
1. Wprowadzenie

1. Wyzwanie
W przypadku reagowania na katastrofy koordynowanie działań osób, które przeżyły katastrofę, a mają różne umiejętności, zasoby i potrzeby w wielu lokalizacjach, wymaga inteligentnego zarządzania danymi i możliwości wyszukiwania. Podczas tych warsztatów dowiesz się, jak zbudować produkcyjny system AI, który łączy:
- 🗄️ Grafowa baza danych (Spanner): przechowywanie złożonych relacji między osobami, które przeżyły katastrofę, ich umiejętnościami i zasobami.
- 🔍 Wyszukiwanie oparte na AI: hybrydowe wyszukiwanie semantyczne i wyszukiwanie słów kluczowych z użyciem wektorów dystrybucyjnych.
- 📸 Przetwarzanie multimodalne: wyodrębnianie uporządkowanych danych z obrazów, tekstu i filmów.
- 🤖 Administrowanie wieloma agentami: koordynowanie wyspecjalizowanych agentów w przypadku złożonych przepływów pracy.
- 🧠 Pamięć długotrwała: personalizacja z użyciem Banku zapamiętanych informacji Vertex AI
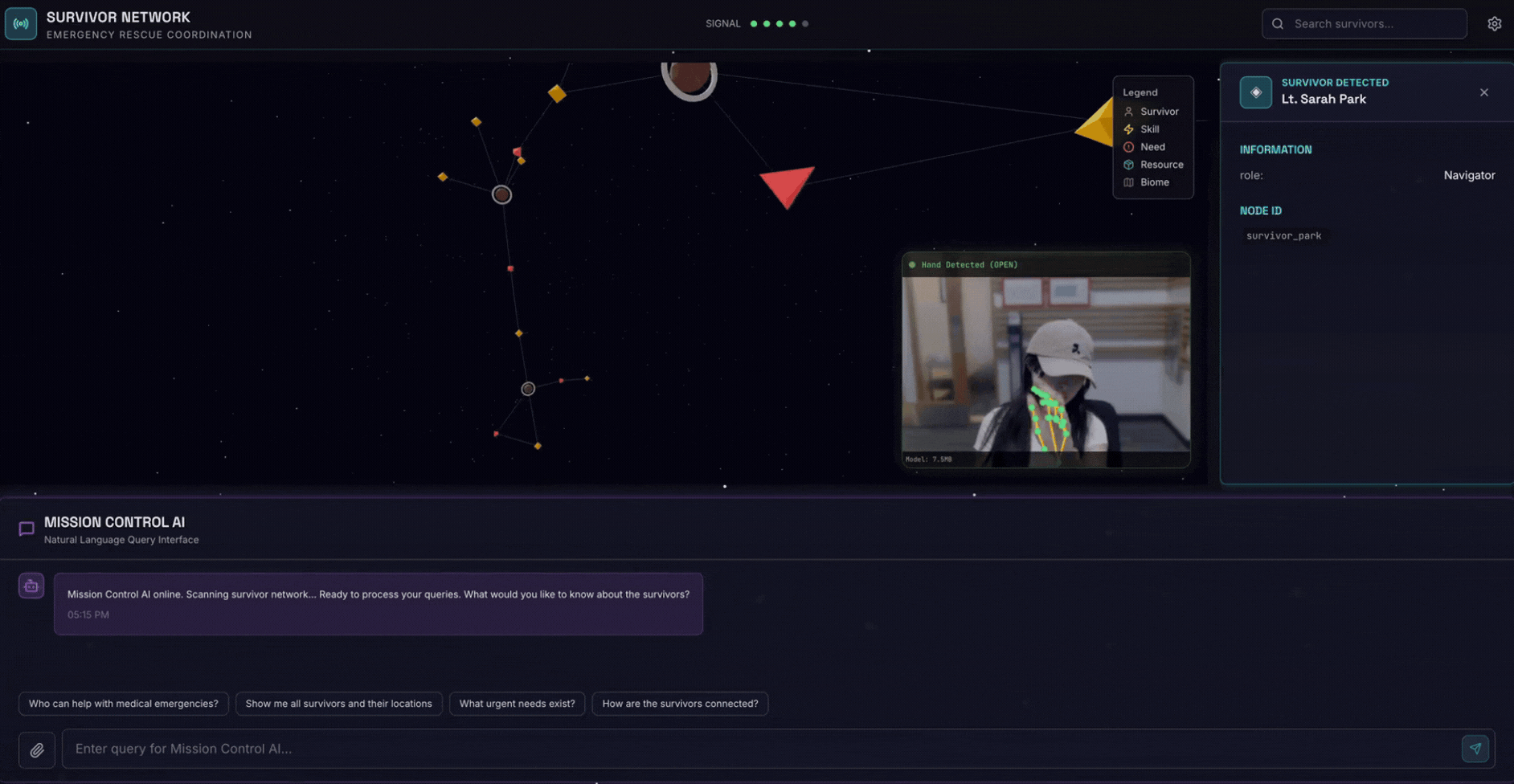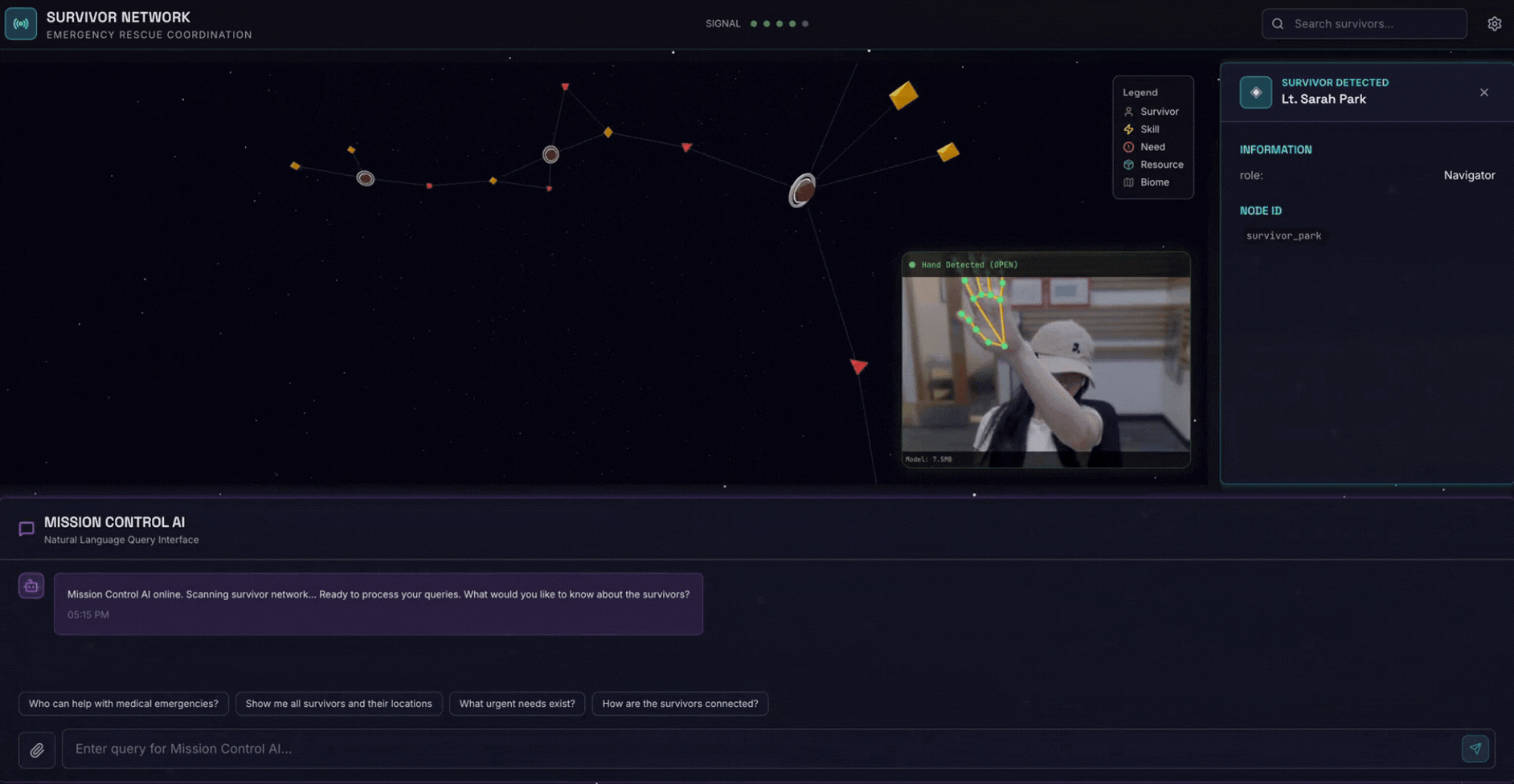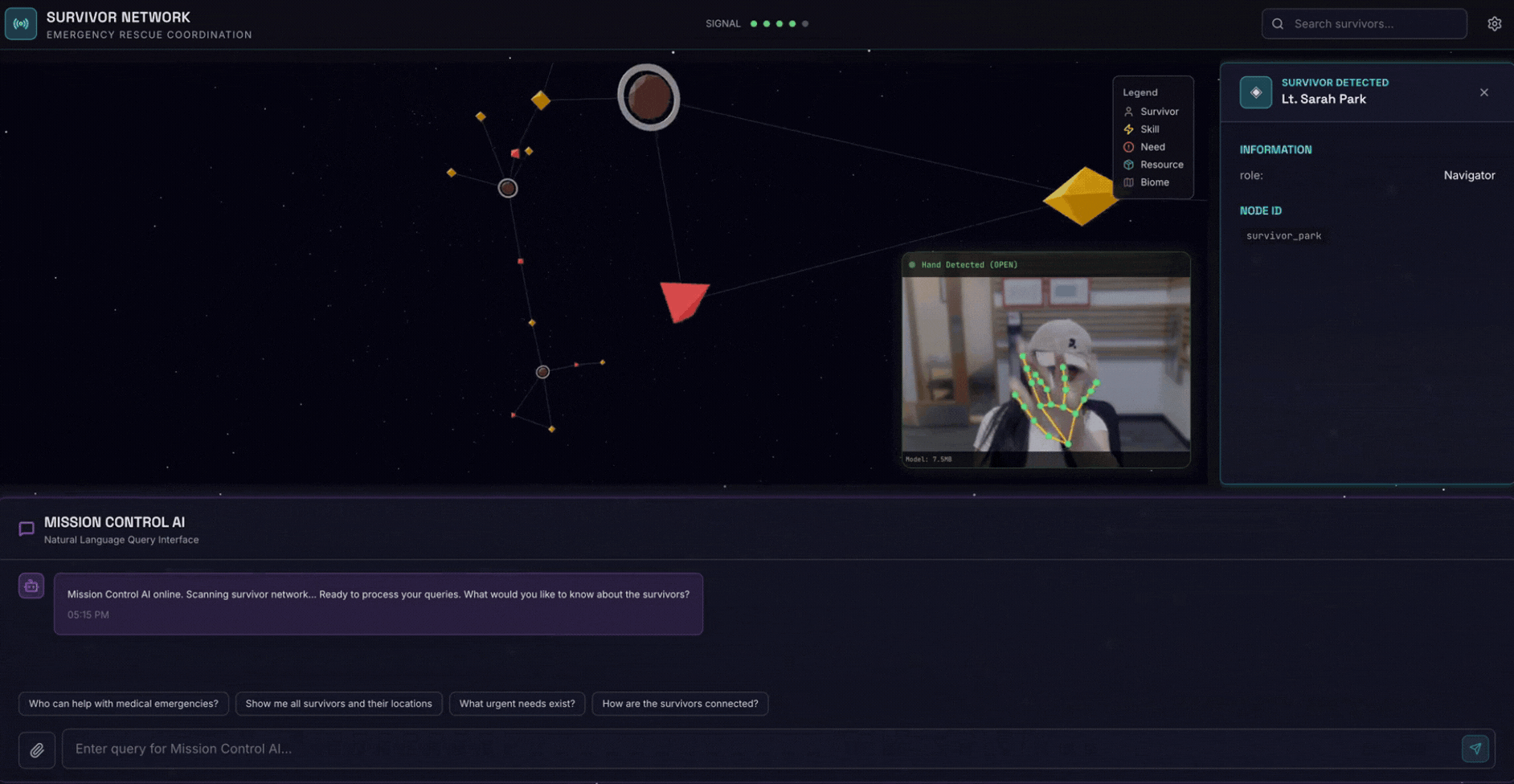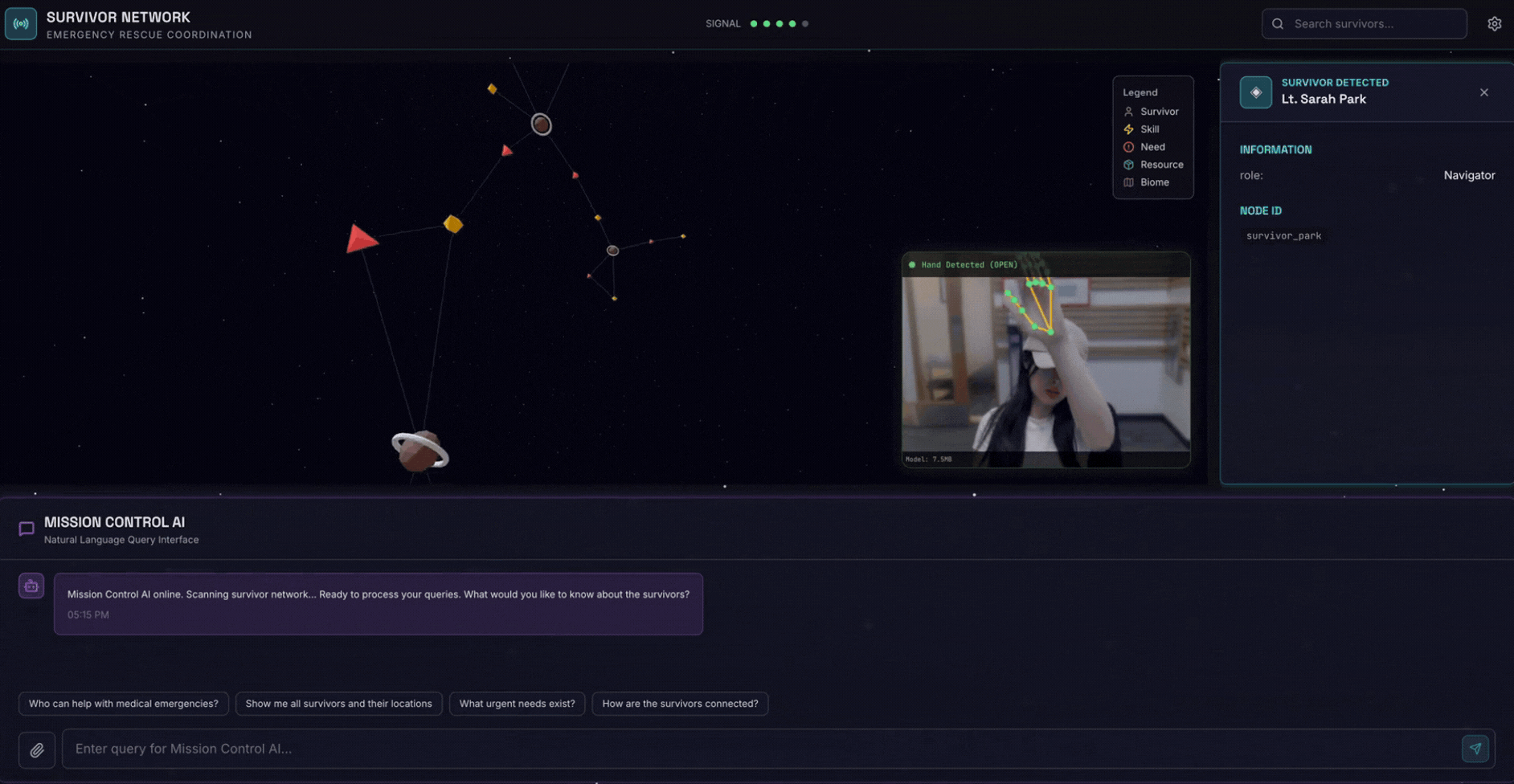
2. Co utworzysz
Baza danych wykresu sieci ocalałych zawierająca:
- 🗺️ Interaktywna wizualizacja graficzna 3D relacji między osobami, które przeżyły Holokaust
- 🔍 Inteligentne wyszukiwanie (słowa kluczowe, semantyczne i hybrydowe)
- 📸 Potok przesyłania multimodalnego (wyodrębnianie elementów z obrazów i filmów)
- 🤖 System wieloagentowy do zarządzania złożonymi zadaniami
- 🧠 Integracja z Bankiem zapamiętanych informacji w celu personalizacji interakcji
3. Technologie podstawowe
Komponent | Technologia | Cel |
Baza danych | Cloud Spanner Graph | Przechowywanie węzłów (osób, umiejętności) i krawędzi (relacji) |
Wyszukiwarka AI | Gemini + Embeddings | Rozumienie semantyczne i wyszukiwanie podobieństw |
Platforma agenta | ADK (Agent Development Kit) | Administrowanie przepływami pracy AI |
Pamięć | Vertex AI Memory Bank | Przechowywanie długoterminowych preferencji użytkownika |
Frontend | React + Three.js | Interaktywna wizualizacja grafu 3D |
2. 🛠️ Przygotowanie środowiska (pomiń, jeśli uczestniczysz w warsztatach)
Część 1. Włączanie konta rozliczeniowego
Aby wykonać to ćwiczenie, musisz mieć konto rozliczeniowe z pewną ilością środków. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Część 2. Środowisko otwarte
- 👉 Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- 👉 Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- 👉 Jeśli terminal nie pojawia się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- 👉💻 W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list - 👉💻 Sklonuj projekt początkowy z GitHuba:
git clone https://github.com/gca-americas/way-back-home.git
Część 3. Tworzenie nowego projektu
👉💻 W terminalu ustaw skrypt inicjujący jako wykonywalny i uruchom go:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Konfiguracja środowiska
1. Otwieranie Cloud Shell
W terminalu edytora Cloud Shell, jeśli terminal nie pojawia się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal.
2. Konfigurowanie projektu
👉💻 W terminalu ustaw identyfikator projektu:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Włącz wymagane interfejsy API (zajmie to około 2–3 minut):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Uruchom skrypt konfiguracji
👉💻 Uruchom skrypt konfiguracji:
cd ~/way-back-home/level_2
./setup.sh
Spowoduje to utworzenie .env. W Cloud Shell otwórz way_back_homeproject. W folderze level_2 zobaczysz utworzony dla Ciebie plik .env. Jeśli nie możesz go znaleźć, kliknij View -> Toggle Hidden File, aby go wyświetlić. 
4. Wczytaj przykładowe dane
👉💻 Przejdź do backendu i zainstaluj zależności:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Wczytaj początkowe dane o osobach, które przeżyły:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Spowoduje to utworzenie:
- Instancja Spannera (
survivor-network) - Baza danych (
graph-db) - Wszystkie tabele węzłów i krawędzi
- Wykresy właściwości do wykonywania zapytań Oczekiwane dane wyjściowe:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
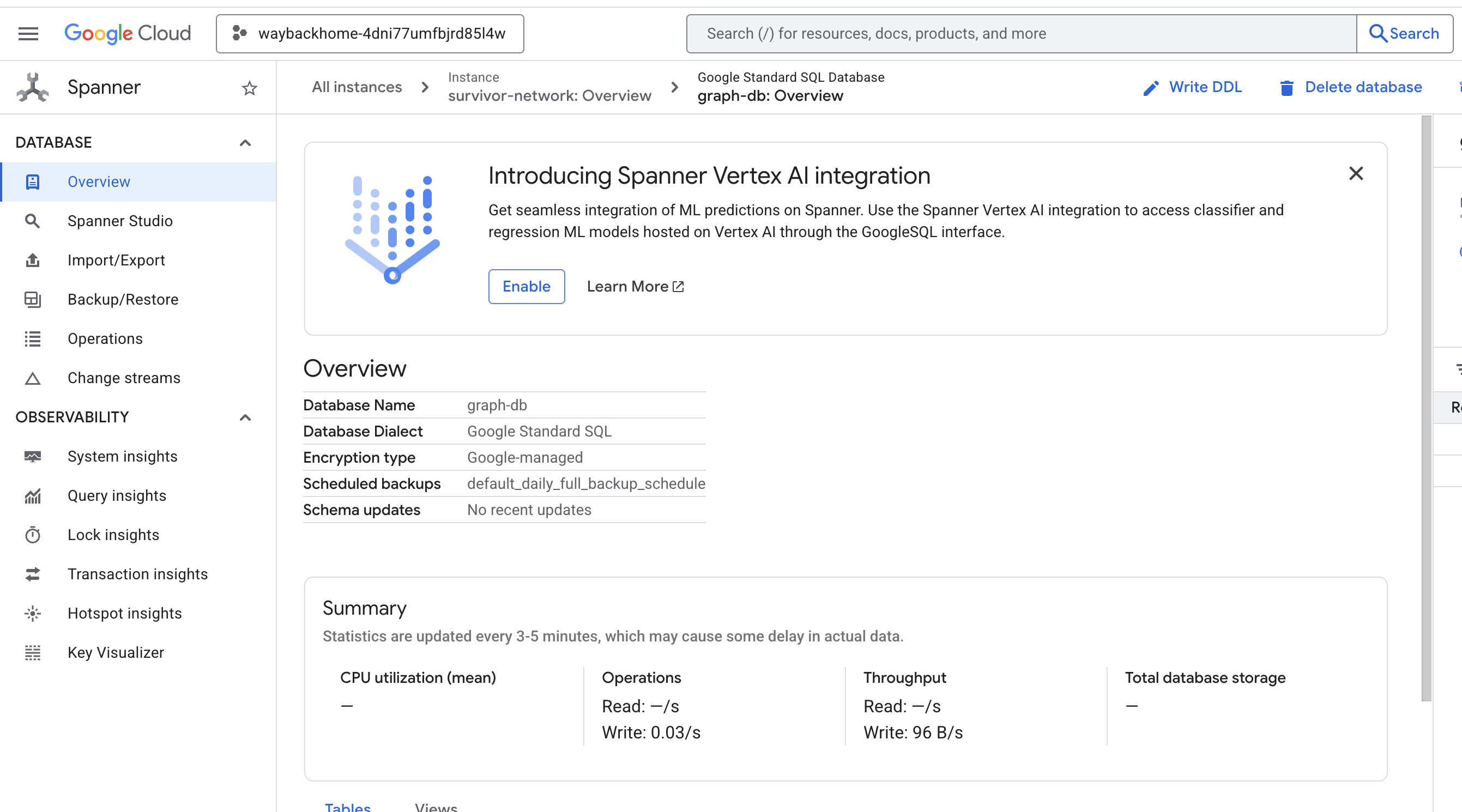
Jeśli klikniesz link po znaku Access your database at w danych wyjściowych, możesz otworzyć Spanner w konsoli Google Cloud.

