
1. บทนำ

1. ความท้าทาย
ในสถานการณ์การตอบสนองต่อภัยพิบัติ การประสานงานผู้รอดชีวิตที่มีทักษะ ทรัพยากร และความต้องการที่แตกต่างกันในหลายสถานที่ต้องใช้การจัดการข้อมูลและการค้นหาอัจฉริยะ เวิร์กช็อปนี้จะสอนวิธีสร้างระบบ AI สำหรับการใช้งานจริงที่ผสานรวมสิ่งต่อไปนี้
- 🗄️ ฐานข้อมูลกราฟ (Spanner): จัดเก็บความสัมพันธ์ที่ซับซ้อนระหว่างผู้รอดชีวิต ทักษะ และทรัพยากร
- 🔍 Search ที่ทำงานด้วยระบบ AI: การค้นหาแบบผสมเชิงความหมาย + คีย์เวิร์ดโดยใช้การฝัง
- 📸 การประมวลผลแบบมัลติโมดัล: ดึง Structured Data จากรูปภาพ ข้อความ และวิดีโอ
- 🤖 การจัดการเป็นกลุ่มแบบหลายเอเจนต์: ประสานงานเอเจนต์เฉพาะทางสำหรับเวิร์กโฟลว์ที่ซับซ้อน
- 🧠 หน่วยความจำระยะยาว: การปรับเปลี่ยนในแบบของคุณด้วย Vertex AI Memory Bank
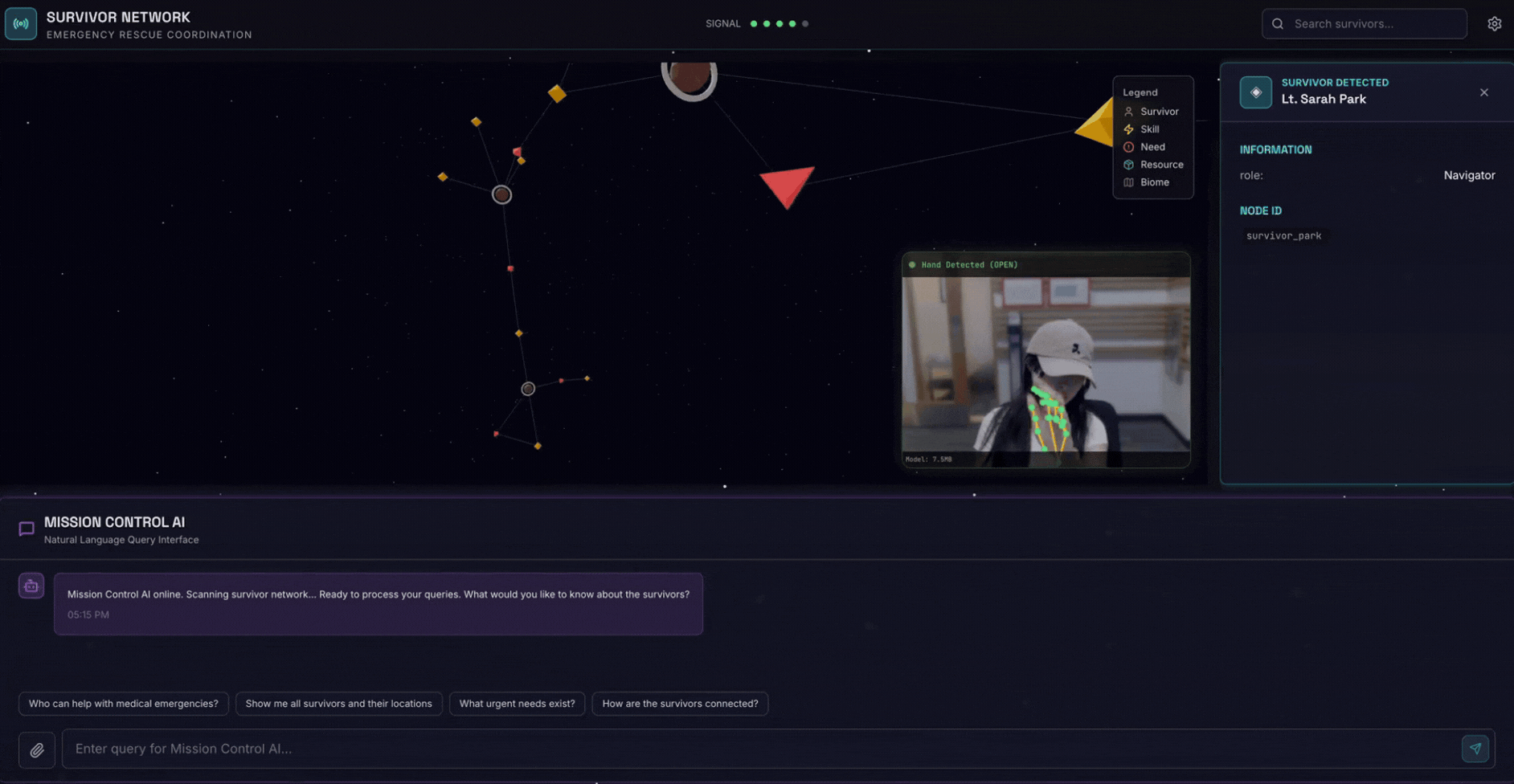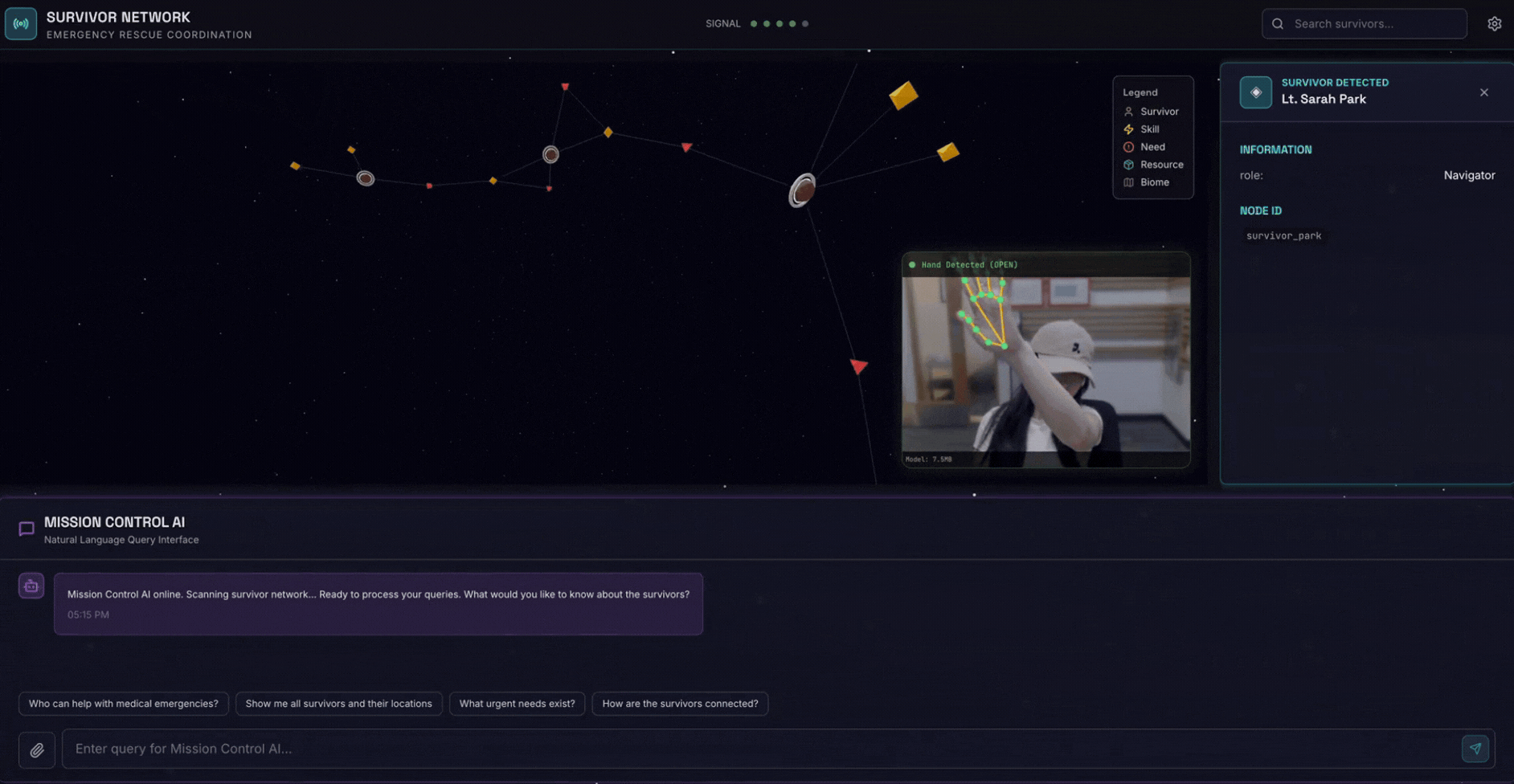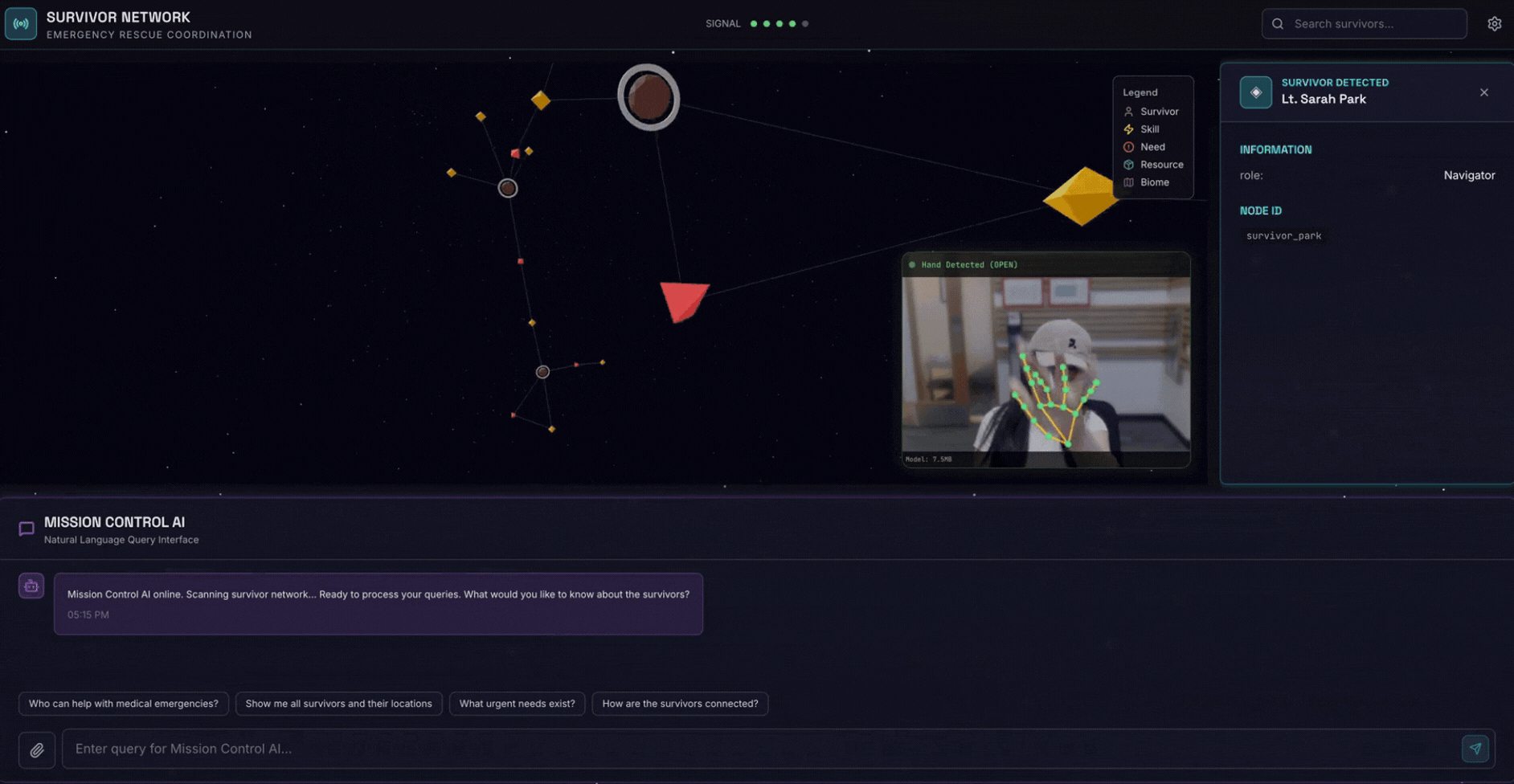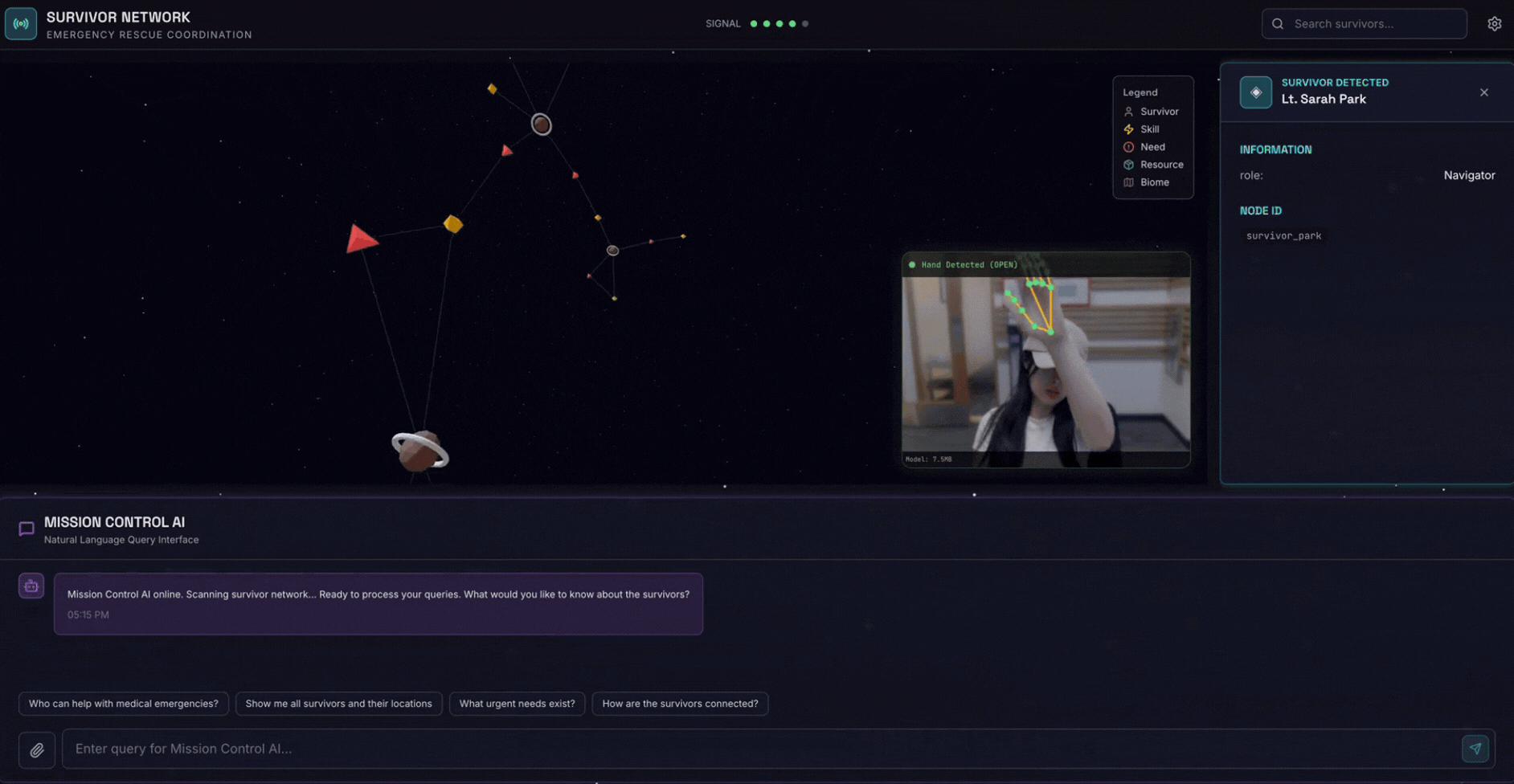
2. สิ่งที่คุณจะสร้าง
ฐานข้อมูลกราฟเครือข่ายผู้รอดชีวิตที่มีข้อมูลต่อไปนี้
- 🗺️ การแสดงภาพกราฟแบบอินเทอร์แอกทีฟ 3 มิติของความสัมพันธ์ของผู้รอดชีวิต
- 🔍 การค้นหาอัจฉริยะ (คีย์เวิร์ด ความหมาย และแบบผสม)
- 📸 ไปป์ไลน์การอัปโหลดแบบมัลติโมดัล (ดึงเอนทิตีจากรูปภาพ/วิดีโอ)
- 🤖 ระบบ Multi-Agent สำหรับการจัดระเบียบงานที่ซับซ้อน
- 🧠 การผสานรวม Memory Bank เพื่อการโต้ตอบที่ปรับเปลี่ยนในแบบของคุณ
3. เทคโนโลยีหลัก
ส่วนประกอบ | เทคโนโลยี | วัตถุประสงค์ |
ฐานข้อมูล | กราฟ Cloud Spanner | จัดเก็บโหนด (ผู้รอดชีวิต ทักษะ) และขอบ (ความสัมพันธ์) |
การค้นหาด้วย AI | Gemini + การฝัง | ความเข้าใจเชิงความหมาย + การค้นหาความคล้ายคลึงกัน |
Agent Framework | ADK (Agent Development Kit) | จัดการเวิร์กโฟลว์ AI |
หน่วยความจำ | Vertex AI Memory Bank | การจัดเก็บค่ากำหนดของผู้ใช้ในระยะยาว |
ฟรอนท์เอนด์ | React + Three.js | การแสดงภาพกราฟ 3 มิติแบบอินเทอร์แอกทีฟ |
2. 🛠️ การเตรียมสภาพแวดล้อม (ข้ามหากคุณอยู่ในเวิร์กช็อป)
ส่วนที่ 1: เปิดใช้บัญชีสำหรับการเรียกเก็บเงิน
หากต้องการเรียกใช้ Codelab นี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่บ้าง ใช้เครดิตจากแบนเนอร์ที่ด้านบนของ Codelab นี้เพื่อเริ่มต้นใช้งาน หากเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินอยู่แล้ว ให้ข้ามขั้นตอนนี้
ส่วนที่ 2: สภาพแวดล้อมแบบเปิด
- 👉 คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- 👉 หากระบบแจ้งให้ให้สิทธิ์ในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- 👉 หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- 👉💻 ในเทอร์มินัล ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list - 👉💻 โคลนโปรเจ็กต์ Bootstrap จาก GitHub
git clone https://github.com/gca-americas/way-back-home.git
ส่วนที่ 3: สร้างโปรเจ็กต์ใหม่
👉💻 ในเทอร์มินัล ให้ตั้งค่าสคริปต์ init ให้เรียกใช้งานได้ แล้วดำเนินการ
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ การตั้งค่าสภาพแวดล้อม
1. เปิด Cloud Shell
ในเทอร์มินัล Cloud Shell Editor หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
2. กำหนดค่าโปรเจ็กต์
👉💻 ในเทอร์มินัล ให้ตั้งรหัสโปรเจ็กต์ดังนี้
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 เปิดใช้ API ที่จำเป็น (ใช้เวลาประมาณ 2-3 นาที)
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. เรียกใช้สคริปต์การตั้งค่า
👉💻 เรียกใช้สคริปต์การตั้งค่า
cd ~/way-back-home/level_2
./setup.sh
ซึ่งจะสร้าง .env ให้คุณ เปิด way_back_homeproject ใน Cloud Shell คุณจะเห็นว่าระบบได้สร้างไฟล์ .env ไว้ให้คุณในโฟลเดอร์ level_2 หากไม่พบ ให้คลิก View -> Toggle Hidden File เพื่อดู 
4. โหลดข้อมูลตัวอย่าง
👉💻 ไปที่แบ็กเอนด์และติดตั้งการอ้างอิง
cd ~/way-back-home/level_2/backend
uv sync
👉💻 โหลดข้อมูลผู้รอดชีวิตเริ่มต้น
uv run python ~/way-back-home/level_2/backend/setup_data.py
ซึ่งจะสร้างสิ่งต่อไปนี้
- อินสแตนซ์ Spanner (
survivor-network) - ฐานข้อมูล (
graph-db) - ตารางโหนดและตารางขอบทั้งหมด
