
1. ก่อนเริ่มต้น
การใช้งานโมเดล TensorFlow.js เติบโตแบบก้าวกระโดดในช่วง 2-3 ปีที่ผ่านมา และตอนนี้ผู้พัฒนา JavaScript จำนวนมากกำลังมองหาโมเดลที่ล้ำสมัยอยู่แล้วและฝึกโมเดลเหล่านั้นใหม่ให้ทำงานร่วมกับข้อมูลที่กำหนดเองซึ่งเป็นข้อมูลเฉพาะของอุตสาหกรรมของตน การนำโมเดลที่มีอยู่ (มักเรียกว่าโมเดลพื้นฐาน) ไปใช้กับโดเมนที่คล้ายกันแต่แตกต่างกันเรียกว่าการเรียนรู้แบบถ่ายโอน
การเรียนรู้แบบถ่ายโอนมีข้อดีหลายอย่างเหนือกว่าการเริ่มต้นจากโมเดลเปล่าๆ คุณสามารถนำความรู้ที่ได้เรียนรู้จากโมเดลที่ฝึกไว้ก่อนหน้านี้กลับมาใช้ซ้ำได้ และต้องใช้ตัวอย่างของรายการใหม่ที่ต้องการจัดประเภทน้อยลง นอกจากนี้ การฝึกยังมักจะเร็วกว่ามากเนื่องจากคุณจะต้องฝึกเลเยอร์ 2-3 เลเยอร์สุดท้ายของสถาปัตยกรรมโมเดลซ้ำเท่านั้นแทนที่จะฝึกทั้งเครือข่าย ด้วยเหตุนี้ การเรียนรู้แบบถ่ายโอนจึงเหมาะอย่างยิ่งกับสภาพแวดล้อมของเว็บเบราว์เซอร์ ซึ่งทรัพยากรอาจแตกต่างกันไปตามอุปกรณ์ที่ใช้ดำเนินการ แต่ก็มีการเข้าถึงเซ็นเซอร์โดยตรงเพื่อให้ได้ข้อมูลอย่างง่ายดาย
Codelab นี้แสดงวิธีสร้างเว็บแอปจากพื้นที่ว่าง โดยสร้างเว็บไซต์ "Teachable Machine" ยอดนิยมของ Google ขึ้นมาใหม่ เว็บไซต์นี้ช่วยให้คุณสร้างเว็บแอปที่ใช้งานได้จริงซึ่งผู้ใช้ทุกคนสามารถใช้เพื่อจดจำออบเจ็กต์ที่กำหนดเองได้โดยใช้รูปภาพตัวอย่างเพียงไม่กี่รูปจากเว็บแคม เราตั้งใจออกแบบเว็บไซต์ให้เรียบง่ายเพื่อให้คุณมุ่งเน้นไปที่ด้านแมชชีนเลิร์นนิงของโค้ดแล็บนี้ อย่างไรก็ตาม เช่นเดียวกับเว็บไซต์ Teachable Machine ต้นฉบับ คุณสามารถใช้ประสบการณ์การเป็นนักพัฒนาเว็บที่มีอยู่เพื่อปรับปรุง UX ได้
ข้อกำหนดเบื้องต้น
Codelab นี้เขียนขึ้นสำหรับนักพัฒนาเว็บที่คุ้นเคยกับโมเดลที่สร้างไว้ล่วงหน้าของ TensorFlow.js และการใช้งาน API ขั้นพื้นฐานอยู่บ้าง และต้องการเริ่มต้นใช้งานการถ่ายโอนการเรียนรู้ใน TensorFlow.js
- ห้องทดลองนี้ถือว่าคุณมีความคุ้นเคยพื้นฐานกับ TensorFlow.js, HTML5, CSS และ JavaScript
หากคุณเพิ่งเริ่มใช้ Tensorflow.js โปรดพิจารณาลงเรียนหลักสูตรฟรีนี้ตั้งแต่ต้นจนจบก่อน ซึ่งหลักสูตรนี้จะถือว่าคุณไม่มีพื้นฐานเกี่ยวกับแมชชีนเลิร์นนิงหรือ TensorFlow.js และจะสอนทุกสิ่งที่คุณจำเป็นต้องรู้ในขั้นตอนเล็กๆ
สิ่งที่คุณจะได้เรียนรู้
- TensorFlow.js คืออะไรและเหตุผลที่ควรใช้ในเว็บแอปถัดไป
- วิธีสร้างหน้าเว็บ HTML/CSS /JS แบบง่ายที่จำลองประสบการณ์ของผู้ใช้ Teachable Machine
- วิธีใช้ TensorFlow.js เพื่อโหลดโมเดลพื้นฐานที่ฝึกไว้ล่วงหน้า โดยเฉพาะ MobileNet เพื่อสร้างฟีเจอร์รูปภาพที่ใช้ในการถ่ายโอนการเรียนรู้ได้
- วิธีกรอกข้อมูลจากเว็บแคมของผู้ใช้สำหรับข้อมูลหลายคลาสที่คุณต้องการจดจำ
- วิธีสร้างและกำหนด Multi-Layer Perceptron ที่ใช้ฟีเจอร์รูปภาพและเรียนรู้ที่จะจัดประเภทออบเจ็กต์ใหม่โดยใช้ฟีเจอร์เหล่านั้น
มาเริ่มแฮ็กกันเลย...
สิ่งที่คุณต้องมี
- เราขอแนะนำให้ใช้บัญชี Glitch.com เพื่อทำตาม หรือคุณจะใช้สภาพแวดล้อมการแสดงผลเว็บที่คุณถนัดในการแก้ไขและเรียกใช้ด้วยตนเองก็ได้
2. TensorFlow.js คืออะไร

TensorFlow.js เป็นไลบรารีแมชชีนเลิร์นนิงแบบโอเพนซอร์สที่ทำงานได้ทุกที่ที่ JavaScript ทำงานได้ โดยอิงตามไลบรารี TensorFlow ดั้งเดิมที่เขียนด้วย Python และมีเป้าหมายที่จะสร้างประสบการณ์การใช้งานของนักพัฒนาซอฟต์แวร์และชุด API นี้ขึ้นมาใหม่สำหรับระบบนิเวศของ JavaScript
ตำแหน่งที่ใช้งานได้
เนื่องจาก JavaScript สามารถพกพาได้ คุณจึงเขียนได้ในภาษาเดียวและใช้แมชชีนเลิร์นนิงในแพลตฟอร์มต่อไปนี้ทั้งหมดได้อย่างง่ายดาย
- ฝั่งไคลเอ็นต์ในเว็บเบราว์เซอร์โดยใช้ JavaScript แบบเดิม
- ฝั่งเซิร์ฟเวอร์และแม้แต่อุปกรณ์ IoT เช่น Raspberry Pi ที่ใช้ Node.js
- แอปบนเดสก์ท็อปที่ใช้ Electron
- แอปที่มากับอุปกรณ์เคลื่อนที่ที่ใช้ React Native
นอกจากนี้ TensorFlow.js ยังรองรับแบ็กเอนด์หลายรายการภายในแต่ละสภาพแวดล้อมเหล่านี้ (สภาพแวดล้อมฮาร์ดแวร์จริงที่สามารถดำเนินการได้ เช่น CPU หรือ WebGL) "แบ็กเอนด์" ในบริบทนี้ไม่ได้หมายถึงสภาพแวดล้อมฝั่งเซิร์ฟเวอร์ แต่แบ็กเอนด์สำหรับการดำเนินการอาจเป็นฝั่งไคลเอ็นต์ใน WebGL เป็นต้น เพื่อให้มั่นใจในความเข้ากันได้และยังคงให้การทำงานเป็นไปอย่างรวดเร็ว ปัจจุบัน TensorFlow.js รองรับ
- การดำเนินการ WebGL ในกราฟิกการ์ดของอุปกรณ์ (GPU) - นี่เป็นวิธีที่เร็วที่สุดในการดำเนินการโมเดลขนาดใหญ่ (ขนาดมากกว่า 3 MB) ด้วยการเร่งความเร็วด้วย GPU
- การดำเนินการ Web Assembly (WASM) ใน CPU - เพื่อปรับปรุงประสิทธิภาพ CPU ในอุปกรณ์ต่างๆ รวมถึงโทรศัพท์มือถือรุ่นเก่าด้วย วิธีนี้เหมาะกับโมเดลขนาดเล็ก (ขนาดน้อยกว่า 3 MB) ซึ่งทำงานบน CPU ด้วย WASM ได้เร็วกว่า WebGL เนื่องจากค่าใช้จ่ายในการอัปโหลดเนื้อหาไปยังหน่วยประมวลผลกราฟิก
- การดำเนินการ CPU - ควรใช้เป็นตัวเลือกสำรองหากไม่มีสภาพแวดล้อมอื่นๆ วิธีนี้ช้าที่สุดใน 3 วิธี แต่ก็พร้อมให้บริการคุณเสมอ
หมายเหตุ: คุณเลือกบังคับใช้แบ็กเอนด์ใดแบ็กเอนด์หนึ่งได้หากทราบว่าอุปกรณ์ใดจะใช้ดำเนินการ หรือจะปล่อยให้ TensorFlow.js ตัดสินใจให้คุณก็ได้หากไม่ได้ระบุ
พลังพิเศษฝั่งไคลเอ็นต์
การเรียกใช้ TensorFlow.js ในเว็บเบราว์เซอร์บนเครื่องไคลเอ็นต์อาจมีประโยชน์หลายประการที่ควรพิจารณา
ความเป็นส่วนตัว
คุณฝึกและจัดประเภทข้อมูลในเครื่องไคลเอ็นต์ได้โดยไม่ต้องส่งข้อมูลไปยังเว็บเซิร์ฟเวอร์ของบุคคลที่สาม บางครั้งคุณอาจต้องดำเนินการดังกล่าวเพื่อปฏิบัติตามกฎหมายท้องถิ่น เช่น GDPR หรือเมื่อประมวลผลข้อมูลใดๆ ที่ผู้ใช้อาจต้องการเก็บไว้ในเครื่องของตนและไม่ส่งไปยังบุคคลที่สาม
ความเร็ว
เนื่องจากคุณไม่ต้องส่งข้อมูลไปยังเซิร์ฟเวอร์ระยะไกล การอนุมาน (การจัดประเภทข้อมูล) จึงทำได้เร็วขึ้น และที่ดียิ่งกว่านั้นคือคุณมีสิทธิ์เข้าถึงเซ็นเซอร์ของอุปกรณ์โดยตรง เช่น กล้อง ไมโครโฟน GPS ตัวตรวจวัดความเร่ง และอื่นๆ หากผู้ใช้ให้สิทธิ์เข้าถึงแก่คุณ
