
۱. مقدمه
در این آموزش، ما یک مدل TensorFlow.js برای تشخیص ارقام دستنویس با استفاده از یک شبکه عصبی کانولوشن خواهیم ساخت. ابتدا، طبقهبندیکننده را با "نگاه کردن" به هزاران تصویر ارقام دستنویس و برچسبهای آنها آموزش میدهیم. سپس دقت طبقهبندیکننده را با استفاده از دادههای آزمایشی که مدل هرگز ندیده است، ارزیابی خواهیم کرد.
این وظیفه، یک وظیفه طبقهبندی محسوب میشود، زیرا ما در حال آموزش مدل برای اختصاص یک دسته (رقمی که در تصویر ظاهر میشود) به تصویر ورودی هستیم. ما مدل را با نشان دادن نمونههای زیادی از ورودیها به همراه خروجی صحیح، آموزش خواهیم داد. به این روش، یادگیری نظارتشده میگویند.
آنچه خواهید ساخت
شما یک صفحه وب ایجاد خواهید کرد که از TensorFlow.js برای آموزش یک مدل در مرورگر استفاده میکند. با توجه به یک تصویر سیاه و سفید با اندازه خاص، این صفحه وب، ارقام موجود در تصویر را طبقهبندی میکند. مراحل انجام این کار عبارتند از:
- دادهها را بارگذاری کنید.
- معماری مدل را تعریف کنید.
- مدل را آموزش دهید و عملکرد آن را در حین آموزش زیر نظر بگیرید.
- مدل آموزشدیده را با انجام برخی پیشبینیها ارزیابی کنید.
آنچه یاد خواهید گرفت
- سینتکس TensorFlow.js برای ایجاد مدلهای کانولوشن با استفاده از API لایههای TensorFlow.js.
- فرمولبندی وظایف طبقهبندی در TensorFlow.js
- نحوه نظارت بر آموزش درون مرورگر با استفاده از کتابخانه tfjs-vis.
آنچه نیاز دارید
- نسخه جدیدی از کروم یا مرورگر مدرن دیگری که از ماژولهای ES6 پشتیبانی میکند.
- یک ویرایشگر متن، چه به صورت محلی روی دستگاه شما اجرا شود و چه از طریق چیزی مانند Codepen یا Glitch روی وب اجرا شود.
- آشنایی با HTML، CSS، جاوا اسکریپت و ابزارهای توسعه کروم (یا ابزارهای توسعه مرورگر مورد نظر شما).
- درک مفهومی سطح بالا از شبکههای عصبی. اگر به مقدمه یا یادآوری نیاز دارید، تماشای این ویدیو از 3blue1brown یا این ویدیو در مورد یادگیری عمیق در جاوا اسکریپت از Ashi Krishnan را در نظر بگیرید.
همچنین باید با مطالب موجود در اولین آموزش ما راحت باشید.
۲. آماده شوید
یک صفحه HTML ایجاد کنید و جاوا اسکریپت را در آن قرار دهید
 کد زیر را در یک فایل html با نام ``` کپی کنید.
کد زیر را در یک فایل html با نام ``` کپی کنید.
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
فایلهای جاوا اسکریپت را برای دادهها و کد ایجاد کنید
- در همان پوشهای که فایل HTML بالا قرار دارد، فایلی به نام data.js ایجاد کنید و محتوای این لینک را در آن فایل کپی کنید.
- در همان پوشه مرحله یک، فایلی به نام script.js ایجاد کنید و کد زیر را در آن قرار دهید.
console.log('Hello TensorFlow');
آن را آزمایش کنید
حالا که فایلهای HTML و جاوا اسکریپت را ایجاد کردهاید، آنها را آزمایش کنید. فایل index.html را در مرورگر خود باز کنید و کنسول devtools را باز کنید.
اگر همه چیز درست کار کند، باید دو متغیر سراسری ایجاد شده باشد. tf ارجاعی به کتابخانه TensorFlow.js و tfvis ارجاعی به کتابخانه tfjs-vis است.
