
1. לפני שמתחילים
השימוש במודלים של TensorFlow.js גדל באופן אקספוננציאלי בשנים האחרונות, ומפתחי JavaScript רבים רוצים עכשיו לקחת מודלים קיימים מתקדמים ולאמן אותם מחדש כדי שיפעלו עם נתונים בהתאמה אישית שייחודיים לתעשייה שלהם. הפעולה של לקיחת מודל קיים (שלרוב נקרא מודל בסיס) ושימוש בו בדומיין דומה אך שונה נקראת למידת העברה.
ללמידת העברה יש הרבה יתרונות לעומת התחלה עם מודל ריק לחלוטין. אתם יכולים לעשות שימוש חוזר בידע שכבר נלמד ממודל שאומן בעבר, ותצטרכו פחות דוגמאות של הפריט החדש שאתם רוצים לסווג. בנוסף, האימון מהיר יותר באופן משמעותי כי צריך לאמן מחדש רק את השכבות האחרונות של ארכיטקטורת המודל, ולא את כל הרשת. לכן, למידה בהעברה מתאימה מאוד לסביבת דפדפן האינטרנט, שבה המשאבים עשויים להשתנות בהתאם למכשיר שבו מתבצעת ההרצה, אבל יש גם גישה ישירה לחיישנים לצורך איסוף נתונים בקלות.
ב-Codelab הזה נדגים איך ליצור אפליקציית אינטרנט מאפס, ולשחזר את האתר הפופולרי Teachable Machine של Google. האתר מאפשר ליצור אפליקציית אינטרנט פונקציונלית שכל משתמש יכול להשתמש בה כדי לזהות אובייקט מותאם אישית באמצעות כמה תמונות לדוגמה ממצלמת האינטרנט שלו. האתר הזה מכיל רק את המינימום הנדרש כדי שתוכלו להתמקד בהיבטים של למידת מכונה ב-codelab הזה. עם זאת, כמו באתר המקורי של Teachable Machine, יש הרבה מקום ליישם את הניסיון הקיים שלכם כמפתחי אתרים כדי לשפר את חוויית המשתמש.
דרישות מוקדמות
ה-Codelab הזה מיועד למפתחי אתרים שמכירים קצת את המודלים המוכנים מראש של TensorFlow.js ואת השימוש הבסיסי ב-API, ורוצים להתחיל להשתמש בהעברת למידה ב-TensorFlow.js.
- בשיעור Lab הזה אנחנו מניחים שיש לכם היכרות בסיסית עם TensorFlow.js, HTML5, CSS ו-JavaScript.
אם אתם חדשים ב-Tensorflow.js, כדאי קודם להירשם לקורס החינמי הזה למתחילים. הקורס לא מניח ידע מוקדם בלמידת מכונה או ב-TensorFlow.js, ומסביר את כל מה שצריך לדעת בשלבים קטנים.
מה תלמדו
- מה זה TensorFlow.js ולמה כדאי להשתמש בו באפליקציית האינטרנט הבאה שלכם.
- איך ליצור דף אינטרנט פשוט ב-HTML/CSS /JS שמשחזר את חוויית המשתמש של Teachable Machine.
- איך משתמשים ב-TensorFlow.js כדי לטעון מודל בסיס שאומן מראש, במיוחד MobileNet, כדי ליצור תכונות של תמונות שאפשר להשתמש בהן בלמידת העברה.
- איך אוספים נתונים ממצלמת אינטרנט של משתמש עבור כמה סוגים של נתונים שרוצים לזהות.
- איך ליצור ולהגדיר רשת רב-שכבתית (MLP) שמקבלת את מאפייני התמונה ולומדת לסווג אובייקטים חדשים באמצעותם.
בואו נתחיל לפרוץ…
מה תצטרכו
- מומלץ להשתמש בחשבון Glitch.com כדי לעקוב אחרי ההוראות, או שתוכלו להשתמש בסביבת אינטרנט שאתם מרגישים בנוח לערוך ולהפעיל בעצמכם.
2. מה זה TensorFlow.js?

TensorFlow.js היא ספריית קוד פתוח ללמידת מכונה שאפשר להריץ בכל מקום שבו אפשר להריץ JavaScript. הוא מבוסס על ספריית TensorFlow המקורית שנכתבה ב-Python ומטרתו ליצור מחדש את חוויית המפתחים הזו ואת קבוצת ממשקי ה-API הזו עבור מערכת האקולוגית של JavaScript.
איפה אפשר להשתמש בו?
הודות לניידות של JavaScript, עכשיו אפשר לכתוב בשפה אחת ולבצע למידת מכונה בקלות בכל הפלטפורמות הבאות:
- בצד הלקוח בדפדפן האינטרנט באמצעות JavaScript רגיל
- בצד השרת ואפילו במכשירי IoT כמו Raspberry Pi באמצעות Node.js
- אפליקציות למחשב שמשתמשות ב-Electron
- אפליקציות שמותאמות לניידים באמצעות React Native
TensorFlow.js תומכת גם במספר קצוות עורפיים בכל אחת מהסביבות האלה (הסביבות שמבוססות על חומרה בפועל, שבהן היא יכולה לפעול, כמו CPU או WebGL). המונח 'בק-אנד' בהקשר הזה לא מתייחס לסביבת צד שרת – הבק-אנד להרצה יכול להיות צד לקוח ב-WebGL למשל) כדי להבטיח תאימות וגם כדי שהדברים יפעלו במהירות. כרגע יש תמיכה ב-TensorFlow.js ב:
- הפעלת WebGL בכרטיס המסך (GPU) של המכשיר – זו הדרך המהירה ביותר להפעיל מודלים גדולים יותר (בגודל של יותר מ-3MB) עם האצת GPU.
- הרצת Web Assembly (WASM) במעבד (CPU) – כדי לשפר את ביצועי המעבד במכשירים, כולל טלפונים ניידים מדורות קודמים. האפשרות הזו מתאימה יותר למודלים קטנים (בגודל של פחות מ-3MB) שיכולים לפעול מהר יותר במעבד עם WASM מאשר עם WebGL, בגלל התקורה של העלאת תוכן למעבד גרפי.
- ביצוע CPU – הגיבוי צריך להיות זמין אם אף אחת מהסביבות האחרות לא זמינה. היא הכי איטית מבין השלוש, אבל היא תמיד זמינה.
הערה: אם אתם יודעים באיזה מכשיר תבצעו את ההפעלה, אתם יכולים לכפות שימוש באחד מהקצוות העורפיים האלה. אם לא תציינו זאת, TensorFlow.js יבחר בשבילכם.
יכולות מתקדמות בצד הלקוח
הפעלת TensorFlow.js בדפדפן האינטרנט במחשב הלקוח יכולה להניב כמה יתרונות שכדאי לקחת בחשבון.
פרטיות
אתם יכולים לאמן את המודל ולסווג את הנתונים במחשב הלקוח בלי לשלוח את הנתונים לשרת אינטרנט של צד שלישי. יכול להיות שיהיו מקרים שבהם תהיה דרישה כזו כדי לעמוד בדרישות של חוקים מקומיים, כמו GDPR למשל, או כשמעבדים נתונים שהמשתמש רוצה לשמור במחשב שלו ולא לשלוח לצד שלישי.
מהירות
מכיוון שלא צריך לשלוח נתונים לשרת מרוחק, ההסקה (הפעולה של סיווג הנתונים) יכולה להיות מהירה יותר. יתרון נוסף: אם המשתמש יאשר לכם גישה, תוכלו לגשת ישירות לחיישנים של המכשיר, כמו מצלמה, מיקרופון, GPS, מד תאוצה ועוד.
היקף החשיפה והתאמה לעומס
בלחיצה אחת, כל אחד בעולם יכול ללחוץ על קישור ששלחתם לו, לפתוח את דף האינטרנט בדפדפן ולהשתמש במה שיצרתם. לא צריך להגדיר Linux מורכב בצד השרת עם מנהלי התקנים של CUDA ועוד הרבה דברים אחרים רק כדי להשתמש במערכת למידת המכונה.
עלות
בלי שרתים, הדבר היחיד שצריך לשלם עליו הוא CDN לאירוח קובצי ה-HTML, ה-CSS, ה-JS והמודל. העלות של CDN נמוכה בהרבה מהעלות של הפעלת שרת (יכול להיות שמחובר אליו כרטיס גרפי) מסביב לשעון.
תכונות בצד השרת
השימוש בהטמעה של TensorFlow.js ב-Node.js מאפשר את התכונות הבאות.
תמיכה מלאה ב-CUDA
בצד השרת, כדי להאיץ את כרטיס המסך, צריך להתקין את הדרייברים של NVIDIA CUDA כדי לאפשר ל-TensorFlow לעבוד עם כרטיס המסך (בניגוד לדפדפן שמשתמש ב-WebGL – לא נדרשת התקנה). עם זאת, תמיכה מלאה ב-CUDA מאפשרת לכם לנצל באופן מלא את היכולות של הכרטיס הגרפי ברמה נמוכה יותר, וכך לקצר את זמני האימון וההסקה. הביצועים זהים לאלה של הטמעת Python TensorFlow, כי שתיהן משתמשות באותו קצה עורפי של C++.
גודל המודל
כדי להשתמש במודלים מתקדמים מהמחקר, יכול להיות שתצטרכו לעבוד עם מודלים גדולים מאוד, אולי בגודל של ג'יגה-בייט. בשל מגבלות השימוש בזיכרון לכל כרטיסייה בדפדפן, אי אפשר להריץ את המודלים האלה בדפדפן אינטרנט. כדי להריץ את המודלים הגדולים האלה, אפשר להשתמש ב-Node.js בשרת שלכם עם מפרטי החומרה שנדרשים להרצה יעילה של מודל כזה.
IOT
Node.js נתמך במחשבים פופולריים עם לוח יחיד כמו Raspberry Pi, מה שאומר שאפשר להריץ מודלים של TensorFlow.js גם במכשירים כאלה.
מהירות
Node.js כתוב ב-JavaScript, ולכן הוא נהנה מקומפילציה בזמן אמת (JIT). המשמעות היא שלעתים קרובות תראו שיפורים בביצועים כשמשתמשים ב-Node.js, כי הוא יעבור אופטימיזציה בזמן הריצה, במיוחד אם אתם מבצעים עיבוד מקדים. דוגמה מצוינת לכך אפשר לראות במקרה לדוגמה הזה, שבו מוסבר איך Hugging Face השתמשו ב-Node.js כדי לשפר פי 2 את הביצועים של המודל לעיבוד שפה טבעית שלהם.
עכשיו, אחרי שהבנתם את היסודות של TensorFlow.js, איפה אפשר להריץ אותו ומה היתרונות שלו, אפשר להתחיל לעשות איתו דברים שימושיים.
