
1. Przegląd
Sztuczna inteligencja jest obecnie częścią wielu systemów oprogramowania, ale tworzenie aplikacji AI nie jest tym samym co tworzenie aplikacji, której użytkownicy mogą zaufać. W wielu rzeczywistych środowiskach wyzwaniem nie jest samo wygenerowanie odpowiedzi. Wyzwaniem jest wygenerowanie odpowiedzi, która będzie aktualna, oparta na faktach, przydatna i zgodna z wiedzą ekspercką.
W tym ćwiczeniu utworzysz symulator trenera wyścigów, który w konkretny i angażujący sposób ilustruje te pomysły. Aplikacja wykorzystuje dane telemetryczne z wirtualnego samochodu wyścigowego, aby animować ruch na torze i generować wskazówki. Chociaż przykład dotyczy wyścigów, te same koncepcje architektoniczne mają zastosowanie w przypadku opieki zdrowotnej, produkcji, logistyki i innych dziedzin, w których zaufanie ma znaczenie.
Będziesz pracować z szybkim strumieniem danych telemetrycznych, przekształcać je w formę przydatną i wydajną na potrzeby rozumowania AI oraz łączyć dane wyjściowe oparte na LLM z zakodowanymi wskazówkami od ludzi, aby uzyskiwać bardziej wiarygodne odpowiedzi.
Co utworzysz
W tym ćwiczeniu z programowania utworzysz prototyp godnej zaufania AI, który:
- Przesyłanie danych telemetrycznych z wirtualnego samochodu wyścigowego działającego w Google Cloud
- Wizualizacja samochodu poruszającego się po torze wyścigowym w Chrome
- Przekształcanie nieprzetworzonych danych telemetrycznych w dane wejściowe gotowe do użycia przez AI
- Stosuje warstwę strategii opartą na Google Gemini
- Łączy dane wyjściowe modelu z zakodowanymi wskazówkami i zasadami bezpieczeństwa
- Przekazywanie opinii o treningu za pomocą interfejsu użytkownika
Czego się nauczysz
Po ukończeniu tego ćwiczenia:
- Wyjaśnij, co sprawia, że system AI jest bardziej godny zaufania
- Wyjaśnienie celu modułowej architektury AI
- Tworzenie prostego symulowanego potoku telemetrii
- Przygotowywanie przydatnych, uporządkowanych danych do użycia z modelem LLM
- Stosowanie zabezpieczeń i reguł opartych na wskazówkach od ludzi w celu zwiększenia zaufania
- Ocena możliwości zastosowania tej architektury w innych domenach
2. Wymagania
Zanim zaczniesz, przygotuj wymagane konta, narzędzia i usługi.
Wymagania wstępne
Musisz mieć:
- osobiste konto Google z adresem Gmail;
- Dostęp do Google Cloud i podstawowa znajomość interfejsu CLI
- aktywne konto rozliczeniowe lub środki w chmurze.
- Ogólne informacje o Google Cloud i generatywnej AI z wykorzystaniem Gemini
Gemini to model AI od Google, który opiera się na najnowocześniejszych funkcjach rozumowania i pomaga realizować każdy pomysł. To doskonały model do rozumienia multimodalnego oraz kodowania agentowego i vibe codingu.
3. Dlaczego godna zaufania AI jest ważna
Wiele systemów AI może generować płynne i przekonujące odpowiedzi, ale płynność nie jest tym samym co wiarygodność. W rzeczywistych systemach użytkownicy często potrzebują aktualnych, wiarygodnych odpowiedzi, które są zgodne z zasadami bezpieczeństwa i oparte na wiedzy z danej dziedziny.
Jest to szczególnie ważne, gdy system przetwarza szybko zmieniające się dane. Odpowiedź, która przyjdzie zbyt późno, może być bezużyteczna. Odpowiedź, która brzmi pewnie, ale ignoruje ważny kontekst, może wprowadzać w błąd. Odpowiedź, która nie ma związku z wiedzą ekspercką, może być trudna do zaufania, nawet jeśli brzmi dobrze.
W scenariuszu z samochodem wyścigowym, który jest używany w tym ćwiczeniu, nie chodzi o to, czy AI może powiedzieć coś interesującego. Chodzi o to, czy system może udzielać porad, które są przydatne, bezpieczne, aktualne i odpowiednie do danej sytuacji.
Przyjrzyjmy się niewielkiej próbce danych telemetrycznych i porównajmy 2 możliwe wyniki:
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Odpowiedź AI bez dodatkowych informacji
"Stay aggressive on the throttle and carry your speed into Turn 1"
Odpowiedź uwzględniająca zaufanie
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
Widzisz różnicę?
Co by się stało, gdybyśmy polegali tylko na naiwnej odpowiedzi AI?
Pierwsza odpowiedź brzmi pewnie, ale ignoruje ryzyko. Druga odpowiedź jest bardziej przydatna, ponieważ uwzględnia kontekst i ograniczenia.
Aby zwiększyć wiarygodność, nie traktuj modelu LLM jako całego systemu, ale jako jego część. Poza tym wiele aplikacji wymaga, aby porady były dostarczane wystarczająco szybko, aby można było na ich podstawie podjąć działania. Dotyczy to np. samochodów wyścigowych, procedur medycznych, lotnictwa, sieci energetycznych, systemów handlowych, nawigacji morskiej itp.
