
1. 简介

1. 面临的挑战
在灾难响应场景中,协调不同地点具有不同技能、资源和需求的幸存者需要智能数据管理和搜索功能。本研讨会将教您构建一个结合了以下要素的生产 AI 系统:
- 🗄️ 图数据库 (Spanner):存储幸存者、技能和资源之间的复杂关系
- 🔍 AI 赋能的搜索:使用嵌入的语义 + 关键字混合搜索
- 📸 多模态处理:从图片、文本和视频中提取结构化数据
- 🤖 多智能体编排:协调专用智能体以处理复杂的工作流
- 🧠 长期记忆:利用 Vertex AI Memory Bank 实现个性化
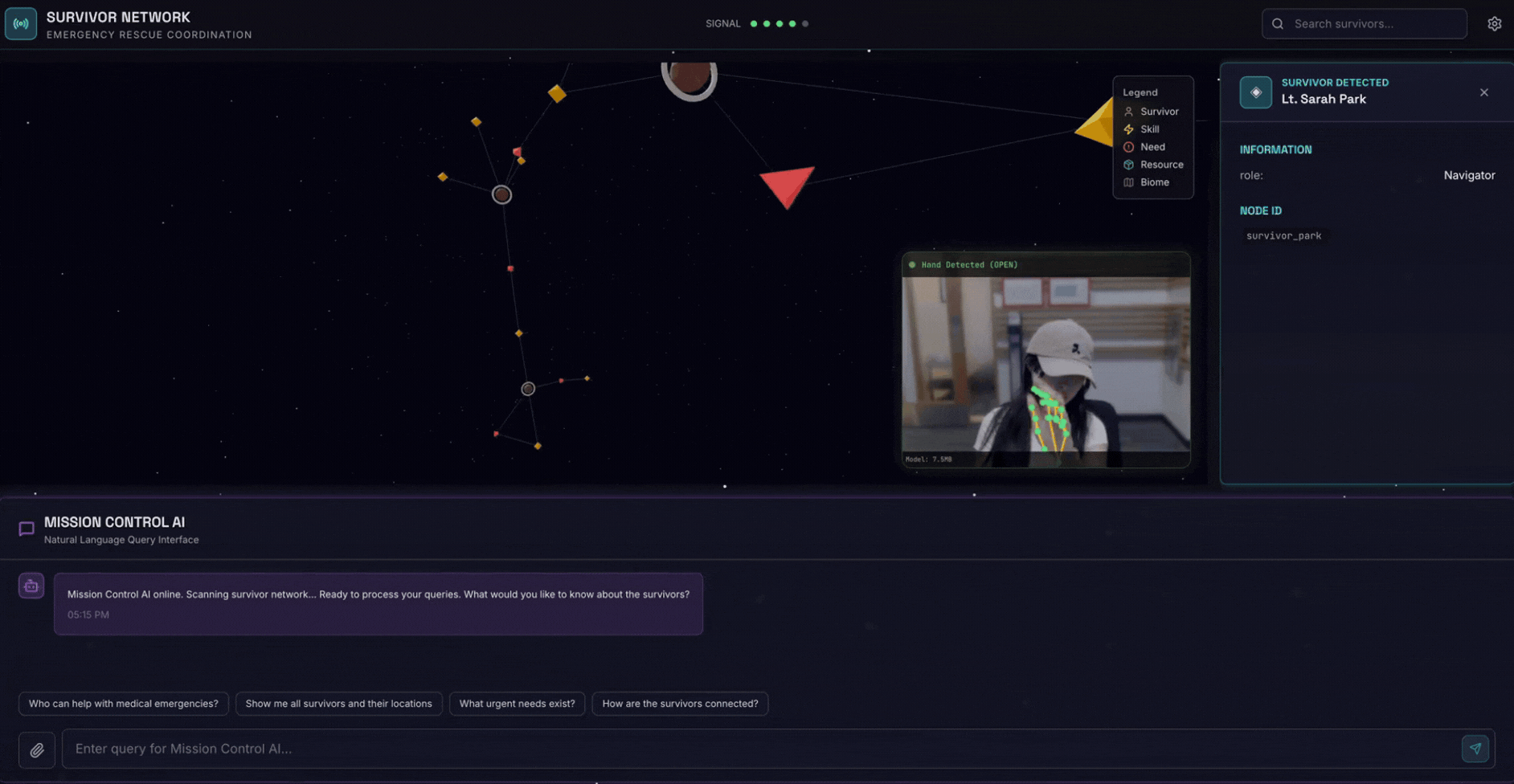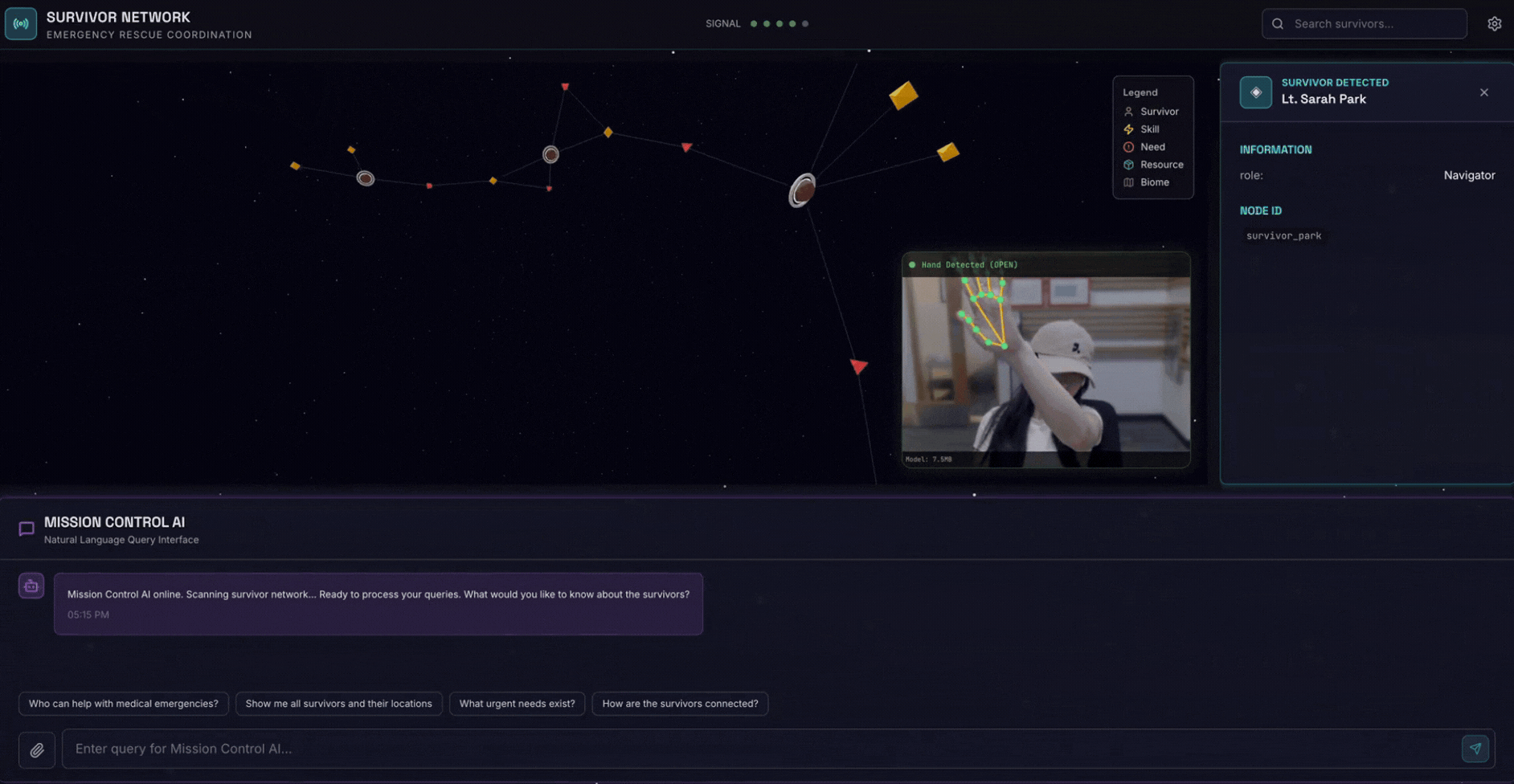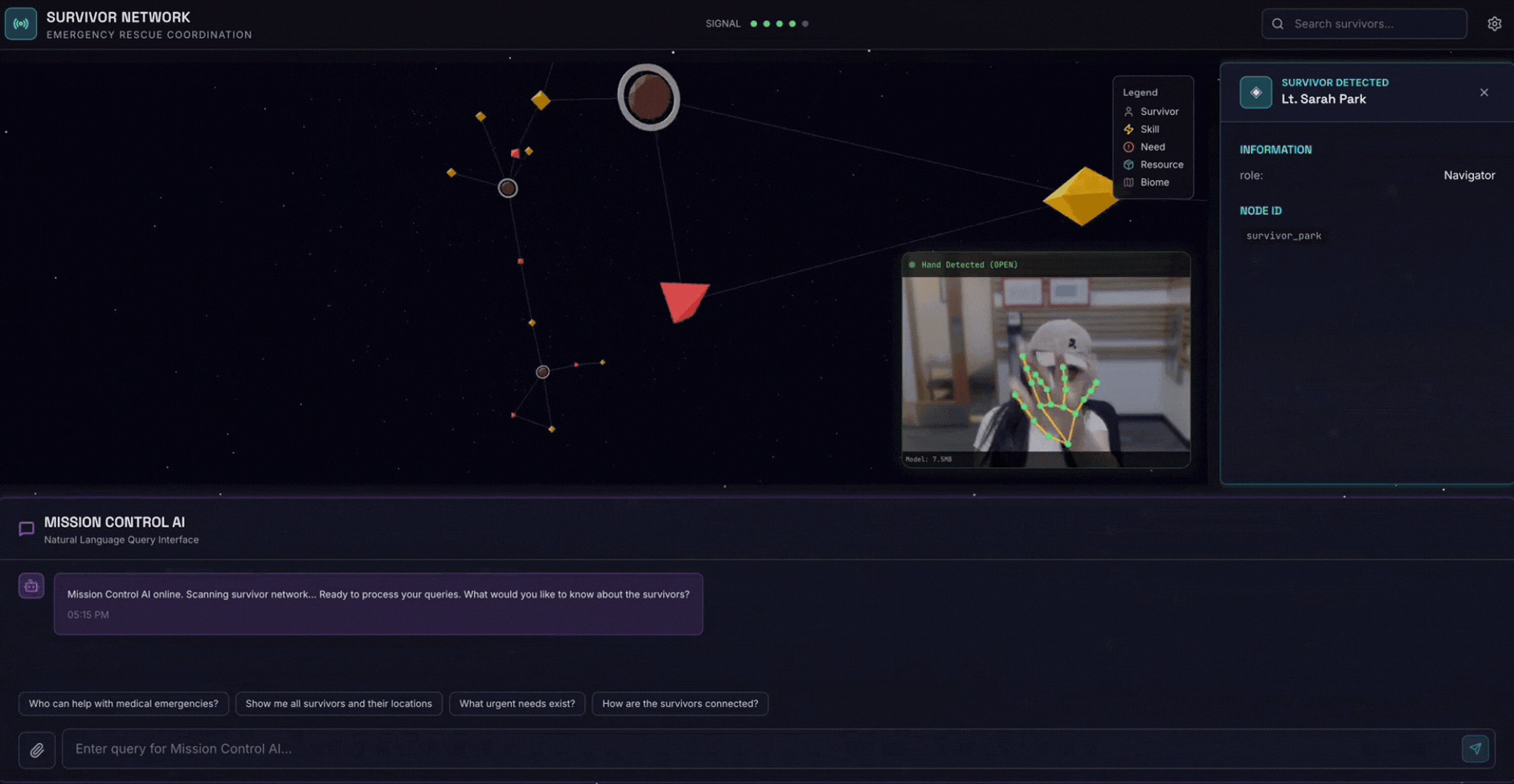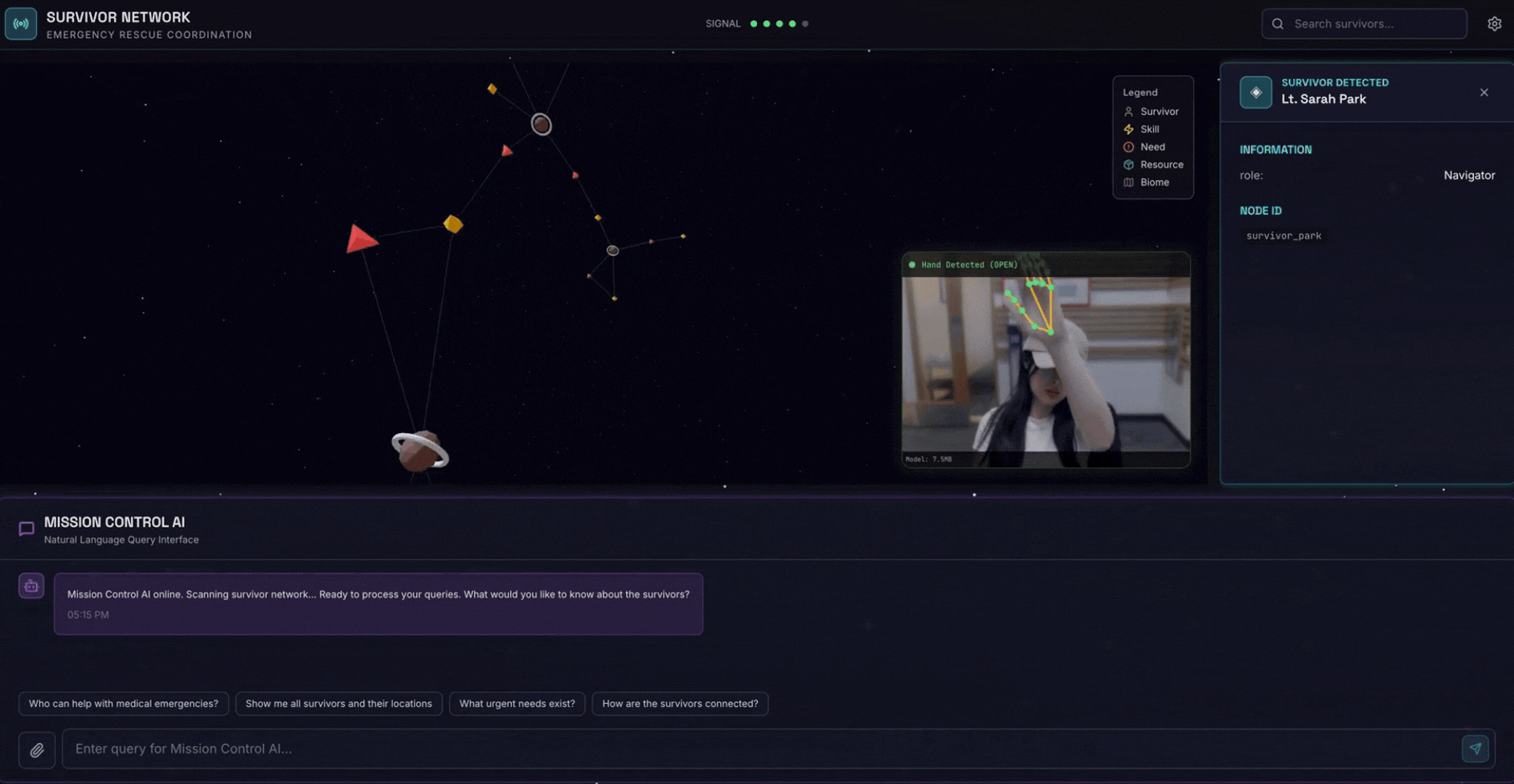
2. 构建内容
包含以下内容的幸存者网络图数据库:
- 🗺️ 幸存者关系的 3D 交互式图表可视化
- 🔍 智能搜索(关键字、语义和混合)
- 📸 多模态上传流水线(从图片/视频中提取实体)
- 🤖 用于复杂任务编排的多智能体系统
- 🧠 记忆库集成,打造个性化互动体验
3. 核心技术
组件 | 技术 | 用途 |
数据库 | Cloud Spanner Graph | 存储节点(幸存者、技能)和边(关系) |
AI Search | Gemini + Embeddings | 语义理解 + 相似度搜索 |
代理框架 | ADK(智能体开发套件) | 编排 AI 工作流 |
内存 | Vertex AI Memory Bank | 长期用户偏好设置存储 |
前端 | React + Three.js | 交互式 3D 图表可视化 |
2. 🛠️ 环境准备(如果您正在参加研讨会,请跳过此步骤)
第 1 部分:启用结算账号
如需运行此 Codelab,您需要拥有一个有一定信用额度的结算账号。使用本 Codelab 顶部横幅中的积分开始学习。如果您已关联结算账号,则可以跳过此步骤。
第二部分:开放环境
- 👉 点击此链接可直接前往 Cloud Shell Editor
- 👉 如果系统在今天任何时间提示您进行授权,请点击授权继续。
- 👉 如果终端未显示在屏幕底部,请打开它:
- 点击查看
- 点击终端
- 👉💻 在终端中,使用以下命令验证您是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list - 👉💻 从 GitHub 克隆引导项目:
git clone https://github.com/gca-americas/way-back-home.git
第 3 部分:创建新项目
👉💻 在终端中,将初始化脚本设为可执行文件并运行该脚本:
cd ~/way-back-home/level_2
./init.sh
3. 🛠️ 环境设置
1. 打开 Cloud Shell
在 Cloud Shell 编辑器终端中,如果终端未显示在屏幕底部,请打开它:
- 点击查看
- 点击终端
2. 配置项目
👉💻 在终端中,设置项目 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 启用必需的 API(这需要大约 2-3 分钟):
gcloud services enable compute.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
spanner.googleapis.com \
storage.googleapis.com
3. 运行设置脚本
👉💻 执行设置脚本:
cd ~/way-back-home/level_2
./setup.sh
这样即可为您创建 .env。在 Cloud Shell 中,打开 way_back_home 项目。在 level_2 文件夹下,您会看到系统为您创建的 .env 文件。如果您找不到该图标,可以点击 View -> Toggle Hidden File 来查看。
4. 加载示例数据
👉💻 导航到后端并安装依赖项:
cd ~/way-back-home/level_2/backend
uv sync
👉💻 加载初始幸存者数据:
uv run python ~/way-back-home/level_2/backend/setup_data.py
这会创建:
- Spanner 实例 (
survivor-network) - 数据库 (
graph-db) - 所有节点和边表
- 用于查询的属性图表预期输出:
============================================================
SUCCESS! Database setup complete.
============================================================
Instance: survivor-network
Database: graph-db
Graph: SurvivorGraph
Access your database at:
https://console.cloud.google.com/spanner/instances/survivor-network/databases/graph-db?project=waybackhome
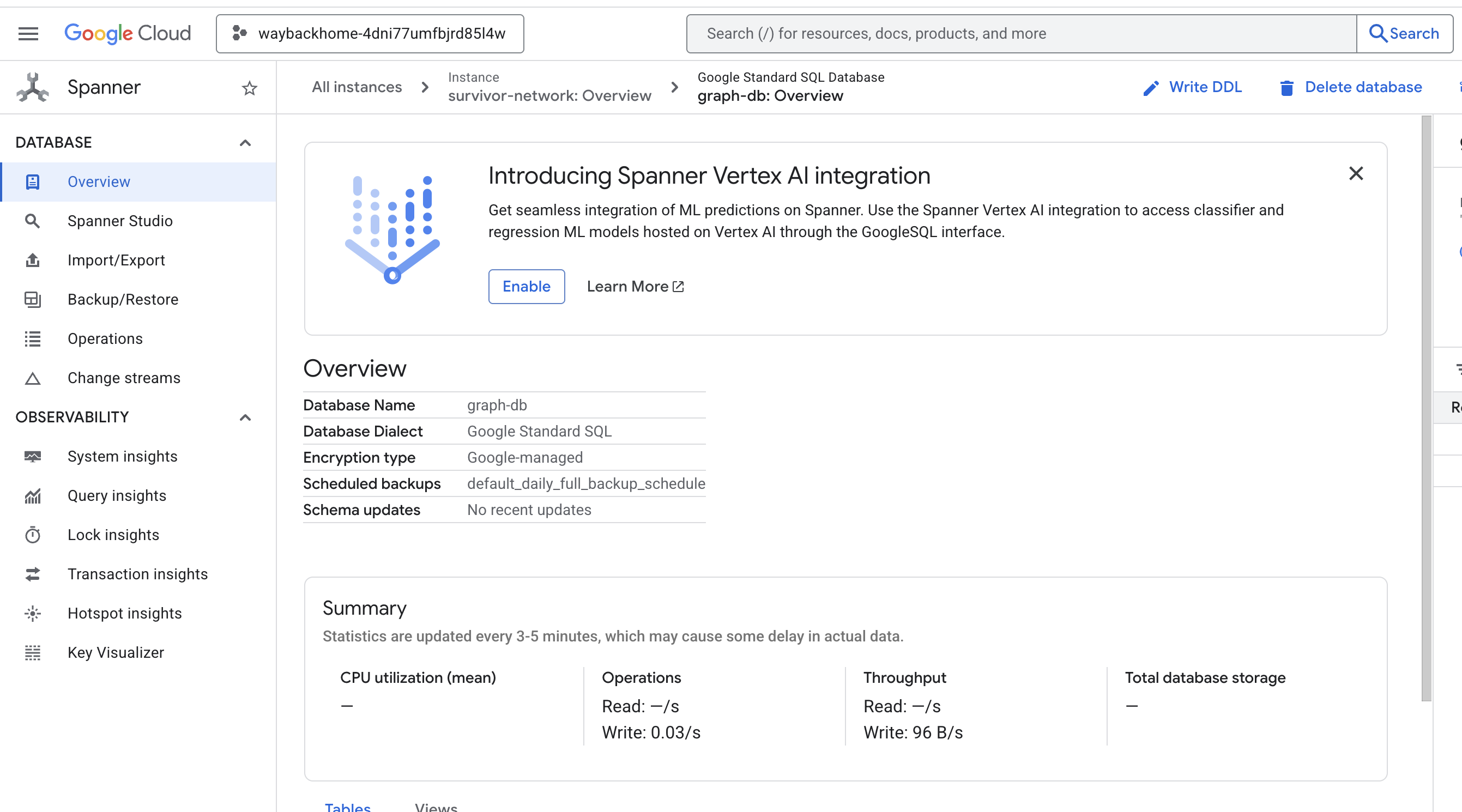
如果您点击输出中 Access your database at 后面的链接,可以打开 Google Cloud 控制台 Spanner。

然后,您将在 Google Cloud 控制台中看到 Spanner!
