Neste codelab, você treinará um modelo para fazer previsões a partir de dados numéricos que descrevem um conjunto de carros.
Este exercício demonstrará etapas comuns para treinar vários tipos diferentes de modelos, mas usará um pequeno conjunto de dados e um modelo simples (cascata). O principal objetivo é ajudar você a se familiarizar com a terminologia, os conceitos e a sintaxe básica dos modelos de treinamento com o TensorFlow.js. Você também terá uma base se quiser se aprofundar e saber mais.
Como estamos treinando um modelo para prever números contínuos, essa tarefa às vezes é chamada de regressão. Vamos treinar o modelo mostrando muitos exemplos de entradas junto com a saída correta. Isso é chamado de aprendizado supervisionado.
O que você criará
Você criará uma página da Web que usa o TensorFlow.js para treinar um modelo no navegador. O modelo aprenderá a prever "milhas por galão" (MPG) de acordo com a "potência".
Para fazer isso, você precisa do seguinte:
- Carregar e preparar os dados para o treinamento
- Definir a arquitetura do modelo
- Treinar o modelo e monitorar o desempenho durante o treinamento
- Fazer algumas previsões para avaliar o modelo treinado
O que você aprenderá
- Práticas recomendadas para a preparação de dados de machine learning, como embaralhamento e normalização
- A sintaxe do TensorFlow.js para a criação de modelos usando a API tf.layers
- O monitoramento do treinamento no navegador com a biblioteca tfjs-vis
Pré-requisitos
- Uma versão moderna do Chrome ou de outro navegador mais recente
- Um editor de texto executado localmente na máquina ou na Web usando um software como o Codepen ou o Glitch
- Conhecimentos sobre HTML, CSS, JavaScript e Chrome DevTools (ou as DevTools do seu navegador preferido)
- Conhecimento conceitual de alto nível das redes neurais. Se você precisar de uma introdução ou revisão, assista a este vídeo da 3blue1brown ou este vídeo sobre aprendizado profundo em JavaScript de Ashi Krishnan (links em inglês)
Criar uma página HTML e incluir o JavaScript
 Copie o código a seguir em um arquivo HTML chamado
Copie o código a seguir em um arquivo HTML chamado
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the main script file -->
<script src="script.js"></script>
</head>
<body>
</body>
</html>
Criar o arquivo JavaScript para o código.
- Na mesma pasta do arquivo HTML acima, crie um arquivo chamado script.js e coloque o código a seguir nele.
console.log('Hello TensorFlow');
Testar
Agora que os arquivos HTML e JavaScript foram criados, faça um teste. Abra o arquivo index.html no navegador e o console do DevTools.
Se tudo estiver funcionando, duas variáveis globais estarão criadas e disponíveis no console do DevTools:
tfé uma referência à biblioteca do TensorFlow.js.tfvisé uma referência à biblioteca tfjs-vis.
Abra as ferramentas para desenvolvedores do navegador. Você verá uma mensagem que diz Hello TensorFlow na saída do console. Se isso acontecer, siga para a próxima etapa.
O primeiro passo é carregar, formatar e visualizar os dados em que queremos treinar o modelo.
Nós carregaremos o conjunto de dados "carros" a partir de um arquivo JSON que hospedamos para você. Ele contém muitos recursos diferentes sobre cada um dos carros. Neste tutorial, queremos extrair apenas os dados sobre potência e milhas por galão.
Adicione o código a seguir ao
arquivo script.js
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Isso também removerá quaisquer entradas sem definição de milhas por galão ou potência. Vamos plotar esses dados em um gráfico de dispersão para ver o resultado.
