
1. قبل البدء
تزايد استخدام نماذج TensorFlow.js بشكل كبير خلال السنوات القليلة الماضية، ويتطلّع العديد من مطوّري JavaScript الآن إلى الاستفادة من النماذج الحالية المتطوّرة وإعادة تدريبها للعمل مع بيانات مخصّصة فريدة في مجالهم. يُعرف استخدام نموذج حالي (يُشار إليه غالبًا باسم النموذج الأساسي) في مجال مشابه ولكن مختلف باسم التعلّم القائم على نقل المهام.
يتميّز التعلّم القائم على نقل المهام بالعديد من المزايا مقارنةً بالبدء بنموذج فارغ تمامًا. يمكنك إعادة استخدام المعرفة التي تم اكتسابها من نموذج تم تدريبه سابقًا، كما تحتاج إلى عدد أقل من الأمثلة على العنصر الجديد الذي تريد تصنيفه. بالإضافة إلى ذلك، يكون التدريب أسرع بكثير في كثير من الأحيان لأنّه لا يلزم إعادة تدريب سوى الطبقات القليلة الأخيرة من بنية النموذج بدلاً من الشبكة بأكملها. لهذا السبب، فإنّ التعلّم القائم على نقل المهام مناسب جدًا لبيئة متصفّح الويب حيث قد تختلف الموارد استنادًا إلى الجهاز الذي يتم التنفيذ عليه، ولكن يمكن أيضًا الوصول مباشرةً إلى أدوات الاستشعار لتسهيل الحصول على البيانات.
يوضّح لك هذا الدرس التطبيقي حول الترميز كيفية إنشاء تطبيق ويب من البداية، وإعادة إنشاء موقع " أداة تعليم الآلة" الإلكتروني الشهير من Google. يتيح لك الموقع الإلكتروني إنشاء تطبيق ويب عملي يمكن لأي مستخدم استخدامه للتعرّف على عنصر مخصّص باستخدام بضع صور نموذجية فقط من كاميرا الويب. تم تصميم الموقع الإلكتروني ليكون بسيطًا قدر الإمكان حتى تتمكّن من التركيز على جوانب تعلُّم الآلة في هذا الدرس البرمجي. كما هو الحال مع موقع أداة تعليم الآلة الإلكتروني الأصلي، هناك الكثير من الفرص لتطبيق خبرتك الحالية في تطوير الويب من أجل تحسين تجربة المستخدم.
المتطلبات الأساسية
هذا الدرس التطبيقي حول الترميز مخصّص لمطوّري الويب الذين لديهم بعض المعرفة بنماذج TensorFlow.js الجاهزة واستخدام واجهة برمجة التطبيقات الأساسية، والذين يريدون البدء في استخدام "التعلّم القائم على نقل المهام" في TensorFlow.js.
- يفترض هذا الدرس التطبيقي معرفة أساسية بـ TensorFlow.js وHTML5 وCSS وJavaScript.
إذا كنت مبتدئًا في Tensorflow.js، ننصحك بالمشاركة أولاً في هذه الدورة التدريبية المجانية للمبتدئين التي لا تتطلّب أي خبرة في تعلُّم الآلة أو TensorFlow.js، وتعلّمك كل ما تحتاج إلى معرفته في خطوات أصغر.
ما ستتعلمه
- ما هي منصة TensorFlow.js وسبب استخدامها في تطبيق الويب التالي
- كيفية إنشاء صفحة ويب مبسطة بلغة HTML/CSS /JS تحاكي تجربة المستخدم في أداة تعليم الآلة
- كيفية استخدام TensorFlow.js لتحميل نموذج أساسي مدرَّب مسبقًا، وتحديدًا MobileNet، لإنشاء ميزات صور يمكن استخدامها في التعلّم القائم على نقل المهام
- كيفية جمع البيانات من كاميرا الويب الخاصة بالمستخدم لفئات متعددة من البيانات التي تريد التعرّف عليها
- كيفية إنشاء وتحديد شبكة عصبية متعددة الطبقات تأخذ ميزات الصورة وتتعلّم تصنيف عناصر جديدة باستخدامها
لنبدأ عملية الاختراق...
المتطلبات
- يُفضّل استخدام حساب على Glitch.com للمتابعة، أو يمكنك استخدام بيئة عرض على الويب يمكنك تعديلها وتشغيلها بنفسك.
2. ما هو TensorFlow.js؟

TensorFlow.js هي مكتبة مفتوحة المصدر لتعلُّم الآلة يمكن تشغيلها في أي مكان يمكن فيه تشغيل JavaScript. وهي تستند إلى مكتبة TensorFlow الأصلية المكتوبة بلغة Python وتهدف إلى إعادة إنشاء تجربة المطوّرين هذه ومجموعة واجهات برمجة التطبيقات لمنظومة JavaScript المتكاملة.
أين يمكن استخدامها؟
بفضل إمكانية نقل JavaScript، يمكنك الآن كتابة التعليمات البرمجية بلغة واحدة وتنفيذ تعلُّم الآلة على جميع المنصات التالية بسهولة:
- من جهة العميل في متصفّح الويب باستخدام JavaScript العادية
- الخادم وحتى أجهزة إنترنت الأشياء، مثل Raspberry Pi باستخدام Node.js
- تطبيقات الكمبيوتر التي تستخدم Electron
- التطبيقات المتوافقة مع نظام تشغيل الجوّال باستخدام React Native
تتيح مكتبة TensorFlow.js أيضًا استخدام عدة أنظمة خلفية في كل من هذه البيئات (البيئات المستندة إلى الأجهزة الفعلية التي يمكن تنفيذها فيها، مثل وحدة المعالجة المركزية أو WebGL على سبيل المثال). لا يعني "الخادم الخلفي" في هذا السياق بيئة من جهة الخادم، بل يمكن أن يكون الخادم الخلفي للتنفيذ من جهة العميل في WebGL مثلاً، وذلك لضمان التوافق والحفاظ على سرعة الأداء. يتوافق TensorFlow.js حاليًا مع ما يلي:
- تنفيذ WebGL على بطاقة الرسومات في الجهاز (وحدة معالجة الرسومات): هذه هي أسرع طريقة لتنفيذ النماذج الأكبر حجمًا (أكثر من 3 ميغابايت) مع تسريع وحدة معالجة الرسومات.
- تنفيذ Web Assembly (WASM) على وحدة المعالجة المركزية (CPU): لتحسين أداء وحدة المعالجة المركزية على جميع الأجهزة، بما في ذلك الهواتف الجوّالة القديمة مثلاً هذا الخيار أنسب للنماذج الأصغر حجمًا (أقل من 3 ميغابايت) التي يمكن تنفيذها بشكل أسرع على وحدة المعالجة المركزية باستخدام WASM مقارنةً بـ WebGL بسبب العبء الناتج عن تحميل المحتوى إلى معالج الرسومات.
- تنفيذ وحدة المعالجة المركزية: يجب أن يكون الخيار الاحتياطي متاحًا في حال عدم توفّر أي من البيئات الأخرى. هذه الطريقة هي الأبطأ من بين الطرق الثلاث، ولكنّها متاحة لك دائمًا.
ملاحظة: يمكنك اختيار فرض إحدى الخلفيات إذا كنت تعرف الجهاز الذي سيتم التنفيذ عليه، أو يمكنك ببساطة السماح لـ TensorFlow.js بتحديد ذلك نيابةً عنك إذا لم تحدّد ذلك.
ميزات خارقة من جهة العميل
يمكن أن يؤدي تشغيل TensorFlow.js في متصفّح الويب على جهاز العميل إلى تحقيق العديد من المزايا التي تستحق أخذها في الاعتبار.
الخصوصية
يمكنك تدريب البيانات وتصنيفها على جهاز العميل بدون إرسال البيانات إلى خادم ويب تابع لجهة خارجية. قد يكون ذلك مطلوبًا في بعض الأحيان للامتثال للقوانين المحلية، مثل اللائحة العامة لحماية البيانات (GDPR)، أو عند معالجة أي بيانات قد يريد المستخدم الاحتفاظ بها على جهازه وعدم إرسالها إلى جهة خارجية.
السرعة
بما أنّك لست مضطرًا إلى إرسال البيانات إلى خادم بعيد، يمكن أن تكون عملية الاستنتاج (تصنيف البيانات) أسرع. والأفضل من ذلك، يمكنك الوصول مباشرةً إلى أدوات الاستشعار في الجهاز، مثل الكاميرا والميكروفون ونظام تحديد المواقع العالمي (GPS) ومقياس التسارع وغيرها، إذا منحك المستخدم إذن الوصول.
الوصول إلى الجمهور على نطاق واسع
بنقرة واحدة، يمكن لأي شخص في العالم النقر على رابط ترسله إليه، وفتح صفحة الويب في المتصفّح، والاستفادة من المحتوى الذي أنشأته. لا حاجة إلى إعداد معقّد لخادم Linux مع برامج تشغيل CUDA وغير ذلك الكثير لمجرّد استخدام نظام تعلُّم الآلة.
التكلفة
عدم الحاجة إلى خوادم يعني أنّ الشيء الوحيد الذي عليك الدفع مقابله هو شبكة توصيل المحتوى (CDN) لاستضافة ملفات HTML وCSS وJS والنماذج. تكلفة شبكة توصيل المحتوى أقل بكثير من تكلفة تشغيل خادم (قد تكون بطاقة الرسومات مرفقة به) على مدار الساعة طوال أيام الأسبوع.
الميزات من جهة الخادم
يتيح استخدام إصدار Node.js من TensorFlow.js الميزات التالية.
توافق كامل مع CUDA
على مستوى الخادم، لتسريع بطاقة الرسومات، يجب تثبيت برامج تشغيل NVIDIA CUDA لتمكين TensorFlow من العمل مع بطاقة الرسومات (على عكس المتصفّح الذي يستخدم WebGL، فلا حاجة إلى التثبيت). ومع ذلك، يمكنك الاستفادة بشكل كامل من إمكانات بطاقة الرسومات ذات المستوى الأدنى من خلال التوافق الكامل مع CUDA، ما يؤدي إلى تقليل وقت التدريب والاستنتاج. ويكون الأداء مماثلاً لتنفيذ Python TensorFlow لأنّهما يشتركان في الخلفية نفسها بلغة C++.
حجم النموذج
بالنسبة إلى أحدث النماذج من الأبحاث، قد تعمل مع نماذج كبيرة جدًا، ربما بحجم الجيجابايت. لا يمكن تشغيل هذه النماذج حاليًا في متصفّح الويب بسبب القيود المفروضة على استخدام الذاكرة لكل علامة تبويب في المتصفّح. لتشغيل هذه النماذج الأكبر حجمًا، يمكنك استخدام Node.js على الخادم الخاص بك مع مواصفات الأجهزة التي تحتاج إليها لتشغيل هذا النموذج بكفاءة.
IOT
يتوافق Node.js مع أجهزة الكمبيوتر الشائعة ذات اللوحة الواحدة، مثل Raspberry Pi، ما يعني بدوره أنّه يمكنك تنفيذ نماذج TensorFlow.js على هذه الأجهزة أيضًا.
السرعة
تمت كتابة Node.js بلغة JavaScript، ما يعني أنّها تستفيد من التجميع أثناء التشغيل. وهذا يعني أنّه قد يتحسّن الأداء غالبًا عند استخدام Node.js لأنّه سيتم تحسينه في وقت التشغيل، خاصةً لأي معالجة مسبقة قد تجريها. يمكن الاطّلاع على مثال رائع على ذلك في دراسة الحالة هذه التي توضّح كيف استخدمت شركة Hugging Face منصة Node.js لتحسين أداء نموذج معالجة اللغة الطبيعية بمقدار الضعف.
