
1. Введение

1. Задача
В ситуациях реагирования на стихийные бедствия координация действий пострадавших с различными навыками, ресурсами и потребностями в разных местах требует интеллектуального управления данными и возможностей поиска. Этот семинар научит вас создавать производственную систему искусственного интеллекта, которая объединяет в себе:
- 🗄️ Графовая база данных (Spanner) : хранит сложные взаимосвязи между выжившими, навыками и ресурсами.
- 🔍 Поиск на основе ИИ : гибридный поиск семантики и ключевых слов с использованием эмбеддингов
- 📸 Мультимодальная обработка : извлечение структурированных данных из изображений, текста и видео.
- 🤖 Многоагентная оркестровка : координация работы специализированных агентов для сложных рабочих процессов
- 🧠 Долговременная память : персонализация с помощью банка памяти Vertex AI
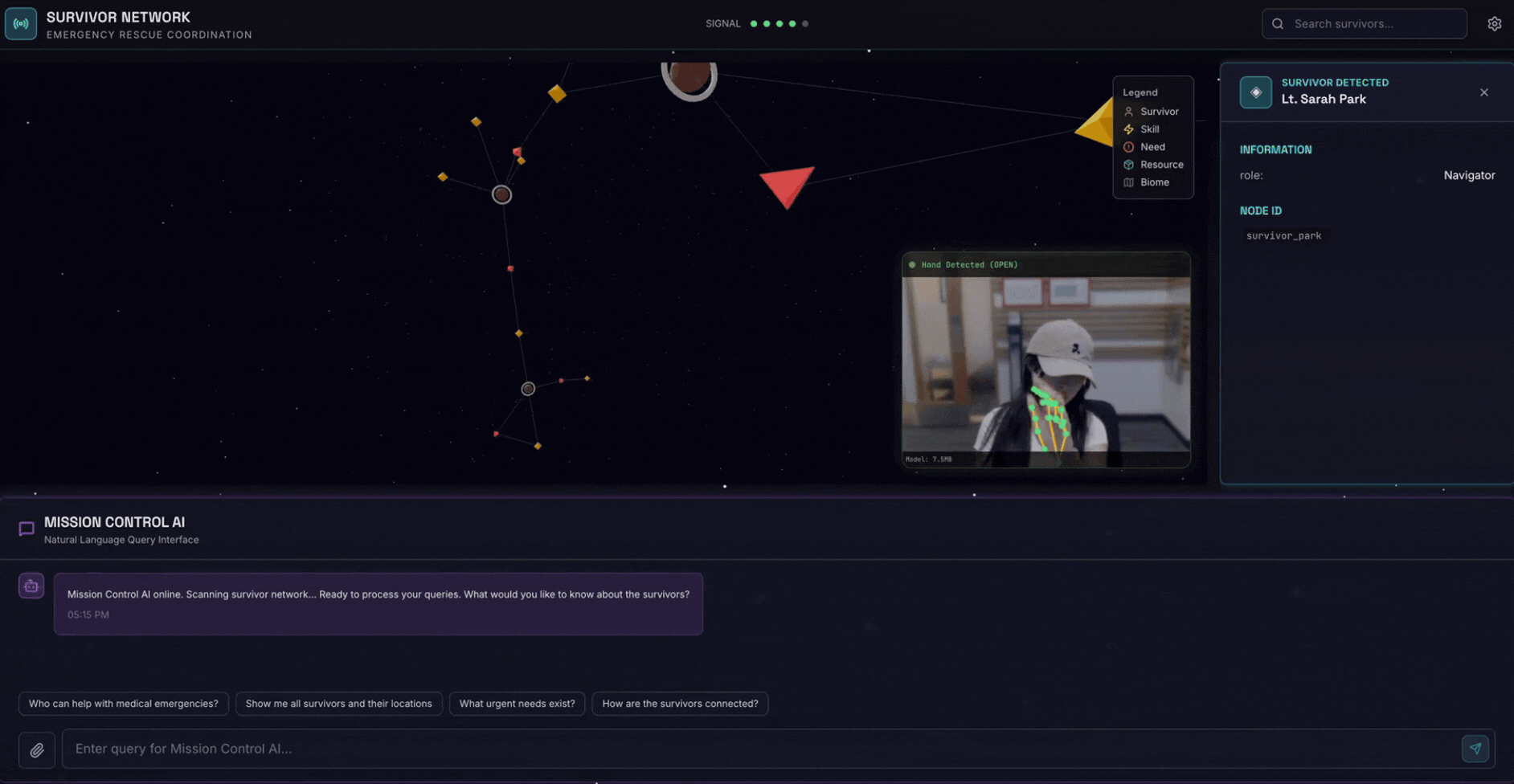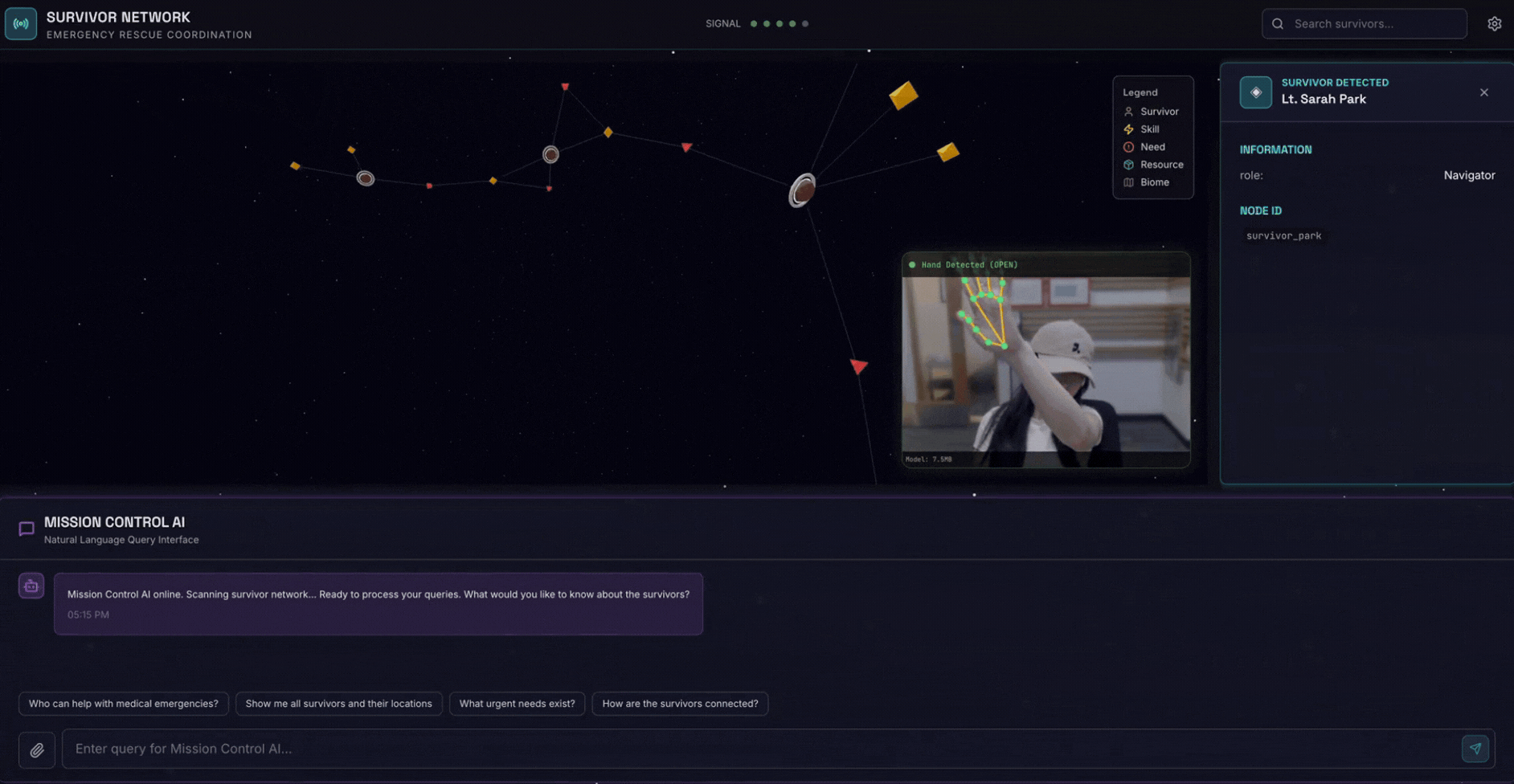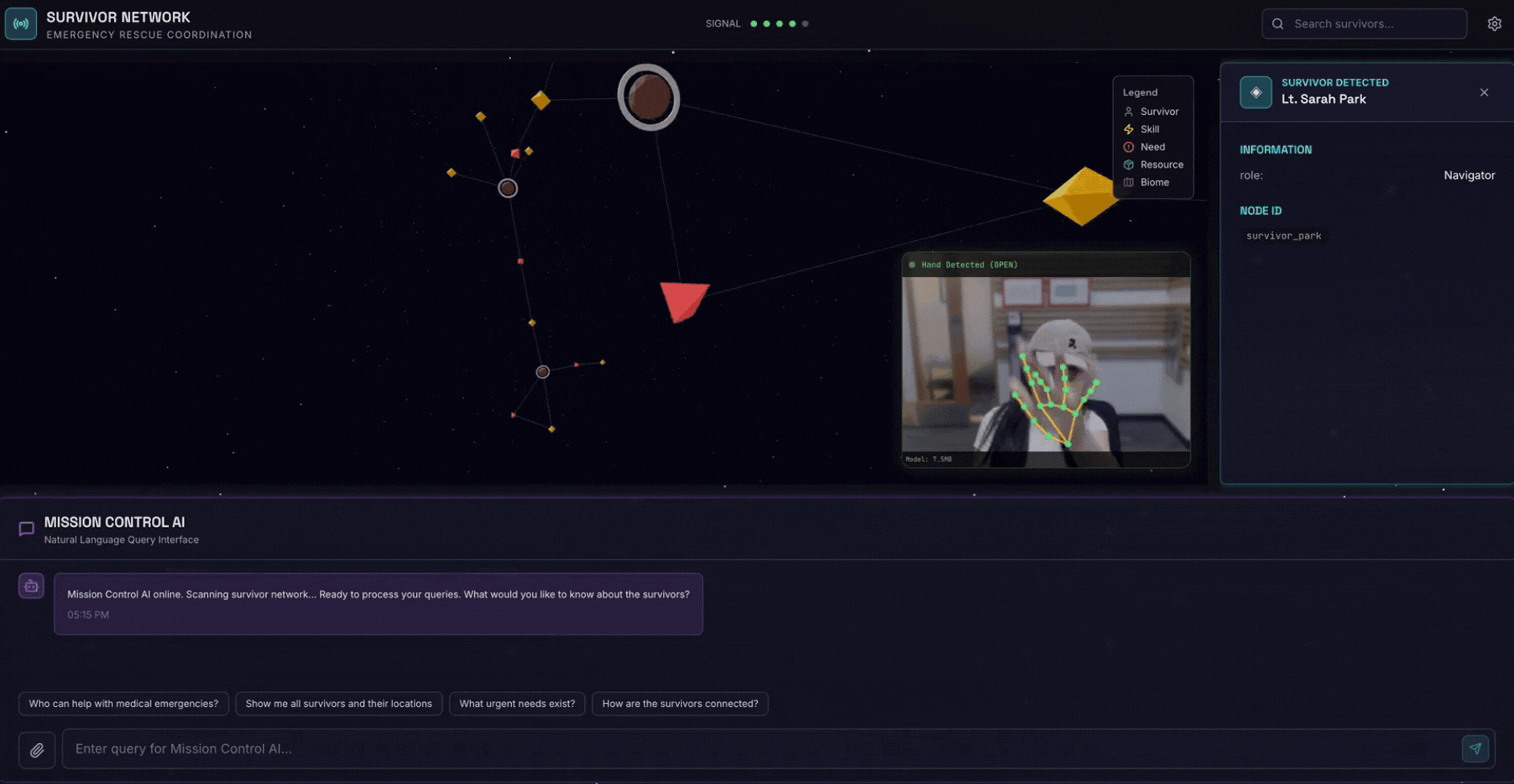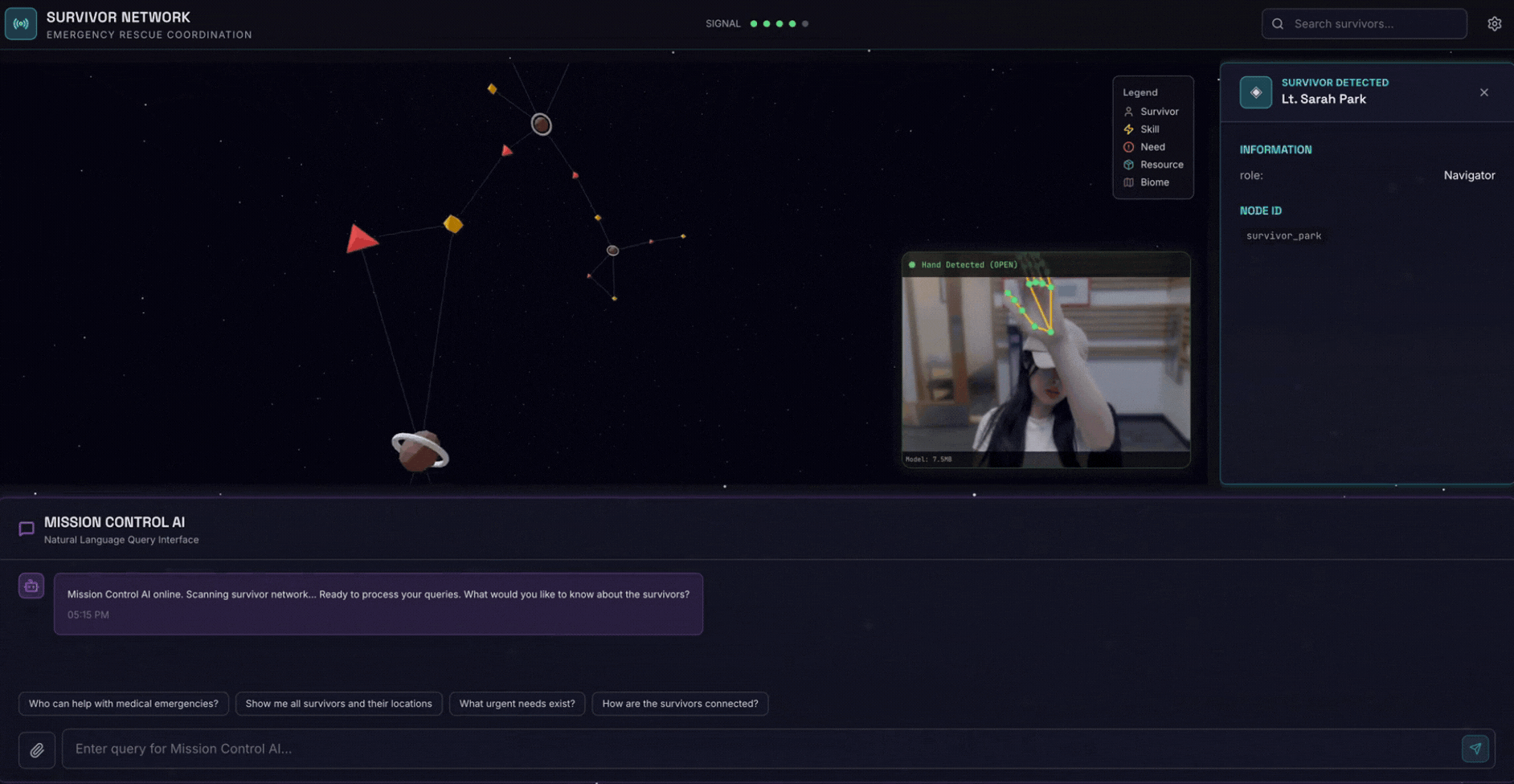
2. Что вы построите
База данных графов сети выживших, включающая:
- 🗺️ Интерактивная 3D-визуализация взаимосвязей между выжившими
- 🔍 Интеллектуальный поиск (по ключевым словам, семантический и гибридный)
- 📸 Многомодальный конвейер загрузки (извлечение объектов из изображений/видео)
- 🤖 Многоагентная система для организации сложных задач
- 🧠 Интеграция с банком памяти для персонализированного взаимодействия
3. Основные технологии
Компонент | Технологии | Цель |
База данных | График Cloud Spanner | Храните узлы (выжившие, навыки) и ребра (связи). |
Поиск с использованием ИИ | Gemini + Embeddings | Семантическое понимание + поиск сходства |
Агентская структура | ADK (комплект для разработки агентов) | Организация рабочих процессов ИИ |
Память | Банк памяти Vertex AI | Долгосрочное хранение пользовательских предпочтений |
Внешний интерфейс | React + Three.js | Интерактивная 3D-визуализация графиков |
2. 🛠️ Подготовка окружающей среды (пропустите, если вы участвуете в мастер-классе)
Часть первая: Включение платёжного аккаунта
Для выполнения этого практического задания вам потребуется платежный аккаунт с достаточным балансом. Используйте средства, указанные в баннере вверху страницы. Если у вас уже есть платежный аккаунт, вы можете пропустить этот шаг.
Часть вторая: Открытая среда
- 👉 Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- 👉 Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- 👉 Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- 👉💻 В терминале убедитесь, что вы уже авторизованы и что проект настроен на ваш идентификатор проекта, используя следующую команду:
gcloud auth list - 👉💻 Клонируйте проект Bootstrap с GitHub:
git clone https://github.com/gca-americas/way-back-home.git
Часть третья: Создание нового проекта
👉💻 В терминале сделайте скрипт инициализации исполняемым и запустите его:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Настройка среды
1. Open Cloud Shell
Если в терминале Cloud Shell Editor окно терминала не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
2. Настройка проекта
👉💻 В терминале укажите идентификатор вашего проекта:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Включите необходимые API (это займет примерно 2-3 минуты):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Запустите скрипт установки.
👉💻 Выполните скрипт установки:
cd ~/way-back-home/level_2
./setup.sh
Это создаст для вас .env . В вашей оболочке Cloudshell откройте проект way_back_home . В папке level_2 вы увидите созданный для вас файл .env . Если вы не можете его найти, вы можете нажать View -> Toggle Hidden File , чтобы увидеть его. 
