
1. บทนำ
ในบทแนะนำนี้ เราจะสร้างโมเดล TensorFlow.js เพื่อจดจำตัวเลขที่เขียนด้วยลายมือด้วยโครงข่ายระบบประสาทเทียมแบบ Convolutional ก่อนอื่น เราจะฝึกตัวแยกประเภทโดยให้ "ดู" รูปภาพตัวเลขที่เขียนด้วยลายมือหลายพันรูปและป้ายกำกับของรูปภาพเหล่านั้น จากนั้นเราจะประเมินความแม่นยำของตัวแยกประเภทโดยใช้ข้อมูลการทดสอบที่โมเดลไม่เคยเห็น
งานนี้ถือเป็นงานการจัดประเภทเนื่องจากเราฝึกโมเดลเพื่อกำหนดหมวดหมู่ (ตัวเลขที่ปรากฏในรูปภาพ) ให้กับรูปภาพอินพุต เราจะฝึกโมเดลโดยแสดงตัวอย่างอินพุตจำนวนมากพร้อมกับเอาต์พุตที่ถูกต้อง ซึ่งเรียกว่าการเรียนรู้ที่มีการควบคุมดูแล
สิ่งที่คุณจะสร้าง
คุณจะสร้างหน้าเว็บที่ใช้ TensorFlow.js เพื่อฝึกโมเดลในเบราว์เซอร์ เมื่อได้รับรูปภาพขาวดำที่มีขนาดหนึ่งๆ โมเดลจะจัดประเภทว่ามีตัวเลขใดปรากฏในรูปภาพ ขั้นตอนที่เกี่ยวข้องมีดังนี้
- โหลดข้อมูล
- กำหนดสถาปัตยกรรมของโมเดล
- ฝึกโมเดลและตรวจสอบประสิทธิภาพขณะฝึก
- ประเมินโมเดลที่ฝึกแล้วโดยทำการคาดการณ์
สิ่งที่คุณจะได้เรียนรู้
- ไวยากรณ์ TensorFlow.js สำหรับการสร้างโมเดล Convolutional โดยใช้ TensorFlow.js Layers API
- การกำหนดงานการแยกประเภทใน TensorFlow.js
- วิธีตรวจสอบการฝึกในเบราว์เซอร์โดยใช้ไลบรารี tfjs-vis
สิ่งที่คุณต้องมี
- Chrome เวอร์ชันล่าสุดหรือเบราว์เซอร์สมัยใหม่อื่นๆ ที่รองรับโมดูล ES6
- โปรแกรมแก้ไขข้อความที่ทำงานในเครื่องหรือบนเว็บผ่านเครื่องมืออย่าง Codepen หรือ Glitch
- ความรู้เกี่ยวกับ HTML, CSS, JavaScript และเครื่องมือสำหรับนักพัฒนาเว็บใน Chrome (หรือเครื่องมือสำหรับนักพัฒนาเว็บของเบราว์เซอร์ที่คุณต้องการ)
- ความเข้าใจเชิงแนวคิดระดับสูงเกี่ยวกับโครงข่ายประสาทเทียม หากต้องการดูข้อมูลเบื้องต้นหรือทบทวนความรู้ โปรดดูวิดีโอนี้จาก 3blue1brown หรือวิดีโอเกี่ยวกับ Deep Learning ใน Javascript โดย Ashi Krishnan
