
1. 事前準備
在先前的程式碼研究室中,您已建構了一個音訊分類應用程式。
如果想自訂音訊分類模型,以辨識預先訓練模型中不同類別的音訊,該怎麼做?或者,如果您想要使用自己的資料來自訂模型,該怎麼做?
在這個程式碼研究室中,您將自訂預先訓練的音訊分類模型,以偵測鳥類的聲音。您也可以使用相同的資料來複製相同的技巧。
必要條件
本程式碼研究室是專為有經驗的行動裝置開發人員所設計,您應該很熟悉:
- 使用 Kotlin 和 Android Studio 進行 Android 開發作業
- 基本 Python 語法
課程內容
- 如何為音訊網域進行遷移學習
- 如何建立自己的資料
- 如何在 Android 應用程式中部署自己的模型
軟硬體需求
- 最新版本的 Android Studio (4.1.2 以上版本)
- 在 Android 23 (Android 6.0) 版本中,有 Android 版本的實體 Android 裝置
- 範例程式碼
- 關於 Android Kotlin 開發作業的基本知識
2. 鳥類資料集
您將使用已完成準備的 Birdsong 資料集,以便使用。所有音訊檔案來自 Xeno-canto 網站。
這個資料集包含以下內容的歌曲:
姓名:Hop Sparrow | 代碼:houspa |
| |
名稱:Red Crossbill | 代碼:redcro |
| |
姓名:White-Breasted Wood-Wren | 程式碼:wbwwre1 |
| |
姓名:Chestnut-crwn Antpitta | 程式碼:chcant2 |
| |
姓名:Azara's Spinetail | 程式碼:azaspi1 |
|



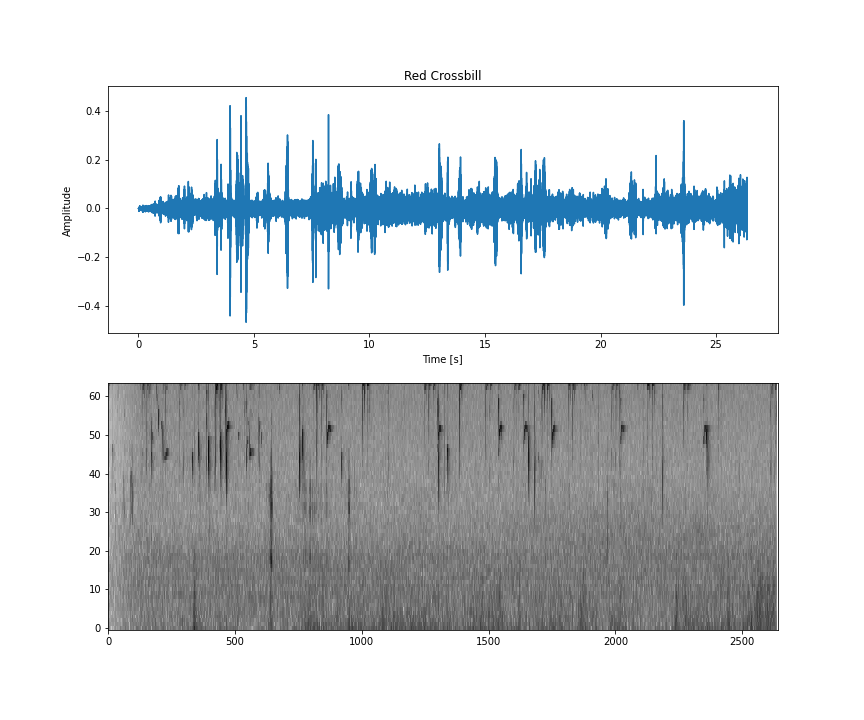

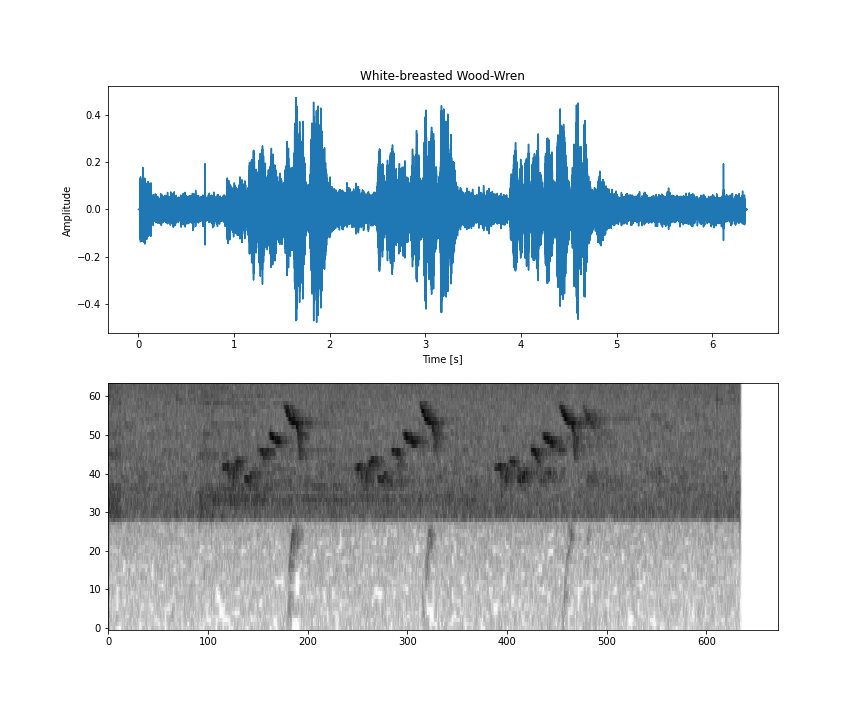



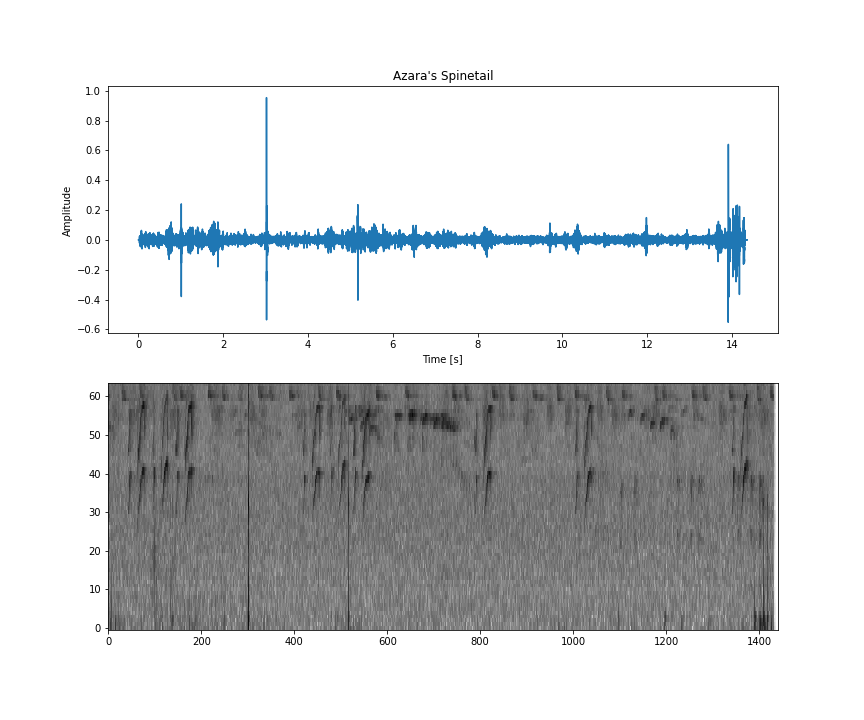
這個資料集位於 ZIP 檔案中,其內容如下:
metadata.csv,內含每個音訊檔案的所有相關資訊,例如誰錄製了音訊、錄製音訊的位置、使用授權,以及鳥類名稱。- 訓練和測試資料夾。
- 火車/測驗資料夾內,每個鳥類程式碼都有一個資料夾。每個元素中都有該組式的 .wav 檔案。
音訊檔案全部都是 wav 格式,並符合下列規格:
這個規格很重要,因為您使用的是基礎模式需要採用此格式的資料。詳情請參閱這篇網誌文章。
為了簡化整個程序,您無須在機器下載資料集,就可以在 Google Colab 中使用此資料集 (本指南稍後會進一步說明)。
如要使用自己的資料,所有音訊檔案也應採用此格式。
3. 取得範例程式碼
下載程式碼
點選下方連結即可下載這個程式碼研究室的所有程式碼:
或者,您也可以視需要複製存放區:
git clone https://github.com/googlecodelabs/odml-pathways.git
將下載的 ZIP 檔案解壓縮。這會將根目錄 (odml-pathways) 與所有您需要的資源一起解壓縮。在這個程式碼研究室中,您只需要 audio_classification/codelab2/android 子目錄中的來源即可。
audio_classification/codelab2/android 存放區中的 android 子目錄包含兩個目錄:
 starter:以這個程式碼研究室建立的程式碼。
starter:以這個程式碼研究室建立的程式碼。- final:完成的範例應用程式的程式碼。
匯入入門應用程式
首先,將入門應用程式匯入 Android Studio:
- 開啟 Android Studio,然後選取 [Import Project (Gradle、Eclipse ADT 等)]。
- 從您先前下載的原始碼中開啟
starter資料夾 (audio_classification/codelab2/android/starter)。

為確保應用程式支援所有依附元件,請在匯入程序完成後將專案與 gradle 檔案同步處理。
- 從 Android Studio 工具列選取 [Sync Project with Gradle Files] (使用 Gradle 檔案同步處理專案) (
 )。
)。
4. 瞭解入門應用程式
這個應用程式與第一個用於音訊分類的程式碼研究室所建構的應用程式相同:建立基本的音訊分類應用程式。
若要更深入瞭解程式碼,建議您先進行該程式碼研究室再繼續。
所有代碼均位於 MainActivity 中 (盡可能簡化)。
總而言之,這個程式碼會執行以下工作:
- 正在載入模型
val classifier = AudioClassifier.createFromFile(this, modelPath)
