
1. Giriş

1. Hedef
Afet müdahale senaryolarında, birden fazla konumdaki farklı becerilere, kaynaklara ve ihtiyaçlara sahip hayatta kalanları koordine etmek için akıllı veri yönetimi ve arama özellikleri gerekir. Bu atölye çalışmasında, aşağıdakileri birleştiren bir üretim yapay zeka sistemi oluşturmayı öğreneceksiniz:
- 🗄️ Grafik Veritabanı (Spanner): Hayatta kalanlar, beceriler ve kaynaklar arasındaki karmaşık ilişkileri depolama
- 🔍 Yapay Zeka Destekli Arama: Yerleştirmeleri kullanarak semantik ve anahtar kelime karma arama
- 📸 Çok Formatlı İşleme: Görüntülerden, metinlerden ve videolardan yapılandırılmış veriler ayıklama
- 🤖 Çoklu Ajan Düzenleme: Karmaşık iş akışları için uzmanlaşmış aracıları koordine edin
- 🧠 Uzun Süreli Bellek: Vertex AI Memory Bank ile Kişiselleştirme
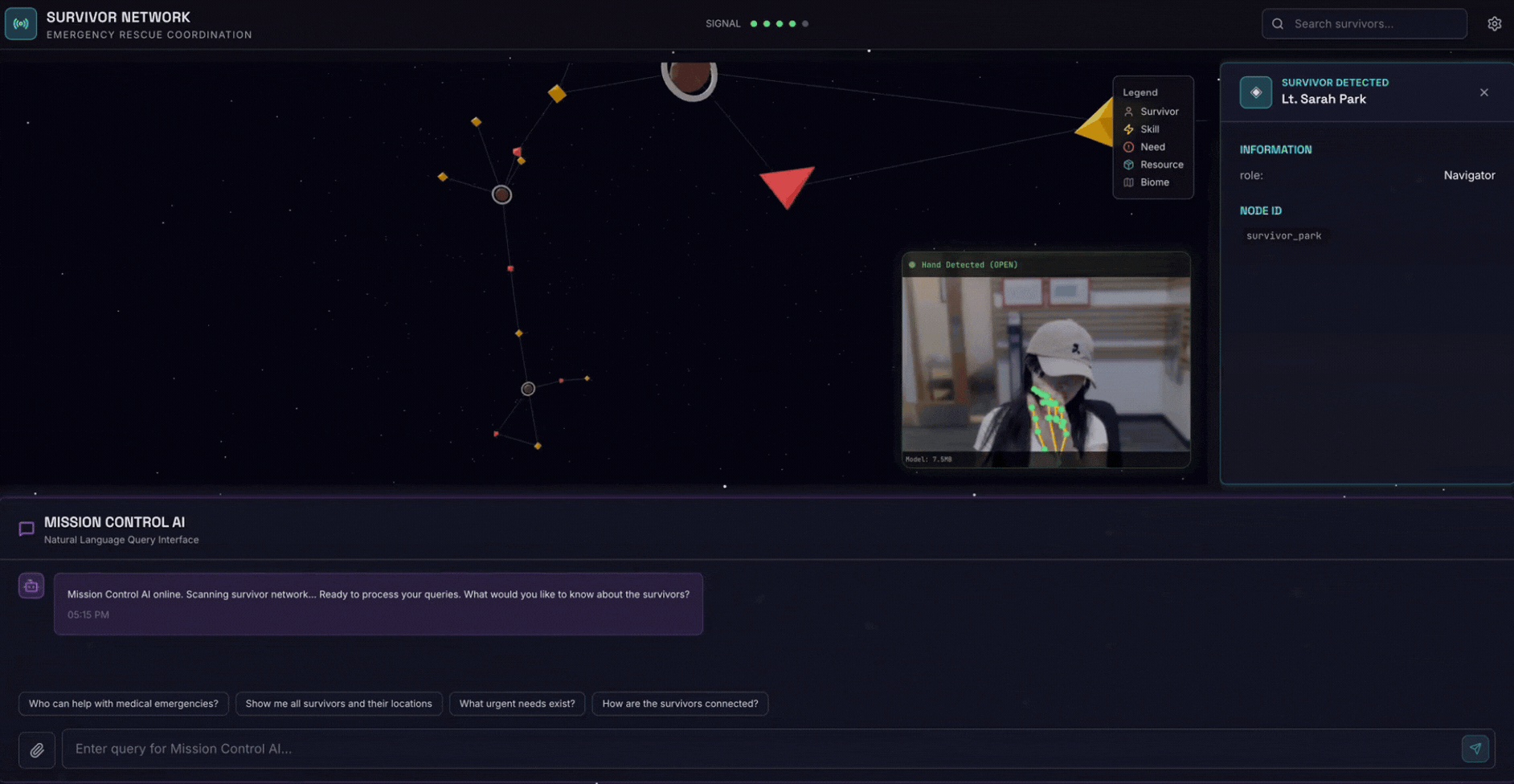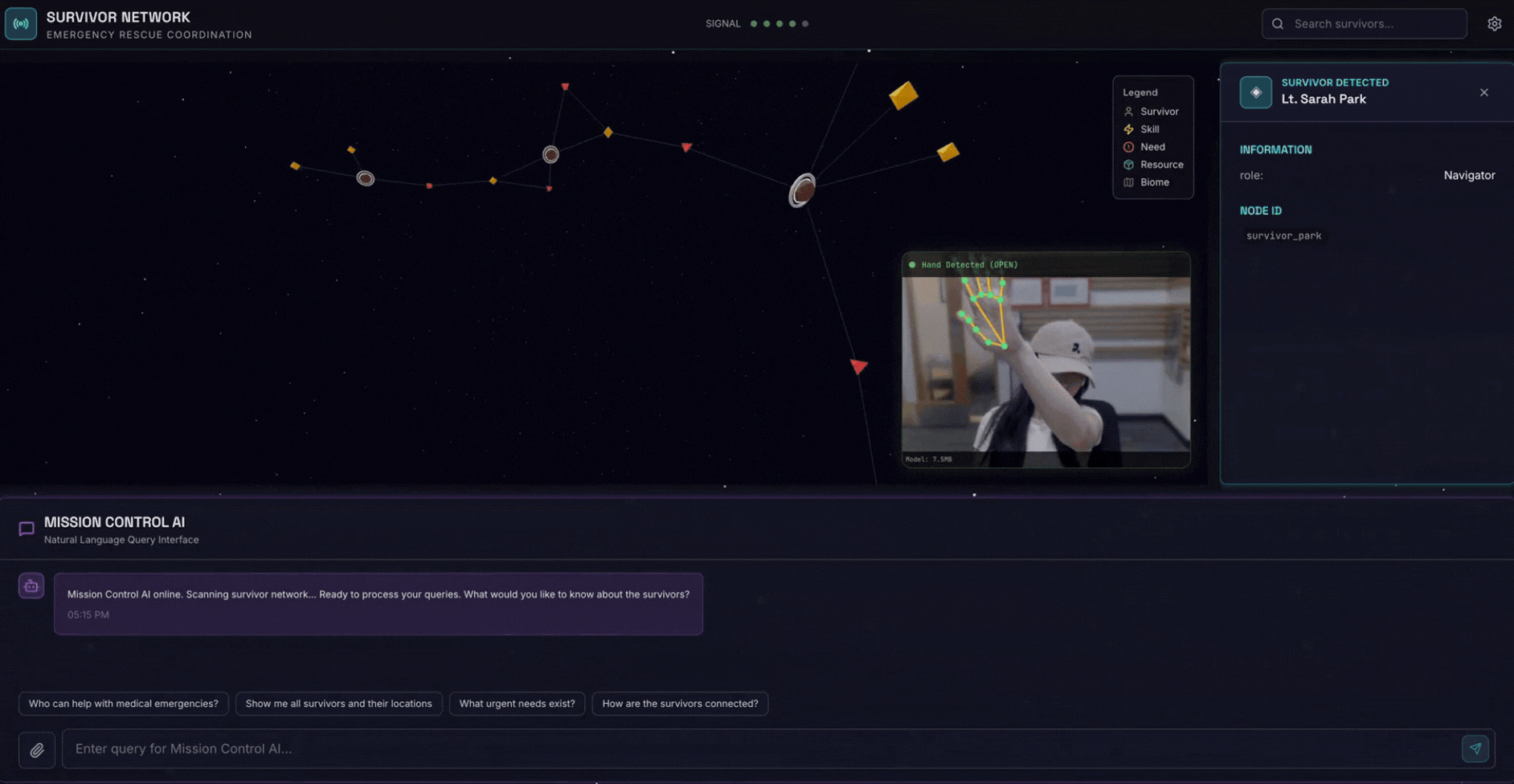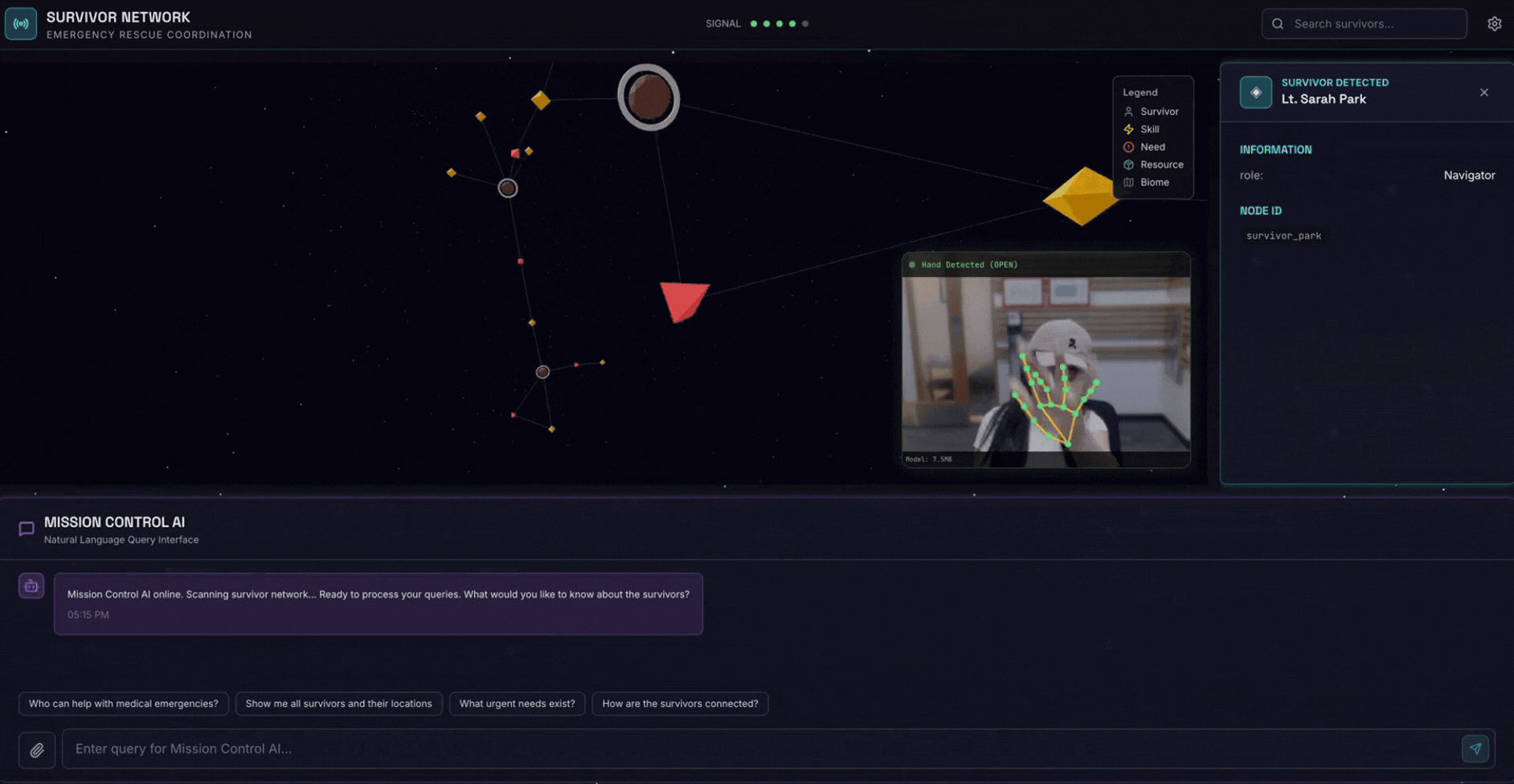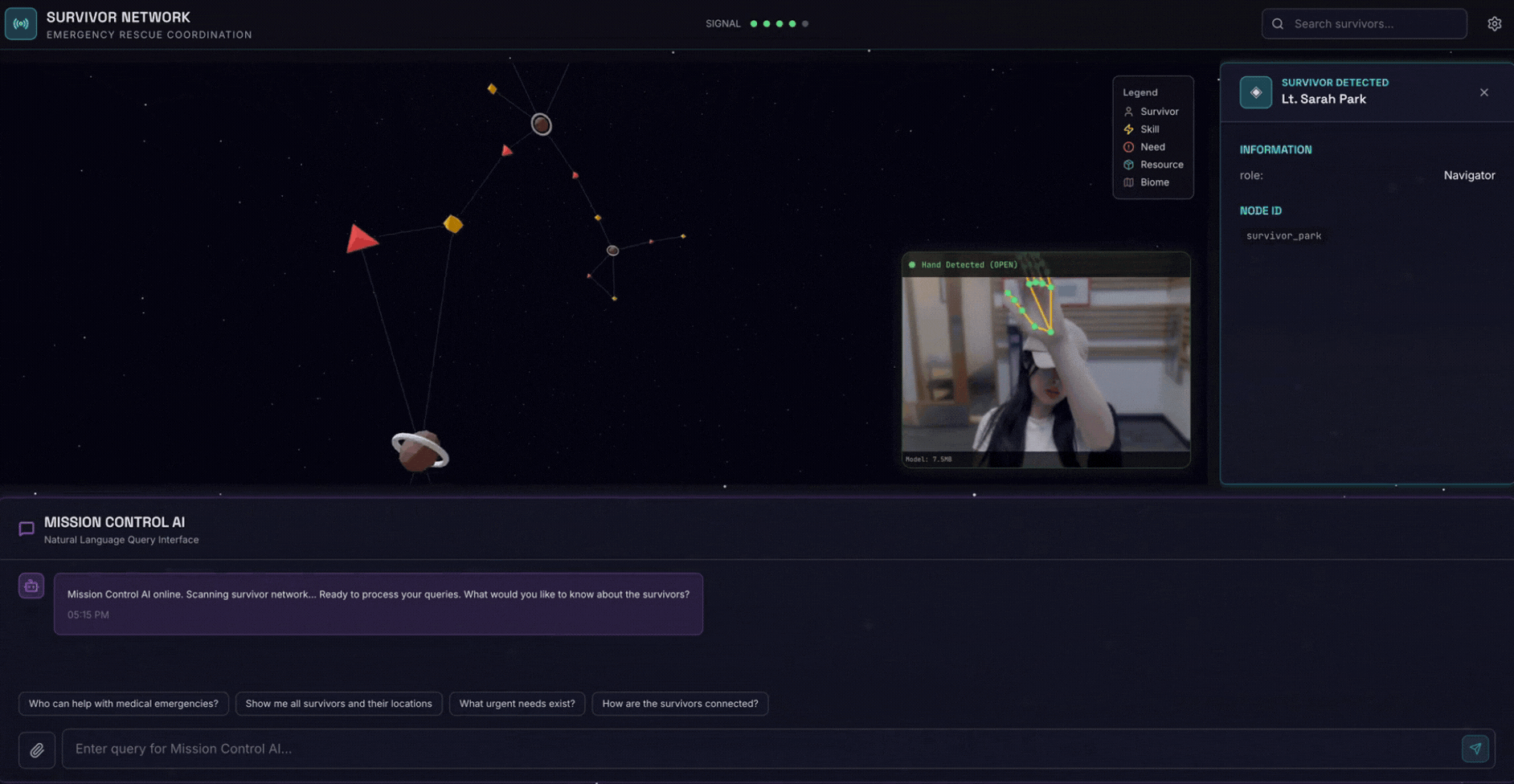
2. Ne Oluşturacaksınız?
Aşağıdakileri içeren bir Survivor Network Graph Database:
- 🗺️ Hayatta kalanlar arasındaki ilişkilerin 3D etkileşimli grafik görselleştirmesi
- 🔍 Akıllı Arama (anahtar kelime, semantik ve karma)
- 📸 Çok formatlı yükleme ardışık düzeni (resimlerden/videolardan öğe çıkarma)
- 🤖 Karmaşık görev düzenleme için çoklu temsilci sistemi
- Kişiselleştirilmiş etkileşimler için 🧠 Memory Bank entegrasyonu
3. Temel Teknolojiler
Bileşen | Teknoloji | Amaç |
Veritabanı | Cloud Spanner Graph | Düğümleri (hayatta kalanlar, beceriler) ve kenarları (ilişkiler) depolama |
Yapay Zeka Arama | Gemini + Embeddings | Semantik anlayış + benzerlik araması |
Agent Framework | ADK (Agent Development Kit) | Yapay zeka iş akışlarını düzenleme |
Bellek | Vertex AI Memory Bank | Uzun süreli kullanıcı tercihi depolama alanı |
Frontend | React + Three.js | Etkileşimli 3D grafik görselleştirme |
2. 🛠️ Ortam Hazırlığı (Atölyedeyseniz bu adımı atlayın)
Birinci Bölüm: Fatura Hesabını Etkinleştirme
Bu codelab'i çalıştırmak için biraz kredisi olan bir faturalandırma hesabına ihtiyacınız var. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
2. Bölüm: Açık Ortam
- 👉 Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- 👉 Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- 👉 Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- 👉💻 Terminalde, aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını doğrulayın:
gcloud auth list - 👉💻 Bootstrap projesini GitHub'dan kopyalayın:
git clone https://github.com/gca-americas/way-back-home.git
Üçüncü Bölüm: Yeni proje oluşturma
👉💻 Terminalde, init komut dosyasını yürütülebilir hale getirin ve çalıştırın:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Ortam Kurulumu
1. Cloud Shell'i açın
Cloud Shell Düzenleyici terminalinde, terminal ekranın alt kısmında görünmüyorsa terminali açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
2. Projeyi yapılandırma
👉💻 Terminalde proje kimliğinizi ayarlayın:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Gerekli API'leri etkinleştirin (bu işlem yaklaşık 2-3 dakika sürer):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Kurulum komut dosyasını çalıştırma
👉💻 Kurulum komut dosyasını çalıştırın:
cd ~/way-back-home/level_2
./setup.sh
Bu işlem sonucunda .env oluşturulur. Cloud Shell'inizde way_back_homeproject dosyasını açın. level_2 klasöründe, sizin için .env dosyasının oluşturulduğunu görebilirsiniz. Bu seçeneği bulamıyorsanız View -> Toggle Hidden File simgesini tıklayarak görebilirsiniz. 
4. Örnek Verileri Yükle
👉💻 Arka uca gidin ve bağımlılıkları yükleyin:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 İlk hayatta kalma verilerini yükleyin:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Bu durumda:
- Spanner örneği (
survivor-network) - Veritabanı (
graph-db) - Tüm düğüm ve kenar tabloları
- Sorgulama için özellik grafikleri Beklenen çıktı:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
Çıktıda Access your database at işaretinden sonraki bağlantıyı tıklarsanız Google Cloud Console Spanner'ı açabilirsiniz.

Google Cloud Console'da Spanner'ı görürsünüz.
