1. Wprowadzenie
W tym ćwiczeniu w Codelabs wytrenujesz model, który będzie dokonywać prognoz na podstawie danych liczbowych opisujących zestaw samochodów.
W tym ćwiczeniu pokażemy kroki typowe dla trenowania wielu różnych rodzajów modeli, ale użyjemy małego zbioru danych i prostego (płytkiego) modelu. Jego głównym celem jest zapoznanie Cię z podstawową terminologią, koncepcjami i składnią związanymi z trenowaniem modeli za pomocą TensorFlow.js oraz stworzenie podstaw do dalszego poznawania tej technologii.
Szkolimy model, aby przewidywał liczby ciągłe, dlatego to zadanie jest czasami nazywane zadaniem regresji. Model będzie trenowany na wielu przykładach danych wejściowych wraz z prawidłowymi danymi wyjściowymi. Nazywamy to uczeniem nadzorowanym.
Co utworzysz
Utworzysz stronę internetową, która będzie używać TensorFlow.js do trenowania modelu w przeglądarce. Na podstawie „Mocy silnika” samochodu model nauczy się przewidywać „Liczbę mil na galon” (MPG).
Aby to zrobić:
- Wczytaj dane i przygotuj je do trenowania.
- Określ architekturę modelu.
- Wytrenuj model i monitoruj jego skuteczność w trakcie trenowania.
- Oceń wytrenowany model, generując prognozy.
Czego się nauczysz
- Sprawdzone metody przygotowywania danych do uczenia maszynowego, w tym tasowanie i normalizacja.
- Składnia TensorFlow.js do tworzenia modeli za pomocą interfejsu tf.layers API.
- Jak monitorować trenowanie w przeglądarce za pomocą biblioteki tfjs-vis.
Czego potrzebujesz
- Najnowsza wersja Chrome lub innej nowoczesnej przeglądarki.
- edytor tekstu uruchomiony lokalnie na komputerze lub w internecie, np. Codepen lub Glitch;
- Znajomość HTML-a, CSS-a, JavaScriptu i Narzędzi deweloperskich w Chrome (lub narzędzi deweloperskich w innej przeglądarce).
- ogólne zrozumienie koncepcji sieci neuronowych; Jeśli potrzebujesz wprowadzenia lub przypomnienia, obejrzyj ten film 3blue1brown lub ten film Ashiego Krishnana o uczeniu głębokim w JavaScript.
2. Konfiguracja
Utwórz stronę HTML i dodaj do niej kod JavaScript.
 Skopiuj ten kod do pliku HTML o nazwie
Skopiuj ten kod do pliku HTML o nazwie
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
Utwórz plik JavaScript z kodem.
- W tym samym folderze co powyższy plik HTML utwórz plik o nazwie script.js i umieść w nim ten kod.
console.log('Hello TensorFlow');
Wypróbuj
Teraz, gdy masz już utworzone pliki HTML i JavaScript, przetestuj je. Otwórz plik index.html w przeglądarce i konsolę narzędzi deweloperskich.
Jeśli wszystko działa prawidłowo, w konsoli narzędzi deweloperskich powinny być utworzone i dostępne 2 zmienne globalne:
tfto odwołanie do biblioteki TensorFlow.js.tfvisodnosi się do biblioteki tfjs-vis.
Otwórz narzędzia programisty w przeglądarce. W danych wyjściowych konsoli powinien pojawić się komunikat Hello TensorFlow. Jeśli tak, możesz przejść do następnego kroku.
3. Wczytywanie, formatowanie i wizualizowanie danych wejściowych
Na początek wczytajmy, sformatujmy i zwizualizujmy dane, na których chcemy wytrenować model.
Załadujemy zbiór danych „cars” z pliku JSON, który hostujemy. Zawiera wiele różnych funkcji dotyczących każdego samochodu. W tym samouczku chcemy wyodrębnić tylko dane dotyczące mocy i liczby mil na galon.