W konsoli Google Cloud zobaczysz Spanner.
4. 🚀 Wizualizacja danych wykresu w Spanner Studio
Z tego przewodnika dowiesz się, jak wizualizować dane z wykresu Survivor Network i wchodzić z nimi w interakcję bezpośrednio w konsoli Google Cloud za pomocą Spanner Studio. To świetny sposób na sprawdzenie danych i zrozumienie struktury wykresu przed utworzeniem agenta AI.
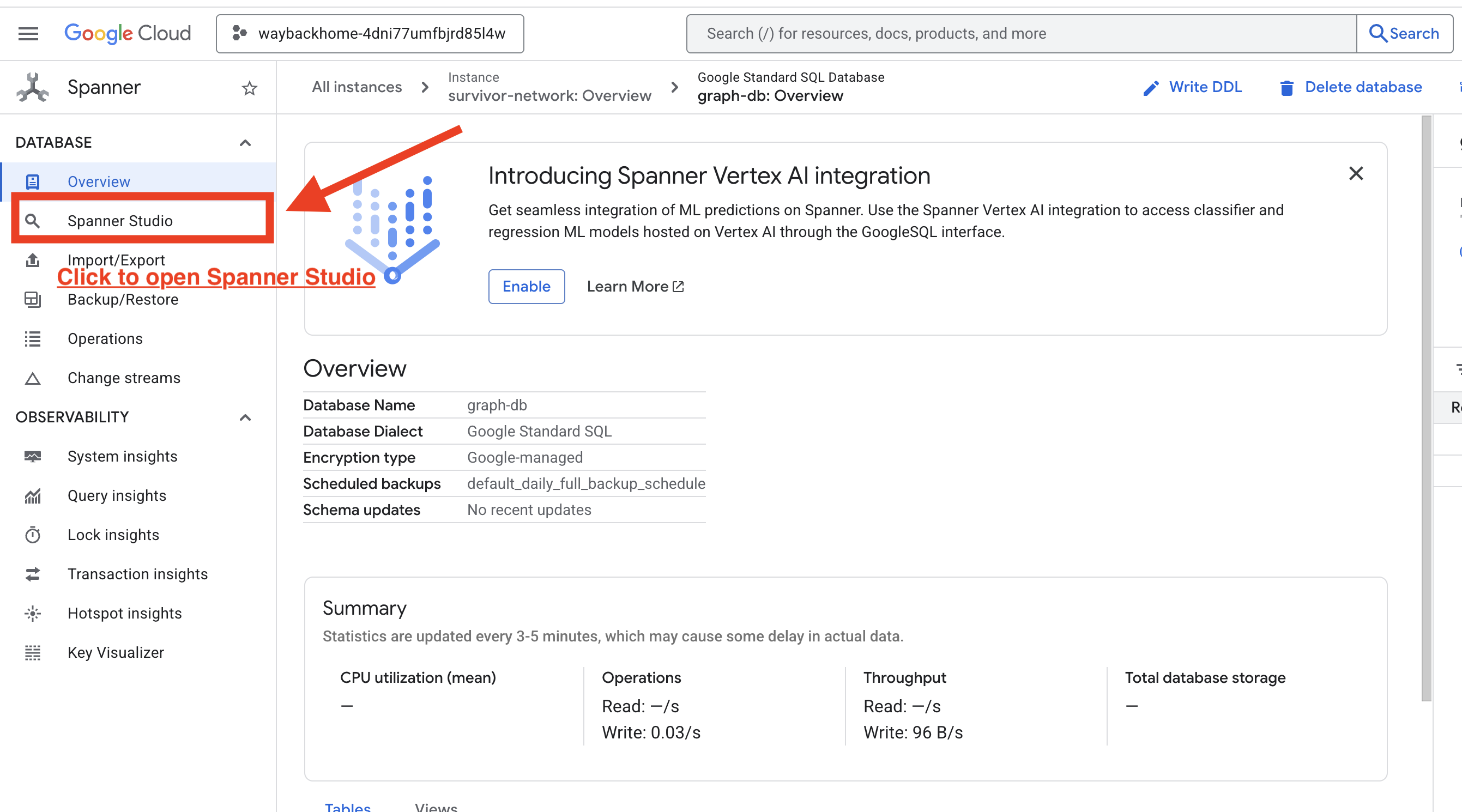
1. Dostęp do Spanner Studio
- W ostatnim kroku kliknij link i otwórz Spanner Studio.
2. Struktura grafu („ogólny obraz”)
Zbiór danych Survivor Network możesz traktować jako łamigłówkę logiczną lub stan gry:
Jednostka | Rola w systemie | Analogie |
Survivors | Agenci/gracze | Gracze |
Biomy | gdzie się znajdują, | Strefy mapy |
Umiejętności | Co mogą zrobić | Umiejętności |
Potrzeby | Czego brakuje (kryzysy) | Zadania/misje |
Materiały | Elementy znalezione na świecie | Łupy |
Cel: zadaniem agenta AI jest łączenie umiejętności (rozwiązań) z potrzebami (problemami) z uwzględnieniem biomów (ograniczeń lokalizacyjnych).
🔗 Krawędzie (relacje):
SurvivorInBiome: śledzenie lokalizacjiSurvivorHasSkill: lista umiejętności.SurvivorHasNeed: lista aktywnych problemówSurvivorFoundResource: asortyment produktów,SurvivorCanHelp: wywnioskowana relacja (obliczona przez AI);
3. Tworzenie zapytań dotyczących grafu
Uruchommy kilka zapytań, aby zobaczyć „Story” w danych.
Spanner Graph używa języka zapytań GQL (Graph Query Language). Aby uruchomić zapytanie, użyj znaku GRAPH SurvivorNetwork, a potem wzorca dopasowania.
👉 Zapytanie 1. Globalny spis (kto gdzie jest?) To podstawa – zrozumienie lokalizacji ma kluczowe znaczenie w przypadku akcji ratunkowych.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Spodziewaj się wyniku jak poniżej: 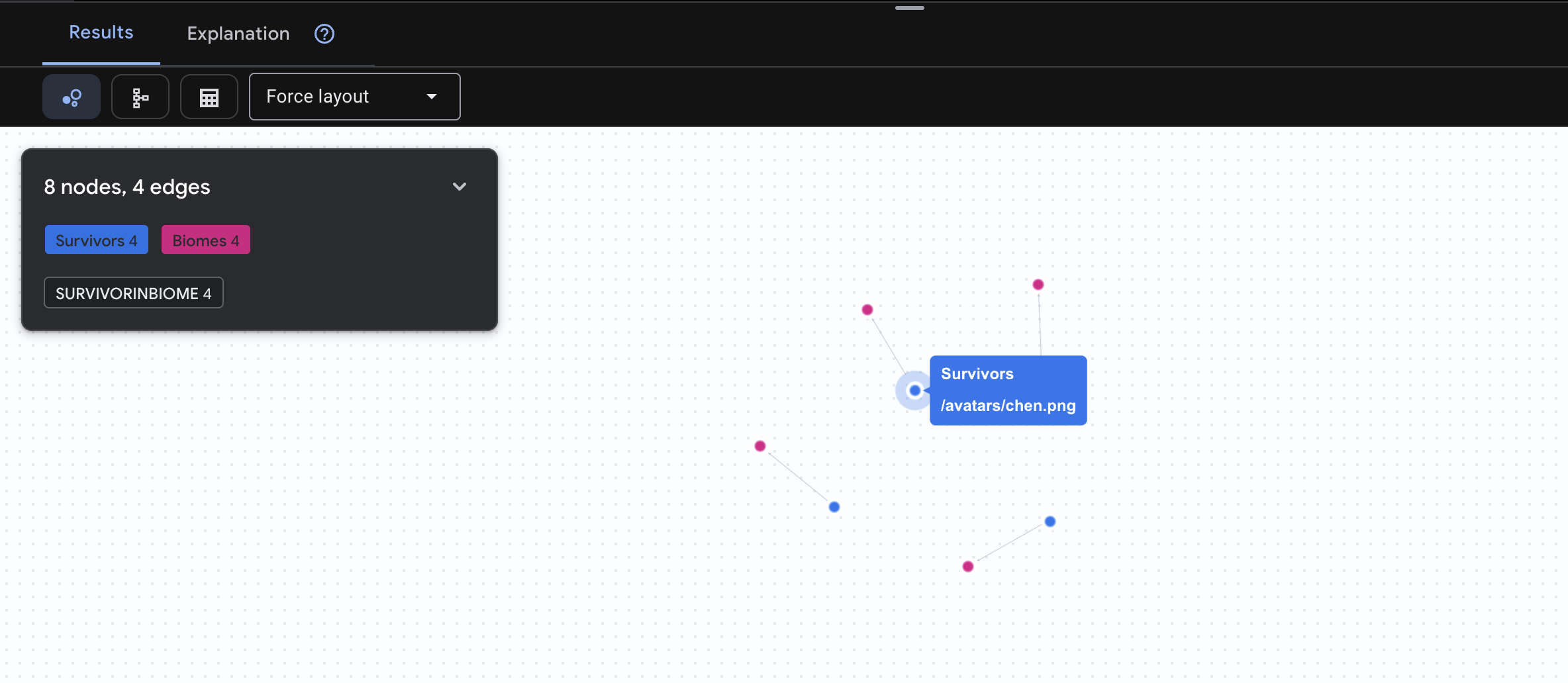
👉 Zapytanie 2. Macierz umiejętności (możliwości): teraz, gdy wiesz, gdzie są poszczególne osoby, dowiedz się, co potrafią.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Spodziewaj się wyniku jak poniżej: 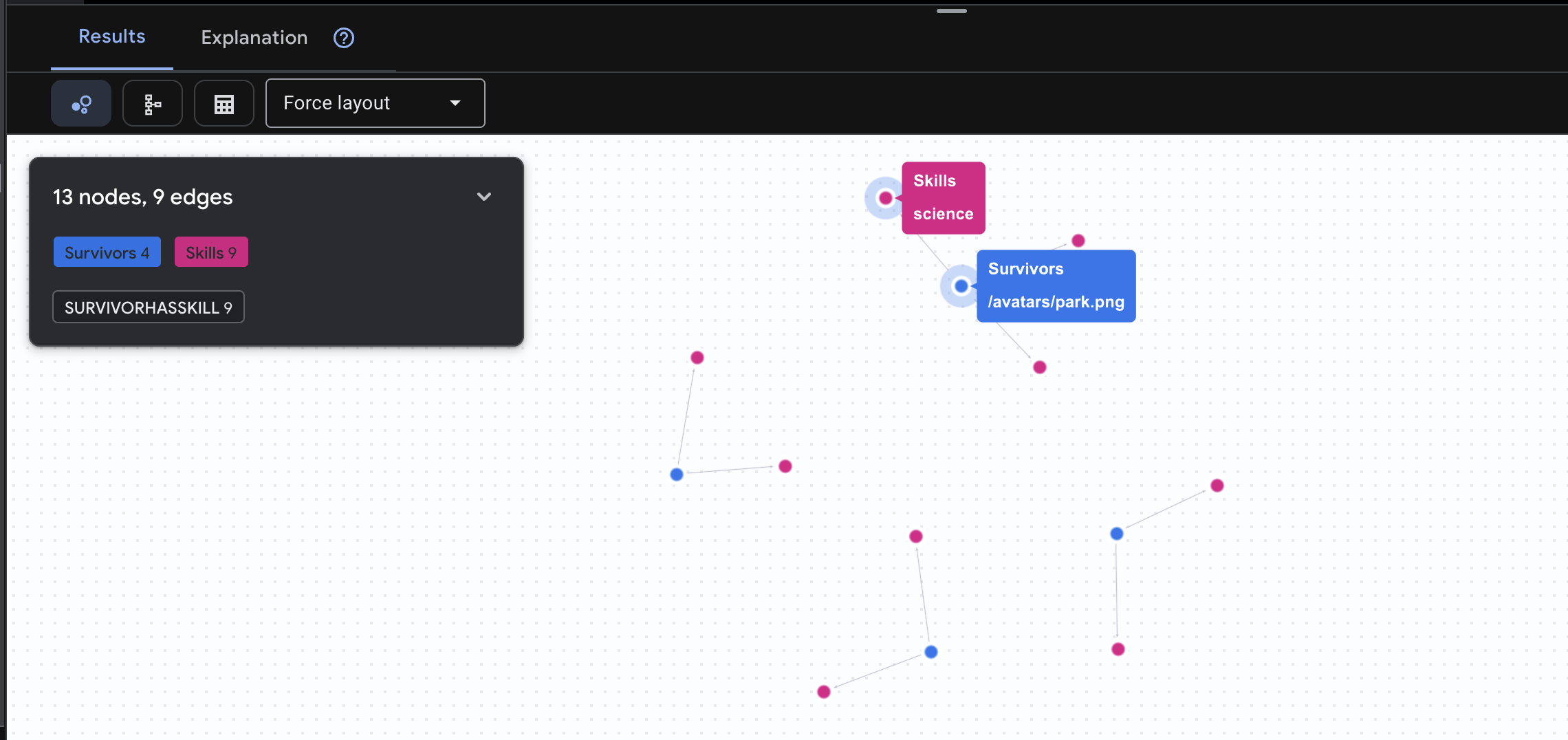
👉 Zapytanie 3. Kto jest w kryzysie? („Tablica misji”) – zobacz, którzy ocaleni potrzebują pomocy i czego potrzebują.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Spodziewaj się wyniku jak poniżej: 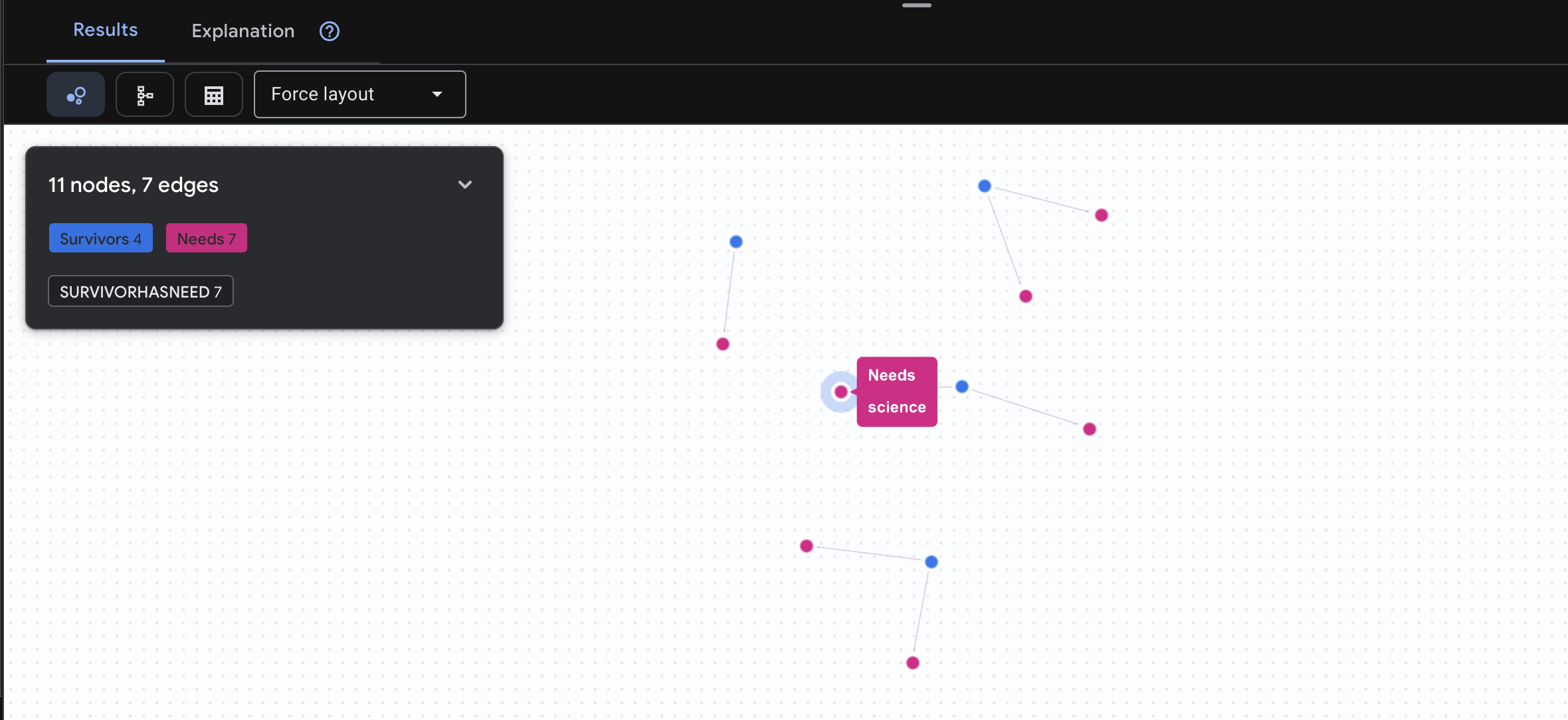
🔎 [Opcjonalnie] Matchmaking – kto może komu pomóc?
