
1. Übersicht
Künstliche Intelligenz ist mittlerweile Teil vieler Softwaresysteme. Eine KI-Anwendung zu entwickeln, ist jedoch nicht dasselbe wie eine Anwendung zu entwickeln, der Nutzer vertrauen können. In vielen realen Umgebungen besteht die Herausforderung nicht nur darin, eine Antwort zu generieren. Die Herausforderung besteht darin, eine Antwort zu generieren, die zeitnah, fundiert, umsetzbar und auf menschliches Fachwissen abgestimmt ist.
In diesem Codelab erstellen Sie einen Renncoach-Simulator, der diese Ideen auf konkrete und ansprechende Weise veranschaulicht. Die Anwendung verwendet Telemetriedaten eines virtuellen Rennwagens, um Bewegungen auf einer Rennstrecke zu animieren und Coaching-Tipps zu generieren. Obwohl es sich um ein Rennszenario handelt, gelten dieselben architektonischen Ideen für das Gesundheitswesen, die Fertigung, die Logistik und andere Bereiche, in denen Vertrauen wichtig ist.
Sie arbeiten mit einem schnellen Stream von Telemetriedaten, wandeln ihn in eine Form um, die für KI-Schlussfolgerungen nützlich und effizient ist, und kombinieren LLM-basierte Ausgaben mit codierten menschlichen Anweisungen, um vertrauenswürdigere Antworten zu erhalten.
Umfang
In diesem Codelab erstellen Sie einen vertrauenswürdigen KI-Prototyp, der folgende Anforderungen erfüllt:
- Streams Telemetry From A Virtual Race Car running in Google Cloud
- Visualisierung des Autos, das sich auf einer Rennstrecke bewegt, mit Chrome
- Rohdaten in KI-kompatible Eingaben umwandeln
- Anwenden einer Strategieebene, die auf Google Gemini basiert
- Kombiniert die Modellausgabe mit codierten menschlichen Anleitungen und Sicherheitsregeln
- Coaching-Feedback über eine nutzerorientierte Schnittstelle bereitstellen
Lerninhalte
Am Ende dieses Codelabs können Sie:
- Erklären, was ein KI-System vertrauenswürdiger macht
- Zweck einer modularen KI-Architektur erläutern
- Einfache simulierte Telemetriepipeline erstellen
- Nützliche, strukturierte Daten für die Verwendung mit einem LLM vorbereiten
- Schutzmaßnahmen und von Menschen erstellte Regeln anwenden, um das Vertrauen zu stärken
- Bewerten, wie diese Architektur auf andere Bereiche angewendet werden kann
2. Voraussetzungen
Bevor Sie beginnen, sollten Sie die erforderlichen Konten, Tools und Dienste eingerichtet haben.
Vorbereitung
Sie benötigen Folgendes:
- Ein privates Google-Konto mit einer Gmail-Adresse
- Zugriff auf Google Cloud und grundlegende Kenntnisse einer CLI
- Ein aktives Rechnungskonto oder Cloud-Guthaben
- Grundlegendes Verständnis von Google Cloud und generativer KI mit Gemini
Gemini ist das KI-Modell von Google, das auf modernster Logik basiert und jede Idee zum Leben erweckt. Es ist ein hervorragendes Modell für multimodales Verstehen sowie für agentisches und Vibe-Coding.
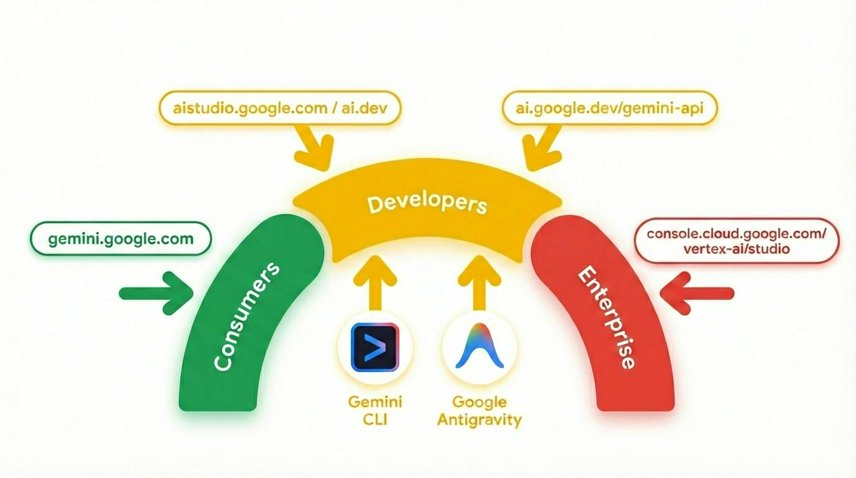
3. Warum vertrauenswürdige KI wichtig ist
Viele KI‑Systeme können flüssige und überzeugende Antworten generieren, aber flüssig ist nicht dasselbe wie vertrauenswürdig. In realen Systemen benötigen Nutzer oft zeitnahe, fundierte Antworten, die durch Sicherheitsregeln eingeschränkt und durch Fachwissen geprägt sind.
Das ist besonders wichtig, wenn ein System mit sich schnell ändernden Daten arbeitet. Eine Antwort, die zu spät eintrifft, ist möglicherweise nutzlos. Eine Antwort, die selbstbewusst klingt, aber wichtigen Kontext ignoriert, kann irreführend sein. Eine Antwort ohne Bezug zu menschlichem Fachwissen ist möglicherweise schwer zu vertrauen, auch wenn sie gut formuliert ist.
Im Rennwagenszenario dieses Codelabs geht es nicht darum, ob KI etwas Interessantes sagen kann. Die Frage ist, ob das System Ratschläge geben kann, die nützlich, sicher, zeitnah und der Situation angemessen sind.