การเข้าถึงและการขยายขนาด
เพียงคลิกเดียว ทุกคนทั่วโลกก็สามารถคลิกลิงก์ที่คุณส่ง เปิดหน้าเว็บในเบราว์เซอร์ และใช้ประโยชน์จากสิ่งที่คุณสร้างขึ้นได้ ไม่จำเป็นต้องตั้งค่า Linux ที่ซับซ้อนฝั่งเซิร์ฟเวอร์ด้วยไดรเวอร์ CUDA และอื่นๆ อีกมากมายเพียงเพื่อใช้ระบบแมชชีนเลิร์นนิง
ค่าใช้จ่าย
การไม่มีเซิร์ฟเวอร์หมายความว่าสิ่งเดียวที่คุณต้องจ่ายคือ CDN เพื่อโฮสต์ไฟล์ HTML, CSS, JS และโมเดล ต้นทุนของ CDN ถูกกว่าการเปิดเซิร์ฟเวอร์ (อาจมีกราฟิกการ์ดติดอยู่) ตลอด 24 ชั่วโมงมาก
ฟีเจอร์ฝั่งเซิร์ฟเวอร์
การใช้ประโยชน์จากการติดตั้งใช้งาน TensorFlow.js ใน Node.js จะช่วยให้ใช้ฟีเจอร์ต่อไปนี้ได้
รองรับ CUDA อย่างเต็มรูปแบบ
ในฝั่งเซิร์ฟเวอร์ สำหรับการเร่งความเร็วการ์ดกราฟิก คุณต้องติดตั้งไดรเวอร์ NVIDIA CUDA เพื่อให้ TensorFlow ทำงานร่วมกับการ์ดกราฟิกได้ (ต่างจากในเบราว์เซอร์ที่ใช้ WebGL ซึ่งไม่ต้องติดตั้ง) แต่การรองรับ CUDA อย่างเต็มรูปแบบจะช่วยให้คุณใช้ความสามารถในระดับล่างของกราฟิกการ์ดได้อย่างเต็มที่ ซึ่งจะช่วยให้การฝึกและเวลาในการอนุมานเร็วขึ้น ประสิทธิภาพเทียบเท่ากับการใช้งาน TensorFlow ใน Python เนื่องจากทั้ง 2 อย่างใช้แบ็กเอนด์ C++ เดียวกัน
ขนาดโมเดล
สำหรับโมเดลที่ล้ำสมัยจากการวิจัย คุณอาจต้องทำงานกับโมเดลขนาดใหญ่มาก ซึ่งอาจมีขนาดเป็นกิกะไบต์ ปัจจุบันโมเดลเหล่านี้ยังไม่สามารถเรียกใช้ในเว็บเบราว์เซอร์ได้เนื่องจากข้อจำกัดของการใช้งานหน่วยความจำต่อแท็บเบราว์เซอร์ หากต้องการเรียกใช้โมเดลขนาดใหญ่เหล่านี้ คุณสามารถใช้ Node.js ในเซิร์ฟเวอร์ของคุณเองโดยมีข้อกำหนดด้านฮาร์ดแวร์ที่คุณต้องการเพื่อเรียกใช้โมเดลดังกล่าวอย่างมีประสิทธิภาพ
IOT
Node.js รองรับคอมพิวเตอร์แบบแผงวงจรเดี่ยวที่ได้รับความนิยม เช่น Raspberry Pi ซึ่งหมายความว่าคุณสามารถเรียกใช้โมเดล TensorFlow.js บนอุปกรณ์ดังกล่าวได้ด้วย
ความเร็ว
Node.js เขียนด้วย JavaScript ซึ่งหมายความว่า Node.js จะได้รับประโยชน์จากการคอมไพล์แบบทันที ซึ่งหมายความว่าคุณอาจเห็นประสิทธิภาพเพิ่มขึ้นบ่อยครั้งเมื่อใช้ Node.js เนื่องจากระบบจะเพิ่มประสิทธิภาพในขณะรันไทม์ โดยเฉพาะอย่างยิ่งสำหรับการประมวลผลล่วงหน้าใดๆ ที่คุณอาจทำ ตัวอย่างที่ยอดเยี่ยมของเรื่องนี้ดูได้ในกรณีศึกษานี้ ซึ่งแสดงให้เห็นว่า Hugging Face ใช้ Node.js เพื่อเพิ่มประสิทธิภาพโมเดลการประมวลผลภาษาธรรมชาติได้ 2 เท่า
ตอนนี้คุณเข้าใจพื้นฐานของ TensorFlow.js, ตำแหน่งที่สามารถเรียกใช้ และประโยชน์บางอย่างแล้ว มาเริ่มทำสิ่งที่มีประโยชน์ด้วยกันเลย
3. การเรียนรู้แบบถ่ายโอน
การเรียนรู้แบบถ่ายโอนคืออะไร
การถ่ายโอนการเรียนรู้เกี่ยวข้องกับการนำความรู้ที่ได้เรียนรู้ไปแล้วมาช่วยในการเรียนรู้สิ่งอื่นที่แตกต่างออกไปแต่มีความคล้ายคลึงกัน
มนุษย์เราทำสิ่งนี้อยู่ตลอดเวลา คุณมีประสบการณ์ตลอดชีวิตที่อยู่ในสมองซึ่งคุณสามารถใช้เพื่อช่วยจดจำสิ่งใหม่ๆ ที่คุณไม่เคยเห็นมาก่อนได้ ลองดูตัวอย่างต้นหลิวนี้

คุณอาจไม่เคยเห็นต้นไม้ประเภทนี้มาก่อน ทั้งนี้ขึ้นอยู่กับว่าคุณอยู่ที่ไหนในโลก
แต่หากฉันขอให้คุณบอกว่ามีต้นวิลโลว์ในรูปภาพใหม่ด้านล่างหรือไม่ คุณก็อาจจะเห็นต้นวิลโลว์ได้อย่างรวดเร็ว แม้ว่าต้นวิลโลว์จะอยู่ในมุมที่แตกต่างกันและแตกต่างจากต้นวิลโลว์เดิมที่ฉันแสดงให้คุณเห็นเล็กน้อยก็ตาม

คุณมีเซลล์ประสาทจำนวนมากในสมองที่รู้วิธีระบุวัตถุที่มีลักษณะคล้ายต้นไม้ และเซลล์ประสาทอื่นๆ ที่ค้นหาสายตรงยาวๆ ได้ดี คุณสามารถนำความรู้ดังกล่าวมาใช้ซ้ำเพื่อจัดประเภทต้นวิลโลว์ได้อย่างรวดเร็ว ซึ่งเป็นวัตถุคล้ายต้นไม้ที่มีกิ่งก้านยาวตรงในแนวตั้งจำนวนมาก
ในทำนองเดียวกัน หากคุณมีโมเดลแมชชีนเลิร์นนิงที่ได้รับการฝึกในโดเมนหนึ่งอยู่แล้ว เช่น การจดจำรูปภาพ คุณสามารถนำโมเดลนั้นกลับมาใช้เพื่อทำงานอื่นที่เกี่ยวข้องได้
คุณทำแบบเดียวกันนี้ได้กับโมเดลขั้นสูงอย่าง MobileNet ซึ่งเป็นโมเดลการวิจัยที่ได้รับความนิยมอย่างมากซึ่งสามารถจดจำรูปภาพในออบเจ็กต์ประเภทต่างๆ ได้ถึง 1, 000 ประเภท ตั้งแต่สุนัขไปจนถึงรถยนต์ โมเดลนี้ได้รับการฝึกด้วยชุดข้อมูลขนาดใหญ่ที่เรียกว่า ImageNet ซึ่งมีรูปภาพที่ติดป้ายกำกับนับล้านรูป
ในภาพเคลื่อนไหวนี้ คุณจะเห็นจำนวนเลเยอร์มหาศาลในโมเดล MobileNet V1 นี้
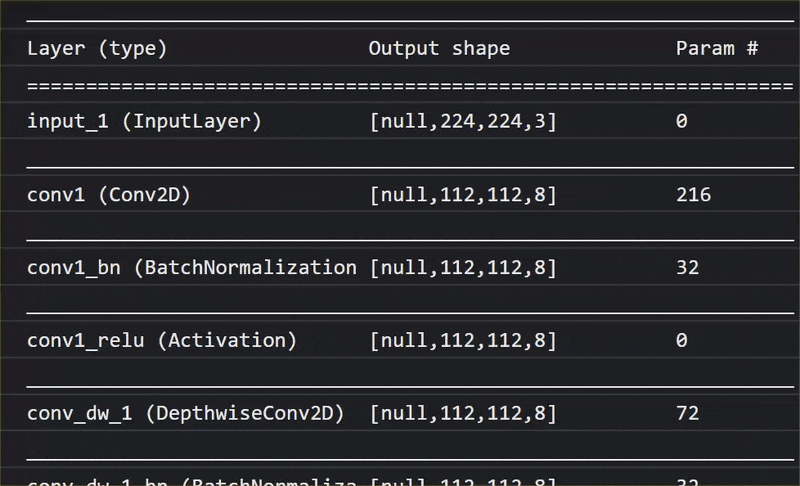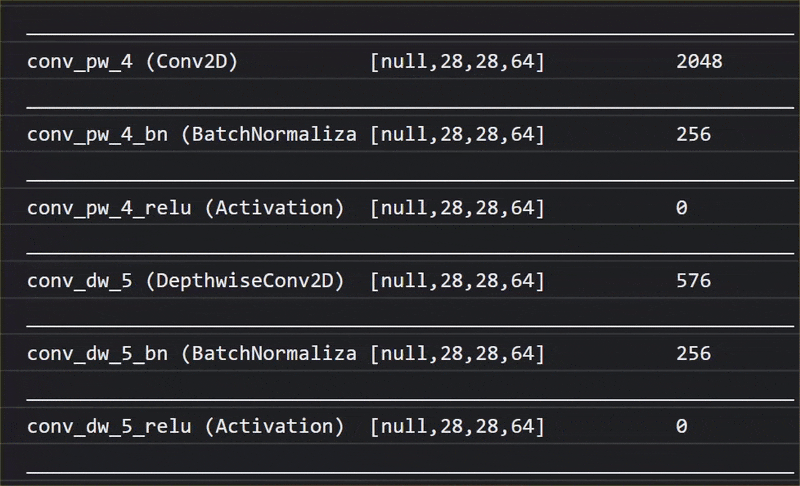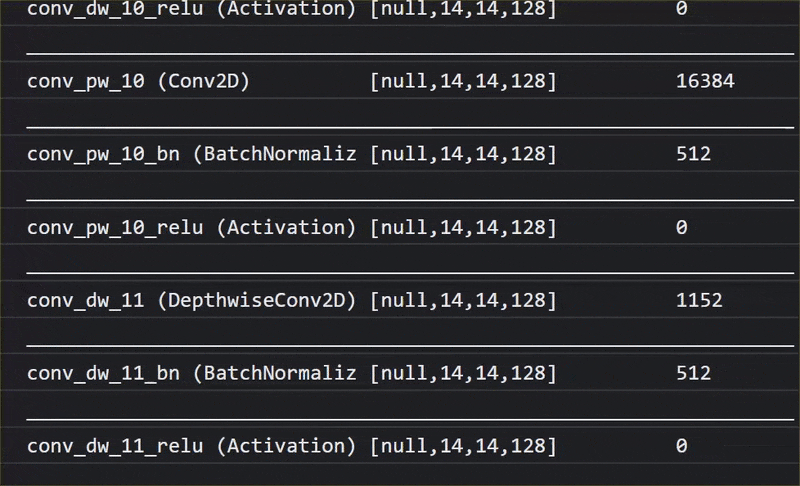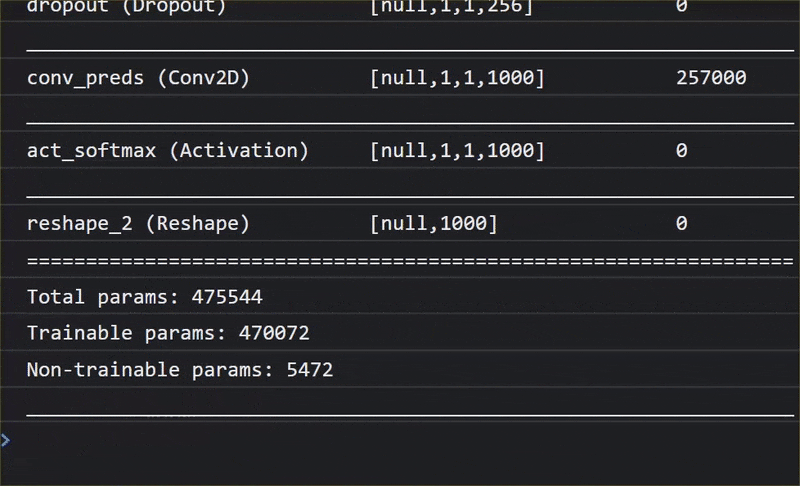
ในระหว่างการฝึก โมเดลนี้ได้เรียนรู้วิธีการแยกฟีเจอร์ทั่วไปที่มีความสำคัญสำหรับออบเจ็กต์ทั้ง 1,000 รายการดังกล่าว และฟีเจอร์ระดับล่างหลายรายการที่ใช้ในการระบุออบเจ็กต์ดังกล่าวอาจมีประโยชน์ในการตรวจหาออบเจ็กต์ใหม่ๆ ที่ไม่เคยเห็นมาก่อนด้วย เพราะท้ายที่สุดแล้วทุกสิ่งทุกอย่างก็เป็นเพียงการผสมผสานของเส้น พื้นผิว และรูปร่าง
มาดูสถาปัตยกรรมของ Convolutional Neural Network (CNN) แบบดั้งเดิม (คล้ายกับ MobileNet) และดูว่า Transfer Learning จะใช้ประโยชน์จากเครือข่ายที่เทรนแล้วนี้เพื่อเรียนรู้สิ่งใหม่ๆ ได้อย่างไร รูปภาพด้านล่างแสดงสถาปัตยกรรมโมเดลทั่วไปของ CNN ซึ่งในกรณีนี้ได้รับการฝึกให้จดจำตัวเลขที่เขียนด้วยลายมือตั้งแต่ 0 ถึง 9
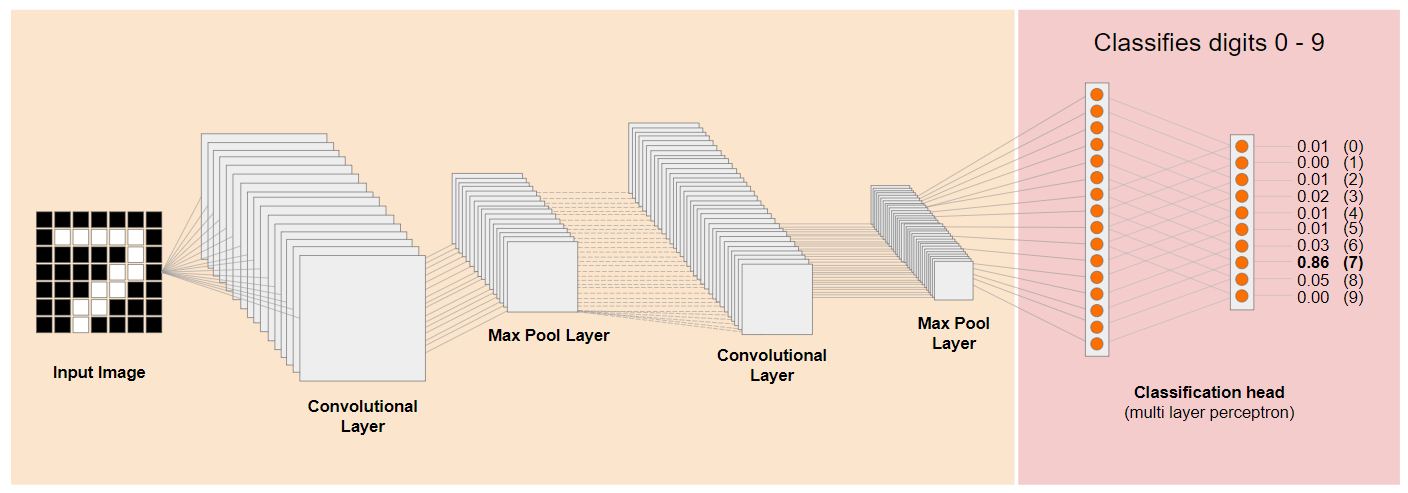
หากแยกเลเยอร์ระดับล่างที่ได้รับการฝึกมาก่อนของโมเดลที่ฝึกแล้วที่มีอยู่ เช่น ที่แสดงทางด้านซ้าย ออกจากเลเยอร์การจัดประเภทใกล้กับจุดสิ้นสุดของโมเดลที่แสดงทางด้านขวา (บางครั้งเรียกว่าส่วนหัวของการจัดประเภทของโมเดล) คุณจะใช้เลเยอร์ระดับล่างเพื่อสร้างฟีเจอร์เอาต์พุตสำหรับรูปภาพที่กำหนดได้โดยอิงตามข้อมูลต้นฉบับที่ใช้ฝึก ต่อไปนี้เป็นเครือข่ายเดียวกันที่นำส่วนหัวของการแยกประเภทออก
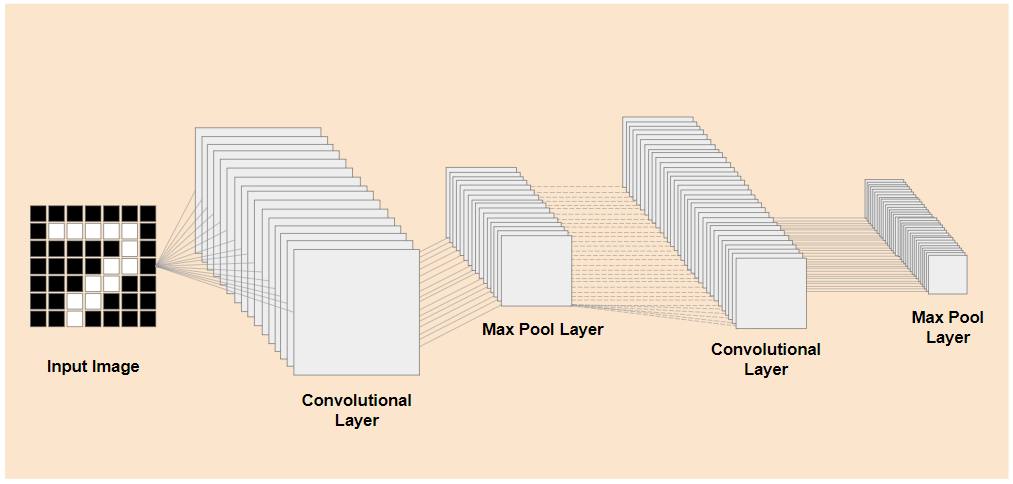
