
1. Introdução

1. O desafio
Em cenários de resposta a desastres, coordenar sobreviventes com diferentes habilidades, recursos e necessidades em vários locais exige recursos inteligentes de gerenciamento e pesquisa de dados. Neste workshop, você vai aprender a criar um sistema de IA de produção que combina:
- 🗄️ Banco de dados de gráficos (Spanner): armazena relações complexas entre sobreviventes, habilidades e recursos.
- 🔍 Pesquisa com tecnologia de IA: pesquisa híbrida semântica e por palavra-chave usando embeddings
- 📸 Processamento multimodal: extraia dados estruturados de imagens, textos e vídeos.
- 🤖 Orquestração de vários agentes: coordene agentes especializados para fluxos de trabalho complexos
- 🧠 Memória de longo prazo: personalização com o Memory Bank da Vertex AI
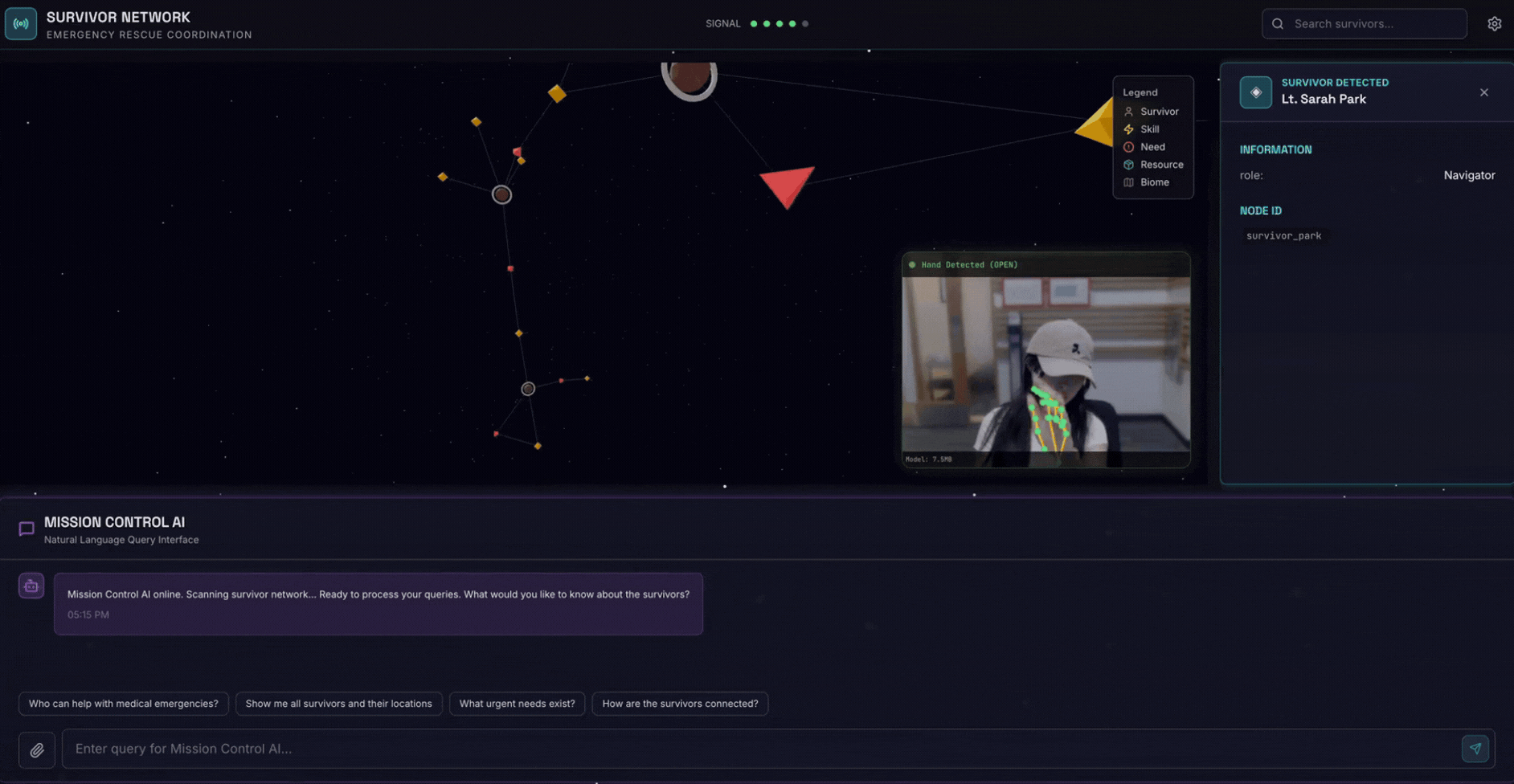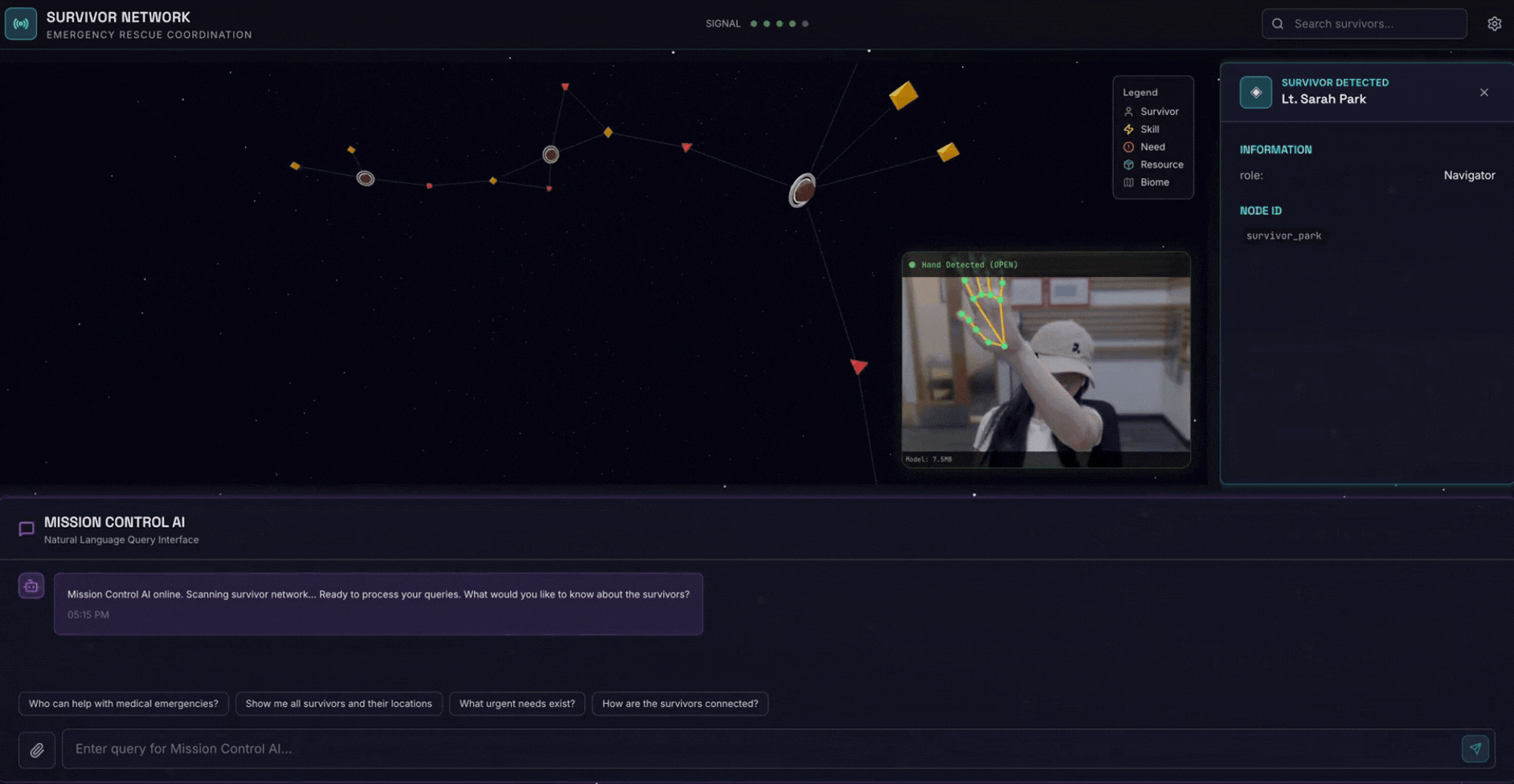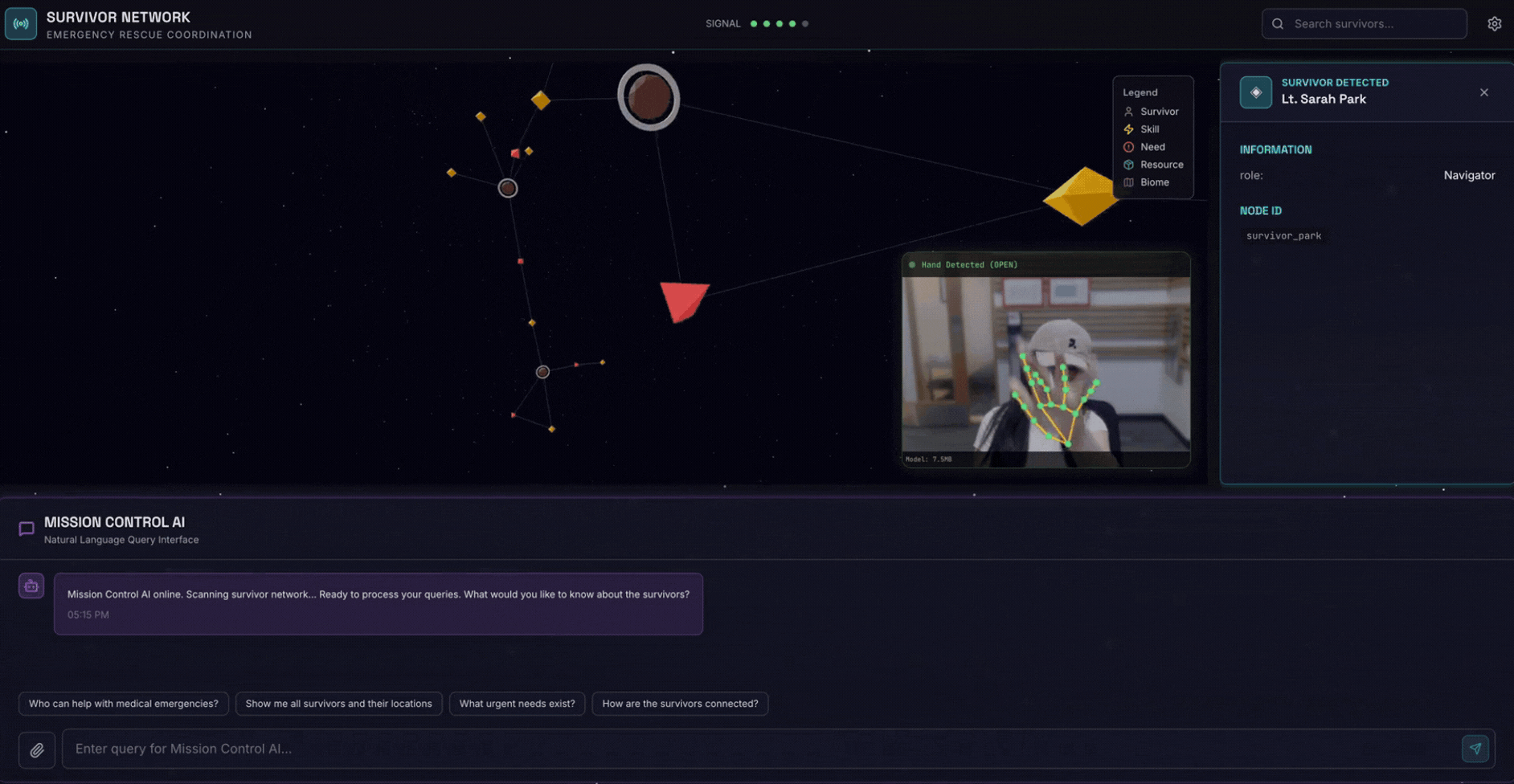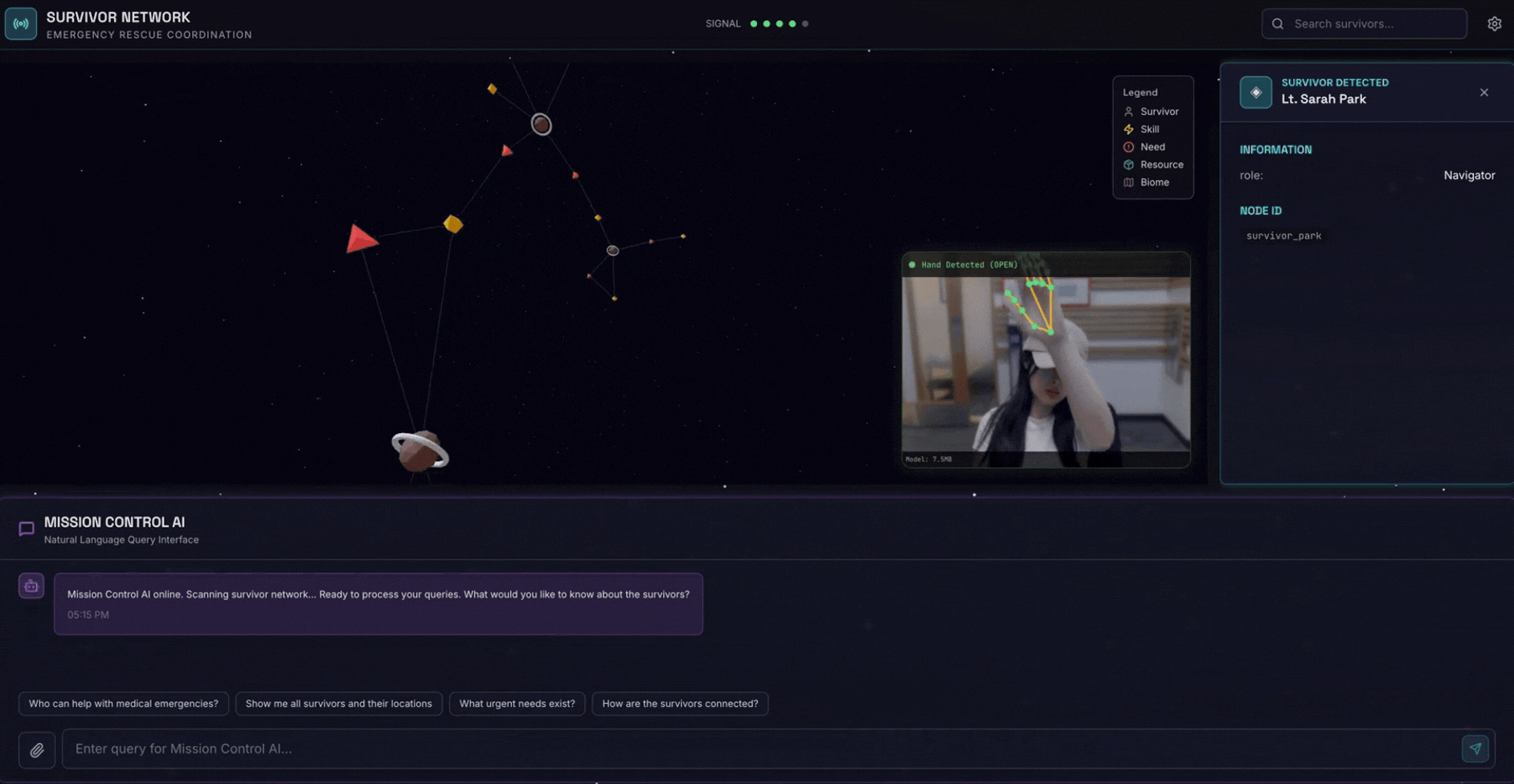
2. O que você criará
Um banco de dados de gráficos de rede de apoio com:
- 🗺️ Visualização interativa de gráficos 3D das relações entre sobreviventes
- 🔍 Pesquisa inteligente (palavra-chave, semântica e híbrida)
- 📸 Pipeline de upload multimodal (extrai entidades de imagens/vídeos)
- 🤖 Sistema multiagente para orquestração de tarefas complexas
- 🧠 Integração do Memory Bank para interações personalizadas
3. Principais tecnologias
Componente | Tecnologia | Finalidade |
banco de dados | Spanner Graph | Armazenar nós (sobreviventes, habilidades) e arestas (relações) |
Pesquisa com IA | Gemini + incorporações | Entendimento semântico + pesquisa de similaridade |
Framework do agente | ADK (Kit de Desenvolvimento de Agente) | Orquestrar fluxos de trabalho de IA |
Memória | Memory Bank do Vertex AI | Armazenamento de preferências de usuários a longo prazo |
Front-end | React + Three.js | Visualização de gráfico 3D interativo |
2. 🛠️ Preparação do ambiente (pule se você estiver no workshop)
Parte 1: ativar a conta de faturamento
Para executar este codelab, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Parte 2: ambiente aberto
- 👉 Clique neste link para acessar diretamente o editor do Cloud Shell.
- 👉 Se for preciso autorizar em algum momento hoje, clique em Autorizar para continuar.
- 👉 Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal
 .
.
- 👉💻 No terminal, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list - 👉💻 Clone o projeto de bootstrap do GitHub:
git clone https://github.com/gca-americas/way-back-home.git
Parte 3: criar um projeto
👉💻 No terminal, torne o script de inicialização executável e execute-o:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Configuração do ambiente
1. Abrir o Cloud Shell
No terminal do Editor do Cloud Shell, se ele não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal.
2. Configurar projeto
👉💻 No terminal, defina o ID do projeto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Ative as APIs necessárias (isso leva de 2 a 3 minutos):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Executar script de configuração
👉💻 Execute o script de configuração:
cd ~/way-back-home/level_2
./setup.sh
Isso vai criar .env para você. No Cloud Shell, abra o projeto way_back_home. Na pasta level_2, você vai encontrar o arquivo .env criado para você. Se não encontrar, clique em View -> Toggle Hidden File para ver. 