Sehen wir uns ein kleines Telemetriebeispiel an und vergleichen wir zwei mögliche Ausgaben:
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Naive KI-Antwort
"Stay aggressive on the throttle and carry your speed into Turn 1"
Vertrauenswürdige Antwort
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
Sehen Sie den Unterschied?
Was würde passieren, wenn wir uns nur auf die naive KI-Antwort verlassen?
Die erste Antwort klingt selbstbewusst, ignoriert aber das Risiko. Die zweite Antwort ist nützlicher, da sie Kontext und Einschränkung berücksichtigt.
Anstatt das LLM als das gesamte System zu betrachten, müssen Sie es als einen Teil einer umfassenderen Architektur behandeln, um die Vertrauenswürdigkeit zu erhöhen. Außerdem muss die Beratung in vielen Anwendungen schnell genug erfolgen, um umsetzbar zu sein, z. B. bei einem Rennwagen, einem medizinischen Verfahren, in der Luftfahrt, im Stromnetz, in einem Handelssystem, in der Seefahrt usw.
Sehen wir uns nun an, wie Sie eine solche Architektur erstellen.
4. High-Velocity AI und modulare vertrauenswürdige Architektur
Einige KI-Systeme erfordern ein ganz anderes Verhalten. Sie müssen schnell auf sich ändernde Bedingungen reagieren und auch langsamere, durchdachtere Überlegungen unterstützen.
Bei einer modularen Architektur werden diese Verantwortlichkeiten in separate Pfade aufgeteilt. Ein Pfad kann reflexiv sein und die sofortige, zeitkritische Interpretation eingehender Signale übernehmen. Ein anderer Pfad kann sich auf die Strategie konzentrieren und das Denken auf höherer Ebene sowie eine kontextbezogenere Entscheidungsfindung unterstützen. Andere Pfade sind auf andere Arten von Funktionen ausgerichtet.
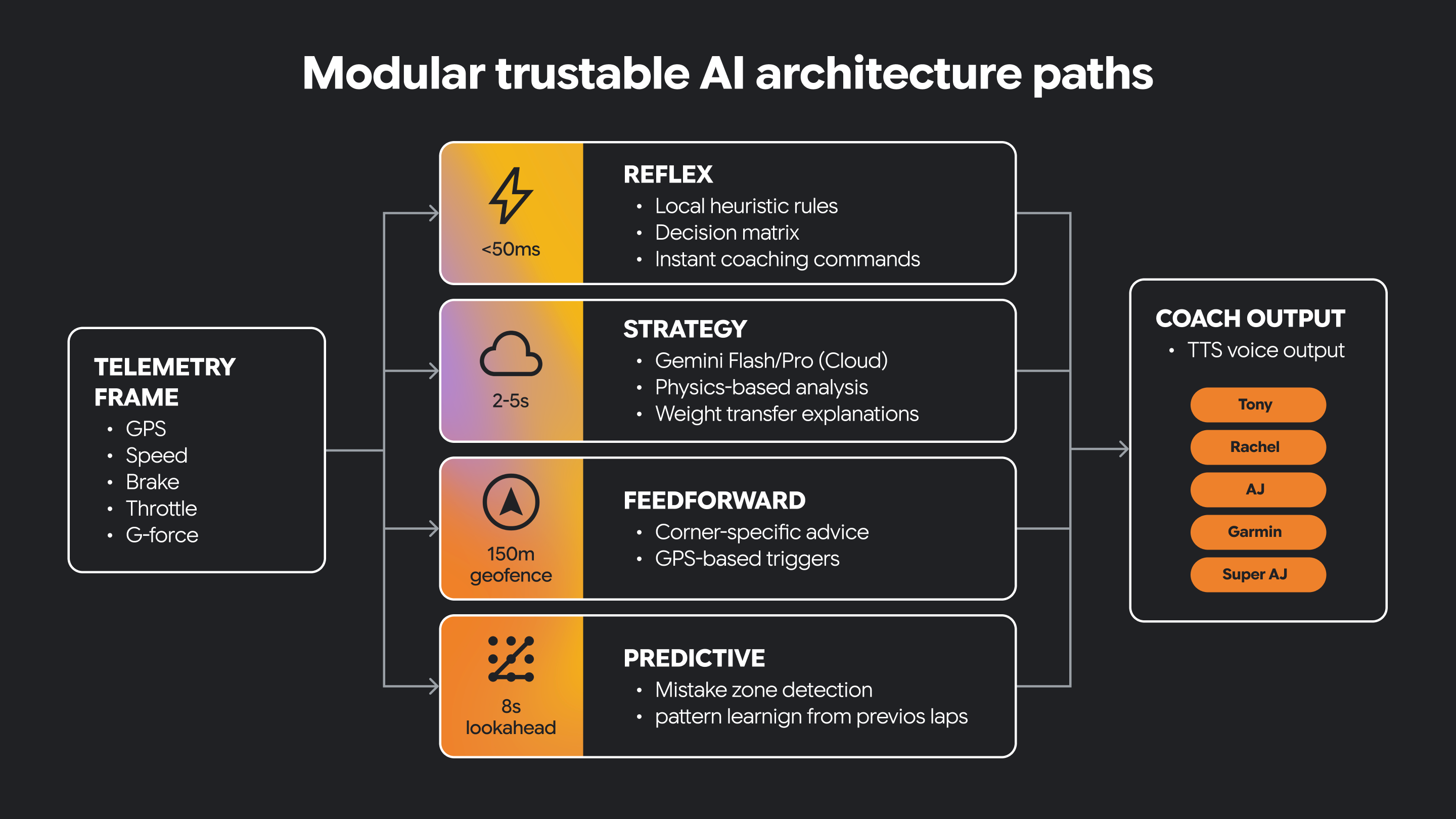
Einige Entscheidungen müssen in Echtzeit getroffen werden. Bei einigen Entscheidungen ist es hilfreich, wenn man sich mehr Zeit zum Nachdenken nimmt.
