
1. Panoramica
L'intelligenza artificiale fa ormai parte di molti sistemi software, ma creare un'applicazione di AI non è la stessa cosa che crearne una di cui gli utenti possano fidarsi. In molti ambienti reali, la sfida non è semplicemente generare una risposta. La sfida consiste nel generare una risposta tempestiva, basata su dati reali, attuabile e in linea con le competenze umane.
In questo codelab, creerai un simulatore di allenatore di corse che dimostra queste idee in modo concreto e coinvolgente. L'applicazione utilizza la telemetria di un'auto da corsa virtuale per animare il movimento su una pista e generare indicazioni di coaching. Sebbene le corse siano lo scenario, le stesse idee architetturali si applicano a sanità, produzione, logistica e altri domini in cui l'affidabilità è importante.
Lavorerai con un flusso ad alta velocità di dati di telemetria, li trasformerai in una forma utile ed efficiente per il ragionamento dell'AI e combinerai l'output basato su LLM con la guida umana codificata per produrre risposte più affidabili.
Cosa creerai
In questo codelab creerai un prototipo di AI affidabile che:
- Trasmette la telemetria da un'auto da corsa virtuale in esecuzione su Google Cloud
- Visualizza l'auto che si muove su una pista da corsa utilizzando Chrome
- Rimodella la telemetria non elaborata in input pronto per l'AI
- Applica un livello di strategia basato su Google Gemini
- Combina l'output del modello con indicazioni umane codificate e regole di sicurezza
- Fornisce feedback sul coaching tramite un'interfaccia rivolta agli utenti
Cosa imparerai a fare
Al termine di questo codelab, sarai in grado di:
- Spiega cosa rende un sistema di AI più affidabile
- Spiegare lo scopo di un'architettura AI modulare
- Crea una semplice pipeline di telemetria simulata
- Preparare dati strutturati utili per l'utilizzo con un LLM
- Applicare misure di protezione e regole guidate da persone per migliorare l'attendibilità
- Valuta in che modo questa architettura può essere applicata ad altri domini
2. Cosa ti servirà
Prima di iniziare, assicurati di avere a disposizione gli account, gli strumenti e i servizi richiesti.
Prerequisiti
Devi avere:
- Un Account Google personale che utilizza un indirizzo Gmail
- Accesso a Google Cloud e conoscenza di base di una CLI
- Un account di fatturazione attivo o crediti cloud
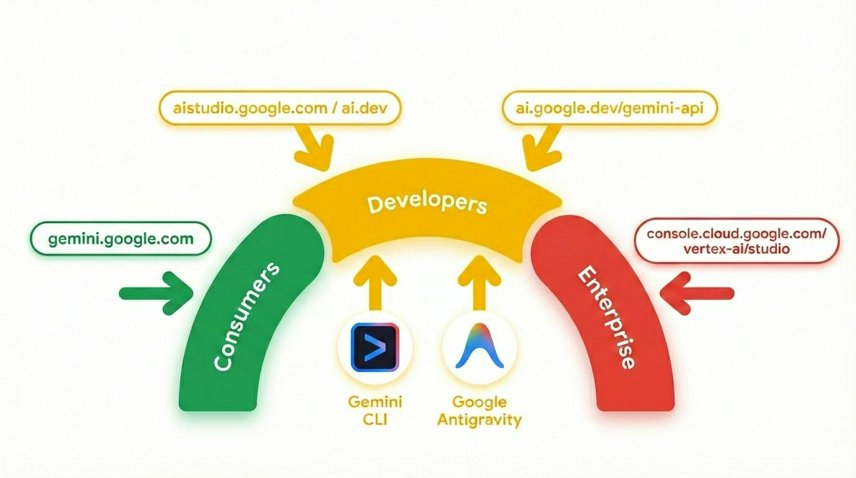
- Comprensione di Google Cloud e dell'AI generativa utilizzando Gemini
Gemini è il modello di AI di Google basato su un ragionamento all'avanguardia che dà vita a qualsiasi idea. È un ottimo modello per la comprensione multimodale e la programmazione agentica e del vibe.
3. Perché l'AI affidabile è importante
Molti sistemi di AI possono produrre risposte fluenti e convincenti, ma fluente non è sinonimo di affidabile. Nei sistemi reali, gli utenti hanno spesso bisogno di risposte tempestive e basate su dati concreti, vincolate da regole di sicurezza e modellate dall'esperienza nel dominio.
Ciò diventa particolarmente importante quando un sistema opera su dati in rapido movimento. Una risposta che arriva troppo tardi potrebbe essere inutile. Una risposta che sembra sicura, ma ignora un contesto importante, può essere fuorviante. Una risposta senza alcun collegamento all'esperienza umana potrebbe essere difficile da considerare attendibile, anche se sembra ben strutturata.
Nello scenario dell'auto da corsa utilizzato in questo codelab, il problema non è se l'AI possa dire qualcosa di interessante. Il problema è se il sistema può fornire consigli utili, sicuri, tempestivi e appropriati alla situazione.
