1. מבוא
ב-Codelab הזה תאמנו מודל כדי ליצור תחזיות מנתונים מספריים שמתארים קבוצה של מכוניות.
בתרגיל הזה נדגים שלבים שמשותפים לאימון של סוגים רבים ושונים של מודלים, אבל נשתמש במערך נתונים קטן ובמודל פשוט (שטחי). המטרה העיקרית היא לעזור לכם להכיר את המינוח, המושגים והתחביר הבסיסיים שקשורים לאימון מודלים באמצעות TensorFlow.js, ולספק לכם בסיס להמשך למידה והתעמקות.
אנחנו מאמנים מודל לחיזוי מספרים רציפים, ולכן המשימה הזו נקראת לפעמים משימת רגרסיה. אנחנו נאמן את המודל על ידי הצגת דוגמאות רבות של קלט יחד עם הפלט הנכון. השיטה הזו נקראת למידה מונחית.
מה תפַתחו
תצרו דף אינטרנט שמשתמש ב-TensorFlow.js כדי לאמן מודל בדפדפן. אם נותנים למודל את הערך 'כוח סוס' של מכונית, הוא ילמד לחזות את הערך 'מיילים לגלון דלק' (MPG).
כדי לעשות את זה:
- טוענים את הנתונים ומכינים אותם לאימון.
- הגדרת הארכיטקטורה של המודל.
- מאמנים את המודל ועוקבים אחרי הביצועים שלו במהלך האימון.
- מעריכים את המודל שאומן על ידי יצירת תחזיות.
מה תלמדו
- שיטות מומלצות להכנת נתונים ללמידת מכונה, כולל ערבוב ונרמול.
- תחביר של TensorFlow.js ליצירת מודלים באמצעות tf.layers API.
- איך עוקבים אחרי אימון בדפדפן באמצעות ספריית tfjs-vis.
הדרישות
- גרסה עדכנית של Chrome או דפדפן מודרני אחר.
- כלי לעריכת טקסט שפועל באופן מקומי במחשב או באינטרנט, למשל Codepen או Glitch.
- ידע ב-HTML, ב-CSS, ב-JavaScript ובכלי הפיתוח ל-Chrome (או בכלי הפיתוח של הדפדפן המועדף).
- הבנה מושגית ברמה גבוהה של רשתות נוירונים. אם אתם צריכים הסבר או תזכורת, מומלץ לצפות בסרטון הזה של 3blue1brown או בסרטון הזה על למידה עמוקה ב-JavaScript של אשי קרישנן.
2. להגדרה
יוצרים דף HTML וכוללים בו את קוד ה-JavaScript
 מעתיקים את הקוד הבא לקובץ HTML בשם
מעתיקים את הקוד הבא לקובץ HTML בשם
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
יוצרים את קובץ ה-JavaScript בשביל הקוד
- באותה תיקייה שבה נמצא קובץ ה-HTML שלמעלה, יוצרים קובץ בשם script.js ומכניסים לתוכו את הקוד הבא.
console.log('Hello TensorFlow');
רוצים לנסות?
אחרי שיצרתם את קובצי ה-HTML וה-JavaScript, אתם יכולים לבדוק אותם. פותחים את הקובץ index.html בדפדפן ופותחים את המסוף של כלי הפיתוח.
אם הכול פועל, אמורים להיווצר שני משתנים גלובליים שיהיו זמינים במסוף כלי הפיתוח:
-
tfהיא הפניה לספריית TensorFlow.js -
tfvisהיא הפניה לספרייה tfjs-vis
פותחים את הכלים למפתחים בדפדפן. בפלט של המסוף אמורה להופיע ההודעה Hello TensorFlow. אם כן, אפשר לעבור לשלב הבא.
3. טעינה, עיצוב והמחשה של נתוני הקלט
בשלב הראשון, נטען את הנתונים שבאמצעותם נאמן את המודל, נבחר את הפורמט שלהם ונציג אותם בצורה חזותית.
נטען את מערך הנתונים 'cars' מקובץ JSON שאירחנו בשבילכם. הוא מכיל תכונות רבות ושונות לגבי כל מכונית נתונה. במדריך הזה, אנחנו רוצים לחלץ רק נתונים לגבי כוח סוס וקילומטרים לליטר.
