1. Introduzione
In questo codelab addestrerai un modello per fare previsioni a partire da dati numerici che descrivono un insieme di auto.
Questo esercizio mostrerà i passaggi comuni all'addestramento di molti tipi diversi di modelli, ma utilizzerà un piccolo set di dati e un modello semplice (superficiale). L'obiettivo principale è aiutarti ad acquisire familiarità con la terminologia, i concetti e la sintassi di base relativi all'addestramento dei modelli con TensorFlow.js e fornire un punto di partenza per ulteriori esplorazioni e apprendimenti.
Poiché stiamo addestrando un modello per prevedere numeri continui, questa attività viene talvolta definita attività di regressione. Addestreremo il modello mostrandogli molti esempi di input insieme all'output corretto. Questo processo è chiamato apprendimento supervisionato.
Cosa creerai
Creerai una pagina web che utilizza TensorFlow.js per addestrare un modello nel browser. Dato il valore "Potenza" di un'auto, il modello imparerà a prevedere le "Miglia per gallone" (MPG).
Per farlo:
- Carica i dati e preparali per l'addestramento.
- Definisci l'architettura del modello.
- Addestra il modello e monitorane le prestazioni durante l'addestramento.
- Valuta il modello addestrato facendo alcune previsioni.
Cosa imparerai a fare
- Best practice per la preparazione dei dati per il machine learning, inclusi rimescolamento e normalizzazione.
- Sintassi TensorFlow.js per la creazione di modelli utilizzando l'API tf.layers.
- Come monitorare l'addestramento nel browser utilizzando la libreria tfjs-vis.
Che cosa ti serve
- Una versione recente di Chrome o di un altro browser moderno.
- Un editor di testo, in esecuzione localmente sul tuo computer o sul web tramite Codepen o Glitch.
- Conoscenza di HTML, CSS, JavaScript e Chrome DevTools (o degli strumenti di sviluppo dei browser che preferisci).
- Una comprensione concettuale di alto livello delle reti neurali. Se hai bisogno di un'introduzione o di un ripasso, ti consigliamo di guardare questo video di 3blue1brown o questo video sul deep learning in JavaScript di Ashi Krishnan.
2. Configurazione
Crea una pagina HTML e includi JavaScript
 Copia il seguente codice in un file HTML denominato
Copia il seguente codice in un file HTML denominato
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
Crea il file JavaScript per il codice
- Nella stessa cartella del file HTML precedente, crea un file chiamato script.js e inserisci il seguente codice.
console.log('Hello TensorFlow');
Prova
Ora che hai creato i file HTML e JavaScript, testali. Apri il file index.html nel browser e la console degli strumenti di sviluppo.
Se tutto funziona, dovrebbero essere create e disponibili due variabili globali nella console degli strumenti di sviluppo:
tfè un riferimento alla libreria TensorFlow.jstfvisè un riferimento alla libreria tfjs-vis
Apri gli strumenti per sviluppatori del browser. Nell'output della console dovrebbe essere visualizzato il messaggio Hello TensorFlow. In questo caso, puoi passare al passaggio successivo.
3. Caricare, formattare e visualizzare i dati di input
Come primo passaggio, carichiamo, formattiamo e visualizziamo i dati su cui vogliamo addestrare il modello.
Caricheremo il set di dati "cars" da un file JSON che abbiamo ospitato per te. Contiene molte funzionalità diverse per ogni auto specificata. Per questo tutorial, vogliamo estrarre solo i dati relativi a cavalli e miglia per gallone.
Aggiungi il seguente codice al tuo
script.js file
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Verranno rimosse anche le voci per cui non sono definiti i chilometri per gallone o la potenza. Tracciamo anche questi dati in un grafico a dispersione per vedere come appaiono.
Aggiungi il seguente codice in fondo al file
script.js file.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Quando aggiorni la pagina. Dovresti vedere un riquadro sul lato sinistro della pagina con un grafico a dispersione dei dati. L'annuncio dovrebbe avere un aspetto simile a questo.
