
1. Visão geral
A inteligência artificial agora faz parte de muitos sistemas de software, mas criar um aplicativo de IA não é o mesmo que criar um em que os usuários possam confiar. Em muitos ambientes do mundo real, o desafio não é apenas gerar uma resposta. O desafio é gerar uma resposta oportuna, embasada, prática e alinhada à experiência humana.
Neste codelab, você vai criar um simulador de treinador de corrida que demonstra essas ideias de maneira concreta e envolvente. O aplicativo usa telemetria de um carro de corrida virtual para animar o movimento em uma pista e gerar orientações de treinamento. Embora o cenário seja de corrida, as mesmas ideias arquitetônicas se aplicam a saúde, indústria, logística e outros domínios em que a confiança é importante.
Você vai trabalhar com um fluxo de dados de telemetria de alta velocidade, transformá-lo em um formato útil e eficiente para o raciocínio de IA e combinar a saída baseada em LLM com orientação humana codificada para produzir respostas mais confiáveis.
O que você criará
Neste codelab, você vai criar um protótipo de IA confiável que:
- Transmite telemetria de um carro de corrida virtual em execução no Google Cloud.
- Visualiza o carro se movendo em uma pista de corrida usando o Chrome
- Reforma a telemetria bruta em entrada pronta para IA
- Aplica uma camada de estratégia com tecnologia do Google Gemini
- Combina a saída do modelo com orientação humana codificada e regras de segurança
- Fornece feedback de treinamento por uma interface voltada ao usuário
O que você vai aprender
Ao final deste codelab, você vai poder:
- Explicar o que torna um sistema de IA mais confiável
- Explicar a finalidade de uma arquitetura de IA modular
- Criar um pipeline de telemetria simulada simples
- Prepare dados úteis e estruturados para uso com um LLM
- Aplicar proteções e regras orientadas por humanos para aumentar a confiança
- Avalie como essa arquitetura pode ser aplicada a outros domínios
2. O que é preciso
Antes de começar, verifique se você tem as contas, ferramentas e serviços necessários.
Pré-requisitos
Você precisa ter o seguinte:
- Uma Conta do Google pessoal usando um endereço do Gmail
- Acesso ao Google Cloud e um entendimento rudimentar de uma CLI
- Uma conta de faturamento ativa ou créditos do Cloud
- Entendimento de alto nível do Google Cloud e da IA generativa usando o Gemini
O Gemini é o modelo de IA do Google criado com base em um raciocínio de última geração que tira qualquer ideia do papel. É um ótimo modelo para compreensão multimodal e programação agêntica e vibe coding.
3. Por que a IA confiável é importante
Muitos sistemas de IA podem produzir respostas fluentes e convincentes, mas fluência não é o mesmo que confiabilidade. Em sistemas do mundo real, os usuários geralmente precisam de respostas oportunas e fundamentadas, restritas por regras de segurança e moldadas pela experiência no domínio.
Isso é especialmente importante quando um sistema opera com dados que mudam rapidamente. Uma resposta que chega tarde demais pode ser inútil. Uma resposta que parece confiante, mas ignora um contexto importante, pode ser enganosa. Uma resposta sem conexão com a experiência humana pode ser difícil de confiar, mesmo que pareça bem elaborada.
No cenário de carro de corrida usado neste codelab, a questão não é se a IA pode dizer algo interessante. A questão é se o sistema pode dar conselhos úteis, seguros, oportunos e adequados à situação.
Vamos analisar uma pequena amostra de telemetria e comparar duas saídas possíveis:
Racing Car Telemetry Data
{
"speedMph": 118,
"throttle": 91,
"frontGrip": "nominal",
"rearGrip": "low",
"trackPosition": "Turn 1 Entry"
}
Resposta ingênua da IA
"Stay aggressive on the throttle and carry your speed into Turn 1"
Resposta com reconhecimento de confiança
"Rear grip is low at Turn 1 entry. Reduce your throttle slightly and prioritize a stable corner entry"
Percebeu a diferença?
O que aconteceria se confiássemos apenas na resposta da IA ingênua?
A primeira resposta parece confiante, mas ignora o risco. A segunda resposta é mais útil porque reflete o contexto e a restrição.
Em vez de tratar o LLM como o sistema inteiro, é preciso considerá-lo como parte de uma arquitetura mais ampla para aumentar a confiabilidade. Além disso, muitos aplicativos exigem que as recomendações sejam entregues com rapidez suficiente para serem úteis, como em carros de corrida, procedimentos médicos, aviação, rede elétrica, sistema de negociação, navegação marítima etc.
Agora, vamos entender como criar essa arquitetura.
4. Entender a IA de alta velocidade e a arquitetura modular confiável
Alguns sistemas de IA precisam de comportamentos muito diferentes. Eles precisam reagir rapidamente a mudanças nas condições e também oferecer suporte a um raciocínio mais lento e elaborado.
Uma arquitetura modular separa essas responsabilidades em caminhos distintos. Um caminho pode ser reflexivo, processando a interpretação imediata e sensível ao tempo dos indicadores recebidos. Outro caminho pode se concentrar na estratégia, apoiando o raciocínio de nível superior e a tomada de decisões mais conscientes do contexto. Outros caminhos segmentam outros tipos de funcionalidade.
