
1. Descripción general
La inteligencia artificial ahora forma parte de muchos sistemas de software, pero crear una aplicación de IA no es lo mismo que crear una en la que los usuarios puedan confiar. En muchos entornos del mundo real, el desafío no es simplemente generar una respuesta. El desafío es generar una respuesta oportuna, fundamentada, práctica y alineada con la experiencia humana.
En este codelab, compilarás un simulador de entrenador de carreras que demuestra estas ideas de una manera concreta y atractiva. La aplicación usa la telemetría de un auto de carreras virtual para animar el movimiento alrededor de una pista y generar orientación de entrenamiento. Si bien las carreras son el escenario, las mismas ideas de arquitectura se aplican a la atención médica, la fabricación, la logística y otros dominios en los que la confianza es importante.
Trabajarás con un flujo de datos de telemetría de alta velocidad, lo transformarás en un formato útil y eficiente para el razonamiento de la IA, y combinarás el resultado basado en LLM con la orientación humana codificada para producir respuestas más confiables.
Qué compilarás
En este codelab, compilarás un prototipo de IA confiable que hará lo siguiente:
- Transmite telemetría desde un auto de carreras virtual que se ejecuta en Google Cloud
- Visualiza el automóvil moviéndose por una pista de carreras con Chrome
- Transforma la telemetría sin procesar en datos de entrada listos para la IA
- Aplica una capa de estrategia potenciada por Google Gemini
- Combina el resultado del modelo con la orientación humana codificada y las reglas de seguridad
- Brinda comentarios de entrenamiento a través de una interfaz para el usuario
Qué aprenderás
Al final de este codelab, podrás hacer lo siguiente:
- Explicar qué hace que un sistema de IA sea más confiable
- Explicar el propósito de una arquitectura de IA modular
- Crea una canalización de telemetría simulada simple
- Prepara datos estructurados y útiles para usarlos con un LLM
- Aplica barreras de seguridad y reglas guiadas por humanos para mejorar la confianza
- Evalúa cómo se puede aplicar esta arquitectura a otros dominios
2. Qué necesitará
Antes de comenzar, asegúrate de tener listas las cuentas, las herramientas y los servicios necesarios.
Requisitos previos
Requisitos:
- Una Cuenta de Google personal que usa una dirección de Gmail
- Acceso a Google Cloud y conocimientos básicos de una CLI
- Una cuenta de facturación activa o créditos de Cloud
- Comprensión general de Google Cloud y la IA generativa con Gemini
Gemini es el modelo de IA de Google que se basa en un razonamiento de vanguardia para dar vida a cualquier idea. Es un excelente modelo para la comprensión multimodal y la programación de agentes y vibe coding.
3. Por qué es importante la IA confiable
Muchos sistemas de IA pueden producir respuestas fluidas y convincentes, pero fluido no es lo mismo que confiable. En los sistemas del mundo real, los usuarios suelen necesitar respuestas oportunas y fundamentadas que estén restringidas por reglas de seguridad y moldeadas por la experiencia en el dominio.
Esto se vuelve especialmente importante cuando un sistema opera con datos que cambian rápidamente. Una respuesta que llega demasiado tarde puede ser inútil. Una respuesta que suena segura, pero que ignora contexto importante, puede ser engañosa. Una respuesta sin conexión con la experiencia humana puede ser difícil de confiar, incluso si suena pulida.
En la situación del auto de carreras que se usa en este codelab, el problema no es si la IA puede decir algo interesante. El problema es si el sistema puede brindar consejos útiles, seguros, oportunos y adecuados para la situación.
Veamos una pequeña muestra de telemetría y comparemos dos resultados posibles:
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Respuesta de IA simple
"Stay aggressive on the throttle and carry your speed into Turn 1"
Respuesta que tiene en cuenta la confianza
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
¿Notaste la diferencia?
¿Qué sucedería si solo confiáramos en la respuesta ingenua de la IA?
La primera respuesta suena segura, pero ignora el riesgo. La segunda respuesta es más útil porque refleja el contexto y la restricción.
En lugar de considerar el LLM como todo el sistema, debes considerarlo como una parte de una arquitectura más amplia para aumentar la confiabilidad. Además, muchas aplicaciones requieren que el asesoramiento se proporcione con la suficiente rapidez como para ser útil, como en el caso de un auto de carreras, un procedimiento médico, la aviación, la red eléctrica, un sistema de comercio, la navegación marítima, etcétera.
Ahora, veamos cómo crear una arquitectura de este tipo.
4. Comprensión de la IA de alta velocidad y la arquitectura modular de confianza
Algunos sistemas de IA necesitan comportamientos muy diferentes. Deben reaccionar rápidamente a las condiciones cambiantes y, también, admitir un razonamiento más lento y reflexivo.
