
1. Прежде чем начать
Использование моделей TensorFlow.js за последние несколько лет выросло в геометрической прогрессии , и многие разработчики JavaScript теперь стремятся взять существующие передовые модели и переобучить их для работы с пользовательскими данными, уникальными для их отрасли. Процесс взятия существующей модели (часто называемой базовой моделью) и использования её в аналогичной, но отличающейся предметной области известен как трансферное обучение.
Перенос обучения имеет множество преимуществ по сравнению с созданием модели с нуля. Вы можете повторно использовать знания, полученные из ранее обученной модели, и вам потребуется меньше примеров нового объекта, который вы хотите классифицировать. Кроме того, обучение часто происходит значительно быстрее, поскольку необходимо переобучить только последние несколько слоев архитектуры модели, а не всю сеть. По этой причине перенос обучения очень хорошо подходит для веб-браузеров, где ресурсы могут различаться в зависимости от устройства выполнения, а также обеспечивает прямой доступ к датчикам для удобного сбора данных.
В этом практическом занятии показано, как создать веб-приложение с нуля, воссоздав популярный веб-сайт Google « Teachable Machine ». Этот сайт позволяет создать функциональное веб-приложение, которое любой пользователь сможет использовать для распознавания заданного объекта, используя всего несколько примеров изображений с веб-камеры. Веб-сайт намеренно сделан минималистичным, чтобы вы могли сосредоточиться на аспектах машинного обучения в этом практическом занятии. Однако, как и в случае с оригинальным сайтом Teachable Machine, здесь есть ample возможности применить свой существующий опыт веб-разработчика для улучшения пользовательского интерфейса.
Предварительные требования
Данный практический урок предназначен для веб-разработчиков, которые в некоторой степени знакомы с готовыми моделями TensorFlow.js и базовым использованием API, и которые хотят начать работу с трансферным обучением в TensorFlow.js.
- Для выполнения этой лабораторной работы предполагается базовое знакомство с TensorFlow.js, HTML5, CSS и JavaScript.
Если вы новичок в TensorFlow.js, рекомендуем сначала пройти этот бесплатный курс «От нуля до героя» , который предполагает отсутствие предварительных знаний в области машинного обучения или TensorFlow.js и шаг за шагом обучает всему необходимому.
Что вы узнаете
- Что такое TensorFlow.js и почему вам следует использовать его в своем следующем веб-приложении.
- Как создать упрощенную веб-страницу на HTML/CSS/JS, которая имитирует пользовательский интерфейс Teachable Machine.
- Как использовать TensorFlow.js для загрузки предварительно обученной базовой модели, в частности MobileNet, для генерации признаков изображений, которые можно использовать в трансферном обучении.
- Как собрать данные с веб-камеры пользователя для распознавания нескольких классов данных.
- Как создать и определить многослойный перцептрон, который принимает признаки изображения и учится классифицировать новые объекты, используя их.
Давайте начнём взламывать...
Что вам понадобится
- Для того чтобы следовать инструкциям, предпочтительнее использовать учетную запись Glitch.com, или же вы можете использовать веб-сервер, который вам удобно редактировать и запускать самостоятельно.
2. Что такое TensorFlow.js?

TensorFlow.js — это библиотека машинного обучения с открытым исходным кодом , которая может работать везде, где работает JavaScript. Она основана на оригинальной библиотеке TensorFlow, написанной на Python , и стремится воссоздать этот опыт разработки и набор API для экосистемы JavaScript.
Где его можно использовать?
Благодаря портативности JavaScript, теперь вы можете писать код на одном языке и с легкостью выполнять машинное обучение на всех следующих платформах:
- Клиентская часть в веб-браузере с использованием чистого JavaScript.
- Node.js используется на стороне сервера и даже для устройств IoT, таких как Raspberry Pi.
- Настольные приложения, использующие Electron
- Нативные мобильные приложения, созданные с использованием React Native.
TensorFlow.js также поддерживает несколько бэкендов в каждой из этих сред (фактические аппаратные среды, в которых он может выполняться, например, ЦП или WebGL. В данном контексте «бэкенд» не означает серверную среду — бэкенд для выполнения может быть клиентской стороной, например, в WebGL), чтобы обеспечить совместимость и высокую скорость работы. В настоящее время TensorFlow.js поддерживает:
- Выполнение WebGL на графическом процессоре устройства (GPU) — это самый быстрый способ выполнения больших моделей (размером более 3 МБ) с ускорением GPU.
- Выполнение Web Assembly (WASM) на ЦП — для повышения производительности ЦП на устройствах, включая, например, мобильные телефоны старого поколения. Это лучше подходит для небольших моделей (размером менее 3 МБ), которые на самом деле могут работать на ЦП быстрее с WASM, чем с WebGL, из-за накладных расходов на загрузку контента в графический процессор.
- Выполнение на ЦП — это резервный вариант на случай, если ни одна из других сред недоступна. Это самый медленный из трех вариантов, но он всегда доступен.
Примечание: Вы можете принудительно выбрать один из этих бэкэндов, если знаете, на каком устройстве будете выполнять программу, или же можете просто позволить TensorFlow.js выбрать его за вас, если не укажете это.
Сверхспособности на стороне клиента
Запуск TensorFlow.js в веб-браузере на клиентском компьютере может привести к ряду преимуществ, которые стоит учитывать.
Конфиденциальность
Вы можете как обучать, так и классифицировать данные на клиентском компьютере, не отправляя их на сторонний веб-сервер. В некоторых случаях это может быть необходимо для соблюдения местных законов, таких как GDPR, или при обработке данных, которые пользователь хочет хранить на своем компьютере и не отправлять третьим лицам.
Скорость
Поскольку вам не нужно отправлять данные на удаленный сервер, процесс классификации данных может быть быстрее. Более того, у вас есть прямой доступ к датчикам устройства, таким как камера, микрофон, GPS, акселерометр и другие, если пользователь предоставит вам такой доступ.
Охват и масштаб
Одним щелчком мыши любой человек в мире может перейти по отправленной вами ссылке, открыть веб-страницу в своем браузере и использовать созданный вами функционал. Нет необходимости в сложной серверной настройке Linux с драйверами CUDA и многим другим, чтобы просто использовать систему машинного обучения.
Расходы
Отсутствие серверов означает, что вам нужно платить только за CDN для размещения ваших HTML, CSS, JS и файлов моделей. Стоимость CDN намного ниже, чем содержание сервера (возможно, с подключенной видеокартой), работающего круглосуточно.
Функции на стороне сервера
Использование реализации TensorFlow.js в Node.js позволяет реализовать следующие возможности.
Полная поддержка CUDA
На стороне сервера для ускорения работы с видеокартой необходимо установить драйверы NVIDIA CUDA , чтобы TensorFlow мог работать с видеокартой (в отличие от браузера, который использует WebGL — установка не требуется). Однако полная поддержка CUDA позволяет в полной мере использовать возможности видеокарты на более низком уровне, что приводит к ускорению обучения и вывода результатов. Производительность сопоставима с реализацией TensorFlow на Python, поскольку обе используют один и тот же бэкенд на C++.
Размер модели
Для передовых моделей, полученных в результате исследований, вы можете работать с очень большими моделями, размером, возможно, в гигабайты. В настоящее время такие модели нельзя запускать в веб-браузере из-за ограничений на использование памяти на вкладку браузера. Для запуска таких больших моделей вы можете использовать Node.js на собственном сервере с необходимыми аппаратными характеристиками для эффективного запуска подобных моделей.
Интернет вещей
Node.js поддерживается на популярных одноплатных компьютерах, таких как Raspberry Pi , что, в свою очередь, означает, что вы можете запускать модели TensorFlow.js и на таких устройствах.
Скорость
Node.js написан на JavaScript, что означает, что он выигрывает от компиляции «на лету». Это значит, что вы часто можете наблюдать повышение производительности при использовании Node.js, поскольку он будет оптимизирован во время выполнения, особенно для любой предварительной обработки, которую вы можете выполнять. Отличный пример этого можно увидеть в этом тематическом исследовании , которое показывает, как Hugging Face использовала Node.js для получения двукратного повышения производительности своей модели обработки естественного языка.
Теперь, когда вы понимаете основы TensorFlow.js, где он может работать и некоторые из его преимуществ, давайте начнем делать с ним полезные вещи!
3. Перенос знаний
Что же такое трансферное обучение?
Перенос знаний предполагает использование уже полученных знаний для изучения чего-то другого, но похожего.
Мы, люди, делаем это постоянно. В вашем мозгу хранится целая жизнь опыта, который вы можете использовать, чтобы распознавать новые вещи, которых вы никогда раньше не видели. Возьмем, к примеру, эту иву:

В зависимости от того, где вы находитесь в мире, возможно, вы никогда раньше не видели деревьев этого вида.
Однако, если я попрошу вас сказать, есть ли на новом изображении ниже ивы, вы, вероятно, сможете заметить их довольно быстро, даже несмотря на то, что они расположены под другим углом и немного отличаются от оригинального изображения, которое я вам показал.

