
1. Prima di iniziare
L'utilizzo dei modelli TensorFlow.js è cresciuto in modo esponenziale negli ultimi anni e molti sviluppatori JavaScript ora vogliono prendere modelli all'avanguardia esistenti e riaddestrarli per funzionare con dati personalizzati unici per il loro settore. L'atto di prendere un modello esistente (spesso chiamato modello di base) e utilizzarlo in un dominio simile ma diverso è noto come transfer learning.
Il transfer learning offre molti vantaggi rispetto all'utilizzo di un modello completamente vuoto. Puoi riutilizzare le conoscenze già apprese da un modello addestrato in precedenza e hai bisogno di meno esempi del nuovo elemento che vuoi classificare. Inoltre, l'addestramento è spesso molto più rapido perché è necessario riaddestrare solo gli ultimi livelli dell'architettura del modello anziché l'intera rete. Per questo motivo, il transfer learning è molto adatto all'ambiente del browser web, in cui le risorse possono variare in base al dispositivo di esecuzione, ma ha anche accesso diretto ai sensori per una facile acquisizione dei dati.
Questo codelab mostra come creare un'app web da una tela vuota, ricreando il popolare sito web "Teachable Machine" di Google. Il sito web ti consente di creare un'app web funzionale che qualsiasi utente può utilizzare per riconoscere un oggetto personalizzato con poche immagini di esempio della propria webcam. Il sito web è volutamente ridotto al minimo per consentirti di concentrarti sugli aspetti di machine learning di questo codelab. Come per il sito web originale di Teachable Machine, tuttavia, c'è ampio spazio per applicare la tua esperienza di sviluppatore web esistente per migliorare la UX.
Prerequisiti
Questo codelab è pensato per gli sviluppatori web che hanno una certa familiarità con i modelli predefiniti di TensorFlow.js e con l'utilizzo di base delle API e che vogliono iniziare a utilizzare l'apprendimento per trasferimento in TensorFlow.js.
- Per questo lab è richiesta una conoscenza di base di TensorFlow.js, HTML5, CSS e JavaScript.
Se non hai mai utilizzato TensorFlow.js, ti consigliamo di seguire prima questo corso senza costi per principianti, che non richiede alcuna conoscenza pregressa di machine learning o TensorFlow.js e ti insegna tutto ciò che devi sapere in passaggi più piccoli.
Cosa imparerai a fare
- Che cos'è TensorFlow.js e perché dovresti utilizzarlo nella tua prossima app web.
- Come creare una pagina web HTML/CSS /JS semplificata che replichi l'esperienza utente di Teachable Machine.
- Come utilizzare TensorFlow.js per caricare un modello di base preaddestrato, in particolare MobileNet, per generare caratteristiche delle immagini che possono essere utilizzate nel transfer learning.
- Come raccogliere dati dalla webcam di un utente per più classi di dati che vuoi riconoscere.
- Come creare e definire un perceptron multistrato che acquisisce le caratteristiche dell'immagine e impara a classificare nuovi oggetti utilizzandole.
Iniziamo a hackerare…
Che cosa ti serve
- Per seguire l'esercitazione, è preferibile un account Glitch.com, ma puoi anche utilizzare un ambiente di pubblicazione web che ti consenta di apportare modifiche ed eseguire il codice.
2. Che cos'è TensorFlow.js?

TensorFlow.js è una libreria di machine learning open source che può essere eseguita ovunque sia possibile eseguire JavaScript. Si basa sulla libreria TensorFlow originale scritta in Python e mira a ricreare questa esperienza per gli sviluppatori e questo insieme di API per l'ecosistema JavaScript.
Dove può essere utilizzata?
Data la portabilità di JavaScript, ora puoi scrivere in una sola lingua ed eseguire il machine learning con facilità su tutte le seguenti piattaforme:
- Lato client nel browser web utilizzando JavaScript vanilla
- Lato server e persino dispositivi IoT come Raspberry Pi utilizzando Node.js
- App desktop che utilizzano Electron
- App native per dispositivi mobili che utilizzano React Native
TensorFlow.js supporta anche più backend all'interno di ciascuno di questi ambienti (gli ambienti basati sull'hardware effettivo in cui può essere eseguito, ad esempio la CPU o WebGL). Un "backend" in questo contesto non indica un ambiente lato server. Il backend per l'esecuzione potrebbe essere lato client in WebGL, ad esempio, per garantire la compatibilità e mantenere la velocità di esecuzione. Al momento TensorFlow.js supporta:
- Esecuzione di WebGL sulla scheda grafica (GPU) del dispositivo: questo è il modo più veloce per eseguire modelli più grandi (di dimensioni superiori a 3 MB) con l'accelerazione GPU.
- Esecuzione di Web Assembly (WASM) sulla CPU: per migliorare le prestazioni della CPU su tutti i dispositivi, inclusi ad esempio i cellulari di vecchia generazione. Questo è più adatto a modelli più piccoli (di dimensioni inferiori a 3 MB) che possono essere eseguiti più velocemente sulla CPU con WASM rispetto a WebGL a causa dell'overhead del caricamento dei contenuti su un processore grafico.
- Esecuzione della CPU: il fallback deve essere eseguito se nessuno degli altri ambienti è disponibile. È il più lento dei tre, ma è sempre a tua disposizione.
Nota:puoi scegliere di forzare uno di questi backend se sai su quale dispositivo verrà eseguito il codice oppure puoi lasciare che TensorFlow.js decida per te se non lo specifichi.
Superpoteri lato client
L'esecuzione di TensorFlow.js nel browser web sul computer client può comportare diversi vantaggi da prendere in considerazione.
Privacy
Puoi addestrare e classificare i dati sulla macchina client senza mai inviarli a un server web di terze parti. A volte, questo potrebbe essere un requisito per rispettare le leggi locali, ad esempio il GDPR, o durante l'elaborazione di dati che l'utente potrebbe voler conservare sul proprio computer e non inviare a terzi.
Velocità
Poiché non devi inviare dati a un server remoto, l'inferenza (l'atto di classificare i dati) può essere più veloce. Ancora meglio, se l'utente ti concede l'accesso, puoi accedere direttamente ai sensori del dispositivo, come fotocamera, microfono, GPS, accelerometro e altro ancora.
Copertura e scalabilità
Con un solo clic, chiunque al mondo può fare clic su un link che gli invii, aprire la pagina web nel browser e utilizzare ciò che hai creato. Non è necessario configurare Linux lato server con driver CUDA e molto altro solo per utilizzare il sistema di machine learning.
Costo
Nessun server significa che l'unica cosa che devi pagare è una CDN per ospitare i file HTML, CSS, JS e modello. Il costo di una CDN è molto inferiore rispetto a quello di un server (potenzialmente con una scheda grafica collegata) in esecuzione 24 ore su 24, 7 giorni su 7.
Funzionalità lato server
L'utilizzo dell'implementazione Node.js di TensorFlow.js consente le seguenti funzionalità.
Supporto completo di CUDA
Sul lato server, per l'accelerazione della scheda grafica, devi installare i driver NVIDIA CUDA per consentire a TensorFlow di funzionare con la scheda grafica (a differenza del browser che utilizza WebGL, senza necessità di installazione). Tuttavia, con il supporto completo di CUDA puoi sfruttare appieno le funzionalità di basso livello della scheda grafica, ottenendo tempi di addestramento e inferenza più rapidi. Il rendimento è alla pari con l'implementazione di TensorFlow Python, in quanto entrambi condividono lo stesso backend C++.
Dimensioni del modello
Per i modelli all'avanguardia della ricerca, potresti lavorare con modelli molto grandi, forse di dimensioni di gigabyte. Al momento questi modelli non possono essere eseguiti nel browser web a causa delle limitazioni della memoria utilizzata per scheda del browser. Per eseguire questi modelli più grandi, puoi utilizzare Node.js sul tuo server con le specifiche hardware necessarie per eseguire un modello di questo tipo in modo efficiente.
IOT
Node.js è supportato su computer a scheda singola popolari come Raspberry Pi, il che significa che puoi eseguire anche modelli TensorFlow.js su questi dispositivi.
Velocità
Node.js è scritto in JavaScript, il che significa che beneficia della compilazione just-in-time. Ciò significa che spesso potresti notare miglioramenti delle prestazioni quando utilizzi Node.js, in quanto verrà ottimizzato in fase di runtime, soprattutto per qualsiasi preelaborazione che potresti eseguire. Un ottimo esempio è visibile in questo case study, che mostra come Hugging Face ha utilizzato Node.js per ottenere un aumento delle prestazioni di due volte per il proprio modello di elaborazione del linguaggio naturale.
Ora che hai compreso le nozioni di base di TensorFlow.js, dove può essere eseguito e alcuni dei suoi vantaggi, iniziamo a fare cose utili.
3. Transfer learning
Che cos'è esattamente il transfer learning?
Il transfer learning consiste nell'utilizzare le conoscenze già acquisite per imparare qualcosa di diverso, ma simile.
Noi esseri umani lo facciamo di continuo. Nel tuo cervello hai una vita di esperienze che puoi usare per riconoscere nuove cose che non hai mai visto prima. Prendiamo ad esempio questo salice:

A seconda della parte del mondo in cui ti trovi, è possibile che tu non abbia mai visto questo tipo di albero.
Tuttavia, se ti chiedo di dirmi se ci sono salici nella nuova immagine qui sotto, probabilmente li individuerai abbastanza velocemente, anche se sono ripresi da un'angolazione diversa e sono leggermente diversi da quelli originali che ti ho mostrato.