Una arquitectura modular separa estas responsabilidades en rutas distintas. Una ruta puede ser reflexiva y controlar la interpretación inmediata y sensible al tiempo de los indicadores entrantes. Otro camino puede centrarse en la estrategia, respaldando el razonamiento de nivel superior y la toma de decisiones más conscientes del contexto. Otros segmentos de ruta se dirigen a otros tipos de funcionalidad.
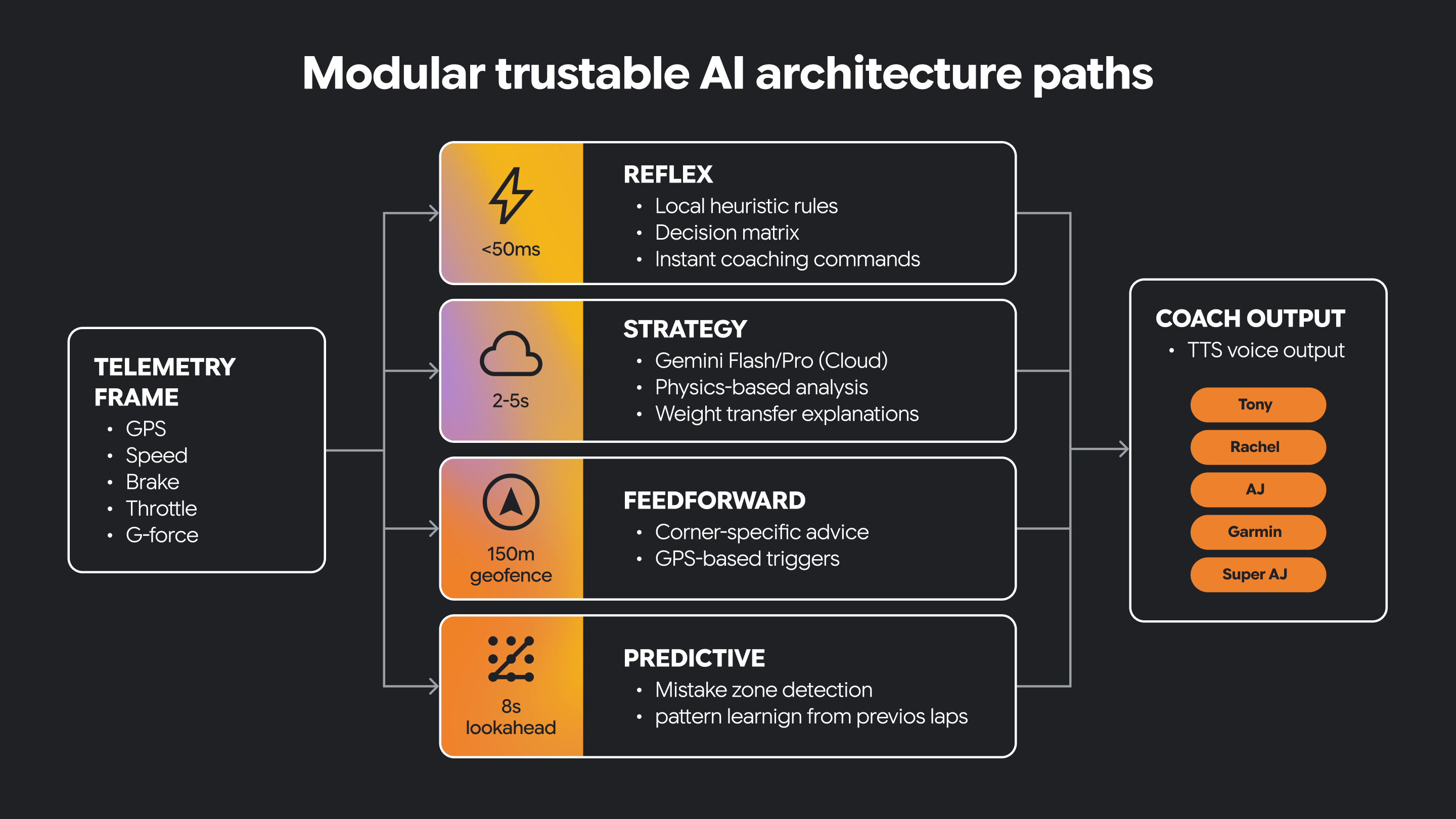
Algunas decisiones deben tomarse en tiempo real. Algunas decisiones se benefician de un análisis más prolongado.
La IA confiable a menudo necesita ambas.
Esta separación arquitectónica ayuda a que el sistema siga siendo responsivo y, al mismo tiempo, admita una orientación más enriquecida basada en la IA. También crea un lugar claro para introducir restricciones guiadas por humanos y conocimientos del dominio.
En este pequeño programa, tenemos una ruta de reflejo y una ruta de estrategia implementadas como funciones de Python.
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
Las dos funciones se comportan de manera diferente con los mismos datos de telemetría. La función de reflejo es una advertencia inmediata. La función de estrategia nos brinda consejos de entrenamiento basados en reglas.
¿Por qué crees que es útil mantener esta lógica separada?