4. Загрузка выборочных данных
👉💻 Перейдите в административную панель и установите зависимости:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Загрузка исходных данных о выживших:
uv run python ~/way-back-home/level_2/backend/setup_data.py
В результате получается:
- Экземпляр Spanner (
survivor-network) - База данных (
graph-db) - Все таблицы узлов и ребер
- Графы свойств для запросов. Ожидаемый результат :
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
Если вы перейдете по ссылке после пункта Access your database at в выходных данных, вы сможете открыть Google Cloud Console Spanner.

И вы увидите Spanner в консоли Google Cloud!
4. 🚀 Визуализация графовых данных в Spanner Studio
Это руководство поможет вам визуализировать данные графа сети выживших и взаимодействовать с ними непосредственно в консоли Google Cloud с помощью Spanner Studio. Это отличный способ проверить ваши данные и понять структуру графа перед созданием вашего ИИ-агента.
1. Доступ к Spanner Studio
- На последнем шаге обязательно перейдите по ссылке и откройте Spanner Studio.
2. Понимание структуры графа («общая картина»)
Представьте себе набор данных Survivor Network как логическую головоломку или состояние игры :
Сущность | Роль в системе | Аналогия |
Выжившие | Агенты/игроки | Игроки |
Биомы | Где они расположены | Зоны на карте |
Навыки | Что они могут сделать | Способности |
Потребности | Чего им не хватает (кризисов) | Задания/Миссии |
Ресурсы | Предметы, найденные в мире | Добыча |
Цель : Задача ИИ-агента — связать навыки (решения) с потребностями (проблемами), учитывая биомы (территориальные ограничения).
🔗 Ребра (связи):
-
SurvivorInBiome: Отслеживание местоположения -
SurvivorHasSkill: Инвентарь способностей -
SurvivorHasNeed: Список актуальных проблем -
SurvivorFoundResource: Инвентаризация предметов -
SurvivorCanHelp: Предполагаемая взаимосвязь (ИИ вычисляет это!)
3. Запрос к графу
Давайте выполним несколько запросов, чтобы увидеть «историю», скрытую в данных.
Spanner Graph использует GQL (Graph Query Language) . Для выполнения запроса используйте GRAPH SurvivorNetwork , за которой следует ваш шаблон соответствия.
👉 Вопрос 1: Глобальный список (Кто где находится?) Это ваша основа — понимание местоположения имеет решающее значение для спасательных операций.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Ожидаемый результат: 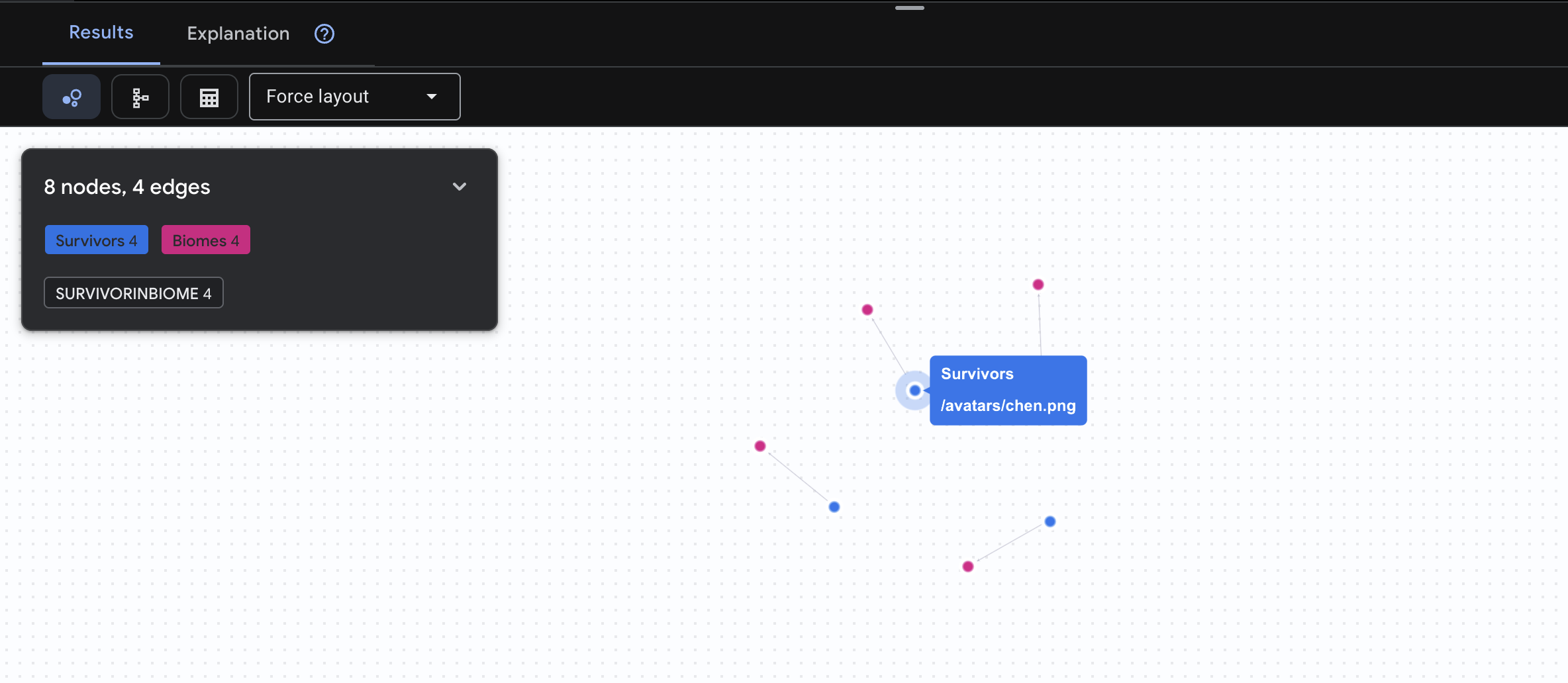
👉 Вопрос 2: Матрица навыков (возможностей) Теперь, когда вы знаете, на каком уровне находится каждый сотрудник, выясните, что он умеет делать .
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Ожидаемый результат: 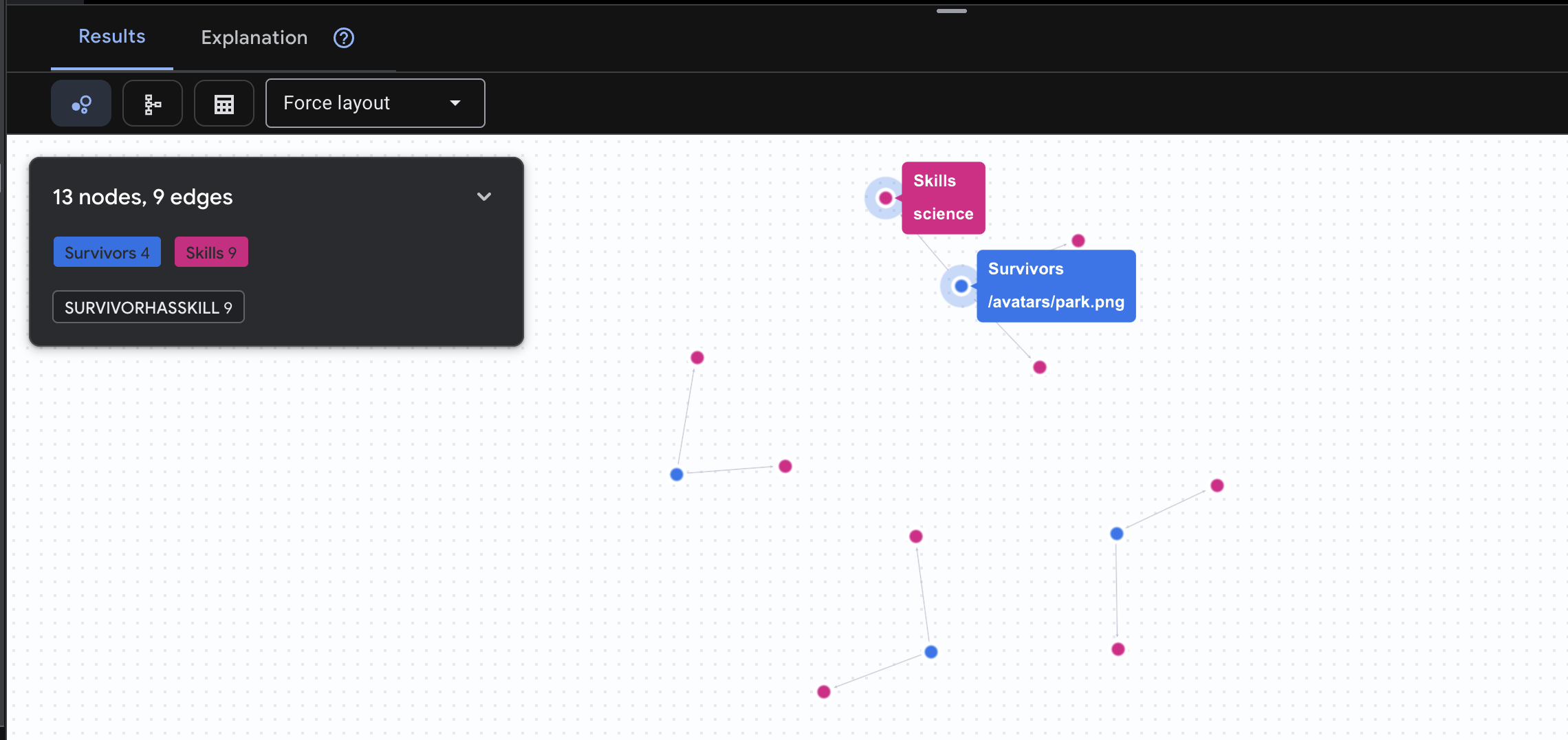
👉 Вопрос 3: Кто находится в кризисной ситуации? («Миссия») Узнайте, кто из пострадавших нуждается в помощи и что им нужно.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Ожидаемый результат: 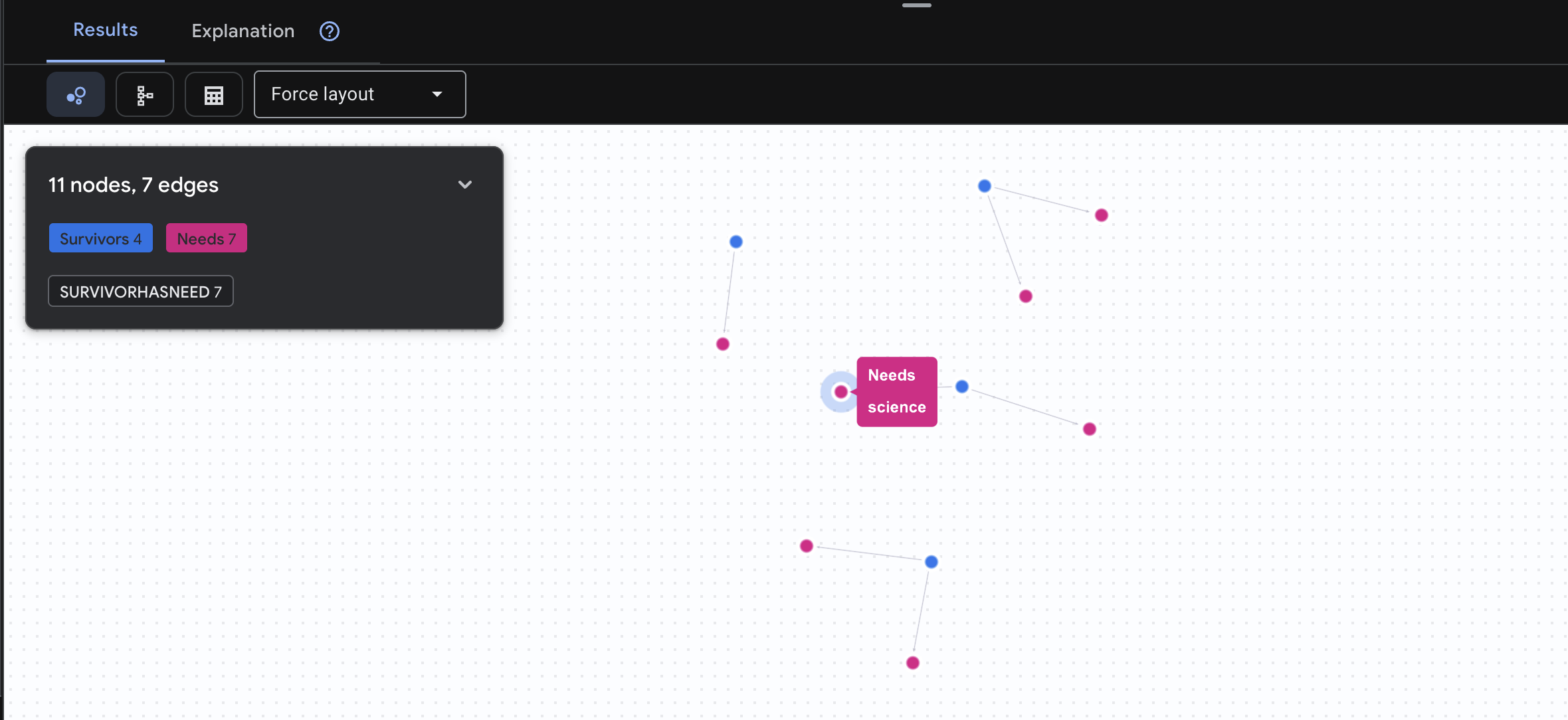
🔎 [Необязательно] Подбор партнеров — кто кому может помочь?
Вот где граф становится по-настоящему мощным! Этот запрос находит выживших, обладающих навыками, позволяющими удовлетворять потребности других выживших .
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Ожидаемый результат: 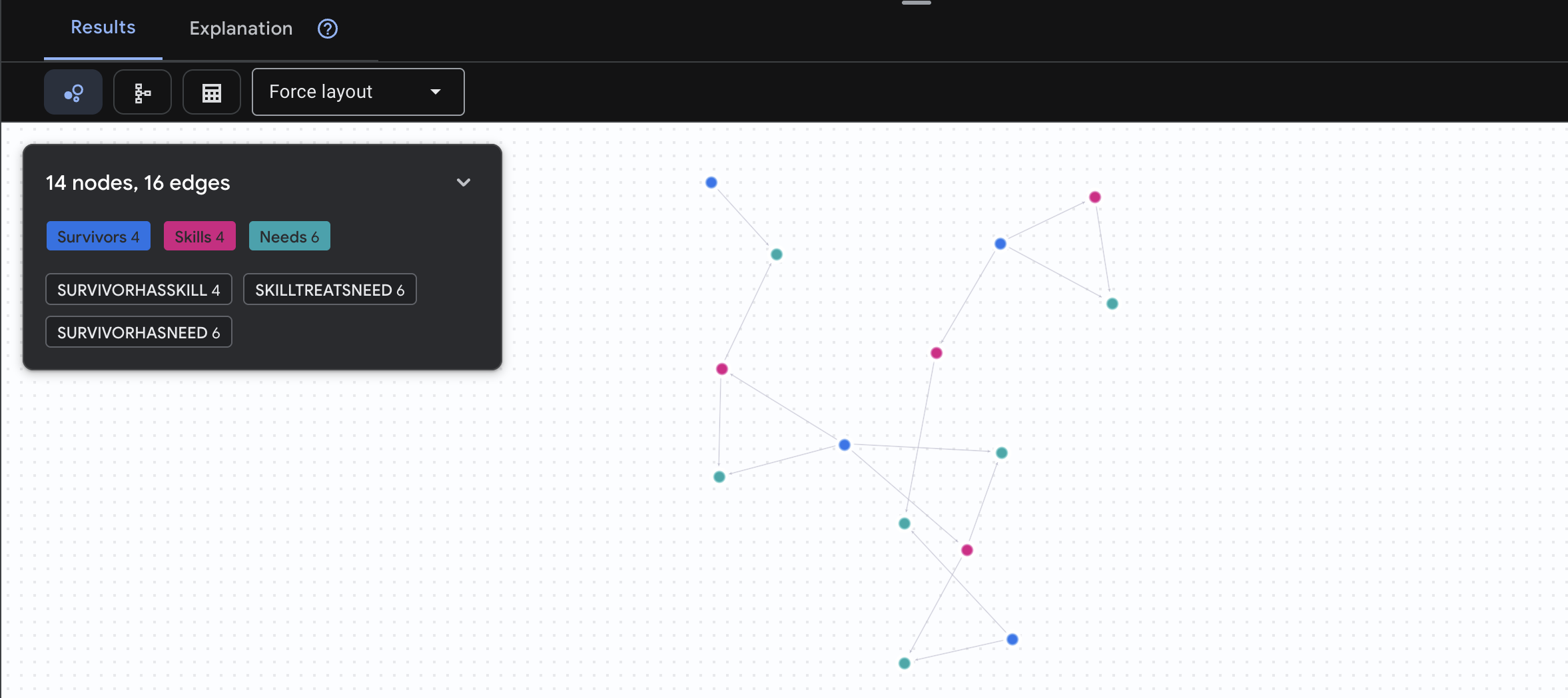
В сторону, положительный аспект. Что делает этот запрос:
Вместо того чтобы просто показать "Первая помощь лечит ожоги" (что очевидно из схемы), этот запрос находит:
- Доктор Елена Фрост (имеющая медицинское образование) → может лечить → капитана Танаку (у которого ожоги)
- Дэвид Чен (обладающий навыками оказания первой помощи) → может оказать помощь → лейтенанту Паку (у которого растяжение лодыжки)
Почему это так важно:
Что будет делать ваш ИИ-агент:
Когда пользователь спрашивает: «Кто может лечить ожоги?» , агент выполнит следующее:
- Выполните аналогичный запрос к графу.
- Ответ: «Доктор Фрост имеет медицинское образование и может помочь капитану Танаке».
- Пользователю не нужно знать о промежуточных таблицах или связях!
5. 🚀 Эмбеддинги на основе ИИ в Spanner
1. Зачем нужны эмбеддинги? (Никаких действий, только для чтения)
В ситуации выживания время имеет решающее значение . Когда выживший сообщает о чрезвычайной ситуации, например I need someone who can treat burns или Looking for a medic , он не может тратить время на угадывание точных названий навыков в базе данных.
Реальный сценарий : Выживший: Captain Tanaka has burns—we need medical help NOW!
Традиционный поиск по ключевому слову "медик" → 0 результатов ❌
Семантический поиск с использованием эмбеддингов → Находит "Медицинское образование", "Первая помощь" ✅
Это именно то, что нужно агентам: интеллектуальный, человекоподобный поиск , который понимает намерения пользователя, а не только ключевые слова.
