
1. Présentation
L'intelligence artificielle fait désormais partie de nombreux systèmes logiciels, mais la création d'une application d'IA n'est pas la même chose que la création d'une application à laquelle les utilisateurs peuvent faire confiance. Dans de nombreux environnements concrets, le défi ne consiste pas simplement à générer une réponse. Le défi consiste à générer une réponse opportune, ancrée, exploitable et conforme à l'expertise humaine.
Dans cet atelier de programmation, vous allez créer un simulateur de coach de course qui illustre ces idées de manière concrète et attrayante. L'application utilise la télémétrie d'une voiture de course virtuelle pour animer les mouvements sur une piste et générer des conseils d'entraînement. Bien que la course soit le scénario, les mêmes idées architecturales s'appliquent aux secteurs de la santé, de la fabrication, de la logistique et à d'autres domaines où la confiance est importante.
Vous travaillerez avec un flux à grande vitesse de données télémétriques, que vous transformerez en un format utile et efficace pour le raisonnement de l'IA. Vous combinerez ensuite la sortie basée sur le LLM avec des conseils humains encodés pour produire des réponses plus fiables.
Objectifs de l'atelier
Dans cet atelier de programmation, vous allez créer un prototype d'IA fiable qui :
- Diffuse la télémétrie d'une voiture de course virtuelle exécutée dans Google Cloud
- Visualizes The Car Moving Around A Racetrack using Chrome
- Remodeler les données télémétriques brutes en entrée prête pour l'IA
- Applique une couche stratégique optimisée par Google Gemini
- Combine la sortie du modèle avec les consignes humaines et les règles de sécurité encodées
- Fournit des commentaires de coaching via une interface utilisateur
Objectifs de l'atelier
À la fin de cet atelier de programmation, vous serez en mesure de :
- Expliquer ce qui rend un système d'IA plus fiable
- Expliquer l'objectif d'une architecture d'IA modulaire
- Créer un pipeline de télémétrie simulé simple
- Préparer des données structurées utiles pour les utiliser avec un LLM
- Appliquer des garde-fous et des règles guidées par des humains pour améliorer la confiance
- Évaluer comment cette architecture peut être appliquée à d'autres domaines
2. Prérequis
Avant de commencer, assurez-vous de disposer des comptes, outils et services requis.
Prérequis
Prérequis :
- Un compte Google personnel utilisant une adresse Gmail
- Accès à Google Cloud et connaissances rudimentaires d'une CLI
- Un compte de facturation actif ou des crédits cloud
- Comprendre les principes de base de Google Cloud et de l'IA générative avec Gemini
Gemini est le modèle d'IA de Google. Il repose sur une logique de pointe qui permet de donner vie à toutes vos idées. Il s'agit d'un excellent modèle pour la compréhension multimodale, le codage agentique et le vibe coding.
3. Pourquoi l'IA fiable est-elle importante ?
De nombreux systèmes d'IA peuvent produire des réponses fluides et convaincantes, mais la fluidité n'est pas synonyme de fiabilité. Dans les systèmes réels, les utilisateurs ont souvent besoin de réponses ancrées et rapides, qui sont limitées par des règles de sécurité et façonnées par l'expertise du domaine.
Cela devient particulièrement important lorsqu'un système fonctionne avec des données en évolution rapide. Une réponse qui arrive trop tard peut être inutile. Une réponse qui semble assurée, mais qui ignore un contexte important peut être trompeuse. Il peut être difficile de faire confiance à une réponse qui n'a aucun lien avec l'expertise humaine, même si elle semble soignée.
Dans le scénario de voiture de course utilisé dans cet atelier de programmation, le problème n'est pas de savoir si l'IA peut dire quelque chose d'intéressant. La question est de savoir si le système peut fournir des conseils utiles, sûrs, opportuns et adaptés à la situation.
Examinons un petit échantillon de données télémétriques et comparons deux résultats possibles :
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Réponse naïve de l'IA
"Stay aggressive on the throttle and carry your speed into Turn 1"
Réponse tenant compte de la confiance
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
Vous voyez la différence ?
Que se passerait-il si nous nous appuyions uniquement sur la réponse naïve de l'IA ?
La première réponse semble confiante, mais elle ignore les risques. La deuxième réponse est plus utile, car elle reflète le contexte et la contrainte.
Plutôt que de considérer le LLM comme l'ensemble du système, vous devez le traiter comme une partie d'une architecture plus large pour accroître la fiabilité. De plus, de nombreuses applications nécessitent que les conseils soient fournis assez rapidement pour être exploitables (par exemple, pour une voiture de course, une procédure médicale, l'aviation, un réseau électrique, un système de trading, la navigation maritime, etc.).
Voyons maintenant comment créer une telle architecture.
4. Comprendre l'IA à haute vélocité et l'architecture modulaire de confiance
Certains systèmes d'IA ont besoin de comportements très différents. Ils doivent réagir rapidement aux conditions changeantes, mais aussi prendre en charge un raisonnement plus lent et plus réfléchi.