Ahora, creemos una aplicación divertida de varias partes y veamos cómo esta arquitectura convierte las reacciones rápidas y el razonamiento más profundo en un sistema de IA confiable que puedes experimentar.
5. Compila un servidor de transmisión de telemetría
Ahora que comprendes el objetivo de la arquitectura, es momento de crear la canalización de datos que impulsa la aplicación.
En esta sección, crearás un flujo de telemetría simple para un auto de carreras virtual. Los datos provendrán de una fuente CSV que contiene datos de GPS o de posición de seguimiento, y tu aplicación los convertirá en una transmisión en vivo que la IU y la capa de IA pueden consumir.
En esta sección, deberás hacer lo siguiente:
- Crea un proyecto nuevo en Google Cloud para nuestro servidor y aplicación de transmisión
- Crea un servidor pequeño para emitir datos de telemetría
- Transmite esos eventos a una IU o consola del navegador
1. Abre Cloud Shell
A. Ve a consola de Google Cloud.
B. Crea un proyecto nuevo para este codelab. Haz clic en el menú desplegable del proyecto en la parte superior.
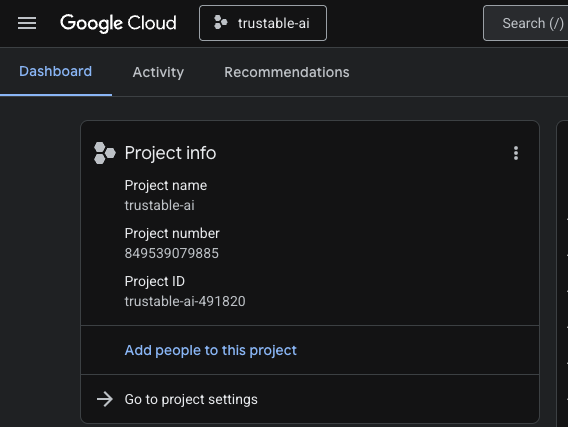
Cuando crees un proyecto, es una buena oportunidad para vincular la cuenta de facturación: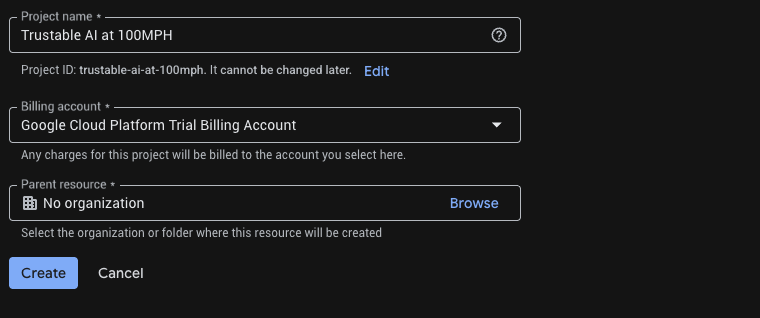
Opcionalmente, si ya creaste un proyecto, puedes abrir el panel izquierdo, hacer clic en Billing y verificar si la cuenta de facturación está vinculada a esta cuenta de GCP.
C. Cómo obtener una clave de API de Gemini
Una vez que hayas habilitado tus créditos de Google Cloud, necesitarás una clave de API de Gemini para acceder a Gemini en Google Cloud.
Para crear una clave de API de Gemini, debemos usar Google Vertex AI Studio para generar claves.
En Vertex AI Studio, haz clic en "Obtener clave de API" en la esquina inferior izquierda, arriba de "Documentación". Crea una clave de API para Gemini (parece una cadena larga de caracteres aparentemente aleatorios). Guarda esta clave en una ubicación segura. Usaremos esta clave de API en el paso 6, "Compila el simulador de autos de carrera", para autenticar nuestro acceso a Gemini en Google Cloud.
D. Haz clic en el ícono de Cloud Shell en la barra superior (ícono de terminal) para abrir una terminal basada en el navegador.
E. Espera a que comience la sesión de la terminal.

2. Obtén el código
Clona el repositorio principal.
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Ten en cuenta que hay dos carpetas en este repo: "koru-application" (aplicación web) y "streaming-telemetry-server" (telemetría simulada en tiempo real de un auto de carreras). En este paso, se describe el "streaming-telemetry-server". Usaremos "koru-application" en el siguiente paso.
3. Habilita las API obligatorias
Ejecuta una vez por proyecto:
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
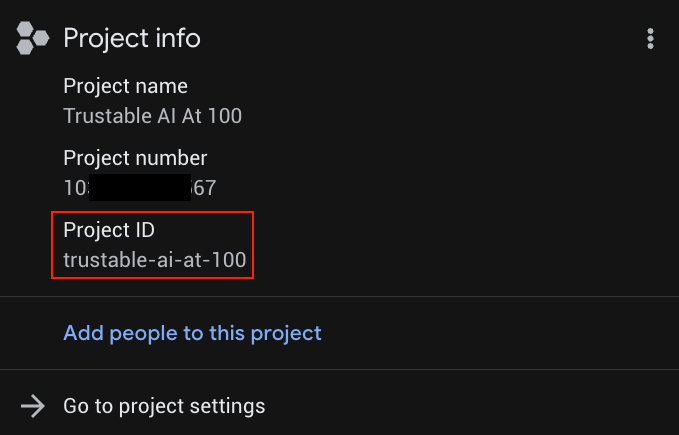
Reemplaza YOUR_PROJECT_ID por el ID de tu proyecto real (o bien omite la primera línea si el proyecto ya está configurado).