นอกจากนี้ คุณควรทำความคุ้นเคยกับเนื้อหาในบทแนะนำการฝึกอบรมแรกของเราด้วย
2. ตั้งค่า
สร้างหน้า HTML และใส่ JavaScript
 คัดลอกโค้ดต่อไปนี้ลงในไฟล์ HTML ที่ชื่อ
คัดลอกโค้ดต่อไปนี้ลงในไฟล์ HTML ที่ชื่อ
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
สร้างไฟล์ JavaScript สำหรับข้อมูลและโค้ด
- ในโฟลเดอร์เดียวกับไฟล์ HTML ด้านบน ให้สร้างไฟล์ชื่อ data.js แล้วคัดลอกเนื้อหาจากลิงก์นี้ลงในไฟล์ดังกล่าว
- ในโฟลเดอร์เดียวกับขั้นตอนที่ 1 ให้สร้างไฟล์ชื่อ script.js แล้ววางโค้ดต่อไปนี้ลงในไฟล์
console.log('Hello TensorFlow');
ทดสอบเลย
ตอนนี้คุณได้สร้างไฟล์ HTML และ JavaScript แล้ว ให้ทดสอบไฟล์เหล่านั้น เปิดไฟล์ index.html ในเบราว์เซอร์และเปิดคอนโซลเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์
หากทุกอย่างทำงานได้ตามปกติ ระบบควรสร้างตัวแปรส่วนกลาง 2 รายการ tf คือการอ้างอิงถึงไลบรารี TensorFlow.js ส่วน tfvis คือการอ้างอิงถึงไลบรารี tfjs-vis
คุณควรเห็นข้อความที่ระบุว่า Hello TensorFlow หากเห็นข้อความดังกล่าว แสดงว่าคุณพร้อมที่จะไปยังขั้นตอนถัดไปแล้ว
3. โหลดข้อมูล
ในบทแนะนำนี้ คุณจะได้ฝึกโมเดลให้เรียนรู้การจดจำตัวเลขในรูปภาพ เช่น รูปภาพด้านล่าง รูปภาพเหล่านี้เป็นรูปภาพแบบระดับสีเทาขนาด 28x28 พิกเซลจากชุดข้อมูลที่เรียกว่า MNIST

เราได้ให้โค้ดเพื่อโหลดรูปภาพเหล่านี้จากไฟล์สไปรท์พิเศษ (~10 MB) ที่เราสร้างขึ้นสำหรับคุณ เพื่อให้เรามุ่งเน้นไปที่ส่วนการฝึกได้
คุณสามารถศึกษาไฟล์ data.js เพื่อทำความเข้าใจวิธีโหลดข้อมูล หรือเมื่อดูบทแนะนำนี้จบแล้ว ให้สร้างวิธีการโหลดข้อมูลของคุณเอง
โค้ดที่ระบุมีคลาส MnistData ซึ่งมีเมธอดสาธารณะ 2 รายการ ดังนี้
nextTrainBatch(batchSize): แสดงผลชุดรูปภาพแบบสุ่มและป้ายกำกับของรูปภาพจากชุดฝึกnextTestBatch(batchSize): แสดงผลชุดรูปภาพและป้ายกำกับจากชุดทดสอบ
