
1. Introduzione
In questo tutorial, creeremo un modello TensorFlow.js per riconoscere le cifre scritte a mano libera con una rete neurale convoluzionale. Innanzitutto, addestreremo il classificatore facendogli "osservare" migliaia di immagini di cifre scritte a mano e le relative etichette. Poi valuteremo l'accuratezza del classificatore utilizzando dati di test che il modello non ha mai visto.
Questa attività è considerata un'attività di classificazione, in quanto addestriamo il modello ad assegnare una categoria (la cifra che appare nell'immagine) all'immagine di input. Addestreremo il modello mostrandogli molti esempi di input insieme all'output corretto. Questo processo è chiamato apprendimento supervisionato.
Cosa creerai
Creerai una pagina web che utilizza TensorFlow.js per addestrare un modello nel browser. Data un'immagine in bianco e nero di una determinata dimensione, classifica quale cifra appare nell'immagine. I passaggi da seguire sono:
- Carica i dati.
- Definisci l'architettura del modello.
- Addestra il modello e monitorane le prestazioni durante l'addestramento.
- Valuta il modello addestrato facendo alcune previsioni.
Cosa imparerai a fare
- Sintassi TensorFlow.js per la creazione di modelli convoluzionali utilizzando l'API TensorFlow.js Layers.
- Formulare attività di classificazione in TensorFlow.js
- Come monitorare l'addestramento nel browser utilizzando la libreria tfjs-vis.
Che cosa ti serve
- Una versione recente di Chrome o un altro browser moderno che supporti i moduli ES6.
- Un editor di testo, in esecuzione localmente sul tuo computer o sul web tramite Codepen o Glitch.
- Conoscenza di HTML, CSS, JavaScript e Chrome DevTools (o degli strumenti di sviluppo dei browser che preferisci).
- Una comprensione concettuale di alto livello delle reti neurali. Se hai bisogno di un'introduzione o di un ripasso, ti consigliamo di guardare questo video di 3blue1brown o questo video sul deep learning in JavaScript di Ashi Krishnan.
Inoltre, dovresti avere familiarità con i contenuti del nostro primo tutorial di formazione.
2. Configurazione
Crea una pagina HTML e includi JavaScript
 Copia il seguente codice in un file HTML denominato
Copia il seguente codice in un file HTML denominato
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Crea i file JavaScript per i dati e il codice
- Nella stessa cartella del file HTML precedente, crea un file denominato data.js e copia al suo interno i contenuti di questo link.
- Nella stessa cartella del passaggio 1, crea un file denominato script.js e inserisci il seguente codice.
console.log('Hello TensorFlow');
Prova
Ora che hai creato i file HTML e JavaScript, testali. Apri il file index.html nel browser e la console degli strumenti di sviluppo.
Se tutto funziona, dovrebbero essere create due variabili globali. tf è un riferimento alla libreria TensorFlow.js, tfvis è un riferimento alla libreria tfjs-vis.
Dovresti visualizzare il messaggio Hello TensorFlow. Se lo visualizzi, puoi passare al passaggio successivo.
3. Caricare i dati
In questo tutorial addestrerai un modello per imparare a riconoscere le cifre nelle immagini come quelle riportate di seguito. Queste immagini sono in scala di grigi e misurano 28x28 pixel. Provengono da un set di dati chiamato MNIST.

Abbiamo fornito il codice per caricare queste immagini da uno speciale file sprite (~10 MB) che abbiamo creato per te, in modo da poterci concentrare sulla parte di addestramento.
Puoi studiare il file data.js per capire come vengono caricati i dati. In alternativa, una volta terminato questo tutorial, crea il tuo approccio per caricare i dati.
Il codice fornito contiene una classe MnistData con due metodi pubblici:
nextTrainBatch(batchSize): restituisce un batch casuale di immagini e le relative etichette dal set di addestramento.nextTestBatch(batchSize): restituisce un batch di immagini e le relative etichette dal test set
La classe MnistData esegue anche i passaggi importanti di riorganizzazione e normalizzazione dei dati.
Ci sono un totale di 65.000 immagini. Ne utilizzeremo fino a 55.000 per addestrare il modello, salvando 10.000 immagini che potremo utilizzare per testare le prestazioni del modello al termine dell'addestramento. E faremo tutto nel browser.
Carichiamo i dati e verifichiamo che siano caricati correttamente.
Aggiungi il seguente codice al file script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Aggiorna la pagina e dopo qualche secondo dovresti vedere un riquadro sulla sinistra con una serie di immagini.

