
1. 概要
人工知能は現在、多くのソフトウェア システムの一部となっていますが、AI アプリケーションの構築は、ユーザーが信頼できるアプリケーションの構築とは異なります。現実世界の多くの環境では、単にレスポンスを生成するだけでは不十分です。課題は、タイムリーで、根拠があり、実用的で、人間の専門知識と一致する回答を生成することです。
この Codelab では、これらのアイデアを具体的かつ魅力的な方法で実証するレーシング コーチ シミュレータを作成します。このアプリケーションは、仮想レーシングカーのテレメトリーを使用して、トラック上の動きをアニメーション化し、コーチング ガイダンスを生成します。レースがシナリオですが、同じアーキテクチャのアイデアは、信頼が重要なヘルスケア、製造、ロジスティクスなどのドメインにも適用できます。
テレメトリー データの高速ストリームを処理し、AI 推論に役立つ効率的な形式に変換します。また、LLM ベースの出力とエンコードされた人間のガイダンスを組み合わせて、より信頼性の高いレスポンスを生成します。
作業内容
この Codelab では、次の機能を備えた信頼できる AI プロトタイプを作成します。
- Google Cloud で実行されている仮想レーシングカーからテレメトリーをストリーミングする
- Chrome を使用してレーストラックを移動する車を視覚化する
- 未加工のテレメトリーを AI 対応の入力に変換
- Google Gemini を利用した戦略レイヤを適用する
- モデルの出力とエンコードされた人間のガイダンスおよび安全ルールを組み合わせる
- ユーザー向けインターフェースを通じてコーチング フィードバックを提供
学習内容
この Codelab を修了すると、次のことができるようになります。
- AI システムの信頼性を高める要素を説明する
- モジュラー AI アーキテクチャの目的を説明する
- シンプルなシミュレートされたテレメトリー パイプラインを作成する
- LLM で使用するための有用な構造化データを準備する
- ガードレールと人間によるガイド付きルールを適用して信頼性を向上させる
- このアーキテクチャを他のドメインに適用する方法を評価する
2. 必要なもの
始める前に、必要なアカウント、ツール、サービスが準備できていることを確認してください。
前提条件
以下のとおりであることを前提としています。
- Gmail アドレスを使用している個人の Google アカウント
- Google Cloud へのアクセスと CLI の基本的な理解
- 有効な請求先アカウントまたはクラウド クレジット
- Gemini を使用した Google Cloud と生成 AI の概要を理解している
Gemini は、最先端の推論を基盤として構築された Google の AI モデルで、あらゆるアイデアを形にします。マルチモーダル理解、エージェント型コーディング、バイブ コーディングに最適なモデルです。
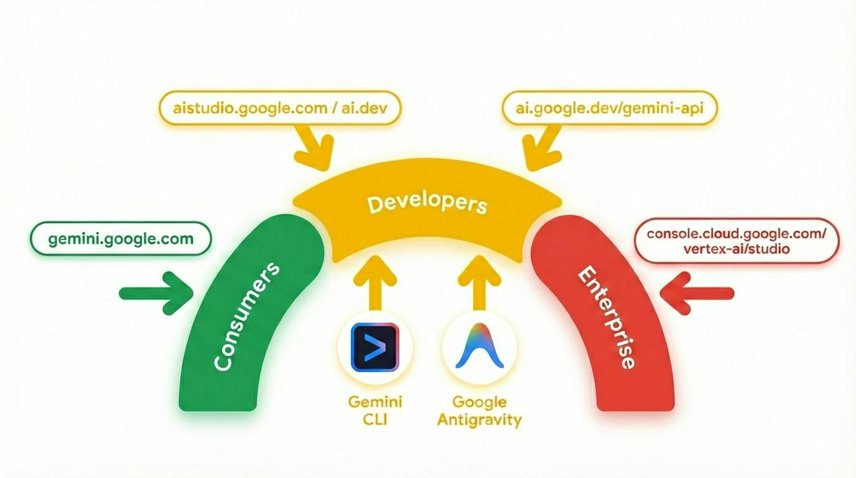
3. 信頼できる AI が重要な理由
多くの AI システムは流暢で説得力のある回答を生成できますが、流暢であることと信頼できることは同じではありません。実際のシステムでは、ユーザーは安全ルールによって制約され、ドメインの専門知識によって形成された、タイムリーで根拠のあるレスポンスを必要とすることがよくあります。
これは、システムが高速で移動するデータを処理する場合に特に重要になります。レスポンスが遅すぎると、役に立たない可能性があります。自信があるように聞こえるが、重要なコンテキストを無視している回答は誤解を招く可能性があります。洗練された回答であっても、人間の専門知識と関連性のない回答は信頼しにくいことがあります。
この Codelab で使用するレーシングカーのシナリオでは、AI が面白いことを言えるかどうかは問題ではありません。問題は、システムが有用で安全かつタイムリーで、状況に適したアドバイスを提供できるかどうかです。
小さなテレメトリー サンプルを見て、2 つの出力の可能性を比較してみましょう。
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Naive AI response
"Stay aggressive on the throttle and carry your speed into Turn 1"
信頼性を考慮した回答
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
違いに気づきましたか?
