
1. Wprowadzenie
W tym samouczku utworzymy model TensorFlow.js do rozpoznawania odręcznie napisanych cyfr za pomocą konwolucyjnej sieci neuronowej. Najpierw wytrenujemy klasyfikator, pokazując mu tysiące obrazów odręcznie napisanych cyfr i ich etykiet. Następnie ocenimy dokładność klasyfikatora, korzystając z danych testowych, których model nigdy nie widział.
To zadanie jest uznawane za zadanie klasyfikacji, ponieważ trenujemy model, aby przypisywał kategorię (cyfrę widoczną na obrazie) do obrazu wejściowego. Model będzie trenowany na wielu przykładach danych wejściowych wraz z prawidłowymi danymi wyjściowymi. Nazywamy to uczeniem nadzorowanym.
Co utworzysz
Utworzysz stronę internetową, która będzie używać TensorFlow.js do trenowania modelu w przeglądarce. Na podstawie czarno-białego obrazu o określonym rozmiarze określa, która cyfra jest na nim widoczna. W tym celu musisz:
- Wczytaj dane.
- Określ architekturę modelu.
- Wytrenuj model i monitoruj jego skuteczność w trakcie trenowania.
- Oceń wytrenowany model, generując prognozy.
Czego się nauczysz
- Składnia TensorFlow.js do tworzenia modeli konwolucyjnych za pomocą interfejsu TensorFlow.js Layers API.
- Formułowanie zadań klasyfikacji w TensorFlow.js
- Jak monitorować trenowanie w przeglądarce za pomocą biblioteki tfjs-vis.
Czego potrzebujesz
- Najnowsza wersja Chrome lub innej nowoczesnej przeglądarki obsługującej moduły ES6.
- edytor tekstu uruchomiony lokalnie na komputerze lub w internecie, np. Codepen lub Glitch;
- Znajomość HTML-a, CSS-a, JavaScriptu i Narzędzi deweloperskich w Chrome (lub narzędzi deweloperskich w innej przeglądarce).
- Ogólne zrozumienie koncepcji sieci neuronowych. Jeśli potrzebujesz wprowadzenia lub przypomnienia, obejrzyj ten film 3blue1brown lub ten film Ashiego Krishnana o uczeniu głębokim w JavaScript.
Warto też zapoznać się z materiałami z pierwszego samouczka szkoleniowego.
2. Konfiguracja
Utwórz stronę HTML i dodaj do niej kod JavaScript.
 Skopiuj ten kod do pliku HTML o nazwie
Skopiuj ten kod do pliku HTML o nazwie
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Utwórz pliki JavaScript dla danych i kodu
- W tym samym folderze co powyższy plik HTML utwórz plik o nazwie data.js i skopiuj do niego treść z tego linku.
- W tym samym folderze co w kroku 1 utwórz plik o nazwie script.js i wklej do niego ten kod.
console.log('Hello TensorFlow');
Wypróbuj
Teraz, gdy masz już utworzone pliki HTML i JavaScript, przetestuj je. Otwórz plik index.html w przeglądarce i konsolę narzędzi deweloperskich.
Jeśli wszystko działa prawidłowo, powinny zostać utworzone 2 zmienne globalne. tf to odwołanie do biblioteki TensorFlow.js, a tfvis to odwołanie do biblioteki tfjs-vis.
Powinien wyświetlić się komunikat Hello TensorFlow. Jeśli tak się stanie, możesz przejść do następnego kroku.
3. Wczytywanie danych
W tym samouczku wytrenujesz model, który będzie rozpoznawać cyfry na obrazach takich jak te poniżej. Są to obrazy w odcieniach szarości o rozmiarze 28 × 28 pikseli pochodzące ze zbioru danych MNIST.
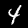

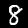
Abyśmy mogli skupić się na części szkoleniowej, udostępniliśmy kod do wczytywania tych obrazów ze specjalnego pliku sprite (~10 MB), który został przez nas utworzony.
Zapoznaj się z data.js, aby dowiedzieć się, jak są wczytywane dane. Możesz też po zakończeniu tego samouczka opracować własną metodę wczytywania danych.