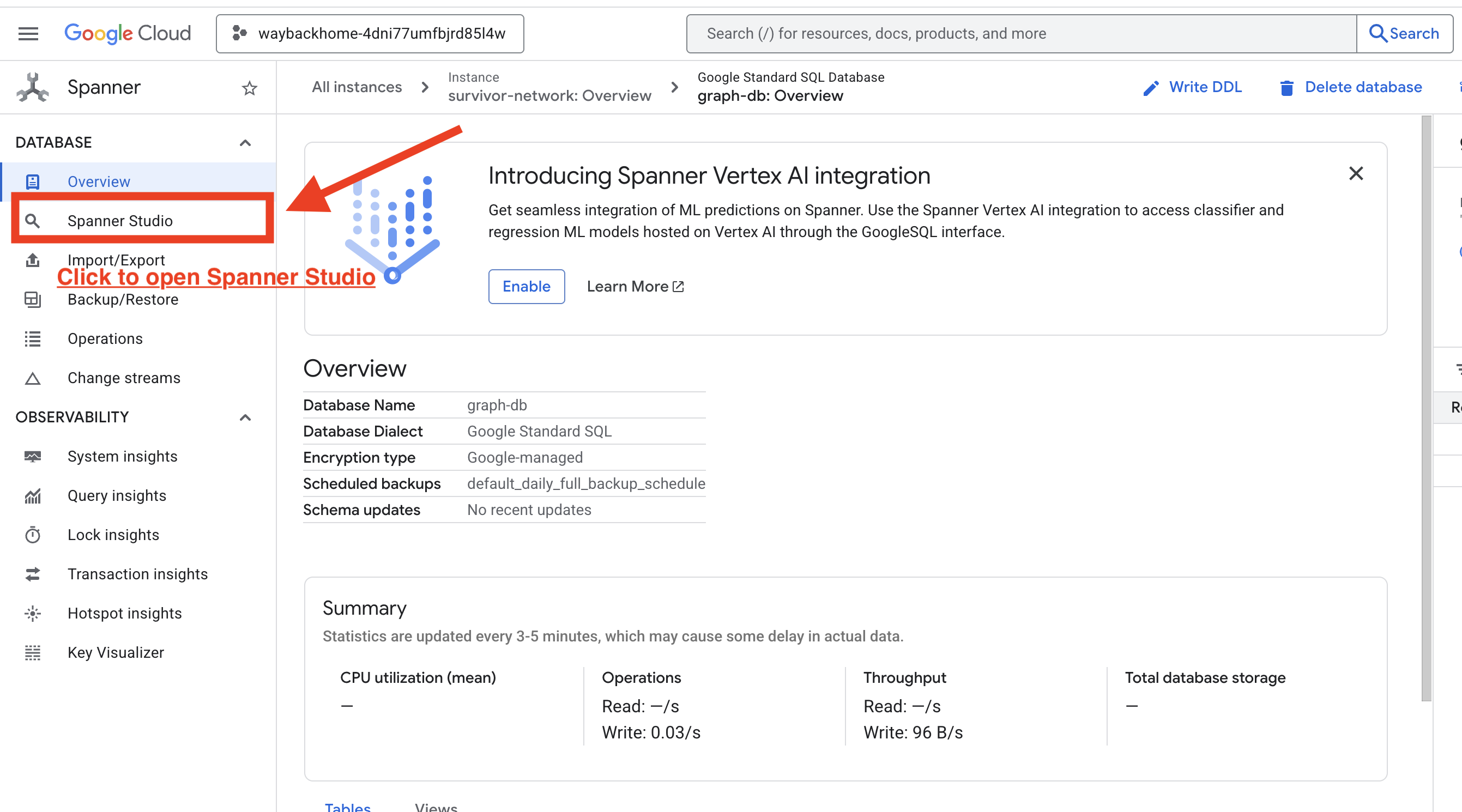
4. 🚀 在 Spanner Studio 中直观呈现图数据
本指南将帮助您使用 Spanner Studio 直接在 Google Cloud 控制台中直观呈现和互动操作幸存者网络图数据。在构建 AI 智能体之前,这是验证数据和了解图结构的好方法。
1. 访问 Spanner Studio
- 在最后一步中,请务必点击链接并打开 Spanner Studio。
2. 了解图结构(“大局观”)
不妨将 Survivor Network 数据集视为一个逻辑谜题或游戏状态:
实体 | 系统中的角色 | 类比 |
幸存者 | 代理/玩家 | 玩家人数 |
生物群系 | 他们身在何处 | 地图区域 |
技能 | 可执行的操作 | 特性 |
需要 | 他们缺乏什么(危机) | 任务 |
资源 | 在现实世界中找到的物品 | 战利品 |
目标:AI 代理的任务是将技能(解决方案)与需求(问题)联系起来,同时考虑生物群落(位置限制)。
🔗 边(关系):
SurvivorInBiome:位置跟踪SurvivorHasSkill:能力清单SurvivorHasNeed:有效问题的列表SurvivorFoundResource:商品库存SurvivorCanHelp:推理关系(由 AI 计算得出!)
3. 查询图
我们来运行几个查询,看看数据中的“故事”。
Spanner Graph 使用 GQL(Graph Query Language)。如需运行查询,请使用 GRAPH SurvivorNetwork,后跟匹配模式。
👉 查询 1:全球名册(谁在哪个位置?)这是基础知识 - 了解位置对于救援行动至关重要。
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[:SurvivorInBiome]->(b:Biomes)
RETURN TO_JSON(result) AS json_result
预期会看到如下结果: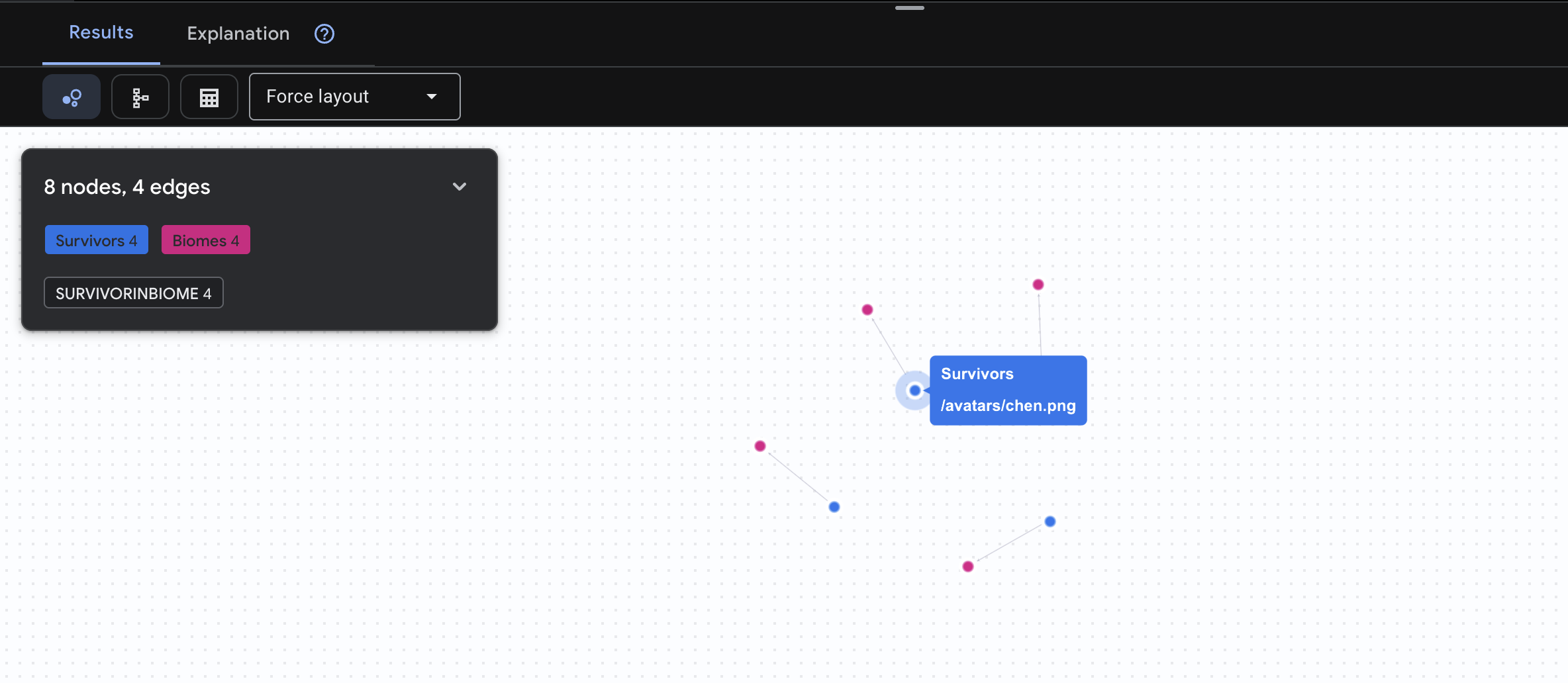
👉 查询 2:技能矩阵(能力)现在,您已经知道每个人的位置,接下来可以了解他们能做什么。
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasSkill]->(k:Skills)
RETURN TO_JSON(result) AS json_result
预期会看到如下结果: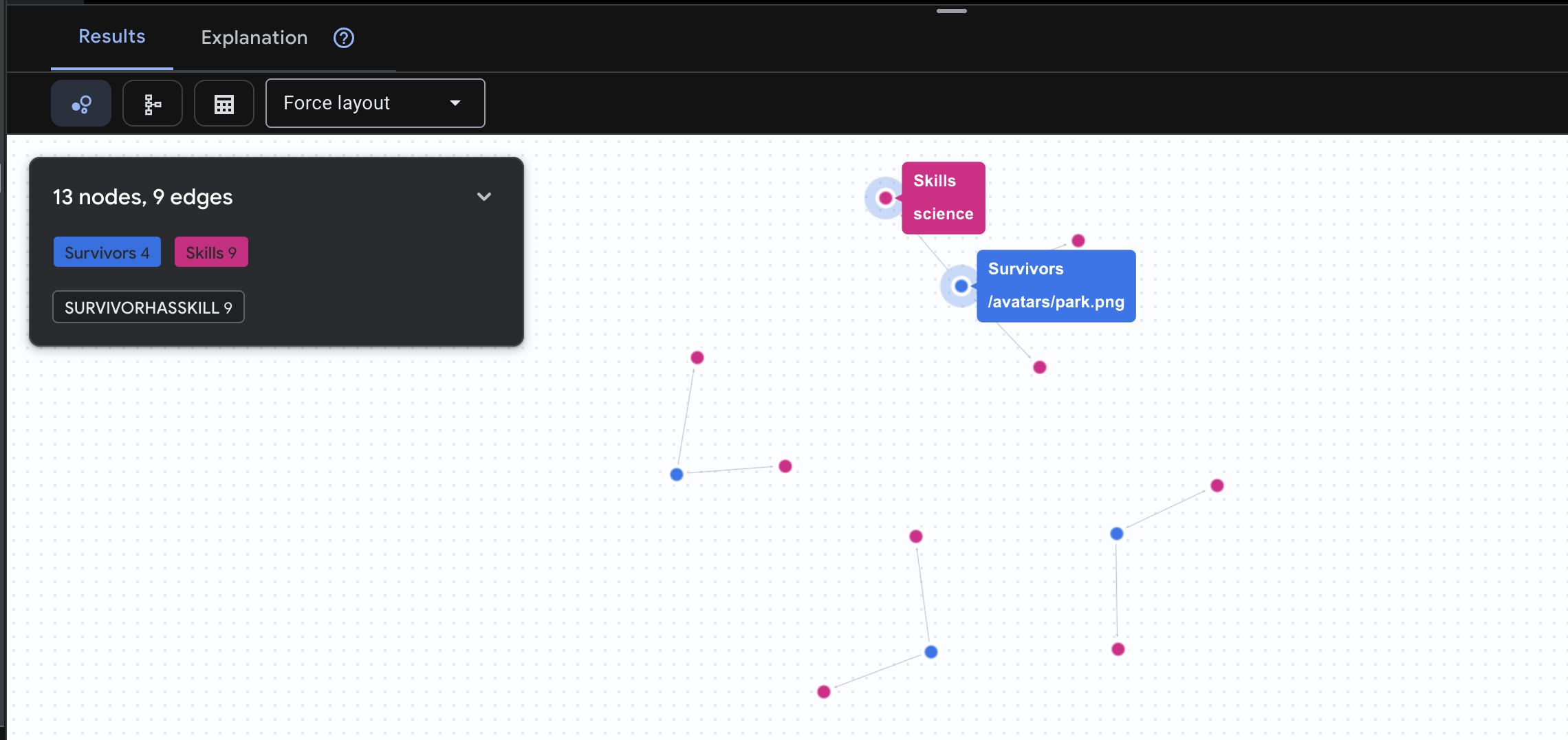
👉 查询 3:谁处于危机之中?(“任务板”)查看需要帮助的幸存者以及他们需要什么。
GRAPH SurvivorNetwork
MATCH result = (s:Survivors)-[h:SurvivorHasNeed]->(n:Needs)
RETURN TO_JSON(result) AS json_result
预期会看到如下结果: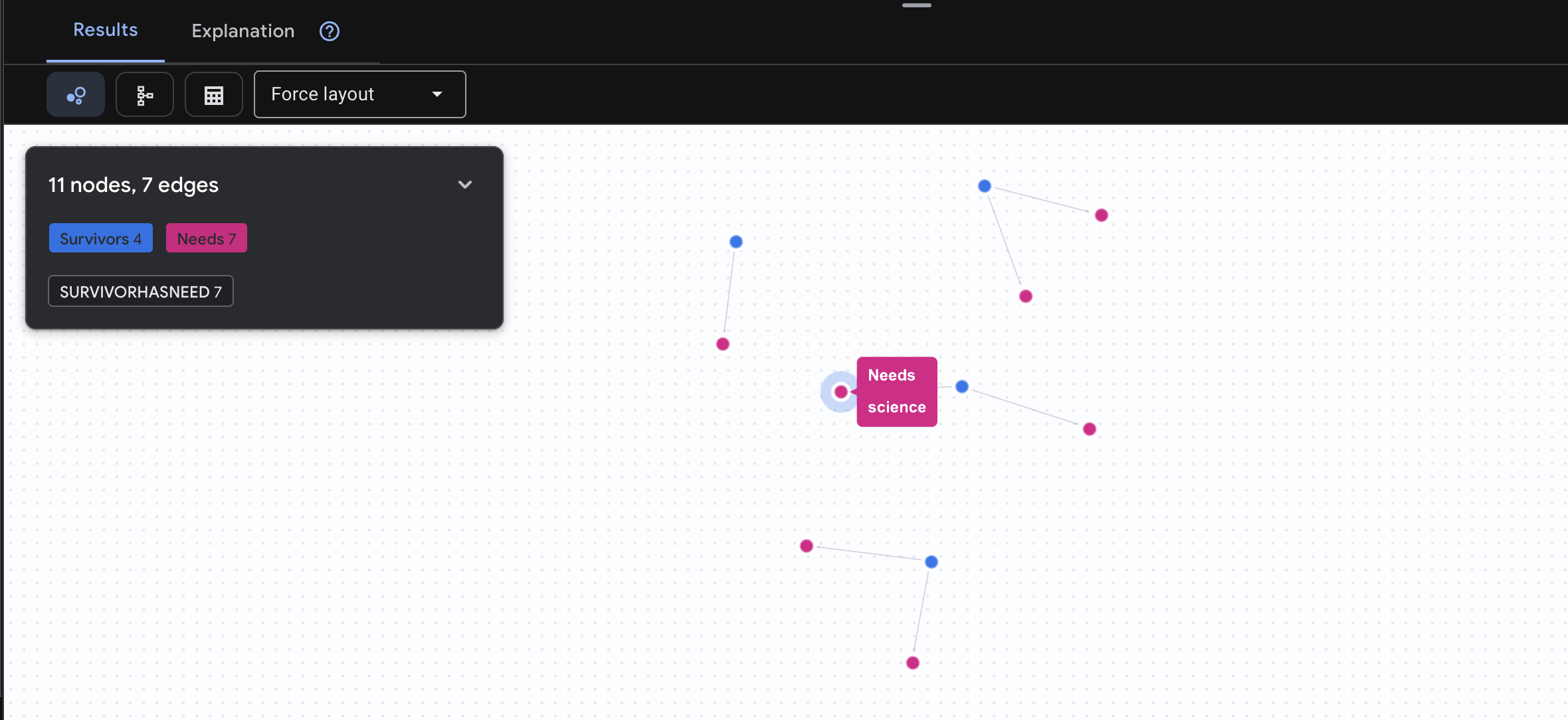
🔎 [可选] 配对 - 谁可以帮助谁?
这正是图表的强大之处!此查询用于查找拥有可满足其他幸存者需求的技能的幸存者。
GRAPH SurvivorNetwork
MATCH result = (helper:Survivors)-[:SurvivorHasSkill]->(skill:Skills)-[:SkillTreatsNeed]->(need:Needs)<-[:SurvivorHasNeed]-(helpee:Survivors)
RETURN TO_JSON(result) AS json_result
预期会看到如下结果: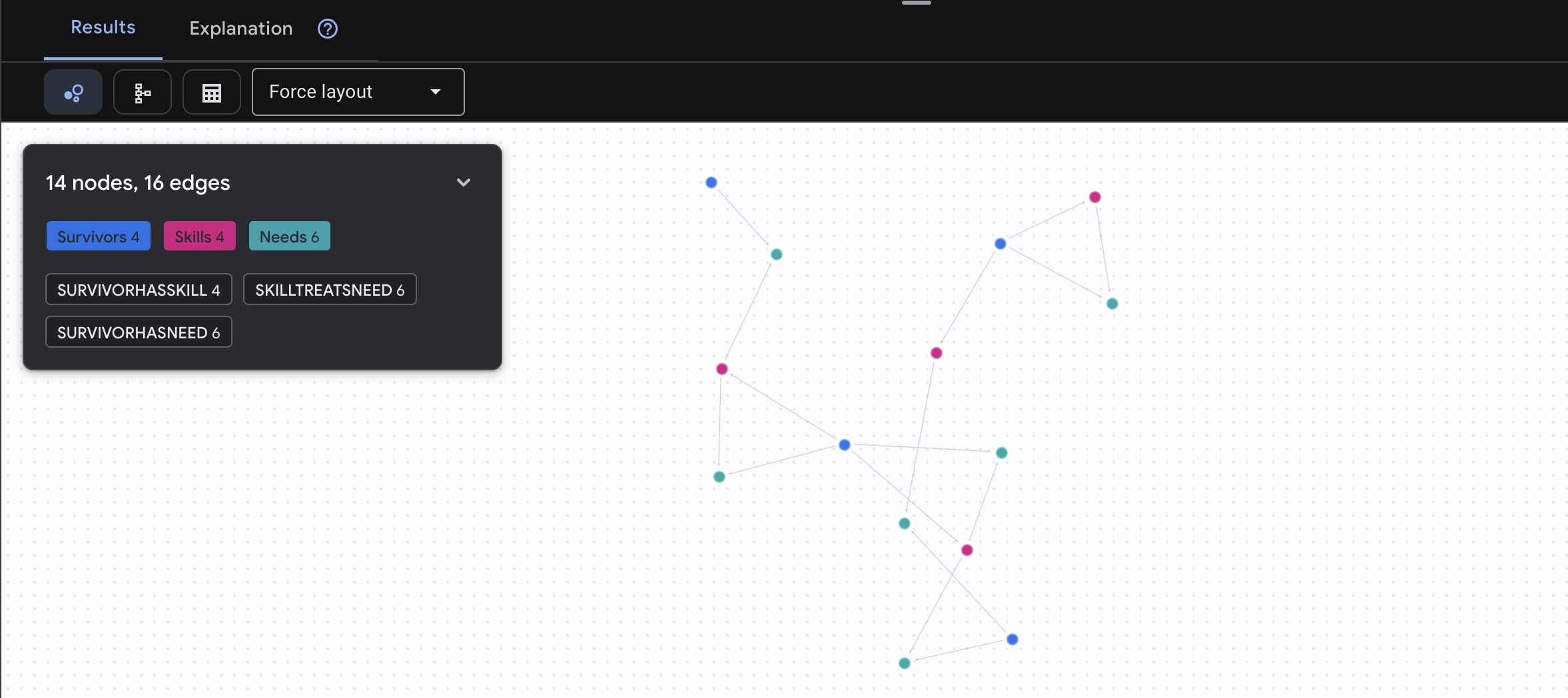
aside positive 此查询的作用:
此查询不仅会显示“急救处理烧伤”(这从架构中可以明显看出),还会查找:
- Elena Frost 医生(接受过医学培训)→ 可以治疗 → 田中队长(烧伤)
- 陈大卫(已接受急救培训)→ 可以治疗 → 朴中尉(脚踝扭伤)
这种方法为何有效:
AI 智能体将执行的操作:
当用户询问“谁可以治疗烧伤?”时,智能体将:
- 运行类似的图表查询
- 返回:“弗罗斯特博士接受过医学培训,可以帮助田中队长”
- 用户无需了解中间表或关系!