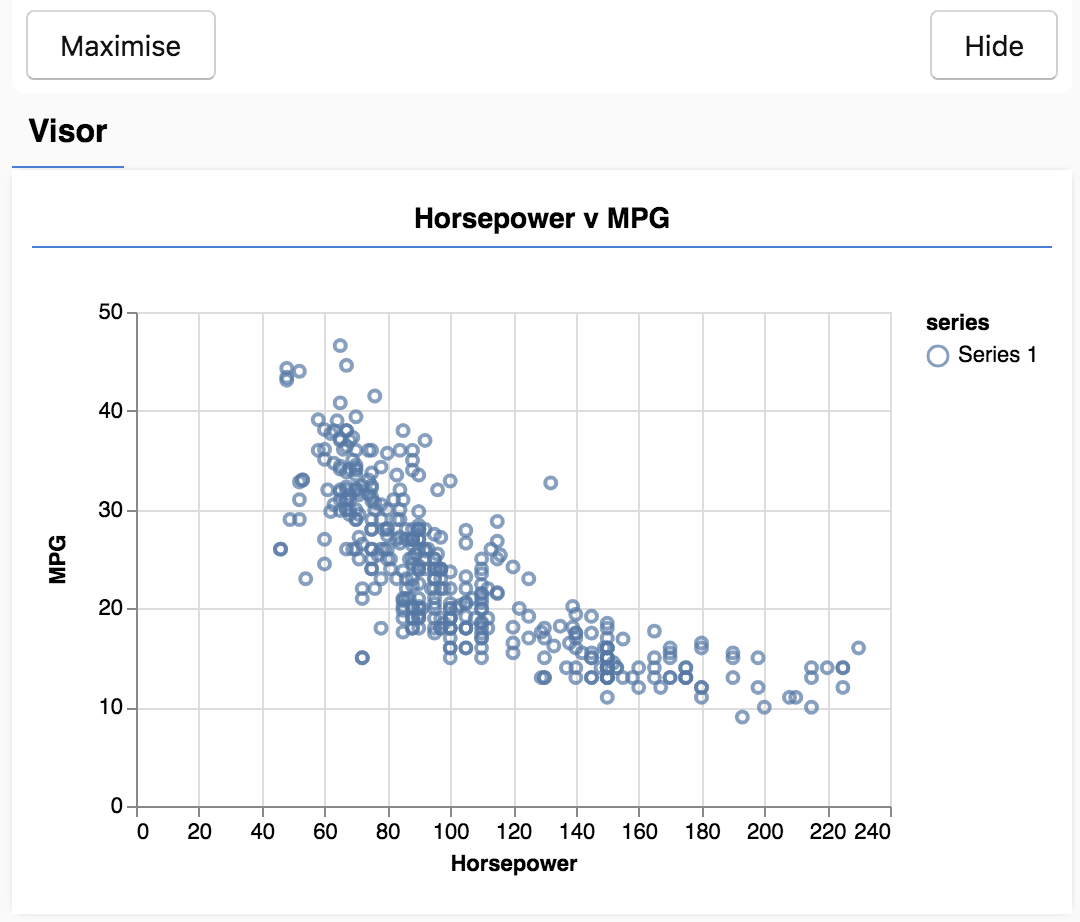
Questo pannello è noto come visore ed è fornito da tfjs-vis. Fornisce un luogo comodo per visualizzare le visualizzazioni.
In generale, quando si lavora con i dati, è una buona idea trovare modi per esaminarli e pulirli, se necessario. In questo caso, abbiamo dovuto rimuovere alcune voci da carsData che non contenevano tutti i campi obbligatori. La visualizzazione dei dati può darci un'idea della struttura dei dati che il modello può apprendere.
Dal grafico sopra riportato si può notare che esiste una correlazione negativa tra la potenza e i chilometri percorsi con un litro di carburante, ovvero all'aumentare della potenza, le auto percorrono generalmente meno chilometri con un litro di carburante.
Concettualizzare la nostra attività
I nostri dati di input ora avranno questo aspetto.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Il nostro obiettivo è addestrare un modello che prenda un numero, la potenza, e impari a prevedere un numero, i chilometri per litro. Ricorda la mappatura uno a uno, perché sarà importante per la sezione successiva.
Inseriremo questi esempi, la potenza e il MPG, in una rete neurale che imparerà da questi esempi una formula (o funzione) per prevedere il MPG in base alla potenza. Questo apprendimento dagli esempi per i quali abbiamo le risposte corrette è chiamato apprendimento supervisionato.