Nel tuo cervello hai già un sacco di neuroni che sanno come identificare oggetti simili ad alberi e altri neuroni che sono bravi a trovare linee rette lunghe. Puoi riutilizzare queste conoscenze per classificare rapidamente un salice, un oggetto simile a un albero con molti rami verticali lunghi e dritti.
Allo stesso modo, se hai un modello di machine learning già addestrato su un dominio, ad esempio il riconoscimento delle immagini, puoi riutilizzarlo per eseguire un'attività diversa, ma correlata.
Puoi fare lo stesso con un modello avanzato come MobileNet, un modello di ricerca molto popolare che può eseguire il riconoscimento delle immagini su 1000 diversi tipi di oggetti. Dai cani alle auto, è stato addestrato su un enorme set di dati noto come ImageNet, che contiene milioni di immagini etichettate.
In questa animazione puoi vedere l'enorme numero di livelli che ha questo modello MobileNet V1:
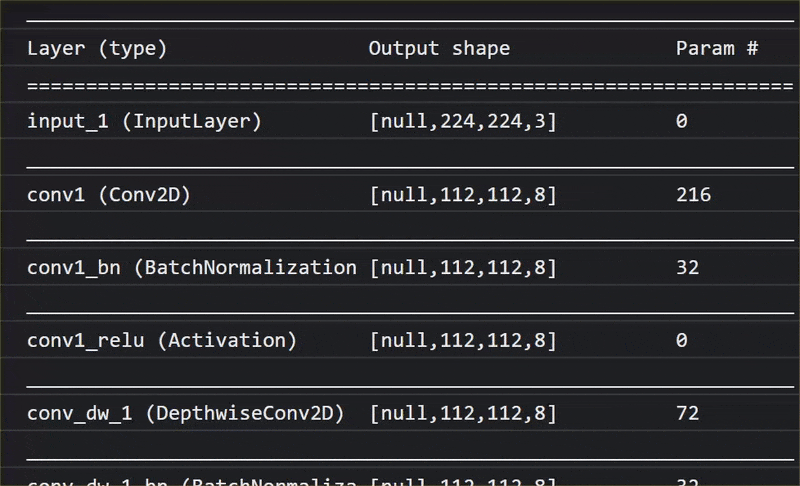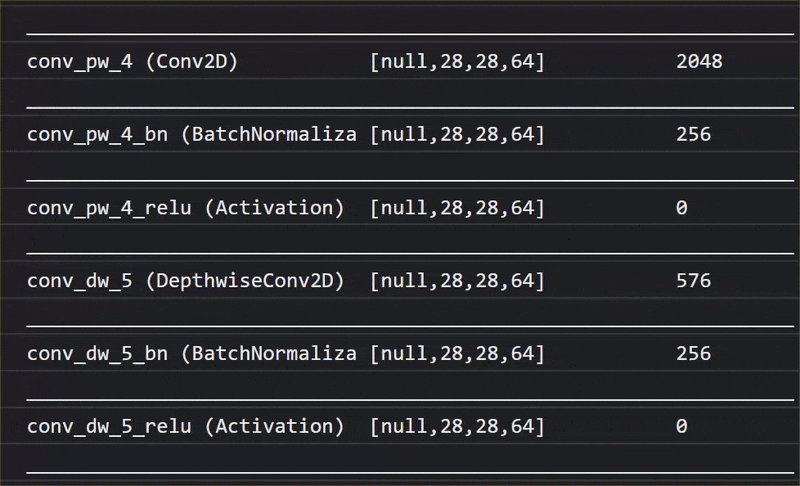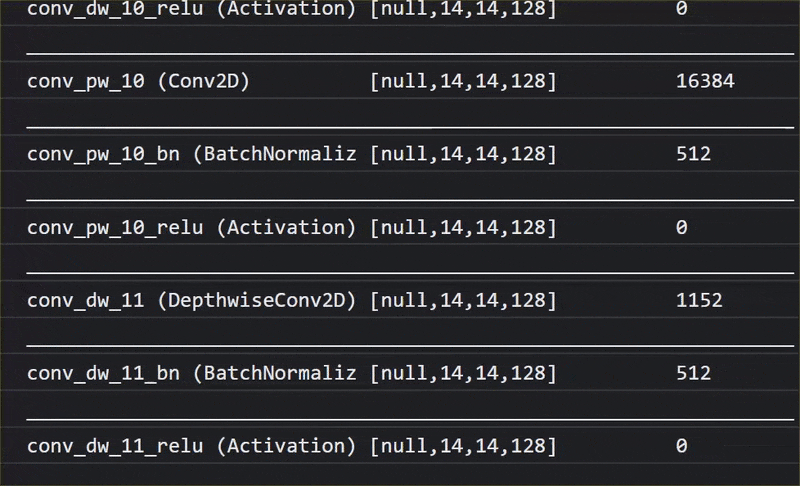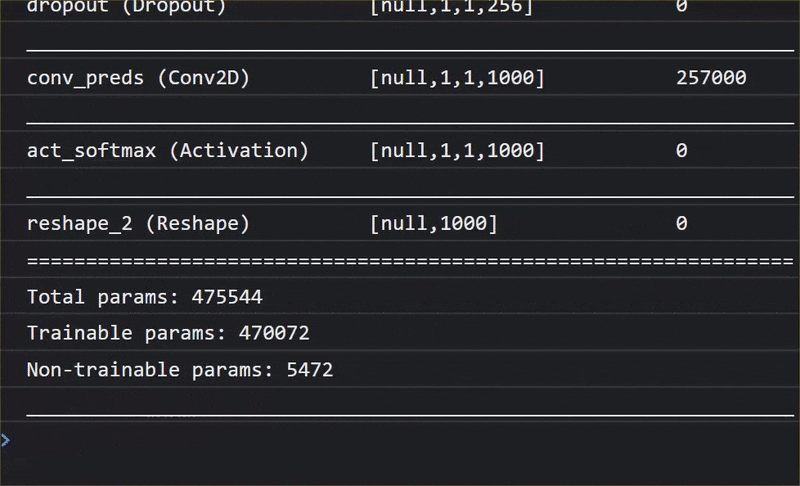
Durante l'addestramento, questo modello ha imparato a estrarre le caratteristiche comuni importanti per tutti i 1000 oggetti e molte delle caratteristiche di livello inferiore che utilizza per identificare questi oggetti possono essere utili anche per rilevare nuovi oggetti che non ha mai visto prima. Dopo tutto, ogni cosa è in definitiva solo una combinazione di linee, trame e forme.
Diamo un'occhiata a un'architettura di rete neurale convoluzionale (CNN) tradizionale (simile a MobileNet) e vediamo come il transfer learning può sfruttare questa rete addestrata per imparare qualcosa di nuovo. L'immagine seguente mostra la tipica architettura del modello di una CNN che in questo caso è stata addestrata a riconoscere i numeri scritti a mano da 0 a 9:
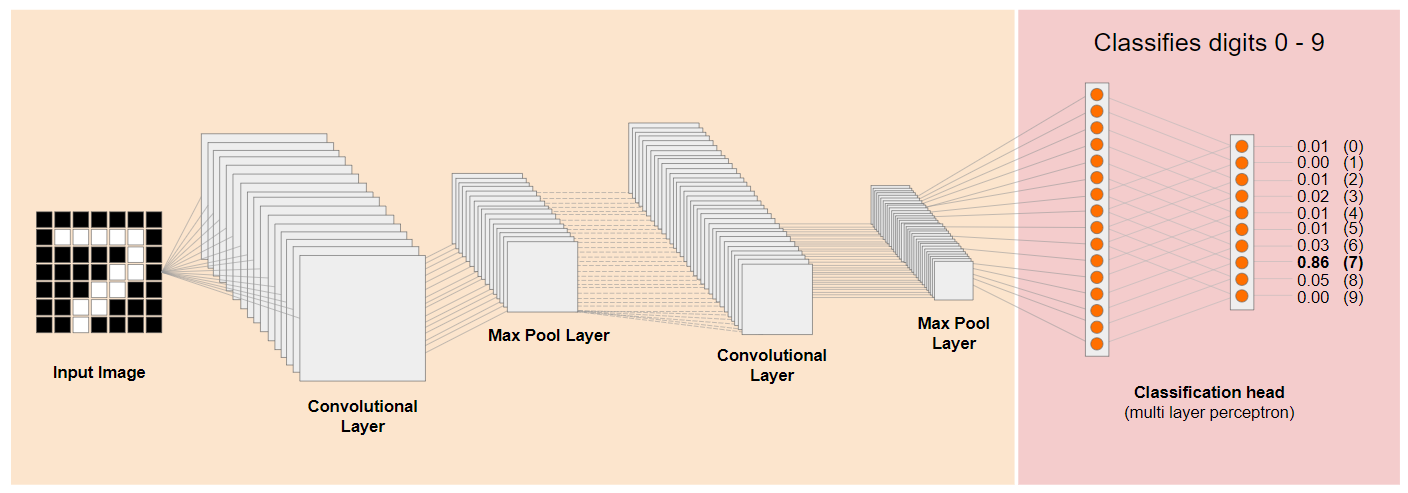
Se potessi separare i livelli di basso livello preaddestrati di un modello addestrato esistente, come mostrato a sinistra, dai livelli di classificazione vicino alla fine del modello mostrato a destra (a volte chiamati intestazione di classificazione del modello), potresti utilizzare i livelli di basso livello per produrre caratteristiche di output per qualsiasi immagine in base ai dati originali su cui è stato addestrato. Ecco la stessa rete con l'intestazione di classificazione rimossa:
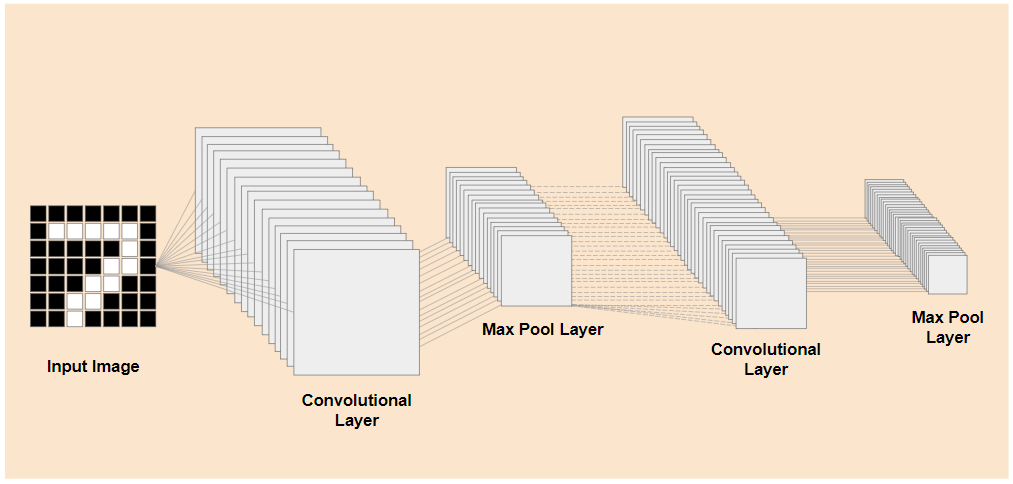
Supponendo che la nuova cosa che stai cercando di riconoscere possa utilizzare anche le funzionalità di output apprese dal modello precedente, è molto probabile che possano essere riutilizzate per un nuovo scopo.