W tym momencie wykres staje się bardzo przydatny. To zapytanie znajduje osoby, które mają umiejętności pozwalające zaspokoić potrzeby innych ocalałych.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Spodziewaj się wyniku jak poniżej: 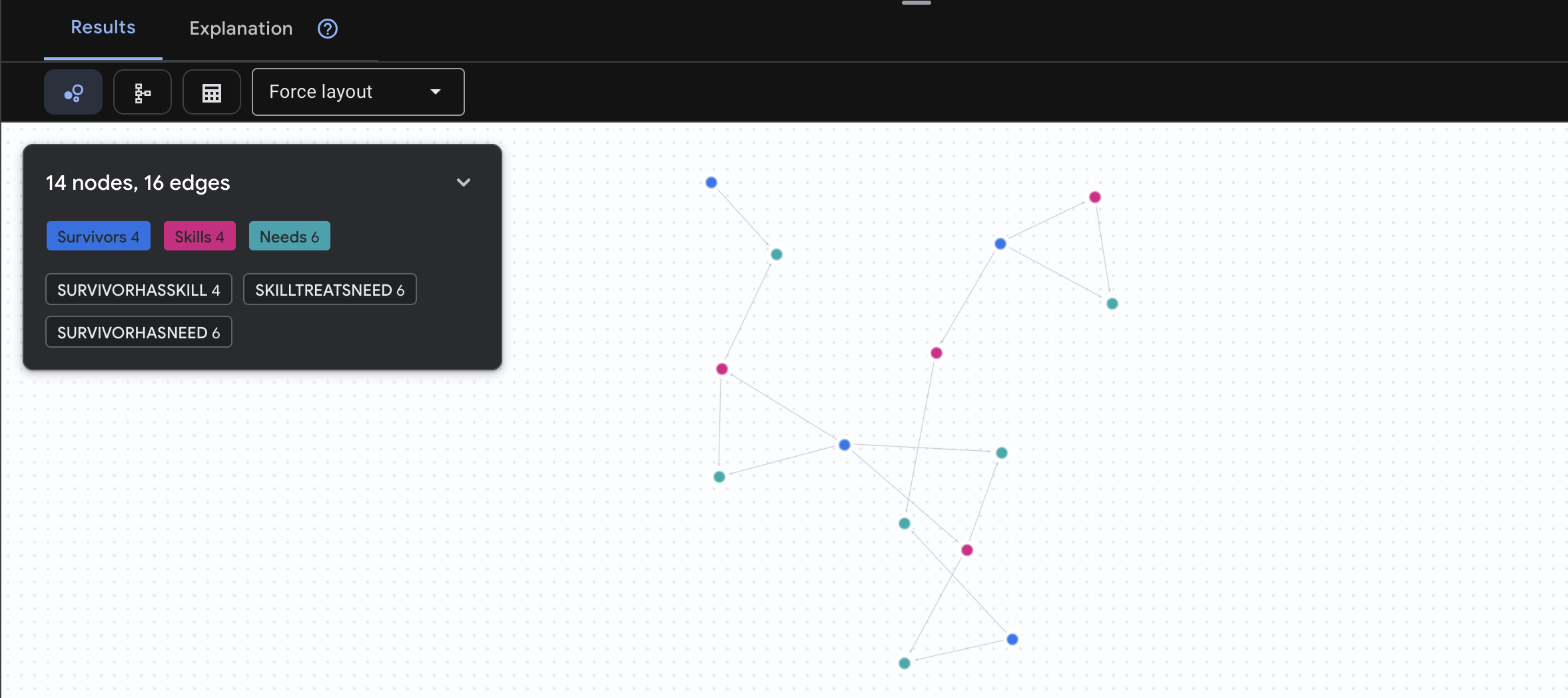
aside positive Działanie zapytania:
Zamiast wyświetlać tylko „Apteczka pierwszej pomocy leczy oparzenia” (co jest oczywiste na podstawie schematu), to zapytanie znajduje:
- Dr Elena Frost (która ma wykształcenie medyczne) → może leczyć → kapitana Tanakę (który ma oparzenia)
- David Chen (który ma wiedzę z zakresu pierwszej pomocy) → może udzielić pomocy → porucznikowi Parkowi (który ma skręconą kostkę).
Dlaczego to jest ważne:
Co będzie robić Twój agent AI:
Gdy użytkownik zapyta „Kto może leczyć oparzenia?”, agent:
- Uruchamianie podobnego zapytania o graf
- Odpowiedź: „Dr Frost ma wykształcenie medyczne i może pomóc kapitanowi Tanaka”
- Użytkownik nie musi znać tabel pośrednich ani relacji.
5. 🚀 Wektory dystrybucyjne oparte na AI w Spannerze
1. Dlaczego warto korzystać z wektorów dystrybucyjnych? (Brak działania, tylko odczyt)
W scenariuszu przetrwania czas jest kluczowy. Gdy osoba, która przeżyła katastrofę, zgłasza sytuację awaryjną, np. I need someone who can treat burns lub Looking for a medic, nie może tracić czasu na zgadywanie dokładnych nazw umiejętności w bazie danych.
Prawdziwy scenariusz: Survivor: Captain Tanaka has burns—we need medical help NOW!
Tradycyjne wyszukiwanie słowa kluczowego „medic” → 0 wyników ❌
Wyszukiwanie semantyczne z użyciem wektorów → znajduje „Szkolenie medyczne”, „Pierwsza pomoc” ✅
To jest dokładnie to, czego potrzebują agenci: inteligentne wyszukiwanie przypominające wyszukiwanie przez człowieka, które rozumie intencje, a nie tylko słowa kluczowe.
2. Tworzenie modelu wektora dystrybucyjnego
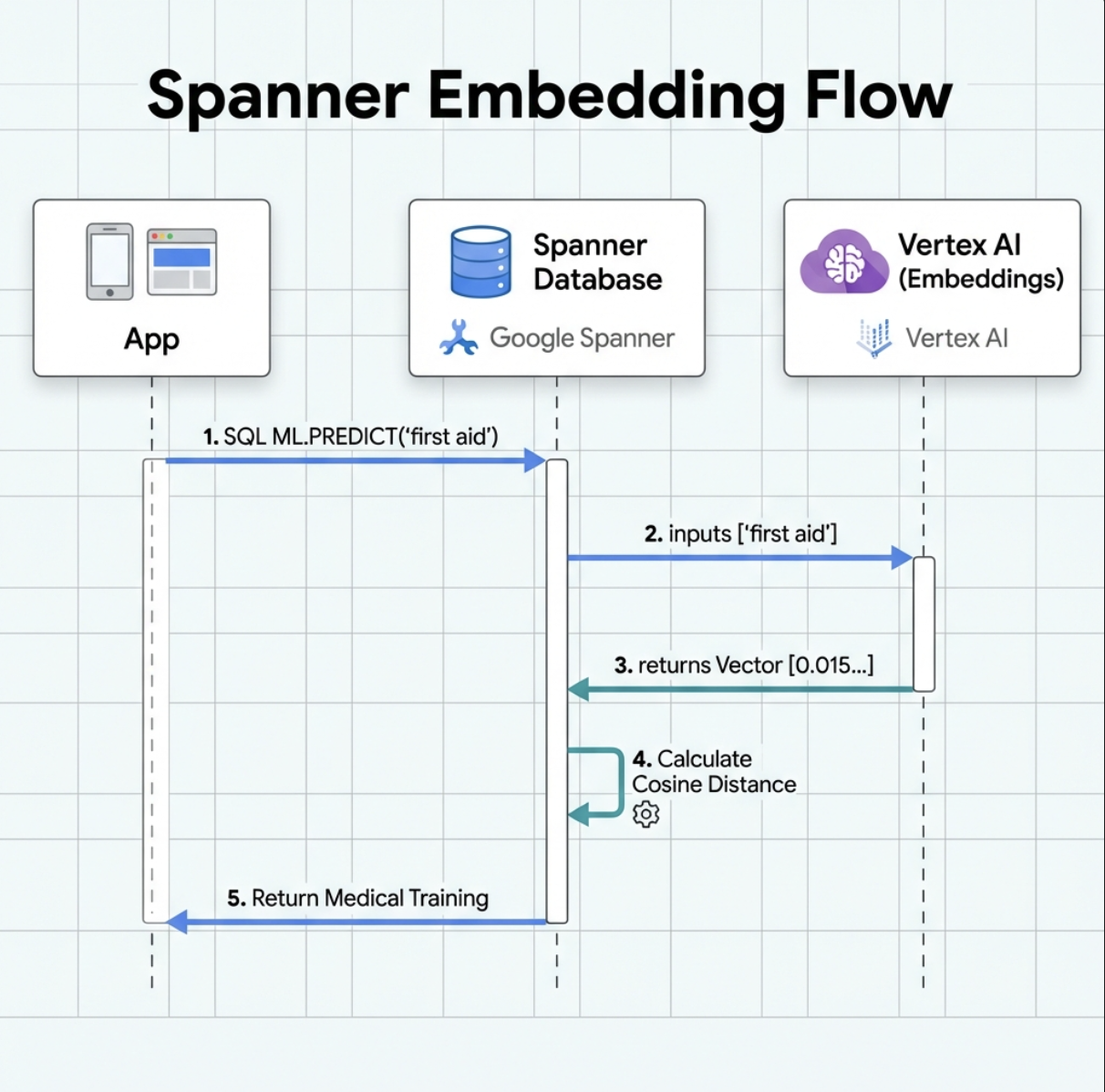
Teraz utwórzmy model, który przekształca tekst w wektory dystrybucyjne za pomocą modelu text-embedding-004 Google.
👉 W Spanner Studio uruchom ten kod SQL (zastąp $YOUR_PROJECT_ID identyfikatorem projektu):
‼️ W edytorze Cloud Shell otwórz File -> Open Folder -> way-back-home/level_2, aby wyświetlić cały projekt.
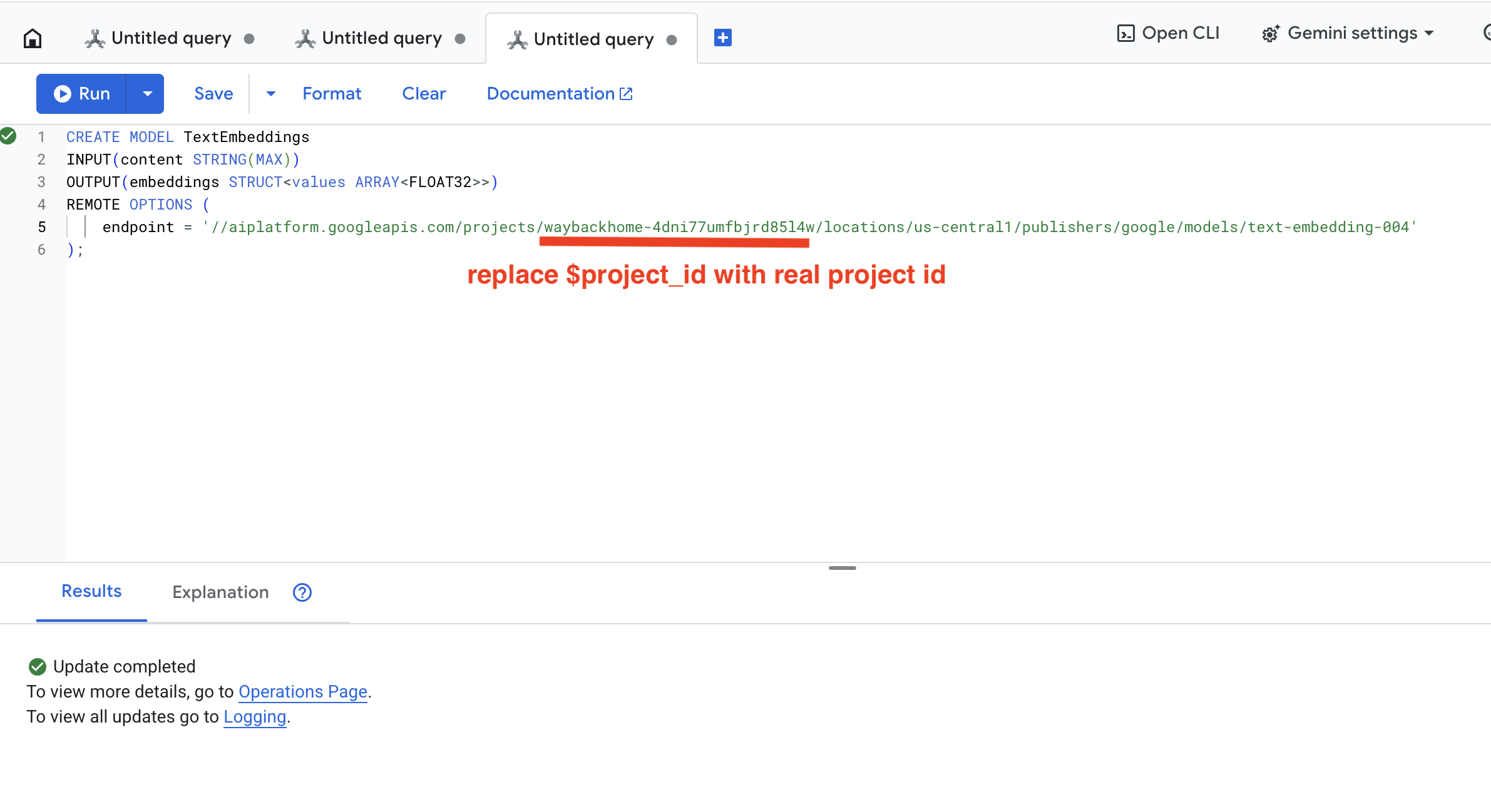
👉 Uruchom to zapytanie w Spanner Studio. W tym celu skopiuj i wklej poniższe zapytanie, a następnie kliknij przycisk Uruchom:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Działanie:
- Tworzy model wirtualny w usłudze Spanner (wagi modelu nie są przechowywane lokalnie).
- Wskazuje
text-embedding-004Google w Vertex AI - Określa umowę: dane wejściowe to tekst, dane wyjściowe to 768-wymiarowa tablica liczb zmiennoprzecinkowych.
Dlaczego „OPCJE ZDALNE”?
- Spanner nie uruchamia samego modelu
- Gdy używasz
ML.PREDICT, wywołuje interfejs Vertex AI API. - Zero-ETL: nie musisz eksportować danych do Pythona, przetwarzać ich i ponownie importować.
Kliknij przycisk Run. Po zakończeniu operacji zobaczysz wynik jak poniżej:
3. Dodawanie kolumny z osadzaniem
👉 Dodaj kolumnę do przechowywania wektorów dystrybucyjnych:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Kliknij przycisk Run. Po zakończeniu operacji zobaczysz wynik jak poniżej:
4. Generowanie wektorów dystrybucyjnych
👉 Użyj AI, aby utworzyć wektory dystrybucyjne dla każdej umiejętności:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Kliknij przycisk Run. Po zakończeniu operacji zobaczysz wynik jak poniżej:
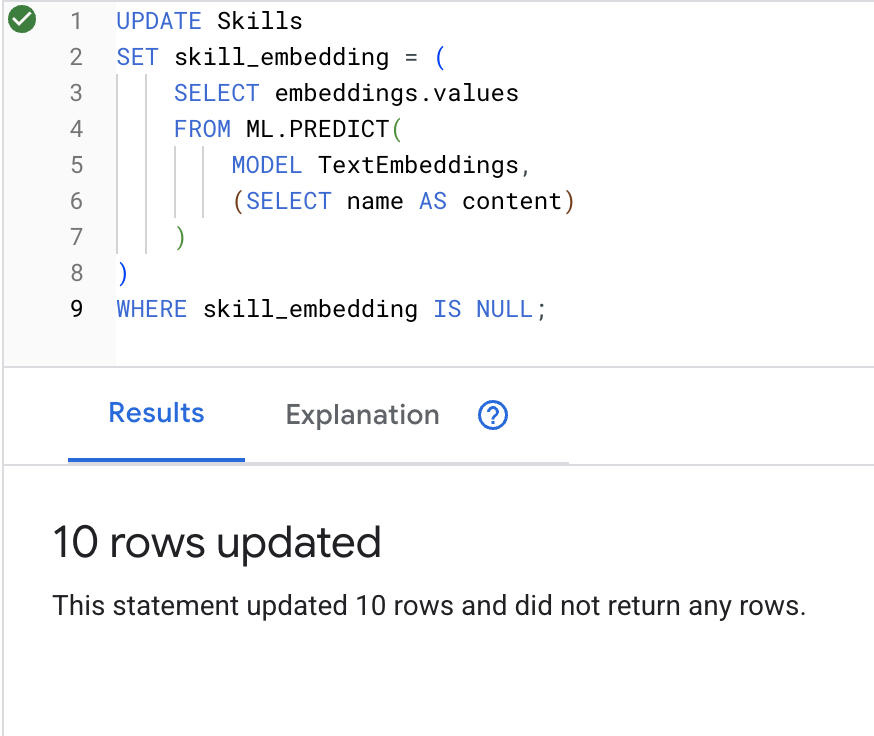
Co się dzieje: każda nazwa umiejętności (np. „pierwsza pomoc”) jest przekształcana w 768-wymiarowy wektor reprezentujący jej znaczenie semantyczne.
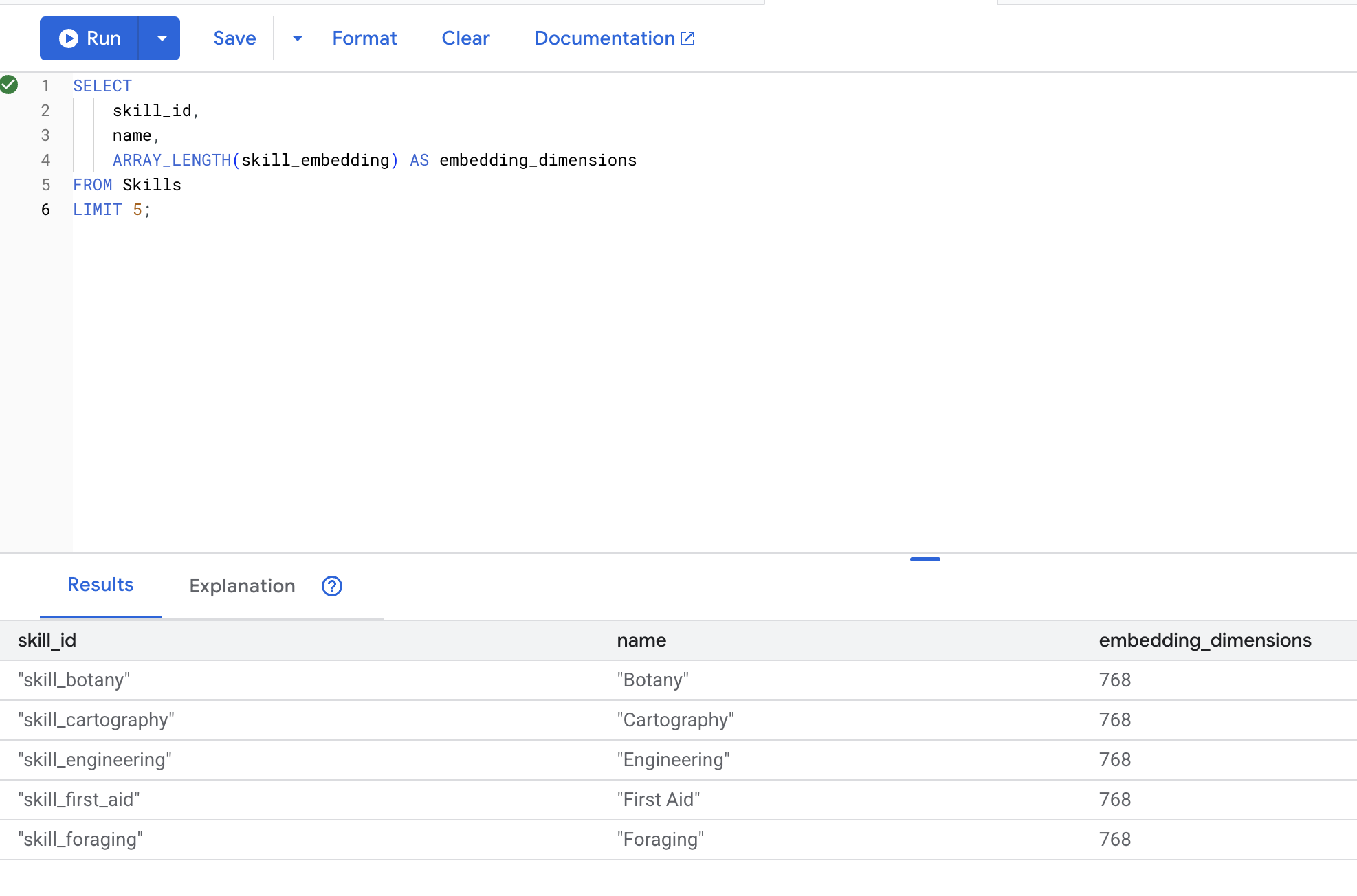
5. Weryfikowanie wektorów dystrybucyjnych
👉 Sprawdź, czy wektory zostały utworzone:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Oczekiwane dane wyjściowe:
6. Testowanie wyszukiwania semantycznego
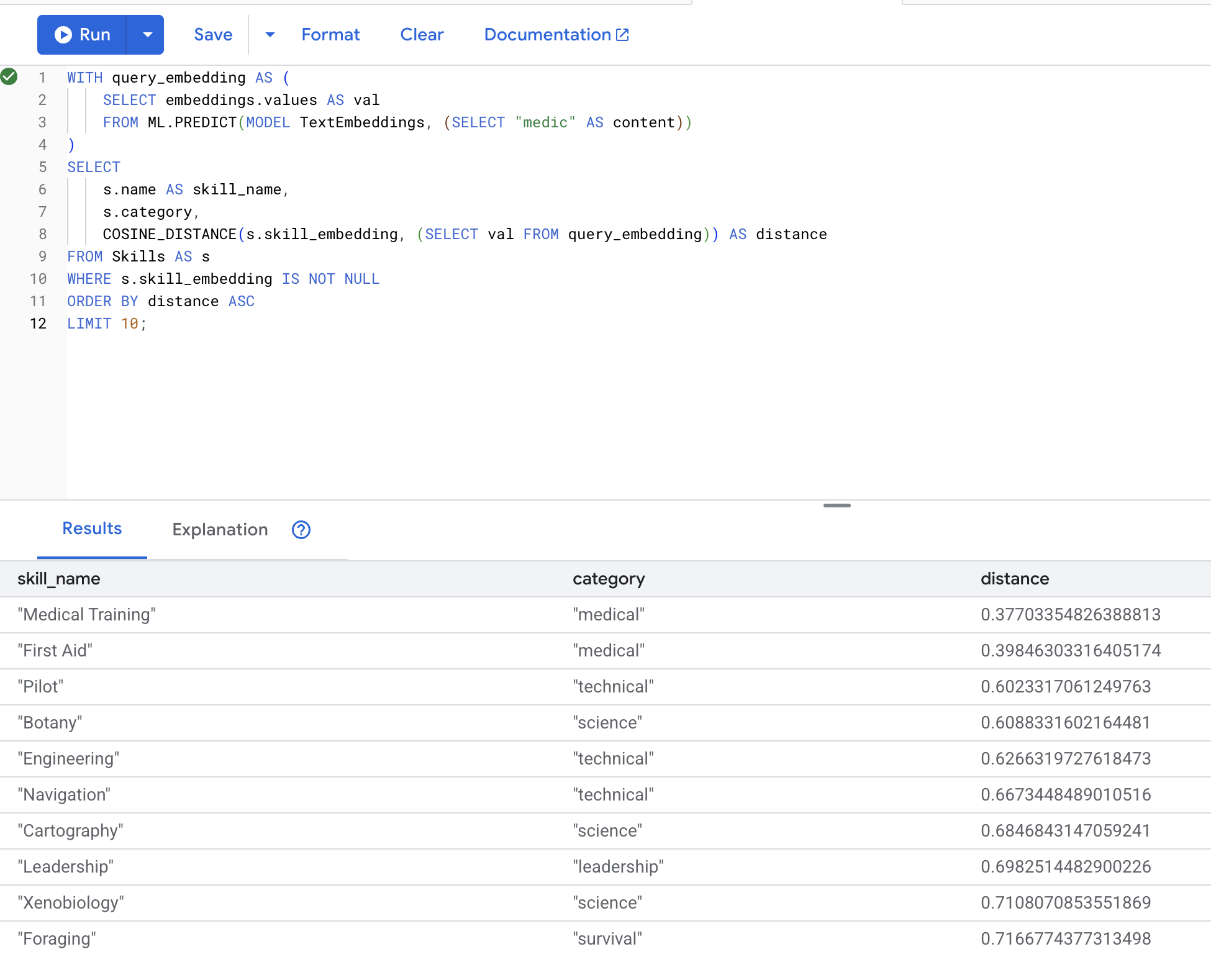
Teraz przetestujemy dokładny przypadek użycia z naszego scenariusza: wyszukiwanie umiejętności medycznych za pomocą terminu „lekarz”.
