
En este instructivo, crearemos un modelo de TensorFlow.js para reconocer dígitos escritos a mano con una red neuronal convolucional. Primero, entrenaremos el clasificador para que "mire" miles de imágenes de dígitos escritos a mano y sus etiquetas. Luego, evaluaremos la exactitud del clasificador con datos de prueba que el modelo nunca ha visto.
Esta tarea se considera de clasificación, ya que entrenaremos el modelo para que le asigne una categoría (el dígito que aparece en la imagen) a la imagen de entrada. Para entrenar el modelo, le mostraremos varios ejemplos de entradas junto con el resultado correcto, lo cual se conoce como aprendizaje supervisado.
Qué compilarás
Crearás una página web que utiliza TensorFlow.js para entrenar un modelo en el navegador. Cuando se le muestre una imagen en blanco y negro de un tamaño determinado, clasificará el dígito que aparece en ella. Sigue estos pasos:
- Carga los datos.
- Define la arquitectura del modelo.
- Entrena el modelo y supervisa su rendimiento mientras se entrena.
- Evalúa el modelo entrenado mediante algunas predicciones.
Qué aprenderás
- La sintaxis de TensorFlow.js para crear modelos convolucionales con la API de Layers de TensorFlow.js
- Cómo formular tareas de clasificación en TensorFlow.js
- Cómo supervisar el entrenamiento en el navegador con la biblioteca tfjs‑vis
Requisitos
- Una versión reciente de Chrome o de otro navegador actualizado que sea compatible con los módulos ES6
- Un editor de texto que se ejecute localmente en tu máquina o en la Web con servicios como CodePen o Glitch
- Conocimientos sobre HTML, CSS, JavaScript y las Herramientas para desarrolladores de Chrome (o las de tu navegador preferido)
- Comprensión conceptual de alto nivel de las redes neuronales (si necesitas una introducción o un repaso, te recomendamos mirar este video de 3blue1brown o este video sobre aprendizaje profundo en JavaScript de Ashi Krishnan)
También debes estar familiarizado con el material de nuestro primer instructivo de entrenamiento.
Crea una página HTML y, luego, incluye el código JavaScript
 Copia el siguiente código en un archivo HTML llamado
Copia el siguiente código en un archivo HTML llamado
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Crea los archivos JavaScript de los datos y el código
- En la misma carpeta que el archivo HTML anterior, crea un archivo llamado data.js y copia el contenido de este vínculo en ese archivo.
- En la misma carpeta que en el primer paso, crea un archivo llamado script.js y agrega el siguiente código.
console.log('Hello TensorFlow');
Pruébalo
Ahora que creaste los archivos HTML y JavaScript, pruébalos. Abre el archivo index.html en el navegador y abre la consola de las Herramientas para desarrolladores.
Si todo funciona bien, debe haber dos variables globales creadas. tf es una referencia a la biblioteca de TensorFlow.js, y tfvis es una referencia a la biblioteca tfjs‑vis.
Deberías ver un mensaje que dice Hello TensorFlow*,* si es así, ya puedes continuar con el paso siguiente.
En este instructivo, entrenarás un modelo para que aprenda a reconocer dígitos en imágenes como las que se muestran a continuación. Estas son imágenes en escala de grises de 28 × 28 px de un conjunto de datos llamado MNIST.
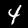

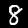
Te proporcionamos código para cargar estas imágenes desde un archivo de objeto especial (de aprox. 10 MB) que creamos para enforcarnos en el entrenamiento.
No dudes en estudiar el archivo data.js para comprender cómo se cargan los datos. O bien, cuando termines este instructivo, crea tu propia estrategia para cargarlos.
El código proporcionado contiene una clase MnistData que tiene los siguientes dos métodos públicos:
nextTrainBatch(batchSize): Muestra un lote aleatorio de imágenes y sus etiquetas del conjunto de entrenamiento.nextTestBatch(batchSize): Muestra un lote de imágenes y sus etiquetas del conjunto de prueba.
La clase MnistData también realiza los pasos importantes de redistribución y normalización de los datos.
Hay un total de 65,000 imágenes. Usaremos hasta 55,000 imágenes para entrenar el modelo y guardaremos 10,000, que usaremos para probar el rendimiento del modelo cuando hayamos terminado. Haremos todo esto en el navegador.
Carguemos los datos y veamos si lo hicieron correctamente.
Agrega el siguiente código a tu archivo script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Actualiza la página y, después de unos segundos, deberías ver un panel a la izquierda con varias imágenes.

