
このチュートリアルでは、畳み込みニューラル ネットワークを使用して手書きの数字を認識する TensorFlow.js モデルを構築します。まず、何千もの手書き数字の画像とそのラベルを読み込み、分類器をトレーニングします。その後、モデルが一度も認識していないテストデータを使用して、分類器の精度を評価します。
このタスクでは、モデルをトレーニングして入力画像にカテゴリ(画像が表している数字)を割り当てるため、分類タスクとみなされます。ここでは、多くの入力例と正しい出力を使用してモデルをトレーニングします。これを教師あり学習といいます。
作業内容
TensorFlow.js を使用して、ブラウザでモデルをトレーニングするためのウェブページを作成します。特定のサイズのモノクロ画像を提供して、画像内に含まれる数字を分類します。手順は次のとおりです。
- データを読み込みます。
- モデルのアーキテクチャを定義します。
- モデルをトレーニングします。トレーニングしながらパフォーマンスをモニタリングします。
- 予測を行い、トレーニングされたモデルを評価します。
ラボの内容
- TensorFlow.js Layers API を使用して畳み込みモデルを作成する TensorFlow.js 構文。
- TensorFlow.js での分類タスクの作成。
- tfjs-vis ライブラリを使用してブラウザ内トレーニングをモニタリングする方法。
必要なもの
- ES6 モジュールをサポートする Chrome などの最新のブラウザの最新バージョン。
- テキスト エディタ。マシンのローカルに実行することも、Codepen や Glitch など使ってウェブ上で実行することもできます。
- HTML、CSS、JavaScript、Chrome DevTools(または、使い慣れたブラウザ開発ツール)に関する知識。
- ニューラル ネットワークのコンセプトの概要。概要の説明が必要な場合は、3blue1brown の動画、または Ashi Krishnan による JavaScript のディープ ラーニングに関する動画をご覧ください。
また、最初のトレーニング チュートリアルの内容もご確認ください。
HTML ページを作成して JavaScript を追加する
 呼び出される html ファイルに次のコードをコピーします。
呼び出される html ファイルに次のコードをコピーします。
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
データとコードの JavaScript ファイルを作成する
- 上の HTML ファイルと同じフォルダに data.js というファイルを作成し、このリンクのコンテンツをコピーします。
- 手順 1 と同じフォルダに script.js というファイルを作成し、次のコードを挿入します。
console.log('Hello TensorFlow');
テストする
HTML ファイルと JavaScript ファイルを作成したら、テストを行います。ブラウザで index.html ファイルを開き、Dialog コンソールを開きます。
すべてが正常に機能している場合、グローバル変数が 2 つ作成されます。tf は TensorFlow.js ライブラリへの参照、tfvis は tfjs-vis ライブラリへの参照です。