2. Создайте модель встраивания.
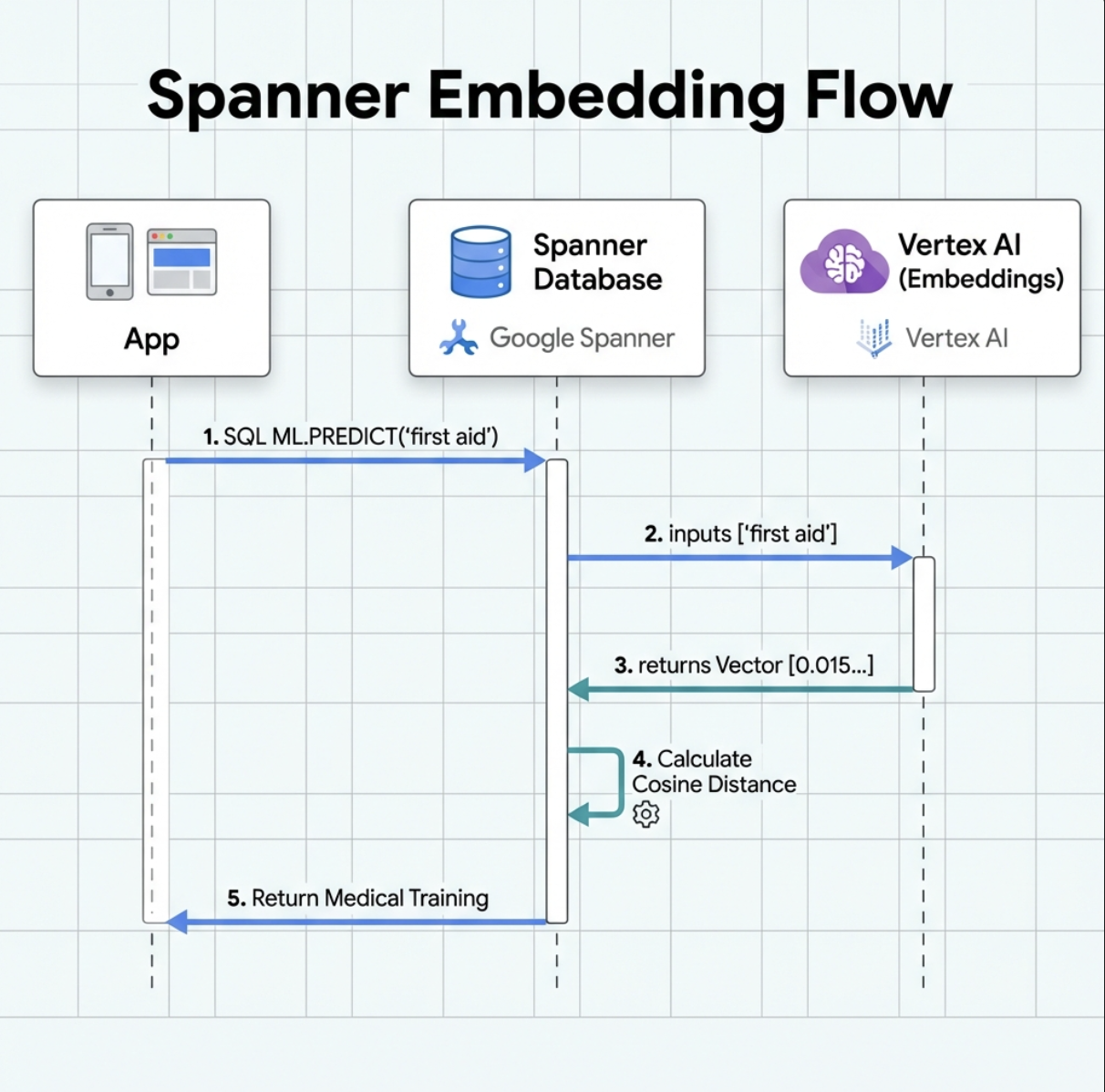
Теперь давайте создадим модель, которая преобразует текст в векторные представления, используя инструмент Google text-embedding-004 .
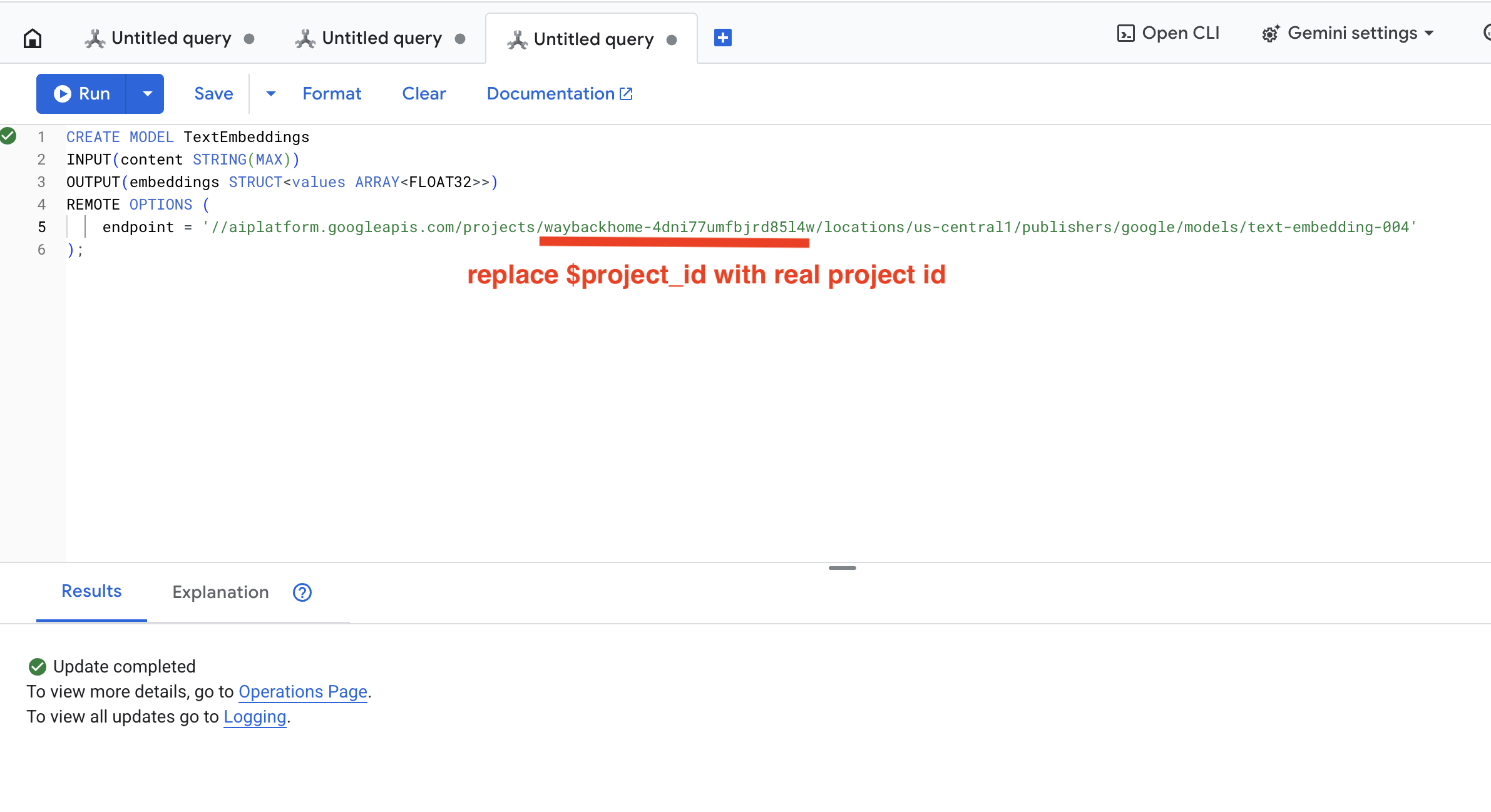
👉 В Spanner Studio выполните следующий SQL-запрос (замените $YOUR_PROJECT_ID на фактический идентификатор вашего проекта):
‼️ В редакторе Cloud Shell откройте File -> Open Folder -> way-back-home/level_2 чтобы увидеть весь проект.
👉 Чтобы выполнить этот запрос в Spanner Studio, скопируйте и вставьте приведенный ниже запрос, а затем нажмите кнопку «Выполнить»:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Что это делает :
- Создает виртуальную модель в Spanner (веса модели не хранятся локально).
- Указывает на библиотеку
text-embedding-004от Google на платформе Vertex AI. - Определяет условия контракта: на входе — текст, на выходе — массив чисел с плавающей запятой размером 768 элементов.
Почему "УДАЛЕННЫЕ ВАРИАНТЫ"?
- Spanner не запускает модель самостоятельно.
- При использовании
ML.PREDICTпроисходит вызов Vertex AI через API. - Zero-ETL : Нет необходимости экспортировать данные в Python, обрабатывать их и повторно импортировать.
Нажмите кнопку Run . После успешного завершения вы увидите результат, как показано ниже:
3. Добавить столбец встраивания.
👉 Добавьте столбец для хранения эмбеддингов:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Нажмите кнопку Run . После успешного завершения вы увидите результат, как показано ниже:
4. Сгенерируйте векторные представления.
👉 Используйте ИИ для создания векторных представлений для каждого навыка:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Нажмите кнопку Run . После успешного завершения вы увидите результат, как показано ниже:
Что происходит : каждое название навыка (например, «первая помощь») преобразуется в 768-мерный вектор, представляющий его семантическое значение.
5. Проверка эмбеддингов
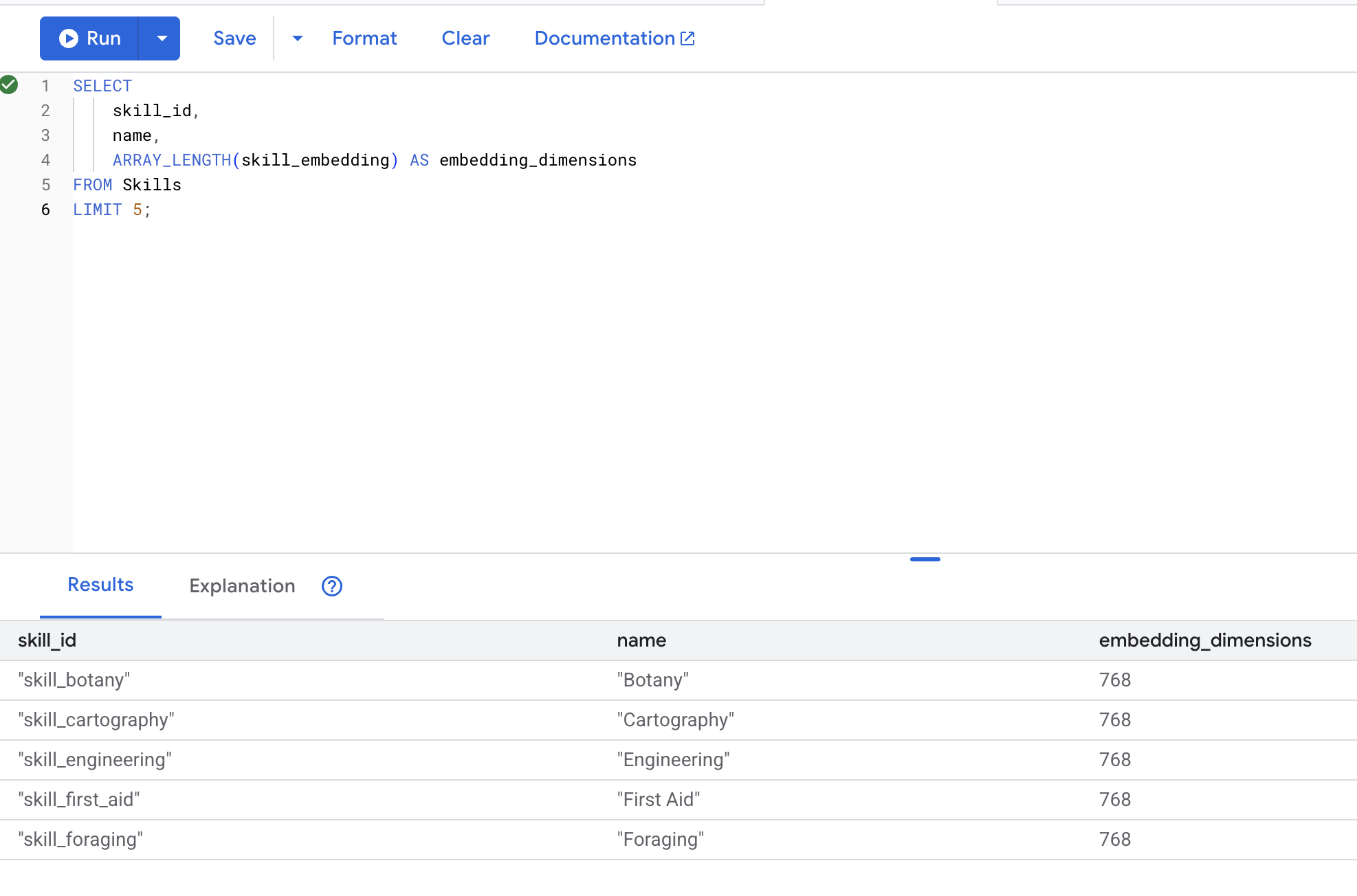
👉 Проверьте, созданы ли эмбеддинги:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Ожидаемый результат :
6. Тестирование семантического поиска
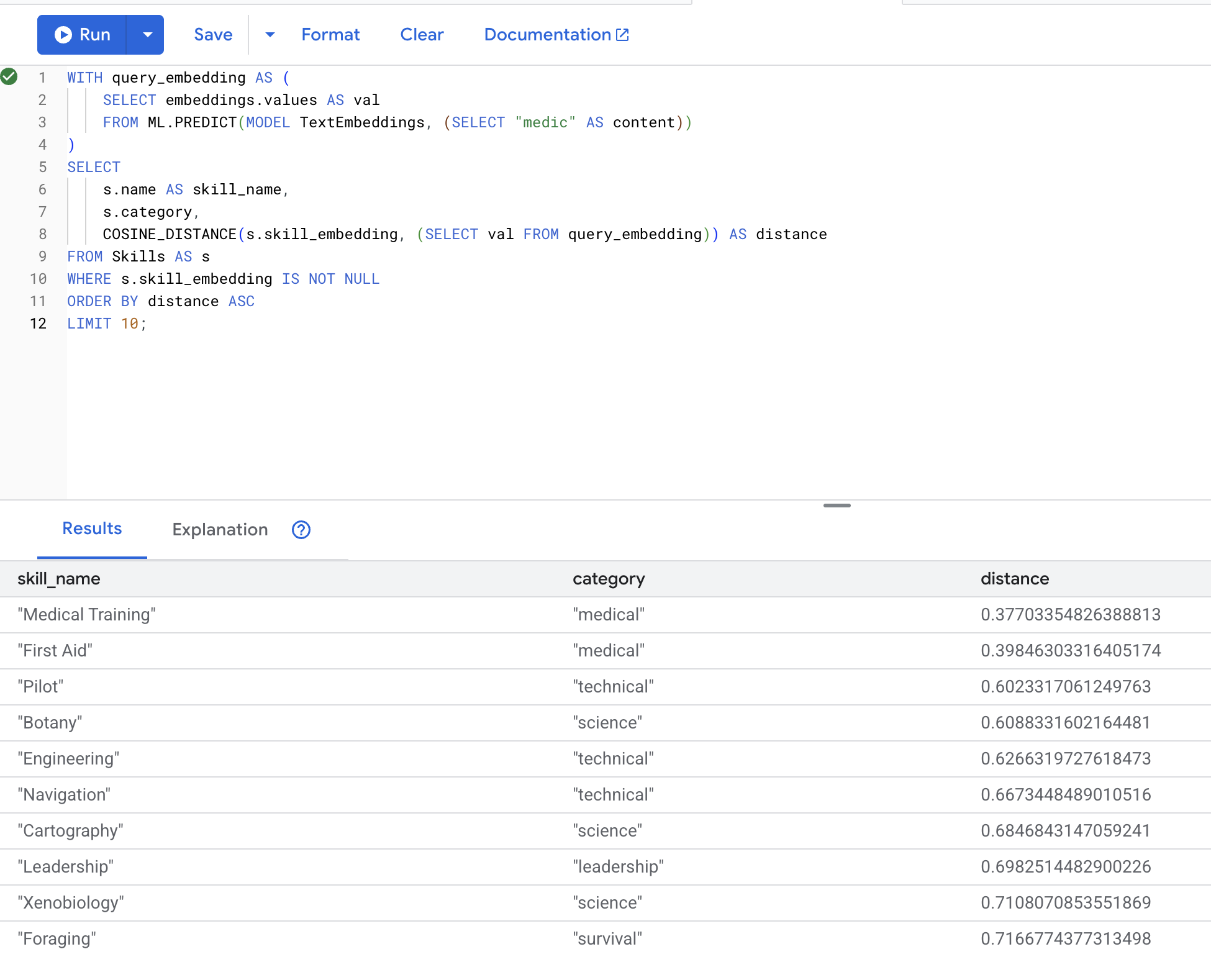
Теперь проверим конкретный пример из нашего сценария : поиск медицинских специалистов по термину "медик".
👉 Найдите навыки, похожие на "медик":
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Преобразует поисковый запрос пользователя "медик" в векторное представление.
- Сохраняет его во временной таблице
query_embedding
Ожидаемые результаты (меньшее расстояние = большее сходство):
7. Создайте модель Gemini для анализа.
