
1. Avant de commencer
Le machine learning est un terme très en vogue ces derniers temps. Ses applications semblent illimitées et il semble prêt à toucher presque tous les secteurs dans un avenir proche. Si vous êtes ingénieur ou concepteur, que vous travailliez sur le front-end ou le back-end, et que vous connaissez JavaScript, cet atelier de programmation a été conçu pour vous aider à ajouter le machine learning à vos compétences.
Prérequis
Cet atelier de programmation a été écrit pour les ingénieurs expérimentés qui connaissent déjà JavaScript.
Objectifs de l'atelier
Dans cet atelier de programmation, vous allez :
- Créez une page Web qui utilise le machine learning directement dans le navigateur Web via TensorFlow.js pour classer et détecter les objets courants (oui, y compris plusieurs à la fois) à partir d'un flux vidéo en direct.
- Utilisez votre webcam habituelle pour identifier des objets et obtenir les coordonnées du cadre de sélection de chacun d'eux.
- Mettez en surbrillance l'objet trouvé dans le flux vidéo, comme indiqué ci-dessous :
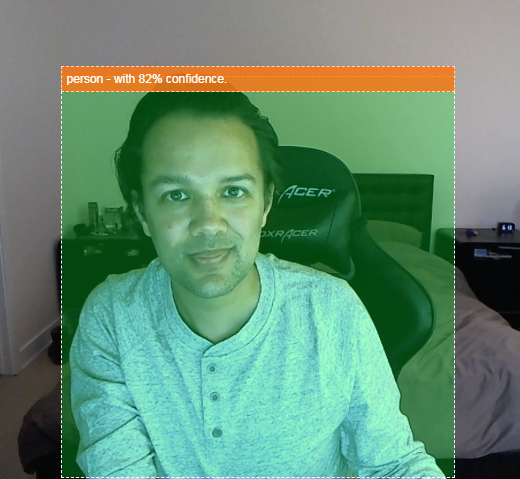
Imaginez pouvoir détecter si une personne est présente dans une vidéo, puis compter le nombre de personnes présentes à un moment donné pour estimer l'affluence d'une zone au cours de la journée, ou vous envoyer une alerte lorsque votre chien est détecté dans une pièce de votre maison où il ne devrait pas être. Si vous y parvenez, vous serez en bonne voie pour créer votre propre version de la caméra Google Nest, qui pourra vous alerter lorsqu'elle détectera un intrus (de n'importe quel type) à l'aide de votre propre matériel personnalisé. Plutôt sympa, non ? Est-ce difficile à faire ? Non. C'est parti pour le piratage !
Points abordés
- Chargement d'un modèle TensorFlow.js pré-entraîné
- Comment récupérer des données à partir d'un flux de webcam en direct et les dessiner sur un canevas.
- Comment classer un frame d'image pour trouver le ou les cadres de délimitation de tout objet que le modèle a été entraîné à reconnaître.
- Comment utiliser les données renvoyées par le modèle pour mettre en évidence les objets trouvés.
Cet atelier de programmation explique comment utiliser les modèles pré-entraînés TensorFlow.js. Les concepts et les blocs de code qui ne sont pas pertinents pour TensorFlow.js et le machine learning ne sont pas expliqués. Ils vous sont fournis afin que vous puissiez simplement les copier et les coller.
2. Qu'est-ce que TensorFlow.js ?

TensorFlow.js est une bibliothèque de machine learning Open Source qui peut s'exécuter partout où JavaScript le peut. Elle est basée sur la bibliothèque TensorFlow d'origine écrite en Python et vise à recréer cette expérience de développement et cet ensemble d'API pour l'écosystème JavaScript.
Où peut-on l'utiliser ?
