
1. Giới thiệu

1. Thách thức
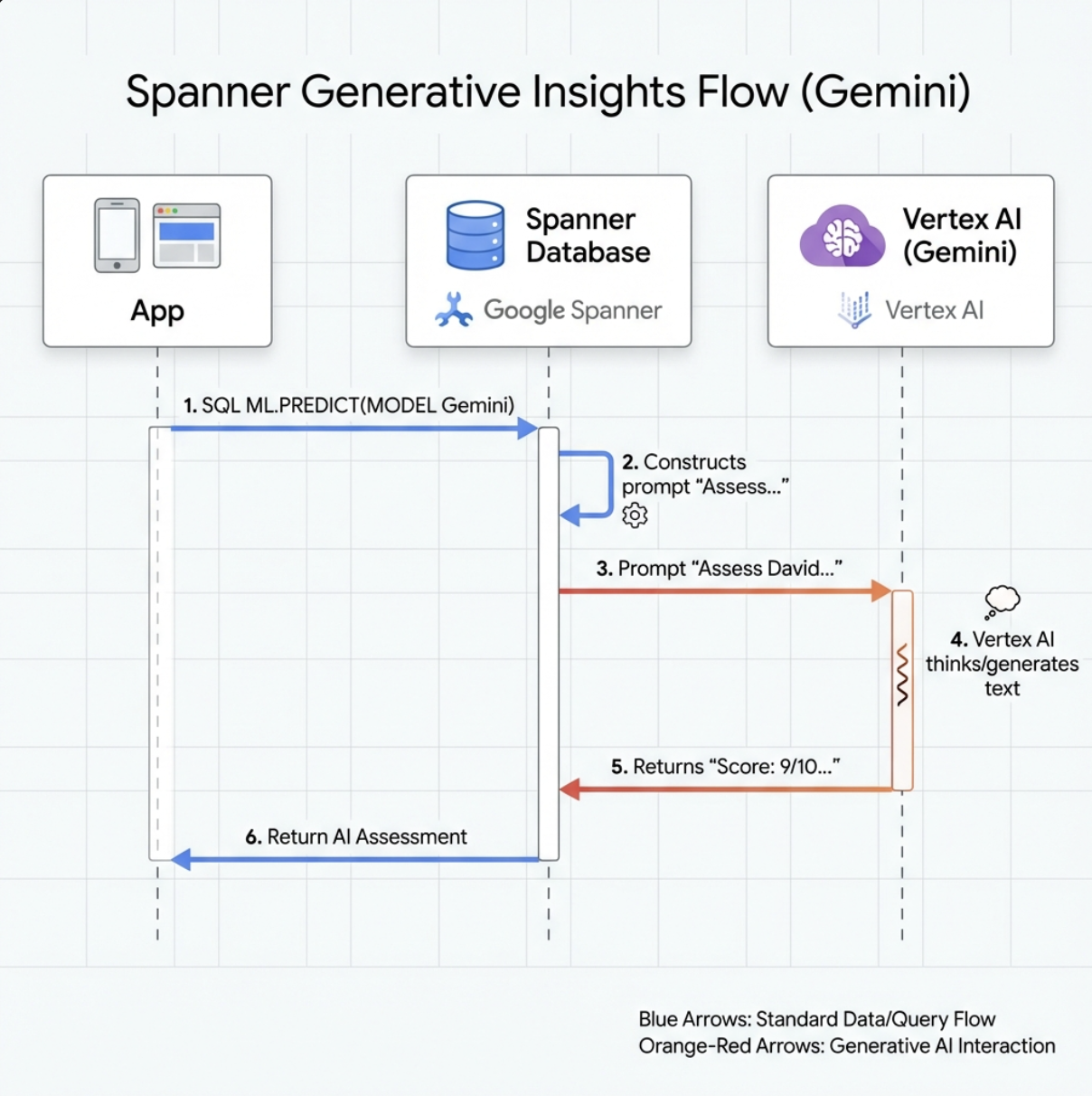
Trong các tình huống ứng phó thảm hoạ, việc điều phối những người sống sót có kỹ năng, nguồn lực và nhu cầu khác nhau ở nhiều địa điểm đòi hỏi khả năng quản lý và tìm kiếm dữ liệu thông minh. Hội thảo này hướng dẫn bạn cách xây dựng một hệ thống AI sản xuất kết hợp:
- 🗄️ Cơ sở dữ liệu đồ thị (Spanner): Lưu trữ các mối quan hệ phức tạp giữa người sống sót, kỹ năng và tài nguyên
- 🔍 Tìm kiếm dựa trên AI: Tìm kiếm kết hợp từ khoá và ngữ nghĩa bằng cách sử dụng các mục nhúng
- 📸 Xử lý đa phương thức: Trích xuất dữ liệu có cấu trúc từ hình ảnh, văn bản và video
- 🤖 Điều phối nhiều tác nhân: Điều phối các tác nhân chuyên biệt cho quy trình làm việc phức tạp
- 🧠 Bộ nhớ dài hạn: Cá nhân hoá bằng Vertex AI Memory Bank
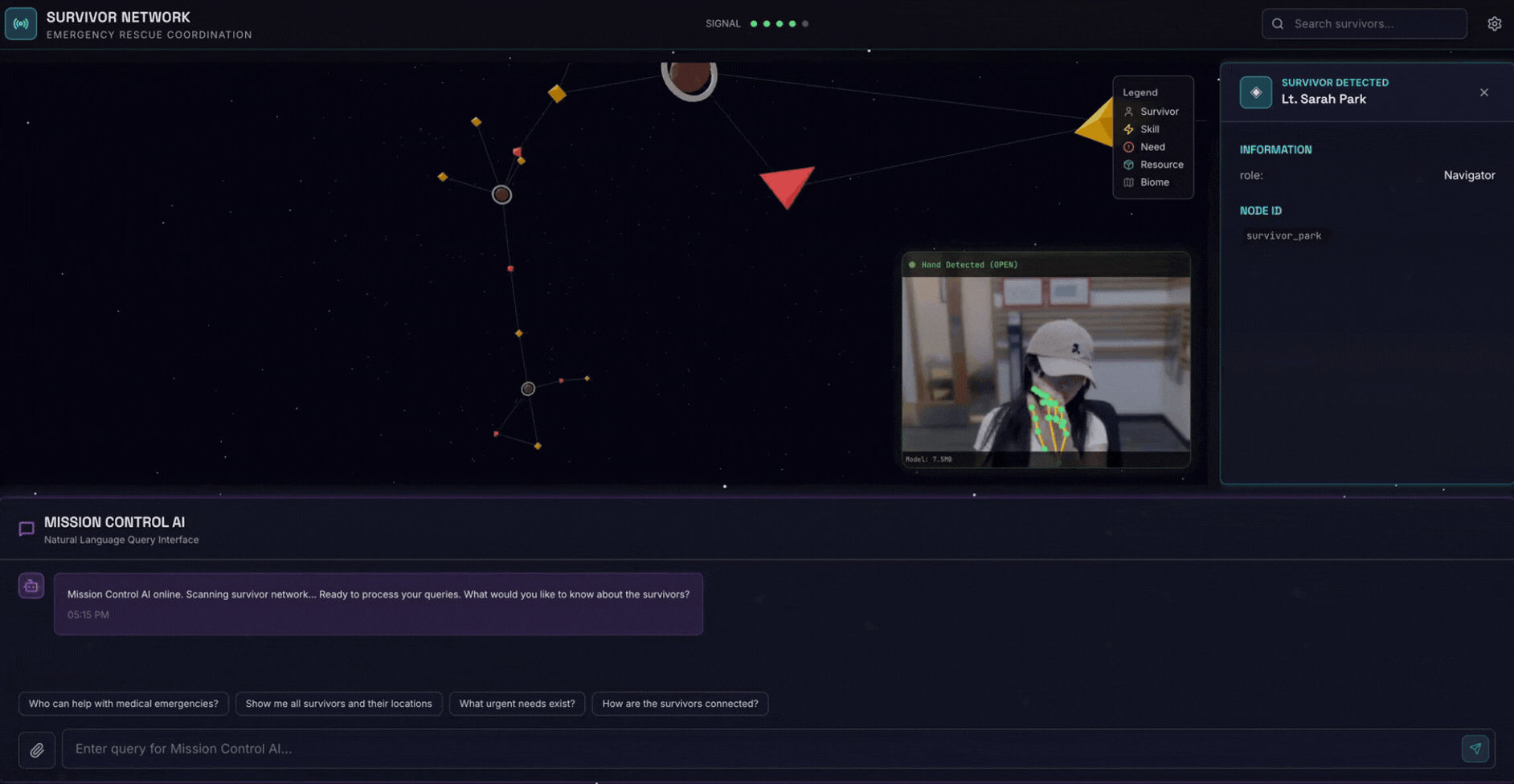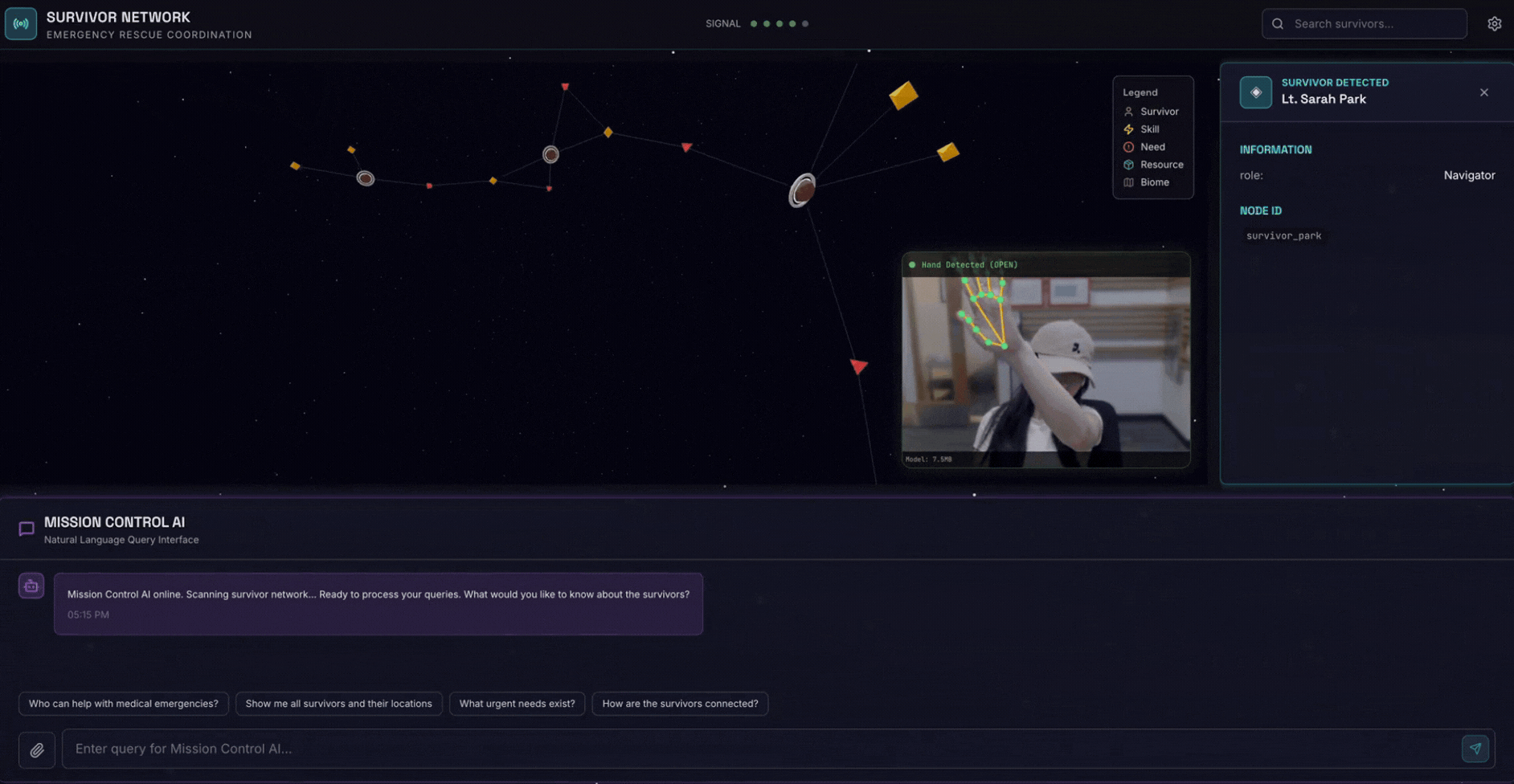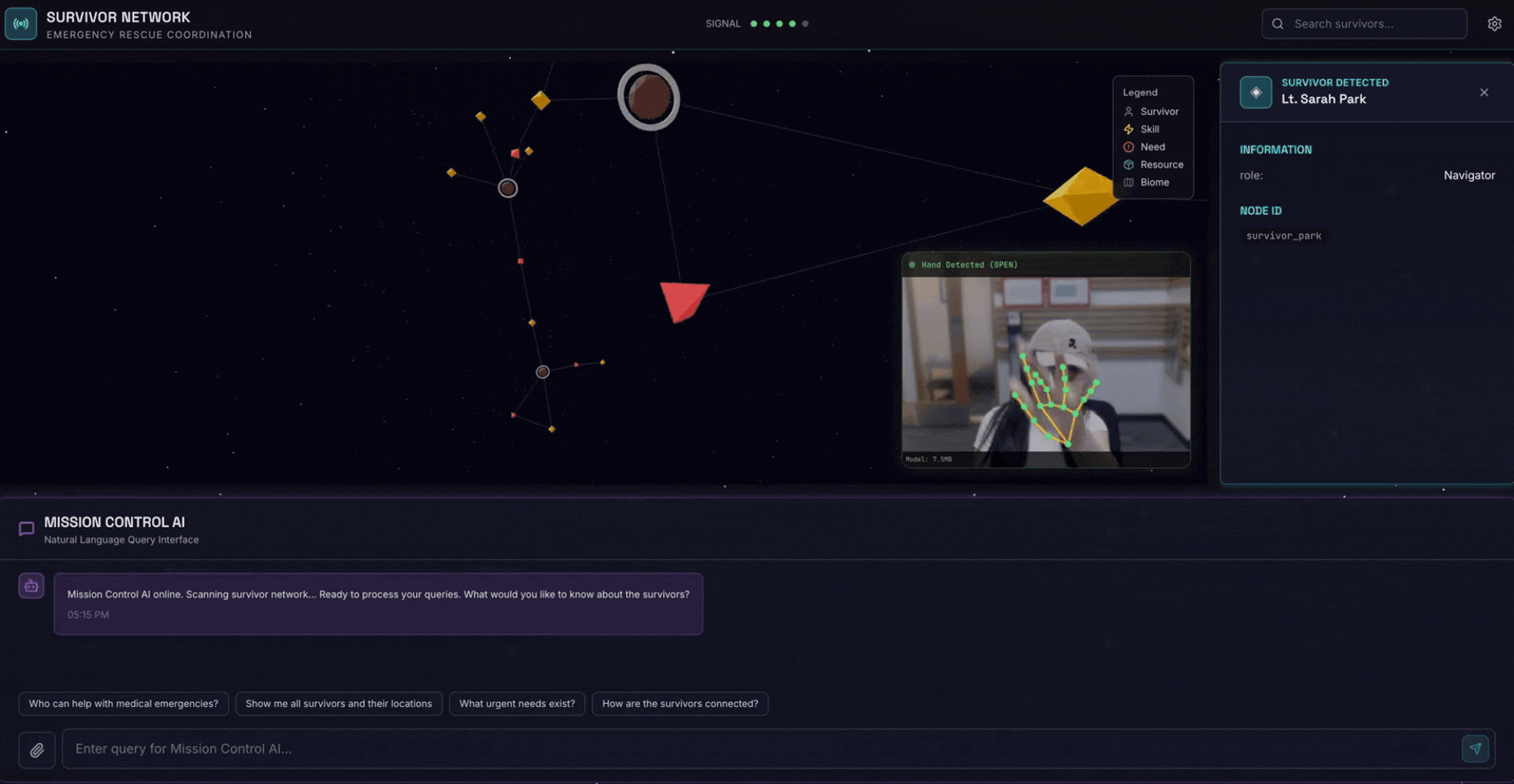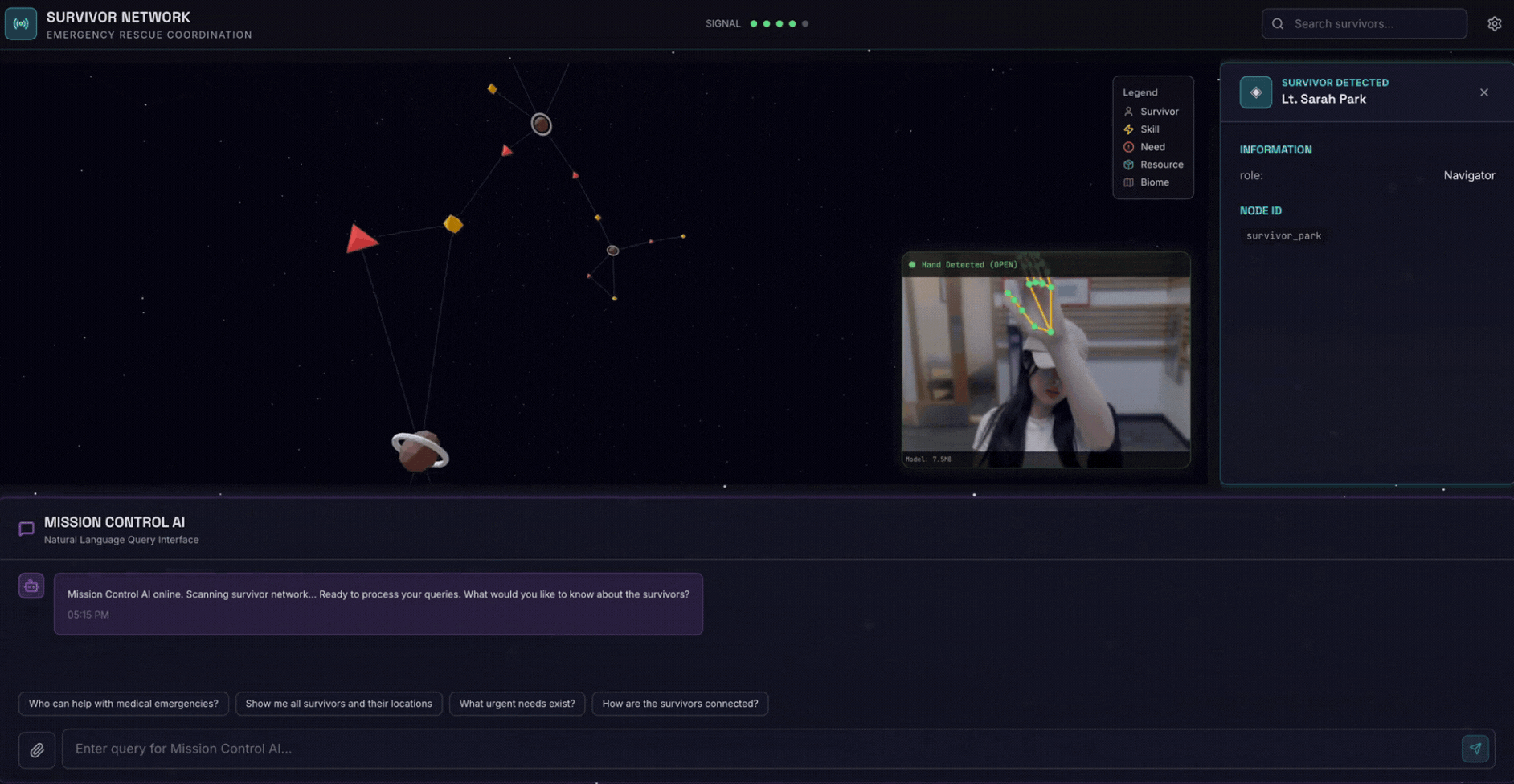
2. Sản phẩm bạn sẽ tạo ra
Một Cơ sở dữ liệu đồ thị mạng lưới cứu trợ với:
- 🗺️ Hình ảnh trực quan về biểu đồ 3D tương tác về mối quan hệ giữa những người sống sót
- 🔍 Tìm kiếm thông minh (từ khoá, ngữ nghĩa và kết hợp)
- 📸 Quy trình tải lên đa phương thức (trích xuất thực thể từ hình ảnh/video)
- 🤖 Hệ thống nhiều tác nhân để điều phối các tác vụ phức tạp
- 🧠 Tích hợp Ngân hàng bộ nhớ để có các lượt tương tác được cá nhân hoá
3. Công nghệ cốt lõi
Thành phần | Công nghệ | Mục đích |
Cơ sở dữ liệu | Biểu đồ Cloud Spanner | Lưu trữ các nút (người sống sót, kỹ năng) và các cạnh (mối quan hệ) |
Tìm kiếm bằng AI | Gemini + Embeddings | Tìm kiếm dựa trên sự hiểu biết về ngữ nghĩa + tìm kiếm tương tự |
Khung tác nhân | ADK (Bộ công cụ phát triển đại lý) | Điều phối quy trình công việc AI |
Bộ nhớ | Vertex AI Memory Bank | Lưu trữ lựa chọn ưu tiên của người dùng trong thời gian dài |
Giao diện người dùng | React + Three.js | Hình ảnh trực quan hoá biểu đồ 3D tương tác |
2. 🛠️ Chuẩn bị môi trường (Bỏ qua nếu bạn đang tham gia Hội thảo)
Phần 1: Bật tài khoản thanh toán
Để chạy lớp học lập trình này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Phần 2: Môi trường mở
- 👉 Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- 👉 Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- 👉 Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- 👉💻 Trong thiết bị đầu cuối, hãy xác minh rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list - 👉💻 Sao chép dự án khởi động trên GitHub:
git clone https://github.com/gca-americas/way-back-home.git
Phần 3: Tạo dự án mới
👉💻 Trong cửa sổ dòng lệnh, hãy thực thi tập lệnh init có thể thực thi và chạy tập lệnh đó:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ Thiết lập môi trường
1. Mở Cloud Shell
Trong cửa sổ dòng lệnh Cloud Shell Editor, nếu cửa sổ dòng lệnh không xuất hiện ở cuối màn hình, hãy mở cửa sổ này:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
2. Định cấu hình dự án
👉💻 Trong thiết bị đầu cuối, hãy đặt mã dự án của bạn:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Bật các API bắt buộc (việc này mất khoảng 2 đến 3 phút):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. Chạy tập lệnh thiết lập
👉💻 Thực thi tập lệnh thiết lập:
cd ~/way-back-home/level_2
./setup.sh
Thao tác này sẽ tạo .env cho bạn. Trong cloudshell, hãy mở dự án way_back_home. Trong thư mục level_2, bạn có thể thấy tệp .env được tạo cho bạn. Nếu không tìm thấy, bạn có thể nhấp vào View -> Toggle Hidden File để xem. 