สมมติว่าสิ่งใหม่ที่คุณพยายามจดจำสามารถใช้ฟีเจอร์เอาต์พุตดังกล่าวที่โมเดลก่อนหน้าได้เรียนรู้มา ก็มีโอกาสสูงที่จะนำฟีเจอร์เหล่านั้นมาใช้ซ้ำเพื่อวัตถุประสงค์ใหม่ได้
ในแผนภาพด้านบน โมเดลสมมตินี้ได้รับการฝึกกับตัวเลข ดังนั้นสิ่งที่เรียนรู้เกี่ยวกับตัวเลขอาจนำไปใช้กับตัวอักษร เช่น a, b และ c ได้ด้วย
ตอนนี้คุณสามารถเพิ่มหัวการจัดประเภทใหม่ที่พยายามคาดการณ์ a, b หรือ c แทนได้ ดังที่แสดง
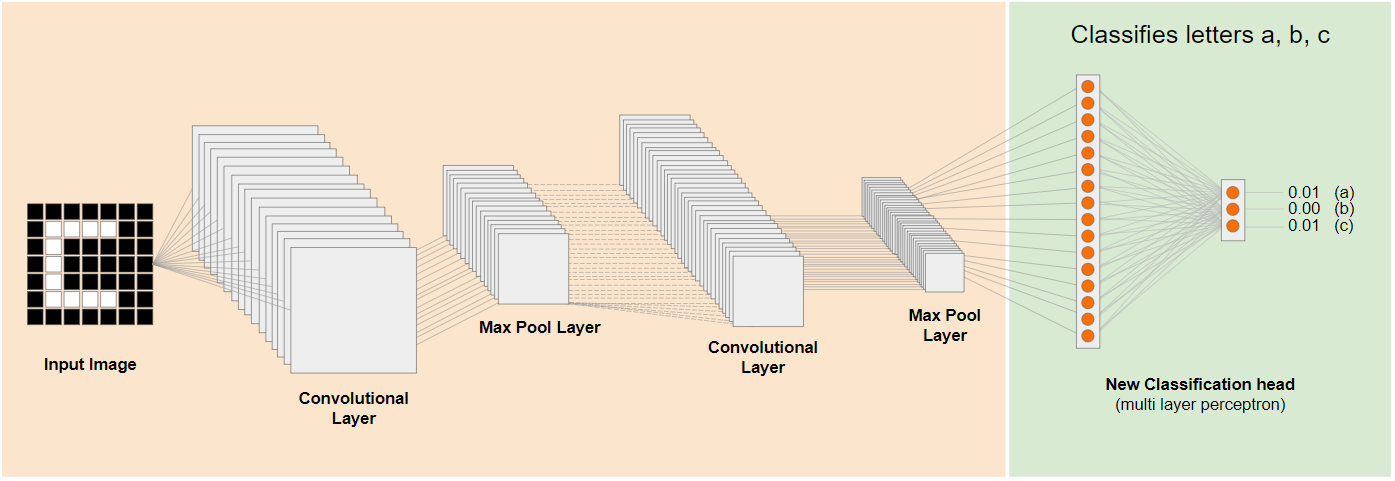
ในที่นี้ เลเยอร์ระดับล่างจะถูกตรึงไว้และไม่ได้ฝึก มีเพียงส่วนหัวของการแยกประเภทใหม่เท่านั้นที่จะอัปเดตตัวเองเพื่อเรียนรู้จากฟีเจอร์ที่ได้จากโมเดลที่ตัดทอนและฝึกไว้ล่วงหน้าทางด้านซ้าย
การดำเนินการนี้เรียกว่าการเรียนรู้แบบถ่ายโอน และเป็นสิ่งที่ Teachable Machine ทำในเบื้องหลัง
นอกจากนี้ คุณยังเห็นได้ว่าการฝึก Multi-Layer Perceptron ที่ส่วนท้ายสุดของเครือข่ายเท่านั้นจะทำให้การฝึกเร็วกว่าการฝึกทั้งเครือข่ายตั้งแต่ต้นมาก
แต่คุณจะเข้าถึงส่วนย่อยของโมเดลได้อย่างไร ไปที่ส่วนถัดไปเพื่อดูข้อมูล
4. TensorFlow Hub - โมเดลพื้นฐาน
ค้นหาโมเดลพื้นฐานที่เหมาะสมเพื่อใช้งาน
สำหรับโมเดลการวิจัยขั้นสูงและเป็นที่นิยมมากขึ้น เช่น MobileNet คุณสามารถไปที่ TensorFlow Hub แล้วกรองหาโมเดลที่เหมาะกับ TensorFlow.js ซึ่งใช้สถาปัตยกรรม MobileNet v3 เพื่อดูผลลัพธ์เช่นที่แสดงที่นี่
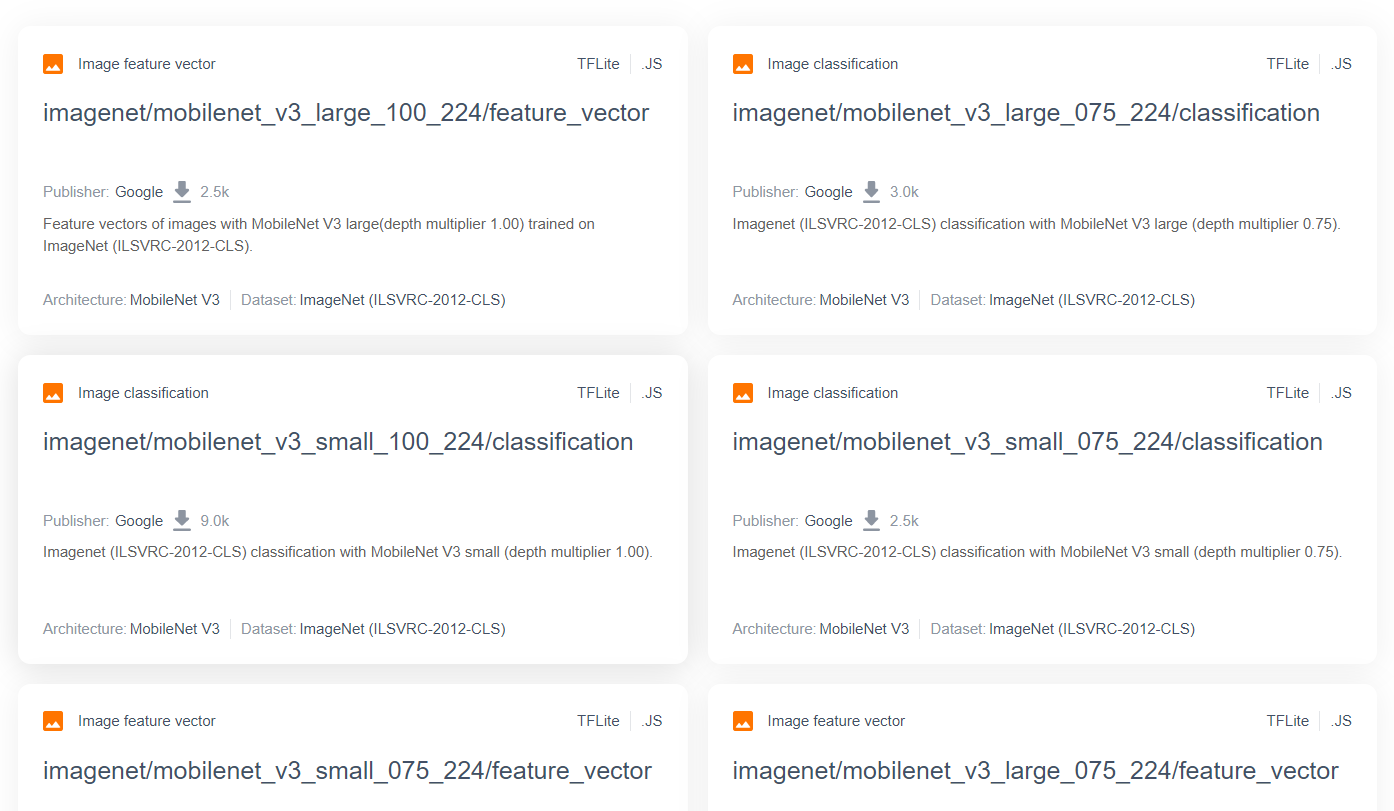
โปรดทราบว่าผลลัพธ์บางส่วนเป็นประเภท "การจัดหมวดหมู่รูปภาพ" (แสดงรายละเอียดที่ด้านซ้ายบนของการ์ดผลลัพธ์ของแต่ละโมเดล) และผลลัพธ์อื่นๆ เป็นประเภท "เวกเตอร์ฟีเจอร์ของรูปภาพ"
ผลลัพธ์เวกเตอร์ฟีเจอร์รูปภาพเหล่านี้เป็น MobileNet เวอร์ชันที่ตัดไว้ล่วงหน้าซึ่งคุณสามารถใช้เพื่อรับเวกเตอร์ฟีเจอร์รูปภาพแทนการแยกประเภทขั้นสุดท้ายได้
โมเดลประเภทนี้มักเรียกว่า "โมเดลพื้นฐาน" ซึ่งคุณสามารถใช้เพื่อดำเนินการ Transfer Learning ในลักษณะเดียวกับที่แสดงในส่วนก่อนหน้าได้โดยการเพิ่มหัวการจัดประเภทใหม่และฝึกด้วยข้อมูลของคุณเอง
สิ่งต่อไปที่ต้องตรวจสอบคือโมเดลพื้นฐานที่สนใจนั้นได้รับการเผยแพร่เป็นรูปแบบ TensorFlow.js ใด หากเปิดหน้าเว็บสำหรับโมเดลเวกเตอร์ฟีเจอร์ MobileNet v3 เหล่านี้ คุณจะเห็นจากเอกสารประกอบ JS ว่าโมเดลอยู่ในรูปแบบของโมเดลกราฟตามข้อมูลโค้ดตัวอย่างในเอกสารประกอบที่ใช้ tf.loadGraphModel()
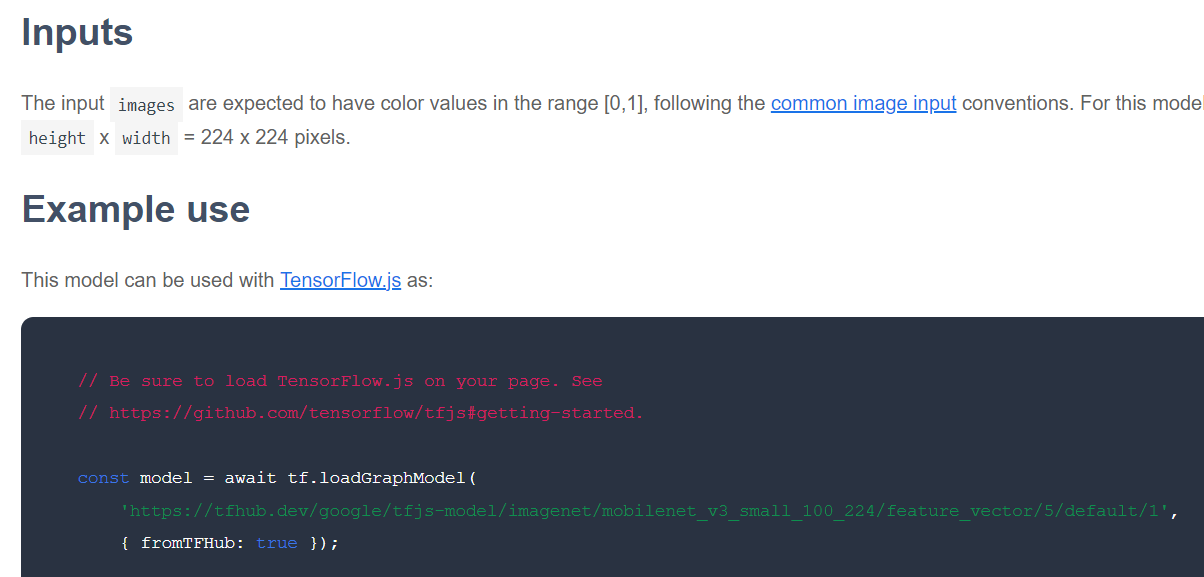
นอกจากนี้ โปรดทราบว่าหากพบโมเดลในรูปแบบเลเยอร์แทนรูปแบบกราฟ คุณสามารถเลือกได้ว่าจะตรึงเลเยอร์ใดและเลเยอร์ใดที่จะเลิกตรึงเพื่อการฝึก ซึ่งจะมีประโยชน์อย่างมากเมื่อสร้างโมเดลสำหรับงานใหม่ ซึ่งมักเรียกว่า "โมเดลการโอน" อย่างไรก็ตาม ในตอนนี้คุณจะใช้ประเภทโมเดลกราฟเริ่มต้นสำหรับบทแนะนำนี้ ซึ่งโมเดล TF Hub ส่วนใหญ่จะได้รับการติดตั้งใช้งานเป็นประเภทนี้ ดูข้อมูลเพิ่มเติมเกี่ยวกับการทำงานกับโมเดลเลเยอร์ได้ในหลักสูตร TensorFlow.js จากระดับเริ่มต้นจนถึงระดับเชี่ยวชาญ
ข้อดีของการเรียนรู้แบบถ่ายโอน
การใช้การเรียนรู้การโอนแทนการฝึกสถาปัตยกรรมโมเดลทั้งหมดตั้งแต่ต้นมีข้อดีอย่างไร
ประการแรก เวลาในการฝึกเป็นข้อได้เปรียบที่สำคัญในการใช้วิธีการเรียนรู้การโอน เนื่องจากคุณมีโมเดลพื้นฐานที่ฝึกแล้วเพื่อใช้ต่อยอด
ประการที่ 2 คุณสามารถแสดงตัวอย่างของสิ่งใหม่ๆ ที่พยายามจัดประเภทได้น้อยลงมากเนื่องจากการฝึกที่เกิดขึ้นแล้ว
ซึ่งเหมาะอย่างยิ่งหากคุณมีเวลาและทรัพยากรจำกัดในการรวบรวมข้อมูลตัวอย่างของสิ่งที่ต้องการจัดประเภท และจำเป็นต้องสร้างต้นแบบอย่างรวดเร็วก่อนที่จะรวบรวมข้อมูลฝึกฝนเพิ่มเติมเพื่อทำให้โมเดลมีความแข็งแกร่งมากขึ้น
การเรียนรู้แบบโอนจะใช้ทรัพยากรน้อยกว่าเนื่องจากต้องการข้อมูลน้อยลงและฝึกเครือข่ายขนาดเล็กได้เร็วกว่า จึงเหมาะอย่างยิ่งสำหรับสภาพแวดล้อมของเบราว์เซอร์ โดยใช้เวลาเพียงไม่กี่สิบวินาทีในเครื่องรุ่นใหม่ แทนที่จะเป็นชั่วโมง วัน หรือสัปดาห์สำหรับการฝึกโมเดลแบบเต็ม
หวัดดี ตอนนี้คุณทราบแล้วว่าการเรียนรู้แบบถ่ายโอนคืออะไร ก็ได้เวลาสร้าง Teachable Machine เวอร์ชันของคุณเองแล้ว มาเริ่มกันเลย
5. เตรียมพร้อมเขียนโค้ด
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ที่ทันสมัย
- ความรู้พื้นฐานเกี่ยวกับ HTML, CSS, JavaScript และเครื่องมือสำหรับนักพัฒนาเว็บใน Chrome (การดูเอาต์พุตของคอนโซล)
มาเริ่มเขียนโค้ดกันเลย
เราได้สร้างเทมเพลตมาตรฐานเพื่อใช้เริ่มต้นสำหรับ Glitch.com หรือ Codepen.io คุณเพียงแค่โคลนเทมเพลตใดเทมเพลตหนึ่งเป็นสถานะพื้นฐานสำหรับโค้ดแล็บนี้ได้ในคลิกเดียว
ใน Glitch ให้คลิกปุ่ม "รีมิกซ์สิ่งนี้" เพื่อฟอร์กและสร้างชุดไฟล์ใหม่ที่คุณแก้ไขได้
หรือใน Codepen ให้คลิก"fork" ที่ด้านขวาล่างของหน้าจอ
โครงสร้างที่เรียบง่ายนี้จะให้ไฟล์ต่อไปนี้แก่คุณ
- หน้า HTML (index.html)
- สไตล์ชีต (style.css)
- ไฟล์สำหรับเขียนโค้ด JavaScript (script.js)
เราได้เพิ่มการนำเข้าในไฟล์ HTML สำหรับไลบรารี TensorFlow.js เพื่ออำนวยความสะดวกให้คุณ โดยจะมีลักษณะดังนี้
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
ทางเลือก: ใช้โปรแกรมแก้ไขเว็บที่คุณต้องการหรือทำงานในเครื่อง
หากต้องการดาวน์โหลดโค้ดและทำงานในเครื่องหรือในโปรแกรมแก้ไขออนไลน์อื่น เพียงสร้างไฟล์ 3 ไฟล์ที่มีชื่อตามที่ระบุไว้ข้างต้นในไดเรกทอรีเดียวกัน แล้วคัดลอกและวางโค้ดจาก Boilerplate ของ Glitch ลงในแต่ละไฟล์
6. Boilerplate HTML ของแอป
ฉันจะเริ่มต้นจากที่ใด
ต้นแบบทั้งหมดต้องมีโครงสร้างพื้นฐานของ HTML เพื่อให้คุณแสดงผลสิ่งที่ค้นพบได้ ตั้งค่าเลย คุณกำลังจะเพิ่มข้อมูลต่อไปนี้
- ชื่อของหน้า
- ข้อความอธิบายบางส่วน
- ย่อหน้าสถานะ
- วิดีโอสำหรับเก็บฟีดเว็บแคมเมื่อพร้อมใช้งาน
- ปุ่มหลายปุ่มสำหรับเริ่มกล้อง รวบรวมข้อมูล หรือรีเซ็ตประสบการณ์การใช้งาน