ナイーブな AI の回答のみに頼るとどうなるでしょうか?
最初の回答は自信に満ちているように聞こえますが、リスクを無視しています。2 番目の回答は、コンテキストと制約を反映しているため、より有用です。
LLM をシステム全体として扱うのではなく、より広範なアーキテクチャの一部として扱うことで、信頼性を高める必要があります。また、レースカー、医療処置、航空、電力網、取引システム、海上ナビゲーションなど、多くのアプリケーションでは、アドバイスが実用的な速度で配信される必要があります。
それでは、このようなアーキテクチャを作成する方法について説明します。
4. 高速 AI とモジュラー型信頼できるアーキテクチャについて
一部の AI システムでは、まったく異なる種類の動作が必要になります。変化する状況に迅速に対応し、より慎重な推論もサポートする必要があります。
モジュラー アーキテクチャでは、これらの責任が別々のパスに分離されます。1 つのパスは反射的で、受信したシグナルの即時的で時間依存性の高い解釈を処理できます。別のパスでは、戦略に焦点を当て、より高度な推論とコンテキスト認識型の意思決定をサポートできます。他のパスは他のタイプの機能を対象としています。
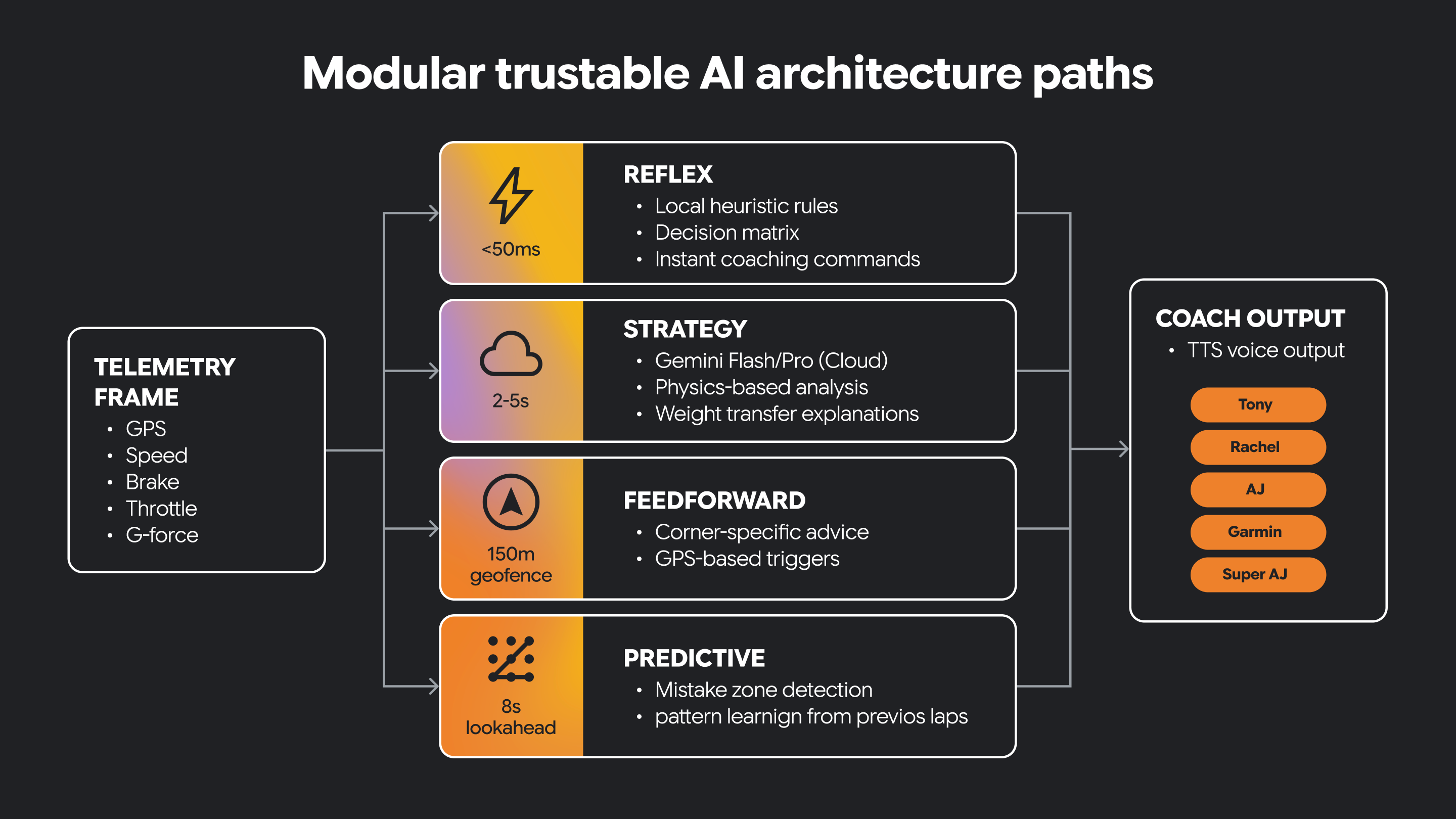
一部の意思決定はリアルタイムで行う必要があります。一部の決定では、時間をかけて考えることが有益です。
信頼できる AI には、両方が必要になることがよくあります。
このアーキテクチャの分離により、システムは応答性を維持しながら、より豊富な AI 駆動型ガイダンスをサポートできます。また、人間が導く制約とドメイン知識を導入するための明確な場所も作成されます。
この小さなプログラムでは、反射パスと戦略パスが Python 関数として実装されています。
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
2 つの関数は、同じテレメトリー データが指定されても異なる動作をします。反射関数は即時警告です。戦略関数は、ルールに基づいてコーチング アドバイスを提供します。
このロジックを分離しておくことが有用である理由を教えてください。
それでは、楽しいマルチパート アプリケーションを構築し、このアーキテクチャが高速な反応と深い推論を信頼できる AI システムに変換して、実際に体験できるようにする仕組みを見ていきましょう。
5. テレメトリー ストリーミング サーバーを構築する
アーキテクチャの目標を理解したので、アプリケーションを駆動するデータ パイプラインを構築します。
このセクションでは、仮想レーシングカーの簡単なテレメトリー ストリームを作成します。データは、GPS データまたはトラック位置データを含む CSV ソースから取得され、アプリケーションによって UI と AI レイヤが使用できるライブ ストリームに変換されます。
このセクションでは、次の作業を行います。
- ストリーミング サーバーとアプリケーション用に Google Cloud に新しいプロジェクトを作成する
- テレメトリー データを送信する小規模なサーバーを作成する
- これらのイベントをブラウザ UI またはコンソールにストリーミングする
1. Cloud Shell を開く
A. Google Cloud コンソールに移動します。
B. この Codelab 用に新しいプロジェクトを作成します。上部のプロジェクト プルダウン メニューをクリックします。
プロジェクトの作成時に請求先アカウントをリンクすることをおすすめします。
または、すでにプロジェクトを作成している場合は、左側のパネルを開いて Billing をクリックし、請求先アカウントがこの GCP アカウントにリンクされているかどうかを確認します。