5. 🚀 Spanner 中已集成 AI 赋能的嵌入功能
1. 为什么要使用嵌入?(无操作,只读)
在生存场景中,时间至关重要。当幸存者报告 I need someone who can treat burns 或 Looking for a medic 等紧急情况时,他们不能浪费时间猜测数据库中的确切技能名称。
真实场景:幸存者:Captain Tanaka has burns—we need medical help NOW!
传统关键字搜索“medic”→ 0 条结果 ❌
使用嵌入执行语义搜索 → 找到“医疗培训”“急救”✅
这正是智能体所需要的:智能、类人搜索,能够理解意图,而不仅仅是关键字。
2. 创建嵌入模型
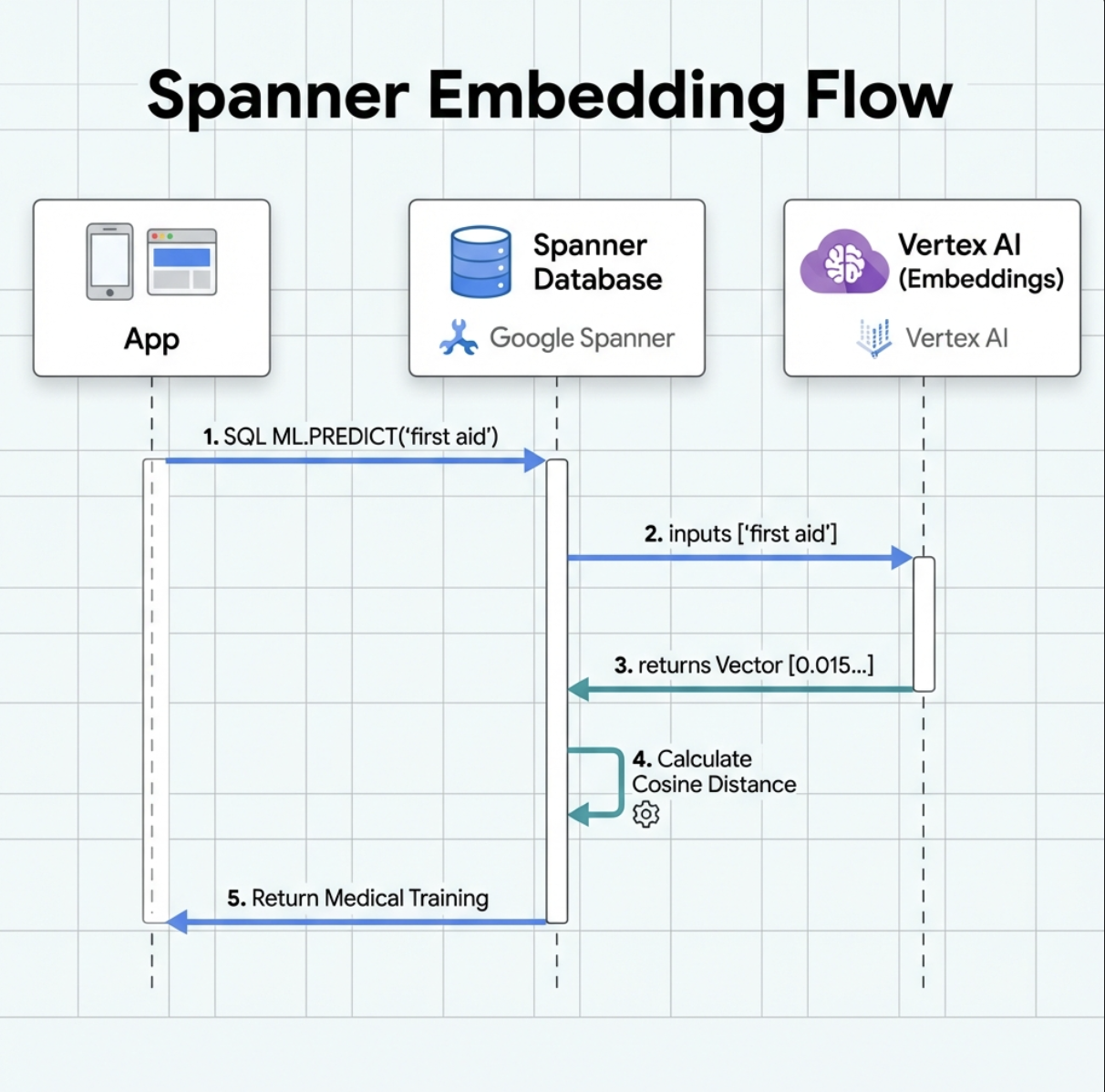
现在,我们来创建一个使用 Google text-embedding-004 将文本转换为嵌入的模型。
👉 在 Spanner Studio 中,运行以下 SQL(将 $YOUR_PROJECT_ID 替换为您的实际项目 ID):
‼️ 在 Cloud Shell 编辑器中,依次打开 File -> Open Folder -> way-back-home/level_2,查看整个项目。
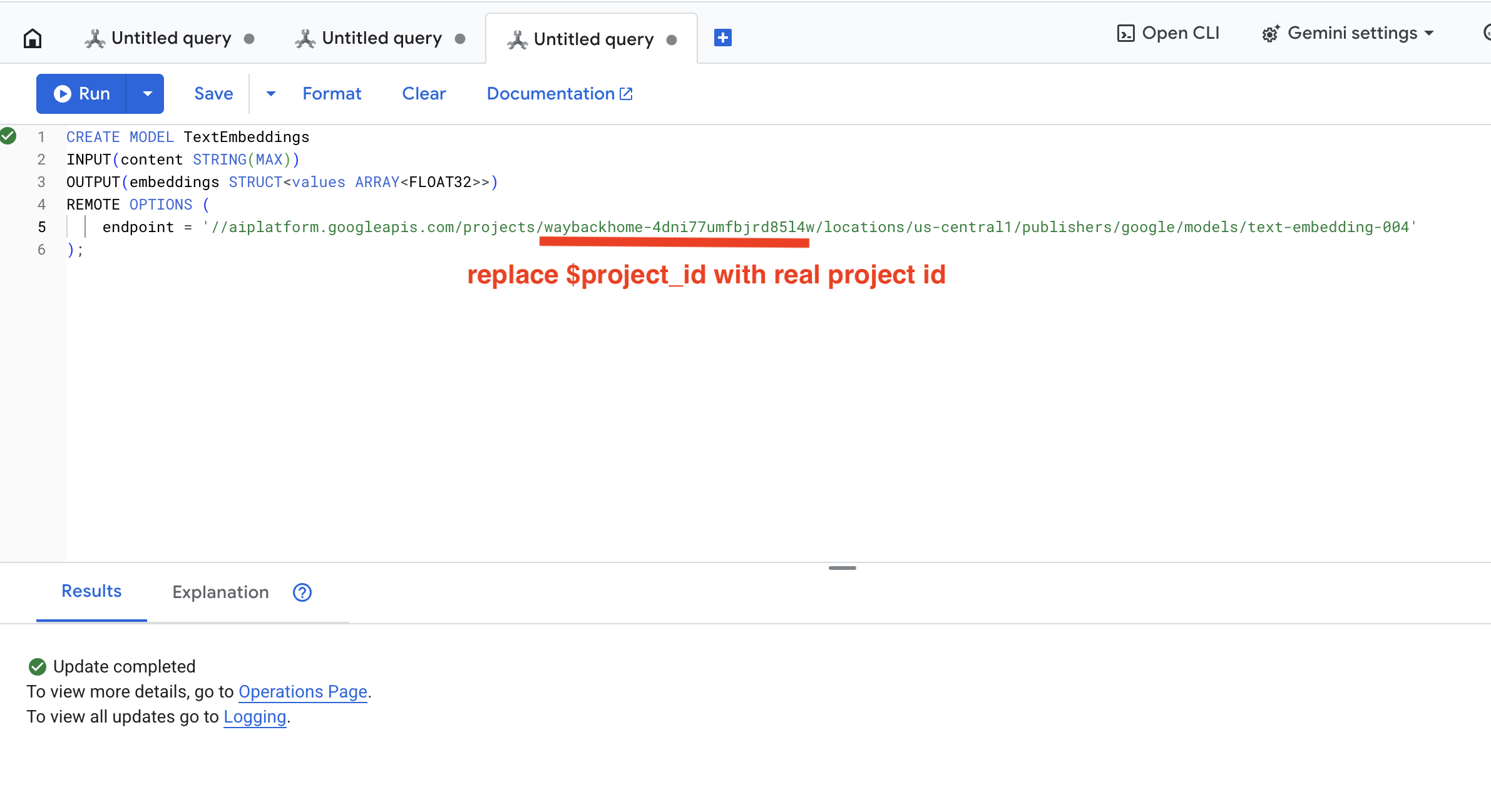
👉 在 Spanner Studio 中运行此查询,方法是复制并粘贴以下查询,然后点击“运行”按钮:
CREATE OR REPLACE MODEL TextEmbeddings
INPUT(content STRING(MAX))
OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-004'
);
作用:
- 在 Spanner 中创建虚拟模型(不在本地存储模型权重)
- 指向 Vertex AI 上的 Google
text-embedding-004 - 定义合同:输入为文本,输出为 768 维浮点数组
为什么是“远程选项”?
- Spanner 本身不运行模型
- 当您使用
ML.PREDICT时,它会通过 API 调用 Vertex AI - 零 ETL:无需将数据导出到 Python、进行处理并重新导入
点击 Run 按钮,成功后,您会看到如下结果:
3. 添加嵌入列
👉 添加一个用于存储嵌入的列:
ALTER TABLE Skills ADD COLUMN skill_embedding ARRAY<FLOAT32>;
点击 Run 按钮,成功后,您会看到如下结果:
4. 生成嵌入
👉 使用 AI 为每项技能创建向量嵌入:
UPDATE Skills
SET skill_embedding = (
SELECT embeddings.values
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT name AS content)
)
)
WHERE skill_embedding IS NULL;
点击 Run 按钮,成功后,您会看到如下结果:
发生的情况:每个技能名称(例如“急救”)都会转换为一个 768 维向量,用于表示其语义。
5. 验证嵌入内容
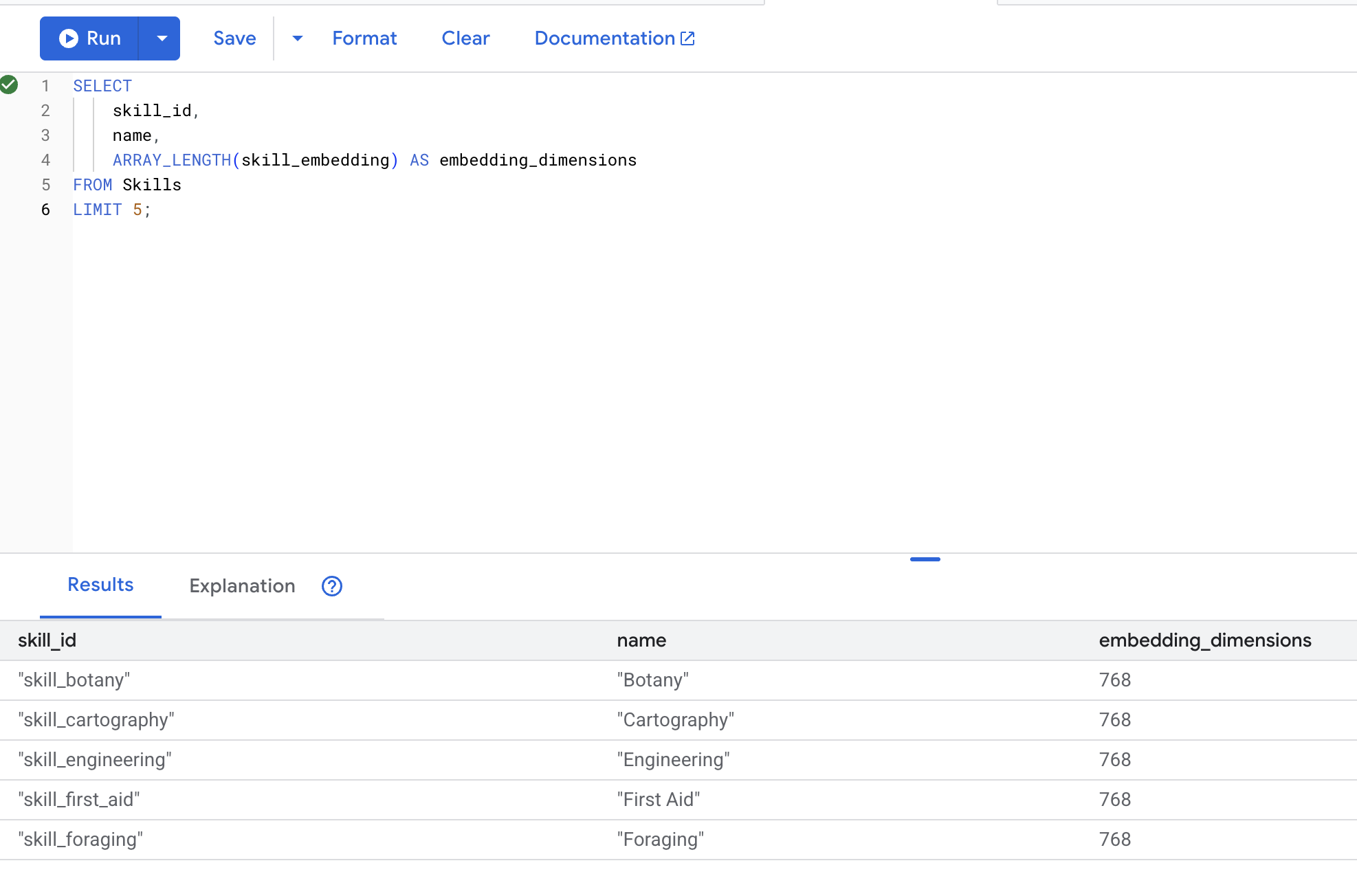
👉 检查是否已创建嵌入内容:
SELECT
skill_id,
name,
ARRAY_LENGTH(skill_embedding) AS embedding_dimensions
FROM Skills
LIMIT 5;
预期输出:
6. 测试语义搜索
现在,我们来测试一下场景中的确切使用情形:使用“医疗人员”一词查找医疗技能。
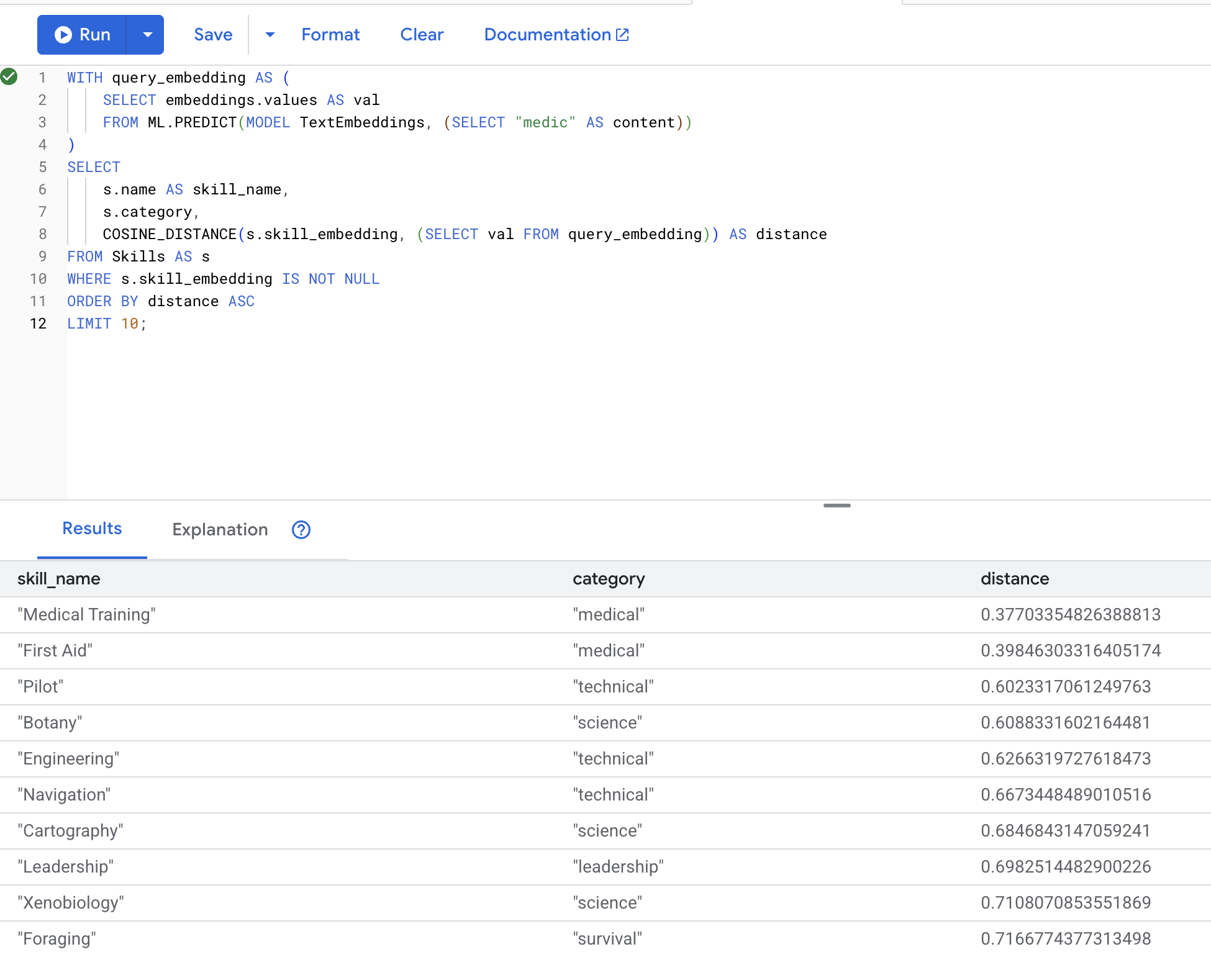
👉 查找与“医护人员”类似的技能:
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(MODEL TextEmbeddings, (SELECT "medic" AS content))
)
SELECT
s.name AS skill_name,
s.category,
COSINE_DISTANCE(s.skill_embedding, (SELECT val FROM query_embedding)) AS distance
FROM Skills AS s
WHERE s.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT 10;
- 将用户的搜索字词“medic”转换为嵌入
- 将其存储在
query_embedding临时表中
预期结果(距离越小,相似度越高):
7. 创建用于分析的 Gemini 模型
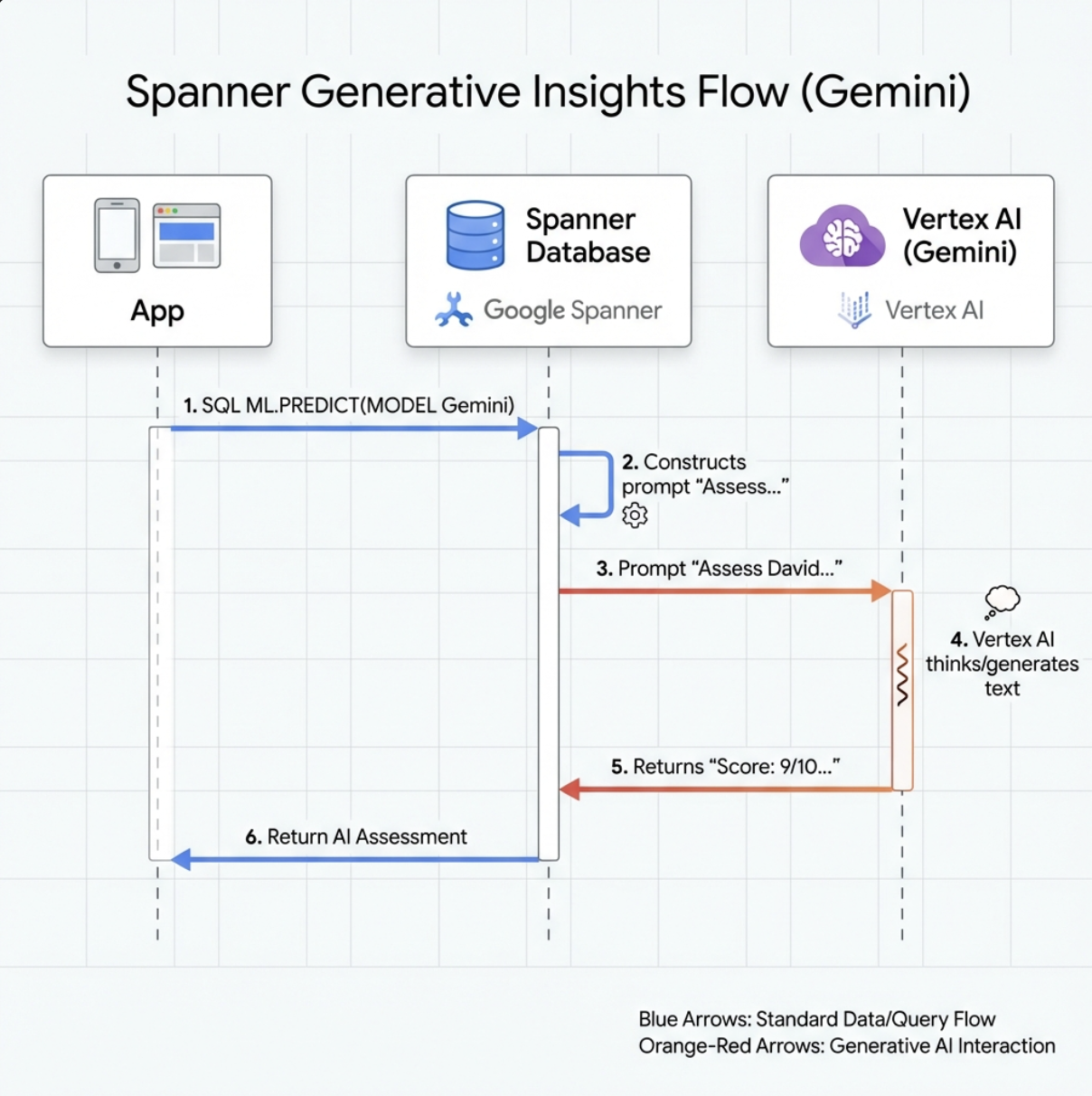
👉 创建生成式 AI 模型引用(将 $YOUR_PROJECT_ID 替换为您的实际项目 ID):
CREATE OR REPLACE MODEL GeminiPro
INPUT(prompt STRING(MAX))
OUTPUT(content STRING(MAX))
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/$YOUR_PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-pro',
default_batch_size = 1
);
与嵌入模型的区别:
- 嵌入:文本 → 向量(用于相似性搜索)
- Gemini:文本 → 生成的文本(用于推理/分析)
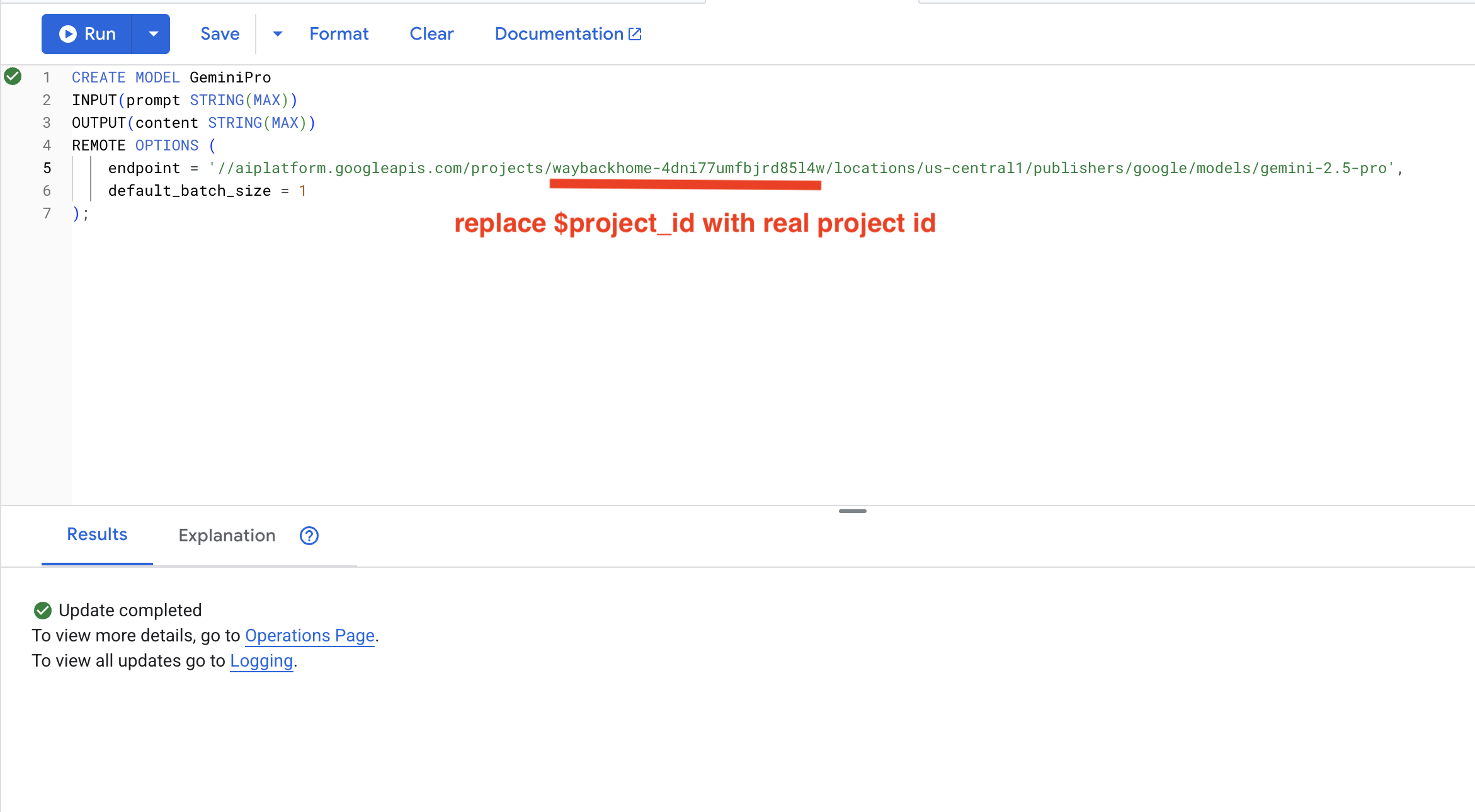
8. 使用 Gemini 进行兼容性分析
👉 分析幸存者配对的任务兼容性:
WITH PairData AS (
SELECT
s1.name AS Name_A,
s2.name AS Name_B,
CONCAT(
"Assess compatibility of these two survivors for a resource-gathering mission. ",
"Survivor 1: ", s1.name, ". ",
"Survivor 2: ", s2.name, ". ",
"Give a score from 1-10 and a 1-sentence reason."
) AS prompt
FROM Survivors s1
JOIN Survivors s2 ON s1.survivor_id < s2.survivor_id
LIMIT 1
)
SELECT
Name_A,
Name_B,
content AS ai_assessment
FROM ML.PREDICT(
MODEL GeminiPro,
(SELECT Name_A, Name_B, prompt FROM PairData)
);
预期输出:
Name_A | Name_B | ai_assessment
----------------|-------------------|----------------
"David Chen" | "Dr. Elena Frost" | "**Score: 9/10** Their compatibility is extremely high as David's practical, hands-on scavenging skills are perfectly complemented by Dr. Frost's specialized knowledge to identify critical medical supplies and avoid biological hazards."
6. 🚀 使用混合搜索构建 Graph RAG 代理
1. 系统架构概览
本部分将构建一个多方法搜索系统,让您的代理能够灵活地处理不同类型的查询。该系统有三个层:代理层、工具层、服务层。
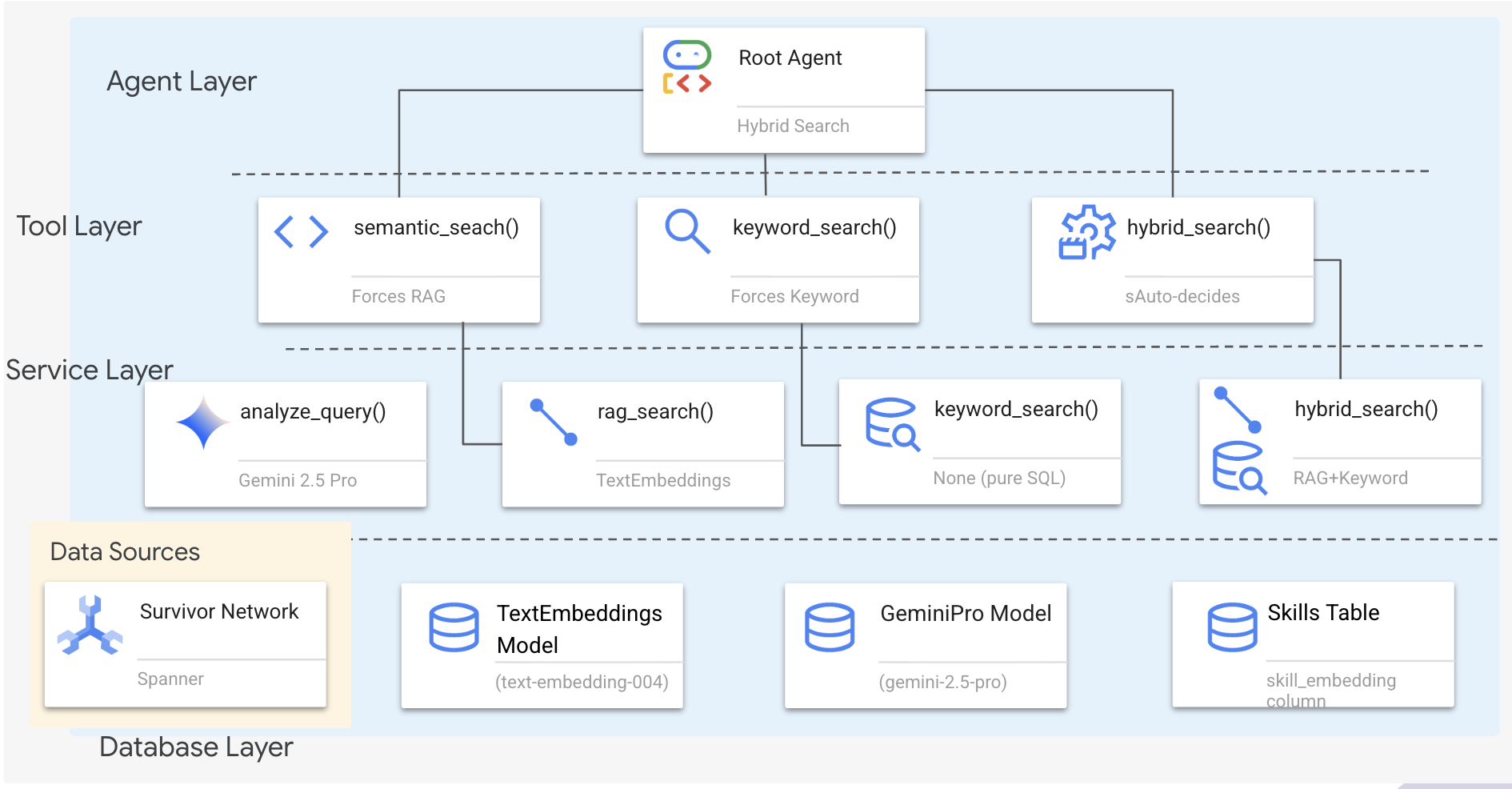
为什么要使用三层?
- 关注点分离:智能体专注于意图,工具专注于界面,服务专注于实现