بعد أن تعرّفت على أساسيات TensorFlow.js، والمكان الذي يمكن تشغيلها فيه، وبعض المزايا، لنبدأ الآن في تنفيذ مهام مفيدة باستخدامها.
3- التعلّم القائم على نقل المهام
ما هو التعلّم القائم على نقل المهام تحديدًا؟
يتضمّن التعلّم القائم على نقل المهام الاستفادة من المعرفة التي تم اكتسابها سابقًا للمساعدة في تعلّم شيء مختلف ولكن مشابه.
ونحن البشر نفعل ذلك طوال الوقت. لديك تجارب عديدة مخزّنة في دماغك يمكنك استخدامها للمساعدة في التعرّف على أشياء جديدة لم ترَها من قبل. لنأخذ شجرة الصفصاف هذه كمثال:

اعتمادًا على مكان إقامتك في العالم، قد لا تكون قد رأيت هذا النوع من الأشجار من قبل.
ومع ذلك، إذا طلبت منك أن تخبرني ما إذا كانت هناك أي أشجار صفصاف في الصورة الجديدة أدناه، يمكنك على الأرجح رصدها بسرعة كبيرة، على الرغم من أنّها تظهر بزاوية مختلفة، وتختلف قليلاً عن الصورة الأصلية التي عرضتها عليك.

لديك بالفعل مجموعة من الخلايا العصبية في دماغك تعرف كيفية تحديد الأشكال الشبيهة بالأشجار، وخلايا عصبية أخرى تجيد العثور على خطوط مستقيمة طويلة. يمكنك إعادة استخدام هذه المعرفة لتصنيف شجرة الصفصاف بسرعة، وهي عبارة عن كائن يشبه الشجرة ويتضمّن الكثير من الأغصان العمودية الطويلة والمستقيمة.
وبالمثل، إذا كان لديك نموذج لتعلُّم الآلة تم تدريبه مسبقًا على مجال معيّن، مثل التعرّف على الصور، يمكنك إعادة استخدامه لتنفيذ مهمة مختلفة ولكنها ذات صلة.
يمكنك إجراء ذلك باستخدام نموذج متقدّم مثل MobileNet، وهو نموذج بحث شائع جدًا يمكنه التعرّف على الصور التي تتضمّن 1, 000 نوع مختلف من العناصر. تم تدريب هذا النموذج على مجموعة بيانات ضخمة تُعرف باسم ImageNet تحتوي على ملايين الصور المصنَّفة، بدءًا من الكلاب وصولاً إلى السيارات.
في هذه الصورة المتحركة، يمكنك الاطّلاع على العدد الكبير من الطبقات التي يتضمّنها نموذج MobileNet V1:
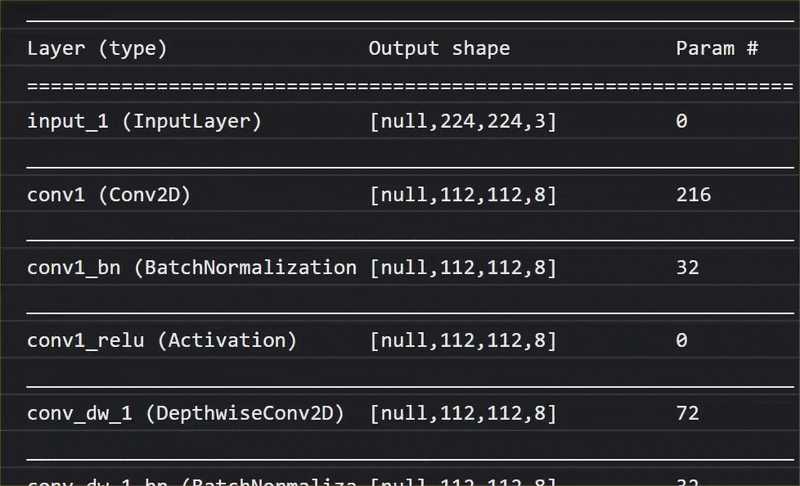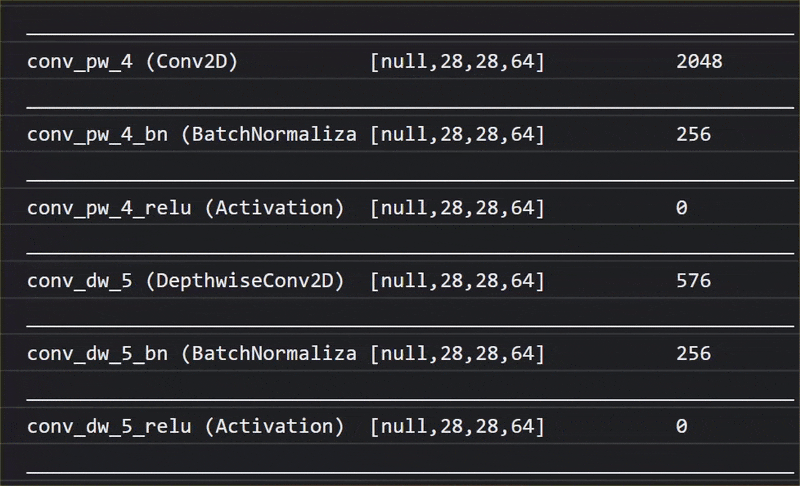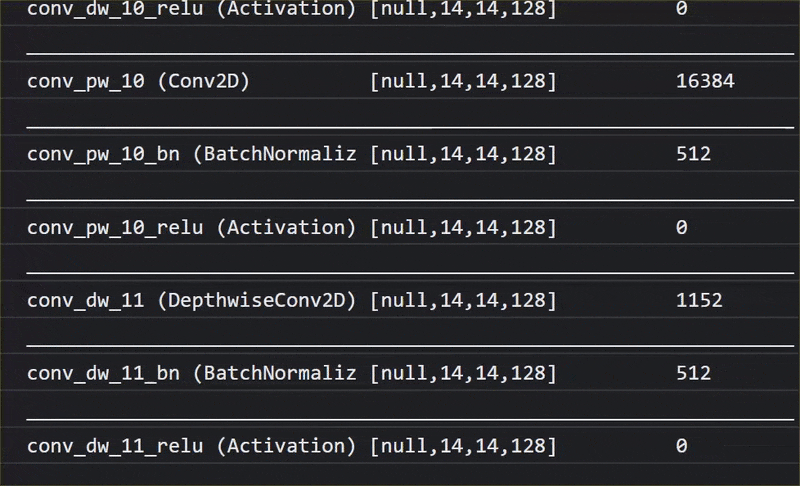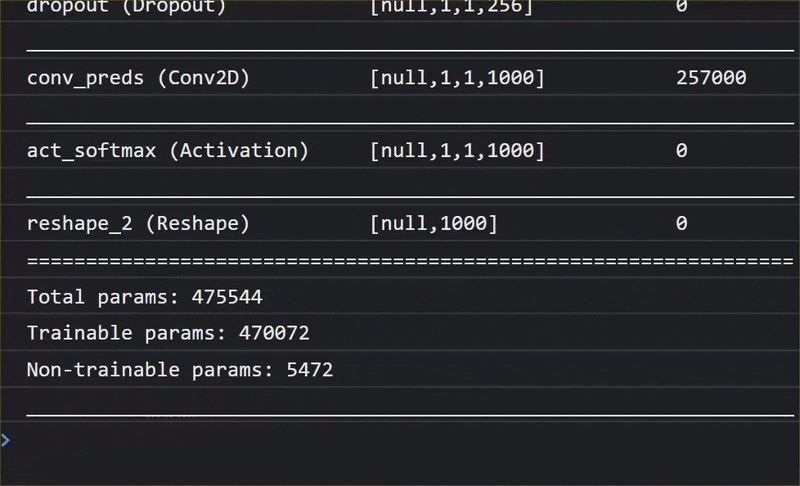
خلال عملية التدريب، تعلّم هذا النموذج كيفية استخراج الميزات الشائعة التي تهمّ جميع هذه العناصر الألف، ويمكن أن تكون العديد من الميزات ذات المستوى الأدنى التي يستخدمها لتحديد هذه العناصر مفيدة أيضًا في رصد عناصر جديدة لم يرَها من قبل. ففي النهاية، كل شيء هو مجرد مزيج من الخطوط والأنسجة والأشكال.
لنلقِ نظرة على بنية تقليدية لشبكة عصبونية التفافية (CNN) (مشابهة لـ MobileNet) ونرى كيف يمكن أن يستفيد التعلّم القائم على نقل المهام من هذه الشبكة المُدرَّبة لتعلُّم شيء جديد. تعرض الصورة أدناه بنية النموذج النموذجية لشبكة عصبية التفافية تم تدريبها في هذه الحالة للتعرّف على الأرقام المكتوبة بخط اليد من 0 إلى 9:
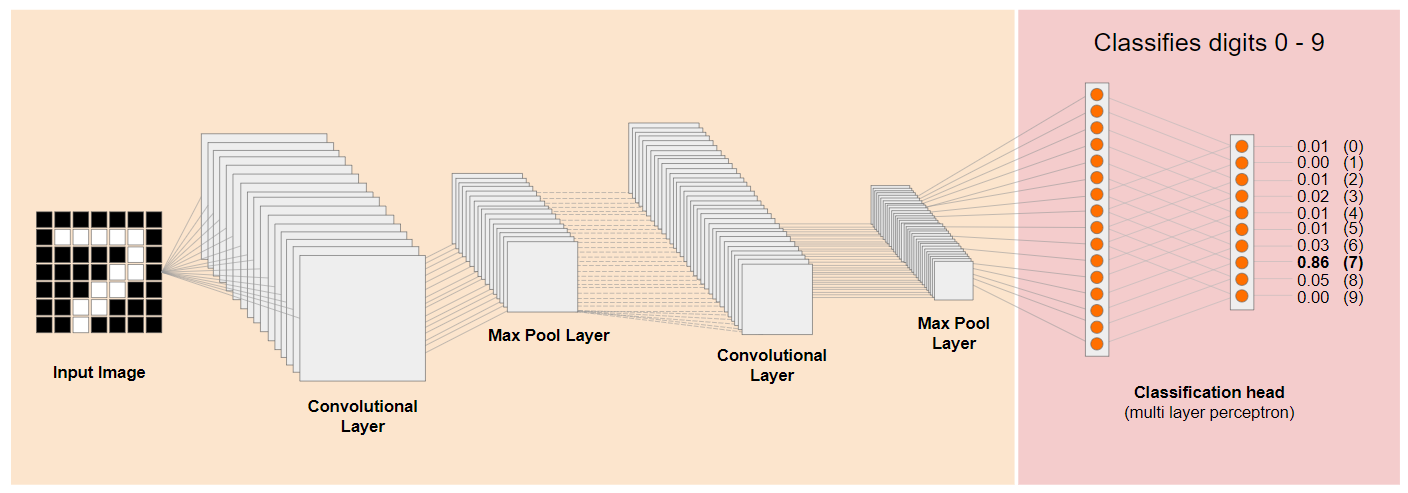
إذا كان بإمكانك فصل الطبقات الأدنى مستوى المدرَّبة مسبقًا من نموذج مدرَّب حالي مثل النموذج المعروض على اليمين، عن طبقات التصنيف بالقرب من نهاية النموذج المعروض على اليسار (يُشار إليها أحيانًا باسم رأس تصنيف النموذج)، يمكنك استخدام الطبقات الأدنى مستوى لإنتاج ميزات الإخراج لأي صورة معيّنة استنادًا إلى البيانات الأصلية التي تم تدريب النموذج عليها. إليك الشبكة نفسها بدون رأس التصنيف:
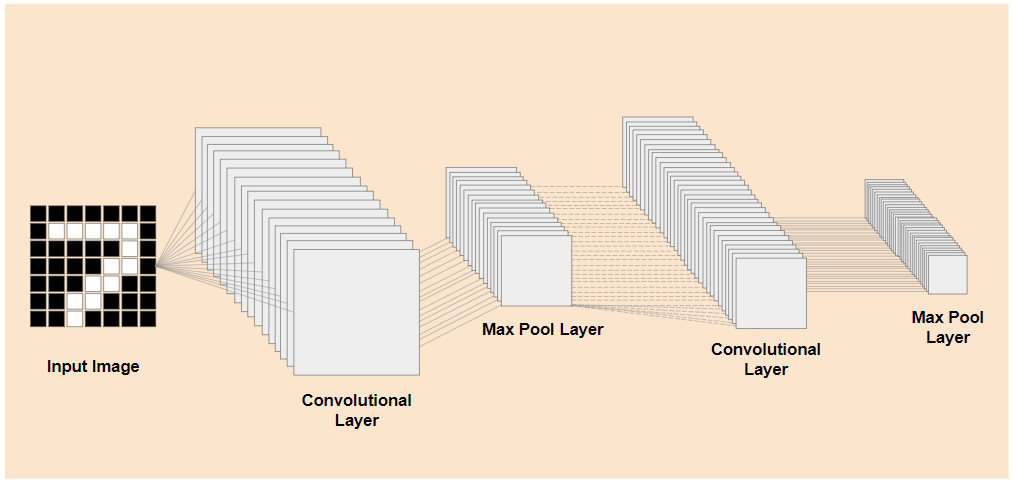
بافتراض أنّ الشيء الجديد الذي تحاول التعرّف عليه يمكنه أيضًا الاستفادة من ميزات الإخراج التي تعلّمها النموذج السابق، هناك فرصة جيدة لإعادة استخدامها لغرض جديد.