3. למידה העברה
מהי בדיוק למידת העברה?
למידת העברה היא תהליך שבו משתמשים בידע שכבר נרכש כדי ללמוד דבר אחר אבל דומה.
אנחנו, בני האדם, עושים את זה כל הזמן. במוח שלכם יש מאגר של חוויות שצברתם במהלך החיים, ואתם יכולים להשתמש בו כדי לזהות דברים חדשים שמעולם לא ראיתם. לדוגמה, עץ הערבה הזה:

יכול להיות שלא ראיתם אף פעם את סוג העץ הזה, בהתאם למיקום שלכם בעולם.
אבל אם אבקש ממך לומר לי אם יש עצי ערבה בתמונה החדשה שלמטה, סביר להניח שתזהה אותם די מהר, למרות שהם מצולמים מזווית שונה, והם קצת שונים מהתמונה המקורית שהראיתי לך.

כבר יש לכם הרבה נוירונים במוח שיודעים לזהות עצמים דמויי-עץ, ונוירונים אחרים שיודעים לזהות קווים ישרים ארוכים. אפשר להשתמש בידע הזה כדי לסווג במהירות עץ ערבה, שהוא אובייקט דמוי עץ עם הרבה ענפים אנכיים ארוכים וישרים.
באופן דומה, אם יש לכם מודל למידת מכונה שכבר אומן בדומיין מסוים, כמו זיהוי תמונות, אתם יכולים להשתמש בו מחדש כדי לבצע משימה אחרת אבל קשורה.
אפשר לעשות את אותו הדבר עם מודל מתקדם כמו MobileNet, שהוא מודל מחקר פופולרי מאוד שיכול לבצע זיהוי תמונות של 1,000 סוגים שונים של אובייקטים. הוא אומן על מערך נתונים עצום שנקרא ImageNet, שכולל מיליוני תמונות עם תוויות, החל מכלבים ועד מכוניות.
באנימציה הזו אפשר לראות את המספר העצום של שכבות שיש במודל MobileNet V1 הזה:
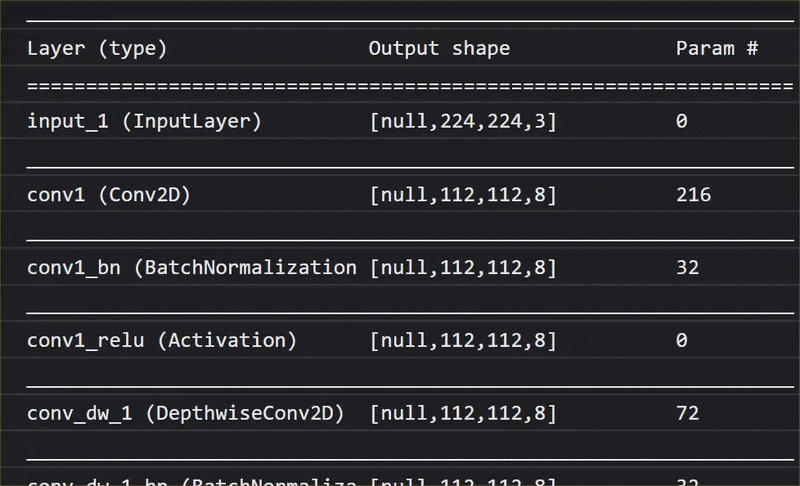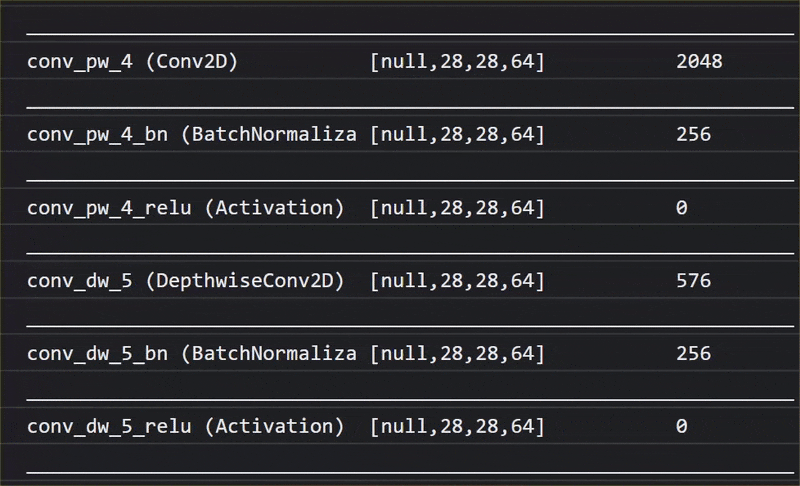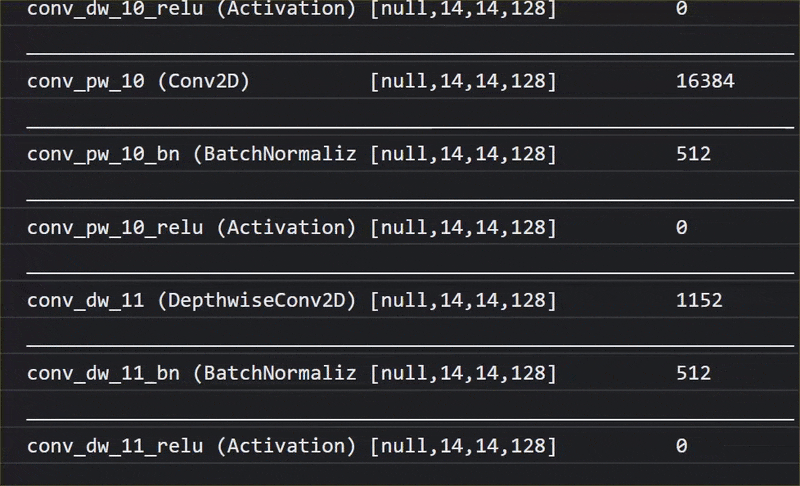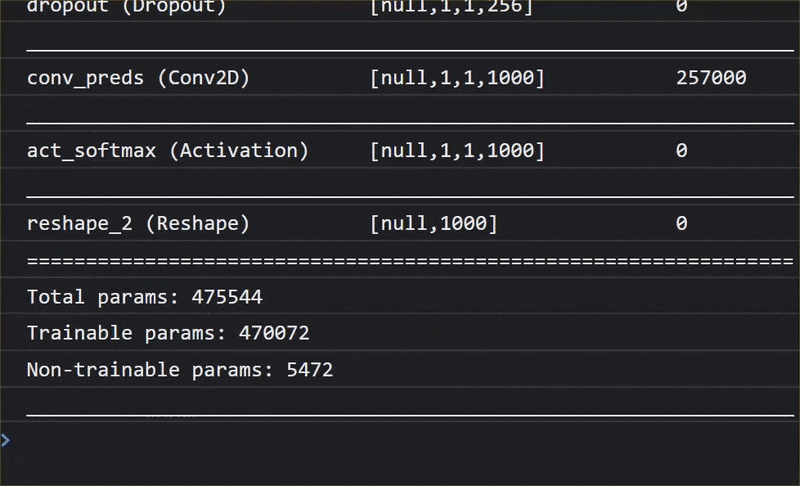
במהלך האימון, המודל הזה למד איך לחלץ תכונות משותפות שחשובות לכל 1,000 האובייקטים האלה, ורבות מהתכונות ברמה הנמוכה שבהן הוא משתמש כדי לזהות אובייקטים כאלה יכולות להיות שימושיות גם לזיהוי אובייקטים חדשים שהוא מעולם לא ראה. בסופו של דבר, כל דבר הוא רק שילוב של קווים, מרקמים וצורות.
בואו נסתכל על ארכיטקטורה מסורתית של רשת נוירונים קונבולוציונית (CNN) (בדומה ל-MobileNet) ונראה איך למידה בהעברה יכולה למנף את הרשת המאומנת הזו כדי ללמוד משהו חדש. בתמונה הבאה מוצגת ארכיטקטורת מודל אופיינית של CNN שאומן במקרה הזה לזיהוי ספרות בכתב יד מ-0 עד 9:
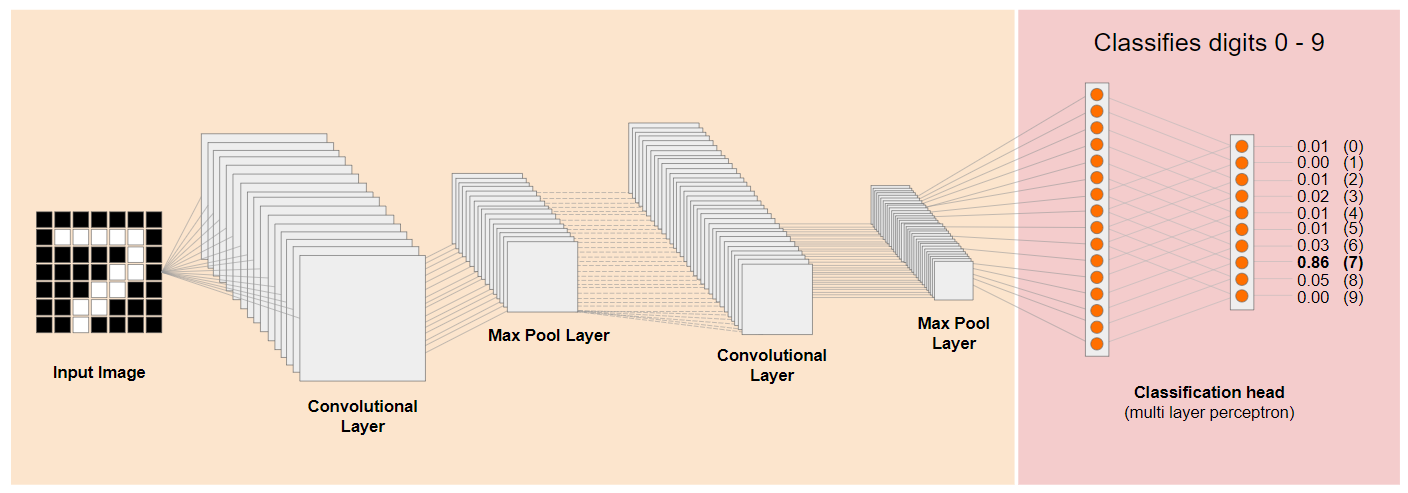
אם הייתם יכולים להפריד בין השכבות ברמה הנמוכה יותר שעברו אימון מראש של מודל קיים שעבר אימון, כמו זה שמוצג בצד ימין, לבין שכבות הסיווג שקרובות לסוף המודל שמוצג בצד שמאל (שנקראות לפעמים ראש הסיווג של המודל), הייתם יכולים להשתמש בשכבות ברמה הנמוכה יותר כדי ליצור תכונות פלט לכל תמונה נתונה על סמך הנתונים המקוריים שעליהם המודל אומן. זו אותה רשת בלי ראש הסיווג:
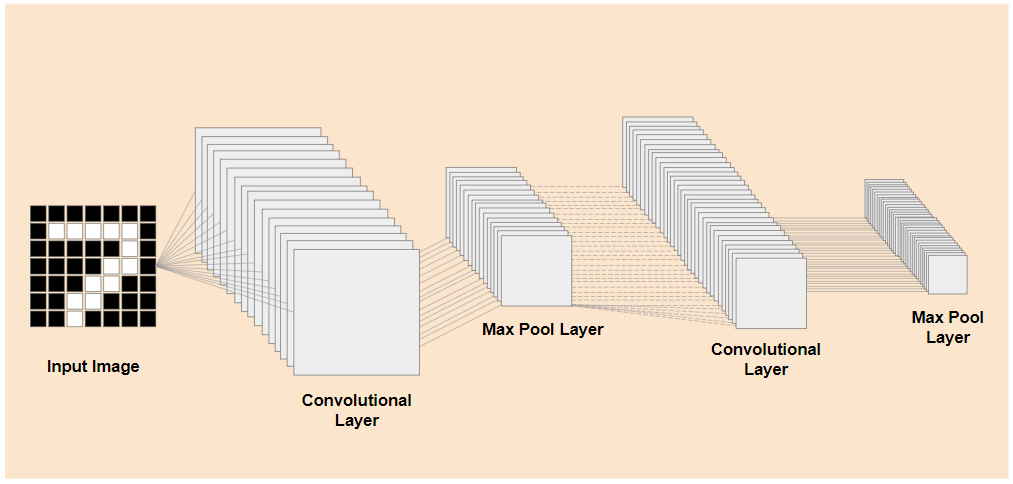
בהנחה שהדבר החדש שאתם מנסים לזהות יכול גם להשתמש בתכונות הפלט שהמודל הקודם למד, יש סיכוי טוב שאפשר יהיה לעשות בהן שימוש חוזר למטרה חדשה.