👉 Znajdź umiejętności podobne do „medic”:
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Konwertuje wyszukiwane hasło użytkownika „medic” na wektor.
- zapisuje go w tabeli tymczasowej
query_embedding.
Oczekiwane wyniki (mniejsza odległość = większe podobieństwo):
7. Tworzenie modelu Gemini na potrzeby analizy
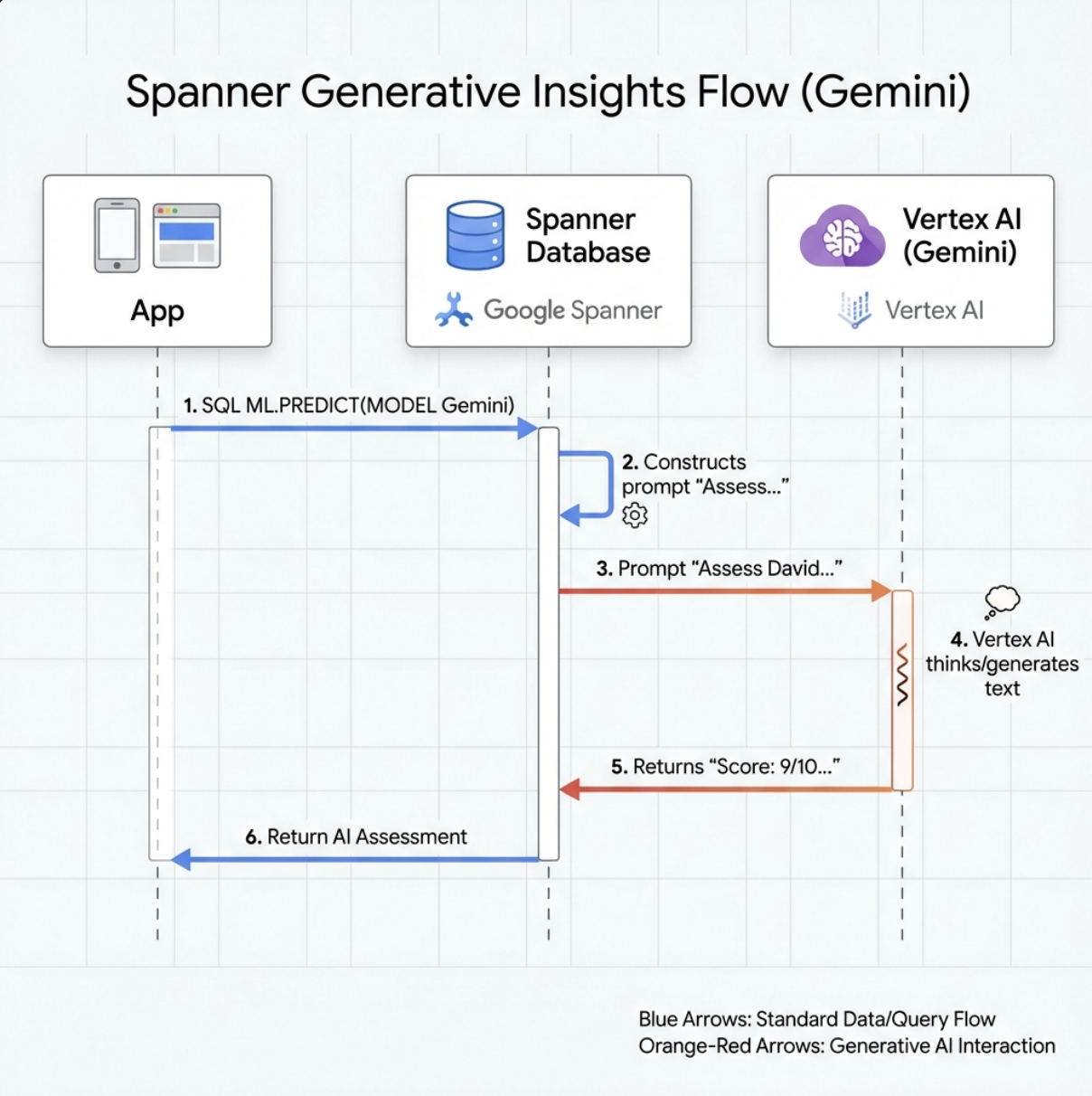
👉 Utwórz odwołanie do modelu generatywnej AI (zastąp $YOUR_PROJECT_ID rzeczywistym identyfikatorem projektu):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Różnica w stosunku do modelu wektorów dystrybucyjnych:
- Wektory dystrybucyjne: tekst → wektor (na potrzeby wyszukiwania podobieństwa)
- Gemini: tekst → wygenerowany tekst (do rozumowania/analizy)
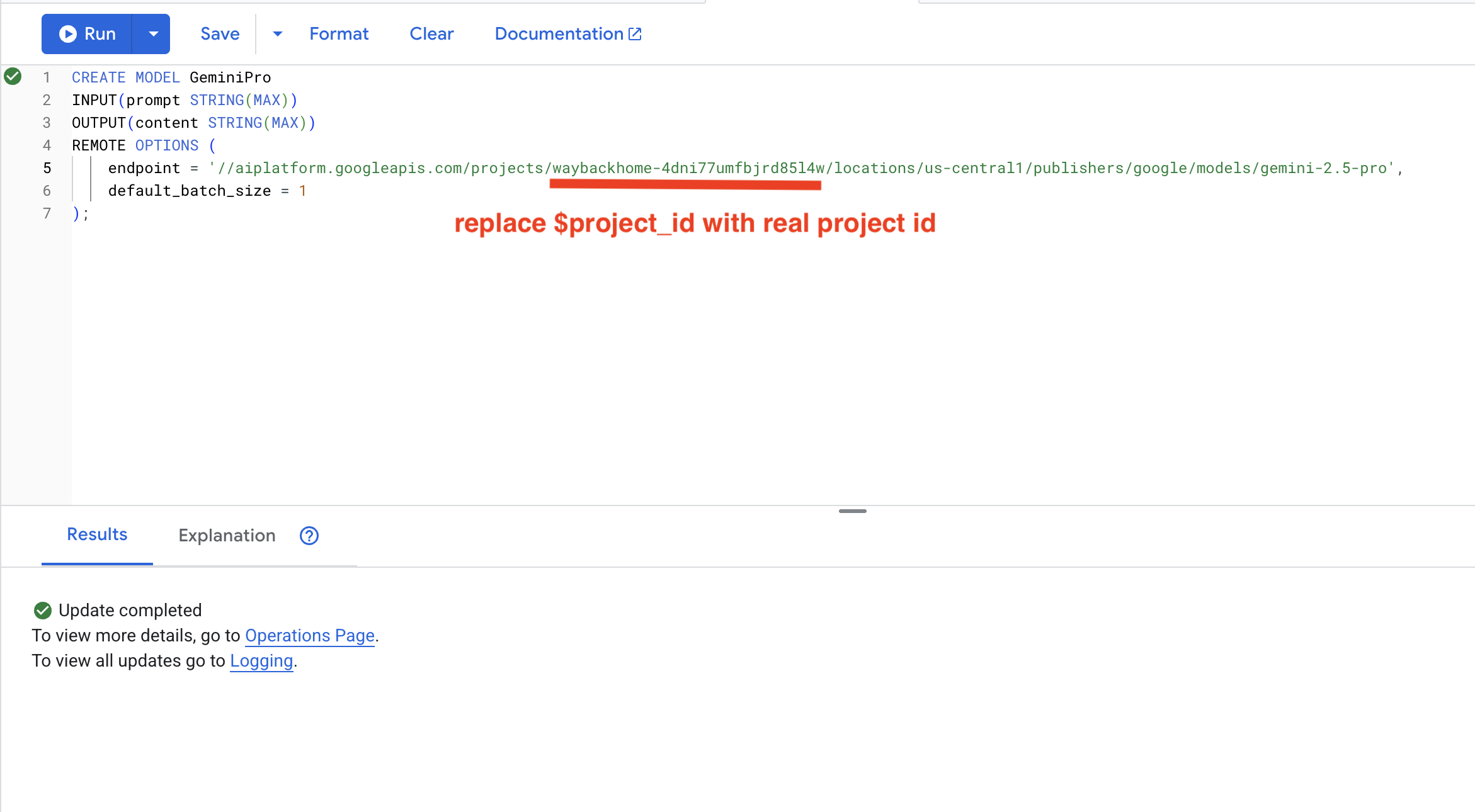
8. Korzystanie z Gemini do analizy zgodności
👉 Analizuj pary ocalałych pod kątem zgodności z misją:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Oczekiwane dane wyjściowe:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Tworzenie agenta Graph RAG z wyszukiwaniem hybrydowym
1. Omówienie architektury systemu
W tej sekcji utworzymy system wyszukiwania wielometodowego, który zapewni agentowi elastyczność w obsłudze różnych typów zapytań. System ma 3 warstwy: warstwę agenta, warstwę narzędzi i warstwę usługi.
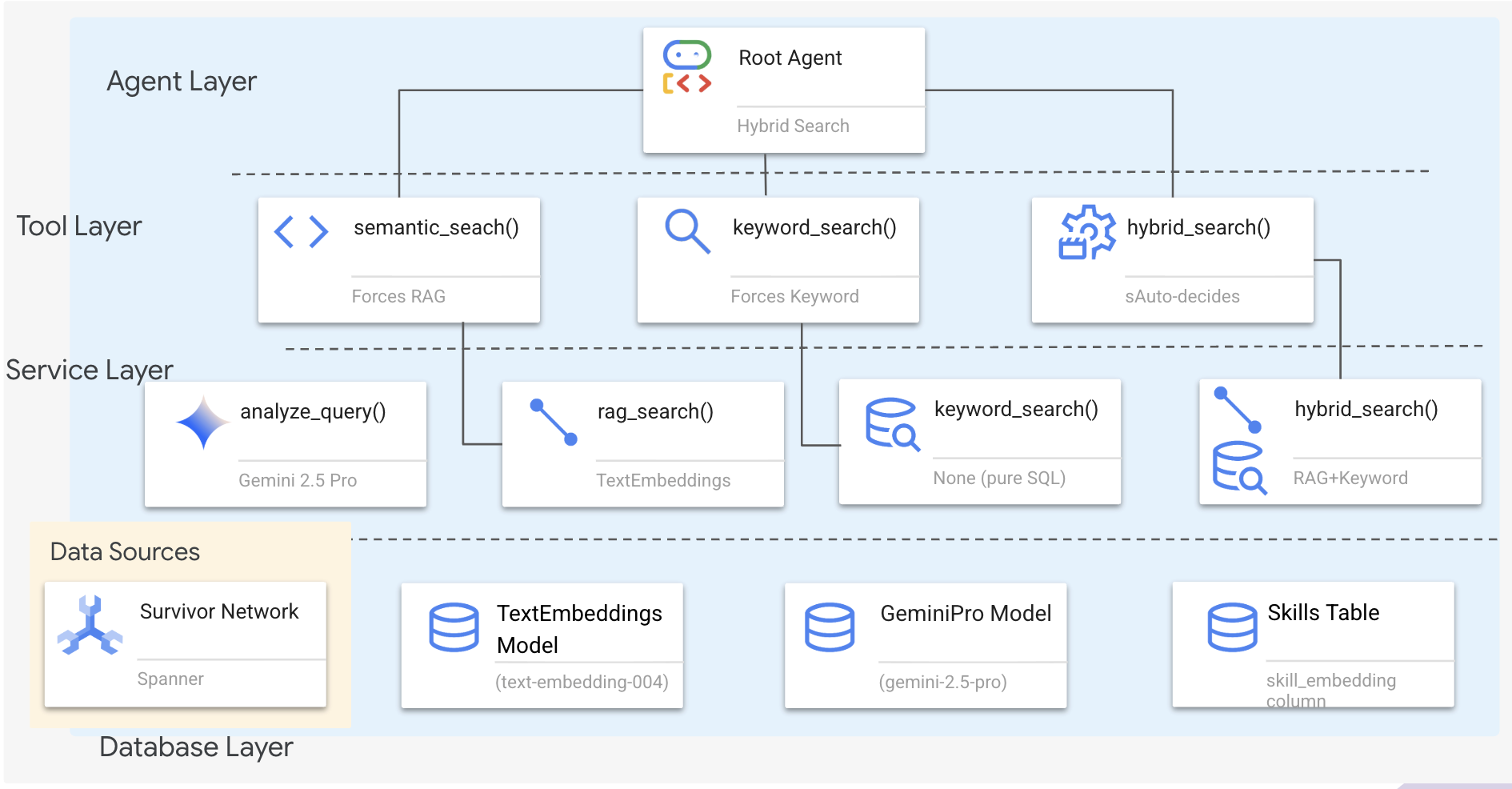
Dlaczego 3 warstwy?
- Rozdzielenie odpowiedzialności: agent skupia się na intencji, narzędzia na interfejsie, a usługa na implementacji.
- Elastyczność: agent może wymuszać określone metody lub zezwalać AI na automatyczne kierowanie.
- Optymalizacja: może pominąć kosztowną analizę AI, gdy metoda jest znana.
W tej sekcji zaimplementujesz przede wszystkim wyszukiwanie semantyczne (RAG), czyli znajdowanie wyników na podstawie znaczenia, a nie tylko słów kluczowych. Później wyjaśnimy, jak wyszukiwanie hybrydowe łączy kilka metod.
2. Wdrażanie usługi RAG
👉💻 W terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Znajdź komentarz # TODO: REPLACE_SQL
Zastąp cały ten wiersz tym kodem:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Definicja narzędzia do wyszukiwania semantycznego
👉💻 W terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
W hybrid_search_tools.py znajdź komentarz # TODO: REPLACE_SEMANTIC_SEARCH_TOOL.
👉Zastąp całą tę linię tym kodem:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Kiedy agent używa:
- zapytania dotyczące podobieństwa („znajdź podobne do X”);
- Zapytania koncepcyjne („zdolności uzdrawiania”)
- Gdy zrozumienie znaczenia jest kluczowe
4. Przewodnik po decyzjach agenta (instrukcje)
W definicji agenta skopiuj i wklej do instrukcji część związaną z wyszukiwaniem semantycznym.
👉💻 W terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Agent używa tej instrukcji do wyboru odpowiedniego narzędzia:
👉W pliku agent.py znajdź komentarz # TODO: REPLACE_SEARCH_LOGIC Replace this whole line i zastąp go tym kodem:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉Znajdź komentarz # TODO: ADD_SEARCH_TOOLReplace this whole line i zastąp go tym kodem:
semantic_search, # Force RAG
5. Jak działa wyszukiwanie hybrydowe (tylko do odczytu, nie wymaga działania)
W krokach 2–4 zaimplementowano wyszukiwanie semantyczne (RAG), czyli podstawową metodę wyszukiwania, która znajduje wyniki na podstawie znaczenia. Możesz jednak zauważyć, że system ten nazywa się „Wyszukiwanie hybrydowe”. Oto jak to wszystko się łączy:
Jak działa scalanie hybrydowe:
W pliku way-back-home/level_2/backend/services/hybrid_search_service.py, gdy wywoływana jest funkcja hybrid_search(), usługa przeprowadza OBA wyszukiwania i scala wyniki:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
W tym ćwiczeniu zaimplementowano komponent wyszukiwania semantycznego (RAG), który jest podstawą. Metody słów kluczowych i hybrydowa są już wdrożone w usłudze – Twój agent może korzystać z nich wszystkich.
Gratulacje! Udało Ci się ukończyć tworzenie agenta Graph RAG z wyszukiwaniem hybrydowym.
7. 🚀 Testowanie agenta za pomocą interfejsu internetowego ADK
Najłatwiej przetestujesz agenta za pomocą polecenia adk web, które uruchamia agenta z wbudowanym interfejsem czatu.
1. Uruchamianie agenta
👉💻 Przejdź do katalogu backendu (w którym zdefiniowany jest Twój agent) i uruchom interfejs internetowy:
cd ~/way-back-home/level_2/backend
uv run adk web
To polecenie uruchamia agenta zdefiniowanego w
agent/agent.py
i otwiera interfejs internetowy do testowania.
👉 Otwórz adres URL:
Polecenie wyświetli lokalny adres URL (zwykle http://127.0.0.1:8000 lub podobny). Otwórz w przeglądarce.
Po kliknięciu adresu URL zobaczysz interfejs internetowy ADK. W lewym górnym rogu wybierz „agent”.
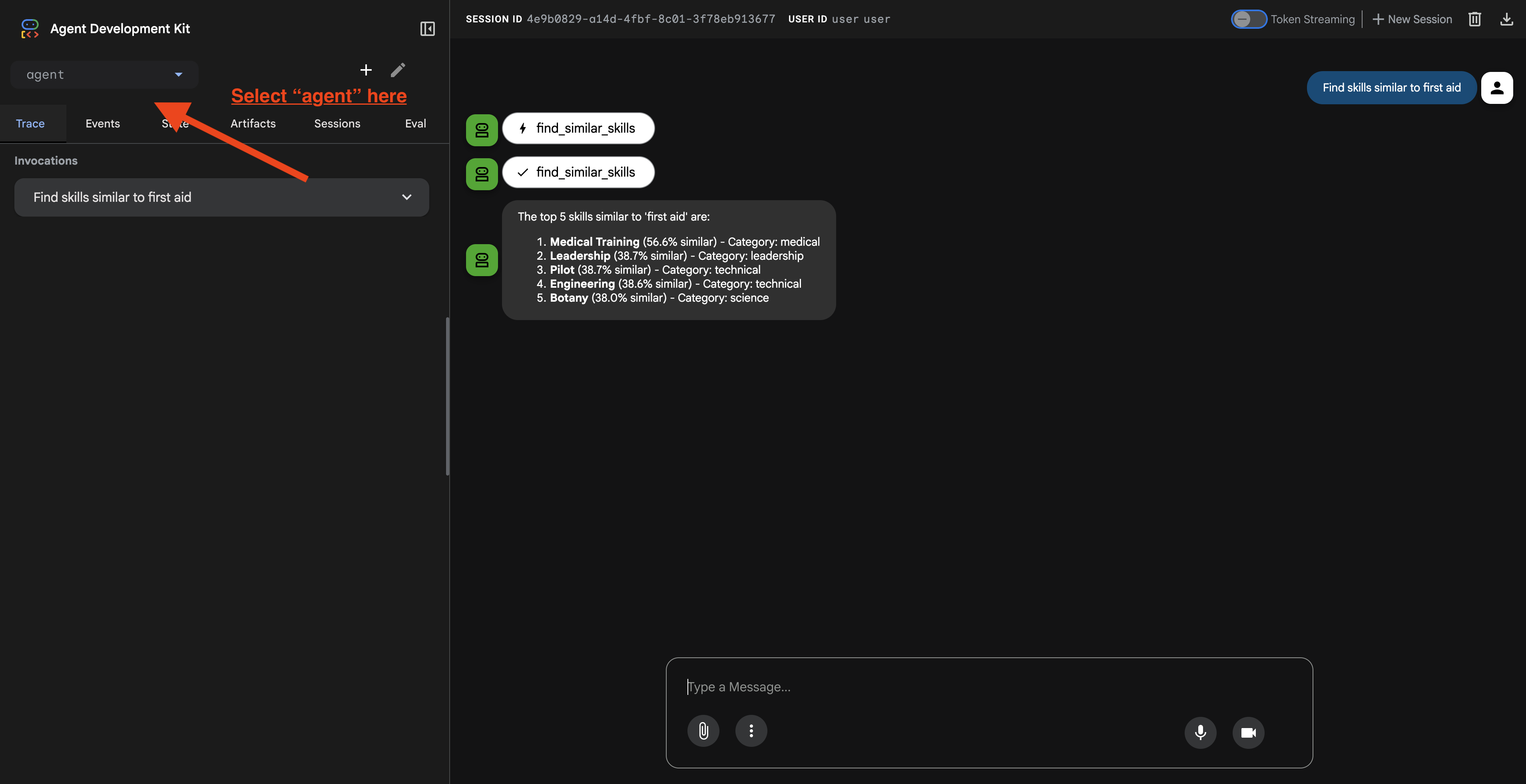
2. Testowanie funkcji wyszukiwania
Agent został zaprojektowany tak, aby inteligentnie kierować Twoje zapytania. Wpisz w oknie czatu poniższe dane, aby zobaczyć różne metody wyszukiwania w działaniu.