Nuestros datos de entrada tienen el siguiente aspecto.
Nuestro objetivo es entrenar un modelo que acepte una imagen y aprenda a predecir una puntuación para cada una de las 10 clases posibles a las que puede pertenecer la imagen (los dígitos del 0 al 9).
Cada imagen tiene 28 px de ancho y 28 px de alto, y contiene 1 canal de color, ya que es una imagen en escala de grises. Por lo tanto, la forma de cada imagen es [28, 28, 1].
Recuerda que hacemos un mapeo de uno a diez y de la forma de cada ejemplo de entrada, ya que es importante para la próxima sección.
En esta sección, escribiremos código para describir la arquitectura del modelo. Arquitectura del modelo es una forma sofisticada de decir “qué funciones ejecutará el modelo cuando esté en funcionamiento” o, de forma alternativa, “qué algoritmo usará el modelo para procesar sus respuestas”.
En el aprendizaje automático, definimos una arquitectura (o algoritmo) y dejamos que el proceso de entrenamiento aprenda los parámetros de ese algoritmo.
Agrega la siguiente función a tu
archivo script.js para definir la arquitectura del modelo
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Veamos esto con más detalle.
Convoluciones
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Aquí usamos un modelo secuencial.
En lugar de una capa densa, usamos una capa de conv2d. No podemos explicar en detalle cómo funcionan las convoluciones, pero estos son algunos recursos en los que se explica la operación subyacente:
- Explicaciones visuales de kernels de imágenes
- Redes neuronales convolucionales para el reconocimiento visual
Desglosemos todos los argumentos del objeto de configuración de conv2d:
inputShape: La forma de los datos que fluyen en la primera capa del modelo. En este caso, los ejemplos de MNIST son imágenes en blanco y negro de 28 × 28 píxeles. El formato canónico para los datos de imagen es[row, column, depth], por lo que aquí queremos configurar una forma de[28, 28, 1]. 28 filas y columnas para la cantidad de píxeles de cada dimensión y una profundidad de 1 porque nuestras imágenes tienen solo 1 canal de color. Ten en cuenta que no especificamos un tamaño de lote en la forma de entrada. Las capas están diseñadas para ser independientes del tamaño de los lotes, de modo que, durante la inferencia, puedas pasar un tensor de cualquier tamaño de lote.kernelSize: El tamaño de las ventanas variables de filtros convolucionales que se aplicarán a los datos de entrada. Aquí, establecemos unkernelSizede5, que especifica una ventana convolucional cuadrada de 5 × 5.filters: La cantidad de ventanas de filtro con un tamaño dekernelSizeque se aplicarán a los datos de entrada. Aquí aplicaremos 8 filtros a los datos.strides: El “tamaño del paso” de la ventana variable; es decir, cuántos píxeles recorrerá el filtro cada vez que se mueva por la imagen. Aquí, especificamos la segmentación de 1, lo que significa que el filtro se desplazará sobre la imagen en pasos de 1 píxel.activation. La función de activación que se aplicará a los datos una vez que se complete la convolución. En este caso, aplicaremos una función de unidad lineal rectificada (ReLU), que es una función de activación muy común en los modelos de AA.kernelInitializer: El método que se usa para inicializar de forma aleatoria las ponderaciones del modelo, lo cual es muy importante para la dinámica del entrenamiento. Aquí no explicaremos en detalle la inicialización, peroVarianceScaling(que se usa en este caso) suele ser una opción adecuada de inicializador.
Compacta la representación de datos
model.add(tf.layers.flatten());
Las imágenes son datos de alta dimensión, y las operaciones convolucionales tienden a aumentar el tamaño de los datos que ingresaron a ellas. Antes de pasarlos a nuestra capa de clasificación final, debemos compactar los datos en un array largo. Las capas densas (que usamos como capa final) solo aceptan tensor1ds, por lo que este paso es habitual en muchas tareas de clasificación.
Calcula la distribución de probabilidad final
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Usaremos una capa densa con una activación de softmax para calcular las distribuciones de probabilidad de las 10 clases posibles. La clase con la puntuación más alta será el dígito previsto.
Elige un optimizador y una función de pérdida
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Compilamos el modelo especificando un optimizador, una función de pérdida y las métricas para las cuales deseamos realizar un seguimiento.
A diferencia de nuestro primer instructivo, aquí usamos categoricalCrossentropy como función de pérdida. Como el nombre implica, se usa cuando el resultado de nuestro modelo es una distribución de probabilidad. categoricalCrossentropy mide el error entre la distribución de probabilidad generada por la última capa del modelo y la distribución de probabilidad proporcionada por la etiqueta de confianza.