คลาส MnistData ยังทำขั้นตอนสำคัญในการสับเปลี่ยนและปรับค่าข้อมูลด้วย
มีรูปภาพทั้งหมด 65,000 รูป เราจะใช้รูปภาพสูงสุด 55,000 รูปเพื่อฝึกโมเดล และเก็บรูปภาพ 10,000 รูปไว้เพื่อใช้ทดสอบประสิทธิภาพของโมเดลเมื่อเสร็จสิ้น และเราจะทำทั้งหมดนี้ในเบราว์เซอร์
มาโหลดข้อมูลและทดสอบว่าโหลดข้อมูลอย่างถูกต้อง
เพิ่มโค้ดต่อไปนี้ลงในไฟล์ script.js
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
รีเฟรชหน้าเว็บ แล้วหลังจากนั้นไม่กี่วินาที คุณจะเห็นแผงทางด้านซ้ายที่มีรูปภาพจำนวนหนึ่ง

4. สร้างแนวคิดเกี่ยวกับงานของเรา
ข้อมูลอินพุตของเรามีลักษณะดังนี้
เป้าหมายของเราคือการฝึกโมเดลที่จะใช้รูปภาพ 1 รูปและเรียนรู้ที่จะคาดการณ์คะแนนสำหรับแต่ละคลาสที่เป็นไปได้ 10 คลาสที่รูปภาพนั้นอาจเป็นของคลาสใดคลาสหนึ่ง (ตัวเลข 0-9)
รูปภาพแต่ละรูปมีความกว้าง 28 พิกเซล สูง 28 พิกเซล และมีช่องสี 1 ช่องเนื่องจากเป็นรูปภาพระดับสีเทา ดังนั้นรูปร่างของแต่ละรูปภาพจึงเป็น [28, 28, 1]
โปรดทราบว่าเราจะทำการแมปแบบ 1 ต่อ 10 รวมถึงรูปร่างของตัวอย่างอินพุตแต่ละรายการ เนื่องจากเป็นสิ่งสำคัญสำหรับส่วนถัดไป
5. กำหนดสถาปัตยกรรมโมเดล
ในส่วนนี้ เราจะเขียนโค้ดเพื่ออธิบายสถาปัตยกรรมของโมเดล สถาปัตยกรรมโมเดลเป็นวิธีที่ซับซ้อนในการพูดว่า "โมเดลจะเรียกใช้ฟังก์ชันใดเมื่อดำเนินการ" หรืออีกนัยหนึ่งคือ "โมเดลของเราจะใช้อัลกอริทึมใดในการคำนวณคำตอบ"
ในแมชชีนเลิร์นนิง เราจะกำหนดสถาปัตยกรรม (หรืออัลกอริทึม) และปล่อยให้กระบวนการฝึกเรียนรู้พารามิเตอร์ของอัลกอริทึมนั้น
เพิ่มฟังก์ชันต่อไปนี้ลงใน
script.js เพื่อกำหนดสถาปัตยกรรมโมเดล
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
มาดูรายละเอียดเพิ่มเติมเกี่ยวกับเรื่องนี้กัน
การบิด
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
ในที่นี้เราใช้โมเดลแบบลำดับ