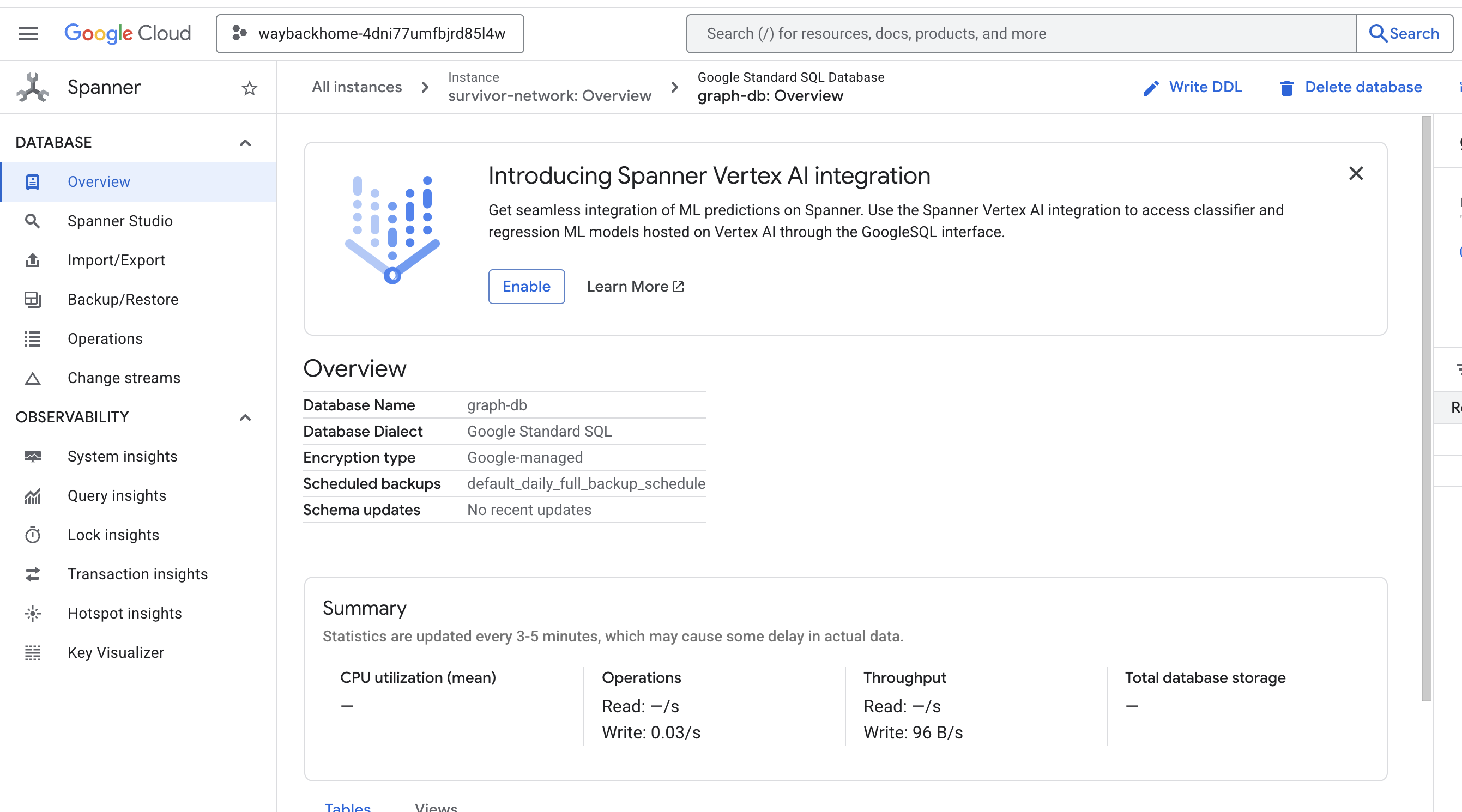
4. 🚀 Spanner Studio'da Grafik Verilerini Görselleştirme
Bu kılavuz, Spanner Studio'yu kullanarak Survivor Network grafik verilerini doğrudan Google Cloud Console'da görselleştirmenize ve bu verilerle etkileşimde bulunmanıza yardımcı olur. Bu, yapay zeka temsilcinizi oluşturmadan önce verilerinizi doğrulamanın ve grafik yapısını anlamanın harika bir yoludur.
1. Spanner Studio'ya erişme
- Son adımda bağlantıyı tıkladığınızdan ve Spanner Studio'yu açtığınızdan emin olun.
2. Grafik Yapısını Anlama ("Genel Resim")
Survivor Network veri kümesini bir mantık bulmacası veya Oyun Durumu olarak düşünün:
Varlık | Sistemdeki Rol | Analoji |
Survivors | Temsilciler/oyuncular | Oyuncular |
Biomes | Bulundukları yer | Harita Bölgeleri |
Beceriler | Yapabilecekleri işlemler | Yetkileri |
İhtiyaçlar (Needs) | Eksiklikleri (Krizler) | Görevler |
Kaynaklar | Dünyada bulunan öğeler | Ganimet |
Amaç: Yapay zeka aracısının görevi, Biyomları (Konum kısıtlamaları) göz önünde bulundurarak Becerileri (Çözümler) İhtiyaçlara (Sorunlar) bağlamaktır.
🔗 Kenarlar (İlişkiler):
SurvivorInBiome: Konum izlemeSurvivorHasSkill: Yetenek envanteriSurvivorHasNeed: Etkin sorunların listesiSurvivorFoundResource: Öğelerin envanteriSurvivorCanHelp: Çıkarılan ilişki (Yapay zeka bunu hesaplar.)
3. Grafiği sorgulama
Verilerdeki "Hikaye"yi görmek için birkaç sorgu çalıştıralım.
Spanner Graph, GQL (Graph Query Language) kullanır. Sorgu çalıştırmak için GRAPH SurvivorNetwork simgesini ve ardından eşleşme kalıbınızı kullanın.
👉 1. Sorgu: Küresel Liste (Kim nerede?) Bu, temelinizdir. Konumu anlamak kurtarma operasyonları için çok önemlidir.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Sonucun aşağıdaki gibi olması beklenir: 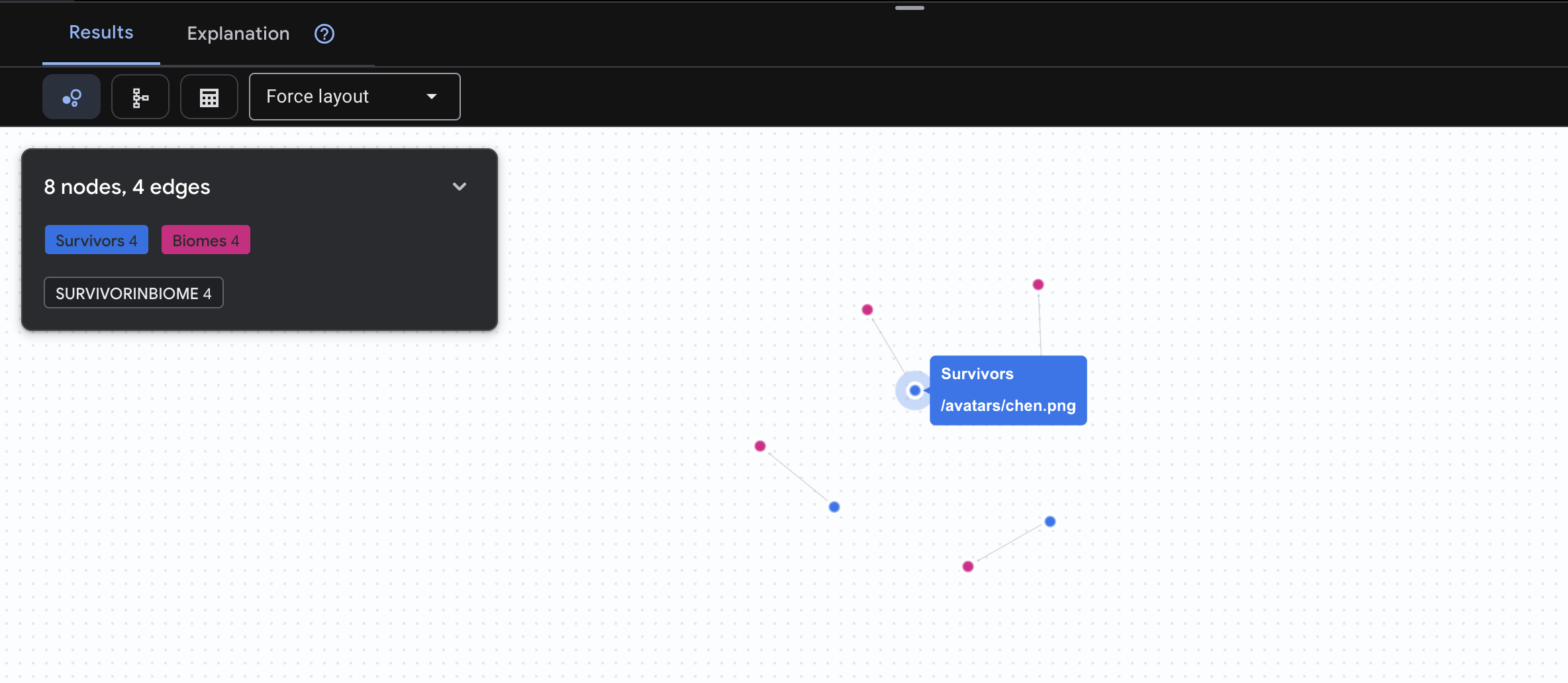
👉 2. Sorgu: Beceri Matrisi (Yetenekler) Herkesin nerede olduğunu öğrendiğinize göre neler yapabileceklerini öğrenin.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Sonucun aşağıdaki gibi olması beklenir: 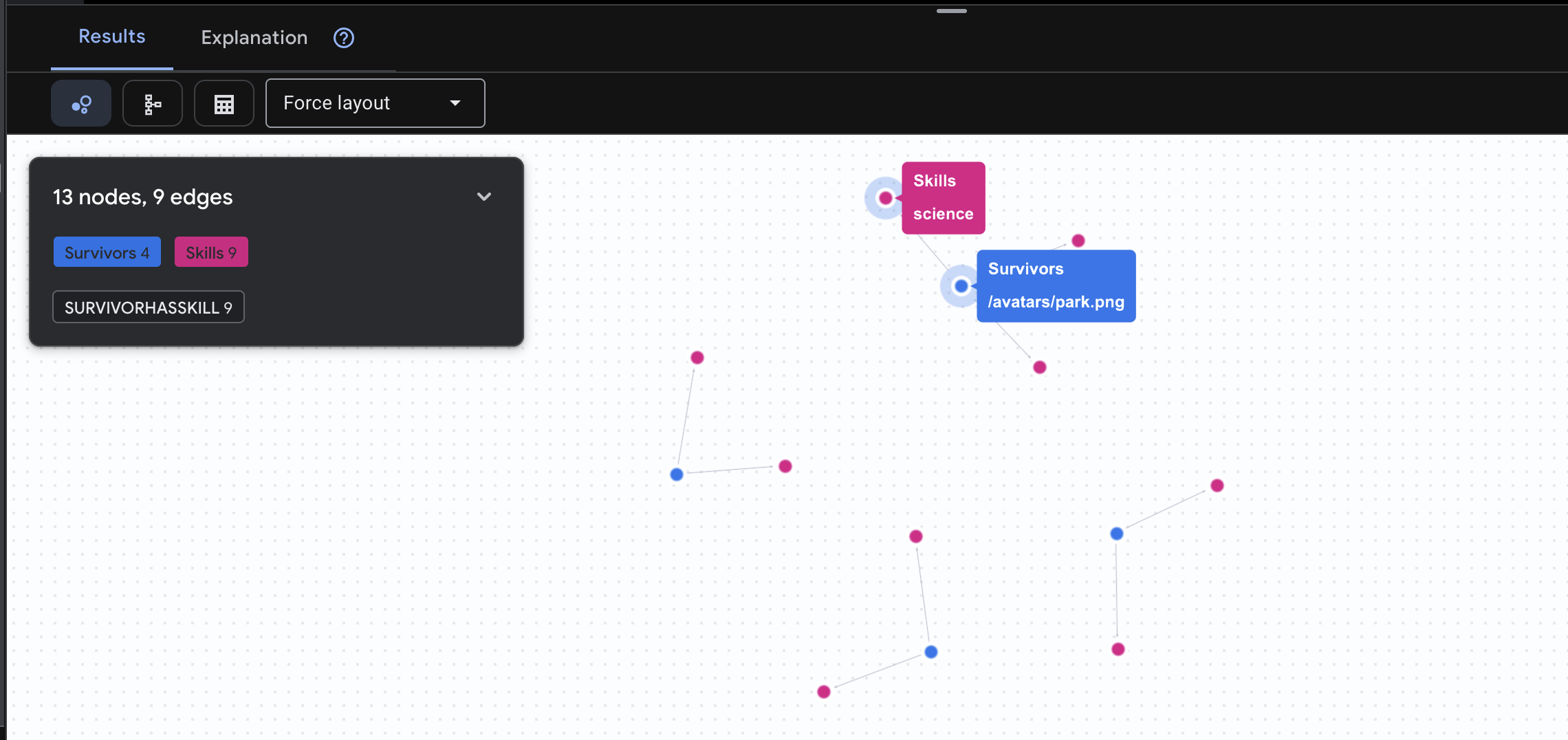
👉 3. Sorgu: Kimler krizde? (Görev Panosu) Yardıma ihtiyacı olan kurtulanları ve ihtiyaçlarını görün.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Sonucun aşağıdaki gibi olması beklenir: 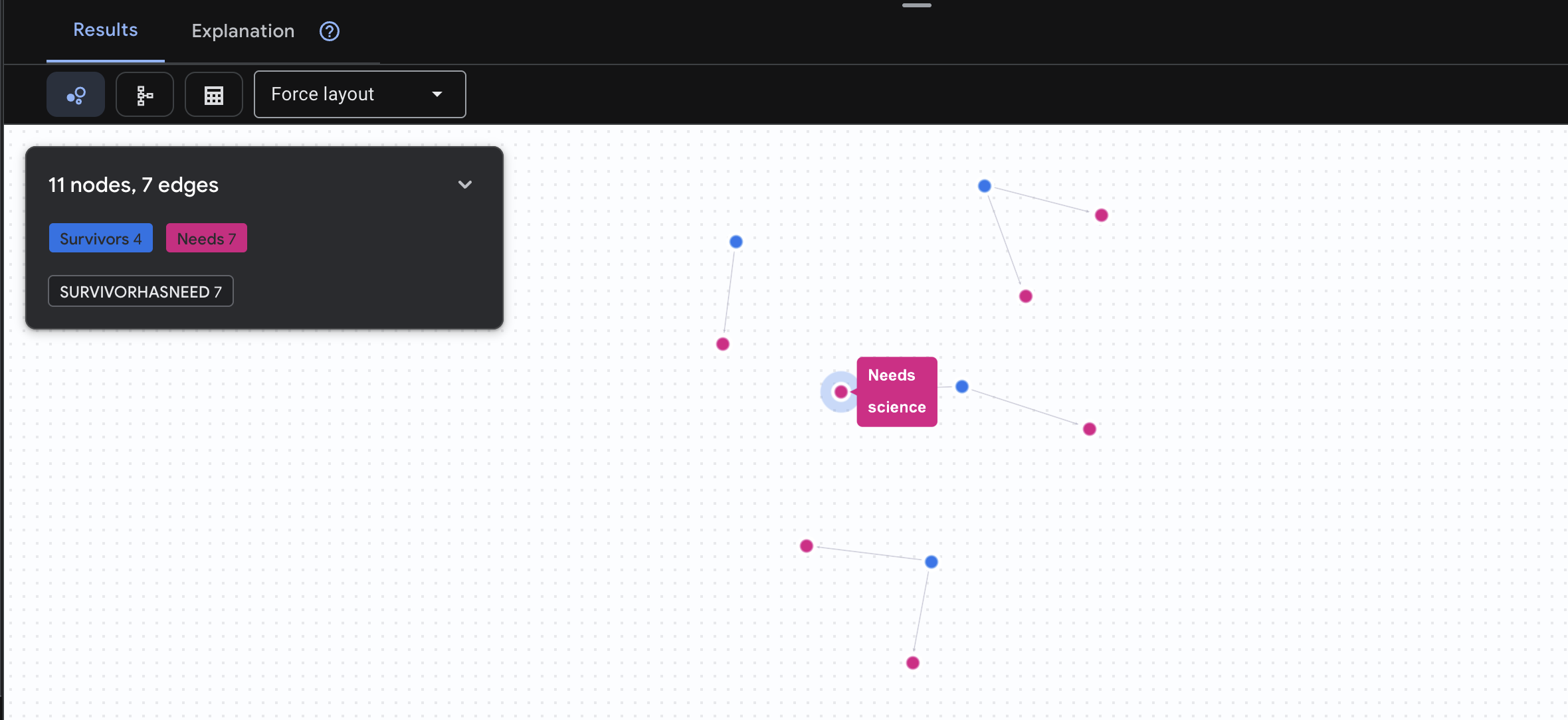
🔎 [İsteğe bağlı] Eşleştirme - Kim Kime Yardım Edebilir?
Grafik bu noktada güçlü hale gelir. Bu sorgu, diğer savaşçıların ihtiyaçlarını karşılayabilecek becerilere sahip savaşçıları bulur.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Sonucun aşağıdaki gibi olması beklenir: 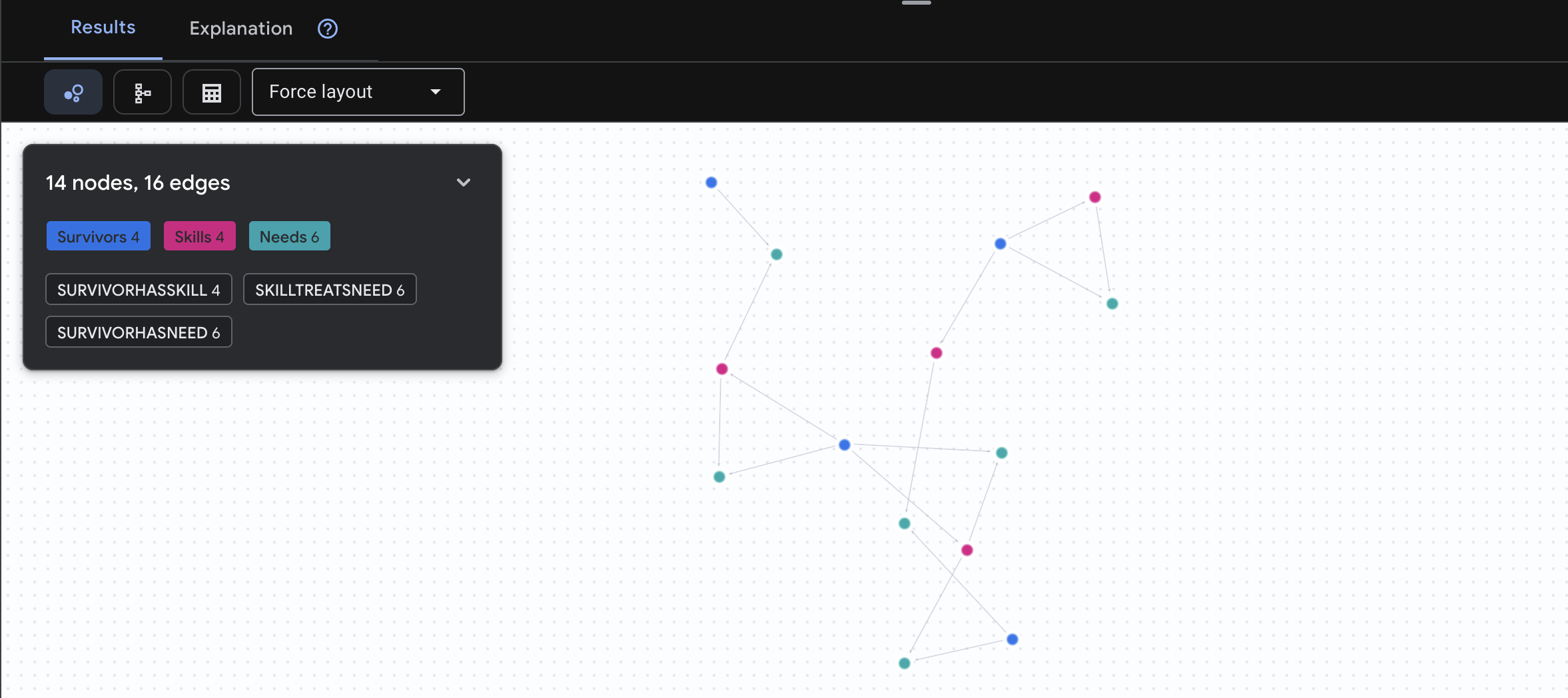
aside positive Bu Sorgu Ne Yapar?