- 灵活性:代理可以强制使用特定方法,也可以让 AI 自动路由
- 优化:如果方法已知,可以跳过昂贵的 AI 分析
在本部分中,您将主要实现语义搜索 (RAG) - 根据含义(而非仅依据关键字)来查找结果。稍后,我们将介绍混合搜索如何融合多种方法。
2. RAG 服务实现
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/services/hybrid_search_service.py
找到相应评论 # TODO: REPLACE_SQL
将整行代码替换为以下代码:
# This is your working query from the successful run!
sql = """
WITH query_embedding AS (
SELECT embeddings.values AS val
FROM ML.PREDICT(
MODEL TextEmbeddings,
(SELECT @query AS content)
)
)
SELECT
s.survivor_id,
s.name AS survivor_name,
s.biome,
sk.skill_id,
sk.name AS skill_name,
sk.category,
COSINE_DISTANCE(
sk.skill_embedding,
(SELECT val FROM query_embedding)
) AS distance
FROM Survivors s
JOIN SurvivorHasSkill shs ON s.survivor_id = shs.survivor_id
JOIN Skills sk ON shs.skill_id = sk.skill_id
WHERE sk.skill_embedding IS NOT NULL
ORDER BY distance ASC
LIMIT @limit
"""
3. 语义搜索工具定义
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/hybrid_search_tools.py
在 hybrid_search_tools.py 中,找到评论 # TODO: REPLACE_SEMANTIC_SEARCH_TOOL
👉将整行代码替换为以下代码:
async def semantic_search(query: str, limit: int = 10) -> str:
"""
Force semantic (RAG) search using embeddings.
Use this when you specifically want to find things by MEANING,
not just matching keywords. Great for:
- Finding conceptually similar items
- Handling vague or abstract queries
- When exact terms are unknown
Example: "healing abilities" will find "first aid", "surgery",
"herbalism" even though no keywords match exactly.
Args:
query: What you're looking for (describe the concept)
limit: Maximum results
Returns:
Semantically similar results ranked by relevance
"""
try:
service = _get_service()
result = service.smart_search(
query,
force_method=SearchMethod.RAG,
limit=limit
)
return _format_results(
result["results"],
result["analysis"],
show_analysis=True
)
except Exception as e:
return f"Error in semantic search: {str(e)}"
智能体使用情况:
- 要求查找相似内容(“查找与 X 类似的内容”)的查询
- 概念性查询(“修复能力”)
- 当理解含义至关重要时
4. 代理决策指南(说明)
在代理定义中,将与语义搜索相关的部分复制粘贴到指令中。
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
智能体使用此指令来选择合适的工具:
👉在 agent.py 文件中,找到注释 # TODO: REPLACE_SEARCH_LOGIC,将整行替换为以下代码:
- `semantic_search`: Force RAG/embedding search
Use for: "Find similar to X", conceptual queries, unknown terminology
Example: "Find skills related to healing"
👉找到注释 # TODO: ADD_SEARCH_TOOLReplace this whole line,将其替换为以下代码:
semantic_search, # Force RAG
5. 了解混合搜索的运作方式(只读,无需采取任何行动)
在第 2-4 步中,您实现了语义搜索 (RAG),这是一种通过含义查找结果的核心搜索方法。不过,您可能已经注意到,该系统被称为“混合搜索”。以下是整个流程的运作方式:
混合合并的工作原理:
在文件 way-back-home/level_2/backend/services/hybrid_search_service.py 中,当调用 hybrid_search() 时,服务会同时运行这两个搜索并合并结果:
# Location: backend/services/hybrid_search_service.py
rank_kw = keyword_ranks.get(surv_id, float('inf'))
rank_rag = rag_ranks.get(surv_id, float('inf'))
rrf_score = 0.0
if rank_kw != float('inf'):
rrf_score += 1.0 / (K + rank_kw)
if rank_rag != float('inf'):
rrf_score += 1.0 / (K + rank_rag)
combined_score = rrf_score
在本 Codelab 中,您实现了作为基础的语义搜索组件 (RAG)。关键字和混合方法已在服务中实现,您的代理可以使用所有这三种方法!
恭喜!您已成功完成具有混合搜索功能的 Graph RAG 代理!
7. 🚀 使用 ADK Web 测试智能体
测试智能体最简单的方法是使用 adk web 命令,该命令会启动您的智能体并显示内置的聊天界面。
1. 运行代理
👉💻 前往后端目录(您的代理定义所在的位置),然后启动 Web 界面:
cd ~/way-back-home/level_2/backend
uv run adk web
此命令会启动 中定义的代理
agent/agent.py
并打开一个用于测试的网页界面。
👉 打开网址:
该命令将输出一个本地网址(通常为 http://127.0.0.1:8000 或类似网址)。在浏览器中打开此链接。
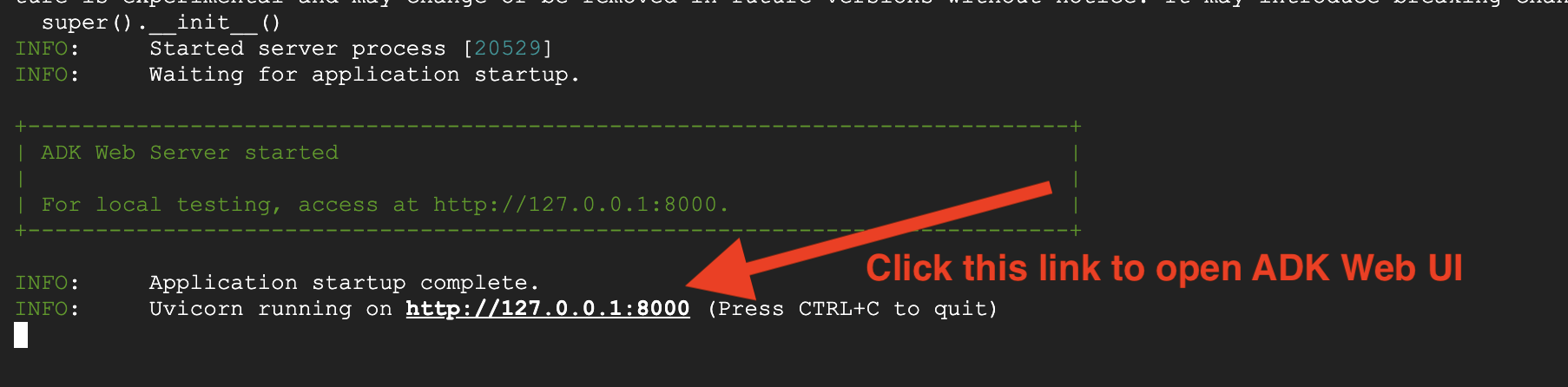
点击网址后,您会看到 ADK Web 界面。确保您从左上角选择了“代理”。
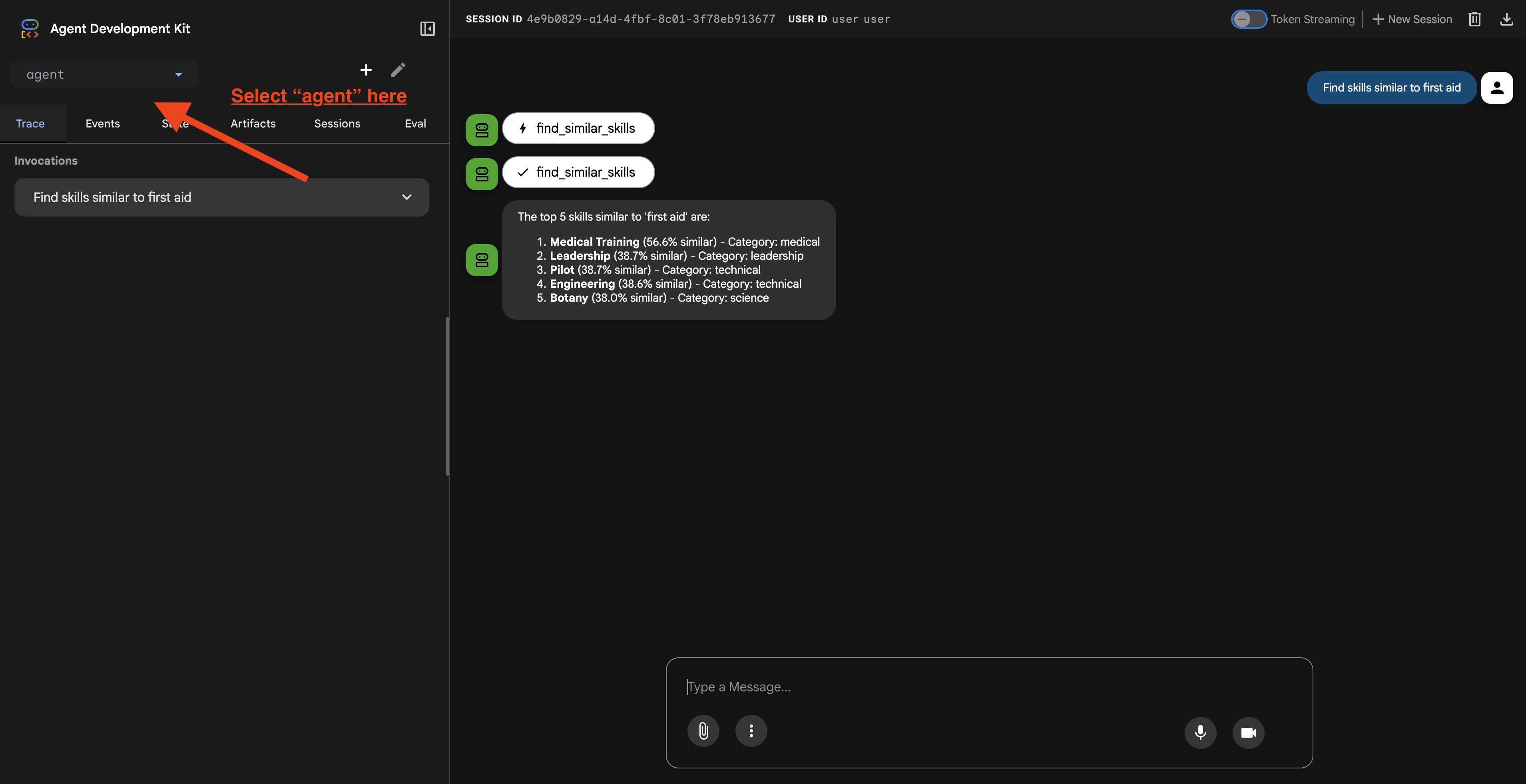
2. 测试搜索功能
该代理旨在智能地路由您的查询。在聊天窗口中尝试输入以下内容,看看不同的搜索方法是如何运作的。
🧬 A. Graph RAG(语义搜索)
根据含义和概念查找商品,即使关键字不匹配也是如此。
测试查询:(选择以下任意一项)
Who can help with injuries?