เราใช้เลเยอร์ conv2d แทนเลเยอร์หนาแน่น เราไม่สามารถลงรายละเอียดทั้งหมดเกี่ยวกับวิธีการทำงานของการสังวัตนาการ แต่มีแหล่งข้อมูลบางส่วนที่อธิบายการทำงานพื้นฐานดังนี้
มาดูรายละเอียดของแต่ละอาร์กิวเมนต์ในออบเจ็กต์การกำหนดค่าสำหรับ conv2d กัน
inputShapeรูปแบบของข้อมูลที่จะไหลเข้าสู่เลเยอร์แรกของโมเดล ในกรณีนี้ ตัวอย่าง MNIST ของเราคือรูปภาพขาวดำขนาด 28x28 พิกเซล รูปแบบ Canonical สำหรับข้อมูลรูปภาพคือ[row, column, depth]ดังนั้นเราจึงต้องการกำหนดค่ารูปร่างเป็น[28, 28, 1]28 แถวและคอลัมน์สำหรับจำนวนพิกเซลในแต่ละมิติข้อมูล และความลึก 1 เนื่องจากรูปภาพมีช่องสีเพียง 1 ช่อง โปรดทราบว่าเราไม่ได้ระบุขนาดกลุ่มในรูปร่างอินพุต เลเยอร์ได้รับการออกแบบมาให้ไม่ขึ้นอยู่กับขนาดกลุ่ม เพื่อให้คุณส่งผ่าน Tensor ที่มีขนาดกลุ่มใดก็ได้ในระหว่างการอนุมานkernelSizeขนาดของหน้าต่างตัวกรองการแปลงแบบเลื่อนที่จะใช้กับข้อมูลอินพุต ในที่นี้ เราตั้งค่าkernelSize5ซึ่งระบุหน้าต่างการแปลงแบบ Convolutional ขนาด 5x5filtersจำนวนหน้าต่างตัวกรองขนาดkernelSizeที่จะใช้กับข้อมูลอินพุต ในที่นี้ เราจะใช้ตัวกรอง 8 รายการกับข้อมูลstrides"ขนาดขั้นตอน" ของหน้าต่างเลื่อน ซึ่งก็คือจำนวนพิกเซลที่ตัวกรองจะเลื่อนในแต่ละครั้งที่เลื่อนผ่านรูปภาพ ในที่นี้ เราจะระบุระยะก้าวย่างเป็น 1 ซึ่งหมายความว่าตัวกรองจะเลื่อนไปเหนือรูปภาพทีละ 1 พิกเซลactivation. ฟังก์ชันการเปิดใช้งานที่จะใช้กับข้อมูลหลังจากที่การสังวัตนาการเสร็จสมบูรณ์ ในกรณีนี้ เราจะใช้ฟังก์ชัน Rectified Linear Unit (ReLU) ซึ่งเป็นฟังก์ชันการเปิดใช้งานที่พบบ่อยมากในโมเดล MLkernelInitializerวิธีที่ใช้ในการเริ่มต้นน้ำหนักของโมเดลแบบสุ่ม ซึ่งมีความสำคัญอย่างยิ่งต่อไดนามิกการฝึก เราจะไม่ลงรายละเอียดเกี่ยวกับการเริ่มต้นที่นี่ แต่โดยทั่วไปแล้วVarianceScaling(ใช้ที่นี่) เป็นตัวเลือกการเริ่มต้นที่ดี
