
এই কোডল্যাব সম্পর্কে
1. তুমি শুরু করার আগে
গত এক দশকে ওয়েব অ্যাপগুলি আরও বেশি সামাজিক এবং ইন্টারেক্টিভ হয়ে উঠেছে, মাল্টিমিডিয়ার সমর্থন সহ, মন্তব্য এবং আরও অনেক কিছু বাস্তব সময়ে ঘটছে এমনকী একটি মাঝারি জনপ্রিয় ওয়েবসাইটে হাজার হাজার লোকের দ্বারা।
এটি স্প্যামারদের এই ধরনের সিস্টেমের অপব্যবহার করার এবং আরও দৃশ্যমানতা অর্জনের প্রয়াসে অন্যদের লেখা নিবন্ধ, ভিডিও এবং পোস্টগুলির সাথে কম মজাদার সামগ্রী যুক্ত করার একটি সুযোগও উপস্থাপন করেছে৷
স্প্যাম সনাক্তকরণের পুরানো পদ্ধতিগুলি, যেমন ব্লক করা শব্দগুলির একটি তালিকা, সহজেই বাইপাস করা যেতে পারে এবং উন্নত স্প্যাম বটগুলির জন্য কোন মিল নয়, যা ক্রমাগত তাদের জটিলতায় বিকশিত হচ্ছে৷ আজকে দ্রুত-ফরওয়ার্ড করুন, এবং আপনি এখন মেশিন লার্নিং মডেলগুলি ব্যবহার করতে পারেন যেগুলিকে এই ধরনের স্প্যাম শনাক্ত করার জন্য প্রশিক্ষিত করা হয়েছে৷
প্রথাগতভাবে, প্রি-ফিল্টার মন্তব্য করার জন্য একটি মেশিন লার্নিং মডেল চালানো সার্ভার সাইডে সঞ্চালিত হত, কিন্তু TensorFlow.js এর সাথে আপনি এখন জাভাস্ক্রিপ্টের মাধ্যমে ব্রাউজারে মেশিন লার্নিং মডেল ক্লায়েন্ট সাইড চালাতে পারেন। আপনি স্প্যাম বন্ধ করতে পারেন এটি এমনকি পিছনের প্রান্ত স্পর্শ করার আগেই, সম্ভাব্য ব্যয়বহুল সার্ভার সাইড সম্পদ সংরক্ষণ করে।
আপনি হয়তো জানেন, মেশিন লার্নিং আজকাল বেশ গুঞ্জন, সেখানে প্রায় প্রতিটি শিল্পকে স্পর্শ করে কিন্তু কিভাবে আপনি ওয়েব ডেভেলপার হিসাবে এই ক্ষমতাগুলি ব্যবহার করার জন্য আপনার প্রথম পদক্ষেপ নিতে পারেন?
এই কোডল্যাবটি আপনাকে দেখাবে কিভাবে একটি ফাঁকা ক্যানভাস থেকে একটি ওয়েব অ্যাপ তৈরি করতে হয়, যা প্রাকৃতিক ভাষা প্রক্রিয়াকরণ (কম্পিউটার দিয়ে মানুষের ভাষা বোঝার শিল্প) ব্যবহার করে মন্তব্য স্প্যামের আসল সমস্যাটি মোকাবেলা করে। অনেক ওয়েব ডেভেলপার এই সমস্যাটির সম্মুখীন হবে কারণ তারা বর্তমানে বিদ্যমান জনপ্রিয় ওয়েব অ্যাপ্লিকেশনগুলির একটিতে কাজ করে এবং এই কোডল্যাব আপনাকে দক্ষতার সাথে এই ধরনের সমস্যাগুলি মোকাবেলা করতে সক্ষম করবে৷
পূর্বশর্ত
এই কোডল্যাবটি এমন ওয়েব ডেভেলপারদের জন্য লেখা হয়েছে যারা মেশিন লার্নিংয়ে নতুন যারা TensorFlow.js এর সাথে প্রাক-প্রশিক্ষিত মডেল ব্যবহার শুরু করতে চাইছেন।
HTML5, CSS, এবং JavaScript এর সাথে পরিচিতি এই ল্যাবের জন্য ধরে নেওয়া হয়।
আপনি কি শিখবেন
আপনি করবেন:
- TensorFlow.js কি এবং প্রাকৃতিক ভাষা প্রক্রিয়াকরণের জন্য কোন মডেল বিদ্যমান সে সম্পর্কে আরও জানুন।
- একটি বাস্তব সময়ের মন্তব্য বিভাগ সহ একটি কাল্পনিক ভিডিও ব্লগের জন্য একটি সাধারণ HTML/CSS/JS ওয়েবপেজ তৈরি করুন৷
- একটি পূর্ব-প্রশিক্ষিত মেশিন লার্নিং মডেল লোড করার জন্য TensorFlow.js ব্যবহার করুন যে একটি বাক্য প্রবেশ করানো স্প্যাম হতে পারে কিনা তা অনুমান করতে সক্ষম, এবং যদি তাই হয়, ব্যবহারকারীকে সতর্ক করুন যে তাদের মন্তব্য সংযমের জন্য রাখা হয়েছে।
- মন্তব্য বাক্যগুলিকে এমনভাবে এনকোড করুন যা মেশিন লার্নিং মডেল দ্বারা শ্রেণীবদ্ধ করার জন্য ব্যবহারযোগ্য।
- আপনি মন্তব্যটিকে স্বয়ংক্রিয়ভাবে ফ্ল্যাগ করতে চান কিনা তা নির্ধারণ করতে মেশিন লার্নিং মডেলের আউটপুট ব্যাখ্যা করুন। এই কাল্পনিক UX যেকোন ওয়েবসাইটে আপনি কাজ করছেন আবার ব্যবহার করা যেতে পারে, এবং যেকোন ক্লায়েন্ট ব্যবহারের ক্ষেত্রে মানানসই হতে পারে — হতে পারে এটি একটি নিয়মিত ব্লগ, ফোরাম বা CMS-এর কিছু ফর্ম যেমন Drupal।
বেশ ঝরঝরে. এটা করতে কঠিন? না। তো চলুন হ্যাকিং করা যাক...
আপনি কি প্রয়োজন হবে
- একটি Glitch.com অ্যাকাউন্ট অনুসরণ করতে পছন্দ করা হয় অথবা আপনি একটি ওয়েব পরিবেশন পরিবেশ ব্যবহার করতে পারেন যা আপনি সম্পাদনা করতে এবং নিজে চালাতে স্বাচ্ছন্দ্যবোধ করেন৷
2. TensorFlow.js কি?

TensorFlow.js হল একটি ওপেন সোর্স মেশিন লার্নিং লাইব্রেরি যা জাভাস্ক্রিপ্ট যে কোন জায়গায় চালাতে পারে। এটি পাইথনে লেখা মূল TensorFlow লাইব্রেরির উপর ভিত্তি করে তৈরি করা হয়েছে এবং জাভাস্ক্রিপ্ট ইকোসিস্টেমের জন্য এই ডেভেলপার অভিজ্ঞতা এবং API-এর সেট পুনরায় তৈরি করা।
এটা কোথায় ব্যবহার করা যেতে পারে?
জাভাস্ক্রিপ্টের বহনযোগ্যতার কারণে, আপনি এখন 1টি ভাষায় লিখতে পারেন এবং নিচের সমস্ত প্ল্যাটফর্মে সহজেই মেশিন লার্নিং করতে পারেন:
- ভ্যানিলা জাভাস্ক্রিপ্ট ব্যবহার করে ওয়েব ব্রাউজারে ক্লায়েন্ট সাইড
- সার্ভার সাইড এবং এমনকি IoT ডিভাইস যেমন Raspberry Pi Node.js ব্যবহার করে
- ইলেক্ট্রন ব্যবহার করে ডেস্কটপ অ্যাপ
- React Native ব্যবহার করে নেটিভ মোবাইল অ্যাপ
TensorFlow.js এই প্রতিটি পরিবেশের মধ্যে একাধিক ব্যাকএন্ডকেও সমর্থন করে (প্রকৃত হার্ডওয়্যার ভিত্তিক পরিবেশে এটি কার্যকর করতে পারে যেমন CPU বা WebGL। এই প্রসঙ্গে একটি "ব্যাকএন্ড" মানে সার্ভার সাইড এনভায়রনমেন্ট নয় - এক্সিকিউশনের জন্য ব্যাকএন্ড WebGL-এ ক্লায়েন্ট সাইড হতে পারে উদাহরণস্বরূপ) সামঞ্জস্য নিশ্চিত করতে এবং জিনিসগুলি দ্রুত চলমান রাখতে। বর্তমানে TensorFlow.js সমর্থন করে:
- ডিভাইসের গ্রাফিক্স কার্ডে (GPU) WebGL এক্সিকিউশন - GPU ত্বরণ সহ বড় মডেল (3MB এর বেশি) চালানোর এটি দ্রুততম উপায়।
- CPU-তে ওয়েব অ্যাসেম্বলি (WASM) এক্সিকিউশন - উদাহরণস্বরূপ পুরানো প্রজন্মের মোবাইল ফোন সহ ডিভাইস জুড়ে CPU কর্মক্ষমতা উন্নত করতে। গ্রাফিক্স প্রসেসরে বিষয়বস্তু আপলোড করার ওভারহেডের কারণে ওয়েবজিএল-এর তুলনায় WASM-এর সাথে CPU-তে আসলে WASM-এর সাথে দ্রুত কার্যকর করতে পারে এমন ছোট মডেলগুলির জন্য এটি আরও উপযুক্ত।
- সিপিইউ এক্সিকিউশন - ফলব্যাক অন্য কোনো পরিবেশে পাওয়া উচিত নয়। এটি তিনটির মধ্যে সবচেয়ে ধীর তবে সর্বদা আপনার জন্য রয়েছে।
দ্রষ্টব্য: আপনি এই ব্যাকএন্ডগুলির মধ্যে একটিকে জোর করে বেছে নিতে পারেন যদি আপনি জানেন যে আপনি কোন ডিভাইসে কাজ করবেন, অথবা আপনি যদি এটি নির্দিষ্ট না করেন তবে আপনি কেবল TensorFlow.js কে আপনার জন্য সিদ্ধান্ত নিতে দিতে পারেন।