Für vertrauenswürdige KI sind oft beide erforderlich.
Diese architektonische Trennung trägt dazu bei, dass das System reaktionsschnell bleibt und gleichzeitig umfangreichere KI-basierte Anleitungen unterstützt werden. Außerdem wird ein klarer Ort geschaffen, an dem von Menschen vorgegebene Einschränkungen und Fachwissen eingeführt werden können.
In diesem kleinen Programm haben wir einen Reflexpfad und einen Strategiepfad als Python-Funktionen implementiert.
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
Die beiden Funktionen verhalten sich bei denselben Telemetriedaten unterschiedlich. Die Reflexfunktion ist eine sofortige Warnung. Die Strategiefunktion gibt uns auf Regeln basierende Coaching-Ratschläge.
Warum ist es Ihrer Meinung nach sinnvoll, diese Logik zu trennen?
Sehen wir uns nun an, wie wir eine unterhaltsame, mehrteilige Anwendung erstellen und wie diese Architektur schnelle Reaktionen und fundiertere Überlegungen in ein vertrauenswürdiges KI-System verwandelt, das Sie tatsächlich nutzen können.
5. Telemetrie-Streaming-Server erstellen
Nachdem Sie das architektonische Ziel verstanden haben, ist es an der Zeit, die Datenpipeline zu erstellen, die die Anwendung steuert.
In diesem Abschnitt erstellen Sie einen einfachen Telemetriestream für ein virtuelles Rennauto. Die Daten stammen aus einer CSV-Quelle mit GPS- oder Trackpositionsdaten. Ihre Anwendung wandelt sie in einen Livestream um, der von der Benutzeroberfläche und der KI-Ebene genutzt werden kann.
In diesem Abschnitt führen Sie folgende Aufgaben aus:
- Neues Projekt in Google Cloud für unseren Streaming-Server und unsere Streaming-Anwendung erstellen
- Kleinen Server zum Ausgeben von Telemetriedaten erstellen
- Streamen Sie diese Ereignisse in eine Browser-UI oder Konsole.
1. Cloud Shell öffnen
A. Rufen Sie die Google Cloud Console auf.
B. Erstellen Sie ein neues Projekt für dieses Codelab. Klicken Sie oben auf das Projekt-Drop-down-Menü.
Beim Erstellen eines Projekts bietet es sich an, das Rechnungskonto zu verknüpfen:
Wenn Sie bereits ein Projekt erstellt haben, können Sie optional das linke Menü öffnen, auf Billing klicken und prüfen, ob das Rechnungskonto mit diesem GCP-Konto verknüpft ist.
C. Gemini API-Schlüssel abrufen
Nachdem Sie Ihre Google Cloud-Guthaben aktiviert haben, benötigen Sie einen Gemini API-Schlüssel, um auf Gemini in Google Cloud zuzugreifen.
Um einen Gemini API-Schlüssel zu erstellen, müssen wir Google Vertex AI Studio verwenden.
Klicken Sie in Vertex AI Studio unten links über „Dokumentation“ auf „API-Schlüssel abrufen“. Erstellen Sie einen API-Schlüssel für Gemini. Er sieht aus wie eine lange Zeichenfolge mit scheinbar zufälligen Zeichen. Bewahren Sie diesen Schlüssel an einem sicheren Ort auf. Wir verwenden diesen API-Schlüssel in Schritt 6 („Rennwagensimulator erstellen“), um unseren Zugriff auf Gemini in Google Cloud zu authentifizieren.
D. Klicken Sie in der oberen Leiste auf das Symbol Cloud Shell (Terminalsymbol), um ein browserbasiertes Terminal zu öffnen.
E. Warten Sie, bis die Terminalsitzung gestartet wird.

2. Code abrufen
Klonen Sie das Master-Repository.
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Dieses Repository enthält zwei Ordner: „koru-application“ (Webanwendung) und „streaming-telemetry-server“ (simulierte Echtzeit-Telemetrie für Rennwagen). In diesem Schritt wird der „streaming-telemetry-server“ beschrieben. Wir verwenden „koru-application“ im nächsten Schritt.
3. Erforderliche APIs aktivieren
Führen Sie den Befehl einmal pro Projekt aus:
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
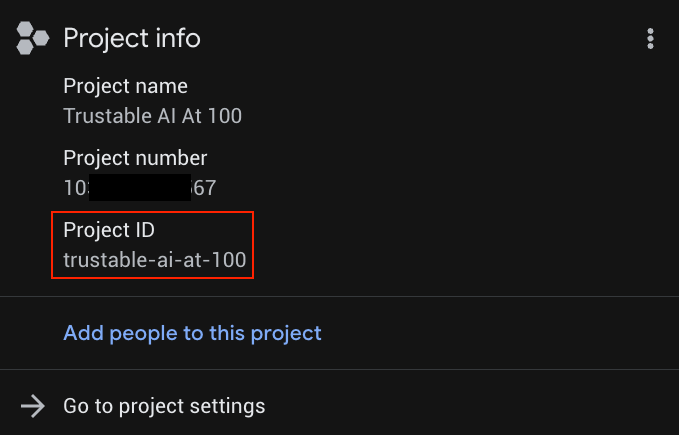
Ersetzen Sie YOUR_PROJECT_ID durch Ihre tatsächliche Projekt-ID (oder überspringen Sie die erste Zeile, wenn das Projekt bereits festgelegt ist).
YOUR_PROJECT_ID finden Sie in der Liste der Projekte.
4. Backend in Cloud Run bereitstellen
Gehen Sie zum Stammverzeichnis des Repositorys (d. h. stellen Sie sicher, dass Sie sich im Ordner trustable-ai-codelab befinden):
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
Möglicherweise müssen Sie bei entsprechender Aufforderung „Y“ drücken.