בתרשים שלמעלה, המודל ההיפותטי הזה אומן על ספרות, ולכן יכול להיות שהידע שנרכש לגבי ספרות יכול לשמש גם לגבי אותיות כמו a, b ו-c.
לכן, עכשיו אפשר להוסיף ראש סיווג חדש שמנסה לחזות את a, b או c במקום זאת, כמו שמוצג:
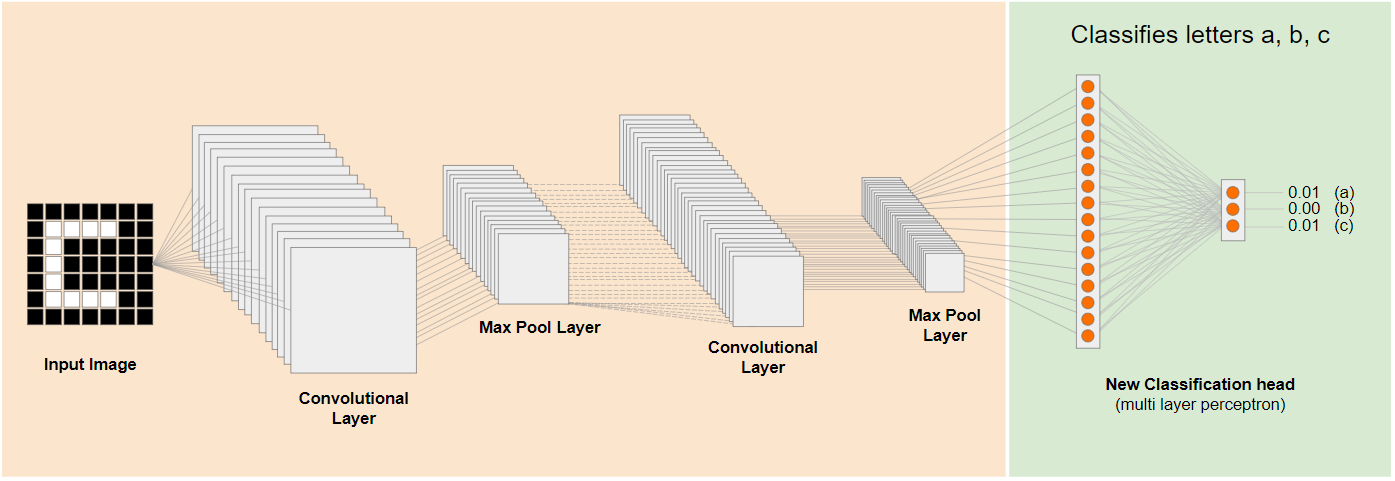
כאן השכבות ברמה הנמוכה קפואות ולא עוברות אימון. רק ראש הסיווג החדש יתעדכן כדי ללמוד מהתכונות שסופקו מהמודל הקצוץ שאומן מראש בצד שמאל.
הפעולה הזו נקראת למידת העברה, והיא מה שקורה מאחורי הקלעים ב-Teachable Machine.
אפשר גם לראות שרק צריך לאמן את הרשת הרב-שכבתית בסוף הרשת, ולכן האימון מהיר יותר מאשר אם הייתם צריכים לאמן את כל הרשת מאפס.
אבל איך אפשר להשתמש בחלקים קטנים יותר של מודל? בקטע הבא מוסבר איך עושים את זה.
4. TensorFlow Hub – מודלים בסיסיים
איך מוצאים מודל בסיסי מתאים לשימוש
כדי למצוא מודלים מתקדמים ופופולריים יותר למחקר, כמו MobileNet, אפשר לעבור אל TensorFlow Hub ואז לסנן את התוצאות כדי למצוא מודלים שמתאימים ל-TensorFlow.js ומשתמשים בארכיטקטורה של MobileNet v3. כך אפשר למצוא תוצאות כמו אלה שמוצגות כאן:
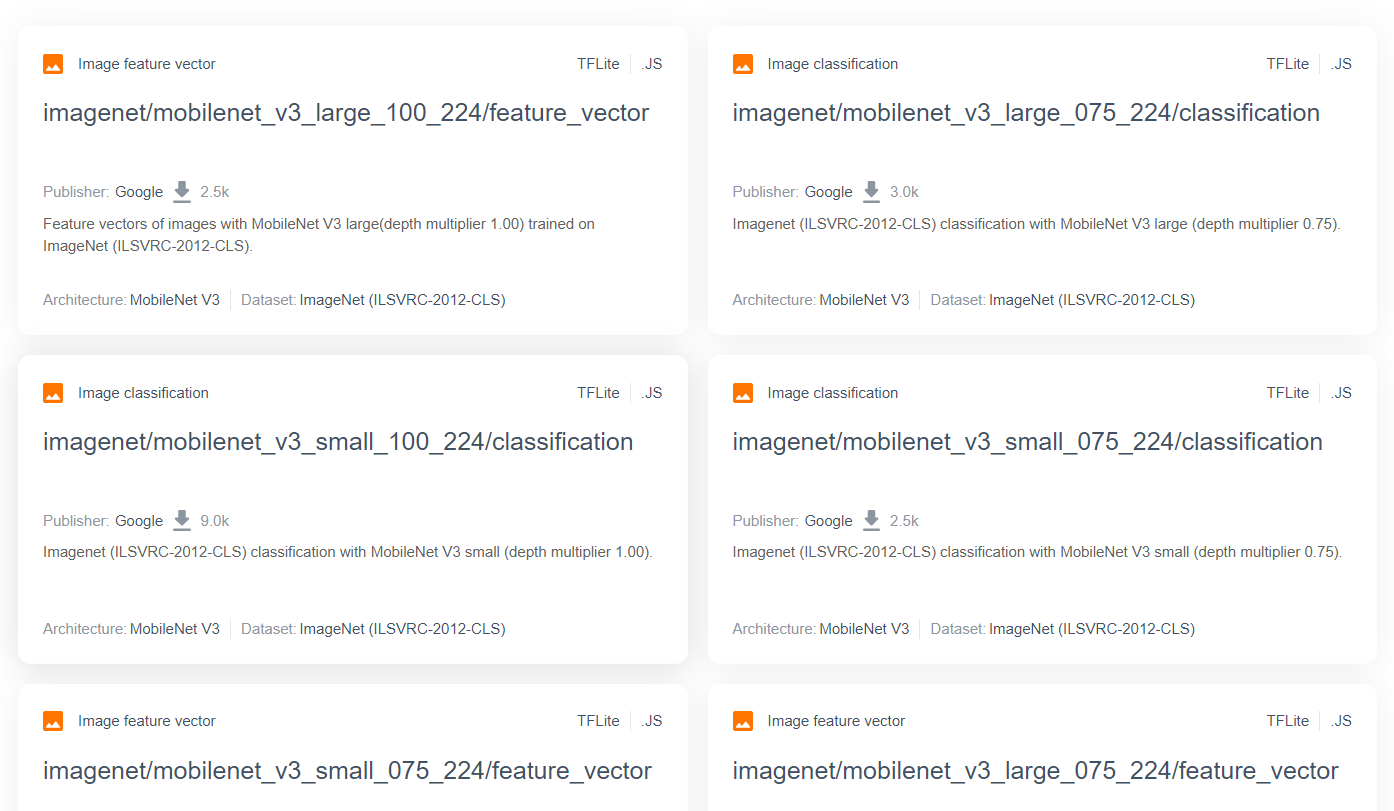
שימו לב שחלק מהתוצאות האלה הן מסוג 'סיווג תמונות' (מפורט בפינה הימנית העליונה של כל כרטיס מודל), וחלקן מסוג 'וקטור תכונות של תמונה'.
תוצאות הווקטורים של תכונות התמונה הן בעצם הגרסאות של MobileNet שחולקו מראש, ואפשר להשתמש בהן כדי לקבל את הווקטורים של תכונות התמונה במקום הסיווג הסופי.
מודלים כאלה נקראים לעיתים קרובות 'מודלים בסיסיים'. לאחר מכן אפשר להשתמש בהם כדי לבצע למידת העברה באותו אופן שמוצג בקטע הקודם: מוסיפים ראש סיווג חדש ומאמנים אותו באמצעות הנתונים שלכם.
הדבר הבא שצריך לבדוק הוא באיזה פורמט של TensorFlow.js המודל פורסם, בהינתן מודל בסיסי מסוים שמעניין אתכם. אם פותחים את הדף של אחד מהמודלים האלה של MobileNet v3 של וקטור תכונות, אפשר לראות מתיעוד ה-JS שהוא בצורה של מודל גרף שמבוסס על קטע קוד לדוגמה בתיעוד שמשתמש ב-tf.loadGraphModel().