4. Concettualizzare l'attività
I nostri dati di input si presentano così.
Il nostro obiettivo è addestrare un modello che prenda un'immagine e impari a prevedere un punteggio per ciascuna delle 10 classi possibili a cui l'immagine può appartenere (le cifre 0-9).
Ogni immagine ha una larghezza di 28 px e un'altezza di 28 px e un canale di colore, in quanto è un'immagine in scala di grigi. Quindi la forma di ogni immagine è [28, 28, 1].
Ricorda che eseguiamo una mappatura da 1 a 10, nonché la forma di ogni esempio di input, poiché è importante per la sezione successiva.
5. Definisci l'architettura del modello
In questa sezione scriveremo il codice per descrivere l'architettura del modello. L'architettura del modello è un modo elegante per dire "quali funzioni verranno eseguite dal modello durante l'esecuzione" o, in alternativa, "quale algoritmo verrà utilizzato dal modello per calcolare le risposte".
Nel machine learning definiamo un'architettura (o un algoritmo) e lasciamo che il processo di addestramento apprenda i parametri di quell'algoritmo.
Aggiungi la seguente funzione a
script.js file per definire l'architettura del modello
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Esaminiamo questo aspetto in modo più dettagliato.
Convoluzioni
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Qui utilizziamo un modello sequenziale.
Utilizziamo un livello conv2d anziché un livello denso. Non possiamo entrare nei dettagli del funzionamento delle convoluzioni, ma ecco alcune risorse che spiegano l'operazione sottostante:
Analizziamo ogni argomento nell'oggetto di configurazione per conv2d:
inputShape. La forma dei dati che verranno inseriti nel primo livello del modello. In questo caso, i nostri esempi MNIST sono immagini in bianco e nero di 28 x 28 pixel. Il formato canonico per i dati delle immagini è[row, column, depth], quindi qui vogliamo configurare una forma di[28, 28, 1]. 28 righe e colonne per il numero di pixel in ogni dimensione e una profondità di 1 perché le nostre immagini hanno un solo canale di colore. Tieni presente che non specifichiamo una dimensione del batch nella forma di input. Gli strati sono progettati per essere indipendenti dalle dimensioni del batch, in modo che durante l'inferenza tu possa passare un tensore di qualsiasi dimensione del batch.kernelSize. Le dimensioni delle finestre del filtro convoluzionale scorrevole da applicare ai dati di input. Qui impostiamo unkernelSizedi5, che specifica una finestra convoluzionale quadrata 5x5.filters. Il numero di finestre di filtro di dimensionekernelSizeda applicare ai dati di input. In questo caso, applicheremo 8 filtri ai dati.strides. Le "dimensioni del passo" della finestra scorrevole, ovvero di quanti pixel si sposterà il filtro ogni volta che si muove sull'immagine. Qui specifichiamo passi di 1, il che significa che il filtro scorrerà sull'immagine con incrementi di 1 pixel.activation. La funzione di attivazione da applicare ai dati al termine della convoluzione. In questo caso, applichiamo una funzione di unità lineare rettificata (ReLU), che è una funzione di attivazione molto comune nei modelli di machine learning.kernelInitializer. Il metodo da utilizzare per inizializzare in modo casuale i pesi del modello, che è molto importante per le dinamiche di addestramento. Non entreremo nei dettagli dell'inizializzazione qui, maVarianceScaling(utilizzato qui) è in genere una buona scelta di inizializzatore.
Appiattimento della rappresentazione dei dati
model.add(tf.layers.flatten());
Le immagini sono dati ad alta dimensionalità e le operazioni di convoluzione tendono ad aumentare le dimensioni dei dati di input. Prima di passarli al nostro livello di classificazione finale, dobbiamo appiattire i dati in un unico array lungo. Gli strati densi (che utilizziamo come strato finale) richiedono solo tensor1d secondi, quindi questo passaggio è comune in molte attività di classificazione.
Calcolare la distribuzione di probabilità finale
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Utilizzeremo un livello denso con un'attivazione softmax per calcolare le distribuzioni di probabilità sulle 10 classi possibili. La classe con il punteggio più alto sarà la cifra prevista.
Scegli un ottimizzatore e una funzione di perdita
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Compiliamo il modello specificando un ottimizzatore, una funzione di perdita e le metriche che vogliamo monitorare.
A differenza del primo tutorial, qui utilizziamo categoricalCrossentropy come funzione di perdita. Come suggerisce il nome, viene utilizzata quando l'output del modello è una distribuzione di probabilità. categoricalCrossentropy misura l'errore tra la distribuzione di probabilità generata dall'ultimo livello del nostro modello e la distribuzione di probabilità fornita dalla nostra etichetta reale.