Teraz dowiedzmy się, jak utworzyć taką architekturę.
4. Omówienie szybkiej AI i modułowej architektury zaufanej
Niektóre systemy AI wymagają zupełnie innego rodzaju działania. Muszą szybko reagować na zmieniające się warunki, a także wspierać wolniejsze, bardziej przemyślane rozumowanie.
Architektura modułowa rozdziela te obowiązki na osobne ścieżki. Jedna ścieżka może być odruchowa i odpowiadać za natychmiastową, wrażliwą na czas interpretację sygnałów przychodzących. Inna ścieżka może koncentrować się na strategii, wspierając wyciąganie wniosków na wyższym poziomie i podejmowanie decyzji z uwzględnieniem kontekstu. Inne ścieżki są kierowane na inne typy funkcji.
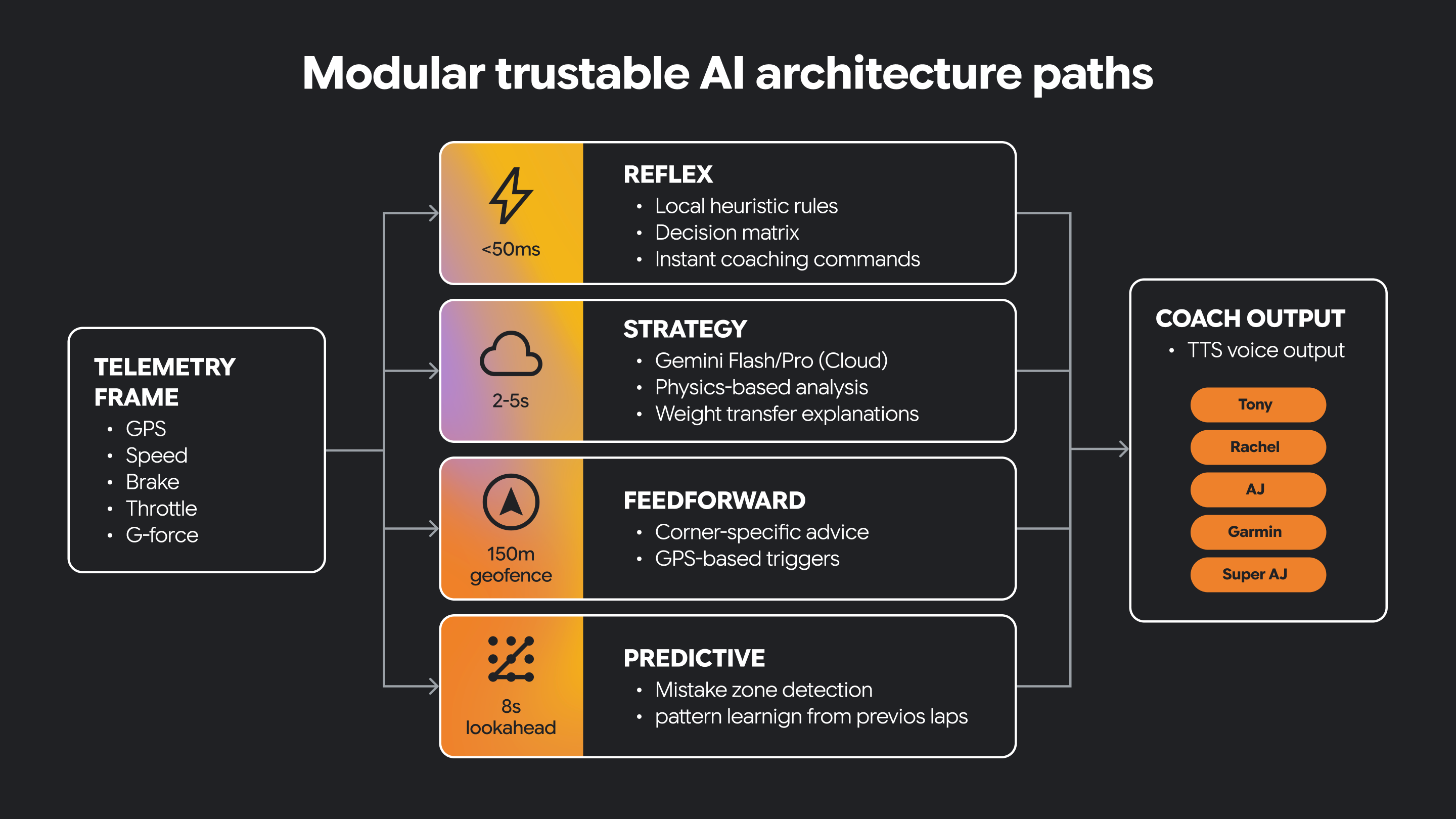
Niektóre decyzje muszą być podejmowane w czasie rzeczywistym. Niektóre decyzje wymagają dłuższego zastanowienia.
Godna zaufania AI często wymaga obu tych elementów.
Taka separacja architektury pomaga zachować responsywność systemu, a jednocześnie zapewniać bardziej zaawansowane wskazówki oparte na AI. Umożliwia też wprowadzenie ograniczeń opartych na wiedzy o domenie i wskazówek od ludzi.
W tym małym programie mamy ścieżkę odruchową i ścieżkę strategii zaimplementowane jako funkcje Pythona.