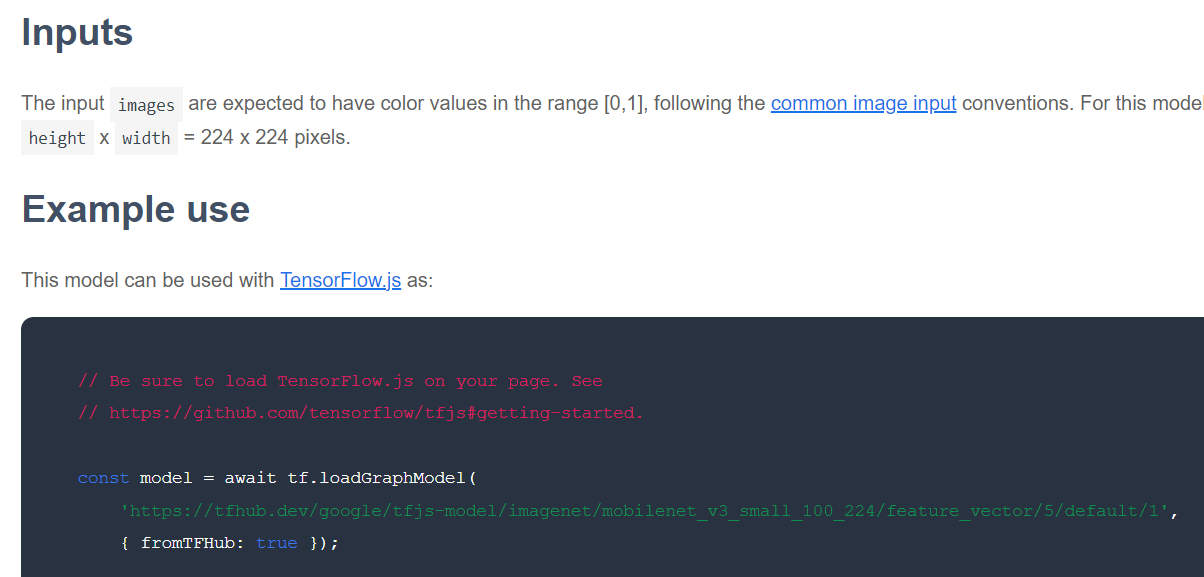
חשוב גם לציין שאם אתם מוצאים מודל בפורמט שכבות במקום בפורמט גרף, אתם יכולים לבחור אילו שכבות להקפיא ואילו להפשיר לצורך אימון. השיטה הזו יכולה להיות יעילה מאוד כשיוצרים מודל למשימה חדשה, שלרוב נקרא 'מודל העברה'. אבל בינתיים, במדריך הזה נשתמש בסוג ברירת המחדל של מודל הגרף, שרוב המודלים ב-TF Hub נפרסים כמותו. כדי לקבל מידע נוסף על עבודה עם מודלים של Layers, אפשר לעיין בקורס zero to hero TensorFlow.js.
היתרונות של למידת העברה
מה היתרונות של שימוש בלמידת העברה במקום לאמן את כל ארכיטקטורת המודל מאפס?
קודם כל, זמן האימון הוא יתרון מרכזי בשימוש בגישת למידת העברות, כי כבר יש לכם מודל בסיסי מאומן שאפשר לבנות עליו.
בנוסף, אפשר להציג הרבה פחות דוגמאות של הדבר החדש שאתם מנסים לסווג, כי כבר בוצע אימון.
האפשרות הזו מצוינת אם יש לכם זמן ומשאבים מוגבלים לאיסוף נתונים לדוגמה של מה שאתם רוצים לסווג, ואתם צריכים ליצור אב טיפוס במהירות לפני שתאספו עוד נתוני אימון כדי להפוך אותו לחזק יותר.
בהתחשב בצורך בפחות נתונים ובמהירות האימון של רשת קטנה יותר, למידת העברה דורשת פחות משאבים. התכונה הזו הופכת את המודל למתאים מאוד לסביבת הדפדפן, והאימון המלא של המודל נמשך עשרות שניות בלבד במחשב מודרני, במקום שעות, ימים או שבועות.
טוב! עכשיו, אחרי שהבנתם מהי למידת העברה, הגיע הזמן ליצור גרסה משלכם של Teachable Machine. קדימה, מתחילים!
5. הגדרת סביבת עבודה לתכנות
מה תצטרכו
- דפדפן אינטרנט מודרני.
- ידע בסיסי ב-HTML, ב-CSS, ב-JavaScript ובכלי הפיתוח ל-Chrome (צפייה בפלט של המסוף).
נתחיל לתכנת
יצרנו תבניות מוכנות לשימוש כדי להתחיל לעבוד עם Glitch.com או עם Codepen.io. אתם יכולים פשוט לשכפל את אחת התבניות כבסיס למעבדת הקוד הזו, בלחיצה אחת בלבד.
ב-Glitch, לוחצים על הלחצן remix this (רמיקס) כדי ליצור העתק של הפרויקט וליצור קבוצה חדשה של קבצים שאפשר לערוך.
לחלופין, ב-Codepen, לוחצים על fork בפינה השמאלית התחתונה של המסך.
השלד הפשוט הזה מספק לכם את הקבצים הבאים:
- דף HTML (index.html)
- גיליון סגנונות (style.css)
- קובץ לכתיבת קוד ה-JavaScript (script.js)
לנוחיותכם, נוסף ייבוא בקובץ ה-HTML לספריית TensorFlow.js. כך הוא נראה:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
אפשרות חלופית: שימוש בכלי עריכה באינטרנט או עבודה מקומית
אם רוצים להוריד את הקוד ולעבוד באופן מקומי או בכלי עריכה אונליין אחר, פשוט יוצרים את 3 הקבצים שצוינו למעלה באותה תיקייה, ומעתיקים את הקוד מה-boilerplate של Glitch ומדביקים אותו בכל אחד מהם.
6. קוד שבלוני של אפליקציית HTML
איפה מתחילים?
כל אבות הטיפוס צריכים לכלול פיגום HTML בסיסי שבו אפשר להציג את הממצאים. אני רוצה להגדיר את זה עכשיו. אתם עומדים להוסיף:
- כותרת לדף.
- טקסט תיאורי כלשהו.
- פסקה של סטטוס.
- סרטון שיוצג בפיד ממצלמת האינטרנט כשהוא יהיה מוכן.
- כמה לחצנים להפעלת המצלמה, לאיסוף נתונים או לאיפוס החוויה.
- ייבוא של קובצי TensorFlow.js ו-JS שתקודדו בהמשך.
פותחים את index.html ומדביקים את הקוד הבא על הקוד הקיים כדי להגדיר את התכונות שלמעלה:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
להסבר מפורט
נפרט חלק מקוד ה-HTML שלמעלה כדי להדגיש כמה דברים חשובים שהוספתם.
- הוספתם תג
<h1>לכותרת הדף ותג<p>עם המזהה status, שבו תדפיסו את המידע, כי אתם משתמשים בחלקים שונים של המערכת כדי להציג את הפלט. - הוספתם רכיב
<video>עם מזהה webcam, שאליו תעבירו את סטרימינג מצלמת האינטרנט מאוחר יותר. - הוספת 5 רכיבים מסוג
<button>. הראשון, עם המזהה enableCam, מפעיל את המצלמה. לשני הלחצנים הבאים יש מחלקה בשם dataCollector, שמאפשרת לאסוף תמונות לדוגמה של האובייקטים שרוצים לזהות. הקוד שתכתבו בהמשך יהיה מתוכנן כך שתוכלו להוסיף כל מספר של כפתורים כאלה והם יפעלו באופן אוטומטי כמצופה.
שימו לב שללחצנים האלה יש גם מאפיין מיוחד שמוגדר על ידי המשתמש שנקרא data-1hot, עם ערך של מספר שלם שמתחיל מ-0 עבור המחלקה הראשונה. זהו האינדקס המספרי שבו תשתמשו כדי לייצג את הנתונים של מחלקה מסוימת. האינדקס ישמש לקידוד נכון של מחלקות הפלט באמצעות ייצוג מספרי במקום מחרוזת, כי מודלים של למידת מכונה יכולים לפעול רק עם מספרים.
יש גם מאפיין data-name שמכיל את השם שניתן לקריאה על ידי בני אדם שרוצים להשתמש בו עבור המחלקה הזו. כך אפשר לספק למשתמש שם משמעותי יותר במקום ערך אינדקס מספרי מהקידוד של 1 hot.
לבסוף, יש לחצן להפעלת תהליך האימון אחרי איסוף הנתונים, ולחצן לאיפוס האפליקציה.
- הוספת גם 2 ייבוא של
<script>. אחד ל-TensorFlow.js והשני ל-script.js שתגדירו בקרוב.
7. הוספת סגנון
ברירות מחדל של רכיבים
מוסיפים סגנונות לרכיבי ה-HTML שזה עתה הוספתם כדי לוודא שהם מוצגים בצורה נכונה. ריכזנו כאן כמה סגנונות שנוספים בצורה נכונה לרכיבי מיקום וגודל. לא משהו מיוחד מדי. בהחלט אפשר להוסיף לזה בהמשך כדי לשפר עוד יותר את חוויית המשתמש, כמו שראיתם בסרטון על המכונה הניתנת ללימוד.
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
מצוין! זה כל מה שצריך. אם תציגו עכשיו תצוגה מקדימה של הפלט, הוא אמור להיראות כך:
8. JavaScript: קבועים ומאזינים של מקשים
הגדרת קבועים מרכזיים
קודם מוסיפים כמה קבועים של מקשים שישמשו אתכם באפליקציה. מתחילים בהחלפת התוכן של script.js בקבועים האלה:
script.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
בואו נסביר מה כל אחד מהם עושה:
STATUSפשוט מחזיק הפניה לתג הפיסקה שבו ייכתבו עדכוני הסטטוס.-
VIDEOמכיל הפניה לרכיב הווידאו ב-HTML שבו יוצג פיד מצלמת האינטרנט. -
ENABLE_CAM_BUTTON,RESET_BUTTONו-TRAIN_BUTTONמאחזרים הפניות ל-DOM לכל לחצני המקשים מדף ה-HTML. -
MOBILE_NET_INPUT_WIDTHו-MOBILE_NET_INPUT_HEIGHTמגדירים את הרוחב והגובה הצפויים של הקלט במודל MobileNet, בהתאמה. אם מאחסנים את הערך הזה כקבוע בחלק העליון של הקובץ, כמו בדוגמה, קל יותר לעדכן את הערכים פעם אחת במקום להחליף אותם במקומות שונים, אם מחליטים להשתמש בגרסה אחרת בשלב מאוחר יותר. - הערך של
STOP_DATA_GATHERהוא - 1. הערך הזה שומר את המצב כדי לדעת מתי המשתמש הפסיק ללחוץ על לחצן כדי לאסוף נתונים מפיד מצלמת האינטרנט. אם נותנים למספר הזה שם משמעותי יותר, קל יותר לקרוא את הקוד בהמשך. -
CLASS_NAMESפועל כחיפוש ומכיל את השמות הקריאים של החיזויים האפשריים של הסיווג. המערך הזה יאוכלס בהמשך.
