
1. Zanim zaczniesz
Wykorzystanie modeli TensorFlow.js w ciągu ostatnich kilku lat wzrosło wykładniczo, a wielu programistów JavaScript chce teraz wykorzystać istniejące, zaawansowane modele i przeszkolić je, aby działały z danymi niestandardowymi, które są unikalne dla ich branży. Wykorzystanie istniejącego modelu (często nazywanego modelem podstawowym) w podobnej, ale innej domenie jest znane jako uczenie transferowe.
Uczenie transferowe ma wiele zalet w porównaniu z rozpoczynaniem pracy z całkowicie pustym modelem. Możesz ponownie wykorzystać wiedzę zdobytą na podstawie wcześniej wytrenowanego modelu i potrzebujesz mniej przykładów nowego elementu, który chcesz sklasyfikować. Proces uczenia jest też często znacznie szybszy, ponieważ trzeba ponownie wytrenować tylko kilka ostatnich warstw architektury modelu, a nie całą sieć. Z tego powodu uczenie przez przenoszenie jest bardzo dobrze dostosowane do środowiska przeglądarki internetowej, w którym zasoby mogą się różnić w zależności od urządzenia, na którym jest wykonywane, ale ma też bezpośredni dostęp do czujników, co ułatwia pozyskiwanie danych.
Z tego ćwiczenia dowiesz się, jak utworzyć aplikację internetową od zera, odtwarzając popularną witrynę Google „Teachable Machine”. Ta witryna umożliwia utworzenie funkcjonalnej aplikacji internetowej, za pomocą której każdy użytkownik może rozpoznać niestandardowy obiekt, korzystając z zaledwie kilku przykładowych zdjęć z kamery internetowej. Witryna jest celowo uproszczona, aby można było skupić się na aspektach uczenia maszynowego w tym ćwiczeniu. Podobnie jak w przypadku oryginalnej witryny Teachable Machine, masz jednak wiele możliwości wykorzystania swojego doświadczenia jako programista stron internetowych, aby poprawić wygodę korzystania z niej.
Wymagania wstępne
Te ćwiczenia są przeznaczone dla programistów internetowych, którzy znają wstępnie przygotowane modele TensorFlow.js i podstawowe zastosowania interfejsu API oraz chcą rozpocząć naukę transferową w TensorFlow.js.
- W tym laboratorium zakłada się podstawową znajomość TensorFlow.js, HTML5, CSS i JavaScriptu.
Jeśli dopiero zaczynasz przygodę z Tensorflow.js, rozważ rozpoczęcie od tego bezpłatnego kursu dla początkujących. Nie wymaga on żadnej wiedzy z zakresu uczenia maszynowego ani TensorFlow.js, a wszystkie potrzebne informacje są w nim przekazywane w przystępny sposób.
Czego się nauczysz
- Wyjaśnij, czym jest TensorFlow.js i dlaczego warto użyć go w kolejnej aplikacji internetowej.
- Jak utworzyć uproszczoną stronę internetową HTML/CSS /JS, która odzwierciedla wygodę korzystania z Teachable Machine.
- Jak używać TensorFlow.js do wczytywania wstępnie wytrenowanego modelu podstawowego, w tym MobileNet, w celu generowania cech obrazu, które można wykorzystać w uczeniu transferowym.
- Jak zbierać dane z kamery internetowej użytkownika dla wielu klas danych, które chcesz rozpoznać.
- Jak utworzyć i zdefiniować wielowarstwowy perceptron, który pobiera cechy obrazu i uczy się klasyfikować nowe obiekty na ich podstawie.
Zaczynamy hakowanie…
Czego potrzebujesz
- Aby móc śledzić postępy, najlepiej mieć konto Glitch.com. Możesz też użyć środowiska serwowania stron internetowych, które znasz i w którym możesz samodzielnie edytować i uruchamiać kod.
2. Czym jest TensorFlow.js?

TensorFlow.js to biblioteka uczenia maszynowego typu open source, która może działać wszędzie tam, gdzie JavaScript. Jest ona oparta na oryginalnej bibliotece TensorFlow napisanej w Pythonie i ma na celu odtworzenie środowiska deweloperskiego i zestawu interfejsów API dla ekosystemu JavaScript.
Gdzie można jej używać?
Dzięki przenośności JavaScript możesz teraz pisać w 1 języku i z łatwością korzystać z uczenia maszynowego na wszystkich tych platformach:
- Po stronie klienta w przeglądarce przy użyciu czystego JavaScriptu.
- po stronie serwera, a nawet na urządzeniach IoT, takich jak Raspberry Pi, przy użyciu Node.js;
- Aplikacje na komputery korzystające z Electrona
- natywnych aplikacji mobilnych korzystających z React Native,
TensorFlow.js obsługuje też wiele backendów w każdym z tych środowisk (rzeczywiste środowiska sprzętowe, w których może działać, np. procesor lub WebGL). „Backend” w tym kontekście nie oznacza środowiska po stronie serwera – backend do wykonywania może być np. po stronie klienta w WebGL, aby zapewnić zgodność i szybkie działanie. Obecnie TensorFlow.js obsługuje:
- Wykonywanie WebGL na karcie graficznej urządzenia (GPU) – to najszybszy sposób wykonywania większych modeli (o rozmiarze powyżej 3 MB) z akceleracją GPU.
- Wykonywanie kodu Web Assembly (WASM) na procesorze – aby zwiększyć wydajność procesora na różnych urządzeniach, np. na starszych telefonach komórkowych. Jest to lepsze rozwiązanie w przypadku mniejszych modeli (o rozmiarze poniżej 3 MB), które mogą działać szybciej na procesorze z użyciem WASM niż z użyciem WebGL ze względu na narzut związany z przesyłaniem treści do procesora graficznego.
- Wykonywanie na procesorze – to rozwiązanie rezerwowe, gdy żadne z pozostałych środowisk nie jest dostępne. Jest to najwolniejsza z tych 3 metod, ale zawsze dostępna.
Uwaga: jeśli wiesz, na jakim urządzeniu będzie wykonywany kod, możesz wymusić użycie jednego z tych backendów. Jeśli tego nie zrobisz, TensorFlow.js sam podejmie decyzję.
Supermoce po stronie klienta
Uruchamianie TensorFlow.js w przeglądarce na komputerze klienckim może przynieść wiele korzyści, które warto wziąć pod uwagę.
Prywatność
Możesz trenować i klasyfikować dane na urządzeniu klienta bez wysyłania ich na serwer WWW. Może to być wymagane w celu zachowania zgodności z lokalnymi przepisami, np. z RODO, lub podczas przetwarzania danych, które użytkownik chce przechowywać na swoim urządzeniu i nie wysyłać do osób trzecich.
Szybkość
Nie musisz wysyłać danych na serwer zdalny, więc wnioskowanie (czyli klasyfikowanie danych) może być szybsze. Co więcej, jeśli użytkownik przyzna Ci dostęp, będziesz mieć bezpośredni dostęp do czujników urządzenia, takich jak aparat, mikrofon, GPS, akcelerometr i inne.
Zasięg i skala
Każda osoba na świecie może jednym kliknięciem otworzyć wysłany przez Ciebie link, otworzyć stronę internetową w przeglądarce i skorzystać z Twojej pracy. Nie musisz przeprowadzać złożonej konfiguracji serwera z systemem Linux, sterownikami CUDA i wieloma innymi elementami, aby korzystać z systemu uczenia maszynowego.
Koszt
Brak serwerów oznacza, że musisz płacić tylko za CDN do hostowania plików HTML, CSS, JS i modeli. Koszt sieci CDN jest znacznie niższy niż utrzymywanie serwera (potencjalnie z kartą graficzną) działającego przez całą dobę.
Funkcje po stronie serwera
Korzystanie z implementacji TensorFlow.js w Node.js umożliwia korzystanie z tych funkcji:
Pełna obsługa CUDA
Po stronie serwera, aby przyspieszyć działanie karty graficznej, musisz zainstalować sterowniki NVIDIA CUDA, aby umożliwić TensorFlow współpracę z kartą graficzną (w przeciwieństwie do przeglądarki, która korzysta z WebGL – nie wymaga instalacji). Pełna obsługa CUDA pozwala jednak w pełni wykorzystać możliwości karty graficznej na niższym poziomie, co przekłada się na krótszy czas trenowania i wnioskowania. Wydajność jest porównywalna z implementacją TensorFlow w Pythonie, ponieważ obie korzystają z tego samego backendu w C++.
Rozmiar modelu
W przypadku najnowocześniejszych modeli z badań możesz pracować z bardzo dużymi modelami, które mogą mieć rozmiar nawet kilku gigabajtów. Obecnie nie można uruchamiać tych modeli w przeglądarce ze względu na ograniczenia dotyczące wykorzystania pamięci na kartę przeglądarki. Aby uruchamiać te większe modele, możesz używać Node.js na własnym serwerze o specyfikacji sprzętowej, która umożliwia wydajne działanie takiego modelu.
IOT
Node.js jest obsługiwany na popularnych komputerach jednopłytkowych, takich jak Raspberry Pi, co oznacza, że możesz na nich uruchamiać modele TensorFlow.js.
Szybkość
Node.js jest napisany w JavaScript, co oznacza, że korzysta z kompilacji JIT. Oznacza to, że w przypadku używania Node.js często można zauważyć wzrost wydajności, ponieważ jest on optymalizowany w czasie działania, zwłaszcza w przypadku wstępnego przetwarzania. Świetny przykład tego zjawiska znajdziesz w tym studium przypadku, które pokazuje, jak Hugging Face użyło Node.js, aby dwukrotnie zwiększyć wydajność swojego modelu przetwarzania języka naturalnego.