C. Gemini API キーの取得
Google Cloud クレジットを有効にしたら、Google Cloud で Gemini にアクセスするために Gemini API キーが必要になります。
Gemini API キーを作成するには、Google Vertex AI Studio を使用してキーを生成する必要があります。
Vertex AI Studio で、左下の [ドキュメント] の上にある [API キーを取得] をクリックします。Gemini の API キーを作成します(ランダムな文字列のように見えます)。このキーは安全な場所に保存してください。この API キーは、ステップ 6「レーシングカー シミュレーターを構築する」で、Google Cloud の Gemini へのアクセスを認証するために使用します。
D. 上部のバーにある Cloud Shell アイコン(ターミナル アイコン)をクリックして、ブラウザベースのターミナルを開きます。
E. ターミナル セッションが開始するまで待ちます。

2. コードを取得する
マスター リポジトリのクローンを作成します。
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
このリポジトリには、「koru-application」(ウェブ アプリケーション)と「streaming-telemetry-server」(シミュレートされたリアルタイムのレーシングカー テレメトリー)の 2 つのフォルダがあります。このステップでは、「streaming-telemetry-server」について説明します。次のステップでは「koru-application」を使用します。
3. 必要な API の有効化
プロジェクトごとに 1 回実行します。
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
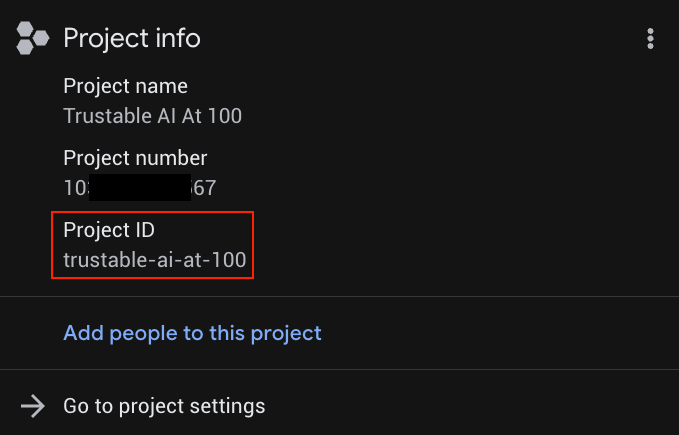
YOUR_PROJECT_ID は、実際のプロジェクト ID に置き換えます(プロジェクトがすでに設定されている場合は、最初の行をスキップします)。
YOUR_PROJECT_ID は、プロジェクトのリストで確認できます。
4. バックエンドを Cloud Run にデプロイする
リポジトリのルートから(つまり、trustable-ai-codelab フォルダにいることを確認します)。
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
プロンプトが表示されたら「Y」キーを押す必要がある場合があります。
- 初回実行時に、API の有効化または Artifact Registry リポジトリの作成を求めるメッセージが表示されることがあります。必要に応じて受け入れます。
us-central1以外のリージョンを使用する場合は、--regionを使用してそのリージョンを指定します。- デプロイが完了すると、gcloud によって service-URL が出力されます。この URL に「events」を追加するだけで、テレメトリー サーバーの完全なエンドポイントとして使用できます。
5. ストリーム URL を使用する
テレメトリー サーバーは、次のような形式のエンドポイントでサーバー送信イベント(SSE)を使用して、シミュレートされたテレメトリー データを送信するようになりました。
service-URL/events // service-URL - the last line displayed by "deploy"