การทำให้การแสดงข้อมูลของเราแบนราบ
model.add(tf.layers.flatten());
รูปภาพเป็นข้อมูลที่มีมิติสูง และการดำเนินการ Convolution มักจะเพิ่มขนาดของข้อมูลที่ป้อนเข้าไป ก่อนส่งข้อมูลไปยังเลเยอร์การจัดประเภทสุดท้าย เราต้องแปลงข้อมูลเป็นอาร์เรย์ยาว 1 รายการ เลเยอร์หนาแน่น (ซึ่งเราใช้เป็นเลเยอร์สุดท้าย) ใช้เวลาเพียง tensor1ds ดังนั้นขั้นตอนนี้จึงเป็นเรื่องปกติในงานการแยกประเภทหลายอย่าง
คำนวณการแจกแจงความน่าจะเป็นสุดท้าย
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
เราจะใช้เลเยอร์หนาแน่นที่มีการเปิดใช้งาน Softmax เพื่อคำนวณการกระจายความน่าจะเป็นใน 10 คลาสที่เป็นไปได้ คลาสที่มีคะแนนสูงสุดจะเป็นตัวเลขที่คาดการณ์
เลือกฟังก์ชันเพิ่มประสิทธิภาพและฟังก์ชันการสูญเสีย
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
เราคอมไพล์โมเดลโดยระบุเครื่องมือเพิ่มประสิทธิภาพ ฟังก์ชันการสูญเสีย และเมตริกที่เราต้องการติดตาม
ในทางตรงกันข้ามกับบทแนะนำแรก เราใช้ categoricalCrossentropy เป็นฟังก์ชันการสูญเสีย ตามชื่อที่สื่อถึง ฟังก์ชันนี้จะใช้เมื่อเอาต์พุตของโมเดลเป็นการกระจายความน่าจะเป็น categoricalCrossentropy วัดข้อผิดพลาดระหว่างการกระจายความน่าจะเป็นที่สร้างขึ้นโดยเลเยอร์สุดท้ายของโมเดลกับการกระจายความน่าจะเป็นที่กำหนดโดยป้ายกำกับจริง
เช่น หากตัวเลขแสดงถึง 7 จริงๆ เราอาจได้ผลลัพธ์ต่อไปนี้
ดัชนี | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
ป้ายกำกับจริง | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
การคาดการณ์ | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
Categorical Cross Entropy จะสร้างตัวเลขเดียวที่บ่งบอกว่าเวกเตอร์การคาดการณ์มีความคล้ายคลึงกับเวกเตอร์ป้ายกำกับจริงของเรามากน้อยเพียงใด