Znasz już podstawy TensorFlow.js, wiesz, gdzie można go używać i jakie są jego zalety. Zacznijmy więc robić z jego pomocą przydatne rzeczy.
3. Transfer learning
Czym dokładnie jest uczenie przez przenoszenie?
Uczenie się przez transfer polega na wykorzystaniu zdobytej już wiedzy do nauczenia się czegoś innego, ale podobnego.
My, ludzie, robimy to cały czas. W mózgu masz zgromadzone doświadczenia z całego życia, które możesz wykorzystać do rozpoznawania nowych rzeczy, których nigdy wcześniej nie widziałeś. Weźmy na przykład tę wierzbę:

W zależności od tego, gdzie mieszkasz, być może nigdy wcześniej nie widziałeś(-aś) tego rodzaju drzewa.
Jeśli jednak poproszę Cię o sprawdzenie, czy na nowym obrazie poniżej znajdują się wierzby, prawdopodobnie szybko je zauważysz, mimo że są pod innym kątem i nieco różnią się od tych, które pokazałem Ci wcześniej.

W mózgu masz już wiele neuronów, które potrafią rozpoznawać obiekty przypominające drzewa, oraz inne neurony, które dobrze radzą sobie z wykrywaniem długich prostych linii. Możesz wykorzystać tę wiedzę, aby szybko sklasyfikować wierzbę, która jest obiektem przypominającym drzewo z wieloma długimi, prostymi, pionowymi gałęziami.
Podobnie jeśli masz model uczenia maszynowego, który został już wytrenowany w określonej dziedzinie, np. rozpoznawania obrazów, możesz go ponownie wykorzystać do wykonania innego, ale powiązanego zadania.
To samo możesz zrobić w przypadku zaawansowanego modelu, takiego jak MobileNet, który jest bardzo popularnym modelem badawczym, który może rozpoznawać obrazy 1000 różnych typów obiektów. Model został wytrenowany na ogromnym zbiorze danych o nazwie ImageNet, który zawiera miliony oznaczonych zdjęć, od psów po samochody.
Na tej animacji widać ogromną liczbę warstw w modelu MobileNet V1:
Podczas trenowania ten model nauczył się wyodrębniać wspólne cechy, które są istotne dla wszystkich 1000 obiektów. Wiele cech niższego poziomu, których używa do identyfikowania tych obiektów, może być przydatnych do wykrywania nowych obiektów, których nigdy wcześniej nie widział. W końcu wszystko jest tylko kombinacją linii, tekstur i kształtów.
Przyjrzyjmy się tradycyjnej architekturze splotowej sieci neuronowej (CNN) (podobnej do MobileNet) i zobaczmy, jak uczenie transferowe może wykorzystać tę wytrenowaną sieć do nauczenia się czegoś nowego. Obraz poniżej przedstawia typową architekturę modelu CNN, który w tym przypadku został wytrenowany do rozpoznawania odręcznych cyfr od 0 do 9:
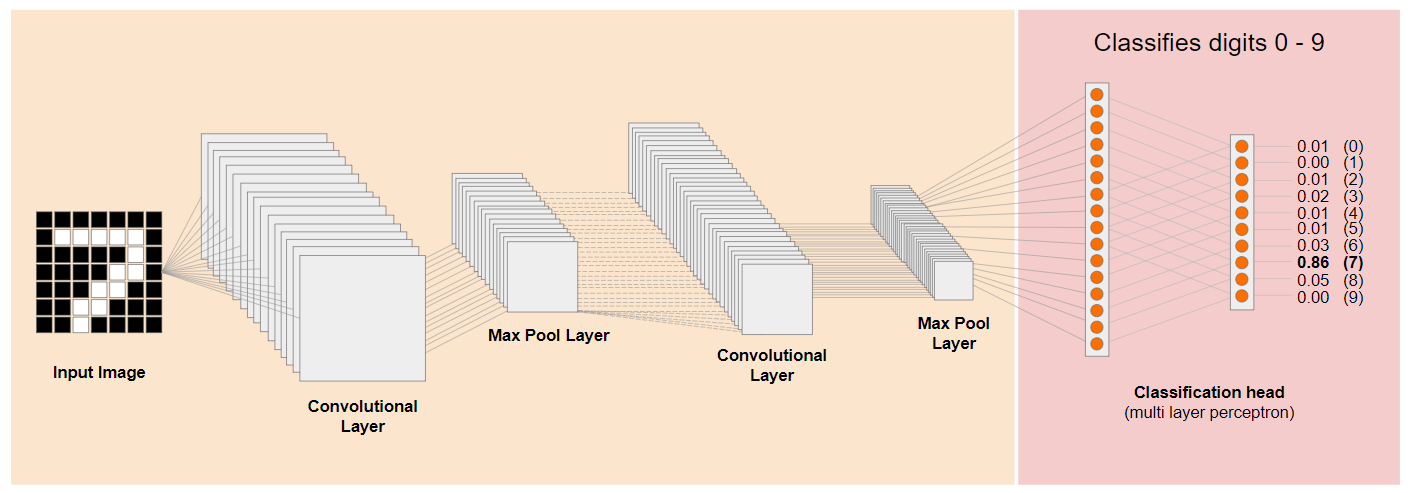
Jeśli uda Ci się oddzielić wstępnie wytrenowane warstwy niższego poziomu istniejącego wytrenowanego modelu, jak pokazano po lewej stronie, od warstw klasyfikacji znajdujących się pod koniec modelu, jak pokazano po prawej stronie (czasami nazywanych głowicą klasyfikacji modelu), możesz użyć warstw niższego poziomu do generowania cech wyjściowych dla dowolnego obrazu na podstawie oryginalnych danych, na których model został wytrenowany. Oto ta sama sieć po usunięciu głowicy klasyfikacji:
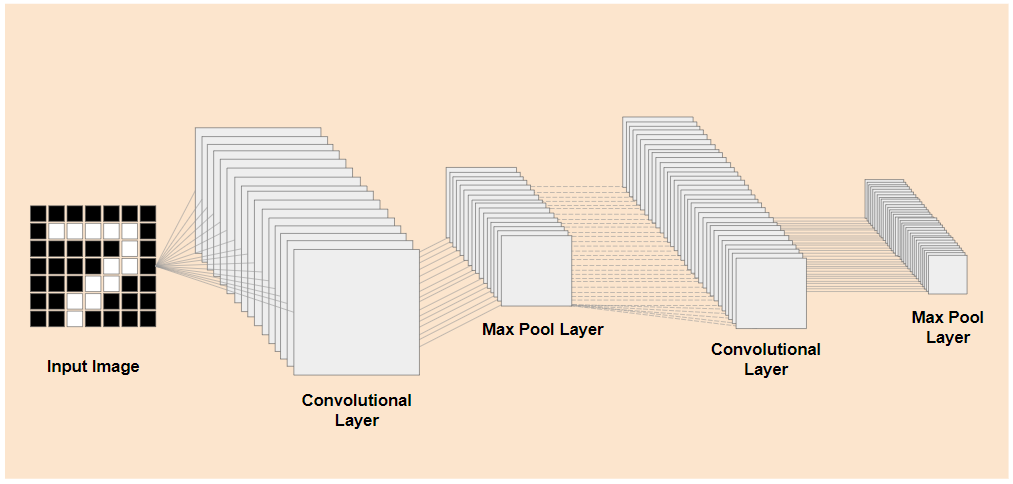
Jeśli nowe elementy, które próbujesz rozpoznać, mogą też korzystać z takich funkcji wyjściowych, których nauczył się poprzedni model, istnieje duża szansa, że będzie można ich użyć do nowego celu.
Na powyższym diagramie ten hipotetyczny model został wytrenowany na cyfrach, więc być może to, czego się nauczył w przypadku cyfr, można też zastosować do liter, takich jak a, b i c.
Możesz teraz dodać nową głowicę klasyfikacji, która będzie próbować przewidzieć a, b lub c, jak pokazano poniżej:
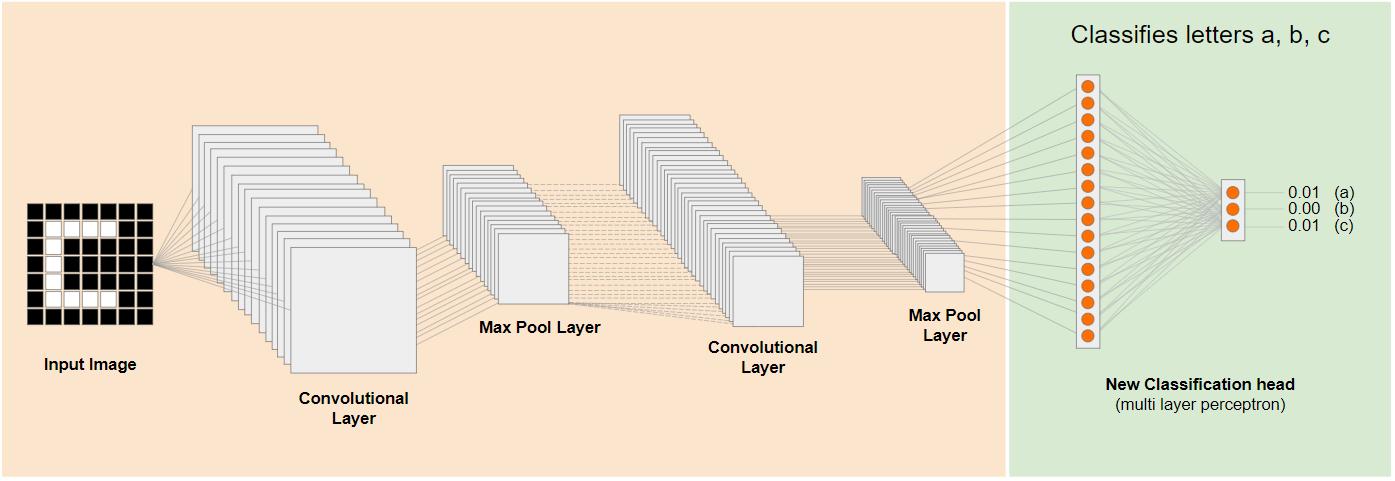
W tym przypadku warstwy niższego poziomu są zamrożone i nie są trenowane. Tylko nowa głowica klasyfikacji będzie się aktualizować, aby uczyć się na podstawie funkcji dostarczanych przez wstępnie wytrenowany, podzielony model po lewej stronie.