Nel diagramma precedente, questo modello ipotetico è stato addestrato su cifre, quindi forse ciò che è stato appreso sulle cifre può essere applicato anche a lettere come a, b e c.
Ora puoi aggiungere una nuova intestazione di classificazione che tenta di prevedere a, b o c, come mostrato di seguito:
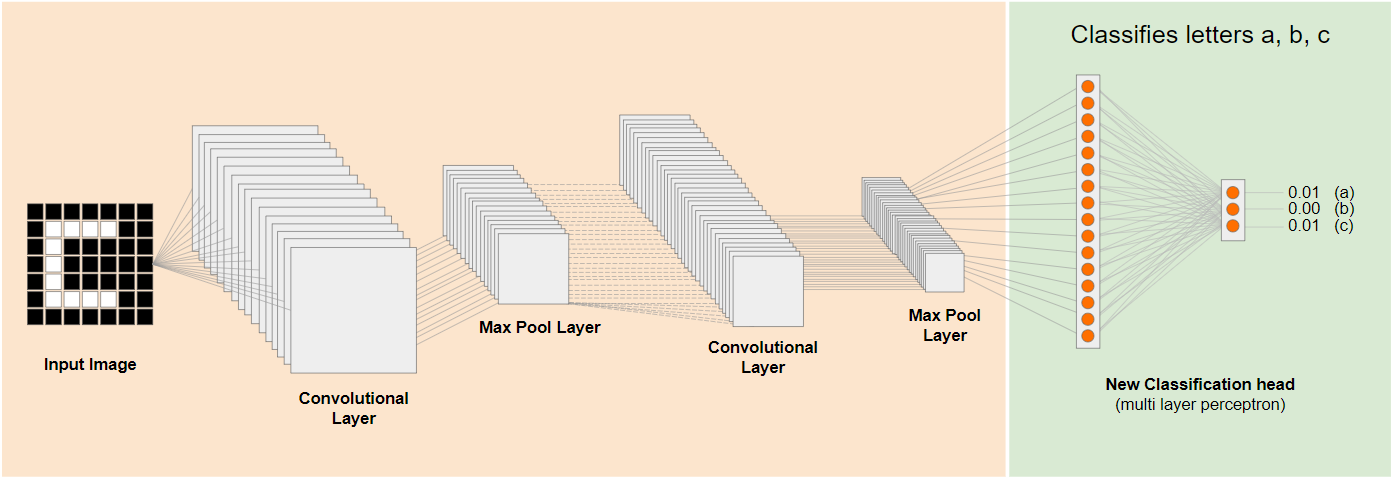
Qui i livelli inferiori sono bloccati e non vengono addestrati. Solo la nuova testa di classificazione si aggiornerà per apprendere dalle funzionalità fornite dal modello pre-addestrato suddiviso a sinistra.
Questa operazione è nota come transfer learning ed è ciò che Teachable Machine fa dietro le quinte.
Puoi anche notare che, dovendo addestrare il percettrone multistrato solo alla fine della rete, l'addestramento è molto più rapido rispetto a quando devi addestrare l'intera rete da zero.
Ma come puoi ottenere le sottoparti di un modello? Continua a leggere per scoprire come fare.
4. TensorFlow Hub - modelli base
Trovare un modello di base adatto da utilizzare
Per modelli di ricerca più avanzati e popolari come MobileNet, puoi andare su TensorFlow Hub e poi filtrare i modelli adatti a TensorFlow.js che utilizzano l'architettura MobileNet v3 per trovare risultati come quelli mostrati qui:
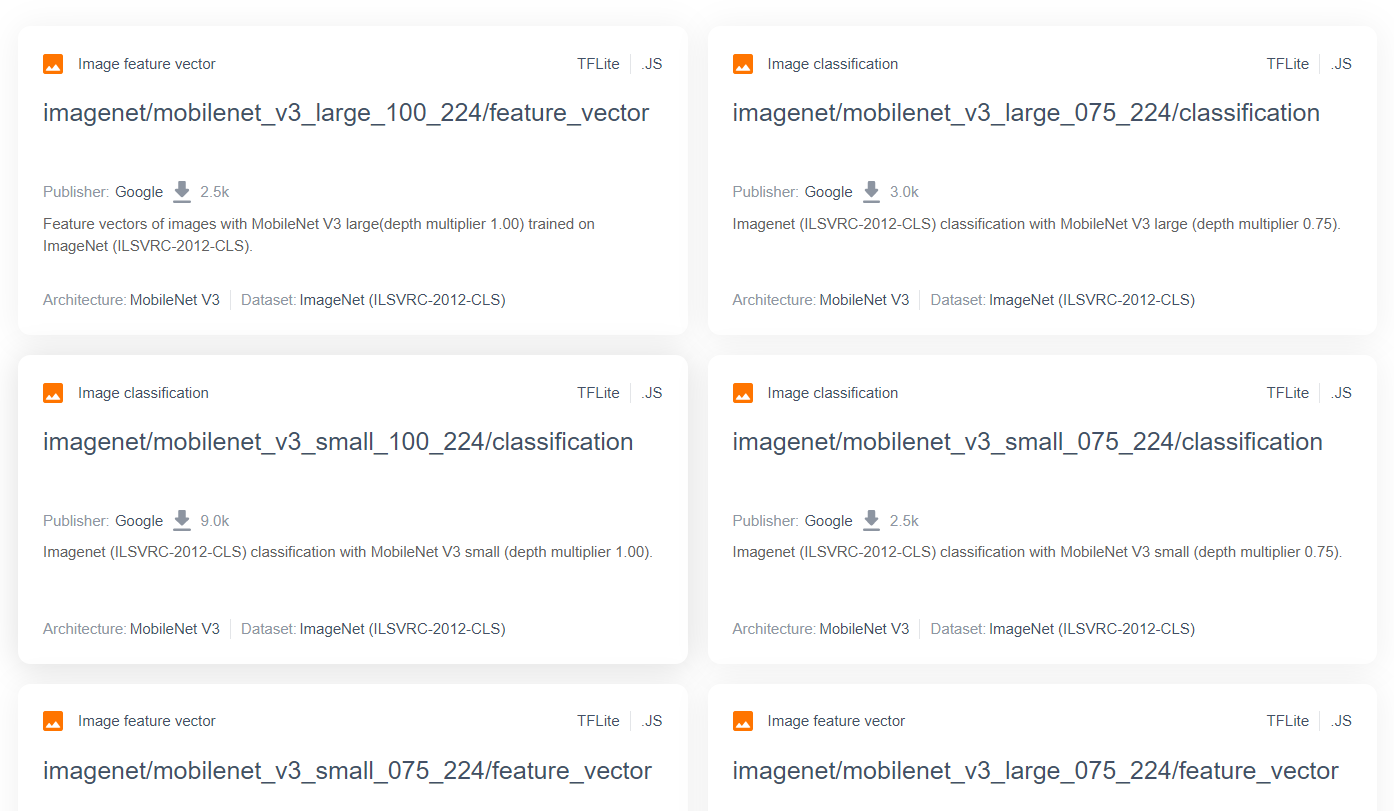
Tieni presente che alcuni di questi risultati sono di tipo "classificazione delle immagini" (descritti in dettaglio in alto a sinistra di ogni risultato della scheda del modello), mentre altri sono di tipo "vettore delle caratteristiche dell'immagine".
Questi risultati del vettore delle caratteristiche dell'immagine sono essenzialmente le versioni pre-tagliate di MobileNet che puoi utilizzare per ottenere i vettori delle caratteristiche dell'immagine anziché la classificazione finale.