ブラウザでテストする: Chrome を使用して、このストリーム エンドポイント URL にアクセスします。ブラウザに受信したストリーミング データが表示されます。これは、レーシングカーのセンサーから出力されたデータをシミュレートしたものです。
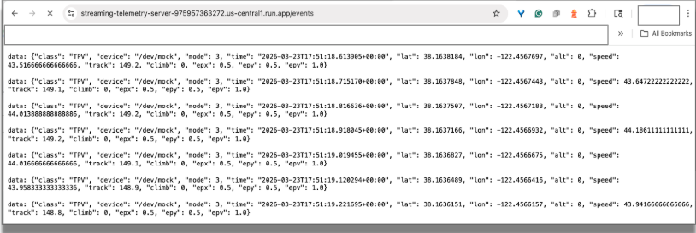
ブラウザタブを閉じると、接続が終了します。
curl でテストする:
シェル コマンドラインからテストしてみましょう。
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
Cloud Shell ウィンドウに受信したストリーミング データが表示されます。
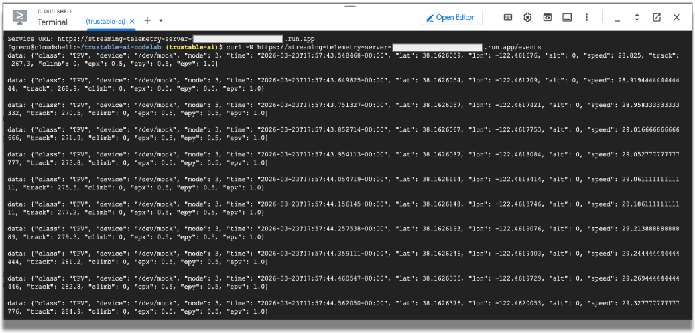
このテレメトリー データを使用して、レーシングカーのセンサーから出力されるデータをシミュレートします。この Codelab の残りの部分では、このデータを使用します。ターミナル ウィンドウで Ctrl+C キーを押すと、curl プログラムを終了できます。
注意すべき点
このセクションを完了する際は、受信データの性質に注意してください。未加工のテレメトリーは、多くの場合、大容量で時間依存性があり、AI 推論にすぐに適しているわけではありません。フロントエンド アプリケーションを構築したら、LLM が迅速に処理できる効率的な形式に生データをフィルタリングする必要があります。
まず、データを可視化するウェブ フロントエンドを構築しましょう。
6. レーシングカー シミュレーターを構築する
このセクションでは、次の作業を行います。
- レーシングカーのシミュレーションを構築する
- テレメトリー サーバーをレーシングカーのウェブ アプリケーションに接続する
- シミュレートされた競合状態を表示する
この時点で、クラウドで実行されているレーシングカーのテレメトリーのシミュレーションが動作しています。次に、ローカルマシンで実行され、Google Cloud に接続してデータを可視化するアプリケーションを構築します。
信頼できる AI アプリケーションは、Google Cloud サービスのパワーと柔軟性、Chrome で実行されるローカル インテリジェンスの両方を使用します。
ストリーミング テレメトリー サービスは Google Cloud で実行されますが、レーシングカー アプリケーションはローカルマシンで実行されます。つまり、リポジトリを再度クローンする必要があります。今回はノートパソコンまたはデスクトップ パソコンにクローンします。
わかりやすくするために、同じリポジトリにストリーミング サーバーとレーシングカー アプリケーションの両方のコードが含まれています。
GitHub からフロントエンド アプリケーションのクローンを作成します。
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
ノートパソコンまたはデスクトップにリポジトリをクローンしたら、アプリケーションを実行しましょう。
cd koru-application # racing car simulation app
npm install
npm run dev

Chrome で、ローカルマシンのポート(上記の例では http://localhost:5173)を開きます。「AI Motorsport Coaching」アプリケーションのランディング ページが表示されます。
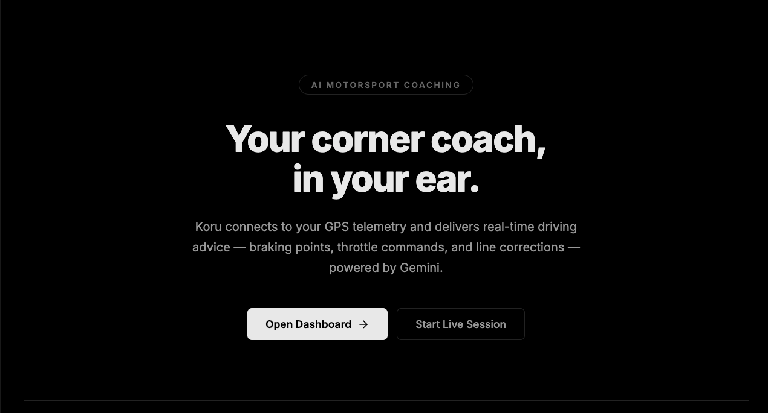
[Open Dashboard ->](ダッシュボードを開く ->)ボタンをクリックします。これにより、アプリケーションの UI が起動します。