「Hello TensorFlow」というメッセージが表示されるはずです。その場合、次のステップに移動する準備ができています。
このチュートリアルでは、以下に示すように画像内の数字を認識するモデルをトレーニングします。これらは、MNIST というデータセットの 28 x 28 ピクセルのグレースケール画像です。

先ほど作成した特別なスプライト ファイル(最大 10 MB)から画像を読み込むためのコードがすでに用意されているので、トレーニングに専念できます。
データの読み込み方法は data.js ファイルで確認できます。このチュートリアルを完了すると、独自の方法でデータを読み込むことができます。
提供されたコードには、次の 2 つのパブリック メソッドを持つクラス MnistData が含まれています。
nextTrainBatch(batchSize): トレーニング セットから画像とそのラベルをランダムに返します。nextTestBatch(batchSize): テストセットから画像とそのラベルのバッチを返します。
MnistData クラスは、データのシャッフルと正規化のステップも行います。
合計で 65,000 個の画像があり、最大 55,000 個の画像を使用してモデルをトレーニングします。残りの 10,000 個の画像は、トレーニング完了後のモデルのパフォーマンス テストで使用します。これらの処理はすべてブラウザで実行します。
では、データを読み込み、読み込みが正しく行われているかテストしてみましょう。
次のコードを script.js ファイルに追加します。
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
ページを更新します。数秒後、パネルの左側にいくつかの画像が表示されます。

入力データは次のようになります。
ここでは、1 つの画像を使用してモデルをトレーニングし、画像が属する可能性がある 10 個のクラスごとのスコア(数字 0~9)を予測します。
各画像は 28 x 28 ピクセルです。グレースケール画像のため、1 カラーチャネルです。各画像のシェイプは [28, 28, 1] です。
各入力例の形状だけでなく、1 対 10 のマッピングを行っていることに注意してください。この点は、次のセクションで重要になります。
このセクションでは、モデル アーキテクチャを記述するコードを作成します。モデル アーキテクチャでは、モデルの実行中に呼び出す関数や、答えの計算にモデルが使用するアルゴリズムを定義できます。
機械学習では、アーキテクチャ(またはアルゴリズム)を定義し、トレーニング プロセスでそのアルゴリズムのパラメータを学習します。
次の関数を
script.js ファイルに追加して、モデル アーキテクチャを定義します。
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
もう少し詳しく見てみましょう。
畳み込み
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
ここでは順次モデルを使用しています。
Dense レイヤではなく conv2d レイヤを使用しています。ここでは、畳み込みの仕組みについて詳しく説明しません。基本となる処理については、次のリソースをご覧ください。