شما باید پیامی با عنوان Hello TensorFlow ببینید ، در این صورت، آمادهاید تا به مرحله بعدی بروید.
۳. بارگذاری دادهها
در این آموزش، شما یک مدل را آموزش خواهید داد تا یاد بگیرد ارقام را در تصاویری مانند تصاویر زیر تشخیص دهد. این تصاویر، تصاویر خاکستری با ابعاد 28x28 پیکسل از مجموعه دادهای به نام MNIST هستند.
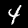

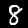
ما کدی را برای بارگذاری این تصاویر از یک فایل sprite ویژه (حدود ۱۰ مگابایت) که برای شما ایجاد کردهایم، ارائه دادهایم تا بتوانیم روی بخش آموزش تمرکز کنیم.
برای درک نحوه بارگذاری دادهها، میتوانید فایل data.js را مطالعه کنید. یا پس از اتمام این آموزش، رویکرد خودتان را برای بارگذاری دادهها ایجاد کنید.
کد ارائه شده شامل کلاسی به نام MnistData است که دو متد عمومی دارد:
-
nextTrainBatch(batchSize): یک دسته تصادفی از تصاویر و برچسبهای آنها را از مجموعه آموزشی برمیگرداند. -
nextTestBatch(batchSize)مجموعهای از تصاویر و برچسبهای آنها را از مجموعه آزمایشی برمیگرداند.
کلاس MnistData همچنین مراحل مهم درهمسازی و نرمالسازی دادهها را انجام میدهد.
در مجموع ۶۵۰۰۰ تصویر وجود دارد، ما تا ۵۵۰۰۰ تصویر را برای آموزش مدل استفاده خواهیم کرد و ۱۰۰۰۰ تصویر را ذخیره میکنیم که میتوانیم پس از اتمام کار، برای آزمایش عملکرد مدل از آنها استفاده کنیم. و قرار است همه این کارها را در مرورگر انجام دهیم!
بیایید دادهها را بارگذاری کنیم و بررسی کنیم که آیا به درستی بارگذاری شدهاند یا خیر.
کد زیر را به فایل script.js خود اضافه کنید.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
صفحه را رفرش کنید و پس از چند ثانیه باید پنلی در سمت چپ با تعدادی تصویر ببینید.

۴. وظیفه خود را مفهومسازی کنید
دادههای ورودی ما به این شکل هستند.
هدف ما آموزش مدلی است که یک تصویر را دریافت کرده و یاد بگیرد که برای هر یک از 10 کلاس ممکن که تصویر ممکن است به آن تعلق داشته باشد (ارقام 0 تا 9)، امتیازی را پیشبینی کند.
هر تصویر ۲۸ پیکسل عرض و ۲۸ پیکسل ارتفاع دارد و از آنجایی که یک تصویر خاکستری است، تنها یک کانال رنگی دارد. بنابراین شکل هر تصویر [28, 28, 1] است.
به یاد داشته باشید که ما یک نگاشت یک به ده و همچنین شکل هر مثال ورودی انجام میدهیم، زیرا برای بخش بعدی مهم است.
۵. معماری مدل را تعریف کنید
در این بخش، کدی برای توصیف معماری مدل خواهیم نوشت. معماری مدل روشی جذاب برای بیان این است که «مدل هنگام اجرا، کدام توابع را اجرا خواهد کرد» یا به عبارت دیگر «مدل ما از چه الگوریتمی برای محاسبه پاسخهای خود استفاده خواهد کرد» .
در یادگیری ماشین، ما یک معماری (یا الگوریتم) تعریف میکنیم و به فرآیند آموزش اجازه میدهیم پارامترهای آن الگوریتم را یاد بگیرد.
تابع زیر را به برنامه خود اضافه کنید
فایل script.js برای تعریف معماری مدل
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
بیایید کمی جزئیتر به این موضوع نگاه کنیم.
پیچشها
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
در اینجا ما از یک مدل ترتیبی استفاده میکنیم.