אחרי שיש לכם הפניות לרכיבים מרכזיים, הגיע הזמן לשייך להם כמה מאזיני אירועים.
הוספת ממשקי event listener לאירועים מרכזיים
מתחילים בהוספה של גורמים מטפלים באירועים מסוג קליק לכפתורים מרכזיים, כמו שמוצג כאן:
script.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON – קורא לפונקציה enableCam כשלוחצים עליו.
TRAIN_BUTTON – קריאות ל-trainAndPredict כשלוחצים עליו.
RESET_BUTTON – השיחות מאופסות כשלוחצים עליהן.
בסיום, בקטע הזה אפשר למצוא את כל הלחצנים עם המחלקה dataCollector באמצעות document.querySelectorAll(). הפונקציה מחזירה מערך של רכיבים שנמצאו במסמך שתואמים ל:
script.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
הסבר על הקוד:
לאחר מכן, חוזרים על הפעולה עבור כל הכפתורים שנמצאו ומשייכים לכל אחד מהם 2 event listeners. אחד בשביל 'mousedown' ואחד בשביל 'mouseup'. כך אפשר להמשיך להקליט דגימות כל עוד הלחצן לחוץ, וזה שימושי לאיסוף נתונים.
שני האירועים קוראים לפונקציה gatherDataForClass שתגדירו בהמשך.
בשלב הזה, אפשר גם להעביר את שמות הכיתות שנמצאו וקריאים לאנשים מנתוני מאפיין לחצן ה-HTML data-name למערך CLASS_NAMES.
לאחר מכן, מוסיפים כמה משתנים לאחסון של דברים חשובים שישמשו בהמשך.
script.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
בואו נסביר אותן.
קודם כל, יש משתנה mobilenet לאחסון מודל mobilenet שנטען. בתחילה, מגדירים את הערך הזה כ-undefined.
אחר כך יש משתנה בשם gatherDataState. אם לוחצים על לחצן dataCollector, הערך משתנה למזהה ה-hot של הלחצן הזה, כפי שמוגדר ב-HTML, כדי שתדעו איזה סוג נתונים אתם אוספים באותו רגע. בתחילה, הערך הזה מוגדר כ-STOP_DATA_GATHER כדי שלולאת איסוף הנתונים שתכתבו בהמשך לא תאסוף נתונים כשלא לוחצים על אף לחצן.
videoPlaying עוקב אחרי הטעינה וההפעלה של הסטרימינג ממצלמת האינטרנט, ומוודא שהוא זמין לשימוש. ההגדרה הזו מוגדרת בהתחלה ל-false כי מצלמת האינטרנט לא מופעלת עד שלוחצים על ENABLE_CAM_BUTTON.
לאחר מכן, מגדירים 2 מערכים, trainingDataInputs ו-trainingDataOutputs. הם מאחסנים את ערכי נתוני האימון שנאספו כשלוחצים על הלחצנים dataCollector של תכונות הקלט שנוצרו על ידי מודל הבסיס של MobileNet, ועל מחלקת הפלט שנדגמה בהתאם.
מערך סופי אחד, examplesCount,, מוגדר כדי לעקוב אחרי מספר הדוגמאות שכלולות בכל מחלקה אחרי שמתחילים להוסיף אותן.
לבסוף, יש משתנה בשם predict ששולט בלולאת החיזוי. ההגדרה הראשונית היא false. לא ניתן לבצע חיזויים עד שההגדרה הזו תשתנה ל-true בהמשך.
אחרי שהגדרנו את כל המשתנים העיקריים, נטען את מודל הבסיס של MobileNet v3 שעבר חיתוך מראש ומספק וקטורים של תכונות תמונה במקום סיווגים.
9. טעינת מודל הבסיס של MobileNet
קודם מגדירים פונקציה חדשה בשם loadMobileNetFeatureModel כמו שמוצג בהמשך. זו חייבת להיות פונקציה אסינכרונית כי פעולת הטעינה של מודל היא אסינכרונית:
script.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
בדוגמת הקוד הזו מוגדר המאפיין URL שבו מצוין המיקום של המודל לטעינה מתוך מסמכי TFHub.
אחר כך אפשר לטעון את המודל באמצעות await tf.loadGraphModel(). חשוב לזכור להגדיר את המאפיין המיוחד fromTFHub לערך true כשאתם טוענים מודל מאתר Google הזה. זהו מקרה מיוחד שרלוונטי רק לשימוש במודלים שמארחים ב-TF Hub, שבו צריך להגדיר את המאפיין הנוסף הזה.
אחרי שהטעינה מסתיימת, אפשר להגדיר את innerText של רכיב STATUS עם הודעה כדי לראות שהטעינה הסתיימה כמו שצריך ושהמערכת מוכנה להתחיל לאסוף נתונים.
הדבר היחיד שנותר לעשות עכשיו הוא להכין את המודל. במודלים גדולים יותר כמו זה, בפעם הראשונה שמשתמשים במודל, יכול לקחת כמה רגעים עד שהכול מוגדר. לכן, כדאי להעביר אפסים דרך המודל כדי להימנע מהמתנה בעתיד, כשזמן התגובה עשוי להיות קריטי יותר.
אפשר להשתמש ב-tf.zeros() שמוקף ב-tf.tidy() כדי לוודא שהטנסורים מושמדים בצורה נכונה, עם גודל אצווה של 1, ועם הגובה והרוחב הנכונים שהגדרתם בקבועים בהתחלה. לבסוף, מציינים גם את ערוצי הצבע, שבמקרה הזה הם 3, כי המודל מצפה לתמונות RGB.
לאחר מכן, מתעדים את הצורה של הטנסור שמוחזר באמצעות answer.shape() כדי להבין את הגודל של תכונות התמונה שהמודל הזה יוצר.
אחרי שמגדירים את הפונקציה הזו, אפשר לקרוא לה באופן מיידי כדי להתחיל בהורדת המודל בטעינת הדף.
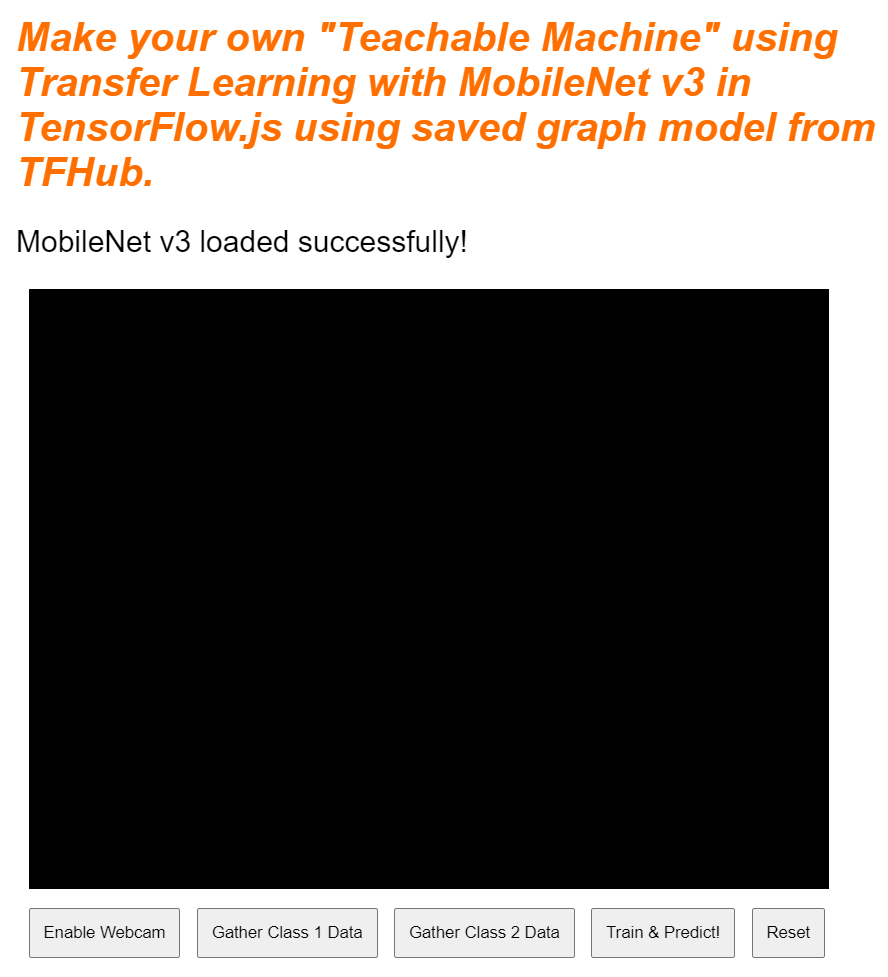
אם תציגו עכשיו את התצוגה המקדימה, אחרי כמה רגעים תראו שהטקסט של הסטטוס ישתנה מ-"Awaiting TF.js load" ל-"MobileNet v3 loaded successfully!" כמו שמוצג בהמשך. חשוב לוודא שהפעולה הזו עובדת לפני שממשיכים.
אפשר גם לבדוק את הפלט של המסוף כדי לראות את הגודל המודפס של תכונות הפלט שהמודל הזה יוצר. אחרי שמריצים אפסים דרך מודל MobileNet, תופיע צורה של [1, 1024]. הפריט הראשון הוא רק גודל האצווה של 1, ואפשר לראות שהוא מחזיר בפועל 1,024 תכונות שאפשר להשתמש בהן כדי לסווג אובייקטים חדשים.
10. הגדרת ראש המודל החדש
עכשיו הגיע הזמן להגדיר את ראש המודל, שהוא בעצם רשת רב-שכבתית מינימלית מאוד.
script.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
בואו נסביר את הקוד הזה. מתחילים בהגדרת מודל tf.sequential שאליו יוסיפו שכבות של מודל.
בשלב הבא, מוסיפים שכבה צפופה כשכבת הקלט למודל הזה. הצורה של הקלט היא 1024 כי הפלט של התכונות של MobileNet v3 הוא בגודל הזה. גיליתם את זה בשלב הקודם אחרי שהעברתם את הנתונים דרך המודל. לשכבה הזו יש 128 נוירונים שמשתמשים בפונקציית ההפעלה ReLU.
אם אתם חדשים בתחום של פונקציות הפעלה ושכבות של מודלים, כדאי לעבור על הקורס שמפורט בתחילת הסדנה הזו כדי להבין מה התכונות האלה עושות מאחורי הקלעים.