Adicione o código a seguir à parte inferior do
arquivo script.js.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Quando atualizar a página, você verá um painel no lado esquerdo da página com um gráfico de dispersão dos dados. Ele será semelhante a este:
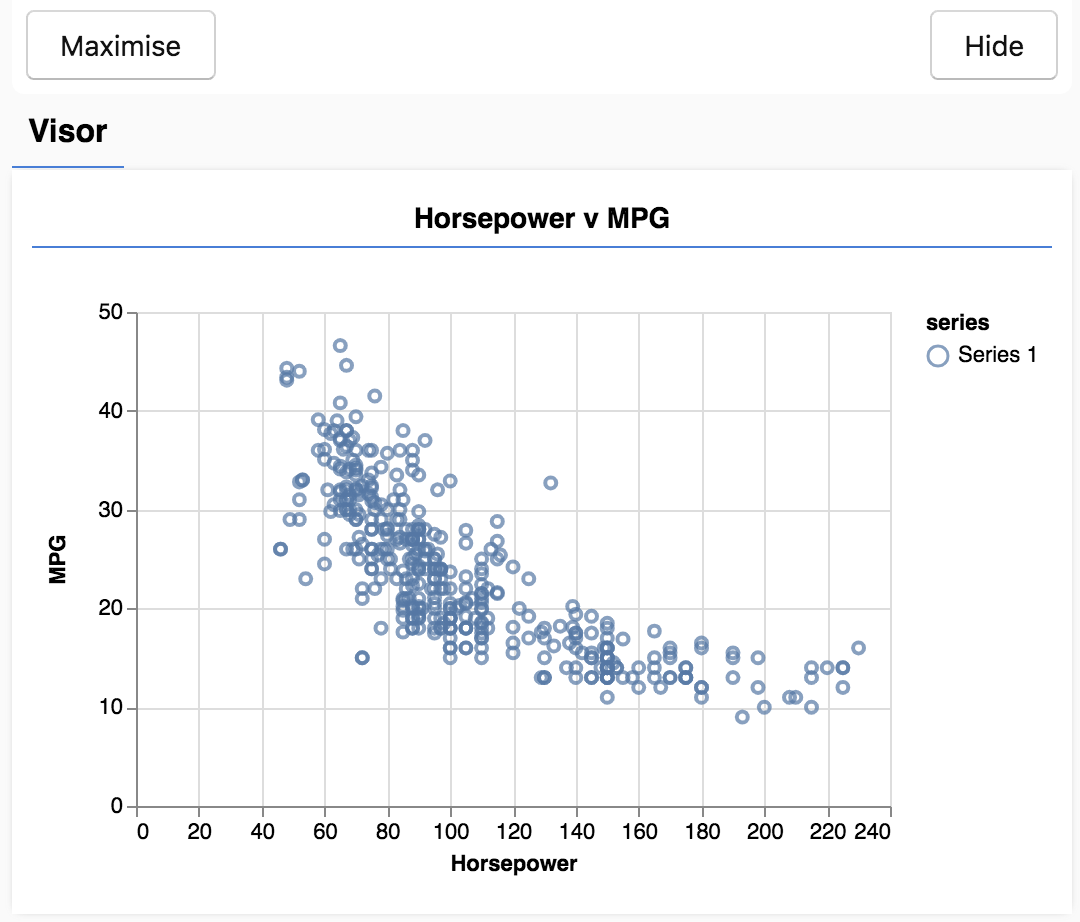
Esse painel é conhecido como o visor e é fornecido pelo tfjs-vis. Ele exibe as visualizações em um local adequado.
Geralmente, ao trabalhar com dados, é interessante encontrar maneiras de analisá-los e limpá-los, se necessário. Nesse caso, tivemos que remover algumas entradas de carsData que não tinham todos os campos obrigatórios. A visualização dos dados pode dar uma ideia da existência de estrutura para os dados que o modelo pode aprender.
O gráfico acima mostra que há uma correlação negativa entre potência e MPG, ou seja, à medida que a potência aumenta, o número de milhas por galão diminui.
Explicar o conceito da tarefa
Agora, os dados de entrada ficarão assim.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Nosso objetivo é treinar um modelo que use um número, potência, e saiba como prever um número, milhas por galão. Lembre-se da correspondência de um para um. Ela será importante na próxima seção.