מוסיפים את הקוד הבא ל-
script.js קובץ
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
הפעולה הזו תסיר גם רשומות שלא מוגדרים בהן מיילים לגלון או כוח סוס. בנוסף, נשרטט את הנתונים האלה בתרשים פיזור כדי לראות איך הם נראים.
מוסיפים את הקוד הבא לתחתית של
script.js קובץ.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
כשמרעננים את הדף. בצד ימין של הדף אמורה להופיע חלונית עם תרשים פיזור של הנתונים. הוא אמור להיראות כך.
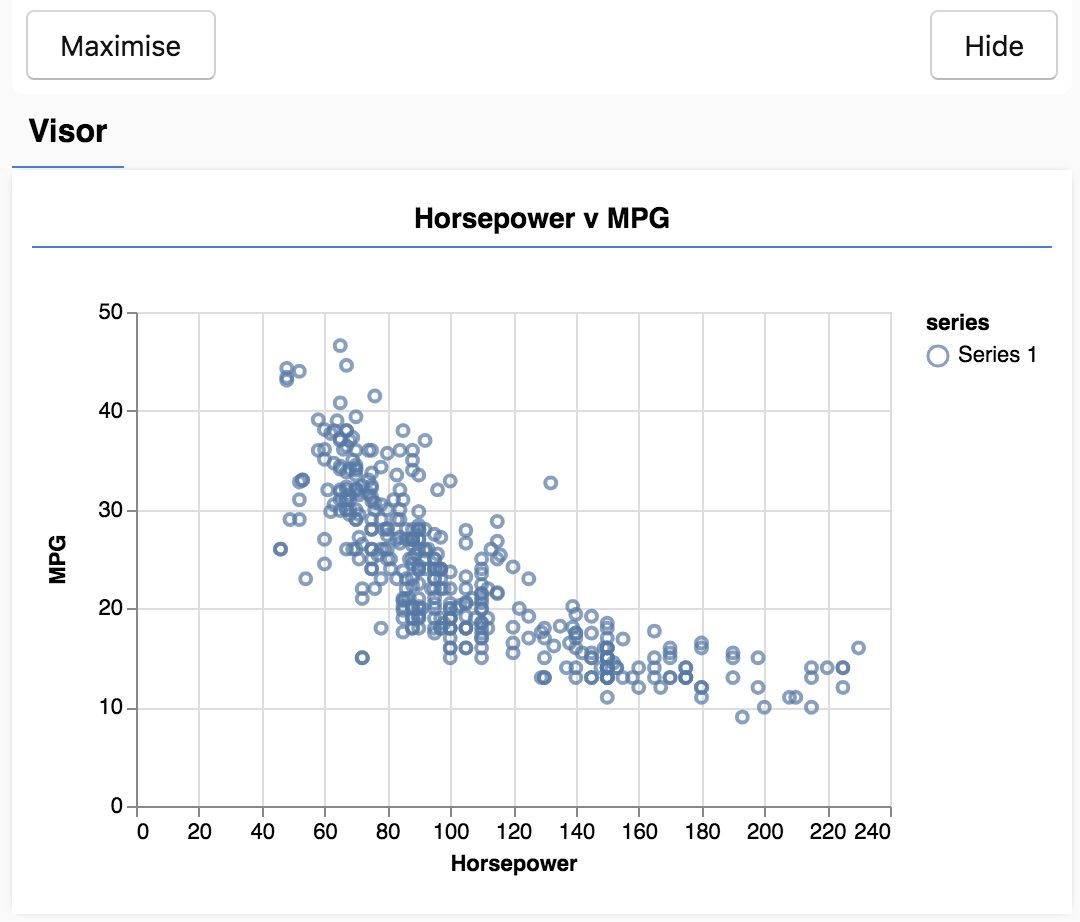
החלונית הזו נקראת visor והיא מסופקת על ידי tfjs-vis. הוא מספק מקום נוח להצגת ויזואליזציות.