4. Definisci l'architettura del modello
In questa sezione scriveremo il codice per descrivere l'architettura del modello. L'architettura del modello è un modo elegante per dire "quali funzioni verranno eseguite dal modello durante l'esecuzione" o, in alternativa, "quale algoritmo verrà utilizzato dal modello per calcolare le risposte".
I modelli di ML sono algoritmi che prendono un input e producono un output. Quando si utilizzano reti neurali, l'algoritmo è un insieme di livelli di neuroni con "pesi" (numeri) che regolano il loro output. Il processo di addestramento apprende i valori ideali per queste ponderazioni.
Aggiungi la seguente funzione a
script.js per definire l'architettura del modello.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Questo è uno dei modelli più semplici che possiamo definire in TensorFlow.js. Analizziamo un po' ogni riga.
Istanzia il modello
const model = tf.sequential();
Viene creata un'istanza di un oggetto tf.Model. Questo modello è sequential perché i suoi input scorrono direttamente al suo output. Altri tipi di modelli possono avere rami o anche più input e output, ma in molti casi i modelli saranno sequenziali. I modelli sequenziali hanno anche un'API più facile da usare.
Aggiungere livelli
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
In questo modo viene aggiunto un livello di input alla rete, che viene connesso automaticamente a un livello dense con un'unità nascosta. Un livello dense è un tipo di livello che moltiplica i suoi input per una matrice (chiamata pesi) e poi aggiunge un numero (chiamato bias) al risultato. Poiché si tratta del primo livello della rete, dobbiamo definire il nostro inputShape. inputShape è [1] perché abbiamo il numero 1 come input (la potenza di una determinata auto).
units imposta le dimensioni della matrice dei pesi nel livello. Se lo imposti su 1, indichi che ci sarà un peso per ciascuna delle funzionalità di input dei dati.
model.add(tf.layers.dense({units: 1}));
Il codice sopra crea il nostro livello di output. Abbiamo impostato units su 1 perché vogliamo restituire il numero 1.
Crea un'istanza
Aggiungi il seguente codice a
run funzione che abbiamo definito in precedenza.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
In questo modo, verrà creata un'istanza del modello e verrà mostrato un riepilogo dei livelli nella pagina web.
5. Preparare i dati per l'addestramento
Per ottenere i vantaggi in termini di prestazioni di TensorFlow.js che rendono pratico l'addestramento dei modelli di machine learning, dobbiamo convertire i nostri dati in tensori. Eseguiremo anche una serie di trasformazioni sui nostri dati che sono best practice, ovvero shuffling e normalizzazione.
Aggiungi il seguente codice al tuo
script.js file
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Analizziamo cosa sta succedendo.
Mescolare i dati
// Step 1. Shuffle the data
tf.util.shuffle(data);
Qui randomizziamo l'ordine degli esempi che forniremo all'algoritmo di addestramento. Il rimescolamento è importante perché in genere durante l'addestramento il set di dati viene suddiviso in sottoinsiemi più piccoli, chiamati batch, su cui viene addestrato il modello. Il rimescolamento aiuta ogni batch ad avere una varietà di dati provenienti da tutta la distribuzione dei dati. In questo modo, aiutiamo il modello a:
- Non apprendere elementi che dipendono esclusivamente dall'ordine in cui sono stati inseriti i dati
- Non essere sensibile alla struttura nei sottogruppi (ad es. se vede solo auto ad alta potenza per la prima metà dell'addestramento, potrebbe apprendere una relazione che non si applica al resto del set di dati).
Converti in tensori
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Qui creiamo due array, uno per i nostri esempi di input (le voci relative alla potenza) e un altro per i valori di output effettivi (noti come etichette nel machine learning).
Quindi, convertiamo ogni dato dell'array in un tensore bidimensionale. Il tensore avrà una forma di [num_examples, num_features_per_example]. Qui abbiamo inputs.length esempi e ogni esempio ha 1 caratteristiche di input (la potenza).
Normalizzare i dati
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Poi, seguiamo un'altra best practice per l'addestramento del machine learning. Normalizziamo i dati. Qui normalizziamo i dati nell'intervallo numerico 0-1 utilizzando la scalabilità min-max. La normalizzazione è importante perché i componenti interni di molti modelli di machine learning che creerai con TensorFlow.js sono progettati per funzionare con numeri non troppo grandi. Gli intervalli comuni per normalizzare i dati includono 0 to 1 o -1 to 1. Avrai più successo nell'addestramento dei modelli se prendi l'abitudine di normalizzare i dati in un intervallo ragionevole.