conv2d の構成オブジェクトの各引数について詳しくみてみましょう。
inputShape。モデルの最初のレイヤに渡されるデータのシェイプ。この場合、MNIST の例は 28 x 28 ピクセルのモノクロ画像です。画像データの正規化された形式は[row, column, depth]です。[28, 28, 1]のシェイプを構成します。各次元のピクセル数は 28 行 x 28 列です。画像のカラーチャネルは 1 つしかないため、深さは 1 です。入力シェイプにバッチサイズは指定していません。レイヤはバッチサイズに依存しないように設計されています。このため、推論の際に任意のバッチサイズのテンソルを渡すことができます。kernelSize。入力データに適用される畳み込みフィルタのスライディング ウィンドウのサイズ。ここでは、kernelSizeを5に設定し、5x5 の畳み込みウィンドウを指定しています。filters。入力データに適用するサイズkernelSizeのフィルタ ウィンドウの数。ここでは、データに 8 つのフィルタを適用します。strides。スライディング ウィンドウの「ステップサイズ」。画像の上を動かすたびにフィルタがシフトするピクセル数です。ここでは、ストライドに 1 を指定しています。これは、フィルタが画像の上を 1 ピクセルずつスライドすることを意味します。activation。畳み込みの完了後にデータに適用される活性化関数。ここでは、Rectified Linear Unit(ReLU)関数を適用します。この関数は、ML モデルでよく使用されている活性化関数です。kernelInitializer。モデルの重みをランダムに初期化するメソッド。これは、トレーニングのダイナミクスに非常に重要です。ここでは、初期化の詳細について説明しませんが、イニシャライザとしてVarianceScalingの使用をおすすめします。
データ表現のフラット化
model.add(tf.layers.flatten());
画像は高次元データで、畳み込み演算によりデータのサイズが大きくなる傾向があります。データは、最終的な分類レイヤに渡す前に 1 つの長い配列にフラット化する必要があります。Dense レイヤ(ここでは最終レイヤとして使用します)は tensor1d のみを取得するため、これは多くの分類タスクで一般的な手順です。
最終的な確率分布を計算する
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
10 個のクラスの確率分布を計算するために、Dense レイヤとソフトマックス活性化関数を使用します。最も高いスコアのクラスが予測数字になります。
オプティマイザーと損失関数を選択する
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
オプティマイザー、損失関数、追跡する指標を指定して、モデルをコンパイルします。
最初のチュートリアルとは対照的に、ここでは categoricalCrossentropy を損失関数として使用します。名前からわかるように、これはモデルの出力が確率分布の場合に使用されます。categoricalCrossentropy では、モデルの最終レイヤで生成された確率分布と、真のラベルによる確率分布の間の誤差を測定します。
たとえば、数字が 7 を表す場合、次のような結果になります。