ক্লায়েন্ট সাইড সুপার পাওয়ার
ক্লায়েন্ট মেশিনে ওয়েব ব্রাউজারে TensorFlow.js চালানোর ফলে বেশ কিছু সুবিধা হতে পারে যা বিবেচনা করার মতো।
গোপনীয়তা
আপনি 3য় পক্ষের ওয়েব সার্ভারে কখনও ডেটা না পাঠিয়ে ক্লায়েন্ট মেশিনে ডেটা প্রশিক্ষণ এবং শ্রেণিবদ্ধ করতে পারেন। এমন কিছু সময় থাকতে পারে যেখানে স্থানীয় আইন মেনে চলার জন্য এটির প্রয়োজন হতে পারে, যেমন GDPR, অথবা কোনো ডেটা প্রক্রিয়া করার সময় যা ব্যবহারকারী তাদের মেশিনে রাখতে চান এবং তৃতীয় পক্ষের কাছে পাঠানো হয়নি।
দ্রুততা
যেহেতু আপনাকে দূরবর্তী সার্ভারে ডেটা পাঠাতে হবে না, অনুমান (ডেটা শ্রেণীবদ্ধ করার কাজ) দ্রুত হতে পারে। আরও ভাল, আপনার ডিভাইসের সেন্সর যেমন ক্যামেরা, মাইক্রোফোন, জিপিএস, অ্যাক্সিলোমিটার এবং আরও অনেক কিছুতে আপনার সরাসরি অ্যাক্সেস আছে ব্যবহারকারী আপনাকে অ্যাক্সেস দেওয়ার অনুমতি দেয়।
পৌঁছান এবং স্কেল করুন
এক ক্লিকে বিশ্বের যে কেউ আপনার পাঠানো একটি লিঙ্কে ক্লিক করতে পারে, তাদের ব্রাউজারে ওয়েব পৃষ্ঠা খুলতে পারে এবং আপনি যা তৈরি করেছেন তা ব্যবহার করতে পারেন। মেশিন লার্নিং সিস্টেম ব্যবহার করার জন্য CUDA ড্রাইভার সহ একটি জটিল সার্ভার সাইড লিনাক্স সেটআপের প্রয়োজন নেই এবং আরও অনেক কিছু।
খরচ
কোনো সার্ভার মানেই আপনার HTML, CSS, JS, এবং মডেল ফাইলগুলি হোস্ট করার জন্য একটি CDN এর জন্য আপনাকে অর্থপ্রদান করতে হবে। একটি CDN-এর খরচ একটি সার্ভার (সম্ভাব্যভাবে একটি গ্রাফিক্স কার্ড সংযুক্ত) 24/7 চালানোর চেয়ে অনেক সস্তা।
সার্ভার সাইড বৈশিষ্ট্য
TensorFlow.js-এর Node.js বাস্তবায়নের কাজে লাগানো নিম্নলিখিত বৈশিষ্ট্যগুলিকে সক্ষম করে।
সম্পূর্ণ CUDA সমর্থন
সার্ভারের দিকে, গ্রাফিক্স কার্ডের ত্বরণের জন্য, আপনাকে অবশ্যই NVIDIA CUDA ড্রাইভার ইনস্টল করতে হবে যাতে TensorFlow গ্রাফিক্স কার্ডের সাথে কাজ করতে সক্ষম হয় (WebGL ব্যবহার করে এমন ব্রাউজার থেকে আলাদা - কোন ইনস্টলের প্রয়োজন নেই)। তবে সম্পূর্ণ CUDA সমর্থনের মাধ্যমে আপনি গ্রাফিক্স কার্ডের নিম্ন স্তরের ক্ষমতাগুলি সম্পূর্ণরূপে লাভ করতে পারেন, যার ফলে দ্রুত প্রশিক্ষণ এবং অনুমান করার সময় হয়। Python TensorFlow ইমপ্লিমেন্টেশনের সাথে পারফরম্যান্স সমানভাবে রয়েছে কারণ তারা উভয়ই একই C++ ব্যাকএন্ড শেয়ার করে।
মডেল সাইজ
গবেষণা থেকে আধুনিক মডেলের জন্য, আপনি খুব বড় মডেলের সাথে কাজ করতে পারেন, হয়তো গিগাবাইট আকারের। প্রতি ব্রাউজার ট্যাবে মেমরি ব্যবহারের সীমাবদ্ধতার কারণে এই মডেলগুলি বর্তমানে ওয়েব ব্রাউজারে চালানো যাবে না। এই বৃহত্তর মডেলগুলি চালানোর জন্য আপনি আপনার নিজের সার্ভারে Node.js ব্যবহার করতে পারেন হার্ডওয়্যার স্পেসিফিকেশনের সাথে এই ধরনের মডেলটি দক্ষতার সাথে চালানোর জন্য।
আইওটি
Node.js Raspberry Pi এর মত জনপ্রিয় একক বোর্ড কম্পিউটারে সমর্থিত, যার মানে হল আপনি এই ধরনের ডিভাইসেও TensorFlow.js মডেলগুলি চালাতে পারেন।
দ্রুততা
Node.js জাভাস্ক্রিপ্টে লেখা হয় যার মানে এটি শুধুমাত্র সময় সংকলন থেকে উপকৃত হয়। এর মানে হল যে আপনি প্রায়শই Node.js ব্যবহার করার সময় পারফরম্যান্স লাভ দেখতে পারেন কারণ এটি রানটাইমে অপ্টিমাইজ করা হবে, বিশেষ করে আপনি যে কোনো প্রিপ্রসেসিং করছেন। এর একটি দুর্দান্ত উদাহরণ এই কেস স্টাডিতে দেখা যায় যা দেখায় যে কীভাবে Hugging Face তাদের প্রাকৃতিক ভাষা প্রক্রিয়াকরণ মডেলের জন্য 2x পারফরম্যান্স বুস্ট পেতে Node.js ব্যবহার করেছে৷
এখন আপনি TensorFlow.js এর মূল বিষয়গুলি বুঝতে পেরেছেন, যেখানে এটি চলতে পারে এবং কিছু সুবিধা, আসুন এটির সাথে দরকারী জিনিসগুলি করা শুরু করি!
3. প্রাক-প্রশিক্ষিত মডেল
কেন আমি একটি প্রাক-প্রশিক্ষিত মডেল ব্যবহার করতে চাই?
একটি জনপ্রিয় প্রাক-প্রশিক্ষিত মডেল দিয়ে শুরু করার অনেকগুলি সুবিধা রয়েছে যদি এটি আপনার পছন্দসই ব্যবহারের ক্ষেত্রে উপযুক্ত হয়, যেমন:
- নিজেকে প্রশিক্ষণের ডেটা সংগ্রহ করার দরকার নেই। সঠিক বিন্যাসে ডেটা প্রস্তুত করা, এবং এটিকে লেবেল করা যাতে একটি মেশিন লার্নিং সিস্টেম এটি থেকে শিখতে ব্যবহার করতে পারে, এটি খুব সময়সাপেক্ষ এবং ব্যয়বহুল হতে পারে।
- কম খরচ এবং সময় সহ একটি ধারণা দ্রুত প্রোটোটাইপ করার ক্ষমতা।
আপনার সৃজনশীল ধারনা বাস্তবায়নের জন্য মডেল দ্বারা প্রদত্ত জ্ঞান ব্যবহার করার উপর মনোনিবেশ করার অনুমতি দেয়, যখন একটি প্রাক-প্রশিক্ষিত মডেল আপনার যা প্রয়োজন তা করার জন্য যথেষ্ট ভাল হতে পারে তখন "চাকা পুনঃউদ্ভাবনের" কোন অর্থ নেই। - শিল্প গবেষণা রাষ্ট্র ব্যবহার. প্রাক-প্রশিক্ষিত মডেলগুলি প্রায়শই জনপ্রিয় গবেষণার উপর ভিত্তি করে তৈরি হয়, যা আপনাকে এই ধরনের মডেলগুলির কাছে এক্সপোজার দেয়, যখন বাস্তব জগতে তাদের কার্যকারিতাও বোঝা যায়।
- ব্যবহারের সহজতা এবং ব্যাপক ডকুমেন্টেশন। এই ধরনের মডেলের জনপ্রিয়তার কারণে।
- শেখার ক্ষমতা স্থানান্তর. কিছু প্রাক-প্রশিক্ষিত মডেল স্থানান্তর শেখার ক্ষমতা প্রদান করে, যা মূলত একটি মেশিন লার্নিং কাজ থেকে শেখা তথ্য অন্য অনুরূপ উদাহরণে স্থানান্তর করার অনুশীলন। উদাহরণস্বরূপ, একটি মডেল যা মূলত বিড়াল চিনতে প্রশিক্ষিত ছিল কুকুরকে চিনতে পুনরায় প্রশিক্ষণ দেওয়া যেতে পারে, যদি আপনি এটিকে নতুন প্রশিক্ষণের ডেটা দেন। এটি দ্রুততর হবে কারণ আপনি একটি ফাঁকা ক্যানভাস দিয়ে শুরু করবেন না। মডেলটি ইতিমধ্যেই বিড়ালকে চিনতে শিখেছে তা ব্যবহার করতে পারে এবং তারপরে নতুন জিনিসটি চিনতে পারে - কুকুরেরও চোখ এবং কান আছে, তাই যদি এটি ইতিমধ্যেই সেই বৈশিষ্ট্যগুলি কীভাবে খুঁজে পেতে হয় তা জানে, আমরা সেখানে অর্ধেক রয়েছি। অনেক দ্রুত উপায়ে আপনার নিজের ডেটাতে মডেলটিকে পুনরায় প্রশিক্ষণ দিন।
একটি প্রাক-প্রশিক্ষিত মন্তব্য স্প্যাম সনাক্তকরণ মডেল