4. Tải dữ liệu mẫu
👉💻 Chuyển đến phần phụ trợ và cài đặt các phần phụ thuộc:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 Tải dữ liệu ban đầu về người sống sót:
uv run python ~/way-back-home/level_2/backend/setup_data.py
Thao tác này sẽ tạo ra:
- Phiên bản Spanner (
survivor-network) - Cơ sở dữ liệu (
graph-db) - Tất cả các bảng nút và cạnh
- Biểu đồ thuộc tính để truy vấn Kết quả đầu ra dự kiến:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
Nếu nhấp vào đường liên kết sau Access your database at trong đầu ra, bạn có thể mở Google Cloud Console Spanner.

Bạn sẽ thấy Spanner trên Google Cloud Console!
4. 🚀 Trực quan hoá dữ liệu biểu đồ trong Spanner Studio
Hướng dẫn này giúp bạn trực quan hoá và tương tác với dữ liệu biểu đồ Mạng lưới người sống sót ngay trong Google Cloud Console bằng Spanner Studio. Đây là một cách hiệu quả để xác minh dữ liệu và tìm hiểu cấu trúc biểu đồ trước khi tạo tác nhân AI.
1. Truy cập vào Spanner Studio
- Ở bước cuối cùng, hãy nhớ nhấp vào đường liên kết và mở Spanner Studio.
2. Tìm hiểu cấu trúc đồ thị ("Tổng quan")
Hãy xem tập dữ liệu Survivor Network (Mạng lưới người sống sót) như một câu đố logic hoặc một Trạng thái trò chơi:
Thực thể | Vai trò trong hệ thống | Phép loại suy |
Survivors | Các tác nhân/người chơi | Người chơi |
Biomes | Vị trí của các nút | Vùng trên bản đồ |
Kỹ năng | Những việc họ có thể làm | Khả năng |
Nhu cầu | Những điều họ thiếu (Khủng hoảng) | Nhiệm vụ |
Tài nguyên | Các vật phẩm tìm thấy trên thế giới | Loot |
Mục tiêu: Nhiệm vụ của tác nhân AI là kết nối Kỹ năng (Giải pháp) với Nhu cầu (Vấn đề), có tính đến Hệ sinh thái (Các hạn chế về vị trí).
🔗 Cạnh (Mối quan hệ):
SurvivorInBiome: Theo dõi vị tríSurvivorHasSkill: Danh sách các khả năngSurvivorHasNeed: Danh sách các vấn đề đang hoạt độngSurvivorFoundResource: Khoảng không quảng cáo của các mặt hàngSurvivorCanHelp: Mối quan hệ suy luận (AI tính toán mối quan hệ này!)
3. Truy vấn biểu đồ
Hãy chạy một vài truy vấn để xem "Câu chuyện" trong dữ liệu.
Biểu đồ Spanner sử dụng GQL (Ngôn ngữ truy vấn đồ thị). Để chạy một truy vấn, hãy sử dụng GRAPH SurvivorNetwork, theo sau là mẫu so khớp.
👉 Truy vấn 1: Danh sách toàn cầu (Ai ở đâu?) Đây là nền tảng của bạn – việc hiểu rõ vị trí là yếu tố quan trọng đối với hoạt động cứu hộ.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
Bạn sẽ thấy kết quả như bên dưới: 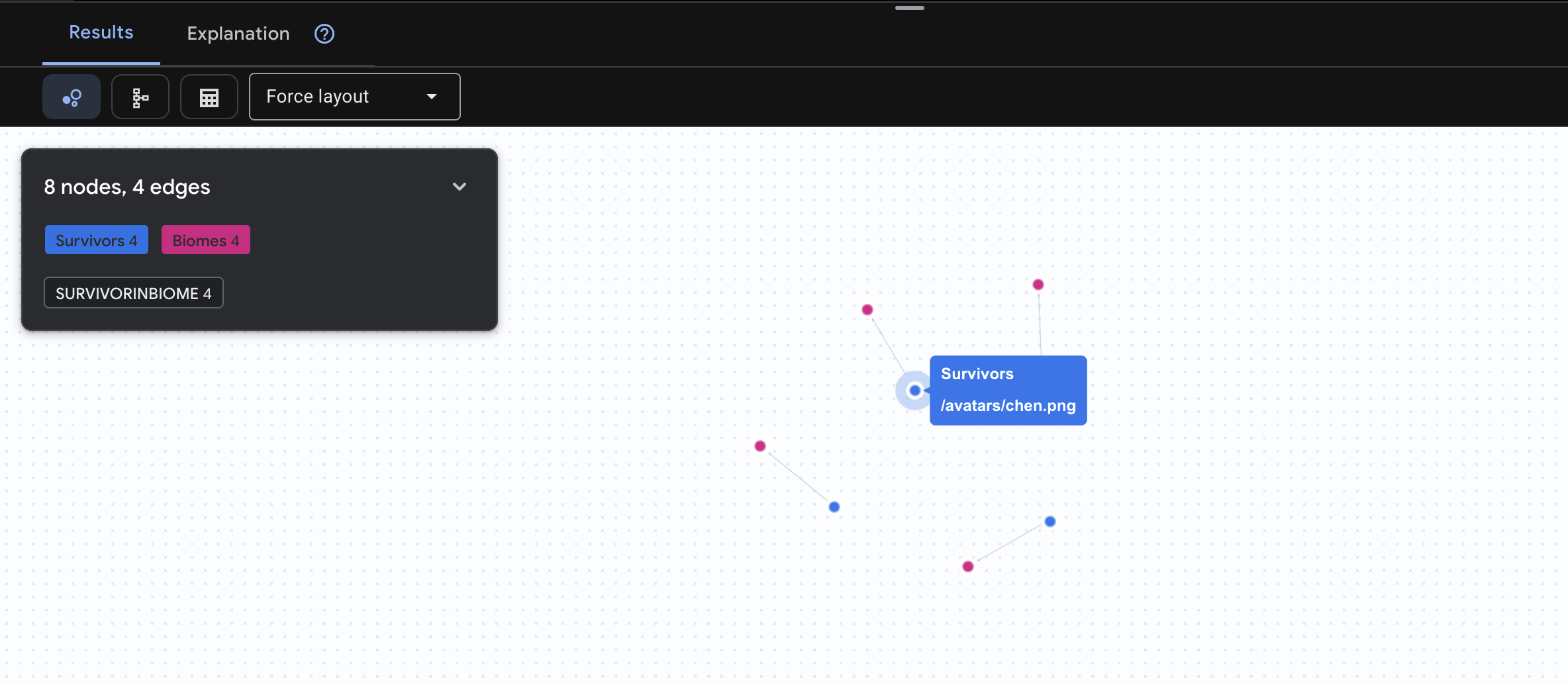
👉 Câu hỏi 2: Ma trận kỹ năng (Khả năng) Giờ đây, khi đã biết vị trí của mọi người, hãy tìm hiểu những việc họ có thể làm.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
Bạn sẽ thấy kết quả như bên dưới: 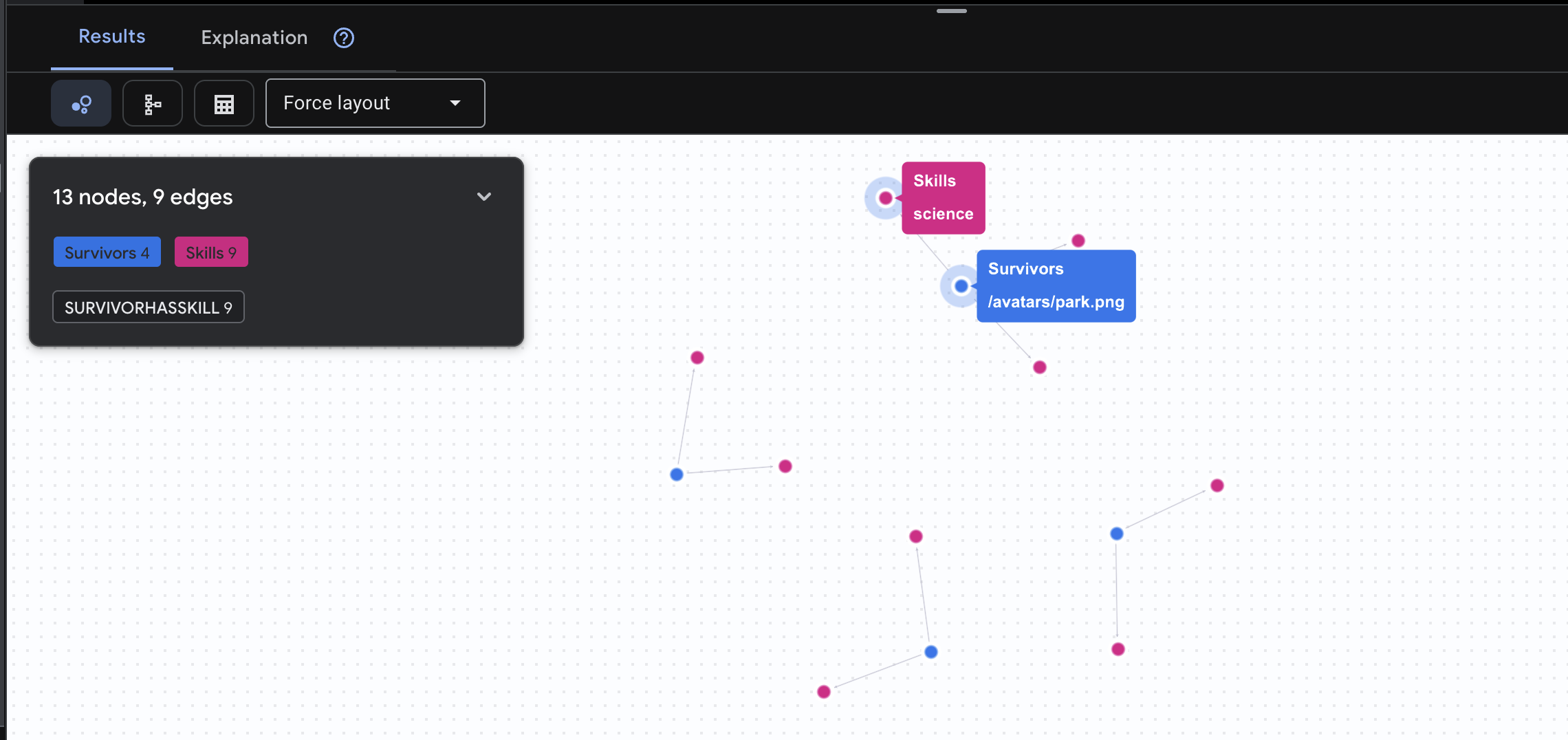
👉 Câu hỏi 3: Ai đang gặp khủng hoảng? (Bảng nhiệm vụ) Xem những người sống sót cần được trợ giúp và những gì họ cần.
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
Bạn sẽ thấy kết quả như bên dưới: 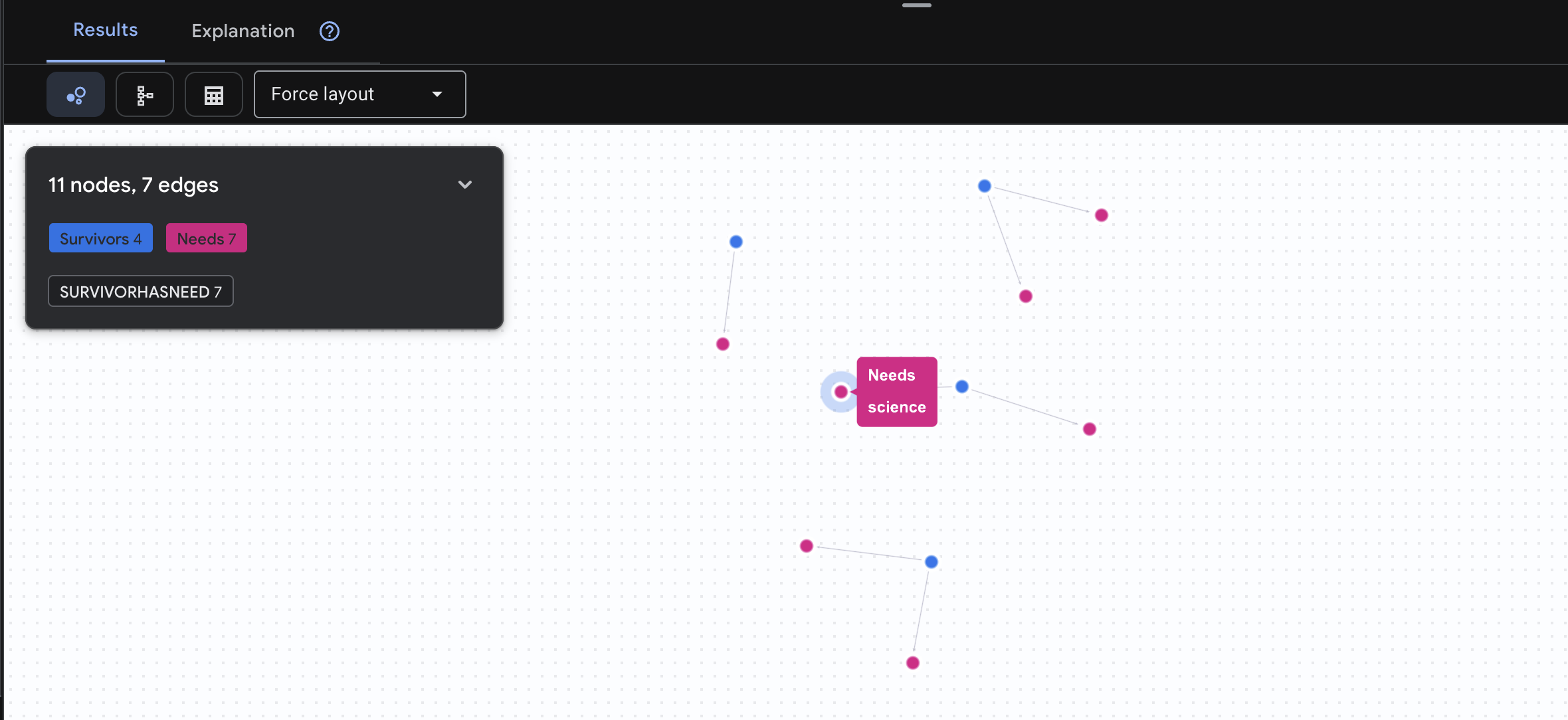
🔎 [Không bắt buộc] Kết nối – Ai có thể giúp ai?
Đây là lúc biểu đồ phát huy sức mạnh! Cụm từ tìm kiếm này sẽ tìm những người sống sót có kỹ năng đáp ứng nhu cầu của những người sống sót khác.
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
Bạn sẽ thấy kết quả như bên dưới: 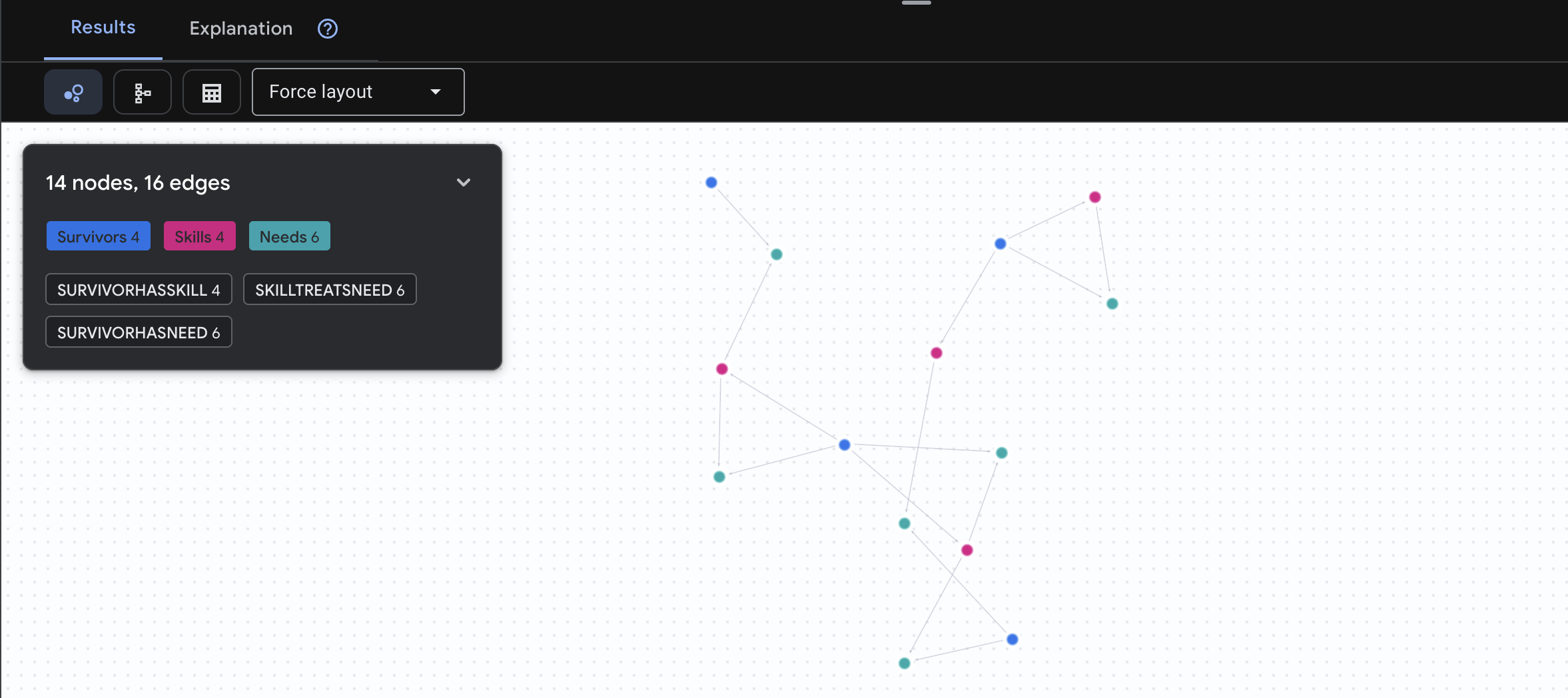
aside positive What This Query Does:
Thay vì chỉ hiển thị "Sơ cứu vết bỏng" (điều này rõ ràng trong giản đồ), truy vấn này sẽ tìm thấy:
- Tiến sĩ Elena Frost (đã được đào tạo về y tế) → có thể điều trị cho → Đội trưởng Tanaka (bị bỏng)
- David Chen (người có kiến thức sơ cứu) → có thể điều trị cho → Trung uý Park (người bị bong gân mắt cá chân)
Lý do khiến tính năng này hiệu quả:
Những việc mà trợ lý AI sẽ làm:
Khi người dùng hỏi "Ai có thể điều trị vết bỏng?", trợ lý sẽ:
- Chạy một truy vấn đồ thị tương tự
- Trả về: "Dr. Frost có kiến thức y khoa và có thể giúp đỡ Đại uý Tanaka"
- Người dùng không cần biết về các bảng hoặc mối quan hệ trung gian!