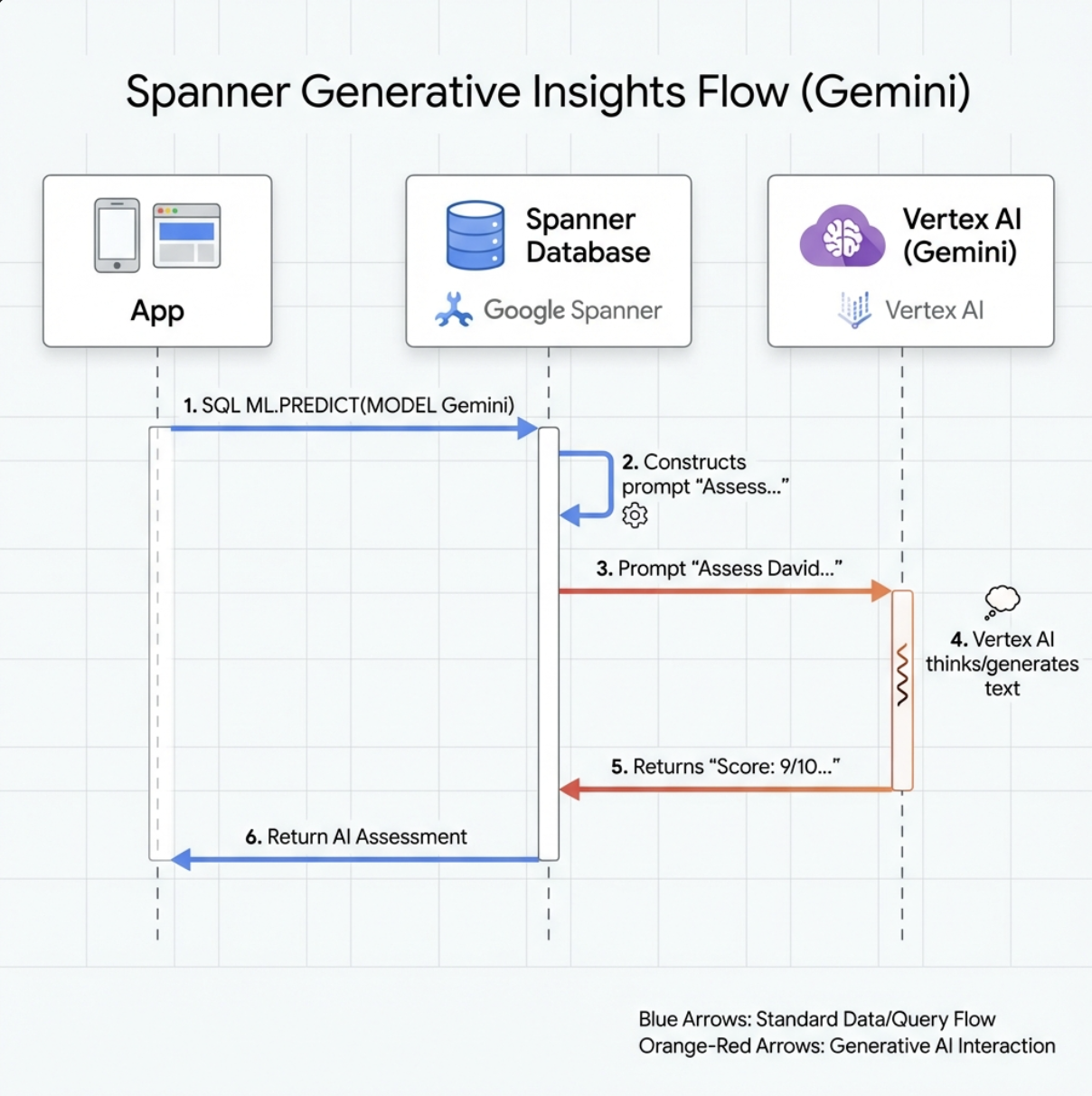
👉 Создайте ссылку на модель генеративного ИИ (замените $YOUR_PROJECT_ID на фактический идентификатор вашего проекта):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Отличие от модели встраивания :
- Встраивание текста : Текст → Вектор (для поиска сходства)
- Близнецы : Текст → Сгенерированный текст (для рассуждений/анализа)
8. Используйте Gemini для анализа совместимости.
👉 Проанализируйте пары выживших на предмет совместимости в выполнении миссии:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Ожидаемый результат :
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Создание агента Graph RAG с гибридным поиском
1. Обзор архитектуры системы
В этом разделе создается многометодовая система поиска , которая предоставляет вашему агенту гибкость в обработке различных типов запросов. Система состоит из трех уровней: уровень агента , уровень инструментов и уровень сервисов .
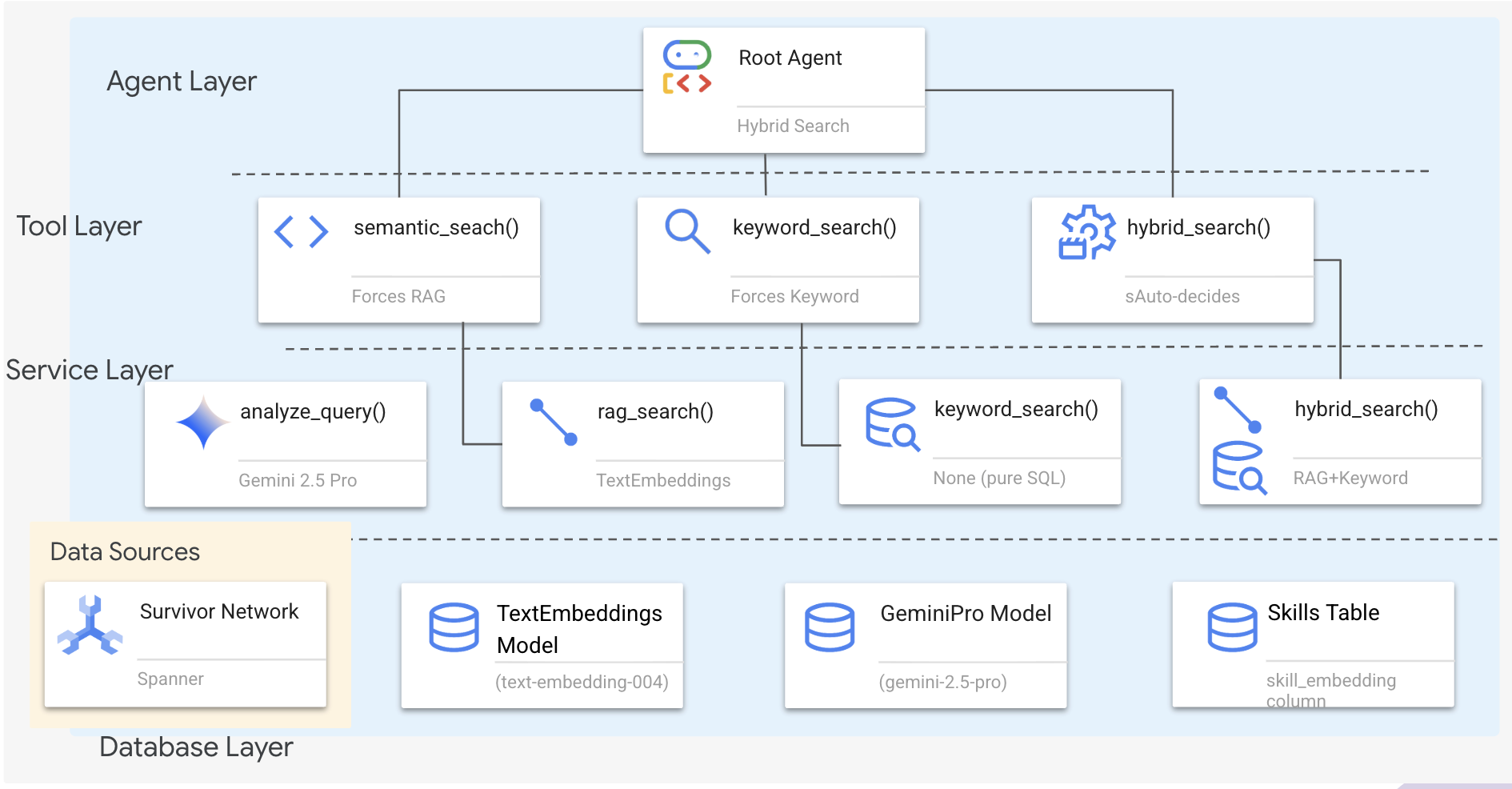
Почему три слоя?
- Разделение задач : агент фокусируется на намерениях, инструменты — на интерфейсе, сервис — на реализации.
- Гибкость : Агент может принудительно использовать определенные методы или позволить ИИ автоматически прокладывать маршрут.
- Оптимизация : позволяет избежать дорогостоящего анализа с использованием ИИ, если метод известен.
В этом разделе вы в основном будете реализовывать семантический поиск (RAG) — поиск результатов по смыслу , а не только по ключевым словам. Позже мы объясним, как гибридный поиск объединяет несколько методов.
2. Внедрение сервиса RAG
👉💻 В терминале откройте файл в редакторе Cloud Shell, выполнив команду:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Найдите комментарий # TODO: REPLACE_SQL
Замените всю эту строку следующим кодом:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Определение инструмента семантического поиска
👉💻 В терминале откройте файл в редакторе Cloud Shell, выполнив команду:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
В файле hybrid_search_tools.py найдите комментарий # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉 Замените всю эту строку следующим кодом:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Когда агент использует :
- Запросы, требующие поиска сходства ("найти похожее на X")
- Концептуальные вопросы («способности к исцелению»)
- Когда понимание смысла имеет решающее значение
4. Руководство по принятию решений агентом (Инструкции)
В определении агента скопируйте и вставьте в инструкцию часть, относящуюся к семантическому поиску.
👉💻 В терминале откройте файл в редакторе Cloud Shell, выполнив команду:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Агент использует эту инструкцию для выбора нужного инструмента:
👉В файле agent.py найдите комментарий # TODO: REPLACE_SEARCH_LOGIC и замените всю эту строку следующим кодом:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉Найдите комментарий # TODO: ADD_SEARCH_TOOL Замените всю эту строку следующим кодом:
semantic_search, # Force RAG
5. Понимание принципа работы гибридного поиска (только для чтения, никаких действий не требуется)
На шагах 2-4 вы реализовали семантический поиск (RAG) , основной метод поиска, который находит результаты по смыслу . Но вы, возможно, заметили, что система называется «гибридным поиском». Вот как всё это работает:
Как работает гибридное слияние :
В файле way-back-home/level_2/backend/services/hybrid_search_service.py при вызове функции hybrid_search() сервис выполняет ОБА поиска и объединяет результаты:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Для этой практической работы вы реализовали компонент семантического поиска (RAG), который является его основой. Методы ключевых слов и гибридные методы уже реализованы в сервисе — ваш агент может использовать все три!
Поздравляем! Вы успешно завершили создание агента Graph RAG с гибридным поиском!
7. 🚀 Тестирование вашего агента с помощью ADK Web
Самый простой способ протестировать вашего агента — использовать adk web , которая запускает агента со встроенным интерфейсом чата.
1. Запуск агента
👉💻 Перейдите в каталог бэкэнда (где определен ваш агент) и запустите веб-интерфейс:
cd ~/way-back-home/level_2/backend
uv run adk web
Эта команда запускает агент, определенный в
agent/agent.py
и открывает веб-интерфейс для тестирования.
👉 Откройте URL:
Эта команда выведет локальный URL-адрес (обычно http://127.0.0.1:8000 или аналогичный). Откройте его в браузере.
После перехода по ссылке вы увидите веб-интерфейс ADK. Убедитесь, что вы выбрали пункт «агент» в верхнем левом углу.
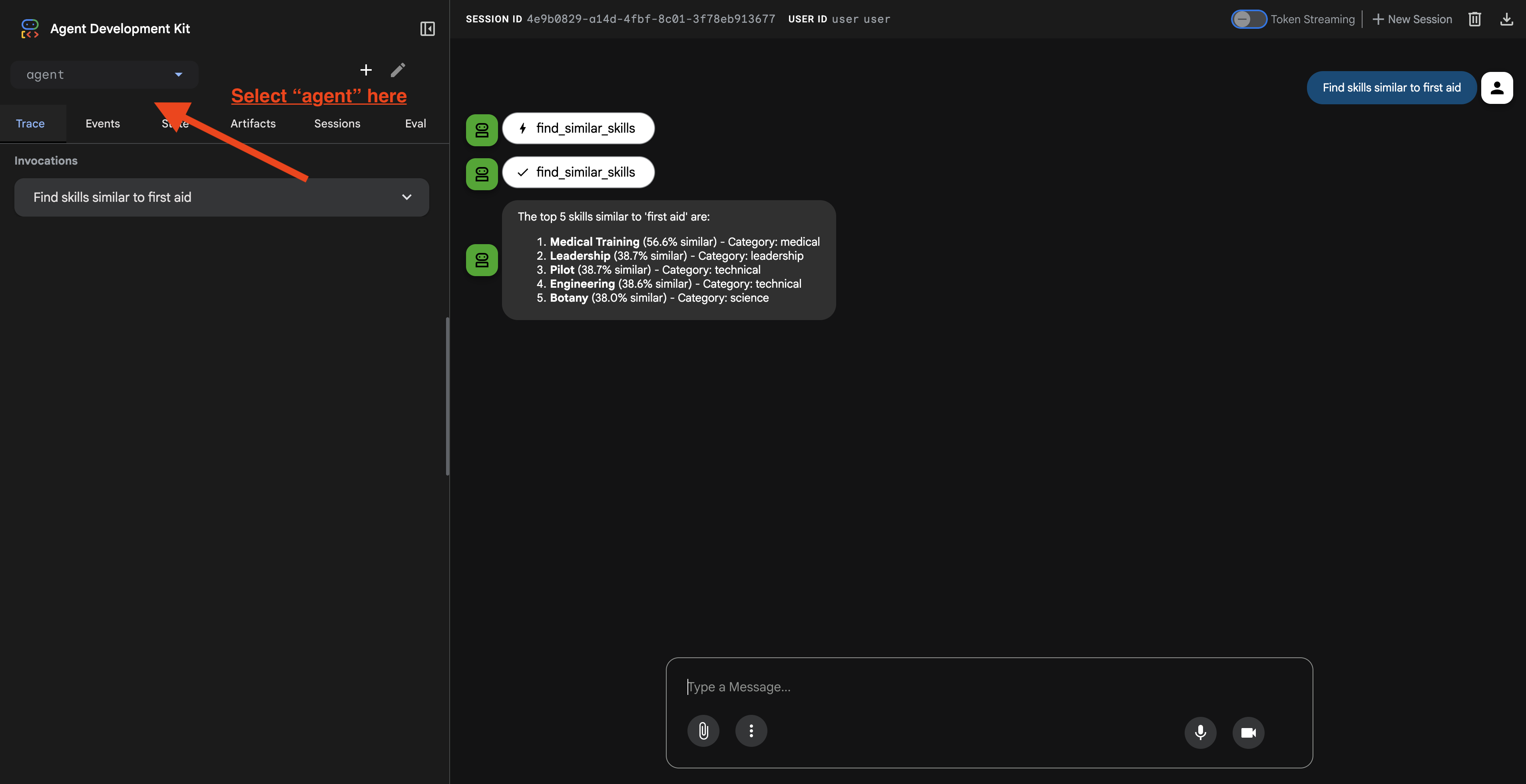
2. Тестирование возможностей поиска
Этот агент разработан для интеллектуальной маршрутизации ваших запросов. Попробуйте ввести следующие данные в окне чата, чтобы увидеть различные методы поиска в действии.
🧬 А. Graph RAG (семантический поиск)
Находит элементы на основе значения и концепции, даже если ключевые слова не совпадают.
Тестовые запросы: (Выберите любой из приведенных ниже вариантов)
Who can help with injuries?
What abilities are related to survival?
На что обратить внимание:
- В обосновании следует упомянуть семантический поиск или поиск по алгоритму RAG .
- Вы должны увидеть результаты, которые концептуально связаны между собой (например, «Хирургия» при запросе «Первая помощь»).
- Результаты будут отмечены значком 🧬.
🔀 B. Гибридный поиск
Сочетает фильтрацию по ключевым словам с семантическим пониманием для обработки сложных запросов.
Тестовые запросы: (Выберите любой из приведенных ниже вариантов)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
На что обратить внимание:
- В обосновании следует упомянуть гибридный поиск.
- Результаты должны соответствовать обоим критериям (концепция + местоположение/категория).
- Результаты, полученные обоими методами, будут отмечены значком 🔀 и будут иметь наивысший рейтинг.
👉💻 После завершения тестирования завершите процесс, нажав Ctrl+C в командной строке.
8. 🚀 Запуск полного приложения
Обзор архитектуры полного стека
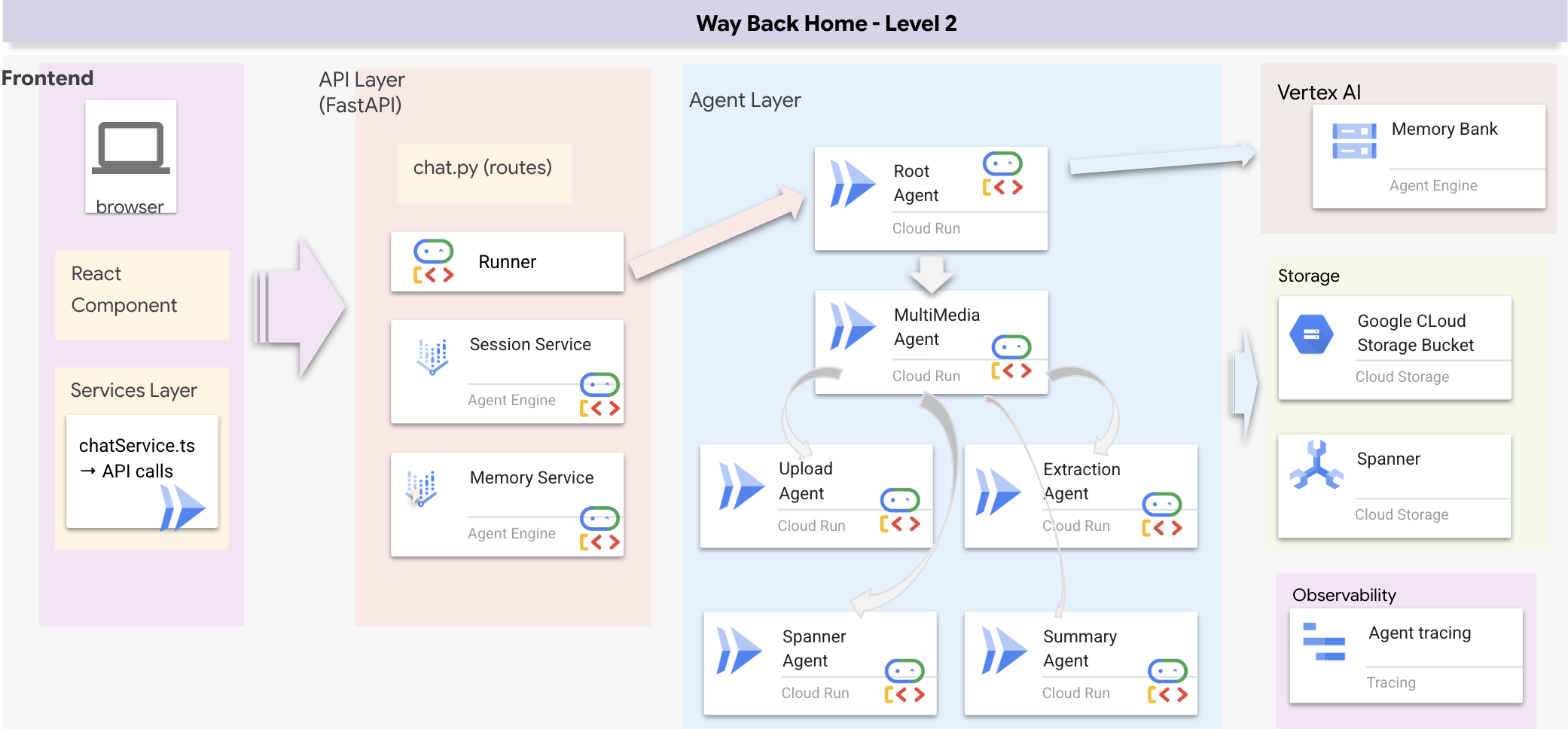
Добавить SessionService и Runner
👉💻 В терминале откройте файл chat.py в редакторе Cloud Shell, выполнив команду (убедитесь, что вы завершили предыдущий процесс, нажав "Ctrl+C", прежде чем продолжить):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉В файле chat.py найдите комментарий # TODO: REPLACE_INMEMORY_SERVICES и замените всю эту строку следующим кодом:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉В файле chat.py найдите комментарий # TODO: REPLACE_RUNNER и замените всю эту строку следующим кодом:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Запустить приложение
Если предыдущий терминал все еще запущен, завершите его, нажав Ctrl+C .