Por ejemplo, si nuestro dígito realmente representa un 7, podríamos obtener los siguientes resultados:
Índice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Etiqueta de confianza | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Predicción | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
La entropía cruzada categórica generará un número único que indicará el grado de similitud que tiene el vector de predicción con nuestro vector de etiqueta de confianza.
La representación de datos que se usa aquí para las etiquetas se denomina codificación one‑hot y es común en los problemas de clasificación. Cada clase tiene una probabilidad asociada por cada ejemplo. Cuando sabemos exactamente cuál debe ser esa probabilidad, podemos establecerla en 1 y las otras, en 0. Consulta esta página para obtener más información sobre la codificación one-hot.
La otra métrica que supervisaremos es accuracy, la que, para un problema de clasificación, es el porcentaje de predicciones correctas en relación con todas las predicciones.
Copia la siguiente función en tu archivo script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Luego, agrega el siguiente código a tu
función run.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Actualiza la página y, después de unos segundos, deberías ver algunos gráficos con el progreso del entrenamiento.
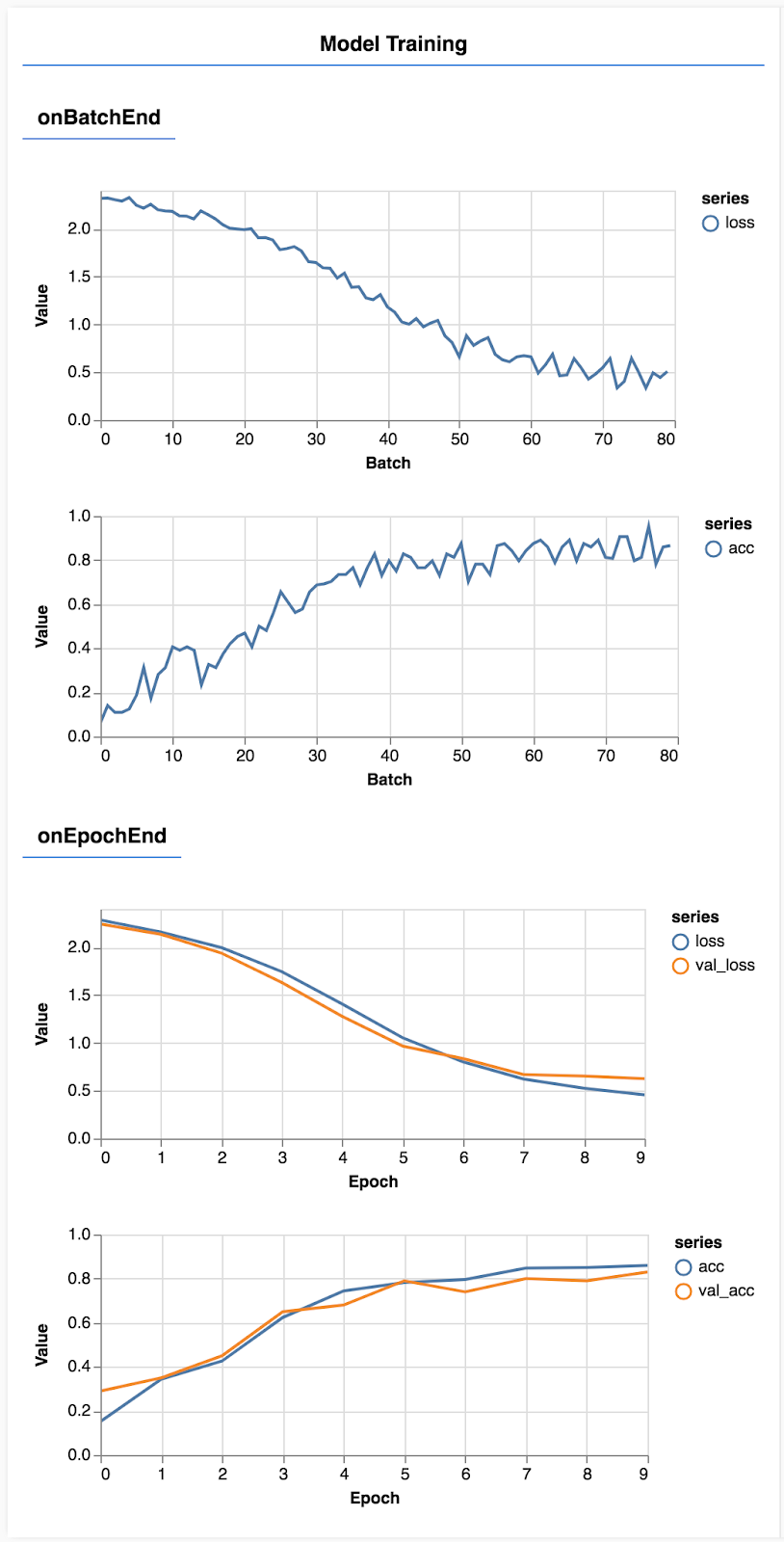
Veamos esto en más detalle.