Esaminiamo un piccolo campione di telemetria e confrontiamo due possibili output:
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Risposta AI ingenua
"Stay aggressive on the throttle and carry your speed into Turn 1"
Risposta consapevole dell'affidabilità
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
Hai notato la differenza?
Cosa succederebbe se ci affidassimo solo alla risposta dell'AI ingenua?
La prima risposta sembra sicura, ma ignora il rischio. La seconda risposta è più utile perché riflette il contesto e il vincolo.
Anziché trattare l'LLM come l'intero sistema, devi considerarlo come una parte di un'architettura più ampia per aumentare l'affidabilità. Inoltre, molte applicazioni richiedono che i consigli vengano forniti abbastanza rapidamente da essere attuabili, ad esempio per auto da corsa, procedure mediche, aviazione, rete elettrica, sistemi di trading, navigazione marittima e così via.
Ora vediamo come creare un'architettura di questo tipo.
4. Informazioni su AI ad alta velocità e architettura modulare attendibile
Alcuni sistemi di AI hanno bisogno di comportamenti molto diversi. Devono reagire rapidamente al mutare delle condizioni e supportare anche un ragionamento più lento e ponderato.
Un'architettura modulare separa queste responsabilità in percorsi distinti. Un percorso può essere riflessivo, gestendo l'interpretazione immediata e sensibile al tempo dei segnali in entrata. Un altro percorso può concentrarsi sulla strategia, supportando il ragionamento di livello superiore e un processo decisionale più consapevole del contesto. Altri percorsi hanno come target altri tipi di funzionalità.
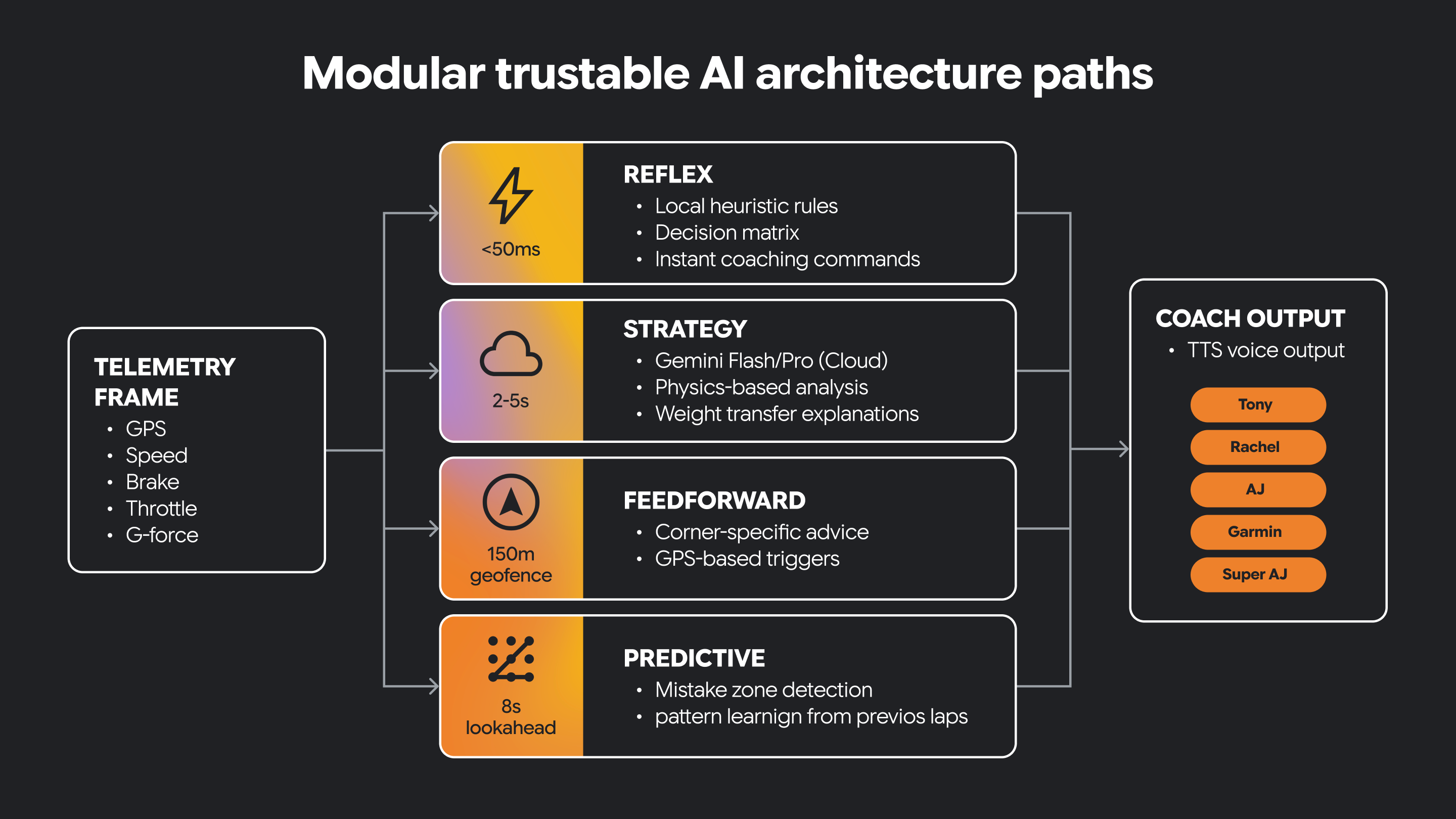
Alcune decisioni devono essere prese in tempo reale. Alcune decisioni traggono vantaggio da una riflessione più lunga.