- กราฟพร็อพเพอร์ตี้สำหรับการค้นหาเอาต์พุตที่คาดไว้
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
หากคลิกลิงก์หลังจาก Access your database at ในเอาต์พุต คุณจะเปิด Spanner ในคอนโซล Google Cloud ได้

และคุณจะเห็น Spanner ในคอนโซล Google Cloud
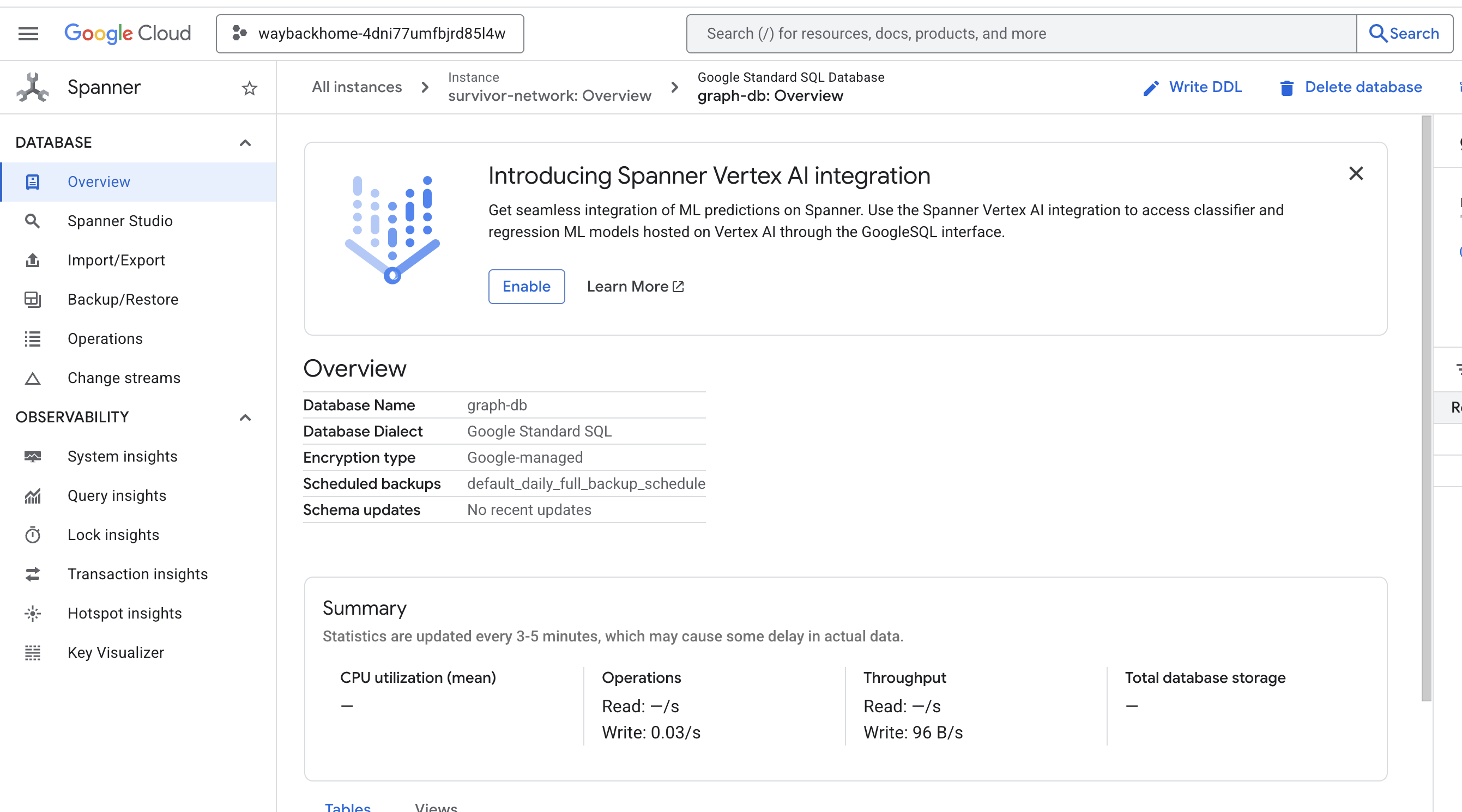
4. 🚀 การแสดงข้อมูลกราฟเป็นภาพใน Spanner Studio
คู่มือนี้จะช่วยให้คุณแสดงภาพและโต้ตอบกับข้อมูลกราฟเครือข่ายผู้รอดชีวิตได้โดยตรงใน คอนโซล Google Cloud โดยใช้ Spanner Studio วิธีนี้เป็นวิธีที่ยอดเยี่ยมในการยืนยันข้อมูลและทำความเข้าใจโครงสร้างกราฟก่อนสร้าง AI Agent
1. เข้าถึง Spanner Studio
- ในขั้นตอนสุดท้าย ให้คลิกลิงก์และเปิด Spanner Studio
2. ทำความเข้าใจโครงสร้างกราฟ ("ภาพรวม")
ให้คิดว่าชุดข้อมูล Survivor Network เป็นเหมือนปริศนาตรรกะหรือสถานะเกม
เอนทิตี | บทบาทในระบบ | การอุปมา |
ผู้รอดชีวิต | ตัวแทน/ผู้เล่น | ผู้เล่น |
ไบโอม | สถานที่ตั้ง | โซนแผนที่ |
ทักษะ | สิ่งที่ทำได้ | ความสามารถ |
สิ่งที่ต้องมี | สิ่งที่ขาด (วิกฤต) | ภารกิจ |
แหล่งข้อมูล | รายการที่พบในโลก | Loot |
เป้าหมาย: หน้าที่ของเอเจนต์ AI คือการเชื่อมต่อทักษะ (โซลูชัน) กับความต้องการ (ปัญหา) โดยพิจารณาไบโอม (ข้อจำกัดด้านสถานที่)
🔗 ขอบ (ความสัมพันธ์):
SurvivorInBiome: การติดตามตำแหน่งSurvivorHasSkill: รายการความสามารถSurvivorHasNeed: รายการปัญหาที่ยังคงเกิดขึ้นSurvivorFoundResource: สินค้าคงคลังSurvivorCanHelp: ความสัมพันธ์ที่อนุมาน (AI คำนวณความสัมพันธ์นี้)
3. การค้นหากราฟ
มาลองเรียกใช้การค้นหา 2-3 รายการเพื่อดู "เรื่องราว" ในข้อมูลกัน
Spanner Graph ใช้ GQL (Graph Query Language) หากต้องการเรียกใช้การค้นหา ให้ใช้ GRAPH SurvivorNetwork ตามด้วยรูปแบบการจับคู่
👉 คำค้นหาที่ 1: รายชื่อทั่วโลก (ใครอยู่ที่ไหน) นี่คือพื้นฐานของคุณ การทำความเข้าใจตำแหน่งเป็นสิ่งสำคัญสำหรับการปฏิบัติการกู้ภัย
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
คุณจะเห็นผลลัพธ์ดังนี้ 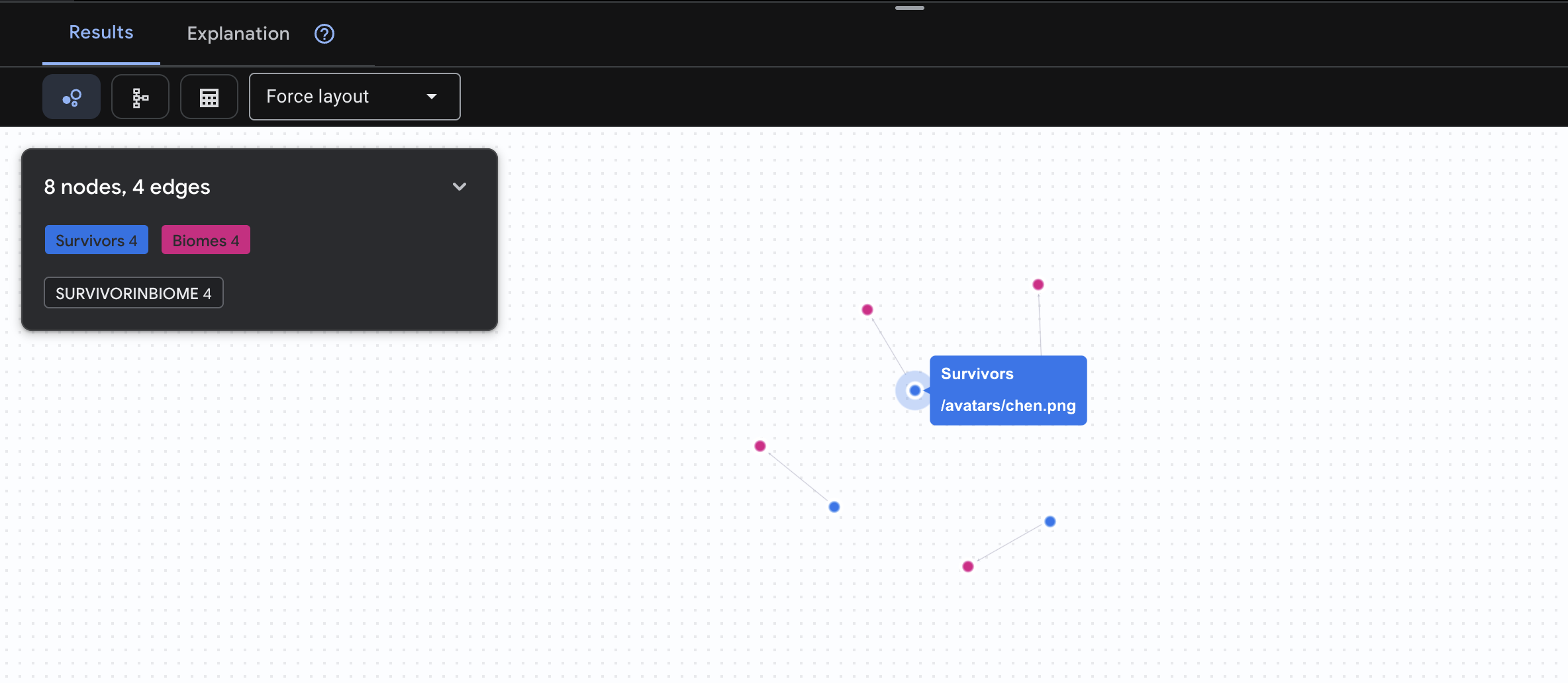
👉 คำค้นหา 2: เมทริกซ์ทักษะ (ความสามารถ) ตอนนี้คุณทราบแล้วว่าทุกคนอยู่ที่ไหน ให้ดูว่าพวกเขาทำอะไรได้บ้าง
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
คุณจะเห็นผลลัพธ์ดังนี้ 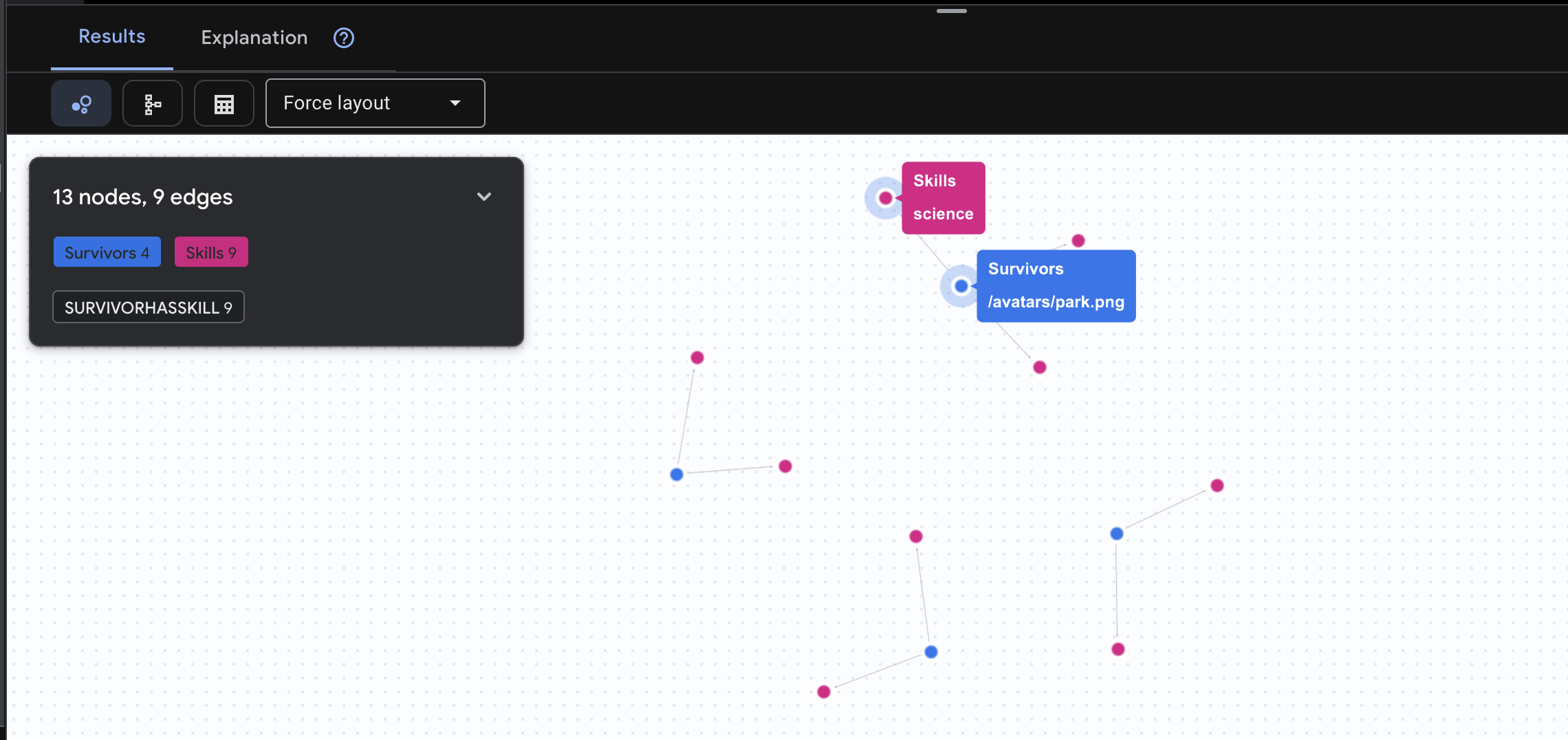
👉 คำค้นหาที่ 3: ใครอยู่ในภาวะวิกฤต ("กระดานภารกิจ") ดูผู้รอดชีวิตที่ต้องการความช่วยเหลือและสิ่งที่พวกเขาต้องการ
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
คุณจะเห็นผลลัพธ์ดังนี้ 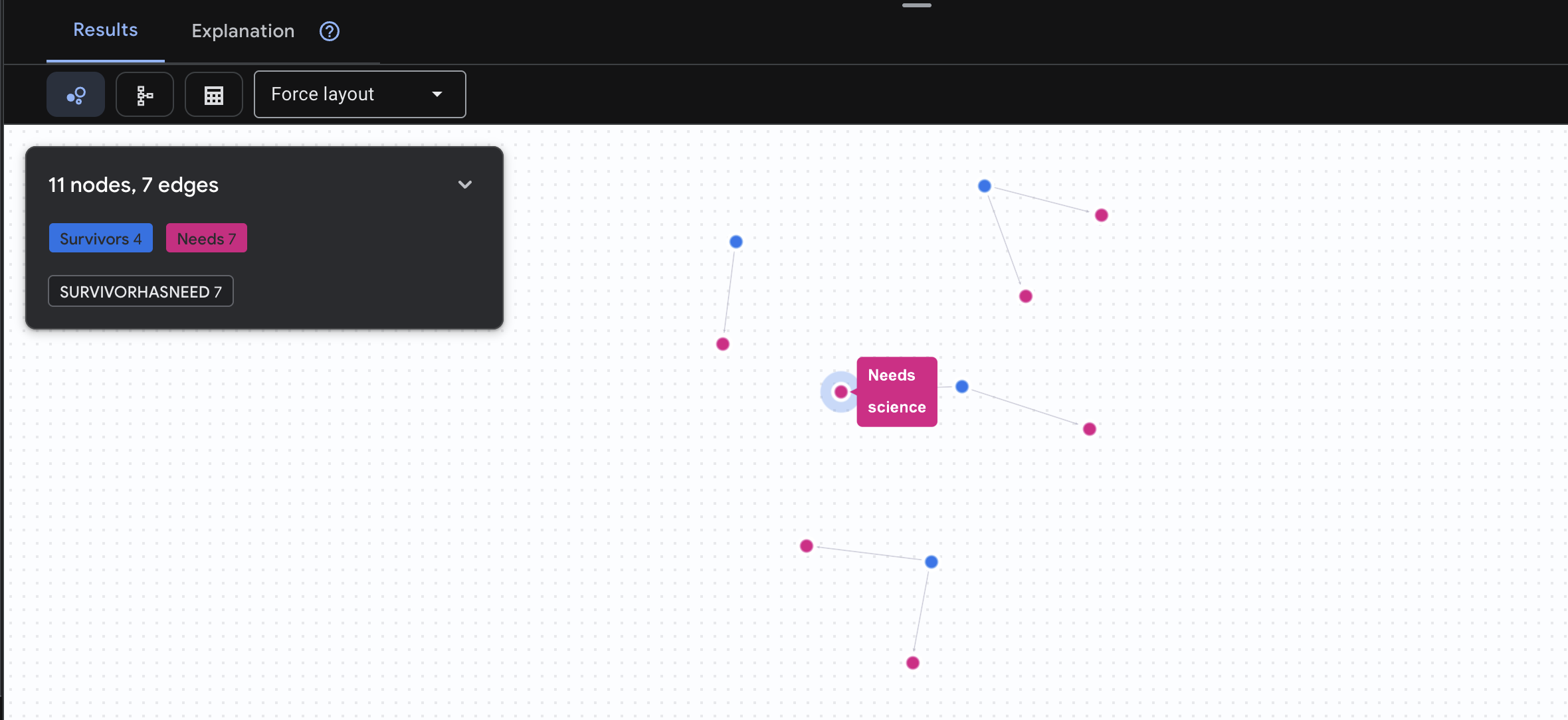
🔎 [ไม่บังคับ] การจับคู่ - ใครช่วยใครได้บ้าง
กราฟจะมีประสิทธิภาพในขั้นตอนนี้ คำค้นหานี้จะค้นหาผู้รอดชีวิตที่มีทักษะที่สามารถตอบสนองความต้องการของผู้รอดชีวิตคนอื่นๆ
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
คุณจะเห็นผลลัพธ์ดังนี้ 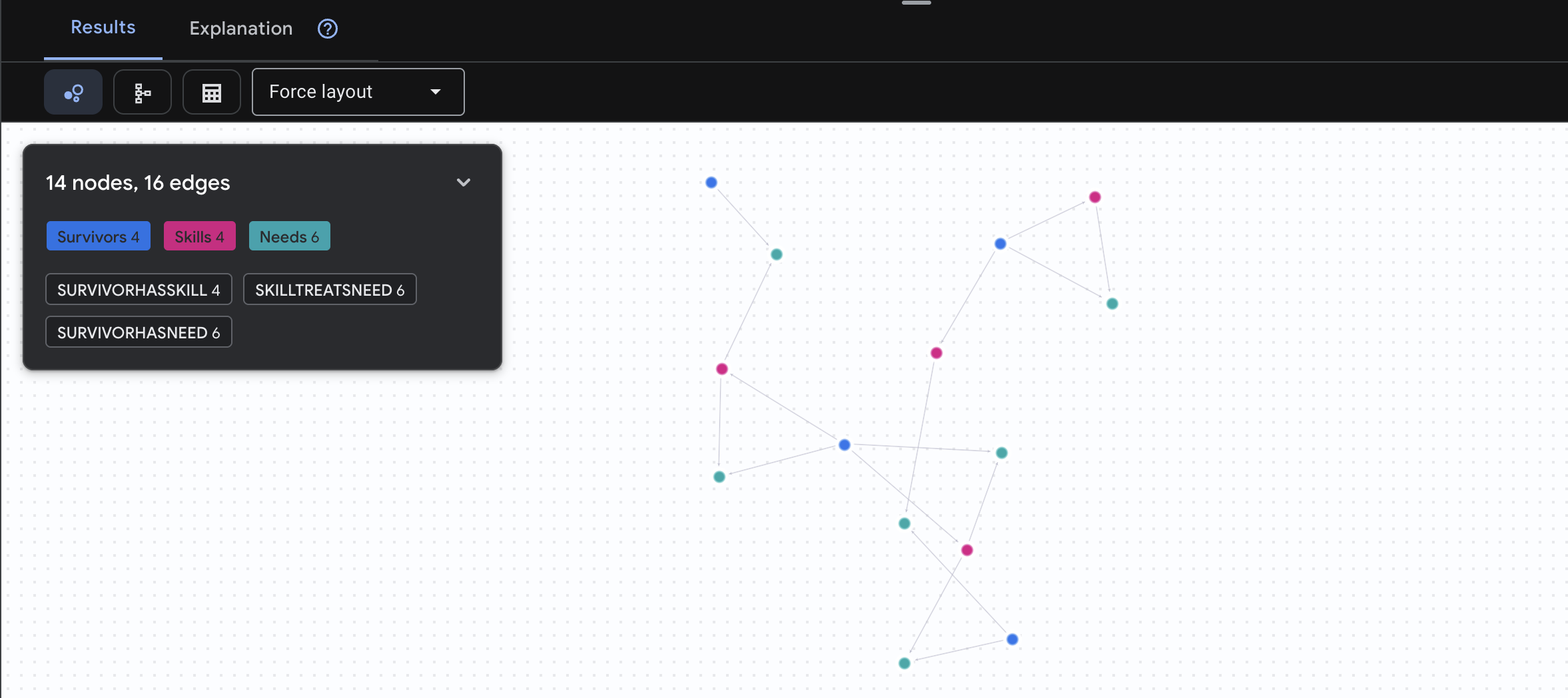
นอกเหนือจากผลลัพธ์เชิงบวก สิ่งที่คำค้นหานี้ทำ:
แทนที่จะแสดงเพียง "การปฐมพยาบาลรักษาแผลไหม้" (ซึ่งเห็นได้ชัดจากสคีมา) การค้นหานี้จะค้นหา
- ดร. เอเลนา ฟรอสต์ (ผู้มีประสบการณ์ด้านการแพทย์) → สามารถรักษา → กัปตันทานากะ (ผู้มีบาดแผลจากไฟไหม้)
- เดวิด เฉิน (ผู้มีความรู้ด้านปฐมพยาบาล) → สามารถรักษา → ร้อยโทปาร์ค (ผู้มีข้อเท้าแพลง)
เหตุผลที่วิธีนี้ได้ผล
สิ่งที่ตัวแทน AI จะทำ
เมื่อผู้ใช้ถามว่า "ใครรักษาแผลไหม้ได้บ้าง" เอเจนต์จะทำดังนี้
- เรียกใช้การค้นหากราฟที่คล้ายกัน
- คำตอบ: "ดร. ฟรอสต์ได้รับการฝึกอบรมทางการแพทย์และช่วยกัปตันทานากะได้"
- ผู้ใช้ไม่จำเป็นต้องทราบเกี่ยวกับตารางหรือความสัมพันธ์ระดับกลาง
5. 🚀 การฝังที่ทำงานด้วยระบบ AI ใน Spanner
1. ทำไมต้องใช้การฝัง (ไม่มีการดำเนินการ อ่านอย่างเดียว)
ในสถานการณ์ที่ต้องเอาชีวิตรอด เวลาเป็นสิ่งสำคัญ เมื่อผู้รอดชีวิตรายงานเหตุฉุกเฉิน เช่น I need someone who can treat burns หรือ Looking for a medic ผู้รอดชีวิตไม่ควรเสียเวลาคาดเดาชื่อทักษะที่แน่นอนในฐานข้อมูล
สถานการณ์จริง: Survivor: Captain Tanaka has burns—we need medical help NOW!