Ten proces nazywa się uczeniem przez przeniesienie i jest tym, co Teachable Machine robi za kulisami.
Możesz też zauważyć, że trenowanie perceptronu wielowarstwowego tylko na samym końcu sieci jest znacznie szybsze niż trenowanie całej sieci od zera.
Ale jak zdobyć podczęści modelu? Aby się tego dowiedzieć, przejdź do następnej sekcji.
4. TensorFlow Hub – modele podstawowe
Znajdowanie odpowiedniego modelu podstawowego
W przypadku bardziej zaawansowanych i popularnych modeli badawczych, takich jak MobileNet, możesz przejść do TensorFlow Hub, a następnie odfiltrować modele odpowiednie dla TensorFlow.js, które korzystają z architektury MobileNet v3, aby znaleźć wyniki podobne do tych, które widzisz tutaj:
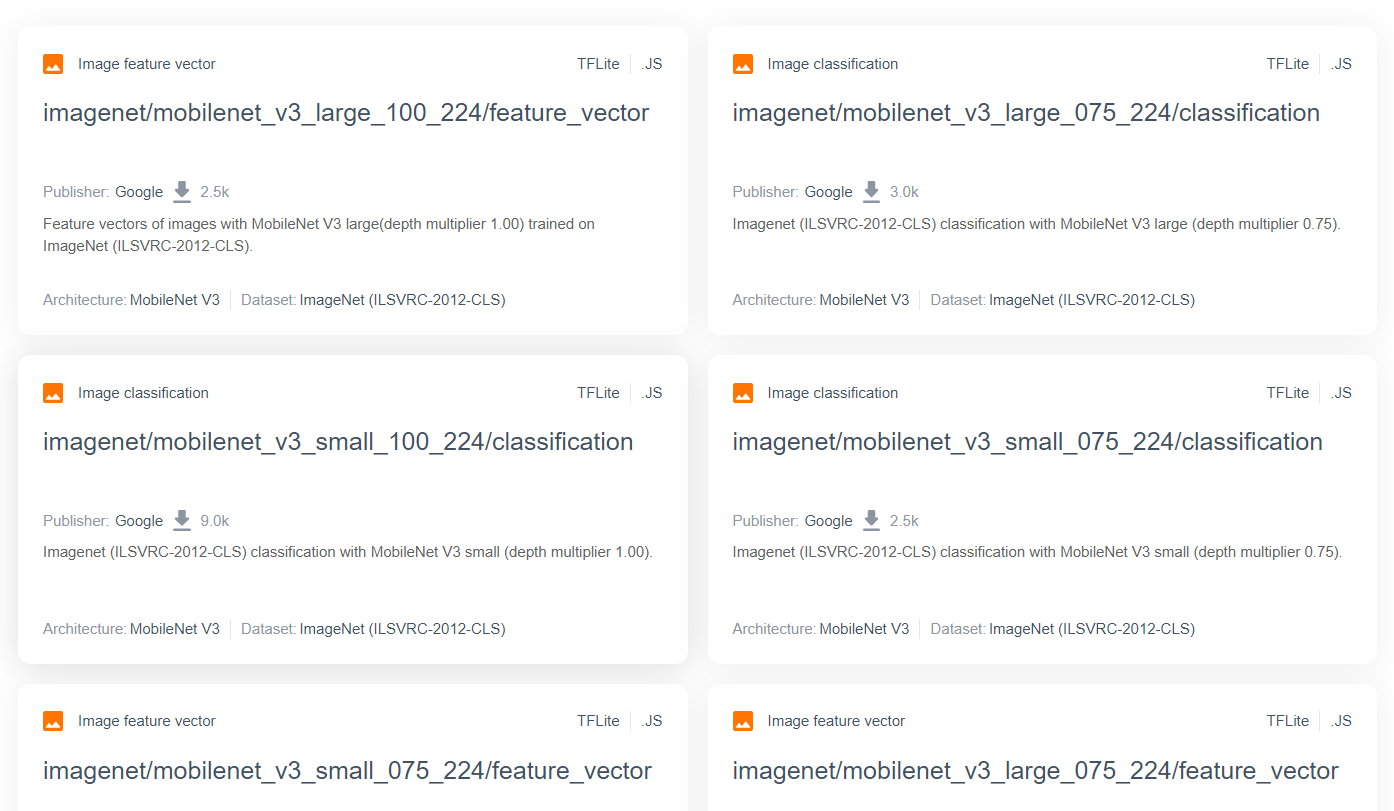
Pamiętaj, że niektóre z tych wyników są typu „klasyfikacja obrazów” (szczegóły w lewym górnym rogu każdej karty modelu), a inne są typu „wektor cech obrazu”.
Wyniki wektorów cech obrazu to w zasadzie wstępnie podzielone wersje MobileNet, których możesz użyć do uzyskania wektorów cech obrazu zamiast ostatecznej klasyfikacji.
Takie modele są często nazywane „modelami bazowymi”. Możesz ich używać do uczenia przez przenoszenie wiedzy w taki sam sposób, jak pokazano w poprzedniej sekcji, dodając nową głowicę klasyfikacji i trenując ją na własnych danych.
Następnie sprawdź, w jakim formacie TensorFlow.js jest udostępniany dany model bazowy. Jeśli otworzysz stronę jednego z tych modeli wektorów cech MobileNet v3, w dokumentacji JS zobaczysz, że jest to model grafu. Możesz to stwierdzić na podstawie przykładowego fragmentu kodu w dokumentacji, który używa funkcji tf.loadGraphModel().
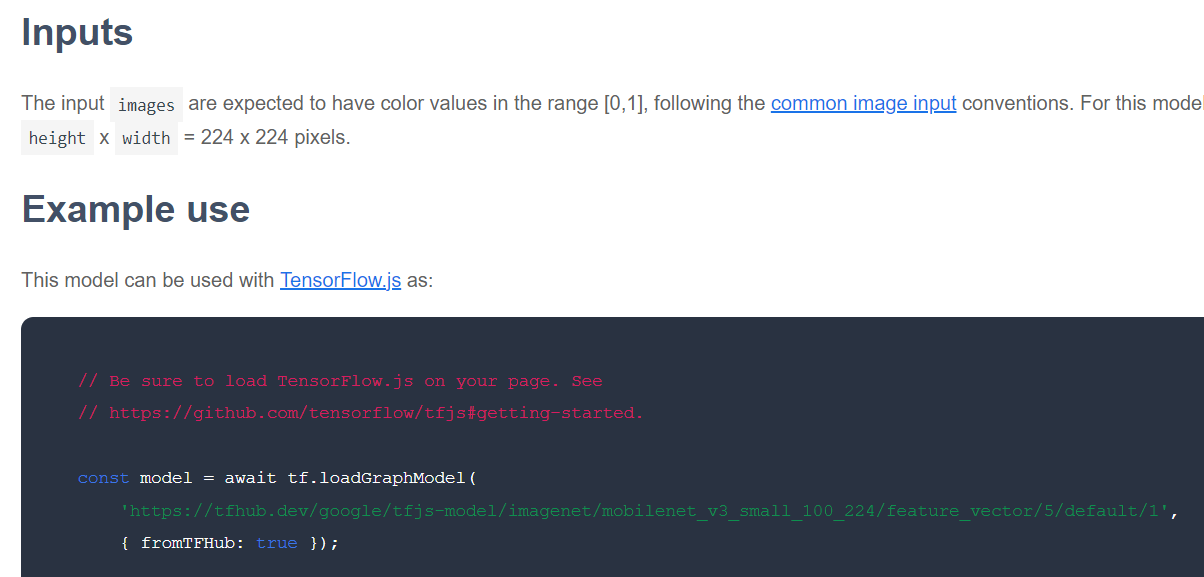
Warto też pamiętać, że jeśli znajdziesz model w formacie warstw zamiast w formacie wykresu, możesz wybrać, które warstwy mają być zamrożone, a które odblokowane na potrzeby trenowania. Może to być bardzo przydatne podczas tworzenia modelu do nowego zadania, co często określa się jako „model transferowy”. Na potrzeby tego samouczka użyjesz jednak domyślnego typu modelu wykresu, w którym wdrażana jest większość modeli TF Hub. Więcej informacji o korzystaniu z modeli Layers znajdziesz w kursie TensorFlow.js dla początkujących.
Zalety uczenia się przez transfer
Jakie są zalety korzystania z uczenia transferowego zamiast trenowania całej architektury modelu od zera?
Po pierwsze, czas trenowania jest kluczową zaletą korzystania z podejścia opartego na uczeniu transferowym, ponieważ masz już wytrenowany model podstawowy, na którym możesz budować.
