로 바꿉니다.
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. 루트 에이전트와 연결
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
# TODO: REPLACE_ADD_SUBAGENT 댓글을 찾습니다. 이 전체 행을 다음 코드로 바꿉니다.
sub_agents=[multimedia_agent],
이 단일 객체는 호출 가능한 하나의 엔티티로 네 명의 '전문가'를 효과적으로 번들로 묶습니다.
4. 에이전트 간 데이터 흐름
각 에이전트는 후속 에이전트가 액세스할 수 있는 공유 컨텍스트에 출력을 저장합니다.
5. 애플리케이션 열기 (앱이 아직 실행 중인 경우 건너뜀)
👉💻 앱 시작:
cd ~/way-back-home/level_2/
./start_app.sh
👉 터미널에서 Local: http://localhost:5173/을 클릭합니다.
6. 테스트 이미지 업로드
👉 채팅 인터페이스에서 다음 사진 중 하나를 선택하고 UI에 업로드합니다.
채팅 인터페이스에서 에이전트에게 구체적인 컨텍스트를 알려줍니다.
Here is the survivor note
그런 다음 여기에 이미지를 첨부합니다.

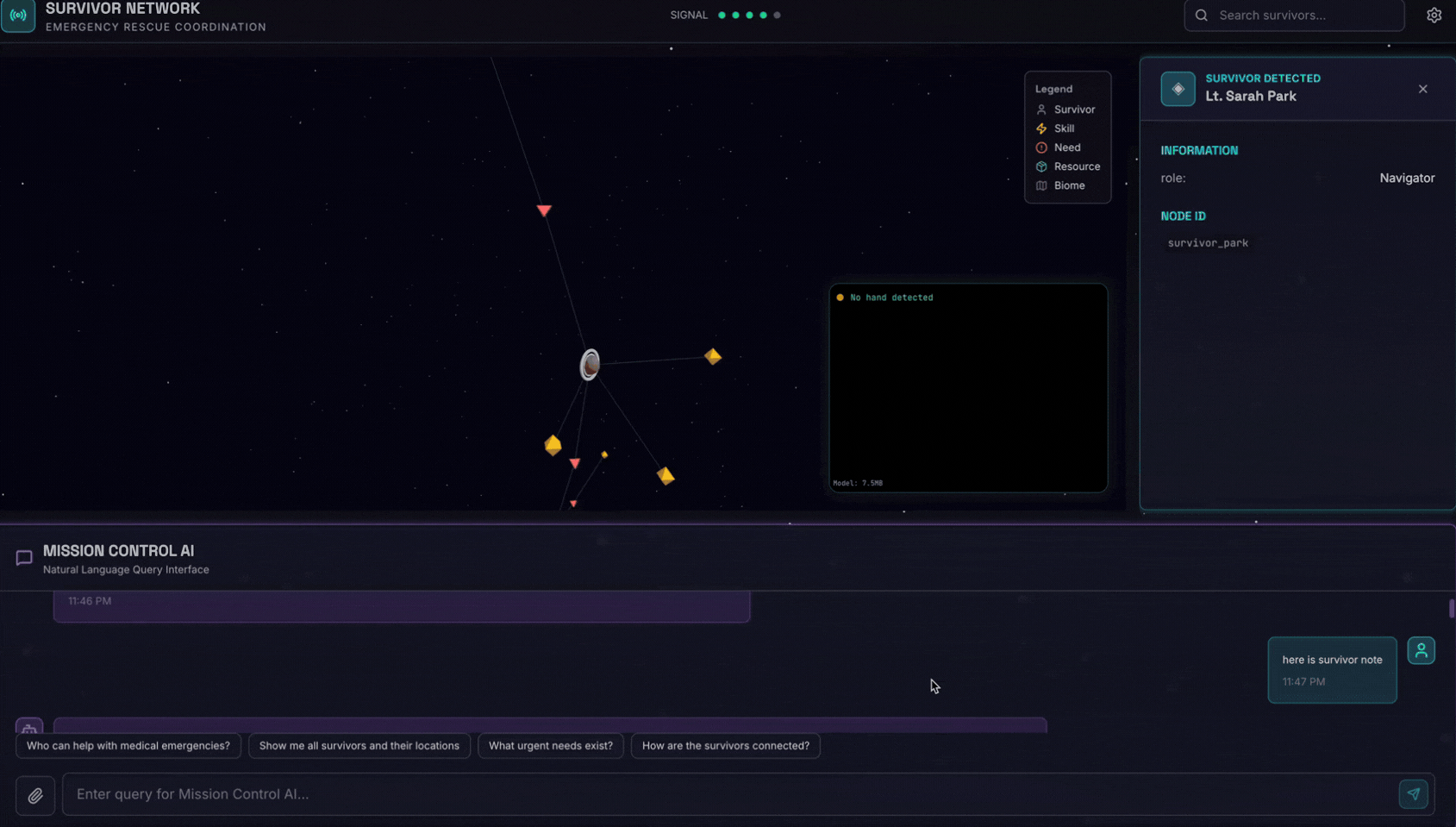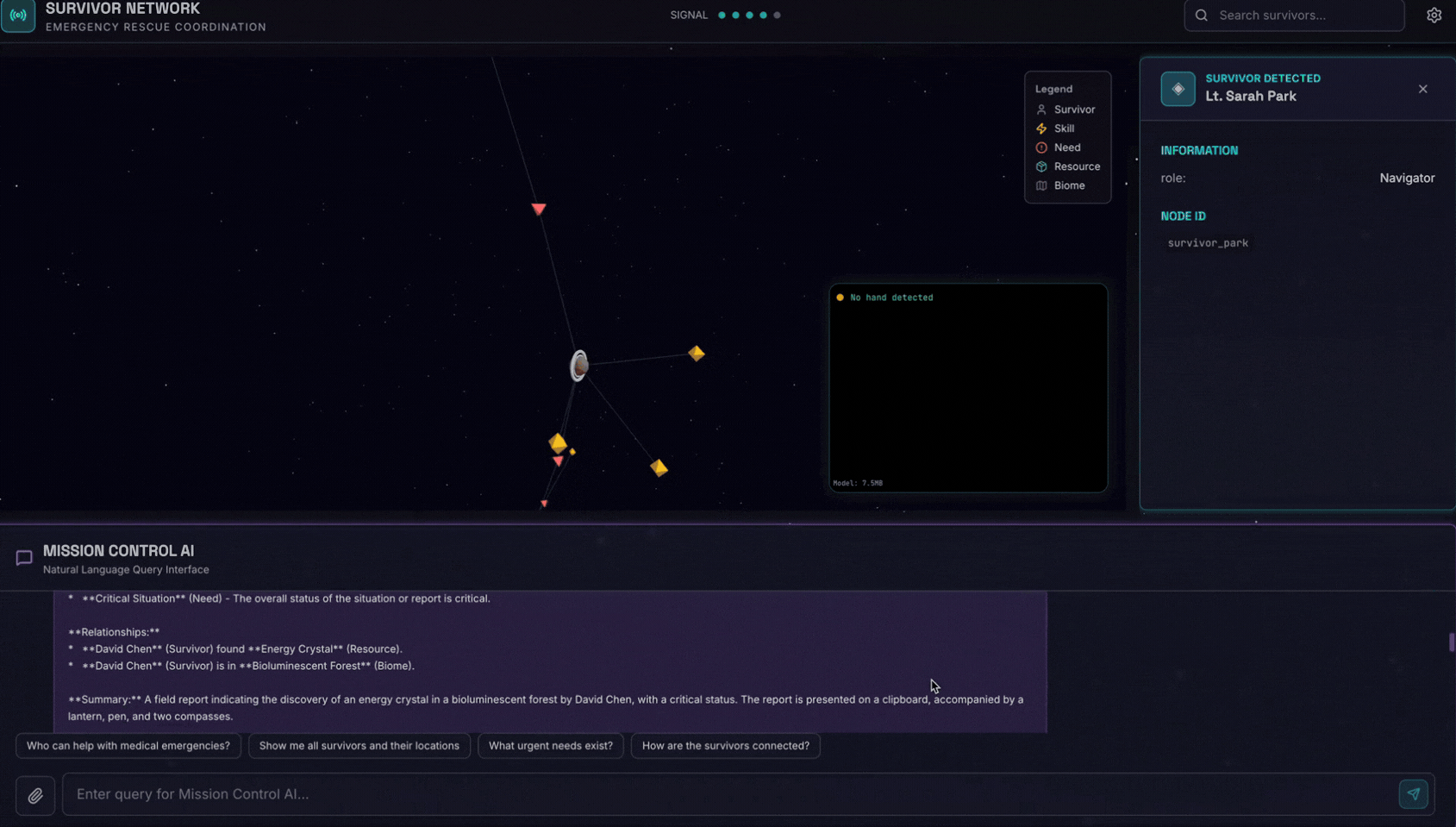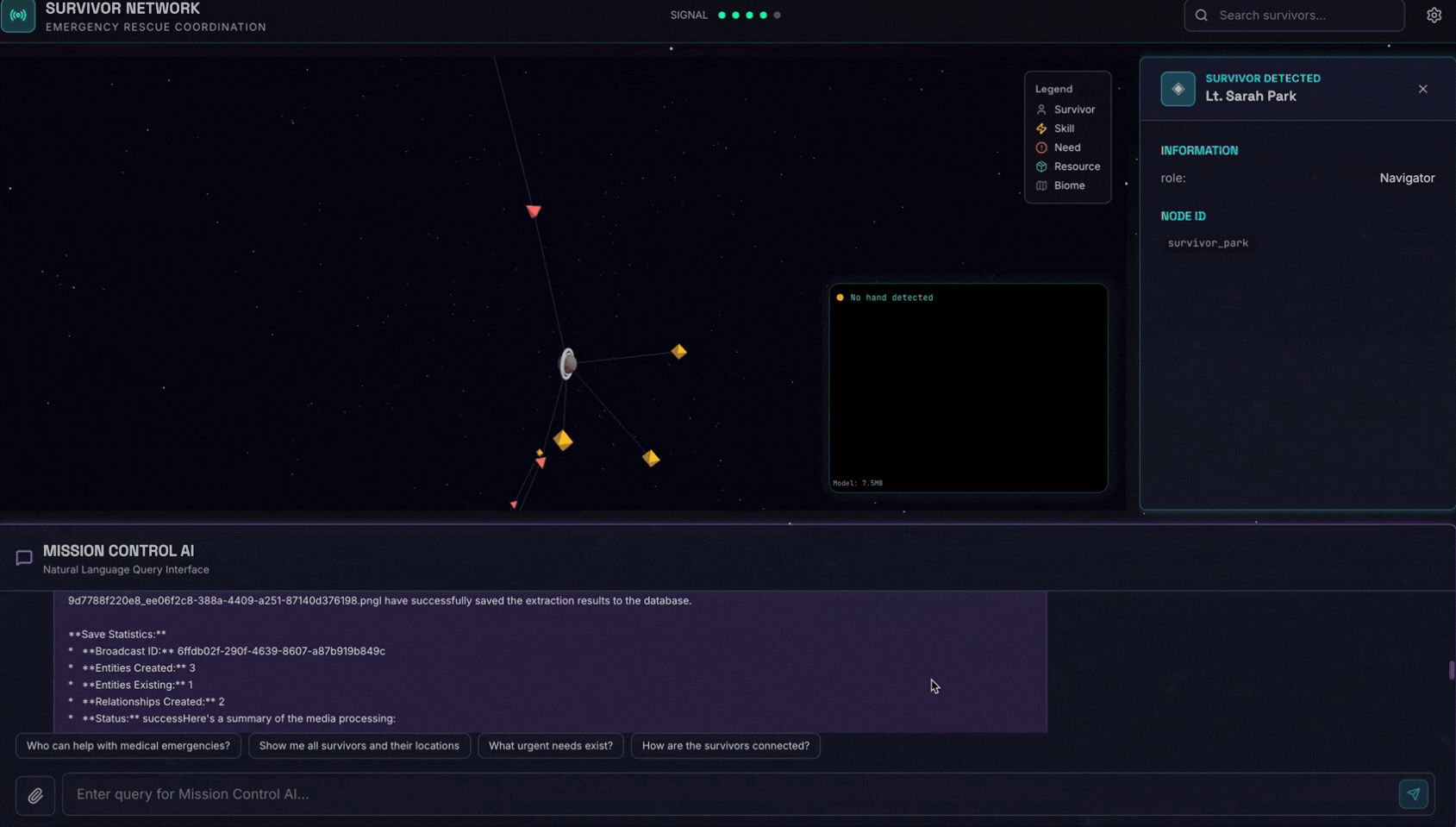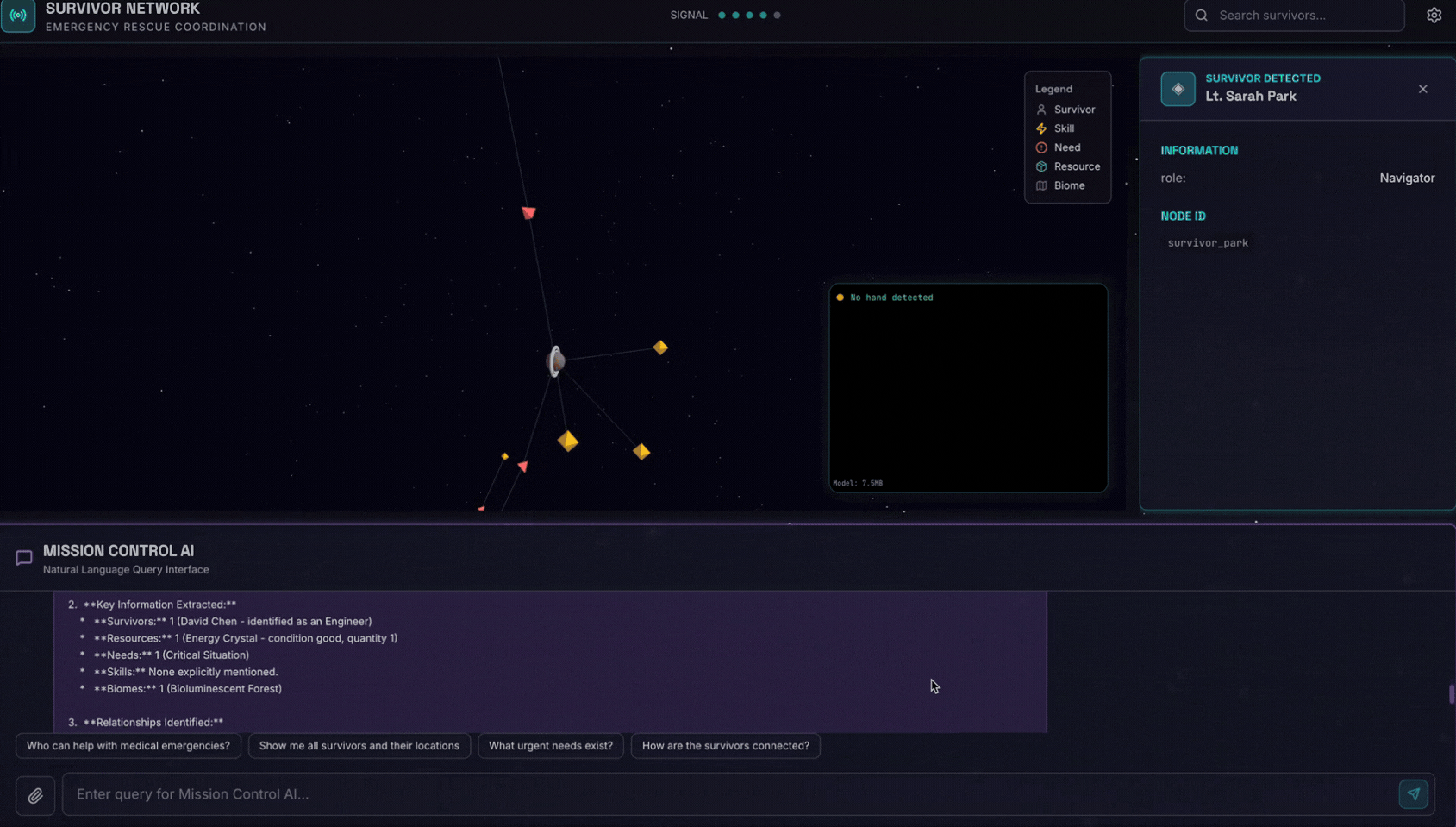
👉💻 터미널에서 테스트를 완료한 후 'Ctrl+C'를 눌러 프로세스를 종료합니다.