আপনি আপনার মন্তব্য স্প্যাম সনাক্তকরণের প্রয়োজনের জন্য গড় ওয়ার্ড এমবেডিং মডেল আর্কিটেকচার ব্যবহার করবেন, তবে আপনি যদি একটি অপ্রশিক্ষিত মডেল ব্যবহার করার চেষ্টা করেন তবে বাক্যগুলি স্প্যাম কিনা তা অনুমান করার র্যান্ডম সুযোগের চেয়ে ভাল হবে না।
মডেলটিকে উপযোগী করার জন্য এটিকে কাস্টম ডেটার উপর প্রশিক্ষণ দেওয়া প্রয়োজন, এই ক্ষেত্রে, এটিকে স্প্যাম বনাম নন-স্প্যাম মন্তব্যগুলি কেমন দেখায় তা শিখতে দেয়৷ সেই শিক্ষা থেকে ভবিষ্যতে জিনিসগুলিকে সঠিকভাবে শ্রেণিবদ্ধ করার আরও ভাল সুযোগ থাকবে।
সৌভাগ্যক্রমে, কেউ ইতিমধ্যে এই মন্তব্য স্প্যাম শ্রেণীবিভাগের টাস্কের জন্য এই সঠিক মডেল আর্কিটেকচারকে প্রশিক্ষিত করেছে, তাই আপনি এটিকে আপনার শুরুর পয়েন্ট হিসাবে ব্যবহার করতে পারেন৷ আপনি একই মডেল আর্কিটেকচার ব্যবহার করে বিভিন্ন কাজ করার জন্য অন্যান্য প্রাক-প্রশিক্ষিত মডেলগুলি খুঁজে পেতে পারেন, যেমন একটি মন্তব্য কোন ভাষায় লেখা হয়েছে তা সনাক্ত করা বা ভবিষ্যদ্বাণী করা যে ওয়েবসাইটের যোগাযোগ ফর্মের ডেটা স্বয়ংক্রিয়ভাবে লেখা টেক্সটের উপর ভিত্তি করে একটি নির্দিষ্ট কোম্পানির দলকে রুট করা হবে। যেমন বিক্রয় (পণ্য অনুসন্ধান) বা প্রকৌশল (প্রযুক্তিগত বাগ বা প্রতিক্রিয়া)। পর্যাপ্ত প্রশিক্ষণ ডেটা সহ, এই ধরনের একটি মডেল আপনার ওয়েব অ্যাপকে সুপার পাওয়ার দিতে এবং আপনার প্রতিষ্ঠানের দক্ষতা উন্নত করতে প্রতিটি ক্ষেত্রে এই ধরনের পাঠ্যকে শ্রেণীবদ্ধ করতে শিখতে পারে।
ভবিষ্যতের কোড ল্যাবে আপনি শিখবেন কিভাবে মডেল মেকার ব্যবহার করতে হয় এই প্রাক-প্রশিক্ষিত মন্তব্য স্প্যাম মডেলটিকে পুনরায় প্রশিক্ষণ দিতে, এবং আপনার নিজের মন্তব্য ডেটাতে এর কার্যকারিতা আরও উন্নত করতে। আপাতত, আপনি প্রথম প্রোটোটাইপ হিসাবে প্রাথমিক ওয়েব অ্যাপটি কাজ করার জন্য একটি সূচনা পয়েন্ট হিসাবে বিদ্যমান মন্তব্য স্প্যাম সনাক্তকরণ মডেলটি ব্যবহার করবেন৷
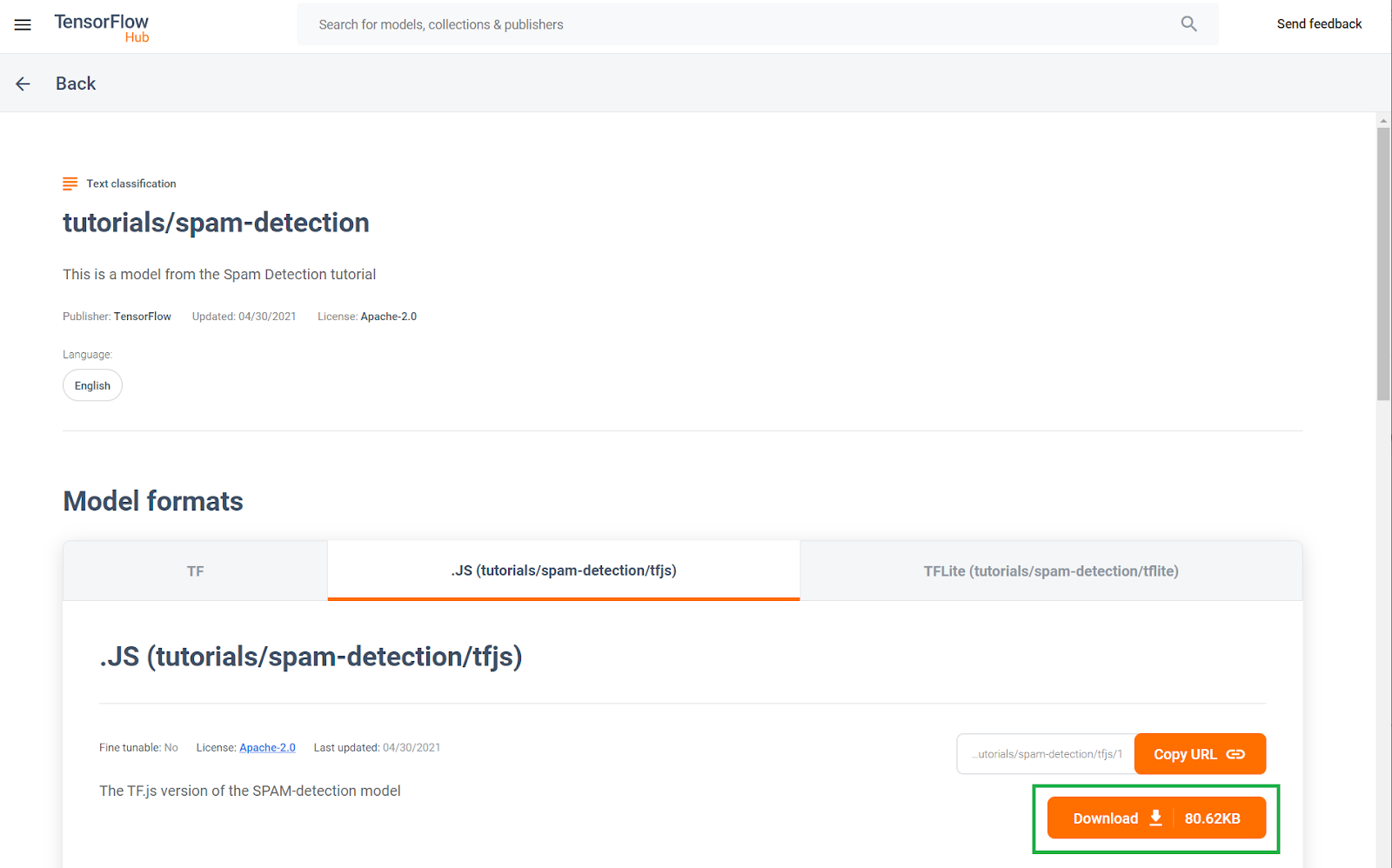
এই প্রাক-প্রশিক্ষিত মন্তব্য স্প্যাম শনাক্তকরণ মডেলটি টিএফ হাব নামে পরিচিত একটি ওয়েবসাইটে প্রকাশিত হয়েছে, যা Google দ্বারা রক্ষণাবেক্ষণ করা একটি মেশিন লার্নিং মডেল ভান্ডার, যেখানে এমএল ইঞ্জিনিয়াররা তাদের পূর্ব-তৈরি মডেলগুলিকে অনেক সাধারণ ব্যবহারের ক্ষেত্রে প্রকাশ করতে পারে (যেমন পাঠ্য, দৃষ্টি, এই বিভাগের প্রতিটির মধ্যে নির্দিষ্ট ব্যবহারের ক্ষেত্রে শব্দ এবং আরও অনেক কিছু)। এগিয়ে যান এবং এই কোডল্যাবে পরে ওয়েব অ্যাপে ব্যবহারের জন্য আপাতত মডেল ফাইলগুলি ডাউনলোড করুন ৷
JS মডেলের জন্য ডাউনলোড বোতামে ক্লিক করুন, নীচে দেখানো হয়েছে:
4. কোড সেট আপ করুন
আপনি কি প্রয়োজন হবে
- একটি আধুনিক ওয়েব ব্রাউজার।
- HTML, CSS, JavaScript এবং Chrome DevTools এর প্রাথমিক জ্ঞান (কনসোল আউটপুট দেখা)।
কোডিং করা যাক.
শুরু করার জন্য আমরা একটি Glitch.com Node.js এক্সপ্রেস বয়লারপ্লেট টেমপ্লেট তৈরি করেছি যেখান থেকে আপনি কেবলমাত্র একটি ক্লিকেই এই কোড ল্যাবের জন্য আপনার বেস স্টেট হিসেবে ক্লোন করতে পারবেন।
Glitch-এ এটিকে কাঁটাচামচ করতে "রিমিক্স এই" বোতামটি ক্লিক করুন এবং আপনি সম্পাদনা করতে পারেন এমন ফাইলগুলির একটি নতুন সেট তৈরি করুন৷
এই খুব সাধারণ কঙ্কাল www ফোল্ডারের মধ্যে নিম্নলিখিত ফাইলগুলি আমাদের সরবরাহ করে:
- HTML পৃষ্ঠা (index.html)
- স্টাইলশীট (style.css)
- আমাদের জাভাস্ক্রিপ্ট কোড লেখার জন্য ফাইল (script.js)
আপনার সুবিধার জন্য আমরা HTML ফাইলে TensorFlow.js লাইব্রেরির জন্য একটি আমদানি যোগ করেছি যা দেখতে এইরকম:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
তারপর আমরা এই www ফোল্ডারটিকে একটি সাধারণ নোড এক্সপ্রেস সার্ভারের মাধ্যমে package.json এবং server.js এর মাধ্যমে পরিবেশন করি
5. অ্যাপ এইচটিএমএল বয়লারপ্লেট
আপনার শুরু বিন্দু কি?
সমস্ত প্রোটোটাইপের জন্য কিছু মৌলিক HTML ভারা প্রয়োজন যার উপর আপনি আপনার ফলাফলগুলি রেন্ডার করতে পারেন। এটা এখন সেট আপ. আপনি যোগ করতে যাচ্ছেন:
- পৃষ্ঠার জন্য একটি শিরোনাম
- কিছু বর্ণনামূলক লেখা
- একটি স্থানধারক ভিডিও ভিডিও ব্লগ এন্ট্রি প্রতিনিধিত্ব করে
- মন্তব্য দেখতে এবং টাইপ করার জন্য একটি এলাকা
index.html খুলুন এবং উপরের বৈশিষ্ট্যগুলি সেট আপ করতে নিম্নলিখিত সহ বিদ্যমান কোডটি পেস্ট করুন:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
ভেঙ্গে ফেলছে
আপনার যোগ করা কিছু মূল জিনিস হাইলাইট করতে উপরের কিছু HTML কোড ভেঙে দেওয়া যাক।
- আপনি পৃষ্ঠার শিরোনামের জন্য একটি
<h1>ট্যাগ যুক্ত করেছেন এবং লগইন বোতামের জন্য একটি<a>ট্যাগ যা<header>-এর মধ্যে রয়েছে। তারপরে আপনি নিবন্ধের শিরোনামের জন্য একটি<h2>এবং ভিডিওর বর্ণনার জন্য একটি<p>ট্যাগ যোগ করেছেন। এখানে বিশেষ কিছু নেই। - আপনি একটি
iframeট্যাগ যোগ করেছেন যা একটি নির্বিচারে YouTube ভিডিও এম্বেড করে। আপাতত আপনি একটি প্লেসহোল্ডার হিসাবে শক্তিশালী TensorFlow.js র্যাপ ব্যবহার করছেন, কিন্তু আপনি শুধুমাত্র iframe এর URL পরিবর্তন করে যেকোন ভিডিও এখানে রাখতে পারেন। প্রকৃতপক্ষে, একটি প্রোডাকশন ওয়েবসাইটে এই সমস্ত মানগুলি ব্যাকএন্ড দ্বারা গতিশীলভাবে রেন্ডার করা হবে, যে পৃষ্ঠাটি দেখা হচ্ছে তার উপর নির্ভর করে। - অবশেষে, আপনি একটি আইডি এবং "মন্তব্য" এর শ্রেণী সহ একটি
sectionযোগ করেছেন যেটিতে একটি বিষয়বস্তু সম্পাদনাযোগ্যdivরয়েছে যাতে নতুন মন্তব্য লেখার জন্য একটিbuttonসহ একটি নতুন মন্তব্য জমা দিতে চান যা আপনি মন্তব্যের একটি ক্রমবিহীন তালিকার সাথে যোগ করতে চান৷ আপনার প্রতিটি তালিকা আইটেমের ভিতরে একটিspanট্যাগের মধ্যে পোস্ট করার ব্যবহারকারীর নাম এবং সময় আছে, এবং তারপর অবশেষে একটিpট্যাগে মন্তব্যটি। 2 উদাহরণ মন্তব্য একটি স্থানধারক হিসাবে এখন জন্য কঠিন কোড করা হয়.
আপনি যদি এখনই আউটপুটটির পূর্বরূপ দেখেন তবে এটি দেখতে এরকম কিছু হওয়া উচিত:
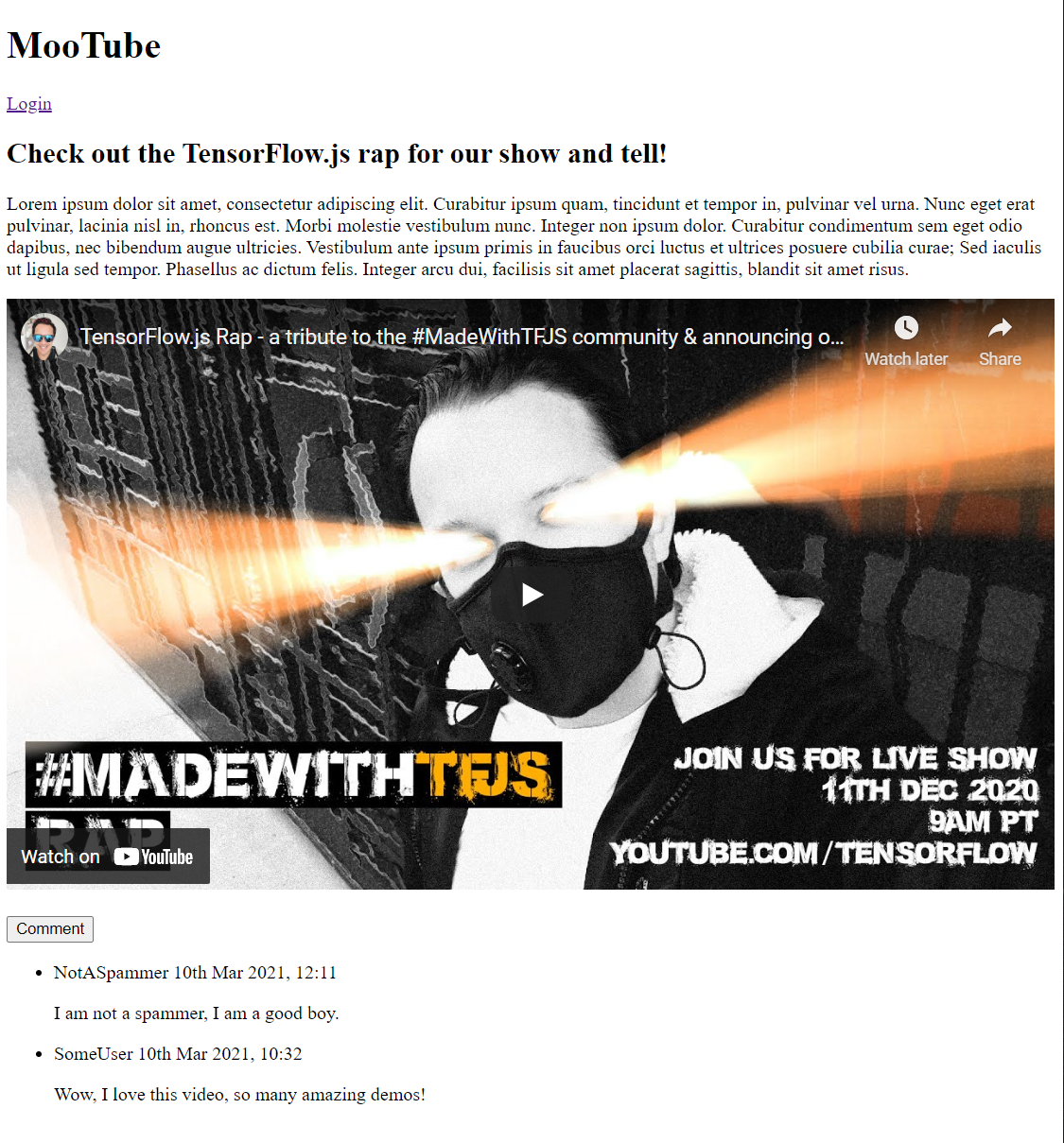
ঠিক আছে যে বেশ ভয়ানক দেখাচ্ছে, তাই এটি কিছু শৈলী যোগ করার সময় ...