Po drugie, dzięki wcześniejszemu trenowaniu możesz wyświetlać znacznie mniej przykładów nowego elementu, który próbujesz sklasyfikować.
Jest to bardzo przydatne, jeśli masz mało czasu i zasobów na zebranie przykładowych danych dotyczących elementu, który chcesz sklasyfikować, i musisz szybko utworzyć prototyp, zanim zbierzesz więcej danych treningowych, aby zwiększyć jego niezawodność.
Ze względu na mniejsze zapotrzebowanie na dane i szybkość trenowania mniejszej sieci uczenie transferowe jest mniej zasobochłonne. Dzięki temu doskonale nadaje się do środowiska przeglądarki, ponieważ pełne trenowanie modelu zajmuje dziesiątki sekund na nowoczesnym urządzeniu, a nie godziny, dni czy tygodnie.
Świetnie! Znasz już podstawy uczenia transferowego, więc możesz teraz utworzyć własną wersję Teachable Machine. Zaczynajmy!
5. Przygotowanie do kodowania
Czego potrzebujesz
- nowoczesnej przeglądarki internetowej,
- Podstawowa znajomość HTML-a, CSS-a, JavaScriptu i narzędzi deweloperskich w Chrome (wyświetlanie danych wyjściowych konsoli).
Zaczynamy kodowanie
Utworzyliśmy szablony do rozpoczęcia pracy na platformach Glitch.com i Codepen.io. Możesz po prostu sklonować dowolny szablon jako stan podstawowy na potrzeby tego modułu za pomocą jednego kliknięcia.
Na platformie Glitch kliknij przycisk „remix this”, aby rozwidlić projekt i utworzyć nowy zestaw plików, które możesz edytować.
Możesz też kliknąć „fork” w prawym dolnym rogu ekranu w Codepen.
Ten bardzo prosty szkielet zawiera te pliki:
- Strona HTML (index.html)
- Arkusz stylów (style.css)
- Plik do zapisywania kodu JavaScript (script.js)
Dla Twojej wygody w pliku HTML dodano import biblioteki TensorFlow.js. Wygląda on następująco:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternatywa: użyj ulubionego edytora internetowego lub pracuj lokalnie
Jeśli chcesz pobrać kod i pracować lokalnie lub w innym edytorze online, utwórz 3 pliki o podanych wyżej nazwach w tym samym katalogu, a następnie skopiuj i wklej do nich kod z naszego szablonu Glitch.
6. Powtarzalny kod HTML aplikacji
Od czego zacząć?
Wszystkie prototypy wymagają podstawowej struktury HTML, w której można wyświetlać wyniki. Skonfiguruj to teraz. Dodasz:
- Tytuł strony.
- Tekst opisu.
- Akapit ze statusem.
- Film, który będzie zawierać obraz z kamery internetowej, gdy będzie gotowy.
- Kilka przycisków do uruchamiania aparatu, zbierania danych i resetowania eksperymentu.
- Importy plików TensorFlow.js i JS, które utworzysz później.
Otwórz index.html i wklej poniższy kod, aby skonfigurować powyższe funkcje:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Wyjaśnij
Przyjrzyjmy się bliżej powyższemu kodowi HTML, aby wyróżnić najważniejsze dodane elementy.
- Dodano tag
<h1>dla tytułu strony oraz tag<p>z identyfikatorem „status”, w którym będą wyświetlane informacje, ponieważ do przeglądania wyników używasz różnych części systemu. - Dodano element
<video>z identyfikatorem „webcam”, do którego później będzie przesyłany strumień z kamery internetowej. - Dodano 5 elementów
<button>. Pierwszy z nich, o identyfikatorze „enableCam”, włącza kamerę. Kolejne 2 przyciski mają klasę „dataCollector”, która umożliwia zbieranie przykładowych obrazów obiektów, które chcesz rozpoznawać. Później napiszesz kod, który umożliwi dodanie dowolnej liczby tych przycisków, a one będą działać zgodnie z przeznaczeniem.
Pamiętaj, że te przyciski mają też specjalny atrybut zdefiniowany przez użytkownika o nazwie data-1hot, którego wartość całkowita zaczyna się od 0 w przypadku pierwszej klasy. Jest to indeks liczbowy, którego będziesz używać do reprezentowania danych określonej klasy. Indeks będzie używany do prawidłowego kodowania klas wyjściowych za pomocą reprezentacji numerycznej zamiast ciągu znaków, ponieważ modele ML mogą działać tylko z liczbami.
Jest też atrybut data-name, który zawiera nazwę czytelną dla człowieka, której chcesz używać w przypadku tej klasy. Dzięki temu możesz podać użytkownikowi bardziej zrozumiałą nazwę zamiast wartości indeksu liczbowego z kodowania 1-hot.
Na koniec masz przycisk trenowania i resetowania, który umożliwia rozpoczęcie procesu trenowania po zebraniu danych lub zresetowanie aplikacji.
- Dodano też 2 importy
<script>. Jeden dla TensorFlow.js, a drugi dla script.js, który zdefiniujesz wkrótce.
7. Dodaj styl
Ustawienia domyślne elementu
Dodaj style do elementów HTML, które właśnie zostały dodane, aby mieć pewność, że będą się prawidłowo renderować. Oto niektóre style, które są dodawane, aby prawidłowo określać położenie i rozmiar elementów. Nic specjalnego. Możesz później dodać do tego więcej elementów, aby jeszcze bardziej ulepszyć UX, tak jak w filmie o uczeniu maszynowym.
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
Świetnie. To wszystko, czego potrzebujesz. Jeśli teraz wyświetlisz podgląd danych wyjściowych, powinny one wyglądać mniej więcej tak:
8. JavaScript: kluczowe stałe i detektory
Zdefiniuj kluczowe stałe
Najpierw dodaj kilka kluczowych stałych, których będziesz używać w całej aplikacji. Zacznij od zastąpienia zawartości pliku script.js tymi stałymi:
script.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
Przyjrzyjmy się, do czego służą te elementy:
STATUSzawiera tylko odwołanie do tagu akapitu, w którym będziesz pisać aktualizacje stanu.VIDEOzawiera odwołanie do elementu wideo HTML, który będzie renderować obraz z kamery internetowej.ENABLE_CAM_BUTTON,RESET_BUTTONiTRAIN_BUTTONpobierają odwołania do DOM wszystkich kluczowych przycisków ze strony HTML.MOBILE_NET_INPUT_WIDTHiMOBILE_NET_INPUT_HEIGHTokreślają odpowiednio oczekiwaną szerokość i wysokość danych wejściowych modelu MobileNet. Jeśli zapiszesz tę wartość w stałej na początku pliku, w przyszłości łatwiej będzie Ci zaktualizować ją w jednym miejscu, zamiast zastępować ją w wielu różnych miejscach.- Wartość
STOP_DATA_GATHERto -1. Przechowuje wartość stanu, dzięki czemu wiesz, kiedy użytkownik przestał klikać przycisk, aby zbierać dane z obrazu z kamery internetowej. Nadanie tej liczbie bardziej znaczącej nazwy sprawi, że kod będzie później bardziej czytelny. CLASS_NAMESdziała jako wyszukiwanie i zawiera nazwy czytelne dla człowieka dla możliwych prognoz klas. Ta tablica zostanie wypełniona później.
OK, teraz, gdy masz odniesienia do kluczowych elementów, możesz powiązać z nimi detektory zdarzeń.
Dodawanie detektorów kluczowych zdarzeń
Zacznij od dodania do kluczowych przycisków obsługi zdarzeń kliknięcia, jak pokazano poniżej:
script.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON – po kliknięciu wywołuje funkcję enableCam.
TRAIN_BUTTON – po kliknięciu wywołuje funkcję trainAndPredict.
RESET_BUTTON – połączenia są resetowane po kliknięciu.
W tej sekcji znajdziesz wszystkie przyciski, które mają klasę „dataCollector” i używają document.querySelectorAll(). Zwraca tablicę elementów znalezionych w dokumencie, które pasują do:
script.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
Wyjaśnienie kodu:
Następnie przechodzisz przez znalezione przyciski i przypisujesz do każdego z nich 2 detektory zdarzeń. jeden dla zdarzenia „mousedown”, a drugi dla zdarzenia „mouseup”. Dzięki temu możesz nagrywać próbki tak długo, jak długo przytrzymujesz przycisk, co jest przydatne do zbierania danych.
Oba zdarzenia wywołują funkcję gatherDataForClass, którą zdefiniujesz później.
Na tym etapie możesz też przenieść znalezione nazwy klas zrozumiałe dla człowieka z atrybutu HTML data-name do tablicy CLASS_NAMES.
Następnie dodaj zmienne do przechowywania kluczowych informacji, które będą używane później.
script.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
Przyjrzyjmy się im.
Najpierw masz zmienną mobilenet do przechowywania załadowanego modelu mobilenet. Początkowo ustaw wartość undefined.
Następnie masz zmienną o nazwie gatherDataState. Jeśli zostanie naciśnięty przycisk „dataCollector”, wartość ta zmieni się na 1 identyfikator hot ID tego przycisku zdefiniowany w HTML-u, dzięki czemu będziesz wiedzieć, jaką klasę danych zbierasz w danym momencie. Początkowo jest ustawiona na STOP_DATA_GATHER, aby pętla zbierania danych, którą napiszesz później, nie zbierała żadnych danych, gdy nie są naciskane żadne przyciski.
videoPlaying śledzi, czy strumień z kamery internetowej został wczytany i jest odtwarzany oraz czy można go używać. Początkowo jest ustawiony na false, ponieważ kamera internetowa jest wyłączona, dopóki nie naciśniesz ENABLE_CAM_BUTTON..