Modelli come questo vengono spesso chiamati "modelli di base", che puoi poi utilizzare per eseguire il transfer learning nello stesso modo mostrato nella sezione precedente aggiungendo una nuova testa di classificazione e addestrandola con i tuoi dati.
La cosa successiva da controllare è il formato TensorFlow.js in cui viene rilasciato un determinato modello di base di interesse. Se apri la pagina di uno di questi modelli MobileNet v3 di vettori delle caratteristiche, puoi vedere dalla documentazione JS che si tratta di un modello grafico basato sullo snippet di codice di esempio nella documentazione che utilizza tf.loadGraphModel().
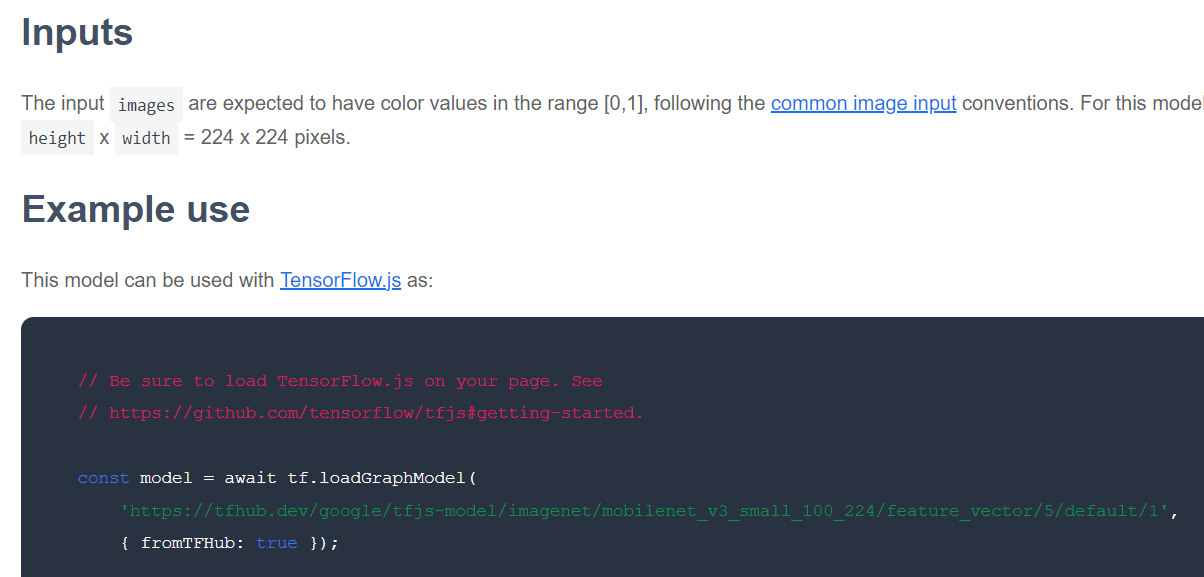
È importante notare anche che, se trovi un modello nel formato a strati anziché in quello a grafo, puoi scegliere quali strati bloccare e quali sbloccare per l'addestramento. Può essere molto utile quando crei un modello per una nuova attività, spesso chiamato "modello di trasferimento". Per ora, tuttavia, utilizzerai il tipo di modello di grafico predefinito per questo tutorial, che è il tipo di deployment della maggior parte dei modelli TF Hub. Per scoprire di più sull'utilizzo dei modelli Layers, consulta il corso zero to hero TensorFlow.js.
Vantaggi del transfer learning
Quali sono i vantaggi dell'utilizzo del Transfer Learning anziché dell'addestramento dell'intera architettura del modello da zero?
Innanzitutto, il tempo di addestramento è un vantaggio fondamentale dell'utilizzo di un approccio di transfer learning, in quanto hai già un modello di base addestrato su cui basarti.
In secondo luogo, puoi cavartela mostrando molti meno esempi della nuova cosa che stai cercando di classificare grazie all'addestramento già eseguito.
Questa funzionalità è molto utile se hai poco tempo e risorse limitate per raccogliere dati di esempio dell'elemento che vuoi classificare e devi creare rapidamente un prototipo prima di raccogliere altri dati di addestramento per renderlo più solido.
Data la necessità di meno dati e la velocità di addestramento di una rete più piccola, il transfer learning richiede meno risorse. Ciò lo rende molto adatto all'ambiente del browser, richiedendo solo decine di secondi su una macchina moderna anziché ore, giorni o settimane per l'addestramento completo del modello.
Perfetto. Ora che conosci l'essenza del Transfer Learning, è il momento di creare la tua versione di Teachable Machine. Iniziamo.
5. Configurare l'ambiente di programmazione
Che cosa ti serve
- Un browser web moderno.
- Conoscenza di base di HTML, CSS, JavaScript e Chrome DevTools (visualizzazione dell'output della console).
Iniziamo a programmare
Sono stati creati modelli boilerplate da cui partire per Glitch.com o Codepen.io. Puoi clonare uno dei due modelli come stato di base per questo lab di codifica con un solo clic.
Su Glitch, fai clic sul pulsante "remixa questo progetto" per creare un fork e un nuovo insieme di file che puoi modificare.
In alternativa, su Codepen, fai clic su"fork" in basso a destra dello schermo.
Questo scheletro molto semplice fornisce i seguenti file:
- Pagina HTML (index.html)
- Foglio di stile (style.css)
- File in cui scrivere il codice JavaScript (script.js)
Per comodità, nel file HTML è presente un'importazione aggiuntiva per la libreria TensorFlow.js. Ha questo aspetto:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternativa: utilizza il tuo web editor preferito o lavora in locale
Se vuoi scaricare il codice e lavorare in locale o in un altro editor online, crea i tre file denominati sopra nella stessa directory e copia e incolla il codice dal boilerplate di Glitch in ciascuno di essi.
6. Boilerplate HTML dell'app
Da dove inizio?
Tutti i prototipi richiedono una struttura HTML di base su cui puoi visualizzare i risultati. Configuralo ora. Stai per aggiungere:
- Un titolo per la pagina.
- Un testo descrittivo.
- Un paragrafo di stato.
- Un video per contenere il feed della webcam una volta pronto.
- Diversi pulsanti per avviare la videocamera, raccogliere dati o reimpostare l'esperienza.
- Importazioni per TensorFlow.js e file JS che codificherai in un secondo momento.
Apri index.html e incolla il codice esistente con il seguente per configurare le funzionalità sopra indicate:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Analizza
Analizziamo parte del codice HTML riportato sopra per evidenziare alcuni elementi chiave che hai aggiunto.
- Hai aggiunto un tag
<h1>per il titolo della pagina e un tag<p>con un ID "status", in cui stamperai le informazioni, poiché utilizzi diverse parti del sistema per visualizzare gli output. - Hai aggiunto un elemento
<video>con un ID "webcam", a cui verrà eseguito il rendering dello stream della webcam in un secondo momento. - Hai aggiunto 5 elementi
<button>. Il primo, con l'ID "enableCam", attiva la videocamera. I due pulsanti successivi hanno la classe "dataCollector", che ti consente di raccogliere immagini di esempio per gli oggetti che vuoi riconoscere. Il codice che scriverai in un secondo momento sarà progettato in modo da poter aggiungere un numero qualsiasi di questi pulsanti e funzioneranno automaticamente come previsto.
Tieni presente che questi pulsanti hanno anche un attributo speciale definito dall'utente chiamato data-1hot, con un valore intero a partire da 0 per la prima classe. Questo è l'indice numerico che utilizzerai per rappresentare i dati di una determinata classe. L'indice verrà utilizzato per codificare correttamente le classi di output con una rappresentazione numerica anziché una stringa, poiché i modelli ML possono funzionare solo con i numeri.
Esiste anche un attributo data-name che contiene il nome leggibile che vuoi utilizzare per questa classe, il che ti consente di fornire all'utente un nome più significativo anziché un valore di indice numerico della codifica hot 1.
Infine, hai un pulsante di addestramento e ripristino per avviare la procedura di addestramento una volta raccolti i dati o per ripristinare l'app.
- Hai anche aggiunto due importazioni
<script>. Uno per TensorFlow.js e l'altro per script.js, che definirai a breve.
7. Aggiungi stile
Valori predefiniti degli elementi
Aggiungi stili per gli elementi HTML che hai appena aggiunto per assicurarti che vengano visualizzati correttamente. Ecco alcuni stili aggiunti per posizionare e dimensionare correttamente gli elementi. Niente di speciale. Potresti sicuramente aggiungere altri elementi in un secondo momento per migliorare ulteriormente l'esperienza utente, come hai visto nel video su Teachable Machine.
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
Bene. Questo è tutto ciò che ti serve. Se visualizzi l'anteprima dell'output in questo momento, dovrebbe avere un aspetto simile a questo:
8. JavaScript: costanti e listener dei tasti
Definisci le costanti chiave
Innanzitutto, aggiungi alcune costanti chiave che utilizzerai in tutta l'app. Inizia sostituendo i contenuti di script.js con queste costanti:
script.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
Vediamo a cosa servono:
STATUScontiene semplicemente un riferimento al tag del paragrafo in cui scriverai gli aggiornamenti di stato.VIDEOcontiene un riferimento all'elemento video HTML che eseguirà il rendering del feed della webcam.ENABLE_CAM_BUTTON,RESET_BUTTONeTRAIN_BUTTONrecuperano i riferimenti DOM a tutti i pulsanti chiave dalla pagina HTML.MOBILE_NET_INPUT_WIDTHeMOBILE_NET_INPUT_HEIGHTdefiniscono rispettivamente la larghezza e l'altezza dell'input previste del modello MobileNet. Se memorizzi questo valore in una costante nella parte superiore del file, come in questo esempio, se in un secondo momento decidi di utilizzare una versione diversa, è più facile aggiornare i valori una sola volta anziché doverli sostituire in molti punti diversi.STOP_DATA_GATHERè impostato su -1. Memorizza un valore di stato per sapere quando l'utente ha smesso di fare clic su un pulsante per raccogliere dati dal feed della webcam. Assegnando a questo numero un nome più significativo, il codice sarà più leggibile in seguito.CLASS_NAMESfunge da ricerca e contiene i nomi leggibili per le possibili previsioni delle classi. Questo array verrà compilato in un secondo momento.