Dodaj ten kod do pliku
script.js plik
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Spowoduje to też usunięcie wszystkich wpisów, w których nie określono ani liczby mil na galon, ani mocy silnika. Wykreślmy też te dane na wykresie punktowym, aby zobaczyć, jak wyglądają.
Dodaj ten kod na końcu pliku
script.js pliku.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Po odświeżeniu strony. Po lewej stronie strony powinien pojawić się panel z wykresem punktowym danych. Powinien on wyglądać mniej więcej tak.
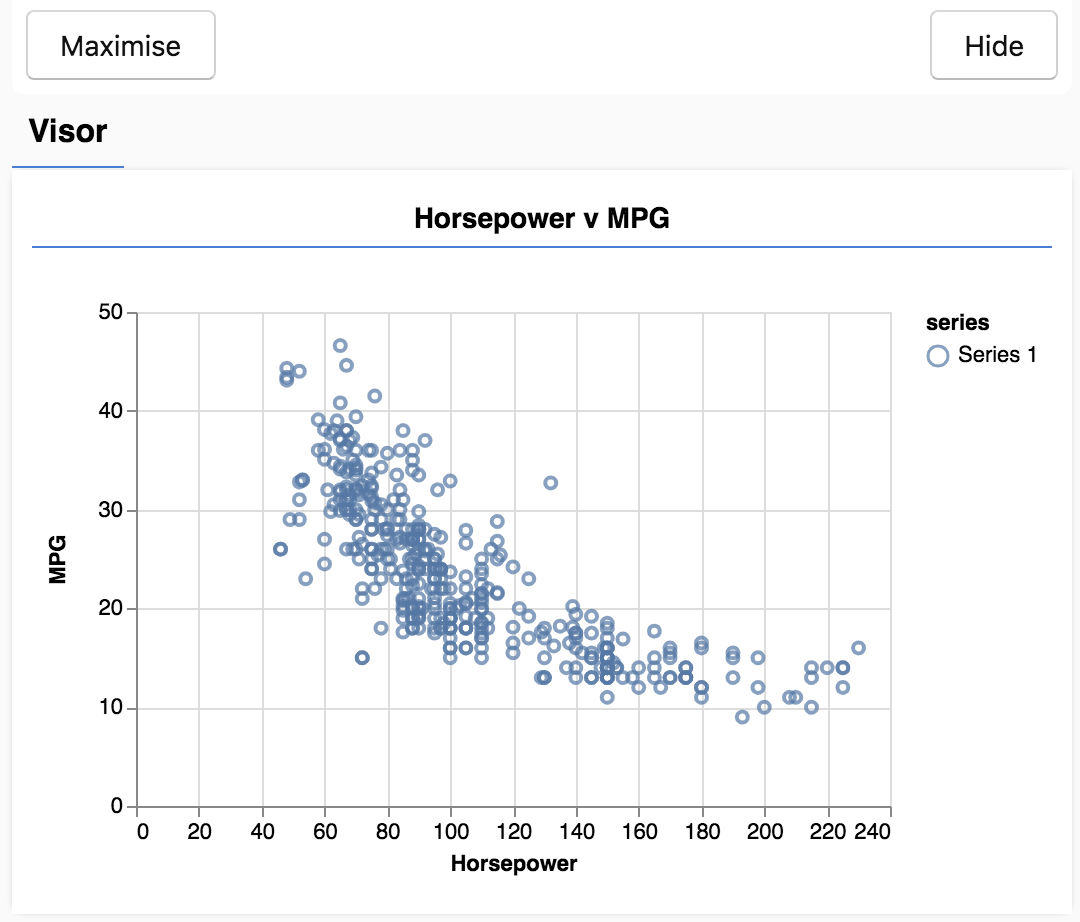
Ten panel nazywa się wizjerem i jest udostępniany przez bibliotekę tfjs-vis. Umożliwia wygodne wyświetlanie wizualizacji.