Następnie zdefiniuj 2 tablice: trainingDataInputs i trainingDataOutputs. Przechowują one zebrane wartości danych treningowych, gdy klikasz przyciski „dataCollector” dla cech wejściowych wygenerowanych przez model podstawowy MobileNet i odpowiednio próbkowaną klasę wyjściową.
Na koniec definiowana jest tablica examplesCount,, która śledzi liczbę przykładów w każdej klasie po rozpoczęciu ich dodawania.
Na koniec masz zmienną o nazwie predict, która kontroluje pętlę prognozowania. Początkowo ma wartość false. Dopóki nie ustawisz tej opcji na true, nie będzie można generować prognoz.
Po zdefiniowaniu wszystkich kluczowych zmiennych wczytajmy wstępnie podzielony model podstawowy MobileNet v3, który zamiast klasyfikacji udostępnia wektory cech obrazu.
9. Wczytywanie modelu podstawowego MobileNet
Najpierw zdefiniuj nową funkcję o nazwie loadMobileNetFeatureModel, jak pokazano poniżej. Musi to być funkcja asynchroniczna, ponieważ wczytywanie modelu jest procesem asynchronicznym:
script.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
W tym kodzie definiujesz URL, gdzie znajduje się model do wczytania z dokumentacji TFHub.
Następnie możesz wczytać model za pomocą funkcji await tf.loadGraphModel(), pamiętając o ustawieniu specjalnej właściwości fromTFHub na true, ponieważ wczytujesz model z tej witryny Google. Jest to specjalny przypadek, który dotyczy tylko korzystania z modeli hostowanych w TF Hub, w którym należy ustawić tę dodatkową właściwość.
Po zakończeniu ładowania możesz ustawić atrybut innerText elementu STATUS za pomocą wiadomości, aby wizualnie sprawdzić, czy został on prawidłowo załadowany i czy możesz rozpocząć zbieranie danych.
Teraz wystarczy tylko rozgrzać model. W przypadku większych modeli, takich jak ten, pierwsze użycie może zająć chwilę, ponieważ trzeba wszystko skonfigurować. Dlatego warto przekazywać przez model zera, aby uniknąć w przyszłości oczekiwania, gdy czas może mieć większe znaczenie.
Możesz użyć funkcji tf.zeros() zawartej w funkcji tf.tidy(), aby mieć pewność, że tensory są prawidłowo usuwane, a wielkość wsadu wynosi 1 oraz że wysokość i szerokość są zgodne z wartościami zdefiniowanymi na początku w stałych. Na koniec określasz też kanały kolorów, które w tym przypadku wynoszą 3, ponieważ model oczekuje obrazów RGB.
Następnie zaloguj wynikowy kształt tensora zwróconego za pomocą answer.shape(), aby lepiej zrozumieć rozmiar funkcji obrazu generowanych przez ten model.
Po zdefiniowaniu tej funkcji możesz ją od razu wywołać, aby rozpocząć pobieranie modelu podczas wczytywania strony.
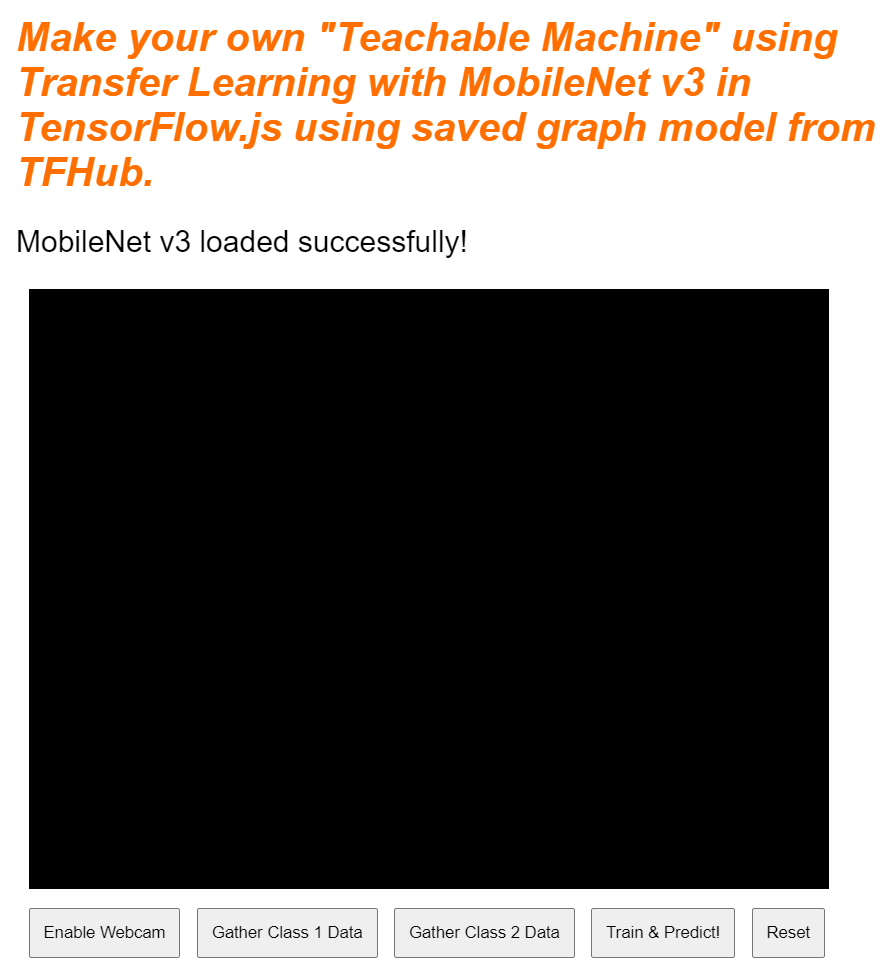
Jeśli teraz wyświetlisz podgląd na żywo, po chwili zobaczysz, że tekst stanu zmieni się z „Awaiting TF.js load” (Oczekiwanie na wczytanie TF.js) na „MobileNet v3 loaded successfully!” (MobileNet v3 wczytano). Zanim przejdziesz dalej, upewnij się, że wszystko działa.
Możesz też sprawdzić dane wyjściowe konsoli, aby zobaczyć wydrukowany rozmiar cech wyjściowych generowanych przez ten model. Po przeprowadzeniu zer przez model MobileNet zobaczysz wydrukowany kształt [1, 1024]. Pierwszy element to wielkość wsadu równa 1. Jak widać, zwraca on 1024 cechy, które można wykorzystać do klasyfikowania nowych obiektów.
10. Zdefiniuj nową głowicę modelu
Teraz zdefiniuj głowicę modelu, która jest w zasadzie bardzo prostym wielowarstwowym perceptronem.
script.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
Przyjrzyjmy się temu kodowi. Zacznij od zdefiniowania modelu tf.sequential, do którego dodasz warstwy modelu.
Następnie dodaj warstwę gęstą jako warstwę wejściową tego modelu. Ma on kształt wejściowy 1024, ponieważ dane wyjściowe z funkcji MobileNet v3 mają taki rozmiar. Zostało to omówione w poprzednim kroku po przekazaniu jedynek do modelu. Ta warstwa ma 128 neuronów, które używają funkcji aktywacji ReLU.
Jeśli nie znasz funkcji aktywacji i warstw modelu, rozważ udział w kursie opisanym na początku tych warsztatów, aby dowiedzieć się, jak te właściwości działają za kulisami.
Następną warstwą do dodania jest warstwa wyjściowa. Liczba neuronów powinna być równa liczbie klas, które chcesz przewidzieć. Aby to zrobić, możesz użyć CLASS_NAMES.length, aby sprawdzić, ile klas planujesz sklasyfikować. Jest to równe liczbie przycisków zbierania danych w interfejsie. Ponieważ jest to problem klasyfikacji, w tej warstwie wyjściowej używasz funkcji softmax, która musi być stosowana podczas tworzenia modelu do rozwiązywania problemów z klasyfikacją zamiast regresji.
Teraz wpisz model.summary(), aby wydrukować w konsoli podsumowanie nowo zdefiniowanego modelu.
Na koniec skompiluj model, aby był gotowy do trenowania. Optymalizator jest tu ustawiony na adam, a funkcja straty będzie miała wartość binaryCrossentropy, jeśli CLASS_NAMES.length jest równe 2, lub wartość categoricalCrossentropy, jeśli do sklasyfikowania są co najmniej 3 klasy. Wymagane są też dane dotyczące dokładności, aby można było je później monitorować w dziennikach na potrzeby debugowania.
W konsoli powinna pojawić się informacja podobna do tej:
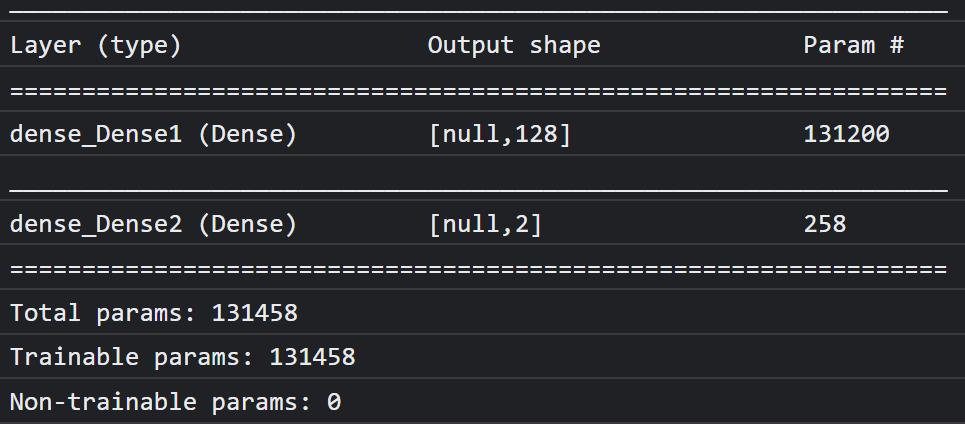
Pamiętaj, że ma on ponad 130 tys. parametrów z możliwością trenowania. Jest to jednak prosta warstwa gęsta zwykłych neuronów, więc trenowanie będzie dość szybkie.