L'AI affidabile spesso ha bisogno di entrambi.
Questa separazione architetturale aiuta il sistema a rimanere reattivo, supportando al contempo indicazioni più ricche basate sull'AI. Inoltre, crea un luogo chiaro per introdurre vincoli guidati da persone e conoscenze del dominio.
In questo piccolo programma, abbiamo un percorso di riflesso e un percorso di strategia implementati come funzioni Python.
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
Le due funzioni si comportano in modo diverso con gli stessi dati di telemetria. La funzione di riflesso è un avviso immediato. La funzione di strategia ci fornisce consigli di coaching basati su regole.
Perché ritieni che sia utile mantenere separata questa logica?
Ora creiamo un'applicazione divertente in più parti e vediamo come questa architettura trasforma le reazioni rapide e il ragionamento più approfondito in un sistema di AI affidabile che puoi provare.
5. Crea un server di streaming di telemetria
Ora che hai compreso l'obiettivo dell'architettura, è il momento di creare la pipeline di dati che gestisce l'applicazione.
In questa sezione creerai un semplice flusso di telemetria per un'auto da corsa virtuale. I dati provengono da un'origine CSV contenente dati GPS o di posizione della traccia e la tua applicazione li convertirà in uno stream live che l'interfaccia utente e il livello AI possono utilizzare.
In questa sezione imparerai a:
- Crea un nuovo progetto in Google Cloud per il nostro server di streaming e la nostra applicazione
- Crea un piccolo server per emettere dati di telemetria
- Trasmetti in streaming questi eventi a un'interfaccia utente o a una console del browser
1. Apri Cloud Shell
A. Vai alla console Google Cloud.
B. Crea un nuovo progetto per questo codelab. Fai clic sul menu a discesa del progetto in alto.
Quando crei un progetto, è una buona opportunità per collegare l'account di fatturazione:
Se hai già creato un progetto, puoi aprire il riquadro a sinistra, fare clic su Billing e verificare se l'account di fatturazione è collegato a questo account GCP.
C. Ottenere una chiave API Gemini
Dopo aver attivato i crediti Google Cloud, devi disporre di una chiave API Gemini per accedere a Gemini in Google Cloud.
Per creare una chiave API Gemini, dobbiamo utilizzare Google Vertex AI Studio per generare le chiavi.
In Vertex AI Studio, fai clic su "Ottieni chiave API" nell'angolo in basso a sinistra sopra "Documentazione". Crea una chiave API per Gemini (si presenta come una lunga stringa di caratteri apparentemente casuali). Salva questa chiave in un luogo sicuro. Utilizzeremo questa chiave API nel passaggio 6 "Crea il simulatore di auto da corsa" per autenticare il nostro accesso a Gemini in Google Cloud.
D. Fai clic sull'icona Cloud Shell nella barra superiore (icona del terminale) per aprire un terminale basato sul browser.
E. Attendi l'avvio della sessione del terminale.

2. Ottieni il codice
Clona il repository principale.
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Nota che in questo repository sono presenti due cartelle: "koru-application" (applicazione web) e "streaming-telemetry-server" (telemetria in tempo reale simulata di un'auto da corsa). Questo passaggio descrive "streaming-telemetry-server". Utilizzeremo "koru-application" nel passaggio successivo.
3. Abilita le API richieste
Esegui una volta per progetto:
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
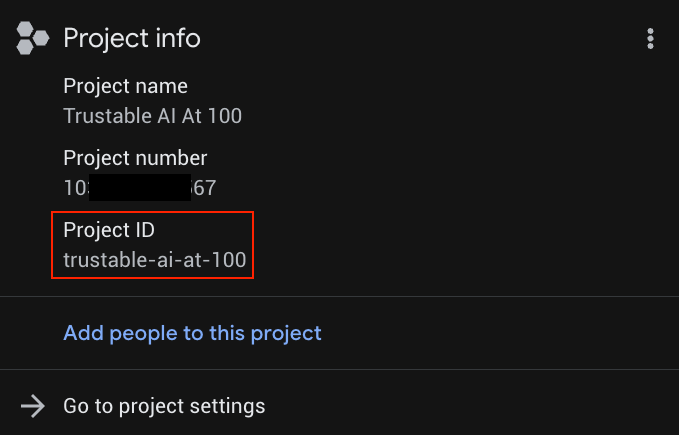
Sostituisci YOUR_PROJECT_ID con l'ID progetto effettivo (o salta la prima riga se il progetto è già impostato).
Puoi trovare YOUR_PROJECT_ID nell'elenco dei progetti.