Podany kod zawiera klasę MnistData z 2 metodami publicznymi:
nextTrainBatch(batchSize): zwraca losową partię obrazów i ich etykiet ze zbioru treningowego.nextTestBatch(batchSize): zwraca partię obrazów i ich etykiet ze zbioru testowego.
Klasa MnistData wykonuje też ważne kroki tasowania i normalizacji danych.
Łącznie mamy 65 tys. obrazów. Do trenowania modelu wykorzystamy maksymalnie 55 tys. obrazów, a 10 tys. obrazów zachowamy, aby po zakończeniu trenowania przetestować skuteczność modelu. A wszystko to zrobimy w przeglądarce.
Załadujmy dane i sprawdźmy, czy zostały załadowane prawidłowo.
Dodaj ten kod do pliku script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Odśwież stronę. Po kilku sekundach po lewej stronie powinien pojawić się panel z liczbą obrazów.

4. Określenie zadania
Nasze dane wejściowe wyglądają tak:
Naszym celem jest wytrenowanie modelu, który będzie przyjmował jeden obraz i uczył się przewidywać wynik dla każdej z 10 możliwych klas, do których może należeć ten obraz (cyfry 0–9).
Każdy obraz ma szerokość 28 pikseli i wysokość 28 pikseli oraz 1 kanał koloru, ponieważ jest obrazem w skali szarości. Kształt każdego obrazu to [28, 28, 1].
Pamiętaj, że wykonujemy mapowanie od 1 do 10, a także kształt każdego przykładu danych wejściowych, ponieważ jest to ważne w następnej sekcji.
5. Określanie architektury modelu
W tej sekcji napiszemy kod opisujący architekturę modelu. Architektura modelu to elegancki sposób na określenie „jakie funkcje będzie wykonywać model podczas działania” lub „jakiego algorytmu będzie używać model do obliczania odpowiedzi”.
W uczeniu maszynowym definiujemy architekturę (lub algorytm) i pozwalamy procesowi trenowania nauczyć się parametrów tego algorytmu.
Dodaj następującą funkcję do
script.js plik do określania architektury modelu
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Przyjrzyjmy się temu bliżej.
Sploty
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Używamy tu modelu sekwencyjnego.
Zamiast warstwy gęstej używamy warstwy conv2d. Nie możemy podać wszystkich szczegółów dotyczących działania splotów, ale oto kilka materiałów, które wyjaśniają podstawowe operacje:
Przyjrzyjmy się poszczególnym argumentom w obiekcie konfiguracji dla conv2d:
inputShape. Kształt danych, które będą przepływać do pierwszej warstwy modelu. W tym przypadku nasze przykłady MNIST to czarno-białe obrazy o rozmiarze 28 x 28 pikseli. Kanonicznym formatem danych obrazu jest[row, column, depth], więc w tym przypadku chcemy skonfigurować kształt[28, 28, 1]. 28 wierszy i kolumn, co odpowiada liczbie pikseli w każdym wymiarze, oraz głębi 1, ponieważ nasze obrazy mają tylko 1 kanał koloru. Pamiętaj, że w kształcie wejściowym nie określamy wielkości wsadu. Warstwy są zaprojektowane tak, aby były niezależne od wielkości wsadu, dzięki czemu podczas wnioskowania można przekazywać Tensor o dowolnej wielkości wsadu.kernelSizeRozmiar okien przesuwnego filtra konwolucyjnego, który ma być stosowany do danych wejściowych. W tym przypadku ustawiamykernelSizena5, co oznacza kwadratowe okno splotu o wymiarach 5x5.filters– liczba okien filtra o rozmiarzekernelSize, które mają być zastosowane do danych wejściowych. Zastosujemy tu do danych 8 filtrów.strides. „Rozmiar kroku” okna przesuwnego, czyli o ile pikseli filtr będzie się przesuwać za każdym razem, gdy będzie się poruszać po obrazie. Określamy tu krok 1, co oznacza, że filtr będzie przesuwać się po obrazie w krokach o 1 piksel.activation. Funkcja aktywacji, która ma być zastosowana do danych po zakończeniu splotu. W tym przypadku stosujemy funkcję Rectified Linear Unit (ReLU), która jest bardzo popularną funkcją aktywacji w modelach ML.kernelInitializer. Metoda losowego inicjowania wag modelu, która jest bardzo ważna dla dynamiki trenowania. Nie będziemy tu omawiać szczegółów inicjowania, aleVarianceScaling(użyte w tym przykładzie) jest na ogół dobrym inicjatorem.