Po zakończeniu projektu możesz spróbować zmienić liczbę neuronów w pierwszej warstwie, aby sprawdzić, jak mała może być ta liczba przy zachowaniu przyzwoitej skuteczności. W przypadku uczenia maszynowego często trzeba przeprowadzić pewną liczbę prób i błędów, aby znaleźć optymalne wartości parametrów, które zapewnią najlepszy kompromis między wykorzystaniem zasobów a szybkością.
11. Włącz kamerę internetową
Teraz rozbuduj funkcję enableCam(), którą zdefiniowano wcześniej. Dodaj nową funkcję o nazwie hasGetUserMedia(), jak pokazano poniżej, a następnie zastąp zawartość wcześniej zdefiniowanej funkcji enableCam() odpowiednim kodem poniżej.
script.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
Najpierw utwórz funkcję o nazwie hasGetUserMedia(), która sprawdzi, czy przeglądarka obsługuje getUserMedia(), sprawdzając, czy istnieją kluczowe właściwości interfejsów API przeglądarki.
W funkcji enableCam() użyj zdefiniowanej powyżej funkcji hasGetUserMedia(), aby sprawdzić, czy jest ona obsługiwana. Jeśli nie, wyświetl w konsoli ostrzeżenie.
Jeśli to możliwe, zdefiniuj pewne ograniczenia dla wywołania getUserMedia(), np. że chcesz tylko strumień wideo, a width filmu ma mieć rozmiar 640 pikseli, a height – 480 pikseli. Dlaczego? Nie ma sensu uzyskiwać większego filmu, ponieważ trzeba go będzie przeskalować do rozmiaru 224 × 224 piksele, aby można go było użyć w modelu MobileNet. Możesz też zaoszczędzić zasoby obliczeniowe, prosząc o mniejszą rozdzielczość. Większość kamer obsługuje rozdzielczość tego rozmiaru.
Następnie wywołaj funkcję navigator.mediaDevices.getUserMedia() z parametrem constraints opisanym powyżej i poczekaj na zwrócenie wartości stream. Gdy funkcja stream zwróci wartość, możesz odtworzyć element VIDEO, ustawiając go jako wartość srcObject.stream
Warto też dodać element eventListener do elementu VIDEO, aby wiedzieć, kiedy element stream został załadowany i jest odtwarzany.
Po załadowaniu strumienia możesz ustawić wartość videoPlaying na „true” i usunąć ENABLE_CAM_BUTTON, aby zapobiec ponownemu kliknięciu, ustawiając jego klasę na „removed”.
Teraz uruchom kod, kliknij przycisk włączania kamery i zezwalaj na dostęp do kamery internetowej. Jeśli robisz to po raz pierwszy, w elemencie wideo na stronie powinna pojawić się Twoja twarz, jak pokazano poniżej:

Czas dodać funkcję obsługującą kliknięcia przycisku dataCollector.
12. Moduł obsługi zdarzeń przycisku zbierania danych
Teraz wypełnij pustą funkcję o nazwie gatherDataForClass().. To ona została przypisana jako moduł obsługi zdarzeń dla przycisków dataCollector na początku tego ćwiczenia.
script.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
Najpierw sprawdź atrybut data-1hot klikniętego przycisku, wywołując funkcję this.getAttribute() z nazwą atrybutu, w tym przypadku data-1hot jako parametrem. Ponieważ jest to ciąg znaków, możesz użyć funkcji parseInt(), aby przekształcić go w liczbę całkowitą i przypisać wynik do zmiennej o nazwie classNumber..
Następnie odpowiednio ustaw zmienną gatherDataState. Jeśli bieżąca wartość gatherDataState jest równa STOP_DATA_GATHER (czyli -1), oznacza to, że nie zbierasz obecnie żadnych danych i zostało wywołane zdarzenie mousedown. Ustaw wartość gatherDataState na classNumber, którą właśnie udało Ci się znaleźć.
W przeciwnym razie oznacza to, że obecnie zbierasz dane, a zdarzenie, które zostało wywołane, to zdarzenie mouseup, i chcesz teraz przestać zbierać dane dotyczące tej klasy. Aby zakończyć pętlę zbierania danych, którą za chwilę zdefiniujesz, przywróć stan STOP_DATA_GATHER.
Na koniec wywołaj funkcję dataGatherLoop(),, która faktycznie nagrywa dane zajęć.
13. Zbieranie danych
Teraz zdefiniuj funkcję dataGatherLoop(). Ta funkcja odpowiada za próbkowanie obrazów z filmu z kamery internetowej, przekazywanie ich do modelu MobileNet i przechwytywanie wyników tego modelu (wektorów cech o długości 1024).
Następnie zapisuje je wraz z gatherDataState identyfikatorem aktualnie naciskanego przycisku, aby można było określić, jakiej klasy dotyczą te dane.
Przyjrzyjmy się temu procesowi:
script.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
Funkcja będzie wykonywana tylko wtedy, gdy videoPlaying ma wartość „prawda”, co oznacza, że kamera internetowa jest aktywna, a gatherDataState nie jest równe STOP_DATA_GATHER i jest obecnie wciśnięty przycisk zbierania danych o klasach.
Następnie umieść kod w bloku tf.tidy(), aby usunąć wszystkie utworzone w nim tensory. Wynik wykonania tego kodu tf.tidy() jest przechowywany w zmiennej o nazwie imageFeatures.
Możesz teraz przechwycić klatkę z kamery internetowej VIDEO za pomocą funkcji tf.browser.fromPixels(). Wynikowy tensor zawierający dane obrazu jest przechowywany w zmiennej o nazwie videoFrameAsTensor.
Następnie zmień rozmiar zmiennej videoFrameAsTensor, aby miała odpowiedni kształt dla danych wejściowych modelu MobileNet. Użyj wywołania tf.image.resizeBilinear() z tensorem, który chcesz przekształcić, jako pierwszego parametru, a następnie kształtu, który definiuje nową wysokość i szerokość zgodnie ze stałymi utworzonymi wcześniej. Na koniec ustaw wartość align corners na true, przekazując trzeci parametr, aby uniknąć problemów z wyrównaniem podczas zmiany rozmiaru. Wynik zmiany rozmiaru jest przechowywany w zmiennej o nazwie resizedTensorFrame.
Pamiętaj, że ta prosta zmiana rozmiaru rozciąga obraz, ponieważ obraz z kamery internetowej ma rozmiar 640 x 480 pikseli, a model wymaga kwadratowego obrazu o rozmiarze 224 x 224 pikseli.
W tym przypadku powinno to wystarczyć. Po ukończeniu tego ćwiczenia możesz spróbować wyciąć z tego obrazu kwadrat, aby uzyskać jeszcze lepsze wyniki w przypadku każdego systemu produkcyjnego, który możesz później utworzyć.
Następnie znormalizuj dane obrazu. Dane obrazu zawsze mieszczą się w zakresie od 0 do 255, gdy używasz funkcji tf.browser.frompixels(). Możesz więc po prostu podzielić resizedTensorFrame przez 255, aby mieć pewność, że wszystkie wartości mieszczą się w zakresie od 0 do 1. Tego właśnie oczekuje model MobileNet jako danych wejściowych.
Na koniec w sekcji tf.tidy() kodu przekaż ten znormalizowany tensor przez załadowany model, wywołując funkcję mobilenet.predict(), do której przekazujesz rozwiniętą wersję tensora normalizedTensorFrame za pomocą funkcji expandDims(), aby był to pakiet 1, ponieważ model oczekuje pakietu danych wejściowych do przetworzenia.
Gdy wynik zostanie zwrócony, możesz od razu wywołać funkcję squeeze() na tym zwróconym wyniku, aby sprowadzić go z powrotem do tensora 1D, który następnie zwracasz i przypisujesz do zmiennej imageFeatures, która rejestruje wynik z tf.tidy().
Teraz, gdy masz imageFeatures z modelu MobileNet, możesz je zarejestrować, umieszczając je w zdefiniowanej wcześniej tablicy trainingDataInputs.
Możesz też zapisać, co reprezentuje to wejście, dodając bieżącą wartość gatherDataState do tablicy trainingDataOutputs.
Pamiętaj, że zmienna gatherDataState została ustawiona na numeryczny identyfikator bieżącej klasy, dla której rejestrujesz dane, gdy w zdefiniowanej wcześniej funkcji gatherDataForClass() kliknięto przycisk.
Na tym etapie możesz też zwiększyć liczbę przykładów dla danej klasy. Aby to zrobić, najpierw sprawdź, czy indeks w tablicy examplesCount został już zainicjowany. Jeśli nie jest zdefiniowany, ustaw wartość 0, aby zainicjować licznik dla identyfikatora numerycznego danych zajęć, a następnie możesz zwiększyć wartość examplesCount dla bieżącego gatherDataState.