6. শৈলী যোগ করুন
এলিমেন্ট ডিফল্ট
প্রথমে, সঠিকভাবে রেন্ডার নিশ্চিত করতে আপনি যে HTML উপাদানগুলি যোগ করেছেন তার জন্য শৈলী যোগ করুন।
সমস্ত ব্রাউজার এবং OS জুড়ে একটি মন্তব্যের সূচনা পয়েন্ট পেতে একটি CSS রিসেট প্রয়োগ করে শুরু করুন৷ নিম্নলিখিতগুলির সাথে style.css বিষয়বস্তু ওভাররাইট করুন:
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
এরপরে, ব্যবহারকারীর ইন্টারফেসকে প্রাণবন্ত করতে কিছু দরকারী CSS যুক্ত করুন।
আপনি উপরে যোগ করা রিসেট CSS কোডের নীচে style.css এর শেষে নিম্নলিখিত যোগ করুন:
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
দারুণ! যে সব আপনার প্রয়োজন. আপনি যদি উপরের কোডের 2 টুকরো দিয়ে আপনার শৈলীগুলি সফলভাবে ওভাররাইট করেন, তাহলে আপনার লাইভ প্রিভিউ এখন এইরকম হওয়া উচিত:
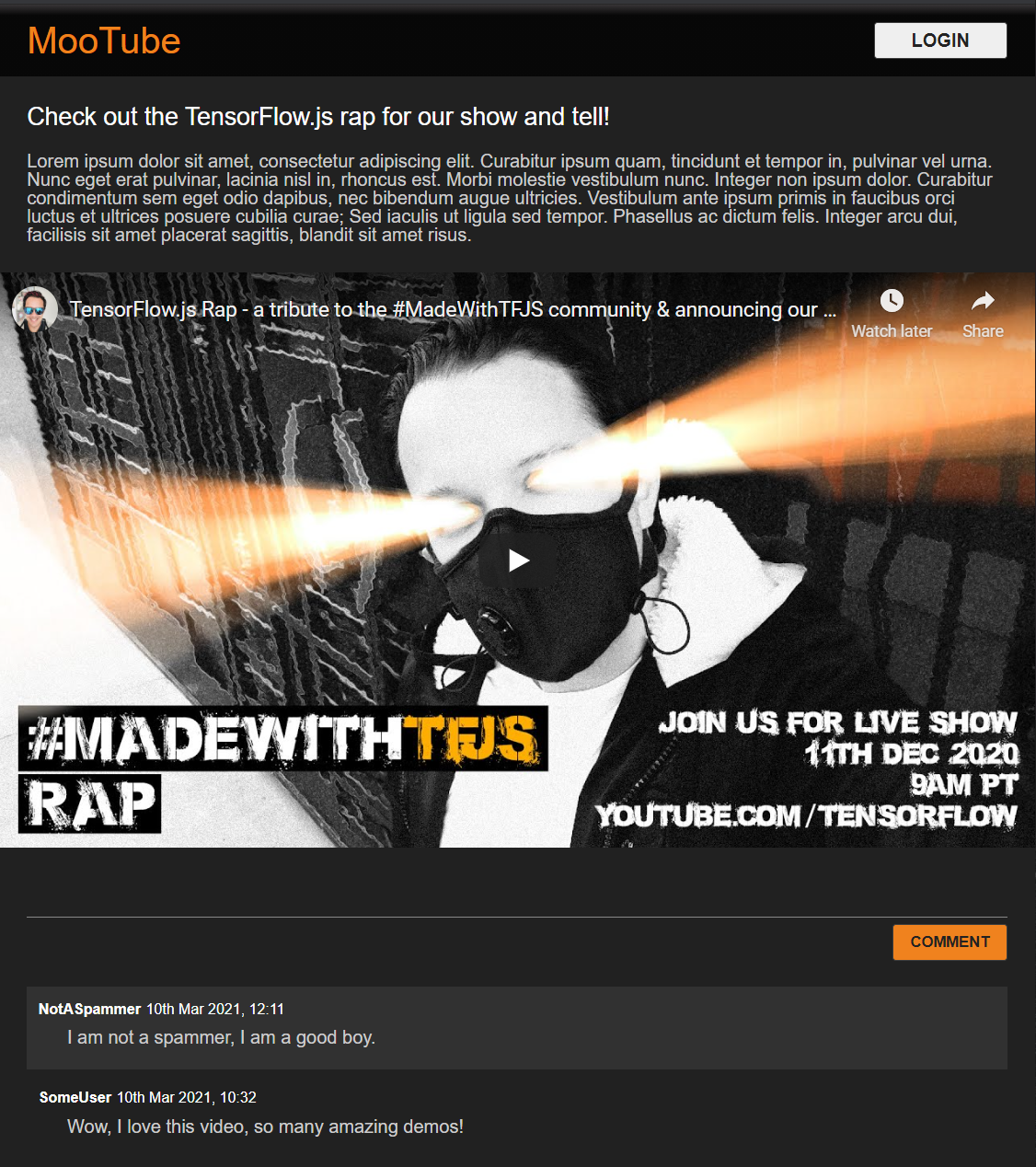
মিষ্টি, ডিফল্টভাবে নাইট মোড, এবং মূল উপাদানগুলিতে হোভার প্রভাবের জন্য কমনীয় CSS রূপান্তর। সুন্দর লাগছে. এখন JavaScript ব্যবহার করে কিছু আচরণগত যুক্তি সংহত করুন।
7. জাভাস্ক্রিপ্ট: DOM ম্যানিপুলেশন এবং ইভেন্ট হ্যান্ডলার
মূল DOM উপাদান উল্লেখ করা
প্রথমে, নিশ্চিত করুন যে আপনি পৃষ্ঠার মূল অংশগুলি অ্যাক্সেস করতে পারেন যা আপনাকে স্টাইলিংয়ের জন্য কিছু CSS ক্লাস ধ্রুবক সংজ্ঞায়িত করার পাশাপাশি কোডটিতে পরে ম্যানিপুলেট করতে বা অ্যাক্সেস করতে হবে।
নিম্নলিখিত ধ্রুবকগুলির সাথে script.js এর বিষয়বস্তু প্রতিস্থাপন করে শুরু করুন:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
মন্তব্য পোস্টিং হ্যান্ডেল
এর পরে, POST_COMMENT_BTN এ একটি ইভেন্ট লিসেনার এবং হ্যান্ডলিং ফাংশন যোগ করুন যাতে এটি লিখিত মন্তব্য পাঠ্যটি ধরতে এবং প্রক্রিয়াকরণ শুরু হয়েছে নির্দেশ করার জন্য একটি CSS ক্লাস সেট করার ক্ষমতা রাখে। নোট করুন যে আপনি চেক করেছেন যে আপনি ইতিমধ্যে বোতামটি ক্লিক করেননি যদি প্রক্রিয়াকরণ ইতিমধ্যেই চলছে।
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
দারুণ! আপনি যদি ওয়েবপৃষ্ঠাটি রিফ্রেশ করেন এবং একটি মন্তব্য পোস্ট করার চেষ্টা করেন তবে আপনার এখন মন্তব্য বোতাম এবং পাঠ্য ধূসর স্কেল দেখতে হবে এবং কনসোলে আপনি মন্তব্যটি এভাবে মুদ্রিত দেখতে পাবেন:
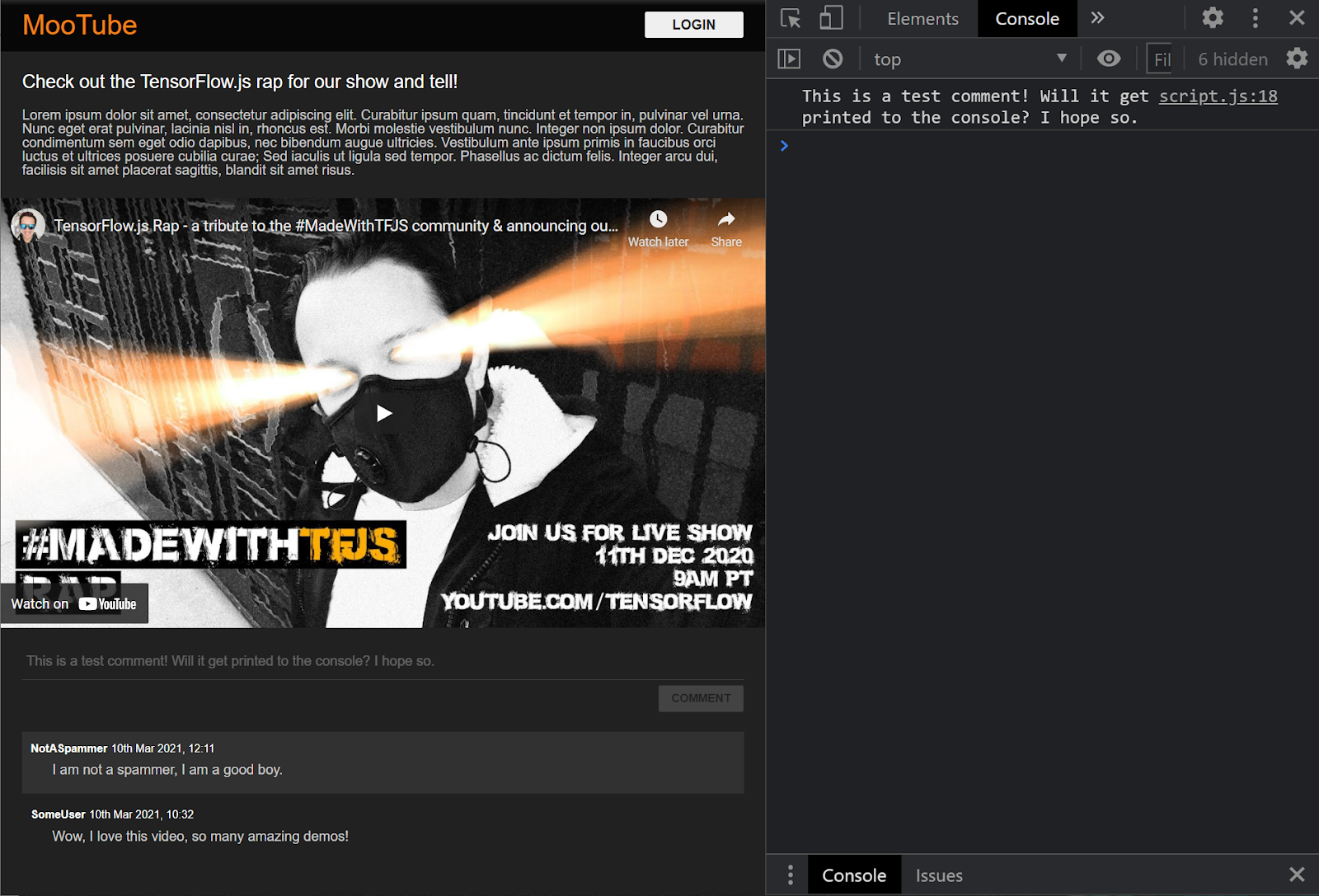
এখন আপনার কাছে একটি বেসিক HTML/CSS/JS কঙ্কাল রয়েছে, এখন সময় এসেছে আপনার মনোযোগ মেশিন লার্নিং মডেলের দিকে ফেরানোর যাতে আপনি সুন্দর ওয়েবপেজের সাথে এটিকে একীভূত করতে পারেন।
8. মেশিন লার্নিং মডেল পরিবেশন করুন
আপনি মডেল লোড করার জন্য প্রায় প্রস্তুত. যদিও আপনি এটি করার আগে, আপনাকে অবশ্যই কোডল্যাবে আগে ডাউনলোড করা মডেল ফাইলগুলিকে আপনার ওয়েবসাইটে আপলোড করতে হবে যাতে এটি কোডের মধ্যে হোস্ট করা এবং ব্যবহারযোগ্য হয়।
প্রথমত, যদি আপনি ইতিমধ্যে এটি না করে থাকেন, তাহলে এই কোডল্যাবের শুরুতে মডেলের জন্য ডাউনলোড করা ফাইলগুলি আনজিপ করুন। আপনি নিম্নলিখিত ফাইলগুলির মধ্যে থাকা একটি ডিরেক্টরি দেখতে পাবেন:
আপনার এখানে কি আছে?