בדרך כלל, כשעובדים עם נתונים, כדאי למצוא דרכים לבדוק את הנתונים ולנקות אותם אם צריך. במקרה כזה, נאלצנו להסיר מ-carsData רשומות מסוימות שלא כללו את כל שדות החובה. הדמיה של הנתונים יכולה לתת לנו מושג אם יש מבנה בנתונים שהמודל יכול ללמוד.
מהתרשים שלמעלה אפשר לראות שיש קורלציה שלילית בין כוחות הסוס לבין MPG, כלומר ככל שכוחות הסוס עולים, המכוניות בדרך כלל מקבלות פחות מיילים לגלון.
גיבוש רעיון למשימה
נתוני הקלט שלנו ייראו עכשיו כך.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
המטרה שלנו היא לאמן מודל שיקבל מספר אחד, כוח סוס, וילמד לחזות מספר אחד, מיילים לגלון. חשוב לזכור את המיפוי אחד לאחד, כי הוא יהיה חשוב בחלק הבא.
אנחנו נזין את הדוגמאות האלה, את כוח הסוס ואת צריכת הדלק, לרשת נוירונים שתלמד מהדוגמאות האלה נוסחה (או פונקציה) לחיזוי צריכת הדלק בהינתן כוח הסוס. הלמידה הזו מדוגמאות שיש לנו לגביהן תשובות נכונות נקראת למידה מפוקחת.
4. הגדרת ארכיטקטורת המודל
בקטע הזה נכתוב קוד לתיאור ארכיטקטורת המודל. ארכיטקטורת המודל היא דרך מתוחכמת לומר "אילו פונקציות יופעלו במודל בזמן ההרצה", או לחלופין "באיזה אלגוריתם ישתמש המודל כדי לחשב את התשובות שלו".
מודלים של למידת מכונה הם אלגוריתמים שמקבלים קלט ומפיקים פלט. כשמשתמשים ברשתות עצביות, האלגוריתם הוא קבוצה של שכבות של נוירונים עם 'משקלים' (מספרים) שקובעים את הפלט שלהם. תהליך האימון לומד את הערכים האידיאליים של המשקלים האלה.
מוסיפים את הפונקציה הבאה אל
script.js קובץ להגדרת ארכיטקטורת המודל.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
זהו אחד המודלים הפשוטים ביותר שאפשר להגדיר ב-TensorFlow.js. בואו נפרט קצת על כל שורה.
יצירת מופע של המודל
const model = tf.sequential();
הפעולה הזו יוצרת מופע של אובייקט tf.Model. המודל הזה הוא sequential כי הקלט שלו זורם ישירות לפלט. למודלים מסוגים אחרים יכולים להיות ענפים, או אפילו כמה קלטים ופלטים, אבל ברוב המקרים המודלים יהיו רציפים. בנוסף, למודלים רציפים יש API קל יותר לשימוש.
הוספת שכבות
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
כך נוספת שכבת קלט לרשת שלנו, שמחוברת אוטומטית לשכבת dense עם יחידה נסתרת אחת. שכבת dense היא סוג של שכבה שמכפילה את נתוני הקלט שלה במטריצה (שנקראת משקלים) ואז מוסיפה מספר (שנקרא הטיה) לתוצאה. מכיוון שזו השכבה הראשונה ברשת, צריך להגדיר את inputShape. הערך של inputShape הוא [1] כי יש לנו את המספר 1 כקלט (כוח הסוס של רכב מסוים).
units מגדיר את הגודל של מטריצת המשקלים בשכבה. אם נגדיר את הערך כאן ל-1, המשמעות היא שיהיה משקל אחד לכל אחת מתכונות הקלט של הנתונים.
model.add(tf.layers.dense({units: 1}));
הקוד שלמעלה יוצר את שכבת הפלט שלנו. הגדרנו את units ל-1 כי רצינו לקבל 1 מספרים.
יצירת מופע
מוסיפים את הקוד הבא אל
run הפונקציה שהגדרנו קודם.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
פעולה זו תיצור מופע של המודל ותציג סיכום של השכבות בדף האינטרנט.