การแสดงข้อมูลที่ใช้ที่นี่สำหรับป้ายกำกับเรียกว่าการเข้ารหัสแบบ One-Hot และเป็นเรื่องปกติในปัญหาการจัดประเภท แต่ละคลาสจะมีโอกาสที่เชื่อมโยงกับตัวอย่างแต่ละรายการ เมื่อทราบแน่ชัดว่าควรเป็นอะไร เราจะตั้งค่าความน่าจะเป็นนั้นเป็น 1 และตั้งค่าอื่นๆ เป็น 0 ดูข้อมูลเพิ่มเติมเกี่ยวกับการเข้ารหัสแบบ One-Hot ได้ที่หน้านี้
เมตริกอีกรายการที่เราจะตรวจสอบคือ accuracy ซึ่งสำหรับปัญหาการจัดประเภทคือเปอร์เซ็นต์ของการคาดการณ์ที่ถูกต้องจากการคาดการณ์ทั้งหมด
6. ฝึกโมเดล
คัดลอกฟังก์ชันต่อไปนี้ไปยังไฟล์ script.js
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
จากนั้นเพิ่มโค้ดต่อไปนี้ลงใน
run ฟังก์ชัน
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
รีเฟรชหน้าเว็บ แล้วหลังจากนั้น 2-3 วินาที คุณจะเห็นกราฟบางส่วนที่รายงานความคืบหน้าในการฝึก
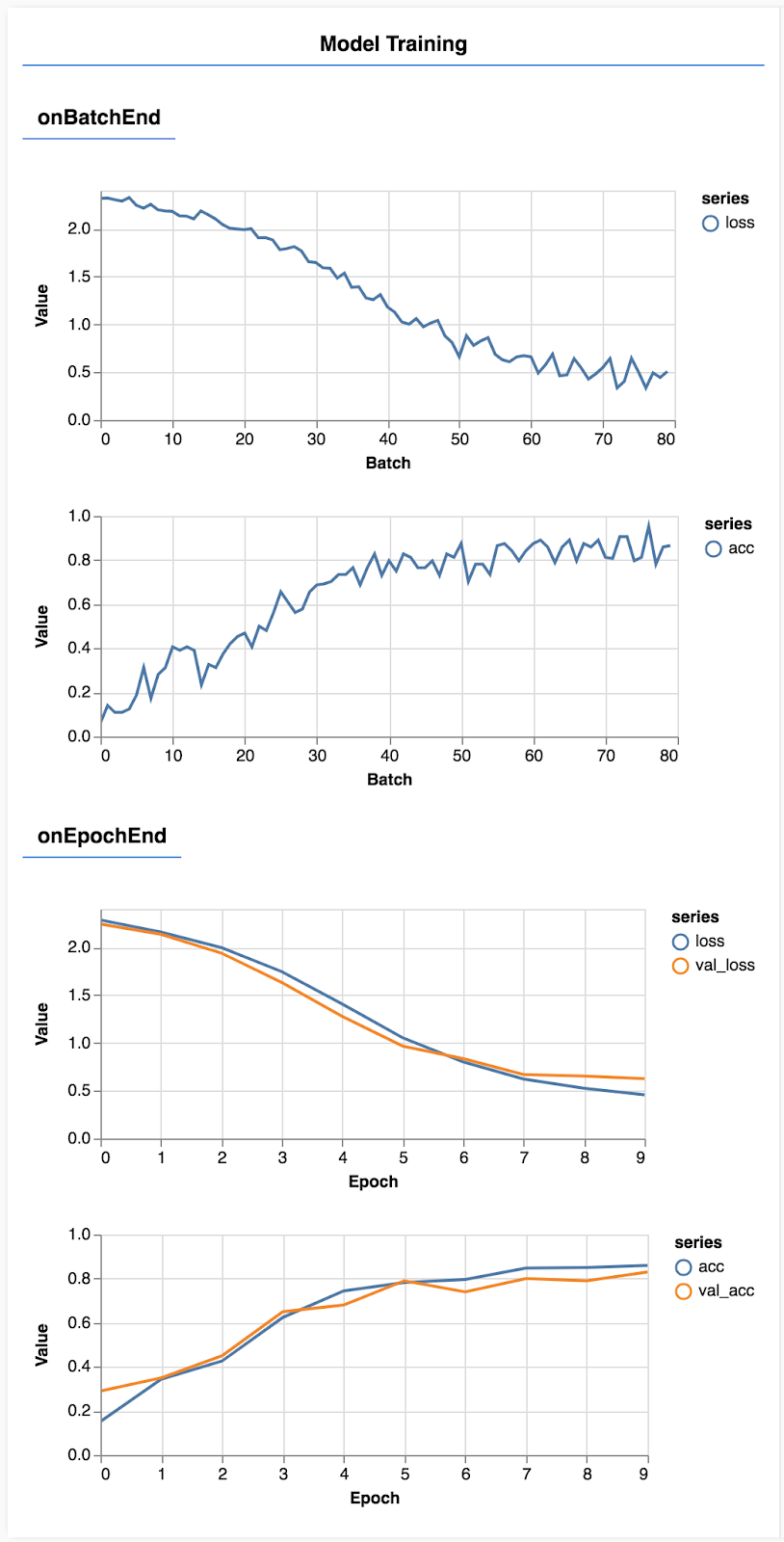
มาดูรายละเอียดเพิ่มเติมกัน
ตรวจสอบเมตริก
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
ในส่วนนี้ เราจะตัดสินใจเลือกเมตริกที่จะตรวจสอบ เราจะตรวจสอบการสูญเสียและความแม่นยำในชุดฝึก รวมถึงการสูญเสียและความแม่นยำในชุดข้อมูลสำหรับตรวจสอบความถูกต้อง (val_loss และ val_acc ตามลำดับ) เราจะพูดถึงชุดข้อมูลสำหรับตรวจสอบความถูกต้องเพิ่มเติมที่ด้านล่าง
เตรียมข้อมูลเป็นเทนเซอร์
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
ในที่นี้ เราจะสร้างชุดข้อมูล 2 ชุด ได้แก่ ชุดฝึกที่จะใช้ฝึกโมเดล และชุดข้อมูลสำหรับตรวจสอบความถูกต้องที่จะใช้ทดสอบโมเดลเมื่อสิ้นสุดแต่ละ Epoch อย่างไรก็ตาม ระบบจะไม่แสดงข้อมูลในชุดข้อมูลสำหรับตรวจสอบความถูกต้องต่อโมเดลระหว่างการฝึก
คลาสข้อมูลที่เราจัดเตรียมไว้ช่วยให้คุณรับ Tensor จากข้อมูลรูปภาพได้อย่างง่ายดาย แต่เรายังคงปรับรูปร่างของเทนเซอร์ให้เป็นรูปร่างที่โมเดลคาดหวัง [num_examples, image_width, image_height, channels] ก่อนที่จะป้อนข้อมูลเหล่านี้ให้กับโมเดล สำหรับชุดข้อมูลแต่ละชุด เรามีทั้งอินพุต (X) และป้ายกำกับ (Y)