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
Te 2 funkcje działają inaczej w przypadku tych samych danych telemetrycznych. Funkcja odruchu to natychmiastowe ostrzeżenie. Funkcja strategii udziela porad na podstawie reguł.
Dlaczego Twoim zdaniem warto rozdzielić tę logikę?
Teraz zbudujmy zabawną, wieloczęściową aplikację i zobaczmy, jak ta architektura przekształca szybkie reakcje i głębsze rozumowanie w godny zaufania system AI, którego możesz używać.
5. Tworzenie serwera strumieniowego telemetrii
Znasz już cel architektoniczny, więc czas zbudować potok danych, który będzie obsługiwać aplikację.
W tej sekcji utworzysz prosty strumień danych telemetrycznych dla wirtualnego samochodu wyścigowego. Dane będą pochodzić ze źródła CSV zawierającego dane GPS lub dane pozycji ścieżki, a aplikacja przekształci je w strumień na żywo, który będzie mógł być wykorzystywany przez interfejs i warstwę AI.
W tej sekcji:
- Utwórz nowy projekt w Google Cloud na potrzeby serwera i aplikacji do przesyłania strumieniowego.
- Tworzenie małego serwera do emitowania danych telemetrycznych
- przesyłać te zdarzenia do interfejsu przeglądarki lub konsoli,
1. Otwieranie Cloud Shell
A. Otwórz konsolę Google Cloud.
B. Utwórz nowy projekt na potrzeby tego laboratorium. U góry kliknij menu projektu.
Podczas tworzenia projektu warto połączyć konto rozliczeniowe:
Opcjonalnie, jeśli masz już utworzony projekt, możesz otworzyć panel po lewej stronie, kliknąć Billing i sprawdzić, czy konto rozliczeniowe jest połączone z tym kontem GCP.
C. Uzyskiwanie klucza interfejsu Gemini API
Po włączeniu środków w Google Cloud musisz mieć klucz interfejsu Gemini API, aby uzyskać dostęp do Gemini w Google Cloud.
Aby utworzyć klucz interfejsu Gemini API, musisz użyć Google Vertex AI Studio do wygenerowania kluczy.
W Vertex AI Studio kliknij „Pobierz klucz interfejsu API” w lewym dolnym rogu nad „Dokumentacją”. Utwórz klucz interfejsu API Gemini (wygląda jak długi ciąg pozornie losowych znaków). Zapisz ten klucz w bezpiecznym miejscu. Użyjemy tego klucza interfejsu API w kroku 6 „Tworzenie symulatora wyścigów samochodowych”, aby uwierzytelnić dostęp do Gemini w Google Cloud.
D. Kliknij ikonę Cloud Shell na pasku u góry (ikonę terminala), aby otworzyć terminal w przeglądarce.
E. Poczekaj na rozpoczęcie sesji terminala.

2. Pobierz kod
Sklonuj repozytorium główne.
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
W tym repozytorium znajdują się 2 foldery: „koru-application” (aplikacja internetowa) i „streaming-telemetry-server” (symulowana telemetria samochodu wyścigowego w czasie rzeczywistym). W tym kroku opisujemy „streaming-telemetry-server”. W następnym kroku użyjemy nazwy „koru-application”.
3. Włącz wymagane interfejsy API
Uruchom raz w każdym projekcie:
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
Zastąp YOUR_PROJECT_ID rzeczywistym identyfikatorem projektu (lub pomiń pierwszy wiersz, jeśli projekt jest już ustawiony).
ID_TWOJEGO_PROJEKTU znajdziesz na liście projektów.
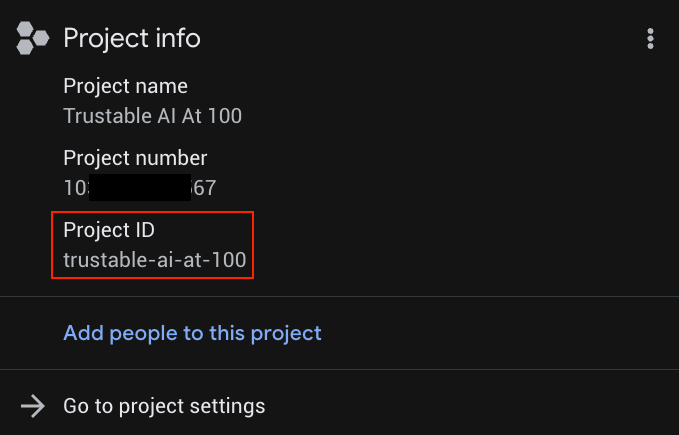
4. Wdrażanie backendu w Cloud Run
W katalogu głównym repozytorium (czyli upewnij się, że jesteś w folderze trustable-ai-codelab):
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
Gdy pojawi się odpowiedni komunikat, może być konieczne naciśnięcie klawisza „Y”.
- Podczas pierwszego uruchomienia może pojawić się prośba o włączenie interfejsów API lub utworzenie repozytorium Artifact Registry. W razie potrzeby zaakceptuj te prośby.
- Jeśli używasz innego regionu niż
us-central1, określ go za pomocą parametru--region. - Po zakończeniu wdrażania gcloud wyświetli adres URL usługi. Aby użyć tego adresu URL jako pełnego punktu końcowego serwera telemetrii, wystarczy dodać do niego słowo „events”.