Grâce à la portabilité de JavaScript, vous pouvez désormais écrire dans une seule langue et effectuer du machine learning sur toutes les plates-formes suivantes en toute simplicité :
- Côté client dans le navigateur Web à l'aide de JavaScript vanilla
- Côté serveur et même sur des appareils IoT comme Raspberry Pi à l'aide de Node.js
- Applications de bureau utilisant Electron
- Applications mobiles natives utilisant React Native
TensorFlow.js est également compatible avec plusieurs backends dans chacun de ces environnements (les environnements matériels réels dans lesquels il peut s'exécuter, tels que le processeur ou WebGL, par exemple). Dans ce contexte, le terme "backend" ne désigne pas un environnement côté serveur (le backend d'exécution peut être côté client dans WebGL, par exemple) pour assurer la compatibilité et maintenir la rapidité d'exécution. TensorFlow.js est actuellement compatible avec :
- Exécution WebGL sur la carte graphique (GPU) de l'appareil : il s'agit du moyen le plus rapide d'exécuter des modèles plus volumineux (de plus de 3 Mo) avec l'accélération GPU.
- Exécution WebAssembly (WASM) sur le processeur : pour améliorer les performances du processeur sur les appareils, y compris les téléphones mobiles de l'ancienne génération, par exemple. Cette approche est mieux adaptée aux modèles plus petits (moins de 3 Mo), qui peuvent en fait s'exécuter plus rapidement sur le processeur avec WASM qu'avec WebGL en raison de la surcharge liée à l'importation de contenu dans un processeur graphique.
- Exécution du CPU : solution de repli si aucun autre environnement n'est disponible. C'est la plus lente des trois, mais elle est toujours disponible.
Remarque : Vous pouvez choisir d'imposer l'un de ces backends si vous savez sur quel appareil vous allez exécuter le code, ou vous pouvez simplement laisser TensorFlow.js décider pour vous si vous ne le spécifiez pas.
Super-pouvoirs côté client
L'exécution de TensorFlow.js dans le navigateur Web sur la machine cliente peut présenter plusieurs avantages à prendre en compte.
Confidentialité
Vous pouvez entraîner et classer des données sur la machine cliente sans jamais envoyer de données à un serveur Web tiers. Il peut arriver que cela soit nécessaire pour se conformer aux lois locales, comme le RGPD par exemple, ou lors du traitement de données que l'utilisateur peut souhaiter conserver sur sa machine et ne pas envoyer à un tiers.
Speed
Comme vous n'avez pas à envoyer de données à un serveur distant, l'inférence (l'acte de classification des données) peut être plus rapide. Mieux encore, vous avez un accès direct aux capteurs de l'appareil (caméra, micro, GPS, accéléromètre, etc.) si l'utilisateur vous y autorise.
Couverture et évolutivité
En un clic, n'importe qui dans le monde peut cliquer sur un lien que vous lui envoyez, ouvrir la page Web dans son navigateur et utiliser ce que vous avez créé. Vous n'avez pas besoin d'une configuration Linux complexe côté serveur avec des pilotes CUDA et bien plus encore pour utiliser le système de machine learning.
Coût
Sans serveur, vous n'avez besoin que d'un CDN pour héberger vos fichiers HTML, CSS, JS et de modèle. Le coût d'un CDN est beaucoup moins élevé que celui d'un serveur fonctionnant 24h/24 et 7j/7 (potentiellement avec une carte graphique).
Fonctionnalités côté serveur
L'utilisation de l'implémentation Node.js de TensorFlow.js permet les fonctionnalités suivantes.
Prise en charge complète de CUDA
Côté serveur, pour l'accélération de la carte graphique, vous devez installer les pilotes NVIDIA CUDA pour permettre à TensorFlow de fonctionner avec la carte graphique (contrairement au navigateur qui utilise WebGL et ne nécessite aucune installation). Toutefois, avec la prise en charge complète de CUDA, vous pouvez exploiter pleinement les capacités de bas niveau de la carte graphique, ce qui permet d'accélérer les temps d'entraînement et d'inférence. Les performances sont équivalentes à celles de l'implémentation Python de TensorFlow, car elles partagent le même backend C++.