👉💻 Запустить приложение:
cd ~/way-back-home/level_2/
./start_app.sh
После успешного запуска бэкэнда вы увидите Local: http://localhost:5173/" , как показано ниже: 
👉 В терминале перейдите по ссылке Local: http://localhost:5173/ .
2. Тестирование семантического поиска
Запрос :
Find skills similar to healing
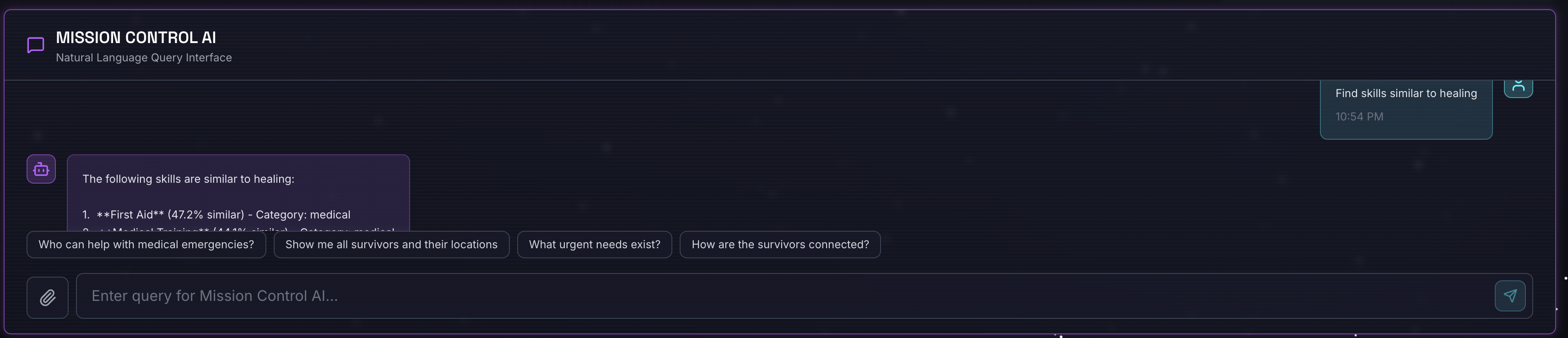
Что происходит :
- Агент распознает запрос на сходство.
- Генерирует встраивание для «исправления».
- Использует косинусное расстояние для поиска семантически схожих навыков.
- Возвращает: первая помощь (хотя названия не соответствуют «лечению»)
3. Тестирование гибридного поиска
Запрос :
Find medical skills in the mountains
Что происходит :
- Компонент ключевого слова : Фильтр по
category='medical' - Семантический компонент : Встроить слово «медицинский» и ранжировать по сходству.
- Объединение : Объединить результаты, отдавая приоритет тем, которые были получены обоими методами 🔀
Запрос (необязательный) :
Who is good at survival and in the forest?
Что происходит :
- Поиск по ключевому слову:
biome='forest' - Семантические данные показывают: навыки, схожие с навыками «выживания».
- Гибрид сочетает в себе оба подхода для достижения наилучших результатов.
👉💻 После завершения тестирования в терминале завершите его, нажав Ctrl+C .
4. (ТОЛЬКО ДЛЯ УЧАСТНИКОВ МАСТЕР-КЛАССА) Обновите свое местоположение
👉💻 Запустите скрипт автодополнения:
cd ~/way-back-home/level_2
./set_level_2.sh
Теперь откройте waybackhome.dev , и вы увидите, что ваше местоположение обновилось. Поздравляем с завершением 2-го уровня!

9. ☕️ [Необязательно] Многомодальный конвейер (только для чтения) — Слой инструментов
Зачем нам нужен многомодальный конвейер?
Сеть поддержки выживших — это не просто текст. Выжившие на местах отправляют неструктурированные данные напрямую через чат:
- 📸 Изображения : Фотографии ресурсов, опасностей или оборудования.
- 🎥 Видео : Отчеты о состоянии или сообщения SOS
- 📄 Текст : Полевые заметки или журналы
Какие файлы мы обрабатываем?
В отличие от предыдущего шага, где мы искали существующие данные, здесь мы обрабатываем файлы, загруженные пользователями . Интерфейс chat.py обрабатывает вложения файлов динамически:
Источник | Содержание | Цель |
Вложение пользователя | Изображение/Видео/Текст | Информация для добавления к графику |
Контекст чата | «Вот фотография припасов» | Намерения и дополнительные сведения |
Плановый подход: Последовательный конвейер агентов
Мы используем последовательный агент ( multimedia_agent.py ), который объединяет специализированных агентов в цепочку:
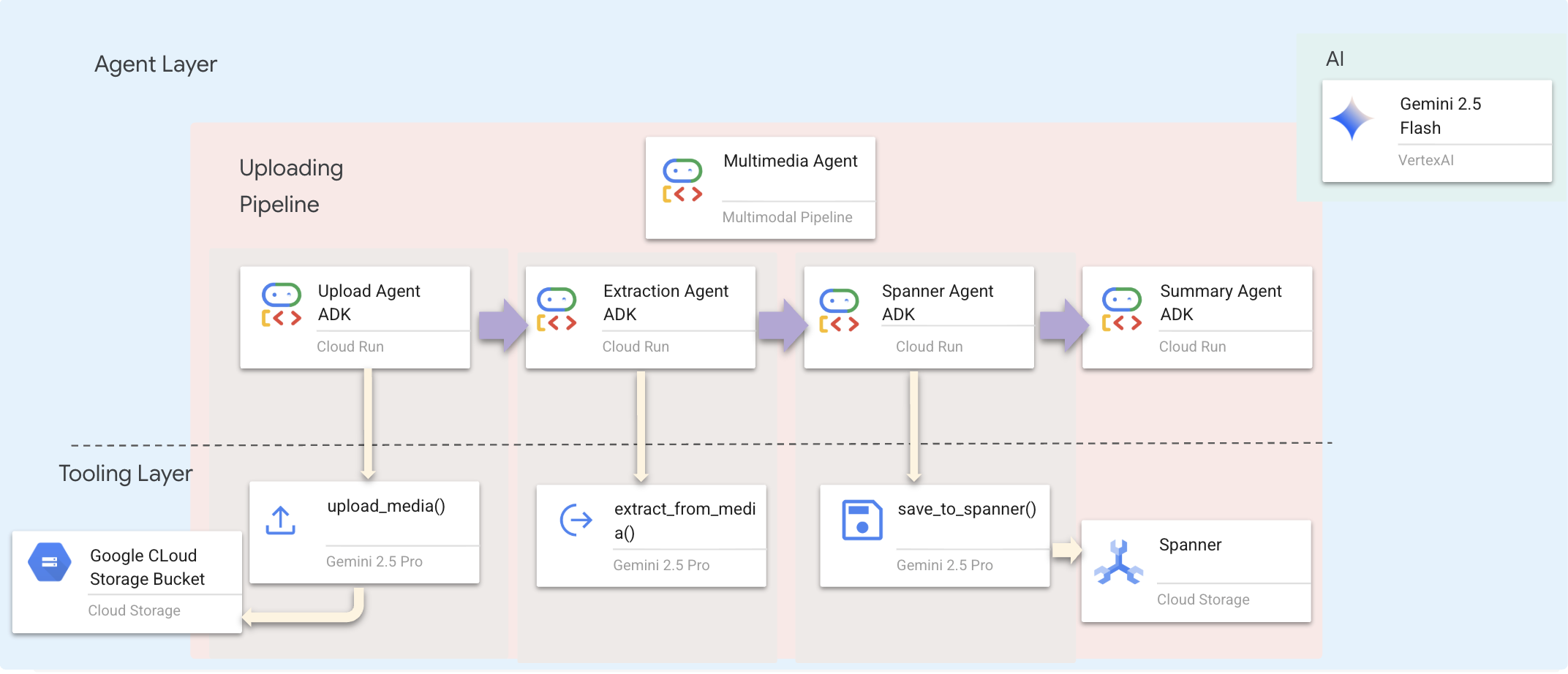
Этот объект определен в backend/agent/multimedia_agent.py как SequentialAgent .
Слой инструментов предоставляет возможности , которые могут вызывать агенты. Инструменты отвечают за «как» — загрузку файлов, извлечение сущностей и сохранение в базу данных.
1. Откройте файл «Инструменты».
👉💻 Откройте файл level_2/backend/agent/tools/extraction_tools.py или введите следующую команду в терминале. Откройте новое окно терминала. В терминале откройте файл в редакторе Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Внедрить инструмент upload_media
Этот инструмент загружает локальный файл в облачное хранилище Google.
👉 В def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: , следующий код описывает, как загружать файлы в GCS и определять их тип:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Реализация инструмента extract_from_media
Этот инструмент представляет собой маршрутизатор — он проверяет media_type и направляет запрос в соответствующий экстрактор (текст, изображение или видео).
👉 В функции async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: , следующий код описывает, как извлекать сущности и связи из загруженных медиафайлов.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Основные детали реализации:
- Мультимодальный ввод : Мы передаем в функцию
generate_contentкак текстовую подсказку (_get_extraction_prompt()), так и объект изображения . - Структурированный вывод :
response_mime_type="application/json"гарантирует, что LLM возвращает корректный JSON, что критически важно для конвейера обработки данных. - Визуальное связывание сущностей : В подсказке указаны известные сущности, чтобы Gemini мог распознавать конкретные символы.
4. Реализуйте инструмент save_to_spanner
Этот инструмент сохраняет извлеченные сущности и связи в базе данных Spanner Graph DB.
👉 В def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: , следующий код описывает, как сохранить извлеченные сущности и связи в базу данных Spanner Graph DB.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Предоставляя агентам высокоуровневые инструменты, мы обеспечиваем целостность данных, одновременно используя их аналитические способности.
5. Обновите службу GCS.
Сервис GCSService обрабатывает фактическую загрузку файлов в Google Cloud Storage.
👉💻 Откройте файл level_2/backend/services/gcs_service.py , или вы можете ввести команду в терминале, чтобы открыть файл в редакторе Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 В def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: следующий код описывает, как сохранить извлеченные сущности и связи в базу данных Spanner Graph DB.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Благодаря абстрагированию этого процесса в сервис, агенту не нужно знать о корзинах GCS, именах больших двоичных объектов или генерации подписанных URL-адресов. Он просто запрашивает "загрузку".
6. Почему агентский рабочий процесс лучше традиционных подходов?
Преимущество агентского подхода:
Особенность | Пакетный конвейер | Событийно-ориентированный | Рабочий процесс агента |
Сложность | Низкий (1 скрипт) | Высокий уровень (5+ услуг) | Низкий уровень (1 файл Python: |
Государственное управление | Глобальные переменные | Жесткий (развязанный) | Объединенное (состояние агента) |
Обработка ошибок | Аварии | Тихие бревна | Интерактивный режим («Я не смог прочитать этот файл») |
Отзывы пользователей | Отпечатки консоли | Необходимо провести опрос. | Мгновенно (Часть чата) |
Адаптируемость | Исправлена логика | Жесткие функции | Разумный (магистр права определяет следующий шаг) |
Контекстная осведомленность | Никто | Никто | Полный доступ (знает намерения пользователя) |
Почему это важно: Используя multimedia_agent.py (SequentialAgent с 4 подагентами: Загрузка → Извлечение → Сохранение → Сводка), мы заменяем сложную инфраструктуру и ненадежные скрипты интеллектуальной, диалоговой логикой приложения .
10. ☕️ [Необязательно] Многомодальный конвейер (только для чтения) — Уровень агентов
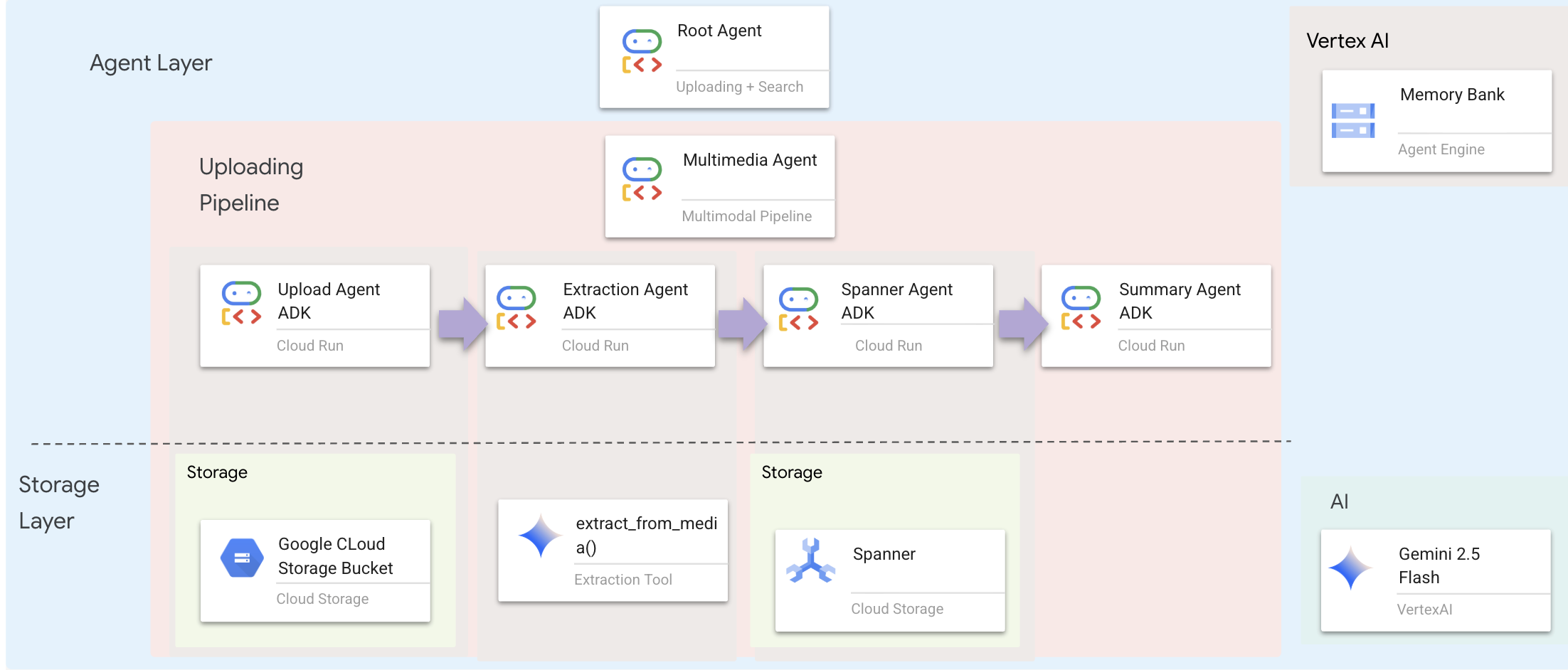
Уровень агентов определяет интеллект — агентов, которые используют инструменты для выполнения задач. Каждый агент выполняет определенную роль и передает контекст следующему. Ниже представлена архитектурная схема многоагентной системы.
1. Откройте файл агента.
👉💻 Откройте файл level_2/backend/agent/multimedia_agent.py или введите следующую команду в терминале. Откройте новое окно терминала. В терминале откройте файл в редакторе Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Определите агента загрузки.
Этот агент извлекает путь к файлу из сообщения пользователя и загружает его в GCS.
👉В файле multimedia_agent.py с помощью следующего кода создается upload_agent , который загружает данные в GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Определите экстракционный агент.
Этот агент «видит» загруженные медиафайлы и извлекает структурированные данные с помощью Gemini Vision.
👉В файле multimedia_agent.py с помощью следующего кода создается extraction_agent , который извлекает информацию из загруженных медиафайлов:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Обратите внимание, что в instruction используется ссылка на {upload_result} — именно так состояние передается между агентами в ADK.
4. Определите агента-гаечного ключа.
Этот агент сохраняет извлеченные сущности и связи в графовую базу данных.
👉В файле multimedia_agent.py с помощью следующего кода создается spanner_agent , который сохраняет извлеченную информацию в базу данных:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Этот агент получает контекст из обоих предыдущих шагов ( upload_result и extraction_result ).
5. Определите агента по составлению сводной информации.
Этот агент обобщает результаты всех предыдущих шагов в удобный для пользователя ответ.
👉В файле multimedia_agent.py , с помощью следующего кода, определяется запрос для summary_agent , который суммирует результат:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Этому агенту не нужны никакие инструменты — он просто считывает общий контекст и генерирует понятное резюме для пользователя.