В вашем мозге уже есть множество нейронов, которые умеют распознавать древовидные объекты, а также другие нейроны, хорошо умеющие находить длинные прямые линии. Вы можете использовать эти знания, чтобы быстро классифицировать иву, которая представляет собой древовидный объект с множеством длинных прямых вертикальных ветвей.
Аналогично, если у вас есть модель машинного обучения, уже обученная в определенной области, например, для распознавания изображений, вы можете повторно использовать ее для выполнения другой, но связанной задачи.
То же самое можно сделать с помощью продвинутой модели, такой как MobileNet, очень популярной исследовательской модели, способной распознавать изображения 1000 различных типов объектов. От собак до автомобилей, она была обучена на огромном наборе данных ImageNet , содержащем миллионы размеченных изображений.
В этой анимации вы можете увидеть огромное количество слоев в модели MobileNet V1:
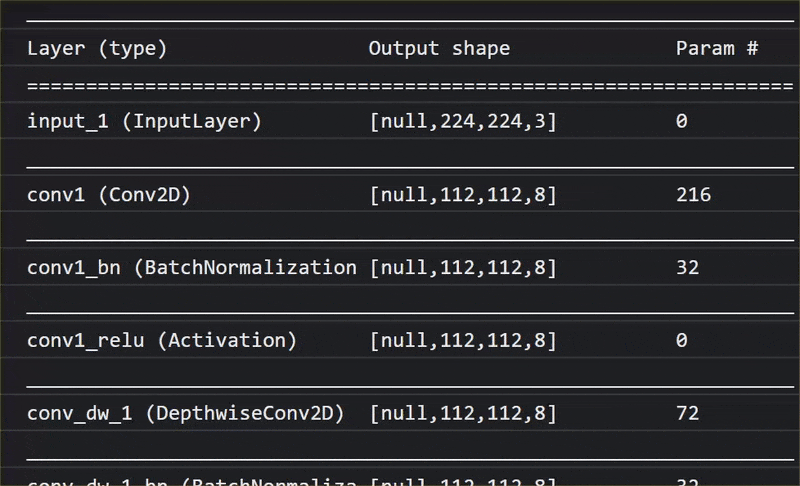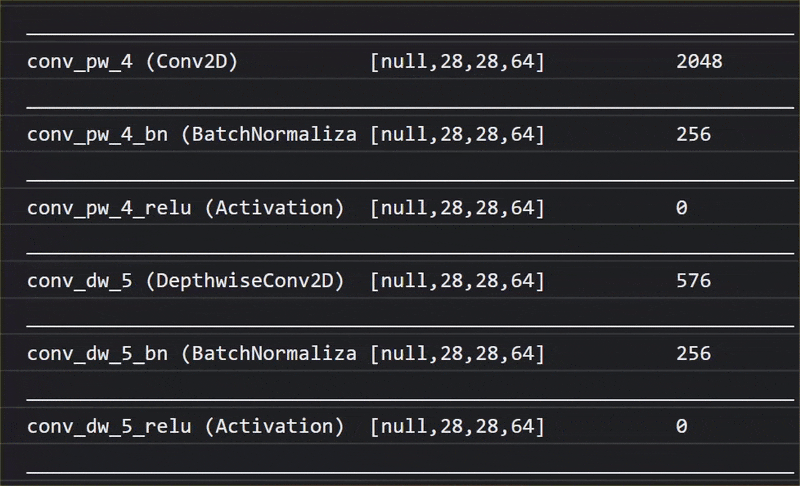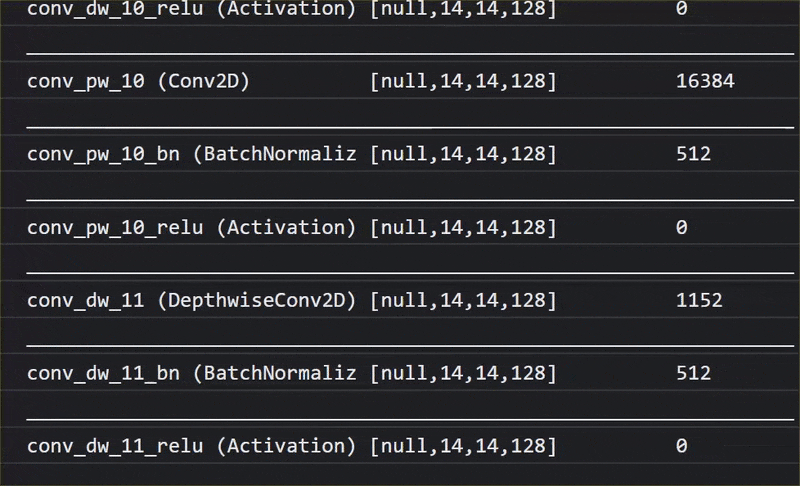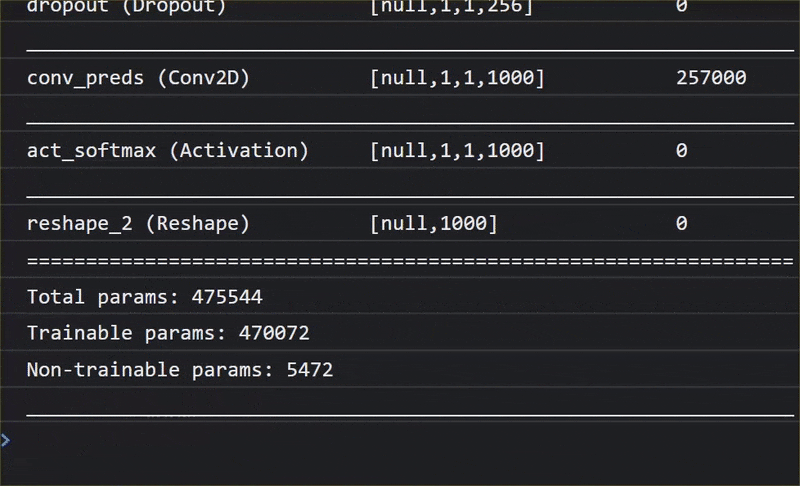
В процессе обучения эта модель научилась извлекать общие признаки, важные для всех этих 1000 объектов, и многие из низкоуровневых признаков, которые она использует для идентификации таких объектов, могут быть полезны и для обнаружения новых объектов, которые она никогда раньше не видела. В конце концов, все в конечном счете — это всего лишь комбинация линий, текстур и форм.
Рассмотрим традиционную архитектуру сверточной нейронной сети (CNN) (похожую на MobileNet) и посмотрим, как трансферное обучение может использовать эту обученную сеть для изучения чего-то нового. На изображении ниже показана типичная архитектура модели CNN, которая в данном случае была обучена распознавать рукописные цифры от 0 до 9:
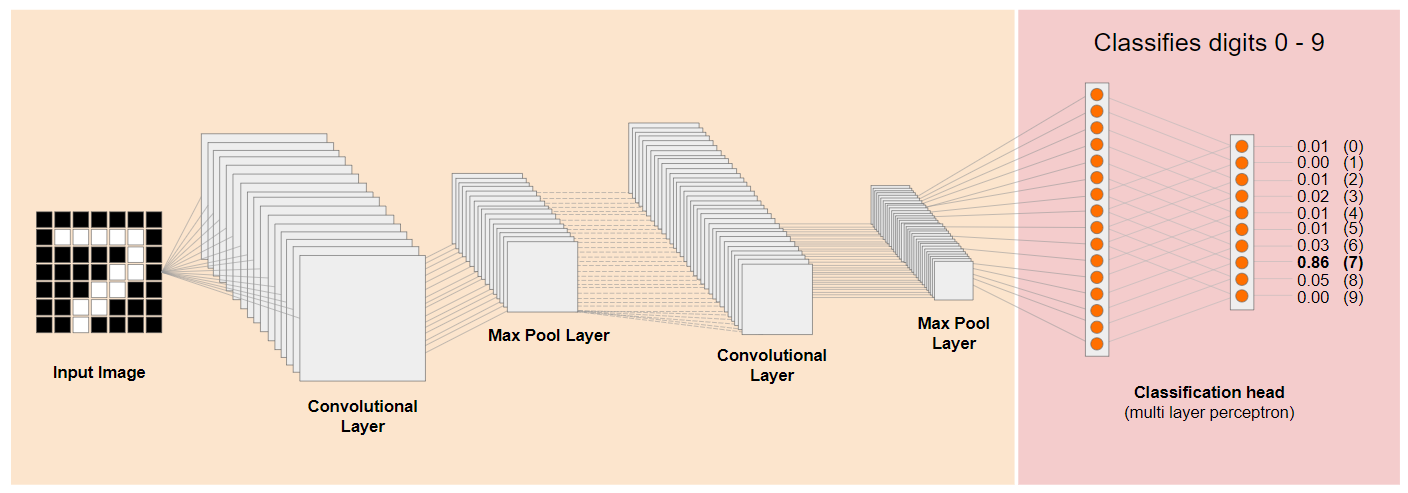
Если бы можно было отделить предварительно обученные нижние слои существующей модели, как показано слева, от слоев классификации, расположенных ближе к концу модели, как показано справа (иногда называемых классификационной частью модели), то нижние слои можно было бы использовать для получения выходных признаков для любого изображения на основе исходных данных, на которых оно было обучено. Вот та же сеть, но без классификационной части:
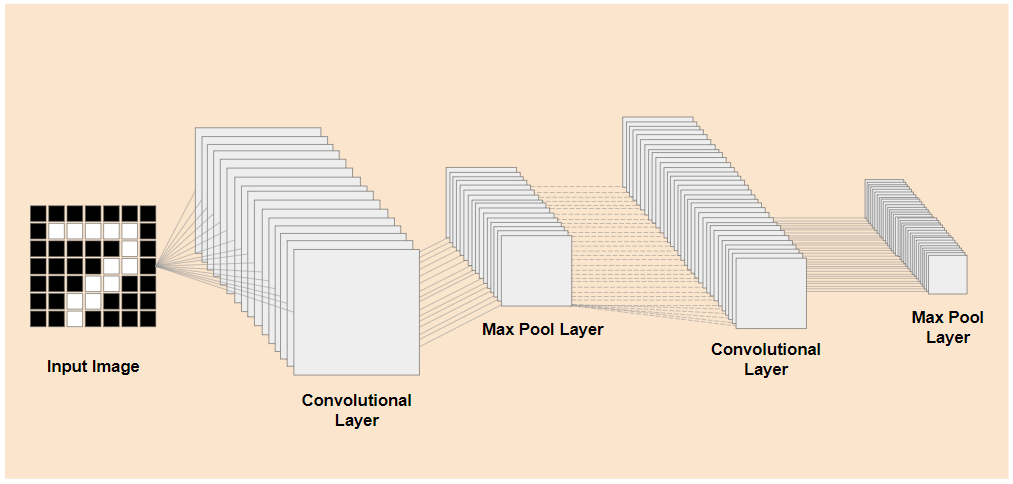
Если предположить, что новый объект, который вы пытаетесь распознать, также может использовать такие выходные характеристики, которым научилась предыдущая модель, то велика вероятность, что их можно будет повторно использовать для новой цели.