4. Carregar dados de amostra
👉💻 Navegue até o back-end e instale as dependências:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Carregar dados iniciais de sobreviventes:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Isso cria:
- Instância do Spanner (
survivor-network) - Banco de dados (
graph-db) - Todas as tabelas de nós e arestas
- Gráficos de propriedades para consultar a saída esperada:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
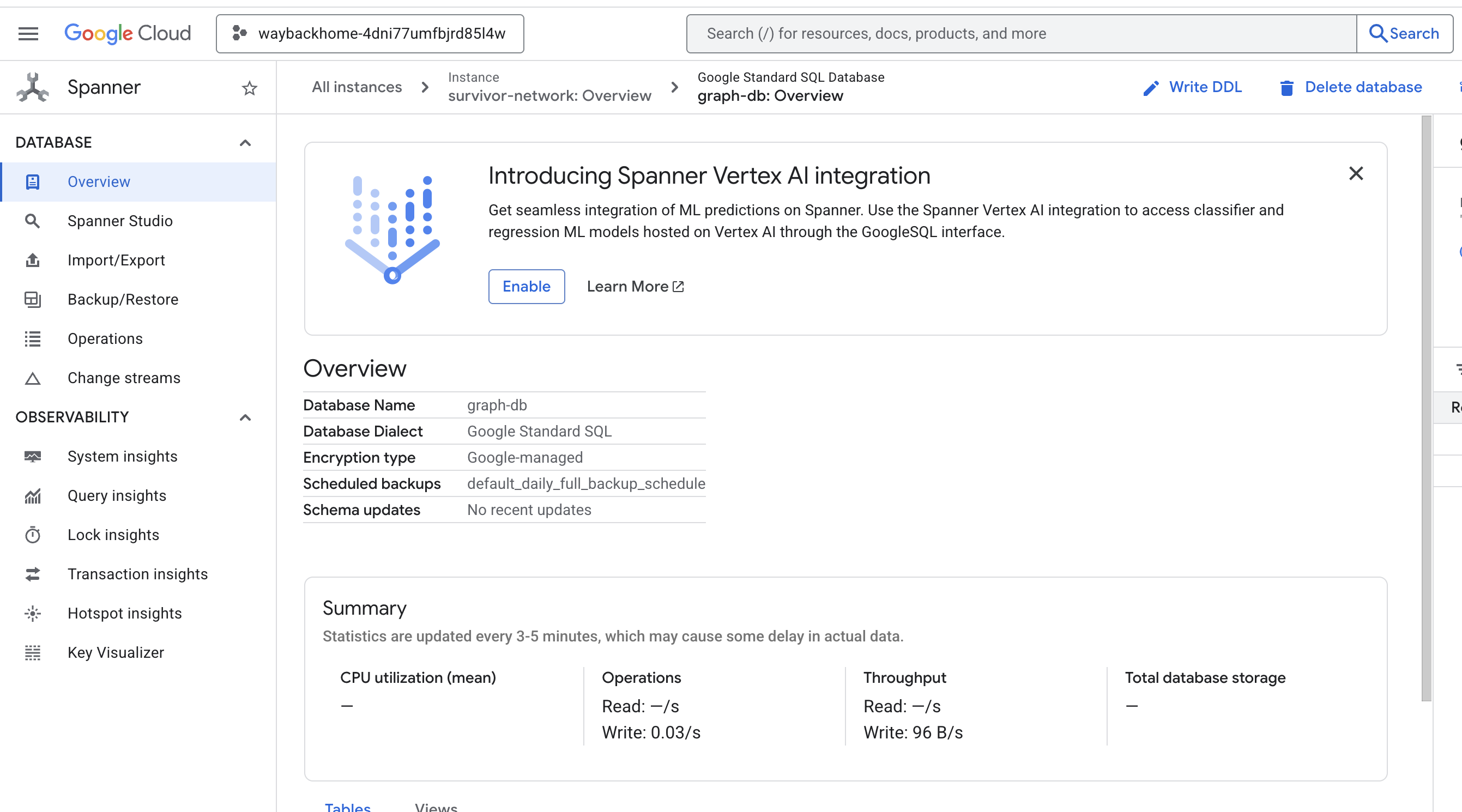
Se você clicar no link depois de Access your database at na saída, poderá abrir o Spanner do console do Google Cloud.

E você vai encontrar o Spanner no console do Google Cloud.
4. 🚀 Como visualizar dados de gráficos no Spanner Studio
Este guia ajuda você a visualizar e interagir com os dados do gráfico da Survivor Network diretamente no console do Google Cloud usando o Spanner Studio. Essa é uma ótima maneira de verificar seus dados e entender a estrutura do gráfico antes de criar seu agente de IA.
1. Acessar o Spanner Studio
- Na última etapa, clique no link e abra o Spanner Studio.
2. Entender a estrutura do gráfico (o panorama geral)
Pense no conjunto de dados da Survivor Network como um quebra-cabeça lógico ou um estado do jogo:
Entidade | Função no sistema | Analogia |
Survivors | Os agentes/jogadores | Jogadores |
Biomas | Onde eles estão | Mapear zonas |
Habilidades | O que eles podem fazer | Recursos |
Necessidades | O que eles não têm (crises) | Quests/missões |
Recursos | Itens encontrados no mundo | Saque |
O objetivo: o trabalho do agente de IA é conectar Habilidades (Soluções) a Necessidades (Problemas), considerando Biomas (Restrições de local).
🔗 Arestas (relacionamentos):
SurvivorInBiome: Monitoramento da localizaçãoSurvivorHasSkill: inventário de habilidadesSurvivorHasNeed: lista de problemas ativos.SurvivorFoundResource: inventário de itensSurvivorCanHelp: relacionamento inferido (a IA calcula isso).
3. Como consultar o gráfico
Vamos executar algumas consultas para ver a "história" nos dados.
O Spanner Graph usa a GQL (Graph Query Language). Para executar uma consulta, use GRAPH SurvivorNetwork seguido do seu padrão de correspondência.
👉 Consulta 1: o quadro global (quem está onde?) Essa é a base: entender a localização é fundamental para operações de resgate.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
O resultado vai aparecer assim: 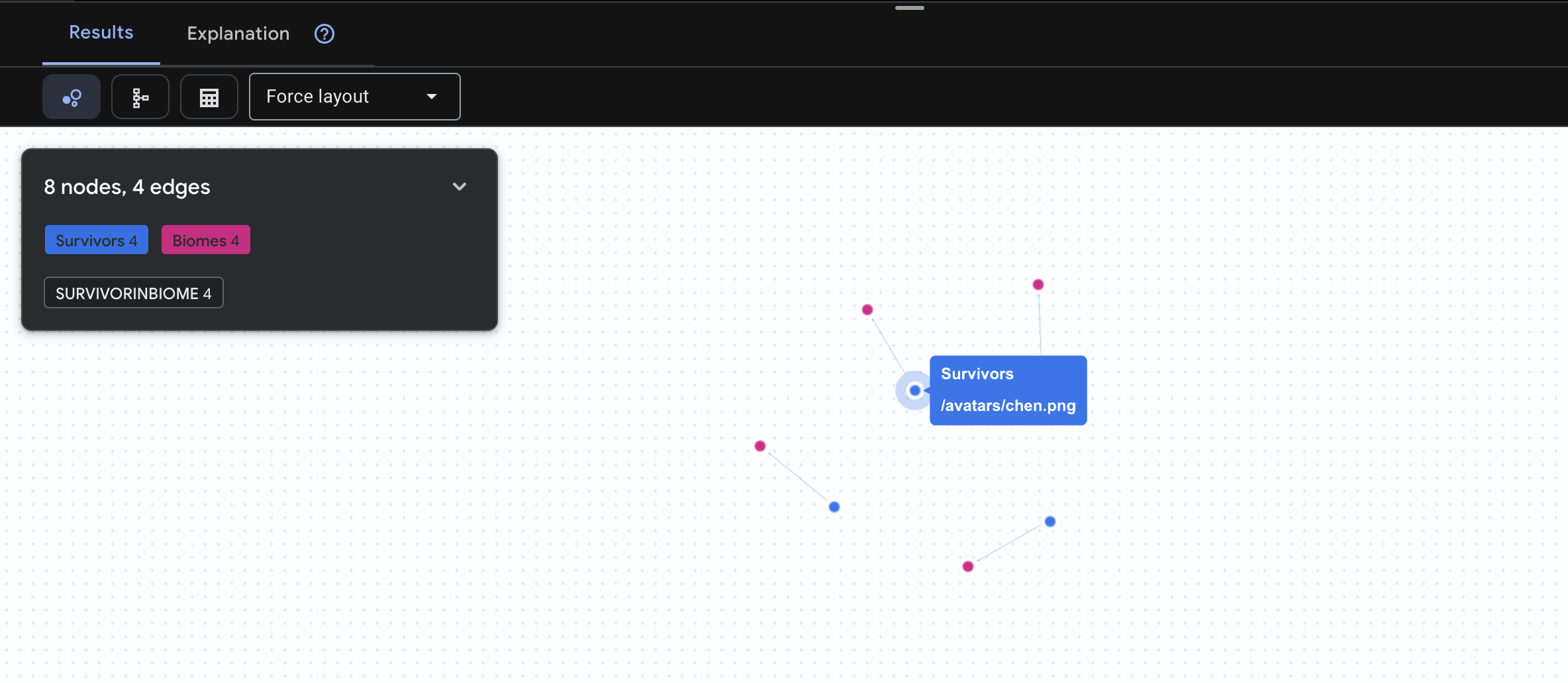
👉 Consulta 2: a matriz de habilidades (capacidades). Agora que você sabe onde todo mundo está, descubra o que cada pessoa pode fazer.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
O resultado vai aparecer assim: 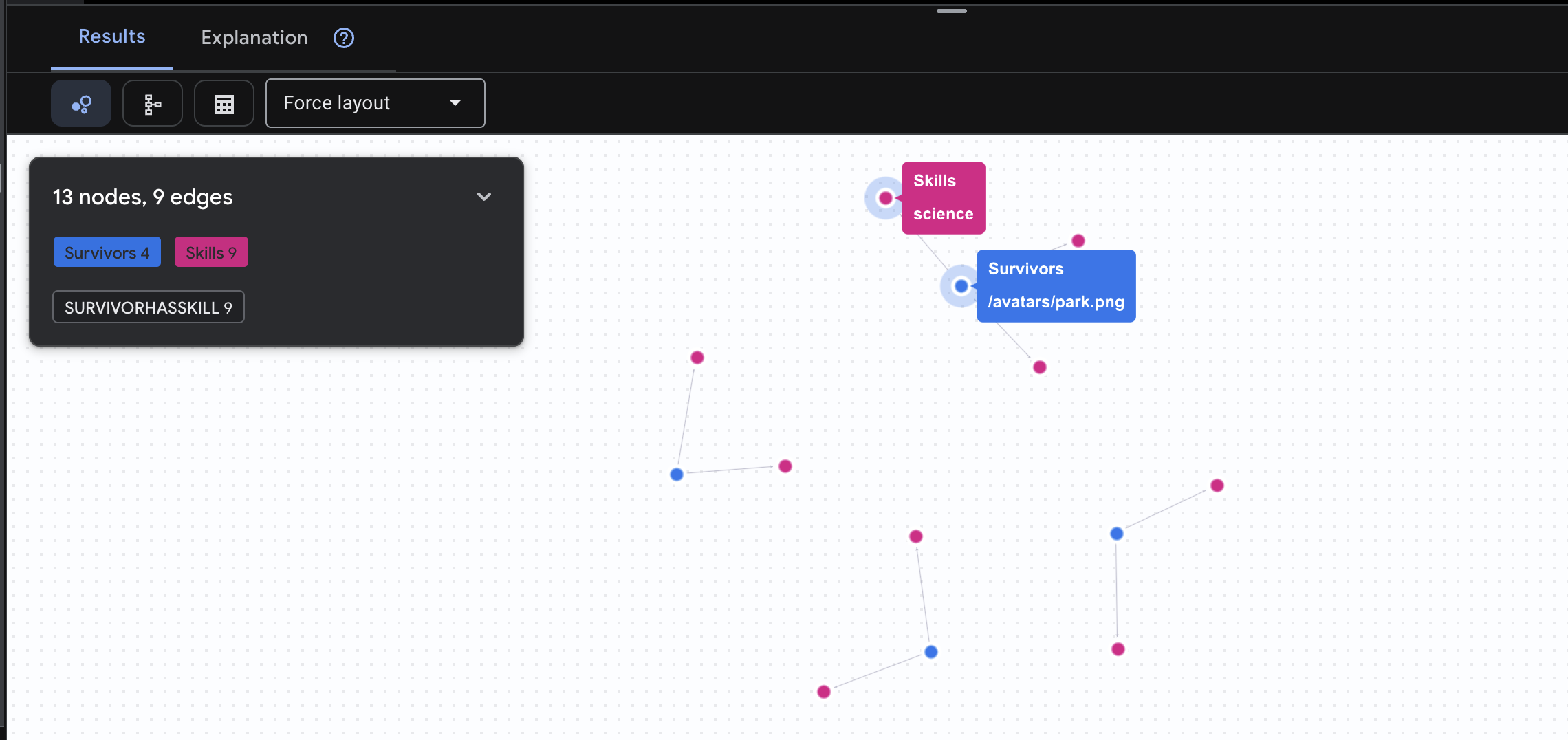
👉 Consulta 3: quem está em crise? (O "Quadro de missões") Veja os sobreviventes que precisam de ajuda e o que eles precisam.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
O resultado vai aparecer assim: 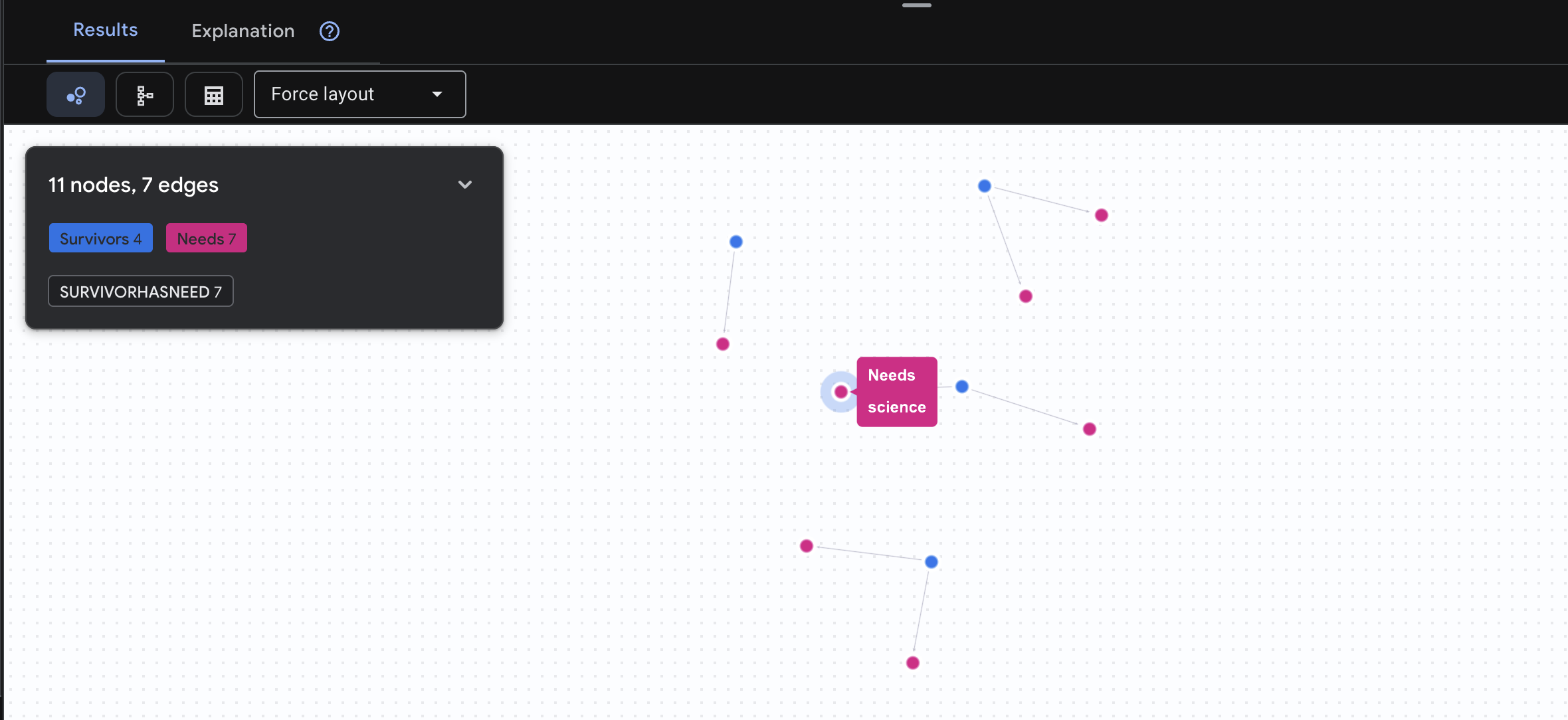
🔎 [Opcional] Matchmaking - Who Can Help Whom?
É aqui que o gráfico se torna poderoso. Essa consulta encontra sobreviventes com habilidades que podem atender às necessidades de outros sobreviventes.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
O resultado vai aparecer assim: 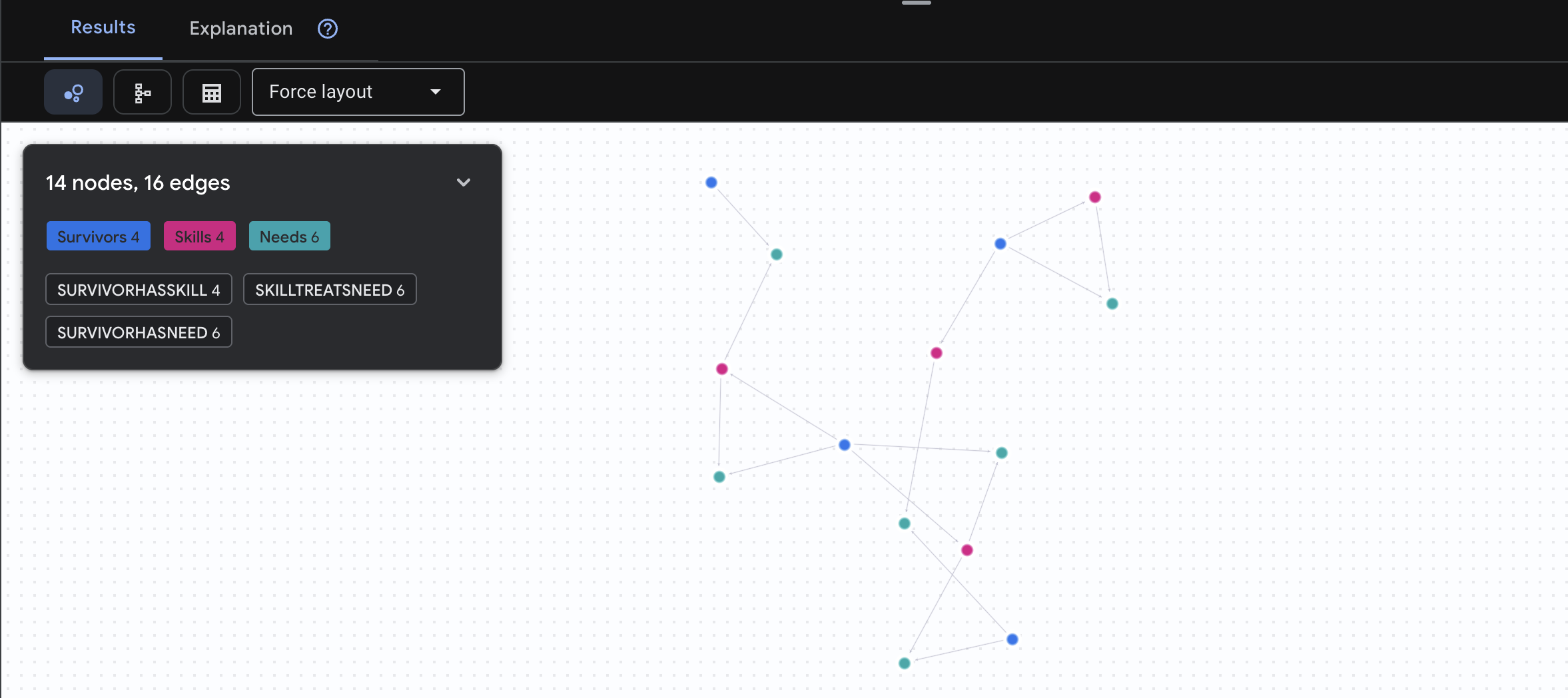
aside positive O que esta consulta faz:
Em vez de apenas mostrar "Primeiros socorros tratam queimaduras" (o que é óbvio no esquema), essa consulta encontra:
- Dra. Elena Frost (que tem treinamento médico) → pode tratar → Capitão Tanaka (que tem queimaduras)
- David Chen (que tem primeiros socorros) → pode tratar → Tenente Park (que tem um tornozelo torcido)
Por que isso é importante:
O que seu agente de IA vai fazer:
Quando um usuário pergunta "Quem pode tratar queimaduras?", o agente:
- Executar uma consulta de gráfico semelhante
- Retorno: "O Dr. Frost tem treinamento médico e pode ajudar o Capitão Tanaka"
- O usuário não precisa saber sobre tabelas ou relações intermediárias.