Podczas pracy z danymi warto znaleźć sposoby na ich sprawdzenie i w razie potrzeby oczyszczenie. W takim przypadku musieliśmy usunąć z carsData niektóre wpisy, które nie zawierały wszystkich wymaganych pól. Wizualizacja danych może pomóc nam określić, czy w danych występuje jakaś struktura, której model może się nauczyć.
Z wykresu powyżej widać, że istnieje ujemna korelacja między mocą a liczbą mil na galon, tzn. wraz ze wzrostem mocy samochody zwykle pokonują mniejszą liczbę mil na galon.
Określanie zadania
Dane wejściowe będą teraz wyglądać tak:
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Naszym celem jest wytrenowanie modelu, który na podstawie jednej liczby, mocy silnika, będzie prognozować jedną liczbę, liczbę mil na galon. Pamiętaj o mapowaniu jeden do jednego, ponieważ będzie ono ważne w następnej sekcji.
Podamy te przykłady, czyli moc i spalanie, sieci neuronowej, która na ich podstawie nauczy się formuły (lub funkcji) do przewidywania spalania na podstawie mocy. Uczenie się na przykładach, dla których mamy poprawne odpowiedzi, nazywamy uczeniem nadzorowanym.
4. Określanie architektury modelu
W tej sekcji napiszemy kod opisujący architekturę modelu. Architektura modelu to po prostu bardziej wyszukany sposób na określenie „jakie funkcje będzie wykonywać model podczas działania” lub „jakiego algorytmu będzie używać model do obliczania odpowiedzi”.
Modele ML to algorytmy, które przyjmują dane wejściowe i generują dane wyjściowe. W przypadku sieci neuronowych algorytm to zestaw warstw neuronów z „wagami” (liczbami) określającymi ich dane wyjściowe. Proces trenowania pozwala określić idealne wartości tych wag.
Dodaj następującą funkcję do
script.js do zdefiniowania architektury modelu.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Jest to jeden z najprostszych modeli, jakie możemy zdefiniować w tensorflow.js. Przyjrzyjmy się bliżej poszczególnym wierszom.
Utwórz instancję modelu
const model = tf.sequential();
Spowoduje to utworzenie obiektu tf.Model. Ten model jest sequential, ponieważ dane wejściowe są przekazywane bezpośrednio do danych wyjściowych. Inne rodzaje modeli mogą mieć rozgałęzienia, a nawet wiele danych wejściowych i wyjściowych, ale w wielu przypadkach modele będą sekwencyjne. Modele sekwencyjne mają też łatwiejszy w obsłudze interfejs API.
Dodawanie warstw
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
Do naszej sieci dodana zostanie warstwa wejściowa, która zostanie automatycznie połączona z warstwą dense z jednostką ukrytą. dense to rodzaj warstwy, która mnoży dane wejściowe przez macierz (zwaną wagami), a następnie dodaje do wyniku liczbę (zwaną odchyleniem). Ponieważ jest to pierwsza warstwa sieci, musimy zdefiniować inputShape. Wartość inputShape wynosi [1], ponieważ jako dane wejściowe mamy liczbę 1 (moc danego samochodu).
units określa rozmiar macierzy wag w warstwie. Ustawiając tutaj wartość 1, informujemy, że każda z cech wejściowych danych będzie miała wagę 1.
model.add(tf.layers.dense({units: 1}));
Powyższy kod tworzy warstwę wyjściową. Ustawiliśmy wartość units na 1, ponieważ chcemy uzyskać liczbę 1.
Tworzenie instancji
Dodaj ten kod do pliku
run funkcji zdefiniowanej wcześniej.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
Spowoduje to utworzenie instancji modelu i wyświetlenie podsumowania warstw na stronie internetowej.