Bu sorgu, yalnızca "İlk yardımda yanıklar tedavi edilir" (şemadan da anlaşılacağı üzere) ifadesini göstermek yerine şunları bulur:
- Dr. Elena Frost (Tıp eğitimi almış) → tedavi edebilir → Kaptan Tanaka (yanıkları var)
- David Chen (ilk yardım bilgisine sahip) → tedavi edebilir → Teğmen Park (ayak bileği burkulmuş)
Neden Etkili?
Yapay Zeka Temsilcinizin Yapacakları:
Bir kullanıcı "Yanıkları kim tedavi edebilir?" diye sorduğunda aracı:
- Benzer bir grafik sorgusu çalıştırma
- Yanıt: "Dr. Frost, tıbbi eğitim almış ve Kaptan Tanaka'ya yardımcı olabilir"
- Kullanıcının ara tablolar veya ilişkiler hakkında bilgi sahibi olması gerekmez.
5. 🚀 Spanner'da Yapay Zeka Destekli Yerleştirmeler
1. Neden yerleştirmeler? (İşlem yok, yalnızca okunabilir)
Hayatta kalma senaryosunda zaman çok önemlidir. Hayatta kalanlar I need someone who can treat burns veya Looking for a medic gibi bir acil durumu bildirdiğinde veritabanındaki beceri adlarını tahmin ederek zaman kaybetmemelidir.
Gerçek Senaryo: Survivor: Captain Tanaka has burns—we need medical help NOW!
"Sağlık görevlisi" için geleneksel anahtar kelime araması → 0 sonuç ❌
Yerleştirmelerle semantik arama → "Tıbbi Eğitim" ve "İlk Yardım"ı bulur. ✅
Bu, temsilcilerin tam olarak ihtiyaç duyduğu şeydir: Akıllı, insana benzer arama, yalnızca anahtar kelimeleri değil, amacı da anlar.
2. Yerleştirme modeli oluşturma
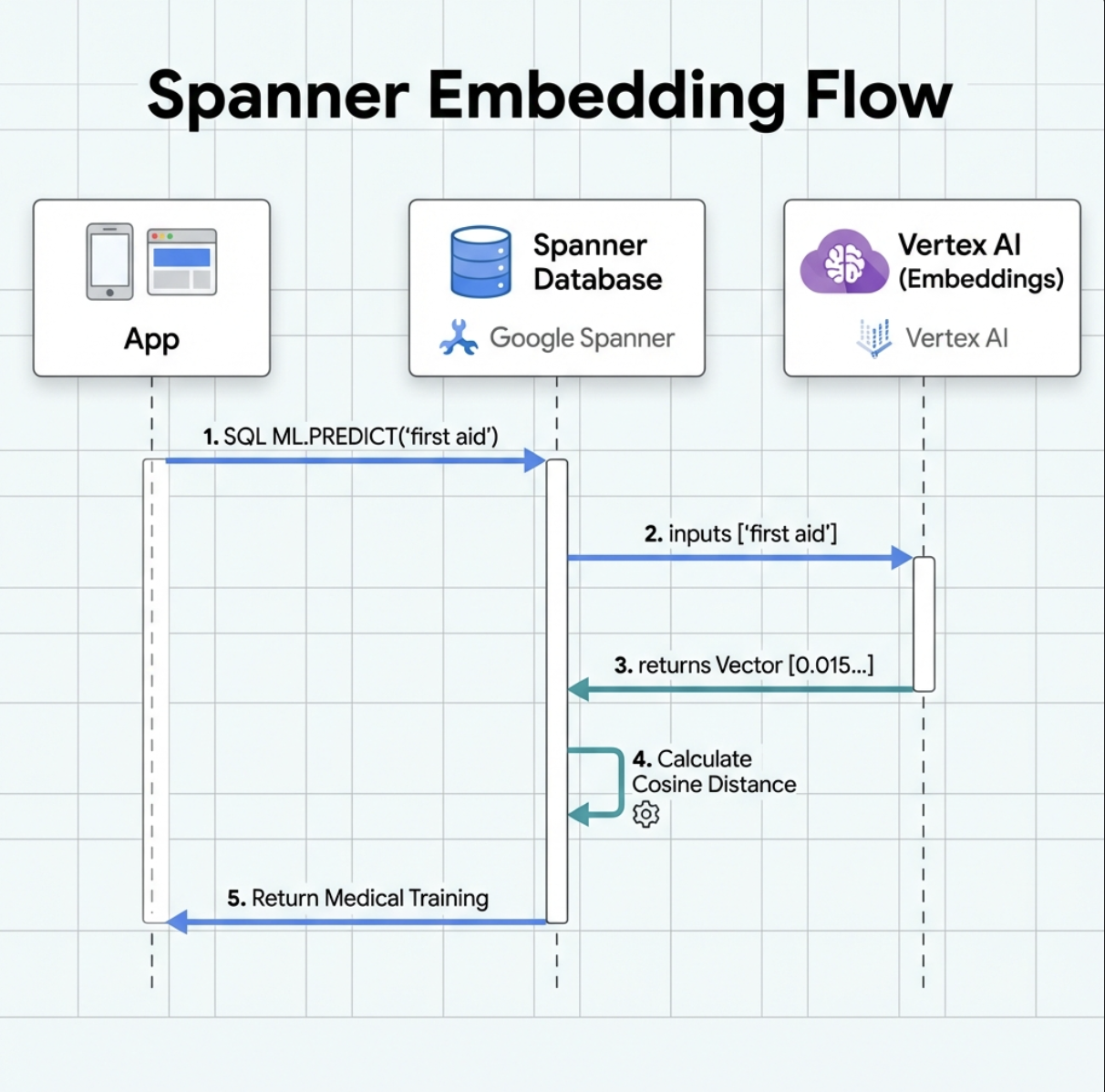
Şimdi de Google'ın text-embedding-004 modelini kullanarak metni yerleştirmelere dönüştüren bir model oluşturalım.
👉 Spanner Studio'da şu SQL'i çalıştırın ($YOUR_PROJECT_ID yerine gerçek proje kimliğinizi girin):
‼️ Cloud Shell düzenleyicisinde, projenin tamamını görmek için File -> Open Folder -> way-back-home/level_2'i açın.
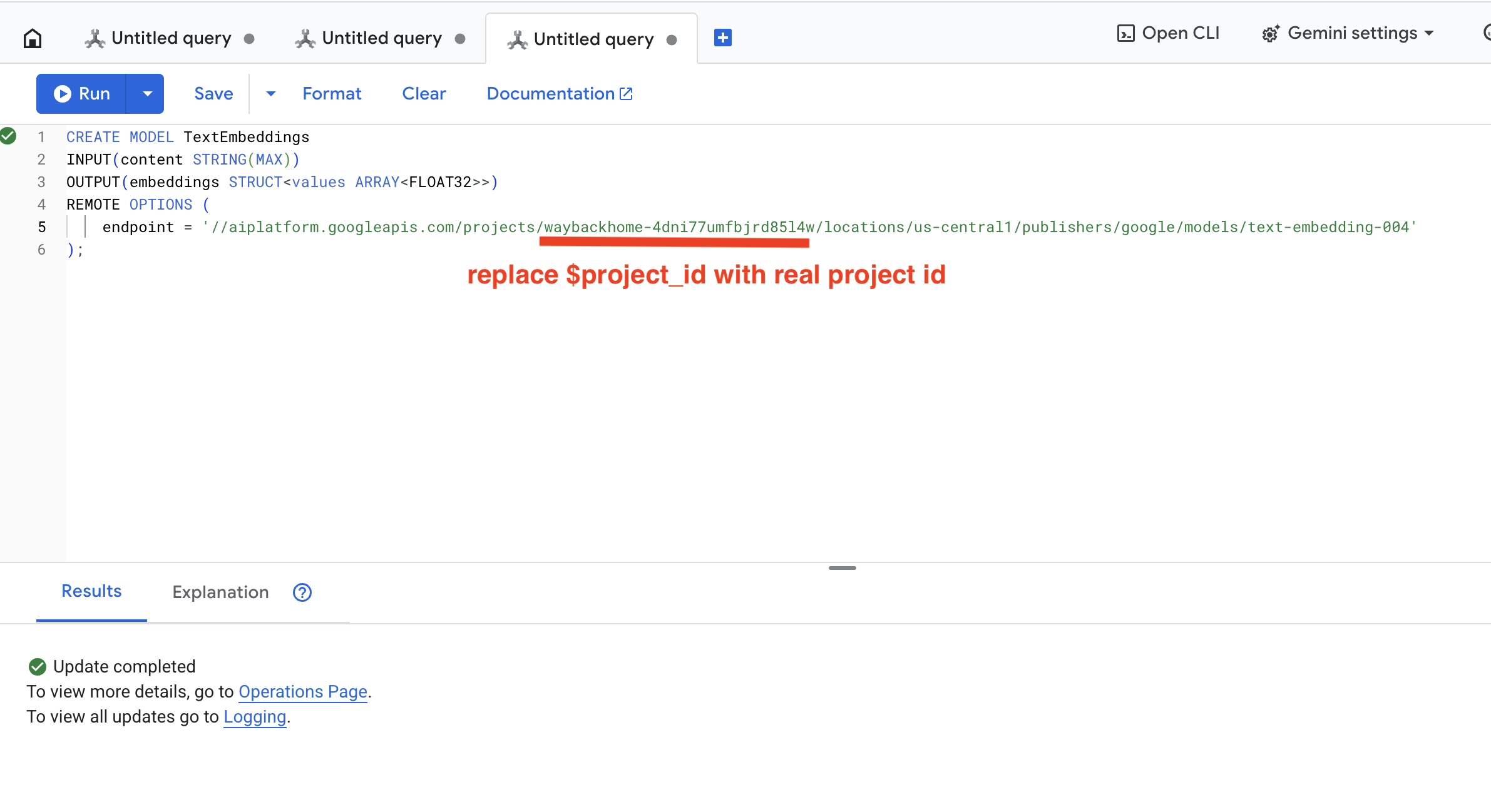
👉 Aşağıdaki sorguyu kopyalayıp yapıştırarak Spanner Studio'da çalıştırın ve Çalıştır düğmesini tıklayın:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Bu İşlem Ne Yapar?
- Spanner'da sanal model oluşturur (model ağırlıkları yerel olarak depolanmaz).
- Vertex AI'da Google'ın
text-embedding-004hizmetine yönlendirir. - Sözleşmeyi tanımlar: Giriş metin, çıkış 768 boyutlu bir kayan nokta dizisidir.
Neden "UZAKTAN SEÇENEKLER"?
- Spanner, modelin kendisini çalıştırmaz
ML.PREDICTkullandığınızda Vertex AI'ı API aracılığıyla çağırır.- Zero-ETL: Verileri Python'a aktarmaya, işlemeye ve yeniden içe aktarmaya gerek yoktur.
Run düğmesini tıklayın. İşlem başarılı olduğunda sonucu aşağıdaki gibi görebilirsiniz:
3. Yerleştirme sütunu ekleme
👉 Yerleştirmeleri depolamak için bir sütun ekleyin:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Run düğmesini tıklayın. İşlem başarılı olduğunda sonucu aşağıdaki gibi görebilirsiniz:
4. Yerleştirilmiş Öğeler Oluşturma
👉 Her beceri için vektör yerleştirmeler oluşturmak üzere yapay zekayı kullanın:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Run düğmesini tıklayın. İşlem başarılı olduğunda sonucu aşağıdaki gibi görebilirsiniz:
Ne olur? Her beceri adı (ör. "ilk yardım"), anlamsal anlamını temsil eden 768 boyutlu bir vektöre dönüştürülür.
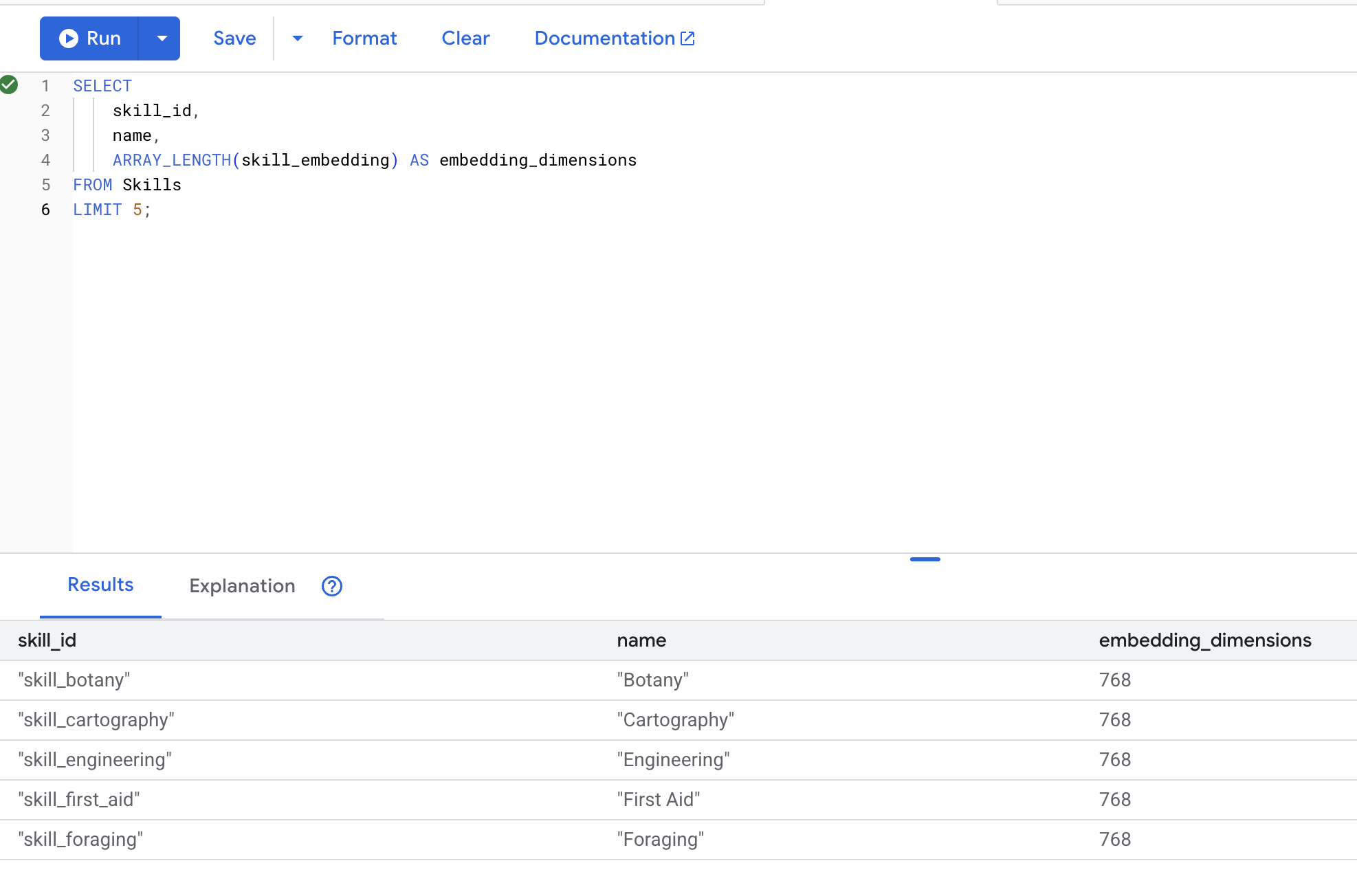
5. Yerleştirilmiş öğeleri doğrulama
👉 Yerleştirmelerin oluşturulduğunu kontrol edin:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Beklenen çıkış:
6. Semantik Arama'yı test etme
Şimdi senaryomuzdaki tam kullanım alanını test ediyoruz: "sağlık görevlisi" terimini kullanarak tıbbi becerileri bulma.
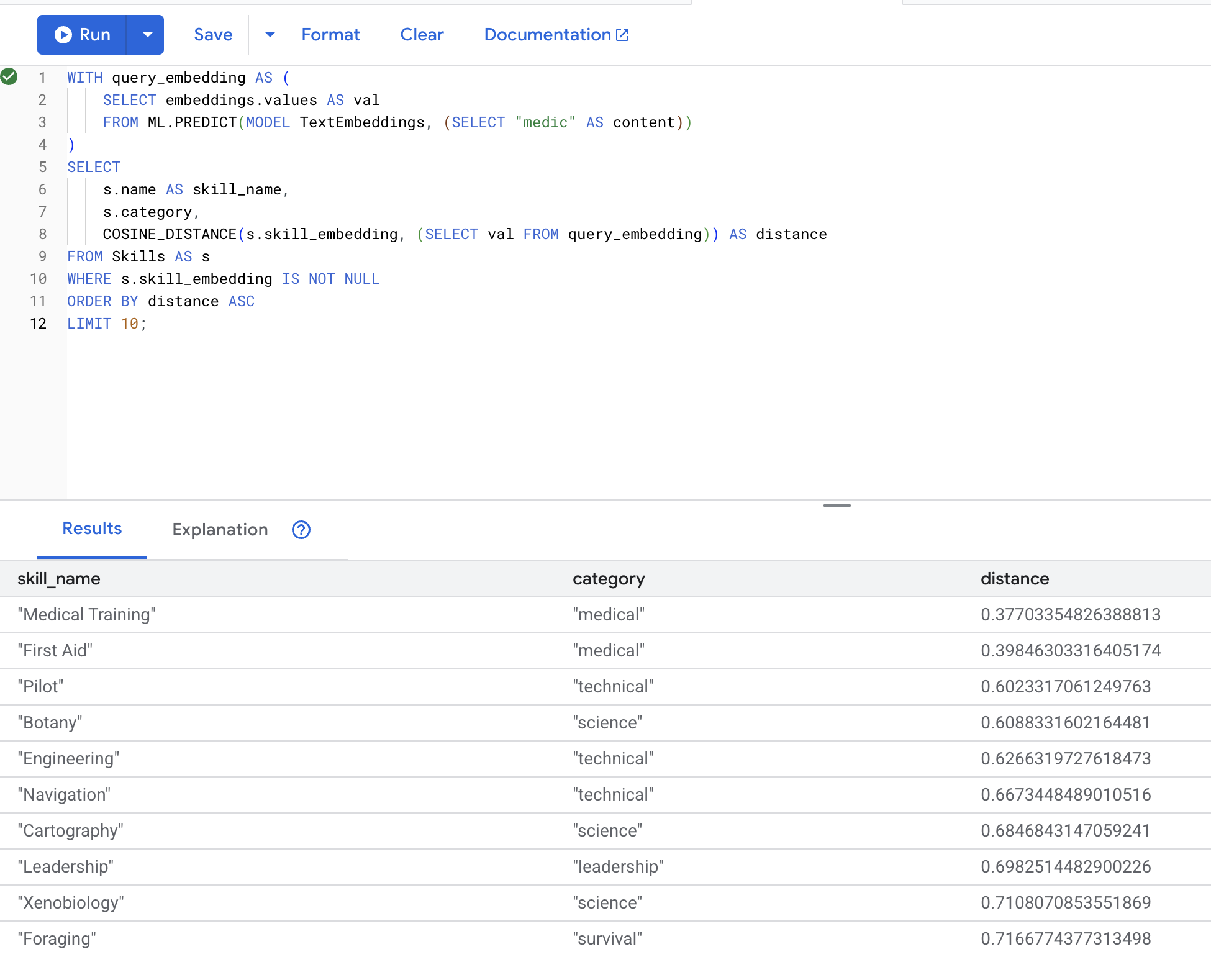
👉 "Sağlık görevlisi"ne benzer becerileri bulma:
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Kullanıcının "doktor" arama terimini yerleştirmeye dönüştürür.
query_embeddinggeçici tablosunda saklar.