Restituisci i dati e i limiti di normalizzazione
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Vogliamo conservare i valori che abbiamo utilizzato per la normalizzazione durante l'addestramento, in modo da poter annullare la normalizzazione degli output per riportarli alla scala originale e per poter normalizzare i dati di input futuri nello stesso modo.
6. Addestra il modello
Ora che l'istanza del modello è stata creata e i dati sono rappresentati come tensori, abbiamo tutto il necessario per iniziare il processo di addestramento.
Copia la seguente funzione nel tuo
script.js file.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Analizziamo la questione nel dettaglio.
Prepararsi per l'addestramento
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
Prima di addestrarlo, dobbiamo "compilare" il modello. A questo scopo, dobbiamo specificare una serie di aspetti molto importanti:
optimizer: questo è l'algoritmo che governerà gli aggiornamenti al modello man mano che vengono visualizzati esempi. In TensorFlow.js sono disponibili molti ottimizzatori. Qui abbiamo scelto l'ottimizzatore Adam perché è molto efficace nella pratica e non richiede alcuna configurazione.loss: questa funzione indica al modello il livello di apprendimento di ciascun batch (sottoinsieme di dati) che gli viene mostrato. Qui utilizziamomeanSquaredErrorper confrontare le previsioni fatte dal modello con i valori effettivi.
const batchSize = 32;
const epochs = 50;
Successivamente scegliamo un batchSize e un numero di epoche:
batchSizesi riferisce alle dimensioni dei sottoinsiemi di dati che il modello vedrà a ogni iterazione dell'addestramento. Le dimensioni comuni dei batch tendono a essere comprese tra 32 e 512. Non esiste una dimensione del batch ideale per tutti i problemi e descrivere le motivazioni matematiche per le varie dimensioni del batch va oltre l'ambito di questo tutorial.epochssi riferisce al numero di volte in cui il modello esaminerà l'intero set di dati che fornisci. Qui eseguiremo 50 iterazioni nel set di dati.
Inizia l'allenamento
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit è la funzione che chiamiamo per avviare il ciclo di addestramento. È una funzione asincrona, quindi restituiamo la promessa che ci fornisce in modo che il chiamante possa determinare quando il training è completato.
Per monitorare l'avanzamento dell'addestramento, passiamo alcuni callback a model.fit. Utilizziamo tfvis.show.fitCallbacks per generare funzioni che tracciano grafici per le metriche "loss" e "mse" specificate in precedenza.
Per riassumere
Ora dobbiamo chiamare le funzioni che abbiamo definito dalla nostra funzione run.
Aggiungi il seguente codice in fondo al file
Funzione run.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Quando aggiorni la pagina, dopo alcuni secondi dovresti vedere l'aggiornamento dei seguenti grafici.