Teraz zaktualizuj tekst elementu STATUS na stronie internetowej, aby wyświetlać bieżące liczby dla każdej klasy w miarę ich rejestrowania. Aby to zrobić, przejdź przez tablicę CLASS_NAMES i wydrukuj nazwę czytelną dla człowieka połączoną z liczbą danych na tym samym indeksie w tablicy examplesCount.
Na koniec wywołaj funkcję window.requestAnimationFrame(), przekazując dataGatherLoop jako parametr, aby rekurencyjnie wywołać tę funkcję ponownie. Będzie on nadal pobierać próbki klatek z filmu, dopóki nie zostanie wykryty przycisk mouseup, a wartość gatherDataState nie zostanie ustawiona na STOP_DATA_GATHER,. W tym momencie pętla zbierania danych zakończy się.
Jeśli teraz uruchomisz kod, powinna pojawić się możliwość kliknięcia przycisku włączania kamery, poczekania na załadowanie kamery internetowej, a następnie kliknięcia i przytrzymania każdego z przycisków zbierania danych, aby zebrać przykłady dla każdej klasy danych. Na tym filmie zbieram dane dotyczące telefonu komórkowego i dłoni.
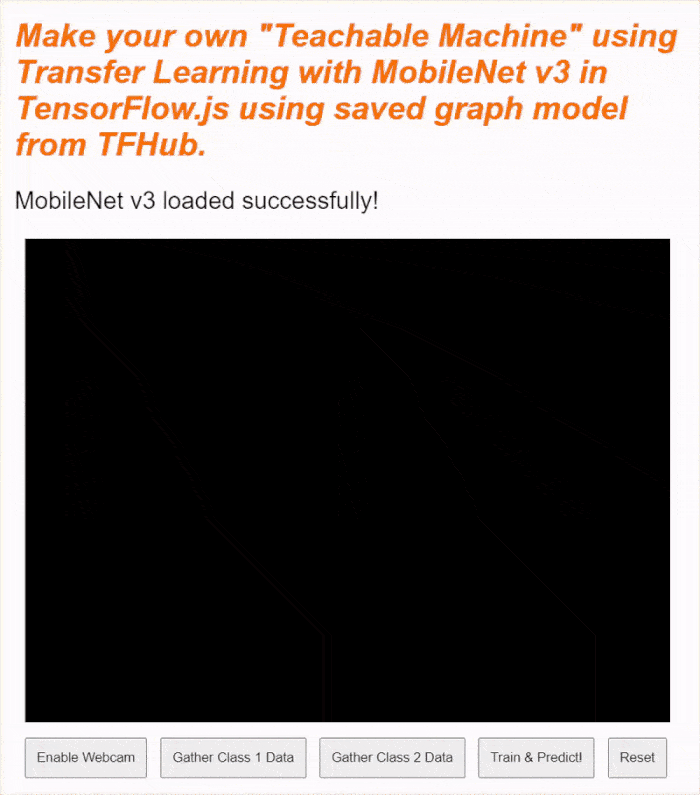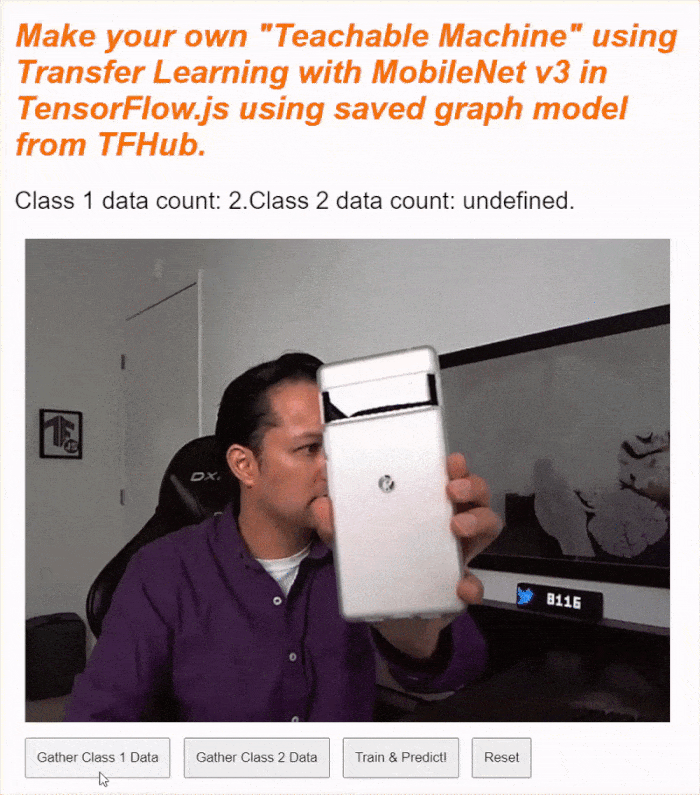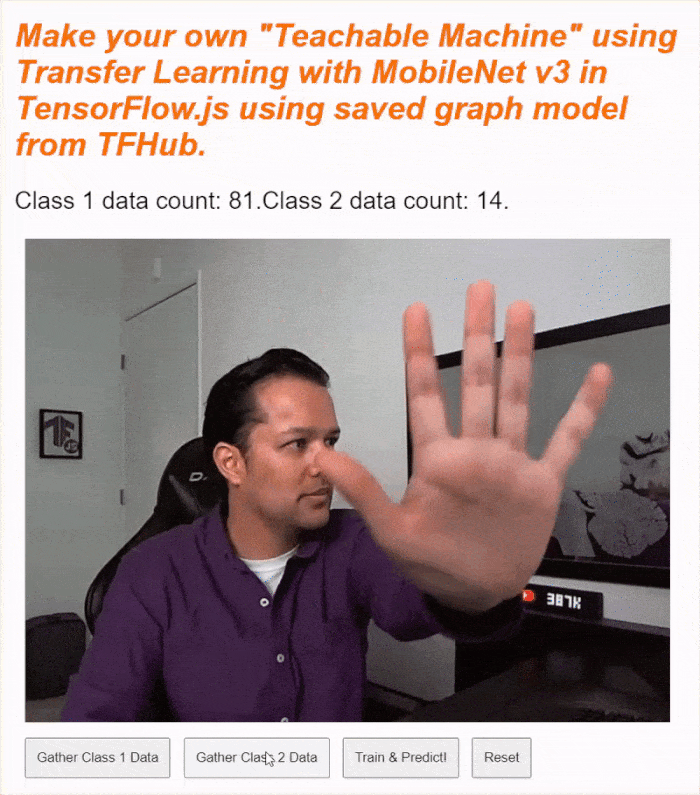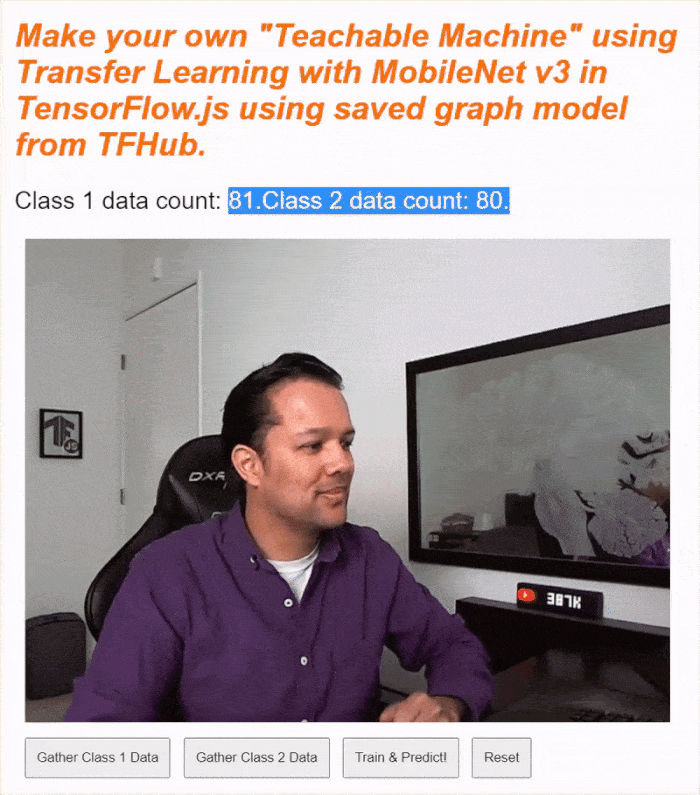
Tekst stanu powinien się zaktualizować, gdy wszystkie tensory zostaną zapisane w pamięci (jak pokazano na zrzucie ekranu powyżej).
14. Wytrenuj i utwórz prognozę
Następnym krokiem jest wdrożenie kodu w obecnie pustej funkcji trainAndPredict(), w której odbywa się uczenie przez przenoszenie. Przyjrzyjmy się kodowi:
script.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
Najpierw zatrzymaj wszystkie bieżące prognozy, ustawiając wartość predict na false.
Następnie przetasuj tablice wejściowe i wyjściowe za pomocą funkcji tf.util.shuffleCombo(), aby upewnić się, że kolejność nie powoduje problemów podczas trenowania.
Przekształć tablicę wyjściową trainingDataOutputs, w tensor1d typu int32, aby można było jej użyć w kodowaniu one-hot. Jest ona przechowywana w zmiennej o nazwie outputsAsTensor.
Użyj funkcji tf.oneHot() ze zmienną outputsAsTensor oraz maksymalną liczbą klas do zakodowania, czyli CLASS_NAMES.length. Dane wyjściowe zakodowane metodą one-hot są teraz przechowywane w nowym tensorze o nazwie oneHotOutputs.
Pamiętaj, że obecnie trainingDataInputs to tablica zarejestrowanych tensorów. Aby użyć ich do trenowania, musisz przekształcić tablicę tensorów w zwykły tensor dwuwymiarowy.