5. 🚀 Incorporações com tecnologia de IA no Spanner
1. Por que usar embeddings? (Nenhuma ação, somente leitura)
No cenário de sobrevivência, o tempo é essencial. Quando um sobrevivente informa uma emergência, como I need someone who can treat burns ou Looking for a medic, ele não pode perder tempo tentando adivinhar os nomes exatos das habilidades no banco de dados.
Cenário real: Survivor: Captain Tanaka has burns—we need medical help NOW!
Pesquisa tradicional por palavra-chave "médico" → 0 resultados ❌
Pesquisa semântica com embeddings → Encontra "Treinamento médico", "Primeiros socorros" ✅
É exatamente isso que os agentes precisam: uma pesquisa inteligente e semelhante à humana que entenda a intenção, não apenas as palavras-chave.
2. Criar modelo de embedding
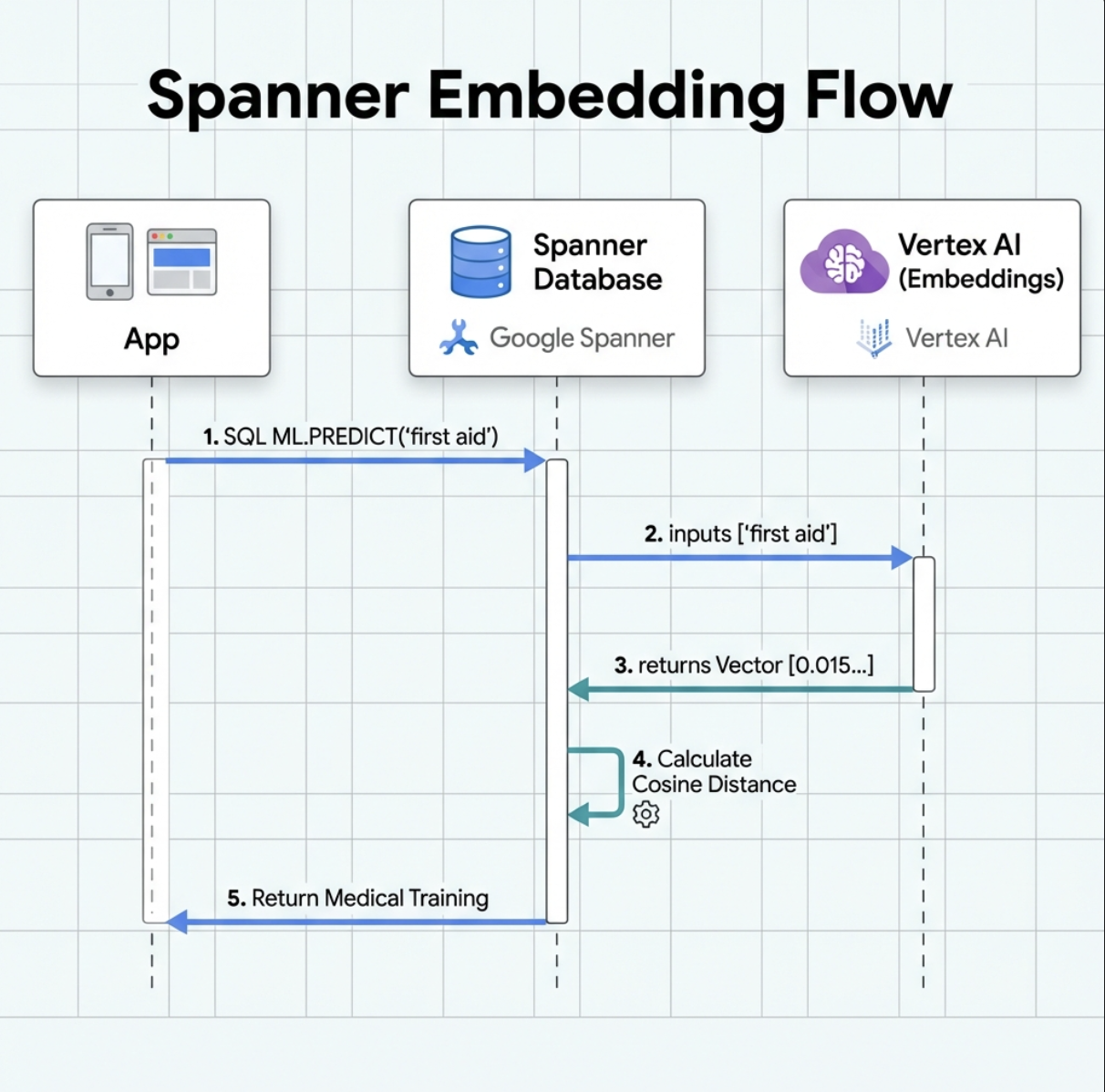
Agora vamos criar um modelo que converte texto em embeddings usando o text-embedding-004 do Google.
👉 No Spanner Studio, execute este SQL (substitua $YOUR_PROJECT_ID pelo ID do projeto real):
‼️ No editor do Cloud Shell, abra File -> Open Folder -> way-back-home/level_2 para conferir o projeto inteiro.
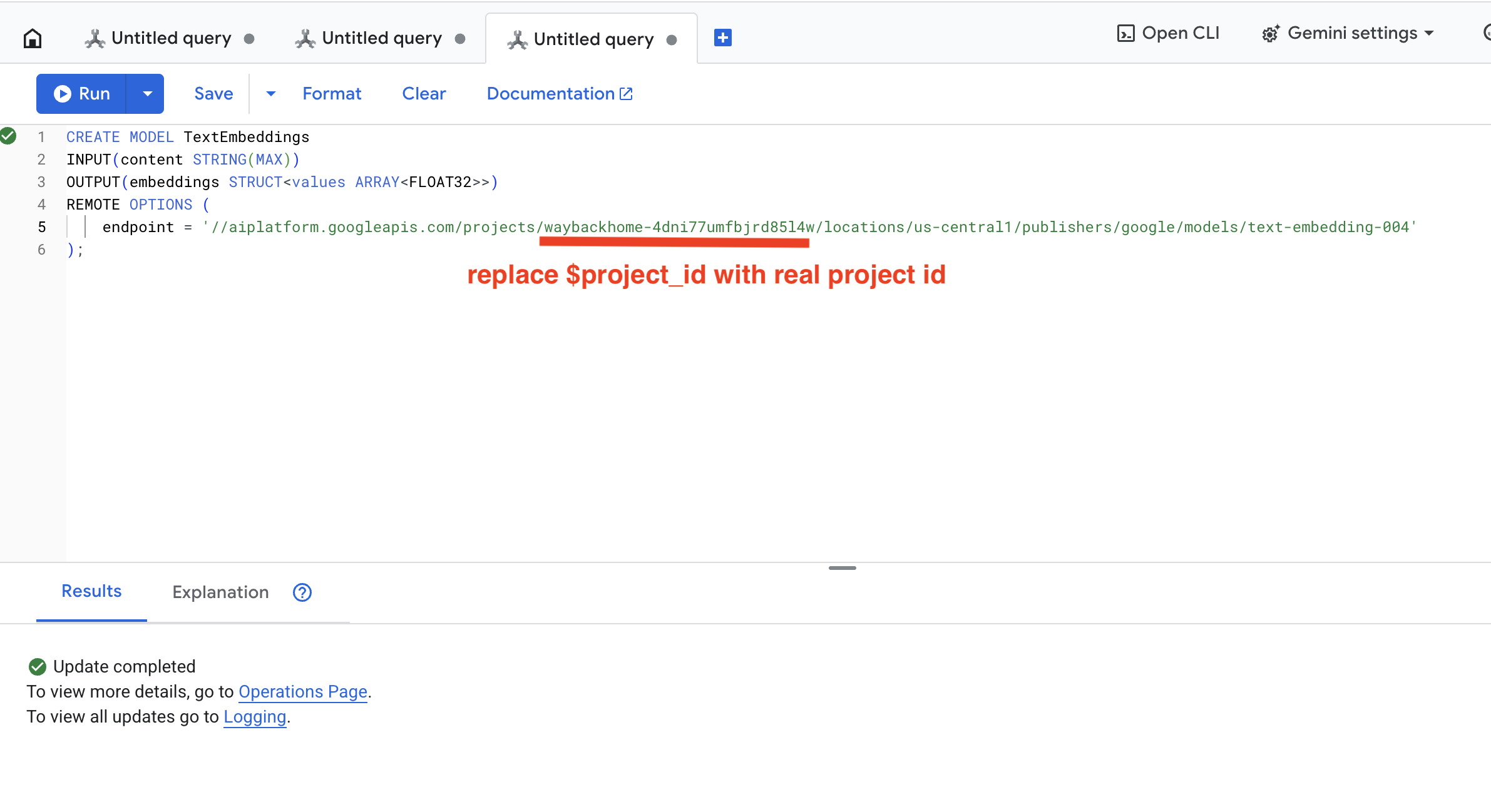
👉 Execute esta consulta no Spanner Studio. Para isso, copie e cole a consulta abaixo e clique no botão "Executar":
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
O que isso faz:
- Cria um modelo virtual no Spanner (sem pesos de modelo armazenados localmente).
- Aponta para o
text-embedding-004do Google na Vertex AI - Define o contrato: a entrada é texto, a saída é uma matriz de ponto flutuante de 768 dimensões.
Por que "OPÇÕES REMOTAS"?
- O Spanner não executa o modelo
- Ele chama a Vertex AI por API quando você usa
ML.PREDICT - Zero-ETL: não é necessário exportar dados para Python, processar e importar novamente
Clique no botão Run. Se a operação for concluída, você verá o resultado abaixo:
3. Adicionar coluna de incorporação
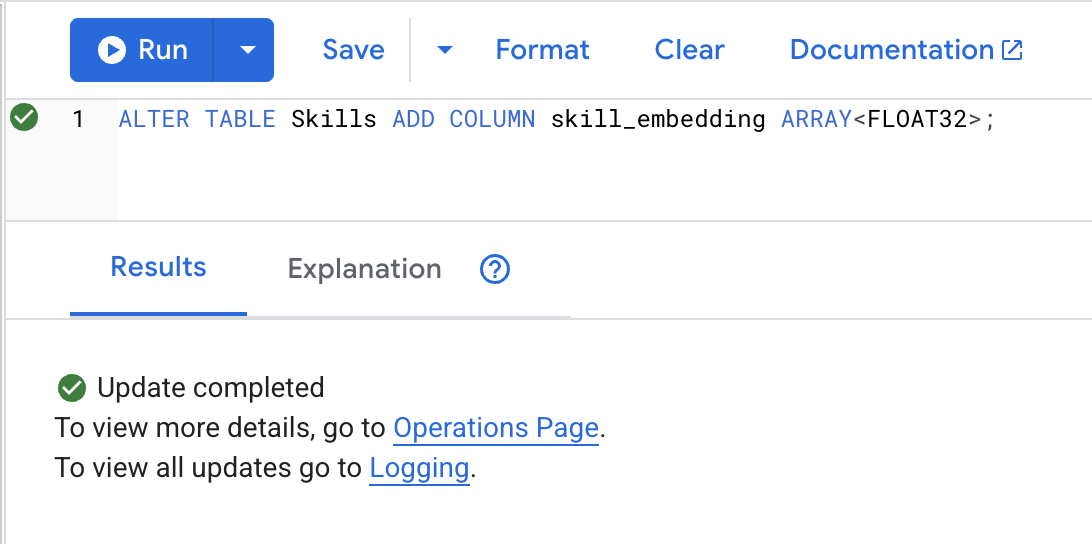
👉 Adicione uma coluna para armazenar embeddings:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Clique no botão Run. Se a operação for concluída, você verá o resultado abaixo:
4. Gerar embeddings
👉 Use a IA para criar embeddings de vetores para cada habilidade:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Clique no botão Run. Se a operação for concluída, você verá o resultado abaixo:
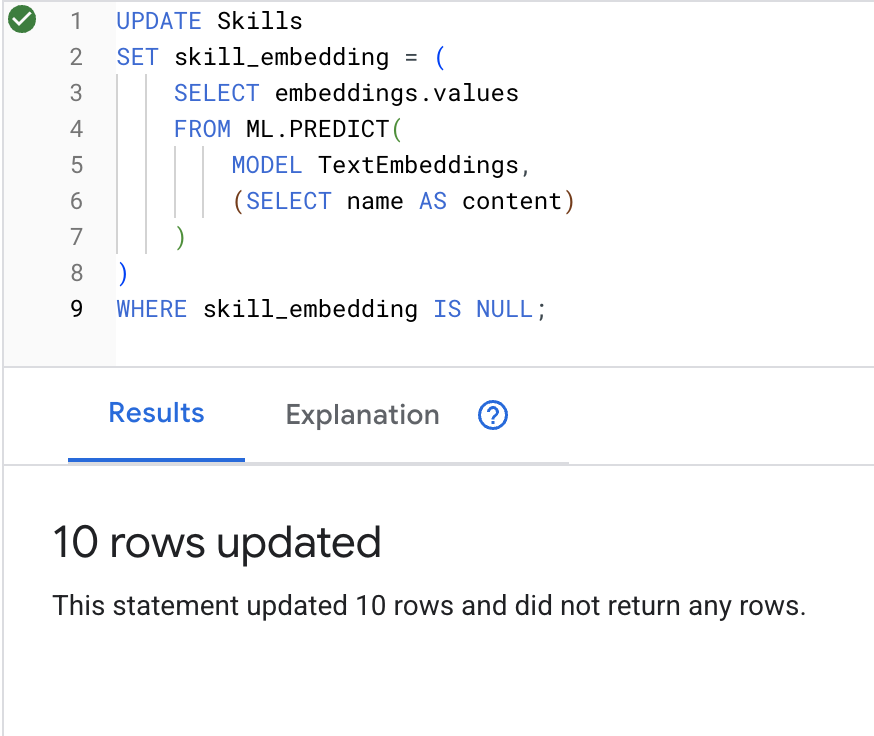
O que acontece: cada nome de habilidade (por exemplo, "primeiros socorros") é convertido em um vetor de 768 dimensões que representa o significado semântico.
5. Verificar embeddings
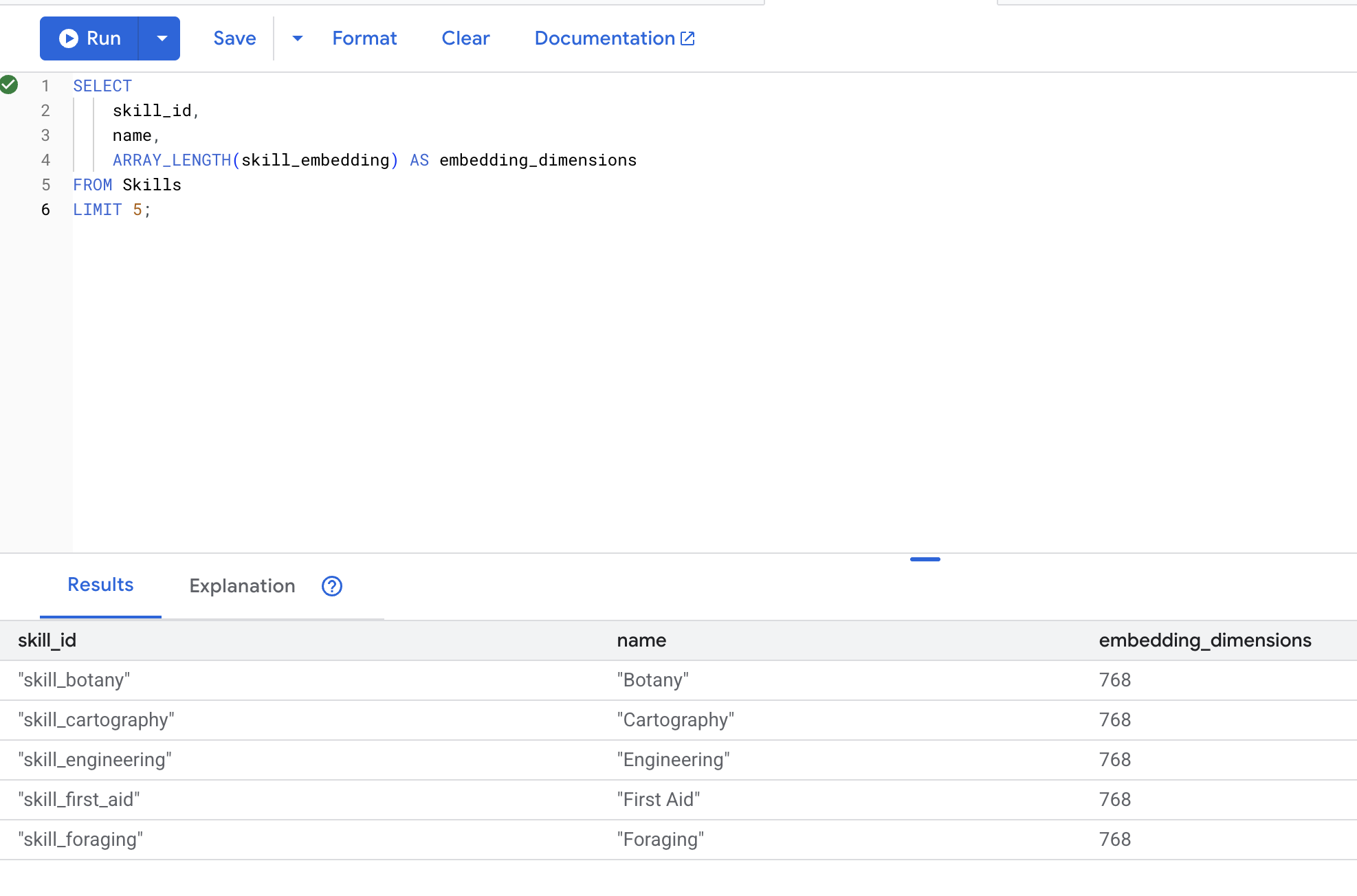
👉 Verifique se os embeddings foram criados:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Saída esperada:
6. Testar a Pesquisa Semântica
Agora vamos testar o caso de uso exato do nosso cenário: encontrar habilidades médicas usando o termo "médico".