4. Esegui il deployment del backend in Cloud Run
Dalla radice del repository (ovvero assicurati di trovarti nella cartella trustable-ai-codelab):
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
Tieni presente che potrebbe essere necessario premere "Y" quando richiesto.
- La prima esecuzione potrebbe richiedere di abilitare le API o creare un repository Artifact Registry. Accetta in base alle esigenze.
- Se utilizzi una regione diversa da
us-central1, specifica la regione utilizzando--region - Al termine del deployment, gcloud stampa l'URL del servizio. Per utilizzarlo come endpoint completo per il server di telemetria, è sufficiente aggiungere "events" a questo URL.
5. Utilizzare l'URL dello stream
Il server di telemetria ora emette dati di telemetria simulati utilizzando Server-Sent-Events (SSE) in un endpoint del modulo :
service-URL/events // service-URL - the last line displayed by "deploy"
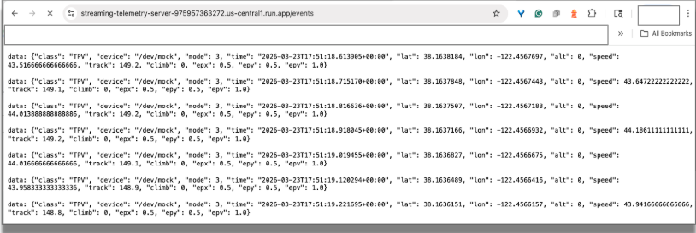
Test in un browser:visita questo URL dell'endpoint di streaming utilizzando Chrome. Nel browser dovresti visualizzare i dati in streaming in entrata, che simulano i dati emessi dai sensori di un'auto da corsa.
Puoi chiudere la scheda del browser per terminare la connessione.
Test con curl:
Ora eseguiamo il test dalla riga di comando della shell.
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
Dovresti vedere i dati in streaming in entrata nella finestra di Cloud Shell.
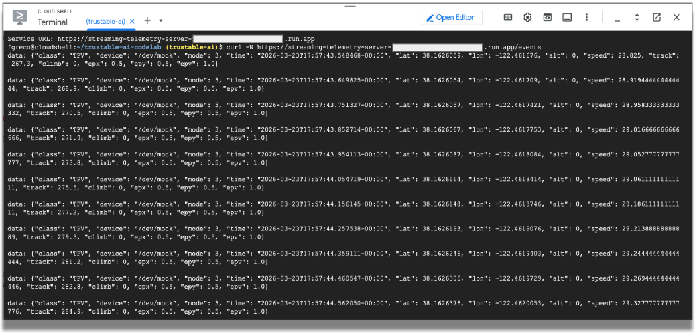
Utilizzeremo questi dati di telemetria per simulare i dati emessi dai sensori di un'auto da corsa. Il resto del codelab utilizzerà questi dati. Puoi terminare il programma curl inserendo Ctrl+C nella finestra del terminale.
Cosa dovresti notare
Quando completi questa sezione, presta attenzione alla natura dei dati in entrata. La telemetria non elaborata è spesso ad alto volume, sensibile al tempo e non immediatamente adatta al ragionamento dell'AI. Una volta creata l'applicazione front-end, dovremo filtrare i dati non elaborati in un formato efficiente che un LLM possa elaborare rapidamente.
Ma prima creiamo il front-end web per visualizzare i dati.
6. Costruire il simulatore di auto da corsa
In questa sezione imparerai a:
- Crea una simulazione di auto da corsa
- Connetti il server di telemetria all'applicazione web dell'auto da corsa
- Visualizza gare simulate
A questo punto, abbiamo una simulazione funzionante della telemetria di un'auto da corsa in esecuzione nel cloud. Ora creiamo l'applicazione che viene eseguita sulla macchina locale, si connette a Google Cloud e visualizza i dati.
La nostra applicazione di AI affidabile utilizza sia la potenza e la flessibilità dei servizi Google Cloud sia l'intelligenza locale in esecuzione in Chrome.
Il servizio di telemetria in streaming viene eseguito in Google Cloud, ma l'applicazione per auto da corsa viene eseguita sulla tua macchina locale. Ciò significa che dovrai clonare di nuovo il repository, questa volta sul tuo laptop o computer.
Per semplicità, lo stesso repository contiene il codice sia per il server di streaming sia per l'applicazione per auto da corsa.
Clona l'applicazione di frontend da GitHub:
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Una volta clonato il repository sul laptop o sul computer, eseguiamo l'applicazione.
cd koru-application # racing car simulation app
npm install
npm run dev

In Chrome, apri la porta sulla tua macchina locale (http://localhost:5173 come nell'esempio precedente). Verrà visualizzata la pagina di destinazione dell'applicazione "AI Motorsport Coaching".