5. 🚀 Các vectơ nhúng dựa trên AI trong Spanner
1. Tại sao nên sử dụng tính năng nhúng? (Không có hành động, chỉ đọc)
Trong tình huống sinh tồn, thời gian là yếu tố quan trọng. Khi báo cáo trường hợp khẩn cấp, chẳng hạn như I need someone who can treat burns hoặc Looking for a medic, người gặp nạn không thể lãng phí thời gian để đoán tên kỹ năng chính xác trong cơ sở dữ liệu.
Tình huống thực tế: Người sống sót: Captain Tanaka has burns—we need medical help NOW!
Tìm kiếm từ khoá truyền thống cho "nhân viên y tế" → 0 kết quả ❌
Tìm kiếm ngữ nghĩa bằng các vectơ nhúng → Tìm thấy "Đào tạo y tế", "Sơ cứu" ✅
Đây chính xác là những gì mà các nhân viên hỗ trợ cần: khả năng tìm kiếm thông minh như con người, hiểu được ý định chứ không chỉ từ khoá.
2. Tạo mô hình nhúng
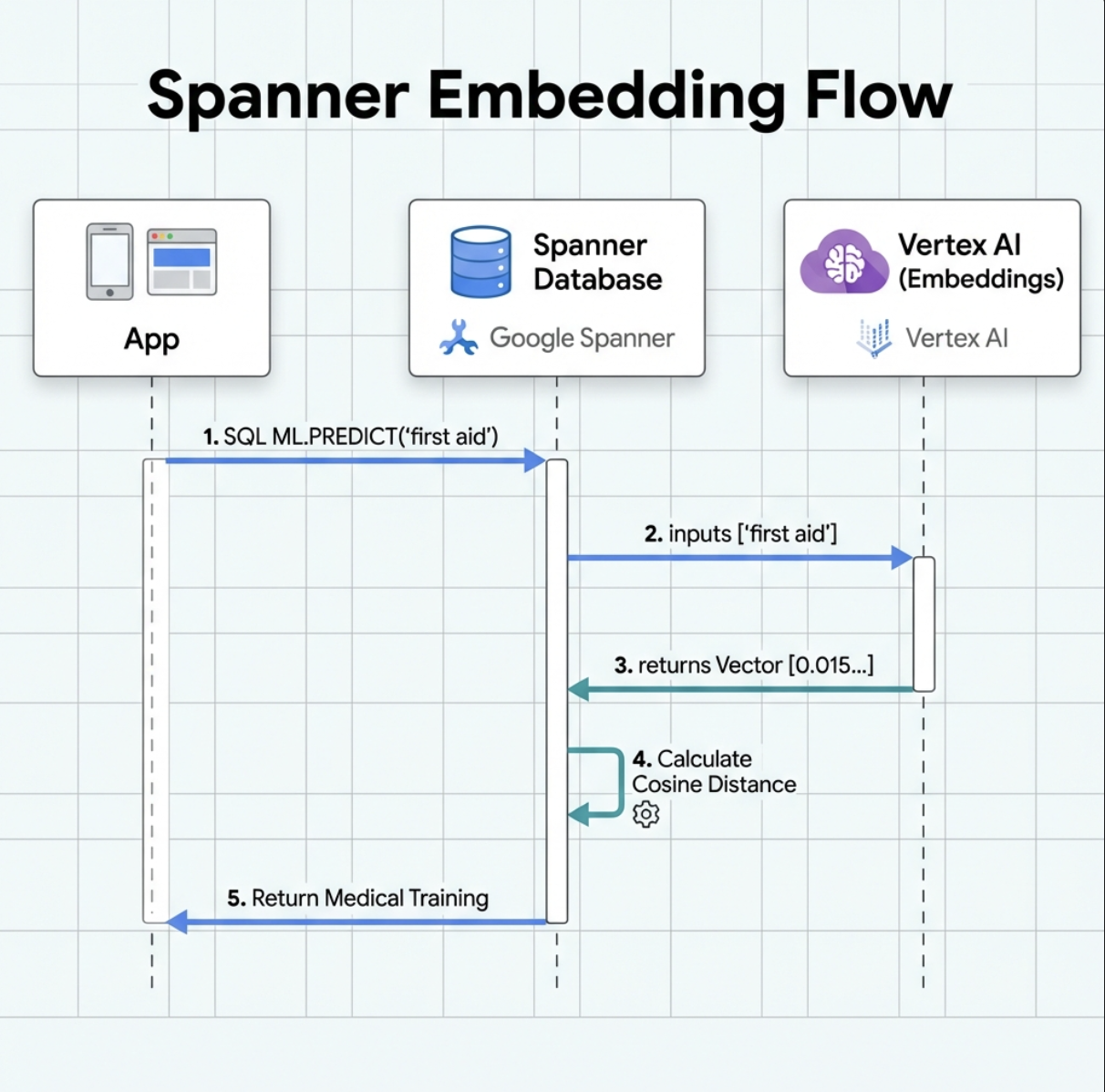
Bây giờ, hãy tạo một mô hình chuyển đổi văn bản thành các mục nhúng bằng cách sử dụng text-embedding-004 của Google.
👉 Trong Spanner Studio, hãy chạy SQL này (thay thế $YOUR_PROJECT_ID bằng mã dự án thực tế của bạn):
‼️ Trong trình chỉnh sửa Cloud Shell, hãy mở File -> Open Folder -> way-back-home/level_2 để xem toàn bộ dự án.
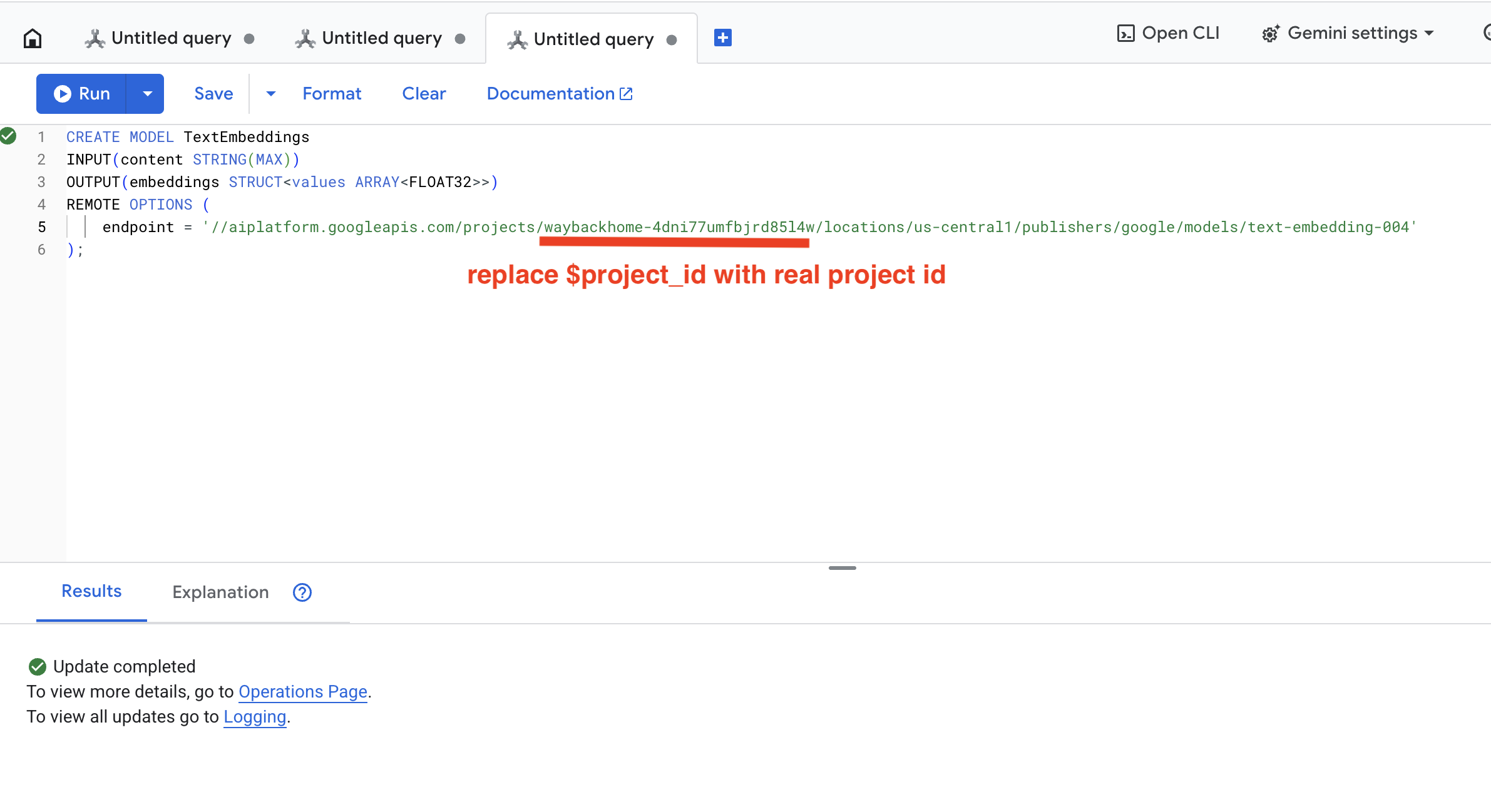
👉 Chạy truy vấn này trong Spanner Studio bằng cách sao chép và dán truy vấn bên dưới, rồi nhấp vào nút Chạy:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
Chức năng của chế độ này:
- Tạo một mô hình ảo trong Spanner (không lưu trữ trọng số mô hình cục bộ)
- Chỉ đến
text-embedding-004của Google trên Vertex AI - Xác định hợp đồng: Đầu vào là văn bản, đầu ra là một mảng số thực 768 chiều
Tại sao lại là "REMOTE OPTIONS" (LỰA CHỌN TỪ XA)?
- Spanner không chạy chính mô hình này
- Công cụ này gọi Vertex AI thông qua API khi bạn sử dụng
ML.PREDICT - Zero-ETL: Không cần xuất dữ liệu sang Python, xử lý và nhập lại
Nhấp vào nút Run. Sau khi thành công, bạn có thể thấy kết quả như sau:
3. Thêm cột nhúng
👉 Thêm một cột để lưu trữ các vectơ nhúng:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
Nhấp vào nút Run. Sau khi thành công, bạn có thể thấy kết quả như sau:
4. Tạo vectơ nhúng
👉 Sử dụng AI để tạo các vectơ nhúng cho từng kỹ năng:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
Nhấp vào nút Run. Sau khi thành công, bạn có thể thấy kết quả như sau:
Điều gì sẽ xảy ra: Mỗi tên kỹ năng (ví dụ: "sơ cứu") được chuyển đổi thành một vectơ 768 chiều biểu thị ý nghĩa ngữ nghĩa của kỹ năng đó.
5. Xác minh các vectơ nhúng
👉 Kiểm tra để đảm bảo bạn đã tạo các thành phần nhúng:
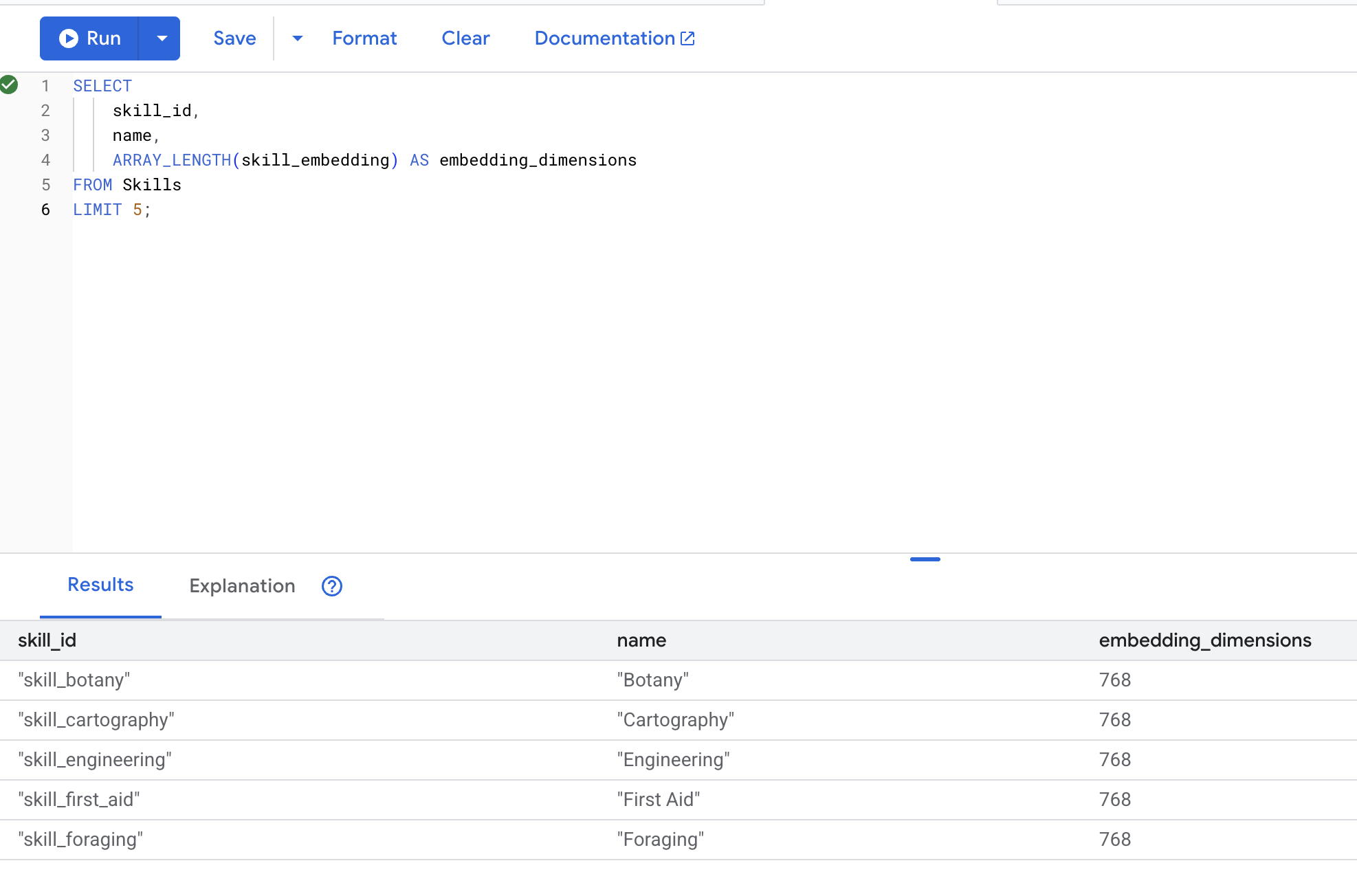
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
Kết quả đầu ra dự kiến:
6. Kiểm thử tính năng Tìm kiếm ngữ nghĩa
Giờ đây, chúng ta sẽ kiểm thử chính xác trường hợp sử dụng trong tình huống của mình: tìm kiếm các kỹ năng y tế bằng cụm từ "nhân viên y tế".