في الرسم البياني أعلاه، تم تدريب هذا النموذج الافتراضي على الأرقام، لذا يمكن تطبيق ما تم تعلّمه عن الأرقام أيضًا على الأحرف مثل أ، ب، ج.
يمكنك الآن إضافة رأس تصنيف جديد يحاول توقّع أ أو ب أو ج بدلاً من ذلك، كما هو موضّح:
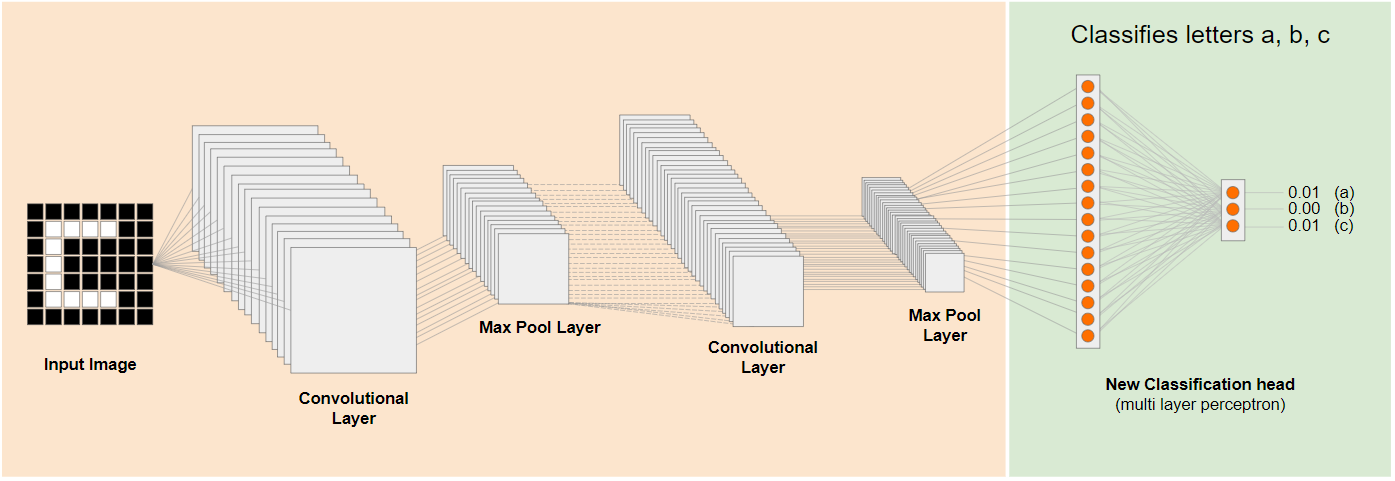
في هذه الحالة، يتم تجميد الطبقات ذات المستوى الأدنى ولا يتم تدريبها، وسيتم تعديل رأس التصنيف الجديد فقط ليتعلّم من الميزات المقدَّمة من النموذج المجزّأ الذي تم تدريبه مسبقًا على اليمين.
ويُعرف هذا الإجراء باسم "التعلّم القائم على نقل المهام"، وهو ما تقوم به أداة تعليم الآلة وراء الكواليس.
يمكنك أيضًا ملاحظة أنّه من خلال تدريب الشبكة العصبية المتعددة الطبقات في نهاية الشبكة فقط، يتم التدريب بشكل أسرع بكثير مما لو كان عليك تدريب الشبكة بأكملها من البداية.
ولكن كيف يمكنك الحصول على أجزاء فرعية من نموذج؟ انتقِل إلى القسم التالي لمعرفة ذلك.
4. TensorFlow Hub - النماذج الأساسية
العثور على نموذج أساسي مناسب للاستخدام
للحصول على المزيد من نماذج البحث المتقدّمة والشائعة، مثل MobileNet، يمكنك الانتقال إلى TensorFlow Hub، ثم فلترة النماذج المناسبة لمنصة TensorFlow.js التي تستخدم بنية MobileNet v3 للعثور على نتائج مثل تلك المعروضة هنا:
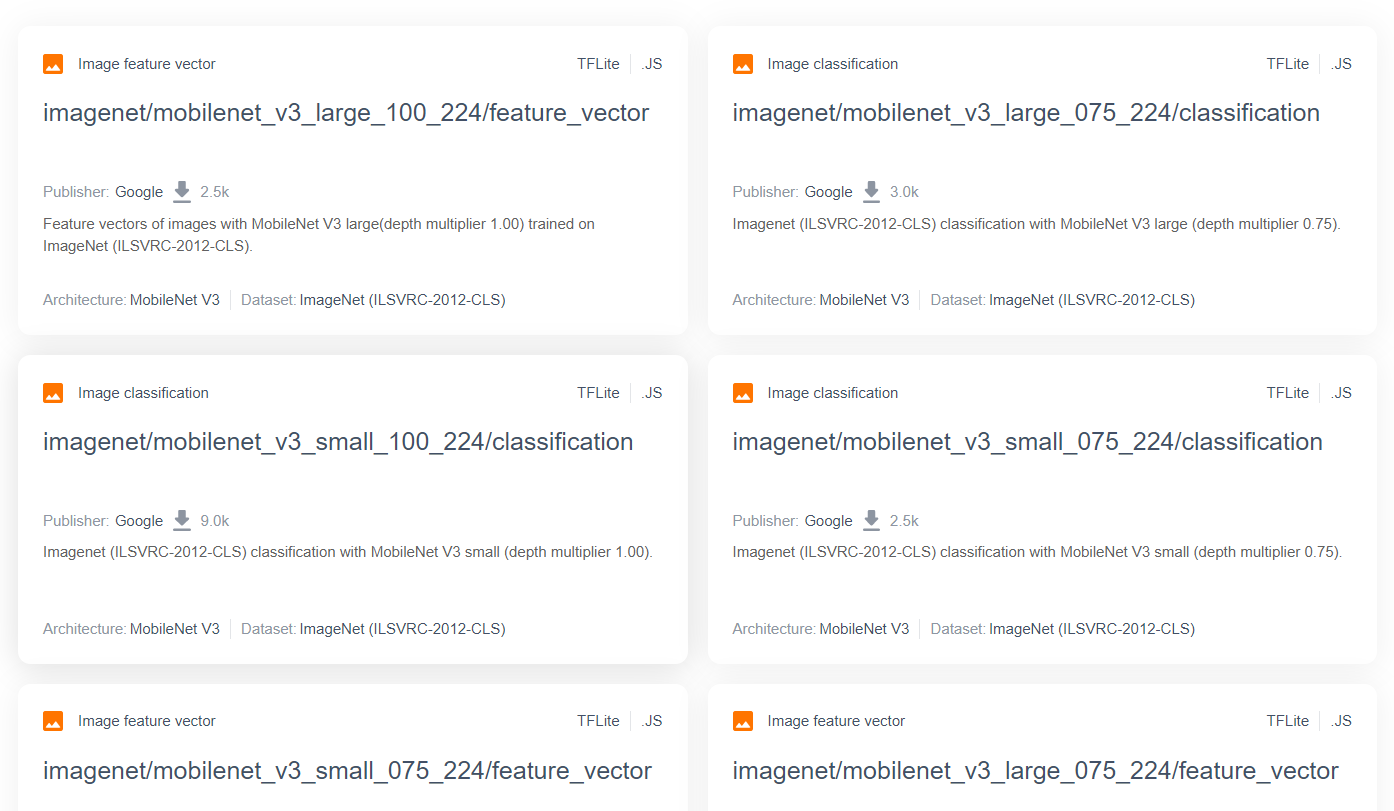
يُرجى العِلم أنّ بعض هذه النتائج هي من النوع "تصنيف الصور" (موضّحة في أعلى يمين كل نتيجة من بطاقة النموذج)، والبعض الآخر من النوع "متّجه ميزات الصور".
إنّ نتائج "متجهات ميزات الصور" هي في الأساس إصدارات مقسّمة مسبقًا من MobileNet يمكنك استخدامها للحصول على متجهات ميزات الصور بدلاً من التصنيف النهائي.
يُطلق على هذه النماذج غالبًا اسم "النماذج الأساسية"، ويمكنك بعد ذلك استخدامها لتنفيذ عملية التعلّم القائم على نقل المهام بالطريقة نفسها الموضّحة في القسم السابق من خلال إضافة رأس تصنيف جديد وتدريبه باستخدام بياناتك.
بعد ذلك، يجب التحقّق من تنسيق TensorFlow.js الذي يتم إصدار النموذج الأساسي المعنيّ به. إذا فتحت صفحة أحد نماذج MobileNet v3 لمتجهات الميزات، يمكنك الاطّلاع من مستندات JavaScript على أنّها تتضمّن نموذج رسم بياني استنادًا إلى مقتطف الرمز البرمجي النموذجي في المستندات الذي يستخدم tf.loadGraphModel().