На приведенной выше диаграмме эта гипотетическая модель была обучена на цифрах, поэтому, возможно, знания, полученные о цифрах, можно применить и к буквам, таким как a, b и c.
Теперь вы можете добавить новый классификационный модуль, который попытается предсказать значения a, b или c, как показано на рисунке:
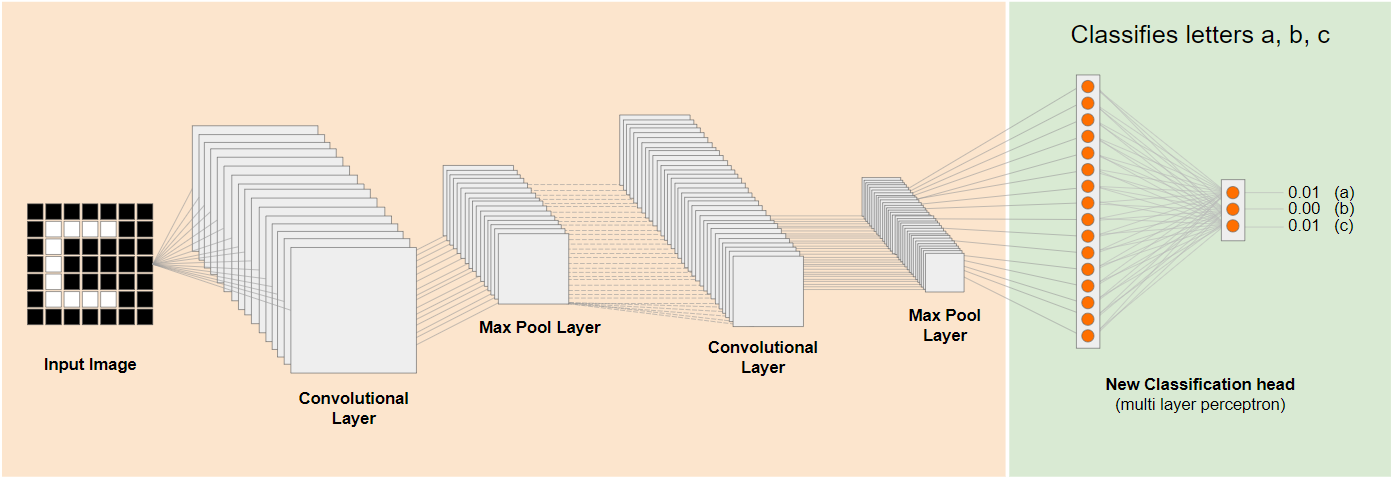
Здесь нижние слои заморожены и не обучаются; только новый классификационный модуль будет обновляться, чтобы обучаться на основе признаков, предоставленных предварительно обученной фрагментированной моделью слева.
Этот процесс известен как трансферное обучение, и именно этим занимается платформа Teachable Machine в фоновом режиме.
Также видно, что, поскольку многослойный перцептрон обучается только в самом конце сети, процесс обучения происходит гораздо быстрее, чем если бы всю сеть обучали с нуля.
Но как можно раздобыть отдельные части модели? Перейдите к следующему разделу, чтобы узнать.
4. TensorFlow Hub - базовые модели
Найдите подходящую базовую модель для использования.
Для более сложных и популярных исследовательских моделей, таких как MobileNet, вы можете перейти в TensorFlow Hub , а затем отфильтровать модели, подходящие для TensorFlow.js и использующие архитектуру MobileNet v3, чтобы получить результаты, подобные показанным здесь:
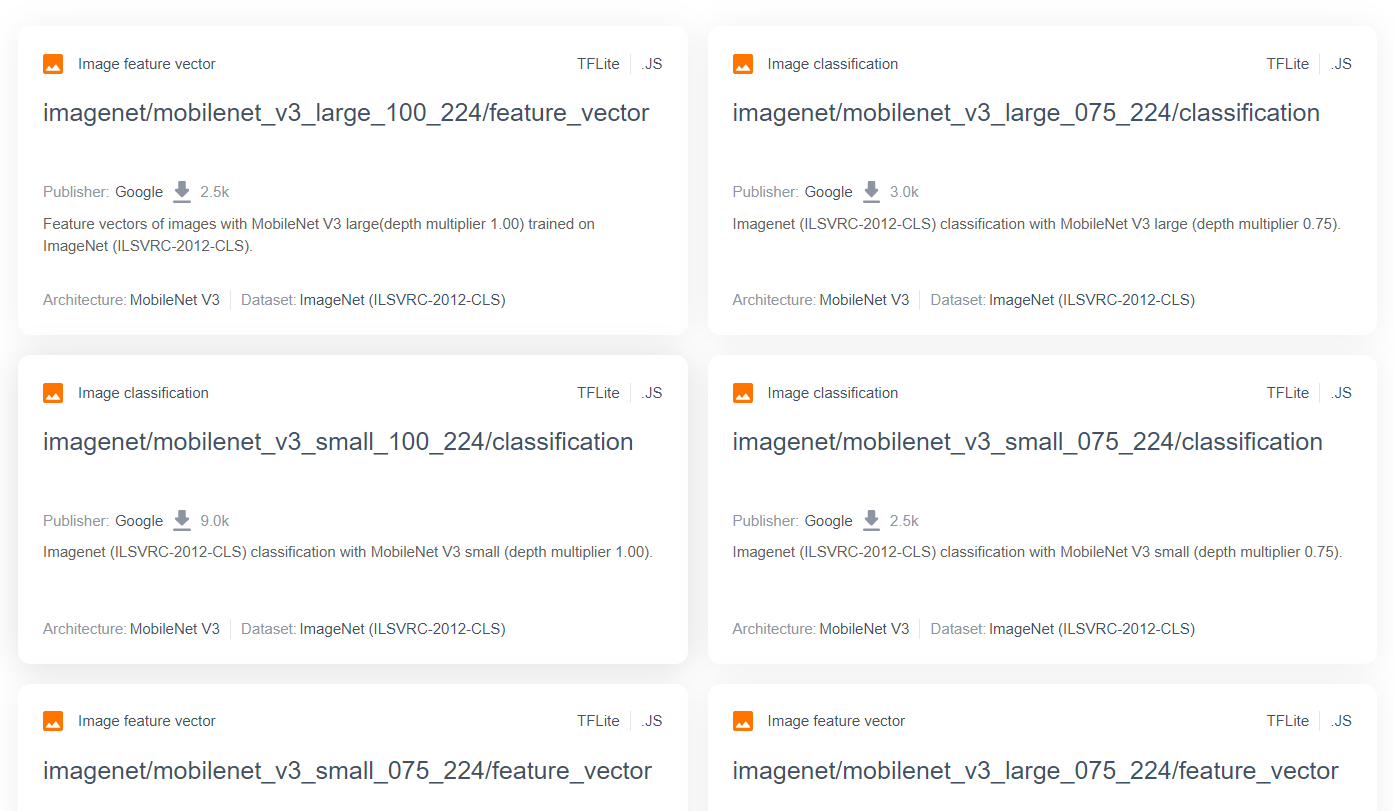
Обратите внимание, что некоторые из этих результатов относятся к типу «классификация изображений» (подробности указаны в верхнем левом углу каждого результата на карточке модели), а другие — к типу «вектор признаков изображения».