👉 Tìm các kỹ năng tương tự như "nhân viên y tế":
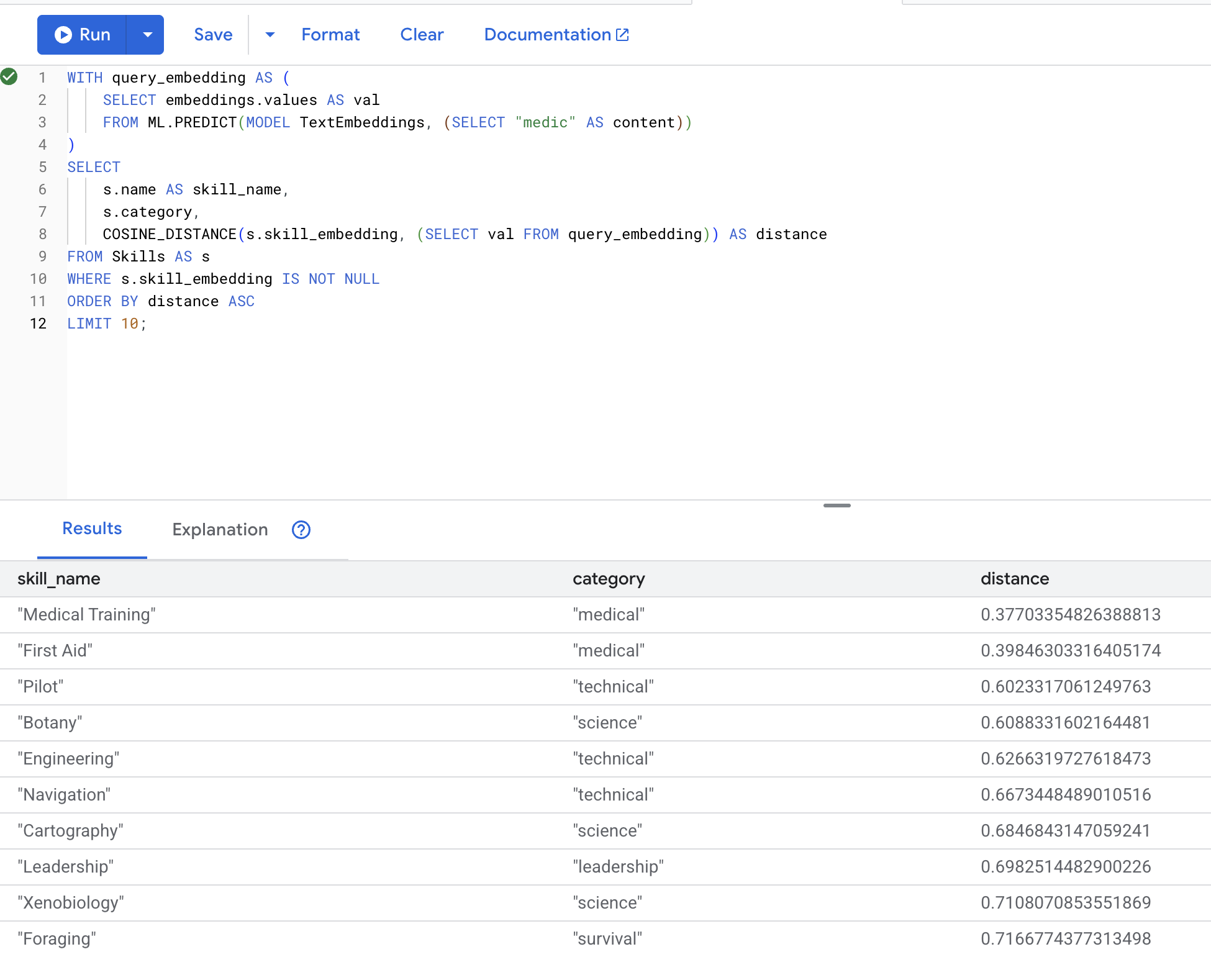
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- Chuyển đổi cụm từ tìm kiếm "medic" của người dùng thành một mục nhúng
- Lưu trữ trong bảng tạm thời
query_embedding
Kết quả dự kiến (khoảng cách càng nhỏ thì càng giống nhau):
7. Tạo mô hình Gemini để phân tích
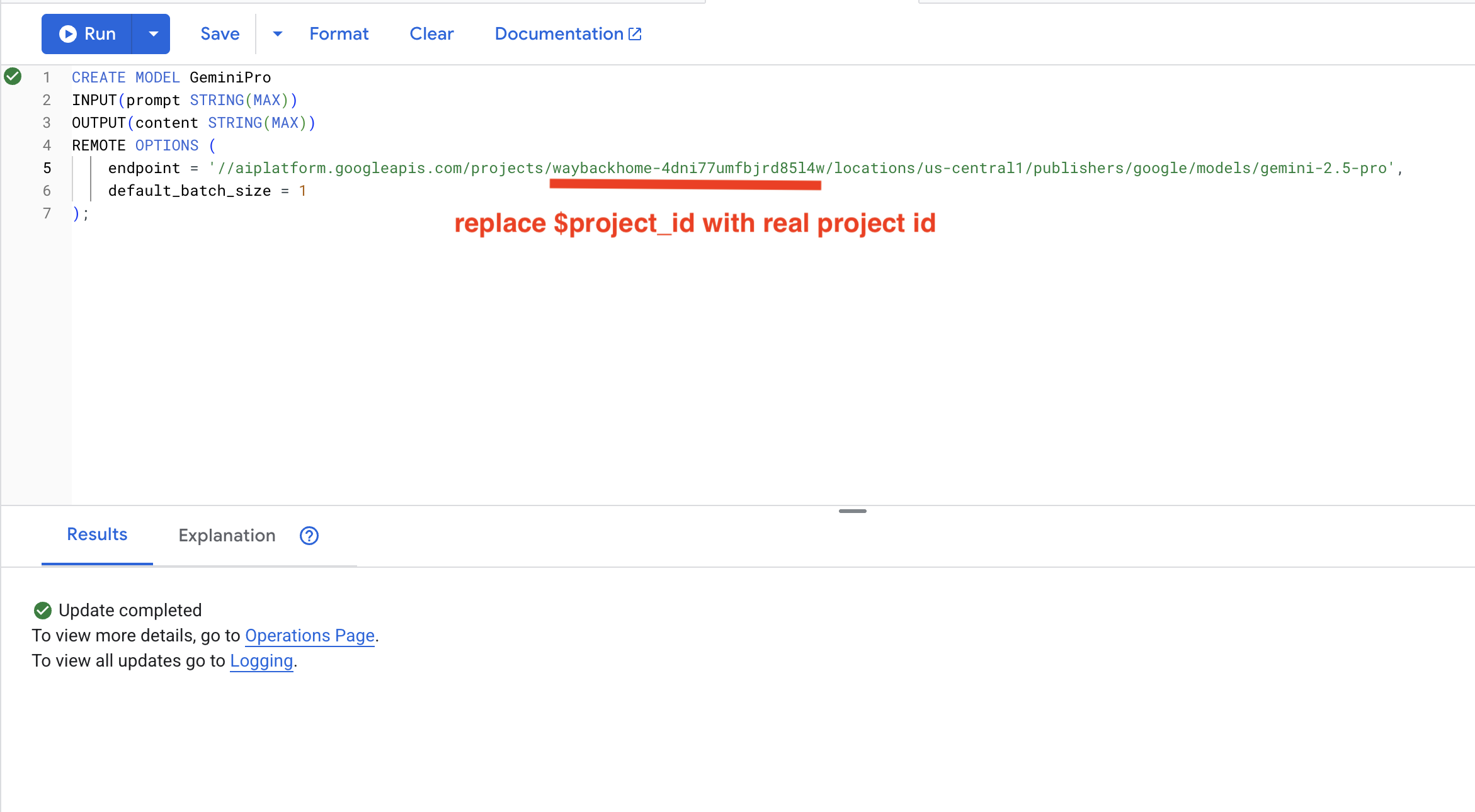
👉 Tạo một tài liệu tham khảo về mô hình AI tạo sinh (thay thế $YOUR_PROJECT_ID bằng mã dự án thực tế của bạn):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
Khác biệt so với Mô hình nhúng:
- Embeddings: Văn bản → Vectơ (để tìm kiếm sự tương đồng)
- Gemini: Văn bản → Văn bản được tạo (để suy luận/phân tích)
8. Dùng Gemini để phân tích khả năng tương thích
👉 Phân tích các cặp người sống sót để xác định khả năng tương thích với nhiệm vụ:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
Kết quả đầu ra dự kiến:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 Xây dựng tác nhân Graph RAG bằng tính năng tìm kiếm kết hợp
1. Tổng quan về cấu trúc hệ thống
Phần này sẽ tạo một hệ thống tìm kiếm đa phương thức giúp tác nhân của bạn linh hoạt xử lý nhiều loại câu hỏi. Hệ thống này có 3 lớp: Lớp tác nhân, Lớp công cụ, Lớp dịch vụ.
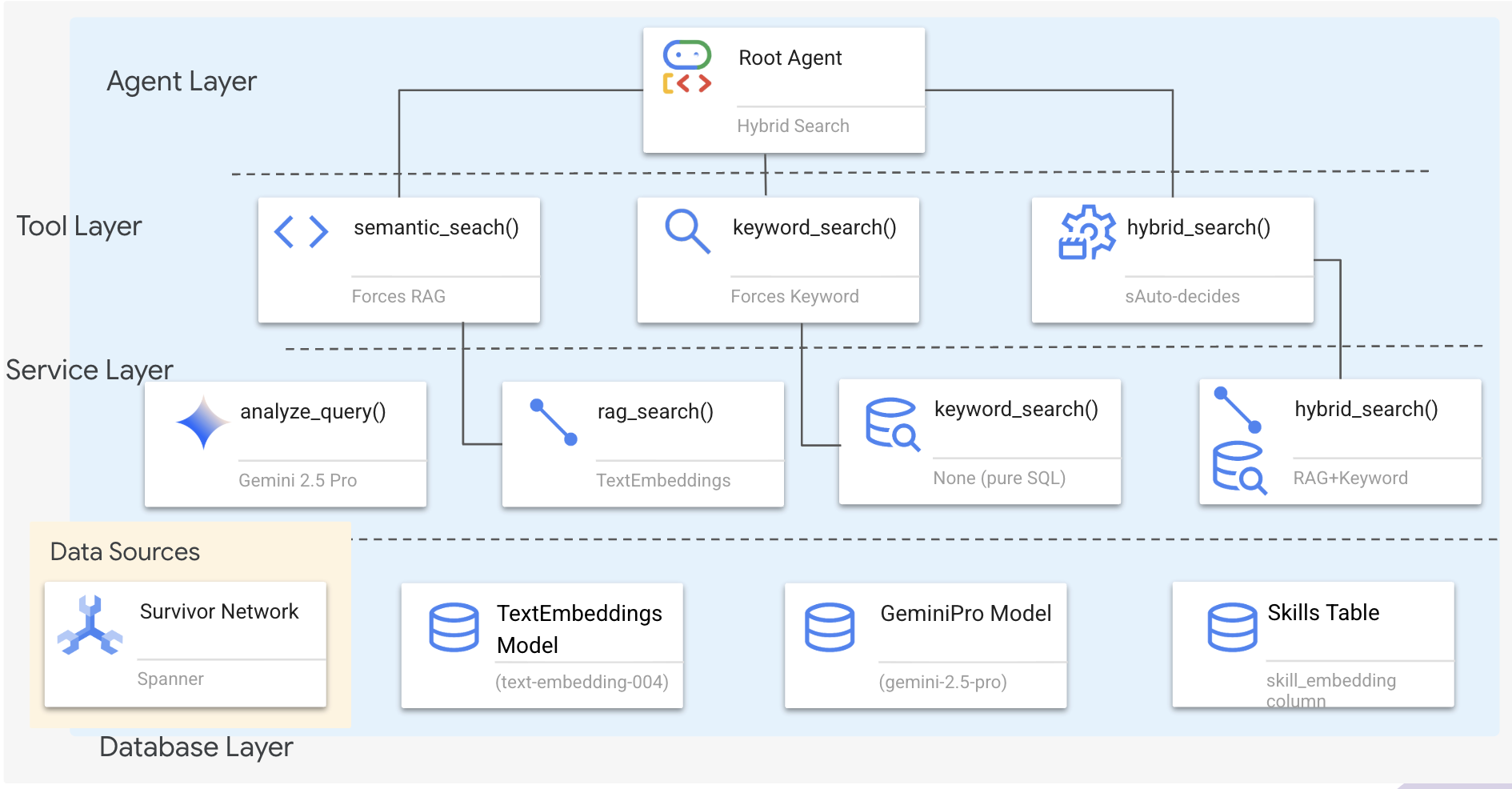
Tại sao lại có 3 lớp?
- Phân tách các mối quan tâm: Tác nhân tập trung vào ý định, công cụ tập trung vào giao diện, dịch vụ tập trung vào việc triển khai
- Tính linh hoạt: Tác nhân có thể buộc các phương thức cụ thể hoặc cho phép AI tự động định tuyến
- Tối ưu hoá: Có thể bỏ qua quy trình phân tích AI tốn kém khi biết phương thức
Trong phần này, bạn sẽ chủ yếu triển khai tìm kiếm ngữ nghĩa (RAG) – tìm kết quả theo ý nghĩa chứ không chỉ theo từ khoá. Sau đó, chúng ta sẽ tìm hiểu cách tìm kiếm kết hợp hợp nhất nhiều phương thức.
2. Triển khai dịch vụ RAG
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
Tìm bình luận # TODO: REPLACE_SQL
Thay thế toàn bộ dòng này bằng đoạn mã sau:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. Định nghĩa về công cụ tìm kiếm ngữ nghĩa
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
Trong hybrid_search_tools.py, hãy tìm nhận xét # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉Thay thế toàn bộ dòng này bằng đoạn mã sau:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
Khi nhân viên hỗ trợ sử dụng:
- Cụm từ tìm kiếm yêu cầu tìm nội dung tương tự ("tìm nội dung tương tự như X")
- Truy vấn theo khái niệm ("khả năng chữa lành")
- Khi việc hiểu rõ ý nghĩa là rất quan trọng
4. Hướng dẫn ra quyết định cho nhân viên hỗ trợ (Hướng dẫn)
Trong định nghĩa về tác nhân, hãy sao chép và dán phần liên quan đến tìm kiếm ngữ nghĩa vào hướng dẫn.
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Tác nhân sử dụng chỉ dẫn này để chọn công cụ phù hợp:
👉Trong tệp agent.py, hãy tìm dòng nhận xét # TODO: REPLACE_SEARCH_LOGIC, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉Tìm bình luận # TODO: ADD_SEARCH_TOOLReplace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
semantic_search, # Force RAG
5. Tìm hiểu cách hoạt động của tính năng Tìm kiếm kết hợp (Chỉ đọc, không cần làm gì)
Trong các bước 2 đến 4, bạn đã triển khai tìm kiếm ngữ nghĩa (RAG), phương thức tìm kiếm cốt lõi giúp tìm kết quả theo ý nghĩa. Nhưng có thể bạn đã nhận thấy hệ thống này có tên là "Tìm kiếm kết hợp". Sau đây là cách các thành phần kết hợp với nhau:
Cách hoạt động của tính năng hợp nhất kết hợp:
Trong tệp way-back-home/level_2/backend/services/hybrid_search_service.py, khi hybrid_search() được gọi, dịch vụ sẽ chạy CẢ HAI lượt tìm kiếm và hợp nhất kết quả:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
Đối với lớp học lập trình này, bạn đã triển khai thành phần tìm kiếm ngữ nghĩa (RAG) làm nền tảng. Phương thức từ khoá và phương thức kết hợp đã được triển khai trong dịch vụ – nhân viên hỗ trợ của bạn có thể sử dụng cả 3 phương thức này!
Xin chúc mừng! Bạn đã hoàn thành thành công Graph RAG Agent bằng tính năng tìm kiếm kết hợp!
7. 🚀 Thử nghiệm tác nhân bằng ADK Web
Cách dễ nhất để kiểm thử tác nhân là sử dụng lệnh adk web. Lệnh này sẽ khởi chạy tác nhân của bạn bằng một giao diện trò chuyện tích hợp.
1. Chạy tác nhân
👉💻 Chuyển đến thư mục phụ trợ (nơi xác định tác nhân của bạn) và khởi chạy Giao diện người dùng web::
cd ~/way-back-home/level_2/backend
uv run adk web
Lệnh này khởi động tác nhân được xác định trong
agent/agent.py
và mở một giao diện web để kiểm thử.
👉 Mở URL:
Lệnh này sẽ xuất ra một URL cục bộ (thường là http://127.0.0.1:8000 hoặc tương tự). Mở nội dung này trong trình duyệt.
Sau khi nhấp vào URL, bạn sẽ thấy giao diện người dùng web ADK. Đảm bảo bạn chọn "nhân viên" ở góc trên cùng bên trái.
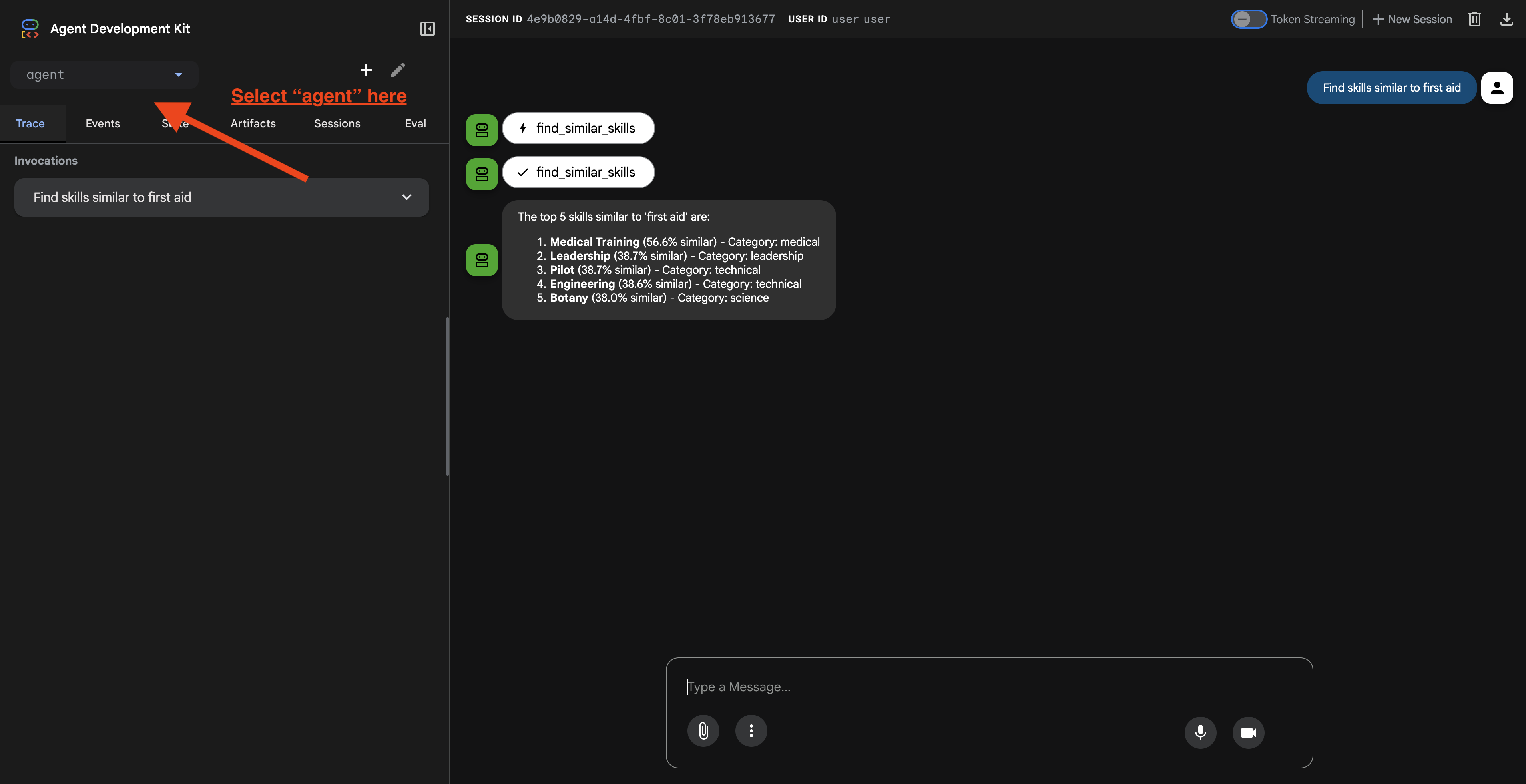
2. Kiểm thử các chức năng tìm kiếm
Tác nhân này được thiết kế để định tuyến các truy vấn của bạn một cách thông minh. Hãy thử nhập các nội dung sau vào cửa sổ trò chuyện để xem các phương thức tìm kiếm khác nhau hoạt động.
🧬 A. Graph RAG (Tìm kiếm ngữ nghĩa)
Tìm các mặt hàng dựa trên ý nghĩa và khái niệm, ngay cả khi từ khoá không khớp.
Cụm từ tìm kiếm kiểm thử: (Chọn một trong các cụm từ bên dưới)
Who can help with injuries?
What abilities are related to survival?
Những điểm cần chú ý:
- Lý do nên đề cập đến tìm kiếm ngữ nghĩa hoặc RAG.
- Bạn sẽ thấy những kết quả có liên quan về mặt khái niệm (ví dụ: "Phẫu thuật" khi hỏi về "Sơ cứu").
- Kết quả sẽ có biểu tượng 🧬.
🔀 B. Tìm kiếm kết hợp
Kết hợp bộ lọc từ khoá với khả năng hiểu ngữ nghĩa cho các truy vấn phức tạp.
Cụm từ tìm kiếm thử nghiệm:(Chọn một trong các cụm từ bên dưới)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
Những điểm cần chú ý:
- Lý do phải đề cập đến tính năng tìm kiếm Kết hợp.
- Kết quả phải đáp ứng CẢ HAI tiêu chí (khái niệm + vị trí/danh mục).
- Kết quả tìm được bằng cả hai phương thức sẽ có biểu tượng 🔀 và được xếp hạng cao nhất.
👉💻 Khi bạn hoàn tất quá trình kiểm thử, hãy kết thúc quy trình bằng cách nhấn Ctrl+C trong dòng lệnh.
