1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ huấn luyện một mô hình để đưa ra dự đoán từ dữ liệu dạng số mô tả một nhóm ô tô.
Bài tập này sẽ minh hoạ các bước thường gặp trong quá trình huấn luyện nhiều loại mô hình khác nhau, nhưng sẽ sử dụng một tập dữ liệu nhỏ và một mô hình đơn giản (nông). Mục tiêu chính là giúp bạn làm quen với thuật ngữ, khái niệm và cú pháp cơ bản về việc huấn luyện mô hình bằng TensorFlow.js, đồng thời cung cấp nền tảng để bạn khám phá và học tập thêm.
Vì chúng ta đang huấn luyện một mô hình để dự đoán các số liên tục, nên đôi khi nhiệm vụ này được gọi là nhiệm vụ hồi quy. Chúng ta sẽ huấn luyện mô hình bằng cách cho mô hình xem nhiều ví dụ về dữ liệu đầu vào cùng với dữ liệu đầu ra chính xác. Đây được gọi là học có giám sát.
Sản phẩm bạn sẽ tạo ra
Bạn sẽ tạo một trang web sử dụng TensorFlow.js để huấn luyện một mô hình trong trình duyệt. Với "Mã lực" của một chiếc ô tô, mô hình sẽ học cách dự đoán "Số dặm trên một gallon" (MPG).
Để làm được việc này, bạn sẽ:
- Tải dữ liệu và chuẩn bị dữ liệu để huấn luyện.
- Xác định cấu trúc của mô hình.
- Huấn luyện mô hình và theo dõi hiệu suất của mô hình trong quá trình huấn luyện.
- Đánh giá mô hình đã huấn luyện bằng cách đưa ra một số dự đoán.
Kiến thức bạn sẽ học được
- Các phương pháp hay nhất để chuẩn bị dữ liệu cho hoạt động học máy, bao gồm cả việc xáo trộn và chuẩn hoá.
- Cú pháp TensorFlow.js để tạo mô hình bằng API tf.layers.
- Cách theo dõi quá trình huấn luyện trong trình duyệt bằng thư viện tfjs-vis.
Bạn cần có
- Phiên bản mới nhất của Chrome hoặc một trình duyệt hiện đại khác.
- Một trình chỉnh sửa văn bản, chạy cục bộ trên máy hoặc trên web thông qua một công cụ như Codepen hoặc Glitch.
- Có kiến thức về HTML, CSS, JavaScript và Chrome DevTools (hoặc công cụ cho nhà phát triển của trình duyệt mà bạn muốn dùng).
- Hiểu biết khái niệm cấp cao về Mạng nơ-ron. Nếu bạn cần xem phần giới thiệu hoặc ôn lại kiến thức, hãy cân nhắc xem video này của 3blue1brown hoặc video này về Học sâu bằng JavaScript của Ashi Krishnan.
2. Bắt đầu thiết lập
Tạo một trang HTML và thêm JavaScript
 Sao chép mã sau vào một tệp html có tên là
Sao chép mã sau vào một tệp html có tên là
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
Tạo tệp JavaScript cho mã
- Trong cùng thư mục với tệp HTML ở trên, hãy tạo một tệp có tên là script.js rồi đặt đoạn mã sau vào đó.
console.log('Hello TensorFlow');
Dùng thử
Bây giờ bạn đã tạo xong các tệp HTML và JavaScript, hãy kiểm thử các tệp đó. Mở tệp index.html trong trình duyệt và mở bảng điều khiển công cụ cho nhà phát triển.
Nếu mọi thứ đều hoạt động, thì sẽ có 2 biến chung được tạo và có sẵn trong bảng điều khiển công cụ cho nhà phát triển:
tflà một tài liệu tham khảo về thư viện TensorFlow.jstfvislà một tài liệu tham khảo cho thư viện tfjs-vis
Mở công cụ dành cho nhà phát triển của trình duyệt, bạn sẽ thấy một thông báo có nội dung Hello TensorFlow trong đầu ra của bảng điều khiển. Nếu có, bạn đã sẵn sàng chuyển sang bước tiếp theo.
3. Tải, định dạng và trực quan hoá dữ liệu đầu vào
Bước đầu tiên, hãy tải, định dạng và trực quan hoá dữ liệu mà chúng ta muốn dùng để huấn luyện mô hình.