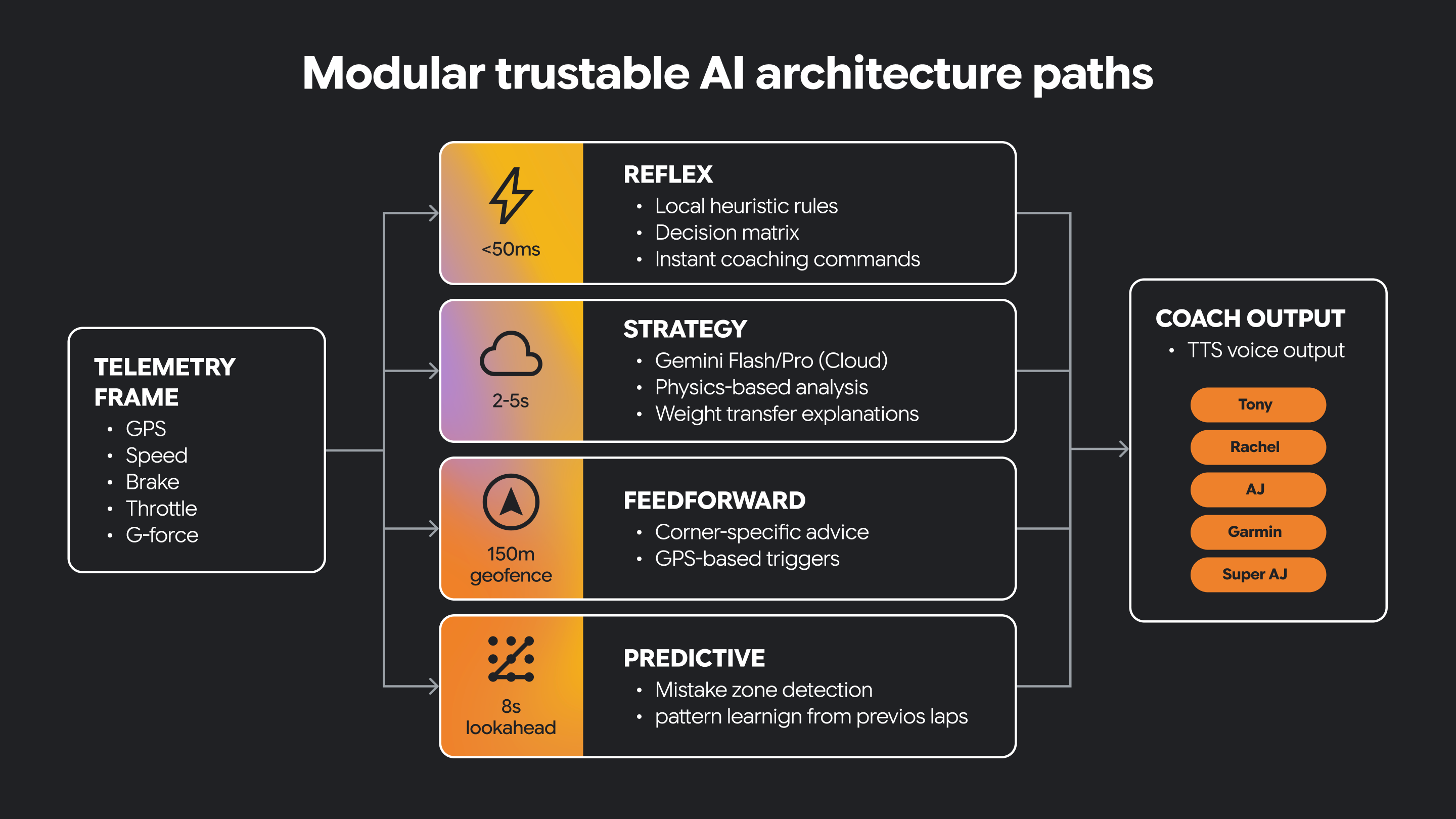
Algumas decisões precisam ser tomadas em tempo real. Algumas decisões se beneficiam de um tempo maior de reflexão.
A IA confiável geralmente precisa dos dois.
Essa separação arquitetônica ajuda o sistema a permanecer responsivo e, ao mesmo tempo, oferecer orientações mais completas com tecnologia de IA. Ele também cria um lugar claro para introduzir restrições guiadas por humanos e conhecimento do domínio.
Neste pequeno programa, temos um caminho de reflexo e um caminho de estratégia implementados como funções Python.
const telemetry = {
speed: 147,
grip: 0.68,
corner_type: "sharp",
lap_trend: "entering_corners_too_fast",
};
function reflexPath(event: typeof telemetry): string {
if (event.grip < 0.70) {
return "REFLEX: Reduce throttle now";
}
return "REFLEX: No urgent issue";
}
function strategyPath(event: typeof telemetry): string {
if (event.lap_trend === "entering_corners_too_fast") {
return "STRATEGY: Brake earlier and prioritize corner exit";
}
return "STRATEGY: Driving pattern looks stable";
}
console.log(reflexPath(telemetry));
console.log(strategyPath(telemetry));
As duas funções se comportam de maneira diferente com os mesmos dados de telemetria. A função de reflexo é um aviso imediato. A função de estratégia nos dá conselhos de coaching com base em regras.