Une architecture modulaire sépare ces responsabilités en chemins distincts. Un chemin peut être réflexif, gérant l'interprétation immédiate et urgente des signaux entrants. Une autre voie peut se concentrer sur la stratégie, en favorisant un raisonnement de niveau supérieur et une prise de décision plus contextuelle. D'autres chemins ciblent d'autres types de fonctionnalités.
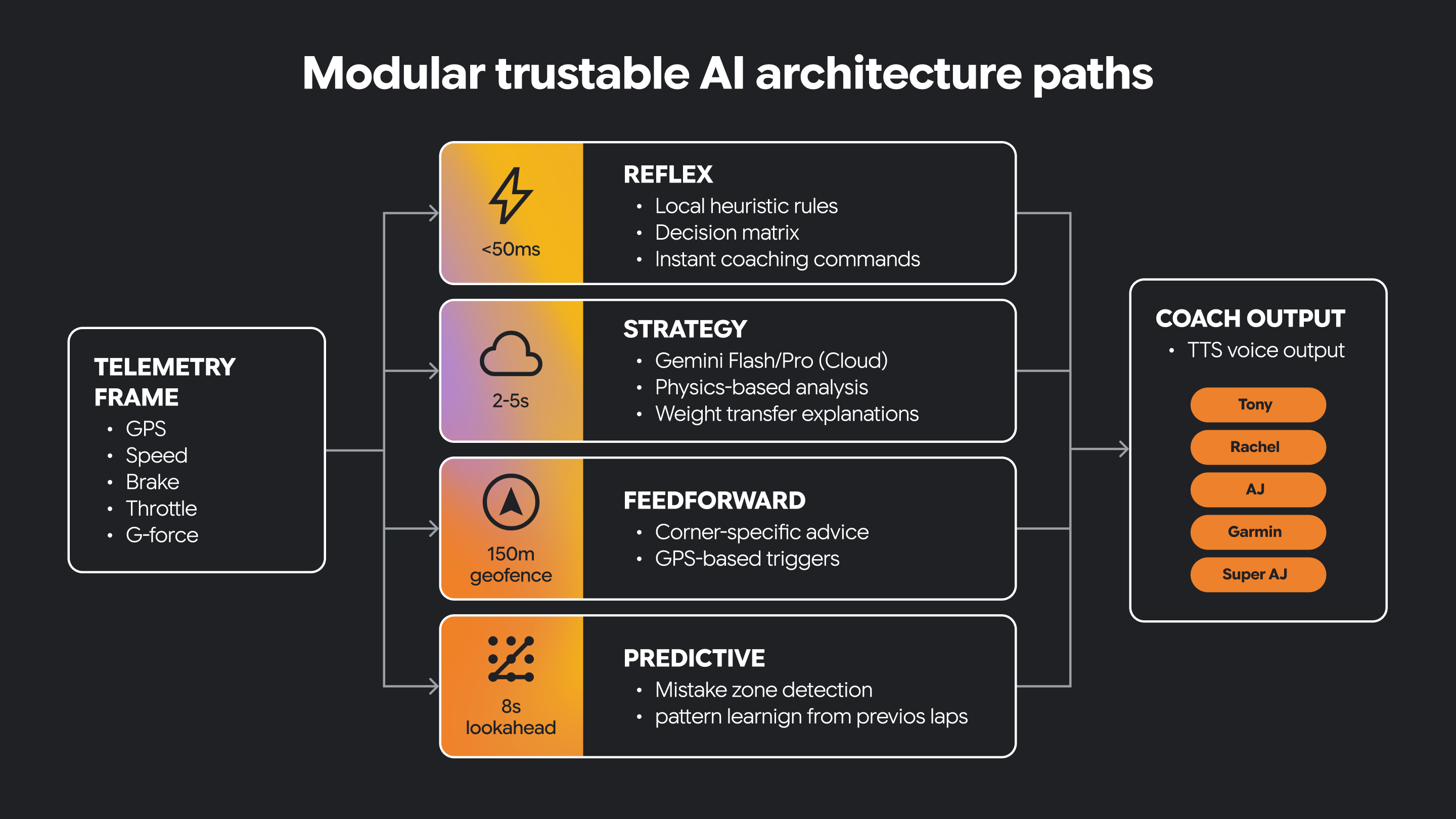
Certaines décisions doivent être prises en temps réel. Certaines décisions nécessitent une réflexion plus longue.
L'IA fiable a souvent besoin des deux.
Cette séparation architecturale permet au système de rester réactif tout en fournissant des conseils plus riches basés sur l'IA. Il permet également d'introduire clairement des contraintes guidées par l'humain et des connaissances du domaine.
Dans ce petit programme, nous avons un chemin réflexe et un chemin stratégique implémentés en tant que fonctions Python.
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
Les deux fonctions se comportent différemment avec les mêmes données de télémétrie. La fonction réflexe est un avertissement immédiat. La fonction de stratégie nous fournit des conseils de coaching basés sur des règles.