- Beim ersten Ausführen werden Sie möglicherweise aufgefordert, APIs zu aktivieren oder ein Artifact Registry-Repository zu erstellen. Akzeptieren Sie die Aufforderung nach Bedarf.
- Wenn Sie eine andere Region als
us-central1verwenden, geben Sie diese Region mit--regionan. - Wenn die Bereitstellung abgeschlossen ist, gibt gcloud die service-URL aus. Wir müssen nur „events“ an diese URL anhängen, um sie als vollständigen Endpunkt für den Telemetrieserver zu verwenden.
5. Stream-URL verwenden
Der Telemetrieserver gibt jetzt simulierte Telemetriedaten über Server-Sent Events (SSE) an einem Endpunkt der folgenden Form aus :
service-URL/events // service-URL - the last line displayed by "deploy"
Im Browser testen:Rufen Sie diese Stream-Endpunkt-URL in Chrome auf. Im Browser sollten eingehende Streamingdaten angezeigt werden, die Daten von Sensoren in einem Rennwagen simulieren.
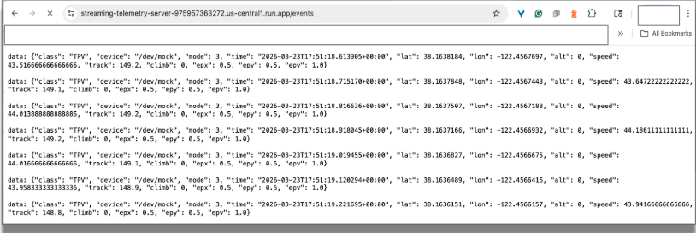
Sie können den Browsertab schließen, um die Verbindung zu beenden.
Mit „curl“ testen:
Jetzt testen wir über die Shell-Befehlszeile.
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
Im Cloud Shell-Fenster sollten eingehende Streamingdaten angezeigt werden.
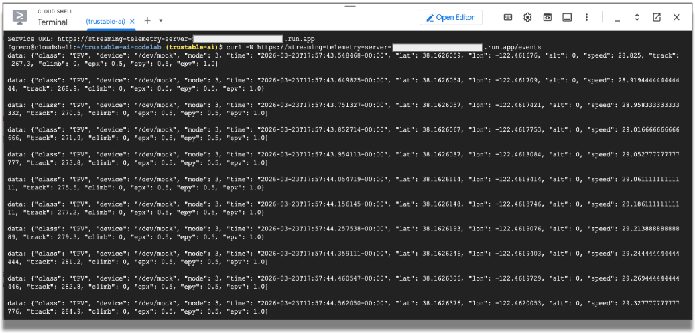
Wir verwenden diese Telemetriedaten, um die von Sensoren in einem Rennwagen ausgegebenen Daten zu simulieren. Im weiteren Verlauf des Codelabs werden diese Daten verwendet. Sie können das curl-Programm beenden, indem Sie im Terminalfenster STRG+C eingeben.
Worauf Sie achten sollten
Achten Sie beim Ausfüllen dieses Abschnitts auf die Art der eingehenden Daten. Rohdaten aus der Telemetrie sind oft umfangreich, zeitkritisch und nicht sofort für KI-Schlussfolgerungen geeignet. Nachdem wir die Front-End-Anwendung erstellt haben, müssen wir die Rohdaten in ein effizientes Format filtern, das ein LLM schnell verarbeiten kann.
Zuerst erstellen wir aber das Web-Frontend, um die Daten zu visualisieren.
6. Rennwagensimulator bauen
In diesem Abschnitt führen Sie folgende Aufgaben aus:
- Rennwagensimulation erstellen
- Telemetrieserver mit der Webanwendung für das Rennauto verbinden
- Simulierte Rennen ansehen
Wir haben jetzt eine funktionierende Simulation der Telemetriedaten eines Rennwagens, die in der Cloud ausgeführt wird. Jetzt erstellen wir die Anwendung, die auf Ihrem lokalen Computer ausgeführt wird, eine Verbindung zu Google Cloud herstellt und die Daten visualisiert.
Unsere vertrauenswürdige KI-Anwendung nutzt sowohl die Leistungsfähigkeit und Flexibilität der Google Cloud-Dienste als auch die lokale Intelligenz in Chrome.
Der Streaming-Telemetriedienst wird in Google Cloud ausgeführt, die Rennwagenanwendung auf Ihrem lokalen Computer. Das bedeutet, dass Sie das Repository noch einmal klonen müssen, diesmal auf Ihren Laptop oder Desktop-Computer.
Aus Gründen der Einfachheit enthält dasselbe Repository den Code für den Streaming-Server und die Rennwagenanwendung.
Klonen Sie die Front-End-Anwendung aus GitHub:
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Nachdem das Repository auf Ihren Laptop oder Desktop geklont wurde, führen wir die Anwendung aus.
cd koru-application # racing car simulation app
npm install
npm run dev

Öffnen Sie in Chrome den Port auf Ihrem lokalen Computer (http://localhost:5173 wie im Beispiel oben). Sie sehen die Landingpage für die Anwendung „AI Motorsport Coaching“.
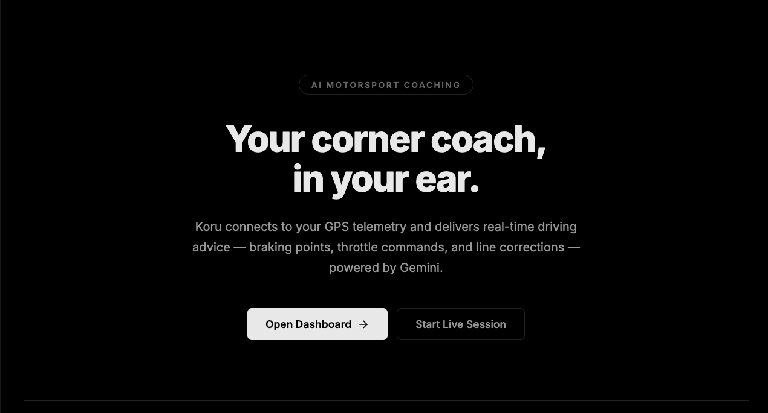
Klicken Sie auf den Button „Dashboard öffnen –>“. Dadurch wird die Benutzeroberfläche der Anwendung gestartet.