5. הכנת הנתונים לאימון
כדי ליהנות מיתרונות הביצועים של TensorFlow.js, שמאפשרים לאמן מודלים של למידת מכונה בצורה מעשית, אנחנו צריכים להמיר את הנתונים לטנסורים. בנוסף, נבצע מספר טרנספורמציות בנתונים שלנו בהתאם לשיטות המומלצות, כלומר ערבוב ונרמול.
מוסיפים את הקוד הבא ל-
script.js קובץ
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
בואו נראה מה קורה כאן.
ערבוב הנתונים
// Step 1. Shuffle the data
tf.util.shuffle(data);
כאן אנחנו מגרילים את סדר הדוגמאות שיוזנו לאלגוריתם האימון. ערבוב חשוב כי בדרך כלל במהלך האימון מערך הנתונים מחולק לקבוצות משנה קטנות יותר, שנקראות אצוות, שהמודל מתאמן עליהן. ערבוב הנתונים עוזר להבטיח שכל אצווה תכיל מגוון נתונים מכל חלקי התפלגות הנתונים. כך אנחנו עוזרים למודל:
- לא ללמוד דברים שתלויים אך ורק בסדר שבו הנתונים הוזנו
- לא להיות רגיש למבנה בקבוצות משנה (לדוגמה, אם הוא רואה רק מכוניות עם כוח סוס גבוה במחצית הראשונה של האימון, הוא עשוי ללמוד קשר שלא חל על שאר מערך הנתונים).
המרה לטנסורים
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
בדוגמה הזו אנחנו יוצרים שני מערכים, אחד לדוגמאות הקלט (ערכי כוחות הסוס) והשני לערכי הפלט האמיתיים (שנקראים תוויות בלמידת מכונה).
לאחר מכן אנחנו ממירים כל נתון מערך לטנזור דו-ממדי. הטנזור יהיה בצורה [num_examples, num_features_per_example]. בדוגמה הזו יש inputs.length דוגמאות, וכל דוגמה כוללת 1 תכונת קלט (כוח הסוס).
נרמול הנתונים
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
לאחר מכן אנחנו מיישמים עוד שיטה מומלצת לאימון למידת מכונה. אנחנו מנרמלים את הנתונים. כאן אנחנו מבצעים נרמול של הנתונים לטווח המספרי 0-1 באמצעות שינוי קנה מידה של מינימום ומקסימום. הנרמול חשוב כי המבנה הפנימי של הרבה מודלים של למידת מכונה שתבנו באמצעות TensorFlow.js מתוכנן לעבוד עם מספרים לא גדולים מדי. טווחים נפוצים לנירמול נתונים כוללים 0 to 1 או -1 to 1. כדי לאמן את המודלים בצורה מוצלחת יותר, כדאי להרגיל את עצמכם לנרמל את הנתונים לטווח סביר.
החזרת הנתונים וגבולות הנורמליזציה
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
אנחנו רוצים לשמור את הערכים שבהם השתמשנו לנרמול במהלך האימון, כדי שנוכל לבטל את הנרמול של התוצאות ולהחזיר אותן לסקאלה המקורית שלנו, וכדי שנוכל לנרמל נתוני קלט עתידיים באותו אופן.
6. אימון המודל
אחרי שיצרנו את מופע המודל והנתונים שלנו מיוצגים כטנסורים, יש לנו את כל מה שצריך כדי להתחיל את תהליך האימון.
מעתיקים את הפונקציה הבאה אל
script.js קובץ.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
נסביר את זה.
הכנה להדרכה
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
אנחנו צריכים 'לקמפל' את המודל לפני שאנחנו מאמנים אותו. כדי לעשות זאת, אנחנו צריכים לציין כמה דברים חשובים מאוד:
-
optimizer: זהו האלגוריתם שיקבע את העדכונים של המודל כשהוא יראה דוגמאות. יש הרבה אופטימיזציות זמינות ב-TensorFlow.js. בחרנו כאן באופטימיזציה של אדם כי היא יעילה מאוד בפועל ולא דורשת הגדרה. -
loss: זו פונקציה שתציין למודל עד כמה הוא מצליח ללמוד כל אחת מהקבוצות (קבוצות משנה של נתונים) שמוצגות לו. כאן אנחנו משתמשים ב-meanSquaredErrorכדי להשוות בין התחזיות של המודל לבין הערכים האמיתיים.