Puedes encontrar YOUR_PROJECT_ID en la lista de proyectos.
4. Implementa el backend en Cloud Run
Desde la raíz del repo (es decir, asegúrate de estar en la carpeta trustable-ai-codelab), haz lo siguiente:
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
Es posible que debas presionar “Y” cuando se te solicite.
- Es posible que la primera ejecución te solicite que habilites APIs o que crees un repo de Artifact Registry. Acepta según sea necesario.
- Si usas una región diferente de
us-central1, especifícala con--region. - Cuando finalice la implementación, gcloud imprimirá la URL del servicio. Solo tenemos que agregar "events" a esta URL para usarla como el extremo completo del servidor de telemetría.
5. Usa la URL de la transmisión
El servidor de telemetría ahora emite datos de telemetría simulados con eventos enviados por el servidor (SSE) en un extremo con el siguiente formato :
service-URL/events // service-URL - the last line displayed by "deploy"
Prueba en un navegador: Visita la URL de este extremo de transmisión con Chrome. Deberías ver los datos transmitidos entrantes en el navegador, que simulan los datos que emiten los sensores de un automóvil de carreras.
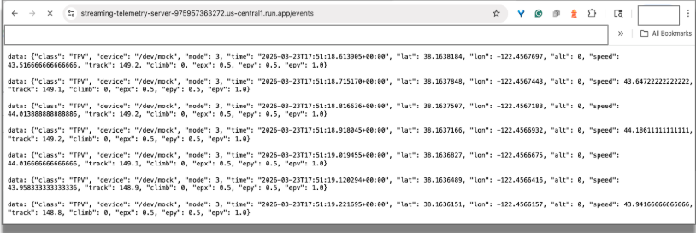
Puedes cerrar la pestaña del navegador para finalizar la conexión.
Prueba con curl:
Ahora, probemos desde la línea de comandos de shell.
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
Deberías ver los datos transmitidos entrantes en la ventana de Cloud Shell.
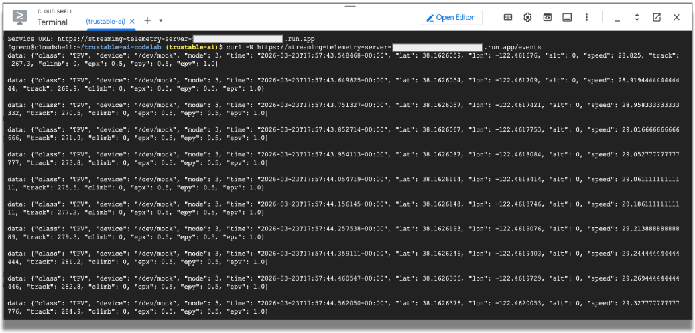
Usaremos estos datos de telemetría para simular los datos que emiten los sensores de un automóvil de carreras. El resto del codelab usará estos datos. Para finalizar el programa curl, ingresa CTRL-C en la ventana de la terminal.
Qué debes notar
A medida que completes esta sección, presta atención a la naturaleza de los datos entrantes. La telemetría sin procesar suele ser de gran volumen, sensible al tiempo y no adecuada de inmediato para el razonamiento de la IA. Una vez que compilemos la aplicación de frontend, deberemos filtrar los datos sin procesar en un formato eficiente que un LLM pueda procesar rápidamente.
Pero primero, compilaremos el frontend web para visualizar los datos.
6. Cómo compilar el simulador de autos de carrera
En esta sección, deberás hacer lo siguiente:
- Crea una simulación de un automóvil de carreras
- Conecta el servidor de telemetría a la aplicación web del automóvil de carreras
- Cómo ver las carreras simuladas
En este punto, tenemos una simulación en funcionamiento de la telemetría de un automóvil de carreras que se ejecuta en la nube. Ahora, compilaremos la aplicación que se ejecuta en tu máquina local, se conecta a Google Cloud y visualiza esos datos.
Nuestra aplicación de IA confiable usa la potencia y la flexibilidad de los servicios de Google Cloud, y la inteligencia local que se ejecuta en Chrome.
El servicio de telemetría de transmisión se ejecuta en Google Cloud, pero la aplicación del auto de carreras se ejecuta en tu máquina local. Esto significa que deberás volver a clonar el repositorio, esta vez en tu laptop o computadora de escritorio.
Para simplificar, el mismo repositorio contiene el código del servidor de transmisión y de la aplicación de autos de carrera.