What abilities are related to survival?
需要注意的事项:
- 推理应提及语义或 RAG 搜索。
- 您应该会看到在概念上相关的结果(例如,在询问“急救”时看到“手术”)。
- 结果将带有 🧬 图标。
🔀 B. 混合搜索
将关键字过滤条件与语义理解相结合,以处理复杂的查询。
测试查询:(选择以下任意一项)
Find someone who can fly a plane in the volcanic area
Who has healing abilities in the FOSSILIZED?
Who has healing abilities in the mountains?
需要注意的事项:
- 推理应提及混合搜索。
- 结果应同时符合这两个条件(概念 + 位置/类别)。
- 通过这两种方法找到的结果会带有 🔀 图标,并且排名最高。
👉💻 完成测试后,请在命令行中按 Ctrl+C 结束该进程。
8. 🚀 运行完整应用
全栈架构概览
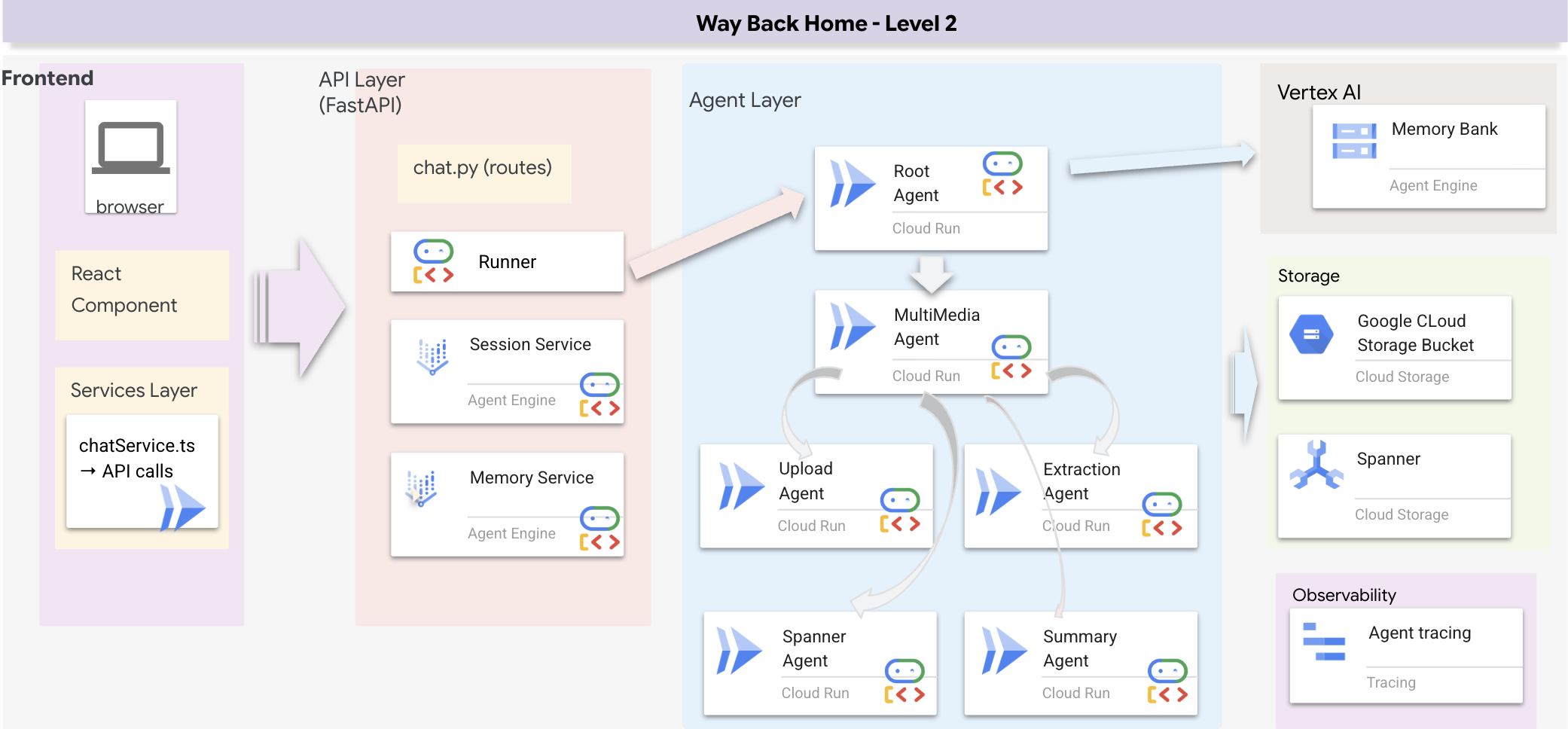
添加了 SessionService 和 Runner
👉💻 在终端中,运行以下命令,在 Cloud Shell 编辑器中打开文件 chat.py(请务必先按“Ctrl+C”结束上一个进程,然后再继续):
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉在 chat.py 文件中,找到注释 # TODO: REPLACE_INMEMORY_SERVICES,将整行替换为以下代码:
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
👉在 chat.py 文件中,找到注释 # TODO: REPLACE_RUNNER,将整行替换为以下代码:
runner = Runner(
agent=root_agent,
session_service=session_service,
memory_service=memory_service,
app_name="survivor-network"
)
1. 开始申请
如果之前的终端仍在运行,请按 Ctrl+C 结束该终端。
👉💻 启动应用:
cd ~/way-back-home/level_2/
./start_app.sh
当后端成功启动时,您会看到如下所示的 Local: http://localhost:5173/":
👉 在终端中点击 Local: http://localhost:5173/。
2. 测试语义搜索
查询:
Find skills similar to healing
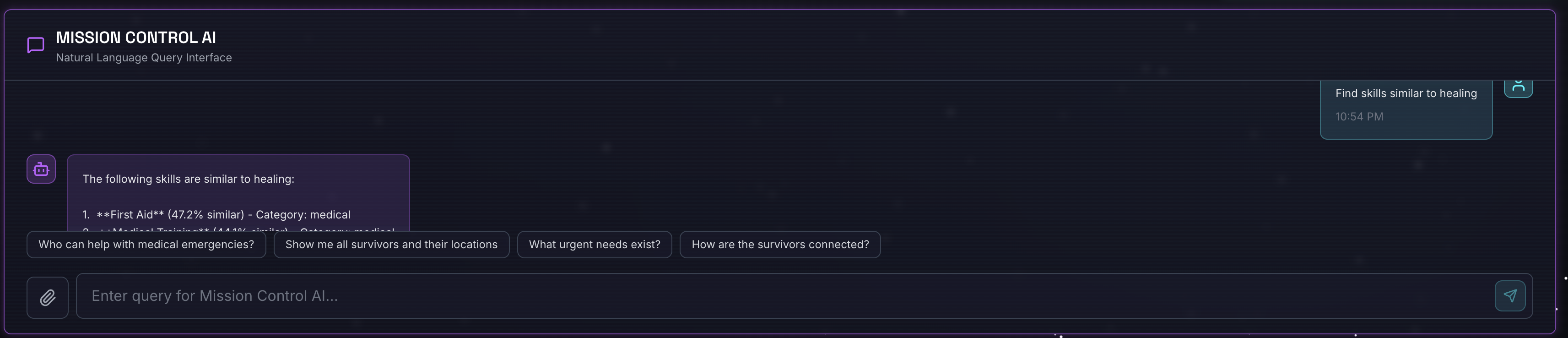
发生的情况:
- 代理识别相似性请求
- 为“healing”生成嵌入
- 使用余弦距离查找语义相似的技能
- 返回:急救(即使名称与“治疗”不匹配)
3. 测试混合搜索
查询:
Find medical skills in the mountains
发生的情况:
- 关键字组件:过滤
category='medical' - 语义组件:嵌入“医疗”并按相似度进行排名
- 合并:合并结果,优先显示通过两种方法找到的结果 🔀
查询(可选):
Who is good at survival and in the forest?
发生的情况:
- 关键字查找次数:
biome='forest' - 语义查找:与“生存”类似的技能
- 混合搜索兼具两者之长,可提供最佳结果
👉💻 测试完成后,在终端中按 Ctrl+C 结束测试。
4. (仅限研讨会参与者)更新您的位置信息
👉💻 运行补全脚本:
cd ~/way-back-home/level_2
./set_level_2.sh
现在打开 waybackhome.dev,您会看到自己的位置信息已更新。恭喜您完成第 2 级!

9. ☕️ [可选] 多模态流水线(只读)- 工具层
为什么需要多模态流水线?
生存网络不仅仅是文字。现场的幸存者直接通过聊天发送非结构化数据:
- 📸 图片:资源、危险或设备的照片
- 🎥 视频:状态报告或 SOS 广播
- 📄 文本:实地记录或日志
我们正在处理哪些文件?
与上一步中搜索现有数据不同,这一步中我们会处理用户上传的文件。chat.py 接口可动态处理文件附件:
来源 | 内容 | 目标 |
用户附件 | 图片/视频/文字 | 要添加到图表中的信息 |
聊天上下文 | “这是用品的照片” | 意图和其他详细信息 |
计划方法:串行代理流水线
我们使用将专业代理串联在一起的序列代理 (multimedia_agent.py):
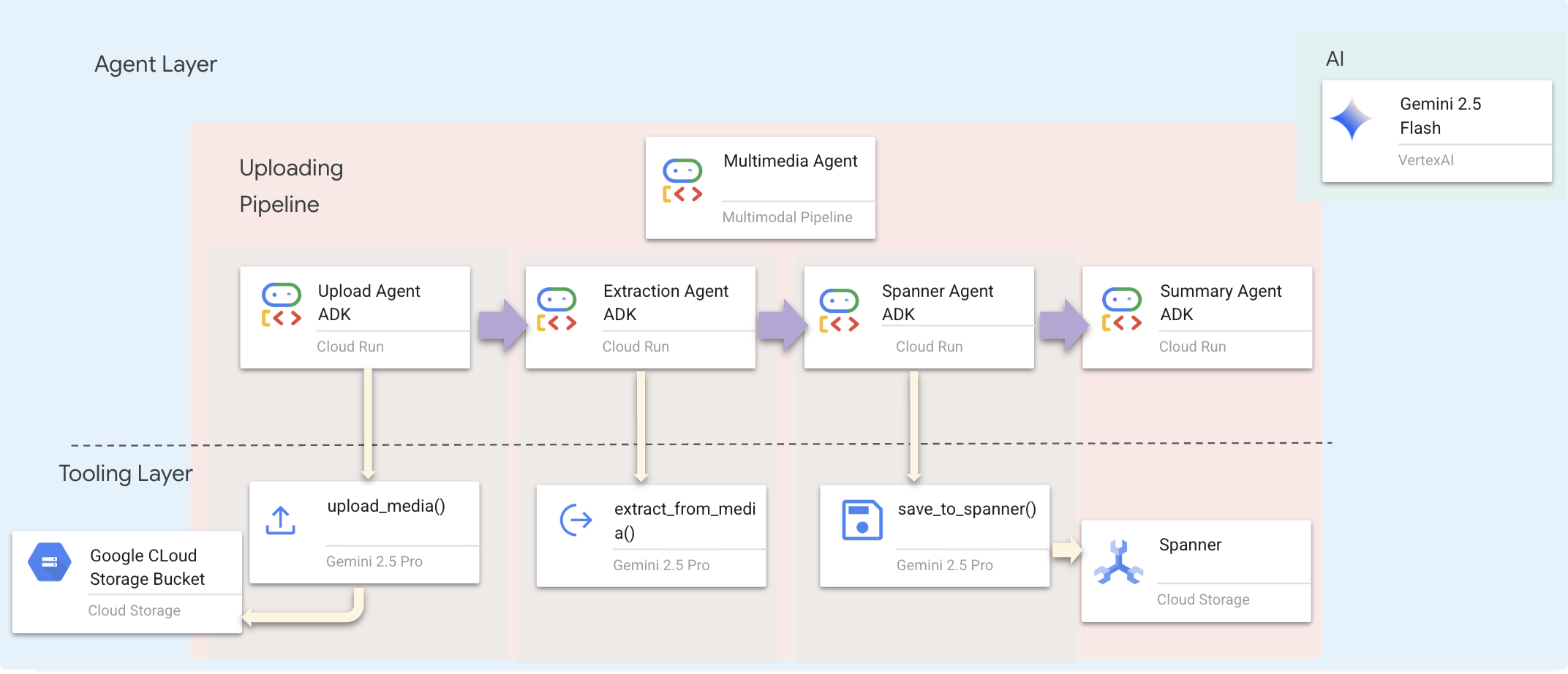
此项在 backend/agent/multimedia_agent.py 中定义为 SequentialAgent。
工具层提供智能体可以调用的功能。工具负责处理“如何”操作,即上传文件、提取实体并保存到数据库。
1. 打开工具文件
👉💻 打开文件 level_2/backend/agent/tools/extraction_tools.py 或在终端中输入以下命令。打开新终端。在终端中,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/tools/extraction_tools.py
2. 实现 upload_media 工具
此工具可将本地文件上传到 Google Cloud Storage。
👉 在 def upload_media(file_path: str, survivor_id: Optional[str] = None) -> Dict[str, Any]: 中,以下代码展示了如何将文件上传到 GCS 并检测其类型:
"""
Upload media file to GCS and detect its type.
Args:
file_path: Path to the local file
survivor_id: Optional survivor ID to associate with upload
Returns:
Dict with gcs_uri, media_type, and status
"""
try:
if not file_path:
return {"status": "error", "error": "No file path provided"}
# Strip quotes if present
file_path = file_path.strip().strip("'").strip('"')
if not os.path.exists(file_path):
return {"status": "error", "error": f"File not found: {file_path}"}
gcs_uri, media_type, signed_url = gcs_service.upload_file(file_path, survivor_id)
return {
"status": "success",
"gcs_uri": gcs_uri,
"signed_url": signed_url,
"media_type": media_type.value,
"file_name": os.path.basename(file_path),
"survivor_id": survivor_id
}
except Exception as e:
logger.error(f"Upload failed: {e}")
return {"status": "error", "error": str(e)}
3. 实现 extract_from_media 工具
此工具是一个路由器,用于检查 media_type 并调度到正确的提取器(文本、图片或视频)。
👉 在 async def extract_from_media(gcs_uri: str, media_type: str, signed_url: Optional[str] = None) -> Dict[str, Any]: 中,以下代码展示了如何从上传的媒体中提取实体和关系。
"""
Extract entities and relationships from uploaded media.
Args:
gcs_uri: GCS URI of the uploaded file
media_type: Type of media (text/image/video)
signed_url: Optional signed URL for public/temporary access
Returns:
Dict with extraction results
"""
try:
if not gcs_uri:
return {"status": "error", "error": "No GCS URI provided"}
# Select appropriate extractor
if media_type == MediaType.TEXT.value or media_type == "text":
result = await text_extractor.extract(gcs_uri)
elif media_type == MediaType.IMAGE.value or media_type == "image":
result = await image_extractor.extract(gcs_uri)
elif media_type == MediaType.VIDEO.value or media_type == "video":
result = await video_extractor.extract(gcs_uri)
else:
return {"status": "error", "error": f"Unsupported media type: {media_type}"}
# Inject signed URL into broadcast info if present
if signed_url:
if not result.broadcast_info:
result.broadcast_info = {}
result.broadcast_info['thumbnail_url'] = signed_url
return {
"status": "success",
"extraction_result": result.to_dict(), # Return valid JSON dict instead of object
"summary": result.summary,
"entities_count": len(result.entities),
"relationships_count": len(result.relationships),
"entities": [e.to_dict() for e in result.entities],
"relationships": [r.to_dict() for r in result.relationships]
}
except Exception as e:
logger.error(f"Extraction failed: {e}")
return {"status": "error", "error": str(e)}
关键实现细节:
- 多模态输入:我们将文本提示 (
_get_extraction_prompt()) 和图片对象都传递给generate_content。 - 结构化输出:
response_mime_type="application/json"可确保 LLM 返回有效的 JSON,这对于流水线至关重要。 - 视觉实体链接:提示包含已知实体,以便 Gemini 识别特定字符。
4. 实现 save_to_spanner 工具
此工具会将提取的实体和关系持久保存到 Spanner Graph 数据库。
👉 在 def save_to_spanner(extraction_result: Any, survivor_id: Optional[str] = None) -> Dict[str, Any]: 中,以下代码展示了如何将提取的实体和关系保存到 Spanner Graph 数据库。
"""
Save extracted entities and relationships to Spanner Graph DB.
Args:
extraction_result: ExtractionResult object (or dict from previous step if passed as dict)
survivor_id: Optional survivor ID to associate with the broadcast
Returns:
Dict with save statistics
"""
try:
# Handle if extraction_result is passed as the wrapper dict from extract_from_media
result_obj = extraction_result
if isinstance(extraction_result, dict) and 'extraction_result' in extraction_result:
result_obj = extraction_result['extraction_result']
# If result_obj is a dict (from to_dict()), reconstruct it
if isinstance(result_obj, dict):
from extractors.base_extractor import ExtractionResult
result_obj = ExtractionResult.from_dict(result_obj)
if not result_obj:
return {"status": "error", "error": "No extraction result provided"}
stats = spanner_service.save_extraction_result(result_obj, survivor_id)
return {
"status": "success",
"entities_created": stats['entities_created'],
"entities_existing": stats['entities_found_existing'],
"relationships_created": stats['relationships_created'],
"broadcast_id": stats['broadcast_id'],
"errors": stats['errors'] if stats['errors'] else None
}
except Exception as e:
logger.error(f"Spanner save failed: {e}")
return {"status": "error", "error": str(e)}
通过为代理提供高级工具,我们可在利用代理的推理能力的同时确保数据完整性。
5. 更新 GCS 服务
GCSService 负责将文件实际上传到 Google Cloud Storage。
👉💻 打开文件 level_2/backend/services/gcs_service.py,或者您可以在终端中输入命令,在 Cloud Shell 编辑器中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/services/gcs_service.py
👉 在 def upload_file(self, file_path: str, survivor_id: Optional[str] = None) -> Tuple[str, MediaType, str]: 中,以下代码展示了如何将提取的实体和关系保存到 Spanner Graph 数据库。
blob = self.bucket.blob(blob_name)
blob.upload_from_filename(file_path)
通过将此功能抽象为服务,代理无需了解 GCS 存储分区、Blob 名称或签名网址生成。它只会要求“上传”。
6. 为何智能体工作流优于传统方法?