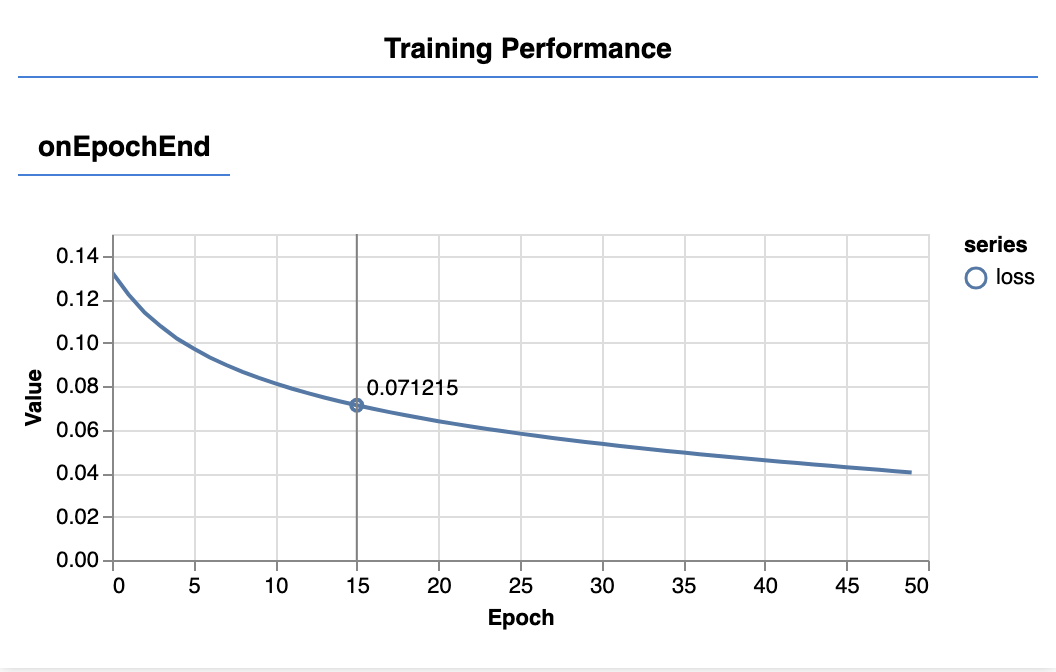
Questi vengono creati dai callback che abbiamo creato in precedenza. Mostrano la perdita e l'errore quadratico medio, calcolati in media sull'intero set di dati, alla fine di ogni epoca.
Durante l'addestramento di un modello, vogliamo che la perdita diminuisca. In questo caso, poiché la nostra metrica è una misura dell'errore, vogliamo che diminuisca.
7. Generare previsioni
Ora che il modello è addestrato, vogliamo fare alcune previsioni. Valutiamo il modello vedendo cosa prevede per un intervallo uniforme di numeri di cavalli da basso ad alto.
Aggiungi la seguente funzione al file script.js
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Alcuni elementi da notare nella funzione precedente.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
Generiamo 100 nuovi "esempi" da fornire al modello. Model.predict è il modo in cui inseriamo questi esempi nel modello. Tieni presente che devono avere una forma simile ([num_examples, num_features_per_example]) a quella che avevamo durante l'addestramento.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
Per riportare i dati all'intervallo originale (anziché 0-1), utilizziamo i valori calcolati durante la normalizzazione, ma invertiamo le operazioni.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() è un metodo che possiamo utilizzare per ottenere un typedarray dei valori memorizzati in un tensore. Ciò ci consente di elaborare questi valori in JavaScript normale. Si tratta di una versione sincrona del metodo .data(), che in genere è preferibile.
Infine, utilizziamo tfjs-vis per tracciare i dati originali e le previsioni del modello.
Aggiungi il seguente codice al tuo
Funzione run.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
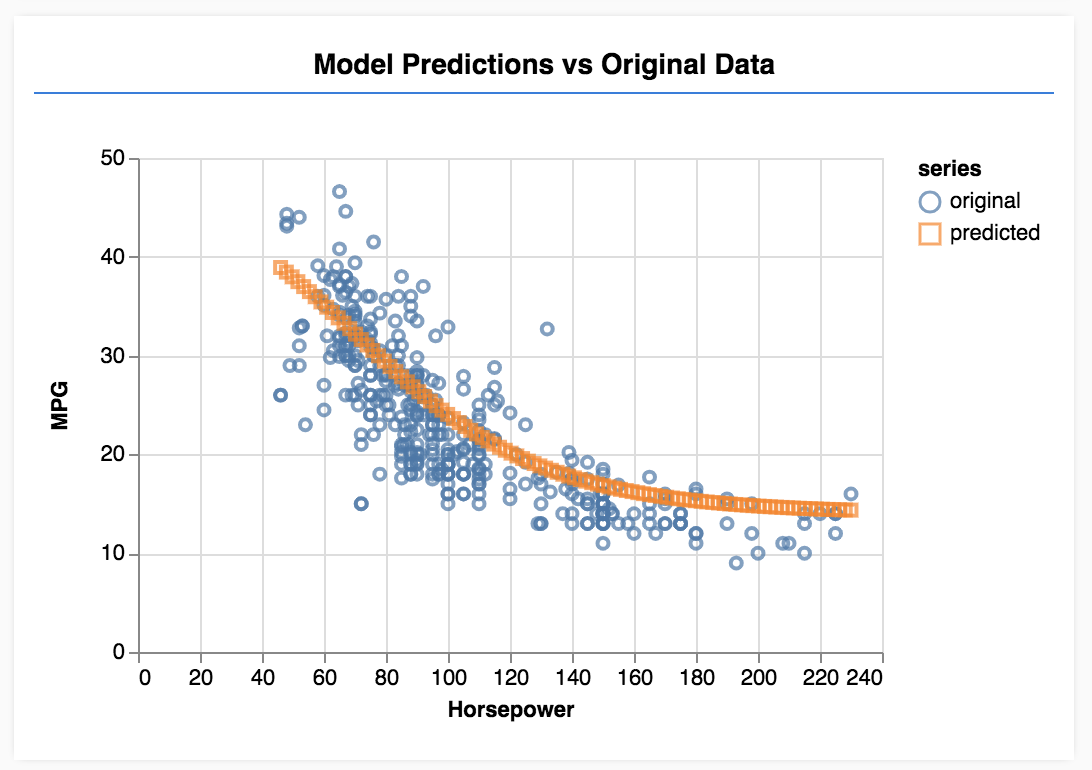
Aggiorna la pagina e, al termine dell'addestramento del modello, dovresti vedere una schermata simile alla seguente.