Clona la aplicación de frontend desde GitHub:
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Una vez que se clone el repo en tu laptop o computadora de escritorio, ejecutemos la aplicación.
cd koru-application # racing car simulation app
npm install
npm run dev

En Chrome, abre el puerto en tu máquina local (http://localhost:5173, como en el ejemplo anterior). Verás la página de destino de la aplicación "AI Motorsport Coaching".
Haz clic en el botón "Open Dashboard ->". Esto iniciará la IU de la aplicación.
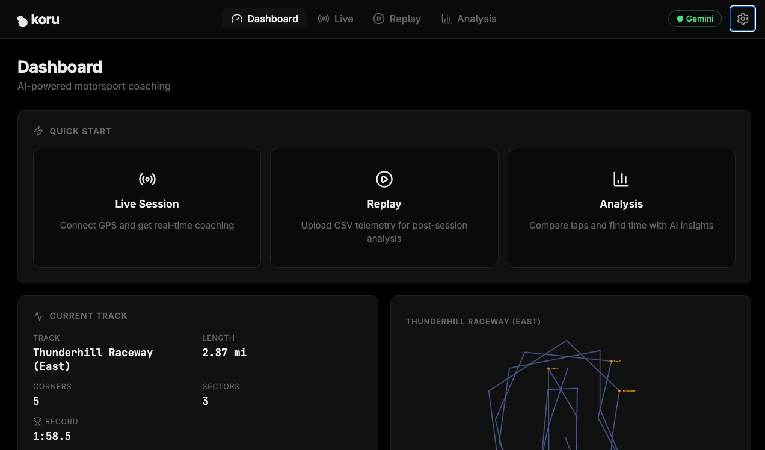
En este punto, tienes un servidor de telemetría que genera telemetría simulada de autos de carrera en Google Cloud y una aplicación web local que puede visualizar esos datos y conectarse a un LLM. Conectemos estos servicios y también los servicios de LLM de Gemini.
En la esquina superior derecha de la aplicación, haz clic en el ícono de ajustes (configuración).
![]()
Ingresa tu clave de API de Gemini del paso 2. Esto te da acceso a los servicios de Gemini en Google Cloud.
Haz clic en "Guardar" para que la aplicación recuerde tu clave de API.
Ahora, conectemos la aplicación al servidor de telemetría. En el panel de la aplicación, haz clic en "Sesión en vivo".
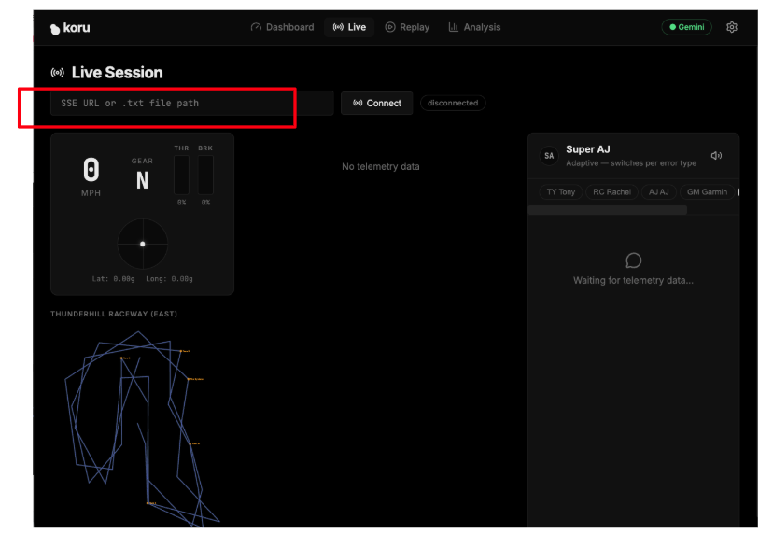
Ingresa la URL específica de tu servidor de telemetría basado en la nube (paso 5) en el campo de texto que dice "SSE URL or .txt file path". Nuestra URL de SSE tenía el siguiente formato:
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
Una vez que hayas ingresado la URL del extremo del servidor de telemetría, haz clic en "Conectar" (a la derecha del campo de texto). No olvides incluir "events" al final de la URL.
Ahora deberías ver la aplicación que visualiza los datos simulados.
Si el volumen del altavoz está alto, puedes escuchar los consejos de carreras de autos de diferentes tipos de entrenadores. Cada entrenador tiene una personalidad diferente. Intenta seleccionar diferentes entrenadores para ver sus variados consejos de carreras y diferentes estilos vocales. Si es necesario, puedes inhabilitar el audio haciendo clic en el ícono de altavoz.