Эти результаты в виде векторов признаков изображения представляют собой, по сути, предварительно обработанные версии MobileNet, которые можно использовать для получения векторов признаков изображения вместо окончательной классификации.
Подобные модели часто называют «базовыми моделями», которые затем можно использовать для переноса обучения тем же способом, что и в предыдущем разделе, добавив новый классификационный модуль и обучив его на собственных данных.
Следующее, что нужно проверить, это в каком формате TensorFlow.js выпущена интересующая вас базовая модель. Если вы откроете страницу одной из этих моделей MobileNet v3, использующих векторные представления признаков, вы увидите в документации JavaScript, что она представлена в виде графовой модели, основанной на примере кода из документации, который использует tf.loadGraphModel() .
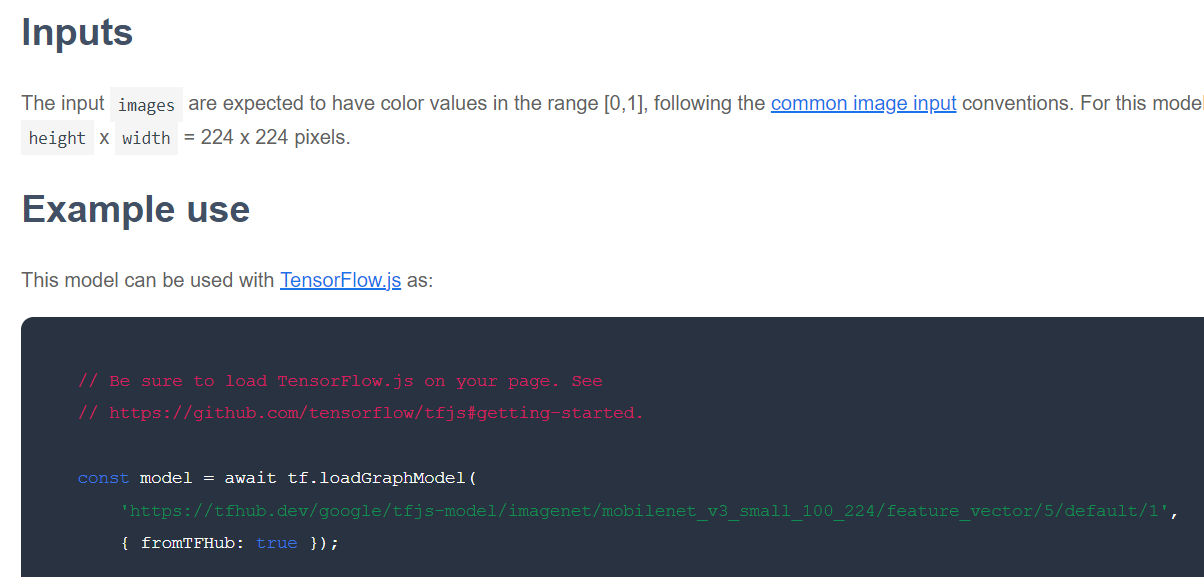
Следует также отметить, что если вы обнаружите модель в формате слоев, а не графа, вы можете выбрать, какие слои заморозить, а какие разморозить для обучения. Это может быть очень полезно при создании модели для новой задачи, которую часто называют «моделью переноса». Однако пока что в этом руководстве вы будете использовать модель графа по умолчанию, в которой развернуто большинство моделей TF Hub. Чтобы узнать больше о работе с моделями слоев, ознакомьтесь с курсом TensorFlow.js «От нуля до героя» .
Преимущества переноса знаний
В чём преимущества использования трансферного обучения по сравнению с обучением всей архитектуры модели с нуля?
Во-первых, ключевым преимуществом использования подхода трансферного обучения является сокращение времени обучения, поскольку у вас уже есть обученная базовая модель, на основе которой можно строить дальнейшую работу.
Во-вторых, благодаря уже пройденному обучению, вы можете обойтись гораздо меньшим количеством примеров нового объекта классификации.
Это действительно здорово, если у вас ограниченное время и ресурсы для сбора примеров данных о том, что вы хотите классифицировать, и вам нужно быстро создать прототип, прежде чем собирать больше обучающих данных, чтобы сделать его более надежным.
Учитывая потребность в меньшем объеме данных и скорость обучения меньшей нейронной сети, трансферное обучение требует меньших ресурсов. Это делает его очень подходящим для браузерной среды, поскольку на современном компьютере оно занимает всего несколько десятков секунд вместо часов, дней или недель, необходимых для полного обучения модели.
Отлично! Теперь, когда вы знаете суть трансферного обучения, пришло время создать свою собственную версию Teachable Machine. Давайте начнём!
5. Подготовьтесь к программированию.
Что вам понадобится
- Современный веб-браузер.
- Базовые знания HTML, CSS, JavaScript и инструментов разработчика Chrome (просмотр вывода в консоль).
Давайте начнём программировать!
Для начала работы были созданы шаблоны от Glitch.com или Codepen.io . Вы можете просто клонировать любой из этих шаблонов в качестве базового состояния для этой практической работы всего одним щелчком мыши.
На Glitch нажмите кнопку " remix this", чтобы создать форк и новый набор файлов для редактирования.
В качестве альтернативы, на Codepen нажмите кнопку « форк» в правом нижнем углу экрана.
Этот очень простой шаблон предоставляет вам следующие файлы:
- HTML-страница (index.html)
- Таблица стилей (style.css)
- Файл для написания нашего JavaScript-кода (script.js)
Для вашего удобства в HTML-файл добавлен импорт библиотеки TensorFlow.js. Он выглядит следующим образом:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Альтернативный вариант: используйте предпочитаемый вами веб-редактор или работайте локально.
Если вы хотите загрузить код и работать локально или в другом онлайн-редакторе, просто создайте 3 файла, указанных выше, в той же директории и скопируйте и вставьте код из нашего шаблона Glitch в каждый из них.
6. Шаблон HTML-приложения
С чего бы начать?
Для создания прототипов необходима базовая HTML-структура, на основе которой можно отобразить полученные результаты. Настройте её сейчас. Вам нужно будет добавить:
- Заголовок страницы.
- Некоторый описательный текст.
- Статусный абзац.
- Видео для фиксации изображения с веб-камеры после его готовности.
- Несколько кнопок для запуска камеры, сбора данных или сброса настроек.
- Импорт файлов TensorFlow.js и JS, которые вы будете кодировать позже.
Откройте index.html и вставьте вместо существующего кода следующий фрагмент, чтобы настроить указанные выше функции:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Разберём по частям
Давайте разберем приведенный выше HTML-код, чтобы выделить некоторые ключевые элементы, которые вы добавили.
- Вы добавили тег
<h1>для заголовка страницы, а также тег<p>с идентификатором 'status', куда будет выводиться информация, поскольку вы используете разные части системы для просмотра результатов. - Вы добавили элемент
<video>с идентификатором 'webcam', на который позже будете отображать видеопоток с веб-камеры. - Вы добавили 5 элементов
<button>. Первый, с ID 'enableCam', включает камеру. Следующие две кнопки имеют класс 'dataCollector', который позволяет собирать примеры изображений объектов, которые вы хотите распознать. Код, который вы напишете позже, будет разработан таким образом, чтобы вы могли добавить любое количество таких кнопок, и они будут работать как положено автоматически.
Обратите внимание, что эти кнопки также имеют специальный пользовательский атрибут data-1hot, значение которого начинается с 0 для первого класса. Это числовой индекс, который вы будете использовать для представления данных определенного класса. Индекс будет использоваться для правильного кодирования выходных классов в числовом представлении вместо строки, поскольку модели машинного обучения могут работать только с числами.
Также имеется атрибут data-name, содержащий удобочитаемое имя, которое вы хотите использовать для этого класса. Это позволяет предоставить пользователю более осмысленное имя вместо числового индекса, полученного методом 1-hot кодирования.
Наконец, у вас есть кнопки «обучение» и «сброс», позволяющие запустить процесс обучения после сбора данных или перезагрузить приложение соответственно.
- Вы также добавили 2 импорта
<script>. Один для TensorFlow.js, а другой для script.js, который вы определите чуть позже.
7. Добавьте стиля
Настройки элементов по умолчанию
Добавьте стили к только что добавленным HTML-элементам, чтобы обеспечить их корректное отображение. Вот несколько стилей, которые правильно определяют положение и размер элементов. Ничего особенного. Конечно, вы можете добавить стили позже, чтобы улучшить пользовательский опыт, как вы видели в видеоролике Teachable Machine.