השכבה הבאה שצריך להוסיף היא שכבת הפלט. מספר הנוירונים צריך להיות שווה למספר הסיווגים שאתם מנסים לחזות. כדי לעשות את זה, אפשר להשתמש בCLASS_NAMES.length כדי לראות כמה סיווגים אתם מתכננים לעשות, שזה שווה למספר הלחצנים לאיסוף נתונים שמופיעים בממשק המשתמש. מכיוון שזו בעיית סיווג, משתמשים בהפעלה softmax בשכבת הפלט הזו, שחובה להשתמש בה כשמנסים ליצור מודל לפתרון בעיות סיווג במקום רגרסיה.
עכשיו מזינים model.summary() כדי להדפיס את סקירת המודל החדש במסוף.
לבסוף, קומפלו את המודל כדי שיהיה מוכן לאימון. כאן האופטימיזציה מוגדרת ל-adam, וההפסד יהיה binaryCrossentropy אם CLASS_NAMES.length שווה ל-2, או שהמערכת תשתמש ב-categoricalCrossentropy אם יש 3 או יותר סוגים לסיווג. בנוסף, נדרשים מדדי דיוק כדי שיהיה אפשר לעקוב אחריהם ביומנים מאוחר יותר למטרות ניפוי באגים.
במסוף אמור להופיע משהו כזה:
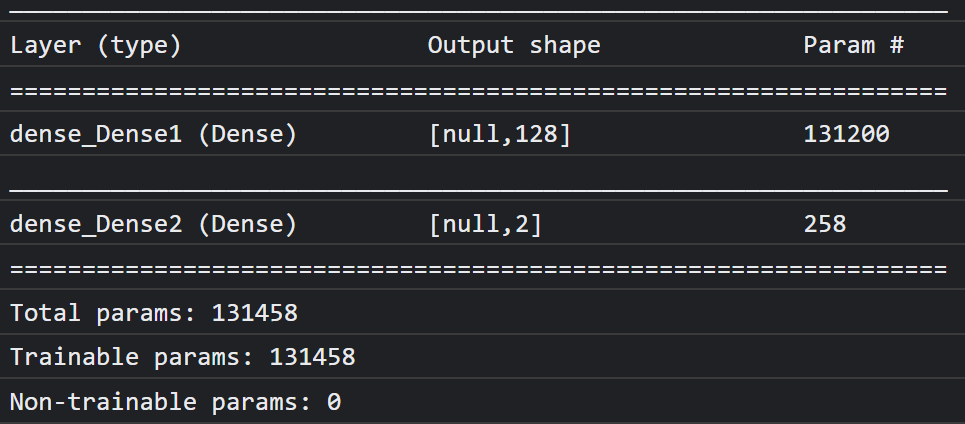
שימו לב שיש לו יותר מ-130 אלף פרמטרים שאפשר לאמן. אבל מכיוון שמדובר בשכבה צפופה פשוטה של נוירונים רגילים, האימון שלה יהיה מהיר למדי.
אחרי שהפרויקט יסתיים, תוכלו לנסות לשנות את מספר הנוירונים בשכבה הראשונה כדי לראות מה המספר הכי נמוך שאפשר להגדיר בלי לפגוע בביצועים. לפעמים, כדי למצוא את ערכי הפרמטרים האופטימליים שיאפשרו לכם להגיע לאיזון הטוב ביותר בין השימוש במשאבים לבין המהירות, צריך לבצע ניסוי וטעייה.
11. הפעלת מצלמת האינטרנט
עכשיו הגיע הזמן להרחיב את הפונקציה enableCam() שהגדרתם קודם. מוסיפים פונקציה חדשה בשם hasGetUserMedia() כמו שמוצג בהמשך, ואז מחליפים את התוכן של הפונקציה enableCam() שהוגדרה קודם בקוד המתאים שמוצג בהמשך.
script.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
קודם כול, יוצרים פונקציה בשם hasGetUserMedia() כדי לבדוק אם הדפדפן תומך ב-getUserMedia(). לשם כך, בודקים אם קיימים מאפיינים של ממשקי API מרכזיים בדפדפן.
בפונקציה enableCam(), משתמשים בפונקציה hasGetUserMedia() שהגדרתם למעלה כדי לבדוק אם היא נתמכת. אם לא, מודפסת אזהרה במסוף.
אם האפליקציה תומכת בכך, מגדירים אילוצים מסוימים לשיחת getUserMedia(), למשל, אם רוצים רק את זרם הווידאו, ואם מעדיפים שהגודל של width יהיה 640 פיקסלים ושל height יהיה 480 פיקסלים. למה? אין טעם להשתמש בסרטון גדול יותר, כי צריך לשנות את הגודל שלו ל-224 על 224 פיקסלים כדי להזין אותו למודל MobileNet. כדאי גם לבקש רזולוציה קטנה יותר כדי לחסוך במשאבי מחשוב. רוב המצלמות תומכות ברזולוציה בגודל הזה.
לאחר מכן, מתקשרים אל navigator.mediaDevices.getUserMedia() עם constraints שמפורט למעלה, וממתינים עד שstream יוחזר. אחרי שהערך stream מוחזר, אפשר להגדיר את הערך srcObject של רכיב VIDEO כ-stream כדי להפעיל את stream.
כדאי גם להוסיף eventListener לרכיב VIDEO כדי לדעת מתי הרכיב stream נטען ופועל בהצלחה.
אחרי שהסטרים נטען, אפשר להגדיר את videoPlaying כ-true ולהסיר את ENABLE_CAM_BUTTON כדי למנוע לחיצה חוזרת עליו, על ידי הגדרת המחלקה שלו כ-removed.
עכשיו מריצים את הקוד, לוחצים על הלחצן להפעלת המצלמה ומאשרים גישה למצלמת האינטרנט. אם זו הפעם הראשונה שאתם עושים את זה, אתם אמורים לראות את עצמכם מוצגים ברכיב הסרטון בדף, כמו שמוצג כאן:

עכשיו הגיע הזמן להוסיף פונקציה שתטפל בקליקים על הלחצן dataCollector.
12. גורם מטפל באירועים של לחצן לאיסוף נתונים
עכשיו צריך למלא את הפונקציה שכרגע ריקה שנקראת gatherDataForClass(). זו הפונקציה שהקציתם כגורם מטפל באירועים ללחצני dataCollector בתחילת ה-Codelab.
script.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
קודם כל, בודקים את המאפיין data-1hot בלחצן שנלחץ כרגע על ידי קריאה ל-this.getAttribute() עם שם המאפיין, במקרה הזה data-1hot כפרמטר. מכיוון שמדובר במחרוזת, אפשר להשתמש ב-parseInt() כדי להמיר אותה למספר שלם ולהקצות את התוצאה למשתנה בשם classNumber.
לאחר מכן, מגדירים את המשתנה gatherDataState בהתאם. אם הערך הנוכחי של gatherDataState שווה ל-STOP_DATA_GATHER (שהגדרתם כ-1-), המשמעות היא שאתם לא אוספים כרגע נתונים, ושהופעל אירוע mousedown. מגדירים את gatherDataState להיות classNumber שמצאתם עכשיו.
אחרת, המשמעות היא שאתם אוספים כרגע נתונים והאירוע שהופעל היה אירוע mouseup, ועכשיו אתם רוצים להפסיק לאסוף נתונים עבור המחלקה הזו. פשוט מחזירים אותו למצב STOP_DATA_GATHER כדי לסיים את לולאת איסוף הנתונים שתגדירו בהמשך.
בסיום, מתחילים את השיחה אל dataGatherLoop(), כדי להקליט את נתוני הכיתה.
13. איסוף נתונים
עכשיו מגדירים את הפונקציה dataGatherLoop(). הפונקציה הזו אחראית לדגימת תמונות מסרטון מצלמת האינטרנט, להעברתן דרך מודל MobileNet ולתיעוד הפלטים של המודל הזה (1, 024 וקטורי התכונות).
לאחר מכן, הנתונים נשמרים יחד עם מזהה gatherDataState של הלחצן שנלחץ כרגע, כדי שתדעו איזו כיתה הנתונים האלה מייצגים.
בואו נעבור על זה:
script.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
הפונקציה תמשיך לפעול רק אם videoPlaying הוא true, כלומר מצלמת האינטרנט פעילה, ו-gatherDataState לא שווה ל-STOP_DATA_GATHER ולחצן לאיסוף נתוני סיווג נלחץ כרגע.
לאחר מכן, עוטפים את הקוד בתג tf.tidy() כדי להשמיד את כל הטנסורים שנוצרו בקוד שבהמשך. התוצאה של הרצת הקוד tf.tidy() הזו מאוחסנת במשתנה שנקרא imageFeatures.
מעכשיו אפשר לצלם פריים ממצלמת האינטרנט VIDEO באמצעות tf.browser.fromPixels(). הטנסור שמתקבל שמכיל את נתוני התמונה מאוחסן במשתנה שנקרא videoFrameAsTensor.
לאחר מכן, משנים את הגודל של המשתנה videoFrameAsTensor כך שיתאים לצורה הנכונה של הקלט של מודל MobileNet. משתמשים בקריאה tf.image.resizeBilinear() עם הטנסור שרוצים לשנות את הצורה שלו כפרמטר הראשון, ואז בצורה שמגדירה את הגובה והרוחב החדשים כפי שהוגדרו על ידי הקבועים שיצרתם קודם. לבסוף, מעבירים את הפרמטר השלישי כדי להגדיר את האפשרות 'יישור פינות' כ-true, וכך למנוע בעיות יישור כשמשנים את הגודל. התוצאה של שינוי הגודל הזה מאוחסנת במשתנה שנקרא resizedTensorFrame.
שימו לב שהשינוי הפשוט הזה של הגודל מותח את התמונה, כי התמונה מהמצלמה היא בגודל 640 על 480 פיקסלים, והמודל צריך תמונה מרובעת בגודל 224 על 224 פיקסלים.
למטרות ההדגמה הזו, זה אמור לעבוד בצורה תקינה. עם זאת, אחרי שתשלימו את ה-Codelab הזה, כדאי לנסות לחתוך ריבוע מהתמונה הזו במקום זאת כדי לקבל תוצאות טובות יותר במערכת ייצור שתצרו בהמשך.
לאחר מכן, מנרמלים את נתוני התמונות. נתוני התמונה תמיד נמצאים בטווח 0 עד 255 כשמשתמשים ב-tf.browser.frompixels(), לכן אפשר פשוט לחלק את resizedTensorFrame ב-255 כדי לוודא שכל הערכים יהיו בין 0 ל-1, שזה מה שמודל MobileNet מצפה לקבל כקלט.
לבסוף, בקטע tf.tidy() של הקוד, מעבירים את הטנסור המנורמל דרך המודל שנטען על ידי קריאה ל-mobilenet.predict(), שאליו מעבירים את הגרסה המורחבת של normalizedTensorFrame באמצעות expandDims() כדי שיהיה אצווה של 1, כי המודל מצפה לאצווה של קלטים לעיבוד.