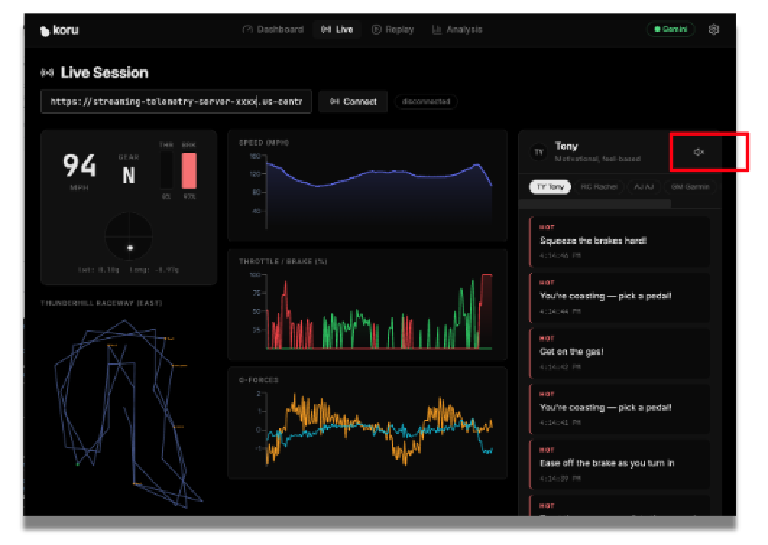
Ahora que tenemos una aplicación que funciona, exploremos cómo preparamos los datos para que el LLM los procese de manera eficiente y cómo podemos agregar funciones adicionales para mejorar la confiabilidad del sistema general.
7. Prepara la telemetría para el razonamiento de la IA
La telemetría sin procesar es útil para la simulación, pero suele ser demasiado detallada y frecuente para enviarse directamente a un LLM. Si envías todos los datos de telemetría sin cambios, es posible que aumentes la latencia, introduzcas ruido y reduzcas la calidad de la orientación resultante.
En esta sección, cambiarás la forma de los datos de telemetría para que sean más útiles.
En esta sección, deberás hacer lo siguiente:
- Inspecciona el JSON de telemetría sin procesar
- Identifica qué campos son más relevantes para el razonamiento.
- Filtrar o resumir los datos
- Reduce los detalles innecesarios
- Prepara una representación del estado de conducción apta para la IA
Este es un paso importante para crear una IA confiable. La calidad de la respuesta no solo depende del modelo, sino también de la estructura y la relevancia de los datos que recibe.
Ahora exploremos los datos específicos de los autos de carrera. Podemos experimentar cambiando valores específicos en la aplicación, volviéndola a cargar y observando el resultado.
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
Las fuerzas G en un automóvil miden la aceleración o la desaceleración. En un automóvil de carreras, comprender las fuerzas G ayuda con el manejo y el rendimiento general del vehículo. Si nuestra aplicación no tiene esta información, es difícil brindarle consejos al conductor. Comenta esas dos líneas, establece los valores de gLat y gLong en 0.0 y vuelve a ejecutar la aplicación.
Observa que no se da ninguna indicación cuando el auto se acerca a una esquina. Esto no es muy útil para un piloto de carreras.
Luego, deshace el cambio y vuelve a ejecutar la aplicación. ¿Notaste los útiles consejos de audio cuando el auto llega a una esquina? Los puntos de datos de fuerza G son fundamentales para brindarle consejos al conductor.
Ahora, restrinjamos artificialmente la velocidad del automóvil a un ritmo pausado de 48 km/h. No ganaremos ninguna carrera a esa velocidad, pero sin duda demostrará el tipo de entrenamiento que recibimos.
En ese mismo archivo (telemetryStreamService.ts), cerca de la línea 158, encontrarás la función processPoint(). En esa función, restrinjamos la velocidad.
Para cambiar:
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
Para:
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
Vuelve a ejecutar la aplicación. ¿Qué tipo de consejos de entrenamiento recibimos ahora? No se necesita mucho si conducimos de forma relajada.
Ahora revierte esos cambios y vuelve a ejecutar la aplicación.
Claramente, la velocidad del automóvil es un dato valioso. Es muy importante comprender qué datos específicos son fundamentales para brindar asesoramiento valioso. También es importante evaluar qué datos no son relevantes.
También deberías comenzar a pensar en la seguridad y la confianza en este punto. Incluso una entrada bien preparada no garantiza una respuesta confiable. Aún necesitamos introducir reglas guiadas por humanos y restricciones explícitas.
La preparación de datos no es solo un paso de procesamiento previo. Es una parte fundamental de la estrategia de confianza. Las entradas más limpias suelen generar resultados más enfocados y confiables.
8. Agrega protecciones y experiencia humana codificada
Un sistema de IA confiable no debe basarse solo en el resultado del modelo. En muchos casos, los sistemas más confiables combinan el razonamiento de los modelos de lenguaje grandes con reglas explícitas, conocimiento del dominio y restricciones guiadas por humanos.
En esta sección, agregarás esa capa.
Puedes considerar esta capa como conocimiento de entrenamiento codificado. Puede incluir patrones de respuesta preferidos, reglas de validación, verificaciones de seguridad o orientación estructurada que ayude al sistema a mantenerse fundamentado y útil.