Ad esempio, se la cifra rappresenta effettivamente un 7, potremmo ottenere i seguenti risultati
Indice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Etichetta True | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Previsione | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
L'entropia incrociata categorica produrrà un singolo numero che indica il grado di somiglianza tra il vettore di previsione e il vettore di etichette vere.
La rappresentazione dei dati utilizzata qui per le etichette è chiamata codifica one-hot ed è comune nei problemi di classificazione. A ogni classe è associata una probabilità per ogni esempio. Quando sappiamo esattamente cosa dovrebbe essere, possiamo impostare la probabilità su 1 e le altre su 0. Per ulteriori informazioni sulla codifica one-hot, consulta questa pagina.
L'altra metrica che monitoreremo è accuracy, che per un problema di classificazione è la percentuale di previsioni corrette sul totale delle previsioni.
6. Addestra il modello
Copia la seguente funzione nel file script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Aggiungi poi il seguente codice al tuo
Funzione run.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Aggiorna la pagina e dopo qualche secondo dovresti visualizzare alcuni grafici che mostrano l'avanzamento dell'addestramento.
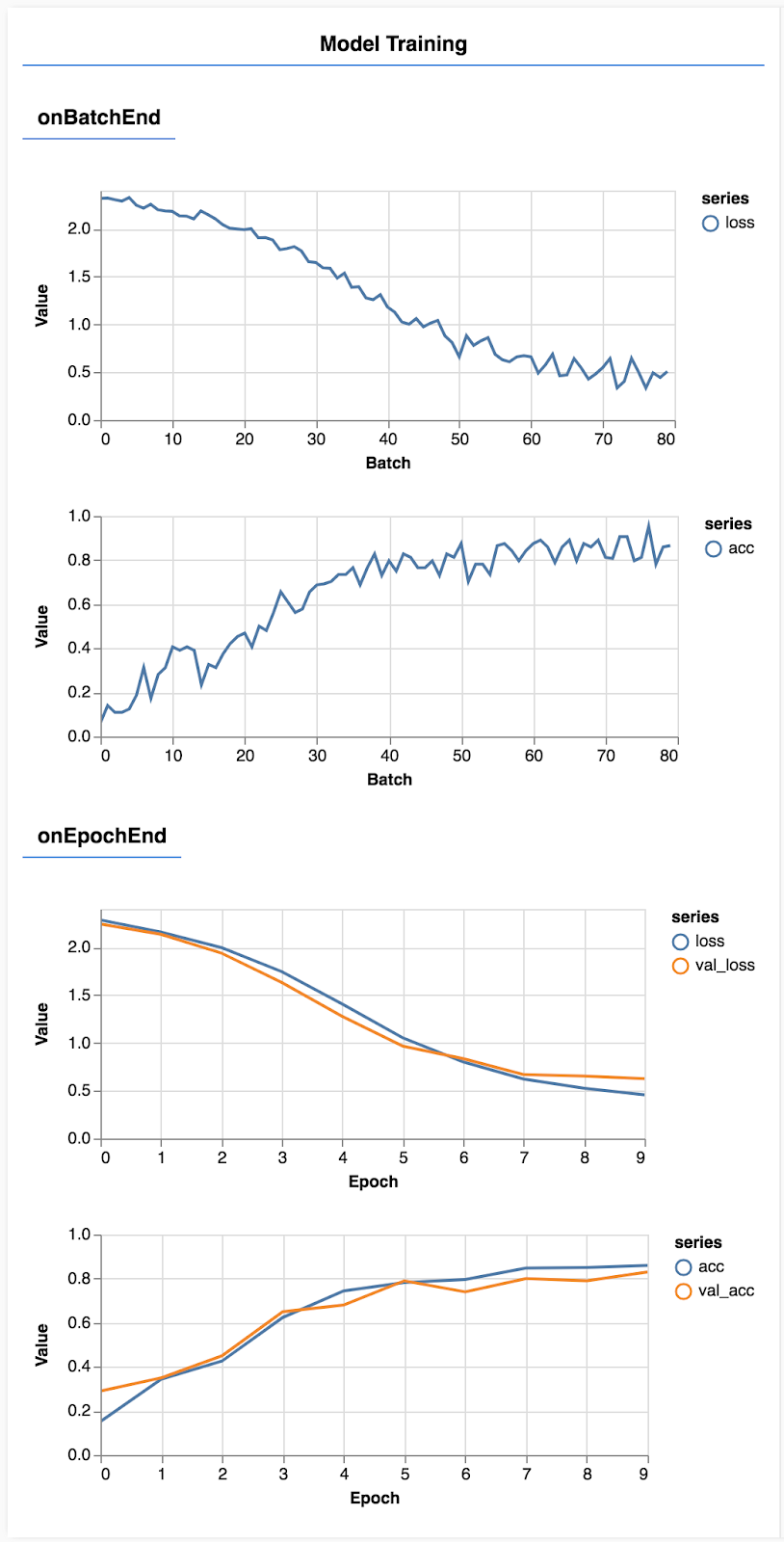
Vediamo più nel dettaglio.