- การนำเข้าสำหรับ TensorFlow.js และไฟล์ JS ที่คุณจะเขียนโค้ดในภายหลัง
เปิด index.html แล้ววางโค้ดต่อไปนี้ทับโค้ดที่มีอยู่เพื่อตั้งค่าฟีเจอร์ด้านบน
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
ดูรายละเอียด
มาดูโค้ด HTML บางส่วนด้านบนเพื่อไฮไลต์สิ่งสำคัญบางอย่างที่คุณเพิ่มกัน
- คุณเพิ่มแท็ก
<h1>สำหรับชื่อหน้าเว็บพร้อมกับแท็ก<p>ที่มีรหัส "status" ซึ่งเป็นตำแหน่งที่คุณจะพิมพ์ข้อมูล เนื่องจากคุณใช้ส่วนต่างๆ ของระบบเพื่อดูเอาต์พุต - คุณเพิ่มองค์ประกอบ
<video>ที่มีรหัส "webcam" ซึ่งคุณจะแสดงสตรีมจากเว็บแคมในภายหลัง - คุณเพิ่มองค์ประกอบ
<button>จำนวน 5 รายการ รายการแรกที่มีรหัส "enableCam" จะเปิดใช้กล้อง ปุ่ม 2 ปุ่มถัดไปมีคลาส "dataCollector" ซึ่งช่วยให้คุณรวบรวมรูปภาพตัวอย่างสำหรับออบเจ็กต์ที่ต้องการจดจำได้ โค้ดที่คุณเขียนในภายหลังจะได้รับการออกแบบเพื่อให้คุณเพิ่มปุ่มเหล่านี้ได้ตามต้องการ และปุ่มจะทำงานตามที่ตั้งใจไว้โดยอัตโนมัติ
โปรดทราบว่าปุ่มเหล่านี้ยังมีแอตทริบิวต์พิเศษที่ผู้ใช้กำหนดเองซึ่งเรียกว่า data-1hot โดยมีค่าจำนวนเต็มเริ่มต้นจาก 0 สำหรับคลาสแรก นี่คือดัชนีตัวเลขที่คุณจะใช้เพื่อแสดงข้อมูลของคลาสหนึ่งๆ ระบบจะใช้ดัชนีเพื่อเข้ารหัสคลาสเอาต์พุตอย่างถูกต้องด้วยการแทนค่าตัวเลขแทนสตริง เนื่องจากโมเดล ML จะใช้ได้เฉพาะตัวเลขเท่านั้น
นอกจากนี้ยังมีแอตทริบิวต์ data-name ซึ่งมีชื่อที่มนุษย์อ่านได้ที่คุณต้องการใช้สำหรับคลาสนี้ ซึ่งช่วยให้คุณระบุชื่อที่มีความหมายมากขึ้นแก่ผู้ใช้แทนค่าดัชนีตัวเลขจากการเข้ารหัสแบบ One-Hot
สุดท้าย คุณจะมีปุ่มฝึกและปุ่มรีเซ็ตเพื่อเริ่มกระบวนการฝึกเมื่อรวบรวมข้อมูลแล้ว หรือเพื่อรีเซ็ตแอปตามลำดับ
- นอกจากนี้ คุณยังเพิ่มการนำเข้า 2 รายการ
<script>ด้วย โดยไฟล์หนึ่งสำหรับ TensorFlow.js และอีกไฟล์สำหรับ script.js ซึ่งคุณจะกำหนดในอีกไม่นาน
7. เพิ่มสไตล์
ค่าเริ่มต้นขององค์ประกอบ
เพิ่มรูปแบบสำหรับองค์ประกอบ HTML ที่คุณเพิ่งเพิ่มเพื่อให้แสดงผลได้อย่างถูกต้อง ต่อไปนี้คือรูปแบบบางส่วนที่เพิ่มเพื่อจัดตำแหน่งและปรับขนาดองค์ประกอบอย่างถูกต้อง ไม่มีอะไรพิเศษ คุณสามารถเพิ่มข้อมูลนี้ในภายหลังเพื่อสร้าง UX ที่ดียิ่งขึ้นได้ เช่น ที่คุณเห็นในวิดีโอเกี่ยวกับ Teachable Machine
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
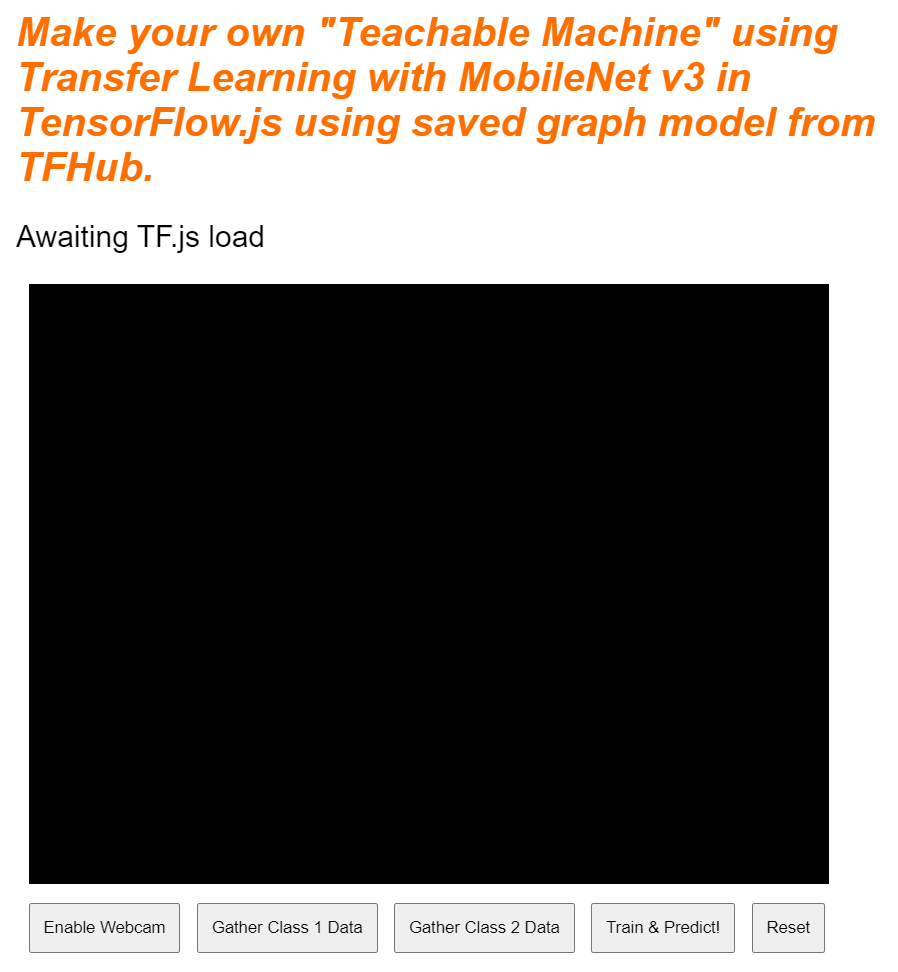
เยี่ยมเลย แค่นี้ก็เรียบร้อย หากคุณดูตัวอย่างเอาต์พุตตอนนี้ เอาต์พุตควรมีลักษณะดังนี้
8. JavaScript: ค่าคงที่และ Listener ที่สำคัญ
กำหนดค่าคงที่หลัก
ก่อนอื่น ให้เพิ่มค่าคงที่หลักบางอย่างที่คุณจะใช้ตลอดทั้งแอป โดยเริ่มจากการแทนที่เนื้อหาของ script.js ด้วยค่าคงที่ต่อไปนี้
script.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
มาดูรายละเอียดของแต่ละอย่างกัน
STATUSเป็นเพียงการอ้างอิงถึงแท็กย่อหน้าที่คุณจะเขียนข้อมูลอัปเดตสถานะVIDEOมีการอ้างอิงถึงองค์ประกอบวิดีโอ HTML ที่จะแสดงฟีดเว็บแคมENABLE_CAM_BUTTON,RESET_BUTTONและTRAIN_BUTTONจะดึงข้อมูลอ้างอิง DOM ไปยังปุ่มคีย์ทั้งหมดจากหน้า HTMLMOBILE_NET_INPUT_WIDTHและMOBILE_NET_INPUT_HEIGHTจะกำหนดความกว้างและความสูงของอินพุตที่คาดไว้ของโมเดล MobileNet ตามลำดับ การจัดเก็บค่านี้ไว้ในค่าคงที่ใกล้กับด้านบนของไฟล์ในลักษณะนี้จะช่วยให้คุณอัปเดตค่าได้ง่ายขึ้นเพียงครั้งเดียวแทนที่จะต้องแทนที่ในหลายๆ ที่ หากตัดสินใจใช้เวอร์ชันอื่นในภายหลัง- ตั้งค่า
STOP_DATA_GATHERเป็น -1 ซึ่งจะจัดเก็บค่าสถานะเพื่อให้คุณทราบเมื่อผู้ใช้หยุดคลิกปุ่มเพื่อรวบรวมข้อมูลจากฟีดเว็บแคม การตั้งชื่อตัวเลขนี้ให้มีความหมายมากขึ้นจะช่วยให้โค้ดอ่านง่ายขึ้นในภายหลัง CLASS_NAMESทำหน้าที่เป็นการค้นหาและเก็บชื่อที่มนุษย์อ่านได้สำหรับการคาดการณ์คลาสที่เป็นไปได้ ระบบจะป้อนข้อมูลอาร์เรย์นี้ในภายหลัง
ตอนนี้คุณมีข้อมูลอ้างอิงถึงองค์ประกอบสำคัญแล้ว ก็ถึงเวลาเชื่อมโยง Listener เหตุการณ์บางอย่างกับองค์ประกอบเหล่านั้น
เพิ่ม Listener เหตุการณ์สำคัญ
เริ่มต้นด้วยการเพิ่มตัวแฮนเดิลกิจกรรมการคลิกไปยังปุ่มสำคัญดังที่แสดง
script.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON - เรียกฟังก์ชัน enableCam เมื่อคลิก
TRAIN_BUTTON - เรียกใช้ trainAndPredict เมื่อคลิก
RESET_BUTTON - การโทรจะรีเซ็ตเมื่อมีการคลิก
สุดท้ายในส่วนนี้ คุณจะเห็นปุ่มทั้งหมดที่มีคลาส "dataCollector" โดยใช้ document.querySelectorAll() ซึ่งจะแสดงผลอาร์เรย์ขององค์ประกอบที่พบจากเอกสารที่ตรงกัน
script.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
คำอธิบายโค้ด:
จากนั้นคุณจะวนซ้ำปุ่มที่พบและเชื่อมโยง Listener เหตุการณ์ 2 รายการกับแต่ละปุ่ม รายการหนึ่งสำหรับ "mousedown" และอีกรายการหนึ่งสำหรับ "mouseup" ซึ่งจะช่วยให้คุณบันทึกตัวอย่างได้ตราบเท่าที่กดปุ่ม ซึ่งมีประโยชน์สำหรับการเก็บรวบรวมข้อมูล
ทั้ง 2 เหตุการณ์จะเรียกใช้gatherDataForClassฟังก์ชันที่คุณจะกำหนดในภายหลัง
ในขั้นตอนนี้ คุณยังสามารถพุชชื่อคลาสที่มนุษย์อ่านได้ซึ่งพบจากแอตทริบิวต์ปุ่ม HTML data-name ไปยังอาร์เรย์ CLASS_NAMES ได้ด้วย
จากนั้นเพิ่มตัวแปรเพื่อจัดเก็บสิ่งสำคัญที่จะใช้ในภายหลัง
script.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
มาดูกันเลย
ก่อนอื่น คุณมีตัวแปร mobilenet สำหรับจัดเก็บโมเดล Mobilenet ที่โหลดแล้ว ตั้งค่านี้เป็น "ไม่ระบุ" ในตอนแรก
จากนั้นคุณจะมีตัวแปรชื่อ gatherDataState หากกดปุ่ม 'dataCollector' ระบบจะเปลี่ยนเป็นรหัสที่ใช้งานอยู่ 1 รายการของปุ่มนั้นแทนตามที่กำหนดไว้ใน HTML เพื่อให้คุณทราบว่ากำลังรวบรวมข้อมูลคลาสใดในขณะนั้น ในตอนแรก เราจะตั้งค่าเป็น STOP_DATA_GATHER เพื่อให้ลูปการรวบรวมข้อมูลที่คุณเขียนในภายหลังจะไม่รวบรวมข้อมูลใดๆ เมื่อไม่มีการกดปุ่ม