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
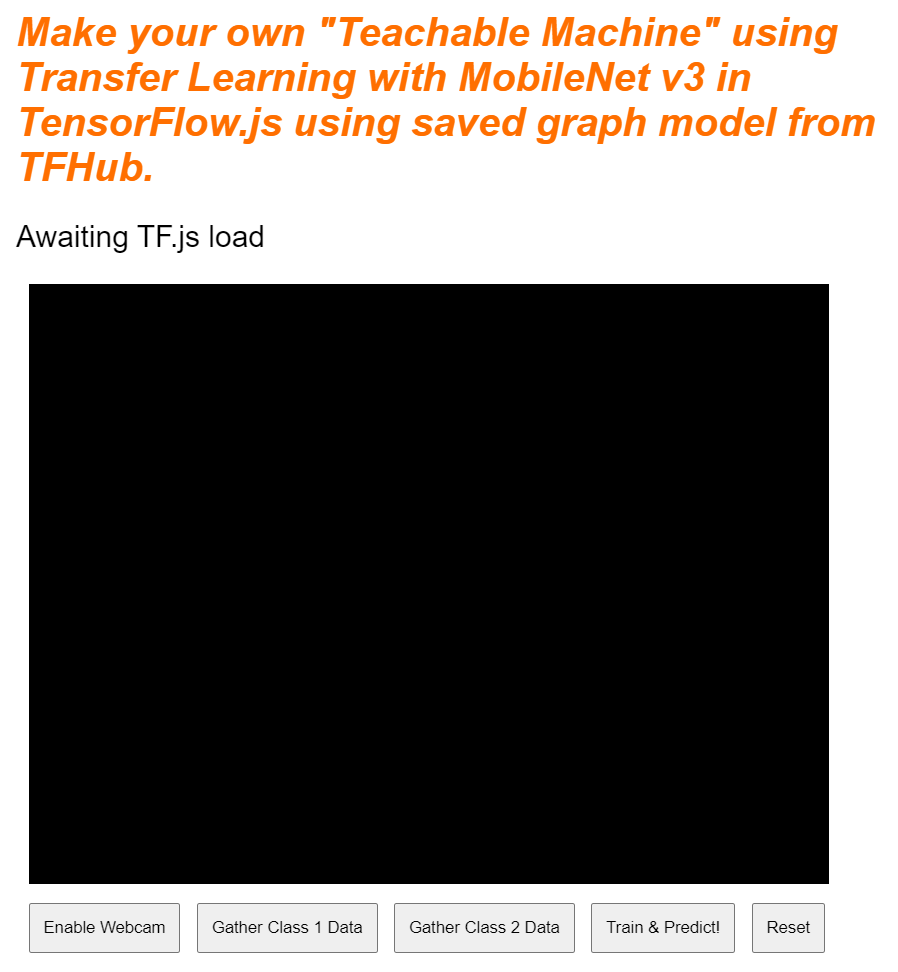
Отлично! Это всё, что вам нужно. Если вы сейчас просмотрите результат, он должен выглядеть примерно так:
8. JavaScript: ключевые константы и обработчики событий
Определите ключевые константы
Для начала добавьте несколько ключевых констант, которые вы будете использовать во всем приложении. Начните с замены содержимого файла script.js следующими константами:
скрипт.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
Давайте разберемся, для чего они нужны:
-
STATUSпросто содержит ссылку на тег абзаца, в который вы будете вносить обновления статуса. -
VIDEOсодержит ссылку на HTML-элемент video, который будет отображать видеопоток с веб-камеры. -
ENABLE_CAM_BUTTON,RESET_BUTTONиTRAIN_BUTTONполучают DOM-ссылки на все кнопки клавиш на HTML-странице. -
MOBILE_NET_INPUT_WIDTHиMOBILE_NET_INPUT_HEIGHTопределяют ожидаемую ширину и высоту входных данных модели MobileNet соответственно. Сохранив эти значения в константе в верхней части файла, вы сможете упростить обновление значений, если решите использовать другую версию позже, вместо того, чтобы заменять их во многих местах. -
STOP_DATA_GATHERустановлен на -1. Он хранит значение состояния, позволяющее определить, когда пользователь перестал нажимать кнопку для сбора данных с веб-камеры. Присвоение этому числу более осмысленного имени делает код более читаемым в дальнейшем. -
CLASS_NAMESслужит для поиска и содержит удобочитаемые названия возможных классов. Этот массив будет заполнен позже.
Итак, теперь, когда у вас есть ссылки на ключевые элементы, пришло время связать с ними обработчики событий.
Добавить обработчики ключевых событий
Для начала добавьте обработчики событий клика к кнопкам, как показано на рисунке:
скрипт.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON — вызывает функцию enableCam при нажатии.
TRAIN_BUTTON — при нажатии вызывает функцию trainAndPredict.
RESET_BUTTON — вызывает функцию сброса при нажатии.
Наконец, в этом разделе вы можете найти все кнопки, имеющие класс 'dataCollector', используя document.querySelectorAll() . Эта функция возвращает массив найденных в документе элементов, соответствующих следующим критериям:
скрипт.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
Пояснение к коду:
Затем вы перебираете найденные кнопки и связываете с каждой по два обработчика событий: один для нажатия кнопки (mousedown), другой для отпускания кнопки (mouseup). Это позволяет записывать данные до тех пор, пока кнопка нажата, что полезно для сбора информации.
Оба события вызывают функцию gatherDataForClass , которую вы определите позже.
На этом этапе вы также можете добавить найденные удобочитаемые имена классов из атрибута data-name HTML-кнопки в массив CLASS_NAMES .
Далее добавьте несколько переменных для хранения ключевых данных, которые будут использованы позже.
скрипт.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
Давайте рассмотрим их подробнее.
Во-первых, у вас есть переменная mobilenet для хранения загруженной модели mobilenet. Изначально установите для неё значение undefined.
Далее у вас есть переменная с именем gatherDataState . Если нажата кнопка «dataCollector», эта переменная изменяется на 1-й ID этой кнопки, как определено в HTML, чтобы вы знали, какой класс данных вы собираете в данный момент. Изначально она установлена в значение STOP_DATA_GATHER , чтобы цикл сбора данных, который вы напишете позже, не собирал данные, когда никакие кнопки не нажаты.
videoPlaying отслеживает, успешно ли загружен и воспроизводится видеопоток с веб-камеры, а также доступен ли он для использования. Изначально для этого параметра установлено значение false , поскольку веб-камера не будет включена, пока вы не нажмете кнопку ENABLE_CAM_BUTTON.
Далее определите два массива: trainingDataInputs и trainingDataOutputs . В них будут храниться значения собранных обучающих данных, полученные при нажатии кнопок «dataCollector» для входных признаков, сгенерированных базовой моделью MobileNet, и выходного класса, выбранного соответственно.
В заключение определяется массив examplesCount, который отслеживает количество примеров для каждого класса после начала их добавления.
Наконец, у вас есть переменная с именем predict , которая управляет циклом прогнозирования. Изначально она имеет значение false . Прогнозирование невозможно, пока позже это значение не будет установлено в true .
Теперь, когда все ключевые переменные определены, давайте загрузим предварительно разобранную базовую модель MobileNet v3, которая предоставляет векторы признаков изображений вместо классификации.
9. Загрузите базовую модель MobileNet.
Сначала определите новую функцию с именем loadMobileNetFeatureModel , как показано ниже. Эта функция должна быть асинхронной, поскольку загрузка модели происходит асинхронно:
скрипт.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
В этом коде вы определяете URL , по которому находится загружаемая модель, согласно документации TFHub.
Затем вы можете загрузить модель, используя await tf.loadGraphModel() , не забыв установить специальное свойство fromTFHub в значение true , поскольку вы загружаете модель с этого веб-сайта Google. Это особый случай, только для моделей, размещенных на TF Hub, где это дополнительное свойство необходимо установить.
После завершения загрузки вы можете установить в innerText элемента STATUS сообщение, чтобы визуально убедиться в корректной загрузке и готовности к сбору данных.
Теперь осталось только прогреть модель. В случае с большими моделями, подобными этой, при первом использовании может потребоваться некоторое время для настройки всего. Поэтому полезно пропускать нули через модель, чтобы избежать ожидания в будущем, когда время может быть более критичным.
Для корректного освобождения тензоров с размером пакета 1 и правильной высотой и шириной, определенными в константах в начале, можно использовать tf.zeros() обернутый в tf.tidy() Наконец, необходимо указать количество цветовых каналов, в данном случае равное 3, поскольку модель ожидает изображения RGB.
Далее, запишите в лог полученную форму тензора, возвращаемого функцией answer.shape() , чтобы лучше понять размер элементов изображения, создаваемых этой моделью.
После определения этой функции вы можете немедленно вызвать её, чтобы инициировать загрузку модели при загрузке страницы.