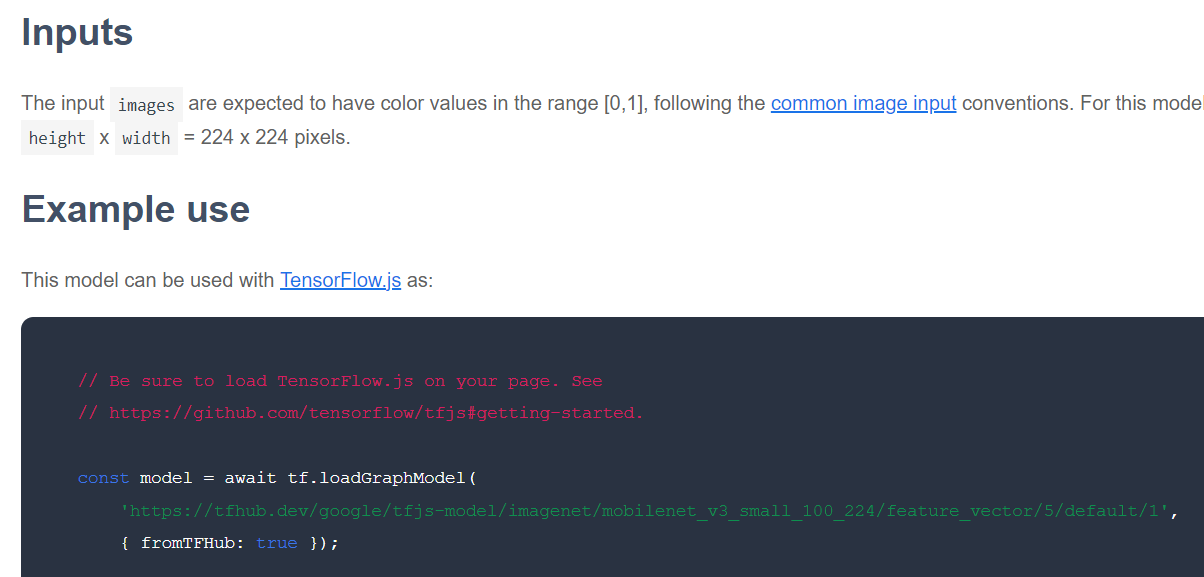
يجب أيضًا ملاحظة أنّه إذا عثرت على نموذج بتنسيق الطبقات بدلاً من تنسيق الرسم البياني، يمكنك اختيار الطبقات التي تريد تجميدها والطبقات التي تريد إلغاء تجميدها للتدريب. يمكن أن يكون ذلك فعّالاً جدًا عند إنشاء نموذج لمهمة جديدة، ويُشار إليه غالبًا باسم "نموذج النقل". في الوقت الحالي، ستستخدم نوع نموذج الرسم البياني التلقائي لهذا البرنامج التعليمي، وهو النوع الذي يتم نشر معظم نماذج TF Hub به. لمزيد من المعلومات حول استخدام نماذج Layers، يمكنك الاطّلاع على دورة zero to hero TensorFlow.js.
مزايا التعلّم القائم على نقل المهام
ما هي مزايا استخدام التعلّم القائم على نقل المهام بدلاً من تدريب بنية النموذج بأكملها من البداية؟
أولاً، يُعدّ وقت التدريب ميزة أساسية لاستخدام أسلوب التعلّم القائم على نقل المهام، إذ يتوفّر لديك نموذج أساسي مُدرَّب يمكنك الاستفادة منه.
ثانيًا، يمكنك عرض عدد أقل بكثير من الأمثلة على الشيء الجديد الذي تحاول تصنيفه بسبب التدريب الذي تم إجراؤه بالفعل.
يكون هذا مفيدًا جدًا إذا كان لديك وقت وموارد محدودة لجمع بيانات أمثلة حول العنصر الذي تريد تصنيفه، وكنت بحاجة إلى إنشاء نموذج أولي بسرعة قبل جمع المزيد من بيانات التدريب لجعله أكثر فعالية.
وبالنظر إلى الحاجة إلى بيانات أقل وسرعة تدريب شبكة أصغر، فإنّ التعلّم القائم على نقل المهام أقل استهلاكًا للموارد. وهذا يجعلها مناسبة جدًا لبيئة المتصفّح، إذ تستغرق عشرات الثواني فقط على جهاز حديث بدلاً من ساعات أو أيام أو أسابيع للتدريب الكامل على النموذج.
حسنًا بعد أن تعرّفت على جوهر التعلّم النقلي، حان الوقت لإنشاء نسختك الخاصة من أداة تعليم الآلة. لِنبدأ.
5- الاستعداد للترميز
المتطلبات
- متصفّح ويب حديث
- معرفة أساسية بلغات HTML وCSS وJavaScript وأدوات مطوّري البرامج في Chrome (عرض نتائج وحدة التحكّم)
لنتعلّم الترميز
تم إنشاء نماذج رموز نموذجية للبدء منها على Glitch.com أو Codepen.io. يمكنك ببساطة استنساخ أيّ من النموذجين كحالة أساسية لهذا الدرس العملي، وذلك بنقرة واحدة فقط.
في Glitch، انقر على الزر إعادة مزج هذا التطبيق لإنشاء نسخة منه ومجموعة جديدة من الملفات التي يمكنك تعديلها.
بدلاً من ذلك، انقر على تشعّب في أسفل يسار الشاشة على Codepen.
يوفّر لك هذا الهيكل البسيط جدًا الملفات التالية:
- صفحة HTML (index.html)
- ورقة الأنماط (style.css)
- ملف لكتابة رمز JavaScript البرمجي (script.js)
لتسهيل الأمر عليك، تمت إضافة عملية استيراد في ملف HTML لمكتبة TensorFlow.js. يبدو على النحو التالي:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
حلّ بديل: استخدام محرّر الويب المفضّل أو العمل على جهازك
إذا كنت تريد تنزيل الرمز البرمجي والعمل عليه محليًا أو على محرّر آخر على الإنترنت، ما عليك سوى إنشاء الملفات الثلاثة المذكورة أعلاه في الدليل نفسه ونسخ الرمز البرمجي من نموذج Glitch ولصقه في كل ملف منها.
6. رمز HTML الأساسي للتطبيق
من أين أبدأ؟
تتطلّب جميع النماذج الأولية بعض البنية الأساسية لرمز HTML التي يمكنك عرض نتائجك عليها. يمكنك إعدادها الآن. ستضيف ما يلي:
- تمثّل هذه السمة عنوان الصفحة.
- بعض النصوص الوصفية.
- فقرة الحالة
- فيديو لعرض خلاصة كاميرا الويب بعد أن تصبح جاهزة
- أزرار متعدّدة لتشغيل الكاميرا أو جمع البيانات أو إعادة ضبط التجربة
- عمليات الاستيراد لملفات TensorFlow.js وملفات JS التي ستكتب رموزها لاحقًا
افتح index.html والصِق الرمز التالي بدلاً من الرمز الحالي لإعداد الميزات أعلاه:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
التبسيط
لنحلّل بعض رموز HTML أعلاه لتسليط الضوء على بعض العناصر الأساسية التي أضفتها.
- أضفت علامة
<h1>لعنوان الصفحة بالإضافة إلى علامة<p>تحمل المعرّف "الحالة"، وهو المكان الذي ستتم فيه طباعة المعلومات، لأنّك تستخدم أجزاء مختلفة من النظام لعرض النتائج. - أضفت عنصر
<video>بمعرّف "webcam"، والذي ستعرض فيه بث كاميرا الويب لاحقًا. - لقد أضفت 5 عناصر
<button>. يسمح الخيار الأول الذي يحمل المعرّف enableCam بتفعيل الكاميرا. يحتوي الزرّان التاليان على فئة "dataCollector"، ما يتيح لك جمع أمثلة على الصور الخاصة بالكائنات التي تريد التعرّف عليها. سيتم تصميم الرمز الذي تكتبه لاحقًا بحيث يمكنك إضافة أي عدد من هذه الأزرار وستعمل على النحو المنشود تلقائيًا.
يُرجى العِلم أنّ هذه الأزرار تتضمّن أيضًا سمة خاصة يحدّدها المستخدم باسم data-1hot، مع قيمة عدد صحيح تبدأ من 0 للفئة الأولى. هذا هو الفهرس الرقمي الذي ستستخدمه لتمثيل بيانات فئة معيّنة. سيتم استخدام الفهرس لترميز فئات الإخراج بشكل صحيح باستخدام تمثيل رقمي بدلاً من سلسلة، لأنّ نماذج تعلُّم الآلة لا يمكنها العمل إلا مع الأرقام.
هناك أيضًا سمة data-name تحتوي على الاسم القابل للقراءة الذي تريد استخدامه لهذه الفئة، ما يتيح لك تقديم اسم أكثر دلالة للمستخدم بدلاً من قيمة فهرس رقمية من الترميز النشط 1.
أخيرًا، يتوفّر زرّان للتدريب وإعادة الضبط لبدء عملية التدريب بعد جمع البيانات، أو لإعادة ضبط التطبيق على التوالي.
- أضفت أيضًا عمليتَي استيراد
<script>. أحدهما لـ TensorFlow.js، والآخر لملف script.js الذي ستحدّده قريبًا.
7. إضافة نمط
الإعدادات التلقائية للعناصر
أضِف أنماطًا لعناصر HTML التي أضفتها للتو لضمان عرضها بشكلٍ صحيح. في ما يلي بعض الأنماط التي تتم إضافتها لتحديد موضع العناصر وحجمها بشكل صحيح. لا شيء مميز. يمكنك بالتأكيد إضافة المزيد من التحسينات لاحقًا لتقديم تجربة مستخدم أفضل، كما رأيت في فيديو "الآلة التعليمية".
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
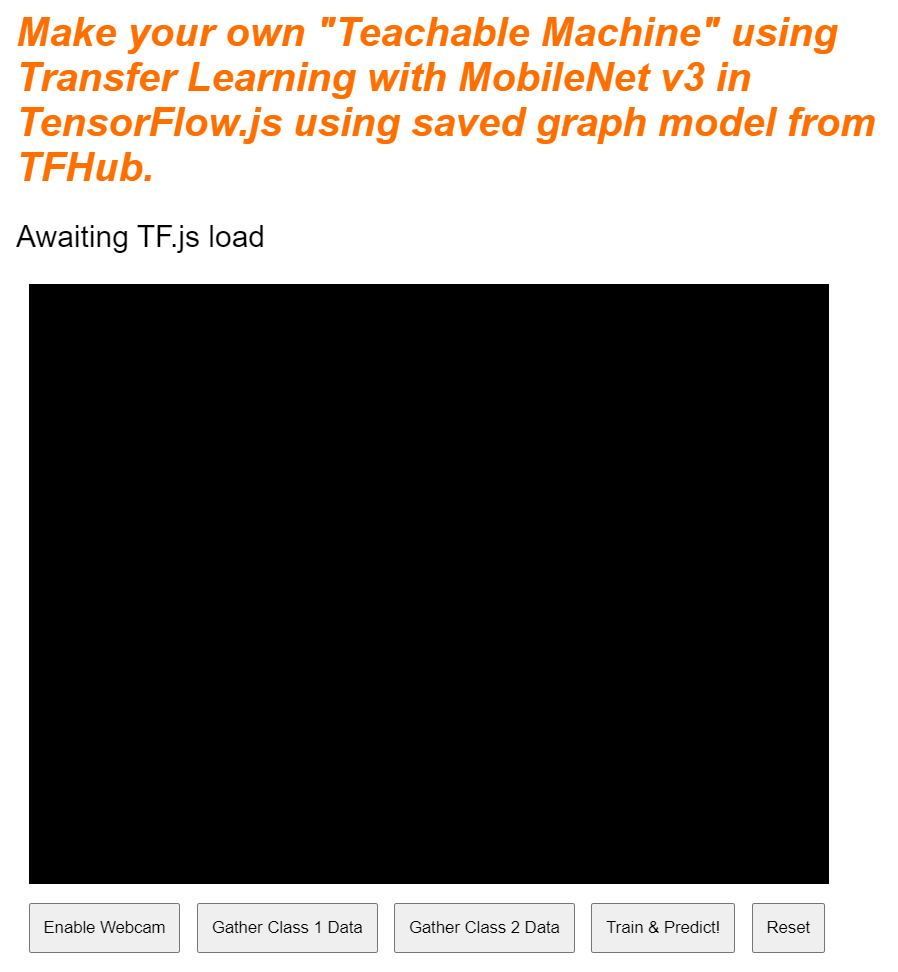
رائع! هذا كل ما تحتاجه. إذا عاينت الناتج الآن، من المفترض أن يظهر على النحو التالي:
8. JavaScript: الثوابت الرئيسية والمعالجات
تحديد الثوابت الرئيسية
أولاً، أضِف بعض الثوابت الأساسية التي ستستخدمها في جميع أنحاء التطبيق. ابدأ باستبدال محتوى script.js بهذه الثوابت:
script.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
في ما يلي تفصيل لأغراض هذه الأذونات:
STATUSما هي إلا مرجع إلى علامة الفقرة التي ستكتب فيها آخر الأخبار حول الحالة.- يحتوي
VIDEOعلى مرجع إلى عنصر فيديو HTML الذي سيعرض خلاصة كاميرا الويب. - تحصل
ENABLE_CAM_BUTTONوRESET_BUTTONوTRAIN_BUTTONعلى مراجع DOM لجميع الأزرار الرئيسية من صفحة HTML. - تحدّد
MOBILE_NET_INPUT_WIDTHوMOBILE_NET_INPUT_HEIGHTعرض وارتفاع الإدخال المتوقّع لنموذج MobileNet على التوالي. من خلال تخزين هذا في ثابت بالقرب من أعلى الملف على هذا النحو، إذا قررت استخدام إصدار مختلف لاحقًا، سيسهّل ذلك تعديل القيم مرة واحدة بدلاً من الاضطرار إلى استبدالها في العديد من الأماكن المختلفة. - تم ضبط قيمة
STOP_DATA_GATHERعلى -1. يخزّن هذا المتغيّر قيمة حالة لتتمكّن من معرفة الوقت الذي توقّف فيه المستخدم عن النقر على زر لجمع البيانات من خلاصة كاميرا الويب. من خلال منح هذا الرقم اسمًا أكثر دلالة، يصبح من الأسهل قراءة الرمز البرمجي لاحقًا. - تعمل السمة
CLASS_NAMESكبحث وتحتوي على الأسماء التي يمكن لشخص عادي قراءتها لتوقّعات الفئات المحتملة. ستتم تعبئة هذه المصفوفة لاحقًا.