6. GCS 버킷에서 멀티모달 업로드 확인
- Google Cloud 콘솔 Storage를 엽니다.
- Cloud Storage에서 '버킷'을 선택합니다.
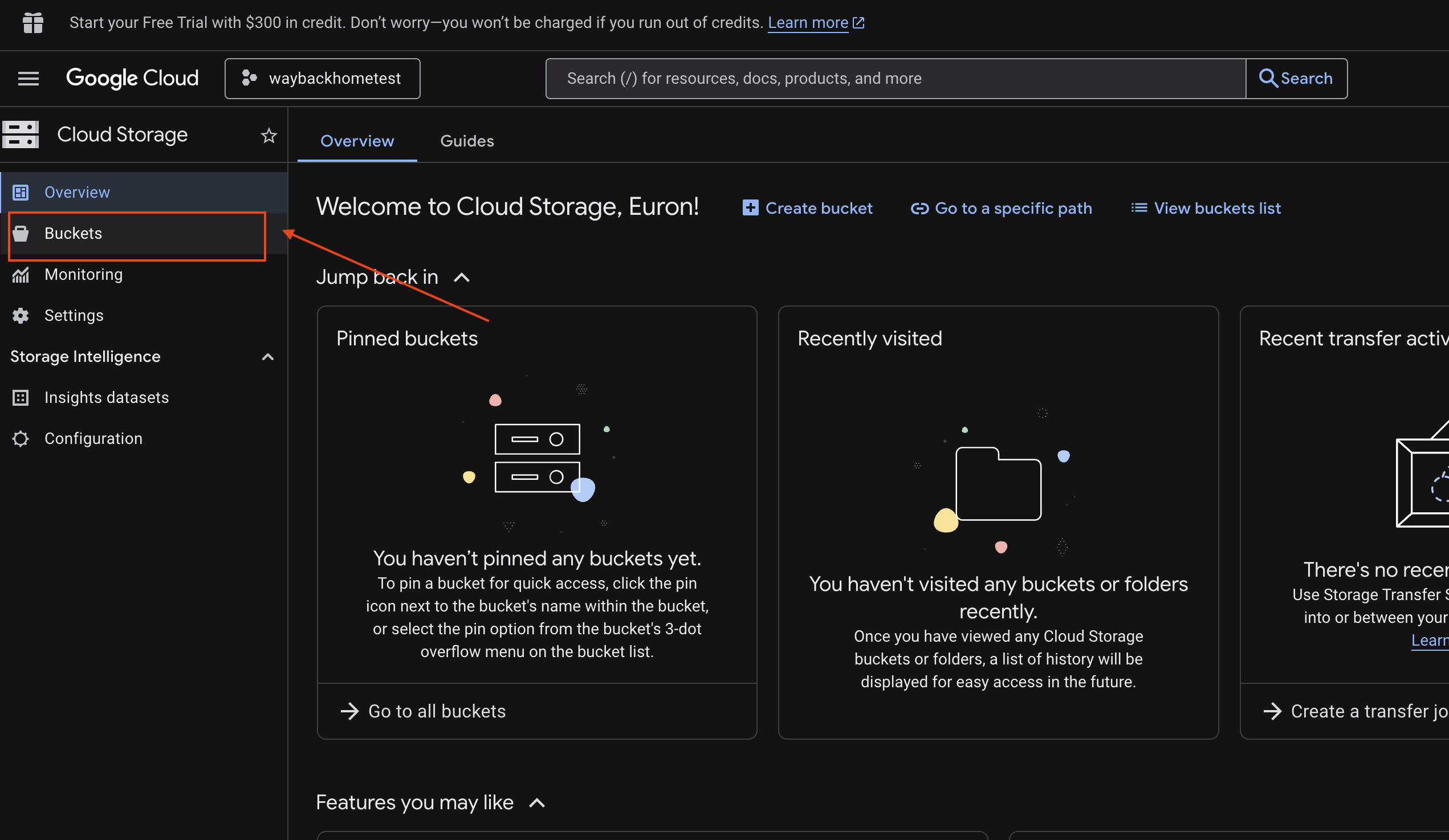
- 버킷을 선택하고
media을 클릭합니다.