Beklenen sonuçlar (daha düşük mesafe = daha benzer):
7. Analiz için Gemini modeli oluşturma
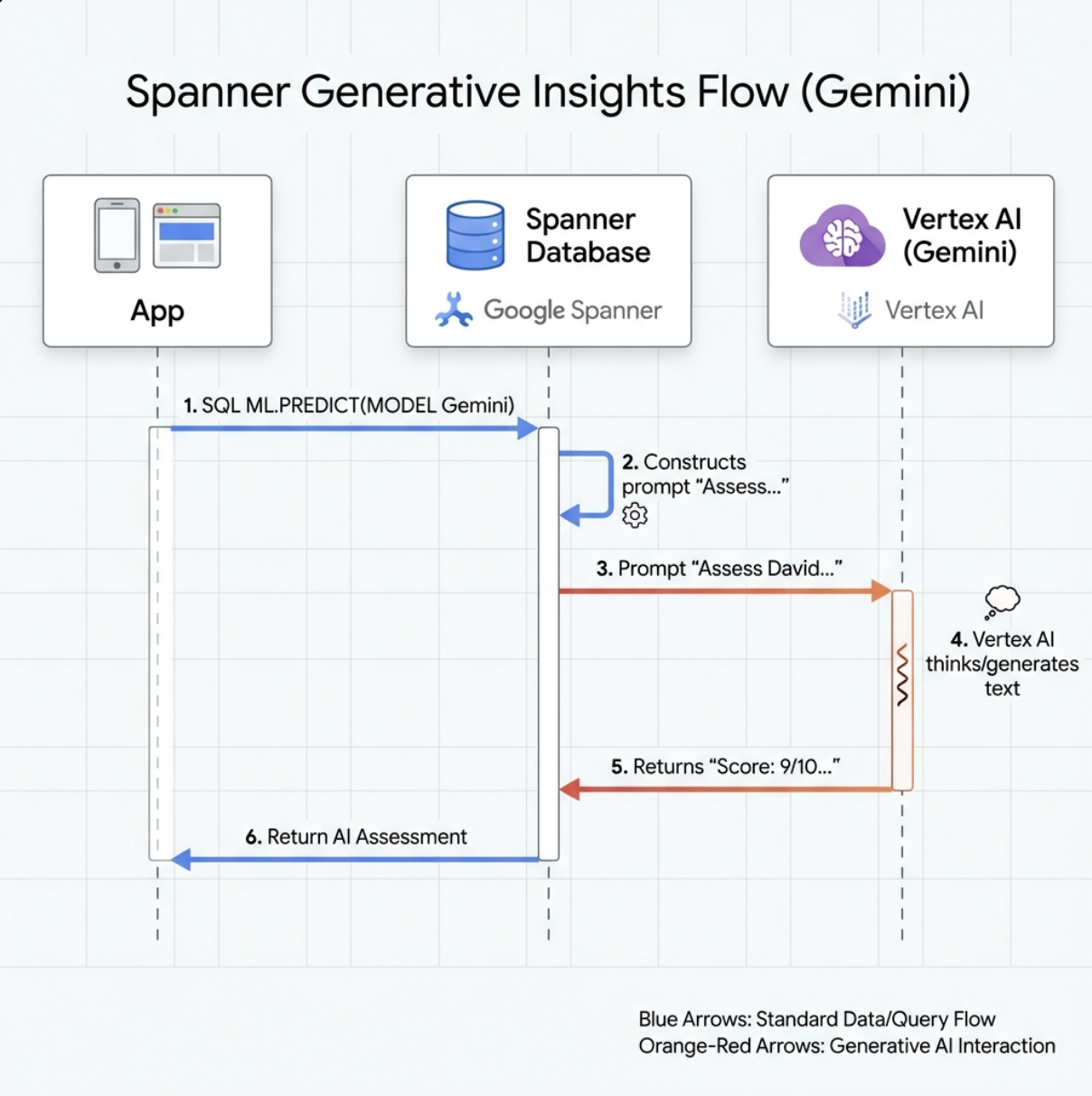
👉 Üretken yapay zeka modeli referansı oluşturun ($YOUR_PROJECT_ID yerine gerçek proje kimliğinizi girin):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Yerleştirme modelinden fark:
- Yerleştirmeler: Metin → Vektör (benzerlik araması için)
- Gemini: Metin → Oluşturulan Metin (akıl yürütme/analiz için)
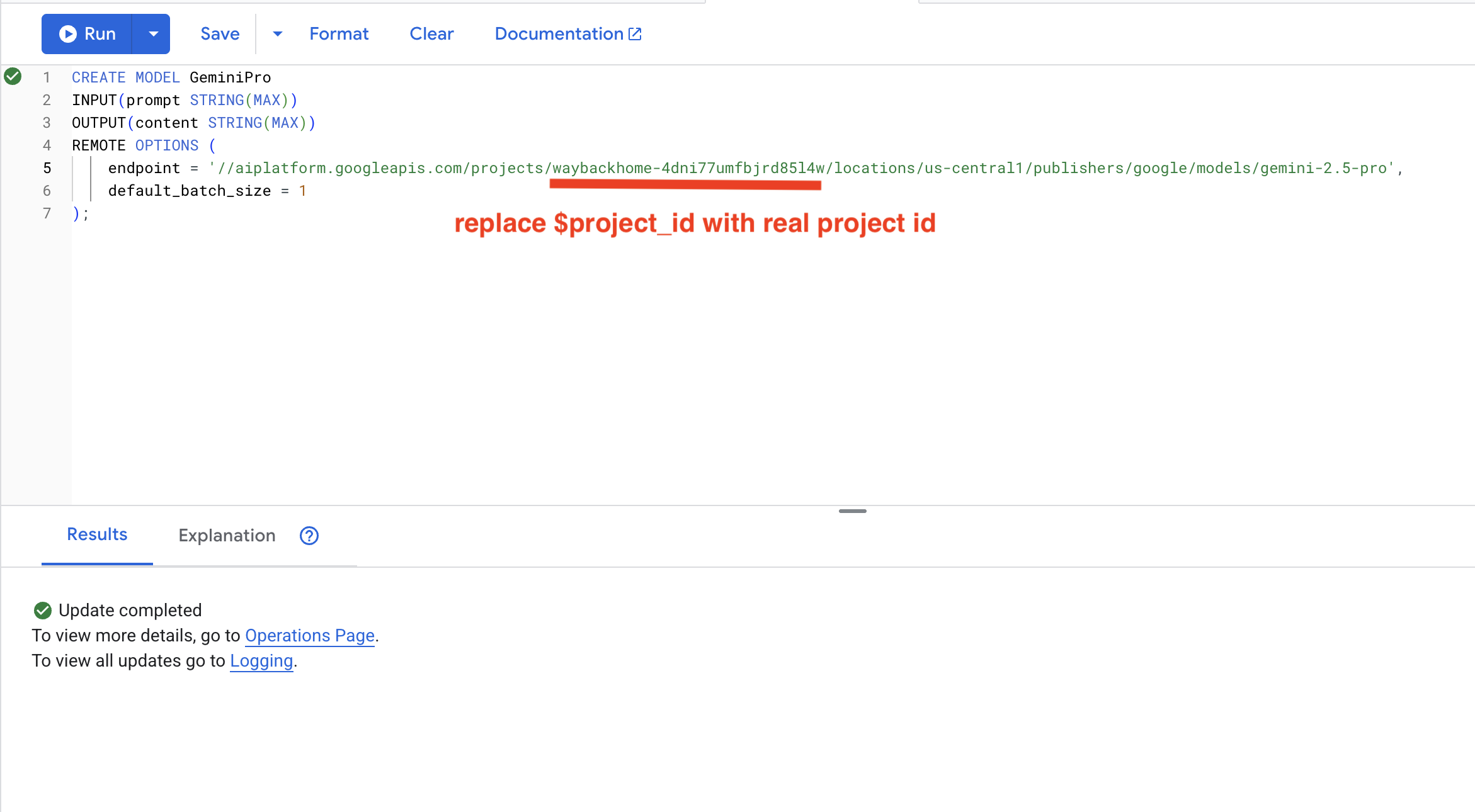
8. Uyumluluk analizi için Gemini'ı kullanma
👉 Görev uyumluluğu için hayatta kalan çiftleri analiz edin:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Beklenen çıkış:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Karma Arama ile Graph RAG Ajanınızı Oluşturma
1. Sistem Mimarisine Genel Bakış
Bu bölümde, aracınıza farklı sorgu türlerini işleme esnekliği sağlayan bir çok yöntemli arama sistemi oluşturulur. Sistem üç katmandan oluşur: Aracı Katmanı, Araç Katmanı, Hizmet Katmanı.
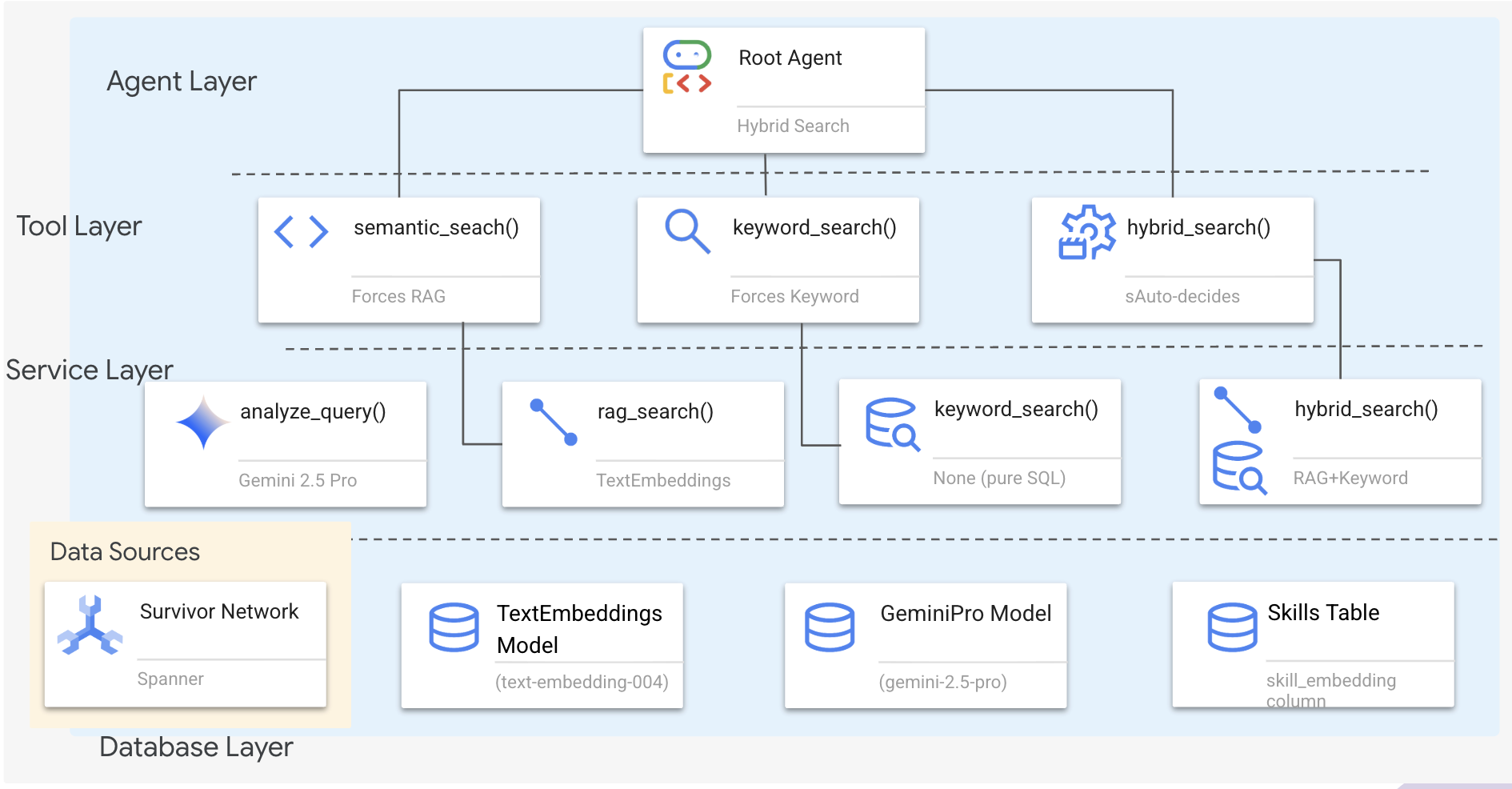
Neden Üç Katman?
- İlgi alanlarının ayrılması: Temsilci amaca, araçlar arayüze, hizmet ise uygulamaya odaklanır.
- Esneklik: Temsilci, belirli yöntemleri zorlayabilir veya yapay zekanın otomatik yönlendirme yapmasına izin verebilir.
- Optimizasyon: Yöntem bilindiğinde pahalı yapay zeka analizi atlanabilir.
Bu bölümde, öncelikle semantik aramayı (RAG) uygulayacaksınız. Bu, sonuçları yalnızca anahtar kelimelere göre değil, anlamlarına göre bulma işlemidir. Daha sonra, karma arama özelliğinin birden fazla yöntemi nasıl birleştirdiğini açıklayacağız.
2. RAG Hizmeti Uygulaması
👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Yorumu bulun # TODO: REPLACE_SQL
Bu satırın tamamını aşağıdaki kodla değiştirin:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Semantik Arama Aracı Tanımı
👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
hybrid_search_tools.py bölümünde, yorumu bulun. # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉Bu satırın tamamını aşağıdaki kodla değiştirin:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Temsilci Kullanımı:
- Benzerlik isteyen sorgular ("X'e benzer bir şey bul")
- Kavramsal sorgular ("iyileştirme yetenekleri")
- Anlamın anlaşılmasının önemli olduğu durumlar
4. Aracı Karar Kılavuzu (Talimatlar)
Aracı tanımında, semantik aramayla ilgili kısmı talimata kopyalayıp yapıştırın.
👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Aracı, doğru aracı seçmek için bu talimatı kullanır:
👉agent.py dosyasında # TODO: REPLACE_SEARCH_LOGIC yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉Yorumu bulun. # TODO: ADD_SEARCH_TOOLReplace this whole line satırını aşağıdaki kodla değiştirin:
semantic_search, # Force RAG
5. Karma Arama'nın İşleyiş Şeklini Anlama (Yalnızca Okuma, İşlem Gerekmez)
2-4. adımlarda, sonuçları anlamlarına göre bulan temel arama yöntemi olan semantik aramayı (RAG) uyguladınız. Ancak sistemin adının "Karma Arama" olduğunu fark etmiş olabilirsiniz. Bu özelliklerin nasıl birlikte çalıştığını aşağıda görebilirsiniz:
Karma Birleştirme Nasıl Çalışır?:
way-back-home/level_2/backend/services/hybrid_search_service.py dosyasında, hybrid_search() çağrıldığında hizmet HEM aramaları çalıştırır HEM de sonuçları birleştirir:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Bu codelab'de, temel olan semantik arama bileşenini (RAG) uyguladınız. Anahtar kelime ve karma yöntemler hizmette zaten uygulanıyor. Aracınız üç yöntemi de kullanabilir.
Tebrikler! Hibrit arama ile Graph RAG Temsilcinizi başarıyla tamamladınız.
7. 🚀 ADK Web ile Temsilcinizi Test Etme
Temsilcinizi test etmenin en kolay yolu, adk web komutunu kullanmaktır. Bu komut, temsilcinizi yerleşik bir sohbet arayüzüyle başlatır.
1. Aracıyı çalıştırma
👉💻 Arka uç dizinine (temsilcinizin tanımlandığı yer) gidin ve web arayüzünü başlatın:
cd ~/way-back-home/level_2/backend
uv run adk web
Bu komut,
agent/agent.py
ve test için bir web arayüzü açar.
👉 URL'yi açın:
Komut, yerel bir URL (genellikle http://127.0.0.1:8000 veya benzeri) oluşturur. Bunu tarayıcınızda açın.
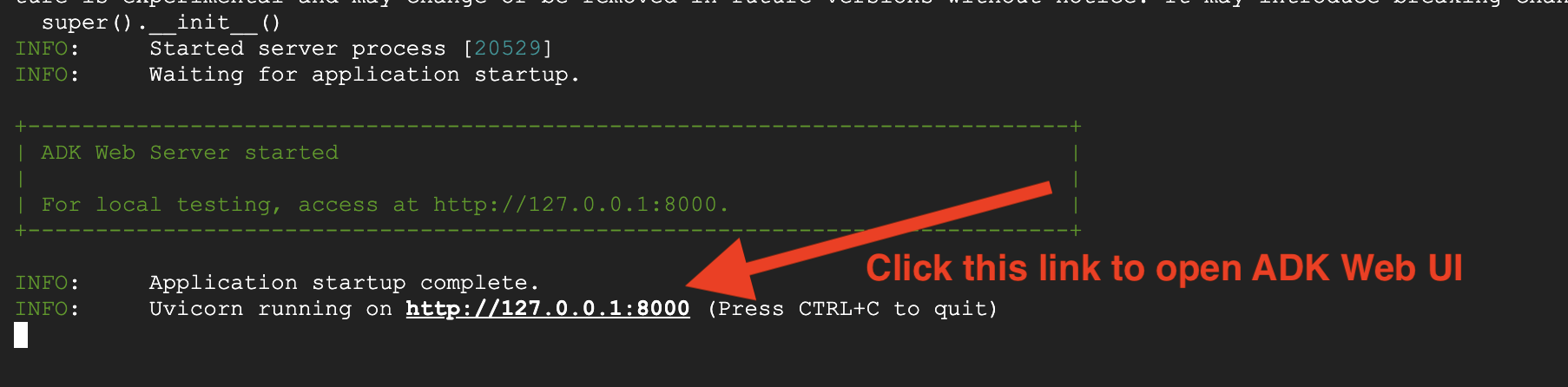
URL'yi tıkladığınızda ADK Web kullanıcı arayüzünü görürsünüz. Sol üst köşeden "aracı"yı seçtiğinizden emin olun.
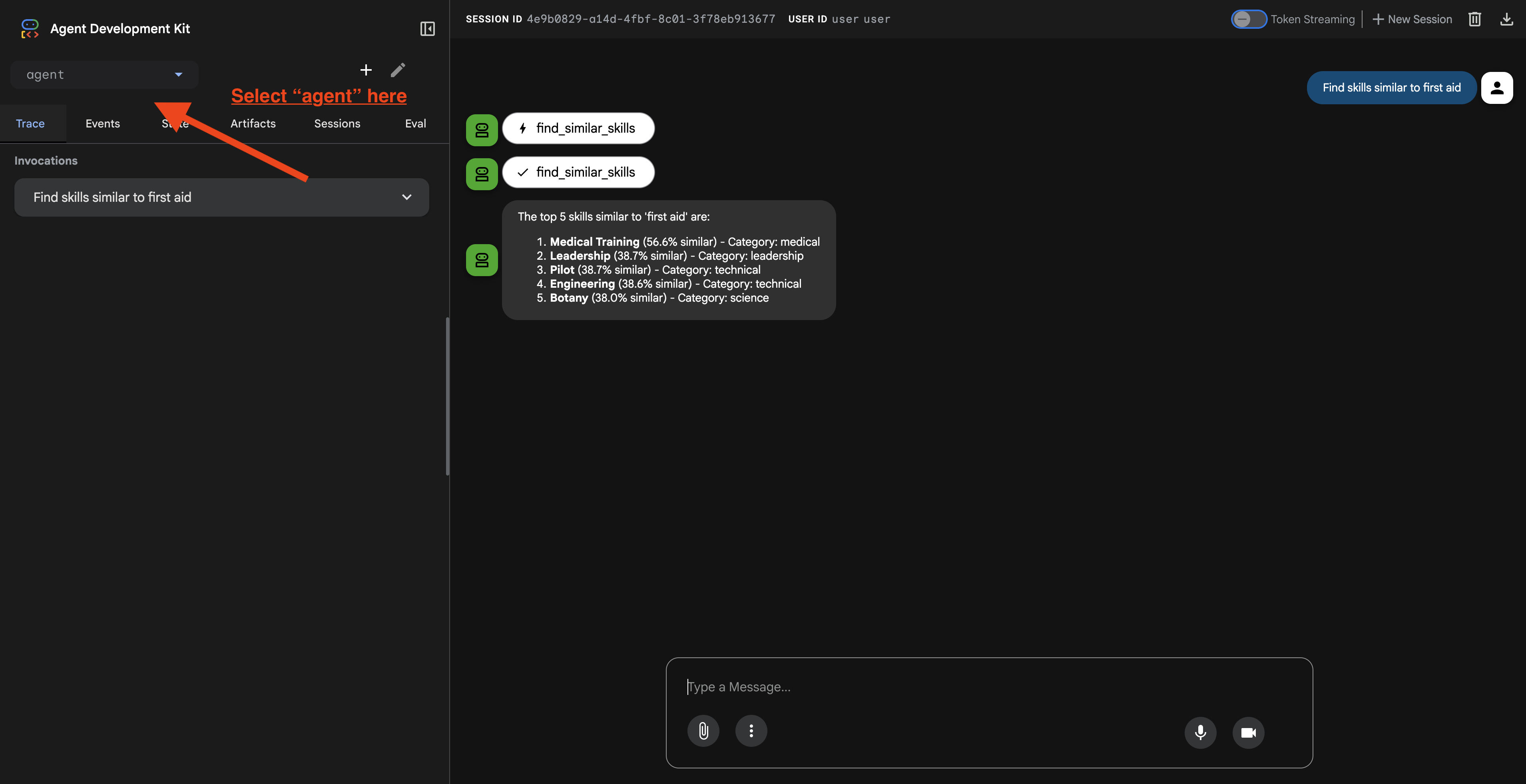
2. Arama Özelliklerini Test Etme
Temsilci, sorgularınızı akıllıca yönlendirmek için tasarlanmıştır. Farklı arama yöntemlerini görmek için sohbet penceresinde aşağıdaki girişleri deneyin.