const batchSize = 32;
const epochs = 50;
לאחר מכן בוחרים את גודל האצווה (batchSize) ואת מספר התקופות של זמן המערכת (epochs):
-
batchSizeמתייחס לגודל של קבוצות המשנה של הנתונים שהמודל יראה בכל איטרציה של אימון. גודלי אצווה נפוצים הם בטווח 32-512. אין גודל אופטימלי לכל הבעיות, והסבר על ההצדקות המתמטיות לגדלים שונים של קבוצות חורג מהיקף המדריך הזה. -
epochsמתייחס למספר הפעמים שהמודל יבדוק את מערך הנתונים כולו שסיפקתם לו. במקרה הזה, נבצע 50 איטרציות על מערך הנתונים.
התחלת הלולאה של הרכבת
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit היא הפונקציה שאנחנו קוראים לה כדי להתחיל את לולאת האימון. זו פונקציה אסינכרונית, ולכן אנחנו מחזירים את אובייקט ה-promise שהיא נותנת לנו כדי שהמתקשר יוכל לקבוע מתי האימון הושלם.
כדי לעקוב אחרי התקדמות האימון, מעבירים כמה קריאות חוזרות (callbacks) אל model.fit. אנחנו משתמשים ב- tfvis.show.fitCallbacks כדי ליצור פונקציות שמשרטטות תרשימים למדדים loss ו-mse שציינו קודם.
סיכום של כל המידע
עכשיו אנחנו צריכים לקרוא לפונקציות שהגדרנו מהפונקציה run.
מוסיפים את הקוד הבא לתחתית של
פונקציית run.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
אחרי כמה שניות, כשתרעננו את הדף, הגרפים הבאים אמורים להתעדכן.
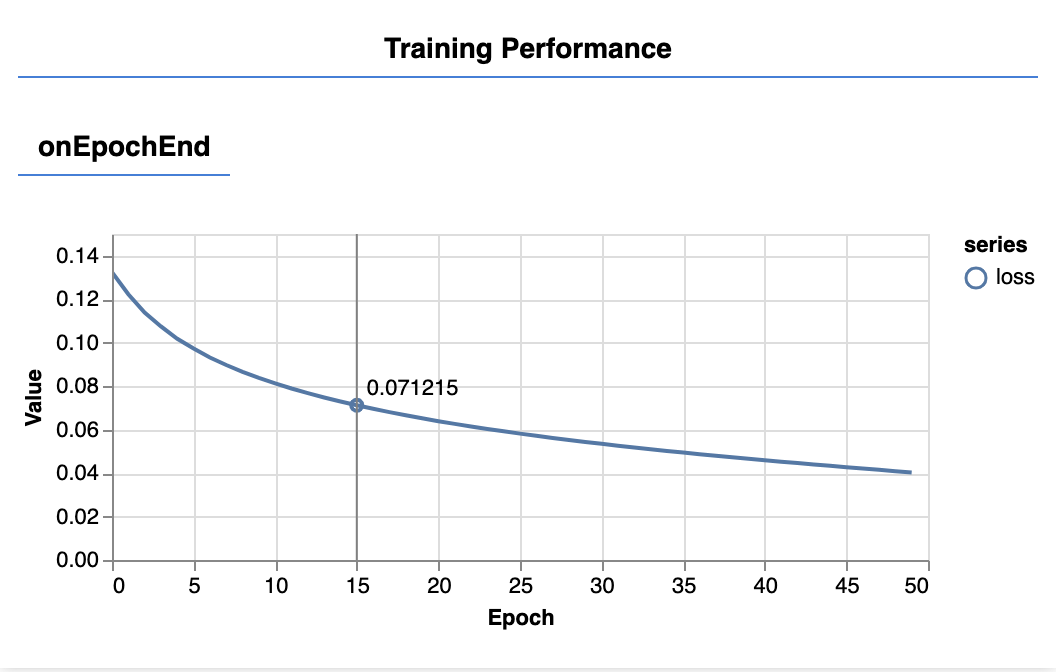
הם נוצרים על ידי פונקציות ה-callback שיצרנו קודם. בסוף כל תקופה, הם מציגים את האובדן ואת ה-MSE, כממוצע על פני כל מערך הנתונים.