この時点で、Google Cloud でシミュレートされたレーシングカーのテレメトリーを生成するテレメトリー サーバーと、そのデータを可視化して LLM に接続できるローカル ウェブ アプリケーションが用意されています。それらを接続し、Gemini LLM サービスにも接続しましょう。
アプリケーションの右上にある歯車アイコン(設定)をクリックします。
![]()
ステップ 2 で取得した Gemini API キーを入力します。これにより、Google Cloud の Gemini サービスにアクセスできます。
[保存] をクリックして、アプリケーションに API キーを記憶させます。
次に、アプリケーションをテレメトリー サーバーに接続します。アプリケーションのダッシュボードで、[Live Session] をクリックします。
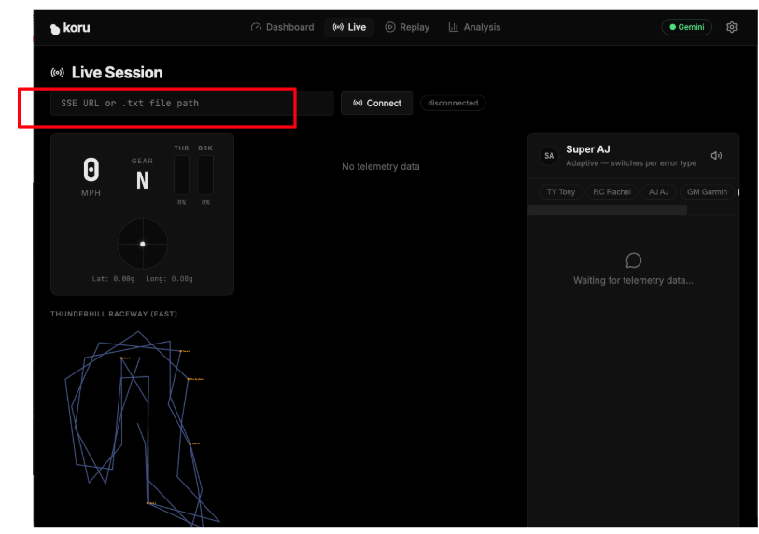
「SSE URL or .txt file path」と表示されているテキスト フィールドに、クラウドベースのテレメトリー サーバーの特定の URL(手順 5)を入力します。SSE URL は次の形式でした。
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
テレメトリー サーバーのエンドポイント URL を入力したら、[接続](テキスト フィールドの右側)をクリックします。URL の末尾にある「events」を忘れないでください。
シミュレートされたデータを可視化するアプリケーションが表示されます。
スピーカーの音量を上げると、さまざまなタイプのコーチからレースのアドバイスを聞くことができます。コーチはそれぞれ異なる個性を持っています。さまざまなコーチを選択して、レースに関するさまざまなアドバイスや音声スタイルを確認してみましょう。必要に応じて、スピーカー アイコンをクリックして音声を無効にできます。
これでアプリケーションが動作するようになったので、LLM による効率的な処理のためにデータを準備した方法と、システム全体の信頼性を高めるために追加機能を追加する方法について説明します。
7. AI 推論用のテレメトリーを準備する
未加工のテレメトリーはシミュレーションに役立ちますが、通常は詳細すぎ、頻度が高すぎるため、LLM に直接送信することはできません。すべてのテレメトリー データを変更せずに送信すると、レイテンシが増加し、ノイズが発生し、結果として得られるガイダンスの品質が低下する可能性があります。
このセクションでは、テレメトリーをより有用な形式に再形成します。
このセクションでは、次の作業を行います。
- 未加工のテレメトリー JSON を検査する
- 推論に最も関連性の高いフィールドを特定する
- データをフィルタリングまたは要約する
- 不要な詳細を減らす
- 運転状態の AI フレンドリーな表現を準備する
これは、信頼できる AI を構築するうえで重要なステップです。回答の質は、モデルだけでなく、受け取るデータの構造と関連性にも左右されます。
では、レーシングカーの具体的なデータを見ていきましょう。アプリケーション内の特定の値の変更、再読み込み、結果の確認を繰り返してテストできます。
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
車の G フォースは、加速または減速を測定します。レーシングカーでは、G 力を把握することで、車の操作性と全体的なパフォーマンスを向上させることができます。この情報がない場合、ドライバーにアドバイスを提供することは困難です。この 2 行をコメントアウトし、gLat と gLong の両方の値を 0.0 に設定して、アプリケーションを再実行します。
車がコーナーに近づいても、アドバイスは表示されません。レースのドライバーにはあまり役に立ちません。