インデックス | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
True ラベル | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
予測 | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
カテゴリのクロス エントロピーは、予測ベクトルと True ラベルベクトルとの類似度を示す単一の数値を生成します。
ここでラベルに使用されるデータ表現はワンホット エンコードと呼ばれ、分類問題でよく使用されます。各クラスには、それぞれの例に関連付けられた確率があります。正確にわかっている場合は確率を 1 に設定し、そうでない場合は 0 に設定します。ワンホット エンコードの詳細については、こちらのページをご覧ください。
この他にモニタリングする指標は accuracy です。分類問題の場合、すべての予測から正しい予測が生成される割合となります。
次の関数を script.js ファイルにコピーします。
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
次のコードを
run 関数に追加します。
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
ページを更新します。数秒後、トレーニングの進行状況を示すグラフが表示されます。
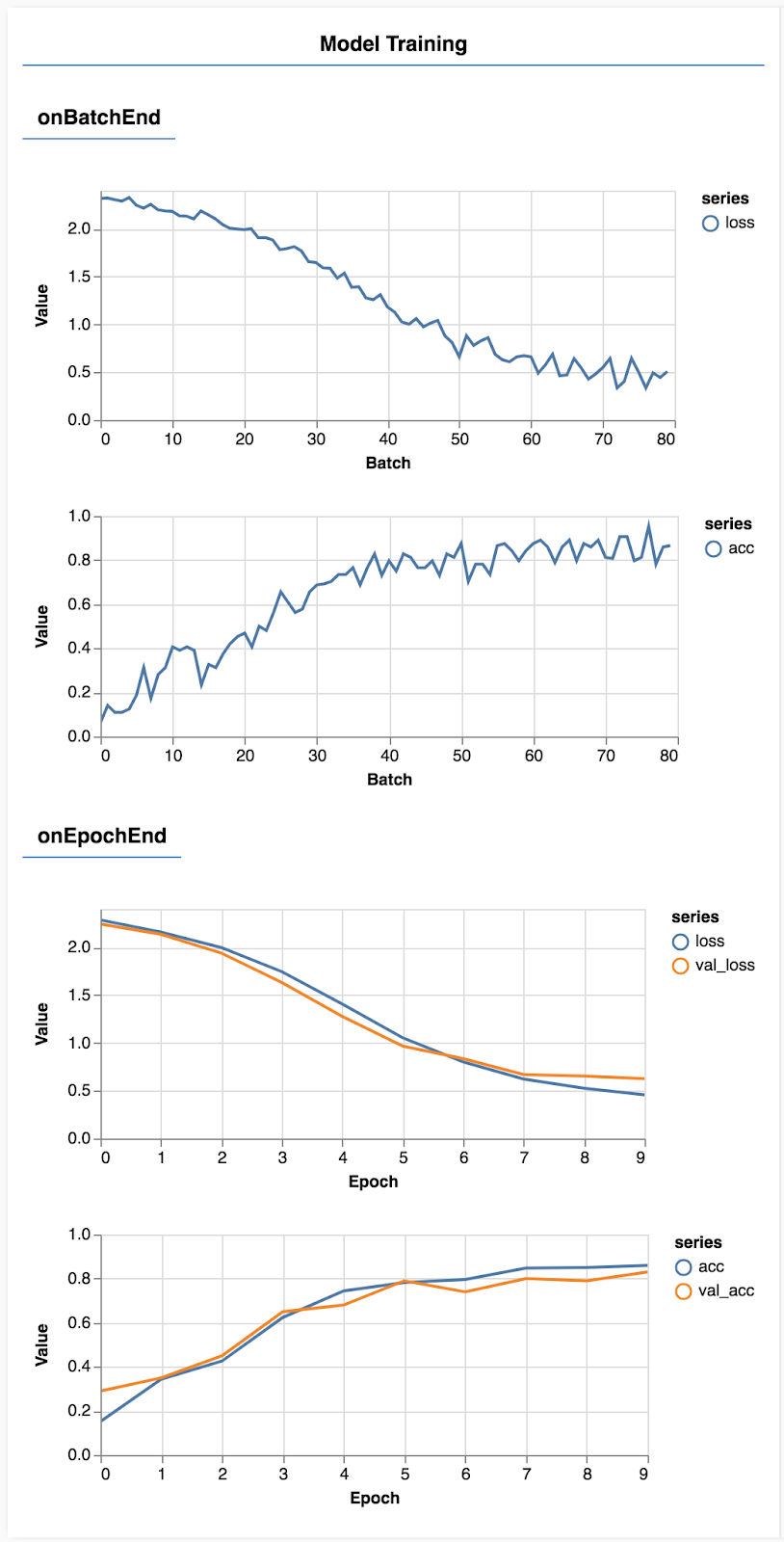
もう少し詳しく見てみましょう。
指標をモニタリングする
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
ここでは、モニタリングする指標を決定します。Google では、トレーニング セットの損失と精度だけでなく、検証セットの損失と精度もモニタリングします(val_loss と href_acc )。検証セットについては後ほど説明します。
テンソルとしてデータを準備する
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
ここでは、モデルをトレーニングするトレーニング セットと、各エポックの最後でモデルをテストする検証セットの 2 つのデータセットを作成します。ただし、検証セットのデータはトレーニング中にはモデルに表示されません。
提供されたデータクラスを使用すると、画像データからテンソルを簡単に取得できますが、モデルに提供する前に、モデルが想定するシェイプ [num_examples, image_width, image_height, channels] にテンソルを変換します。各データセットには入力(X)とラベル(Y)が両方ともあります。
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
model.fit を呼び出してトレーニング ループを開始します。また、各エポックの後に、モデルのトレーニングではなくテストに使用するデータを指定するために validationData プロパティを渡します。
トレーニング データで問題がなく、検証データでうまくいかない場合、モデルがトレーニング データに過剰適合し、まだ見たことのない入力に対して一般化がうまく行われていないことを意味します。