Supervisa las métricas
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Aquí decidimos qué métricas supervisaremos. Supervisaremos la pérdida y la precisión en el conjunto de entrenamiento, así como la pérdida y precisión en el conjunto de validación (val_loss y val_acc, respectivamente). Encontrarás más información sobre el conjunto de validación a continuación.
Prepara datos como tensores
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Aquí, creamos dos conjuntos de datos, un conjunto de entrenamiento en el que entrenaremos al modelo y un conjunto de validación en el que probaremos el modelo al final de cada ciclo de entrenamiento. Sin embargo, los datos del conjunto de validación nunca se muestran al modelo durante el entrenamiento.
La clase de datos que proporcionamos facilita la obtención de tensores desde los datos de imágenes. Sin embargo, remodelamos los tensores en la forma que espera el modelo, [num_examples, image_width, image_height, channels], antes de ingresarlos al modelo. Para cada conjunto de datos, tenemos entradas (las X) y etiquetas (las Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Llamamos a model.fit para iniciar el bucle de entrenamiento. También pasamos una propiedad validationData a fin de indicar los datos que debe usar el modelo para que se pruebe después de cada ciclo de entrenamiento (pero no se debe usar para el entrenamiento).
Si obtenemos buenos resultados con nuestros datos de entrenamiento, pero no con los datos de validación, significa que el modelo probablemente se sobreajusta a los datos de entrenamiento y que no generalizará bien las entradas que no haya visto antes.
La precisión de la validación proporciona una buena estimación del rendimiento que tendrá el modelo con los datos que no ha visto antes (siempre y cuando estos datos sean similares de alguna manera al conjunto de validación). Sin embargo, es posible que se quiera obtener un desglose más detallado del rendimiento en las diferentes clases.
tfjs‑vis cuenta con algunos métodos que pueden ayudarte a obtener esta información.
Agrega el siguiente código al final del archivo script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
¿Qué hace este código?
- Realiza una predicción.
- Calcula las métricas de precisión.
- Muestra las métricas.
Analicemos con más detalle cada paso.
Realiza predicciones
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Primero, debemos hacer algunas predicciones. Aquí, tomaremos 500 imágenes y predeciremos el dígito que contienen (puedes aumentar esta cantidad más adelante para probar un conjunto más grande de imágenes).
En particular, la función argmax es la que nos proporciona el índice de la clase con la probabilidad más alta. Recuerda que el modelo da como resultado una probabilidad para cada clase. Aquí descubrimos la probabilidad más alta y la asignamos como predicción.
También notarás que podemos realizar predicciones en los 500 ejemplos a la vez. Esta es la potencia de la vectorización que proporciona TensorFlow.js.
Muestra la precisión por clase
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Con un conjunto de predicciones y etiquetas, podemos calcular la precisión de cada clase.
Muestra una matriz de confusión
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Una matriz de confusión es similar a la precisión por clase, pero se desglosa aún más para mostrar patrones de clasificación incorrecta. Te permite ver si el modelo se confunde con respecto a un par de clases en particular.
Muestra la evaluación
Agrega el siguiente código al final de la función de ejecución para mostrar la evaluación.