ما به جای یک لایه متراکم از یک لایه conv2d استفاده میکنیم. نمیتوانیم به تمام جزئیات نحوه کار کانولوشنها بپردازیم، اما در اینجا چند منبع وجود دارد که عملیات اساسی را توضیح میدهند:
بیایید هر آرگومان را در شیء پیکربندی برای conv2d تجزیه کنیم:
-
inputShape. شکل دادههایی که به لایه اول مدل جریان مییابند. در این حالت، نمونههای MNIST ما تصاویر سیاه و سفید ۲۸x۲۸ پیکسلی هستند. قالب استاندارد برای دادههای تصویر[row, column, depth]است، بنابراین در اینجا میخواهیم شکلی با[28, 28, 1]پیکربندی کنیم. ۲۸ سطر و ستون برای تعداد پیکسلها در هر بعد و عمق ۱ زیرا تصاویر ما فقط ۱ کانال رنگ دارند. توجه داشته باشید که ما اندازه دسته را در شکل ورودی مشخص نمیکنیم. لایهها به گونهای طراحی شدهاند که اندازه دسته را ندانند، به طوری که در طول استنتاج میتوانید یک تانسور با هر اندازه دستهای را به آن منتقل کنید. -
kernelSize. اندازه پنجرههای فیلتر کانولوشنی لغزان که قرار است روی دادههای ورودی اعمال شوند. در اینجا، ماkernelSizeرا روی5تنظیم میکنیم که یک پنجره کانولوشنی مربعی ۵x۵ را مشخص میکند. -
filters. تعداد پنجرههای فیلتر با اندازهkernelSizeکه باید روی دادههای ورودی اعمال شوند. در اینجا، ما ۸ فیلتر روی دادهها اعمال خواهیم کرد. -
strides. «اندازه گام» پنجره کشویی - یعنی اینکه فیلتر هر بار که روی تصویر حرکت میکند، چند پیکسل جابجا میشود. در اینجا، گامها را برابر با ۱ تعیین میکنیم، به این معنی که فیلتر با گامهای ۱ پیکسلی روی تصویر میلغزد. -
activation. تابع فعالسازی که پس از تکمیل کانولوشن روی دادهها اعمال میشود. در این حالت، ما یک تابع واحد خطی یکسو شده (ReLU) را اعمال میکنیم که یک تابع فعالسازی بسیار رایج در مدلهای یادگیری ماشین است. -
kernelInitializer. روشی که برای مقداردهی اولیه تصادفی وزنهای مدل استفاده میشود، که برای دینامیک آموزش بسیار مهم است. ما در اینجا وارد جزئیات مقداردهی اولیه نمیشویم، اماVarianceScaling(که در اینجا استفاده میشود) عموماً یک انتخاب مقداردهی اولیه خوب است.
مسطحسازی نمایش دادهها
model.add(tf.layers.flatten());
تصاویر دادههایی با ابعاد بالا هستند و عملیات کانولوشن معمولاً اندازه دادههایی را که در آنها قرار گرفتهاند افزایش میدهد. قبل از انتقال آنها به لایه طبقهبندی نهایی، باید دادهها را در یک آرایه طولانی مسطح کنیم. لایههای متراکم (که ما به عنوان لایه نهایی خود استفاده میکنیم) فقط tensor1d را میپذیرند، بنابراین این مرحله در بسیاری از وظایف طبقهبندی رایج است.
توزیع احتمال نهایی ما را محاسبه کنید
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
ما از یک لایه متراکم با فعالسازی softmax برای محاسبه توزیع احتمال روی 10 کلاس ممکن استفاده خواهیم کرد. کلاسی که بالاترین امتیاز را داشته باشد، رقم پیشبینیشده خواهد بود.
یک بهینهساز و تابع زیان انتخاب کنید
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
ما مدل را کامپایل میکنیم و یک بهینهساز ، تابع زیان و معیارهایی را که میخواهیم پیگیری کنیم، مشخص میکنیم.
برخلاف آموزش اولمان، در اینجا از تابع زیان categoricalCrossentropy استفاده میکنیم. همانطور که از نامش پیداست، این تابع زمانی استفاده میشود که خروجی مدل ما یک توزیع احتمال باشد. categoricalCrossentropy خطای بین توزیع احتمال تولید شده توسط آخرین لایه مدل ما و توزیع احتمال داده شده توسط برچسب واقعی ما را اندازهگیری میکند.