videoPlaying จะติดตามว่าสตรีมจากเว็บแคมโหลดและเล่นได้สำเร็จหรือไม่ และพร้อมใช้งานหรือไม่ โดยค่าเริ่มต้น ระบบจะตั้งค่านี้เป็น false เนื่องจากเว็บแคมจะปิดอยู่จนกว่าคุณจะกด ENABLE_CAM_BUTTON.
จากนั้นกำหนดอาร์เรย์ 2 รายการ ได้แก่ trainingDataInputs และ trainingDataOutputs ซึ่งจะจัดเก็บค่าข้อมูลฝึกฝนที่รวบรวมไว้เมื่อคุณคลิกปุ่ม "dataCollector" สำหรับฟีเจอร์อินพุตที่สร้างโดยโมเดลพื้นฐานของ MobileNet และคลาสเอาต์พุตที่สุ่มตัวอย่างตามลำดับ
จากนั้นจะกำหนดอาร์เรย์สุดท้าย examplesCount, เพื่อติดตามจำนวนตัวอย่างที่อยู่ในแต่ละคลาสเมื่อคุณเริ่มเพิ่มตัวอย่าง
สุดท้าย คุณมีตัวแปรชื่อ predict ที่ควบคุมลูปการคาดการณ์ โดยค่าเริ่มต้น ระบบจะตั้งค่าเป็น false จะไม่มีการคาดการณ์จนกว่าจะมีการตั้งค่าเป็น true ในภายหลัง
ตอนนี้เราได้กำหนดตัวแปรสำคัญทั้งหมดแล้ว ไปโหลดโมเดลพื้นฐาน MobileNet v3 ที่ตัดไว้ล่วงหน้าซึ่งให้เวกเตอร์ฟีเจอร์รูปภาพแทนการจัดประเภทกัน
9. โหลดโมเดลพื้นฐานของ MobileNet
ก่อนอื่น ให้กำหนดฟังก์ชันใหม่ชื่อ loadMobileNetFeatureModel ดังที่แสดงด้านล่าง ฟังก์ชันนี้ต้องเป็นฟังก์ชันแบบไม่พร้อมกัน เนื่องจากโมเดลการโหลดเป็นแบบไม่พร้อมกัน
script.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
ในโค้ดนี้ คุณจะกำหนด URL ที่โมเดลที่จะโหลดอยู่จากเอกสารประกอบของ TFHub
จากนั้นคุณจะโหลดโมเดลได้โดยใช้ await tf.loadGraphModel() โดยอย่าลืมตั้งค่าพร็อพเพอร์ตี้พิเศษ fromTFHub เป็น true ขณะโหลดโมเดลจากเว็บไซต์ของ Google นี้ นี่เป็นกรณีพิเศษสำหรับการใช้โมเดลที่โฮสต์ใน TF Hub เท่านั้น ซึ่งจะต้องตั้งค่าพร็อพเพอร์ตี้เพิ่มเติมนี้
เมื่อโหลดเสร็จแล้ว คุณจะตั้งค่า STATUS ขององค์ประกอบ innerText พร้อมข้อความเพื่อให้เห็นด้วยภาพว่าโหลดอย่างถูกต้องและพร้อมเริ่มรวบรวมข้อมูล
ตอนนี้สิ่งเดียวที่เหลือให้ทำคือการวอร์มอัพโมเดล เมื่อใช้โมเดลขนาดใหญ่เช่นนี้เป็นครั้งแรก ระบบอาจใช้เวลาสักครู่ในการตั้งค่าทุกอย่าง ดังนั้นการส่งค่า 0 ผ่านโมเดลจึงช่วยหลีกเลี่ยงการรอในอนาคตได้ ซึ่งอาจเป็นช่วงเวลาที่สำคัญกว่า
คุณสามารถใช้ tf.zeros() ที่อยู่ใน tf.tidy() เพื่อให้มั่นใจว่าระบบจะทิ้งเทนเซอร์อย่างถูกต้อง โดยมีขนาดกลุ่มเท่ากับ 1 และความสูงและความกว้างที่ถูกต้องซึ่งคุณกำหนดไว้ในค่าคงที่ตอนเริ่มต้น สุดท้าย คุณยังระบุแชแนลสีได้ด้วย ซึ่งในกรณีนี้คือ 3 เนื่องจากโมเดลคาดหวังรูปภาพ RGB
จากนั้นบันทึกรูปร่างของ Tensor ที่ได้โดยใช้ answer.shape() เพื่อช่วยให้คุณเข้าใจขนาดของฟีเจอร์รูปภาพที่โมเดลนี้สร้างขึ้น
หลังจากกำหนดฟังก์ชันนี้แล้ว คุณจะเรียกใช้ฟังก์ชันนี้ได้ทันทีเพื่อเริ่มดาวน์โหลดโมเดลเมื่อการโหลดหน้าเว็บ
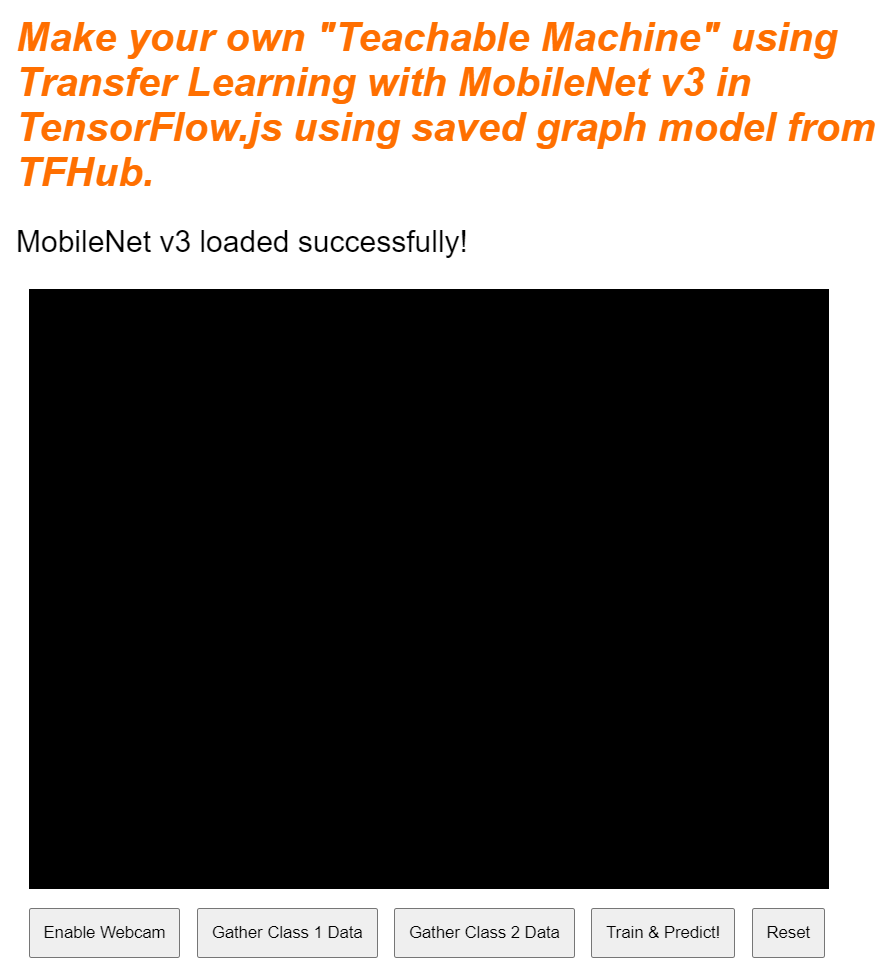
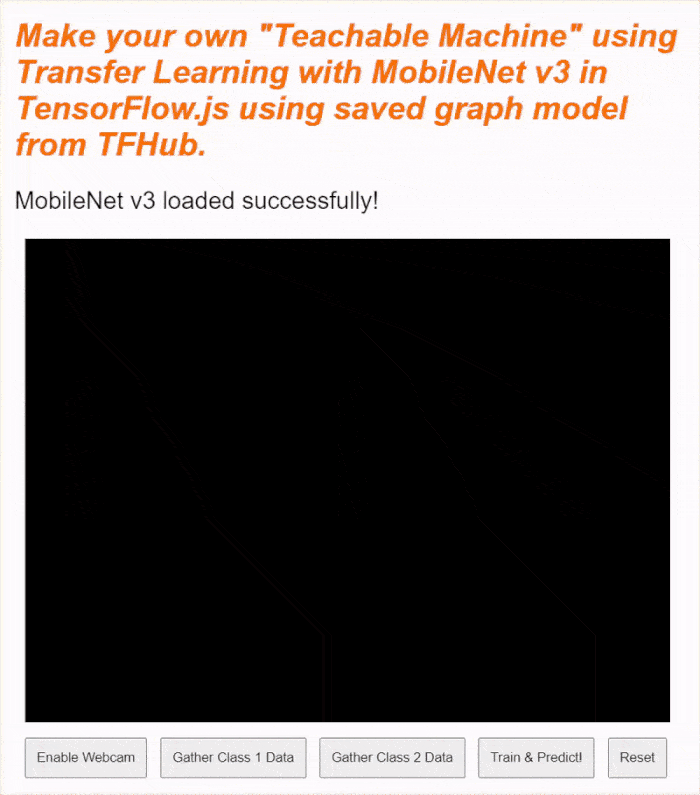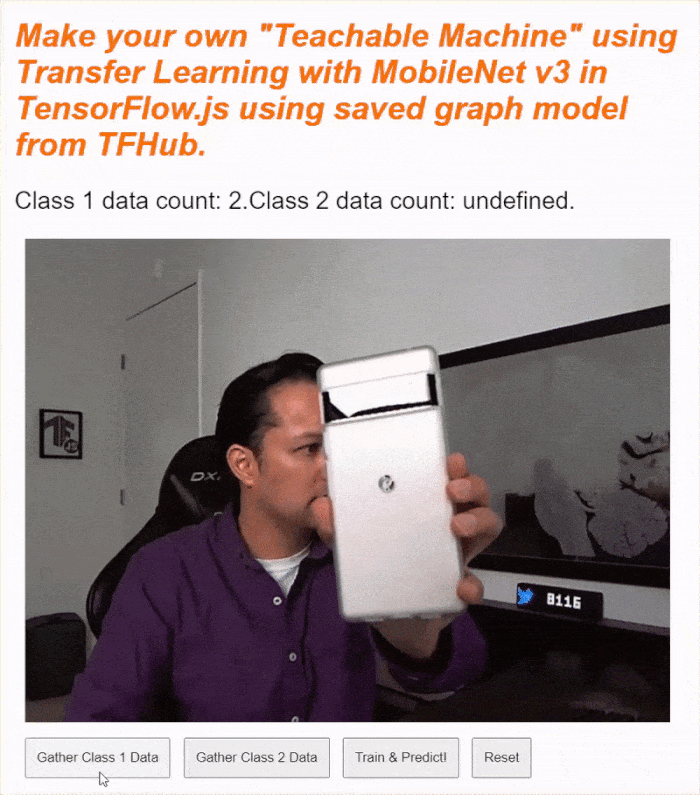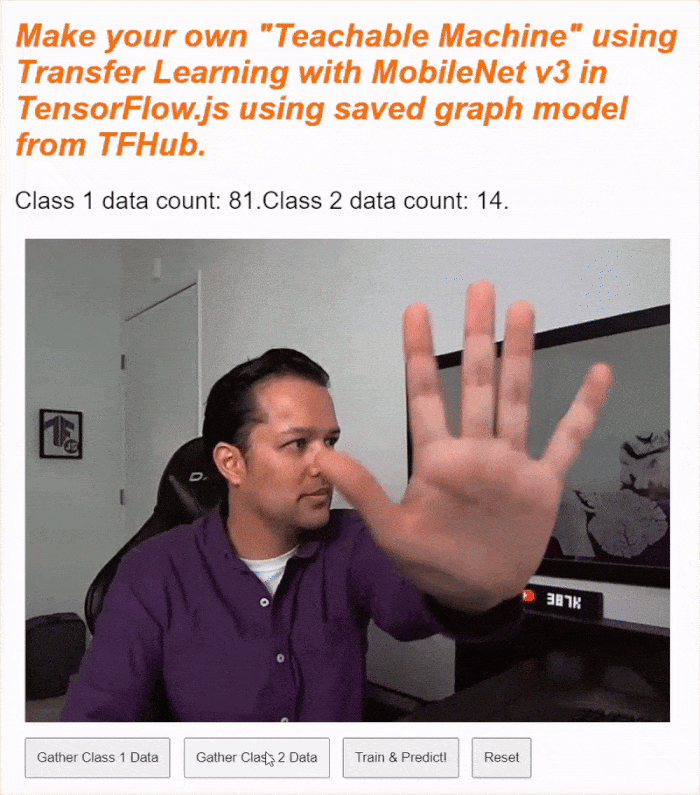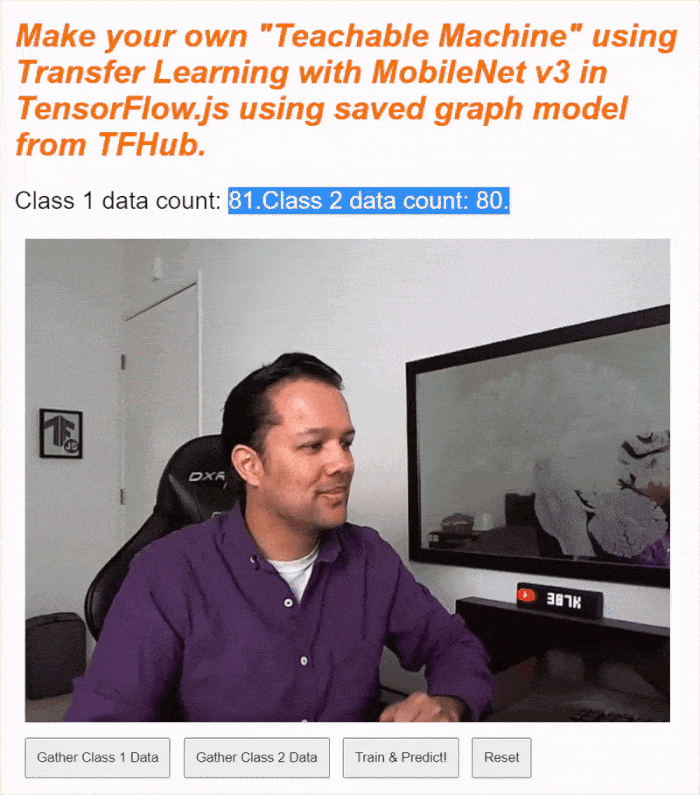
หากดูตัวอย่างแบบเรียลไทม์ในตอนนี้ หลังจากผ่านไปสักครู่ คุณจะเห็นข้อความสถานะเปลี่ยนจาก "รอการโหลด TF.js" เป็น "โหลด MobileNet v3 สำเร็จแล้ว!" ดังที่แสดงด้านล่าง โปรดตรวจสอบว่าการตั้งค่านี้ใช้งานได้ก่อนดำเนินการต่อ
นอกจากนี้ คุณยังตรวจสอบเอาต์พุตของคอนโซลเพื่อดูขนาดที่พิมพ์ของฟีเจอร์เอาต์พุตที่โมเดลนี้สร้างขึ้นได้ด้วย หลังจากเรียกใช้ค่าศูนย์ผ่านโมเดล MobileNet คุณจะเห็นรูปร่างของ [1, 1024] ที่พิมพ์ออกมา รายการแรกมีขนาดกลุ่มเพียง 1 รายการ และคุณจะเห็นว่ารายการนี้จะแสดงฟีเจอร์ 1024 รายการที่สามารถใช้เพื่อช่วยคุณจัดประเภทออบเจ็กต์ใหม่ได้
10. กำหนดหัวโมเดลใหม่
ตอนนี้ถึงเวลาที่จะกำหนดหัวโมเดล ซึ่งเป็นเพอร์เซ็ปตรอนแบบหลายชั้นที่เรียบง่ายมาก
script.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
มาดูโค้ดนี้กัน คุณเริ่มต้นด้วยการกำหนดโมเดล tf.sequential ซึ่งคุณจะเพิ่มเลเยอร์โมเดลลงในโมเดลนั้น
จากนั้นเพิ่มเลเยอร์ Dense เป็นเลเยอร์อินพุตให้กับโมเดลนี้ โดยมีรูปร่างอินพุตเป็น 1024 เนื่องจากเอาต์พุตจากฟีเจอร์ MobileNet v3 มีขนาดนี้ คุณได้ค้นพบสิ่งนี้ในขั้นตอนก่อนหน้าหลังจากส่งผ่านค่า 1 ผ่านโมเดล เลเยอร์นี้มีนิวรอน 128 ตัวที่ใช้ฟังก์ชันกระตุ้น ReLU
หากคุณเพิ่งเริ่มใช้ฟังก์ชันการเปิดใช้งานและเลเยอร์โมเดล โปรดพิจารณาเข้าร่วมหลักสูตรที่มีรายละเอียดที่จุดเริ่มต้นของเวิร์กช็อปนี้เพื่อทำความเข้าใจว่าพร็อพเพอร์ตี้เหล่านี้ทำอะไรอยู่เบื้องหลัง
ชั้นถัดไปที่ต้องเพิ่มคือชั้นเอาต์พุต จำนวนนิวรอนควรเท่ากับจำนวนคลาสที่คุณพยายามคาดการณ์ โดยคุณสามารถใช้ CLASS_NAMES.length เพื่อดูจำนวนชั้นเรียนที่คุณวางแผนจะจัดประเภท ซึ่งเท่ากับจำนวนปุ่มรวบรวมข้อมูลที่พบในอินเทอร์เฟซผู้ใช้ เนื่องจากนี่คือปัญหาการแยกประเภท คุณจึงใช้การเปิดใช้งาน softmax ในเลเยอร์เอาต์พุตนี้ ซึ่งต้องใช้เมื่อพยายามสร้างโมเดลเพื่อแก้ปัญหาการแยกประเภทแทนการถดถอย
ตอนนี้ให้พิมพ์ model.summary() เพื่อพิมพ์ภาพรวมของโมเดลที่กำหนดใหม่ไปยังคอนโซล
สุดท้าย ให้คอมไพล์โมเดลเพื่อให้พร้อมสำหรับการฝึก ในที่นี้ ตัวเพิ่มประสิทธิภาพตั้งค่าเป็น adam และการสูญเสียจะเป็น binaryCrossentropy หาก CLASS_NAMES.length เท่ากับ 2 หรือจะใช้ categoricalCrossentropy หากมีคลาสตั้งแต่ 3 คลาสขึ้นไปที่จะจัดประเภท นอกจากนี้ยังมีการขอเมตริกความแม่นยำเพื่อให้สามารถตรวจสอบในบันทึกได้ในภายหลังเพื่อวัตถุประสงค์ในการแก้ไขข้อบกพร่อง
คุณควรเห็นข้อความต่อไปนี้ในคอนโซล
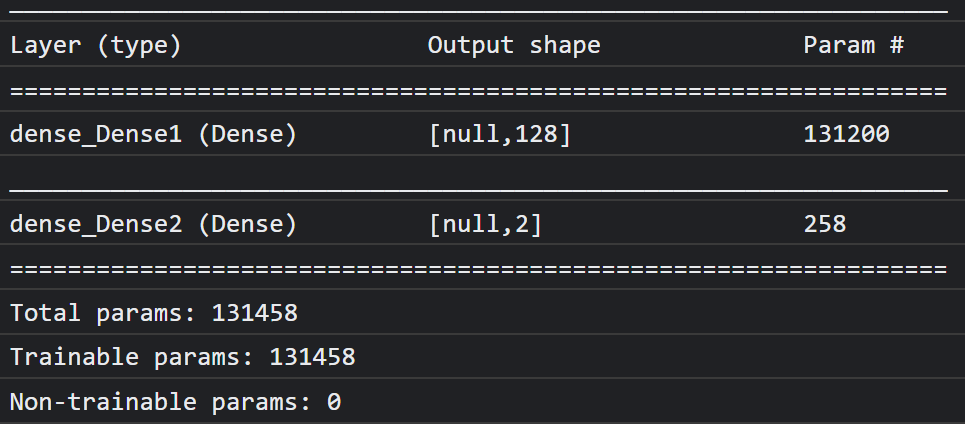
โปรดทราบว่าโมเดลนี้มีพารามิเตอร์ที่ฝึกได้มากกว่า 130,000 รายการ แต่เนื่องจากเป็นเลเยอร์แบบหนาแน่นธรรมดาของนิวรอนปกติ จึงจะฝึกได้อย่างรวดเร็ว