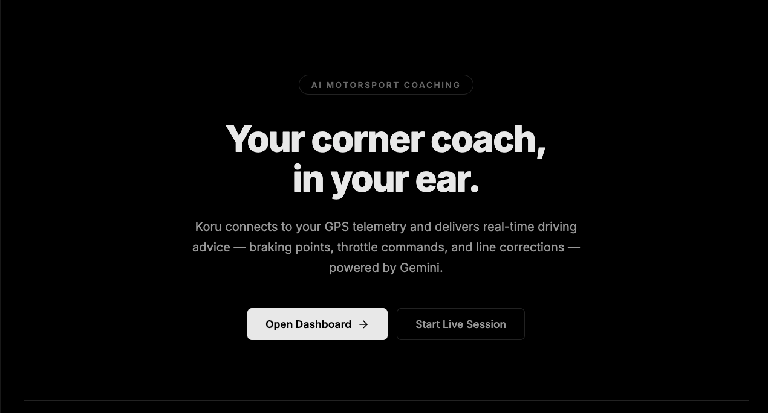
Fai clic sul pulsante "Apri dashboard ->". Verrà avviata l'interfaccia utente dell'applicazione.
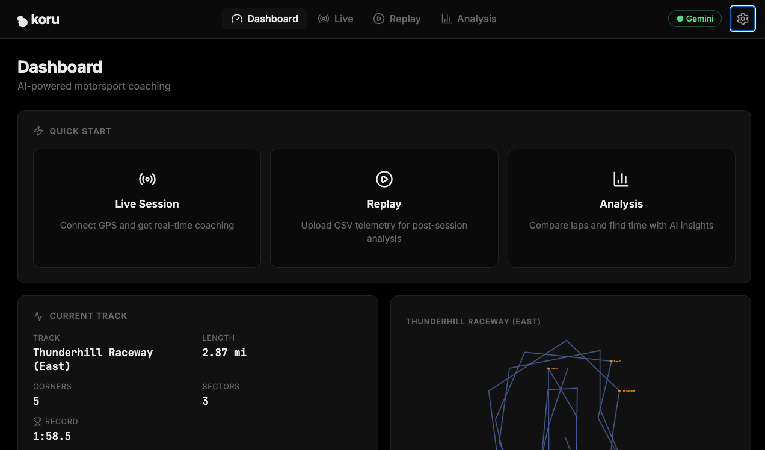
A questo punto, hai un server di telemetria che genera una telemetria simulata di un'auto da corsa in Google Cloud e un'applicazione web locale che può visualizzare i dati e connettersi a un LLM. Colleghiamoli e connettiamoci anche ai servizi LLM di Gemini.
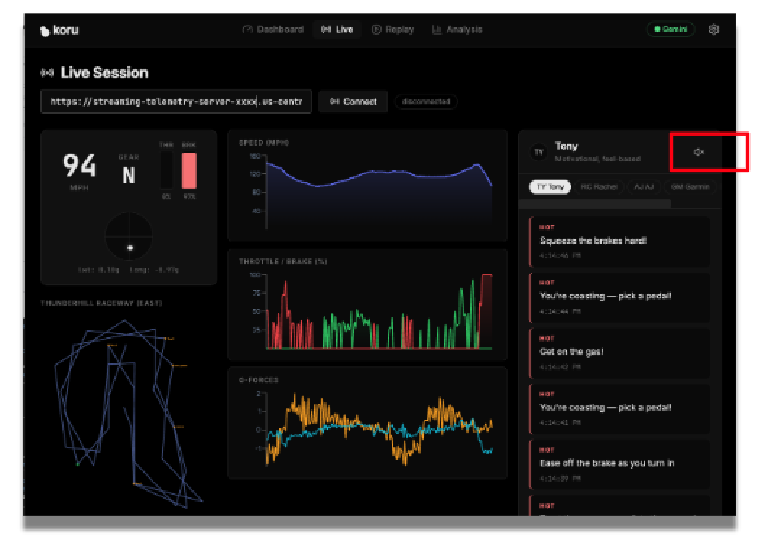
Nell'angolo in alto a destra dell'applicazione, fai clic sull'icona a forma di ingranaggio (impostazioni).
![]()
Inserisci la chiave API Gemini del passaggio 2. In questo modo, puoi accedere ai servizi Gemini in Google Cloud.
Fai clic su "Salva" in modo che l'applicazione ricordi la tua chiave API.
Ora colleghiamo l'applicazione al server di telemetria. Nella dashboard dell'applicazione, fai clic su "Live Session" (Sessione live).