برای مثال، اگر رقم ما واقعاً نشاندهندهی عدد ۷ باشد، ممکن است نتایج زیر را داشته باشیم:
فهرست | 0 | ۱ | ۲ | ۳ | ۴ | ۵ | ۶ | ۷ | ۸ | ۹ |
برچسب واقعی | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ۱ | 0 | 0 |
پیشبینی | ۰.۱ | ۰.۰۱ | ۰.۰۱ | ۰.۰۱ | ۰.۲۰ | ۰.۰۱ | ۰.۰۱ | ۰.۶۰ | ۰.۰۳ | ۰.۰۲ |
آنتروپی متقاطع دستهبندیشده یک عدد واحد تولید میکند که نشان میدهد بردار پیشبینی چقدر به بردار برچسب واقعی ما شبیه است.
نمایش دادههایی که در اینجا برای برچسبها استفاده میشود، کدگذاری وان-هات (one-hot encoding) نام دارد و در مسائل طبقهبندی رایج است. هر کلاس برای هر مثال، احتمالی دارد که به آن مرتبط است. وقتی دقیقاً بدانیم که چه مقدار باید باشد، میتوانیم آن احتمال را روی ۱ و بقیه را روی ۰ تنظیم کنیم. برای اطلاعات بیشتر در مورد کدگذاری وان-هات به این صفحه مراجعه کنید.
معیار دیگری که بررسی خواهیم کرد، accuracy است که برای یک مسئله طبقهبندی، درصد پیشبینیهای صحیح از بین تمام پیشبینیها است.
۶. مدل را آموزش دهید
تابع زیر را در فایل script.js خود کپی کنید.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
سپس کد زیر را به قالب خود اضافه کنید
تابع را run .
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
صفحه را رفرش کنید و پس از چند ثانیه باید نمودارهایی را مشاهده کنید که پیشرفت آموزش را گزارش میدهند.
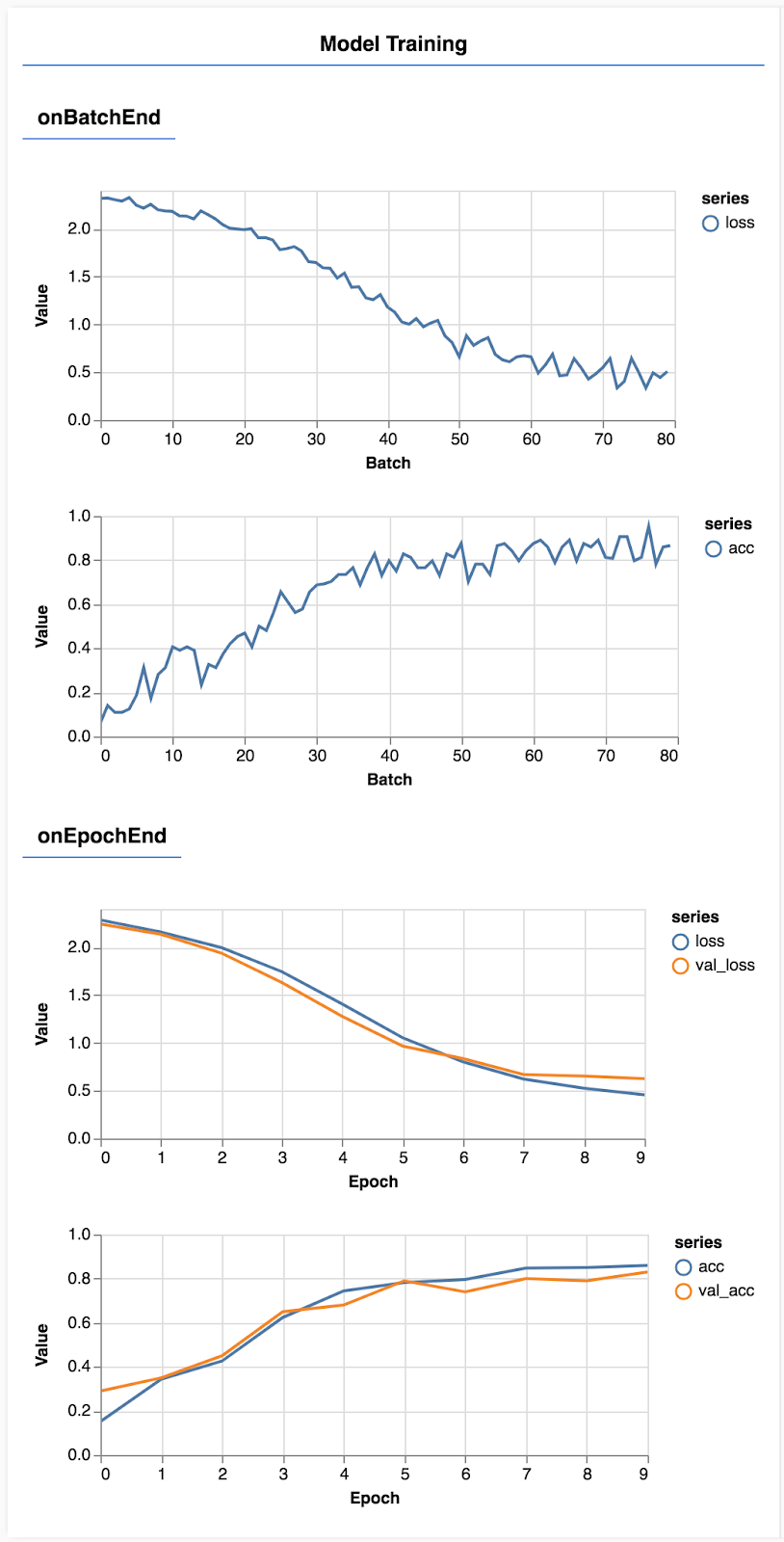
بیایید کمی جزئیتر به آن نگاه کنیم.
نظارت بر معیارها
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