智能体优势:
功能 | 批处理流水线 | 事件驱动型 | 智能体工作流 |
复杂性 | 低(1 个脚本) | 高(5 项以上服务) | 低(1 个 Python 文件: |
状态管理 | 全局变量 | 硬性(解耦) | Unified(代理状态) |
错误处理 | 崩溃 | 静默日志 | 互动式(“我无法读取该文件”) |
用户反馈 | 控制台打印 | 需要轮询 | 立即(聊天的一部分) |
自适应 | 修复了逻辑 | 刚性函数 | 智能(由 LLM 决定下一步) |
情境感知 | 无 | 无 | 完整(了解用户意图) |
重要性:通过使用 multimedia_agent.py(包含 4 个子代理的 SequentialAgent:上传 → 提取 → 保存 → 总结),我们用智能对话式应用逻辑取代了复杂的基础设施和脆弱的脚本。
10. ☕️ [可选] 多模态流水线(只读)- 代理层
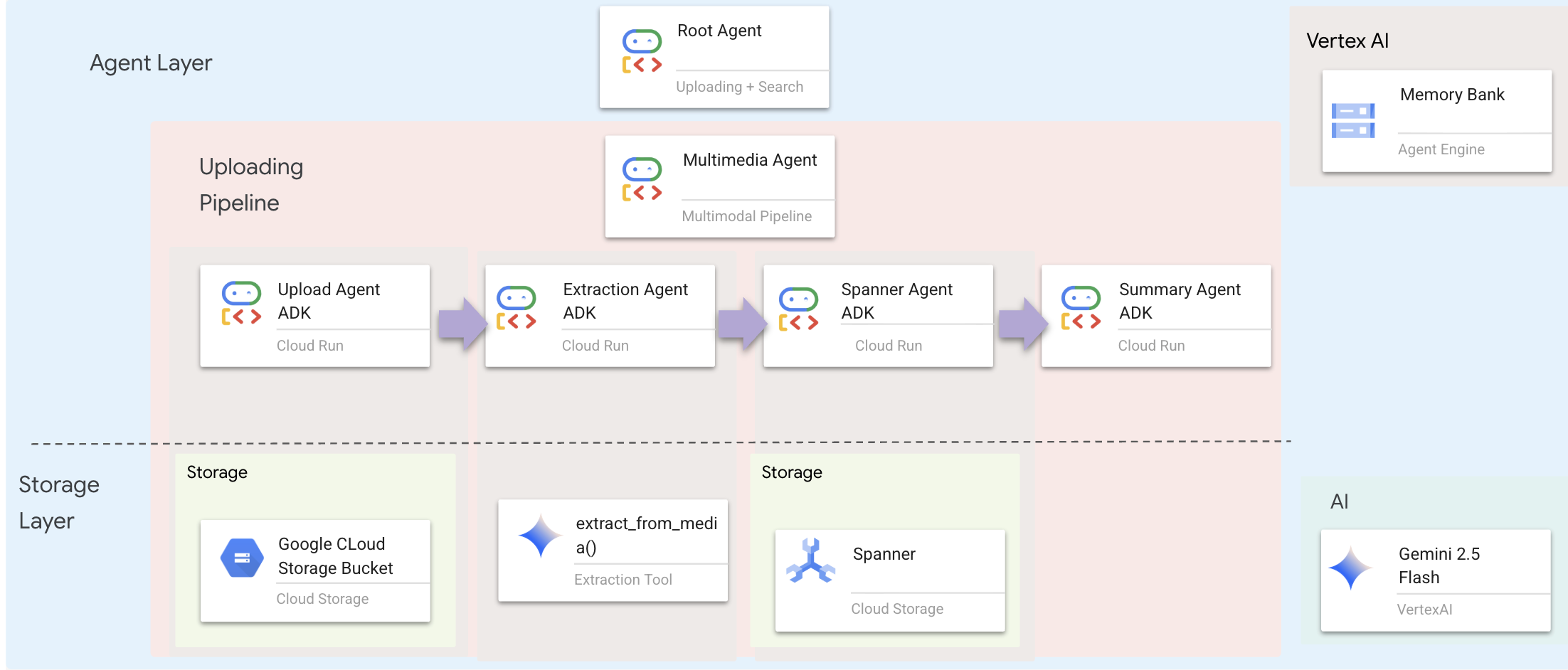
智能体层定义了智能,即使用工具来完成任务的智能体。每个代理都有特定角色,并将上下文传递给下一个代理。下图是多代理系统的架构图。
1. 打开代理文件
👉💻 打开文件 level_2/backend/agent/multimedia_agent.py 或在终端中输入以下命令。打开新终端。在终端中,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
2. 定义上传代理
此代理会从用户消息中提取文件路径,并将其上传到 GCS。
👉在文件 multimedia_agent.py 中,使用以下代码创建上传到 GCS 的 upload_agent:
upload_agent = LlmAgent(
name="UploadAgent",
model="gemini-2.5-flash",
instruction="""Extract the file path from the user's message and upload it.
Use `upload_media(file_path, survivor_id)` to upload the file.
The survivor_id is optional - include it if the user mentions a specific survivor (e.g., "survivor Sarah" -> "Sarah").
If the user provides a path like "/path/to/file", use that.
Return the upload result with gcs_uri and media_type.""",
tools=[upload_media],
output_key="upload_result"
)
3. 定义提取代理
此代理会“看到”上传的媒体,并使用 Gemini Vision 提取结构化数据。
👉在文件 multimedia_agent.py 中,使用以下代码创建 extraction_agent,以从上传的媒体中提取信息:
extraction_agent = LlmAgent(
name="ExtractionAgent",
model="gemini-2.5-flash",
instruction="""Extract information from the uploaded media.
Previous step result: {upload_result}
Use `extract_from_media(gcs_uri, media_type, signed_url)` with the values from the upload result.
The gcs_uri is in upload_result['gcs_uri'], media_type in upload_result['media_type'], and signed_url in upload_result['signed_url'].
Return the extraction results including entities and relationships found.""",
tools=[extract_from_media],
output_key="extraction_result"
)
请注意 instruction 如何引用 {upload_result} - 这就是在 ADK 中在代理之间传递状态的方式。
4. 定义 Spanner 代理
此代理会将提取的实体和关系保存到图数据库中。
👉在文件 multimedia_agent.py 中,使用以下代码创建 spanner_agent,以将提取的信息保存到数据库:
spanner_agent = LlmAgent(
name="SpannerAgent",
model="gemini-2.5-flash",
instruction="""Save the extracted information to the database.
Upload result: {upload_result}
Extraction result: {extraction_result}
Use `save_to_spanner(extraction_result, survivor_id)` to save to Spanner.
Pass the WHOLE `extraction_result` object/dict from the previous step.
Include survivor_id if it was provided in the upload step.
Return the save statistics.""",
tools=[save_to_spanner],
output_key="spanner_result"
)
此代理会从之前的两个步骤(upload_result 和 extraction_result)接收上下文。
5. 定义总结代理
此代理会将之前所有步骤的结果综合成一个用户友好的回答。
👉在文件 multimedia_agent.py 中,以下代码定义了用于总结结果的 summary_agent 的提示:
USE_MEMORY_BANK = os.getenv("USE_MEMORY_BANK", "false").lower() == "true"