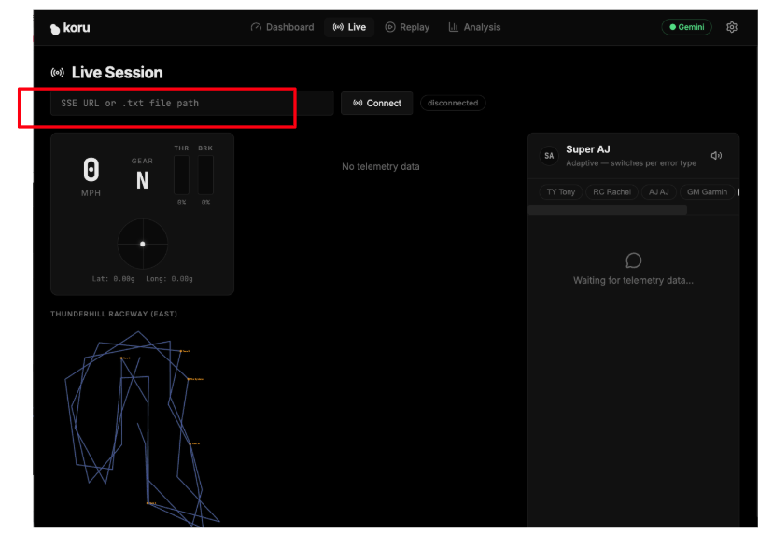
Inserisci l'URL specifico del tuo server di telemetria basato sul cloud (passaggio 5) nel campo di testo "SSE URL or .txt file path". Il nostro URL SSE aveva il seguente formato:
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
Dopo aver inserito l'URL dell'endpoint del server di telemetria, fai clic su "Connetti" (a destra del campo di testo). Non dimenticare la parola "events " alla fine dell'URL.
Ora dovresti vedere l'applicazione che visualizza i dati simulati.
Se il volume dello speaker è alto, puoi ascoltare i consigli di guida di diversi tipi di allenatori. Ogni coach ha una personalità diversa. Prova a selezionare diversi coach per ascoltare i loro consigli di corsa e i diversi stili vocali. Se necessario, puoi disattivare l'audio facendo clic sull'icona dell'altoparlante.
Ora che abbiamo un'applicazione funzionante, vediamo come abbiamo preparato i dati per l'elaborazione efficiente da parte del modello LLM e come possiamo aggiungere funzionalità aggiuntive per migliorare l'affidabilità del sistema complessivo.
7. Preparare la telemetria per il ragionamento dell'AI
La telemetria non elaborata è utile per la simulazione, ma di solito è troppo dettagliata e troppo frequente per essere inviata direttamente a un LLM. Se invii tutti i dati di telemetria invariati, potresti aumentare la latenza, introdurre rumore e ridurre la qualità delle indicazioni risultanti.
In questa sezione, rimodellerai la telemetria in una forma più utile.
In questa sezione imparerai a:
- Esamina il JSON della telemetria non elaborata
- Identificare i campi più pertinenti per il ragionamento
- Filtrare o riepilogare i dati
- Riduci i dettagli non necessari
- Prepara una rappresentazione dello stato di guida adatta all'AI
Si tratta di un passaggio importante per creare un'AI affidabile. La qualità della risposta dipende non solo dal modello, ma anche dalla struttura e dalla pertinenza dei dati che riceve.
Ora esaminiamo i dati specifici per le auto da corsa. Possiamo sperimentare modificando valori specifici nell'applicazione, ricaricandola e osservando il risultato.
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
Le forze G in un'auto misurano l'accelerazione o la decelerazione. In un'auto da corsa, la comprensione delle forze G aiuta a gestire l'auto e le sue prestazioni complessive. Se la nostra app non dispone di queste informazioni, è difficile fornire consigli al conducente. Rimuovi il commento da queste due righe, imposta entrambi i valori gLat e gLong su 0, 0 ed esegui di nuovo l'applicazione.
Nota che non vengono forniti consigli quando l'auto si avvicina a una curva. Non è molto utile per un pilota di auto da corsa.
Quindi annulla la modifica ed esegui di nuovo l'applicazione. Hai notato i suggerimenti audio utili quando l'auto raggiunge un angolo? I punti dati della forza G sono fondamentali per i consigli al conducente.
Ora, limitiamo artificialmente la velocità dell'auto a un ritmo tranquillo di 48 km/h. A questa velocità non vinceremo nessuna gara, ma dimostreremo sicuramente il tipo di coaching che riceviamo.
Nello stesso file (telemetryStreamService.ts) vicino alla riga 158, troverai la funzione processPoint(). In questa funzione, vincoliamo la velocità.
Cambia:
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
A:
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
Esegui di nuovo l'applicazione. Che tipo di consigli di coaching riceviamo ora? Non è necessario molto se guidiamo con calma.
Ora ripristina le modifiche ed esegui di nuovo l'applicazione.
Chiaramente, la velocità dell'auto è un punto dati prezioso. È molto importante capire quali dati specifici sono fondamentali per fornire consigli utili. È altrettanto importante valutare quali dati non sono pertinenti.
In questa fase, devi anche iniziare a pensare alla sicurezza e all'affidabilità. Anche un input ben preparato non garantisce una risposta affidabile. Dobbiamo ancora introdurre regole guidate da persone e vincoli espliciti.
La preparazione dei dati non è solo un passaggio di pre-elaborazione. È una parte fondamentale della strategia di fiducia. Input più puliti spesso portano a output più mirati e affidabili.
8. Aggiungere misure di salvaguardia e competenze umane codificate
Un sistema di AI affidabile non deve basarsi solo sull'output del modello. In molti casi, i sistemi più affidabili combinano il ragionamento del modello linguistico di grandi dimensioni con regole esplicite, conoscenza del dominio e vincoli guidati dall'uomo.
In questa sezione aggiungerai questo livello.