حسنًا، بعد أن أصبحت لديك مراجع للعناصر الأساسية، حان الوقت لربط بعض أدوات معالجة الأحداث بها.
إضافة أدوات معالجة الأحداث الرئيسية
ابدأ بإضافة معالِجات أحداث النقر إلى الأزرار الرئيسية كما هو موضّح:
script.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON: يستدعي الدالة enableCam عند النقر عليه.
TRAIN_BUTTON: يتم استدعاء trainAndPredict عند النقر.
RESET_BUTTON: تتم إعادة ضبط المكالمات عند النقر عليها.
أخيرًا، في هذا القسم، يمكنك العثور على جميع الأزرار التي تحمل الفئة "dataCollector" باستخدام document.querySelectorAll(). تعرض هذه الطريقة مصفوفة من العناصر التي تم العثور عليها في المستند والتي تتطابق مع ما يلي:
script.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
شرح الرمز البرمجي:
بعد ذلك، يمكنك تكرار الأزرار التي تم العثور عليها وربط مستمعَي أحداث بكل زر. أحدهما لـ mousedown والآخر لـ mouseup. يتيح لك ذلك مواصلة تسجيل العيّنات طالما أنّ الزر مضغوط، وهو أمر مفيد لجمع البيانات.
يستدعي كلا الحدثين الدالة gatherDataForClass التي ستحدّدها لاحقًا.
في هذه المرحلة، يمكنك أيضًا إرسال أسماء الفئات التي يمكن قراءتها من قِبل الإنسان من بيانات سمة زر HTML data-name إلى مصفوفة CLASS_NAMES.
بعد ذلك، أضِف بعض المتغيّرات لتخزين العناصر الأساسية التي سيتم استخدامها لاحقًا.
script.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
لنستعرض هذه الخطوات.
أولاً، لديك متغيّر mobilenet لتخزين نموذج Mobilenet الذي تم تحميله. اضبط هذه القيمة في البداية على "غير محدّدة".
بعد ذلك، لديك متغيّر باسم gatherDataState. في حال الضغط على زرّ "dataCollector"، يتغيّر ذلك إلى رقم التعريف السريع 1 الخاص بهذا الزرّ بدلاً من ذلك، كما هو محدّد في HTML، حتى تعرف فئة البيانات التي تجمعها في تلك اللحظة. في البداية، يتم ضبط هذا الخيار على STOP_DATA_GATHER حتى لا تجمع حلقة جمع البيانات التي ستكتبها لاحقًا أي بيانات عندما لا يتم الضغط على أي أزرار.
يتتبّع videoPlaying ما إذا كان يتم تحميل بث كاميرا الويب وتشغيله بنجاح وما إذا كان متاحًا للاستخدام. يتم ضبط هذا الخيار مبدئيًا على false لأنّ كاميرا الويب لا تكون مفعّلة إلى أن تضغط على ENABLE_CAM_BUTTON.
بعد ذلك، حدِّد مصفوفتَين، trainingDataInputs وtrainingDataOutputs. تخزِّن هذه الحقول قيم بيانات التدريب التي تم جمعها، وذلك عند النقر على أزرار dataCollector لميزات الإدخال التي أنشأها نموذج MobileNet الأساسي، وفئة الإخراج التي تم أخذ عيّنة منها على التوالي.
بعد ذلك، يتم تحديد مصفوفة نهائية واحدة، examplesCount,، لتتبُّع عدد الأمثلة المتضمّنة في كل فئة بعد البدء في إضافتها.
أخيرًا، لديك متغيّر باسم predict يتحكّم في حلقة التوقّع. يتم ضبط هذا الخيار على false في البداية. لا يمكن إجراء أي توقّعات إلى أن يتم ضبط هذا الخيار على true لاحقًا.
بعد تحديد جميع المتغيرات الرئيسية، لننتقل الآن إلى تحميل نموذج MobileNet v3 الأساسي الذي تم تقسيمه مسبقًا والذي يوفّر متجهات ميزات الصور بدلاً من التصنيفات.
9- تحميل النموذج الأساسي لشبكة MobileNet
أولاً، حدِّد دالة جديدة باسم loadMobileNetFeatureModel كما هو موضّح أدناه. يجب أن تكون هذه الدالة غير متزامنة لأنّ عملية تحميل نموذج غير متزامنة:
script.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
في هذا الرمز، يمكنك تحديد URL حيث يتم تحميل النموذج من مستندات TFHub.
يمكنك بعد ذلك تحميل النموذج باستخدام await tf.loadGraphModel()، مع تذكُّر ضبط السمة الخاصة fromTFHub على true لأنّك تحمّل نموذجًا من موقع Google الإلكتروني هذا. هذه حالة خاصة فقط لاستخدام النماذج المستضافة على TF Hub حيث يجب ضبط هذه السمة الإضافية.
بعد اكتمال التحميل، يمكنك ضبط innerText لعنصر STATUS باستخدام رسالة لتتمكّن من رؤية أنّه تم تحميله بشكل صحيح وأنّك جاهز لبدء جمع البيانات.
كل ما عليك فعله الآن هو تسخين النموذج. مع النماذج الأكبر حجمًا، مثل هذا النموذج، قد يستغرق إعداد كل شيء بعض الوقت عند استخدامه لأول مرة. لذلك، من المفيد تمرير أصفار عبر النموذج لتجنُّب أي انتظار في المستقبل حيث قد يكون التوقيت أكثر أهمية.
يمكنك استخدام tf.zeros() مضمّنًا في tf.tidy() لضمان التخلص من الموترات بشكل صحيح، مع حجم دفعة يبلغ 1، والارتفاع والعرض الصحيحَين اللذين حدّدتهما في الثوابت في البداية. أخيرًا، عليك تحديد قنوات الألوان، وهي 3 في هذه الحالة لأنّ النموذج يتوقّع صورًا بنموذج أحمر أخضر أزرق.
بعد ذلك، سجِّل شكل المتّجه متعدّد الأبعاد الناتج الذي تم عرضه باستخدام answer.shape() لمساعدتك في فهم حجم ميزات الصور التي ينتجها هذا النموذج.
بعد تحديد هذه الدالة، يمكنك استدعاؤها على الفور لبدء تنزيل النموذج عند تحميل الصفحة.
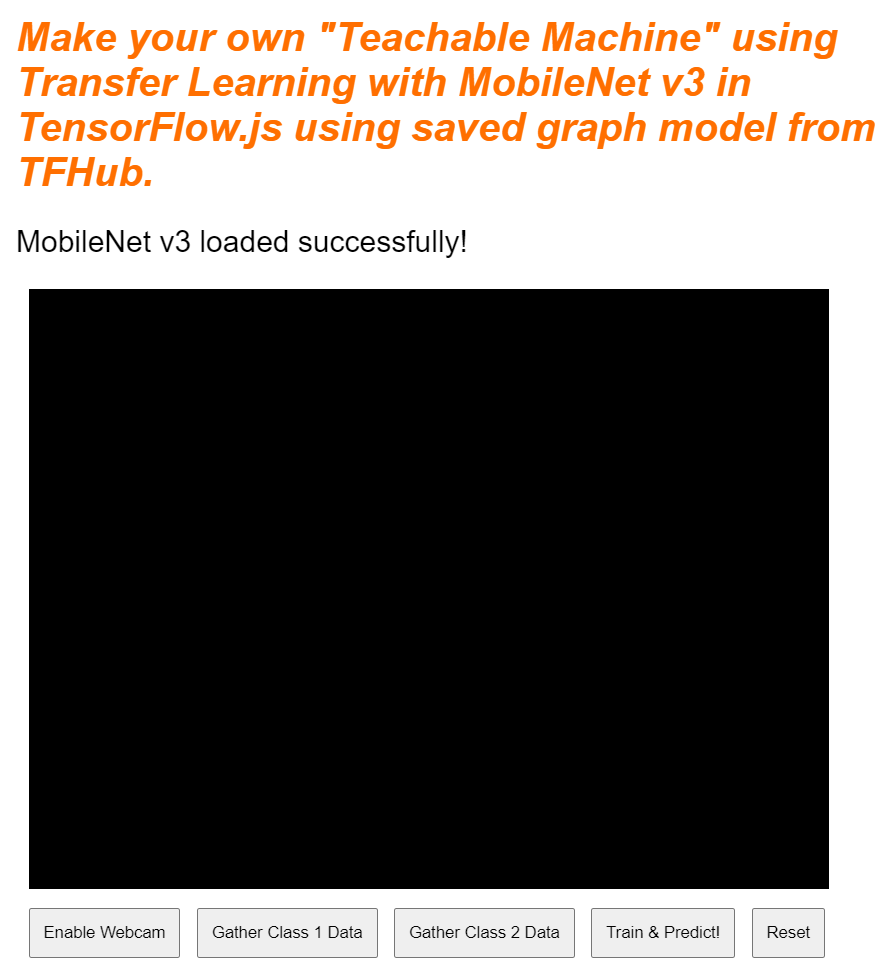
إذا اطّلعت على المعاينة المباشرة الآن، ستلاحظ بعد لحظات أنّ نص الحالة يتغيّر من "في انتظار تحميل TF.js" إلى "تم تحميل MobileNet v3 بنجاح!" كما هو موضّح أدناه. تأكَّد من أنّ هذه الخطوة تعمل قبل المتابعة.
يمكنك أيضًا التحقّق من ناتج وحدة التحكّم لمعرفة الحجم المطبوع للميزات الناتجة التي ينتجها هذا النموذج. بعد تشغيل الأصفار من خلال نموذج MobileNet، سيظهر لك شكل [1, 1024] مطبوعًا. العنصر الأول هو مجرد حجم دفعة يبلغ 1، ويمكنك أن ترى أنّه يعرض في الواقع 1024 ميزة يمكن استخدامها بعد ذلك لمساعدتك في تصنيف عناصر جديدة.