Taille du modèle
Pour les modèles de pointe issus de la recherche, vous pouvez travailler avec des modèles très volumineux, peut-être de plusieurs gigaoctets. Ces modèles ne peuvent pas être exécutés dans le navigateur Web pour le moment en raison des limites d'utilisation de la mémoire par onglet de navigateur. Pour exécuter ces modèles plus volumineux, vous pouvez utiliser Node.js sur votre propre serveur avec les spécifications matérielles requises pour exécuter efficacement un tel modèle.
IOT
Node.js est compatible avec les ordinateurs monocartes populaires tels que Raspberry Pi, ce qui signifie que vous pouvez également exécuter des modèles TensorFlow.js sur ces appareils.
Speed
Node.js est écrit en JavaScript, ce qui signifie qu'il bénéficie de la compilation juste-à-temps. Cela signifie que vous pouvez souvent constater des améliorations de performances lorsque vous utilisez Node.js, car il sera optimisé au moment de l'exécution, en particulier pour tout prétraitement que vous pourriez effectuer. Un excellent exemple est présenté dans cette étude de cas, qui montre comment Hugging Face a utilisé Node.js pour doubler les performances de son modèle de traitement du langage naturel.
Maintenant que vous connaissez les bases de TensorFlow.js, où il peut s'exécuter et certains de ses avantages, commençons à faire des choses utiles avec !
3. Modèles pré-entraînés
TensorFlow.js fournit divers modèles de machine learning (ML) pré-entraînés. Ces modèles ont été entraînés par l'équipe TensorFlow.js et encapsulés dans une classe facile à utiliser. Ils constituent un excellent moyen de faire vos premiers pas avec le machine learning. Au lieu de créer et d'entraîner un modèle pour résoudre votre problème, vous pouvez importer un modèle pré-entraîné comme point de départ.
Vous trouverez une liste croissante de modèles pré-entraînés faciles à utiliser sur la page Modèles pour JavaScript de Tensorflow.js. Vous pouvez également obtenir des modèles TensorFlow convertis fonctionnant dans TensorFlow.js, y compris sur TensorFlow Hub.
Pourquoi utiliser un modèle pré-entraîné ?
Si un modèle pré-entraîné populaire correspond à votre cas d'utilisation, vous pouvez bénéficier de plusieurs avantages en commençant par celui-ci :
- Vous n'avez pas besoin de collecter vous-même des données d'entraînement. Préparer les données dans le bon format et les étiqueter pour qu'un système de machine learning puisse les utiliser pour apprendre peut être très chronophage et coûteux.
- La possibilité de prototyper rapidement une idée à moindre coût et en moins de temps.
Il est inutile de "réinventer la roue" lorsqu'un modèle pré-entraîné peut suffire à répondre à vos besoins. Vous pouvez ainsi vous concentrer sur l'utilisation des connaissances fournies par le modèle pour mettre en œuvre vos idées créatives. - Utilisation de recherches de pointe. Les modèles pré-entraînés sont souvent basés sur des recherches populaires. Vous pouvez ainsi les découvrir et comprendre leurs performances dans le monde réel.
- Simplicité d'utilisation et documentation complète : en raison de la popularité de ces modèles.
- Capacités d'apprentissage par transfert. Certains modèles pré-entraînés offrent des capacités d'apprentissage par transfert, qui consiste essentiellement à transférer les informations apprises d'une tâche de machine learning à un autre exemple similaire. Par exemple, un modèle initialement entraîné à reconnaître les chats pourrait être réentraîné à reconnaître les chiens, si vous lui fournissiez de nouvelles données d'entraînement. Cette méthode est plus rapide, car vous ne partez pas d'un canevas vide. Le modèle peut utiliser ce qu'il a déjà appris pour reconnaître les chats et identifier ensuite la nouvelle chose (les chiens ont aussi des yeux et des oreilles, donc s'il sait déjà comment trouver ces caractéristiques, nous sommes à mi-chemin). Réentraînez le modèle sur vos propres données beaucoup plus rapidement.