Puoi pensare a questo livello come a una conoscenza di coaching codificata. Possono includere pattern di risposta preferiti, regole di convalida, controlli di sicurezza o indicazioni strutturate che aiutano il sistema a rimanere affidabile e utile.
In questa sezione imparerai a:
- Introdurre regole di risposta che modellano il comportamento del modello
- Applicare controlli di sicurezza per ridurre i consigli fuorvianti
- Incorporare competenze umane codificate nella pipeline
- Confrontare le risposte prima e dopo queste aggiunte
Vediamo come viene aggiunta l'esperienza nel dominio alla nostra applicazione.
Un LLM in genere non è addestrato nelle corse o nella fisica delle prestazioni delle auto da corsa. Se la nostra applicazione includesse questa competenza nel dominio, gli utenti potrebbero riporre maggiore fiducia nelle sue indicazioni. Queste indicazioni derivano da regole basate sull'esperienza umana, in altre parole, da un livello di esperienza nel settore.
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
Questi principi delle auto da corsa sono un ingrediente fondamentale per fornire risultati affidabili. Cosa succederebbe se non avessimo questa competenza? Scopriamolo.
Rimuoviamo RACING_PHYSICS_KNOWLEDGE ed esploriamo i nostri consigli sulle corse.
export const RACING_PHYSICS_KNOWLEDGE = ``;
Esegui di nuovo l'applicazione. Che tipo di consigli di coaching riceviamo ora?
Nota i consigli generici.
Non riceviamo più informazioni dettagliate su attrito, trasferimento di peso, velocità di uscita e così via. La nostra affidabilità è inferiore senza queste informazioni. Ripristina le competenze di corsa e riesegui l'applicazione.
Questo passaggio è un aspetto fondamentale di un sistema di AI affidabile. La fiducia non viene creata magicamente da un prompt più efficace. La fiducia nasce dalla progettazione del sistema e dal pensiero critico.
L'LLM fa parte della soluzione, ma non è la soluzione completa. La fiducia migliora quando l'output dell'AI è guidato da conoscenze umane esplicite.
9. Progettare le buyer persona del coaching e l'esperienza utente
Una volta implementata la pipeline di ragionamento, la domanda successiva è come il sistema deve comunicare con l'utente.
In questa sezione, definirai l'esperienza di coaching definendo il modo in cui il livello di strategia comunica con il conducente. Perfezionerai il prompt di sistema per una delle persona di coaching e valuterai come fornire le indicazioni in modo chiaro, tempestivo e, soprattutto, pratico.
In questa sezione imparerai a:
- Creare o perfezionare un prompt di sistema per una persona di coaching
- Sperimenta diversi stili di coaching
- Osserva in che modo le modifiche al prompt influiscono sulle risposte
- Definisci i requisiti dell'interfaccia utente per un feedback affidabile
- Comprendere il supporto della sintesi vocale (TTS) per i messaggi urgenti e non urgenti
La nostra applicazione include diverse personalità di coaching. Ognuno fornisce diversi tipi di consigli di coaching.
PERSONA | CARATTERISTICHE |
Tony | Motivazionale, basato sulle sensazioni |
Rachele | Tecnico, incentrato sulla fisica |
AJ | Comandi diretti e bruschi |
Garmin | Ottimizzazione delta incentrata sui dati |
Super AJ | Adattivo, interruttori per tipo di errore |
Queste buyer persona sono definite nel file ../src/utils/coachingKnowledge.ts.
In questo file noterai una mappa degli oggetti (COACHES) che associa le chiavi stringa a CoachPersonas. Un CoachPersona contiene gli attributi di ogni tipo di allenatore. Un attributo importante è systemPrompt. Ogni persona ha il proprio systemPrompt che guida il LLM nel modo in cui rispondere.
Modifichiamo una di queste system prompts e vediamo come risponde il modello LLM.
Verso la riga 31, vedrai systemPrompt per "AJ", che è molto diretto e schietto nei suoi consigli. Cambiamo systemPrompt in modo che AJ sia eccessivamente educato.
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
Esegui di nuovo l'applicazione, seleziona AJ come coach e vedi che tipo di risposte vengono generate.
Ora ripristina il systemPrompt originale ed esegui di nuovo l'applicazione. Tieni presente che il prompt di sistema è fondamentale per guidare l'LLM a fornire una risposta adatta al personaggio.
L'attendibilità non riguarda solo la correttezza. Si tratta anche di consegna. Un consiglio tecnicamente accurato può comunque essere inefficace se non è chiaro, è fuori tempo o distrae.
Un sistema affidabile deve comunicare bene. L'esperienza utente fa parte dell'architettura di attendibilità.
10. Esamina l'architettura end-to-end
A questo punto, hai creato i componenti principali del sistema. Ora è il momento di fare un passo indietro e rivedere come funzionano insieme.
La tua applicazione ora include questi componenti:
- Stream di telemetria
- Livello di visualizzazione
- Fase di trasformazione dei dati pronti per l'AI
- Componenti della strategia basati su un LLM di ragionamento
- Sistemi di protezione e indicazioni umane codificate
- Esperienza di coaching rivolta all'utente
Un modo utile e semplice per comprendere il flusso complessivo di questi componenti è aggiungere la registrazione alla nostra applicazione.