Spłaszczanie reprezentacji danych
model.add(tf.layers.flatten());
Obrazy to dane o wielu wymiarach, a operacje splotu zwykle zwiększają rozmiar danych, które zostały w nich użyte. Zanim przekażemy je do ostatniej warstwy klasyfikacji, musimy spłaszczyć dane do jednej długiej tablicy. Gęste warstwy (których używamy jako warstwy końcowej) zajmują tylko tensor1d, więc ten krok jest powszechny w wielu zadaniach klasyfikacji.
Obliczanie końcowego rozkładu prawdopodobieństwa
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Użyjemy warstwy gęstej z funkcją aktywacji softmax, aby obliczyć rozkłady prawdopodobieństwa w 10 możliwych klasach. Klasa z najwyższym wynikiem będzie przewidywaną cyfrą.
Wybierz optymalizator i funkcję straty
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Kompilujemy model, określając optymalizator, funkcję straty i dane, które chcemy śledzić.
W przeciwieństwie do pierwszego samouczka używamy tutaj funkcji straty categoricalCrossentropy. Jak sama nazwa wskazuje, jest ona używana, gdy dane wyjściowe modelu to rozkład prawdopodobieństwa. categoricalCrossentropy mierzy błąd między rozkładem prawdopodobieństwa wygenerowanym przez ostatnią warstwę naszego modelu a rozkładem prawdopodobieństwa podanym przez prawdziwą etykietę.
Jeśli na przykład cyfra rzeczywiście reprezentuje liczbę 7, możemy uzyskać te wyniki:
Indeks | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Etykieta z wartością „Prawda” | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Prognoza | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0.60 | 0,03 | 0,02 |
Kategorialna entropia krzyżowa wygeneruje jedną liczbę wskazującą, jak podobny jest wektor prognozy do wektora prawdziwej etykiety.
Reprezentacja danych używana tutaj w przypadku etykiet to kodowanie 1-z-N, które jest powszechne w problemach z klasyfikacją. Każda klasa ma przypisane prawdopodobieństwo dla każdego przykładu. Gdy będziemy mieć pewność, co to jest, możemy ustawić prawdopodobieństwo na 1, a pozostałe na 0. Więcej informacji o kodowaniu 1-z-N znajdziesz na tej stronie.
Drugą miarą, którą będziemy monitorować, jest accuracy, która w przypadku problemu klasyfikacji jest odsetkiem prawidłowych prognoz ze wszystkich prognoz.
6. Trenowanie modelu
Skopiuj tę funkcję do pliku script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Następnie dodaj ten kod do pliku
run funkcji.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Odśwież stronę. Po kilku sekundach powinny pojawić się wykresy pokazujące postęp trenowania.