🧠 Краткое описание архитектуры
Слой | Файл | Ответственность |
Инструменты | | Как — Загрузка, распаковка, сохранение |
Агент | | Что — Организовать конвейер |
11. 🚀 Многомодальный конвейер обработки данных — оркестровка
Основой нашей новой системы является MultimediaExtractionPipeline определенный в backend/agent/multimedia_agent.py . Он использует шаблон Sequential Agent из ADK (Agent Development Kit).
1. Почему последовательный подход?
Обработка загружаемого файла представляет собой линейную цепочку зависимостей:
- Извлечение данных невозможно, пока у вас нет файла (не загруженного).
- Вы не сможете сохранить данные, пока не извлечете их (Извлечение).
- Вы не сможете составить итоговую сводку, пока не получите результаты (Сохранить).
Для этого идеально подходит SequentialAgent . Он передает выходные данные одного агента в качестве контекста/входных данных следующему.
2. Определение агента
Давайте посмотрим, как собирается конвейер обработки данных в нижней части файла multimedia_agent.py : 👉💻 В терминале откройте файл в редакторе Cloud Shell, выполнив команду:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Он получает входные данные с обоих предыдущих шагов. Найдите комментарий # TODO: REPLACE_ORCHESTRATION . Замените всю эту строку следующим кодом:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Подключитесь к корневому агенту.
👉💻 В терминале откройте файл в редакторе Cloud Shell, выполнив команду:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Найдите комментарий # TODO: REPLACE_ADD_SUBAGENT . Замените всю эту строку следующим кодом:
sub_agents=[multimedia_agent],
Этот единственный объект фактически объединяет четырех «экспертов» в одну вызываемую сущность.
4. Поток данных между агентами
Each agent stores its output in a shared context that subsequent agents can access:
5. Open application (skip if app is still running)
👉💻 Start App:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Click Local: http://localhost:5173/ from the terminal.
6. Test Image Upload
👉 In the chat interface, choose any of the photo here and upload to the UI:
In the chat interface, tell the agent about your specific context:
Here is the survivor note
And then attach the image here.

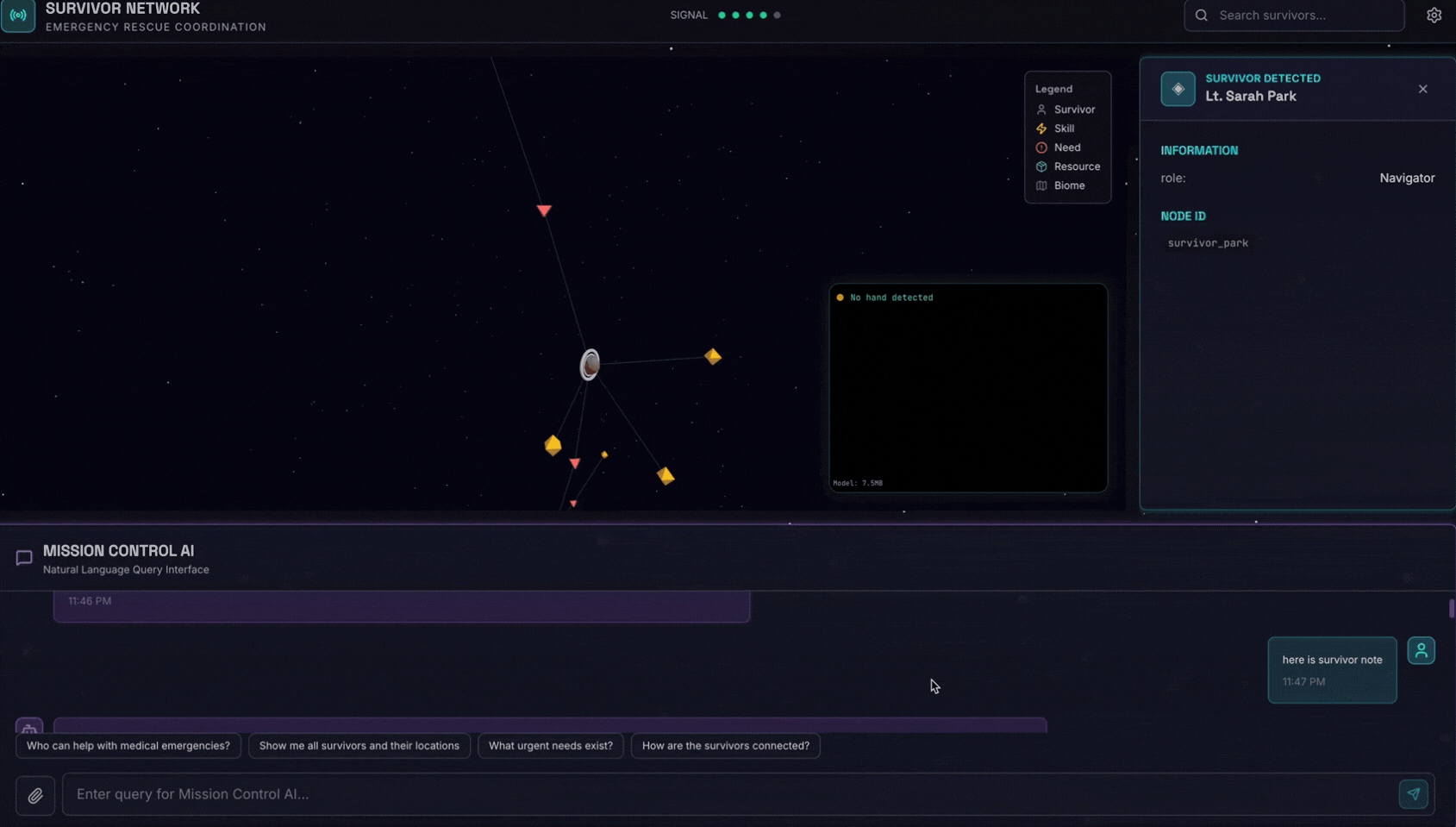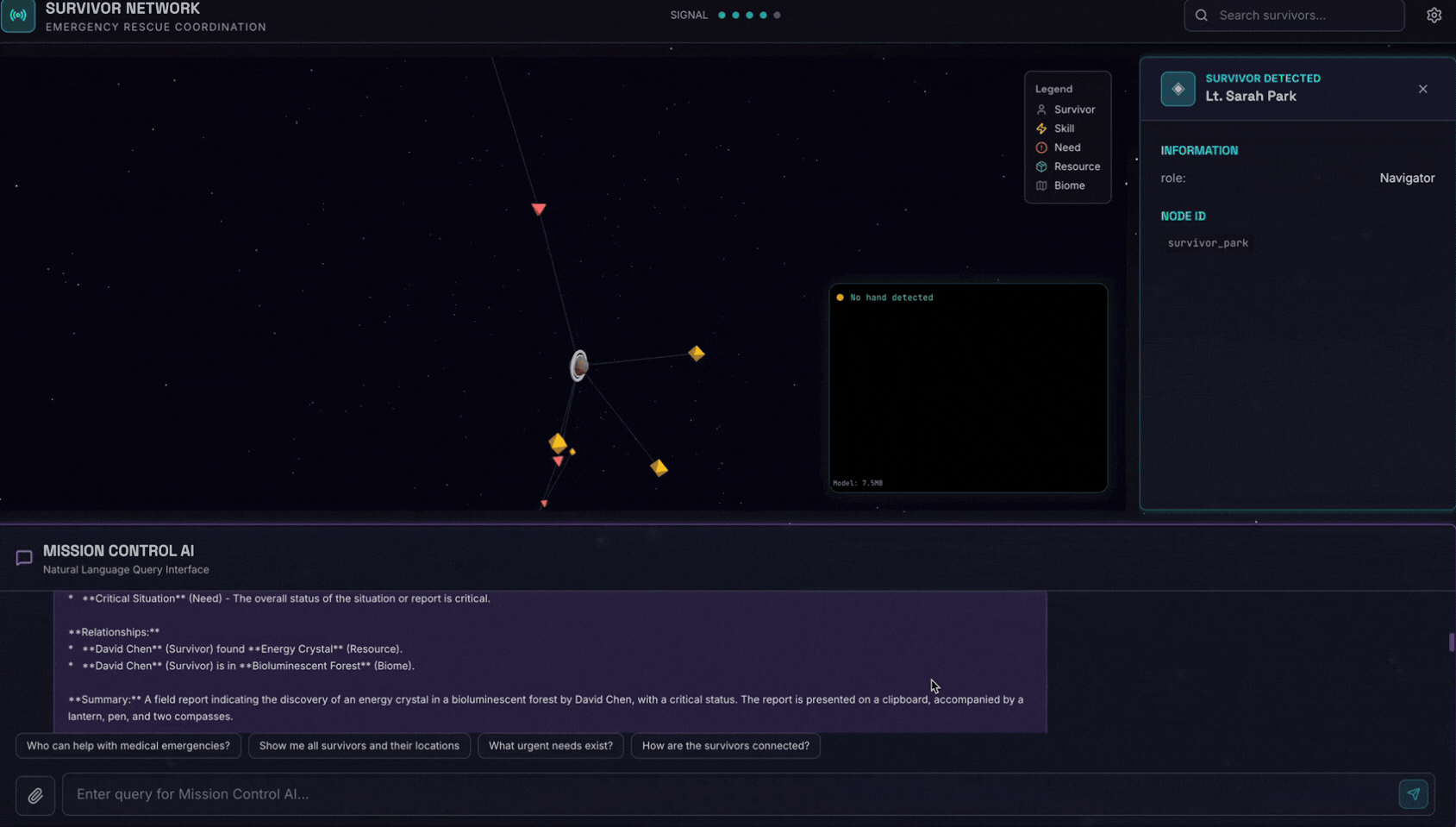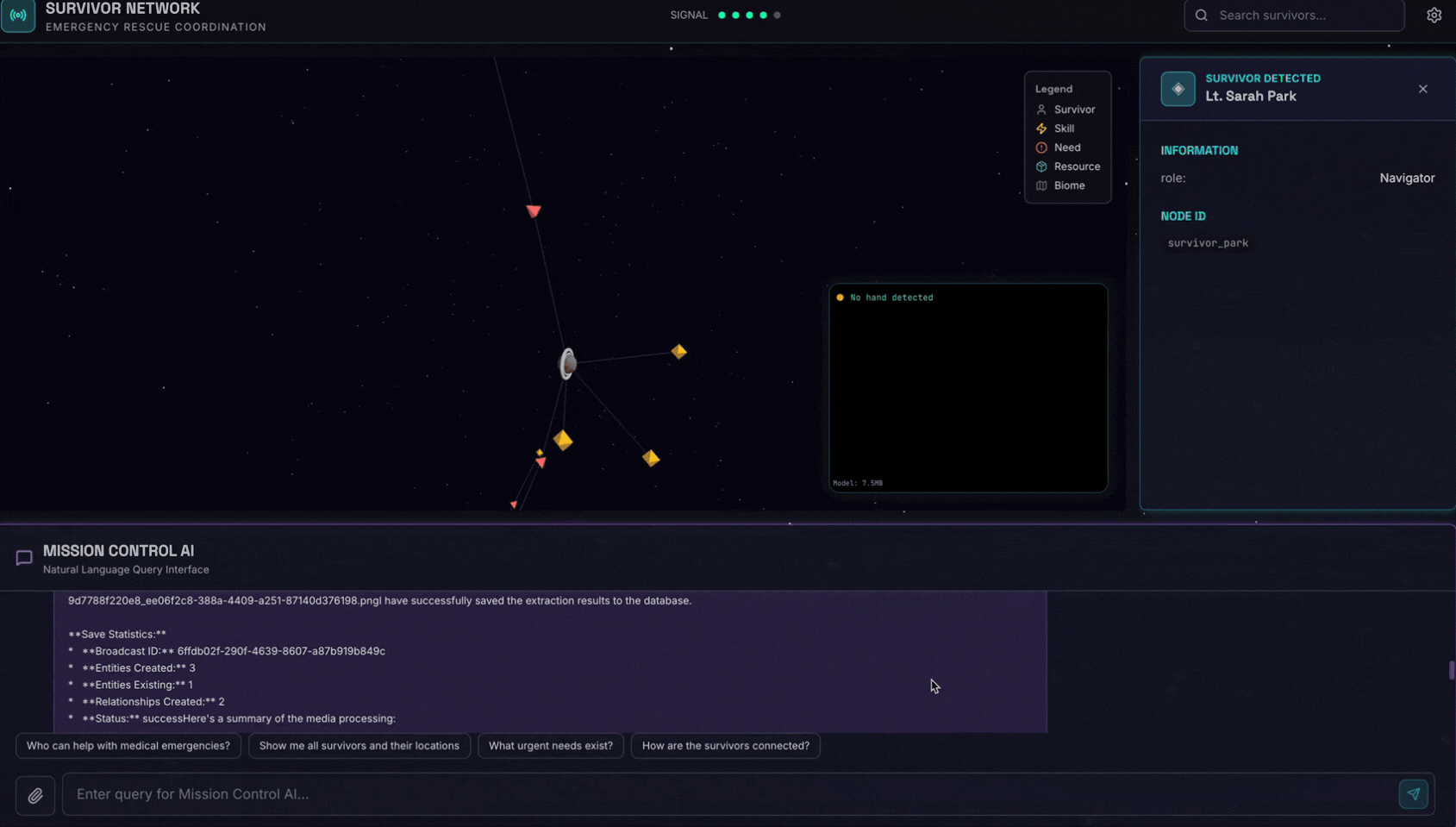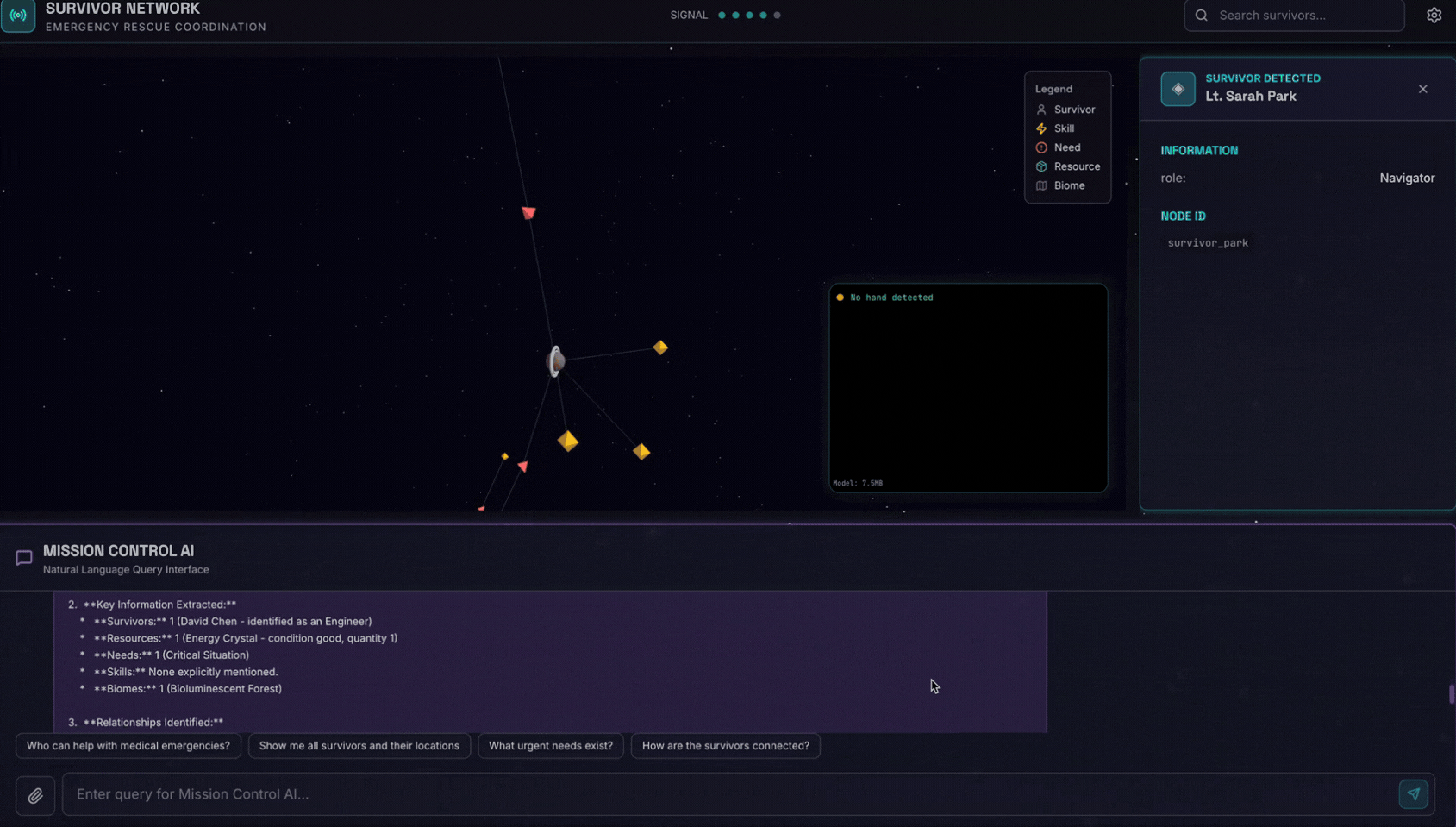
👉💻 In the terminal, when you finished testing, press "Ctrl+C" to end the process.
6. Verify Multimodal Uploading in GCS Bucket
- Open the Google Cloud Console Storage .