Qu'est-ce que COCO-SSD ?
COCO-SSD est le nom d'un modèle ML de détection d'objets pré-entraîné que vous utiliserez lors de cet atelier de programmation. Il vise à localiser et à identifier plusieurs objets dans une même image. En d'autres termes, il peut vous indiquer le cadre de délimitation des objets qu'il a été entraîné à trouver pour vous donner l'emplacement de cet objet dans n'importe quelle image que vous lui présentez. Voici un exemple :

S'il y avait plus d'un chien dans l'image ci-dessus, vous recevriez les coordonnées de deux cadres de délimitation, décrivant l'emplacement de chacun. COCO-SSD a été pré-entraîné pour reconnaître 90 objets courants du quotidien, comme une personne, une voiture, un chat, etc.
D'où vient le nom ?
Ce nom peut paraître étrange, mais il provient de deux acronymes :
- COCO : indique que le modèle a été entraîné sur l'ensemble de données COCO (Common Objects in Context), qui est disponible en téléchargement sans frais pour tous ceux qui souhaitent l'utiliser pour entraîner leurs propres modèles. L'ensemble de données contient plus de 200 000 images étiquetées qui peuvent être utilisées pour l'apprentissage.
- SSD (Single Shot MultiBox Detection) : fait référence à une partie de l'architecture du modèle qui a été utilisée dans son implémentation. Vous n'avez pas besoin de comprendre cela pour l'atelier de programmation, mais si vous êtes curieux, vous pouvez en savoir plus sur les SSD ici.
4. Configuration
Prérequis
- Un navigateur Web récent.
- Des connaissances de base du HTML, CSS, JavaScript et des Outils pour les développeurs Chrome (affichage de la sortie de la console)
Commençons à coder
Des modèles récurrents ont été créés pour Glitch.com ou Codepen.io. Vous pouvez simplement cloner l'un des modèles comme état de base pour cet atelier de programmation, en un seul clic.
Sur Glitch, cliquez sur le bouton Remix this (Remixer) pour créer un fork et un nouvel ensemble de fichiers que vous pouvez modifier.
Sur CodePen, vous pouvez également cliquer sur fork (fork) en bas à droite de l'écran.
Ce squelette très simple vous fournit les fichiers suivants :
- Page HTML (index.html)
- Feuille de style (style.css)
- Fichier pour écrire notre code JavaScript (script.js)
Pour plus de commodité, une importation a été ajoutée au fichier HTML pour la bibliothèque TensorFlow.js. Elle se présente comme suit :
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Autre option : utiliser l'éditeur Web de votre choix ou travailler en local
Si vous souhaitez télécharger le code et travailler en local ou sur un autre éditeur en ligne, il vous suffit de créer les trois fichiers mentionnés ci-dessus dans le même répertoire, puis de copier et coller le code de notre boilerplate Glitch dans chacun d'eux.
5. Remplir le squelette HTML
Tous les prototypes nécessitent une structure HTML de base. Vous l'utiliserez pour afficher la sortie du modèle de machine learning ultérieurement. Configurons-le maintenant :
- Titre de la page
- Texte descriptif
- Bouton permettant d'activer la webcam
- Tag vidéo pour afficher le flux de la webcam
Pour configurer ces fonctionnalités, ouvrez index.html et collez le code suivant sur le code existant :
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
Comprendre le code
Notez quelques éléments clés que vous avez ajoutés :
- Vous avez ajouté une balise
<h1>et des balises<p>pour l'en-tête, ainsi que des informations sur l'utilisation de la page. Rien de spécial à signaler.
Vous avez également ajouté un tag de section représentant votre espace de démonstration :
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- Dans un premier temps, vous allez attribuer à ce
sectionla classe "invisible". Cela vous permet d'indiquer visuellement à l'utilisateur quand le modèle est prêt et qu'il peut cliquer sur le bouton Activer la webcam. - Vous avez ajouté le bouton enable webcam (activer la webcam), que vous allez styliser dans votre CSS.