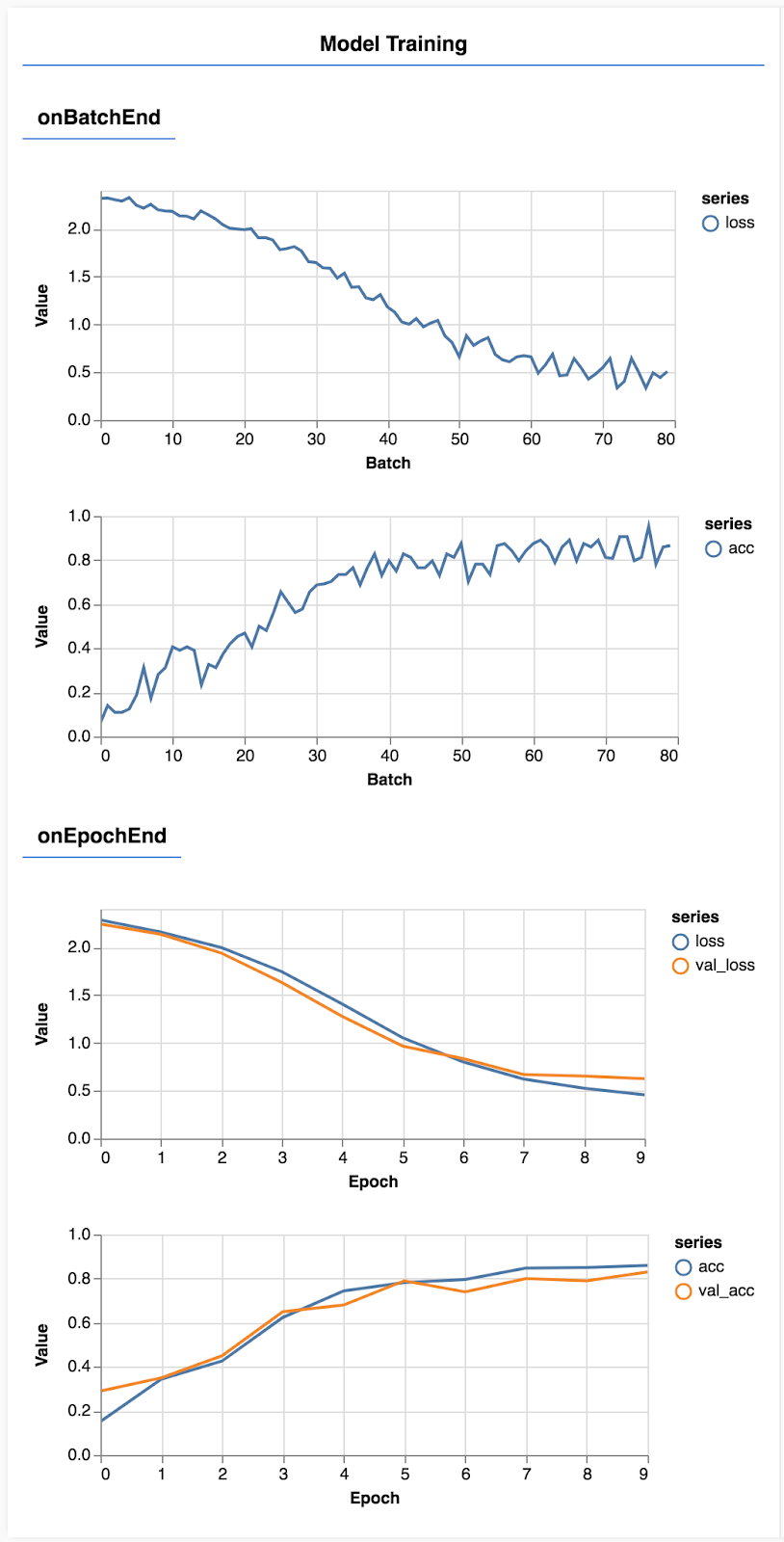
Przyjrzyjmy się temu bliżej.
Monitorowanie danych
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Tutaj decydujemy, które dane będziemy monitorować. Będziemy monitorować utratę i dokładność w zbiorze treningowym, a także utratę i dokładność w zbiorze walidacyjnym (odpowiednio val_loss i val_acc). Więcej informacji o zbiorze weryfikacyjnym znajdziesz poniżej.
Przygotowywanie danych w postaci tensorów
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Tworzymy tu 2 zbiory danych: zbiór treningowy, na którym będziemy trenować model, oraz zbiór weryfikacyjny, na którym będziemy testować model na końcu każdej epoki. Dane w zbiorze weryfikacyjnym nigdy nie są pokazywane modelowi podczas trenowania.