Por que você acha que é útil manter essa lógica separada?
Agora, vamos criar um aplicativo divertido de várias partes e ver como essa arquitetura transforma reações rápidas e raciocínios mais profundos em um sistema de IA confiável que você pode usar.
5. Criar um servidor de streaming de telemetria
Agora que você entende a meta arquitetônica, é hora de criar o pipeline de dados que impulsiona o aplicativo.
Nesta seção, você vai criar um stream de telemetria simples para um carro de corrida virtual. Os dados vão vir de uma fonte CSV com informações de GPS ou posição de rastreamento, e seu aplicativo vai convertê-los em um stream ao vivo que a interface e a camada de IA podem consumir.
Nesta seção, você:
- Crie um projeto no Google Cloud para nosso servidor e aplicativo de streaming
- Criar um pequeno servidor para emitir dados de telemetria
- Transmitir esses eventos para uma interface do navegador ou um console
1. Abrir o Cloud Shell
A. Acesse o console do Google Cloud.
B. Crie um projeto para este codelab. Clique no menu suspenso do projeto na parte de cima.
Ao criar um projeto, é uma boa oportunidade para vincular a conta de faturamento:
Se você já tiver criado um projeto, abra o painel à esquerda, clique em Billing e verifique se a conta de faturamento está vinculada a essa conta GCP.
C. Como receber uma chave da API Gemini
Depois de ativar os créditos do Google Cloud, você precisa de uma chave de API Gemini para acessar o Gemini no Google Cloud.
Para criar uma chave de API Gemini, precisamos usar o Google Vertex AI Studio para gerar chaves.
No Vertex AI Studio, clique em "Receber chave de API" no canto inferior esquerdo, acima de "Documentação". Crie uma chave de API para o Gemini (parece uma string longa de caracteres aparentemente aleatórios). Salve essa chave em um local seguro. Vamos usar essa chave de API na etapa 6 "Criar o simulador de carro de corrida" para autenticar nosso acesso ao Gemini no Google Cloud.
D. Clique no ícone Cloud Shell na barra superior (ícone do terminal) para abrir um terminal baseado em navegador.
E. Aguarde o início da sessão do terminal.

2. Acessar o código
Clone o repositório principal.
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Há duas pastas neste repositório: "koru-application" (aplicativo da Web) e "streaming-telemetry-server" (telemetria simulada de carro de corrida em tempo real). Esta etapa descreve o "streaming-telemetry-server". Vamos usar "koru-application" na próxima etapa.
3. Ativar APIs obrigatórias
Execute uma vez por projeto:
# Set Project ID
gcloud config set project YOUR_PROJECT_ID
# Enable APIs
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
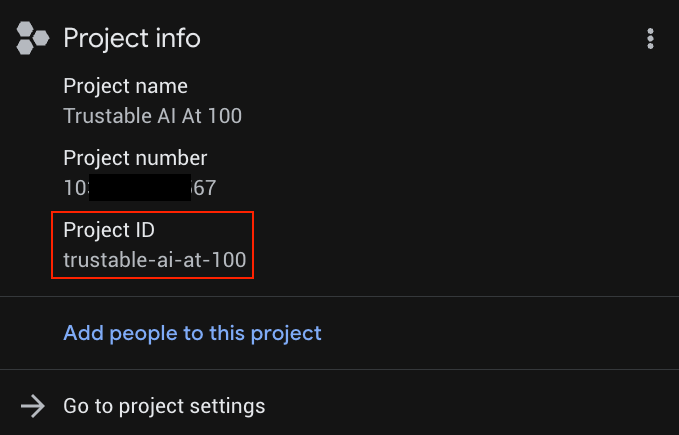
Substitua YOUR_PROJECT_ID pelo ID do projeto (ou pule a primeira linha se o projeto já estiver definido).
É possível encontrar YOUR_PROJECT_ID na lista de projetos.
4. Implantar o back-end no Cloud Run
Na raiz do repositório (ou seja, verifique se você está na pasta trustable-ai-codelab):
gcloud run deploy streaming-telemetry-server \
--source streaming-telemetry-server \
--platform managed \
--region us-central1 \
--allow-unauthenticated
Talvez seja necessário pressionar "Y" quando solicitado.
- A primeira execução pode pedir que você ative APIs ou crie um repositório do Artifact Registry. Aceite conforme necessário.
- Se você usar uma região diferente de
us-central1, especifique essa região usando--region - Quando a implantação terminar, a gcloud vai imprimir o service-URL. Basta adicionar "events" ao final desse URL para usá-lo como o endpoint completo do servidor de telemetria.