Chúng ta sẽ tải tập dữ liệu "cars" từ một tệp JSON mà chúng tôi đã lưu trữ cho bạn. Tệp này chứa nhiều tính năng khác nhau về từng chiếc xe cụ thể. Trong hướng dẫn này, chúng ta chỉ muốn trích xuất dữ liệu về Mã lực và Số dặm trên mỗi gallon.
Thêm mã sau vào
script.js tệp
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Thao tác này cũng sẽ xoá mọi mục không có thông tin về số dặm trên một gallon hoặc mã lực. Hãy vẽ dữ liệu này trong biểu đồ phân tán để xem dữ liệu trông như thế nào.
Thêm mã sau vào cuối
script.js file.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Khi bạn làm mới trang. Bạn sẽ thấy một bảng điều khiển ở bên trái trang có biểu đồ phân tán về dữ liệu. Nó phải trông giống như thế này.
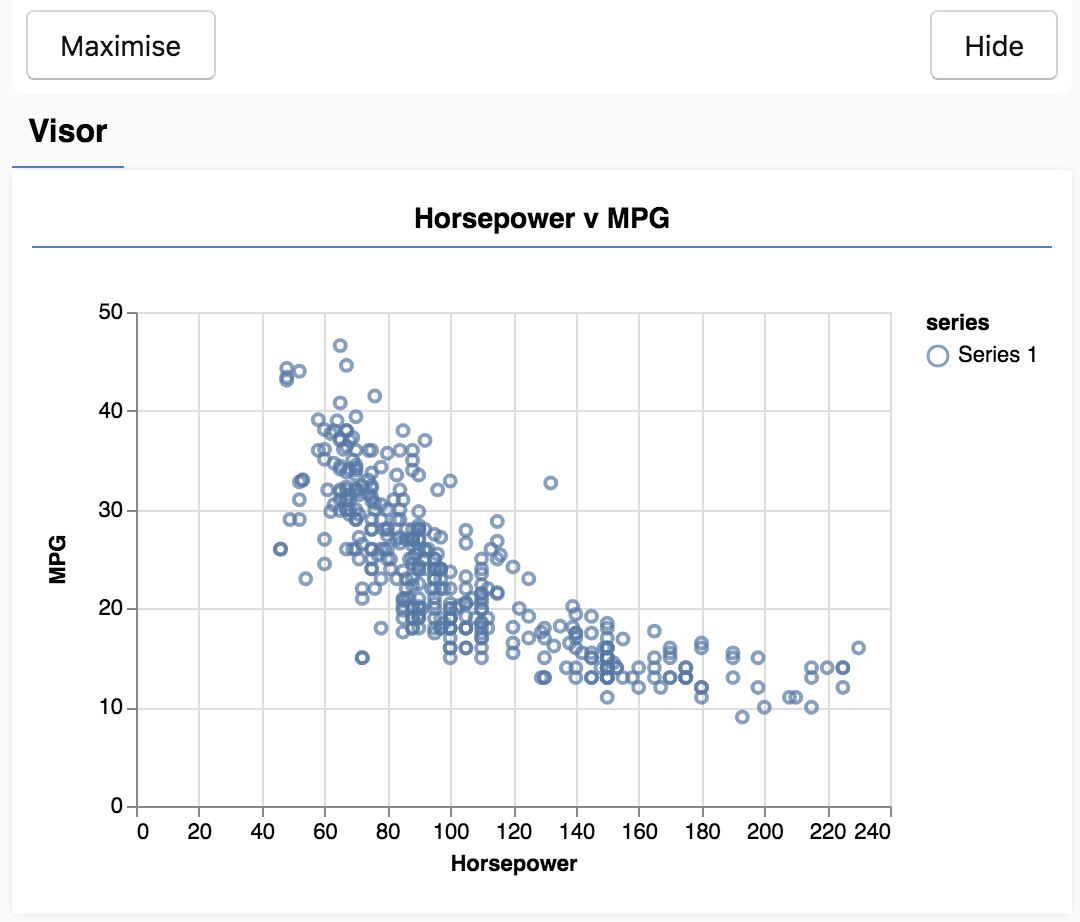
Bảng điều khiển này được gọi là visor và do tfjs-vis cung cấp. Đây là một nơi thuận tiện để hiển thị các hình ảnh trực quan.