8. 🚀 Chạy ứng dụng đầy đủ
Tổng quan về cấu trúc Full Stack
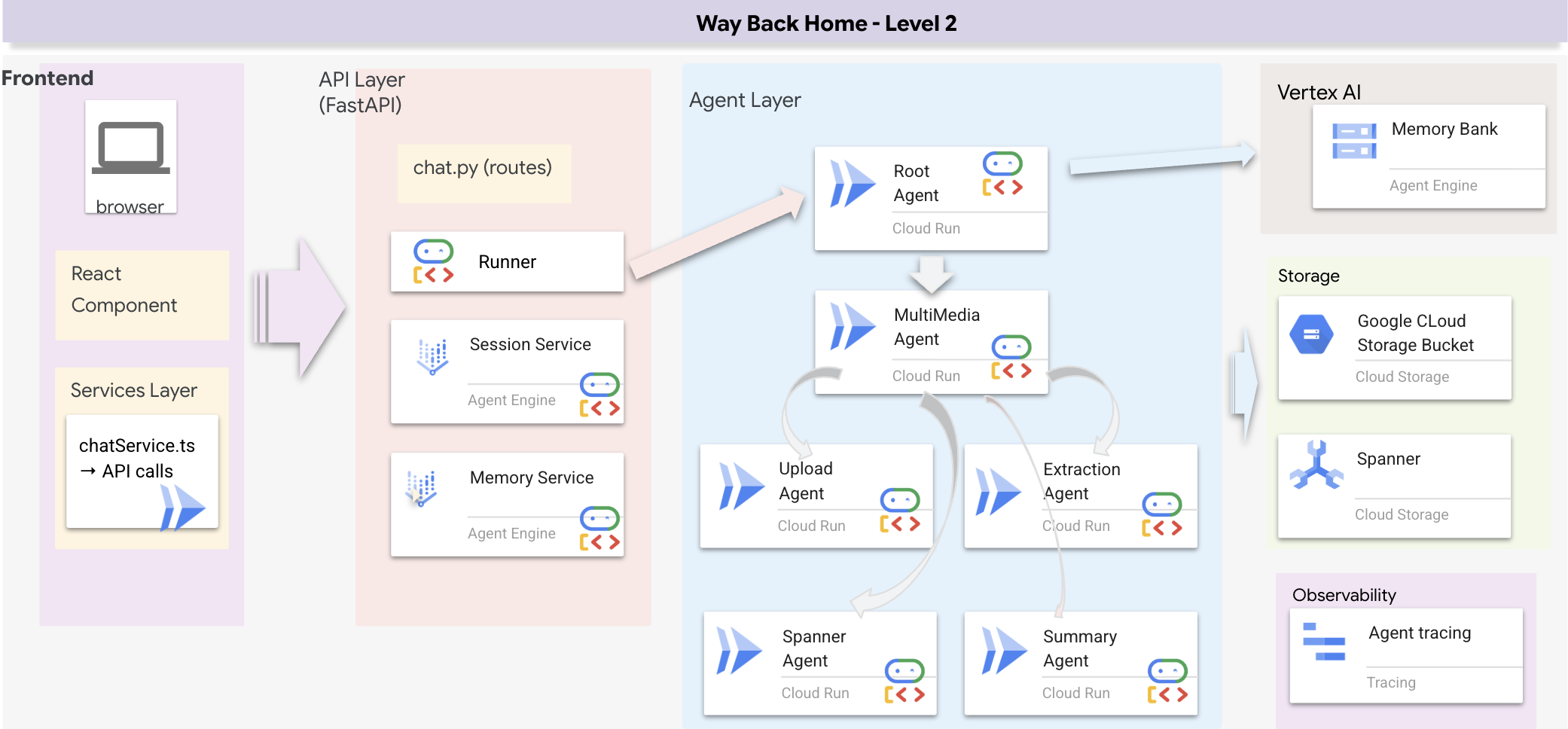
Thêm SessionService và Runner
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp chat.py trong Cloud Shell Editor bằng cách chạy (hãy nhớ nhấn "ctrl+C" để kết thúc quy trình trước khi tiếp tục):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉Trong tệp chat.py, hãy tìm dòng nhận xét # TODO: REPLACE_INMEMORY_SERVICES, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉Trong tệp chat.py, hãy tìm dòng nhận xét # TODO: REPLACE_RUNNER, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. Bắt đầu đăng ký
Nếu thiết bị đầu cuối trước đó vẫn đang chạy, hãy kết thúc bằng cách nhấn Ctrl+C.
👉💻 Ứng dụng Start:
cd ~/way-back-home/level_2/
./start_app.sh
Khi khởi động thành công phần phụ trợ, bạn sẽ thấy Local: http://localhost:5173/" như bên dưới: 
👉 Nhấp vào Local: http://localhost:5173/ trên thiết bị đầu cuối.
2. Kiểm thử tính năng Tìm kiếm ngữ nghĩa
Cụm từ tìm kiếm:
Find skills similar to healing
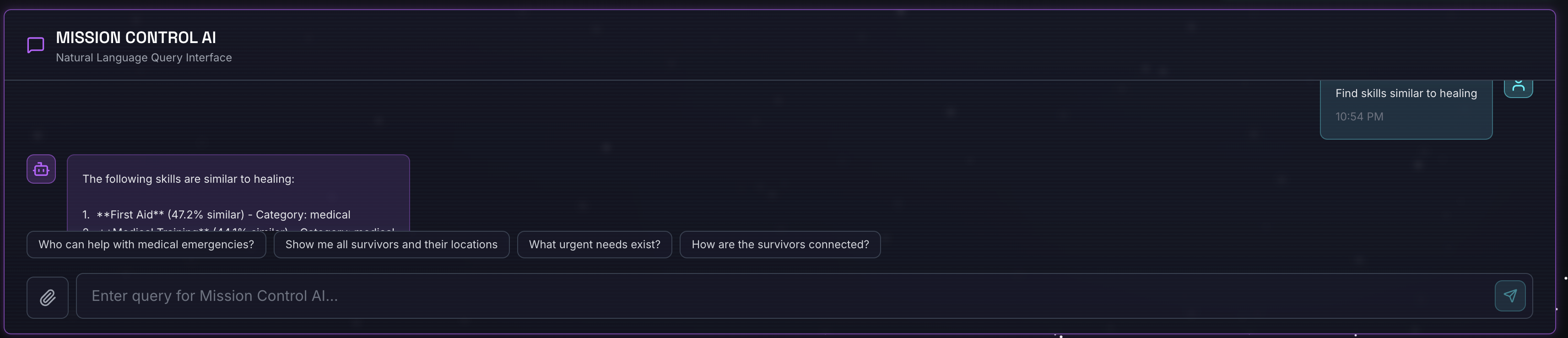
Điều sẽ xảy ra:
- Trợ lý nhận ra yêu cầu tương tự
- Tạo mục nhúng cho "chữa lành"
- Sử dụng khoảng cách cosine để tìm các kỹ năng tương tự về mặt ngữ nghĩa
- Trả về: sơ cứu (mặc dù tên không khớp với "chữa bệnh")
3. Kiểm thử tính năng Tìm kiếm kết hợp
Cụm từ tìm kiếm:
Find medical skills in the mountains
Điều sẽ xảy ra:
- Thành phần từ khoá: Bộ lọc cho
category='medical' - Thành phần ngữ nghĩa: Nhúng "y tế" và xếp hạng theo mức độ tương đồng
- Hợp nhất: Kết hợp các kết quả, ưu tiên những kết quả được tìm thấy bằng cả hai phương thức 🔀
Truy vấn(không bắt buộc):
Who is good at survival and in the forest?
Điều sẽ xảy ra:
- Từ khoá tìm thấy:
biome='forest' - Tìm kiếm ngữ nghĩa: các kỹ năng tương tự như "sinh tồn"
- Chế độ kết hợp kết hợp cả hai để có kết quả tốt nhất
👉💻 Khi bạn hoàn tất kiểm thử, hãy kết thúc bằng cách nhấn Ctrl+C trong cửa sổ dòng lệnh.
4. (!CHỈ DÀNH CHO NGƯỜI THAM DỰ HỘI THẢO) Cập nhật vị trí của bạn
👉💻 Chạy tập lệnh hoàn tất:
cd ~/way-back-home/level_2
./set_level_2.sh
Bây giờ, hãy mở waybackhome.dev và bạn sẽ thấy vị trí của mình đã được cập nhật. Chúc mừng bạn đã hoàn thành cấp độ 2!

9. ☕️ [Không bắt buộc] Quy trình đa phương thức (Chỉ đọc) – Lớp công cụ
Tại sao chúng ta cần một quy trình đa phương thức?
Mạng lưới hỗ trợ không chỉ có văn bản. Những người sống sót tại hiện trường gửi dữ liệu không có cấu trúc trực tiếp qua cuộc trò chuyện:
- 📸 Hình ảnh: Ảnh chụp tài nguyên, mối nguy hiểm hoặc thiết bị
- 🎥 Video: Báo cáo trạng thái hoặc thông báo SOS
- 📄 Văn bản: Ghi chú hoặc nhật ký thực địa
Chúng tôi đang xử lý những tệp nào?
Không giống như bước trước (tìm kiếm dữ liệu hiện có), ở bước này, chúng ta sẽ xử lý Tệp do người dùng tải lên. Giao diện chat.py xử lý các tệp đính kèm một cách linh hoạt:
Nguồn | Nội dung | Mục tiêu |
Tệp đính kèm của người dùng | Hình ảnh/Video/Văn bản | Thông tin cần thêm vào biểu đồ |
Ngữ cảnh trong cuộc trò chuyện | "Đây là ảnh chụp các vật tư" | Ý định và thông tin chi tiết khác |
Phương pháp lập kế hoạch: Quy trình tuần tự của tác nhân
Chúng tôi sử dụng Tác nhân tuần tự (multimedia_agent.py) để liên kết các tác nhân chuyên biệt với nhau:
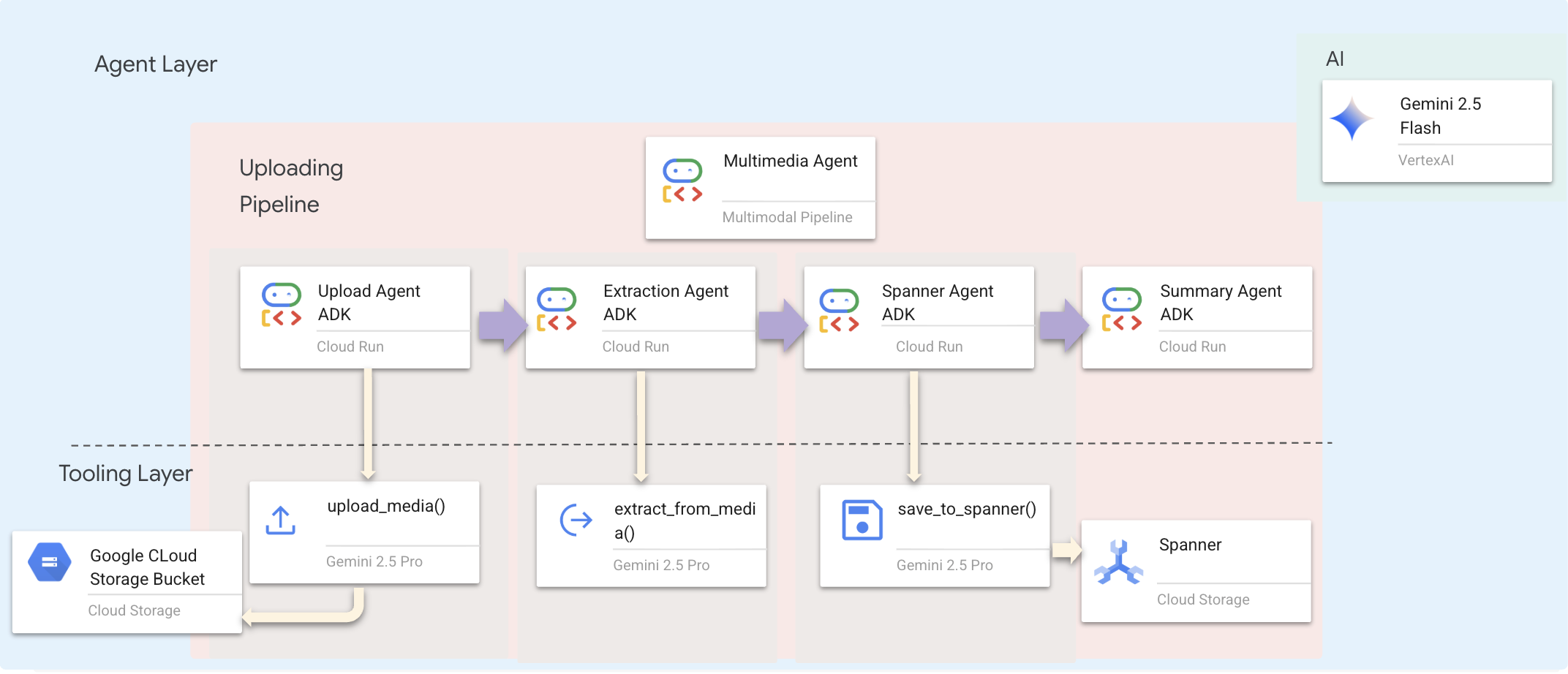
Tham số này được xác định trong backend/agent/multimedia_agent.py dưới dạng một SequentialAgent.
Lớp công cụ cung cấp các chức năng mà các tác nhân có thể gọi. Các công cụ xử lý "cách thức" – tải tệp lên, trích xuất thực thể và lưu vào cơ sở dữ liệu.
1. Mở tệp Công cụ
👉💻 Mở tệp level_2/backend/agent/tools/extraction_tools.py hoặc bằng cách nhập lệnh sau vào dòng lệnh. Mở một cửa sổ dòng lệnh mới. Trong thiết bị đầu cuối, hãy mở tệp trong Trình chỉnh sửa Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. Triển khai công cụ upload_media
Công cụ này tải một tệp cục bộ lên Google Cloud Storage.
👉 Trong def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]:, đoạn mã sau đây cho biết cách tải tệp lên GCS để phát hiện loại tệp:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. Triển khai công cụ extract_from_media
Công cụ này là một bộ định tuyến – công cụ này kiểm tra media_type và gửi đến trình trích xuất chính xác (văn bản, hình ảnh hoặc video).
👉 Trong async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]:, đoạn mã sau đây cho biết cách trích xuất các thực thể và mối quan hệ từ nội dung nghe nhìn đã tải lên.
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
Thông tin chi tiết quan trọng về việc triển khai:
- Đầu vào đa phương thức: Chúng tôi truyền cả câu lệnh dạng văn bản (
_get_extraction_prompt()) và đối tượng hình ảnh đếngenerate_content. - Đầu ra có cấu trúc:
response_mime_type="application/json"đảm bảo LLM trả về JSON hợp lệ, điều này rất quan trọng đối với quy trình. - Liên kết thực thể bằng hình ảnh: Câu lệnh bao gồm các thực thể đã biết để Gemini có thể nhận dạng các nhân vật cụ thể.
4. Triển khai công cụ save_to_spanner
Công cụ này duy trì các thực thể và mối quan hệ đã trích xuất vào Spanner Graph DB.
👉 Trong def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]:, đoạn mã sau đây cho biết cách lưu các thực thể và mối quan hệ đã trích xuất vào Spanner Graph DB.
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
Bằng cách cung cấp cho các trợ lý ảo những công cụ cấp cao, chúng tôi đảm bảo tính toàn vẹn của dữ liệu trong khi tận dụng khả năng suy luận của trợ lý ảo.
5. Cập nhật dịch vụ GCS
GCSService xử lý việc tải tệp thực tế lên Google Cloud Storage.
👉💻 Mở tệp level_2/backend/services/gcs_service.py hoặc bạn có thể nhập vào dòng lệnh để mở tệp trong Trình chỉnh sửa Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 Trong def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]:, đoạn mã sau đây cho biết cách lưu các thực thể và mối quan hệ đã trích xuất vào Spanner Graph DB.
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
Bằng cách trừu tượng hóa việc này thành một dịch vụ, Tác nhân không cần phải biết về các bộ chứa GCS, tên BLOB hoặc quá trình tạo URL đã ký. Ứng dụng chỉ yêu cầu "tải lên".
6. Tại sao nên dùng Quy trình công việc dựa trên tác nhân > Các phương pháp truyền thống?
Lợi thế của trợ lý AI:
Tính năng | Quy trình xử lý theo lô | Dựa trên sự kiện | Quy trình làm việc của trợ lý AI |
Độ phức tạp | Thấp (1 tập lệnh) | Cao (từ 5 dịch vụ trở lên) | Thấp (1 tệp Python: |
Quản lý trạng thái | Biến toàn cục | Cứng (đã tách rời) | Hợp nhất (Trạng thái của nhân viên hỗ trợ) |
Xử lý lỗi | Sự cố | Nhật ký im lặng | Tương tác ("Tôi không đọc được tệp đó") |
Ý kiến phản hồi của người dùng | Bản in trên bảng điều khiển | Cần thăm dò ý kiến | Ngay lập tức (Trong cuộc trò chuyện) |
Khả năng thích ứng | Logic cố định | Hàm cố định | Thông minh (LLM quyết định bước tiếp theo) |
Nhận biết bối cảnh | Không có | Không có | Đầy đủ (Biết ý định của người dùng) |
Tại sao điều này lại quan trọng: Bằng cách sử dụng multimedia_agent.py (SequentialAgent có 4 tác nhân phụ: Tải lên → Trích xuất → Lưu → Tóm tắt), chúng ta sẽ thay thế cơ sở hạ tầng phức tạp VÀ các tập lệnh dễ bị lỗi bằng logic ứng dụng đàm thoại thông minh.
10. ☕️ [Không bắt buộc] Quy trình đa phương thức (Chỉ đọc) – Lớp tác nhân
Lớp tác nhân xác định trí thông minh – các tác nhân sử dụng công cụ để hoàn thành các việc cần làm. Mỗi tác nhân đều có một vai trò cụ thể và truyền ngữ cảnh cho tác nhân tiếp theo. Dưới đây là biểu đồ cấu trúc cho hệ thống nhiều tác nhân.
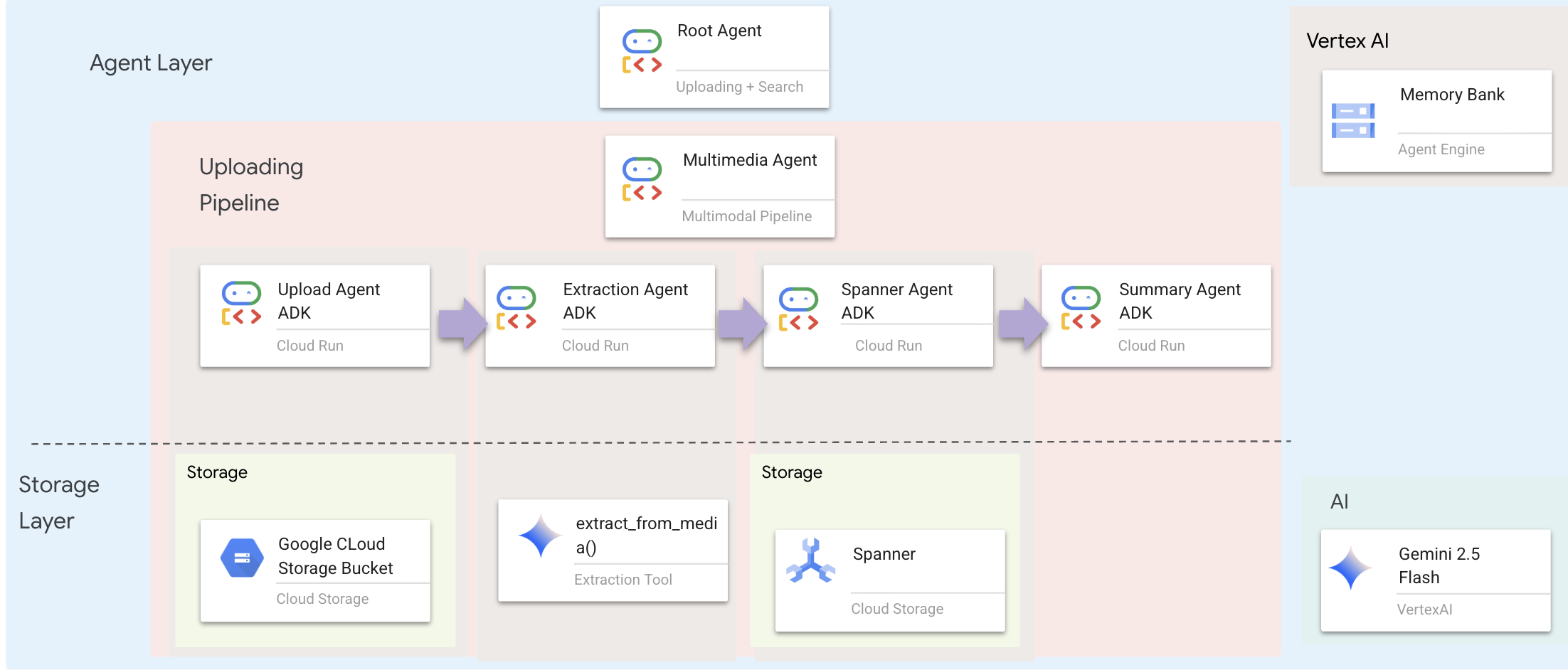
1. Mở tệp Agent
👉💻 Mở tệp level_2/backend/agent/multimedia_agent.py hoặc bằng cách nhập lệnh sau vào dòng lệnh. Mở một cửa sổ dòng lệnh mới. Trong thiết bị đầu cuối, hãy mở tệp trong Trình chỉnh sửa Cloud Shell:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. Xác định Tác nhân tải lên
Tác nhân này trích xuất một đường dẫn tệp từ tin nhắn của người dùng và tải đường dẫn đó lên GCS.