-
model.json- এটি এমন একটি ফাইল যা প্রশিক্ষিত TensorFlow.js মডেল তৈরি করে। আপনি আসলে এই নির্দিষ্ট ফাইলটি পরে আপনার TensorFlow.js কোডে উল্লেখ করবেন। -
group1-shard1of1.bin- এটি TensorFlow.js মডেলের প্রশিক্ষিত ওজন (মূলত একগুচ্ছ সংখ্যা যা এটি তার শ্রেণীবিভাগের কাজটি ভালভাবে করতে শিখেছে) ধারণকারী একটি বাইনারি ফাইল এবং ডাউনলোডের জন্য আপনার সার্ভারে কোথাও হোস্ট করা প্রয়োজন। -
vocab- কোন এক্সটেনশন ছাড়াই এই অদ্ভুত ফাইলটি Model Maker থেকে এমন কিছু যা আমাদের দেখায় কিভাবে বাক্যে শব্দগুলিকে এনকোড করতে হয় যাতে মডেল বুঝতে পারে সেগুলি কীভাবে ব্যবহার করতে হয়৷ আপনি পরবর্তী বিভাগে এই বিষয়ে আরও ডুব দেবেন। -
labels.txt- এটিতে কেবল ফলের ক্লাসনাম রয়েছে যা মডেলটি ভবিষ্যদ্বাণী করবে। এই মডেলের জন্য আপনি যদি এই ফাইলটি আপনার টেক্সট এডিটরে খোলেন তবে এতে কেবল "মিথ্যা" এবং "সত্য" তালিকাভুক্ত রয়েছে, যা "স্প্যাম নয়" বা "স্প্যাম" এর ভবিষ্যদ্বাণী আউটপুট হিসাবে নির্দেশ করে।
TensorFlow.js মডেল ফাইল হোস্ট করুন
প্রথমে মডেল.json এবং *.bin model.json ফাইলগুলি যা একটি ওয়েব সার্ভারে তৈরি করা হয়েছিল যাতে আপনি ওয়েব পৃষ্ঠার মাধ্যমে তাদের অ্যাক্সেস করতে পারেন৷
গ্লিচে ফাইল আপলোড করুন
- আপনার গ্লিচ প্রকল্পের বাম হাতের প্যানেলে সম্পদ ফোল্ডারে ক্লিক করুন।
- একটি সম্পদ আপলোড ক্লিক করুন এবং এই ফোল্ডারে আপলোড করতে
group1-shard1of1.binনির্বাচন করুন৷ একবার আপলোড করা হলে এটি এখন এইরকম হওয়া উচিত:
- দারুণ! এখন
model.jsonফাইলের জন্য একই কাজ করুন। 2টি ফাইল আপনার সম্পদ ফোল্ডারে এইরকম হওয়া উচিত:
- আপনি এইমাত্র আপলোড করা
group1-shard1of1.binফাইলটিতে ক্লিক করুন। আপনি URLটিকে এর অবস্থানে অনুলিপি করতে সক্ষম হবেন। দেখানো হিসাবে এখন এই পথটি অনুলিপি করুন:
- এখন স্ক্রিনের নীচে বাম দিকে, Tools > Terminal এ ক্লিক করুন। টার্মিনাল উইন্ডো লোড হওয়ার জন্য অপেক্ষা করুন। একবার লোড হয়ে গেলে, নিম্নলিখিতটি টাইপ করুন এবং তারপর
wwwফোল্ডারে ডিরেক্টরি পরিবর্তন করতে এন্টার টিপুন:
টার্মিনাল:
cd www
- এরপর, Glitch-এ সম্পদ ফোল্ডারে ফাইলগুলির জন্য তৈরি করা URLগুলির সাথে নীচের URLগুলি প্রতিস্থাপন করে মাত্র আপলোড করা 2টি ফাইল ডাউনলোড করতে
wgetব্যবহার করুন (প্রতিটি ফাইলের কাস্টম URL-এর জন্য সম্পদ ফোল্ডারটি পরীক্ষা করুন)৷ দুটি ইউআরএল-এর মধ্যবর্তী স্থান এবং আপনার যে ইউআরএলগুলি ব্যবহার করতে হবে সেগুলি নীচেরগুলির থেকে আলাদা হবে, কিন্তু একই রকম দেখাবে:
টার্মিনাল
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
সুপার, আপনি এখন www ফোল্ডারে আপলোড করা ফাইলগুলির একটি অনুলিপি তৈরি করেছেন তবে এখনই তারা অদ্ভুত নাম দিয়ে ডাউনলোড করবে।
- টার্মিনালে
lsটাইপ করুন এবং এন্টার টিপুন। আপনি এই মত কিছু দেখতে পাবেন:

-
mvকমান্ড ব্যবহার করে আপনি ফাইলগুলির নাম পরিবর্তন করতে পারেন। কনসোলে নিম্নলিখিতটি টাইপ করুন এবং প্রতিটি লাইনের পরে <kbd>এন্টার</kbd> বা <kbd>রিটার্ন</kbd> টিপুন:
টার্মিনাল:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- অবশেষে, টার্মিনালে
refreshটাইপ করে এবং <kbd>Enter</kbd> টিপে গ্লিচ প্রজেক্ট রিফ্রেশ করুন:
টার্মিনাল:
refresh
- রিফ্রেশ করার পরে, আপনি এখন ইউজার ইন্টারফেসের
wwwফোল্ডারেmodel.jsonএবংgroup1-shard1of1.binদেখতে পাবেন:
দারুণ! আপনি এখন ব্রাউজারে কিছু প্রকৃত কোড সহ আপলোড করা মডেল ফাইলগুলি ব্যবহার করার জন্য প্রস্তুত৷
9. হোস্ট করা TensorFlow.js মডেল লোড করুন এবং ব্যবহার করুন
আপনি এখন এমন একটি স্থানে আছেন যেখানে আপনি আপলোড করা TensorFlow.js মডেলটি কাজ করে কিনা তা পরীক্ষা করতে কিছু ডেটা সহ লোডিং পরীক্ষা করতে পারেন৷
এই মুহূর্তে, আপনি নীচে যে উদাহরণ ইনপুট ডেটা দেখতে পাবেন তা বরং রহস্যময় দেখাবে (সংখ্যার একটি অ্যারে), এবং কীভাবে সেগুলি তৈরি হয়েছিল তা পরবর্তী বিভাগে ব্যাখ্যা করা হবে। আপাতত এটিকে সংখ্যার একটি অ্যারে হিসাবে দেখুন। এই পর্যায়ে এটি সহজভাবে পরীক্ষা করা গুরুত্বপূর্ণ যে মডেলটি আমাদের ত্রুটি ছাড়াই একটি উত্তর দেয়।
আপনার script.js ফাইলের শেষে নিম্নলিখিত কোডটি যোগ করুন, এবং MODEL_JSON_URL স্ট্রিং মানটিকে মডেল. model.json ফাইলের পাথের সাথে প্রতিস্থাপন করতে ভুলবেন না যখন আপনি আগের ধাপে আপনার Glitch সম্পদ ফোল্ডারে ফাইলটি আপলোড করেছিলেন। (মনে রাখবেন, আপনি কেবলমাত্র তার URL খুঁজে পেতে Glitch-এ সম্পদ ফোল্ডারে ফাইলটিতে ক্লিক করতে পারেন)।
প্রতিটি লাইন কি করছে তা বুঝতে নীচের নতুন কোডের মন্তব্য পড়ুন:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
যদি প্রজেক্টটি সঠিকভাবে সেট আপ করা হয়, তাহলে আপনার কনসোল উইন্ডোতে প্রিন্ট করা নিচের মত কিছু দেখতে হবে, যখন আপনি লোড করা মডেলটি ব্যবহার করবেন তখন এটিতে দেওয়া ইনপুট থেকে ফলাফলের পূর্বাভাস দিতে হবে:
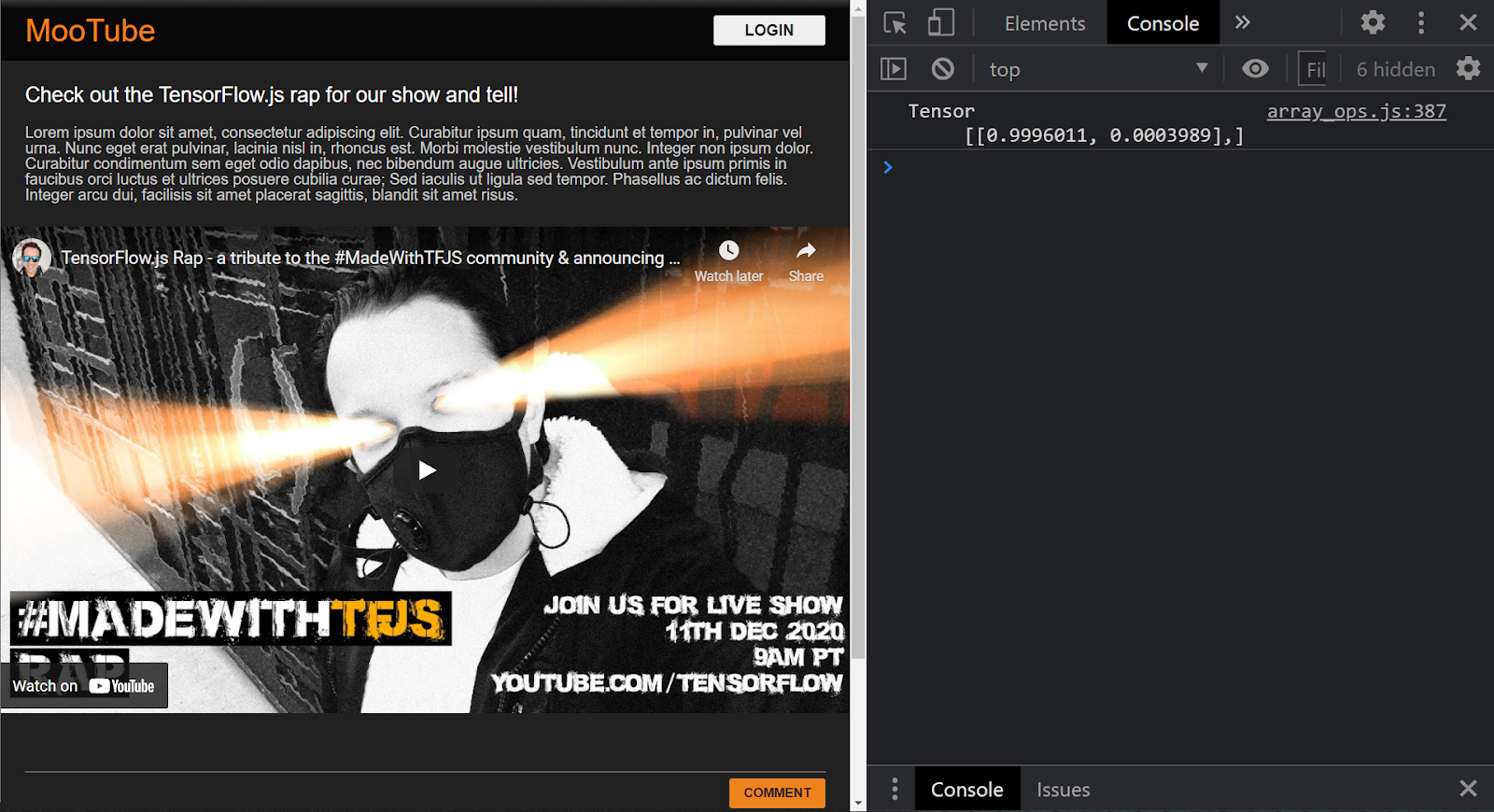
কনসোলে, আপনি 2টি সংখ্যা মুদ্রিত দেখতে পাচ্ছেন:
- 0.9996011
- 0.0003989
যদিও এটি রহস্যজনক বলে মনে হতে পারে, এই সংখ্যাগুলি আসলে মডেলটি কি মনে করে যে শ্রেণীবিভাগ আপনি দেওয়া ইনপুটটির জন্য সম্ভাব্যতার প্রতিনিধিত্ব করে৷ কিন্তু তারা কি প্রতিনিধিত্ব করে?