5. Usar o URL da transmissão
O servidor de telemetria agora está emitindo dados simulados usando eventos enviados pelo servidor (SSE) em um endpoint do tipo :
service-URL/events // service-URL - the last line displayed by "deploy"
Teste em um navegador:acesse o URL do endpoint de transmissão usando o Chrome. Você vai ver os dados transmitidos chegando no navegador, simulando os dados emitidos pelos sensores de um carro de corrida.
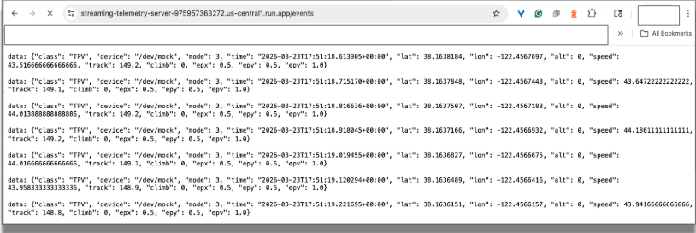
Você pode fechar a guia do navegador para encerrar a conexão.
Testar com curl:
Agora vamos testar na linha de comando do shell.
curl -N service-URL/events # Replace service-URL with actual deployment endpoint
Você vai ver os dados transmitidos na janela do Cloud Shell.
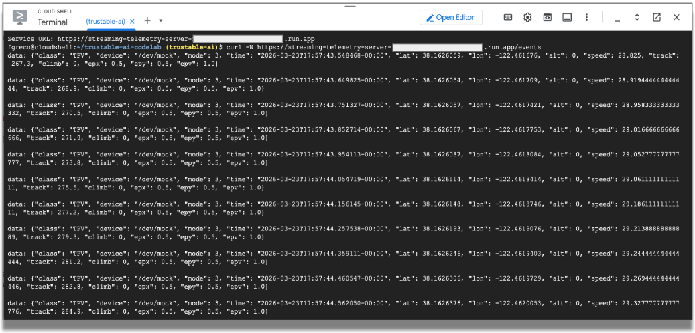
Vamos usar esses dados de telemetria para simular os dados emitidos por sensores em um carro de corrida. O restante do codelab vai usar esses dados. Para encerrar o programa curl, digite CTRL-C na janela do terminal.
O que você precisa observar
Ao concluir esta seção, preste atenção à natureza dos dados recebidos. A telemetria bruta geralmente é de alto volume, sensível ao tempo e não é imediatamente adequada para o raciocínio de IA. Depois de criar o aplicativo front-end, vamos precisar filtrar os dados brutos em um formato eficiente que um LLM possa processar rapidamente.
Mas primeiro, vamos criar o front-end da Web para visualizar os dados.
6. Criar o simulador de carro de corrida
Nesta seção, você:
- Criar uma simulação de carro de corrida
- Conecte o servidor de telemetria ao aplicativo da Web do carro de corrida
- Ver corridas simuladas
Neste ponto, temos uma simulação funcional da telemetria de um carro de corrida em execução na nuvem. Agora vamos criar o aplicativo que é executado na sua máquina local, se conecta ao Google Cloud e visualiza esses dados.
Nosso aplicativo de IA confiável usa a potência e a flexibilidade dos serviços do Google Cloud e a inteligência local executada no Chrome.
O serviço de telemetria de streaming é executado no Google Cloud, mas o aplicativo de carro de corrida é executado na sua máquina local. Isso significa que você precisará clonar o repositório novamente, desta vez no seu laptop ou computador.
Para simplificar, o mesmo repositório contém o código do servidor de streaming e do aplicativo de carro de corrida.
Clone o aplicativo front-end do GitHub:
git clone https://github.com/ocupop/trustable-ai-codelab.git
cd trustable-ai-codelab
Depois que o repositório for clonado no laptop ou computador, vamos executar o aplicativo.
cd koru-application # racing car simulation app
npm install
npm run dev

No Chrome, abra a porta na sua máquina local (http://localhost:5173, como no exemplo acima). A página de destino do aplicativo "AI Motorsport Coaching" vai aparecer.
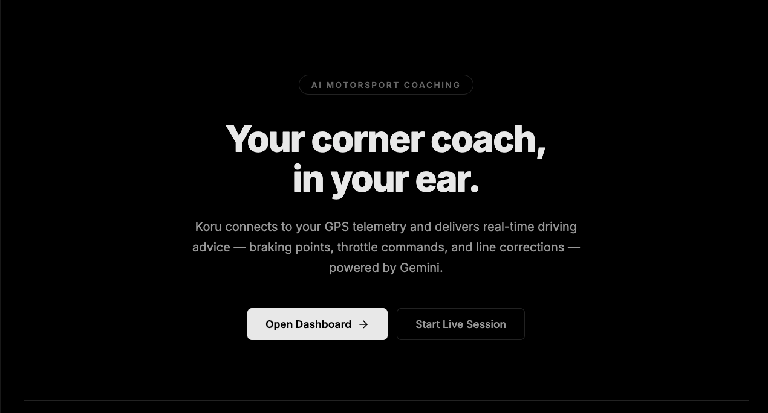
Clique no botão "Abrir painel ->". Isso vai iniciar a interface do aplicativo.