- 建立錄音工具並開始錄音
val tensor = classifier.createInputTensorAudio()
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
val record = classifier.createAudioRecord()
record.startRecording()
- 建立執行推論的計時器執行緒。方法
scheduleAtFixedRate的參數表示等待開始執行的時間長度,以及持續執行工作之間的間隔時間。在下方的程式碼中,系統將在 1 毫秒內開始執行,並每隔 500 毫秒重新執行一次。
Timer().scheduleAtFixedRate(1, 500) {
...
}
- 針對擷取的音訊執行推論
val numberOfSamples = tensor.load(record)
val output = classifier.classify(tensor)
- 分數偏低的篩選器分類
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
- 在螢幕上顯示結果
val outputStr = filteredModelOutput.map { "${it.label} -> ${it.score} " }
.joinToString(separator = "\n")
runOnUiThread {
textView.text = outputStr
}
您現在可以執行應用程式並依原樣執行,但請注意,應用程式是使用較預先訓練的通用模型。
5. 使用 Model Maker 訓練自訂音訊分類模型
在上一個步驟中,您下載的應用程式使用了預先訓練的模型將音訊事件分類。不過,有時您可能必須針對這個模型自訂感興趣的模型,或將此模型設為更專業的版本。
如前所述,您會把「鳥」的聲音模型專門用來處理。這個資料集包含 Xeno-canto 網站收錄的鳥叫聲資訊。
Colaboratory
接下來,請前往 Google Colab 訓練自訂模型。
訓練自訂模型大約需要 30 分鐘。
如要略過這個步驟,你可以下載自己根據 Colab 提供的資料集在 Colab 上訓練的模型,然後繼續進行下一步。
6. 在 Android 應用程式中加入自訂 TFLite 模型