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
เราเรียกใช้ model.fit เพื่อเริ่มลูปการฝึก นอกจากนี้ เรายังส่งพร็อพเพอร์ตี้ validationData เพื่อระบุข้อมูลที่โมเดลควรใช้ทดสอบตัวเองหลังจากแต่ละ Epoch (แต่ไม่ใช้สำหรับการฝึก)
หากโมเดลทำงานได้ดีกับข้อมูลฝึกฝน แต่ไม่ดีกับข้อมูลการตรวจสอบ แสดงว่าโมเดลมีแนวโน้มที่จะโอเวอร์ฟิตกับข้อมูลฝึกฝน และไม่สามารถสรุปอินพุตที่ไม่เคยเห็นมาก่อนได้ดี
7. ประเมินโมเดลของเรา
ความแม่นยำในการตรวจสอบให้ค่าประมาณที่ดีเกี่ยวกับประสิทธิภาพของโมเดลในข้อมูลที่ไม่เคยเห็นมาก่อน (ตราบใดที่ข้อมูลนั้นคล้ายกับชุดข้อมูลสำหรับตรวจสอบความถูกต้องในบางลักษณะ) แต่เราอาจต้องการรายละเอียดเพิ่มเติมเกี่ยวกับประสิทธิภาพในชั้นเรียนต่างๆ
tfjs-vis มี 2-3 วิธีที่จะช่วยคุณในเรื่องนี้ได้
เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของไฟล์ script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
โค้ดนี้ทำอะไร
- ทำการคาดการณ์
- คำนวณเมตริกความแม่นยำ
- แสดงเมตริก
มาดูรายละเอียดเกี่ยวกับแต่ละขั้นตอนกัน
ทายผล
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
ก่อนอื่นเราต้องทำการคาดการณ์ ในที่นี้ เราจะใช้รูปภาพ 500 รูปและคาดการณ์ว่ารูปภาพเหล่านั้นมีตัวเลขใด (คุณสามารถเพิ่มจำนวนนี้ในภายหลังเพื่อทดสอบกับชุดรูปภาพที่ใหญ่ขึ้นได้)
โดยเฉพาะอย่างยิ่ง argmax ฟังก์ชันนี้จะให้ดัชนีของคลาสที่มีความน่าจะเป็นสูงสุด โปรดทราบว่าโมเดลจะแสดงผลความน่าจะเป็นสำหรับแต่ละคลาส ในที่นี้ เราจะดูความน่าจะเป็นสูงสุดและกำหนดให้ความน่าจะเป็นนั้นเป็นการคาดการณ์
นอกจากนี้ คุณอาจสังเกตเห็นว่าเราสามารถคาดการณ์ตัวอย่างทั้ง 500 รายการได้พร้อมกัน นี่คือประสิทธิภาพของการเวกเตอร์ที่ TensorFlow.js มีให้