Nhìn chung, khi làm việc với dữ liệu, bạn nên tìm cách xem xét dữ liệu và làm sạch dữ liệu nếu cần. Trong trường hợp này, chúng tôi phải xoá một số mục trong carsData vì thiếu tất cả các trường bắt buộc. Việc trực quan hoá dữ liệu có thể giúp chúng ta biết liệu dữ liệu có cấu trúc nào mà mô hình có thể học hay không.
Từ biểu đồ trên, chúng ta có thể thấy rằng có mối tương quan âm giữa mã lực và MPG, tức là khi mã lực tăng lên, ô tô thường đi được ít dặm hơn trên mỗi gallon.
Lên ý tưởng cho việc cần làm
Dữ liệu đầu vào của chúng ta sẽ có dạng như sau.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Mục tiêu của chúng ta là huấn luyện một mô hình sẽ lấy một số, Mã lực và học cách dự đoán một số, Số dặm trên mỗi gallon. Hãy nhớ rằng việc lập bản đồ một-một sẽ rất quan trọng đối với phần tiếp theo.
Chúng ta sẽ cung cấp những ví dụ này (mã lực và mức tiêu thụ nhiên liệu) cho một mạng nơ-ron. Mạng nơ-ron này sẽ học từ những ví dụ này một công thức (hoặc hàm) để dự đoán mức tiêu thụ nhiên liệu dựa trên mã lực. Việc học từ các ví dụ mà chúng ta có câu trả lời đúng được gọi là Học có giám sát.
4. Xác định cấu trúc mô hình
Trong phần này, chúng ta sẽ viết mã để mô tả cấu trúc mô hình. Cấu trúc mô hình chỉ là một cách nói hoa mỹ của câu "mô hình sẽ chạy những hàm nào khi đang thực thi", hoặc "mô hình của chúng ta sẽ dùng thuật toán nào để tính toán câu trả lời".
Mô hình học máy là các thuật toán nhận dữ liệu đầu vào và tạo ra dữ liệu đầu ra. Khi sử dụng mạng nơ-ron, thuật toán là một tập hợp các lớp nơ-ron có "trọng số" (các con số) chi phối đầu ra của chúng. Quá trình huấn luyện sẽ tìm hiểu các giá trị lý tưởng cho những trọng số đó.
Thêm hàm sau vào
script.js để xác định cấu trúc mô hình.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Đây là một trong những mô hình đơn giản nhất mà chúng ta có thể xác định trong tensorflow.js. Hãy phân tích từng dòng một chút.
Tạo thực thể cho mô hình
const model = tf.sequential();
Thao tác này sẽ tạo thực thể cho một đối tượng tf.Model. Mô hình này là sequential vì các đầu vào của mô hình này sẽ đi thẳng xuống đầu ra. Các loại mô hình khác có thể có các nhánh, hoặc thậm chí nhiều đầu vào và đầu ra, nhưng trong nhiều trường hợp, các mô hình của bạn sẽ có tính tuần tự. Các mô hình tuần tự cũng có API dễ sử dụng hơn.
Thêm lớp
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
Thao tác này sẽ thêm một lớp đầu vào vào mạng của chúng ta, lớp này sẽ tự động kết nối với một lớp dense có một đơn vị ẩn. Lớp dense là một loại lớp nhân các đầu vào của nó với một ma trận (gọi là trọng số) rồi cộng một số (gọi là độ lệch) vào kết quả. Vì đây là lớp đầu tiên của mạng, nên chúng ta cần xác định inputShape. inputShape là [1] vì chúng ta có 1 làm dữ liệu đầu vào (mã lực của một chiếc ô tô nhất định).
units đặt kích thước của ma trận trọng số trong lớp. Bằng cách đặt giá trị này thành 1, chúng ta đang nói rằng sẽ có 1 trọng số cho mỗi đặc điểm đầu vào của dữ liệu.
model.add(tf.layers.dense({units: 1}));
Đoạn mã trên tạo lớp đầu ra của chúng ta. Chúng ta đặt units thành 1 vì muốn xuất số 1.
Tạo một thực thể
Thêm mã sau vào
run hàm mà chúng ta đã xác định trước đó.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
Thao tác này sẽ tạo một phiên bản của mô hình và cho thấy bản tóm tắt về các lớp trên trang web.