🧬 A. Grafik RAG (Semantik Arama)
Anahtar kelimeler eşleşmese bile anlam ve konsepte göre öğeler bulur.
Test Sorguları: (Aşağıdakilerden herhangi birini seçin)
Who can help with injuries?
What abilities are related to survival?
Dikkat edilecek noktalar:
- Gerekçede Semantik veya RAG aramadan bahsedilmelidir.
- Kavramsal olarak alakalı sonuçlar görmelisiniz (ör. "İlk yardım" istediğinizde "Ameliyat").
- Sonuçlarda 🧬 simgesi bulunur.
🔀 B. Karma Arama
Karmaşık sorgular için anahtar kelime filtrelerini semantik anlamayla birleştirir.
Test Sorguları:(Aşağıdakilerden herhangi birini seçin)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Dikkat edilecek noktalar:
- Gerekçede karma aramadan bahsedilmelidir.
- Sonuçlar HER İKİ ölçütle (kavram + konum/kategori) eşleşmelidir.
- Her iki yöntemle de bulunan sonuçlar 🔀 simgesine sahip olur ve en üstte yer alır.
👉💻 Testi tamamladığınızda komut satırınızda Ctrl+C tuşuna basarak işlemi sonlandırın.
8. 🚀 Tam Uygulamayı Çalıştırma
Full Stack Architecture Overview (Tam Yığın Mimari Genel Bakışı)
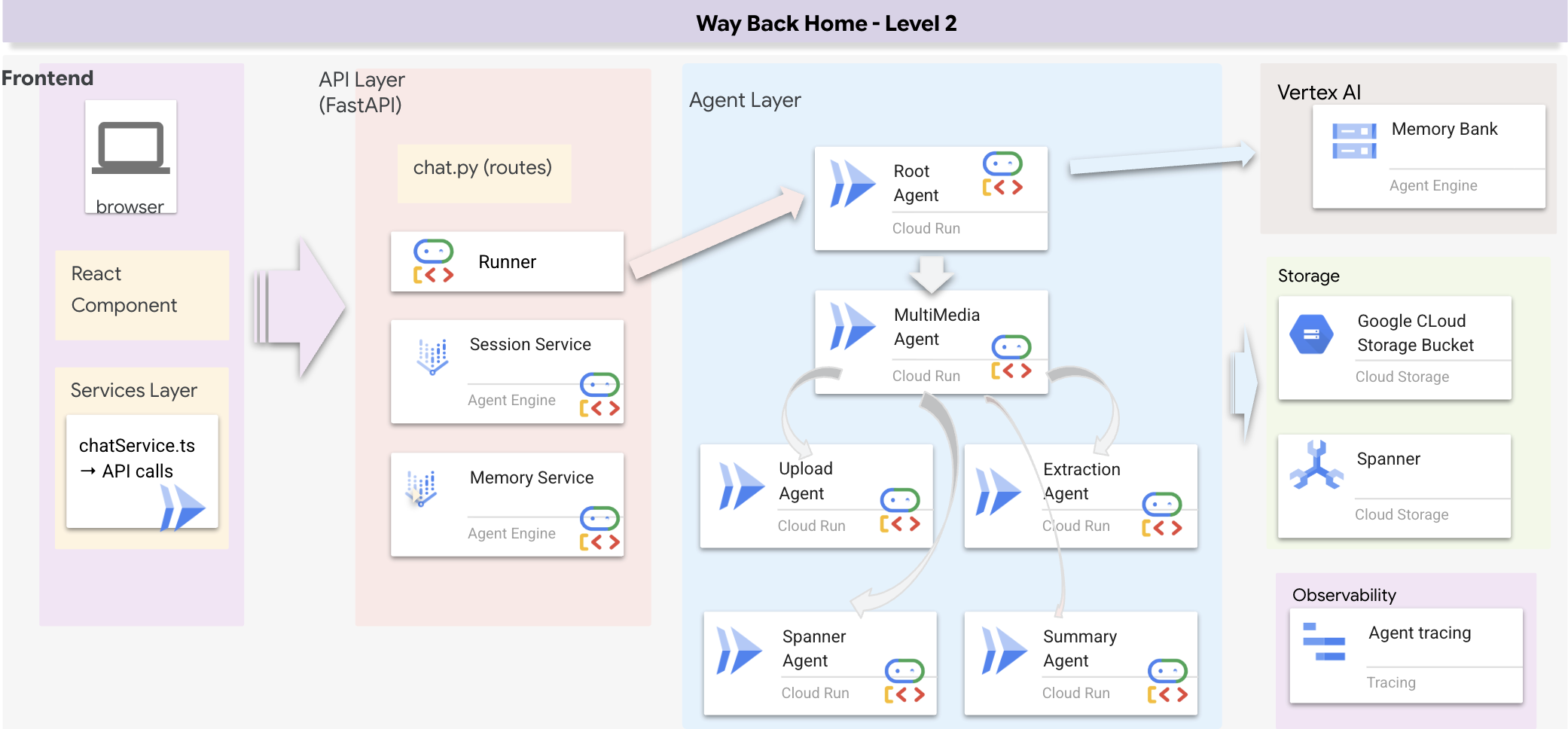
SessionService ve Runner ekleme
👉💻 Terminalde, chat.py dosyasını Cloud Shell Düzenleyici'de aşağıdaki komutu çalıştırarak açın (devam etmeden önce önceki işlemi "ctrl+C" ile sonlandırdığınızdan emin olun):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉chat.py dosyasında # TODO: REPLACE_INMEMORY_SERVICES yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉chat.py dosyasında # TODO: REPLACE_RUNNER yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Başvuruyu başlatma
Önceki terminal hâlâ çalışıyorsa Ctrl+C tuşuna basarak sonlandırın.
👉💻 Uygulamayı başlatma:
cd ~/way-back-home/level_2/
./start_app.sh
Arka uç başarıyla başlatıldığında aşağıdaki gibi Local: http://localhost:5173/" simgesini görürsünüz: 
👉 Terminalde Local: http://localhost:5173/ seçeneğini tıklayın.
2. Semantik Arama'yı test etme
Sorgu:
Find skills similar to healing
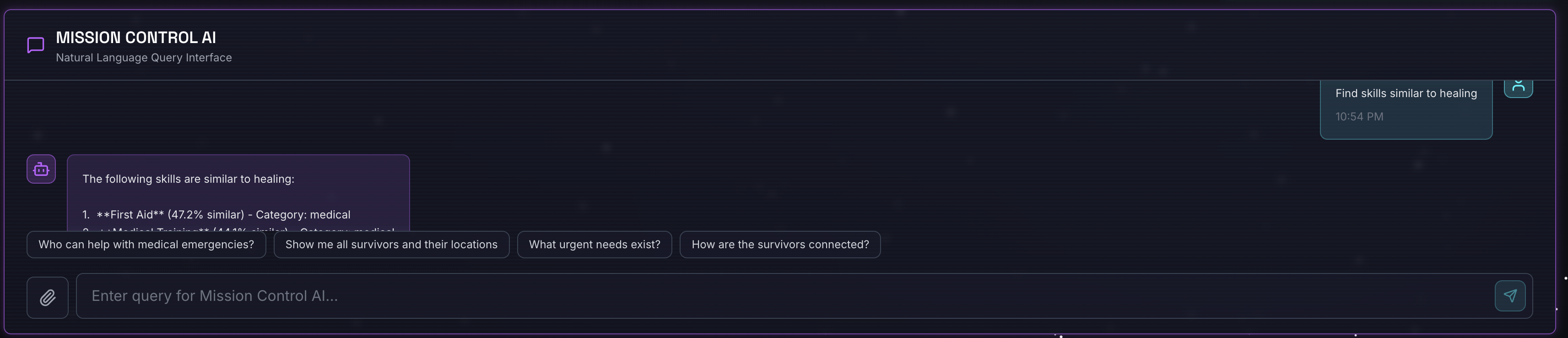
Ne olur?
- Temsilci, benzerlik isteğini tanıyor
- "İyileşme" için yerleştirilmiş öğe oluşturur.
- Anlamsal olarak benzer becerileri bulmak için kosinüs uzaklığını kullanır.
- Döndürülür: İlk yardım (adlar "iyileşme" ile eşleşmese bile)
3. Karma aramayı test etme
Sorgu:
Find medical skills in the mountains
Ne olur?
- Anahtar kelime bileşeni:
category='medical'için filtreleme - Anlamsal bileşen: "Tıbbi" kelimesini yerleştirin ve benzerliğe göre sıralayın
- Birleştir: Sonuçları birleştirin ve her iki yöntemle de bulunanlara öncelik verin 🔀
Sorgu(isteğe bağlı):
Who is good at survival and in the forest?
Ne olur?
- Anahtar kelime bulguları:
biome='forest' - Anlamsal bulgular: "Hayatta kalma" ile benzer beceriler
- En iyi sonuçlar için her ikisini de birleştiren hibrit
👉💻 Testi tamamladığınızda terminalde Ctrl+C tuşuna basarak testi sonlandırın.
4. (YALNIZCA WORKSHOP KATILIMCILARI İÇİN) Konumunuzu güncelleme
👉💻 Tamamlama komut dosyasını çalıştırın:
cd ~/way-back-home/level_2
./set_level_2.sh
Şimdi waybackhome.dev uygulamasını açtığınızda konumunuzun güncellendiğini görürsünüz. 2. seviyeyi tamamladığınız için tebrikler.

9. ☕️ [İsteğe bağlı] Çok formatlı işlem hattı (salt okunur) - Araç katmanı
Neden Çok Modlu Bir Ardışık Düzene İhtiyacımız Var?
Hayatta kalma ağı yalnızca metinden ibaret değildir. Sahadaki kurtulanlar, yapılandırılmamış verileri doğrudan sohbet üzerinden gönderir:
- 📸 Görseller: Kaynakların, tehlikelerin veya ekipmanların fotoğrafları
- 🎥 Videolar: Durum raporları veya SOS yayınları
- 📄 Metin: Saha notları veya günlükler
Hangi Dosyaları İşliyoruz?
Mevcut verileri aradığımız önceki adımın aksine, burada kullanıcı tarafından yüklenen dosyaları işleriz. chat.py arayüzü, dosya eklerini dinamik olarak işler:
Kaynak | İçerik | Hedef |
Kullanıcı eki | Resim/Video/Metin | Grafiğe eklenecek bilgiler |
Sohbet Bağlamı | "Here is a photo of the supplies" (Malzemelerin fotoğrafı) | Amaç ve ek ayrıntılar |
Planlanan Yaklaşım: Sıralı Ajan İşlem Hattı
Uzmanlaşmış aracıları birbirine bağlayan bir Sıralı Aracı (multimedia_agent.py) kullanırız:
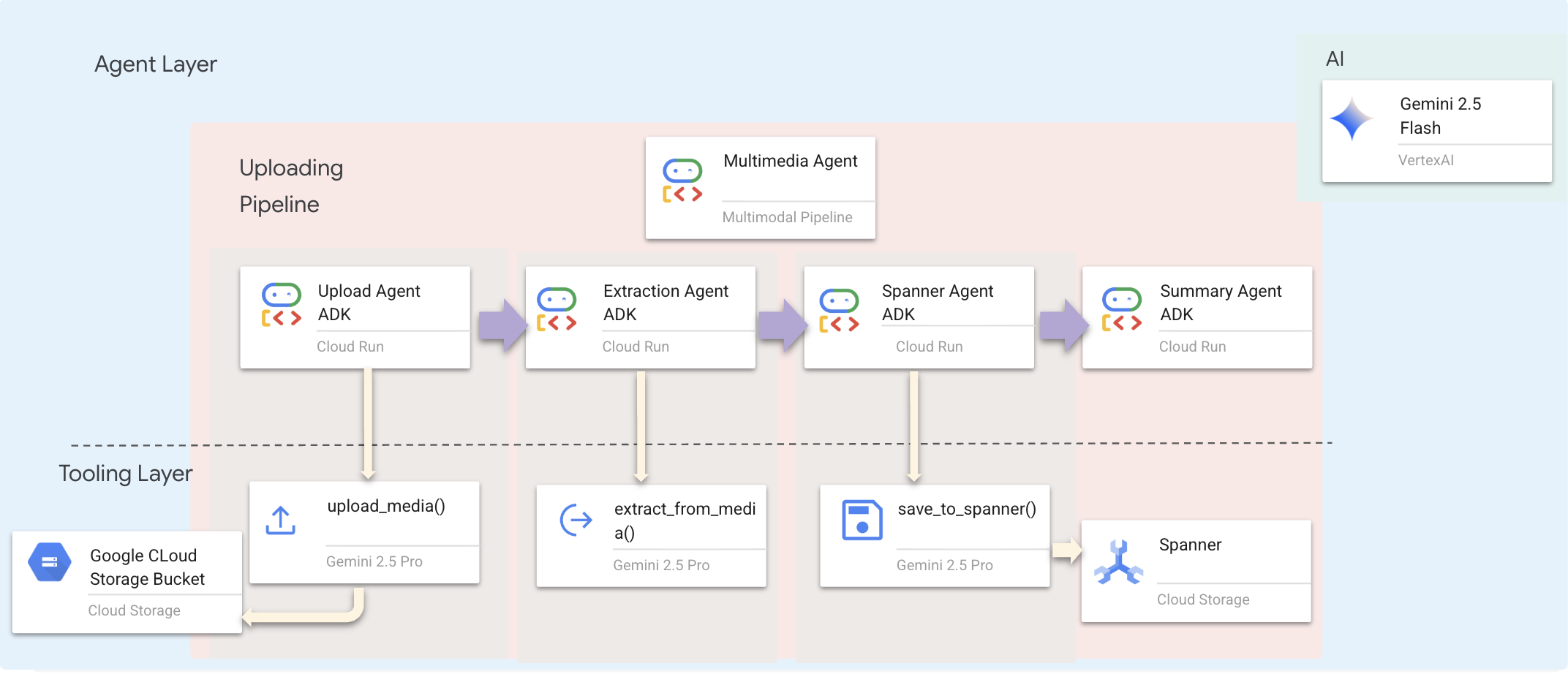
Bu, backend/agent/multimedia_agent.py içinde SequentialAgent olarak tanımlanır.
Araç katmanı, aracıların çağırabileceği özellikleri sağlar. Araçlar, "nasıl" sorusunun cevabını verir: dosyaları yükleme, varlıkları ayıklama ve veritabanına kaydetme.
1. Araçlar dosyasını açın
👉💻 Dosyayı açın level_2/backend/agent/tools/extraction_tools.py veya terminalde aşağıdaki komutu yazın. Yeni bir terminal açın. Terminalde dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. upload_media aracını uygulama
Bu araç, yerel bir dosyayı Google Cloud Storage'a yükler.
👉 def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: bölümündeki aşağıdaki kod, dosyaların GCS'ye nasıl yükleneceği ve türünün nasıl tespit edileceği ile ilgilidir:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. extract_from_media aracını uygulama
Bu araç bir yönlendiricidir. media_type öğesini kontrol eder ve doğru ayıklayıcıya (metin, resim veya video) gönderir.
👉 async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: bölümündeki kod, yüklenen medyadan nasıl varlık ve ilişki çıkarılacağıyla ilgilidir.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Önemli uygulama ayrıntıları:
- Çok formatlı giriş:
generate_content'a hem metin istemini (_get_extraction_prompt()) hem de görüntü nesnesini iletiyoruz. - Yapılandırılmış Çıkış:
response_mime_type="application/json", LLM'nin geçerli JSON döndürmesini sağlar. Bu, işlem hattı için kritik öneme sahiptir. - Görsel Varlık Bağlantısı: İstemde bilinen varlıklar yer aldığından Gemini, belirli karakterleri tanıyabilir.
4. save_to_spanner aracını uygulama
Bu araç, çıkarılan öğeleri ve ilişkileri Spanner Graph DB'de kalıcı hale getirir.
👉 def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: bölümündeki kod, çıkarılan öğelerin ve ilişkilerin Spanner Graph veritabanına nasıl kaydedileceğiyle ilgilidir.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Temsilcilere üst düzey araçlar sunarak, temsilcinin muhakeme yeteneklerinden yararlanırken veri bütünlüğünü sağlıyoruz.
5. GCS Hizmetini Güncelleme
GCSService, dosyanın Google Cloud Storage'a yüklenmesini sağlar.
👉💻 level_2/backend/services/gcs_service.py dosyasını açın veya dosyayı Cloud Shell Düzenleyici'de açmak için terminale şunu yazın:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: bölümündeki kod, çıkarılan öğelerin ve ilişkilerin Spanner Graph veritabanına nasıl kaydedileceğiyle ilgilidir.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Bu işlem bir hizmete dönüştürüldüğünde, aracı GCS paketleri, büyük ikili nesne (BLOB) adları veya imzalı URL oluşturma hakkında bilgi sahibi olmak zorunda kalmaz. Sadece "yükle" seçeneği sunuluyor.
6. Neden Temsilci İş Akışı > Geleneksel Yaklaşımlar?
Temsilci Tabanlı Özelliklerin Avantajı:
Özellik | Toplu İşleme Ardışık Düzeni | Etkinliğe Dayalı | Temsilci tabanlı iş akışı |
Karmaşıklık | Düşük (1 komut dosyası) | Yüksek (5'ten fazla hizmet) | Düşük (1 Python dosyası: |
Durum Yönetimi | Genel değişkenler | Zor (ayrılmış) | Birleştirilmiş (Agent durumu) |
Hata İşleme | Kilitlenme sayısı | Sessiz günlükler | Etkileşimli ("Bu dosyayı okuyamadım") |
Kullanıcı Geri Bildirimi | Konsol baskıları | Yoklama yapılması gerekiyor | Anında (Sohbetin bir parçası) |
Uyarlanabilirlik | Sabit mantık | Sert işlevler | Akıllı (LLM, sonraki adıma karar verir) |
Bağlama Duyarlılığı (Context Awareness) | Yok | Yok | Tam (Kullanıcı niyetini bilir) |
Neden Önemli? multimedia_agent.py (4 alt aracılı bir SequentialAgent: Yükle → Çıkar → Kaydet → Özet) kullanarak karmaşık altyapıyı VE kırılgan komut dosyalarını akıllı, etkileşimli uygulama mantığıyla değiştiriyoruz.
10. ☕️ [İsteğe bağlı] Çok formatlı işlem hattı (salt okunur) - aracı katmanı
Aracı katmanı, görevleri tamamlamak için araçları kullanan yapay zeka temsilcilerini tanımlar. Her aracının belirli bir rolü vardır ve bağlamı bir sonraki aracıya iletir. Aşağıda, çoklu aracı sisteminin mimari diyagramı yer almaktadır.