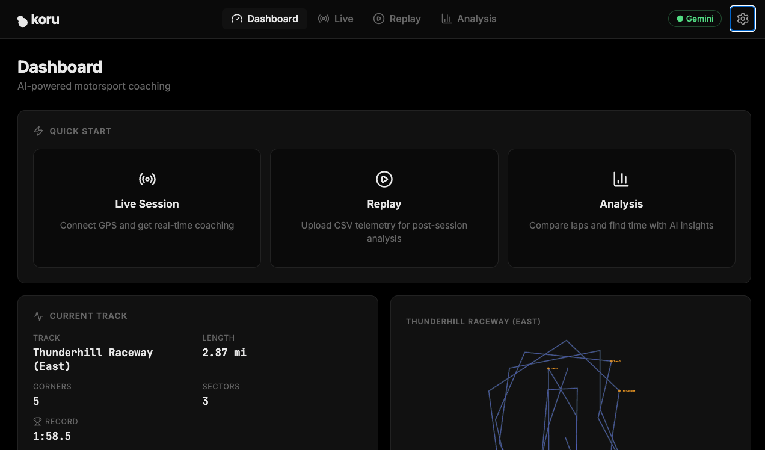
Neste ponto, você tem um servidor de telemetria gerando telemetria simulada de carro de corrida no Google Cloud e um aplicativo da Web local que pode visualizar esses dados e se conectar a um LLM. Vamos conectá-los e também aos serviços de LLM do Gemini.
No canto superior direito do aplicativo, clique no ícone de engrenagem (configurações).
![]()
Insira a chave da API Gemini da etapa 2. Isso dá acesso aos serviços do Gemini no Google Cloud.
Clique em "Salvar" para que o aplicativo se lembre da sua chave de API.
Agora vamos conectar o aplicativo ao servidor de telemetria. No painel do aplicativo, clique em "Sessão Live".
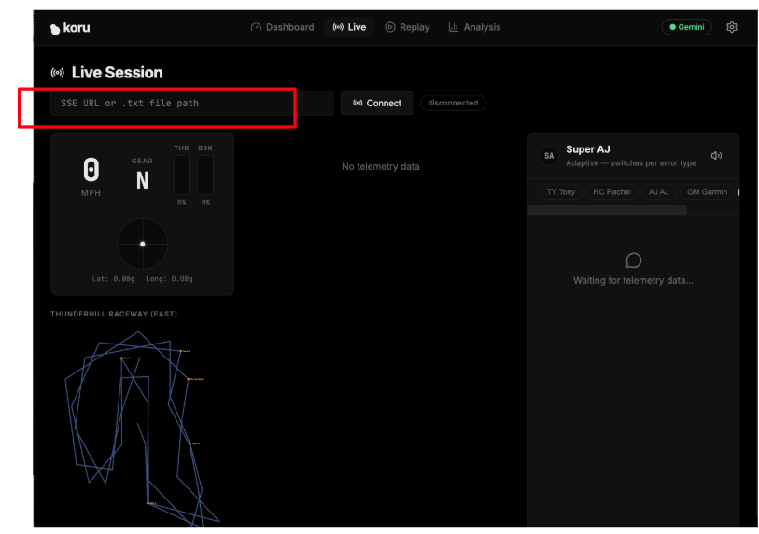
Insira o URL específico do seu servidor de telemetria baseado na nuvem (etapa 5) no campo de texto que diz "SSE URL or .txt file path". Nosso URL de SSE tinha o seguinte formato:
https://streaming-telemetry-server-${PROJECT_NUMBER}.${REGION}.run.app/events
Depois de inserir o URL do endpoint do servidor de telemetria, clique em "Conectar" (à direita do campo de texto). Não se esqueça de "events" no final do URL.
Agora você vai ver o aplicativo mostrando os dados simulados.
Se o volume do alto-falante estiver alto, você poderá ouvir dicas de corrida de carro de diferentes tipos de treinadores. Cada treinador tem uma personalidade diferente. Selecione diferentes treinadores para conferir dicas de corrida variadas e estilos vocais diferentes. Se necessário, clique no ícone de alto-falante para desativar o áudio.
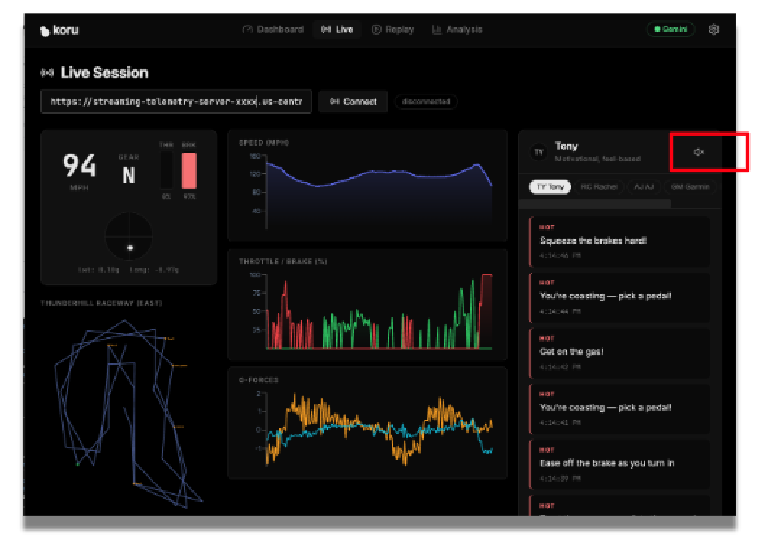
Agora que temos um aplicativo funcionando, vamos explorar como preparamos os dados para um processamento eficiente pelo LLM e como podemos adicionar outros recursos para aumentar a confiabilidade do sistema geral.