5. Używanie adresu URL transmisji
Serwer telemetrii emituje teraz symulowane dane telemetryczne za pomocą zdarzeń wysyłanych przez serwer (SSE) w punkcie końcowym w formacie :
service-URL/events // service-URL - the last line displayed by "deploy"
Testowanie w przeglądarce: otwórz adres URL punktu końcowego strumienia w Chrome. W przeglądarce powinny pojawić się przychodzące dane przesyłane strumieniowo, symulujące dane emitowane przez czujniki w samochodzie wyścigowym.
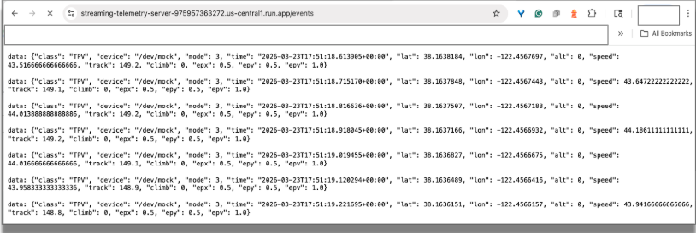
Aby zakończyć połączenie, możesz zamknąć kartę przeglądarki.
Testowanie za pomocą narzędzia curl:
Teraz przetestujmy to w wierszu poleceń powłoki.
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
W oknie Cloud Shell powinny wyświetlić się przychodzące dane przesyłane strumieniowo.
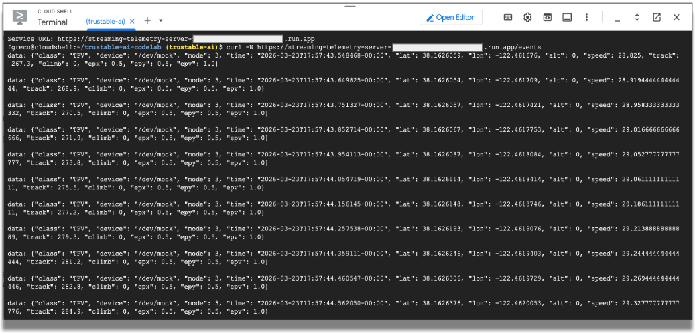
Użyjemy tych danych telemetrycznych do symulowania danych emitowanych przez czujniki w samochodzie wyścigowym. W pozostałej części tego laboratorium użyjemy tych danych. Możesz zakończyć działanie programu curl, wpisując CTRL-C w oknie terminala.
Na co zwrócić uwagę
Podczas wypełniania tej sekcji zwróć uwagę na charakter przychodzących danych. Surowe dane telemetryczne często mają dużą objętość, są wrażliwe na czas i nie nadają się od razu do wnioskowania przez AI. Po utworzeniu aplikacji front-end musimy przefiltrować nieprzetworzone dane do wydajnego formatu, który duży model językowy może szybko przetworzyć.
Najpierw jednak zbudujmy interfejs internetowy do wizualizacji danych.
6. Budowanie symulatora wyścigów
W tej sekcji:
- Tworzenie symulacji samochodu wyścigowego
- Połącz serwer telemetryczny z aplikacją internetową samochodu wyścigowego
- Wyświetlanie symulowanych wyścigów
W tym momencie mamy działającą symulację danych telemetrycznych z samochodu wyścigowego działającą w chmurze. Teraz utworzymy aplikację, która będzie działać na komputerze lokalnym, łączyć się z Google Cloud i wyświetlać te dane.
Nasza godna zaufania aplikacja AI korzysta zarówno z mocy i elastyczności usług Google Cloud, jak i z lokalnej inteligencji działającej w Chrome.
Usługa telemetrii strumieniowej działa w Google Cloud, ale aplikacja samochodu wyścigowego jest uruchamiana na komputerze lokalnym. Oznacza to, że musisz ponownie sklonować repozytorium, tym razem na laptopa lub komputer stacjonarny.
Dla uproszczenia w tym samym repozytorium znajduje się kod zarówno serwera strumieniowego, jak i aplikacji samochodu wyścigowego.
Sklonuj aplikację front-end z GitHuba:
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Po sklonowaniu repozytorium na laptopie lub komputerze stacjonarnym uruchom aplikację.
cd koru-application # racing car simulation app
npm install
npm run dev

W Chrome otwórz port na komputerze lokalnym (http://localhost:5173, jak w przykładzie powyżej). Wyświetli się strona docelowa aplikacji „AI Motorsport Coaching”.
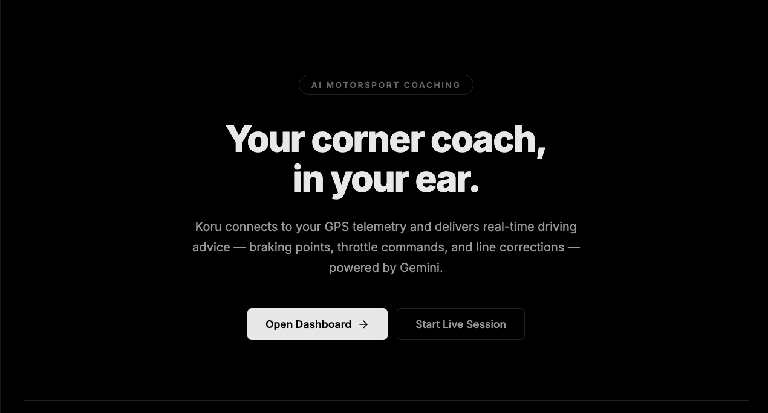
Kliknij przycisk „Open Dashboard ->” (Otwórz panel ->). Spowoduje to uruchomienie interfejsu aplikacji.