save_msg = "6. Mention that the data is also being synced to the memory bank." if USE_MEMORY_BANK else ""
summary_instruction = f"""Provide a user-friendly summary of the media processing.
Upload: {{upload_result}}
Extraction: {{extraction_result}}
Database: {{spanner_result}}
Summarize:
1. What file was processed (name and type)
2. Key information extracted (survivors, skills, needs, resources found) - list names and counts
3. Relationships identified
4. What was saved to the database (broadcast ID, number of entities)
5. Any issues encountered
{save_msg}
Be concise but informative."""
此代理不需要工具,只需读取共享的上下文,然后为用户生成简洁的摘要。
🧠 架构摘要
图层 | 文件 | 责任 |
工具 |
| 操作方法 - 上传、提取、保存 |
Agent |
| 内容 - 编排流水线 |
11. 🚀 多模态数据流水线 - 编排
新系统的核心是 backend/agent/multimedia_agent.py 中定义的 MultimediaExtractionPipeline。它使用 ADK(智能体开发套件)中的顺序智能体模式。
1. 为什么选择顺序播放?
处理上传内容是一个线性依赖链:
- 在获得文件(上传)之前,您无法提取数据。
- 您必须先提取数据(提取),然后才能保存数据。
- 您必须先获得结果(保存),然后才能进行总结。
SequentialAgent 非常适合此用途。它将一个代理的输出作为上下文/输入传递给下一个代理。
2. 代理定义
我们来看看 multimedia_agent.py 底部的流水线是如何组装的:👉💻 在终端中,运行以下命令,在 Cloud Shell 编辑器中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/multimedia_agent.py
它会接收前两个步骤的输入。找到注释 # TODO: REPLACE_ORCHESTRATION。将整行代码替换为以下代码:
sub_agents=[upload_agent, extraction_agent, spanner_agent, summary_agent]
3. 与根代理建立连接
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
找到注释 # TODO: REPLACE_ADD_SUBAGENT。将整行代码替换为以下代码:
sub_agents=[multimedia_agent],
此单个对象可有效地将四位“专家”捆绑到一个可调用的实体中。
4. 智能体之间的数据流
每个代理都会将其输出存储在共享的上下文中,后续代理可以访问该上下文:
5. 打开应用(如果应用仍在运行,请跳过此步骤)
👉💻 启动应用:
cd ~/way-back-home/level_2/
./start_app.sh
👉 在终端中点击 Local: http://localhost:5173/。
6. 测试图片上传
👉 在聊天界面中,选择此处的任意照片并上传到界面:
在聊天界面中,向智能体说明您的具体情况:
Here is the survivor note
然后在此处附上图片。

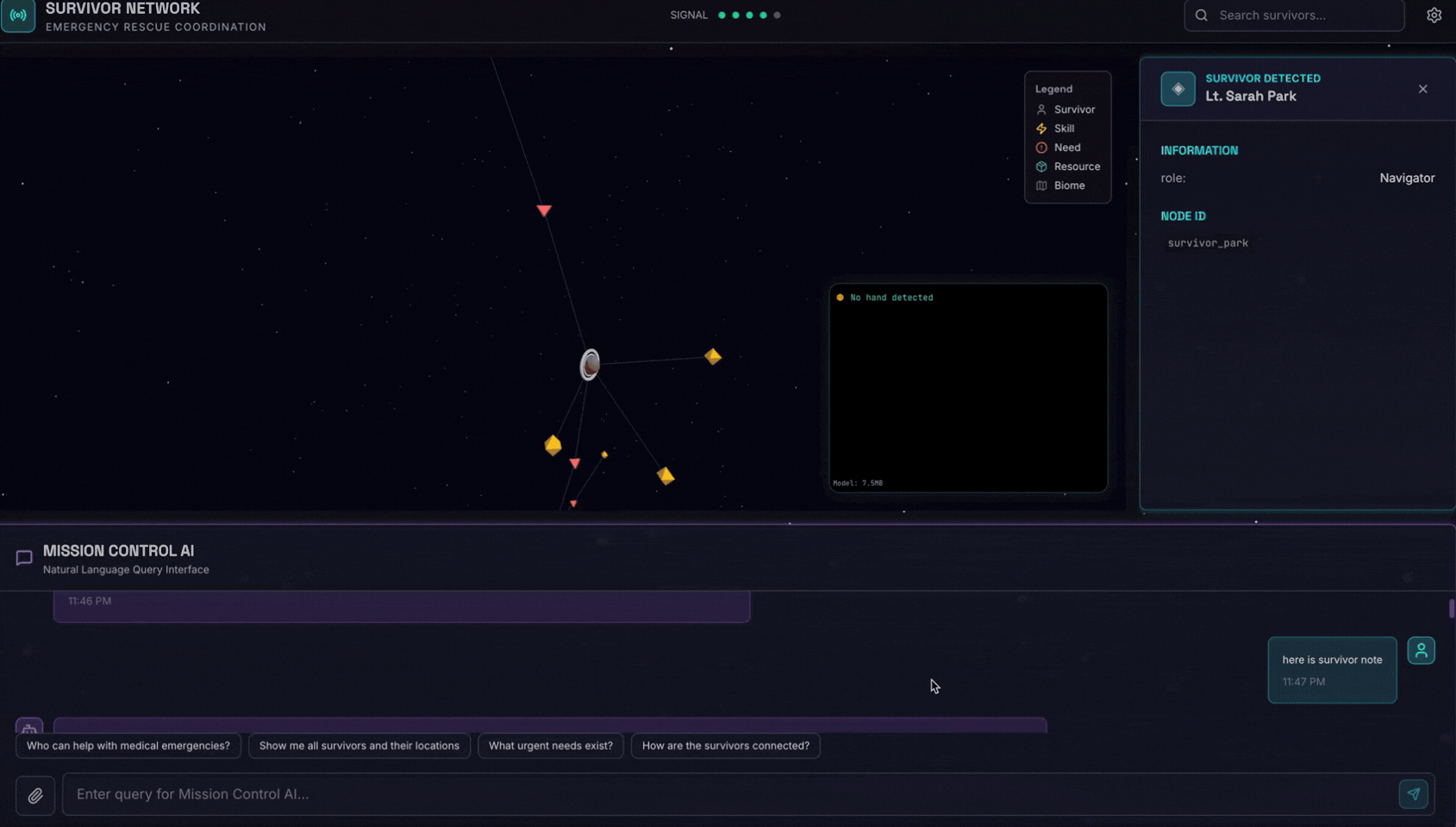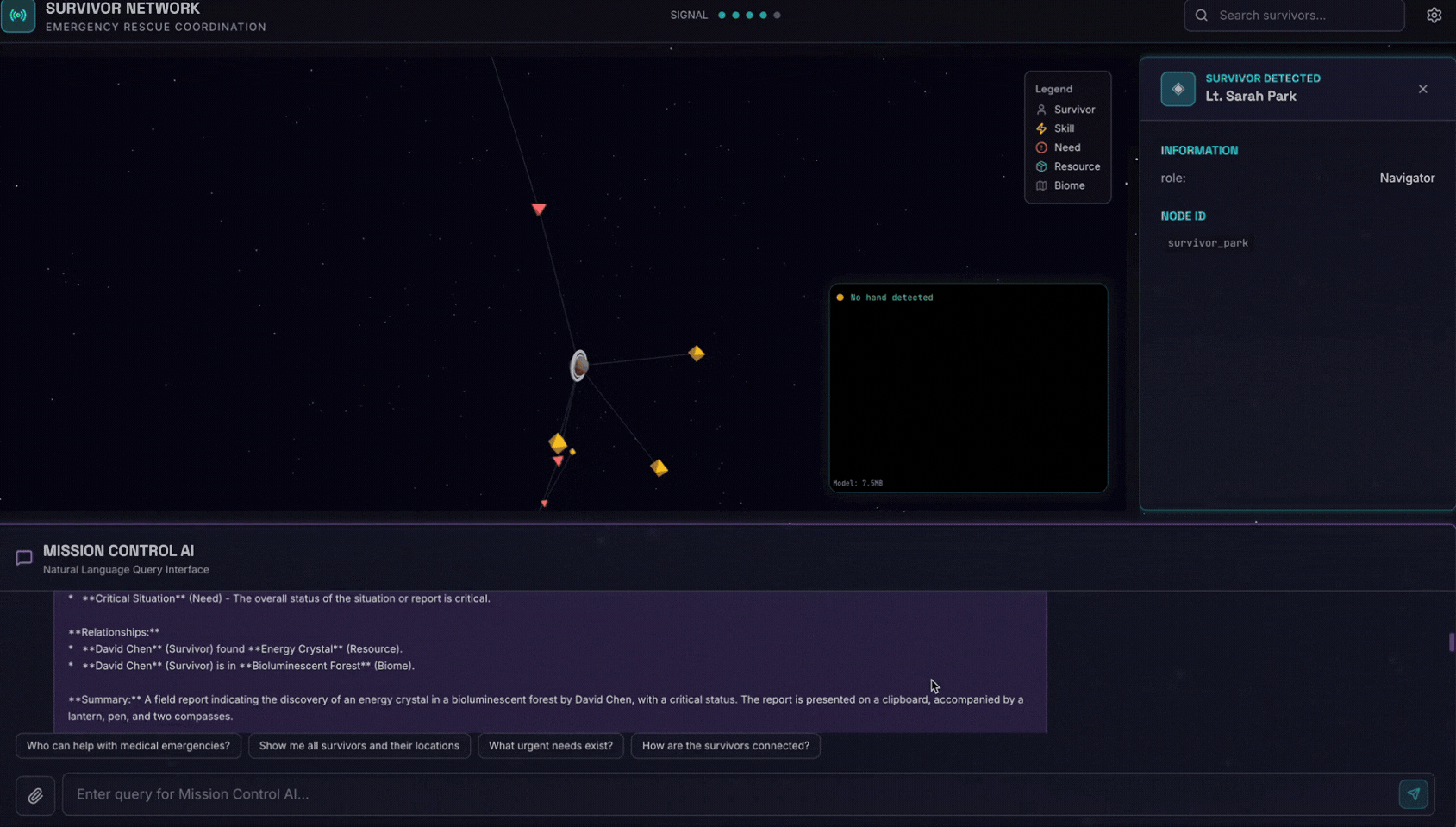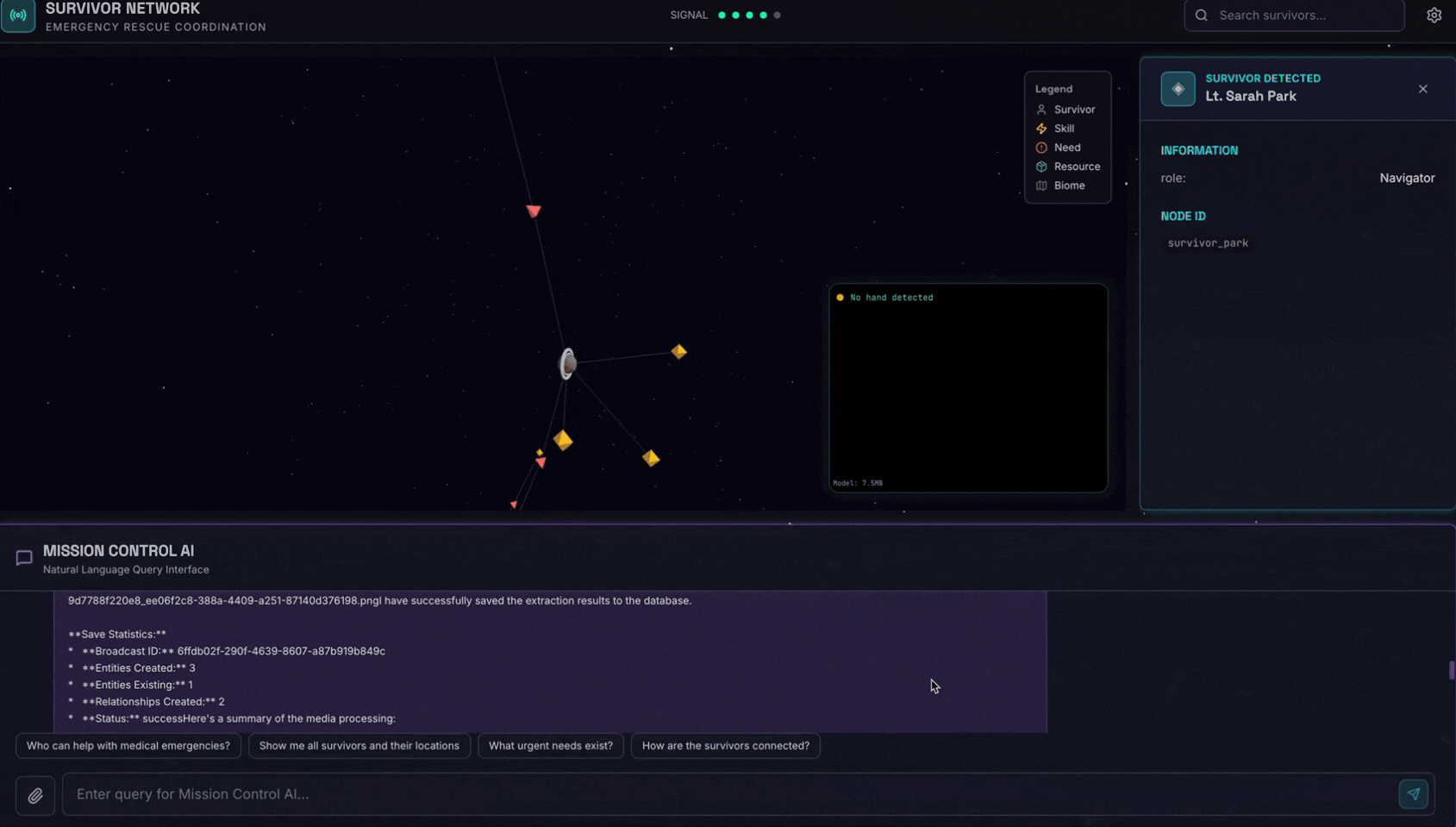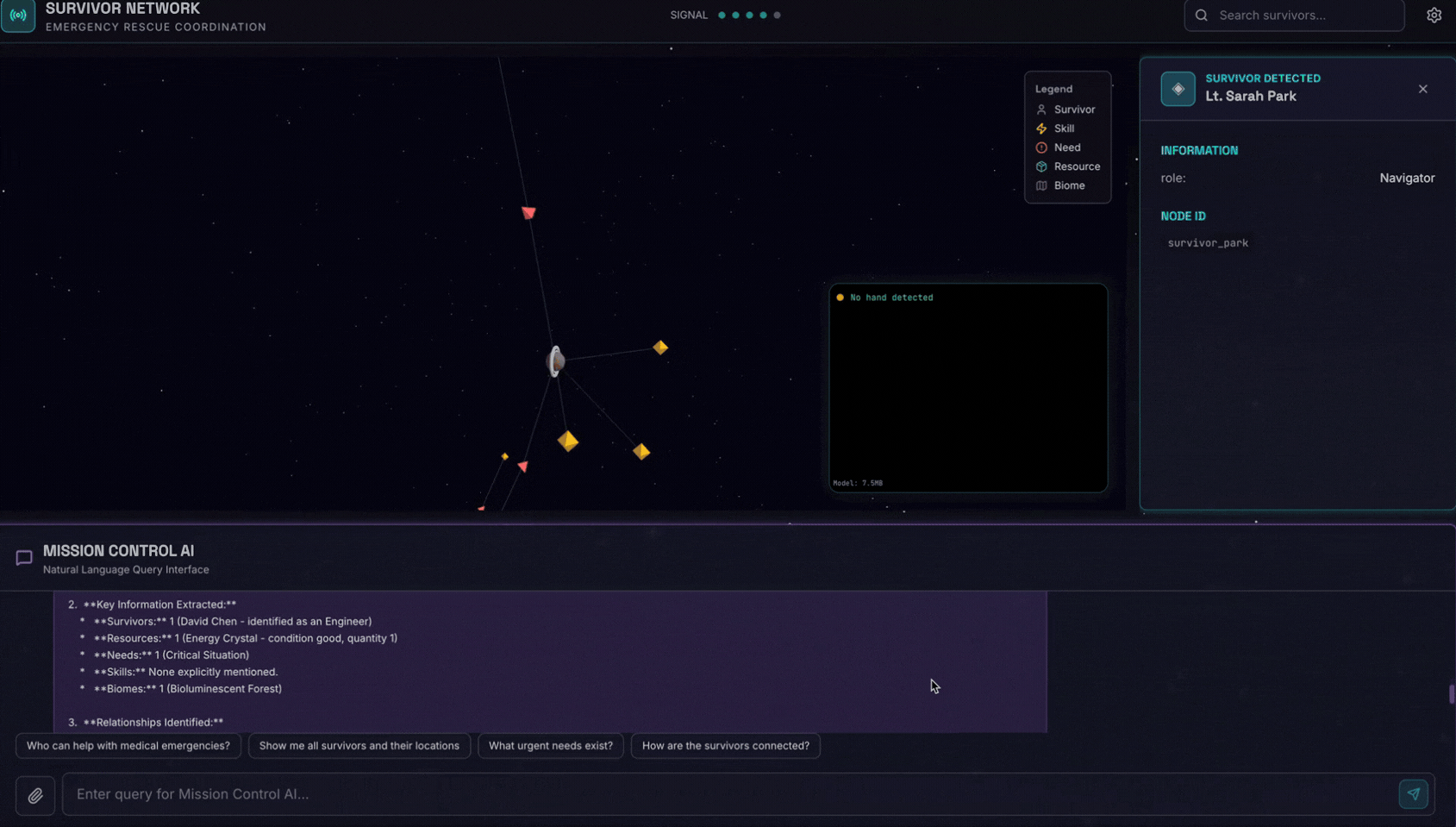
👉💻 在终端中,测试完成后,按“Ctrl+C”结束进程。
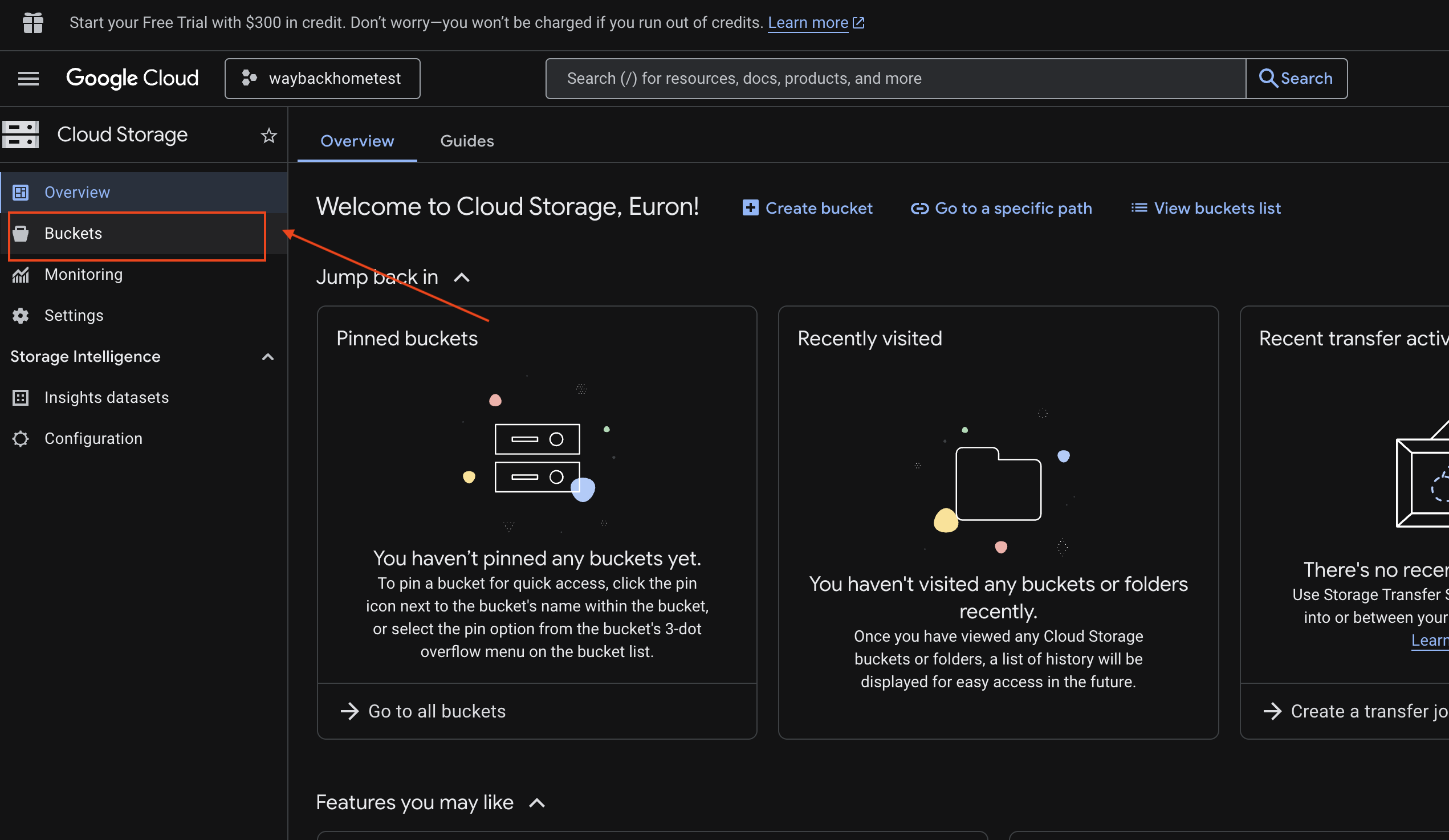
6. 验证 GCS 存储分区中的多模态上传
- 打开 Google Cloud 控制台中的 Storage。
- 选择 Cloud Storage 中的“存储分区”
- 选择您的存储分区,然后点击
media。
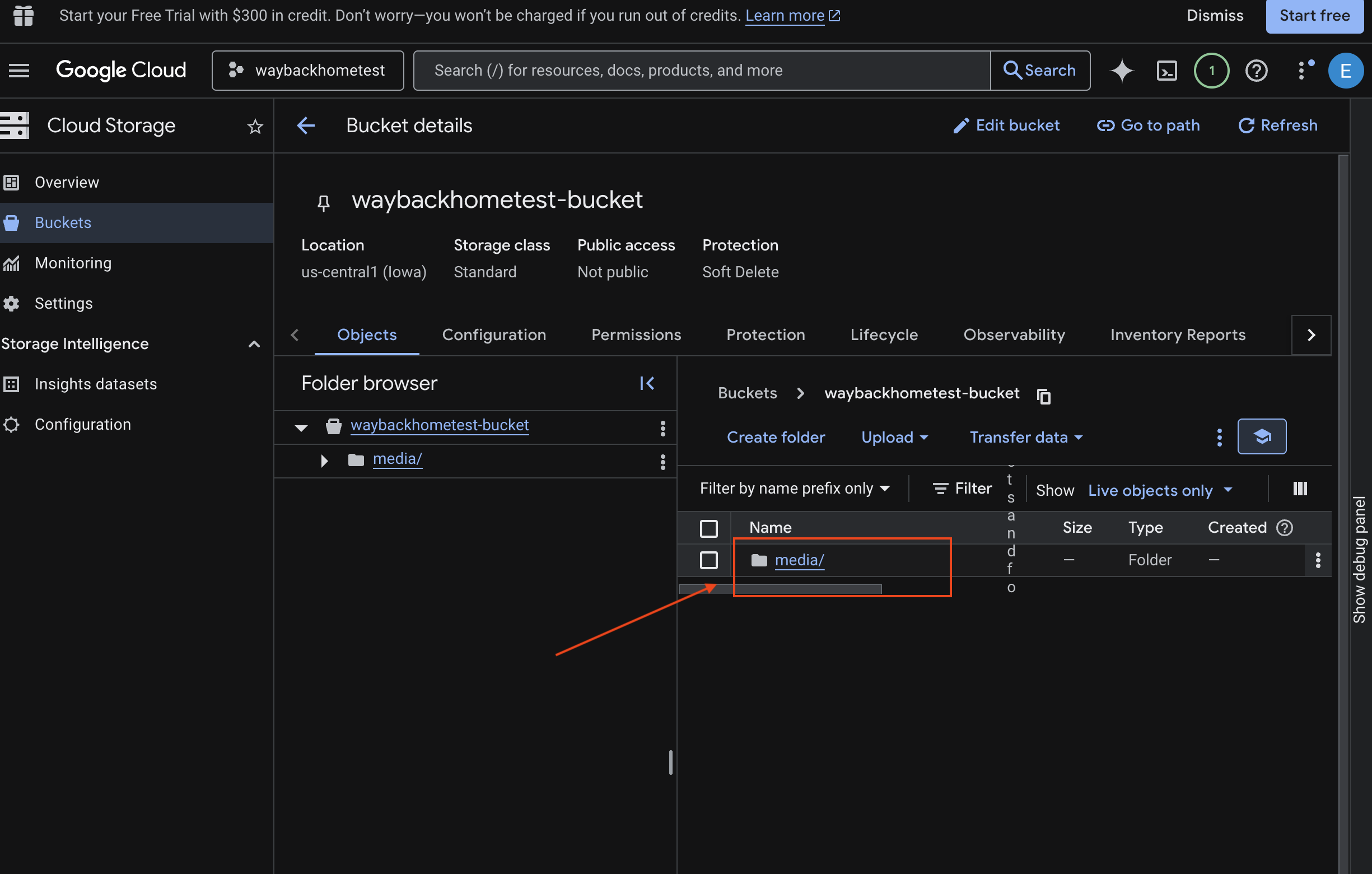
- 您上传的图片会显示在此处。
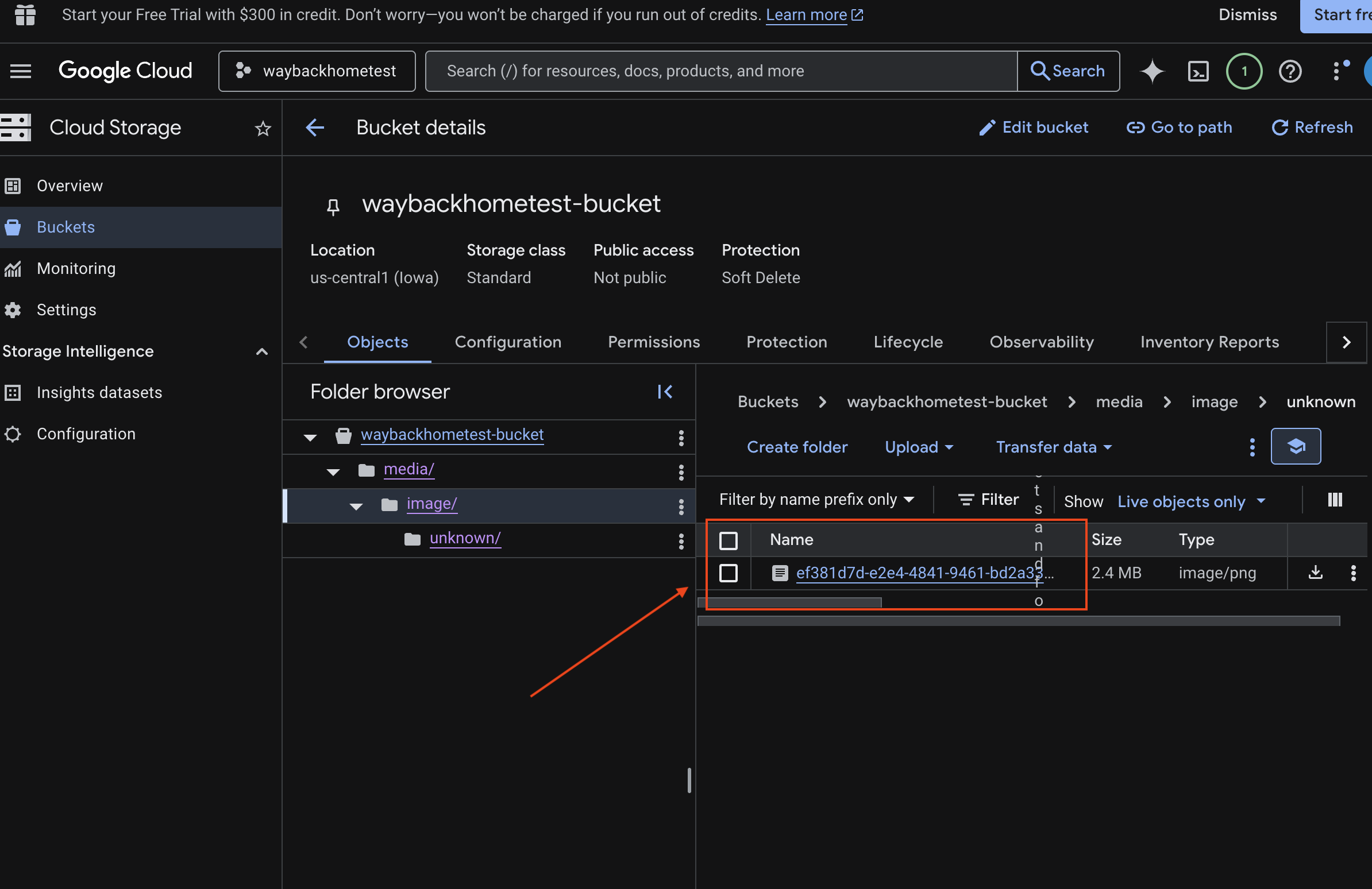
7. 验证 Spanner 中的多模态上传功能(可选)
以下是 test_photo1 在界面中的输出示例。
- 打开 Google Cloud 控制台 Spanner。
- 选择您的实例:
Survivor Network - 选择数据库:
graph-db - 在左侧边栏中,点击 Spanner Studio
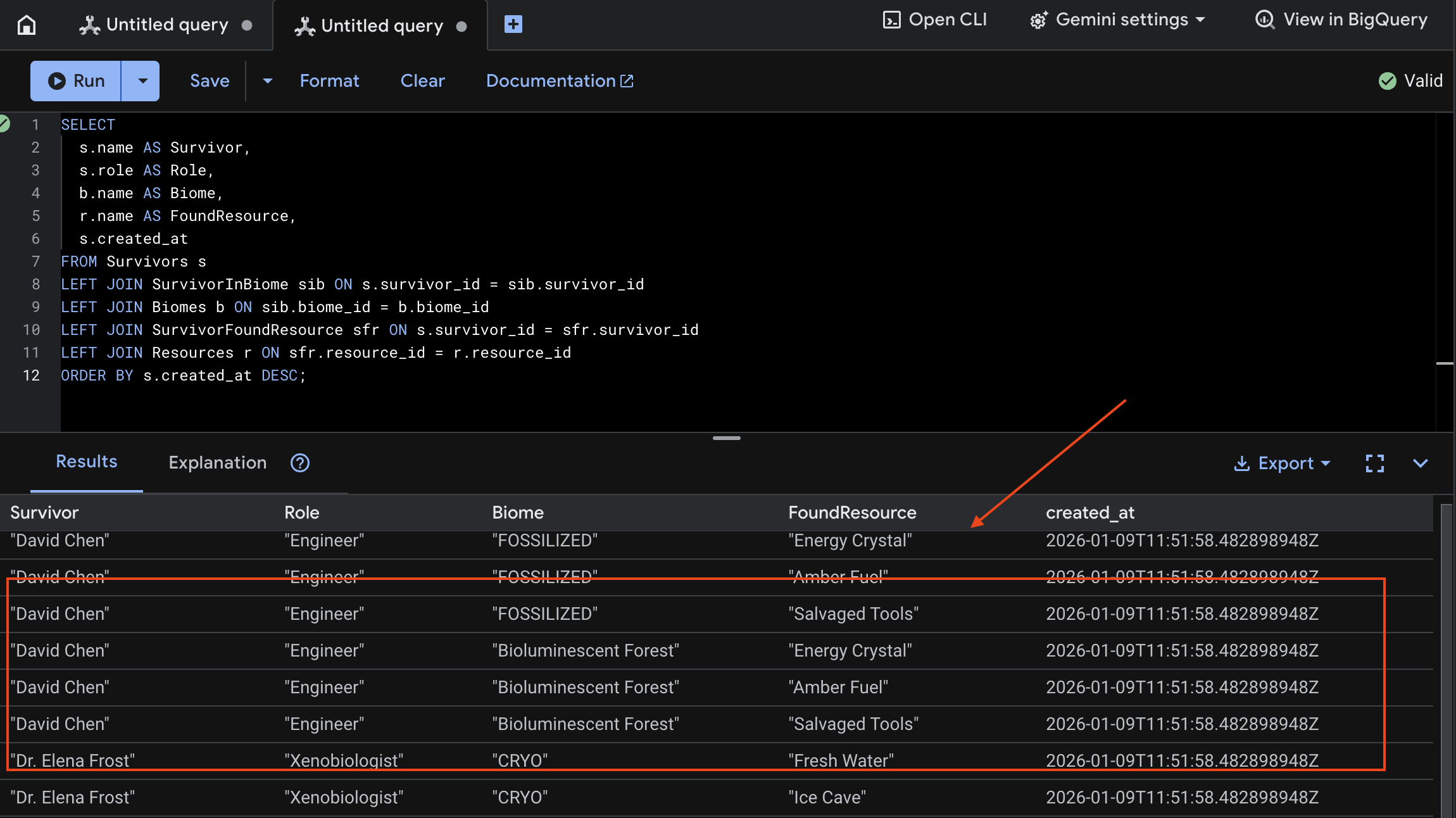
👉 在 Spanner Studio 中,查询新数据:
SELECT
s.name AS Survivor,
s.role AS Role,
b.name AS Biome,
r.name AS FoundResource,
s.created_at
FROM Survivors s
LEFT JOIN SurvivorInBiome sib ON s.survivor_id = sib.survivor_id
LEFT JOIN Biomes b ON sib.biome_id = b.biome_id
LEFT JOIN SurvivorFoundResource sfr ON s.survivor_id = sfr.survivor_id
LEFT JOIN Resources r ON sfr.resource_id = r.resource_id
ORDER BY s.created_at DESC;
我们可以通过查看以下结果来验证这一点:
12. ☕️ [可选] 搭配 Agent Engine 的记忆库
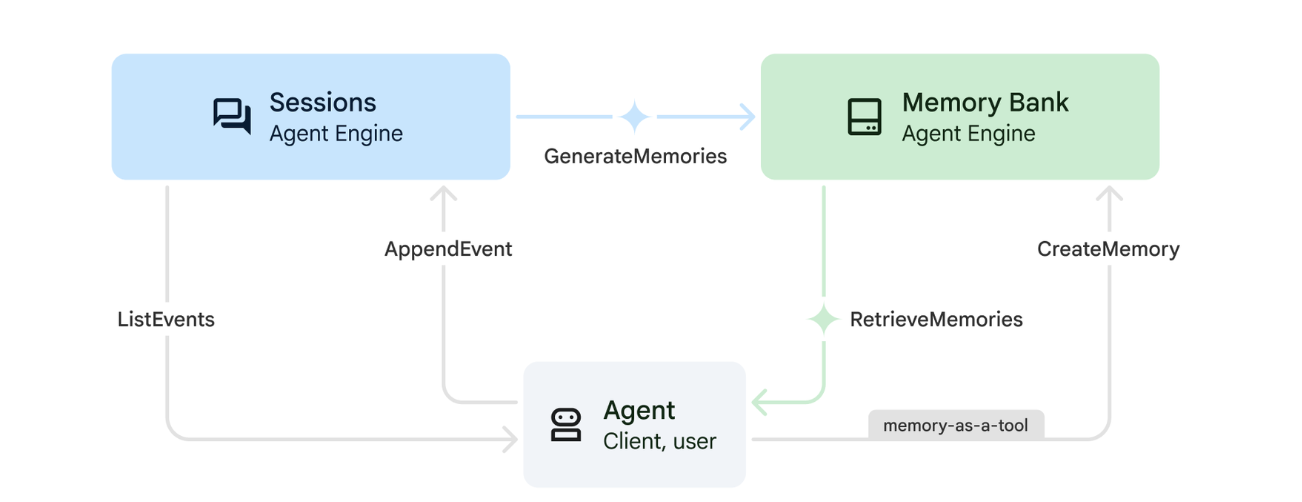
1. 记忆的运作方式
该系统采用双重记忆方法来处理即时上下文和长期学习。
2. 什么是记忆主题?