Если вы посмотрите предварительную версию прямо сейчас, через несколько мгновений текст статуса изменится с «Ожидание загрузки TF.js» на «MobileNet v3 успешно загружен!», как показано ниже. Убедитесь, что это работает, прежде чем продолжить.
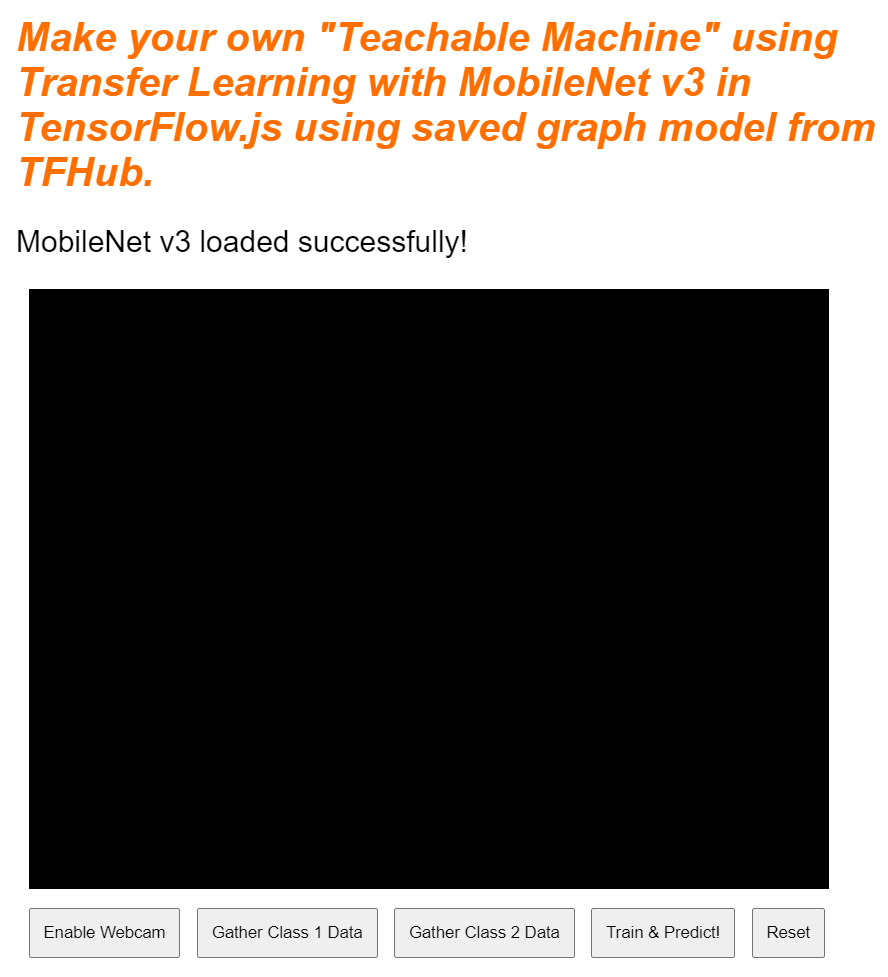
Вы также можете проверить вывод в консоль, чтобы увидеть размер выходных признаков, которые выдает эта модель. После обработки модели MobileNet нулями вы увидите вывод формы [1, 1024] . Первый элемент — это просто размер пакета, равный 1, и вы можете увидеть, что на самом деле возвращается 1024 признака, которые затем можно использовать для классификации новых объектов.
10. Определите новую модель заголовка.
Теперь пришло время определить вашу модель головы, которая по сути представляет собой очень минимальный многослойный перцептрон.
скрипт.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
Давайте разберем этот код. Для начала вы определяете модель tf.sequential, к которой будете добавлять слои модели.
Далее добавьте в эту модель полносвязный слой в качестве входного. Его входной формат составляет 1024 поскольку выходные данные признаков MobileNet v3 имеют именно такой размер. Вы обнаружили это на предыдущем шаге после обработки модели. Этот слой содержит 128 нейронов, использующих функцию активации ReLU.
Если вы новичок в функциях активации и слоях модели, рекомендуем пройти курс, подробно описанный в начале этого семинара, чтобы понять, как эти свойства работают на практике.
Следующий слой, который нужно добавить, — это выходной слой. Количество нейронов должно равняться количеству классов, которые вы пытаетесь предсказать. Для этого можно использовать CLASS_NAMES.length , чтобы узнать, сколько классов вы планируете классифицировать, что равно количеству кнопок сбора данных в пользовательском интерфейсе. Поскольку это задача классификации, на этом выходном слое используется функция активации softmax , которую необходимо использовать при создании модели для решения задач классификации, а не регрессии.
Теперь выведите в консоль краткий обзор новой модели с помощью ` model.summary() .
Наконец, скомпилируйте модель, чтобы она была готова к обучению. Здесь оптимизатор установлен на adam , а функция потерь будет либо binaryCrossentropy если CLASS_NAMES.length равно 2 , либо categoricalCrossentropy если нужно классифицировать 3 или более классов. Также запрашиваются метрики точности, чтобы их можно было отслеживать в логах в дальнейшем для целей отладки.
В консоли вы должны увидеть что-то подобное:
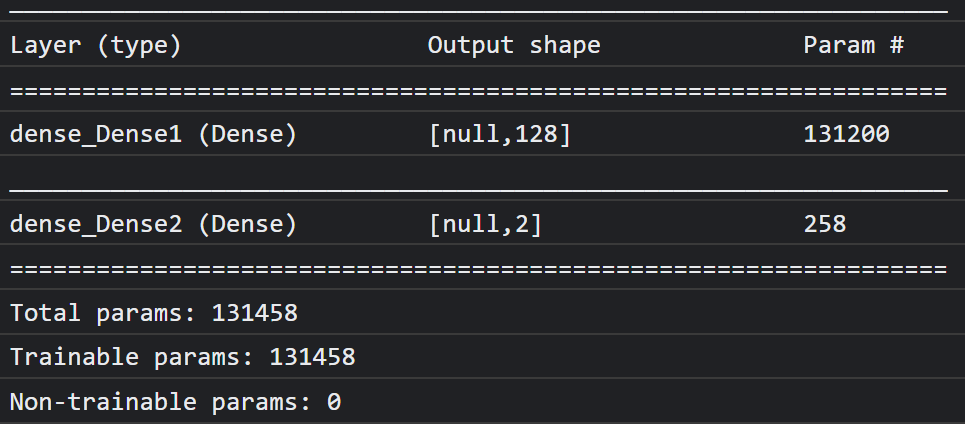
Обратите внимание, что здесь более 130 тысяч обучаемых параметров. Но поскольку это простой плотный слой обычных нейронов, обучение будет проходить довольно быстро.
В качестве дополнительного задания после завершения проекта можно попробовать изменить количество нейронов в первом слое, чтобы определить, насколько низким оно может быть при сохранении приемлемой производительности. В машинном обучении часто приходится методом проб и ошибок искать оптимальные значения параметров, обеспечивающие наилучший баланс между использованием ресурсов и скоростью.
11. Включите веб-камеру.
Теперь пришло время дополнить функцию enableCam() которую вы определили ранее. Добавьте новую функцию с именем hasGetUserMedia() как показано ниже, а затем замените содержимое ранее определенной функции enableCam() соответствующим кодом ниже.
скрипт.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
Сначала создайте функцию с именем hasGetUserMedia() , чтобы проверить, поддерживает ли браузер getUserMedia() , проверив наличие ключевых свойств API браузера.
В функции enableCam() используйте функцию hasGetUserMedia() которую вы только что определили выше, чтобы проверить, поддерживается ли она. Если нет, выведите предупреждение в консоль.
Если это поддерживается, задайте некоторые ограничения для вызова getUserMedia() , например, вам нужен только видеопоток, а также предпочтительно, чтобы width видео составляла 640 пикселей, а height — 480 пикселей. Почему? Дело в том, что нет особого смысла запрашивать видео большего размера, так как его нужно будет уменьшить до 224 на 224 пикселей для передачи в модель MobileNet. Вы также можете сэкономить вычислительные ресурсы, запросив меньшее разрешение. Большинство камер поддерживают разрешение такого размера.
Далее вызовите navigator.mediaDevices.getUserMedia() с указанными выше constraints и дождитесь возврата stream . После возврата stream вы можете заставить элемент VIDEO воспроизводить stream , установив его значение в качестве значения srcObject .
Также следует добавить обработчик событий к элементу VIDEO , чтобы знать, когда stream загружен и успешно воспроизводится.
После загрузки Steam вы можете установить videoPlaying в значение true и удалить параметр ENABLE_CAM_BUTTON , чтобы предотвратить его повторное нажатие, установив для него класс " removed ".
Теперь запустите свой код, нажмите кнопку «Включить камеру» и разрешите доступ к веб-камере. Если вы делаете это впервые, вы должны увидеть себя отображаемым в видеоэлементе на странице, как показано на рисунке:

Итак, теперь пришло время добавить функцию для обработки нажатий на кнопку dataCollector .