Alimentaremos esses exemplos, a potência e o MPG, em uma rede neural que aprenderá uma fórmula (ou função) a partir desses exemplos para prever a MPG de acordo com a potência. Esse tipo de aprendizado para que temos as respostas corretas é chamado de aprendizado supervisionado.
Nesta seção, criaremos um código para descrever a arquitetura do modelo. A arquitetura do modelo é apenas um jeito sofisticado de dizer "que funções o modelo executará quando estiver em execução" ou "qual algoritmo o modelo usará para calcular as respostas".
Modelos de ML são algoritmos que recebem uma entrada e produzem uma saída. Ao usar redes neurais, o algoritmo é um conjunto de camadas de neurônios com "pesos" (números) que controlam a saída. O processo de treinamento aprende os valores ideais para esses pesos.
Adicione a função a seguir ao arquivo
script.js para definir a arquitetura do modelo.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Este é um dos modelos mais simples que podemos definir em tensorflow.js. Vamos detalhar um pouco cada linha.
Instanciar o modelo
const model = tf.sequential();
Isso instancia um objeto tf.Model. Esse modelo é sequential porque as entradas fluem diretamente para baixo em direção à saída. Outros tipos de modelos podem ter ramificações ou várias entradas e saídas, mas, em muitos casos, os modelos serão sequenciais. Modelos sequenciais também têm uma API mais fácil de usar.
Adicionar camadas
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
Essa ação adiciona uma camada de entrada à nossa rede, que é conectada automaticamente a uma camada dense com uma unidade oculta. A dense é um tipo de camada que multiplica as entradas por uma matriz chamadas pesos e, em seguida, adiciona um número chamado de viés ao resultado. Como esta é a primeira camada da rede, precisamos definir o inputShape. O inputShape é [1] porque temos 1 número como entrada (a potência do carro em questão).
O units define o tamanho da matriz de peso na camada. Ao defini-lo como 1, estamos dizendo que haverá 1 peso para cada recurso de entrada dos dados.
model.add(tf.layers.dense({units: 1}));
O código acima cria a camada final. Definimos units como 1 porque queremos produzir o número 1.
Criar uma instância
Adicione o código a seguir à função
run que definimos anteriormente.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
Isso criará uma instância do modelo e exibirá um resumo das camadas na página da Web.
Para aproveitar os benefícios de desempenho do TensorFlow.js que tornam os modelos de machine learning de treinamento práticos, precisamos converter os dados em tensores. Também faremos várias transformações nos dados que são práticas recomendadas, ou seja, o embaralhamento e a normalização.
Adicione o código a seguir ao
arquivo script.js
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Vamos detalhar o que está acontecendo aqui.
Embaralhar os dados
// Step 1. Shuffle the data
tf.util.shuffle(data);
Aqui, deixamos os exemplos que serão alimentados no algoritmo de treinamento em ordem aleatória. O embaralhamento é importante porque, durante o treinamento, o conjunto de dados costuma ser dividido em subconjuntos menores, chamados de lotes, para o treinamento do modelo. Isso permite que cada lote tenha uma grande variedade de dados em toda a distribuição de dados. Ao fazer isso, ajudamos o modelo a:
- não aprender o que depende apenas da ordem em que os dados foram alimentados;
- não ser sensível à estrutura em subgrupos. Por exemplo, se ele vir apenas carros de alta potência na primeira metade do treinamento, poderá aprender um relacionamento que não se aplica ao restante do conjunto de dados.
Converter em tensores
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Aqui, criamos duas matrizes, uma para nossos exemplos de entrada (as entradas de potência) e outra para os valores de saída verdadeiros (conhecidos como rótulos em machine learning).
Em seguida, convertemos cada dado da matriz em um tensor 2d. O tensor terá o formato [num_examples, num_features_per_example]. Temos exemplos de inputs.length, e cada um deles tem um recurso de entrada 1 (a potência).