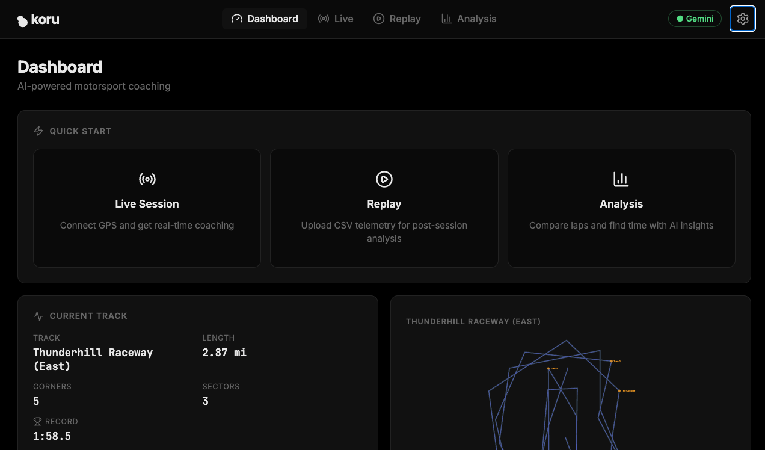
W tym momencie masz serwer telemetryczny generujący w Google Cloud symulowane dane telemetryczne samochodu wyścigowego oraz lokalną aplikację internetową, która może wizualizować te dane i łączyć się z LLM. Połączmy je, a także połączmy się z usługami Gemini LLM.
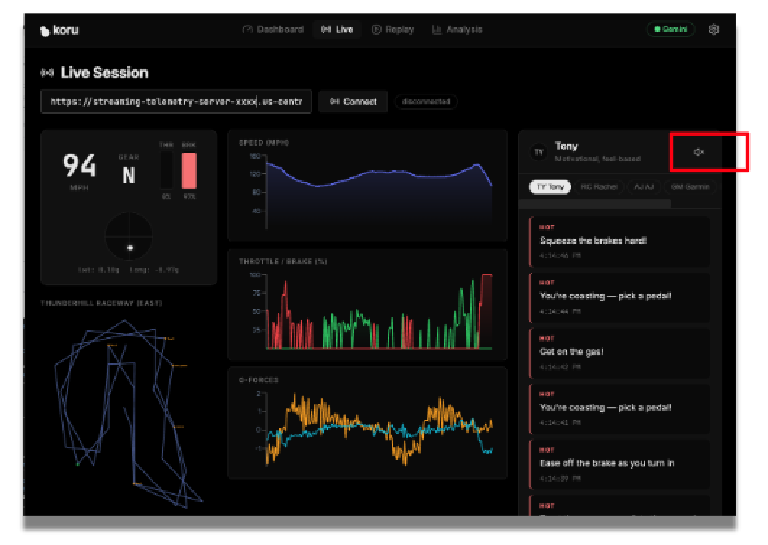
W prawym górnym rogu aplikacji kliknij ikonę koła zębatego (ustawienia).
![]()
Wpisz klucz interfejsu Gemini API z kroku 2. Dzięki temu uzyskasz dostęp do usług Gemini w Google Cloud.
Kliknij „Zapisz”, aby aplikacja zapamiętała Twój klucz interfejsu API.
Teraz połączmy aplikację z serwerem telemetrycznym. W panelu aplikacji kliknij „Sesja na żywo”.
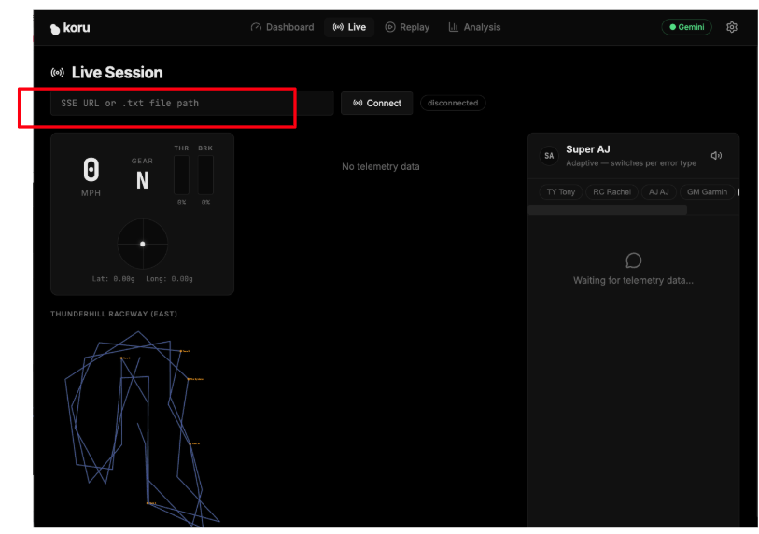
Wpisz konkretny adres URL serwera telemetrycznego działającego w chmurze (krok 5) w polu tekstowym „SSE URL or .txt file path”. Nasz adres URL SSE miał postać:
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
Po wpisaniu adresu URL punktu końcowego serwera telemetrii kliknij „Połącz” (po prawej stronie pola tekstowego). Nie zapomnij o słowie „events” na końcu adresu URL.