Dostarczona przez nas klasa danych ułatwia uzyskiwanie tensorów z danych obrazu. Zanim jednak przekażemy je do modelu, przekształcamy tensory do kształtu oczekiwanego przez model, czyli [num_examples, image_width, image_height, channels]. W przypadku każdego zbioru danych mamy zarówno dane wejściowe (X), jak i etykiety (Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Aby rozpocząć pętlę trenowania, wywołujemy funkcję model.fit. Przekazujemy też właściwość validationData, aby wskazać, których danych model powinien używać do testowania się po każdej epoce (ale nie do trenowania).
Jeśli model dobrze radzi sobie z danymi treningowymi, ale nie z danymi weryfikacyjnymi, oznacza to, że prawdopodobnie nadmiernie dopasowuje się do danych treningowych i nie będzie dobrze uogólniał na dane wejściowe, których wcześniej nie widział.
7. Ocena naszego modelu
Dokładność walidacji jest dobrym przybliżeniem tego, jak dobrze model będzie działać na danych, których wcześniej nie widział (o ile dane te są w jakiś sposób podobne do zbioru walidacyjnego). Możemy jednak potrzebować bardziej szczegółowego podziału wyników na poszczególne klasy.
W tfjs-vis znajdziesz kilka metod, które mogą Ci w tym pomóc.
Dodaj ten kod na końcu pliku script.js.
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Co robi ten kod?
- generuje prognozę,
- Oblicza dane dotyczące dokładności.
- Wyświetlanie danych
Przyjrzyjmy się dokładniej każdemu etapowi tego procesu.
Tworzenie prognoz
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Najpierw musimy dokonać kilku prognoz. W tym miejscu weźmiemy 500 obrazów i spróbujemy przewidzieć, jaka cyfra się na nich znajduje (później możesz zwiększyć tę liczbę, aby przetestować większy zestaw obrazów).
Funkcja argmax zwraca indeks klasy o najwyższym prawdopodobieństwie. Pamiętaj, że model zwraca prawdopodobieństwo dla każdej klasy. Wybieramy najwyższe prawdopodobieństwo i przypisujemy je jako prognozę.
