
Informazioni su questo codelab
1. Prima di iniziare
In questo codelab, imparerai il "base, World" di ML, dove invece di programmare regole esplicite in un linguaggio, come Java o C++, creerai un sistema addestrato sui dati per dedurre le regole che determinano una relazione tra numeri.
Tieni presente il seguente problema: stai creando un sistema che esegue il riconoscimento dell'attività per il monitoraggio dell'attività fisica. Potresti avere accesso alla velocità alla quale una persona cammina e tentare di dedurre la sua attività in base a tale velocità utilizzando una condizione.

if(speed<4){
status=WALKING;
}
Puoi estendere questa esecuzione con un'altra condizione.

if(speed<4){
status=WALKING;
} else {
status=RUNNING;
}
In una condizione finale, potresti anche rilevare la bicicletta.

if(speed<4){
status=WALKING;
} else if(speed<12){
status=RUNNING;
} else {
status=BIKING;
}
Ora, chiediti cosa succede quando vuoi includere un'attività, ad esempio il golf. È meno ovvio come creare una regola per determinare l'attività.

// Now what?
Scrivere un programma che riesca a riconoscere l'attività del golf è molto difficile. Cosa fai? Puoi utilizzare il machine learning per risolvere il problema.
Prerequisiti
Prima di provare questo codelab, devi avere:
- Una solida conoscenza di Python
- Competenze di programmazione di base
Cosa imparerai a fare:
- Nozioni di base sul machine learning
Cosa imparerai a realizzare
- Il tuo primo modello di machine learning
Che cosa ti serve
Se non hai mai creato un modello di machine learning utilizzando TensorFlow, puoi utilizzare Colaboratory, un ambiente basato su browser che contiene tutte le dipendenze richieste. Puoi trovare il codice per il resto del codelab in esecuzione in Colab.
Se utilizzi un IDE diverso, assicurati di aver installato Python. Avrai bisogno anche di TensorFlow e della libreria NumPy. Scopri di più sull'installazione di TensorFlow qui. Installa NumPy qui.
2. Che cos'è il machine learning?
Considera la modalità tradizionale di creazione delle app, come illustrato nel seguente diagramma:

Le regole sono espresse in un linguaggio di programmazione. Agiscono sulla base dei dati e il tuo programma fornisce risposte**.** Nel caso del rilevamento di attività, le regole (il codice che hai scritto per definire i tipi di attività) hanno agito sui dati (la velocità di movimento della persona) per produrre una risposta: il valore restituito dalla funzione per determinare lo stato dell'attività dell'utente (a piedi, in corsa, in bicicletta o effettuando qualcos'altro).
Il processo per rilevare lo stato dell'attività tramite machine learning è molto simile, solo gli assi sono diversi.