データが検証セットに類似している限り、検証精度は未確認のデータに対するモデルの性能を表す適切な推定値となります。また、クラスごとにパフォーマンスを分析したい場合もあります。
tfjs-vis には、この目的で使用できるメソッドがいくつかあります。
script.js ファイルの末尾に次のコードを追加します。
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
このコードは次の処理を行います。
- 予測を行う。
- 精度指標を計算する。
- 指標を表示する。
ここでは、各ステップについて詳しく説明します。
予測を行う
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
最初に予測を行う必要があります。ここでは、画像を 500 枚用意し、画像に含まれている数字を予測します(数値を増やすと、より大きな画像でテストできます)。
特に argmax 関数は、最も高い確率クラスのインデックスを返します。モデルはクラスごとに確率を出力します。ここでは、可能性が最も高いパターンを探し、それを予測として割り当てます。
また、500 枚をすべて一度に予測することも可能です。その場合は、TensorFlow.js が提供するベクトル化の機能を使用します。
クラス単位の精度を表示する
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
一連の予測とラベルを使用して、クラスごとに精度を計算できます。
混同行列を表示する
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
混同行列はクラスごとの精度に類似していますが、さらに分類が細分化され、間違った分類のパターンが表示されます。特定のクラスペアについて、モデルが混同していないかどうかわかります。
評価を表示する
実行関数の最後に次のコードを追加し、評価を表示するように変更します。
await showAccuracy(model, data);
await showConfusion(model, data);
次のような画面が表示されます。
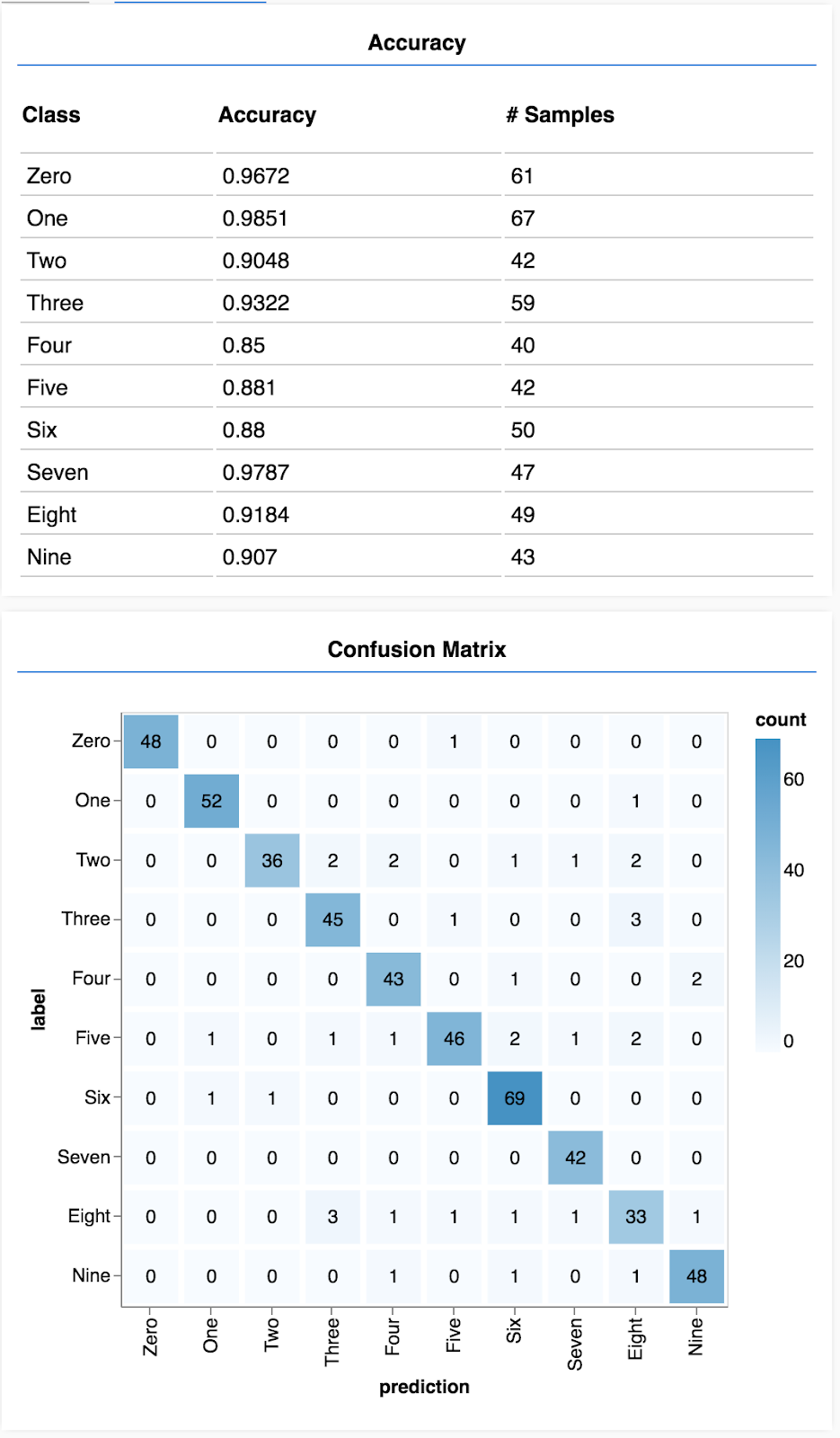
これで完了です。畳み込みニューラル ネットワークのトレーニングが終わりました。
入力データのカテゴリの予測は分類タスクと呼ばれます。
分類タスクを行うには、ラベルに適したデータ表現が必要です
- ラベルの一般的な表現には、カテゴリのワンホット エンコードなどがあります。
データの準備:
- モデルの評価に使用できるように、トレーニング時に使用していないデータ以外を用意しておくと便利です。これを検証セットと呼びます。
モデルの構築と実行:
- 畳み込みモデルは画像タスクでうまく機能します。
- 分類問題は通常、損失関数にカテゴリのクロス エントロピーを使用します。
- トレーニングをモニタリングして、損失が低下し、正確さが向上していることを確認します。
モデルの評価
- トレーニング後にモデルを評価し、最初に解決しようとした問題がどの程度うまく処理されているのかを判断します。
- クラスごとの精度と混同行列を使用することで、全体的な精度ではなく、モデルのパフォーマンスをより詳細に把握できます。