Pourquoi pensez-vous qu'il est utile de séparer cette logique ?
Maintenant, créons une application amusante en plusieurs parties et voyons comment cette architecture transforme les réactions rapides et le raisonnement approfondi en un système d'IA fiable que vous pouvez réellement expérimenter.
5. Créer un serveur de streaming de télémétrie
Maintenant que vous comprenez l'objectif architectural, il est temps de créer le pipeline de données qui alimente l'application.
Dans cette section, vous allez créer un flux de télémétrie simple pour une voiture de course virtuelle. Les données proviendront d'une source CSV contenant des données GPS ou de position de suivi, et votre application les convertira en flux en direct que l'UI et la couche d'IA pourront utiliser.
Dans cette section, vous allez effectuer les tâches suivantes :
- Créez un projet dans Google Cloud pour notre serveur et notre application de streaming.
- Créer un petit serveur pour émettre des données de télémétrie
- Diffuser ces événements vers une interface utilisateur de navigateur ou une console
1. Ouvrir Cloud Shell
A. Accédez à la console Google Cloud.
B. Créez un projet pour cet atelier de programmation. Cliquez sur le menu déroulant des projets en haut de la page.
Lorsque vous créez un projet, c'est une bonne occasion d'associer le compte de facturation :
Si vous avez déjà créé un projet, vous pouvez ouvrir le panneau de gauche, cliquer sur Billing et vérifier si le compte de facturation est associé à ce compte GCP.
C. Obtenir une clé API Gemini
Une fois que vous avez activé vos crédits Google Cloud, vous avez besoin d'une clé API Gemini pour accéder à Gemini dans Google Cloud.
Pour créer une clé API Gemini, nous devons utiliser Google Vertex AI Studio afin de générer des clés.
Dans Vertex AI Studio, cliquez sur "Obtenir une clé API" en bas à gauche, au-dessus de "Documentation". Créez une clé API pour Gemini (elle ressemble à une longue chaîne de caractères apparemment aléatoires). Enregistrez cette clé dans un emplacement sécurisé. Nous utiliserons cette clé API à l'étape 6 "Créer le simulateur de voiture de course" pour authentifier notre accès à Gemini dans Google Cloud.
D. Cliquez sur l'icône Cloud Shell (icône de terminal) dans la barre supérieure pour ouvrir un terminal basé sur le navigateur.
E. Attendez que la session de terminal démarre.

2. Obtenir le code
Clonez le dépôt principal.
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Notez que ce dépôt contient deux dossiers : "koru-application" (application Web) et "streaming-telemetry-server" (télémétrie de voiture de course simulée en temps réel). Cette étape décrit le "streaming-telemetry-server". Nous utiliserons "koru-application" à l'étape suivante.
3. Activer les API requises
Exécutez la commande une seule fois par projet :
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
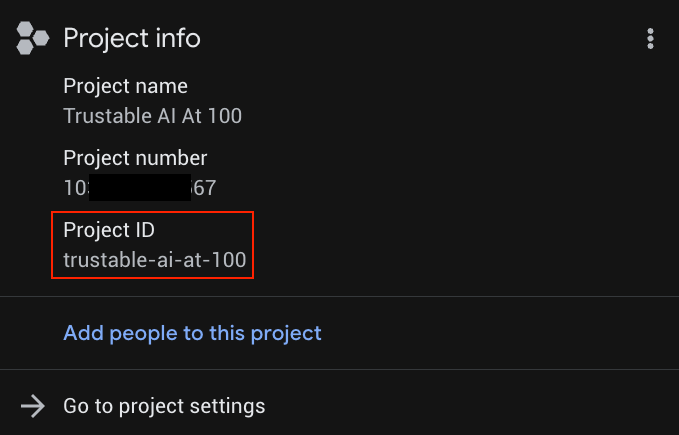
Remplacez YOUR_PROJECT_ID par l'ID de votre projet (ou ignorez la première ligne si le projet est déjà défini).
Vous trouverez YOUR_PROJECT_ID dans la liste des projets.
4. Déployer le backend sur Cloud Run
À partir de la racine du dépôt (c'est-à-dire, assurez-vous d'être dans le dossier trustable-ai-codelab) :
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
Remarque : Vous devrez peut-être appuyer sur "Y" lorsque vous y êtes invité.
- Lors de la première exécution, vous serez peut-être invité à activer des API ou à créer un dépôt Artifact Registry. Acceptez si nécessaire.
- Si vous utilisez une autre région que
us-central1, spécifiez-la à l'aide de--region. - Une fois le déploiement terminé, gcloud affiche l'URL du service. Il nous suffit d'ajouter "events" à cette URL pour l'utiliser comme point de terminaison complet pour le serveur de télémétrie.