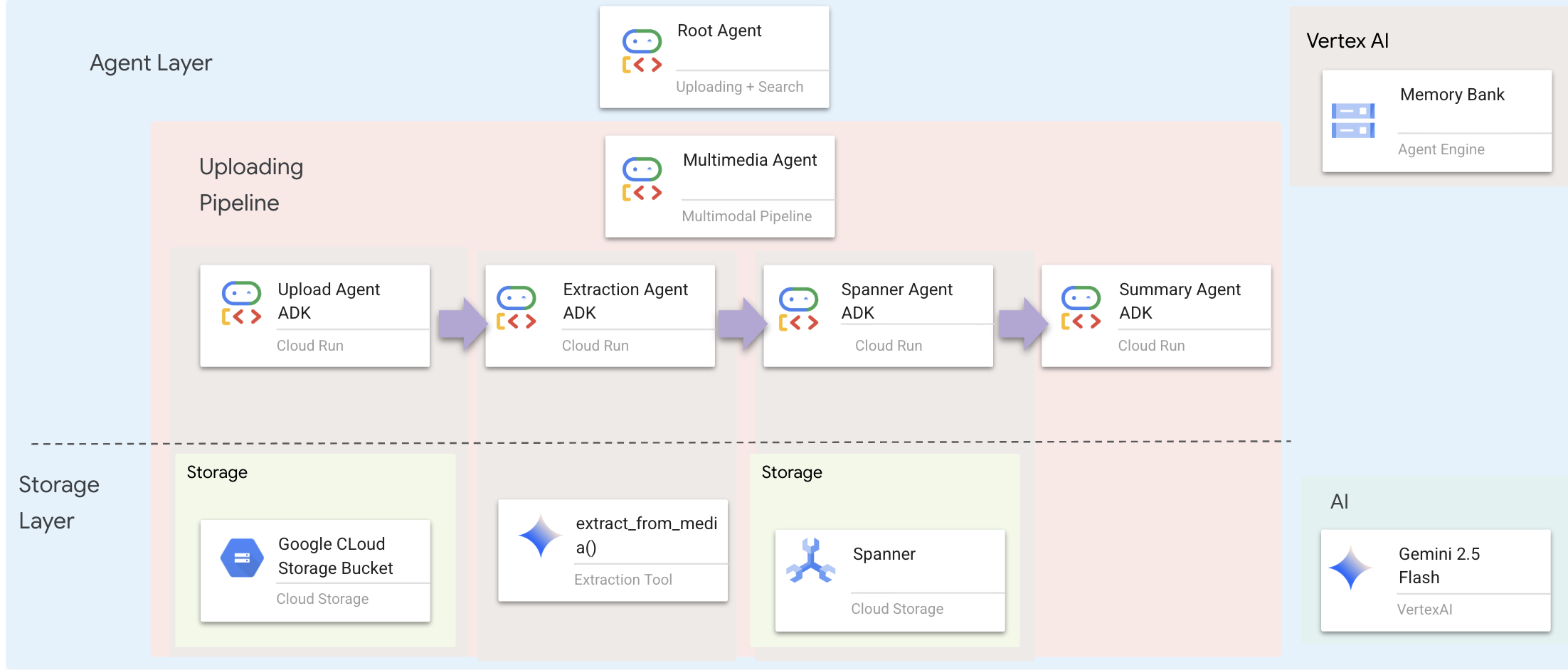
1. Temsilci Dosyasını Açma
👉💻 Dosyayı açın level_2/backend/agent/multimedia_agent.py veya terminalde aşağıdaki komutu yazın. Yeni bir terminal açın. Terminalde dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Yükleme aracısını tanımlama
Bu temsilci, kullanıcının mesajından bir dosya yolu çıkarır ve bunu GCS'ye yükler.
👉multimedia_agent.py dosyasında, aşağıdaki kodla birlikte GCS'ye yüklenen upload_agent oluşturulur:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Ayıklama aracısını tanımlama
Bu aracı, yüklenen medyayı "görür" ve Gemini Vision'ı kullanarak yapılandırılmış verileri ayıklar.
👉Dosyada multimedia_agent.py, aşağıdaki kodla birlikte, yüklenen medyadan bilgi ayıklayan extraction_agent oluşturulur:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
instructionReferansların{upload_result} nasıl kullanıldığına dikkat edin. ADK'daki aracılar arasında durum bu şekilde aktarılır.
4. Spanner aracısını tanımlama
Bu ajan, çıkarılan öğeleri ve ilişkileri grafik veritabanına kaydeder.
👉Dosyada multimedia_agent.py, aşağıdaki kodla birlikte, ayıklanan bilgileri veritabanına kaydeden spanner_agent oluşturulur:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Bu temsilci, önceki her iki adımdan (upload_result ve extraction_result) bağlam bilgisi alır.
5. Özetleme aracısını tanımlama
Bu aracı, önceki tüm adımlardaki sonuçları kullanıcı dostu bir yanıt hâlinde birleştirir.
👉multimedia_agent.py dosyasında, aşağıdaki kodla birlikte sonucu özetleyen summary_agent istemi tanımlanır:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Bu aracının araçlara ihtiyacı yoktur. Paylaşılan bağlamı okur ve kullanıcı için net bir özet oluşturur.
🧠 Mimari Özeti
Katman | Dosya | Sorumluluk |
Araçlar |
| Nasıl: Yükleme, ayıklama, kaydetme |
Ajan |
| Ne? Ardışık düzeni düzenleyin. |
11. 🚀 Çok formatlı veri ardışık düzeni — düzenleme
Yeni sistemimizin temelini, backend/agent/multimedia_agent.py içinde tanımlanan MultimediaExtractionPipeline oluşturur. ADK'daki (Agent Development Kit) Sequential Agent (Sıralı Ajan) düzenini kullanır.
1. Neden Sıralı?
Yükleme işleme, doğrusal bir bağımlılık zinciridir:
- Dosyanız (yükleme) olmadan verileri ayıklayamazsınız.
- Verileri ayıklamadığınız (çıkarma) sürece kaydedemezsiniz.
- Sonuçları alana (Kaydet) kadar özetleme yapamazsınız.
Bu işlem için SequentialAgent idealdir. Bir aracının çıkışını bir sonraki aracının bağlamı/girişi olarak iletir.
2. Ajan tanımı
İşlem hattının nasıl bir araya getirildiğine multimedia_agent.py bölümünün en alt kısmında bakalım: 👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Her iki önceki adımdan giriş alır. Yorumu bulun # TODO: REPLACE_ORCHESTRATION. Bu satırın tamamını aşağıdaki kodla değiştirin:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Kök temsilciyle bağlantı kurma
👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Yorumu bulun # TODO: REPLACE_ADD_SUBAGENT. Bu satırın tamamını aşağıdaki kodla değiştirin:
sub_agents=[multimedia_agent],
Bu tek nesne, dört "uzmanı" tek bir çağrılabilir varlıkta etkili bir şekilde birleştirir.
4. Ajanlar Arasındaki Veri Akışı
Her aracı, çıktısını sonraki aracıların erişebileceği paylaşılan bir bağlamda depolar:
5. Uygulamayı açın (Uygulama hâlâ çalışıyorsa bu adımı atlayın)
👉💻 Uygulamayı başlatma:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Terminalde Local: http://localhost:5173/ seçeneğini tıklayın.
6. Test resmi yükleme
👉 Sohbet arayüzünde, buradaki fotoğraflardan herhangi birini seçip kullanıcı arayüzüne yükleyin:
Sohbet arayüzünde, temsilciye bağlamınızla ilgili ayrıntıları verin:
Here is the survivor note
Ardından, görüntüyü buraya ekleyin.

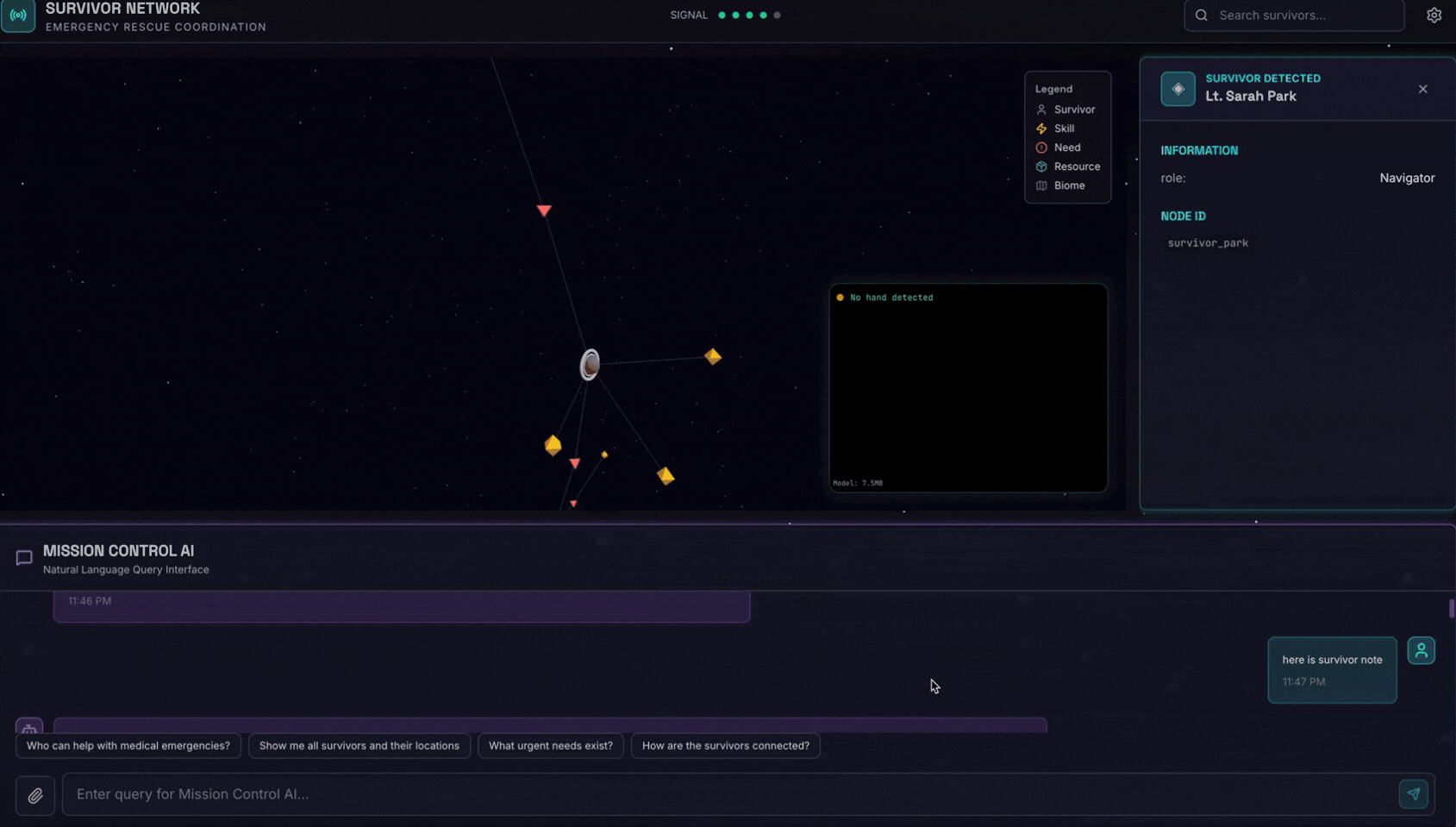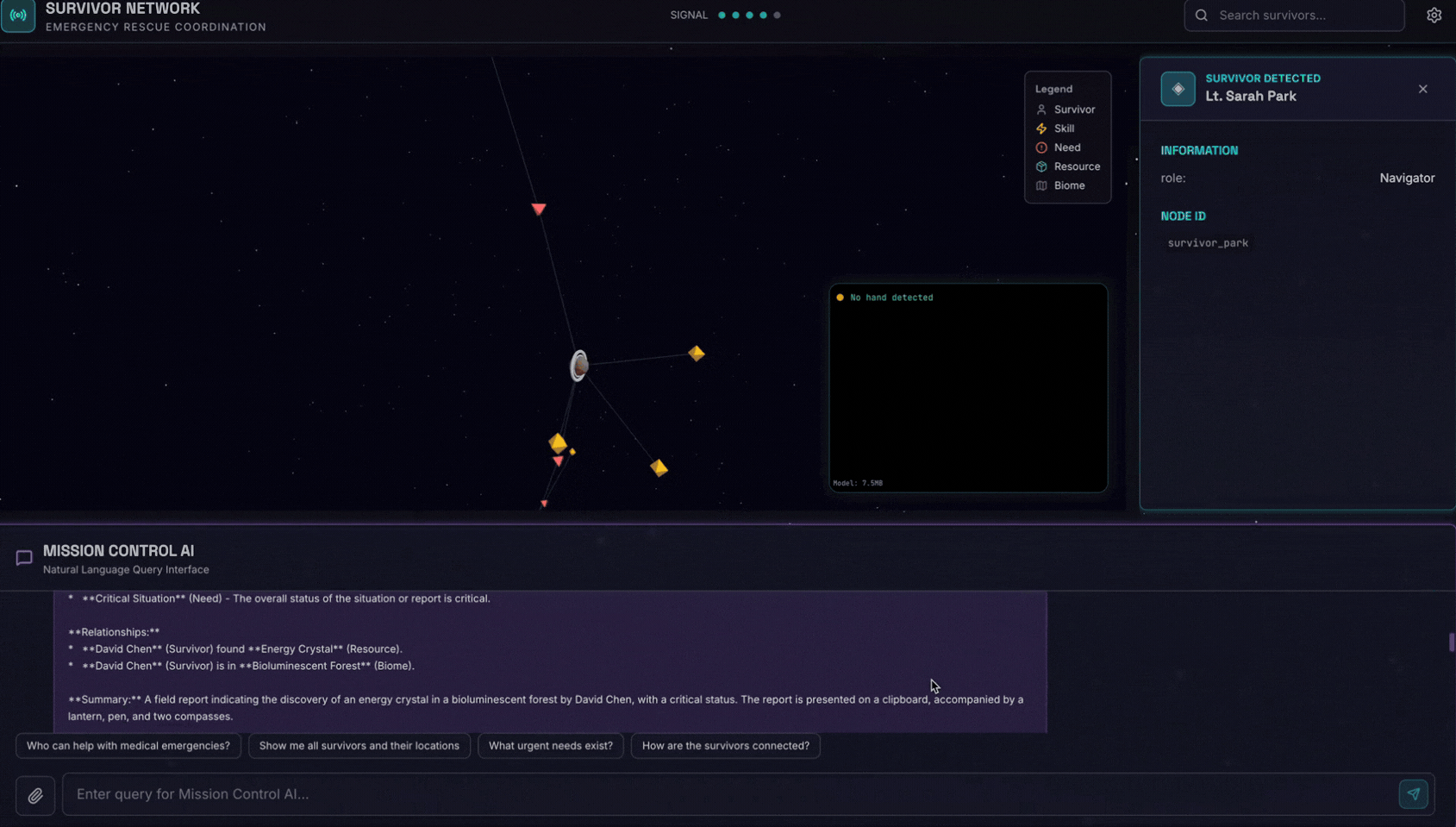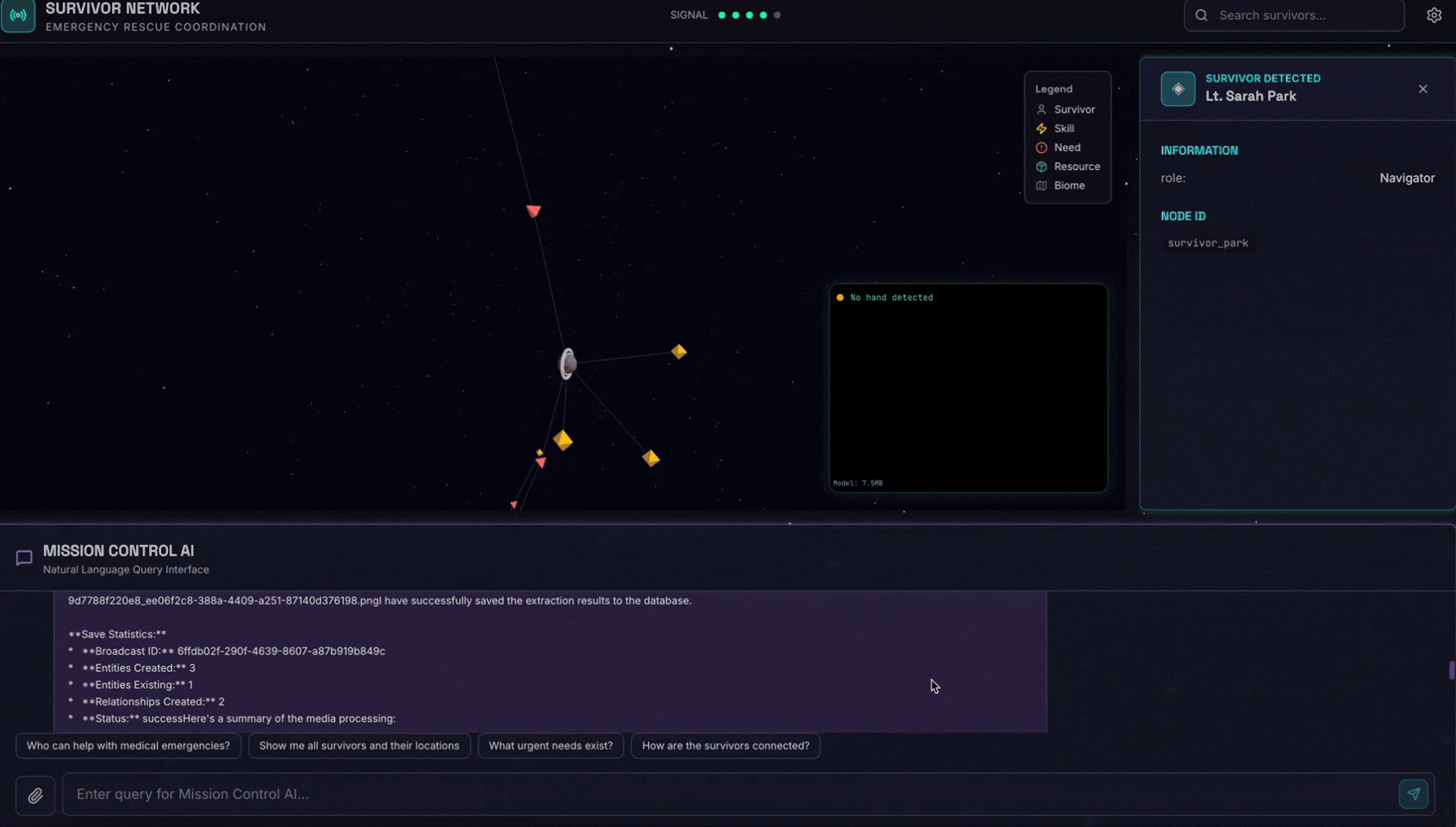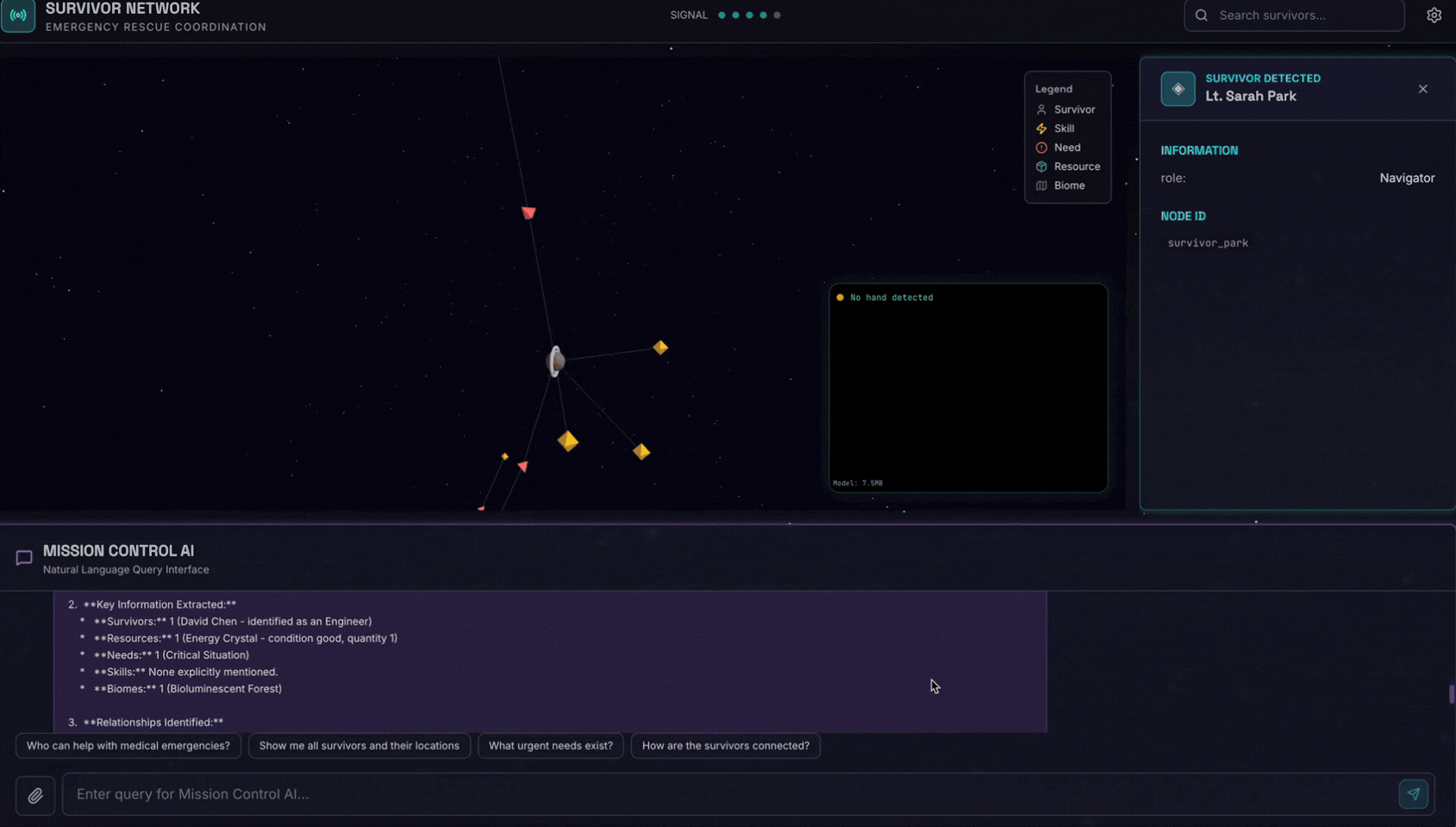
👉💻 Terminalde, testi tamamladığınızda işlemi sonlandırmak için "Ctrl+C" tuşlarına basın.