คุณอาจลองเปลี่ยนจำนวนนิวรอนในชั้นแรกเพื่อดูว่าลดจำนวนได้ต่ำสุดเท่าใดในขณะที่ยังคงได้รับประสิทธิภาพที่เหมาะสม โดยปกติแล้ว แมชชีนเลิร์นนิงมักต้องมีการลองผิดลองถูกในระดับหนึ่งเพื่อค้นหาค่าพารามิเตอร์ที่เหมาะสมที่สุด ซึ่งจะช่วยให้คุณได้ข้อแลกเปลี่ยนที่ดีที่สุดระหว่างการใช้ทรัพยากรและความเร็ว
11. เปิดใช้เว็บแคม
ตอนนี้ก็ถึงเวลาที่จะขยายความฟังก์ชัน enableCam() ที่คุณกำหนดไว้ก่อนหน้านี้ เพิ่มฟังก์ชันใหม่ชื่อ hasGetUserMedia() ดังที่แสดงด้านล่าง จากนั้นแทนที่เนื้อหาของฟังก์ชัน enableCam() ที่กำหนดไว้ก่อนหน้านี้ด้วยโค้ดที่เกี่ยวข้องด้านล่าง
script.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
ก่อนอื่น ให้สร้างฟังก์ชันชื่อ hasGetUserMedia() เพื่อตรวจสอบว่าเบราว์เซอร์รองรับ getUserMedia() หรือไม่ โดยตรวจสอบว่ามีพร็อพเพอร์ตี้ API ของเบราว์เซอร์หลักๆ หรือไม่
ในฟังก์ชัน enableCam() ให้ใช้ฟังก์ชัน hasGetUserMedia() ที่คุณเพิ่งกำหนดไว้ด้านบนเพื่อตรวจสอบว่าระบบรองรับหรือไม่ หากไม่ใช่ ให้พิมพ์คำเตือนไปยังคอนโซล
หากอุปกรณ์รองรับ ให้กำหนดข้อจำกัดบางอย่างสำหรับการเรียก getUserMedia() เช่น คุณต้องการเฉพาะสตรีมวิดีโอ และต้องการให้ width ของวิดีโอมีขนาด 640 พิกเซล และ height มีขนาด 480 พิกเซล เหตุผล แต่ก็ไม่มีประโยชน์มากนักที่จะมีวิดีโอขนาดใหญ่กว่านี้ เนื่องจากจะต้องปรับขนาดเป็น 224x224 พิกเซลเพื่อป้อนลงในโมเดล MobileNet คุณอาจประหยัดทรัพยากรการประมวลผลได้ด้วยการขอความละเอียดที่เล็กลง กล้องส่วนใหญ่รองรับความละเอียดขนาดนี้
จากนั้นเรียกใช้ navigator.mediaDevices.getUserMedia() โดยมีconstraints ตามรายละเอียดด้านบน แล้วรอให้ระบบส่งคืน stream เมื่อได้รับ stream แล้ว คุณจะทำให้องค์ประกอบ VIDEO เล่น stream ได้โดยตั้งค่าเป็นค่า srcObject
นอกจากนี้ คุณควรเพิ่ม eventListener ในองค์ประกอบ VIDEO เพื่อให้ทราบเมื่อ stream โหลดและเล่นสำเร็จ
เมื่อสตรีมโหลดแล้ว คุณสามารถตั้งค่า videoPlaying เป็น จริง และนำ ENABLE_CAM_BUTTON ออกเพื่อป้องกันไม่ให้คลิกอีกครั้งโดยตั้งค่าคลาสเป็น "removed"
ตอนนี้ให้เรียกใช้โค้ด คลิกปุ่มเปิดใช้กล้อง และอนุญาตการเข้าถึงเว็บแคม หากนี่เป็นการใช้งานครั้งแรก คุณจะเห็นตัวเองแสดงผลในองค์ประกอบวิดีโอบนหน้าเว็บดังที่แสดง

ตอนนี้ได้เวลาเพิ่มฟังก์ชันเพื่อจัดการกับการคลิกปุ่ม dataCollector แล้ว
12. เครื่องจัดการเหตุการณ์ปุ่มการเก็บรวบรวมข้อมูล
ตอนนี้ก็ถึงเวลาเขียนฟังก์ชันที่ว่างอยู่ซึ่งชื่อว่า gatherDataForClass(). นี่คือฟังก์ชันที่คุณกำหนดเป็นฟังก์ชันตัวแฮนเดิลเหตุการณ์สำหรับปุ่ม dataCollector เมื่อเริ่ม Codelab
script.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
ก่อนอื่น ให้ตรวจสอบแอตทริบิวต์ data-1hot ในปุ่มที่คลิกอยู่ในปัจจุบันโดยเรียกใช้ this.getAttribute() พร้อมชื่อแอตทริบิวต์ ในกรณีนี้คือ data-1hot เป็นพารามิเตอร์ เนื่องจากเป็นสตริง คุณจึงใช้ parseInt() เพื่อแคสต์ไปยังจำนวนเต็มและกำหนดผลลัพธ์นี้ให้กับตัวแปรชื่อ classNumber. ได้
จากนั้นตั้งค่าตัวแปร gatherDataState ตามนั้น หาก gatherDataState ปัจจุบันเท่ากับ STOP_DATA_GATHER (ซึ่งคุณตั้งค่าเป็น -1) แสดงว่าขณะนี้คุณไม่ได้รวบรวมข้อมูลใดๆ และเป็นเหตุการณ์ mousedown ที่เริ่มทำงาน ตั้งค่า gatherDataState เป็น classNumber ที่คุณเพิ่งพบ
มิเช่นนั้น หมายความว่าคุณกำลังรวบรวมข้อมูลและเหตุการณ์ที่เริ่มทำงานคือเหตุการณ์ mouseup และตอนนี้คุณต้องการหยุดรวบรวมข้อมูลสำหรับคลาสนั้น เพียงตั้งค่ากลับเป็นสถานะ STOP_DATA_GATHER เพื่อสิ้นสุดลูปการรวบรวมข้อมูลที่คุณจะกำหนดในอีกไม่ช้า
สุดท้าย ให้เริ่มการเรียกใช้ dataGatherLoop(), ซึ่งจะบันทึกข้อมูลชั้นเรียนจริงๆ
13. การรวบรวมข้อมูล
ตอนนี้ให้กำหนดdataGatherLoop()ฟังก์ชัน ฟังก์ชันนี้มีหน้าที่สุ่มตัวอย่างรูปภาพจากวิดีโอเว็บแคม ส่งผ่านไปยังโมเดล MobileNet และบันทึกเอาต์พุตของโมเดลนั้น (เวกเตอร์ฟีเจอร์ 1024)
จากนั้นจะจัดเก็บข้อมูลดังกล่าวพร้อมกับgatherDataStateรหัสของปุ่มที่กำลังกดอยู่เพื่อให้คุณทราบว่าข้อมูลนี้แสดงถึงคลาสใด
มาดูขั้นตอนกัน
script.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
คุณจะดำเนินการฟังก์ชันนี้ต่อไปก็ต่อเมื่อ videoPlaying เป็นจริง ซึ่งหมายความว่าเว็บแคมทำงานอยู่ และ gatherDataState ไม่เท่ากับ STOP_DATA_GATHER และขณะนี้มีการกดปุ่มสำหรับการรวบรวมข้อมูลในชั้นเรียน
จากนั้น ให้ใส่โค้ดของคุณใน tf.tidy() เพื่อทิ้ง Tensor ที่สร้างขึ้นในโค้ดที่ตามมา ผลลัพธ์ของการtf.tidy()ดำเนินการโค้ดนี้จะจัดเก็บไว้ในตัวแปรที่ชื่อ imageFeatures
ตอนนี้คุณสามารถจับภาพเฟรมจากเว็บแคม VIDEO โดยใช้ tf.browser.fromPixels() ได้แล้ว ระบบจะจัดเก็บ Tensor ที่ได้ซึ่งมีข้อมูลรูปภาพไว้ในตัวแปรที่ชื่อ videoFrameAsTensor
จากนั้นปรับขนาดvideoFrameAsTensorตัวแปรให้มีรูปร่างที่ถูกต้องสำหรับอินพุตของโมเดล MobileNet ใช้tf.image.resizeBilinear()การเรียกที่มี Tensor ที่คุณต้องการเปลี่ยนรูปร่างเป็นพารามิเตอร์แรก จากนั้นใช้รูปร่างที่กำหนดความสูงและความกว้างใหม่ตามค่าคงที่ที่คุณสร้างไว้ก่อนหน้านี้ สุดท้าย ให้ตั้งค่า align corners เป็น true โดยส่งพารามิเตอร์ที่ 3 เพื่อหลีกเลี่ยงปัญหาการจัดแนวเมื่อปรับขนาด ระบบจะจัดเก็บผลลัพธ์ของการปรับขนาดนี้ไว้ในตัวแปรที่ชื่อ resizedTensorFrame
โปรดทราบว่าการปรับขนาดแบบพื้นฐานนี้จะยืดรูปภาพ เนื่องจากรูปภาพจากเว็บแคมมีขนาด 640x480 พิกเซล และโมเดลต้องการรูปภาพสี่เหลี่ยมจัตุรัสขนาด 224x224 พิกเซล
ซึ่งควรจะใช้งานได้ดีสำหรับการสาธิตนี้ อย่างไรก็ตาม เมื่อทำ Codelab นี้เสร็จแล้ว คุณอาจต้องการลองครอบตัดสี่เหลี่ยมจัตุรัสจากรูปภาพนี้แทนเพื่อให้ได้ผลลัพธ์ที่ดียิ่งขึ้นสำหรับระบบการผลิตที่คุณอาจสร้างขึ้นในภายหลัง