5. Utiliser l'URL de la diffusion
Le serveur de télémétrie émet désormais des données de télémétrie simulées à l'aide d'événements envoyés par le serveur (SSE) à un point de terminaison du formulaire :
service-URL/events // service-URL - the last line displayed by "deploy"
Testez dans un navigateur : accédez à l'URL de ce point de terminaison de flux à l'aide de Chrome. Vous devriez voir les données diffusées en continu dans le navigateur, simulant les données émises par les capteurs d'une voiture de course.
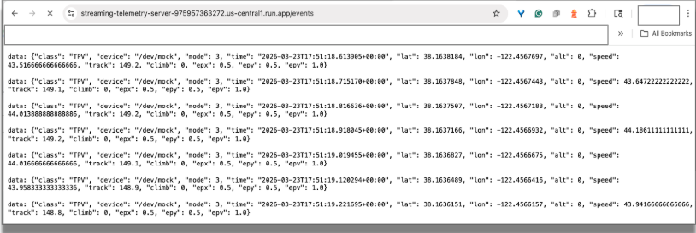
Vous pouvez fermer l'onglet du navigateur pour mettre fin à la connexion.
Tester avec curl :
Testons maintenant à partir de la ligne de commande du shell.
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
Les données de flux entrantes doivent s'afficher dans la fenêtre Cloud Shell.
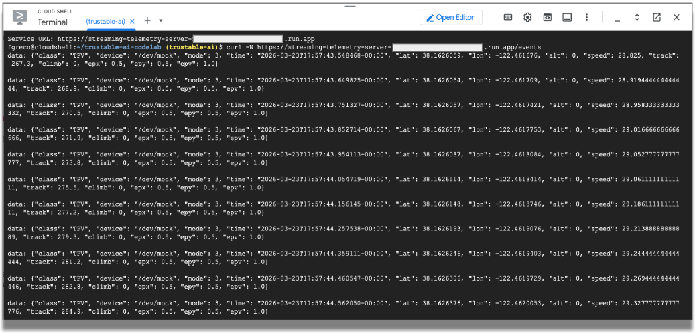
Nous utiliserons ces données de télémétrie pour simuler les données émises par les capteurs d'une voiture de course. Le reste de l'atelier de programmation utilisera ces données. Vous pouvez arrêter le programme curl en saisissant CTRL+C dans la fenêtre du terminal.
Points à noter
Lorsque vous remplissez cette section, faites attention à la nature des données entrantes. La télémétrie brute est souvent volumineuse, sensible au temps et ne convient pas immédiatement au raisonnement de l'IA. Une fois l'application front-end créée, nous devrons filtrer les données brutes pour obtenir un format efficace qu'un LLM pourra traiter rapidement.
Mais commençons par créer l'interface Web pour visualiser les données.
6. Créer le simulateur de voiture de course
Dans cette section, vous allez effectuer les tâches suivantes :
- Créer une simulation de voiture de course
- Connecter le serveur de télémétrie à l'application Web de la voiture de course
- Afficher les courses simulées
À ce stade, nous disposons d'une simulation fonctionnelle de la télémétrie d'une voiture de course s'exécutant dans le cloud. Nous allons maintenant créer l'application qui s'exécute sur votre ordinateur local, se connecte à Google Cloud et visualise ces données.
Notre application d'IA fiable utilise à la fois la puissance et la flexibilité des services Google Cloud, ainsi que l'intelligence locale exécutée dans Chrome.
Le service de télémétrie en streaming s'exécute dans Google Cloud, mais l'application de voiture de course s'exécute sur votre machine locale. Cela signifie que vous devrez cloner à nouveau le dépôt, cette fois sur votre ordinateur portable ou de bureau.
Par souci de simplicité, le même dépôt contient le code du serveur de streaming et de l'application de voiture de course.
Clonez l'application de frontend depuis GitHub :
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Une fois le dépôt cloné sur votre ordinateur portable ou de bureau, exécutons l'application.
cd koru-application # racing car simulation app
npm install
npm run dev

Dans Chrome, ouvrez le port sur votre machine locale (http://localhost:5173, comme dans l'exemple ci-dessus). La page de destination de l'application "AI Motorsport Coaching" s'affiche.
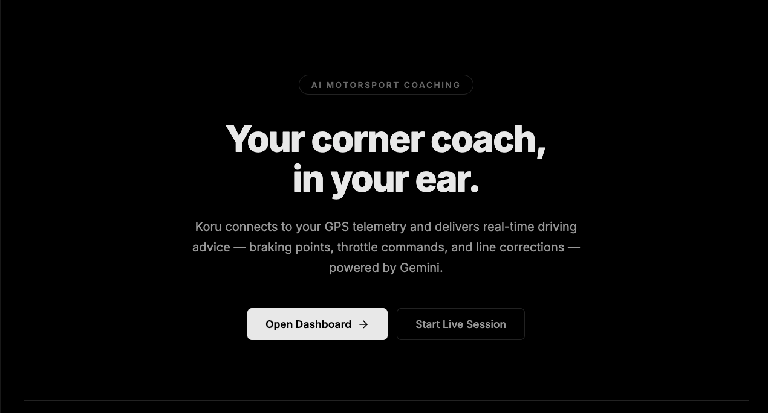
Cliquez sur le bouton "Open Dashboard ->" (Ouvrir le tableau de bord >). L'UI de l'application démarre.