7. Preparar a telemetria para o raciocínio de IA
A telemetria bruta é útil para simulação, mas geralmente é muito detalhada e frequente para ser enviada diretamente a um LLM. Se você enviar todos os dados de telemetria sem alterações, poderá aumentar a latência, introduzir ruído e reduzir a qualidade da orientação resultante.
Nesta seção, você vai remodelar a telemetria para uma forma mais útil.
Nesta seção, você:
- Inspecionar o JSON de telemetria bruta
- Identificar quais campos são mais relevantes para o raciocínio
- Filtrar ou resumir os dados
- Reduza detalhes desnecessários
- Preparar uma representação do estado de direção compatível com IA
Essa é uma etapa importante para criar uma IA confiável. A qualidade da resposta depende não apenas do modelo, mas também da estrutura e da relevância dos dados que ele recebe.
Agora vamos analisar os dados específicos de carros de corrida. Podemos fazer um teste mudando valores específicos no aplicativo, recarregando-o e observando o resultado.
../src/services/telemetryStreamService.ts near line 180
// Clamp G-forces
gLat = Math.max(-3, Math.min(3, gLat)); // sideways G-force
gLong = Math.max(-3, Math.min(3, gLong)); // front/back G-force
As forças G em um carro medem a aceleração ou a desaceleração. Em um carro de corrida, entender as forças G ajuda no manuseio e na performance geral do veículo. Se o aplicativo não tiver essas informações, será difícil dar conselhos ao motorista. Transforme essas duas linhas em comentários, defina os valores de gLat e gLong como 0, 0 e execute o aplicativo novamente.
Nenhuma orientação é dada quando o carro se aproxima de uma curva. Isso não é muito útil para um piloto de corrida!
Em seguida, desfaça a mudança e execute o aplicativo novamente. Percebeu as dicas de áudio úteis quando o carro chega a uma esquina? Os pontos de dados de força G são essenciais para dar conselhos ao motorista.
Agora, vamos restringir artificialmente a velocidade do carro a um ritmo tranquilo de 48 km/h. Não vamos ganhar nenhuma corrida nessa velocidade, mas isso certamente vai demonstrar o tipo de treinamento que recebemos.
No mesmo arquivo (telemetryStreamService.ts), perto da linha 158, você vai encontrar a função processPoint(). Nela, vamos restringir a velocidade.
Mudar:
private processPoint(point: GpsSSEPoint) {
...
const speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
...
Para:
private processPoint(point: GpsSSEPoint) {
...
let speedKmh = point.speed > 200 ? point.speed : point.speed * 3.6;
speedKmh = Math.min(speedKmh, 48); // 48 kmh is approx 30 mph
...
Execute o app novamente. Que tipo de orientação de coaching recebemos agora? Não é preciso muito se estivermos dirigindo com calma.
Agora reverta essas mudanças e execute o aplicativo novamente.
A velocidade do carro é um ponto de dados valioso. É muito importante entender quais dados específicos são essenciais para oferecer conselhos valiosos. É igualmente importante avaliar quais dados não são relevantes.
Também é importante começar a pensar em segurança e confiança. Mesmo uma entrada bem preparada não garante uma resposta confiável. Ainda precisamos introduzir regras guiadas por humanos e restrições explícitas.
A preparação de dados não é apenas uma etapa de pré-processamento. É uma parte essencial da estratégia de confiança. Entradas mais limpas geralmente levam a resultados mais focados e confiáveis.
8. Adicionar mecanismos de segurança e experiência humana codificada
Um sistema de IA confiável não pode depender apenas da saída do modelo. Em muitos casos, os sistemas mais confiáveis combinam o raciocínio de modelos de linguagem grandes com regras explícitas, conhecimento do domínio e restrições guiadas por humanos.
Nesta seção, você vai adicionar essa camada.
Pense nessa camada como um conhecimento de treinamento codificado. Isso pode incluir padrões de resposta preferidos, regras de validação, verificações de segurança ou orientações estruturadas que ajudam o sistema a se manter fundamentado e útil.
Nesta seção, você:
- Introduzir regras de resposta que moldam o comportamento do modelo
- Aplicar verificações de segurança para reduzir conselhos enganosos
- Incorporar experiência humana codificada ao pipeline
- Comparar respostas antes e depois dessas adições
Vamos investigar como a experiência em domínio é adicionada ao nosso aplicativo.