אחרי שהתוצאה מוחזרת, אפשר לקרוא מיד ל-squeeze() על התוצאה המוחזרת הזו כדי להחזיר אותה לטנסור חד-ממדי, ואז להחזיר אותה ולהקצות אותה למשתנה imageFeatures שתופס את התוצאה מ-tf.tidy().
עכשיו, כשיש לכם את imageFeatures מהמודל MobileNet, אתם יכולים לתעד אותם על ידי העברה שלהם למערך trainingDataInputs שהגדרתם קודם.
אפשר גם לתעד את מה שהקלט הזה מייצג על ידי העברת הערך הנוכחי של gatherDataState למערך trainingDataOutputs.
שימו לב שהמשתנה gatherDataState היה מוגדר למזהה המספרי של המחלקה הנוכחית שאתם מתעדים עבורה נתונים, כשהמשתמש לחץ על הלחצן בפונקציה gatherDataForClass() שהוגדרה קודם.
בשלב הזה אפשר גם להגדיל את מספר הדוגמאות שיש לכם עבור כיתה מסוימת. כדי לעשות את זה, קודם צריך לבדוק אם האינדקס במערך examplesCount עבר אתחול או לא. אם הוא לא מוגדר, צריך להגדיר אותו כ-0 כדי לאתחל את המונה למזהה המספרי של כיתה מסוימת, ואז אפשר להגדיל את examplesCount עבור gatherDataState הנוכחי.
עכשיו מעדכנים את הטקסט של רכיב STATUS בדף האינטרנט כדי להציג את המספרים הנוכחיים של כל מחלקה בזמן שהם נרשמים. כדי לעשות את זה, צריך להשתמש בלולאה כדי לעבור על המערך CLASS_NAMES ולהדפיס את השם שקל לקרוא בשילוב עם מספר הנתונים באותו אינדקס ב-examplesCount.
לבסוף, קוראים לפונקציה window.requestAnimationFrame() עם dataGatherLoop כפרמטר, כדי לקרוא לפונקציה הזו שוב באופן רקורסיבי. הדגימה של פריימים מהסרטון תימשך עד שהלחצן mouseup יזוהה, והערך של gatherDataState יהיה STOP_DATA_GATHER,. בשלב הזה, הלולאה של איסוף הנתונים תסתיים.
אם מריצים את הקוד עכשיו, אמורה להיות אפשרות ללחוץ על הלחצן להפעלת המצלמה, לחכות עד שהמצלמה תיטען ואז ללחוץ לחיצה ארוכה על כל אחד מהלחצנים לאיסוף נתונים כדי לאסוף דוגמאות לכל סוג נתונים. כאן אפשר לראות אותי אוסף נתונים לגבי הטלפון הנייד והיד שלי, בהתאמה.
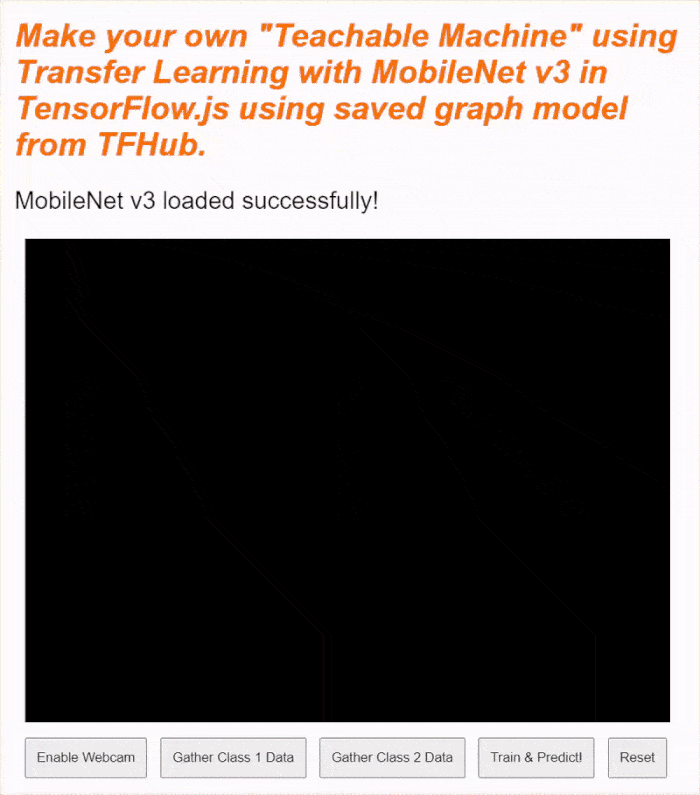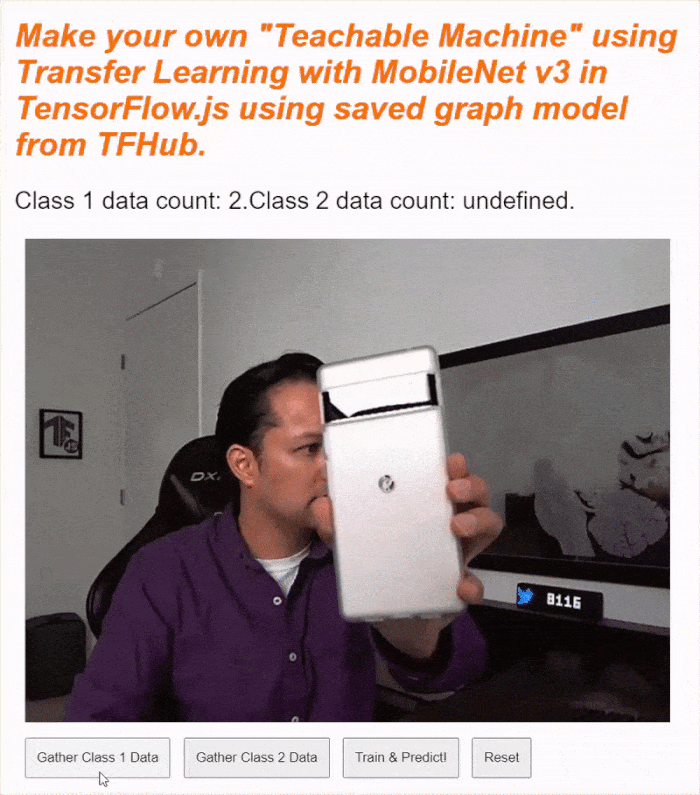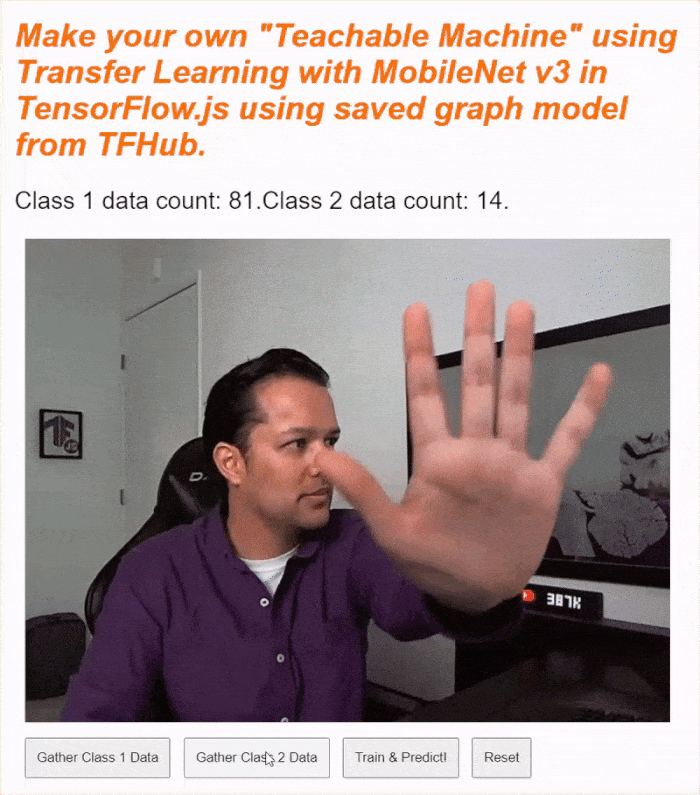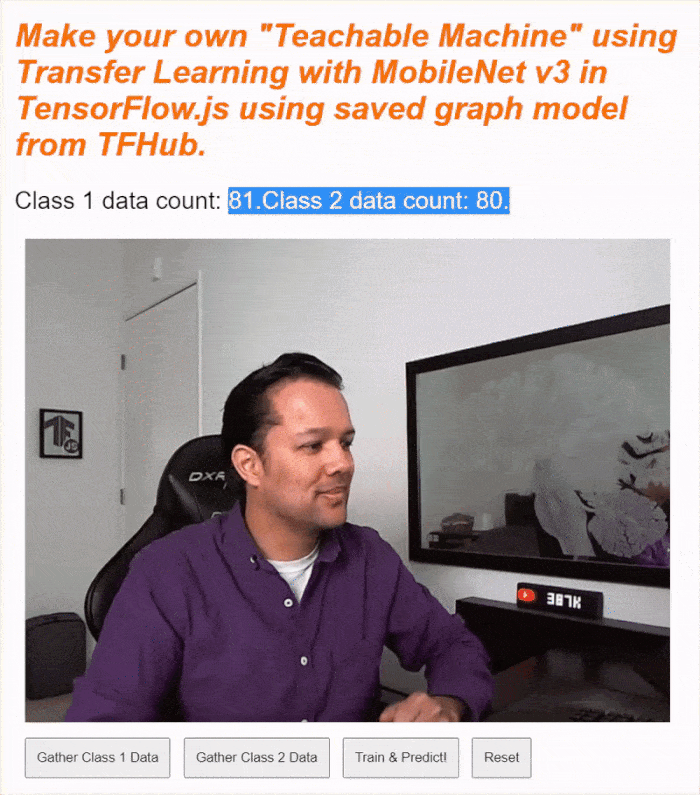
טקסט הסטטוס אמור להתעדכן בזמן שהוא מאחסן את כל הטנסורים בזיכרון, כמו שמוצג בצילום המסך שלמעלה.
14. אימון וחיזוי
השלב הבא הוא הטמעה של קוד בפונקציה trainAndPredict(), שכרגע ריקה. זה המקום שבו מתבצעת למידת ההעברה. בואו נסתכל על הקוד:
script.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
קודם כול, צריך להגדיר את predict ל-false כדי להפסיק את כל התחזיות שפועלות כרגע.
לאחר מכן, מערבבים את מערכי הקלט והפלט באמצעות tf.util.shuffleCombo() כדי לוודא שהסדר לא גורם לבעיות באימון.