5. Przygotowywanie danych do trenowania
Aby uzyskać korzyści z TensorFlow.js, które sprawiają, że trenowanie modeli uczenia maszynowego jest praktyczne, musimy przekonwertować nasze dane na tensory. Przeprowadzimy też na naszych danych szereg przekształceń, które są sprawdzonymi metodami, a mianowicie tasowanie i normalizację.
Dodaj ten kod do pliku
script.js plik
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Przyjrzyjmy się temu bliżej.
Tasowanie danych
// Step 1. Shuffle the data
tf.util.shuffle(data);
Tutaj losujemy kolejność przykładów, które przekażemy algorytmowi trenującemu. Tasowanie jest ważne, ponieważ podczas trenowania zbiór danych jest zwykle dzielony na mniejsze podzbiory, zwane partiami, na których trenowany jest model. Tasowanie sprawia, że każda partia zawiera różne dane z całego rozkładu danych. W ten sposób pomagamy modelowi:
- nie uczyć się rzeczy, które zależą wyłącznie od kolejności wprowadzania danych;
- Nie powinny być wrażliwe na strukturę w podgrupach (np. jeśli w pierwszej połowie procesu trenowania widzą tylko samochody o dużej mocy, mogą nauczyć się relacji, która nie ma zastosowania do pozostałej części zbioru danych).
Przekształcanie na tensory
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Tworzymy tu 2 tablice: jedną z przykładami danych wejściowych (wartościami mocy silnika) i drugą z prawdziwymi wartościami wyjściowymi (w uczeniu maszynowym nazywanymi etykietami).
Następnie przekształcamy każdy zbiór danych w tensor 2D. Tensor będzie miał kształt [num_examples, num_features_per_example]. Mamy tu inputs.length przykłady, a każdy z nich ma 1 cechę wejściową (moc).
Normalizowanie danych
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Następnie stosujemy kolejną sprawdzoną metodę trenowania modeli uczenia maszynowego. Normalizujemy dane. Dane są tu normalizowane do zakresu liczbowego 0-1 za pomocą skalowania min-max. Normalizacja jest ważna, ponieważ wiele modeli uczenia maszynowego, które utworzysz za pomocą TensorFlow.js, jest zaprojektowanych do pracy z liczbami, które nie są zbyt duże. Typowe zakresy normalizacji danych obejmują 0 to 1 lub -1 to 1. Jeśli przyzwyczaisz się do normalizowania danych do rozsądnego zakresu, będziesz skuteczniej trenować modele.
Zwracanie danych i granic normalizacji
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Chcemy zachować wartości, których użyliśmy do normalizacji podczas trenowania, aby móc cofnąć normalizację wyników i przywrócić je do pierwotnej skali oraz aby móc w ten sam sposób normalizować przyszłe dane wejściowe.
6. Wytrenuj model
Po utworzeniu instancji modelu i przedstawieniu danych w postaci tensorów mamy wszystko, co potrzebne do rozpoczęcia procesu trenowania.
Skopiuj tę funkcję do
script.js pliku.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Przeanalizujmy to.
Przygotowanie do trenowania
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
Zanim wytrenujemy model, musimy go „skompilować”. Aby to zrobić, musimy określić kilka bardzo ważnych kwestii:
optimizer: jest to algorytm, który będzie zarządzać aktualizacjami modelu w miarę pojawiania się przykładów. W TensorFlow.js dostępnych jest wiele optymalizatorów. Wybraliśmy optymalizator Adam, ponieważ jest on bardzo skuteczny w praktyce i nie wymaga konfiguracji.loss: ta funkcja informuje model o tym, jak dobrze radzi sobie z uczeniem się poszczególnych partii (podzbiorów danych), które mu są prezentowane. Używamy tutajmeanSquaredError, aby porównać prognozy modelu z rzeczywistymi wartościami.
const batchSize = 32;
const epochs = 50;
Następnie wybieramy rozmiar partii i liczbę epok:
batchSizeodnosi się do rozmiaru podzbiorów danych, które model będzie widzieć w każdej iteracji trenowania. Typowe wielkości wsadu mieszczą się w zakresie 32–512. Nie ma idealnej wielkości wsadu dla wszystkich problemów, a opisanie matematycznych motywacji różnych wielkości wsadów wykracza poza zakres tego samouczka.epochsoznacza liczbę razy, kiedy model będzie analizować cały zbiór danych, który mu udostępnisz. W tym przypadku wykonamy 50 iteracji w zbiorze danych.