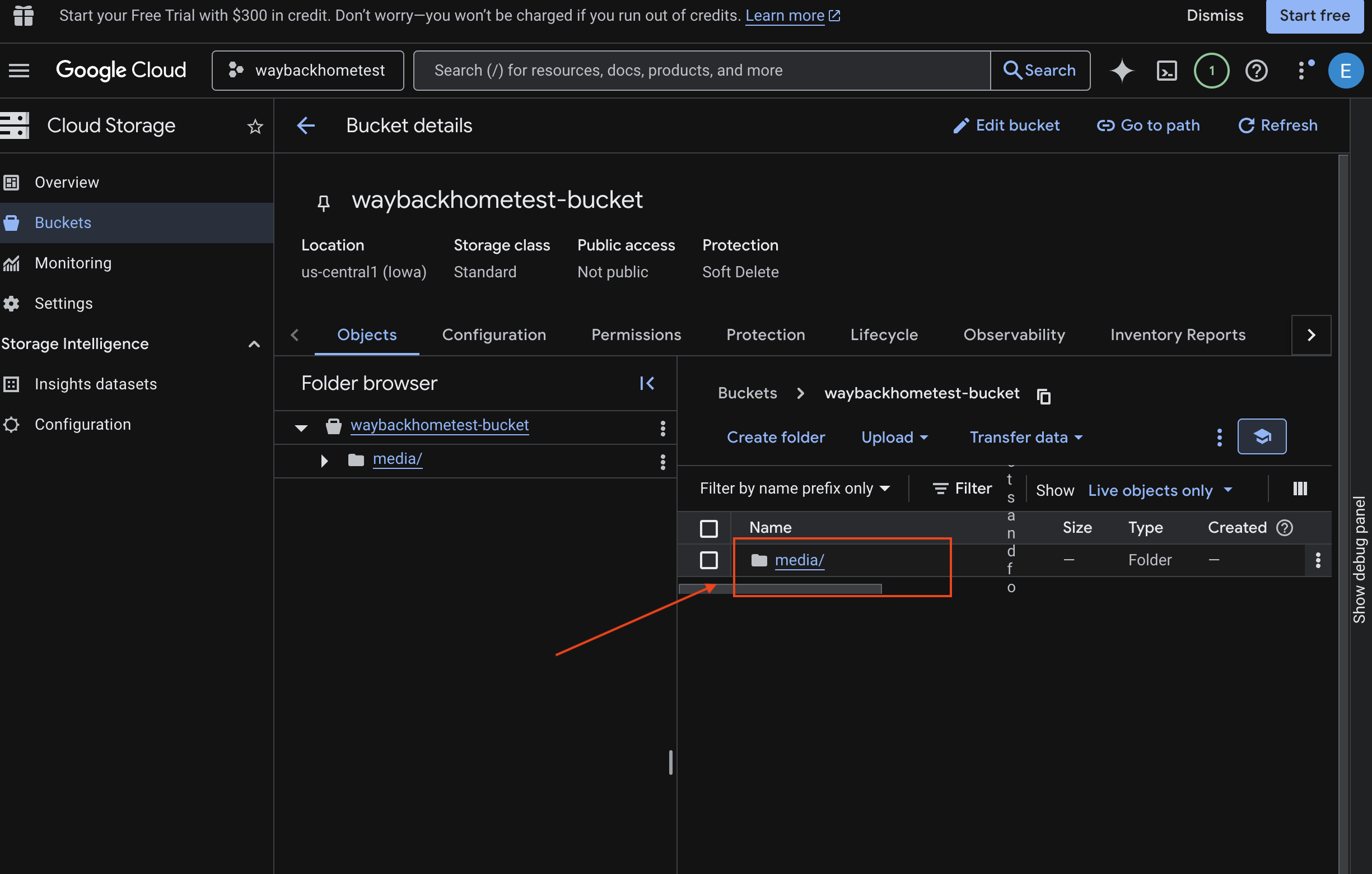
- 업로드한 이미지를 여기에서 확인하세요.
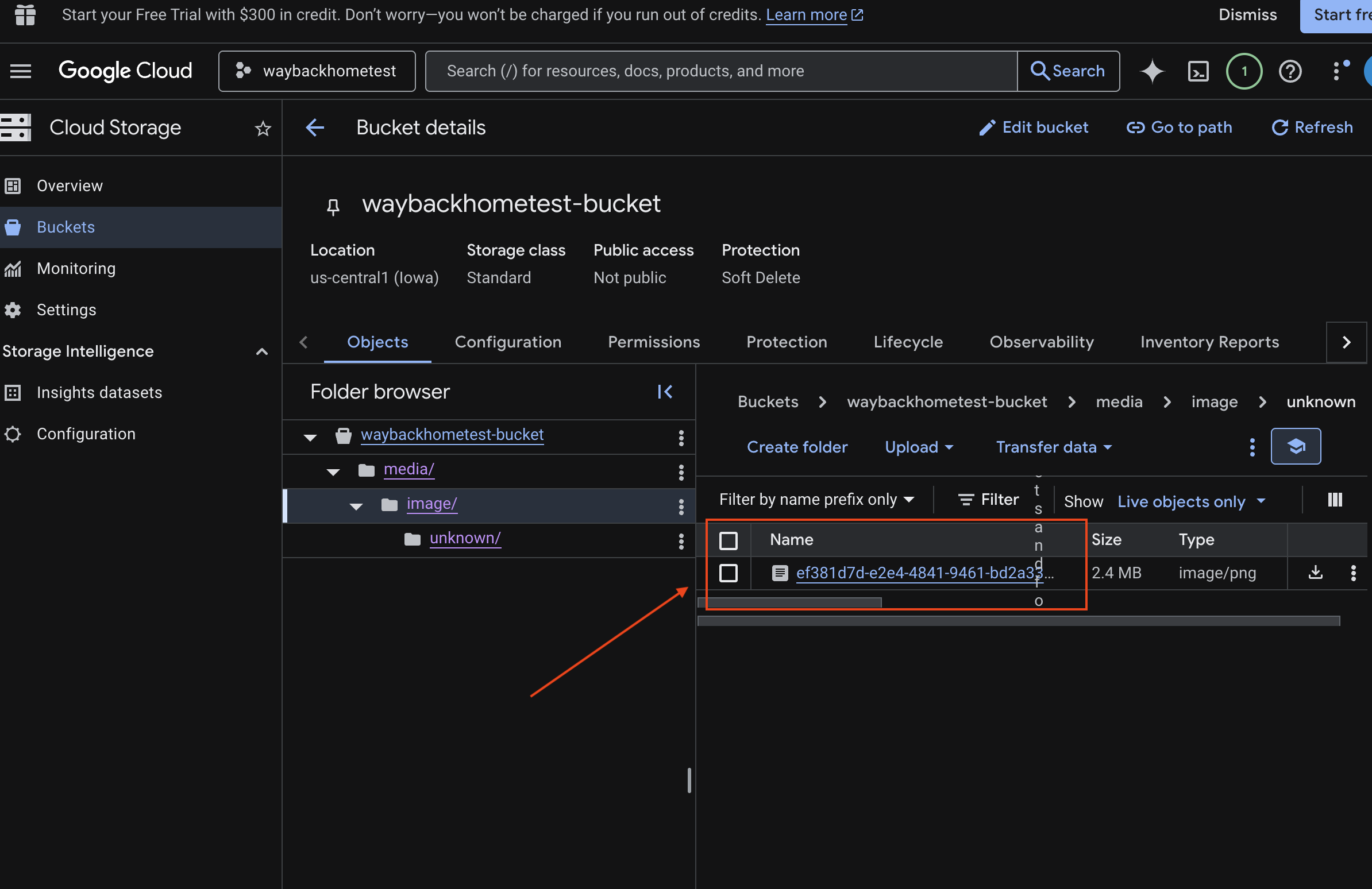
7. Spanner에서 멀티모달 업로드 확인 (선택사항)
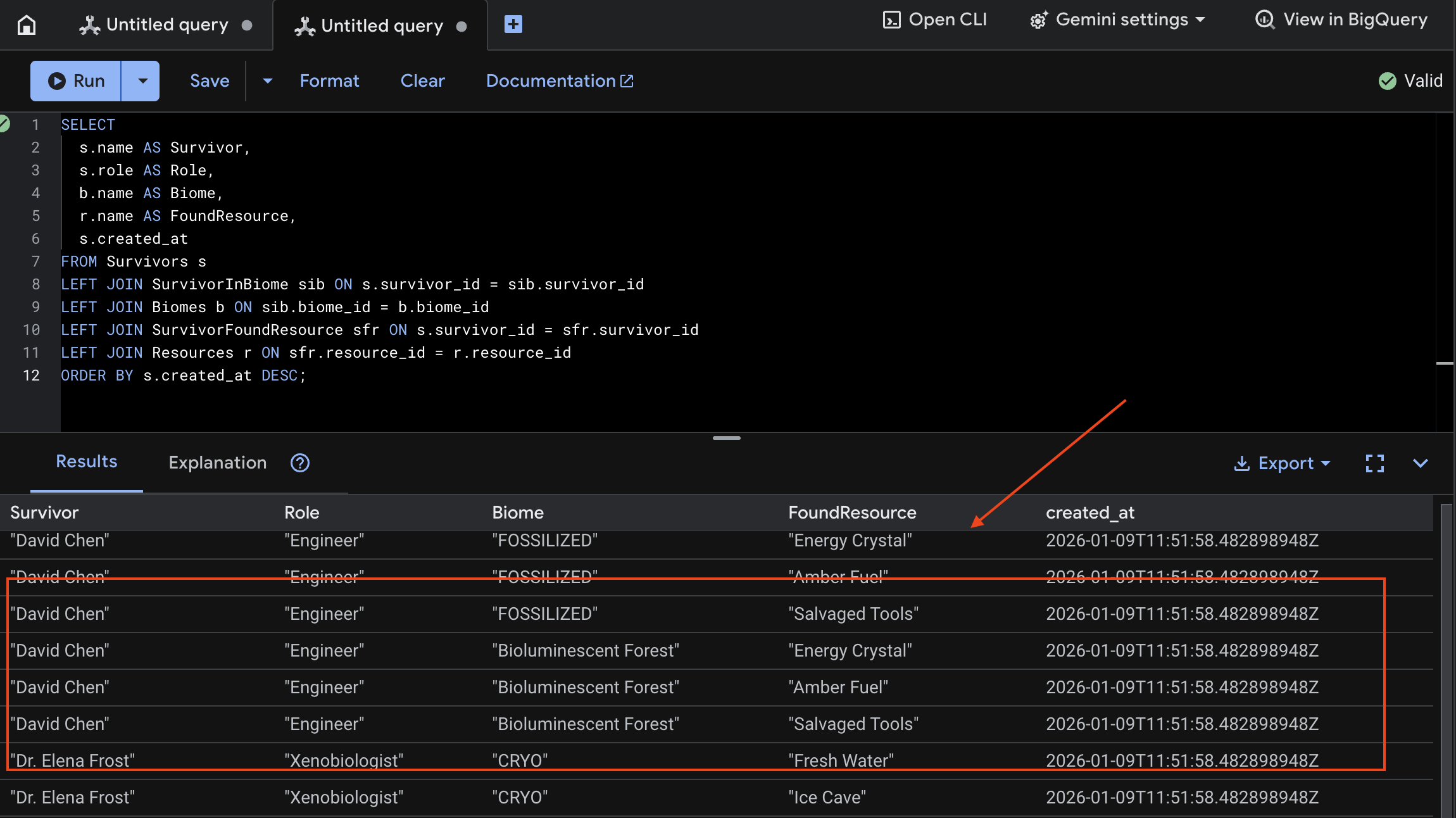
다음은 test_photo1의 UI 출력 예입니다.
- Google Cloud 콘솔 Spanner를 엽니다.
- 인스턴스를 선택합니다.
Survivor Network - 데이터베이스를 선택합니다.
graph-db - 왼쪽 사이드바에서 Spanner 스튜디오를 클릭합니다.
👉 Spanner Studio에서 새 데이터를 쿼리합니다.
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
아래 결과를 통해 확인할 수 있습니다.
12. ☕️ [선택사항] 에이전트 엔진이 있는 메모리 뱅크
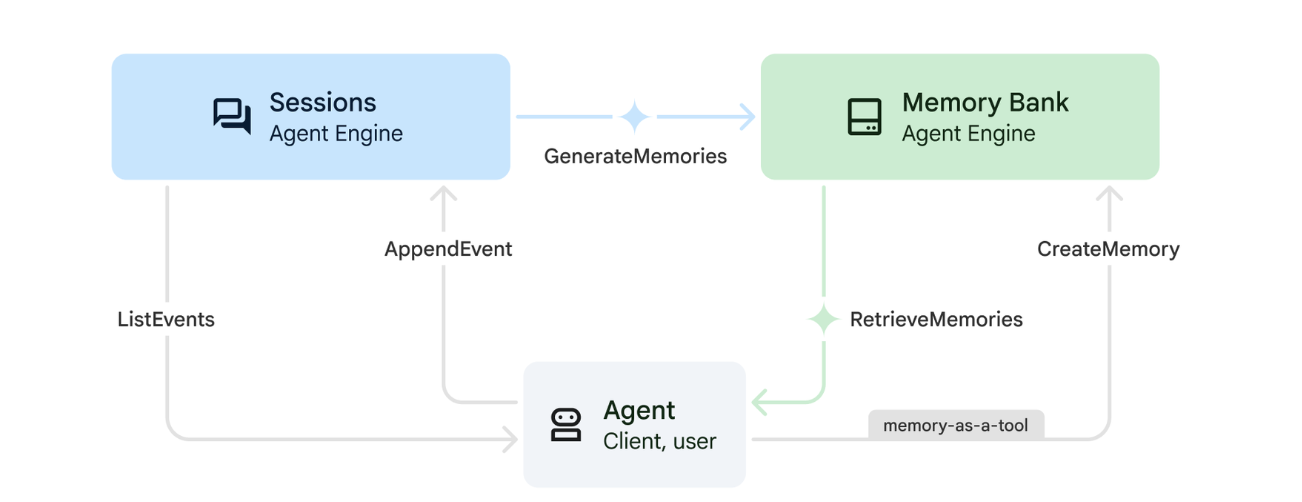
1. 메모리 작동 방식
이 시스템은 이중 메모리 접근 방식을 사용하여 즉각적인 컨텍스트와 장기 학습을 모두 처리합니다.
2. 메모리 주제란 무엇인가요?
메모리 주제는 에이전트가 대화 전반에 걸쳐 기억해야 하는 정보의 카테고리를 정의합니다. 다양한 유형의 사용자 환경설정을 위한 자료실이라고 생각하면 됩니다.
2가지 주제:
search_preferences: 사용자가 검색하는 방식을 나타냅니다.- 키워드 검색과 시맨틱 검색 중 어떤 것을 선호하나요?
- 어떤 기술/생물 군계를 자주 검색하나요?
- 메모리 예시: '사용자는 의료 기술에 시맨틱 검색을 선호합니다.'
urgent_needs_context: 추적 중인 위기- 어떤 리소스를 모니터링하고 있나요?
- 어떤 생존자를 우려하고 있나요?
- 예시 메모리: '사용자가 북쪽 캠프의 의약품 부족을 추적하고 있습니다.'
3. 메모리 주제 설정
맞춤 메모리 주제는 에이전트가 무엇을 기억해야 하는지 정의합니다. 이는 에이전트 엔진을 배포할 때 구성됩니다.
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
그러면 편집기에서 ~/way-back-home/level_2/backend/deploy_agent.py이 열립니다.
구조 MemoryTopic 객체를 정의하여 추출하고 저장할 정보에 관해 LLM에 안내합니다.