12. Обработчик события кнопки сбора данных
Теперь пришло время заполнить вашу пока пустую функцию под названием gatherDataForClass(). Именно её вы назначили в качестве обработчика событий для кнопок dataCollector в начале этого практического занятия.
скрипт.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
Сначала проверьте атрибут data-1hot на текущей нажатой кнопке, вызвав метод this.getAttribute() с именем атрибута, в данном случае data-1hot в качестве параметра. Поскольку это строка, вы можете затем использовать parseInt() для преобразования ее в целое число и присвоить этот результат переменной с именем classNumber.
Next, set the gatherDataState variable accordingly. If the current gatherDataState is equal to STOP_DATA_GATHER (which you set to be -1), then that means you are not currently gathering any data and it was a mousedown event that fired. Set the gatherDataState to be the classNumber you just found.
Otherwise, it means that you are currently gathering data and the event that fired was a mouseup event, and you now want to stop gathering data for that class. Just set it back to the STOP_DATA_GATHER state to end the data gathering loop you will define shortly.
Finally, kick off the call to dataGatherLoop(), which actually performs the recording of class data.
13. Data collection
Now, define the dataGatherLoop() function. This function is responsible for sampling images from the webcam video, passing them through the MobileNet model, and capturing the outputs of that model (the 1024 feature vectors).
It then stores them along with the gatherDataState ID of the button that is currently being pressed so you know what class this data represents.
Let's walk through it:
скрипт.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
You are only going to continue this function's execution if videoPlaying is true, meaning that the webcam is active, and gatherDataState is not equal to STOP_DATA_GATHER and a button for class data gathering is currently being pressed.
Next, wrap your code in a tf.tidy() to dispose of any created tensors in the code that follows. The result of this tf.tidy() code execution is stored in a variable called imageFeatures .
You can now grab a frame of the webcam VIDEO using tf.browser.fromPixels() . The resulting tensor containing the image data is stored in a variable called videoFrameAsTensor .
Next, resize the videoFrameAsTensor variable to be of the correct shape for the MobileNet model's input. Use a tf.image.resizeBilinear() call with the tensor you want to reshape as the first parameter, and then a shape that defines the new height and width as defined by the constants you already created earlier. Finally, set align corners to true by passing the third parameter to avoid any alignment issues when resizing. The result of this resize is stored in a variable called resizedTensorFrame .
Note that this primitive resize stretches the image, as your webcam image is 640 by 480 pixels in size, and the model needs a square image of 224 by 224 pixels.
For the purposes of this demo this should work fine. However, once you complete this codelab, you may want to try and crop a square from this image instead for even better results for any production system you may create later.
Next, normalize the image data. Image data is always in the range of 0 to 255 when using tf.browser.frompixels() , so you can simply divide resizedTensorFrame by 255 to ensure all values are between 0 and 1 instead, which is what the MobileNet model expects as inputs.
Finally, in the tf.tidy() section of the code, push this normalized tensor through the loaded model by calling mobilenet.predict() , to which you pass the expanded version of the normalizedTensorFrame using expandDims() so that it is a batch of 1, as the model expects a batch of inputs for processing.
Once the result comes back, you can then immediately call squeeze() on that returned result to squash it back down to a 1D tensor, which you then return and assign to the imageFeatures variable that captures the result from tf.tidy() .
Now that you have the imageFeatures from the MobileNet model, you can record those by pushing them onto the trainingDataInputs array that you defined previously.
You can also record what this input represents by pushing the current gatherDataState to the trainingDataOutputs array too.
Note that the gatherDataState variable would have been set to the current class's numerical ID you are recording data for when the button was clicked in the previously defined gatherDataForClass() function.
At this point you can also increment the number of examples you have for a given class. To do this, first check if the index within the examplesCount array has been initialized before or not. If it is undefined, set it to 0 to initialize the counter for a given class's numerical ID, and then you can increment the examplesCount for the current gatherDataState .
Now update the STATUS element's text on the web page to show the current counts for each class as they're captured. To do this, loop through the CLASS_NAMES array, and print the human readable name combined with the data count at the same index in examplesCount .
Finally, call window.requestAnimationFrame() with dataGatherLoop passed as a parameter, to recursively call this function again. This will continue to sample frames from the video until the button's mouseup is detected, and gatherDataState is set to STOP_DATA_GATHER, at which point the data gather loop will end.
If you run your code now, you should be able to click the enable camera button, await the webcam to load, and then click and hold each of the data gather buttons to gather examples for each class of data. Here you see me gather data for my mobile phone and my hand respectively.
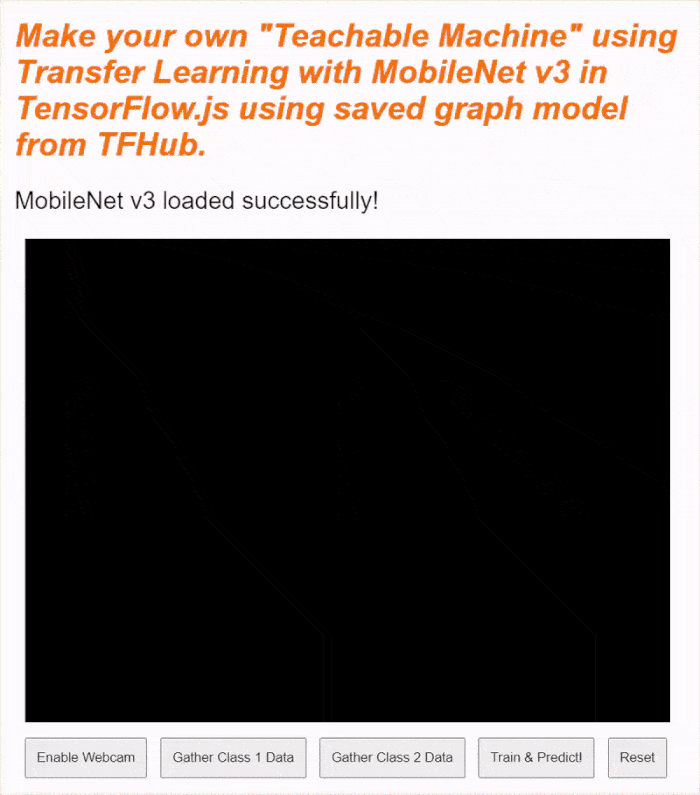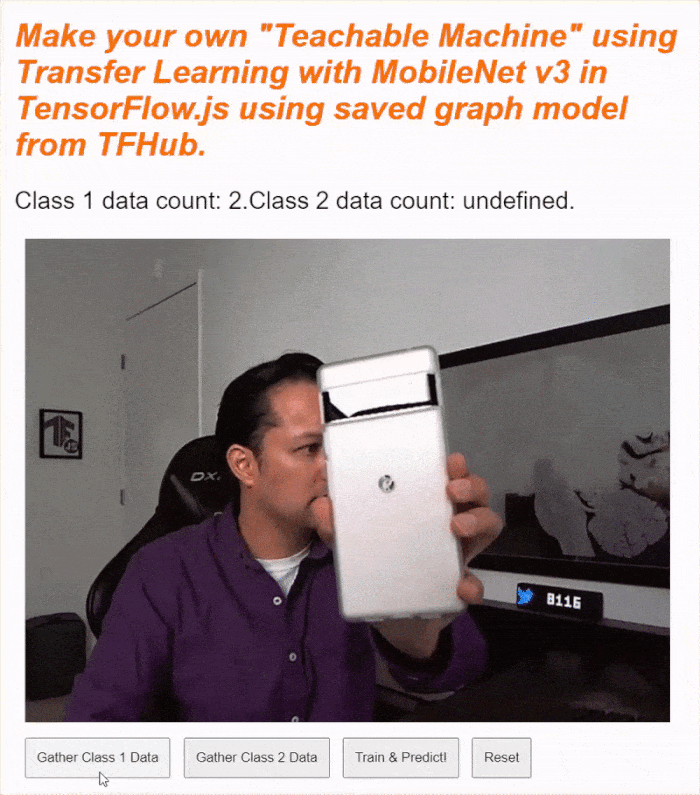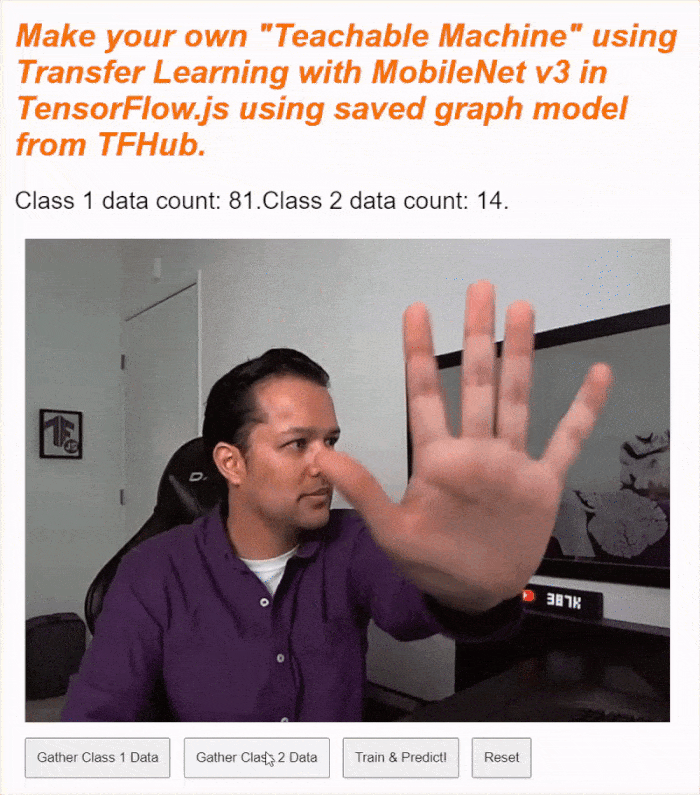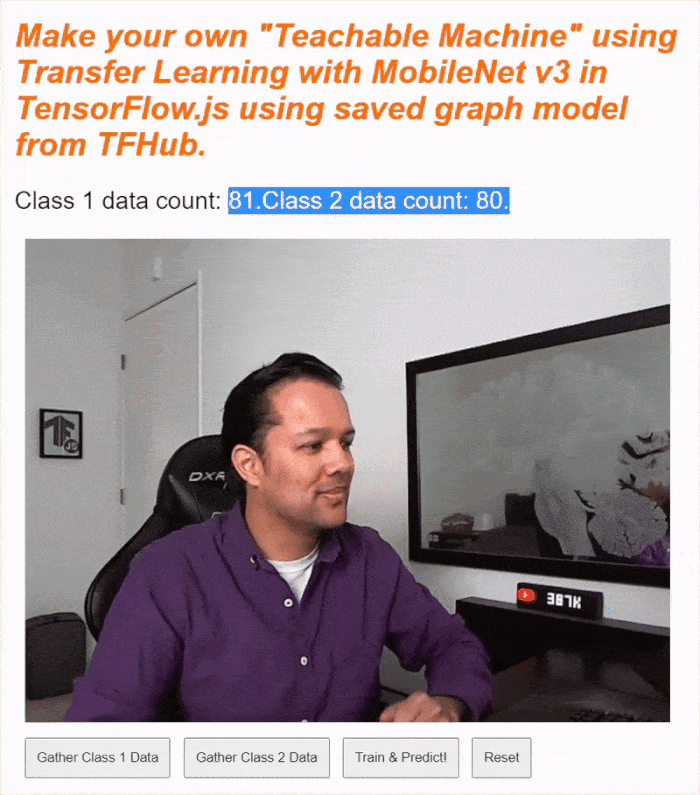
You should see the status text updated as it stores all the tensors in memory as shown in the screen capture above.
14. Train and predict
The next step is to implement code for your currently empty trainAndPredict() function, which is where the transfer learning takes place. Let's take a look at the code:
скрипт.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
First, ensure you stop any current predictions from taking place by setting predict to false .
Next, shuffle your input and output arrays using tf.util.shuffleCombo() to ensure the order does not cause issues in training.
Convert your output array, trainingDataOutputs, to be a tensor1d of type int32 so it is ready to be used in a one hot encoding . This is stored in a variable named outputsAsTensor .
Use the tf.oneHot() function with this outputsAsTensor variable along with the max number of classes to encode, which is just the CLASS_NAMES.length . Your one hot encoded outputs are now stored in a new tensor called oneHotOutputs .
Note that currently trainingDataInputs is an array of recorded tensors. In order to use these for training you will need to convert the array of tensors to become a regular 2D tensor.
To do that there is a great function within the TensorFlow.js library called tf.stack() ,