Rozpocznij pętlę treningową
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit to funkcja, której używamy do rozpoczęcia pętli trenowania. Jest to funkcja asynchroniczna, więc zwracamy obietnicę, którą nam daje, aby element wywołujący mógł określić, kiedy szkolenie zostanie zakończone.
Aby monitorować postępy trenowania, przekazujemy do model.fit kilka wywołań zwrotnych. Używamy tfvis.show.fitCallbacks do generowania funkcji, które wykreślają wykresy dla danych „loss” i „mse” określonych wcześniej.
Podsumowanie zdobytej wiedzy
Teraz musimy wywołać zdefiniowane funkcje z funkcji run.
Dodaj ten kod na końcu pliku
run funkcji.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Po odświeżeniu strony po kilku sekundach powinny się zaktualizować te wykresy:
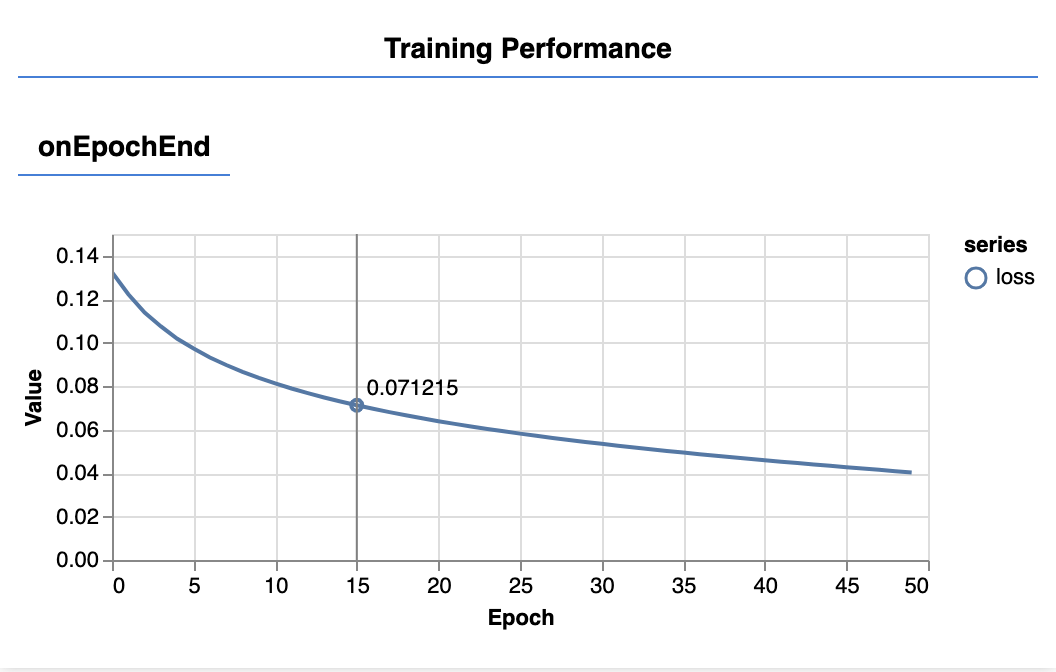
Zostały one utworzone przez wywołania zwrotne, które utworzyliśmy wcześniej. Na końcu każdej epoki wyświetlają one wartość funkcji straty i błędu średniokwadratowego uśrednioną dla całego zbioru danych.