Normalizar os dados
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Depois, adotamos outra prática recomendada para o treinamento de machine learning. Normalizamos os dados. Faremos isso no intervalo numérico 0-1 usando escalonamento mínimo e máximo. A normalização é importante porque os componentes internos de muitos modelos de machine learning que você criará com o tensorflow.js foram projetados para funcionar com números que não são grandes. Intervalos comuns para normalizar dados e incluir 0 to 1 ou -1 to 1. O treinamento terá melhores resultados se você sempre normalizar os dados até um intervalo razoável.
Retornar os dados e os limites de normalização
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Queremos manter os valores usados para a normalização feita durante o treinamento para desnormalizar os resultados e retorná-los à escala original. Assim, será possível normalizar dados de entrada futuros da mesma maneira.
Com a instância de modelo criada e os dados representados como tensores, temos tudo pronto para iniciar o processo de treinamento.
Copie a função a seguir para o
arquivo script.js.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Veja mais detalhes a seguir.
Preparar para o treinamento
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
"Compile" o modelo antes do treinamento. Para isso, precisamos explicar várias informações importantes:
optimizer: é o algoritmo que controla as atualizações do modelo conforme vê exemplos. Há muitos otimizadores disponíveis no TensorFlow.js. Aqui, escolhemos o otimizador adam porque ele é bastante eficaz na prática e não requer configuração.loss: é uma função que informa ao modelo o desempenho dele no aprendizado de cada um dos lotes (subconjuntos de dados) mostrados. Aqui, usamosmeanSquaredErrorpara comparar as previsões feitas pelo modelo com os valores verdadeiros.
const batchSize = 32;
const epochs = 50;
Depois, escolhemos um batchSize e um número de períodos:
batchSizeé ao tamanho dos subconjuntos de dados que o modelo verá em cada iteração de treinamento. Os tamanhos de lotes comuns tendem a estar na faixa de 32 a 512. Não existe um tamanho de lote ideal para todos os problemas, e está fora do escopo deste tutorial descrever as razões matemáticas para a existência de vários tamanhos de lote.epochsé o número de vezes que o modelo analisará todo o conjunto de dados fornecido. Aqui, serão feitas 50 iterações usando o conjunto de dados.
Iniciar a repetição do treinamento
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit é a função que chamamos para iniciar a repetição do treinamento. Ela é uma função assíncrona e, por isso, retornamos a promessa que ela nos faz de que o autor da chamada pode determinar o momento da conclusão do treinamento.
Para monitorar o progresso do treinamento, transmitimos alguns retornos de chamada para model.fit. Usamos tfvis.show.fitCallbacks para gerar funções que representam gráficos para as métricas "perda" e "EQM" especificadas anteriormente.
Funcionamento em conjunto
Agora, precisamos chamar as funções que definimos a partir da função run.
Adicione o código a seguir na parte inferior da
função run.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Depois de atualizar a página, você verá os gráficos a seguir após alguns segundos.
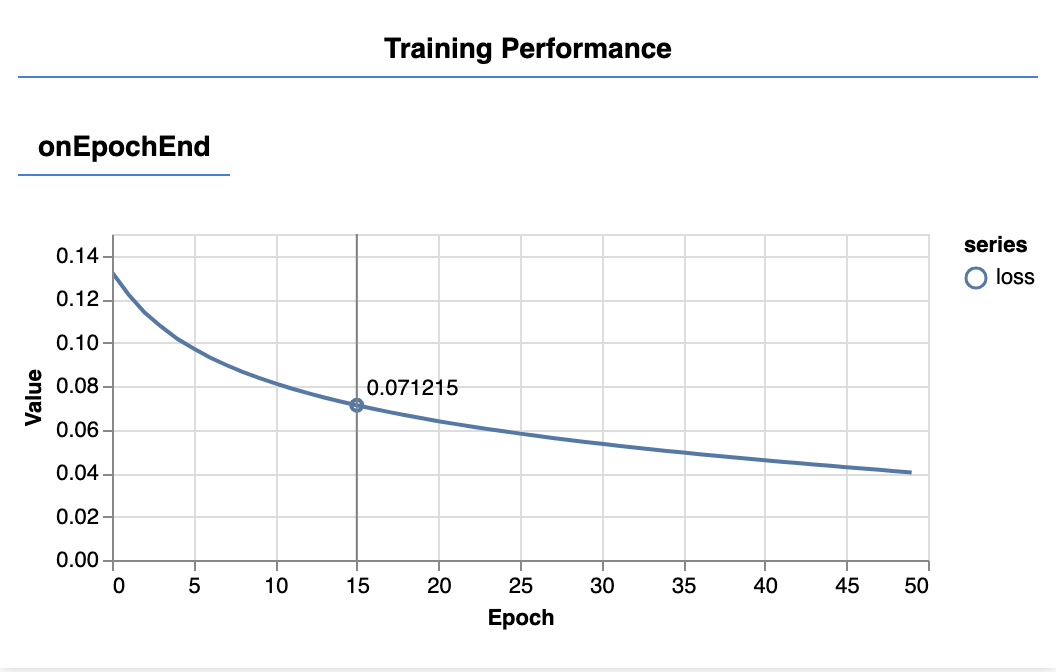
Eles são criados pelos retornos de chamada criados anteriormente. Eles exibem a perda e EQM, com base na média de todo o conjunto de dados, no final de cada período.