その後、変更を元に戻してアプリケーションを再実行します。車が角に差し掛かると、音声によるアドバイスが表示されることに気づきましたか?G フォースのデータポイントは、ドライバーへのアドバイスに不可欠です。
ここで、車の速度を時速 30 マイルのゆったりとしたペースに制限してみましょう。そのスピードではレースに勝てませんが、どのようなコーチングを受けているかは確実に示せます。
同じファイル(telemetryStreamService.ts)の 158 行付近に、関数 processPoint() があります。この関数で、速度を制限しましょう。
変更:
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
宛先:
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
アプリケーションを再実行します。どのようなコーチング アドバイスが表示されるようになりましたか?ゆっくり運転するなら、それほど必要ありません。
これらの変更を元に戻して、アプリケーションを再度実行します。
明らかに、車の速度は貴重なデータポイントです。価値のあるアドバイスを提供するために、どのデータが重要であるかを理解することが非常に重要です。関連性のないデータを評価することも同様に重要です。
この段階で、安全性と信頼性についても検討し始める必要があります。入力が適切に準備されていても、信頼できる回答が得られるとは限りません。人間が導いたルールと明示的な制約を導入する必要があります。
データ準備は前処理のステップだけではありません。これは、信頼戦略の重要な部分です。入力がクリーンであるほど、より的確で信頼性の高い出力が得られる傾向があります。
8. ガードレールとエンコードされた人間の専門知識を追加する
信頼できる AI システムは、モデル出力だけに依存すべきではありません。多くの場合、最も信頼性の高いシステムは、大規模言語モデルの推論と、明示的なルール、ドメイン知識、人間が導く制約を組み合わせたものです。
このセクションでは、そのレイヤを追加します。
このレイヤは、エンコードされたコーチングの知識と考えることができます。これには、システムが根拠を持ち、有用性を維持するのに役立つ、優先されるレスポンス パターン、検証ルール、安全性チェック、構造化されたガイダンスが含まれる場合があります。
このセクションでは、次の作業を行います。
- モデルの動作を形作るレスポンス ルールを導入する
- 安全チェックを適用して誤解を招くアドバイスを減らす
- エンコードされた人間の専門知識をパイプラインに組み込む
- これらの追加の前後のレスポンスを比較する
ドメインの専門知識をアプリケーションに追加する方法について説明します。
通常、LLM はレースやレーシングカーのパフォーマンスの物理学についてトレーニングされていません。アプリケーションにそのドメインの専門知識が含まれていれば、ユーザーはアプリケーションのガイダンスをより信頼できるでしょう。このガイダンスは、人間の専門知識に基づくルール、つまりドメインの専門知識レイヤから提供されます。
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
このレーシングカーの原則は、信頼できる出力を提供するための重要な要素です。この専門知識がなかったらどうなっていましたか?Let's find out.(HONEY の節約額を確認してみましょう。)
RACING_PHYSICS_KNOWLEDGE を削除して、レースに関するアドバイスを見てみましょう。
export const RACING_PHYSICS_KNOWLEDGE = ``;
アプリケーションを再実行します。どのようなコーチング アドバイスが表示されるようになりましたか?