- Select "bucket" in cloud storage
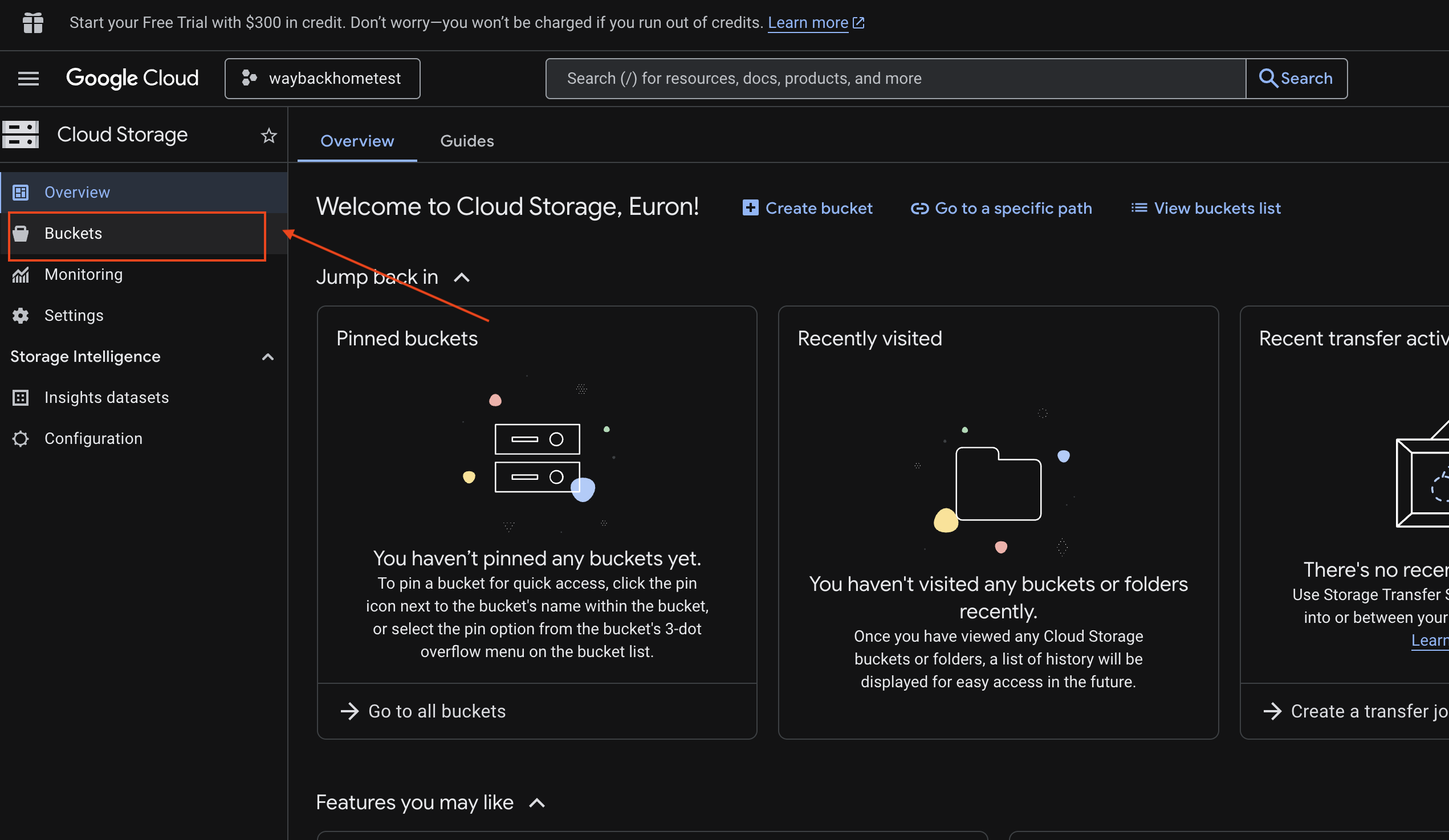
- Select your bucket and click into
media.
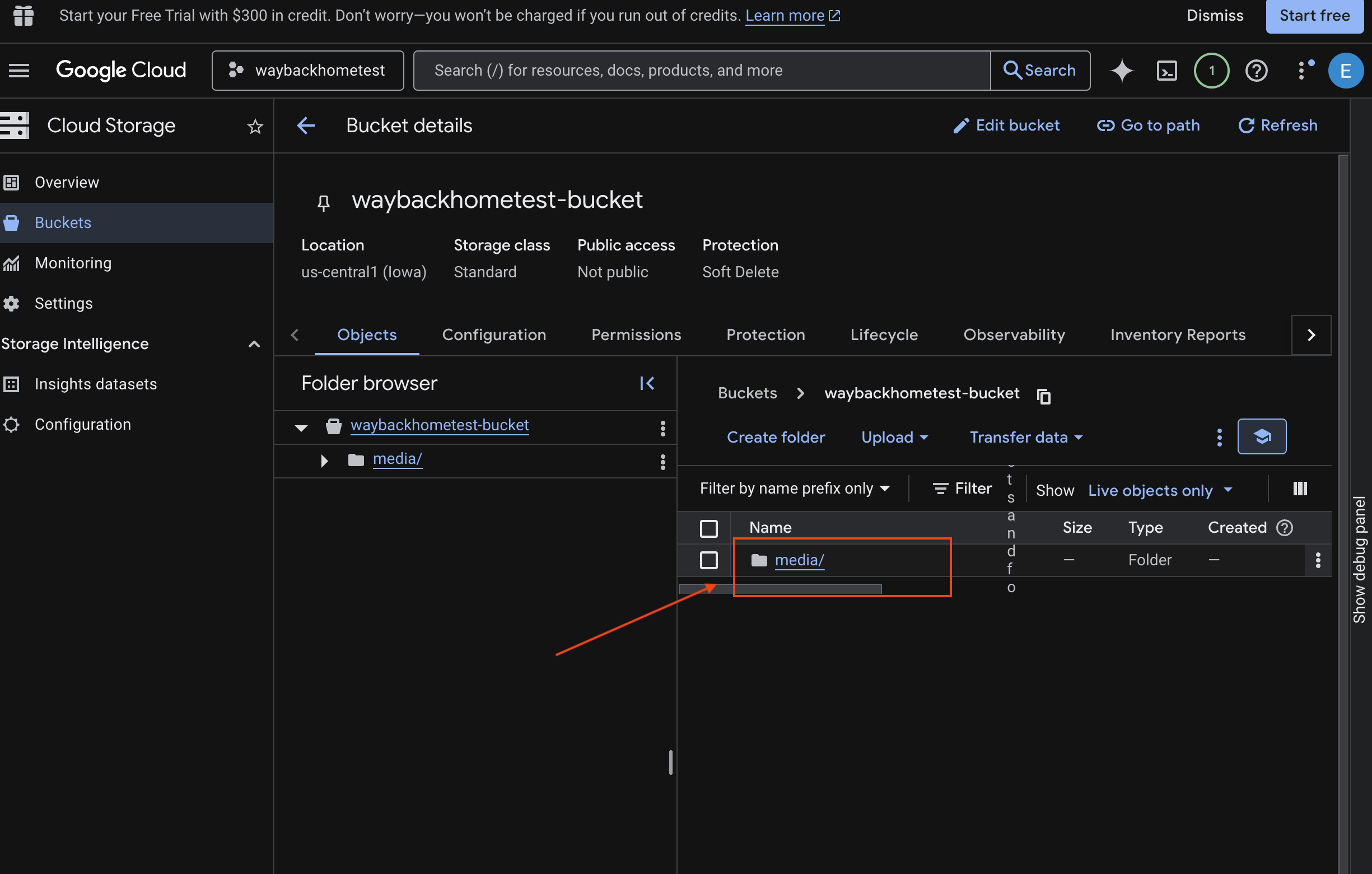
- View your uploaded image here.
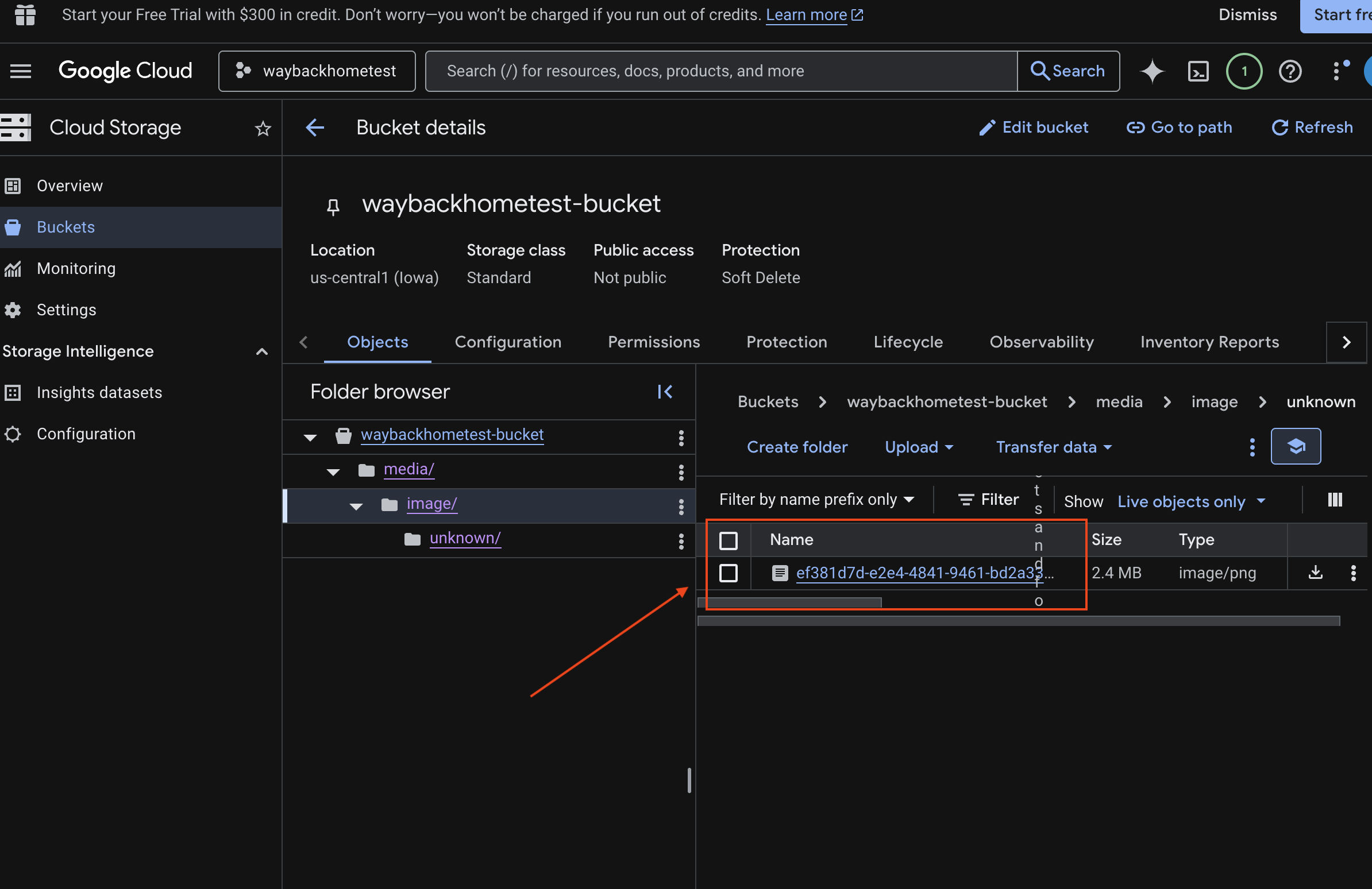
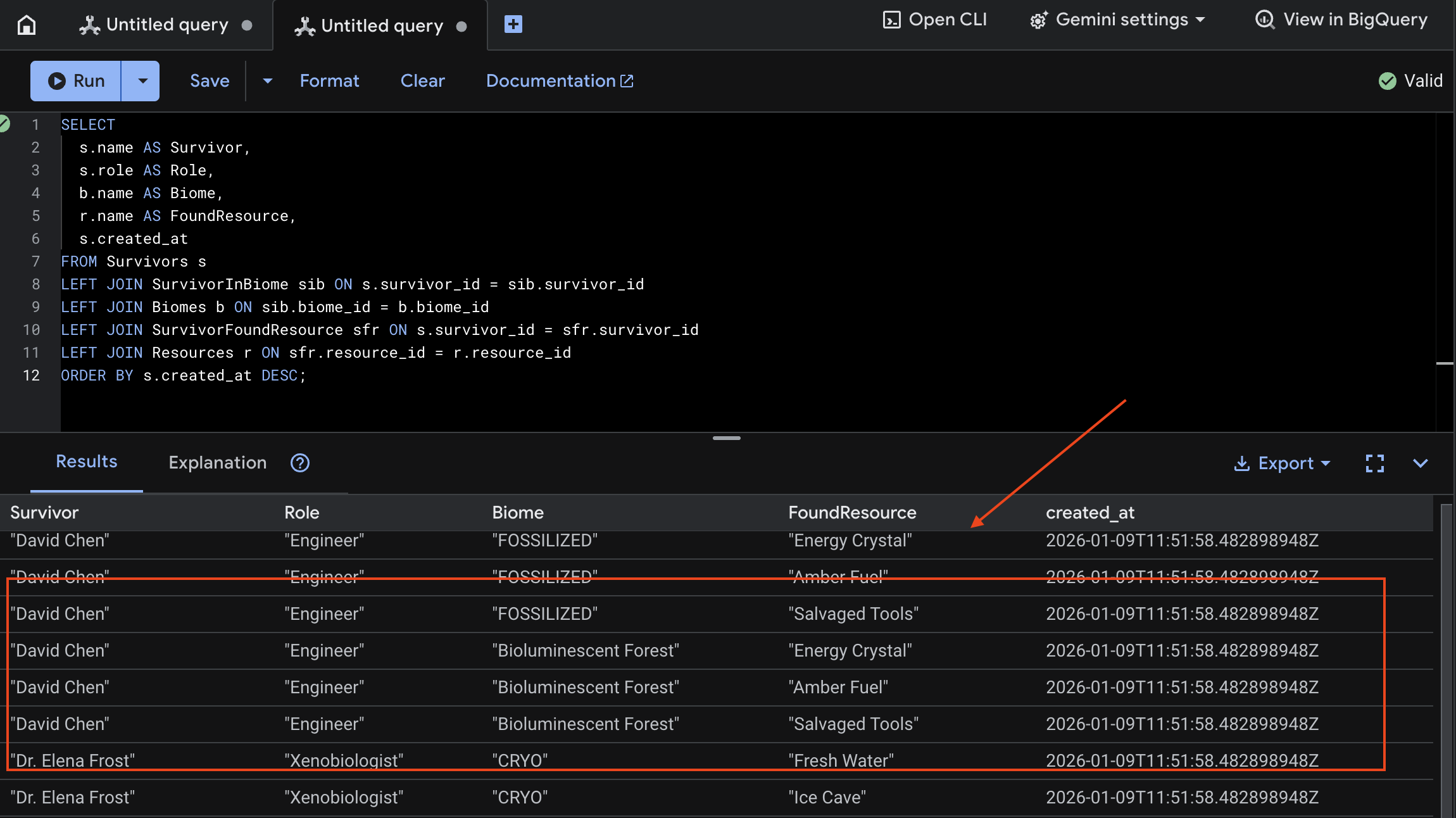
7. Verify Multimodal Uploading in Spanner (Optional)
Below is example output in UI for test_photo1 .
- Open the Google Cloud Console Spanner .
- Select your instance:
Survivor Network - Select your database:
graph-db - In the left sidebar, click Spanner Studio
👉 In Spanner Studio, query the new data:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
We can verify it by see the result below:
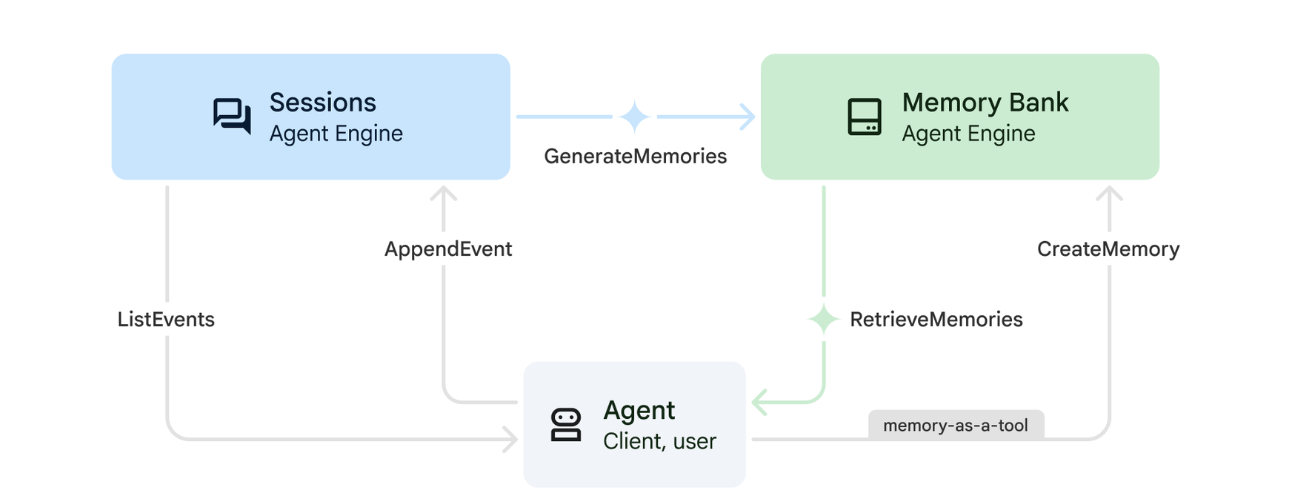
12. ☕️ [Optional] Memory Bank with Agent Engine
1. How Memory Works
The system uses a dual-memory approach to handle both immediate context and long-term learning.
2. What Are Memory Topics?
Memory Topics define the categories of information the agent should remember across conversations. Think of them as filing cabinets for different types of user preferences.
Our 2 Topics:
-
search_preferences: How the user likes to search- Do they prefer keyword or semantic search?
- What skills/biomes do they search for often?
- Example memory: "User prefers semantic search for medical skills"
-
urgent_needs_context: What crises they're tracking- What resources are they monitoring?
- Which survivors are they concerned about?
- Example memory: "User is tracking medicine shortage in Northern Camp"
3. Setting Up Memory Topics
Custom memory topics define what the agent should remember. These are configured when deploying the Agent Engine.
👉💻 In the terminal, open the file in the Cloud Shell Editor by running:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
This opens ~/way-back-home/level_2/backend/deploy_agent.py in your editor.
We define structure MemoryTopic objects to guide the LLM on what information to extract and save.
👉In the file deploy_agent.py , replace the # TODO: SET_UP_TOPIC with the following:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Agent Integration
The agent code must be aware of the Memory Bank to save and retrieve information.
👉💻 In the terminal, open the file in the Cloud Shell Editor by running:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
This opens ~/way-back-home/level_2/backend/agent/agent.py in your editor.
Agent Creation
When creating the agent, we pass the after_agent_callback to ensure sessions are saved to memory after interactions. The add_session_to_memory function runs asynchronously to avoid slowing down the chat response.