Podczas trenowania modelu chcemy, aby wartość funkcji straty malała. W tym przypadku, ponieważ nasz wskaźnik jest miarą błędu, chcemy, aby jego wartość również się zmniejszała.
7. Tworzenie prognoz
Po wytrenowaniu modelu chcemy dokonać prognoz. Sprawdźmy model, analizując jego prognozy dla jednolitego zakresu mocy silnika od niskiej do wysokiej.
Dodaj do pliku script.js tę funkcję:
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Kilka rzeczy, na które warto zwrócić uwagę w powyższej funkcji.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
Generujemy 100 nowych „przykładów”, które przekazujemy modelowi. Funkcja Model.predict służy do przekazywania tych przykładów do modelu. Pamiętaj, że muszą mieć podobny kształt ([num_examples, num_features_per_example]) jak podczas trenowania.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
Aby przywrócić dane do pierwotnego zakresu (zamiast 0–1), używamy wartości obliczonych podczas normalizacji, ale odwracamy operacje.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() to metoda, której możemy użyć, aby uzyskać typedarray wartości przechowywanych w tensorze. Dzięki temu możemy przetwarzać te wartości w zwykłym JavaScript. Jest to synchroniczna wersja metody .data(), która jest zwykle preferowana.
Na koniec używamy tfjs-vis do wykreślenia oryginalnych danych i prognoz z modelu.
Dodaj ten kod do pliku
run funkcji.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
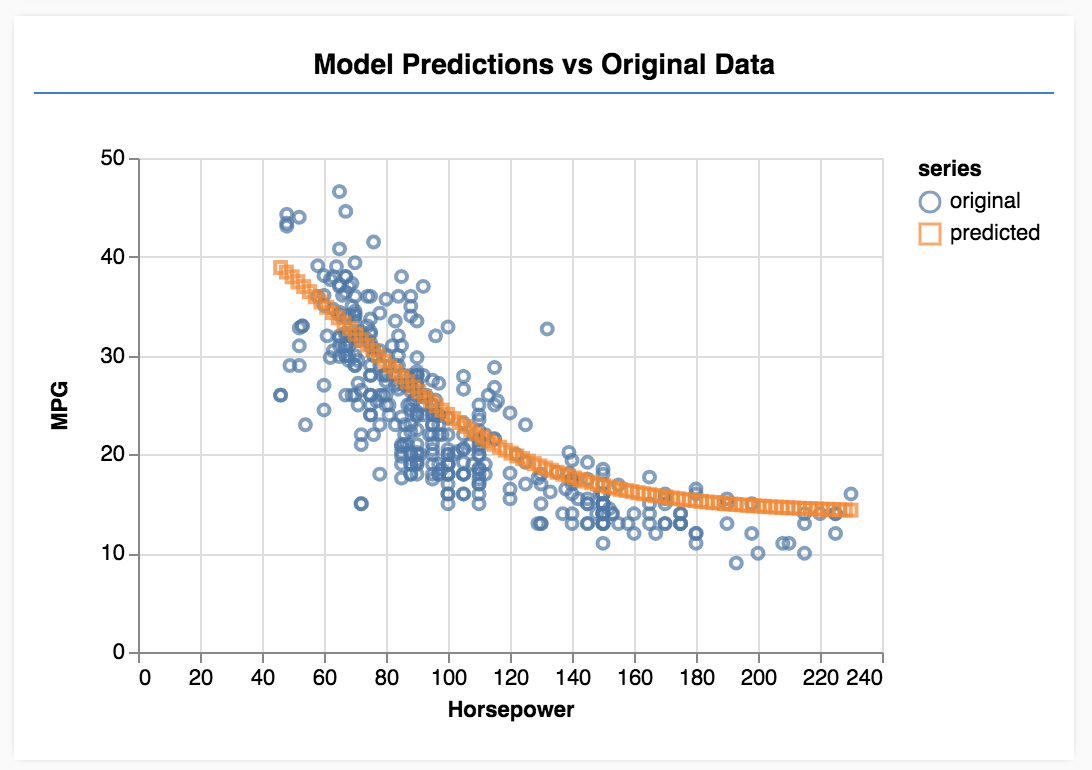
Odśwież stronę. Po zakończeniu trenowania modelu powinna się wyświetlić tabela podobna do tej poniżej.