Aggiungeremo la registrazione per visualizzare i dati di telemetria mentre scorrono nei percorsi.
Innanzitutto, visualizziamo i dati di telemetria. In telemetryStreamService.ts, intorno alla riga 212 (prima di this.emit(frame)), aggiungi una riga che mostri la velocità, la forza G laterale (accelerazione laterale) e la pressione esercitata dal conducente sul pedale del freno.
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
Ricarica l'applicazione. Prima di eseguire l'applicazione, apriamo la console in DevTools di Chrome per visualizzare queste informazioni di debug.
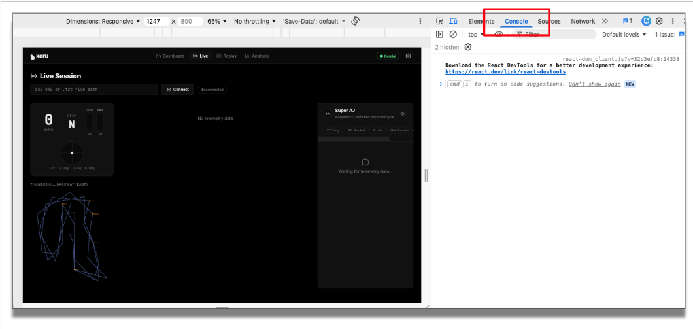
Nell'applicazione, inserisci l'endpoint di telemetria e fai clic su "Connetti". Ora puoi visualizzare i dati di telemetria in entrata.
Ora aggiungiamo la registrazione per il percorso riflesso e il percorso della strategia.
In ../src/services/coachingService.ts intorno alla riga 71 prima di this.emit(), aggiungi una riga di logging per il percorso reflex:
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
Nello stesso file, intorno alla riga 287, prima di this.emit(), aggiungi una riga di logging simile per il percorso strategy (aggiungiamo la risposta di coaching text restituita dall'API Gemini):
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
Esegui di nuovo l'applicazione. Nella console noterai come i dati di telemetria fluiscono dall'origine attraverso questi percorsi. Lo stream in entrata viene filtrato, inviato al LLM, verificato con competenze umane affidabili e presentato all'utente utilizzando un'interfaccia utente appropriata.
Nota che abbiamo collegato i vari componenti tecnici per raggiungere l'obiettivo più ampio di un'AI affidabile. Il valore dell'architettura non risiede in un singolo componente. Il valore deriva dal modo in cui le parti si rafforzano a vicenda.
L'AI affidabile è il risultato di un'architettura, non una singola funzionalità.
Smantellamento (rimozione del servizio)
È importante ricordarsi di rimuovere il servizio quando non ti serve più. Una volta terminato il test del server di telemetria insieme all'applicazione, devi eliminare il servizio Cloud Run e interrompere la fatturazione:
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
Se necessario, ricorda di sostituire us-central1 con la regione che hai utilizzato durante il deployment. Conferma quando ti viene richiesto.
11. Sfide
Ora che l'applicazione principale funziona e hai compreso i vari componenti, prova a estendere il design.
Sfide suggerite
- Spostare una parte maggiore della logica di coaching sull'edge
- Modifica la simulazione per supportare la pioggia o la trazione ridotta
- Scopri in che modo l'ottimizzazione o il fine tuning del modello potrebbe migliorare il rendimento
- Adattare l'architettura a un altro dominio, come medicina, produzione o logistica
Ad esempio, considera queste domande quando applichi le lezioni apprese in questo lab a un altro dominio:
- Qual è l'equivalente della telemetria delle corse, ovvero dei dati continui, in un altro campo?
- Quali decisioni devono essere immediate e quali sono più strategiche?
- Quale tipo di competenza umana dovrebbe essere codificata?
- Cosa dovrebbero vedere gli utenti per ritenere che il sistema sia affidabile?
Queste sfide ti incoraggiano a pensare oltre l'esempio delle corse e a riconoscere il pattern di progettazione più ampio dell'affidabilità alla base di questo codelab.
12. Conclusione e passaggi successivi
In questo codelab hai creato più di una demo di corse. Hai creato un esempio concreto di come possono essere progettati sistemi di AI affidabili.
Hai iniziato con la telemetria non elaborata, l'hai trasformata in un formato utile per un LLM, hai applicato il ragionamento dell'AI e hai rafforzato l'output con indicazioni umane codificate e vincoli di risposta. Lungo il percorso, hai visto che l'affidabilità deriva dall'architettura, non solo dall'output del modello.
Un sistema di AI affidabile spesso combina:
- Dati strutturati in tempo reale
- Ragionamento basato su modelli
- Competenze nel dominio codificate
- Contromisure esplicite
- Progettazione dell'esperienza utente ponderata
Lo scenario delle corse ha contribuito a rendere tangibili queste idee, ma lo stesso approccio può essere utilizzato ovunque le raccomandazioni dell'AI debbano essere tempestive, attuabili e affidabili.