การค้นหาคีย์เวิร์ดแบบดั้งเดิมสำหรับ "medic" → 0 ผลลัพธ์ ❌
การค้นหาเชิงความหมายด้วยการฝัง → ค้นหา "การฝึกอบรมทางการแพทย์" "การปฐมพยาบาล" ✅
นี่คือสิ่งที่เอเจนต์ต้องการอย่างแท้จริง นั่นคือการค้นหาอัจฉริยะที่เหมือนมนุษย์ซึ่งเข้าใจเจตนา ไม่ใช่แค่คีย์เวิร์ด
2. สร้างโมเดลการฝัง
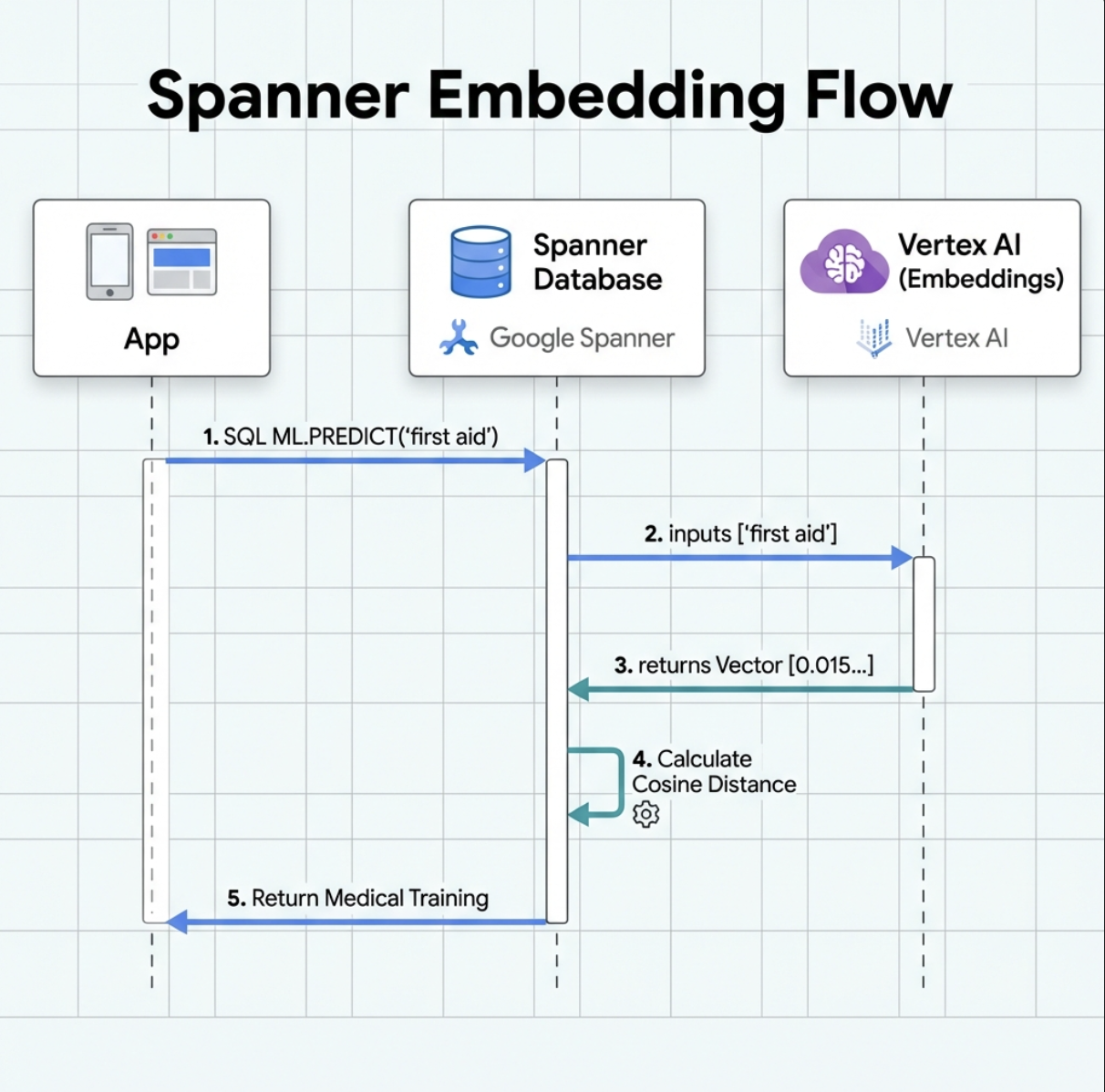
ตอนนี้เรามาสร้างโมเดลที่แปลงข้อความเป็น Embedding โดยใช้ text-embedding-004 ของ Google กัน
👉 ใน Spanner Studio ให้เรียกใช้ SQL นี้ (แทนที่ $YOUR_PROJECT_ID ด้วยรหัสโปรเจ็กต์จริง)
‼️ ในเอดิเตอร์ของ Cloud Shell ให้เปิด File -> Open Folder -> way-back-home/level_2 เพื่อดูทั้งโปรเจ็กต์
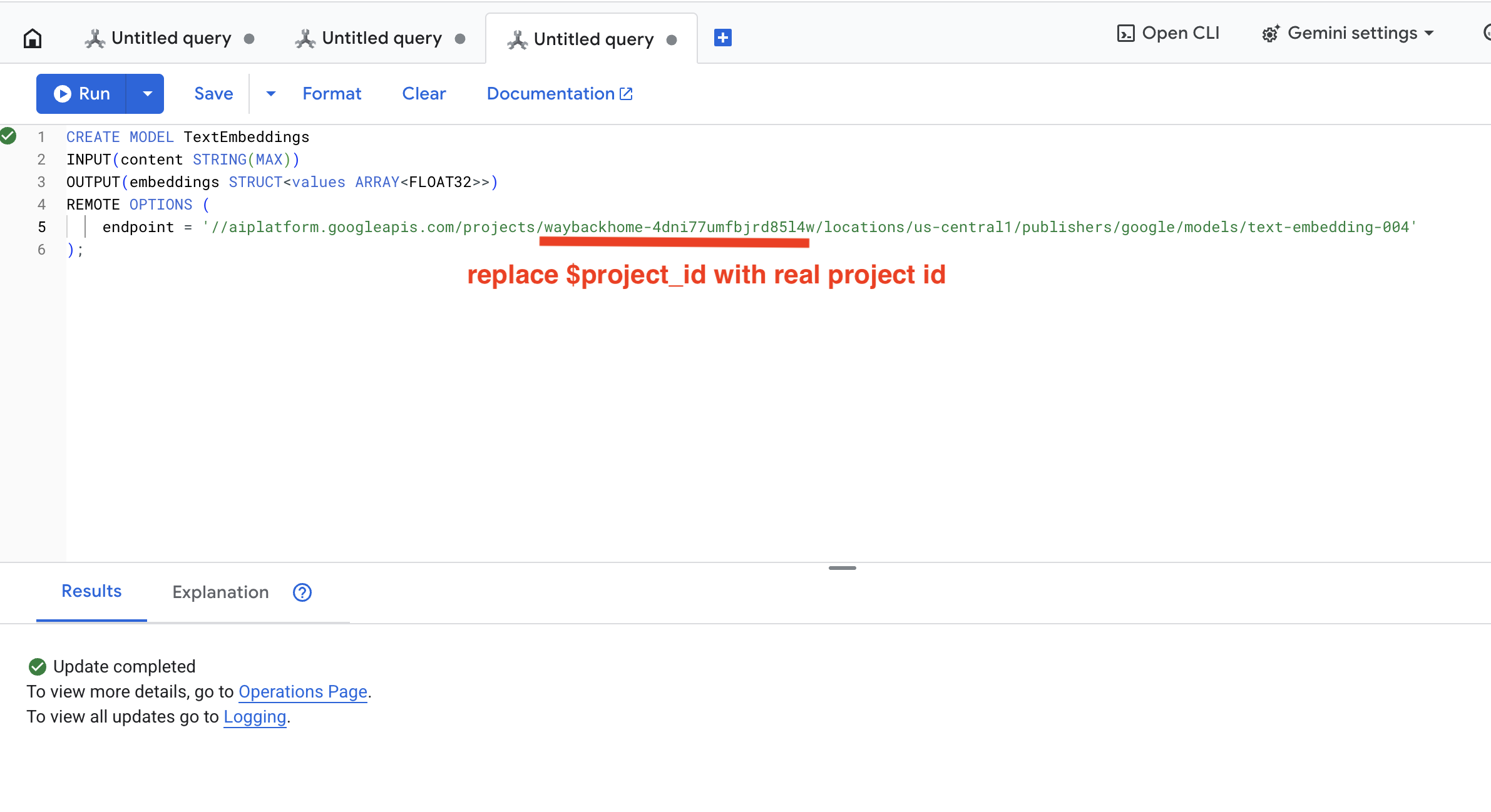
👉 เรียกใช้การค้นหานี้ใน Spanner Studio โดยคัดลอกและวางการค้นหาด้านล่าง แล้วคลิกปุ่มเรียกใช้
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
สิ่งที่ฟีเจอร์นี้ทำ
- สร้างโมเดลเสมือนใน Spanner (ไม่มีการจัดเก็บน้ำหนักของโมเดลไว้ในเครื่อง)
- ชี้ให้เห็นถึง
text-embedding-004ของ Google ใน Vertex AI - กำหนดสัญญา: อินพุตเป็นข้อความ ส่วนเอาต์พุตเป็นอาร์เรย์จำนวนลอยตัว 768 มิติ
เหตุใดจึงต้องมี "ตัวเลือกการทำงานจากระยะไกล"
- Spanner ไม่ได้เรียกใช้โมเดลด้วยตัวเอง
- โดยจะเรียกใช้ Vertex AI ผ่าน API เมื่อคุณใช้
ML.PREDICT - Zero-ETL: ไม่จำเป็นต้องส่งออกข้อมูลไปยัง Python ประมวลผล และนำเข้าอีกครั้ง
คลิกปุ่ม Run เมื่อดำเนินการสำเร็จแล้ว คุณจะเห็นผลลัพธ์ดังนี้
3. เพิ่มคอลัมน์การฝัง
👉 เพิ่มคอลัมน์เพื่อจัดเก็บการฝัง
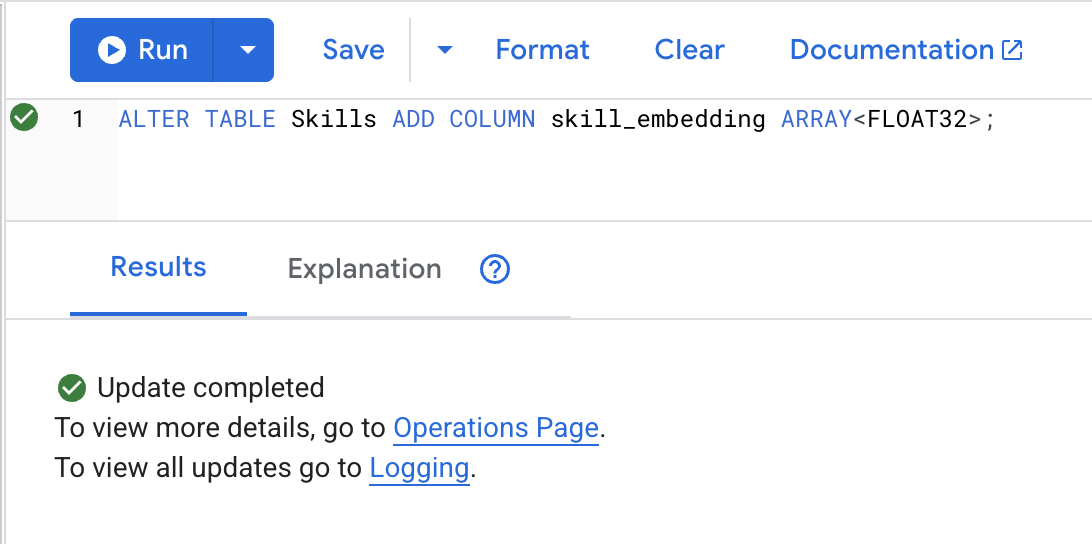
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
คลิกปุ่ม Run เมื่อดำเนินการสำเร็จแล้ว คุณจะเห็นผลลัพธ์ดังนี้
4. สร้างการฝัง
👉 ใช้ AI เพื่อสร้างการฝังเวกเตอร์สำหรับแต่ละทักษะ
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
คลิกปุ่ม Run เมื่อดำเนินการสำเร็จแล้ว คุณจะเห็นผลลัพธ์ดังนี้
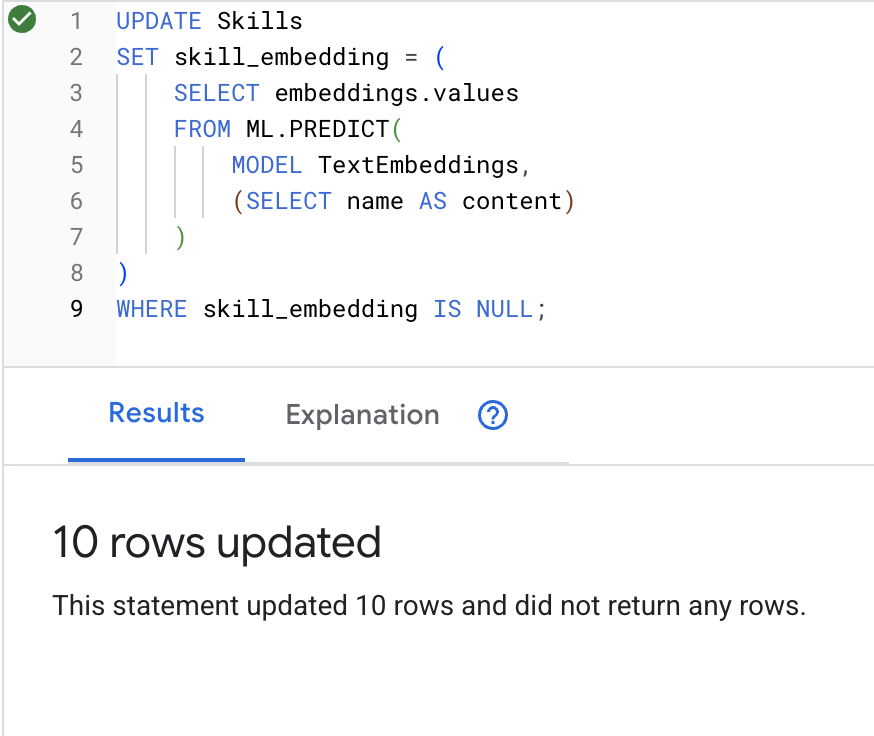
สิ่งที่เกิดขึ้น: ระบบจะแปลงชื่อทักษะแต่ละชื่อ (เช่น "ปฐมพยาบาล") เป็นเวกเตอร์ 768 มิติที่แสดงความหมายเชิงความหมายของทักษะนั้น
5. ยืนยันการฝัง
👉 ตรวจสอบว่ามีการสร้างการฝังแล้ว
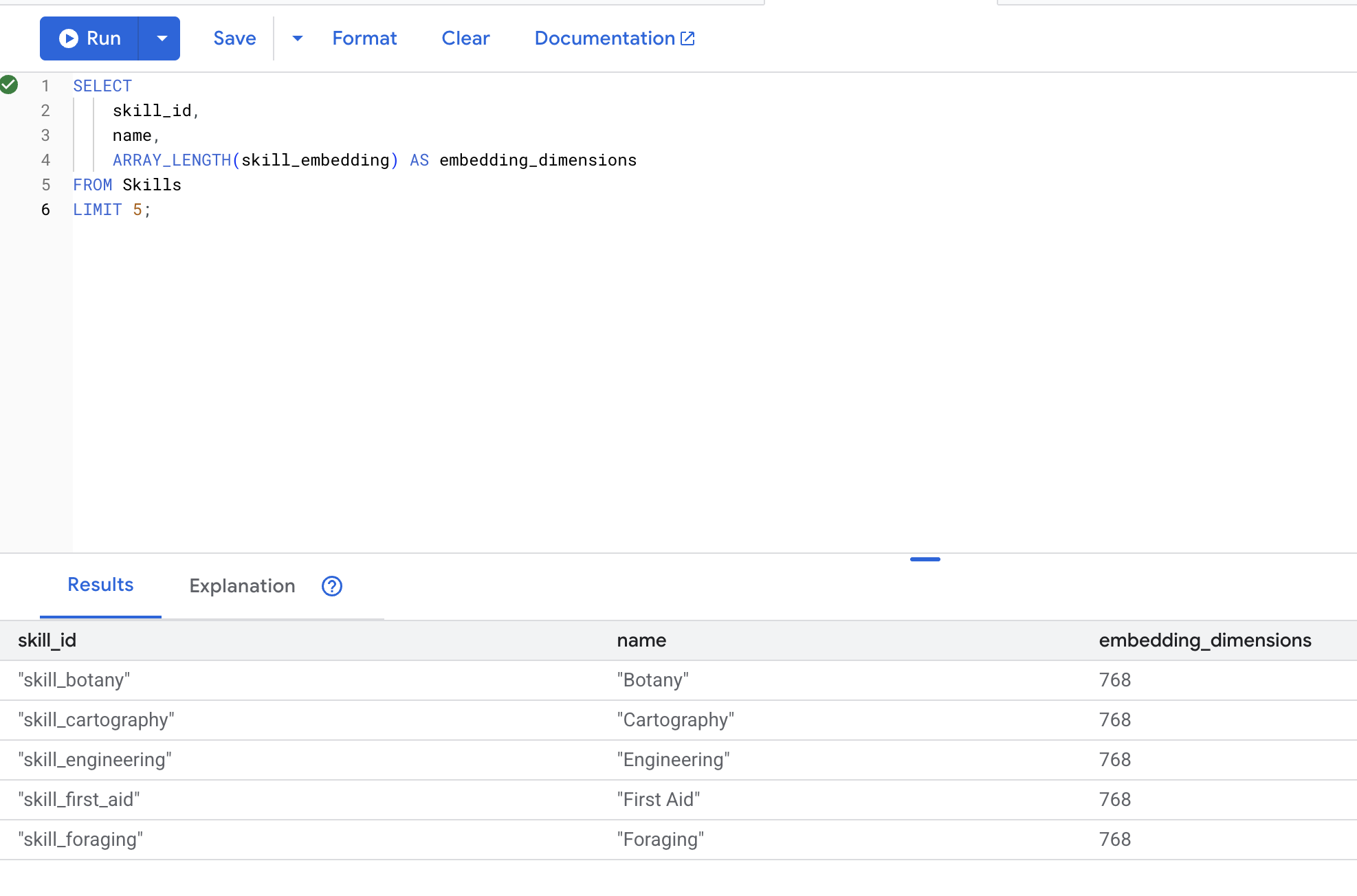
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
ผลลัพธ์ที่คาดไว้:
6. ทดสอบการค้นหาเชิงความหมาย
ตอนนี้เราจะทดสอบกรณีการใช้งานที่แน่นอนจากสถานการณ์ของเรา นั่นคือการค้นหาทักษะทางการแพทย์โดยใช้คำว่า "แพทย์"
👉 ค้นหาทักษะที่คล้ายกับ "แพทย์"
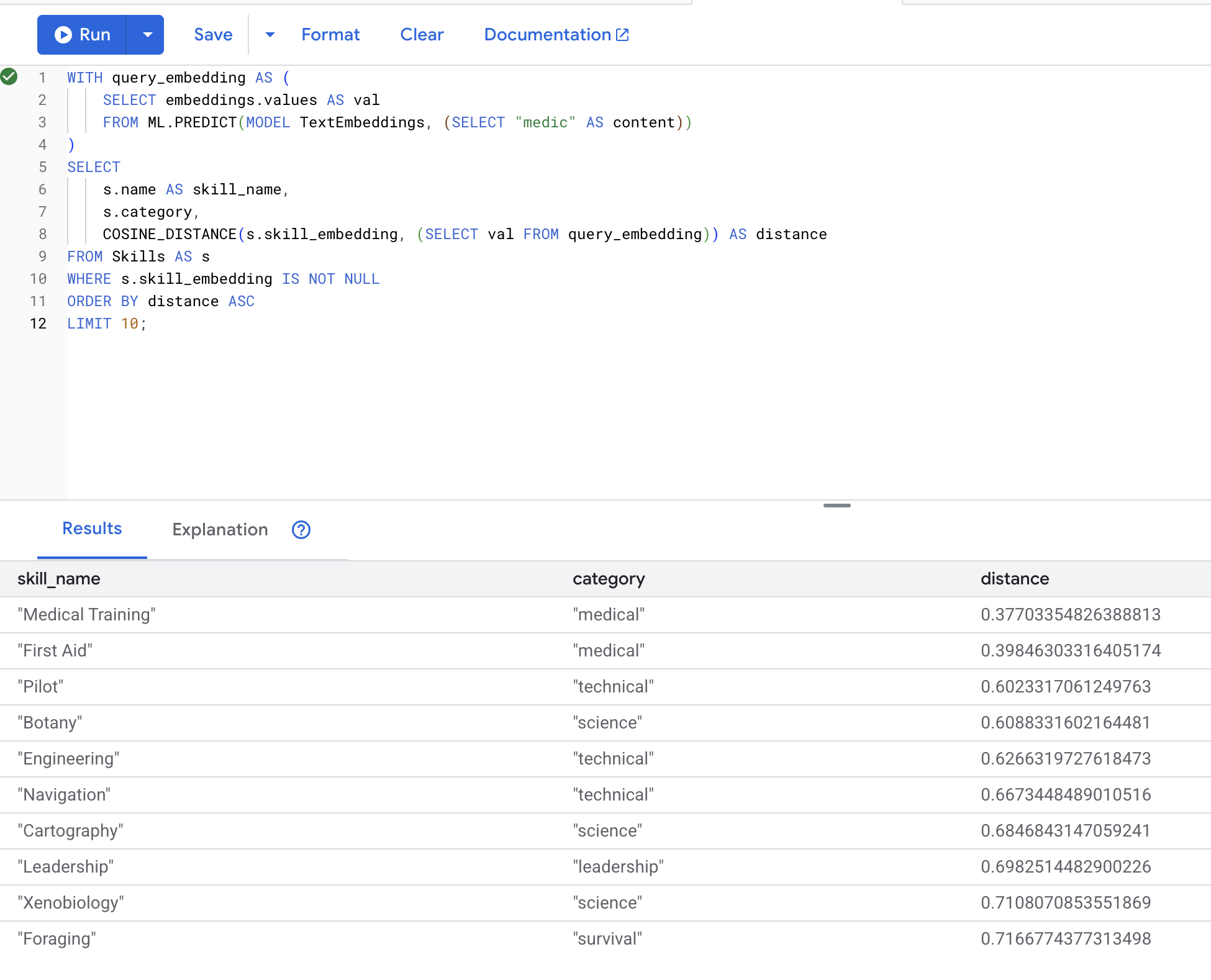
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- แปลงข้อความค้นหา "medic" ของผู้ใช้เป็น Embedding
- จัดเก็บไว้ใน
query_embeddingตารางชั่วคราว
ผลลัพธ์ที่คาดไว้ (ระยะทางยิ่งน้อย = ยิ่งคล้ายกัน):
7. สร้างโมเดล Gemini สำหรับการวิเคราะห์
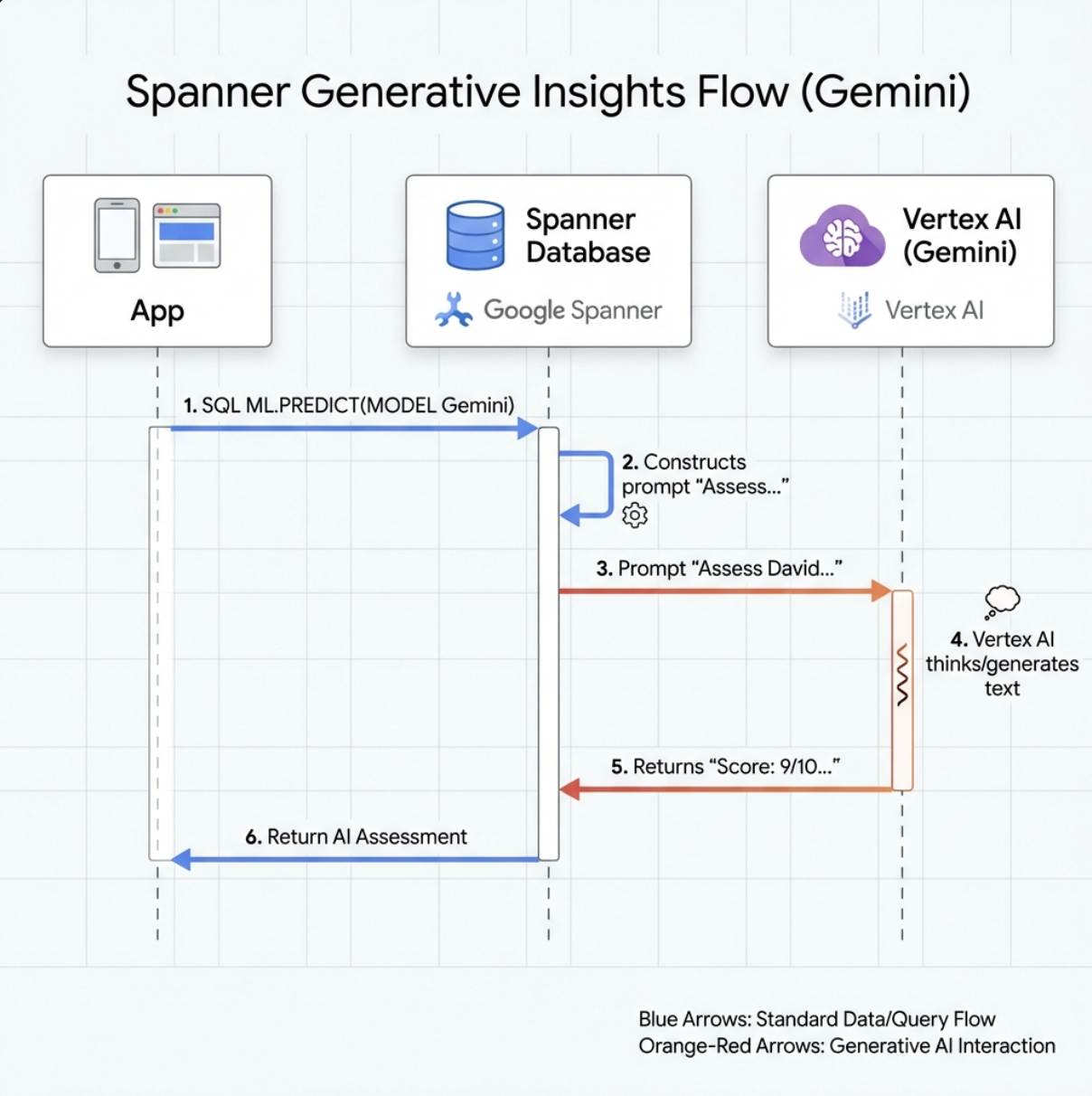
👉 สร้างการอ้างอิงโมเดล Generative AI (แทนที่ $YOUR_PROJECT_ID ด้วยรหัสโปรเจ็กต์จริงของคุณ)
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
ความแตกต่างจากโมเดลการฝัง:
- การฝัง: ข้อความ → เวกเตอร์ (สำหรับการค้นหาความคล้ายคลึง)
- Gemini: ข้อความ → ข้อความที่สร้างขึ้น (สำหรับการให้เหตุผล/การวิเคราะห์)
8. ใช้ Gemini เพื่อวิเคราะห์ความเข้ากันได้
👉 วิเคราะห์คู่ผู้รอดชีวิตเพื่อดูความเข้ากันได้ของภารกิจ
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
ผลลัพธ์ที่คาดไว้:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 การสร้าง Graph RAG Agent ด้วยการค้นหาแบบไฮบริด
1. ภาพรวมสถาปัตยกรรมของระบบ
ส่วนนี้จะสร้างระบบการค้นหาแบบหลายวิธีที่ช่วยให้ Agent ของคุณมีความยืดหยุ่นในการจัดการคำค้นหาประเภทต่างๆ ระบบมี 3 เลเยอร์ ได้แก่ เลเยอร์เอเจนต์ เลเยอร์เครื่องมือ และเลเยอร์บริการ