Możesz też zauważyć, że możemy dokonywać prognoz na podstawie wszystkich 500 przykładów naraz. To właśnie możliwości wektoryzacji, jakie zapewnia TensorFlow.js.
Wyświetlanie dokładności według klasy
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Na podstawie zbioru prognoz i etykiet możemy obliczyć dokładność dla każdej klasy.
Wyświetlanie macierzy pomyłek
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Tablica pomyłek jest podobna do dokładności wg klasy, ale zawiera dodatkowe informacje o wzorcach błędnej klasyfikacji. Dzięki niej możesz sprawdzić, czy model myli jakieś konkretne pary klas.
Wyświetlanie oceny
Dodaj ten kod na końcu funkcji run, aby wyświetlić ocenę.
await showAccuracy(model, data);
await showConfusion(model, data);
Wyświetli się ekran podobny do tego poniżej.
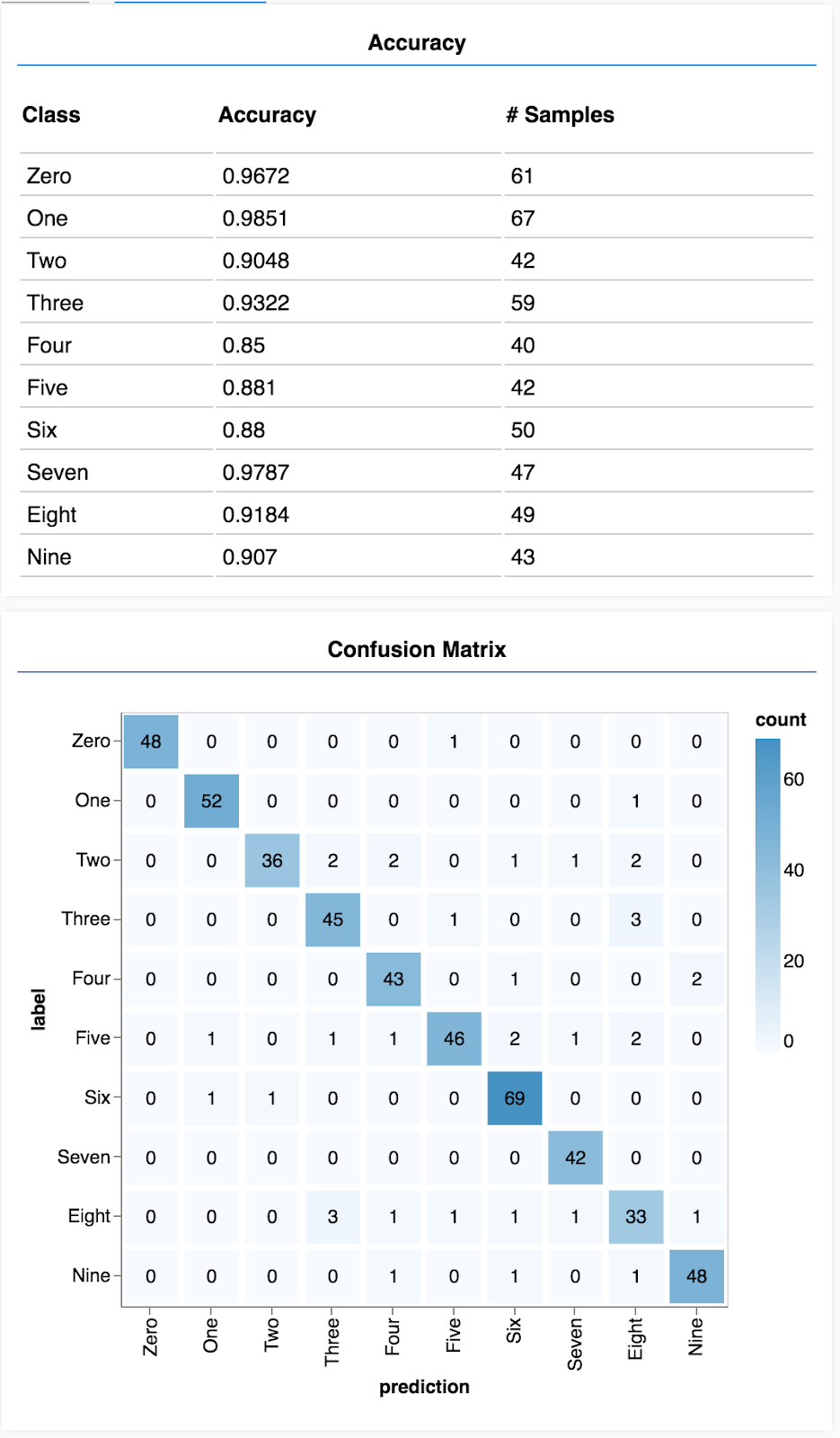
Gratulacje! Właśnie udało Ci się wytrenować splotową sieć neuronową.
8. Najważniejsze informacje
Prognozowanie kategorii dla danych wejściowych to zadanie klasyfikacji.
Zadania klasyfikacji wymagają odpowiedniej reprezentacji danych dla etykiet
- Typowe reprezentacje etykiet obejmują kodowanie 1 z n kategorii.
Przygotuj dane:
- Warto odłożyć na bok część danych, których model nigdy nie widzi podczas trenowania, aby można było ich użyć do oceny modelu. Jest to tzw. zbiór walidacyjny.
Utwórz i uruchom model:
- Modele konwolucyjne dobrze sprawdzają się w przypadku zadań związanych z obrazami.
- W przypadku problemów z klasyfikacją zwykle stosuje się funkcje straty oparte na entropii krzyżowej kategorii.
- Monitoruj trenowanie, aby sprawdzić, czy wartość funkcji straty maleje, a dokładność rośnie.
Ocenianie modelu
- Określ sposób oceny modelu po jego wytrenowaniu, aby sprawdzić, jak dobrze radzi sobie z początkowym problemem, który chcesz rozwiązać.
- Dokładność poszczególnych klas i tablice pomyłek mogą dać Ci bardziej szczegółowy obraz skuteczności modelu niż tylko ogólna dokładność.