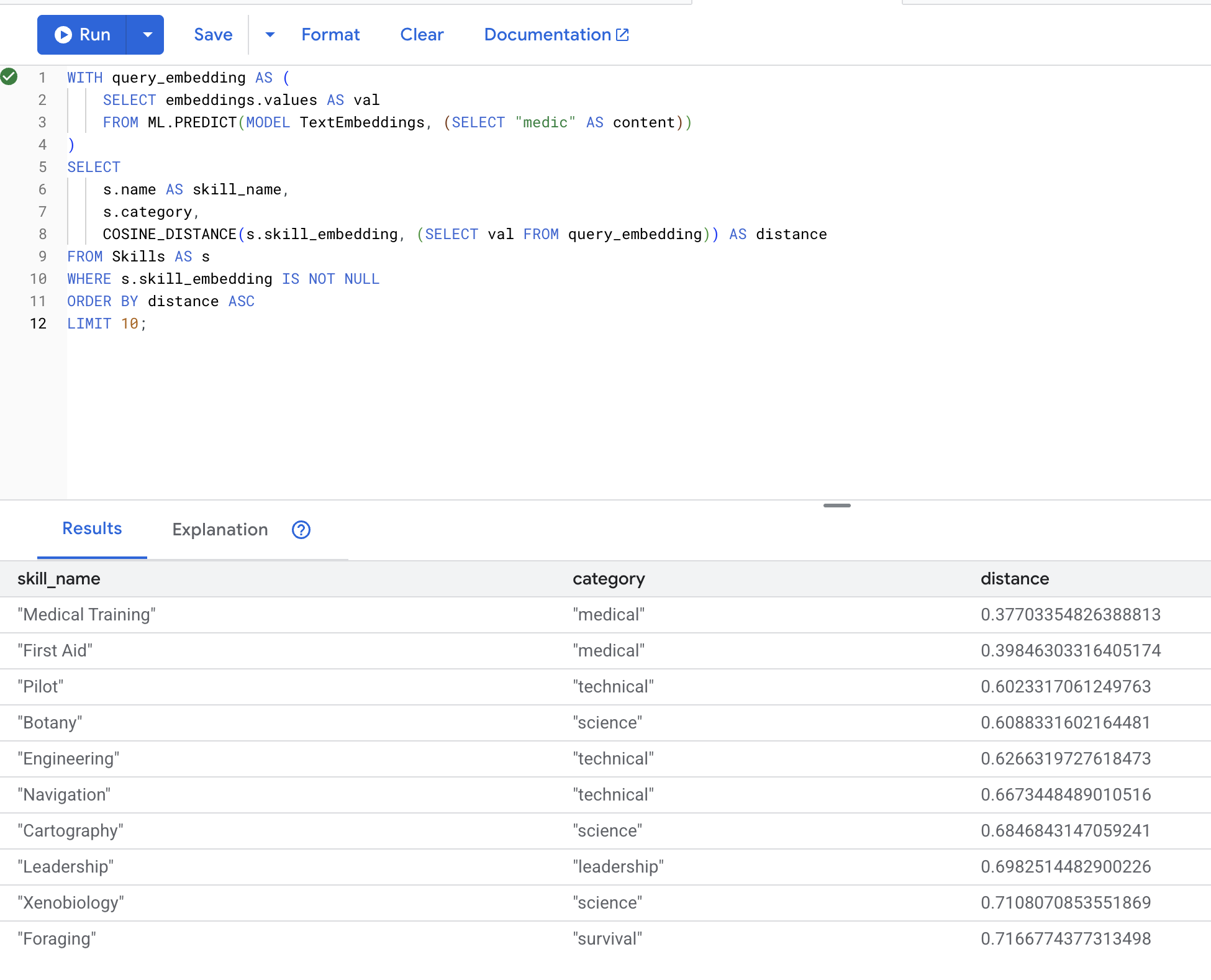
👉 Encontre habilidades semelhantes a "médico":
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Converte o termo de pesquisa do usuário "medic" em um embedding
- Armazena na tabela temporária
query_embedding
Resultados esperados (quanto menor a distância, mais semelhantes são os resultados):
7. Criar um modelo do Gemini para análise
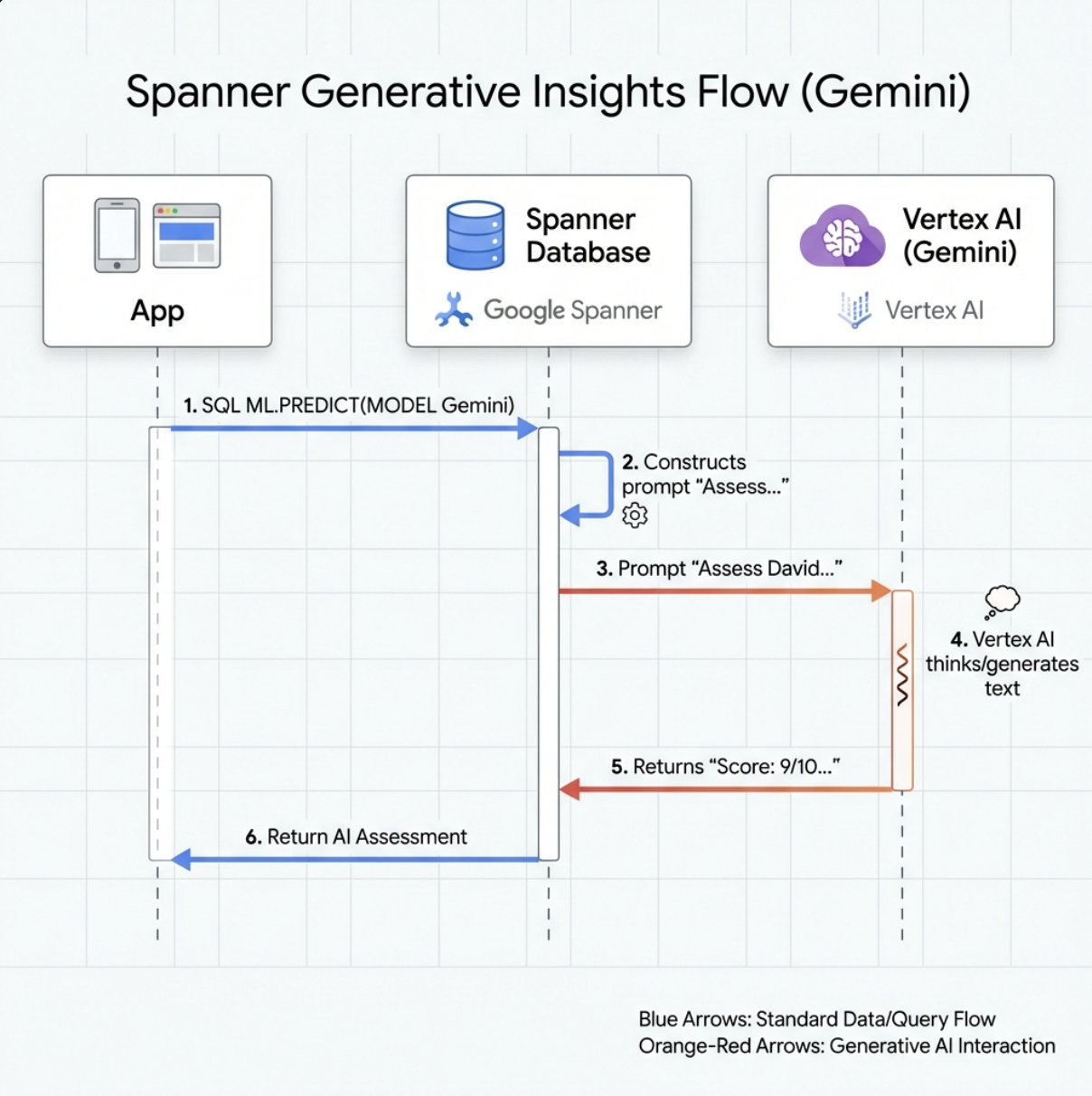
👉 Crie uma referência de modelo de IA generativa (substitua $YOUR_PROJECT_ID pelo ID do projeto):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Diferença do modelo de embeddings:
- Embeddings: texto → vetor (para pesquisa por similaridade)
- Gemini: texto → texto gerado (para raciocínio/análise)
8. Usar o Gemini para análise de compatibilidade
👉 Analise os pares de sobreviventes para verificar a compatibilidade com a missão:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Saída esperada:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Como criar seu agente Graph RAG com pesquisa híbrida
1. Visão geral da arquitetura do sistema
Esta seção cria um sistema de pesquisa multimétodo que oferece flexibilidade ao seu agente para lidar com diferentes tipos de consultas. O sistema tem três camadas: camada de agente, camada de ferramenta e camada de serviço.
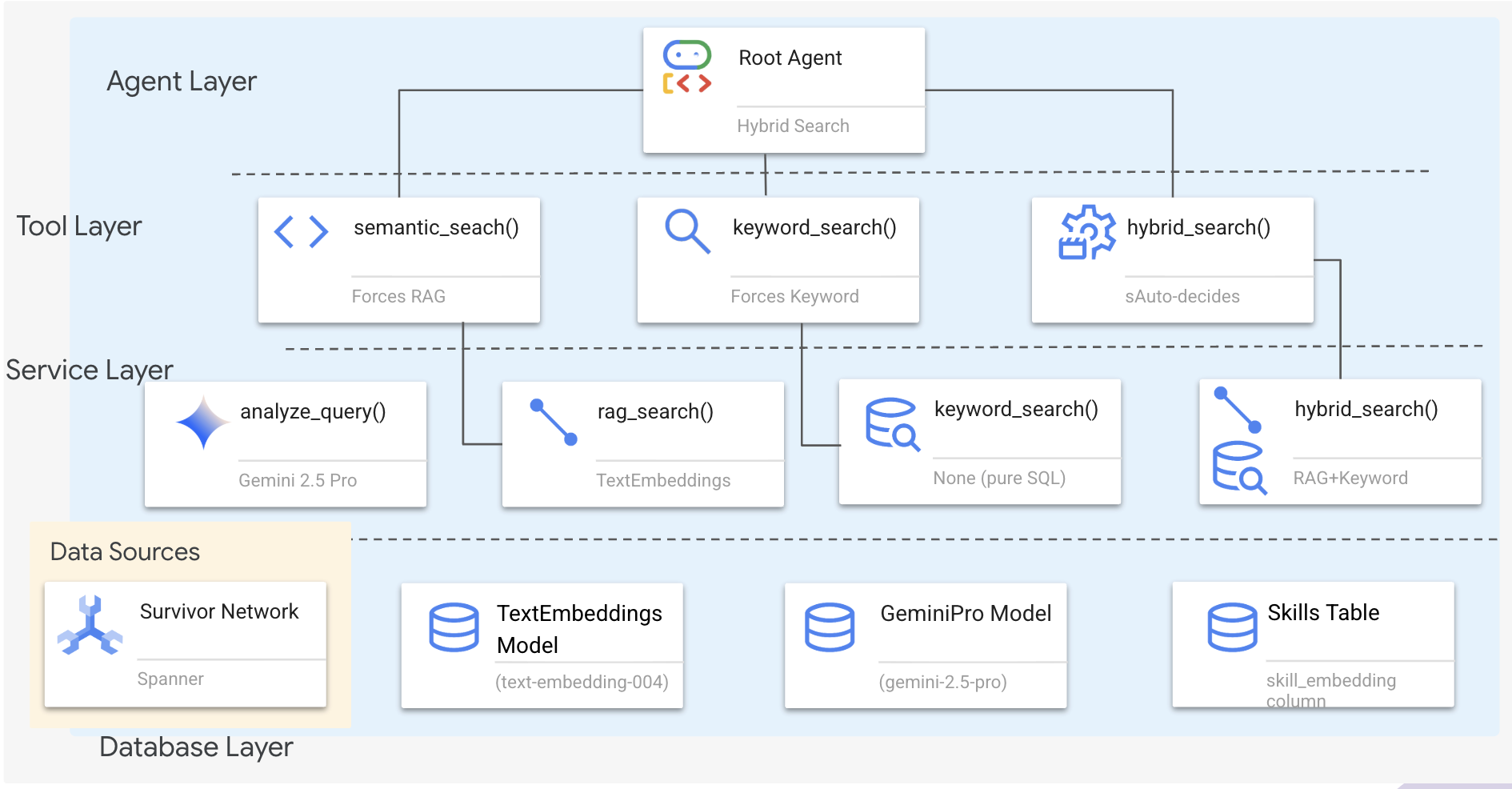
Por que três camadas?
- Separação de responsabilidades: o agente se concentra na intenção, as ferramentas na interface e o serviço na implementação.
- Flexibilidade: o agente pode forçar métodos específicos ou permitir o encaminhamento automático pela IA
- Otimização: é possível pular análises de IA caras quando o método é conhecido.
Nesta seção, você vai implementar principalmente a pesquisa semântica (RAG), que encontra resultados por significado, não apenas por palavras-chave. Mais adiante, vamos explicar como a pesquisa híbrida mescla vários métodos.
2. Implementação do serviço de RAG
👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Localize o comentário # TODO: REPLACE_SQL
Substitua toda essa linha pelo seguinte código:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Definição da ferramenta de pesquisa semântica
👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
Em hybrid_search_tools.py, localize o comentário # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉Substitua toda essa linha pelo seguinte código:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Quando o agente usa:
- Consultas que pedem similaridade ("encontrar algo parecido com X")
- Consultas conceituais ("habilidades de cura")
- Quando entender o significado é fundamental
4. Guia de decisões do agente (instruções)
Na definição do agente, copie e cole a parte relacionada à pesquisa semântica na instrução.
👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
O agente usa essa instrução para selecionar a ferramenta certa:
👉No arquivo agent.py, encontre o comentário # TODO: REPLACE_SEARCH_LOGIC, Substitua toda esta linha pelo seguinte código:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉Localize o comentário # TODO: ADD_SEARCH_TOOLReplace this whole line e substitua-o pelo seguinte código:
semantic_search, # Force RAG
5. Entender como a pesquisa híbrida funciona (somente leitura, nenhuma ação necessária)
Nas etapas 2 a 4, você implementou a pesquisa semântica (RAG), o principal método de pesquisa que encontra resultados por significado. Mas talvez você tenha notado que o sistema se chama "Pesquisa híbrida". Confira como tudo isso se encaixa:
Como a fusão híbrida funciona:
No arquivo way-back-home/level_2/backend/services/hybrid_search_service.py, quando hybrid_search() é chamado, o serviço executa AS DUAS pesquisas e mescla os resultados:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Neste codelab, você implementou o componente de pesquisa semântica (RAG), que é a base. A palavra-chave e os métodos híbridos já estão implementados no serviço. Seu agente pode usar os três.
Parabéns! Você concluiu o agente Graph RAG com pesquisa híbrida.
7. 🚀 Testar seu agente com a Web do ADK
A maneira mais fácil de testar seu agente é usando o comando adk web, que inicia o agente com uma interface de chat integrada.
1. Como executar o agente
👉💻 Navegue até o diretório de back-end (onde o agente está definido) e inicie a interface da Web::
cd ~/way-back-home/level_2/backend
uv run adk web
Esse comando inicia o agente definido em
agent/agent.py
e abre uma interface da Web para testes.
👉 Abra o URL:
O comando vai gerar um URL local (geralmente http://127.0.0.1:8000 ou semelhante). Abra isso no seu navegador.
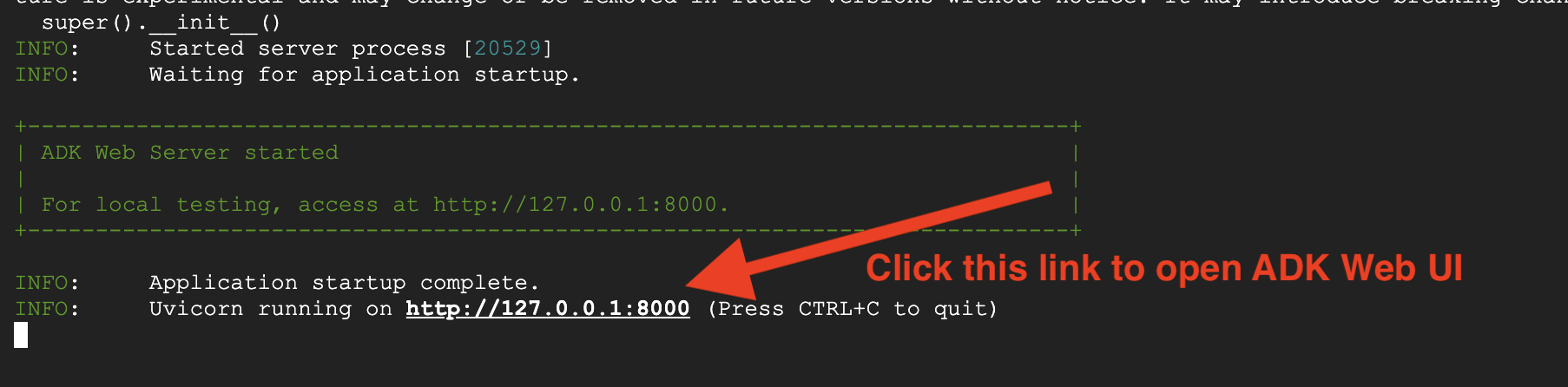
Depois de clicar no URL, você vai ver a interface da Web do ADK. Selecione "agente" no canto superior esquerdo.