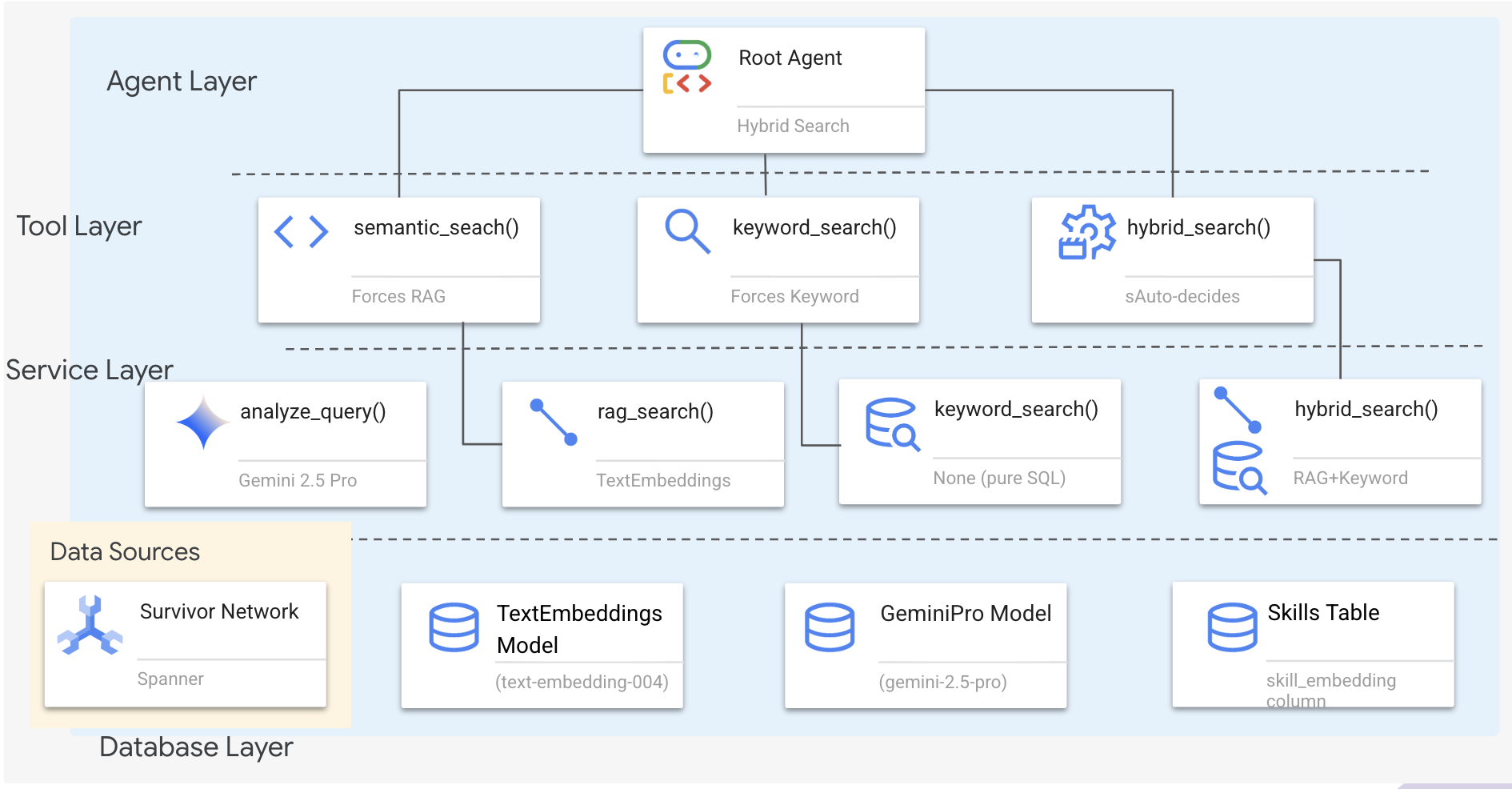
เหตุผลที่ต้องมี 3 เลเยอร์
- การแยกความกังวล: เอเจนต์มุ่งเน้นที่ความตั้งใจ เครื่องมือมุ่งเน้นที่อินเทอร์เฟซ และบริการมุ่งเน้นที่การติดตั้งใช้งาน
- ความยืดหยุ่น: Agent สามารถบังคับใช้เมธอดที่เฉพาะเจาะจงหรือปล่อยให้ AI กำหนดเส้นทางโดยอัตโนมัติ
- การเพิ่มประสิทธิภาพ: ข้ามการวิเคราะห์ AI ที่มีค่าใช้จ่ายสูงได้เมื่อทราบวิธีการ
ในส่วนนี้ คุณจะใช้การค้นหาเชิงความหมาย (RAG) เป็นหลัก ซึ่งเป็นการค้นหาผลลัพธ์ตามความหมาย ไม่ใช่แค่คีย์เวิร์ด ต่อมา เราจะอธิบายว่าการค้นหาแบบไฮบริดผสานรวมหลายวิธีได้อย่างไร
2. การติดตั้งใช้งานบริการ RAG
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
ค้นหาความคิดเห็น # TODO: REPLACE_SQL
แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. คำจำกัดความของเครื่องมือค้นหาเชิงความหมาย
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
ใน hybrid_search_tools.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
เมื่อ Agent ใช้
- คำค้นหาที่ถามถึงความคล้ายกัน ("ค้นหาที่คล้ายกับ X")
- คำค้นหาเชิงแนวคิด ("ความสามารถในการรักษา")
- เมื่อความเข้าใจความหมายเป็นสิ่งสำคัญ
4. คำแนะนำในการตัดสินใจของตัวแทน (วิธีการ)
ในคำจำกัดความของเอเจนต์ ให้คัดลอกและวางส่วนที่เกี่ยวข้องกับการค้นหาเชิงความหมายลงในคำสั่ง
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Agent จะใช้คำสั่งนี้เพื่อเลือกเครื่องมือที่เหมาะสม
👉ในไฟล์ agent.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_SEARCH_LOGIC, Replace this whole line ด้วยโค้ดต่อไปนี้
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉ค้นหาความคิดเห็น # TODO: ADD_SEARCH_TOOLReplace this whole line ด้วยโค้ดต่อไปนี้
semantic_search, # Force RAG
5. ทำความเข้าใจวิธีการทำงานของการค้นหาแบบไฮบริด (อ่านอย่างเดียว ไม่ต้องดำเนินการใดๆ)
ในขั้นตอนที่ 2-4 คุณได้ใช้การค้นหาเชิงความหมาย (RAG) ซึ่งเป็นวิธีการค้นหาหลักที่ค้นหาผลลัพธ์ตามความหมาย แต่คุณอาจสังเกตเห็นว่าระบบนี้มีชื่อว่า "Hybrid Search" โดยวิธีการทำงานมีดังนี้
วิธีการทำงานของการผสานแบบไฮบริด
ในไฟล์ way-back-home/level_2/backend/services/hybrid_search_service.py เมื่อมีการเรียกใช้ hybrid_search() บริการจะทำการค้นหาทั้ง 2 รายการและผสานผลลัพธ์
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
สำหรับ Codelab นี้ คุณได้ติดตั้งใช้งานคอมโพเนนต์การค้นหาเชิงความหมาย (RAG) ซึ่งเป็นรากฐาน เราได้ใช้คีย์เวิร์ดและวิธีการแบบผสมในบริการแล้ว ตัวแทนของคุณจึงใช้ทั้ง 3 วิธีได้
ยินดีด้วย คุณสร้างเอเจนต์ Graph RAG ด้วยการค้นหาแบบไฮบริดเสร็จสมบูรณ์แล้ว
7. 🚀 การทดสอบ Agent ด้วย ADK Web
วิธีที่ง่ายที่สุดในการทดสอบ Agent คือการใช้คำสั่ง adk web ซึ่งจะเปิดตัว Agent พร้อมอินเทอร์เฟซแชทในตัว
1. การเรียกใช้ Agent
👉💻 ไปยังไดเรกทอรีแบ็กเอนด์ (ที่กำหนด Agent) แล้วเปิดอินเทอร์เฟซเว็บ::
cd ~/way-back-home/level_2/backend
uv run adk web
คำสั่งนี้จะเริ่มเอเจนต์ที่กำหนดไว้ใน
agent/agent.py
และเปิดอินเทอร์เฟซทางเว็บสำหรับการทดสอบ
👉 เปิด URL โดยทำดังนี้
คำสั่งจะแสดง URL ในเครื่อง (โดยปกติคือ http://127.0.0.1:8000 หรือคล้ายกัน) เปิดหน้านี้ในเบราว์เซอร์
เมื่อคลิก URL แล้ว คุณจะเห็น ADK Web UI ตรวจสอบว่าคุณเลือก "ตัวแทน" จากมุมซ้ายบน
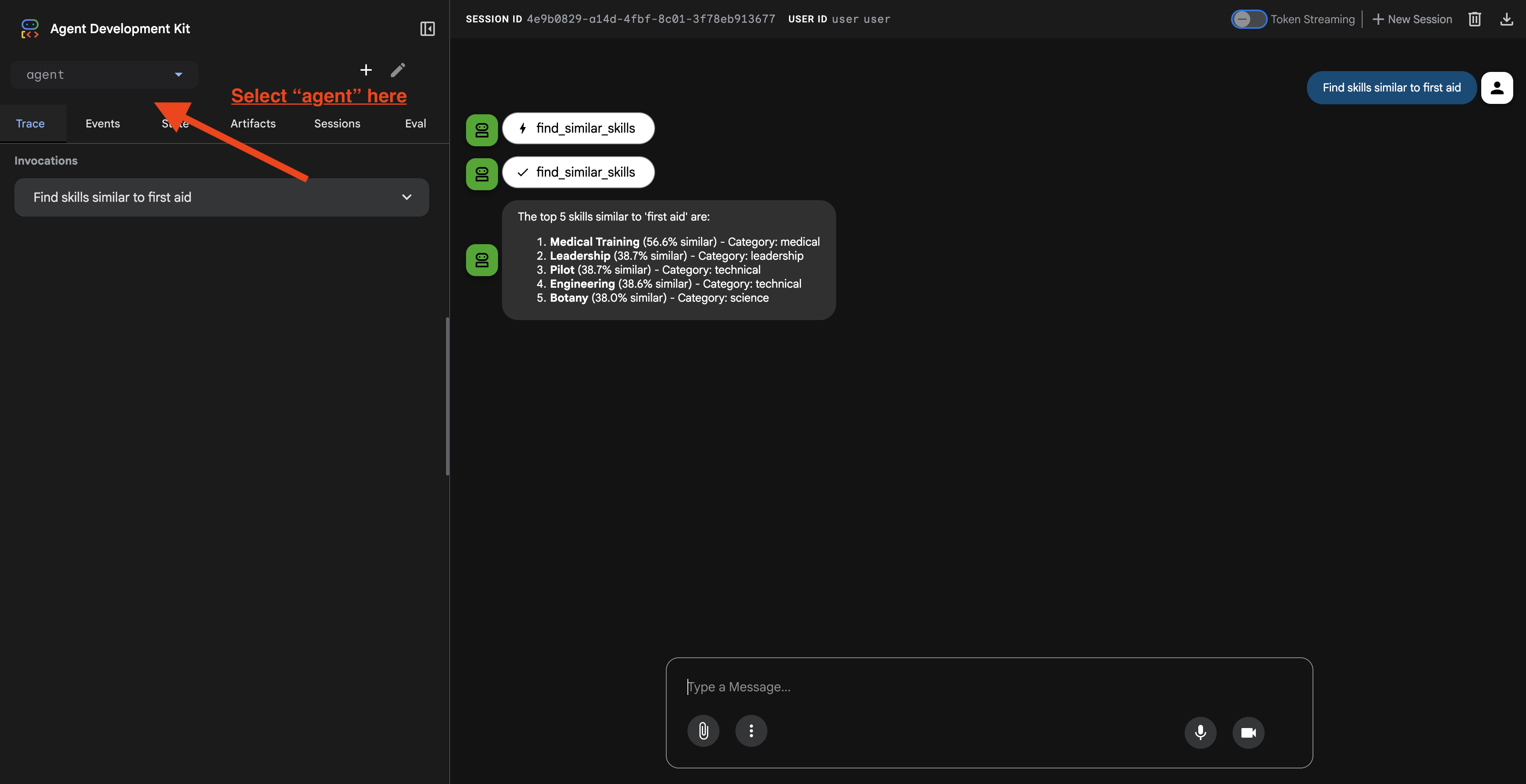
2. การทดสอบความสามารถของ Search
Agent ออกแบบมาเพื่อกำหนดเส้นทางการค้นหาของคุณอย่างชาญฉลาด ลองป้อนข้อมูลต่อไปนี้ในหน้าต่างแชทเพื่อดูวิธีการค้นหาต่างๆ
🧬 ก. Graph RAG (การค้นหาเชิงความหมาย)
ค้นหารายการตามความหมายและแนวคิด แม้ว่าคีย์เวิร์ดจะไม่ตรงกันก็ตาม
คำค้นหาทดสอบ: (เลือกคำค้นหาใดก็ได้จากด้านล่าง)
Who can help with injuries?