10. تحديد رأس النموذج الجديد
حان الآن وقت تحديد رأس النموذج، وهو في الأساس شبكة عصبية متعددة الطبقات بسيطة للغاية.
script.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
لنستعرض هذه التعليمات البرمجية. تبدأ بتحديد نموذج tf.sequential ستضيف إليه طبقات النموذج.
بعد ذلك، أضِف طبقة كثيفة كطبقة أولى إلى هذا النموذج. يحتوي هذا النموذج على شكل إدخال 1024 لأنّ نواتج ميزات MobileNet v3 بهذا الحجم. لقد اكتشفت ذلك في الخطوة السابقة بعد تمرير القيم من خلال النموذج. تحتوي هذه الطبقة على 128 عصبونًا يستخدمون دالة التنشيط ReLU.
إذا كنت لا تعرف وظائف التفعيل وطبقات النماذج، ننصحك بإكمال الدورة التدريبية المفصّلة في بداية ورشة العمل هذه لفهم وظيفة هذه الخصائص وراء الكواليس.
الطبقة التالية التي يجب إضافتها هي طبقة الإخراج. يجب أن يساوي عدد الخلايا العصبية عدد الفئات التي تحاول توقّعها. لإجراء ذلك، يمكنك استخدام CLASS_NAMES.length لمعرفة عدد الفئات التي تخطّط لتصنيفها، وهو ما يساوي عدد أزرار جمع البيانات التي تظهر في واجهة المستخدم. بما أنّ هذه مشكلة تصنيف، يمكنك استخدام عملية التفعيل softmax في الطبقة النهائية هذه، والتي يجب استخدامها عند محاولة إنشاء نموذج لحلّ مشاكل التصنيف بدلاً من الانحدار.
الآن، اطبع model.summary() لعرض نظرة عامة على النموذج الذي تم تحديده حديثًا في وحدة التحكّم.
أخيرًا، عليك تجميع النموذج ليكون جاهزًا للتدريب. تم ضبط المحسِّن هنا على adam، وستكون الخسارة إما binaryCrossentropy إذا كانت CLASS_NAMES.length تساوي 2، أو سيتم استخدام categoricalCrossentropy إذا كان هناك 3 فئات أو أكثر لتصنيفها. يُطلب أيضًا توفير مقاييس الدقة حتى يمكن مراقبتها في السجلات لاحقًا لأغراض تصحيح الأخطاء.
من المفترض أن يظهر في وحدة التحكّم ما يلي:
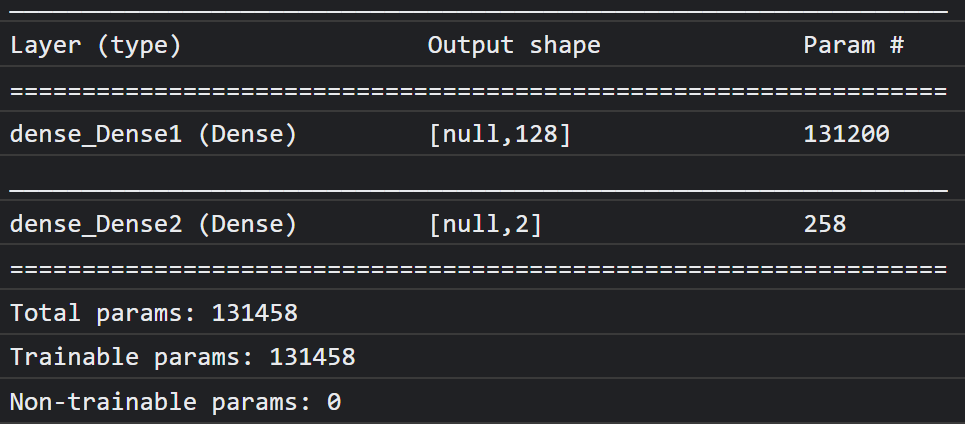
يُرجى العِلم أنّ هذا النموذج يحتوي على أكثر من 130 ألف مَعلمة قابلة للتدريب. ولكن بما أنّ هذه طبقة كثيفة بسيطة من الخلايا العصبية العادية، سيتم تدريبها بسرعة كبيرة.
كأحد الأنشطة التي يمكنك تنفيذها بعد اكتمال المشروع، يمكنك محاولة تغيير عدد الخلايا العصبية في الطبقة الأولى لمعرفة الحدّ الأدنى الذي يمكنك الوصول إليه مع الحفاظ على أداء جيد. في كثير من الأحيان، يتضمّن تعلُّم الآلة بعض المحاولات والأخطاء للعثور على قيم المَعلمات المثالية التي تمنحك أفضل حل وسط بين استخدام الموارد والسرعة.
11. تفعيل كاميرا الويب
حان الوقت الآن لتفصيل الدالة enableCam() التي حدّدتها سابقًا. أضِف دالة جديدة باسم hasGetUserMedia() كما هو موضّح أدناه، ثم استبدِل محتوى الدالة enableCam() التي تم تحديدها سابقًا بالرمز البرمجي المناسب أدناه.
script.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
أولاً، أنشئ دالة باسم hasGetUserMedia() للتحقّق مما إذا كان المتصفّح يتيح استخدام getUserMedia() من خلال التحقّق من توفّر خصائص واجهات برمجة التطبيقات الرئيسية للمتصفّح.
في الدالة enableCam()، استخدِم الدالة hasGetUserMedia() التي حدّدتها للتوّ أعلاه للتحقّق مما إذا كانت متوافقة. إذا لم يكن كذلك، اطبع تحذيرًا في وحدة التحكّم.
إذا كان الجهاز يتيح ذلك، حدِّد بعض القيود لطلب getUserMedia()، مثل أن تريد بث الفيديو فقط، وأن تفضّل أن يكون حجم الفيديو width بكسل، وأن يكون height 480 بكسل.640 لماذا؟ حسنًا، ليس من المنطقي الحصول على فيديو أكبر من هذا الحجم لأنّه يجب تغيير حجمه إلى 224 × 224 بكسل ليتم إدخاله في نموذج MobileNet. يمكنك أيضًا توفير بعض موارد الحوسبة من خلال طلب دقة أقل. تتيح معظم الكاميرات درجة دقة بهذا الحجم.
بعد ذلك، اتّصِل بالرقم navigator.mediaDevices.getUserMedia() مع تضمين التفاصيل constraints الموضّحة أعلاه، ثم انتظِر إلى أن يتم عرض stream. بعد إرجاع stream، يمكنك الحصول على العنصر VIDEO لتشغيل stream من خلال ضبطه كقيمة srcObject.
يجب أيضًا إضافة eventListener إلى العنصر VIDEO لمعرفة وقت تحميل stream وتشغيله بنجاح.
بعد تحميل البث، يمكنك ضبط videoPlaying على "صحيح" وإزالة ENABLE_CAM_BUTTON لمنع النقر عليه مرة أخرى من خلال ضبط فئته على "removed".
الآن، شغِّل الرمز وانقر على زر "تفعيل الكاميرا" واسمح بالوصول إلى كاميرا الويب. إذا كانت هذه المرّة الأولى التي تنفّذ فيها هذه العملية، من المفترض أن يظهر لك الفيديو الذي تم عرضه في عنصر الفيديو على الصفحة كما هو موضّح أدناه:

حسنًا، حان الوقت الآن لإضافة دالة للتعامل مع نقرات الزر dataCollector.
12. معالج أحداث زر جمع البيانات
حان الوقت الآن لملء الدالة gatherDataForClass(). التي لا تحتوي على أي بيانات حاليًا. هذه هي الدالة التي حدّدتها كدالة معالجة الأحداث لأزرار dataCollector في بداية الدرس التطبيقي حول الترميز.
script.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
أولاً، تحقَّق من السمة data-1hot في الزر الذي تم النقر عليه حاليًا من خلال استدعاء this.getAttribute() مع اسم السمة، وفي هذه الحالة data-1hot كالمَعلمة. بما أنّ هذا النص هو سلسلة، يمكنك بعد ذلك استخدام parseInt() لتحويله إلى عدد صحيح وتعيين هذه النتيجة إلى متغيّر باسم classNumber.
بعد ذلك، اضبط المتغيّر gatherDataState وفقًا لذلك. إذا كانت قيمة gatherDataState الحالية تساوي STOP_DATA_GATHER (التي ضبطتها على -1)، يعني ذلك أنّك لا تجمع حاليًا أي بيانات وأنّه تم تنشيط حدث mousedown. اضبط قيمة gatherDataState لتكون classNumber التي عثرت عليها للتو.
بخلاف ذلك، يعني أنّك تجمع البيانات حاليًا وأنّ الحدث الذي تم تنشيطه كان حدث mouseup، وتريد الآن إيقاف جمع البيانات لهذه الفئة. ما عليك سوى إعادة ضبطها على الحالة STOP_DATA_GATHER لإنهاء حلقة جمع البيانات التي ستحدّدها قريبًا.
أخيرًا، ابدأ طلب dataGatherLoop(), الذي يسجّل بيانات الصف.
13. جمع البيانات
الآن، حدِّد الدالة dataGatherLoop(). هذه الدالة مسؤولة عن أخذ عيّنات من الصور من فيديو كاميرا الويب، وتمريرها عبر نموذج MobileNet، وتسجيل نواتج هذا النموذج (الخطوط المتجهة للخصائص التي يبلغ عددها 1024).
بعد ذلك، يتم تخزينها مع معرّف gatherDataState للزر الذي يتم الضغط عليه حاليًا حتى تعرف الفئة التي تمثّلها هذه البيانات.
لنستعرض الخطوات:
script.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
لن تواصل تنفيذ هذه الدالة إلا إذا كانت قيمة videoPlaying صحيحة، ما يعني أنّ كاميرا الويب نشطة، وأنّ قيمة gatherDataState لا تساوي STOP_DATA_GATHER، ويتم حاليًا الضغط على زر لجمع بيانات الصف.
بعد ذلك، ضع الرمز البرمجي في tf.tidy() للتخلص من أي متّجهات متعدّدة الأبعاد تم إنشاؤها في الرمز البرمجي التالي. يتم تخزين نتيجة تنفيذ الرمز tf.tidy() في متغيّر يُسمى imageFeatures.
يمكنك الآن التقاط إطار من كاميرا الويب VIDEO باستخدام tf.browser.fromPixels(). يتم تخزين المتّجه متعدّد الأبعاد الناتج الذي يحتوي على بيانات الصورة في مُتغيِّر يُسمى videoFrameAsTensor.
بعد ذلك، غيِّر حجم المتغيّر videoFrameAsTensor ليكون بالشكل الصحيح لإدخال نموذج MobileNet. استخدِم استدعاء tf.image.resizeBilinear() مع المتّجه متعدّد الأبعاد الذي تريد إعادة تشكيله كالمَعلمة الأولى، ثمّ استخدِم شكلاً يحدّد الارتفاع والعرض الجديدَين كما هو محدّد بالثوابت التي أنشأتها سابقًا. وأخيرًا، اضبط align corners على true من خلال تمرير المَعلمة الثالثة لتجنُّب أي مشاكل في المحاذاة عند تغيير الحجم. يتم تخزين نتيجة تغيير الحجم هذه في متغيّر يُسمى resizedTensorFrame.
يُرجى العِلم أنّ عملية تغيير الحجم الأساسية هذه تؤدي إلى تمديد الصورة، لأنّ صورة كاميرا الويب تبلغ 640 × 480 بكسل، بينما يحتاج النموذج إلى صورة مربّعة بحجم 224 × 224 بكسل.
من المفترض أن يكون هذا الإعداد مناسبًا لأغراض العرض التوضيحي. ومع ذلك، بعد إكمال هذا الدرس التطبيقي حول الترميز، قد تحتاج إلى محاولة اقتصاص مربّع من هذه الصورة بدلاً من ذلك للحصول على نتائج أفضل لأي نظام إنتاج قد تنشئه لاحقًا.