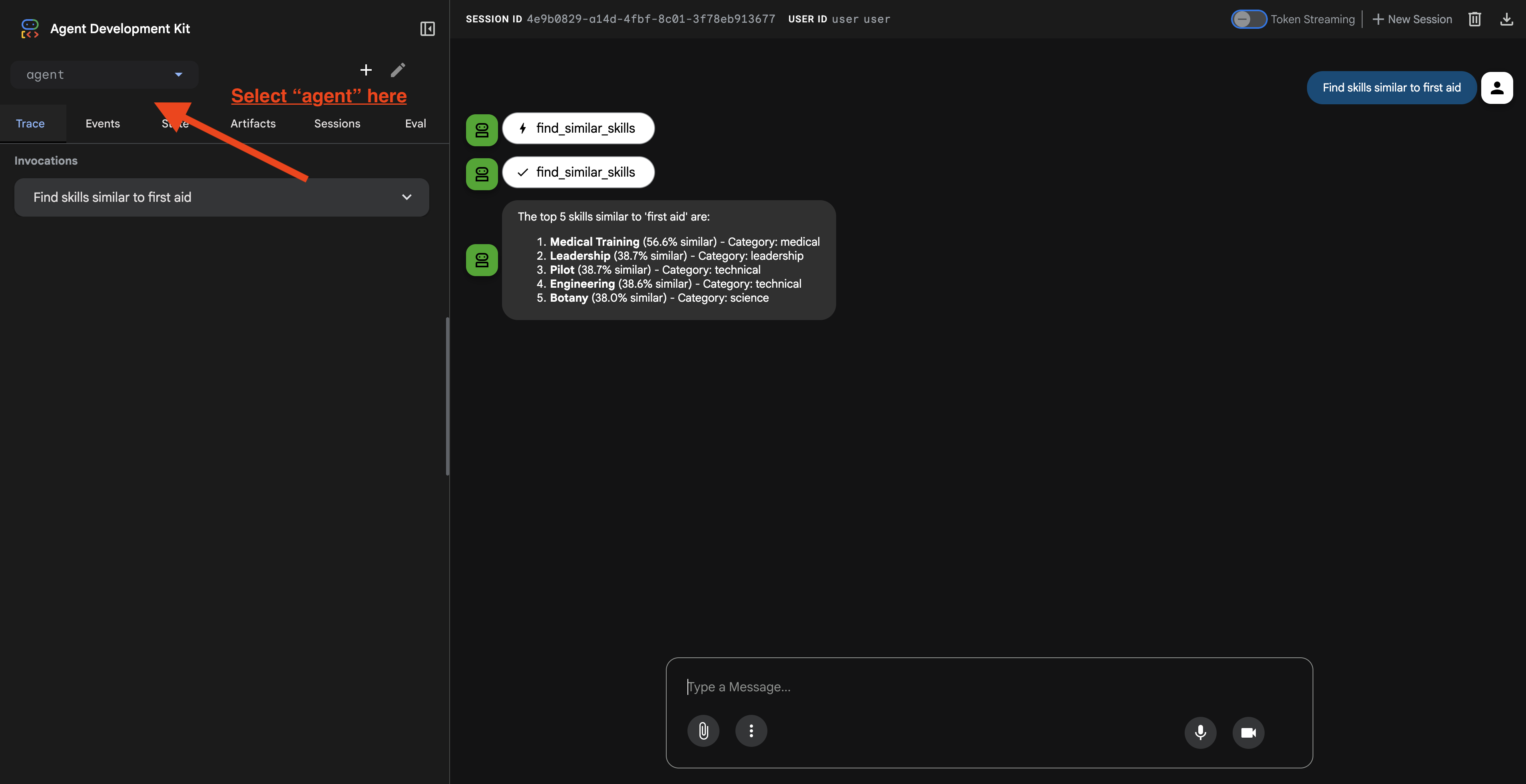
2. Como testar recursos de pesquisa
O agente foi projetado para encaminhar suas consultas de forma inteligente. Teste as entradas a seguir na janela de chat para ver diferentes métodos de pesquisa em ação.
🧬 A. Graph RAG (pesquisa semântica)
Encontra itens com base no significado e no conceito, mesmo que as palavras-chave não correspondam.
Consultas de teste:escolha uma das opções abaixo.
Who can help with injuries?
What abilities are related to survival?
O que procurar:
- O raciocínio precisa mencionar a pesquisa semântica ou RAG.
- Você vai ver resultados que estão conceitualmente relacionados (por exemplo, "Cirurgia" ao pedir "Primeiros socorros").
- Os resultados vão ter o ícone 🧬.
🔀 B. Pesquisa híbrida
Combina filtros de palavras-chave com compreensão semântica para consultas complexas.
Consultas de teste:escolha uma das opções abaixo.
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
O que procurar:
- O motivo precisa mencionar a pesquisa híbrida.
- Os resultados precisam corresponder aos DOIS critérios (conceito + local/categoria).
- Os resultados encontrados pelos dois métodos têm o ícone 🔀 e ficam no topo da lista.
👉💻 Quando terminar o teste, encerre o processo pressionando Ctrl+C na linha de comando.
8. 🚀 Executar o aplicativo completo
Visão geral da arquitetura full-stack
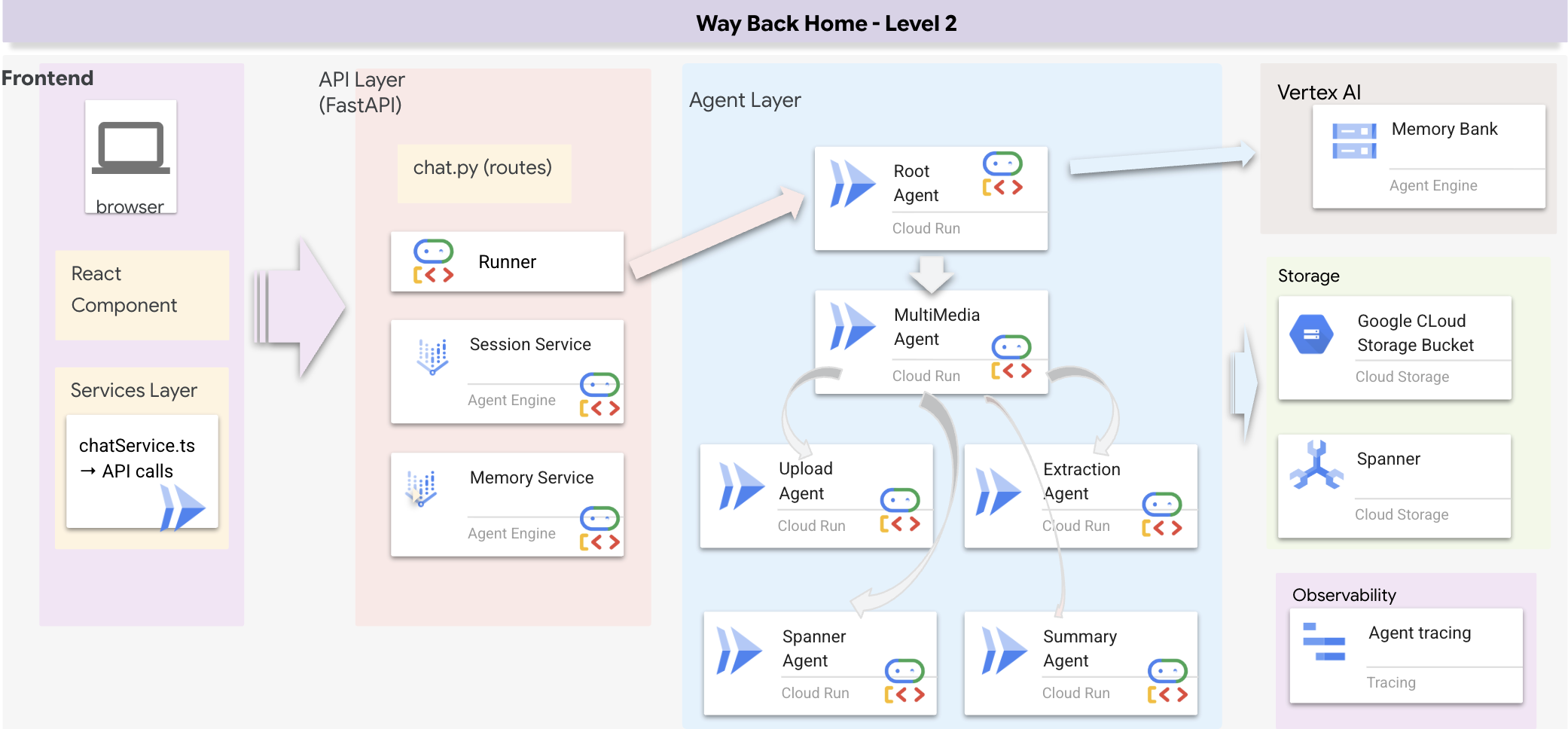
Adicionar SessionService e Runner
👉💻 No terminal, abra o arquivo chat.py no editor do Cloud Shell executando (confira se você pressionou "ctrl+C" para encerrar o processo anterior antes de continuar):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉No arquivo chat.py, encontre o comentário # TODO: REPLACE_INMEMORY_SERVICES, Substitua toda esta linha pelo seguinte código:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉No arquivo chat.py, encontre o comentário # TODO: REPLACE_RUNNER, Substitua toda esta linha pelo seguinte código:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Iniciar inscrição
Se o terminal anterior ainda estiver em execução, pressione Ctrl+C para encerrá-lo.
👉💻 Iniciar o app:
cd ~/way-back-home/level_2/
./start_app.sh
Quando o back-end for iniciado, você verá Local: http://localhost:5173/", como abaixo: 
👉 Clique em Local: http://localhost:5173/ no terminal.
2. Testar a Pesquisa Semântica
Consulta:
Find skills similar to healing
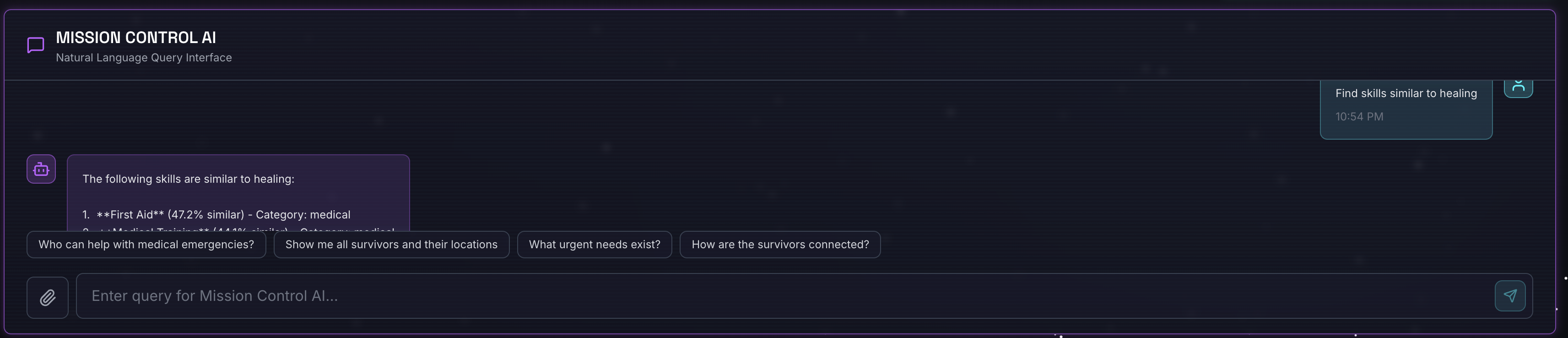
O que acontece:
- O agente reconhece o pedido de similaridade
- Gera um embedding para "cura"
- Usa a distância de cosseno para encontrar habilidades semanticamente semelhantes
- Retorna: primeiros socorros (mesmo que os nomes não correspondam a "cura")
3. Testar a pesquisa híbrida
Consulta:
Find medical skills in the mountains
O que acontece:
- Componente de palavra-chave: filtrar por
category='medical' - Componente semântico: incorporar "médico" e classificar por semelhança
- Mesclar: combina os resultados, priorizando aqueles encontrados pelos dois métodos 🔀
Consulta(opcional):
Who is good at survival and in the forest?
O que acontece:
- Palavras-chave encontradas:
biome='forest' - Descobertas semânticas: habilidades semelhantes a "sobrevivência"
- O híbrido combina os dois para ter os melhores resultados
👉💻 Quando terminar o teste, pressione Ctrl+C no terminal.
4. (!SOMENTE PARA PARTICIPANTES DO WORKSHOP) Atualizar sua localização
👉💻 Execute o script de conclusão:
cd ~/way-back-home/level_2
./set_level_2.sh
Agora abra waybackhome.dev. Sua localização vai estar atualizada. Parabéns por concluir o nível 2!

9. ☕️ [Opcional] Pipeline multimodal (somente leitura): camada de ferramentas
Por que precisamos de um pipeline multimodal?
A rede de sobrevivência não é apenas texto. Os sobreviventes no campo enviam dados não estruturados diretamente pelo chat:
- 📸 Imagens: fotos de recursos, perigos ou equipamentos
- 🎥 Vídeos: relatórios de status ou transmissões de SOS
- 📄 Texto: observações ou registros de campo
Quais arquivos processamos?
Ao contrário da etapa anterior, em que pesquisamos dados existentes, aqui processamos Arquivos enviados pelo usuário. A interface chat.py processa anexos de arquivos de forma dinâmica:
Origem | Conteúdo | Meta |
Associação de usuários | Imagem/vídeo/texto | Informações para adicionar ao gráfico |
Contexto do chat | "Aqui está uma foto dos materiais" | Objetivo e mais detalhes |
A abordagem planejada: pipeline de agente sequencial
Usamos um agente sequencial (multimedia_agent.py) que encadeia agentes especializados:
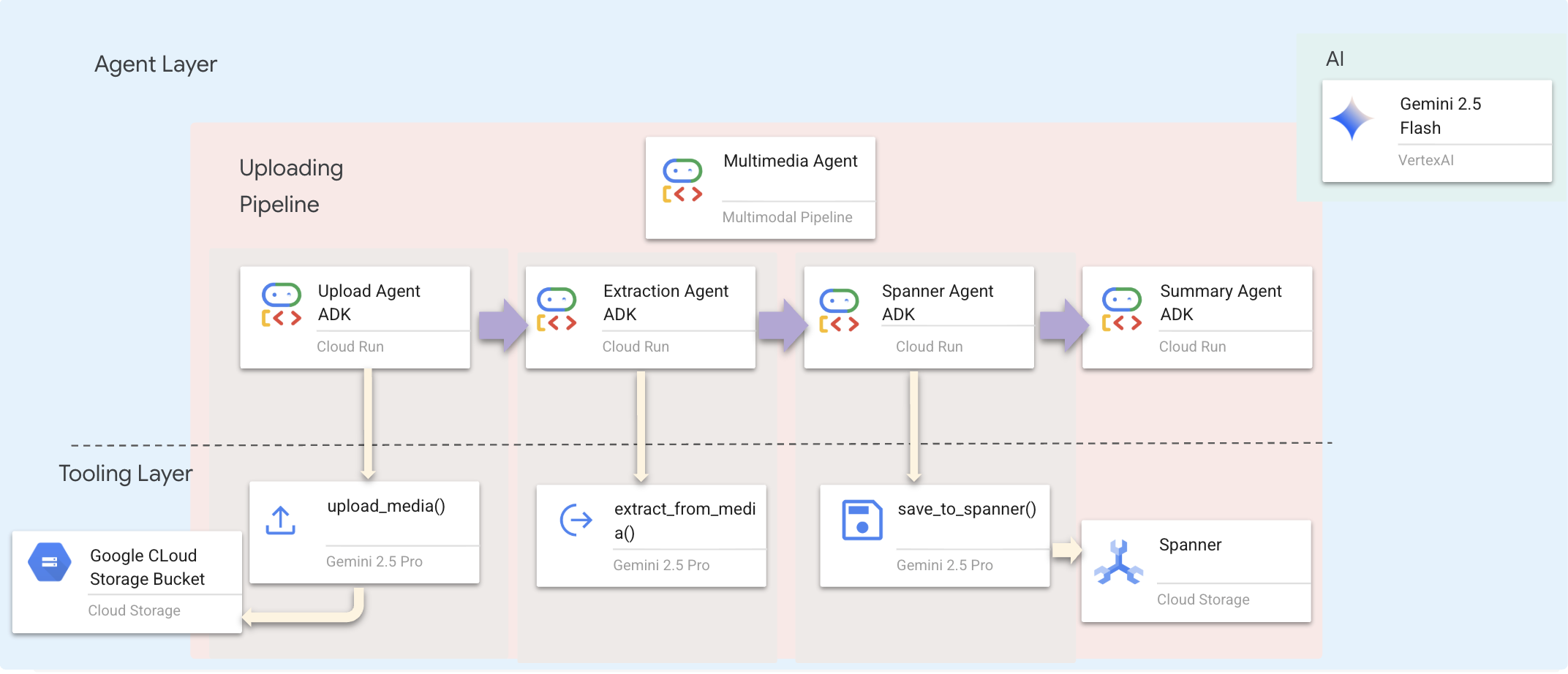
Isso é definido em backend/agent/multimedia_agent.py como um SequentialAgent.
A camada de ferramentas oferece os recursos que os agentes podem invocar. As ferramentas cuidam do "como": upload de arquivos, extração de entidades e salvamento no banco de dados.
1. Abra o arquivo de ferramentas
👉💻 Abra o arquivo level_2/backend/agent/tools/extraction_tools.py ou digite o seguinte comando no terminal. Abra um novo terminal. No terminal, abra o arquivo no editor do Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Implementar a ferramenta upload_media
Essa ferramenta faz upload de um arquivo local para o Google Cloud Storage.
👉 Em def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, o código a seguir mostra como fazer upload de arquivos para o GCS e detectar o tipo deles:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Implementar a ferramenta extract_from_media
Essa ferramenta é um roteador: ela verifica o media_type e envia para o extrator correto (texto, imagem ou vídeo).
👉 Em async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, o código a seguir mostra como extrair entidades e relacionamentos da mídia enviada.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Principais detalhes da implementação:
- Entrada multimodal: transmitimos o comando de texto (
_get_extraction_prompt()) e o objeto de imagem paragenerate_content. - Saída estruturada: o
response_mime_type="application/json"garante que o LLM retorne um JSON válido, o que é fundamental para o pipeline. - Vinculação de entidades visuais: o comando inclui entidades conhecidas para que o Gemini possa reconhecer personagens específicos.
4. Implementar a ferramenta save_to_spanner
Essa ferramenta mantém as entidades e relações extraídas no banco de dados do Spanner Graph.
Em def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, o código a seguir mostra como salvar entidades e relações extraídas no banco de dados do Spanner Graph.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Ao oferecer ferramentas de alto nível aos agentes, garantimos a integridade de dados e aproveitamos as capacidades de raciocínio do agente.
5. Atualizar o serviço do GCS
O GCSService processa o upload do arquivo real para o Google Cloud Storage.
👉💻 Abra o arquivo level_2/backend/services/gcs_service.py ou digite no terminal para abrir o arquivo no editor do Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
Em def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, o código a seguir mostra como salvar entidades e relações extraídas no banco de dados do Spanner Graph.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Ao abstrair isso em um serviço, o agente não precisa saber sobre buckets do GCS, nomes de blobs ou geração de URLs assinados. Ele só pede para "fazer upload".
6. Por que o fluxo de trabalho com agentes é melhor do que as abordagens tradicionais?
A vantagem da agência:
Recurso | Pipeline em lote | Com base em eventos | Fluxo de trabalho agente |
Complexidade | Baixa (1 script) | Alta (mais de cinco serviços) | Baixa (1 arquivo Python: |
Gerenciamento de estado | Variáveis globais | Difícil (desacoplado) | Unificado (estado do agente) |
Tratamento de Erros | Falhas | Registros silenciosos | Interativo ("Não consegui ler esse arquivo") |
Feedback dos usuários | Impressões em tela | Pesquisa necessária | Imediato (parte da conversa) |
Adaptabilidade | Lógica fixa | Funções rígidas | Inteligente (o LLM decide a próxima etapa) |
Reconhecimento de contexto | Nenhum | Nenhum | Completa (conhece a intenção do usuário) |
Por que isso é importante:ao usar multimedia_agent.py (um SequentialAgent com quatro subagentes: Upload → Extract → Save → Summary), substituímos a infraestrutura complexa E os scripts frágeis por lógica de aplicativo inteligente e conversacional.
10. ☕️ [Opcional] Pipeline multimodal (somente leitura) — camada de agente
A camada de agente define a inteligência, ou seja, agentes que usam ferramentas para realizar tarefas. Cada agente tem uma função específica e transmite o contexto para o próximo. Confira abaixo um diagrama de arquitetura para um sistema multiagente.