🧬 A. Graph RAG (wyszukiwanie semantyczne)
Znajduje produkty na podstawie znaczenia i koncepcji, nawet jeśli słowa kluczowe nie pasują.
Zapytania testowe: (wybierz dowolne z poniższych)
Who can help with injuries?
What abilities are related to survival?
Na co zwrócić uwagę:
- Uzasadnienie powinno zawierać wzmiankę o wyszukiwaniu semantycznym lub RAG.
- Powinny pojawić się wyniki powiązane koncepcyjnie (np. „Chirurgia” w odpowiedzi na zapytanie „Pierwsza pomoc”).
- Wyniki będą oznaczone ikoną 🧬.
🔀 B. Wyszukiwanie hybrydowe
Łączy filtry słów kluczowych z semantycznym rozumieniem złożonych zapytań.
Zapytania testowe:(wybierz dowolne z poniższych)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Na co zwrócić uwagę:
- Uzasadnienie powinno zawierać wzmiankę o wyszukiwaniu hybrydowym.
- Wyniki powinny spełniać OBA kryteria (koncepcja + lokalizacja/kategoria).
- Wyniki znalezione obiema metodami będą oznaczone ikoną 🔀 i będą miały najwyższą pozycję.
👉💻 Po zakończeniu testowania zakończ proces, naciskając Ctrl+C w wierszu poleceń.
8. 🚀 Uruchamianie pełnej aplikacji
Omówienie architektury pełnego stosu
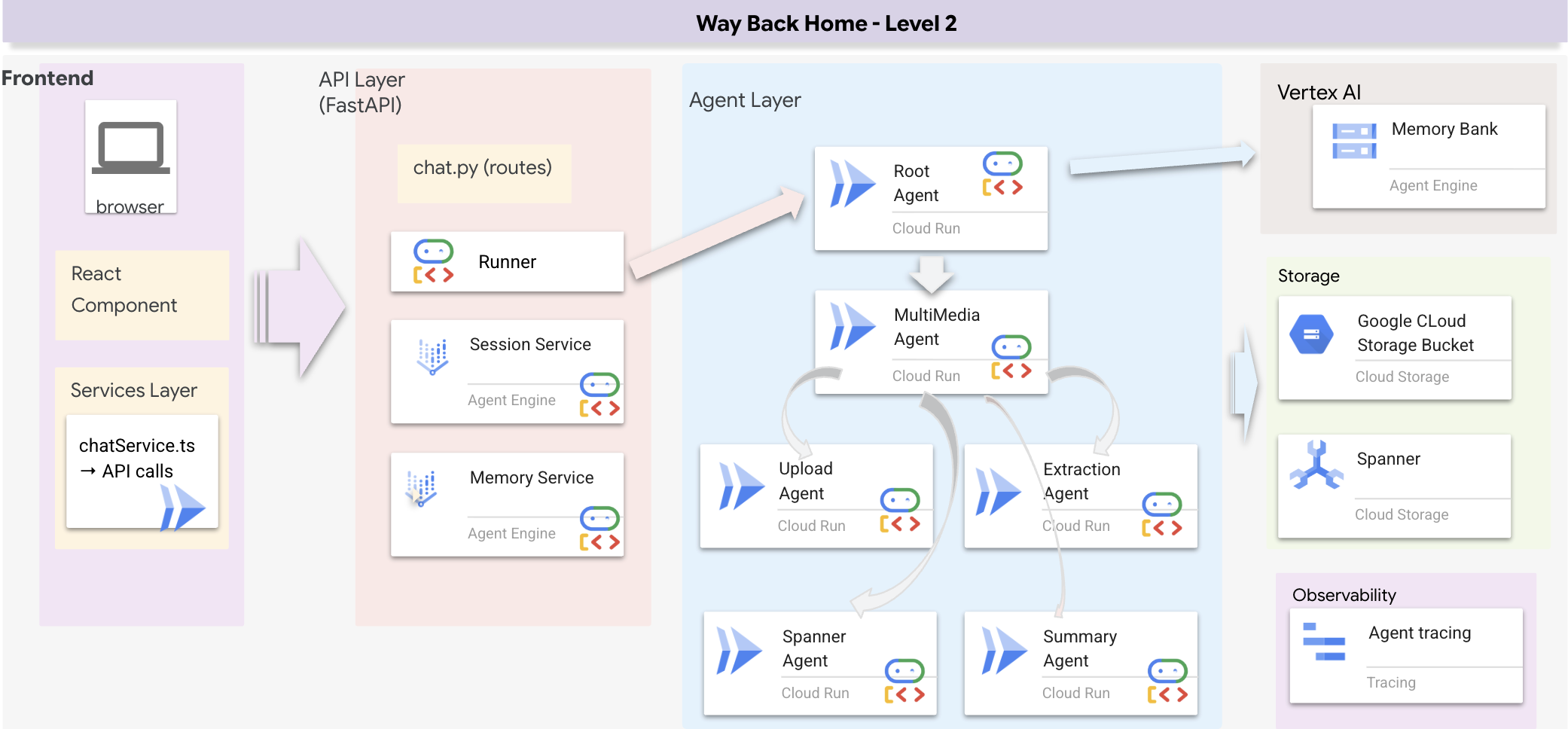
Dodawanie SessionService i Runnera
👉💻 W terminalu otwórz plik chat.py w edytorze Cloud Shell, uruchamiając to polecenie (przed przejściem dalej upewnij się, że poprzedni proces został zakończony za pomocą kombinacji klawiszy Ctrl+C):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 W pliku chat.py znajdź komentarz # TODO: REPLACE_INMEMORY_SERVICES Replace this whole line i zastąp go tym kodem:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉 W pliku chat.py znajdź komentarz # TODO: REPLACE_RUNNER Replace this whole line i zastąp go tym kodem:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Rozpocznij składanie wniosku
Jeśli poprzedni terminal nadal działa, zakończ go, naciskając Ctrl+C.
👉💻 Uruchom aplikację:
cd ~/way-back-home/level_2/
./start_app.sh
Gdy backend zostanie uruchomiony, zobaczysz Local: http://localhost:5173/", jak poniżej: 
👉 W terminalu kliknij Local: http://localhost:5173/.
2. Testowanie wyszukiwania semantycznego
Zapytanie:
Find skills similar to healing
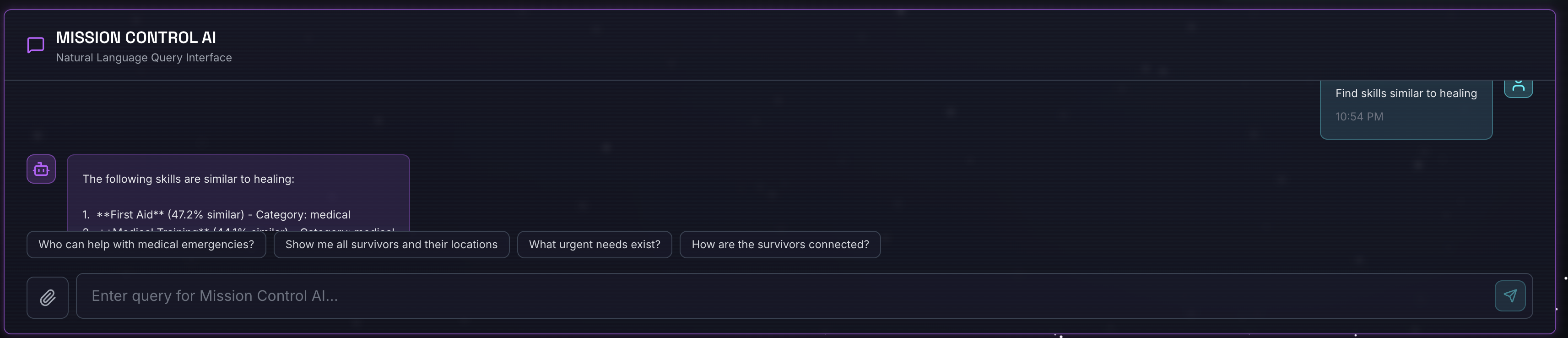
Co się dzieje:
- Agent rozpoznaje prośbę o podobieństwo
- Generuje osadzanie dla słowa „healing”
- Używa odległości cosinusowej do znajdowania podobnych pod względem semantycznym umiejętności
- Zwroty: pierwsza pomoc (mimo że nazwy nie pasują do „leczenia”)
3. Testowanie wyszukiwania hybrydowego
Zapytanie:
Find medical skills in the mountains
Co się dzieje:
- Komponent słowa kluczowego: filtr dla
category='medical' - Komponent semantyczny: umieść „medyczne” i sortuj według podobieństwa.
- Scal: połącz wyniki, nadając priorytet tym, które zostały znalezione obiema metodami. 🔀
Zapytanie(opcjonalnie):
Who is good at survival and in the forest?
Co się dzieje:
- Znalezione słowa kluczowe:
biome='forest' - Wyniki semantyczne: umiejętności podobne do „przetrwanie”
- Hybrydowe łączenie obu tych metod zapewnia najlepsze wyniki.
👉💻 Gdy skończysz testowanie, w terminalu zakończ je, naciskając Ctrl+C.
4. (TYLKO DLA UCZESTNIKÓW WARSZTATÓW) Aktualizowanie lokalizacji
👉💻 Uruchom skrypt uzupełniania:
cd ~/way-back-home/level_2
./set_level_2.sh
Otwórz teraz waybackhome.dev. Zobaczysz, że Twoja lokalizacja została zaktualizowana. Gratulujemy ukończenia poziomu 2!

9. ☕️ [Opcjonalnie] Potok multimodalny (tylko do odczytu) – warstwa narzędziowa
Dlaczego potrzebujemy potoku multimodalnego?
Sieć przetrwania to nie tylko tekst. Osoby, które przeżyły katastrofę, wysyłają nieustrukturyzowane dane bezpośrednio na czacie:
- 📸 Obrazy: zdjęcia zasobów, zagrożeń lub sprzętu.
- 🎥 Filmy: raporty o stanie lub transmisje SOS.
- 📄 Tekst: notatki lub dzienniki z terenu.
Jakie pliki przetwarzamy?
W przeciwieństwie do poprzedniego kroku, w którym wyszukiwaliśmy istniejące dane, tutaj przetwarzamy pliki przesłane przez użytkownika. Interfejs chat.py dynamicznie obsługuje załączniki do plików:
Źródło | Treść | Cel |
Załącznik użytkownika | Obraz/film/tekst | Informacje do dodania na wykresie |
Kontekst czatu | „Oto zdjęcie materiałów”. | Cel i dodatkowe informacje |
Planowane podejście: sekwencyjny potok agentów
Używamy agenta sekwencyjnego (multimedia_agent.py), który łączy ze sobą wyspecjalizowanych agentów:
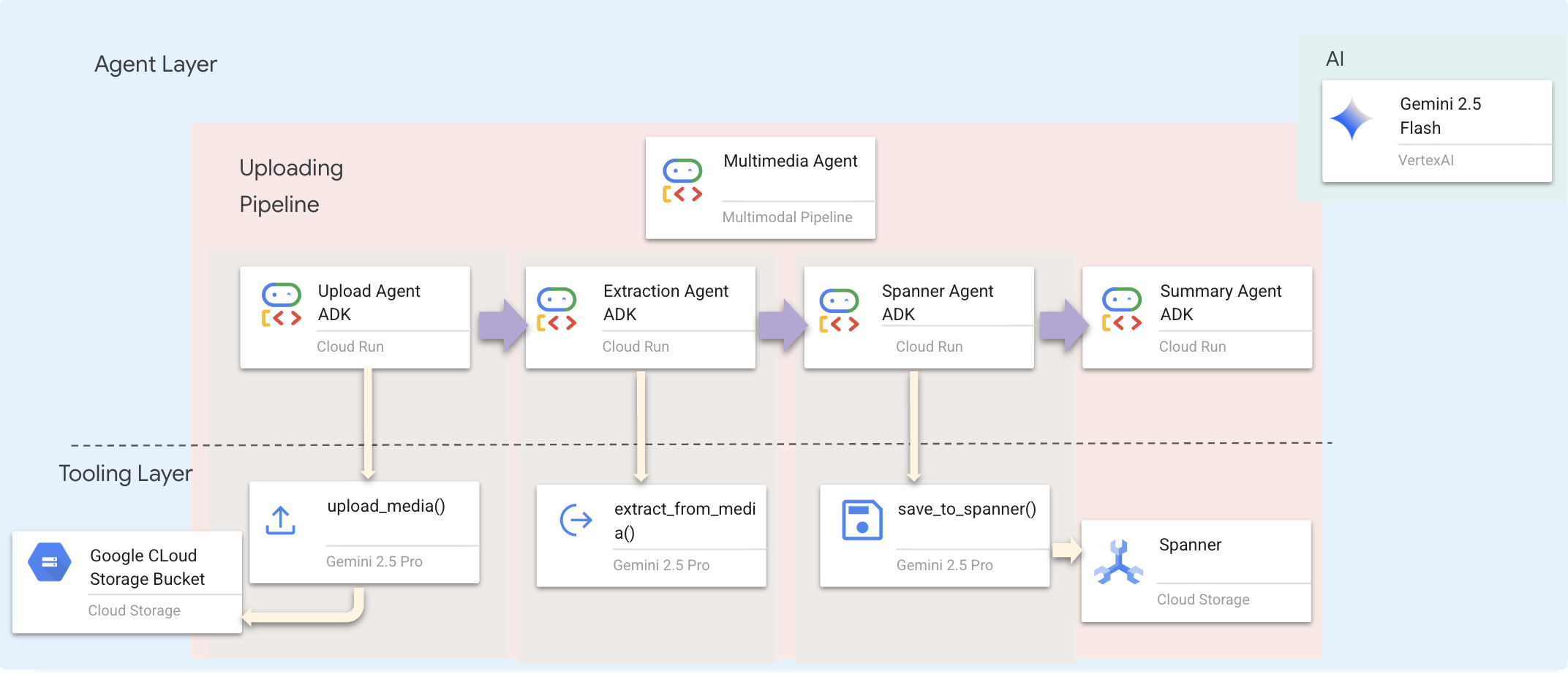
Jest to zdefiniowane w backend/agent/multimedia_agent.py jako SequentialAgent.
Warstwa narzędzi udostępnia funkcje, z których mogą korzystać agenci. Narzędzia zajmują się „jak” – przesyłaniem plików, wyodrębnianiem elementów i zapisywaniem ich w bazie danych.
1. Otwieranie pliku narzędzi
👉💻 Otwórz plik level_2/backend/agent/tools/extraction_tools.py lub wpisz w terminalu to polecenie: Otwórz nowy terminal. W terminalu otwórz plik w edytorze Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Wdrażanie narzędzia upload_media
To narzędzie przesyła plik lokalny do Google Cloud Storage.
👉 W def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: poniższy kod pokazuje, jak przesyłać pliki do GCS i wykrywać ich typ:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Wdrażanie narzędzia extract_from_media
To narzędzie to router – sprawdza media_type i przekazuje informacje do odpowiedniego ekstraktora (tekstu, obrazu lub filmu).
👉 W async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: poniższy kod pokazuje, jak wyodrębniać elementy i relacje z przesłanych multimediów.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Najważniejsze szczegóły implementacji:
- Dane wejściowe multimodalne: do
generate_contentprzekazujemy zarówno prompt tekstowy (_get_extraction_prompt()), jak i obiekt obrazu. - Ustrukturyzowane dane wyjściowe:
response_mime_type="application/json"zapewnia, że LLM zwraca prawidłowy plik JSON, co ma kluczowe znaczenie dla potoku. - Łączenie elementów wizualnych: prompt zawiera znane elementy, dzięki czemu Gemini może rozpoznawać konkretne postacie.
4. Wdrażanie narzędzia save_to_spanner
To narzędzie zapisuje wyodrębnione encje i relacje w bazie danych grafów Spanner.
👉 W def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: znajdziesz kod dotyczący zapisywania wyodrębnionych encji i relacji w bazie danych Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Dzięki udostępnieniu agentom zaawansowanych narzędzi zapewniamy integralność danych, wykorzystując jednocześnie ich możliwości rozumowania.
5. Aktualizowanie usługi GCS
GCSService odpowiada za przesłanie pliku do Google Cloud Storage.
👉💻 Otwórz plik level_2/backend/services/gcs_service.py lub wpisz w terminalu, aby otworzyć plik w edytorze Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 W def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: znajdziesz kod dotyczący zapisywania wyodrębnionych encji i relacji w bazie danych Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Dzięki temu, że jest to usługa, agent nie musi znać zasobników GCS, nazw obiektów blob ani generowania podpisanych adresów URL. Prosi tylko o „przesłanie”.
6. Dlaczego przepływ pracy oparty na agentach jest lepszy od tradycyjnych metod?
Przewaga agentowa:
Funkcja | Potok wsadowy | Oparte na zdarzeniach | Proces agentowy |
Złożoność | Niski (1 skrypt) | Wysoki (5 usług lub więcej) | Niski (1 plik Pythona: |
Zarządzanie stanem | Zmienne globalne | Trudne (rozdzielone) | Ujednolicony (stan agenta) |
Obsługa błędów | Awarie | Ciche logi | Interaktywny („Nie udało się odczytać tego pliku”) |
Opinie użytkowników | Odbitki na płótnie | Wymaga odpytywania | Natychmiastowe (część czatu) |
Możliwość dostosowania | Stała logika | Funkcje sztywne | Inteligentny (LLM decyduje o następnym kroku) |
Świadomość kontekstu | Brak | Brak | Pełna (zna intencje użytkownika) |
Dlaczego to jest ważne: używając multimedia_agent.py (SequentialAgent z 4 podagentami: Upload → Extract → Save → Summary), zastępujemy złożoną infrastrukturę I niestabilne skrypty inteligentną logiką aplikacji konwersacyjnej.