بعد ذلك، عليك تسوية بيانات الصورة. تكون بيانات الصور دائمًا في النطاق من 0 إلى 255 عند استخدام tf.browser.frompixels()، لذا يمكنك ببساطة قسمة resizedTensorFrame على 255 لضمان أن تكون جميع القيم بين 0 و1 بدلاً من ذلك، وهو ما يتوقّعه نموذج MobileNet كمدخلات.
أخيرًا، في قسم tf.tidy() من الرمز، يمكنك إدخال هذا المتّجه المتعدّد الأبعاد الذي تمت تسويته في النموذج الذي تم تحميله من خلال استدعاء mobilenet.predict()، والذي يمكنك تمرير النسخة الموسّعة من normalizedTensorFrame إليه باستخدام expandDims() ليكون عبارة عن دفعة من 1، لأنّ النموذج يتوقّع دفعة من المدخلات للمعالجة.
بعد الحصول على النتيجة، يمكنك استدعاء squeeze() على الفور بشأن تلك النتيجة التي تم إرجاعها لضغطها مرة أخرى إلى متّجه متعدّد الأبعاد أحادي الأبعاد، ثم إرجاعها وتعيينها إلى المُتغيِّر imageFeatures الذي يلتقط النتيجة من tf.tidy().
بعد الحصول على imageFeatures من نموذج MobileNet، يمكنك تسجيلها عن طريق إضافتها إلى مصفوفة trainingDataInputs التي حدّدتها سابقًا.
يمكنك أيضًا تسجيل ما يمثّله هذا الإدخال عن طريق إضافة gatherDataState الحالي إلى مصفوفة trainingDataOutputs أيضًا.
يُرجى العِلم أنّه كان سيتم ضبط المتغيّر gatherDataState على رقم التعريف العددي للفئة الحالية التي تسجّل البيانات لها عند النقر على الزر في الدالة gatherDataForClass() المحدّدة سابقًا.
في هذه المرحلة، يمكنك أيضًا زيادة عدد الأمثلة المتوفرة لديك لفئة معيّنة. لإجراء ذلك، تحقَّق أولاً مما إذا تمت تهيئة الفهرس داخل مصفوفة examplesCount من قبل أم لا. إذا كانت القيمة غير محدّدة، اضبطها على 0 لتهيئة العداد لرقم التعريف العددي لفئة معيّنة، وبعد ذلك يمكنك زيادة examplesCount بمقدار 1 gatherDataState الحالي.
عدِّل الآن نص عنصر STATUS على صفحة الويب لعرض الأعداد الحالية لكل فئة عند تسجيلها. لإجراء ذلك، كرِّر عناصر مصفوفة CLASS_NAMES، واطبع الاسم القابل للقراءة من قِبل الإنسان مع عدد البيانات في الفهرس نفسه في examplesCount.
أخيرًا، استدعِ window.requestAnimationFrame() مع تمرير dataGatherLoop كمَعلمة لاستدعاء هذه الدالة بشكل متكرّر مرة أخرى. سيستمر ذلك في أخذ عيّنات من إطارات الفيديو إلى أن يتم رصد mouseup للزر، ويتم ضبط gatherDataState على STOP_DATA_GATHER,، وعندها ستنتهي حلقة جمع البيانات.
إذا شغّلت الرمز الآن، من المفترض أن تتمكّن من النقر على زر تفعيل الكاميرا، وانتظار تحميل كاميرا الويب، ثم النقر مع الاستمرار على كل زر من أزرار جمع البيانات لجمع أمثلة لكل فئة من فئات البيانات. هنا تراني أجمع البيانات لهاتفي المحمول ويدي على التوالي.
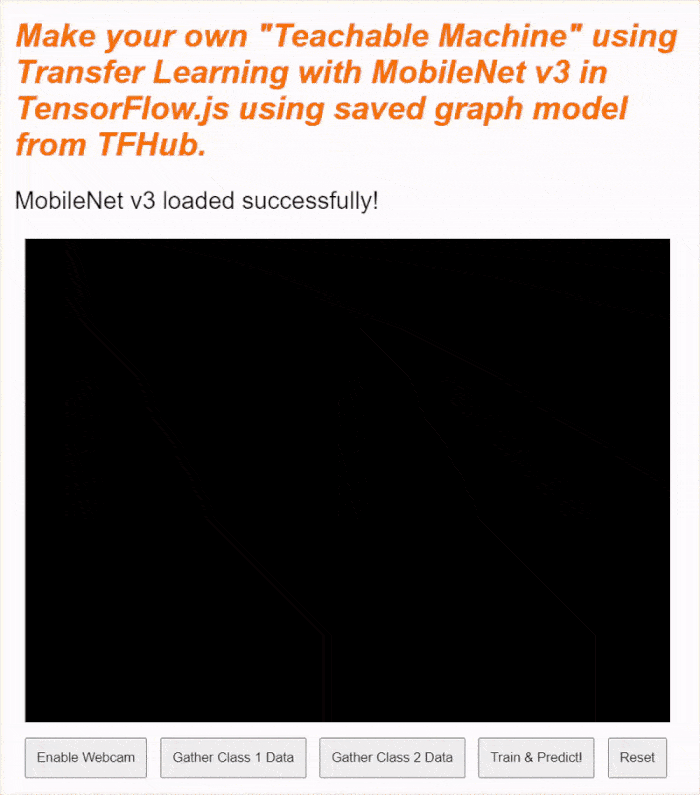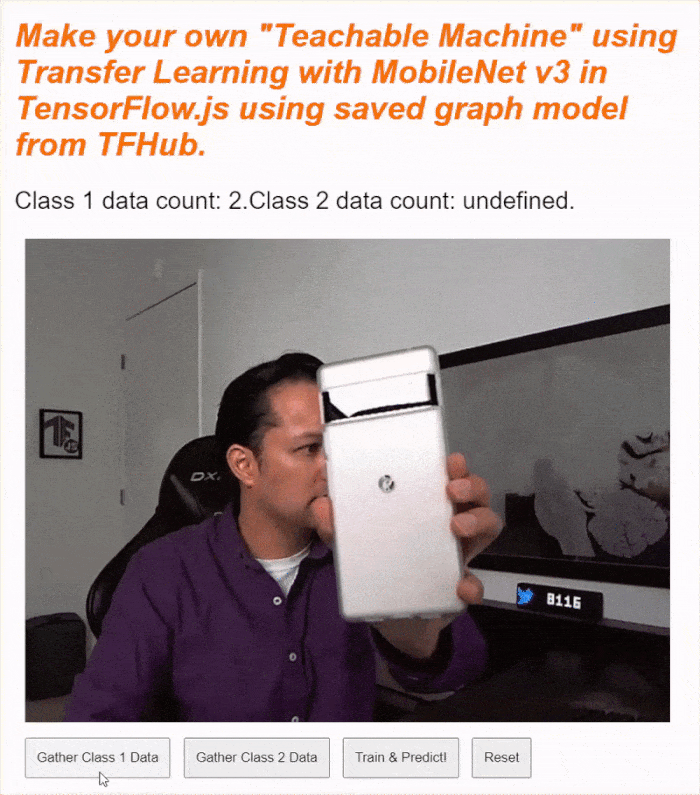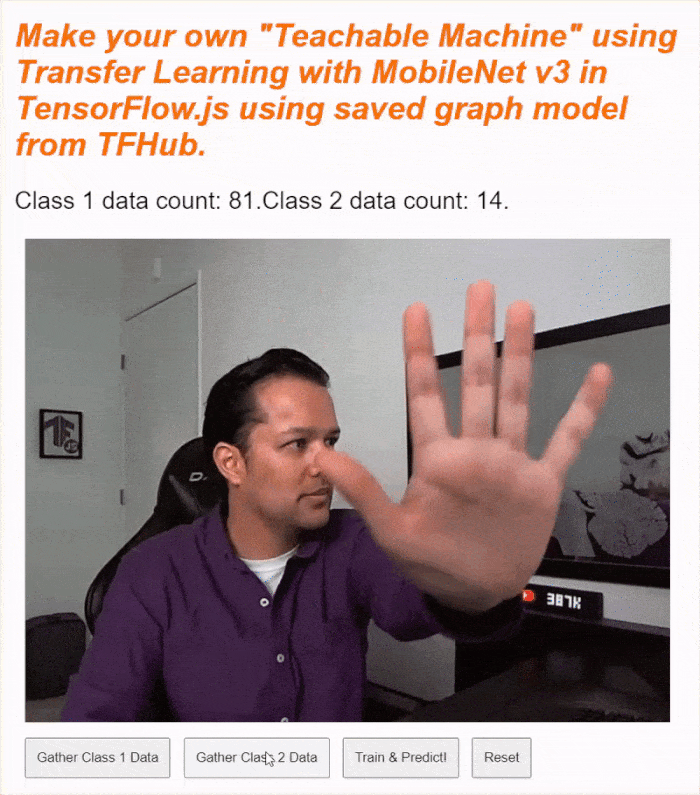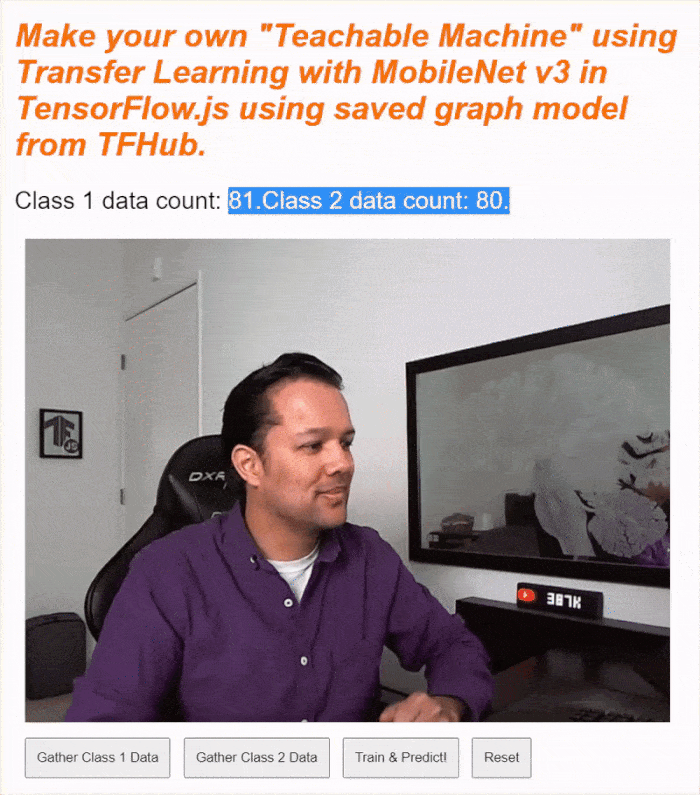
من المفترض أن يظهر نص الحالة المعدَّل أثناء تخزين جميع المتّجهات متعدّدة الأبعاد في الذاكرة كما هو موضّح في لقطة الشاشة أعلاه.
14. التدريب والتوقّع
الخطوة التالية هي تنفيذ الرمز لوظيفة trainAndPredict() الفارغة حاليًا، وهي المكان الذي يتم فيه التعلّم القائم على نقل المهام. لنلقِ نظرة على الرمز:
script.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
أولاً، تأكَّد من إيقاف أي تنبؤات حالية من خلال ضبط predict على false.
بعد ذلك، بدِّل ترتيب مصفوفتَي الإدخال والإخراج باستخدام tf.util.shuffleCombo() للتأكّد من أنّ الترتيب لا يتسبّب في حدوث مشاكل أثناء التدريب.