👉Trong tệp multimedia_agent.py, với đoạn mã sau, tệp này sẽ tạo upload_agent để tải lên GCS:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. Xác định Tác nhân trích xuất
Tác nhân này "nhìn thấy" nội dung nghe nhìn được tải lên và trích xuất dữ liệu có cấu trúc bằng Gemini Vision.
👉Trong tệp multimedia_agent.py, với mã sau, tệp này sẽ tạo ra extraction_agent để trích xuất thông tin từ nội dung nghe nhìn đã tải lên:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
Lưu ý cách instruction tham chiếu {upload_result} – đây là cách trạng thái được truyền giữa các tác nhân trong ADK.
4. Xác định Spanner Agent
Tác nhân này lưu các thực thể và mối quan hệ đã trích xuất vào cơ sở dữ liệu đồ thị.
👉Trong tệp multimedia_agent.py, với đoạn mã sau, tệp này sẽ tạo spanner_agent để lưu thông tin đã trích xuất vào cơ sở dữ liệu:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
Nhân viên hỗ trợ này nhận được ngữ cảnh từ cả các bước trước đó (upload_result và extraction_result).
5. Xác định Summary Agent
Tác nhân này tổng hợp kết quả từ tất cả các bước trước đó thành một câu trả lời thân thiện với người dùng.
👉Trong tệp multimedia_agent.py, với đoạn mã sau, tệp này xác định câu lệnh cho summary_agent để tóm tắt kết quả:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
Tác nhân này không cần công cụ mà chỉ cần đọc bối cảnh được chia sẻ và tạo bản tóm tắt rõ ràng cho người dùng.
🧠 Tóm tắt về cấu trúc
Lớp | Tệp | Trách nhiệm |
Công cụ |
| Cách thực hiện – Tải lên, trích xuất, lưu |
Tác nhân |
| Nội dung – Sắp xếp quy trình |
11. 🚀 Quy trình dữ liệu đa phương thức – Điều phối
Cốt lõi của hệ thống mới là MultimediaExtractionPipeline được xác định trong backend/agent/multimedia_agent.py. Thư viện này sử dụng mẫu Tác nhân tuần tự trong ADK (Bộ công cụ phát triển tác nhân).
1. Tại sao lại là Sequential?
Xử lý tệp tải lên là một chuỗi phụ thuộc tuyến tính:
- Bạn không thể trích xuất dữ liệu cho đến khi có tệp (Tải lên).
- Bạn không thể lưu dữ liệu cho đến khi trích xuất (Trích xuất).
- Bạn không thể tóm tắt cho đến khi có kết quả (Lưu).
SequentialAgent là lựa chọn hoàn hảo cho việc này. Thao tác này sẽ truyền đầu ra của một tác nhân làm ngữ cảnh/đầu vào cho tác nhân tiếp theo.
2. Định nghĩa về tác nhân
Hãy xem cách tập hợp quy trình ở cuối multimedia_agent.py: 👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Cloud Shell Editor bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
Thao tác này nhận dữ liệu đầu vào từ cả hai bước trước đó. Tìm bình luận # TODO: REPLACE_ORCHESTRATION. Thay thế toàn bộ dòng này bằng đoạn mã sau:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. Kết nối với Nhân viên hỗ trợ cấp cao
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Tìm bình luận # TODO: REPLACE_ADD_SUBAGENT. Thay thế toàn bộ dòng này bằng đoạn mã sau:
sub_agents=[multimedia_agent],
Đối tượng duy nhất này kết hợp hiệu quả 4 "chuyên gia" thành một thực thể có thể gọi.
4. Luồng dữ liệu giữa các tác nhân
Mỗi tác nhân lưu trữ đầu ra của mình trong một ngữ cảnh chung mà các tác nhân tiếp theo có thể truy cập:
5. Mở ứng dụng (bỏ qua bước này nếu ứng dụng vẫn đang chạy)
👉💻 Ứng dụng Start:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Nhấp vào Local: http://localhost:5173/ trên thiết bị đầu cuối.
6. Tải hình ảnh lên để kiểm thử
👉 Trong giao diện trò chuyện, hãy chọn một bức ảnh bất kỳ tại đây rồi tải lên giao diện người dùng:
Trong giao diện trò chuyện, hãy cho nhân viên hỗ trợ biết về bối cảnh cụ thể của bạn:
Here is the survivor note
Sau đó, hãy đính kèm hình ảnh tại đây.

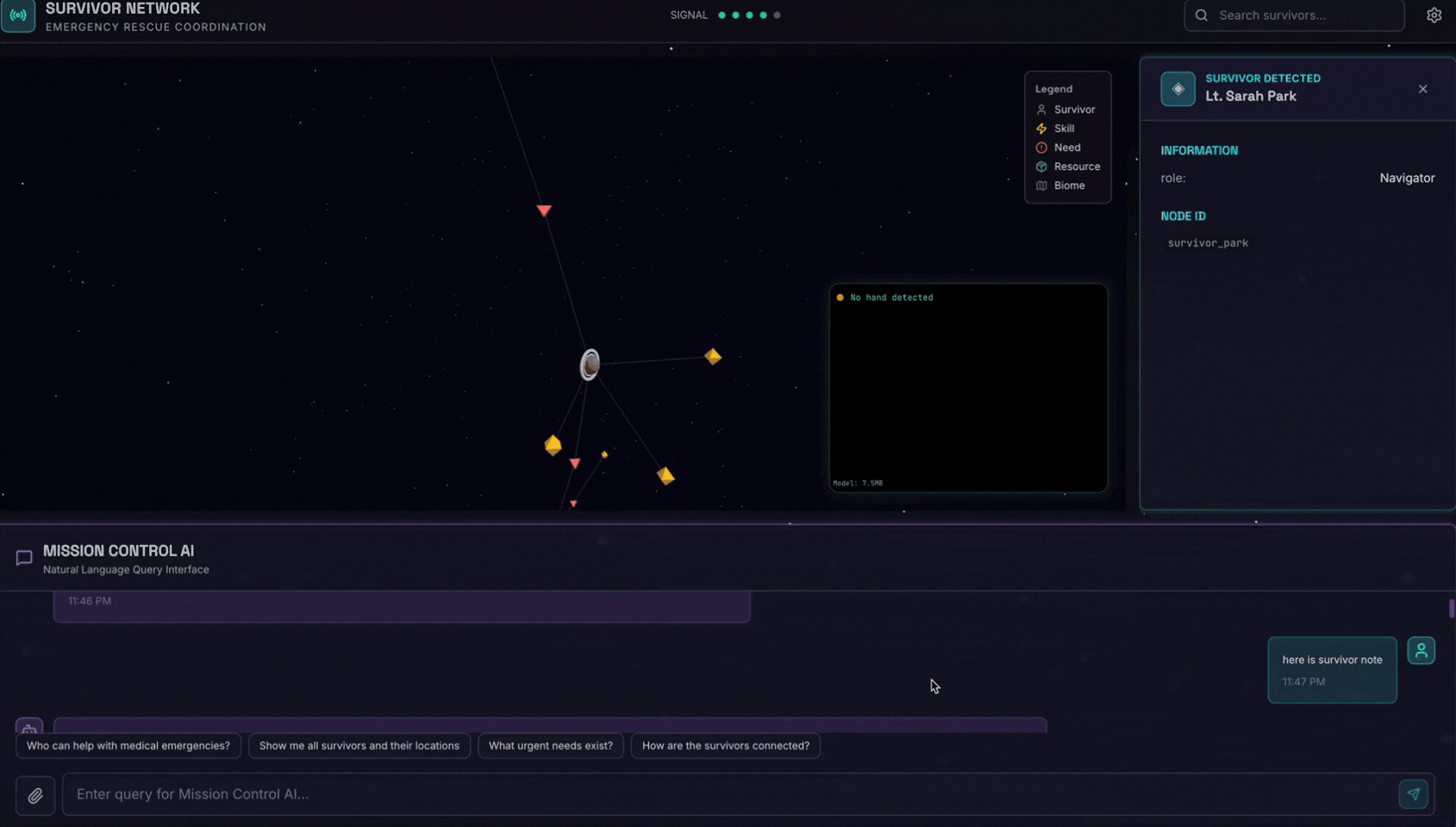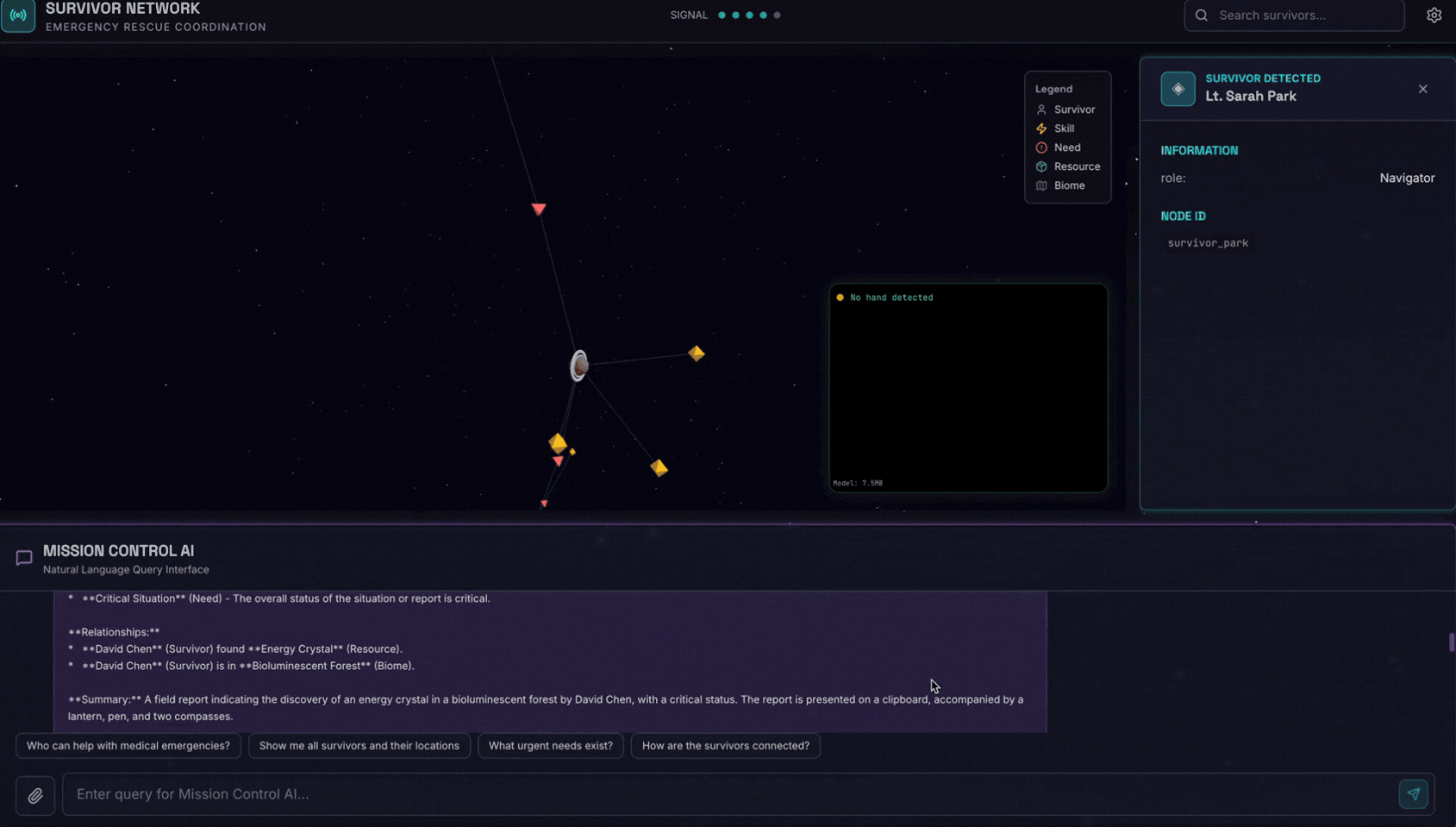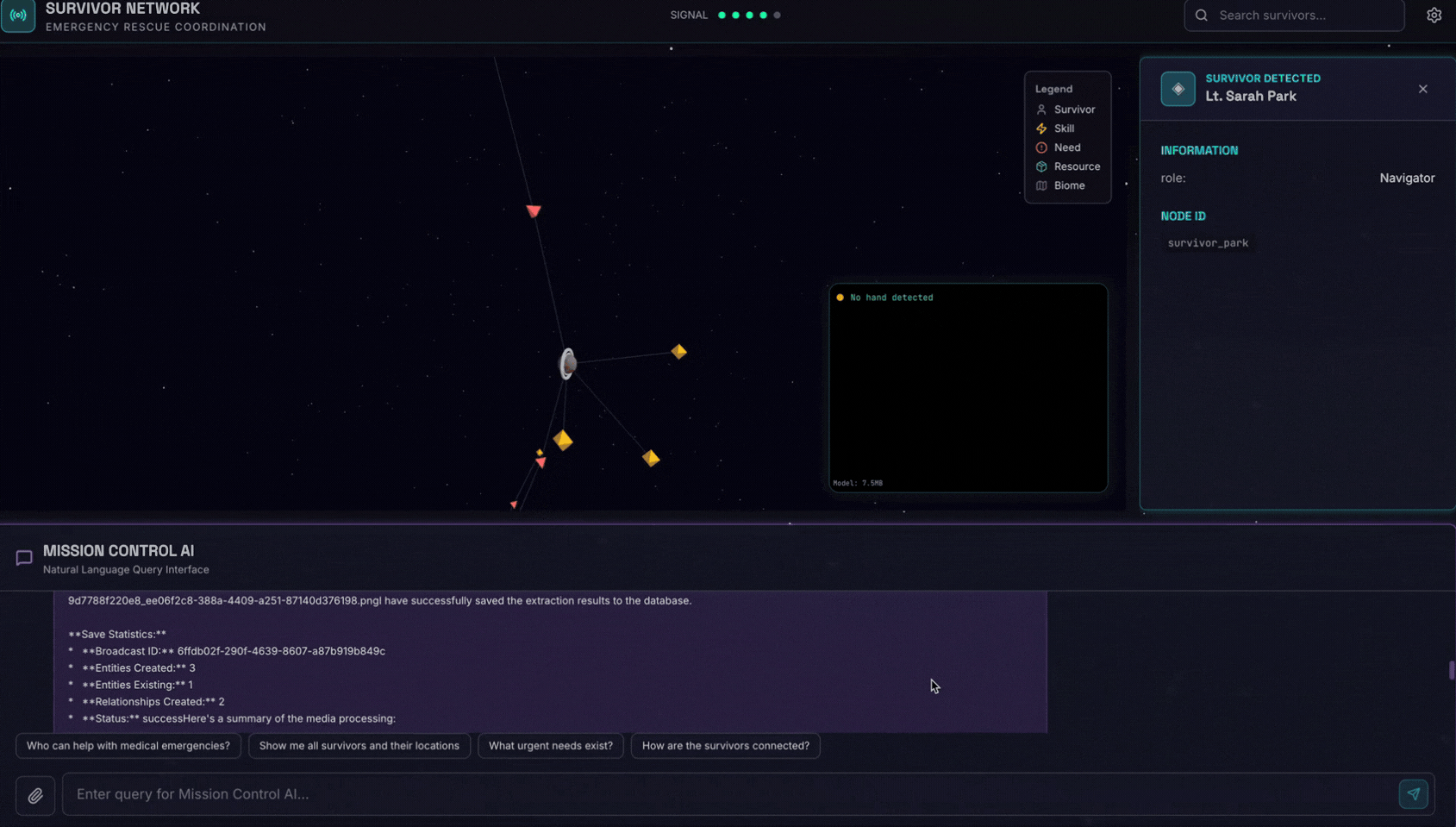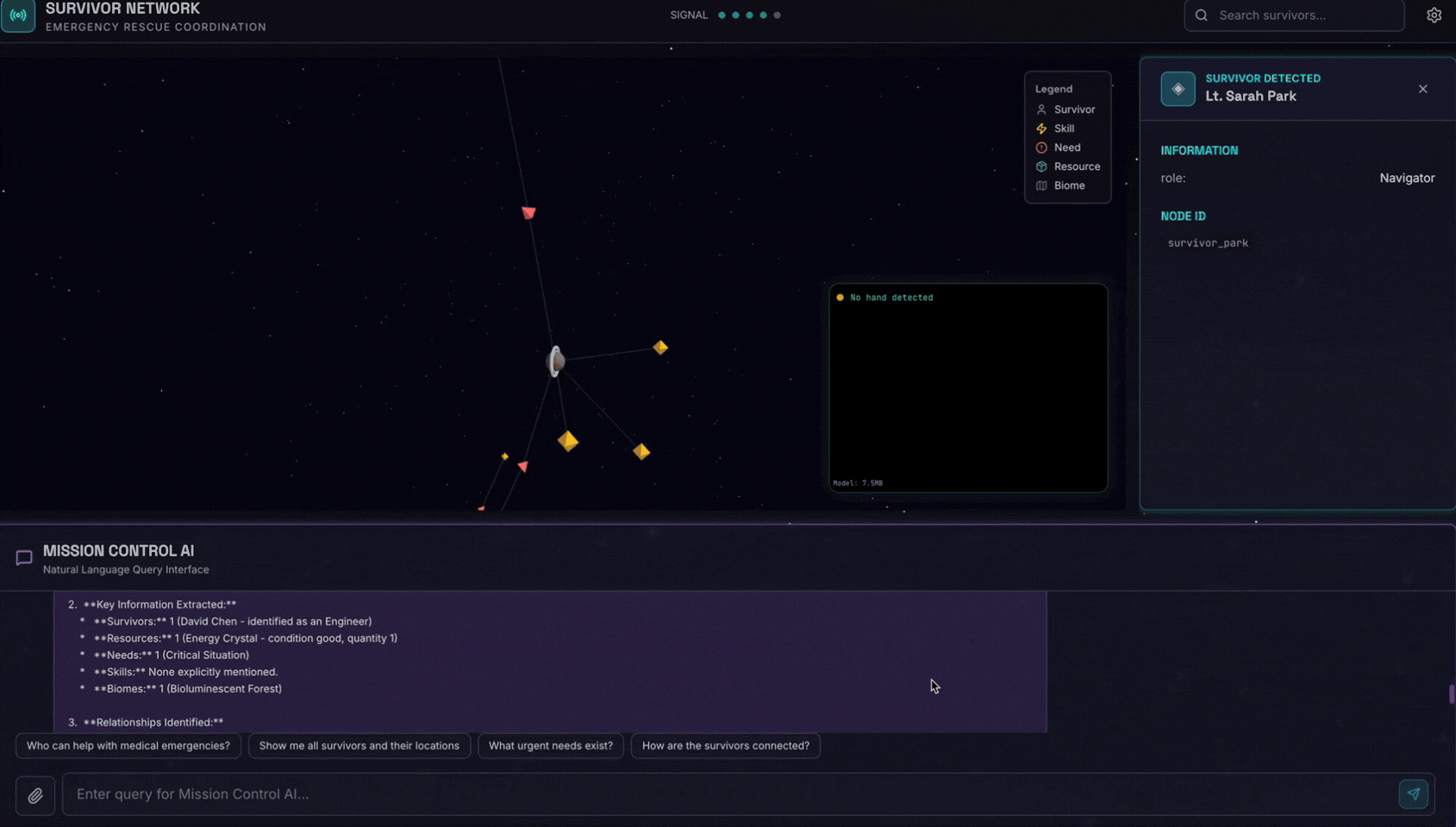
👉💻 Trong cửa sổ dòng lệnh, khi bạn kiểm thử xong, hãy nhấn "Ctrl+C" để kết thúc quy trình.