6. GCS paketinde çok formatlı yüklemeyi doğrulama
- Google Cloud Console Storage'ı açın.
- Cloud Storage'da "paket"i seçin.
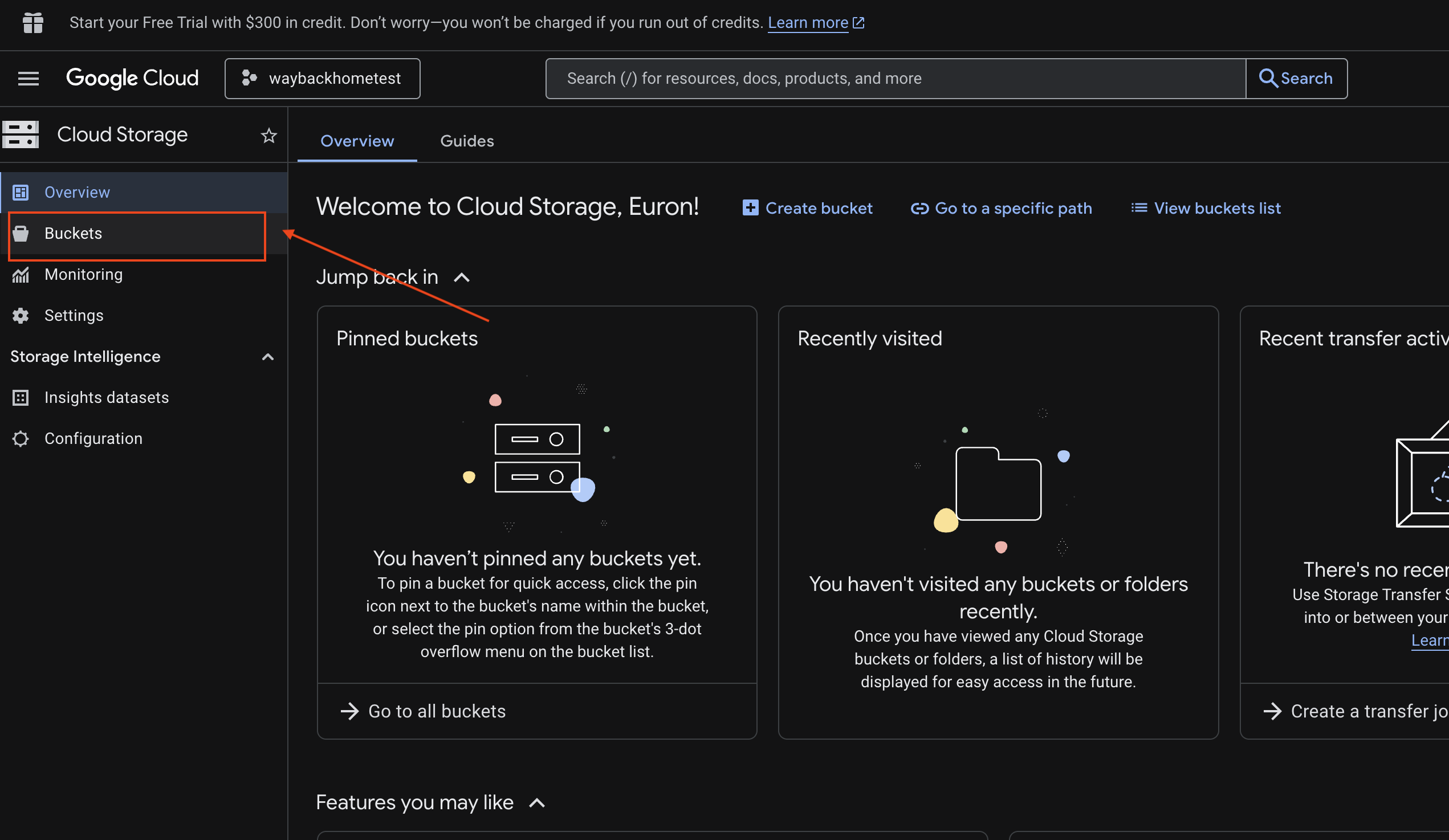
- Paketinizi seçin ve
mediasimgesini tıklayın.
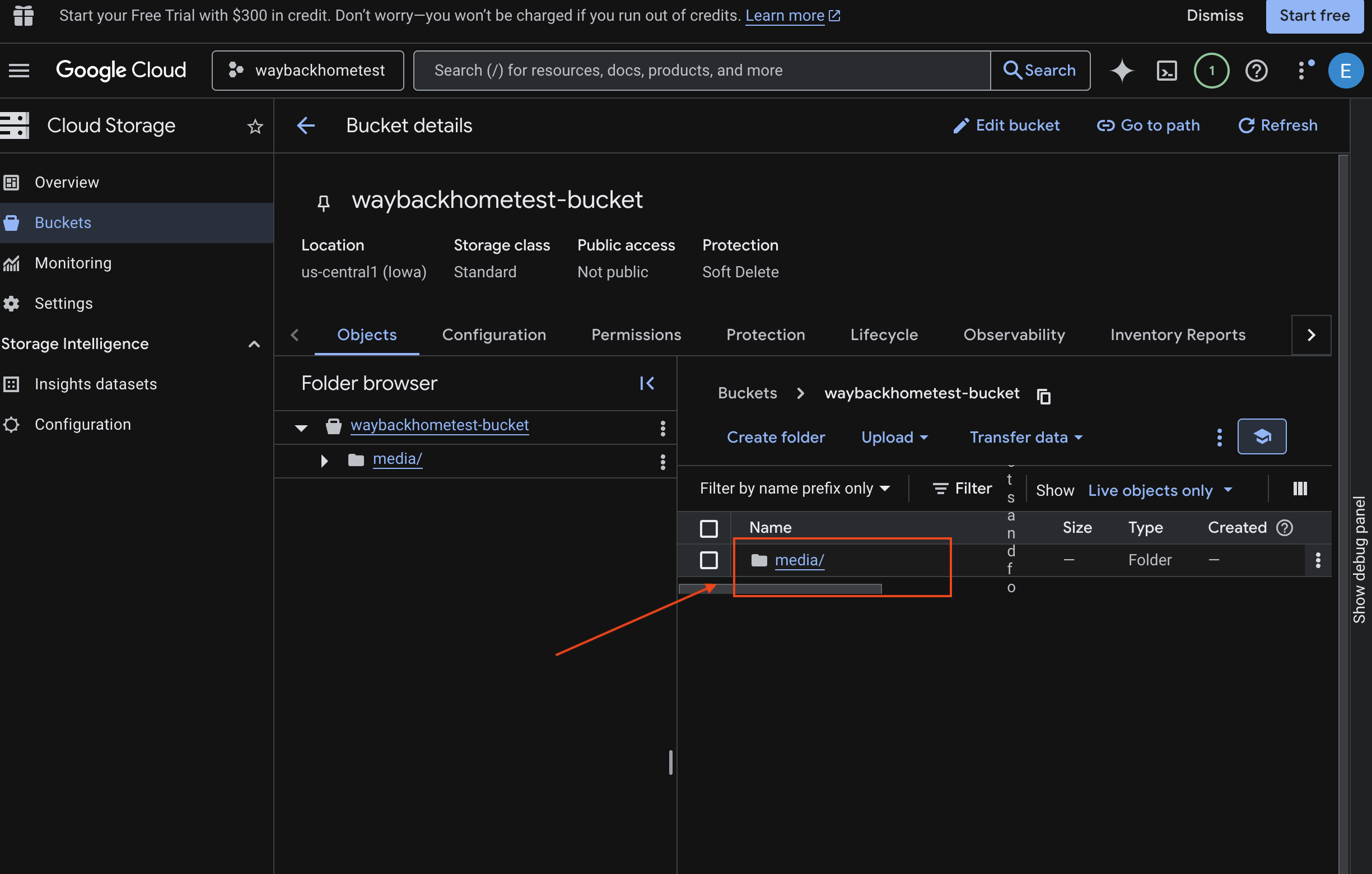
- Yüklediğiniz resmi buradan görüntüleyebilirsiniz.
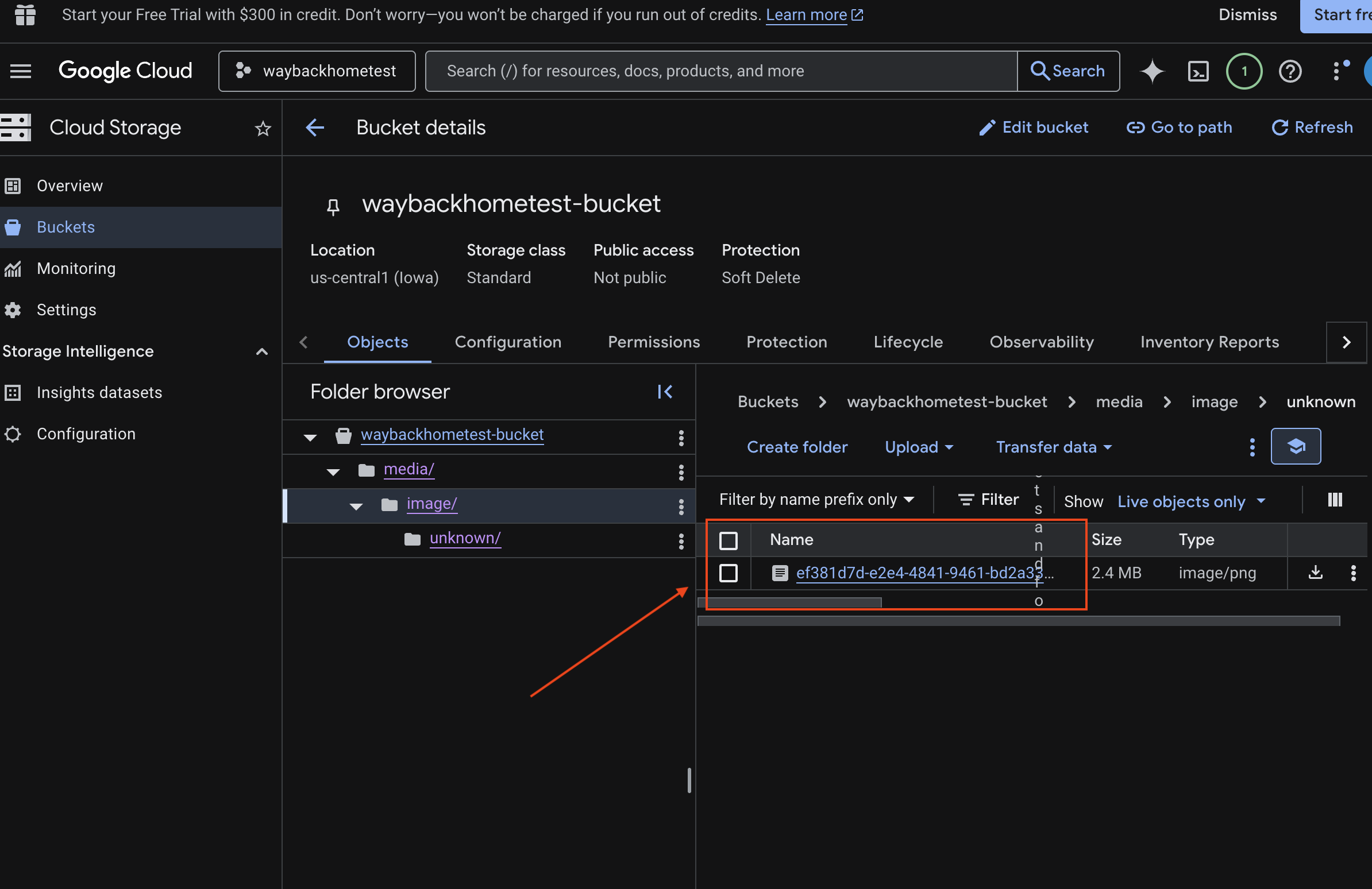
7. Spanner'da çok formatlı yüklemeyi doğrulama (isteğe bağlı)
Aşağıda, test_photo1 için kullanıcı arayüzündeki örnek çıktı verilmiştir.
- Google Cloud Console Spanner'ı açın.
- Örneğinizi seçin:
Survivor Network - Veritabanınızı seçin:
graph-db - Sol kenar çubuğunda Spanner Studio'yu tıklayın.
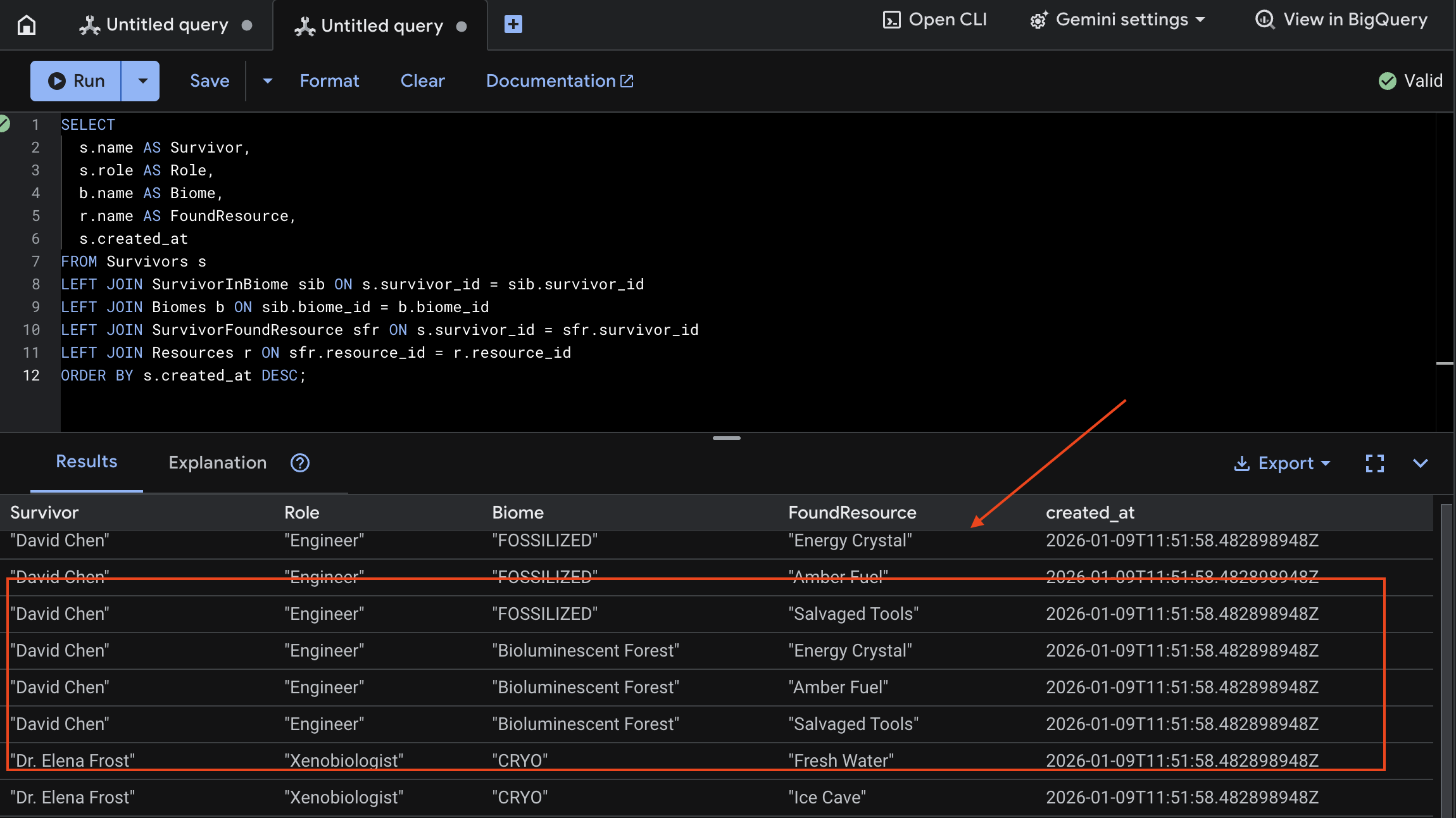
👉 Spanner Studio'da yeni verileri sorgulayın:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Aşağıdaki sonuçtan bunu doğrulayabiliriz:
12. ☕️ [İsteğe bağlı] Agent Engine ile Memory Bank
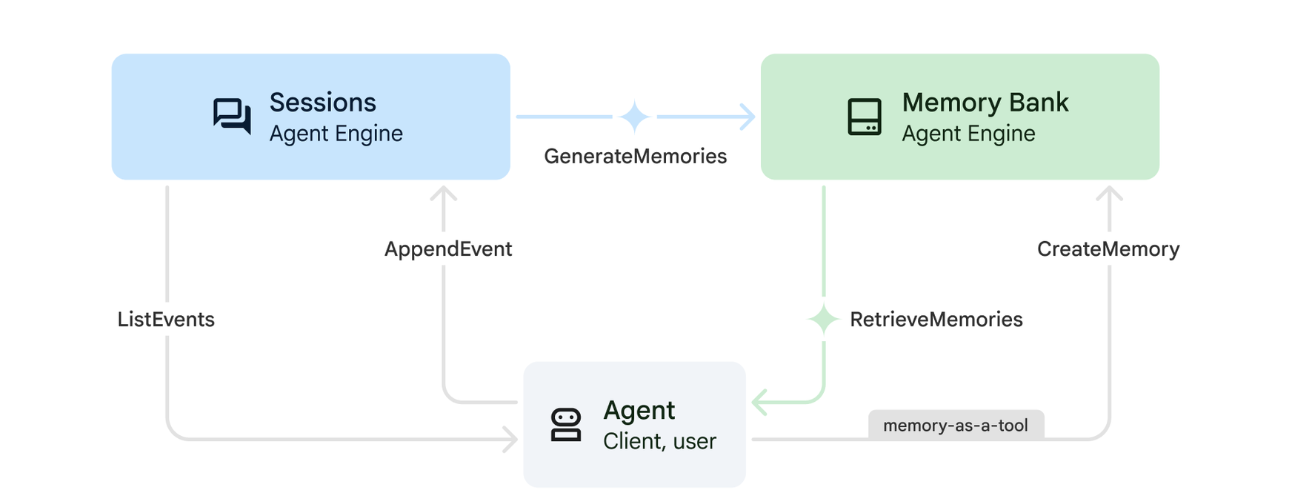
1. Belleğin işleyiş şekli
Sistem, hem anlık bağlamı hem de uzun vadeli öğrenmeyi işlemek için çift bellekli bir yaklaşım kullanır.