5. Chuẩn bị dữ liệu để huấn luyện
Để tận dụng những lợi ích về hiệu suất của TensorFlow.js giúp việc huấn luyện các mô hình học máy trở nên thiết thực, chúng ta cần chuyển đổi dữ liệu sang tensor. Chúng tôi cũng sẽ thực hiện một số phép biến đổi trên dữ liệu của mình theo các phương pháp hay nhất, cụ thể là trộn và chuẩn hoá.
Thêm mã sau vào
script.js tệp
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Hãy cùng phân tích những gì đang diễn ra ở đây.
Trộn dữ liệu
// Step 1. Shuffle the data
tf.util.shuffle(data);
Ở đây, chúng ta sẽ ngẫu nhiên hoá thứ tự của các ví dụ mà chúng ta sẽ cung cấp cho thuật toán huấn luyện. Việc xáo trộn là rất quan trọng vì thông thường trong quá trình huấn luyện, tập dữ liệu sẽ được chia thành các tập hợp con nhỏ hơn (gọi là lô) mà mô hình được huấn luyện trên đó. Việc xáo trộn giúp mỗi lô có nhiều dữ liệu từ toàn bộ phân phối dữ liệu. Bằng cách này, chúng ta sẽ giúp mô hình:
- Không học những thứ hoàn toàn phụ thuộc vào thứ tự mà dữ liệu được đưa vào
- Không nhạy cảm với cấu trúc trong các nhóm nhỏ (ví dụ: nếu chỉ thấy những chiếc xe có mã lực cao trong nửa đầu quá trình huấn luyện, thì mô hình có thể học được một mối quan hệ không áp dụng cho phần còn lại của tập dữ liệu).
Chuyển đổi thành tensor
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Ở đây, chúng ta tạo hai mảng, một mảng cho các ví dụ đầu vào (các mục về mã lực) và một mảng khác cho các giá trị đầu ra thực (được gọi là nhãn trong học máy).
Sau đó, chúng ta chuyển đổi từng dữ liệu mảng thành một tensor 2 chiều. Tensor sẽ có hình dạng [num_examples, num_features_per_example]. Ở đây, chúng ta có các ví dụ về inputs.length và mỗi ví dụ đều có 1 tính năng đầu vào (mã lực).
Chuẩn hoá dữ liệu
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Tiếp theo, chúng ta sẽ thực hiện một phương pháp hay nhất khác để huấn luyện công nghệ học máy. Chúng tôi chuẩn hoá dữ liệu. Ở đây, chúng ta chuẩn hoá dữ liệu thành phạm vi số 0-1 bằng cách sử dụng phương pháp chuyển tỉ lệ min-max. Việc chuẩn hoá là rất quan trọng vì nội bộ của nhiều mô hình học máy mà bạn sẽ xây dựng bằng tensorflow.js được thiết kế để hoạt động với những con số không quá lớn. Các dải ô phổ biến để chuẩn hoá dữ liệu bao gồm 0 to 1 hoặc -1 to 1. Bạn sẽ huấn luyện mô hình thành công hơn nếu có thói quen chuẩn hoá dữ liệu trong một phạm vi hợp lý.
Trả về dữ liệu và các giới hạn chuẩn hoá
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Chúng ta muốn giữ lại các giá trị đã dùng để chuẩn hoá trong quá trình huấn luyện để có thể huỷ chuẩn hoá các đầu ra, đưa chúng trở lại tỷ lệ ban đầu và cho phép chúng ta chuẩn hoá dữ liệu đầu vào trong tương lai theo cách tương tự.
6. Huấn luyện mô hình
Sau khi tạo phiên bản mô hình và biểu thị dữ liệu dưới dạng tensor, chúng ta đã có mọi thứ cần thiết để bắt đầu quy trình huấn luyện.
Sao chép hàm sau vào
script.js file.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Hãy cùng phân tích vấn đề này.
Chuẩn bị cho buổi huấn luyện
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
Chúng ta phải "biên dịch" mô hình trước khi huấn luyện. Để làm như vậy, chúng ta phải chỉ định một số điều rất quan trọng:
optimizer: Đây là thuật toán sẽ chi phối các bản cập nhật cho mô hình khi mô hình thấy các ví dụ. Có nhiều trình tối ưu hoá trong TensorFlow.js. Ở đây, chúng ta đã chọn trình tối ưu hoá adam vì trình tối ưu hoá này khá hiệu quả trong thực tế và không yêu cầu cấu hình.loss: đây là một hàm cho biết hiệu suất của mô hình trong việc học từng lô (tập hợp con dữ liệu) mà mô hình được hiển thị. Ở đây, chúng ta sử dụngmeanSquaredErrorđể so sánh kết quả dự đoán của mô hình với các giá trị thực.