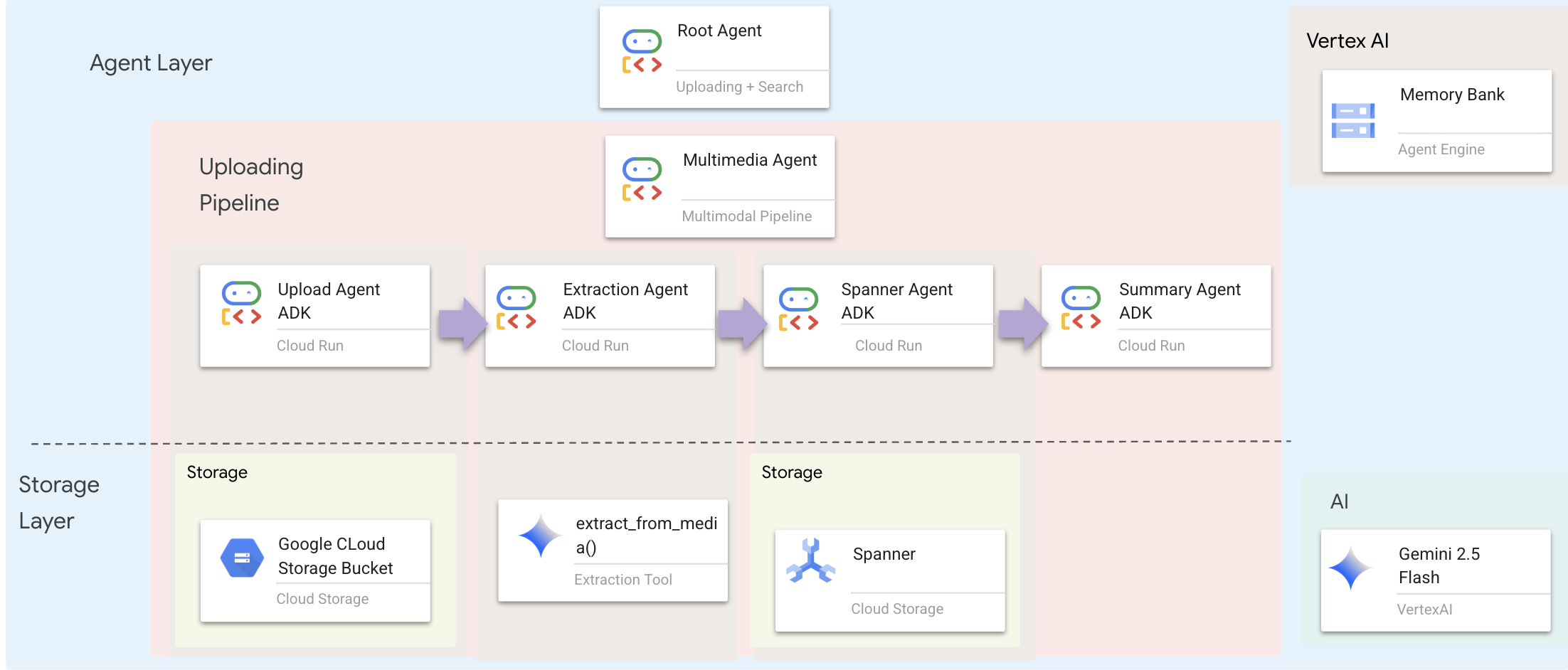
1. Abra o arquivo do agente
👉💻 Abra o arquivo level_2/backend/agent/multimedia_agent.py ou digite o seguinte comando no terminal. Abra um novo terminal. No terminal, abra o arquivo no editor do Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Definir o agente de upload
Esse agente extrai um caminho de arquivo da mensagem do usuário e faz upload dele para o GCS.
👉No arquivo multimedia_agent.py, com o código a seguir, ele cria upload_agent que será enviado ao GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Definir o agente de extração
Esse agente "vê" a mídia enviada e extrai dados estruturados usando o Gemini Vision.
👉No arquivo multimedia_agent.py, com o seguinte código, ele cria extraction_agent que extrai informações da mídia enviada:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Observe como o instruction faz referência ao {upload_result}. É assim que o estado é transmitido entre agentes no ADK.
4. Definir o agente do Spanner
Esse agente salva as entidades e relações extraídas no banco de dados de grafo.
👉No arquivo multimedia_agent.py, com o código a seguir, ele cria spanner_agent que salva as informações extraídas no banco de dados:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Esse agente recebe contexto das duas etapas anteriores (upload_result e extraction_result).
5. Definir o agente de resumo
Esse agente sintetiza os resultados de todas as etapas anteriores em uma resposta fácil de usar.
👉No arquivo multimedia_agent.py, com o código a seguir, ele define o comando para summary_agent que resume o resultado:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Esse agente não precisa de ferramentas. Ele apenas lê o contexto compartilhado e gera um resumo limpo para o usuário.
🧠 Resumo da arquitetura
Camada | Arquivo | Responsabilidade |
Ferramentas |
| Como: fazer upload, extrair e salvar |
Agente |
| O quê: orquestre o pipeline |
11. 🚀 Pipeline de dados multimodais: orquestração
O núcleo do nosso novo sistema é o MultimediaExtractionPipeline definido em backend/agent/multimedia_agent.py. Ele usa o padrão Agente sequencial do ADK (Kit de Desenvolvimento de Agente).
1. Por que usar o Sequential?
O processamento de um upload é uma cadeia de dependência linear:
- Não é possível extrair dados até que você tenha o arquivo (upload).
- Não é possível salvar dados até que eles sejam extraídos (extração).
- Não é possível fazer um resumo até ter os resultados (Salvar).
Um SequentialAgent é perfeito para isso. Ele transmite a saída de um agente como contexto/entrada para o próximo.
2. A definição do agente
Vamos ver como o pipeline é montado na parte de baixo de multimedia_agent.py: 👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Ele recebe entradas das duas etapas anteriores. Localize o comentário # TODO: REPLACE_ORCHESTRATION. Substitua toda essa linha pelo seguinte código:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Conectar-se ao agente raiz
👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Localize o comentário # TODO: REPLACE_ADD_SUBAGENT. Substitua toda essa linha pelo seguinte código:
sub_agents=[multimedia_agent],
Esse único objeto agrupa quatro "especialistas" em uma entidade chamável.
4. Fluxo de dados entre agentes
Cada agente armazena a saída em um contexto compartilhado que os agentes subsequentes podem acessar:
5. Abra o aplicativo (pule esta etapa se o app ainda estiver em execução)
👉💻 Iniciar o app:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Clique em Local: http://localhost:5173/ no terminal.
6. Teste de upload de imagem
👉 Na interface de chat, escolha qualquer uma das fotos e faça upload para a interface:
Na interface de chat, informe ao agente sobre seu contexto específico:
Here is the survivor note
e anexe a imagem aqui.

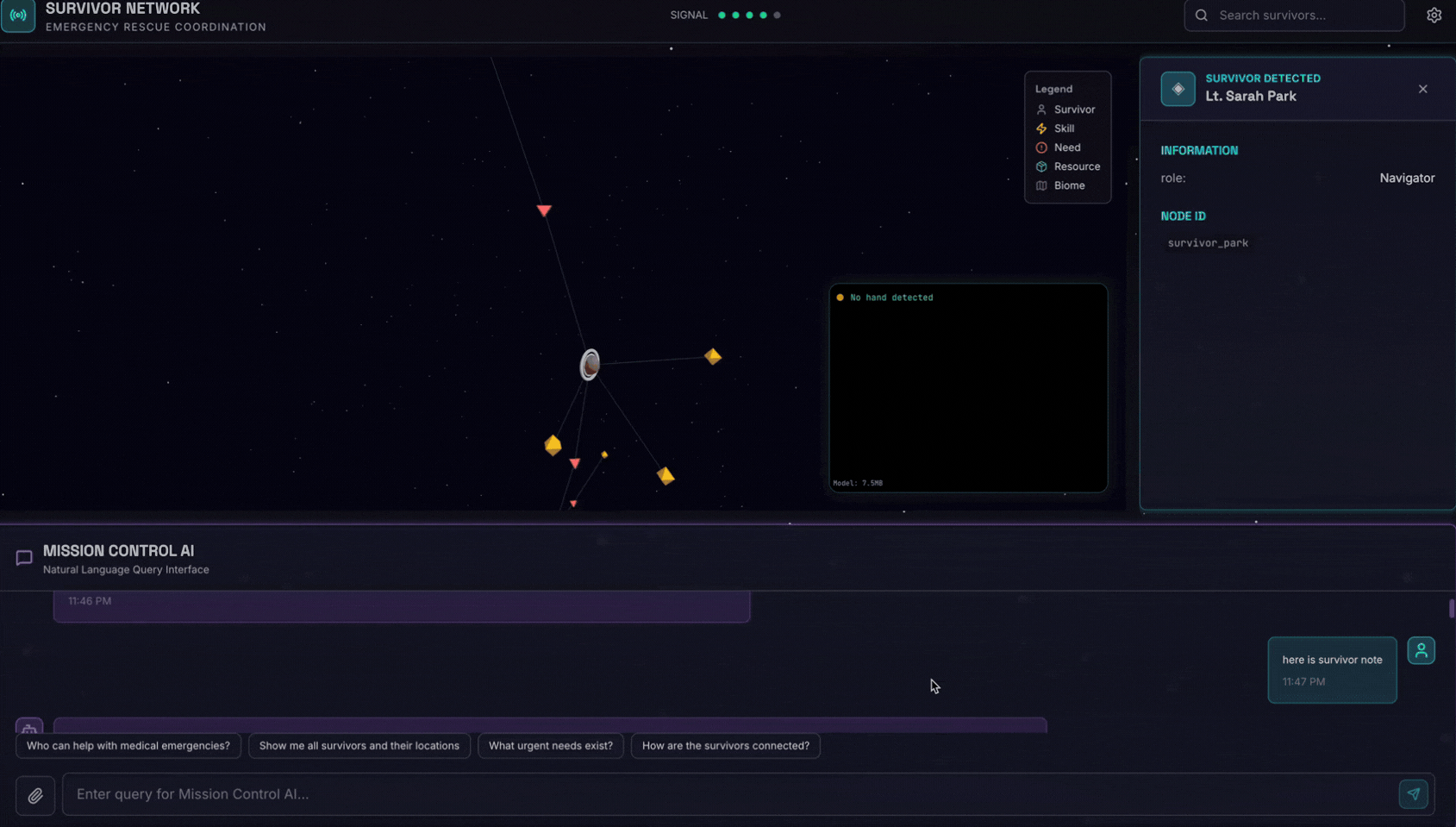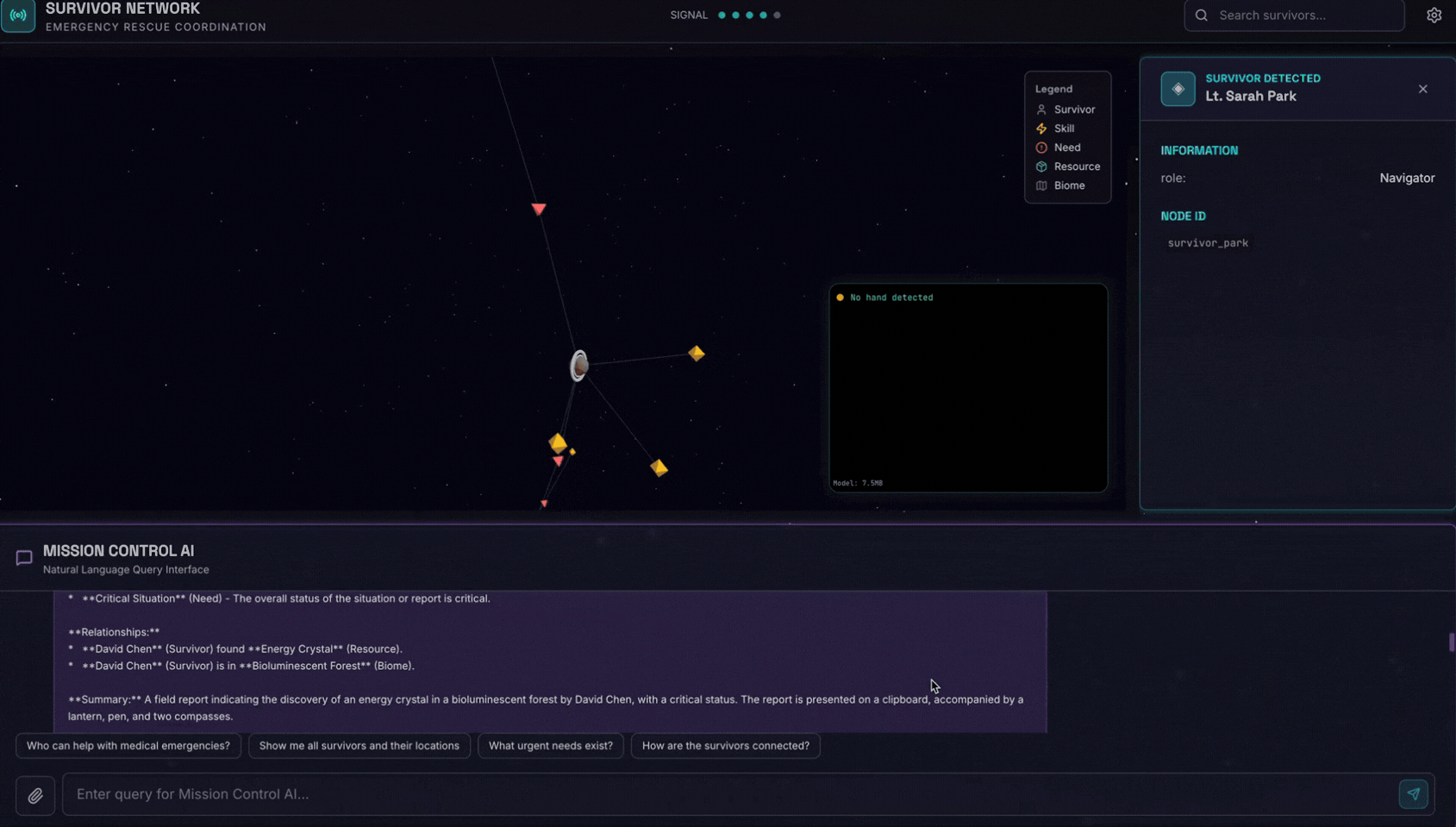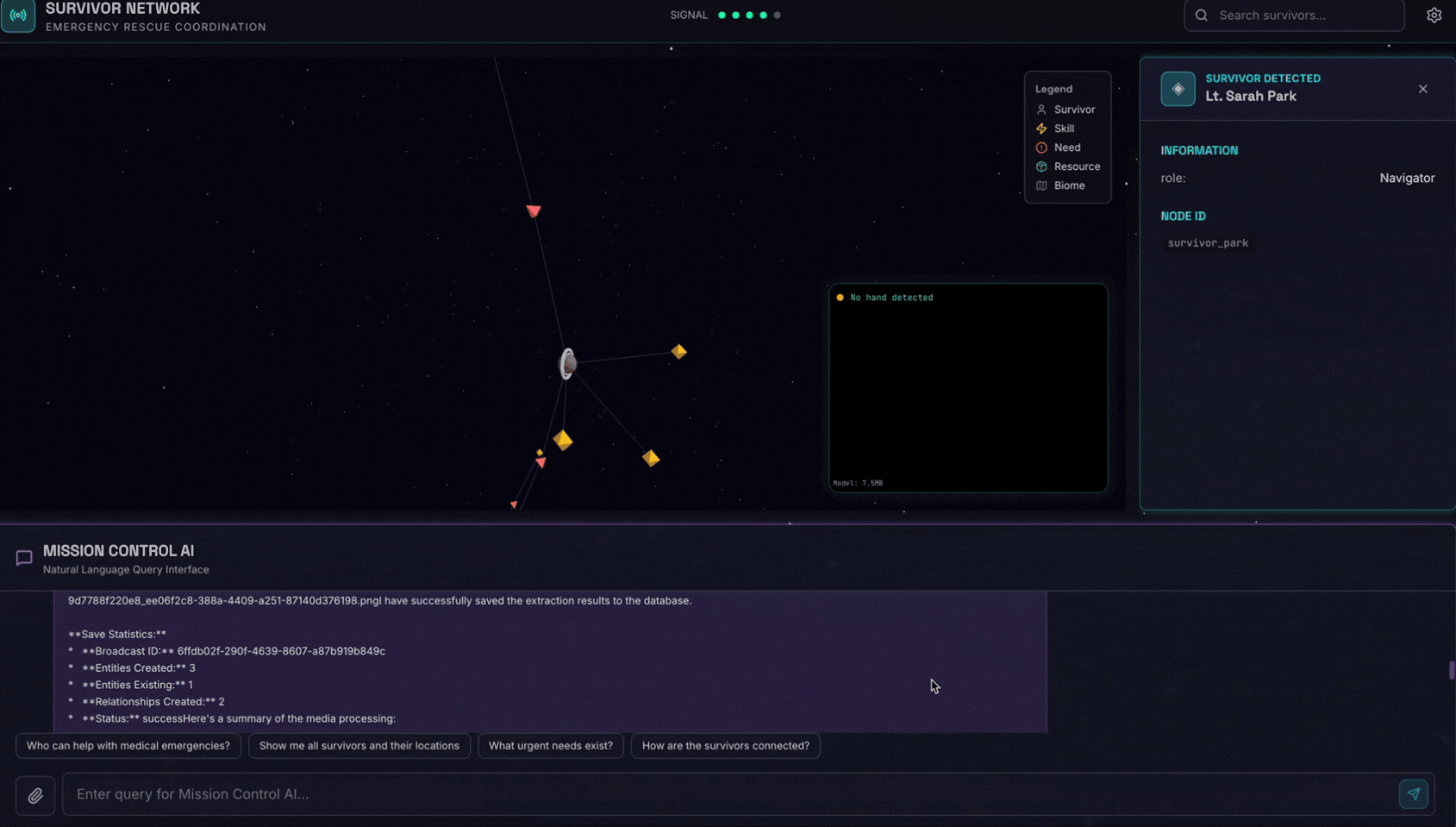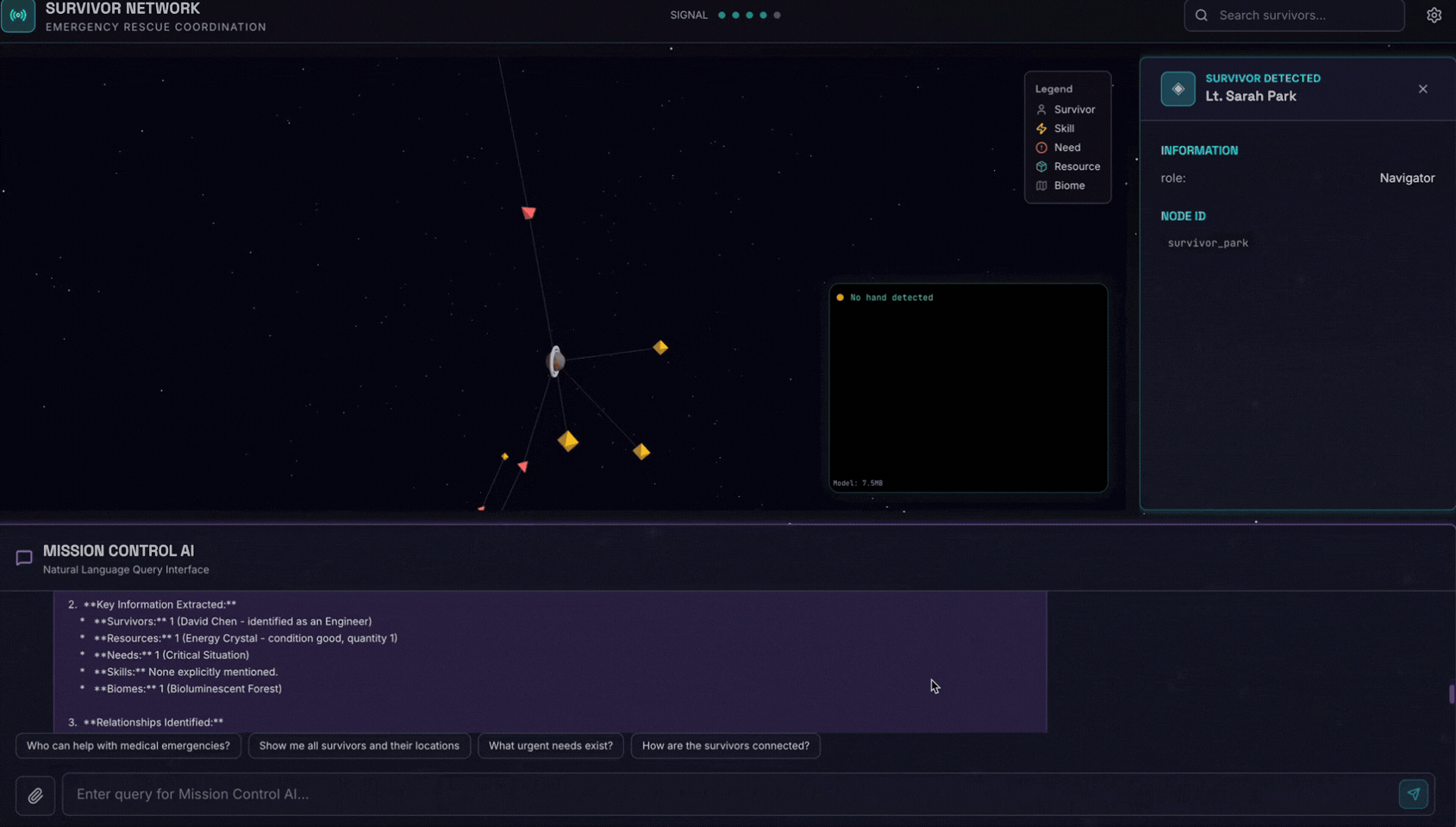
👉💻 No terminal, quando terminar o teste, pressione "Ctrl+C" para encerrar o processo.