Gratulacje! Właśnie wytrenowano prosty model uczenia maszynowego. Obecnie wykonuje regresję liniową, która próbuje dopasować linię do trendu występującego w danych wejściowych.
8. Najważniejsze informacje
Proces trenowania modelu uczenia maszynowego obejmuje te etapy:
Sformułuj zadanie:
- Czy jest to problem regresji czy klasyfikacji?
- Czy można to zrobić za pomocą uczenia nadzorowanego lub nienadzorowanego?
- Jakie są kształty danych wejściowych? Jak powinny wyglądać dane wyjściowe?
Przygotuj dane:
- W miarę możliwości oczyść dane i ręcznie sprawdź, czy nie występują w nich wzorce.
- Przed użyciem danych do trenowania modelu przetasuj je
- Znormalizuj dane do rozsądnego zakresu dla sieci neuronowej. W przypadku danych liczbowych zwykle dobre zakresy to 0–1 lub -1–1.
- Przekształcanie danych w tensory
Utwórz i uruchom model:
- Zdefiniuj model za pomocą
tf.sequentiallubtf.model, a następnie dodaj do niego warstwy za pomocątf.layers.*. - Wybierz optymalizator ( adam jest zwykle dobrym wyborem) i parametry, takie jak wielkość wsadu i liczba epok.
- Wybierz odpowiednią funkcję straty dla swojego problemu oraz wskaźnik dokładności, który pomoże Ci ocenić postępy.
meanSquaredErrorto typowa funkcja straty w przypadku problemów z regresją. - Monitoruj trenowanie, aby sprawdzić, czy wartość funkcji straty maleje.
Ocenianie modelu
- Wybierz dane oceny modelu, które możesz monitorować podczas trenowania. Po wytrenowaniu modelu spróbuj przeprowadzić kilka prognoz testowych, aby ocenić jakość prognoz.
9. Dodatkowe informacje: co warto wypróbować
- Eksperymentuj ze zmianą liczby epok. Ile epok potrzebujesz, zanim wykres się wypłaszczy.
- Eksperymentuj ze zwiększaniem liczby jednostek w warstwie ukrytej.
- Eksperymentuj z dodawaniem większej liczby warstw ukrytych pomiędzy pierwszą dodaną warstwą ukrytą a ostatnią warstwą wyjściową. Kod tych dodatkowych warstw powinien wyglądać mniej więcej tak:
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
Najważniejszą nowością w przypadku tych warstw ukrytych jest wprowadzenie nieliniowej funkcji aktywacji, w tym przypadku aktywacji sigmoid. Więcej informacji o funkcjach aktywacji znajdziesz w tym artykule.
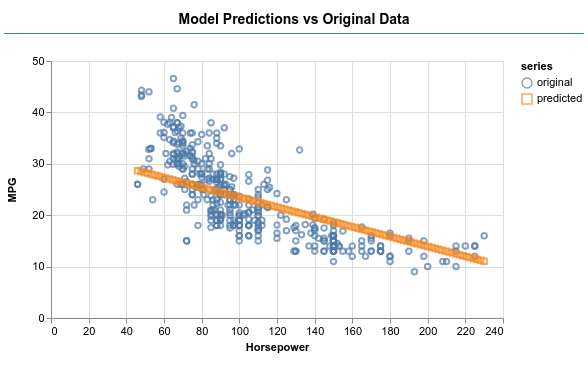
Sprawdź, czy model może wygenerować dane wyjściowe podobne do tych na obrazie poniżej.