Metriche di monitoraggio
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Qui decidiamo quali metriche monitorare. Monitoreremo la perdita e l'accuratezza nel set di addestramento, nonché la perdita e l'accuratezza nel set di validazione (rispettivamente val_loss e val_acc). Di seguito parleremo più nel dettaglio del set di validazione.
Preparare i dati come tensori
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Qui creiamo due set di dati: un set di addestramento su cui addestreremo il modello e un set di validazione su cui testeremo il modello alla fine di ogni epoca. Tuttavia, i dati nel set di validazione non vengono mai mostrati al modello durante l'addestramento.
La classe di dati che abbiamo fornito semplifica l'ottenimento di tensori dai dati delle immagini. Tuttavia, rimodelliamo i tensori nella forma prevista dal modello, [num_examples, image_width, image_height, channels], prima di poterli inserire nel modello. Per ogni set di dati abbiamo sia gli input (le X) sia le etichette (le Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Chiamiamo model.fit per avviare il ciclo di addestramento. Passiamo anche una proprietà validationData per indicare quali dati il modello deve utilizzare per testarsi dopo ogni epoca (ma non per l'addestramento).
Se otteniamo buoni risultati con i dati di addestramento, ma non con i dati di convalida, significa che il modello probabilmente è soggetto a overfitting rispetto ai dati di addestramento e non generalizzerà bene l'input che non ha mai visto prima.
7. Valuta il nostro modello
L'accuratezza della convalida fornisce una buona stima del rendimento del modello con dati mai utilizzati prima (a condizione che questi dati assomiglino in qualche modo al set di validazione). Tuttavia, potremmo volere una suddivisione più dettagliata del rendimento nelle diverse classi.
Esistono un paio di metodi in tfjs-vis che possono aiutarti in questo.
Aggiungi il seguente codice alla fine del file script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Che cosa fa questo codice?
- Effettua una previsione.
- Calcola le metriche di accuratezza.
- Mostra le metriche
Esaminiamo più da vicino ogni passaggio.
Fare previsioni
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Prima dobbiamo fare alcune previsioni. Qui prenderemo 500 immagini e prevederemo quale cifra contengono (potrai aumentare questo numero in un secondo momento per eseguire il test su un insieme più grande di immagini).
In particolare, la funzione argmax ci fornisce l'indice della classe con la probabilità più alta. Ricorda che il modello restituisce una probabilità per ogni classe. Qui troviamo la probabilità più alta e la utilizziamo come previsione.
Potresti anche notare che possiamo fare previsioni su tutti i 500 esempi contemporaneamente. Questo è il potere della vettorizzazione fornita da TensorFlow.js.
Mostra l'accuratezza per classe
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Con un insieme di previsioni ed etichette possiamo calcolare l'accuratezza per ogni classe.
Mostrare una matrice di confusione
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Una matrice di confusione è simile all'accuratezza per classe, ma la suddivide ulteriormente per mostrare i pattern di classificazione errata. Ti consente di vedere se il modello confonde coppie particolari di classi.
Visualizzare la valutazione
Aggiungi il seguente codice alla fine della funzione run per mostrare la valutazione.
await showAccuracy(model, data);
await showConfusion(model, data);
Dovresti visualizzare un display simile al seguente.