一般的なアドバイスが表示されます。
摩擦、重量移動、出口速度などの詳細な情報が得られなくなりました。この情報がないと、信頼性が低下します。レースの専門知識を復元して、アプリケーションを再実行します。
このステップは、信頼できる AI システムの重要な側面です。信頼は、より強力なプロンプトによって魔法のように生まれるものではありません。信頼は、システム設計とクリティカル シンキングから生まれます。
LLM はソリューションの一部ですが、ソリューション全体ではありません。AI の出力が人間の明示的な知識に基づいて行われると、信頼性が向上します。
9. コーチング ペルソナとユーザー エクスペリエンスを設計する
推論パイプラインが整ったら、次はシステムがユーザーとどのようにコミュニケーションを取るべきかという問題です。
このセクションでは、戦略レイヤがドライバと通信する方法を定義して、コーチング エクスペリエンスを形作ります。コーチング ペルソナの 1 つのシステム プロンプトを調整し、明確でタイムリーかつ、最も重要なこととして、実行可能なガイダンスをどのように提供すべきかを検討します。
このセクションでは、次の作業を行います。
- コーチング ペルソナのシステム プロンプトを作成または調整する
- さまざまなコーチング スタイルを試す
- プロンプトの変更が回答に与える影響を確認する
- 信頼できるフィードバックの UI 要件を定義する
- 緊急メッセージと緊急でないメッセージのテキスト読み上げ(TTS)のサポートについて
このアプリケーションには、複数のコーチング ペルソナが含まれています。それぞれ異なる種類のコーチング アドバイスを提供します。
PERSONA | 特性 |
Tony | モチベーション、感覚ベース |
Rachel | 技術的、物理学に重点を置いている |
AJ | 直接的でぶっきらぼうなコマンド |
Garmin | データに焦点を当てたデルタ最適化 |
Super AJ | アダプティブ、エラータイプごとに切り替え |
これらのペルソナは、../src/utils/coachingKnowledge.ts ファイルで定義されています。
このファイルには、文字列キーを CoachPersonas に関連付けるオブジェクト マップ(COACHES)があります。CoachPersona には、各タイプのコーチの属性が含まれています。重要な属性の 1 つは systemPrompt です。各ペルソナには、LLM の回答方法をガイドする独自の systemPrompt があります。
これらの system prompts の 1 つを変更して、LLM がどのように応答するかを確認してみましょう。
31 行目付近に、アドバイスが非常に直接的で率直な「AJ」の systemPrompt があります。systemPrompt を変更して、AJ が過度に丁寧になるようにしましょう。
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
アプリケーションを再実行し、コーチとして AJ を選択して、どのような回答が生成されるかを確認します。
元の systemPrompt を復元して、アプリケーションを再度実行します。システム プロンプトは、LLM がペルソナに合った回答を生成するうえで非常に重要です。
信頼は正確性だけではありません。また、配信についても同様です。技術的に正確なアドバイスでも、不明瞭であったり、タイミングが悪かったり、気が散るようなものであったりすると、効果がないことがあります。
信頼できるシステムは、適切にコミュニケーションをとる必要があります。ユーザー エクスペリエンスは信頼アーキテクチャの一部です。
10. エンドツーエンドのアーキテクチャを確認する
これで、システムの主要な部分が構築されました。ここで、それらがどのように連携して動作するかを振り返ってみましょう。
アプリケーションに次のコンポーネントが含まれるようになりました。
- テレメトリー ストリーム
- 可視化レイヤ
- AI 対応のデータ変換ステージ
- 推論 LLM を活用した戦略コンポーネント
- ガードレールとエンコードされた人間のガイダンス
- ユーザー向けのコーチング エクスペリエンス
これらのコンポーネントの全体的なフローを理解するのに役立つ簡単な方法は、アプリケーションにロギングを追加することです。
パスを通過するテレメトリー データを表示するために、ロギングを追加します。
まず、テレメトリー データを表示してみましょう。telemetryStreamService.ts の 212 行目付近(this.emit(frame) の前)に、速度、横方向の G フォース(横方向の加速度)、ドライバーがブレーキ ペダルをどの程度踏んでいるかを表示する行を追加します。