Ao treinar um modelo, queremos que a perda diminua. Nesse caso, como a métrica é uma medida de erro, queremos que ela também diminua.
Agora que nosso modelo está treinado, queremos fazer algumas previsões. Vamos avaliar o modelo vendo o que ele prevê para um intervalo uniforme de números de potências baixas a altas.
Adicione a seguinte função ao seu arquivo script.js
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Alguns pontos a observar na função acima.
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
Geramos 100 novos "exemplos" para alimentar o modelo. Model.predict é como alimentamos esses exemplos. Eles precisam ter um formato semelhante ([num_examples, num_features_per_example]) aos dados de treinamento.
// Un-normalize the data
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
Para retornar os dados ao intervalo original (em vez de 0 a 1), usamos os valores que calculamos durante a normalização, apenas invertendo as operações.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() é um método que podemos usar para receber um typedarray dos valores armazenados em um tensor, o que permite processar esses valores em JavaScript comum. Essa é uma versão síncrona do método .data() e costuma ser a preferida.
Por fim, usamos o tfjs-vis para traçar os dados originais e as previsões do modelo.
Adicione o código a seguir à
função run.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
Após a conclusão do treinamento, atualize a página para ver algo semelhante ao exemplo a seguir.
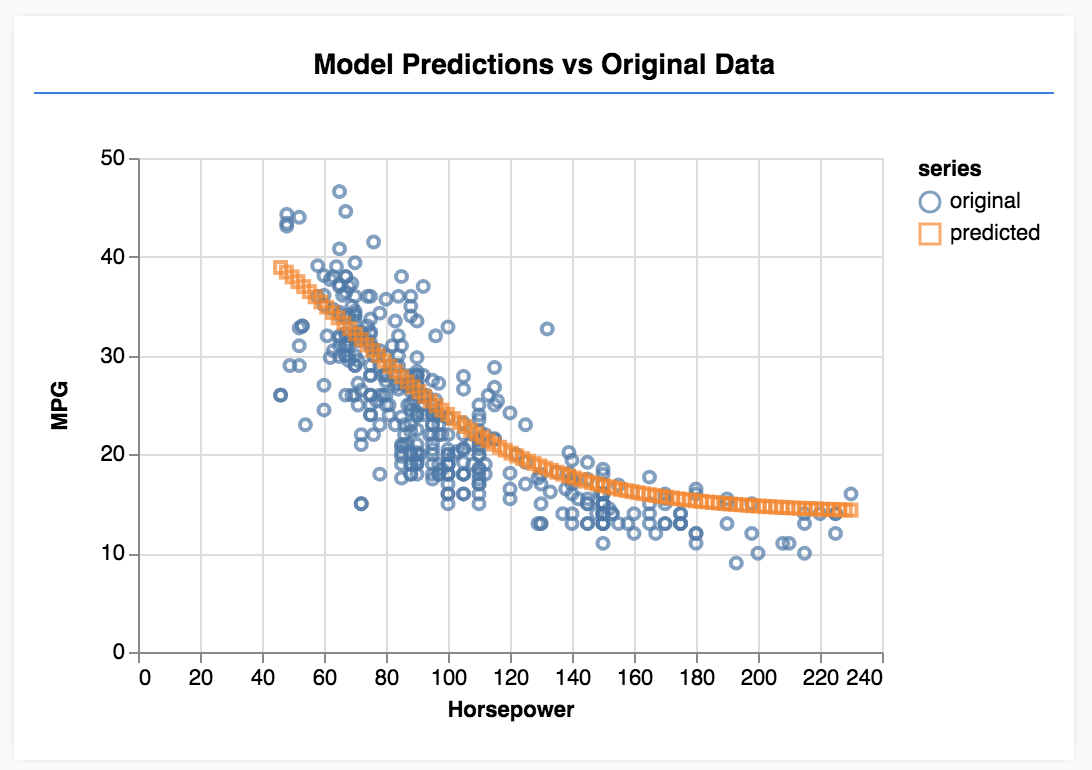
Parabéns! Você treinou um modelo de machine learning simples. No momento, ele executa o que é conhecido como regressão linear, que tenta encaixar uma linha na tendência presente em dados de entrada.
As etapas no treinamento de um modelo de machine learning incluem:
Formular a tarefa:
- É um problema de regressão ou uma classificação?