W tym celu w bibliotece TensorFlow.js dostępna jest świetna funkcja o nazwie tf.stack().
która przyjmuje tablicę tensorów i układa je w stos, aby utworzyć tensor o większej liczbie wymiarów. W tym przypadku zwracany jest tensor 2D, czyli partia 1-wymiarowych danych wejściowych o długości 1024 elementów, zawierających zarejestrowane cechy. Jest to potrzebne do trenowania.
Następnie kliknij await model.fit(), aby wytrenować niestandardową głowicę modelu. Tutaj przekazujesz inputsAsTensor zmienną wraz z oneHotOutputs, aby reprezentować dane treningowe, które mają być używane odpowiednio jako przykładowe dane wejściowe i wyjściowe. W obiekcie konfiguracji 3 parametru ustaw shuffle na true, użyj batchSize z 5, z epochs ustawionym na 10, a następnie określ callback dla onEpochEnd w funkcji logProgress, którą zdefiniujesz wkrótce.
Na koniec możesz usunąć utworzone tensory, ponieważ model jest już wytrenowany. Następnie możesz ustawić predict z powrotem na true, aby ponownie włączyć prognozowanie, a potem wywołać funkcję predictLoop(), aby rozpocząć prognozowanie obrazów z kamery internetowej na żywo.
Możesz też zdefiniować funkcję logProcess(), która rejestruje stan trenowania. Jest ona używana w model.fit() powyżej i wyświetla wyniki w konsoli po każdej rundzie trenowania.
Następny poziom jest bardzo blisko! Czas na dodanie funkcji predictLoop(), aby tworzyć prognozy.
Podstawowa pętla prognozowania
W tym miejscu zaimplementujesz główną pętlę prognozowania, która próbkuje klatki z kamery internetowej i stale przewiduje, co znajduje się w każdej klatce, z wynikami w czasie rzeczywistym w przeglądarce.
Sprawdźmy kod:
script.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
Najpierw sprawdź, czy wartość predict to „prawda”, aby prognozy były generowane tylko po wytrenowaniu modelu i udostępnieniu go do użycia.
Następnie możesz uzyskać cechy obrazu dla bieżącego obrazu, tak jak w funkcji dataGatherLoop(). W zasadzie pobierasz klatkę z kamery internetowej za pomocą funkcji tf.browser.from pixels(), normalizujesz ją, zmieniasz jej rozmiar na 224 × 224 piksele, a następnie przekazujesz te dane przez model MobileNet, aby uzyskać wynikowe cechy obrazu.
Teraz możesz jednak użyć nowo wytrenowanej głowy modelu, aby faktycznie przeprowadzić prognozę, przekazując uzyskany wynik imageFeatures przez funkcję predict() wytrenowanego modelu. Następnie możesz zmniejszyć wynikowy tensor, aby ponownie był jednowymiarowy, i przypisać go do zmiennej o nazwie prediction.
Za pomocą tej funkcji prediction możesz znaleźć indeks o najwyższej wartości, używając funkcji argMax(), a następnie przekonwertować wynikowy tensor na tablicę za pomocą funkcji arraySync(), aby uzyskać dostęp do danych bazowych w JavaScript i odkryć pozycję elementu o najwyższej wartości. Ta wartość jest przechowywana w zmiennej o nazwie highestIndex.
W ten sam sposób możesz też uzyskać rzeczywiste wyniki pewności prognozy, wywołując funkcję arraySync() bezpośrednio na tensorze prediction.
Masz już wszystko, czego potrzebujesz, aby zaktualizować tekst STATUS za pomocą danych prediction. Aby uzyskać zrozumiały dla człowieka ciąg znaków dla klasy, wystarczy wyszukać highestIndex w tablicy CLASS_NAMES, a następnie pobrać poziom ufności z predictionArray. Aby uzyskać bardziej czytelny wynik w procentach, pomnóż go przez 100 i math.floor().
Gdy będziesz gotowy, możesz ponownie użyć window.requestAnimationFrame(), aby zadzwonić predictionLoop() i uzyskać klasyfikację strumienia wideo w czasie rzeczywistym. Ten proces będzie trwać, dopóki wartość predict nie zostanie ustawiona na false, jeśli zdecydujesz się wytrenować nowy model na podstawie nowych danych.
To ostatni element układanki. Wdrażanie przycisku resetowania.
15. Wdrażanie przycisku resetowania
Prawie gotowe! Ostatnim elementem układanki jest przycisk resetowania, który umożliwia rozpoczęcie od nowa. Poniżej znajdziesz kod funkcji reset(), która jest obecnie pusta. Zaktualizuj go w ten sposób:
script.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
Najpierw zatrzymaj wszystkie uruchomione pętle prognozowania, ustawiając wartość predict na false. Następnie usuń całą zawartość tablicy examplesCount, ustawiając jej długość na 0. To wygodny sposób na wyczyszczenie całej zawartości tablicy.
Teraz przejrzyj wszystkie aktualnie zarejestrowane tensory trainingDataInputs i upewnij się, że dispose() każdego tensora w nich zawartego, aby ponownie zwolnić pamięć, ponieważ tensory nie są czyszczone przez moduł odśmiecania JavaScriptu.
Gdy to zrobisz, możesz bezpiecznie ustawić długość tablicy na 0 w przypadku tablic trainingDataInputs i trainingDataOutputs, aby je wyczyścić.
Na koniec ustaw tekst STATUS na coś sensownego i wyświetl tensory pozostawione w pamięci, aby sprawdzić, czy wszystko jest w porządku.
Pamiętaj, że w pamięci pozostanie jeszcze kilkaset tensorów, ponieważ model MobileNet i zdefiniowany przez Ciebie perceptron wielowarstwowy nie zostały usunięte. Jeśli po zresetowaniu zdecydujesz się ponownie wytrenować model, musisz użyć tych samych ustawień z nowymi danymi treningowymi.
16. Wypróbujmy to
Czas przetestować własną wersję Teachable Machine.
Przejdź do podglądu na żywo, włącz kamerę internetową, zbierz co najmniej 30 próbek dla klasy 1 dla wybranego obiektu w pomieszczeniu, a następnie zrób to samo dla klasy 2 dla innego obiektu. Kliknij trenuj i sprawdź dziennik konsoli, aby zobaczyć postępy. Trenowanie powinno przebiegać dość szybko:

Po wytrenowaniu pokaż obiekty kamerze, aby uzyskać prognozy na żywo, które zostaną wydrukowane w obszarze tekstu stanu na stronie internetowej w pobliżu górnej krawędzi. Jeśli masz problemy, sprawdź ukończony kod, aby zobaczyć, czy czegoś nie pominąłeś(-aś).
17. Gratulacje
Gratulacje! Właśnie udało Ci się ukończyć pierwszy przykład uczenia transferowego z użyciem TensorFlow.js na żywo w przeglądarce.
Wypróbuj tę funkcję na różnych obiektach. Zauważysz, że niektóre z nich są trudniejsze do rozpoznania niż inne, zwłaszcza jeśli są podobne do czegoś innego. Aby je odróżnić, może być konieczne dodanie większej liczby klas lub danych treningowych.
Podsumowanie
W tym ćwiczeniu dowiedziałeś się:
- czym jest uczenie transferowe i jakie ma zalety w porównaniu z trenowaniem pełnego modelu;
- Jak pobierać modele do ponownego wykorzystania z TensorFlow Hub.
- Jak skonfigurować aplikację internetową odpowiednią do uczenia przez przenoszenie.
- Jak wczytać i użyć modelu podstawowego do generowania cech obrazu.
- Jak wytrenować nową głowicę predykcyjną, która będzie rozpoznawać niestandardowe obiekty na obrazach z kamery internetowej.
- Jak używać uzyskanych modeli do klasyfikowania danych w czasie rzeczywistym.
Co dalej?
Masz już działającą bazę, od której możesz zacząć. Jakie kreatywne pomysły możesz wykorzystać, aby rozszerzyć ten szablon modelu uczenia maszynowego na rzeczywisty przypadek użycia, nad którym pracujesz? Może uda Ci się zrewolucjonizować branżę, w której obecnie pracujesz, i pomóc pracownikom Twojej firmy w trenowaniu modeli do klasyfikowania rzeczy ważnych w ich codziennej pracy? Możliwości są nieograniczone.
Aby dowiedzieć się więcej, rozważ bezpłatne ukończenie tego pełnego kursu, który pokazuje, jak połączyć 2 modele, które masz obecnie w tych ćwiczeniach z programowania, w 1 model, aby zwiększyć wydajność.
Jeśli chcesz dowiedzieć się więcej o teorii, na której opiera się oryginalna aplikacja do uczenia maszynowego, zapoznaj się z tym samouczkiem.
Udostępnianie nam swoich treści
Możesz łatwo rozszerzyć to, co udało Ci się dziś stworzyć, na inne kreatywne zastosowania. Zachęcamy Cię do nieszablonowego myślenia i dalszego eksperymentowania.
Nie zapomnij oznaczyć nas w mediach społecznościowych, używając hashtagu #MadeWithTFJS. Dzięki temu Twój projekt może zostać zaprezentowany na naszym blogu TensorFlow lub podczas przyszłych wydarzeń. Chętnie zobaczymy, co stworzysz.
Witryny, które warto sprawdzić
- Oficjalna strona TensorFlow.js
- Gotowe modele TensorFlow.js
- Interfejs API TensorFlow.js
- TensorFlow.js Show & Tell – zainspiruj się i zobacz, co stworzyli inni.