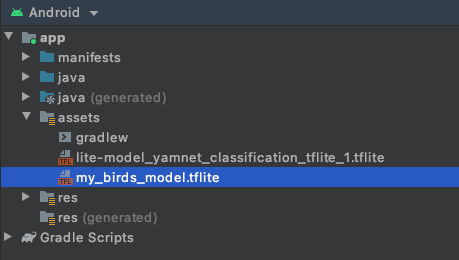
現在您已訓練自己的音訊分類模型,並儲存在本機,接下來請將該模型放入 Android 應用程式的素材資源資料夾。
第一個步驟是將下載的模型從上一個步驟移到應用程式的素材資源資料夾。
- 在 Android Studio 中,使用 Android 專案檢視畫面的資產資料夾按一下滑鼠右鍵。
- 系統隨即會顯示一個內含選項清單的彈出式視窗。其中一個選項就是在檔案系統中開啟資料夾。找出您的作業系統適用的選項,並予以選取。在 Mac 上,這會是「在 Finder 中顯示」,在 Windows 中則是「在檔案總管中開啟」,在 Ubuntu 中則為「在檔案中顯示」。

- 將下載的模型複製到資料夾。
完成這個步驟後,請返回 Android Studio,您應該會在資產資料夾內看見檔案。
7. 在基礎應用程式上載入新模型
基礎應用程式已使用預先訓練模型。您將以剛才訓練的課程取代它。
- 待辦事項 1:如要在新增 assets 資料夾後載入新模型,請變更
modelPath變數的值:
var modelPath = "my_birds_model.tflite"
新模型包含兩個輸出 (頭):
- 原始基本模型的輸出,較一般的輸出,本例為 YAMNet。
- 次要訓練的輸出,也就是用於訓練的鳥類。
這是必要的功能,因為 YAMNet 確實識別出多個常見類別 (例如 Silence)。如此一來,您不用擔心未將其他類別加入資料集中的類別。
您現在要做的是,如果 YAMNet 分類顯示了鳥類的高分,則您要對其他種類的鳥類進行研究。
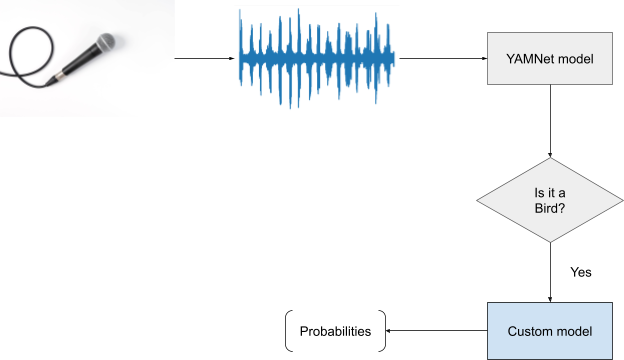
- TODO 2:您可以在這裡更改篩選條件,同時排除「鳥」以外的任何對象:
val filteredModelOuput = output[0].categories.filter {
it.label.contains("Bird") && it.score > .3
}
- TODO 3:如果模型的基本頭部偵測到音訊中有一隻鳥類的可能性很高,你會在第二個頭處看到哪一隻:
if (filteredModelOutput.isNotEmpty()) {
Log.i("Yamnet", "bird sound detected!")