Ok, ora che hai i riferimenti agli elementi chiave, è il momento di associare alcuni listener di eventi.
Aggiungere listener di eventi chiave
Inizia aggiungendo i gestori di eventi di clic ai pulsanti chiave come mostrato di seguito:
script.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON: chiama la funzione enableCam quando viene selezionata.
TRAIN_BUTTON - calls trainAndPredict when clicked.
RESET_BUTTON: le chiamate vengono reimpostate quando viene fatto clic.
Infine, in questa sezione puoi trovare tutti i pulsanti con la classe "dataCollector" che utilizzano document.querySelectorAll(). Restituisce un array di elementi trovati nel documento che corrispondono a:
script.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
Spiegazione del codice:
Dopodiché, scorri i pulsanti trovati e associa due listener di eventi a ciascuno. Uno per "mousedown" e uno per "mouseup". In questo modo, puoi continuare a registrare campioni finché il pulsante è premuto, il che è utile per la raccolta dei dati.
Entrambi gli eventi chiamano una funzione gatherDataForClass che definirai in un secondo momento.
A questo punto, puoi anche trasferire i nomi delle classi leggibili trovati dall'attributo del pulsante HTML data-name all'array CLASS_NAMES.
Poi, aggiungi alcune variabili per memorizzare gli elementi chiave che verranno utilizzati in un secondo momento.
script.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
Vediamo quali sono.
Innanzitutto, hai una variabile mobilenet per archiviare il modello mobilenet caricato. Inizialmente, impostalo su non definito.
Poi c'è una variabile chiamata gatherDataState. Se viene premuto un pulsante "dataCollector", questo diventa l'ID one-hot del pulsante, come definito nel codice HTML, in modo da sapere quale classe di dati stai raccogliendo in quel momento. Inizialmente, questo valore è impostato su STOP_DATA_GATHER in modo che il ciclo di raccolta dei dati che scrivi in un secondo momento non raccolga dati quando non vengono premuti pulsanti.
videoPlaying tiene traccia del caricamento e della riproduzione corretti dello stream della webcam ed è disponibile per l'uso. Inizialmente, questo valore è impostato su false perché la webcam non è attiva finché non premi il tasto ENABLE_CAM_BUTTON..
Successivamente, definisci due array, trainingDataInputs e trainingDataOutputs. Questi valori memorizzano i valori dei dati di addestramento raccolti quando fai clic sui pulsanti "dataCollector" per le funzionalità di input generate dal modello di base MobileNet e la classe di output campionata rispettivamente.
Viene quindi definita una matrice finale, examplesCount,, per tenere traccia del numero di esempi contenuti per ogni classe una volta iniziata l'aggiunta.
Infine, hai una variabile chiamata predict che controlla il ciclo di previsione. Inizialmente è impostato su false. Non è possibile effettuare previsioni finché questa impostazione non viene impostata su true in un secondo momento.
Ora che tutte le variabili chiave sono state definite, carichiamo il modello di base MobileNet v3 pre-sezionato che fornisce vettori delle caratteristiche delle immagini anziché classificazioni.
9. Carica il modello di base MobileNet
Innanzitutto, definisci una nuova funzione denominata loadMobileNetFeatureModel come mostrato di seguito. Deve essere una funzione asincrona, poiché il caricamento di un modello è asincrono:
script.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
In questo codice definisci URL dove si trova il modello da caricare dalla documentazione di TF Hub.
Puoi quindi caricare il modello utilizzando await tf.loadGraphModel(), ricordandoti di impostare la proprietà speciale fromTFHub su true, poiché stai caricando un modello da questo sito web di Google. Si tratta di un caso speciale solo per l'utilizzo di modelli ospitati su TF Hub in cui deve essere impostata questa proprietà aggiuntiva.
Una volta completato il caricamento, puoi impostare innerText dell'elemento STATUS con un messaggio per verificare visivamente che il caricamento sia avvenuto correttamente e che tu sia pronto per iniziare a raccogliere i dati.
L'unica cosa che ti resta da fare ora è riscaldare il modello. Con modelli più grandi come questo, la prima volta che lo utilizzi, potrebbe essere necessario un po' di tempo per configurare tutto. Pertanto, è utile passare gli zeri attraverso il modello per evitare attese in futuro, quando la tempistica potrebbe essere più critica.
Puoi utilizzare tf.zeros() racchiuso in tf.tidy() per assicurarti che i tensori vengano eliminati correttamente, con una dimensione del batch pari a 1 e l'altezza e la larghezza corrette che hai definito nelle costanti all'inizio. Infine, specifichi anche i canali colore, che in questo caso sono 3, poiché il modello prevede immagini RGB.
Successivamente, registra la forma risultante del tensore restituito utilizzando answer.shape() per comprendere le dimensioni delle caratteristiche dell'immagine prodotte da questo modello.
Dopo aver definito questa funzione, puoi chiamarla immediatamente per avviare il download del modello al caricamento pagina.
Se visualizzi l'anteprima live in questo momento, dopo qualche istante vedrai il testo di stato cambiare da "In attesa del caricamento di TF.js" a "MobileNet v3 caricato correttamente!", come mostrato di seguito. Assicurati che funzioni prima di continuare.
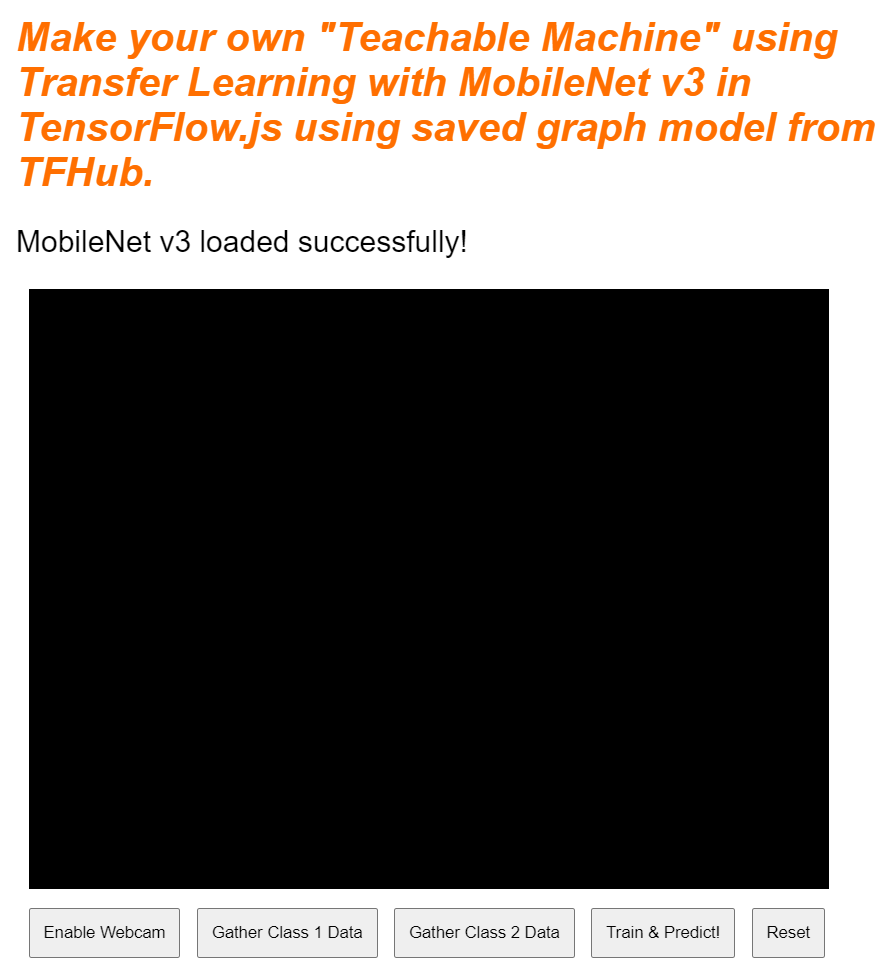
Puoi anche controllare l'output della console per visualizzare le dimensioni stampate delle funzionalità di output prodotte da questo modello. Dopo aver eseguito gli zeri tramite il modello MobileNet, vedrai stampata una forma di [1, 1024]. Il primo elemento è solo la dimensione del batch pari a 1 e puoi vedere che restituisce effettivamente 1024 caratteristiche che possono essere utilizzate per classificare nuovi oggetti.
10. Definisci la nuova testa del modello
Ora è il momento di definire l'intestazione del modello, che è essenzialmente un perceptron multistrato molto minimale.
script.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
Analizziamo questo codice. Inizia definendo un modello tf.sequential a cui aggiungere i livelli del modello.