👉deploy_agent.py 파일에서 # TODO: SET_UP_TOPIC를 다음으로 바꿉니다.
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. 에이전트 통합
에이전트 코드는 정보를 저장하고 검색하기 위해 메모리 뱅크를 인식해야 합니다.
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
그러면 편집기에서 ~/way-back-home/level_2/backend/agent/agent.py이 열립니다.
에이전트 만들기
에이전트를 만들 때 after_agent_callback를 전달하여 상호작용 후 세션이 메모리에 저장되도록 합니다. add_session_to_memory 함수는 채팅 응답 속도를 늦추지 않도록 비동기식으로 실행됩니다.
👉agent.py 파일에서 # TODO: REPLACE_ADD_SESSION_MEMORY 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
백그라운드 저장
👉agent.py 파일에서 # TODO: REPLACE_ADD_MEMORY_BANK_TOOL 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉agent.py 파일에서 # TODO: REPLACE_ADD_CALLBACK 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Vertex AI 세션 서비스 설정
👉💻 터미널에서 다음을 실행하여 Cloud Shell 편집기에서 chat.py 파일을 엽니다.
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉chat.py 파일에서 # TODO: REPLACE_VERTEXAI_SERVICES 주석을 찾아 이 전체 줄을 다음 코드로 바꿉니다.
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [선택사항] Agent Engine으로 에이전트 연결
1. 설정 및 배포
메모리 기능을 테스트하기 전에 새 메모리 주제로 에이전트를 배포하고 환경이 올바르게 구성되어 있는지 확인해야 합니다.
이 프로세스를 처리하기 위한 편의 스크립트가 제공됩니다.
배포 스크립트 실행
👉💻 터미널에서 배포 스크립트를 실행합니다.
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
이 스크립트는 다음 작업을 실행합니다.
backend/deploy_agent.py를 실행하여 Vertex AI에 에이전트 및 메모리 주제를 등록합니다.- 새 Agent Engine ID를 캡처합니다.