const batchSize = 32;
const epochs = 50;
Tiếp theo, chúng ta chọn batchSize và số lượng epoch:
batchSizeđề cập đến kích thước của các tập hợp con dữ liệu mà mô hình sẽ thấy trong mỗi lần lặp lại của quá trình huấn luyện. Kích thước lô thông thường thường nằm trong khoảng từ 32 đến 512. Không có kích thước lô lý tưởng cho mọi vấn đề và việc mô tả động lực toán học cho nhiều kích thước lô nằm ngoài phạm vi của hướng dẫn này.epochsđề cập đến số lần mô hình sẽ xem xét toàn bộ tập dữ liệu mà bạn cung cấp. Ở đây, chúng ta sẽ thực hiện 50 lần lặp qua tập dữ liệu.
Bắt đầu vòng lặp huấn luyện
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit là hàm mà chúng ta gọi để bắt đầu vòng lặp huấn luyện. Đây là một hàm không đồng bộ, vì vậy chúng ta sẽ trả về lời hứa mà hàm này đưa ra để phương thức gọi có thể xác định thời điểm quá trình huấn luyện hoàn tất.
Để theo dõi tiến trình huấn luyện, chúng ta sẽ truyền một số lệnh gọi lại đến model.fit. Chúng ta sử dụng tfvis.show.fitCallbacks để tạo các hàm vẽ biểu đồ cho chỉ số "loss" và "mse" mà chúng ta đã chỉ định trước đó.
Tổng hợp kiến thức đã học
Bây giờ, chúng ta phải gọi các hàm mà chúng ta đã xác định từ hàm run.
Thêm mã sau vào cuối
run hàm.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Khi làm mới trang, sau vài giây, bạn sẽ thấy các biểu đồ sau đây cập nhật.
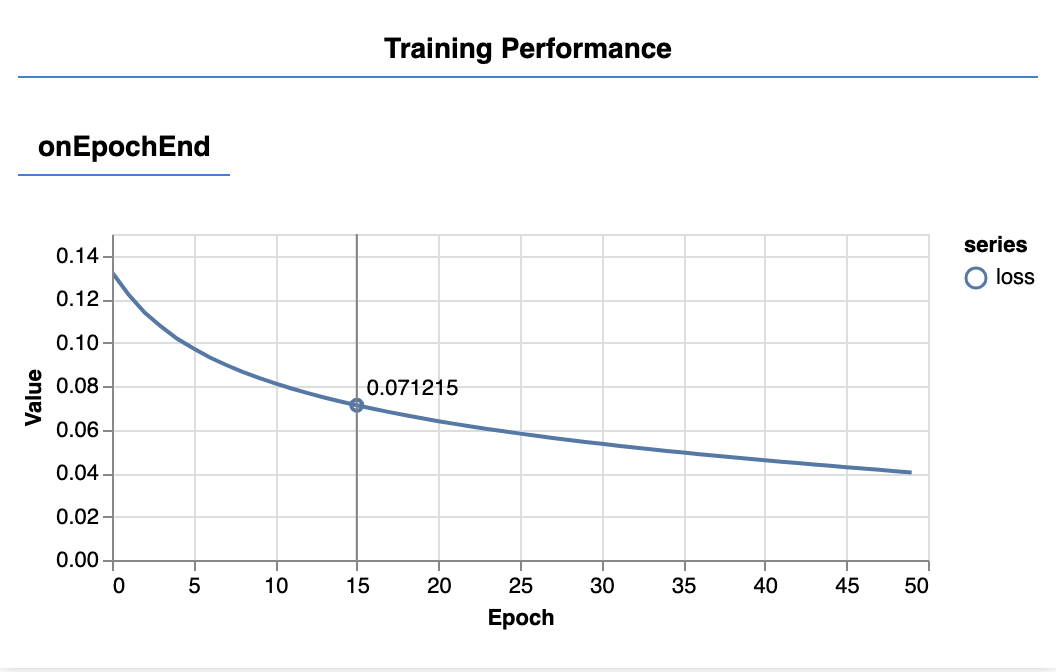
Các đối tượng này được tạo bằng các lệnh gọi lại mà chúng ta đã tạo trước đó. Chúng hiển thị tổn thất và mse, được tính trung bình trên toàn bộ tập dữ liệu, vào cuối mỗi giai đoạn.