Successivamente, aggiungi un livello denso come livello di input a questo modello. Ha una forma di input di 1024 perché gli output delle funzionalità di MobileNet v3 hanno questa dimensione. Lo hai scoperto nel passaggio precedente dopo aver passato quelli attraverso il modello. Questo livello ha 128 neuroni che utilizzano la funzione di attivazione ReLU.
Se non hai familiarità con le funzioni di attivazione e i livelli del modello, ti consigliamo di seguire il corso descritto all'inizio di questo workshop per capire cosa fanno queste proprietà dietro le quinte.
Il prossimo strato da aggiungere è quello di output. Il numero di neuroni deve essere uguale al numero di classi che stai cercando di prevedere. Per farlo, puoi utilizzare CLASS_NAMES.length per scoprire quante classi prevedi di classificare, che è uguale al numero di pulsanti di raccolta dei dati presenti nell'interfaccia utente. Poiché si tratta di un problema di classificazione, utilizzi l'attivazione softmax su questo livello di output, che deve essere utilizzata quando si tenta di creare un modello per risolvere problemi di classificazione anziché di regressione.
Ora stampa un model.summary() per stampare la panoramica del modello appena definito nella console.
Infine, compila il modello in modo che sia pronto per l'addestramento. Qui l'ottimizzatore è impostato su adam e la perdita sarà binaryCrossentropy se CLASS_NAMES.length è uguale a 2 oppure verrà utilizzato categoricalCrossentropy se ci sono tre o più classi da classificare. Vengono richieste anche le metriche di accuratezza, in modo che possano essere monitorate nei log in un secondo momento per scopi di debug.
Nella console dovresti vedere un risultato simile a questo:
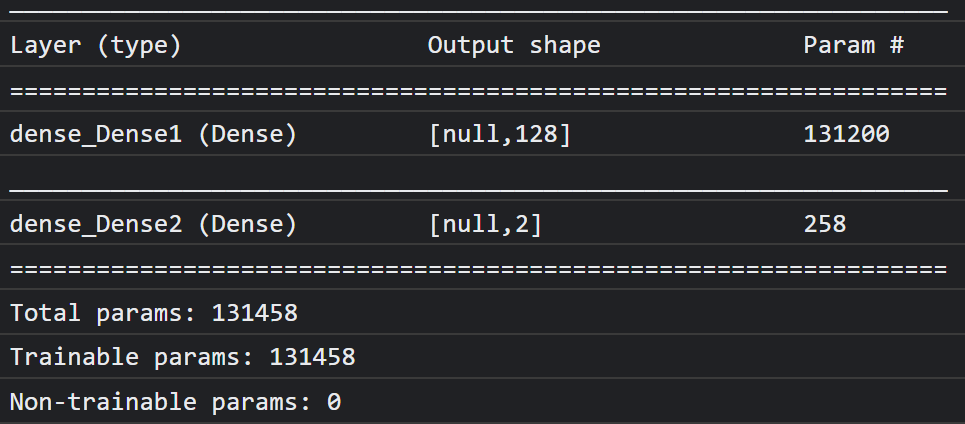
Tieni presente che questo modello ha oltre 130.000 parametri addestrabili. Ma poiché si tratta di un semplice livello denso di neuroni regolari, l'addestramento sarà piuttosto rapido.
Come attività da svolgere una volta completato il progetto, puoi provare a modificare il numero di neuroni nel primo livello per vedere quanto puoi ridurlo mantenendo comunque un rendimento decente. Spesso con il machine learning è necessario un certo livello di tentativi ed errori per trovare i valori dei parametri ottimali che offrano il miglior compromesso tra utilizzo delle risorse e velocità.
11. Attivare la webcam
Ora è il momento di completare la funzione enableCam() che hai definito in precedenza. Aggiungi una nuova funzione denominata hasGetUserMedia() come mostrato di seguito, quindi sostituisci i contenuti della funzione enableCam() definita in precedenza con il codice corrispondente riportato di seguito.
script.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
Innanzitutto, crea una funzione denominata hasGetUserMedia() per verificare se il browser supporta getUserMedia() controllando l'esistenza delle proprietà delle API chiave del browser.
Nella funzione enableCam() utilizza la funzione hasGetUserMedia() che hai appena definito sopra per verificare se è supportata. In caso contrario, stampa un avviso nella console.
Se lo supporta, definisci alcuni vincoli per la chiamata getUserMedia(), ad esempio se vuoi solo lo stream video e se preferisci che le dimensioni del width del video siano di 640 pixel e che il height sia di 480 pixel. Perché? Non ha molto senso utilizzare un video più grande, perché dovrebbe essere ridimensionato a 224 x 224 pixel per essere inserito nel modello MobileNet. Puoi anche risparmiare risorse di calcolo richiedendo una risoluzione più piccola. La maggior parte delle videocamere supporta una risoluzione di queste dimensioni.
Dopodiché, chiama il numero navigator.mediaDevices.getUserMedia() con il constraints descritto sopra e attendi la restituzione del stream. Una volta restituito l'stream, puoi riprodurre l'stream nell'elemento VIDEO impostandolo come valore srcObject.
Devi anche aggiungere un eventListener all'elemento VIDEO per sapere quando stream è stato caricato e viene riprodotto correttamente.
Una volta caricato lo stream, puoi impostare videoPlaying su true e rimuovere ENABLE_CAM_BUTTON per evitare che venga cliccato di nuovo impostando la relativa classe su "removed".
Ora esegui il codice, fai clic sul pulsante per attivare la videocamera e consenti l'accesso alla webcam. Se è la prima volta che esegui questa operazione, dovresti vederti visualizzato nell'elemento video della pagina come mostrato di seguito:

Ok, ora è il momento di aggiungere una funzione per gestire i clic sul pulsante dataCollector.
12. Gestore di eventi del pulsante di raccolta dei dati
Ora è il momento di compilare la funzione attualmente vuota denominata gatherDataForClass().. Si tratta della funzione che hai assegnato come gestore di eventi per i pulsanti dataCollector all'inizio del codelab.
script.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
Innanzitutto, controlla l'attributo data-1hot del pulsante su cui è stato fatto clic chiamando this.getAttribute() con il nome dell'attributo, in questo caso data-1hot come parametro. Poiché si tratta di una stringa, puoi utilizzare parseInt() per convertirla in un numero intero e assegnare questo risultato a una variabile denominata classNumber..
Poi, imposta la variabile gatherDataState di conseguenza. Se l'gatherDataState attuale è uguale a STOP_DATA_GATHER (che hai impostato su -1), significa che al momento non stai raccogliendo dati ed è stato attivato un evento mousedown. Imposta gatherDataState in modo che corrisponda a classNumber che hai appena trovato.
In caso contrario, significa che stai raccogliendo dati e l'evento attivato era un evento mouseup e ora vuoi interrompere la raccolta dei dati per questa classe. Imposta di nuovo lo stato STOP_DATA_GATHER per terminare il ciclo di raccolta dei dati che definirai a breve.
Infine, avvia la chiamata a dataGatherLoop(),, che esegue effettivamente la registrazione dei dati del corso.
13. Raccolta dei dati
Ora definisci la funzione dataGatherLoop(). Questa funzione è responsabile del campionamento delle immagini dal video della webcam, del loro passaggio attraverso il modello MobileNet e dell'acquisizione degli output di questo modello (i 1024 vettori delle funzionalità).
Quindi li memorizza insieme all'ID gatherDataState del pulsante attualmente premuto, in modo da sapere a quale classe si riferiscono questi dati.
Vediamo come fare:
script.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
Continuerai l'esecuzione di questa funzione solo se videoPlaying è true, il che significa che la webcam è attiva, e gatherDataState non è uguale a STOP_DATA_GATHER e un pulsante per la raccolta dei dati della classe è attualmente premuto.
Poi, racchiudi il codice in un tf.tidy() per eliminare i tensori creati nel codice che segue. Il risultato dell'esecuzione di questo codice tf.tidy() viene memorizzato in una variabile denominata imageFeatures.
Ora puoi acquisire un frame della webcam VIDEO utilizzando tf.browser.fromPixels(). Il tensore risultante contenente i dati dell'immagine viene memorizzato in una variabile denominata videoFrameAsTensor.
Successivamente, ridimensiona la variabile videoFrameAsTensor in modo che abbia la forma corretta per l'input del modello MobileNet. Utilizza una chiamata tf.image.resizeBilinear() con il tensore che vuoi rimodellare come primo parametro, quindi una forma che definisce la nuova altezza e la nuova larghezza come definito dalle costanti che hai già creato in precedenza. Infine, imposta align corners su true passando il terzo parametro per evitare problemi di allineamento durante il ridimensionamento. Il risultato di questo ridimensionamento viene memorizzato in una variabile denominata resizedTensorFrame.
Tieni presente che questo ridimensionamento primitivo allunga l'immagine, poiché l'immagine della webcam ha dimensioni di 640 x 480 pixel e il modello richiede un'immagine quadrata di 224 x 224 pixel.
Ai fini di questa demo, dovrebbe funzionare correttamente. Tuttavia, una volta completato questo codelab, potresti provare a ritagliare un quadrato da questa immagine per ottenere risultati ancora migliori per qualsiasi sistema di produzione che potresti creare in un secondo momento.
Poi, normalizza i dati delle immagini. I dati delle immagini sono sempre compresi tra 0 e 255 quando utilizzi tf.browser.frompixels(), quindi puoi semplicemente dividere resizedTensorFrame per 255 per assicurarti che tutti i valori siano compresi tra 0 e 1, come previsto dal modello MobileNet come input.