2. Anı konuları nedir?
Hafıza Konuları, temsilcinin görüşmelerde hatırlaması gereken bilgi kategorilerini tanımlar. Bunları, farklı kullanıcı tercihlerinin bulunduğu dosya dolapları olarak düşünebilirsiniz.
2 Konumuz:
search_preferences: Kullanıcının arama yapma şekli- Anahtar kelime aramayı mı yoksa semantik aramayı mı tercih ediyorlar?
- Hangi becerileri/biyomları sık sık arıyorlar?
- Örnek bellek: "Kullanıcı, tıbbi beceriler için semantik aramayı tercih ediyor"
urgent_needs_context: Hangi krizleri takip ediyorlar?- Hangi kaynakları izliyorlar?
- Hangi hayatta kalanlarla ilgili endişeleri var?
- Örnek bellek: "Kullanıcı, Kuzey Kampı'nda ilaç kıtlığını takip ediyor"
3. Anı Konularını Ayarlama
Özel bellek konuları, aracının neyi hatırlaması gerektiğini tanımlar. Bunlar, Agent Engine dağıtılırken yapılandırılır.
👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Bu işlemle düzenleyicinizde ~/way-back-home/level_2/backend/deploy_agent.py açılır.
Hangi bilgilerin ayıklanıp kaydedileceği konusunda LLM'ye yol göstermek için yapı MemoryTopic nesnelerini tanımlarız.
👉 deploy_agent.py dosyasında # TODO: SET_UP_TOPIC yerine aşağıdakileri girin:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Aracı Entegrasyonu
Aracı kodu, bilgileri kaydetmek ve almak için Memory Bank'i bilmelidir.
👉💻 Terminalde, aşağıdaki komutu çalıştırarak dosyayı Cloud Shell Düzenleyici'de açın:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Bu işlemle düzenleyicinizde ~/way-back-home/level_2/backend/agent/agent.py açılır.
Aracı Oluşturma
Aracı oluştururken, oturumların etkileşimlerden sonra belleğe kaydedilmesini sağlamak için after_agent_callback değerini iletiyoruz. add_session_to_memory işlevi, sohbet yanıtını yavaşlatmamak için eşzamansız olarak çalışır.
👉 agent.py dosyasında # TODO: REPLACE_ADD_SESSION_MEMORY yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Arka planda kaydetme
👉 agent.py dosyasında # TODO: REPLACE_ADD_MEMORY_BANK_TOOL yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉 agent.py dosyasında # TODO: REPLACE_ADD_CALLBACK yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Vertex AI Session Service'i ayarlama
👉💻 Terminalde, aşağıdaki komutu çalıştırarak Cloud Shell Düzenleyici'de chat.py dosyasını açın:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉chat.py dosyasında # TODO: REPLACE_VERTEXAI_SERVICES yorumunu bulun, Replace this whole line ifadesini aşağıdaki kodla değiştirin:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [İsteğe bağlı] Agent Engine ile temsilci ekleme
1. Kurulum ve Dağıtım
Bellek özelliklerini test etmeden önce aracıyı yeni bellek konularıyla dağıtmanız ve ortamınızın doğru şekilde yapılandırıldığından emin olmanız gerekir.
Bu işlemi kolayca yapabilmeniz için bir komut dosyası sağladık.
Dağıtım Komut Dosyasını Çalıştırma
👉💻 Terminalde dağıtım komut dosyasını çalıştırın:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Bu komut dosyası aşağıdaki işlemleri gerçekleştirir:
- Ajanı ve bellek konularını Vertex AI'ye kaydetmek için
backend/deploy_agent.pykomutunu çalıştırır. - Yeni Agent Engine kimliğini yakalar.
.envdosyanızıAGENT_ENGINE_IDile otomatik olarak günceller.USE_MEMORY_BANK=TRUEöğesinin.envdosyanızda ayarlandığından emin olun.
[!IMPORTANT] custom_topics içinde deploy_agent.py ile ilgili değişiklik yaparsanız Agent Engine'i güncellemek için bu komut dosyasını yeniden çalıştırmanız gerekir.
Memory Bank'ı doğrulama
Artık temsilciye bir tercih öğreterek ve bu tercihin oturumlar arasında kalıcı olup olmadığını kontrol ederek bellek bankasının çalıştığını doğrulayabilirsiniz.
Birinci adım Uygulamayı açın.
Aşağıdaki talimatları uygulayarak uygulamayı tekrar açın: Önceki terminal hâlâ çalışıyorsa Ctrls+C tuşuna basarak sonlandırın.
👉💻 Uygulamayı başlatma:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Terminalde Local: http://localhost:5173/ seçeneğini tıklayın.
İkinci adım Metinle Bellek Bankası'nı Test Etme
Sohbet arayüzünde, temsilciye bağlamınızla ilgili ayrıntıları verin:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Belleğin arka planda işlenmesi için yaklaşık 30 saniye bekleyin.
Üçüncü adım: Yeni oturum başlatma
Mevcut görüşme geçmişini (kısa süreli bellek) temizlemek için sayfayı yenileyin.
Daha önce sağladığınız bağlama dayalı bir soru sorun:
"What kind of missions am I interested in?"
Beklenen Yanıt:
"Önceki görüşmelerinize göre, ilgilendiğiniz konular:
- Tıbbi kurtarma görevleri
- Dağ/yüksek rakım operasyonları
- Gerekli beceriler: ilk yardım, tırmanma
Bu ölçütlere uyan hayatta kalanları bulmamı ister misiniz?"
Dördüncü adım. Resim yükleme ile test etme
Bir resim yükleyip şu soruyu sorun:
remember this
Buradaki fotoğraflardan veya kendi fotoğraflarınızdan birini seçip kullanıcı arayüzüne yükleyebilirsiniz:
Beşinci adım. Vertex AI Agent Engine'de doğrulama
Google Cloud Console Agent Engine'e gidin.
- Sol üstteki proje seçiciden projeyi seçtiğinizden emin olun:
- Önceki komuttan yeni dağıttığınız aracı motorunu doğrulayın
use_memory_bank.sh: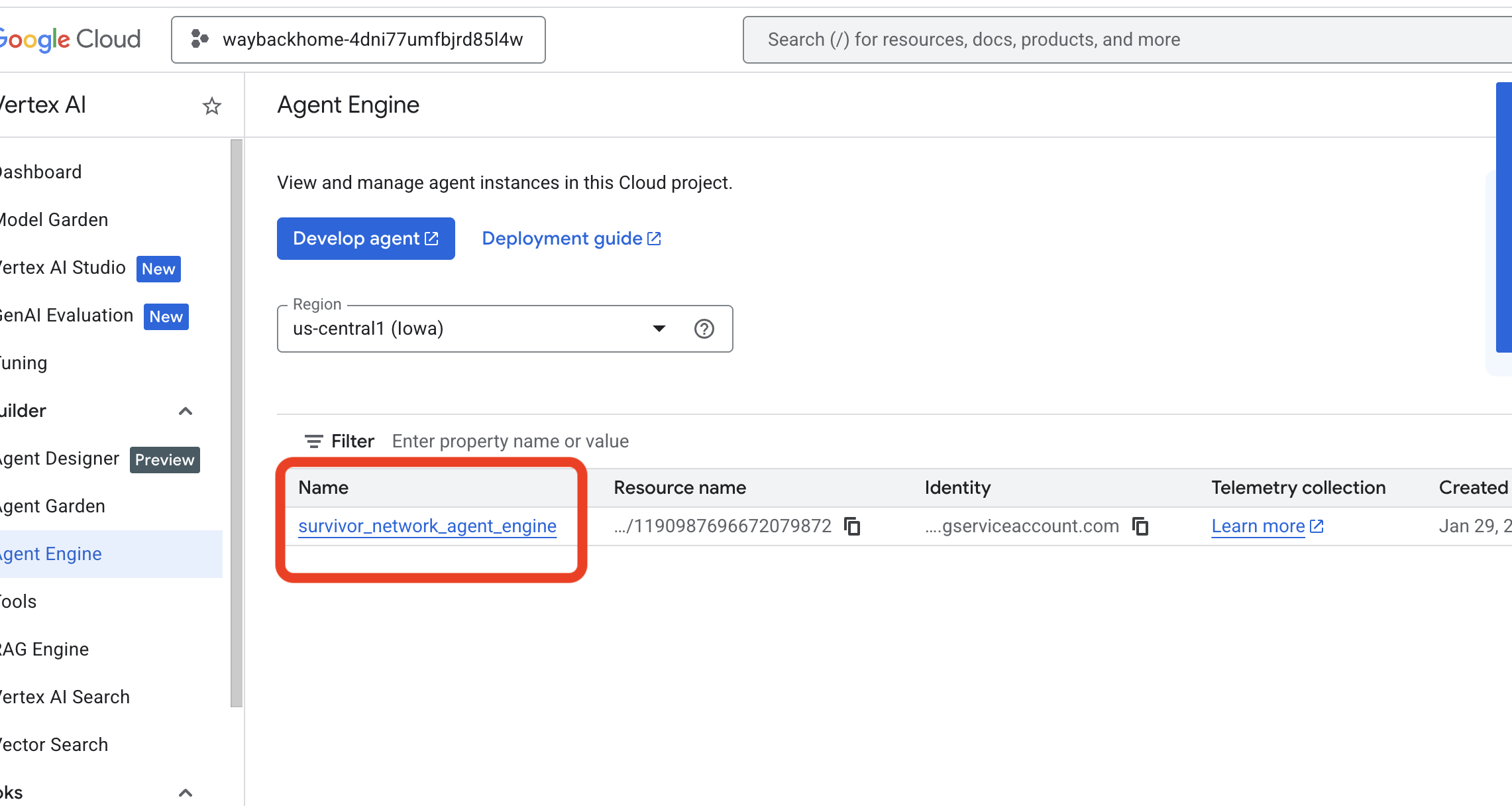 Yeni oluşturduğunuz aracı motorunu tıklayın.
Yeni oluşturduğunuz aracı motorunu tıklayın. - Bu dağıtılmış aracının
Memoriessekmesini tıkladığınızda tüm anıları burada görüntüleyebilirsiniz.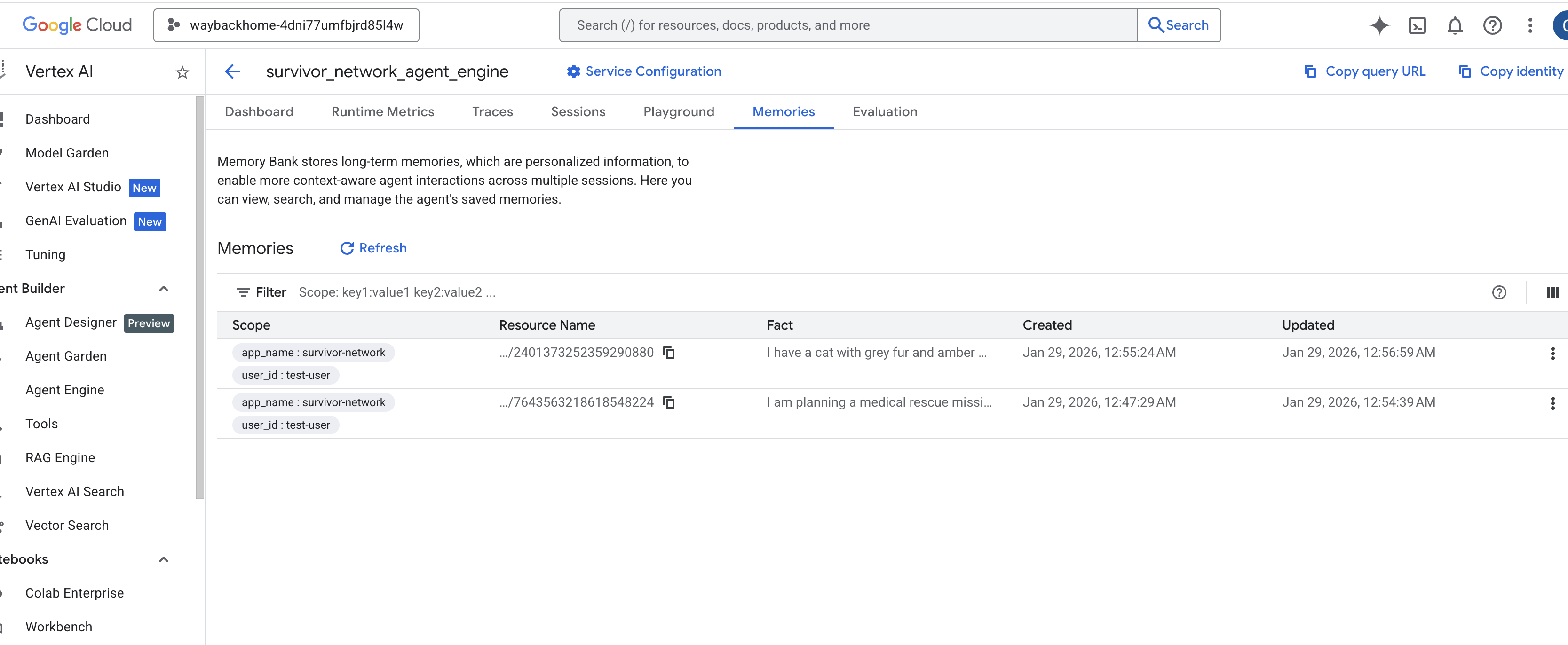
👉💻 Testi tamamladığınızda işlemi sonlandırmak için terminalinizde "Ctrl + C"yi tıklayın.
🎉 Tebrikler! Hafıza bankasını aracınıza bağladınız.
14. ☕️ [İsteğe bağlı] Cloud Run'a dağıtma
1. Dağıtım komut dosyasını çalıştırın
👉💻 Dağıtım komut dosyasını çalıştırın:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Başarıyla dağıtıldıktan sonra URL'yi alırsınız. Bu, sizin için dağıtılan URL'dir. 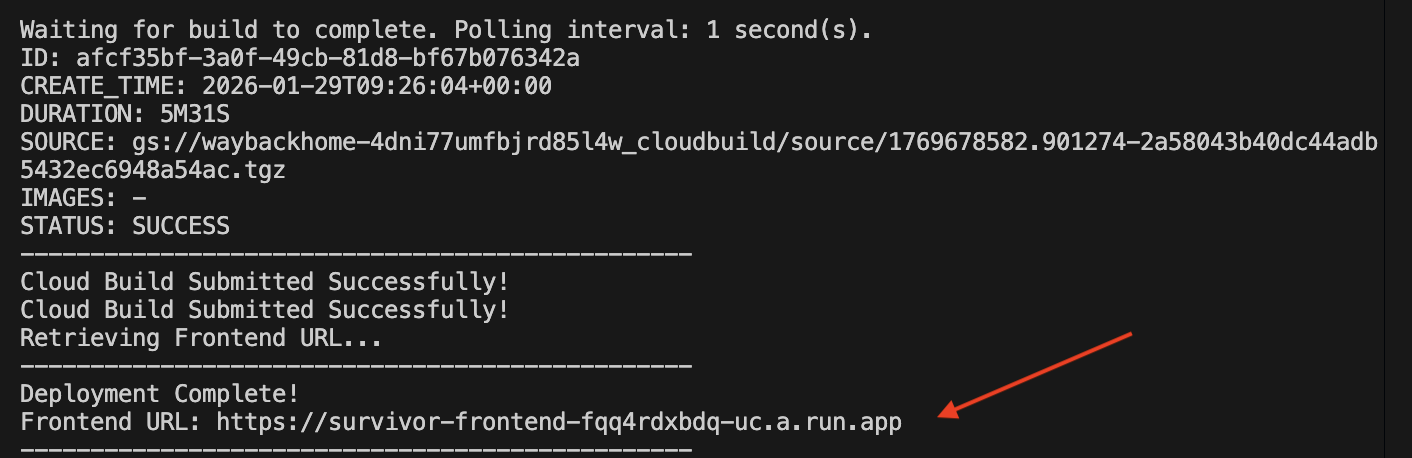
👉💻 URL'yi almadan önce şu komutu çalıştırarak izni verin:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Dağıtılan URL'ye gidin. Uygulamanızın yayında olduğunu göreceksiniz.
2. Derleme ardışık düzenini anlama
cloudbuild.yaml dosyası aşağıdaki sıralı adımları tanımlar:
- Arka uç derlemesi:
backend/Dockerfilekonumundan Docker görüntüsünü oluşturur. - Arka Uç Dağıtımı: Arka uç container'ını Cloud Run'a dağıtır.
- URL'yi yakala: Yeni arka uç URL'sini alır.
- Frontend Build:
- Bağımlılıkları yükler.
VITE_API_URL=öğesini yerleştirerek React uygulamasını oluşturur.
- Frontend Image:
frontend/Dockerfiledosyasından Docker görüntüsü oluşturur (statik öğeleri paketler). - Frontend Deploy: Ön uç kapsayıcısını dağıtır.
3. Dağıtımı doğrulama
Derleme tamamlandıktan sonra (komut dosyası tarafından sağlanan günlükler bağlantısını kontrol edin) şunları doğrulayabilirsiniz:
- Cloud Run Console'a gidin.
survivor-frontendhizmetini bulun.- Uygulamayı açmak için URL'yi tıklayın.
- Ön ucun arka uçla iletişim kurabildiğinden emin olmak için bir arama sorgusu yapın.
(İSTEĞE BAĞLI) 4. Manuel Dağıtım
Komutları manuel olarak çalıştırmayı veya süreci daha iyi anlamayı tercih ederseniz cloudbuild.yaml doğrudan nasıl kullanılacağını burada bulabilirsiniz.
Yazma cloudbuild.yaml
cloudbuild.yaml dosyası, Google Cloud Build'e hangi adımların yürütüleceğini bildirir.
- steps: Sıralı işlemlerin listesi. Her adım bir kapsayıcıda (ör.
docker,gcloud,node,bash) çalışır. - substitutions: Derleme süresinde iletilebilen değişkenler (ör.
$_REGION). - workspace: Adımların dosya paylaşabileceği ortak bir dizin (ör.
backend_url.txtpaylaşımı).
Dağıtımı çalıştırma
Komut dosyası olmadan manuel olarak dağıtmak için gcloud builds submit komutunu kullanın. Gerekli değiştirme değişkenlerini İLETMEK ZORUNLUDUR.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Sonuç
1. Oluşturduklarınız
✅ Grafik Veritabanı: Düğümler (hayatta kalanlar, beceriler) ve kenarlar (ilişkiler) içeren Spanner
✅ Yapay Zeka Arama: Yerleştirmelerle anahtar kelime, anlamsal ve karma arama
✅ Çok Formatlı İşlem Hattı: Gemini ile resimlerden/videolardan öğe çıkarma
✅ Çok Aracılı Sistem: ADK ile koordineli iş akışı
✅ Bellek Bankası: Vertex AI ile uzun vadeli kişiselleştirme
✅ Üretim Dağıtımı: Cloud Run + Agent Engine
2. Mimari Özeti
3. En önemli noktalar
- Graph RAG: Akıllı arama için grafik veritabanı yapısını semantik yerleştirmelerle birleştirir.
- Çoklu Ajan Kalıpları: Karmaşık ve çok adımlı iş akışları için sıralı işlem hatları
- Çok formatlı yapay zeka: Yapılandırılmamış medyadan (resimler/video) yapılandırılmış verileri ayıklama
- Durumlu Ajanlar: Memory Bank, oturumlar arasında kişiselleştirme yapılmasını sağlar.
4. Atölye İçeriği
- Level0: Kendinizi Tanıtın
- Level1: Pinpoint Konumu
- Level2 This One: Graph RAG, ADK ve Memory Bank ile Çok Formatlı Yapay Zeka Ajanı Oluşturma
- Level3: ADK Çift Yönlü Akış Aracısı Oluşturma
- Level4: Live Bidirectional Multi-Agent system
- Level5: Google ADK, A2A ve Kafka ile Olay Odaklı Mimari
5. Kaynaklar
- ADK Dokümanları
- Spanner Graph
- Memory Bank Guide (Bellek Bankası Kılavuzu)
- GitHub deposu