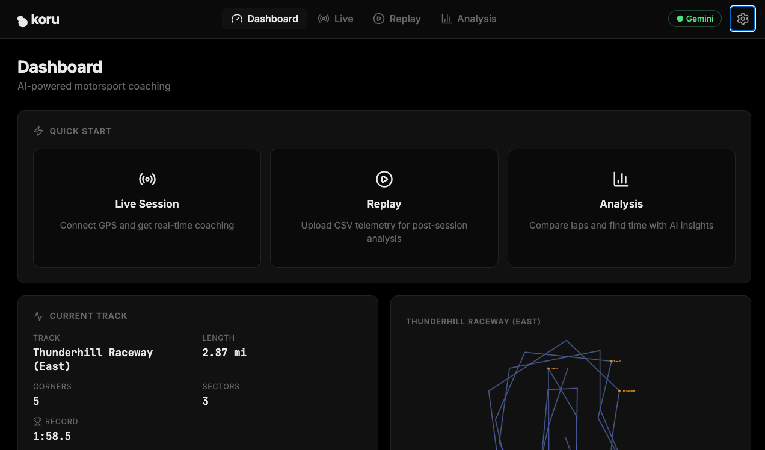
Sie haben jetzt einen Telemetrieserver, der in Google Cloud simulierte Rennwagen-Telemetriedaten generiert, und eine lokale Webanwendung, die diese Daten visualisieren und eine Verbindung zu einem LLM herstellen kann. Wir verbinden sie und stellen auch eine Verbindung zu Gemini-LLM-Diensten her.
Klicken Sie rechts oben in der Anwendung auf das Zahnradsymbol (Einstellungen).
![]()
Geben Sie Ihren Gemini API-Schlüssel aus Schritt 2 ein. So erhalten Sie Zugriff auf Gemini-Dienste in Google Cloud.
Klicken Sie auf „Speichern“, damit sich die Anwendung Ihren API-Schlüssel merkt.
Als Nächstes verbinden wir die Anwendung mit dem Telemetrieserver. Klicken Sie im Anwendungs-Dashboard auf „Live-Sitzung“.
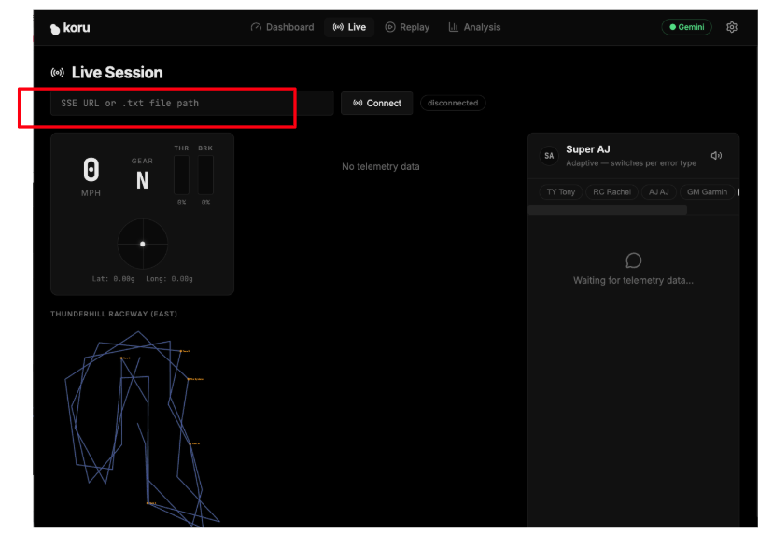
Geben Sie die spezifische URL Ihres cloudbasierten Telemetrieservers (Schritt 5) in das Textfeld ein, in dem „SSE URL or .txt file path“ steht. Unsere SSE-URL hatte das folgende Format:
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
Klicken Sie nach der Eingabe der URL des Telemetrieserver-Endpunkts rechts neben dem Textfeld auf „Verbinden“. Vergessen Sie nicht, „events“ am Ende der URL anzugeben.
Die Anwendung sollte jetzt die simulierten Daten visualisieren.
Wenn die Lautstärke Ihres Lautsprechers aufgedreht ist, können Sie die Tipps für das Autorennen von verschiedenen Arten von Coaches hören. Jeder Coach hat eine andere Persönlichkeit. Wähle verschiedene Coaches aus, um dir ihre unterschiedlichen Lauftipps und Gesangsstile anzuhören. Bei Bedarf können Sie die Audioausgabe deaktivieren, indem Sie auf das Lautsprechersymbol klicken.