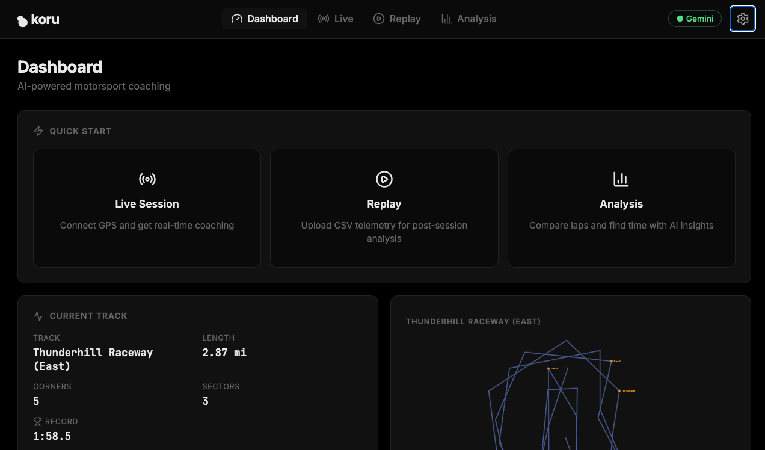
À ce stade, vous disposez d'un serveur de télémétrie qui génère des données de télémétrie de voiture de course simulées dans Google Cloud, ainsi que d'une application Web locale capable de visualiser ces données et de se connecter à un LLM. Connectons-les, ainsi que les services de LLM Gemini.
En haut à droite de l'application, cliquez sur l'icône en forme de roue dentée (paramètres).
![]()
Saisissez votre clé API Gemini de l'étape 2. Vous avez ainsi accès aux services Gemini dans Google Cloud.
Cliquez sur "Enregistrer" pour que l'application mémorise votre clé API.
Connectons maintenant l'application au serveur de télémétrie. Dans le tableau de bord de l'application, cliquez sur "Live Session" (Session en direct).
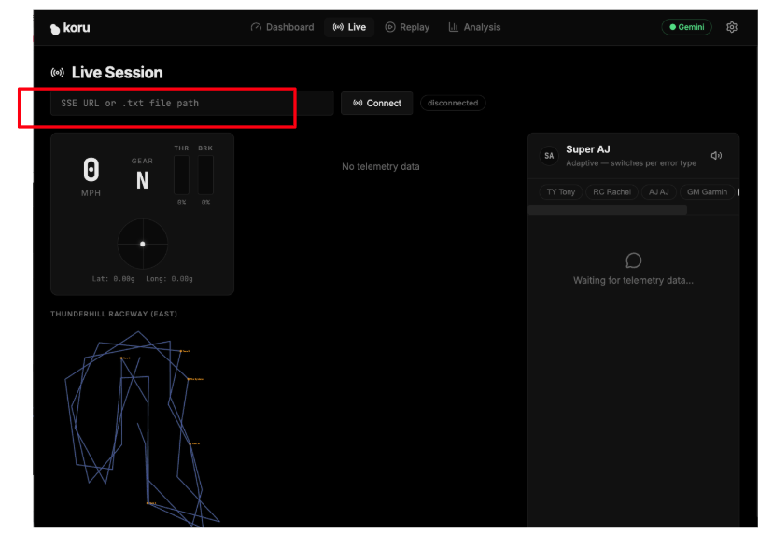
Saisissez l'URL spécifique de votre serveur de télémétrie dans le cloud (étape 5) dans le champ de texte SSE URL or .txt file path. Notre URL SSE était au format suivant :
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
Une fois que vous avez saisi l'URL du point de terminaison du serveur de télémétrie, cliquez sur "Connecter" (à droite du champ de texte). N'oubliez pas d'ajouter "events" à la fin de l'URL.
L'application devrait maintenant visualiser les données simulées.
Si le volume de votre enceinte est élevé, vous pouvez entendre les conseils de course automobile de différents types de coachs. Chaque coach a une personnalité différente. Essayez de sélectionner différents coachs pour découvrir leurs conseils de course variés et leurs différents styles vocaux. Si nécessaire, vous pouvez désactiver le son en cliquant sur l'icône Haut-parleur.