6. Xác minh tính năng tải lên đa phương thức trong bộ chứa GCS
- Mở Google Cloud Console Storage.
- Chọn "bucket" trong bộ nhớ trên đám mây
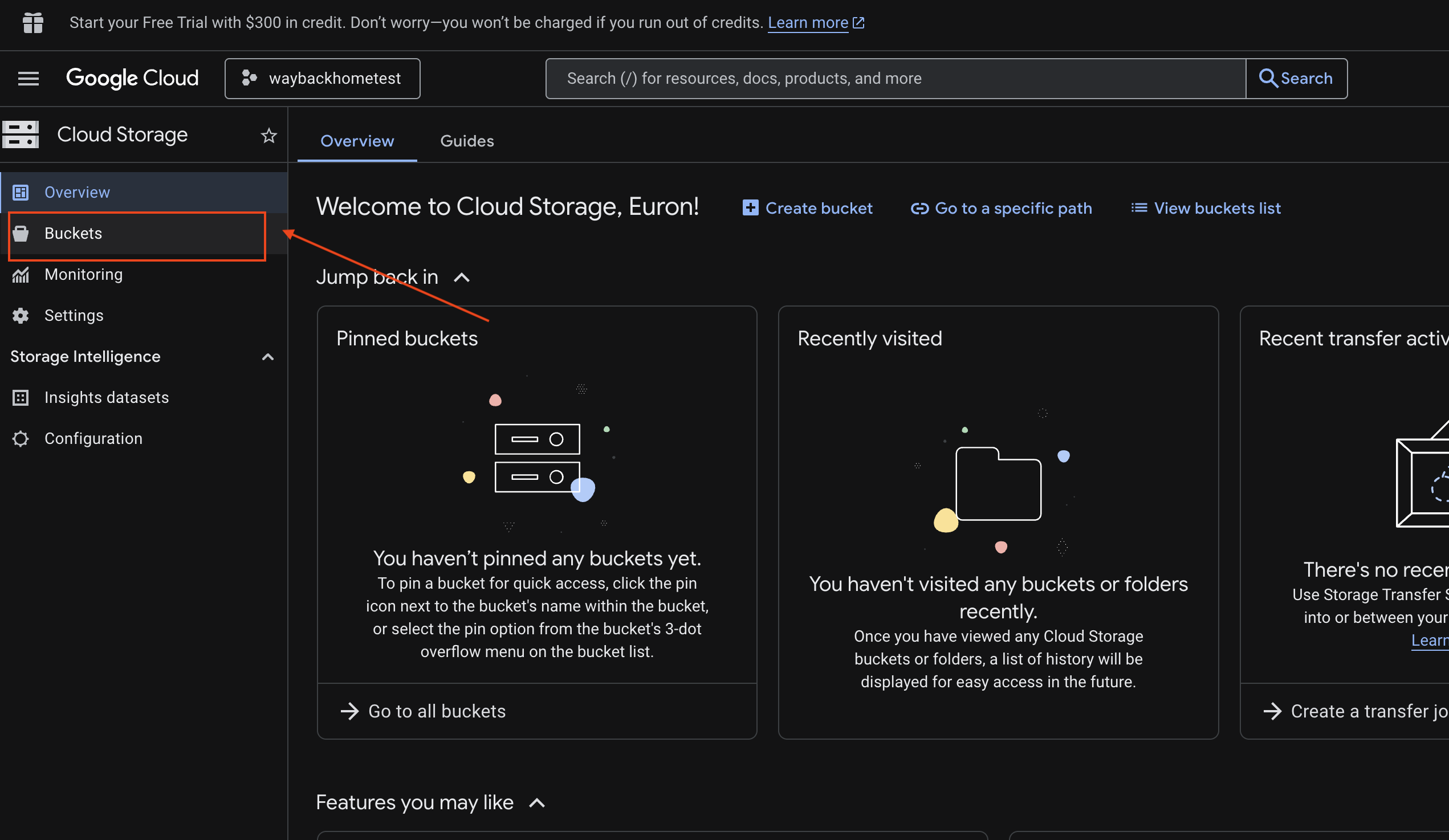
- Chọn nhóm của bạn rồi nhấp vào
media.
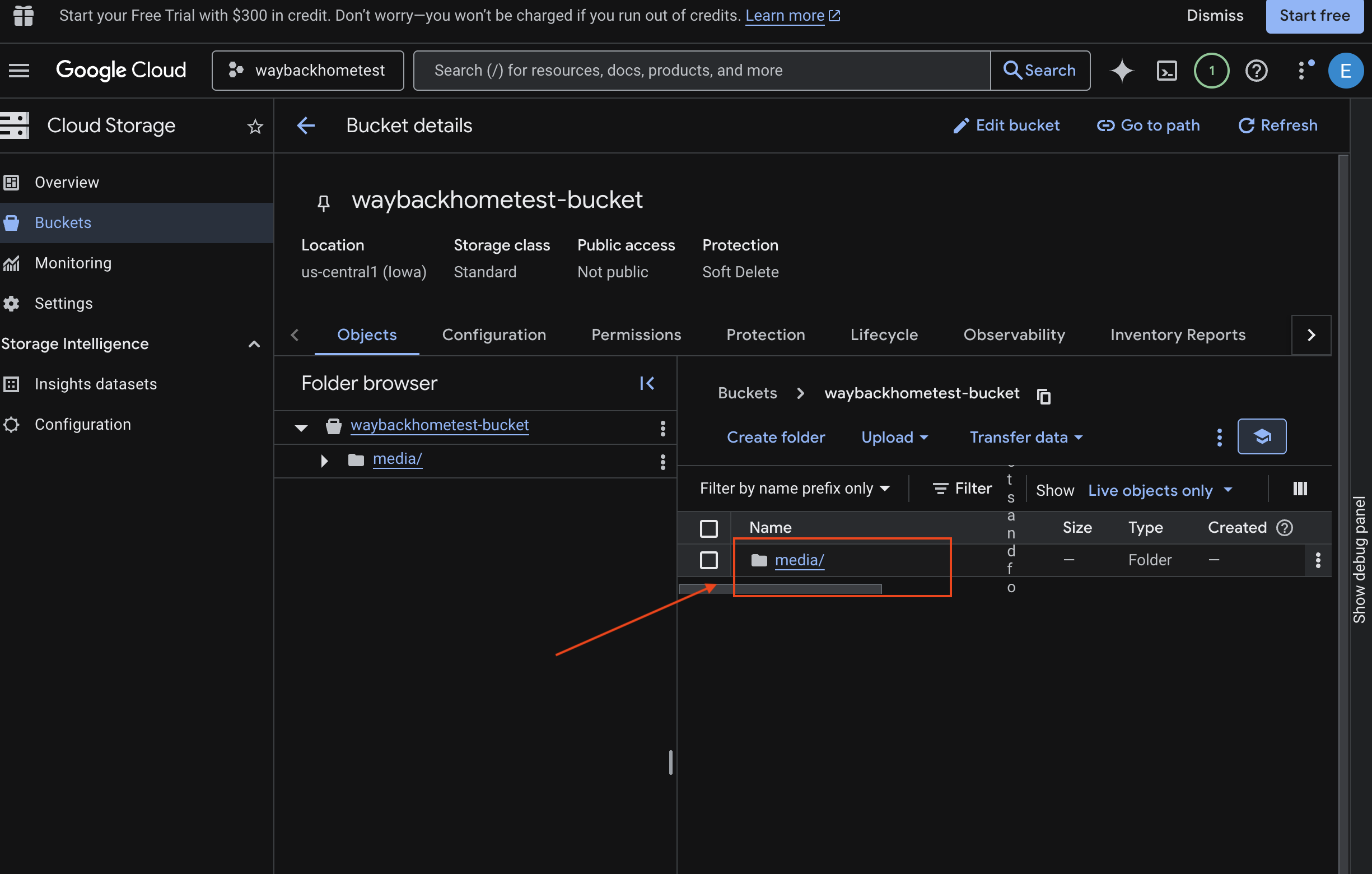
- Xem hình ảnh bạn tải lên tại đây.
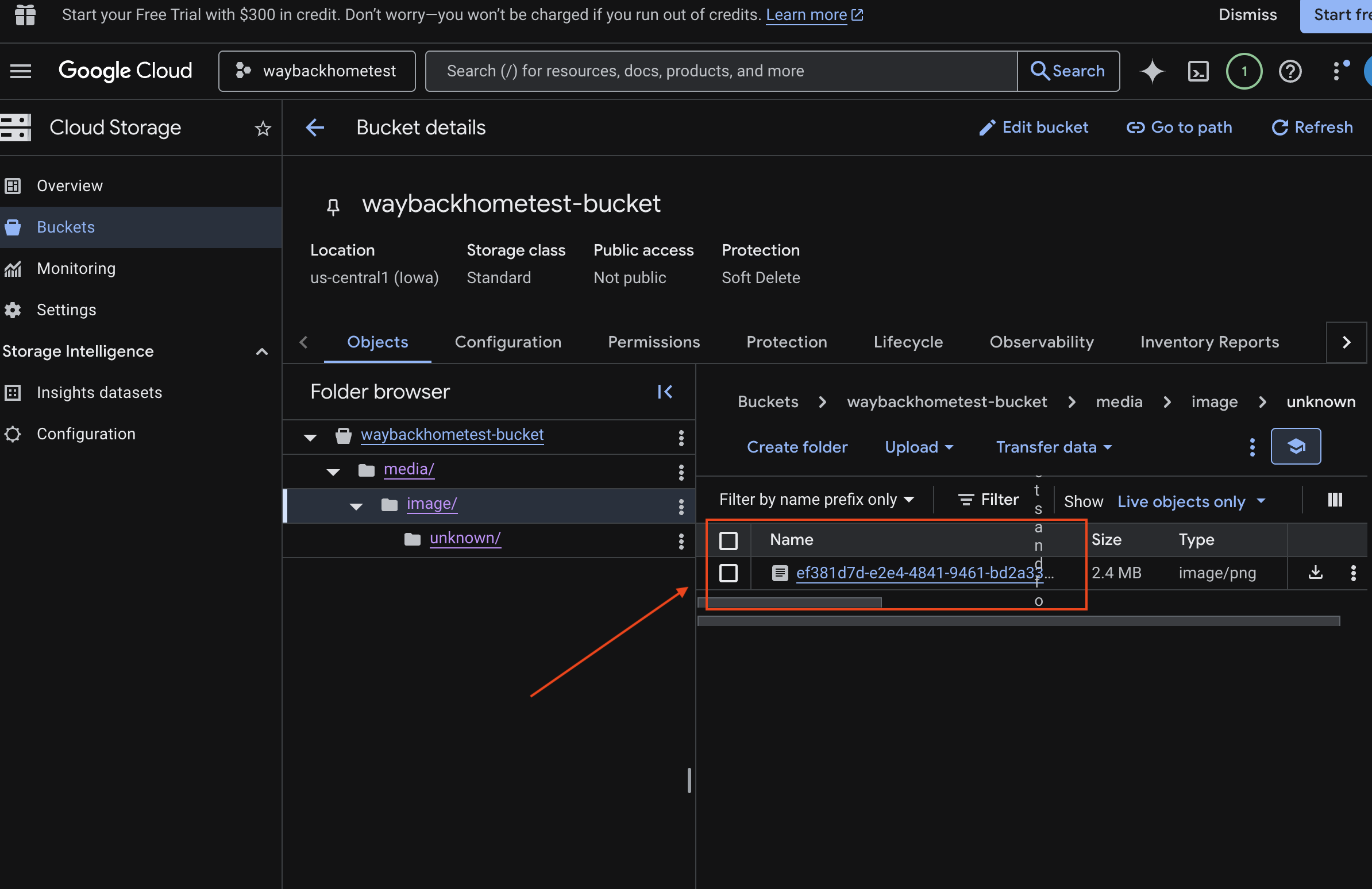
7. Xác minh tính năng Tải lên đa phương thức trong Spanner (Không bắt buộc)
Dưới đây là kết quả đầu ra mẫu trong giao diện người dùng cho test_photo1.
- Mở Google Cloud Console Spanner.
- Chọn phiên bản của bạn:
Survivor Network - Chọn cơ sở dữ liệu:
graph-db - Trong thanh bên trái, hãy nhấp vào Spanner Studio
👉 Trong Spanner Studio, hãy truy vấn dữ liệu mới:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
Chúng ta có thể xác minh bằng cách xem kết quả bên dưới:
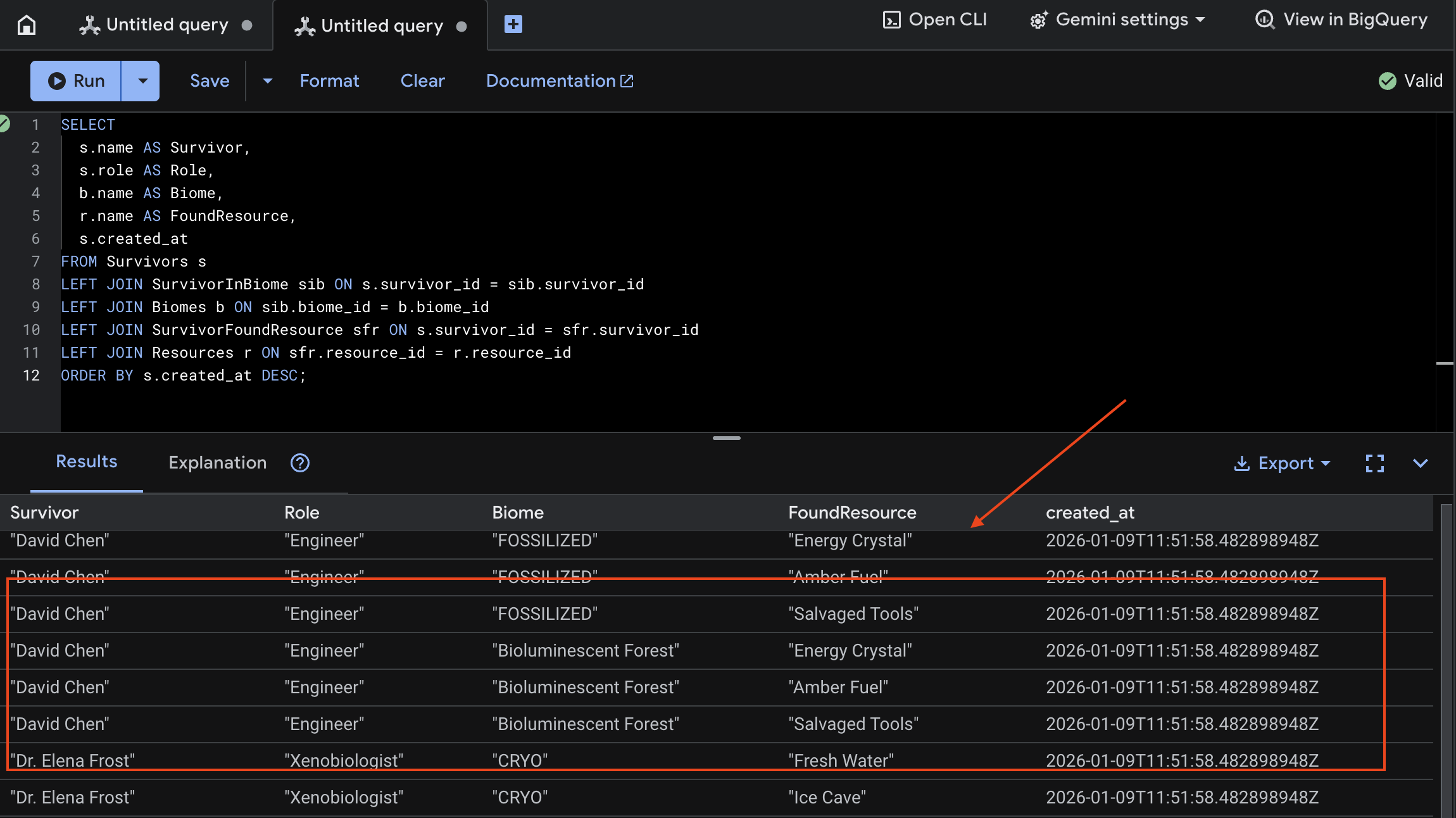
12. ☕️ [Không bắt buộc] Ngân hàng bộ nhớ có công cụ đại lý
1. Cách hoạt động của tính năng Kỷ niệm
Hệ thống sử dụng phương pháp bộ nhớ kép để xử lý cả ngữ cảnh tức thì và quá trình học tập dài hạn.
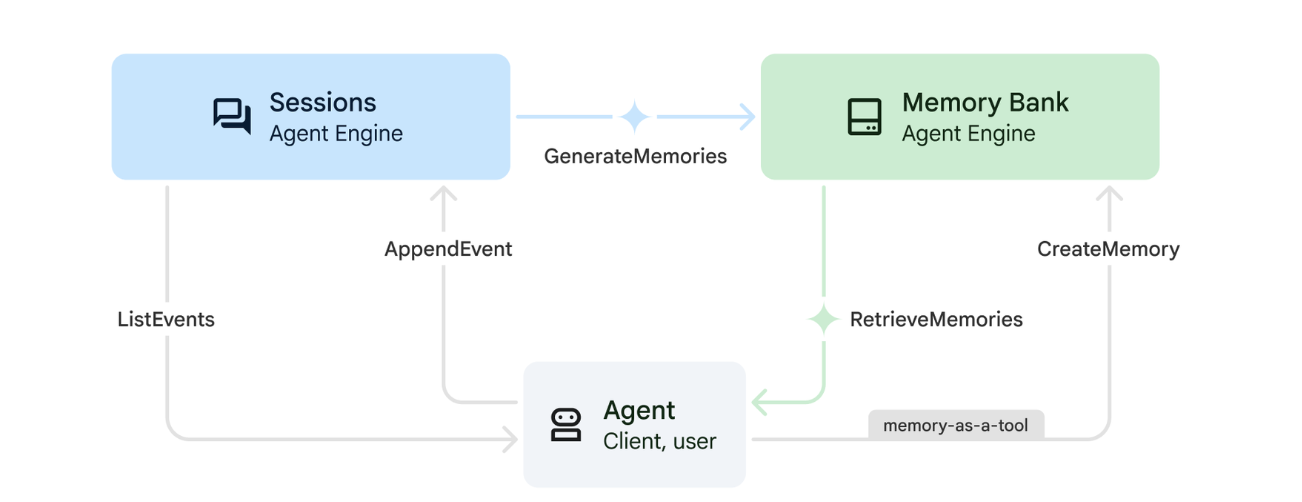
2. Chủ đề kỷ niệm là gì?
Chủ đề trong bộ nhớ xác định danh mục thông tin mà trợ lý ảo cần ghi nhớ trong các cuộc trò chuyện. Hãy coi chúng như những tủ hồ sơ cho nhiều loại lựa chọn ưu tiên của người dùng.
2 chủ đề của chúng tôi:
search_preferences: Cách người dùng muốn tìm kiếm- Họ thích tìm kiếm bằng từ khoá hay tìm kiếm ngữ nghĩa?
- Họ thường tìm kiếm những kỹ năng/quần xã sinh vật nào?
- Ví dụ về bộ nhớ: "Người dùng thích tìm kiếm ngữ nghĩa cho các kỹ năng y tế"
urgent_needs_context: Những cuộc khủng hoảng mà họ đang theo dõi- Họ đang giám sát những tài nguyên nào?