حوِّل مصفوفة الإخراج، trainingDataOutputs,، إلى tensor1d من النوع int32 لتكون جاهزة للاستخدام في ترميز one-hot. يتم تخزين هذا المعرّف في متغيّر باسم outputsAsTensor.
استخدِم الدالة tf.oneHot() مع المتغيّر outputsAsTensor بالإضافة إلى الحد الأقصى لعدد الفئات المطلوب ترميزها، وهو CLASS_NAMES.length فقط. يتم الآن تخزين النتائج التي تم ترميزها بشكل أحادي في موتر جديد باسم oneHotOutputs.
يُرجى العِلم أنّ trainingDataInputs هو حاليًا مجموعة من الموترات المسجّلة. من أجل استخدامها في التدريب، عليك تحويل مصفوفة الموترات إلى موتر ثنائي الأبعاد عادي.
لإجراء ذلك، تتوفّر دالة رائعة ضمن مكتبة TensorFlow.js تُسمى tf.stack()،
التي تأخذ مصفوفة من المتّجهات متعدّدة الأبعاد وتكدّسها معًا لإنتاج متّجه متعدّد الأبعاد ذي أبعاد أعلى كناتج. في هذه الحالة، يتم عرض متّجه متعدّد الأبعاد ثنائي الأبعاد، وهو عبارة عن دفعة من المدخلات أحادية الأبعاد التي يبلغ طول كل منها 1024، وتحتوي على الميزات المسجّلة، وهو ما تحتاج إليه للتدريب.
بعد ذلك، انقر على await model.fit() لتدريب رأس النموذج المخصّص. يمكنك هنا تمرير متغيّر inputsAsTensor مع oneHotOutputs لتمثيل بيانات التدريب التي سيتم استخدامها في إدخالات الأمثلة والمخرجات المستهدَفة على التوالي. في عنصر الإعدادات الخاص بالمَعلمة الثالثة، اضبط shuffle على true، واستخدِم batchSize من 5، مع ضبط epochs على 10، ثم حدِّد callback لـ onEpochEnd في الدالة logProgress التي ستحدِّدها قريبًا.
أخيرًا، يمكنك التخلّص من الموترات التي تم إنشاؤها بعد تدريب النموذج. يمكنك بعد ذلك ضبط predict على true للسماح بتفعيل التوقعات مرة أخرى، ثم استدعاء الدالة predictLoop() لبدء توقّع صور كاميرا الويب المباشرة.
يمكنك أيضًا تحديد الدالة logProcess() لتسجيل حالة التدريب، والتي يتم استخدامها في model.fit() أعلاه وتطبع النتائج في وحدة التحكّم بعد كل جولة تدريب.
أنت على وشك الانتهاء حان الوقت لإضافة الدالة predictLoop() لتقديم التوقعات.
حلقة التوقّع الأساسية
في هذا القسم، يمكنك تنفيذ حلقة التوقّع الرئيسية التي تأخذ عيّنات من اللقطات من كاميرا الويب وتتوقّع باستمرار ما يظهر في كل لقطة مع عرض النتائج في الوقت الفعلي في المتصفّح.
لنتحقّق من الرمز:
script.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
تحقَّق أولاً من أنّ predict مضبوط على "صحيح"، حتى لا يتم إجراء التوقعات إلا بعد تدريب النموذج وإتاحته للاستخدام.
بعد ذلك، يمكنك الحصول على ميزات الصورة الحالية تمامًا كما فعلت في الدالة dataGatherLoop(). بشكل أساسي، يمكنك الحصول على إطار من كاميرا الويب باستخدام tf.browser.from pixels()، ثم تسويته وتغيير حجمه إلى 224 × 224 بكسل، ثم تمرير هذه البيانات من خلال نموذج MobileNet للحصول على ميزات الصورة الناتجة.
في المقابل، يمكنك الآن استخدام رأس النموذج الذي تم تدريبه حديثًا لإجراء عملية توقّع من خلال تمرير imageFeatures الناتج الذي تم العثور عليه للتو من خلال دالة predict() الخاصة بالنموذج المدرَّب. يمكنك بعد ذلك ضغط المتّجه متعدّد الأبعاد الناتج لجعله أحادي السمة مرة أخرى وتعيينه إلى مُتغيِّر باسم prediction.
باستخدام prediction، يمكنك العثور على الفهرس الذي يحتوي على أعلى قيمة باستخدام argMax()، ثم تحويل هذا المتّجه المتعدّد الأبعاد الناتج إلى مصفوفة باستخدام arraySync() للوصول إلى البيانات الأساسية في JavaScript من أجل تحديد موضع العنصر الأعلى قيمة. يتم تخزين هذه القيمة في المتغيّر highestIndex.
يمكنك أيضًا الحصول على نتائج الثقة الفعلية للتوقّعات بالطريقة نفسها من خلال استدعاء arraySync() على موتر prediction مباشرةً.
لديك الآن كل ما تحتاج إليه لتعديل النص STATUS باستخدام البيانات prediction. للحصول على السلسلة القابلة للقراءة الخاصة بالفئة، يمكنك البحث عن highestIndex في مصفوفة CLASS_NAMES، ثم الحصول على قيمة الثقة من predictionArray. لجعلها أكثر قابلية للقراءة كنسبة مئوية، ما عليك سوى الضرب في 100 وmath.floor() النتيجة.
أخيرًا، يمكنك استخدام window.requestAnimationFrame() للاتصال predictionLoop() مرة أخرى عندما تكون مستعدًا، وذلك للحصول على تصنيف في الوقت الفعلي لبث الفيديو. يستمر ذلك إلى أن يتم ضبط predict على false إذا اخترت تدريب نموذج جديد باستخدام بيانات جديدة.
وهذا يقودك إلى الجزء الأخير من اللغز. تنفيذ زر إعادة الضبط
15. تنفيذ زر إعادة الضبط
أوشكت على الانتهاء! الجزء الأخير من اللغز هو تنفيذ زر إعادة الضبط للبدء من جديد. في ما يلي رمز الدالة reset() الفارغة حاليًا. يُرجى تعديلها باتّباع الخطوات التالية:
script.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
أولاً، أوقِف أي حلقات تنبؤ قيد التشغيل من خلال ضبط predict على false. بعد ذلك، احذف كل المحتوى في مصفوفة examplesCount من خلال ضبط طولها على 0، وهي طريقة مفيدة لمحو كل المحتوى من مصفوفة.
الآن، راجِع جميع trainingDataInputs المسجّلة الحالية وتأكَّد من dispose() كل متّجه متعدّد الأبعاد مضمّن فيها لتحرير الذاكرة مرة أخرى، لأنّ أداة جمع البيانات غير المرغوب فيها في JavaScript لا تنظّف المتّجهات متعدّدة الأبعاد.
بعد الانتهاء من ذلك، يمكنك الآن ضبط طول المصفوفة على 0 بأمان في كل من مصفوفتَي trainingDataInputs وtrainingDataOutputs لمحو هاتين المصفوفتين أيضًا.
أخيرًا، اضبط نص STATUS على قيمة منطقية، واطبع الموترات المتبقية في الذاكرة كفحص للتأكّد من صحة البيانات.
يُرجى العِلم أنّه ستبقى بضع مئات من الموترات في الذاكرة لأنّه لم يتم التخلص من نموذج MobileNet والشبكة العصبية المتعددة الطبقات التي حدّدتها. سيكون عليك إعادة استخدامها مع بيانات تدريب جديدة إذا قرّرت التدريب مرة أخرى بعد إعادة الضبط هذه.
16. لنجرّب ذلك
حان الوقت لتجربة نسختك الخاصة من أداة تعليم الآلة!
انتقِل إلى المعاينة المباشرة، وفعِّل كاميرا الويب، واجمع 30 عينة على الأقل للفئة 1 لبعض العناصر في غرفتك، ثم افعل الشيء نفسه للفئة 2 لعنصر مختلف، وانقر على "تدريب"، وتحقّق من سجلّ وحدة التحكّم لمعرفة مستوى التقدّم. يجب أن يتم التدريب بسرعة كبيرة:

بعد التدريب، اعرض الكائنات على الكاميرا للحصول على توقّعات مباشرة ستتم طباعتها في مساحة نص الحالة على صفحة الويب بالقرب من أعلى الصفحة. إذا كنت تواجه مشكلة، تحقَّق من الرمز العامل الذي أكملته لمعرفة ما إذا فاتك نسخ أي شيء.
17. تهانينا
تهانينا! لقد أكملت للتو مثالك الأول على التعلّم القائم على نقل المهام باستخدام TensorFlow.js مباشرةً في المتصفّح.
جرِّب هذه الميزة واختبرها على مجموعة متنوعة من العناصر، فقد تلاحظ أنّ بعض العناصر يصعب التعرّف عليها أكثر من غيرها، خاصةً إذا كانت تشبه عناصر أخرى. قد تحتاج إلى إضافة المزيد من الفئات أو بيانات التدريب لتتمكّن من التمييز بينها.
ملخّص
في هذا الدرس التطبيقي حول الترميز، تعلّمت ما يلي:
- مفهوم التعلّم القائم على نقل المهام ومزاياه مقارنةً بتدريب نموذج كامل
- كيفية الحصول على نماذج لإعادة استخدامها من TensorFlow Hub
- كيفية إعداد تطبيق ويب مناسب للتعلّم القائم على نقل المهام
- كيفية تحميل نموذج أساسي واستخدامه لإنشاء ميزات الصور
- كيفية تدريب رأس تنبؤ جديد يمكنه التعرّف على كائنات مخصّصة من صور كاميرا الويب
- كيفية استخدام النماذج الناتجة لتصنيف البيانات في الوقت الفعلي
ما هي الخطوات التالية؟
بعد أن أصبح لديك أساس عملي يمكنك البدء منه، ما هي الأفكار الإبداعية التي يمكنك التوصّل إليها لتوسيع نطاق نموذج تعلُّم الآلة هذا ليشمل حالة استخدام واقعية قد تعمل عليها؟ ربما يمكنك إحداث ثورة في المجال الذي تعمل فيه حاليًا لمساعدة زملائك في الشركة على تدريب النماذج لتصنيف الأشياء المهمة في عملهم اليومي. بإمكانك الحصول على خيارات لا تُعدّ ولا تُحصى.
للمضي قدمًا، ننصحك بإكمال هذه الدورة التدريبية الكاملة مجانًا، والتي توضّح لك كيفية دمج النموذجين اللذين تستخدمهما حاليًا في هذا الدرس التطبيقي حول الترميز إلى نموذج واحد لتحقيق الكفاءة.
إذا كنت مهتمًا بمعرفة المزيد عن النظرية الكامنة وراء تطبيق "الآلة التعليمية" الأصلي، يمكنك الاطّلاع على هذا البرنامج التعليمي.
مشاركة المحتوى الذي تصنعه معنا
يمكنك بسهولة توسيع نطاق استخدام ما صنعته اليوم ليشمل حالات إبداعية أخرى أيضًا، ونشجّعك على التفكير بأسلوب جديد ومواصلة الابتكار.
لا تنسَ الإشارة إلينا على وسائل التواصل الاجتماعي باستخدام الهاشتاغ #MadeWithTFJS للحصول على فرصة عرض مشروعك على مدونة TensorFlow أو حتى في الفعاليات المستقبلية. نتشوّق لرؤية ابتكاراتك.
مواقع إلكترونية ننصحك بالاطّلاع عليها
- الموقع الإلكتروني الرسمي لـ TensorFlow.js
- نماذج TensorFlow.js الجاهزة
- TensorFlow.js API
- TensorFlow.js Show & Tell: استلهِم الأفكار واطّلِع على ما أنشأه الآخرون.