Powinna być teraz widoczna aplikacja wizualizująca symulowane dane.
Jeśli głośność głośnika jest zwiększona, możesz słyszeć porady dotyczące wyścigów samochodowych od różnych typów trenerów. Każdy trener ma inną osobowość. Wybierz różnych trenerów, aby poznać ich porady dotyczące wyścigów i różne style mówienia. W razie potrzeby możesz wyłączyć dźwięk, klikając ikonę głośnika.
Teraz, gdy mamy działającą aplikację, zobaczmy, jak przygotowaliśmy dane do wydajnego przetwarzania przez LLM i jak możemy dodać dodatkowe funkcje, aby zwiększyć wiarygodność całego systemu.
7. Przygotowywanie telemetrii do wnioskowania opartego na AI
Surowe dane telemetryczne są przydatne w symulacjach, ale zwykle są zbyt szczegółowe i zbyt często przesyłane, aby można je było wysyłać bezpośrednio do LLM. Jeśli wyślesz wszystkie dane telemetryczne bez zmian, możesz zwiększyć opóźnienie, wprowadzić szum i obniżyć jakość uzyskanych wskazówek.
W tej sekcji przekształcisz dane telemetryczne w bardziej przydatną formę.
W tej sekcji:
- Sprawdzanie nieprzetworzonego kodu JSON telemetrii
- określać, które pola są najbardziej istotne dla rozumowania;
- Filtrowanie lub podsumowywanie danych
- Ogranicz niepotrzebne szczegóły
- Przygotowanie reprezentacji stanu jazdy, która będzie odpowiednia dla AI
To ważny krok w budowaniu godnej zaufania AI. Jakość odpowiedzi zależy nie tylko od modelu, ale też od struktury i trafności otrzymywanych przez niego danych.
Przyjrzyjmy się teraz konkretnym danym dotyczącym samochodów wyścigowych. Możemy eksperymentować, zmieniając określone wartości w aplikacji, ponownie ją wczytując i obserwując wynik.
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
Siły G w samochodzie mierzą przyspieszenie lub zwalnianie. W samochodzie wyścigowym znajomość sił G pomaga w prowadzeniu pojazdu i ogólnej wydajności. Jeśli nasza aplikacja nie ma tych informacji, trudno jest udzielić kierowcy porady. Zakomentuj te 2 wiersze, ustaw wartości gLat i gLong na 0, 0 i uruchom ponownie aplikację.
Zwróć uwagę, że gdy samochód zbliża się do zakrętu, nie pojawia się żadna wskazówka. To nie jest zbyt pomocne dla kierowcy wyścigowego.
Następnie cofnij zmianę i ponownie uruchom aplikację. Czy zauważasz przydatne wskazówki dźwiękowe, gdy samochód zbliża się do zakrętu? Dane dotyczące siły G są kluczowe dla porad udzielanych kierowcy.
Teraz sztucznie ograniczmy prędkość samochodu do 48 km/h. Przy takiej prędkości nie wygramy żadnego wyścigu, ale na pewno pokaże to, jakiego rodzaju coaching otrzymujemy.
W tym samym pliku (telemetryStreamService.ts) w pobliżu wiersza 158 znajdziesz funkcję processPoint(). W tej funkcji ograniczmy prędkość.
Zmień:
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
Do:
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
Uruchom ponownie aplikację. Jakie porady dotyczące coachingu teraz otrzymujemy? Jeśli jedziemy spokojnie, nie potrzebujemy wiele.
Teraz cofnij te zmiany i ponownie uruchom aplikację.
Prędkość samochodu jest oczywiście cennym punktem danych. Bardzo ważne jest, aby wiedzieć, które dane są kluczowe do udzielania wartościowych porad. Równie ważne jest określenie, które dane nie są istotne.
Warto też zacząć myśleć o bezpieczeństwie i zaufaniu. Nawet dobrze przygotowane dane wejściowe nie gwarantują wiarygodnej odpowiedzi. Nadal musimy wprowadzić reguły oparte na wskazówkach od ludzi i wyraźne ograniczenia.
Przygotowywanie danych to nie tylko krok przetwarzania wstępnego. Jest to kluczowy element strategii budowania zaufania. Czyste dane wejściowe często prowadzą do bardziej ukierunkowanych i wiarygodnych wyników.
8. Dodawanie zabezpieczeń i zakodowanej wiedzy eksperckiej
Godny zaufania system AI nie powinien opierać się wyłącznie na danych wyjściowych modelu. W wielu przypadkach najbardziej niezawodne systemy łączą wnioskowanie dużego modelu językowego z wyraźnymi regułami, wiedzą o domenie i ograniczeniami określonymi przez człowieka.
W tej sekcji dodasz tę warstwę.
Można ją traktować jako zakodowaną wiedzę trenerską. Może ona obejmować preferowane wzorce odpowiedzi, reguły sprawdzania, kontrole bezpieczeństwa lub strukturalne wskazówki, które pomagają systemowi zachować wiarygodność i użyteczność.
W tej sekcji:
- Wprowadzenie reguł odpowiedzi, które kształtują zachowanie modelu
- Stosowanie kontroli bezpieczeństwa w celu ograniczenia wprowadzających w błąd porad
- Włączenie do potoku zakodowanej wiedzy eksperckiej
- Porównaj odpowiedzi przed dodaniem tych elementów i po ich dodaniu.