במהלך אימון מודל, אנחנו רוצים לראות שההפסד יורד. במקרה הזה, המדד שלנו הוא מדד של שגיאה, ולכן אנחנו רוצים לראות שהוא יורד.
7. יצירת תחזיות
עכשיו, אחרי שהמודל שלנו עבר אימון, אנחנו רוצים לבצע כמה חיזויים. נבדוק את המודל על ידי חיזוי של טווח אחיד של מספרים של כוחות סוס נמוכים עד גבוהים.
מוסיפים את הפונקציה הבאה לקובץ script.js
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
כמה דברים שכדאי לשים לב אליהם בפונקציה שלמעלה.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
אנחנו יוצרים 100 'דוגמאות' חדשות כדי להזין אותן למודל. הפונקציה Model.predict היא הדרך שבה אנחנו מזינים את הדוגמאות האלה למודל. חשוב לשים לב שהן צריכות להיות בצורה דומה ([num_examples, num_features_per_example]) כמו בזמן האימון.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
כדי להחזיר את הנתונים לטווח המקורי (ולא לטווח 0-1), אנחנו משתמשים בערכים שחישבנו במהלך הנרמול, אבל פשוט הופכים את הפעולות.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() היא שיטה שבה אפשר להשתמש כדי לקבל typedarray של הערכים שמאוחסנים בטנסור. כך נוכל לעבד את הערכים האלה ב-JavaScript רגיל. זו גרסה סינכרונית של השיטה .data(), שהיא בדרך כלל מועדפת.
לבסוף, אנחנו משתמשים ב-tfjs-vis כדי לשרטט את הנתונים המקוריים ואת התחזיות מהמודל.
מוסיפים את הקוד הבא ל-
פונקציית run.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
אחרי שהמודל יסיים את האימון, תצטרכו לרענן את הדף כדי לראות משהו כמו הדוגמה הבאה.
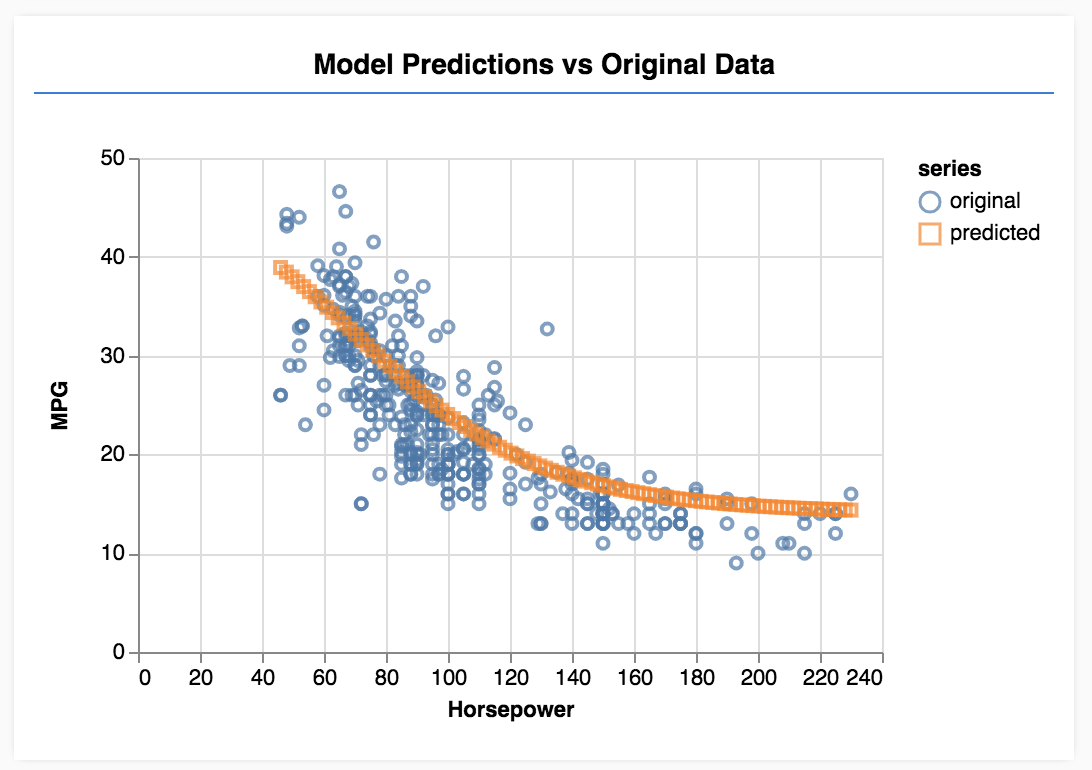
מזל טוב! הרגע אימנתם מודל פשוט של למידת מכונה. בשלב הזה, המודל מבצע רגרסיה לינארית, שמנסה להתאים קו למגמה שקיימת בנתוני הקלט.