در اینجا تصمیم میگیریم که کدام معیارها را میخواهیم رصد کنیم. ما زیان و دقت را در مجموعه آموزش و همچنین زیان و دقت را در مجموعه اعتبارسنجی (به ترتیب val_loss و val_acc) رصد خواهیم کرد. در ادامه بیشتر در مورد مجموعه اعتبارسنجی صحبت خواهیم کرد.
آمادهسازی دادهها به عنوان تانسور
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
در اینجا ما دو مجموعه داده ایجاد میکنیم، یک مجموعه آموزشی که مدل را روی آن آموزش میدهیم و یک مجموعه اعتبارسنجی که مدل را در پایان هر دوره روی آن آزمایش میکنیم، با این حال دادههای موجود در مجموعه اعتبارسنجی هرگز در طول آموزش به مدل نشان داده نمیشوند.
کلاس دادهای که ارائه دادیم، دریافت تانسورها از دادههای تصویر را آسان میکند. اما ما هنوز تانسورها را به شکل مورد انتظار مدل، [num_examples, image_width, image_height, channels] ، تغییر شکل میدهیم، قبل از اینکه بتوانیم آنها را به مدل بدهیم. برای هر مجموعه داده، هم ورودی (Xها) و هم برچسب (Yها) داریم.
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
ما model.fit را برای شروع حلقه آموزش فراخوانی میکنیم. همچنین یک ویژگی validationData را برای نشان دادن اینکه مدل باید از کدام دادهها برای آزمایش خود پس از هر دوره استفاده کند (اما برای آموزش استفاده نکند) ارسال میکنیم.
اگر روی دادههای آموزشی خوب عمل کنیم اما روی دادههای اعتبارسنجی خوب عمل نکنیم، به این معنی است که مدل احتمالاً روی دادههای آموزشی بیشبرازش دارد و به ورودیهایی که قبلاً ندیده است، به خوبی تعمیم نمیدهد.