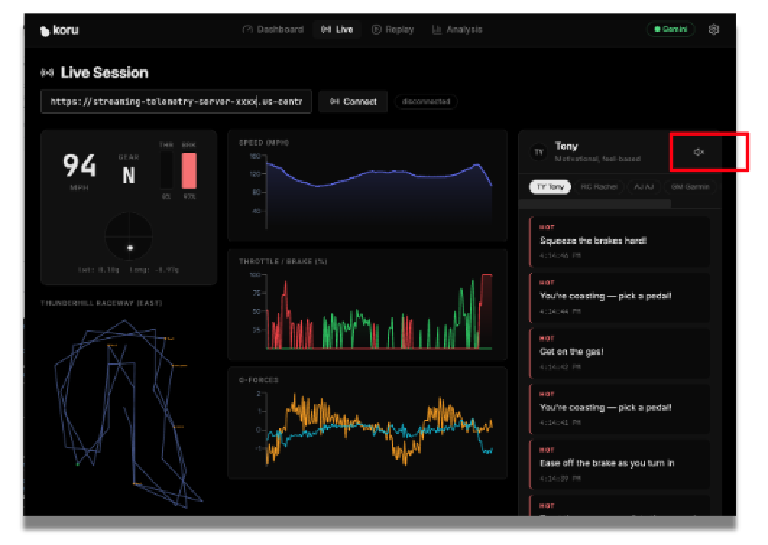
Maintenant que nous avons une application fonctionnelle, voyons comment nous avons préparé les données pour un traitement efficace par le LLM et comment nous pouvons ajouter des fonctionnalités supplémentaires pour améliorer la fiabilité du système global.
7. Préparer la télémétrie pour le raisonnement de l'IA
La télémétrie brute est utile pour la simulation, mais elle est généralement trop détaillée et trop fréquente pour être envoyée directement à un LLM. Si vous envoyez toutes les données de télémétrie sans les modifier, vous risquez d'augmenter la latence, d'introduire du bruit et de réduire la qualité des conseils obtenus.
Dans cette section, vous allez remodeler la télémétrie pour la rendre plus utile.
Dans cette section, vous allez effectuer les tâches suivantes :
- Inspecter le fichier JSON de télémétrie brute
- Identifier les champs les plus pertinents pour le raisonnement
- Filtrer ou résumer les données
- Réduire les détails inutiles
- Préparer une représentation de l'état de conduite adaptée à l'IA
Il s'agit d'une étape importante pour créer une IA digne de confiance. La qualité de la réponse dépend non seulement du modèle, mais aussi de la structure et de la pertinence des données qu'il reçoit.
Explorons maintenant les données spécifiques aux voitures de course. Nous pouvons effectuer des tests en modifiant des valeurs spécifiques dans l'application, en la rechargeant et en observant le résultat.
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
Les forces G dans une voiture mesurent l'accélération ou la décélération. Dans une voiture de course, la compréhension des forces G permet d'améliorer la maniabilité et les performances globales du véhicule. Si notre application ne dispose pas de ces informations, il est difficile de fournir des conseils au conducteur. Mettez ces deux lignes en commentaire, définissez les valeurs gLat et gLong sur 0.0, puis réexécutez l'application.
Notez qu'aucun conseil n'est donné lorsque la voiture approche d'un virage. Ce n'est pas très utile pour un pilote de course !
Annulez ensuite votre modification et réexécutez l'application. Avez-vous remarqué les conseils audio utiles lorsque la voiture arrive à un virage ? Les points de données sur la force G sont essentiels pour fournir des conseils au conducteur.
Maintenant, limitons artificiellement la vitesse de la voiture à 48 km/h. Nous ne gagnerons aucune course à cette vitesse, mais cela démontrera certainement le type de coaching que nous recevons.
Dans ce même fichier (telemetryStreamService.ts), près de la ligne 158, vous trouverez la fonction processPoint(). Dans cette fonction, limitons la vitesse.
Modification :
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
À :
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
Relancez l'application. Quel type de conseils d'entraînement recevons-nous désormais ? Si nous conduisons tranquillement, nous n'avons pas besoin de grand-chose !
Annulez ces modifications et réexécutez l'application.
La vitesse de la voiture est clairement un point de données précieux. Il est très important de comprendre quelles données spécifiques sont essentielles pour fournir des conseils utiles. Il est tout aussi important d'évaluer les données non pertinentes.
Vous devez également commencer à réfléchir à la sécurité et à la confiance. Même une entrée bien préparée ne garantit pas une réponse fiable. Nous devons encore introduire des règles guidées par l'humain et des contraintes explicites.
La préparation des données n'est pas qu'une étape de prétraitement. Il s'agit d'un élément essentiel de la stratégie de confiance. Des entrées plus claires permettent souvent d'obtenir des résultats plus ciblés et plus fiables.
8. Ajouter des garde-fous et une expertise humaine encodée
Un système d'IA fiable ne doit pas s'appuyer uniquement sur la sortie du modèle. Dans de nombreux cas, les systèmes les plus fiables combinent le raisonnement des grands modèles de langage avec des règles explicites, des connaissances du domaine et des contraintes guidées par l'humain.
Dans cette section, vous allez ajouter cette couche.
Vous pouvez considérer cette couche comme des connaissances de coaching encodées. Il peut s'agir de modèles de réponse préférés, de règles de validation, de contrôles de sécurité ou de conseils structurés qui aident le système à rester ancré et utile.