Normalmente, um LLM não é treinado em corridas ou na física do desempenho de carros de corrida. Se o aplicativo incluísse essa experiência, os usuários poderiam confiar mais nas orientações dele. Essa orientação vem de regras baseadas na experiência humana, ou seja, uma camada de experiência no domínio.
../src/utils/coachingKnowledge.ts near line 115
...
export const RACING_PHYSICS_KNOWLEDGE = `
CORE PRINCIPLES:
1. **The Friction Circle:** A tire has 100% grip. If you use 100% for braking, you have 0% for turning.
- *Error:* Turning while 100% braking = Understeer (Plowing).
- *Fix:* "Trail braking" (releasing brake pressure as steering angle increases).
2. **Weight Transfer:**
- Braking shifts weight forward (Front grip UP, Rear grip DOWN).
- Accelerating shifts weight backward (Front grip DOWN, Rear grip UP).
- *Error:* Lifting off throttle mid-corner shifts weight forward abruptly -> Oversteer (Spin risk).
3. **The racing line:**
...
Esses princípios são um ingrediente fundamental para oferecer resultados confiáveis. O que aconteceria se não tivéssemos essa experiência? Vamos descobrir.
Vamos remover RACING_PHYSICS_KNOWLEDGE e conferir nossas dicas de corrida.
export const RACING_PHYSICS_KNOWLEDGE = ``;
Execute o app novamente. Que tipo de orientação de coaching recebemos agora?
Observe o conselho genérico.
Não recebemos mais informações detalhadas sobre atrito, transferência de peso, velocidade de saída etc. Nossa confiabilidade é menor sem essas informações. Recupere essa experiência em corridas e execute o aplicativo novamente.
Essa etapa é um aspecto fundamental de um sistema de IA confiável. A confiança não é criada magicamente por um comando mais forte. A confiança surge do design do sistema e do pensamento crítico.
O LLM faz parte da solução, mas não é a solução completa. A confiança aumenta quando a saída da IA é orientada por conhecimento humano explícito.
9. Projetar as personas de coaching e a experiência do usuário
Depois que o pipeline de raciocínio estiver pronto, a próxima questão é como o sistema deve se comunicar com o usuário.
Nesta seção, você vai moldar a experiência de coaching definindo como a camada de estratégia se comunica com o motorista. Você vai refinar o comando do sistema para uma das personas de coaching e considerar como a orientação dela deve ser entregue para ser clara, oportuna e, mais importante, prática.
Nesta seção, você:
- Criar ou refinar um comando do sistema para uma persona de treinamento
- Teste diferentes estilos de treinamento
- Observe como as mudanças no comando afetam as respostas
- Definir requisitos de interface para feedback confiável
- Entenda o suporte de conversão de texto em voz (TTS) para mensagens urgentes e não urgentes
Nosso aplicativo inclui várias personas de coaching. Cada um oferece diferentes tipos de orientação.
PERSONA | CARACTERÍSTICAS |
Tony | Motivacional, baseado em sentimentos |
Rachel | Técnico, com foco em física |
AJ | Comandos diretos e objetivos |
Garmin | Otimização delta focada em dados |
Super AJ | Adaptativo, alternâncias por tipo de erro |
Essas personas são definidas no arquivo ../src/utils/coachingKnowledge.ts.
Nesse arquivo, você vai notar um mapa de objetos (COACHES) que associa chaves de string a CoachPersonas. Um CoachPersona contém atributos de cada tipo de coach. Um atributo importante é systemPrompt. Cada persona tem um systemPrompt que orienta o LLM sobre como responder.
Vamos alterar um desses system prompts e ver como o LLM responde.
Perto da linha 31, você vai encontrar o systemPrompt de "AJ", que é muito direto e objetivo nos conselhos. Vamos mudar esse systemPrompt para que o AJ seja excessivamente educado.
systemPrompt: `You are AJ, a race engineer that is excessively polite.
Use telemtry terminology. Be actionable
Examples: "Lat G settling. please throttle",
"Brake when its convenient."
Keep responses under 12 words. Never explain — just command.`
Execute o aplicativo novamente, selecione AJ como o coach e confira o tipo de respostas geradas.
Agora restaure o systemPrompt original e execute o aplicativo novamente. O comando do sistema é essencial para orientar o LLM a fornecer uma resposta que se encaixe no perfil.
A confiança não é apenas uma questão de correção. Também é sobre entrega. Um conselho tecnicamente preciso ainda pode ser ineficaz se for confuso, mal cronometrado ou distrair.
Um sistema confiável precisa se comunicar bem. A experiência do usuário faz parte da arquitetura de confiança.
10. Analise a arquitetura de ponta a ponta
Neste ponto, você já criou as principais partes do sistema. Agora é hora de voltar e analisar como eles funcionam juntos.
Seu aplicativo agora inclui estes componentes:
- Stream de telemetria
- Camada de visualização
- Etapa de transformação de dados pronta para IA
- Componentes estratégicos com tecnologia de um LLM de raciocínio
- Proteções e orientação humana codificada
- Experiência de treinamento voltada para o usuário
Uma maneira útil e simples de entender o fluxo geral desses componentes é adicionar registros ao aplicativo.