- Isso pode ser feito com o aprendizado supervisionado ou com o aprendizado não supervisionado?
- Qual é o formato dos dados de entrada? Como devem ser os dados de saída?
Preparar os dados:
- Limpe e inspecione os dados manualmente, quando possível, em busca de padrões.
- Embaralhe os dados antes do treinamento.
- Normalize os dados em um intervalo razoável para a rede neural. Normalmente, 0-1 ou -1-1 são intervalos adequados para dados numéricos.
- Converta dados em tensores.
Criar e executar o modelo:
- Defina o modelo usando
tf.sequentialoutf.modele adicione camadas a ele comtf.layers.*. - Escolha um otimizador (o adam costuma ser bom) e os parâmetros como tamanho do lote e número de períodos.
- Escolha a função de perda apropriada para seu problema e uma métrica de precisão para ajudar a avaliar o progresso.
meanSquaredErroré uma função de perda comum para problemas de regressão. - Monitore o treinamento para ver se a perda está diminuindo.
Avalie o modelo
- Escolha uma métrica de avaliação para o modelo que você possa monitorar durante o treinamento. Depois de fazer o treinamento, tente fazer algumas previsões de teste para ter uma ideia da qualidade delas.
- Altere o número de períodos. De quantos períodos você precisa para nivelar o gráfico.
- Tente aumentar o número de unidades na camada oculta.
- Tente adicionar mais camadas ocultas entre a primeira camada oculta que adicionamos e a camada final. O código dessas camadas extras deve ser parecido com este:
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
A novidade mais importante sobre essas camadas ocultas é que elas introduzem uma função de ativação não linear. Neste caso, a ativação sigmoid. Para saber mais sobre as funções de ativação, consulte este artigo.
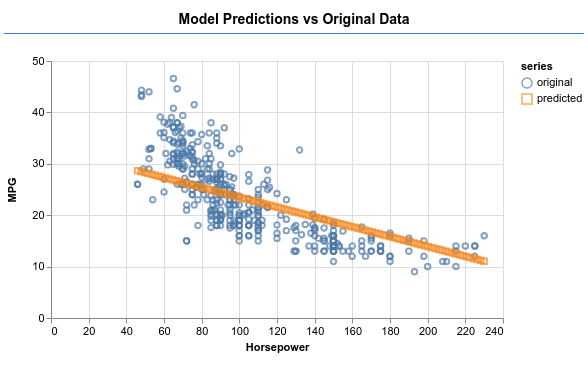
Veja se o modelo consegue produzir uma saída como a da imagem abaixo.