۷. مدل خود را ارزیابی کنید
دقت اعتبارسنجی، تخمین خوبی از میزان عملکرد مدل ما روی دادههایی که قبلاً ندیده است، ارائه میدهد (البته تا زمانی که آن دادهها به نوعی شبیه به مجموعه اعتبارسنجی باشند). با این حال، ممکن است بخواهیم جزئیات بیشتری از عملکرد در کلاسهای مختلف را بررسی کنیم.
چند روش در tfjs-vis وجود دارد که میتواند در این زمینه به شما کمک کند.
کد زیر را به انتهای فایل script.js خود اضافه کنید.
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
این کد چه کاری انجام میدهد؟
- پیشبینی انجام میدهد.
- معیارهای دقت را محاسبه میکند.
- معیارها را نشان میدهد
بیایید نگاهی دقیقتر به هر مرحله بیندازیم.
پیشبینی کنید
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
ابتدا باید پیشبینیهایی انجام دهیم. در اینجا ۵۰۰ تصویر میگیریم و پیشبینی میکنیم که چه رقمی در آنها وجود دارد (میتوانید بعداً این تعداد را افزایش دهید تا روی مجموعه بزرگتری از تصاویر آزمایش کنید).
به طور خاص، تابع argmax چیزی است که شاخص بالاترین کلاس احتمال را به ما میدهد. به یاد داشته باشید که مدل برای هر کلاس یک احتمال تولید میکند. در اینجا ما بالاترین احتمال را پیدا میکنیم و از آن به عنوان پیشبینی استفاده میکنیم.
همچنین ممکن است متوجه شده باشید که میتوانیم پیشبینیها را روی هر ۵۰۰ مثال به طور همزمان انجام دهیم. این قدرت برداریسازی است که TensorFlow.js ارائه میدهد.
نمایش دقت در هر کلاس
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
با مجموعهای از پیشبینیها و برچسبها میتوانیم دقت را برای هر کلاس محاسبه کنیم.
نمایش ماتریس درهمریختگی
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