Anziché provare a definire le regole ed esprimerle in un linguaggio di programmazione, fornisci le risposte (in genere chiamate etichette) insieme ai dati e la macchina deduce le regole che determinano la relazione tra le risposte e i dati. Ad esempio, il tuo scenario di rilevamento delle attività potrebbe avere il seguente aspetto nel contesto del machine learning:
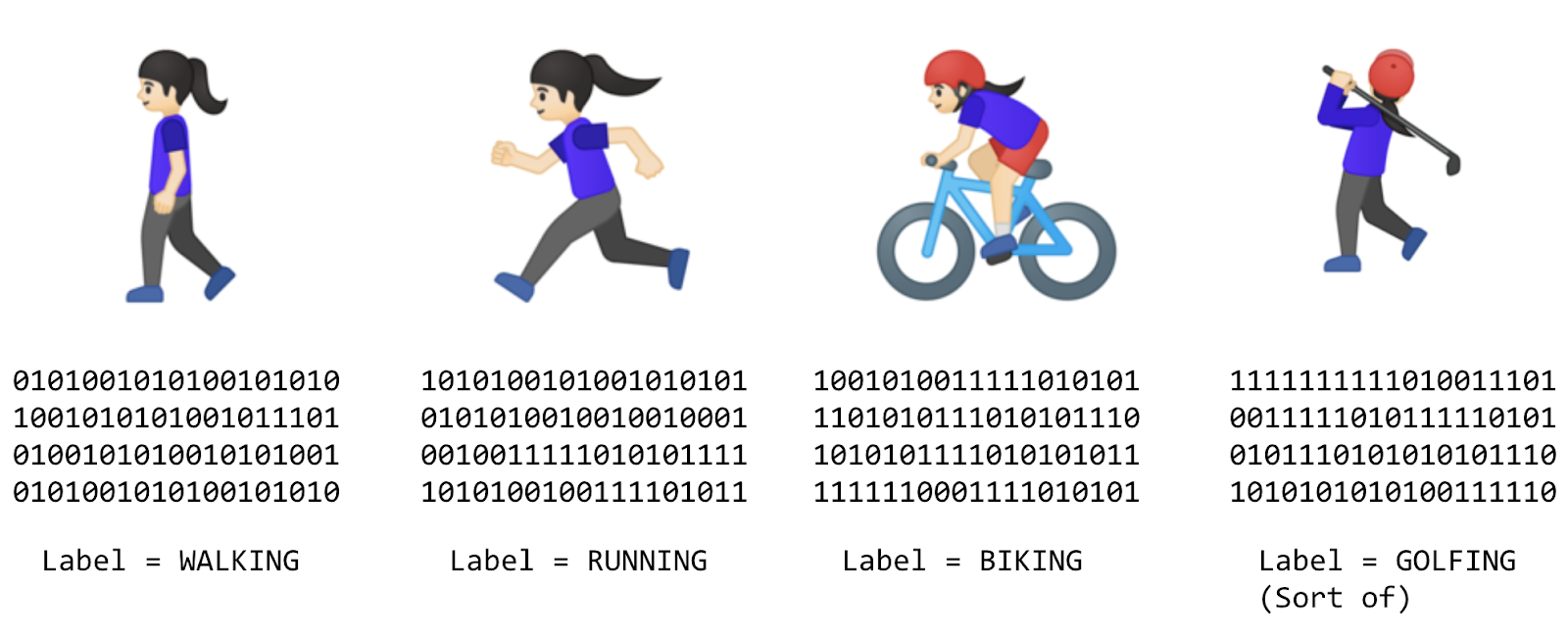
Raccogli molti dati ed etichettali per dire, in modo efficace, come si presenta una camminata, o "Questo è l'aspetto della corsa". Quindi, il computer può dedurre le regole che determinano, dai dati, quali sono i pattern distinti che indicano una determinata attività.
Oltre a essere un metodo alternativo per programmare lo scenario, tale approccio ti offre anche la possibilità di aprire nuovi scenari, come quello da golf che non sarebbe stato possibile con l'approccio di programmazione tradizionale basato su regole.
Nella programmazione tradizionale, il tuo codice compila un programma binario, che in genere è chiamato programma. In ML, l'elemento che crei dai dati e dalle etichette viene chiamato modello.
Quindi, se torni a questo diagramma:

Il risultato è un modello, utilizzato in questo modo al momento dell'esecuzione:

Passi al modello alcuni dati e il modello utilizza le regole che ha dedotto dall'addestramento per fare una previsione, come: "I dati sembrano camminare", o "I dati sembrano bicicletta".
3. Crea il tuo primo modello di machine learning
Prendi in considerazione i seguenti insiemi di numeri. Riesci a capire qual è la relazione tra questi due elementi?
X: | -1 | 0 | 1 | 2 | 3 | 4 |
Y: | -2 | 1 | 4 | 7 | 10 | 13 |
Mentre li vedi, potresti notare che il valore di X aumenta di 1 mentre leggi da sinistra a destra e il valore corrispondente di Y aumenta di 3. Probabilmente pensi che Y corrisponda a 3 volte più o meno qualcosa. Quindi potresti guardare lo 0 su X e vedere che Y è 1 e ricava la relazione Y=3X+1.
È quasi esattamente come useresti il codice per addestrare un modello a rilevare i pattern nei dati!
A questo punto, controlla il codice per farlo.
Come addestreresti una rete neurale per svolgere l'attività equivalente? Utilizzo dei dati... Se le inserisci in un set di X's e un insieme di Y's, dovrebbe essere in grado di stabilire la relazione tra le due.
Importazioni
Inizia con le importazioni. Stai importando TensorFlow e chiamandolo tf per facilità d'uso.
Dopodiché, importa una libreria denominata numpy, che rappresenta i tuoi dati sotto forma di elenchi in modo facile e veloce.
Il framework per definire una rete neurale come un insieme di livelli sequenziali è chiamato keras, quindi importa anche questo.
import tensorflow as tf
import numpy as np
from tensorflow import keras
Definire e compilare la rete neurale
Quindi, crea la rete neurale più semplice possibile. È disponibile un solo livello, il livello contiene un neurone e la forma di immissione è un solo valore.
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
Quindi, scrivi il codice per compilare la tua rete neurale. Quando esegui questa operazione, devi specificare due funzioni: loss e optimizer.
In questo esempio, sai che la relazione tra i numeri è Y=3X+1.
Quando il computer cerca di impararerlo, indovina un po', forse Y=10X+10. La funzione loss misura le risposte indovinate in base alle risposte corrette note e misura le prestazioni dell'app.
Il modello utilizza poi la funzione optimizer per formulare un'altra ipotesi. In base al risultato della funzione di perdita, cerca di ridurre al minimo la perdita. A questo punto, forse ti verrà in mente qualcosa come Y=5X+5. Anche se è ancora un pessimo risultato, è più vicino al risultato corretto (la perdita è inferiore).
Il modello lo ripete per il numero di periodi che visualizzerai a breve.
Innanzitutto, ecco come utilizzare il mean_squared_error per la perdita e la discendenza gradiente stocastico (sgd) per l'ottimizzazione. Non hai ancora bisogno di capire la matematica per queste persone, ma puoi vedere che funzionano!
Nel tempo, imparerai le diverse funzioni di ottimizzazione e ottimizzazione adatte a scenari diversi.
model.compile(optimizer='sgd', loss='mean_squared_error')
Fornire i dati
Ora fornisci dei dati. In questo caso, prendi le sei variabili X e sei Y dalla precedente. Puoi vedere che la relazione tra questi due valori è Y=3X+1, quindi dove X è -1, Y è -2.
A questo scopo, una libreria Python chiamata NumPy fornisce molte strutture di dati di tipo array. Specifica i valori come array in NumPy con np.array[].
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-2.0, 1.0, 4.0, 7.0, 10.0, 13.0], dtype=float)
Ora disponi di tutto il codice necessario per definire la rete neurale. Il passaggio successivo consiste nell'addestrarlo per vedere se è in grado di dedurre i pattern tra tali numeri e utilizzarli per creare un modello.
4. Addestrare la rete neurale
Il processo di addestramento della rete neurale, in cui apprende la relazione tra X's e Y's, è incluso nella chiamata model.fit. È per questo che attraverserà il ciclo prima di formulare un'ipotesi, misurandone la qualità (o la perdita) o utilizzando l'ottimizzatore per formulare un'altra ipotesi. Lo farà per il numero di periodi specificato. Quando esegui il codice, vedrai la perdita per ogni periodo.
model.fit(xs, ys, epochs=500)
Ad esempio, per i primi periodi puoi vedere che il valore della perdita è piuttosto elevato, ma ad ogni passaggio si riduce.

Man mano che l'addestramento progredisce, la perdita diventa presto molto ridotta.

Quando l'addestramento è terminato, la perdita è estremamente ridotta, a dimostrazione del fatto che il nostro modello è un ottimo modo di dedurre la relazione tra i numeri.

Probabilmente non hai bisogno di tutti i 500 periodi e puoi sperimentare con importi diversi. Come puoi vedere dall'esempio, dopo 50 periodi la perdita è davvero modesta, pertanto potrebbe essere sufficiente.
5. Utilizza il modello
Hai un modello che è stato addestrato per conoscere la relazione tra X e Y. Puoi utilizzare il metodo model.predict per determinare la Y di una X precedentemente sconosciuta. Ad esempio, se X è 10, quale pensi sarà Y? Prova a indovinare prima di eseguire il seguente codice:
print(model.predict([10.0]))
Magari avresti pensato 31, ma alla fine è stato un po' troppo. A cosa è dovuta?
Le reti neurali gestiscono le probabilità, quindi ha calcolato che c'è una probabilità molto alta che la relazione tra X e Y sia Y=3X+1, ma non sa per certo con solo sei punti dati. Il risultato è molto vicino a 31, ma non necessariamente 31.
Man mano che utilizzi le reti neurali, vedrai questo pattern ricorrente. Affronterai quasi sempre le probabilità, non le certezza, e dovrai scrivere un po' di programmazione per capire su cosa si basa il risultato, in particolare sulla classificazione.
6. Complimenti
Indipendentemente dalla tua esperienza, hai trattato la maggior parte dei concetti di machine learning che utilizzerai in scenari molto più complessi. Hai imparato ad addestrare una rete neurale in modo che individui la relazione tra due insiemi di numeri definendo la rete. Hai definito un insieme di livelli (in questo caso solo uno) che contenevano neuroni (anche in questo caso uno solo) che hai poi compilato con una funzione di perdita e un ottimizzatore.
La raccolta di una rete, di una funzione di perdita e dello strumento di ottimizzazione gestisce il processo di indovinare il rapporto tra i numeri, misurare il rendimento e quindi generare nuovi parametri per nuove ipotesi. Scopri di più su TensorFlow.org.
Scopri di più
Per saperne di più su come ML e TensorFlow possono essere utili con i tuoi modelli di visione artificiale, consulta Creare un modello di visione artificiale con TensorFlow.