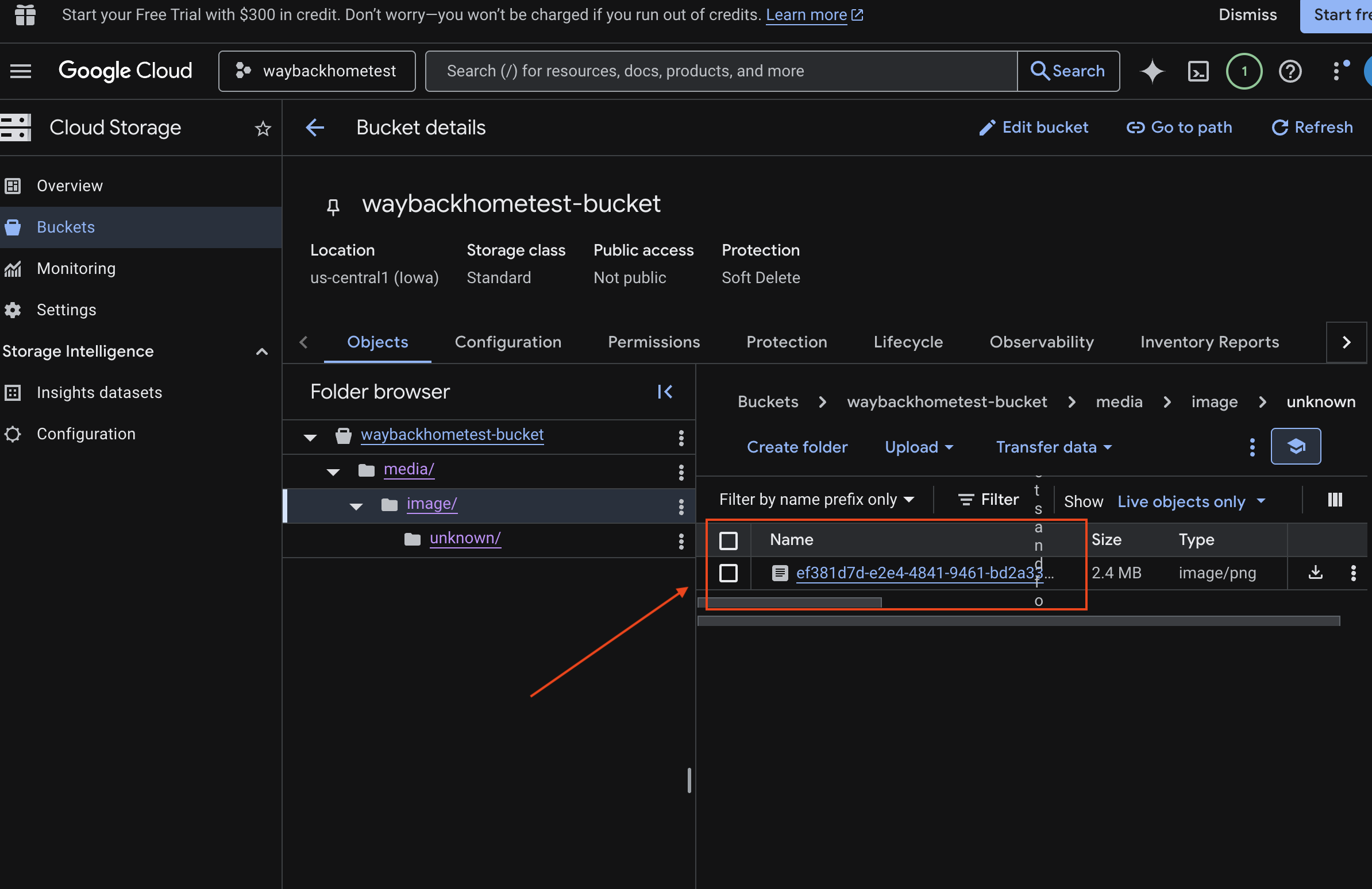
6. Verificar o upload multimodal no bucket do GCS
- Abra o console do Google Cloud Storage.
- Selecione "bucket" no Cloud Storage
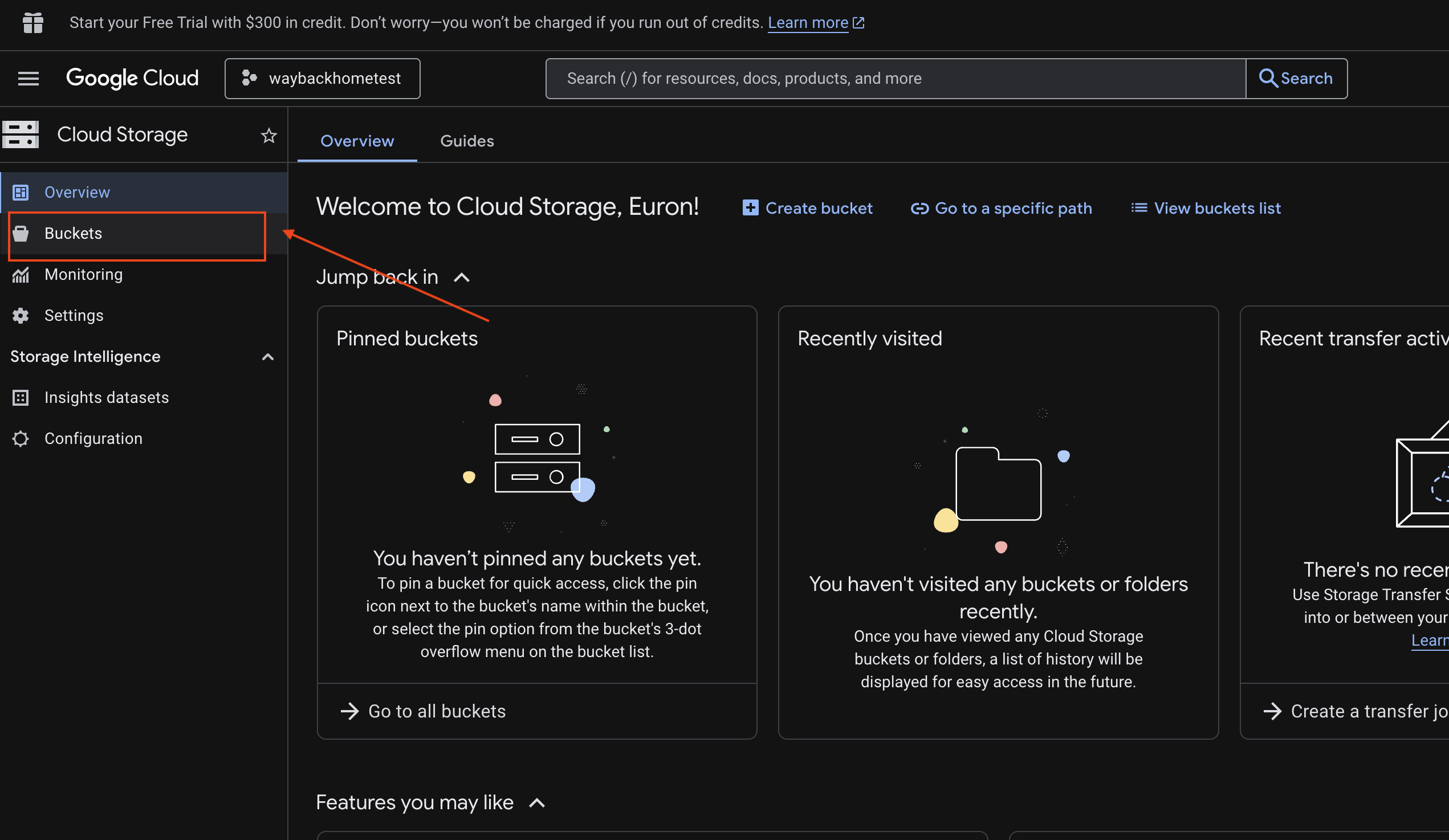
- Selecione seu bucket e clique em
media.
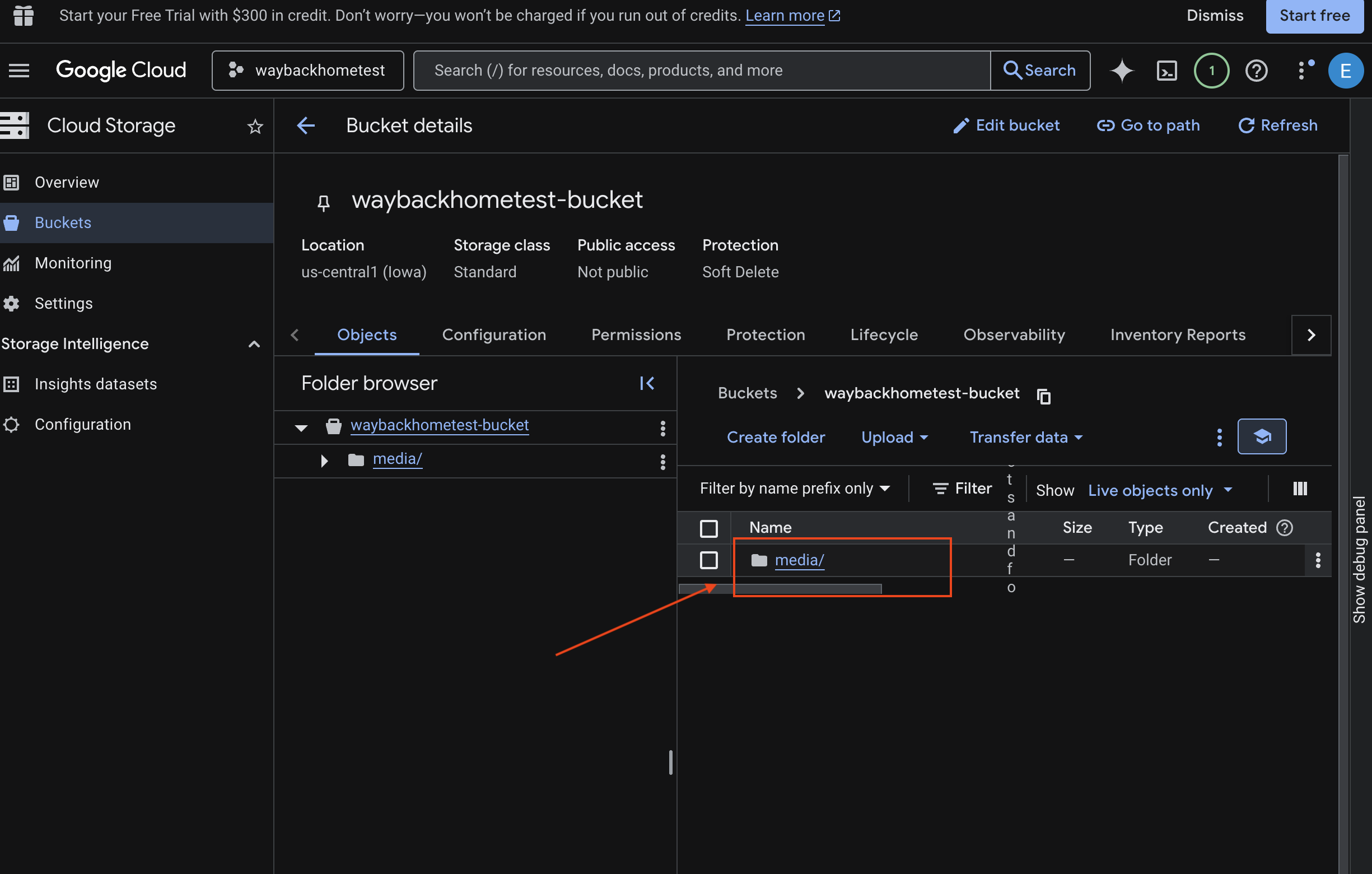
- Confira a imagem enviada aqui.
7. Verificar o upload multimodal no Spanner (opcional)
Confira abaixo um exemplo de saída na interface para test_photo1.
- Abra o Spanner do console do Google Cloud.
- Selecione sua instância:
Survivor Network - Selecione seu banco de dados:
graph-db - Na barra lateral esquerda, clique em Spanner Studio.
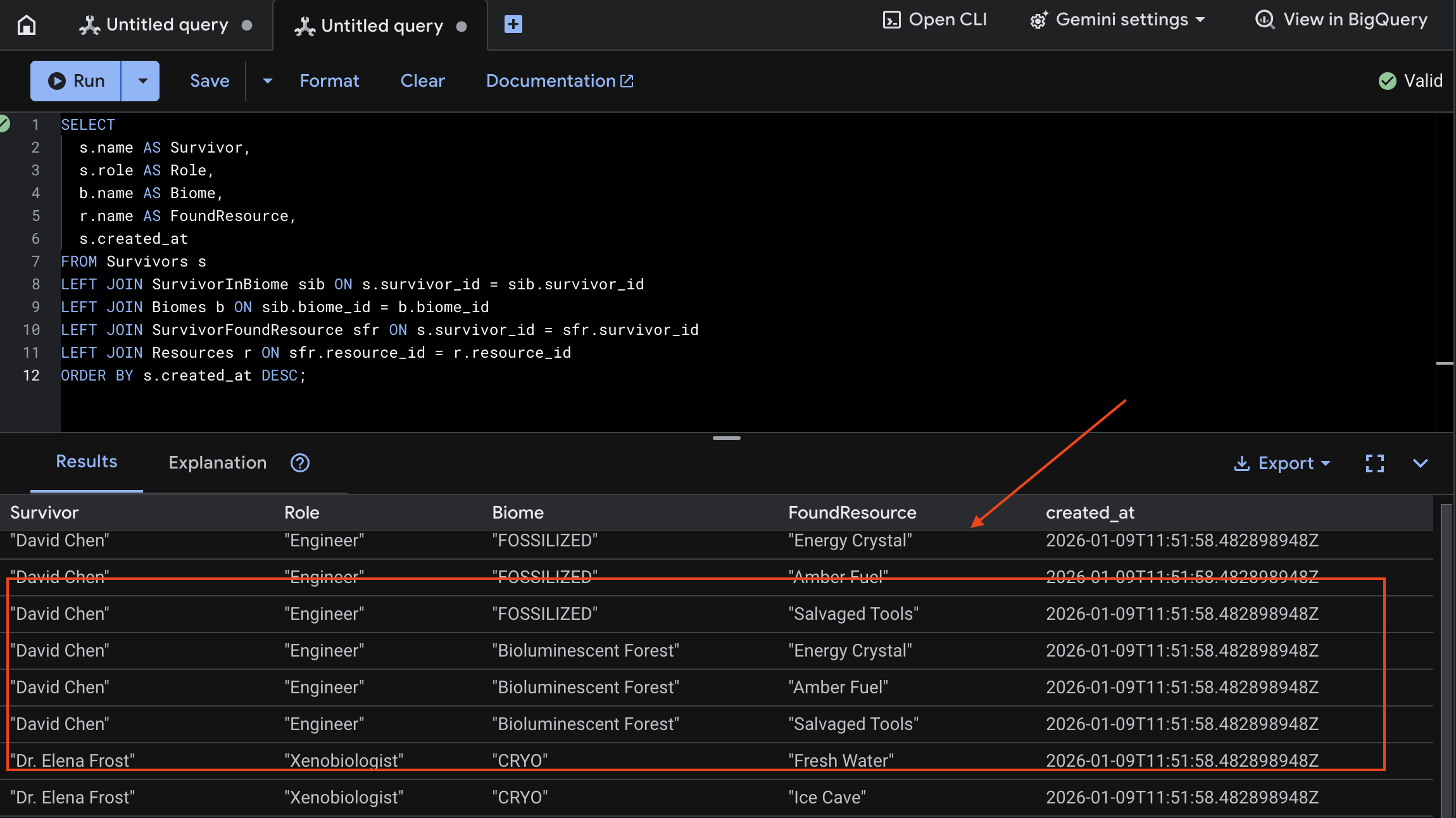
👉 No Spanner Studio, consulte os novos dados:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Podemos verificar isso conferindo o resultado abaixo:
12. ☕️ [Opcional] Memory Bank com o Agent Engine
1. Como a Memória funciona
O sistema usa uma abordagem de memória dupla para lidar com o contexto imediato e o aprendizado de longo prazo.