What abilities are related to survival?
สิ่งที่ควรตรวจสอบ
- การให้เหตุผลควรกล่าวถึงการค้นหาเชิงความหมายหรือRAG
- คุณควรเห็นผลการค้นหาที่เกี่ยวข้องในเชิงแนวคิด (เช่น "การผ่าตัด" เมื่อถามถึง "การปฐมพยาบาล")
- ผลการค้นหาจะมีไอคอน 🧬
🔀 ข. การค้นหาแบบผสม
รวมตัวกรองคีย์เวิร์ดเข้ากับความเข้าใจเชิงความหมายสำหรับการค้นหาที่ซับซ้อน
คำค้นหาทดสอบ:(เลือกคำค้นหาใดก็ได้จากด้านล่าง)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
สิ่งที่ควรตรวจสอบ
- เหตุผลควรกล่าวถึงการค้นหาไฮบริด
- ผลลัพธ์ควรตรงกับทั้ง 2 เกณฑ์ (แนวคิด + สถานที่/หมวดหมู่)
- ผลลัพธ์ที่พบโดยทั้ง 2 วิธีจะมีไอคอน 🔀 และได้รับการจัดอันดับสูงสุด
👉💻 เมื่อทดสอบเสร็จแล้ว ให้สิ้นสุดกระบวนการโดยกด Ctrl+C ในบรรทัดคำสั่ง
8. 🚀 การเรียกใช้แอปพลิเคชันแบบเต็ม
ภาพรวมสถาปัตยกรรมแบบ Full Stack
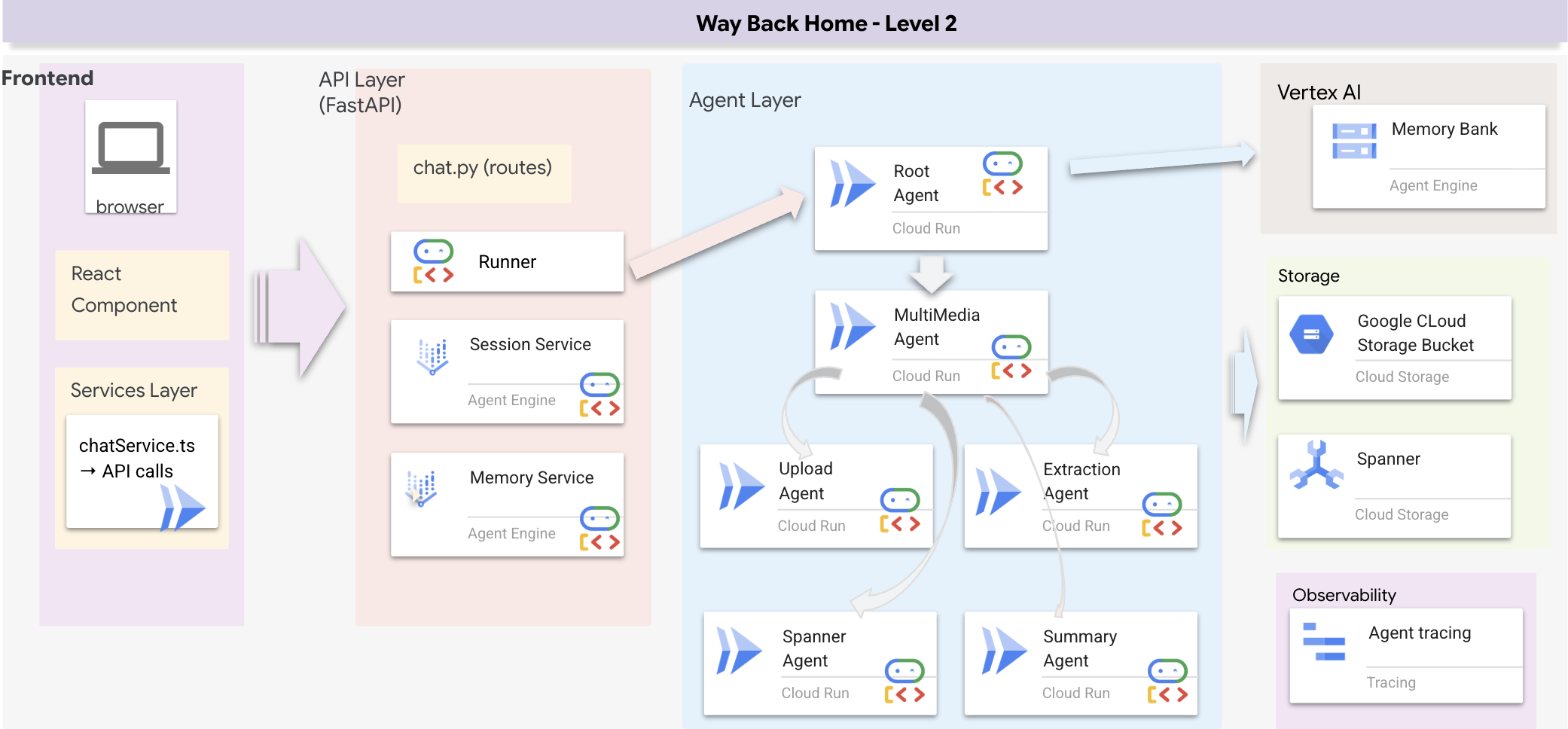
เพิ่ม SessionService และ Runner
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ chat.py ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้ (ตรวจสอบว่าคุณได้กด "ctrl+C" เพื่อสิ้นสุดกระบวนการก่อนหน้าแล้วก่อนดำเนินการต่อ)
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉ในไฟล์ chat.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_INMEMORY_SERVICES, แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉ในไฟล์ chat.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_RUNNER, แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. เริ่มสมัคร
หากเทอร์มินัลก่อนหน้ายังทำงานอยู่ ให้ปิดโดยกด Ctrl+C
👉💻 เริ่มแอป:
cd ~/way-back-home/level_2/
./start_app.sh
เมื่อเริ่มแบ็กเอนด์สำเร็จ คุณจะเห็น Local: http://localhost:5173/" ดังนี้ 
👉 คลิก Local: http://localhost:5173/ จากเทอร์มินัล
2. ทดสอบการค้นหาเชิงความหมาย
คำค้นหา
Find skills similar to healing
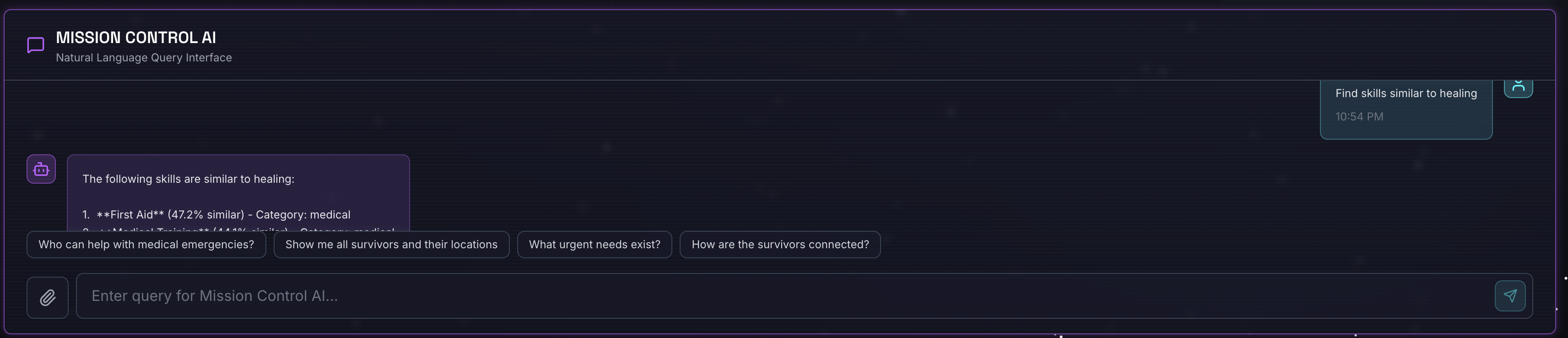
สิ่งที่เกิดขึ้น
- ตัวแทนรับทราบคำขอความคล้ายกัน
- สร้างการฝังสำหรับ "healing"
- ใช้ระยะทางโคไซน์เพื่อค้นหาทักษะที่มีความหมายคล้ายกัน
- การคืนสินค้า: การปฐมพยาบาล (แม้ว่าชื่อจะไม่ตรงกับ "การรักษา")
3. ทดสอบการค้นหาแบบไฮบริด
คำค้นหา
Find medical skills in the mountains
สิ่งที่เกิดขึ้น
- คอมโพเนนต์คีย์เวิร์ด: กรองสำหรับ
category='medical' - คอมโพเนนต์เชิงความหมาย: ฝัง "การแพทย์" และจัดอันดับตามความคล้ายคลึงกัน
- ผสาน: รวมผลลัพธ์ โดยให้ความสำคัญกับผลลัพธ์ที่พบจากทั้ง 2 วิธี 🔀
คำค้นหา(ไม่บังคับ):
Who is good at survival and in the forest?
สิ่งที่เกิดขึ้น
- คีย์เวิร์ดที่พบ:
biome='forest' - การค้นหาเชิงความหมาย: ทักษะที่คล้ายกับ "การเอาตัวรอด"
- ไฮบริดรวมทั้ง 2 อย่างเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด
👉💻 เมื่อทดสอบเสร็จแล้ว ให้สิ้นสุดการทดสอบในเทอร์มินัลโดยกด Ctrl+C
4. (!สำหรับผู้เข้าร่วมเวิร์กช็อปเท่านั้น) อัปเดตตำแหน่งของคุณ
👉💻 เรียกใช้สคริปต์การเติมข้อความอัตโนมัติ
cd ~/way-back-home/level_2
./set_level_2.sh
ตอนนี้ให้เปิด waybackhome.dev แล้วคุณจะเห็นว่าระบบได้อัปเดตตำแหน่งของคุณแล้ว ขอแสดงความยินดีที่จบเลเวล 2

9. ☕️ [ไม่บังคับ] ไปป์ไลน์แบบมัลติโมดัล (อ่านอย่างเดียว) - เลเยอร์เครื่องมือ
ทำไมเราจึงต้องมีไปป์ไลน์มัลติโมดัล
เครือข่ายการเอาตัวรอดไม่ได้มีแค่ข้อความ ผู้รอดชีวิตในพื้นที่ส่งข้อมูลที่ไม่มีโครงสร้างผ่านแชทโดยตรง
- 📸 รูปภาพ: รูปภาพของทรัพยากร อันตราย หรืออุปกรณ์
- 🎥 วิดีโอ: รายงานสถานะหรือการออกอากาศ SOS
- 📄 ข้อความ: บันทึกภาคสนามหรือบันทึก
เราประมวลผลไฟล์ใดบ้าง
ซึ่งแตกต่างจากขั้นตอนก่อนหน้าที่เราค้นหาข้อมูลที่มีอยู่ ในขั้นตอนนี้เราจะประมวลผลไฟล์ที่ผู้ใช้อัปโหลด อินเทอร์เฟซ chat.py จะจัดการไฟล์แนบแบบไดนามิกดังนี้
แหล่งที่มา | เนื้อหา | เป้าหมาย |
การแนบผู้ใช้ | รูปภาพ/วิดีโอ/ข้อความ | ข้อมูลที่จะเพิ่มลงในกราฟ |
บริบทของแชท | "นี่คือรูปภาพของอุปกรณ์" | เจตนาและรายละเอียดเพิ่มเติม |
แนวทางที่วางแผนไว้: ไปป์ไลน์ของ Agent แบบลำดับ
เราใช้ Sequential Agent (multimedia_agent.py) ที่เชื่อมโยงเอเจนต์เฉพาะทางเข้าด้วยกัน
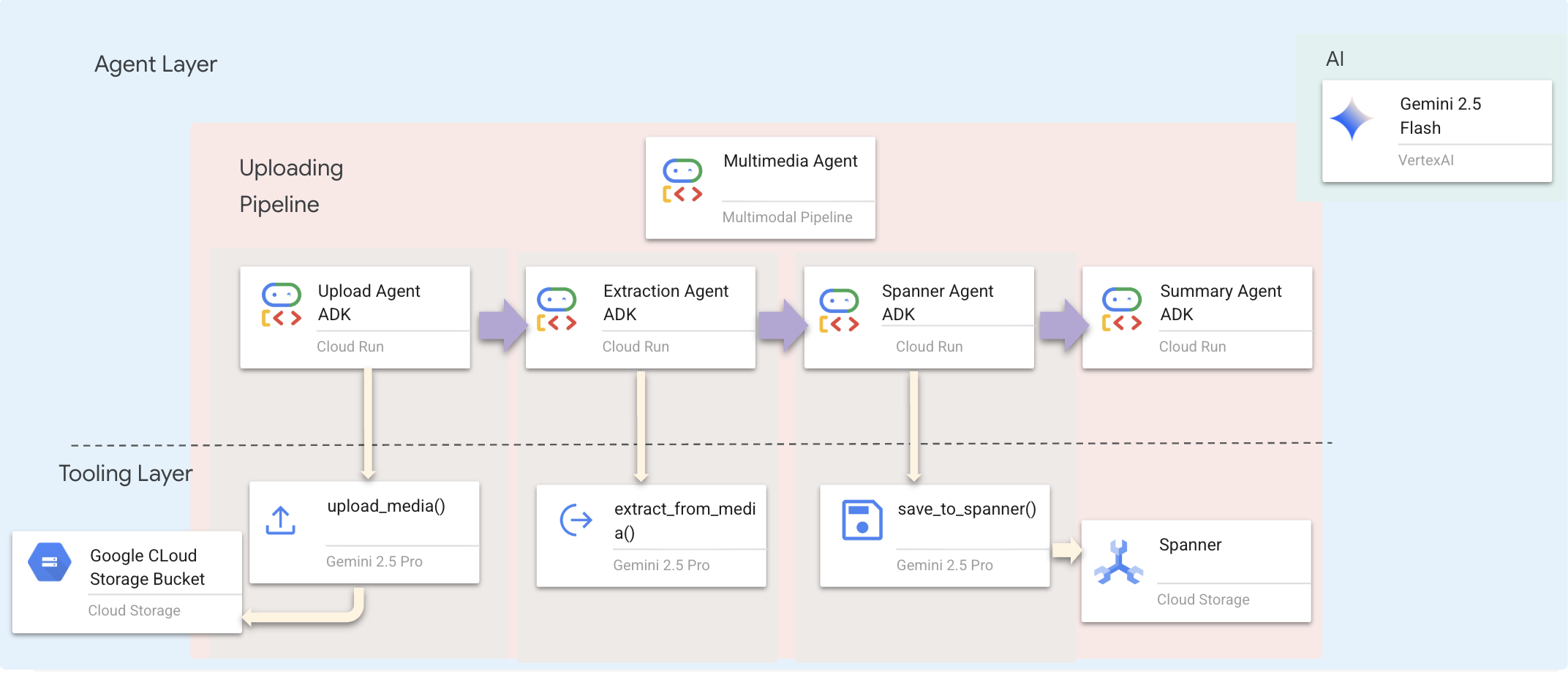
ซึ่งกำหนดไว้ใน backend/agent/multimedia_agent.py เป็น SequentialAgent
เลเยอร์เครื่องมือมีความสามารถที่ Agent เรียกใช้ได้ เครื่องมือจะจัดการ "วิธี" ซึ่งก็คือการอัปโหลดไฟล์ การแยกเอนทิตี และการบันทึกลงในฐานข้อมูล
1. เปิดไฟล์เครื่องมือ
👉💻 เปิดไฟล์ level_2/backend/agent/tools/extraction_tools.py หรือโดยการพิมพ์คำสั่งต่อไปนี้ในเทอร์มินัล เปิดเทอร์มินัลใหม่ ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. ติดตั้งใช้งานupload_mediaเครื่องมือ
เครื่องมือนี้จะอัปโหลดไฟล์ในเครื่องไปยัง Google Cloud Storage
👉 ใน def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: โค้ดต่อไปนี้จะอธิบายวิธีอัปโหลดไฟล์ไปยัง GCS และตรวจหาประเภทของไฟล์
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. ติดตั้งใช้งานextract_from_mediaเครื่องมือ
เครื่องมือนี้เป็นเราเตอร์ ซึ่งจะตรวจสอบ media_type และส่งไปยังตัวแยกที่ถูกต้อง (ข้อความ รูปภาพ หรือวิดีโอ)
👉 ใน async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: โค้ดต่อไปนี้จะอธิบายวิธีแยกเอนทิตีและความสัมพันธ์จากสื่อที่อัปโหลด
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
รายละเอียดการติดตั้งใช้งานที่สำคัญ
- อินพุตหลายรูปแบบ: เราส่งทั้งพรอมต์ข้อความ (
_get_extraction_prompt()) และออบเจ็กต์รูปภาพไปยังgenerate_content - เอาต์พุตที่มีโครงสร้าง:
response_mime_type="application/json"ช่วยให้ LLM แสดงผล JSON ที่ถูกต้อง ซึ่งมีความสําคัญต่อไปป์ไลน์ - การลิงก์เอนทิตีภาพ: พรอมต์มีเอนทิตีที่รู้จักเพื่อให้ Gemini จดจำตัวละครที่เฉพาะเจาะจงได้
4. ติดตั้งใช้งานsave_to_spannerเครื่องมือ
เครื่องมือนี้จะเก็บเอนทิตีและความสัมพันธ์ที่แยกออกมาไว้ใน Spanner Graph DB
👉 ใน def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: โค้ดต่อไปนี้จะอธิบายวิธีบันทึกเอนทิตีและความสัมพันธ์ที่แยกออกมาไปยัง Spanner Graph DB
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
การมอบเครื่องมือระดับสูงให้กับเอเจนต์ช่วยให้เรามั่นใจได้ถึงความสมบูรณ์ของข้อมูลในขณะที่ใช้ประโยชน์จากความสามารถในการให้เหตุผลของเอเจนต์
5. อัปเดตบริการ GCS
GCSService จะจัดการการอัปโหลดไฟล์จริงไปยัง Google Cloud Storage
👉💻 เปิดไฟล์ level_2/backend/services/gcs_service.py หรือจะพิมพ์ในเทอร์มินัลเพื่อเปิดไฟล์ใน Cloud Shell Editor ก็ได้
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 ใน def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: โค้ดต่อไปนี้จะอธิบายวิธีบันทึกเอนทิตีและความสัมพันธ์ที่แยกออกมาไปยัง Spanner Graph DB
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
การแยกสิ่งนี้ออกเป็นบริการทำให้ Agent ไม่จำเป็นต้องทราบเกี่ยวกับที่เก็บข้อมูล GCS, ชื่อ Blob หรือการสร้าง URL ที่ลงนาม โดยจะขอให้ "อัปโหลด" เท่านั้น
6. เหตุใดเวิร์กโฟลว์แบบ Agent จึงดีกว่าแนวทางแบบเดิม
ข้อได้เปรียบของ AI ในการดำเนินการได้เอง
ฟีเจอร์ | ไปป์ไลน์การประมวลผลแบบกลุ่ม | อิงตามเหตุการณ์ | เวิร์กโฟลว์ของ Agent |
ความซับซ้อน | ต่ำ (1 สคริปต์) | สูง (5 บริการขึ้นไป) | ต่ำ (ไฟล์ Python 1 ไฟล์: |
การจัดการสถานะ | ตัวแปรร่วม | ฮาร์ด (แยก) | รวม (สถานะของตัวแทน) |
การจัดการข้อผิดพลาด | ข้อขัดข้อง | บันทึกแบบเงียบ | โต้ตอบได้ ("ฉันอ่านไฟล์นั้นไม่ได้") |
ความคิดเห็นของผู้ใช้ | ภาพพิมพ์แคนวาส | ต้องทำการสำรวจ | ทันที (ส่วนหนึ่งของแชท) |
ความสามารถในการปรับตัว | ตรรกะคงที่ | ฟังก์ชันที่เข้มงวด | อัจฉริยะ (LLM ตัดสินใจขั้นตอนถัดไป) |
การรับรู้บริบท | ไม่มี | ไม่มี | สมบูรณ์ (ทราบความตั้งใจของผู้ใช้) |
เหตุผลที่เรื่องนี้สำคัญ: การใช้ multimedia_agent.py (SequentialAgent ที่มีเอเจนต์ย่อย 4 ตัว ได้แก่ อัปโหลด → แยก → บันทึก → สรุป) ช่วยให้เราไม่ต้องใช้โครงสร้างพื้นฐานที่ซับซ้อนและสคริปต์ที่เปราะบาง แต่หันมาใช้ตรรกะของแอปพลิเคชันแบบสนทนาอัจฉริยะแทน
10. ☕️ [ไม่บังคับ] ไปป์ไลน์มัลติโมดัล (อ่านอย่างเดียว) - เลเยอร์ Agent
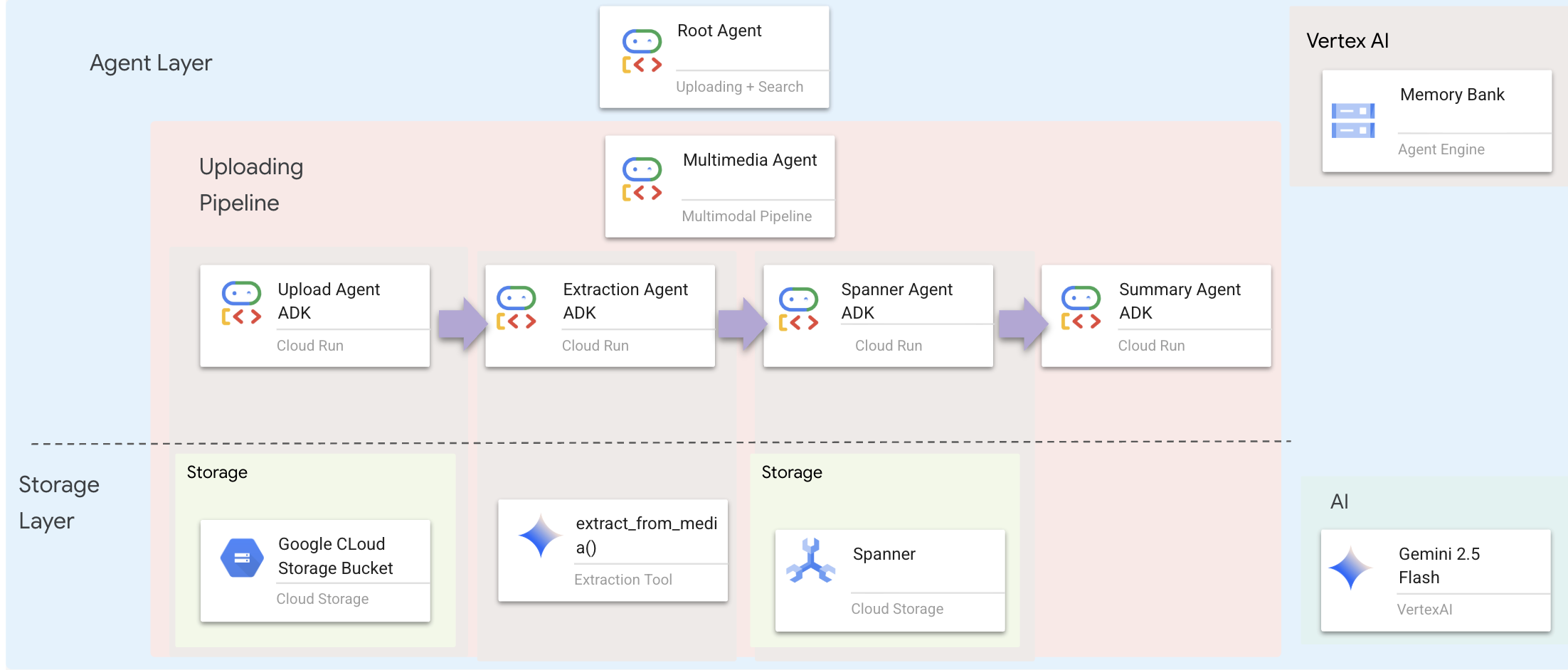
เลเยอร์เอเจนต์กำหนดความอัจฉริยะ ซึ่งก็คือเอเจนต์ที่ใช้เครื่องมือเพื่อทำงานให้สำเร็จ เอเจนต์แต่ละตัวมีบทบาทเฉพาะและส่งต่อบริบทไปยังเอเจนต์ตัวถัดไป ด้านล่างคือแผนภาพสถาปัตยกรรมสำหรับระบบหลายเอเจนต์
1. เปิดไฟล์ตัวแทน
👉💻 เปิดไฟล์ level_2/backend/agent/multimedia_agent.py หรือโดยการพิมพ์คำสั่งต่อไปนี้ในเทอร์มินัล เปิดเทอร์มินัลใหม่ ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. กำหนด Upload Agent
เอเจนต์นี้จะดึงเส้นทางไฟล์จากข้อความของผู้ใช้และอัปโหลดไปยัง GCS
👉ในไฟล์ multimedia_agent.py ที่มีโค้ดต่อไปนี้ จะสร้าง upload_agent ที่อัปโหลดไปยัง GCS
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. กำหนด Extraction Agent
Agent นี้จะ "เห็น" สื่อที่อัปโหลดและแยก Structured Data โดยใช้ Gemini Vision
👉ในไฟล์ multimedia_agent.py ที่มีโค้ดต่อไปนี้ จะสร้าง extraction_agent ที่ดึงข้อมูลจากสื่อที่อัปโหลด
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
โปรดสังเกตว่า instruction อ้างอิง {upload_result} อย่างไร ซึ่งเป็นวิธีที่ ส่งต่อสถานะระหว่างเอเจนต์ใน ADK
4. กำหนด Spanner Agent
Agent นี้จะบันทึกเอนทิตีและความสัมพันธ์ที่แยกออกมาลงในฐานข้อมูลกราฟ
👉ในไฟล์ multimedia_agent.py ที่มีโค้ดต่อไปนี้ จะสร้าง spanner_agent ที่บันทึกข้อมูลที่ดึงมาลงในฐานข้อมูล
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
เอเจนต์นี้จะได้รับบริบทจากขั้นตอนก่อนหน้าทั้ง 2 ขั้นตอน (upload_result และ extraction_result)
5. กำหนด Agent สรุป
Agent นี้จะสังเคราะห์ผลลัพธ์จากขั้นตอนก่อนหน้าทั้งหมดเป็นคำตอบที่ใช้งานง่าย
👉ในไฟล์ multimedia_agent.py ที่มีโค้ดต่อไปนี้ จะกำหนดพรอมต์สำหรับ summary_agent ที่สรุปผลลัพธ์
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
เอเจนต์นี้ไม่จำเป็นต้องใช้เครื่องมือ เพียงแค่อ่านบริบทที่แชร์และสร้างข้อมูลสรุปที่ชัดเจนสำหรับผู้ใช้
🧠 สรุปสถาปัตยกรรม
เลเยอร์ | ไฟล์ | ความรับผิดชอบ |
เครื่องมือ |
| วิธี — อัปโหลด แยกข้อมูล บันทึก |
Agent |
| อะไร - จัดการไปป์ไลน์ |
11. 🚀 ไปป์ไลน์ข้อมูลหลายรูปแบบ - การจัดระเบียบ
หัวใจสำคัญของระบบใหม่คือ MultimediaExtractionPipeline ที่กำหนดไว้ใน backend/agent/multimedia_agent.py โดยใช้รูปแบบ Sequential Agent จาก ADK (Agent Development Kit)
1. เหตุผลที่ต้องใช้แบบตามลำดับ
การประมวลผลการอัปโหลดเป็นห่วงโซ่การขึ้นต่อกันเชิงเส้น ดังนี้
- คุณจะแยกข้อมูลไม่ได้จนกว่าจะมีไฟล์ (อัปโหลด)
- คุณจะบันทึกข้อมูลไม่ได้จนกว่าจะดึงข้อมูลออกมา (การดึงข้อมูล)
- คุณจะสรุปไม่ได้จนกว่าจะมีผลลัพธ์ (บันทึก)
SequentialAgent เหมาะสำหรับงานนี้ โดยจะส่งเอาต์พุตของ Agent หนึ่งเป็นบริบท/อินพุตไปยัง Agent ถัดไป
2. คำจำกัดความของ Agent
มาดูวิธีประกอบไปป์ไลน์ที่ด้านล่างของ multimedia_agent.py กัน 👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
โดยจะรับอินพุตจากขั้นตอนก่อนหน้าทั้ง 2 ขั้นตอน ค้นหาความคิดเห็น # TODO: REPLACE_ORCHESTRATION แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. ติดต่อตัวแทนรูท