- Vous avez également ajouté une balise vidéo à laquelle vous allez diffuser l'entrée de votre webcam. Vous allez configurer cela dans votre code JavaScript dans quelques instants.
Si vous prévisualisez le résultat maintenant, il devrait ressembler à ceci :

6. Ajouter style
Valeurs par défaut des éléments
Commençons par ajouter des styles aux éléments HTML que nous venons d'ajouter pour nous assurer qu'ils s'affichent correctement :
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
Ensuite, ajoutez des classes CSS utiles pour gérer les différents états de notre interface utilisateur, par exemple lorsque nous voulons masquer le bouton ou rendre la zone de démonstration indisponible si le modèle n'est pas encore prêt.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
Parfait ! C'est tout ce dont vous avez besoin. Si vous avez bien remplacé vos styles par les deux extraits de code ci-dessus, votre aperçu en direct devrait maintenant se présenter comme suit :

Notez que le texte et le bouton de la zone de démonstration ne sont pas disponibles, car la classe "invisible" est appliquée au code HTML par défaut. Vous utiliserez JavaScript pour supprimer cette classe une fois que le modèle sera prêt à être utilisé.
7. Créer un squelette JavaScript
Référencer les éléments DOM clés
Tout d'abord, assurez-vous de pouvoir accéder aux éléments clés de la page que vous devrez manipuler ou auxquels vous devrez accéder plus tard dans notre code :
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
Vérifier la compatibilité de la webcam
Vous pouvez désormais ajouter des fonctions d'assistance pour vérifier si le navigateur que vous utilisez permet d'accéder au flux de la webcam via getUserMedia :
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
Récupérer le flux de la webcam
Ensuite, complétez le code de la fonction enableCam précédemment vide que nous avons définie ci-dessus en copiant et en collant le code ci-dessous :
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
Enfin, ajoutez du code temporaire pour vérifier si la webcam fonctionne.
Le code ci-dessous fera semblant que votre modèle est chargé et activera le bouton de la caméra, afin que vous puissiez cliquer dessus. Vous allez remplacer tout ce code à l'étape suivante. Préparez-vous donc à le supprimer à nouveau dans un instant :
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
Parfait ! Si vous avez exécuté le code et cliqué sur le bouton tel qu'il est actuellement, vous devriez voir quelque chose comme ceci :

8. Utilisation des modèles de machine learning
Charger le modèle
Vous êtes maintenant prêt à charger le modèle COCO-SSD.
Une fois l'initialisation terminée, activez la zone de démonstration et le bouton sur votre page Web (collez ce code sur le code temporaire que vous avez ajouté à la fin de la dernière étape) :
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
Une fois le code ci-dessus ajouté et la vue en direct actualisée, vous remarquerez que quelques secondes après le chargement de la page (en fonction de la vitesse de votre réseau), le bouton enable webcam (activer la webcam) s'affiche automatiquement lorsque le modèle est prêt à être utilisé. Cependant, vous avez également collé la fonction predictWebcam. Il est maintenant temps de définir complètement cette fonction, car notre code ne fera rien pour le moment.
Passons à l'étape suivante.
Classer un frame à partir de la webcam
Exécutez le code ci-dessous pour permettre à l'application de capturer en continu une image du flux de la webcam lorsque le navigateur est prêt et de la transmettre au modèle pour qu'elle soit classée.
Le modèle analysera ensuite les résultats et dessinera une balise <p> aux coordonnées renvoyées. Il définira le texte sur l'étiquette de l'objet, si le niveau de confiance est supérieur à un certain seuil.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
L'appel vraiment important dans ce nouveau code est model.detect().
Tous les modèles prédéfinis pour TensorFlow.js disposent d'une fonction de ce type (dont le nom peut varier d'un modèle à l'autre, alors consultez la documentation pour en savoir plus) qui effectue réellement l'inférence du machine learning.