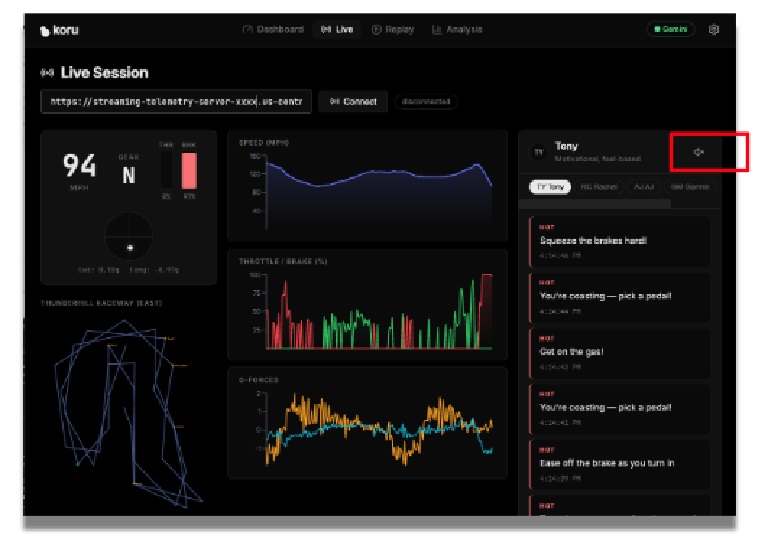
Nachdem wir nun eine funktionierende Anwendung haben, sehen wir uns an, wie wir die Daten für die effiziente Verarbeitung durch das LLM vorbereitet haben und wie wir zusätzliche Funktionen hinzufügen können, um die Vertrauenswürdigkeit des Gesamtsystems zu verbessern.
7. Telemetrie für KI-Schlussfolgerungen vorbereiten
Rohdaten aus der Telemetrie sind für die Simulation nützlich, aber in der Regel zu detailliert und zu häufig, um direkt an ein LLM gesendet zu werden. Wenn Sie alle Telemetriedaten unverändert senden, kann dies zu einer erhöhten Latenz, Rauschen und einer geringeren Qualität der resultierenden Empfehlungen führen.
In diesem Abschnitt formen Sie die Telemetriedaten in eine nützlichere Form um.
In diesem Abschnitt führen Sie folgende Aufgaben aus:
- Rohe Telemetrie-JSON prüfen
- Ermitteln, welche Felder für die Argumentation am relevantesten sind
- Daten filtern oder zusammenfassen
- Unnötige Details reduzieren
- KI-freundliche Darstellung des Fahrzustands vorbereiten
Dies ist ein wichtiger Schritt, um vertrauenswürdige KI zu entwickeln. Die Qualität der Antwort hängt nicht nur vom Modell ab, sondern auch von der Struktur und Relevanz der Daten, die es erhält.
Sehen wir uns nun die spezifischen Daten für Rennwagen an. Wir können experimentieren, indem wir bestimmte Werte in der Anwendung ändern, sie neu laden und das Ergebnis beobachten.
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
G-Kräfte in einem Auto messen die Beschleunigung oder Verlangsamung. In einem Rennwagen hilft das Verständnis von G-Kräften, das Fahrverhalten und die Gesamtleistung des Autos zu verbessern. Wenn unsere App diese Informationen nicht enthält, ist es schwierig, dem Fahrer Ratschläge zu geben. Kommentieren Sie diese beiden Zeilen aus, setzen Sie die Werte für gLat und gLong auf 0, 0 und führen Sie die Anwendung noch einmal aus.
Beachten Sie, dass keine Hinweise gegeben werden, wenn sich das Auto einer Kurve nähert. Das ist für einen Rennfahrer nicht sehr hilfreich.
Machen Sie die Änderung dann rückgängig und führen Sie die Anwendung noch einmal aus. Haben Sie die hilfreichen Audio-Hinweise bemerkt, als das Auto eine Kurve erreicht hat? G-Kraft-Datenpunkte sind für die Beratung des Fahrers von entscheidender Bedeutung.
Jetzt begrenzen wir die Geschwindigkeit des Autos künstlich auf 30 mph. Mit dieser Geschwindigkeit werden wir keine Rennen gewinnen, aber es zeigt auf jeden Fall, welche Art von Coaching wir erhalten.
In derselben Datei (telemetryStreamService.ts) in der Nähe von Zeile 158 finden Sie die Funktion processPoint(). Beschränken wir die Geschwindigkeit in dieser Funktion.
Ändern Sie:
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
An:
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
Führen Sie die Anwendung noch einmal aus. Welche Art von Coaching-Tipps erhalten wir jetzt? Wenn wir gemütlich fahren, ist nicht viel nötig.
Machen Sie die Änderungen nun rückgängig und führen Sie die Anwendung noch einmal aus.
Die Geschwindigkeit des Autos ist eindeutig ein wertvoller Datenpunkt. Es ist sehr wichtig zu verstehen, welche spezifischen Daten für eine fundierte Beratung erforderlich sind. Ebenso wichtig ist es, zu bewerten, welche Daten nicht relevant sind.
Sie sollten sich auch Gedanken über Sicherheit und Vertrauen machen. Selbst gut vorbereitete Eingaben garantieren keine zuverlässige Antwort. Wir müssen weiterhin von Menschen erstellte Regeln und explizite Einschränkungen einführen.
Die Datenvorbereitung ist nicht nur ein Vorverarbeitungsschritt. Sie ist ein wichtiger Bestandteil der Vertrauensstrategie. Saubere Eingaben führen oft zu fokussierteren und zuverlässigeren Ergebnissen.
8. Schutzmaßnahmen und codiertes menschliches Fachwissen hinzufügen
Ein vertrauenswürdiges KI-System sollte sich nicht nur auf die Modellausgabe verlassen. In vielen Fällen kombinieren die zuverlässigsten Systeme die Logik von Large Language Models mit expliziten Regeln, Fachwissen und von Menschen vorgegebenen Einschränkungen.
In diesem Abschnitt fügen Sie diese Ebene hinzu.
Diese Ebene kann als codiertes Coaching-Wissen betrachtet werden. Dazu können bevorzugte Antwortmuster, Validierungsregeln, Sicherheitsprüfungen oder strukturierte Anleitungen gehören, die dem System helfen, fundiert und nützlich zu bleiben.