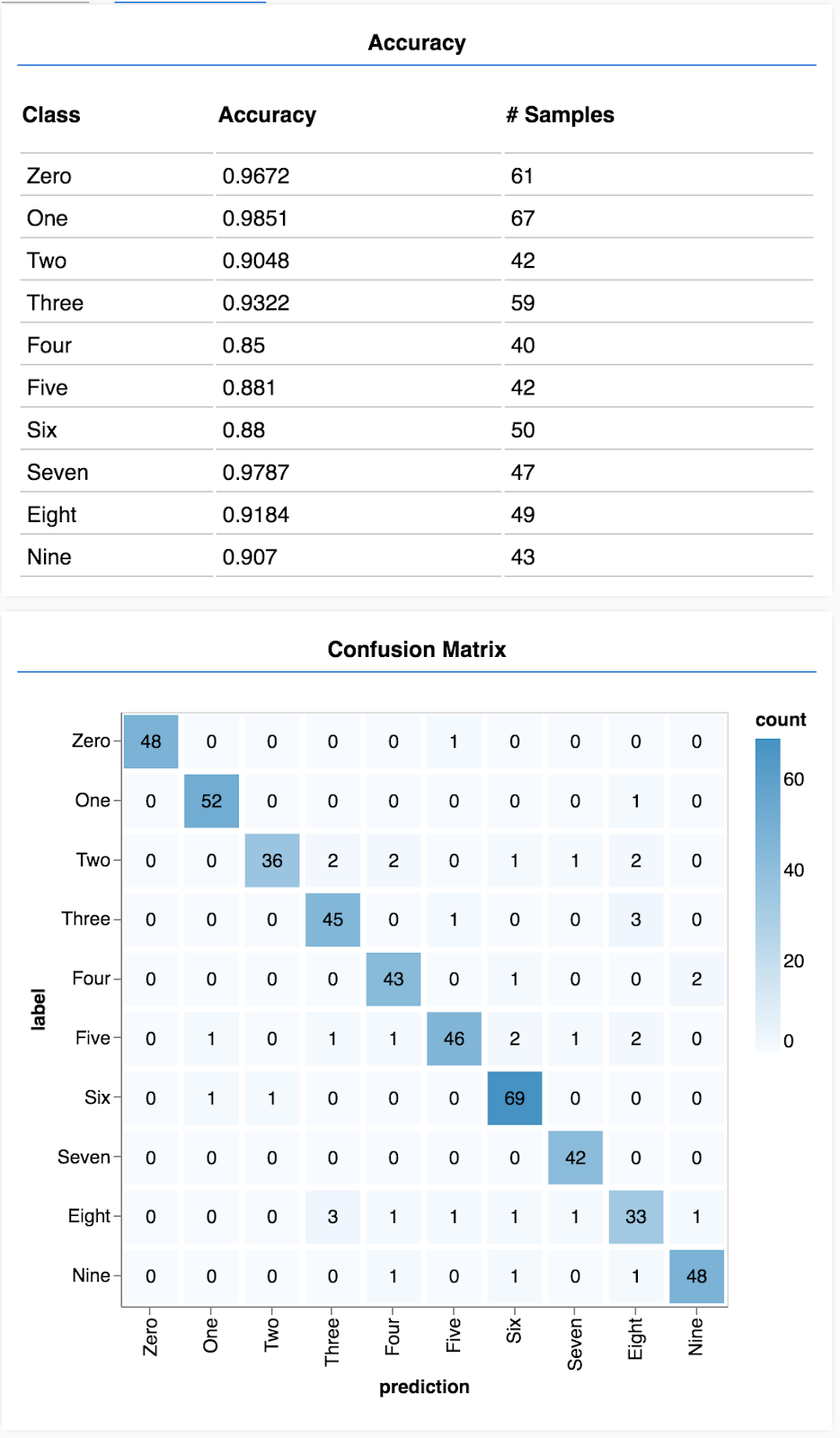
Complimenti! Hai appena addestrato una rete neurale convoluzionale.
8. Concetti chiave
La previsione delle categorie per i dati di input è chiamata attività di classificazione.
Le attività di classificazione richiedono una rappresentazione dei dati appropriata per le etichette
- Le rappresentazioni comuni delle etichette includono la codifica one-hot delle categorie
Prepara i dati:
- È utile mettere da parte alcuni dati che il modello non vede mai durante l'addestramento e che puoi utilizzare per valutarlo. Questo è chiamato set di validazione.
Crea ed esegui il modello:
- È stato dimostrato che i modelli convoluzionali funzionano bene nelle attività di elaborazione delle immagini.
- I problemi di classificazione di solito utilizzano l'entropia incrociata categorica per le funzioni di perdita.
- Monitora l'addestramento per vedere se la perdita sta diminuendo e l'accuratezza sta aumentando.
valuta il modello
- Decidi un modo per valutare il modello una volta addestrato per vedere come si comporta rispetto al problema iniziale che volevi risolvere.
- L'accuratezza per classe e le matrici di confusione possono fornire una suddivisione più dettagliata del rendimento del modello rispetto alla sola accuratezza complessiva.