আপনি আপনার স্থানীয় মেশিনে ডাউনলোড করা মডেল ফাইলগুলি থেকে আপনার labels.txt ফাইলটি খুললে, আপনি দেখতে পাবেন যে এতে 2টি ক্ষেত্র রয়েছে:
- মিথ্যা
- সত্য
সুতরাং, এই ক্ষেত্রে মডেলটি বলছে এটি 99.96011% নিশ্চিত (ফলাফল অবজেক্টে 0.9996011 হিসাবে দেখানো হয়েছে) যে আপনি যে ইনপুটটি দিয়েছেন (যা ছিল [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] স্প্যাম ছিল না (অর্থাৎ মিথ্যা)।
লক্ষ্য করুন যে মিথ্যা ছিল labels.txt এর প্রথম লেবেল এবং কনসোল প্রিন্টের প্রথম আউটপুট দ্বারা উপস্থাপিত হয় যা আপনি কীভাবে জানেন যে আউটপুট পূর্বাভাসটি কী সম্পর্কিত।
ঠিক আছে, তাই এখন আপনি জানেন কিভাবে আউটপুট ব্যাখ্যা করতে হয়, কিন্তু ইনপুট হিসাবে দেওয়া সংখ্যার সেই বড় গুচ্ছটি ঠিক কী ছিল এবং আপনি মডেলটিকে ব্যবহারের জন্য এই বিন্যাসে বাক্যগুলিকে কীভাবে রূপান্তর করবেন? এর জন্য, আপনাকে টোকেনাইজিং এবং টেনসর সম্পর্কে শিখতে হবে। পড়তে!
10. টোকেনাইজেশন এবং টেনসর
টোকেনাইজেশন
সুতরাং দেখা যাচ্ছে যে মেশিন লার্নিং মডেলগুলি শুধুমাত্র ইনপুট হিসাবে একগুচ্ছ সংখ্যা গ্রহণ করতে পারে। কেন? ঠিক আছে, মূলত, এটি হল কারণ একটি মেশিন লার্নিং মডেল মূলত শৃঙ্খলিত গাণিতিক ক্রিয়াকলাপগুলির একটি গুচ্ছ, তাই আপনি যদি এটিতে এমন কিছু পাস করেন যা একটি সংখ্যা নয়, তবে এটির সাথে মোকাবিলা করা কঠিন সময় হতে চলেছে। তাহলে এখন প্রশ্ন হল আপনি যে মডেলটি লোড করেছেন তার সাথে ব্যবহারের জন্য বাক্যগুলোকে সংখ্যায় রূপান্তর করবেন কিভাবে?
ঠিক আছে সঠিক প্রক্রিয়াটি মডেল থেকে মডেলে আলাদা, তবে এর জন্য আপনার ডাউনলোড করা মডেল ফাইলগুলিতে vocab, নামে আরও একটি ফাইল রয়েছে এবং এটি আপনি কীভাবে ডেটা এনকোড করেন তার মূল চাবিকাঠি।
এগিয়ে যান এবং আপনার মেশিনে একটি স্থানীয় পাঠ্য সম্পাদকে vocab খুলুন এবং আপনি এরকম কিছু দেখতে পাবেন:
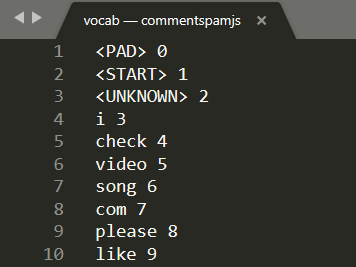
মূলত এটি একটি লুকআপ সারণী যেটি কীভাবে অর্থপূর্ণ শব্দগুলিকে রূপান্তর করতে হয় যেটি মডেলটি বুঝতে পারে এমন সংখ্যাগুলিতে শিখেছে৷ <PAD> , <START> , এবং <UNKNOWN> ফাইলের শীর্ষে কিছু বিশেষ ক্ষেত্রেও রয়েছে:
-
<PAD>- এটি "প্যাডিং" এর জন্য সংক্ষিপ্ত। এটি দেখা যাচ্ছে যে মেশিন লার্নিং মডেলগুলি আপনার বাক্য যতই দীর্ঘ হোক না কেন একটি নির্দিষ্ট সংখ্যক ইনপুট পেতে পছন্দ করে। ব্যবহৃত মডেলটি আশা করে যে ইনপুটের জন্য সর্বদা 20টি সংখ্যা থাকে (এটি মডেলের নির্মাতা দ্বারা সংজ্ঞায়িত করা হয়েছিল এবং আপনি যদি মডেলটিকে পুনরায় প্রশিক্ষণ দেন তবে এটি পরিবর্তন করা যেতে পারে)। সুতরাং আপনার যদি "আমি ভিডিও পছন্দ করি" এর মত একটি বাক্যাংশ থাকে তবে আপনি অ্যারের অবশিষ্ট স্থানগুলি 0 দিয়ে পূরণ করবেন যা<PAD>টোকেনকে প্রতিনিধিত্ব করে। বাক্যটি 20 শব্দের বেশি হলে, আপনাকে এটিকে বিভক্ত করতে হবে যাতে এটি এই প্রয়োজনীয়তার সাথে খাপ খায় এবং পরিবর্তে অনেক ছোট বাক্যে একাধিক শ্রেণিবিন্যাস করতে পারে। -
<START>- বাক্যটির শুরু নির্দেশ করার জন্য এটি সর্বদা প্রথম টোকেন। আপনি পূর্ববর্তী ধাপে উদাহরণ ইনপুটে লক্ষ্য করবেন যে সংখ্যার অ্যারে একটি "1" দিয়ে শুরু হয়েছে - এটি<START>টোকেনকে প্রতিনিধিত্ব করছিল। -
<UNKNOWN>- আপনি অনুমান করতে পারেন, শব্দের এই সন্ধানে যদি শব্দটি বিদ্যমান না থাকে, তাহলে আপনি কেবল সংখ্যা হিসাবে<UNKNOWN>টোকেন (একটি "2" দ্বারা উপস্থাপিত) ব্যবহার করুন৷
অন্য প্রতিটি শব্দের জন্য, এটি হয় লুকআপে বিদ্যমান এবং এটির সাথে যুক্ত একটি বিশেষ নম্বর রয়েছে, তাই আপনি এটি ব্যবহার করবেন, বা এটি বিদ্যমান নেই, এই ক্ষেত্রে আপনি পরিবর্তে <UNKNOWN> টোকেন নম্বর ব্যবহার করবেন।
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
এটি থেকে আপনি এখন দেখতে পাচ্ছেন যে এটি 4টি শব্দের একটি বাক্য ছিল কারণ বাকিগুলি হয় <START> বা <PAD> টোকেন এবং অ্যারেতে 20টি সংখ্যা রয়েছে। ঠিক আছে, একটু বেশি বোধগম্য করতে শুরু করছি।
আমি আসলে এর জন্য যে বাক্যটি লিখেছিলাম তা হল "আমি আমার কুকুরকে ভালবাসি"। আপনি উপরের স্ক্রিনশট থেকে দেখতে পাচ্ছেন যে "I" কে "3" নম্বরে রূপান্তর করা হয়েছে যা সঠিক। আপনি যদি অন্য শব্দগুলি দেখেন তবে আপনি তাদের সংশ্লিষ্ট সংখ্যাগুলিও খুঁজে পাবেন।
টেনসর
এমএল মডেল আপনার সংখ্যাসূচক ইনপুট গ্রহণ করার আগে একটি চূড়ান্ত বাধা আছে। আপনাকে অবশ্যই সংখ্যার অ্যারেকে টেনসর নামে পরিচিত কিছুতে রূপান্তর করতে হবে, এবং হ্যাঁ, আপনি অনুমান করেছেন, টেনসরফ্লো এই জিনিসগুলির নামানুসারে নামকরণ করা হয়েছে - মূলত একটি মডেলের মাধ্যমে টেনসরের প্রবাহ।
একটি টেনসর কি?
TensorFlow.org থেকে অফিসিয়াল সংজ্ঞা বলে:
"টেনসরগুলি একটি অভিন্ন প্রকার সহ বহু-মাত্রিক অ্যারে৷ সমস্ত টেনসর অপরিবর্তনীয়: আপনি কখনই একটি টেনসরের বিষয়বস্তু আপডেট করতে পারবেন না, শুধুমাত্র একটি নতুন তৈরি করুন৷"
সরল ইংরেজিতে, এটি যেকোন মাত্রার একটি অ্যারের জন্য একটি অভিনব গাণিতিক নাম যা টেনসর অবজেক্টে তৈরি কিছু অন্যান্য ফাংশন রয়েছে যা মেশিন লার্নিং বিকাশকারী হিসাবে আমাদের জন্য দরকারী। তবে একটি মনে রাখা উচিত যে টেনসরগুলি শুধুমাত্র 1 প্রকারের ডেটা সংরক্ষণ করে, যেমন সমস্ত পূর্ণসংখ্যা, বা সমস্ত ফ্লোটিং পয়েন্ট সংখ্যা, এবং একবার তৈরি হয়ে গেলে আপনি কখনই টেনসরের বিষয়বস্তু পরিবর্তন করতে পারবেন না- এইভাবে আপনি এটিকে সংখ্যার জন্য একটি স্থায়ী স্টোরেজ বাক্স হিসাবে ভাবতে পারেন!
আপাতত এই নিয়ে বেশি চিন্তা করবেন না। অন্ততপক্ষে, এটিকে মেশিন লার্নিং মডেলগুলির সাথে কাজ করার জন্য একটি বহুমাত্রিক স্টোরেজ পদ্ধতি হিসাবে ভাবুন, যতক্ষণ না আপনি এই ধরনের একটি ভাল বইয়ের সাথে গভীরভাবে ডুব দিচ্ছেন — আপনি যদি Tensors এবং কীভাবে সেগুলি ব্যবহার করতে চান সে সম্পর্কে আরও জানতে চাইলে এটি অত্যন্ত প্রস্তাবিত৷
এটি সব একসাথে রাখুন: কোডিং টেনসর এবং টোকেনাইজেশন
তাহলে আপনি কিভাবে কোডে সেই vocab ফাইলটি ব্যবহার করবেন? দারুণ প্রশ্ন!