Przyjrzyjmy się, jak wiedza dziedzinowa jest dodawana do naszej aplikacji.
LLM nie jest zwykle trenowany w zakresie wyścigów ani fizyki osiągów samochodów wyścigowych. Gdyby nasza aplikacja uwzględniała tę wiedzę, użytkownicy mogliby bardziej ufać jej wskazówkom. Wskazówki te pochodzą z zasad opartych na wiedzy specjalistycznej, czyli z warstwy wiedzy specjalistycznej.
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
Te zasady dotyczące samochodów wyścigowych są kluczowym elementem zapewniającym wiarygodne wyniki. Co by się stało, gdybyśmy nie mieli tej wiedzy? Zaraz się dowiemy.
Usuńmy RACING_PHYSICS_KNOWLEDGE i sprawdźmy nasze porady dotyczące wyścigów.
export const RACING_PHYSICS_KNOWLEDGE = ``;
Uruchom ponownie aplikację. Jakie porady dotyczące coachingu teraz otrzymujemy?
Zwróć uwagę na ogólne porady.
Nie otrzymujemy już szczegółowych informacji o tarciu, przenoszeniu ciężaru, prędkości wyjścia itp. Bez tych informacji wiarygodność jest mniejsza. Przywróć tę wiedzę o wyścigach i uruchom ponownie aplikację.
Ten krok jest kluczowym aspektem godnego zaufania systemu AI. Zaufanie nie powstaje magicznie dzięki bardziej precyzyjnemu promptowi. Zaufanie wynika z projektu systemu i krytycznego myślenia.
LLM jest częścią rozwiązania, ale nie jest nim w całości. Zaufanie wzrasta, gdy wyniki AI są oparte na wyraźnej wiedzy człowieka.
9. Projektowanie profili trenerów i wrażeń użytkowników
Gdy masz już gotowy potok wnioskowania, pojawia się kolejne pytanie: jak system powinien komunikować się z użytkownikiem?
W tej sekcji określisz, jak warstwa strategii komunikuje się z kierowcą, aby dostosować sposób udzielania wskazówek. Ulepszysz prompt systemowy dla jednej z osób prowadzących szkolenie i zastanowisz się, jak przekazywać wskazówki, aby były jasne, aktualne i przede wszystkim przydatne.
W tej sekcji:
- Tworzenie lub ulepszanie prompta systemowego dla osoby trenującej
- Eksperymentuj z różnymi stylami coachingu
- Obserwuj, jak zmiany prompta wpływają na odpowiedzi
- Określanie wymagań interfejsu użytkownika dotyczących wiarygodnych opinii
- Poznaj obsługę zamiany tekstu na mowę (TTS) w przypadku pilnych i niepilnych wiadomości.
Nasza aplikacja zawiera kilka profili trenerskich. Każda z nich zawiera różne rodzaje porad.
PERSONA | CHARAKTERYSTYKA |
Tony | Motywacyjne, oparte na odczuciach |
Rachel | Techniczne, oparte na fizyce |
AJ | Bezpośrednie, dosadne polecenia |
Garmin | Optymalizacja delta oparta na danych |
Super AJ | Przełączniki adaptacyjne według typu błędu |
Te persony są zdefiniowane w pliku ../src/utils/coachingKnowledge.ts.
W tym pliku zobaczysz mapę obiektów (COACHES), która łączy klucze ciągów znaków z CoachPersonas. CoachPersona zawiera atrybuty każdego typu trenera. Ważnym atrybutem jest systemPrompt. Każda persona ma własny systemPrompt, który podpowiada LLM, jak odpowiadać.
Zmieńmy jeden z tych znaków system prompts i zobaczmy, jak zareaguje LLM.
W pobliżu wiersza 31 zobaczysz systemPrompt „AJ”, który udziela bardzo bezpośrednich i szczerych porad. Zmieńmy to systemPrompt, aby AJ był przesadnie uprzejmy.
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
Uruchom ponownie aplikację, wybierz AJ jako trenera i sprawdź, jakie typy odpowiedzi są generowane.
Teraz przywróć pierwotną wartość systemPrompt i ponownie uruchom aplikację. Zwróć uwagę, że prompt systemowy ma kluczowe znaczenie dla kierowania modelem LLM w celu uzyskania odpowiedzi pasującej do persony.
Zaufanie nie zależy tylko od poprawności. Chodzi też o dostawę. Rady, które są technicznie poprawne, mogą być nieskuteczne, jeśli są niejasne, nieodpowiednio dobrane lub rozpraszające.
Godny zaufania system musi dobrze komunikować się z użytkownikiem. Wrażenia użytkownika są częścią architektury zaufania.
10. Sprawdź architekturę kompleksową
W tym momencie masz już główne elementy systemu. Teraz czas się cofnąć i sprawdzić, jak ze sobą współpracują.
Aplikacja zawiera teraz te komponenty:
- Strumień danych telemetrycznych
- Warstwa wizualizacji
- Etap przekształcania danych gotowych do współpracy z AI
- Komponenty strategii oparte na modelu LLM z funkcją rozumowania
- Ograniczenia i zakodowane wskazówki od ludzi
- Wskazówki dla użytkowników
Przydatnym i prostym sposobem na zrozumienie ogólnego przepływu tych komponentów jest dodanie do aplikacji rejestrowania.
Dodamy rejestrowanie, aby wyświetlać dane telemetryczne przepływające przez ścieżki.