แสดงความแม่นยำต่อคลาส
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
เมื่อมีชุดการคาดการณ์และป้ายกำกับ เราจะคำนวณความแม่นยำสำหรับแต่ละคลาสได้
แสดงเมตริกความสับสน
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
เมทริกซ์ความสับสนคล้ายกับความแม่นยำต่อคลาส แต่จะแบ่งย่อยออกไปอีกเพื่อแสดงรูปแบบของการแยกประเภทที่ไม่ถูกต้อง ซึ่งจะช่วยให้คุณทราบว่าโมเดลสับสนเกี่ยวกับคู่คลาสใดๆ หรือไม่
แสดงการประเมิน
เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของฟังก์ชัน run เพื่อแสดงการประเมิน
await showAccuracy(model, data);
await showConfusion(model, data);
คุณควรเห็นจอแสดงผลที่มีลักษณะดังต่อไปนี้
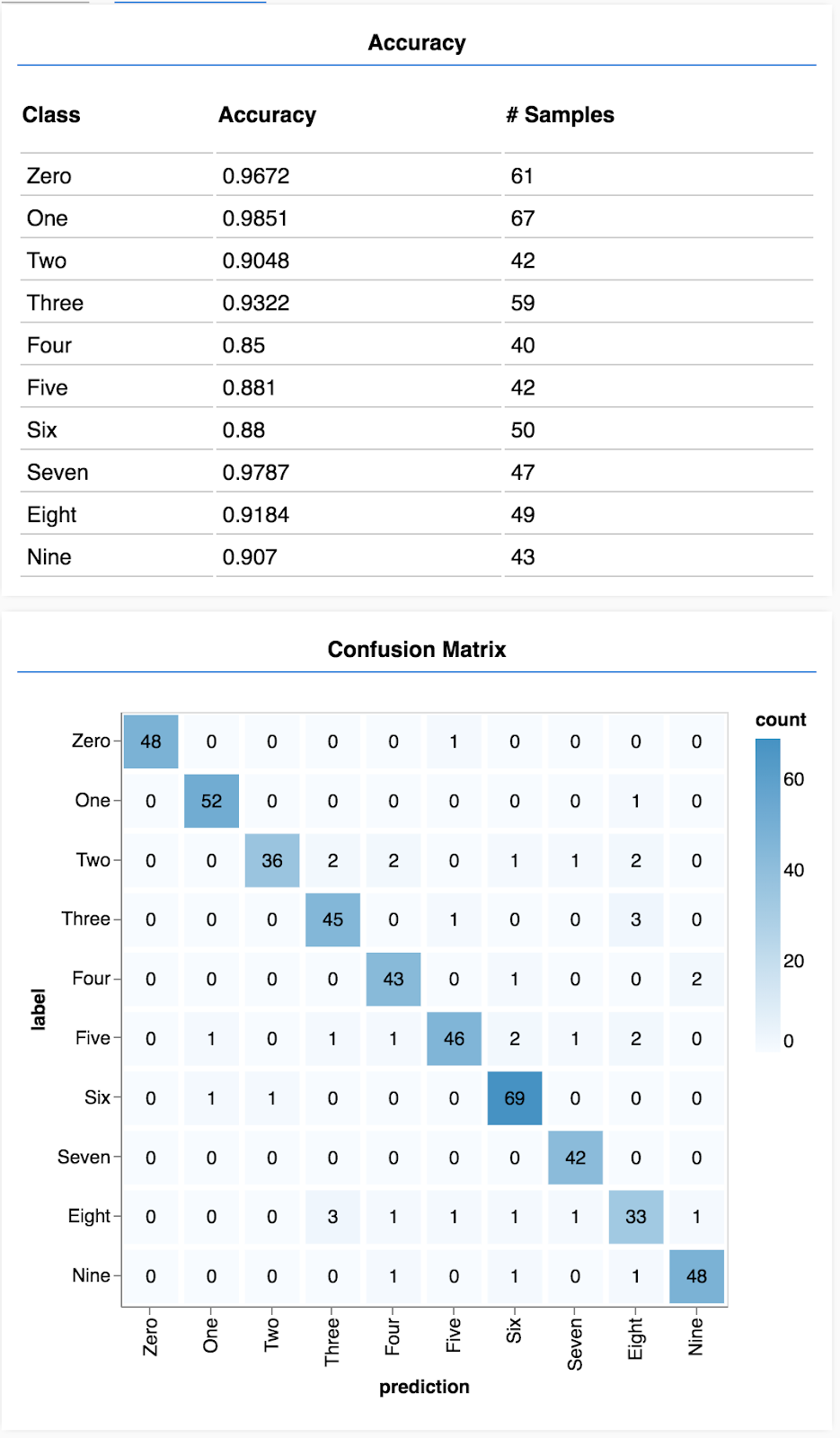
ยินดีด้วย คุณเพิ่งฝึกโครงข่ายประสาทเทียมแบบ Convolutional
8. ประเด็นสำคัญ
การคาดการณ์หมวดหมู่สำหรับข้อมูลอินพุตเรียกว่างานการแยกประเภท
งานการแยกประเภทต้องมีการแสดงข้อมูลที่เหมาะสมสำหรับป้ายกำกับ
- การแสดงป้ายกำกับที่พบบ่อย ได้แก่ การเข้ารหัสแบบ One-Hot ของหมวดหมู่
เตรียมข้อมูล
- การเก็บข้อมูลบางส่วนไว้ต่างหากซึ่งโมเดลไม่เคยเห็นระหว่างการฝึกจะเป็นประโยชน์ต่อการประเมินโมเดล ซึ่งเรียกว่าชุดข้อมูลสำหรับตรวจสอบความถูกต้อง
สร้างและเรียกใช้โมเดล
- โมเดล Convolutional แสดงให้เห็นว่าทำงานได้ดีในงานเกี่ยวกับรูปภาพ
- โดยปกติแล้วปัญหาการจัดประเภทจะใช้ Cross-Entropy แบบ Categorical สำหรับฟังก์ชันการสูญเสีย
- ตรวจสอบการฝึกเพื่อดูว่าการสูญเสียลดลงและความแม่นยำเพิ่มขึ้นหรือไม่
ประเมินโมเดล
- หาวิธีประเมินโมเดลเมื่อฝึกแล้วเพื่อดูว่าโมเดลทำงานได้ดีเพียงใดกับปัญหาเริ่มต้นที่คุณต้องการแก้ไข
- ความแม่นยำต่อคลาสและเมทริกซ์ความสับสนจะช่วยให้คุณเห็นรายละเอียดประสิทธิภาพของโมเดลได้ดีกว่าแค่ความแม่นยำโดยรวม