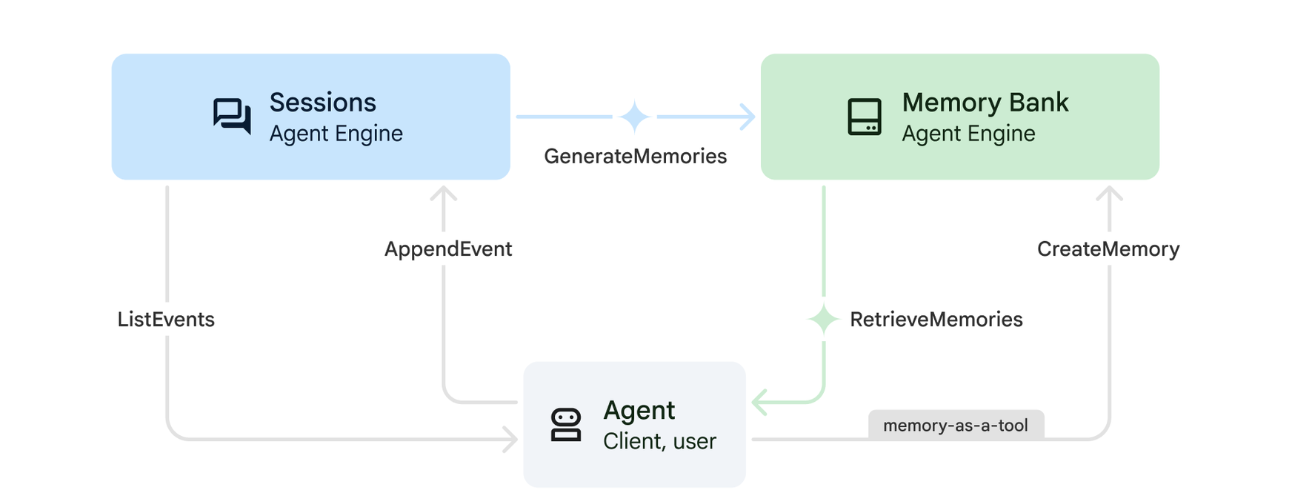
2. O que são os temas de recordação?
Os Temas da memória definem as categorias de informações que o agente precisa lembrar nas conversas. Pense neles como arquivos para diferentes tipos de preferências do usuário.
Nossos dois tópicos:
search_preferences: como o usuário gosta de pesquisar- Eles preferem pesquisa por palavra-chave ou semântica?
- Quais habilidades/biomas eles pesquisam com frequência?
- Exemplo de memória: "O usuário prefere a pesquisa semântica para habilidades médicas"
urgent_needs_context: quais crises estão sendo monitoradas- Quais recursos eles estão monitorando?
- Quais sobreviventes são importantes para eles?
- Exemplo de memória: "O usuário está monitorando a escassez de medicamentos no acampamento do norte"
3. Como configurar temas de memória
Os tópicos de memória personalizada definem o que o agente precisa lembrar. Elas são configuradas ao implantar o Agent Engine.
👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Isso abre ~/way-back-home/level_2/backend/deploy_agent.py no editor.
Definimos objetos de estrutura MemoryTopic para orientar o LLM sobre quais informações extrair e salvar.
👉No arquivo deploy_agent.py, substitua # TODO: SET_UP_TOPIC pelo seguinte:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Integração do agente
O código do agente precisa conhecer o Memory Bank para salvar e recuperar informações.
👉💻 No terminal, abra o arquivo no Editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Isso abre ~/way-back-home/level_2/backend/agent/agent.py no editor.
Criação de agente
Ao criar o agente, transmitimos o after_agent_callback para garantir que as sessões sejam salvas na memória após as interações. A função add_session_to_memory é executada de forma assíncrona para evitar a lentidão da resposta do chat.
👉No arquivo agent.py, encontre o comentário # TODO: REPLACE_ADD_SESSION_MEMORY, Substitua toda esta linha pelo seguinte código:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Salvar em segundo plano
👉No arquivo agent.py, encontre o comentário # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, Substitua toda esta linha pelo seguinte código:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉No arquivo agent.py, encontre o comentário # TODO: REPLACE_ADD_CALLBACK, Substitua toda esta linha pelo seguinte código:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Configurar o serviço de sessão da Vertex AI
👉💻 No terminal, abra o arquivo chat.py no editor do Cloud Shell executando:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉No arquivo chat.py, encontre o comentário # TODO: REPLACE_VERTEXAI_SERVICES, Substitua toda esta linha pelo seguinte código:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Opcional] Anexar agente ao Agent Engine
1. Configuração e implantação
Antes de testar os recursos de memória, implante o agente com os novos tópicos de memória e verifique se o ambiente está configurado corretamente.
Fornecemos um script de conveniência para lidar com esse processo.
Como executar o script de implantação
👉💻 No terminal, execute o script de implantação:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Esse script executa as seguintes ações:
- Executa
backend/deploy_agent.pypara registrar os tópicos do agente e da memória com a Vertex AI. - Captura o novo ID do mecanismo de agente.
- Atualiza automaticamente seu arquivo
.envcomAGENT_ENGINE_ID. - Garante que
USE_MEMORY_BANK=TRUEesteja definido no arquivo.env.
[!IMPORTANT] Se você fizer mudanças em custom_topics em deploy_agent.py, será necessário executar o script novamente para atualizar o Agent Engine.
Verificar o Memory Bank
Agora você pode verificar se o Memory Bank está funcionando ensinando uma preferência ao agente e verificando se ela persiste em várias sessões.
Etapa 1. Abra o aplicativo
Abra o aplicativo novamente seguindo as instruções abaixo: se o terminal anterior ainda estiver em execução, encerre-o pressionando Ctrls+C.
👉💻 Iniciar o app:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Clique em Local: http://localhost:5173/ no terminal.
Etapa 2. Testar o Memory Bank com texto
Na interface de chat, informe ao agente sobre seu contexto específico:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Aguarde cerca de 30 segundos para que a memória seja processada em segundo plano.
Etapa 3. Iniciar uma nova sessão
Atualize a página para limpar o histórico de conversa atual (memória de curto prazo).
Faça uma pergunta com base no contexto que você forneceu antes:
"What kind of missions am I interested in?"
Resposta esperada:
"Com base nas suas conversas anteriores, você tem interesse em:
- Missões de resgate médico
- Operações em montanhas/altitudes elevadas
- Habilidades necessárias: primeiros socorros, escalada
Quer que eu encontre sobreviventes que atendam a esses critérios?"
Etapa 4. Teste com upload de imagem
Envie uma imagem e pergunte:
remember this
Você pode escolher qualquer uma das fotos aqui ou usar uma própria e fazer upload na interface:
Etapa 5. Verificar no Vertex AI Agent Engine
Acesse o Agent Engine no console do Google Cloud.
- Selecione o projeto no seletor no canto superior esquerdo:
- Verifique o mecanismo de agente que você acabou de implantar com o comando anterior
use_memory_bank.sh: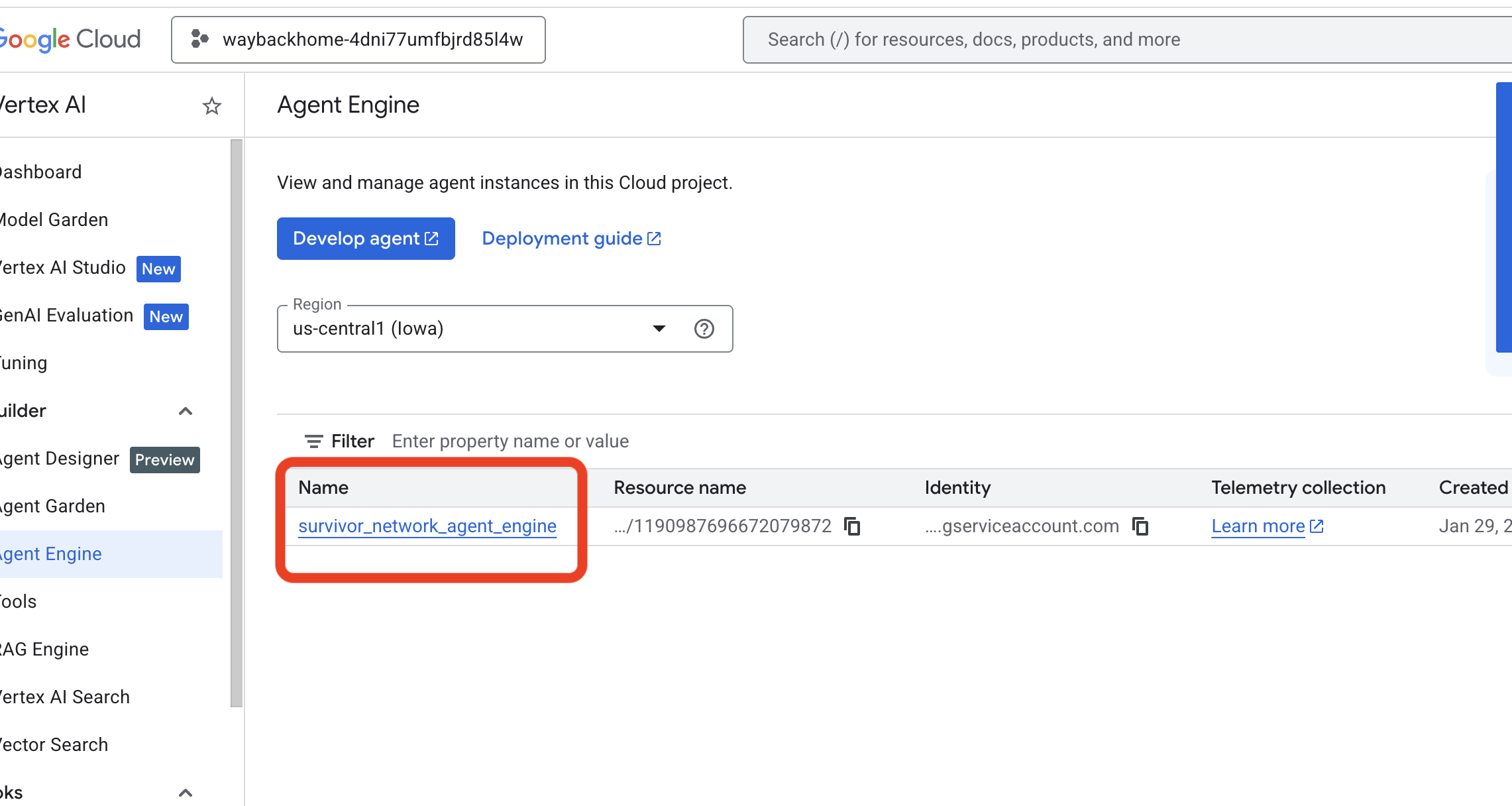 Clique no mecanismo de agente que você acabou de criar.
Clique no mecanismo de agente que você acabou de criar. - Clique na guia
Memoriesdesse agente implantado para ver toda a memória.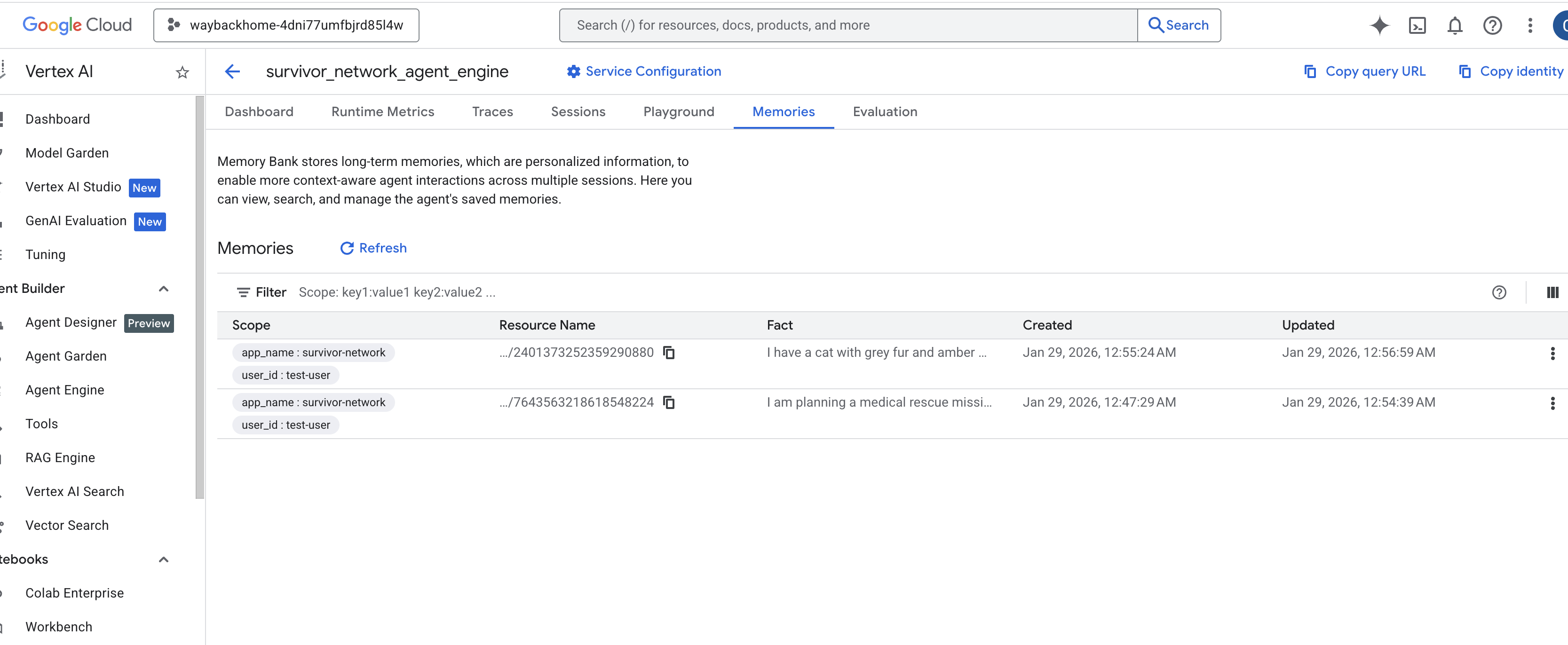
👉💻 Quando terminar o teste, clique em "Ctrl + C" no terminal para encerrar o processo.
🎉 Parabéns! Você acabou de anexar o banco de memória ao seu agente.
14. ☕️ [Opcional] Implantar no Cloud Run
1. Executar o script de implantação
👉💻 Execute o script de implantação:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Depois que ele for implantado, você terá o URL. Este é o URL implantado para você! 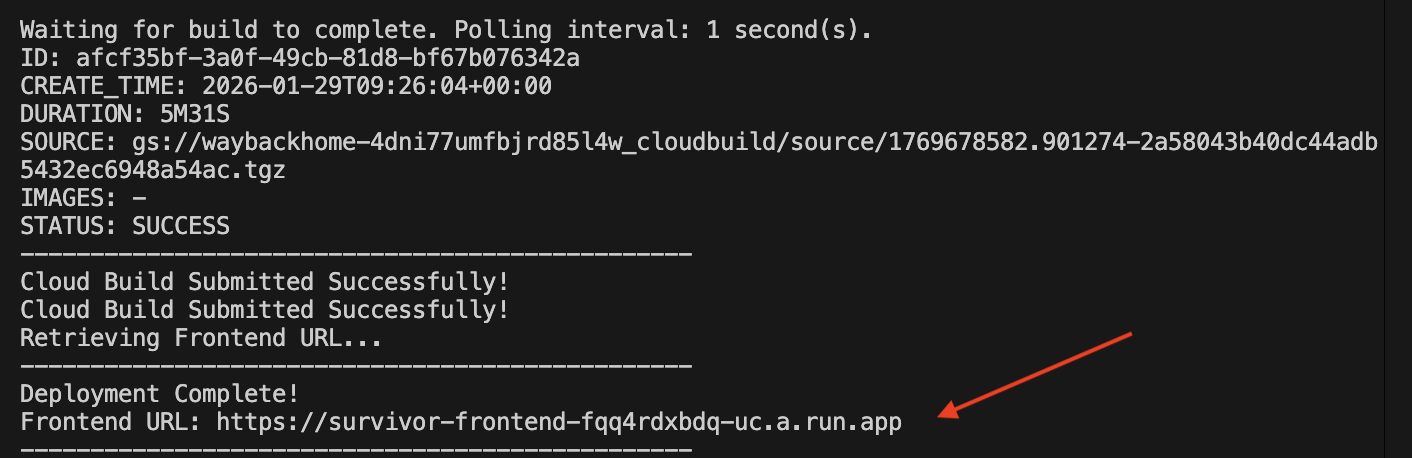
👉💻 Antes de copiar o URL, conceda a permissão executando:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Acesse o URL implantado e veja seu aplicativo ativo.
2. Noções básicas sobre o pipeline de build
O arquivo cloudbuild.yaml define as seguintes etapas sequenciais:
- Build do back-end: cria a imagem Docker em
backend/Dockerfile. - Implantação do back-end: implanta o contêiner de back-end no Cloud Run.
- URL de captura: recebe o novo URL de back-end.
- Build do front-end:
- Instala dependências.
- Cria o app React, injetando
VITE_API_URL=.
- Imagem do front-end: cria a imagem Docker de
frontend/Dockerfile(empacotando os recursos estáticos). - Implantação do front-end: implanta o contêiner de front-end.
3. Verifique a implantação
Depois que o build for concluído (confira o link de registros fornecido pelo script), verifique:
- Acesse o console do Cloud Run.
- Encontre o serviço
survivor-frontend. - Clique no URL para abrir o aplicativo.
- Faça uma consulta de pesquisa para garantir que o front-end possa se comunicar com o back-end.
(OPCIONAL) 4. Implantação manual
Se você preferir executar os comandos manualmente ou entender melhor o processo, saiba como usar cloudbuild.yaml diretamente.
Gravando cloudbuild.yaml
Um arquivo cloudbuild.yaml informa ao Google Cloud Build quais etapas executar.
- steps: uma lista de ações sequenciais. Cada etapa é executada em um contêiner (por exemplo,
docker,gcloud,node,bash). - substituições: variáveis que podem ser transmitidas no tempo de build (por exemplo,
$_REGION). - workspace: um diretório compartilhado em que as etapas podem compartilhar arquivos (como compartilhamos
backend_url.txt).
Como executar a implantação
Para fazer a implantação manual sem o script, use o comando gcloud builds submit. É OBRIGATÓRIO transmitir as variáveis de substituição necessárias.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Conclusão
1. O que você criou
✅ Banco de dados de grafos: Spanner com nós (sobreviventes, habilidades) e arestas (relacionamentos)
✅ Pesquisa de IA: pesquisa por palavra-chave, semântica e híbrida com embeddings
✅ Pipeline multimodal: extraia entidades de imagens/vídeos com o Gemini
✅ Sistema multiagente: fluxo de trabalho coordenado com o ADK
✅ Memory Bank: personalização de longo prazo com a Vertex AI
✅ Implantação em produção: Cloud Run + Agent Engine
2. Resumo da arquitetura
3. Principais pontos
- Graph RAG: combina a estrutura do banco de dados de gráficos com embeddings semânticos para uma pesquisa inteligente.
- Padrões multiagente: pipelines sequenciais para fluxos de trabalho complexos e de várias etapas
- IA multimodal: extrair dados estruturados de mídia não estruturada (imagens/vídeo)
- Agentes com estado: o Memory Bank permite a personalização em várias sessões
4. Conteúdo do workshop
- Level0: Identifique-se
- Level1: Localização exata
- Nível 2: This One: Crie um agente de IA multimodal com Graph RAG, ADK e Memory Bank
- Level3: Como criar um agente de streaming bidirecional do ADK
- Level4: sistema multiagente bidirecional ativo
- Level5: Arquitetura orientada a eventos com Google ADK, A2A e Kafka