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
ค้นหาความคิดเห็น # TODO: REPLACE_ADD_SUBAGENT แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
sub_agents=[multimedia_agent],
ออบเจ็กต์เดียวนี้จะรวม "ผู้เชี่ยวชาญ" 4 คนไว้ในเอนทิตีที่เรียกใช้ได้
4. โฟลว์ข้อมูลระหว่างเอเจนต์
เอเจนต์แต่ละตัวจะจัดเก็บเอาต์พุตไว้ในบริบทที่แชร์ซึ่งเอเจนต์ตัวต่อๆ ไปจะเข้าถึงได้
5. เปิดแอปพลิเคชัน (ข้ามหากแอปยังทํางานอยู่)
👉💻 เริ่มแอป:
cd ~/way-back-home/level_2/
./start_app.sh
👉 คลิก Local: http://localhost:5173/ จากเทอร์มินัล
6. ทดสอบการอัปโหลดรูปภาพ
👉 ในอินเทอร์เฟซแชท ให้เลือกรูปภาพที่ต้องการจากที่นี่แล้วอัปโหลดไปยัง UI
ในอินเทอร์เฟซแชท ให้บอกตัวแทนเกี่ยวกับบริบทที่เฉพาะเจาะจงของคุณ
Here is the survivor note
จากนั้นแนบรูปภาพที่นี่

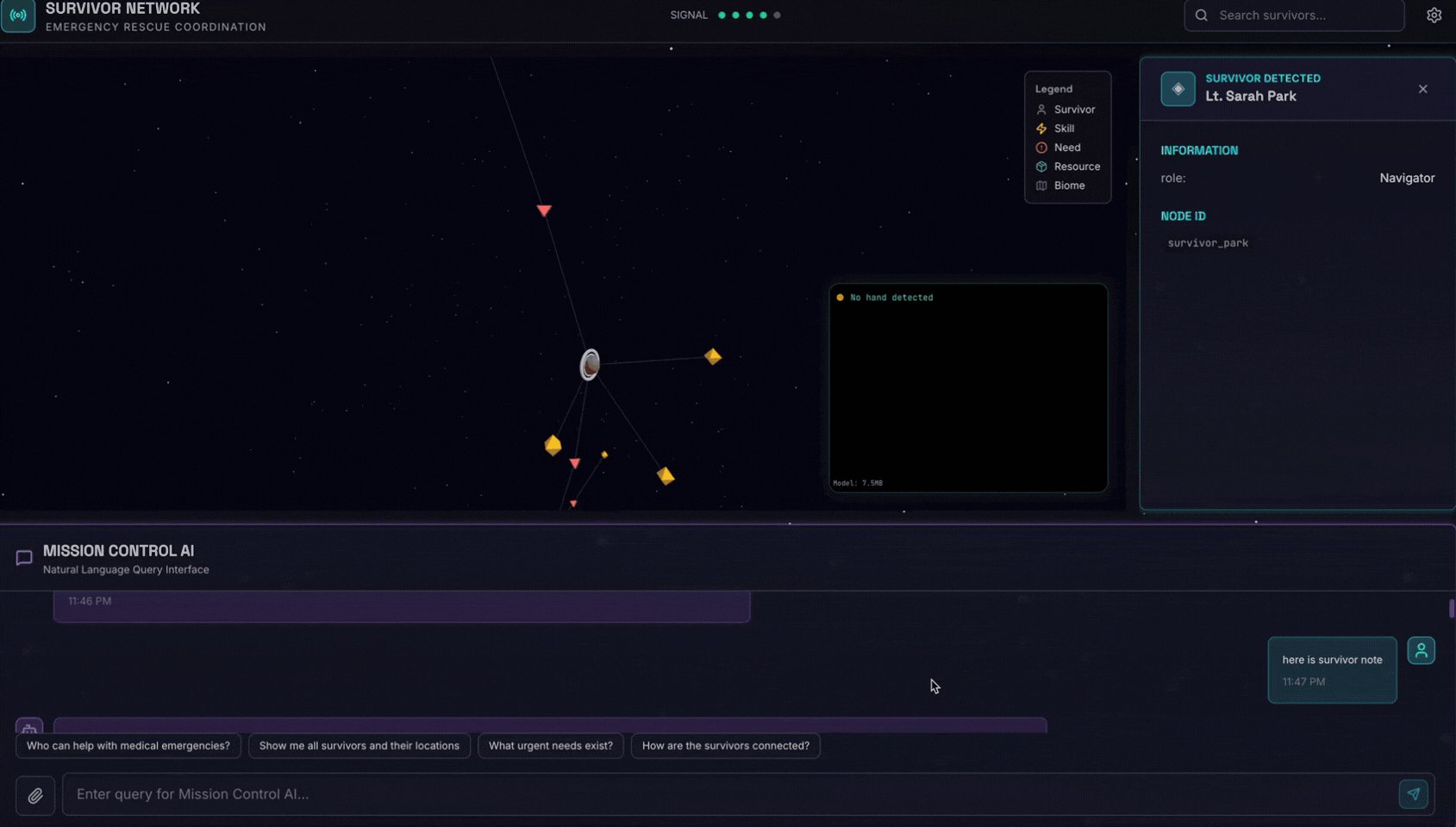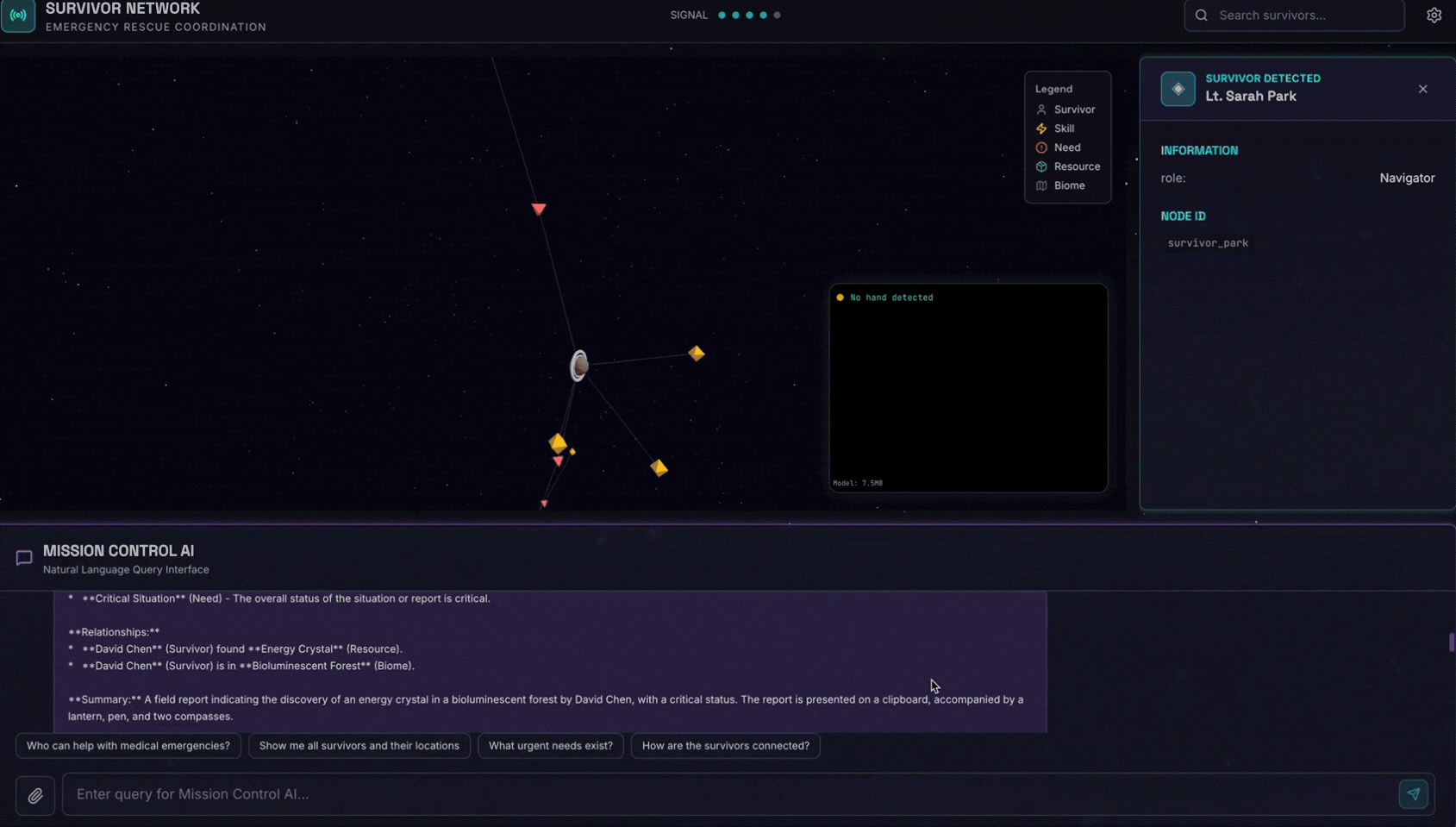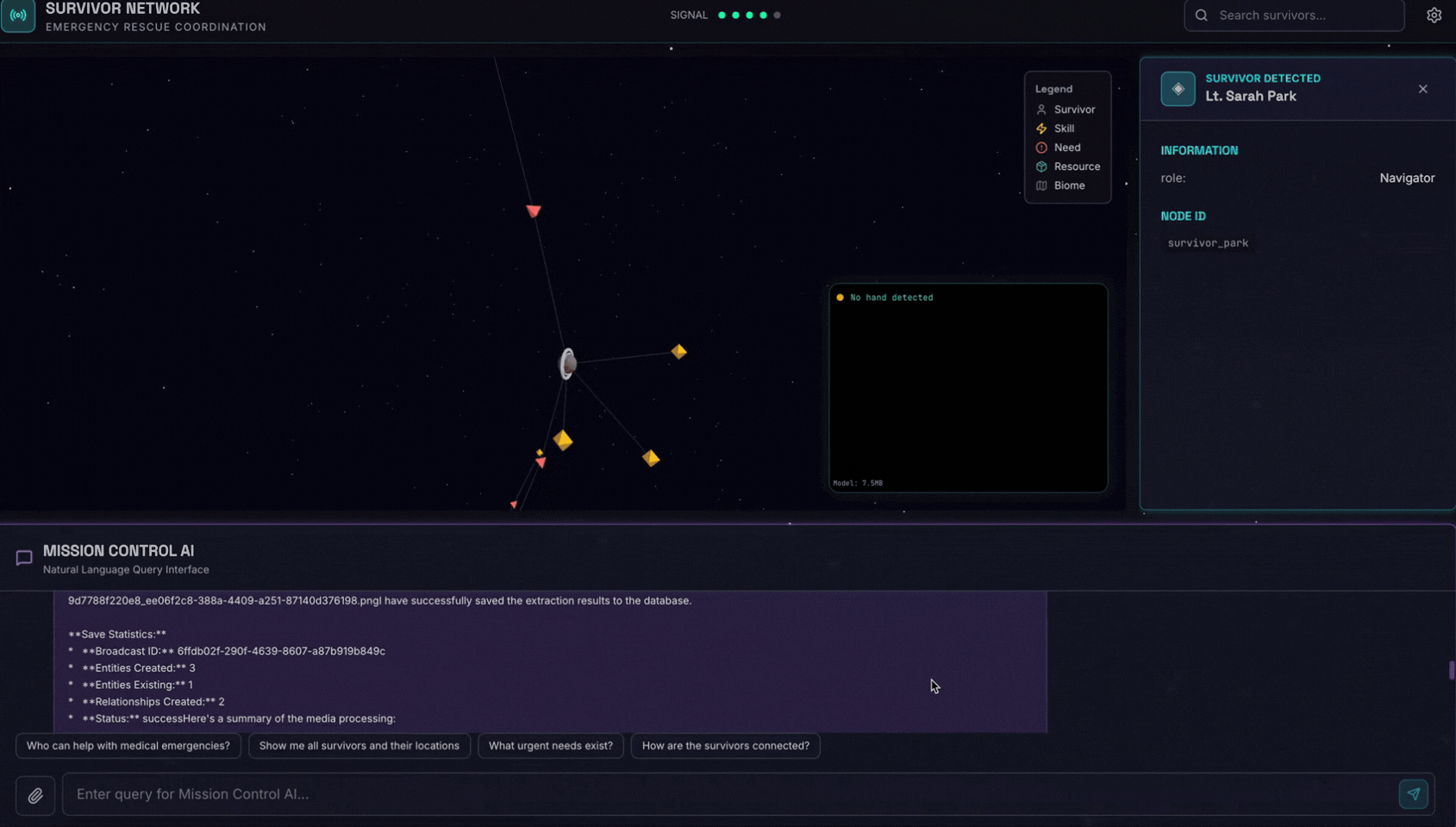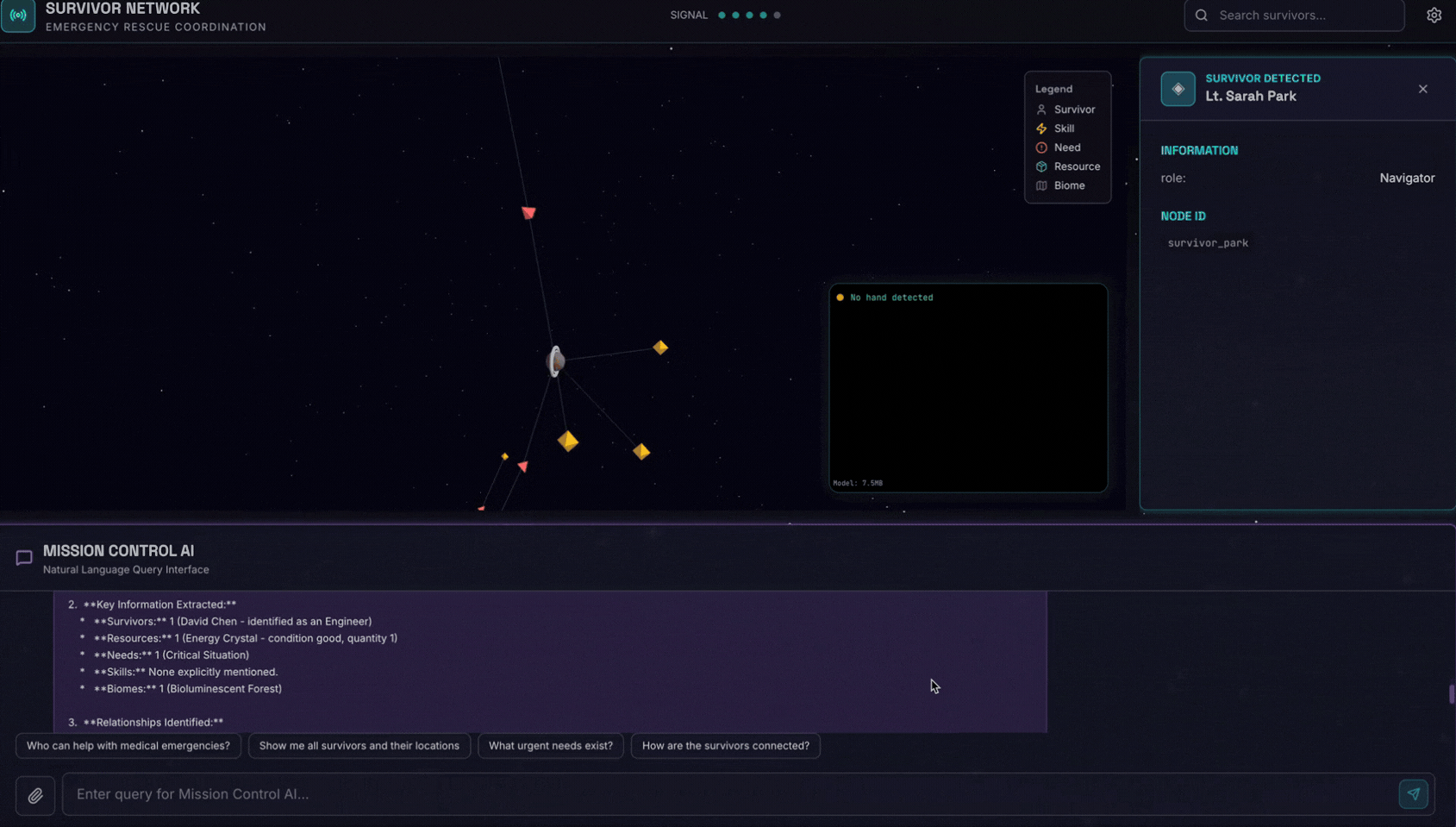
👉💻 ในเทอร์มินัล เมื่อทดสอบเสร็จแล้ว ให้กด "Ctrl+C" เพื่อสิ้นสุดกระบวนการ
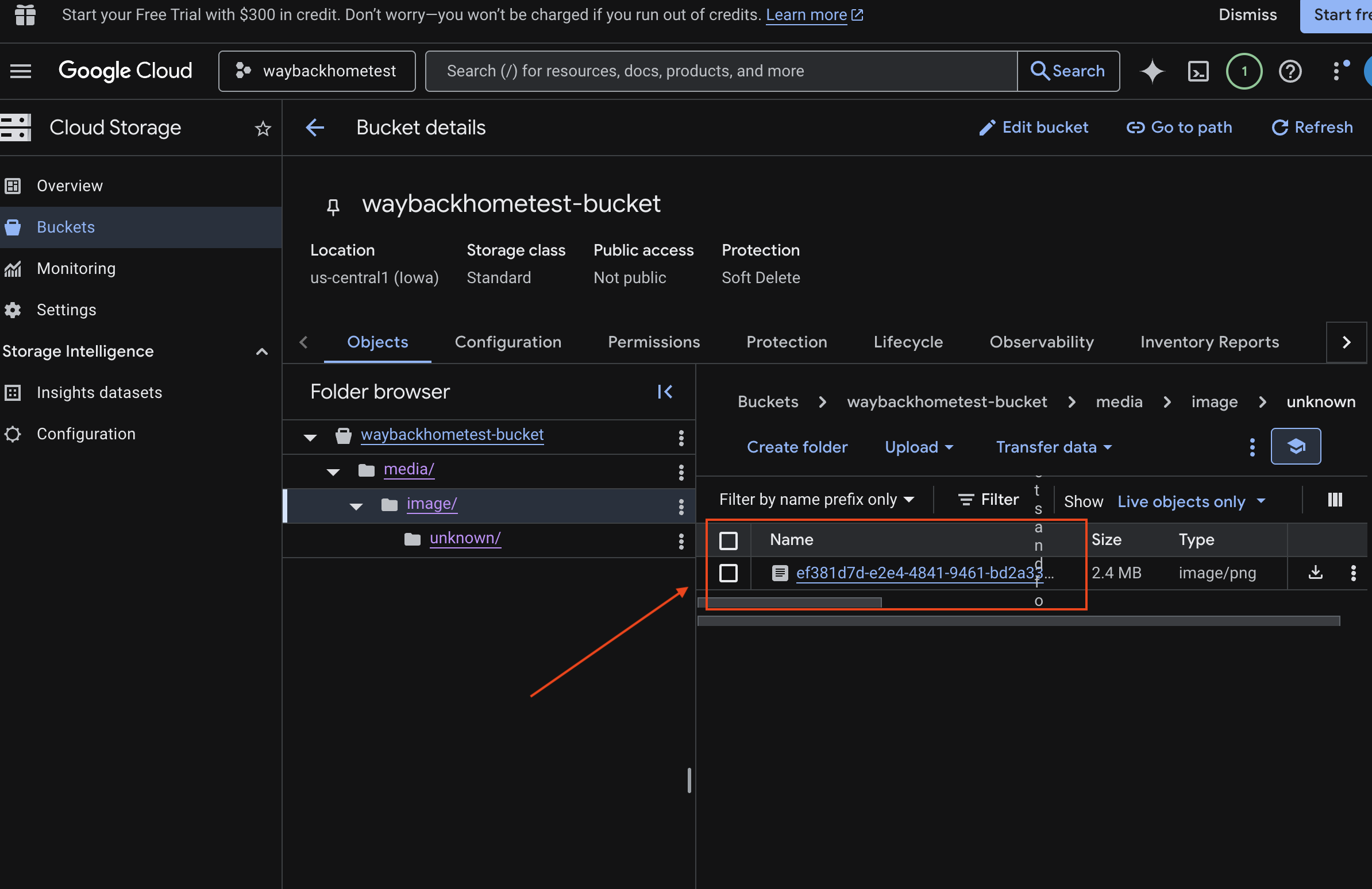
6. ยืนยันการอัปโหลดมัลติโมดัลใน Bucket ของ GCS
- เปิด Google Cloud Console Storage
- เลือก "Bucket" ใน Cloud Storage
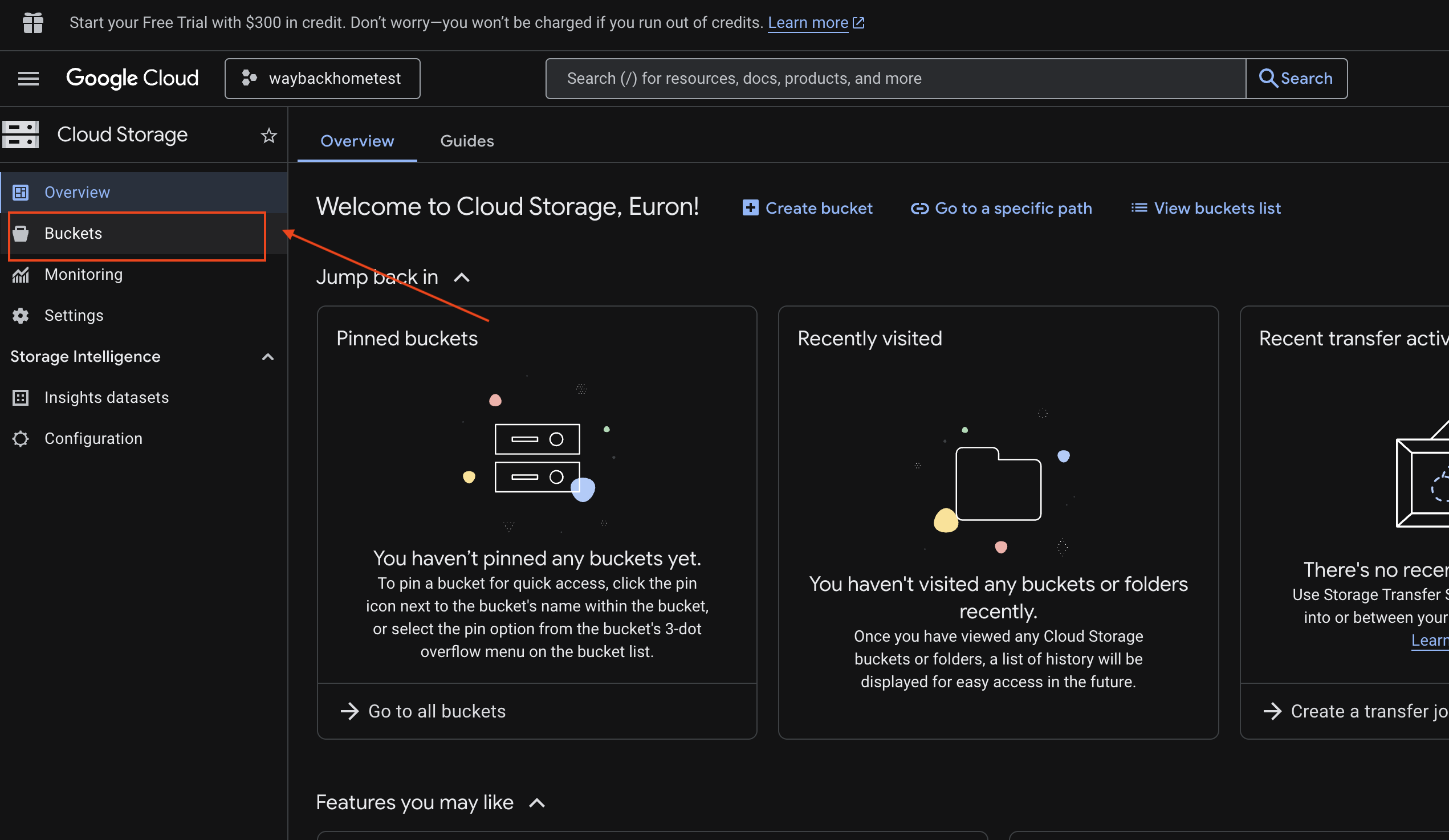
- เลือกที่เก็บข้อมูลแล้วคลิก
media
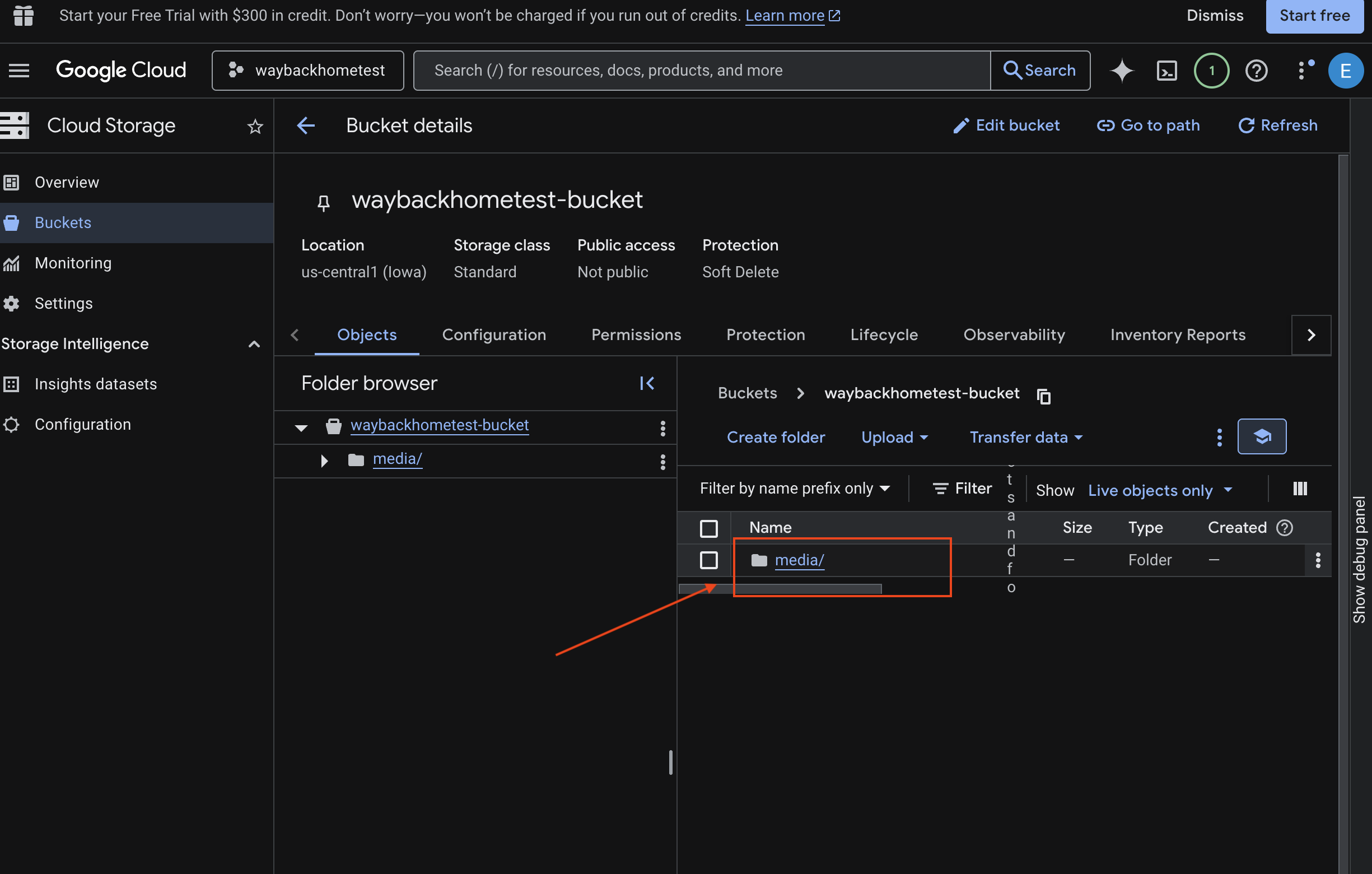
- ดูรูปภาพที่คุณอัปโหลดได้ที่นี่
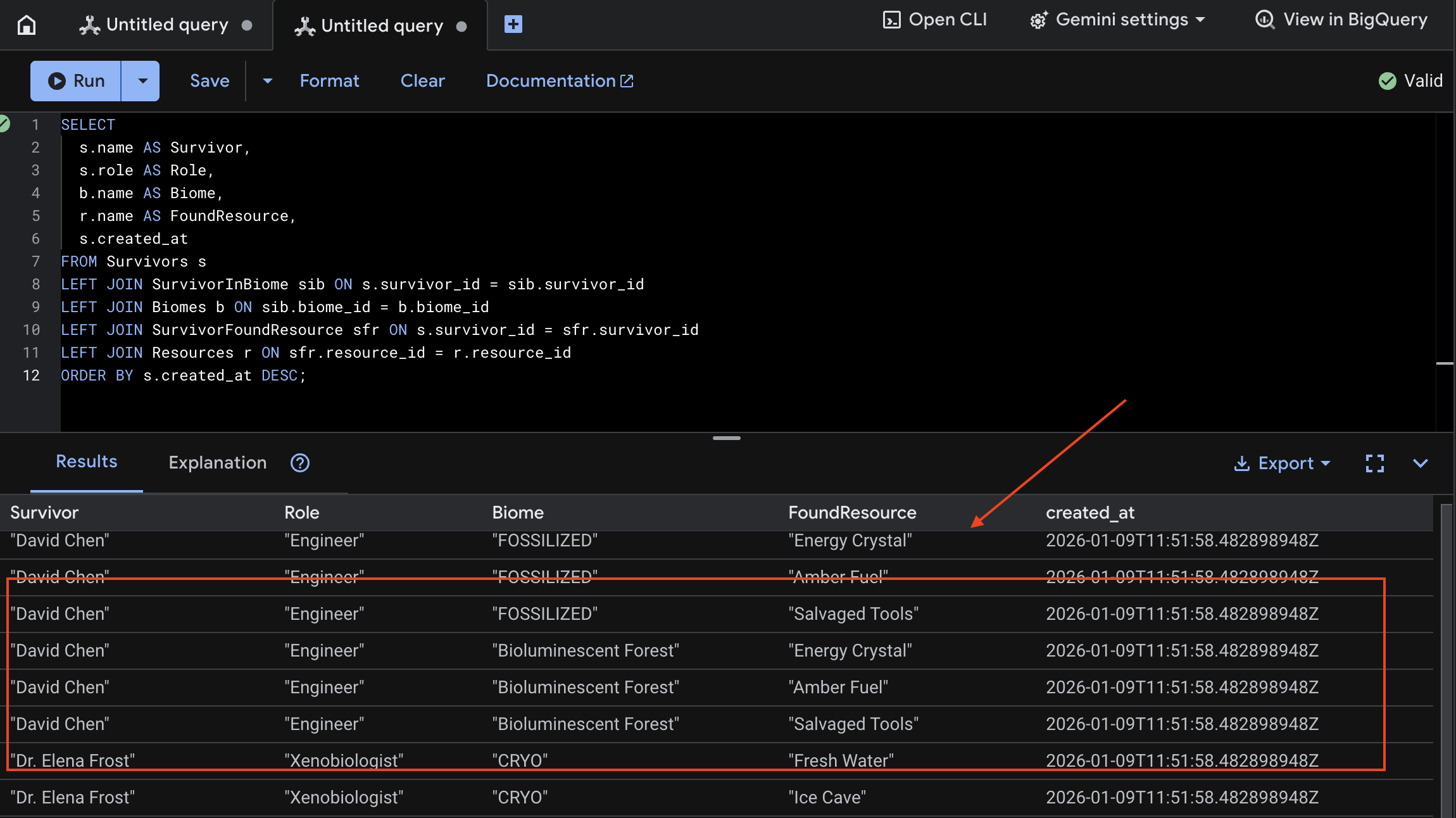
7. ยืนยันการอัปโหลดมัลติโมดัลใน Spanner (ไม่บังคับ)
ด้านล่างนี้คือตัวอย่างเอาต์พุตใน UI สำหรับ test_photo1
- เปิด คอนโซล Google Cloud Spanner
- เลือกอินสแตนซ์
Survivor Network - เลือกฐานข้อมูล:
graph-db - คลิก Spanner Studio ในแถบด้านข้างทางซ้าย
👉 ใน Spanner Studio ให้ค้นหาข้อมูลใหม่โดยใช้คำสั่งต่อไปนี้
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
เราสามารถยืนยันได้โดยดูผลลัพธ์ด้านล่าง
12. ☕️ [ไม่บังคับ] ธนาคารความทรงจำที่มี Agent Engine
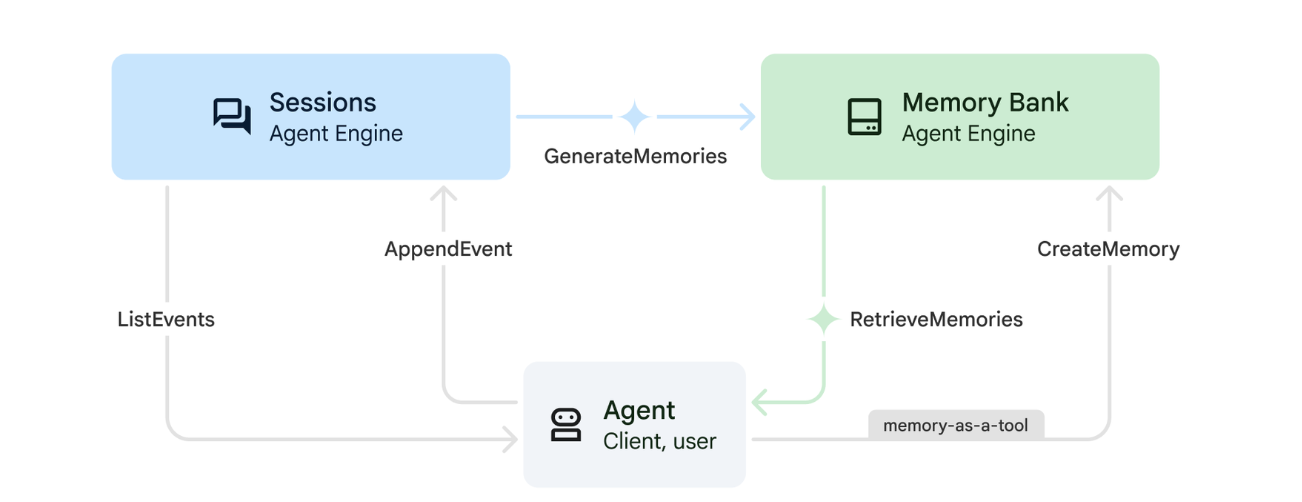
1. วิธีการทำงานของฟีเจอร์ความทรงจำ
ระบบใช้แนวทางหน่วยความจำคู่เพื่อจัดการทั้งบริบทในทันทีและการเรียนรู้ระยะยาว
2. หัวข้อความทรงจำคืออะไร
หัวข้อความทรงจำจะกำหนดหมวดหมู่ของข้อมูลที่เอเจนต์ควรจดจำในการสนทนา ให้คิดว่าคุกกี้เป็นตู้เก็บเอกสารสำหรับค่ากำหนดของผู้ใช้ประเภทต่างๆ
หัวข้อ 2 หัวข้อของเรา
search_preferences: วิธีที่ผู้ใช้ต้องการค้นหา- ลูกค้าชอบการค้นหาด้วยคีย์เวิร์ดหรือการค้นหาเชิงความหมาย
- ผู้เล่นมักค้นหาทักษะ/ชีวนิเวศใด
- ตัวอย่างหน่วยความจำ: "ผู้ใช้ชอบการค้นหาเชิงความหมายสำหรับทักษะทางการแพทย์"
urgent_needs_context: วิกฤตที่ติดตาม- โดยจะตรวจสอบทรัพยากรใด
- ผู้รอดชีวิตกลุ่มใดที่ผู้ใช้กังวล
- ตัวอย่างหน่วยความจำ: "ผู้ใช้กำลังติดตามการขาดแคลนยาในค่ายทางเหนือ"
3. การตั้งค่าหัวข้อความทรงจำ
หัวข้อความจำที่กำหนดเองจะกำหนดสิ่งที่เอเจนต์ควรจดจำ การตั้งค่าเหล่านี้จะได้รับการกำหนดค่าเมื่อติดตั้งใช้งาน Agent Engine
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
ซึ่งจะเปิด ~/way-back-home/level_2/backend/deploy_agent.py ในเครื่องมือแก้ไข
เรากำหนดออบเจ็กต์โครงสร้าง MemoryTopic เพื่อเป็นแนวทางให้ LLM ทราบว่าจะดึงและบันทึกข้อมูลใด
👉ในไฟล์ deploy_agent.py ให้แทนที่ # TODO: SET_UP_TOPIC ด้วยค่าต่อไปนี้
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. การผสานรวมเอเจนต์
รหัสเอเจนต์ต้องรู้จัก Memory Bank เพื่อบันทึกและดึงข้อมูล
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
ซึ่งจะเปิด ~/way-back-home/level_2/backend/agent/agent.py ในเครื่องมือแก้ไข
การสร้าง Agent
เมื่อสร้างเอเจนต์ เราจะส่ง after_agent_callback เพื่อให้มั่นใจว่าระบบจะบันทึกเซสชันไว้ในหน่วยความจำหลังจากการโต้ตอบ add_session_to_memory ฟังก์ชันจะทำงานแบบไม่พร้อมกันเพื่อไม่ให้การตอบกลับของแชทช้าลง
👉ในไฟล์ agent.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_ADD_SESSION_MEMORY แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
การบันทึกในเบื้องหลัง
👉ในไฟล์ agent.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_ADD_MEMORY_BANK_TOOL แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉ในไฟล์ agent.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_ADD_CALLBACK แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
ตั้งค่าบริการเซสชัน Vertex AI
👉💻 ในเทอร์มินัล ให้เปิดไฟล์ chat.py ใน Cloud Shell Editor โดยเรียกใช้คำสั่งต่อไปนี้
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉ในไฟล์ chat.py ให้ค้นหาความคิดเห็น # TODO: REPLACE_VERTEXAI_SERVICES, แทนที่ทั้งบรรทัดนี้ด้วยโค้ดต่อไปนี้
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [ไม่บังคับ] แนบ Agent กับ Agent Engine
1. การตั้งค่าและการติดตั้งใช้งาน
ก่อนทดสอบฟีเจอร์หน่วยความจำ คุณต้องติดตั้งใช้งาน Agent ด้วยหัวข้อหน่วยความจำใหม่และตรวจสอบว่าได้กำหนดค่าสภาพแวดล้อมอย่างถูกต้องแล้ว
เราได้จัดเตรียมสคริปต์อำนวยความสะดวกเพื่อจัดการกระบวนการนี้
การเรียกใช้สคริปต์การติดตั้งใช้งาน
👉💻 เรียกใช้สคริปต์การติดตั้งใช้งานในเทอร์มินัล
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
สคริปต์นี้จะดำเนินการต่อไปนี้
- เรียกใช้
backend/deploy_agent.pyเพื่อลงทะเบียนหัวข้อของ Agent และหน่วยความจำกับ Vertex AI - บันทึกรหัส Agent Engine ใหม่
- อัปเดตไฟล์
.envด้วยAGENT_ENGINE_IDโดยอัตโนมัติ - ตรวจสอบว่าได้ตั้งค่า
USE_MEMORY_BANK=TRUEในไฟล์.env