In diesem Abschnitt führen Sie folgende Aufgaben aus:
- Antwortregeln einführen, die das Verhalten des Modells beeinflussen
- Sicherheitsprüfungen anwenden, um irreführende Ratschläge zu reduzieren
- Codiertes menschliches Fachwissen in die Pipeline einbinden
- Antworten vor und nach diesen Ergänzungen vergleichen
Sehen wir uns an, wie Domainwissen in unsere Anwendung aufgenommen wird.
Ein LLM wird in der Regel nicht für Rennen oder die Physik der Leistung von Rennwagen trainiert. Wenn unsere Anwendung diese Fachkenntnisse enthalten würde, könnten Nutzer den Empfehlungen mehr Vertrauen schenken. Diese Anleitung basiert auf Regeln, die auf menschlichem Fachwissen beruhen, also auf einer Ebene mit Fachwissen.
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
Diese Prinzipien sind ein wichtiger Bestandteil, um vertrauenswürdige Ergebnisse zu liefern. Was würde passieren, wenn wir dieses Know-how nicht hätten? Das lässt sich ganz einfach herausfinden.
Entfernen wir RACING_PHYSICS_KNOWLEDGE und sehen uns unsere Renn-Tipps an.
export const RACING_PHYSICS_KNOWLEDGE = ``;
Führen Sie die Anwendung noch einmal aus. Welche Art von Coaching-Tipps erhalten wir jetzt?
Beachten Sie die allgemeinen Hinweise.
Wir erhalten keine detaillierten Informationen mehr zu Reibung, Gewichtsverlagerung, Ausfahrgeschwindigkeit usw. Ohne diese Informationen ist unsere Vertrauenswürdigkeit geringer. Stellen Sie diese Expertise wieder her und führen Sie die Anwendung noch einmal aus.
Dieser Schritt ist ein wichtiger Aspekt eines vertrauenswürdigen KI-Systems. Vertrauen entsteht nicht durch einen besseren Prompt. Vertrauen entsteht durch Systemdesign und kritisches Denken.
Das LLM ist Teil der Lösung, aber nicht die gesamte Lösung. Das Vertrauen steigt, wenn KI-Ausgaben durch explizites menschliches Wissen gesteuert werden.
9. Coaching-Personas und User Experience gestalten
Wenn Ihre Reasoning-Pipeline eingerichtet ist, stellt sich als Nächstes die Frage, wie das System mit dem Nutzer kommunizieren soll.
In diesem Abschnitt legen Sie fest, wie die Strategieebene mit dem Fahrer kommuniziert. Sie verfeinern den Systemprompt für eine der Coaching-Personas und überlegen, wie die Anleitung klar, zeitnah und vor allem umsetzbar vermittelt werden kann.
In diesem Abschnitt führen Sie folgende Aufgaben aus:
- Systemaufforderung für eine Coaching-Persona erstellen oder optimieren
- Mit verschiedenen Coaching-Stilen experimentieren
- Auswirkungen von Prompt-Änderungen auf die Antworten beobachten
- UI-Anforderungen für vertrauenswürdiges Feedback definieren
- Unterstützung von Text-zu-Sprache (TTS) für dringende und nicht dringende Nachrichten
Unsere Anwendung umfasst mehrere Coaching-Personas. Jeder bietet unterschiedliche Arten von Coaching-Tipps.
PERSONA | MERKMALE |
Tony | Motivierend, gefühlsbasiert |
Rachel | Technisch, physikorientiert |
AJ | Direkte, unverblümte Befehle |
Garmin | Datenorientierte Delta-Optimierung |
Super AJ | Adaptiv, Switches pro Fehlertyp |
Diese Rollen sind in der Datei ../src/utils/coachingKnowledge.ts definiert.
In dieser Datei finden Sie eine Objektzuordnung (COACHES), die String-Schlüssel mit CoachPersonas verknüpft. Ein CoachPersona enthält Attribute für jeden Coach-Typ. Ein wichtiges Attribut ist systemPrompt. Jede Persona hat einen eigenen systemPrompt, der das LLM bei der Reaktion leitet.
Wir ändern eine dieser system prompts und sehen, wie das LLM reagiert.
In der Nähe von Zeile 31 sehen Sie die systemPrompt für „AJ“, der sehr direkt und unverblümt mit seinen Ratschlägen ist. Ändern wir das systemPrompt so, dass AJ übertrieben höflich ist.
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
Führen Sie die Anwendung noch einmal aus, wählen Sie AJ als Coach aus und sehen Sie sich an, welche Art von Antworten generiert werden.
Stellen Sie nun den ursprünglichen systemPrompt wieder her und führen Sie die Anwendung noch einmal aus. Der Systemprompt ist entscheidend, um das LLM dazu zu bringen, eine Antwort zu geben, die zur Persona passt.
Vertrauen hängt nicht nur von der Richtigkeit ab. Es geht auch um die Auslieferung. Auch wenn Ratschläge technisch korrekt sind, können sie ineffektiv sein, wenn sie unklar, schlecht getimt oder ablenkend sind.
Ein vertrauenswürdiges System muss gut kommunizieren. Die User Experience ist Teil der Vertrauensarchitektur.
10. End-to-End-Architektur prüfen
An diesem Punkt haben Sie die wichtigsten Teile des Systems erstellt. Sehen wir uns nun an, wie sie zusammenarbeiten.
Ihre Anwendung enthält jetzt die folgenden Komponenten:
- Telemetriestream
- Visualisierungsebene
- KI-fähige Datentransformationsphase
- Strategiekomponenten, die auf einem Reasoning-LLM basieren
- Schutzmaßnahmen und codierte menschliche Anleitung
- Coaching für Nutzer
Eine nützliche und einfache Möglichkeit, den Gesamtfluss dieser Komponenten zu verstehen, besteht darin, unserer Anwendung die Protokollierung hinzuzufügen.
Wir fügen die Protokollierung hinzu, um die Telemetriedaten zu sehen, während sie durch die Pfade fließen.