Dans cette section, vous allez effectuer les tâches suivantes :
- Présenter les règles de réponse qui façonnent le comportement du modèle
- Appliquer des contrôles de sécurité pour réduire les conseils trompeurs
- Intégrer l'expertise humaine encodée dans le pipeline
- Comparer les réponses avant et après ces ajouts
Examinons comment l'expertise du domaine est ajoutée à notre application.
Un LLM n'est généralement pas entraîné à la course ni à la physique des performances des voitures de course. Si notre application incluait cette expertise du domaine, les utilisateurs pourraient faire davantage confiance à ses conseils. Ces conseils proviennent de règles basées sur l'expertise humaine, c'est-à-dire une couche d'expertise du domaine.
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
Ces principes de course automobile sont essentiels pour fournir des résultats fiables. Que se passerait-il si nous n'avions pas cette expertise ? Vérifions-le dès maintenant.
Supprimons RACING_PHYSICS_KNOWLEDGE et explorons nos conseils de course.
export const RACING_PHYSICS_KNOWLEDGE = ``;
Relancez l'application. Quel type de conseils d'entraînement recevons-nous désormais ?
Notez les conseils génériques.
Nous n'obtenons plus d'informations détaillées sur la friction, le transfert de poids, la vitesse de sortie, etc. Notre fiabilité est donc plus faible. Restaurez cette expertise en course et réexécutez l'application.
Cette étape est essentielle pour un système d'IA fiable. La confiance ne se crée pas comme par magie grâce à une requête plus pertinente. La confiance découle de la conception du système et de l'esprit critique.
Le LLM fait partie de la solution, mais il ne constitue pas la solution complète. La confiance s'améliore lorsque les résultats de l'IA sont guidés par des connaissances humaines explicites.
9. Concevoir les personas de coaching et l'expérience utilisateur
Une fois votre pipeline de raisonnement en place, la question suivante est de savoir comment le système doit communiquer avec l'utilisateur.
Dans cette section, vous allez façonner l'expérience de coaching en définissant la façon dont la couche de stratégie communique avec le conducteur. Vous allez affiner l'invite système pour l'un des personas de coaching et réfléchir à la manière dont ses conseils doivent être fournis pour être clairs, opportuns et, surtout, exploitables.
Dans cette section, vous allez effectuer les tâches suivantes :
- Créer ou affiner un prompt système pour un persona de coaching
- Tester différents styles de coaching
- Observez l'impact des modifications apportées aux requêtes sur les réponses.
- Définir les exigences de l'UI pour des commentaires fiables
- Comprendre la compatibilité de la synthèse vocale avec les messages urgents et non urgents
Notre application inclut plusieurs personas de coaching. Chacun d'eux fournit différents types de conseils de coaching.
PERSONA | CARACTÉRISTIQUES |
Tony | Motivation, basé sur les émotions |
Rachel | Technique, axé sur la physique |
AJ | Commandes directes et brutes |
Garmin | Optimisation delta axée sur les données |
Super AJ | Adaptatif, commutateurs par type d'erreur |
Ces personas sont définis dans le fichier ../src/utils/coachingKnowledge.ts.
Dans ce fichier, vous remarquerez une carte d'objet (COACHES) qui associe des clés de chaîne à CoachPersonas. Un CoachPersona contient les attributs de chaque type de coach. L'attribut systemPrompt est important. Chaque persona possède son propre systemPrompt qui guide le LLM dans sa façon de répondre.
Modifions l'un de ces system prompts et voyons comment le LLM réagit.
Près de la ligne 31, vous verrez le systemPrompt pour "AJ", qui est très direct et franc dans ses conseils. Modifions systemPrompt pour que AJ soit excessivement poli.
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
Réexécutez l'application, sélectionnez AJ comme coach et voyez quel type de réponses sont générées.
Restaurez maintenant le systemPrompt d'origine et réexécutez l'application. Notez que le prompt système est essentiel pour guider le LLM et lui permettre de fournir une réponse adaptée à la personnalité.
La confiance ne se limite pas à l'exactitude. Il s'agit également de la diffusion. Un conseil techniquement exact peut tout de même être inefficace s'il est peu clair, mal adapté ou distrayant.
Un système fiable doit bien communiquer. L'expérience utilisateur fait partie de l'architecture de confiance.
10. Examiner l'architecture de bout en bout
À ce stade, vous avez créé les principaux éléments du système. Il est maintenant temps de prendre du recul et de voir comment ils fonctionnent ensemble.
Votre application inclut désormais les composants suivants :
- Flux de télémétrie
- Couche de visualisation
- Étape de transformation des données prête pour l'IA
- Composants stratégiques optimisés par un LLM de raisonnement
- Garde-fous et conseils humains encodés
- Expérience de coaching destinée aux utilisateurs
Un moyen simple et utile de comprendre le flux global de ces composants consiste à ajouter la journalisation à notre application.
Nous ajouterons la journalisation pour afficher les données télémétriques lorsqu'elles transitent par les chemins d'accès.