Vamos adicionar o registro para ver os dados de telemetria à medida que eles fluem pelos caminhos.
Primeiro, vamos apenas visualizar os dados de telemetria. Em telemetryStreamService.ts, por volta da linha 212 (antes de this.emit(frame)), adicione uma linha que mostre a velocidade, a força G lateral (aceleração lateral) e a intensidade com que o motorista está pisando no pedal do freio.
console.log('FRAME', {
speed: frame.speed.toFixed(1),
gLat: frame.gLat.toFixed(2),
brake: frame.brake.toFixed(0) }
);
Recarregue o aplicativo. Antes de executar o aplicativo, abra o console nas DevTools do Chrome para conferir essas informações de depuração.
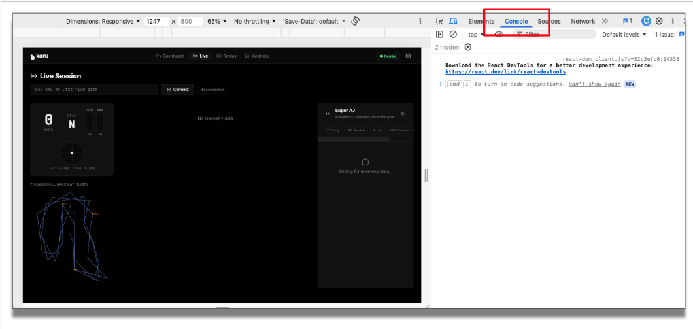
No aplicativo, insira o endpoint de telemetria e clique em "Conectar". Agora você pode ver os dados de telemetria recebidos.
Agora, vamos adicionar o registro em log para o caminho de reflexão e o caminho de estratégia.
Em ../src/services/coachingService.ts, por volta da linha 71, antes de this.emit(), adicione uma linha de registro para o caminho reflex:
console.log('Reflex', {
action: rule.action,
text,
coach: this.coachId }
);
No mesmo arquivo, por volta da linha 287, antes de this.emit(), adicione uma linha de registro semelhante para o caminho strategy. Vamos adicionar a resposta de coaching text retornada pela API Gemini:
console.log('Strategy', {
coach: coach.id,
chars: text.length,
preview: text.slice(0, 60) }
);
Execute o app novamente. No console, você vai notar como os dados de telemetria fluem da origem por esses caminhos. O fluxo de entrada é filtrado, enviado ao LLM, verificado com a experiência humana confiável e apresentado ao usuário usando uma interface adequada.
Perceba que conectamos os vários componentes técnicos para alcançar o objetivo maior de uma IA confiável. O valor da arquitetura não está em nenhum componente isolado. O valor vem de como as partes se reforçam.
A IA confiável é um resultado arquitetônico, não um único recurso.
Desativar (remover o serviço)
É importante remover o serviço quando ele não for mais necessário. Depois de testar o servidor de telemetria com o aplicativo, exclua o serviço do Cloud Run e interrompa o faturamento dele:
gcloud run services delete streaming-telemetry-server \
--region us-central1 \
--platform managed
Substitua us-central1 pela região usada na implantação, se necessário. Confirme quando solicitado.
11. Desafios
Agora que o aplicativo principal está funcionando e você entende os vários componentes, tente estender o design.
Desafios sugeridos
- Mova mais da lógica de coaching para a borda
- Modifique a simulação para incluir chuva ou tração reduzida
- Saiba como o ajuste ou o ajuste refinado de modelos pode melhorar a performance
- Adaptar a arquitetura para outro domínio, como medicina, manufatura ou logística
Por exemplo, considere estas perguntas ao aplicar as lições aprendidas neste laboratório a outro domínio:
- Qual é o equivalente da telemetria de corrida, ou seja, dados contínuos, em outro campo?
- Quais decisões precisam ser imediatas e quais são mais estratégicas?
- Que tipo de conhecimento humano precisaria ser codificado?
- O que os usuários precisam ver para acreditar que o sistema é confiável?
Esses desafios incentivam você a pensar além do exemplo de corrida e reconhecer o padrão de design mais amplo de confiabilidade por trás deste codelab.
12. Conclusão e próximas etapas
Neste codelab, você criou mais do que uma demonstração de corrida. Você criou um exemplo concreto de como sistemas de IA confiáveis podem ser projetados.
Você começou com telemetria bruta, transformou em um formato útil para um LLM, aplicou o raciocínio de IA e fortaleceu a saída com orientação humana codificada e restrições de resposta. Ao longo do caminho, você viu que a confiança vem da arquitetura, não apenas da saída do modelo.
Um sistema de IA confiável geralmente combina:
- Dados estruturados em tempo real
- Raciocínio com base em modelos
- Conhecimento codificado do domínio
- Proteções explícitas
- Design de experiência do usuário inteligente
O cenário de corrida ajudou a tornar essas ideias tangíveis, mas a mesma abordagem pode ser usada em qualquer lugar em que as recomendações de IA precisam ser oportunas, práticas e confiáveis.