En esta sección, deberás hacer lo siguiente:
- Presentamos reglas de respuesta que dan forma al comportamiento del modelo
- Aplicar verificaciones de seguridad para reducir los consejos engañosos
- Incorpora la experiencia humana codificada en la canalización
- Comparar las respuestas antes y después de estas adiciones
Investiguemos cómo se agrega la experiencia en el dominio a nuestra aplicación.
Por lo general, un LLM no se entrena en carreras ni en la física del rendimiento de los autos de carrera. Si nuestra aplicación incluyera esa experiencia en el dominio, los usuarios podrían confiar más en su orientación. Esta orientación proviene de reglas basadas en la experiencia humana, es decir, una capa de experiencia en el dominio.
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
Estos principios de los autos de carrera son un ingrediente clave para proporcionar resultados confiables. ¿Qué sucedería si no tuviéramos esta experiencia? Averigüémoslo.
Quitemos RACING_PHYSICS_KNOWLEDGE y exploremos nuestros consejos de carreras.
export const RACING_PHYSICS_KNOWLEDGE = ``;
Vuelve a ejecutar la aplicación. ¿Qué tipo de consejos de entrenamiento recibimos ahora?
Observa el consejo genérico.
Ya no obtenemos información detallada sobre la fricción, la transferencia de peso, la velocidad de salida, etc. Nuestra confiabilidad es menor sin esta información. Restablece esa experiencia en carreras y vuelve a ejecutar la aplicación.
Este paso es un aspecto fundamental de un sistema de IA confiable. Una instrucción más sólida no genera confianza mágicamente. La confianza surge del diseño del sistema y el pensamiento crítico.
El LLM es parte de la solución, pero no es la solución completa. La confianza mejora cuando el conocimiento humano explícito guía el resultado de la IA.
9. Diseña los arquetipos de entrenador y la experiencia del usuario
Una vez que tu canalización de razonamiento esté en funcionamiento, la siguiente pregunta es cómo debería comunicarse el sistema con el usuario.
En esta sección, definirás cómo la capa de estrategia se comunica con el conductor para dar forma a la experiencia de coaching. Refinarás la instrucción del sistema para uno de los arquetipos de entrenador y considerarás cómo se debe brindar su orientación para que sea clara, oportuna y, lo más importante, práctica.
En esta sección, deberás hacer lo siguiente:
- Crea o perfecciona una instrucción del sistema para un arquetipo de entrenador
- Experimenta con diferentes estilos de entrenamiento
- Observa cómo los cambios en las instrucciones afectan las respuestas
- Define los requisitos de la IU para obtener comentarios confiables
- Comprende la compatibilidad de texto a voz (TTS) para mensajes urgentes y no urgentes
Nuestra aplicación incluye varios arquetipos de entrenador. Cada uno proporciona diferentes tipos de consejos de entrenamiento.
PERSONA | CARACTERÍSTICAS |
Tony | Motivacional y basado en sensaciones |
Raquel | Técnico y enfocado en la física |
AJ | Comandos directos y contundentes |
Garmin | Optimización delta centrada en los datos |
Super AJ | Adaptativo, cambia según el tipo de error |
Estos arquetipos se definen en el archivo ../src/utils/coachingKnowledge.ts.
En este archivo, verás un mapa de objetos (COACHES) que asocia claves de cadena con CoachPersonas. Un CoachPersona contiene atributos de cada tipo de entrenador. Un atributo importante es systemPrompt. Cada arquetipo tiene su propio systemPrompt que guía al LLM sobre cómo responder.
Cambiemos uno de esos system prompts y veamos cómo responde el LLM.
Cerca de la línea 31, verás el systemPrompt de "AJ", quien es muy directo y franco con sus consejos. Cambiemos ese systemPrompt para que AJ sea excesivamente cortés.
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
Vuelve a ejecutar la aplicación, selecciona a AJ como entrenador y observa qué tipo de respuestas se generan.
Ahora, restablece el systemPrompt original y vuelve a ejecutar la aplicación. Ten en cuenta que la instrucción del sistema es fundamental para guiar al LLM a proporcionar una respuesta que se ajuste al arquetipo.
La confianza no se trata solo de la corrección. También se trata de la entrega. El asesoramiento técnicamente preciso puede ser ineficaz si no es claro, si se brinda en el momento inadecuado o si distrae.
Un sistema confiable debe comunicarse bien. La experiencia del usuario forma parte de la arquitectura de confianza.
10. Revisa la arquitectura de extremo a extremo
En este punto, ya creaste las partes principales del sistema. Ahora es momento de dar un paso atrás y revisar cómo funcionan en conjunto.
Tu aplicación ahora incluye estos componentes:
- Flujo de telemetría
- Capa de visualización
- Etapa de transformación de datos lista para la IA
- Componentes de estrategia potenciados por un LLM de razonamiento
- Protecciones y orientación humana codificada
- Experiencia de entrenamiento para el usuario
Una forma útil y sencilla de comprender el flujo general de estos componentes es agregar registros a nuestra aplicación.