L'inférence consiste simplement à prendre une entrée, à l'exécuter dans le modèle de machine learning (essentiellement de nombreuses opérations mathématiques), puis à fournir des résultats. Avec les modèles TensorFlow.js prédéfinis, nous renvoyons nos prédictions sous forme d'objets JSON, ce qui les rend faciles à utiliser.
Vous trouverez tous les détails de cette fonction de prédiction dans notre documentation GitHub pour le modèle COCO-SSD. Cette fonction effectue un travail important en arrière-plan : elle peut accepter n'importe quel objet "image" comme paramètre, tel qu'une image, une vidéo, un canevas, etc. L'utilisation de modèles prédéfinis peut vous faire gagner beaucoup de temps et d'efforts, car vous n'aurez pas besoin d'écrire ce code vous-même et vous pourrez l'utiliser "tel quel".
L'exécution de ce code devrait maintenant vous donner une image qui ressemble à ceci :
Enfin, voici un exemple de code détectant plusieurs objets en même temps :

Excellent ! Vous pouvez maintenant imaginer à quel point il serait simple de créer un appareil comme une Nest Cam à l'aide d'un ancien téléphone pour vous alerter lorsqu'il voit votre chien sur le canapé ou votre chat sur le fauteuil. Si vous rencontrez des problèmes avec votre code, consultez ma version finale fonctionnelle ici pour vérifier si vous avez fait une erreur de copie.
9. Félicitations
Félicitations ! Vous venez de faire vos premiers pas dans l'utilisation de TensorFlow.js et du machine learning dans le navigateur Web. À présent, c'est à vous de prendre ces humbles débuts et de les transformer en quelque chose de créatif. Qu'allez-vous créer ?
Résumé
Voici les connaissances que vous avez acquises au cours de cet atelier de programmation :
- Vous avez découvert les avantages de l'utilisation de TensorFlow.js par rapport aux autres formes de TensorFlow.
- Vous avez appris dans quelles situations il peut être judicieux de commencer avec un modèle de machine learning pré-entraîné.
- Création d'une page Web entièrement fonctionnelle capable de classer des objets en temps réel à l'aide de votre webcam, y compris :
- Créer une structure HTML pour le contenu
- Définir des styles pour les éléments et les classes HTML
- Configurer l'échafaudage JavaScript pour interagir avec le code HTML et détecter la présence d'une webcam
- Charger un modèle TensorFlow.js pré-entraîné
- Utiliser le modèle chargé pour classer en continu le flux de la webcam et dessiner un cadre de délimitation autour des objets de l'image.
Étapes suivantes
Partagez vos créations avec nous ! Vous pouvez facilement étendre ce que vous avez créé pour cet atelier de programmation à d'autres cas d'utilisation créatifs. Nous vous encourageons à sortir des sentiers battus et à continuer à innover une fois que vous avez terminé.
- Découvrez tous les objets que ce modèle peut reconnaître et réfléchissez à la manière dont vous pourriez utiliser ces connaissances pour effectuer une action. Quelles idées créatives pourriez-vous mettre en œuvre en développant ce que vous avez créé aujourd'hui ?
(Vous pouvez peut-être ajouter une simple couche côté serveur pour envoyer une notification à un autre appareil lorsqu'il détecte un certain objet de votre choix à l'aide de WebSockets. C'est un excellent moyen de recycler un ancien smartphone et de lui donner une nouvelle utilité. Les possibilités sont illimitées !)
- Taguez-nous sur les réseaux sociaux avec le hashtag #MadeWithTFJS, et votre projet sera peut-être mis en avant sur notre blog TensorFlow ou lors de prochains événements TensorFlow.
Plus d'ateliers de programmation TensorFlow.js pour aller plus loin
- Créer un réseau de neurones à partir de zéro dans TensorFlow.js
- Reconnaissance audio à l'aide de l'apprentissage par transfert dans TensorFlow.js
- Classification d'images personnalisées à l'aide de l'apprentissage par transfert dans TensorFlow.js