এই ফাইলটি নিজে থেকে একটি JS বিকাশকারী হিসাবে আপনার কাছে বেশ অকেজো। এটি আরও ভাল হবে যদি এটি একটি জাভাস্ক্রিপ্ট অবজেক্ট হয় যা আপনি সহজভাবে আমদানি করতে এবং ব্যবহার করতে পারেন। কেউ দেখতে পাচ্ছেন যে এই ফাইলের ডেটাকে আরও এইরকম ফর্ম্যাটে রূপান্তর করা কতটা সহজ হবে:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
আপনার প্রিয় টেক্সট এডিটর ব্যবহার করে, আপনি সহজেই vocab ফাইলটিকে এমন একটি বিন্যাসে রূপান্তর করতে পারেন যা কিছু সন্ধান এবং প্রতিস্থাপন করে। যাইহোক, আপনি এটি সহজ করতে এই পূর্ব-তৈরি টুল ব্যবহার করতে পারেন।
এই কাজটি আগে থেকে করে এবং সঠিক বিন্যাসে vocab ফাইল সংরক্ষণ করে, আপনি এই রূপান্তর এবং প্রতিটি পৃষ্ঠা লোডের উপর পার্সিং করতে বাধা পাচ্ছেন, যা CPU সম্পদের অপচয়। আরও ভাল, জাভাস্ক্রিপ্ট অবজেক্টের নিম্নলিখিত বৈশিষ্ট্য রয়েছে:
"একটি বস্তুর সম্পত্তির নাম যেকোন বৈধ জাভাস্ক্রিপ্ট স্ট্রিং হতে পারে, বা খালি স্ট্রিং সহ স্ট্রিং-এ রূপান্তরিত হতে পারে এমন কিছু। যাইহোক, যে কোনও সম্পত্তির নাম যেটি বৈধ জাভাস্ক্রিপ্ট শনাক্তকারী নয় (উদাহরণস্বরূপ, একটি সম্পত্তির নাম যাতে একটি স্থান থাকে অথবা একটি হাইফেন, অথবা যেটি একটি সংখ্যা দিয়ে শুরু হয়) শুধুমাত্র বর্গাকার বন্ধনী স্বরলিপি ব্যবহার করে অ্যাক্সেস করা যেতে পারে"।
এইভাবে যতক্ষণ আপনি বর্গাকার বন্ধনী স্বরলিপি ব্যবহার করেন ততক্ষণ আপনি এই সাধারণ রূপান্তরের মাধ্যমে একটি বরং দক্ষ লুকআপ টেবিল তৈরি করতে পারেন।
একটি আরো দরকারী বিন্যাসে রূপান্তর
আপনার ভোকাব ফাইলটিকে উপরের ফরম্যাটে রূপান্তর করুন, হয় ম্যানুয়ালি আপনার টেক্সট এডিটরের মাধ্যমে, অথবা এখানে এই টুলটি ব্যবহার করে । আপনার www ফোল্ডারের মধ্যে dictionary.js .js হিসাবে ফলাফল আউটপুট সংরক্ষণ করুন.
Glitch-এ আপনি এই অবস্থানে সহজভাবে একটি নতুন ফাইল তৈরি করতে পারেন এবং আপনার রূপান্তরের ফলাফলে দেখানো হিসাবে সংরক্ষণ করতে পেস্ট করতে পারেন:
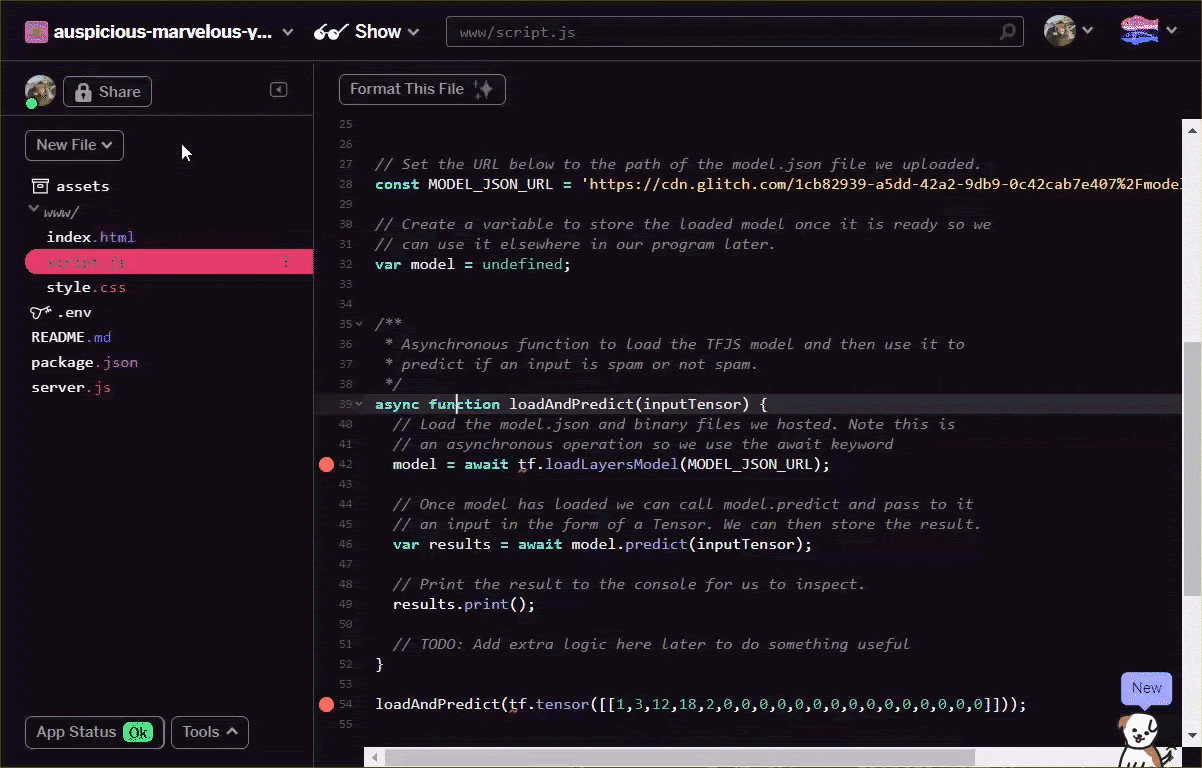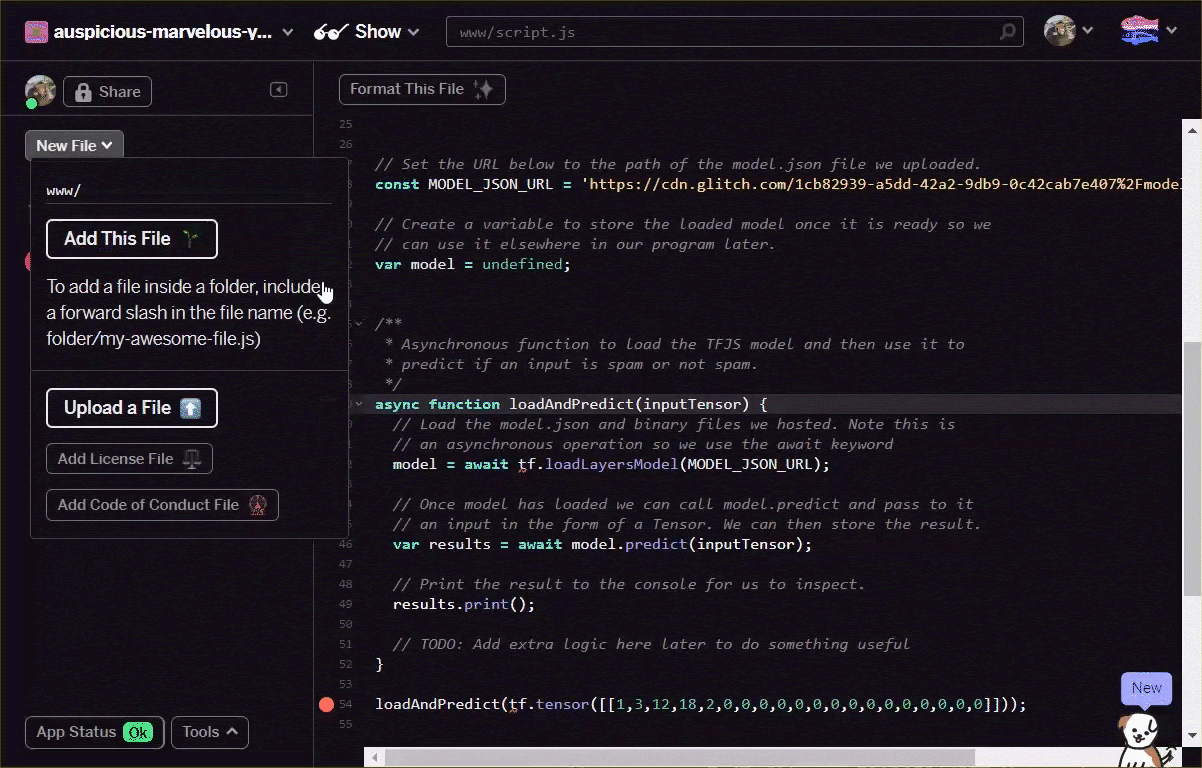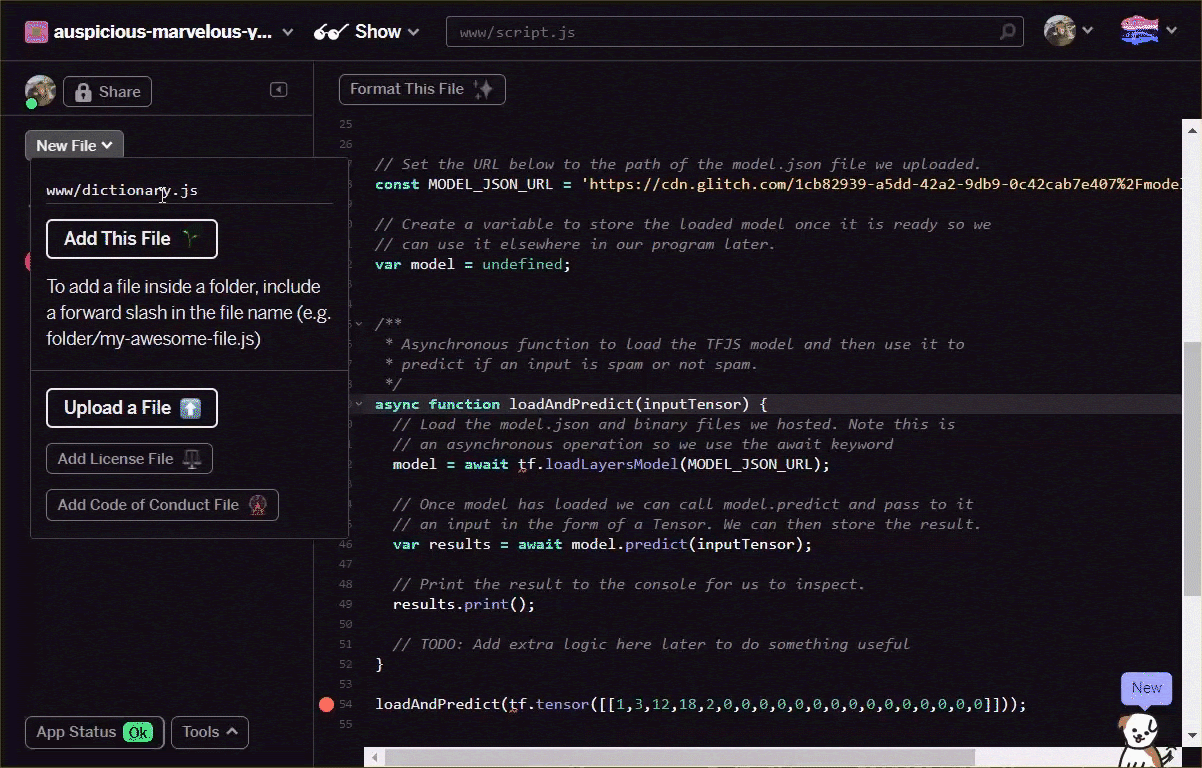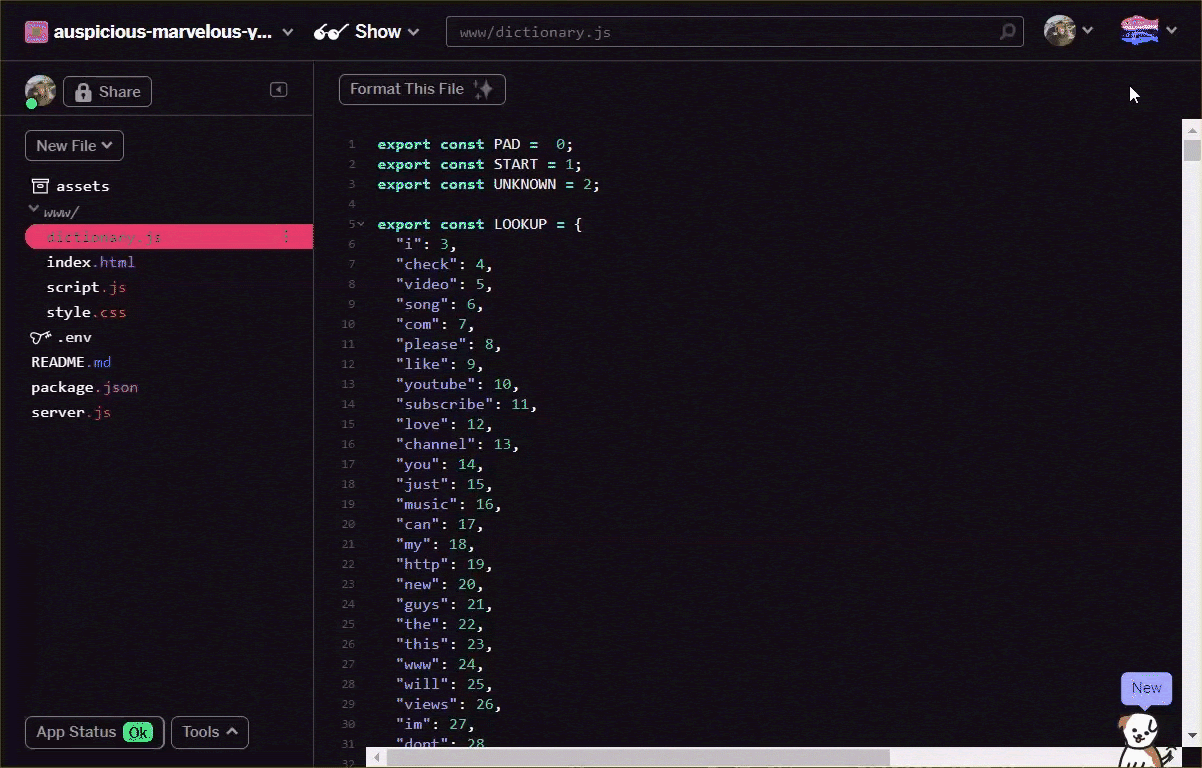
উপরে বর্ণিত ফরম্যাটে আপনার কাছে একবার সংরক্ষিত dictionary.js ফাইলটি হয়ে গেলে, আপনি এখন এইমাত্র লেখা dictionary.js মডিউলটি আমদানি করতে script.js এর একেবারে উপরে নিচের কোডটি প্রিপেন্ড করতে পারেন। এখানে আপনি একটি অতিরিক্ত ধ্রুবক ENCODING_LENGTH সংজ্ঞায়িত করেন যাতে আপনি জানেন যে কোডের পরে কতটা প্যাড করতে হবে, একটি tokenize ফাংশন সহ আপনি শব্দের অ্যারেকে একটি উপযুক্ত টেনসরে রূপান্তর করতে ব্যবহার করবেন যা মডেলটিতে একটি ইনপুট হিসাবে ব্যবহার করা যেতে পারে।
প্রতিটি লাইন কি করে তার আরও বিশদ বিবরণের জন্য নীচের কোডে মন্তব্যগুলি দেখুন:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
দারুণ, এখন handleCommentPost() ফাংশনে ফিরে যান এবং ফাংশনের এই নতুন সংস্করণ দিয়ে এটি প্রতিস্থাপন করুন।
আপনি কি যোগ করেছেন মন্তব্যের জন্য কোড দেখুন:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
সবশেষে, স্টাইল সেট করতে loadAndPredict() ফাংশন আপডেট করুন যদি কোনো মন্তব্য স্প্যাম হিসেবে শনাক্ত হয়।
For now you will simply change the style, but later you can choose to hold the comment in some sort of moderation queue or stop it from sending.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Real-time updates: Node.js + Websockets
Now you have a working frontend with spam detection, the final piece of the puzzle is to use Node.js with some websockets for real-time communication and update in real time any comments that are added that are not spam.