Agregaremos el registro para ver los datos de telemetría a medida que fluyen por las rutas.
Primero, veamos los datos de telemetría. En telemetryStreamService.ts, alrededor de la línea 212 (antes de this.emit(frame)), agrega una línea que muestre la velocidad, la fuerza G lateral (aceleración lateral) y la intensidad con la que el conductor presiona el pedal de freno.
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
Vuelve a cargar la aplicación. Antes de ejecutar la aplicación, abramos la consola en las Herramientas para desarrolladores de Chrome para ver esta información de depuración.
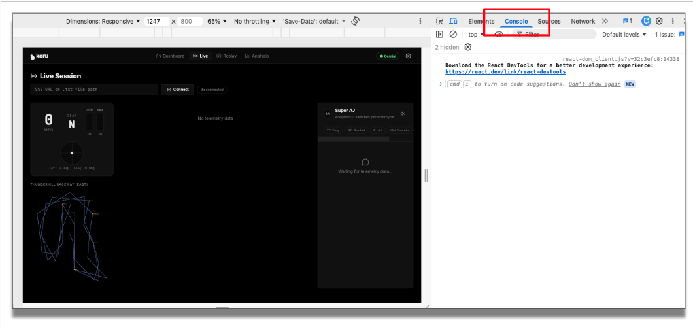
En la aplicación, ingresa el endpoint de telemetría y haz clic en "Conectar". Ahora puedes ver los datos de telemetría entrantes.
Ahora, agreguemos el registro para la ruta de acceso reflex y la ruta de acceso de la estrategia.
En ../src/services/coachingService.ts, alrededor de la línea 71, antes de this.emit(), agrega una línea de registro para la ruta de acceso reflex:
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
En el mismo archivo, alrededor de la línea 287, antes de this.emit(), agrega una línea de registro similar para la ruta de acceso strategy (agreguemos la respuesta de orientación text que devuelve la API de Gemini):
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
Vuelve a ejecutar la aplicación. En la consola, observarás cómo los datos de telemetría fluyen desde la fuente a través de estas rutas. El flujo entrante se filtra, se envía al LLM, se verifica con la experiencia humana de confianza y se presenta al usuario con una interfaz de usuario adecuada.
Observa que conectamos los diversos componentes técnicos para lograr el objetivo más amplio de una IA confiable. El valor de la arquitectura no se encuentra en ningún componente por sí solo. El valor proviene de cómo las partes se refuerzan entre sí.
La IA confiable es un resultado arquitectónico, no una sola función.
Desmantelamiento (eliminación del servicio)
Es importante recordar que debes quitar el servicio cuando ya no lo necesites. Cuando termines de probar el servidor de telemetría junto con la aplicación, debes borrar el servicio de Cloud Run y detener la facturación correspondiente:
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
Recuerda reemplazar us-central1 por la región que usaste durante la implementación, si es necesario. Confirma cuando se te solicite.
11. Desafíos
Ahora que la aplicación principal funciona y comprendes los distintos componentes, intenta extender el diseño.
Desafíos sugeridos
- Trasladar más lógica de entrenamiento al borde
- Modifica la simulación para que admita lluvia o tracción reducida
- Explorar cómo el ajuste o el ajuste fino de modelos podrían mejorar el rendimiento
- Adaptar la arquitectura para otro dominio, como medicina, fabricación o logística
Por ejemplo, ten en cuenta estas preguntas cuando apliques las lecciones aprendidas en este lab a otro dominio:
- ¿Cuál es el equivalente de la telemetría de carreras, es decir, los datos continuos, en otro campo?
- ¿Qué decisiones deben ser inmediatas y cuáles son más estratégicas?
- ¿Qué tipo de experiencia humana se debería codificar?
- ¿Qué deberían ver los usuarios para creer que el sistema es confiable?
Estos desafíos te alientan a pensar más allá del ejemplo de carreras y a reconocer el patrón de diseño más amplio de confiabilidad detrás de este codelab.
12. Conclusión y próximos pasos
En este codelab, creaste más que una demostración de carreras. Creaste un ejemplo concreto de cómo se pueden diseñar sistemas de IA confiables.
Comenzaste con telemetría sin procesar, la transformaste en un formato útil para un LLM, aplicaste razonamiento de IA y fortaleciste el resultado con orientación humana codificada y restricciones de respuesta. En el camino, viste que la confianza proviene de la arquitectura, no solo del resultado del modelo.
Un sistema de IA confiable suele combinar lo siguiente:
- Datos estructurados en tiempo real
- Razonamiento basado en modelos
- Conocimiento del dominio codificado
- Protecciones explícitas
- Diseño de experiencia del usuario reflexivo
La situación de la carrera ayudó a concretar estas ideas, pero el mismo enfoque se puede usar en cualquier lugar en el que las recomendaciones de IA deban ser oportunas, prácticas y confiables.