จากนั้นทําให้ข้อมูลรูปภาพเป็นมาตรฐาน ข้อมูลรูปภาพจะอยู่ในช่วง 0 ถึง 255 เสมอเมื่อใช้ tf.browser.frompixels() ดังนั้นคุณจึงหาร resizedTensorFrame ด้วย 255 ได้โดยตรงเพื่อให้แน่ใจว่าค่าทั้งหมดอยู่ระหว่าง 0 ถึง 1 แทน ซึ่งเป็นค่าที่โมเดล MobileNet คาดหวังเป็นอินพุต
สุดท้ายในส่วน tf.tidy() ของโค้ด ให้ส่ง Tensor ที่ผ่านการแปลงเป็นรูปแบบมาตรฐานนี้ผ่านโมเดลที่โหลดโดยเรียกใช้ mobilenet.predict() ซึ่งคุณส่งเวอร์ชันที่ขยายของ normalizedTensorFrame ไปยัง expandDims() เพื่อให้เป็นกลุ่มขนาด 1 เนื่องจากโมเดลคาดหวังอินพุตแบบกลุ่มสำหรับการประมวลผล
เมื่อได้ผลลัพธ์แล้ว คุณจะเรียกใช้ squeeze() ในผลลัพธ์ที่ส่งคืนนั้นได้ทันทีเพื่อย่อให้เหลือ Tensor 1 มิติ จากนั้นส่งคืนและกำหนดให้กับตัวแปร imageFeatures ที่บันทึกผลลัพธ์จาก tf.tidy()
ตอนนี้คุณมี imageFeatures จากโมเดล MobileNet แล้ว คุณสามารถบันทึกค่าเหล่านั้นได้โดยการส่งไปยังอาร์เรย์ trainingDataInputs ที่คุณกำหนดไว้ก่อนหน้านี้
นอกจากนี้ คุณยังบันทึกสิ่งที่อินพุตนี้แสดงได้โดยการพุช gatherDataState ปัจจุบันไปยังอาร์เรย์ trainingDataOutputs ด้วย
โปรดทราบว่าระบบจะตั้งค่าตัวแปร gatherDataState เป็นรหัสตัวเลขของชั้นเรียนปัจจุบันที่คุณบันทึกข้อมูลเมื่อมีการคลิกปุ่มในฟังก์ชัน gatherDataForClass() ที่กําหนดไว้ก่อนหน้านี้
ในขั้นตอนนี้ คุณยังเพิ่มจำนวนตัวอย่างที่มีสำหรับคลาสที่กำหนดได้ด้วย โดยก่อนอื่นให้ตรวจสอบว่าได้เริ่มต้นดัชนีภายในอาร์เรย์ examplesCount แล้วหรือไม่ หากไม่ได้กำหนด ให้ตั้งค่าเป็น 0 เพื่อเริ่มต้นตัวนับสำหรับรหัสตัวเลขของคลาสที่กำหนด จากนั้นคุณจะเพิ่ม examplesCount สำหรับ gatherDataState ปัจจุบันได้
ตอนนี้ให้อัปเดตข้อความขององค์ประกอบ STATUS ในหน้าเว็บเพื่อแสดงจำนวนปัจจุบันของแต่ละคลาสเมื่อมีการบันทึก โดยให้วนซ้ำในอาร์เรย์ CLASS_NAMES และพิมพ์ชื่อที่มนุษย์อ่านได้ร่วมกับจำนวนข้อมูลที่ดัชนีเดียวกันใน examplesCount
สุดท้าย ให้เรียกใช้ window.requestAnimationFrame() โดยส่ง dataGatherLoop เป็นพารามิเตอร์เพื่อเรียกใช้ฟังก์ชันนี้อีกครั้งแบบเรียกซ้ำ ระบบจะสุ่มตัวอย่างเฟรมจากวิดีโอต่อไปจนกว่าจะตรวจพบ mouseup ของปุ่ม และตั้งค่า gatherDataState เป็น STOP_DATA_GATHER, จากนั้นลูปการรวบรวมข้อมูลจะสิ้นสุดลง
หากเรียกใช้โค้ดตอนนี้ คุณควรจะคลิกปุ่มเปิดใช้กล้อง รอให้เว็บแคมโหลด จากนั้นคลิกปุ่มรวบรวมข้อมูลแต่ละปุ่มค้างไว้เพื่อรวบรวมตัวอย่างสำหรับข้อมูลแต่ละคลาส ในภาพนี้ คุณจะเห็นว่าฉันกำลังรวบรวมข้อมูลสำหรับโทรศัพท์มือถือและมือของฉัน
คุณควรเห็นข้อความสถานะอัปเดตขณะที่ระบบจัดเก็บ Tensor ทั้งหมดไว้ในหน่วยความจำตามที่แสดงในการจับภาพหน้าจอด้านบน
14. ฝึกและคาดการณ์
ขั้นตอนถัดไปคือการใช้โค้ดสำหรับฟังก์ชัน trainAndPredict() ที่ว่างอยู่ในปัจจุบัน ซึ่งเป็นที่ที่การเรียนรู้แบบถ่ายโอนเกิดขึ้น มาดูโค้ดกัน
script.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
ก่อนอื่น ให้หยุดการคาดการณ์ปัจจุบันทั้งหมดโดยตั้งค่า predict เป็น false
จากนั้นสับเปลี่ยนอาร์เรย์อินพุตและเอาต์พุตโดยใช้ tf.util.shuffleCombo() เพื่อให้แน่ใจว่าลำดับจะไม่ทำให้เกิดปัญหาในการฝึก
แปลงอาร์เรย์เอาต์พุต trainingDataOutputs, เป็น Tensor1d ประเภท int32 เพื่อให้พร้อมใช้งานใน One-Hot Encoding ซึ่งจะจัดเก็บไว้ในตัวแปรที่ชื่อ outputsAsTensor
ใช้ฟังก์ชัน tf.oneHot() กับตัวแปร outputsAsTensor นี้พร้อมกับจำนวนสูงสุดของคลาสที่จะเข้ารหัส ซึ่งก็คือ CLASS_NAMES.length ตอนนี้เอาต์พุตที่เข้ารหัสแบบ One-Hot จะจัดเก็บไว้ในเทนเซอร์ใหม่ชื่อ oneHotOutputs
โปรดทราบว่าขณะนี้ trainingDataInputs เป็นอาร์เรย์ของเทนเซอร์ที่บันทึกไว้ หากต้องการใช้ข้อมูลเหล่านี้ในการฝึก คุณจะต้องแปลงอาร์เรย์ของ Tensor ให้เป็น Tensor 2 มิติปกติ
ซึ่งทำได้โดยใช้ฟังก์ชันที่ยอดเยี่ยมในไลบรารี TensorFlow.js ที่ชื่อ tf.stack()
ซึ่งรับอาร์เรย์ของเทนเซอร์และซ้อนกันเพื่อสร้างเทนเซอร์ที่มีมิติสูงกว่าเป็นเอาต์พุต ในกรณีนี้ ระบบจะแสดงผลเทนเซอร์ 2 มิติ ซึ่งเป็นอินพุตแบบ 1 มิติแบบกลุ่มที่มีความยาว 1024 แต่ละรายการซึ่งมีฟีเจอร์ที่บันทึกไว้ ซึ่งเป็นสิ่งที่คุณต้องการสำหรับการฝึก
จากนั้น await model.fit() เพื่อฝึกส่วนหัวของโมเดลที่กำหนดเอง ในที่นี้ คุณจะส่งตัวแปร inputsAsTensor พร้อมกับ oneHotOutputs เพื่อแสดงข้อมูลฝึกฝนที่จะใช้สำหรับอินพุตตัวอย่างและเอาต์พุตเป้าหมายตามลำดับ ในออบเจ็กต์การกำหนดค่าสำหรับพารามิเตอร์ที่ 3 ให้ตั้งค่า shuffle เป็น true ใช้ batchSize ของ 5 โดยตั้งค่า epochs เป็น 10 จากนั้นระบุ callback สำหรับ onEpochEnd ไปยังฟังก์ชัน logProgress ที่คุณจะกำหนดในอีกไม่ช้า
สุดท้าย คุณสามารถทิ้งเทนเซอร์ที่สร้างขึ้นได้เนื่องจากตอนนี้โมเดลได้รับการฝึกแล้ว จากนั้นคุณสามารถตั้งค่า predict กลับเป็น true เพื่ออนุญาตให้มีการคาดคะเนอีกครั้ง แล้วเรียกใช้ฟังก์ชัน predictLoop() เพื่อเริ่มคาดคะเนภาพจากเว็บแคมแบบเรียลไทม์
นอกจากนี้ คุณยังกำหนดฟังก์ชัน logProcess() เพื่อบันทึกสถานะของการฝึกได้ ซึ่งใช้ใน model.fit() ด้านบนและพิมพ์ผลลัพธ์ไปยังคอนโซลหลังจากการฝึกแต่ละรอบ
เกือบถูกแล้ว ถึงเวลาเพิ่มฟังก์ชัน predictLoop() เพื่อทำการคาดการณ์
วงจรการคาดคะเนหลัก
ที่นี่คุณจะใช้ลูปการคาดการณ์หลักที่สุ่มตัวอย่างเฟรมจากเว็บแคมและคาดการณ์อย่างต่อเนื่องว่ามีอะไรอยู่ในแต่ละเฟรมพร้อมผลลัพธ์แบบเรียลไทม์ในเบราว์เซอร์
มาตรวจสอบโค้ดกัน
script.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
ก่อนอื่น ให้ตรวจสอบว่า predict เป็นจริง เพื่อให้ระบบทำการคาดการณ์หลังจากฝึกโมเดลและพร้อมใช้งานแล้วเท่านั้น
จากนั้นคุณจะใช้ฟีเจอร์รูปภาพสำหรับรูปภาพปัจจุบันได้เช่นเดียวกับที่ทำในฟังก์ชัน dataGatherLoop() โดยพื้นฐานแล้ว คุณจะดึงเฟรมจากเว็บแคมโดยใช้ tf.browser.from pixels() ปรับให้เป็นปกติ ปรับขนาดเป็น 224 x 224 พิกเซล แล้วส่งข้อมูลนั้นผ่านโมเดล MobileNet เพื่อรับฟีเจอร์รูปภาพที่ได้