Khi huấn luyện một mô hình, chúng ta muốn thấy tổn thất giảm xuống. Trong trường hợp này, vì chỉ số của chúng ta là một thước đo lỗi, nên chúng ta cũng muốn chỉ số này giảm xuống.
7. Dự đoán
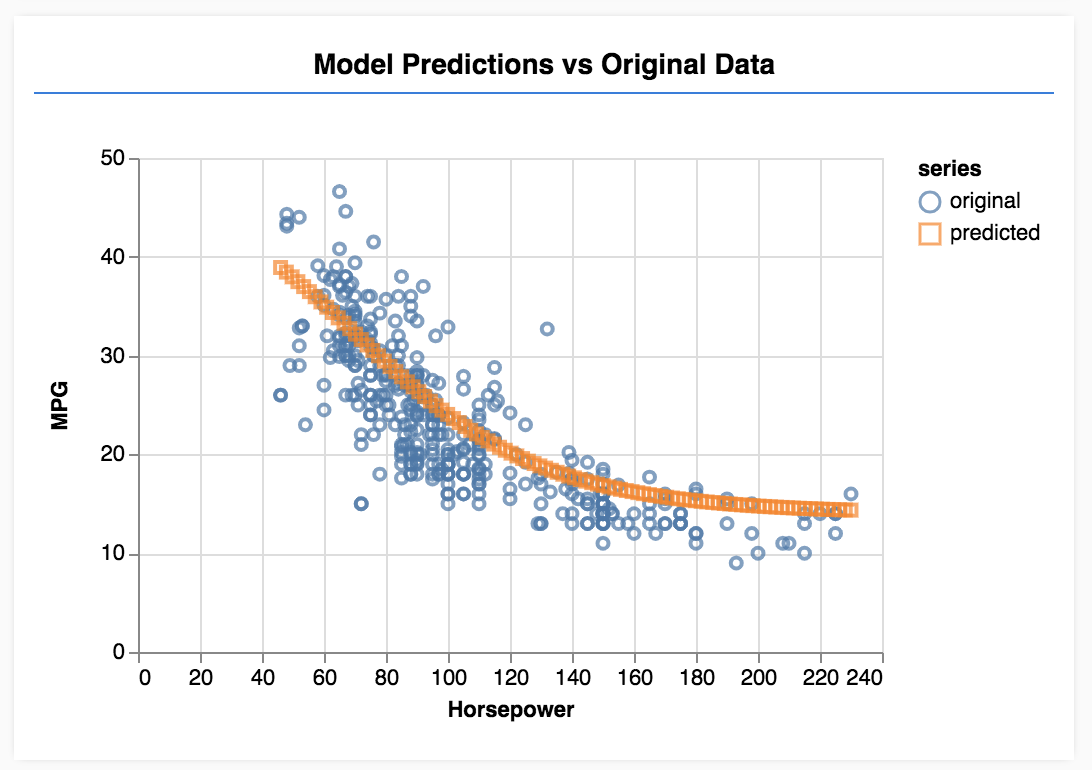
Bây giờ, sau khi huấn luyện mô hình, chúng ta muốn đưa ra một số dự đoán. Hãy đánh giá mô hình bằng cách xem mô hình dự đoán những gì cho một phạm vi đồng nhất về số lượng mã lực từ thấp đến cao.
Thêm hàm sau vào tệp script.js
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Một số điều cần lưu ý trong hàm ở trên.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
Chúng tôi tạo 100 "ví dụ" mới để cung cấp cho mô hình. Model.predict là cách chúng ta đưa những ví dụ đó vào mô hình. Lưu ý rằng các đối tượng này cần có hình dạng tương tự ([num_examples, num_features_per_example]) như khi chúng ta huấn luyện.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
Để đưa dữ liệu trở lại phạm vi ban đầu (thay vì 0-1), chúng ta sử dụng các giá trị đã tính toán trong khi chuẩn hoá, nhưng chỉ cần đảo ngược các thao tác.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() là một phương thức mà chúng ta có thể dùng để lấy typedarray của các giá trị được lưu trữ trong một tensor. Điều này cho phép chúng tôi xử lý các giá trị đó trong JavaScript thông thường. Đây là phiên bản đồng bộ của phương thức .data() thường được ưu tiên.