[!IMPORTANT] หากทำการเปลี่ยนแปลงใน custom_topics ใน deploy_agent.py คุณต้องเรียกใช้สคริปต์นี้อีกครั้งเพื่ออัปเดต Agent Engine
ยืนยัน Memory Bank
ตอนนี้คุณสามารถยืนยันได้ว่าธนาคารความจำทำงานได้โดยการสอนตัวแทนให้รู้จักค่ากำหนดและตรวจสอบว่าค่ากำหนดนั้นยังคงอยู่ตลอดเซสชันหรือไม่
ขั้นตอนที่ 1 เปิดแอปพลิเคชัน
เปิดแอปพลิเคชันอีกครั้งโดยทำตามวิธีการด้านล่าง หากเทอร์มินัลก่อนหน้ายังทำงานอยู่ ให้สิ้นสุดโดยกด Ctrls+C
👉💻 เริ่มแอป:
cd ~/way-back-home/level_2/
./start_app.sh
👉 คลิก Local: http://localhost:5173/ จากเทอร์มินัล
ขั้นตอนที่ 2 การทดสอบ Memory Bank ด้วยข้อความ
ในอินเทอร์เฟซแชท ให้บอกตัวแทนเกี่ยวกับบริบทที่เฉพาะเจาะจงของคุณ
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 รอประมาณ 30 วินาทีเพื่อให้ฟีเจอร์ความทรงจำประมวลผลในเบื้องหลัง
ขั้นตอนที่ 3 เริ่มเซสชันใหม่
รีเฟรชหน้าเพื่อล้างประวัติการสนทนาปัจจุบัน (ความจำระยะสั้น)
ถามคำถามที่อิงตามบริบทที่คุณระบุไว้ก่อนหน้านี้
"What kind of missions am I interested in?"
การตอบกลับที่คาดหวัง:
"จากการสนทนาก่อนหน้าของคุณ เราทราบว่าคุณสนใจเรื่องต่อไปนี้
- ภารกิจกู้ภัยทางการแพทย์
- การปฏิบัติการบนภูเขา/ที่สูง
- ทักษะที่จำเป็น: การปฐมพยาบาล การปีนเขา
คุณต้องการให้ฉันค้นหาผู้รอดชีวิตที่มีคุณสมบัติตรงตามเกณฑ์เหล่านี้ไหม"
ขั้นตอนที่ 4 ทดสอบด้วยการอัปโหลดรูปภาพ
อัปโหลดรูปภาพ แล้วถามว่า
remember this
คุณเลือกรูปภาพใดก็ได้ที่นี่หรือรูปภาพของคุณเอง แล้วอัปโหลดไปยัง UI
ขั้นตอนที่ 5 ยืนยันใน Vertex AI Agent Engine
ไปที่ Google Cloud Console Agent Engine
- ตรวจสอบว่าคุณเลือกโปรเจ็กต์จากเครื่องมือเลือกโปรเจ็กต์ด้านซ้ายบน
- ยืนยันเครื่องมือตัวแทนที่คุณเพิ่งติดตั้งใช้งานจากคำสั่งก่อนหน้า
use_memory_bank.sh: คลิกเครื่องมือตัวแทนที่คุณเพิ่งสร้าง
คลิกเครื่องมือตัวแทนที่คุณเพิ่งสร้าง - คลิกแท็บ
Memoriesในเอเจนต์ที่ติดตั้งใช้งานนี้ คุณจะดูความทรงจำทั้งหมดได้ที่นี่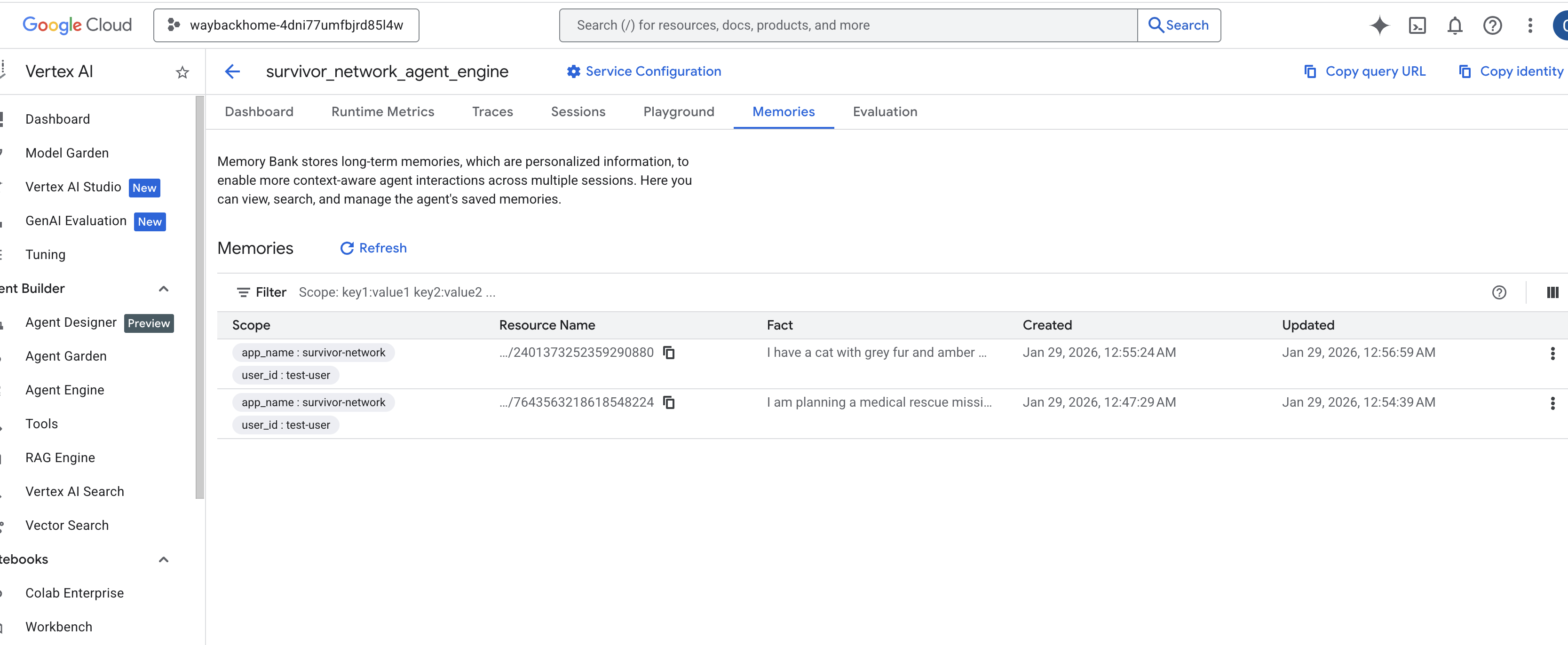
👉💻 เมื่อทดสอบเสร็จแล้ว ให้คลิก "Ctrl + C" ในเทอร์มินัลเพื่อสิ้นสุดกระบวนการ
🎉 ยินดีด้วย คุณเพิ่งเชื่อมต่อธนาคารความทรงจำกับเอเจนต์
14. ☕️ [ไม่บังคับ] ทำให้ใช้งานได้กับ Cloud Run
1. เรียกใช้สคริปต์การติดตั้งใช้งาน
👉💻 เรียกใช้สคริปต์การติดตั้งใช้งาน
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
หลังจากติดตั้งใช้งานสำเร็จแล้ว คุณจะได้รับ URL ซึ่งเป็น URL ที่ติดตั้งใช้งานสำหรับคุณ 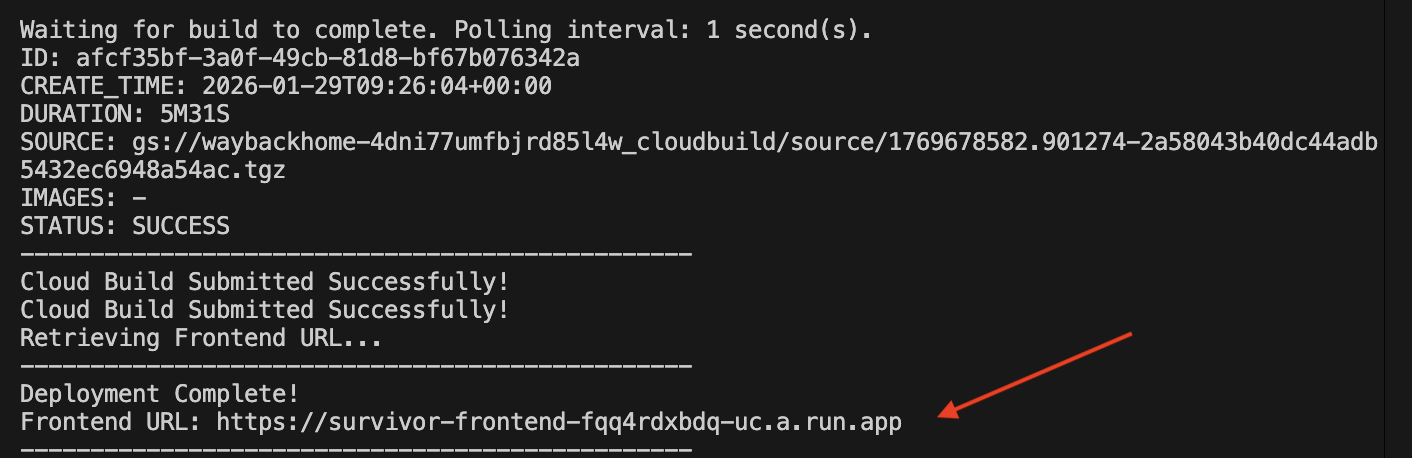
👉💻 ก่อนคัดลอก URL ให้ให้สิทธิ์โดยเรียกใช้คำสั่งต่อไปนี้
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
ไปที่ URL ที่ทำให้ใช้งานได้แล้ว แล้วคุณจะเห็นแอปพลิเคชันของคุณทำงานอยู่ที่นั่น
2. ทำความเข้าใจไปป์ไลน์การสร้าง
cloudbuild.yaml ไฟล์จะกำหนดขั้นตอนตามลำดับต่อไปนี้
- การสร้างแบ็กเอนด์: สร้างอิมเมจ Docker จาก
backend/Dockerfile - การติดตั้งใช้งานแบ็กเอนด์: ติดตั้งใช้งานคอนเทนเนอร์แบ็กเอนด์ใน Cloud Run
- จับภาพ URL: รับ URL ของแบ็กเอนด์ใหม่
- บิลด์ส่วนหน้า:
- ติดตั้งการอ้างอิง
- สร้างแอป React โดยแทรก
VITE_API_URL=
- รูปภาพส่วนหน้า: สร้างอิมเมจ Docker จาก
frontend/Dockerfile(การสร้างแพ็กเกจชิ้นงานแบบคงที่) - การทำให้ฟรอนท์เอนด์ใช้งานได้: ทำให้คอนเทนเนอร์ฟรอนท์เอนด์ใช้งานได้
3. ยืนยันการติดตั้งใช้งาน
เมื่อบิลด์เสร็จสมบูรณ์ (ดูลิงก์บันทึกที่สคริปต์ระบุ) คุณจะยืนยันได้ดังนี้
- ไปที่ Cloud Run Console
- ค้นหา
survivor-frontend - คลิก URL เพื่อเปิดแอปพลิเคชัน
- ทำการค้นหาเพื่อให้แน่ใจว่าส่วนหน้าสามารถสื่อสารกับส่วนหลังได้
(ไม่บังคับ) 4. การติดตั้งใช้งานด้วยตนเอง
หากต้องการเรียกใช้คำสั่งด้วยตนเองหรือทำความเข้าใจกระบวนการให้ดียิ่งขึ้น โปรดดูวิธีใช้ cloudbuild.yaml โดยตรง
การเขียน cloudbuild.yaml
ไฟล์ cloudbuild.yaml จะบอก Google Cloud Build ว่าต้องดำเนินการขั้นตอนใด
- ขั้นตอน: รายการการดำเนินการตามลำดับ แต่ละขั้นตอนจะทำงานในคอนเทนเนอร์ (เช่น
docker,gcloud,node,bash) - การแทนที่: ตัวแปรที่ส่งได้ในเวลาบิลด์ (เช่น
$_REGION) - Workspace: ไดเรกทอรีที่แชร์ซึ่งขั้นตอนต่างๆ สามารถแชร์ไฟล์ได้ (เช่น วิธีที่เราแชร์
backend_url.txt)
การเรียกใช้การทำให้ใช้งานได้
หากต้องการติดตั้งใช้งานด้วยตนเองโดยไม่ใช้สคริปต์ ให้ใช้คำสั่ง gcloud builds submit คุณต้องส่งตัวแปรแทนที่จำเป็น
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. บทสรุป
1. สิ่งที่คุณสร้าง
✅ ฐานข้อมูลกราฟ: Spanner ที่มีโหนด (ผู้รอดชีวิต ทักษะ) และขอบ (ความสัมพันธ์)
✅ AI Search: การค้นหาคีย์เวิร์ด การค้นหาเชิงความหมาย และการค้นหาแบบไฮบริดด้วยการฝัง
✅ ไปป์ไลน์แบบมัลติโมดัล: แยกเอนทิตีจากรูปภาพ/วิดีโอด้วย Gemini
✅ ระบบแบบหลายเอเจนต์: เวิร์กโฟลว์ที่ประสานงานด้วย ADK
✅ ธนาคารความจำ: การปรับเปลี่ยนในแบบของคุณระยะยาวด้วย Vertex AI
✅ การติดตั้งใช้งานจริง: Cloud Run + Agent Engine
2. สรุปสถาปัตยกรรม
3. ข้อมูลสำคัญ
- Graph RAG: รวมโครงสร้างฐานข้อมูลกราฟเข้ากับการฝังเชิงความหมายเพื่อการค้นหาอัจฉริยะ
- รูปแบบหลาย Agent: ไปป์ไลน์แบบลำดับสำหรับเวิร์กโฟลว์ที่ซับซ้อนและมีหลายขั้นตอน
- AI แบบมัลติโมดอล: แยก Structured Data จากสื่อที่ไม่มีโครงสร้าง (รูปภาพ/วิดีโอ)
- Agent แบบมีสถานะ: Memory Bank ช่วยให้ปรับเปลี่ยนในแบบของคุณได้ในทุกเซสชัน
4. เนื้อหาเวิร์กช็อป
- Level0: ยืนยันตัวตน
- Level1: ระบุตำแหน่งที่แน่นอน
- Level2 This One: สร้าง AI Agent แบบมัลติโมดัลด้วย Graph RAG, ADK และ Memory Bank
- Level3: การสร้างเอเจนต์การสตรีมแบบ 2 ทางของ ADK
- Level4: ระบบแบบหลายเอเจนต์แบบสองทิศทางแบบเรียลไทม์
- Level5: สถาปัตยกรรมที่ขับเคลื่อนด้วยเหตุการณ์ด้วย Google ADK, A2A และ Kafka