AGENT_ENGINE_ID으로.env파일을 자동으로 업데이트합니다..env파일에USE_MEMORY_BANK=TRUE가 설정되어 있는지 확인합니다.
[!IMPORTANT] deploy_agent.py에서 custom_topics를 변경하는 경우 이 스크립트를 다시 실행하여 에이전트 엔진을 업데이트해야 합니다.
메모리 뱅크 확인
이제 에이전트에게 선호도를 가르치고 세션 간에 유지되는지 확인하여 메모리 뱅크가 작동하는지 확인할 수 있습니다.
1단계 애플리케이션 열기
아래 안내에 따라 애플리케이션을 다시 엽니다. 이전 터미널이 아직 실행 중인 경우 Ctrls+C를 눌러 종료합니다.
👉💻 앱 시작:
cd ~/way-back-home/level_2/
./start_app.sh
👉 터미널에서 Local: http://localhost:5173/을 클릭합니다.
2단계 텍스트로 메모리 뱅크 테스트하기
채팅 인터페이스에서 에이전트에게 구체적인 컨텍스트를 알려줍니다.
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 메모리가 백그라운드에서 처리될 때까지 30초 정도 기다립니다.
3단계 새 세션 시작
페이지를 새로고침하여 현재 대화 기록 (단기 기억)을 지웁니다.
이전에 제공한 컨텍스트를 기반으로 하는 질문을 합니다.
"What kind of missions am I interested in?"
예상 대답:
'이전 대화를 바탕으로 다음과 같은 주제에 관심이 있으신 것 같습니다.
- 의료 구조 임무
- 산/고지대 작업
- 필요한 기술: 응급 처치, 등반
이 기준에 맞는 생존자를 찾아 드릴까요?'
4단계 이미지 업로드로 테스트
이미지를 업로드하고 다음과 같이 질문합니다.
remember this
여기에서 사진을 선택하거나 직접 찍은 사진을 선택하여 UI에 업로드할 수 있습니다.
5단계: Vertex AI Agent Engine에서 확인
Google Cloud 콘솔 Agent Engine으로 이동
- 왼쪽 상단의 프로젝트 선택기에서 프로젝트를 선택해야 합니다.
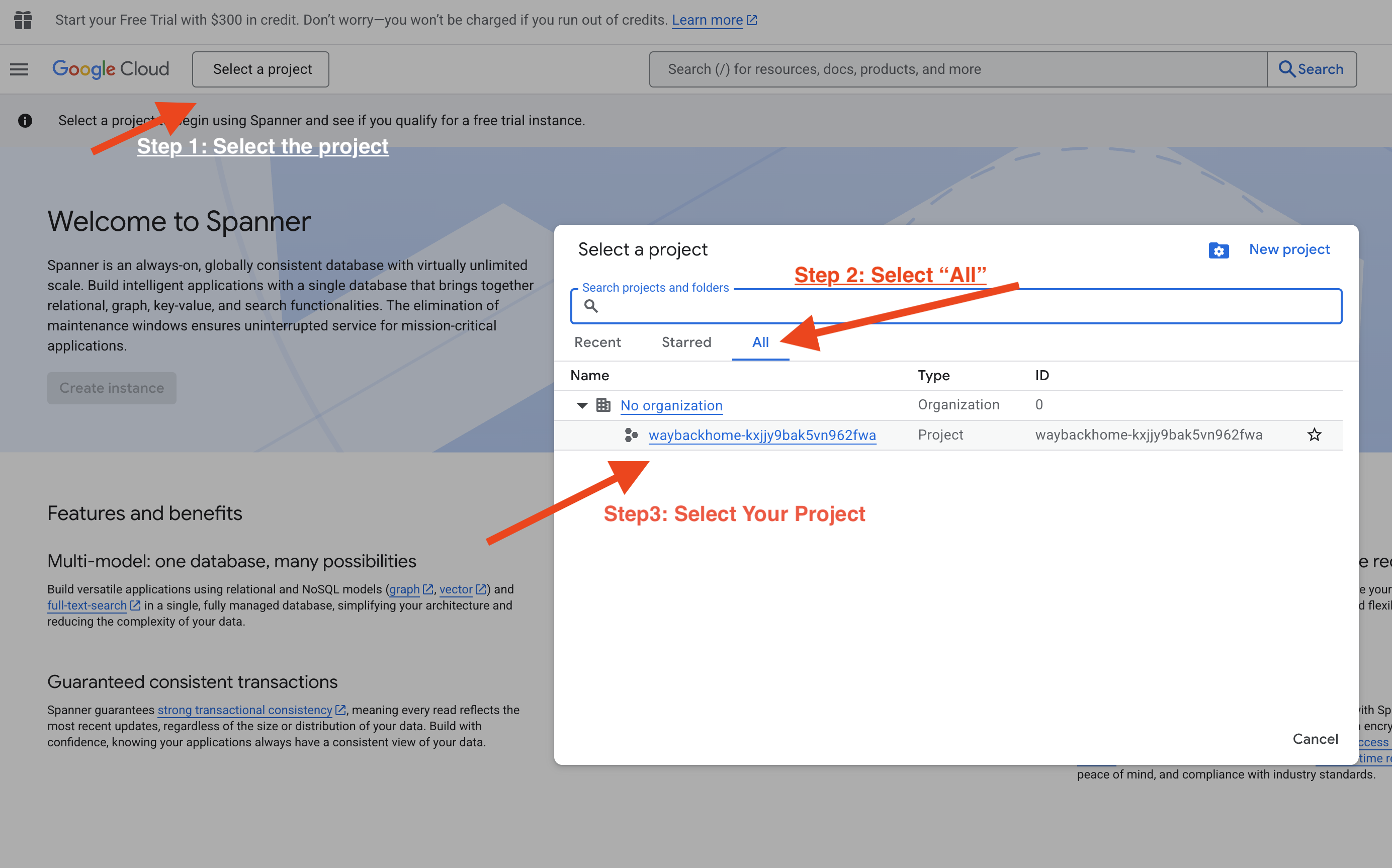
- 이전 명령
use_memory_bank.sh에서 배포한 에이전트 엔진을 확인합니다.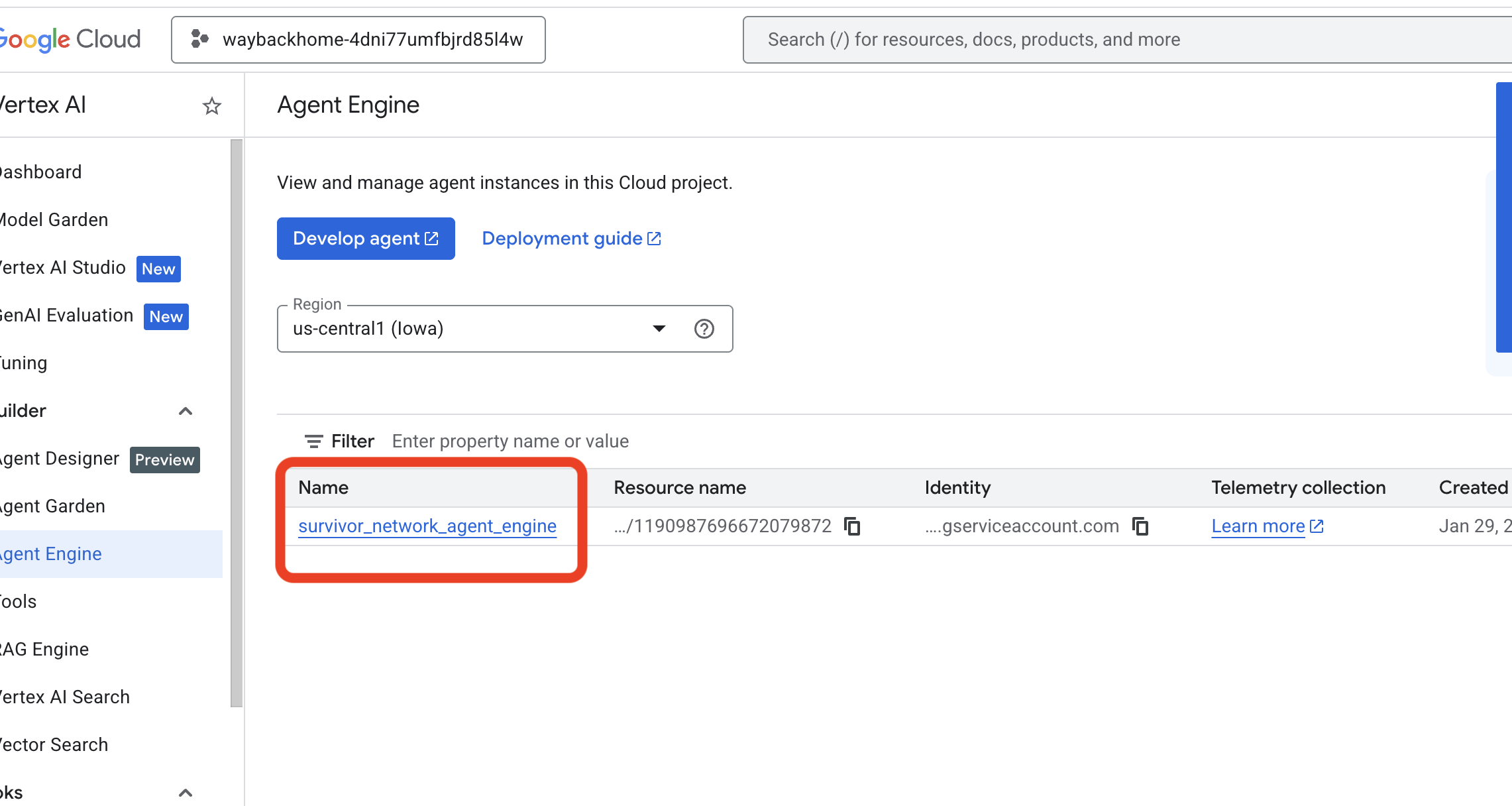 방금 만든 에이전트 엔진을 클릭합니다.
방금 만든 에이전트 엔진을 클릭합니다. - 배포된 이 에이전트에서
Memories탭을 클릭하면 모든 메모리를 확인할 수 있습니다.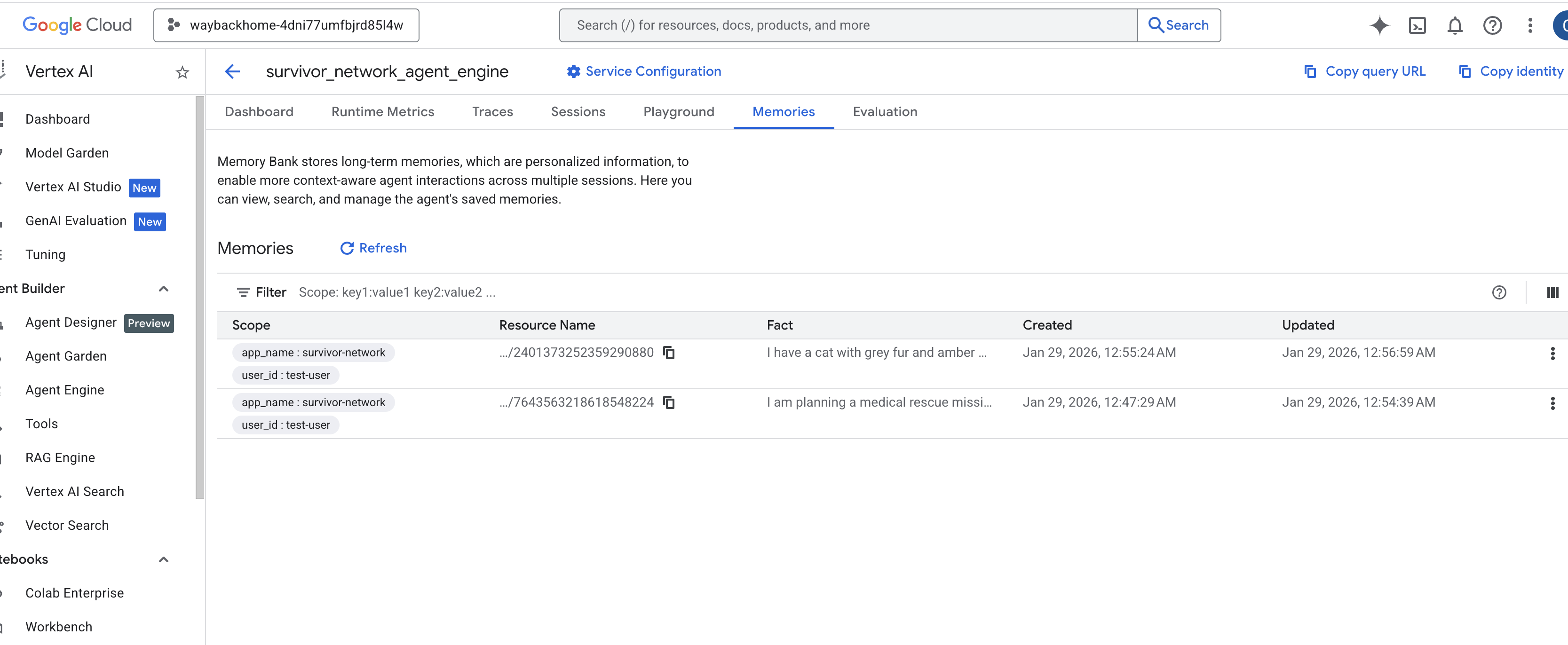
👉💻 테스트를 완료한 후 터미널에서 'Ctrl + C'를 클릭하여 프로세스를 종료합니다.