👉In the file agent.py , locate the comment # TODO: REPLACE_ADD_SESSION_MEMORY , Replace this whole line with the following code:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Background Saving
👉In the file agent.py , locate the comment # TODO: REPLACE_ADD_MEMORY_BANK_TOOL , Replace this whole line with the following code:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉In the file agent.py , locate the comment # TODO: REPLACE_ADD_CALLBACK , Replace this whole line with the following code:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Set Up Vertex AI Session Service
👉💻 In the terminal, open the file chat.py in the Cloud Shell Editor by running:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉In chat.py file, locate the comment # TODO: REPLACE_VERTEXAI_SERVICES , Replace this whole line with the following code:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Optional] Attach Agent with Agent Engine
1. Setup & Deployment
Before testing the memory features, you need to deploy the agent with the new memory topics and ensure your environment is configured correctly.
We have provided a convenience script to handle this process.
Running the Deployment Script
👉💻 In the terminal, run the deployment script:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
This script performs the following actions:
- Runs
backend/deploy_agent.pyto register the agent and memory topics with Vertex AI. - Captures the new Agent Engine ID .
- Automatically updates your
.envfile withAGENT_ENGINE_ID. - Ensures
USE_MEMORY_BANK=TRUEis set in your.envfile.
[!IMPORTANT] If you make changes to custom_topics in deploy_agent.py , you must re-run this script to update the Agent Engine.
Verify Memory Bank
Now you can verify that the memory bank is working by teaching the agent a preference and checking if it persists across sessions.
Step One. Open the application
Open the Application again by following the instruction below: If the previous terminal is still running, end it by pressing Ctrls+C .
👉💻 Start App:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Click Local: http://localhost:5173/ from the terminal.
Step Two. Testing Memory Bank with Text
In the chat interface, tell the agent about your specific context:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Wait ~30 seconds for the memory to process in the background.
Step Three. Start a New Session
Refresh the page to clear the current conversation history (short-term memory).
Ask a question that relies on the context you provided earlier:
"What kind of missions am I interested in?"
Expected Response :
"Based on your previous conversations, you're interested in:
- Medical rescue missions
- Mountain/high-altitude operations
- Skills needed: first aid, climbing
Would you like me to find survivors matching these criteria?"
Step Four. Test with Image Upload
Upload an image, and ask:
remember this
You can choose any of the photo here or your own and upload to the UI:
Step Five. Verify in Vertex AI Agent Engine
Go to Google Cloud Console Agent Engine
- Make sure you select the project from top left project selector:
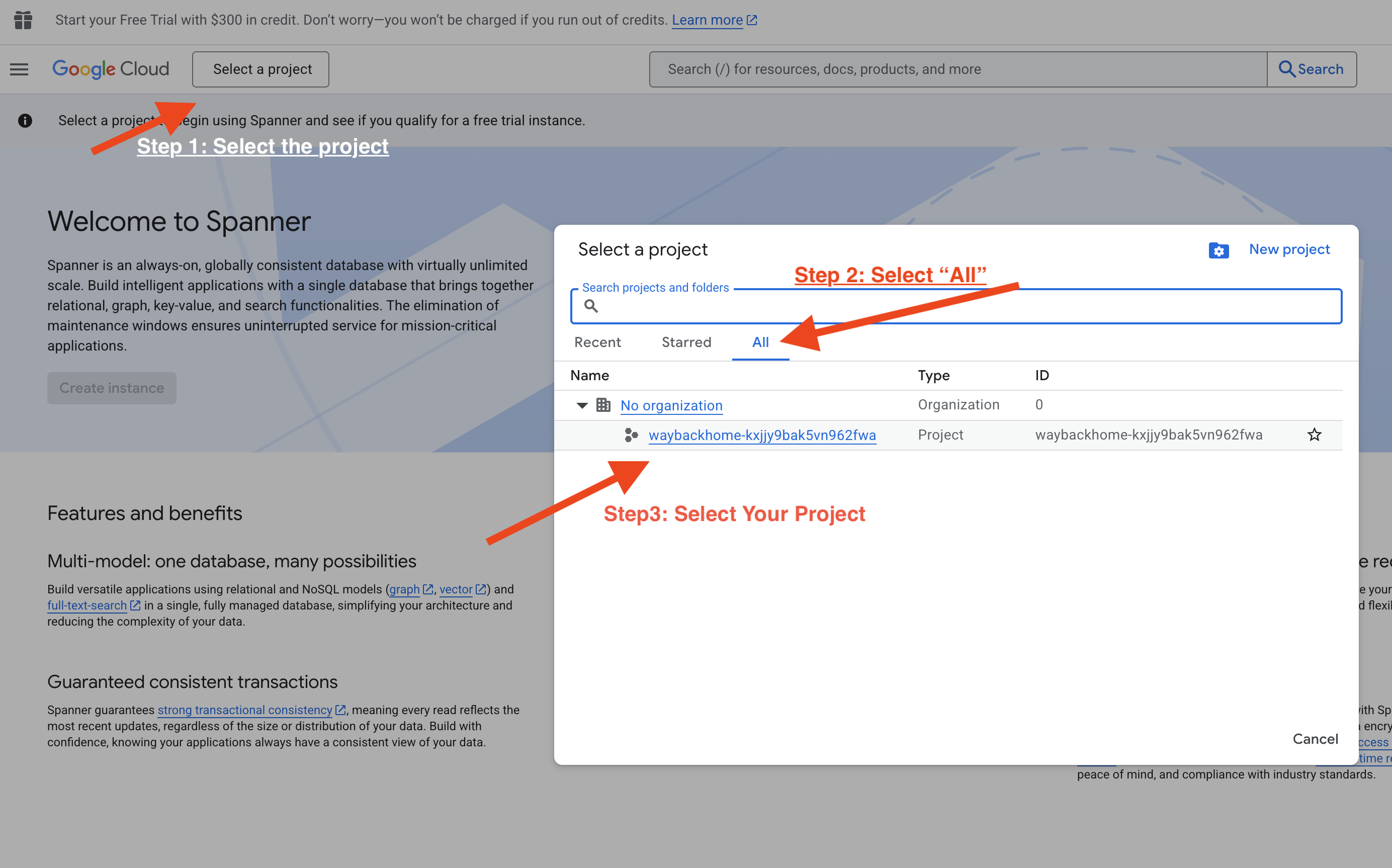
- Verify the agent engine you just deployed from previous command
use_memory_bank.sh: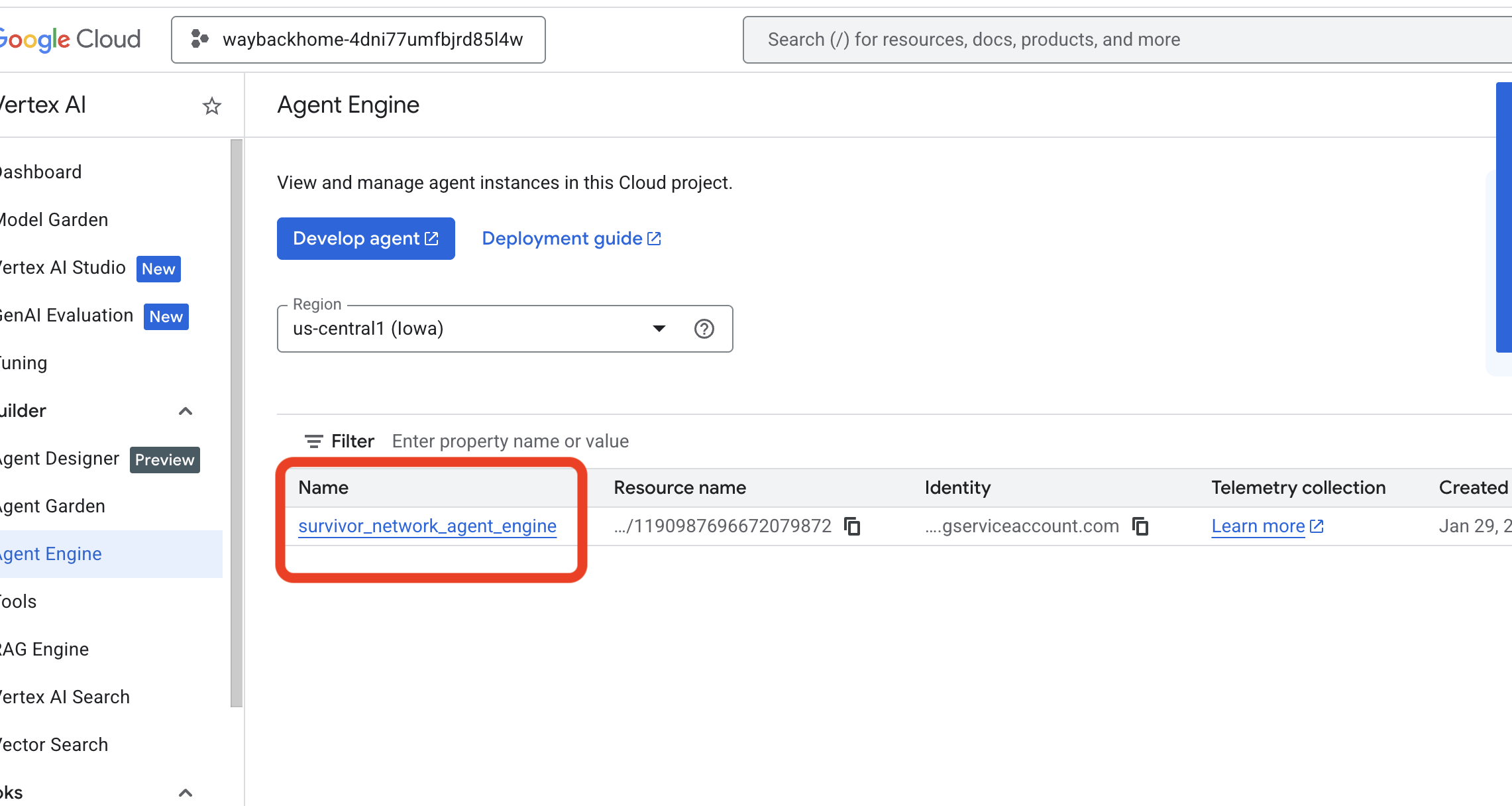 Click into the agent engine you just created.
Click into the agent engine you just created. - Click the
MemoriesTab in this deployed agent, you can view all the memory here.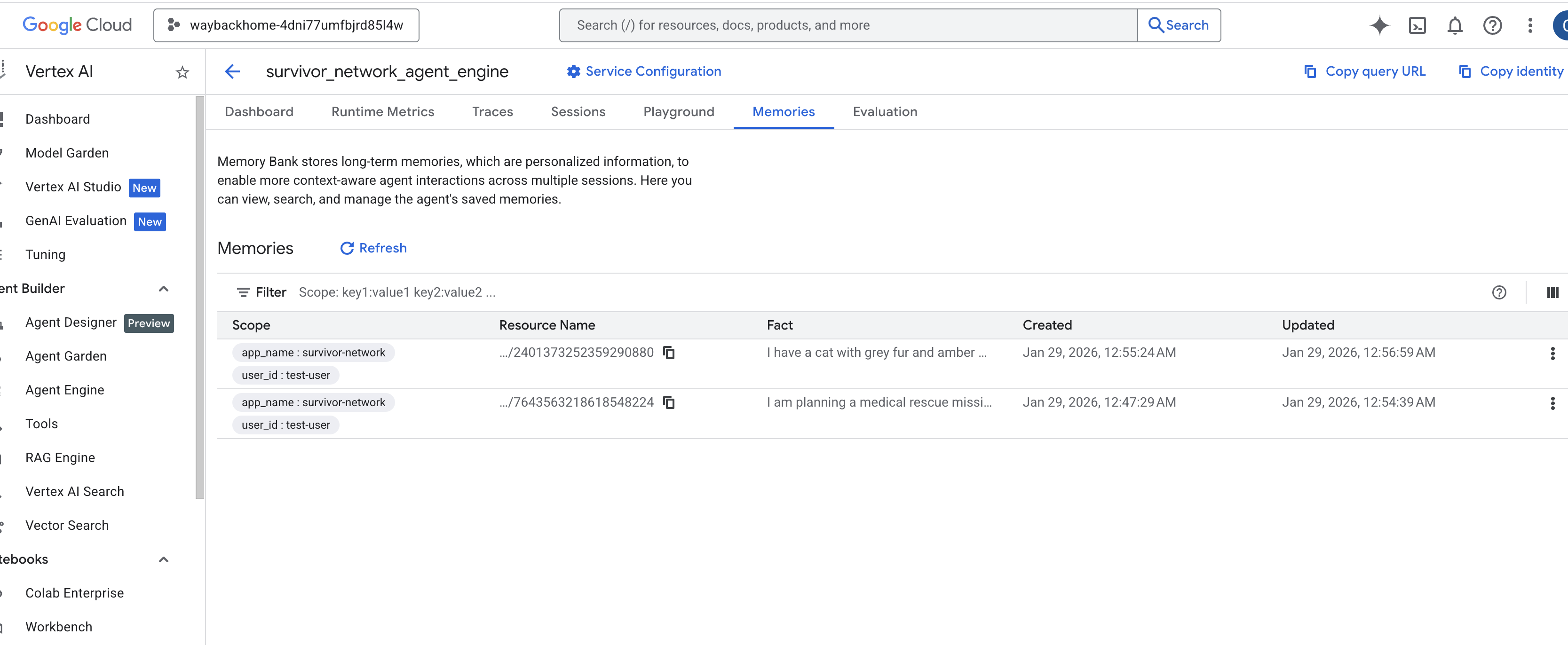
👉💻 When you finish testing, in you terminal, click "Ctrl + C" to end the process.
🎉 Congratulations! You just attached the memory bank to your agent!
14. ☕️ [Optional] Deploy to Cloud Run
1. Run the Deployment Script
👉💻 Run the deployment script:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
After it successfully deployed, you will have the url, this is deployed url for you! 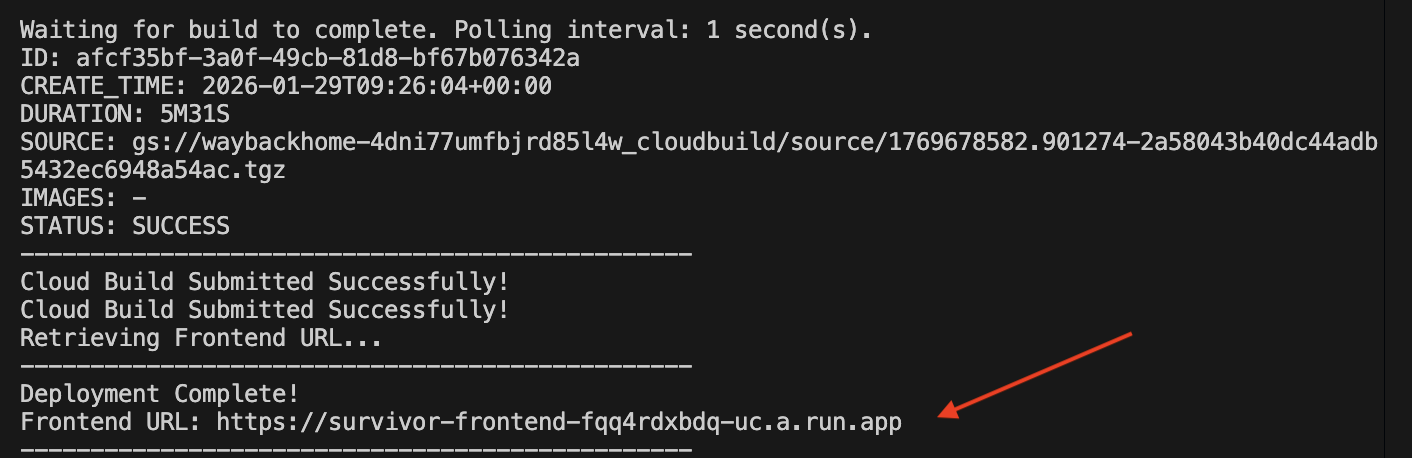
👉💻 Before you grab the url, grant the permission by running:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Go to the deployed url, and you will see you application live there!
2. Understanding the Build Pipeline
The cloudbuild.yaml file defines the following sequential steps:
- Backend Build : Builds the Docker image from
backend/Dockerfile. - Backend Deploy : Deploys the backend container to Cloud Run.
- Capture URL : Gets the new Backend URL.
- Frontend Build :
- Installs dependencies.
- Builds the React app, injecting
VITE_API_URL=.
- Frontend Image : Builds the Docker image from
frontend/Dockerfile(packaging the static assets). - Frontend Deploy : Deploys the frontend container.
3. Verify Deployment
Once the build completes (check the logs link provided by the script), you can verify:
- Go to the Cloud Run Console .
- Find the
survivor-frontendservice. - Click the URL to open the application.
- Perform a search query to ensure the frontend can talk to the backend.
(OPTIONAL) 4. Manual Deployment
If you prefer to run the commands manually or understand the process better, here is how to use cloudbuild.yaml directly.
Writing cloudbuild.yaml
A cloudbuild.yaml file tells Google Cloud Build what steps to execute.
- steps : A list of sequential actions. Each step runs in a container (eg,
docker,gcloud,node,bash). - substitutions : Variables that can be passed at build time (eg,
$_REGION). - workspace : A shared directory where steps can share files (like how we share
backend_url.txt).
Running the Deployment
To deploy manually without the script, use the gcloud builds submit command. You MUST pass the required substitution variables.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Conclusion
1. What You've Built
✅ Graph Database : Spanner with nodes (survivors, skills) and edges (relationships)
✅ AI Search : Keyword, semantic, and hybrid search with embeddings
✅ Multimodal Pipeline : Extract entities from images/video with Gemini
✅ Multi-Agent System : Coordinated workflow with ADK
✅ Memory Bank : Long-term personalization with Vertex AI
✅ Production Deployment : Cloud Run + Agent Engine
2. Architecture Summary
3. Key Learnings
- Graph RAG : Combines graph database structure with semantic embeddings for intelligent search
- Multi-Agent Patterns : Sequential pipelines for complex, multi-step workflows
- Multimodal AI : Extract structured data from unstructured media (images/video)
- Stateful Agents : Memory Bank enables personalization across sessions
4. Workshop Content
- Level0 : Identify Yourself
- Level1 : Pinpoint Location
- Level2 This One : Build a Multimodal AI Agent with Graph RAG, ADK & Memory Bank
- Level3 : Building an ADK Bi-Directional Streaming Agent
- Level4 : Live Bidirectional Multi-Agent system
- Level5 : Event-Driven Architecture with Google ADK, A2A, and Kafka