10. ☕️ [Opcjonalnie] Potok multimodalny (tylko do odczytu) – warstwa agenta
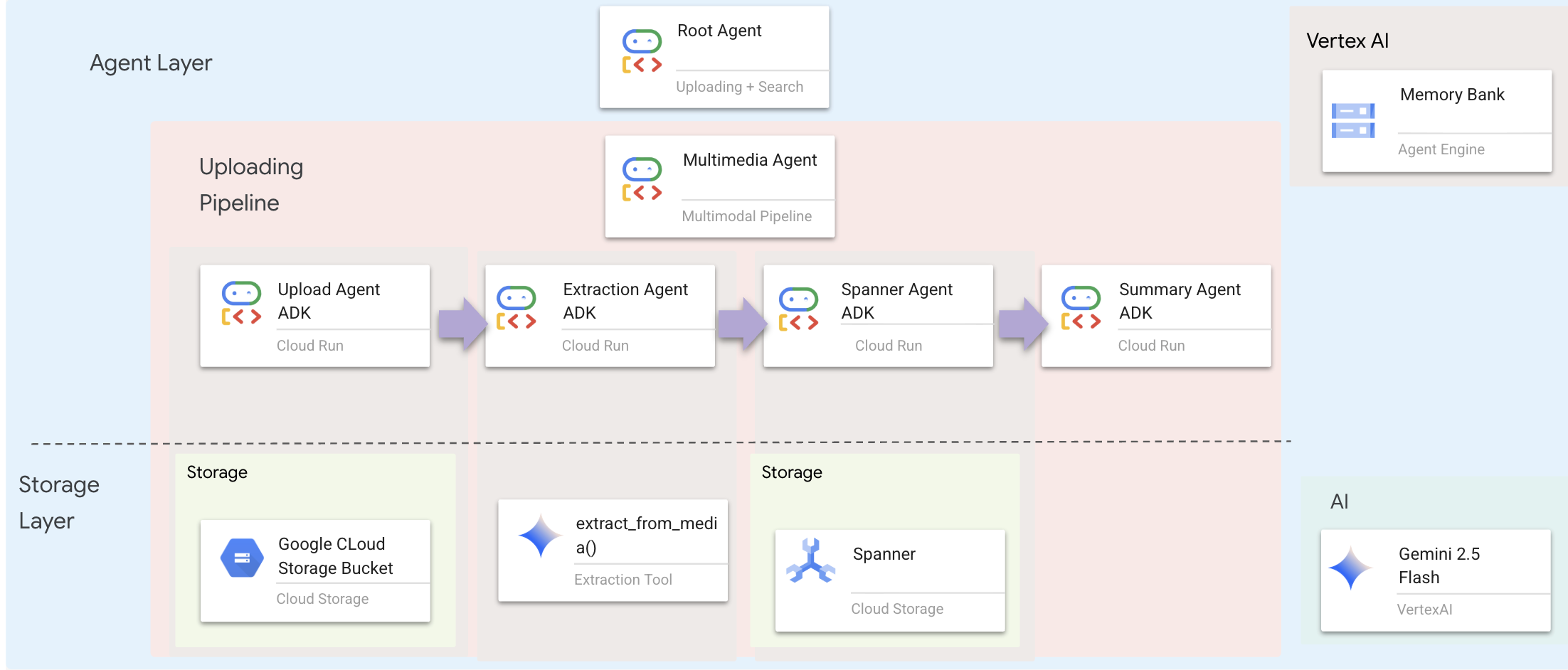
Warstwa agentów określa inteligencję, czyli agenty, które używają narzędzi do wykonywania zadań. Każdy agent ma określoną rolę i przekazuje kontekst do następnego. Poniżej znajduje się schemat architektury systemu wieloagentowego.
1. Otwieranie pliku agenta
👉💻 Otwórz plik level_2/backend/agent/multimedia_agent.py lub wpisz w terminalu to polecenie: Otwórz nowy terminal. W terminalu otwórz plik w edytorze Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Określanie agenta przesyłania
Ten agent wyodrębnia ścieżkę pliku z wiadomości użytkownika i przesyła ją do GCS.
👉W pliku multimedia_agent.py ten kod tworzy upload_agent, który jest przesyłany do GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Określanie agenta wyodrębniania
Ten agent „widzi” przesłane multimedia i wyodrębnia z nich dane strukturalne za pomocą Gemini Vision.
👉W pliku multimedia_agent.py ten kod tworzy extraction_agent, które wyodrębniają informacje z przesłanych multimediów:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Zwróć uwagę, jak instruction odwołuje się do {upload_result} – w ten sposób stan jest przekazywany między agentami w ADK.
4. Zdefiniuj agenta Spanner
Ten agent zapisuje wyodrębnione encje i relacje w bazie danych grafu.
👉W pliku multimedia_agent.py ten kod tworzy spanner_agent, który zapisuje wyodrębnione informacje w bazie danych:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Ten agent otrzymuje kontekst z obu poprzednich kroków (upload_result i extraction_result).
5. Określanie agenta podsumowującego
Ten agent łączy wyniki wszystkich poprzednich kroków w przyjazną dla użytkownika odpowiedź.
👉W pliku multimedia_agent.py ten kod definiuje prompt dla summary_agent, który podsumowuje wynik:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Ten agent nie potrzebuje narzędzi – wystarczy, że odczyta udostępniony kontekst i wygeneruje dla użytkownika przejrzyste podsumowanie.
🧠 Podsumowanie architektury
Warstwa | Plik | Odpowiedzialność |
Narzędzia |
| Jak – przesyłanie, wyodrębnianie, zapisywanie |
Agent |
| Co – zarządzanie potokiem |
11. 🚀 Potok danych multimodalnych – orkiestracja
Podstawą naszego nowego systemu jest MultimediaExtractionPipeline zdefiniowany w backend/agent/multimedia_agent.py. Wykorzystuje on wzorzec Sequential Agent z pakietu ADK (Agent Development Kit).
1. Dlaczego sekwencyjne?
Przetwarzanie przesłanego pliku to liniowy łańcuch zależności:
- Nie możesz wyodrębnić danych, dopóki nie masz pliku (przesłanego).
- Nie możesz zapisać danych, dopóki ich nie wyodrębnisz (ekstrakcja).
- Podsumowanie można utworzyć dopiero po uzyskaniu wyników (zapisaniu).
Idealnie sprawdzi się SequentialAgent. Przekazuje dane wyjściowe jednego agenta jako kontekst lub dane wejściowe do następnego.
2. Definicja agenta
Zobaczmy, jak potok jest składany u dołu pliku multimedia_agent.py: 👉💻 w terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Otrzymuje dane wejściowe z obu poprzednich kroków. Znajdź komentarz # TODO: REPLACE_ORCHESTRATION. Zastąp cały ten wiersz tym kodem:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Połącz się z pracownikiem obsługi klienta
👉💻 W terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Znajdź komentarz # TODO: REPLACE_ADD_SUBAGENT. Zastąp cały ten wiersz tym kodem:
sub_agents=[multimedia_agent],
Ten pojedynczy obiekt skutecznie łączy 4 „ekspertów” w 1 obiekt, który można wywołać.
4. Przepływ danych między agentami
Każdy agent zapisuje swoje dane wyjściowe we wspólnym kontekście, do którego mogą uzyskać dostęp kolejni agenci:
5. Otwórz aplikację (pomiń ten krok, jeśli aplikacja jest nadal uruchomiona)
👉💻 Uruchom aplikację:
cd ~/way-back-home/level_2/
./start_app.sh
👉 W terminalu kliknij Local: http://localhost:5173/.
6. Testowe przesyłanie obrazu
👉 W interfejsie czatu wybierz dowolne zdjęcie i prześlij je do interfejsu:
W interfejsie czatu opisz agentowi swój konkretny kontekst:
Here is the survivor note
Następnie załącz obraz tutaj.

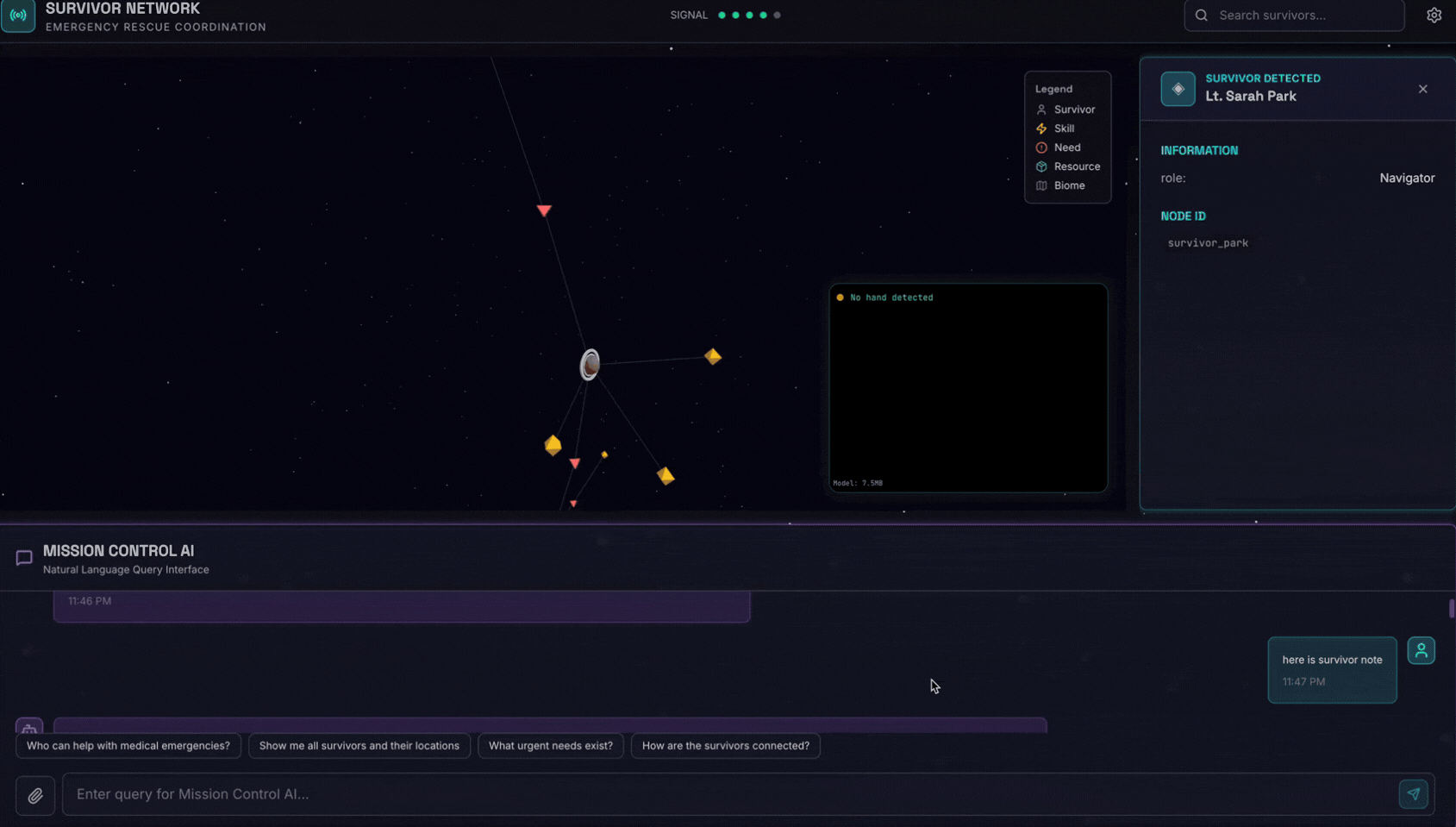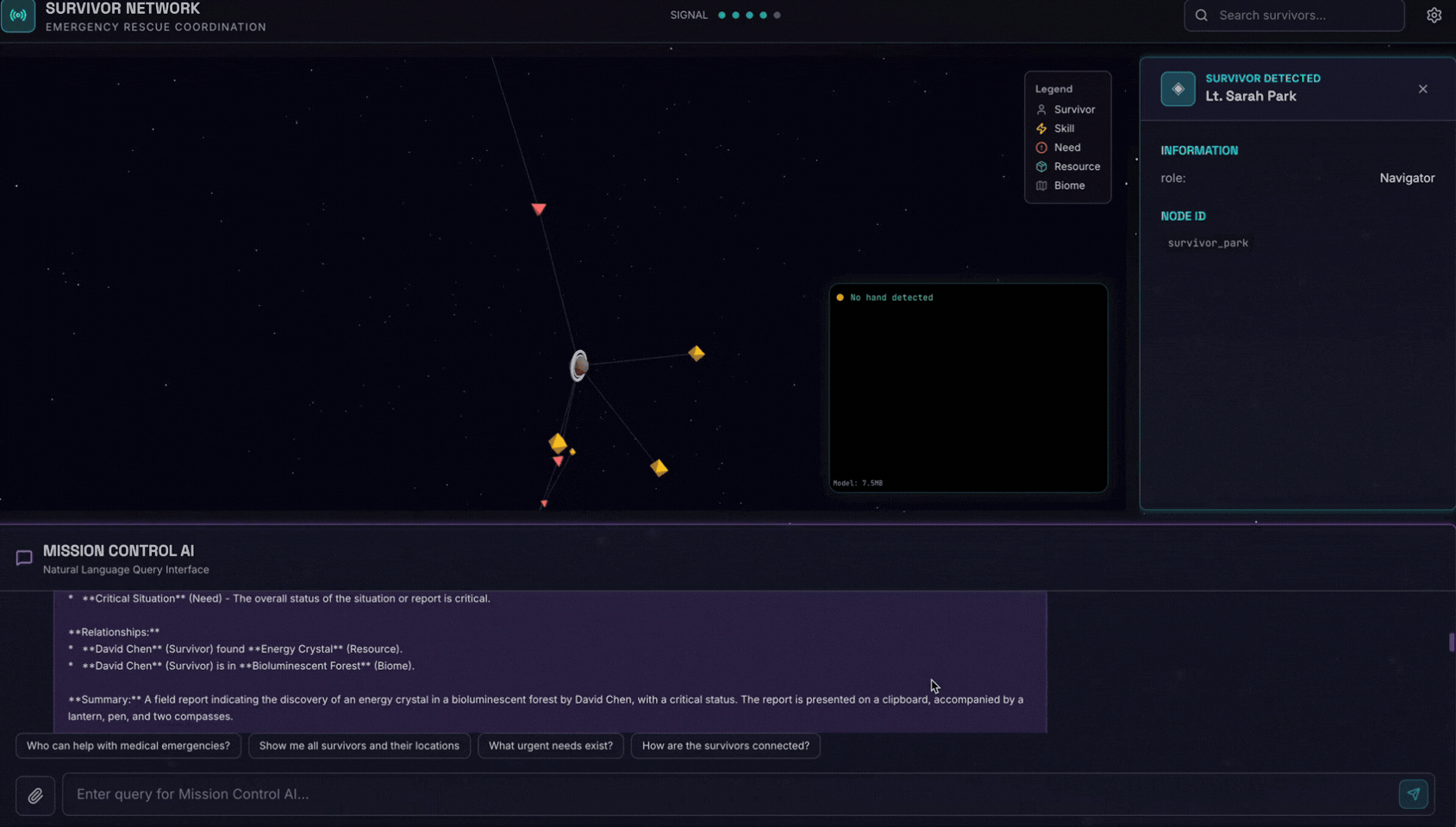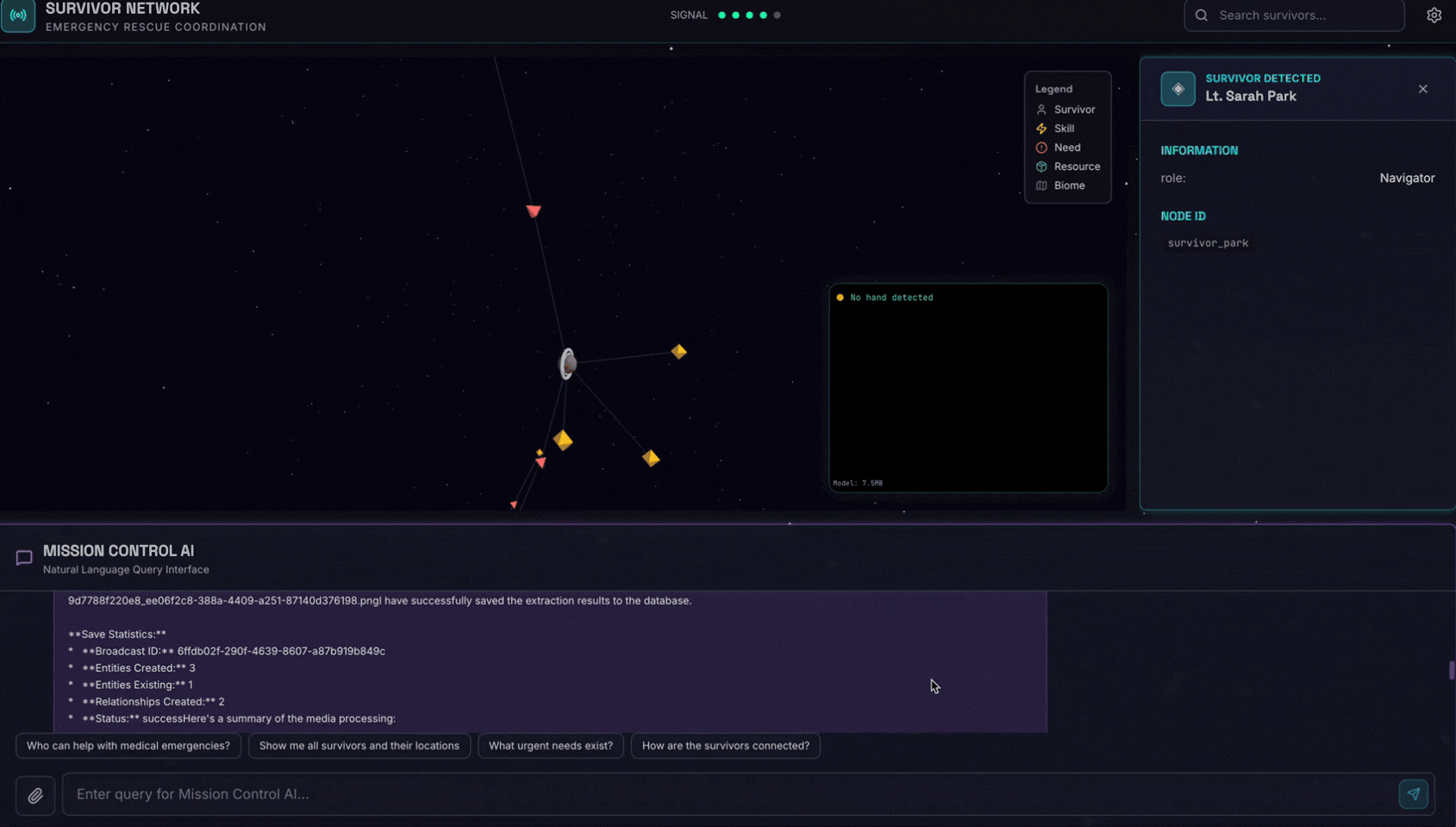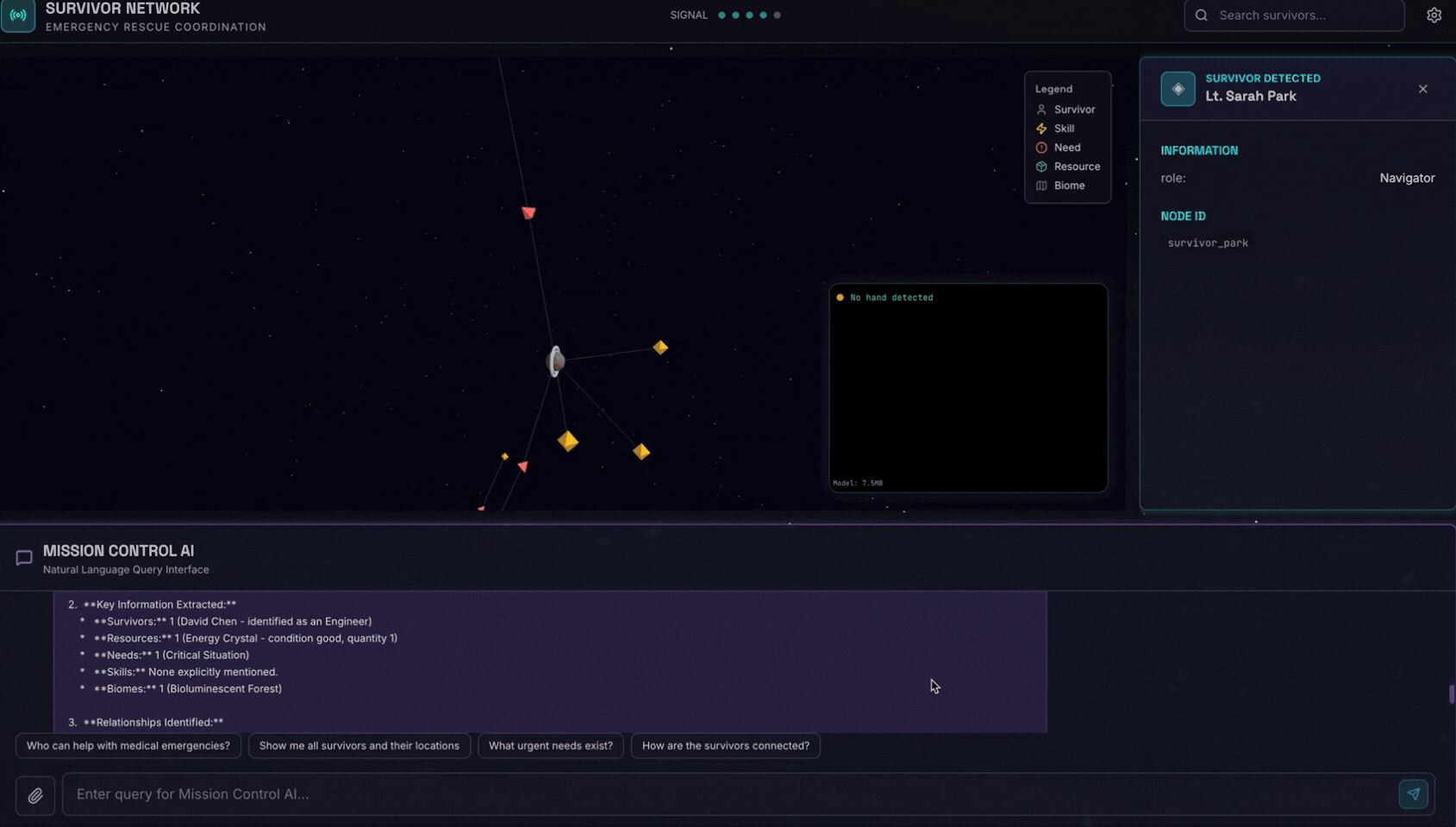
👉💻 Po zakończeniu testowania naciśnij „Ctrl+C”, aby zakończyć proces.