Infine, nella sezione tf.tidy() del codice, inserisci questo tensore normalizzato nel modello caricato chiamando mobilenet.predict(), a cui passi la versione espansa di normalizedTensorFrame utilizzando expandDims() in modo che sia un batch di 1, poiché il modello prevede un batch di input per l'elaborazione.
Una volta ottenuto il risultato, puoi chiamare immediatamente squeeze() su quel risultato restituito per ridurlo a un tensore 1D, che poi restituisci e assegni alla variabile imageFeatures che acquisisce il risultato da tf.tidy().
Ora che hai imageFeatures dal modello MobileNet, puoi registrarli inserendoli nell'array trainingDataInputs che hai definito in precedenza.
Puoi anche registrare ciò che rappresenta questo input inserendo l'attuale gatherDataState anche nell'array trainingDataOutputs.
Tieni presente che la variabile gatherDataState sarebbe stata impostata sull'ID numerico della classe corrente per cui stai registrando i dati quando è stato fatto clic sul pulsante nella funzione gatherDataForClass() definita in precedenza.
A questo punto puoi anche aumentare il numero di esempi che hai per una determinata classe. Per farlo, controlla innanzitutto se l'indice all'interno dell'array examplesCount è stato inizializzato o meno. Se non è definito, impostalo su 0 per inizializzare il contatore per l'ID numerico di una determinata classe, quindi puoi incrementare examplesCount per l'attuale gatherDataState.
Ora aggiorna il testo dell'elemento STATUS nella pagina web per mostrare i conteggi attuali per ogni classe man mano che vengono acquisiti. Per farlo, scorri l'array CLASS_NAMES e stampa il nome leggibile combinato con il conteggio dei dati nello stesso indice di examplesCount.
Infine, chiama window.requestAnimationFrame() con dataGatherLoop passato come parametro per chiamare di nuovo questa funzione in modo ricorsivo. Continuerà a campionare i fotogrammi del video finché non viene rilevato il mouseup del pulsante e gatherDataState non viene impostato su STOP_DATA_GATHER,, a quel punto il ciclo di raccolta dei dati terminerà.
Se esegui il codice ora, dovresti essere in grado di fare clic sul pulsante per attivare la videocamera, attendere il caricamento della webcam e poi fare clic e tenere premuto ciascuno dei pulsanti di raccolta dei dati per raccogliere esempi per ogni classe di dati. Qui mi vedi raccogliere i dati per il mio cellulare e la mia mano, rispettivamente.
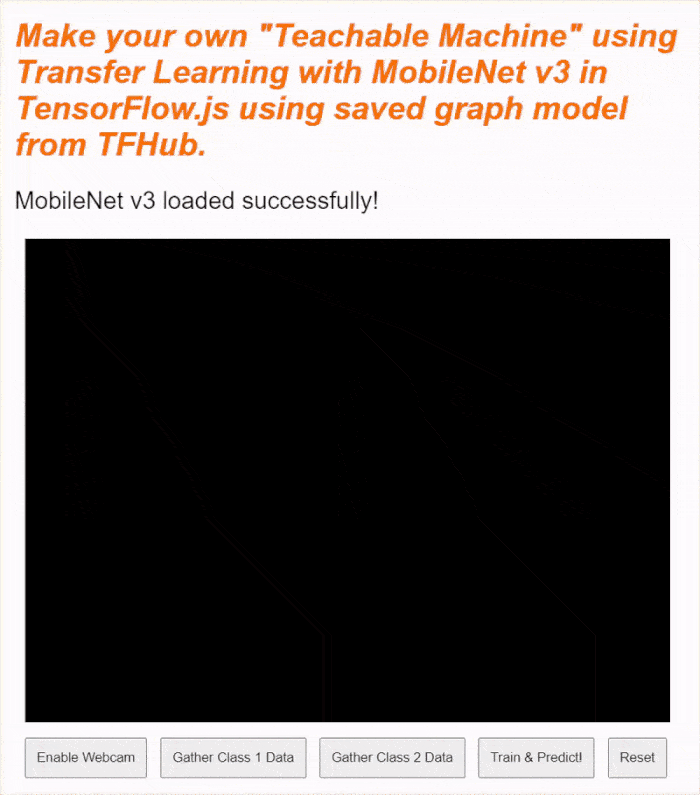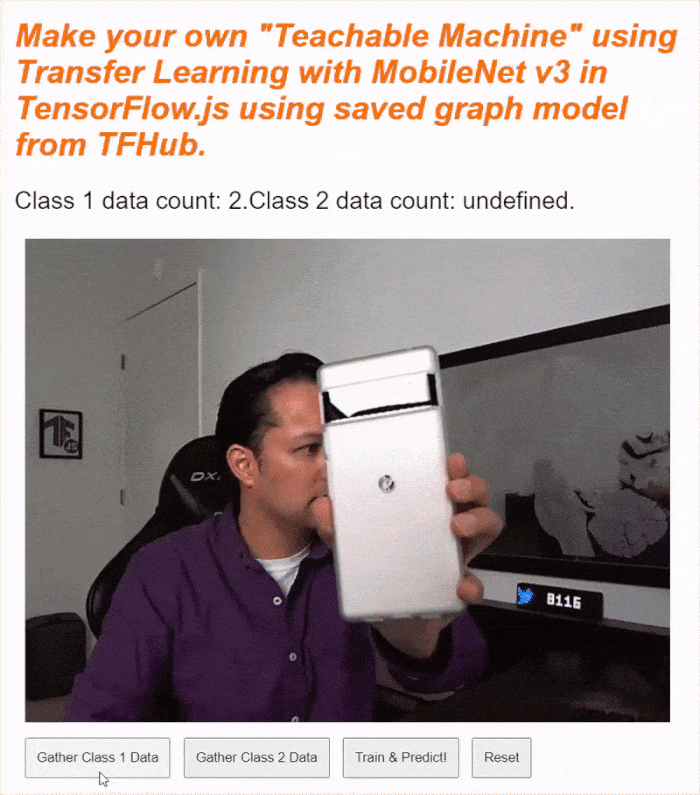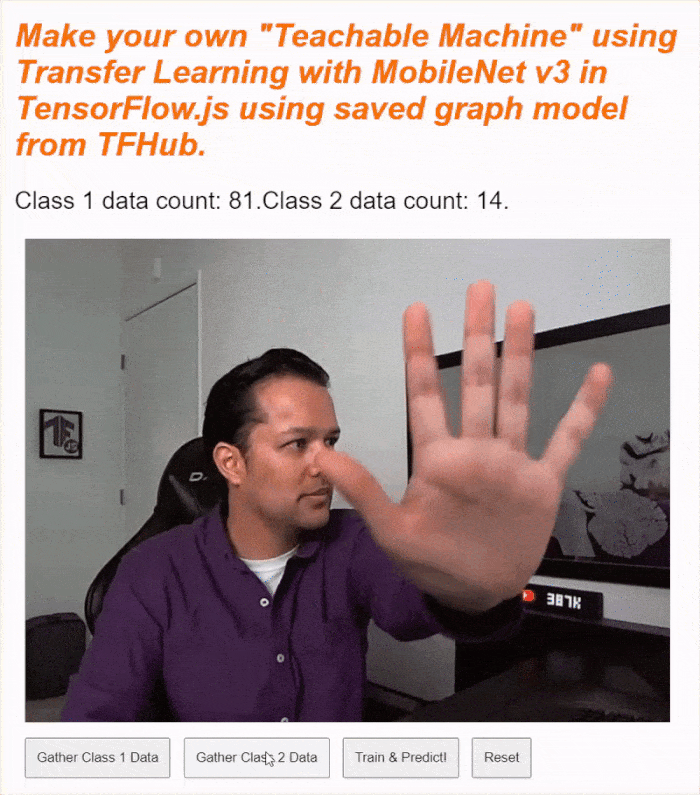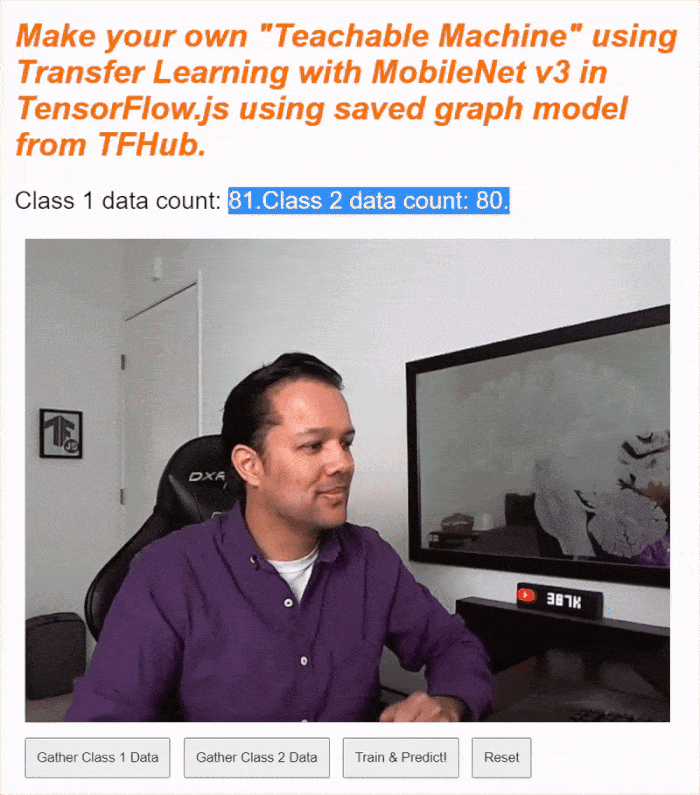
Dovresti vedere il testo di stato aggiornato man mano che memorizza tutti i tensori in memoria, come mostrato nella schermata sopra.