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
アプリケーションを再読み込みします。アプリケーションを実行する前に、Chrome の DevTools でコンソールを開いて、このデバッグ情報を確認しましょう。
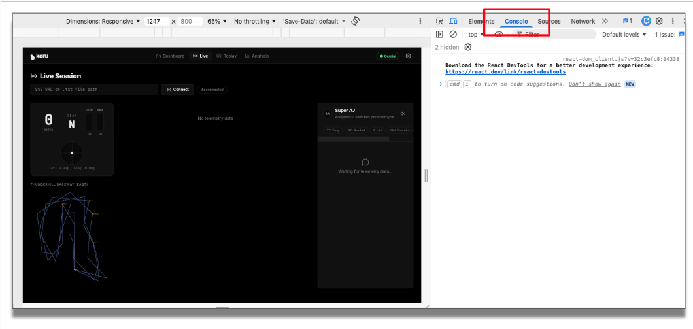
アプリケーションでテレメトリー エンドポイントを入力し、[接続] をクリックします。受信したテレメトリー データが表示されます。
次に、反射パスと戦略パスのロギングを追加します。
../src/services/coachingService.ts の 71 行目付近の this.emit() の前に、reflex パスのロギング行を追加します。
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
同じファイルの 287 行目付近の this.emit() の前に、strategy パス用の同様のロギング行を追加します(Gemini API から返されたコーチング レスポンス text を追加しましょう)。
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
アプリケーションを再実行します。コンソールで、テレメトリー データがソースからこれらのパスを介してどのように流れるかを確認します。受信ストリームはフィルタリングされ、LLM に送信されて、信頼できる人間の専門知識で検証され、適切なユーザー インターフェースを使用してユーザーに提示されます。
さまざまな技術コンポーネントを接続して、信頼できる AI という大きな目標を達成していることに注目してください。アーキテクチャの価値は、単一のコンポーネントだけでは実現できません。その価値は、各部分が互いに補強し合うことで生まれます。
信頼できる AI は、単一の機能ではなく、アーキテクチャの成果です。
破棄(サービスの削除)
サービスが不要になったら、忘れずに削除してください。アプリケーションとともにテレメトリー サーバーのテストが完了したら、Cloud Run サービスを削除して、その課金を停止する必要があります。
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
必要に応じて、us-central1 をデプロイ時に使用したリージョンに置き換えてください。表示されるメッセージを確認します。
11. 課題
コア アプリケーションが動作し、さまざまなコンポーネントを理解できたので、設計を拡張してみましょう。
おすすめのチャレンジ
- コーチング ロジックの大部分をエッジに移動
- 雨やトラクションの低下に対応するようにシミュレーションを変更する
- モデルのチューニングまたはファインチューニングによってパフォーマンスが向上する仕組みを理解する
- 医療、製造、ロジスティクスなどの別のドメインに合わせてアーキテクチャを調整する
たとえば、このラボで学んだことを別のドメインに適用する場合は、次の点を考慮してください。
- レースのテレメトリー(継続的なデータ)に相当するものは、他の分野では何ですか?
- どの決定を直ちに行う必要があり、どの決定がより戦略的ですか?
- どのような種類の人間の専門知識をエンコードする必要がありますか?
- ユーザーがシステムを信頼できると判断するために必要な情報はどのようなものですか?
これらの課題に取り組むことで、レースの例にとどまらず、この Codelab の背後にある信頼性のより広範な設計パターンを認識できます。
12. まとめと次のステップ
この Codelab では、レースのデモ以上のものを作成しました。信頼できる AI システムの設計方法の具体的な例を構築しました。
まず、未加工のテレメトリーから始めて、LLM に適した形式に変換し、AI 推論を適用して、エンコードされた人間のガイダンスとレスポンス制約で出力を強化しました。この過程で、信頼はモデルの出力だけではなく、アーキテクチャからも得られることがわかりました。
信頼できる AI システムは、多くの場合、次のものを組み合わせています。
- 構造化されたリアルタイム データ
- モデルベースの推論
- エンコードされたドメインの専門知識
- 明示的なガードレール
- ユーザー エクスペリエンスを考慮した設計
レースのシナリオは、これらのアイデアを具体化するのに役立ちましたが、AI の推奨事項がタイムリーで、実用的で、信頼できる必要がある場所であれば、どこでも同じアプローチを使用できます。