6. Weryfikowanie przesyłania multimodalnego w zasobniku GCS
- Otwórz konsolę Google Cloud Storage.
- Wybierz „zasobnik” w Cloud Storage.
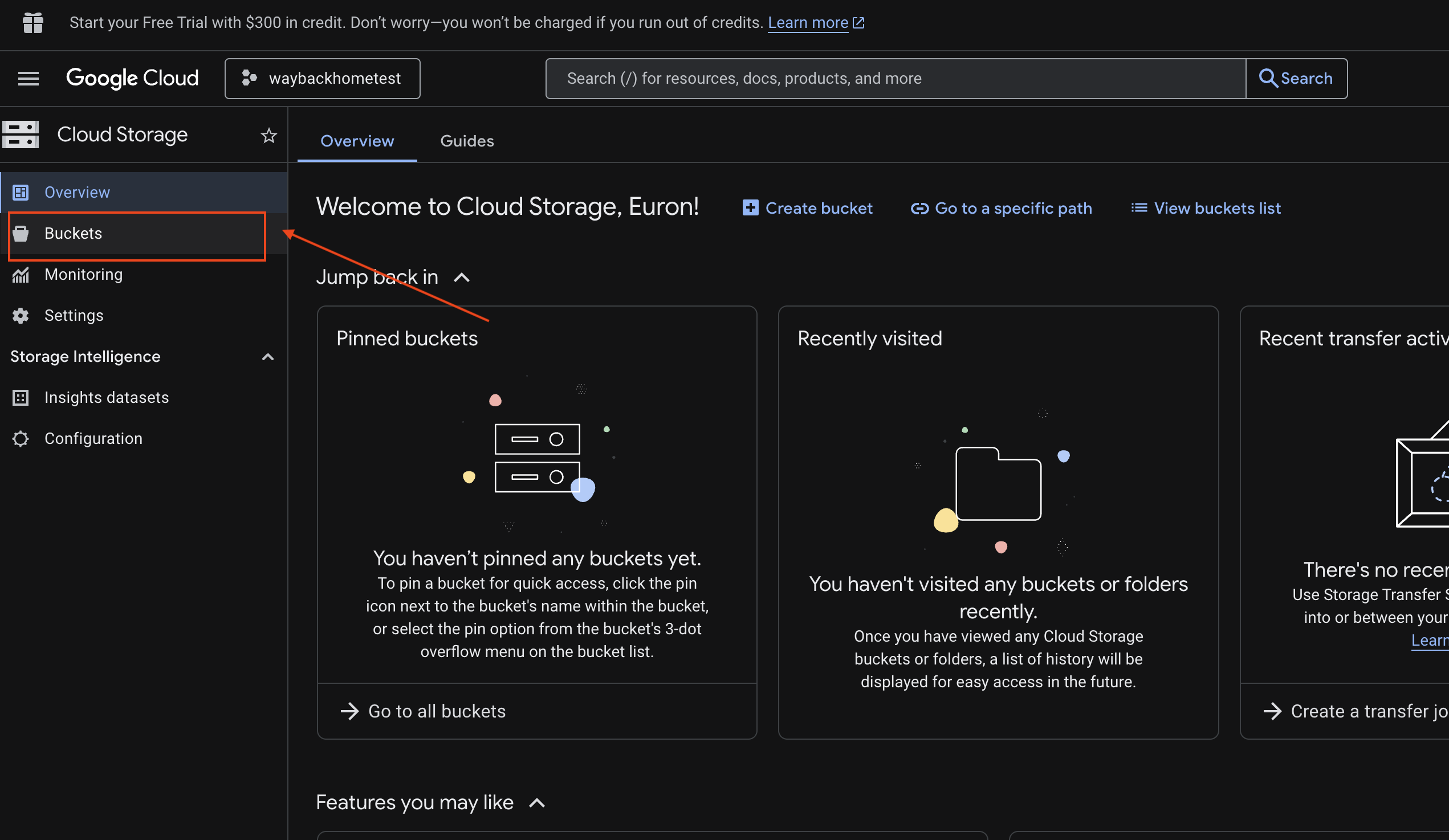
- Wybierz zasobnik i kliknij
media.
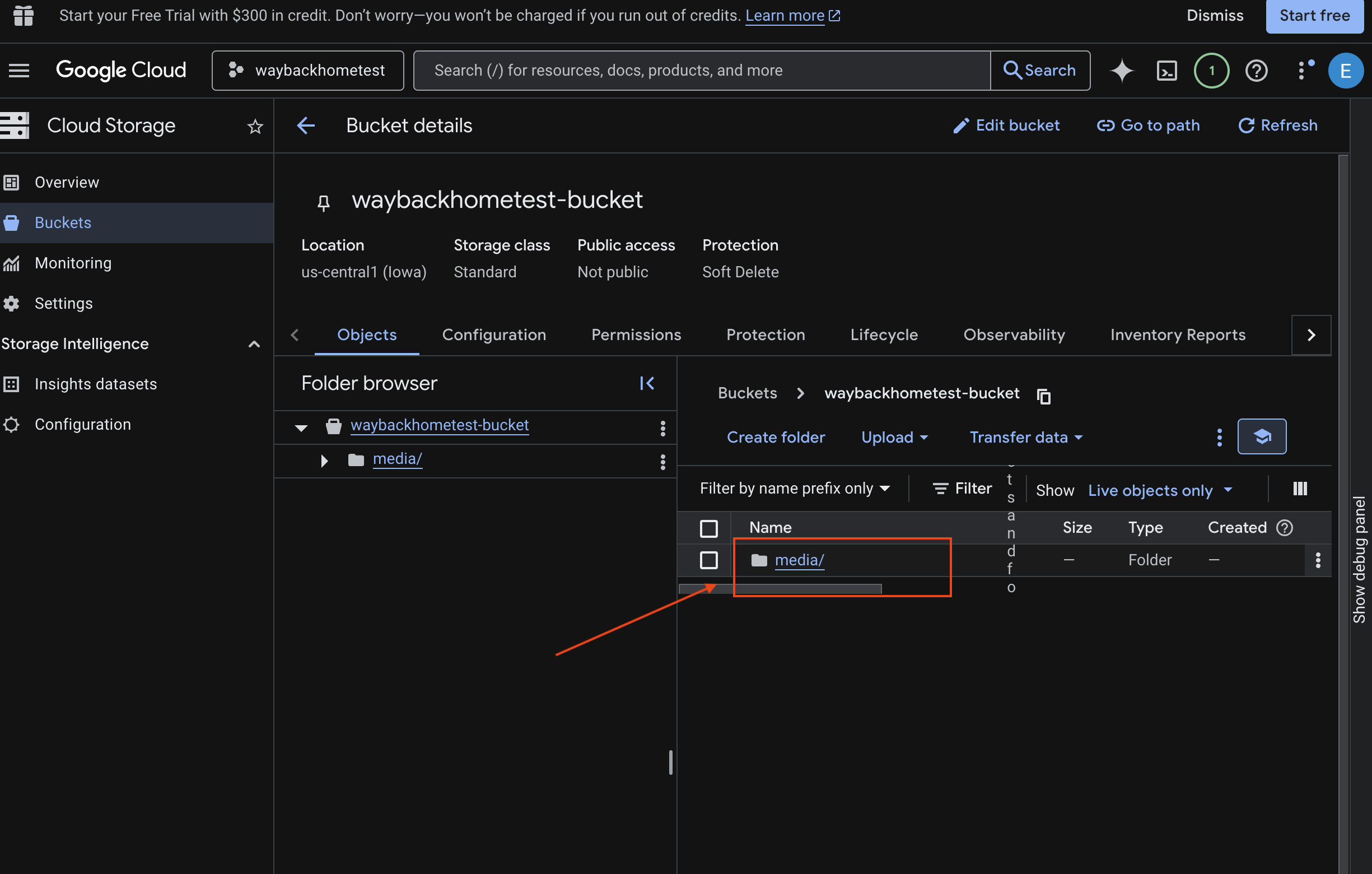
- Przesłany obraz możesz wyświetlić tutaj.
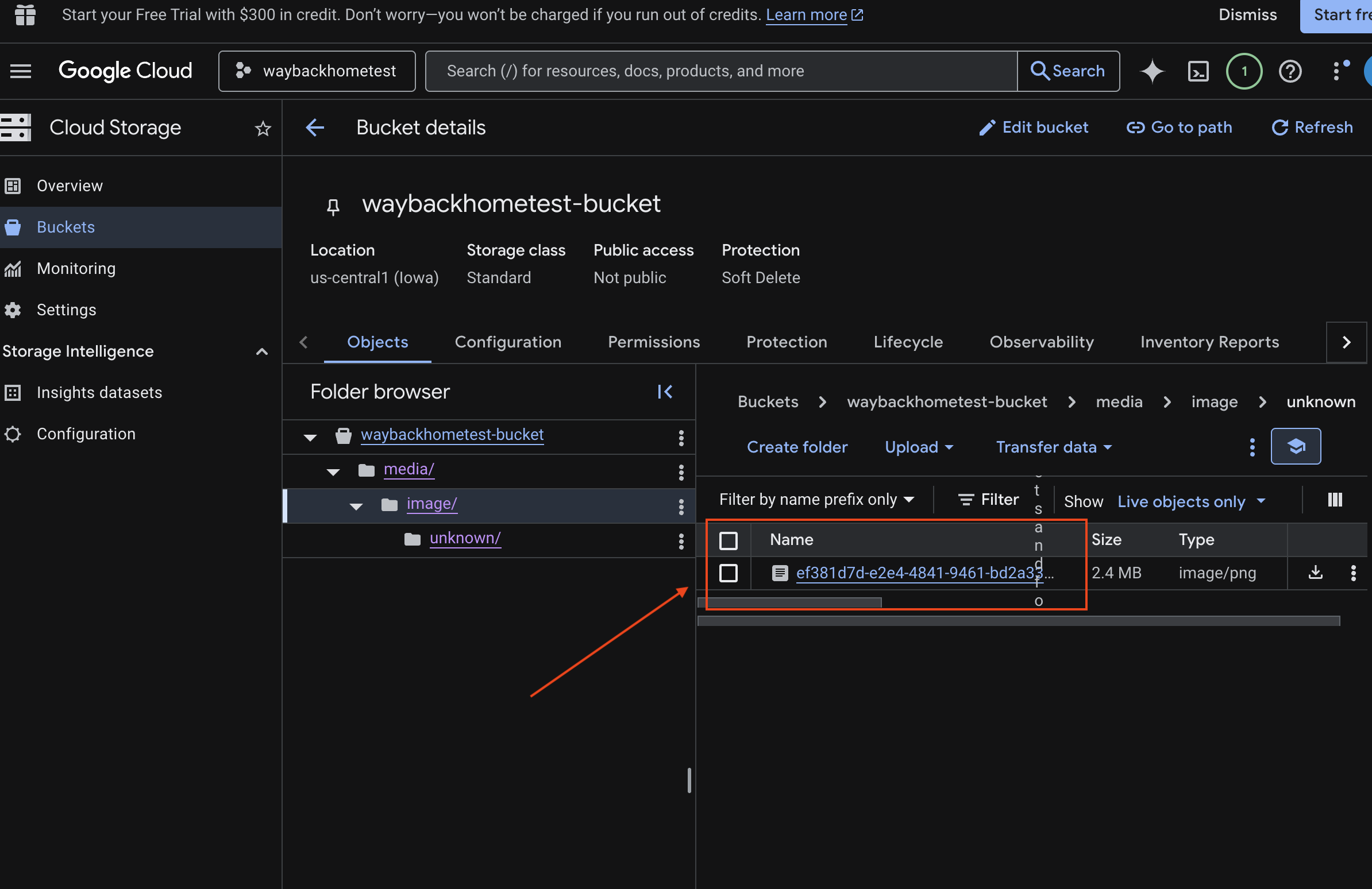
7. Weryfikowanie przesyłania multimodalnego w Spannerze (opcjonalnie)
Poniżej znajdziesz przykładowe dane wyjściowe w interfejsie dla test_photo1.
- Otwórz konsolę Google Cloud Spanner.
- Wybierz instancję:
Survivor Network - Wybierz bazę danych:
graph-db - Na pasku bocznym po lewej stronie kliknij Spanner Studio.
👉 W Spanner Studio wyślij zapytanie o nowe dane:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Możemy to sprawdzić, patrząc na wynik poniżej:
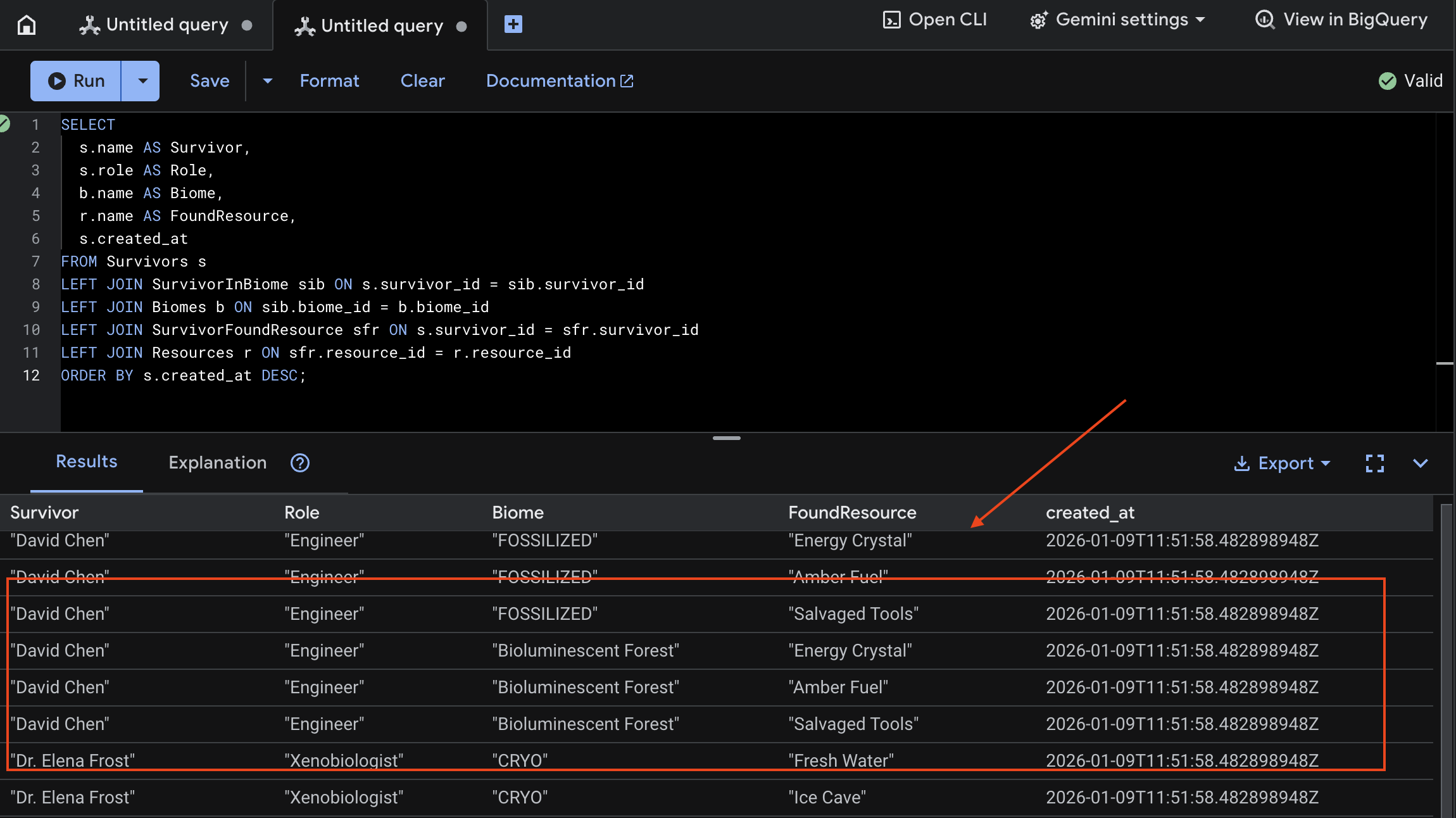
12. ☕️ [Opcjonalnie] Bank zapamiętanych informacji z silnikiem agenta
1. Jak działa Pamięć
System wykorzystuje podejście oparte na podwójnej pamięci, aby obsługiwać zarówno bezpośredni kontekst, jak i uczenie długoterminowe.
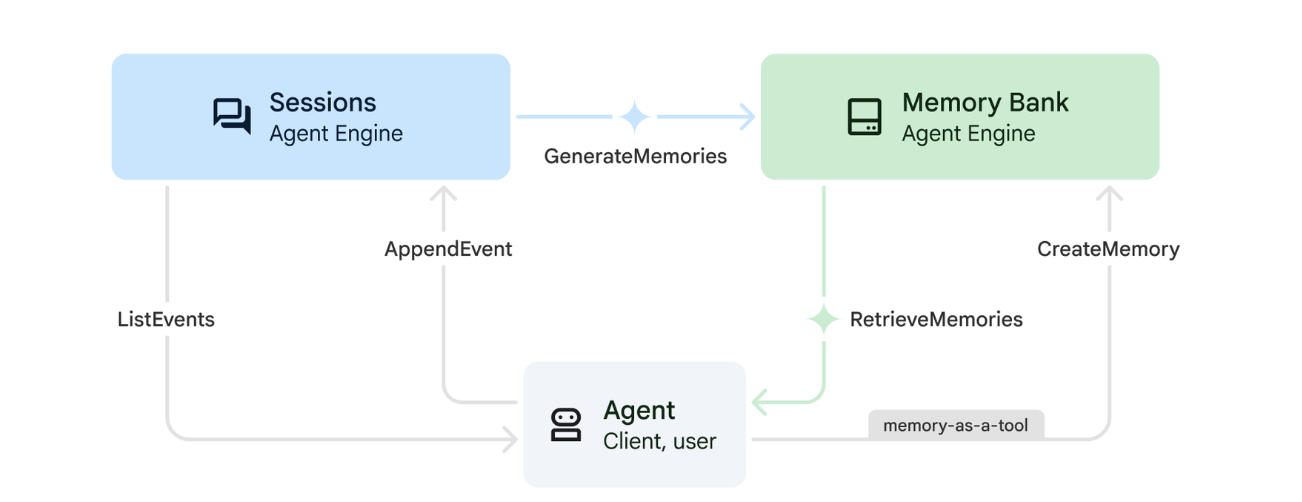
2. Czym są tematy pamięci?
Tematy pamięci określają kategorie informacji, które agent powinien zapamiętywać w trakcie rozmów. Można je traktować jako szafy na dokumenty z różnymi rodzajami preferencji użytkowników.
Nasze 2 tematy:
search_preferences: sposób wyszukiwania przez użytkownika- Czy wolą wyszukiwanie słów kluczowych czy semantyczne?
- Jakich umiejętności lub biomów często szukają?
- Przykład pamięci: „Użytkownik woli wyszukiwanie semantyczne w przypadku umiejętności medycznych”.
urgent_needs_context: jakie kryzysy są monitorowane- Jakie zasoby są monitorowane?
- Które osoby ocalałe są dla nich ważne?
- Przykładowa pamięć: „Użytkownik śledzi niedobór leków w obozie północnym”.
3. Konfigurowanie tematów wspomnień
Tematy pamięci niestandardowej określają, co ma zapamiętać agent. Są one konfigurowane podczas wdrażania Agent Engine.
👉💻 W terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Otworzy się ~/way-back-home/level_2/backend/deploy_agent.py w edytorze.
Definiujemy obiekty struktury MemoryTopic, aby wskazać LLM, jakie informacje ma wyodrębnić i zapisać.
👉W pliku deploy_agent.py zastąp # TODO: SET_UP_TOPIC tym kodem:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Integracja agenta
Kod agenta musi mieć dostęp do Banku zapamiętanych informacji, aby zapisywać i pobierać informacje.
👉💻 W terminalu otwórz plik w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Otworzy się ~/way-back-home/level_2/backend/agent/agent.py w edytorze.
Tworzenie agenta
Podczas tworzenia agenta przekazujemy parametr after_agent_callback, aby sesje były zapisywane w pamięci po interakcjach. Funkcja add_session_to_memory działa asynchronicznie, aby nie spowalniać odpowiedzi na czacie.