ממירים את מערך הפלט, trainingDataOutputs, לטנזור חד-ממדי מסוג int32 כדי שיהיה מוכן לשימוש בקידוד one-hot. הערך הזה מאוחסן במשתנה שנקרא outputsAsTensor.
משתמשים בפונקציה tf.oneHot() עם המשתנה outputsAsTensor ועם המספר המקסימלי של סיווגים לקודד, שהוא פשוט CLASS_NAMES.length. הפלט של הקידוד one-hot מאוחסן עכשיו בטנסור חדש שנקרא oneHotOutputs.
שימו לב שכרגע trainingDataInputs הוא מערך של טנסורים מוקלטים. כדי להשתמש בהם לאימון, צריך להמיר את מערך הטנסורים לטנסור רגיל דו-ממדי.
לשם כך, יש פונקציה מצוינת בספריית TensorFlow.js שנקראת tf.stack(),
שמקבל מערך של טנסורים ומערם אותם כדי ליצור טנסור רב-ממדי כפלט. במקרה הזה, מוחזר טנסור דו-ממדי, שהוא קבוצת נתונים של קלט חד-ממדי, שכל אחד מהם באורך 1,024 ומכיל את התכונות שתועדו, וזה מה שצריך לאימון.
בשלב הבא, מריצים את הפקודה await model.fit() כדי לאמן את ראש המודל המותאם אישית. כאן מעבירים את המשתנה inputsAsTensor יחד עם המשתנה oneHotOutputs כדי לייצג את נתוני האימון שישמשו כקלט לדוגמה ופלט יעד בהתאמה. באובייקט ההגדרה של הפרמטר השלישי, מגדירים את shuffle ל-true, משתמשים ב-batchSize של 5, מגדירים את epochs ל-10, ואז מציינים callback ל-onEpochEnd בפונקציה logProgress שתגדירו בהמשך.
לבסוף, אפשר למחוק את הטנסורים שנוצרו כי המודל כבר אומן. אחר כך אפשר להגדיר את predict בחזרה ל-true כדי לאפשר שוב חיזויים, ואז לקרוא לפונקציה predictLoop() כדי להתחיל לחזות תמונות ממצלמת האינטרנט בשידור חי.
אפשר גם להגדיר את הפונקציה logProcess() כדי לרשום ביומן את מצב האימון, שמשמש בפונקציה model.fit() שלמעלה ומדפיס את התוצאות במסוף אחרי כל סבב אימון.
כמעט סיימת! הגיע הזמן להוסיף את הפונקציה predictLoop() כדי ליצור תחזיות.
לולאת החיזוי המרכזית
כאן מטמיעים את לולאת החיזוי הראשית שמבצעת דגימה של פריימים ממצלמת אינטרנט ומבצעת חיזוי רציף של מה שמופיע בכל פרים, עם תוצאות בזמן אמת בדפדפן.
בואו נבדוק את הקוד:
script.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
קודם כול, צריך לוודא שהערך של predict הוא true, כדי שהתחזיות יתבצעו רק אחרי שהמודל אומן וזמין לשימוש.
לאחר מכן, אפשר לקבל את מאפייני התמונה הנוכחית בדיוק כמו בפונקציה dataGatherLoop(). בעצם, לוקחים פריים ממצלמת האינטרנט באמצעות tf.browser.from pixels(), מבצעים נורמליזציה, משנים את הגודל ל-224 על 224 פיקסלים, ואז מעבירים את הנתונים האלה דרך מודל MobileNet כדי לקבל את מאפייני התמונה שמתקבלים.
עם זאת, עכשיו אפשר להשתמש בראש המודל שאומן לאחרונה כדי לבצע בפועל חיזוי על ידי העברת imageFeatures שהתקבל דרך הפונקציה predict() של המודל שאומן. אחר כך אפשר לכווץ את הטנזור שמתקבל כדי להפוך אותו שוב לחד-ממדי ולהקצות אותו למשתנה שנקרא prediction.
בעזרת prediction אפשר למצוא את האינדקס עם הערך הכי גבוה באמצעות argMax(), ואז להמיר את הטנסור שמתקבל למערך באמצעות arraySync() כדי לגשת לנתונים הבסיסיים ב-JavaScript ולגלות את המיקום של הרכיב עם הערך הכי גבוה. הערך הזה מאוחסן במשתנה שנקרא highestIndex.
אפשר גם לקבל את ציוני רמת הסמך של התחזית בפועל באותו אופן, על ידי קריאה ל-arraySync() בטנזור prediction ישירות.
עכשיו יש לכם את כל מה שצריך כדי לעדכן את הטקסט STATUS עם הנתונים prediction. כדי לקבל את המחרוזת שקריאה לאנשים עבור הכיתה, אפשר פשוט לחפש את highestIndex במערך CLASS_NAMES, ואז לאחזר את ערך מהימנות (confidence value) מ-predictionArray. כדי להציג את התוצאה באחוזים, פשוט מכפילים ב-100 ומוסיפים את הסימן math.floor().
לבסוף, תוכלו להשתמש שוב ב-window.requestAnimationFrame() כדי להתקשר אל predictionLoop() כשאתם מוכנים, ולקבל סיווג בזמן אמת של שידור הווידאו. התהליך הזה נמשך עד ש-predict מוגדר ל-false אם בוחרים לאמן מודל חדש עם נתונים חדשים.
כך מגיעים לחלק האחרון של הפאזל. הטמעה של לחצן האיפוס.
15. הטמעה של לחצן האיפוס
כמעט סיימת! השלב האחרון הוא להטמיע לחצן איפוס כדי להתחיל מחדש. בהמשך מופיע הקוד של הפונקציה reset(), שכרגע ריקה. אפשר לעדכן אותו באופן הבא:
script.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
קודם כול, מפסיקים את כל לולאות החיזוי הפעילות על ידי הגדרת predict ל-false. לאחר מכן, מוחקים את כל התוכן במערך examplesCount על ידי הגדרת האורך שלו ל-0. זו דרך נוחה לנקות את כל התוכן ממערך.
עכשיו צריך לעבור על כל ה-trainingDataInputs שהוקלטו כרגע ולוודא שdispose() כל טנסור שכלול בהם כדי לפנות שוב זיכרון, כי אי אפשר לנקות טנסורים באמצעות איסוף האשפה של JavaScript.
אחרי שמסיימים, אפשר להגדיר בבטחה את אורך המערך ל-0 במערכים trainingDataInputs ו-trainingDataOutputs כדי לנקות גם אותם.
לבסוף, מגדירים את הטקסט STATUS למשהו הגיוני ומדפיסים את הטנסורים שנותרו בזיכרון כבדיקה.
חשוב לזכור שעדיין יהיו כמה מאות טנסורים בזיכרון, כי גם מודל MobileNet וגם תפיסת השכבות המרובות שהגדרתם לא מושמדים. אם תחליטו לאמן מחדש אחרי האיפוס הזה, תצטרכו להשתמש בהם מחדש עם נתוני אימון חדשים.
16. אני רוצה לנסות
הגיע הזמן לבדוק את הגרסה של Teachable Machine שמתאימה לכם!
עוברים לתצוגה המקדימה של השידור החי, מפעילים את מצלמת האינטרנט, אוספים לפחות 30 דוגמאות לכיתה 1 עבור אובייקט מסוים בחדר, ואז עושים את אותו הדבר לכיתה 2 עבור אובייקט אחר, לוחצים על train (אימון) ובודקים את יומן המסוף כדי לראות את ההתקדמות. האימון אמור להיות מהיר למדי:

אחרי האימון, מציגים את האובייקטים למצלמה כדי לקבל תחזיות בזמן אמת שיוצגו באזור הטקסט של הסטטוס בחלק העליון של דף האינטרנט. אם נתקלתם בבעיה, כדאי לבדוק את קוד העבודה המלא שלי כדי לראות אם פספסתם העתקה של משהו.
17. מזל טוב
מעולה! סיימתם את הדוגמה הראשונה של למידת העברות באמצעות TensorFlow.js בדפדפן.
נסו את התכונה, בדקו אותה על מגוון אובייקטים, ותוכלו לראות שזיהוי של חלק מהדברים קשה יותר מאחרים, במיוחד אם הם דומים למשהו אחר. יכול להיות שתצטרכו להוסיף עוד כיתות או נתוני אימון כדי להבחין ביניהן.
סיכום
ב-Codelab הזה למדתם:
- מהי למידת העברה, ומה היתרונות שלה לעומת אימון של מודל מלא.
- איך מקבלים מודלים לשימוש חוזר מ-TensorFlow Hub.
- איך מגדירים אפליקציית אינטרנט שמתאימה להעברת ידע.
- איך טוענים מודל בסיסי ומשתמשים בו כדי ליצור תכונות של תמונות.
- איך מאמנים ראש חיזוי חדש שיכול לזהות אובייקטים מותאמים אישית מתמונות שמגיעות ממצלמת אינטרנט.
- איך משתמשים במודלים שנוצרו כדי לסווג נתונים בזמן אמת.
מה השלב הבא?
עכשיו שיש לכם בסיס עבודה להתחיל ממנו, אילו רעיונות יצירתיים יכולים לעלות לכם כדי להרחיב את תבנית הקוד הזו של מודל למידת מכונה לתרחיש שימוש בעולם האמיתי שאתם עובדים עליו? אולי תוכלו לחולל מהפכה בתחום שבו אתם עובדים כרגע, כדי לעזור לאנשים בחברה שלכם לאמן מודלים לסיווג של דברים שחשובים בעבודה היומיומית שלהם? האפשרויות הן אינסופיות.
כדי להעמיק בנושא, מומלץ להירשם לקורס המלא הזה בחינם. בקורס הזה מוסבר איך לשלב את שני המודלים שיש לכם כרגע ב-codelab למודל אחד יעיל.
אם אתם רוצים לדעת עוד על התיאוריה שמאחורי אפליקציית Teachable Machine המקורית, אתם יכולים לעיין במדריך הזה.
שיתוף התוצרים עם Google
אתם יכולים בקלות להרחיב את מה שיצרתם היום גם לתרחישי שימוש יצירתיים אחרים, ואנחנו ממליצים לכם לחשוב מחוץ לקופסה ולהמשיך ליצור.
אל תשכחו לתייג אותנו ברשתות החברתיות באמצעות ההאשטאג #MadeWithTFJS כדי לקבל הזדמנות שהפרויקט שלכם יוצג בבלוג של TensorFlow או אפילו באירועים עתידיים. נשמח לראות מה יצא לך ליצור.
אתרים שכדאי לבדוק
- האתר הרשמי של TensorFlow.js
- מודלים מוכנים מראש של TensorFlow.js
- TensorFlow.js API
- TensorFlow.js Show & Tell – קבלו השראה וראו מה אחרים יצרו.