Complimenti! Hai appena addestrato un semplice modello di machine learning. Attualmente esegue la cosiddetta regressione lineare, che tenta di adattare una linea alla tendenza presente nei dati di input.
8. Concetti principali
I passaggi per l'addestramento di un modello di machine learning includono:
Formula la tua attività:
- È un problema di regressione o di classificazione?
- Può essere fatto con l'apprendimento supervisionato o non supervisionato?
- Qual è la forma dei dati di input? Come devono essere strutturati i dati di output?
Prepara i dati:
- Pulisci i dati ed esaminali manualmente per individuare pattern, se possibile
- Mescola i dati prima di utilizzarli per l'addestramento
- Normalizza i dati in un intervallo ragionevole per la rete neurale. In genere, 0-1 o -1-1 sono intervalli adatti per i dati numerici.
- Convertire i dati in tensori
Crea ed esegui il modello:
- Definisci il modello utilizzando
tf.sequentialotf.model, poi aggiungi i livelli utilizzandotf.layers.* - Scegli un ottimizzatore ( adam è in genere una buona scelta) e parametri come la dimensione del batch e il numero di epoche.
- Scegli una funzione di perdita appropriata per il tuo problema e una metrica di accuratezza per valutare i progressi.
meanSquaredErrorè una funzione di perdita comune per i problemi di regressione. - Monitora l'addestramento per vedere se la perdita sta diminuendo
valuta il modello
- Scegli una metrica di valutazione per il modello che puoi monitorare durante l'addestramento. Una volta addestrato, prova a fare alcune previsioni di test per farti un'idea della qualità della previsione.
9. Crediti extra: cose da provare
- Prova a modificare il numero di epoche. Di quante epoche hai bisogno prima che il grafico si appiattisca.
- Prova ad aumentare il numero di unità nello strato nascosto.
- Prova ad aggiungere altri strati nascosti tra il primo strato nascosto che abbiamo aggiunto e lo strato di output finale. Il codice per questi livelli aggiuntivi dovrebbe avere un aspetto simile a questo.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
La novità più importante di questi strati nascosti è che introducono una funzione di attivazione non lineare, in questo caso l'attivazione sigmoid. Per scoprire di più sulle funzioni di attivazione, consulta questo articolo.
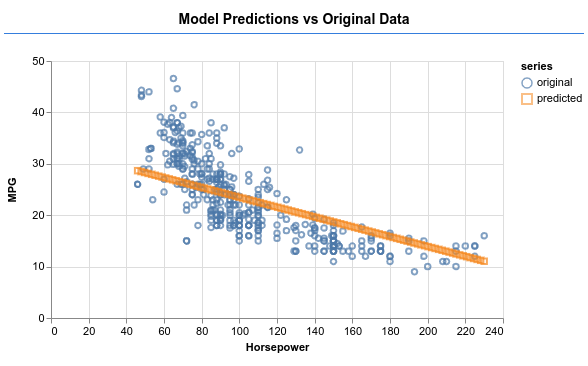
Prova a fare in modo che il modello produca un output come quello nell'immagine qui sotto.