👉W pliku agent.py znajdź komentarz # TODO: REPLACE_ADD_SESSION_MEMORY Replace this whole line i zastąp go tym kodem:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Zapisywanie w tle
👉W pliku agent.py znajdź komentarz # TODO: REPLACE_ADD_MEMORY_BANK_TOOL Replace this whole line i zastąp go tym kodem:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉W pliku agent.py znajdź komentarz # TODO: REPLACE_ADD_CALLBACK Replace this whole line i zastąp go tym kodem:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Konfigurowanie usługi sesji Vertex AI
👉💻 W terminalu otwórz plik chat.py w edytorze Cloud Shell, uruchamiając to polecenie:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉 W pliku chat.py znajdź komentarz # TODO: REPLACE_VERTEXAI_SERVICES Replace this whole line i zastąp go tym kodem:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Opcjonalnie] Dołączanie agenta za pomocą Agent Engine
1. Konfiguracja i wdrożenie
Zanim przetestujesz funkcje pamięci, musisz wdrożyć agenta z nowymi tematami pamięci i upewnić się, że środowisko jest prawidłowo skonfigurowane.
Aby ułatwić ten proces, udostępniliśmy skrypt.
Uruchamianie skryptu wdrażania
👉💻 W terminalu uruchom skrypt wdrażania:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Ten skrypt wykonuje te działania:
- Uruchamia
backend/deploy_agent.py, aby zarejestrować agenta i tematy pamięci w Vertex AI. - Rejestruje nowy identyfikator Agent Engine.
- Automatycznie aktualizuje plik
.envza pomocąAGENT_ENGINE_ID. - Sprawdź, czy w pliku
.envjest ustawiona wartośćUSE_MEMORY_BANK=TRUE.
[!IMPORTANT] Jeśli wprowadzisz zmiany w custom_topics w deploy_agent.py, musisz ponownie uruchomić ten skrypt, aby zaktualizować Agent Engine.
Weryfikacja banku zapamiętanych informacji
Teraz możesz sprawdzić, czy bank pamięci działa, ucząc agenta preferencji i sprawdzając, czy utrzymuje się ona w różnych sesjach.
Krok 1. Otwórz aplikację
Ponownie otwórz aplikację, wykonując te czynności: jeśli poprzedni terminal nadal działa, zakończ go, naciskając Ctrls+C.
👉💻 Uruchom aplikację:
cd ~/way-back-home/level_2/
./start_app.sh
👉 W terminalu kliknij Local: http://localhost:5173/.
Krok 2. Testowanie banku zapamiętanych informacji za pomocą tekstu
W interfejsie czatu opisz agentowi swój konkretny kontekst:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Poczekaj około 30 sekund, aż pamięć zostanie przetworzona w tle.
Krok 3. Rozpocznij nową sesję
Odśwież stronę, aby wyczyścić bieżącą historię rozmowy (pamięć krótkotrwałą).
Zadaj pytanie, które odnosi się do podanego wcześniej kontekstu:
"What kind of missions am I interested in?"
Oczekiwana odpowiedź:
„Na podstawie Twoich poprzednich rozmów wynika, że interesują Cię:
- Misje ratownictwa medycznego
- Operacje górskie i na dużych wysokościach
- Wymagane umiejętności: pierwsza pomoc, wspinaczka
Czy mam znaleźć osoby, które przeżyły, spełniające te kryteria?
Krok 4. Testowanie za pomocą przesyłania obrazów
Prześlij obraz i zadaj pytanie:
remember this
Możesz wybrać dowolne zdjęcie z tej listy lub przesłać własne:
Krok 5. Weryfikacja w Vertex AI Agent Engine
Otwórz konsolę Google Cloud Agent Engine.
- Wybierz projekt w selektorze projektów w lewym górnym rogu:
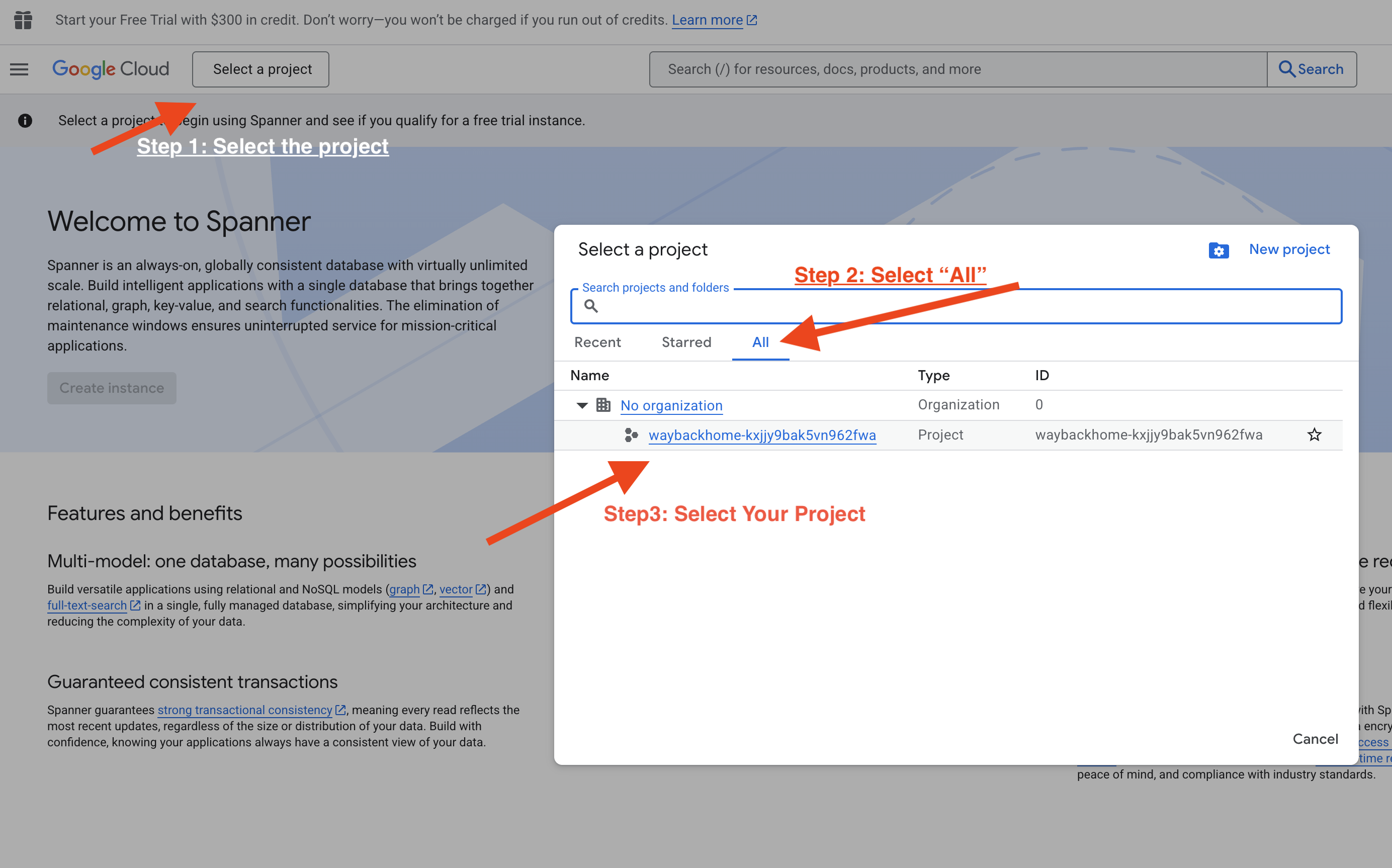
- Sprawdź silnik agenta, który został wdrożony za pomocą poprzedniego polecenia
use_memory_bank.sh: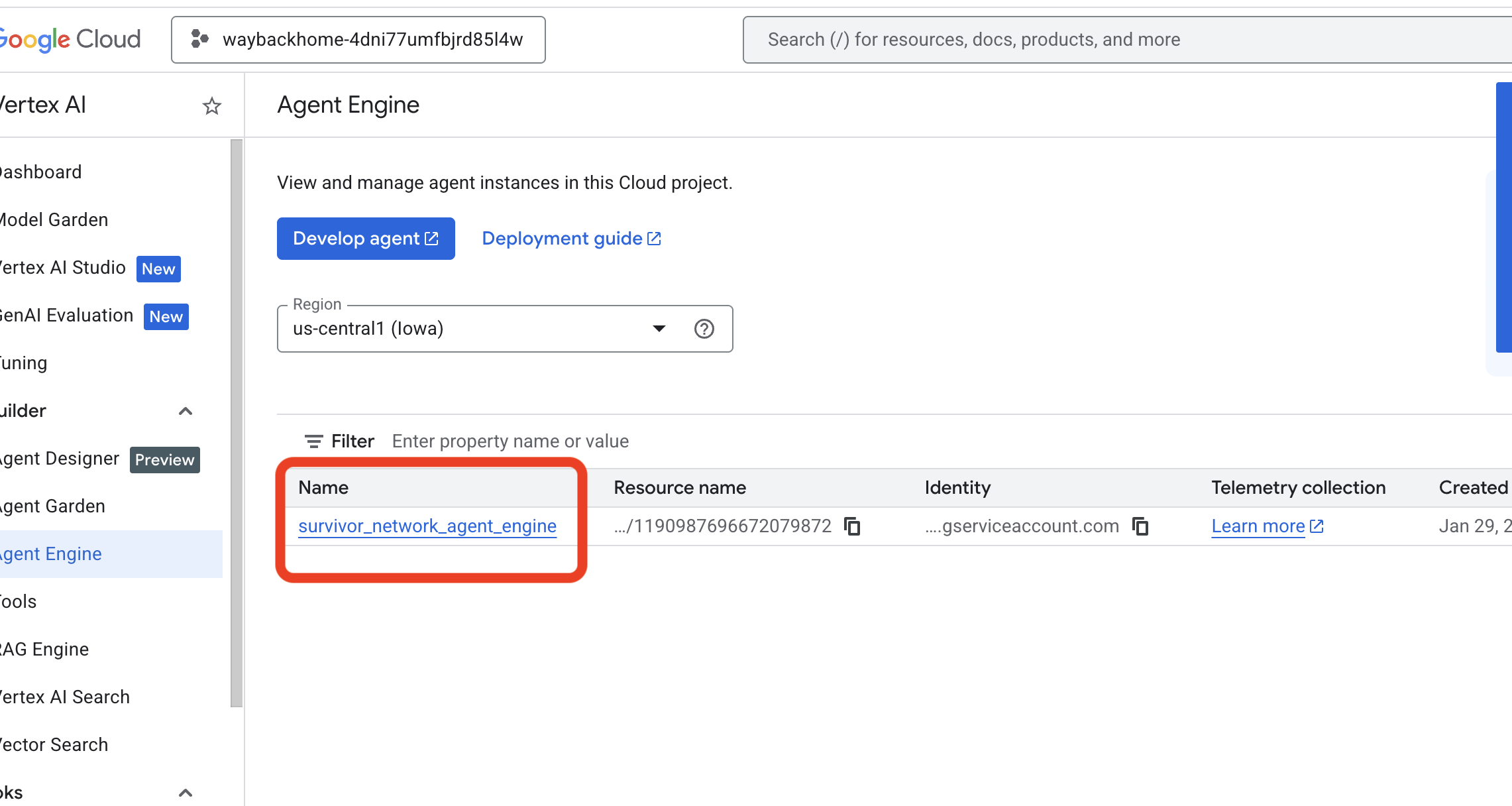 kliknij utworzony silnik agenta.
kliknij utworzony silnik agenta. - Kliknij kartę
Memoriesw tym wdrożonym agencie, aby wyświetlić wszystkie zapamiętane informacje.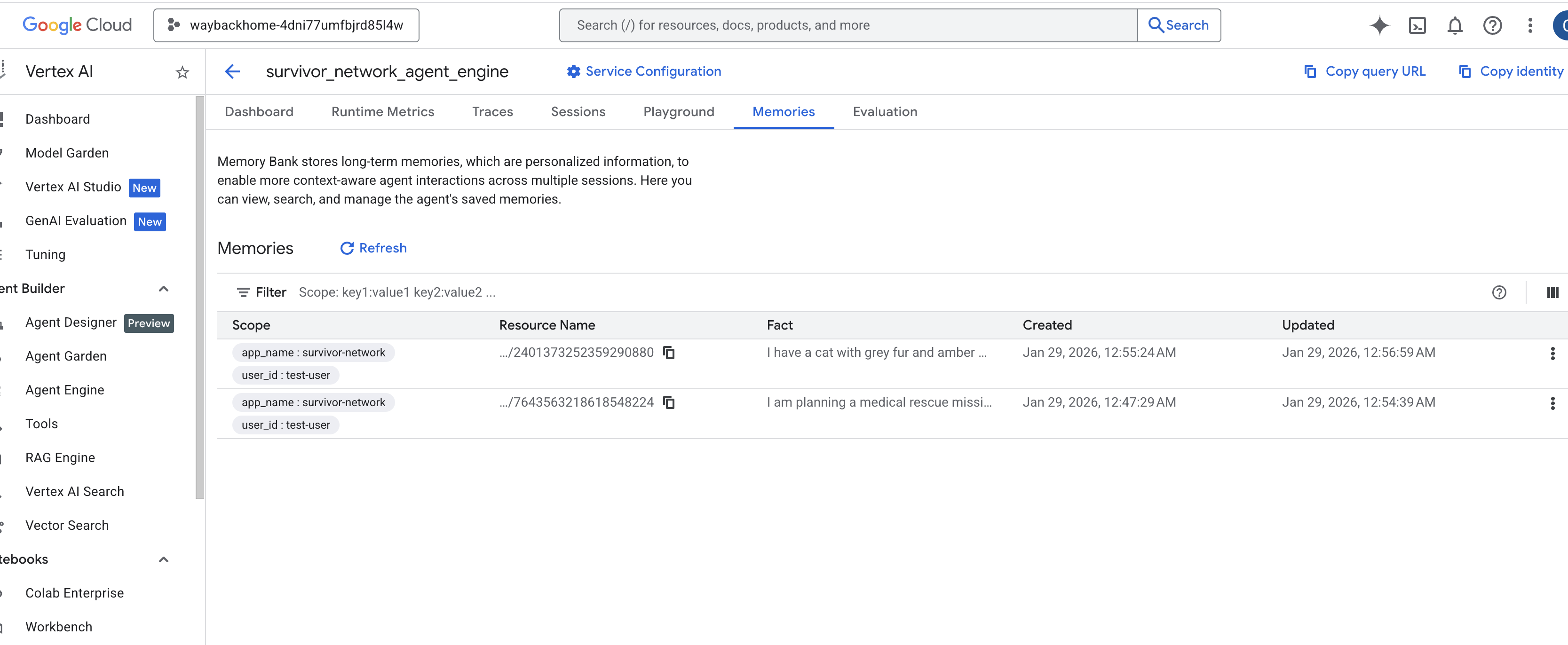
👉💻 Po zakończeniu testowania kliknij „Ctrl + C” w terminalu, aby zakończyć proces.
🎉 Gratulacje! Bank zapamiętanych informacji został właśnie dołączony do agenta.
14. ☕️ [Opcjonalnie] Wdróż w Cloud Run
1. Uruchamianie skryptu wdrażania
👉💻 Uruchom skrypt wdrażania:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Po pomyślnym wdrożeniu otrzymasz adres URL. To jest wdrożony adres URL. 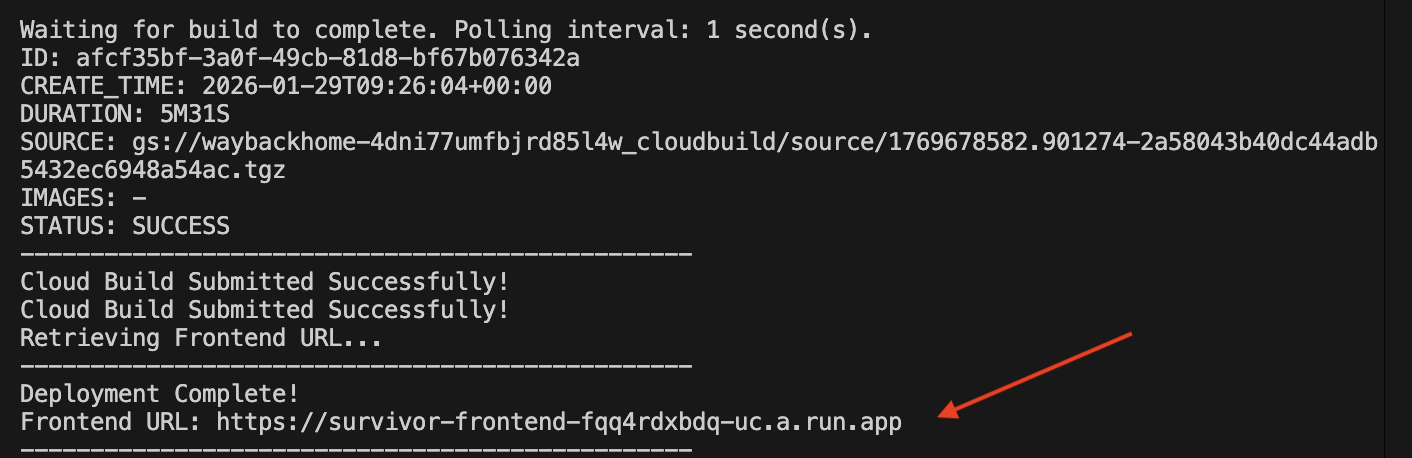
👉💻 Zanim pobierzesz adres URL, przyznaj uprawnienia, uruchamiając to polecenie:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Otwórz wdrożony adres URL, a zobaczysz tam swoją aplikację.
2. Informacje o potoku kompilacji
Plik cloudbuild.yaml określa te kolejne kroki:
- Kompilacja backendu: kompiluje obraz Dockera z pliku
backend/Dockerfile. - Backend Deploy (Wdrażanie backendu): wdraża kontener backendu w Cloud Run.
- Capture URL (Przechwyć adres URL): pobiera nowy adres URL backendu.
- Kompilacja interfejsu:
- Instaluje zależności.
- Tworzy aplikację React, wstawiając
VITE_API_URL=.
- Frontend Image (Obraz frontendu): tworzy obraz Dockera z
frontend/Dockerfile(pakując statyczne komponenty). - Frontend Deploy (Wdrażanie frontendu): wdraża kontener frontendu.
3. Sprawdzanie wdrożenia
Po zakończeniu kompilacji (sprawdź link do dzienników podany przez skrypt) możesz sprawdzić:
- Otwórz konsolę Cloud Run.
- Znajdź usługę
survivor-frontend. - Kliknij adres URL, aby otworzyć aplikację.
- Wyszukaj hasło, aby sprawdzić, czy frontend może komunikować się z backendem.
(OPCJONALNIE) 4. Ręczne wdrażanie
Jeśli wolisz uruchamiać polecenia ręcznie lub chcesz lepiej zrozumieć ten proces, dowiedz się, jak korzystać z cloudbuild.yaml bezpośrednio.
Pisanie cloudbuild.yaml
Plik cloudbuild.yaml informuje Google Cloud Build, jakie kroki należy wykonać.
- steps: lista kolejnych działań. Każdy krok jest wykonywany w kontenerze (np.
docker,gcloud,node,bash). - substitutions: zmienne, które można przekazywać w czasie kompilacji (np.
$_REGION). - workspace: wspólny katalog, w którym kroki mogą udostępniać pliki (tak jak udostępniamy
backend_url.txt).
Uruchamianie wdrożenia
Aby wdrożyć ręcznie bez użycia skryptu, użyj polecenia gcloud builds submit. MUSISZ przekazać wymagane zmienne do podstawienia.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Podsumowanie
1. Co utworzysz
✅ Baza danych grafów: Spanner z węzłami (osoby, umiejętności) i krawędziami (relacje)
✅ Wyszukiwanie AI: wyszukiwanie słów kluczowych, semantyczne i hybrydowe z osadzaniem
✅ Potok multimodalny: wyodrębnianie jednostek z obrazów i filmów za pomocą Gemini
✅ System wieloagentowy: skoordynowany przepływ pracy z pakietem ADK
✅ Bank zapamiętanych informacji: długoterminowa personalizacja za pomocą Vertex AI
✅ Wdrożenie produkcyjne: Cloud Run + Agent Engine
2. Podsumowanie architektury
3. Najważniejsze wnioski
- Graph RAG: łączy strukturę bazy danych wykresu z wektorami dystrybucyjnymi semantycznymi, aby umożliwić inteligentne wyszukiwanie.
- Wzorce wieloagentowe: sekwencyjne potoki do złożonych procesów wieloetapowych
- AI multimodalna: wyodrębnianie uporządkowanych danych z nieuporządkowanych mediów (obrazów i filmów).
- Agenci z pamięcią: Bank zapamiętanych informacji umożliwia personalizację w różnych sesjach.
4. Treści warsztatów
- Level0 potwierdzenie tożsamości
- Level1 dokładna lokalizacja
- Level2 This One: Tworzenie multimodalnego agenta AI za pomocą Graph RAG, pakietu ADK i Banku zapamiętanych informacji
- Level3 tworzenie dwukierunkowego agenta przesyłania strumieniowego ADK
- Level4 system dwukierunkowej komunikacji z wieloma agentami na żywo
- Level5 architektura oparta na zdarzeniach z użyciem Google ADK, A2A i Kafka