await showAccuracy(model, data);
await showConfusion(model, data);
Deberías ver una pantalla similar a la siguiente:
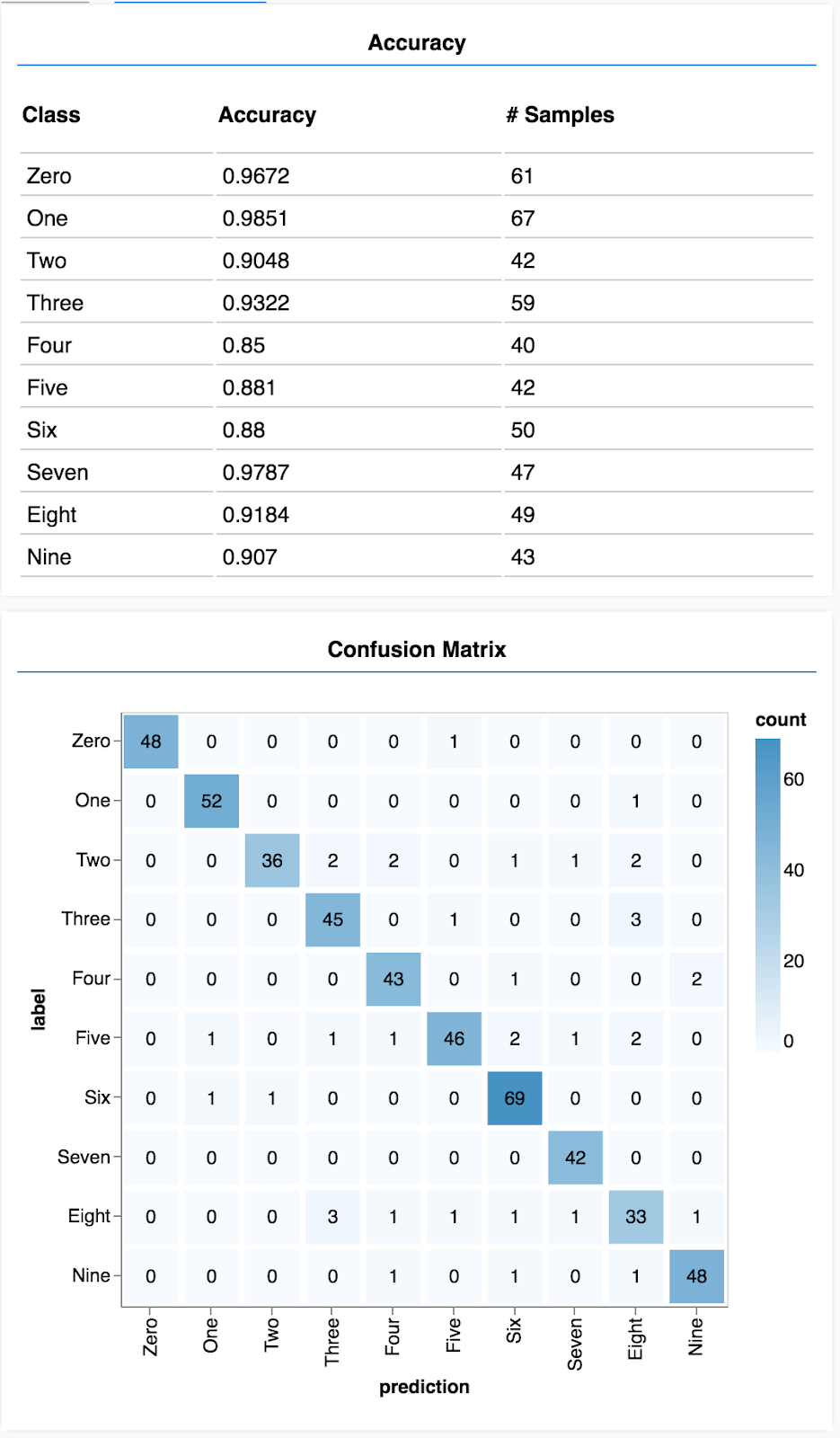
¡Felicitaciones! Acabas de entrenar una red neuronal convolucional.
La predicción de las categorías de los datos de entrada se denomina tarea de clasificación.
Las tareas de clasificación requieren una representación de datos adecuada para las etiquetas
- Las representaciones comunes de las etiquetas incluyen la codificación one‑hot de las categorías.
Prepara los datos:
- Resulta útil mantener algunos datos separados que el modelo nunca verá durante el entrenamiento para usarlos a fin de evaluar el modelo. Esto se llama conjunto de validación.
Compila y ejecuta tu modelo:
- Se demostró que los modelos convolucionales funcionan bien en las tareas de imagen.
- Los problemas de clasificación generalmente usan la entropía categórica cruzada para sus funciones de pérdida.
- Supervisa el entrenamiento para ver si disminuye la pérdida y aumenta la precisión.
Evalúa tu modelo
- Decide cómo evaluar el modelo una vez que se haya entrenado para ver qué tan bien funciona en el problema inicial que querías resolver.
- Las matrices de confusión y la precisión por clase pueden brindarte un desglose más preciso del rendimiento del modelo que la precisión general.