Socket.io
Socket.io is one of the most popular ways (at time of writing) to use websockets with Node.js. Go ahead and tell Glitch you want to include the Socket.io library in the build by editing package.json in the top level directory (in the parent folder of www folder) to include socket.io as one of the dependencies:
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
দারুণ! Once updated, next update index.html within the www folder to include the socket.io library.
Simply place this line of code above the HTML script tag import for script.js near the end of the index.html file:
index.html
<script src="/socket.io/socket.io.js"></script>
You should now have 3 script tags in your index.html file:
- the first importing the TensorFlow.js library
- the 2nd importing socket.io that you just added
- and the last should be importing the script.js code.
Next, edit server.js to setup socket.io within node and create a simple backend to relay messages received to all connected clients.
See code comments below for an explanation of what the Node.js code is doing:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
দারুণ! You now have a web server that is listening for socket.io events. Namely you have a comment event when a new comment comes in from a client, and the server emits remoteComment events which the client side code will listen for to know to render a remote comment. So the last thing to do is to add the socket.io logic to the client side code to emit and handle these events.
First, add the following code to the end of script.js to connect to the socket.io server and listen out / handle remoteComment events received:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Finally, add some code to the loadAndPredict function to emit a socket.io event if a comment is not spam. This allows you to update the other connected clients with this new comment as the content of this message will be relayed to them via the server.js code you wrote above.
Simply replace your existing loadAndPredict function with the following code that adds an else statement to the final spam check where if the comment is not spam, you call socket.emit() to send all the comment data:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
দারূন কাজ! If you followed along correctly, you should now be able to open up 2 instances of your index.html page.
As you post comments that are not spam, you should see them rendered on the other client almost instantly. If the comment is spam, it simply will never be sent and instead be marked as spam on the frontend that generated it only like this:
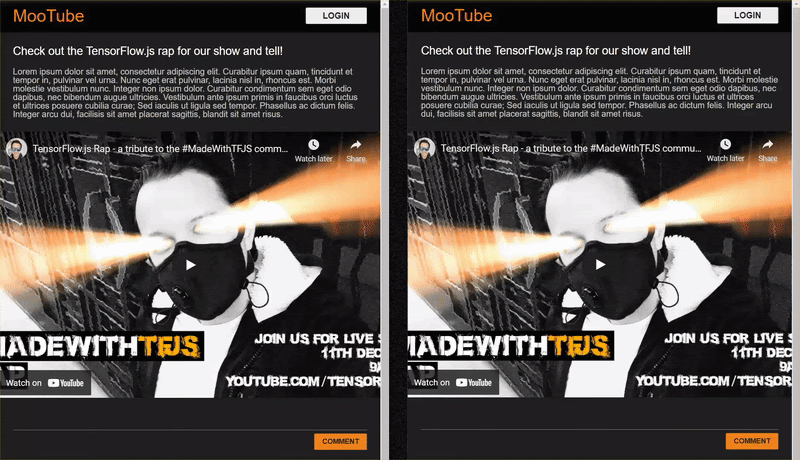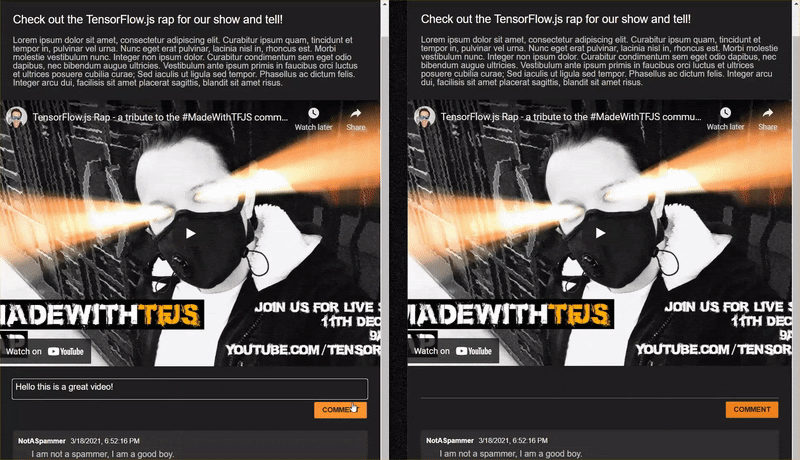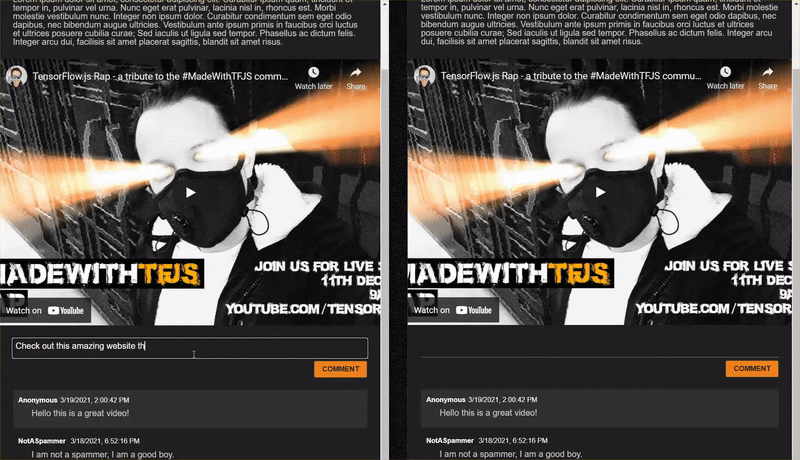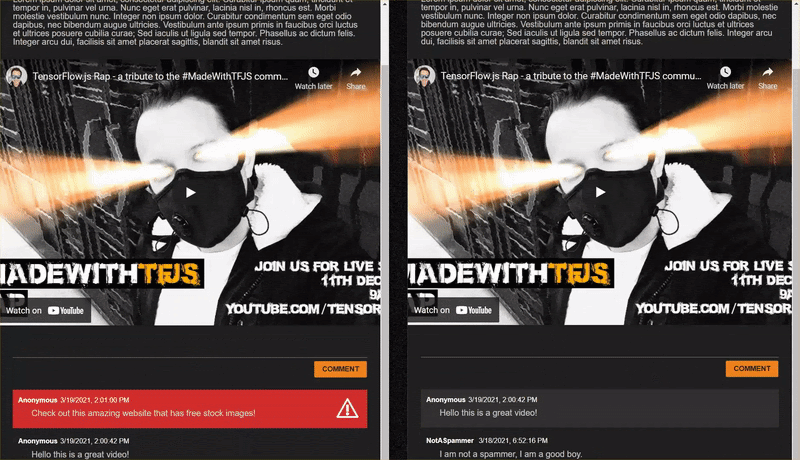
12. অভিনন্দন
Congratulations, you have taken your first steps in using machine learning with TensorFlow.js in the web browser for a real world application - to detect comment spam!
Try it out, test it on a variety of comments, you may notice some things still get through. You will also notice that if you enter a sentence that is longer than 20 words, it will currently fail as the model expects 20 words as input.
In that case you may need to break long sentences into groups of 20 words and then take the spam likelihood of each sub sentence into consideration to determine if to show or not. We will leave this as an optional extra task for you to experiment with as there are many approaches you could take for this.
In the next codelab we will show you how to retrain this model with your custom comment data for edge cases it does not currently detect, or even to change the input expectation of the model so it can handle sentences that are larger than 20 words, and then export and use that model with TensorFlow.js.
If for some reason you are having issues, compare your code to this completed version available here , and check if you missed anything.
Recap
In this codelab you:
- Learned what TensorFlow.js is and what models exist for natural language processing
- Created a fictitious website that allows real time comments for an example website.
- Loaded a pre-trained machine learning model suitable for comment spam detection via TensorFlow.js on the web page.
- Learned how to encode sentences for use with the loaded machine learning model and encapsulate that encoding inside a Tensor.
- Interpreted the output of the machine learning model to decide if you want to hold the comment for review, and if not, sent to the server to relay to other connected clients in real time.
What's next?
Now that you have a working base to start from, what creative ideas can you come up with to extend this machine learning model boilerplate for a real world use case you may be working on?
Share what you make with us
You can easily extend what you made today for other creative use cases too and we encourage you to think outside the box and keep hacking.
Remember to tag us on social media using the #MadeWithTFJS hashtag for a chance for your project to be featured on our TensorFlow blog or even future events . We would love to see what you make.
More TensorFlow.js codelabs to go deeper
- Check out part 2 of this series to learn how to retrain the comment spam model to account for edge cases that it does not currently detect as spam.
- Use Firebase hosting to deploy and host a TensorFlow.js model at scale.
- Make a smart webcam using a pre-made object detection model with TensorFlow.js
Websites to check out
- TensorFlow.js official website
- TensorFlow.js pre-made models
- TensorFlow.js API
- TensorFlow.js Show & Tell — get inspired and see what others have made.