- Họ lo ngại về những người sống sót nào?
- Ví dụ về thông tin được ghi nhớ: "Người dùng đang theo dõi tình trạng thiếu thuốc ở Trại phía Bắc"
3. Thiết lập chủ đề kỷ niệm
Chủ đề bộ nhớ tuỳ chỉnh xác định những gì mà tác nhân nên ghi nhớ. Các chế độ cài đặt này được định cấu hình khi triển khai Agent Engine.
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
Thao tác này sẽ mở ~/way-back-home/level_2/backend/deploy_agent.py trong trình chỉnh sửa.
Chúng ta xác định các đối tượng MemoryTopic có cấu trúc để hướng dẫn LLM về thông tin cần trích xuất và lưu.
👉Trong tệp deploy_agent.py, hãy thay thế # TODO: SET_UP_TOPIC bằng nội dung sau:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. Tích hợp tác nhân
Mã tác nhân phải nhận biết được Ngân hàng bộ nhớ để lưu và truy xuất thông tin.
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
Thao tác này sẽ mở ~/way-back-home/level_2/backend/agent/agent.py trong trình chỉnh sửa.
Tạo tác nhân
Khi tạo tác nhân, chúng ta sẽ truyền after_agent_callback để đảm bảo các phiên được lưu vào bộ nhớ sau khi tương tác. Hàm add_session_to_memory chạy không đồng bộ để tránh làm chậm phản hồi của cuộc trò chuyện.
👉Trong tệp agent.py, hãy tìm nhận xét # TODO: REPLACE_ADD_SESSION_MEMORY, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
Lưu ở chế độ nền
👉Trong tệp agent.py, hãy tìm nhận xét # TODO: REPLACE_ADD_MEMORY_BANK_TOOL, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉Trong tệp agent.py, hãy tìm nhận xét # TODO: REPLACE_ADD_CALLBACK, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
Thiết lập Vertex AI Session Service
👉💻 Trong cửa sổ dòng lệnh, hãy mở tệp chat.py trong Trình chỉnh sửa Cloud Shell bằng cách chạy:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉Trong tệp chat.py, hãy tìm dòng nhận xét # TODO: REPLACE_VERTEXAI_SERVICES, Replace this whole line (Thay thế toàn bộ dòng này) bằng đoạn mã sau:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [Không bắt buộc] Đính kèm Nhân viên hỗ trợ bằng Công cụ Nhân viên hỗ trợ
1. Thiết lập và triển khai
Trước khi kiểm thử các tính năng bộ nhớ, bạn cần triển khai tác nhân bằng các chủ đề bộ nhớ mới và đảm bảo môi trường của bạn được định cấu hình đúng cách.
Chúng tôi đã cung cấp một tập lệnh tiện lợi để xử lý quy trình này.
Chạy tập lệnh triển khai
👉💻 Trong cửa sổ dòng lệnh, hãy chạy tập lệnh triển khai:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
Tập lệnh này thực hiện những thao tác sau:
- Chạy
backend/deploy_agent.pyđể đăng ký các chủ đề về tác nhân và bộ nhớ với Vertex AI. - Ghi lại Mã nhận dạng công cụ đại lý mới.
- Tự động cập nhật tệp
.envbằngAGENT_ENGINE_ID. - Đảm bảo rằng
USE_MEMORY_BANK=TRUEđược đặt trong tệp.env.
[QUAN TRỌNG] Nếu thay đổi custom_topics trong deploy_agent.py, bạn phải chạy lại tập lệnh này để cập nhật Agent Engine.
Xác minh Ngân hàng bộ nhớ
Giờ đây, bạn có thể xác minh rằng bộ nhớ đang hoạt động bằng cách dạy cho tác nhân một lựa chọn ưu tiên và kiểm tra xem lựa chọn đó có duy trì trong các phiên hay không.
Bước 1. Mở ứng dụng
Mở lại Ứng dụng bằng cách làm theo hướng dẫn bên dưới: Nếu thiết bị đầu cuối trước đó vẫn đang chạy, hãy kết thúc bằng cách nhấn Ctrls+C.
👉💻 Ứng dụng Start:
cd ~/way-back-home/level_2/
./start_app.sh
👉 Nhấp vào Local: http://localhost:5173/ trên thiết bị đầu cuối.
Bước 2. Thử nghiệm Ngân hàng bộ nhớ bằng văn bản
Trong giao diện trò chuyện, hãy cho nhân viên hỗ trợ biết về bối cảnh cụ thể của bạn:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 Chờ khoảng 30 giây để bộ nhớ xử lý ở chế độ nền.
Bước 3. Bắt đầu một phiên mới
Làm mới trang để xoá nhật ký trò chuyện hiện tại (bộ nhớ ngắn hạn).
Đặt câu hỏi dựa trên bối cảnh mà bạn đã cung cấp trước đó:
"What kind of missions am I interested in?"
Phản hồi dự kiến:
"Dựa trên các cuộc trò chuyện trước đây, bạn quan tâm đến:
- Nhiệm vụ cứu hộ y tế
- Hoạt động trên núi/ở độ cao
- Kỹ năng cần thiết: sơ cứu, leo núi
Bạn có muốn tôi tìm những người sống sót đáp ứng các tiêu chí này không?"
Bước 4. Thử nghiệm bằng tính năng Tải hình ảnh lên
Tải hình ảnh lên rồi đặt câu hỏi:
remember this
Bạn có thể chọn bất kỳ bức ảnh nào ở đây hoặc ảnh của riêng bạn rồi tải lên giao diện người dùng:
Bước 5. Xác minh trong Vertex AI Agent Engine
Chuyển đến Google Cloud Console Agent Engine
- Nhớ chọn dự án trong bộ chọn dự án ở trên cùng bên trái:
- Xác minh công cụ tác nhân mà bạn vừa triển khai từ lệnh trước đó
use_memory_bank.sh: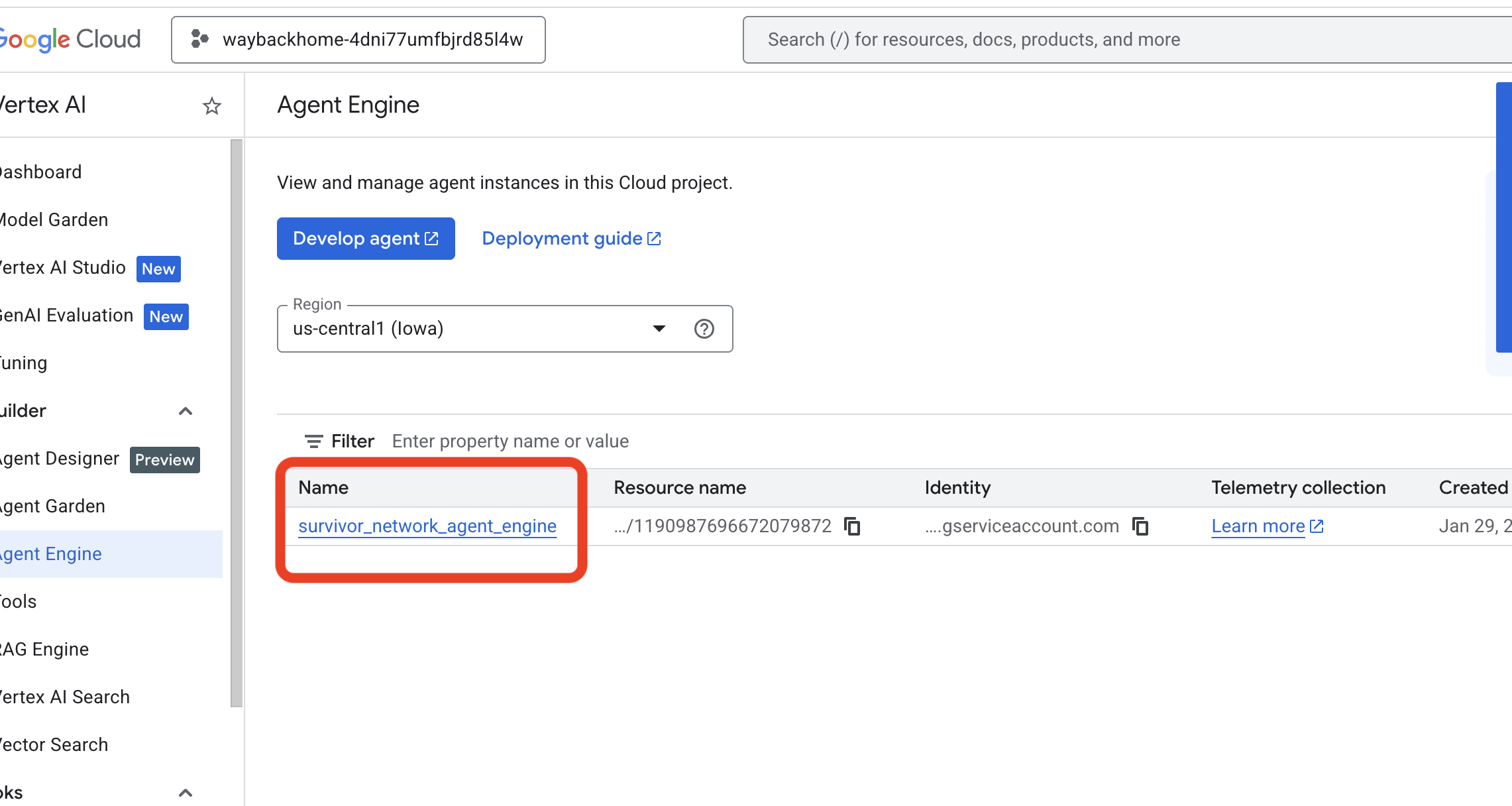 Nhấp vào công cụ tác nhân mà bạn vừa tạo.
Nhấp vào công cụ tác nhân mà bạn vừa tạo. - Nhấp vào thẻ
Memoriestrong tác nhân đã triển khai này, bạn có thể xem tất cả bộ nhớ tại đây.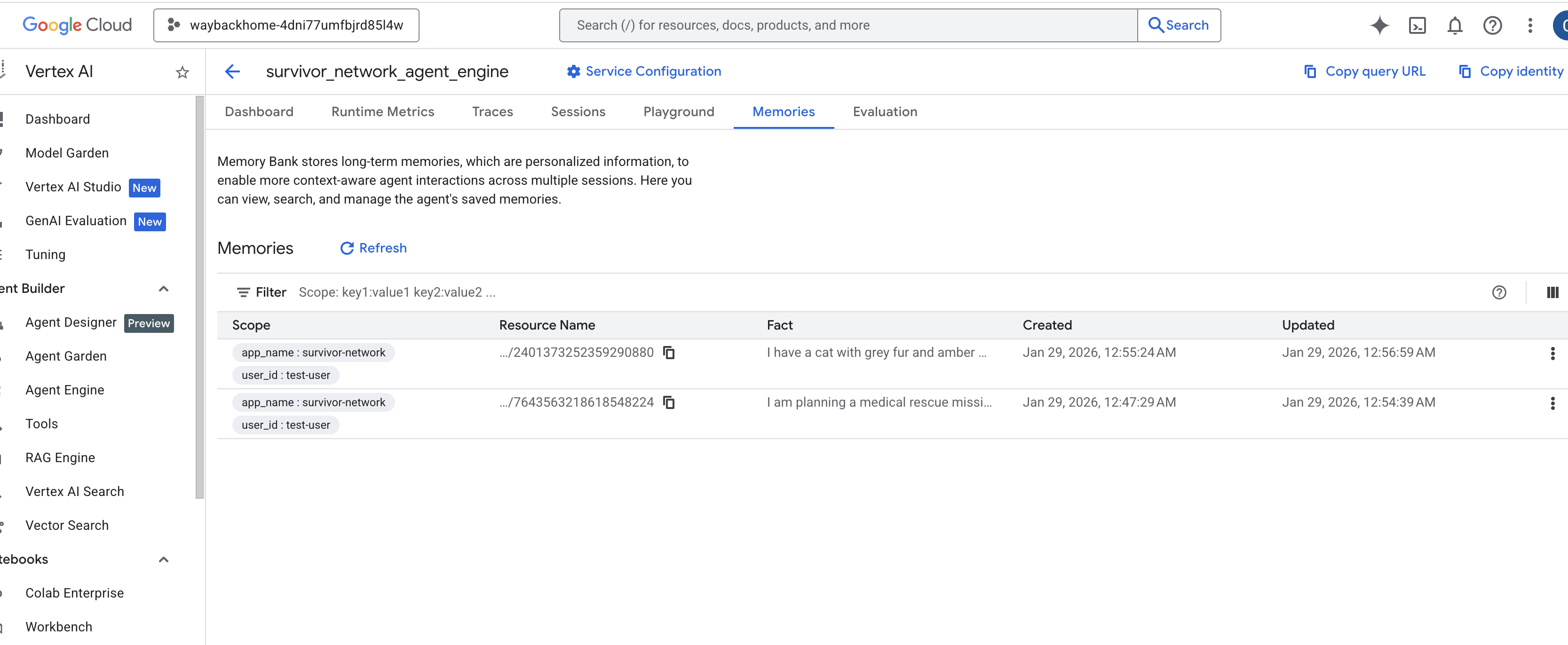
👉💻 Khi bạn hoàn tất kiểm thử, trong dòng lệnh, hãy nhấp vào "Ctrl + C" để kết thúc quy trình.
🎉 Xin chúc mừng! Bạn vừa đính kèm bộ nhớ vào tác nhân!
14. ☕️ [Không bắt buộc] Triển khai lên Cloud Run
1. Chạy tập lệnh triển khai
👉💻 Chạy tập lệnh triển khai:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
Sau khi triển khai thành công, bạn sẽ có URL. Đây là URL đã triển khai dành cho bạn! 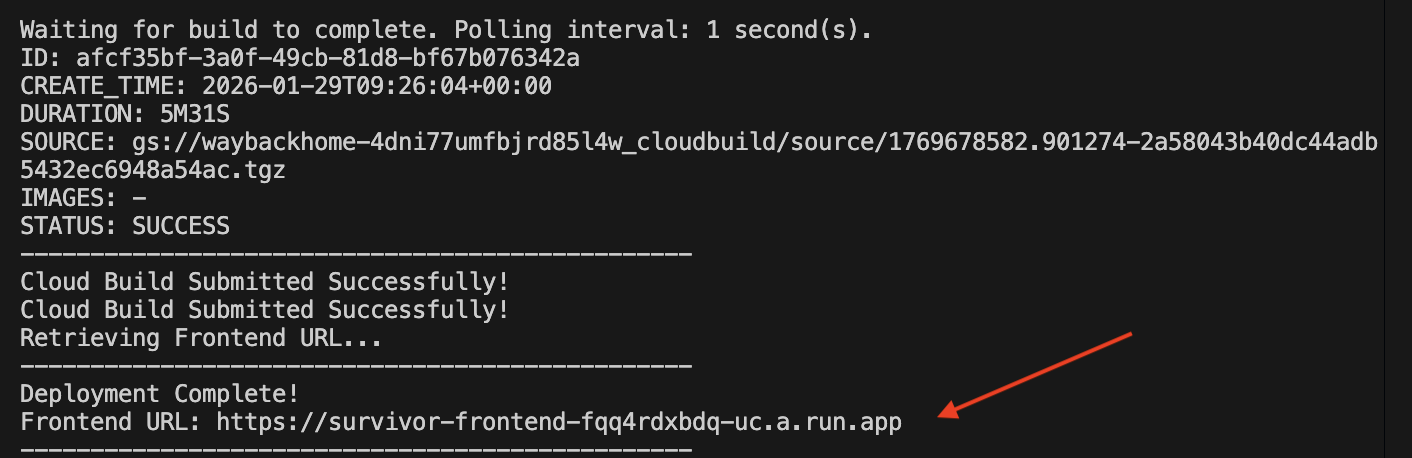
👉💻 Trước khi lấy URL, hãy cấp quyền bằng cách chạy:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
Truy cập vào URL đã triển khai và bạn sẽ thấy ứng dụng của mình hoạt động ở đó!
2. Tìm hiểu về quy trình tạo bản dựng
Tệp cloudbuild.yaml xác định các bước tuần tự sau:
- Backend Build: Tạo hình ảnh Docker từ
backend/Dockerfile. - Triển khai phụ trợ: Triển khai vùng chứa phụ trợ lên Cloud Run.
- Capture URL (Chụp URL): Lấy URL phụ trợ mới.
- Frontend Build:
- Cài đặt các phần phụ thuộc.
- Tạo ứng dụng React, chèn
VITE_API_URL=.
- Hình ảnh giao diện người dùng: Tạo hình ảnh Docker từ
frontend/Dockerfile(đóng gói các thành phần tĩnh). - Triển khai giao diện người dùng: Triển khai vùng chứa giao diện người dùng.
3. Xác minh quá trình triển khai
Sau khi quá trình tạo bản dựng hoàn tất (kiểm tra đường liên kết nhật ký do tập lệnh cung cấp), bạn có thể xác minh:
- Chuyển đến Cloud Run Console.
- Tìm dịch vụ
survivor-frontend. - Nhấp vào URL để mở ứng dụng.
- Thực hiện một truy vấn tìm kiếm để đảm bảo giao diện người dùng có thể giao tiếp với phần phụ trợ.
(KHÔNG BẮT BUỘC) 4. Triển khai thủ công
Nếu bạn muốn chạy các lệnh theo cách thủ công hoặc hiểu rõ hơn về quy trình này, hãy xem cách sử dụng trực tiếp cloudbuild.yaml.
Viết cloudbuild.yaml
Tệp cloudbuild.yaml cho Google Cloud Build biết những bước cần thực hiện.
- steps: Danh sách các hành động tuần tự. Mỗi bước chạy trong một vùng chứa (ví dụ:
docker,gcloud,node,bash). - substitutions: Các biến có thể được truyền tại thời gian xây dựng (ví dụ:
$_REGION). - workspace: Một thư mục dùng chung nơi các bước có thể chia sẻ tệp (giống như cách chúng ta chia sẻ
backend_url.txt).
Chạy quy trình triển khai
Để triển khai theo cách thủ công mà không cần tập lệnh, hãy dùng lệnh gcloud builds submit. Bạn PHẢI truyền các biến thay thế bắt buộc.
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. Kết luận
1. Những gì bạn đã tạo
✅ Cơ sở dữ liệu đồ thị: Spanner có các nút (người sống sót, kỹ năng) và cạnh (mối quan hệ)
✅ Tìm kiếm bằng AI: Tìm kiếm bằng từ khoá, tìm kiếm ngữ nghĩa và tìm kiếm kết hợp bằng các mục nhúng
✅ Quy trình đa phương thức: Trích xuất thực thể từ hình ảnh/video bằng Gemini
✅ Hệ thống đa tác nhân: Quy trình làm việc phối hợp bằng ADK
✅ Ngân hàng bộ nhớ: Cá nhân hoá dài hạn bằng Vertex AI
✅ Triển khai sản xuất: Cloud Run + Agent Engine
2. Tóm tắt về cấu trúc
3. Kiến thức quan trọng cần ghi nhớ
- Graph RAG: Kết hợp cấu trúc cơ sở dữ liệu đồ thị với các thành phần nhúng ngữ nghĩa để tìm kiếm thông minh
- Mẫu nhiều tác nhân: Các quy trình tuần tự cho quy trình công việc phức tạp, nhiều bước
- AI đa phương thức: Trích xuất dữ liệu có cấu trúc từ nội dung nghe nhìn không có cấu trúc (hình ảnh/video)
- Tác nhân có trạng thái: Ngân hàng bộ nhớ cho phép cá nhân hoá trên nhiều phiên
4. Nội dung hội thảo
- Level0: Xác định danh tính của bạn
- Level1: Vị trí chính xác
- Level2 This One: Xây dựng tác nhân AI đa phương thức bằng Graph RAG, ADK và Memory Bank
- Level3: Tạo một tác nhân truyền phát trực tiếp hai chiều ADK
- Level4: Hệ thống nhiều tác nhân song phương trực tiếp
- Level5: Kiến trúc hướng sự kiện bằng Google ADK, A2A và Kafka