🎉 수고하셨습니다. 에이전트에 메모리 뱅크를 연결했습니다.
14. ☕️ [선택사항] Cloud Run에 배포
1. 배포 스크립트 실행
👉💻 배포 스크립트를 실행합니다.
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
배포가 완료되면 URL이 표시됩니다. 이 URL이 배포된 URL입니다. 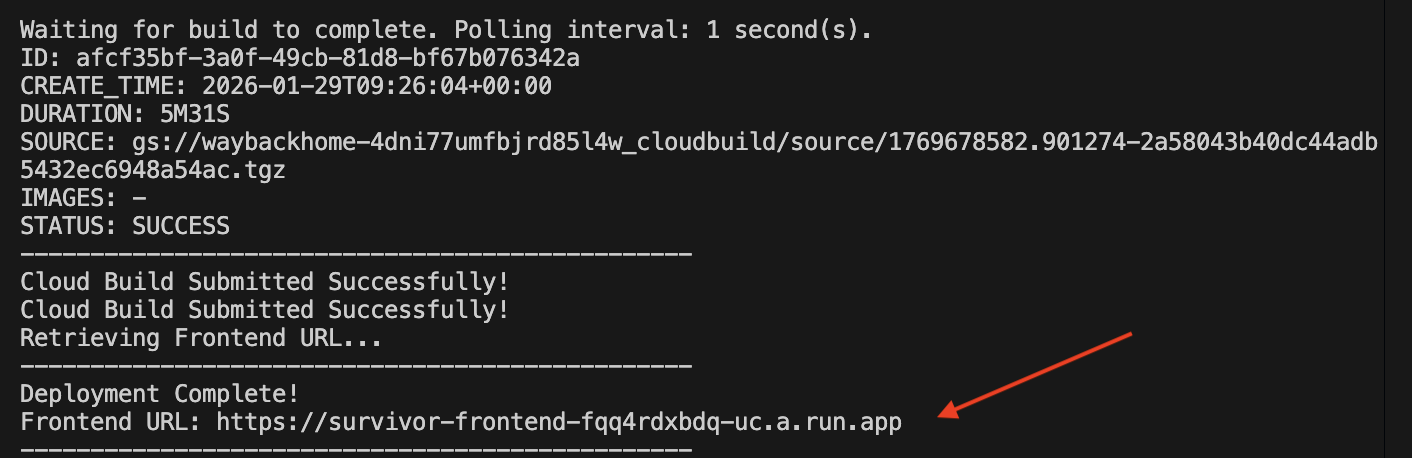
👉💻 URL을 가져오기 전에 다음을 실행하여 권한을 부여하세요.
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
배포된 URL로 이동하면 애플리케이션이 라이브로 표시됩니다.
2. 빌드 파이프라인 이해
cloudbuild.yaml 파일은 다음과 같은 순차적 단계를 정의합니다.
- 백엔드 빌드:
backend/Dockerfile에서 Docker 이미지를 빌드합니다. - 백엔드 배포: 백엔드 컨테이너를 Cloud Run에 배포합니다.
- Capture URL: 새 백엔드 URL을 가져옵니다.
- 프런트엔드 빌드:
- 종속 항목을 설치합니다.
VITE_API_URL=를 삽입하여 React 앱을 빌드합니다.
- 프런트엔드 이미지:
frontend/Dockerfile에서 Docker 이미지를 빌드합니다 (정적 애셋 패키징). - 프런트엔드 배포: 프런트엔드 컨테이너를 배포합니다.
3. 배포 확인
빌드가 완료되면 (스크립트에서 제공하는 로그 링크 확인) 다음을 확인할 수 있습니다.
- Cloud Run 콘솔로 이동합니다.
survivor-frontend서비스를 찾습니다.- URL을 클릭하여 애플리케이션을 엽니다.
- 검색어를 실행하여 프런트엔드가 백엔드와 통신할 수 있는지 확인합니다.
(선택사항) 4. 수동 배포
명령어를 수동으로 실행하거나 프로세스를 더 잘 이해하려면 cloudbuild.yaml를 직접 사용하는 방법을 참고하세요.
cloudbuild.yaml 작성
cloudbuild.yaml 파일은 Google Cloud Build에 실행할 단계를 알려줍니다.
- steps: 순차적 작업 목록입니다. 각 단계는 컨테이너 (예:
docker,gcloud,node,bash)에서 실행됩니다. - substitutions: 빌드 시간에 전달할 수 있는 변수 (예:
$_REGION) - workspace: 단계에서 파일을 공유할 수 있는 공유 디렉터리입니다 (
backend_url.txt를 공유하는 방식과 유사).
배포 실행
스크립트 없이 수동으로 배포하려면 gcloud builds submit 명령어를 사용하세요. 필수 대체 변수를 전달해야 합니다(MUST).
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. 결론
1. 빌드한 항목
✅ 그래프 데이터베이스: 노드 (생존자, 기술) 및 에지 (관계)가 있는 Spanner
✅ AI 검색: 임베딩을 사용한 키워드, 시맨틱, 하이브리드 검색
✅ 멀티모달 파이프라인: Gemini로 이미지/동영상에서 엔티티 추출
✅ 멀티 에이전트 시스템: ADK를 사용한 조정된 워크플로
✅ 메모리 뱅크: Vertex AI를 사용한 장기 개인화
✅ 프로덕션 배포: Cloud Run + 에이전트 엔진
2. 아키텍처 요약
3. 주요 학습 내용
- 그래프 RAG: 그래프 데이터베이스 구조와 시맨틱 임베딩을 결합하여 지능형 검색
- 멀티 에이전트 패턴: 복잡한 다단계 워크플로를 위한 순차적 파이프라인
- 멀티모달 AI: 비정형 미디어 (이미지/동영상)에서 구조화된 데이터 추출
- 스테이트풀 에이전트: 메모리 뱅크를 사용하면 세션 전반에서 맞춤설정이 가능합니다.
4. 워크숍 콘텐츠
- Level0: 본인 인증
- Level1: Pinpoint Location
- 레벨2: 그래프 RAG, ADK, 메모리 뱅크를 사용하여 멀티모달 AI 에이전트 빌드
- Level3: ADK 양방향 스트리밍 에이전트 빌드
- Level4: 실시간 양방향 멀티 에이전트 시스템
- Level5: Google ADK, A2A, Kafka를 사용한 이벤트 기반 아키텍처