filteredModelOutput = output[1].categories.filter {
it.score > probabilityThreshold
}
}
就是這麼簡單!將模型變更為使用你剛訓練的模型,就是這麼簡單。
下一步是測試。
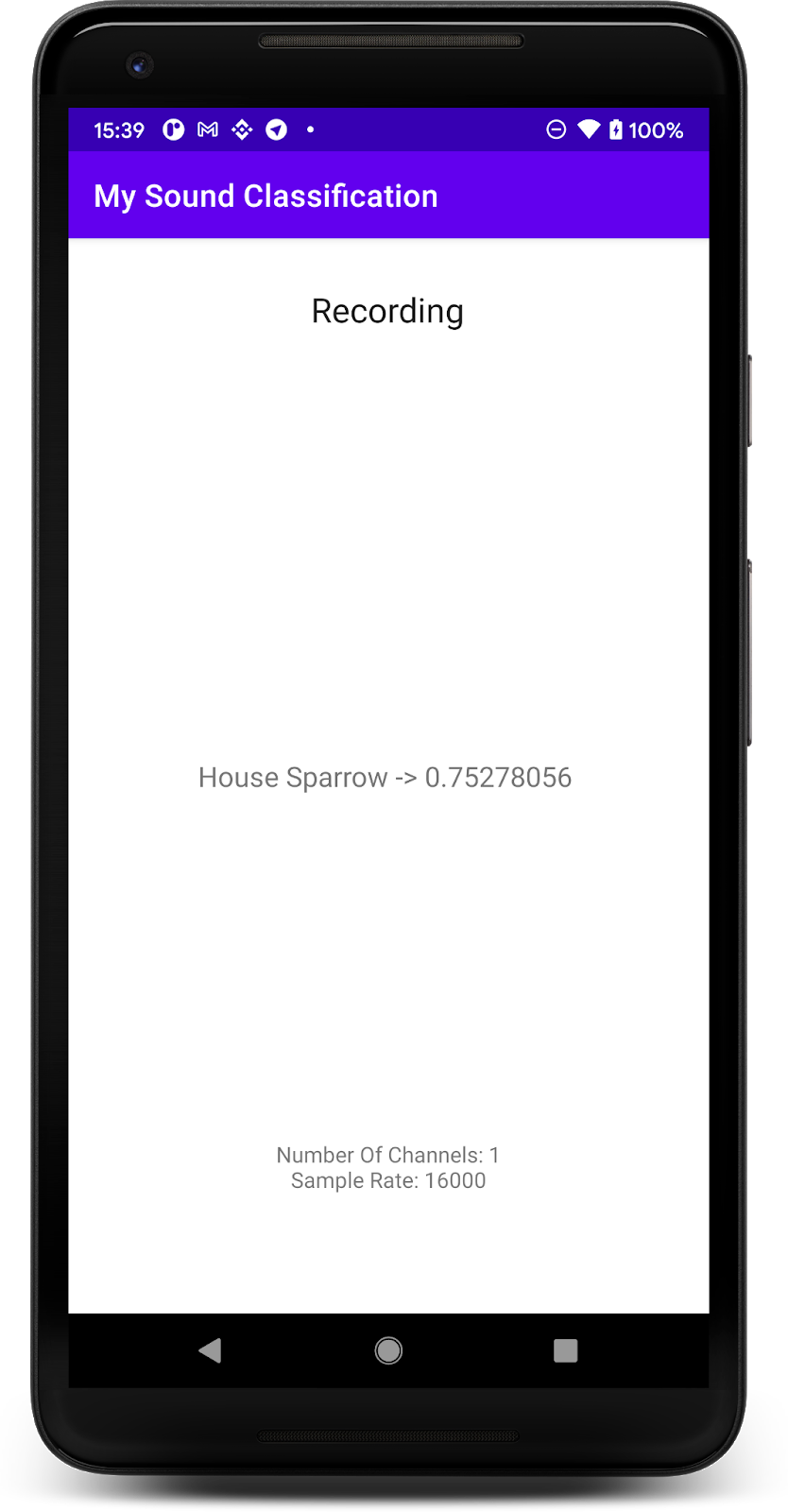
8. 使用新模型測試應用程式
您已將音訊分類模型整合到應用程式中,因此請測試模型。
- 連結您的 Android 裝置,然後按一下 Android Studio 工具列中的 [執行 (
 )]。
)]。
應用程式必須要能正確預測鳥類的聲音。測試過程很簡單,只要播放電腦中的音訊 (執行上一個步驟),手機應該就能偵測到這種情況。如此一來,螢幕上就會顯示鳥類名稱並正確判斷出機率。
9. 恭喜
在本程式碼研究室中,您已瞭解如何使用 Model Maker 建立自己的音訊分類模型,並使用 TensorFlow Lite 將模型部署到您的行動應用程式。如要進一步瞭解 TFLite,請參考其他 TFLite 範例。
報表主題
- 如何準備您自己的資料集
- 如何使用 Model Maker 進行音訊學習遷移音訊分類
- 如何在 Android 應用程式中使用模型
後續步驟
- 使用自己的資料
- 與我們分享您的建構成果