Sehen wir uns zuerst die Telemetriedaten an. Fügen Sie in telemetryStreamService.ts um Zeile 212 (vor this.emit(frame)) eine Zeile hinzu, in der die Geschwindigkeit, die seitliche G-Kraft (seitliche Beschleunigung) und die Stärke des Bremsvorgangs angezeigt werden.
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
Laden Sie die Anwendung neu. Bevor wir die Anwendung ausführen, öffnen wir die Konsole in den Chrome-Entwicklertools, um diese Debugging-Informationen aufzurufen.
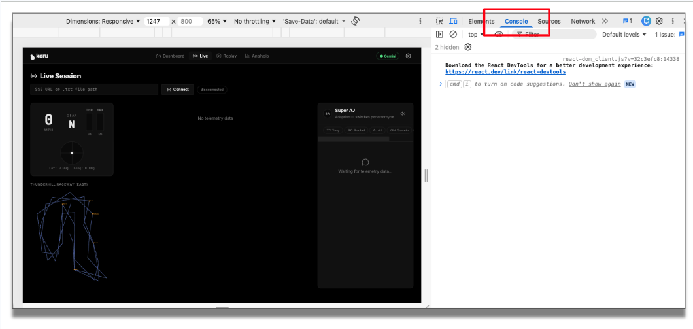
Geben Sie in der Anwendung den Telemetrie-Endpunkt ein und klicken Sie auf „Verbinden“. Sie können jetzt die eingehenden Telemetriedaten sehen.
Fügen wir nun die Protokollierung für den Reflex- und den Strategiepfad hinzu.
Fügen Sie in ../src/services/coachingService.ts um Zeile 71 vor this.emit() eine Protokollierungszeile für den Pfad reflex hinzu:
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
Fügen Sie in derselben Datei um Zeile 287 herum vor this.emit() eine ähnliche Protokollierungszeile für den Pfad strategy hinzu. Fügen wir die von der Gemini API zurückgegebene Coaching-Antwort text hinzu:
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
Führen Sie die Anwendung noch einmal aus. In der Console sehen Sie, wie die Telemetriedaten von der Quelle durch diese Pfade fließen. Der eingehende Stream wird gefiltert, an das LLM gesendet, mit vertrauenswürdiger menschlicher Expertise überprüft und dem Nutzer über eine geeignete Benutzeroberfläche präsentiert.
Wir haben die verschiedenen technischen Komponenten miteinander verbunden, um das übergeordnete Ziel einer vertrauenswürdigen KI zu erreichen. Der Wert der Architektur liegt nicht in einer einzelnen Komponente. Der Wert ergibt sich daraus, wie sich die einzelnen Teile gegenseitig verstärken.
Vertrauenswürdige KI ist ein architektonisches Ergebnis und keine einzelne Funktion.
Löschen (Dienst entfernen)
Denken Sie daran, den Dienst zu entfernen, wenn Sie ihn nicht mehr benötigen. Wenn Sie den Telemetrieserver zusammen mit der Anwendung getestet haben, sollten Sie den Cloud Run-Dienst löschen, damit keine Abrechnung mehr erfolgt:
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
Ersetzen Sie us-central1 bei Bedarf durch die Region, die Sie bei der Bereitstellung verwendet haben. Bestätigen Sie den Vorgang, wenn Sie dazu aufgefordert werden.
11. Herausforderungen
Nachdem die Kernanwendung funktioniert und Sie die verschiedenen Komponenten kennen, können Sie das Design erweitern.
Vorgeschlagene Challenges
- Mehr Coaching-Logik auf das Edge-Gerät verlagern
- Simulation anpassen, um Regen oder reduzierte Traktion zu berücksichtigen
- Möglichkeiten zur Leistungssteigerung durch Modellabstimmung oder Feinabstimmung
- Die Architektur für eine andere Branche anpassen, z. B. Medizin, Fertigung oder Logistik
Hier sind einige Fragen, die Sie sich stellen sollten, wenn Sie die in diesem Lab gewonnenen Erkenntnisse auf eine andere Domain anwenden:
- Was ist das Äquivalent von Renntelemetrie, d. h. kontinuierlichen Daten, in einem anderen Bereich?
- Welche Entscheidungen müssen sofort getroffen werden und welche sind eher strategischer Natur?
- Welche Art von menschlichem Fachwissen müsste codiert werden?
- Was müssen Nutzer sehen, damit sie dem System vertrauen?
Diese Aufgaben sollen Sie dazu anregen, über das Beispiel mit dem Rennen hinauszudenken und das breitere Designmuster der Vertrauenswürdigkeit zu erkennen, das diesem Codelab zugrunde liegt.
12. Zusammenfassung und weitere Informationen
In diesem Codelab haben Sie mehr als nur eine Renn-Demo erstellt. Sie haben ein konkretes Beispiel dafür entwickelt, wie vertrauenswürdige KI-Systeme konzipiert werden können.
Sie haben mit Rohdaten aus der Telemetrie begonnen, diese in ein für ein LLM nützliches Format umgewandelt, KI-Schlussfolgerungen angewendet und die Ausgabe mit codierten menschlichen Anleitungen und Antwortbeschränkungen optimiert. Sie haben gesehen, dass Vertrauen auf Architektur beruht und nicht nur auf der Modellausgabe.
Ein vertrauenswürdiges KI-System kombiniert oft:
- Strukturierte Echtzeitdaten
- Modellbasiertes Reasoning
- Codierte Fachkenntnisse
- Explizite Schutzmaßnahmen
- Durchdachtes User Experience Design
Das Rennszenario hat dazu beigetragen, diese Ideen greifbar zu machen. Derselbe Ansatz kann jedoch überall dort verwendet werden, wo KI-Empfehlungen zeitnah, umsetzbar und zuverlässig sein müssen.