8. מסקנות עיקריות
השלבים באימון של מודל למידת מכונה כוללים:
מנסחים את המשימה:
- האם זו בעיית רגרסיה או בעיית סיווג?
- האם אפשר לעשות את זה באמצעות למידה מונחית או למידה לא מונחית?
- מה הצורה של נתוני הקלט? איך נראים נתוני הפלט?
מכינים את הנתונים:
- כדאי לנקות את הנתונים ולבדוק אותם ידנית כדי לזהות דפוסים, אם אפשר
- ערבוב הנתונים לפני השימוש בהם לאימון
- מנרמלים את הנתונים לטווח סביר עבור הרשת הנוירונית. בדרך כלל, טווחים של 0 עד 1 או של -1 עד 1 מתאימים לנתונים מספריים.
- המרת הנתונים לטנסורים
מפתחים ומריצים את המודל:
- מגדירים את המודל באמצעות
tf.sequentialאוtf.modelואז מוסיפים לו שכבות באמצעותtf.layers.* - בוחרים אופטימיזציה ( בדרך כלל adam היא בחירה טובה) ופרמטרים כמו גודל אצווה ומספר האפוקים.
- בוחרים פונקציית הפסד מתאימה לבעיה ומדד דיוק שיעזור להעריך את ההתקדמות.
meanSquaredErrorהיא פונקציית הפסד נפוצה לבעיות רגרסיה. - עוקבים אחרי האימון כדי לראות אם ההפסד יורד
הערכת המודל
- בוחרים מדד להערכה של המודל שאפשר לעקוב אחריו במהלך האימון. אחרי האימון, כדאי לנסות ליצור כמה חיזויים כדי להבין את איכות החיזוי.
9. קרדיט נוסף: דברים שאפשר לנסות
- כדאי לנסות לשנות את מספר התקופות של זמן המערכת. כמה תקופות אימון צריך עד שהגרף מתיישר.
- נסו להגדיל את מספר היחידות בשכבה הנסתרת.
- אפשר לנסות להוסיף עוד שכבות מוסתרות בין השכבה המוסתרת הראשונה שהוספנו לבין שכבת הפלט הסופית. הקוד של השכבות הנוספות האלה צריך להיראות בערך כך.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
הדבר החדש והחשוב ביותר בשכבות הנסתרות האלה הוא שהן מציגות פונקציית הפעלה לא לינארית, ובמקרה הזה הפעלה sigmoid. מידע נוסף על פונקציות הפעלה זמין במאמר הזה.
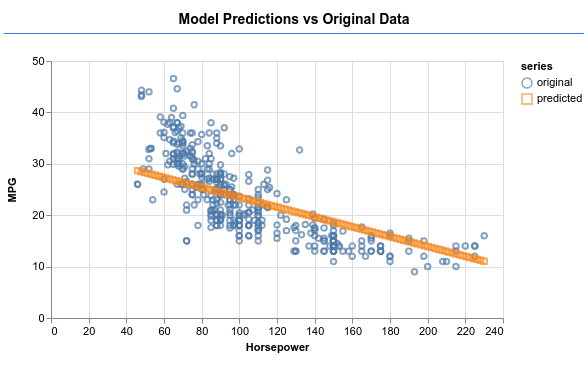
נסו לגרום למודל להפיק פלט כמו בתמונה שלמטה.