Commençons par afficher les données de télémétrie. Dans telemetryStreamService.ts, vers la ligne 212 (avant this.emit(frame)), ajoutez une ligne qui affiche la vitesse, l'accélération latérale (accélération sur le côté) et la force avec laquelle le conducteur appuie sur la pédale de frein.
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
Actualisez l'application. Avant d'exécuter l'application, ouvrons la console dans les outils de développement Chrome pour afficher ces informations de débogage.
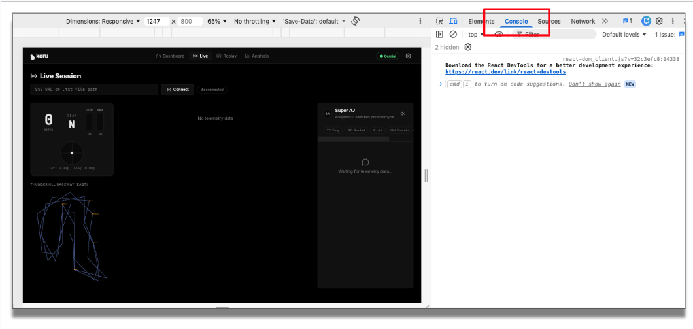
Dans l'application, saisissez le point de terminaison de télémétrie, puis cliquez sur "Connect" (Se connecter). Vous pouvez maintenant voir les données de télémétrie entrantes.
Ajoutons maintenant la journalisation pour le chemin réflexe et le chemin stratégique.
Dans ../src/services/coachingService.ts, vers la ligne 71 avant this.emit(), ajoutez une ligne de journalisation pour le chemin d'accès reflex :
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
Dans le même fichier, vers la ligne 287, avant this.emit(), ajoutez une ligne de journalisation similaire pour le chemin d'accès strategy (ajoutons la réponse de coaching text renvoyée par l'API Gemini) :
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
Relancez l'application. Dans la console, vous remarquerez comment les données de télémétrie circulent de la source à travers ces chemins. Le flux entrant est filtré, envoyé au LLM, vérifié par des experts humains de confiance et présenté à l'utilisateur à l'aide d'une interface utilisateur appropriée.
Notez que nous avons associé les différents composants techniques pour atteindre l'objectif plus général d'une IA fiable. La valeur de l'architecture ne réside pas dans un seul composant. La valeur provient de la façon dont les parties se renforcent mutuellement.
L'IA fiable est un résultat architectural, et non une fonctionnalité unique.
Démantèlement (suppression du service)
N'oubliez pas de supprimer le service lorsque vous n'en avez plus besoin. Une fois que vous avez terminé de tester le serveur de télémétrie avec l'application, vous devez supprimer le service Cloud Run et arrêter la facturation :
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
N'oubliez pas de remplacer us-central1 par la région que vous avez utilisée lors du déploiement, si nécessaire. Confirmez l'opération lorsque vous y êtes invité.
11. Défis
Maintenant que l'application principale fonctionne et que vous comprenez les différents composants, essayez d'étendre la conception.
Défis suggérés
- Déplacer une plus grande partie de la logique de coaching vers la périphérie
- Modifier la simulation pour prendre en compte la pluie ou la réduction de la traction
- Découvrez comment le réglage ou le réglage fin des modèles peut améliorer les performances.
- Adapter l'architecture à un autre domaine, comme la médecine, la fabrication ou la logistique
Par exemple, posez-vous les questions suivantes lorsque vous appliquez les leçons tirées de cet atelier à un autre domaine :
- Quel est l'équivalent de la télémétrie de course, c'est-à-dire des données continues, dans un autre domaine ?
- Quelles décisions doivent être immédiates et lesquelles sont plus stratégiques ?
- Quel type d'expertise humaine devrait être encodé ?
- Qu'est-ce qui pourrait convaincre les utilisateurs que le système est fiable ?
Ces défis vous encouragent à aller au-delà de l'exemple de course et à reconnaître le modèle de conception plus large de fiabilité derrière cet atelier de programmation.
12. Conclusion et prochaines étapes
Dans cet atelier de programmation, vous avez créé plus qu'une démo de course. Vous avez créé un exemple concret de conception de systèmes d'IA fiables.
Vous avez commencé avec des données de télémétrie brutes, que vous avez transformées en un format utile pour un LLM. Vous avez ensuite appliqué le raisonnement de l'IA et renforcé le résultat avec des conseils humains encodés et des contraintes de réponse. Vous avez vu que la confiance provient de l'architecture, et pas seulement de la sortie du modèle.
Un système d'IA fiable combine souvent :
- Données structurées en temps réel
- Raisonnement basé sur un modèle
- Expertise du domaine encodée
- Garde-fous explicites
- Conception d'une expérience utilisateur réfléchie
Le scénario de course a permis de rendre ces idées concrètes, mais la même approche peut être utilisée partout où les recommandations de l'IA doivent être opportunes, exploitables et fiables.