记忆主题用于定义代理应在对话中记住的信息类别。您可以将它们视为用于存放不同类型用户偏好的文件柜。
我们的 2 个主题:
search_preferences:用户喜欢的搜索方式- 他们更喜欢关键字搜索还是语义搜索?
- 他们经常搜索哪些技能/群系?
- 示例记忆:“用户偏好于使用语义搜索来查询医疗技能”
urgent_needs_context:他们正在跟踪哪些危机- 他们监控哪些资源?
- 他们关注哪些幸存者?
- 示例记忆:“用户正在跟踪北部营地的药品短缺情况”
3. 设置记忆主题
自定义记忆主题用于定义代理应记住哪些内容。这些是在部署 Agent Engine 时配置的。
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/deploy_agent.py
这会在编辑器中打开 ~/way-back-home/level_2/backend/deploy_agent.py。
我们定义了结构 MemoryTopic 对象,以指导 LLM 提取和保存哪些信息。
👉在文件 deploy_agent.py 中,将 # TODO: SET_UP_TOPIC 替换为以下内容:
# backend/deploy_agent.py
custom_topics = [
# Topic 1: Survivor Search Preferences
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="search_preferences",
description="""Extract the user's preferences for how they search for survivors. Include:
- Preferred search methods (keyword, semantic, direct lookup)
- Common filters used (biome, role, status)
- Specific skills they value or frequently look for
- Geographic areas of interest (e.g., "forest biome", "mountain outpost")
Example: "User prefers semantic search for finding similar skills."
Example: "User frequently checks for survivors in the Swamp Biome."
""",
)
),
# Topic 2: Urgent Needs Context
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="urgent_needs_context",
description="""Track the user's focus on urgent needs and resource shortages. Include:
- Specific resources they are monitoring (food, medicine, ammo)
- Critical situations they are tracking
- Survivors they are particularly concerned about
Example: "User is monitoring the medicine shortage in the Northern Camp."
Example: "User is looking for a doctor for the injured survivors."
""",
)
)
]
4. 代理集成
代理代码必须知道记忆库,才能保存和检索信息。
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开该文件:
cloudshell edit ~/way-back-home/level_2/backend/agent/agent.py
这会在编辑器中打开 ~/way-back-home/level_2/backend/agent/agent.py。
代理创建
创建代理时,我们传递 after_agent_callback 以确保会话在互动后保存到内存中。add_session_to_memory 函数以异步方式运行,以避免减慢聊天响应速度。
👉在 agent.py 文件中,找到注释 # TODO: REPLACE_ADD_SESSION_MEMORY,将整行替换为以下代码:
async def add_session_to_memory(
callback_context: CallbackContext
) -> Optional[types.Content]:
"""Automatically save completed sessions to memory bank in the background"""
if hasattr(callback_context, "_invocation_context"):
invocation_context = callback_context._invocation_context
if invocation_context.memory_service:
# Use create_task to run this in the background without blocking the response
asyncio.create_task(
invocation_context.memory_service.add_session_to_memory(
invocation_context.session
)
)
logger.info("Scheduled session save to memory bank in background")
后台保存
👉在 agent.py 文件中,找到注释 # TODO: REPLACE_ADD_MEMORY_BANK_TOOL,将整行替换为以下代码:
if USE_MEMORY_BANK:
agent_tools.append(PreloadMemoryTool())
👉在 agent.py 文件中,找到注释 # TODO: REPLACE_ADD_CALLBACK,将整行替换为以下代码:
after_agent_callback=add_session_to_memory if USE_MEMORY_BANK else None
设置 Vertex AI 会话服务
👉💻 在终端中,运行以下命令,在 Cloud Shell Editor 中打开文件 chat.py:
cloudshell edit ~/way-back-home/level_2/backend/api/routes/chat.py
👉在 chat.py 文件中,找到注释 # TODO: REPLACE_VERTEXAI_SERVICES,将整行替换为以下代码:
session_service = VertexAiSessionService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=project_id,
location=location,
agent_engine_id=agent_engine_id
)
13. ☕️ [可选] 将代理与 Agent Engine 相关联
1. 设置和部署
在测试记忆功能之前,您需要部署包含新记忆主题的代理,并确保环境配置正确。
我们提供了一个便捷脚本来处理此流程。
运行部署脚本
👉💻 在终端中,运行部署脚本:
cd ~/way-back-home/level_2
./deploy_and_update_env.sh
此脚本会执行以下操作:
- 运行
backend/deploy_agent.py以向 Vertex AI 注册代理和记忆主题。 - 捕获新的代理引擎 ID。
- 使用
AGENT_ENGINE_ID自动更新.env文件。 - 确保在
.env文件中设置了USE_MEMORY_BANK=TRUE。
[!IMPORTANT] 如果您在 deploy_agent.py 中更改了 custom_topics,则必须重新运行此脚本以更新代理引擎。
验证记忆库
现在,您可以教智能体一项偏好,然后检查该偏好是否会跨会话保留,从而验证记忆库是否正常运行。
第 1 步。打开应用
按照以下说明再次打开应用:如果之前的终端仍在运行,请按 Ctrls+C 结束该终端。
👉💻 启动应用:
cd ~/way-back-home/level_2/
./start_app.sh
👉 在终端中点击 Local: http://localhost:5173/。
第 2 步。使用文本测试记忆库
在聊天界面中,向智能体说明您的具体情况:
"I'm planning a medical rescue mission in the mountains. I need survivors with first aid and climbing skills."
👉 等待约 30 秒,让系统在后台处理记忆。
第三步。开始新会话
刷新页面可清除当前对话记录(短期记忆)。
提出一个依赖于您之前提供的上下文的问题:
"What kind of missions am I interested in?"
预期响应:
“根据您之前的对话,您对以下内容感兴趣:
- 医疗救援任务
- 山区/高海拔地区作业
- 所需技能:急救、攀岩
您是否希望我查找符合这些条件的幸存者?
第 4 步。使用图片上传功能进行测试
上传图片,然后提出以下问题:
remember this
您可以选择此处的任意照片或您自己的照片,然后将其上传到界面:
第 5 步。在 Vertex AI Agent Engine 中验证
前往 Google Cloud 控制台 Agent Engine
- 请确保您从左上角的项目选择器中选择了项目:
- 验证您刚刚通过上一个命令
use_memory_bank.sh部署的代理引擎: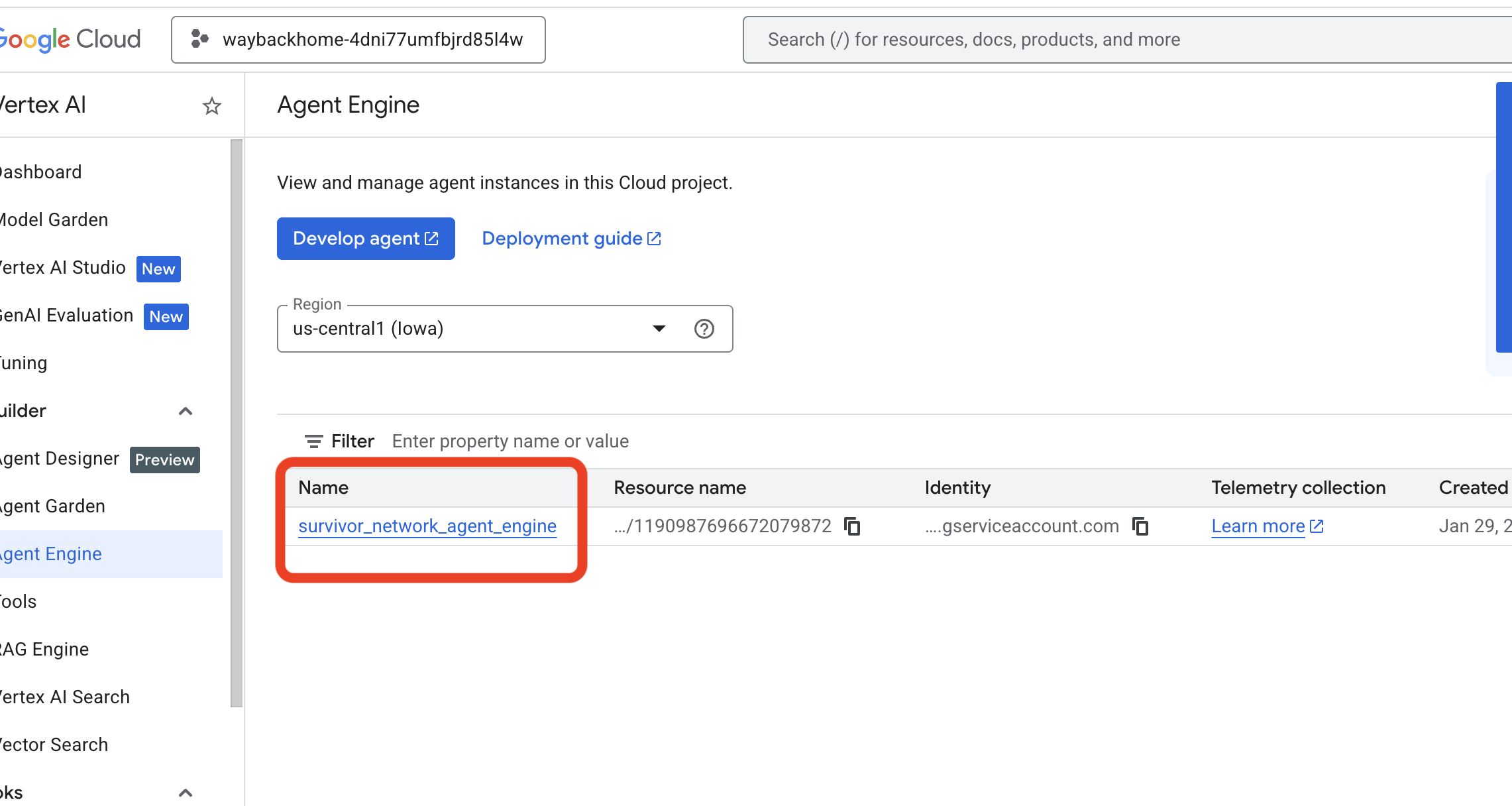 点击您刚刚创建的代理引擎。
点击您刚刚创建的代理引擎。 - 点击已部署的代理中的
Memories标签页,即可在此处查看所有记忆。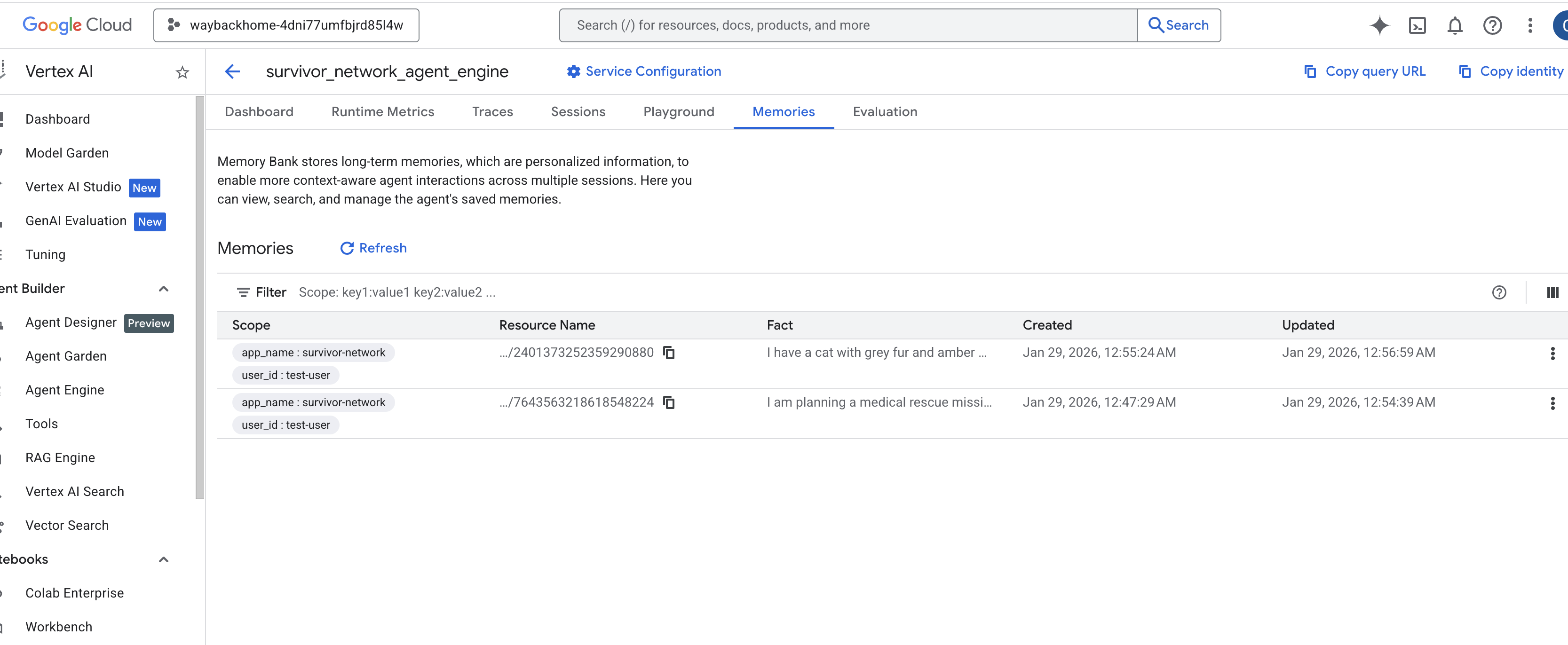
👉💻 测试完成后,在终端中点击“Ctrl + C”以结束该进程。
🎉 恭喜!您刚刚将记忆库附加到智能体!
14. ☕️ [可选] 部署到 Cloud Run
1. 运行部署脚本
👉💻 运行部署脚本:
cd ~/way-back-home/level_2
./deploy_cloud_run.sh
成功部署后,您将获得网址,这就是为您部署的网址!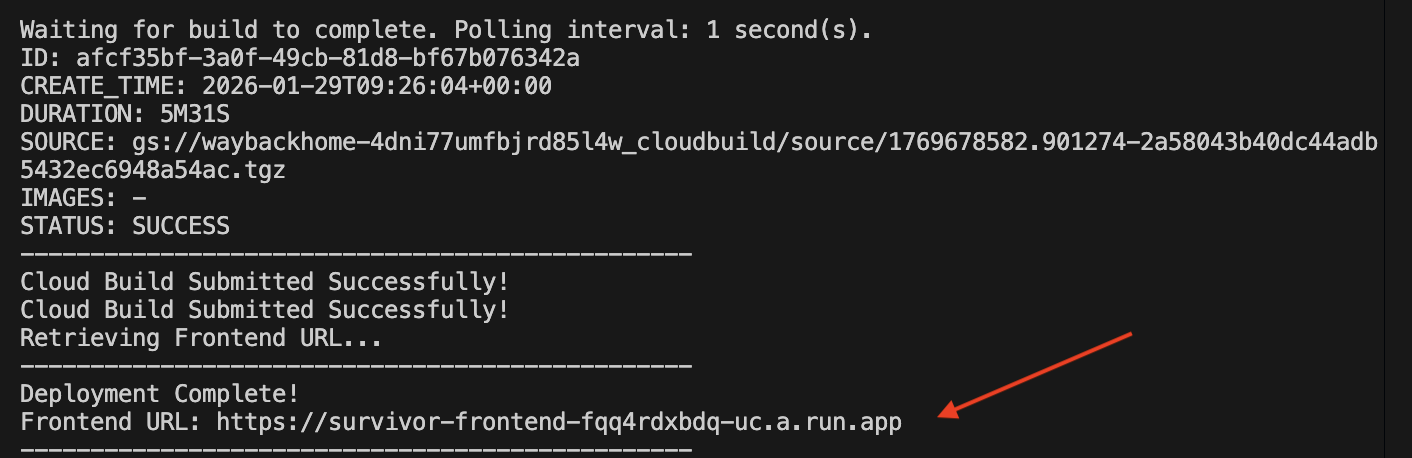
👉💻 在获取网址之前,请运行以下命令来授予权限:
source .env && gcloud run services add-iam-policy-binding survivor-frontend --region $REGION --member=allUsers --role=roles/run.invoker && gcloud run services add-iam-policy-binding survivor-backend --region $REGION --member=allUsers --role=roles/run.invoker
前往已部署的网址,您会看到您的应用已在其中上线!
2. 了解 build 流水线
cloudbuild.yaml 文件定义了以下顺序步骤:
- 后端 build:从
backend/Dockerfile构建 Docker 映像。 - 后端部署:将后端容器部署到 Cloud Run。
- 捕获网址:获取新的后端网址。
- 前端 build:
- 安装依赖项。
- 构建 React 应用,注入
VITE_API_URL=。
- 前端映像:从
frontend/Dockerfile构建 Docker 映像(打包静态资源)。 - 前端部署:部署前端容器。
3. 验证部署
构建完成后(查看脚本提供的日志链接),您可以验证:
- 前往 Cloud Run 控制台。
- 找到
survivor-frontend服务。 - 点击网址即可打开应用。
- 执行搜索查询,以确保前端可以与后端通信。
(可选)4. 手动部署
如果您希望手动运行命令或更好地了解该流程,请按以下步骤直接使用 cloudbuild.yaml。
写入 cloudbuild.yaml
cloudbuild.yaml 文件会告知 Google Cloud Build 要执行哪些步骤。
- steps:一系列按顺序执行的操作。每个步骤都在容器中运行(例如
docker、gcloud、node、bash)。 - 替换变量:可在构建时传递的变量(例如
$_REGION)。 - workspace:一个共享目录,其中包含的步骤可以共享文件(就像我们共享
backend_url.txt一样)。
运行部署
如需在不使用脚本的情况下手动部署,请使用 gcloud builds submit 命令。您必须传递所需的替换变量。
# Load your env vars first or replace these values manually
export PROJECT_ID=your-project-id
export REGION=us-central1
gcloud builds submit --config cloudbuild.yaml \
--project "$PROJECT_ID" \
--substitutions _REGION="us-central1",_GOOGLE_API_KEY="",_AGENT_ENGINE_ID="your-agent-id",_USE_MEMORY_BANK="TRUE",_GOOGLE_GENAI_USE_VERTEXAI="TRUE"
15. 总结
1. 您已构建的内容
✅ 图数据库:包含节点(幸存者、技能)和边(关系)的 Spanner
✅ AI Search:使用嵌入的关键字搜索、语义搜索和混合搜索
✅ 多模态流水线:使用 Gemini 从图片/视频中提取实体
✅ 多代理系统:使用 ADK 的协调工作流
✅ 记忆库:使用 Vertex AI 实现长期个性化
✅ 生产部署:Cloud Run + Agent Engine
2. 架构摘要
3. 重要经验
- Graph RAG:将图数据库结构与语义嵌入相结合,实现智能搜索
- 多智能体模式:用于复杂多步骤工作流的顺序流水线
- 多模态 AI:从非结构化媒体(图片/视频)中提取结构化数据
- 有状态智能体:记忆库可实现跨会话的个性化
4. 研讨会内容
- Level0:Identify Yourself
- Level1:精确定位
- 第 2 级:使用图 RAG、ADK 和记忆库构建多模态 AI 智能体
- Level3: 构建 ADK 双向流式传输代理
- Level4: Live Bidirectional Multi-Agent system
- Level5:使用 Google ADK、A2A 和 Kafka 的事件驱动型架构