แต่ตอนนี้คุณสามารถใช้ส่วนหัวของโมเดลที่ฝึกใหม่เพื่อทำการคาดการณ์จริงได้โดยส่ง imageFeatures ที่ได้ผ่านฟังก์ชัน predict() ของโมเดลที่ฝึก จากนั้นคุณสามารถบีบอัด Tensor ที่ได้เพื่อให้เป็น 1 มิติอีกครั้ง แล้วกำหนดให้กับตัวแปรที่ชื่อ prediction
ด้วย prediction นี้ คุณจะค้นหาดัชนีที่มีค่าสูงสุดได้โดยใช้ argMax() จากนั้นแปลงเทนเซอร์ผลลัพธ์นี้เป็นอาร์เรย์โดยใช้ arraySync() เพื่อเข้าถึงข้อมูลพื้นฐานใน JavaScript เพื่อค้นหาตำแหน่งขององค์ประกอบที่มีค่าสูงสุด ค่านี้จะจัดเก็บไว้ในตัวแปรที่ชื่อ highestIndex
นอกจากนี้ คุณยังดูคะแนนความเชื่อมั่นในการคาดการณ์จริงได้ด้วยวิธีเดียวกันโดยเรียกใช้ arraySync() ใน Tensor prediction โดยตรง
ตอนนี้คุณมีทุกอย่างที่จำเป็นในการอัปเดตSTATUSข้อความด้วยข้อมูลpredictionแล้ว หากต้องการรับสตริงที่มนุษย์อ่านได้สำหรับคลาส คุณเพียงแค่ค้นหา highestIndex ในอาร์เรย์ CLASS_NAMES แล้วดึงค่า Confidence จาก predictionArray หากต้องการให้อ่านง่ายขึ้นในรูปแบบเปอร์เซ็นต์ เพียงคูณด้วย 100 แล้วmath.floor()ผลลัพธ์
สุดท้ายนี้ คุณสามารถใช้ window.requestAnimationFrame() เพื่อเรียกใช้ predictionLoop() อีกครั้งเมื่อพร้อม เพื่อรับการจัดประเภทแบบเรียลไทม์ในสตรีมวิดีโอ กระบวนการนี้จะดำเนินต่อไปจนกว่าจะตั้งค่า predict เป็น false หากคุณเลือกฝึกโมเดลใหม่ด้วยข้อมูลใหม่
ซึ่งจะนำคุณไปสู่ชิ้นส่วนสุดท้ายของปริศนา การติดตั้งใช้งานปุ่มรีเซ็ต
15. ติดตั้งใช้งานปุ่มรีเซ็ต
เกือบเสร็จแล้ว ส่วนสุดท้ายของปริศนาคือการติดตั้งปุ่มรีเซ็ตเพื่อเริ่มต้นใหม่ โค้ดสำหรับฟังก์ชัน reset() ที่ว่างเปล่าในขณะนี้อยู่ด้านล่าง โปรดอัปเดตดังนี้
script.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
ก่อนอื่น ให้หยุดลูปการคาดการณ์ที่กำลังทำงานโดยตั้งค่า predict เป็น false จากนั้น ให้ลบเนื้อหาทั้งหมดในอาร์เรย์ examplesCount โดยตั้งค่าความยาวเป็น 0 ซึ่งเป็นวิธีที่สะดวกในการล้างเนื้อหาทั้งหมดจากอาร์เรย์
ตอนนี้ให้ไปที่ trainingDataInputs ที่บันทึกไว้ทั้งหมดในปัจจุบัน และตรวจสอบว่าคุณได้ dispose() ของแต่ละ Tensor ที่อยู่ในนั้นเพื่อเพิ่มพื้นที่ว่างในหน่วยความจำอีกครั้ง เนื่องจาก JavaScript Garbage Collector จะไม่ล้างข้อมูล Tensor
เมื่อดำเนินการเสร็จแล้ว คุณจะตั้งค่าความยาวของอาร์เรย์เป็น 0 ในอาร์เรย์ trainingDataInputs และ trainingDataOutputs ได้อย่างปลอดภัยเพื่อล้างอาร์เรย์เหล่านั้นด้วย
สุดท้าย ให้ตั้งค่าSTATUSข้อความเป็นข้อความที่เหมาะสม และพิมพ์เทนเซอร์ที่เหลืออยู่ในหน่วยความจำเพื่อตรวจสอบความถูกต้อง
โปรดทราบว่าจะมี Tensor อีกหลายร้อยรายการที่ยังอยู่ในหน่วยความจำ เนื่องจากทั้งโมเดล MobileNet และเพอร์เซปตรอนแบบหลายชั้นที่คุณกำหนดไว้จะยังไม่ถูกกำจัด คุณจะต้องนำไปใช้ซ้ำกับข้อมูลฝึกฝนใหม่หากตัดสินใจฝึกอีกครั้งหลังจากรีเซ็ต
16. มาลองใช้กันเลย
ได้เวลาทดสอบ Teachable Machine ในเวอร์ชันของคุณเองแล้ว
ไปที่ตัวอย่างสด เปิดใช้เว็บแคม รวบรวมตัวอย่างอย่างน้อย 30 รายการสำหรับคลาส 1 สำหรับวัตถุบางอย่างในห้อง จากนั้นทำเช่นเดียวกันสำหรับคลาส 2 สำหรับวัตถุอื่น คลิกฝึก และตรวจสอบบันทึกคอนโซลเพื่อดูความคืบหน้า ซึ่งควรจะฝึกได้เร็วพอสมควร

เมื่อฝึกแล้ว ให้แสดงวัตถุต่อกล้องเพื่อรับการคาดการณ์แบบเรียลไทม์ที่จะพิมพ์ลงในพื้นที่ข้อความสถานะบนหน้าเว็บใกล้ด้านบน หากพบปัญหา ให้ตรวจสอบโค้ดที่ใช้งานได้ที่ฉันเขียนเสร็จแล้วเพื่อดูว่าคุณลืมคัดลอกอะไรไปหรือไม่
17. ขอแสดงความยินดี
ยินดีด้วย คุณเพิ่งทำตัวอย่างการเรียนรู้แบบถ่ายโอนครั้งแรกโดยใช้ TensorFlow.js แบบเรียลไทม์ในเบราว์เซอร์
ลองใช้ฟีเจอร์นี้และทดสอบกับวัตถุต่างๆ คุณอาจสังเกตเห็นว่าบางสิ่งจดจำได้ยากกว่าสิ่งอื่นๆ โดยเฉพาะอย่างยิ่งหากวัตถุนั้นคล้ายกับวัตถุอื่น คุณอาจต้องเพิ่มชั้นเรียนหรือข้อมูลฝึกฝนเพิ่มเติมเพื่อให้แยกความแตกต่างได้
สรุป
ใน Codelab นี้ คุณได้เรียนรู้สิ่งต่อไปนี้
- การเรียนรู้แบบถ่ายโอนคืออะไร และข้อดีของการเรียนรู้แบบถ่ายโอนเมื่อเทียบกับการฝึกโมเดลแบบเต็ม
- วิธีรับโมเดลเพื่อนำกลับมาใช้ซ้ำจาก TensorFlow Hub
- วิธีตั้งค่าเว็บแอปที่เหมาะกับการเรียนรู้แบบถ่ายโอน
- วิธีโหลดและใช้โมเดลพื้นฐานเพื่อสร้างฟีเจอร์รูปภาพ
- วิธีฝึกส่วนหัวของการคาดการณ์ใหม่ที่จดจำออบเจ็กต์ที่กำหนดเองจากภาพเว็บแคมได้
- วิธีใช้โมเดลที่ได้เพื่อจัดประเภทข้อมูลแบบเรียลไทม์
สิ่งต่อไปที่ควรทำ
ตอนนี้คุณมีฐานที่ใช้งานได้เพื่อเริ่มต้นแล้ว คุณจะคิดไอเดียสร้างสรรค์อะไรได้บ้างเพื่อขยายเพลตแมชชีนเลิร์นนิงนี้สำหรับกรณีการใช้งานจริงที่คุณอาจกำลังดำเนินการอยู่ คุณอาจปฏิวัติอุตสาหกรรมที่คุณทำงานอยู่เพื่อช่วยให้ผู้คนในบริษัทฝึกโมเดลเพื่อจัดประเภทสิ่งสำคัญในงานประจำวันได้ ทุกอย่างเป็นไปได้
หากต้องการเรียนรู้เพิ่มเติม ลองเรียนหลักสูตรฉบับเต็มนี้ฟรี ซึ่งจะแสดงวิธีรวมโมเดล 2 รายการที่คุณมีอยู่ใน Codelab นี้ให้เป็นโมเดลเดียวเพื่อประสิทธิภาพ
นอกจากนี้ หากคุณอยากรู้ทฤษฎีเบื้องหลังแอปพลิเคชัน Teachable Machine ต้นฉบับ โปรดดูบทแนะนำนี้
แชร์ผลงานของคุณกับเรา
คุณสามารถขยายผลงานที่สร้างในวันนี้ไปใช้ในกรณีการใช้งานอื่นๆ ที่สร้างสรรค์ได้ด้วย และเราขอแนะนำให้คุณคิดนอกกรอบและสร้างสรรค์ต่อไป
อย่าลืมแท็กเราบนโซเชียลมีเดียโดยใช้แฮชแท็ก #MadeWithTFJS เพื่อให้โปรเจ็กต์ของคุณมีโอกาสได้แสดงในบล็อก TensorFlow หรือแม้แต่กิจกรรมในอนาคต เราอยากเห็นผลงานของคุณ
เว็บไซต์ที่ควรดู
- เว็บไซต์ทางการของ TensorFlow.js
- โมเดล TensorFlow.js ที่สร้างไว้ล่วงหน้า
- TensorFlow.js API
- TensorFlow.js Show & Tell - รับแรงบันดาลใจและดูว่าคนอื่นๆ สร้างอะไรกันบ้าง