which takes an array of tensors and stacks them together to produce a higher dimensional tensor as an output. In this case a tensor 2D is returned, that's a batch of 1 dimensional inputs that are each 1024 in length containing the features recorded, which is what you need for training.
Next, await model.fit() to train the custom model head. Here you pass your inputsAsTensor variable along with the oneHotOutputs to represent the training data to use for example inputs and target outputs respectively. In the configuration object for the 3rd parameter, set shuffle to true , use batchSize of 5 , with epochs set to 10 , and then specify a callback for onEpochEnd to the logProgress function that you will define shortly.
Finally, you can dispose of the created tensors as the model is now trained. You can then set predict back to true to allow predictions to take place again, and then call the predictLoop() function to start predicting live webcam images.
You can also define the logProcess() function to log the state of training, which is used in model.fit() above and that prints results to console after each round of training.
You're almost there! Time to add the predictLoop() function to make predictions.
Core prediction loop
Here you implement the main prediction loop that samples frames from a webcam and continuously predicts what is in each frame with real time results in the browser.
Let's check the code:
скрипт.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
First, check that predict is true, so that predictions are only made after a model is trained and is available to use.
Next, you can get the image features for the current image just like you did in the dataGatherLoop() function. Essentially, you grab a frame from the webcam using tf.browser.from pixels() , normalise it, resize it to be 224 by 224 pixels in size, and then pass that data through the MobileNet model to get the resulting image features.
Now, however, you can use your newly trained model head to actually perform a prediction by passing the resulting imageFeatures just found through the trained model's predict() function. You can then squeeze the resulting tensor to make it 1 dimensional again and assign it to a variable called prediction .
With this prediction you can find the index that has the highest value using argMax() , and then convert this resulting tensor to an array using arraySync() to get at the underlying data in JavaScript to discover the position of the highest valued element. This value is stored in the variable called highestIndex .
You can also get the actual prediction confidence scores in the same way by calling arraySync() on the prediction tensor directly.
You now have everything you need to update the STATUS text with the prediction data. To get the human readable string for the class you can just look up the highestIndex in the CLASS_NAMES array, and then grab the confidence value from the predictionArray . To make it more readable as a percentage, just multiply by 100 and math.floor() the result.
Finally, you can use window.requestAnimationFrame() to call predictionLoop() all over again once ready, to get real time classification on your video stream. This continues until predict is set to false if you choose to train a new model with new data.
Which brings you to the final piece of the puzzle. Implementing the reset button.
15. Implement the reset button
Almost complete! The final piece of the puzzle is to implement a reset button to start over. The code for your currently empty reset() function is below. Go ahead and update it as follows:
скрипт.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
First, stop any running prediction loops by setting predict to false . Next, delete all contents in the examplesCount array by setting its length to 0, which is a handy way to clear all contents from an array.
Now go through all the current recorded trainingDataInputs and ensure you dispose() of each tensor contained within it to free up memory again, as Tensors are not cleaned up by the JavaScript garbage collector.
Once that is done you can now safely set the array length to 0 on both the trainingDataInputs and trainingDataOutputs arrays to clear those too.
Finally set the STATUS text to something sensible, and print out the tensors left in memory as a sanity check.
Note that there will be a few hundred tensors still in memory as both the MobileNet model and the multi-layer perceptron you defined are not disposed of. You will need to reuse them with new training data if you decide to train again after this reset.
16. Let's try it out
It's time to test out your very own version of Teachable Machine!
Head to the live preview, enable the webcam, gather at least 30 samples for class 1 for some object in your room, and then do the same for class 2 for a different object, click train, and check the console log to see progress. It should train pretty fast:

Once trained, show the objects to the camera to get live predictions that will be printed to the status text area on the web page near the top. If you are having trouble, check my completed working code to see if you missed copying over anything.
17. Поздравляем!
Congratulations! You have just completed your very first transfer learning example using TensorFlow.js live in the browser.
Try it out, test it on a variety of objects, you may notice some things are harder to recognize than others, especially if they are similar to something else. You may need to add more classes or training data to be able to tell them apart.
Краткий обзор
In this codelab you learned:
- What transfer learning is, and its advantages over training a full model.
- How to get models for re-use from TensorFlow Hub.
- How to set up a web app suitable for transfer learning.
- How to load and use a base model to generate image features.
- How to train a new prediction head that can recognize custom objects from webcam imagery.
- How to use the resulting models to classify data in real time.
Что дальше?
Now that you have a working base to start from, what creative ideas can you come up with to extend this machine learning model boilerplate for a real world use case you may be working on? Maybe you could revolutionize the industry that you currently work in to help folk at your company train models to classify things that are important in their day-to-day work? The possibilities are endless.
To go further, consider taking this full course for free , which shows you how to combine the 2 models you currently have in this codelab into 1 single model for efficiency.
Also if you are curious more around the theory behind the original teachable machine application check out this tutorial .
Share what you make with us
You can easily extend what you made today for other creative use cases too and we encourage you to think outside the box and keep hacking.
Remember to tag us on social media using the #MadeWithTFJS hashtag for a chance for your project to be featured on our TensorFlow blog or even future events . We would love to see what you make.
Websites to check out
- TensorFlow.js official website
- TensorFlow.js pre-made models
- TensorFlow.js API
- TensorFlow.js Show & Tell — get inspired and see what others have made.