14. Addestra e prevedi
Il passaggio successivo consiste nell'implementare il codice per la funzione trainAndPredict() attualmente vuota, in cui avviene il transfer learning. Diamo un'occhiata al codice:
script.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
Innanzitutto, assicurati di interrompere le previsioni in corso impostando predict su false.
Successivamente, mescola gli array di input e output utilizzando tf.util.shuffleCombo() per assicurarti che l'ordine non causi problemi nell'addestramento.
Converti l'array di output, trainingDataOutputs,, in un tensore 1D di tipo int32 in modo che sia pronto per essere utilizzato in una codifica one-hot. Queste informazioni vengono archiviate in una variabile denominata outputsAsTensor.
Utilizza la funzione tf.oneHot() con questa variabile outputsAsTensor insieme al numero massimo di classi da codificare, ovvero CLASS_NAMES.length. Gli output codificati con codifica one-hot ora sono archiviati in un nuovo tensore denominato oneHotOutputs.
Tieni presente che al momento trainingDataInputs è un array di tensori registrati. Per utilizzarli per l'addestramento, devi convertire l'array di tensori in un tensore 2D normale.
A questo scopo, nella libreria TensorFlow.js esiste una funzione fantastica chiamata tf.stack(),
che accetta un array di tensori e li impila per produrre un tensore di dimensioni superiori come output. In questo caso viene restituito un tensore 2D, ovvero un batch di input unidimensionali di lunghezza 1024 contenenti le funzionalità registrate, che è ciò che ti serve per l'addestramento.
Poi, await model.fit() per addestrare l'intestazione del modello personalizzato. Qui passi la variabile inputsAsTensor insieme a oneHotOutputs per rappresentare i dati di addestramento da utilizzare rispettivamente per gli input di esempio e gli output target. Nell'oggetto di configurazione per il terzo parametro, imposta shuffle su true, utilizza batchSize di 5, con epochs impostato su 10, quindi specifica un callback per onEpochEnd nella funzione logProgress che definirai a breve.
Infine, puoi eliminare i tensori creati, poiché il modello è ora addestrato. Puoi quindi impostare predict di nuovo su true per consentire nuovamente le previsioni e poi chiamare la funzione predictLoop() per iniziare a prevedere le immagini della webcam in diretta.
Puoi anche definire la funzione logProcess() per registrare lo stato dell'addestramento, che viene utilizzato in model.fit() sopra e che stampa i risultati nella console dopo ogni ciclo di addestramento.
Ci sei quasi. È il momento di aggiungere la funzione predictLoop() per fare previsioni.
Ciclo di previsione principale
Qui implementi il ciclo di previsione principale che campiona i frame di una webcam e prevede continuamente cosa c'è in ogni frame con risultati in tempo reale nel browser.
Controlliamo il codice:
script.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
Per prima cosa, verifica che predict sia true, in modo che le previsioni vengano effettuate solo dopo che un modello è stato addestrato ed è disponibile per l'uso.
Successivamente, puoi ottenere le caratteristiche dell'immagine corrente proprio come hai fatto nella funzione dataGatherLoop(). In sostanza, acquisisci un frame dalla webcam utilizzando tf.browser.from pixels(), lo normalizzi, lo ridimensioni a 224 x 224 pixel e poi passi i dati attraverso il modello MobileNet per ottenere le caratteristiche dell'immagine risultante.
Ora, tuttavia, puoi utilizzare la testa del modello appena addestrato per eseguire una previsione passando il imageFeatures risultante appena trovato tramite la funzione predict() del modello addestrato. Puoi quindi comprimere il tensore risultante per renderlo di nuovo unidimensionale e assegnarlo a una variabile denominata prediction.
Con questo prediction puoi trovare l'indice con il valore più alto utilizzando argMax() e poi convertire questo tensore risultante in un array utilizzando arraySync() per accedere ai dati sottostanti in JavaScript e scoprire la posizione dell'elemento con il valore più alto. Questo valore è memorizzato nella variabile denominata highestIndex.
Puoi anche ottenere i punteggi di confidenza della previsione effettiva nello stesso modo chiamando arraySync() sul tensore prediction direttamente.
Ora hai tutto ciò che ti serve per aggiornare il testo STATUS con i dati prediction. Per ottenere la stringa leggibile per la classe, puoi cercare highestIndex nell'array CLASS_NAMES e poi recuperare il valore di affidabilità da predictionArray. Per renderlo più leggibile come percentuale, moltiplica per 100 e math.floor() il risultato.
Infine, puoi utilizzare window.requestAnimationFrame() per chiamare di nuovo predictionLoop() quando è pronto, per ottenere la classificazione in tempo reale del tuo stream video. Questa operazione continua fino a quando predict non è impostato su false se scegli di addestrare un nuovo modello con nuovi dati.
E questo ti porta all'ultimo pezzo del puzzle. Implementazione del pulsante di ripristino.
15. Implementare il pulsante di ripristino
Quasi completato. L'ultimo pezzo del puzzle è l'implementazione di un pulsante di ripristino per ricominciare da capo. Di seguito è riportato il codice della funzione reset() attualmente vuota. Aggiornalo come segue:
script.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
Innanzitutto, interrompi tutti i cicli di previsione in esecuzione impostando predict su false. Successivamente, elimina tutti i contenuti nell'array examplesCount impostando la lunghezza su 0, un modo pratico per cancellare tutti i contenuti da un array.
Ora esamina tutti i trainingDataInputs registrati attualmente e assicurati di dispose() ogni tensore contenuto al suo interno per liberare di nuovo memoria, poiché i tensori non vengono puliti dal garbage collector JavaScript.
Una volta fatto, puoi impostare in modo sicuro la lunghezza dell'array su 0 sia negli array trainingDataInputs che trainingDataOutputs per cancellarli.
Infine, imposta il testo STATUS su un valore sensato e stampa i tensori rimasti in memoria come controllo di integrità.
Tieni presente che in memoria rimarranno ancora alcune centinaia di tensori, poiché sia il modello MobileNet sia il perceptron multilivello che hai definito non vengono eliminati. Se decidi di eseguire di nuovo l'addestramento dopo questo ripristino, dovrai riutilizzarli con nuovi dati di addestramento.
16. Proviamola
È ora di provare la tua versione di Teachable Machine.
Vai all'anteprima live, attiva la webcam, raccogli almeno 30 campioni per la classe 1 per un oggetto nella stanza, quindi fai lo stesso per la classe 2 per un altro oggetto, fai clic su Train (Addestra) e controlla il log della console per vedere l'avanzamento. L'addestramento dovrebbe essere piuttosto rapido:

Una volta addestrato, mostra gli oggetti alla videocamera per ottenere previsioni in tempo reale che verranno stampate nell'area di testo dello stato nella parte superiore della pagina web. Se hai difficoltà, controlla il codice funzionante che ho completato per verificare di non aver dimenticato di copiare nulla.
17. Complimenti
Complimenti! Hai appena completato il tuo primo esempio di transfer learning utilizzando TensorFlow.js live nel browser.
Provalo, testalo su una serie di oggetti. Potresti notare che alcuni sono più difficili da riconoscere rispetto ad altri, soprattutto se sono simili a qualcos'altro. Potresti dover aggiungere altre classi o dati di addestramento per poterle distinguere.
Riepilogo
In questo codelab hai imparato:
- Che cos'è il transfer learning e i suoi vantaggi rispetto all'addestramento di un modello completo.
- Come ottenere modelli per il riutilizzo da TensorFlow Hub.
- Come configurare un'app web adatta al transfer learning.
- Come caricare e utilizzare un modello di base per generare caratteristiche delle immagini.
- Come addestrare una nuova testa di previsione in grado di riconoscere oggetti personalizzati dalle immagini della webcam.
- Come utilizzare i modelli risultanti per classificare i dati in tempo reale.
Passaggi successivi
Ora che hai una base di partenza funzionante, quali idee creative puoi trovare per estendere questo boilerplate del modello di machine learning a un caso d'uso reale su cui potresti lavorare? Magari potresti rivoluzionare il settore in cui lavori attualmente per aiutare i tuoi colleghi ad addestrare modelli per classificare le cose importanti nel loro lavoro quotidiano. Le possibilità sono infinite.
Per approfondire, ti consigliamo di seguire questo corso completo senza costi, che ti mostra come combinare i due modelli che hai attualmente in questo codelab in un unico modello per una maggiore efficienza.
Se vuoi saperne di più sulla teoria alla base dell'applicazione originale Teachable Machine, consulta questo tutorial.
Condividi con noi i tuoi contenuti
Puoi facilmente estendere ciò che hai creato oggi anche ad altri casi d'uso creativi e ti invitiamo a pensare fuori dagli schemi e a continuare a sperimentare.
Ricordati di taggarci sui social media utilizzando l'hashtag #MadeWithTFJS per avere la possibilità che il tuo progetto venga pubblicato sul nostro blog di TensorFlow o addirittura in eventi futuri. Ci piacerebbe vedere cosa crei.
Siti web da visitare
- Sito web ufficiale di TensorFlow.js
- Modelli TensorFlow.js predefiniti
- API TensorFlow.js
- TensorFlow.js Show & Tell: lasciati ispirare e scopri cosa hanno creato gli altri.