Najpierw wyświetlmy dane telemetryczne. W telemetryStreamService.ts, około wiersza 212 (przed this.emit(frame)), dodaj wiersz, który wyświetla prędkość, boczne przeciążenie (przyspieszenie boczne) i siłę nacisku kierowcy na pedał hamulca.
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
Załaduj ponownie aplikację. Zanim uruchomimy aplikację, otwórzmy konsolę w Narzędziach deweloperskich w Chrome, aby wyświetlić informacje na potrzeby debugowania.
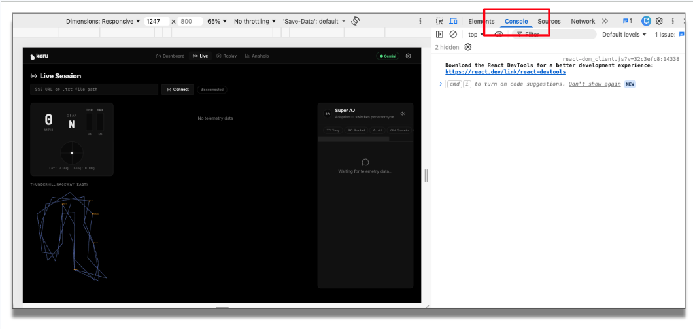
W aplikacji wpisz punkt końcowy telemetrii i kliknij „Połącz”. Możesz teraz zobaczyć przychodzące dane telemetryczne.
Teraz dodajmy rejestrowanie ścieżki odruchu i ścieżki strategii.
W ../src/services/coachingService.ts w okolicach wiersza 71 przed this.emit() dodaj wiersz logowania dla ścieżki reflex:
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
W tym samym pliku, około wiersza 287, przed this.emit() dodaj podobny wiersz logowania dla ścieżki strategy (dodajmy odpowiedź z treningiem text zwróconą przez Gemini API):
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
Uruchom ponownie aplikację. W konsoli zobaczysz, jak dane telemetryczne przepływają ze źródła przez te ścieżki. Strumień przychodzący jest filtrowany, wysyłany do LLM, weryfikowany przez zaufanych ekspertów i prezentowany użytkownikowi w odpowiednim interfejsie.
Zwróć uwagę, że połączyliśmy różne komponenty techniczne, aby osiągnąć większy cel, jakim jest zaufana AI. Wartość architektury nie tkwi w żadnym pojedynczym komponencie. Wartość wynika z tego, jak poszczególne części się uzupełniają.
Godna zaufania AI to wynik architektury, a nie pojedyncza funkcja.
Demontaż (usunięcie usługi)
Pamiętaj, aby usunąć usługę, gdy nie będzie Ci już potrzebna. Po zakończeniu testowania serwera telemetrii wraz z aplikacją usuń usługę Cloud Run i zatrzymaj naliczanie opłat:
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
W razie potrzeby zastąp us-central1 regionem używanym podczas wdrażania. Potwierdź, gdy wyświetli się monit.
11. Wyzwania
Gdy podstawowa aplikacja działa i znasz już jej różne komponenty, spróbuj rozbudować projekt.
Sugerowane wyzwania
- Przeniesienie większej części logiki coachingu na urządzenia
- Modyfikowanie symulacji w celu uwzględnienia deszczu lub zmniejszonej przyczepności
- Dowiedz się, jak dostrajanie lub precyzyjne dostrajanie modelu może poprawić skuteczność.
- Dostosowywanie architektury do innej domeny, np. medycyny, produkcji lub logistyki
Na przykład podczas stosowania wniosków wyciągniętych w tym module w przypadku innej domeny zadaj sobie te pytania:
- Jakie dane w innej dziedzinie są odpowiednikiem telemetrycznych danych wyścigowych, czyli danych ciągłych?
- Które decyzje muszą być natychmiastowe, a które mają charakter bardziej strategiczny?
- Jakiego rodzaju wiedza ekspercka musi zostać zakodowana?
- Co użytkownicy muszą zobaczyć, aby uznać system za godny zaufania?
Te wyzwania zachęcają do wyjścia poza przykład wyścigów i zauważenia szerszego wzorca projektowego wiarygodności, który kryje się za tym ćwiczeniem z programowania.
12. Podsumowanie i dalsze kroki
W tym ćwiczeniu z programowania powstało coś więcej niż tylko wersja demonstracyjna wyścigów. Udało Ci się stworzyć konkretny przykład tego, jak można projektować godne zaufania systemy AI.
Zaczęliśmy od surowych danych telemetrycznych, przekształciliśmy je w format przydatny dla LLM, zastosowaliśmy rozumowanie AI i wzmocniliśmy wynik za pomocą zakodowanych wskazówek i ograniczeń odpowiedzi. Po drodze przekonaliśmy się, że zaufanie wynika z architektury, a nie tylko z danych wyjściowych modelu.
Godny zaufania system AI często łączy w sobie:
- Uporządkowane dane w czasie rzeczywistym
- Rozumowanie na podstawie modelu
- Zakodowana wiedza o domenie
- Jawne zabezpieczenia
- Przemyślane projektowanie interfejsu użytkownika
Scenariusz wyścigowy pomógł w przedstawieniu tych pomysłów w praktyce, ale to samo podejście można zastosować wszędzie tam, gdzie rekomendacje AI muszą być aktualne, przydatne i wiarygodne.