Cuối cùng, chúng ta sẽ dùng tfjs-vis để vẽ biểu đồ dữ liệu gốc và các dự đoán từ mô hình.
Thêm mã sau vào
run hàm.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
Làm mới trang và bạn sẽ thấy nội dung tương tự như sau sau khi mô hình hoàn tất quá trình huấn luyện.
Xin chúc mừng! Bạn vừa huấn luyện một mô hình học máy đơn giản. Hiện tại, mô hình này thực hiện cái gọi là hồi quy tuyến tính, tức là cố gắng điều chỉnh một đường thẳng cho phù hợp với xu hướng có trong dữ liệu đầu vào.
8. Nội dung chính
Các bước trong quy trình huấn luyện một mô hình học máy bao gồm:
Xây dựng việc cần làm:
- Đây là vấn đề hồi quy hay phân loại?
- Tôi có thể thực hiện việc này bằng phương pháp học có giám sát hoặc học không có giám sát không?
- Dữ liệu đầu vào có dạng như thế nào? Dữ liệu đầu ra sẽ có dạng như thế nào?
Chuẩn bị dữ liệu:
- Dọn dẹp dữ liệu và kiểm tra dữ liệu theo cách thủ công để tìm các mẫu nếu có thể
- Trộn dữ liệu trước khi sử dụng để huấn luyện
- Chuẩn hoá dữ liệu của bạn thành một phạm vi hợp lý cho mạng nơ-ron. Thường thì 0-1 hoặc -1-1 là các dải giá trị phù hợp cho dữ liệu dạng số.
- Chuyển đổi dữ liệu thành tensor
Tạo và chạy mô hình của bạn:
- Xác định mô hình bằng cách sử dụng
tf.sequentialhoặctf.model, sau đó thêm các lớp vào mô hình bằng cách sử dụngtf.layers.* - Chọn một trình tối ưu hoá ( adam thường là một lựa chọn tốt) và các tham số như kích thước lô và số lượng giai đoạn.
- Chọn một hàm tổn thất phù hợp cho vấn đề của bạn và một chỉ số độ chính xác để giúp bạn đánh giá tiến trình.
meanSquaredErrorlà một hàm tổn thất phổ biến cho các vấn đề về hồi quy. - Theo dõi quá trình huấn luyện để xem tổn thất có giảm hay không
Đánh giá mô hình của bạn
- Chọn một chỉ số đánh giá cho mô hình mà bạn có thể theo dõi trong quá trình huấn luyện. Sau khi huấn luyện, hãy thử đưa ra một số dự đoán kiểm thử để nắm được chất lượng dự đoán.
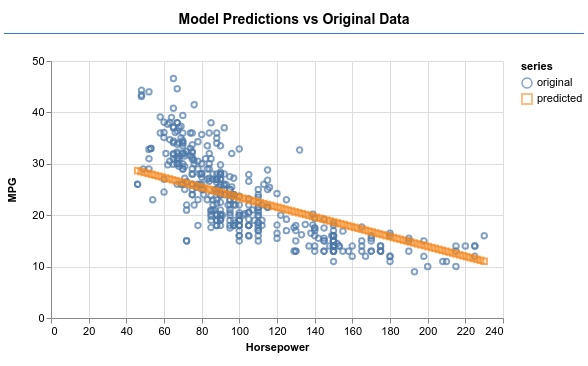
9. Mở rộng kiến thức: Những điều cần thử
- Thử nghiệm thay đổi số lượng giai đoạn. Bạn cần bao nhiêu epoch trước khi biểu đồ trở nên bằng phẳng.
- Thử nghiệm bằng cách tăng số lượng đơn vị trong lớp ẩn.
- Thử nghiệm bằng cách thêm nhiều lớp ẩn hơn ở giữa lớp ẩn đầu tiên mà chúng ta đã thêm và lớp đầu ra cuối cùng. Mã cho các lớp bổ sung này sẽ có dạng như sau.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
Điều mới mẻ quan trọng nhất về các lớp ẩn này là chúng giới thiệu một hàm kích hoạt phi tuyến tính, trong trường hợp này là hàm kích hoạt sigmoid. Để tìm hiểu thêm về các hàm kích hoạt, hãy xem bài viết này.
Xem liệu bạn có thể yêu cầu mô hình tạo ra kết quả như trong hình ảnh bên dưới hay không.