ماتریس سردرگمی مشابه دقت به ازای هر کلاس است، اما آن را بیشتر تجزیه میکند تا الگوهای طبقهبندی نادرست را نشان دهد. این ماتریس به شما امکان میدهد ببینید که آیا مدل در مورد هر جفت کلاس خاص دچار سردرگمی میشود یا خیر.
نمایش ارزیابی
کد زیر را به انتهای تابع run خود اضافه کنید تا ارزیابی نمایش داده شود.
await showAccuracy(model, data);
await showConfusion(model, data);
شما باید صفحهای شبیه به تصویر زیر ببینید.
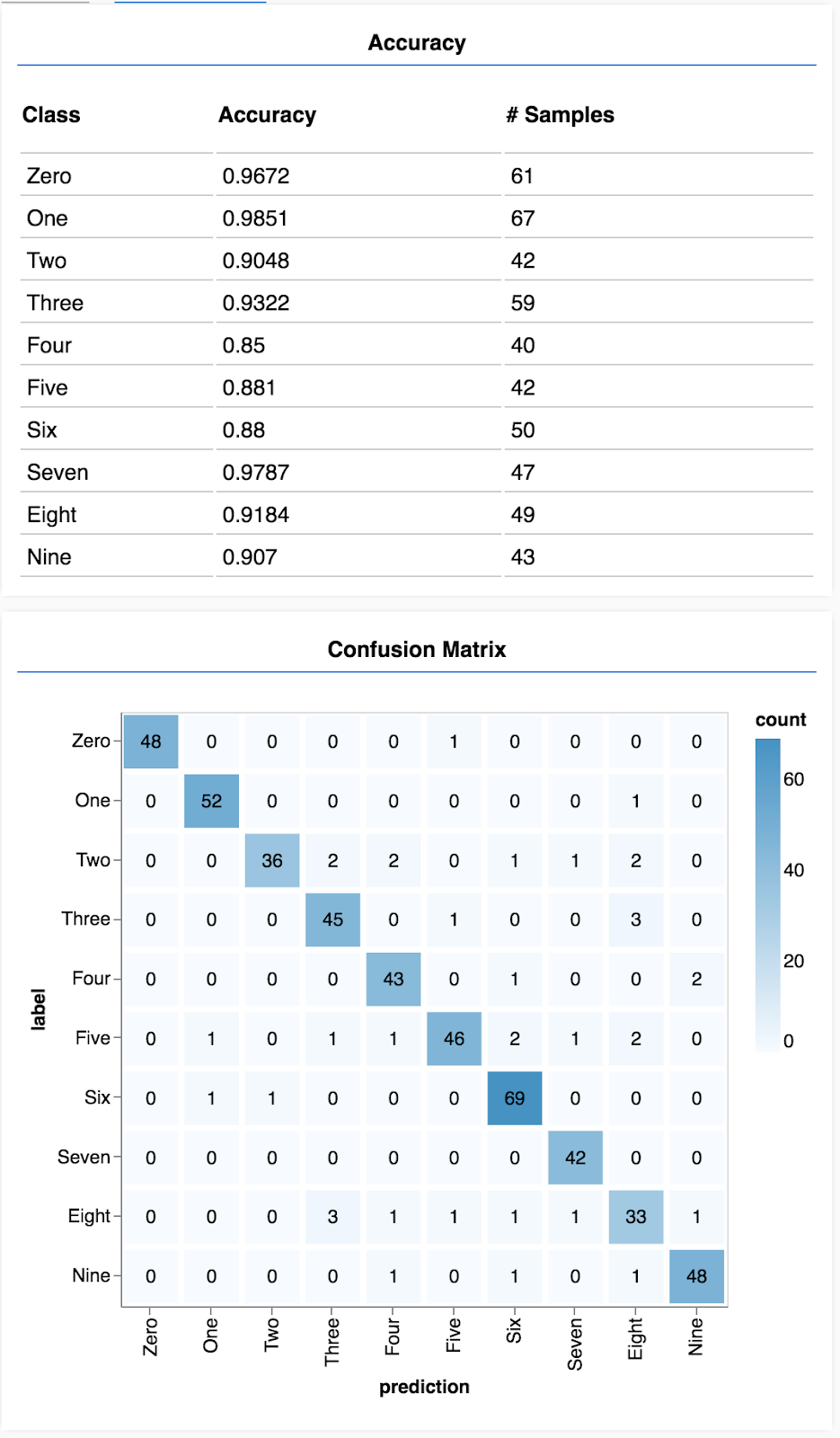
تبریک! شما به تازگی یک شبکه عصبی کانولوشنی آموزش دادهاید!
۸. غذاهای اصلی بیرونبر
پیشبینی دستهها برای دادههای ورودی، وظیفه طبقهبندی نامیده میشود.
وظایف طبقهبندی نیاز به نمایش دادههای مناسب برای برچسبها دارند.
- نمایشهای رایج برچسبها شامل کدگذاری وان-هات (one-hot) دستهها میشود.
دادههای خود را آماده کنید:
- مفید است که برخی از دادهها را که مدل در طول آموزش هرگز نمیبیند، کنار بگذارید تا بتوانید از آنها برای ارزیابی مدل استفاده کنید. به این مجموعه، مجموعه اعتبارسنجی گفته میشود.
مدل خود را بسازید و اجرا کنید:
- مدلهای کانولوشنی نشان دادهاند که در وظایف مربوط به تصویر عملکرد خوبی دارند.
- مسائل طبقهبندی معمولاً از آنتروپی متقاطع دستهبندیشده برای توابع زیان خود استفاده میکنند.
- آموزش را زیر نظر داشته باشید تا ببینید آیا میزان خطا کاهش و دقت افزایش مییابد یا خیر.
مدل خود را ارزیابی کنید
- پس از آموزش مدل، روشی را برای ارزیابی آن تعیین کنید تا ببینید در حل مسئله اولیهای که میخواستید حل کنید، چقدر خوب عمل میکند.
- ماتریسهای دقت و آشفتگی به ازای هر کلاس میتوانند تفکیک دقیقتری از عملکرد مدل نسبت به دقت کلی به شما ارائه دهند.